
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_22569
|
rasdani/github-patches
|
git_diff
|
wemake-services__wemake-python-styleguide-1649
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add Exceptions for String Constant Overuse
# Rule request
I feel it would be good to be able to declare exceptions for WPS226
## Thesis / Reasoning
In a file on a current project, I tend to use `" ".join(iterable)` a lot.
It feels unnatural to declare a CONSTANT for that.
Also, I don't think it is good in this case to disable WPS226 for the entire file as there could be other common string constants.
Alternative: Excluse `" "`, `""`, "`\n"` & friends from this by default.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wemake_python_styleguide/visitors/ast/complexity/overuses.py`
Content:
```
1 import ast
2 from collections import defaultdict
3 from typing import Callable, ClassVar, DefaultDict, List, Tuple
4
5 from typing_extensions import final
6
7 from wemake_python_styleguide.compat.aliases import FunctionNodes
8 from wemake_python_styleguide.logic import source, walk
9 from wemake_python_styleguide.logic.complexity import overuses
10 from wemake_python_styleguide.types import AnyNodes, AnyText, AnyTextPrimitive
11 from wemake_python_styleguide.violations import complexity
12 from wemake_python_styleguide.visitors import base, decorators
13
14 #: We use these types to store the number of nodes usage in different contexts.
15 _Expressions = DefaultDict[str, List[ast.AST]]
16 _FunctionExpressions = DefaultDict[ast.AST, _Expressions]
17
18
19 @final
20 @decorators.alias('visit_any_string', (
21 'visit_Str',
22 'visit_Bytes',
23 ))
24 class StringOveruseVisitor(base.BaseNodeVisitor):
25 """Restricts several string usages."""
26
27 def __init__(self, *args, **kwargs) -> None:
28 """Inits the counter for constants."""
29 super().__init__(*args, **kwargs)
30 self._string_constants: DefaultDict[
31 AnyTextPrimitive, int,
32 ] = defaultdict(int)
33
34 def visit_any_string(self, node: AnyText) -> None:
35 """
36 Restricts to over-use string constants.
37
38 Raises:
39 OverusedStringViolation
40
41 """
42 self._check_string_constant(node)
43 self.generic_visit(node)
44
45 def _check_string_constant(self, node: AnyText) -> None:
46 if overuses.is_annotation(node):
47 return
48
49 self._string_constants[node.s] += 1
50
51 def _post_visit(self) -> None:
52 for string, usage_count in self._string_constants.items():
53 if usage_count > self.options.max_string_usages:
54 self.add_violation(
55 complexity.OverusedStringViolation(
56 text=source.render_string(string) or "''",
57 baseline=self.options.max_string_usages,
58 ),
59 )
60
61
62 @final
63 class ExpressionOveruseVisitor(base.BaseNodeVisitor):
64 """Finds overused expressions."""
65
66 _expressions: ClassVar[AnyNodes] = (
67 # We do not treat `ast.Attribute`s as expressions
68 # because they are too widely used. That's a compromise.
69 ast.Assert,
70 ast.BoolOp,
71 ast.BinOp,
72 ast.Call,
73 ast.Compare,
74 ast.Subscript,
75 ast.UnaryOp,
76 ast.Lambda,
77
78 ast.DictComp,
79 ast.Dict,
80 ast.List,
81 ast.ListComp,
82 ast.Tuple,
83 ast.GeneratorExp,
84 ast.Set,
85 ast.SetComp,
86 )
87
88 _ignore_predicates: Tuple[Callable[[ast.AST], bool], ...] = (
89 overuses.is_decorator,
90 overuses.is_self,
91 overuses.is_annotation,
92 overuses.is_class_context,
93 overuses.is_super_call,
94 overuses.is_primitive,
95 )
96
97 _msg: ClassVar[str] = '{0}; used {1}'
98
99 def __init__(self, *args, **kwargs) -> None:
100 """We need to track expression usage in functions and modules."""
101 super().__init__(*args, **kwargs)
102 self._module_expressions: _Expressions = defaultdict(list)
103 self._function_expressions: _FunctionExpressions = defaultdict(
104 lambda: defaultdict(list),
105 )
106
107 def visit(self, node: ast.AST) -> None:
108 """
109 Visits all nodes in a module to find overused values.
110
111 Raises:
112 OverusedExpressionViolation
113
114 """
115 if isinstance(node, self._expressions):
116 self._add_expression(node)
117 self.generic_visit(node)
118
119 def _add_expression(self, node: ast.AST) -> None:
120 if any(ignore(node) for ignore in self._ignore_predicates):
121 return
122
123 source_code = source.node_to_string(node)
124 self._module_expressions[source_code].append(node)
125
126 maybe_function = walk.get_closest_parent(node, FunctionNodes)
127 if maybe_function is not None:
128 self._function_expressions[maybe_function][source_code].append(
129 node,
130 )
131
132 def _post_visit(self) -> None:
133 for mod_source, module_nodes in self._module_expressions.items():
134 if len(module_nodes) > self.options.max_module_expressions:
135 self.add_violation(
136 complexity.OverusedExpressionViolation(
137 module_nodes[0],
138 text=self._msg.format(mod_source, len(module_nodes)),
139 baseline=self.options.max_module_expressions,
140 ),
141 )
142
143 for function_contexts in self._function_expressions.values():
144 for src, function_nodes in function_contexts.items():
145 if len(function_nodes) > self.options.max_function_expressions:
146 self.add_violation(
147 complexity.OverusedExpressionViolation(
148 function_nodes[0],
149 text=self._msg.format(src, len(function_nodes)),
150 baseline=self.options.max_function_expressions,
151 ),
152 )
153
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wemake_python_styleguide/visitors/ast/complexity/overuses.py b/wemake_python_styleguide/visitors/ast/complexity/overuses.py
--- a/wemake_python_styleguide/visitors/ast/complexity/overuses.py
+++ b/wemake_python_styleguide/visitors/ast/complexity/overuses.py
@@ -22,7 +22,25 @@
'visit_Bytes',
))
class StringOveruseVisitor(base.BaseNodeVisitor):
- """Restricts several string usages."""
+ """
+ Restricts repeated usage of the same string constant.
+
+ NB: Some short strings are ignored, as their use is very common and
+ forcing assignment would not make much sense (i.e. newlines or "").
+ """
+
+ _ignored_string_constants = frozenset((
+ ' ',
+ '',
+ '\n',
+ '\r\n',
+ '\t',
+ b' ',
+ b'',
+ b'\n',
+ b'\r\n',
+ b'\t',
+ ))
def __init__(self, *args, **kwargs) -> None:
"""Inits the counter for constants."""
@@ -46,6 +64,11 @@
if overuses.is_annotation(node):
return
+ # Some strings are so common, that it makes no sense to check if
+ # they are overused.
+ if node.s in self._ignored_string_constants:
+ return
+
self._string_constants[node.s] += 1
def _post_visit(self) -> None:
|
{"golden_diff": "diff --git a/wemake_python_styleguide/visitors/ast/complexity/overuses.py b/wemake_python_styleguide/visitors/ast/complexity/overuses.py\n--- a/wemake_python_styleguide/visitors/ast/complexity/overuses.py\n+++ b/wemake_python_styleguide/visitors/ast/complexity/overuses.py\n@@ -22,7 +22,25 @@\n 'visit_Bytes',\n ))\n class StringOveruseVisitor(base.BaseNodeVisitor):\n- \"\"\"Restricts several string usages.\"\"\"\n+ \"\"\"\n+ Restricts repeated usage of the same string constant.\n+\n+ NB: Some short strings are ignored, as their use is very common and\n+ forcing assignment would not make much sense (i.e. newlines or \"\").\n+ \"\"\"\n+\n+ _ignored_string_constants = frozenset((\n+ ' ',\n+ '',\n+ '\\n',\n+ '\\r\\n',\n+ '\\t',\n+ b' ',\n+ b'',\n+ b'\\n',\n+ b'\\r\\n',\n+ b'\\t',\n+ ))\n \n def __init__(self, *args, **kwargs) -> None:\n \"\"\"Inits the counter for constants.\"\"\"\n@@ -46,6 +64,11 @@\n if overuses.is_annotation(node):\n return\n \n+ # Some strings are so common, that it makes no sense to check if\n+ # they are overused.\n+ if node.s in self._ignored_string_constants:\n+ return\n+\n self._string_constants[node.s] += 1\n \n def _post_visit(self) -> None:\n", "issue": "Add Exceptions for String Constant Overuse\n# Rule request\r\n\r\nI feel it would be good to be able to declare exceptions for WPS226\r\n\r\n## Thesis / Reasoning\r\n\r\nIn a file on a current project, I tend to use `\" \".join(iterable)` a lot.\r\nIt feels unnatural to declare a CONSTANT for that.\r\nAlso, I don't think it is good in this case to disable WPS226 for the entire file as there could be other common string constants.\r\n\r\nAlternative: Excluse `\" \"`, `\"\"`, \"`\\n\"` & friends from this by default.\n", "before_files": [{"content": "import ast\nfrom collections import defaultdict\nfrom typing import Callable, ClassVar, DefaultDict, List, Tuple\n\nfrom typing_extensions import final\n\nfrom wemake_python_styleguide.compat.aliases import FunctionNodes\nfrom wemake_python_styleguide.logic import source, walk\nfrom wemake_python_styleguide.logic.complexity import overuses\nfrom wemake_python_styleguide.types import AnyNodes, AnyText, AnyTextPrimitive\nfrom wemake_python_styleguide.violations import complexity\nfrom wemake_python_styleguide.visitors import base, decorators\n\n#: We use these types to store the number of nodes usage in different contexts.\n_Expressions = DefaultDict[str, List[ast.AST]]\n_FunctionExpressions = DefaultDict[ast.AST, _Expressions]\n\n\n@final\[email protected]('visit_any_string', (\n 'visit_Str',\n 'visit_Bytes',\n))\nclass StringOveruseVisitor(base.BaseNodeVisitor):\n \"\"\"Restricts several string usages.\"\"\"\n\n def __init__(self, *args, **kwargs) -> None:\n \"\"\"Inits the counter for constants.\"\"\"\n super().__init__(*args, **kwargs)\n self._string_constants: DefaultDict[\n AnyTextPrimitive, int,\n ] = defaultdict(int)\n\n def visit_any_string(self, node: AnyText) -> None:\n \"\"\"\n Restricts to over-use string constants.\n\n Raises:\n OverusedStringViolation\n\n \"\"\"\n self._check_string_constant(node)\n self.generic_visit(node)\n\n def _check_string_constant(self, node: AnyText) -> None:\n if overuses.is_annotation(node):\n return\n\n self._string_constants[node.s] += 1\n\n def _post_visit(self) -> None:\n for string, usage_count in self._string_constants.items():\n if usage_count > self.options.max_string_usages:\n self.add_violation(\n complexity.OverusedStringViolation(\n text=source.render_string(string) or \"''\",\n baseline=self.options.max_string_usages,\n ),\n )\n\n\n@final\nclass ExpressionOveruseVisitor(base.BaseNodeVisitor):\n \"\"\"Finds overused expressions.\"\"\"\n\n _expressions: ClassVar[AnyNodes] = (\n # We do not treat `ast.Attribute`s as expressions\n # because they are too widely used. That's a compromise.\n ast.Assert,\n ast.BoolOp,\n ast.BinOp,\n ast.Call,\n ast.Compare,\n ast.Subscript,\n ast.UnaryOp,\n ast.Lambda,\n\n ast.DictComp,\n ast.Dict,\n ast.List,\n ast.ListComp,\n ast.Tuple,\n ast.GeneratorExp,\n ast.Set,\n ast.SetComp,\n )\n\n _ignore_predicates: Tuple[Callable[[ast.AST], bool], ...] = (\n overuses.is_decorator,\n overuses.is_self,\n overuses.is_annotation,\n overuses.is_class_context,\n overuses.is_super_call,\n overuses.is_primitive,\n )\n\n _msg: ClassVar[str] = '{0}; used {1}'\n\n def __init__(self, *args, **kwargs) -> None:\n \"\"\"We need to track expression usage in functions and modules.\"\"\"\n super().__init__(*args, **kwargs)\n self._module_expressions: _Expressions = defaultdict(list)\n self._function_expressions: _FunctionExpressions = defaultdict(\n lambda: defaultdict(list),\n )\n\n def visit(self, node: ast.AST) -> None:\n \"\"\"\n Visits all nodes in a module to find overused values.\n\n Raises:\n OverusedExpressionViolation\n\n \"\"\"\n if isinstance(node, self._expressions):\n self._add_expression(node)\n self.generic_visit(node)\n\n def _add_expression(self, node: ast.AST) -> None:\n if any(ignore(node) for ignore in self._ignore_predicates):\n return\n\n source_code = source.node_to_string(node)\n self._module_expressions[source_code].append(node)\n\n maybe_function = walk.get_closest_parent(node, FunctionNodes)\n if maybe_function is not None:\n self._function_expressions[maybe_function][source_code].append(\n node,\n )\n\n def _post_visit(self) -> None:\n for mod_source, module_nodes in self._module_expressions.items():\n if len(module_nodes) > self.options.max_module_expressions:\n self.add_violation(\n complexity.OverusedExpressionViolation(\n module_nodes[0],\n text=self._msg.format(mod_source, len(module_nodes)),\n baseline=self.options.max_module_expressions,\n ),\n )\n\n for function_contexts in self._function_expressions.values():\n for src, function_nodes in function_contexts.items():\n if len(function_nodes) > self.options.max_function_expressions:\n self.add_violation(\n complexity.OverusedExpressionViolation(\n function_nodes[0],\n text=self._msg.format(src, len(function_nodes)),\n baseline=self.options.max_function_expressions,\n ),\n )\n", "path": "wemake_python_styleguide/visitors/ast/complexity/overuses.py"}], "after_files": [{"content": "import ast\nfrom collections import defaultdict\nfrom typing import Callable, ClassVar, DefaultDict, List, Tuple\n\nfrom typing_extensions import final\n\nfrom wemake_python_styleguide.compat.aliases import FunctionNodes\nfrom wemake_python_styleguide.logic import source, walk\nfrom wemake_python_styleguide.logic.complexity import overuses\nfrom wemake_python_styleguide.types import AnyNodes, AnyText, AnyTextPrimitive\nfrom wemake_python_styleguide.violations import complexity\nfrom wemake_python_styleguide.visitors import base, decorators\n\n#: We use these types to store the number of nodes usage in different contexts.\n_Expressions = DefaultDict[str, List[ast.AST]]\n_FunctionExpressions = DefaultDict[ast.AST, _Expressions]\n\n\n@final\[email protected]('visit_any_string', (\n 'visit_Str',\n 'visit_Bytes',\n))\nclass StringOveruseVisitor(base.BaseNodeVisitor):\n \"\"\"\n Restricts repeated usage of the same string constant.\n\n NB: Some short strings are ignored, as their use is very common and\n forcing assignment would not make much sense (i.e. newlines or \"\").\n \"\"\"\n\n _ignored_string_constants = frozenset((\n ' ',\n '',\n '\\n',\n '\\r\\n',\n '\\t',\n b' ',\n b'',\n b'\\n',\n b'\\r\\n',\n b'\\t',\n ))\n\n def __init__(self, *args, **kwargs) -> None:\n \"\"\"Inits the counter for constants.\"\"\"\n super().__init__(*args, **kwargs)\n self._string_constants: DefaultDict[\n AnyTextPrimitive, int,\n ] = defaultdict(int)\n\n def visit_any_string(self, node: AnyText) -> None:\n \"\"\"\n Restricts to over-use string constants.\n\n Raises:\n OverusedStringViolation\n\n \"\"\"\n self._check_string_constant(node)\n self.generic_visit(node)\n\n def _check_string_constant(self, node: AnyText) -> None:\n if overuses.is_annotation(node):\n return\n\n # Some strings are so common, that it makes no sense to check if\n # they are overused.\n if node.s in self._ignored_string_constants:\n return\n\n self._string_constants[node.s] += 1\n\n def _post_visit(self) -> None:\n for string, usage_count in self._string_constants.items():\n if usage_count > self.options.max_string_usages:\n self.add_violation(\n complexity.OverusedStringViolation(\n text=source.render_string(string) or \"''\",\n baseline=self.options.max_string_usages,\n ),\n )\n\n\n@final\nclass ExpressionOveruseVisitor(base.BaseNodeVisitor):\n \"\"\"Finds overused expressions.\"\"\"\n\n _expressions: ClassVar[AnyNodes] = (\n # We do not treat `ast.Attribute`s as expressions\n # because they are too widely used. That's a compromise.\n ast.Assert,\n ast.BoolOp,\n ast.BinOp,\n ast.Call,\n ast.Compare,\n ast.Subscript,\n ast.UnaryOp,\n ast.Lambda,\n\n ast.DictComp,\n ast.Dict,\n ast.List,\n ast.ListComp,\n ast.Tuple,\n ast.GeneratorExp,\n ast.Set,\n ast.SetComp,\n )\n\n _ignore_predicates: Tuple[Callable[[ast.AST], bool], ...] = (\n overuses.is_decorator,\n overuses.is_self,\n overuses.is_annotation,\n overuses.is_class_context,\n overuses.is_super_call,\n overuses.is_primitive,\n )\n\n _msg: ClassVar[str] = '{0}; used {1}'\n\n def __init__(self, *args, **kwargs) -> None:\n \"\"\"We need to track expression usage in functions and modules.\"\"\"\n super().__init__(*args, **kwargs)\n self._module_expressions: _Expressions = defaultdict(list)\n self._function_expressions: _FunctionExpressions = defaultdict(\n lambda: defaultdict(list),\n )\n\n def visit(self, node: ast.AST) -> None:\n \"\"\"\n Visits all nodes in a module to find overused values.\n\n Raises:\n OverusedExpressionViolation\n\n \"\"\"\n if isinstance(node, self._expressions):\n self._add_expression(node)\n self.generic_visit(node)\n\n def _add_expression(self, node: ast.AST) -> None:\n if any(ignore(node) for ignore in self._ignore_predicates):\n return\n\n source_code = source.node_to_string(node)\n self._module_expressions[source_code].append(node)\n\n maybe_function = walk.get_closest_parent(node, FunctionNodes)\n if maybe_function is not None:\n self._function_expressions[maybe_function][source_code].append(\n node,\n )\n\n def _post_visit(self) -> None:\n for mod_source, module_nodes in self._module_expressions.items():\n if len(module_nodes) > self.options.max_module_expressions:\n self.add_violation(\n complexity.OverusedExpressionViolation(\n module_nodes[0],\n text=self._msg.format(mod_source, len(module_nodes)),\n baseline=self.options.max_module_expressions,\n ),\n )\n\n for function_contexts in self._function_expressions.values():\n for src, function_nodes in function_contexts.items():\n if len(function_nodes) > self.options.max_function_expressions:\n self.add_violation(\n complexity.OverusedExpressionViolation(\n function_nodes[0],\n text=self._msg.format(src, len(function_nodes)),\n baseline=self.options.max_function_expressions,\n ),\n )\n", "path": "wemake_python_styleguide/visitors/ast/complexity/overuses.py"}]}
| 1,818 | 361 |
gh_patches_debug_9022
|
rasdani/github-patches
|
git_diff
|
python-trio__trio-1423
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Potential memory leak on windows
I was recently running some scripts overnight that failed due to a MemoryError, but was unable to find anything obvious that would be leaking memory in my scripts.
During my investigation process, I have found that the following script increases memory usage by ~1 MB/s while running. If the `await trio.sleep(0)` is replaced by `pass` the process runs at a constant 9.7 MB of memory usage.
```python
import trio
async def main():
while True:
await trio.sleep(0)
if __name__ == '__main__':
trio.run(main)
```
## Version Info
Python 3.8.1
Trio 0.13.0
Windows 10
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 from setuptools import setup, find_packages
2
3 exec(open("trio/_version.py", encoding="utf-8").read())
4
5 LONG_DESC = """\
6 .. image:: https://cdn.rawgit.com/python-trio/trio/9b0bec646a31e0d0f67b8b6ecc6939726faf3e17/logo/logo-with-background.svg
7 :width: 200px
8 :align: right
9
10 The Trio project's goal is to produce a production-quality, `permissively
11 licensed <https://github.com/python-trio/trio/blob/master/LICENSE>`__,
12 async/await-native I/O library for Python. Like all async libraries,
13 its main purpose is to help you write programs that do **multiple
14 things at the same time** with **parallelized I/O**. A web spider that
15 wants to fetch lots of pages in parallel, a web server that needs to
16 juggle lots of downloads and websocket connections at the same time, a
17 process supervisor monitoring multiple subprocesses... that sort of
18 thing. Compared to other libraries, Trio attempts to distinguish
19 itself with an obsessive focus on **usability** and
20 **correctness**. Concurrency is complicated; we try to make it *easy*
21 to get things *right*.
22
23 Trio was built from the ground up to take advantage of the `latest
24 Python features <https://www.python.org/dev/peps/pep-0492/>`__, and
25 draws inspiration from `many sources
26 <https://github.com/python-trio/trio/wiki/Reading-list>`__, in
27 particular Dave Beazley's `Curio <https://curio.readthedocs.io/>`__.
28 The resulting design is radically simpler than older competitors like
29 `asyncio <https://docs.python.org/3/library/asyncio.html>`__ and
30 `Twisted <https://twistedmatrix.com/>`__, yet just as capable. Trio is
31 the Python I/O library I always wanted; I find it makes building
32 I/O-oriented programs easier, less error-prone, and just plain more
33 fun. `Perhaps you'll find the same
34 <https://github.com/python-trio/trio/wiki/Testimonials>`__.
35
36 This project is young and still somewhat experimental: the overall
37 design is solid and the existing features are fully tested and
38 documented, but you may encounter missing functionality or rough
39 edges. We *do* encourage you do use it, but you should `read and
40 subscribe to issue #1
41 <https://github.com/python-trio/trio/issues/1>`__ to get warning and a
42 chance to give feedback about any compatibility-breaking changes.
43
44 Vital statistics:
45
46 * Supported environments: Linux, macOS, or Windows running some kind of Python
47 3.5-or-better (either CPython or PyPy3 is fine). \\*BSD and illumos likely
48 work too, but are not tested.
49
50 * Install: ``python3 -m pip install -U trio`` (or on Windows, maybe
51 ``py -3 -m pip install -U trio``). No compiler needed.
52
53 * Tutorial and reference manual: https://trio.readthedocs.io
54
55 * Bug tracker and source code: https://github.com/python-trio/trio
56
57 * Real-time chat: https://gitter.im/python-trio/general
58
59 * Discussion forum: https://trio.discourse.group
60
61 * License: MIT or Apache 2, your choice
62
63 * Contributor guide: https://trio.readthedocs.io/en/latest/contributing.html
64
65 * Code of conduct: Contributors are requested to follow our `code of
66 conduct
67 <https://trio.readthedocs.io/en/latest/code-of-conduct.html>`_
68 in all project spaces.
69 """
70
71 setup(
72 name="trio",
73 version=__version__,
74 description="A friendly Python library for async concurrency and I/O",
75 long_description=LONG_DESC,
76 author="Nathaniel J. Smith",
77 author_email="[email protected]",
78 url="https://github.com/python-trio/trio",
79 license="MIT -or- Apache License 2.0",
80 packages=find_packages(),
81 install_requires=[
82 "attrs >= 19.2.0", # for eq
83 "sortedcontainers",
84 "async_generator >= 1.9",
85 "idna",
86 "outcome",
87 "sniffio",
88 # cffi 1.12 adds from_buffer(require_writable=True) and ffi.release()
89 "cffi>=1.12; os_name == 'nt'", # "cffi is required on windows"
90 "contextvars>=2.1; python_version < '3.7'"
91 ],
92 # This means, just install *everything* you see under trio/, even if it
93 # doesn't look like a source file, so long as it appears in MANIFEST.in:
94 include_package_data=True,
95 python_requires=">=3.5",
96 keywords=["async", "io", "networking", "trio"],
97 classifiers=[
98 "Development Status :: 3 - Alpha",
99 "Intended Audience :: Developers",
100 "License :: OSI Approved :: MIT License",
101 "License :: OSI Approved :: Apache Software License",
102 "Operating System :: POSIX :: Linux",
103 "Operating System :: MacOS :: MacOS X",
104 "Operating System :: POSIX :: BSD",
105 "Operating System :: Microsoft :: Windows",
106 "Programming Language :: Python :: Implementation :: CPython",
107 "Programming Language :: Python :: Implementation :: PyPy",
108 "Programming Language :: Python :: 3 :: Only",
109 "Programming Language :: Python :: 3.5",
110 "Programming Language :: Python :: 3.6",
111 "Topic :: System :: Networking",
112 "Framework :: Trio",
113 ],
114 )
115
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -86,7 +86,8 @@
"outcome",
"sniffio",
# cffi 1.12 adds from_buffer(require_writable=True) and ffi.release()
- "cffi>=1.12; os_name == 'nt'", # "cffi is required on windows"
+ # cffi 1.14 fixes memory leak inside ffi.getwinerror()
+ "cffi>=1.14; os_name == 'nt'", # "cffi is required on windows"
"contextvars>=2.1; python_version < '3.7'"
],
# This means, just install *everything* you see under trio/, even if it
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -86,7 +86,8 @@\n \"outcome\",\n \"sniffio\",\n # cffi 1.12 adds from_buffer(require_writable=True) and ffi.release()\n- \"cffi>=1.12; os_name == 'nt'\", # \"cffi is required on windows\"\n+ # cffi 1.14 fixes memory leak inside ffi.getwinerror()\n+ \"cffi>=1.14; os_name == 'nt'\", # \"cffi is required on windows\"\n \"contextvars>=2.1; python_version < '3.7'\"\n ],\n # This means, just install *everything* you see under trio/, even if it\n", "issue": "Potential memory leak on windows\nI was recently running some scripts overnight that failed due to a MemoryError, but was unable to find anything obvious that would be leaking memory in my scripts.\r\n\r\nDuring my investigation process, I have found that the following script increases memory usage by ~1 MB/s while running. If the `await trio.sleep(0)` is replaced by `pass` the process runs at a constant 9.7 MB of memory usage.\r\n\r\n```python\r\nimport trio\r\n\r\nasync def main():\r\n while True:\r\n await trio.sleep(0)\r\n\r\nif __name__ == '__main__':\r\n trio.run(main)\r\n```\r\n\r\n## Version Info\r\n\r\nPython 3.8.1\r\nTrio 0.13.0\r\nWindows 10\r\n\n", "before_files": [{"content": "from setuptools import setup, find_packages\n\nexec(open(\"trio/_version.py\", encoding=\"utf-8\").read())\n\nLONG_DESC = \"\"\"\\\n.. image:: https://cdn.rawgit.com/python-trio/trio/9b0bec646a31e0d0f67b8b6ecc6939726faf3e17/logo/logo-with-background.svg\n :width: 200px\n :align: right\n\nThe Trio project's goal is to produce a production-quality, `permissively\nlicensed <https://github.com/python-trio/trio/blob/master/LICENSE>`__,\nasync/await-native I/O library for Python. Like all async libraries,\nits main purpose is to help you write programs that do **multiple\nthings at the same time** with **parallelized I/O**. A web spider that\nwants to fetch lots of pages in parallel, a web server that needs to\njuggle lots of downloads and websocket connections at the same time, a\nprocess supervisor monitoring multiple subprocesses... that sort of\nthing. Compared to other libraries, Trio attempts to distinguish\nitself with an obsessive focus on **usability** and\n**correctness**. Concurrency is complicated; we try to make it *easy*\nto get things *right*.\n\nTrio was built from the ground up to take advantage of the `latest\nPython features <https://www.python.org/dev/peps/pep-0492/>`__, and\ndraws inspiration from `many sources\n<https://github.com/python-trio/trio/wiki/Reading-list>`__, in\nparticular Dave Beazley's `Curio <https://curio.readthedocs.io/>`__.\nThe resulting design is radically simpler than older competitors like\n`asyncio <https://docs.python.org/3/library/asyncio.html>`__ and\n`Twisted <https://twistedmatrix.com/>`__, yet just as capable. Trio is\nthe Python I/O library I always wanted; I find it makes building\nI/O-oriented programs easier, less error-prone, and just plain more\nfun. `Perhaps you'll find the same\n<https://github.com/python-trio/trio/wiki/Testimonials>`__.\n\nThis project is young and still somewhat experimental: the overall\ndesign is solid and the existing features are fully tested and\ndocumented, but you may encounter missing functionality or rough\nedges. We *do* encourage you do use it, but you should `read and\nsubscribe to issue #1\n<https://github.com/python-trio/trio/issues/1>`__ to get warning and a\nchance to give feedback about any compatibility-breaking changes.\n\nVital statistics:\n\n* Supported environments: Linux, macOS, or Windows running some kind of Python\n 3.5-or-better (either CPython or PyPy3 is fine). \\\\*BSD and illumos likely\n work too, but are not tested.\n\n* Install: ``python3 -m pip install -U trio`` (or on Windows, maybe\n ``py -3 -m pip install -U trio``). No compiler needed.\n\n* Tutorial and reference manual: https://trio.readthedocs.io\n\n* Bug tracker and source code: https://github.com/python-trio/trio\n\n* Real-time chat: https://gitter.im/python-trio/general\n\n* Discussion forum: https://trio.discourse.group\n\n* License: MIT or Apache 2, your choice\n\n* Contributor guide: https://trio.readthedocs.io/en/latest/contributing.html\n\n* Code of conduct: Contributors are requested to follow our `code of\n conduct\n <https://trio.readthedocs.io/en/latest/code-of-conduct.html>`_\n in all project spaces.\n\"\"\"\n\nsetup(\n name=\"trio\",\n version=__version__,\n description=\"A friendly Python library for async concurrency and I/O\",\n long_description=LONG_DESC,\n author=\"Nathaniel J. Smith\",\n author_email=\"[email protected]\",\n url=\"https://github.com/python-trio/trio\",\n license=\"MIT -or- Apache License 2.0\",\n packages=find_packages(),\n install_requires=[\n \"attrs >= 19.2.0\", # for eq\n \"sortedcontainers\",\n \"async_generator >= 1.9\",\n \"idna\",\n \"outcome\",\n \"sniffio\",\n # cffi 1.12 adds from_buffer(require_writable=True) and ffi.release()\n \"cffi>=1.12; os_name == 'nt'\", # \"cffi is required on windows\"\n \"contextvars>=2.1; python_version < '3.7'\"\n ],\n # This means, just install *everything* you see under trio/, even if it\n # doesn't look like a source file, so long as it appears in MANIFEST.in:\n include_package_data=True,\n python_requires=\">=3.5\",\n keywords=[\"async\", \"io\", \"networking\", \"trio\"],\n classifiers=[\n \"Development Status :: 3 - Alpha\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: POSIX :: Linux\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX :: BSD\",\n \"Operating System :: Microsoft :: Windows\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Topic :: System :: Networking\",\n \"Framework :: Trio\",\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "from setuptools import setup, find_packages\n\nexec(open(\"trio/_version.py\", encoding=\"utf-8\").read())\n\nLONG_DESC = \"\"\"\\\n.. image:: https://cdn.rawgit.com/python-trio/trio/9b0bec646a31e0d0f67b8b6ecc6939726faf3e17/logo/logo-with-background.svg\n :width: 200px\n :align: right\n\nThe Trio project's goal is to produce a production-quality, `permissively\nlicensed <https://github.com/python-trio/trio/blob/master/LICENSE>`__,\nasync/await-native I/O library for Python. Like all async libraries,\nits main purpose is to help you write programs that do **multiple\nthings at the same time** with **parallelized I/O**. A web spider that\nwants to fetch lots of pages in parallel, a web server that needs to\njuggle lots of downloads and websocket connections at the same time, a\nprocess supervisor monitoring multiple subprocesses... that sort of\nthing. Compared to other libraries, Trio attempts to distinguish\nitself with an obsessive focus on **usability** and\n**correctness**. Concurrency is complicated; we try to make it *easy*\nto get things *right*.\n\nTrio was built from the ground up to take advantage of the `latest\nPython features <https://www.python.org/dev/peps/pep-0492/>`__, and\ndraws inspiration from `many sources\n<https://github.com/python-trio/trio/wiki/Reading-list>`__, in\nparticular Dave Beazley's `Curio <https://curio.readthedocs.io/>`__.\nThe resulting design is radically simpler than older competitors like\n`asyncio <https://docs.python.org/3/library/asyncio.html>`__ and\n`Twisted <https://twistedmatrix.com/>`__, yet just as capable. Trio is\nthe Python I/O library I always wanted; I find it makes building\nI/O-oriented programs easier, less error-prone, and just plain more\nfun. `Perhaps you'll find the same\n<https://github.com/python-trio/trio/wiki/Testimonials>`__.\n\nThis project is young and still somewhat experimental: the overall\ndesign is solid and the existing features are fully tested and\ndocumented, but you may encounter missing functionality or rough\nedges. We *do* encourage you do use it, but you should `read and\nsubscribe to issue #1\n<https://github.com/python-trio/trio/issues/1>`__ to get warning and a\nchance to give feedback about any compatibility-breaking changes.\n\nVital statistics:\n\n* Supported environments: Linux, macOS, or Windows running some kind of Python\n 3.5-or-better (either CPython or PyPy3 is fine). \\\\*BSD and illumos likely\n work too, but are not tested.\n\n* Install: ``python3 -m pip install -U trio`` (or on Windows, maybe\n ``py -3 -m pip install -U trio``). No compiler needed.\n\n* Tutorial and reference manual: https://trio.readthedocs.io\n\n* Bug tracker and source code: https://github.com/python-trio/trio\n\n* Real-time chat: https://gitter.im/python-trio/general\n\n* Discussion forum: https://trio.discourse.group\n\n* License: MIT or Apache 2, your choice\n\n* Contributor guide: https://trio.readthedocs.io/en/latest/contributing.html\n\n* Code of conduct: Contributors are requested to follow our `code of\n conduct\n <https://trio.readthedocs.io/en/latest/code-of-conduct.html>`_\n in all project spaces.\n\"\"\"\n\nsetup(\n name=\"trio\",\n version=__version__,\n description=\"A friendly Python library for async concurrency and I/O\",\n long_description=LONG_DESC,\n author=\"Nathaniel J. Smith\",\n author_email=\"[email protected]\",\n url=\"https://github.com/python-trio/trio\",\n license=\"MIT -or- Apache License 2.0\",\n packages=find_packages(),\n install_requires=[\n \"attrs >= 19.2.0\", # for eq\n \"sortedcontainers\",\n \"async_generator >= 1.9\",\n \"idna\",\n \"outcome\",\n \"sniffio\",\n # cffi 1.12 adds from_buffer(require_writable=True) and ffi.release()\n # cffi 1.14 fixes memory leak inside ffi.getwinerror()\n \"cffi>=1.14; os_name == 'nt'\", # \"cffi is required on windows\"\n \"contextvars>=2.1; python_version < '3.7'\"\n ],\n # This means, just install *everything* you see under trio/, even if it\n # doesn't look like a source file, so long as it appears in MANIFEST.in:\n include_package_data=True,\n python_requires=\">=3.5\",\n keywords=[\"async\", \"io\", \"networking\", \"trio\"],\n classifiers=[\n \"Development Status :: 3 - Alpha\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: POSIX :: Linux\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX :: BSD\",\n \"Operating System :: Microsoft :: Windows\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Topic :: System :: Networking\",\n \"Framework :: Trio\",\n ],\n)\n", "path": "setup.py"}]}
| 1,881 | 174 |
gh_patches_debug_4088
|
rasdani/github-patches
|
git_diff
|
plotly__plotly.py-2015
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Error when using two image scrappers together
### Introduction to the problem
I am trying to move the current Jupyter Notebook examples of the [poliastro project](https://github.com/poliastro/poliastro) to an [Sphinx-Gallery](https://github.com/sphinx-gallery/sphinx-gallery) set. Since we are making use of **plotly figures** we need to **capture them** as output figures and therefore, make use of the **plotly image scrapper**. We also need to capture `matplotlib` figures, so this image scrapper must be also added to the `conf.py` file.
#### How to reproduce this issue :beetle:
If you download the [official example repository](https://github.com/plotly/plotly-sphinx-gallery) from @emmanuelle for achieving this task and you add the following [simple Python file](https://gist.github.com/jorgepiloto/db807a7ee3a0bcfbaea38fc9cd7ac95e) in the `examples/` directory for plotting a sinusoidal wave with `matplotlib` and error is raised:
```bash
generating gallery...
generating gallery for auto_examples... [ 25%] plot_sin.py
Exception occurred:
File "/home/lobo/anaconda3/envs/poliastro/lib/python3.7/site-packages/plotly/io/_sg_scraper.py", line 91, in figure_rst
figure_name = figure_paths[0]
IndexError: list index out of range
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `packages/python/plotly/plotly/io/_sg_scraper.py`
Content:
```
1 # This module defines an image scraper for sphinx-gallery
2 # https://sphinx-gallery.github.io/
3 # which can be used by projects using plotly in their documentation.
4 import inspect, os
5
6 import plotly
7 from glob import glob
8 import shutil
9
10 plotly.io.renderers.default = "sphinx_gallery"
11
12
13 def plotly_sg_scraper(block, block_vars, gallery_conf, **kwargs):
14 """Scrape Plotly figures for galleries of examples using
15 sphinx-gallery.
16
17 Examples should use ``plotly.io.show()`` to display the figure with
18 the custom sphinx_gallery renderer.
19
20 Since the sphinx_gallery renderer generates both html and static png
21 files, we simply crawl these files and give them the appropriate path.
22
23 Parameters
24 ----------
25 block : tuple
26 A tuple containing the (label, content, line_number) of the block.
27 block_vars : dict
28 Dict of block variables.
29 gallery_conf : dict
30 Contains the configuration of Sphinx-Gallery
31 **kwargs : dict
32 Additional keyword arguments to pass to
33 :meth:`~matplotlib.figure.Figure.savefig`, e.g. ``format='svg'``.
34 The ``format`` kwarg in particular is used to set the file extension
35 of the output file (currently only 'png' and 'svg' are supported).
36
37 Returns
38 -------
39 rst : str
40 The ReSTructuredText that will be rendered to HTML containing
41 the images.
42
43 Notes
44 -----
45 Add this function to the image scrapers
46 """
47 examples_dirs = gallery_conf["examples_dirs"]
48 if isinstance(examples_dirs, (list, tuple)):
49 examples_dirs = examples_dirs[0]
50 pngs = sorted(glob(os.path.join(examples_dirs, "*.png")))
51 htmls = sorted(glob(os.path.join(examples_dirs, "*.html")))
52 image_path_iterator = block_vars["image_path_iterator"]
53 image_names = list()
54 seen = set()
55 for html, png in zip(htmls, pngs):
56 if png not in seen:
57 seen |= set(png)
58 this_image_path_png = next(image_path_iterator)
59 this_image_path_html = os.path.splitext(this_image_path_png)[0] + ".html"
60 image_names.append(this_image_path_html)
61 shutil.move(png, this_image_path_png)
62 shutil.move(html, this_image_path_html)
63 # Use the `figure_rst` helper function to generate rST for image files
64 return figure_rst(image_names, gallery_conf["src_dir"])
65
66
67 def figure_rst(figure_list, sources_dir):
68 """Generate RST for a list of PNG filenames.
69
70 Depending on whether we have one or more figures, we use a
71 single rst call to 'image' or a horizontal list.
72
73 Parameters
74 ----------
75 figure_list : list
76 List of strings of the figures' absolute paths.
77 sources_dir : str
78 absolute path of Sphinx documentation sources
79
80 Returns
81 -------
82 images_rst : str
83 rst code to embed the images in the document
84 """
85
86 figure_paths = [
87 os.path.relpath(figure_path, sources_dir).replace(os.sep, "/").lstrip("/")
88 for figure_path in figure_list
89 ]
90 images_rst = ""
91 figure_name = figure_paths[0]
92 ext = os.path.splitext(figure_name)[1]
93 figure_path = os.path.join("images", os.path.basename(figure_name))
94 images_rst = SINGLE_HTML % figure_path
95 return images_rst
96
97
98 SINGLE_HTML = """
99 .. raw:: html
100 :file: %s
101 """
102
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/packages/python/plotly/plotly/io/_sg_scraper.py b/packages/python/plotly/plotly/io/_sg_scraper.py
--- a/packages/python/plotly/plotly/io/_sg_scraper.py
+++ b/packages/python/plotly/plotly/io/_sg_scraper.py
@@ -88,6 +88,8 @@
for figure_path in figure_list
]
images_rst = ""
+ if not figure_paths:
+ return images_rst
figure_name = figure_paths[0]
ext = os.path.splitext(figure_name)[1]
figure_path = os.path.join("images", os.path.basename(figure_name))
|
{"golden_diff": "diff --git a/packages/python/plotly/plotly/io/_sg_scraper.py b/packages/python/plotly/plotly/io/_sg_scraper.py\n--- a/packages/python/plotly/plotly/io/_sg_scraper.py\n+++ b/packages/python/plotly/plotly/io/_sg_scraper.py\n@@ -88,6 +88,8 @@\n for figure_path in figure_list\n ]\n images_rst = \"\"\n+ if not figure_paths:\n+ return images_rst\n figure_name = figure_paths[0]\n ext = os.path.splitext(figure_name)[1]\n figure_path = os.path.join(\"images\", os.path.basename(figure_name))\n", "issue": "Error when using two image scrappers together\n### Introduction to the problem \r\nI am trying to move the current Jupyter Notebook examples of the [poliastro project](https://github.com/poliastro/poliastro) to an [Sphinx-Gallery](https://github.com/sphinx-gallery/sphinx-gallery) set. Since we are making use of **plotly figures** we need to **capture them** as output figures and therefore, make use of the **plotly image scrapper**. We also need to capture `matplotlib` figures, so this image scrapper must be also added to the `conf.py` file.\r\n\r\n#### How to reproduce this issue :beetle: \r\n\r\nIf you download the [official example repository](https://github.com/plotly/plotly-sphinx-gallery) from @emmanuelle for achieving this task and you add the following [simple Python file](https://gist.github.com/jorgepiloto/db807a7ee3a0bcfbaea38fc9cd7ac95e) in the `examples/` directory for plotting a sinusoidal wave with `matplotlib` and error is raised:\r\n\r\n```bash\r\ngenerating gallery...\r\ngenerating gallery for auto_examples... [ 25%] plot_sin.py \r\nException occurred:\r\n File \"/home/lobo/anaconda3/envs/poliastro/lib/python3.7/site-packages/plotly/io/_sg_scraper.py\", line 91, in figure_rst\r\n figure_name = figure_paths[0]\r\nIndexError: list index out of range\r\n```\n", "before_files": [{"content": "# This module defines an image scraper for sphinx-gallery\n# https://sphinx-gallery.github.io/\n# which can be used by projects using plotly in their documentation.\nimport inspect, os\n\nimport plotly\nfrom glob import glob\nimport shutil\n\nplotly.io.renderers.default = \"sphinx_gallery\"\n\n\ndef plotly_sg_scraper(block, block_vars, gallery_conf, **kwargs):\n \"\"\"Scrape Plotly figures for galleries of examples using\n sphinx-gallery.\n\n Examples should use ``plotly.io.show()`` to display the figure with\n the custom sphinx_gallery renderer.\n\n Since the sphinx_gallery renderer generates both html and static png\n files, we simply crawl these files and give them the appropriate path.\n\n Parameters\n ----------\n block : tuple\n A tuple containing the (label, content, line_number) of the block.\n block_vars : dict\n Dict of block variables.\n gallery_conf : dict\n Contains the configuration of Sphinx-Gallery\n **kwargs : dict\n Additional keyword arguments to pass to\n :meth:`~matplotlib.figure.Figure.savefig`, e.g. ``format='svg'``.\n The ``format`` kwarg in particular is used to set the file extension\n of the output file (currently only 'png' and 'svg' are supported).\n\n Returns\n -------\n rst : str\n The ReSTructuredText that will be rendered to HTML containing\n the images.\n\n Notes\n -----\n Add this function to the image scrapers \n \"\"\"\n examples_dirs = gallery_conf[\"examples_dirs\"]\n if isinstance(examples_dirs, (list, tuple)):\n examples_dirs = examples_dirs[0]\n pngs = sorted(glob(os.path.join(examples_dirs, \"*.png\")))\n htmls = sorted(glob(os.path.join(examples_dirs, \"*.html\")))\n image_path_iterator = block_vars[\"image_path_iterator\"]\n image_names = list()\n seen = set()\n for html, png in zip(htmls, pngs):\n if png not in seen:\n seen |= set(png)\n this_image_path_png = next(image_path_iterator)\n this_image_path_html = os.path.splitext(this_image_path_png)[0] + \".html\"\n image_names.append(this_image_path_html)\n shutil.move(png, this_image_path_png)\n shutil.move(html, this_image_path_html)\n # Use the `figure_rst` helper function to generate rST for image files\n return figure_rst(image_names, gallery_conf[\"src_dir\"])\n\n\ndef figure_rst(figure_list, sources_dir):\n \"\"\"Generate RST for a list of PNG filenames.\n\n Depending on whether we have one or more figures, we use a\n single rst call to 'image' or a horizontal list.\n\n Parameters\n ----------\n figure_list : list\n List of strings of the figures' absolute paths.\n sources_dir : str\n absolute path of Sphinx documentation sources\n\n Returns\n -------\n images_rst : str\n rst code to embed the images in the document\n \"\"\"\n\n figure_paths = [\n os.path.relpath(figure_path, sources_dir).replace(os.sep, \"/\").lstrip(\"/\")\n for figure_path in figure_list\n ]\n images_rst = \"\"\n figure_name = figure_paths[0]\n ext = os.path.splitext(figure_name)[1]\n figure_path = os.path.join(\"images\", os.path.basename(figure_name))\n images_rst = SINGLE_HTML % figure_path\n return images_rst\n\n\nSINGLE_HTML = \"\"\"\n.. raw:: html\n :file: %s\n\"\"\"\n", "path": "packages/python/plotly/plotly/io/_sg_scraper.py"}], "after_files": [{"content": "# This module defines an image scraper for sphinx-gallery\n# https://sphinx-gallery.github.io/\n# which can be used by projects using plotly in their documentation.\nimport inspect, os\n\nimport plotly\nfrom glob import glob\nimport shutil\n\nplotly.io.renderers.default = \"sphinx_gallery\"\n\n\ndef plotly_sg_scraper(block, block_vars, gallery_conf, **kwargs):\n \"\"\"Scrape Plotly figures for galleries of examples using\n sphinx-gallery.\n\n Examples should use ``plotly.io.show()`` to display the figure with\n the custom sphinx_gallery renderer.\n\n Since the sphinx_gallery renderer generates both html and static png\n files, we simply crawl these files and give them the appropriate path.\n\n Parameters\n ----------\n block : tuple\n A tuple containing the (label, content, line_number) of the block.\n block_vars : dict\n Dict of block variables.\n gallery_conf : dict\n Contains the configuration of Sphinx-Gallery\n **kwargs : dict\n Additional keyword arguments to pass to\n :meth:`~matplotlib.figure.Figure.savefig`, e.g. ``format='svg'``.\n The ``format`` kwarg in particular is used to set the file extension\n of the output file (currently only 'png' and 'svg' are supported).\n\n Returns\n -------\n rst : str\n The ReSTructuredText that will be rendered to HTML containing\n the images.\n\n Notes\n -----\n Add this function to the image scrapers \n \"\"\"\n examples_dirs = gallery_conf[\"examples_dirs\"]\n if isinstance(examples_dirs, (list, tuple)):\n examples_dirs = examples_dirs[0]\n pngs = sorted(glob(os.path.join(examples_dirs, \"*.png\")))\n htmls = sorted(glob(os.path.join(examples_dirs, \"*.html\")))\n image_path_iterator = block_vars[\"image_path_iterator\"]\n image_names = list()\n seen = set()\n for html, png in zip(htmls, pngs):\n if png not in seen:\n seen |= set(png)\n this_image_path_png = next(image_path_iterator)\n this_image_path_html = os.path.splitext(this_image_path_png)[0] + \".html\"\n image_names.append(this_image_path_html)\n shutil.move(png, this_image_path_png)\n shutil.move(html, this_image_path_html)\n # Use the `figure_rst` helper function to generate rST for image files\n return figure_rst(image_names, gallery_conf[\"src_dir\"])\n\n\ndef figure_rst(figure_list, sources_dir):\n \"\"\"Generate RST for a list of PNG filenames.\n\n Depending on whether we have one or more figures, we use a\n single rst call to 'image' or a horizontal list.\n\n Parameters\n ----------\n figure_list : list\n List of strings of the figures' absolute paths.\n sources_dir : str\n absolute path of Sphinx documentation sources\n\n Returns\n -------\n images_rst : str\n rst code to embed the images in the document\n \"\"\"\n\n figure_paths = [\n os.path.relpath(figure_path, sources_dir).replace(os.sep, \"/\").lstrip(\"/\")\n for figure_path in figure_list\n ]\n images_rst = \"\"\n if not figure_paths:\n return images_rst\n figure_name = figure_paths[0]\n ext = os.path.splitext(figure_name)[1]\n figure_path = os.path.join(\"images\", os.path.basename(figure_name))\n images_rst = SINGLE_HTML % figure_path\n return images_rst\n\n\nSINGLE_HTML = \"\"\"\n.. raw:: html\n :file: %s\n\"\"\"\n", "path": "packages/python/plotly/plotly/io/_sg_scraper.py"}]}
| 1,572 | 148 |
gh_patches_debug_4537
|
rasdani/github-patches
|
git_diff
|
pandas-dev__pandas-21362
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DOC: error in 0.23.0 concat sort warning?
#### Problem description
Pandas 0.23.0 adds a new warning when calling `concat` with misaligned axes (#20613):
```
FutureWarning: Sorting because non-concatenation axis is not aligned. A future version
of pandas will change to not sort by default.
To accept the future behavior, pass 'sort=True'.
To retain the current behavior and silence the warning, pass sort=False
```
This seems strange; I'd assume that `sort=True` would give the current behaviour, and `sort=False` the future behaviour, as in the docs for `concat`:
```
Explicitly pass sort=True to silence the warning and sort. Explicitly pass
sort=False to silence the warning and not sort.
```
I'm assuming the docs are right and the warning is wrong?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pandas/core/indexes/api.py`
Content:
```
1 import textwrap
2 import warnings
3
4 from pandas.core.indexes.base import (Index,
5 _new_Index,
6 _ensure_index,
7 _ensure_index_from_sequences,
8 InvalidIndexError) # noqa
9 from pandas.core.indexes.category import CategoricalIndex # noqa
10 from pandas.core.indexes.multi import MultiIndex # noqa
11 from pandas.core.indexes.interval import IntervalIndex # noqa
12 from pandas.core.indexes.numeric import (NumericIndex, Float64Index, # noqa
13 Int64Index, UInt64Index)
14 from pandas.core.indexes.range import RangeIndex # noqa
15 from pandas.core.indexes.timedeltas import TimedeltaIndex
16 from pandas.core.indexes.period import PeriodIndex
17 from pandas.core.indexes.datetimes import DatetimeIndex
18
19 import pandas.core.common as com
20 from pandas._libs import lib
21 from pandas._libs.tslib import NaT
22
23 _sort_msg = textwrap.dedent("""\
24 Sorting because non-concatenation axis is not aligned. A future version
25 of pandas will change to not sort by default.
26
27 To accept the future behavior, pass 'sort=True'.
28
29 To retain the current behavior and silence the warning, pass sort=False
30 """)
31
32
33 # TODO: there are many places that rely on these private methods existing in
34 # pandas.core.index
35 __all__ = ['Index', 'MultiIndex', 'NumericIndex', 'Float64Index', 'Int64Index',
36 'CategoricalIndex', 'IntervalIndex', 'RangeIndex', 'UInt64Index',
37 'InvalidIndexError', 'TimedeltaIndex',
38 'PeriodIndex', 'DatetimeIndex',
39 '_new_Index', 'NaT',
40 '_ensure_index', '_ensure_index_from_sequences',
41 '_get_combined_index',
42 '_get_objs_combined_axis', '_union_indexes',
43 '_get_consensus_names',
44 '_all_indexes_same']
45
46
47 def _get_objs_combined_axis(objs, intersect=False, axis=0, sort=True):
48 # Extract combined index: return intersection or union (depending on the
49 # value of "intersect") of indexes on given axis, or None if all objects
50 # lack indexes (e.g. they are numpy arrays)
51 obs_idxes = [obj._get_axis(axis) for obj in objs
52 if hasattr(obj, '_get_axis')]
53 if obs_idxes:
54 return _get_combined_index(obs_idxes, intersect=intersect, sort=sort)
55
56
57 def _get_combined_index(indexes, intersect=False, sort=False):
58 # TODO: handle index names!
59 indexes = com._get_distinct_objs(indexes)
60 if len(indexes) == 0:
61 index = Index([])
62 elif len(indexes) == 1:
63 index = indexes[0]
64 elif intersect:
65 index = indexes[0]
66 for other in indexes[1:]:
67 index = index.intersection(other)
68 else:
69 index = _union_indexes(indexes, sort=sort)
70 index = _ensure_index(index)
71
72 if sort:
73 try:
74 index = index.sort_values()
75 except TypeError:
76 pass
77 return index
78
79
80 def _union_indexes(indexes, sort=True):
81 if len(indexes) == 0:
82 raise AssertionError('Must have at least 1 Index to union')
83 if len(indexes) == 1:
84 result = indexes[0]
85 if isinstance(result, list):
86 result = Index(sorted(result))
87 return result
88
89 indexes, kind = _sanitize_and_check(indexes)
90
91 def _unique_indices(inds):
92 def conv(i):
93 if isinstance(i, Index):
94 i = i.tolist()
95 return i
96
97 return Index(
98 lib.fast_unique_multiple_list([conv(i) for i in inds], sort=sort))
99
100 if kind == 'special':
101 result = indexes[0]
102
103 if hasattr(result, 'union_many'):
104 return result.union_many(indexes[1:])
105 else:
106 for other in indexes[1:]:
107 result = result.union(other)
108 return result
109 elif kind == 'array':
110 index = indexes[0]
111 for other in indexes[1:]:
112 if not index.equals(other):
113
114 if sort is None:
115 # TODO: remove once pd.concat sort default changes
116 warnings.warn(_sort_msg, FutureWarning, stacklevel=8)
117 sort = True
118
119 return _unique_indices(indexes)
120
121 name = _get_consensus_names(indexes)[0]
122 if name != index.name:
123 index = index._shallow_copy(name=name)
124 return index
125 else: # kind='list'
126 return _unique_indices(indexes)
127
128
129 def _sanitize_and_check(indexes):
130 kinds = list({type(index) for index in indexes})
131
132 if list in kinds:
133 if len(kinds) > 1:
134 indexes = [Index(com._try_sort(x))
135 if not isinstance(x, Index) else
136 x for x in indexes]
137 kinds.remove(list)
138 else:
139 return indexes, 'list'
140
141 if len(kinds) > 1 or Index not in kinds:
142 return indexes, 'special'
143 else:
144 return indexes, 'array'
145
146
147 def _get_consensus_names(indexes):
148
149 # find the non-none names, need to tupleify to make
150 # the set hashable, then reverse on return
151 consensus_names = set(tuple(i.names) for i in indexes
152 if com._any_not_none(*i.names))
153 if len(consensus_names) == 1:
154 return list(list(consensus_names)[0])
155 return [None] * indexes[0].nlevels
156
157
158 def _all_indexes_same(indexes):
159 first = indexes[0]
160 for index in indexes[1:]:
161 if not first.equals(index):
162 return False
163 return True
164
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pandas/core/indexes/api.py b/pandas/core/indexes/api.py
--- a/pandas/core/indexes/api.py
+++ b/pandas/core/indexes/api.py
@@ -24,9 +24,9 @@
Sorting because non-concatenation axis is not aligned. A future version
of pandas will change to not sort by default.
-To accept the future behavior, pass 'sort=True'.
+To accept the future behavior, pass 'sort=False'.
-To retain the current behavior and silence the warning, pass sort=False
+To retain the current behavior and silence the warning, pass 'sort=True'.
""")
|
{"golden_diff": "diff --git a/pandas/core/indexes/api.py b/pandas/core/indexes/api.py\n--- a/pandas/core/indexes/api.py\n+++ b/pandas/core/indexes/api.py\n@@ -24,9 +24,9 @@\n Sorting because non-concatenation axis is not aligned. A future version\n of pandas will change to not sort by default.\n \n-To accept the future behavior, pass 'sort=True'.\n+To accept the future behavior, pass 'sort=False'.\n \n-To retain the current behavior and silence the warning, pass sort=False\n+To retain the current behavior and silence the warning, pass 'sort=True'.\n \"\"\")\n", "issue": "DOC: error in 0.23.0 concat sort warning?\n#### Problem description\r\n\r\nPandas 0.23.0 adds a new warning when calling `concat` with misaligned axes (#20613):\r\n\r\n```\r\nFutureWarning: Sorting because non-concatenation axis is not aligned. A future version\r\nof pandas will change to not sort by default.\r\n\r\nTo accept the future behavior, pass 'sort=True'.\r\n\r\nTo retain the current behavior and silence the warning, pass sort=False\r\n```\r\n\r\nThis seems strange; I'd assume that `sort=True` would give the current behaviour, and `sort=False` the future behaviour, as in the docs for `concat`: \r\n\r\n```\r\nExplicitly pass sort=True to silence the warning and sort. Explicitly pass\r\nsort=False to silence the warning and not sort.\r\n```\r\n\r\nI'm assuming the docs are right and the warning is wrong?\n", "before_files": [{"content": "import textwrap\nimport warnings\n\nfrom pandas.core.indexes.base import (Index,\n _new_Index,\n _ensure_index,\n _ensure_index_from_sequences,\n InvalidIndexError) # noqa\nfrom pandas.core.indexes.category import CategoricalIndex # noqa\nfrom pandas.core.indexes.multi import MultiIndex # noqa\nfrom pandas.core.indexes.interval import IntervalIndex # noqa\nfrom pandas.core.indexes.numeric import (NumericIndex, Float64Index, # noqa\n Int64Index, UInt64Index)\nfrom pandas.core.indexes.range import RangeIndex # noqa\nfrom pandas.core.indexes.timedeltas import TimedeltaIndex\nfrom pandas.core.indexes.period import PeriodIndex\nfrom pandas.core.indexes.datetimes import DatetimeIndex\n\nimport pandas.core.common as com\nfrom pandas._libs import lib\nfrom pandas._libs.tslib import NaT\n\n_sort_msg = textwrap.dedent(\"\"\"\\\nSorting because non-concatenation axis is not aligned. A future version\nof pandas will change to not sort by default.\n\nTo accept the future behavior, pass 'sort=True'.\n\nTo retain the current behavior and silence the warning, pass sort=False\n\"\"\")\n\n\n# TODO: there are many places that rely on these private methods existing in\n# pandas.core.index\n__all__ = ['Index', 'MultiIndex', 'NumericIndex', 'Float64Index', 'Int64Index',\n 'CategoricalIndex', 'IntervalIndex', 'RangeIndex', 'UInt64Index',\n 'InvalidIndexError', 'TimedeltaIndex',\n 'PeriodIndex', 'DatetimeIndex',\n '_new_Index', 'NaT',\n '_ensure_index', '_ensure_index_from_sequences',\n '_get_combined_index',\n '_get_objs_combined_axis', '_union_indexes',\n '_get_consensus_names',\n '_all_indexes_same']\n\n\ndef _get_objs_combined_axis(objs, intersect=False, axis=0, sort=True):\n # Extract combined index: return intersection or union (depending on the\n # value of \"intersect\") of indexes on given axis, or None if all objects\n # lack indexes (e.g. they are numpy arrays)\n obs_idxes = [obj._get_axis(axis) for obj in objs\n if hasattr(obj, '_get_axis')]\n if obs_idxes:\n return _get_combined_index(obs_idxes, intersect=intersect, sort=sort)\n\n\ndef _get_combined_index(indexes, intersect=False, sort=False):\n # TODO: handle index names!\n indexes = com._get_distinct_objs(indexes)\n if len(indexes) == 0:\n index = Index([])\n elif len(indexes) == 1:\n index = indexes[0]\n elif intersect:\n index = indexes[0]\n for other in indexes[1:]:\n index = index.intersection(other)\n else:\n index = _union_indexes(indexes, sort=sort)\n index = _ensure_index(index)\n\n if sort:\n try:\n index = index.sort_values()\n except TypeError:\n pass\n return index\n\n\ndef _union_indexes(indexes, sort=True):\n if len(indexes) == 0:\n raise AssertionError('Must have at least 1 Index to union')\n if len(indexes) == 1:\n result = indexes[0]\n if isinstance(result, list):\n result = Index(sorted(result))\n return result\n\n indexes, kind = _sanitize_and_check(indexes)\n\n def _unique_indices(inds):\n def conv(i):\n if isinstance(i, Index):\n i = i.tolist()\n return i\n\n return Index(\n lib.fast_unique_multiple_list([conv(i) for i in inds], sort=sort))\n\n if kind == 'special':\n result = indexes[0]\n\n if hasattr(result, 'union_many'):\n return result.union_many(indexes[1:])\n else:\n for other in indexes[1:]:\n result = result.union(other)\n return result\n elif kind == 'array':\n index = indexes[0]\n for other in indexes[1:]:\n if not index.equals(other):\n\n if sort is None:\n # TODO: remove once pd.concat sort default changes\n warnings.warn(_sort_msg, FutureWarning, stacklevel=8)\n sort = True\n\n return _unique_indices(indexes)\n\n name = _get_consensus_names(indexes)[0]\n if name != index.name:\n index = index._shallow_copy(name=name)\n return index\n else: # kind='list'\n return _unique_indices(indexes)\n\n\ndef _sanitize_and_check(indexes):\n kinds = list({type(index) for index in indexes})\n\n if list in kinds:\n if len(kinds) > 1:\n indexes = [Index(com._try_sort(x))\n if not isinstance(x, Index) else\n x for x in indexes]\n kinds.remove(list)\n else:\n return indexes, 'list'\n\n if len(kinds) > 1 or Index not in kinds:\n return indexes, 'special'\n else:\n return indexes, 'array'\n\n\ndef _get_consensus_names(indexes):\n\n # find the non-none names, need to tupleify to make\n # the set hashable, then reverse on return\n consensus_names = set(tuple(i.names) for i in indexes\n if com._any_not_none(*i.names))\n if len(consensus_names) == 1:\n return list(list(consensus_names)[0])\n return [None] * indexes[0].nlevels\n\n\ndef _all_indexes_same(indexes):\n first = indexes[0]\n for index in indexes[1:]:\n if not first.equals(index):\n return False\n return True\n", "path": "pandas/core/indexes/api.py"}], "after_files": [{"content": "import textwrap\nimport warnings\n\nfrom pandas.core.indexes.base import (Index,\n _new_Index,\n _ensure_index,\n _ensure_index_from_sequences,\n InvalidIndexError) # noqa\nfrom pandas.core.indexes.category import CategoricalIndex # noqa\nfrom pandas.core.indexes.multi import MultiIndex # noqa\nfrom pandas.core.indexes.interval import IntervalIndex # noqa\nfrom pandas.core.indexes.numeric import (NumericIndex, Float64Index, # noqa\n Int64Index, UInt64Index)\nfrom pandas.core.indexes.range import RangeIndex # noqa\nfrom pandas.core.indexes.timedeltas import TimedeltaIndex\nfrom pandas.core.indexes.period import PeriodIndex\nfrom pandas.core.indexes.datetimes import DatetimeIndex\n\nimport pandas.core.common as com\nfrom pandas._libs import lib\nfrom pandas._libs.tslib import NaT\n\n_sort_msg = textwrap.dedent(\"\"\"\\\nSorting because non-concatenation axis is not aligned. A future version\nof pandas will change to not sort by default.\n\nTo accept the future behavior, pass 'sort=False'.\n\nTo retain the current behavior and silence the warning, pass 'sort=True'.\n\"\"\")\n\n\n# TODO: there are many places that rely on these private methods existing in\n# pandas.core.index\n__all__ = ['Index', 'MultiIndex', 'NumericIndex', 'Float64Index', 'Int64Index',\n 'CategoricalIndex', 'IntervalIndex', 'RangeIndex', 'UInt64Index',\n 'InvalidIndexError', 'TimedeltaIndex',\n 'PeriodIndex', 'DatetimeIndex',\n '_new_Index', 'NaT',\n '_ensure_index', '_ensure_index_from_sequences',\n '_get_combined_index',\n '_get_objs_combined_axis', '_union_indexes',\n '_get_consensus_names',\n '_all_indexes_same']\n\n\ndef _get_objs_combined_axis(objs, intersect=False, axis=0, sort=True):\n # Extract combined index: return intersection or union (depending on the\n # value of \"intersect\") of indexes on given axis, or None if all objects\n # lack indexes (e.g. they are numpy arrays)\n obs_idxes = [obj._get_axis(axis) for obj in objs\n if hasattr(obj, '_get_axis')]\n if obs_idxes:\n return _get_combined_index(obs_idxes, intersect=intersect, sort=sort)\n\n\ndef _get_combined_index(indexes, intersect=False, sort=False):\n # TODO: handle index names!\n indexes = com._get_distinct_objs(indexes)\n if len(indexes) == 0:\n index = Index([])\n elif len(indexes) == 1:\n index = indexes[0]\n elif intersect:\n index = indexes[0]\n for other in indexes[1:]:\n index = index.intersection(other)\n else:\n index = _union_indexes(indexes, sort=sort)\n index = _ensure_index(index)\n\n if sort:\n try:\n index = index.sort_values()\n except TypeError:\n pass\n return index\n\n\ndef _union_indexes(indexes, sort=True):\n if len(indexes) == 0:\n raise AssertionError('Must have at least 1 Index to union')\n if len(indexes) == 1:\n result = indexes[0]\n if isinstance(result, list):\n result = Index(sorted(result))\n return result\n\n indexes, kind = _sanitize_and_check(indexes)\n\n def _unique_indices(inds):\n def conv(i):\n if isinstance(i, Index):\n i = i.tolist()\n return i\n\n return Index(\n lib.fast_unique_multiple_list([conv(i) for i in inds], sort=sort))\n\n if kind == 'special':\n result = indexes[0]\n\n if hasattr(result, 'union_many'):\n return result.union_many(indexes[1:])\n else:\n for other in indexes[1:]:\n result = result.union(other)\n return result\n elif kind == 'array':\n index = indexes[0]\n for other in indexes[1:]:\n if not index.equals(other):\n\n if sort is None:\n # TODO: remove once pd.concat sort default changes\n warnings.warn(_sort_msg, FutureWarning, stacklevel=8)\n sort = True\n\n return _unique_indices(indexes)\n\n name = _get_consensus_names(indexes)[0]\n if name != index.name:\n index = index._shallow_copy(name=name)\n return index\n else: # kind='list'\n return _unique_indices(indexes)\n\n\ndef _sanitize_and_check(indexes):\n kinds = list({type(index) for index in indexes})\n\n if list in kinds:\n if len(kinds) > 1:\n indexes = [Index(com._try_sort(x))\n if not isinstance(x, Index) else\n x for x in indexes]\n kinds.remove(list)\n else:\n return indexes, 'list'\n\n if len(kinds) > 1 or Index not in kinds:\n return indexes, 'special'\n else:\n return indexes, 'array'\n\n\ndef _get_consensus_names(indexes):\n\n # find the non-none names, need to tupleify to make\n # the set hashable, then reverse on return\n consensus_names = set(tuple(i.names) for i in indexes\n if com._any_not_none(*i.names))\n if len(consensus_names) == 1:\n return list(list(consensus_names)[0])\n return [None] * indexes[0].nlevels\n\n\ndef _all_indexes_same(indexes):\n first = indexes[0]\n for index in indexes[1:]:\n if not first.equals(index):\n return False\n return True\n", "path": "pandas/core/indexes/api.py"}]}
| 2,071 | 135 |
gh_patches_debug_25049
|
rasdani/github-patches
|
git_diff
|
uclapi__uclapi-976
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Scaling of PostgreSQL Connections
We have tried in the past to implement connection pooling for Django <==> PostgreSQL. We should try this again so that the system doesn't get pulled down by too many parallel requests (as could happen in the event of UCL Assistant).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `backend/uclapi/uclapi/settings.py`
Content:
```
1 """
2 Django settings for uclapi project.
3
4 Generated by 'django-admin startproject' using Django 1.10.4.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/1.10/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/1.10/ref/settings/
11 """
12
13 import os
14 import requests
15 from distutils.util import strtobool
16
17 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
18 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
19
20
21 # Quick-start development settings - unsuitable for production
22 # See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/
23
24 # SECURITY WARNING: keep the secret key used in production secret!
25 SECRET_KEY = os.environ.get("SECRET_KEY")
26
27 # SECURITY WARNING: don't run with debug turned on in production!
28 # This value should be set by the UCLAPI_PRODUCTION environment
29 # variable anyway. If in production, debug should be false.
30 DEBUG = not strtobool(os.environ.get("UCLAPI_PRODUCTION"))
31
32 ALLOWED_HOSTS = ["localhost"]
33
34 # If a domain is specified then make this an allowed host
35 if os.environ.get("UCLAPI_DOMAIN"):
36 ALLOWED_HOSTS.append(os.environ.get("UCLAPI_DOMAIN"))
37
38 # If we are running under the AWS Elastic Load Balancer then enable internal
39 # requests so that the ELB and Health Checks work
40 if strtobool(os.environ.get("UCLAPI_RUNNING_ON_AWS_ELB")):
41 EC2_PRIVATE_IP = None
42 try:
43 EC2_PRIVATE_IP = requests.get(
44 "http://169.254.169.254/latest/meta-data/local-ipv4",
45 timeout=0.01
46 ).text
47 except requests.exceptions.RequestException:
48 pass
49
50 if EC2_PRIVATE_IP:
51 ALLOWED_HOSTS.append(EC2_PRIVATE_IP)
52
53 # Application definition
54
55 INSTALLED_APPS = [
56 'django.contrib.admin',
57 'django.contrib.auth',
58 'django.contrib.contenttypes',
59 'django.contrib.sessions',
60 'django.contrib.messages',
61 'django.contrib.staticfiles',
62 'rest_framework',
63 'dashboard',
64 'marketplace',
65 'roombookings',
66 'oauth',
67 'timetable',
68 'common',
69 'raven.contrib.django.raven_compat',
70 'corsheaders',
71 'workspaces',
72 'webpack_loader'
73 ]
74
75 MIDDLEWARE = [
76 'django.middleware.security.SecurityMiddleware',
77 'django.contrib.sessions.middleware.SessionMiddleware',
78 'corsheaders.middleware.CorsMiddleware',
79 'django.middleware.common.CommonMiddleware',
80 'django.middleware.csrf.CsrfViewMiddleware',
81 'django.contrib.auth.middleware.AuthenticationMiddleware',
82 'django.contrib.messages.middleware.MessageMiddleware',
83 'django.middleware.clickjacking.XFrameOptionsMiddleware',
84 ]
85
86 if DEBUG:
87 MIDDLEWARE.append(
88 'dashboard.middleware.fake_shibboleth_middleware'
89 '.FakeShibbolethMiddleWare'
90 )
91
92 ROOT_URLCONF = 'uclapi.urls'
93
94 TEMPLATES = [
95 {
96 'BACKEND': 'django.template.backends.django.DjangoTemplates',
97 'DIRS': [],
98 'APP_DIRS': True,
99 'OPTIONS': {
100 'context_processors': [
101 'django.template.context_processors.debug',
102 'django.template.context_processors.request',
103 'django.contrib.auth.context_processors.auth',
104 'django.contrib.messages.context_processors.messages',
105 ],
106 },
107 },
108 ]
109
110 WSGI_APPLICATION = 'uclapi.wsgi.application'
111
112
113 # Database
114 # https://docs.djangoproject.com/en/1.10/ref/settings/#databases
115
116 DATABASES = {
117 'default': {
118 'ENGINE': 'django.db.backends.postgresql',
119 'NAME': os.environ.get("DB_UCLAPI_NAME"),
120 'USER': os.environ.get("DB_UCLAPI_USERNAME"),
121 'PASSWORD': os.environ.get("DB_UCLAPI_PASSWORD"),
122 'HOST': os.environ.get("DB_UCLAPI_HOST"),
123 'PORT': os.environ.get("DB_UCLAPI_PORT")
124 },
125 'roombookings': {
126 'ENGINE': 'django.db.backends.oracle',
127 'NAME': os.environ.get("DB_ROOMS_NAME"),
128 'USER': os.environ.get("DB_ROOMS_USERNAME"),
129 'PASSWORD': os.environ.get("DB_ROOMS_PASSWORD"),
130 'HOST': '',
131 'PORT': ''
132 },
133 'gencache': {
134 'ENGINE': 'django.db.backends.postgresql',
135 'NAME': os.environ.get("DB_CACHE_NAME"),
136 'USER': os.environ.get("DB_CACHE_USERNAME"),
137 'PASSWORD': os.environ.get("DB_CACHE_PASSWORD"),
138 'HOST': os.environ.get("DB_CACHE_HOST"),
139 'PORT': os.environ.get("DB_CACHE_PORT")
140 }
141 }
142
143 DATABASE_ROUTERS = ['uclapi.dbrouters.ModelRouter']
144
145 RAVEN_CONFIG = {
146 'dsn': os.environ.get("SENTRY_DSN"),
147 }
148
149
150 # Password validation
151 # https://docs.djangoproject.com/en/1.10/ref/settings/#auth-password-validators
152
153 AUTH_PASSWORD_VALIDATORS = [
154 {
155 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', # noqa
156 },
157 {
158 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', # noqa
159 },
160 {
161 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', # noqa
162 },
163 {
164 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', # noqa
165 },
166 ]
167
168
169 # Internationalization
170 # https://docs.djangoproject.com/en/1.10/topics/i18n/
171
172 LANGUAGE_CODE = 'en-us'
173
174 TIME_ZONE = 'UTC'
175
176 USE_I18N = True
177
178 USE_L10N = True
179
180 USE_TZ = False
181
182 # Cross Origin settings
183 CORS_ORIGIN_ALLOW_ALL = True
184 CORS_URLS_REGEX = r'^/roombookings/.*$'
185
186 # Fair use policy
187 fair_use_policy_path = os.path.join(
188 BASE_DIR,
189 'uclapi/UCLAPIAcceptableUsePolicy.txt'
190 )
191 with open(fair_use_policy_path, 'r', encoding='utf-8') as fp:
192 FAIR_USE_POLICY = list(fp)
193
194 REDIS_UCLAPI_HOST = os.environ["REDIS_UCLAPI_HOST"]
195
196 # Celery Settings
197 CELERY_BROKER_URL = 'redis://' + REDIS_UCLAPI_HOST
198 CELERY_ACCEPT_CONTENT = ['json']
199 CELERY_TASK_SERIALIZER = 'json'
200 CELERY_RESULT_SERIALIZER = 'json'
201
202 ROOMBOOKINGS_SETID = 'LIVE-18-19'
203
204 # This dictates how many Medium articles we scrape
205 MEDIUM_ARTICLE_QUANTITY = 3
206
207 # We need to specify a tuple of STATICFILES_DIRS instead of a
208 # STATIC_ROOT so that collectstatic picks up the WebPack bundles
209 STATICFILES_DIRS = (
210 os.path.join(BASE_DIR, 'static'),
211 )
212
213 # S3 file storage settings
214 # There are three scenarios to consider:
215 # 1) Local development
216 # In local dev, AWS_S3_STATICS = False
217 # AWS_S3_STATICS_CREDENTIALS_ENABLED = False
218 # These allow you to use local statics using /static/ in the
219 # same way as you would normally.
220 # 2) Production
221 # In prod, AWS_S3_STATICS = True
222 # AWS_S3_STATICS_CREDENTIALS_ENABLED = False
223 # This means that S3 statics will be used, but no creds are
224 # needed on the boxes because web servers should never do
225 # uploads to the remote S3 bucket.
226 # 3) Deployment
227 # In deployment, AWS_S3_STATICS = True
228 # AWS_S3_STATICS_CREDENTIALS_ENABLED = True
229 # This will be done either from CI/CD or from the computer
230 # of a person who has permission to upload new statics to
231 # S3.
232
233 if strtobool(os.environ.get("AWS_S3_STATICS", "False")):
234 DEFAULT_FILE_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'
235 STATICFILES_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'
236 AWS_STORAGE_BUCKET_NAME = os.environ["AWS_S3_BUCKET_NAME"]
237 AWS_LOCATION = os.environ["AWS_S3_BUCKET_PATH"]
238 AWS_S3_REGION_NAME = os.environ["AWS_S3_REGION"]
239
240 # This is a hack to not require AWS Access Credentials
241 # when the system is running in the Cloud. This avoids us from
242 # needing to store AWS credentials.
243 # https://github.com/jschneier/django-storages/issues/254#issuecomment-329813295 # noqa
244 AWS_S3_CUSTOM_DOMAIN = "{}.s3.amazonaws.com".format(
245 AWS_STORAGE_BUCKET_NAME
246 )
247
248 # We set the default ACL data on all stacks we upload to public-read
249 # so that the files are world readable.
250 # This is required for the statics to be served up directly.
251 # Often this is a security risk, but in this case it's
252 # actually required to serve the website.
253 AWS_DEFAULT_ACL = "public-read"
254
255 # If credentials are enabled, collectstatic can do uploads
256 if strtobool(os.environ["AWS_S3_STATICS_CREDENTIALS_ENABLED"]):
257 AWS_ACCESS_KEY_ID = os.environ["AWS_ACCESS_KEY_ID"]
258 AWS_SECRET_ACCESS_KEY = os.environ["AWS_ACCESS_SECRET"]
259 AWS_S3_OBJECT_PARAMETERS = {
260 'CacheControl': 'max-age=86400',
261 }
262 AWS_S3_ENCRYPTION = False
263 else:
264 AWS_QUERYSTRING_AUTH = False
265
266 # Since we are hosting on AWS, we should set the Static URL to it
267 STATIC_URL = "{}/{}".format(
268 AWS_S3_CUSTOM_DOMAIN,
269 AWS_LOCATION
270 )
271 # Set up the WebPack loader for remote loading
272 WEBPACK_LOADER = {
273 'DEFAULT': {
274 'CACHE': not DEBUG,
275 'BUNDLE_DIR_NAME': './', # must end with slash
276 'STATS_URL': "https://{}webpack-stats.json".format(
277 STATIC_URL
278 ),
279 'POLL_INTERVAL': 0.1,
280 'TIMEOUT': None,
281 'IGNORE': [r'.+\.hot-update.js', r'.+\.map']
282 }
283 }
284 else:
285 # https://docs.djangoproject.com/en/1.10/howto/static-files/
286 # The default Static URL is /static/ which is fine for when statics
287 # have been built and placed into their respective folders.
288 STATIC_URL = os.environ.get("STATIC_URL", '/static/')
289
290 # Set up the WebPack loader for local loading
291 WEBPACK_LOADER = {
292 'DEFAULT': {
293 'CACHE': not DEBUG,
294 'BUNDLE_DIR_NAME': './', # must end with slash
295 'STATS_FILE': os.path.join(
296 BASE_DIR,
297 'static',
298 'webpack-stats.json'
299 ),
300 'POLL_INTERVAL': 0.1,
301 'TIMEOUT': None,
302 'IGNORE': [r'.+\.hot-update.js', r'.+\.map']
303 }
304 }
305
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/backend/uclapi/uclapi/settings.py b/backend/uclapi/uclapi/settings.py
--- a/backend/uclapi/uclapi/settings.py
+++ b/backend/uclapi/uclapi/settings.py
@@ -115,7 +115,7 @@
DATABASES = {
'default': {
- 'ENGINE': 'django.db.backends.postgresql',
+ 'ENGINE': 'django_postgrespool2',
'NAME': os.environ.get("DB_UCLAPI_NAME"),
'USER': os.environ.get("DB_UCLAPI_USERNAME"),
'PASSWORD': os.environ.get("DB_UCLAPI_PASSWORD"),
@@ -131,7 +131,7 @@
'PORT': ''
},
'gencache': {
- 'ENGINE': 'django.db.backends.postgresql',
+ 'ENGINE': 'django_postgrespool2',
'NAME': os.environ.get("DB_CACHE_NAME"),
'USER': os.environ.get("DB_CACHE_USERNAME"),
'PASSWORD': os.environ.get("DB_CACHE_PASSWORD"),
@@ -140,6 +140,15 @@
}
}
+# Max connections is pool_size + max_overflow
+# Will idle at pool_size connections, overflow are for spikes in traffic
+
+DATABASE_POOL_ARGS = {
+ 'max_overflow': 15,
+ 'pool_size': 5,
+ 'recycle': 300
+}
+
DATABASE_ROUTERS = ['uclapi.dbrouters.ModelRouter']
RAVEN_CONFIG = {
|
{"golden_diff": "diff --git a/backend/uclapi/uclapi/settings.py b/backend/uclapi/uclapi/settings.py\n--- a/backend/uclapi/uclapi/settings.py\n+++ b/backend/uclapi/uclapi/settings.py\n@@ -115,7 +115,7 @@\n \n DATABASES = {\n 'default': {\n- 'ENGINE': 'django.db.backends.postgresql',\n+ 'ENGINE': 'django_postgrespool2',\n 'NAME': os.environ.get(\"DB_UCLAPI_NAME\"),\n 'USER': os.environ.get(\"DB_UCLAPI_USERNAME\"),\n 'PASSWORD': os.environ.get(\"DB_UCLAPI_PASSWORD\"),\n@@ -131,7 +131,7 @@\n 'PORT': ''\n },\n 'gencache': {\n- 'ENGINE': 'django.db.backends.postgresql',\n+ 'ENGINE': 'django_postgrespool2',\n 'NAME': os.environ.get(\"DB_CACHE_NAME\"),\n 'USER': os.environ.get(\"DB_CACHE_USERNAME\"),\n 'PASSWORD': os.environ.get(\"DB_CACHE_PASSWORD\"),\n@@ -140,6 +140,15 @@\n }\n }\n \n+# Max connections is pool_size + max_overflow\n+# Will idle at pool_size connections, overflow are for spikes in traffic\n+\n+DATABASE_POOL_ARGS = {\n+ 'max_overflow': 15,\n+ 'pool_size': 5,\n+ 'recycle': 300\n+}\n+\n DATABASE_ROUTERS = ['uclapi.dbrouters.ModelRouter']\n \n RAVEN_CONFIG = {\n", "issue": "Scaling of PostgreSQL Connections\nWe have tried in the past to implement connection pooling for Django <==> PostgreSQL. We should try this again so that the system doesn't get pulled down by too many parallel requests (as could happen in the event of UCL Assistant).\n", "before_files": [{"content": "\"\"\"\nDjango settings for uclapi project.\n\nGenerated by 'django-admin startproject' using Django 1.10.4.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.10/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.10/ref/settings/\n\"\"\"\n\nimport os\nimport requests\nfrom distutils.util import strtobool\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = os.environ.get(\"SECRET_KEY\")\n\n# SECURITY WARNING: don't run with debug turned on in production!\n# This value should be set by the UCLAPI_PRODUCTION environment\n# variable anyway. If in production, debug should be false.\nDEBUG = not strtobool(os.environ.get(\"UCLAPI_PRODUCTION\"))\n\nALLOWED_HOSTS = [\"localhost\"]\n\n# If a domain is specified then make this an allowed host\nif os.environ.get(\"UCLAPI_DOMAIN\"):\n ALLOWED_HOSTS.append(os.environ.get(\"UCLAPI_DOMAIN\"))\n\n# If we are running under the AWS Elastic Load Balancer then enable internal\n# requests so that the ELB and Health Checks work\nif strtobool(os.environ.get(\"UCLAPI_RUNNING_ON_AWS_ELB\")):\n EC2_PRIVATE_IP = None\n try:\n EC2_PRIVATE_IP = requests.get(\n \"http://169.254.169.254/latest/meta-data/local-ipv4\",\n timeout=0.01\n ).text\n except requests.exceptions.RequestException:\n pass\n\n if EC2_PRIVATE_IP:\n ALLOWED_HOSTS.append(EC2_PRIVATE_IP)\n\n# Application definition\n\nINSTALLED_APPS = [\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'rest_framework',\n 'dashboard',\n 'marketplace',\n 'roombookings',\n 'oauth',\n 'timetable',\n 'common',\n 'raven.contrib.django.raven_compat',\n 'corsheaders',\n 'workspaces',\n 'webpack_loader'\n]\n\nMIDDLEWARE = [\n 'django.middleware.security.SecurityMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'corsheaders.middleware.CorsMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nif DEBUG:\n MIDDLEWARE.append(\n 'dashboard.middleware.fake_shibboleth_middleware'\n '.FakeShibbolethMiddleWare'\n )\n\nROOT_URLCONF = 'uclapi.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'uclapi.wsgi.application'\n\n\n# Database\n# https://docs.djangoproject.com/en/1.10/ref/settings/#databases\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.postgresql',\n 'NAME': os.environ.get(\"DB_UCLAPI_NAME\"),\n 'USER': os.environ.get(\"DB_UCLAPI_USERNAME\"),\n 'PASSWORD': os.environ.get(\"DB_UCLAPI_PASSWORD\"),\n 'HOST': os.environ.get(\"DB_UCLAPI_HOST\"),\n 'PORT': os.environ.get(\"DB_UCLAPI_PORT\")\n },\n 'roombookings': {\n 'ENGINE': 'django.db.backends.oracle',\n 'NAME': os.environ.get(\"DB_ROOMS_NAME\"),\n 'USER': os.environ.get(\"DB_ROOMS_USERNAME\"),\n 'PASSWORD': os.environ.get(\"DB_ROOMS_PASSWORD\"),\n 'HOST': '',\n 'PORT': ''\n },\n 'gencache': {\n 'ENGINE': 'django.db.backends.postgresql',\n 'NAME': os.environ.get(\"DB_CACHE_NAME\"),\n 'USER': os.environ.get(\"DB_CACHE_USERNAME\"),\n 'PASSWORD': os.environ.get(\"DB_CACHE_PASSWORD\"),\n 'HOST': os.environ.get(\"DB_CACHE_HOST\"),\n 'PORT': os.environ.get(\"DB_CACHE_PORT\")\n }\n}\n\nDATABASE_ROUTERS = ['uclapi.dbrouters.ModelRouter']\n\nRAVEN_CONFIG = {\n 'dsn': os.environ.get(\"SENTRY_DSN\"),\n}\n\n\n# Password validation\n# https://docs.djangoproject.com/en/1.10/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', # noqa\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.10/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'UTC'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = False\n\n# Cross Origin settings\nCORS_ORIGIN_ALLOW_ALL = True\nCORS_URLS_REGEX = r'^/roombookings/.*$'\n\n# Fair use policy\nfair_use_policy_path = os.path.join(\n BASE_DIR,\n 'uclapi/UCLAPIAcceptableUsePolicy.txt'\n)\nwith open(fair_use_policy_path, 'r', encoding='utf-8') as fp:\n FAIR_USE_POLICY = list(fp)\n\nREDIS_UCLAPI_HOST = os.environ[\"REDIS_UCLAPI_HOST\"]\n\n# Celery Settings\nCELERY_BROKER_URL = 'redis://' + REDIS_UCLAPI_HOST\nCELERY_ACCEPT_CONTENT = ['json']\nCELERY_TASK_SERIALIZER = 'json'\nCELERY_RESULT_SERIALIZER = 'json'\n\nROOMBOOKINGS_SETID = 'LIVE-18-19'\n\n# This dictates how many Medium articles we scrape\nMEDIUM_ARTICLE_QUANTITY = 3\n\n# We need to specify a tuple of STATICFILES_DIRS instead of a\n# STATIC_ROOT so that collectstatic picks up the WebPack bundles\nSTATICFILES_DIRS = (\n os.path.join(BASE_DIR, 'static'),\n)\n\n# S3 file storage settings\n# There are three scenarios to consider:\n# 1) Local development\n# In local dev, AWS_S3_STATICS = False\n# AWS_S3_STATICS_CREDENTIALS_ENABLED = False\n# These allow you to use local statics using /static/ in the\n# same way as you would normally.\n# 2) Production\n# In prod, AWS_S3_STATICS = True\n# AWS_S3_STATICS_CREDENTIALS_ENABLED = False\n# This means that S3 statics will be used, but no creds are\n# needed on the boxes because web servers should never do\n# uploads to the remote S3 bucket.\n# 3) Deployment\n# In deployment, AWS_S3_STATICS = True\n# AWS_S3_STATICS_CREDENTIALS_ENABLED = True\n# This will be done either from CI/CD or from the computer\n# of a person who has permission to upload new statics to\n# S3.\n\nif strtobool(os.environ.get(\"AWS_S3_STATICS\", \"False\")):\n DEFAULT_FILE_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'\n STATICFILES_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'\n AWS_STORAGE_BUCKET_NAME = os.environ[\"AWS_S3_BUCKET_NAME\"]\n AWS_LOCATION = os.environ[\"AWS_S3_BUCKET_PATH\"]\n AWS_S3_REGION_NAME = os.environ[\"AWS_S3_REGION\"]\n\n # This is a hack to not require AWS Access Credentials\n # when the system is running in the Cloud. This avoids us from\n # needing to store AWS credentials.\n # https://github.com/jschneier/django-storages/issues/254#issuecomment-329813295 # noqa\n AWS_S3_CUSTOM_DOMAIN = \"{}.s3.amazonaws.com\".format(\n AWS_STORAGE_BUCKET_NAME\n )\n\n # We set the default ACL data on all stacks we upload to public-read\n # so that the files are world readable.\n # This is required for the statics to be served up directly.\n # Often this is a security risk, but in this case it's\n # actually required to serve the website.\n AWS_DEFAULT_ACL = \"public-read\"\n\n # If credentials are enabled, collectstatic can do uploads\n if strtobool(os.environ[\"AWS_S3_STATICS_CREDENTIALS_ENABLED\"]):\n AWS_ACCESS_KEY_ID = os.environ[\"AWS_ACCESS_KEY_ID\"]\n AWS_SECRET_ACCESS_KEY = os.environ[\"AWS_ACCESS_SECRET\"]\n AWS_S3_OBJECT_PARAMETERS = {\n 'CacheControl': 'max-age=86400',\n }\n AWS_S3_ENCRYPTION = False\n else:\n AWS_QUERYSTRING_AUTH = False\n\n # Since we are hosting on AWS, we should set the Static URL to it\n STATIC_URL = \"{}/{}\".format(\n AWS_S3_CUSTOM_DOMAIN,\n AWS_LOCATION\n )\n # Set up the WebPack loader for remote loading\n WEBPACK_LOADER = {\n 'DEFAULT': {\n 'CACHE': not DEBUG,\n 'BUNDLE_DIR_NAME': './', # must end with slash\n 'STATS_URL': \"https://{}webpack-stats.json\".format(\n STATIC_URL\n ),\n 'POLL_INTERVAL': 0.1,\n 'TIMEOUT': None,\n 'IGNORE': [r'.+\\.hot-update.js', r'.+\\.map']\n }\n }\nelse:\n # https://docs.djangoproject.com/en/1.10/howto/static-files/\n # The default Static URL is /static/ which is fine for when statics\n # have been built and placed into their respective folders.\n STATIC_URL = os.environ.get(\"STATIC_URL\", '/static/')\n\n # Set up the WebPack loader for local loading\n WEBPACK_LOADER = {\n 'DEFAULT': {\n 'CACHE': not DEBUG,\n 'BUNDLE_DIR_NAME': './', # must end with slash\n 'STATS_FILE': os.path.join(\n BASE_DIR,\n 'static',\n 'webpack-stats.json'\n ),\n 'POLL_INTERVAL': 0.1,\n 'TIMEOUT': None,\n 'IGNORE': [r'.+\\.hot-update.js', r'.+\\.map']\n }\n }\n", "path": "backend/uclapi/uclapi/settings.py"}], "after_files": [{"content": "\"\"\"\nDjango settings for uclapi project.\n\nGenerated by 'django-admin startproject' using Django 1.10.4.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.10/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.10/ref/settings/\n\"\"\"\n\nimport os\nimport requests\nfrom distutils.util import strtobool\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = os.environ.get(\"SECRET_KEY\")\n\n# SECURITY WARNING: don't run with debug turned on in production!\n# This value should be set by the UCLAPI_PRODUCTION environment\n# variable anyway. If in production, debug should be false.\nDEBUG = not strtobool(os.environ.get(\"UCLAPI_PRODUCTION\"))\n\nALLOWED_HOSTS = [\"localhost\"]\n\n# If a domain is specified then make this an allowed host\nif os.environ.get(\"UCLAPI_DOMAIN\"):\n ALLOWED_HOSTS.append(os.environ.get(\"UCLAPI_DOMAIN\"))\n\n# If we are running under the AWS Elastic Load Balancer then enable internal\n# requests so that the ELB and Health Checks work\nif strtobool(os.environ.get(\"UCLAPI_RUNNING_ON_AWS_ELB\")):\n EC2_PRIVATE_IP = None\n try:\n EC2_PRIVATE_IP = requests.get(\n \"http://169.254.169.254/latest/meta-data/local-ipv4\",\n timeout=0.01\n ).text\n except requests.exceptions.RequestException:\n pass\n\n if EC2_PRIVATE_IP:\n ALLOWED_HOSTS.append(EC2_PRIVATE_IP)\n\n# Application definition\n\nINSTALLED_APPS = [\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'rest_framework',\n 'dashboard',\n 'marketplace',\n 'roombookings',\n 'oauth',\n 'timetable',\n 'common',\n 'raven.contrib.django.raven_compat',\n 'corsheaders',\n 'workspaces',\n 'webpack_loader'\n]\n\nMIDDLEWARE = [\n 'django.middleware.security.SecurityMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'corsheaders.middleware.CorsMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nif DEBUG:\n MIDDLEWARE.append(\n 'dashboard.middleware.fake_shibboleth_middleware'\n '.FakeShibbolethMiddleWare'\n )\n\nROOT_URLCONF = 'uclapi.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'uclapi.wsgi.application'\n\n\n# Database\n# https://docs.djangoproject.com/en/1.10/ref/settings/#databases\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django_postgrespool2',\n 'NAME': os.environ.get(\"DB_UCLAPI_NAME\"),\n 'USER': os.environ.get(\"DB_UCLAPI_USERNAME\"),\n 'PASSWORD': os.environ.get(\"DB_UCLAPI_PASSWORD\"),\n 'HOST': os.environ.get(\"DB_UCLAPI_HOST\"),\n 'PORT': os.environ.get(\"DB_UCLAPI_PORT\")\n },\n 'roombookings': {\n 'ENGINE': 'django.db.backends.oracle',\n 'NAME': os.environ.get(\"DB_ROOMS_NAME\"),\n 'USER': os.environ.get(\"DB_ROOMS_USERNAME\"),\n 'PASSWORD': os.environ.get(\"DB_ROOMS_PASSWORD\"),\n 'HOST': '',\n 'PORT': ''\n },\n 'gencache': {\n 'ENGINE': 'django_postgrespool2',\n 'NAME': os.environ.get(\"DB_CACHE_NAME\"),\n 'USER': os.environ.get(\"DB_CACHE_USERNAME\"),\n 'PASSWORD': os.environ.get(\"DB_CACHE_PASSWORD\"),\n 'HOST': os.environ.get(\"DB_CACHE_HOST\"),\n 'PORT': os.environ.get(\"DB_CACHE_PORT\")\n }\n}\n\n# Max connections is pool_size + max_overflow\n# Will idle at pool_size connections, overflow are for spikes in traffic\n\nDATABASE_POOL_ARGS = {\n 'max_overflow': 15,\n 'pool_size': 5,\n 'recycle': 300\n}\n\nDATABASE_ROUTERS = ['uclapi.dbrouters.ModelRouter']\n\nRAVEN_CONFIG = {\n 'dsn': os.environ.get(\"SENTRY_DSN\"),\n}\n\n\n# Password validation\n# https://docs.djangoproject.com/en/1.10/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', # noqa\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.10/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'UTC'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = False\n\n# Cross Origin settings\nCORS_ORIGIN_ALLOW_ALL = True\nCORS_URLS_REGEX = r'^/roombookings/.*$'\n\n# Fair use policy\nfair_use_policy_path = os.path.join(\n BASE_DIR,\n 'uclapi/UCLAPIAcceptableUsePolicy.txt'\n)\nwith open(fair_use_policy_path, 'r', encoding='utf-8') as fp:\n FAIR_USE_POLICY = list(fp)\n\nREDIS_UCLAPI_HOST = os.environ[\"REDIS_UCLAPI_HOST\"]\n\n# Celery Settings\nCELERY_BROKER_URL = 'redis://' + REDIS_UCLAPI_HOST\nCELERY_ACCEPT_CONTENT = ['json']\nCELERY_TASK_SERIALIZER = 'json'\nCELERY_RESULT_SERIALIZER = 'json'\n\nROOMBOOKINGS_SETID = 'LIVE-18-19'\n\n# This dictates how many Medium articles we scrape\nMEDIUM_ARTICLE_QUANTITY = 3\n\n# We need to specify a tuple of STATICFILES_DIRS instead of a\n# STATIC_ROOT so that collectstatic picks up the WebPack bundles\nSTATICFILES_DIRS = (\n os.path.join(BASE_DIR, 'static'),\n)\n\n# S3 file storage settings\n# There are three scenarios to consider:\n# 1) Local development\n# In local dev, AWS_S3_STATICS = False\n# AWS_S3_STATICS_CREDENTIALS_ENABLED = False\n# These allow you to use local statics using /static/ in the\n# same way as you would normally.\n# 2) Production\n# In prod, AWS_S3_STATICS = True\n# AWS_S3_STATICS_CREDENTIALS_ENABLED = False\n# This means that S3 statics will be used, but no creds are\n# needed on the boxes because web servers should never do\n# uploads to the remote S3 bucket.\n# 3) Deployment\n# In deployment, AWS_S3_STATICS = True\n# AWS_S3_STATICS_CREDENTIALS_ENABLED = True\n# This will be done either from CI/CD or from the computer\n# of a person who has permission to upload new statics to\n# S3.\n\nif strtobool(os.environ.get(\"AWS_S3_STATICS\", \"False\")):\n DEFAULT_FILE_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'\n STATICFILES_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'\n AWS_STORAGE_BUCKET_NAME = os.environ[\"AWS_S3_BUCKET_NAME\"]\n AWS_LOCATION = os.environ[\"AWS_S3_BUCKET_PATH\"]\n AWS_S3_REGION_NAME = os.environ[\"AWS_S3_REGION\"]\n\n # This is a hack to not require AWS Access Credentials\n # when the system is running in the Cloud. This avoids us from\n # needing to store AWS credentials.\n # https://github.com/jschneier/django-storages/issues/254#issuecomment-329813295 # noqa\n AWS_S3_CUSTOM_DOMAIN = \"{}.s3.amazonaws.com\".format(\n AWS_STORAGE_BUCKET_NAME\n )\n\n # We set the default ACL data on all stacks we upload to public-read\n # so that the files are world readable.\n # This is required for the statics to be served up directly.\n # Often this is a security risk, but in this case it's\n # actually required to serve the website.\n AWS_DEFAULT_ACL = \"public-read\"\n\n # If credentials are enabled, collectstatic can do uploads\n if strtobool(os.environ[\"AWS_S3_STATICS_CREDENTIALS_ENABLED\"]):\n AWS_ACCESS_KEY_ID = os.environ[\"AWS_ACCESS_KEY_ID\"]\n AWS_SECRET_ACCESS_KEY = os.environ[\"AWS_ACCESS_SECRET\"]\n AWS_S3_OBJECT_PARAMETERS = {\n 'CacheControl': 'max-age=86400',\n }\n AWS_S3_ENCRYPTION = False\n else:\n AWS_QUERYSTRING_AUTH = False\n\n # Since we are hosting on AWS, we should set the Static URL to it\n STATIC_URL = \"{}/{}\".format(\n AWS_S3_CUSTOM_DOMAIN,\n AWS_LOCATION\n )\n # Set up the WebPack loader for remote loading\n WEBPACK_LOADER = {\n 'DEFAULT': {\n 'CACHE': not DEBUG,\n 'BUNDLE_DIR_NAME': './', # must end with slash\n 'STATS_URL': \"https://{}webpack-stats.json\".format(\n STATIC_URL\n ),\n 'POLL_INTERVAL': 0.1,\n 'TIMEOUT': None,\n 'IGNORE': [r'.+\\.hot-update.js', r'.+\\.map']\n }\n }\nelse:\n # https://docs.djangoproject.com/en/1.10/howto/static-files/\n # The default Static URL is /static/ which is fine for when statics\n # have been built and placed into their respective folders.\n STATIC_URL = os.environ.get(\"STATIC_URL\", '/static/')\n\n # Set up the WebPack loader for local loading\n WEBPACK_LOADER = {\n 'DEFAULT': {\n 'CACHE': not DEBUG,\n 'BUNDLE_DIR_NAME': './', # must end with slash\n 'STATS_FILE': os.path.join(\n BASE_DIR,\n 'static',\n 'webpack-stats.json'\n ),\n 'POLL_INTERVAL': 0.1,\n 'TIMEOUT': None,\n 'IGNORE': [r'.+\\.hot-update.js', r'.+\\.map']\n }\n }\n", "path": "backend/uclapi/uclapi/settings.py"}]}
| 3,561 | 331 |
gh_patches_debug_4606
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-2450
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
EllipticCurvePrivateNumbers and EllipticCurvePublicNumbers should have an __repr__
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cryptography/hazmat/primitives/asymmetric/ec.py`
Content:
```
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7 import abc
8
9 import six
10
11 from cryptography import utils
12
13
14 @six.add_metaclass(abc.ABCMeta)
15 class EllipticCurve(object):
16 @abc.abstractproperty
17 def name(self):
18 """
19 The name of the curve. e.g. secp256r1.
20 """
21
22 @abc.abstractproperty
23 def key_size(self):
24 """
25 The bit length of the base point of the curve.
26 """
27
28
29 @six.add_metaclass(abc.ABCMeta)
30 class EllipticCurveSignatureAlgorithm(object):
31 @abc.abstractproperty
32 def algorithm(self):
33 """
34 The digest algorithm used with this signature.
35 """
36
37
38 @six.add_metaclass(abc.ABCMeta)
39 class EllipticCurvePrivateKey(object):
40 @abc.abstractmethod
41 def signer(self, signature_algorithm):
42 """
43 Returns an AsymmetricSignatureContext used for signing data.
44 """
45
46 @abc.abstractmethod
47 def exchange(self, algorithm, peer_public_key):
48 """
49 Performs a key exchange operation using the provided algorithm with the
50 provided peer's public key.
51 """
52
53 @abc.abstractmethod
54 def public_key(self):
55 """
56 The EllipticCurvePublicKey for this private key.
57 """
58
59 @abc.abstractproperty
60 def curve(self):
61 """
62 The EllipticCurve that this key is on.
63 """
64
65
66 @six.add_metaclass(abc.ABCMeta)
67 class EllipticCurvePrivateKeyWithSerialization(EllipticCurvePrivateKey):
68 @abc.abstractmethod
69 def private_numbers(self):
70 """
71 Returns an EllipticCurvePrivateNumbers.
72 """
73
74 @abc.abstractmethod
75 def private_bytes(self, encoding, format, encryption_algorithm):
76 """
77 Returns the key serialized as bytes.
78 """
79
80
81 @six.add_metaclass(abc.ABCMeta)
82 class EllipticCurvePublicKey(object):
83 @abc.abstractmethod
84 def verifier(self, signature, signature_algorithm):
85 """
86 Returns an AsymmetricVerificationContext used for signing data.
87 """
88
89 @abc.abstractproperty
90 def curve(self):
91 """
92 The EllipticCurve that this key is on.
93 """
94
95 @abc.abstractmethod
96 def public_numbers(self):
97 """
98 Returns an EllipticCurvePublicNumbers.
99 """
100
101 @abc.abstractmethod
102 def public_bytes(self, encoding, format):
103 """
104 Returns the key serialized as bytes.
105 """
106
107
108 EllipticCurvePublicKeyWithSerialization = EllipticCurvePublicKey
109
110
111 @utils.register_interface(EllipticCurve)
112 class SECT571R1(object):
113 name = "sect571r1"
114 key_size = 571
115
116
117 @utils.register_interface(EllipticCurve)
118 class SECT409R1(object):
119 name = "sect409r1"
120 key_size = 409
121
122
123 @utils.register_interface(EllipticCurve)
124 class SECT283R1(object):
125 name = "sect283r1"
126 key_size = 283
127
128
129 @utils.register_interface(EllipticCurve)
130 class SECT233R1(object):
131 name = "sect233r1"
132 key_size = 233
133
134
135 @utils.register_interface(EllipticCurve)
136 class SECT163R2(object):
137 name = "sect163r2"
138 key_size = 163
139
140
141 @utils.register_interface(EllipticCurve)
142 class SECT571K1(object):
143 name = "sect571k1"
144 key_size = 571
145
146
147 @utils.register_interface(EllipticCurve)
148 class SECT409K1(object):
149 name = "sect409k1"
150 key_size = 409
151
152
153 @utils.register_interface(EllipticCurve)
154 class SECT283K1(object):
155 name = "sect283k1"
156 key_size = 283
157
158
159 @utils.register_interface(EllipticCurve)
160 class SECT233K1(object):
161 name = "sect233k1"
162 key_size = 233
163
164
165 @utils.register_interface(EllipticCurve)
166 class SECT163K1(object):
167 name = "sect163k1"
168 key_size = 163
169
170
171 @utils.register_interface(EllipticCurve)
172 class SECP521R1(object):
173 name = "secp521r1"
174 key_size = 521
175
176
177 @utils.register_interface(EllipticCurve)
178 class SECP384R1(object):
179 name = "secp384r1"
180 key_size = 384
181
182
183 @utils.register_interface(EllipticCurve)
184 class SECP256R1(object):
185 name = "secp256r1"
186 key_size = 256
187
188
189 @utils.register_interface(EllipticCurve)
190 class SECP256K1(object):
191 name = "secp256k1"
192 key_size = 256
193
194
195 @utils.register_interface(EllipticCurve)
196 class SECP224R1(object):
197 name = "secp224r1"
198 key_size = 224
199
200
201 @utils.register_interface(EllipticCurve)
202 class SECP192R1(object):
203 name = "secp192r1"
204 key_size = 192
205
206
207 _CURVE_TYPES = {
208 "prime192v1": SECP192R1,
209 "prime256v1": SECP256R1,
210
211 "secp192r1": SECP192R1,
212 "secp224r1": SECP224R1,
213 "secp256r1": SECP256R1,
214 "secp384r1": SECP384R1,
215 "secp521r1": SECP521R1,
216 "secp256k1": SECP256K1,
217
218 "sect163k1": SECT163K1,
219 "sect233k1": SECT233K1,
220 "sect283k1": SECT283K1,
221 "sect409k1": SECT409K1,
222 "sect571k1": SECT571K1,
223
224 "sect163r2": SECT163R2,
225 "sect233r1": SECT233R1,
226 "sect283r1": SECT283R1,
227 "sect409r1": SECT409R1,
228 "sect571r1": SECT571R1,
229 }
230
231
232 @utils.register_interface(EllipticCurveSignatureAlgorithm)
233 class ECDSA(object):
234 def __init__(self, algorithm):
235 self._algorithm = algorithm
236
237 algorithm = utils.read_only_property("_algorithm")
238
239
240 def generate_private_key(curve, backend):
241 return backend.generate_elliptic_curve_private_key(curve)
242
243
244 class EllipticCurvePublicNumbers(object):
245 def __init__(self, x, y, curve):
246 if (
247 not isinstance(x, six.integer_types) or
248 not isinstance(y, six.integer_types)
249 ):
250 raise TypeError("x and y must be integers.")
251
252 if not isinstance(curve, EllipticCurve):
253 raise TypeError("curve must provide the EllipticCurve interface.")
254
255 self._y = y
256 self._x = x
257 self._curve = curve
258
259 def public_key(self, backend):
260 return backend.load_elliptic_curve_public_numbers(self)
261
262 def encode_point(self):
263 # key_size is in bits. Convert to bytes and round up
264 byte_length = (self.curve.key_size + 7) // 8
265 return (
266 b'\x04' + utils.int_to_bytes(self.x, byte_length) +
267 utils.int_to_bytes(self.y, byte_length)
268 )
269
270 @classmethod
271 def from_encoded_point(cls, curve, data):
272 if not isinstance(curve, EllipticCurve):
273 raise TypeError("curve must be an EllipticCurve instance")
274
275 if data.startswith(b'\x04'):
276 # key_size is in bits. Convert to bytes and round up
277 byte_length = (curve.key_size + 7) // 8
278 if len(data) == 2 * byte_length + 1:
279 x = utils.int_from_bytes(data[1:byte_length + 1], 'big')
280 y = utils.int_from_bytes(data[byte_length + 1:], 'big')
281 return cls(x, y, curve)
282 else:
283 raise ValueError('Invalid elliptic curve point data length')
284 else:
285 raise ValueError('Unsupported elliptic curve point type')
286
287 curve = utils.read_only_property("_curve")
288 x = utils.read_only_property("_x")
289 y = utils.read_only_property("_y")
290
291 def __eq__(self, other):
292 if not isinstance(other, EllipticCurvePublicNumbers):
293 return NotImplemented
294
295 return (
296 self.x == other.x and
297 self.y == other.y and
298 self.curve.name == other.curve.name and
299 self.curve.key_size == other.curve.key_size
300 )
301
302 def __ne__(self, other):
303 return not self == other
304
305
306 class EllipticCurvePrivateNumbers(object):
307 def __init__(self, private_value, public_numbers):
308 if not isinstance(private_value, six.integer_types):
309 raise TypeError("private_value must be an integer.")
310
311 if not isinstance(public_numbers, EllipticCurvePublicNumbers):
312 raise TypeError(
313 "public_numbers must be an EllipticCurvePublicNumbers "
314 "instance."
315 )
316
317 self._private_value = private_value
318 self._public_numbers = public_numbers
319
320 def private_key(self, backend):
321 return backend.load_elliptic_curve_private_numbers(self)
322
323 private_value = utils.read_only_property("_private_value")
324 public_numbers = utils.read_only_property("_public_numbers")
325
326 def __eq__(self, other):
327 if not isinstance(other, EllipticCurvePrivateNumbers):
328 return NotImplemented
329
330 return (
331 self.private_value == other.private_value and
332 self.public_numbers == other.public_numbers
333 )
334
335 def __ne__(self, other):
336 return not self == other
337
338
339 class ECDH(object):
340 pass
341
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cryptography/hazmat/primitives/asymmetric/ec.py b/src/cryptography/hazmat/primitives/asymmetric/ec.py
--- a/src/cryptography/hazmat/primitives/asymmetric/ec.py
+++ b/src/cryptography/hazmat/primitives/asymmetric/ec.py
@@ -302,6 +302,12 @@
def __ne__(self, other):
return not self == other
+ def __repr__(self):
+ return (
+ "<EllipticCurvePublicNumbers(curve={0.curve.name}, x={0.x}, "
+ "y={0.y}>".format(self)
+ )
+
class EllipticCurvePrivateNumbers(object):
def __init__(self, private_value, public_numbers):
|
{"golden_diff": "diff --git a/src/cryptography/hazmat/primitives/asymmetric/ec.py b/src/cryptography/hazmat/primitives/asymmetric/ec.py\n--- a/src/cryptography/hazmat/primitives/asymmetric/ec.py\n+++ b/src/cryptography/hazmat/primitives/asymmetric/ec.py\n@@ -302,6 +302,12 @@\n def __ne__(self, other):\n return not self == other\n \n+ def __repr__(self):\n+ return (\n+ \"<EllipticCurvePublicNumbers(curve={0.curve.name}, x={0.x}, \"\n+ \"y={0.y}>\".format(self)\n+ )\n+\n \n class EllipticCurvePrivateNumbers(object):\n def __init__(self, private_value, public_numbers):\n", "issue": "EllipticCurvePrivateNumbers and EllipticCurvePublicNumbers should have an __repr__\n\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport abc\n\nimport six\n\nfrom cryptography import utils\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurve(object):\n @abc.abstractproperty\n def name(self):\n \"\"\"\n The name of the curve. e.g. secp256r1.\n \"\"\"\n\n @abc.abstractproperty\n def key_size(self):\n \"\"\"\n The bit length of the base point of the curve.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurveSignatureAlgorithm(object):\n @abc.abstractproperty\n def algorithm(self):\n \"\"\"\n The digest algorithm used with this signature.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurvePrivateKey(object):\n @abc.abstractmethod\n def signer(self, signature_algorithm):\n \"\"\"\n Returns an AsymmetricSignatureContext used for signing data.\n \"\"\"\n\n @abc.abstractmethod\n def exchange(self, algorithm, peer_public_key):\n \"\"\"\n Performs a key exchange operation using the provided algorithm with the\n provided peer's public key.\n \"\"\"\n\n @abc.abstractmethod\n def public_key(self):\n \"\"\"\n The EllipticCurvePublicKey for this private key.\n \"\"\"\n\n @abc.abstractproperty\n def curve(self):\n \"\"\"\n The EllipticCurve that this key is on.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurvePrivateKeyWithSerialization(EllipticCurvePrivateKey):\n @abc.abstractmethod\n def private_numbers(self):\n \"\"\"\n Returns an EllipticCurvePrivateNumbers.\n \"\"\"\n\n @abc.abstractmethod\n def private_bytes(self, encoding, format, encryption_algorithm):\n \"\"\"\n Returns the key serialized as bytes.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurvePublicKey(object):\n @abc.abstractmethod\n def verifier(self, signature, signature_algorithm):\n \"\"\"\n Returns an AsymmetricVerificationContext used for signing data.\n \"\"\"\n\n @abc.abstractproperty\n def curve(self):\n \"\"\"\n The EllipticCurve that this key is on.\n \"\"\"\n\n @abc.abstractmethod\n def public_numbers(self):\n \"\"\"\n Returns an EllipticCurvePublicNumbers.\n \"\"\"\n\n @abc.abstractmethod\n def public_bytes(self, encoding, format):\n \"\"\"\n Returns the key serialized as bytes.\n \"\"\"\n\n\nEllipticCurvePublicKeyWithSerialization = EllipticCurvePublicKey\n\n\[email protected]_interface(EllipticCurve)\nclass SECT571R1(object):\n name = \"sect571r1\"\n key_size = 571\n\n\[email protected]_interface(EllipticCurve)\nclass SECT409R1(object):\n name = \"sect409r1\"\n key_size = 409\n\n\[email protected]_interface(EllipticCurve)\nclass SECT283R1(object):\n name = \"sect283r1\"\n key_size = 283\n\n\[email protected]_interface(EllipticCurve)\nclass SECT233R1(object):\n name = \"sect233r1\"\n key_size = 233\n\n\[email protected]_interface(EllipticCurve)\nclass SECT163R2(object):\n name = \"sect163r2\"\n key_size = 163\n\n\[email protected]_interface(EllipticCurve)\nclass SECT571K1(object):\n name = \"sect571k1\"\n key_size = 571\n\n\[email protected]_interface(EllipticCurve)\nclass SECT409K1(object):\n name = \"sect409k1\"\n key_size = 409\n\n\[email protected]_interface(EllipticCurve)\nclass SECT283K1(object):\n name = \"sect283k1\"\n key_size = 283\n\n\[email protected]_interface(EllipticCurve)\nclass SECT233K1(object):\n name = \"sect233k1\"\n key_size = 233\n\n\[email protected]_interface(EllipticCurve)\nclass SECT163K1(object):\n name = \"sect163k1\"\n key_size = 163\n\n\[email protected]_interface(EllipticCurve)\nclass SECP521R1(object):\n name = \"secp521r1\"\n key_size = 521\n\n\[email protected]_interface(EllipticCurve)\nclass SECP384R1(object):\n name = \"secp384r1\"\n key_size = 384\n\n\[email protected]_interface(EllipticCurve)\nclass SECP256R1(object):\n name = \"secp256r1\"\n key_size = 256\n\n\[email protected]_interface(EllipticCurve)\nclass SECP256K1(object):\n name = \"secp256k1\"\n key_size = 256\n\n\[email protected]_interface(EllipticCurve)\nclass SECP224R1(object):\n name = \"secp224r1\"\n key_size = 224\n\n\[email protected]_interface(EllipticCurve)\nclass SECP192R1(object):\n name = \"secp192r1\"\n key_size = 192\n\n\n_CURVE_TYPES = {\n \"prime192v1\": SECP192R1,\n \"prime256v1\": SECP256R1,\n\n \"secp192r1\": SECP192R1,\n \"secp224r1\": SECP224R1,\n \"secp256r1\": SECP256R1,\n \"secp384r1\": SECP384R1,\n \"secp521r1\": SECP521R1,\n \"secp256k1\": SECP256K1,\n\n \"sect163k1\": SECT163K1,\n \"sect233k1\": SECT233K1,\n \"sect283k1\": SECT283K1,\n \"sect409k1\": SECT409K1,\n \"sect571k1\": SECT571K1,\n\n \"sect163r2\": SECT163R2,\n \"sect233r1\": SECT233R1,\n \"sect283r1\": SECT283R1,\n \"sect409r1\": SECT409R1,\n \"sect571r1\": SECT571R1,\n}\n\n\[email protected]_interface(EllipticCurveSignatureAlgorithm)\nclass ECDSA(object):\n def __init__(self, algorithm):\n self._algorithm = algorithm\n\n algorithm = utils.read_only_property(\"_algorithm\")\n\n\ndef generate_private_key(curve, backend):\n return backend.generate_elliptic_curve_private_key(curve)\n\n\nclass EllipticCurvePublicNumbers(object):\n def __init__(self, x, y, curve):\n if (\n not isinstance(x, six.integer_types) or\n not isinstance(y, six.integer_types)\n ):\n raise TypeError(\"x and y must be integers.\")\n\n if not isinstance(curve, EllipticCurve):\n raise TypeError(\"curve must provide the EllipticCurve interface.\")\n\n self._y = y\n self._x = x\n self._curve = curve\n\n def public_key(self, backend):\n return backend.load_elliptic_curve_public_numbers(self)\n\n def encode_point(self):\n # key_size is in bits. Convert to bytes and round up\n byte_length = (self.curve.key_size + 7) // 8\n return (\n b'\\x04' + utils.int_to_bytes(self.x, byte_length) +\n utils.int_to_bytes(self.y, byte_length)\n )\n\n @classmethod\n def from_encoded_point(cls, curve, data):\n if not isinstance(curve, EllipticCurve):\n raise TypeError(\"curve must be an EllipticCurve instance\")\n\n if data.startswith(b'\\x04'):\n # key_size is in bits. Convert to bytes and round up\n byte_length = (curve.key_size + 7) // 8\n if len(data) == 2 * byte_length + 1:\n x = utils.int_from_bytes(data[1:byte_length + 1], 'big')\n y = utils.int_from_bytes(data[byte_length + 1:], 'big')\n return cls(x, y, curve)\n else:\n raise ValueError('Invalid elliptic curve point data length')\n else:\n raise ValueError('Unsupported elliptic curve point type')\n\n curve = utils.read_only_property(\"_curve\")\n x = utils.read_only_property(\"_x\")\n y = utils.read_only_property(\"_y\")\n\n def __eq__(self, other):\n if not isinstance(other, EllipticCurvePublicNumbers):\n return NotImplemented\n\n return (\n self.x == other.x and\n self.y == other.y and\n self.curve.name == other.curve.name and\n self.curve.key_size == other.curve.key_size\n )\n\n def __ne__(self, other):\n return not self == other\n\n\nclass EllipticCurvePrivateNumbers(object):\n def __init__(self, private_value, public_numbers):\n if not isinstance(private_value, six.integer_types):\n raise TypeError(\"private_value must be an integer.\")\n\n if not isinstance(public_numbers, EllipticCurvePublicNumbers):\n raise TypeError(\n \"public_numbers must be an EllipticCurvePublicNumbers \"\n \"instance.\"\n )\n\n self._private_value = private_value\n self._public_numbers = public_numbers\n\n def private_key(self, backend):\n return backend.load_elliptic_curve_private_numbers(self)\n\n private_value = utils.read_only_property(\"_private_value\")\n public_numbers = utils.read_only_property(\"_public_numbers\")\n\n def __eq__(self, other):\n if not isinstance(other, EllipticCurvePrivateNumbers):\n return NotImplemented\n\n return (\n self.private_value == other.private_value and\n self.public_numbers == other.public_numbers\n )\n\n def __ne__(self, other):\n return not self == other\n\n\nclass ECDH(object):\n pass\n", "path": "src/cryptography/hazmat/primitives/asymmetric/ec.py"}], "after_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport abc\n\nimport six\n\nfrom cryptography import utils\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurve(object):\n @abc.abstractproperty\n def name(self):\n \"\"\"\n The name of the curve. e.g. secp256r1.\n \"\"\"\n\n @abc.abstractproperty\n def key_size(self):\n \"\"\"\n The bit length of the base point of the curve.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurveSignatureAlgorithm(object):\n @abc.abstractproperty\n def algorithm(self):\n \"\"\"\n The digest algorithm used with this signature.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurvePrivateKey(object):\n @abc.abstractmethod\n def signer(self, signature_algorithm):\n \"\"\"\n Returns an AsymmetricSignatureContext used for signing data.\n \"\"\"\n\n @abc.abstractmethod\n def exchange(self, algorithm, peer_public_key):\n \"\"\"\n Performs a key exchange operation using the provided algorithm with the\n provided peer's public key.\n \"\"\"\n\n @abc.abstractmethod\n def public_key(self):\n \"\"\"\n The EllipticCurvePublicKey for this private key.\n \"\"\"\n\n @abc.abstractproperty\n def curve(self):\n \"\"\"\n The EllipticCurve that this key is on.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurvePrivateKeyWithSerialization(EllipticCurvePrivateKey):\n @abc.abstractmethod\n def private_numbers(self):\n \"\"\"\n Returns an EllipticCurvePrivateNumbers.\n \"\"\"\n\n @abc.abstractmethod\n def private_bytes(self, encoding, format, encryption_algorithm):\n \"\"\"\n Returns the key serialized as bytes.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass EllipticCurvePublicKey(object):\n @abc.abstractmethod\n def verifier(self, signature, signature_algorithm):\n \"\"\"\n Returns an AsymmetricVerificationContext used for signing data.\n \"\"\"\n\n @abc.abstractproperty\n def curve(self):\n \"\"\"\n The EllipticCurve that this key is on.\n \"\"\"\n\n @abc.abstractmethod\n def public_numbers(self):\n \"\"\"\n Returns an EllipticCurvePublicNumbers.\n \"\"\"\n\n @abc.abstractmethod\n def public_bytes(self, encoding, format):\n \"\"\"\n Returns the key serialized as bytes.\n \"\"\"\n\n\nEllipticCurvePublicKeyWithSerialization = EllipticCurvePublicKey\n\n\[email protected]_interface(EllipticCurve)\nclass SECT571R1(object):\n name = \"sect571r1\"\n key_size = 571\n\n\[email protected]_interface(EllipticCurve)\nclass SECT409R1(object):\n name = \"sect409r1\"\n key_size = 409\n\n\[email protected]_interface(EllipticCurve)\nclass SECT283R1(object):\n name = \"sect283r1\"\n key_size = 283\n\n\[email protected]_interface(EllipticCurve)\nclass SECT233R1(object):\n name = \"sect233r1\"\n key_size = 233\n\n\[email protected]_interface(EllipticCurve)\nclass SECT163R2(object):\n name = \"sect163r2\"\n key_size = 163\n\n\[email protected]_interface(EllipticCurve)\nclass SECT571K1(object):\n name = \"sect571k1\"\n key_size = 571\n\n\[email protected]_interface(EllipticCurve)\nclass SECT409K1(object):\n name = \"sect409k1\"\n key_size = 409\n\n\[email protected]_interface(EllipticCurve)\nclass SECT283K1(object):\n name = \"sect283k1\"\n key_size = 283\n\n\[email protected]_interface(EllipticCurve)\nclass SECT233K1(object):\n name = \"sect233k1\"\n key_size = 233\n\n\[email protected]_interface(EllipticCurve)\nclass SECT163K1(object):\n name = \"sect163k1\"\n key_size = 163\n\n\[email protected]_interface(EllipticCurve)\nclass SECP521R1(object):\n name = \"secp521r1\"\n key_size = 521\n\n\[email protected]_interface(EllipticCurve)\nclass SECP384R1(object):\n name = \"secp384r1\"\n key_size = 384\n\n\[email protected]_interface(EllipticCurve)\nclass SECP256R1(object):\n name = \"secp256r1\"\n key_size = 256\n\n\[email protected]_interface(EllipticCurve)\nclass SECP256K1(object):\n name = \"secp256k1\"\n key_size = 256\n\n\[email protected]_interface(EllipticCurve)\nclass SECP224R1(object):\n name = \"secp224r1\"\n key_size = 224\n\n\[email protected]_interface(EllipticCurve)\nclass SECP192R1(object):\n name = \"secp192r1\"\n key_size = 192\n\n\n_CURVE_TYPES = {\n \"prime192v1\": SECP192R1,\n \"prime256v1\": SECP256R1,\n\n \"secp192r1\": SECP192R1,\n \"secp224r1\": SECP224R1,\n \"secp256r1\": SECP256R1,\n \"secp384r1\": SECP384R1,\n \"secp521r1\": SECP521R1,\n \"secp256k1\": SECP256K1,\n\n \"sect163k1\": SECT163K1,\n \"sect233k1\": SECT233K1,\n \"sect283k1\": SECT283K1,\n \"sect409k1\": SECT409K1,\n \"sect571k1\": SECT571K1,\n\n \"sect163r2\": SECT163R2,\n \"sect233r1\": SECT233R1,\n \"sect283r1\": SECT283R1,\n \"sect409r1\": SECT409R1,\n \"sect571r1\": SECT571R1,\n}\n\n\[email protected]_interface(EllipticCurveSignatureAlgorithm)\nclass ECDSA(object):\n def __init__(self, algorithm):\n self._algorithm = algorithm\n\n algorithm = utils.read_only_property(\"_algorithm\")\n\n\ndef generate_private_key(curve, backend):\n return backend.generate_elliptic_curve_private_key(curve)\n\n\nclass EllipticCurvePublicNumbers(object):\n def __init__(self, x, y, curve):\n if (\n not isinstance(x, six.integer_types) or\n not isinstance(y, six.integer_types)\n ):\n raise TypeError(\"x and y must be integers.\")\n\n if not isinstance(curve, EllipticCurve):\n raise TypeError(\"curve must provide the EllipticCurve interface.\")\n\n self._y = y\n self._x = x\n self._curve = curve\n\n def public_key(self, backend):\n return backend.load_elliptic_curve_public_numbers(self)\n\n def encode_point(self):\n # key_size is in bits. Convert to bytes and round up\n byte_length = (self.curve.key_size + 7) // 8\n return (\n b'\\x04' + utils.int_to_bytes(self.x, byte_length) +\n utils.int_to_bytes(self.y, byte_length)\n )\n\n @classmethod\n def from_encoded_point(cls, curve, data):\n if not isinstance(curve, EllipticCurve):\n raise TypeError(\"curve must be an EllipticCurve instance\")\n\n if data.startswith(b'\\x04'):\n # key_size is in bits. Convert to bytes and round up\n byte_length = (curve.key_size + 7) // 8\n if len(data) == 2 * byte_length + 1:\n x = utils.int_from_bytes(data[1:byte_length + 1], 'big')\n y = utils.int_from_bytes(data[byte_length + 1:], 'big')\n return cls(x, y, curve)\n else:\n raise ValueError('Invalid elliptic curve point data length')\n else:\n raise ValueError('Unsupported elliptic curve point type')\n\n curve = utils.read_only_property(\"_curve\")\n x = utils.read_only_property(\"_x\")\n y = utils.read_only_property(\"_y\")\n\n def __eq__(self, other):\n if not isinstance(other, EllipticCurvePublicNumbers):\n return NotImplemented\n\n return (\n self.x == other.x and\n self.y == other.y and\n self.curve.name == other.curve.name and\n self.curve.key_size == other.curve.key_size\n )\n\n def __ne__(self, other):\n return not self == other\n\n def __repr__(self):\n return (\n \"<EllipticCurvePublicNumbers(curve={0.curve.name}, x={0.x}, \"\n \"y={0.y}>\".format(self)\n )\n\n\nclass EllipticCurvePrivateNumbers(object):\n def __init__(self, private_value, public_numbers):\n if not isinstance(private_value, six.integer_types):\n raise TypeError(\"private_value must be an integer.\")\n\n if not isinstance(public_numbers, EllipticCurvePublicNumbers):\n raise TypeError(\n \"public_numbers must be an EllipticCurvePublicNumbers \"\n \"instance.\"\n )\n\n self._private_value = private_value\n self._public_numbers = public_numbers\n\n def private_key(self, backend):\n return backend.load_elliptic_curve_private_numbers(self)\n\n private_value = utils.read_only_property(\"_private_value\")\n public_numbers = utils.read_only_property(\"_public_numbers\")\n\n def __eq__(self, other):\n if not isinstance(other, EllipticCurvePrivateNumbers):\n return NotImplemented\n\n return (\n self.private_value == other.private_value and\n self.public_numbers == other.public_numbers\n )\n\n def __ne__(self, other):\n return not self == other\n\n\nclass ECDH(object):\n pass\n", "path": "src/cryptography/hazmat/primitives/asymmetric/ec.py"}]}
| 3,591 | 164 |
gh_patches_debug_1528
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-3896
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `colossalai/cli/launcher/run.py`
Content:
```
1 import os
2 import sys
3 from typing import List
4
5 import click
6 import torch
7 from packaging import version
8
9 from colossalai.context import Config
10
11 from .hostinfo import HostInfo, HostInfoList
12 from .multinode_runner import MultiNodeRunner
13
14 # Constants that define our syntax
15 NODE_SEP = ','
16
17
18 def fetch_hostfile(hostfile_path: str, ssh_port: int) -> HostInfoList:
19 """
20 Parse the hostfile to obtain a list of hosts.
21
22 A hostfile should look like:
23 worker-0
24 worker-1
25 worker-2
26 ...
27
28 Args:
29 hostfile_path (str): the path to the hostfile
30 ssh_port (int): the port to connect to the host
31 """
32
33 if not os.path.isfile(hostfile_path):
34 click.echo(f"Error: Unable to find the hostfile, no such file: {hostfile_path}")
35 exit()
36
37 with open(hostfile_path, 'r') as fd:
38 device_pool = HostInfoList()
39
40 for line in fd.readlines():
41 line = line.strip()
42 if line == '':
43 # skip empty lines
44 continue
45
46 # build the HostInfo object
47 hostname = line.strip()
48 hostinfo = HostInfo(hostname=hostname, port=ssh_port)
49
50 if device_pool.has(hostname):
51 click.echo(f"Error: found duplicate host {hostname} in the hostfile")
52 exit()
53
54 device_pool.append(hostinfo)
55 return device_pool
56
57
58 def parse_device_filter(device_pool: HostInfoList, include_str=None, exclude_str=None) -> HostInfoList:
59 '''Parse an inclusion or exclusion string and filter a hostfile dictionary.
60
61 Examples:
62 include_str="worker-0,worker-1" will execute jobs only on worker-0 and worker-1.
63 exclude_str="worker-1" will use all available devices except worker-1.
64
65 Args:
66 device_pool (HostInfoList): a list of HostInfo objects
67 include_str (str): --include option passed by user, default None
68 exclude_str (str): --exclude option passed by user, default None
69
70 Returns:
71 filtered_hosts (HostInfoList): filtered hosts after inclusion/exclusion
72 '''
73
74 # Ensure include/exclude are mutually exclusive
75 if include_str and exclude_str:
76 click.echo("--include and --exclude are mutually exclusive, only one can be used")
77 exit()
78
79 # no-op
80 if include_str is None and exclude_str is None:
81 return device_pool
82
83 # Either build from scratch or remove items
84 if include_str:
85 parse_str = include_str
86 filtered_hosts = HostInfoList()
87 elif exclude_str:
88 parse_str = exclude_str
89 filtered_hosts = device_pool
90
91 # foreach node in the list
92 for node_config in parse_str.split(NODE_SEP):
93 hostname = node_config
94 hostinfo = device_pool.get_hostinfo(hostname)
95 # sanity check hostname
96 if not device_pool.has(hostname):
97 click.echo(f"Error: Hostname '{hostname}' not found in hostfile")
98 exit()
99
100 if include_str:
101 filtered_hosts.append(hostinfo)
102 elif exclude_str:
103 filtered_hosts.remove(hostname)
104
105 return filtered_hosts
106
107
108 def get_launch_command(
109 master_addr: str,
110 master_port: int,
111 nproc_per_node: int,
112 user_script: str,
113 user_args: List[str],
114 node_rank: int,
115 num_nodes: int,
116 extra_launch_args: str = None,
117 ) -> str:
118 """
119 Generate a command for distributed training.
120
121 Args:
122 master_addr (str): the host of the master node
123 master_port (str): the port of the master node
124 nproc_per_node (str): the number of processes to launch on each node
125 user_script (str): the user Python file
126 user_args (str): the arguments for the user script
127 node_rank (int): the unique ID for the node
128 num_nodes (int): the number of nodes to execute jobs
129
130 Returns:
131 cmd (str): the command the start distributed training
132 """
133
134 def _arg_dict_to_list(arg_dict):
135 ret = []
136
137 for k, v in arg_dict.items():
138 if v:
139 ret.append(f'--{k}={v}')
140 else:
141 ret.append(f'--{k}')
142 return ret
143
144 if extra_launch_args:
145 extra_launch_args_dict = dict()
146 for arg in extra_launch_args.split(','):
147 if '=' in arg:
148 k, v = arg.split('=')
149 extra_launch_args_dict[k] = v
150 else:
151 extra_launch_args_dict[arg] = None
152 extra_launch_args = extra_launch_args_dict
153 else:
154 extra_launch_args = dict()
155
156 torch_version = version.parse(torch.__version__)
157 assert torch_version.major == 1
158
159 if torch_version.minor < 9:
160 cmd = [
161 sys.executable, "-m", "torch.distributed.launch", f"--nproc_per_node={nproc_per_node}",
162 f"--master_addr={master_addr}", f"--master_port={master_port}", f"--nnodes={num_nodes}",
163 f"--node_rank={node_rank}"
164 ]
165 else:
166 # extra launch args for torch distributed launcher with torch >= 1.9
167 default_torchrun_rdzv_args = dict(rdzv_backend="c10d",
168 rdzv_endpoint=f"{master_addr}:{master_port}",
169 rdzv_id="colossalai-default-job")
170
171 # update rdzv arguments
172 for key in default_torchrun_rdzv_args.keys():
173 if key in extra_launch_args:
174 value = extra_launch_args.pop(key)
175 default_torchrun_rdzv_args[key] = value
176
177 if torch_version.minor < 10:
178 cmd = [
179 sys.executable, "-m", "torch.distributed.run", f"--nproc_per_node={nproc_per_node}",
180 f"--nnodes={num_nodes}", f"--node_rank={node_rank}"
181 ]
182 else:
183 cmd = [
184 "torchrun", f"--nproc_per_node={nproc_per_node}", f"--nnodes={num_nodes}", f"--node_rank={node_rank}"
185 ]
186 cmd += _arg_dict_to_list(default_torchrun_rdzv_args)
187
188 cmd += _arg_dict_to_list(extra_launch_args) + [user_script] + user_args
189 cmd = ' '.join(cmd)
190 return cmd
191
192
193 def launch_multi_processes(args: Config) -> None:
194 """
195 Launch multiple processes on a single node or multiple nodes.
196
197 The overall logic can be summarized as the pseudo code below:
198
199 if hostfile given:
200 hostinfo = parse_hostfile(hostfile)
201 hostinfo = include_or_exclude_hosts(hostinfo)
202 launch_on_multi_nodes(hostinfo)
203 elif hosts given:
204 hostinfo = parse_hosts(hosts)
205 launch_on_multi_nodes(hostinfo)
206 else:
207 launch_on_current_node()
208
209 Args:
210 args (Config): the arguments taken from command line
211
212 """
213 assert isinstance(args, Config)
214
215 if args.nproc_per_node is None:
216 click.echo("--nproc_per_node did not receive any value")
217 exit()
218
219 # cannot accept hosts and hostfile at the same time
220 if args.host and args.hostfile:
221 click.echo("Error: hostfile and hosts are mutually exclusive, only one is required")
222
223 # check if hostfile is given
224 if args.hostfile:
225 device_pool = fetch_hostfile(args.hostfile, ssh_port=args.ssh_port)
226 active_device_pool = parse_device_filter(device_pool, args.include, args.exclude)
227
228 if args.num_nodes > 0:
229 # only keep the first num_nodes to execute jobs
230 updated_active_device_pool = HostInfoList()
231 for count, hostinfo in enumerate(active_device_pool):
232 if args.num_nodes == count:
233 break
234 updated_active_device_pool.append(hostinfo)
235 active_device_pool = updated_active_device_pool
236 else:
237 active_device_pool = None
238
239 env = os.environ.copy()
240
241 # use hosts if hostfile is not given
242 if args.host and active_device_pool is None:
243 active_device_pool = HostInfoList()
244 host_list = args.host.strip().split(NODE_SEP)
245 for hostname in host_list:
246 hostinfo = HostInfo(hostname=hostname, port=args.ssh_port)
247 active_device_pool.append(hostinfo)
248
249 if not active_device_pool:
250 # run on local node if not hosts or hostfile is given
251 # add local node to host info list
252 active_device_pool = HostInfoList()
253 localhost_info = HostInfo(hostname='127.0.0.1', port=args.ssh_port)
254 active_device_pool.append(localhost_info)
255
256 # launch distributed processes
257 runner = MultiNodeRunner()
258 curr_path = os.path.abspath('.')
259
260 # collect current path env
261 env = dict()
262 for k, v in os.environ.items():
263 # do not support multi-line env var
264 if v and '\n' not in v:
265 env[k] = v
266
267 # establish remote connection
268 runner.connect(host_info_list=active_device_pool, workdir=curr_path, env=env)
269
270 # execute distributed launching command
271 for node_id, hostinfo in enumerate(active_device_pool):
272 cmd = get_launch_command(master_addr=args.master_addr,
273 master_port=args.master_port,
274 nproc_per_node=args.nproc_per_node,
275 user_script=args.user_script,
276 user_args=args.user_args,
277 node_rank=node_id,
278 num_nodes=len(active_device_pool),
279 extra_launch_args=args.extra_launch_args)
280 runner.send(hostinfo=hostinfo, cmd=cmd)
281
282 # start training
283 msg_from_node = runner.recv_from_all()
284 has_error = False
285
286 # print node status
287 click.echo("\n====== Training on All Nodes =====")
288 for hostname, msg in msg_from_node.items():
289 click.echo(f"{hostname}: {msg}")
290
291 # check if a process failed
292 if msg == "failure":
293 has_error = True
294
295 # stop all nodes
296 runner.stop_all()
297
298 # receive the stop status
299 msg_from_node = runner.recv_from_all()
300
301 # print node status
302 click.echo("\n====== Stopping All Nodes =====")
303 for hostname, msg in msg_from_node.items():
304 click.echo(f"{hostname}: {msg}")
305
306 # give the process an exit code
307 # so that it behaves like a normal process
308 if has_error:
309 sys.exit(1)
310 else:
311 sys.exit(0)
312
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/colossalai/cli/launcher/run.py b/colossalai/cli/launcher/run.py
--- a/colossalai/cli/launcher/run.py
+++ b/colossalai/cli/launcher/run.py
@@ -154,7 +154,7 @@
extra_launch_args = dict()
torch_version = version.parse(torch.__version__)
- assert torch_version.major == 1
+ assert torch_version.major >= 1
if torch_version.minor < 9:
cmd = [
|
{"golden_diff": "diff --git a/colossalai/cli/launcher/run.py b/colossalai/cli/launcher/run.py\n--- a/colossalai/cli/launcher/run.py\n+++ b/colossalai/cli/launcher/run.py\n@@ -154,7 +154,7 @@\n extra_launch_args = dict()\n \n torch_version = version.parse(torch.__version__)\n- assert torch_version.major == 1\n+ assert torch_version.major >= 1\n \n if torch_version.minor < 9:\n cmd = [\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "import os\nimport sys\nfrom typing import List\n\nimport click\nimport torch\nfrom packaging import version\n\nfrom colossalai.context import Config\n\nfrom .hostinfo import HostInfo, HostInfoList\nfrom .multinode_runner import MultiNodeRunner\n\n# Constants that define our syntax\nNODE_SEP = ','\n\n\ndef fetch_hostfile(hostfile_path: str, ssh_port: int) -> HostInfoList:\n \"\"\"\n Parse the hostfile to obtain a list of hosts.\n\n A hostfile should look like:\n worker-0\n worker-1\n worker-2\n ...\n\n Args:\n hostfile_path (str): the path to the hostfile\n ssh_port (int): the port to connect to the host\n \"\"\"\n\n if not os.path.isfile(hostfile_path):\n click.echo(f\"Error: Unable to find the hostfile, no such file: {hostfile_path}\")\n exit()\n\n with open(hostfile_path, 'r') as fd:\n device_pool = HostInfoList()\n\n for line in fd.readlines():\n line = line.strip()\n if line == '':\n # skip empty lines\n continue\n\n # build the HostInfo object\n hostname = line.strip()\n hostinfo = HostInfo(hostname=hostname, port=ssh_port)\n\n if device_pool.has(hostname):\n click.echo(f\"Error: found duplicate host {hostname} in the hostfile\")\n exit()\n\n device_pool.append(hostinfo)\n return device_pool\n\n\ndef parse_device_filter(device_pool: HostInfoList, include_str=None, exclude_str=None) -> HostInfoList:\n '''Parse an inclusion or exclusion string and filter a hostfile dictionary.\n\n Examples:\n include_str=\"worker-0,worker-1\" will execute jobs only on worker-0 and worker-1.\n exclude_str=\"worker-1\" will use all available devices except worker-1.\n\n Args:\n device_pool (HostInfoList): a list of HostInfo objects\n include_str (str): --include option passed by user, default None\n exclude_str (str): --exclude option passed by user, default None\n\n Returns:\n filtered_hosts (HostInfoList): filtered hosts after inclusion/exclusion\n '''\n\n # Ensure include/exclude are mutually exclusive\n if include_str and exclude_str:\n click.echo(\"--include and --exclude are mutually exclusive, only one can be used\")\n exit()\n\n # no-op\n if include_str is None and exclude_str is None:\n return device_pool\n\n # Either build from scratch or remove items\n if include_str:\n parse_str = include_str\n filtered_hosts = HostInfoList()\n elif exclude_str:\n parse_str = exclude_str\n filtered_hosts = device_pool\n\n # foreach node in the list\n for node_config in parse_str.split(NODE_SEP):\n hostname = node_config\n hostinfo = device_pool.get_hostinfo(hostname)\n # sanity check hostname\n if not device_pool.has(hostname):\n click.echo(f\"Error: Hostname '{hostname}' not found in hostfile\")\n exit()\n\n if include_str:\n filtered_hosts.append(hostinfo)\n elif exclude_str:\n filtered_hosts.remove(hostname)\n\n return filtered_hosts\n\n\ndef get_launch_command(\n master_addr: str,\n master_port: int,\n nproc_per_node: int,\n user_script: str,\n user_args: List[str],\n node_rank: int,\n num_nodes: int,\n extra_launch_args: str = None,\n) -> str:\n \"\"\"\n Generate a command for distributed training.\n\n Args:\n master_addr (str): the host of the master node\n master_port (str): the port of the master node\n nproc_per_node (str): the number of processes to launch on each node\n user_script (str): the user Python file\n user_args (str): the arguments for the user script\n node_rank (int): the unique ID for the node\n num_nodes (int): the number of nodes to execute jobs\n\n Returns:\n cmd (str): the command the start distributed training\n \"\"\"\n\n def _arg_dict_to_list(arg_dict):\n ret = []\n\n for k, v in arg_dict.items():\n if v:\n ret.append(f'--{k}={v}')\n else:\n ret.append(f'--{k}')\n return ret\n\n if extra_launch_args:\n extra_launch_args_dict = dict()\n for arg in extra_launch_args.split(','):\n if '=' in arg:\n k, v = arg.split('=')\n extra_launch_args_dict[k] = v\n else:\n extra_launch_args_dict[arg] = None\n extra_launch_args = extra_launch_args_dict\n else:\n extra_launch_args = dict()\n\n torch_version = version.parse(torch.__version__)\n assert torch_version.major == 1\n\n if torch_version.minor < 9:\n cmd = [\n sys.executable, \"-m\", \"torch.distributed.launch\", f\"--nproc_per_node={nproc_per_node}\",\n f\"--master_addr={master_addr}\", f\"--master_port={master_port}\", f\"--nnodes={num_nodes}\",\n f\"--node_rank={node_rank}\"\n ]\n else:\n # extra launch args for torch distributed launcher with torch >= 1.9\n default_torchrun_rdzv_args = dict(rdzv_backend=\"c10d\",\n rdzv_endpoint=f\"{master_addr}:{master_port}\",\n rdzv_id=\"colossalai-default-job\")\n\n # update rdzv arguments\n for key in default_torchrun_rdzv_args.keys():\n if key in extra_launch_args:\n value = extra_launch_args.pop(key)\n default_torchrun_rdzv_args[key] = value\n\n if torch_version.minor < 10:\n cmd = [\n sys.executable, \"-m\", \"torch.distributed.run\", f\"--nproc_per_node={nproc_per_node}\",\n f\"--nnodes={num_nodes}\", f\"--node_rank={node_rank}\"\n ]\n else:\n cmd = [\n \"torchrun\", f\"--nproc_per_node={nproc_per_node}\", f\"--nnodes={num_nodes}\", f\"--node_rank={node_rank}\"\n ]\n cmd += _arg_dict_to_list(default_torchrun_rdzv_args)\n\n cmd += _arg_dict_to_list(extra_launch_args) + [user_script] + user_args\n cmd = ' '.join(cmd)\n return cmd\n\n\ndef launch_multi_processes(args: Config) -> None:\n \"\"\"\n Launch multiple processes on a single node or multiple nodes.\n\n The overall logic can be summarized as the pseudo code below:\n\n if hostfile given:\n hostinfo = parse_hostfile(hostfile)\n hostinfo = include_or_exclude_hosts(hostinfo)\n launch_on_multi_nodes(hostinfo)\n elif hosts given:\n hostinfo = parse_hosts(hosts)\n launch_on_multi_nodes(hostinfo)\n else:\n launch_on_current_node()\n\n Args:\n args (Config): the arguments taken from command line\n\n \"\"\"\n assert isinstance(args, Config)\n\n if args.nproc_per_node is None:\n click.echo(\"--nproc_per_node did not receive any value\")\n exit()\n\n # cannot accept hosts and hostfile at the same time\n if args.host and args.hostfile:\n click.echo(\"Error: hostfile and hosts are mutually exclusive, only one is required\")\n\n # check if hostfile is given\n if args.hostfile:\n device_pool = fetch_hostfile(args.hostfile, ssh_port=args.ssh_port)\n active_device_pool = parse_device_filter(device_pool, args.include, args.exclude)\n\n if args.num_nodes > 0:\n # only keep the first num_nodes to execute jobs\n updated_active_device_pool = HostInfoList()\n for count, hostinfo in enumerate(active_device_pool):\n if args.num_nodes == count:\n break\n updated_active_device_pool.append(hostinfo)\n active_device_pool = updated_active_device_pool\n else:\n active_device_pool = None\n\n env = os.environ.copy()\n\n # use hosts if hostfile is not given\n if args.host and active_device_pool is None:\n active_device_pool = HostInfoList()\n host_list = args.host.strip().split(NODE_SEP)\n for hostname in host_list:\n hostinfo = HostInfo(hostname=hostname, port=args.ssh_port)\n active_device_pool.append(hostinfo)\n\n if not active_device_pool:\n # run on local node if not hosts or hostfile is given\n # add local node to host info list\n active_device_pool = HostInfoList()\n localhost_info = HostInfo(hostname='127.0.0.1', port=args.ssh_port)\n active_device_pool.append(localhost_info)\n\n # launch distributed processes\n runner = MultiNodeRunner()\n curr_path = os.path.abspath('.')\n\n # collect current path env\n env = dict()\n for k, v in os.environ.items():\n # do not support multi-line env var\n if v and '\\n' not in v:\n env[k] = v\n\n # establish remote connection\n runner.connect(host_info_list=active_device_pool, workdir=curr_path, env=env)\n\n # execute distributed launching command\n for node_id, hostinfo in enumerate(active_device_pool):\n cmd = get_launch_command(master_addr=args.master_addr,\n master_port=args.master_port,\n nproc_per_node=args.nproc_per_node,\n user_script=args.user_script,\n user_args=args.user_args,\n node_rank=node_id,\n num_nodes=len(active_device_pool),\n extra_launch_args=args.extra_launch_args)\n runner.send(hostinfo=hostinfo, cmd=cmd)\n\n # start training\n msg_from_node = runner.recv_from_all()\n has_error = False\n\n # print node status\n click.echo(\"\\n====== Training on All Nodes =====\")\n for hostname, msg in msg_from_node.items():\n click.echo(f\"{hostname}: {msg}\")\n\n # check if a process failed\n if msg == \"failure\":\n has_error = True\n\n # stop all nodes\n runner.stop_all()\n\n # receive the stop status\n msg_from_node = runner.recv_from_all()\n\n # print node status\n click.echo(\"\\n====== Stopping All Nodes =====\")\n for hostname, msg in msg_from_node.items():\n click.echo(f\"{hostname}: {msg}\")\n\n # give the process an exit code\n # so that it behaves like a normal process\n if has_error:\n sys.exit(1)\n else:\n sys.exit(0)\n", "path": "colossalai/cli/launcher/run.py"}], "after_files": [{"content": "import os\nimport sys\nfrom typing import List\n\nimport click\nimport torch\nfrom packaging import version\n\nfrom colossalai.context import Config\n\nfrom .hostinfo import HostInfo, HostInfoList\nfrom .multinode_runner import MultiNodeRunner\n\n# Constants that define our syntax\nNODE_SEP = ','\n\n\ndef fetch_hostfile(hostfile_path: str, ssh_port: int) -> HostInfoList:\n \"\"\"\n Parse the hostfile to obtain a list of hosts.\n\n A hostfile should look like:\n worker-0\n worker-1\n worker-2\n ...\n\n Args:\n hostfile_path (str): the path to the hostfile\n ssh_port (int): the port to connect to the host\n \"\"\"\n\n if not os.path.isfile(hostfile_path):\n click.echo(f\"Error: Unable to find the hostfile, no such file: {hostfile_path}\")\n exit()\n\n with open(hostfile_path, 'r') as fd:\n device_pool = HostInfoList()\n\n for line in fd.readlines():\n line = line.strip()\n if line == '':\n # skip empty lines\n continue\n\n # build the HostInfo object\n hostname = line.strip()\n hostinfo = HostInfo(hostname=hostname, port=ssh_port)\n\n if device_pool.has(hostname):\n click.echo(f\"Error: found duplicate host {hostname} in the hostfile\")\n exit()\n\n device_pool.append(hostinfo)\n return device_pool\n\n\ndef parse_device_filter(device_pool: HostInfoList, include_str=None, exclude_str=None) -> HostInfoList:\n '''Parse an inclusion or exclusion string and filter a hostfile dictionary.\n\n Examples:\n include_str=\"worker-0,worker-1\" will execute jobs only on worker-0 and worker-1.\n exclude_str=\"worker-1\" will use all available devices except worker-1.\n\n Args:\n device_pool (HostInfoList): a list of HostInfo objects\n include_str (str): --include option passed by user, default None\n exclude_str (str): --exclude option passed by user, default None\n\n Returns:\n filtered_hosts (HostInfoList): filtered hosts after inclusion/exclusion\n '''\n\n # Ensure include/exclude are mutually exclusive\n if include_str and exclude_str:\n click.echo(\"--include and --exclude are mutually exclusive, only one can be used\")\n exit()\n\n # no-op\n if include_str is None and exclude_str is None:\n return device_pool\n\n # Either build from scratch or remove items\n if include_str:\n parse_str = include_str\n filtered_hosts = HostInfoList()\n elif exclude_str:\n parse_str = exclude_str\n filtered_hosts = device_pool\n\n # foreach node in the list\n for node_config in parse_str.split(NODE_SEP):\n hostname = node_config\n hostinfo = device_pool.get_hostinfo(hostname)\n # sanity check hostname\n if not device_pool.has(hostname):\n click.echo(f\"Error: Hostname '{hostname}' not found in hostfile\")\n exit()\n\n if include_str:\n filtered_hosts.append(hostinfo)\n elif exclude_str:\n filtered_hosts.remove(hostname)\n\n return filtered_hosts\n\n\ndef get_launch_command(\n master_addr: str,\n master_port: int,\n nproc_per_node: int,\n user_script: str,\n user_args: List[str],\n node_rank: int,\n num_nodes: int,\n extra_launch_args: str = None,\n) -> str:\n \"\"\"\n Generate a command for distributed training.\n\n Args:\n master_addr (str): the host of the master node\n master_port (str): the port of the master node\n nproc_per_node (str): the number of processes to launch on each node\n user_script (str): the user Python file\n user_args (str): the arguments for the user script\n node_rank (int): the unique ID for the node\n num_nodes (int): the number of nodes to execute jobs\n\n Returns:\n cmd (str): the command the start distributed training\n \"\"\"\n\n def _arg_dict_to_list(arg_dict):\n ret = []\n\n for k, v in arg_dict.items():\n if v:\n ret.append(f'--{k}={v}')\n else:\n ret.append(f'--{k}')\n return ret\n\n if extra_launch_args:\n extra_launch_args_dict = dict()\n for arg in extra_launch_args.split(','):\n if '=' in arg:\n k, v = arg.split('=')\n extra_launch_args_dict[k] = v\n else:\n extra_launch_args_dict[arg] = None\n extra_launch_args = extra_launch_args_dict\n else:\n extra_launch_args = dict()\n\n torch_version = version.parse(torch.__version__)\n assert torch_version.major >= 1\n\n if torch_version.minor < 9:\n cmd = [\n sys.executable, \"-m\", \"torch.distributed.launch\", f\"--nproc_per_node={nproc_per_node}\",\n f\"--master_addr={master_addr}\", f\"--master_port={master_port}\", f\"--nnodes={num_nodes}\",\n f\"--node_rank={node_rank}\"\n ]\n else:\n # extra launch args for torch distributed launcher with torch >= 1.9\n default_torchrun_rdzv_args = dict(rdzv_backend=\"c10d\",\n rdzv_endpoint=f\"{master_addr}:{master_port}\",\n rdzv_id=\"colossalai-default-job\")\n\n # update rdzv arguments\n for key in default_torchrun_rdzv_args.keys():\n if key in extra_launch_args:\n value = extra_launch_args.pop(key)\n default_torchrun_rdzv_args[key] = value\n\n if torch_version.minor < 10:\n cmd = [\n sys.executable, \"-m\", \"torch.distributed.run\", f\"--nproc_per_node={nproc_per_node}\",\n f\"--nnodes={num_nodes}\", f\"--node_rank={node_rank}\"\n ]\n else:\n cmd = [\n \"torchrun\", f\"--nproc_per_node={nproc_per_node}\", f\"--nnodes={num_nodes}\", f\"--node_rank={node_rank}\"\n ]\n cmd += _arg_dict_to_list(default_torchrun_rdzv_args)\n\n cmd += _arg_dict_to_list(extra_launch_args) + [user_script] + user_args\n cmd = ' '.join(cmd)\n return cmd\n\n\ndef launch_multi_processes(args: Config) -> None:\n \"\"\"\n Launch multiple processes on a single node or multiple nodes.\n\n The overall logic can be summarized as the pseudo code below:\n\n if hostfile given:\n hostinfo = parse_hostfile(hostfile)\n hostinfo = include_or_exclude_hosts(hostinfo)\n launch_on_multi_nodes(hostinfo)\n elif hosts given:\n hostinfo = parse_hosts(hosts)\n launch_on_multi_nodes(hostinfo)\n else:\n launch_on_current_node()\n\n Args:\n args (Config): the arguments taken from command line\n\n \"\"\"\n assert isinstance(args, Config)\n\n if args.nproc_per_node is None:\n click.echo(\"--nproc_per_node did not receive any value\")\n exit()\n\n # cannot accept hosts and hostfile at the same time\n if args.host and args.hostfile:\n click.echo(\"Error: hostfile and hosts are mutually exclusive, only one is required\")\n\n # check if hostfile is given\n if args.hostfile:\n device_pool = fetch_hostfile(args.hostfile, ssh_port=args.ssh_port)\n active_device_pool = parse_device_filter(device_pool, args.include, args.exclude)\n\n if args.num_nodes > 0:\n # only keep the first num_nodes to execute jobs\n updated_active_device_pool = HostInfoList()\n for count, hostinfo in enumerate(active_device_pool):\n if args.num_nodes == count:\n break\n updated_active_device_pool.append(hostinfo)\n active_device_pool = updated_active_device_pool\n else:\n active_device_pool = None\n\n env = os.environ.copy()\n\n # use hosts if hostfile is not given\n if args.host and active_device_pool is None:\n active_device_pool = HostInfoList()\n host_list = args.host.strip().split(NODE_SEP)\n for hostname in host_list:\n hostinfo = HostInfo(hostname=hostname, port=args.ssh_port)\n active_device_pool.append(hostinfo)\n\n if not active_device_pool:\n # run on local node if not hosts or hostfile is given\n # add local node to host info list\n active_device_pool = HostInfoList()\n localhost_info = HostInfo(hostname='127.0.0.1', port=args.ssh_port)\n active_device_pool.append(localhost_info)\n\n # launch distributed processes\n runner = MultiNodeRunner()\n curr_path = os.path.abspath('.')\n\n # collect current path env\n env = dict()\n for k, v in os.environ.items():\n # do not support multi-line env var\n if v and '\\n' not in v:\n env[k] = v\n\n # establish remote connection\n runner.connect(host_info_list=active_device_pool, workdir=curr_path, env=env)\n\n # execute distributed launching command\n for node_id, hostinfo in enumerate(active_device_pool):\n cmd = get_launch_command(master_addr=args.master_addr,\n master_port=args.master_port,\n nproc_per_node=args.nproc_per_node,\n user_script=args.user_script,\n user_args=args.user_args,\n node_rank=node_id,\n num_nodes=len(active_device_pool),\n extra_launch_args=args.extra_launch_args)\n runner.send(hostinfo=hostinfo, cmd=cmd)\n\n # start training\n msg_from_node = runner.recv_from_all()\n has_error = False\n\n # print node status\n click.echo(\"\\n====== Training on All Nodes =====\")\n for hostname, msg in msg_from_node.items():\n click.echo(f\"{hostname}: {msg}\")\n\n # check if a process failed\n if msg == \"failure\":\n has_error = True\n\n # stop all nodes\n runner.stop_all()\n\n # receive the stop status\n msg_from_node = runner.recv_from_all()\n\n # printe node status\n click.echo(\"\\n====== Stopping All Nodes =====\")\n for hostname, msg in msg_from_node.items():\n click.echo(f\"{hostname}: {msg}\")\n\n # give the process an exit code\n # so that it behaves like a normal process\n if has_error:\n sys.exit(1)\n else:\n sys.exit(0)\n", "path": "colossalai/cli/launcher/run.py"}]}
| 3,411 | 114 |
gh_patches_debug_14414
|
rasdani/github-patches
|
git_diff
|
electricitymaps__electricitymaps-contrib-2106
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Nova Scotia new URL (CA_NS)
Quick note, I haven't had a chance to dig into it in detail yet:
Looks like the website has been redesigned and things shuffled around a bit.
New page URL is https://www.nspower.ca/clean-energy/todays-energy-stats
JSON URL is now https://www.nspower.ca/library/CurrentLoad/CurrentMix.json
JSON format looks similar to before so it might just be a matter of swapping the URL.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `parsers/CA_NS.py`
Content:
```
1 #!/usr/bin/env python3
2
3 # The arrow library is used to handle datetimes
4 import arrow
5 # The request library is used to fetch content through HTTP
6 import requests
7
8
9 def _get_ns_info(requests_obj, logger):
10 zone_key = 'CA-NS'
11
12 # This is based on validation logic in https://www.nspower.ca/site/renewables/assets/js/site.js
13 # In practical terms, I've seen hydro production go way too high (>70%) which is way more
14 # than reported capacity.
15 valid_percent = {
16 # The validation JS reports error when Solid Fuel (coal) is over 85%,
17 # but as far as I can tell, that can actually be a valid result, I've seen it a few times.
18 # Use 98% instead.
19 'coal': (0.25, 0.98),
20 'gas': (0, 0.5),
21 'biomass': (0, 0.15),
22 'hydro': (0, 0.60),
23 'wind': (0, 0.55),
24 'imports': (0, 0.20)
25 }
26
27 # Sanity checks: verify that reported production doesn't exceed listed capacity by a lot.
28 # In particular, we've seen error cases where hydro production ends up calculated as 900 MW
29 # which greatly exceeds known capacity of 418 MW.
30 valid_absolute = {
31 'coal': 1300,
32 'gas': 700,
33 'biomass': 100,
34 'hydro': 500,
35 'wind': 700
36 }
37
38 # As of November 2018, NSPower redirects their web traffic to HTTPS. However we've been
39 # getting SSL errors in Python, even though loading these URLs in Firefox 63 gives no errors.
40 # This isn't confidential or security-sensitive data, so ignore the SSL errors.
41 mix_url = 'https://www.nspower.ca/system_report/today/currentmix.json'
42 mix_data = requests_obj.get(mix_url, verify=False).json()
43
44 load_url = 'https://www.nspower.ca/system_report/today/currentload.json'
45 load_data = requests_obj.get(load_url, verify=False).json()
46
47 production = []
48 imports = []
49 for mix in mix_data:
50 percent_mix = {
51 'coal': mix['Solid Fuel'] / 100.0,
52 'gas': (mix['HFO/Natural Gas'] + mix['CT\'s'] + mix['LM 6000\'s']) / 100.0,
53 'biomass': mix['Biomass'] / 100.0,
54 'hydro': mix['Hydro'] / 100.0,
55 'wind': mix['Wind'] / 100.0,
56 'imports': mix['Imports'] / 100.0
57 }
58
59 # datetime is in format '/Date(1493924400000)/'
60 # get the timestamp 1493924400 (cutting out last three zeros as well)
61 data_timestamp = int(mix['datetime'][6:-5])
62 data_date = arrow.get(data_timestamp).datetime
63
64 # validate
65 valid = True
66 for gen_type, value in percent_mix.items():
67 percent_bounds = valid_percent[gen_type]
68 if not (percent_bounds[0] <= value <= percent_bounds[1]):
69 # skip this datapoint in the loop
70 valid = False
71 logger.warning(
72 'discarding datapoint at {dt} due to {fuel} percentage '
73 'out of bounds: {value}'.format(dt=data_date, fuel=gen_type, value=value),
74 extra={'key': zone_key})
75 if not valid:
76 # continue the outer loop, not the inner
77 continue
78
79 # in mix_data, the values are expressed as percentages,
80 # and have to be multiplied by load to find the actual MW value.
81 corresponding_load = [load_period for load_period in load_data
82 if load_period['datetime'] == mix['datetime']]
83 if corresponding_load:
84 load = corresponding_load[0]['Base Load']
85 else:
86 # if not found, assume 1244 MW, based on average yearly electricity available for use
87 # in 2014 and 2015 (Statistics Canada table Table 127-0008 for Nova Scotia)
88 load = 1244
89 logger.warning('unable to find load for {}, assuming 1244 MW'.format(data_date),
90 extra={'key': zone_key})
91
92 electricity_mix = {
93 gen_type: percent_value * load
94 for gen_type, percent_value in percent_mix.items()
95 }
96
97 # validate again
98 valid = True
99 for gen_type, value in electricity_mix.items():
100 absolute_bound = valid_absolute.get(gen_type) # imports are not in valid_absolute
101 if absolute_bound and value > absolute_bound:
102 valid = False
103 logger.warning(
104 'discarding datapoint at {dt} due to {fuel} '
105 'too high: {value} MW'.format(dt=data_date, fuel=gen_type, value=value),
106 extra={'key': zone_key})
107 if not valid:
108 # continue the outer loop, not the inner
109 continue
110
111 production.append({
112 'zoneKey': zone_key,
113 'datetime': data_date,
114 'production': {key: value
115 for key, value in electricity_mix.items()
116 if key != 'imports'},
117 'source': 'nspower.ca'
118 })
119
120 # In this source, imports are positive. In the expected result for CA-NB->CA-NS,
121 # "net" represents a flow from NB to NS, that is, an import to NS.
122 # So the value can be used directly.
123 # Note that this API only specifies imports. When NS is exporting energy, the API returns 0.
124 imports.append({
125 'datetime': data_date,
126 'netFlow': electricity_mix['imports'],
127 'sortedZoneKeys': 'CA-NB->CA-NS',
128 'source': 'nspower.ca'
129 })
130
131 return production, imports
132
133
134 def fetch_production(zone_key='CA-NS', session=None, target_datetime=None, logger=None):
135 """Requests the last known production mix (in MW) of a given country
136
137 Arguments:
138 zone_key (optional) -- used in case a parser is able to fetch multiple countries
139 session (optional) -- request session passed in order to re-use an existing session
140
141 Return:
142 A dictionary in the form:
143 {
144 'zoneKey': 'FR',
145 'datetime': '2017-01-01T00:00:00Z',
146 'production': {
147 'biomass': 0.0,
148 'coal': 0.0,
149 'gas': 0.0,
150 'hydro': 0.0,
151 'nuclear': null,
152 'oil': 0.0,
153 'solar': 0.0,
154 'wind': 0.0,
155 'geothermal': 0.0,
156 'unknown': 0.0
157 },
158 'storage': {
159 'hydro': -10.0,
160 },
161 'source': 'mysource.com'
162 }
163 """
164 if target_datetime:
165 raise NotImplementedError('This parser is unable to give information more than 24 hours in the past')
166
167 r = session or requests.session()
168
169 production, imports = _get_ns_info(r, logger)
170
171 return production
172
173
174 def fetch_exchange(zone_key1, zone_key2, session=None, target_datetime=None, logger=None):
175 """Requests the last known power exchange (in MW) between two regions.
176
177 Note: As of early 2017, Nova Scotia only has an exchange with New Brunswick (CA-NB).
178 (An exchange with Newfoundland, "Maritime Link", is scheduled to open in "late 2017").
179
180 The API for Nova Scotia only specifies imports. When NS is exporting energy,
181 the API returns 0.
182 """
183 if target_datetime:
184 raise NotImplementedError('This parser is unable to give information more than 24 hours in the past')
185
186 sorted_zone_keys = '->'.join(sorted([zone_key1, zone_key2]))
187
188 if sorted_zone_keys != 'CA-NB->CA-NS':
189 raise NotImplementedError('This exchange pair is not implemented')
190
191 requests_obj = session or requests.session()
192 _, imports = _get_ns_info(requests_obj, logger)
193
194 return imports
195
196
197 if __name__ == '__main__':
198 """Main method, never used by the Electricity Map backend, but handy for testing."""
199
200 from pprint import pprint
201 import logging
202 test_logger = logging.getLogger()
203
204 print('fetch_production() ->')
205 pprint(fetch_production(logger=test_logger))
206
207 print('fetch_exchange("CA-NS", "CA-NB") ->')
208 pprint(fetch_exchange("CA-NS", "CA-NB", logger=test_logger))
209
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/parsers/CA_NS.py b/parsers/CA_NS.py
--- a/parsers/CA_NS.py
+++ b/parsers/CA_NS.py
@@ -35,14 +35,11 @@
'wind': 700
}
- # As of November 2018, NSPower redirects their web traffic to HTTPS. However we've been
- # getting SSL errors in Python, even though loading these URLs in Firefox 63 gives no errors.
- # This isn't confidential or security-sensitive data, so ignore the SSL errors.
- mix_url = 'https://www.nspower.ca/system_report/today/currentmix.json'
- mix_data = requests_obj.get(mix_url, verify=False).json()
-
- load_url = 'https://www.nspower.ca/system_report/today/currentload.json'
- load_data = requests_obj.get(load_url, verify=False).json()
+ mix_url = 'https://www.nspower.ca/library/CurrentLoad/CurrentMix.json'
+ mix_data = requests_obj.get(mix_url).json()
+
+ load_url = 'https://www.nspower.ca/library/CurrentLoad/CurrentLoad.json'
+ load_data = requests_obj.get(load_url).json()
production = []
imports = []
|
{"golden_diff": "diff --git a/parsers/CA_NS.py b/parsers/CA_NS.py\n--- a/parsers/CA_NS.py\n+++ b/parsers/CA_NS.py\n@@ -35,14 +35,11 @@\n 'wind': 700\n }\n \n- # As of November 2018, NSPower redirects their web traffic to HTTPS. However we've been\n- # getting SSL errors in Python, even though loading these URLs in Firefox 63 gives no errors.\n- # This isn't confidential or security-sensitive data, so ignore the SSL errors.\n- mix_url = 'https://www.nspower.ca/system_report/today/currentmix.json'\n- mix_data = requests_obj.get(mix_url, verify=False).json()\n-\n- load_url = 'https://www.nspower.ca/system_report/today/currentload.json'\n- load_data = requests_obj.get(load_url, verify=False).json()\n+ mix_url = 'https://www.nspower.ca/library/CurrentLoad/CurrentMix.json'\n+ mix_data = requests_obj.get(mix_url).json()\n+\n+ load_url = 'https://www.nspower.ca/library/CurrentLoad/CurrentLoad.json'\n+ load_data = requests_obj.get(load_url).json()\n \n production = []\n imports = []\n", "issue": "Nova Scotia new URL (CA_NS)\nQuick note, I haven't had a chance to dig into it in detail yet:\r\n\r\nLooks like the website has been redesigned and things shuffled around a bit.\r\n\r\nNew page URL is https://www.nspower.ca/clean-energy/todays-energy-stats\r\n\r\nJSON URL is now https://www.nspower.ca/library/CurrentLoad/CurrentMix.json\r\n\r\nJSON format looks similar to before so it might just be a matter of swapping the URL.\n", "before_files": [{"content": "#!/usr/bin/env python3\n\n# The arrow library is used to handle datetimes\nimport arrow\n# The request library is used to fetch content through HTTP\nimport requests\n\n\ndef _get_ns_info(requests_obj, logger):\n zone_key = 'CA-NS'\n\n # This is based on validation logic in https://www.nspower.ca/site/renewables/assets/js/site.js\n # In practical terms, I've seen hydro production go way too high (>70%) which is way more\n # than reported capacity.\n valid_percent = {\n # The validation JS reports error when Solid Fuel (coal) is over 85%,\n # but as far as I can tell, that can actually be a valid result, I've seen it a few times.\n # Use 98% instead.\n 'coal': (0.25, 0.98),\n 'gas': (0, 0.5),\n 'biomass': (0, 0.15),\n 'hydro': (0, 0.60),\n 'wind': (0, 0.55),\n 'imports': (0, 0.20)\n }\n\n # Sanity checks: verify that reported production doesn't exceed listed capacity by a lot.\n # In particular, we've seen error cases where hydro production ends up calculated as 900 MW\n # which greatly exceeds known capacity of 418 MW.\n valid_absolute = {\n 'coal': 1300,\n 'gas': 700,\n 'biomass': 100,\n 'hydro': 500,\n 'wind': 700\n }\n\n # As of November 2018, NSPower redirects their web traffic to HTTPS. However we've been\n # getting SSL errors in Python, even though loading these URLs in Firefox 63 gives no errors.\n # This isn't confidential or security-sensitive data, so ignore the SSL errors.\n mix_url = 'https://www.nspower.ca/system_report/today/currentmix.json'\n mix_data = requests_obj.get(mix_url, verify=False).json()\n\n load_url = 'https://www.nspower.ca/system_report/today/currentload.json'\n load_data = requests_obj.get(load_url, verify=False).json()\n\n production = []\n imports = []\n for mix in mix_data:\n percent_mix = {\n 'coal': mix['Solid Fuel'] / 100.0,\n 'gas': (mix['HFO/Natural Gas'] + mix['CT\\'s'] + mix['LM 6000\\'s']) / 100.0,\n 'biomass': mix['Biomass'] / 100.0,\n 'hydro': mix['Hydro'] / 100.0,\n 'wind': mix['Wind'] / 100.0,\n 'imports': mix['Imports'] / 100.0\n }\n\n # datetime is in format '/Date(1493924400000)/'\n # get the timestamp 1493924400 (cutting out last three zeros as well)\n data_timestamp = int(mix['datetime'][6:-5])\n data_date = arrow.get(data_timestamp).datetime\n\n # validate\n valid = True\n for gen_type, value in percent_mix.items():\n percent_bounds = valid_percent[gen_type]\n if not (percent_bounds[0] <= value <= percent_bounds[1]):\n # skip this datapoint in the loop\n valid = False\n logger.warning(\n 'discarding datapoint at {dt} due to {fuel} percentage '\n 'out of bounds: {value}'.format(dt=data_date, fuel=gen_type, value=value),\n extra={'key': zone_key})\n if not valid:\n # continue the outer loop, not the inner\n continue\n\n # in mix_data, the values are expressed as percentages,\n # and have to be multiplied by load to find the actual MW value.\n corresponding_load = [load_period for load_period in load_data\n if load_period['datetime'] == mix['datetime']]\n if corresponding_load:\n load = corresponding_load[0]['Base Load']\n else:\n # if not found, assume 1244 MW, based on average yearly electricity available for use\n # in 2014 and 2015 (Statistics Canada table Table 127-0008 for Nova Scotia)\n load = 1244\n logger.warning('unable to find load for {}, assuming 1244 MW'.format(data_date),\n extra={'key': zone_key})\n\n electricity_mix = {\n gen_type: percent_value * load\n for gen_type, percent_value in percent_mix.items()\n }\n\n # validate again\n valid = True\n for gen_type, value in electricity_mix.items():\n absolute_bound = valid_absolute.get(gen_type) # imports are not in valid_absolute\n if absolute_bound and value > absolute_bound:\n valid = False\n logger.warning(\n 'discarding datapoint at {dt} due to {fuel} '\n 'too high: {value} MW'.format(dt=data_date, fuel=gen_type, value=value),\n extra={'key': zone_key})\n if not valid:\n # continue the outer loop, not the inner\n continue\n\n production.append({\n 'zoneKey': zone_key,\n 'datetime': data_date,\n 'production': {key: value\n for key, value in electricity_mix.items()\n if key != 'imports'},\n 'source': 'nspower.ca'\n })\n\n # In this source, imports are positive. In the expected result for CA-NB->CA-NS,\n # \"net\" represents a flow from NB to NS, that is, an import to NS.\n # So the value can be used directly.\n # Note that this API only specifies imports. When NS is exporting energy, the API returns 0.\n imports.append({\n 'datetime': data_date,\n 'netFlow': electricity_mix['imports'],\n 'sortedZoneKeys': 'CA-NB->CA-NS',\n 'source': 'nspower.ca'\n })\n\n return production, imports\n\n\ndef fetch_production(zone_key='CA-NS', session=None, target_datetime=None, logger=None):\n \"\"\"Requests the last known production mix (in MW) of a given country\n\n Arguments:\n zone_key (optional) -- used in case a parser is able to fetch multiple countries\n session (optional) -- request session passed in order to re-use an existing session\n\n Return:\n A dictionary in the form:\n {\n 'zoneKey': 'FR',\n 'datetime': '2017-01-01T00:00:00Z',\n 'production': {\n 'biomass': 0.0,\n 'coal': 0.0,\n 'gas': 0.0,\n 'hydro': 0.0,\n 'nuclear': null,\n 'oil': 0.0,\n 'solar': 0.0,\n 'wind': 0.0,\n 'geothermal': 0.0,\n 'unknown': 0.0\n },\n 'storage': {\n 'hydro': -10.0,\n },\n 'source': 'mysource.com'\n }\n \"\"\"\n if target_datetime:\n raise NotImplementedError('This parser is unable to give information more than 24 hours in the past')\n\n r = session or requests.session()\n\n production, imports = _get_ns_info(r, logger)\n\n return production\n\n\ndef fetch_exchange(zone_key1, zone_key2, session=None, target_datetime=None, logger=None):\n \"\"\"Requests the last known power exchange (in MW) between two regions.\n\n Note: As of early 2017, Nova Scotia only has an exchange with New Brunswick (CA-NB).\n (An exchange with Newfoundland, \"Maritime Link\", is scheduled to open in \"late 2017\").\n\n The API for Nova Scotia only specifies imports. When NS is exporting energy,\n the API returns 0.\n \"\"\"\n if target_datetime:\n raise NotImplementedError('This parser is unable to give information more than 24 hours in the past')\n\n sorted_zone_keys = '->'.join(sorted([zone_key1, zone_key2]))\n\n if sorted_zone_keys != 'CA-NB->CA-NS':\n raise NotImplementedError('This exchange pair is not implemented')\n\n requests_obj = session or requests.session()\n _, imports = _get_ns_info(requests_obj, logger)\n\n return imports\n\n\nif __name__ == '__main__':\n \"\"\"Main method, never used by the Electricity Map backend, but handy for testing.\"\"\"\n\n from pprint import pprint\n import logging\n test_logger = logging.getLogger()\n\n print('fetch_production() ->')\n pprint(fetch_production(logger=test_logger))\n\n print('fetch_exchange(\"CA-NS\", \"CA-NB\") ->')\n pprint(fetch_exchange(\"CA-NS\", \"CA-NB\", logger=test_logger))\n", "path": "parsers/CA_NS.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\n# The arrow library is used to handle datetimes\nimport arrow\n# The request library is used to fetch content through HTTP\nimport requests\n\n\ndef _get_ns_info(requests_obj, logger):\n zone_key = 'CA-NS'\n\n # This is based on validation logic in https://www.nspower.ca/site/renewables/assets/js/site.js\n # In practical terms, I've seen hydro production go way too high (>70%) which is way more\n # than reported capacity.\n valid_percent = {\n # The validation JS reports error when Solid Fuel (coal) is over 85%,\n # but as far as I can tell, that can actually be a valid result, I've seen it a few times.\n # Use 98% instead.\n 'coal': (0.25, 0.98),\n 'gas': (0, 0.5),\n 'biomass': (0, 0.15),\n 'hydro': (0, 0.60),\n 'wind': (0, 0.55),\n 'imports': (0, 0.20)\n }\n\n # Sanity checks: verify that reported production doesn't exceed listed capacity by a lot.\n # In particular, we've seen error cases where hydro production ends up calculated as 900 MW\n # which greatly exceeds known capacity of 418 MW.\n valid_absolute = {\n 'coal': 1300,\n 'gas': 700,\n 'biomass': 100,\n 'hydro': 500,\n 'wind': 700\n }\n\n mix_url = 'https://www.nspower.ca/library/CurrentLoad/CurrentMix.json'\n mix_data = requests_obj.get(mix_url).json()\n\n load_url = 'https://www.nspower.ca/library/CurrentLoad/CurrentLoad.json'\n load_data = requests_obj.get(load_url).json()\n\n production = []\n imports = []\n for mix in mix_data:\n percent_mix = {\n 'coal': mix['Solid Fuel'] / 100.0,\n 'gas': (mix['HFO/Natural Gas'] + mix['CT\\'s'] + mix['LM 6000\\'s']) / 100.0,\n 'biomass': mix['Biomass'] / 100.0,\n 'hydro': mix['Hydro'] / 100.0,\n 'wind': mix['Wind'] / 100.0,\n 'imports': mix['Imports'] / 100.0\n }\n\n # datetime is in format '/Date(1493924400000)/'\n # get the timestamp 1493924400 (cutting out last three zeros as well)\n data_timestamp = int(mix['datetime'][6:-5])\n data_date = arrow.get(data_timestamp).datetime\n\n # validate\n valid = True\n for gen_type, value in percent_mix.items():\n percent_bounds = valid_percent[gen_type]\n if not (percent_bounds[0] <= value <= percent_bounds[1]):\n # skip this datapoint in the loop\n valid = False\n logger.warning(\n 'discarding datapoint at {dt} due to {fuel} percentage '\n 'out of bounds: {value}'.format(dt=data_date, fuel=gen_type, value=value),\n extra={'key': zone_key})\n if not valid:\n # continue the outer loop, not the inner\n continue\n\n # in mix_data, the values are expressed as percentages,\n # and have to be multiplied by load to find the actual MW value.\n corresponding_load = [load_period for load_period in load_data\n if load_period['datetime'] == mix['datetime']]\n if corresponding_load:\n load = corresponding_load[0]['Base Load']\n else:\n # if not found, assume 1244 MW, based on average yearly electricity available for use\n # in 2014 and 2015 (Statistics Canada table Table 127-0008 for Nova Scotia)\n load = 1244\n logger.warning('unable to find load for {}, assuming 1244 MW'.format(data_date),\n extra={'key': zone_key})\n\n electricity_mix = {\n gen_type: percent_value * load\n for gen_type, percent_value in percent_mix.items()\n }\n\n # validate again\n valid = True\n for gen_type, value in electricity_mix.items():\n absolute_bound = valid_absolute.get(gen_type) # imports are not in valid_absolute\n if absolute_bound and value > absolute_bound:\n valid = False\n logger.warning(\n 'discarding datapoint at {dt} due to {fuel} '\n 'too high: {value} MW'.format(dt=data_date, fuel=gen_type, value=value),\n extra={'key': zone_key})\n if not valid:\n # continue the outer loop, not the inner\n continue\n\n production.append({\n 'zoneKey': zone_key,\n 'datetime': data_date,\n 'production': {key: value\n for key, value in electricity_mix.items()\n if key != 'imports'},\n 'source': 'nspower.ca'\n })\n\n # In this source, imports are positive. In the expected result for CA-NB->CA-NS,\n # \"net\" represents a flow from NB to NS, that is, an import to NS.\n # So the value can be used directly.\n # Note that this API only specifies imports. When NS is exporting energy, the API returns 0.\n imports.append({\n 'datetime': data_date,\n 'netFlow': electricity_mix['imports'],\n 'sortedZoneKeys': 'CA-NB->CA-NS',\n 'source': 'nspower.ca'\n })\n\n return production, imports\n\n\ndef fetch_production(zone_key='CA-NS', session=None, target_datetime=None, logger=None):\n \"\"\"Requests the last known production mix (in MW) of a given country\n\n Arguments:\n zone_key (optional) -- used in case a parser is able to fetch multiple countries\n session (optional) -- request session passed in order to re-use an existing session\n\n Return:\n A dictionary in the form:\n {\n 'zoneKey': 'FR',\n 'datetime': '2017-01-01T00:00:00Z',\n 'production': {\n 'biomass': 0.0,\n 'coal': 0.0,\n 'gas': 0.0,\n 'hydro': 0.0,\n 'nuclear': null,\n 'oil': 0.0,\n 'solar': 0.0,\n 'wind': 0.0,\n 'geothermal': 0.0,\n 'unknown': 0.0\n },\n 'storage': {\n 'hydro': -10.0,\n },\n 'source': 'mysource.com'\n }\n \"\"\"\n if target_datetime:\n raise NotImplementedError('This parser is unable to give information more than 24 hours in the past')\n\n r = session or requests.session()\n\n production, imports = _get_ns_info(r, logger)\n\n return production\n\n\ndef fetch_exchange(zone_key1, zone_key2, session=None, target_datetime=None, logger=None):\n \"\"\"Requests the last known power exchange (in MW) between two regions.\n\n Note: As of early 2017, Nova Scotia only has an exchange with New Brunswick (CA-NB).\n (An exchange with Newfoundland, \"Maritime Link\", is scheduled to open in \"late 2017\").\n\n The API for Nova Scotia only specifies imports. When NS is exporting energy,\n the API returns 0.\n \"\"\"\n if target_datetime:\n raise NotImplementedError('This parser is unable to give information more than 24 hours in the past')\n\n sorted_zone_keys = '->'.join(sorted([zone_key1, zone_key2]))\n\n if sorted_zone_keys != 'CA-NB->CA-NS':\n raise NotImplementedError('This exchange pair is not implemented')\n\n requests_obj = session or requests.session()\n _, imports = _get_ns_info(requests_obj, logger)\n\n return imports\n\n\nif __name__ == '__main__':\n \"\"\"Main method, never used by the Electricity Map backend, but handy for testing.\"\"\"\n\n from pprint import pprint\n import logging\n test_logger = logging.getLogger()\n\n print('fetch_production() ->')\n pprint(fetch_production(logger=test_logger))\n\n print('fetch_exchange(\"CA-NS\", \"CA-NB\") ->')\n pprint(fetch_exchange(\"CA-NS\", \"CA-NB\", logger=test_logger))\n", "path": "parsers/CA_NS.py"}]}
| 2,884 | 286 |
gh_patches_debug_7996
|
rasdani/github-patches
|
git_diff
|
zestedesavoir__zds-site-3662
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[v18] Date incorrecte dans les notifications
J'ai reçu une notification pour un topic que je suivais avant la v18.
Selon la notification elle datait d'il y'a 7h, sauf qu'en cliquant dessus, je suis tombé sur un message qui date d'il y'a 7 minutes. On peut le voir sur les screens ci-dessous.
**Notification avant le clic** :

**Notification après le clic** :

Il faudrait retomber sur ce cas pour identifier facilement le bug. Si jamais j'ai une meilleur idée du truc j'édite le titre qui n'est pas très parlant.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zds/notification/models.py`
Content:
```
1 # -*- coding: utf-8 -*-s
2 from smtplib import SMTPException
3
4 from django.contrib.auth.models import User
5 from django.contrib.contenttypes.fields import GenericForeignKey
6 from django.contrib.contenttypes.models import ContentType
7 from django.core.mail import EmailMultiAlternatives
8 from django.db import models
9 from django.template.loader import render_to_string
10 from django.utils.translation import ugettext_lazy as _
11
12 from zds import settings
13 from zds.forum.models import Topic
14 from zds.notification.managers import NotificationManager, SubscriptionManager, TopicFollowedManager, \
15 TopicAnswerSubscriptionManager
16 from zds.utils.misc import convert_camel_to_underscore
17
18
19 class Subscription(models.Model):
20 """
21 Model used to register the subscription of a user to a set of notifications (regarding a tutorial, a forum, ...)
22 """
23
24 class Meta:
25 verbose_name = _(u'Abonnement')
26 verbose_name_plural = _(u'Abonnements')
27
28 user = models.ForeignKey(User, related_name='subscriber', db_index=True)
29 pubdate = models.DateTimeField(_(u'Date de création'), auto_now_add=True, db_index=True)
30 is_active = models.BooleanField(_(u'Actif'), default=True, db_index=True)
31 by_email = models.BooleanField(_(u'Recevoir un email'), default=False)
32 content_type = models.ForeignKey(ContentType)
33 object_id = models.PositiveIntegerField(db_index=True)
34 content_object = GenericForeignKey('content_type', 'object_id')
35 last_notification = models.ForeignKey(u'Notification', related_name="last_notification", null=True, default=None)
36
37 def __unicode__(self):
38 return _(u'<Abonnement du membre "{0}" aux notifications pour le {1}, #{2}>')\
39 .format(self.user.username, self.content_type, self.object_id)
40
41 def activate(self):
42 """
43 Activates the subscription if it's inactive. Does nothing otherwise
44 """
45 if not self.is_active:
46 self.is_active = True
47 self.save()
48
49 def activate_email(self):
50 """
51 Activates the notifications by email (and the subscription itself if needed)
52 """
53 if not self.is_active or not self.by_email:
54 self.is_active = True
55 self.by_email = True
56 self.save()
57
58 def deactivate(self):
59 """
60 Deactivate the subscription if it is active. Does nothing otherwise
61 """
62 if self.is_active:
63 self.is_active = False
64 self.save()
65
66 def deactivate_email(self):
67 """
68 Deactivate the email if it is active. Does nothing otherwise
69 """
70 if self.is_active and self.by_email:
71 self.by_email = False
72 self.save()
73
74 def set_last_notification(self, notification):
75 """
76 Replace last_notification by the one given
77 """
78 self.last_notification = notification
79 self.save()
80
81 def send_email(self, notification):
82 """
83 Sends an email notification
84 """
85
86 assert hasattr(self, "module")
87
88 subject = _(u"{} - {} : {}").format(settings.ZDS_APP['site']['litteral_name'], self.module, notification.title)
89 from_email = _(u"{} <{}>").format(settings.ZDS_APP['site']['litteral_name'],
90 settings.ZDS_APP['site']['email_noreply'])
91
92 receiver = self.user
93 context = {
94 'username': receiver.username,
95 'title': notification.title,
96 'url': settings.ZDS_APP['site']['url'] + notification.url,
97 'author': notification.sender.username,
98 'site_name': settings.ZDS_APP['site']['litteral_name']
99 }
100 message_html = render_to_string(
101 'email/notification/' + convert_camel_to_underscore(self._meta.object_name) + '.html', context)
102 message_txt = render_to_string(
103 'email/notification/' + convert_camel_to_underscore(self._meta.object_name) + '.txt', context)
104
105 msg = EmailMultiAlternatives(subject, message_txt, from_email, [receiver.email])
106 msg.attach_alternative(message_html, "text/html")
107 try:
108 msg.send()
109 except SMTPException:
110 pass
111
112
113 class SingleNotificationMixin(object):
114 """
115 Mixin for the subscription that can only have one active notification at a time
116 """
117 def send_notification(self, content=None, send_email=True, sender=None):
118 """
119 Sends the notification about the given content
120 :param content: the content the notification is about
121 :param sender: the user whose action triggered the notification
122 :param send_email : whether an email must be sent if the subscription by email is active
123 """
124 assert hasattr(self, 'last_notification')
125 assert hasattr(self, 'set_last_notification')
126 assert hasattr(self, 'get_notification_url')
127 assert hasattr(self, 'get_notification_title')
128 assert hasattr(self, 'send_email')
129
130 if self.last_notification is None or self.last_notification.is_read:
131 # If there isn't a notification yet or the last one is read, we generate a new one.
132 try:
133 notification = Notification.objects.get(subscription=self)
134 except Notification.DoesNotExist:
135 notification = Notification(subscription=self, content_object=content, sender=sender)
136 notification.content_object = content
137 notification.sender = sender
138 notification.url = self.get_notification_url(content)
139 notification.title = self.get_notification_title(content)
140 notification.is_read = False
141 notification.save()
142 self.set_last_notification(notification)
143 self.save()
144
145 if send_email and self.by_email:
146 self.send_email(notification)
147 elif self.last_notification is not None:
148 # Update last notification if the new content is older (case of unreading answer)
149 if not self.last_notification.is_read and self.last_notification.pubdate > content.pubdate:
150 self.last_notification.content_object = content
151 self.last_notification.save()
152
153 def mark_notification_read(self):
154 """
155 Marks the notification of the subscription as read.
156 As there's only one active unread notification at all time,
157 no need for more precision
158 """
159 if self.last_notification is not None:
160 self.last_notification.is_read = True
161 self.last_notification.save()
162
163
164 class MultipleNotificationsMixin(object):
165
166 def send_notification(self, content=None, send_email=True, sender=None):
167 """
168 Sends the notification about the given content
169 :param content: the content the notification is about
170 :param sender: the user whose action triggered the notification
171 :param send_email : whether an email must be sent if the subscription by email is active
172 """
173
174 assert hasattr(self, "get_notification_url")
175 assert hasattr(self, "get_notification_title")
176 assert hasattr(self, "send_email")
177
178 notification = Notification(subscription=self, content_object=content, sender=sender)
179 notification.url = self.get_notification_url(content)
180 notification.title = self.get_notification_title(content)
181 notification.save()
182 self.set_last_notification(notification)
183
184 if send_email and self.by_email:
185 self.send_email(notification)
186
187 def mark_notification_read(self, content):
188 """
189 Marks the notification of the subscription as read.
190 :param content : the content whose notification has been read
191 """
192 if content is None:
193 raise Exception('Object content of notification must be defined')
194
195 content_notification_type = ContentType.objects.get_for_model(content)
196 try:
197 notification = Notification.objects.get(subscription=self,
198 content_type__pk=content_notification_type.pk,
199 object_id=content.pk, is_read=False)
200 if notification is not None:
201 notification.is_read = True
202 notification.save()
203 except Notification.DoesNotExist:
204 pass
205
206
207 class AnswerSubscription(Subscription):
208 """
209 Subscription to new answer, either in a topic, a article or a tutorial
210 NOT used directly, use one of its subtype
211 """
212 def __unicode__(self):
213 return _(u'<Abonnement du membre "{0}" aux réponses au {1} #{2}>')\
214 .format(self.user.username, self.content_type, self.object_id)
215
216 def get_notification_url(self, answer):
217 return answer.get_absolute_url()
218
219 def get_notification_title(self, answer):
220 return self.content_object.title
221
222
223 class TopicAnswerSubscription(AnswerSubscription, SingleNotificationMixin):
224 """
225 Subscription to new answer in a topic
226 """
227 module = _(u'Forum')
228 objects = TopicAnswerSubscriptionManager()
229
230 def __unicode__(self):
231 return _(u'<Abonnement du membre "{0}" aux réponses au sujet #{1}>')\
232 .format(self.user.username, self.object_id)
233
234
235 class PrivateTopicAnswerSubscription(AnswerSubscription, SingleNotificationMixin):
236 """
237 Subscription to new answer in a private topic.
238 """
239 module = _(u'Message privé')
240 objects = SubscriptionManager()
241
242 def __unicode__(self):
243 return _(u'<Abonnement du membre "{0}" aux réponses à la conversation privée #{1}>')\
244 .format(self.user.username, self.object_id)
245
246
247 class ContentReactionAnswerSubscription(AnswerSubscription, SingleNotificationMixin):
248 """
249 Subscription to new answer in a publishable content.
250 """
251 module = _(u'Contenu')
252 objects = SubscriptionManager()
253
254 def __unicode__(self):
255 return _(u'<Abonnement du membre "{0}" aux réponses du contenu #{1}>')\
256 .format(self.user.username, self.object_id)
257
258
259 class Notification(models.Model):
260 """
261 A notification
262 """
263 class Meta:
264 verbose_name = _(u'Notification')
265 verbose_name_plural = _(u'Notifications')
266
267 subscription = models.ForeignKey(Subscription, related_name='subscription', db_index=True)
268 pubdate = models.DateTimeField(_(u'Date de création'), auto_now_add=True, db_index=True)
269 content_type = models.ForeignKey(ContentType)
270 object_id = models.PositiveIntegerField(db_index=True)
271 content_object = GenericForeignKey('content_type', 'object_id')
272 is_read = models.BooleanField(_(u'Lue'), default=False, db_index=True)
273 url = models.CharField('URL', max_length=255)
274 sender = models.ForeignKey(User, related_name='sender', db_index=True)
275 title = models.CharField('Titre', max_length=200)
276 objects = NotificationManager()
277
278 def __unicode__(self):
279 return _(u'Notification du membre "{0}" à propos de : {1} #{2} ({3})')\
280 .format(self.subscription.user, self.content_type, self.content_object.pk, self.subscription)
281
282
283 class TopicFollowed(models.Model):
284 """
285 This model tracks which user follows which topic.
286 It serves only to manual topic following.
287 This model also indicates if the topic is followed by email.
288 """
289
290 class Meta:
291 verbose_name = 'Sujet suivi'
292 verbose_name_plural = 'Sujets suivis'
293
294 topic = models.ForeignKey(Topic, db_index=True)
295 user = models.ForeignKey(User, related_name='topics_followed', db_index=True)
296 email = models.BooleanField('Notification par courriel', default=False, db_index=True)
297 objects = TopicFollowedManager()
298
299 def __unicode__(self):
300 return u'<Sujet "{0}" suivi par {1}>'.format(self.topic.title,
301 self.user.username)
302
303 # used to fix Django 1.9 Warning
304 # https://github.com/zestedesavoir/zds-site/issues/3451
305 import receivers # noqa
306
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zds/notification/models.py b/zds/notification/models.py
--- a/zds/notification/models.py
+++ b/zds/notification/models.py
@@ -137,6 +137,7 @@
notification.sender = sender
notification.url = self.get_notification_url(content)
notification.title = self.get_notification_title(content)
+ notification.pubdate = content.pubdate
notification.is_read = False
notification.save()
self.set_last_notification(notification)
|
{"golden_diff": "diff --git a/zds/notification/models.py b/zds/notification/models.py\n--- a/zds/notification/models.py\n+++ b/zds/notification/models.py\n@@ -137,6 +137,7 @@\n notification.sender = sender\n notification.url = self.get_notification_url(content)\n notification.title = self.get_notification_title(content)\n+ notification.pubdate = content.pubdate\n notification.is_read = False\n notification.save()\n self.set_last_notification(notification)\n", "issue": "[v18] Date incorrecte dans les notifications\nJ'ai re\u00e7u une notification pour un topic que je suivais avant la v18.\n\nSelon la notification elle datait d'il y'a 7h, sauf qu'en cliquant dessus, je suis tomb\u00e9 sur un message qui date d'il y'a 7 minutes. On peut le voir sur les screens ci-dessous.\n\n**Notification avant le clic** : \n\n\n\n**Notification apr\u00e8s le clic** : \n\n\n\nIl faudrait retomber sur ce cas pour identifier facilement le bug. Si jamais j'ai une meilleur id\u00e9e du truc j'\u00e9dite le titre qui n'est pas tr\u00e8s parlant.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-s\nfrom smtplib import SMTPException\n\nfrom django.contrib.auth.models import User\nfrom django.contrib.contenttypes.fields import GenericForeignKey\nfrom django.contrib.contenttypes.models import ContentType\nfrom django.core.mail import EmailMultiAlternatives\nfrom django.db import models\nfrom django.template.loader import render_to_string\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom zds import settings\nfrom zds.forum.models import Topic\nfrom zds.notification.managers import NotificationManager, SubscriptionManager, TopicFollowedManager, \\\n TopicAnswerSubscriptionManager\nfrom zds.utils.misc import convert_camel_to_underscore\n\n\nclass Subscription(models.Model):\n \"\"\"\n Model used to register the subscription of a user to a set of notifications (regarding a tutorial, a forum, ...)\n \"\"\"\n\n class Meta:\n verbose_name = _(u'Abonnement')\n verbose_name_plural = _(u'Abonnements')\n\n user = models.ForeignKey(User, related_name='subscriber', db_index=True)\n pubdate = models.DateTimeField(_(u'Date de cr\u00e9ation'), auto_now_add=True, db_index=True)\n is_active = models.BooleanField(_(u'Actif'), default=True, db_index=True)\n by_email = models.BooleanField(_(u'Recevoir un email'), default=False)\n content_type = models.ForeignKey(ContentType)\n object_id = models.PositiveIntegerField(db_index=True)\n content_object = GenericForeignKey('content_type', 'object_id')\n last_notification = models.ForeignKey(u'Notification', related_name=\"last_notification\", null=True, default=None)\n\n def __unicode__(self):\n return _(u'<Abonnement du membre \"{0}\" aux notifications pour le {1}, #{2}>')\\\n .format(self.user.username, self.content_type, self.object_id)\n\n def activate(self):\n \"\"\"\n Activates the subscription if it's inactive. Does nothing otherwise\n \"\"\"\n if not self.is_active:\n self.is_active = True\n self.save()\n\n def activate_email(self):\n \"\"\"\n Activates the notifications by email (and the subscription itself if needed)\n \"\"\"\n if not self.is_active or not self.by_email:\n self.is_active = True\n self.by_email = True\n self.save()\n\n def deactivate(self):\n \"\"\"\n Deactivate the subscription if it is active. Does nothing otherwise\n \"\"\"\n if self.is_active:\n self.is_active = False\n self.save()\n\n def deactivate_email(self):\n \"\"\"\n Deactivate the email if it is active. Does nothing otherwise\n \"\"\"\n if self.is_active and self.by_email:\n self.by_email = False\n self.save()\n\n def set_last_notification(self, notification):\n \"\"\"\n Replace last_notification by the one given\n \"\"\"\n self.last_notification = notification\n self.save()\n\n def send_email(self, notification):\n \"\"\"\n Sends an email notification\n \"\"\"\n\n assert hasattr(self, \"module\")\n\n subject = _(u\"{} - {} : {}\").format(settings.ZDS_APP['site']['litteral_name'], self.module, notification.title)\n from_email = _(u\"{} <{}>\").format(settings.ZDS_APP['site']['litteral_name'],\n settings.ZDS_APP['site']['email_noreply'])\n\n receiver = self.user\n context = {\n 'username': receiver.username,\n 'title': notification.title,\n 'url': settings.ZDS_APP['site']['url'] + notification.url,\n 'author': notification.sender.username,\n 'site_name': settings.ZDS_APP['site']['litteral_name']\n }\n message_html = render_to_string(\n 'email/notification/' + convert_camel_to_underscore(self._meta.object_name) + '.html', context)\n message_txt = render_to_string(\n 'email/notification/' + convert_camel_to_underscore(self._meta.object_name) + '.txt', context)\n\n msg = EmailMultiAlternatives(subject, message_txt, from_email, [receiver.email])\n msg.attach_alternative(message_html, \"text/html\")\n try:\n msg.send()\n except SMTPException:\n pass\n\n\nclass SingleNotificationMixin(object):\n \"\"\"\n Mixin for the subscription that can only have one active notification at a time\n \"\"\"\n def send_notification(self, content=None, send_email=True, sender=None):\n \"\"\"\n Sends the notification about the given content\n :param content: the content the notification is about\n :param sender: the user whose action triggered the notification\n :param send_email : whether an email must be sent if the subscription by email is active\n \"\"\"\n assert hasattr(self, 'last_notification')\n assert hasattr(self, 'set_last_notification')\n assert hasattr(self, 'get_notification_url')\n assert hasattr(self, 'get_notification_title')\n assert hasattr(self, 'send_email')\n\n if self.last_notification is None or self.last_notification.is_read:\n # If there isn't a notification yet or the last one is read, we generate a new one.\n try:\n notification = Notification.objects.get(subscription=self)\n except Notification.DoesNotExist:\n notification = Notification(subscription=self, content_object=content, sender=sender)\n notification.content_object = content\n notification.sender = sender\n notification.url = self.get_notification_url(content)\n notification.title = self.get_notification_title(content)\n notification.is_read = False\n notification.save()\n self.set_last_notification(notification)\n self.save()\n\n if send_email and self.by_email:\n self.send_email(notification)\n elif self.last_notification is not None:\n # Update last notification if the new content is older (case of unreading answer)\n if not self.last_notification.is_read and self.last_notification.pubdate > content.pubdate:\n self.last_notification.content_object = content\n self.last_notification.save()\n\n def mark_notification_read(self):\n \"\"\"\n Marks the notification of the subscription as read.\n As there's only one active unread notification at all time,\n no need for more precision\n \"\"\"\n if self.last_notification is not None:\n self.last_notification.is_read = True\n self.last_notification.save()\n\n\nclass MultipleNotificationsMixin(object):\n\n def send_notification(self, content=None, send_email=True, sender=None):\n \"\"\"\n Sends the notification about the given content\n :param content: the content the notification is about\n :param sender: the user whose action triggered the notification\n :param send_email : whether an email must be sent if the subscription by email is active\n \"\"\"\n\n assert hasattr(self, \"get_notification_url\")\n assert hasattr(self, \"get_notification_title\")\n assert hasattr(self, \"send_email\")\n\n notification = Notification(subscription=self, content_object=content, sender=sender)\n notification.url = self.get_notification_url(content)\n notification.title = self.get_notification_title(content)\n notification.save()\n self.set_last_notification(notification)\n\n if send_email and self.by_email:\n self.send_email(notification)\n\n def mark_notification_read(self, content):\n \"\"\"\n Marks the notification of the subscription as read.\n :param content : the content whose notification has been read\n \"\"\"\n if content is None:\n raise Exception('Object content of notification must be defined')\n\n content_notification_type = ContentType.objects.get_for_model(content)\n try:\n notification = Notification.objects.get(subscription=self,\n content_type__pk=content_notification_type.pk,\n object_id=content.pk, is_read=False)\n if notification is not None:\n notification.is_read = True\n notification.save()\n except Notification.DoesNotExist:\n pass\n\n\nclass AnswerSubscription(Subscription):\n \"\"\"\n Subscription to new answer, either in a topic, a article or a tutorial\n NOT used directly, use one of its subtype\n \"\"\"\n def __unicode__(self):\n return _(u'<Abonnement du membre \"{0}\" aux r\u00e9ponses au {1} #{2}>')\\\n .format(self.user.username, self.content_type, self.object_id)\n\n def get_notification_url(self, answer):\n return answer.get_absolute_url()\n\n def get_notification_title(self, answer):\n return self.content_object.title\n\n\nclass TopicAnswerSubscription(AnswerSubscription, SingleNotificationMixin):\n \"\"\"\n Subscription to new answer in a topic\n \"\"\"\n module = _(u'Forum')\n objects = TopicAnswerSubscriptionManager()\n\n def __unicode__(self):\n return _(u'<Abonnement du membre \"{0}\" aux r\u00e9ponses au sujet #{1}>')\\\n .format(self.user.username, self.object_id)\n\n\nclass PrivateTopicAnswerSubscription(AnswerSubscription, SingleNotificationMixin):\n \"\"\"\n Subscription to new answer in a private topic.\n \"\"\"\n module = _(u'Message priv\u00e9')\n objects = SubscriptionManager()\n\n def __unicode__(self):\n return _(u'<Abonnement du membre \"{0}\" aux r\u00e9ponses \u00e0 la conversation priv\u00e9e #{1}>')\\\n .format(self.user.username, self.object_id)\n\n\nclass ContentReactionAnswerSubscription(AnswerSubscription, SingleNotificationMixin):\n \"\"\"\n Subscription to new answer in a publishable content.\n \"\"\"\n module = _(u'Contenu')\n objects = SubscriptionManager()\n\n def __unicode__(self):\n return _(u'<Abonnement du membre \"{0}\" aux r\u00e9ponses du contenu #{1}>')\\\n .format(self.user.username, self.object_id)\n\n\nclass Notification(models.Model):\n \"\"\"\n A notification\n \"\"\"\n class Meta:\n verbose_name = _(u'Notification')\n verbose_name_plural = _(u'Notifications')\n\n subscription = models.ForeignKey(Subscription, related_name='subscription', db_index=True)\n pubdate = models.DateTimeField(_(u'Date de cr\u00e9ation'), auto_now_add=True, db_index=True)\n content_type = models.ForeignKey(ContentType)\n object_id = models.PositiveIntegerField(db_index=True)\n content_object = GenericForeignKey('content_type', 'object_id')\n is_read = models.BooleanField(_(u'Lue'), default=False, db_index=True)\n url = models.CharField('URL', max_length=255)\n sender = models.ForeignKey(User, related_name='sender', db_index=True)\n title = models.CharField('Titre', max_length=200)\n objects = NotificationManager()\n\n def __unicode__(self):\n return _(u'Notification du membre \"{0}\" \u00e0 propos de : {1} #{2} ({3})')\\\n .format(self.subscription.user, self.content_type, self.content_object.pk, self.subscription)\n\n\nclass TopicFollowed(models.Model):\n \"\"\"\n This model tracks which user follows which topic.\n It serves only to manual topic following.\n This model also indicates if the topic is followed by email.\n \"\"\"\n\n class Meta:\n verbose_name = 'Sujet suivi'\n verbose_name_plural = 'Sujets suivis'\n\n topic = models.ForeignKey(Topic, db_index=True)\n user = models.ForeignKey(User, related_name='topics_followed', db_index=True)\n email = models.BooleanField('Notification par courriel', default=False, db_index=True)\n objects = TopicFollowedManager()\n\n def __unicode__(self):\n return u'<Sujet \"{0}\" suivi par {1}>'.format(self.topic.title,\n self.user.username)\n\n# used to fix Django 1.9 Warning\n# https://github.com/zestedesavoir/zds-site/issues/3451\nimport receivers # noqa\n", "path": "zds/notification/models.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-s\nfrom smtplib import SMTPException\n\nfrom django.contrib.auth.models import User\nfrom django.contrib.contenttypes.fields import GenericForeignKey\nfrom django.contrib.contenttypes.models import ContentType\nfrom django.core.mail import EmailMultiAlternatives\nfrom django.db import models\nfrom django.template.loader import render_to_string\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom zds import settings\nfrom zds.forum.models import Topic\nfrom zds.notification.managers import NotificationManager, SubscriptionManager, TopicFollowedManager, \\\n TopicAnswerSubscriptionManager\nfrom zds.utils.misc import convert_camel_to_underscore\n\n\nclass Subscription(models.Model):\n \"\"\"\n Model used to register the subscription of a user to a set of notifications (regarding a tutorial, a forum, ...)\n \"\"\"\n\n class Meta:\n verbose_name = _(u'Abonnement')\n verbose_name_plural = _(u'Abonnements')\n\n user = models.ForeignKey(User, related_name='subscriber', db_index=True)\n pubdate = models.DateTimeField(_(u'Date de cr\u00e9ation'), auto_now_add=True, db_index=True)\n is_active = models.BooleanField(_(u'Actif'), default=True, db_index=True)\n by_email = models.BooleanField(_(u'Recevoir un email'), default=False)\n content_type = models.ForeignKey(ContentType)\n object_id = models.PositiveIntegerField(db_index=True)\n content_object = GenericForeignKey('content_type', 'object_id')\n last_notification = models.ForeignKey(u'Notification', related_name=\"last_notification\", null=True, default=None)\n\n def __unicode__(self):\n return _(u'<Abonnement du membre \"{0}\" aux notifications pour le {1}, #{2}>')\\\n .format(self.user.username, self.content_type, self.object_id)\n\n def activate(self):\n \"\"\"\n Activates the subscription if it's inactive. Does nothing otherwise\n \"\"\"\n if not self.is_active:\n self.is_active = True\n self.save()\n\n def activate_email(self):\n \"\"\"\n Activates the notifications by email (and the subscription itself if needed)\n \"\"\"\n if not self.is_active or not self.by_email:\n self.is_active = True\n self.by_email = True\n self.save()\n\n def deactivate(self):\n \"\"\"\n Deactivate the subscription if it is active. Does nothing otherwise\n \"\"\"\n if self.is_active:\n self.is_active = False\n self.save()\n\n def deactivate_email(self):\n \"\"\"\n Deactivate the email if it is active. Does nothing otherwise\n \"\"\"\n if self.is_active and self.by_email:\n self.by_email = False\n self.save()\n\n def set_last_notification(self, notification):\n \"\"\"\n Replace last_notification by the one given\n \"\"\"\n self.last_notification = notification\n self.save()\n\n def send_email(self, notification):\n \"\"\"\n Sends an email notification\n \"\"\"\n\n assert hasattr(self, \"module\")\n\n subject = _(u\"{} - {} : {}\").format(settings.ZDS_APP['site']['litteral_name'], self.module, notification.title)\n from_email = _(u\"{} <{}>\").format(settings.ZDS_APP['site']['litteral_name'],\n settings.ZDS_APP['site']['email_noreply'])\n\n receiver = self.user\n context = {\n 'username': receiver.username,\n 'title': notification.title,\n 'url': settings.ZDS_APP['site']['url'] + notification.url,\n 'author': notification.sender.username,\n 'site_name': settings.ZDS_APP['site']['litteral_name']\n }\n message_html = render_to_string(\n 'email/notification/' + convert_camel_to_underscore(self._meta.object_name) + '.html', context)\n message_txt = render_to_string(\n 'email/notification/' + convert_camel_to_underscore(self._meta.object_name) + '.txt', context)\n\n msg = EmailMultiAlternatives(subject, message_txt, from_email, [receiver.email])\n msg.attach_alternative(message_html, \"text/html\")\n try:\n msg.send()\n except SMTPException:\n pass\n\n\nclass SingleNotificationMixin(object):\n \"\"\"\n Mixin for the subscription that can only have one active notification at a time\n \"\"\"\n def send_notification(self, content=None, send_email=True, sender=None):\n \"\"\"\n Sends the notification about the given content\n :param content: the content the notification is about\n :param sender: the user whose action triggered the notification\n :param send_email : whether an email must be sent if the subscription by email is active\n \"\"\"\n assert hasattr(self, 'last_notification')\n assert hasattr(self, 'set_last_notification')\n assert hasattr(self, 'get_notification_url')\n assert hasattr(self, 'get_notification_title')\n assert hasattr(self, 'send_email')\n\n if self.last_notification is None or self.last_notification.is_read:\n # If there isn't a notification yet or the last one is read, we generate a new one.\n try:\n notification = Notification.objects.get(subscription=self)\n except Notification.DoesNotExist:\n notification = Notification(subscription=self, content_object=content, sender=sender)\n notification.content_object = content\n notification.sender = sender\n notification.url = self.get_notification_url(content)\n notification.title = self.get_notification_title(content)\n notification.pubdate = content.pubdate\n notification.is_read = False\n notification.save()\n self.set_last_notification(notification)\n self.save()\n\n if send_email and self.by_email:\n self.send_email(notification)\n elif self.last_notification is not None:\n # Update last notification if the new content is older (case of unreading answer)\n if not self.last_notification.is_read and self.last_notification.pubdate > content.pubdate:\n self.last_notification.content_object = content\n self.last_notification.save()\n\n def mark_notification_read(self):\n \"\"\"\n Marks the notification of the subscription as read.\n As there's only one active unread notification at all time,\n no need for more precision\n \"\"\"\n if self.last_notification is not None:\n self.last_notification.is_read = True\n self.last_notification.save()\n\n\nclass MultipleNotificationsMixin(object):\n\n def send_notification(self, content=None, send_email=True, sender=None):\n \"\"\"\n Sends the notification about the given content\n :param content: the content the notification is about\n :param sender: the user whose action triggered the notification\n :param send_email : whether an email must be sent if the subscription by email is active\n \"\"\"\n\n assert hasattr(self, \"get_notification_url\")\n assert hasattr(self, \"get_notification_title\")\n assert hasattr(self, \"send_email\")\n\n notification = Notification(subscription=self, content_object=content, sender=sender)\n notification.url = self.get_notification_url(content)\n notification.title = self.get_notification_title(content)\n notification.save()\n self.set_last_notification(notification)\n\n if send_email and self.by_email:\n self.send_email(notification)\n\n def mark_notification_read(self, content):\n \"\"\"\n Marks the notification of the subscription as read.\n :param content : the content whose notification has been read\n \"\"\"\n if content is None:\n raise Exception('Object content of notification must be defined')\n\n content_notification_type = ContentType.objects.get_for_model(content)\n try:\n notification = Notification.objects.get(subscription=self,\n content_type__pk=content_notification_type.pk,\n object_id=content.pk, is_read=False)\n if notification is not None:\n notification.is_read = True\n notification.save()\n except Notification.DoesNotExist:\n pass\n\n\nclass AnswerSubscription(Subscription):\n \"\"\"\n Subscription to new answer, either in a topic, a article or a tutorial\n NOT used directly, use one of its subtype\n \"\"\"\n def __unicode__(self):\n return _(u'<Abonnement du membre \"{0}\" aux r\u00e9ponses au {1} #{2}>')\\\n .format(self.user.username, self.content_type, self.object_id)\n\n def get_notification_url(self, answer):\n return answer.get_absolute_url()\n\n def get_notification_title(self, answer):\n return self.content_object.title\n\n\nclass TopicAnswerSubscription(AnswerSubscription, SingleNotificationMixin):\n \"\"\"\n Subscription to new answer in a topic\n \"\"\"\n module = _(u'Forum')\n objects = TopicAnswerSubscriptionManager()\n\n def __unicode__(self):\n return _(u'<Abonnement du membre \"{0}\" aux r\u00e9ponses au sujet #{1}>')\\\n .format(self.user.username, self.object_id)\n\n\nclass PrivateTopicAnswerSubscription(AnswerSubscription, SingleNotificationMixin):\n \"\"\"\n Subscription to new answer in a private topic.\n \"\"\"\n module = _(u'Message priv\u00e9')\n objects = SubscriptionManager()\n\n def __unicode__(self):\n return _(u'<Abonnement du membre \"{0}\" aux r\u00e9ponses \u00e0 la conversation priv\u00e9e #{1}>')\\\n .format(self.user.username, self.object_id)\n\n\nclass ContentReactionAnswerSubscription(AnswerSubscription, SingleNotificationMixin):\n \"\"\"\n Subscription to new answer in a publishable content.\n \"\"\"\n module = _(u'Contenu')\n objects = SubscriptionManager()\n\n def __unicode__(self):\n return _(u'<Abonnement du membre \"{0}\" aux r\u00e9ponses du contenu #{1}>')\\\n .format(self.user.username, self.object_id)\n\n\nclass Notification(models.Model):\n \"\"\"\n A notification\n \"\"\"\n class Meta:\n verbose_name = _(u'Notification')\n verbose_name_plural = _(u'Notifications')\n\n subscription = models.ForeignKey(Subscription, related_name='subscription', db_index=True)\n pubdate = models.DateTimeField(_(u'Date de cr\u00e9ation'), auto_now_add=True, db_index=True)\n content_type = models.ForeignKey(ContentType)\n object_id = models.PositiveIntegerField(db_index=True)\n content_object = GenericForeignKey('content_type', 'object_id')\n is_read = models.BooleanField(_(u'Lue'), default=False, db_index=True)\n url = models.CharField('URL', max_length=255)\n sender = models.ForeignKey(User, related_name='sender', db_index=True)\n title = models.CharField('Titre', max_length=200)\n objects = NotificationManager()\n\n def __unicode__(self):\n return _(u'Notification du membre \"{0}\" \u00e0 propos de : {1} #{2} ({3})')\\\n .format(self.subscription.user, self.content_type, self.content_object.pk, self.subscription)\n\n\nclass TopicFollowed(models.Model):\n \"\"\"\n This model tracks which user follows which topic.\n It serves only to manual topic following.\n This model also indicates if the topic is followed by email.\n \"\"\"\n\n class Meta:\n verbose_name = 'Sujet suivi'\n verbose_name_plural = 'Sujets suivis'\n\n topic = models.ForeignKey(Topic, db_index=True)\n user = models.ForeignKey(User, related_name='topics_followed', db_index=True)\n email = models.BooleanField('Notification par courriel', default=False, db_index=True)\n objects = TopicFollowedManager()\n\n def __unicode__(self):\n return u'<Sujet \"{0}\" suivi par {1}>'.format(self.topic.title,\n self.user.username)\n\n# used to fix Django 1.9 Warning\n# https://github.com/zestedesavoir/zds-site/issues/3451\nimport receivers # noqa\n", "path": "zds/notification/models.py"}]}
| 3,810 | 100 |
gh_patches_debug_3006
|
rasdani/github-patches
|
git_diff
|
googleapis__google-api-python-client-1629
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Python 3.10 compatibility issue
#### Environment details
- OS type and version: Windows 10
- Python version: `python --version` 3.10.1
- pip version: `pip --version` 21.2.4
- `google-api-python-client` version: `pip show google-api-python-client` - 2.33.0
uritemplate package 3.0.0 is not compatible with python 3.10. Need to update the requirements.
Partial Stack Trace
service = build('gmail', 'v1', credentials=creds)
File "C:\JA\Envs\GIC\lib\site-packages\googleapiclient\_helpers.py", line 130, in positional_wrapper
return wrapped(*args, **kwargs)
File "C:\JA\Envs\GIC\lib\site-packages\googleapiclient\discovery.py", line 219, in build
requested_url = uritemplate.expand(discovery_url, params)
File "C:\JA\Envs\GIC\lib\site-packages\uritemplate\api.py", line 33, in expand
return URITemplate(uri).expand(var_dict, **kwargs)
File "C:\JA\Envs\GIC\lib\site-packages\uritemplate\template.py", line 132, in expand
return self._expand(_merge(var_dict, kwargs), False)
File "C:\JA\Envs\GIC\lib\site-packages\uritemplate\template.py", line 97, in _expand
expanded.update(v.expand(expansion))
File "C:\JA\Envs\GIC\lib\site-packages\uritemplate\variable.py", line 338, in expand
expanded = expansion(name, value, opts['explode'], opts['prefix'])
File "C:\JA\Envs\GIC\lib\site-packages\uritemplate\variable.py", line 278, in _string_expansion
if dict_test(value) or tuples:
File "C:\JA\Envs\GIC\lib\site-packages\uritemplate\variable.py", line 363, in dict_test
return isinstance(value, (dict, collections.MutableMapping))
AttributeError: module 'collections' has no attribute 'MutableMapping'
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2014 Google Inc. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Setup script for Google API Python client.
16
17 Also installs included versions of third party libraries, if those libraries
18 are not already installed.
19 """
20 from __future__ import print_function
21
22 import sys
23
24 if sys.version_info < (3, 6):
25 print("google-api-python-client requires python3 version >= 3.6.", file=sys.stderr)
26 sys.exit(1)
27
28 import io
29 import os
30 from setuptools import setup
31
32 packages = ["apiclient", "googleapiclient", "googleapiclient/discovery_cache"]
33
34 install_requires = [
35 "httplib2>=0.15.0,<1dev",
36 # NOTE: Maintainers, please do not require google-auth>=2.x.x
37 # Until this issue is closed
38 # https://github.com/googleapis/google-cloud-python/issues/10566
39 "google-auth>=1.16.0,<3.0.0dev",
40 "google-auth-httplib2>=0.1.0",
41 # NOTE: Maintainers, please do not require google-api-core>=2.x.x
42 # Until this issue is closed
43 # https://github.com/googleapis/google-cloud-python/issues/10566
44 "google-api-core>=1.21.0,<3.0.0dev",
45 "uritemplate>=3.0.0,<5",
46 ]
47
48 package_root = os.path.abspath(os.path.dirname(__file__))
49
50 readme_filename = os.path.join(package_root, "README.md")
51 with io.open(readme_filename, encoding="utf-8") as readme_file:
52 readme = readme_file.read()
53
54 package_root = os.path.abspath(os.path.dirname(__file__))
55
56 version = {}
57 with open(os.path.join(package_root, "googleapiclient/version.py")) as fp:
58 exec(fp.read(), version)
59 version = version["__version__"]
60
61 setup(
62 name="google-api-python-client",
63 version=version,
64 description="Google API Client Library for Python",
65 long_description=readme,
66 long_description_content_type='text/markdown',
67 author="Google LLC",
68 author_email="[email protected]",
69 url="https://github.com/googleapis/google-api-python-client/",
70 install_requires=install_requires,
71 python_requires=">=3.6",
72 packages=packages,
73 package_data={"googleapiclient": ["discovery_cache/documents/*.json"]},
74 license="Apache 2.0",
75 keywords="google api client",
76 classifiers=[
77 "Programming Language :: Python :: 3",
78 "Programming Language :: Python :: 3.6",
79 "Programming Language :: Python :: 3.7",
80 "Programming Language :: Python :: 3.8",
81 "Programming Language :: Python :: 3.9",
82 "Programming Language :: Python :: 3.10",
83 "Development Status :: 5 - Production/Stable",
84 "Intended Audience :: Developers",
85 "License :: OSI Approved :: Apache Software License",
86 "Operating System :: OS Independent",
87 "Topic :: Internet :: WWW/HTTP",
88 ],
89 )
90
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -42,7 +42,7 @@
# Until this issue is closed
# https://github.com/googleapis/google-cloud-python/issues/10566
"google-api-core>=1.21.0,<3.0.0dev",
- "uritemplate>=3.0.0,<5",
+ "uritemplate>=3.0.1,<5",
]
package_root = os.path.abspath(os.path.dirname(__file__))
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -42,7 +42,7 @@\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-api-core>=1.21.0,<3.0.0dev\",\n- \"uritemplate>=3.0.0,<5\",\n+ \"uritemplate>=3.0.1,<5\",\n ]\n \n package_root = os.path.abspath(os.path.dirname(__file__))\n", "issue": "Python 3.10 compatibility issue\n\r\n\r\n#### Environment details\r\n\r\n - OS type and version: Windows 10\r\n - Python version: `python --version` 3.10.1\r\n - pip version: `pip --version` 21.2.4\r\n - `google-api-python-client` version: `pip show google-api-python-client` - 2.33.0\r\n\r\nuritemplate package 3.0.0 is not compatible with python 3.10. Need to update the requirements.\r\n\r\nPartial Stack Trace\r\n\r\nservice = build('gmail', 'v1', credentials=creds)\r\n File \"C:\\JA\\Envs\\GIC\\lib\\site-packages\\googleapiclient\\_helpers.py\", line 130, in positional_wrapper\r\n return wrapped(*args, **kwargs)\r\n File \"C:\\JA\\Envs\\GIC\\lib\\site-packages\\googleapiclient\\discovery.py\", line 219, in build\r\n requested_url = uritemplate.expand(discovery_url, params)\r\n File \"C:\\JA\\Envs\\GIC\\lib\\site-packages\\uritemplate\\api.py\", line 33, in expand\r\n return URITemplate(uri).expand(var_dict, **kwargs)\r\n File \"C:\\JA\\Envs\\GIC\\lib\\site-packages\\uritemplate\\template.py\", line 132, in expand\r\n return self._expand(_merge(var_dict, kwargs), False)\r\n File \"C:\\JA\\Envs\\GIC\\lib\\site-packages\\uritemplate\\template.py\", line 97, in _expand\r\n expanded.update(v.expand(expansion))\r\n File \"C:\\JA\\Envs\\GIC\\lib\\site-packages\\uritemplate\\variable.py\", line 338, in expand\r\n expanded = expansion(name, value, opts['explode'], opts['prefix'])\r\n File \"C:\\JA\\Envs\\GIC\\lib\\site-packages\\uritemplate\\variable.py\", line 278, in _string_expansion\r\n if dict_test(value) or tuples:\r\n File \"C:\\JA\\Envs\\GIC\\lib\\site-packages\\uritemplate\\variable.py\", line 363, in dict_test\r\n return isinstance(value, (dict, collections.MutableMapping))\r\nAttributeError: module 'collections' has no attribute 'MutableMapping'\r\n\n", "before_files": [{"content": "# Copyright 2014 Google Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Setup script for Google API Python client.\n\nAlso installs included versions of third party libraries, if those libraries\nare not already installed.\n\"\"\"\nfrom __future__ import print_function\n\nimport sys\n\nif sys.version_info < (3, 6):\n print(\"google-api-python-client requires python3 version >= 3.6.\", file=sys.stderr)\n sys.exit(1)\n\nimport io\nimport os\nfrom setuptools import setup\n\npackages = [\"apiclient\", \"googleapiclient\", \"googleapiclient/discovery_cache\"]\n\ninstall_requires = [\n \"httplib2>=0.15.0,<1dev\",\n # NOTE: Maintainers, please do not require google-auth>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-auth>=1.16.0,<3.0.0dev\",\n \"google-auth-httplib2>=0.1.0\",\n # NOTE: Maintainers, please do not require google-api-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-api-core>=1.21.0,<3.0.0dev\",\n \"uritemplate>=3.0.0,<5\",\n]\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.md\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nversion = {}\nwith open(os.path.join(package_root, \"googleapiclient/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\nsetup(\n name=\"google-api-python-client\",\n version=version,\n description=\"Google API Client Library for Python\",\n long_description=readme,\n long_description_content_type='text/markdown',\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n url=\"https://github.com/googleapis/google-api-python-client/\",\n install_requires=install_requires,\n python_requires=\">=3.6\",\n packages=packages,\n package_data={\"googleapiclient\": [\"discovery_cache/documents/*.json\"]},\n license=\"Apache 2.0\",\n keywords=\"google api client\",\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet :: WWW/HTTP\",\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright 2014 Google Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Setup script for Google API Python client.\n\nAlso installs included versions of third party libraries, if those libraries\nare not already installed.\n\"\"\"\nfrom __future__ import print_function\n\nimport sys\n\nif sys.version_info < (3, 6):\n print(\"google-api-python-client requires python3 version >= 3.6.\", file=sys.stderr)\n sys.exit(1)\n\nimport io\nimport os\nfrom setuptools import setup\n\npackages = [\"apiclient\", \"googleapiclient\", \"googleapiclient/discovery_cache\"]\n\ninstall_requires = [\n \"httplib2>=0.15.0,<1dev\",\n # NOTE: Maintainers, please do not require google-auth>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-auth>=1.16.0,<3.0.0dev\",\n \"google-auth-httplib2>=0.1.0\",\n # NOTE: Maintainers, please do not require google-api-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-api-core>=1.21.0,<3.0.0dev\",\n \"uritemplate>=3.0.1,<5\",\n]\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.md\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nversion = {}\nwith open(os.path.join(package_root, \"googleapiclient/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\nsetup(\n name=\"google-api-python-client\",\n version=version,\n description=\"Google API Client Library for Python\",\n long_description=readme,\n long_description_content_type='text/markdown',\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n url=\"https://github.com/googleapis/google-api-python-client/\",\n install_requires=install_requires,\n python_requires=\">=3.6\",\n packages=packages,\n package_data={\"googleapiclient\": [\"discovery_cache/documents/*.json\"]},\n license=\"Apache 2.0\",\n keywords=\"google api client\",\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet :: WWW/HTTP\",\n ],\n)\n", "path": "setup.py"}]}
| 1,740 | 123 |
gh_patches_debug_80
|
rasdani/github-patches
|
git_diff
|
scverse__scanpy-1807
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Report pynndescent version in sc.logging.print_header
Hi,
Thank you for the great tool. I think this is not a bug.
Recently I upgraded some packages and found my results were different from the previous runs. I figured out that it is caused by different versions of `pynndescent` (0.4.7 vs 0.5.1), which is recommended to use in UMAP. So I think `pynndescent` should be included in the output of `sc.logging.print_header()`.
#### Versions
<details>
-----
anndata 0.7.5
scanpy 1.6.1
sinfo 0.3.1
-----
PIL 8.1.0
anndata 0.7.5
constants NA
cycler 0.10.0
cython_runtime NA
dateutil 2.8.1
get_version 2.1
h5py 3.1.0
highs_wrapper NA
igraph 0.8.3
joblib 1.0.0
kiwisolver 1.3.1
legacy_api_wrap 1.2
leidenalg 0.8.3
llvmlite 0.35.0
louvain 0.7.0
matplotlib 3.3.3
mpl_toolkits NA
natsort 7.1.1
numba 0.52.0
numexpr 2.7.2
numpy 1.19.5
packaging 20.8
pandas 1.2.1
pkg_resources NA
pynndescent 0.5.1
pyparsing 2.4.7
pytz 2020.5
scanpy 1.6.1
scipy 1.6.0
setuptools_scm NA
sinfo 0.3.1
six 1.15.0
sklearn 0.24.1
statsmodels 0.12.1
tables 3.6.1
texttable 1.6.3
umap 0.4.6
-----
Python 3.8.5 (default, Sep 4 2020, 07:30:14) [GCC 7.3.0]
Linux-3.10.0-1160.11.1.el7.x86_64-x86_64-with-glibc2.10
40 logical CPU cores, x86_64
</details>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scanpy/logging.py`
Content:
```
1 """Logging and Profiling
2 """
3 import io
4 import logging
5 import sys
6 from functools import update_wrapper, partial
7 from logging import CRITICAL, ERROR, WARNING, INFO, DEBUG, NOTSET
8 from datetime import datetime, timedelta, timezone
9 from typing import Optional
10
11 import anndata.logging
12 from sinfo import sinfo
13
14
15 HINT = (INFO + DEBUG) // 2
16 logging.addLevelName(HINT, 'HINT')
17
18
19 class _RootLogger(logging.RootLogger):
20 def __init__(self, level):
21 super().__init__(level)
22 self.propagate = False
23 _RootLogger.manager = logging.Manager(self)
24
25 def log(
26 self,
27 level: int,
28 msg: str,
29 *,
30 extra: Optional[dict] = None,
31 time: datetime = None,
32 deep: Optional[str] = None,
33 ) -> datetime:
34 from . import settings
35
36 now = datetime.now(timezone.utc)
37 time_passed: timedelta = None if time is None else now - time
38 extra = {
39 **(extra or {}),
40 'deep': deep if settings.verbosity.level < level else None,
41 'time_passed': time_passed,
42 }
43 super().log(level, msg, extra=extra)
44 return now
45
46 def critical(self, msg, *, time=None, deep=None, extra=None) -> datetime:
47 return self.log(CRITICAL, msg, time=time, deep=deep, extra=extra)
48
49 def error(self, msg, *, time=None, deep=None, extra=None) -> datetime:
50 return self.log(ERROR, msg, time=time, deep=deep, extra=extra)
51
52 def warning(self, msg, *, time=None, deep=None, extra=None) -> datetime:
53 return self.log(WARNING, msg, time=time, deep=deep, extra=extra)
54
55 def info(self, msg, *, time=None, deep=None, extra=None) -> datetime:
56 return self.log(INFO, msg, time=time, deep=deep, extra=extra)
57
58 def hint(self, msg, *, time=None, deep=None, extra=None) -> datetime:
59 return self.log(HINT, msg, time=time, deep=deep, extra=extra)
60
61 def debug(self, msg, *, time=None, deep=None, extra=None) -> datetime:
62 return self.log(DEBUG, msg, time=time, deep=deep, extra=extra)
63
64
65 def _set_log_file(settings):
66 file = settings.logfile
67 name = settings.logpath
68 root = settings._root_logger
69 h = logging.StreamHandler(file) if name is None else logging.FileHandler(name)
70 h.setFormatter(_LogFormatter())
71 h.setLevel(root.level)
72 if len(root.handlers) == 1:
73 root.removeHandler(root.handlers[0])
74 elif len(root.handlers) > 1:
75 raise RuntimeError('Scanpy’s root logger somehow got more than one handler')
76 root.addHandler(h)
77
78
79 def _set_log_level(settings, level: int):
80 root = settings._root_logger
81 root.setLevel(level)
82 (h,) = root.handlers # may only be 1
83 h.setLevel(level)
84
85
86 class _LogFormatter(logging.Formatter):
87 def __init__(
88 self, fmt='{levelname}: {message}', datefmt='%Y-%m-%d %H:%M', style='{'
89 ):
90 super().__init__(fmt, datefmt, style)
91
92 def format(self, record: logging.LogRecord):
93 format_orig = self._style._fmt
94 if record.levelno == INFO:
95 self._style._fmt = '{message}'
96 elif record.levelno == HINT:
97 self._style._fmt = '--> {message}'
98 elif record.levelno == DEBUG:
99 self._style._fmt = ' {message}'
100 if record.time_passed:
101 # strip microseconds
102 if record.time_passed.microseconds:
103 record.time_passed = timedelta(
104 seconds=int(record.time_passed.total_seconds())
105 )
106 if '{time_passed}' in record.msg:
107 record.msg = record.msg.replace(
108 '{time_passed}', str(record.time_passed)
109 )
110 else:
111 self._style._fmt += ' ({time_passed})'
112 if record.deep:
113 record.msg = f'{record.msg}: {record.deep}'
114 result = logging.Formatter.format(self, record)
115 self._style._fmt = format_orig
116 return result
117
118
119 print_memory_usage = anndata.logging.print_memory_usage
120 get_memory_usage = anndata.logging.get_memory_usage
121
122
123 _DEPENDENCIES_NUMERICS = [
124 'anndata', # anndata actually shouldn't, but as long as it's in development
125 'umap',
126 'numpy',
127 'scipy',
128 'pandas',
129 ('sklearn', 'scikit-learn'),
130 'statsmodels',
131 ('igraph', 'python-igraph'),
132 'louvain',
133 'leidenalg',
134 ]
135
136
137 def _versions_dependencies(dependencies):
138 # this is not the same as the requirements!
139 for mod in dependencies:
140 mod_name, dist_name = mod if isinstance(mod, tuple) else (mod, mod)
141 try:
142 imp = __import__(mod_name)
143 yield dist_name, imp.__version__
144 except (ImportError, AttributeError):
145 pass
146
147
148 def print_header(*, file=None):
149 """\
150 Versions that might influence the numerical results.
151 Matplotlib and Seaborn are excluded from this.
152 """
153
154 modules = ['scanpy'] + _DEPENDENCIES_NUMERICS
155 print(
156 ' '.join(f'{mod}=={ver}' for mod, ver in _versions_dependencies(modules)),
157 file=file or sys.stdout,
158 )
159
160
161 def print_versions(*, file=None):
162 """Print print versions of imported packages"""
163 if file is None: # Inform people about the behavior change
164 warning('If you miss a compact list, please try `print_header`!')
165 stdout = sys.stdout
166 try:
167 buf = sys.stdout = io.StringIO()
168 sinfo(
169 dependencies=True,
170 excludes=[
171 'builtins',
172 'stdlib_list',
173 'importlib_metadata',
174 # Special module present if test coverage being calculated
175 # https://gitlab.com/joelostblom/sinfo/-/issues/10
176 "$coverage",
177 ],
178 )
179 finally:
180 sys.stdout = stdout
181 output = buf.getvalue()
182 print(output, file=file)
183
184
185 def print_version_and_date(*, file=None):
186 """\
187 Useful for starting a notebook so you see when you started working.
188 """
189 from . import __version__
190
191 if file is None:
192 file = sys.stdout
193 print(
194 f'Running Scanpy {__version__}, ' f'on {datetime.now():%Y-%m-%d %H:%M}.',
195 file=file,
196 )
197
198
199 def _copy_docs_and_signature(fn):
200 return partial(update_wrapper, wrapped=fn, assigned=['__doc__', '__annotations__'])
201
202
203 def error(
204 msg: str,
205 *,
206 time: datetime = None,
207 deep: Optional[str] = None,
208 extra: Optional[dict] = None,
209 ) -> datetime:
210 """\
211 Log message with specific level and return current time.
212
213 Parameters
214 ==========
215 msg
216 Message to display.
217 time
218 A time in the past. If this is passed, the time difference from then
219 to now is appended to `msg` as ` (HH:MM:SS)`.
220 If `msg` contains `{time_passed}`, the time difference is instead
221 inserted at that position.
222 deep
223 If the current verbosity is higher than the log function’s level,
224 this gets displayed as well
225 extra
226 Additional values you can specify in `msg` like `{time_passed}`.
227 """
228 from ._settings import settings
229
230 return settings._root_logger.error(msg, time=time, deep=deep, extra=extra)
231
232
233 @_copy_docs_and_signature(error)
234 def warning(msg, *, time=None, deep=None, extra=None) -> datetime:
235 from ._settings import settings
236
237 return settings._root_logger.warning(msg, time=time, deep=deep, extra=extra)
238
239
240 @_copy_docs_and_signature(error)
241 def info(msg, *, time=None, deep=None, extra=None) -> datetime:
242 from ._settings import settings
243
244 return settings._root_logger.info(msg, time=time, deep=deep, extra=extra)
245
246
247 @_copy_docs_and_signature(error)
248 def hint(msg, *, time=None, deep=None, extra=None) -> datetime:
249 from ._settings import settings
250
251 return settings._root_logger.hint(msg, time=time, deep=deep, extra=extra)
252
253
254 @_copy_docs_and_signature(error)
255 def debug(msg, *, time=None, deep=None, extra=None) -> datetime:
256 from ._settings import settings
257
258 return settings._root_logger.debug(msg, time=time, deep=deep, extra=extra)
259
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scanpy/logging.py b/scanpy/logging.py
--- a/scanpy/logging.py
+++ b/scanpy/logging.py
@@ -131,6 +131,7 @@
('igraph', 'python-igraph'),
'louvain',
'leidenalg',
+ 'pynndescent',
]
|
{"golden_diff": "diff --git a/scanpy/logging.py b/scanpy/logging.py\n--- a/scanpy/logging.py\n+++ b/scanpy/logging.py\n@@ -131,6 +131,7 @@\n ('igraph', 'python-igraph'),\n 'louvain',\n 'leidenalg',\n+ 'pynndescent',\n ]\n", "issue": "Report pynndescent version in sc.logging.print_header\nHi,\r\n\r\nThank you for the great tool. I think this is not a bug. \r\n\r\nRecently I upgraded some packages and found my results were different from the previous runs. I figured out that it is caused by different versions of `pynndescent` (0.4.7 vs 0.5.1), which is recommended to use in UMAP. So I think `pynndescent` should be included in the output of `sc.logging.print_header()`.\r\n\r\n#### Versions\r\n\r\n<details>\r\n\r\n-----\r\nanndata 0.7.5\r\nscanpy 1.6.1\r\nsinfo 0.3.1\r\n-----\r\nPIL 8.1.0\r\nanndata 0.7.5\r\nconstants NA\r\ncycler 0.10.0\r\ncython_runtime NA\r\ndateutil 2.8.1\r\nget_version 2.1\r\nh5py 3.1.0\r\nhighs_wrapper NA\r\nigraph 0.8.3\r\njoblib 1.0.0\r\nkiwisolver 1.3.1\r\nlegacy_api_wrap 1.2\r\nleidenalg 0.8.3\r\nllvmlite 0.35.0\r\nlouvain 0.7.0\r\nmatplotlib 3.3.3\r\nmpl_toolkits NA\r\nnatsort 7.1.1\r\nnumba 0.52.0\r\nnumexpr 2.7.2\r\nnumpy 1.19.5\r\npackaging 20.8\r\npandas 1.2.1\r\npkg_resources NA\r\npynndescent 0.5.1\r\npyparsing 2.4.7\r\npytz 2020.5\r\nscanpy 1.6.1\r\nscipy 1.6.0\r\nsetuptools_scm NA\r\nsinfo 0.3.1\r\nsix 1.15.0\r\nsklearn 0.24.1\r\nstatsmodels 0.12.1\r\ntables 3.6.1\r\ntexttable 1.6.3\r\numap 0.4.6\r\n-----\r\nPython 3.8.5 (default, Sep 4 2020, 07:30:14) [GCC 7.3.0]\r\nLinux-3.10.0-1160.11.1.el7.x86_64-x86_64-with-glibc2.10\r\n40 logical CPU cores, x86_64\r\n\r\n</details>\r\n\n", "before_files": [{"content": "\"\"\"Logging and Profiling\n\"\"\"\nimport io\nimport logging\nimport sys\nfrom functools import update_wrapper, partial\nfrom logging import CRITICAL, ERROR, WARNING, INFO, DEBUG, NOTSET\nfrom datetime import datetime, timedelta, timezone\nfrom typing import Optional\n\nimport anndata.logging\nfrom sinfo import sinfo\n\n\nHINT = (INFO + DEBUG) // 2\nlogging.addLevelName(HINT, 'HINT')\n\n\nclass _RootLogger(logging.RootLogger):\n def __init__(self, level):\n super().__init__(level)\n self.propagate = False\n _RootLogger.manager = logging.Manager(self)\n\n def log(\n self,\n level: int,\n msg: str,\n *,\n extra: Optional[dict] = None,\n time: datetime = None,\n deep: Optional[str] = None,\n ) -> datetime:\n from . import settings\n\n now = datetime.now(timezone.utc)\n time_passed: timedelta = None if time is None else now - time\n extra = {\n **(extra or {}),\n 'deep': deep if settings.verbosity.level < level else None,\n 'time_passed': time_passed,\n }\n super().log(level, msg, extra=extra)\n return now\n\n def critical(self, msg, *, time=None, deep=None, extra=None) -> datetime:\n return self.log(CRITICAL, msg, time=time, deep=deep, extra=extra)\n\n def error(self, msg, *, time=None, deep=None, extra=None) -> datetime:\n return self.log(ERROR, msg, time=time, deep=deep, extra=extra)\n\n def warning(self, msg, *, time=None, deep=None, extra=None) -> datetime:\n return self.log(WARNING, msg, time=time, deep=deep, extra=extra)\n\n def info(self, msg, *, time=None, deep=None, extra=None) -> datetime:\n return self.log(INFO, msg, time=time, deep=deep, extra=extra)\n\n def hint(self, msg, *, time=None, deep=None, extra=None) -> datetime:\n return self.log(HINT, msg, time=time, deep=deep, extra=extra)\n\n def debug(self, msg, *, time=None, deep=None, extra=None) -> datetime:\n return self.log(DEBUG, msg, time=time, deep=deep, extra=extra)\n\n\ndef _set_log_file(settings):\n file = settings.logfile\n name = settings.logpath\n root = settings._root_logger\n h = logging.StreamHandler(file) if name is None else logging.FileHandler(name)\n h.setFormatter(_LogFormatter())\n h.setLevel(root.level)\n if len(root.handlers) == 1:\n root.removeHandler(root.handlers[0])\n elif len(root.handlers) > 1:\n raise RuntimeError('Scanpy\u2019s root logger somehow got more than one handler')\n root.addHandler(h)\n\n\ndef _set_log_level(settings, level: int):\n root = settings._root_logger\n root.setLevel(level)\n (h,) = root.handlers # may only be 1\n h.setLevel(level)\n\n\nclass _LogFormatter(logging.Formatter):\n def __init__(\n self, fmt='{levelname}: {message}', datefmt='%Y-%m-%d %H:%M', style='{'\n ):\n super().__init__(fmt, datefmt, style)\n\n def format(self, record: logging.LogRecord):\n format_orig = self._style._fmt\n if record.levelno == INFO:\n self._style._fmt = '{message}'\n elif record.levelno == HINT:\n self._style._fmt = '--> {message}'\n elif record.levelno == DEBUG:\n self._style._fmt = ' {message}'\n if record.time_passed:\n # strip microseconds\n if record.time_passed.microseconds:\n record.time_passed = timedelta(\n seconds=int(record.time_passed.total_seconds())\n )\n if '{time_passed}' in record.msg:\n record.msg = record.msg.replace(\n '{time_passed}', str(record.time_passed)\n )\n else:\n self._style._fmt += ' ({time_passed})'\n if record.deep:\n record.msg = f'{record.msg}: {record.deep}'\n result = logging.Formatter.format(self, record)\n self._style._fmt = format_orig\n return result\n\n\nprint_memory_usage = anndata.logging.print_memory_usage\nget_memory_usage = anndata.logging.get_memory_usage\n\n\n_DEPENDENCIES_NUMERICS = [\n 'anndata', # anndata actually shouldn't, but as long as it's in development\n 'umap',\n 'numpy',\n 'scipy',\n 'pandas',\n ('sklearn', 'scikit-learn'),\n 'statsmodels',\n ('igraph', 'python-igraph'),\n 'louvain',\n 'leidenalg',\n]\n\n\ndef _versions_dependencies(dependencies):\n # this is not the same as the requirements!\n for mod in dependencies:\n mod_name, dist_name = mod if isinstance(mod, tuple) else (mod, mod)\n try:\n imp = __import__(mod_name)\n yield dist_name, imp.__version__\n except (ImportError, AttributeError):\n pass\n\n\ndef print_header(*, file=None):\n \"\"\"\\\n Versions that might influence the numerical results.\n Matplotlib and Seaborn are excluded from this.\n \"\"\"\n\n modules = ['scanpy'] + _DEPENDENCIES_NUMERICS\n print(\n ' '.join(f'{mod}=={ver}' for mod, ver in _versions_dependencies(modules)),\n file=file or sys.stdout,\n )\n\n\ndef print_versions(*, file=None):\n \"\"\"Print print versions of imported packages\"\"\"\n if file is None: # Inform people about the behavior change\n warning('If you miss a compact list, please try `print_header`!')\n stdout = sys.stdout\n try:\n buf = sys.stdout = io.StringIO()\n sinfo(\n dependencies=True,\n excludes=[\n 'builtins',\n 'stdlib_list',\n 'importlib_metadata',\n # Special module present if test coverage being calculated\n # https://gitlab.com/joelostblom/sinfo/-/issues/10\n \"$coverage\",\n ],\n )\n finally:\n sys.stdout = stdout\n output = buf.getvalue()\n print(output, file=file)\n\n\ndef print_version_and_date(*, file=None):\n \"\"\"\\\n Useful for starting a notebook so you see when you started working.\n \"\"\"\n from . import __version__\n\n if file is None:\n file = sys.stdout\n print(\n f'Running Scanpy {__version__}, ' f'on {datetime.now():%Y-%m-%d %H:%M}.',\n file=file,\n )\n\n\ndef _copy_docs_and_signature(fn):\n return partial(update_wrapper, wrapped=fn, assigned=['__doc__', '__annotations__'])\n\n\ndef error(\n msg: str,\n *,\n time: datetime = None,\n deep: Optional[str] = None,\n extra: Optional[dict] = None,\n) -> datetime:\n \"\"\"\\\n Log message with specific level and return current time.\n\n Parameters\n ==========\n msg\n Message to display.\n time\n A time in the past. If this is passed, the time difference from then\n to now is appended to `msg` as ` (HH:MM:SS)`.\n If `msg` contains `{time_passed}`, the time difference is instead\n inserted at that position.\n deep\n If the current verbosity is higher than the log function\u2019s level,\n this gets displayed as well\n extra\n Additional values you can specify in `msg` like `{time_passed}`.\n \"\"\"\n from ._settings import settings\n\n return settings._root_logger.error(msg, time=time, deep=deep, extra=extra)\n\n\n@_copy_docs_and_signature(error)\ndef warning(msg, *, time=None, deep=None, extra=None) -> datetime:\n from ._settings import settings\n\n return settings._root_logger.warning(msg, time=time, deep=deep, extra=extra)\n\n\n@_copy_docs_and_signature(error)\ndef info(msg, *, time=None, deep=None, extra=None) -> datetime:\n from ._settings import settings\n\n return settings._root_logger.info(msg, time=time, deep=deep, extra=extra)\n\n\n@_copy_docs_and_signature(error)\ndef hint(msg, *, time=None, deep=None, extra=None) -> datetime:\n from ._settings import settings\n\n return settings._root_logger.hint(msg, time=time, deep=deep, extra=extra)\n\n\n@_copy_docs_and_signature(error)\ndef debug(msg, *, time=None, deep=None, extra=None) -> datetime:\n from ._settings import settings\n\n return settings._root_logger.debug(msg, time=time, deep=deep, extra=extra)\n", "path": "scanpy/logging.py"}], "after_files": [{"content": "\"\"\"Logging and Profiling\n\"\"\"\nimport io\nimport logging\nimport sys\nfrom functools import update_wrapper, partial\nfrom logging import CRITICAL, ERROR, WARNING, INFO, DEBUG, NOTSET\nfrom datetime import datetime, timedelta, timezone\nfrom typing import Optional\n\nimport anndata.logging\nfrom sinfo import sinfo\n\n\nHINT = (INFO + DEBUG) // 2\nlogging.addLevelName(HINT, 'HINT')\n\n\nclass _RootLogger(logging.RootLogger):\n def __init__(self, level):\n super().__init__(level)\n self.propagate = False\n _RootLogger.manager = logging.Manager(self)\n\n def log(\n self,\n level: int,\n msg: str,\n *,\n extra: Optional[dict] = None,\n time: datetime = None,\n deep: Optional[str] = None,\n ) -> datetime:\n from . import settings\n\n now = datetime.now(timezone.utc)\n time_passed: timedelta = None if time is None else now - time\n extra = {\n **(extra or {}),\n 'deep': deep if settings.verbosity.level < level else None,\n 'time_passed': time_passed,\n }\n super().log(level, msg, extra=extra)\n return now\n\n def critical(self, msg, *, time=None, deep=None, extra=None) -> datetime:\n return self.log(CRITICAL, msg, time=time, deep=deep, extra=extra)\n\n def error(self, msg, *, time=None, deep=None, extra=None) -> datetime:\n return self.log(ERROR, msg, time=time, deep=deep, extra=extra)\n\n def warning(self, msg, *, time=None, deep=None, extra=None) -> datetime:\n return self.log(WARNING, msg, time=time, deep=deep, extra=extra)\n\n def info(self, msg, *, time=None, deep=None, extra=None) -> datetime:\n return self.log(INFO, msg, time=time, deep=deep, extra=extra)\n\n def hint(self, msg, *, time=None, deep=None, extra=None) -> datetime:\n return self.log(HINT, msg, time=time, deep=deep, extra=extra)\n\n def debug(self, msg, *, time=None, deep=None, extra=None) -> datetime:\n return self.log(DEBUG, msg, time=time, deep=deep, extra=extra)\n\n\ndef _set_log_file(settings):\n file = settings.logfile\n name = settings.logpath\n root = settings._root_logger\n h = logging.StreamHandler(file) if name is None else logging.FileHandler(name)\n h.setFormatter(_LogFormatter())\n h.setLevel(root.level)\n if len(root.handlers) == 1:\n root.removeHandler(root.handlers[0])\n elif len(root.handlers) > 1:\n raise RuntimeError('Scanpy\u2019s root logger somehow got more than one handler')\n root.addHandler(h)\n\n\ndef _set_log_level(settings, level: int):\n root = settings._root_logger\n root.setLevel(level)\n (h,) = root.handlers # may only be 1\n h.setLevel(level)\n\n\nclass _LogFormatter(logging.Formatter):\n def __init__(\n self, fmt='{levelname}: {message}', datefmt='%Y-%m-%d %H:%M', style='{'\n ):\n super().__init__(fmt, datefmt, style)\n\n def format(self, record: logging.LogRecord):\n format_orig = self._style._fmt\n if record.levelno == INFO:\n self._style._fmt = '{message}'\n elif record.levelno == HINT:\n self._style._fmt = '--> {message}'\n elif record.levelno == DEBUG:\n self._style._fmt = ' {message}'\n if record.time_passed:\n # strip microseconds\n if record.time_passed.microseconds:\n record.time_passed = timedelta(\n seconds=int(record.time_passed.total_seconds())\n )\n if '{time_passed}' in record.msg:\n record.msg = record.msg.replace(\n '{time_passed}', str(record.time_passed)\n )\n else:\n self._style._fmt += ' ({time_passed})'\n if record.deep:\n record.msg = f'{record.msg}: {record.deep}'\n result = logging.Formatter.format(self, record)\n self._style._fmt = format_orig\n return result\n\n\nprint_memory_usage = anndata.logging.print_memory_usage\nget_memory_usage = anndata.logging.get_memory_usage\n\n\n_DEPENDENCIES_NUMERICS = [\n 'anndata', # anndata actually shouldn't, but as long as it's in development\n 'umap',\n 'numpy',\n 'scipy',\n 'pandas',\n ('sklearn', 'scikit-learn'),\n 'statsmodels',\n ('igraph', 'python-igraph'),\n 'louvain',\n 'leidenalg',\n 'pynndescent',\n]\n\n\ndef _versions_dependencies(dependencies):\n # this is not the same as the requirements!\n for mod in dependencies:\n mod_name, dist_name = mod if isinstance(mod, tuple) else (mod, mod)\n try:\n imp = __import__(mod_name)\n yield dist_name, imp.__version__\n except (ImportError, AttributeError):\n pass\n\n\ndef print_header(*, file=None):\n \"\"\"\\\n Versions that might influence the numerical results.\n Matplotlib and Seaborn are excluded from this.\n \"\"\"\n\n modules = ['scanpy'] + _DEPENDENCIES_NUMERICS\n print(\n ' '.join(f'{mod}=={ver}' for mod, ver in _versions_dependencies(modules)),\n file=file or sys.stdout,\n )\n\n\ndef print_versions(*, file=None):\n \"\"\"Print print versions of imported packages\"\"\"\n if file is None: # Inform people about the behavior change\n warning('If you miss a compact list, please try `print_header`!')\n stdout = sys.stdout\n try:\n buf = sys.stdout = io.StringIO()\n sinfo(\n dependencies=True,\n excludes=[\n 'builtins',\n 'stdlib_list',\n 'importlib_metadata',\n # Special module present if test coverage being calculated\n # https://gitlab.com/joelostblom/sinfo/-/issues/10\n \"$coverage\",\n ],\n )\n finally:\n sys.stdout = stdout\n output = buf.getvalue()\n print(output, file=file)\n\n\ndef print_version_and_date(*, file=None):\n \"\"\"\\\n Useful for starting a notebook so you see when you started working.\n \"\"\"\n from . import __version__\n\n if file is None:\n file = sys.stdout\n print(\n f'Running Scanpy {__version__}, ' f'on {datetime.now():%Y-%m-%d %H:%M}.',\n file=file,\n )\n\n\ndef _copy_docs_and_signature(fn):\n return partial(update_wrapper, wrapped=fn, assigned=['__doc__', '__annotations__'])\n\n\ndef error(\n msg: str,\n *,\n time: datetime = None,\n deep: Optional[str] = None,\n extra: Optional[dict] = None,\n) -> datetime:\n \"\"\"\\\n Log message with specific level and return current time.\n\n Parameters\n ==========\n msg\n Message to display.\n time\n A time in the past. If this is passed, the time difference from then\n to now is appended to `msg` as ` (HH:MM:SS)`.\n If `msg` contains `{time_passed}`, the time difference is instead\n inserted at that position.\n deep\n If the current verbosity is higher than the log function\u2019s level,\n this gets displayed as well\n extra\n Additional values you can specify in `msg` like `{time_passed}`.\n \"\"\"\n from ._settings import settings\n\n return settings._root_logger.error(msg, time=time, deep=deep, extra=extra)\n\n\n@_copy_docs_and_signature(error)\ndef warning(msg, *, time=None, deep=None, extra=None) -> datetime:\n from ._settings import settings\n\n return settings._root_logger.warning(msg, time=time, deep=deep, extra=extra)\n\n\n@_copy_docs_and_signature(error)\ndef info(msg, *, time=None, deep=None, extra=None) -> datetime:\n from ._settings import settings\n\n return settings._root_logger.info(msg, time=time, deep=deep, extra=extra)\n\n\n@_copy_docs_and_signature(error)\ndef hint(msg, *, time=None, deep=None, extra=None) -> datetime:\n from ._settings import settings\n\n return settings._root_logger.hint(msg, time=time, deep=deep, extra=extra)\n\n\n@_copy_docs_and_signature(error)\ndef debug(msg, *, time=None, deep=None, extra=None) -> datetime:\n from ._settings import settings\n\n return settings._root_logger.debug(msg, time=time, deep=deep, extra=extra)\n", "path": "scanpy/logging.py"}]}
| 3,455 | 77 |
gh_patches_debug_21659
|
rasdani/github-patches
|
git_diff
|
readthedocs__readthedocs.org-4721
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Adopting a projected as gold user fails
### How to reproduce it
1. sign up as Gold member
1. go to https://readthedocs.org/accounts/gold/subscription/
1. select the project that you want to adopt
### Expected Result
Adopts the project.
### Actual Result
Fails with a 500.
https://sentry.io/read-the-docs/readthedocs-org/issues/587668658/
### The problem
This line
https://github.com/rtfd/readthedocs.org/blob/44e02def230b937e4eca396864de9fc81f4ef33f/readthedocs/gold/views.py#L109
cause the problem since we are receiving a "project name" and using it as "project slug".
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `readthedocs/gold/forms.py`
Content:
```
1 """Gold subscription forms."""
2
3 from __future__ import absolute_import
4
5 from builtins import object
6 from django import forms
7
8 from readthedocs.payments.forms import StripeModelForm, StripeResourceMixin
9
10 from .models import LEVEL_CHOICES, GoldUser
11
12
13 class GoldSubscriptionForm(StripeResourceMixin, StripeModelForm):
14
15 """
16 Gold subscription payment form.
17
18 This extends the common base form for handling Stripe subscriptions. Credit
19 card fields for card number, expiry, and CVV are extended from
20 :py:class:`StripeModelForm`, with additional methods from
21 :py:class:`StripeResourceMixin` for common operations against the Stripe API.
22 """
23
24 class Meta(object):
25 model = GoldUser
26 fields = ['last_4_card_digits', 'level']
27
28 last_4_card_digits = forms.CharField(
29 required=True,
30 min_length=4,
31 max_length=4,
32 widget=forms.HiddenInput(attrs={
33 'data-bind': 'valueInit: last_4_card_digits, value: last_4_card_digits',
34 })
35 )
36
37 level = forms.ChoiceField(
38 required=True,
39 choices=LEVEL_CHOICES,
40 )
41
42 def clean(self):
43 self.instance.user = self.customer
44 return super(GoldSubscriptionForm, self).clean()
45
46 def validate_stripe(self):
47 subscription = self.get_subscription()
48 self.instance.stripe_id = subscription.customer
49 self.instance.subscribed = True
50
51 def get_customer_kwargs(self):
52 return {
53 'description': self.customer.get_full_name() or self.customer.username,
54 'email': self.customer.email,
55 'id': self.instance.stripe_id or None
56 }
57
58 def get_subscription(self):
59 customer = self.get_customer()
60
61 # TODO get the first subscription more intelligently
62 subscriptions = customer.subscriptions.all(limit=5)
63 if subscriptions.data:
64 # Update an existing subscription - Stripe prorates by default
65 subscription = subscriptions.data[0]
66 subscription.plan = self.cleaned_data['level']
67 if 'stripe_token' in self.cleaned_data and self.cleaned_data['stripe_token']:
68 # Optionally update the card
69 subscription.source = self.cleaned_data['stripe_token']
70 subscription.save()
71 else:
72 # Add a new subscription
73 subscription = customer.subscriptions.create(
74 plan=self.cleaned_data['level'],
75 source=self.cleaned_data['stripe_token']
76 )
77
78 return subscription
79
80
81 class GoldProjectForm(forms.Form):
82 project = forms.CharField(
83 required=True,
84 )
85
86 def __init__(self, *args, **kwargs):
87 self.user = kwargs.pop('user', None)
88 self.projects = kwargs.pop('projects', None)
89 super(GoldProjectForm, self).__init__(*args, **kwargs)
90
91 def clean(self):
92 cleaned_data = super(GoldProjectForm, self).clean()
93 if self.projects.count() < self.user.num_supported_projects:
94 return cleaned_data
95
96 self.add_error(None, 'You already have the max number of supported projects.')
97
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/readthedocs/gold/forms.py b/readthedocs/gold/forms.py
--- a/readthedocs/gold/forms.py
+++ b/readthedocs/gold/forms.py
@@ -5,7 +5,10 @@
from builtins import object
from django import forms
+from django.utils.translation import ugettext_lazy as _
+
from readthedocs.payments.forms import StripeModelForm, StripeResourceMixin
+from readthedocs.projects.models import Project
from .models import LEVEL_CHOICES, GoldUser
@@ -88,6 +91,14 @@
self.projects = kwargs.pop('projects', None)
super(GoldProjectForm, self).__init__(*args, **kwargs)
+ def clean_project(self):
+ project_slug = self.cleaned_data.get('project', '')
+ project_instance = Project.objects.filter(slug=project_slug)
+ if not project_instance.exists():
+ raise forms.ValidationError(_('No project found.'))
+ else:
+ return project_slug
+
def clean(self):
cleaned_data = super(GoldProjectForm, self).clean()
if self.projects.count() < self.user.num_supported_projects:
|
{"golden_diff": "diff --git a/readthedocs/gold/forms.py b/readthedocs/gold/forms.py\n--- a/readthedocs/gold/forms.py\n+++ b/readthedocs/gold/forms.py\n@@ -5,7 +5,10 @@\n from builtins import object\n from django import forms\n \n+from django.utils.translation import ugettext_lazy as _\n+\n from readthedocs.payments.forms import StripeModelForm, StripeResourceMixin\n+from readthedocs.projects.models import Project\n \n from .models import LEVEL_CHOICES, GoldUser\n \n@@ -88,6 +91,14 @@\n self.projects = kwargs.pop('projects', None)\n super(GoldProjectForm, self).__init__(*args, **kwargs)\n \n+ def clean_project(self):\n+ project_slug = self.cleaned_data.get('project', '')\n+ project_instance = Project.objects.filter(slug=project_slug)\n+ if not project_instance.exists():\n+ raise forms.ValidationError(_('No project found.'))\n+ else:\n+ return project_slug\n+\n def clean(self):\n cleaned_data = super(GoldProjectForm, self).clean()\n if self.projects.count() < self.user.num_supported_projects:\n", "issue": "Adopting a projected as gold user fails\n### How to reproduce it\r\n\r\n1. sign up as Gold member\r\n1. go to https://readthedocs.org/accounts/gold/subscription/\r\n1. select the project that you want to adopt\r\n\r\n### Expected Result\r\n\r\nAdopts the project.\r\n\r\n### Actual Result\r\n\r\nFails with a 500.\r\n\r\nhttps://sentry.io/read-the-docs/readthedocs-org/issues/587668658/\r\n\r\n### The problem\r\n\r\nThis line\r\n\r\nhttps://github.com/rtfd/readthedocs.org/blob/44e02def230b937e4eca396864de9fc81f4ef33f/readthedocs/gold/views.py#L109\r\n\r\ncause the problem since we are receiving a \"project name\" and using it as \"project slug\".\n", "before_files": [{"content": "\"\"\"Gold subscription forms.\"\"\"\n\nfrom __future__ import absolute_import\n\nfrom builtins import object\nfrom django import forms\n\nfrom readthedocs.payments.forms import StripeModelForm, StripeResourceMixin\n\nfrom .models import LEVEL_CHOICES, GoldUser\n\n\nclass GoldSubscriptionForm(StripeResourceMixin, StripeModelForm):\n\n \"\"\"\n Gold subscription payment form.\n\n This extends the common base form for handling Stripe subscriptions. Credit\n card fields for card number, expiry, and CVV are extended from\n :py:class:`StripeModelForm`, with additional methods from\n :py:class:`StripeResourceMixin` for common operations against the Stripe API.\n \"\"\"\n\n class Meta(object):\n model = GoldUser\n fields = ['last_4_card_digits', 'level']\n\n last_4_card_digits = forms.CharField(\n required=True,\n min_length=4,\n max_length=4,\n widget=forms.HiddenInput(attrs={\n 'data-bind': 'valueInit: last_4_card_digits, value: last_4_card_digits',\n })\n )\n\n level = forms.ChoiceField(\n required=True,\n choices=LEVEL_CHOICES,\n )\n\n def clean(self):\n self.instance.user = self.customer\n return super(GoldSubscriptionForm, self).clean()\n\n def validate_stripe(self):\n subscription = self.get_subscription()\n self.instance.stripe_id = subscription.customer\n self.instance.subscribed = True\n\n def get_customer_kwargs(self):\n return {\n 'description': self.customer.get_full_name() or self.customer.username,\n 'email': self.customer.email,\n 'id': self.instance.stripe_id or None\n }\n\n def get_subscription(self):\n customer = self.get_customer()\n\n # TODO get the first subscription more intelligently\n subscriptions = customer.subscriptions.all(limit=5)\n if subscriptions.data:\n # Update an existing subscription - Stripe prorates by default\n subscription = subscriptions.data[0]\n subscription.plan = self.cleaned_data['level']\n if 'stripe_token' in self.cleaned_data and self.cleaned_data['stripe_token']:\n # Optionally update the card\n subscription.source = self.cleaned_data['stripe_token']\n subscription.save()\n else:\n # Add a new subscription\n subscription = customer.subscriptions.create(\n plan=self.cleaned_data['level'],\n source=self.cleaned_data['stripe_token']\n )\n\n return subscription\n\n\nclass GoldProjectForm(forms.Form):\n project = forms.CharField(\n required=True,\n )\n\n def __init__(self, *args, **kwargs):\n self.user = kwargs.pop('user', None)\n self.projects = kwargs.pop('projects', None)\n super(GoldProjectForm, self).__init__(*args, **kwargs)\n\n def clean(self):\n cleaned_data = super(GoldProjectForm, self).clean()\n if self.projects.count() < self.user.num_supported_projects:\n return cleaned_data\n\n self.add_error(None, 'You already have the max number of supported projects.')\n", "path": "readthedocs/gold/forms.py"}], "after_files": [{"content": "\"\"\"Gold subscription forms.\"\"\"\n\nfrom __future__ import absolute_import\n\nfrom builtins import object\nfrom django import forms\n\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom readthedocs.payments.forms import StripeModelForm, StripeResourceMixin\nfrom readthedocs.projects.models import Project\n\nfrom .models import LEVEL_CHOICES, GoldUser\n\n\nclass GoldSubscriptionForm(StripeResourceMixin, StripeModelForm):\n\n \"\"\"\n Gold subscription payment form.\n\n This extends the common base form for handling Stripe subscriptions. Credit\n card fields for card number, expiry, and CVV are extended from\n :py:class:`StripeModelForm`, with additional methods from\n :py:class:`StripeResourceMixin` for common operations against the Stripe API.\n \"\"\"\n\n class Meta(object):\n model = GoldUser\n fields = ['last_4_card_digits', 'level']\n\n last_4_card_digits = forms.CharField(\n required=True,\n min_length=4,\n max_length=4,\n widget=forms.HiddenInput(attrs={\n 'data-bind': 'valueInit: last_4_card_digits, value: last_4_card_digits',\n })\n )\n\n level = forms.ChoiceField(\n required=True,\n choices=LEVEL_CHOICES,\n )\n\n def clean(self):\n self.instance.user = self.customer\n return super(GoldSubscriptionForm, self).clean()\n\n def validate_stripe(self):\n subscription = self.get_subscription()\n self.instance.stripe_id = subscription.customer\n self.instance.subscribed = True\n\n def get_customer_kwargs(self):\n return {\n 'description': self.customer.get_full_name() or self.customer.username,\n 'email': self.customer.email,\n 'id': self.instance.stripe_id or None\n }\n\n def get_subscription(self):\n customer = self.get_customer()\n\n # TODO get the first subscription more intelligently\n subscriptions = customer.subscriptions.all(limit=5)\n if subscriptions.data:\n # Update an existing subscription - Stripe prorates by default\n subscription = subscriptions.data[0]\n subscription.plan = self.cleaned_data['level']\n if 'stripe_token' in self.cleaned_data and self.cleaned_data['stripe_token']:\n # Optionally update the card\n subscription.source = self.cleaned_data['stripe_token']\n subscription.save()\n else:\n # Add a new subscription\n subscription = customer.subscriptions.create(\n plan=self.cleaned_data['level'],\n source=self.cleaned_data['stripe_token']\n )\n\n return subscription\n\n\nclass GoldProjectForm(forms.Form):\n project = forms.CharField(\n required=True,\n )\n\n def __init__(self, *args, **kwargs):\n self.user = kwargs.pop('user', None)\n self.projects = kwargs.pop('projects', None)\n super(GoldProjectForm, self).__init__(*args, **kwargs)\n\n def clean_project(self):\n project_slug = self.cleaned_data.get('project', '')\n project_instance = Project.objects.filter(slug=project_slug)\n if not project_instance.exists():\n raise forms.ValidationError(_('No project found.'))\n else:\n return project_slug\n\n def clean(self):\n cleaned_data = super(GoldProjectForm, self).clean()\n if self.projects.count() < self.user.num_supported_projects:\n return cleaned_data\n\n self.add_error(None, 'You already have the max number of supported projects.')\n", "path": "readthedocs/gold/forms.py"}]}
| 1,270 | 246 |
gh_patches_debug_25241
|
rasdani/github-patches
|
git_diff
|
nvaccess__nvda-14703
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
nvda logs a lot of '\r\n\r\n' if UIA support for Windows console is enabled
### Steps to reproduce:
1. In NVDA's Advanced Settings panel, make the following settings:
- Windows Console support: combo box: UIA when available
2. Open cmd or git bash and press NVDA+Shift+M(Laptop);
### Actual behavior:
There are a lot of '\r\n' in the log.
### Expected behavior:
There won't be so many '\r\n' in the log
### NVDA logs, crash dumps and other attachments:
[log.txt](https://github.com/nvaccess/nvda/files/10866869/log.txt)
### System configuration
#### NVDA installed/portable/running from source:
Installed
#### NVDA version:
2023.1Beta2
#### Windows version:
Windows 10 22H2 (AMD64) build 19045.2604
#### Name and version of other software in use when reproducing the issue:
None
#### Other information about your system:
None
### Other questions
#### Does the issue still occur after restarting your computer?
Yes
#### Have you tried any other versions of NVDA? If so, please report their behaviors.
2022.4 is the same
#### If NVDA add-ons are disabled, is your problem still occurring?
Yes
#### Does the issue still occur after you run the COM Registration Fixing Tool in NVDA's tools menu?
Yes
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `source/speechDictHandler/__init__.py`
Content:
```
1 # A part of NonVisual Desktop Access (NVDA)
2 # Copyright (C) 2006-2023 NVDA Contributors <http://www.nvda-project.org/>
3 # This file is covered by the GNU General Public License.
4 # See the file COPYING for more details.
5
6 import re
7 import globalVars
8 from logHandler import log
9 import os
10 import codecs
11 import api
12 import config
13 from . import dictFormatUpgrade
14 from .speechDictVars import speechDictsPath
15
16 dictionaries = {}
17 dictTypes = ("temp", "voice", "default", "builtin") # ordered by their priority E.G. voice specific speech dictionary is processed before the default
18
19 # Types of speech dictionary entries:
20 ENTRY_TYPE_ANYWHERE = 0 # String can match anywhere
21 ENTRY_TYPE_WORD = 2 # String must have word boundaries on both sides to match
22 ENTRY_TYPE_REGEXP = 1 # Regular expression
23
24 class SpeechDictEntry:
25
26 def __init__(self, pattern, replacement,comment,caseSensitive=True,type=ENTRY_TYPE_ANYWHERE):
27 self.pattern = pattern
28 flags = re.U
29 if not caseSensitive: flags|=re.IGNORECASE
30 if type == ENTRY_TYPE_REGEXP:
31 tempPattern = pattern
32 elif type == ENTRY_TYPE_WORD:
33 tempPattern = r"\b" + re.escape(pattern) + r"\b"
34 else:
35 tempPattern= re.escape(pattern)
36 type = ENTRY_TYPE_ANYWHERE # Insure sane values.
37 self.compiled = re.compile(tempPattern,flags)
38 self.replacement = replacement
39 self.comment=comment
40 self.caseSensitive=caseSensitive
41 self.type=type
42
43 def sub(self, text: str) -> str:
44 if self.type == ENTRY_TYPE_REGEXP:
45 replacement = self.replacement
46 else:
47 # Escape the backslashes for non-regexp replacements
48 replacement = self.replacement.replace('\\', '\\\\')
49 return self.compiled.sub(replacement, text)
50
51 class SpeechDict(list):
52
53 fileName = None
54
55 def load(self, fileName):
56 self.fileName=fileName
57 comment=""
58 del self[:]
59 log.debug("Loading speech dictionary '%s'..." % fileName)
60 if not os.path.isfile(fileName):
61 log.debug("file '%s' not found." % fileName)
62 return
63 file = codecs.open(fileName,"r","utf_8_sig",errors="replace")
64 for line in file:
65 if line.isspace():
66 comment=""
67 continue
68 line=line.rstrip('\r\n')
69 if line.startswith('#'):
70 if comment:
71 comment+=" "
72 comment+=line[1:]
73 else:
74 temp=line.split("\t")
75 if len(temp) ==4:
76 pattern = temp[0].replace(r'\#','#')
77 replace = temp[1].replace(r'\#','#')
78 try:
79 dictionaryEntry=SpeechDictEntry(pattern, replace, comment, caseSensitive=bool(int(temp[2])), type=int(temp[3]))
80 self.append(dictionaryEntry)
81 except Exception as e:
82 log.exception("Dictionary (\"%s\") entry invalid for \"%s\" error raised: \"%s\"" % (fileName, line, e))
83 comment=""
84 else:
85 log.warning("can't parse line '%s'" % line)
86 log.debug("%d loaded records." % len(self))
87 file.close()
88 return
89
90 def save(self,fileName=None):
91 if not fileName:
92 fileName=getattr(self,'fileName',None)
93 if not fileName:
94 return
95 dirName=os.path.dirname(fileName)
96 if not os.path.isdir(dirName):
97 os.makedirs(dirName)
98 file = codecs.open(fileName,"w","utf_8_sig",errors="replace")
99 for entry in self:
100 if entry.comment:
101 file.write("#%s\r\n"%entry.comment)
102 file.write("%s\t%s\t%s\t%s\r\n"%(entry.pattern.replace('#',r'\#'),entry.replacement.replace('#',r'\#'),int(entry.caseSensitive),entry.type))
103 file.close()
104
105 def sub(self, text):
106 invalidEntries = []
107 for index, entry in enumerate(self):
108 try:
109 text = entry.sub(text)
110 except re.error as exc:
111 dictName = self.fileName or "temporary dictionary"
112 log.error(f"Invalid dictionary entry {index+1} in {dictName}: \"{entry.pattern}\", {exc}")
113 invalidEntries.append(index)
114 for index in reversed(invalidEntries):
115 del self[index]
116 return text
117
118 def processText(text):
119 if not globalVars.speechDictionaryProcessing:
120 return text
121 for type in dictTypes:
122 text=dictionaries[type].sub(text)
123 return text
124
125 def initialize():
126 for type in dictTypes:
127 dictionaries[type]=SpeechDict()
128 dictionaries["default"].load(os.path.join(speechDictsPath, "default.dic"))
129 dictionaries["builtin"].load(os.path.join(globalVars.appDir, "builtin.dic"))
130
131 def loadVoiceDict(synth):
132 """Loads appropriate dictionary for the given synthesizer.
133 It handles case when the synthesizer doesn't support voice setting.
134 """
135 try:
136 dictFormatUpgrade.doAnyUpgrades(synth)
137 except:
138 log.error("error trying to upgrade dictionaries", exc_info=True)
139 pass
140 if synth.isSupported("voice"):
141 voice = synth.availableVoices[synth.voice].displayName
142 baseName = dictFormatUpgrade.createVoiceDictFileName(synth.name, voice)
143 else:
144 baseName=r"{synth}.dic".format(synth=synth.name)
145 voiceDictsPath = dictFormatUpgrade.voiceDictsPath
146 fileName= os.path.join(voiceDictsPath, synth.name, baseName)
147 dictionaries["voice"].load(fileName)
148
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/source/speechDictHandler/__init__.py b/source/speechDictHandler/__init__.py
--- a/source/speechDictHandler/__init__.py
+++ b/source/speechDictHandler/__init__.py
@@ -8,8 +8,8 @@
from logHandler import log
import os
import codecs
+import review
import api
-import config
from . import dictFormatUpgrade
from .speechDictVars import speechDictsPath
@@ -115,9 +115,26 @@
del self[index]
return text
+
def processText(text):
if not globalVars.speechDictionaryProcessing:
return text
+ # #14689: older (IMPROVED and END_INCLUSIVE) UIA consoles have many blank lines,
+ # which slows processing to a halt
+ focus = api.getFocusObject()
+ try:
+ # get TextInfo implementation for object review mode
+ textInfo, obj = review.getObjectPosition(focus)
+ except AttributeError: # no makeTextInfo
+ textInfo = None
+ # late import to prevent circular dependency
+ # ConsoleUIATextInfo is used by IMPROVED and END_INCLUSIVE consoles
+ from NVDAObjects.UIA.winConsoleUIA import ConsoleUIATextInfo
+ if isinstance(textInfo, ConsoleUIATextInfo):
+ stripText = text.rstrip()
+ IGNORE_TRAILING_WHITESPACE_LENGTH = 100
+ if len(text) - len(stripText) > IGNORE_TRAILING_WHITESPACE_LENGTH:
+ text = stripText
for type in dictTypes:
text=dictionaries[type].sub(text)
return text
|
{"golden_diff": "diff --git a/source/speechDictHandler/__init__.py b/source/speechDictHandler/__init__.py\n--- a/source/speechDictHandler/__init__.py\n+++ b/source/speechDictHandler/__init__.py\n@@ -8,8 +8,8 @@\n from logHandler import log\r\n import os\r\n import codecs\r\n+import review\r\n import api\r\n-import config\r\n from . import dictFormatUpgrade\r\n from .speechDictVars import speechDictsPath\r\n \r\n@@ -115,9 +115,26 @@\n \t\t\t\tdel self[index]\r\n \t\treturn text\r\n \r\n+\r\n def processText(text):\r\n \tif not globalVars.speechDictionaryProcessing:\r\n \t\treturn text\r\n+\t# #14689: older (IMPROVED and END_INCLUSIVE) UIA consoles have many blank lines,\r\n+\t# which slows processing to a halt\r\n+\tfocus = api.getFocusObject()\r\n+\ttry:\r\n+\t\t# get TextInfo implementation for object review mode\r\n+\t\ttextInfo, obj = review.getObjectPosition(focus)\r\n+\texcept AttributeError: # no makeTextInfo\r\n+\t\ttextInfo = None\r\n+\t# late import to prevent circular dependency\r\n+\t# ConsoleUIATextInfo is used by IMPROVED and END_INCLUSIVE consoles\r\n+\tfrom NVDAObjects.UIA.winConsoleUIA import ConsoleUIATextInfo\r\n+\tif isinstance(textInfo, ConsoleUIATextInfo):\r\n+\t\tstripText = text.rstrip()\r\n+\t\tIGNORE_TRAILING_WHITESPACE_LENGTH = 100\r\n+\t\tif len(text) - len(stripText) > IGNORE_TRAILING_WHITESPACE_LENGTH:\r\n+\t\t\ttext = stripText\r\n \tfor type in dictTypes:\r\n \t\ttext=dictionaries[type].sub(text)\r\n \treturn text\n", "issue": "nvda logs a lot of '\\r\\n\\r\\n' if UIA support for Windows console is enabled\n\r\n### Steps to reproduce:\r\n1. In NVDA's Advanced Settings panel, make the following settings:\r\n - Windows Console support: combo box: UIA when available\r\n2. Open cmd or git bash and press NVDA+Shift+M(Laptop);\r\n### Actual behavior:\r\nThere are a lot of '\\r\\n' in the log.\r\n\r\n### Expected behavior:\r\nThere won't be so many '\\r\\n' in the log\r\n### NVDA logs, crash dumps and other attachments:\r\n[log.txt](https://github.com/nvaccess/nvda/files/10866869/log.txt)\r\n\r\n### System configuration\r\n#### NVDA installed/portable/running from source:\r\nInstalled\r\n#### NVDA version:\r\n2023.1Beta2\r\n#### Windows version:\r\nWindows 10 22H2 (AMD64) build 19045.2604\r\n#### Name and version of other software in use when reproducing the issue:\r\nNone\r\n#### Other information about your system:\r\nNone\r\n### Other questions\r\n#### Does the issue still occur after restarting your computer?\r\nYes\r\n#### Have you tried any other versions of NVDA? If so, please report their behaviors.\r\n2022.4 is the same\r\n#### If NVDA add-ons are disabled, is your problem still occurring?\r\nYes\r\n#### Does the issue still occur after you run the COM Registration Fixing Tool in NVDA's tools menu?\r\nYes\n", "before_files": [{"content": "# A part of NonVisual Desktop Access (NVDA)\r\n# Copyright (C) 2006-2023 NVDA Contributors <http://www.nvda-project.org/>\r\n# This file is covered by the GNU General Public License.\r\n# See the file COPYING for more details.\r\n\r\nimport re\r\nimport globalVars\r\nfrom logHandler import log\r\nimport os\r\nimport codecs\r\nimport api\r\nimport config\r\nfrom . import dictFormatUpgrade\r\nfrom .speechDictVars import speechDictsPath\r\n\r\ndictionaries = {}\r\ndictTypes = (\"temp\", \"voice\", \"default\", \"builtin\") # ordered by their priority E.G. voice specific speech dictionary is processed before the default\r\n\r\n# Types of speech dictionary entries:\r\nENTRY_TYPE_ANYWHERE = 0 # String can match anywhere\r\nENTRY_TYPE_WORD = 2 # String must have word boundaries on both sides to match\r\nENTRY_TYPE_REGEXP = 1 # Regular expression\r\n\r\nclass SpeechDictEntry:\r\n\r\n\tdef __init__(self, pattern, replacement,comment,caseSensitive=True,type=ENTRY_TYPE_ANYWHERE):\r\n\t\tself.pattern = pattern\r\n\t\tflags = re.U\r\n\t\tif not caseSensitive: flags|=re.IGNORECASE\r\n\t\tif type == ENTRY_TYPE_REGEXP:\r\n\t\t\ttempPattern = pattern\r\n\t\telif type == ENTRY_TYPE_WORD:\r\n\t\t\ttempPattern = r\"\\b\" + re.escape(pattern) + r\"\\b\"\r\n\t\telse:\r\n\t\t\ttempPattern= re.escape(pattern)\r\n\t\t\ttype = ENTRY_TYPE_ANYWHERE # Insure sane values.\r\n\t\tself.compiled = re.compile(tempPattern,flags)\r\n\t\tself.replacement = replacement\r\n\t\tself.comment=comment\r\n\t\tself.caseSensitive=caseSensitive\r\n\t\tself.type=type\r\n\r\n\tdef sub(self, text: str) -> str:\r\n\t\tif self.type == ENTRY_TYPE_REGEXP:\r\n\t\t\treplacement = self.replacement\r\n\t\telse:\r\n\t\t\t# Escape the backslashes for non-regexp replacements\r\n\t\t\treplacement = self.replacement.replace('\\\\', '\\\\\\\\')\r\n\t\treturn self.compiled.sub(replacement, text)\r\n\r\nclass SpeechDict(list):\r\n\r\n\tfileName = None\r\n\r\n\tdef load(self, fileName):\r\n\t\tself.fileName=fileName\r\n\t\tcomment=\"\"\r\n\t\tdel self[:]\r\n\t\tlog.debug(\"Loading speech dictionary '%s'...\" % fileName)\r\n\t\tif not os.path.isfile(fileName): \r\n\t\t\tlog.debug(\"file '%s' not found.\" % fileName)\r\n\t\t\treturn\r\n\t\tfile = codecs.open(fileName,\"r\",\"utf_8_sig\",errors=\"replace\")\r\n\t\tfor line in file:\r\n\t\t\tif line.isspace():\r\n\t\t\t\tcomment=\"\"\r\n\t\t\t\tcontinue\r\n\t\t\tline=line.rstrip('\\r\\n')\r\n\t\t\tif line.startswith('#'):\r\n\t\t\t\tif comment:\r\n\t\t\t\t\tcomment+=\" \"\r\n\t\t\t\tcomment+=line[1:]\r\n\t\t\telse:\r\n\t\t\t\ttemp=line.split(\"\\t\")\r\n\t\t\t\tif len(temp) ==4:\r\n\t\t\t\t\tpattern = temp[0].replace(r'\\#','#')\r\n\t\t\t\t\treplace = temp[1].replace(r'\\#','#')\r\n\t\t\t\t\ttry:\r\n\t\t\t\t\t\tdictionaryEntry=SpeechDictEntry(pattern, replace, comment, caseSensitive=bool(int(temp[2])), type=int(temp[3]))\r\n\t\t\t\t\t\tself.append(dictionaryEntry)\r\n\t\t\t\t\texcept Exception as e:\r\n\t\t\t\t\t\tlog.exception(\"Dictionary (\\\"%s\\\") entry invalid for \\\"%s\\\" error raised: \\\"%s\\\"\" % (fileName, line, e))\r\n\t\t\t\t\tcomment=\"\"\r\n\t\t\t\telse:\r\n\t\t\t\t\tlog.warning(\"can't parse line '%s'\" % line)\r\n\t\tlog.debug(\"%d loaded records.\" % len(self))\r\n\t\tfile.close()\r\n\t\treturn\r\n\r\n\tdef save(self,fileName=None):\r\n\t\tif not fileName:\r\n\t\t\tfileName=getattr(self,'fileName',None)\r\n\t\tif not fileName:\r\n\t\t\treturn\r\n\t\tdirName=os.path.dirname(fileName)\r\n\t\tif not os.path.isdir(dirName):\r\n\t\t\tos.makedirs(dirName)\r\n\t\tfile = codecs.open(fileName,\"w\",\"utf_8_sig\",errors=\"replace\")\r\n\t\tfor entry in self:\r\n\t\t\tif entry.comment:\r\n\t\t\t\tfile.write(\"#%s\\r\\n\"%entry.comment)\r\n\t\t\tfile.write(\"%s\\t%s\\t%s\\t%s\\r\\n\"%(entry.pattern.replace('#',r'\\#'),entry.replacement.replace('#',r'\\#'),int(entry.caseSensitive),entry.type))\r\n\t\tfile.close()\r\n\r\n\tdef sub(self, text):\r\n\t\tinvalidEntries = []\r\n\t\tfor index, entry in enumerate(self):\r\n\t\t\ttry:\r\n\t\t\t\ttext = entry.sub(text)\r\n\t\t\texcept re.error as exc:\r\n\t\t\t\tdictName = self.fileName or \"temporary dictionary\"\r\n\t\t\t\tlog.error(f\"Invalid dictionary entry {index+1} in {dictName}: \\\"{entry.pattern}\\\", {exc}\")\r\n\t\t\t\tinvalidEntries.append(index)\r\n\t\t\tfor index in reversed(invalidEntries):\r\n\t\t\t\tdel self[index]\r\n\t\treturn text\r\n\r\ndef processText(text):\r\n\tif not globalVars.speechDictionaryProcessing:\r\n\t\treturn text\r\n\tfor type in dictTypes:\r\n\t\ttext=dictionaries[type].sub(text)\r\n\treturn text\r\n\r\ndef initialize():\r\n\tfor type in dictTypes:\r\n\t\tdictionaries[type]=SpeechDict()\r\n\tdictionaries[\"default\"].load(os.path.join(speechDictsPath, \"default.dic\"))\r\n\tdictionaries[\"builtin\"].load(os.path.join(globalVars.appDir, \"builtin.dic\"))\r\n\r\ndef loadVoiceDict(synth):\r\n\t\"\"\"Loads appropriate dictionary for the given synthesizer.\r\nIt handles case when the synthesizer doesn't support voice setting.\r\n\"\"\"\r\n\ttry:\r\n\t\tdictFormatUpgrade.doAnyUpgrades(synth)\r\n\texcept:\r\n\t\tlog.error(\"error trying to upgrade dictionaries\", exc_info=True)\r\n\t\tpass\r\n\tif synth.isSupported(\"voice\"):\r\n\t\tvoice = synth.availableVoices[synth.voice].displayName\r\n\t\tbaseName = dictFormatUpgrade.createVoiceDictFileName(synth.name, voice)\r\n\telse:\r\n\t\tbaseName=r\"{synth}.dic\".format(synth=synth.name)\r\n\tvoiceDictsPath = dictFormatUpgrade.voiceDictsPath\r\n\tfileName= os.path.join(voiceDictsPath, synth.name, baseName)\r\n\tdictionaries[\"voice\"].load(fileName)\r\n", "path": "source/speechDictHandler/__init__.py"}], "after_files": [{"content": "# A part of NonVisual Desktop Access (NVDA)\r\n# Copyright (C) 2006-2023 NVDA Contributors <http://www.nvda-project.org/>\r\n# This file is covered by the GNU General Public License.\r\n# See the file COPYING for more details.\r\n\r\nimport re\r\nimport globalVars\r\nfrom logHandler import log\r\nimport os\r\nimport codecs\r\nimport review\r\nimport api\r\nfrom . import dictFormatUpgrade\r\nfrom .speechDictVars import speechDictsPath\r\n\r\ndictionaries = {}\r\ndictTypes = (\"temp\", \"voice\", \"default\", \"builtin\") # ordered by their priority E.G. voice specific speech dictionary is processed before the default\r\n\r\n# Types of speech dictionary entries:\r\nENTRY_TYPE_ANYWHERE = 0 # String can match anywhere\r\nENTRY_TYPE_WORD = 2 # String must have word boundaries on both sides to match\r\nENTRY_TYPE_REGEXP = 1 # Regular expression\r\n\r\nclass SpeechDictEntry:\r\n\r\n\tdef __init__(self, pattern, replacement,comment,caseSensitive=True,type=ENTRY_TYPE_ANYWHERE):\r\n\t\tself.pattern = pattern\r\n\t\tflags = re.U\r\n\t\tif not caseSensitive: flags|=re.IGNORECASE\r\n\t\tif type == ENTRY_TYPE_REGEXP:\r\n\t\t\ttempPattern = pattern\r\n\t\telif type == ENTRY_TYPE_WORD:\r\n\t\t\ttempPattern = r\"\\b\" + re.escape(pattern) + r\"\\b\"\r\n\t\telse:\r\n\t\t\ttempPattern= re.escape(pattern)\r\n\t\t\ttype = ENTRY_TYPE_ANYWHERE # Insure sane values.\r\n\t\tself.compiled = re.compile(tempPattern,flags)\r\n\t\tself.replacement = replacement\r\n\t\tself.comment=comment\r\n\t\tself.caseSensitive=caseSensitive\r\n\t\tself.type=type\r\n\r\n\tdef sub(self, text: str) -> str:\r\n\t\tif self.type == ENTRY_TYPE_REGEXP:\r\n\t\t\treplacement = self.replacement\r\n\t\telse:\r\n\t\t\t# Escape the backslashes for non-regexp replacements\r\n\t\t\treplacement = self.replacement.replace('\\\\', '\\\\\\\\')\r\n\t\treturn self.compiled.sub(replacement, text)\r\n\r\nclass SpeechDict(list):\r\n\r\n\tfileName = None\r\n\r\n\tdef load(self, fileName):\r\n\t\tself.fileName=fileName\r\n\t\tcomment=\"\"\r\n\t\tdel self[:]\r\n\t\tlog.debug(\"Loading speech dictionary '%s'...\" % fileName)\r\n\t\tif not os.path.isfile(fileName): \r\n\t\t\tlog.debug(\"file '%s' not found.\" % fileName)\r\n\t\t\treturn\r\n\t\tfile = codecs.open(fileName,\"r\",\"utf_8_sig\",errors=\"replace\")\r\n\t\tfor line in file:\r\n\t\t\tif line.isspace():\r\n\t\t\t\tcomment=\"\"\r\n\t\t\t\tcontinue\r\n\t\t\tline=line.rstrip('\\r\\n')\r\n\t\t\tif line.startswith('#'):\r\n\t\t\t\tif comment:\r\n\t\t\t\t\tcomment+=\" \"\r\n\t\t\t\tcomment+=line[1:]\r\n\t\t\telse:\r\n\t\t\t\ttemp=line.split(\"\\t\")\r\n\t\t\t\tif len(temp) ==4:\r\n\t\t\t\t\tpattern = temp[0].replace(r'\\#','#')\r\n\t\t\t\t\treplace = temp[1].replace(r'\\#','#')\r\n\t\t\t\t\ttry:\r\n\t\t\t\t\t\tdictionaryEntry=SpeechDictEntry(pattern, replace, comment, caseSensitive=bool(int(temp[2])), type=int(temp[3]))\r\n\t\t\t\t\t\tself.append(dictionaryEntry)\r\n\t\t\t\t\texcept Exception as e:\r\n\t\t\t\t\t\tlog.exception(\"Dictionary (\\\"%s\\\") entry invalid for \\\"%s\\\" error raised: \\\"%s\\\"\" % (fileName, line, e))\r\n\t\t\t\t\tcomment=\"\"\r\n\t\t\t\telse:\r\n\t\t\t\t\tlog.warning(\"can't parse line '%s'\" % line)\r\n\t\tlog.debug(\"%d loaded records.\" % len(self))\r\n\t\tfile.close()\r\n\t\treturn\r\n\r\n\tdef save(self,fileName=None):\r\n\t\tif not fileName:\r\n\t\t\tfileName=getattr(self,'fileName',None)\r\n\t\tif not fileName:\r\n\t\t\treturn\r\n\t\tdirName=os.path.dirname(fileName)\r\n\t\tif not os.path.isdir(dirName):\r\n\t\t\tos.makedirs(dirName)\r\n\t\tfile = codecs.open(fileName,\"w\",\"utf_8_sig\",errors=\"replace\")\r\n\t\tfor entry in self:\r\n\t\t\tif entry.comment:\r\n\t\t\t\tfile.write(\"#%s\\r\\n\"%entry.comment)\r\n\t\t\tfile.write(\"%s\\t%s\\t%s\\t%s\\r\\n\"%(entry.pattern.replace('#',r'\\#'),entry.replacement.replace('#',r'\\#'),int(entry.caseSensitive),entry.type))\r\n\t\tfile.close()\r\n\r\n\tdef sub(self, text):\r\n\t\tinvalidEntries = []\r\n\t\tfor index, entry in enumerate(self):\r\n\t\t\ttry:\r\n\t\t\t\ttext = entry.sub(text)\r\n\t\t\texcept re.error as exc:\r\n\t\t\t\tdictName = self.fileName or \"temporary dictionary\"\r\n\t\t\t\tlog.error(f\"Invalid dictionary entry {index+1} in {dictName}: \\\"{entry.pattern}\\\", {exc}\")\r\n\t\t\t\tinvalidEntries.append(index)\r\n\t\t\tfor index in reversed(invalidEntries):\r\n\t\t\t\tdel self[index]\r\n\t\treturn text\r\n\r\n\r\ndef processText(text):\r\n\tif not globalVars.speechDictionaryProcessing:\r\n\t\treturn text\r\n\t# #14689: older (IMPROVED and END_INCLUSIVE) UIA consoles have many blank lines,\r\n\t# which slows processing to a halt\r\n\tfocus = api.getFocusObject()\r\n\ttry:\r\n\t\t# get TextInfo implementation for object review mode\r\n\t\ttextInfo, obj = review.getObjectPosition(focus)\r\n\texcept AttributeError: # no makeTextInfo\r\n\t\ttextInfo = None\r\n\t# late import to prevent circular dependency\r\n\t# ConsoleUIATextInfo is used by IMPROVED and END_INCLUSIVE consoles\r\n\tfrom NVDAObjects.UIA.winConsoleUIA import ConsoleUIATextInfo\r\n\tif isinstance(textInfo, ConsoleUIATextInfo):\r\n\t\tstripText = text.rstrip()\r\n\t\tIGNORE_TRAILING_WHITESPACE_LENGTH = 100\r\n\t\tif len(text) - len(stripText) > IGNORE_TRAILING_WHITESPACE_LENGTH:\r\n\t\t\ttext = stripText\r\n\tfor type in dictTypes:\r\n\t\ttext=dictionaries[type].sub(text)\r\n\treturn text\r\n\r\ndef initialize():\r\n\tfor type in dictTypes:\r\n\t\tdictionaries[type]=SpeechDict()\r\n\tdictionaries[\"default\"].load(os.path.join(speechDictsPath, \"default.dic\"))\r\n\tdictionaries[\"builtin\"].load(os.path.join(globalVars.appDir, \"builtin.dic\"))\r\n\r\ndef loadVoiceDict(synth):\r\n\t\"\"\"Loads appropriate dictionary for the given synthesizer.\r\nIt handles case when the synthesizer doesn't support voice setting.\r\n\"\"\"\r\n\ttry:\r\n\t\tdictFormatUpgrade.doAnyUpgrades(synth)\r\n\texcept:\r\n\t\tlog.error(\"error trying to upgrade dictionaries\", exc_info=True)\r\n\t\tpass\r\n\tif synth.isSupported(\"voice\"):\r\n\t\tvoice = synth.availableVoices[synth.voice].displayName\r\n\t\tbaseName = dictFormatUpgrade.createVoiceDictFileName(synth.name, voice)\r\n\telse:\r\n\t\tbaseName=r\"{synth}.dic\".format(synth=synth.name)\r\n\tvoiceDictsPath = dictFormatUpgrade.voiceDictsPath\r\n\tfileName= os.path.join(voiceDictsPath, synth.name, baseName)\r\n\tdictionaries[\"voice\"].load(fileName)\r\n", "path": "source/speechDictHandler/__init__.py"}]}
| 2,160 | 371 |
gh_patches_debug_17614
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-1164
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
FieldError: Cannot resolve keyword 'registration' into field. Choices are: cancel_deadline, category, descrip...
Sentry Issue: [CONCREXIT-2Z](https://sentry.io/organizations/thalia/issues/1761243401/?referrer=github_integration)
```
FieldError: Cannot resolve keyword 'registration' into field. Choices are: cancel_deadline, category, description_en, description_nl, documents, end, eventregistration, fine, id, location_en, location_nl, map_location, max_participants, no_registration_message_en, no_registration_message_nl, organiser, organiser_id, pizzaevent, price, published, registration_end, registration_reminder, registration_reminder_id, registration_start, registrationinformationfield, send_cancel_email, slide, slide_id, start, start_reminde...
(14 additional frame(s) were not displayed)
...
File "django/db/models/sql/query.py", line 1371, in _add_q
child_clause, needed_inner = self._add_q(
File "django/db/models/sql/query.py", line 1378, in _add_q
child_clause, needed_inner = self.build_filter(
File "django/db/models/sql/query.py", line 1251, in build_filter
lookups, parts, reffed_expression = self.solve_lookup_type(arg)
File "django/db/models/sql/query.py", line 1088, in solve_lookup_type
_, field, _, lookup_parts = self.names_to_path(lookup_splitted, self.get_meta())
File "django/db/models/sql/query.py", line 1483, in names_to_path
raise FieldError("Cannot resolve keyword '%s' into field. "
```
FieldError: Cannot resolve keyword 'registration' into field. Choices are: cancel_deadline, category, descrip...
Sentry Issue: [CONCREXIT-2Z](https://sentry.io/organizations/thalia/issues/1761243401/?referrer=github_integration)
```
FieldError: Cannot resolve keyword 'registration' into field. Choices are: cancel_deadline, category, description_en, description_nl, documents, end, eventregistration, fine, id, location_en, location_nl, map_location, max_participants, no_registration_message_en, no_registration_message_nl, organiser, organiser_id, pizzaevent, price, published, registration_end, registration_reminder, registration_reminder_id, registration_start, registrationinformationfield, send_cancel_email, slide, slide_id, start, start_reminde...
(14 additional frame(s) were not displayed)
...
File "django/db/models/sql/query.py", line 1371, in _add_q
child_clause, needed_inner = self._add_q(
File "django/db/models/sql/query.py", line 1378, in _add_q
child_clause, needed_inner = self.build_filter(
File "django/db/models/sql/query.py", line 1251, in build_filter
lookups, parts, reffed_expression = self.solve_lookup_type(arg)
File "django/db/models/sql/query.py", line 1088, in solve_lookup_type
_, field, _, lookup_parts = self.names_to_path(lookup_splitted, self.get_meta())
File "django/db/models/sql/query.py", line 1483, in names_to_path
raise FieldError("Cannot resolve keyword '%s' into field. "
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `website/events/feeds.py`
Content:
```
1 """The feeds defined by the events package"""
2 from django.conf import settings
3 from django.db.models.query_utils import Q
4 from django.urls import reverse
5 from django.utils.translation import activate
6 from django.utils.translation import gettext as _
7 from django_ical.views import ICalFeed
8
9 from events.models import Event, FeedToken
10
11
12 class EventFeed(ICalFeed):
13 """Output an iCal feed containing all published events"""
14
15 def __init__(self, lang="en"):
16 super().__init__()
17 self.lang = lang
18 self.user = None
19
20 def __call__(self, request, *args, **kwargs):
21 if "u" in request.GET:
22 self.user = FeedToken.get_member(request.GET["u"])
23 else:
24 self.user = None
25
26 return super().__call__(request, args, kwargs)
27
28 def product_id(self):
29 return f"-//{settings.SITE_DOMAIN}//EventCalendar//{self.lang.upper()}"
30
31 def file_name(self):
32 return "thalia_{}.ics".format(self.lang)
33
34 def title(self):
35 activate(self.lang)
36 return _("Study Association Thalia event calendar")
37
38 def items(self):
39 query = Q(published=True)
40
41 if self.user:
42 query &= Q(registration_start__isnull=True) | (
43 Q(registration__member=self.user) & Q(registration__date_cancelled=None)
44 )
45
46 return Event.objects.filter(query).order_by("-start")
47
48 def item_title(self, item):
49 return item.title
50
51 def item_description(self, item):
52 return f'{item.description} <a href="' f'{self.item_link(item)}">Website</a>'
53
54 def item_start_datetime(self, item):
55 return item.start
56
57 def item_end_datetime(self, item):
58 return item.end
59
60 def item_link(self, item):
61 return settings.BASE_URL + reverse("events:event", kwargs={"pk": item.id})
62
63 def item_location(self, item):
64 return "{} - {}".format(item.location, item.map_location)
65
```
Path: `website/events/decorators.py`
Content:
```
1 """The decorators defined by the events package"""
2 from django.core.exceptions import PermissionDenied
3
4 from events import services
5 from events.models import Event
6
7
8 def organiser_only(view_function):
9 """See OrganiserOnly"""
10 return OrganiserOnly(view_function)
11
12
13 class OrganiserOnly:
14 """
15 Decorator that denies access to the page if:
16 1. There is no `pk` or `registration` in the request
17 2. The specified event does not exist
18 3. The user is no organiser of the specified event
19 """
20
21 def __init__(self, view_function):
22 self.view_function = view_function
23
24 def __call__(self, request, *args, **kwargs):
25 event = None
26
27 if "pk" in kwargs:
28 try:
29 event = Event.objects.get(pk=kwargs.get("pk"))
30 except Event.DoesNotExist:
31 pass
32 elif "registration" in kwargs:
33 try:
34 event = Event.objects.get(registration__pk=kwargs.get("registration"))
35 except Event.DoesNotExist:
36 pass
37
38 if event and services.is_organiser(request.member, event):
39 return self.view_function(request, *args, **kwargs)
40
41 raise PermissionDenied
42
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/website/events/decorators.py b/website/events/decorators.py
--- a/website/events/decorators.py
+++ b/website/events/decorators.py
@@ -31,7 +31,9 @@
pass
elif "registration" in kwargs:
try:
- event = Event.objects.get(registration__pk=kwargs.get("registration"))
+ event = Event.objects.get(
+ eventregistration__pk=kwargs.get("registration")
+ )
except Event.DoesNotExist:
pass
diff --git a/website/events/feeds.py b/website/events/feeds.py
--- a/website/events/feeds.py
+++ b/website/events/feeds.py
@@ -40,7 +40,8 @@
if self.user:
query &= Q(registration_start__isnull=True) | (
- Q(registration__member=self.user) & Q(registration__date_cancelled=None)
+ Q(eventregistration__member=self.user)
+ & Q(eventregistration__date_cancelled=None)
)
return Event.objects.filter(query).order_by("-start")
|
{"golden_diff": "diff --git a/website/events/decorators.py b/website/events/decorators.py\n--- a/website/events/decorators.py\n+++ b/website/events/decorators.py\n@@ -31,7 +31,9 @@\n pass\n elif \"registration\" in kwargs:\n try:\n- event = Event.objects.get(registration__pk=kwargs.get(\"registration\"))\n+ event = Event.objects.get(\n+ eventregistration__pk=kwargs.get(\"registration\")\n+ )\n except Event.DoesNotExist:\n pass\n \ndiff --git a/website/events/feeds.py b/website/events/feeds.py\n--- a/website/events/feeds.py\n+++ b/website/events/feeds.py\n@@ -40,7 +40,8 @@\n \n if self.user:\n query &= Q(registration_start__isnull=True) | (\n- Q(registration__member=self.user) & Q(registration__date_cancelled=None)\n+ Q(eventregistration__member=self.user)\n+ & Q(eventregistration__date_cancelled=None)\n )\n \n return Event.objects.filter(query).order_by(\"-start\")\n", "issue": "FieldError: Cannot resolve keyword 'registration' into field. Choices are: cancel_deadline, category, descrip...\nSentry Issue: [CONCREXIT-2Z](https://sentry.io/organizations/thalia/issues/1761243401/?referrer=github_integration)\n\n```\nFieldError: Cannot resolve keyword 'registration' into field. Choices are: cancel_deadline, category, description_en, description_nl, documents, end, eventregistration, fine, id, location_en, location_nl, map_location, max_participants, no_registration_message_en, no_registration_message_nl, organiser, organiser_id, pizzaevent, price, published, registration_end, registration_reminder, registration_reminder_id, registration_start, registrationinformationfield, send_cancel_email, slide, slide_id, start, start_reminde...\n(14 additional frame(s) were not displayed)\n...\n File \"django/db/models/sql/query.py\", line 1371, in _add_q\n child_clause, needed_inner = self._add_q(\n File \"django/db/models/sql/query.py\", line 1378, in _add_q\n child_clause, needed_inner = self.build_filter(\n File \"django/db/models/sql/query.py\", line 1251, in build_filter\n lookups, parts, reffed_expression = self.solve_lookup_type(arg)\n File \"django/db/models/sql/query.py\", line 1088, in solve_lookup_type\n _, field, _, lookup_parts = self.names_to_path(lookup_splitted, self.get_meta())\n File \"django/db/models/sql/query.py\", line 1483, in names_to_path\n raise FieldError(\"Cannot resolve keyword '%s' into field. \"\n```\nFieldError: Cannot resolve keyword 'registration' into field. Choices are: cancel_deadline, category, descrip...\nSentry Issue: [CONCREXIT-2Z](https://sentry.io/organizations/thalia/issues/1761243401/?referrer=github_integration)\n\n```\nFieldError: Cannot resolve keyword 'registration' into field. Choices are: cancel_deadline, category, description_en, description_nl, documents, end, eventregistration, fine, id, location_en, location_nl, map_location, max_participants, no_registration_message_en, no_registration_message_nl, organiser, organiser_id, pizzaevent, price, published, registration_end, registration_reminder, registration_reminder_id, registration_start, registrationinformationfield, send_cancel_email, slide, slide_id, start, start_reminde...\n(14 additional frame(s) were not displayed)\n...\n File \"django/db/models/sql/query.py\", line 1371, in _add_q\n child_clause, needed_inner = self._add_q(\n File \"django/db/models/sql/query.py\", line 1378, in _add_q\n child_clause, needed_inner = self.build_filter(\n File \"django/db/models/sql/query.py\", line 1251, in build_filter\n lookups, parts, reffed_expression = self.solve_lookup_type(arg)\n File \"django/db/models/sql/query.py\", line 1088, in solve_lookup_type\n _, field, _, lookup_parts = self.names_to_path(lookup_splitted, self.get_meta())\n File \"django/db/models/sql/query.py\", line 1483, in names_to_path\n raise FieldError(\"Cannot resolve keyword '%s' into field. \"\n```\n", "before_files": [{"content": "\"\"\"The feeds defined by the events package\"\"\"\nfrom django.conf import settings\nfrom django.db.models.query_utils import Q\nfrom django.urls import reverse\nfrom django.utils.translation import activate\nfrom django.utils.translation import gettext as _\nfrom django_ical.views import ICalFeed\n\nfrom events.models import Event, FeedToken\n\n\nclass EventFeed(ICalFeed):\n \"\"\"Output an iCal feed containing all published events\"\"\"\n\n def __init__(self, lang=\"en\"):\n super().__init__()\n self.lang = lang\n self.user = None\n\n def __call__(self, request, *args, **kwargs):\n if \"u\" in request.GET:\n self.user = FeedToken.get_member(request.GET[\"u\"])\n else:\n self.user = None\n\n return super().__call__(request, args, kwargs)\n\n def product_id(self):\n return f\"-//{settings.SITE_DOMAIN}//EventCalendar//{self.lang.upper()}\"\n\n def file_name(self):\n return \"thalia_{}.ics\".format(self.lang)\n\n def title(self):\n activate(self.lang)\n return _(\"Study Association Thalia event calendar\")\n\n def items(self):\n query = Q(published=True)\n\n if self.user:\n query &= Q(registration_start__isnull=True) | (\n Q(registration__member=self.user) & Q(registration__date_cancelled=None)\n )\n\n return Event.objects.filter(query).order_by(\"-start\")\n\n def item_title(self, item):\n return item.title\n\n def item_description(self, item):\n return f'{item.description} <a href=\"' f'{self.item_link(item)}\">Website</a>'\n\n def item_start_datetime(self, item):\n return item.start\n\n def item_end_datetime(self, item):\n return item.end\n\n def item_link(self, item):\n return settings.BASE_URL + reverse(\"events:event\", kwargs={\"pk\": item.id})\n\n def item_location(self, item):\n return \"{} - {}\".format(item.location, item.map_location)\n", "path": "website/events/feeds.py"}, {"content": "\"\"\"The decorators defined by the events package\"\"\"\nfrom django.core.exceptions import PermissionDenied\n\nfrom events import services\nfrom events.models import Event\n\n\ndef organiser_only(view_function):\n \"\"\"See OrganiserOnly\"\"\"\n return OrganiserOnly(view_function)\n\n\nclass OrganiserOnly:\n \"\"\"\n Decorator that denies access to the page if:\n 1. There is no `pk` or `registration` in the request\n 2. The specified event does not exist\n 3. The user is no organiser of the specified event\n \"\"\"\n\n def __init__(self, view_function):\n self.view_function = view_function\n\n def __call__(self, request, *args, **kwargs):\n event = None\n\n if \"pk\" in kwargs:\n try:\n event = Event.objects.get(pk=kwargs.get(\"pk\"))\n except Event.DoesNotExist:\n pass\n elif \"registration\" in kwargs:\n try:\n event = Event.objects.get(registration__pk=kwargs.get(\"registration\"))\n except Event.DoesNotExist:\n pass\n\n if event and services.is_organiser(request.member, event):\n return self.view_function(request, *args, **kwargs)\n\n raise PermissionDenied\n", "path": "website/events/decorators.py"}], "after_files": [{"content": "\"\"\"The feeds defined by the events package\"\"\"\nfrom django.conf import settings\nfrom django.db.models.query_utils import Q\nfrom django.urls import reverse\nfrom django.utils.translation import activate\nfrom django.utils.translation import gettext as _\nfrom django_ical.views import ICalFeed\n\nfrom events.models import Event, FeedToken\n\n\nclass EventFeed(ICalFeed):\n \"\"\"Output an iCal feed containing all published events\"\"\"\n\n def __init__(self, lang=\"en\"):\n super().__init__()\n self.lang = lang\n self.user = None\n\n def __call__(self, request, *args, **kwargs):\n if \"u\" in request.GET:\n self.user = FeedToken.get_member(request.GET[\"u\"])\n else:\n self.user = None\n\n return super().__call__(request, args, kwargs)\n\n def product_id(self):\n return f\"-//{settings.SITE_DOMAIN}//EventCalendar//{self.lang.upper()}\"\n\n def file_name(self):\n return \"thalia_{}.ics\".format(self.lang)\n\n def title(self):\n activate(self.lang)\n return _(\"Study Association Thalia event calendar\")\n\n def items(self):\n query = Q(published=True)\n\n if self.user:\n query &= Q(registration_start__isnull=True) | (\n Q(eventregistration__member=self.user)\n & Q(eventregistration__date_cancelled=None)\n )\n\n return Event.objects.filter(query).order_by(\"-start\")\n\n def item_title(self, item):\n return item.title\n\n def item_description(self, item):\n return f'{item.description} <a href=\"' f'{self.item_link(item)}\">Website</a>'\n\n def item_start_datetime(self, item):\n return item.start\n\n def item_end_datetime(self, item):\n return item.end\n\n def item_link(self, item):\n return settings.BASE_URL + reverse(\"events:event\", kwargs={\"pk\": item.id})\n\n def item_location(self, item):\n return \"{} - {}\".format(item.location, item.map_location)\n", "path": "website/events/feeds.py"}, {"content": "\"\"\"The decorators defined by the events package\"\"\"\nfrom django.core.exceptions import PermissionDenied\n\nfrom events import services\nfrom events.models import Event\n\n\ndef organiser_only(view_function):\n \"\"\"See OrganiserOnly\"\"\"\n return OrganiserOnly(view_function)\n\n\nclass OrganiserOnly:\n \"\"\"\n Decorator that denies access to the page if:\n 1. There is no `pk` or `registration` in the request\n 2. The specified event does not exist\n 3. The user is no organiser of the specified event\n \"\"\"\n\n def __init__(self, view_function):\n self.view_function = view_function\n\n def __call__(self, request, *args, **kwargs):\n event = None\n\n if \"pk\" in kwargs:\n try:\n event = Event.objects.get(pk=kwargs.get(\"pk\"))\n except Event.DoesNotExist:\n pass\n elif \"registration\" in kwargs:\n try:\n event = Event.objects.get(\n eventregistration__pk=kwargs.get(\"registration\")\n )\n except Event.DoesNotExist:\n pass\n\n if event and services.is_organiser(request.member, event):\n return self.view_function(request, *args, **kwargs)\n\n raise PermissionDenied\n", "path": "website/events/decorators.py"}]}
| 1,921 | 239 |
gh_patches_debug_34965
|
rasdani/github-patches
|
git_diff
|
fidals__shopelectro-987
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Render only first-leveled children at the header menu
Now we have too many categories at the header menu

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `shopelectro/logic/header.py`
Content:
```
1 from django.conf import settings
2 from django.db.models import Q
3
4 from pages import models as pages_models
5 from shopelectro import models
6
7
8 def menu_qs() -> pages_models.PageQuerySet:
9 """
10 QuerySet with header menu items.
11
12 Contains root categories.
13 Result can be tuned HEADER_LINKS settings option.
14 """
15 return (
16 pages_models.Page.objects.active()
17 .filter(
18 Q(slug__in=settings.HEADER_LINKS['add'])
19 | (
20 # @todo #974:30m Optimize the header menu query.
21 # Fetch catalog page for the header menu at the same query.
22 # root category pages.
23 Q(parent=pages_models.CustomPage.objects.filter(slug='catalog'))
24 & Q(type='model')
25 & Q(related_model_name=models.Category._meta.db_table)
26 & ~Q(slug__in=settings.HEADER_LINKS['exclude'])
27 )
28 )
29 .order_by('position')
30 )
31
```
Path: `shopelectro/templatetags/se_extras.py`
Content:
```
1 import datetime
2 import math
3
4 from django import template
5 from django.conf import settings
6 from django.contrib.humanize.templatetags.humanize import intcomma
7 from django.template.defaultfilters import floatformat
8 from django.urls import reverse
9
10 from images.models import ImageMixin
11 from pages.models import Page
12 from shopelectro import logic
13
14 register = template.Library()
15
16
17 @register.simple_tag
18 def roots():
19 return logic.header.menu_qs()
20
21
22 @register.simple_tag
23 def footer_links():
24 return settings.FOOTER_LINKS
25
26
27 @register.filter
28 def class_name(model):
29 """Return Model name."""
30 return type(model).__name__
31
32
33 @register.simple_tag
34 def time_to_call():
35 def is_weekend(t):
36 return t.weekday() > 4
37
38 def is_friday(t):
39 return t.weekday() == 4
40
41 def not_yet_opened(t):
42 current_time = (t.hour, t.minute)
43 open_time = (10, 00)
44 return current_time < open_time and not is_weekend(t)
45
46 def is_closed(t):
47 current_time = (t.hour, t.minute)
48 closing_time = (16, 30) if is_friday(t) else (17, 30)
49 return current_time > closing_time
50
51 when_we_call = {
52 lambda now: is_weekend(now) or (is_friday(now) and is_closed(now)): 'В понедельник в 10:30',
53 lambda now: not_yet_opened(now): 'Сегодня в 10:30',
54 lambda now: is_closed(now) and not (is_friday(now) or is_weekend(now)): 'Завтра в 10:30',
55 lambda _: True: 'В течение 30 минут'
56 }
57
58 time_ = datetime.datetime.now()
59 call = ' позвонит менеджер и обсудит детали доставки.'
60 for condition, time in when_we_call.items():
61 if condition(time_):
62 return time + call
63
64
65 @register.simple_tag
66 def full_url(url_name, *args):
67 return settings.BASE_URL + reverse(url_name, args=args)
68
69
70 @register.filter
71 def humanize_price(price):
72 return intcomma(floatformat(price, 0))
73
74
75 @register.filter
76 def show_price_in_units(item):
77 if (getattr(item, 'in_pack', 1) > 1):
78 return 'руб / упаковка'
79 return 'руб / шт'
80
81
82 # Not good code, but duker at 06/10/2016 don't know how to fix it.
83 # It makes Image model very complex.
84 @register.simple_tag
85 def get_img_alt(entity: ImageMixin):
86 product_alt = 'Фотография {}'
87 logo_alt = 'Логотип компании Shopelectro'
88
89 if not isinstance(entity, Page):
90 return logo_alt
91
92 # try one of this attributes to get pages name
93 name_attrs = ['h1', 'title', 'name']
94 entity_name = next(
95 getattr(entity, attr)
96 for attr in name_attrs
97 if getattr(entity, attr)
98 )
99 return product_alt.format(entity_name)
100
101
102 @register.simple_tag
103 def main_image_or_logo(page: Page):
104 """Used for microdata."""
105 if hasattr(page, 'main_image') and page.main_image:
106 return page.main_image.url
107 else:
108 return settings.STATIC_URL + 'images/logo.png'
109
110
111 @register.inclusion_tag('catalog/product_feedbacks_icons.html')
112 def icon_stars(rating=0):
113 """Render set of rating icons based on 1 through 5 rating values."""
114 full_icons = int(math.floor(rating))
115 half_icons = 0 if rating == int(rating) else 1
116 empty_icons = 5 - full_icons - half_icons
117
118 return {
119 'full_icons': range(full_icons),
120 'half_icons': range(half_icons),
121 'empty_icons': range(empty_icons),
122 }
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/shopelectro/logic/header.py b/shopelectro/logic/header.py
--- a/shopelectro/logic/header.py
+++ b/shopelectro/logic/header.py
@@ -1,3 +1,6 @@
+import typing
+from functools import lru_cache
+
from django.conf import settings
from django.db.models import Q
@@ -5,26 +8,41 @@
from shopelectro import models
-def menu_qs() -> pages_models.PageQuerySet:
- """
- QuerySet with header menu items.
+class Menu:
+ DICT_TYPE = typing.Dict[models.CategoryPage, typing.List[models.CategoryPage]]
+
+ @staticmethod
+ def roots() -> pages_models.PageQuerySet:
+ """
+ QuerySet with header menu items.
- Contains root categories.
- Result can be tuned HEADER_LINKS settings option.
- """
- return (
- pages_models.Page.objects.active()
- .filter(
- Q(slug__in=settings.HEADER_LINKS['add'])
- | (
- # @todo #974:30m Optimize the header menu query.
- # Fetch catalog page for the header menu at the same query.
- # root category pages.
- Q(parent=pages_models.CustomPage.objects.filter(slug='catalog'))
- & Q(type='model')
- & Q(related_model_name=models.Category._meta.db_table)
- & ~Q(slug__in=settings.HEADER_LINKS['exclude'])
+ Contains root categories.
+ Result can be tuned HEADER_LINKS settings option.
+ """
+ return (
+ pages_models.Page.objects.active()
+ .filter(
+ Q(slug__in=settings.HEADER_LINKS['add'])
+ | (
+ # @todo #974:30m Optimize the header menu query.
+ # Fetch catalog page for the header menu at the same query.
+ # root category pages.
+ Q(parent=pages_models.CustomPage.objects.filter(slug='catalog'))
+ & Q(type='model')
+ & Q(related_model_name=models.Category._meta.db_table)
+ & ~Q(slug__in=settings.HEADER_LINKS['exclude'])
+ )
)
+ .order_by('position')
)
- .order_by('position')
- )
+
+ @lru_cache(maxsize=1)
+ def as_dict(self) -> DICT_TYPE:
+ return {
+ root: list(
+ root.get_children()
+ .filter(type='model')
+ .filter(related_model_name=models.Category._meta.db_table)
+ )
+ for root in self.roots().iterator()
+ }
diff --git a/shopelectro/templatetags/se_extras.py b/shopelectro/templatetags/se_extras.py
--- a/shopelectro/templatetags/se_extras.py
+++ b/shopelectro/templatetags/se_extras.py
@@ -15,8 +15,8 @@
@register.simple_tag
-def roots():
- return logic.header.menu_qs()
+def header_menu() -> logic.header.Menu:
+ return logic.header.Menu()
@register.simple_tag
|
{"golden_diff": "diff --git a/shopelectro/logic/header.py b/shopelectro/logic/header.py\n--- a/shopelectro/logic/header.py\n+++ b/shopelectro/logic/header.py\n@@ -1,3 +1,6 @@\n+import typing\n+from functools import lru_cache\n+\n from django.conf import settings\n from django.db.models import Q\n \n@@ -5,26 +8,41 @@\n from shopelectro import models\n \n \n-def menu_qs() -> pages_models.PageQuerySet:\n- \"\"\"\n- QuerySet with header menu items.\n+class Menu:\n+ DICT_TYPE = typing.Dict[models.CategoryPage, typing.List[models.CategoryPage]]\n+\n+ @staticmethod\n+ def roots() -> pages_models.PageQuerySet:\n+ \"\"\"\n+ QuerySet with header menu items.\n \n- Contains root categories.\n- Result can be tuned HEADER_LINKS settings option.\n- \"\"\"\n- return (\n- pages_models.Page.objects.active()\n- .filter(\n- Q(slug__in=settings.HEADER_LINKS['add'])\n- | (\n- # @todo #974:30m Optimize the header menu query.\n- # Fetch catalog page for the header menu at the same query.\n- # root category pages.\n- Q(parent=pages_models.CustomPage.objects.filter(slug='catalog'))\n- & Q(type='model')\n- & Q(related_model_name=models.Category._meta.db_table)\n- & ~Q(slug__in=settings.HEADER_LINKS['exclude'])\n+ Contains root categories.\n+ Result can be tuned HEADER_LINKS settings option.\n+ \"\"\"\n+ return (\n+ pages_models.Page.objects.active()\n+ .filter(\n+ Q(slug__in=settings.HEADER_LINKS['add'])\n+ | (\n+ # @todo #974:30m Optimize the header menu query.\n+ # Fetch catalog page for the header menu at the same query.\n+ # root category pages.\n+ Q(parent=pages_models.CustomPage.objects.filter(slug='catalog'))\n+ & Q(type='model')\n+ & Q(related_model_name=models.Category._meta.db_table)\n+ & ~Q(slug__in=settings.HEADER_LINKS['exclude'])\n+ )\n )\n+ .order_by('position')\n )\n- .order_by('position')\n- )\n+\n+ @lru_cache(maxsize=1)\n+ def as_dict(self) -> DICT_TYPE:\n+ return {\n+ root: list(\n+ root.get_children()\n+ .filter(type='model')\n+ .filter(related_model_name=models.Category._meta.db_table)\n+ )\n+ for root in self.roots().iterator()\n+ }\ndiff --git a/shopelectro/templatetags/se_extras.py b/shopelectro/templatetags/se_extras.py\n--- a/shopelectro/templatetags/se_extras.py\n+++ b/shopelectro/templatetags/se_extras.py\n@@ -15,8 +15,8 @@\n \n \n @register.simple_tag\n-def roots():\n- return logic.header.menu_qs()\n+def header_menu() -> logic.header.Menu:\n+ return logic.header.Menu()\n \n \n @register.simple_tag\n", "issue": "Render only first-leveled children at the header menu\nNow we have too many categories at the header menu\r\n\r\n\n", "before_files": [{"content": "from django.conf import settings\nfrom django.db.models import Q\n\nfrom pages import models as pages_models\nfrom shopelectro import models\n\n\ndef menu_qs() -> pages_models.PageQuerySet:\n \"\"\"\n QuerySet with header menu items.\n\n Contains root categories.\n Result can be tuned HEADER_LINKS settings option.\n \"\"\"\n return (\n pages_models.Page.objects.active()\n .filter(\n Q(slug__in=settings.HEADER_LINKS['add'])\n | (\n # @todo #974:30m Optimize the header menu query.\n # Fetch catalog page for the header menu at the same query.\n # root category pages.\n Q(parent=pages_models.CustomPage.objects.filter(slug='catalog'))\n & Q(type='model')\n & Q(related_model_name=models.Category._meta.db_table)\n & ~Q(slug__in=settings.HEADER_LINKS['exclude'])\n )\n )\n .order_by('position')\n )\n", "path": "shopelectro/logic/header.py"}, {"content": "import datetime\nimport math\n\nfrom django import template\nfrom django.conf import settings\nfrom django.contrib.humanize.templatetags.humanize import intcomma\nfrom django.template.defaultfilters import floatformat\nfrom django.urls import reverse\n\nfrom images.models import ImageMixin\nfrom pages.models import Page\nfrom shopelectro import logic\n\nregister = template.Library()\n\n\[email protected]_tag\ndef roots():\n return logic.header.menu_qs()\n\n\[email protected]_tag\ndef footer_links():\n return settings.FOOTER_LINKS\n\n\[email protected]\ndef class_name(model):\n \"\"\"Return Model name.\"\"\"\n return type(model).__name__\n\n\[email protected]_tag\ndef time_to_call():\n def is_weekend(t):\n return t.weekday() > 4\n\n def is_friday(t):\n return t.weekday() == 4\n\n def not_yet_opened(t):\n current_time = (t.hour, t.minute)\n open_time = (10, 00)\n return current_time < open_time and not is_weekend(t)\n\n def is_closed(t):\n current_time = (t.hour, t.minute)\n closing_time = (16, 30) if is_friday(t) else (17, 30)\n return current_time > closing_time\n\n when_we_call = {\n lambda now: is_weekend(now) or (is_friday(now) and is_closed(now)): '\u0412 \u043f\u043e\u043d\u0435\u0434\u0435\u043b\u044c\u043d\u0438\u043a \u0432 10:30',\n lambda now: not_yet_opened(now): '\u0421\u0435\u0433\u043e\u0434\u043d\u044f \u0432 10:30',\n lambda now: is_closed(now) and not (is_friday(now) or is_weekend(now)): '\u0417\u0430\u0432\u0442\u0440\u0430 \u0432 10:30',\n lambda _: True: '\u0412 \u0442\u0435\u0447\u0435\u043d\u0438\u0435 30 \u043c\u0438\u043d\u0443\u0442'\n }\n\n time_ = datetime.datetime.now()\n call = ' \u043f\u043e\u0437\u0432\u043e\u043d\u0438\u0442 \u043c\u0435\u043d\u0435\u0434\u0436\u0435\u0440 \u0438 \u043e\u0431\u0441\u0443\u0434\u0438\u0442 \u0434\u0435\u0442\u0430\u043b\u0438 \u0434\u043e\u0441\u0442\u0430\u0432\u043a\u0438.'\n for condition, time in when_we_call.items():\n if condition(time_):\n return time + call\n\n\[email protected]_tag\ndef full_url(url_name, *args):\n return settings.BASE_URL + reverse(url_name, args=args)\n\n\[email protected]\ndef humanize_price(price):\n return intcomma(floatformat(price, 0))\n\n\[email protected]\ndef show_price_in_units(item):\n if (getattr(item, 'in_pack', 1) > 1):\n return '\u0440\u0443\u0431 / \u0443\u043f\u0430\u043a\u043e\u0432\u043a\u0430'\n return '\u0440\u0443\u0431 / \u0448\u0442'\n\n\n# Not good code, but duker at 06/10/2016 don't know how to fix it.\n# It makes Image model very complex.\[email protected]_tag\ndef get_img_alt(entity: ImageMixin):\n product_alt = '\u0424\u043e\u0442\u043e\u0433\u0440\u0430\u0444\u0438\u044f {}'\n logo_alt = '\u041b\u043e\u0433\u043e\u0442\u0438\u043f \u043a\u043e\u043c\u043f\u0430\u043d\u0438\u0438 Shopelectro'\n\n if not isinstance(entity, Page):\n return logo_alt\n\n # try one of this attributes to get pages name\n name_attrs = ['h1', 'title', 'name']\n entity_name = next(\n getattr(entity, attr)\n for attr in name_attrs\n if getattr(entity, attr)\n )\n return product_alt.format(entity_name)\n\n\[email protected]_tag\ndef main_image_or_logo(page: Page):\n \"\"\"Used for microdata.\"\"\"\n if hasattr(page, 'main_image') and page.main_image:\n return page.main_image.url\n else:\n return settings.STATIC_URL + 'images/logo.png'\n\n\[email protected]_tag('catalog/product_feedbacks_icons.html')\ndef icon_stars(rating=0):\n \"\"\"Render set of rating icons based on 1 through 5 rating values.\"\"\"\n full_icons = int(math.floor(rating))\n half_icons = 0 if rating == int(rating) else 1\n empty_icons = 5 - full_icons - half_icons\n\n return {\n 'full_icons': range(full_icons),\n 'half_icons': range(half_icons),\n 'empty_icons': range(empty_icons),\n }\n", "path": "shopelectro/templatetags/se_extras.py"}], "after_files": [{"content": "import typing\nfrom functools import lru_cache\n\nfrom django.conf import settings\nfrom django.db.models import Q\n\nfrom pages import models as pages_models\nfrom shopelectro import models\n\n\nclass Menu:\n DICT_TYPE = typing.Dict[models.CategoryPage, typing.List[models.CategoryPage]]\n\n @staticmethod\n def roots() -> pages_models.PageQuerySet:\n \"\"\"\n QuerySet with header menu items.\n\n Contains root categories.\n Result can be tuned HEADER_LINKS settings option.\n \"\"\"\n return (\n pages_models.Page.objects.active()\n .filter(\n Q(slug__in=settings.HEADER_LINKS['add'])\n | (\n # @todo #974:30m Optimize the header menu query.\n # Fetch catalog page for the header menu at the same query.\n # root category pages.\n Q(parent=pages_models.CustomPage.objects.filter(slug='catalog'))\n & Q(type='model')\n & Q(related_model_name=models.Category._meta.db_table)\n & ~Q(slug__in=settings.HEADER_LINKS['exclude'])\n )\n )\n .order_by('position')\n )\n\n @lru_cache(maxsize=1)\n def as_dict(self) -> DICT_TYPE:\n return {\n root: list(\n root.get_children()\n .filter(type='model')\n .filter(related_model_name=models.Category._meta.db_table)\n )\n for root in self.roots().iterator()\n }\n", "path": "shopelectro/logic/header.py"}, {"content": "import datetime\nimport math\n\nfrom django import template\nfrom django.conf import settings\nfrom django.contrib.humanize.templatetags.humanize import intcomma\nfrom django.template.defaultfilters import floatformat\nfrom django.urls import reverse\n\nfrom images.models import ImageMixin\nfrom pages.models import Page\nfrom shopelectro import logic\n\nregister = template.Library()\n\n\[email protected]_tag\ndef header_menu() -> logic.header.Menu:\n return logic.header.Menu()\n\n\[email protected]_tag\ndef footer_links():\n return settings.FOOTER_LINKS\n\n\[email protected]\ndef class_name(model):\n \"\"\"Return Model name.\"\"\"\n return type(model).__name__\n\n\[email protected]_tag\ndef time_to_call():\n def is_weekend(t):\n return t.weekday() > 4\n\n def is_friday(t):\n return t.weekday() == 4\n\n def not_yet_opened(t):\n current_time = (t.hour, t.minute)\n open_time = (10, 00)\n return current_time < open_time and not is_weekend(t)\n\n def is_closed(t):\n current_time = (t.hour, t.minute)\n closing_time = (16, 30) if is_friday(t) else (17, 30)\n return current_time > closing_time\n\n when_we_call = {\n lambda now: is_weekend(now) or (is_friday(now) and is_closed(now)): '\u0412 \u043f\u043e\u043d\u0435\u0434\u0435\u043b\u044c\u043d\u0438\u043a \u0432 10:30',\n lambda now: not_yet_opened(now): '\u0421\u0435\u0433\u043e\u0434\u043d\u044f \u0432 10:30',\n lambda now: is_closed(now) and not (is_friday(now) or is_weekend(now)): '\u0417\u0430\u0432\u0442\u0440\u0430 \u0432 10:30',\n lambda _: True: '\u0412 \u0442\u0435\u0447\u0435\u043d\u0438\u0435 30 \u043c\u0438\u043d\u0443\u0442'\n }\n\n time_ = datetime.datetime.now()\n call = ' \u043f\u043e\u0437\u0432\u043e\u043d\u0438\u0442 \u043c\u0435\u043d\u0435\u0434\u0436\u0435\u0440 \u0438 \u043e\u0431\u0441\u0443\u0434\u0438\u0442 \u0434\u0435\u0442\u0430\u043b\u0438 \u0434\u043e\u0441\u0442\u0430\u0432\u043a\u0438.'\n for condition, time in when_we_call.items():\n if condition(time_):\n return time + call\n\n\[email protected]_tag\ndef full_url(url_name, *args):\n return settings.BASE_URL + reverse(url_name, args=args)\n\n\[email protected]\ndef humanize_price(price):\n return intcomma(floatformat(price, 0))\n\n\[email protected]\ndef show_price_in_units(item):\n if (getattr(item, 'in_pack', 1) > 1):\n return '\u0440\u0443\u0431 / \u0443\u043f\u0430\u043a\u043e\u0432\u043a\u0430'\n return '\u0440\u0443\u0431 / \u0448\u0442'\n\n\n# Not good code, but duker at 06/10/2016 don't know how to fix it.\n# It makes Image model very complex.\[email protected]_tag\ndef get_img_alt(entity: ImageMixin):\n product_alt = '\u0424\u043e\u0442\u043e\u0433\u0440\u0430\u0444\u0438\u044f {}'\n logo_alt = '\u041b\u043e\u0433\u043e\u0442\u0438\u043f \u043a\u043e\u043c\u043f\u0430\u043d\u0438\u0438 Shopelectro'\n\n if not isinstance(entity, Page):\n return logo_alt\n\n # try one of this attributes to get pages name\n name_attrs = ['h1', 'title', 'name']\n entity_name = next(\n getattr(entity, attr)\n for attr in name_attrs\n if getattr(entity, attr)\n )\n return product_alt.format(entity_name)\n\n\[email protected]_tag\ndef main_image_or_logo(page: Page):\n \"\"\"Used for microdata.\"\"\"\n if hasattr(page, 'main_image') and page.main_image:\n return page.main_image.url\n else:\n return settings.STATIC_URL + 'images/logo.png'\n\n\[email protected]_tag('catalog/product_feedbacks_icons.html')\ndef icon_stars(rating=0):\n \"\"\"Render set of rating icons based on 1 through 5 rating values.\"\"\"\n full_icons = int(math.floor(rating))\n half_icons = 0 if rating == int(rating) else 1\n empty_icons = 5 - full_icons - half_icons\n\n return {\n 'full_icons': range(full_icons),\n 'half_icons': range(half_icons),\n 'empty_icons': range(empty_icons),\n }\n", "path": "shopelectro/templatetags/se_extras.py"}]}
| 1,776 | 711 |
gh_patches_debug_4043
|
rasdani/github-patches
|
git_diff
|
hylang__hy-139
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Quote doesn't return valid lists
```
=> (car (quote [if 1 2 3]))
u'if'
=> (cdr (quote [if 1 2 3]))
[1, 2, 3]
```
=> OK
```
=> (car (quote (if 1 2 3)))
u'_hy_hoisted_fn_1'
=> (car (car (quote (if 1 2 3))))
u'_'
=> (cdr (quote (if 1 2 3)))
[]
```
=> Not ok
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hy/core/mangles.py`
Content:
```
1 # Copyright (c) 2013 Paul Tagliamonte <[email protected]>
2 #
3 # Permission is hereby granted, free of charge, to any person obtaining a
4 # copy of this software and associated documentation files (the "Software"),
5 # to deal in the Software without restriction, including without limitation
6 # the rights to use, copy, modify, merge, publish, distribute, sublicense,
7 # and/or sell copies of the Software, and to permit persons to whom the
8 # Software is furnished to do so, subject to the following conditions:
9 #
10 # The above copyright notice and this permission notice shall be included in
11 # all copies or substantial portions of the Software.
12 #
13 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
14 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
15 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
16 # THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
17 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
18 # FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
19 # DEALINGS IN THE SOFTWARE.
20
21 from hy.models.expression import HyExpression
22 from hy.models.symbol import HySymbol
23 from hy.models.list import HyList
24
25 import hy.mangle
26
27
28 class HoistableMangle(hy.mangle.Mangle):
29 def should_hoist(self):
30 for frame in self.stack:
31 if frame is self.scope:
32 return False
33
34 if isinstance(frame, HyExpression) and frame != []:
35 call = frame[0]
36 if call in self.ignore:
37 continue
38 return True
39 return False
40
41
42 class FunctionMangle(HoistableMangle):
43 hoistable = ["fn"]
44 ignore = ["def", "decorate_with", "setf", "setv", "foreach", "do"]
45
46 def __init__(self):
47 self.series = 0
48
49 def unique_name(self):
50 self.series += 1
51 return "_hy_hoisted_fn_%s" % (self.series)
52
53 def visit(self, tree):
54 if isinstance(tree, HyExpression) and tree != []:
55 call = tree[0]
56 if call == "fn" and self.should_hoist():
57 new_name = HySymbol(self.unique_name())
58 new_name.replace(tree)
59 fn_def = HyExpression([HySymbol("def"),
60 new_name,
61 tree])
62 fn_def.replace(tree)
63 self.hoist(fn_def)
64 return new_name
65
66
67 class IfMangle(HoistableMangle):
68 ignore = ["foreach", "do"]
69
70 def __init__(self):
71 self.series = 0
72
73 def visit(self, tree):
74 if isinstance(tree, HyExpression) and tree != []:
75 call = tree[0]
76 if call == "if" and self.should_hoist():
77 fn = HyExpression([HyExpression([HySymbol("fn"),
78 HyList([]),
79 tree])])
80 fn.replace(tree)
81 return fn
82
83
84 hy.mangle.MANGLES.append(IfMangle)
85 hy.mangle.MANGLES.append(FunctionMangle)
86
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hy/core/mangles.py b/hy/core/mangles.py
--- a/hy/core/mangles.py
+++ b/hy/core/mangles.py
@@ -27,6 +27,11 @@
class HoistableMangle(hy.mangle.Mangle):
def should_hoist(self):
+ for frame in self.stack:
+ if (isinstance(frame, HyExpression) and
+ frame and frame[0] == "quote"):
+ return False
+
for frame in self.stack:
if frame is self.scope:
return False
|
{"golden_diff": "diff --git a/hy/core/mangles.py b/hy/core/mangles.py\n--- a/hy/core/mangles.py\n+++ b/hy/core/mangles.py\n@@ -27,6 +27,11 @@\n \n class HoistableMangle(hy.mangle.Mangle):\n def should_hoist(self):\n+ for frame in self.stack:\n+ if (isinstance(frame, HyExpression) and\n+ frame and frame[0] == \"quote\"):\n+ return False\n+\n for frame in self.stack:\n if frame is self.scope:\n return False\n", "issue": "Quote doesn't return valid lists\n```\n=> (car (quote [if 1 2 3]))\nu'if'\n=> (cdr (quote [if 1 2 3]))\n[1, 2, 3]\n```\n\n=> OK\n\n```\n=> (car (quote (if 1 2 3)))\nu'_hy_hoisted_fn_1'\n=> (car (car (quote (if 1 2 3))))\nu'_'\n=> (cdr (quote (if 1 2 3)))\n[]\n```\n\n=> Not ok\n\n", "before_files": [{"content": "# Copyright (c) 2013 Paul Tagliamonte <[email protected]>\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the \"Software\"),\n# to deal in the Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish, distribute, sublicense,\n# and/or sell copies of the Software, and to permit persons to whom the\n# Software is furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL\n# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.\n\nfrom hy.models.expression import HyExpression\nfrom hy.models.symbol import HySymbol\nfrom hy.models.list import HyList\n\nimport hy.mangle\n\n\nclass HoistableMangle(hy.mangle.Mangle):\n def should_hoist(self):\n for frame in self.stack:\n if frame is self.scope:\n return False\n\n if isinstance(frame, HyExpression) and frame != []:\n call = frame[0]\n if call in self.ignore:\n continue\n return True\n return False\n\n\nclass FunctionMangle(HoistableMangle):\n hoistable = [\"fn\"]\n ignore = [\"def\", \"decorate_with\", \"setf\", \"setv\", \"foreach\", \"do\"]\n\n def __init__(self):\n self.series = 0\n\n def unique_name(self):\n self.series += 1\n return \"_hy_hoisted_fn_%s\" % (self.series)\n\n def visit(self, tree):\n if isinstance(tree, HyExpression) and tree != []:\n call = tree[0]\n if call == \"fn\" and self.should_hoist():\n new_name = HySymbol(self.unique_name())\n new_name.replace(tree)\n fn_def = HyExpression([HySymbol(\"def\"),\n new_name,\n tree])\n fn_def.replace(tree)\n self.hoist(fn_def)\n return new_name\n\n\nclass IfMangle(HoistableMangle):\n ignore = [\"foreach\", \"do\"]\n\n def __init__(self):\n self.series = 0\n\n def visit(self, tree):\n if isinstance(tree, HyExpression) and tree != []:\n call = tree[0]\n if call == \"if\" and self.should_hoist():\n fn = HyExpression([HyExpression([HySymbol(\"fn\"),\n HyList([]),\n tree])])\n fn.replace(tree)\n return fn\n\n\nhy.mangle.MANGLES.append(IfMangle)\nhy.mangle.MANGLES.append(FunctionMangle)\n", "path": "hy/core/mangles.py"}], "after_files": [{"content": "# Copyright (c) 2013 Paul Tagliamonte <[email protected]>\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the \"Software\"),\n# to deal in the Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish, distribute, sublicense,\n# and/or sell copies of the Software, and to permit persons to whom the\n# Software is furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL\n# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.\n\nfrom hy.models.expression import HyExpression\nfrom hy.models.symbol import HySymbol\nfrom hy.models.list import HyList\n\nimport hy.mangle\n\n\nclass HoistableMangle(hy.mangle.Mangle):\n def should_hoist(self):\n for frame in self.stack:\n if (isinstance(frame, HyExpression) and\n frame and frame[0] == \"quote\"):\n return False\n\n for frame in self.stack:\n if frame is self.scope:\n return False\n\n if isinstance(frame, HyExpression) and frame != []:\n call = frame[0]\n if call in self.ignore:\n continue\n return True\n return False\n\n\nclass FunctionMangle(HoistableMangle):\n hoistable = [\"fn\"]\n ignore = [\"def\", \"decorate_with\", \"setf\", \"setv\", \"foreach\", \"do\"]\n\n def __init__(self):\n self.series = 0\n\n def unique_name(self):\n self.series += 1\n return \"_hy_hoisted_fn_%s\" % (self.series)\n\n def visit(self, tree):\n if isinstance(tree, HyExpression) and tree != []:\n call = tree[0]\n if call == \"fn\" and self.should_hoist():\n new_name = HySymbol(self.unique_name())\n new_name.replace(tree)\n fn_def = HyExpression([HySymbol(\"def\"),\n new_name,\n tree])\n fn_def.replace(tree)\n self.hoist(fn_def)\n return new_name\n\n\nclass IfMangle(HoistableMangle):\n ignore = [\"foreach\", \"do\"]\n\n def __init__(self):\n self.series = 0\n\n def visit(self, tree):\n if isinstance(tree, HyExpression) and tree != []:\n call = tree[0]\n if call == \"if\" and self.should_hoist():\n fn = HyExpression([HyExpression([HySymbol(\"fn\"),\n HyList([]),\n tree])])\n fn.replace(tree)\n return fn\n\n\nhy.mangle.MANGLES.append(IfMangle)\nhy.mangle.MANGLES.append(FunctionMangle)\n", "path": "hy/core/mangles.py"}]}
| 1,214 | 128 |
gh_patches_debug_6693
|
rasdani/github-patches
|
git_diff
|
sosreport__sos-3342
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[hpssm] controller collection misses Gen10+ controllers and above slot 9.
1. Gen10+ controllers changed the naming from **Smart Array** for at least some controllers.
* `HPE SR932i-p Gen10+ in Slot 3`
2. Controllers are showing up above slot 9 even when there is only 1 or two total controllers.
* `HPE Smart Array P816i-a SR Gen10 in Slot 12`
This system had no controller in slot 0, a new naming style in slot 3, and the old naming style in slot 12.
The `ssacli ctrl all show status` still lists them, and `ssacli ctrl all show config detail` still gets the config details of each. The current pattern fails to identify the slots in both cases, leading to not executing individual slot based commands or executing on the wrong slot.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sos/report/plugins/hpssm.py`
Content:
```
1 # This file is part of the sos project: https://github.com/sosreport/sos
2 #
3 # This copyrighted material is made available to anyone wishing to use,
4 # modify, copy, or redistribute it subject to the terms and conditions of
5 # version 2 of the GNU General Public License.
6 #
7 # See the LICENSE file in the source distribution for further information.
8
9 from sos.report.plugins import Plugin, IndependentPlugin, PluginOpt
10 import re
11
12
13 class Hpssm(Plugin, IndependentPlugin):
14 """
15 This plugin will capture details for each controller from Smart Storage
16 Array Administrator, an Array diagnostic report from Smart Storage
17 Administrator Diagnostics Utility and, when the plugins debug option is
18 enabled will gather the Active Health System log via the RESTful Interface
19 Tool (iLOREST).
20 """
21 short_desc = 'HP Smart Storage Management'
22
23 plugin_name = 'hpssm'
24 profiles = ('system', 'storage', 'hardware',)
25 packages = ('ilorest', 'ssacli', 'ssaducli',)
26
27 option_list = [
28 PluginOpt('debug', default=False, desc='capture debug data')
29 ]
30
31 def setup(self):
32 cmd = 'ssacli'
33 subcmds = [
34 'ctrl all show status'
35 ]
36 slot_subcmds = [
37 'array all show detail',
38 'ld all show',
39 'ld all show detail',
40 'pd all show',
41 'pd all show detail',
42 'show detail'
43 ]
44 self.add_cmd_output(
45 ["%s %s" % (cmd, subcmd) for subcmd in subcmds]
46 )
47
48 pattern = re.compile("^HP.*Smart Array (.*) in Slot ([0123456789])")
49 config_detail_cmd = cmd + ' ctrl all show config detail'
50 config_detail = self.collect_cmd_output(config_detail_cmd)
51 ctrl_slots = []
52 if config_detail['status'] == 0:
53 ctrl_slots = [m.group(2)
54 for line in config_detail['output'].splitlines()
55 for m in [pattern.search(line)] if m]
56 ssacli_ctrl_slot_cmd = cmd + ' ctrl slot='
57 self.add_cmd_output(
58 ["%s%s %s" % (
59 ssacli_ctrl_slot_cmd,
60 slot,
61 slot_subcmd
62 )
63 for slot in ctrl_slots
64 for slot_subcmd in slot_subcmds]
65 )
66
67 logpath = self.get_cmd_output_path()
68
69 self.add_cmd_output(
70 'ssaducli -v -adu -f %s/adu-log.zip' % logpath,
71 suggest_filename='ssaducli_-v_-adu.log'
72 )
73
74 if self.get_option("debug"):
75 self.do_debug(logpath)
76
77 def do_debug(self, logpath):
78 self.add_cmd_output(
79 'ilorest serverlogs --selectlog=AHS --directorypath=%s' % logpath,
80 runat=logpath, suggest_filename='ilorest.log'
81 )
82
83 # vim: set et ts=4 sw=4 :
84
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sos/report/plugins/hpssm.py b/sos/report/plugins/hpssm.py
--- a/sos/report/plugins/hpssm.py
+++ b/sos/report/plugins/hpssm.py
@@ -45,7 +45,7 @@
["%s %s" % (cmd, subcmd) for subcmd in subcmds]
)
- pattern = re.compile("^HP.*Smart Array (.*) in Slot ([0123456789])")
+ pattern = re.compile("^HP[E] (.*) in Slot ([0123456789]+)")
config_detail_cmd = cmd + ' ctrl all show config detail'
config_detail = self.collect_cmd_output(config_detail_cmd)
ctrl_slots = []
|
{"golden_diff": "diff --git a/sos/report/plugins/hpssm.py b/sos/report/plugins/hpssm.py\n--- a/sos/report/plugins/hpssm.py\n+++ b/sos/report/plugins/hpssm.py\n@@ -45,7 +45,7 @@\n [\"%s %s\" % (cmd, subcmd) for subcmd in subcmds]\n )\n \n- pattern = re.compile(\"^HP.*Smart Array (.*) in Slot ([0123456789])\")\n+ pattern = re.compile(\"^HP[E] (.*) in Slot ([0123456789]+)\")\n config_detail_cmd = cmd + ' ctrl all show config detail'\n config_detail = self.collect_cmd_output(config_detail_cmd)\n ctrl_slots = []\n", "issue": "[hpssm] controller collection misses Gen10+ controllers and above slot 9.\n1. Gen10+ controllers changed the naming from **Smart Array** for at least some controllers.\r\n * `HPE SR932i-p Gen10+ in Slot 3`\r\n2. Controllers are showing up above slot 9 even when there is only 1 or two total controllers.\r\n * `HPE Smart Array P816i-a SR Gen10 in Slot 12`\r\n\r\nThis system had no controller in slot 0, a new naming style in slot 3, and the old naming style in slot 12. \r\nThe `ssacli ctrl all show status` still lists them, and `ssacli ctrl all show config detail` still gets the config details of each. The current pattern fails to identify the slots in both cases, leading to not executing individual slot based commands or executing on the wrong slot.\r\n\r\n\n", "before_files": [{"content": "# This file is part of the sos project: https://github.com/sosreport/sos\n#\n# This copyrighted material is made available to anyone wishing to use,\n# modify, copy, or redistribute it subject to the terms and conditions of\n# version 2 of the GNU General Public License.\n#\n# See the LICENSE file in the source distribution for further information.\n\nfrom sos.report.plugins import Plugin, IndependentPlugin, PluginOpt\nimport re\n\n\nclass Hpssm(Plugin, IndependentPlugin):\n \"\"\"\n This plugin will capture details for each controller from Smart Storage\n Array Administrator, an Array diagnostic report from Smart Storage\n Administrator Diagnostics Utility and, when the plugins debug option is\n enabled will gather the Active Health System log via the RESTful Interface\n Tool (iLOREST).\n \"\"\"\n short_desc = 'HP Smart Storage Management'\n\n plugin_name = 'hpssm'\n profiles = ('system', 'storage', 'hardware',)\n packages = ('ilorest', 'ssacli', 'ssaducli',)\n\n option_list = [\n PluginOpt('debug', default=False, desc='capture debug data')\n ]\n\n def setup(self):\n cmd = 'ssacli'\n subcmds = [\n 'ctrl all show status'\n ]\n slot_subcmds = [\n 'array all show detail',\n 'ld all show',\n 'ld all show detail',\n 'pd all show',\n 'pd all show detail',\n 'show detail'\n ]\n self.add_cmd_output(\n [\"%s %s\" % (cmd, subcmd) for subcmd in subcmds]\n )\n\n pattern = re.compile(\"^HP.*Smart Array (.*) in Slot ([0123456789])\")\n config_detail_cmd = cmd + ' ctrl all show config detail'\n config_detail = self.collect_cmd_output(config_detail_cmd)\n ctrl_slots = []\n if config_detail['status'] == 0:\n ctrl_slots = [m.group(2)\n for line in config_detail['output'].splitlines()\n for m in [pattern.search(line)] if m]\n ssacli_ctrl_slot_cmd = cmd + ' ctrl slot='\n self.add_cmd_output(\n [\"%s%s %s\" % (\n ssacli_ctrl_slot_cmd,\n slot,\n slot_subcmd\n )\n for slot in ctrl_slots\n for slot_subcmd in slot_subcmds]\n )\n\n logpath = self.get_cmd_output_path()\n\n self.add_cmd_output(\n 'ssaducli -v -adu -f %s/adu-log.zip' % logpath,\n suggest_filename='ssaducli_-v_-adu.log'\n )\n\n if self.get_option(\"debug\"):\n self.do_debug(logpath)\n\n def do_debug(self, logpath):\n self.add_cmd_output(\n 'ilorest serverlogs --selectlog=AHS --directorypath=%s' % logpath,\n runat=logpath, suggest_filename='ilorest.log'\n )\n\n# vim: set et ts=4 sw=4 :\n", "path": "sos/report/plugins/hpssm.py"}], "after_files": [{"content": "# This file is part of the sos project: https://github.com/sosreport/sos\n#\n# This copyrighted material is made available to anyone wishing to use,\n# modify, copy, or redistribute it subject to the terms and conditions of\n# version 2 of the GNU General Public License.\n#\n# See the LICENSE file in the source distribution for further information.\n\nfrom sos.report.plugins import Plugin, IndependentPlugin, PluginOpt\nimport re\n\n\nclass Hpssm(Plugin, IndependentPlugin):\n \"\"\"\n This plugin will capture details for each controller from Smart Storage\n Array Administrator, an Array diagnostic report from Smart Storage\n Administrator Diagnostics Utility and, when the plugins debug option is\n enabled will gather the Active Health System log via the RESTful Interface\n Tool (iLOREST).\n \"\"\"\n short_desc = 'HP Smart Storage Management'\n\n plugin_name = 'hpssm'\n profiles = ('system', 'storage', 'hardware',)\n packages = ('ilorest', 'ssacli', 'ssaducli',)\n\n option_list = [\n PluginOpt('debug', default=False, desc='capture debug data')\n ]\n\n def setup(self):\n cmd = 'ssacli'\n subcmds = [\n 'ctrl all show status'\n ]\n slot_subcmds = [\n 'array all show detail',\n 'ld all show',\n 'ld all show detail',\n 'pd all show',\n 'pd all show detail',\n 'show detail'\n ]\n self.add_cmd_output(\n [\"%s %s\" % (cmd, subcmd) for subcmd in subcmds]\n )\n\n pattern = re.compile(\"^HP[E] (.*) in Slot ([0123456789]+)\")\n config_detail_cmd = cmd + ' ctrl all show config detail'\n config_detail = self.collect_cmd_output(config_detail_cmd)\n ctrl_slots = []\n if config_detail['status'] == 0:\n ctrl_slots = [m.group(2)\n for line in config_detail['output'].splitlines()\n for m in [pattern.search(line)] if m]\n ssacli_ctrl_slot_cmd = cmd + ' ctrl slot='\n self.add_cmd_output(\n [\"%s%s %s\" % (\n ssacli_ctrl_slot_cmd,\n slot,\n slot_subcmd\n )\n for slot in ctrl_slots\n for slot_subcmd in slot_subcmds]\n )\n\n logpath = self.get_cmd_output_path()\n\n self.add_cmd_output(\n 'ssaducli -v -adu -f %s/adu-log.zip' % logpath,\n suggest_filename='ssaducli_-v_-adu.log'\n )\n\n if self.get_option(\"debug\"):\n self.do_debug(logpath)\n\n def do_debug(self, logpath):\n self.add_cmd_output(\n 'ilorest serverlogs --selectlog=AHS --directorypath=%s' % logpath,\n runat=logpath, suggest_filename='ilorest.log'\n )\n\n# vim: set et ts=4 sw=4 :\n", "path": "sos/report/plugins/hpssm.py"}]}
| 1,274 | 170 |
gh_patches_debug_56607
|
rasdani/github-patches
|
git_diff
|
spacetelescope__jwql-662
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Switch EDB to use MAST token from config.json always
Currently the EDB feature of the JWQL web app attempts to authenticate users with whichever MAST token is currently cached (https://github.com/spacetelescope/jwql/blob/develop/jwql/utils/credentials.py#L45), and if that doesn't succeed, _then_ it uses the `mast_token` key in the `config.json` file. This seems problematic if users are creating new tokens but then attempting to perform EDB queries in the same browser. We should probably switch this to just use the `mast_token` key in `config.json` file always.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `jwql/utils/credentials.py`
Content:
```
1 """Utility functions related to accessing remote services and databases.
2
3 Authors
4 -------
5
6 - Johannes Sahlmann
7 - Lauren Chambers
8
9 Use
10 ---
11
12 This module can be imported as such:
13 ::
14
15 import credentials
16 token = credentials.get_mast_token()
17
18 """
19 import os
20
21 from astroquery.mast import Mast
22
23 from jwql.utils.utils import get_config, check_config_for_key
24
25
26 def get_mast_token(request=None):
27 """Return MAST token from either Astroquery.Mast, webpage cookies, the
28 JWQL configuration file, or an environment variable.
29
30 Parameters
31 ----------
32 request : HttpRequest object
33 Incoming request from the webpage
34
35 Returns
36 -------
37 token : str or None
38 User-specific MAST token string, if available
39 """
40 if Mast.authenticated():
41 print('Authenticated with Astroquery MAST magic')
42 return None
43 else:
44 if request is not None:
45 token = str(request.POST.get('access_token'))
46 if token != 'None':
47 print('Authenticated with cached MAST token.')
48 return token
49 try:
50 # check if token is available via config file
51 check_config_for_key('mast_token')
52 token = get_config()['mast_token']
53 print('Authenticated with config.json MAST token.')
54 return token
55 except (KeyError, ValueError):
56 # check if token is available via environment variable
57 # see https://auth.mast.stsci.edu/info
58 try:
59 token = os.environ['MAST_API_TOKEN']
60 print('Authenticated with MAST token environment variable.')
61 return token
62 except KeyError:
63 return None
64
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/jwql/utils/credentials.py b/jwql/utils/credentials.py
--- a/jwql/utils/credentials.py
+++ b/jwql/utils/credentials.py
@@ -41,11 +41,6 @@
print('Authenticated with Astroquery MAST magic')
return None
else:
- if request is not None:
- token = str(request.POST.get('access_token'))
- if token != 'None':
- print('Authenticated with cached MAST token.')
- return token
try:
# check if token is available via config file
check_config_for_key('mast_token')
|
{"golden_diff": "diff --git a/jwql/utils/credentials.py b/jwql/utils/credentials.py\n--- a/jwql/utils/credentials.py\n+++ b/jwql/utils/credentials.py\n@@ -41,11 +41,6 @@\n print('Authenticated with Astroquery MAST magic')\n return None\n else:\n- if request is not None:\n- token = str(request.POST.get('access_token'))\n- if token != 'None':\n- print('Authenticated with cached MAST token.')\n- return token\n try:\n # check if token is available via config file\n check_config_for_key('mast_token')\n", "issue": "Switch EDB to use MAST token from config.json always\nCurrently the EDB feature of the JWQL web app attempts to authenticate users with whichever MAST token is currently cached (https://github.com/spacetelescope/jwql/blob/develop/jwql/utils/credentials.py#L45), and if that doesn't succeed, _then_ it uses the `mast_token` key in the `config.json` file. This seems problematic if users are creating new tokens but then attempting to perform EDB queries in the same browser. We should probably switch this to just use the `mast_token` key in `config.json` file always. \n", "before_files": [{"content": "\"\"\"Utility functions related to accessing remote services and databases.\n\nAuthors\n-------\n\n - Johannes Sahlmann\n - Lauren Chambers\n\nUse\n---\n\n This module can be imported as such:\n ::\n\n import credentials\n token = credentials.get_mast_token()\n\n \"\"\"\nimport os\n\nfrom astroquery.mast import Mast\n\nfrom jwql.utils.utils import get_config, check_config_for_key\n\n\ndef get_mast_token(request=None):\n \"\"\"Return MAST token from either Astroquery.Mast, webpage cookies, the\n JWQL configuration file, or an environment variable.\n\n Parameters\n ----------\n request : HttpRequest object\n Incoming request from the webpage\n\n Returns\n -------\n token : str or None\n User-specific MAST token string, if available\n \"\"\"\n if Mast.authenticated():\n print('Authenticated with Astroquery MAST magic')\n return None\n else:\n if request is not None:\n token = str(request.POST.get('access_token'))\n if token != 'None':\n print('Authenticated with cached MAST token.')\n return token\n try:\n # check if token is available via config file\n check_config_for_key('mast_token')\n token = get_config()['mast_token']\n print('Authenticated with config.json MAST token.')\n return token\n except (KeyError, ValueError):\n # check if token is available via environment variable\n # see https://auth.mast.stsci.edu/info\n try:\n token = os.environ['MAST_API_TOKEN']\n print('Authenticated with MAST token environment variable.')\n return token\n except KeyError:\n return None\n", "path": "jwql/utils/credentials.py"}], "after_files": [{"content": "\"\"\"Utility functions related to accessing remote services and databases.\n\nAuthors\n-------\n\n - Johannes Sahlmann\n - Lauren Chambers\n\nUse\n---\n\n This module can be imported as such:\n ::\n\n import credentials\n token = credentials.get_mast_token()\n\n \"\"\"\nimport os\n\nfrom astroquery.mast import Mast\n\nfrom jwql.utils.utils import get_config, check_config_for_key\n\n\ndef get_mast_token(request=None):\n \"\"\"Return MAST token from either Astroquery.Mast, webpage cookies, the\n JWQL configuration file, or an environment variable.\n\n Parameters\n ----------\n request : HttpRequest object\n Incoming request from the webpage\n\n Returns\n -------\n token : str or None\n User-specific MAST token string, if available\n \"\"\"\n if Mast.authenticated():\n print('Authenticated with Astroquery MAST magic')\n return None\n else:\n try:\n # check if token is available via config file\n check_config_for_key('mast_token')\n token = get_config()['mast_token']\n print('Authenticated with config.json MAST token.')\n return token\n except (KeyError, ValueError):\n # check if token is available via environment variable\n # see https://auth.mast.stsci.edu/info\n try:\n token = os.environ['MAST_API_TOKEN']\n print('Authenticated with MAST token environment variable.')\n return token\n except KeyError:\n return None\n", "path": "jwql/utils/credentials.py"}]}
| 868 | 138 |
gh_patches_debug_27187
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-430
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add FAQ RE: how to use xml2json CLI tool
# Description
Add a section to the FAQ RE: how to install the `xmlimport` optional dependencies and how to use the `xml2json` CLI tool.
This could also be an entire example Jupyter notebook on using the CLI and then have the FAQ be just on how to install the `xmlimport` dependencies.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyhf/commandline.py`
Content:
```
1 import logging
2
3 import click
4 import json
5 import os
6 import jsonpatch
7 import sys
8
9 from . import writexml
10 from .utils import hypotest
11 from .pdf import Model
12 from .version import __version__
13
14 logging.basicConfig()
15 log = logging.getLogger(__name__)
16
17 # This is only needed for Python 2/3 compatibility
18 def ensure_dirs(path):
19 try:
20 os.makedirs(path, exist_ok=True)
21 except TypeError:
22 if not os.path.exists(path):
23 os.makedirs(path)
24
25
26 @click.group(context_settings=dict(help_option_names=['-h', '--help']))
27 @click.version_option(version=__version__)
28 def pyhf():
29 pass
30
31
32 @pyhf.command()
33 @click.argument('entrypoint-xml', type=click.Path(exists=True))
34 @click.option(
35 '--basedir',
36 help='The base directory for the XML files to point relative to.',
37 type=click.Path(exists=True),
38 default=os.getcwd(),
39 )
40 @click.option(
41 '--output-file',
42 help='The location of the output json file. If not specified, prints to screen.',
43 default=None,
44 )
45 @click.option('--track-progress/--hide-progress', default=True)
46 def xml2json(entrypoint_xml, basedir, output_file, track_progress):
47 """ Entrypoint XML: The top-level XML file for the PDF definition. """
48 try:
49 import uproot
50
51 assert uproot
52 except ImportError:
53 log.error(
54 "xml2json requires uproot, please install pyhf using the "
55 "xmlimport extra: pip install pyhf[xmlimport] or install uproot "
56 "manually: pip install uproot"
57 )
58 from . import readxml
59
60 spec = readxml.parse(entrypoint_xml, basedir, track_progress=track_progress)
61 if output_file is None:
62 print(json.dumps(spec, indent=4, sort_keys=True))
63 else:
64 with open(output_file, 'w+') as out_file:
65 json.dump(spec, out_file, indent=4, sort_keys=True)
66 log.debug("Written to {0:s}".format(output_file))
67 sys.exit(0)
68
69
70 @pyhf.command()
71 @click.argument('workspace', default='-')
72 @click.option('--output-dir', type=click.Path(exists=True), default='.')
73 @click.option('--specroot', default='config')
74 @click.option('--dataroot', default='data')
75 @click.option('--resultprefix', default='FitConfig')
76 def json2xml(workspace, output_dir, specroot, dataroot, resultprefix):
77 ensure_dirs(output_dir)
78 with click.open_file(workspace, 'r') as specstream:
79 d = json.load(specstream)
80 ensure_dirs(os.path.join(output_dir, specroot))
81 ensure_dirs(os.path.join(output_dir, dataroot))
82 with click.open_file(
83 os.path.join(output_dir, '{0:s}.xml'.format(resultprefix)), 'w'
84 ) as outstream:
85 outstream.write(
86 writexml.writexml(
87 d,
88 os.path.join(output_dir, specroot),
89 os.path.join(output_dir, dataroot),
90 resultprefix,
91 ).decode('utf-8')
92 )
93
94 sys.exit(0)
95
96
97 @pyhf.command()
98 @click.argument('workspace', default='-')
99 @click.option(
100 '--output-file',
101 help='The location of the output json file. If not specified, prints to screen.',
102 default=None,
103 )
104 @click.option('--measurement', default=None)
105 @click.option('-p', '--patch', multiple=True)
106 @click.option('--testpoi', default=1.0)
107 def cls(workspace, output_file, measurement, patch, testpoi):
108 with click.open_file(workspace, 'r') as specstream:
109 d = json.load(specstream)
110 measurements = d['toplvl']['measurements']
111 measurement_names = [m['name'] for m in measurements]
112 measurement_index = 0
113
114 log.debug('measurements defined:\n\t{0:s}'.format('\n\t'.join(measurement_names)))
115 if measurement and measurement not in measurement_names:
116 log.error(
117 'no measurement by name \'{0:s}\' exists, pick from one of the valid ones above'.format(
118 measurement
119 )
120 )
121 sys.exit(1)
122 else:
123 if not measurement and len(measurements) > 1:
124 log.warning('multiple measurements defined. Taking the first measurement.')
125 measurement_index = 0
126 elif measurement:
127 measurement_index = measurement_names.index(measurement)
128
129 log.debug(
130 'calculating CLs for measurement {0:s}'.format(
131 measurements[measurement_index]['name']
132 )
133 )
134 spec = {
135 'channels': d['channels'],
136 'parameters': d['toplvl']['measurements'][measurement_index]['config'].get(
137 'parameters', []
138 ),
139 }
140
141 for p in patch:
142 with click.open_file(p, 'r') as read_file:
143 p = jsonpatch.JsonPatch(json.loads(read_file.read()))
144 spec = p.apply(spec)
145 p = Model(spec, poiname=measurements[measurement_index]['config']['poi'])
146 observed = sum((d['data'][c] for c in p.config.channels), []) + p.config.auxdata
147 result = hypotest(testpoi, observed, p, return_expected_set=True)
148 result = {
149 'CLs_obs': result[0].tolist()[0],
150 'CLs_exp': result[-1].ravel().tolist(),
151 }
152 if output_file is None:
153 print(json.dumps(result, indent=4, sort_keys=True))
154 else:
155 with open(output_file, 'w+') as out_file:
156 json.dump(result, out_file, indent=4, sort_keys=True)
157 log.debug("Written to {0:s}".format(output_file))
158 sys.exit(0)
159
```
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 from setuptools import setup, find_packages
4 from os import path
5 import sys
6
7 this_directory = path.abspath(path.dirname(__file__))
8 if sys.version_info.major < 3:
9 from io import open
10 with open(path.join(this_directory, 'README.md'), encoding='utf-8') as readme_md:
11 long_description = readme_md.read()
12
13 extras_require = {
14 'tensorflow': [
15 'tensorflow~=1.13',
16 'tensorflow-probability~=0.5',
17 'numpy<=1.14.5,>=1.14.0', # Lower of 1.14.0 instead of 1.13.3 to ensure doctest pass
18 'setuptools<=39.1.0',
19 ],
20 'torch': ['torch~=1.0'],
21 'mxnet': ['mxnet~=1.0', 'requests~=2.18.4', 'numpy<1.15.0,>=1.8.2'],
22 # 'dask': [
23 # 'dask[array]'
24 # ],
25 'xmlimport': ['uproot'],
26 'minuit': ['iminuit'],
27 'develop': [
28 'pyflakes',
29 'pytest~=3.5',
30 'pytest-cov>=2.5.1',
31 'pytest-mock',
32 'pytest-benchmark[histogram]',
33 'pytest-console-scripts',
34 'python-coveralls',
35 'coverage>=4.0', # coveralls
36 'matplotlib',
37 'jupyter',
38 'nbdime',
39 'uproot~=3.3',
40 'papermill~=0.16',
41 'graphviz',
42 'bumpversion',
43 'sphinx',
44 'sphinxcontrib-bibtex',
45 'sphinxcontrib-napoleon',
46 'sphinx_rtd_theme',
47 'nbsphinx',
48 'sphinx-issues',
49 'm2r',
50 'jsonpatch',
51 'ipython<7', # jupyter_console and ipython clash in dependency requirement -- downgrade ipython for now
52 'pre-commit',
53 'black;python_version>="3.6"', # Black is Python3 only
54 'twine',
55 ],
56 }
57 extras_require['complete'] = sorted(set(sum(extras_require.values(), [])))
58
59 setup(
60 name='pyhf',
61 version='0.0.16',
62 description='(partial) pure python histfactory implementation',
63 long_description=long_description,
64 long_description_content_type='text/markdown',
65 url='https://github.com/diana-hep/pyhf',
66 author='Lukas Heinrich',
67 author_email='[email protected]',
68 license='Apache',
69 keywords='physics fitting numpy scipy tensorflow pytorch mxnet dask',
70 classifiers=[
71 "Programming Language :: Python :: 2",
72 "Programming Language :: Python :: 2.7",
73 "Programming Language :: Python :: 3",
74 "Programming Language :: Python :: 3.6",
75 "Programming Language :: Python :: 3.7",
76 ],
77 packages=find_packages(),
78 include_package_data=True,
79 python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*",
80 install_requires=[
81 'scipy', # requires numpy, which is required by pyhf, tensorflow, and mxnet
82 'click>=6.0', # for console scripts,
83 'tqdm', # for readxml
84 'six', # for modifiers
85 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6
86 'jsonpatch',
87 ],
88 extras_require=extras_require,
89 entry_points={'console_scripts': ['pyhf=pyhf.commandline:pyhf']},
90 dependency_links=[],
91 )
92
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pyhf/commandline.py b/pyhf/commandline.py
--- a/pyhf/commandline.py
+++ b/pyhf/commandline.py
@@ -52,7 +52,7 @@
except ImportError:
log.error(
"xml2json requires uproot, please install pyhf using the "
- "xmlimport extra: pip install pyhf[xmlimport] or install uproot "
+ "xmlio extra: pip install pyhf[xmlio] or install uproot "
"manually: pip install uproot"
)
from . import readxml
@@ -74,6 +74,17 @@
@click.option('--dataroot', default='data')
@click.option('--resultprefix', default='FitConfig')
def json2xml(workspace, output_dir, specroot, dataroot, resultprefix):
+ try:
+ import uproot
+
+ assert uproot
+ except ImportError:
+ log.error(
+ "json2xml requires uproot, please install pyhf using the "
+ "xmlio extra: pip install pyhf[xmlio] or install uproot "
+ "manually: pip install uproot"
+ )
+
ensure_dirs(output_dir)
with click.open_file(workspace, 'r') as specstream:
d = json.load(specstream)
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -22,7 +22,7 @@
# 'dask': [
# 'dask[array]'
# ],
- 'xmlimport': ['uproot'],
+ 'xmlio': ['uproot'],
'minuit': ['iminuit'],
'develop': [
'pyflakes',
|
{"golden_diff": "diff --git a/pyhf/commandline.py b/pyhf/commandline.py\n--- a/pyhf/commandline.py\n+++ b/pyhf/commandline.py\n@@ -52,7 +52,7 @@\n except ImportError:\n log.error(\n \"xml2json requires uproot, please install pyhf using the \"\n- \"xmlimport extra: pip install pyhf[xmlimport] or install uproot \"\n+ \"xmlio extra: pip install pyhf[xmlio] or install uproot \"\n \"manually: pip install uproot\"\n )\n from . import readxml\n@@ -74,6 +74,17 @@\n @click.option('--dataroot', default='data')\n @click.option('--resultprefix', default='FitConfig')\n def json2xml(workspace, output_dir, specroot, dataroot, resultprefix):\n+ try:\n+ import uproot\n+\n+ assert uproot\n+ except ImportError:\n+ log.error(\n+ \"json2xml requires uproot, please install pyhf using the \"\n+ \"xmlio extra: pip install pyhf[xmlio] or install uproot \"\n+ \"manually: pip install uproot\"\n+ )\n+\n ensure_dirs(output_dir)\n with click.open_file(workspace, 'r') as specstream:\n d = json.load(specstream)\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -22,7 +22,7 @@\n # 'dask': [\n # 'dask[array]'\n # ],\n- 'xmlimport': ['uproot'],\n+ 'xmlio': ['uproot'],\n 'minuit': ['iminuit'],\n 'develop': [\n 'pyflakes',\n", "issue": "Add FAQ RE: how to use xml2json CLI tool\n# Description\r\n\r\nAdd a section to the FAQ RE: how to install the `xmlimport` optional dependencies and how to use the `xml2json` CLI tool.\r\n\r\nThis could also be an entire example Jupyter notebook on using the CLI and then have the FAQ be just on how to install the `xmlimport` dependencies.\r\n\n", "before_files": [{"content": "import logging\n\nimport click\nimport json\nimport os\nimport jsonpatch\nimport sys\n\nfrom . import writexml\nfrom .utils import hypotest\nfrom .pdf import Model\nfrom .version import __version__\n\nlogging.basicConfig()\nlog = logging.getLogger(__name__)\n\n# This is only needed for Python 2/3 compatibility\ndef ensure_dirs(path):\n try:\n os.makedirs(path, exist_ok=True)\n except TypeError:\n if not os.path.exists(path):\n os.makedirs(path)\n\n\[email protected](context_settings=dict(help_option_names=['-h', '--help']))\[email protected]_option(version=__version__)\ndef pyhf():\n pass\n\n\[email protected]()\[email protected]('entrypoint-xml', type=click.Path(exists=True))\[email protected](\n '--basedir',\n help='The base directory for the XML files to point relative to.',\n type=click.Path(exists=True),\n default=os.getcwd(),\n)\[email protected](\n '--output-file',\n help='The location of the output json file. If not specified, prints to screen.',\n default=None,\n)\[email protected]('--track-progress/--hide-progress', default=True)\ndef xml2json(entrypoint_xml, basedir, output_file, track_progress):\n \"\"\" Entrypoint XML: The top-level XML file for the PDF definition. \"\"\"\n try:\n import uproot\n\n assert uproot\n except ImportError:\n log.error(\n \"xml2json requires uproot, please install pyhf using the \"\n \"xmlimport extra: pip install pyhf[xmlimport] or install uproot \"\n \"manually: pip install uproot\"\n )\n from . import readxml\n\n spec = readxml.parse(entrypoint_xml, basedir, track_progress=track_progress)\n if output_file is None:\n print(json.dumps(spec, indent=4, sort_keys=True))\n else:\n with open(output_file, 'w+') as out_file:\n json.dump(spec, out_file, indent=4, sort_keys=True)\n log.debug(\"Written to {0:s}\".format(output_file))\n sys.exit(0)\n\n\[email protected]()\[email protected]('workspace', default='-')\[email protected]('--output-dir', type=click.Path(exists=True), default='.')\[email protected]('--specroot', default='config')\[email protected]('--dataroot', default='data')\[email protected]('--resultprefix', default='FitConfig')\ndef json2xml(workspace, output_dir, specroot, dataroot, resultprefix):\n ensure_dirs(output_dir)\n with click.open_file(workspace, 'r') as specstream:\n d = json.load(specstream)\n ensure_dirs(os.path.join(output_dir, specroot))\n ensure_dirs(os.path.join(output_dir, dataroot))\n with click.open_file(\n os.path.join(output_dir, '{0:s}.xml'.format(resultprefix)), 'w'\n ) as outstream:\n outstream.write(\n writexml.writexml(\n d,\n os.path.join(output_dir, specroot),\n os.path.join(output_dir, dataroot),\n resultprefix,\n ).decode('utf-8')\n )\n\n sys.exit(0)\n\n\[email protected]()\[email protected]('workspace', default='-')\[email protected](\n '--output-file',\n help='The location of the output json file. If not specified, prints to screen.',\n default=None,\n)\[email protected]('--measurement', default=None)\[email protected]('-p', '--patch', multiple=True)\[email protected]('--testpoi', default=1.0)\ndef cls(workspace, output_file, measurement, patch, testpoi):\n with click.open_file(workspace, 'r') as specstream:\n d = json.load(specstream)\n measurements = d['toplvl']['measurements']\n measurement_names = [m['name'] for m in measurements]\n measurement_index = 0\n\n log.debug('measurements defined:\\n\\t{0:s}'.format('\\n\\t'.join(measurement_names)))\n if measurement and measurement not in measurement_names:\n log.error(\n 'no measurement by name \\'{0:s}\\' exists, pick from one of the valid ones above'.format(\n measurement\n )\n )\n sys.exit(1)\n else:\n if not measurement and len(measurements) > 1:\n log.warning('multiple measurements defined. Taking the first measurement.')\n measurement_index = 0\n elif measurement:\n measurement_index = measurement_names.index(measurement)\n\n log.debug(\n 'calculating CLs for measurement {0:s}'.format(\n measurements[measurement_index]['name']\n )\n )\n spec = {\n 'channels': d['channels'],\n 'parameters': d['toplvl']['measurements'][measurement_index]['config'].get(\n 'parameters', []\n ),\n }\n\n for p in patch:\n with click.open_file(p, 'r') as read_file:\n p = jsonpatch.JsonPatch(json.loads(read_file.read()))\n spec = p.apply(spec)\n p = Model(spec, poiname=measurements[measurement_index]['config']['poi'])\n observed = sum((d['data'][c] for c in p.config.channels), []) + p.config.auxdata\n result = hypotest(testpoi, observed, p, return_expected_set=True)\n result = {\n 'CLs_obs': result[0].tolist()[0],\n 'CLs_exp': result[-1].ravel().tolist(),\n }\n if output_file is None:\n print(json.dumps(result, indent=4, sort_keys=True))\n else:\n with open(output_file, 'w+') as out_file:\n json.dump(result, out_file, indent=4, sort_keys=True)\n log.debug(\"Written to {0:s}\".format(output_file))\n sys.exit(0)\n", "path": "pyhf/commandline.py"}, {"content": "#!/usr/bin/env python\n\nfrom setuptools import setup, find_packages\nfrom os import path\nimport sys\n\nthis_directory = path.abspath(path.dirname(__file__))\nif sys.version_info.major < 3:\n from io import open\nwith open(path.join(this_directory, 'README.md'), encoding='utf-8') as readme_md:\n long_description = readme_md.read()\n\nextras_require = {\n 'tensorflow': [\n 'tensorflow~=1.13',\n 'tensorflow-probability~=0.5',\n 'numpy<=1.14.5,>=1.14.0', # Lower of 1.14.0 instead of 1.13.3 to ensure doctest pass\n 'setuptools<=39.1.0',\n ],\n 'torch': ['torch~=1.0'],\n 'mxnet': ['mxnet~=1.0', 'requests~=2.18.4', 'numpy<1.15.0,>=1.8.2'],\n # 'dask': [\n # 'dask[array]'\n # ],\n 'xmlimport': ['uproot'],\n 'minuit': ['iminuit'],\n 'develop': [\n 'pyflakes',\n 'pytest~=3.5',\n 'pytest-cov>=2.5.1',\n 'pytest-mock',\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'python-coveralls',\n 'coverage>=4.0', # coveralls\n 'matplotlib',\n 'jupyter',\n 'nbdime',\n 'uproot~=3.3',\n 'papermill~=0.16',\n 'graphviz',\n 'bumpversion',\n 'sphinx',\n 'sphinxcontrib-bibtex',\n 'sphinxcontrib-napoleon',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n 'sphinx-issues',\n 'm2r',\n 'jsonpatch',\n 'ipython<7', # jupyter_console and ipython clash in dependency requirement -- downgrade ipython for now\n 'pre-commit',\n 'black;python_version>=\"3.6\"', # Black is Python3 only\n 'twine',\n ],\n}\nextras_require['complete'] = sorted(set(sum(extras_require.values(), [])))\n\nsetup(\n name='pyhf',\n version='0.0.16',\n description='(partial) pure python histfactory implementation',\n long_description=long_description,\n long_description_content_type='text/markdown',\n url='https://github.com/diana-hep/pyhf',\n author='Lukas Heinrich',\n author_email='[email protected]',\n license='Apache',\n keywords='physics fitting numpy scipy tensorflow pytorch mxnet dask',\n classifiers=[\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n ],\n packages=find_packages(),\n include_package_data=True,\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*\",\n install_requires=[\n 'scipy', # requires numpy, which is required by pyhf, tensorflow, and mxnet\n 'click>=6.0', # for console scripts,\n 'tqdm', # for readxml\n 'six', # for modifiers\n 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6\n 'jsonpatch',\n ],\n extras_require=extras_require,\n entry_points={'console_scripts': ['pyhf=pyhf.commandline:pyhf']},\n dependency_links=[],\n)\n", "path": "setup.py"}], "after_files": [{"content": "import logging\n\nimport click\nimport json\nimport os\nimport jsonpatch\nimport sys\n\nfrom . import writexml\nfrom .utils import hypotest\nfrom .pdf import Model\nfrom .version import __version__\n\nlogging.basicConfig()\nlog = logging.getLogger(__name__)\n\n# This is only needed for Python 2/3 compatibility\ndef ensure_dirs(path):\n try:\n os.makedirs(path, exist_ok=True)\n except TypeError:\n if not os.path.exists(path):\n os.makedirs(path)\n\n\[email protected](context_settings=dict(help_option_names=['-h', '--help']))\[email protected]_option(version=__version__)\ndef pyhf():\n pass\n\n\[email protected]()\[email protected]('entrypoint-xml', type=click.Path(exists=True))\[email protected](\n '--basedir',\n help='The base directory for the XML files to point relative to.',\n type=click.Path(exists=True),\n default=os.getcwd(),\n)\[email protected](\n '--output-file',\n help='The location of the output json file. If not specified, prints to screen.',\n default=None,\n)\[email protected]('--track-progress/--hide-progress', default=True)\ndef xml2json(entrypoint_xml, basedir, output_file, track_progress):\n \"\"\" Entrypoint XML: The top-level XML file for the PDF definition. \"\"\"\n try:\n import uproot\n\n assert uproot\n except ImportError:\n log.error(\n \"xml2json requires uproot, please install pyhf using the \"\n \"xmlio extra: pip install pyhf[xmlio] or install uproot \"\n \"manually: pip install uproot\"\n )\n from . import readxml\n\n spec = readxml.parse(entrypoint_xml, basedir, track_progress=track_progress)\n if output_file is None:\n print(json.dumps(spec, indent=4, sort_keys=True))\n else:\n with open(output_file, 'w+') as out_file:\n json.dump(spec, out_file, indent=4, sort_keys=True)\n log.debug(\"Written to {0:s}\".format(output_file))\n sys.exit(0)\n\n\[email protected]()\[email protected]('workspace', default='-')\[email protected]('--output-dir', type=click.Path(exists=True), default='.')\[email protected]('--specroot', default='config')\[email protected]('--dataroot', default='data')\[email protected]('--resultprefix', default='FitConfig')\ndef json2xml(workspace, output_dir, specroot, dataroot, resultprefix):\n try:\n import uproot\n\n assert uproot\n except ImportError:\n log.error(\n \"json2xml requires uproot, please install pyhf using the \"\n \"xmlio extra: pip install pyhf[xmlio] or install uproot \"\n \"manually: pip install uproot\"\n )\n\n ensure_dirs(output_dir)\n with click.open_file(workspace, 'r') as specstream:\n d = json.load(specstream)\n ensure_dirs(os.path.join(output_dir, specroot))\n ensure_dirs(os.path.join(output_dir, dataroot))\n with click.open_file(\n os.path.join(output_dir, '{0:s}.xml'.format(resultprefix)), 'w'\n ) as outstream:\n outstream.write(\n writexml.writexml(\n d,\n os.path.join(output_dir, specroot),\n os.path.join(output_dir, dataroot),\n resultprefix,\n ).decode('utf-8')\n )\n\n sys.exit(0)\n\n\[email protected]()\[email protected]('workspace', default='-')\[email protected](\n '--output-file',\n help='The location of the output json file. If not specified, prints to screen.',\n default=None,\n)\[email protected]('--measurement', default=None)\[email protected]('-p', '--patch', multiple=True)\[email protected]('--testpoi', default=1.0)\ndef cls(workspace, output_file, measurement, patch, testpoi):\n with click.open_file(workspace, 'r') as specstream:\n d = json.load(specstream)\n measurements = d['toplvl']['measurements']\n measurement_names = [m['name'] for m in measurements]\n measurement_index = 0\n\n log.debug('measurements defined:\\n\\t{0:s}'.format('\\n\\t'.join(measurement_names)))\n if measurement and measurement not in measurement_names:\n log.error(\n 'no measurement by name \\'{0:s}\\' exists, pick from one of the valid ones above'.format(\n measurement\n )\n )\n sys.exit(1)\n else:\n if not measurement and len(measurements) > 1:\n log.warning('multiple measurements defined. Taking the first measurement.')\n measurement_index = 0\n elif measurement:\n measurement_index = measurement_names.index(measurement)\n\n log.debug(\n 'calculating CLs for measurement {0:s}'.format(\n measurements[measurement_index]['name']\n )\n )\n spec = {\n 'channels': d['channels'],\n 'parameters': d['toplvl']['measurements'][measurement_index]['config'].get(\n 'parameters', []\n ),\n }\n\n for p in patch:\n with click.open_file(p, 'r') as read_file:\n p = jsonpatch.JsonPatch(json.loads(read_file.read()))\n spec = p.apply(spec)\n p = Model(spec, poiname=measurements[measurement_index]['config']['poi'])\n observed = sum((d['data'][c] for c in p.config.channels), []) + p.config.auxdata\n result = hypotest(testpoi, observed, p, return_expected_set=True)\n result = {\n 'CLs_obs': result[0].tolist()[0],\n 'CLs_exp': result[-1].ravel().tolist(),\n }\n if output_file is None:\n print(json.dumps(result, indent=4, sort_keys=True))\n else:\n with open(output_file, 'w+') as out_file:\n json.dump(result, out_file, indent=4, sort_keys=True)\n log.debug(\"Written to {0:s}\".format(output_file))\n sys.exit(0)\n", "path": "pyhf/commandline.py"}, {"content": "#!/usr/bin/env python\n\nfrom setuptools import setup, find_packages\nfrom os import path\nimport sys\n\nthis_directory = path.abspath(path.dirname(__file__))\nif sys.version_info.major < 3:\n from io import open\nwith open(path.join(this_directory, 'README.md'), encoding='utf-8') as readme_md:\n long_description = readme_md.read()\n\nextras_require = {\n 'tensorflow': [\n 'tensorflow~=1.13',\n 'tensorflow-probability~=0.5',\n 'numpy<=1.14.5,>=1.14.0', # Lower of 1.14.0 instead of 1.13.3 to ensure doctest pass\n 'setuptools<=39.1.0',\n ],\n 'torch': ['torch~=1.0'],\n 'mxnet': ['mxnet~=1.0', 'requests~=2.18.4', 'numpy<1.15.0,>=1.8.2'],\n # 'dask': [\n # 'dask[array]'\n # ],\n 'xmlio': ['uproot'],\n 'minuit': ['iminuit'],\n 'develop': [\n 'pyflakes',\n 'pytest~=3.5',\n 'pytest-cov>=2.5.1',\n 'pytest-mock',\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'python-coveralls',\n 'coverage>=4.0', # coveralls\n 'matplotlib',\n 'jupyter',\n 'nbdime',\n 'uproot~=3.3',\n 'papermill~=0.16',\n 'graphviz',\n 'bumpversion',\n 'sphinx',\n 'sphinxcontrib-bibtex',\n 'sphinxcontrib-napoleon',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n 'sphinx-issues',\n 'm2r',\n 'jsonpatch',\n 'ipython<7', # jupyter_console and ipython clash in dependency requirement -- downgrade ipython for now\n 'pre-commit',\n 'black;python_version>=\"3.6\"', # Black is Python3 only\n 'twine',\n ],\n}\nextras_require['complete'] = sorted(set(sum(extras_require.values(), [])))\n\nsetup(\n name='pyhf',\n version='0.0.16',\n description='(partial) pure python histfactory implementation',\n long_description=long_description,\n long_description_content_type='text/markdown',\n url='https://github.com/diana-hep/pyhf',\n author='Lukas Heinrich',\n author_email='[email protected]',\n license='Apache',\n keywords='physics fitting numpy scipy tensorflow pytorch mxnet dask',\n classifiers=[\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n ],\n packages=find_packages(),\n include_package_data=True,\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*\",\n install_requires=[\n 'scipy', # requires numpy, which is required by pyhf, tensorflow, and mxnet\n 'click>=6.0', # for console scripts,\n 'tqdm', # for readxml\n 'six', # for modifiers\n 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6\n 'jsonpatch',\n ],\n extras_require=extras_require,\n entry_points={'console_scripts': ['pyhf=pyhf.commandline:pyhf']},\n dependency_links=[],\n)\n", "path": "setup.py"}]}
| 2,990 | 380 |
gh_patches_debug_29749
|
rasdani/github-patches
|
git_diff
|
archlinux__archinstall-2151
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Functions `select_language()` and `select_kb_layout()` are identical
https://github.com/archlinux/archinstall/blob/edbc13590366e93bb8a85eacf104d5613bc5793a/archinstall/lib/interactions/general_conf.py#L88-L111
https://github.com/archlinux/archinstall/blob/edbc13590366e93bb8a85eacf104d5613bc5793a/archinstall/lib/locale/locale_menu.py#L132-L155
The function `select_language()` is not used.
The function `select_kb_layout()` is used once:
https://github.com/archlinux/archinstall/blob/edbc13590366e93bb8a85eacf104d5613bc5793a/archinstall/lib/locale/locale_menu.py#L90
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `archinstall/lib/interactions/general_conf.py`
Content:
```
1 from __future__ import annotations
2
3 import pathlib
4 from typing import List, Any, Optional, TYPE_CHECKING
5
6 from ..locale import list_timezones, list_keyboard_languages
7 from ..menu import MenuSelectionType, Menu, TextInput
8 from ..models.audio_configuration import Audio, AudioConfiguration
9 from ..output import warn
10 from ..packages.packages import validate_package_list
11 from ..storage import storage
12 from ..translationhandler import Language
13
14 if TYPE_CHECKING:
15 _: Any
16
17
18 def ask_ntp(preset: bool = True) -> bool:
19 prompt = str(_('Would you like to use automatic time synchronization (NTP) with the default time servers?\n'))
20 prompt += str(_('Hardware time and other post-configuration steps might be required in order for NTP to work.\nFor more information, please check the Arch wiki'))
21 if preset:
22 preset_val = Menu.yes()
23 else:
24 preset_val = Menu.no()
25 choice = Menu(prompt, Menu.yes_no(), skip=False, preset_values=preset_val, default_option=Menu.yes()).run()
26
27 return False if choice.value == Menu.no() else True
28
29
30 def ask_hostname(preset: str = '') -> str:
31 hostname = TextInput(
32 str(_('Desired hostname for the installation: ')),
33 preset
34 ).run().strip()
35
36 if not hostname:
37 return preset
38
39 return hostname
40
41
42 def ask_for_a_timezone(preset: Optional[str] = None) -> Optional[str]:
43 timezones = list_timezones()
44 default = 'UTC'
45
46 choice = Menu(
47 _('Select a timezone'),
48 timezones,
49 preset_values=preset,
50 default_option=default
51 ).run()
52
53 match choice.type_:
54 case MenuSelectionType.Skip: return preset
55 case MenuSelectionType.Selection: return choice.single_value
56
57 return None
58
59
60 def ask_for_audio_selection(
61 current: Optional[AudioConfiguration] = None
62 ) -> Optional[AudioConfiguration]:
63 choices = [
64 Audio.Pipewire.name,
65 Audio.Pulseaudio.name,
66 Audio.no_audio_text()
67 ]
68
69 preset = current.audio.name if current else None
70
71 choice = Menu(
72 _('Choose an audio server'),
73 choices,
74 preset_values=preset
75 ).run()
76
77 match choice.type_:
78 case MenuSelectionType.Skip: return current
79 case MenuSelectionType.Selection:
80 value = choice.single_value
81 if value == Audio.no_audio_text():
82 return None
83 else:
84 return AudioConfiguration(Audio[value])
85
86 return None
87
88
89 def select_language(preset: Optional[str] = None) -> Optional[str]:
90 """
91 Asks the user to select a language
92 Usually this is combined with :ref:`archinstall.list_keyboard_languages`.
93
94 :return: The language/dictionary key of the selected language
95 :rtype: str
96 """
97 kb_lang = list_keyboard_languages()
98 # sort alphabetically and then by length
99 sorted_kb_lang = sorted(kb_lang, key=lambda x: (len(x), x))
100
101 choice = Menu(
102 _('Select keyboard layout'),
103 sorted_kb_lang,
104 preset_values=preset,
105 sort=False
106 ).run()
107
108 match choice.type_:
109 case MenuSelectionType.Skip: return preset
110 case MenuSelectionType.Selection: return choice.single_value
111
112 return None
113
114
115 def select_archinstall_language(languages: List[Language], preset: Language) -> Language:
116 # these are the displayed language names which can either be
117 # the english name of a language or, if present, the
118 # name of the language in its own language
119 options = {lang.display_name: lang for lang in languages}
120
121 title = 'NOTE: If a language can not displayed properly, a proper font must be set manually in the console.\n'
122 title += 'All available fonts can be found in "/usr/share/kbd/consolefonts"\n'
123 title += 'e.g. setfont LatGrkCyr-8x16 (to display latin/greek/cyrillic characters)\n'
124
125 choice = Menu(
126 title,
127 list(options.keys()),
128 default_option=preset.display_name,
129 preview_size=0.5
130 ).run()
131
132 match choice.type_:
133 case MenuSelectionType.Skip: return preset
134 case MenuSelectionType.Selection: return options[choice.single_value]
135
136 raise ValueError('Language selection not handled')
137
138
139 def ask_additional_packages_to_install(preset: List[str] = []) -> List[str]:
140 # Additional packages (with some light weight error handling for invalid package names)
141 print(_('Only packages such as base, base-devel, linux, linux-firmware, efibootmgr and optional profile packages are installed.'))
142 print(_('If you desire a web browser, such as firefox or chromium, you may specify it in the following prompt.'))
143
144 def read_packages(p: List = []) -> list:
145 display = ' '.join(p)
146 input_packages = TextInput(_('Write additional packages to install (space separated, leave blank to skip): '), display).run().strip()
147 return input_packages.split() if input_packages else []
148
149 preset = preset if preset else []
150 packages = read_packages(preset)
151
152 if not storage['arguments']['offline'] and not storage['arguments']['no_pkg_lookups']:
153 while True:
154 if len(packages):
155 # Verify packages that were given
156 print(_("Verifying that additional packages exist (this might take a few seconds)"))
157 valid, invalid = validate_package_list(packages)
158
159 if invalid:
160 warn(f"Some packages could not be found in the repository: {invalid}")
161 packages = read_packages(valid)
162 continue
163 break
164
165 return packages
166
167
168 def add_number_of_parallel_downloads(input_number :Optional[int] = None) -> Optional[int]:
169 max_recommended = 5
170 print(_(f"This option enables the number of parallel downloads that can occur during package downloads"))
171 print(_("Enter the number of parallel downloads to be enabled.\n\nNote:\n"))
172 print(str(_(" - Maximum recommended value : {} ( Allows {} parallel downloads at a time )")).format(max_recommended, max_recommended))
173 print(_(" - Disable/Default : 0 ( Disables parallel downloading, allows only 1 download at a time )\n"))
174
175 while True:
176 try:
177 input_number = int(TextInput(_("[Default value: 0] > ")).run().strip() or 0)
178 if input_number <= 0:
179 input_number = 0
180 break
181 except:
182 print(str(_("Invalid input! Try again with a valid input [or 0 to disable]")).format(max_recommended))
183
184 pacman_conf_path = pathlib.Path("/etc/pacman.conf")
185 with pacman_conf_path.open() as f:
186 pacman_conf = f.read().split("\n")
187
188 with pacman_conf_path.open("w") as fwrite:
189 for line in pacman_conf:
190 if "ParallelDownloads" in line:
191 fwrite.write(f"ParallelDownloads = {input_number}\n") if not input_number == 0 else fwrite.write("#ParallelDownloads = 0\n")
192 else:
193 fwrite.write(f"{line}\n")
194
195 return input_number
196
197
198 def select_additional_repositories(preset: List[str]) -> List[str]:
199 """
200 Allows the user to select additional repositories (multilib, and testing) if desired.
201
202 :return: The string as a selected repository
203 :rtype: string
204 """
205
206 repositories = ["multilib", "testing"]
207
208 choice = Menu(
209 _('Choose which optional additional repositories to enable'),
210 repositories,
211 sort=False,
212 multi=True,
213 preset_values=preset,
214 allow_reset=True
215 ).run()
216
217 match choice.type_:
218 case MenuSelectionType.Skip: return preset
219 case MenuSelectionType.Reset: return []
220 case MenuSelectionType.Selection: return choice.single_value
221
222 return []
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/archinstall/lib/interactions/general_conf.py b/archinstall/lib/interactions/general_conf.py
--- a/archinstall/lib/interactions/general_conf.py
+++ b/archinstall/lib/interactions/general_conf.py
@@ -3,7 +3,7 @@
import pathlib
from typing import List, Any, Optional, TYPE_CHECKING
-from ..locale import list_timezones, list_keyboard_languages
+from ..locale import list_timezones
from ..menu import MenuSelectionType, Menu, TextInput
from ..models.audio_configuration import Audio, AudioConfiguration
from ..output import warn
@@ -87,29 +87,16 @@
def select_language(preset: Optional[str] = None) -> Optional[str]:
- """
- Asks the user to select a language
- Usually this is combined with :ref:`archinstall.list_keyboard_languages`.
-
- :return: The language/dictionary key of the selected language
- :rtype: str
- """
- kb_lang = list_keyboard_languages()
- # sort alphabetically and then by length
- sorted_kb_lang = sorted(kb_lang, key=lambda x: (len(x), x))
+ from ..locale.locale_menu import select_kb_layout
- choice = Menu(
- _('Select keyboard layout'),
- sorted_kb_lang,
- preset_values=preset,
- sort=False
- ).run()
+ # We'll raise an exception in an upcoming version.
+ # from ..exceptions import Deprecated
+ # raise Deprecated("select_language() has been deprecated, use select_kb_layout() instead.")
- match choice.type_:
- case MenuSelectionType.Skip: return preset
- case MenuSelectionType.Selection: return choice.single_value
+ # No need to translate this i feel, as it's a short lived message.
+ warn("select_language() is deprecated, use select_kb_layout() instead. select_language() will be removed in a future version")
- return None
+ return select_kb_layout(preset)
def select_archinstall_language(languages: List[Language], preset: Language) -> Language:
|
{"golden_diff": "diff --git a/archinstall/lib/interactions/general_conf.py b/archinstall/lib/interactions/general_conf.py\n--- a/archinstall/lib/interactions/general_conf.py\n+++ b/archinstall/lib/interactions/general_conf.py\n@@ -3,7 +3,7 @@\n import pathlib\n from typing import List, Any, Optional, TYPE_CHECKING\n \n-from ..locale import list_timezones, list_keyboard_languages\n+from ..locale import list_timezones\n from ..menu import MenuSelectionType, Menu, TextInput\n from ..models.audio_configuration import Audio, AudioConfiguration\n from ..output import warn\n@@ -87,29 +87,16 @@\n \n \n def select_language(preset: Optional[str] = None) -> Optional[str]:\n-\t\"\"\"\n-\tAsks the user to select a language\n-\tUsually this is combined with :ref:`archinstall.list_keyboard_languages`.\n-\n-\t:return: The language/dictionary key of the selected language\n-\t:rtype: str\n-\t\"\"\"\n-\tkb_lang = list_keyboard_languages()\n-\t# sort alphabetically and then by length\n-\tsorted_kb_lang = sorted(kb_lang, key=lambda x: (len(x), x))\n+\tfrom ..locale.locale_menu import select_kb_layout\n \n-\tchoice = Menu(\n-\t\t_('Select keyboard layout'),\n-\t\tsorted_kb_lang,\n-\t\tpreset_values=preset,\n-\t\tsort=False\n-\t).run()\n+\t# We'll raise an exception in an upcoming version.\n+\t# from ..exceptions import Deprecated\n+\t# raise Deprecated(\"select_language() has been deprecated, use select_kb_layout() instead.\")\n \n-\tmatch choice.type_:\n-\t\tcase MenuSelectionType.Skip: return preset\n-\t\tcase MenuSelectionType.Selection: return choice.single_value\n+\t# No need to translate this i feel, as it's a short lived message.\n+\twarn(\"select_language() is deprecated, use select_kb_layout() instead. select_language() will be removed in a future version\")\n \n-\treturn None\n+\treturn select_kb_layout(preset)\n \n \n def select_archinstall_language(languages: List[Language], preset: Language) -> Language:\n", "issue": "Functions `select_language()` and `select_kb_layout()` are identical\nhttps://github.com/archlinux/archinstall/blob/edbc13590366e93bb8a85eacf104d5613bc5793a/archinstall/lib/interactions/general_conf.py#L88-L111\r\n\r\nhttps://github.com/archlinux/archinstall/blob/edbc13590366e93bb8a85eacf104d5613bc5793a/archinstall/lib/locale/locale_menu.py#L132-L155\r\n\r\nThe function `select_language()` is not used.\r\n\r\nThe function `select_kb_layout()` is used once:\r\n\r\nhttps://github.com/archlinux/archinstall/blob/edbc13590366e93bb8a85eacf104d5613bc5793a/archinstall/lib/locale/locale_menu.py#L90\n", "before_files": [{"content": "from __future__ import annotations\n\nimport pathlib\nfrom typing import List, Any, Optional, TYPE_CHECKING\n\nfrom ..locale import list_timezones, list_keyboard_languages\nfrom ..menu import MenuSelectionType, Menu, TextInput\nfrom ..models.audio_configuration import Audio, AudioConfiguration\nfrom ..output import warn\nfrom ..packages.packages import validate_package_list\nfrom ..storage import storage\nfrom ..translationhandler import Language\n\nif TYPE_CHECKING:\n\t_: Any\n\n\ndef ask_ntp(preset: bool = True) -> bool:\n\tprompt = str(_('Would you like to use automatic time synchronization (NTP) with the default time servers?\\n'))\n\tprompt += str(_('Hardware time and other post-configuration steps might be required in order for NTP to work.\\nFor more information, please check the Arch wiki'))\n\tif preset:\n\t\tpreset_val = Menu.yes()\n\telse:\n\t\tpreset_val = Menu.no()\n\tchoice = Menu(prompt, Menu.yes_no(), skip=False, preset_values=preset_val, default_option=Menu.yes()).run()\n\n\treturn False if choice.value == Menu.no() else True\n\n\ndef ask_hostname(preset: str = '') -> str:\n\thostname = TextInput(\n\t\tstr(_('Desired hostname for the installation: ')),\n\t\tpreset\n\t).run().strip()\n\n\tif not hostname:\n\t\treturn preset\n\n\treturn hostname\n\n\ndef ask_for_a_timezone(preset: Optional[str] = None) -> Optional[str]:\n\ttimezones = list_timezones()\n\tdefault = 'UTC'\n\n\tchoice = Menu(\n\t\t_('Select a timezone'),\n\t\ttimezones,\n\t\tpreset_values=preset,\n\t\tdefault_option=default\n\t).run()\n\n\tmatch choice.type_:\n\t\tcase MenuSelectionType.Skip: return preset\n\t\tcase MenuSelectionType.Selection: return choice.single_value\n\n\treturn None\n\n\ndef ask_for_audio_selection(\n\tcurrent: Optional[AudioConfiguration] = None\n) -> Optional[AudioConfiguration]:\n\tchoices = [\n\t\tAudio.Pipewire.name,\n\t\tAudio.Pulseaudio.name,\n\t\tAudio.no_audio_text()\n\t]\n\n\tpreset = current.audio.name if current else None\n\n\tchoice = Menu(\n\t\t_('Choose an audio server'),\n\t\tchoices,\n\t\tpreset_values=preset\n\t).run()\n\n\tmatch choice.type_:\n\t\tcase MenuSelectionType.Skip: return current\n\t\tcase MenuSelectionType.Selection:\n\t\t\tvalue = choice.single_value\n\t\t\tif value == Audio.no_audio_text():\n\t\t\t\treturn None\n\t\t\telse:\n\t\t\t\treturn AudioConfiguration(Audio[value])\n\n\treturn None\n\n\ndef select_language(preset: Optional[str] = None) -> Optional[str]:\n\t\"\"\"\n\tAsks the user to select a language\n\tUsually this is combined with :ref:`archinstall.list_keyboard_languages`.\n\n\t:return: The language/dictionary key of the selected language\n\t:rtype: str\n\t\"\"\"\n\tkb_lang = list_keyboard_languages()\n\t# sort alphabetically and then by length\n\tsorted_kb_lang = sorted(kb_lang, key=lambda x: (len(x), x))\n\n\tchoice = Menu(\n\t\t_('Select keyboard layout'),\n\t\tsorted_kb_lang,\n\t\tpreset_values=preset,\n\t\tsort=False\n\t).run()\n\n\tmatch choice.type_:\n\t\tcase MenuSelectionType.Skip: return preset\n\t\tcase MenuSelectionType.Selection: return choice.single_value\n\n\treturn None\n\n\ndef select_archinstall_language(languages: List[Language], preset: Language) -> Language:\n\t# these are the displayed language names which can either be\n\t# the english name of a language or, if present, the\n\t# name of the language in its own language\n\toptions = {lang.display_name: lang for lang in languages}\n\n\ttitle = 'NOTE: If a language can not displayed properly, a proper font must be set manually in the console.\\n'\n\ttitle += 'All available fonts can be found in \"/usr/share/kbd/consolefonts\"\\n'\n\ttitle += 'e.g. setfont LatGrkCyr-8x16 (to display latin/greek/cyrillic characters)\\n'\n\n\tchoice = Menu(\n\t\ttitle,\n\t\tlist(options.keys()),\n\t\tdefault_option=preset.display_name,\n\t\tpreview_size=0.5\n\t).run()\n\n\tmatch choice.type_:\n\t\tcase MenuSelectionType.Skip: return preset\n\t\tcase MenuSelectionType.Selection: return options[choice.single_value]\n\n\traise ValueError('Language selection not handled')\n\n\ndef ask_additional_packages_to_install(preset: List[str] = []) -> List[str]:\n\t# Additional packages (with some light weight error handling for invalid package names)\n\tprint(_('Only packages such as base, base-devel, linux, linux-firmware, efibootmgr and optional profile packages are installed.'))\n\tprint(_('If you desire a web browser, such as firefox or chromium, you may specify it in the following prompt.'))\n\n\tdef read_packages(p: List = []) -> list:\n\t\tdisplay = ' '.join(p)\n\t\tinput_packages = TextInput(_('Write additional packages to install (space separated, leave blank to skip): '), display).run().strip()\n\t\treturn input_packages.split() if input_packages else []\n\n\tpreset = preset if preset else []\n\tpackages = read_packages(preset)\n\n\tif not storage['arguments']['offline'] and not storage['arguments']['no_pkg_lookups']:\n\t\twhile True:\n\t\t\tif len(packages):\n\t\t\t\t# Verify packages that were given\n\t\t\t\tprint(_(\"Verifying that additional packages exist (this might take a few seconds)\"))\n\t\t\t\tvalid, invalid = validate_package_list(packages)\n\n\t\t\t\tif invalid:\n\t\t\t\t\twarn(f\"Some packages could not be found in the repository: {invalid}\")\n\t\t\t\t\tpackages = read_packages(valid)\n\t\t\t\t\tcontinue\n\t\t\tbreak\n\n\treturn packages\n\n\ndef add_number_of_parallel_downloads(input_number :Optional[int] = None) -> Optional[int]:\n\tmax_recommended = 5\n\tprint(_(f\"This option enables the number of parallel downloads that can occur during package downloads\"))\n\tprint(_(\"Enter the number of parallel downloads to be enabled.\\n\\nNote:\\n\"))\n\tprint(str(_(\" - Maximum recommended value : {} ( Allows {} parallel downloads at a time )\")).format(max_recommended, max_recommended))\n\tprint(_(\" - Disable/Default : 0 ( Disables parallel downloading, allows only 1 download at a time )\\n\"))\n\n\twhile True:\n\t\ttry:\n\t\t\tinput_number = int(TextInput(_(\"[Default value: 0] > \")).run().strip() or 0)\n\t\t\tif input_number <= 0:\n\t\t\t\tinput_number = 0\n\t\t\tbreak\n\t\texcept:\n\t\t\tprint(str(_(\"Invalid input! Try again with a valid input [or 0 to disable]\")).format(max_recommended))\n\n\tpacman_conf_path = pathlib.Path(\"/etc/pacman.conf\")\n\twith pacman_conf_path.open() as f:\n\t\tpacman_conf = f.read().split(\"\\n\")\n\n\twith pacman_conf_path.open(\"w\") as fwrite:\n\t\tfor line in pacman_conf:\n\t\t\tif \"ParallelDownloads\" in line:\n\t\t\t\tfwrite.write(f\"ParallelDownloads = {input_number}\\n\") if not input_number == 0 else fwrite.write(\"#ParallelDownloads = 0\\n\")\n\t\t\telse:\n\t\t\t\tfwrite.write(f\"{line}\\n\")\n\n\treturn input_number\n\n\ndef select_additional_repositories(preset: List[str]) -> List[str]:\n\t\"\"\"\n\tAllows the user to select additional repositories (multilib, and testing) if desired.\n\n\t:return: The string as a selected repository\n\t:rtype: string\n\t\"\"\"\n\n\trepositories = [\"multilib\", \"testing\"]\n\n\tchoice = Menu(\n\t\t_('Choose which optional additional repositories to enable'),\n\t\trepositories,\n\t\tsort=False,\n\t\tmulti=True,\n\t\tpreset_values=preset,\n\t\tallow_reset=True\n\t).run()\n\n\tmatch choice.type_:\n\t\tcase MenuSelectionType.Skip: return preset\n\t\tcase MenuSelectionType.Reset: return []\n\t\tcase MenuSelectionType.Selection: return choice.single_value\n\n\treturn []", "path": "archinstall/lib/interactions/general_conf.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport pathlib\nfrom typing import List, Any, Optional, TYPE_CHECKING\n\nfrom ..locale import list_timezones\nfrom ..menu import MenuSelectionType, Menu, TextInput\nfrom ..models.audio_configuration import Audio, AudioConfiguration\nfrom ..output import warn\nfrom ..packages.packages import validate_package_list\nfrom ..storage import storage\nfrom ..translationhandler import Language\n\nif TYPE_CHECKING:\n\t_: Any\n\n\ndef ask_ntp(preset: bool = True) -> bool:\n\tprompt = str(_('Would you like to use automatic time synchronization (NTP) with the default time servers?\\n'))\n\tprompt += str(_('Hardware time and other post-configuration steps might be required in order for NTP to work.\\nFor more information, please check the Arch wiki'))\n\tif preset:\n\t\tpreset_val = Menu.yes()\n\telse:\n\t\tpreset_val = Menu.no()\n\tchoice = Menu(prompt, Menu.yes_no(), skip=False, preset_values=preset_val, default_option=Menu.yes()).run()\n\n\treturn False if choice.value == Menu.no() else True\n\n\ndef ask_hostname(preset: str = '') -> str:\n\thostname = TextInput(\n\t\tstr(_('Desired hostname for the installation: ')),\n\t\tpreset\n\t).run().strip()\n\n\tif not hostname:\n\t\treturn preset\n\n\treturn hostname\n\n\ndef ask_for_a_timezone(preset: Optional[str] = None) -> Optional[str]:\n\ttimezones = list_timezones()\n\tdefault = 'UTC'\n\n\tchoice = Menu(\n\t\t_('Select a timezone'),\n\t\ttimezones,\n\t\tpreset_values=preset,\n\t\tdefault_option=default\n\t).run()\n\n\tmatch choice.type_:\n\t\tcase MenuSelectionType.Skip: return preset\n\t\tcase MenuSelectionType.Selection: return choice.single_value\n\n\treturn None\n\n\ndef ask_for_audio_selection(\n\tcurrent: Optional[AudioConfiguration] = None\n) -> Optional[AudioConfiguration]:\n\tchoices = [\n\t\tAudio.Pipewire.name,\n\t\tAudio.Pulseaudio.name,\n\t\tAudio.no_audio_text()\n\t]\n\n\tpreset = current.audio.name if current else None\n\n\tchoice = Menu(\n\t\t_('Choose an audio server'),\n\t\tchoices,\n\t\tpreset_values=preset\n\t).run()\n\n\tmatch choice.type_:\n\t\tcase MenuSelectionType.Skip: return current\n\t\tcase MenuSelectionType.Selection:\n\t\t\tvalue = choice.single_value\n\t\t\tif value == Audio.no_audio_text():\n\t\t\t\treturn None\n\t\t\telse:\n\t\t\t\treturn AudioConfiguration(Audio[value])\n\n\treturn None\n\n\ndef select_language(preset: Optional[str] = None) -> Optional[str]:\n\tfrom ..locale.locale_menu import select_kb_layout\n\n\t# We'll raise an exception in an upcoming version.\n\t# from ..exceptions import Deprecated\n\t# raise Deprecated(\"select_language() has been deprecated, use select_kb_layout() instead.\")\n\n\t# No need to translate this i feel, as it's a short lived message.\n\twarn(\"select_language() is deprecated, use select_kb_layout() instead. select_language() will be removed in a future version\")\n\n\treturn select_kb_layout(preset)\n\n\ndef select_archinstall_language(languages: List[Language], preset: Language) -> Language:\n\t# these are the displayed language names which can either be\n\t# the english name of a language or, if present, the\n\t# name of the language in its own language\n\toptions = {lang.display_name: lang for lang in languages}\n\n\ttitle = 'NOTE: If a language can not displayed properly, a proper font must be set manually in the console.\\n'\n\ttitle += 'All available fonts can be found in \"/usr/share/kbd/consolefonts\"\\n'\n\ttitle += 'e.g. setfont LatGrkCyr-8x16 (to display latin/greek/cyrillic characters)\\n'\n\n\tchoice = Menu(\n\t\ttitle,\n\t\tlist(options.keys()),\n\t\tdefault_option=preset.display_name,\n\t\tpreview_size=0.5\n\t).run()\n\n\tmatch choice.type_:\n\t\tcase MenuSelectionType.Skip: return preset\n\t\tcase MenuSelectionType.Selection: return options[choice.single_value]\n\n\traise ValueError('Language selection not handled')\n\n\ndef ask_additional_packages_to_install(preset: List[str] = []) -> List[str]:\n\t# Additional packages (with some light weight error handling for invalid package names)\n\tprint(_('Only packages such as base, base-devel, linux, linux-firmware, efibootmgr and optional profile packages are installed.'))\n\tprint(_('If you desire a web browser, such as firefox or chromium, you may specify it in the following prompt.'))\n\n\tdef read_packages(p: List = []) -> list:\n\t\tdisplay = ' '.join(p)\n\t\tinput_packages = TextInput(_('Write additional packages to install (space separated, leave blank to skip): '), display).run().strip()\n\t\treturn input_packages.split() if input_packages else []\n\n\tpreset = preset if preset else []\n\tpackages = read_packages(preset)\n\n\tif not storage['arguments']['offline'] and not storage['arguments']['no_pkg_lookups']:\n\t\twhile True:\n\t\t\tif len(packages):\n\t\t\t\t# Verify packages that were given\n\t\t\t\tprint(_(\"Verifying that additional packages exist (this might take a few seconds)\"))\n\t\t\t\tvalid, invalid = validate_package_list(packages)\n\n\t\t\t\tif invalid:\n\t\t\t\t\twarn(f\"Some packages could not be found in the repository: {invalid}\")\n\t\t\t\t\tpackages = read_packages(valid)\n\t\t\t\t\tcontinue\n\t\t\tbreak\n\n\treturn packages\n\n\ndef add_number_of_parallel_downloads(input_number :Optional[int] = None) -> Optional[int]:\n\tmax_recommended = 5\n\tprint(_(f\"This option enables the number of parallel downloads that can occur during package downloads\"))\n\tprint(_(\"Enter the number of parallel downloads to be enabled.\\n\\nNote:\\n\"))\n\tprint(str(_(\" - Maximum recommended value : {} ( Allows {} parallel downloads at a time )\")).format(max_recommended, max_recommended))\n\tprint(_(\" - Disable/Default : 0 ( Disables parallel downloading, allows only 1 download at a time )\\n\"))\n\n\twhile True:\n\t\ttry:\n\t\t\tinput_number = int(TextInput(_(\"[Default value: 0] > \")).run().strip() or 0)\n\t\t\tif input_number <= 0:\n\t\t\t\tinput_number = 0\n\t\t\tbreak\n\t\texcept:\n\t\t\tprint(str(_(\"Invalid input! Try again with a valid input [or 0 to disable]\")).format(max_recommended))\n\n\tpacman_conf_path = pathlib.Path(\"/etc/pacman.conf\")\n\twith pacman_conf_path.open() as f:\n\t\tpacman_conf = f.read().split(\"\\n\")\n\n\twith pacman_conf_path.open(\"w\") as fwrite:\n\t\tfor line in pacman_conf:\n\t\t\tif \"ParallelDownloads\" in line:\n\t\t\t\tfwrite.write(f\"ParallelDownloads = {input_number}\\n\") if not input_number == 0 else fwrite.write(\"#ParallelDownloads = 0\\n\")\n\t\t\telse:\n\t\t\t\tfwrite.write(f\"{line}\\n\")\n\n\treturn input_number\n\n\ndef select_additional_repositories(preset: List[str]) -> List[str]:\n\t\"\"\"\n\tAllows the user to select additional repositories (multilib, and testing) if desired.\n\n\t:return: The string as a selected repository\n\t:rtype: string\n\t\"\"\"\n\n\trepositories = [\"multilib\", \"testing\"]\n\n\tchoice = Menu(\n\t\t_('Choose which optional additional repositories to enable'),\n\t\trepositories,\n\t\tsort=False,\n\t\tmulti=True,\n\t\tpreset_values=preset,\n\t\tallow_reset=True\n\t).run()\n\n\tmatch choice.type_:\n\t\tcase MenuSelectionType.Skip: return preset\n\t\tcase MenuSelectionType.Reset: return []\n\t\tcase MenuSelectionType.Selection: return choice.single_value\n\n\treturn []", "path": "archinstall/lib/interactions/general_conf.py"}]}
| 2,790 | 454 |
gh_patches_debug_19238
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-3921
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Duplicate checks CKV_K8S_29 and CKV_K8S_30 ?
It seem that both checks are the same, at least in the description :
```
Check: CKV_K8S_29: "Apply security context to your pods and containers"
FAILED for resource: module.some_module.kubernetes_deployment.app
File: /base/main.tf:12-355
Calling File: /some_module.tf:1-116
Check: CKV_K8S_30: "Apply security context to your pods and containers"
FAILED for resource: module.some_module.kubernetes_deployment.app
File: /base/main.tf:12-355
Calling File: /some_module.tf:1-116
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/kubernetes/checks/resource/k8s/ContainerSecurityContext.py`
Content:
```
1 from typing import Any, Dict
2
3 from checkov.common.models.enums import CheckResult
4 from checkov.kubernetes.checks.resource.base_container_check import BaseK8sContainerCheck
5
6
7 class ContainerSecurityContext(BaseK8sContainerCheck):
8 def __init__(self) -> None:
9 # CIS-1.5 5.7.3
10 name = "Apply security context to your pods and containers"
11 # Security context can be set at pod or container level.
12 # Location: container .securityContext
13 id = "CKV_K8S_30"
14 super().__init__(name=name, id=id)
15
16 def scan_container_conf(self, metadata: Dict[str, Any], conf: Dict[str, Any]) -> CheckResult:
17 self.evaluated_container_keys = ["securityContext"]
18 if conf.get("securityContext"):
19 return CheckResult.PASSED
20 return CheckResult.FAILED
21
22
23 check = ContainerSecurityContext()
24
```
Path: `checkov/terraform/checks/resource/kubernetes/PodSecurityContext.py`
Content:
```
1 from checkov.common.models.enums import CheckCategories, CheckResult
2 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
3
4
5 class PodSecurityContext(BaseResourceCheck):
6
7 def __init__(self):
8 # CIS-1.5 5.7.3
9 name = "Apply security context to your pods and containers"
10 # Security context can be set at pod or container level.
11 id = "CKV_K8S_29"
12
13 supported_resources = ('kubernetes_pod', 'kubernetes_pod_v1',
14 'kubernetes_deployment', 'kubernetes_deployment_v1',
15 'kubernetes_daemonset', 'kubernetes_daemon_set_v1')
16 categories = (CheckCategories.GENERAL_SECURITY,)
17 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
18
19 def scan_resource_conf(self, conf) -> CheckResult:
20 if "spec" not in conf:
21 self.evaluated_keys = [""]
22 return CheckResult.FAILED
23 spec = conf['spec'][0]
24 if spec.get("container"):
25 containers = spec.get("container")
26
27 for idx, container in enumerate(containers):
28 if type(container) != dict:
29 return CheckResult.UNKNOWN
30
31 if not container.get("security_context"):
32 self.evaluated_keys = [f"spec/[0]/container/{idx}"]
33 return CheckResult.FAILED
34 return CheckResult.PASSED
35
36 if spec.get("template") and isinstance(spec.get("template"), list):
37 template = spec.get("template")[0]
38 if template.get("spec") and isinstance(template.get("spec"), list):
39 temp_spec = template.get("spec")[0]
40 if temp_spec.get("container"):
41 containers = temp_spec.get("container")
42
43 for idx, container in enumerate(containers):
44 if type(container) != dict:
45 return CheckResult.UNKNOWN
46
47 if not container.get("security_context"):
48 self.evaluated_keys = [f"spec/[0]/template/[0]/spec/[0]/container/{idx}"]
49 return CheckResult.FAILED
50 return CheckResult.PASSED
51 return CheckResult.FAILED
52
53
54 check = PodSecurityContext()
55
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/checkov/kubernetes/checks/resource/k8s/ContainerSecurityContext.py b/checkov/kubernetes/checks/resource/k8s/ContainerSecurityContext.py
--- a/checkov/kubernetes/checks/resource/k8s/ContainerSecurityContext.py
+++ b/checkov/kubernetes/checks/resource/k8s/ContainerSecurityContext.py
@@ -7,7 +7,7 @@
class ContainerSecurityContext(BaseK8sContainerCheck):
def __init__(self) -> None:
# CIS-1.5 5.7.3
- name = "Apply security context to your pods and containers"
+ name = "Apply security context to your containers"
# Security context can be set at pod or container level.
# Location: container .securityContext
id = "CKV_K8S_30"
diff --git a/checkov/terraform/checks/resource/kubernetes/PodSecurityContext.py b/checkov/terraform/checks/resource/kubernetes/PodSecurityContext.py
--- a/checkov/terraform/checks/resource/kubernetes/PodSecurityContext.py
+++ b/checkov/terraform/checks/resource/kubernetes/PodSecurityContext.py
@@ -6,7 +6,7 @@
def __init__(self):
# CIS-1.5 5.7.3
- name = "Apply security context to your pods and containers"
+ name = "Apply security context to your pods, deployments and daemon_sets"
# Security context can be set at pod or container level.
id = "CKV_K8S_29"
|
{"golden_diff": "diff --git a/checkov/kubernetes/checks/resource/k8s/ContainerSecurityContext.py b/checkov/kubernetes/checks/resource/k8s/ContainerSecurityContext.py\n--- a/checkov/kubernetes/checks/resource/k8s/ContainerSecurityContext.py\n+++ b/checkov/kubernetes/checks/resource/k8s/ContainerSecurityContext.py\n@@ -7,7 +7,7 @@\n class ContainerSecurityContext(BaseK8sContainerCheck):\n def __init__(self) -> None:\n # CIS-1.5 5.7.3\n- name = \"Apply security context to your pods and containers\"\n+ name = \"Apply security context to your containers\"\n # Security context can be set at pod or container level.\n # Location: container .securityContext\n id = \"CKV_K8S_30\"\ndiff --git a/checkov/terraform/checks/resource/kubernetes/PodSecurityContext.py b/checkov/terraform/checks/resource/kubernetes/PodSecurityContext.py\n--- a/checkov/terraform/checks/resource/kubernetes/PodSecurityContext.py\n+++ b/checkov/terraform/checks/resource/kubernetes/PodSecurityContext.py\n@@ -6,7 +6,7 @@\n \n def __init__(self):\n # CIS-1.5 5.7.3\n- name = \"Apply security context to your pods and containers\"\n+ name = \"Apply security context to your pods, deployments and daemon_sets\"\n # Security context can be set at pod or container level.\n id = \"CKV_K8S_29\"\n", "issue": "Duplicate checks CKV_K8S_29 and CKV_K8S_30 ?\nIt seem that both checks are the same, at least in the description :\r\n\r\n```\r\nCheck: CKV_K8S_29: \"Apply security context to your pods and containers\"\r\n\tFAILED for resource: module.some_module.kubernetes_deployment.app\r\n\tFile: /base/main.tf:12-355\r\n\tCalling File: /some_module.tf:1-116\r\n\r\nCheck: CKV_K8S_30: \"Apply security context to your pods and containers\"\r\n\tFAILED for resource: module.some_module.kubernetes_deployment.app\r\n\tFile: /base/main.tf:12-355\r\n\tCalling File: /some_module.tf:1-116\r\n```\n", "before_files": [{"content": "from typing import Any, Dict\n\nfrom checkov.common.models.enums import CheckResult\nfrom checkov.kubernetes.checks.resource.base_container_check import BaseK8sContainerCheck\n\n\nclass ContainerSecurityContext(BaseK8sContainerCheck):\n def __init__(self) -> None:\n # CIS-1.5 5.7.3\n name = \"Apply security context to your pods and containers\"\n # Security context can be set at pod or container level.\n # Location: container .securityContext\n id = \"CKV_K8S_30\"\n super().__init__(name=name, id=id)\n\n def scan_container_conf(self, metadata: Dict[str, Any], conf: Dict[str, Any]) -> CheckResult:\n self.evaluated_container_keys = [\"securityContext\"]\n if conf.get(\"securityContext\"):\n return CheckResult.PASSED\n return CheckResult.FAILED\n\n\ncheck = ContainerSecurityContext()\n", "path": "checkov/kubernetes/checks/resource/k8s/ContainerSecurityContext.py"}, {"content": "from checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass PodSecurityContext(BaseResourceCheck):\n\n def __init__(self):\n # CIS-1.5 5.7.3\n name = \"Apply security context to your pods and containers\"\n # Security context can be set at pod or container level.\n id = \"CKV_K8S_29\"\n\n supported_resources = ('kubernetes_pod', 'kubernetes_pod_v1',\n 'kubernetes_deployment', 'kubernetes_deployment_v1',\n 'kubernetes_daemonset', 'kubernetes_daemon_set_v1')\n categories = (CheckCategories.GENERAL_SECURITY,)\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf) -> CheckResult:\n if \"spec\" not in conf:\n self.evaluated_keys = [\"\"]\n return CheckResult.FAILED\n spec = conf['spec'][0]\n if spec.get(\"container\"):\n containers = spec.get(\"container\")\n\n for idx, container in enumerate(containers):\n if type(container) != dict:\n return CheckResult.UNKNOWN\n\n if not container.get(\"security_context\"):\n self.evaluated_keys = [f\"spec/[0]/container/{idx}\"]\n return CheckResult.FAILED\n return CheckResult.PASSED\n\n if spec.get(\"template\") and isinstance(spec.get(\"template\"), list):\n template = spec.get(\"template\")[0]\n if template.get(\"spec\") and isinstance(template.get(\"spec\"), list):\n temp_spec = template.get(\"spec\")[0]\n if temp_spec.get(\"container\"):\n containers = temp_spec.get(\"container\")\n\n for idx, container in enumerate(containers):\n if type(container) != dict:\n return CheckResult.UNKNOWN\n\n if not container.get(\"security_context\"):\n self.evaluated_keys = [f\"spec/[0]/template/[0]/spec/[0]/container/{idx}\"]\n return CheckResult.FAILED\n return CheckResult.PASSED\n return CheckResult.FAILED\n\n\ncheck = PodSecurityContext()\n", "path": "checkov/terraform/checks/resource/kubernetes/PodSecurityContext.py"}], "after_files": [{"content": "from typing import Any, Dict\n\nfrom checkov.common.models.enums import CheckResult\nfrom checkov.kubernetes.checks.resource.base_container_check import BaseK8sContainerCheck\n\n\nclass ContainerSecurityContext(BaseK8sContainerCheck):\n def __init__(self) -> None:\n # CIS-1.5 5.7.3\n name = \"Apply security context to your containers\"\n # Security context can be set at pod or container level.\n # Location: container .securityContext\n id = \"CKV_K8S_30\"\n super().__init__(name=name, id=id)\n\n def scan_container_conf(self, metadata: Dict[str, Any], conf: Dict[str, Any]) -> CheckResult:\n self.evaluated_container_keys = [\"securityContext\"]\n if conf.get(\"securityContext\"):\n return CheckResult.PASSED\n return CheckResult.FAILED\n\n\ncheck = ContainerSecurityContext()\n", "path": "checkov/kubernetes/checks/resource/k8s/ContainerSecurityContext.py"}, {"content": "from checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass PodSecurityContext(BaseResourceCheck):\n\n def __init__(self):\n # CIS-1.5 5.7.3\n name = \"Apply security context to your pods, deployments and daemon_sets\"\n # Security context can be set at pod or container level.\n id = \"CKV_K8S_29\"\n\n supported_resources = ('kubernetes_pod', 'kubernetes_pod_v1',\n 'kubernetes_deployment', 'kubernetes_deployment_v1',\n 'kubernetes_daemonset', 'kubernetes_daemon_set_v1')\n categories = (CheckCategories.GENERAL_SECURITY,)\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf) -> CheckResult:\n if \"spec\" not in conf:\n self.evaluated_keys = [\"\"]\n return CheckResult.FAILED\n spec = conf['spec'][0]\n if spec.get(\"container\"):\n containers = spec.get(\"container\")\n\n for idx, container in enumerate(containers):\n if type(container) != dict:\n return CheckResult.UNKNOWN\n\n if not container.get(\"security_context\"):\n self.evaluated_keys = [f\"spec/[0]/container/{idx}\"]\n return CheckResult.FAILED\n return CheckResult.PASSED\n\n if spec.get(\"template\") and isinstance(spec.get(\"template\"), list):\n template = spec.get(\"template\")[0]\n if template.get(\"spec\") and isinstance(template.get(\"spec\"), list):\n temp_spec = template.get(\"spec\")[0]\n if temp_spec.get(\"container\"):\n containers = temp_spec.get(\"container\")\n\n for idx, container in enumerate(containers):\n if type(container) != dict:\n return CheckResult.UNKNOWN\n\n if not container.get(\"security_context\"):\n self.evaluated_keys = [f\"spec/[0]/template/[0]/spec/[0]/container/{idx}\"]\n return CheckResult.FAILED\n return CheckResult.PASSED\n return CheckResult.FAILED\n\n\ncheck = PodSecurityContext()\n", "path": "checkov/terraform/checks/resource/kubernetes/PodSecurityContext.py"}]}
| 1,280 | 327 |
gh_patches_debug_1977
|
rasdani/github-patches
|
git_diff
|
xorbitsai__inference-1096
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ENH: Add the option to use CPU to inference even there is GPU device
### Is your feature request related to a problem? Please describe
There is a GPU in my server, but when load some LLM model, I need load it into my memory because the model size is bigger
than GPU memory.
However, when I launch the model from web page, the N-GPU setting only contains auto, 0, 1 options, if I select 0, system will complain the following error:
> Server error: 400 - [address=0.0.0.0:19270, pid=2063850] The parameter `n_gpu` must be greater than 0 and not greater than the number of GPUs: 1 on the machine.
### Describe the solution you'd like
I think when the N GPU setting is set to 0, it should use CPU as inference device.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `xinference/device_utils.py`
Content:
```
1 # Copyright 2022-2023 XProbe Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16
17 import torch
18 from typing_extensions import Literal, Union
19
20 DeviceType = Literal["cuda", "mps", "xpu", "cpu"]
21
22
23 def is_xpu_available() -> bool:
24 return hasattr(torch, "xpu") and torch.xpu.is_available()
25
26
27 def get_available_device() -> DeviceType:
28 if torch.cuda.is_available():
29 return "cuda"
30 elif torch.backends.mps.is_available():
31 return "mps"
32 elif is_xpu_available():
33 return "xpu"
34 return "cpu"
35
36
37 def is_device_available(device: str) -> bool:
38 if device == "cuda":
39 return torch.cuda.is_available()
40 elif device == "mps":
41 return torch.backends.mps.is_available()
42 elif device == "xpu":
43 return is_xpu_available()
44 elif device == "cpu":
45 return True
46
47 return False
48
49
50 def move_model_to_available_device(model):
51 device = get_available_device()
52
53 if device == "cpu":
54 return model
55
56 return model.to(device)
57
58
59 def get_device_preferred_dtype(device: str) -> Union[torch.dtype, None]:
60 if device == "cpu":
61 return torch.float32
62 elif device == "cuda" or device == "mps":
63 return torch.float16
64 elif device == "xpu":
65 return torch.bfloat16
66
67 return None
68
69
70 def is_hf_accelerate_supported(device: str) -> bool:
71 return device == "cuda" or device == "xpu"
72
73
74 def empty_cache():
75 if torch.cuda.is_available():
76 torch.cuda.empty_cache()
77 if torch.backends.mps.is_available():
78 torch.mps.empty_cache()
79 if is_xpu_available():
80 torch.xpu.empty_cache()
81
82
83 def gpu_count():
84 if torch.cuda.is_available():
85 cuda_visible_devices_env = os.getenv("CUDA_VISIBLE_DEVICES", None)
86
87 if cuda_visible_devices_env is None:
88 return torch.cuda.device_count()
89
90 cuda_visible_devices = (
91 cuda_visible_devices_env.split(",") if cuda_visible_devices_env else []
92 )
93
94 return min(torch.cuda.device_count(), len(cuda_visible_devices))
95 elif torch.backends.mps.is_available():
96 return 1
97 elif is_xpu_available():
98 return torch.xpu.device_count()
99 else:
100 return 0
101
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/xinference/device_utils.py b/xinference/device_utils.py
--- a/xinference/device_utils.py
+++ b/xinference/device_utils.py
@@ -92,8 +92,6 @@
)
return min(torch.cuda.device_count(), len(cuda_visible_devices))
- elif torch.backends.mps.is_available():
- return 1
elif is_xpu_available():
return torch.xpu.device_count()
else:
|
{"golden_diff": "diff --git a/xinference/device_utils.py b/xinference/device_utils.py\n--- a/xinference/device_utils.py\n+++ b/xinference/device_utils.py\n@@ -92,8 +92,6 @@\n )\n \n return min(torch.cuda.device_count(), len(cuda_visible_devices))\n- elif torch.backends.mps.is_available():\n- return 1\n elif is_xpu_available():\n return torch.xpu.device_count()\n else:\n", "issue": "ENH: Add the option to use CPU to inference even there is GPU device\n### Is your feature request related to a problem? Please describe\r\nThere is a GPU in my server, but when load some LLM model, I need load it into my memory because the model size is bigger\r\nthan GPU memory.\r\n\r\nHowever, when I launch the model from web page, the N-GPU setting only contains auto, 0, 1 options, if I select 0, system will complain the following error:\r\n\r\n> Server error: 400 - [address=0.0.0.0:19270, pid=2063850] The parameter `n_gpu` must be greater than 0 and not greater than the number of GPUs: 1 on the machine.\r\n\r\n### Describe the solution you'd like\r\nI think when the N GPU setting is set to 0, it should use CPU as inference device.\r\n\n", "before_files": [{"content": "# Copyright 2022-2023 XProbe Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\n\nimport torch\nfrom typing_extensions import Literal, Union\n\nDeviceType = Literal[\"cuda\", \"mps\", \"xpu\", \"cpu\"]\n\n\ndef is_xpu_available() -> bool:\n return hasattr(torch, \"xpu\") and torch.xpu.is_available()\n\n\ndef get_available_device() -> DeviceType:\n if torch.cuda.is_available():\n return \"cuda\"\n elif torch.backends.mps.is_available():\n return \"mps\"\n elif is_xpu_available():\n return \"xpu\"\n return \"cpu\"\n\n\ndef is_device_available(device: str) -> bool:\n if device == \"cuda\":\n return torch.cuda.is_available()\n elif device == \"mps\":\n return torch.backends.mps.is_available()\n elif device == \"xpu\":\n return is_xpu_available()\n elif device == \"cpu\":\n return True\n\n return False\n\n\ndef move_model_to_available_device(model):\n device = get_available_device()\n\n if device == \"cpu\":\n return model\n\n return model.to(device)\n\n\ndef get_device_preferred_dtype(device: str) -> Union[torch.dtype, None]:\n if device == \"cpu\":\n return torch.float32\n elif device == \"cuda\" or device == \"mps\":\n return torch.float16\n elif device == \"xpu\":\n return torch.bfloat16\n\n return None\n\n\ndef is_hf_accelerate_supported(device: str) -> bool:\n return device == \"cuda\" or device == \"xpu\"\n\n\ndef empty_cache():\n if torch.cuda.is_available():\n torch.cuda.empty_cache()\n if torch.backends.mps.is_available():\n torch.mps.empty_cache()\n if is_xpu_available():\n torch.xpu.empty_cache()\n\n\ndef gpu_count():\n if torch.cuda.is_available():\n cuda_visible_devices_env = os.getenv(\"CUDA_VISIBLE_DEVICES\", None)\n\n if cuda_visible_devices_env is None:\n return torch.cuda.device_count()\n\n cuda_visible_devices = (\n cuda_visible_devices_env.split(\",\") if cuda_visible_devices_env else []\n )\n\n return min(torch.cuda.device_count(), len(cuda_visible_devices))\n elif torch.backends.mps.is_available():\n return 1\n elif is_xpu_available():\n return torch.xpu.device_count()\n else:\n return 0\n", "path": "xinference/device_utils.py"}], "after_files": [{"content": "# Copyright 2022-2023 XProbe Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\n\nimport torch\nfrom typing_extensions import Literal, Union\n\nDeviceType = Literal[\"cuda\", \"mps\", \"xpu\", \"cpu\"]\n\n\ndef is_xpu_available() -> bool:\n return hasattr(torch, \"xpu\") and torch.xpu.is_available()\n\n\ndef get_available_device() -> DeviceType:\n if torch.cuda.is_available():\n return \"cuda\"\n elif torch.backends.mps.is_available():\n return \"mps\"\n elif is_xpu_available():\n return \"xpu\"\n return \"cpu\"\n\n\ndef is_device_available(device: str) -> bool:\n if device == \"cuda\":\n return torch.cuda.is_available()\n elif device == \"mps\":\n return torch.backends.mps.is_available()\n elif device == \"xpu\":\n return is_xpu_available()\n elif device == \"cpu\":\n return True\n\n return False\n\n\ndef move_model_to_available_device(model):\n device = get_available_device()\n\n if device == \"cpu\":\n return model\n\n return model.to(device)\n\n\ndef get_device_preferred_dtype(device: str) -> Union[torch.dtype, None]:\n if device == \"cpu\":\n return torch.float32\n elif device == \"cuda\" or device == \"mps\":\n return torch.float16\n elif device == \"xpu\":\n return torch.bfloat16\n\n return None\n\n\ndef is_hf_accelerate_supported(device: str) -> bool:\n return device == \"cuda\" or device == \"xpu\"\n\n\ndef empty_cache():\n if torch.cuda.is_available():\n torch.cuda.empty_cache()\n if torch.backends.mps.is_available():\n torch.mps.empty_cache()\n if is_xpu_available():\n torch.xpu.empty_cache()\n\n\ndef gpu_count():\n if torch.cuda.is_available():\n cuda_visible_devices_env = os.getenv(\"CUDA_VISIBLE_DEVICES\", None)\n\n if cuda_visible_devices_env is None:\n return torch.cuda.device_count()\n\n cuda_visible_devices = (\n cuda_visible_devices_env.split(\",\") if cuda_visible_devices_env else []\n )\n\n return min(torch.cuda.device_count(), len(cuda_visible_devices))\n elif is_xpu_available():\n return torch.xpu.device_count()\n else:\n return 0\n", "path": "xinference/device_utils.py"}]}
| 1,288 | 98 |
gh_patches_debug_12186
|
rasdani/github-patches
|
git_diff
|
cookiecutter__cookiecutter-528
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
chg: be more precise in error message on config file.
We can be more helpful when the main config file throws a parser error.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cookiecutter/config.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 """
5 cookiecutter.config
6 -------------------
7
8 Global configuration handling
9 """
10
11 from __future__ import unicode_literals
12 import copy
13 import logging
14 import os
15 import io
16
17 import yaml
18
19 from .exceptions import ConfigDoesNotExistException
20 from .exceptions import InvalidConfiguration
21
22
23 logger = logging.getLogger(__name__)
24
25 DEFAULT_CONFIG = {
26 'cookiecutters_dir': os.path.expanduser('~/.cookiecutters/'),
27 'replay_dir': os.path.expanduser('~/.cookiecutter_replay/'),
28 'default_context': {}
29 }
30
31
32 def get_config(config_path):
33 """
34 Retrieve the config from the specified path, returning it as a config dict.
35 """
36
37 if not os.path.exists(config_path):
38 raise ConfigDoesNotExistException
39
40 logger.debug('config_path is {0}'.format(config_path))
41 with io.open(config_path, encoding='utf-8') as file_handle:
42 try:
43 yaml_dict = yaml.safe_load(file_handle)
44 except yaml.scanner.ScannerError:
45 raise InvalidConfiguration(
46 '{0} is no a valid YAML file'.format(config_path))
47
48 config_dict = copy.copy(DEFAULT_CONFIG)
49 config_dict.update(yaml_dict)
50
51 return config_dict
52
53
54 def get_user_config():
55 """
56 Retrieve config from the user's ~/.cookiecutterrc, if it exists.
57 Otherwise, return None.
58 """
59
60 # TODO: test on windows...
61 USER_CONFIG_PATH = os.path.expanduser('~/.cookiecutterrc')
62
63 if os.path.exists(USER_CONFIG_PATH):
64 return get_config(USER_CONFIG_PATH)
65 return copy.copy(DEFAULT_CONFIG)
66
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cookiecutter/config.py b/cookiecutter/config.py
--- a/cookiecutter/config.py
+++ b/cookiecutter/config.py
@@ -41,9 +41,12 @@
with io.open(config_path, encoding='utf-8') as file_handle:
try:
yaml_dict = yaml.safe_load(file_handle)
- except yaml.scanner.ScannerError:
+ except yaml.scanner.ScannerError as e:
raise InvalidConfiguration(
- '{0} is no a valid YAML file'.format(config_path))
+ '{0} is not a valid YAML file: line {1}: {2}'.format(
+ config_path,
+ e.problem_mark.line,
+ e.problem))
config_dict = copy.copy(DEFAULT_CONFIG)
config_dict.update(yaml_dict)
|
{"golden_diff": "diff --git a/cookiecutter/config.py b/cookiecutter/config.py\n--- a/cookiecutter/config.py\n+++ b/cookiecutter/config.py\n@@ -41,9 +41,12 @@\n with io.open(config_path, encoding='utf-8') as file_handle:\n try:\n yaml_dict = yaml.safe_load(file_handle)\n- except yaml.scanner.ScannerError:\n+ except yaml.scanner.ScannerError as e:\n raise InvalidConfiguration(\n- '{0} is no a valid YAML file'.format(config_path))\n+ '{0} is not a valid YAML file: line {1}: {2}'.format(\n+ config_path,\n+ e.problem_mark.line,\n+ e.problem))\n \n config_dict = copy.copy(DEFAULT_CONFIG)\n config_dict.update(yaml_dict)\n", "issue": "chg: be more precise in error message on config file.\nWe can be more helpful when the main config file throws a parser error.\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\ncookiecutter.config\n-------------------\n\nGlobal configuration handling\n\"\"\"\n\nfrom __future__ import unicode_literals\nimport copy\nimport logging\nimport os\nimport io\n\nimport yaml\n\nfrom .exceptions import ConfigDoesNotExistException\nfrom .exceptions import InvalidConfiguration\n\n\nlogger = logging.getLogger(__name__)\n\nDEFAULT_CONFIG = {\n 'cookiecutters_dir': os.path.expanduser('~/.cookiecutters/'),\n 'replay_dir': os.path.expanduser('~/.cookiecutter_replay/'),\n 'default_context': {}\n}\n\n\ndef get_config(config_path):\n \"\"\"\n Retrieve the config from the specified path, returning it as a config dict.\n \"\"\"\n\n if not os.path.exists(config_path):\n raise ConfigDoesNotExistException\n\n logger.debug('config_path is {0}'.format(config_path))\n with io.open(config_path, encoding='utf-8') as file_handle:\n try:\n yaml_dict = yaml.safe_load(file_handle)\n except yaml.scanner.ScannerError:\n raise InvalidConfiguration(\n '{0} is no a valid YAML file'.format(config_path))\n\n config_dict = copy.copy(DEFAULT_CONFIG)\n config_dict.update(yaml_dict)\n\n return config_dict\n\n\ndef get_user_config():\n \"\"\"\n Retrieve config from the user's ~/.cookiecutterrc, if it exists.\n Otherwise, return None.\n \"\"\"\n\n # TODO: test on windows...\n USER_CONFIG_PATH = os.path.expanduser('~/.cookiecutterrc')\n\n if os.path.exists(USER_CONFIG_PATH):\n return get_config(USER_CONFIG_PATH)\n return copy.copy(DEFAULT_CONFIG)\n", "path": "cookiecutter/config.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\ncookiecutter.config\n-------------------\n\nGlobal configuration handling\n\"\"\"\n\nfrom __future__ import unicode_literals\nimport copy\nimport logging\nimport os\nimport io\n\nimport yaml\n\nfrom .exceptions import ConfigDoesNotExistException\nfrom .exceptions import InvalidConfiguration\n\n\nlogger = logging.getLogger(__name__)\n\nDEFAULT_CONFIG = {\n 'cookiecutters_dir': os.path.expanduser('~/.cookiecutters/'),\n 'replay_dir': os.path.expanduser('~/.cookiecutter_replay/'),\n 'default_context': {}\n}\n\n\ndef get_config(config_path):\n \"\"\"\n Retrieve the config from the specified path, returning it as a config dict.\n \"\"\"\n\n if not os.path.exists(config_path):\n raise ConfigDoesNotExistException\n\n logger.debug('config_path is {0}'.format(config_path))\n with io.open(config_path, encoding='utf-8') as file_handle:\n try:\n yaml_dict = yaml.safe_load(file_handle)\n except yaml.scanner.ScannerError as e:\n raise InvalidConfiguration(\n '{0} is not a valid YAML file: line {1}: {2}'.format(\n config_path,\n e.problem_mark.line,\n e.problem))\n\n config_dict = copy.copy(DEFAULT_CONFIG)\n config_dict.update(yaml_dict)\n\n return config_dict\n\n\ndef get_user_config():\n \"\"\"\n Retrieve config from the user's ~/.cookiecutterrc, if it exists.\n Otherwise, return None.\n \"\"\"\n\n # TODO: test on windows...\n USER_CONFIG_PATH = os.path.expanduser('~/.cookiecutterrc')\n\n if os.path.exists(USER_CONFIG_PATH):\n return get_config(USER_CONFIG_PATH)\n return copy.copy(DEFAULT_CONFIG)\n", "path": "cookiecutter/config.py"}]}
| 765 | 176 |
gh_patches_debug_7505
|
rasdani/github-patches
|
git_diff
|
encode__starlette-813
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Gzip Middleware content-length is incorrect
The following exception is thrown when I use uvicorn to drive my starlette project. After control variates, I am sure this is caused by Gzip Middleware.
```
File "C:\Users\AberS\Documents\Github\index.py\.venv\lib\site-packages\h11\_writers.py", line 102, in send_eom
raise LocalProtocolError("Too little data for declared Content-Length")
h11._util.LocalProtocolError: Too little data for declared Content-Length
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `starlette/middleware/wsgi.py`
Content:
```
1 import asyncio
2 import io
3 import sys
4 import typing
5
6 from starlette.concurrency import run_in_threadpool
7 from starlette.types import Message, Receive, Scope, Send
8
9
10 def build_environ(scope: Scope, body: bytes) -> dict:
11 """
12 Builds a scope and request body into a WSGI environ object.
13 """
14 environ = {
15 "REQUEST_METHOD": scope["method"],
16 "SCRIPT_NAME": scope.get("root_path", ""),
17 "PATH_INFO": scope["path"],
18 "QUERY_STRING": scope["query_string"].decode("ascii"),
19 "SERVER_PROTOCOL": f"HTTP/{scope['http_version']}",
20 "wsgi.version": (1, 0),
21 "wsgi.url_scheme": scope.get("scheme", "http"),
22 "wsgi.input": io.BytesIO(body),
23 "wsgi.errors": sys.stdout,
24 "wsgi.multithread": True,
25 "wsgi.multiprocess": True,
26 "wsgi.run_once": False,
27 }
28
29 # Get server name and port - required in WSGI, not in ASGI
30 server = scope.get("server") or ("localhost", 80)
31 environ["SERVER_NAME"] = server[0]
32 environ["SERVER_PORT"] = server[1]
33
34 # Get client IP address
35 if scope.get("client"):
36 environ["REMOTE_ADDR"] = scope["client"][0]
37
38 # Go through headers and make them into environ entries
39 for name, value in scope.get("headers", []):
40 name = name.decode("latin1")
41 if name == "content-length":
42 corrected_name = "CONTENT_LENGTH"
43 elif name == "content-type":
44 corrected_name = "CONTENT_TYPE"
45 else:
46 corrected_name = f"HTTP_{name}".upper().replace("-", "_")
47 # HTTPbis say only ASCII chars are allowed in headers, but we latin1 just in case
48 value = value.decode("latin1")
49 if corrected_name in environ:
50 value = environ[corrected_name] + "," + value
51 environ[corrected_name] = value
52 return environ
53
54
55 class WSGIMiddleware:
56 def __init__(self, app: typing.Callable, workers: int = 10) -> None:
57 self.app = app
58
59 async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:
60 assert scope["type"] == "http"
61 responder = WSGIResponder(self.app, scope)
62 await responder(receive, send)
63
64
65 class WSGIResponder:
66 def __init__(self, app: typing.Callable, scope: Scope) -> None:
67 self.app = app
68 self.scope = scope
69 self.status = None
70 self.response_headers = None
71 self.send_event = asyncio.Event()
72 self.send_queue = [] # type: typing.List[typing.Optional[Message]]
73 self.loop = asyncio.get_event_loop()
74 self.response_started = False
75 self.exc_info = None # type: typing.Any
76
77 async def __call__(self, receive: Receive, send: Send) -> None:
78 body = b""
79 more_body = True
80 while more_body:
81 message = await receive()
82 body += message.get("body", b"")
83 more_body = message.get("more_body", False)
84 environ = build_environ(self.scope, body)
85 sender = None
86 try:
87 sender = self.loop.create_task(self.sender(send))
88 await run_in_threadpool(self.wsgi, environ, self.start_response)
89 self.send_queue.append(None)
90 self.send_event.set()
91 await asyncio.wait_for(sender, None)
92 if self.exc_info is not None:
93 raise self.exc_info[0].with_traceback(
94 self.exc_info[1], self.exc_info[2]
95 )
96 finally:
97 if sender and not sender.done():
98 sender.cancel() # pragma: no cover
99
100 async def sender(self, send: Send) -> None:
101 while True:
102 if self.send_queue:
103 message = self.send_queue.pop(0)
104 if message is None:
105 return
106 await send(message)
107 else:
108 await self.send_event.wait()
109 self.send_event.clear()
110
111 def start_response(
112 self,
113 status: str,
114 response_headers: typing.List[typing.Tuple[str, str]],
115 exc_info: typing.Any = None,
116 ) -> None:
117 self.exc_info = exc_info
118 if not self.response_started:
119 self.response_started = True
120 status_code_string, _ = status.split(" ", 1)
121 status_code = int(status_code_string)
122 headers = [
123 (name.strip().encode("ascii"), value.strip().encode("ascii"))
124 for name, value in response_headers
125 ]
126 self.send_queue.append(
127 {
128 "type": "http.response.start",
129 "status": status_code,
130 "headers": headers,
131 }
132 )
133 self.loop.call_soon_threadsafe(self.send_event.set)
134
135 def wsgi(self, environ: dict, start_response: typing.Callable) -> None:
136 for chunk in self.app(environ, start_response):
137 self.send_queue.append(
138 {"type": "http.response.body", "body": chunk, "more_body": True}
139 )
140 self.loop.call_soon_threadsafe(self.send_event.set)
141
142 self.send_queue.append({"type": "http.response.body", "body": b""})
143 self.loop.call_soon_threadsafe(self.send_event.set)
144
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/starlette/middleware/wsgi.py b/starlette/middleware/wsgi.py
--- a/starlette/middleware/wsgi.py
+++ b/starlette/middleware/wsgi.py
@@ -120,7 +120,7 @@
status_code_string, _ = status.split(" ", 1)
status_code = int(status_code_string)
headers = [
- (name.strip().encode("ascii"), value.strip().encode("ascii"))
+ (name.strip().encode("ascii").lower(), value.strip().encode("ascii"))
for name, value in response_headers
]
self.send_queue.append(
|
{"golden_diff": "diff --git a/starlette/middleware/wsgi.py b/starlette/middleware/wsgi.py\n--- a/starlette/middleware/wsgi.py\n+++ b/starlette/middleware/wsgi.py\n@@ -120,7 +120,7 @@\n status_code_string, _ = status.split(\" \", 1)\n status_code = int(status_code_string)\n headers = [\n- (name.strip().encode(\"ascii\"), value.strip().encode(\"ascii\"))\n+ (name.strip().encode(\"ascii\").lower(), value.strip().encode(\"ascii\"))\n for name, value in response_headers\n ]\n self.send_queue.append(\n", "issue": "Gzip Middleware content-length is incorrect\nThe following exception is thrown when I use uvicorn to drive my starlette project. After control variates, I am sure this is caused by Gzip Middleware.\r\n\r\n```\r\n File \"C:\\Users\\AberS\\Documents\\Github\\index.py\\.venv\\lib\\site-packages\\h11\\_writers.py\", line 102, in send_eom\r\n raise LocalProtocolError(\"Too little data for declared Content-Length\") \r\nh11._util.LocalProtocolError: Too little data for declared Content-Length\r\n```\r\n\n", "before_files": [{"content": "import asyncio\nimport io\nimport sys\nimport typing\n\nfrom starlette.concurrency import run_in_threadpool\nfrom starlette.types import Message, Receive, Scope, Send\n\n\ndef build_environ(scope: Scope, body: bytes) -> dict:\n \"\"\"\n Builds a scope and request body into a WSGI environ object.\n \"\"\"\n environ = {\n \"REQUEST_METHOD\": scope[\"method\"],\n \"SCRIPT_NAME\": scope.get(\"root_path\", \"\"),\n \"PATH_INFO\": scope[\"path\"],\n \"QUERY_STRING\": scope[\"query_string\"].decode(\"ascii\"),\n \"SERVER_PROTOCOL\": f\"HTTP/{scope['http_version']}\",\n \"wsgi.version\": (1, 0),\n \"wsgi.url_scheme\": scope.get(\"scheme\", \"http\"),\n \"wsgi.input\": io.BytesIO(body),\n \"wsgi.errors\": sys.stdout,\n \"wsgi.multithread\": True,\n \"wsgi.multiprocess\": True,\n \"wsgi.run_once\": False,\n }\n\n # Get server name and port - required in WSGI, not in ASGI\n server = scope.get(\"server\") or (\"localhost\", 80)\n environ[\"SERVER_NAME\"] = server[0]\n environ[\"SERVER_PORT\"] = server[1]\n\n # Get client IP address\n if scope.get(\"client\"):\n environ[\"REMOTE_ADDR\"] = scope[\"client\"][0]\n\n # Go through headers and make them into environ entries\n for name, value in scope.get(\"headers\", []):\n name = name.decode(\"latin1\")\n if name == \"content-length\":\n corrected_name = \"CONTENT_LENGTH\"\n elif name == \"content-type\":\n corrected_name = \"CONTENT_TYPE\"\n else:\n corrected_name = f\"HTTP_{name}\".upper().replace(\"-\", \"_\")\n # HTTPbis say only ASCII chars are allowed in headers, but we latin1 just in case\n value = value.decode(\"latin1\")\n if corrected_name in environ:\n value = environ[corrected_name] + \",\" + value\n environ[corrected_name] = value\n return environ\n\n\nclass WSGIMiddleware:\n def __init__(self, app: typing.Callable, workers: int = 10) -> None:\n self.app = app\n\n async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:\n assert scope[\"type\"] == \"http\"\n responder = WSGIResponder(self.app, scope)\n await responder(receive, send)\n\n\nclass WSGIResponder:\n def __init__(self, app: typing.Callable, scope: Scope) -> None:\n self.app = app\n self.scope = scope\n self.status = None\n self.response_headers = None\n self.send_event = asyncio.Event()\n self.send_queue = [] # type: typing.List[typing.Optional[Message]]\n self.loop = asyncio.get_event_loop()\n self.response_started = False\n self.exc_info = None # type: typing.Any\n\n async def __call__(self, receive: Receive, send: Send) -> None:\n body = b\"\"\n more_body = True\n while more_body:\n message = await receive()\n body += message.get(\"body\", b\"\")\n more_body = message.get(\"more_body\", False)\n environ = build_environ(self.scope, body)\n sender = None\n try:\n sender = self.loop.create_task(self.sender(send))\n await run_in_threadpool(self.wsgi, environ, self.start_response)\n self.send_queue.append(None)\n self.send_event.set()\n await asyncio.wait_for(sender, None)\n if self.exc_info is not None:\n raise self.exc_info[0].with_traceback(\n self.exc_info[1], self.exc_info[2]\n )\n finally:\n if sender and not sender.done():\n sender.cancel() # pragma: no cover\n\n async def sender(self, send: Send) -> None:\n while True:\n if self.send_queue:\n message = self.send_queue.pop(0)\n if message is None:\n return\n await send(message)\n else:\n await self.send_event.wait()\n self.send_event.clear()\n\n def start_response(\n self,\n status: str,\n response_headers: typing.List[typing.Tuple[str, str]],\n exc_info: typing.Any = None,\n ) -> None:\n self.exc_info = exc_info\n if not self.response_started:\n self.response_started = True\n status_code_string, _ = status.split(\" \", 1)\n status_code = int(status_code_string)\n headers = [\n (name.strip().encode(\"ascii\"), value.strip().encode(\"ascii\"))\n for name, value in response_headers\n ]\n self.send_queue.append(\n {\n \"type\": \"http.response.start\",\n \"status\": status_code,\n \"headers\": headers,\n }\n )\n self.loop.call_soon_threadsafe(self.send_event.set)\n\n def wsgi(self, environ: dict, start_response: typing.Callable) -> None:\n for chunk in self.app(environ, start_response):\n self.send_queue.append(\n {\"type\": \"http.response.body\", \"body\": chunk, \"more_body\": True}\n )\n self.loop.call_soon_threadsafe(self.send_event.set)\n\n self.send_queue.append({\"type\": \"http.response.body\", \"body\": b\"\"})\n self.loop.call_soon_threadsafe(self.send_event.set)\n", "path": "starlette/middleware/wsgi.py"}], "after_files": [{"content": "import asyncio\nimport io\nimport sys\nimport typing\n\nfrom starlette.concurrency import run_in_threadpool\nfrom starlette.types import Message, Receive, Scope, Send\n\n\ndef build_environ(scope: Scope, body: bytes) -> dict:\n \"\"\"\n Builds a scope and request body into a WSGI environ object.\n \"\"\"\n environ = {\n \"REQUEST_METHOD\": scope[\"method\"],\n \"SCRIPT_NAME\": scope.get(\"root_path\", \"\"),\n \"PATH_INFO\": scope[\"path\"],\n \"QUERY_STRING\": scope[\"query_string\"].decode(\"ascii\"),\n \"SERVER_PROTOCOL\": f\"HTTP/{scope['http_version']}\",\n \"wsgi.version\": (1, 0),\n \"wsgi.url_scheme\": scope.get(\"scheme\", \"http\"),\n \"wsgi.input\": io.BytesIO(body),\n \"wsgi.errors\": sys.stdout,\n \"wsgi.multithread\": True,\n \"wsgi.multiprocess\": True,\n \"wsgi.run_once\": False,\n }\n\n # Get server name and port - required in WSGI, not in ASGI\n server = scope.get(\"server\") or (\"localhost\", 80)\n environ[\"SERVER_NAME\"] = server[0]\n environ[\"SERVER_PORT\"] = server[1]\n\n # Get client IP address\n if scope.get(\"client\"):\n environ[\"REMOTE_ADDR\"] = scope[\"client\"][0]\n\n # Go through headers and make them into environ entries\n for name, value in scope.get(\"headers\", []):\n name = name.decode(\"latin1\")\n if name == \"content-length\":\n corrected_name = \"CONTENT_LENGTH\"\n elif name == \"content-type\":\n corrected_name = \"CONTENT_TYPE\"\n else:\n corrected_name = f\"HTTP_{name}\".upper().replace(\"-\", \"_\")\n # HTTPbis say only ASCII chars are allowed in headers, but we latin1 just in case\n value = value.decode(\"latin1\")\n if corrected_name in environ:\n value = environ[corrected_name] + \",\" + value\n environ[corrected_name] = value\n return environ\n\n\nclass WSGIMiddleware:\n def __init__(self, app: typing.Callable, workers: int = 10) -> None:\n self.app = app\n\n async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:\n assert scope[\"type\"] == \"http\"\n responder = WSGIResponder(self.app, scope)\n await responder(receive, send)\n\n\nclass WSGIResponder:\n def __init__(self, app: typing.Callable, scope: Scope) -> None:\n self.app = app\n self.scope = scope\n self.status = None\n self.response_headers = None\n self.send_event = asyncio.Event()\n self.send_queue = [] # type: typing.List[typing.Optional[Message]]\n self.loop = asyncio.get_event_loop()\n self.response_started = False\n self.exc_info = None # type: typing.Any\n\n async def __call__(self, receive: Receive, send: Send) -> None:\n body = b\"\"\n more_body = True\n while more_body:\n message = await receive()\n body += message.get(\"body\", b\"\")\n more_body = message.get(\"more_body\", False)\n environ = build_environ(self.scope, body)\n sender = None\n try:\n sender = self.loop.create_task(self.sender(send))\n await run_in_threadpool(self.wsgi, environ, self.start_response)\n self.send_queue.append(None)\n self.send_event.set()\n await asyncio.wait_for(sender, None)\n if self.exc_info is not None:\n raise self.exc_info[0].with_traceback(\n self.exc_info[1], self.exc_info[2]\n )\n finally:\n if sender and not sender.done():\n sender.cancel() # pragma: no cover\n\n async def sender(self, send: Send) -> None:\n while True:\n if self.send_queue:\n message = self.send_queue.pop(0)\n if message is None:\n return\n await send(message)\n else:\n await self.send_event.wait()\n self.send_event.clear()\n\n def start_response(\n self,\n status: str,\n response_headers: typing.List[typing.Tuple[str, str]],\n exc_info: typing.Any = None,\n ) -> None:\n self.exc_info = exc_info\n if not self.response_started:\n self.response_started = True\n status_code_string, _ = status.split(\" \", 1)\n status_code = int(status_code_string)\n headers = [\n (name.strip().encode(\"ascii\").lower(), value.strip().encode(\"ascii\"))\n for name, value in response_headers\n ]\n self.send_queue.append(\n {\n \"type\": \"http.response.start\",\n \"status\": status_code,\n \"headers\": headers,\n }\n )\n self.loop.call_soon_threadsafe(self.send_event.set)\n\n def wsgi(self, environ: dict, start_response: typing.Callable) -> None:\n for chunk in self.app(environ, start_response):\n self.send_queue.append(\n {\"type\": \"http.response.body\", \"body\": chunk, \"more_body\": True}\n )\n self.loop.call_soon_threadsafe(self.send_event.set)\n\n self.send_queue.append({\"type\": \"http.response.body\", \"body\": b\"\"})\n self.loop.call_soon_threadsafe(self.send_event.set)\n", "path": "starlette/middleware/wsgi.py"}]}
| 1,885 | 134 |
gh_patches_debug_2801
|
rasdani/github-patches
|
git_diff
|
nilearn__nilearn-1152
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Automatically loading colormaps when importing nilearn (or cm?)
The colormaps that are created in [cm.py](https://github.com/KirstieJane/nilearn/blob/40069cb14b43333a73137797eac895cfb054db29/nilearn/plotting/cm.py) are really nice!
Currently, if I want to use them in one of my wrapper scripts I have the following hack:
```
from nilearn.plotting import cm
cmap = 'cold_white_hot'
if hasattr(cm, cmap):
cmap = getatt(cm, cmap)
```
Would it be possible to have these colormaps already loaded so they're available by name without this code?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nilearn/plotting/cm.py`
Content:
```
1 # emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: nil -*-
2 # vi: set ft=python sts=4 ts=4 sw=4 et:
3 """
4 Matplotlib colormaps useful for neuroimaging.
5 """
6 import numpy as _np
7
8 from matplotlib import cm as _cm
9 from matplotlib import colors as _colors
10
11 ################################################################################
12 # Custom colormaps for two-tailed symmetric statistics
13 ################################################################################
14
15 ################################################################################
16 # Helper functions
17
18 def _rotate_cmap(cmap, swap_order=('green', 'red', 'blue')):
19 """ Utility function to swap the colors of a colormap.
20 """
21 orig_cdict = cmap._segmentdata.copy()
22
23 cdict = dict()
24 cdict['green'] = [(p, c1, c2)
25 for (p, c1, c2) in orig_cdict[swap_order[0]]]
26 cdict['blue'] = [(p, c1, c2)
27 for (p, c1, c2) in orig_cdict[swap_order[1]]]
28 cdict['red'] = [(p, c1, c2)
29 for (p, c1, c2) in orig_cdict[swap_order[2]]]
30
31 return cdict
32
33
34 def _pigtailed_cmap(cmap, swap_order=('green', 'red', 'blue')):
35 """ Utility function to make a new colormap by concatenating a
36 colormap with its reverse.
37 """
38 orig_cdict = cmap._segmentdata.copy()
39
40 cdict = dict()
41 cdict['green'] = [(0.5*(1-p), c1, c2)
42 for (p, c1, c2) in reversed(orig_cdict[swap_order[0]])]
43 cdict['blue'] = [(0.5*(1-p), c1, c2)
44 for (p, c1, c2) in reversed(orig_cdict[swap_order[1]])]
45 cdict['red'] = [(0.5*(1-p), c1, c2)
46 for (p, c1, c2) in reversed(orig_cdict[swap_order[2]])]
47
48 for color in ('red', 'green', 'blue'):
49 cdict[color].extend([(0.5*(1+p), c1, c2)
50 for (p, c1, c2) in orig_cdict[color]])
51
52 return cdict
53
54
55 def _concat_cmap(cmap1, cmap2):
56 """ Utility function to make a new colormap by concatenating two
57 colormaps.
58 """
59 cdict = dict()
60
61 cdict1 = cmap1._segmentdata.copy()
62 cdict2 = cmap2._segmentdata.copy()
63 if not hasattr(cdict1['red'], '__call__'):
64 for c in ['red', 'green', 'blue']:
65 cdict[c] = [(0.5*p, c1, c2) for (p, c1, c2) in cdict1[c]]
66 else:
67 for c in ['red', 'green', 'blue']:
68 cdict[c] = []
69 ps = _np.linspace(0, 1, 10)
70 colors = cmap1(ps)
71 for p, (r, g, b, a) in zip(ps, colors):
72 cdict['red'].append((.5*p, r, r))
73 cdict['green'].append((.5*p, g, g))
74 cdict['blue'].append((.5*p, b, b))
75 if not hasattr(cdict2['red'], '__call__'):
76 for c in ['red', 'green', 'blue']:
77 cdict[c].extend([(0.5*(1+p), c1, c2) for (p, c1, c2) in cdict2[c]])
78 else:
79 ps = _np.linspace(0, 1, 10)
80 colors = cmap2(ps)
81 for p, (r, g, b, a) in zip(ps, colors):
82 cdict['red'].append((.5*(1+p), r, r))
83 cdict['green'].append((.5*(1+p), g, g))
84 cdict['blue'].append((.5*(1+p), b, b))
85
86 return cdict
87
88
89 def alpha_cmap(color, name='', alpha_min=0.5, alpha_max=1.):
90 """ Return a colormap with the given color, and alpha going from
91 zero to 1.
92
93 Parameters
94 ----------
95 color: (r, g, b), or a string
96 A triplet of floats ranging from 0 to 1, or a matplotlib
97 color string
98 """
99 red, green, blue = _colors.colorConverter.to_rgb(color)
100 if name == '' and hasattr(color, 'startswith'):
101 name = color
102 cmapspec = [(red, green, blue, 1.),
103 (red, green, blue, 1.),
104 ]
105 cmap = _colors.LinearSegmentedColormap.from_list(
106 '%s_transparent' % name, cmapspec, _cm.LUTSIZE)
107 cmap._init()
108 cmap._lut[:, -1] = _np.linspace(alpha_min, alpha_max, cmap._lut.shape[0])
109 cmap._lut[-1, -1] = 0
110 return cmap
111
112
113
114 ################################################################################
115 # Our colormaps definition
116 _cmaps_data = dict(
117 cold_hot = _pigtailed_cmap(_cm.hot),
118 cold_white_hot = _pigtailed_cmap(_cm.hot_r),
119 brown_blue = _pigtailed_cmap(_cm.bone),
120 cyan_copper = _pigtailed_cmap(_cm.copper),
121 cyan_orange = _pigtailed_cmap(_cm.YlOrBr_r),
122 blue_red = _pigtailed_cmap(_cm.Reds_r),
123 brown_cyan = _pigtailed_cmap(_cm.Blues_r),
124 purple_green = _pigtailed_cmap(_cm.Greens_r,
125 swap_order=('red', 'blue', 'green')),
126 purple_blue = _pigtailed_cmap(_cm.Blues_r,
127 swap_order=('red', 'blue', 'green')),
128 blue_orange = _pigtailed_cmap(_cm.Oranges_r,
129 swap_order=('green', 'red', 'blue')),
130 black_blue = _rotate_cmap(_cm.hot),
131 black_purple = _rotate_cmap(_cm.hot,
132 swap_order=('blue', 'red', 'green')),
133 black_pink = _rotate_cmap(_cm.hot,
134 swap_order=('blue', 'green', 'red')),
135 black_green = _rotate_cmap(_cm.hot,
136 swap_order=('red', 'blue', 'green')),
137 black_red = _cm.hot._segmentdata.copy(),
138 )
139
140 if hasattr(_cm, 'ocean'):
141 # MPL 0.99 doesn't have Ocean
142 _cmaps_data['ocean_hot'] = _concat_cmap(_cm.ocean, _cm.hot_r)
143 if hasattr(_cm, 'afmhot'): # or afmhot
144 _cmaps_data['hot_white_bone'] = _concat_cmap(_cm.afmhot, _cm.bone_r)
145 _cmaps_data['hot_black_bone'] = _concat_cmap(_cm.afmhot_r, _cm.bone)
146
147 # Copied from matplotlib 1.2.0 for matplotlib 0.99 compatibility.
148 _bwr_data = ((0.0, 0.0, 1.0), (1.0, 1.0, 1.0), (1.0, 0.0, 0.0))
149 _cmaps_data['bwr'] = _colors.LinearSegmentedColormap.from_list(
150 'bwr', _bwr_data)._segmentdata.copy()
151
152 ################################################################################
153 # Build colormaps and their reverse.
154 _cmap_d = dict()
155
156 for _cmapname in list(_cmaps_data.keys()): # needed as dict changes within loop
157 _cmapname_r = _cmapname + '_r'
158 _cmapspec = _cmaps_data[_cmapname]
159 _cmaps_data[_cmapname_r] = _cm.revcmap(_cmapspec)
160 _cmap_d[_cmapname] = _colors.LinearSegmentedColormap(
161 _cmapname, _cmapspec, _cm.LUTSIZE)
162 _cmap_d[_cmapname_r] = _colors.LinearSegmentedColormap(
163 _cmapname_r, _cmaps_data[_cmapname_r],
164 _cm.LUTSIZE)
165
166 ################################################################################
167 # A few transparent colormaps
168 for color, name in (((1, 0, 0), 'red'),
169 ((0, 1, 0), 'blue'),
170 ((0, 0, 1), 'green'),
171 ):
172 _cmap_d['%s_transparent' % name] = alpha_cmap(color, name=name)
173 _cmap_d['%s_transparent_full_alpha_range' % name] = alpha_cmap(
174 color, alpha_min=0,
175 alpha_max=1, name=name)
176
177
178 locals().update(_cmap_d)
179
180
181 ################################################################################
182 # Utility to replace a colormap by another in an interval
183 ################################################################################
184
185 def dim_cmap(cmap, factor=.3, to_white=True):
186 """ Dim a colormap to white, or to black.
187 """
188 assert factor >= 0 and factor <=1, ValueError(
189 'Dimming factor must be larger than 0 and smaller than 1, %s was passed.'
190 % factor)
191 if to_white:
192 dimmer = lambda c: 1 - factor*(1-c)
193 else:
194 dimmer = lambda c: factor*c
195 cdict = cmap._segmentdata.copy()
196 for c_index, color in enumerate(('red', 'green', 'blue')):
197 color_lst = list()
198 for value, c1, c2 in cdict[color]:
199 color_lst.append((value, dimmer(c1), dimmer(c2)))
200 cdict[color] = color_lst
201
202 return _colors.LinearSegmentedColormap(
203 '%s_dimmed' % cmap.name,
204 cdict,
205 _cm.LUTSIZE)
206
207
208 def replace_inside(outer_cmap, inner_cmap, vmin, vmax):
209 """ Replace a colormap by another inside a pair of values.
210 """
211 assert vmin < vmax, ValueError('vmin must be smaller than vmax')
212 assert vmin >= 0, ValueError('vmin must be larger than 0, %s was passed.'
213 % vmin)
214 assert vmax <= 1, ValueError('vmax must be smaller than 1, %s was passed.'
215 % vmax)
216 outer_cdict = outer_cmap._segmentdata.copy()
217 inner_cdict = inner_cmap._segmentdata.copy()
218
219 cdict = dict()
220 for this_cdict, cmap in [(outer_cdict, outer_cmap),
221 (inner_cdict, inner_cmap)]:
222 if hasattr(this_cdict['red'], '__call__'):
223 ps = _np.linspace(0, 1, 25)
224 colors = cmap(ps)
225 this_cdict['red'] = list()
226 this_cdict['green'] = list()
227 this_cdict['blue'] = list()
228 for p, (r, g, b, a) in zip(ps, colors):
229 this_cdict['red'].append((p, r, r))
230 this_cdict['green'].append((p, g, g))
231 this_cdict['blue'].append((p, b, b))
232
233
234 for c_index, color in enumerate(('red', 'green', 'blue')):
235 color_lst = list()
236
237 for value, c1, c2 in outer_cdict[color]:
238 if value >= vmin:
239 break
240 color_lst.append((value, c1, c2))
241
242 color_lst.append((vmin, outer_cmap(vmin)[c_index],
243 inner_cmap(vmin)[c_index]))
244
245 for value, c1, c2 in inner_cdict[color]:
246 if value <= vmin:
247 continue
248 if value >= vmax:
249 break
250 color_lst.append((value, c1, c2))
251
252 color_lst.append((vmax, inner_cmap(vmax)[c_index],
253 outer_cmap(vmax)[c_index]))
254
255 for value, c1, c2 in outer_cdict[color]:
256 if value <= vmax:
257 continue
258 color_lst.append((value, c1, c2))
259
260 cdict[color] = color_lst
261
262 return _colors.LinearSegmentedColormap(
263 '%s_inside_%s' % (inner_cmap.name, outer_cmap.name),
264 cdict,
265 _cm.LUTSIZE)
266
267
268
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nilearn/plotting/cm.py b/nilearn/plotting/cm.py
--- a/nilearn/plotting/cm.py
+++ b/nilearn/plotting/cm.py
@@ -175,7 +175,11 @@
alpha_max=1, name=name)
+# Save colormaps in the scope of the module
locals().update(_cmap_d)
+# Register cmaps in matplotlib too
+for k, v in _cmap_d.items():
+ _cm.register_cmap(name=k, cmap=v)
################################################################################
|
{"golden_diff": "diff --git a/nilearn/plotting/cm.py b/nilearn/plotting/cm.py\n--- a/nilearn/plotting/cm.py\n+++ b/nilearn/plotting/cm.py\n@@ -175,7 +175,11 @@\n alpha_max=1, name=name)\n \n \n+# Save colormaps in the scope of the module\n locals().update(_cmap_d)\n+# Register cmaps in matplotlib too\n+for k, v in _cmap_d.items():\n+ _cm.register_cmap(name=k, cmap=v)\n \n \n ################################################################################\n", "issue": "Automatically loading colormaps when importing nilearn (or cm?)\nThe colormaps that are created in [cm.py](https://github.com/KirstieJane/nilearn/blob/40069cb14b43333a73137797eac895cfb054db29/nilearn/plotting/cm.py) are really nice!\n\nCurrently, if I want to use them in one of my wrapper scripts I have the following hack:\n\n```\nfrom nilearn.plotting import cm\n\ncmap = 'cold_white_hot'\n\nif hasattr(cm, cmap):\n cmap = getatt(cm, cmap)\n```\n\nWould it be possible to have these colormaps already loaded so they're available by name without this code?\n\n", "before_files": [{"content": "# emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: nil -*-\n# vi: set ft=python sts=4 ts=4 sw=4 et:\n\"\"\"\nMatplotlib colormaps useful for neuroimaging.\n\"\"\"\nimport numpy as _np\n\nfrom matplotlib import cm as _cm\nfrom matplotlib import colors as _colors\n\n################################################################################\n# Custom colormaps for two-tailed symmetric statistics\n################################################################################\n\n################################################################################\n# Helper functions\n\ndef _rotate_cmap(cmap, swap_order=('green', 'red', 'blue')):\n \"\"\" Utility function to swap the colors of a colormap.\n \"\"\"\n orig_cdict = cmap._segmentdata.copy()\n\n cdict = dict()\n cdict['green'] = [(p, c1, c2)\n for (p, c1, c2) in orig_cdict[swap_order[0]]]\n cdict['blue'] = [(p, c1, c2)\n for (p, c1, c2) in orig_cdict[swap_order[1]]]\n cdict['red'] = [(p, c1, c2)\n for (p, c1, c2) in orig_cdict[swap_order[2]]]\n\n return cdict\n\n\ndef _pigtailed_cmap(cmap, swap_order=('green', 'red', 'blue')):\n \"\"\" Utility function to make a new colormap by concatenating a\n colormap with its reverse.\n \"\"\"\n orig_cdict = cmap._segmentdata.copy()\n\n cdict = dict()\n cdict['green'] = [(0.5*(1-p), c1, c2)\n for (p, c1, c2) in reversed(orig_cdict[swap_order[0]])]\n cdict['blue'] = [(0.5*(1-p), c1, c2)\n for (p, c1, c2) in reversed(orig_cdict[swap_order[1]])]\n cdict['red'] = [(0.5*(1-p), c1, c2)\n for (p, c1, c2) in reversed(orig_cdict[swap_order[2]])]\n\n for color in ('red', 'green', 'blue'):\n cdict[color].extend([(0.5*(1+p), c1, c2) \n for (p, c1, c2) in orig_cdict[color]])\n\n return cdict\n\n\ndef _concat_cmap(cmap1, cmap2):\n \"\"\" Utility function to make a new colormap by concatenating two\n colormaps.\n \"\"\"\n cdict = dict()\n\n cdict1 = cmap1._segmentdata.copy()\n cdict2 = cmap2._segmentdata.copy()\n if not hasattr(cdict1['red'], '__call__'):\n for c in ['red', 'green', 'blue']:\n cdict[c] = [(0.5*p, c1, c2) for (p, c1, c2) in cdict1[c]]\n else:\n for c in ['red', 'green', 'blue']:\n cdict[c] = []\n ps = _np.linspace(0, 1, 10)\n colors = cmap1(ps)\n for p, (r, g, b, a) in zip(ps, colors):\n cdict['red'].append((.5*p, r, r))\n cdict['green'].append((.5*p, g, g))\n cdict['blue'].append((.5*p, b, b))\n if not hasattr(cdict2['red'], '__call__'):\n for c in ['red', 'green', 'blue']:\n cdict[c].extend([(0.5*(1+p), c1, c2) for (p, c1, c2) in cdict2[c]])\n else:\n ps = _np.linspace(0, 1, 10)\n colors = cmap2(ps)\n for p, (r, g, b, a) in zip(ps, colors):\n cdict['red'].append((.5*(1+p), r, r))\n cdict['green'].append((.5*(1+p), g, g))\n cdict['blue'].append((.5*(1+p), b, b))\n\n return cdict\n\n\ndef alpha_cmap(color, name='', alpha_min=0.5, alpha_max=1.):\n \"\"\" Return a colormap with the given color, and alpha going from\n zero to 1.\n\n Parameters\n ----------\n color: (r, g, b), or a string\n A triplet of floats ranging from 0 to 1, or a matplotlib\n color string\n \"\"\"\n red, green, blue = _colors.colorConverter.to_rgb(color)\n if name == '' and hasattr(color, 'startswith'):\n name = color\n cmapspec = [(red, green, blue, 1.),\n (red, green, blue, 1.),\n ]\n cmap = _colors.LinearSegmentedColormap.from_list(\n '%s_transparent' % name, cmapspec, _cm.LUTSIZE)\n cmap._init()\n cmap._lut[:, -1] = _np.linspace(alpha_min, alpha_max, cmap._lut.shape[0])\n cmap._lut[-1, -1] = 0\n return cmap\n\n\n\n################################################################################\n# Our colormaps definition\n_cmaps_data = dict(\n cold_hot = _pigtailed_cmap(_cm.hot),\n cold_white_hot = _pigtailed_cmap(_cm.hot_r),\n brown_blue = _pigtailed_cmap(_cm.bone),\n cyan_copper = _pigtailed_cmap(_cm.copper),\n cyan_orange = _pigtailed_cmap(_cm.YlOrBr_r),\n blue_red = _pigtailed_cmap(_cm.Reds_r),\n brown_cyan = _pigtailed_cmap(_cm.Blues_r),\n purple_green = _pigtailed_cmap(_cm.Greens_r,\n swap_order=('red', 'blue', 'green')),\n purple_blue = _pigtailed_cmap(_cm.Blues_r,\n swap_order=('red', 'blue', 'green')),\n blue_orange = _pigtailed_cmap(_cm.Oranges_r,\n swap_order=('green', 'red', 'blue')),\n black_blue = _rotate_cmap(_cm.hot),\n black_purple = _rotate_cmap(_cm.hot,\n swap_order=('blue', 'red', 'green')),\n black_pink = _rotate_cmap(_cm.hot,\n swap_order=('blue', 'green', 'red')),\n black_green = _rotate_cmap(_cm.hot,\n swap_order=('red', 'blue', 'green')),\n black_red = _cm.hot._segmentdata.copy(),\n)\n\nif hasattr(_cm, 'ocean'):\n # MPL 0.99 doesn't have Ocean\n _cmaps_data['ocean_hot'] = _concat_cmap(_cm.ocean, _cm.hot_r)\nif hasattr(_cm, 'afmhot'): # or afmhot\n _cmaps_data['hot_white_bone'] = _concat_cmap(_cm.afmhot, _cm.bone_r)\n _cmaps_data['hot_black_bone'] = _concat_cmap(_cm.afmhot_r, _cm.bone)\n\n# Copied from matplotlib 1.2.0 for matplotlib 0.99 compatibility.\n_bwr_data = ((0.0, 0.0, 1.0), (1.0, 1.0, 1.0), (1.0, 0.0, 0.0))\n_cmaps_data['bwr'] = _colors.LinearSegmentedColormap.from_list(\n 'bwr', _bwr_data)._segmentdata.copy()\n\n################################################################################\n# Build colormaps and their reverse.\n_cmap_d = dict()\n\nfor _cmapname in list(_cmaps_data.keys()): # needed as dict changes within loop\n _cmapname_r = _cmapname + '_r'\n _cmapspec = _cmaps_data[_cmapname]\n _cmaps_data[_cmapname_r] = _cm.revcmap(_cmapspec)\n _cmap_d[_cmapname] = _colors.LinearSegmentedColormap(\n _cmapname, _cmapspec, _cm.LUTSIZE)\n _cmap_d[_cmapname_r] = _colors.LinearSegmentedColormap(\n _cmapname_r, _cmaps_data[_cmapname_r],\n _cm.LUTSIZE)\n\n################################################################################\n# A few transparent colormaps\nfor color, name in (((1, 0, 0), 'red'),\n ((0, 1, 0), 'blue'),\n ((0, 0, 1), 'green'),\n ):\n _cmap_d['%s_transparent' % name] = alpha_cmap(color, name=name)\n _cmap_d['%s_transparent_full_alpha_range' % name] = alpha_cmap(\n color, alpha_min=0,\n alpha_max=1, name=name)\n\n\nlocals().update(_cmap_d)\n\n\n################################################################################\n# Utility to replace a colormap by another in an interval\n################################################################################\n\ndef dim_cmap(cmap, factor=.3, to_white=True):\n \"\"\" Dim a colormap to white, or to black.\n \"\"\"\n assert factor >= 0 and factor <=1, ValueError(\n 'Dimming factor must be larger than 0 and smaller than 1, %s was passed.' \n % factor)\n if to_white:\n dimmer = lambda c: 1 - factor*(1-c)\n else:\n dimmer = lambda c: factor*c\n cdict = cmap._segmentdata.copy()\n for c_index, color in enumerate(('red', 'green', 'blue')):\n color_lst = list()\n for value, c1, c2 in cdict[color]:\n color_lst.append((value, dimmer(c1), dimmer(c2)))\n cdict[color] = color_lst\n\n return _colors.LinearSegmentedColormap(\n '%s_dimmed' % cmap.name,\n cdict,\n _cm.LUTSIZE)\n\n\ndef replace_inside(outer_cmap, inner_cmap, vmin, vmax):\n \"\"\" Replace a colormap by another inside a pair of values.\n \"\"\"\n assert vmin < vmax, ValueError('vmin must be smaller than vmax')\n assert vmin >= 0, ValueError('vmin must be larger than 0, %s was passed.' \n % vmin)\n assert vmax <= 1, ValueError('vmax must be smaller than 1, %s was passed.' \n % vmax)\n outer_cdict = outer_cmap._segmentdata.copy()\n inner_cdict = inner_cmap._segmentdata.copy()\n\n cdict = dict()\n for this_cdict, cmap in [(outer_cdict, outer_cmap),\n (inner_cdict, inner_cmap)]:\n if hasattr(this_cdict['red'], '__call__'):\n ps = _np.linspace(0, 1, 25)\n colors = cmap(ps)\n this_cdict['red'] = list()\n this_cdict['green'] = list()\n this_cdict['blue'] = list()\n for p, (r, g, b, a) in zip(ps, colors):\n this_cdict['red'].append((p, r, r))\n this_cdict['green'].append((p, g, g))\n this_cdict['blue'].append((p, b, b))\n\n\n for c_index, color in enumerate(('red', 'green', 'blue')):\n color_lst = list()\n\n for value, c1, c2 in outer_cdict[color]:\n if value >= vmin:\n break\n color_lst.append((value, c1, c2))\n\n color_lst.append((vmin, outer_cmap(vmin)[c_index], \n inner_cmap(vmin)[c_index]))\n\n for value, c1, c2 in inner_cdict[color]:\n if value <= vmin:\n continue\n if value >= vmax:\n break\n color_lst.append((value, c1, c2))\n\n color_lst.append((vmax, inner_cmap(vmax)[c_index],\n outer_cmap(vmax)[c_index]))\n\n for value, c1, c2 in outer_cdict[color]:\n if value <= vmax:\n continue\n color_lst.append((value, c1, c2))\n\n cdict[color] = color_lst\n\n return _colors.LinearSegmentedColormap(\n '%s_inside_%s' % (inner_cmap.name, outer_cmap.name),\n cdict,\n _cm.LUTSIZE)\n\n\n", "path": "nilearn/plotting/cm.py"}], "after_files": [{"content": "# emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: nil -*-\n# vi: set ft=python sts=4 ts=4 sw=4 et:\n\"\"\"\nMatplotlib colormaps useful for neuroimaging.\n\"\"\"\nimport numpy as _np\n\nfrom matplotlib import cm as _cm\nfrom matplotlib import colors as _colors\n\n################################################################################\n# Custom colormaps for two-tailed symmetric statistics\n################################################################################\n\n################################################################################\n# Helper functions\n\ndef _rotate_cmap(cmap, swap_order=('green', 'red', 'blue')):\n \"\"\" Utility function to swap the colors of a colormap.\n \"\"\"\n orig_cdict = cmap._segmentdata.copy()\n\n cdict = dict()\n cdict['green'] = [(p, c1, c2)\n for (p, c1, c2) in orig_cdict[swap_order[0]]]\n cdict['blue'] = [(p, c1, c2)\n for (p, c1, c2) in orig_cdict[swap_order[1]]]\n cdict['red'] = [(p, c1, c2)\n for (p, c1, c2) in orig_cdict[swap_order[2]]]\n\n return cdict\n\n\ndef _pigtailed_cmap(cmap, swap_order=('green', 'red', 'blue')):\n \"\"\" Utility function to make a new colormap by concatenating a\n colormap with its reverse.\n \"\"\"\n orig_cdict = cmap._segmentdata.copy()\n\n cdict = dict()\n cdict['green'] = [(0.5*(1-p), c1, c2)\n for (p, c1, c2) in reversed(orig_cdict[swap_order[0]])]\n cdict['blue'] = [(0.5*(1-p), c1, c2)\n for (p, c1, c2) in reversed(orig_cdict[swap_order[1]])]\n cdict['red'] = [(0.5*(1-p), c1, c2)\n for (p, c1, c2) in reversed(orig_cdict[swap_order[2]])]\n\n for color in ('red', 'green', 'blue'):\n cdict[color].extend([(0.5*(1+p), c1, c2) \n for (p, c1, c2) in orig_cdict[color]])\n\n return cdict\n\n\ndef _concat_cmap(cmap1, cmap2):\n \"\"\" Utility function to make a new colormap by concatenating two\n colormaps.\n \"\"\"\n cdict = dict()\n\n cdict1 = cmap1._segmentdata.copy()\n cdict2 = cmap2._segmentdata.copy()\n if not hasattr(cdict1['red'], '__call__'):\n for c in ['red', 'green', 'blue']:\n cdict[c] = [(0.5*p, c1, c2) for (p, c1, c2) in cdict1[c]]\n else:\n for c in ['red', 'green', 'blue']:\n cdict[c] = []\n ps = _np.linspace(0, 1, 10)\n colors = cmap1(ps)\n for p, (r, g, b, a) in zip(ps, colors):\n cdict['red'].append((.5*p, r, r))\n cdict['green'].append((.5*p, g, g))\n cdict['blue'].append((.5*p, b, b))\n if not hasattr(cdict2['red'], '__call__'):\n for c in ['red', 'green', 'blue']:\n cdict[c].extend([(0.5*(1+p), c1, c2) for (p, c1, c2) in cdict2[c]])\n else:\n ps = _np.linspace(0, 1, 10)\n colors = cmap2(ps)\n for p, (r, g, b, a) in zip(ps, colors):\n cdict['red'].append((.5*(1+p), r, r))\n cdict['green'].append((.5*(1+p), g, g))\n cdict['blue'].append((.5*(1+p), b, b))\n\n return cdict\n\n\ndef alpha_cmap(color, name='', alpha_min=0.5, alpha_max=1.):\n \"\"\" Return a colormap with the given color, and alpha going from\n zero to 1.\n\n Parameters\n ----------\n color: (r, g, b), or a string\n A triplet of floats ranging from 0 to 1, or a matplotlib\n color string\n \"\"\"\n red, green, blue = _colors.colorConverter.to_rgb(color)\n if name == '' and hasattr(color, 'startswith'):\n name = color\n cmapspec = [(red, green, blue, 1.),\n (red, green, blue, 1.),\n ]\n cmap = _colors.LinearSegmentedColormap.from_list(\n '%s_transparent' % name, cmapspec, _cm.LUTSIZE)\n cmap._init()\n cmap._lut[:, -1] = _np.linspace(alpha_min, alpha_max, cmap._lut.shape[0])\n cmap._lut[-1, -1] = 0\n return cmap\n\n\n\n################################################################################\n# Our colormaps definition\n_cmaps_data = dict(\n cold_hot = _pigtailed_cmap(_cm.hot),\n cold_white_hot = _pigtailed_cmap(_cm.hot_r),\n brown_blue = _pigtailed_cmap(_cm.bone),\n cyan_copper = _pigtailed_cmap(_cm.copper),\n cyan_orange = _pigtailed_cmap(_cm.YlOrBr_r),\n blue_red = _pigtailed_cmap(_cm.Reds_r),\n brown_cyan = _pigtailed_cmap(_cm.Blues_r),\n purple_green = _pigtailed_cmap(_cm.Greens_r,\n swap_order=('red', 'blue', 'green')),\n purple_blue = _pigtailed_cmap(_cm.Blues_r,\n swap_order=('red', 'blue', 'green')),\n blue_orange = _pigtailed_cmap(_cm.Oranges_r,\n swap_order=('green', 'red', 'blue')),\n black_blue = _rotate_cmap(_cm.hot),\n black_purple = _rotate_cmap(_cm.hot,\n swap_order=('blue', 'red', 'green')),\n black_pink = _rotate_cmap(_cm.hot,\n swap_order=('blue', 'green', 'red')),\n black_green = _rotate_cmap(_cm.hot,\n swap_order=('red', 'blue', 'green')),\n black_red = _cm.hot._segmentdata.copy(),\n)\n\nif hasattr(_cm, 'ocean'):\n # MPL 0.99 doesn't have Ocean\n _cmaps_data['ocean_hot'] = _concat_cmap(_cm.ocean, _cm.hot_r)\nif hasattr(_cm, 'afmhot'): # or afmhot\n _cmaps_data['hot_white_bone'] = _concat_cmap(_cm.afmhot, _cm.bone_r)\n _cmaps_data['hot_black_bone'] = _concat_cmap(_cm.afmhot_r, _cm.bone)\n\n# Copied from matplotlib 1.2.0 for matplotlib 0.99 compatibility.\n_bwr_data = ((0.0, 0.0, 1.0), (1.0, 1.0, 1.0), (1.0, 0.0, 0.0))\n_cmaps_data['bwr'] = _colors.LinearSegmentedColormap.from_list(\n 'bwr', _bwr_data)._segmentdata.copy()\n\n################################################################################\n# Build colormaps and their reverse.\n_cmap_d = dict()\n\nfor _cmapname in list(_cmaps_data.keys()): # needed as dict changes within loop\n _cmapname_r = _cmapname + '_r'\n _cmapspec = _cmaps_data[_cmapname]\n _cmaps_data[_cmapname_r] = _cm.revcmap(_cmapspec)\n _cmap_d[_cmapname] = _colors.LinearSegmentedColormap(\n _cmapname, _cmapspec, _cm.LUTSIZE)\n _cmap_d[_cmapname_r] = _colors.LinearSegmentedColormap(\n _cmapname_r, _cmaps_data[_cmapname_r],\n _cm.LUTSIZE)\n\n################################################################################\n# A few transparent colormaps\nfor color, name in (((1, 0, 0), 'red'),\n ((0, 1, 0), 'blue'),\n ((0, 0, 1), 'green'),\n ):\n _cmap_d['%s_transparent' % name] = alpha_cmap(color, name=name)\n _cmap_d['%s_transparent_full_alpha_range' % name] = alpha_cmap(\n color, alpha_min=0,\n alpha_max=1, name=name)\n\n\n# Save colormaps in the scope of the module\nlocals().update(_cmap_d)\n# Register cmaps in matplotlib too\nfor k, v in _cmap_d.items():\n _cm.register_cmap(name=k, cmap=v)\n\n\n################################################################################\n# Utility to replace a colormap by another in an interval\n################################################################################\n\ndef dim_cmap(cmap, factor=.3, to_white=True):\n \"\"\" Dim a colormap to white, or to black.\n \"\"\"\n assert factor >= 0 and factor <=1, ValueError(\n 'Dimming factor must be larger than 0 and smaller than 1, %s was passed.' \n % factor)\n if to_white:\n dimmer = lambda c: 1 - factor*(1-c)\n else:\n dimmer = lambda c: factor*c\n cdict = cmap._segmentdata.copy()\n for c_index, color in enumerate(('red', 'green', 'blue')):\n color_lst = list()\n for value, c1, c2 in cdict[color]:\n color_lst.append((value, dimmer(c1), dimmer(c2)))\n cdict[color] = color_lst\n\n return _colors.LinearSegmentedColormap(\n '%s_dimmed' % cmap.name,\n cdict,\n _cm.LUTSIZE)\n\n\ndef replace_inside(outer_cmap, inner_cmap, vmin, vmax):\n \"\"\" Replace a colormap by another inside a pair of values.\n \"\"\"\n assert vmin < vmax, ValueError('vmin must be smaller than vmax')\n assert vmin >= 0, ValueError('vmin must be larger than 0, %s was passed.' \n % vmin)\n assert vmax <= 1, ValueError('vmax must be smaller than 1, %s was passed.' \n % vmax)\n outer_cdict = outer_cmap._segmentdata.copy()\n inner_cdict = inner_cmap._segmentdata.copy()\n\n cdict = dict()\n for this_cdict, cmap in [(outer_cdict, outer_cmap),\n (inner_cdict, inner_cmap)]:\n if hasattr(this_cdict['red'], '__call__'):\n ps = _np.linspace(0, 1, 25)\n colors = cmap(ps)\n this_cdict['red'] = list()\n this_cdict['green'] = list()\n this_cdict['blue'] = list()\n for p, (r, g, b, a) in zip(ps, colors):\n this_cdict['red'].append((p, r, r))\n this_cdict['green'].append((p, g, g))\n this_cdict['blue'].append((p, b, b))\n\n\n for c_index, color in enumerate(('red', 'green', 'blue')):\n color_lst = list()\n\n for value, c1, c2 in outer_cdict[color]:\n if value >= vmin:\n break\n color_lst.append((value, c1, c2))\n\n color_lst.append((vmin, outer_cmap(vmin)[c_index], \n inner_cmap(vmin)[c_index]))\n\n for value, c1, c2 in inner_cdict[color]:\n if value <= vmin:\n continue\n if value >= vmax:\n break\n color_lst.append((value, c1, c2))\n\n color_lst.append((vmax, inner_cmap(vmax)[c_index],\n outer_cmap(vmax)[c_index]))\n\n for value, c1, c2 in outer_cdict[color]:\n if value <= vmax:\n continue\n color_lst.append((value, c1, c2))\n\n cdict[color] = color_lst\n\n return _colors.LinearSegmentedColormap(\n '%s_inside_%s' % (inner_cmap.name, outer_cmap.name),\n cdict,\n _cm.LUTSIZE)\n\n\n", "path": "nilearn/plotting/cm.py"}]}
| 3,921 | 125 |
gh_patches_debug_1013
|
rasdani/github-patches
|
git_diff
|
magenta__magenta-785
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
numpy dependency missing?
magenta/models/sketch_rnn/utils.py has ```import numpy as np```, but magenta/tools/pip/setup.py doesn't list it as a dependency.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `magenta/tools/pip/setup.py`
Content:
```
1 # Copyright 2016 Google Inc. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """A setuptools based setup module for magenta."""
15
16 from setuptools import find_packages
17 from setuptools import setup
18
19 # Bit of a hack to parse the version string stored in version.py without
20 # executing __init__.py, which will end up requiring a bunch of dependencies to
21 # execute (e.g., tensorflow, pretty_midi, etc.).
22 # Makes the __version__ variable available.
23 execfile('magenta/version.py')
24
25
26 REQUIRED_PACKAGES = [
27 'IPython',
28 'Pillow >= 3.4.2',
29 'bokeh >= 0.12.0',
30 'futures',
31 'intervaltree >= 2.1.0',
32 'matplotlib >= 1.5.3',
33 'mido == 1.2.6',
34 'pandas >= 0.18.1',
35 'pretty_midi >= 0.2.6',
36 'python-rtmidi',
37 'scipy >= 0.18.1',
38 'tensorflow >= 1.1.0',
39 'wheel',
40 ]
41
42 CONSOLE_SCRIPTS = [
43 'magenta.interfaces.midi.magenta_midi',
44 'magenta.interfaces.midi.midi_clock',
45 'magenta.models.drums_rnn.drums_rnn_create_dataset',
46 'magenta.models.drums_rnn.drums_rnn_generate',
47 'magenta.models.drums_rnn.drums_rnn_train',
48 'magenta.models.image_stylization.image_stylization_create_dataset',
49 'magenta.models.image_stylization.image_stylization_evaluate',
50 'magenta.models.image_stylization.image_stylization_finetune',
51 'magenta.models.image_stylization.image_stylization_train',
52 'magenta.models.image_stylization.image_stylization_transform',
53 'magenta.models.improv_rnn.improv_rnn_create_dataset',
54 'magenta.models.improv_rnn.improv_rnn_generate',
55 'magenta.models.improv_rnn.improv_rnn_train',
56 'magenta.models.melody_rnn.melody_rnn_create_dataset',
57 'magenta.models.melody_rnn.melody_rnn_generate',
58 'magenta.models.melody_rnn.melody_rnn_train',
59 'magenta.models.nsynth.wavenet.nsynth_generate',
60 'magenta.models.nsynth.wavenet.nsynth_save_embeddings',
61 'magenta.models.performance_rnn.performance_rnn_create_dataset',
62 'magenta.models.performance_rnn.performance_rnn_generate',
63 'magenta.models.performance_rnn.performance_rnn_train',
64 'magenta.models.pianoroll_rnn_nade.pianoroll_rnn_nade_create_dataset',
65 'magenta.models.pianoroll_rnn_nade.pianoroll_rnn_nade_generate',
66 'magenta.models.pianoroll_rnn_nade.pianoroll_rnn_nade_train',
67 'magenta.models.polyphony_rnn.polyphony_rnn_create_dataset',
68 'magenta.models.polyphony_rnn.polyphony_rnn_generate',
69 'magenta.models.polyphony_rnn.polyphony_rnn_train',
70 'magenta.models.rl_tuner.rl_tuner_train',
71 'magenta.models.sketch_rnn.sketch_rnn_train',
72 'magenta.scripts.convert_dir_to_note_sequences',
73 ]
74
75 setup(
76 name='magenta',
77 version=__version__, # pylint: disable=undefined-variable
78 description='Use machine learning to create art and music',
79 long_description='',
80 url='https://magenta.tensorflow.org/',
81 author='Google Inc.',
82 author_email='[email protected]',
83 license='Apache 2',
84 # PyPI package information.
85 classifiers=[
86 'Development Status :: 4 - Beta',
87 'Intended Audience :: Developers',
88 'Intended Audience :: Education',
89 'Intended Audience :: Science/Research',
90 'License :: OSI Approved :: Apache Software License',
91 'Programming Language :: Python :: 2.7',
92 'Topic :: Scientific/Engineering :: Mathematics',
93 'Topic :: Software Development :: Libraries :: Python Modules',
94 'Topic :: Software Development :: Libraries',
95 ],
96 keywords='tensorflow machine learning magenta music art',
97
98 packages=find_packages(),
99 install_requires=REQUIRED_PACKAGES,
100 entry_points={
101 'console_scripts': ['%s = %s:console_entry_point' % (n, p) for n, p in
102 ((s.split('.')[-1], s) for s in CONSOLE_SCRIPTS)],
103 },
104
105 include_package_data=True,
106 package_data={
107 'magenta': ['models/image_stylization/evaluation_images/*.jpg'],
108 },
109 )
110
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/magenta/tools/pip/setup.py b/magenta/tools/pip/setup.py
--- a/magenta/tools/pip/setup.py
+++ b/magenta/tools/pip/setup.py
@@ -31,6 +31,7 @@
'intervaltree >= 2.1.0',
'matplotlib >= 1.5.3',
'mido == 1.2.6',
+ 'numpy >= 1.11.0',
'pandas >= 0.18.1',
'pretty_midi >= 0.2.6',
'python-rtmidi',
|
{"golden_diff": "diff --git a/magenta/tools/pip/setup.py b/magenta/tools/pip/setup.py\n--- a/magenta/tools/pip/setup.py\n+++ b/magenta/tools/pip/setup.py\n@@ -31,6 +31,7 @@\n 'intervaltree >= 2.1.0',\n 'matplotlib >= 1.5.3',\n 'mido == 1.2.6',\n+ 'numpy >= 1.11.0',\n 'pandas >= 0.18.1',\n 'pretty_midi >= 0.2.6',\n 'python-rtmidi',\n", "issue": "numpy dependency missing?\nmagenta/models/sketch_rnn/utils.py has ```import numpy as np```, but magenta/tools/pip/setup.py doesn't list it as a dependency.\n", "before_files": [{"content": "# Copyright 2016 Google Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"A setuptools based setup module for magenta.\"\"\"\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n# Bit of a hack to parse the version string stored in version.py without\n# executing __init__.py, which will end up requiring a bunch of dependencies to\n# execute (e.g., tensorflow, pretty_midi, etc.).\n# Makes the __version__ variable available.\nexecfile('magenta/version.py')\n\n\nREQUIRED_PACKAGES = [\n 'IPython',\n 'Pillow >= 3.4.2',\n 'bokeh >= 0.12.0',\n 'futures',\n 'intervaltree >= 2.1.0',\n 'matplotlib >= 1.5.3',\n 'mido == 1.2.6',\n 'pandas >= 0.18.1',\n 'pretty_midi >= 0.2.6',\n 'python-rtmidi',\n 'scipy >= 0.18.1',\n 'tensorflow >= 1.1.0',\n 'wheel',\n]\n\nCONSOLE_SCRIPTS = [\n 'magenta.interfaces.midi.magenta_midi',\n 'magenta.interfaces.midi.midi_clock',\n 'magenta.models.drums_rnn.drums_rnn_create_dataset',\n 'magenta.models.drums_rnn.drums_rnn_generate',\n 'magenta.models.drums_rnn.drums_rnn_train',\n 'magenta.models.image_stylization.image_stylization_create_dataset',\n 'magenta.models.image_stylization.image_stylization_evaluate',\n 'magenta.models.image_stylization.image_stylization_finetune',\n 'magenta.models.image_stylization.image_stylization_train',\n 'magenta.models.image_stylization.image_stylization_transform',\n 'magenta.models.improv_rnn.improv_rnn_create_dataset',\n 'magenta.models.improv_rnn.improv_rnn_generate',\n 'magenta.models.improv_rnn.improv_rnn_train',\n 'magenta.models.melody_rnn.melody_rnn_create_dataset',\n 'magenta.models.melody_rnn.melody_rnn_generate',\n 'magenta.models.melody_rnn.melody_rnn_train',\n 'magenta.models.nsynth.wavenet.nsynth_generate',\n 'magenta.models.nsynth.wavenet.nsynth_save_embeddings',\n 'magenta.models.performance_rnn.performance_rnn_create_dataset',\n 'magenta.models.performance_rnn.performance_rnn_generate',\n 'magenta.models.performance_rnn.performance_rnn_train',\n 'magenta.models.pianoroll_rnn_nade.pianoroll_rnn_nade_create_dataset',\n 'magenta.models.pianoroll_rnn_nade.pianoroll_rnn_nade_generate',\n 'magenta.models.pianoroll_rnn_nade.pianoroll_rnn_nade_train',\n 'magenta.models.polyphony_rnn.polyphony_rnn_create_dataset',\n 'magenta.models.polyphony_rnn.polyphony_rnn_generate',\n 'magenta.models.polyphony_rnn.polyphony_rnn_train',\n 'magenta.models.rl_tuner.rl_tuner_train',\n 'magenta.models.sketch_rnn.sketch_rnn_train',\n 'magenta.scripts.convert_dir_to_note_sequences',\n]\n\nsetup(\n name='magenta',\n version=__version__, # pylint: disable=undefined-variable\n description='Use machine learning to create art and music',\n long_description='',\n url='https://magenta.tensorflow.org/',\n author='Google Inc.',\n author_email='[email protected]',\n license='Apache 2',\n # PyPI package information.\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python :: 2.7',\n 'Topic :: Scientific/Engineering :: Mathematics',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Software Development :: Libraries',\n ],\n keywords='tensorflow machine learning magenta music art',\n\n packages=find_packages(),\n install_requires=REQUIRED_PACKAGES,\n entry_points={\n 'console_scripts': ['%s = %s:console_entry_point' % (n, p) for n, p in\n ((s.split('.')[-1], s) for s in CONSOLE_SCRIPTS)],\n },\n\n include_package_data=True,\n package_data={\n 'magenta': ['models/image_stylization/evaluation_images/*.jpg'],\n },\n)\n", "path": "magenta/tools/pip/setup.py"}], "after_files": [{"content": "# Copyright 2016 Google Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"A setuptools based setup module for magenta.\"\"\"\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n# Bit of a hack to parse the version string stored in version.py without\n# executing __init__.py, which will end up requiring a bunch of dependencies to\n# execute (e.g., tensorflow, pretty_midi, etc.).\n# Makes the __version__ variable available.\nexecfile('magenta/version.py')\n\n\nREQUIRED_PACKAGES = [\n 'IPython',\n 'Pillow >= 3.4.2',\n 'bokeh >= 0.12.0',\n 'futures',\n 'intervaltree >= 2.1.0',\n 'matplotlib >= 1.5.3',\n 'mido == 1.2.6',\n 'numpy >= 1.11.0',\n 'pandas >= 0.18.1',\n 'pretty_midi >= 0.2.6',\n 'python-rtmidi',\n 'scipy >= 0.18.1',\n 'tensorflow >= 1.1.0',\n 'wheel',\n]\n\nCONSOLE_SCRIPTS = [\n 'magenta.interfaces.midi.magenta_midi',\n 'magenta.interfaces.midi.midi_clock',\n 'magenta.models.drums_rnn.drums_rnn_create_dataset',\n 'magenta.models.drums_rnn.drums_rnn_generate',\n 'magenta.models.drums_rnn.drums_rnn_train',\n 'magenta.models.image_stylization.image_stylization_create_dataset',\n 'magenta.models.image_stylization.image_stylization_evaluate',\n 'magenta.models.image_stylization.image_stylization_finetune',\n 'magenta.models.image_stylization.image_stylization_train',\n 'magenta.models.image_stylization.image_stylization_transform',\n 'magenta.models.improv_rnn.improv_rnn_create_dataset',\n 'magenta.models.improv_rnn.improv_rnn_generate',\n 'magenta.models.improv_rnn.improv_rnn_train',\n 'magenta.models.melody_rnn.melody_rnn_create_dataset',\n 'magenta.models.melody_rnn.melody_rnn_generate',\n 'magenta.models.melody_rnn.melody_rnn_train',\n 'magenta.models.nsynth.wavenet.nsynth_generate',\n 'magenta.models.nsynth.wavenet.nsynth_save_embeddings',\n 'magenta.models.performance_rnn.performance_rnn_create_dataset',\n 'magenta.models.performance_rnn.performance_rnn_generate',\n 'magenta.models.performance_rnn.performance_rnn_train',\n 'magenta.models.pianoroll_rnn_nade.pianoroll_rnn_nade_create_dataset',\n 'magenta.models.pianoroll_rnn_nade.pianoroll_rnn_nade_generate',\n 'magenta.models.pianoroll_rnn_nade.pianoroll_rnn_nade_train',\n 'magenta.models.polyphony_rnn.polyphony_rnn_create_dataset',\n 'magenta.models.polyphony_rnn.polyphony_rnn_generate',\n 'magenta.models.polyphony_rnn.polyphony_rnn_train',\n 'magenta.models.rl_tuner.rl_tuner_train',\n 'magenta.models.sketch_rnn.sketch_rnn_train',\n 'magenta.scripts.convert_dir_to_note_sequences',\n]\n\nsetup(\n name='magenta',\n version=__version__, # pylint: disable=undefined-variable\n description='Use machine learning to create art and music',\n long_description='',\n url='https://magenta.tensorflow.org/',\n author='Google Inc.',\n author_email='[email protected]',\n license='Apache 2',\n # PyPI package information.\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python :: 2.7',\n 'Topic :: Scientific/Engineering :: Mathematics',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Software Development :: Libraries',\n ],\n keywords='tensorflow machine learning magenta music art',\n\n packages=find_packages(),\n install_requires=REQUIRED_PACKAGES,\n entry_points={\n 'console_scripts': ['%s = %s:console_entry_point' % (n, p) for n, p in\n ((s.split('.')[-1], s) for s in CONSOLE_SCRIPTS)],\n },\n\n include_package_data=True,\n package_data={\n 'magenta': ['models/image_stylization/evaluation_images/*.jpg'],\n },\n)\n", "path": "magenta/tools/pip/setup.py"}]}
| 1,611 | 135 |
gh_patches_debug_9117
|
rasdani/github-patches
|
git_diff
|
vllm-project__vllm-5402
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug]: TorchSDPAMetadata is out of date
### Your current environment
alexr@roxy:~$ python collect_env.py
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Clang version: Could not collect
CMake version: version 3.26.3
Libc version: glibc-2.35
Python version: 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-105-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.5.119
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3070
Nvidia driver version: 535.161.08
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Vendor ID: GenuineIntel
Model name: Intel(R) Core(TM) i7-10700K CPU @ 3.80GHz
CPU family: 6
Model: 165
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
Stepping: 5
CPU max MHz: 5100.0000
CPU min MHz: 800.0000
BogoMIPS: 7599.80
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts pku ospke md_clear flush_l1d arch_capabilities
L1d cache: 256 KiB (8 instances)
L1i cache: 256 KiB (8 instances)
L2 cache: 2 MiB (8 instances)
L3 cache: 16 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-15
Vulnerability Gather data sampling: Mitigation; Microcode
Vulnerability Itlb multihit: KVM: Mitigation: VMX unsupported
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec rstack overflow: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Mitigation; Microcode
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] flake8==6.0.0
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.24.2
[pip3] nvidia-nccl-cu11==2.14.3
[pip3] sentence-transformers==2.2.2
[pip3] torch==2.0.0
[pip3] torchvision==0.15.1
[pip3] transformers==4.26.0
[pip3] triton==2.0.0
[conda] Could not collect
ROCM Version: Could not collect
Neuron SDK Version: N/A
vLLM Version: N/A
vLLM Build Flags:
CUDA Archs: Not Set; ROCm: Disabled; Neuron: Disabled
GPU Topology:
GPU0 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X 0-15 0 N/A
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
### 🐛 Describe the bug
I believe the TorchSDPA backend for attention is no longer compatible. I received a crash message that said as much and did some debugging. If you set `export VLLM_ATTENTION_BACKEND=TORCH_SDPA`, then the metadata is set with
```
attn_metadata = self.attn_backend.make_metadata(
num_prefills=0,
num_prefill_tokens=0,
num_decode_tokens=batch_size,
slot_mapping=slot_mapping[:batch_size],
seq_lens=None,
seq_lens_tensor=seq_lens[:batch_size],
max_query_len=None,
max_prefill_seq_len=0,
max_decode_seq_len=self.max_seq_len_to_capture,
query_start_loc=None,
seq_start_loc=None,
context_lens_tensor=None,
block_tables=block_tables[:batch_size],
use_cuda_graph=True,
)
```
which is sent to
```
@staticmethod
def make_metadata(*args, **kwargs) -> "TorchSDPAMetadata":
return TorchSDPAMetadata(*args, **kwargs)
```
and neither TorchSDPAMetadata (nor its superclasses) have most of those values
```
@dataclass
class TorchSDPAMetadata(AttentionMetadata, PagedAttentionMetadata):
"""Metadata for TorchSDPABackend.
"""
# Currently, input sequences can only contain all prompts
# or all decoding. True if all sequences are prompts.
is_prompt: bool
slot_mapping: torch.Tensor
seq_lens: Optional[List[int]]
# Maximum query length in the batch. None for decoding.
max_query_len: Optional[int]
```
Am I correct in my diagnosis? I can send a crash log if necessary, but I believe this is pretty self evidently an error (and a CI test should be added or the backend should be removed probably.)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `vllm/attention/selector.py`
Content:
```
1 import enum
2 from functools import lru_cache
3 from typing import Optional, Type
4
5 import torch
6
7 import vllm.envs as envs
8 from vllm.attention.backends.abstract import AttentionBackend
9 from vllm.logger import init_logger
10 from vllm.utils import is_cpu, is_hip
11
12 logger = init_logger(__name__)
13
14
15 class _Backend(enum.Enum):
16 FLASH_ATTN = enum.auto()
17 XFORMERS = enum.auto()
18 ROCM_FLASH = enum.auto()
19 TORCH_SDPA = enum.auto()
20 FLASHINFER = enum.auto()
21
22
23 @lru_cache(maxsize=None)
24 def get_attn_backend(
25 num_heads: int,
26 head_size: int,
27 num_kv_heads: int,
28 sliding_window: Optional[int],
29 dtype: torch.dtype,
30 kv_cache_dtype: Optional[str],
31 block_size: int,
32 is_blocksparse: bool = False,
33 ) -> Type[AttentionBackend]:
34 """Selects which attention backend to use and lazily imports it."""
35
36 if is_blocksparse:
37 logger.info("Using BlocksparseFlashAttention backend.")
38 from vllm.attention.backends.blocksparse_attn import (
39 BlocksparseFlashAttentionBackend)
40 return BlocksparseFlashAttentionBackend
41
42 backend = which_attn_to_use(num_heads, head_size, num_kv_heads,
43 sliding_window, dtype, kv_cache_dtype,
44 block_size)
45 if backend == _Backend.FLASH_ATTN:
46 from vllm.attention.backends.flash_attn import ( # noqa: F401
47 FlashAttentionBackend)
48 return FlashAttentionBackend
49 if backend == _Backend.XFORMERS:
50 logger.info("Using XFormers backend.")
51 from vllm.attention.backends.xformers import ( # noqa: F401
52 XFormersBackend)
53 return XFormersBackend
54 elif backend == _Backend.ROCM_FLASH:
55 logger.info("Using ROCmFlashAttention backend.")
56 from vllm.attention.backends.rocm_flash_attn import ( # noqa: F401
57 ROCmFlashAttentionBackend)
58 return ROCmFlashAttentionBackend
59 elif backend == _Backend.TORCH_SDPA:
60 logger.info("Using Torch SDPA backend.")
61 from vllm.attention.backends.torch_sdpa import TorchSDPABackend
62 return TorchSDPABackend
63 elif backend == _Backend.FLASHINFER:
64 logger.info("Using Flashinfer backend.")
65 logger.warning("Eager mode is required for the Flashinfer backend. "
66 "Please make sure --enforce-eager is set.")
67 from vllm.attention.backends.flashinfer import FlashInferBackend
68 return FlashInferBackend
69 else:
70 raise ValueError("Invalid attention backend.")
71
72
73 def which_attn_to_use(
74 num_heads: int,
75 head_size: int,
76 num_kv_heads: int,
77 sliding_window: Optional[int],
78 dtype: torch.dtype,
79 kv_cache_dtype: Optional[str],
80 block_size: int,
81 ) -> _Backend:
82 """Returns which flash attention backend to use."""
83
84 # Default case.
85 selected_backend = _Backend.FLASH_ATTN
86
87 # Check the environment variable and override if specified
88 backend_by_env_var: Optional[str] = envs.VLLM_ATTENTION_BACKEND
89 if backend_by_env_var is not None:
90 backend_members = _Backend.__members__
91 if backend_by_env_var not in backend_members:
92 raise ValueError(
93 f"Invalid attention backend '{backend_by_env_var}'. "
94 f"Available backends: {', '.join(backend_members)} "
95 "(case-sensitive).")
96 selected_backend = _Backend[backend_by_env_var]
97
98 if is_cpu():
99 if selected_backend != _Backend.TORCH_SDPA:
100 logger.info("Cannot use %s backend on CPU.", selected_backend)
101 return _Backend.TORCH_SDPA
102
103 if is_hip():
104 # AMD GPUs.
105 selected_backend = (_Backend.ROCM_FLASH if selected_backend
106 == _Backend.FLASH_ATTN else selected_backend)
107 if selected_backend == _Backend.ROCM_FLASH:
108 if torch.cuda.get_device_capability()[0] != 9:
109 # not Instinct series GPUs.
110 logger.info("flash_attn is not supported on NAVI GPUs.")
111 else:
112 logger.info("%s is not supported in AMD GPUs.", selected_backend)
113 return _Backend.ROCM_FLASH
114
115 # FlashAttn in NVIDIA GPUs.
116 if selected_backend == _Backend.FLASH_ATTN:
117 if torch.cuda.get_device_capability()[0] < 8:
118 # Volta and Turing NVIDIA GPUs.
119 logger.info(
120 "Cannot use FlashAttention-2 backend for Volta and Turing "
121 "GPUs.")
122 selected_backend = _Backend.XFORMERS
123 elif dtype not in (torch.float16, torch.bfloat16):
124 logger.info(
125 "Cannot use FlashAttention-2 backend for dtype other than "
126 "torch.float16 or torch.bfloat16.")
127 selected_backend = _Backend.XFORMERS
128 elif kv_cache_dtype is not None and kv_cache_dtype.startswith("fp8"):
129 logger.info(
130 "Cannot use FlashAttention-2 backend for FP8 KV cache.")
131 selected_backend = _Backend.XFORMERS
132 elif block_size % 16 != 0:
133 logger.info(
134 "Cannot use FlashAttention-2 backend for block size not "
135 "divisible by 16.")
136 selected_backend = _Backend.XFORMERS
137 elif sliding_window is not None:
138 logger.info(
139 "Cannot use FlashAttention-2 backend due to sliding window.")
140 selected_backend = _Backend.XFORMERS
141
142 # FlashAttn is valid for the model, checking if the package is installed.
143 if selected_backend == _Backend.FLASH_ATTN:
144 try:
145 import vllm_flash_attn # noqa: F401
146
147 from vllm.attention.backends.flash_attn import ( # noqa: F401
148 FlashAttentionBackend)
149
150 supported_sizes = FlashAttentionBackend.get_supported_head_sizes()
151 if head_size not in supported_sizes:
152 logger.info(
153 "Cannot use FlashAttention-2 backend for head size %d.",
154 head_size)
155 selected_backend = _Backend.XFORMERS
156 except ImportError:
157 logger.info(
158 "Cannot use FlashAttention-2 backend because the "
159 "vllm_flash_attn package is not found. "
160 "`pip install vllm-flash-attn` for better performance.")
161 selected_backend = _Backend.XFORMERS
162
163 return selected_backend
164
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/vllm/attention/selector.py b/vllm/attention/selector.py
--- a/vllm/attention/selector.py
+++ b/vllm/attention/selector.py
@@ -57,6 +57,9 @@
ROCmFlashAttentionBackend)
return ROCmFlashAttentionBackend
elif backend == _Backend.TORCH_SDPA:
+ # TODO: make XPU backend available here.
+ assert is_cpu(), RuntimeError(
+ "Torch SDPA backend is only used for the CPU device.")
logger.info("Using Torch SDPA backend.")
from vllm.attention.backends.torch_sdpa import TorchSDPABackend
return TorchSDPABackend
|
{"golden_diff": "diff --git a/vllm/attention/selector.py b/vllm/attention/selector.py\n--- a/vllm/attention/selector.py\n+++ b/vllm/attention/selector.py\n@@ -57,6 +57,9 @@\n ROCmFlashAttentionBackend)\n return ROCmFlashAttentionBackend\n elif backend == _Backend.TORCH_SDPA:\n+ # TODO: make XPU backend available here.\n+ assert is_cpu(), RuntimeError(\n+ \"Torch SDPA backend is only used for the CPU device.\")\n logger.info(\"Using Torch SDPA backend.\")\n from vllm.attention.backends.torch_sdpa import TorchSDPABackend\n return TorchSDPABackend\n", "issue": "[Bug]: TorchSDPAMetadata is out of date\n### Your current environment\n\nalexr@roxy:~$ python collect_env.py\r\nCollecting environment information...\r\nPyTorch version: 2.0.0+cu117\r\nIs debug build: False\r\nCUDA used to build PyTorch: 11.7\r\nROCM used to build PyTorch: N/A\r\n\r\nOS: Ubuntu 22.04.1 LTS (x86_64)\r\nGCC version: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0\r\nClang version: Could not collect\r\nCMake version: version 3.26.3\r\nLibc version: glibc-2.35\r\n\r\nPython version: 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0] (64-bit runtime)\r\nPython platform: Linux-5.15.0-105-generic-x86_64-with-glibc2.35\r\nIs CUDA available: True\r\nCUDA runtime version: 11.5.119\r\nCUDA_MODULE_LOADING set to: LAZY\r\nGPU models and configuration: GPU 0: NVIDIA GeForce RTX 3070\r\nNvidia driver version: 535.161.08\r\ncuDNN version: Could not collect\r\nHIP runtime version: N/A\r\nMIOpen runtime version: N/A\r\nIs XNNPACK available: True\r\n\r\nCPU:\r\nArchitecture: x86_64\r\nCPU op-mode(s): 32-bit, 64-bit\r\nAddress sizes: 39 bits physical, 48 bits virtual\r\nByte Order: Little Endian\r\nCPU(s): 16\r\nOn-line CPU(s) list: 0-15\r\nVendor ID: GenuineIntel\r\nModel name: Intel(R) Core(TM) i7-10700K CPU @ 3.80GHz\r\nCPU family: 6\r\nModel: 165\r\nThread(s) per core: 2\r\nCore(s) per socket: 8\r\nSocket(s): 1\r\nStepping: 5\r\nCPU max MHz: 5100.0000\r\nCPU min MHz: 800.0000\r\nBogoMIPS: 7599.80\r\nFlags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts pku ospke md_clear flush_l1d arch_capabilities\r\nL1d cache: 256 KiB (8 instances)\r\nL1i cache: 256 KiB (8 instances)\r\nL2 cache: 2 MiB (8 instances)\r\nL3 cache: 16 MiB (1 instance)\r\nNUMA node(s): 1\r\nNUMA node0 CPU(s): 0-15\r\nVulnerability Gather data sampling: Mitigation; Microcode\r\nVulnerability Itlb multihit: KVM: Mitigation: VMX unsupported\r\nVulnerability L1tf: Not affected\r\nVulnerability Mds: Not affected\r\nVulnerability Meltdown: Not affected\r\nVulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable\r\nVulnerability Retbleed: Mitigation; Enhanced IBRS\r\nVulnerability Spec rstack overflow: Not affected\r\nVulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp\r\nVulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization\r\nVulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence\r\nVulnerability Srbds: Mitigation; Microcode\r\nVulnerability Tsx async abort: Not affected\r\n\r\nVersions of relevant libraries:\r\n[pip3] flake8==6.0.0\r\n[pip3] mypy-extensions==1.0.0\r\n[pip3] numpy==1.24.2\r\n[pip3] nvidia-nccl-cu11==2.14.3\r\n[pip3] sentence-transformers==2.2.2\r\n[pip3] torch==2.0.0\r\n[pip3] torchvision==0.15.1\r\n[pip3] transformers==4.26.0\r\n[pip3] triton==2.0.0\r\n[conda] Could not collect\r\nROCM Version: Could not collect\r\nNeuron SDK Version: N/A\r\nvLLM Version: N/A\r\nvLLM Build Flags:\r\nCUDA Archs: Not Set; ROCm: Disabled; Neuron: Disabled\r\nGPU Topology:\r\nGPU0\tCPU Affinity\tNUMA Affinity\tGPU NUMA ID\r\nGPU0\t X \t0-15\t0\t\tN/A\r\n\r\nLegend:\r\n\r\n X = Self\r\n SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)\r\n NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node\r\n PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)\r\n PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)\r\n PIX = Connection traversing at most a single PCIe bridge\r\n NV# = Connection traversing a bonded set of # NVLinks\r\n\n\n### \ud83d\udc1b Describe the bug\n\nI believe the TorchSDPA backend for attention is no longer compatible. I received a crash message that said as much and did some debugging. If you set `export VLLM_ATTENTION_BACKEND=TORCH_SDPA`, then the metadata is set with\r\n```\r\n attn_metadata = self.attn_backend.make_metadata(\r\n num_prefills=0,\r\n num_prefill_tokens=0,\r\n num_decode_tokens=batch_size,\r\n slot_mapping=slot_mapping[:batch_size],\r\n seq_lens=None,\r\n seq_lens_tensor=seq_lens[:batch_size],\r\n max_query_len=None,\r\n max_prefill_seq_len=0,\r\n max_decode_seq_len=self.max_seq_len_to_capture,\r\n query_start_loc=None,\r\n seq_start_loc=None,\r\n context_lens_tensor=None,\r\n block_tables=block_tables[:batch_size],\r\n use_cuda_graph=True,\r\n )\r\n```\r\n\r\nwhich is sent to \r\n\r\n```\r\n @staticmethod\r\n def make_metadata(*args, **kwargs) -> \"TorchSDPAMetadata\":\r\n return TorchSDPAMetadata(*args, **kwargs)\r\n```\r\n\r\nand neither TorchSDPAMetadata (nor its superclasses) have most of those values\r\n```\r\n@dataclass\r\nclass TorchSDPAMetadata(AttentionMetadata, PagedAttentionMetadata):\r\n \"\"\"Metadata for TorchSDPABackend.\r\n \"\"\"\r\n # Currently, input sequences can only contain all prompts\r\n # or all decoding. True if all sequences are prompts.\r\n is_prompt: bool\r\n slot_mapping: torch.Tensor\r\n seq_lens: Optional[List[int]]\r\n # Maximum query length in the batch. None for decoding.\r\n max_query_len: Optional[int]\r\n```\r\n\r\nAm I correct in my diagnosis? I can send a crash log if necessary, but I believe this is pretty self evidently an error (and a CI test should be added or the backend should be removed probably.)\n", "before_files": [{"content": "import enum\nfrom functools import lru_cache\nfrom typing import Optional, Type\n\nimport torch\n\nimport vllm.envs as envs\nfrom vllm.attention.backends.abstract import AttentionBackend\nfrom vllm.logger import init_logger\nfrom vllm.utils import is_cpu, is_hip\n\nlogger = init_logger(__name__)\n\n\nclass _Backend(enum.Enum):\n FLASH_ATTN = enum.auto()\n XFORMERS = enum.auto()\n ROCM_FLASH = enum.auto()\n TORCH_SDPA = enum.auto()\n FLASHINFER = enum.auto()\n\n\n@lru_cache(maxsize=None)\ndef get_attn_backend(\n num_heads: int,\n head_size: int,\n num_kv_heads: int,\n sliding_window: Optional[int],\n dtype: torch.dtype,\n kv_cache_dtype: Optional[str],\n block_size: int,\n is_blocksparse: bool = False,\n) -> Type[AttentionBackend]:\n \"\"\"Selects which attention backend to use and lazily imports it.\"\"\"\n\n if is_blocksparse:\n logger.info(\"Using BlocksparseFlashAttention backend.\")\n from vllm.attention.backends.blocksparse_attn import (\n BlocksparseFlashAttentionBackend)\n return BlocksparseFlashAttentionBackend\n\n backend = which_attn_to_use(num_heads, head_size, num_kv_heads,\n sliding_window, dtype, kv_cache_dtype,\n block_size)\n if backend == _Backend.FLASH_ATTN:\n from vllm.attention.backends.flash_attn import ( # noqa: F401\n FlashAttentionBackend)\n return FlashAttentionBackend\n if backend == _Backend.XFORMERS:\n logger.info(\"Using XFormers backend.\")\n from vllm.attention.backends.xformers import ( # noqa: F401\n XFormersBackend)\n return XFormersBackend\n elif backend == _Backend.ROCM_FLASH:\n logger.info(\"Using ROCmFlashAttention backend.\")\n from vllm.attention.backends.rocm_flash_attn import ( # noqa: F401\n ROCmFlashAttentionBackend)\n return ROCmFlashAttentionBackend\n elif backend == _Backend.TORCH_SDPA:\n logger.info(\"Using Torch SDPA backend.\")\n from vllm.attention.backends.torch_sdpa import TorchSDPABackend\n return TorchSDPABackend\n elif backend == _Backend.FLASHINFER:\n logger.info(\"Using Flashinfer backend.\")\n logger.warning(\"Eager mode is required for the Flashinfer backend. \"\n \"Please make sure --enforce-eager is set.\")\n from vllm.attention.backends.flashinfer import FlashInferBackend\n return FlashInferBackend\n else:\n raise ValueError(\"Invalid attention backend.\")\n\n\ndef which_attn_to_use(\n num_heads: int,\n head_size: int,\n num_kv_heads: int,\n sliding_window: Optional[int],\n dtype: torch.dtype,\n kv_cache_dtype: Optional[str],\n block_size: int,\n) -> _Backend:\n \"\"\"Returns which flash attention backend to use.\"\"\"\n\n # Default case.\n selected_backend = _Backend.FLASH_ATTN\n\n # Check the environment variable and override if specified\n backend_by_env_var: Optional[str] = envs.VLLM_ATTENTION_BACKEND\n if backend_by_env_var is not None:\n backend_members = _Backend.__members__\n if backend_by_env_var not in backend_members:\n raise ValueError(\n f\"Invalid attention backend '{backend_by_env_var}'. \"\n f\"Available backends: {', '.join(backend_members)} \"\n \"(case-sensitive).\")\n selected_backend = _Backend[backend_by_env_var]\n\n if is_cpu():\n if selected_backend != _Backend.TORCH_SDPA:\n logger.info(\"Cannot use %s backend on CPU.\", selected_backend)\n return _Backend.TORCH_SDPA\n\n if is_hip():\n # AMD GPUs.\n selected_backend = (_Backend.ROCM_FLASH if selected_backend\n == _Backend.FLASH_ATTN else selected_backend)\n if selected_backend == _Backend.ROCM_FLASH:\n if torch.cuda.get_device_capability()[0] != 9:\n # not Instinct series GPUs.\n logger.info(\"flash_attn is not supported on NAVI GPUs.\")\n else:\n logger.info(\"%s is not supported in AMD GPUs.\", selected_backend)\n return _Backend.ROCM_FLASH\n\n # FlashAttn in NVIDIA GPUs.\n if selected_backend == _Backend.FLASH_ATTN:\n if torch.cuda.get_device_capability()[0] < 8:\n # Volta and Turing NVIDIA GPUs.\n logger.info(\n \"Cannot use FlashAttention-2 backend for Volta and Turing \"\n \"GPUs.\")\n selected_backend = _Backend.XFORMERS\n elif dtype not in (torch.float16, torch.bfloat16):\n logger.info(\n \"Cannot use FlashAttention-2 backend for dtype other than \"\n \"torch.float16 or torch.bfloat16.\")\n selected_backend = _Backend.XFORMERS\n elif kv_cache_dtype is not None and kv_cache_dtype.startswith(\"fp8\"):\n logger.info(\n \"Cannot use FlashAttention-2 backend for FP8 KV cache.\")\n selected_backend = _Backend.XFORMERS\n elif block_size % 16 != 0:\n logger.info(\n \"Cannot use FlashAttention-2 backend for block size not \"\n \"divisible by 16.\")\n selected_backend = _Backend.XFORMERS\n elif sliding_window is not None:\n logger.info(\n \"Cannot use FlashAttention-2 backend due to sliding window.\")\n selected_backend = _Backend.XFORMERS\n\n # FlashAttn is valid for the model, checking if the package is installed.\n if selected_backend == _Backend.FLASH_ATTN:\n try:\n import vllm_flash_attn # noqa: F401\n\n from vllm.attention.backends.flash_attn import ( # noqa: F401\n FlashAttentionBackend)\n\n supported_sizes = FlashAttentionBackend.get_supported_head_sizes()\n if head_size not in supported_sizes:\n logger.info(\n \"Cannot use FlashAttention-2 backend for head size %d.\",\n head_size)\n selected_backend = _Backend.XFORMERS\n except ImportError:\n logger.info(\n \"Cannot use FlashAttention-2 backend because the \"\n \"vllm_flash_attn package is not found. \"\n \"`pip install vllm-flash-attn` for better performance.\")\n selected_backend = _Backend.XFORMERS\n\n return selected_backend\n", "path": "vllm/attention/selector.py"}], "after_files": [{"content": "import enum\nfrom functools import lru_cache\nfrom typing import Optional, Type\n\nimport torch\n\nimport vllm.envs as envs\nfrom vllm.attention.backends.abstract import AttentionBackend\nfrom vllm.logger import init_logger\nfrom vllm.utils import is_cpu, is_hip\n\nlogger = init_logger(__name__)\n\n\nclass _Backend(enum.Enum):\n FLASH_ATTN = enum.auto()\n XFORMERS = enum.auto()\n ROCM_FLASH = enum.auto()\n TORCH_SDPA = enum.auto()\n FLASHINFER = enum.auto()\n\n\n@lru_cache(maxsize=None)\ndef get_attn_backend(\n num_heads: int,\n head_size: int,\n num_kv_heads: int,\n sliding_window: Optional[int],\n dtype: torch.dtype,\n kv_cache_dtype: Optional[str],\n block_size: int,\n is_blocksparse: bool = False,\n) -> Type[AttentionBackend]:\n \"\"\"Selects which attention backend to use and lazily imports it.\"\"\"\n\n if is_blocksparse:\n logger.info(\"Using BlocksparseFlashAttention backend.\")\n from vllm.attention.backends.blocksparse_attn import (\n BlocksparseFlashAttentionBackend)\n return BlocksparseFlashAttentionBackend\n\n backend = which_attn_to_use(num_heads, head_size, num_kv_heads,\n sliding_window, dtype, kv_cache_dtype,\n block_size)\n if backend == _Backend.FLASH_ATTN:\n from vllm.attention.backends.flash_attn import ( # noqa: F401\n FlashAttentionBackend)\n return FlashAttentionBackend\n if backend == _Backend.XFORMERS:\n logger.info(\"Using XFormers backend.\")\n from vllm.attention.backends.xformers import ( # noqa: F401\n XFormersBackend)\n return XFormersBackend\n elif backend == _Backend.ROCM_FLASH:\n logger.info(\"Using ROCmFlashAttention backend.\")\n from vllm.attention.backends.rocm_flash_attn import ( # noqa: F401\n ROCmFlashAttentionBackend)\n return ROCmFlashAttentionBackend\n elif backend == _Backend.TORCH_SDPA:\n # TODO: make XPU backend available here.\n assert is_cpu(), RuntimeError(\n \"Torch SDPA backend is only used for the CPU device.\")\n logger.info(\"Using Torch SDPA backend.\")\n from vllm.attention.backends.torch_sdpa import TorchSDPABackend\n return TorchSDPABackend\n elif backend == _Backend.FLASHINFER:\n logger.info(\"Using Flashinfer backend.\")\n logger.warning(\"Eager mode is required for the Flashinfer backend. \"\n \"Please make sure --enforce-eager is set.\")\n from vllm.attention.backends.flashinfer import FlashInferBackend\n return FlashInferBackend\n else:\n raise ValueError(\"Invalid attention backend.\")\n\n\ndef which_attn_to_use(\n num_heads: int,\n head_size: int,\n num_kv_heads: int,\n sliding_window: Optional[int],\n dtype: torch.dtype,\n kv_cache_dtype: Optional[str],\n block_size: int,\n) -> _Backend:\n \"\"\"Returns which flash attention backend to use.\"\"\"\n\n # Default case.\n selected_backend = _Backend.FLASH_ATTN\n\n # Check the environment variable and override if specified\n backend_by_env_var: Optional[str] = envs.VLLM_ATTENTION_BACKEND\n if backend_by_env_var is not None:\n backend_members = _Backend.__members__\n if backend_by_env_var not in backend_members:\n raise ValueError(\n f\"Invalid attention backend '{backend_by_env_var}'. \"\n f\"Available backends: {', '.join(backend_members)} \"\n \"(case-sensitive).\")\n selected_backend = _Backend[backend_by_env_var]\n\n if is_cpu():\n if selected_backend != _Backend.TORCH_SDPA:\n logger.info(\"Cannot use %s backend on CPU.\", selected_backend)\n return _Backend.TORCH_SDPA\n\n if is_hip():\n # AMD GPUs.\n selected_backend = (_Backend.ROCM_FLASH if selected_backend\n == _Backend.FLASH_ATTN else selected_backend)\n if selected_backend == _Backend.ROCM_FLASH:\n if torch.cuda.get_device_capability()[0] != 9:\n # not Instinct series GPUs.\n logger.info(\"flash_attn is not supported on NAVI GPUs.\")\n else:\n logger.info(\"%s is not supported in AMD GPUs.\", selected_backend)\n return _Backend.ROCM_FLASH\n\n # FlashAttn in NVIDIA GPUs.\n if selected_backend == _Backend.FLASH_ATTN:\n if torch.cuda.get_device_capability()[0] < 8:\n # Volta and Turing NVIDIA GPUs.\n logger.info(\n \"Cannot use FlashAttention-2 backend for Volta and Turing \"\n \"GPUs.\")\n selected_backend = _Backend.XFORMERS\n elif dtype not in (torch.float16, torch.bfloat16):\n logger.info(\n \"Cannot use FlashAttention-2 backend for dtype other than \"\n \"torch.float16 or torch.bfloat16.\")\n selected_backend = _Backend.XFORMERS\n elif kv_cache_dtype is not None and kv_cache_dtype.startswith(\"fp8\"):\n logger.info(\n \"Cannot use FlashAttention-2 backend for FP8 KV cache.\")\n selected_backend = _Backend.XFORMERS\n elif block_size % 16 != 0:\n logger.info(\n \"Cannot use FlashAttention-2 backend for block size not \"\n \"divisible by 16.\")\n selected_backend = _Backend.XFORMERS\n elif sliding_window is not None:\n logger.info(\n \"Cannot use FlashAttention-2 backend due to sliding window.\")\n selected_backend = _Backend.XFORMERS\n\n # FlashAttn is valid for the model, checking if the package is installed.\n if selected_backend == _Backend.FLASH_ATTN:\n try:\n import vllm_flash_attn # noqa: F401\n\n from vllm.attention.backends.flash_attn import ( # noqa: F401\n FlashAttentionBackend)\n\n supported_sizes = FlashAttentionBackend.get_supported_head_sizes()\n if head_size not in supported_sizes:\n logger.info(\n \"Cannot use FlashAttention-2 backend for head size %d.\",\n head_size)\n selected_backend = _Backend.XFORMERS\n except ImportError:\n logger.info(\n \"Cannot use FlashAttention-2 backend because the \"\n \"vllm_flash_attn package is not found. \"\n \"`pip install vllm-flash-attn` for better performance.\")\n selected_backend = _Backend.XFORMERS\n\n return selected_backend\n", "path": "vllm/attention/selector.py"}]}
| 3,934 | 158 |
gh_patches_debug_10421
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-974
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unable to play Dailymotion live stream
### Checklist
- [x] This is a bug report.
- [ ] This is a feature request.
- [ ] This is a plugin (improvement) request.
- [ ] I have read the contribution guidelines.
### Description
Streamlink cannot read the live stream http://www.dailymotion.com/video/x3b68jn
### Reproduction steps / Explicit stream URLs to test
```
$ streamlink -l debug http://www.dailymotion.com/video/x3b68jn
[cli][info] Found matching plugin dailymotion for URL http://www.dailymotion.com/video/x3b68jn
[plugin.dailymotion][debug] Found media ID: x3b68jn
error: Unable to parse manifest XML: syntax error: line 1, column 0 ('#EXTM3U\n#EXT-X-STREAM-INF:BANDWID ...)
```
### Environment details
Operating system and version: Fedora 25
Streamlink version: https://github.com/streamlink/streamlink/commit/0c31ca9115bb62550fb3af7b626ef5496b6cf81b (latest snapshot today)
Python version: 3.5.3
### Comments, logs, screenshots, etc.
This is the only live stream on DM I've found with this issue. All the others I tested are OK.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/dailymotion.py`
Content:
```
1 import json
2 import re
3
4 from functools import reduce
5
6 from streamlink.compat import urlparse, range
7 from streamlink.plugin import Plugin
8 from streamlink.plugin.api import http, validate
9 from streamlink.stream import HDSStream, HLSStream, HTTPStream, RTMPStream
10 from streamlink.stream.playlist import FLVPlaylist
11
12 COOKIES = {
13 "family_filter": "off",
14 "ff": "off"
15 }
16 QUALITY_MAP = {
17 "ld": "240p",
18 "sd": "360p",
19 "hq": "480p",
20 "hd720": "720p",
21 "hd1080": "1080p",
22 "custom": "live",
23 "auto": "hds",
24 "source": "hds"
25 }
26 STREAM_INFO_URL = "http://www.dailymotion.com/sequence/full/{0}"
27 USER_INFO_URL = "https://api.dailymotion.com/user/{0}"
28
29 _rtmp_re = re.compile(r"""
30 (?P<host>rtmp://[^/]+)
31 /(?P<app>[^/]+)
32 /(?P<playpath>.+)
33 """, re.VERBOSE)
34 _url_re = re.compile(r"""
35 http(s)?://(\w+\.)?
36 dailymotion.com
37 (?:
38 (/embed)?/(video|live)
39 /(?P<media_id>[^_?/]+)
40 |
41 /(?P<channel_name>[A-Za-z0-9-_]+)
42 )
43 """, re.VERBOSE)
44 username_re = re.compile(r'''data-username\s*=\s*"(.*?)"''')
45 chromecast_re = re.compile(r'''stream_chromecast_url"\s*:\s*(?P<url>".*?")''')
46
47 _media_inner_schema = validate.Schema([{
48 "layerList": [{
49 "name": validate.text,
50 validate.optional("sequenceList"): [{
51 "layerList": validate.all(
52 [{
53 "name": validate.text,
54 validate.optional("param"): dict
55 }],
56 validate.filter(lambda l: l["name"] in ("video", "reporting"))
57 )
58 }]
59 }]
60 }])
61 _media_schema = validate.Schema(
62 validate.any(
63 _media_inner_schema,
64 validate.all(
65 {"sequence": _media_inner_schema},
66 validate.get("sequence")
67 )
68 )
69 )
70 _vod_playlist_schema = validate.Schema({
71 "duration": float,
72 "fragments": [[int, float]],
73 "template": validate.text
74 })
75 _vod_manifest_schema = validate.Schema({
76 "alternates": [{
77 "height": int,
78 "template": validate.text,
79 validate.optional("failover"): [validate.text]
80 }]
81 })
82
83
84 class DailyMotion(Plugin):
85 @classmethod
86 def can_handle_url(self, url):
87 return _url_re.match(url)
88
89 def _get_streams_from_media(self, media_id):
90 res = http.get(STREAM_INFO_URL.format(media_id), cookies=COOKIES)
91 media = http.json(res, schema=_media_schema)
92
93 params = extra_params = swf_url = None
94 for __ in media:
95 for __ in __["layerList"]:
96 for __ in __.get("sequenceList", []):
97 for layer in __["layerList"]:
98 name = layer["name"]
99 if name == "video":
100 params = layer.get("param")
101 elif name == "reporting":
102 extra_params = layer.get("param", {})
103 extra_params = extra_params.get("extraParams", {})
104
105 if not params:
106 return
107
108 if extra_params:
109 swf_url = extra_params.get("videoSwfURL")
110
111 mode = params.get("mode")
112 if mode == "live":
113 return self._get_live_streams(params, swf_url)
114 elif mode == "vod":
115 return self._get_vod_streams(params)
116
117 def _get_live_streams(self, params, swf_url):
118 for key, quality in QUALITY_MAP.items():
119 key_url = "{0}URL".format(key)
120 url = params.get(key_url)
121
122 if not url:
123 continue
124
125 try:
126 res = http.get(url, exception=IOError)
127 except IOError:
128 continue
129
130 if quality == "hds":
131 streams = HDSStream.parse_manifest(self.session, res.url)
132 for name, stream in streams.items():
133 if key == "source":
134 name += "+"
135
136 yield name, stream
137 elif res.text.startswith("rtmp"):
138 match = _rtmp_re.match(res.text)
139 if not match:
140 continue
141
142 stream = RTMPStream(self.session, {
143 "rtmp": match.group("host"),
144 "app": match.group("app"),
145 "playpath": match.group("playpath"),
146 "swfVfy": swf_url,
147 "live": True
148 })
149
150 yield quality, stream
151
152 def _create_flv_playlist(self, template):
153 res = http.get(template)
154 playlist = http.json(res, schema=_vod_playlist_schema)
155
156 parsed = urlparse(template)
157 url_template = "{0}://{1}{2}".format(
158 parsed.scheme, parsed.netloc, playlist["template"]
159 )
160 segment_max = reduce(lambda i, j: i + j[0], playlist["fragments"], 0)
161
162 substreams = [HTTPStream(self.session,
163 url_template.replace("$fragment$", str(i)))
164 for i in range(1, segment_max + 1)]
165
166 return FLVPlaylist(self.session,
167 duration=playlist["duration"],
168 flatten_timestamps=True,
169 skip_header=True,
170 streams=substreams)
171
172 def _get_vod_streams(self, params):
173 manifest_url = params.get("autoURL")
174 if not manifest_url:
175 return
176
177 res = http.get(manifest_url)
178 if res.headers.get("Content-Type") == "application/f4m+xml":
179 streams = HDSStream.parse_manifest(self.session, res.url)
180
181 # TODO: Replace with "yield from" when dropping Python 2.
182 for __ in streams.items():
183 yield __
184 elif res.headers.get("Content-Type") == "application/vnd.apple.mpegurl":
185 streams = HLSStream.parse_variant_playlist(self.session, res.url)
186
187 # TODO: Replace with "yield from" when dropping Python 2.
188 for __ in streams.items():
189 yield __
190 else:
191 manifest = http.json(res, schema=_vod_manifest_schema)
192 for params in manifest["alternates"]:
193 name = "{0}p".format(params["height"])
194 stream = self._create_flv_playlist(params["template"])
195 yield name, stream
196
197 failovers = params.get("failover", [])
198 for failover in failovers:
199 stream = self._create_flv_playlist(failover)
200 yield name, stream
201
202 def _chrome_cast_stream_fallback(self):
203 self.logger.debug("Trying to find Chromecast URL as a fallback")
204 # get the page if not already available
205 page = http.get(self.url, cookies=COOKIES)
206 m = chromecast_re.search(page.text)
207 if m:
208 url = json.loads(m.group("url"))
209 return HLSStream.parse_variant_playlist(self.session, url)
210
211 def get_featured_video(self):
212 self.logger.debug("Channel page, attempting to play featured video")
213 page = http.get(self.url, cookies=COOKIES)
214 username_m = username_re.search(page.text)
215 username = username_m and username_m.group(1)
216 if username:
217 self.logger.debug("Found username: {0}", username)
218 res = http.get(USER_INFO_URL.format(username),
219 params={"fields": "videostar.url"})
220
221 data = http.json(res)
222 if "videostar.url" in data and self.can_handle_url(data["videostar.url"]):
223 return data["videostar.url"]
224
225 def _get_streams(self):
226 match = _url_re.match(self.url)
227 media_id = match.group("media_id")
228
229 if not media_id and match.group("channel_name"):
230 self.url = self.get_featured_video()
231 match = _url_re.match(self.url)
232 media_id = match.group("media_id")
233
234 if media_id:
235 self.logger.debug("Found media ID: {0}", media_id)
236 streams = list(self._get_streams_from_media(media_id))
237 if streams:
238 return streams
239
240 return self._chrome_cast_stream_fallback()
241
242
243 __plugin__ = DailyMotion
244
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/streamlink/plugins/dailymotion.py b/src/streamlink/plugins/dailymotion.py
--- a/src/streamlink/plugins/dailymotion.py
+++ b/src/streamlink/plugins/dailymotion.py
@@ -128,7 +128,12 @@
continue
if quality == "hds":
- streams = HDSStream.parse_manifest(self.session, res.url)
+ self.logger.debug('PLAYLIST URL: {0}'.format(res.url))
+ try:
+ streams = HDSStream.parse_manifest(self.session, res.url)
+ except:
+ streams = HLSStream.parse_variant_playlist(self.session, res.url)
+
for name, stream in streams.items():
if key == "source":
name += "+"
|
{"golden_diff": "diff --git a/src/streamlink/plugins/dailymotion.py b/src/streamlink/plugins/dailymotion.py\n--- a/src/streamlink/plugins/dailymotion.py\n+++ b/src/streamlink/plugins/dailymotion.py\n@@ -128,7 +128,12 @@\n continue\n \n if quality == \"hds\":\n- streams = HDSStream.parse_manifest(self.session, res.url)\n+ self.logger.debug('PLAYLIST URL: {0}'.format(res.url))\n+ try:\n+ streams = HDSStream.parse_manifest(self.session, res.url)\n+ except:\n+ streams = HLSStream.parse_variant_playlist(self.session, res.url)\n+\n for name, stream in streams.items():\n if key == \"source\":\n name += \"+\"\n", "issue": "Unable to play Dailymotion live stream\n### Checklist\r\n\r\n- [x] This is a bug report.\r\n- [ ] This is a feature request.\r\n- [ ] This is a plugin (improvement) request.\r\n- [ ] I have read the contribution guidelines.\r\n\r\n### Description\r\n\r\nStreamlink cannot read the live stream http://www.dailymotion.com/video/x3b68jn\r\n\r\n### Reproduction steps / Explicit stream URLs to test\r\n\r\n```\r\n$ streamlink -l debug http://www.dailymotion.com/video/x3b68jn\r\n[cli][info] Found matching plugin dailymotion for URL http://www.dailymotion.com/video/x3b68jn\r\n[plugin.dailymotion][debug] Found media ID: x3b68jn\r\nerror: Unable to parse manifest XML: syntax error: line 1, column 0 ('#EXTM3U\\n#EXT-X-STREAM-INF:BANDWID ...)\r\n```\r\n\r\n### Environment details\r\n\r\nOperating system and version: Fedora 25\r\nStreamlink version: https://github.com/streamlink/streamlink/commit/0c31ca9115bb62550fb3af7b626ef5496b6cf81b (latest snapshot today)\r\nPython version: 3.5.3\r\n\r\n### Comments, logs, screenshots, etc.\r\nThis is the only live stream on DM I've found with this issue. All the others I tested are OK.\n", "before_files": [{"content": "import json\nimport re\n\nfrom functools import reduce\n\nfrom streamlink.compat import urlparse, range\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import http, validate\nfrom streamlink.stream import HDSStream, HLSStream, HTTPStream, RTMPStream\nfrom streamlink.stream.playlist import FLVPlaylist\n\nCOOKIES = {\n \"family_filter\": \"off\",\n \"ff\": \"off\"\n}\nQUALITY_MAP = {\n \"ld\": \"240p\",\n \"sd\": \"360p\",\n \"hq\": \"480p\",\n \"hd720\": \"720p\",\n \"hd1080\": \"1080p\",\n \"custom\": \"live\",\n \"auto\": \"hds\",\n \"source\": \"hds\"\n}\nSTREAM_INFO_URL = \"http://www.dailymotion.com/sequence/full/{0}\"\nUSER_INFO_URL = \"https://api.dailymotion.com/user/{0}\"\n\n_rtmp_re = re.compile(r\"\"\"\n (?P<host>rtmp://[^/]+)\n /(?P<app>[^/]+)\n /(?P<playpath>.+)\n\"\"\", re.VERBOSE)\n_url_re = re.compile(r\"\"\"\n http(s)?://(\\w+\\.)?\n dailymotion.com\n (?:\n (/embed)?/(video|live)\n /(?P<media_id>[^_?/]+)\n |\n /(?P<channel_name>[A-Za-z0-9-_]+)\n )\n\"\"\", re.VERBOSE)\nusername_re = re.compile(r'''data-username\\s*=\\s*\"(.*?)\"''')\nchromecast_re = re.compile(r'''stream_chromecast_url\"\\s*:\\s*(?P<url>\".*?\")''')\n\n_media_inner_schema = validate.Schema([{\n \"layerList\": [{\n \"name\": validate.text,\n validate.optional(\"sequenceList\"): [{\n \"layerList\": validate.all(\n [{\n \"name\": validate.text,\n validate.optional(\"param\"): dict\n }],\n validate.filter(lambda l: l[\"name\"] in (\"video\", \"reporting\"))\n )\n }]\n }]\n}])\n_media_schema = validate.Schema(\n validate.any(\n _media_inner_schema,\n validate.all(\n {\"sequence\": _media_inner_schema},\n validate.get(\"sequence\")\n )\n )\n)\n_vod_playlist_schema = validate.Schema({\n \"duration\": float,\n \"fragments\": [[int, float]],\n \"template\": validate.text\n})\n_vod_manifest_schema = validate.Schema({\n \"alternates\": [{\n \"height\": int,\n \"template\": validate.text,\n validate.optional(\"failover\"): [validate.text]\n }]\n})\n\n\nclass DailyMotion(Plugin):\n @classmethod\n def can_handle_url(self, url):\n return _url_re.match(url)\n\n def _get_streams_from_media(self, media_id):\n res = http.get(STREAM_INFO_URL.format(media_id), cookies=COOKIES)\n media = http.json(res, schema=_media_schema)\n\n params = extra_params = swf_url = None\n for __ in media:\n for __ in __[\"layerList\"]:\n for __ in __.get(\"sequenceList\", []):\n for layer in __[\"layerList\"]:\n name = layer[\"name\"]\n if name == \"video\":\n params = layer.get(\"param\")\n elif name == \"reporting\":\n extra_params = layer.get(\"param\", {})\n extra_params = extra_params.get(\"extraParams\", {})\n\n if not params:\n return\n\n if extra_params:\n swf_url = extra_params.get(\"videoSwfURL\")\n\n mode = params.get(\"mode\")\n if mode == \"live\":\n return self._get_live_streams(params, swf_url)\n elif mode == \"vod\":\n return self._get_vod_streams(params)\n\n def _get_live_streams(self, params, swf_url):\n for key, quality in QUALITY_MAP.items():\n key_url = \"{0}URL\".format(key)\n url = params.get(key_url)\n\n if not url:\n continue\n\n try:\n res = http.get(url, exception=IOError)\n except IOError:\n continue\n\n if quality == \"hds\":\n streams = HDSStream.parse_manifest(self.session, res.url)\n for name, stream in streams.items():\n if key == \"source\":\n name += \"+\"\n\n yield name, stream\n elif res.text.startswith(\"rtmp\"):\n match = _rtmp_re.match(res.text)\n if not match:\n continue\n\n stream = RTMPStream(self.session, {\n \"rtmp\": match.group(\"host\"),\n \"app\": match.group(\"app\"),\n \"playpath\": match.group(\"playpath\"),\n \"swfVfy\": swf_url,\n \"live\": True\n })\n\n yield quality, stream\n\n def _create_flv_playlist(self, template):\n res = http.get(template)\n playlist = http.json(res, schema=_vod_playlist_schema)\n\n parsed = urlparse(template)\n url_template = \"{0}://{1}{2}\".format(\n parsed.scheme, parsed.netloc, playlist[\"template\"]\n )\n segment_max = reduce(lambda i, j: i + j[0], playlist[\"fragments\"], 0)\n\n substreams = [HTTPStream(self.session,\n url_template.replace(\"$fragment$\", str(i)))\n for i in range(1, segment_max + 1)]\n\n return FLVPlaylist(self.session,\n duration=playlist[\"duration\"],\n flatten_timestamps=True,\n skip_header=True,\n streams=substreams)\n\n def _get_vod_streams(self, params):\n manifest_url = params.get(\"autoURL\")\n if not manifest_url:\n return\n\n res = http.get(manifest_url)\n if res.headers.get(\"Content-Type\") == \"application/f4m+xml\":\n streams = HDSStream.parse_manifest(self.session, res.url)\n\n # TODO: Replace with \"yield from\" when dropping Python 2.\n for __ in streams.items():\n yield __\n elif res.headers.get(\"Content-Type\") == \"application/vnd.apple.mpegurl\":\n streams = HLSStream.parse_variant_playlist(self.session, res.url)\n\n # TODO: Replace with \"yield from\" when dropping Python 2.\n for __ in streams.items():\n yield __\n else:\n manifest = http.json(res, schema=_vod_manifest_schema)\n for params in manifest[\"alternates\"]:\n name = \"{0}p\".format(params[\"height\"])\n stream = self._create_flv_playlist(params[\"template\"])\n yield name, stream\n\n failovers = params.get(\"failover\", [])\n for failover in failovers:\n stream = self._create_flv_playlist(failover)\n yield name, stream\n\n def _chrome_cast_stream_fallback(self):\n self.logger.debug(\"Trying to find Chromecast URL as a fallback\")\n # get the page if not already available\n page = http.get(self.url, cookies=COOKIES)\n m = chromecast_re.search(page.text)\n if m:\n url = json.loads(m.group(\"url\"))\n return HLSStream.parse_variant_playlist(self.session, url)\n\n def get_featured_video(self):\n self.logger.debug(\"Channel page, attempting to play featured video\")\n page = http.get(self.url, cookies=COOKIES)\n username_m = username_re.search(page.text)\n username = username_m and username_m.group(1)\n if username:\n self.logger.debug(\"Found username: {0}\", username)\n res = http.get(USER_INFO_URL.format(username),\n params={\"fields\": \"videostar.url\"})\n\n data = http.json(res)\n if \"videostar.url\" in data and self.can_handle_url(data[\"videostar.url\"]):\n return data[\"videostar.url\"]\n\n def _get_streams(self):\n match = _url_re.match(self.url)\n media_id = match.group(\"media_id\")\n\n if not media_id and match.group(\"channel_name\"):\n self.url = self.get_featured_video()\n match = _url_re.match(self.url)\n media_id = match.group(\"media_id\")\n\n if media_id:\n self.logger.debug(\"Found media ID: {0}\", media_id)\n streams = list(self._get_streams_from_media(media_id))\n if streams:\n return streams\n\n return self._chrome_cast_stream_fallback()\n\n\n__plugin__ = DailyMotion\n", "path": "src/streamlink/plugins/dailymotion.py"}], "after_files": [{"content": "import json\nimport re\n\nfrom functools import reduce\n\nfrom streamlink.compat import urlparse, range\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import http, validate\nfrom streamlink.stream import HDSStream, HLSStream, HTTPStream, RTMPStream\nfrom streamlink.stream.playlist import FLVPlaylist\n\nCOOKIES = {\n \"family_filter\": \"off\",\n \"ff\": \"off\"\n}\nQUALITY_MAP = {\n \"ld\": \"240p\",\n \"sd\": \"360p\",\n \"hq\": \"480p\",\n \"hd720\": \"720p\",\n \"hd1080\": \"1080p\",\n \"custom\": \"live\",\n \"auto\": \"hds\",\n \"source\": \"hds\"\n}\nSTREAM_INFO_URL = \"http://www.dailymotion.com/sequence/full/{0}\"\nUSER_INFO_URL = \"https://api.dailymotion.com/user/{0}\"\n\n_rtmp_re = re.compile(r\"\"\"\n (?P<host>rtmp://[^/]+)\n /(?P<app>[^/]+)\n /(?P<playpath>.+)\n\"\"\", re.VERBOSE)\n_url_re = re.compile(r\"\"\"\n http(s)?://(\\w+\\.)?\n dailymotion.com\n (?:\n (/embed)?/(video|live)\n /(?P<media_id>[^_?/]+)\n |\n /(?P<channel_name>[A-Za-z0-9-_]+)\n )\n\"\"\", re.VERBOSE)\nusername_re = re.compile(r'''data-username\\s*=\\s*\"(.*?)\"''')\nchromecast_re = re.compile(r'''stream_chromecast_url\"\\s*:\\s*(?P<url>\".*?\")''')\n\n_media_inner_schema = validate.Schema([{\n \"layerList\": [{\n \"name\": validate.text,\n validate.optional(\"sequenceList\"): [{\n \"layerList\": validate.all(\n [{\n \"name\": validate.text,\n validate.optional(\"param\"): dict\n }],\n validate.filter(lambda l: l[\"name\"] in (\"video\", \"reporting\"))\n )\n }]\n }]\n}])\n_media_schema = validate.Schema(\n validate.any(\n _media_inner_schema,\n validate.all(\n {\"sequence\": _media_inner_schema},\n validate.get(\"sequence\")\n )\n )\n)\n_vod_playlist_schema = validate.Schema({\n \"duration\": float,\n \"fragments\": [[int, float]],\n \"template\": validate.text\n})\n_vod_manifest_schema = validate.Schema({\n \"alternates\": [{\n \"height\": int,\n \"template\": validate.text,\n validate.optional(\"failover\"): [validate.text]\n }]\n})\n\n\nclass DailyMotion(Plugin):\n @classmethod\n def can_handle_url(self, url):\n return _url_re.match(url)\n\n def _get_streams_from_media(self, media_id):\n res = http.get(STREAM_INFO_URL.format(media_id), cookies=COOKIES)\n media = http.json(res, schema=_media_schema)\n\n params = extra_params = swf_url = None\n for __ in media:\n for __ in __[\"layerList\"]:\n for __ in __.get(\"sequenceList\", []):\n for layer in __[\"layerList\"]:\n name = layer[\"name\"]\n if name == \"video\":\n params = layer.get(\"param\")\n elif name == \"reporting\":\n extra_params = layer.get(\"param\", {})\n extra_params = extra_params.get(\"extraParams\", {})\n\n if not params:\n return\n\n if extra_params:\n swf_url = extra_params.get(\"videoSwfURL\")\n\n mode = params.get(\"mode\")\n if mode == \"live\":\n return self._get_live_streams(params, swf_url)\n elif mode == \"vod\":\n return self._get_vod_streams(params)\n\n def _get_live_streams(self, params, swf_url):\n for key, quality in QUALITY_MAP.items():\n key_url = \"{0}URL\".format(key)\n url = params.get(key_url)\n\n if not url:\n continue\n\n try:\n res = http.get(url, exception=IOError)\n except IOError:\n continue\n\n if quality == \"hds\":\n self.logger.debug('PLAYLIST URL: {0}'.format(res.url))\n try:\n streams = HDSStream.parse_manifest(self.session, res.url)\n except:\n streams = HLSStream.parse_variant_playlist(self.session, res.url)\n\n for name, stream in streams.items():\n if key == \"source\":\n name += \"+\"\n\n yield name, stream\n elif res.text.startswith(\"rtmp\"):\n match = _rtmp_re.match(res.text)\n if not match:\n continue\n\n stream = RTMPStream(self.session, {\n \"rtmp\": match.group(\"host\"),\n \"app\": match.group(\"app\"),\n \"playpath\": match.group(\"playpath\"),\n \"swfVfy\": swf_url,\n \"live\": True\n })\n\n yield quality, stream\n\n def _create_flv_playlist(self, template):\n res = http.get(template)\n playlist = http.json(res, schema=_vod_playlist_schema)\n\n parsed = urlparse(template)\n url_template = \"{0}://{1}{2}\".format(\n parsed.scheme, parsed.netloc, playlist[\"template\"]\n )\n segment_max = reduce(lambda i, j: i + j[0], playlist[\"fragments\"], 0)\n\n substreams = [HTTPStream(self.session,\n url_template.replace(\"$fragment$\", str(i)))\n for i in range(1, segment_max + 1)]\n\n return FLVPlaylist(self.session,\n duration=playlist[\"duration\"],\n flatten_timestamps=True,\n skip_header=True,\n streams=substreams)\n\n def _get_vod_streams(self, params):\n manifest_url = params.get(\"autoURL\")\n if not manifest_url:\n return\n\n res = http.get(manifest_url)\n if res.headers.get(\"Content-Type\") == \"application/f4m+xml\":\n streams = HDSStream.parse_manifest(self.session, res.url)\n\n # TODO: Replace with \"yield from\" when dropping Python 2.\n for __ in streams.items():\n yield __\n elif res.headers.get(\"Content-Type\") == \"application/vnd.apple.mpegurl\":\n streams = HLSStream.parse_variant_playlist(self.session, res.url)\n\n # TODO: Replace with \"yield from\" when dropping Python 2.\n for __ in streams.items():\n yield __\n else:\n manifest = http.json(res, schema=_vod_manifest_schema)\n for params in manifest[\"alternates\"]:\n name = \"{0}p\".format(params[\"height\"])\n stream = self._create_flv_playlist(params[\"template\"])\n yield name, stream\n\n failovers = params.get(\"failover\", [])\n for failover in failovers:\n stream = self._create_flv_playlist(failover)\n yield name, stream\n\n def _chrome_cast_stream_fallback(self):\n self.logger.debug(\"Trying to find Chromecast URL as a fallback\")\n # get the page if not already available\n page = http.get(self.url, cookies=COOKIES)\n m = chromecast_re.search(page.text)\n if m:\n url = json.loads(m.group(\"url\"))\n return HLSStream.parse_variant_playlist(self.session, url)\n\n def get_featured_video(self):\n self.logger.debug(\"Channel page, attempting to play featured video\")\n page = http.get(self.url, cookies=COOKIES)\n username_m = username_re.search(page.text)\n username = username_m and username_m.group(1)\n if username:\n self.logger.debug(\"Found username: {0}\", username)\n res = http.get(USER_INFO_URL.format(username),\n params={\"fields\": \"videostar.url\"})\n\n data = http.json(res)\n if \"videostar.url\" in data and self.can_handle_url(data[\"videostar.url\"]):\n return data[\"videostar.url\"]\n\n def _get_streams(self):\n match = _url_re.match(self.url)\n media_id = match.group(\"media_id\")\n\n if not media_id and match.group(\"channel_name\"):\n self.url = self.get_featured_video()\n match = _url_re.match(self.url)\n media_id = match.group(\"media_id\")\n\n if media_id:\n self.logger.debug(\"Found media ID: {0}\", media_id)\n streams = list(self._get_streams_from_media(media_id))\n if streams:\n return streams\n\n return self._chrome_cast_stream_fallback()\n\n\n__plugin__ = DailyMotion\n", "path": "src/streamlink/plugins/dailymotion.py"}]}
| 3,034 | 166 |
gh_patches_debug_1017
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-2283
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
OK failing since at least 2018-05-06
OK has been failing since 2018-05-06
Based on automated runs it appears that OK has not run successfully in 2 days (2018-05-06).
```
/opt/openstates/venv-pupa/lib/python3.5/site-packages/psycopg2/__init__.py:144: UserWarning: The psycopg2 wheel package will be renamed from release 2.8; in order to keep installing from binary please use "pip install psycopg2-binary" instead. For details see: <http://initd.org/psycopg/docs/install.html#binary-install-from-pypi>.
""")
01:03:53 CRITICAL pupa: Session(s) 2019 Regular Session were reported by Oklahoma.get_session_list() but were not found in Oklahoma.legislative_sessions or Oklahoma.ignored_scraped_sessions.
loaded Open States pupa settings...
ok (scrape, import)
bills: {}
people: {}
committees: {}
```
Visit http://bobsled.openstates.org for more info.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `openstates/ok/__init__.py`
Content:
```
1 from pupa.scrape import Jurisdiction, Organization
2 from .people import OKPersonScraper
3 from .committees import OKCommitteeScraper
4 # from .events import OKEventScraper
5 from .bills import OKBillScraper
6
7
8 class Oklahoma(Jurisdiction):
9 division_id = "ocd-division/country:us/state:ok"
10 classification = "government"
11 name = "Oklahoma"
12 url = "http://www.oklegislature.gov/"
13 scrapers = {
14 'people': OKPersonScraper,
15 'committees': OKCommitteeScraper,
16 # 'events': OKEventScraper,
17 'bills': OKBillScraper,
18 }
19 # Sessions are named on OK's website as "{odd year} regular session" until the even year,
20 # when all data rolls over. For example, even year sessions include all odd-year-session bills.
21 # We have opted to name sessions {odd-even} Regular Session and treat them as such.
22 # - If adding a new odd-year session, add a new entry and copy the biennium pattern as above
23 # - If adding an even-year session, all you'll need to do is:
24 # - update the `_scraped_name`
25 # - update the session slug in the Bill scraper
26 # - ignore the odd-year session
27 legislative_sessions = [
28 {
29 "_scraped_name": "2012 Regular Session",
30 "identifier": "2011-2012",
31 "name": "2011-2012 Regular Session"
32 },
33 {
34 "_scraped_name": "2012 Special Session",
35 "identifier": "2012SS1",
36 "name": "2012 Special Session"
37 },
38 {
39 "_scraped_name": "2014 Regular Session",
40 "identifier": "2013-2014",
41 "name": "2013-2014 Regular Session"
42 },
43 {
44 "_scraped_name": "2013 Special Session",
45 "identifier": "2013SS1",
46 "name": "2013 Special Session"
47 },
48 {
49 "_scraped_name": "2016 Regular Session",
50 "identifier": "2015-2016",
51 "name": "2015-2016 Regular Session"
52 },
53 {
54 "_scraped_name": "2017 First Special Session",
55 "identifier": "2017SS1",
56 "name": "2017 First Special Session"
57 },
58 {
59 "_scraped_name": "2017 Second Special Session",
60 "identifier": "2017SS2",
61 "name": "2017 Second Special Session"
62 },
63 {
64 "_scraped_name": "2018 Regular Session",
65 "identifier": "2017-2018",
66 "name": "2017-2018 Regular Session",
67 "start_date": "2017-02-06",
68 "end_date": "2018-05-25",
69 },
70 ]
71 ignored_scraped_sessions = [
72 "2017 Regular Session",
73 "2015 Regular Session",
74 "2013 Regular Session",
75 "2011 Regular Session",
76 "2010 Regular Session",
77 "2009 Regular Session",
78 "2008 Regular Session",
79 "2007 Regular Session",
80 "2006 Second Special Session",
81 "2006 Regular Session",
82 "2005 Special Session",
83 "2005 Regular Session",
84 "2004 Special Session",
85 "2004 Regular Session",
86 "2003 Regular Session",
87 "2002 Regular Session",
88 "2001 Special Session",
89 "2001 Regular Session",
90 "2000 Regular Session",
91 "1999 Special Session",
92 "1999 Regular Session",
93 "1998 Regular Session",
94 "1997 Regular Session",
95 "1996 Regular Session",
96 "1995 Regular Session",
97 "1994 Second Special Session",
98 "1994 First Special Session",
99 "1994 Regular Session",
100 "1993 Regular Session"
101 ]
102
103 def get_organizations(self):
104 legislature_name = "Oklahoma Legislature"
105 lower_chamber_name = "House"
106 lower_seats = 101
107 lower_title = "Senator"
108 upper_chamber_name = "Senate"
109 upper_seats = 48
110 upper_title = "Senator"
111
112 legislature = Organization(name=legislature_name,
113 classification="legislature")
114 upper = Organization(upper_chamber_name, classification='upper',
115 parent_id=legislature._id)
116 lower = Organization(lower_chamber_name, classification='lower',
117 parent_id=legislature._id)
118
119 for n in range(1, upper_seats + 1):
120 upper.add_post(
121 label=str(n), role=upper_title,
122 division_id='{}/sldu:{}'.format(self.division_id, n))
123 for n in range(1, lower_seats + 1):
124 lower.add_post(
125 label=str(n), role=lower_title,
126 division_id='{}/sldl:{}'.format(self.division_id, n))
127
128 yield legislature
129 yield upper
130 yield lower
131
132 def get_session_list(self):
133 from openstates.utils import url_xpath
134 sessions = url_xpath('http://webserver1.lsb.state.ok.us/WebApplication2/WebForm1.aspx',
135 "//select[@name='cbxSession']/option/text()")
136 # OK Sometimes appends (Mainsys) to their session listings
137 sessions = [s.replace('(Mainsys)', '').strip() for s in sessions]
138 return sessions
139
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/openstates/ok/__init__.py b/openstates/ok/__init__.py
--- a/openstates/ok/__init__.py
+++ b/openstates/ok/__init__.py
@@ -69,6 +69,7 @@
},
]
ignored_scraped_sessions = [
+ "2019 Regular Session",
"2017 Regular Session",
"2015 Regular Session",
"2013 Regular Session",
|
{"golden_diff": "diff --git a/openstates/ok/__init__.py b/openstates/ok/__init__.py\n--- a/openstates/ok/__init__.py\n+++ b/openstates/ok/__init__.py\n@@ -69,6 +69,7 @@\n },\n ]\n ignored_scraped_sessions = [\n+ \"2019 Regular Session\",\n \"2017 Regular Session\",\n \"2015 Regular Session\",\n \"2013 Regular Session\",\n", "issue": "OK failing since at least 2018-05-06\nOK has been failing since 2018-05-06\n\nBased on automated runs it appears that OK has not run successfully in 2 days (2018-05-06).\n\n\n```\n /opt/openstates/venv-pupa/lib/python3.5/site-packages/psycopg2/__init__.py:144: UserWarning: The psycopg2 wheel package will be renamed from release 2.8; in order to keep installing from binary please use \"pip install psycopg2-binary\" instead. For details see: <http://initd.org/psycopg/docs/install.html#binary-install-from-pypi>.\n \"\"\")\n01:03:53 CRITICAL pupa: Session(s) 2019 Regular Session were reported by Oklahoma.get_session_list() but were not found in Oklahoma.legislative_sessions or Oklahoma.ignored_scraped_sessions.\nloaded Open States pupa settings...\nok (scrape, import)\n bills: {}\n people: {}\n committees: {}\n```\n\nVisit http://bobsled.openstates.org for more info.\n\n", "before_files": [{"content": "from pupa.scrape import Jurisdiction, Organization\nfrom .people import OKPersonScraper\nfrom .committees import OKCommitteeScraper\n# from .events import OKEventScraper\nfrom .bills import OKBillScraper\n\n\nclass Oklahoma(Jurisdiction):\n division_id = \"ocd-division/country:us/state:ok\"\n classification = \"government\"\n name = \"Oklahoma\"\n url = \"http://www.oklegislature.gov/\"\n scrapers = {\n 'people': OKPersonScraper,\n 'committees': OKCommitteeScraper,\n # 'events': OKEventScraper,\n 'bills': OKBillScraper,\n }\n # Sessions are named on OK's website as \"{odd year} regular session\" until the even year,\n # when all data rolls over. For example, even year sessions include all odd-year-session bills.\n # We have opted to name sessions {odd-even} Regular Session and treat them as such.\n # - If adding a new odd-year session, add a new entry and copy the biennium pattern as above\n # - If adding an even-year session, all you'll need to do is:\n # - update the `_scraped_name`\n # - update the session slug in the Bill scraper\n # - ignore the odd-year session\n legislative_sessions = [\n {\n \"_scraped_name\": \"2012 Regular Session\",\n \"identifier\": \"2011-2012\",\n \"name\": \"2011-2012 Regular Session\"\n },\n {\n \"_scraped_name\": \"2012 Special Session\",\n \"identifier\": \"2012SS1\",\n \"name\": \"2012 Special Session\"\n },\n {\n \"_scraped_name\": \"2014 Regular Session\",\n \"identifier\": \"2013-2014\",\n \"name\": \"2013-2014 Regular Session\"\n },\n {\n \"_scraped_name\": \"2013 Special Session\",\n \"identifier\": \"2013SS1\",\n \"name\": \"2013 Special Session\"\n },\n {\n \"_scraped_name\": \"2016 Regular Session\",\n \"identifier\": \"2015-2016\",\n \"name\": \"2015-2016 Regular Session\"\n },\n {\n \"_scraped_name\": \"2017 First Special Session\",\n \"identifier\": \"2017SS1\",\n \"name\": \"2017 First Special Session\"\n },\n {\n \"_scraped_name\": \"2017 Second Special Session\",\n \"identifier\": \"2017SS2\",\n \"name\": \"2017 Second Special Session\"\n },\n {\n \"_scraped_name\": \"2018 Regular Session\",\n \"identifier\": \"2017-2018\",\n \"name\": \"2017-2018 Regular Session\",\n \"start_date\": \"2017-02-06\",\n \"end_date\": \"2018-05-25\",\n },\n ]\n ignored_scraped_sessions = [\n \"2017 Regular Session\",\n \"2015 Regular Session\",\n \"2013 Regular Session\",\n \"2011 Regular Session\",\n \"2010 Regular Session\",\n \"2009 Regular Session\",\n \"2008 Regular Session\",\n \"2007 Regular Session\",\n \"2006 Second Special Session\",\n \"2006 Regular Session\",\n \"2005 Special Session\",\n \"2005 Regular Session\",\n \"2004 Special Session\",\n \"2004 Regular Session\",\n \"2003 Regular Session\",\n \"2002 Regular Session\",\n \"2001 Special Session\",\n \"2001 Regular Session\",\n \"2000 Regular Session\",\n \"1999 Special Session\",\n \"1999 Regular Session\",\n \"1998 Regular Session\",\n \"1997 Regular Session\",\n \"1996 Regular Session\",\n \"1995 Regular Session\",\n \"1994 Second Special Session\",\n \"1994 First Special Session\",\n \"1994 Regular Session\",\n \"1993 Regular Session\"\n ]\n\n def get_organizations(self):\n legislature_name = \"Oklahoma Legislature\"\n lower_chamber_name = \"House\"\n lower_seats = 101\n lower_title = \"Senator\"\n upper_chamber_name = \"Senate\"\n upper_seats = 48\n upper_title = \"Senator\"\n\n legislature = Organization(name=legislature_name,\n classification=\"legislature\")\n upper = Organization(upper_chamber_name, classification='upper',\n parent_id=legislature._id)\n lower = Organization(lower_chamber_name, classification='lower',\n parent_id=legislature._id)\n\n for n in range(1, upper_seats + 1):\n upper.add_post(\n label=str(n), role=upper_title,\n division_id='{}/sldu:{}'.format(self.division_id, n))\n for n in range(1, lower_seats + 1):\n lower.add_post(\n label=str(n), role=lower_title,\n division_id='{}/sldl:{}'.format(self.division_id, n))\n\n yield legislature\n yield upper\n yield lower\n\n def get_session_list(self):\n from openstates.utils import url_xpath\n sessions = url_xpath('http://webserver1.lsb.state.ok.us/WebApplication2/WebForm1.aspx',\n \"//select[@name='cbxSession']/option/text()\")\n # OK Sometimes appends (Mainsys) to their session listings\n sessions = [s.replace('(Mainsys)', '').strip() for s in sessions]\n return sessions\n", "path": "openstates/ok/__init__.py"}], "after_files": [{"content": "from pupa.scrape import Jurisdiction, Organization\nfrom .people import OKPersonScraper\nfrom .committees import OKCommitteeScraper\n# from .events import OKEventScraper\nfrom .bills import OKBillScraper\n\n\nclass Oklahoma(Jurisdiction):\n division_id = \"ocd-division/country:us/state:ok\"\n classification = \"government\"\n name = \"Oklahoma\"\n url = \"http://www.oklegislature.gov/\"\n scrapers = {\n 'people': OKPersonScraper,\n 'committees': OKCommitteeScraper,\n # 'events': OKEventScraper,\n 'bills': OKBillScraper,\n }\n # Sessions are named on OK's website as \"{odd year} regular session\" until the even year,\n # when all data rolls over. For example, even year sessions include all odd-year-session bills.\n # We have opted to name sessions {odd-even} Regular Session and treat them as such.\n # - If adding a new odd-year session, add a new entry and copy the biennium pattern as above\n # - If adding an even-year session, all you'll need to do is:\n # - update the `_scraped_name`\n # - update the session slug in the Bill scraper\n # - ignore the odd-year session\n legislative_sessions = [\n {\n \"_scraped_name\": \"2012 Regular Session\",\n \"identifier\": \"2011-2012\",\n \"name\": \"2011-2012 Regular Session\"\n },\n {\n \"_scraped_name\": \"2012 Special Session\",\n \"identifier\": \"2012SS1\",\n \"name\": \"2012 Special Session\"\n },\n {\n \"_scraped_name\": \"2014 Regular Session\",\n \"identifier\": \"2013-2014\",\n \"name\": \"2013-2014 Regular Session\"\n },\n {\n \"_scraped_name\": \"2013 Special Session\",\n \"identifier\": \"2013SS1\",\n \"name\": \"2013 Special Session\"\n },\n {\n \"_scraped_name\": \"2016 Regular Session\",\n \"identifier\": \"2015-2016\",\n \"name\": \"2015-2016 Regular Session\"\n },\n {\n \"_scraped_name\": \"2017 First Special Session\",\n \"identifier\": \"2017SS1\",\n \"name\": \"2017 First Special Session\"\n },\n {\n \"_scraped_name\": \"2017 Second Special Session\",\n \"identifier\": \"2017SS2\",\n \"name\": \"2017 Second Special Session\"\n },\n {\n \"_scraped_name\": \"2018 Regular Session\",\n \"identifier\": \"2017-2018\",\n \"name\": \"2017-2018 Regular Session\",\n \"start_date\": \"2017-02-06\",\n \"end_date\": \"2018-05-25\",\n },\n ]\n ignored_scraped_sessions = [\n \"2019 Regular Session\",\n \"2017 Regular Session\",\n \"2015 Regular Session\",\n \"2013 Regular Session\",\n \"2011 Regular Session\",\n \"2010 Regular Session\",\n \"2009 Regular Session\",\n \"2008 Regular Session\",\n \"2007 Regular Session\",\n \"2006 Second Special Session\",\n \"2006 Regular Session\",\n \"2005 Special Session\",\n \"2005 Regular Session\",\n \"2004 Special Session\",\n \"2004 Regular Session\",\n \"2003 Regular Session\",\n \"2002 Regular Session\",\n \"2001 Special Session\",\n \"2001 Regular Session\",\n \"2000 Regular Session\",\n \"1999 Special Session\",\n \"1999 Regular Session\",\n \"1998 Regular Session\",\n \"1997 Regular Session\",\n \"1996 Regular Session\",\n \"1995 Regular Session\",\n \"1994 Second Special Session\",\n \"1994 First Special Session\",\n \"1994 Regular Session\",\n \"1993 Regular Session\"\n ]\n\n def get_organizations(self):\n legislature_name = \"Oklahoma Legislature\"\n lower_chamber_name = \"House\"\n lower_seats = 101\n lower_title = \"Senator\"\n upper_chamber_name = \"Senate\"\n upper_seats = 48\n upper_title = \"Senator\"\n\n legislature = Organization(name=legislature_name,\n classification=\"legislature\")\n upper = Organization(upper_chamber_name, classification='upper',\n parent_id=legislature._id)\n lower = Organization(lower_chamber_name, classification='lower',\n parent_id=legislature._id)\n\n for n in range(1, upper_seats + 1):\n upper.add_post(\n label=str(n), role=upper_title,\n division_id='{}/sldu:{}'.format(self.division_id, n))\n for n in range(1, lower_seats + 1):\n lower.add_post(\n label=str(n), role=lower_title,\n division_id='{}/sldl:{}'.format(self.division_id, n))\n\n yield legislature\n yield upper\n yield lower\n\n def get_session_list(self):\n from openstates.utils import url_xpath\n sessions = url_xpath('http://webserver1.lsb.state.ok.us/WebApplication2/WebForm1.aspx',\n \"//select[@name='cbxSession']/option/text()\")\n # OK Sometimes appends (Mainsys) to their session listings\n sessions = [s.replace('(Mainsys)', '').strip() for s in sessions]\n return sessions\n", "path": "openstates/ok/__init__.py"}]}
| 2,143 | 105 |
gh_patches_debug_20932
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-2770
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Traceback appears in Status Bar, when trying to run Mitmproxy with --proxyauth ldap (ldaps) argument
##### Steps to reproduce the problem:
Run Mitmproxy with argument: `mitmproxy --proxyauth ldap` or `mitmproxy --proxyauth ldaps`
I am seeing:

##### Any other comments? What have you tried so far?
This issue is occured, because mitmproxy doesn't control the syntax of ldap authentication argument.
https://github.com/mitmproxy/mitmproxy/blob/master/mitmproxy/addons/proxyauth.py#L147-L152
##### System information
Mitmproxy: 3.0.0.dev1101 (commit d9d4d15) binary
Python: 3.5.2
OpenSSL: OpenSSL 1.1.0g 2 Nov 2017
Platform: Linux-4.4.0-104-generic-x86_64-with-debian-stretch-sid
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mitmproxy/addons/proxyauth.py`
Content:
```
1 import binascii
2 import weakref
3 import ldap3
4 from typing import Optional
5 from typing import MutableMapping # noqa
6 from typing import Tuple
7
8 import passlib.apache
9
10 import mitmproxy.net.http
11 from mitmproxy import connections # noqa
12 from mitmproxy import exceptions
13 from mitmproxy import http
14 from mitmproxy import ctx
15 from mitmproxy.net.http import status_codes
16
17 REALM = "mitmproxy"
18
19
20 def mkauth(username: str, password: str, scheme: str = "basic") -> str:
21 """
22 Craft a basic auth string
23 """
24 v = binascii.b2a_base64(
25 (username + ":" + password).encode("utf8")
26 ).decode("ascii")
27 return scheme + " " + v
28
29
30 def parse_http_basic_auth(s: str) -> Tuple[str, str, str]:
31 """
32 Parse a basic auth header.
33 Raises a ValueError if the input is invalid.
34 """
35 scheme, authinfo = s.split()
36 if scheme.lower() != "basic":
37 raise ValueError("Unknown scheme")
38 try:
39 user, password = binascii.a2b_base64(authinfo.encode()).decode("utf8", "replace").split(":")
40 except binascii.Error as e:
41 raise ValueError(str(e))
42 return scheme, user, password
43
44
45 class ProxyAuth:
46 def __init__(self):
47 self.nonanonymous = False
48 self.htpasswd = None
49 self.singleuser = None
50 self.ldapconn = None
51 self.ldapserver = None
52 self.authenticated = weakref.WeakKeyDictionary() # type: MutableMapping[connections.ClientConnection, Tuple[str, str]]
53 """Contains all connections that are permanently authenticated after an HTTP CONNECT"""
54
55 def enabled(self) -> bool:
56 return any([self.nonanonymous, self.htpasswd, self.singleuser, self.ldapconn, self.ldapserver])
57
58 def is_proxy_auth(self) -> bool:
59 """
60 Returns:
61 - True, if authentication is done as if mitmproxy is a proxy
62 - False, if authentication is done as if mitmproxy is a HTTP server
63 """
64 return ctx.options.mode == "regular" or ctx.options.mode.startswith("upstream:")
65
66 def which_auth_header(self) -> str:
67 if self.is_proxy_auth():
68 return 'Proxy-Authorization'
69 else:
70 return 'Authorization'
71
72 def auth_required_response(self) -> http.HTTPResponse:
73 if self.is_proxy_auth():
74 return http.make_error_response(
75 status_codes.PROXY_AUTH_REQUIRED,
76 headers=mitmproxy.net.http.Headers(Proxy_Authenticate='Basic realm="{}"'.format(REALM)),
77 )
78 else:
79 return http.make_error_response(
80 status_codes.UNAUTHORIZED,
81 headers=mitmproxy.net.http.Headers(WWW_Authenticate='Basic realm="{}"'.format(REALM)),
82 )
83
84 def check(self, f: http.HTTPFlow) -> Optional[Tuple[str, str]]:
85 """
86 Check if a request is correctly authenticated.
87 Returns:
88 - a (username, password) tuple if successful,
89 - None, otherwise.
90 """
91 auth_value = f.request.headers.get(self.which_auth_header(), "")
92 try:
93 scheme, username, password = parse_http_basic_auth(auth_value)
94 except ValueError:
95 return None
96
97 if self.nonanonymous:
98 return username, password
99 elif self.singleuser:
100 if self.singleuser == [username, password]:
101 return username, password
102 elif self.htpasswd:
103 if self.htpasswd.check_password(username, password):
104 return username, password
105 elif self.ldapconn:
106 if not username or not password:
107 return None
108 self.ldapconn.search(ctx.options.proxyauth.split(':')[4], '(cn=' + username + ')')
109 if self.ldapconn.response:
110 conn = ldap3.Connection(
111 self.ldapserver,
112 self.ldapconn.response[0]['dn'],
113 password,
114 auto_bind=True)
115 if conn:
116 return username, password
117 return None
118
119 def authenticate(self, f: http.HTTPFlow) -> bool:
120 valid_credentials = self.check(f)
121 if valid_credentials:
122 f.metadata["proxyauth"] = valid_credentials
123 del f.request.headers[self.which_auth_header()]
124 return True
125 else:
126 f.response = self.auth_required_response()
127 return False
128
129 # Handlers
130 def configure(self, updated):
131 if "proxyauth" in updated:
132 self.nonanonymous = False
133 self.singleuser = None
134 self.htpasswd = None
135 self.ldapserver = None
136 if ctx.options.proxyauth:
137 if ctx.options.proxyauth == "any":
138 self.nonanonymous = True
139 elif ctx.options.proxyauth.startswith("@"):
140 p = ctx.options.proxyauth[1:]
141 try:
142 self.htpasswd = passlib.apache.HtpasswdFile(p)
143 except (ValueError, OSError) as v:
144 raise exceptions.OptionsError(
145 "Could not open htpasswd file: %s" % p
146 )
147 elif ctx.options.proxyauth.startswith("ldap"):
148 parts = ctx.options.proxyauth.split(':')
149 security = parts[0]
150 ldap_server = parts[1]
151 dn_baseauth = parts[2]
152 password_baseauth = parts[3]
153 if len(parts) != 5:
154 raise exceptions.OptionsError(
155 "Invalid ldap specification"
156 )
157 if security == "ldaps":
158 server = ldap3.Server(ldap_server, use_ssl=True)
159 elif security == "ldap":
160 server = ldap3.Server(ldap_server)
161 else:
162 raise exceptions.OptionsError(
163 "Invalid ldap specfication on the first part"
164 )
165 conn = ldap3.Connection(
166 server,
167 dn_baseauth,
168 password_baseauth,
169 auto_bind=True)
170 self.ldapconn = conn
171 self.ldapserver = server
172 else:
173 parts = ctx.options.proxyauth.split(':')
174 if len(parts) != 2:
175 raise exceptions.OptionsError(
176 "Invalid single-user auth specification."
177 )
178 self.singleuser = parts
179 if self.enabled():
180 if ctx.options.mode == "transparent":
181 raise exceptions.OptionsError(
182 "Proxy Authentication not supported in transparent mode."
183 )
184 if ctx.options.mode == "socks5":
185 raise exceptions.OptionsError(
186 "Proxy Authentication not supported in SOCKS mode. "
187 "https://github.com/mitmproxy/mitmproxy/issues/738"
188 )
189 # TODO: check for multiple auth options
190
191 def http_connect(self, f: http.HTTPFlow) -> None:
192 if self.enabled():
193 if self.authenticate(f):
194 self.authenticated[f.client_conn] = f.metadata["proxyauth"]
195
196 def requestheaders(self, f: http.HTTPFlow) -> None:
197 if self.enabled():
198 # Is this connection authenticated by a previous HTTP CONNECT?
199 if f.client_conn in self.authenticated:
200 f.metadata["proxyauth"] = self.authenticated[f.client_conn]
201 return
202 self.authenticate(f)
203
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mitmproxy/addons/proxyauth.py b/mitmproxy/addons/proxyauth.py
--- a/mitmproxy/addons/proxyauth.py
+++ b/mitmproxy/addons/proxyauth.py
@@ -146,14 +146,14 @@
)
elif ctx.options.proxyauth.startswith("ldap"):
parts = ctx.options.proxyauth.split(':')
- security = parts[0]
- ldap_server = parts[1]
- dn_baseauth = parts[2]
- password_baseauth = parts[3]
if len(parts) != 5:
raise exceptions.OptionsError(
"Invalid ldap specification"
)
+ security = parts[0]
+ ldap_server = parts[1]
+ dn_baseauth = parts[2]
+ password_baseauth = parts[3]
if security == "ldaps":
server = ldap3.Server(ldap_server, use_ssl=True)
elif security == "ldap":
|
{"golden_diff": "diff --git a/mitmproxy/addons/proxyauth.py b/mitmproxy/addons/proxyauth.py\n--- a/mitmproxy/addons/proxyauth.py\n+++ b/mitmproxy/addons/proxyauth.py\n@@ -146,14 +146,14 @@\n )\n elif ctx.options.proxyauth.startswith(\"ldap\"):\n parts = ctx.options.proxyauth.split(':')\n- security = parts[0]\n- ldap_server = parts[1]\n- dn_baseauth = parts[2]\n- password_baseauth = parts[3]\n if len(parts) != 5:\n raise exceptions.OptionsError(\n \"Invalid ldap specification\"\n )\n+ security = parts[0]\n+ ldap_server = parts[1]\n+ dn_baseauth = parts[2]\n+ password_baseauth = parts[3]\n if security == \"ldaps\":\n server = ldap3.Server(ldap_server, use_ssl=True)\n elif security == \"ldap\":\n", "issue": "Traceback appears in Status Bar, when trying to run Mitmproxy with --proxyauth ldap (ldaps) argument\n##### Steps to reproduce the problem:\r\n\r\nRun Mitmproxy with argument: `mitmproxy --proxyauth ldap` or `mitmproxy --proxyauth ldaps`\r\n\r\nI am seeing:\r\n\r\n\r\n##### Any other comments? What have you tried so far?\r\nThis issue is occured, because mitmproxy doesn't control the syntax of ldap authentication argument. \r\nhttps://github.com/mitmproxy/mitmproxy/blob/master/mitmproxy/addons/proxyauth.py#L147-L152\r\n\r\n##### System information\r\n\r\nMitmproxy: 3.0.0.dev1101 (commit d9d4d15) binary\r\nPython: 3.5.2\r\nOpenSSL: OpenSSL 1.1.0g 2 Nov 2017\r\nPlatform: Linux-4.4.0-104-generic-x86_64-with-debian-stretch-sid\r\n \n", "before_files": [{"content": "import binascii\nimport weakref\nimport ldap3\nfrom typing import Optional\nfrom typing import MutableMapping # noqa\nfrom typing import Tuple\n\nimport passlib.apache\n\nimport mitmproxy.net.http\nfrom mitmproxy import connections # noqa\nfrom mitmproxy import exceptions\nfrom mitmproxy import http\nfrom mitmproxy import ctx\nfrom mitmproxy.net.http import status_codes\n\nREALM = \"mitmproxy\"\n\n\ndef mkauth(username: str, password: str, scheme: str = \"basic\") -> str:\n \"\"\"\n Craft a basic auth string\n \"\"\"\n v = binascii.b2a_base64(\n (username + \":\" + password).encode(\"utf8\")\n ).decode(\"ascii\")\n return scheme + \" \" + v\n\n\ndef parse_http_basic_auth(s: str) -> Tuple[str, str, str]:\n \"\"\"\n Parse a basic auth header.\n Raises a ValueError if the input is invalid.\n \"\"\"\n scheme, authinfo = s.split()\n if scheme.lower() != \"basic\":\n raise ValueError(\"Unknown scheme\")\n try:\n user, password = binascii.a2b_base64(authinfo.encode()).decode(\"utf8\", \"replace\").split(\":\")\n except binascii.Error as e:\n raise ValueError(str(e))\n return scheme, user, password\n\n\nclass ProxyAuth:\n def __init__(self):\n self.nonanonymous = False\n self.htpasswd = None\n self.singleuser = None\n self.ldapconn = None\n self.ldapserver = None\n self.authenticated = weakref.WeakKeyDictionary() # type: MutableMapping[connections.ClientConnection, Tuple[str, str]]\n \"\"\"Contains all connections that are permanently authenticated after an HTTP CONNECT\"\"\"\n\n def enabled(self) -> bool:\n return any([self.nonanonymous, self.htpasswd, self.singleuser, self.ldapconn, self.ldapserver])\n\n def is_proxy_auth(self) -> bool:\n \"\"\"\n Returns:\n - True, if authentication is done as if mitmproxy is a proxy\n - False, if authentication is done as if mitmproxy is a HTTP server\n \"\"\"\n return ctx.options.mode == \"regular\" or ctx.options.mode.startswith(\"upstream:\")\n\n def which_auth_header(self) -> str:\n if self.is_proxy_auth():\n return 'Proxy-Authorization'\n else:\n return 'Authorization'\n\n def auth_required_response(self) -> http.HTTPResponse:\n if self.is_proxy_auth():\n return http.make_error_response(\n status_codes.PROXY_AUTH_REQUIRED,\n headers=mitmproxy.net.http.Headers(Proxy_Authenticate='Basic realm=\"{}\"'.format(REALM)),\n )\n else:\n return http.make_error_response(\n status_codes.UNAUTHORIZED,\n headers=mitmproxy.net.http.Headers(WWW_Authenticate='Basic realm=\"{}\"'.format(REALM)),\n )\n\n def check(self, f: http.HTTPFlow) -> Optional[Tuple[str, str]]:\n \"\"\"\n Check if a request is correctly authenticated.\n Returns:\n - a (username, password) tuple if successful,\n - None, otherwise.\n \"\"\"\n auth_value = f.request.headers.get(self.which_auth_header(), \"\")\n try:\n scheme, username, password = parse_http_basic_auth(auth_value)\n except ValueError:\n return None\n\n if self.nonanonymous:\n return username, password\n elif self.singleuser:\n if self.singleuser == [username, password]:\n return username, password\n elif self.htpasswd:\n if self.htpasswd.check_password(username, password):\n return username, password\n elif self.ldapconn:\n if not username or not password:\n return None\n self.ldapconn.search(ctx.options.proxyauth.split(':')[4], '(cn=' + username + ')')\n if self.ldapconn.response:\n conn = ldap3.Connection(\n self.ldapserver,\n self.ldapconn.response[0]['dn'],\n password,\n auto_bind=True)\n if conn:\n return username, password\n return None\n\n def authenticate(self, f: http.HTTPFlow) -> bool:\n valid_credentials = self.check(f)\n if valid_credentials:\n f.metadata[\"proxyauth\"] = valid_credentials\n del f.request.headers[self.which_auth_header()]\n return True\n else:\n f.response = self.auth_required_response()\n return False\n\n # Handlers\n def configure(self, updated):\n if \"proxyauth\" in updated:\n self.nonanonymous = False\n self.singleuser = None\n self.htpasswd = None\n self.ldapserver = None\n if ctx.options.proxyauth:\n if ctx.options.proxyauth == \"any\":\n self.nonanonymous = True\n elif ctx.options.proxyauth.startswith(\"@\"):\n p = ctx.options.proxyauth[1:]\n try:\n self.htpasswd = passlib.apache.HtpasswdFile(p)\n except (ValueError, OSError) as v:\n raise exceptions.OptionsError(\n \"Could not open htpasswd file: %s\" % p\n )\n elif ctx.options.proxyauth.startswith(\"ldap\"):\n parts = ctx.options.proxyauth.split(':')\n security = parts[0]\n ldap_server = parts[1]\n dn_baseauth = parts[2]\n password_baseauth = parts[3]\n if len(parts) != 5:\n raise exceptions.OptionsError(\n \"Invalid ldap specification\"\n )\n if security == \"ldaps\":\n server = ldap3.Server(ldap_server, use_ssl=True)\n elif security == \"ldap\":\n server = ldap3.Server(ldap_server)\n else:\n raise exceptions.OptionsError(\n \"Invalid ldap specfication on the first part\"\n )\n conn = ldap3.Connection(\n server,\n dn_baseauth,\n password_baseauth,\n auto_bind=True)\n self.ldapconn = conn\n self.ldapserver = server\n else:\n parts = ctx.options.proxyauth.split(':')\n if len(parts) != 2:\n raise exceptions.OptionsError(\n \"Invalid single-user auth specification.\"\n )\n self.singleuser = parts\n if self.enabled():\n if ctx.options.mode == \"transparent\":\n raise exceptions.OptionsError(\n \"Proxy Authentication not supported in transparent mode.\"\n )\n if ctx.options.mode == \"socks5\":\n raise exceptions.OptionsError(\n \"Proxy Authentication not supported in SOCKS mode. \"\n \"https://github.com/mitmproxy/mitmproxy/issues/738\"\n )\n # TODO: check for multiple auth options\n\n def http_connect(self, f: http.HTTPFlow) -> None:\n if self.enabled():\n if self.authenticate(f):\n self.authenticated[f.client_conn] = f.metadata[\"proxyauth\"]\n\n def requestheaders(self, f: http.HTTPFlow) -> None:\n if self.enabled():\n # Is this connection authenticated by a previous HTTP CONNECT?\n if f.client_conn in self.authenticated:\n f.metadata[\"proxyauth\"] = self.authenticated[f.client_conn]\n return\n self.authenticate(f)\n", "path": "mitmproxy/addons/proxyauth.py"}], "after_files": [{"content": "import binascii\nimport weakref\nimport ldap3\nfrom typing import Optional\nfrom typing import MutableMapping # noqa\nfrom typing import Tuple\n\nimport passlib.apache\n\nimport mitmproxy.net.http\nfrom mitmproxy import connections # noqa\nfrom mitmproxy import exceptions\nfrom mitmproxy import http\nfrom mitmproxy import ctx\nfrom mitmproxy.net.http import status_codes\n\nREALM = \"mitmproxy\"\n\n\ndef mkauth(username: str, password: str, scheme: str = \"basic\") -> str:\n \"\"\"\n Craft a basic auth string\n \"\"\"\n v = binascii.b2a_base64(\n (username + \":\" + password).encode(\"utf8\")\n ).decode(\"ascii\")\n return scheme + \" \" + v\n\n\ndef parse_http_basic_auth(s: str) -> Tuple[str, str, str]:\n \"\"\"\n Parse a basic auth header.\n Raises a ValueError if the input is invalid.\n \"\"\"\n scheme, authinfo = s.split()\n if scheme.lower() != \"basic\":\n raise ValueError(\"Unknown scheme\")\n try:\n user, password = binascii.a2b_base64(authinfo.encode()).decode(\"utf8\", \"replace\").split(\":\")\n except binascii.Error as e:\n raise ValueError(str(e))\n return scheme, user, password\n\n\nclass ProxyAuth:\n def __init__(self):\n self.nonanonymous = False\n self.htpasswd = None\n self.singleuser = None\n self.ldapconn = None\n self.ldapserver = None\n self.authenticated = weakref.WeakKeyDictionary() # type: MutableMapping[connections.ClientConnection, Tuple[str, str]]\n \"\"\"Contains all connections that are permanently authenticated after an HTTP CONNECT\"\"\"\n\n def enabled(self) -> bool:\n return any([self.nonanonymous, self.htpasswd, self.singleuser, self.ldapconn, self.ldapserver])\n\n def is_proxy_auth(self) -> bool:\n \"\"\"\n Returns:\n - True, if authentication is done as if mitmproxy is a proxy\n - False, if authentication is done as if mitmproxy is a HTTP server\n \"\"\"\n return ctx.options.mode == \"regular\" or ctx.options.mode.startswith(\"upstream:\")\n\n def which_auth_header(self) -> str:\n if self.is_proxy_auth():\n return 'Proxy-Authorization'\n else:\n return 'Authorization'\n\n def auth_required_response(self) -> http.HTTPResponse:\n if self.is_proxy_auth():\n return http.make_error_response(\n status_codes.PROXY_AUTH_REQUIRED,\n headers=mitmproxy.net.http.Headers(Proxy_Authenticate='Basic realm=\"{}\"'.format(REALM)),\n )\n else:\n return http.make_error_response(\n status_codes.UNAUTHORIZED,\n headers=mitmproxy.net.http.Headers(WWW_Authenticate='Basic realm=\"{}\"'.format(REALM)),\n )\n\n def check(self, f: http.HTTPFlow) -> Optional[Tuple[str, str]]:\n \"\"\"\n Check if a request is correctly authenticated.\n Returns:\n - a (username, password) tuple if successful,\n - None, otherwise.\n \"\"\"\n auth_value = f.request.headers.get(self.which_auth_header(), \"\")\n try:\n scheme, username, password = parse_http_basic_auth(auth_value)\n except ValueError:\n return None\n\n if self.nonanonymous:\n return username, password\n elif self.singleuser:\n if self.singleuser == [username, password]:\n return username, password\n elif self.htpasswd:\n if self.htpasswd.check_password(username, password):\n return username, password\n elif self.ldapconn:\n if not username or not password:\n return None\n self.ldapconn.search(ctx.options.proxyauth.split(':')[4], '(cn=' + username + ')')\n if self.ldapconn.response:\n conn = ldap3.Connection(\n self.ldapserver,\n self.ldapconn.response[0]['dn'],\n password,\n auto_bind=True)\n if conn:\n return username, password\n return None\n\n def authenticate(self, f: http.HTTPFlow) -> bool:\n valid_credentials = self.check(f)\n if valid_credentials:\n f.metadata[\"proxyauth\"] = valid_credentials\n del f.request.headers[self.which_auth_header()]\n return True\n else:\n f.response = self.auth_required_response()\n return False\n\n # Handlers\n def configure(self, updated):\n if \"proxyauth\" in updated:\n self.nonanonymous = False\n self.singleuser = None\n self.htpasswd = None\n self.ldapserver = None\n if ctx.options.proxyauth:\n if ctx.options.proxyauth == \"any\":\n self.nonanonymous = True\n elif ctx.options.proxyauth.startswith(\"@\"):\n p = ctx.options.proxyauth[1:]\n try:\n self.htpasswd = passlib.apache.HtpasswdFile(p)\n except (ValueError, OSError) as v:\n raise exceptions.OptionsError(\n \"Could not open htpasswd file: %s\" % p\n )\n elif ctx.options.proxyauth.startswith(\"ldap\"):\n parts = ctx.options.proxyauth.split(':')\n if len(parts) != 5:\n raise exceptions.OptionsError(\n \"Invalid ldap specification\"\n )\n security = parts[0]\n ldap_server = parts[1]\n dn_baseauth = parts[2]\n password_baseauth = parts[3]\n if security == \"ldaps\":\n server = ldap3.Server(ldap_server, use_ssl=True)\n elif security == \"ldap\":\n server = ldap3.Server(ldap_server)\n else:\n raise exceptions.OptionsError(\n \"Invalid ldap specfication on the first part\"\n )\n conn = ldap3.Connection(\n server,\n dn_baseauth,\n password_baseauth,\n auto_bind=True)\n self.ldapconn = conn\n self.ldapserver = server\n else:\n parts = ctx.options.proxyauth.split(':')\n if len(parts) != 2:\n raise exceptions.OptionsError(\n \"Invalid single-user auth specification.\"\n )\n self.singleuser = parts\n if self.enabled():\n if ctx.options.mode == \"transparent\":\n raise exceptions.OptionsError(\n \"Proxy Authentication not supported in transparent mode.\"\n )\n if ctx.options.mode == \"socks5\":\n raise exceptions.OptionsError(\n \"Proxy Authentication not supported in SOCKS mode. \"\n \"https://github.com/mitmproxy/mitmproxy/issues/738\"\n )\n # TODO: check for multiple auth options\n\n def http_connect(self, f: http.HTTPFlow) -> None:\n if self.enabled():\n if self.authenticate(f):\n self.authenticated[f.client_conn] = f.metadata[\"proxyauth\"]\n\n def requestheaders(self, f: http.HTTPFlow) -> None:\n if self.enabled():\n # Is this connection authenticated by a previous HTTP CONNECT?\n if f.client_conn in self.authenticated:\n f.metadata[\"proxyauth\"] = self.authenticated[f.client_conn]\n return\n self.authenticate(f)\n", "path": "mitmproxy/addons/proxyauth.py"}]}
| 2,581 | 212 |
gh_patches_debug_1278
|
rasdani/github-patches
|
git_diff
|
microsoft__botbuilder-python-1637
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
botbuilder-testing is missing install requirements
## Version
botbuilder-testing 4.12.0
## Describe the bug
While installing botbuilder-testing for CI I got errors about missing dependencies.
## To Reproduce
1. `python3 -m venv .venv`
2. `. .venv/bin/activate`
3. `pip install -U pip wheel`
4. `pip install botbuilder-testing`
5. `python -c "from botbuilder.testing import DialogTestClient"`
First error is missing `pytest`:
```python
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/calum/sureswift/jell/jell-bot-teams-v2/.venv-test/lib/python3.8/site-packages/botbuilder/testing/__init__.py", line 6, in <module>
from .storage_base_tests import StorageBaseTests
File "/home/calum/sureswift/jell/jell-bot-teams-v2/.venv-test/lib/python3.8/site-packages/botbuilder/testing/storage_base_tests.py", line 26, in <module>
import pytest
ModuleNotFoundError: No module named 'pytest'
```
6. `pip install pytest`
7. `python -c 'from botbuilder.testing import DialogTestClient'`
Next error is missing `botbuilder-azure`:
```python
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/calum/sureswift/jell/jell-bot-teams-v2/.venv-test/lib/python3.8/site-packages/botbuilder/testing/__init__.py", line 6, in <module>
from .storage_base_tests import StorageBaseTests
File "/home/calum/sureswift/jell/jell-bot-teams-v2/.venv-test/lib/python3.8/site-packages/botbuilder/testing/storage_base_tests.py", line 27, in <module>
from botbuilder.azure import CosmosDbStorage
ModuleNotFoundError: No module named 'botbuilder.azure'
```
8. `pip install botbuilder-azure`
9. `python -c 'from botbuilder.testing import DialogTestClient'`
Command works!
## Expected behavior
No errors after installing botbuilder-testing and importing module
I do wonder if the requirement for pytest is not necessary, leaving the lib test-suite agnostic and could be refactored out?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `libraries/botbuilder-testing/setup.py`
Content:
```
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3
4 import os
5 from setuptools import setup
6
7 REQUIRES = [
8 "botbuilder-schema==4.13.0",
9 "botbuilder-core==4.13.0",
10 "botbuilder-dialogs==4.13.0",
11 ]
12
13 TESTS_REQUIRES = ["aiounittest==1.3.0"]
14
15 root = os.path.abspath(os.path.dirname(__file__))
16
17 with open(os.path.join(root, "botbuilder", "testing", "about.py")) as f:
18 package_info = {}
19 info = f.read()
20 exec(info, package_info)
21
22 with open(os.path.join(root, "README.rst"), encoding="utf-8") as f:
23 long_description = f.read()
24
25 setup(
26 name=package_info["__title__"],
27 version=package_info["__version__"],
28 url=package_info["__uri__"],
29 author=package_info["__author__"],
30 description=package_info["__description__"],
31 keywords="botbuilder-testing bots ai testing botframework botbuilder",
32 long_description=long_description,
33 long_description_content_type="text/x-rst",
34 license=package_info["__license__"],
35 packages=["botbuilder.testing"],
36 install_requires=REQUIRES + TESTS_REQUIRES,
37 tests_require=TESTS_REQUIRES,
38 include_package_data=True,
39 classifiers=[
40 "Programming Language :: Python :: 3.7",
41 "Intended Audience :: Developers",
42 "License :: OSI Approved :: MIT License",
43 "Operating System :: OS Independent",
44 "Development Status :: 5 - Production/Stable",
45 "Topic :: Scientific/Engineering :: Artificial Intelligence",
46 ],
47 )
48
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/libraries/botbuilder-testing/setup.py b/libraries/botbuilder-testing/setup.py
--- a/libraries/botbuilder-testing/setup.py
+++ b/libraries/botbuilder-testing/setup.py
@@ -8,6 +8,8 @@
"botbuilder-schema==4.13.0",
"botbuilder-core==4.13.0",
"botbuilder-dialogs==4.13.0",
+ "botbuilder-azure==4.13.0",
+ "pytest~=6.2.3",
]
TESTS_REQUIRES = ["aiounittest==1.3.0"]
|
{"golden_diff": "diff --git a/libraries/botbuilder-testing/setup.py b/libraries/botbuilder-testing/setup.py\n--- a/libraries/botbuilder-testing/setup.py\n+++ b/libraries/botbuilder-testing/setup.py\n@@ -8,6 +8,8 @@\n \"botbuilder-schema==4.13.0\",\n \"botbuilder-core==4.13.0\",\n \"botbuilder-dialogs==4.13.0\",\n+ \"botbuilder-azure==4.13.0\",\n+ \"pytest~=6.2.3\",\n ]\n \n TESTS_REQUIRES = [\"aiounittest==1.3.0\"]\n", "issue": "botbuilder-testing is missing install requirements\n## Version\r\n\r\nbotbuilder-testing 4.12.0\r\n\r\n## Describe the bug\r\nWhile installing botbuilder-testing for CI I got errors about missing dependencies. \r\n\r\n## To Reproduce\r\n\r\n1. `python3 -m venv .venv`\r\n2. `. .venv/bin/activate`\r\n3. `pip install -U pip wheel`\r\n4. `pip install botbuilder-testing`\r\n5. `python -c \"from botbuilder.testing import DialogTestClient\"`\r\n\r\nFirst error is missing `pytest`:\r\n```python\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/calum/sureswift/jell/jell-bot-teams-v2/.venv-test/lib/python3.8/site-packages/botbuilder/testing/__init__.py\", line 6, in <module>\r\n from .storage_base_tests import StorageBaseTests\r\n File \"/home/calum/sureswift/jell/jell-bot-teams-v2/.venv-test/lib/python3.8/site-packages/botbuilder/testing/storage_base_tests.py\", line 26, in <module>\r\n import pytest\r\nModuleNotFoundError: No module named 'pytest'\r\n```\r\n\r\n6. `pip install pytest`\r\n7. `python -c 'from botbuilder.testing import DialogTestClient'`\r\n\r\nNext error is missing `botbuilder-azure`:\r\n```python\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \"/home/calum/sureswift/jell/jell-bot-teams-v2/.venv-test/lib/python3.8/site-packages/botbuilder/testing/__init__.py\", line 6, in <module>\r\n from .storage_base_tests import StorageBaseTests\r\n File \"/home/calum/sureswift/jell/jell-bot-teams-v2/.venv-test/lib/python3.8/site-packages/botbuilder/testing/storage_base_tests.py\", line 27, in <module>\r\n from botbuilder.azure import CosmosDbStorage\r\nModuleNotFoundError: No module named 'botbuilder.azure'\r\n```\r\n\r\n8. `pip install botbuilder-azure`\r\n9. `python -c 'from botbuilder.testing import DialogTestClient'`\r\n\r\nCommand works!\r\n\r\n## Expected behavior\r\nNo errors after installing botbuilder-testing and importing module\r\n\r\nI do wonder if the requirement for pytest is not necessary, leaving the lib test-suite agnostic and could be refactored out?\r\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\nimport os\nfrom setuptools import setup\n\nREQUIRES = [\n \"botbuilder-schema==4.13.0\",\n \"botbuilder-core==4.13.0\",\n \"botbuilder-dialogs==4.13.0\",\n]\n\nTESTS_REQUIRES = [\"aiounittest==1.3.0\"]\n\nroot = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(root, \"botbuilder\", \"testing\", \"about.py\")) as f:\n package_info = {}\n info = f.read()\n exec(info, package_info)\n\nwith open(os.path.join(root, \"README.rst\"), encoding=\"utf-8\") as f:\n long_description = f.read()\n\nsetup(\n name=package_info[\"__title__\"],\n version=package_info[\"__version__\"],\n url=package_info[\"__uri__\"],\n author=package_info[\"__author__\"],\n description=package_info[\"__description__\"],\n keywords=\"botbuilder-testing bots ai testing botframework botbuilder\",\n long_description=long_description,\n long_description_content_type=\"text/x-rst\",\n license=package_info[\"__license__\"],\n packages=[\"botbuilder.testing\"],\n install_requires=REQUIRES + TESTS_REQUIRES,\n tests_require=TESTS_REQUIRES,\n include_package_data=True,\n classifiers=[\n \"Programming Language :: Python :: 3.7\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n \"Development Status :: 5 - Production/Stable\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n)\n", "path": "libraries/botbuilder-testing/setup.py"}], "after_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\nimport os\nfrom setuptools import setup\n\nREQUIRES = [\n \"botbuilder-schema==4.13.0\",\n \"botbuilder-core==4.13.0\",\n \"botbuilder-dialogs==4.13.0\",\n \"botbuilder-azure==4.13.0\",\n \"pytest~=6.2.3\",\n]\n\nTESTS_REQUIRES = [\"aiounittest==1.3.0\"]\n\nroot = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(root, \"botbuilder\", \"testing\", \"about.py\")) as f:\n package_info = {}\n info = f.read()\n exec(info, package_info)\n\nwith open(os.path.join(root, \"README.rst\"), encoding=\"utf-8\") as f:\n long_description = f.read()\n\nsetup(\n name=package_info[\"__title__\"],\n version=package_info[\"__version__\"],\n url=package_info[\"__uri__\"],\n author=package_info[\"__author__\"],\n description=package_info[\"__description__\"],\n keywords=\"botbuilder-testing bots ai testing botframework botbuilder\",\n long_description=long_description,\n long_description_content_type=\"text/x-rst\",\n license=package_info[\"__license__\"],\n packages=[\"botbuilder.testing\"],\n install_requires=REQUIRES + TESTS_REQUIRES,\n tests_require=TESTS_REQUIRES,\n include_package_data=True,\n classifiers=[\n \"Programming Language :: Python :: 3.7\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n \"Development Status :: 5 - Production/Stable\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n)\n", "path": "libraries/botbuilder-testing/setup.py"}]}
| 1,240 | 138 |
gh_patches_debug_15584
|
rasdani/github-patches
|
git_diff
|
mirumee__ariadne-719
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Handle optional args in query cost multiplers
Query cost validator supports complexity multipliers which multiply given complexity by sum of specified values:
```graphql
type Query {
news(promoted: Int, regular: Int): Post @cost(complexity: 1, multipliers: ["promoted", "regular"])
}
```
In situation when one of those arguments is skipped, its passed to complexity calculation as `None`, causing the `unsupported operand type(s) for +: 'int' and 'NoneType'` error within validator.
Relevant lines:
https://github.com/mirumee/ariadne/blob/master/ariadne/validation/query_cost.py#L283
https://github.com/mirumee/ariadne/blob/master/ariadne/validation/query_cost.py#L187
We should default missing variables to 0, so they are filtered out at next line. We should also consider filtering off negative numbers.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ariadne/validation/query_cost.py`
Content:
```
1 from functools import reduce
2 from operator import add, mul
3 from typing import Any, Dict, List, Optional, Type, Union, cast
4
5 from graphql import (
6 GraphQLError,
7 GraphQLInterfaceType,
8 GraphQLObjectType,
9 GraphQLSchema,
10 get_named_type,
11 )
12 from graphql.execution.values import get_argument_values
13 from graphql.language import (
14 BooleanValueNode,
15 FieldNode,
16 FragmentDefinitionNode,
17 FragmentSpreadNode,
18 InlineFragmentNode,
19 IntValueNode,
20 ListValueNode,
21 Node,
22 OperationDefinitionNode,
23 OperationType,
24 StringValueNode,
25 )
26 from graphql.type import GraphQLFieldMap
27 from graphql.validation import ValidationContext
28 from graphql.validation.rules import ASTValidationRule, ValidationRule
29
30 cost_directive = """
31 directive @cost(complexity: Int, multipliers: [String!], useMultipliers: Boolean) on FIELD | FIELD_DEFINITION
32 """
33
34
35 CostAwareNode = Union[
36 FieldNode,
37 FragmentDefinitionNode,
38 FragmentSpreadNode,
39 InlineFragmentNode,
40 OperationDefinitionNode,
41 ]
42
43
44 class CostValidator(ValidationRule):
45 context: ValidationContext
46 maximum_cost: int
47 default_cost: int = 0
48 default_complexity: int = 1
49 variables: Optional[Dict] = None
50 cost_map: Optional[Dict[str, Dict[str, Any]]] = None
51
52 def __init__(
53 self,
54 context: ValidationContext,
55 maximum_cost: int,
56 *,
57 default_cost: int = 0,
58 default_complexity: int = 1,
59 variables: Optional[Dict] = None,
60 cost_map: Optional[Dict[str, Dict[str, Any]]] = None,
61 ): # pylint: disable=super-init-not-called
62 self.context = context
63 self.maximum_cost = maximum_cost
64 self.variables = variables
65 self.cost_map = cost_map
66 self.default_cost = default_cost
67 self.default_complexity = default_complexity
68 self.cost = 0
69 self.operation_multipliers: List[Any] = []
70
71 def compute_node_cost(self, node: CostAwareNode, type_def, parent_multipliers=None):
72 if parent_multipliers is None:
73 parent_multipliers = []
74 if isinstance(node, FragmentSpreadNode) or not node.selection_set:
75 return 0
76 fields: GraphQLFieldMap = {}
77 if isinstance(type_def, (GraphQLObjectType, GraphQLInterfaceType)):
78 fields = type_def.fields
79 total = 0
80 for child_node in node.selection_set.selections:
81 self.operation_multipliers = parent_multipliers[:]
82 node_cost = self.default_cost
83 if isinstance(child_node, FieldNode):
84 field = fields.get(child_node.name.value)
85 if not field:
86 continue
87 field_type = get_named_type(field.type)
88 try:
89 field_args: Dict[str, Any] = get_argument_values(
90 field, child_node, self.variables
91 )
92 except Exception as e:
93 report_error(self.context, e)
94 field_args = {}
95 if self.cost_map:
96 cost_map_args = (
97 self.get_args_from_cost_map(
98 child_node, type_def.name, field_args
99 )
100 if type_def and type_def.name
101 else None
102 )
103 if cost_map_args is not None:
104 try:
105 node_cost = self.compute_cost(**cost_map_args)
106 except (TypeError, ValueError) as e:
107 report_error(self.context, e)
108 else:
109 cost_is_computed = False
110 if field.ast_node and field.ast_node.directives:
111 directives_args = self.get_args_from_directives(
112 field.ast_node.directives, field_args
113 )
114 if directives_args is not None:
115 try:
116 node_cost = self.compute_cost(**directives_args)
117 except (TypeError, ValueError) as e:
118 report_error(self.context, e)
119 cost_is_computed = True
120 if (
121 field_type
122 and field_type.ast_node
123 and field_type.ast_node.directives
124 ):
125 if not cost_is_computed and isinstance(
126 field_type, GraphQLObjectType
127 ):
128 directives_args = self.get_args_from_directives(
129 field_type.ast_node.directives, field_args
130 )
131 if directives_args is not None:
132 try:
133 node_cost = self.compute_cost(**directives_args)
134 except (TypeError, ValueError) as e:
135 report_error(self.context, e)
136 child_cost = self.compute_node_cost(
137 child_node, field_type, self.operation_multipliers
138 )
139 node_cost += child_cost
140 if isinstance(child_node, FragmentSpreadNode):
141 fragment = self.context.get_fragment(child_node.name.value)
142 if fragment:
143 fragment_type = self.context.schema.get_type(
144 fragment.type_condition.name.value
145 )
146 node_cost = self.compute_node_cost(fragment, fragment_type)
147 if isinstance(child_node, InlineFragmentNode):
148 inline_fragment_type = type_def
149 if child_node.type_condition and child_node.type_condition.name:
150 inline_fragment_type = self.context.schema.get_type(
151 child_node.type_condition.name.value
152 )
153 node_cost = self.compute_node_cost(child_node, inline_fragment_type)
154 total += node_cost
155 return total
156
157 def enter_operation_definition(
158 self, node, key, parent, path, ancestors
159 ): # pylint: disable=unused-argument
160 if self.cost_map:
161 try:
162 validate_cost_map(self.cost_map, self.context.schema)
163 except GraphQLError as cost_map_error:
164 self.context.report_error(cost_map_error)
165 return
166
167 if node.operation is OperationType.QUERY:
168 self.cost += self.compute_node_cost(node, self.context.schema.query_type)
169 if node.operation is OperationType.MUTATION:
170 self.cost += self.compute_node_cost(node, self.context.schema.mutation_type)
171 if node.operation is OperationType.SUBSCRIPTION:
172 self.cost += self.compute_node_cost(
173 node, self.context.schema.subscription_type
174 )
175
176 def leave_operation_definition(
177 self, node, key, parent, path, ancestors
178 ): # pylint: disable=unused-argument
179 if self.cost > self.maximum_cost:
180 self.context.report_error(self.get_cost_exceeded_error())
181
182 def compute_cost(self, multipliers=None, use_multipliers=True, complexity=None):
183 if complexity is None:
184 complexity = self.default_complexity
185 if use_multipliers:
186 if multipliers:
187 multiplier = reduce(add, multipliers, 0)
188 self.operation_multipliers = self.operation_multipliers + [multiplier]
189 return reduce(mul, self.operation_multipliers, complexity)
190 return complexity
191
192 def get_args_from_cost_map(
193 self, node: FieldNode, parent_type: str, field_args: Dict
194 ):
195 cost_args = None
196 cost_map = cast(Dict[Any, Dict], self.cost_map)
197 if parent_type in cost_map:
198 cost_args = cost_map[parent_type].get(node.name.value)
199 if not cost_args:
200 return None
201 cost_args = cost_args.copy()
202 if "multipliers" in cost_args:
203 cost_args["multipliers"] = self.get_multipliers_from_string(
204 cost_args["multipliers"], field_args
205 )
206 return cost_args
207
208 def get_args_from_directives(self, directives, field_args):
209 cost_directive = next(
210 (directive for directive in directives if directive.name.value == "cost"),
211 None,
212 )
213 if cost_directive and cost_directive.arguments:
214 complexity_arg = next(
215 (
216 argument
217 for argument in cost_directive.arguments
218 if argument.name.value == "complexity"
219 ),
220 None,
221 )
222 use_multipliers_arg = next(
223 (
224 argument
225 for argument in cost_directive.arguments
226 if argument.name.value == "useMultipliers"
227 ),
228 None,
229 )
230 multipliers_arg = next(
231 (
232 argument
233 for argument in cost_directive.arguments
234 if argument.name.value == "multipliers"
235 ),
236 None,
237 )
238 use_multipliers = (
239 use_multipliers_arg.value.value
240 if use_multipliers_arg
241 and use_multipliers_arg.value
242 and isinstance(use_multipliers_arg.value, BooleanValueNode)
243 else True
244 )
245 multipliers = (
246 self.get_multipliers_from_list_node(
247 multipliers_arg.value.values, field_args
248 )
249 if multipliers_arg
250 and multipliers_arg.value
251 and isinstance(multipliers_arg.value, ListValueNode)
252 else []
253 )
254 complexity = (
255 int(complexity_arg.value.value)
256 if complexity_arg
257 and complexity_arg.value
258 and isinstance(complexity_arg.value, IntValueNode)
259 else None
260 )
261 return {
262 "complexity": complexity,
263 "multipliers": multipliers,
264 "use_multipliers": use_multipliers,
265 }
266
267 return None
268
269 def get_multipliers_from_list_node(self, multipliers: List[Node], field_args):
270 multipliers = [
271 node.value # type: ignore
272 for node in multipliers
273 if isinstance(node, StringValueNode)
274 ]
275 return self.get_multipliers_from_string(multipliers, field_args) # type: ignore
276
277 def get_multipliers_from_string(self, multipliers: List[str], field_args):
278 accessors = [s.split(".") for s in multipliers]
279 multipliers = []
280 for accessor in accessors:
281 val = field_args
282 for key in accessor:
283 val = val.get(key)
284 multipliers.append(val)
285 multipliers = [
286 len(multiplier) if isinstance(multiplier, (list, tuple)) else multiplier
287 for multiplier in multipliers
288 ]
289 return [m for m in multipliers if m != 0]
290
291 def get_cost_exceeded_error(self) -> GraphQLError:
292 return GraphQLError(
293 cost_analysis_message(self.maximum_cost, self.cost),
294 extensions={
295 "cost": {
296 "requestedQueryCost": self.cost,
297 "maximumAvailable": self.maximum_cost,
298 }
299 },
300 )
301
302
303 def validate_cost_map(cost_map: Dict[str, Dict[str, Any]], schema: GraphQLSchema):
304 for type_name, type_fields in cost_map.items():
305 if type_name not in schema.type_map:
306 raise GraphQLError(
307 "The query cost could not be calculated because cost map specifies a type "
308 f"{type_name} that is not defined by the schema."
309 )
310
311 if not isinstance(schema.type_map[type_name], GraphQLObjectType):
312 raise GraphQLError(
313 "The query cost could not be calculated because cost map specifies a type "
314 f"{type_name} that is defined by the schema, but is not an object type."
315 )
316
317 for field_name in type_fields:
318 graphql_type = cast(GraphQLObjectType, schema.type_map[type_name])
319 if field_name not in graphql_type.fields:
320 raise GraphQLError(
321 "The query cost could not be calculated because cost map contains "
322 f"a field {field_name} not defined by the {type_name} type."
323 )
324
325
326 def report_error(context: ValidationContext, error: Exception):
327 context.report_error(GraphQLError(str(error), original_error=error))
328
329
330 def cost_analysis_message(maximum_cost: int, cost: int) -> str:
331 return "The query exceeds the maximum cost of %d. Actual cost is %d" % (
332 maximum_cost,
333 cost,
334 )
335
336
337 def cost_validator(
338 maximum_cost: int,
339 *,
340 default_cost: int = 0,
341 default_complexity: int = 1,
342 variables: Optional[Dict] = None,
343 cost_map: Optional[Dict[str, Dict[str, Any]]] = None,
344 ) -> Type[ASTValidationRule]:
345 class _CostValidator(CostValidator):
346 def __init__(self, context: ValidationContext):
347 super().__init__(
348 context,
349 maximum_cost=maximum_cost,
350 default_cost=default_cost,
351 default_complexity=default_complexity,
352 variables=variables,
353 cost_map=cost_map,
354 )
355
356 return cast(Type[ASTValidationRule], _CostValidator)
357
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ariadne/validation/query_cost.py b/ariadne/validation/query_cost.py
--- a/ariadne/validation/query_cost.py
+++ b/ariadne/validation/query_cost.py
@@ -281,12 +281,15 @@
val = field_args
for key in accessor:
val = val.get(key)
- multipliers.append(val)
+ try:
+ multipliers.append(int(val)) # type: ignore
+ except (ValueError, TypeError):
+ pass
multipliers = [
len(multiplier) if isinstance(multiplier, (list, tuple)) else multiplier
for multiplier in multipliers
]
- return [m for m in multipliers if m != 0]
+ return [m for m in multipliers if m > 0] # type: ignore
def get_cost_exceeded_error(self) -> GraphQLError:
return GraphQLError(
|
{"golden_diff": "diff --git a/ariadne/validation/query_cost.py b/ariadne/validation/query_cost.py\n--- a/ariadne/validation/query_cost.py\n+++ b/ariadne/validation/query_cost.py\n@@ -281,12 +281,15 @@\n val = field_args\n for key in accessor:\n val = val.get(key)\n- multipliers.append(val)\n+ try:\n+ multipliers.append(int(val)) # type: ignore\n+ except (ValueError, TypeError):\n+ pass\n multipliers = [\n len(multiplier) if isinstance(multiplier, (list, tuple)) else multiplier\n for multiplier in multipliers\n ]\n- return [m for m in multipliers if m != 0]\n+ return [m for m in multipliers if m > 0] # type: ignore\n \n def get_cost_exceeded_error(self) -> GraphQLError:\n return GraphQLError(\n", "issue": "Handle optional args in query cost multiplers\nQuery cost validator supports complexity multipliers which multiply given complexity by sum of specified values:\r\n\r\n```graphql\r\ntype Query {\r\n news(promoted: Int, regular: Int): Post @cost(complexity: 1, multipliers: [\"promoted\", \"regular\"])\r\n}\r\n```\r\n\r\nIn situation when one of those arguments is skipped, its passed to complexity calculation as `None`, causing the `unsupported operand type(s) for +: 'int' and 'NoneType'` error within validator.\r\n\r\nRelevant lines:\r\n\r\nhttps://github.com/mirumee/ariadne/blob/master/ariadne/validation/query_cost.py#L283\r\nhttps://github.com/mirumee/ariadne/blob/master/ariadne/validation/query_cost.py#L187\r\n\r\nWe should default missing variables to 0, so they are filtered out at next line. We should also consider filtering off negative numbers.\n", "before_files": [{"content": "from functools import reduce\nfrom operator import add, mul\nfrom typing import Any, Dict, List, Optional, Type, Union, cast\n\nfrom graphql import (\n GraphQLError,\n GraphQLInterfaceType,\n GraphQLObjectType,\n GraphQLSchema,\n get_named_type,\n)\nfrom graphql.execution.values import get_argument_values\nfrom graphql.language import (\n BooleanValueNode,\n FieldNode,\n FragmentDefinitionNode,\n FragmentSpreadNode,\n InlineFragmentNode,\n IntValueNode,\n ListValueNode,\n Node,\n OperationDefinitionNode,\n OperationType,\n StringValueNode,\n)\nfrom graphql.type import GraphQLFieldMap\nfrom graphql.validation import ValidationContext\nfrom graphql.validation.rules import ASTValidationRule, ValidationRule\n\ncost_directive = \"\"\"\ndirective @cost(complexity: Int, multipliers: [String!], useMultipliers: Boolean) on FIELD | FIELD_DEFINITION\n\"\"\"\n\n\nCostAwareNode = Union[\n FieldNode,\n FragmentDefinitionNode,\n FragmentSpreadNode,\n InlineFragmentNode,\n OperationDefinitionNode,\n]\n\n\nclass CostValidator(ValidationRule):\n context: ValidationContext\n maximum_cost: int\n default_cost: int = 0\n default_complexity: int = 1\n variables: Optional[Dict] = None\n cost_map: Optional[Dict[str, Dict[str, Any]]] = None\n\n def __init__(\n self,\n context: ValidationContext,\n maximum_cost: int,\n *,\n default_cost: int = 0,\n default_complexity: int = 1,\n variables: Optional[Dict] = None,\n cost_map: Optional[Dict[str, Dict[str, Any]]] = None,\n ): # pylint: disable=super-init-not-called\n self.context = context\n self.maximum_cost = maximum_cost\n self.variables = variables\n self.cost_map = cost_map\n self.default_cost = default_cost\n self.default_complexity = default_complexity\n self.cost = 0\n self.operation_multipliers: List[Any] = []\n\n def compute_node_cost(self, node: CostAwareNode, type_def, parent_multipliers=None):\n if parent_multipliers is None:\n parent_multipliers = []\n if isinstance(node, FragmentSpreadNode) or not node.selection_set:\n return 0\n fields: GraphQLFieldMap = {}\n if isinstance(type_def, (GraphQLObjectType, GraphQLInterfaceType)):\n fields = type_def.fields\n total = 0\n for child_node in node.selection_set.selections:\n self.operation_multipliers = parent_multipliers[:]\n node_cost = self.default_cost\n if isinstance(child_node, FieldNode):\n field = fields.get(child_node.name.value)\n if not field:\n continue\n field_type = get_named_type(field.type)\n try:\n field_args: Dict[str, Any] = get_argument_values(\n field, child_node, self.variables\n )\n except Exception as e:\n report_error(self.context, e)\n field_args = {}\n if self.cost_map:\n cost_map_args = (\n self.get_args_from_cost_map(\n child_node, type_def.name, field_args\n )\n if type_def and type_def.name\n else None\n )\n if cost_map_args is not None:\n try:\n node_cost = self.compute_cost(**cost_map_args)\n except (TypeError, ValueError) as e:\n report_error(self.context, e)\n else:\n cost_is_computed = False\n if field.ast_node and field.ast_node.directives:\n directives_args = self.get_args_from_directives(\n field.ast_node.directives, field_args\n )\n if directives_args is not None:\n try:\n node_cost = self.compute_cost(**directives_args)\n except (TypeError, ValueError) as e:\n report_error(self.context, e)\n cost_is_computed = True\n if (\n field_type\n and field_type.ast_node\n and field_type.ast_node.directives\n ):\n if not cost_is_computed and isinstance(\n field_type, GraphQLObjectType\n ):\n directives_args = self.get_args_from_directives(\n field_type.ast_node.directives, field_args\n )\n if directives_args is not None:\n try:\n node_cost = self.compute_cost(**directives_args)\n except (TypeError, ValueError) as e:\n report_error(self.context, e)\n child_cost = self.compute_node_cost(\n child_node, field_type, self.operation_multipliers\n )\n node_cost += child_cost\n if isinstance(child_node, FragmentSpreadNode):\n fragment = self.context.get_fragment(child_node.name.value)\n if fragment:\n fragment_type = self.context.schema.get_type(\n fragment.type_condition.name.value\n )\n node_cost = self.compute_node_cost(fragment, fragment_type)\n if isinstance(child_node, InlineFragmentNode):\n inline_fragment_type = type_def\n if child_node.type_condition and child_node.type_condition.name:\n inline_fragment_type = self.context.schema.get_type(\n child_node.type_condition.name.value\n )\n node_cost = self.compute_node_cost(child_node, inline_fragment_type)\n total += node_cost\n return total\n\n def enter_operation_definition(\n self, node, key, parent, path, ancestors\n ): # pylint: disable=unused-argument\n if self.cost_map:\n try:\n validate_cost_map(self.cost_map, self.context.schema)\n except GraphQLError as cost_map_error:\n self.context.report_error(cost_map_error)\n return\n\n if node.operation is OperationType.QUERY:\n self.cost += self.compute_node_cost(node, self.context.schema.query_type)\n if node.operation is OperationType.MUTATION:\n self.cost += self.compute_node_cost(node, self.context.schema.mutation_type)\n if node.operation is OperationType.SUBSCRIPTION:\n self.cost += self.compute_node_cost(\n node, self.context.schema.subscription_type\n )\n\n def leave_operation_definition(\n self, node, key, parent, path, ancestors\n ): # pylint: disable=unused-argument\n if self.cost > self.maximum_cost:\n self.context.report_error(self.get_cost_exceeded_error())\n\n def compute_cost(self, multipliers=None, use_multipliers=True, complexity=None):\n if complexity is None:\n complexity = self.default_complexity\n if use_multipliers:\n if multipliers:\n multiplier = reduce(add, multipliers, 0)\n self.operation_multipliers = self.operation_multipliers + [multiplier]\n return reduce(mul, self.operation_multipliers, complexity)\n return complexity\n\n def get_args_from_cost_map(\n self, node: FieldNode, parent_type: str, field_args: Dict\n ):\n cost_args = None\n cost_map = cast(Dict[Any, Dict], self.cost_map)\n if parent_type in cost_map:\n cost_args = cost_map[parent_type].get(node.name.value)\n if not cost_args:\n return None\n cost_args = cost_args.copy()\n if \"multipliers\" in cost_args:\n cost_args[\"multipliers\"] = self.get_multipliers_from_string(\n cost_args[\"multipliers\"], field_args\n )\n return cost_args\n\n def get_args_from_directives(self, directives, field_args):\n cost_directive = next(\n (directive for directive in directives if directive.name.value == \"cost\"),\n None,\n )\n if cost_directive and cost_directive.arguments:\n complexity_arg = next(\n (\n argument\n for argument in cost_directive.arguments\n if argument.name.value == \"complexity\"\n ),\n None,\n )\n use_multipliers_arg = next(\n (\n argument\n for argument in cost_directive.arguments\n if argument.name.value == \"useMultipliers\"\n ),\n None,\n )\n multipliers_arg = next(\n (\n argument\n for argument in cost_directive.arguments\n if argument.name.value == \"multipliers\"\n ),\n None,\n )\n use_multipliers = (\n use_multipliers_arg.value.value\n if use_multipliers_arg\n and use_multipliers_arg.value\n and isinstance(use_multipliers_arg.value, BooleanValueNode)\n else True\n )\n multipliers = (\n self.get_multipliers_from_list_node(\n multipliers_arg.value.values, field_args\n )\n if multipliers_arg\n and multipliers_arg.value\n and isinstance(multipliers_arg.value, ListValueNode)\n else []\n )\n complexity = (\n int(complexity_arg.value.value)\n if complexity_arg\n and complexity_arg.value\n and isinstance(complexity_arg.value, IntValueNode)\n else None\n )\n return {\n \"complexity\": complexity,\n \"multipliers\": multipliers,\n \"use_multipliers\": use_multipliers,\n }\n\n return None\n\n def get_multipliers_from_list_node(self, multipliers: List[Node], field_args):\n multipliers = [\n node.value # type: ignore\n for node in multipliers\n if isinstance(node, StringValueNode)\n ]\n return self.get_multipliers_from_string(multipliers, field_args) # type: ignore\n\n def get_multipliers_from_string(self, multipliers: List[str], field_args):\n accessors = [s.split(\".\") for s in multipliers]\n multipliers = []\n for accessor in accessors:\n val = field_args\n for key in accessor:\n val = val.get(key)\n multipliers.append(val)\n multipliers = [\n len(multiplier) if isinstance(multiplier, (list, tuple)) else multiplier\n for multiplier in multipliers\n ]\n return [m for m in multipliers if m != 0]\n\n def get_cost_exceeded_error(self) -> GraphQLError:\n return GraphQLError(\n cost_analysis_message(self.maximum_cost, self.cost),\n extensions={\n \"cost\": {\n \"requestedQueryCost\": self.cost,\n \"maximumAvailable\": self.maximum_cost,\n }\n },\n )\n\n\ndef validate_cost_map(cost_map: Dict[str, Dict[str, Any]], schema: GraphQLSchema):\n for type_name, type_fields in cost_map.items():\n if type_name not in schema.type_map:\n raise GraphQLError(\n \"The query cost could not be calculated because cost map specifies a type \"\n f\"{type_name} that is not defined by the schema.\"\n )\n\n if not isinstance(schema.type_map[type_name], GraphQLObjectType):\n raise GraphQLError(\n \"The query cost could not be calculated because cost map specifies a type \"\n f\"{type_name} that is defined by the schema, but is not an object type.\"\n )\n\n for field_name in type_fields:\n graphql_type = cast(GraphQLObjectType, schema.type_map[type_name])\n if field_name not in graphql_type.fields:\n raise GraphQLError(\n \"The query cost could not be calculated because cost map contains \"\n f\"a field {field_name} not defined by the {type_name} type.\"\n )\n\n\ndef report_error(context: ValidationContext, error: Exception):\n context.report_error(GraphQLError(str(error), original_error=error))\n\n\ndef cost_analysis_message(maximum_cost: int, cost: int) -> str:\n return \"The query exceeds the maximum cost of %d. Actual cost is %d\" % (\n maximum_cost,\n cost,\n )\n\n\ndef cost_validator(\n maximum_cost: int,\n *,\n default_cost: int = 0,\n default_complexity: int = 1,\n variables: Optional[Dict] = None,\n cost_map: Optional[Dict[str, Dict[str, Any]]] = None,\n) -> Type[ASTValidationRule]:\n class _CostValidator(CostValidator):\n def __init__(self, context: ValidationContext):\n super().__init__(\n context,\n maximum_cost=maximum_cost,\n default_cost=default_cost,\n default_complexity=default_complexity,\n variables=variables,\n cost_map=cost_map,\n )\n\n return cast(Type[ASTValidationRule], _CostValidator)\n", "path": "ariadne/validation/query_cost.py"}], "after_files": [{"content": "from functools import reduce\nfrom operator import add, mul\nfrom typing import Any, Dict, List, Optional, Type, Union, cast\n\nfrom graphql import (\n GraphQLError,\n GraphQLInterfaceType,\n GraphQLObjectType,\n GraphQLSchema,\n get_named_type,\n)\nfrom graphql.execution.values import get_argument_values\nfrom graphql.language import (\n BooleanValueNode,\n FieldNode,\n FragmentDefinitionNode,\n FragmentSpreadNode,\n InlineFragmentNode,\n IntValueNode,\n ListValueNode,\n Node,\n OperationDefinitionNode,\n OperationType,\n StringValueNode,\n)\nfrom graphql.type import GraphQLFieldMap\nfrom graphql.validation import ValidationContext\nfrom graphql.validation.rules import ASTValidationRule, ValidationRule\n\ncost_directive = \"\"\"\ndirective @cost(complexity: Int, multipliers: [String!], useMultipliers: Boolean) on FIELD | FIELD_DEFINITION\n\"\"\"\n\n\nCostAwareNode = Union[\n FieldNode,\n FragmentDefinitionNode,\n FragmentSpreadNode,\n InlineFragmentNode,\n OperationDefinitionNode,\n]\n\n\nclass CostValidator(ValidationRule):\n context: ValidationContext\n maximum_cost: int\n default_cost: int = 0\n default_complexity: int = 1\n variables: Optional[Dict] = None\n cost_map: Optional[Dict[str, Dict[str, Any]]] = None\n\n def __init__(\n self,\n context: ValidationContext,\n maximum_cost: int,\n *,\n default_cost: int = 0,\n default_complexity: int = 1,\n variables: Optional[Dict] = None,\n cost_map: Optional[Dict[str, Dict[str, Any]]] = None,\n ): # pylint: disable=super-init-not-called\n self.context = context\n self.maximum_cost = maximum_cost\n self.variables = variables\n self.cost_map = cost_map\n self.default_cost = default_cost\n self.default_complexity = default_complexity\n self.cost = 0\n self.operation_multipliers: List[Any] = []\n\n def compute_node_cost(self, node: CostAwareNode, type_def, parent_multipliers=None):\n if parent_multipliers is None:\n parent_multipliers = []\n if isinstance(node, FragmentSpreadNode) or not node.selection_set:\n return 0\n fields: GraphQLFieldMap = {}\n if isinstance(type_def, (GraphQLObjectType, GraphQLInterfaceType)):\n fields = type_def.fields\n total = 0\n for child_node in node.selection_set.selections:\n self.operation_multipliers = parent_multipliers[:]\n node_cost = self.default_cost\n if isinstance(child_node, FieldNode):\n field = fields.get(child_node.name.value)\n if not field:\n continue\n field_type = get_named_type(field.type)\n try:\n field_args: Dict[str, Any] = get_argument_values(\n field, child_node, self.variables\n )\n except Exception as e:\n report_error(self.context, e)\n field_args = {}\n if self.cost_map:\n cost_map_args = (\n self.get_args_from_cost_map(\n child_node, type_def.name, field_args\n )\n if type_def and type_def.name\n else None\n )\n if cost_map_args is not None:\n try:\n node_cost = self.compute_cost(**cost_map_args)\n except (TypeError, ValueError) as e:\n report_error(self.context, e)\n else:\n cost_is_computed = False\n if field.ast_node and field.ast_node.directives:\n directives_args = self.get_args_from_directives(\n field.ast_node.directives, field_args\n )\n if directives_args is not None:\n try:\n node_cost = self.compute_cost(**directives_args)\n except (TypeError, ValueError) as e:\n report_error(self.context, e)\n cost_is_computed = True\n if (\n field_type\n and field_type.ast_node\n and field_type.ast_node.directives\n ):\n if not cost_is_computed and isinstance(\n field_type, GraphQLObjectType\n ):\n directives_args = self.get_args_from_directives(\n field_type.ast_node.directives, field_args\n )\n if directives_args is not None:\n try:\n node_cost = self.compute_cost(**directives_args)\n except (TypeError, ValueError) as e:\n report_error(self.context, e)\n child_cost = self.compute_node_cost(\n child_node, field_type, self.operation_multipliers\n )\n node_cost += child_cost\n if isinstance(child_node, FragmentSpreadNode):\n fragment = self.context.get_fragment(child_node.name.value)\n if fragment:\n fragment_type = self.context.schema.get_type(\n fragment.type_condition.name.value\n )\n node_cost = self.compute_node_cost(fragment, fragment_type)\n if isinstance(child_node, InlineFragmentNode):\n inline_fragment_type = type_def\n if child_node.type_condition and child_node.type_condition.name:\n inline_fragment_type = self.context.schema.get_type(\n child_node.type_condition.name.value\n )\n node_cost = self.compute_node_cost(child_node, inline_fragment_type)\n total += node_cost\n return total\n\n def enter_operation_definition(\n self, node, key, parent, path, ancestors\n ): # pylint: disable=unused-argument\n if self.cost_map:\n try:\n validate_cost_map(self.cost_map, self.context.schema)\n except GraphQLError as cost_map_error:\n self.context.report_error(cost_map_error)\n return\n\n if node.operation is OperationType.QUERY:\n self.cost += self.compute_node_cost(node, self.context.schema.query_type)\n if node.operation is OperationType.MUTATION:\n self.cost += self.compute_node_cost(node, self.context.schema.mutation_type)\n if node.operation is OperationType.SUBSCRIPTION:\n self.cost += self.compute_node_cost(\n node, self.context.schema.subscription_type\n )\n\n def leave_operation_definition(\n self, node, key, parent, path, ancestors\n ): # pylint: disable=unused-argument\n if self.cost > self.maximum_cost:\n self.context.report_error(self.get_cost_exceeded_error())\n\n def compute_cost(self, multipliers=None, use_multipliers=True, complexity=None):\n if complexity is None:\n complexity = self.default_complexity\n if use_multipliers:\n if multipliers:\n multiplier = reduce(add, multipliers, 0)\n self.operation_multipliers = self.operation_multipliers + [multiplier]\n return reduce(mul, self.operation_multipliers, complexity)\n return complexity\n\n def get_args_from_cost_map(\n self, node: FieldNode, parent_type: str, field_args: Dict\n ):\n cost_args = None\n cost_map = cast(Dict[Any, Dict], self.cost_map)\n if parent_type in cost_map:\n cost_args = cost_map[parent_type].get(node.name.value)\n if not cost_args:\n return None\n cost_args = cost_args.copy()\n if \"multipliers\" in cost_args:\n cost_args[\"multipliers\"] = self.get_multipliers_from_string(\n cost_args[\"multipliers\"], field_args\n )\n return cost_args\n\n def get_args_from_directives(self, directives, field_args):\n cost_directive = next(\n (directive for directive in directives if directive.name.value == \"cost\"),\n None,\n )\n if cost_directive and cost_directive.arguments:\n complexity_arg = next(\n (\n argument\n for argument in cost_directive.arguments\n if argument.name.value == \"complexity\"\n ),\n None,\n )\n use_multipliers_arg = next(\n (\n argument\n for argument in cost_directive.arguments\n if argument.name.value == \"useMultipliers\"\n ),\n None,\n )\n multipliers_arg = next(\n (\n argument\n for argument in cost_directive.arguments\n if argument.name.value == \"multipliers\"\n ),\n None,\n )\n use_multipliers = (\n use_multipliers_arg.value.value\n if use_multipliers_arg\n and use_multipliers_arg.value\n and isinstance(use_multipliers_arg.value, BooleanValueNode)\n else True\n )\n multipliers = (\n self.get_multipliers_from_list_node(\n multipliers_arg.value.values, field_args\n )\n if multipliers_arg\n and multipliers_arg.value\n and isinstance(multipliers_arg.value, ListValueNode)\n else []\n )\n complexity = (\n int(complexity_arg.value.value)\n if complexity_arg\n and complexity_arg.value\n and isinstance(complexity_arg.value, IntValueNode)\n else None\n )\n return {\n \"complexity\": complexity,\n \"multipliers\": multipliers,\n \"use_multipliers\": use_multipliers,\n }\n\n return None\n\n def get_multipliers_from_list_node(self, multipliers: List[Node], field_args):\n multipliers = [\n node.value # type: ignore\n for node in multipliers\n if isinstance(node, StringValueNode)\n ]\n return self.get_multipliers_from_string(multipliers, field_args) # type: ignore\n\n def get_multipliers_from_string(self, multipliers: List[str], field_args):\n accessors = [s.split(\".\") for s in multipliers]\n multipliers = []\n for accessor in accessors:\n val = field_args\n for key in accessor:\n val = val.get(key)\n try:\n multipliers.append(int(val)) # type: ignore\n except (ValueError, TypeError):\n pass\n multipliers = [\n len(multiplier) if isinstance(multiplier, (list, tuple)) else multiplier\n for multiplier in multipliers\n ]\n return [m for m in multipliers if m > 0] # type: ignore\n\n def get_cost_exceeded_error(self) -> GraphQLError:\n return GraphQLError(\n cost_analysis_message(self.maximum_cost, self.cost),\n extensions={\n \"cost\": {\n \"requestedQueryCost\": self.cost,\n \"maximumAvailable\": self.maximum_cost,\n }\n },\n )\n\n\ndef validate_cost_map(cost_map: Dict[str, Dict[str, Any]], schema: GraphQLSchema):\n for type_name, type_fields in cost_map.items():\n if type_name not in schema.type_map:\n raise GraphQLError(\n \"The query cost could not be calculated because cost map specifies a type \"\n f\"{type_name} that is not defined by the schema.\"\n )\n\n if not isinstance(schema.type_map[type_name], GraphQLObjectType):\n raise GraphQLError(\n \"The query cost could not be calculated because cost map specifies a type \"\n f\"{type_name} that is defined by the schema, but is not an object type.\"\n )\n\n for field_name in type_fields:\n graphql_type = cast(GraphQLObjectType, schema.type_map[type_name])\n if field_name not in graphql_type.fields:\n raise GraphQLError(\n \"The query cost could not be calculated because cost map contains \"\n f\"a field {field_name} not defined by the {type_name} type.\"\n )\n\n\ndef report_error(context: ValidationContext, error: Exception):\n context.report_error(GraphQLError(str(error), original_error=error))\n\n\ndef cost_analysis_message(maximum_cost: int, cost: int) -> str:\n return \"The query exceeds the maximum cost of %d. Actual cost is %d\" % (\n maximum_cost,\n cost,\n )\n\n\ndef cost_validator(\n maximum_cost: int,\n *,\n default_cost: int = 0,\n default_complexity: int = 1,\n variables: Optional[Dict] = None,\n cost_map: Optional[Dict[str, Dict[str, Any]]] = None,\n) -> Type[ASTValidationRule]:\n class _CostValidator(CostValidator):\n def __init__(self, context: ValidationContext):\n super().__init__(\n context,\n maximum_cost=maximum_cost,\n default_cost=default_cost,\n default_complexity=default_complexity,\n variables=variables,\n cost_map=cost_map,\n )\n\n return cast(Type[ASTValidationRule], _CostValidator)\n", "path": "ariadne/validation/query_cost.py"}]}
| 3,997 | 209 |
gh_patches_debug_10966
|
rasdani/github-patches
|
git_diff
|
docker__docker-py-2534
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support OpenSSH's IdentityFile config option
# Description
As a developer I want `docker-py` to load the identity file according to my setting specified in `~/.ssh/config`, not only the "default" `id_rsa` file.
# Example
I have a `~/.ssh/config` file with contents:
```ssh
Host myHost
User myUser
HostName myIp
IdentityFile C:/Users/me/.ssh/id_rsa_custom_file
IdentitiesOnly yes
```
Now I would like `docker-py` to pick up `C:/Users/me/.ssh/id_rsa_custom_file` for trying to connect to the remote host (For example when I want to run `docker-compose -H "ssh://myHost" ps`. However right now it does not.
When I rename `C:/Users/me/.ssh/id_rsa_custom_file` to `C:/Users/me/.ssh/id_rsa` it works just fine. However this is not an option for me since I have multiple identity files and hosts that I want to use.
# Proposal
Add something like this to the [`sshcon.py`](https://github.com/docker/docker-py/blob/c285bee1bc59f6b2d65cee952b5522c88047a3bc/docker/transport/sshconn.py#L105):
```python
if 'identityfile' in host_config:
self.ssh_params['key_filename '] = host_config['identityfile']
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docker/transport/sshconn.py`
Content:
```
1 import paramiko
2 import requests.adapters
3 import six
4 import logging
5 import os
6
7 from docker.transport.basehttpadapter import BaseHTTPAdapter
8 from .. import constants
9
10 if six.PY3:
11 import http.client as httplib
12 else:
13 import httplib
14
15 try:
16 import requests.packages.urllib3 as urllib3
17 except ImportError:
18 import urllib3
19
20 RecentlyUsedContainer = urllib3._collections.RecentlyUsedContainer
21
22
23 class SSHConnection(httplib.HTTPConnection, object):
24 def __init__(self, ssh_transport, timeout=60):
25 super(SSHConnection, self).__init__(
26 'localhost', timeout=timeout
27 )
28 self.ssh_transport = ssh_transport
29 self.timeout = timeout
30
31 def connect(self):
32 sock = self.ssh_transport.open_session()
33 sock.settimeout(self.timeout)
34 sock.exec_command('docker system dial-stdio')
35 self.sock = sock
36
37
38 class SSHConnectionPool(urllib3.connectionpool.HTTPConnectionPool):
39 scheme = 'ssh'
40
41 def __init__(self, ssh_client, timeout=60, maxsize=10):
42 super(SSHConnectionPool, self).__init__(
43 'localhost', timeout=timeout, maxsize=maxsize
44 )
45 self.ssh_transport = ssh_client.get_transport()
46 self.timeout = timeout
47
48 def _new_conn(self):
49 return SSHConnection(self.ssh_transport, self.timeout)
50
51 # When re-using connections, urllib3 calls fileno() on our
52 # SSH channel instance, quickly overloading our fd limit. To avoid this,
53 # we override _get_conn
54 def _get_conn(self, timeout):
55 conn = None
56 try:
57 conn = self.pool.get(block=self.block, timeout=timeout)
58
59 except AttributeError: # self.pool is None
60 raise urllib3.exceptions.ClosedPoolError(self, "Pool is closed.")
61
62 except six.moves.queue.Empty:
63 if self.block:
64 raise urllib3.exceptions.EmptyPoolError(
65 self,
66 "Pool reached maximum size and no more "
67 "connections are allowed."
68 )
69 pass # Oh well, we'll create a new connection then
70
71 return conn or self._new_conn()
72
73
74 class SSHHTTPAdapter(BaseHTTPAdapter):
75
76 __attrs__ = requests.adapters.HTTPAdapter.__attrs__ + [
77 'pools', 'timeout', 'ssh_client', 'ssh_params'
78 ]
79
80 def __init__(self, base_url, timeout=60,
81 pool_connections=constants.DEFAULT_NUM_POOLS):
82 logging.getLogger("paramiko").setLevel(logging.WARNING)
83 self.ssh_client = paramiko.SSHClient()
84 base_url = six.moves.urllib_parse.urlparse(base_url)
85 self.ssh_params = {
86 "hostname": base_url.hostname,
87 "port": base_url.port,
88 "username": base_url.username
89 }
90 ssh_config_file = os.path.expanduser("~/.ssh/config")
91 if os.path.exists(ssh_config_file):
92 conf = paramiko.SSHConfig()
93 with open(ssh_config_file) as f:
94 conf.parse(f)
95 host_config = conf.lookup(base_url.hostname)
96 self.ssh_conf = host_config
97 if 'proxycommand' in host_config:
98 self.ssh_params["sock"] = paramiko.ProxyCommand(
99 self.ssh_conf['proxycommand']
100 )
101 if 'hostname' in host_config:
102 self.ssh_params['hostname'] = host_config['hostname']
103 if base_url.port is None and 'port' in host_config:
104 self.ssh_params['port'] = self.ssh_conf['port']
105 if base_url.username is None and 'user' in host_config:
106 self.ssh_params['username'] = self.ssh_conf['user']
107
108 self.ssh_client.load_system_host_keys()
109 self.ssh_client.set_missing_host_key_policy(paramiko.WarningPolicy())
110
111 self._connect()
112 self.timeout = timeout
113 self.pools = RecentlyUsedContainer(
114 pool_connections, dispose_func=lambda p: p.close()
115 )
116 super(SSHHTTPAdapter, self).__init__()
117
118 def _connect(self):
119 self.ssh_client.connect(**self.ssh_params)
120
121 def get_connection(self, url, proxies=None):
122 with self.pools.lock:
123 pool = self.pools.get(url)
124 if pool:
125 return pool
126
127 # Connection is closed try a reconnect
128 if not self.ssh_client.get_transport():
129 self._connect()
130
131 pool = SSHConnectionPool(
132 self.ssh_client, self.timeout
133 )
134 self.pools[url] = pool
135
136 return pool
137
138 def close(self):
139 super(SSHHTTPAdapter, self).close()
140 self.ssh_client.close()
141
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docker/transport/sshconn.py b/docker/transport/sshconn.py
--- a/docker/transport/sshconn.py
+++ b/docker/transport/sshconn.py
@@ -100,6 +100,8 @@
)
if 'hostname' in host_config:
self.ssh_params['hostname'] = host_config['hostname']
+ if 'identityfile' in host_config:
+ self.ssh_params['key_filename'] = host_config['identityfile']
if base_url.port is None and 'port' in host_config:
self.ssh_params['port'] = self.ssh_conf['port']
if base_url.username is None and 'user' in host_config:
|
{"golden_diff": "diff --git a/docker/transport/sshconn.py b/docker/transport/sshconn.py\n--- a/docker/transport/sshconn.py\n+++ b/docker/transport/sshconn.py\n@@ -100,6 +100,8 @@\n )\n if 'hostname' in host_config:\n self.ssh_params['hostname'] = host_config['hostname']\n+ if 'identityfile' in host_config:\n+ self.ssh_params['key_filename'] = host_config['identityfile']\n if base_url.port is None and 'port' in host_config:\n self.ssh_params['port'] = self.ssh_conf['port']\n if base_url.username is None and 'user' in host_config:\n", "issue": "Support OpenSSH's IdentityFile config option\n# Description\r\nAs a developer I want `docker-py` to load the identity file according to my setting specified in `~/.ssh/config`, not only the \"default\" `id_rsa` file.\r\n\r\n# Example\r\nI have a `~/.ssh/config` file with contents:\r\n```ssh\r\nHost myHost\r\n User myUser\r\n HostName myIp\r\n IdentityFile C:/Users/me/.ssh/id_rsa_custom_file\r\n IdentitiesOnly yes\r\n```\r\n\r\nNow I would like `docker-py` to pick up `C:/Users/me/.ssh/id_rsa_custom_file` for trying to connect to the remote host (For example when I want to run `docker-compose -H \"ssh://myHost\" ps`. However right now it does not.\r\n\r\nWhen I rename `C:/Users/me/.ssh/id_rsa_custom_file` to `C:/Users/me/.ssh/id_rsa` it works just fine. However this is not an option for me since I have multiple identity files and hosts that I want to use.\r\n\r\n# Proposal\r\nAdd something like this to the [`sshcon.py`](https://github.com/docker/docker-py/blob/c285bee1bc59f6b2d65cee952b5522c88047a3bc/docker/transport/sshconn.py#L105):\r\n```python\r\nif 'identityfile' in host_config:\r\n self.ssh_params['key_filename '] = host_config['identityfile']\r\n```\n", "before_files": [{"content": "import paramiko\nimport requests.adapters\nimport six\nimport logging\nimport os\n\nfrom docker.transport.basehttpadapter import BaseHTTPAdapter\nfrom .. import constants\n\nif six.PY3:\n import http.client as httplib\nelse:\n import httplib\n\ntry:\n import requests.packages.urllib3 as urllib3\nexcept ImportError:\n import urllib3\n\nRecentlyUsedContainer = urllib3._collections.RecentlyUsedContainer\n\n\nclass SSHConnection(httplib.HTTPConnection, object):\n def __init__(self, ssh_transport, timeout=60):\n super(SSHConnection, self).__init__(\n 'localhost', timeout=timeout\n )\n self.ssh_transport = ssh_transport\n self.timeout = timeout\n\n def connect(self):\n sock = self.ssh_transport.open_session()\n sock.settimeout(self.timeout)\n sock.exec_command('docker system dial-stdio')\n self.sock = sock\n\n\nclass SSHConnectionPool(urllib3.connectionpool.HTTPConnectionPool):\n scheme = 'ssh'\n\n def __init__(self, ssh_client, timeout=60, maxsize=10):\n super(SSHConnectionPool, self).__init__(\n 'localhost', timeout=timeout, maxsize=maxsize\n )\n self.ssh_transport = ssh_client.get_transport()\n self.timeout = timeout\n\n def _new_conn(self):\n return SSHConnection(self.ssh_transport, self.timeout)\n\n # When re-using connections, urllib3 calls fileno() on our\n # SSH channel instance, quickly overloading our fd limit. To avoid this,\n # we override _get_conn\n def _get_conn(self, timeout):\n conn = None\n try:\n conn = self.pool.get(block=self.block, timeout=timeout)\n\n except AttributeError: # self.pool is None\n raise urllib3.exceptions.ClosedPoolError(self, \"Pool is closed.\")\n\n except six.moves.queue.Empty:\n if self.block:\n raise urllib3.exceptions.EmptyPoolError(\n self,\n \"Pool reached maximum size and no more \"\n \"connections are allowed.\"\n )\n pass # Oh well, we'll create a new connection then\n\n return conn or self._new_conn()\n\n\nclass SSHHTTPAdapter(BaseHTTPAdapter):\n\n __attrs__ = requests.adapters.HTTPAdapter.__attrs__ + [\n 'pools', 'timeout', 'ssh_client', 'ssh_params'\n ]\n\n def __init__(self, base_url, timeout=60,\n pool_connections=constants.DEFAULT_NUM_POOLS):\n logging.getLogger(\"paramiko\").setLevel(logging.WARNING)\n self.ssh_client = paramiko.SSHClient()\n base_url = six.moves.urllib_parse.urlparse(base_url)\n self.ssh_params = {\n \"hostname\": base_url.hostname,\n \"port\": base_url.port,\n \"username\": base_url.username\n }\n ssh_config_file = os.path.expanduser(\"~/.ssh/config\")\n if os.path.exists(ssh_config_file):\n conf = paramiko.SSHConfig()\n with open(ssh_config_file) as f:\n conf.parse(f)\n host_config = conf.lookup(base_url.hostname)\n self.ssh_conf = host_config\n if 'proxycommand' in host_config:\n self.ssh_params[\"sock\"] = paramiko.ProxyCommand(\n self.ssh_conf['proxycommand']\n )\n if 'hostname' in host_config:\n self.ssh_params['hostname'] = host_config['hostname']\n if base_url.port is None and 'port' in host_config:\n self.ssh_params['port'] = self.ssh_conf['port']\n if base_url.username is None and 'user' in host_config:\n self.ssh_params['username'] = self.ssh_conf['user']\n\n self.ssh_client.load_system_host_keys()\n self.ssh_client.set_missing_host_key_policy(paramiko.WarningPolicy())\n\n self._connect()\n self.timeout = timeout\n self.pools = RecentlyUsedContainer(\n pool_connections, dispose_func=lambda p: p.close()\n )\n super(SSHHTTPAdapter, self).__init__()\n\n def _connect(self):\n self.ssh_client.connect(**self.ssh_params)\n\n def get_connection(self, url, proxies=None):\n with self.pools.lock:\n pool = self.pools.get(url)\n if pool:\n return pool\n\n # Connection is closed try a reconnect\n if not self.ssh_client.get_transport():\n self._connect()\n\n pool = SSHConnectionPool(\n self.ssh_client, self.timeout\n )\n self.pools[url] = pool\n\n return pool\n\n def close(self):\n super(SSHHTTPAdapter, self).close()\n self.ssh_client.close()\n", "path": "docker/transport/sshconn.py"}], "after_files": [{"content": "import paramiko\nimport requests.adapters\nimport six\nimport logging\nimport os\n\nfrom docker.transport.basehttpadapter import BaseHTTPAdapter\nfrom .. import constants\n\nif six.PY3:\n import http.client as httplib\nelse:\n import httplib\n\ntry:\n import requests.packages.urllib3 as urllib3\nexcept ImportError:\n import urllib3\n\nRecentlyUsedContainer = urllib3._collections.RecentlyUsedContainer\n\n\nclass SSHConnection(httplib.HTTPConnection, object):\n def __init__(self, ssh_transport, timeout=60):\n super(SSHConnection, self).__init__(\n 'localhost', timeout=timeout\n )\n self.ssh_transport = ssh_transport\n self.timeout = timeout\n\n def connect(self):\n sock = self.ssh_transport.open_session()\n sock.settimeout(self.timeout)\n sock.exec_command('docker system dial-stdio')\n self.sock = sock\n\n\nclass SSHConnectionPool(urllib3.connectionpool.HTTPConnectionPool):\n scheme = 'ssh'\n\n def __init__(self, ssh_client, timeout=60, maxsize=10):\n super(SSHConnectionPool, self).__init__(\n 'localhost', timeout=timeout, maxsize=maxsize\n )\n self.ssh_transport = ssh_client.get_transport()\n self.timeout = timeout\n\n def _new_conn(self):\n return SSHConnection(self.ssh_transport, self.timeout)\n\n # When re-using connections, urllib3 calls fileno() on our\n # SSH channel instance, quickly overloading our fd limit. To avoid this,\n # we override _get_conn\n def _get_conn(self, timeout):\n conn = None\n try:\n conn = self.pool.get(block=self.block, timeout=timeout)\n\n except AttributeError: # self.pool is None\n raise urllib3.exceptions.ClosedPoolError(self, \"Pool is closed.\")\n\n except six.moves.queue.Empty:\n if self.block:\n raise urllib3.exceptions.EmptyPoolError(\n self,\n \"Pool reached maximum size and no more \"\n \"connections are allowed.\"\n )\n pass # Oh well, we'll create a new connection then\n\n return conn or self._new_conn()\n\n\nclass SSHHTTPAdapter(BaseHTTPAdapter):\n\n __attrs__ = requests.adapters.HTTPAdapter.__attrs__ + [\n 'pools', 'timeout', 'ssh_client', 'ssh_params'\n ]\n\n def __init__(self, base_url, timeout=60,\n pool_connections=constants.DEFAULT_NUM_POOLS):\n logging.getLogger(\"paramiko\").setLevel(logging.WARNING)\n self.ssh_client = paramiko.SSHClient()\n base_url = six.moves.urllib_parse.urlparse(base_url)\n self.ssh_params = {\n \"hostname\": base_url.hostname,\n \"port\": base_url.port,\n \"username\": base_url.username\n }\n ssh_config_file = os.path.expanduser(\"~/.ssh/config\")\n if os.path.exists(ssh_config_file):\n conf = paramiko.SSHConfig()\n with open(ssh_config_file) as f:\n conf.parse(f)\n host_config = conf.lookup(base_url.hostname)\n self.ssh_conf = host_config\n if 'proxycommand' in host_config:\n self.ssh_params[\"sock\"] = paramiko.ProxyCommand(\n self.ssh_conf['proxycommand']\n )\n if 'hostname' in host_config:\n self.ssh_params['hostname'] = host_config['hostname']\n if 'identityfile' in host_config:\n self.ssh_params['key_filename'] = host_config['identityfile']\n if base_url.port is None and 'port' in host_config:\n self.ssh_params['port'] = self.ssh_conf['port']\n if base_url.username is None and 'user' in host_config:\n self.ssh_params['username'] = self.ssh_conf['user']\n\n self.ssh_client.load_system_host_keys()\n self.ssh_client.set_missing_host_key_policy(paramiko.WarningPolicy())\n\n self._connect()\n self.timeout = timeout\n self.pools = RecentlyUsedContainer(\n pool_connections, dispose_func=lambda p: p.close()\n )\n super(SSHHTTPAdapter, self).__init__()\n\n def _connect(self):\n self.ssh_client.connect(**self.ssh_params)\n\n def get_connection(self, url, proxies=None):\n with self.pools.lock:\n pool = self.pools.get(url)\n if pool:\n return pool\n\n # Connection is closed try a reconnect\n if not self.ssh_client.get_transport():\n self._connect()\n\n pool = SSHConnectionPool(\n self.ssh_client, self.timeout\n )\n self.pools[url] = pool\n\n return pool\n\n def close(self):\n super(SSHHTTPAdapter, self).close()\n self.ssh_client.close()\n", "path": "docker/transport/sshconn.py"}]}
| 1,903 | 153 |
gh_patches_debug_12850
|
rasdani/github-patches
|
git_diff
|
DataDog__integrations-extras-1550
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add support for filebeat version 7.x
**Docker image:** custom docker image based on `datadog/agent:7.28.0` with this added to the `Dockerfile` `RUN agent integration install -r -t datadog-filebeat==1.0.0`
Since filebeat version `7.x`, the registry file is moved to [directory format][0]. Therefore, the current config will not work as the registry is not in a single file format anymore.
[Snippet][1] from the config example for filebeat:
```
instances:
## @param registry_file_path - string - required
## The absolute path to the registry file used by Filebeat.
##
## See https://www.elastic.co/guide/en/beats/filebeat/current/migration-registry-file.html
#
- registry_file_path: /var/lib/filebeat/registry
```
The error message from `docker logs datadog-agent`
```
2021-06-17 03:20:33 UTC | CORE | ERROR | (pkg/collector/python/datadog_agent.go:120 in LogMessage) | filebeat:71abd2e9bec66d7b | (filebeat.py:251) | Cannot read the registry log file at /usr/share/filebeat/data/registry: [Errno 21] Is a directory: '/usr/share/filebeat/data/registry'
```
So datadog-agent and filebeat integration will not work with filebeat version 7.x for now.
[1]: https://github.com/DataDog/integrations-extras/blob/master/filebeat/datadog_checks/filebeat/data/conf.yaml.example#L46-L53
[0]: https://www.elastic.co/guide/en/beats/filebeat/current/configuration-general-options.html#_registry_migrate_file
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `filebeat/datadog_checks/filebeat/filebeat.py`
Content:
```
1 # (C) Datadog, Inc. 2010-2016
2 # All rights reserved
3 # Licensed under Simplified BSD License (see LICENSE)
4
5 # stdlib
6 import errno
7 import json
8 import os
9 import re
10 import sre_constants
11
12 import six
13 from six import iteritems
14
15 from datadog_checks.base import AgentCheck, is_affirmative
16 from datadog_checks.base.utils.containers import hash_mutable
17
18 if six.PY3:
19 from collections.abc import MutableMapping
20 else:
21 from collections import MutableMapping
22
23 EVENT_TYPE = SOURCE_TYPE_NAME = "filebeat"
24
25
26 class FilebeatCheckHttpProfiler:
27 """
28 Filebeat's HTTP profiler gives a bunch of counter variables; their value holds little interest,
29 what we really want is the delta in between runs. This class is responsible for caching the
30 values from the previous run
31 """
32
33 INCREMENT_METRIC_NAMES = [
34 "filebeat.events.done",
35 "filebeat.harvester.closed",
36 "filebeat.harvester.files.truncated",
37 "filebeat.harvester.open_files",
38 "filebeat.harvester.skipped",
39 "filebeat.harvester.started",
40 "filebeat.prospector.log.files.renamed",
41 "filebeat.prospector.log.files.truncated",
42 "libbeat.config.module.running",
43 "libbeat.config.module.starts",
44 "libbeat.config.module.stops",
45 "libbeat.config.reloads",
46 "libbeat.es.call_count.PublishEvents",
47 "libbeat.es.publish.read_bytes",
48 "libbeat.es.publish.read_errors",
49 "libbeat.es.publish.write_bytes",
50 "libbeat.es.publish.write_errors",
51 "libbeat.es.published_and_acked_events",
52 "libbeat.es.published_but_not_acked_events",
53 "libbeat.kafka.call_count.PublishEvents",
54 "libbeat.kafka.published_and_acked_events",
55 "libbeat.kafka.published_but_not_acked_events",
56 "libbeat.logstash.call_count.PublishEvents",
57 "libbeat.logstash.publish.read_bytes",
58 "libbeat.logstash.publish.read_errors",
59 "libbeat.logstash.publish.write_bytes",
60 "libbeat.logstash.publish.write_errors",
61 "libbeat.logstash.published_and_acked_events",
62 "libbeat.logstash.published_but_not_acked_events",
63 "libbeat.output.events.acked",
64 "libbeat.output.events.dropped",
65 "libbeat.output.events.failed",
66 "libbeat.output.events.total",
67 "libbeat.pipeline.events.dropped",
68 "libbeat.pipeline.events.failed",
69 "libbeat.pipeline.events.filtered",
70 "libbeat.pipeline.events.published",
71 "libbeat.pipeline.events.total",
72 "libbeat.publisher.messages_in_worker_queues",
73 "libbeat.publisher.published_events",
74 "libbeat.redis.publish.read_bytes",
75 "libbeat.redis.publish.read_errors",
76 "libbeat.redis.publish.write_bytes",
77 "libbeat.redis.publish.write_errors",
78 "publish.events",
79 "registrar.states.cleanup",
80 "registrar.states.current",
81 "registrar.states.update",
82 "registrar.writes",
83 ]
84
85 GAUGE_METRIC_NAMES = ["filebeat.harvester.running"]
86
87 VARS_ROUTE = "debug/vars"
88
89 def __init__(self, config, http):
90 self._config = config
91 self._http = http
92 self._previous_increment_values = {}
93 # regex matching ain't free, let's cache this
94 self._should_keep_metrics = {}
95
96 def gather_metrics(self):
97 if not self._config.stats_endpoint:
98 return {}
99
100 response = self._make_request()
101
102 return {"increment": self._gather_increment_metrics(response), "gauge": self._gather_gauge_metrics(response)}
103
104 def _make_request(self):
105
106 response = self._http.get(self._config.stats_endpoint)
107 response.raise_for_status()
108
109 return self.flatten(response.json())
110
111 def _gather_increment_metrics(self, response):
112 new_values = {
113 name: response[name]
114 for name in self.INCREMENT_METRIC_NAMES
115 if self._should_keep_metric(name) and name in response
116 }
117
118 deltas = self._compute_increment_deltas(new_values)
119
120 self._previous_increment_values = new_values
121
122 return deltas
123
124 def _compute_increment_deltas(self, new_values):
125 deltas = {}
126
127 for name, new_value in iteritems(new_values):
128 if name not in self._previous_increment_values or self._previous_increment_values[name] > new_value:
129 # either the agent or filebeat got restarted, we're not
130 # reporting anything this time around
131 return {}
132 deltas[name] = new_value - self._previous_increment_values[name]
133
134 return deltas
135
136 def _gather_gauge_metrics(self, response):
137 return {
138 name: response[name]
139 for name in self.GAUGE_METRIC_NAMES
140 if self._should_keep_metric(name) and name in response
141 }
142
143 def _should_keep_metric(self, name):
144 if name not in self._should_keep_metrics:
145 self._should_keep_metrics[name] = self._config.should_keep_metric(name)
146 return self._should_keep_metrics[name]
147
148 def flatten(self, d, parent_key="", sep="."):
149 items = []
150 for k, v in d.items():
151 new_key = parent_key + sep + k if parent_key else k
152 if isinstance(v, MutableMapping):
153 items.extend(self.flatten(v, new_key, sep=sep).items())
154 else:
155 items.append((new_key, v))
156 return dict(items)
157
158
159 class FilebeatCheckInstanceConfig:
160
161 _only_metrics_regexes = None
162
163 def __init__(self, instance):
164 self._registry_file_path = instance.get("registry_file_path")
165 if self._registry_file_path is None:
166 raise Exception("An absolute path to a filebeat registry path must be specified")
167
168 self._stats_endpoint = instance.get("stats_endpoint")
169
170 self._only_metrics = instance.get("only_metrics", [])
171
172 self._ignore_registry = instance.get("ignore_registry", False)
173
174 if not isinstance(self._only_metrics, list):
175 raise Exception(
176 "If given, filebeat's only_metrics must be a list of regexes, got %s" % (self._only_metrics,)
177 )
178
179 @property
180 def registry_file_path(self):
181 return self._registry_file_path
182
183 @property
184 def stats_endpoint(self):
185 return self._stats_endpoint
186
187 @property
188 def ignore_registry(self):
189 return self._ignore_registry
190
191 def should_keep_metric(self, metric_name):
192
193 if not self._only_metrics:
194 return True
195
196 return any(re.search(regex, metric_name) for regex in self._compiled_regexes())
197
198 def _compiled_regexes(self):
199 if self._only_metrics_regexes is None:
200 self._only_metrics_regexes = self._compile_regexes()
201 return self._only_metrics_regexes
202
203 def _compile_regexes(self):
204 compiled_regexes = []
205
206 for regex in self._only_metrics:
207 try:
208 compiled_regexes.append(re.compile(regex))
209 except sre_constants.error as ex:
210 raise Exception('Invalid only_metric regex for filebeat: "%s", error: %s' % (regex, ex))
211
212 return compiled_regexes
213
214
215 class FilebeatCheck(AgentCheck):
216
217 SERVICE_CHECK_NAME = 'can_connect'
218
219 __NAMESPACE__ = "filebeat"
220
221 def __init__(self, *args, **kwargs):
222 AgentCheck.__init__(self, *args, **kwargs)
223 self.instance_cache = {}
224 self.tags = []
225
226 if self.instance:
227 self.tags = self.instance.get('tags', [])
228 # preserve backwards compatible default timeouts
229 if self.instance.get('timeout') is None:
230 if self.init_config.get('timeout') is None:
231 self.instance['timeout'] = 2
232
233 def check(self, instance):
234 normalize_metrics = is_affirmative(instance.get("normalize_metrics", False))
235
236 instance_key = hash_mutable(instance)
237 if instance_key in self.instance_cache:
238 config = self.instance_cache[instance_key]["config"]
239 profiler = self.instance_cache[instance_key]["profiler"]
240 else:
241 config = FilebeatCheckInstanceConfig(instance)
242 profiler = FilebeatCheckHttpProfiler(config, self.http)
243 self.instance_cache[instance_key] = {"config": config, "profiler": profiler}
244
245 if not config.ignore_registry:
246 self._process_registry(config)
247
248 self._gather_http_profiler_metrics(config, profiler, normalize_metrics)
249
250 def _process_registry(self, config):
251 registry_contents = self._parse_registry_file(config.registry_file_path)
252
253 if isinstance(registry_contents, dict):
254 # filebeat version < 5
255 registry_contents = registry_contents.values()
256
257 for item in registry_contents:
258 self._process_registry_item(item)
259
260 def _parse_registry_file(self, registry_file_path):
261 try:
262 with open(registry_file_path) as registry_file:
263 return json.load(registry_file)
264 except IOError as ex:
265 self.log.error("Cannot read the registry log file at %s: %s", registry_file_path, ex)
266
267 if ex.errno == errno.EACCES:
268 self.log.error(
269 "You might be interesting in having a look at " "https://github.com/elastic/beats/pull/6455"
270 )
271
272 return []
273
274 def _process_registry_item(self, item):
275 source = item["source"]
276 offset = item["offset"]
277 tags = self.tags + ["source:{0}".format(source)]
278
279 try:
280 stats = os.stat(source)
281
282 if self._is_same_file(stats, item["FileStateOS"]):
283 unprocessed_bytes = stats.st_size - offset
284
285 self.gauge("registry.unprocessed_bytes", unprocessed_bytes, tags=tags)
286 else:
287 self.log.debug("Filebeat source %s appears to have changed", source)
288 except OSError:
289 self.log.debug("Unable to get stats on filebeat source %s", source)
290
291 def _is_same_file(self, stats, file_state_os):
292 return stats.st_dev == file_state_os["device"] and stats.st_ino == file_state_os["inode"]
293
294 def _gather_http_profiler_metrics(self, config, profiler, normalize_metrics):
295 tags = self.tags + ["stats_endpoint:{0}".format(config.stats_endpoint)]
296 try:
297 all_metrics = profiler.gather_metrics()
298 except Exception as ex:
299 self.log.error("Error when fetching metrics from %s: %s", config.stats_endpoint, ex)
300 self.service_check(
301 self.SERVICE_CHECK_NAME,
302 AgentCheck.CRITICAL,
303 message="Error {0} when hitting {1}".format(ex, config.stats_endpoint),
304 )
305 return
306
307 for action, metrics in iteritems(all_metrics):
308 method = getattr(self, action)
309
310 for name, value in iteritems(metrics):
311 if not name.startswith(self.__NAMESPACE__) and normalize_metrics:
312 method(name, value, tags)
313 else:
314 method(name, value, tags, raw=True)
315 self.service_check(self.SERVICE_CHECK_NAME, AgentCheck.OK, tags=tags)
316
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/filebeat/datadog_checks/filebeat/filebeat.py b/filebeat/datadog_checks/filebeat/filebeat.py
--- a/filebeat/datadog_checks/filebeat/filebeat.py
+++ b/filebeat/datadog_checks/filebeat/filebeat.py
@@ -261,6 +261,16 @@
try:
with open(registry_file_path) as registry_file:
return json.load(registry_file)
+
+ except ValueError:
+ contents = []
+ with open(registry_file_path) as registry_file:
+ for line in registry_file:
+ content = json.loads(line)
+ if 'op' not in content.keys():
+ contents.append(content['v'])
+ return contents
+
except IOError as ex:
self.log.error("Cannot read the registry log file at %s: %s", registry_file_path, ex)
|
{"golden_diff": "diff --git a/filebeat/datadog_checks/filebeat/filebeat.py b/filebeat/datadog_checks/filebeat/filebeat.py\n--- a/filebeat/datadog_checks/filebeat/filebeat.py\n+++ b/filebeat/datadog_checks/filebeat/filebeat.py\n@@ -261,6 +261,16 @@\n try:\n with open(registry_file_path) as registry_file:\n return json.load(registry_file)\n+\n+ except ValueError:\n+ contents = []\n+ with open(registry_file_path) as registry_file:\n+ for line in registry_file:\n+ content = json.loads(line)\n+ if 'op' not in content.keys():\n+ contents.append(content['v'])\n+ return contents\n+\n except IOError as ex:\n self.log.error(\"Cannot read the registry log file at %s: %s\", registry_file_path, ex)\n", "issue": "Add support for filebeat version 7.x\n**Docker image:** custom docker image based on `datadog/agent:7.28.0` with this added to the `Dockerfile` `RUN agent integration install -r -t datadog-filebeat==1.0.0`\r\n\r\nSince filebeat version `7.x`, the registry file is moved to [directory format][0]. Therefore, the current config will not work as the registry is not in a single file format anymore.\r\n\r\n[Snippet][1] from the config example for filebeat:\r\n```\r\ninstances:\r\n\r\n ## @param registry_file_path - string - required\r\n ## The absolute path to the registry file used by Filebeat.\r\n ##\r\n ## See https://www.elastic.co/guide/en/beats/filebeat/current/migration-registry-file.html\r\n #\r\n - registry_file_path: /var/lib/filebeat/registry\r\n```\r\n\r\nThe error message from `docker logs datadog-agent`\r\n```\r\n2021-06-17 03:20:33 UTC | CORE | ERROR | (pkg/collector/python/datadog_agent.go:120 in LogMessage) | filebeat:71abd2e9bec66d7b | (filebeat.py:251) | Cannot read the registry log file at /usr/share/filebeat/data/registry: [Errno 21] Is a directory: '/usr/share/filebeat/data/registry'\r\n```\r\n\r\nSo datadog-agent and filebeat integration will not work with filebeat version 7.x for now.\r\n\r\n\r\n[1]: https://github.com/DataDog/integrations-extras/blob/master/filebeat/datadog_checks/filebeat/data/conf.yaml.example#L46-L53\r\n[0]: https://www.elastic.co/guide/en/beats/filebeat/current/configuration-general-options.html#_registry_migrate_file\r\n\n", "before_files": [{"content": "# (C) Datadog, Inc. 2010-2016\n# All rights reserved\n# Licensed under Simplified BSD License (see LICENSE)\n\n# stdlib\nimport errno\nimport json\nimport os\nimport re\nimport sre_constants\n\nimport six\nfrom six import iteritems\n\nfrom datadog_checks.base import AgentCheck, is_affirmative\nfrom datadog_checks.base.utils.containers import hash_mutable\n\nif six.PY3:\n from collections.abc import MutableMapping\nelse:\n from collections import MutableMapping\n\nEVENT_TYPE = SOURCE_TYPE_NAME = \"filebeat\"\n\n\nclass FilebeatCheckHttpProfiler:\n \"\"\"\n Filebeat's HTTP profiler gives a bunch of counter variables; their value holds little interest,\n what we really want is the delta in between runs. This class is responsible for caching the\n values from the previous run\n \"\"\"\n\n INCREMENT_METRIC_NAMES = [\n \"filebeat.events.done\",\n \"filebeat.harvester.closed\",\n \"filebeat.harvester.files.truncated\",\n \"filebeat.harvester.open_files\",\n \"filebeat.harvester.skipped\",\n \"filebeat.harvester.started\",\n \"filebeat.prospector.log.files.renamed\",\n \"filebeat.prospector.log.files.truncated\",\n \"libbeat.config.module.running\",\n \"libbeat.config.module.starts\",\n \"libbeat.config.module.stops\",\n \"libbeat.config.reloads\",\n \"libbeat.es.call_count.PublishEvents\",\n \"libbeat.es.publish.read_bytes\",\n \"libbeat.es.publish.read_errors\",\n \"libbeat.es.publish.write_bytes\",\n \"libbeat.es.publish.write_errors\",\n \"libbeat.es.published_and_acked_events\",\n \"libbeat.es.published_but_not_acked_events\",\n \"libbeat.kafka.call_count.PublishEvents\",\n \"libbeat.kafka.published_and_acked_events\",\n \"libbeat.kafka.published_but_not_acked_events\",\n \"libbeat.logstash.call_count.PublishEvents\",\n \"libbeat.logstash.publish.read_bytes\",\n \"libbeat.logstash.publish.read_errors\",\n \"libbeat.logstash.publish.write_bytes\",\n \"libbeat.logstash.publish.write_errors\",\n \"libbeat.logstash.published_and_acked_events\",\n \"libbeat.logstash.published_but_not_acked_events\",\n \"libbeat.output.events.acked\",\n \"libbeat.output.events.dropped\",\n \"libbeat.output.events.failed\",\n \"libbeat.output.events.total\",\n \"libbeat.pipeline.events.dropped\",\n \"libbeat.pipeline.events.failed\",\n \"libbeat.pipeline.events.filtered\",\n \"libbeat.pipeline.events.published\",\n \"libbeat.pipeline.events.total\",\n \"libbeat.publisher.messages_in_worker_queues\",\n \"libbeat.publisher.published_events\",\n \"libbeat.redis.publish.read_bytes\",\n \"libbeat.redis.publish.read_errors\",\n \"libbeat.redis.publish.write_bytes\",\n \"libbeat.redis.publish.write_errors\",\n \"publish.events\",\n \"registrar.states.cleanup\",\n \"registrar.states.current\",\n \"registrar.states.update\",\n \"registrar.writes\",\n ]\n\n GAUGE_METRIC_NAMES = [\"filebeat.harvester.running\"]\n\n VARS_ROUTE = \"debug/vars\"\n\n def __init__(self, config, http):\n self._config = config\n self._http = http\n self._previous_increment_values = {}\n # regex matching ain't free, let's cache this\n self._should_keep_metrics = {}\n\n def gather_metrics(self):\n if not self._config.stats_endpoint:\n return {}\n\n response = self._make_request()\n\n return {\"increment\": self._gather_increment_metrics(response), \"gauge\": self._gather_gauge_metrics(response)}\n\n def _make_request(self):\n\n response = self._http.get(self._config.stats_endpoint)\n response.raise_for_status()\n\n return self.flatten(response.json())\n\n def _gather_increment_metrics(self, response):\n new_values = {\n name: response[name]\n for name in self.INCREMENT_METRIC_NAMES\n if self._should_keep_metric(name) and name in response\n }\n\n deltas = self._compute_increment_deltas(new_values)\n\n self._previous_increment_values = new_values\n\n return deltas\n\n def _compute_increment_deltas(self, new_values):\n deltas = {}\n\n for name, new_value in iteritems(new_values):\n if name not in self._previous_increment_values or self._previous_increment_values[name] > new_value:\n # either the agent or filebeat got restarted, we're not\n # reporting anything this time around\n return {}\n deltas[name] = new_value - self._previous_increment_values[name]\n\n return deltas\n\n def _gather_gauge_metrics(self, response):\n return {\n name: response[name]\n for name in self.GAUGE_METRIC_NAMES\n if self._should_keep_metric(name) and name in response\n }\n\n def _should_keep_metric(self, name):\n if name not in self._should_keep_metrics:\n self._should_keep_metrics[name] = self._config.should_keep_metric(name)\n return self._should_keep_metrics[name]\n\n def flatten(self, d, parent_key=\"\", sep=\".\"):\n items = []\n for k, v in d.items():\n new_key = parent_key + sep + k if parent_key else k\n if isinstance(v, MutableMapping):\n items.extend(self.flatten(v, new_key, sep=sep).items())\n else:\n items.append((new_key, v))\n return dict(items)\n\n\nclass FilebeatCheckInstanceConfig:\n\n _only_metrics_regexes = None\n\n def __init__(self, instance):\n self._registry_file_path = instance.get(\"registry_file_path\")\n if self._registry_file_path is None:\n raise Exception(\"An absolute path to a filebeat registry path must be specified\")\n\n self._stats_endpoint = instance.get(\"stats_endpoint\")\n\n self._only_metrics = instance.get(\"only_metrics\", [])\n\n self._ignore_registry = instance.get(\"ignore_registry\", False)\n\n if not isinstance(self._only_metrics, list):\n raise Exception(\n \"If given, filebeat's only_metrics must be a list of regexes, got %s\" % (self._only_metrics,)\n )\n\n @property\n def registry_file_path(self):\n return self._registry_file_path\n\n @property\n def stats_endpoint(self):\n return self._stats_endpoint\n\n @property\n def ignore_registry(self):\n return self._ignore_registry\n\n def should_keep_metric(self, metric_name):\n\n if not self._only_metrics:\n return True\n\n return any(re.search(regex, metric_name) for regex in self._compiled_regexes())\n\n def _compiled_regexes(self):\n if self._only_metrics_regexes is None:\n self._only_metrics_regexes = self._compile_regexes()\n return self._only_metrics_regexes\n\n def _compile_regexes(self):\n compiled_regexes = []\n\n for regex in self._only_metrics:\n try:\n compiled_regexes.append(re.compile(regex))\n except sre_constants.error as ex:\n raise Exception('Invalid only_metric regex for filebeat: \"%s\", error: %s' % (regex, ex))\n\n return compiled_regexes\n\n\nclass FilebeatCheck(AgentCheck):\n\n SERVICE_CHECK_NAME = 'can_connect'\n\n __NAMESPACE__ = \"filebeat\"\n\n def __init__(self, *args, **kwargs):\n AgentCheck.__init__(self, *args, **kwargs)\n self.instance_cache = {}\n self.tags = []\n\n if self.instance:\n self.tags = self.instance.get('tags', [])\n # preserve backwards compatible default timeouts\n if self.instance.get('timeout') is None:\n if self.init_config.get('timeout') is None:\n self.instance['timeout'] = 2\n\n def check(self, instance):\n normalize_metrics = is_affirmative(instance.get(\"normalize_metrics\", False))\n\n instance_key = hash_mutable(instance)\n if instance_key in self.instance_cache:\n config = self.instance_cache[instance_key][\"config\"]\n profiler = self.instance_cache[instance_key][\"profiler\"]\n else:\n config = FilebeatCheckInstanceConfig(instance)\n profiler = FilebeatCheckHttpProfiler(config, self.http)\n self.instance_cache[instance_key] = {\"config\": config, \"profiler\": profiler}\n\n if not config.ignore_registry:\n self._process_registry(config)\n\n self._gather_http_profiler_metrics(config, profiler, normalize_metrics)\n\n def _process_registry(self, config):\n registry_contents = self._parse_registry_file(config.registry_file_path)\n\n if isinstance(registry_contents, dict):\n # filebeat version < 5\n registry_contents = registry_contents.values()\n\n for item in registry_contents:\n self._process_registry_item(item)\n\n def _parse_registry_file(self, registry_file_path):\n try:\n with open(registry_file_path) as registry_file:\n return json.load(registry_file)\n except IOError as ex:\n self.log.error(\"Cannot read the registry log file at %s: %s\", registry_file_path, ex)\n\n if ex.errno == errno.EACCES:\n self.log.error(\n \"You might be interesting in having a look at \" \"https://github.com/elastic/beats/pull/6455\"\n )\n\n return []\n\n def _process_registry_item(self, item):\n source = item[\"source\"]\n offset = item[\"offset\"]\n tags = self.tags + [\"source:{0}\".format(source)]\n\n try:\n stats = os.stat(source)\n\n if self._is_same_file(stats, item[\"FileStateOS\"]):\n unprocessed_bytes = stats.st_size - offset\n\n self.gauge(\"registry.unprocessed_bytes\", unprocessed_bytes, tags=tags)\n else:\n self.log.debug(\"Filebeat source %s appears to have changed\", source)\n except OSError:\n self.log.debug(\"Unable to get stats on filebeat source %s\", source)\n\n def _is_same_file(self, stats, file_state_os):\n return stats.st_dev == file_state_os[\"device\"] and stats.st_ino == file_state_os[\"inode\"]\n\n def _gather_http_profiler_metrics(self, config, profiler, normalize_metrics):\n tags = self.tags + [\"stats_endpoint:{0}\".format(config.stats_endpoint)]\n try:\n all_metrics = profiler.gather_metrics()\n except Exception as ex:\n self.log.error(\"Error when fetching metrics from %s: %s\", config.stats_endpoint, ex)\n self.service_check(\n self.SERVICE_CHECK_NAME,\n AgentCheck.CRITICAL,\n message=\"Error {0} when hitting {1}\".format(ex, config.stats_endpoint),\n )\n return\n\n for action, metrics in iteritems(all_metrics):\n method = getattr(self, action)\n\n for name, value in iteritems(metrics):\n if not name.startswith(self.__NAMESPACE__) and normalize_metrics:\n method(name, value, tags)\n else:\n method(name, value, tags, raw=True)\n self.service_check(self.SERVICE_CHECK_NAME, AgentCheck.OK, tags=tags)\n", "path": "filebeat/datadog_checks/filebeat/filebeat.py"}], "after_files": [{"content": "# (C) Datadog, Inc. 2010-2016\n# All rights reserved\n# Licensed under Simplified BSD License (see LICENSE)\n\n# stdlib\nimport errno\nimport json\nimport os\nimport re\nimport sre_constants\n\nimport six\nfrom six import iteritems\n\nfrom datadog_checks.base import AgentCheck, is_affirmative\nfrom datadog_checks.base.utils.containers import hash_mutable\n\nif six.PY3:\n from collections.abc import MutableMapping\nelse:\n from collections import MutableMapping\n\nEVENT_TYPE = SOURCE_TYPE_NAME = \"filebeat\"\n\n\nclass FilebeatCheckHttpProfiler:\n \"\"\"\n Filebeat's HTTP profiler gives a bunch of counter variables; their value holds little interest,\n what we really want is the delta in between runs. This class is responsible for caching the\n values from the previous run\n \"\"\"\n\n INCREMENT_METRIC_NAMES = [\n \"filebeat.events.done\",\n \"filebeat.harvester.closed\",\n \"filebeat.harvester.files.truncated\",\n \"filebeat.harvester.open_files\",\n \"filebeat.harvester.skipped\",\n \"filebeat.harvester.started\",\n \"filebeat.prospector.log.files.renamed\",\n \"filebeat.prospector.log.files.truncated\",\n \"libbeat.config.module.running\",\n \"libbeat.config.module.starts\",\n \"libbeat.config.module.stops\",\n \"libbeat.config.reloads\",\n \"libbeat.es.call_count.PublishEvents\",\n \"libbeat.es.publish.read_bytes\",\n \"libbeat.es.publish.read_errors\",\n \"libbeat.es.publish.write_bytes\",\n \"libbeat.es.publish.write_errors\",\n \"libbeat.es.published_and_acked_events\",\n \"libbeat.es.published_but_not_acked_events\",\n \"libbeat.kafka.call_count.PublishEvents\",\n \"libbeat.kafka.published_and_acked_events\",\n \"libbeat.kafka.published_but_not_acked_events\",\n \"libbeat.logstash.call_count.PublishEvents\",\n \"libbeat.logstash.publish.read_bytes\",\n \"libbeat.logstash.publish.read_errors\",\n \"libbeat.logstash.publish.write_bytes\",\n \"libbeat.logstash.publish.write_errors\",\n \"libbeat.logstash.published_and_acked_events\",\n \"libbeat.logstash.published_but_not_acked_events\",\n \"libbeat.output.events.acked\",\n \"libbeat.output.events.dropped\",\n \"libbeat.output.events.failed\",\n \"libbeat.output.events.total\",\n \"libbeat.pipeline.events.dropped\",\n \"libbeat.pipeline.events.failed\",\n \"libbeat.pipeline.events.filtered\",\n \"libbeat.pipeline.events.published\",\n \"libbeat.pipeline.events.total\",\n \"libbeat.publisher.messages_in_worker_queues\",\n \"libbeat.publisher.published_events\",\n \"libbeat.redis.publish.read_bytes\",\n \"libbeat.redis.publish.read_errors\",\n \"libbeat.redis.publish.write_bytes\",\n \"libbeat.redis.publish.write_errors\",\n \"publish.events\",\n \"registrar.states.cleanup\",\n \"registrar.states.current\",\n \"registrar.states.update\",\n \"registrar.writes\",\n ]\n\n GAUGE_METRIC_NAMES = [\"filebeat.harvester.running\"]\n\n VARS_ROUTE = \"debug/vars\"\n\n def __init__(self, config, http):\n self._config = config\n self._http = http\n self._previous_increment_values = {}\n # regex matching ain't free, let's cache this\n self._should_keep_metrics = {}\n\n def gather_metrics(self):\n if not self._config.stats_endpoint:\n return {}\n\n response = self._make_request()\n\n return {\"increment\": self._gather_increment_metrics(response), \"gauge\": self._gather_gauge_metrics(response)}\n\n def _make_request(self):\n\n response = self._http.get(self._config.stats_endpoint)\n response.raise_for_status()\n\n return self.flatten(response.json())\n\n def _gather_increment_metrics(self, response):\n new_values = {\n name: response[name]\n for name in self.INCREMENT_METRIC_NAMES\n if self._should_keep_metric(name) and name in response\n }\n\n deltas = self._compute_increment_deltas(new_values)\n\n self._previous_increment_values = new_values\n\n return deltas\n\n def _compute_increment_deltas(self, new_values):\n deltas = {}\n\n for name, new_value in iteritems(new_values):\n if name not in self._previous_increment_values or self._previous_increment_values[name] > new_value:\n # either the agent or filebeat got restarted, we're not\n # reporting anything this time around\n return {}\n deltas[name] = new_value - self._previous_increment_values[name]\n\n return deltas\n\n def _gather_gauge_metrics(self, response):\n return {\n name: response[name]\n for name in self.GAUGE_METRIC_NAMES\n if self._should_keep_metric(name) and name in response\n }\n\n def _should_keep_metric(self, name):\n if name not in self._should_keep_metrics:\n self._should_keep_metrics[name] = self._config.should_keep_metric(name)\n return self._should_keep_metrics[name]\n\n def flatten(self, d, parent_key=\"\", sep=\".\"):\n items = []\n for k, v in d.items():\n new_key = parent_key + sep + k if parent_key else k\n if isinstance(v, MutableMapping):\n items.extend(self.flatten(v, new_key, sep=sep).items())\n else:\n items.append((new_key, v))\n return dict(items)\n\n\nclass FilebeatCheckInstanceConfig:\n\n _only_metrics_regexes = None\n\n def __init__(self, instance):\n self._registry_file_path = instance.get(\"registry_file_path\")\n if self._registry_file_path is None:\n raise Exception(\"An absolute path to a filebeat registry path must be specified\")\n\n self._stats_endpoint = instance.get(\"stats_endpoint\")\n\n self._only_metrics = instance.get(\"only_metrics\", [])\n\n self._ignore_registry = instance.get(\"ignore_registry\", False)\n\n if not isinstance(self._only_metrics, list):\n raise Exception(\n \"If given, filebeat's only_metrics must be a list of regexes, got %s\" % (self._only_metrics,)\n )\n\n @property\n def registry_file_path(self):\n return self._registry_file_path\n\n @property\n def stats_endpoint(self):\n return self._stats_endpoint\n\n @property\n def ignore_registry(self):\n return self._ignore_registry\n\n def should_keep_metric(self, metric_name):\n\n if not self._only_metrics:\n return True\n\n return any(re.search(regex, metric_name) for regex in self._compiled_regexes())\n\n def _compiled_regexes(self):\n if self._only_metrics_regexes is None:\n self._only_metrics_regexes = self._compile_regexes()\n return self._only_metrics_regexes\n\n def _compile_regexes(self):\n compiled_regexes = []\n\n for regex in self._only_metrics:\n try:\n compiled_regexes.append(re.compile(regex))\n except sre_constants.error as ex:\n raise Exception('Invalid only_metric regex for filebeat: \"%s\", error: %s' % (regex, ex))\n\n return compiled_regexes\n\n\nclass FilebeatCheck(AgentCheck):\n\n SERVICE_CHECK_NAME = 'can_connect'\n\n __NAMESPACE__ = \"filebeat\"\n\n def __init__(self, *args, **kwargs):\n AgentCheck.__init__(self, *args, **kwargs)\n self.instance_cache = {}\n self.tags = []\n\n if self.instance:\n self.tags = self.instance.get('tags', [])\n # preserve backwards compatible default timeouts\n if self.instance.get('timeout') is None:\n if self.init_config.get('timeout') is None:\n self.instance['timeout'] = 2\n\n def check(self, instance):\n normalize_metrics = is_affirmative(instance.get(\"normalize_metrics\", False))\n\n instance_key = hash_mutable(instance)\n if instance_key in self.instance_cache:\n config = self.instance_cache[instance_key][\"config\"]\n profiler = self.instance_cache[instance_key][\"profiler\"]\n else:\n config = FilebeatCheckInstanceConfig(instance)\n profiler = FilebeatCheckHttpProfiler(config, self.http)\n self.instance_cache[instance_key] = {\"config\": config, \"profiler\": profiler}\n\n if not config.ignore_registry:\n self._process_registry(config)\n\n self._gather_http_profiler_metrics(config, profiler, normalize_metrics)\n\n def _process_registry(self, config):\n registry_contents = self._parse_registry_file(config.registry_file_path)\n\n if isinstance(registry_contents, dict):\n # filebeat version < 5\n registry_contents = registry_contents.values()\n\n for item in registry_contents:\n self._process_registry_item(item)\n\n def _parse_registry_file(self, registry_file_path):\n try:\n with open(registry_file_path) as registry_file:\n return json.load(registry_file)\n\n except ValueError:\n contents = []\n with open(registry_file_path) as registry_file:\n for line in registry_file:\n content = json.loads(line)\n if 'op' not in content.keys():\n contents.append(content['v'])\n return contents\n\n except IOError as ex:\n self.log.error(\"Cannot read the registry log file at %s: %s\", registry_file_path, ex)\n\n if ex.errno == errno.EACCES:\n self.log.error(\n \"You might be interesting in having a look at \" \"https://github.com/elastic/beats/pull/6455\"\n )\n\n return []\n\n def _process_registry_item(self, item):\n source = item[\"source\"]\n offset = item[\"offset\"]\n tags = self.tags + [\"source:{0}\".format(source)]\n\n try:\n stats = os.stat(source)\n\n if self._is_same_file(stats, item[\"FileStateOS\"]):\n unprocessed_bytes = stats.st_size - offset\n\n self.gauge(\"registry.unprocessed_bytes\", unprocessed_bytes, tags=tags)\n else:\n self.log.debug(\"Filebeat source %s appears to have changed\", source)\n except OSError:\n self.log.debug(\"Unable to get stats on filebeat source %s\", source)\n\n def _is_same_file(self, stats, file_state_os):\n return stats.st_dev == file_state_os[\"device\"] and stats.st_ino == file_state_os[\"inode\"]\n\n def _gather_http_profiler_metrics(self, config, profiler, normalize_metrics):\n tags = self.tags + [\"stats_endpoint:{0}\".format(config.stats_endpoint)]\n try:\n all_metrics = profiler.gather_metrics()\n except Exception as ex:\n self.log.error(\"Error when fetching metrics from %s: %s\", config.stats_endpoint, ex)\n self.service_check(\n self.SERVICE_CHECK_NAME,\n AgentCheck.CRITICAL,\n message=\"Error {0} when hitting {1}\".format(ex, config.stats_endpoint),\n )\n return\n\n for action, metrics in iteritems(all_metrics):\n method = getattr(self, action)\n\n for name, value in iteritems(metrics):\n if not name.startswith(self.__NAMESPACE__) and normalize_metrics:\n method(name, value, tags)\n else:\n method(name, value, tags, raw=True)\n self.service_check(self.SERVICE_CHECK_NAME, AgentCheck.OK, tags=tags)\n", "path": "filebeat/datadog_checks/filebeat/filebeat.py"}]}
| 3,910 | 189 |
gh_patches_debug_31823
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-1980
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
StaticFilesConfig and virtual directories
I'm trying to write a ``FileSystemProtocol`` to load files from the package data using [importlib_resources](https://importlib-resources.readthedocs.io/en/latest/using.html#). But because ``directories`` is defined as ``DirectoryPath``, pydantic checks if the given directories exist in the local filesystem.
This is not generally true, especially in any kind of virtual filesystem (e.g. a zipped package). I think this condition should be relaxed to support virtual filesystems.
https://github.com/starlite-api/starlite/blob/9bb6dcd57c10a591377cf8e3a537e9292566d5b9/starlite/config/static_files.py#L32
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `litestar/_openapi/path_item.py`
Content:
```
1 from __future__ import annotations
2
3 from inspect import cleandoc
4 from typing import TYPE_CHECKING
5
6 from litestar._openapi.parameters import create_parameter_for_handler
7 from litestar._openapi.request_body import create_request_body
8 from litestar._openapi.responses import create_responses
9 from litestar._openapi.schema_generation import SchemaCreator
10 from litestar._openapi.utils import SEPARATORS_CLEANUP_PATTERN
11 from litestar.openapi.spec.path_item import PathItem
12 from litestar.utils.helpers import unwrap_partial
13
14 __all__ = ("create_path_item", "extract_layered_values", "get_description_for_handler")
15
16
17 if TYPE_CHECKING:
18 from litestar.handlers.http_handlers import HTTPRouteHandler
19 from litestar.openapi.spec import Schema, SecurityRequirement
20 from litestar.plugins import OpenAPISchemaPluginProtocol
21 from litestar.routes import HTTPRoute
22 from litestar.types.callable_types import OperationIDCreator
23
24
25 def get_description_for_handler(route_handler: HTTPRouteHandler, use_handler_docstrings: bool) -> str | None:
26 """Produce the operation description for a route handler, either by using the description value if provided,
27
28 or the docstring - if config is enabled.
29
30 Args:
31 route_handler: A route handler instance.
32 use_handler_docstrings: If ``True`` and `route_handler.description`` is ``None` returns docstring of wrapped
33 handler function.
34
35 Returns:
36 An optional description string
37 """
38 handler_description = route_handler.description
39 if handler_description is None and use_handler_docstrings:
40 fn = unwrap_partial(route_handler.fn.value)
41 return cleandoc(fn.__doc__) if fn.__doc__ else None
42 return handler_description
43
44
45 def extract_layered_values(
46 route_handler: HTTPRouteHandler,
47 ) -> tuple[list[str] | None, list[dict[str, list[str]]] | None]:
48 """Extract the tags and security values from the route handler layers.
49
50 Args:
51 route_handler: A Route Handler instance.
52
53 Returns:
54 A tuple of optional lists.
55 """
56 tags: list[str] = []
57 security: list[SecurityRequirement] = []
58 for layer in route_handler.ownership_layers:
59 if layer.tags:
60 tags.extend(layer.tags)
61 if layer.security:
62 security.extend(layer.security)
63 return sorted(set(tags)) if tags else None, security or None
64
65
66 def create_path_item(
67 create_examples: bool,
68 operation_id_creator: OperationIDCreator,
69 plugins: list[OpenAPISchemaPluginProtocol],
70 route: HTTPRoute,
71 schemas: dict[str, Schema],
72 use_handler_docstrings: bool,
73 ) -> tuple[PathItem, list[str]]:
74 """Create a PathItem for the given route parsing all http_methods into Operation Models.
75
76 Args:
77 create_examples: Whether to auto-generate examples.
78 operation_id_creator: A function to generate operation ids.
79 plugins: A list of plugins.
80 route: An HTTPRoute instance.
81 schemas: A mapping of schemas.
82 use_handler_docstrings: Whether to use the handler docstring.
83
84 Returns:
85 A tuple containing the path item and a list of operation ids.
86 """
87 path_item = PathItem()
88 operation_ids: list[str] = []
89
90 request_schema_creator = SchemaCreator(create_examples, plugins, schemas, prefer_alias=True)
91 response_schema_creator = SchemaCreator(create_examples, plugins, schemas, prefer_alias=False)
92 for http_method, handler_tuple in route.route_handler_map.items():
93 route_handler, _ = handler_tuple
94
95 if route_handler.include_in_schema:
96 handler_fields = route_handler.signature_model._fields if route_handler.signature_model else {}
97 parameters = (
98 create_parameter_for_handler(
99 route_handler=route_handler,
100 handler_fields=handler_fields,
101 path_parameters=route.path_parameters,
102 schema_creator=request_schema_creator,
103 )
104 or None
105 )
106 raises_validation_error = bool("data" in handler_fields or path_item.parameters or parameters)
107
108 request_body = None
109 if "data" in handler_fields:
110 request_body = create_request_body(
111 route_handler=route_handler, field=handler_fields["data"], schema_creator=request_schema_creator
112 )
113 operation_id = route_handler.operation_id or operation_id_creator(
114 route_handler, http_method, route.path_components
115 )
116 tags, security = extract_layered_values(route_handler)
117 operation = route_handler.operation_class(
118 operation_id=operation_id,
119 tags=tags,
120 summary=route_handler.summary or SEPARATORS_CLEANUP_PATTERN.sub("", route_handler.handler_name.title()),
121 description=get_description_for_handler(route_handler, use_handler_docstrings),
122 deprecated=route_handler.deprecated,
123 responses=create_responses(
124 route_handler=route_handler,
125 raises_validation_error=raises_validation_error,
126 schema_creator=response_schema_creator,
127 ),
128 request_body=request_body,
129 parameters=parameters, # type: ignore[arg-type]
130 security=security,
131 )
132 operation_ids.append(operation_id)
133 setattr(path_item, http_method.lower(), operation)
134
135 return path_item, operation_ids
136
```
Path: `litestar/contrib/pydantic/pydantic_init_plugin.py`
Content:
```
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING, Any, Callable, TypeVar, cast
4 from uuid import UUID
5
6 from msgspec import ValidationError
7
8 from litestar.exceptions import MissingDependencyException
9 from litestar.plugins import InitPluginProtocol
10 from litestar.serialization._msgspec_utils import ExtendedMsgSpecValidationError
11 from litestar.utils import is_class_and_subclass, is_pydantic_model_class
12
13 if TYPE_CHECKING:
14 from litestar.config.app import AppConfig
15
16 try:
17 import pydantic
18 except ImportError as e:
19 raise MissingDependencyException("pydantic") from e
20
21 T = TypeVar("T")
22
23
24 def _dec_pydantic(model_type: type[pydantic.BaseModel], value: Any) -> pydantic.BaseModel:
25 try:
26 return (
27 model_type.model_validate(value, strict=False)
28 if hasattr(model_type, "model_validate")
29 else model_type.parse_obj(value)
30 )
31 except pydantic.ValidationError as e:
32 raise ExtendedMsgSpecValidationError(errors=cast("list[dict[str, Any]]", e.errors())) from e
33
34
35 def _dec_pydantic_uuid(
36 uuid_type: type[pydantic.UUID1] | type[pydantic.UUID3] | type[pydantic.UUID4] | type[pydantic.UUID5],
37 value: Any,
38 ) -> type[pydantic.UUID1] | type[pydantic.UUID3] | type[pydantic.UUID4] | type[pydantic.UUID5]: # pragma: no cover
39 if isinstance(value, str):
40 value = uuid_type(value)
41
42 elif isinstance(value, (bytes, bytearray)):
43 try:
44 value = uuid_type(value.decode())
45 except ValueError:
46 # 16 bytes in big-endian order as the bytes argument fail
47 # the above check
48 value = uuid_type(bytes=value)
49 elif isinstance(value, UUID):
50 value = uuid_type(str(value))
51
52 if not isinstance(value, uuid_type):
53 raise ValidationError(f"Invalid UUID: {value!r}")
54
55 if value._required_version != value.version: # pyright: ignore
56 raise ValidationError(f"Invalid UUID version: {value!r}")
57
58 return cast("type[pydantic.UUID1] | type[pydantic.UUID3] | type[pydantic.UUID4] | type[pydantic.UUID5]", value)
59
60
61 def _is_pydantic_uuid(value: Any) -> bool: # pragma: no cover
62 return is_class_and_subclass(value, (pydantic.UUID1, pydantic.UUID3, pydantic.UUID4, pydantic.UUID5))
63
64
65 _base_encoders: dict[Any, Callable[[Any], Any]] = {
66 pydantic.EmailStr: str,
67 pydantic.NameEmail: str,
68 pydantic.ByteSize: lambda val: val.real,
69 }
70
71
72 class PydanticInitPlugin(InitPluginProtocol):
73 @classmethod
74 def encoders(cls) -> dict[Any, Callable[[Any], Any]]:
75 if pydantic.VERSION.startswith("1"): # pragma: no cover
76 return {**_base_encoders, **cls._create_pydantic_v1_encoders()}
77 return {**_base_encoders, **cls._create_pydantic_v2_encoders()}
78
79 @classmethod
80 def decoders(cls) -> list[tuple[Callable[[Any], bool], Callable[[Any, Any], Any]]]:
81 decoders: list[tuple[Callable[[Any], bool], Callable[[Any, Any], Any]]] = [
82 (is_pydantic_model_class, _dec_pydantic)
83 ]
84
85 if pydantic.VERSION.startswith("1"): # pragma: no cover
86 decoders.append((_is_pydantic_uuid, _dec_pydantic_uuid))
87
88 return decoders
89
90 @staticmethod
91 def _create_pydantic_v1_encoders() -> dict[Any, Callable[[Any], Any]]: # pragma: no cover
92 return {
93 pydantic.BaseModel: lambda model: {
94 k: v.decode() if isinstance(v, bytes) else v for k, v in model.dict().items()
95 },
96 pydantic.SecretField: str,
97 pydantic.StrictBool: int,
98 pydantic.color.Color: str, # pyright: ignore
99 pydantic.ConstrainedBytes: lambda val: val.decode("utf-8"),
100 pydantic.ConstrainedDate: lambda val: val.isoformat(),
101 }
102
103 @staticmethod
104 def _create_pydantic_v2_encoders() -> dict[Any, Callable[[Any], Any]]:
105 from pydantic_extra_types import color
106
107 return {
108 pydantic.BaseModel: lambda model: model.model_dump(mode="json"),
109 color.Color: str,
110 pydantic.types.SecretStr: lambda val: "**********" if val else "",
111 pydantic.types.SecretBytes: lambda val: "**********" if val else "",
112 }
113
114 def on_app_init(self, app_config: AppConfig) -> AppConfig:
115 app_config.type_encoders = {**(app_config.type_encoders or {}), **self.encoders()}
116 app_config.type_decoders = [*(app_config.type_decoders or []), *self.decoders()]
117 return app_config
118
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/litestar/_openapi/path_item.py b/litestar/_openapi/path_item.py
--- a/litestar/_openapi/path_item.py
+++ b/litestar/_openapi/path_item.py
@@ -88,7 +88,7 @@
operation_ids: list[str] = []
request_schema_creator = SchemaCreator(create_examples, plugins, schemas, prefer_alias=True)
- response_schema_creator = SchemaCreator(create_examples, plugins, schemas, prefer_alias=False)
+ response_schema_creator = SchemaCreator(create_examples, plugins, schemas, prefer_alias=True)
for http_method, handler_tuple in route.route_handler_map.items():
route_handler, _ = handler_tuple
diff --git a/litestar/contrib/pydantic/pydantic_init_plugin.py b/litestar/contrib/pydantic/pydantic_init_plugin.py
--- a/litestar/contrib/pydantic/pydantic_init_plugin.py
+++ b/litestar/contrib/pydantic/pydantic_init_plugin.py
@@ -102,16 +102,20 @@
@staticmethod
def _create_pydantic_v2_encoders() -> dict[Any, Callable[[Any], Any]]:
- from pydantic_extra_types import color
-
- return {
+ try:
+ from pydantic_extra_types import color
+ except ImportError:
+ color = None # type: ignore[assignment]
+ encoders: dict[Any, Callable[[Any], Any]] = {
pydantic.BaseModel: lambda model: model.model_dump(mode="json"),
- color.Color: str,
pydantic.types.SecretStr: lambda val: "**********" if val else "",
pydantic.types.SecretBytes: lambda val: "**********" if val else "",
}
+ if color:
+ encoders[color.Color] = str
+ return encoders
def on_app_init(self, app_config: AppConfig) -> AppConfig:
- app_config.type_encoders = {**(app_config.type_encoders or {}), **self.encoders()}
- app_config.type_decoders = [*(app_config.type_decoders or []), *self.decoders()]
+ app_config.type_encoders = {**self.encoders(), **(app_config.type_encoders or {})}
+ app_config.type_decoders = [*self.decoders(), *(app_config.type_decoders or [])]
return app_config
|
{"golden_diff": "diff --git a/litestar/_openapi/path_item.py b/litestar/_openapi/path_item.py\n--- a/litestar/_openapi/path_item.py\n+++ b/litestar/_openapi/path_item.py\n@@ -88,7 +88,7 @@\n operation_ids: list[str] = []\n \n request_schema_creator = SchemaCreator(create_examples, plugins, schemas, prefer_alias=True)\n- response_schema_creator = SchemaCreator(create_examples, plugins, schemas, prefer_alias=False)\n+ response_schema_creator = SchemaCreator(create_examples, plugins, schemas, prefer_alias=True)\n for http_method, handler_tuple in route.route_handler_map.items():\n route_handler, _ = handler_tuple\n \ndiff --git a/litestar/contrib/pydantic/pydantic_init_plugin.py b/litestar/contrib/pydantic/pydantic_init_plugin.py\n--- a/litestar/contrib/pydantic/pydantic_init_plugin.py\n+++ b/litestar/contrib/pydantic/pydantic_init_plugin.py\n@@ -102,16 +102,20 @@\n \n @staticmethod\n def _create_pydantic_v2_encoders() -> dict[Any, Callable[[Any], Any]]:\n- from pydantic_extra_types import color\n-\n- return {\n+ try:\n+ from pydantic_extra_types import color\n+ except ImportError:\n+ color = None # type: ignore[assignment]\n+ encoders: dict[Any, Callable[[Any], Any]] = {\n pydantic.BaseModel: lambda model: model.model_dump(mode=\"json\"),\n- color.Color: str,\n pydantic.types.SecretStr: lambda val: \"**********\" if val else \"\",\n pydantic.types.SecretBytes: lambda val: \"**********\" if val else \"\",\n }\n+ if color:\n+ encoders[color.Color] = str\n+ return encoders\n \n def on_app_init(self, app_config: AppConfig) -> AppConfig:\n- app_config.type_encoders = {**(app_config.type_encoders or {}), **self.encoders()}\n- app_config.type_decoders = [*(app_config.type_decoders or []), *self.decoders()]\n+ app_config.type_encoders = {**self.encoders(), **(app_config.type_encoders or {})}\n+ app_config.type_decoders = [*self.decoders(), *(app_config.type_decoders or [])]\n return app_config\n", "issue": "StaticFilesConfig and virtual directories\nI'm trying to write a ``FileSystemProtocol`` to load files from the package data using [importlib_resources](https://importlib-resources.readthedocs.io/en/latest/using.html#). But because ``directories`` is defined as ``DirectoryPath``, pydantic checks if the given directories exist in the local filesystem. \r\n\r\nThis is not generally true, especially in any kind of virtual filesystem (e.g. a zipped package). I think this condition should be relaxed to support virtual filesystems.\r\n\r\nhttps://github.com/starlite-api/starlite/blob/9bb6dcd57c10a591377cf8e3a537e9292566d5b9/starlite/config/static_files.py#L32\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom inspect import cleandoc\nfrom typing import TYPE_CHECKING\n\nfrom litestar._openapi.parameters import create_parameter_for_handler\nfrom litestar._openapi.request_body import create_request_body\nfrom litestar._openapi.responses import create_responses\nfrom litestar._openapi.schema_generation import SchemaCreator\nfrom litestar._openapi.utils import SEPARATORS_CLEANUP_PATTERN\nfrom litestar.openapi.spec.path_item import PathItem\nfrom litestar.utils.helpers import unwrap_partial\n\n__all__ = (\"create_path_item\", \"extract_layered_values\", \"get_description_for_handler\")\n\n\nif TYPE_CHECKING:\n from litestar.handlers.http_handlers import HTTPRouteHandler\n from litestar.openapi.spec import Schema, SecurityRequirement\n from litestar.plugins import OpenAPISchemaPluginProtocol\n from litestar.routes import HTTPRoute\n from litestar.types.callable_types import OperationIDCreator\n\n\ndef get_description_for_handler(route_handler: HTTPRouteHandler, use_handler_docstrings: bool) -> str | None:\n \"\"\"Produce the operation description for a route handler, either by using the description value if provided,\n\n or the docstring - if config is enabled.\n\n Args:\n route_handler: A route handler instance.\n use_handler_docstrings: If ``True`` and `route_handler.description`` is ``None` returns docstring of wrapped\n handler function.\n\n Returns:\n An optional description string\n \"\"\"\n handler_description = route_handler.description\n if handler_description is None and use_handler_docstrings:\n fn = unwrap_partial(route_handler.fn.value)\n return cleandoc(fn.__doc__) if fn.__doc__ else None\n return handler_description\n\n\ndef extract_layered_values(\n route_handler: HTTPRouteHandler,\n) -> tuple[list[str] | None, list[dict[str, list[str]]] | None]:\n \"\"\"Extract the tags and security values from the route handler layers.\n\n Args:\n route_handler: A Route Handler instance.\n\n Returns:\n A tuple of optional lists.\n \"\"\"\n tags: list[str] = []\n security: list[SecurityRequirement] = []\n for layer in route_handler.ownership_layers:\n if layer.tags:\n tags.extend(layer.tags)\n if layer.security:\n security.extend(layer.security)\n return sorted(set(tags)) if tags else None, security or None\n\n\ndef create_path_item(\n create_examples: bool,\n operation_id_creator: OperationIDCreator,\n plugins: list[OpenAPISchemaPluginProtocol],\n route: HTTPRoute,\n schemas: dict[str, Schema],\n use_handler_docstrings: bool,\n) -> tuple[PathItem, list[str]]:\n \"\"\"Create a PathItem for the given route parsing all http_methods into Operation Models.\n\n Args:\n create_examples: Whether to auto-generate examples.\n operation_id_creator: A function to generate operation ids.\n plugins: A list of plugins.\n route: An HTTPRoute instance.\n schemas: A mapping of schemas.\n use_handler_docstrings: Whether to use the handler docstring.\n\n Returns:\n A tuple containing the path item and a list of operation ids.\n \"\"\"\n path_item = PathItem()\n operation_ids: list[str] = []\n\n request_schema_creator = SchemaCreator(create_examples, plugins, schemas, prefer_alias=True)\n response_schema_creator = SchemaCreator(create_examples, plugins, schemas, prefer_alias=False)\n for http_method, handler_tuple in route.route_handler_map.items():\n route_handler, _ = handler_tuple\n\n if route_handler.include_in_schema:\n handler_fields = route_handler.signature_model._fields if route_handler.signature_model else {}\n parameters = (\n create_parameter_for_handler(\n route_handler=route_handler,\n handler_fields=handler_fields,\n path_parameters=route.path_parameters,\n schema_creator=request_schema_creator,\n )\n or None\n )\n raises_validation_error = bool(\"data\" in handler_fields or path_item.parameters or parameters)\n\n request_body = None\n if \"data\" in handler_fields:\n request_body = create_request_body(\n route_handler=route_handler, field=handler_fields[\"data\"], schema_creator=request_schema_creator\n )\n operation_id = route_handler.operation_id or operation_id_creator(\n route_handler, http_method, route.path_components\n )\n tags, security = extract_layered_values(route_handler)\n operation = route_handler.operation_class(\n operation_id=operation_id,\n tags=tags,\n summary=route_handler.summary or SEPARATORS_CLEANUP_PATTERN.sub(\"\", route_handler.handler_name.title()),\n description=get_description_for_handler(route_handler, use_handler_docstrings),\n deprecated=route_handler.deprecated,\n responses=create_responses(\n route_handler=route_handler,\n raises_validation_error=raises_validation_error,\n schema_creator=response_schema_creator,\n ),\n request_body=request_body,\n parameters=parameters, # type: ignore[arg-type]\n security=security,\n )\n operation_ids.append(operation_id)\n setattr(path_item, http_method.lower(), operation)\n\n return path_item, operation_ids\n", "path": "litestar/_openapi/path_item.py"}, {"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, Any, Callable, TypeVar, cast\nfrom uuid import UUID\n\nfrom msgspec import ValidationError\n\nfrom litestar.exceptions import MissingDependencyException\nfrom litestar.plugins import InitPluginProtocol\nfrom litestar.serialization._msgspec_utils import ExtendedMsgSpecValidationError\nfrom litestar.utils import is_class_and_subclass, is_pydantic_model_class\n\nif TYPE_CHECKING:\n from litestar.config.app import AppConfig\n\ntry:\n import pydantic\nexcept ImportError as e:\n raise MissingDependencyException(\"pydantic\") from e\n\nT = TypeVar(\"T\")\n\n\ndef _dec_pydantic(model_type: type[pydantic.BaseModel], value: Any) -> pydantic.BaseModel:\n try:\n return (\n model_type.model_validate(value, strict=False)\n if hasattr(model_type, \"model_validate\")\n else model_type.parse_obj(value)\n )\n except pydantic.ValidationError as e:\n raise ExtendedMsgSpecValidationError(errors=cast(\"list[dict[str, Any]]\", e.errors())) from e\n\n\ndef _dec_pydantic_uuid(\n uuid_type: type[pydantic.UUID1] | type[pydantic.UUID3] | type[pydantic.UUID4] | type[pydantic.UUID5],\n value: Any,\n) -> type[pydantic.UUID1] | type[pydantic.UUID3] | type[pydantic.UUID4] | type[pydantic.UUID5]: # pragma: no cover\n if isinstance(value, str):\n value = uuid_type(value)\n\n elif isinstance(value, (bytes, bytearray)):\n try:\n value = uuid_type(value.decode())\n except ValueError:\n # 16 bytes in big-endian order as the bytes argument fail\n # the above check\n value = uuid_type(bytes=value)\n elif isinstance(value, UUID):\n value = uuid_type(str(value))\n\n if not isinstance(value, uuid_type):\n raise ValidationError(f\"Invalid UUID: {value!r}\")\n\n if value._required_version != value.version: # pyright: ignore\n raise ValidationError(f\"Invalid UUID version: {value!r}\")\n\n return cast(\"type[pydantic.UUID1] | type[pydantic.UUID3] | type[pydantic.UUID4] | type[pydantic.UUID5]\", value)\n\n\ndef _is_pydantic_uuid(value: Any) -> bool: # pragma: no cover\n return is_class_and_subclass(value, (pydantic.UUID1, pydantic.UUID3, pydantic.UUID4, pydantic.UUID5))\n\n\n_base_encoders: dict[Any, Callable[[Any], Any]] = {\n pydantic.EmailStr: str,\n pydantic.NameEmail: str,\n pydantic.ByteSize: lambda val: val.real,\n}\n\n\nclass PydanticInitPlugin(InitPluginProtocol):\n @classmethod\n def encoders(cls) -> dict[Any, Callable[[Any], Any]]:\n if pydantic.VERSION.startswith(\"1\"): # pragma: no cover\n return {**_base_encoders, **cls._create_pydantic_v1_encoders()}\n return {**_base_encoders, **cls._create_pydantic_v2_encoders()}\n\n @classmethod\n def decoders(cls) -> list[tuple[Callable[[Any], bool], Callable[[Any, Any], Any]]]:\n decoders: list[tuple[Callable[[Any], bool], Callable[[Any, Any], Any]]] = [\n (is_pydantic_model_class, _dec_pydantic)\n ]\n\n if pydantic.VERSION.startswith(\"1\"): # pragma: no cover\n decoders.append((_is_pydantic_uuid, _dec_pydantic_uuid))\n\n return decoders\n\n @staticmethod\n def _create_pydantic_v1_encoders() -> dict[Any, Callable[[Any], Any]]: # pragma: no cover\n return {\n pydantic.BaseModel: lambda model: {\n k: v.decode() if isinstance(v, bytes) else v for k, v in model.dict().items()\n },\n pydantic.SecretField: str,\n pydantic.StrictBool: int,\n pydantic.color.Color: str, # pyright: ignore\n pydantic.ConstrainedBytes: lambda val: val.decode(\"utf-8\"),\n pydantic.ConstrainedDate: lambda val: val.isoformat(),\n }\n\n @staticmethod\n def _create_pydantic_v2_encoders() -> dict[Any, Callable[[Any], Any]]:\n from pydantic_extra_types import color\n\n return {\n pydantic.BaseModel: lambda model: model.model_dump(mode=\"json\"),\n color.Color: str,\n pydantic.types.SecretStr: lambda val: \"**********\" if val else \"\",\n pydantic.types.SecretBytes: lambda val: \"**********\" if val else \"\",\n }\n\n def on_app_init(self, app_config: AppConfig) -> AppConfig:\n app_config.type_encoders = {**(app_config.type_encoders or {}), **self.encoders()}\n app_config.type_decoders = [*(app_config.type_decoders or []), *self.decoders()]\n return app_config\n", "path": "litestar/contrib/pydantic/pydantic_init_plugin.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom inspect import cleandoc\nfrom typing import TYPE_CHECKING\n\nfrom litestar._openapi.parameters import create_parameter_for_handler\nfrom litestar._openapi.request_body import create_request_body\nfrom litestar._openapi.responses import create_responses\nfrom litestar._openapi.schema_generation import SchemaCreator\nfrom litestar._openapi.utils import SEPARATORS_CLEANUP_PATTERN\nfrom litestar.openapi.spec.path_item import PathItem\nfrom litestar.utils.helpers import unwrap_partial\n\n__all__ = (\"create_path_item\", \"extract_layered_values\", \"get_description_for_handler\")\n\n\nif TYPE_CHECKING:\n from litestar.handlers.http_handlers import HTTPRouteHandler\n from litestar.openapi.spec import Schema, SecurityRequirement\n from litestar.plugins import OpenAPISchemaPluginProtocol\n from litestar.routes import HTTPRoute\n from litestar.types.callable_types import OperationIDCreator\n\n\ndef get_description_for_handler(route_handler: HTTPRouteHandler, use_handler_docstrings: bool) -> str | None:\n \"\"\"Produce the operation description for a route handler, either by using the description value if provided,\n\n or the docstring - if config is enabled.\n\n Args:\n route_handler: A route handler instance.\n use_handler_docstrings: If ``True`` and `route_handler.description`` is ``None` returns docstring of wrapped\n handler function.\n\n Returns:\n An optional description string\n \"\"\"\n handler_description = route_handler.description\n if handler_description is None and use_handler_docstrings:\n fn = unwrap_partial(route_handler.fn.value)\n return cleandoc(fn.__doc__) if fn.__doc__ else None\n return handler_description\n\n\ndef extract_layered_values(\n route_handler: HTTPRouteHandler,\n) -> tuple[list[str] | None, list[dict[str, list[str]]] | None]:\n \"\"\"Extract the tags and security values from the route handler layers.\n\n Args:\n route_handler: A Route Handler instance.\n\n Returns:\n A tuple of optional lists.\n \"\"\"\n tags: list[str] = []\n security: list[SecurityRequirement] = []\n for layer in route_handler.ownership_layers:\n if layer.tags:\n tags.extend(layer.tags)\n if layer.security:\n security.extend(layer.security)\n return sorted(set(tags)) if tags else None, security or None\n\n\ndef create_path_item(\n create_examples: bool,\n operation_id_creator: OperationIDCreator,\n plugins: list[OpenAPISchemaPluginProtocol],\n route: HTTPRoute,\n schemas: dict[str, Schema],\n use_handler_docstrings: bool,\n) -> tuple[PathItem, list[str]]:\n \"\"\"Create a PathItem for the given route parsing all http_methods into Operation Models.\n\n Args:\n create_examples: Whether to auto-generate examples.\n operation_id_creator: A function to generate operation ids.\n plugins: A list of plugins.\n route: An HTTPRoute instance.\n schemas: A mapping of schemas.\n use_handler_docstrings: Whether to use the handler docstring.\n\n Returns:\n A tuple containing the path item and a list of operation ids.\n \"\"\"\n path_item = PathItem()\n operation_ids: list[str] = []\n\n request_schema_creator = SchemaCreator(create_examples, plugins, schemas, prefer_alias=True)\n response_schema_creator = SchemaCreator(create_examples, plugins, schemas, prefer_alias=True)\n for http_method, handler_tuple in route.route_handler_map.items():\n route_handler, _ = handler_tuple\n\n if route_handler.include_in_schema:\n handler_fields = route_handler.signature_model._fields if route_handler.signature_model else {}\n parameters = (\n create_parameter_for_handler(\n route_handler=route_handler,\n handler_fields=handler_fields,\n path_parameters=route.path_parameters,\n schema_creator=request_schema_creator,\n )\n or None\n )\n raises_validation_error = bool(\"data\" in handler_fields or path_item.parameters or parameters)\n\n request_body = None\n if \"data\" in handler_fields:\n request_body = create_request_body(\n route_handler=route_handler, field=handler_fields[\"data\"], schema_creator=request_schema_creator\n )\n operation_id = route_handler.operation_id or operation_id_creator(\n route_handler, http_method, route.path_components\n )\n tags, security = extract_layered_values(route_handler)\n operation = route_handler.operation_class(\n operation_id=operation_id,\n tags=tags,\n summary=route_handler.summary or SEPARATORS_CLEANUP_PATTERN.sub(\"\", route_handler.handler_name.title()),\n description=get_description_for_handler(route_handler, use_handler_docstrings),\n deprecated=route_handler.deprecated,\n responses=create_responses(\n route_handler=route_handler,\n raises_validation_error=raises_validation_error,\n schema_creator=response_schema_creator,\n ),\n request_body=request_body,\n parameters=parameters, # type: ignore[arg-type]\n security=security,\n )\n operation_ids.append(operation_id)\n setattr(path_item, http_method.lower(), operation)\n\n return path_item, operation_ids\n", "path": "litestar/_openapi/path_item.py"}, {"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, Any, Callable, TypeVar, cast\nfrom uuid import UUID\n\nfrom msgspec import ValidationError\n\nfrom litestar.exceptions import MissingDependencyException\nfrom litestar.plugins import InitPluginProtocol\nfrom litestar.serialization._msgspec_utils import ExtendedMsgSpecValidationError\nfrom litestar.utils import is_class_and_subclass, is_pydantic_model_class\n\nif TYPE_CHECKING:\n from litestar.config.app import AppConfig\n\ntry:\n import pydantic\nexcept ImportError as e:\n raise MissingDependencyException(\"pydantic\") from e\n\nT = TypeVar(\"T\")\n\n\ndef _dec_pydantic(model_type: type[pydantic.BaseModel], value: Any) -> pydantic.BaseModel:\n try:\n return (\n model_type.model_validate(value, strict=False)\n if hasattr(model_type, \"model_validate\")\n else model_type.parse_obj(value)\n )\n except pydantic.ValidationError as e:\n raise ExtendedMsgSpecValidationError(errors=cast(\"list[dict[str, Any]]\", e.errors())) from e\n\n\ndef _dec_pydantic_uuid(\n uuid_type: type[pydantic.UUID1] | type[pydantic.UUID3] | type[pydantic.UUID4] | type[pydantic.UUID5],\n value: Any,\n) -> type[pydantic.UUID1] | type[pydantic.UUID3] | type[pydantic.UUID4] | type[pydantic.UUID5]: # pragma: no cover\n if isinstance(value, str):\n value = uuid_type(value)\n\n elif isinstance(value, (bytes, bytearray)):\n try:\n value = uuid_type(value.decode())\n except ValueError:\n # 16 bytes in big-endian order as the bytes argument fail\n # the above check\n value = uuid_type(bytes=value)\n elif isinstance(value, UUID):\n value = uuid_type(str(value))\n\n if not isinstance(value, uuid_type):\n raise ValidationError(f\"Invalid UUID: {value!r}\")\n\n if value._required_version != value.version: # pyright: ignore\n raise ValidationError(f\"Invalid UUID version: {value!r}\")\n\n return cast(\"type[pydantic.UUID1] | type[pydantic.UUID3] | type[pydantic.UUID4] | type[pydantic.UUID5]\", value)\n\n\ndef _is_pydantic_uuid(value: Any) -> bool: # pragma: no cover\n return is_class_and_subclass(value, (pydantic.UUID1, pydantic.UUID3, pydantic.UUID4, pydantic.UUID5))\n\n\n_base_encoders: dict[Any, Callable[[Any], Any]] = {\n pydantic.EmailStr: str,\n pydantic.NameEmail: str,\n pydantic.ByteSize: lambda val: val.real,\n}\n\n\nclass PydanticInitPlugin(InitPluginProtocol):\n @classmethod\n def encoders(cls) -> dict[Any, Callable[[Any], Any]]:\n if pydantic.VERSION.startswith(\"1\"): # pragma: no cover\n return {**_base_encoders, **cls._create_pydantic_v1_encoders()}\n return {**_base_encoders, **cls._create_pydantic_v2_encoders()}\n\n @classmethod\n def decoders(cls) -> list[tuple[Callable[[Any], bool], Callable[[Any, Any], Any]]]:\n decoders: list[tuple[Callable[[Any], bool], Callable[[Any, Any], Any]]] = [\n (is_pydantic_model_class, _dec_pydantic)\n ]\n\n if pydantic.VERSION.startswith(\"1\"): # pragma: no cover\n decoders.append((_is_pydantic_uuid, _dec_pydantic_uuid))\n\n return decoders\n\n @staticmethod\n def _create_pydantic_v1_encoders() -> dict[Any, Callable[[Any], Any]]: # pragma: no cover\n return {\n pydantic.BaseModel: lambda model: {\n k: v.decode() if isinstance(v, bytes) else v for k, v in model.dict().items()\n },\n pydantic.SecretField: str,\n pydantic.StrictBool: int,\n pydantic.color.Color: str, # pyright: ignore\n pydantic.ConstrainedBytes: lambda val: val.decode(\"utf-8\"),\n pydantic.ConstrainedDate: lambda val: val.isoformat(),\n }\n\n @staticmethod\n def _create_pydantic_v2_encoders() -> dict[Any, Callable[[Any], Any]]:\n try:\n from pydantic_extra_types import color\n except ImportError:\n color = None # type: ignore[assignment]\n encoders: dict[Any, Callable[[Any], Any]] = {\n pydantic.BaseModel: lambda model: model.model_dump(mode=\"json\"),\n pydantic.types.SecretStr: lambda val: \"**********\" if val else \"\",\n pydantic.types.SecretBytes: lambda val: \"**********\" if val else \"\",\n }\n if color:\n encoders[color.Color] = str\n return encoders\n\n def on_app_init(self, app_config: AppConfig) -> AppConfig:\n app_config.type_encoders = {**self.encoders(), **(app_config.type_encoders or {})}\n app_config.type_decoders = [*self.decoders(), *(app_config.type_decoders or [])]\n return app_config\n", "path": "litestar/contrib/pydantic/pydantic_init_plugin.py"}]}
| 3,214 | 524 |
gh_patches_debug_33368
|
rasdani/github-patches
|
git_diff
|
e-valuation__EvaP-329
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Disable results link for courses without published votes
Currently in the results overview, you can click on courses which have no published votes. The course page is not helpful then, so the link should be disabled.
if the course has comments but no votes, the link should be enabled for the respective contributors.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `evap/results/views.py`
Content:
```
1 from django.conf import settings
2 from django.http import HttpResponse
3 from django.shortcuts import get_object_or_404, render_to_response
4 from django.template import RequestContext
5 from django.utils.translation import get_language
6
7 from evap.evaluation.auth import login_required, fsr_required
8 from evap.evaluation.models import Semester
9 from evap.evaluation.tools import calculate_results, calculate_average_grade, TextResult
10
11 from evap.results.exporters import ExcelExporter
12
13
14 @login_required
15 def index(request):
16 semesters = Semester.get_all_with_published_courses()
17
18 return render_to_response(
19 "results_index.html",
20 dict(semesters=semesters),
21 context_instance=RequestContext(request))
22
23
24 @login_required
25 def semester_detail(request, semester_id):
26 semester = get_object_or_404(Semester, id=semester_id)
27 courses = list(semester.course_set.filter(state="published"))
28
29 # annotate each course object with its grade
30 for course in courses:
31 # first, make sure that there is no preexisting grade attribute
32 course.grade = calculate_average_grade(course)
33
34 return render_to_response(
35 "results_semester_detail.html",
36 dict(
37 semester=semester,
38 courses=courses
39 ),
40 context_instance=RequestContext(request))
41
42
43 @fsr_required
44 def semester_export(request, semester_id):
45 semester = get_object_or_404(Semester, id=semester_id)
46
47 filename = "Evaluation-%s-%s.xls" % (semester.name, get_language())
48
49 response = HttpResponse(mimetype="application/vnd.ms-excel")
50 response["Content-Disposition"] = "attachment; filename=\"%s\"" % filename
51
52 exporter = ExcelExporter(semester)
53
54 if 'all' in request.GET:
55 exporter.export(response, True)
56 else:
57 exporter.export(response)
58
59 return response
60
61
62 @login_required
63 def course_detail(request, semester_id, course_id):
64 semester = get_object_or_404(Semester, id=semester_id)
65 course = get_object_or_404(semester.course_set.filter(state="published"), id=course_id)
66
67 sections = calculate_results(course, request.user.is_staff)
68
69 if (request.user.is_staff == False): # if user is not a student representative
70 # remove TextResults if user is neither the evaluated person (or a delegate) nor responsible for the course (or a delegate)
71 for section in sections:
72 if not user_can_see_textresults(request.user, course, section):
73 for index, result in list(enumerate(section.results))[::-1]:
74 if isinstance(section.results[index], TextResult):
75 del section.results[index]
76
77 # remove empty sections
78 sections = [section for section in sections if section.results]
79
80 # check whether results are published
81 published = course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE
82
83 # show a publishing warning to fsr members when the results are not publicly available
84 warning = (not published) and request.user.is_staff
85
86 return render_to_response(
87 "results_course_detail.html",
88 dict(
89 course=course,
90 sections=sections,
91 warning=warning
92 ),
93 context_instance=RequestContext(request))
94
95
96 def user_can_see_textresults(user, course, section):
97 if section.contributor == user:
98 return True
99 if course.is_user_responsible_or_delegate(user):
100 return True
101
102 represented_userprofiles = user.represented_users.all()
103 represented_users = [profile.user for profile in represented_userprofiles]
104 if section.contributor in represented_users:
105 return True
106
107 return False
108
```
Path: `evap/evaluation/tools.py`
Content:
```
1 from django.conf import settings
2 from django.core.cache import cache
3 from django.db.models import Min, Count
4 from django.utils.datastructures import SortedDict
5 from django.utils.translation import ugettext_lazy as _
6 from evap.evaluation.models import GradeAnswer, TextAnswer
7
8
9 from collections import namedtuple
10
11 GRADE_NAMES = {
12 1: _(u"Strongly agree"),
13 2: _(u"Agree"),
14 3: _(u"Neither agree nor disagree"),
15 4: _(u"Disagree"),
16 5: _(u"Strongly disagree"),
17 6: _(u"no answer"),
18 }
19
20 STATES_ORDERED = SortedDict((
21 ('new', _('new')),
22 ('prepared', _('prepared')),
23 ('lecturerApproved', _('lecturer approved')),
24 ('approved', _('approved')),
25 ('inEvaluation', _('in evaluation')),
26 ('evaluated', _('evaluated')),
27 ('reviewed', _('reviewed')),
28 ('published', _('published'))
29 ))
30
31
32 # see calculate_results
33 ResultSection = namedtuple('ResultSection', ('questionnaire', 'contributor', 'results', 'average'))
34 GradeResult = namedtuple('GradeResult', ('question', 'count', 'average', 'variance', 'distribution', 'show'))
35 TextResult = namedtuple('TextResult', ('question', 'texts'))
36
37
38 def avg(iterable):
39 """Simple arithmetic average function. Returns `None` if the length of
40 `iterable` is 0 or no items except None exist."""
41 items = [item for item in iterable if item is not None]
42 if len(items) == 0:
43 return None
44 return float(sum(items)) / len(items)
45
46
47 def calculate_results(course, staff_member=False):
48 """Calculates the result data for a single course. Returns a list of
49 `ResultSection` tuples. Each of those tuples contains the questionnaire, the
50 contributor (or None), a list of single result elements and the average grade
51 for that section (or None). The result elements are either `GradeResult` or
52 `TextResult` instances."""
53
54 # return cached results if available
55 cache_key = str.format('evap.fsr.results.views.calculate_results-{:d}-{:d}', course.id, staff_member)
56 prior_results = cache.get(cache_key)
57 if prior_results:
58 return prior_results
59
60 # check if grades for the course will be published
61 show = staff_member or (course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE)
62
63 # there will be one section per relevant questionnaire--contributor pair
64 sections = []
65
66 for questionnaire, contribution in questionnaires_and_contributions(course):
67 # will contain one object per question
68 results = []
69 for question in questionnaire.question_set.all():
70 if question.is_grade_question():
71 # gather all numeric answers as a simple list
72 answers = GradeAnswer.objects.filter(
73 contribution__course=course,
74 contribution__contributor=contribution.contributor,
75 question=question
76 ).values_list('answer', flat=True)
77
78 # calculate average and distribution
79 if answers:
80 # average
81 average = avg(answers)
82 # variance
83 variance = avg((average - answer) ** 2 for answer in answers)
84 # calculate relative distribution (histogram) of answers:
85 # set up a sorted dictionary with a count of zero for each grade
86 distribution = SortedDict()
87 for i in range(1, 6):
88 distribution[i] = 0
89 # count the answers
90 for answer in answers:
91 distribution[answer] += 1
92 # divide by the number of answers to get relative 0..1 values
93 for k in distribution:
94 distribution[k] = float(distribution[k]) / len(answers) * 100.0
95 else:
96 average = None
97 variance = None
98 distribution = None
99
100 # produce the result element
101 results.append(GradeResult(
102 question=question,
103 count=len(answers),
104 average=average,
105 variance=variance,
106 distribution=distribution,
107 show=show
108 ))
109
110 elif question.is_text_question():
111 # gather text answers for this question
112 answers = TextAnswer.objects.filter(
113 contribution__course=course,
114 contribution__contributor=contribution.contributor,
115 question=question,
116 hidden=False
117 )
118 # only add to the results if answers exist at all
119 if answers:
120 results.append(TextResult(
121 question=question,
122 texts=[answer.answer for answer in answers]
123 ))
124
125 # skip section if there were no questions with results
126 if not results:
127 continue
128
129 # compute average grade for this section, will return None if
130 # no GradeResults exist in this section
131 average_grade = avg([result.average for result
132 in results
133 if isinstance(result, GradeResult)])
134 sections.append(ResultSection(questionnaire, contribution.contributor, results, average_grade))
135
136 # store results into cache
137 # XXX: What would be a good timeout here? Once public, data is not going to
138 # change anyway.
139 cache.set(cache_key, sections, 24 * 60 * 60)
140
141 return sections
142
143
144 def calculate_average_grade(course):
145 """Determines the final grade for a course."""
146 generic_grades = []
147 personal_grades = []
148
149 for questionnaire, contributor, results, average in calculate_results(course):
150 if average:
151 (personal_grades if contributor else generic_grades).append(average)
152
153 if not generic_grades:
154 # not final grade without any generic grade
155 return None
156 elif not personal_grades:
157 # determine final grade by using the average of the generic grades
158 return avg(generic_grades)
159 else:
160 # determine final grade by building the equally-weighted average of the
161 # generic and person-specific averages
162 return avg((avg(generic_grades), avg(personal_grades)))
163
164
165 def questionnaires_and_contributions(course):
166 """Yields tuples of (questionnaire, contribution) for the given course."""
167 result = []
168
169 for contribution in course.contributions.annotate(Min("questionnaires__index")).order_by("questionnaires__is_for_contributors", "questionnaires__index__min"):
170 for questionnaire in contribution.questionnaires.all():
171 result.append((questionnaire, contribution))
172
173 # sort questionnaires without contributors first
174 result.sort(key=lambda t: t[1].contributor is not None)
175
176 return result
177
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/evap/evaluation/tools.py b/evap/evaluation/tools.py
--- a/evap/evaluation/tools.py
+++ b/evap/evaluation/tools.py
@@ -44,6 +44,9 @@
return float(sum(items)) / len(items)
+def can_publish_grades(course, staff_member=False):
+ return staff_member or (course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE)
+
def calculate_results(course, staff_member=False):
"""Calculates the result data for a single course. Returns a list of
`ResultSection` tuples. Each of those tuples contains the questionnaire, the
@@ -58,7 +61,7 @@
return prior_results
# check if grades for the course will be published
- show = staff_member or (course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE)
+ show = can_publish_grades(course, staff_member)
# there will be one section per relevant questionnaire--contributor pair
sections = []
diff --git a/evap/results/views.py b/evap/results/views.py
--- a/evap/results/views.py
+++ b/evap/results/views.py
@@ -6,7 +6,7 @@
from evap.evaluation.auth import login_required, fsr_required
from evap.evaluation.models import Semester
-from evap.evaluation.tools import calculate_results, calculate_average_grade, TextResult
+from evap.evaluation.tools import calculate_results, calculate_average_grade, TextResult, can_publish_grades
from evap.results.exporters import ExcelExporter
@@ -30,6 +30,7 @@
for course in courses:
# first, make sure that there is no preexisting grade attribute
course.grade = calculate_average_grade(course)
+ course.can_publish_grades = can_publish_grades(course, request.user.is_staff)
return render_to_response(
"results_semester_detail.html",
|
{"golden_diff": "diff --git a/evap/evaluation/tools.py b/evap/evaluation/tools.py\n--- a/evap/evaluation/tools.py\n+++ b/evap/evaluation/tools.py\n@@ -44,6 +44,9 @@\n return float(sum(items)) / len(items)\n \n \n+def can_publish_grades(course, staff_member=False):\n+ return staff_member or (course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE)\n+\n def calculate_results(course, staff_member=False):\n \"\"\"Calculates the result data for a single course. Returns a list of\n `ResultSection` tuples. Each of those tuples contains the questionnaire, the\n@@ -58,7 +61,7 @@\n return prior_results\n \n # check if grades for the course will be published\n- show = staff_member or (course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE)\n+ show = can_publish_grades(course, staff_member)\n \n # there will be one section per relevant questionnaire--contributor pair\n sections = []\ndiff --git a/evap/results/views.py b/evap/results/views.py\n--- a/evap/results/views.py\n+++ b/evap/results/views.py\n@@ -6,7 +6,7 @@\n \n from evap.evaluation.auth import login_required, fsr_required\n from evap.evaluation.models import Semester\n-from evap.evaluation.tools import calculate_results, calculate_average_grade, TextResult\n+from evap.evaluation.tools import calculate_results, calculate_average_grade, TextResult, can_publish_grades\n \n from evap.results.exporters import ExcelExporter\n \n@@ -30,6 +30,7 @@\n for course in courses:\n # first, make sure that there is no preexisting grade attribute\n course.grade = calculate_average_grade(course)\n+ course.can_publish_grades = can_publish_grades(course, request.user.is_staff)\n \n return render_to_response(\n \"results_semester_detail.html\",\n", "issue": "Disable results link for courses without published votes\nCurrently in the results overview, you can click on courses which have no published votes. The course page is not helpful then, so the link should be disabled.\n\nif the course has comments but no votes, the link should be enabled for the respective contributors.\n\n", "before_files": [{"content": "from django.conf import settings\nfrom django.http import HttpResponse\nfrom django.shortcuts import get_object_or_404, render_to_response\nfrom django.template import RequestContext\nfrom django.utils.translation import get_language\n\nfrom evap.evaluation.auth import login_required, fsr_required\nfrom evap.evaluation.models import Semester\nfrom evap.evaluation.tools import calculate_results, calculate_average_grade, TextResult\n\nfrom evap.results.exporters import ExcelExporter\n\n\n@login_required\ndef index(request):\n semesters = Semester.get_all_with_published_courses()\n\n return render_to_response(\n \"results_index.html\",\n dict(semesters=semesters),\n context_instance=RequestContext(request))\n\n\n@login_required\ndef semester_detail(request, semester_id):\n semester = get_object_or_404(Semester, id=semester_id)\n courses = list(semester.course_set.filter(state=\"published\"))\n\n # annotate each course object with its grade\n for course in courses:\n # first, make sure that there is no preexisting grade attribute\n course.grade = calculate_average_grade(course)\n\n return render_to_response(\n \"results_semester_detail.html\",\n dict(\n semester=semester,\n courses=courses\n ),\n context_instance=RequestContext(request))\n\n\n@fsr_required\ndef semester_export(request, semester_id):\n semester = get_object_or_404(Semester, id=semester_id)\n\n filename = \"Evaluation-%s-%s.xls\" % (semester.name, get_language())\n\n response = HttpResponse(mimetype=\"application/vnd.ms-excel\")\n response[\"Content-Disposition\"] = \"attachment; filename=\\\"%s\\\"\" % filename\n\n exporter = ExcelExporter(semester)\n\n if 'all' in request.GET:\n exporter.export(response, True)\n else:\n exporter.export(response)\n\n return response\n\n\n@login_required\ndef course_detail(request, semester_id, course_id):\n semester = get_object_or_404(Semester, id=semester_id)\n course = get_object_or_404(semester.course_set.filter(state=\"published\"), id=course_id)\n\n sections = calculate_results(course, request.user.is_staff)\n\n if (request.user.is_staff == False): # if user is not a student representative\n # remove TextResults if user is neither the evaluated person (or a delegate) nor responsible for the course (or a delegate)\n for section in sections:\n if not user_can_see_textresults(request.user, course, section):\n for index, result in list(enumerate(section.results))[::-1]:\n if isinstance(section.results[index], TextResult):\n del section.results[index]\n\n # remove empty sections\n sections = [section for section in sections if section.results]\n\n # check whether results are published\n published = course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE\n\n # show a publishing warning to fsr members when the results are not publicly available\n warning = (not published) and request.user.is_staff\n\n return render_to_response(\n \"results_course_detail.html\",\n dict(\n course=course,\n sections=sections,\n warning=warning\n ),\n context_instance=RequestContext(request))\n\n\ndef user_can_see_textresults(user, course, section):\n if section.contributor == user:\n return True\n if course.is_user_responsible_or_delegate(user):\n return True\n\n represented_userprofiles = user.represented_users.all()\n represented_users = [profile.user for profile in represented_userprofiles]\n if section.contributor in represented_users:\n return True\n\n return False\n", "path": "evap/results/views.py"}, {"content": "from django.conf import settings\nfrom django.core.cache import cache\nfrom django.db.models import Min, Count\nfrom django.utils.datastructures import SortedDict\nfrom django.utils.translation import ugettext_lazy as _\nfrom evap.evaluation.models import GradeAnswer, TextAnswer\n\n\nfrom collections import namedtuple\n\nGRADE_NAMES = {\n 1: _(u\"Strongly agree\"),\n 2: _(u\"Agree\"),\n 3: _(u\"Neither agree nor disagree\"),\n 4: _(u\"Disagree\"),\n 5: _(u\"Strongly disagree\"),\n 6: _(u\"no answer\"),\n}\n\nSTATES_ORDERED = SortedDict((\n ('new', _('new')),\n ('prepared', _('prepared')),\n ('lecturerApproved', _('lecturer approved')),\n ('approved', _('approved')),\n ('inEvaluation', _('in evaluation')),\n ('evaluated', _('evaluated')),\n ('reviewed', _('reviewed')),\n ('published', _('published'))\n))\n\n\n# see calculate_results\nResultSection = namedtuple('ResultSection', ('questionnaire', 'contributor', 'results', 'average'))\nGradeResult = namedtuple('GradeResult', ('question', 'count', 'average', 'variance', 'distribution', 'show'))\nTextResult = namedtuple('TextResult', ('question', 'texts'))\n\n\ndef avg(iterable):\n \"\"\"Simple arithmetic average function. Returns `None` if the length of\n `iterable` is 0 or no items except None exist.\"\"\"\n items = [item for item in iterable if item is not None]\n if len(items) == 0:\n return None\n return float(sum(items)) / len(items)\n\n\ndef calculate_results(course, staff_member=False):\n \"\"\"Calculates the result data for a single course. Returns a list of\n `ResultSection` tuples. Each of those tuples contains the questionnaire, the\n contributor (or None), a list of single result elements and the average grade\n for that section (or None). The result elements are either `GradeResult` or\n `TextResult` instances.\"\"\"\n\n # return cached results if available\n cache_key = str.format('evap.fsr.results.views.calculate_results-{:d}-{:d}', course.id, staff_member)\n prior_results = cache.get(cache_key)\n if prior_results:\n return prior_results\n\n # check if grades for the course will be published\n show = staff_member or (course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE)\n\n # there will be one section per relevant questionnaire--contributor pair\n sections = []\n\n for questionnaire, contribution in questionnaires_and_contributions(course):\n # will contain one object per question\n results = []\n for question in questionnaire.question_set.all():\n if question.is_grade_question():\n # gather all numeric answers as a simple list\n answers = GradeAnswer.objects.filter(\n contribution__course=course,\n contribution__contributor=contribution.contributor,\n question=question\n ).values_list('answer', flat=True)\n\n # calculate average and distribution\n if answers:\n # average\n average = avg(answers)\n # variance\n variance = avg((average - answer) ** 2 for answer in answers)\n # calculate relative distribution (histogram) of answers:\n # set up a sorted dictionary with a count of zero for each grade\n distribution = SortedDict()\n for i in range(1, 6):\n distribution[i] = 0\n # count the answers\n for answer in answers:\n distribution[answer] += 1\n # divide by the number of answers to get relative 0..1 values\n for k in distribution:\n distribution[k] = float(distribution[k]) / len(answers) * 100.0\n else:\n average = None\n variance = None\n distribution = None\n\n # produce the result element\n results.append(GradeResult(\n question=question,\n count=len(answers),\n average=average,\n variance=variance,\n distribution=distribution,\n show=show\n ))\n\n elif question.is_text_question():\n # gather text answers for this question\n answers = TextAnswer.objects.filter(\n contribution__course=course,\n contribution__contributor=contribution.contributor,\n question=question,\n hidden=False\n )\n # only add to the results if answers exist at all\n if answers:\n results.append(TextResult(\n question=question,\n texts=[answer.answer for answer in answers]\n ))\n\n # skip section if there were no questions with results\n if not results:\n continue\n\n # compute average grade for this section, will return None if\n # no GradeResults exist in this section\n average_grade = avg([result.average for result\n in results\n if isinstance(result, GradeResult)])\n sections.append(ResultSection(questionnaire, contribution.contributor, results, average_grade))\n\n # store results into cache\n # XXX: What would be a good timeout here? Once public, data is not going to\n # change anyway.\n cache.set(cache_key, sections, 24 * 60 * 60)\n\n return sections\n\n\ndef calculate_average_grade(course):\n \"\"\"Determines the final grade for a course.\"\"\"\n generic_grades = []\n personal_grades = []\n\n for questionnaire, contributor, results, average in calculate_results(course):\n if average:\n (personal_grades if contributor else generic_grades).append(average)\n\n if not generic_grades:\n # not final grade without any generic grade\n return None\n elif not personal_grades:\n # determine final grade by using the average of the generic grades\n return avg(generic_grades)\n else:\n # determine final grade by building the equally-weighted average of the\n # generic and person-specific averages\n return avg((avg(generic_grades), avg(personal_grades)))\n\n\ndef questionnaires_and_contributions(course):\n \"\"\"Yields tuples of (questionnaire, contribution) for the given course.\"\"\"\n result = []\n\n for contribution in course.contributions.annotate(Min(\"questionnaires__index\")).order_by(\"questionnaires__is_for_contributors\", \"questionnaires__index__min\"):\n for questionnaire in contribution.questionnaires.all():\n result.append((questionnaire, contribution))\n\n # sort questionnaires without contributors first\n result.sort(key=lambda t: t[1].contributor is not None)\n\n return result\n", "path": "evap/evaluation/tools.py"}], "after_files": [{"content": "from django.conf import settings\nfrom django.http import HttpResponse\nfrom django.shortcuts import get_object_or_404, render_to_response\nfrom django.template import RequestContext\nfrom django.utils.translation import get_language\n\nfrom evap.evaluation.auth import login_required, fsr_required\nfrom evap.evaluation.models import Semester\nfrom evap.evaluation.tools import calculate_results, calculate_average_grade, TextResult, can_publish_grades\n\nfrom evap.results.exporters import ExcelExporter\n\n\n@login_required\ndef index(request):\n semesters = Semester.get_all_with_published_courses()\n\n return render_to_response(\n \"results_index.html\",\n dict(semesters=semesters),\n context_instance=RequestContext(request))\n\n\n@login_required\ndef semester_detail(request, semester_id):\n semester = get_object_or_404(Semester, id=semester_id)\n courses = list(semester.course_set.filter(state=\"published\"))\n\n # annotate each course object with its grade\n for course in courses:\n # first, make sure that there is no preexisting grade attribute\n course.grade = calculate_average_grade(course)\n course.can_publish_grades = can_publish_grades(course, request.user.is_staff)\n\n return render_to_response(\n \"results_semester_detail.html\",\n dict(\n semester=semester,\n courses=courses\n ),\n context_instance=RequestContext(request))\n\n\n@fsr_required\ndef semester_export(request, semester_id):\n semester = get_object_or_404(Semester, id=semester_id)\n\n filename = \"Evaluation-%s-%s.xls\" % (semester.name, get_language())\n\n response = HttpResponse(mimetype=\"application/vnd.ms-excel\")\n response[\"Content-Disposition\"] = \"attachment; filename=\\\"%s\\\"\" % filename\n\n exporter = ExcelExporter(semester)\n\n if 'all' in request.GET:\n exporter.export(response, True)\n else:\n exporter.export(response)\n\n return response\n\n\n@login_required\ndef course_detail(request, semester_id, course_id):\n semester = get_object_or_404(Semester, id=semester_id)\n course = get_object_or_404(semester.course_set.filter(state=\"published\"), id=course_id)\n\n sections = calculate_results(course, request.user.is_staff)\n\n if (request.user.is_staff == False): # if user is not a student representative\n # remove TextResults if user is neither the evaluated person (or a delegate) nor responsible for the course (or a delegate)\n for section in sections:\n if not user_can_see_textresults(request.user, course, section):\n for index, result in list(enumerate(section.results))[::-1]:\n if isinstance(section.results[index], TextResult):\n del section.results[index]\n\n # remove empty sections\n sections = [section for section in sections if section.results]\n\n # check whether results are published\n published = course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE\n\n # show a publishing warning to fsr members when the results are not publicly available\n warning = (not published) and request.user.is_staff\n\n return render_to_response(\n \"results_course_detail.html\",\n dict(\n course=course,\n sections=sections,\n warning=warning\n ),\n context_instance=RequestContext(request))\n\n\ndef user_can_see_textresults(user, course, section):\n if section.contributor == user:\n return True\n if course.is_user_responsible_or_delegate(user):\n return True\n\n represented_userprofiles = user.represented_users.all()\n represented_users = [profile.user for profile in represented_userprofiles]\n if section.contributor in represented_users:\n return True\n\n return False\n", "path": "evap/results/views.py"}, {"content": "from django.conf import settings\nfrom django.core.cache import cache\nfrom django.db.models import Min, Count\nfrom django.utils.datastructures import SortedDict\nfrom django.utils.translation import ugettext_lazy as _\nfrom evap.evaluation.models import GradeAnswer, TextAnswer\n\n\nfrom collections import namedtuple\n\nGRADE_NAMES = {\n 1: _(u\"Strongly agree\"),\n 2: _(u\"Agree\"),\n 3: _(u\"Neither agree nor disagree\"),\n 4: _(u\"Disagree\"),\n 5: _(u\"Strongly disagree\"),\n 6: _(u\"no answer\"),\n}\n\nSTATES_ORDERED = SortedDict((\n ('new', _('new')),\n ('prepared', _('prepared')),\n ('lecturerApproved', _('lecturer approved')),\n ('approved', _('approved')),\n ('inEvaluation', _('in evaluation')),\n ('evaluated', _('evaluated')),\n ('reviewed', _('reviewed')),\n ('published', _('published'))\n))\n\n\n# see calculate_results\nResultSection = namedtuple('ResultSection', ('questionnaire', 'contributor', 'results', 'average'))\nGradeResult = namedtuple('GradeResult', ('question', 'count', 'average', 'variance', 'distribution', 'show'))\nTextResult = namedtuple('TextResult', ('question', 'texts'))\n\n\ndef avg(iterable):\n \"\"\"Simple arithmetic average function. Returns `None` if the length of\n `iterable` is 0 or no items except None exist.\"\"\"\n items = [item for item in iterable if item is not None]\n if len(items) == 0:\n return None\n return float(sum(items)) / len(items)\n\n\ndef can_publish_grades(course, staff_member=False):\n return staff_member or (course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE)\n\ndef calculate_results(course, staff_member=False):\n \"\"\"Calculates the result data for a single course. Returns a list of\n `ResultSection` tuples. Each of those tuples contains the questionnaire, the\n contributor (or None), a list of single result elements and the average grade\n for that section (or None). The result elements are either `GradeResult` or\n `TextResult` instances.\"\"\"\n\n # return cached results if available\n cache_key = str.format('evap.fsr.results.views.calculate_results-{:d}-{:d}', course.id, staff_member)\n prior_results = cache.get(cache_key)\n if prior_results:\n return prior_results\n\n # check if grades for the course will be published\n show = can_publish_grades(course, staff_member)\n\n # there will be one section per relevant questionnaire--contributor pair\n sections = []\n\n for questionnaire, contribution in questionnaires_and_contributions(course):\n # will contain one object per question\n results = []\n for question in questionnaire.question_set.all():\n if question.is_grade_question():\n # gather all numeric answers as a simple list\n answers = GradeAnswer.objects.filter(\n contribution__course=course,\n contribution__contributor=contribution.contributor,\n question=question\n ).values_list('answer', flat=True)\n\n # calculate average and distribution\n if answers:\n # average\n average = avg(answers)\n # variance\n variance = avg((average - answer) ** 2 for answer in answers)\n # calculate relative distribution (histogram) of answers:\n # set up a sorted dictionary with a count of zero for each grade\n distribution = SortedDict()\n for i in range(1, 6):\n distribution[i] = 0\n # count the answers\n for answer in answers:\n distribution[answer] += 1\n # divide by the number of answers to get relative 0..1 values\n for k in distribution:\n distribution[k] = float(distribution[k]) / len(answers) * 100.0\n else:\n average = None\n variance = None\n distribution = None\n\n # produce the result element\n results.append(GradeResult(\n question=question,\n count=len(answers),\n average=average,\n variance=variance,\n distribution=distribution,\n show=show\n ))\n\n elif question.is_text_question():\n # gather text answers for this question\n answers = TextAnswer.objects.filter(\n contribution__course=course,\n contribution__contributor=contribution.contributor,\n question=question,\n hidden=False\n )\n # only add to the results if answers exist at all\n if answers:\n results.append(TextResult(\n question=question,\n texts=[answer.answer for answer in answers]\n ))\n\n # skip section if there were no questions with results\n if not results:\n continue\n\n # compute average grade for this section, will return None if\n # no GradeResults exist in this section\n average_grade = avg([result.average for result\n in results\n if isinstance(result, GradeResult)])\n sections.append(ResultSection(questionnaire, contribution.contributor, results, average_grade))\n\n # store results into cache\n # XXX: What would be a good timeout here? Once public, data is not going to\n # change anyway.\n cache.set(cache_key, sections, 24 * 60 * 60)\n\n return sections\n\n\ndef calculate_average_grade(course):\n \"\"\"Determines the final grade for a course.\"\"\"\n generic_grades = []\n personal_grades = []\n\n for questionnaire, contributor, results, average in calculate_results(course):\n if average:\n (personal_grades if contributor else generic_grades).append(average)\n\n if not generic_grades:\n # not final grade without any generic grade\n return None\n elif not personal_grades:\n # determine final grade by using the average of the generic grades\n return avg(generic_grades)\n else:\n # determine final grade by building the equally-weighted average of the\n # generic and person-specific averages\n return avg((avg(generic_grades), avg(personal_grades)))\n\n\ndef questionnaires_and_contributions(course):\n \"\"\"Yields tuples of (questionnaire, contribution) for the given course.\"\"\"\n result = []\n\n for contribution in course.contributions.annotate(Min(\"questionnaires__index\")).order_by(\"questionnaires__is_for_contributors\", \"questionnaires__index__min\"):\n for questionnaire in contribution.questionnaires.all():\n result.append((questionnaire, contribution))\n\n # sort questionnaires without contributors first\n result.sort(key=lambda t: t[1].contributor is not None)\n\n return result\n", "path": "evap/evaluation/tools.py"}]}
| 3,173 | 452 |
gh_patches_debug_22227
|
rasdani/github-patches
|
git_diff
|
horovod__horovod-1444
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DistributedOptimzer is not compatible with keras.Optimizer
**Environment:**
1. Framework: (TensorFlow, Keras, PyTorch, MXNet)
2. Framework version: 1.14
3. Horovod version: 0.16.4
7. Python version: 3.6.8
**Checklist:**
1. Did you search issues to find if somebody asked this question before?
2. If your question is about hang, did you read [this doc](https://github.com/horovod/horovod/blob/master/docs/running.rst)?
3. If your question is about docker, did you read [this doc](https://github.com/horovod/horovod/blob/master/docs/docker.rst)?
4. Did you check if you question is answered in the [troubleshooting guide](https://github.com/horovod/horovod/blob/master/docs/troubleshooting.rst)?
**Bug report:**
Please describe errorneous behavior you're observing and steps to reproduce it.
Horovod DistributedOptimzer wrapper is not compatible with keras:
```
import tensorflow as tf
import horovod.tensorflow.keras as hvd
hvd.init()
opt = tf.keras.optimizers.Adam()
hopt = hvd.DistributedOptimizer(opt)
opt.get_config()
cfg = hopt.get_config()
opt_copy = opt.from_config(cfg)
opt_copy = opt.__class__.from_config(cfg)
hopt_copy = hopt.from_config(cfg) # TypeError: __init__() got an unexpected keyword argument 'learning_rate'
hopt_copy = hopt.__class__.from_config(cfg) # TypeError: __init__() got an unexpected keyword argument 'learning_rate'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `horovod/common/util.py`
Content:
```
1 # Copyright 2016 The TensorFlow Authors. All Rights Reserved.
2 # Modifications copyright (C) 2019 Uber Technologies, Inc.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 # =============================================================================
16
17 from contextlib import contextmanager
18 import importlib
19 from multiprocessing import Process, Queue
20 import os
21 import sysconfig
22
23 EXTENSIONS = ['tensorflow', 'torch', 'mxnet']
24
25
26 def get_ext_suffix():
27 """Determine library extension for various versions of Python."""
28 ext_suffix = sysconfig.get_config_var('EXT_SUFFIX')
29 if ext_suffix:
30 return ext_suffix
31
32 ext_suffix = sysconfig.get_config_var('SO')
33 if ext_suffix:
34 return ext_suffix
35
36 return '.so'
37
38
39 def get_extension_full_path(pkg_path, *args):
40 assert len(args) >= 1
41 dir_path = os.path.join(os.path.dirname(pkg_path), *args[:-1])
42 full_path = os.path.join(dir_path, args[-1] + get_ext_suffix())
43 return full_path
44
45
46 def check_extension(ext_name, ext_env_var, pkg_path, *args):
47 full_path = get_extension_full_path(pkg_path, *args)
48 if not os.path.exists(full_path):
49 raise ImportError(
50 'Extension %s has not been built. If this is not expected, reinstall '
51 'Horovod with %s=1 to debug the build error.' % (ext_name, ext_env_var))
52
53
54 def _check_extension_lambda(ext_base_name, fn, fn_desc, verbose):
55 """
56 Tries to load the extension in a new process. If successful, puts fn(ext)
57 to the queue or False otherwise. Mutes all stdout/stderr.
58 """
59 def _target_fn(ext_base_name, fn, fn_desc, queue, verbose):
60 import importlib
61 import sys
62 import traceback
63
64 if verbose:
65 print('Checking whether extension {ext_base_name} was {fn_desc}.'.format(
66 ext_base_name=ext_base_name, fn_desc=fn_desc))
67 else:
68 # Suppress output
69 sys.stdout = open(os.devnull, 'w')
70 sys.stderr = open(os.devnull, 'w')
71
72 try:
73 ext = importlib.import_module('.' + ext_base_name, 'horovod')
74 result = fn(ext)
75 except:
76 traceback.print_exc()
77 result = None
78
79 if verbose:
80 print('Extension {ext_base_name} {flag} {fn_desc}.'.format(
81 ext_base_name=ext_base_name, flag=('was' if result else 'was NOT'),
82 fn_desc=fn_desc))
83
84 queue.put(result)
85
86 queue = Queue()
87 p = Process(target=_target_fn,
88 args=(ext_base_name, fn, fn_desc, queue, verbose))
89 p.daemon = True
90 p.start()
91 p.join()
92 return queue.get_nowait()
93
94
95 def extension_available(ext_base_name, verbose=False):
96 available_fn = lambda ext: ext is not None
97 return _check_extension_lambda(
98 ext_base_name, available_fn, 'built', verbose) or False
99
100
101 def mpi_built(verbose=False):
102 for ext_base_name in EXTENSIONS:
103 built_fn = lambda ext: ext.mpi_built()
104 result = _check_extension_lambda(
105 ext_base_name, built_fn, 'built with MPI', verbose)
106 if result is not None:
107 return result
108 return False
109
110
111 def gloo_built(verbose=False):
112 for ext_base_name in EXTENSIONS:
113 built_fn = lambda ext: ext.gloo_built()
114 result = _check_extension_lambda(
115 ext_base_name, built_fn, 'built with Gloo', verbose)
116 if result is not None:
117 return result
118 return False
119
120
121 def nccl_built(verbose=False):
122 for ext_base_name in EXTENSIONS:
123 built_fn = lambda ext: ext.nccl_built()
124 result = _check_extension_lambda(
125 ext_base_name, built_fn, 'built with NCCL', verbose)
126 if result is not None:
127 return result
128 return False
129
130
131 def ddl_built(verbose=False):
132 for ext_base_name in EXTENSIONS:
133 built_fn = lambda ext: ext.ddl_built()
134 result = _check_extension_lambda(
135 ext_base_name, built_fn, 'built with DDL', verbose)
136 if result is not None:
137 return result
138 return False
139
140
141 def mlsl_built(verbose=False):
142 for ext_base_name in EXTENSIONS:
143 built_fn = lambda ext: ext.mlsl_built()
144 result = _check_extension_lambda(
145 ext_base_name, built_fn, 'built with MLSL', verbose)
146 if result is not None:
147 return result
148 return False
149
150
151 @contextmanager
152 def env(**kwargs):
153 # ignore args with None values
154 for k in list(kwargs.keys()):
155 if kwargs[k] is None:
156 del kwargs[k]
157
158 # backup environment
159 backup = {}
160 for k in kwargs.keys():
161 backup[k] = os.environ.get(k)
162
163 # set new values & yield
164 for k, v in kwargs.items():
165 os.environ[k] = v
166
167 try:
168 yield
169 finally:
170 # restore environment
171 for k in kwargs.keys():
172 if backup[k] is not None:
173 os.environ[k] = backup[k]
174 else:
175 del os.environ[k]
176
```
Path: `horovod/_keras/__init__.py`
Content:
```
1 # Copyright 2017 Uber Technologies, Inc. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15
16 import horovod.tensorflow as hvd
17 import tensorflow as tf
18
19
20 def create_distributed_optimizer(keras, optimizer, name, device_dense, device_sparse,
21 compression, sparse_as_dense):
22 class _DistributedOptimizer(keras.optimizers.Optimizer):
23 def __init__(self, name, device_dense, device_sparse, compression, sparse_as_dense,
24 config):
25 if name is None:
26 name = "Distributed%s" % self.__class__.__base__.__name__
27 self._name = name
28 self._device_dense = device_dense
29 self._device_sparse = device_sparse
30 self._compression = compression
31 self._sparse_as_dense = sparse_as_dense
32 self._get_gradients_used = False
33 super(self.__class__, self).__init__(**config)
34
35 def get_gradients(self, loss, params):
36 """
37 Compute gradients of all trainable variables.
38
39 See Optimizer.get_gradients() for more info.
40
41 In DistributedOptimizer, get_gradients() is overriden to also
42 allreduce the gradients before returning them.
43 """
44 self._get_gradients_used = True
45 gradients = super(self.__class__, self).get_gradients(loss, params)
46 if hvd.size() > 1:
47 averaged_gradients = []
48 with tf.name_scope(self._name + "_Allreduce"):
49 for grad in gradients:
50 if grad is not None:
51 if self._sparse_as_dense and \
52 isinstance(grad, tf.IndexedSlices):
53 grad = tf.convert_to_tensor(grad)
54 avg_grad = hvd.allreduce(grad,
55 device_dense=self._device_dense,
56 device_sparse=self._device_sparse,
57 compression=self._compression)
58 averaged_gradients.append(avg_grad)
59 else:
60 averaged_gradients.append(None)
61 return averaged_gradients
62 else:
63 return gradients
64
65 def apply_gradients(self, *args, **kwargs):
66 if not self._get_gradients_used:
67 raise Exception('`apply_gradients()` was called without a call to '
68 '`get_gradients()`. If you\'re using TensorFlow 2.0, '
69 'please specify `experimental_run_tf_function=False` in '
70 '`compile()`.')
71 return super(self.__class__, self).apply_gradients(*args, **kwargs)
72
73 # We dynamically create a new class that inherits from the optimizer that was passed in.
74 # The goal is to override get_gradients() method with an allreduce implementation.
75 # This class will have the same name as the optimizer it's wrapping, so that the saved
76 # model could be easily restored without Horovod.
77 cls = type(optimizer.__class__.__name__, (optimizer.__class__,),
78 dict(_DistributedOptimizer.__dict__))
79 return cls(name, device_dense, device_sparse, compression, sparse_as_dense,
80 optimizer.get_config())
81
82
83 def _eval(backend, op_or_result):
84 if hvd._executing_eagerly():
85 return op_or_result
86 else:
87 return backend.get_session().run(op_or_result)
88
89
90 if hasattr(hvd, 'broadcast_global_variables'):
91 def broadcast_global_variables(backend, root_rank):
92 return _eval(backend, hvd.broadcast_global_variables(root_rank))
93
94
95 def allreduce(backend, value, name, average):
96 return _eval(backend, hvd.allreduce(tf.constant(value, name=name), average=average))
97
98
99 def allgather(backend, value, name):
100 return _eval(backend, hvd.allgather(tf.constant(value, name=name)))
101
102
103 def broadcast(backend, value, root_rank, name):
104 return _eval(backend, hvd.broadcast(tf.constant(value, name=name), root_rank))
105
106
107 def load_model(keras, wrap_optimizer, filepath, custom_optimizers, custom_objects):
108 horovod_objects = {
109 subclass.__name__.lower(): wrap_optimizer(subclass)
110 for subclass in keras.optimizers.Optimizer.__subclasses__()
111 if subclass.__module__ == keras.optimizers.Optimizer.__module__
112 }
113
114 if custom_optimizers is not None:
115 horovod_objects.update({
116 cls.__name__: wrap_optimizer(cls)
117 for cls in custom_optimizers
118 })
119
120 if custom_objects is not None:
121 horovod_objects.update(custom_objects)
122
123 return keras.models.load_model(filepath, custom_objects=horovod_objects)
124
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/horovod/_keras/__init__.py b/horovod/_keras/__init__.py
--- a/horovod/_keras/__init__.py
+++ b/horovod/_keras/__init__.py
@@ -70,6 +70,10 @@
'`compile()`.')
return super(self.__class__, self).apply_gradients(*args, **kwargs)
+ @classmethod
+ def from_config(cls, cfg):
+ return cls(name, device_dense, device_sparse, compression, sparse_as_dense, cfg)
+
# We dynamically create a new class that inherits from the optimizer that was passed in.
# The goal is to override get_gradients() method with an allreduce implementation.
# This class will have the same name as the optimizer it's wrapping, so that the saved
diff --git a/horovod/common/util.py b/horovod/common/util.py
--- a/horovod/common/util.py
+++ b/horovod/common/util.py
@@ -15,7 +15,6 @@
# =============================================================================
from contextlib import contextmanager
-import importlib
from multiprocessing import Process, Queue
import os
import sysconfig
|
{"golden_diff": "diff --git a/horovod/_keras/__init__.py b/horovod/_keras/__init__.py\n--- a/horovod/_keras/__init__.py\n+++ b/horovod/_keras/__init__.py\n@@ -70,6 +70,10 @@\n '`compile()`.')\n return super(self.__class__, self).apply_gradients(*args, **kwargs)\n \n+ @classmethod\n+ def from_config(cls, cfg):\n+ return cls(name, device_dense, device_sparse, compression, sparse_as_dense, cfg)\n+\n # We dynamically create a new class that inherits from the optimizer that was passed in.\n # The goal is to override get_gradients() method with an allreduce implementation.\n # This class will have the same name as the optimizer it's wrapping, so that the saved\ndiff --git a/horovod/common/util.py b/horovod/common/util.py\n--- a/horovod/common/util.py\n+++ b/horovod/common/util.py\n@@ -15,7 +15,6 @@\n # =============================================================================\n \n from contextlib import contextmanager\n-import importlib\n from multiprocessing import Process, Queue\n import os\n import sysconfig\n", "issue": "DistributedOptimzer is not compatible with keras.Optimizer\n**Environment:**\r\n1. Framework: (TensorFlow, Keras, PyTorch, MXNet)\r\n2. Framework version: 1.14\r\n3. Horovod version: 0.16.4\r\n7. Python version: 3.6.8\r\n\r\n**Checklist:**\r\n1. Did you search issues to find if somebody asked this question before?\r\n2. If your question is about hang, did you read [this doc](https://github.com/horovod/horovod/blob/master/docs/running.rst)?\r\n3. If your question is about docker, did you read [this doc](https://github.com/horovod/horovod/blob/master/docs/docker.rst)?\r\n4. Did you check if you question is answered in the [troubleshooting guide](https://github.com/horovod/horovod/blob/master/docs/troubleshooting.rst)?\r\n\r\n**Bug report:**\r\nPlease describe errorneous behavior you're observing and steps to reproduce it.\r\nHorovod DistributedOptimzer wrapper is not compatible with keras:\r\n\r\n\r\n\r\n```\r\nimport tensorflow as tf\r\nimport horovod.tensorflow.keras as hvd\r\n\r\nhvd.init()\r\nopt = tf.keras.optimizers.Adam()\r\nhopt = hvd.DistributedOptimizer(opt)\r\nopt.get_config()\r\ncfg = hopt.get_config()\r\nopt_copy = opt.from_config(cfg)\r\nopt_copy = opt.__class__.from_config(cfg)\r\nhopt_copy = hopt.from_config(cfg) # TypeError: __init__() got an unexpected keyword argument 'learning_rate'\r\nhopt_copy = hopt.__class__.from_config(cfg) # TypeError: __init__() got an unexpected keyword argument 'learning_rate'\r\n```\r\n\n", "before_files": [{"content": "# Copyright 2016 The TensorFlow Authors. All Rights Reserved.\n# Modifications copyright (C) 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# =============================================================================\n\nfrom contextlib import contextmanager\nimport importlib\nfrom multiprocessing import Process, Queue\nimport os\nimport sysconfig\n\nEXTENSIONS = ['tensorflow', 'torch', 'mxnet']\n\n\ndef get_ext_suffix():\n \"\"\"Determine library extension for various versions of Python.\"\"\"\n ext_suffix = sysconfig.get_config_var('EXT_SUFFIX')\n if ext_suffix:\n return ext_suffix\n\n ext_suffix = sysconfig.get_config_var('SO')\n if ext_suffix:\n return ext_suffix\n\n return '.so'\n\n\ndef get_extension_full_path(pkg_path, *args):\n assert len(args) >= 1\n dir_path = os.path.join(os.path.dirname(pkg_path), *args[:-1])\n full_path = os.path.join(dir_path, args[-1] + get_ext_suffix())\n return full_path\n\n\ndef check_extension(ext_name, ext_env_var, pkg_path, *args):\n full_path = get_extension_full_path(pkg_path, *args)\n if not os.path.exists(full_path):\n raise ImportError(\n 'Extension %s has not been built. If this is not expected, reinstall '\n 'Horovod with %s=1 to debug the build error.' % (ext_name, ext_env_var))\n\n\ndef _check_extension_lambda(ext_base_name, fn, fn_desc, verbose):\n \"\"\"\n Tries to load the extension in a new process. If successful, puts fn(ext)\n to the queue or False otherwise. Mutes all stdout/stderr.\n \"\"\"\n def _target_fn(ext_base_name, fn, fn_desc, queue, verbose):\n import importlib\n import sys\n import traceback\n\n if verbose:\n print('Checking whether extension {ext_base_name} was {fn_desc}.'.format(\n ext_base_name=ext_base_name, fn_desc=fn_desc))\n else:\n # Suppress output\n sys.stdout = open(os.devnull, 'w')\n sys.stderr = open(os.devnull, 'w')\n\n try:\n ext = importlib.import_module('.' + ext_base_name, 'horovod')\n result = fn(ext)\n except:\n traceback.print_exc()\n result = None\n\n if verbose:\n print('Extension {ext_base_name} {flag} {fn_desc}.'.format(\n ext_base_name=ext_base_name, flag=('was' if result else 'was NOT'),\n fn_desc=fn_desc))\n\n queue.put(result)\n\n queue = Queue()\n p = Process(target=_target_fn,\n args=(ext_base_name, fn, fn_desc, queue, verbose))\n p.daemon = True\n p.start()\n p.join()\n return queue.get_nowait()\n\n\ndef extension_available(ext_base_name, verbose=False):\n available_fn = lambda ext: ext is not None\n return _check_extension_lambda(\n ext_base_name, available_fn, 'built', verbose) or False\n\n\ndef mpi_built(verbose=False):\n for ext_base_name in EXTENSIONS:\n built_fn = lambda ext: ext.mpi_built()\n result = _check_extension_lambda(\n ext_base_name, built_fn, 'built with MPI', verbose)\n if result is not None:\n return result\n return False\n\n\ndef gloo_built(verbose=False):\n for ext_base_name in EXTENSIONS:\n built_fn = lambda ext: ext.gloo_built()\n result = _check_extension_lambda(\n ext_base_name, built_fn, 'built with Gloo', verbose)\n if result is not None:\n return result\n return False\n\n\ndef nccl_built(verbose=False):\n for ext_base_name in EXTENSIONS:\n built_fn = lambda ext: ext.nccl_built()\n result = _check_extension_lambda(\n ext_base_name, built_fn, 'built with NCCL', verbose)\n if result is not None:\n return result\n return False\n\n\ndef ddl_built(verbose=False):\n for ext_base_name in EXTENSIONS:\n built_fn = lambda ext: ext.ddl_built()\n result = _check_extension_lambda(\n ext_base_name, built_fn, 'built with DDL', verbose)\n if result is not None:\n return result\n return False\n\n\ndef mlsl_built(verbose=False):\n for ext_base_name in EXTENSIONS:\n built_fn = lambda ext: ext.mlsl_built()\n result = _check_extension_lambda(\n ext_base_name, built_fn, 'built with MLSL', verbose)\n if result is not None:\n return result\n return False\n\n\n@contextmanager\ndef env(**kwargs):\n # ignore args with None values\n for k in list(kwargs.keys()):\n if kwargs[k] is None:\n del kwargs[k]\n\n # backup environment\n backup = {}\n for k in kwargs.keys():\n backup[k] = os.environ.get(k)\n\n # set new values & yield\n for k, v in kwargs.items():\n os.environ[k] = v\n\n try:\n yield\n finally:\n # restore environment\n for k in kwargs.keys():\n if backup[k] is not None:\n os.environ[k] = backup[k]\n else:\n del os.environ[k]\n", "path": "horovod/common/util.py"}, {"content": "# Copyright 2017 Uber Technologies, Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\nimport horovod.tensorflow as hvd\nimport tensorflow as tf\n\n\ndef create_distributed_optimizer(keras, optimizer, name, device_dense, device_sparse,\n compression, sparse_as_dense):\n class _DistributedOptimizer(keras.optimizers.Optimizer):\n def __init__(self, name, device_dense, device_sparse, compression, sparse_as_dense,\n config):\n if name is None:\n name = \"Distributed%s\" % self.__class__.__base__.__name__\n self._name = name\n self._device_dense = device_dense\n self._device_sparse = device_sparse\n self._compression = compression\n self._sparse_as_dense = sparse_as_dense\n self._get_gradients_used = False\n super(self.__class__, self).__init__(**config)\n\n def get_gradients(self, loss, params):\n \"\"\"\n Compute gradients of all trainable variables.\n\n See Optimizer.get_gradients() for more info.\n\n In DistributedOptimizer, get_gradients() is overriden to also\n allreduce the gradients before returning them.\n \"\"\"\n self._get_gradients_used = True\n gradients = super(self.__class__, self).get_gradients(loss, params)\n if hvd.size() > 1:\n averaged_gradients = []\n with tf.name_scope(self._name + \"_Allreduce\"):\n for grad in gradients:\n if grad is not None:\n if self._sparse_as_dense and \\\n isinstance(grad, tf.IndexedSlices):\n grad = tf.convert_to_tensor(grad)\n avg_grad = hvd.allreduce(grad,\n device_dense=self._device_dense,\n device_sparse=self._device_sparse,\n compression=self._compression)\n averaged_gradients.append(avg_grad)\n else:\n averaged_gradients.append(None)\n return averaged_gradients\n else:\n return gradients\n\n def apply_gradients(self, *args, **kwargs):\n if not self._get_gradients_used:\n raise Exception('`apply_gradients()` was called without a call to '\n '`get_gradients()`. If you\\'re using TensorFlow 2.0, '\n 'please specify `experimental_run_tf_function=False` in '\n '`compile()`.')\n return super(self.__class__, self).apply_gradients(*args, **kwargs)\n\n # We dynamically create a new class that inherits from the optimizer that was passed in.\n # The goal is to override get_gradients() method with an allreduce implementation.\n # This class will have the same name as the optimizer it's wrapping, so that the saved\n # model could be easily restored without Horovod.\n cls = type(optimizer.__class__.__name__, (optimizer.__class__,),\n dict(_DistributedOptimizer.__dict__))\n return cls(name, device_dense, device_sparse, compression, sparse_as_dense,\n optimizer.get_config())\n\n\ndef _eval(backend, op_or_result):\n if hvd._executing_eagerly():\n return op_or_result\n else:\n return backend.get_session().run(op_or_result)\n\n\nif hasattr(hvd, 'broadcast_global_variables'):\n def broadcast_global_variables(backend, root_rank):\n return _eval(backend, hvd.broadcast_global_variables(root_rank))\n\n\ndef allreduce(backend, value, name, average):\n return _eval(backend, hvd.allreduce(tf.constant(value, name=name), average=average))\n\n\ndef allgather(backend, value, name):\n return _eval(backend, hvd.allgather(tf.constant(value, name=name)))\n\n\ndef broadcast(backend, value, root_rank, name):\n return _eval(backend, hvd.broadcast(tf.constant(value, name=name), root_rank))\n\n\ndef load_model(keras, wrap_optimizer, filepath, custom_optimizers, custom_objects):\n horovod_objects = {\n subclass.__name__.lower(): wrap_optimizer(subclass)\n for subclass in keras.optimizers.Optimizer.__subclasses__()\n if subclass.__module__ == keras.optimizers.Optimizer.__module__\n }\n\n if custom_optimizers is not None:\n horovod_objects.update({\n cls.__name__: wrap_optimizer(cls)\n for cls in custom_optimizers\n })\n\n if custom_objects is not None:\n horovod_objects.update(custom_objects)\n\n return keras.models.load_model(filepath, custom_objects=horovod_objects)\n", "path": "horovod/_keras/__init__.py"}], "after_files": [{"content": "# Copyright 2016 The TensorFlow Authors. All Rights Reserved.\n# Modifications copyright (C) 2019 Uber Technologies, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# =============================================================================\n\nfrom contextlib import contextmanager\nfrom multiprocessing import Process, Queue\nimport os\nimport sysconfig\n\nEXTENSIONS = ['tensorflow', 'torch', 'mxnet']\n\n\ndef get_ext_suffix():\n \"\"\"Determine library extension for various versions of Python.\"\"\"\n ext_suffix = sysconfig.get_config_var('EXT_SUFFIX')\n if ext_suffix:\n return ext_suffix\n\n ext_suffix = sysconfig.get_config_var('SO')\n if ext_suffix:\n return ext_suffix\n\n return '.so'\n\n\ndef get_extension_full_path(pkg_path, *args):\n assert len(args) >= 1\n dir_path = os.path.join(os.path.dirname(pkg_path), *args[:-1])\n full_path = os.path.join(dir_path, args[-1] + get_ext_suffix())\n return full_path\n\n\ndef check_extension(ext_name, ext_env_var, pkg_path, *args):\n full_path = get_extension_full_path(pkg_path, *args)\n if not os.path.exists(full_path):\n raise ImportError(\n 'Extension %s has not been built. If this is not expected, reinstall '\n 'Horovod with %s=1 to debug the build error.' % (ext_name, ext_env_var))\n\n\ndef _check_extension_lambda(ext_base_name, fn, fn_desc, verbose):\n \"\"\"\n Tries to load the extension in a new process. If successful, puts fn(ext)\n to the queue or False otherwise. Mutes all stdout/stderr.\n \"\"\"\n def _target_fn(ext_base_name, fn, fn_desc, queue, verbose):\n import importlib\n import sys\n import traceback\n\n if verbose:\n print('Checking whether extension {ext_base_name} was {fn_desc}.'.format(\n ext_base_name=ext_base_name, fn_desc=fn_desc))\n else:\n # Suppress output\n sys.stdout = open(os.devnull, 'w')\n sys.stderr = open(os.devnull, 'w')\n\n try:\n ext = importlib.import_module('.' + ext_base_name, 'horovod')\n result = fn(ext)\n except:\n traceback.print_exc()\n result = None\n\n if verbose:\n print('Extension {ext_base_name} {flag} {fn_desc}.'.format(\n ext_base_name=ext_base_name, flag=('was' if result else 'was NOT'),\n fn_desc=fn_desc))\n\n queue.put(result)\n\n queue = Queue()\n p = Process(target=_target_fn,\n args=(ext_base_name, fn, fn_desc, queue, verbose))\n p.daemon = True\n p.start()\n p.join()\n return queue.get_nowait()\n\n\ndef extension_available(ext_base_name, verbose=False):\n available_fn = lambda ext: ext is not None\n return _check_extension_lambda(\n ext_base_name, available_fn, 'built', verbose) or False\n\n\ndef mpi_built(verbose=False):\n for ext_base_name in EXTENSIONS:\n built_fn = lambda ext: ext.mpi_built()\n result = _check_extension_lambda(\n ext_base_name, built_fn, 'built with MPI', verbose)\n if result is not None:\n return result\n return False\n\n\ndef gloo_built(verbose=False):\n for ext_base_name in EXTENSIONS:\n built_fn = lambda ext: ext.gloo_built()\n result = _check_extension_lambda(\n ext_base_name, built_fn, 'built with Gloo', verbose)\n if result is not None:\n return result\n return False\n\n\ndef nccl_built(verbose=False):\n for ext_base_name in EXTENSIONS:\n built_fn = lambda ext: ext.nccl_built()\n result = _check_extension_lambda(\n ext_base_name, built_fn, 'built with NCCL', verbose)\n if result is not None:\n return result\n return False\n\n\ndef ddl_built(verbose=False):\n for ext_base_name in EXTENSIONS:\n built_fn = lambda ext: ext.ddl_built()\n result = _check_extension_lambda(\n ext_base_name, built_fn, 'built with DDL', verbose)\n if result is not None:\n return result\n return False\n\n\ndef mlsl_built(verbose=False):\n for ext_base_name in EXTENSIONS:\n built_fn = lambda ext: ext.mlsl_built()\n result = _check_extension_lambda(\n ext_base_name, built_fn, 'built with MLSL', verbose)\n if result is not None:\n return result\n return False\n\n\n@contextmanager\ndef env(**kwargs):\n # ignore args with None values\n for k in list(kwargs.keys()):\n if kwargs[k] is None:\n del kwargs[k]\n\n # backup environment\n backup = {}\n for k in kwargs.keys():\n backup[k] = os.environ.get(k)\n\n # set new values & yield\n for k, v in kwargs.items():\n os.environ[k] = v\n\n try:\n yield\n finally:\n # restore environment\n for k in kwargs.keys():\n if backup[k] is not None:\n os.environ[k] = backup[k]\n else:\n del os.environ[k]\n", "path": "horovod/common/util.py"}, {"content": "# Copyright 2017 Uber Technologies, Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\nimport horovod.tensorflow as hvd\nimport tensorflow as tf\n\n\ndef create_distributed_optimizer(keras, optimizer, name, device_dense, device_sparse,\n compression, sparse_as_dense):\n class _DistributedOptimizer(keras.optimizers.Optimizer):\n def __init__(self, name, device_dense, device_sparse, compression, sparse_as_dense,\n config):\n if name is None:\n name = \"Distributed%s\" % self.__class__.__base__.__name__\n self._name = name\n self._device_dense = device_dense\n self._device_sparse = device_sparse\n self._compression = compression\n self._sparse_as_dense = sparse_as_dense\n self._get_gradients_used = False\n super(self.__class__, self).__init__(**config)\n\n def get_gradients(self, loss, params):\n \"\"\"\n Compute gradients of all trainable variables.\n\n See Optimizer.get_gradients() for more info.\n\n In DistributedOptimizer, get_gradients() is overriden to also\n allreduce the gradients before returning them.\n \"\"\"\n self._get_gradients_used = True\n gradients = super(self.__class__, self).get_gradients(loss, params)\n if hvd.size() > 1:\n averaged_gradients = []\n with tf.name_scope(self._name + \"_Allreduce\"):\n for grad in gradients:\n if grad is not None:\n if self._sparse_as_dense and \\\n isinstance(grad, tf.IndexedSlices):\n grad = tf.convert_to_tensor(grad)\n avg_grad = hvd.allreduce(grad,\n device_dense=self._device_dense,\n device_sparse=self._device_sparse,\n compression=self._compression)\n averaged_gradients.append(avg_grad)\n else:\n averaged_gradients.append(None)\n return averaged_gradients\n else:\n return gradients\n\n def apply_gradients(self, *args, **kwargs):\n if not self._get_gradients_used:\n raise Exception('`apply_gradients()` was called without a call to '\n '`get_gradients()`. If you\\'re using TensorFlow 2.0, '\n 'please specify `experimental_run_tf_function=False` in '\n '`compile()`.')\n return super(self.__class__, self).apply_gradients(*args, **kwargs)\n\n @classmethod\n def from_config(cls, cfg):\n return cls(name, device_dense, device_sparse, compression, sparse_as_dense, cfg)\n\n # We dynamically create a new class that inherits from the optimizer that was passed in.\n # The goal is to override get_gradients() method with an allreduce implementation.\n # This class will have the same name as the optimizer it's wrapping, so that the saved\n # model could be easily restored without Horovod.\n cls = type(optimizer.__class__.__name__, (optimizer.__class__,),\n dict(_DistributedOptimizer.__dict__))\n return cls(name, device_dense, device_sparse, compression, sparse_as_dense,\n optimizer.get_config())\n\n\ndef _eval(backend, op_or_result):\n if hvd._executing_eagerly():\n return op_or_result\n else:\n return backend.get_session().run(op_or_result)\n\n\nif hasattr(hvd, 'broadcast_global_variables'):\n def broadcast_global_variables(backend, root_rank):\n return _eval(backend, hvd.broadcast_global_variables(root_rank))\n\n\ndef allreduce(backend, value, name, average):\n return _eval(backend, hvd.allreduce(tf.constant(value, name=name), average=average))\n\n\ndef allgather(backend, value, name):\n return _eval(backend, hvd.allgather(tf.constant(value, name=name)))\n\n\ndef broadcast(backend, value, root_rank, name):\n return _eval(backend, hvd.broadcast(tf.constant(value, name=name), root_rank))\n\n\ndef load_model(keras, wrap_optimizer, filepath, custom_optimizers, custom_objects):\n horovod_objects = {\n subclass.__name__.lower(): wrap_optimizer(subclass)\n for subclass in keras.optimizers.Optimizer.__subclasses__()\n if subclass.__module__ == keras.optimizers.Optimizer.__module__\n }\n\n if custom_optimizers is not None:\n horovod_objects.update({\n cls.__name__: wrap_optimizer(cls)\n for cls in custom_optimizers\n })\n\n if custom_objects is not None:\n horovod_objects.update(custom_objects)\n\n return keras.models.load_model(filepath, custom_objects=horovod_objects)\n", "path": "horovod/_keras/__init__.py"}]}
| 3,656 | 263 |
gh_patches_debug_61215
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-1124
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Top-Level Python API methods don't have docstrings rendered in docs
# Description
The top level Python API methods pages on the docs website doesn't contain any of the rendered docstrings. For example, the `pyhf.set_backend()` API has examples (and it rather important for new users)
https://github.com/scikit-hep/pyhf/blob/e55eea408d7c28e3109338de96252119ac63f87a/src/pyhf/__init__.py#L42-L52
but the docs website doesn't show any of this

# Expected Behavior
Have the docstrings be rendered in the docs
# Actual Behavior
c.f. above
# Steps to Reproduce
Build the docs
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/pyhf/events.py`
Content:
```
1 import weakref
2
3 __events = {}
4 __disabled_events = set([])
5
6
7 def noop(*args, **kwargs):
8 pass
9
10
11 class WeakList(list):
12 def append(self, item):
13 list.append(self, weakref.WeakMethod(item, self.remove))
14
15
16 class Callables(WeakList):
17 def __call__(self, *args, **kwargs):
18 for func in self:
19 # weakref: needs to be de-ref'd first before calling
20 func()(*args, **kwargs)
21
22 def __repr__(self):
23 return "Callables(%s)" % list.__repr__(self)
24
25
26 def subscribe(event):
27 """
28 This is meant to be used as a decorator.
29 """
30 # Example:
31 #
32 # >>> @pyhf.events.subscribe('myevent')
33 # ... def test(a,b):
34 # ... print a+b
35 # ...
36 # >>> pyhf.events.trigger_myevent(1,2)
37 # 3
38 global __events
39
40 def __decorator(func):
41 __events.setdefault(event, Callables()).append(func)
42 return func
43
44 return __decorator
45
46
47 def register(event):
48 """
49 This is meant to be used as a decorator to register a function for triggering events.
50
51 This creates two events: "<event_name>::before" and "<event_name>::after"
52 """
53 # Examples:
54 #
55 # >>> @pyhf.events.register('test_func')
56 # ... def test(a,b):
57 # ... print a+b
58 # ...
59 # >>> @pyhf.events.subscribe('test_func::before')
60 # ... def precall():
61 # ... print 'before call'
62 # ...
63 # >>> @pyhf.events.subscribe('test_func::after')
64 # ... def postcall():
65 # ... print 'after call'
66 # ...
67 # >>> test(1,2)
68 # "before call"
69 # 3
70 # "after call"
71 # >>>
72
73 def _register(func):
74 def register_wrapper(*args, **kwargs):
75 trigger("{0:s}::before".format(event))()
76 result = func(*args, **kwargs)
77 trigger("{0:s}::after".format(event))()
78 return result
79
80 return register_wrapper
81
82 return _register
83
84
85 def trigger(event):
86 """
87 Trigger an event if not disabled.
88 """
89 global __events, __disabled_events, noop
90 is_noop = bool(event in __disabled_events or event not in __events)
91 return noop if is_noop else __events.get(event)
92
93
94 def disable(event):
95 """
96 Disable an event from firing.
97 """
98 global __disabled_events
99 __disabled_events.add(event)
100
101
102 def enable(event):
103 """
104 Enable an event to be fired if disabled.
105 """
106 global __disabled_events
107 __disabled_events.remove(event)
108
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/pyhf/events.py b/src/pyhf/events.py
--- a/src/pyhf/events.py
+++ b/src/pyhf/events.py
@@ -1,4 +1,5 @@
import weakref
+from functools import wraps
__events = {}
__disabled_events = set([])
@@ -71,6 +72,7 @@
# >>>
def _register(func):
+ @wraps(func)
def register_wrapper(*args, **kwargs):
trigger("{0:s}::before".format(event))()
result = func(*args, **kwargs)
|
{"golden_diff": "diff --git a/src/pyhf/events.py b/src/pyhf/events.py\n--- a/src/pyhf/events.py\n+++ b/src/pyhf/events.py\n@@ -1,4 +1,5 @@\n import weakref\n+from functools import wraps\n \n __events = {}\n __disabled_events = set([])\n@@ -71,6 +72,7 @@\n # >>>\n \n def _register(func):\n+ @wraps(func)\n def register_wrapper(*args, **kwargs):\n trigger(\"{0:s}::before\".format(event))()\n result = func(*args, **kwargs)\n", "issue": "Top-Level Python API methods don't have docstrings rendered in docs\n# Description\r\n\r\nThe top level Python API methods pages on the docs website doesn't contain any of the rendered docstrings. For example, the `pyhf.set_backend()` API has examples (and it rather important for new users)\r\n\r\nhttps://github.com/scikit-hep/pyhf/blob/e55eea408d7c28e3109338de96252119ac63f87a/src/pyhf/__init__.py#L42-L52\r\n\r\nbut the docs website doesn't show any of this\r\n\r\n\r\n\r\n\r\n# Expected Behavior\r\n\r\nHave the docstrings be rendered in the docs \r\n\r\n# Actual Behavior\r\n\r\nc.f. above\r\n\r\n# Steps to Reproduce\r\n\r\nBuild the docs\r\n\r\n# Checklist\r\n\r\n- [x] Run `git fetch` to get the most up to date version of `master`\r\n- [x] Searched through existing Issues to confirm this is not a duplicate issue\r\n- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue\r\n\n", "before_files": [{"content": "import weakref\n\n__events = {}\n__disabled_events = set([])\n\n\ndef noop(*args, **kwargs):\n pass\n\n\nclass WeakList(list):\n def append(self, item):\n list.append(self, weakref.WeakMethod(item, self.remove))\n\n\nclass Callables(WeakList):\n def __call__(self, *args, **kwargs):\n for func in self:\n # weakref: needs to be de-ref'd first before calling\n func()(*args, **kwargs)\n\n def __repr__(self):\n return \"Callables(%s)\" % list.__repr__(self)\n\n\ndef subscribe(event):\n \"\"\"\n This is meant to be used as a decorator.\n \"\"\"\n # Example:\n #\n # >>> @pyhf.events.subscribe('myevent')\n # ... def test(a,b):\n # ... print a+b\n # ...\n # >>> pyhf.events.trigger_myevent(1,2)\n # 3\n global __events\n\n def __decorator(func):\n __events.setdefault(event, Callables()).append(func)\n return func\n\n return __decorator\n\n\ndef register(event):\n \"\"\"\n This is meant to be used as a decorator to register a function for triggering events.\n\n This creates two events: \"<event_name>::before\" and \"<event_name>::after\"\n \"\"\"\n # Examples:\n #\n # >>> @pyhf.events.register('test_func')\n # ... def test(a,b):\n # ... print a+b\n # ...\n # >>> @pyhf.events.subscribe('test_func::before')\n # ... def precall():\n # ... print 'before call'\n # ...\n # >>> @pyhf.events.subscribe('test_func::after')\n # ... def postcall():\n # ... print 'after call'\n # ...\n # >>> test(1,2)\n # \"before call\"\n # 3\n # \"after call\"\n # >>>\n\n def _register(func):\n def register_wrapper(*args, **kwargs):\n trigger(\"{0:s}::before\".format(event))()\n result = func(*args, **kwargs)\n trigger(\"{0:s}::after\".format(event))()\n return result\n\n return register_wrapper\n\n return _register\n\n\ndef trigger(event):\n \"\"\"\n Trigger an event if not disabled.\n \"\"\"\n global __events, __disabled_events, noop\n is_noop = bool(event in __disabled_events or event not in __events)\n return noop if is_noop else __events.get(event)\n\n\ndef disable(event):\n \"\"\"\n Disable an event from firing.\n \"\"\"\n global __disabled_events\n __disabled_events.add(event)\n\n\ndef enable(event):\n \"\"\"\n Enable an event to be fired if disabled.\n \"\"\"\n global __disabled_events\n __disabled_events.remove(event)\n", "path": "src/pyhf/events.py"}], "after_files": [{"content": "import weakref\nfrom functools import wraps\n\n__events = {}\n__disabled_events = set([])\n\n\ndef noop(*args, **kwargs):\n pass\n\n\nclass WeakList(list):\n def append(self, item):\n list.append(self, weakref.WeakMethod(item, self.remove))\n\n\nclass Callables(WeakList):\n def __call__(self, *args, **kwargs):\n for func in self:\n # weakref: needs to be de-ref'd first before calling\n func()(*args, **kwargs)\n\n def __repr__(self):\n return \"Callables(%s)\" % list.__repr__(self)\n\n\ndef subscribe(event):\n \"\"\"\n This is meant to be used as a decorator.\n \"\"\"\n # Example:\n #\n # >>> @pyhf.events.subscribe('myevent')\n # ... def test(a,b):\n # ... print a+b\n # ...\n # >>> pyhf.events.trigger_myevent(1,2)\n # 3\n global __events\n\n def __decorator(func):\n __events.setdefault(event, Callables()).append(func)\n return func\n\n return __decorator\n\n\ndef register(event):\n \"\"\"\n This is meant to be used as a decorator to register a function for triggering events.\n\n This creates two events: \"<event_name>::before\" and \"<event_name>::after\"\n \"\"\"\n # Examples:\n #\n # >>> @pyhf.events.register('test_func')\n # ... def test(a,b):\n # ... print a+b\n # ...\n # >>> @pyhf.events.subscribe('test_func::before')\n # ... def precall():\n # ... print 'before call'\n # ...\n # >>> @pyhf.events.subscribe('test_func::after')\n # ... def postcall():\n # ... print 'after call'\n # ...\n # >>> test(1,2)\n # \"before call\"\n # 3\n # \"after call\"\n # >>>\n\n def _register(func):\n @wraps(func)\n def register_wrapper(*args, **kwargs):\n trigger(\"{0:s}::before\".format(event))()\n result = func(*args, **kwargs)\n trigger(\"{0:s}::after\".format(event))()\n return result\n\n return register_wrapper\n\n return _register\n\n\ndef trigger(event):\n \"\"\"\n Trigger an event if not disabled.\n \"\"\"\n global __events, __disabled_events, noop\n is_noop = bool(event in __disabled_events or event not in __events)\n return noop if is_noop else __events.get(event)\n\n\ndef disable(event):\n \"\"\"\n Disable an event from firing.\n \"\"\"\n global __disabled_events\n __disabled_events.add(event)\n\n\ndef enable(event):\n \"\"\"\n Enable an event to be fired if disabled.\n \"\"\"\n global __disabled_events\n __disabled_events.remove(event)\n", "path": "src/pyhf/events.py"}]}
| 1,401 | 125 |
gh_patches_debug_2836
|
rasdani/github-patches
|
git_diff
|
interlegis__sapl-2645
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Total de registros encontrados em relatório está por página e não por total
Em Comissões, Matérias em Tramitação, a contagem está relacionada ao número de matérias por página e não pelo total na unidade.
Ex:
https://sapl.divinopolis.mg.leg.br/comissao/101/materias-em-tramitacao
## Comportamento Esperado
A tela deve trazer a quantidade total de registros recuperados, não o total por página.
## Comportamento Atual
A página traz a quantidade de registros por página.
## Passos para Reproduzir (para bugs)
1. Acesse o link https://sapl.divinopolis.mg.leg.br/comissao/101/materias-em-tramitacao
## Seu Ambiente
<!--- Inclua detalhes relevantes sobre o ambiente em que você presenciou/experienciou o bug. -->
* Versão usada (_Release_): 3.1.147
* Nome e versão do navegador: Chrome
* Nome e versão do Sistema Operacional (desktop ou mobile): Linux
* Link para o seu projeto (Caso de fork deste projeto):
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sapl/comissoes/views.py`
Content:
```
1 import logging
2
3 from django.core.urlresolvers import reverse
4 from django.db.models import F
5 from django.http.response import HttpResponseRedirect
6 from django.views.decorators.clickjacking import xframe_options_exempt
7 from django.views.generic import ListView
8 from django.views.generic.base import RedirectView
9 from django.views.generic.detail import DetailView
10 from django.views.generic.edit import FormMixin
11
12 from sapl.base.models import AppConfig as AppsAppConfig
13 from sapl.comissoes.apps import AppConfig
14 from sapl.comissoes.forms import (ComissaoForm, ComposicaoForm,
15 DocumentoAcessorioCreateForm,
16 DocumentoAcessorioEditForm,
17 ParticipacaoCreateForm, ParticipacaoEditForm,
18 PeriodoForm, ReuniaoForm)
19 from sapl.crud.base import (RP_DETAIL, RP_LIST, Crud, CrudAux,
20 MasterDetailCrud,
21 PermissionRequiredForAppCrudMixin)
22 from sapl.materia.models import MateriaLegislativa, Tramitacao
23
24 from .models import (CargoComissao, Comissao, Composicao, DocumentoAcessorio,
25 Participacao, Periodo, Reuniao, TipoComissao)
26
27
28 def pegar_url_composicao(pk):
29 participacao = Participacao.objects.get(id=pk)
30 comp_pk = participacao.composicao.pk
31 url = reverse('sapl.comissoes:composicao_detail', kwargs={'pk': comp_pk})
32 return url
33
34
35 def pegar_url_reuniao(pk):
36 documentoacessorio = DocumentoAcessorio.objects.get(id=pk)
37 r_pk = documentoacessorio.reuniao.pk
38 url = reverse('sapl.comissoes:reuniao_detail', kwargs={'pk': r_pk})
39 return url
40
41 CargoCrud = CrudAux.build(CargoComissao, 'cargo_comissao')
42
43 TipoComissaoCrud = CrudAux.build(
44 TipoComissao, 'tipo_comissao', list_field_names=[
45 'sigla', 'nome', 'natureza', 'dispositivo_regimental'])
46
47
48 class PeriodoComposicaoCrud(CrudAux):
49 model = Periodo
50
51 class CreateView(CrudAux.CreateView):
52 form_class = PeriodoForm
53
54 class UpdateView(CrudAux.UpdateView):
55 form_class = PeriodoForm
56
57 # class ListView(CrudAux.ListView):
58
59
60 class ParticipacaoCrud(MasterDetailCrud):
61 model = Participacao
62 parent_field = 'composicao__comissao'
63 public = [RP_DETAIL, ]
64 ListView = None
65 link_return_to_parent_field = True
66
67 class BaseMixin(MasterDetailCrud.BaseMixin):
68 list_field_names = ['composicao', 'parlamentar', 'cargo']
69
70 class CreateView(MasterDetailCrud.CreateView):
71 form_class = ParticipacaoCreateForm
72
73 def get_initial(self):
74 initial = super().get_initial()
75 initial['parent_pk'] = self.kwargs['pk']
76 return initial
77
78 class UpdateView(MasterDetailCrud.UpdateView):
79 layout_key = 'ParticipacaoEdit'
80 form_class = ParticipacaoEditForm
81
82 class DeleteView(MasterDetailCrud.DeleteView):
83
84 def get_success_url(self):
85 composicao_comissao_pk = self.object.composicao.comissao.pk
86 composicao_pk = self.object.composicao.pk
87 return '{}?pk={}'.format(reverse('sapl.comissoes:composicao_list',
88 args=[composicao_comissao_pk]),
89 composicao_pk)
90
91
92 class ComposicaoCrud(MasterDetailCrud):
93 model = Composicao
94 parent_field = 'comissao'
95 model_set = 'participacao_set'
96 public = [RP_LIST, RP_DETAIL, ]
97
98 class CreateView(MasterDetailCrud.CreateView):
99 form_class = ComposicaoForm
100
101 def get_initial(self):
102 comissao = Comissao.objects.get(id=self.kwargs['pk'])
103 return {'comissao': comissao}
104
105 class ListView(MasterDetailCrud.ListView):
106 logger = logging.getLogger(__name__)
107 template_name = "comissoes/composicao_list.html"
108 paginate_by = None
109
110 def take_composicao_pk(self):
111
112 username = self.request.user.username
113 try:
114 self.logger.debug('user=' + username + '. Tentando obter pk da composição.')
115 return int(self.request.GET['pk'])
116 except Exception as e:
117 self.logger.error('user=' + username + '. Erro ao obter pk da composição. Retornado 0. ' + str(e))
118 return 0
119
120 def get_context_data(self, **kwargs):
121 context = super().get_context_data(**kwargs)
122
123 composicao_pk = self.take_composicao_pk()
124
125 if composicao_pk == 0:
126 # Composicao eh ordenada por Periodo, que por sua vez esta em
127 # ordem descrescente de data de inicio (issue #1920)
128 ultima_composicao = context['composicao_list'].first()
129 if ultima_composicao:
130 context['composicao_pk'] = ultima_composicao.pk
131 else:
132 context['composicao_pk'] = 0
133 else:
134 context['composicao_pk'] = composicao_pk
135
136 context['participacao_set'] = Participacao.objects.filter(
137 composicao__pk=context['composicao_pk']
138 ).order_by('id')
139 return context
140
141
142 class ComissaoCrud(Crud):
143 model = Comissao
144 help_topic = 'modulo_comissoes'
145 public = [RP_LIST, RP_DETAIL, ]
146
147 class BaseMixin(Crud.BaseMixin):
148 list_field_names = ['nome', 'sigla', 'tipo',
149 'data_criacao', 'data_extincao', 'ativa']
150 ordering = '-ativa', 'sigla'
151
152 class CreateView(Crud.CreateView):
153 form_class = ComissaoForm
154
155 def form_valid(self, form):
156 return super(Crud.CreateView, self).form_valid(form)
157
158 class UpdateView(Crud.UpdateView):
159 form_class = ComissaoForm
160
161 def form_valid(self, form):
162 return super(Crud.UpdateView, self).form_valid(form)
163
164
165 class MateriasTramitacaoListView(ListView):
166 template_name = "comissoes/materias_em_tramitacao.html"
167 paginate_by = 10
168
169 def get_queryset(self):
170 # FIXME: Otimizar consulta
171 ts = Tramitacao.objects.order_by(
172 'materia', '-data_tramitacao', '-id').annotate(
173 comissao=F('unidade_tramitacao_destino__comissao')).distinct(
174 'materia').values_list('materia', 'comissao')
175
176 ts = list(filter(lambda x: x[1] == int(self.kwargs['pk']), ts))
177 ts = list(zip(*ts))
178 ts = ts[0] if ts else []
179
180 materias = MateriaLegislativa.objects.filter(
181 pk__in=ts).order_by('tipo', '-ano', '-numero')
182
183 return materias
184
185 def get_context_data(self, **kwargs):
186 context = super(
187 MateriasTramitacaoListView, self).get_context_data(**kwargs)
188 context['object'] = Comissao.objects.get(id=self.kwargs['pk'])
189 return context
190
191
192 class ReuniaoCrud(MasterDetailCrud):
193 model = Reuniao
194 parent_field = 'comissao'
195 model_set = 'documentoacessorio_set'
196 public = [RP_LIST, RP_DETAIL, ]
197
198 class BaseMixin(MasterDetailCrud.BaseMixin):
199 list_field_names = ['data', 'nome', 'tema']
200
201 class ListView(MasterDetailCrud.ListView):
202 logger = logging.getLogger(__name__)
203 paginate_by = 10
204
205 def take_reuniao_pk(self):
206
207 username = self.request.user.username
208 try:
209 self.logger.debug('user=' + username + '. Tentando obter pk da reunião.')
210 return int(self.request.GET['pk'])
211 except Exception as e:
212 self.logger.error('user=' + username + '. Erro ao obter pk da reunião. Retornado 0. ' + str(e))
213 return 0
214
215 def get_context_data(self, **kwargs):
216 context = super().get_context_data(**kwargs)
217
218 reuniao_pk = self.take_reuniao_pk()
219
220 if reuniao_pk == 0:
221 ultima_reuniao = list(context['reuniao_list'])
222 if len(ultima_reuniao) > 0:
223 ultimo = ultima_reuniao[-1]
224 context['reuniao_pk'] = ultimo.pk
225 else:
226 context['reuniao_pk'] = 0
227 else:
228 context['reuniao_pk'] = reuniao_pk
229
230 context['documentoacessorio_set'] = DocumentoAcessorio.objects.filter(
231 reuniao__pk=context['reuniao_pk']
232 ).order_by('id')
233 return context
234
235 class UpdateView(MasterDetailCrud.UpdateView):
236 form_class = ReuniaoForm
237
238 def get_initial(self):
239 return {'comissao': self.object.comissao}
240
241 class CreateView(MasterDetailCrud.CreateView):
242 form_class = ReuniaoForm
243
244 def get_initial(self):
245 comissao = Comissao.objects.get(id=self.kwargs['pk'])
246
247 return {'comissao': comissao}
248
249
250 class DocumentoAcessorioCrud(MasterDetailCrud):
251 model = DocumentoAcessorio
252 parent_field = 'reuniao__comissao'
253 public = [RP_DETAIL, ]
254 ListView = None
255 link_return_to_parent_field = True
256
257 class BaseMixin(MasterDetailCrud.BaseMixin):
258 list_field_names = ['nome', 'tipo', 'data', 'autor', 'arquivo']
259
260 class CreateView(MasterDetailCrud.CreateView):
261 form_class = DocumentoAcessorioCreateForm
262
263 def get_initial(self):
264 initial = super().get_initial()
265 initial['parent_pk'] = self.kwargs['pk']
266 return initial
267
268 class UpdateView(MasterDetailCrud.UpdateView):
269 layout_key = 'DocumentoAcessorioEdit'
270 form_class = DocumentoAcessorioEditForm
271
272 class DeleteView(MasterDetailCrud.DeleteView):
273
274 def delete(self, *args, **kwargs):
275 obj = self.get_object()
276 obj.delete()
277 return HttpResponseRedirect(
278 reverse('sapl.comissoes:reuniao_detail',
279 kwargs={'pk': obj.reuniao.pk}))
280
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sapl/comissoes/views.py b/sapl/comissoes/views.py
--- a/sapl/comissoes/views.py
+++ b/sapl/comissoes/views.py
@@ -186,6 +186,7 @@
context = super(
MateriasTramitacaoListView, self).get_context_data(**kwargs)
context['object'] = Comissao.objects.get(id=self.kwargs['pk'])
+ context['qtde'] = self.object_list.count()
return context
|
{"golden_diff": "diff --git a/sapl/comissoes/views.py b/sapl/comissoes/views.py\n--- a/sapl/comissoes/views.py\n+++ b/sapl/comissoes/views.py\n@@ -186,6 +186,7 @@\n context = super(\n MateriasTramitacaoListView, self).get_context_data(**kwargs)\n context['object'] = Comissao.objects.get(id=self.kwargs['pk'])\n+ context['qtde'] = self.object_list.count()\n return context\n", "issue": "Total de registros encontrados em relat\u00f3rio est\u00e1 por p\u00e1gina e n\u00e3o por total\nEm Comiss\u00f5es, Mat\u00e9rias em Tramita\u00e7\u00e3o, a contagem est\u00e1 relacionada ao n\u00famero de mat\u00e9rias por p\u00e1gina e n\u00e3o pelo total na unidade.\r\n\r\nEx:\r\n\r\nhttps://sapl.divinopolis.mg.leg.br/comissao/101/materias-em-tramitacao\r\n\r\n## Comportamento Esperado\r\nA tela deve trazer a quantidade total de registros recuperados, n\u00e3o o total por p\u00e1gina.\r\n\r\n## Comportamento Atual\r\nA p\u00e1gina traz a quantidade de registros por p\u00e1gina.\r\n\r\n## Passos para Reproduzir (para bugs)\r\n1. Acesse o link https://sapl.divinopolis.mg.leg.br/comissao/101/materias-em-tramitacao\r\n\r\n## Seu Ambiente\r\n<!--- Inclua detalhes relevantes sobre o ambiente em que voc\u00ea presenciou/experienciou o bug. -->\r\n* Vers\u00e3o usada (_Release_): 3.1.147\r\n* Nome e vers\u00e3o do navegador: Chrome\r\n* Nome e vers\u00e3o do Sistema Operacional (desktop ou mobile): Linux\r\n* Link para o seu projeto (Caso de fork deste projeto):\r\n\n", "before_files": [{"content": "import logging\n\nfrom django.core.urlresolvers import reverse\nfrom django.db.models import F\nfrom django.http.response import HttpResponseRedirect\nfrom django.views.decorators.clickjacking import xframe_options_exempt\nfrom django.views.generic import ListView\nfrom django.views.generic.base import RedirectView\nfrom django.views.generic.detail import DetailView\nfrom django.views.generic.edit import FormMixin\n\nfrom sapl.base.models import AppConfig as AppsAppConfig\nfrom sapl.comissoes.apps import AppConfig\nfrom sapl.comissoes.forms import (ComissaoForm, ComposicaoForm,\n DocumentoAcessorioCreateForm,\n DocumentoAcessorioEditForm,\n ParticipacaoCreateForm, ParticipacaoEditForm,\n PeriodoForm, ReuniaoForm)\nfrom sapl.crud.base import (RP_DETAIL, RP_LIST, Crud, CrudAux,\n MasterDetailCrud,\n PermissionRequiredForAppCrudMixin)\nfrom sapl.materia.models import MateriaLegislativa, Tramitacao\n\nfrom .models import (CargoComissao, Comissao, Composicao, DocumentoAcessorio,\n Participacao, Periodo, Reuniao, TipoComissao)\n\n\ndef pegar_url_composicao(pk):\n participacao = Participacao.objects.get(id=pk)\n comp_pk = participacao.composicao.pk\n url = reverse('sapl.comissoes:composicao_detail', kwargs={'pk': comp_pk})\n return url\n\n\ndef pegar_url_reuniao(pk):\n documentoacessorio = DocumentoAcessorio.objects.get(id=pk)\n r_pk = documentoacessorio.reuniao.pk\n url = reverse('sapl.comissoes:reuniao_detail', kwargs={'pk': r_pk})\n return url\n\nCargoCrud = CrudAux.build(CargoComissao, 'cargo_comissao')\n\nTipoComissaoCrud = CrudAux.build(\n TipoComissao, 'tipo_comissao', list_field_names=[\n 'sigla', 'nome', 'natureza', 'dispositivo_regimental'])\n\n\nclass PeriodoComposicaoCrud(CrudAux):\n model = Periodo\n\n class CreateView(CrudAux.CreateView):\n form_class = PeriodoForm\n\n class UpdateView(CrudAux.UpdateView):\n form_class = PeriodoForm\n\n # class ListView(CrudAux.ListView):\n\n\nclass ParticipacaoCrud(MasterDetailCrud):\n model = Participacao\n parent_field = 'composicao__comissao'\n public = [RP_DETAIL, ]\n ListView = None\n link_return_to_parent_field = True\n\n class BaseMixin(MasterDetailCrud.BaseMixin):\n list_field_names = ['composicao', 'parlamentar', 'cargo']\n\n class CreateView(MasterDetailCrud.CreateView):\n form_class = ParticipacaoCreateForm\n\n def get_initial(self):\n initial = super().get_initial()\n initial['parent_pk'] = self.kwargs['pk']\n return initial\n\n class UpdateView(MasterDetailCrud.UpdateView):\n layout_key = 'ParticipacaoEdit'\n form_class = ParticipacaoEditForm\n\n class DeleteView(MasterDetailCrud.DeleteView):\n\n def get_success_url(self):\n composicao_comissao_pk = self.object.composicao.comissao.pk\n composicao_pk = self.object.composicao.pk\n return '{}?pk={}'.format(reverse('sapl.comissoes:composicao_list',\n args=[composicao_comissao_pk]),\n composicao_pk)\n\n\nclass ComposicaoCrud(MasterDetailCrud):\n model = Composicao\n parent_field = 'comissao'\n model_set = 'participacao_set'\n public = [RP_LIST, RP_DETAIL, ]\n\n class CreateView(MasterDetailCrud.CreateView):\n form_class = ComposicaoForm\n\n def get_initial(self):\n comissao = Comissao.objects.get(id=self.kwargs['pk'])\n return {'comissao': comissao}\n\n class ListView(MasterDetailCrud.ListView):\n logger = logging.getLogger(__name__)\n template_name = \"comissoes/composicao_list.html\"\n paginate_by = None\n\n def take_composicao_pk(self):\n \n username = self.request.user.username\n try:\n self.logger.debug('user=' + username + '. Tentando obter pk da composi\u00e7\u00e3o.')\n return int(self.request.GET['pk'])\n except Exception as e:\n self.logger.error('user=' + username + '. Erro ao obter pk da composi\u00e7\u00e3o. Retornado 0. ' + str(e))\n return 0\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n\n composicao_pk = self.take_composicao_pk()\n\n if composicao_pk == 0:\n # Composicao eh ordenada por Periodo, que por sua vez esta em\n # ordem descrescente de data de inicio (issue #1920)\n ultima_composicao = context['composicao_list'].first()\n if ultima_composicao:\n context['composicao_pk'] = ultima_composicao.pk\n else:\n context['composicao_pk'] = 0\n else:\n context['composicao_pk'] = composicao_pk\n\n context['participacao_set'] = Participacao.objects.filter(\n composicao__pk=context['composicao_pk']\n ).order_by('id')\n return context\n\n\nclass ComissaoCrud(Crud):\n model = Comissao\n help_topic = 'modulo_comissoes'\n public = [RP_LIST, RP_DETAIL, ]\n\n class BaseMixin(Crud.BaseMixin):\n list_field_names = ['nome', 'sigla', 'tipo',\n 'data_criacao', 'data_extincao', 'ativa']\n ordering = '-ativa', 'sigla'\n\n class CreateView(Crud.CreateView):\n form_class = ComissaoForm\n\n def form_valid(self, form):\n return super(Crud.CreateView, self).form_valid(form)\n\n class UpdateView(Crud.UpdateView):\n form_class = ComissaoForm\n\n def form_valid(self, form):\n return super(Crud.UpdateView, self).form_valid(form)\n\n\nclass MateriasTramitacaoListView(ListView):\n template_name = \"comissoes/materias_em_tramitacao.html\"\n paginate_by = 10\n\n def get_queryset(self):\n # FIXME: Otimizar consulta\n ts = Tramitacao.objects.order_by(\n 'materia', '-data_tramitacao', '-id').annotate(\n comissao=F('unidade_tramitacao_destino__comissao')).distinct(\n 'materia').values_list('materia', 'comissao')\n\n ts = list(filter(lambda x: x[1] == int(self.kwargs['pk']), ts))\n ts = list(zip(*ts))\n ts = ts[0] if ts else []\n\n materias = MateriaLegislativa.objects.filter(\n pk__in=ts).order_by('tipo', '-ano', '-numero')\n\n return materias\n\n def get_context_data(self, **kwargs):\n context = super(\n MateriasTramitacaoListView, self).get_context_data(**kwargs)\n context['object'] = Comissao.objects.get(id=self.kwargs['pk'])\n return context\n\n\nclass ReuniaoCrud(MasterDetailCrud):\n model = Reuniao\n parent_field = 'comissao'\n model_set = 'documentoacessorio_set'\n public = [RP_LIST, RP_DETAIL, ]\n\n class BaseMixin(MasterDetailCrud.BaseMixin):\n list_field_names = ['data', 'nome', 'tema']\n\n class ListView(MasterDetailCrud.ListView):\n logger = logging.getLogger(__name__)\n paginate_by = 10\n\n def take_reuniao_pk(self):\n\n username = self.request.user.username\n try:\n self.logger.debug('user=' + username + '. Tentando obter pk da reuni\u00e3o.')\n return int(self.request.GET['pk'])\n except Exception as e:\n self.logger.error('user=' + username + '. Erro ao obter pk da reuni\u00e3o. Retornado 0. ' + str(e))\n return 0\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n\n reuniao_pk = self.take_reuniao_pk()\n\n if reuniao_pk == 0:\n ultima_reuniao = list(context['reuniao_list'])\n if len(ultima_reuniao) > 0:\n ultimo = ultima_reuniao[-1]\n context['reuniao_pk'] = ultimo.pk\n else:\n context['reuniao_pk'] = 0\n else:\n context['reuniao_pk'] = reuniao_pk\n\n context['documentoacessorio_set'] = DocumentoAcessorio.objects.filter(\n reuniao__pk=context['reuniao_pk']\n ).order_by('id')\n return context\n\n class UpdateView(MasterDetailCrud.UpdateView):\n form_class = ReuniaoForm\n\n def get_initial(self):\n return {'comissao': self.object.comissao}\n\n class CreateView(MasterDetailCrud.CreateView):\n form_class = ReuniaoForm\n\n def get_initial(self):\n comissao = Comissao.objects.get(id=self.kwargs['pk'])\n\n return {'comissao': comissao}\n\n\nclass DocumentoAcessorioCrud(MasterDetailCrud):\n model = DocumentoAcessorio\n parent_field = 'reuniao__comissao'\n public = [RP_DETAIL, ]\n ListView = None\n link_return_to_parent_field = True\n\n class BaseMixin(MasterDetailCrud.BaseMixin):\n list_field_names = ['nome', 'tipo', 'data', 'autor', 'arquivo']\n\n class CreateView(MasterDetailCrud.CreateView):\n form_class = DocumentoAcessorioCreateForm\n\n def get_initial(self):\n initial = super().get_initial()\n initial['parent_pk'] = self.kwargs['pk']\n return initial\n\n class UpdateView(MasterDetailCrud.UpdateView):\n layout_key = 'DocumentoAcessorioEdit'\n form_class = DocumentoAcessorioEditForm\n\n class DeleteView(MasterDetailCrud.DeleteView):\n\n def delete(self, *args, **kwargs):\n obj = self.get_object()\n obj.delete()\n return HttpResponseRedirect(\n reverse('sapl.comissoes:reuniao_detail',\n kwargs={'pk': obj.reuniao.pk}))\n", "path": "sapl/comissoes/views.py"}], "after_files": [{"content": "import logging\n\nfrom django.core.urlresolvers import reverse\nfrom django.db.models import F\nfrom django.http.response import HttpResponseRedirect\nfrom django.views.decorators.clickjacking import xframe_options_exempt\nfrom django.views.generic import ListView\nfrom django.views.generic.base import RedirectView\nfrom django.views.generic.detail import DetailView\nfrom django.views.generic.edit import FormMixin\n\nfrom sapl.base.models import AppConfig as AppsAppConfig\nfrom sapl.comissoes.apps import AppConfig\nfrom sapl.comissoes.forms import (ComissaoForm, ComposicaoForm,\n DocumentoAcessorioCreateForm,\n DocumentoAcessorioEditForm,\n ParticipacaoCreateForm, ParticipacaoEditForm,\n PeriodoForm, ReuniaoForm)\nfrom sapl.crud.base import (RP_DETAIL, RP_LIST, Crud, CrudAux,\n MasterDetailCrud,\n PermissionRequiredForAppCrudMixin)\nfrom sapl.materia.models import MateriaLegislativa, Tramitacao\n\nfrom .models import (CargoComissao, Comissao, Composicao, DocumentoAcessorio,\n Participacao, Periodo, Reuniao, TipoComissao)\n\n\ndef pegar_url_composicao(pk):\n participacao = Participacao.objects.get(id=pk)\n comp_pk = participacao.composicao.pk\n url = reverse('sapl.comissoes:composicao_detail', kwargs={'pk': comp_pk})\n return url\n\n\ndef pegar_url_reuniao(pk):\n documentoacessorio = DocumentoAcessorio.objects.get(id=pk)\n r_pk = documentoacessorio.reuniao.pk\n url = reverse('sapl.comissoes:reuniao_detail', kwargs={'pk': r_pk})\n return url\n\nCargoCrud = CrudAux.build(CargoComissao, 'cargo_comissao')\n\nTipoComissaoCrud = CrudAux.build(\n TipoComissao, 'tipo_comissao', list_field_names=[\n 'sigla', 'nome', 'natureza', 'dispositivo_regimental'])\n\n\nclass PeriodoComposicaoCrud(CrudAux):\n model = Periodo\n\n class CreateView(CrudAux.CreateView):\n form_class = PeriodoForm\n\n class UpdateView(CrudAux.UpdateView):\n form_class = PeriodoForm\n\n # class ListView(CrudAux.ListView):\n\n\nclass ParticipacaoCrud(MasterDetailCrud):\n model = Participacao\n parent_field = 'composicao__comissao'\n public = [RP_DETAIL, ]\n ListView = None\n link_return_to_parent_field = True\n\n class BaseMixin(MasterDetailCrud.BaseMixin):\n list_field_names = ['composicao', 'parlamentar', 'cargo']\n\n class CreateView(MasterDetailCrud.CreateView):\n form_class = ParticipacaoCreateForm\n\n def get_initial(self):\n initial = super().get_initial()\n initial['parent_pk'] = self.kwargs['pk']\n return initial\n\n class UpdateView(MasterDetailCrud.UpdateView):\n layout_key = 'ParticipacaoEdit'\n form_class = ParticipacaoEditForm\n\n class DeleteView(MasterDetailCrud.DeleteView):\n\n def get_success_url(self):\n composicao_comissao_pk = self.object.composicao.comissao.pk\n composicao_pk = self.object.composicao.pk\n return '{}?pk={}'.format(reverse('sapl.comissoes:composicao_list',\n args=[composicao_comissao_pk]),\n composicao_pk)\n\n\nclass ComposicaoCrud(MasterDetailCrud):\n model = Composicao\n parent_field = 'comissao'\n model_set = 'participacao_set'\n public = [RP_LIST, RP_DETAIL, ]\n\n class CreateView(MasterDetailCrud.CreateView):\n form_class = ComposicaoForm\n\n def get_initial(self):\n comissao = Comissao.objects.get(id=self.kwargs['pk'])\n return {'comissao': comissao}\n\n class ListView(MasterDetailCrud.ListView):\n logger = logging.getLogger(__name__)\n template_name = \"comissoes/composicao_list.html\"\n paginate_by = None\n\n def take_composicao_pk(self):\n \n username = self.request.user.username\n try:\n self.logger.debug('user=' + username + '. Tentando obter pk da composi\u00e7\u00e3o.')\n return int(self.request.GET['pk'])\n except Exception as e:\n self.logger.error('user=' + username + '. Erro ao obter pk da composi\u00e7\u00e3o. Retornado 0. ' + str(e))\n return 0\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n\n composicao_pk = self.take_composicao_pk()\n\n if composicao_pk == 0:\n # Composicao eh ordenada por Periodo, que por sua vez esta em\n # ordem descrescente de data de inicio (issue #1920)\n ultima_composicao = context['composicao_list'].first()\n if ultima_composicao:\n context['composicao_pk'] = ultima_composicao.pk\n else:\n context['composicao_pk'] = 0\n else:\n context['composicao_pk'] = composicao_pk\n\n context['participacao_set'] = Participacao.objects.filter(\n composicao__pk=context['composicao_pk']\n ).order_by('id')\n return context\n\n\nclass ComissaoCrud(Crud):\n model = Comissao\n help_topic = 'modulo_comissoes'\n public = [RP_LIST, RP_DETAIL, ]\n\n class BaseMixin(Crud.BaseMixin):\n list_field_names = ['nome', 'sigla', 'tipo',\n 'data_criacao', 'data_extincao', 'ativa']\n ordering = '-ativa', 'sigla'\n\n class CreateView(Crud.CreateView):\n form_class = ComissaoForm\n\n def form_valid(self, form):\n return super(Crud.CreateView, self).form_valid(form)\n\n class UpdateView(Crud.UpdateView):\n form_class = ComissaoForm\n\n def form_valid(self, form):\n return super(Crud.UpdateView, self).form_valid(form)\n\n\nclass MateriasTramitacaoListView(ListView):\n template_name = \"comissoes/materias_em_tramitacao.html\"\n paginate_by = 10\n\n def get_queryset(self):\n # FIXME: Otimizar consulta\n ts = Tramitacao.objects.order_by(\n 'materia', '-data_tramitacao', '-id').annotate(\n comissao=F('unidade_tramitacao_destino__comissao')).distinct(\n 'materia').values_list('materia', 'comissao')\n\n ts = list(filter(lambda x: x[1] == int(self.kwargs['pk']), ts))\n ts = list(zip(*ts))\n ts = ts[0] if ts else []\n\n materias = MateriaLegislativa.objects.filter(\n pk__in=ts).order_by('tipo', '-ano', '-numero')\n\n return materias\n\n def get_context_data(self, **kwargs):\n context = super(\n MateriasTramitacaoListView, self).get_context_data(**kwargs)\n context['object'] = Comissao.objects.get(id=self.kwargs['pk'])\n context['qtde'] = self.object_list.count()\n return context\n\n\nclass ReuniaoCrud(MasterDetailCrud):\n model = Reuniao\n parent_field = 'comissao'\n model_set = 'documentoacessorio_set'\n public = [RP_LIST, RP_DETAIL, ]\n\n class BaseMixin(MasterDetailCrud.BaseMixin):\n list_field_names = ['data', 'nome', 'tema']\n\n class ListView(MasterDetailCrud.ListView):\n logger = logging.getLogger(__name__)\n paginate_by = 10\n\n def take_reuniao_pk(self):\n\n username = self.request.user.username\n try:\n self.logger.debug('user=' + username + '. Tentando obter pk da reuni\u00e3o.')\n return int(self.request.GET['pk'])\n except Exception as e:\n self.logger.error('user=' + username + '. Erro ao obter pk da reuni\u00e3o. Retornado 0. ' + str(e))\n return 0\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n\n reuniao_pk = self.take_reuniao_pk()\n\n if reuniao_pk == 0:\n ultima_reuniao = list(context['reuniao_list'])\n if len(ultima_reuniao) > 0:\n ultimo = ultima_reuniao[-1]\n context['reuniao_pk'] = ultimo.pk\n else:\n context['reuniao_pk'] = 0\n else:\n context['reuniao_pk'] = reuniao_pk\n\n context['documentoacessorio_set'] = DocumentoAcessorio.objects.filter(\n reuniao__pk=context['reuniao_pk']\n ).order_by('id')\n return context\n\n class UpdateView(MasterDetailCrud.UpdateView):\n form_class = ReuniaoForm\n\n def get_initial(self):\n return {'comissao': self.object.comissao}\n\n class CreateView(MasterDetailCrud.CreateView):\n form_class = ReuniaoForm\n\n def get_initial(self):\n comissao = Comissao.objects.get(id=self.kwargs['pk'])\n\n return {'comissao': comissao}\n\n\nclass DocumentoAcessorioCrud(MasterDetailCrud):\n model = DocumentoAcessorio\n parent_field = 'reuniao__comissao'\n public = [RP_DETAIL, ]\n ListView = None\n link_return_to_parent_field = True\n\n class BaseMixin(MasterDetailCrud.BaseMixin):\n list_field_names = ['nome', 'tipo', 'data', 'autor', 'arquivo']\n\n class CreateView(MasterDetailCrud.CreateView):\n form_class = DocumentoAcessorioCreateForm\n\n def get_initial(self):\n initial = super().get_initial()\n initial['parent_pk'] = self.kwargs['pk']\n return initial\n\n class UpdateView(MasterDetailCrud.UpdateView):\n layout_key = 'DocumentoAcessorioEdit'\n form_class = DocumentoAcessorioEditForm\n\n class DeleteView(MasterDetailCrud.DeleteView):\n\n def delete(self, *args, **kwargs):\n obj = self.get_object()\n obj.delete()\n return HttpResponseRedirect(\n reverse('sapl.comissoes:reuniao_detail',\n kwargs={'pk': obj.reuniao.pk}))\n", "path": "sapl/comissoes/views.py"}]}
| 3,593 | 114 |
gh_patches_debug_3486
|
rasdani/github-patches
|
git_diff
|
deepchecks__deepchecks-1076
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[FEAT] Exclude tests from the package distribution
Currently, the tests folder is shipped with the dist package. This shouldn't happen.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 import typing as t
12 import pathlib
13 import setuptools
14 import re
15 from functools import lru_cache
16
17
18 DEEPCHECKS = "deepchecks"
19 SUPPORTED_PYTHON_VERSIONS = '>=3.6, <=3.10'
20
21 SETUP_MODULE = pathlib.Path(__file__).absolute()
22 DEEPCHECKS_DIR = SETUP_MODULE.parent
23 LICENSE_FILE = DEEPCHECKS_DIR / "LICENSE"
24 VERSION_FILE = DEEPCHECKS_DIR / "VERSION"
25 DESCRIPTION_FILE = DEEPCHECKS_DIR / "DESCRIPTION.rst"
26
27
28 SEMANTIC_VERSIONING_RE = re.compile(
29 r"^(0|[1-9]\d*)\.(0|[1-9]\d*)\.(0|[1-9]\d*)"
30 r"(?:-((?:0|[1-9]\d*|\d*[a-zA-Z-][0-9a-zA-Z-]*)"
31 r"(?:\.(?:0|[1-9]\d*|\d*[a-zA-Z-][0-9a-zA-Z-]*))*))"
32 r"?(?:\+([0-9a-zA-Z-]+(?:\.[0-9a-zA-Z-]+)*))?$"
33 )
34
35
36 PYTHON_VERSIONING_RE = re.compile(
37 r"^([1-9][0-9]*!)?(0|[1-9][0-9]*)(\.(0|[1-9][0-9]*))*"
38 r"((a|b|rc)(0|[1-9][0-9]*))?(\.post(0|[1-9][0-9]*))?"
39 r"(\.dev(0|[1-9][0-9]*))?$"
40 )
41
42
43 @lru_cache(maxsize=None)
44 def is_correct_version_string(value: str) -> bool:
45 match = PYTHON_VERSIONING_RE.match(value)
46 return match is not None
47
48
49 @lru_cache(maxsize=None)
50 def get_version_string() -> str:
51 if not (VERSION_FILE.exists() and VERSION_FILE.is_file()):
52 raise RuntimeError(
53 "Version file does not exist! "
54 f"(filepath: {str(VERSION_FILE)})")
55 else:
56 version = VERSION_FILE.open("r").readline()
57 if not is_correct_version_string(version):
58 raise RuntimeError(
59 "Incorrect version string! "
60 f"(filepath: {str(VERSION_FILE)})"
61 )
62 return version
63
64
65 @lru_cache(maxsize=None)
66 def get_description() -> t.Tuple[str, str]:
67 if not (DESCRIPTION_FILE.exists() and DESCRIPTION_FILE.is_file()):
68 raise RuntimeError(
69 "DESCRIPTION.rst file does not exist! "
70 f"(filepath: {str(DESCRIPTION_FILE)})"
71 )
72 else:
73 return (
74 "Package for validating your machine learning model and data",
75 DESCRIPTION_FILE.open("r", encoding="utf8").read()
76 )
77
78
79 def read_requirements_file(path):
80 dependencies = []
81 dependencies_links = []
82 for line in path.open("r").readlines():
83 if "-f" in line or "--find-links" in line:
84 dependencies_links.append(
85 line
86 .replace("-f", "")
87 .replace("--find-links", "")
88 .strip()
89 )
90 else:
91 dependencies.append(line)
92 return dependencies, dependencies_links
93
94
95 @lru_cache(maxsize=None)
96 def read_requirements() -> t.Dict[str,t.List[str]]:
97 requirements_folder = DEEPCHECKS_DIR / "requirements"
98
99 if not (requirements_folder.exists() and requirements_folder.is_dir()):
100 raise RuntimeError(
101 "Cannot find folder with requirements files."
102 f"(path: {str(requirements_folder)})"
103 )
104 else:
105 main, main_dep_links = read_requirements_file(requirements_folder / "requirements.txt")
106 vision, vision_dep_links = read_requirements_file(requirements_folder / "vision-requirements.txt")
107 nlp, nlp_dep_links = read_requirements_file(requirements_folder / "nlp-requirements.txt")
108
109 return {
110 "dependency_links": main_dep_links + vision_dep_links,
111 "main": main,
112 "vision": vision,
113 # "nlp": nlp,
114 }
115
116
117 # =================================================================================
118
119 VERSION = get_version_string()
120 short_desc, long_desc = get_description()
121
122 requirements = read_requirements()
123 main_requirements = requirements.pop('main')
124 dependency_links = requirements.pop('dependency_links', [])
125 extra_requirements = requirements
126
127
128 setuptools.setup(
129 # -- description --------------------------------
130 name=DEEPCHECKS,
131 author='deepchecks',
132 author_email='[email protected]',
133 version=VERSION,
134 description=short_desc,
135 long_description=long_desc,
136 keywords = ['Software Development', 'Machine Learning'],
137 classifiers = [
138 'Intended Audience :: Developers',
139 'Intended Audience :: Science/Research',
140 'Topic :: Software Development',
141 'Topic :: Scientific/Engineering',
142 'License :: OSI Approved :: GNU Affero General Public License v3 or later (AGPLv3+)',
143 'Programming Language :: Python :: 3',
144 'Programming Language :: Python :: 3.6',
145 'Programming Language :: Python :: 3.7',
146 'Programming Language :: Python :: 3.8',
147 'Programming Language :: Python :: 3.9',
148 'Programming Language :: Python :: 3.10',
149 ],
150 license_files=('LICENSE', ),
151 url = 'https://github.com/deepchecks/deepchecks',
152 download_url = "https://github.com/deepchecks/deepchecks/releases/download/{0}/deepchecks-{0}.tar.gz".format(VERSION),
153 project_urls={
154 'Documentation': 'https://docs.deepchecks.com',
155 'Bug Reports': 'https://github.com/deepchecks/deepchecks',
156 'Source': 'https://github.com/deepchecks/deepchecks',
157 'Contribute!': 'https://github.com/deepchecks/deepchecks/blob/master/CONTRIBUTING.md',
158 },
159
160 # -- dependencies --------------------------------
161 packages=setuptools.find_packages(),
162 install_requires=main_requirements,
163 extras_require=extra_requirements,
164 dependency_links=dependency_links,
165 include_package_data=True,
166 )
167
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -158,7 +158,7 @@
},
# -- dependencies --------------------------------
- packages=setuptools.find_packages(),
+ packages=setuptools.find_packages(exclude=['tests', 'tests.*']),
install_requires=main_requirements,
extras_require=extra_requirements,
dependency_links=dependency_links,
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -158,7 +158,7 @@\n },\n \n # -- dependencies --------------------------------\n- packages=setuptools.find_packages(),\n+ packages=setuptools.find_packages(exclude=['tests', 'tests.*']),\n install_requires=main_requirements,\n extras_require=extra_requirements,\n dependency_links=dependency_links,\n", "issue": "[FEAT] Exclude tests from the package distribution\n\r\nCurrently, the tests folder is shipped with the dist package. This shouldn't happen.\n", "before_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\nimport typing as t\nimport pathlib\nimport setuptools\nimport re\nfrom functools import lru_cache\n\n\nDEEPCHECKS = \"deepchecks\"\nSUPPORTED_PYTHON_VERSIONS = '>=3.6, <=3.10'\n\nSETUP_MODULE = pathlib.Path(__file__).absolute()\nDEEPCHECKS_DIR = SETUP_MODULE.parent\nLICENSE_FILE = DEEPCHECKS_DIR / \"LICENSE\" \nVERSION_FILE = DEEPCHECKS_DIR / \"VERSION\" \nDESCRIPTION_FILE = DEEPCHECKS_DIR / \"DESCRIPTION.rst\" \n\n\nSEMANTIC_VERSIONING_RE = re.compile(\n r\"^(0|[1-9]\\d*)\\.(0|[1-9]\\d*)\\.(0|[1-9]\\d*)\"\n r\"(?:-((?:0|[1-9]\\d*|\\d*[a-zA-Z-][0-9a-zA-Z-]*)\"\n r\"(?:\\.(?:0|[1-9]\\d*|\\d*[a-zA-Z-][0-9a-zA-Z-]*))*))\"\n r\"?(?:\\+([0-9a-zA-Z-]+(?:\\.[0-9a-zA-Z-]+)*))?$\"\n)\n\n\nPYTHON_VERSIONING_RE = re.compile(\n r\"^([1-9][0-9]*!)?(0|[1-9][0-9]*)(\\.(0|[1-9][0-9]*))*\"\n r\"((a|b|rc)(0|[1-9][0-9]*))?(\\.post(0|[1-9][0-9]*))?\"\n r\"(\\.dev(0|[1-9][0-9]*))?$\"\n)\n\n\n@lru_cache(maxsize=None)\ndef is_correct_version_string(value: str) -> bool:\n match = PYTHON_VERSIONING_RE.match(value)\n return match is not None\n\n\n@lru_cache(maxsize=None)\ndef get_version_string() -> str:\n if not (VERSION_FILE.exists() and VERSION_FILE.is_file()):\n raise RuntimeError(\n \"Version file does not exist! \"\n f\"(filepath: {str(VERSION_FILE)})\")\n else:\n version = VERSION_FILE.open(\"r\").readline()\n if not is_correct_version_string(version):\n raise RuntimeError(\n \"Incorrect version string! \"\n f\"(filepath: {str(VERSION_FILE)})\"\n )\n return version\n\n\n@lru_cache(maxsize=None)\ndef get_description() -> t.Tuple[str, str]:\n if not (DESCRIPTION_FILE.exists() and DESCRIPTION_FILE.is_file()):\n raise RuntimeError(\n \"DESCRIPTION.rst file does not exist! \"\n f\"(filepath: {str(DESCRIPTION_FILE)})\"\n )\n else:\n return (\n \"Package for validating your machine learning model and data\", \n DESCRIPTION_FILE.open(\"r\", encoding=\"utf8\").read()\n )\n\n\ndef read_requirements_file(path):\n dependencies = []\n dependencies_links = []\n for line in path.open(\"r\").readlines():\n if \"-f\" in line or \"--find-links\" in line:\n dependencies_links.append(\n line\n .replace(\"-f\", \"\")\n .replace(\"--find-links\", \"\")\n .strip()\n )\n else:\n dependencies.append(line)\n return dependencies, dependencies_links\n\n\n@lru_cache(maxsize=None)\ndef read_requirements() -> t.Dict[str,t.List[str]]:\n requirements_folder = DEEPCHECKS_DIR / \"requirements\"\n \n if not (requirements_folder.exists() and requirements_folder.is_dir()):\n raise RuntimeError(\n \"Cannot find folder with requirements files.\"\n f\"(path: {str(requirements_folder)})\"\n )\n else:\n main, main_dep_links = read_requirements_file(requirements_folder / \"requirements.txt\")\n vision, vision_dep_links = read_requirements_file(requirements_folder / \"vision-requirements.txt\")\n nlp, nlp_dep_links = read_requirements_file(requirements_folder / \"nlp-requirements.txt\")\n\n return {\n \"dependency_links\": main_dep_links + vision_dep_links,\n \"main\": main,\n \"vision\": vision,\n # \"nlp\": nlp,\n }\n\n\n# =================================================================================\n\nVERSION = get_version_string()\nshort_desc, long_desc = get_description()\n\nrequirements = read_requirements()\nmain_requirements = requirements.pop('main')\ndependency_links = requirements.pop('dependency_links', [])\nextra_requirements = requirements\n\n\nsetuptools.setup(\n # -- description --------------------------------\n name=DEEPCHECKS,\n author='deepchecks', \n author_email='[email protected]', \n version=VERSION,\n description=short_desc,\n long_description=long_desc,\n keywords = ['Software Development', 'Machine Learning'],\n classifiers = [\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Topic :: Software Development',\n 'Topic :: Scientific/Engineering',\n 'License :: OSI Approved :: GNU Affero General Public License v3 or later (AGPLv3+)',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Programming Language :: Python :: 3.10',\n ],\n license_files=('LICENSE', ),\n url = 'https://github.com/deepchecks/deepchecks',\n download_url = \"https://github.com/deepchecks/deepchecks/releases/download/{0}/deepchecks-{0}.tar.gz\".format(VERSION),\n project_urls={\n 'Documentation': 'https://docs.deepchecks.com',\n 'Bug Reports': 'https://github.com/deepchecks/deepchecks',\n 'Source': 'https://github.com/deepchecks/deepchecks',\n 'Contribute!': 'https://github.com/deepchecks/deepchecks/blob/master/CONTRIBUTING.md',\n },\n \n # -- dependencies --------------------------------\n packages=setuptools.find_packages(),\n install_requires=main_requirements,\n extras_require=extra_requirements,\n dependency_links=dependency_links,\n include_package_data=True,\n)\n", "path": "setup.py"}], "after_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\nimport typing as t\nimport pathlib\nimport setuptools\nimport re\nfrom functools import lru_cache\n\n\nDEEPCHECKS = \"deepchecks\"\nSUPPORTED_PYTHON_VERSIONS = '>=3.6, <=3.10'\n\nSETUP_MODULE = pathlib.Path(__file__).absolute()\nDEEPCHECKS_DIR = SETUP_MODULE.parent\nLICENSE_FILE = DEEPCHECKS_DIR / \"LICENSE\" \nVERSION_FILE = DEEPCHECKS_DIR / \"VERSION\" \nDESCRIPTION_FILE = DEEPCHECKS_DIR / \"DESCRIPTION.rst\" \n\n\nSEMANTIC_VERSIONING_RE = re.compile(\n r\"^(0|[1-9]\\d*)\\.(0|[1-9]\\d*)\\.(0|[1-9]\\d*)\"\n r\"(?:-((?:0|[1-9]\\d*|\\d*[a-zA-Z-][0-9a-zA-Z-]*)\"\n r\"(?:\\.(?:0|[1-9]\\d*|\\d*[a-zA-Z-][0-9a-zA-Z-]*))*))\"\n r\"?(?:\\+([0-9a-zA-Z-]+(?:\\.[0-9a-zA-Z-]+)*))?$\"\n)\n\n\nPYTHON_VERSIONING_RE = re.compile(\n r\"^([1-9][0-9]*!)?(0|[1-9][0-9]*)(\\.(0|[1-9][0-9]*))*\"\n r\"((a|b|rc)(0|[1-9][0-9]*))?(\\.post(0|[1-9][0-9]*))?\"\n r\"(\\.dev(0|[1-9][0-9]*))?$\"\n)\n\n\n@lru_cache(maxsize=None)\ndef is_correct_version_string(value: str) -> bool:\n match = PYTHON_VERSIONING_RE.match(value)\n return match is not None\n\n\n@lru_cache(maxsize=None)\ndef get_version_string() -> str:\n if not (VERSION_FILE.exists() and VERSION_FILE.is_file()):\n raise RuntimeError(\n \"Version file does not exist! \"\n f\"(filepath: {str(VERSION_FILE)})\")\n else:\n version = VERSION_FILE.open(\"r\").readline()\n if not is_correct_version_string(version):\n raise RuntimeError(\n \"Incorrect version string! \"\n f\"(filepath: {str(VERSION_FILE)})\"\n )\n return version\n\n\n@lru_cache(maxsize=None)\ndef get_description() -> t.Tuple[str, str]:\n if not (DESCRIPTION_FILE.exists() and DESCRIPTION_FILE.is_file()):\n raise RuntimeError(\n \"DESCRIPTION.rst file does not exist! \"\n f\"(filepath: {str(DESCRIPTION_FILE)})\"\n )\n else:\n return (\n \"Package for validating your machine learning model and data\", \n DESCRIPTION_FILE.open(\"r\", encoding=\"utf8\").read()\n )\n\n\ndef read_requirements_file(path):\n dependencies = []\n dependencies_links = []\n for line in path.open(\"r\").readlines():\n if \"-f\" in line or \"--find-links\" in line:\n dependencies_links.append(\n line\n .replace(\"-f\", \"\")\n .replace(\"--find-links\", \"\")\n .strip()\n )\n else:\n dependencies.append(line)\n return dependencies, dependencies_links\n\n\n@lru_cache(maxsize=None)\ndef read_requirements() -> t.Dict[str,t.List[str]]:\n requirements_folder = DEEPCHECKS_DIR / \"requirements\"\n \n if not (requirements_folder.exists() and requirements_folder.is_dir()):\n raise RuntimeError(\n \"Cannot find folder with requirements files.\"\n f\"(path: {str(requirements_folder)})\"\n )\n else:\n main, main_dep_links = read_requirements_file(requirements_folder / \"requirements.txt\")\n vision, vision_dep_links = read_requirements_file(requirements_folder / \"vision-requirements.txt\")\n nlp, nlp_dep_links = read_requirements_file(requirements_folder / \"nlp-requirements.txt\")\n\n return {\n \"dependency_links\": main_dep_links + vision_dep_links,\n \"main\": main,\n \"vision\": vision,\n # \"nlp\": nlp,\n }\n\n\n# =================================================================================\n\nVERSION = get_version_string()\nshort_desc, long_desc = get_description()\n\nrequirements = read_requirements()\nmain_requirements = requirements.pop('main')\ndependency_links = requirements.pop('dependency_links', [])\nextra_requirements = requirements\n\n\nsetuptools.setup(\n # -- description --------------------------------\n name=DEEPCHECKS,\n author='deepchecks', \n author_email='[email protected]', \n version=VERSION,\n description=short_desc,\n long_description=long_desc,\n keywords = ['Software Development', 'Machine Learning'],\n classifiers = [\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Topic :: Software Development',\n 'Topic :: Scientific/Engineering',\n 'License :: OSI Approved :: GNU Affero General Public License v3 or later (AGPLv3+)',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Programming Language :: Python :: 3.10',\n ],\n license_files=('LICENSE', ),\n url = 'https://github.com/deepchecks/deepchecks',\n download_url = \"https://github.com/deepchecks/deepchecks/releases/download/{0}/deepchecks-{0}.tar.gz\".format(VERSION),\n project_urls={\n 'Documentation': 'https://docs.deepchecks.com',\n 'Bug Reports': 'https://github.com/deepchecks/deepchecks',\n 'Source': 'https://github.com/deepchecks/deepchecks',\n 'Contribute!': 'https://github.com/deepchecks/deepchecks/blob/master/CONTRIBUTING.md',\n },\n \n # -- dependencies --------------------------------\n packages=setuptools.find_packages(exclude=['tests', 'tests.*']),\n install_requires=main_requirements,\n extras_require=extra_requirements,\n dependency_links=dependency_links,\n include_package_data=True,\n)\n", "path": "setup.py"}]}
| 2,086 | 88 |
gh_patches_debug_22018
|
rasdani/github-patches
|
git_diff
|
MycroftAI__mycroft-core-2535
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Italian language with Google TTS
I'm running Mycroft on Manjaro Linux, with Italian language.
I tried both the "British male" and "American male" voices, and they do not speak Italian at all. So I decided to try the Google Voice.
That way, no sound is emitted. Whenever Mycroft tries to speak, I see this error in logs (file audio.log):
```
2020-04-13 10:45:39.632 | INFO | 195922 | mycroft.audio.speech:mute_and_speak:127 | Speak: Va uno spettacolo
2020-04-13 10:45:40.070 | ERROR | 195922 | mycroft.audio.speech:handle_speak:99 | Error in mute_and_speak
Traceback (most recent call last):
File "/home/luke/git/mycroft-core/mycroft/audio/speech.py", line 95, in handle_speak
mute_and_speak(chunk, ident, listen)
File "/home/luke/git/mycroft-core/mycroft/audio/speech.py", line 129, in mute_and_speak
tts.execute(utterance, ident, listen)
File "/home/luke/git/mycroft-core/mycroft/tts/tts.py", line 337, in execute
wav_file, phonemes = self.get_tts(sentence, wav_file)
File "/home/luke/git/mycroft-core/mycroft/tts/google_tts.py", line 35, in get_tts
tts = gTTS(text=sentence, lang=self.lang)
File "/home/luke/git/mycroft-core/.venv/lib/python3.8/site-packages/gtts/tts.py", line 121, in __init__
raise ValueError("Language not supported: %s" % lang)
ValueError: Language not supported: it-it
```
The problem is that Google TTS can handle "it", but it cannot handle "it-it".
I will release a PR shortly for fixing this. (So far, Google Voice seems my only option for Italian language, so I really need that).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mycroft/tts/google_tts.py`
Content:
```
1 # Copyright 2017 Mycroft AI Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 #
15 from gtts import gTTS
16
17 from .tts import TTS, TTSValidator
18
19
20 class GoogleTTS(TTS):
21 """Interface to google TTS."""
22 def __init__(self, lang, config):
23 super(GoogleTTS, self).__init__(lang, config, GoogleTTSValidator(
24 self), 'mp3')
25
26 def get_tts(self, sentence, wav_file):
27 """Fetch tts audio using gTTS.
28
29 Arguments:
30 sentence (str): Sentence to generate audio for
31 wav_file (str): output file path
32 Returns:
33 Tuple ((str) written file, None)
34 """
35 tts = gTTS(text=sentence, lang=self.lang)
36 tts.save(wav_file)
37 return (wav_file, None) # No phonemes
38
39
40 class GoogleTTSValidator(TTSValidator):
41 def __init__(self, tts):
42 super(GoogleTTSValidator, self).__init__(tts)
43
44 def validate_lang(self):
45 # TODO
46 pass
47
48 def validate_connection(self):
49 try:
50 gTTS(text='Hi').save(self.tts.filename)
51 except Exception:
52 raise Exception(
53 'GoogleTTS server could not be verified. Please check your '
54 'internet connection.')
55
56 def get_tts_class(self):
57 return GoogleTTS
58
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mycroft/tts/google_tts.py b/mycroft/tts/google_tts.py
--- a/mycroft/tts/google_tts.py
+++ b/mycroft/tts/google_tts.py
@@ -13,13 +13,19 @@
# limitations under the License.
#
from gtts import gTTS
+from gtts.lang import tts_langs
from .tts import TTS, TTSValidator
+supported_langs = tts_langs()
+
class GoogleTTS(TTS):
"""Interface to google TTS."""
def __init__(self, lang, config):
+ if lang.lower() not in supported_langs and \
+ lang[:2].lower() in supported_langs:
+ lang = lang[:2]
super(GoogleTTS, self).__init__(lang, config, GoogleTTSValidator(
self), 'mp3')
@@ -42,8 +48,10 @@
super(GoogleTTSValidator, self).__init__(tts)
def validate_lang(self):
- # TODO
- pass
+ lang = self.tts.lang
+ if lang.lower() not in supported_langs:
+ raise ValueError("Language not supported by gTTS: {}"
+ .format(lang))
def validate_connection(self):
try:
|
{"golden_diff": "diff --git a/mycroft/tts/google_tts.py b/mycroft/tts/google_tts.py\n--- a/mycroft/tts/google_tts.py\n+++ b/mycroft/tts/google_tts.py\n@@ -13,13 +13,19 @@\n # limitations under the License.\n #\n from gtts import gTTS\n+from gtts.lang import tts_langs\n \n from .tts import TTS, TTSValidator\n \n+supported_langs = tts_langs()\n+\n \n class GoogleTTS(TTS):\n \"\"\"Interface to google TTS.\"\"\"\n def __init__(self, lang, config):\n+ if lang.lower() not in supported_langs and \\\n+ lang[:2].lower() in supported_langs:\n+ lang = lang[:2]\n super(GoogleTTS, self).__init__(lang, config, GoogleTTSValidator(\n self), 'mp3')\n \n@@ -42,8 +48,10 @@\n super(GoogleTTSValidator, self).__init__(tts)\n \n def validate_lang(self):\n- # TODO\n- pass\n+ lang = self.tts.lang\n+ if lang.lower() not in supported_langs:\n+ raise ValueError(\"Language not supported by gTTS: {}\"\n+ .format(lang))\n \n def validate_connection(self):\n try:\n", "issue": "Italian language with Google TTS\nI'm running Mycroft on Manjaro Linux, with Italian language.\r\nI tried both the \"British male\" and \"American male\" voices, and they do not speak Italian at all. So I decided to try the Google Voice.\r\nThat way, no sound is emitted. Whenever Mycroft tries to speak, I see this error in logs (file audio.log):\r\n\r\n```\r\n2020-04-13 10:45:39.632 | INFO | 195922 | mycroft.audio.speech:mute_and_speak:127 | Speak: Va uno spettacolo\r\n2020-04-13 10:45:40.070 | ERROR | 195922 | mycroft.audio.speech:handle_speak:99 | Error in mute_and_speak\r\nTraceback (most recent call last):\r\n File \"/home/luke/git/mycroft-core/mycroft/audio/speech.py\", line 95, in handle_speak\r\n mute_and_speak(chunk, ident, listen)\r\n File \"/home/luke/git/mycroft-core/mycroft/audio/speech.py\", line 129, in mute_and_speak\r\n tts.execute(utterance, ident, listen)\r\n File \"/home/luke/git/mycroft-core/mycroft/tts/tts.py\", line 337, in execute\r\n wav_file, phonemes = self.get_tts(sentence, wav_file)\r\n File \"/home/luke/git/mycroft-core/mycroft/tts/google_tts.py\", line 35, in get_tts\r\n tts = gTTS(text=sentence, lang=self.lang)\r\n File \"/home/luke/git/mycroft-core/.venv/lib/python3.8/site-packages/gtts/tts.py\", line 121, in __init__\r\n raise ValueError(\"Language not supported: %s\" % lang)\r\nValueError: Language not supported: it-it\r\n```\r\n\r\nThe problem is that Google TTS can handle \"it\", but it cannot handle \"it-it\".\r\n\r\nI will release a PR shortly for fixing this. (So far, Google Voice seems my only option for Italian language, so I really need that).\r\n\n", "before_files": [{"content": "# Copyright 2017 Mycroft AI Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\nfrom gtts import gTTS\n\nfrom .tts import TTS, TTSValidator\n\n\nclass GoogleTTS(TTS):\n \"\"\"Interface to google TTS.\"\"\"\n def __init__(self, lang, config):\n super(GoogleTTS, self).__init__(lang, config, GoogleTTSValidator(\n self), 'mp3')\n\n def get_tts(self, sentence, wav_file):\n \"\"\"Fetch tts audio using gTTS.\n\n Arguments:\n sentence (str): Sentence to generate audio for\n wav_file (str): output file path\n Returns:\n Tuple ((str) written file, None)\n \"\"\"\n tts = gTTS(text=sentence, lang=self.lang)\n tts.save(wav_file)\n return (wav_file, None) # No phonemes\n\n\nclass GoogleTTSValidator(TTSValidator):\n def __init__(self, tts):\n super(GoogleTTSValidator, self).__init__(tts)\n\n def validate_lang(self):\n # TODO\n pass\n\n def validate_connection(self):\n try:\n gTTS(text='Hi').save(self.tts.filename)\n except Exception:\n raise Exception(\n 'GoogleTTS server could not be verified. Please check your '\n 'internet connection.')\n\n def get_tts_class(self):\n return GoogleTTS\n", "path": "mycroft/tts/google_tts.py"}], "after_files": [{"content": "# Copyright 2017 Mycroft AI Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\nfrom gtts import gTTS\nfrom gtts.lang import tts_langs\n\nfrom .tts import TTS, TTSValidator\n\nsupported_langs = tts_langs()\n\n\nclass GoogleTTS(TTS):\n \"\"\"Interface to google TTS.\"\"\"\n def __init__(self, lang, config):\n if lang.lower() not in supported_langs and \\\n lang[:2].lower() in supported_langs:\n lang = lang[:2]\n super(GoogleTTS, self).__init__(lang, config, GoogleTTSValidator(\n self), 'mp3')\n\n def get_tts(self, sentence, wav_file):\n \"\"\"Fetch tts audio using gTTS.\n\n Arguments:\n sentence (str): Sentence to generate audio for\n wav_file (str): output file path\n Returns:\n Tuple ((str) written file, None)\n \"\"\"\n tts = gTTS(text=sentence, lang=self.lang)\n tts.save(wav_file)\n return (wav_file, None) # No phonemes\n\n\nclass GoogleTTSValidator(TTSValidator):\n def __init__(self, tts):\n super(GoogleTTSValidator, self).__init__(tts)\n\n def validate_lang(self):\n lang = self.tts.lang\n if lang.lower() not in supported_langs:\n raise ValueError(\"Language not supported by gTTS: {}\"\n .format(lang))\n\n def validate_connection(self):\n try:\n gTTS(text='Hi').save(self.tts.filename)\n except Exception:\n raise Exception(\n 'GoogleTTS server could not be verified. Please check your '\n 'internet connection.')\n\n def get_tts_class(self):\n return GoogleTTS\n", "path": "mycroft/tts/google_tts.py"}]}
| 1,282 | 290 |
gh_patches_debug_17811
|
rasdani/github-patches
|
git_diff
|
hedyorg__hedy-683
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add tests for all adventure, start and demo programs
Sometimes little errors happen in the code we ship in various examples, f.e. a typo, or when we change the grammar. Going forward, these should all be tested too.
This entails more or less:
* Parse adventure yamls and extract all code between ```'s
* Parse level defaults yamls and extract all start code
* Parse level defaults yamls and extract all demo code in all commands
Parse all these as a unittest and see if they all parse (in a later stage we could even define outcome to test against, but for now just seeing that they parse is ok)
We also need to think about proper reporting, so not just a failing test but "story adventure fails in Hungarian" as output.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `utils.py`
Content:
```
1 import contextlib
2 import datetime
3 import time
4 import pickle
5 import functools
6 import os
7 import re
8 import string
9 import random
10 from ruamel import yaml
11 from website import querylog
12
13
14 IS_WINDOWS = os.name == 'nt'
15
16
17 class Timer:
18 """A quick and dirty timer."""
19 def __init__(self, name):
20 self.name = name
21
22 def __enter__(self):
23 self.start = time.time()
24
25 def __exit__(self, type, value, tb):
26 delta = time.time() - self.start
27 print(f'{self.name}: {delta}s')
28
29
30 def timer(fn):
31 """Decoractor for fn."""
32 @functools.wraps(fn)
33 def wrapper(*args, **kwargs):
34 with Timer(fn.__name__):
35 return fn(*args, **kwargs)
36 return wrapper
37
38
39
40 def timems ():
41 return int (round (time.time () * 1000))
42
43 def times ():
44 return int (round (time.time ()))
45
46
47
48
49 DEBUG_MODE = False
50
51 def is_debug_mode():
52 """Return whether or not we're in debug mode.
53
54 We do more expensive things that are better for development in debug mode.
55 """
56 return DEBUG_MODE
57
58
59 def set_debug_mode(debug_mode):
60 """Switch debug mode to given value."""
61 global DEBUG_MODE
62 DEBUG_MODE = debug_mode
63
64
65 YAML_CACHE = {}
66
67 @querylog.timed
68 def load_yaml(filename):
69 """Load the given YAML file.
70
71 The file load will be cached in production, but reloaded everytime in
72 development mode for much iterating. Because YAML loading is still
73 somewhat slow, in production we'll have two levels of caching:
74
75 - In-memory cache: each of the N processes on the box will only need to
76 load the YAML file once (per restart).
77
78 - On-disk pickle cache: "pickle" is a more efficient Python serialization
79 format, and loads 400x quicker than YAML. We will prefer loading a pickle
80 file to loading the source YAML file if possible. Hopefully only 1/N
81 processes on the box will have to do the full load per deploy.
82
83 We should be generating the pickled files at build time, but Heroku doesn't
84 make it easy to have a build/deploy time... so for now let's just make sure
85 we only do it once per box per deploy.
86 """
87 if is_debug_mode():
88 return load_yaml_uncached(filename)
89
90 # Production mode, check our two-level cache
91 if filename not in YAML_CACHE:
92 data = load_yaml_pickled(filename)
93 YAML_CACHE[filename] = data
94 return data
95 else:
96 return YAML_CACHE[filename]
97
98
99 def load_yaml_pickled(filename):
100 # Let's not even attempt the pickling on Windows, because we have
101 # no pattern to atomatically write the pickled result file.
102 if IS_WINDOWS:
103 return load_yaml_uncached(filename)
104
105 pickle_file = f'{filename}.pickle'
106 if not os.path.exists(pickle_file):
107 data = load_yaml_uncached(filename)
108
109 # Write a pickle file, first write to a tempfile then rename
110 # into place because multiple processes might try to do this in parallel,
111 # plus we only want `path.exists(pickle_file)` to return True once the
112 # file is actually complete and readable.
113 with atomic_write_file(pickle_file) as f:
114 pickle.dump(data, f)
115
116 return data
117 else:
118 with open(pickle_file, 'rb') as f:
119 return pickle.load(f)
120
121
122 def load_yaml_uncached(filename):
123 try:
124 y = yaml.YAML(typ='safe', pure=True)
125 with open(filename, 'r', encoding='utf-8') as f:
126 return y.load(f)
127 except IOError:
128 return {}
129
130
131 def load_yaml_rt(filename):
132 """Load YAML with the round trip loader."""
133 try:
134 with open(filename, 'r', encoding='utf-8') as f:
135 return yaml.round_trip_load(f, preserve_quotes=True)
136 except IOError:
137 return {}
138
139
140 def dump_yaml_rt(data):
141 """Dump round-tripped YAML."""
142 return yaml.round_trip_dump(data, indent=4, width=999)
143
144 def slash_join(*args):
145 ret = []
146 for arg in args:
147 if not arg: continue
148
149 if ret and not ret[-1].endswith('/'):
150 ret.append('/')
151 ret.append(arg.lstrip('/') if ret else arg)
152 return ''.join(ret)
153
154 def is_testing_request(request):
155 return bool ('X-Testing' in request.headers and request.headers ['X-Testing'])
156
157 def extract_bcrypt_rounds (hash):
158 return int (re.match ('\$2b\$\d+', hash) [0].replace ('$2b$', ''))
159
160 def isoformat(timestamp):
161 """Turn a timestamp into an ISO formatted string."""
162 dt = datetime.datetime.utcfromtimestamp(timestamp)
163 return dt.isoformat() + 'Z'
164
165
166 def is_production():
167 """Whether we are serving production traffic."""
168 return os.getenv('IS_PRODUCTION', '') != ''
169
170
171 def is_heroku():
172 """Whether we are running on Heroku.
173
174 Only use this flag if you are making a decision that really has to do with
175 Heroku-based hosting or not.
176
177 If you are trying to make a decision whether something needs to be done
178 "for real" or not, prefer using:
179
180 - `is_production()` to see if we're serving customer traffic and trying to
181 optimize for safety and speed.
182 - `is_debug_mode()` to see if we're on a developer machine and we're trying
183 to optimize for developer productivity.
184
185 """
186 return os.getenv('DYNO', '') != ''
187
188
189 def version():
190 """Get the version from the Heroku environment variables."""
191 if not is_heroku():
192 return 'DEV'
193
194 vrz = os.getenv('HEROKU_RELEASE_CREATED_AT')
195 the_date = datetime.date.fromisoformat(vrz[:10]) if vrz else datetime.date.today()
196
197 commit = os.getenv('HEROKU_SLUG_COMMIT', '????')[0:6]
198 return the_date.strftime('%b %d') + f' ({commit})'
199
200 def valid_email(s):
201 return bool (re.match ('^(([a-zA-Z0-9_+\.\-]+)@([\da-zA-Z\.\-]+)\.([a-zA-Z\.]{2,6})\s*)$', s))
202
203
204 @contextlib.contextmanager
205 def atomic_write_file(filename, mode='wb'):
206 """Write to a filename atomically.
207
208 First write to a unique tempfile, then rename the tempfile into
209 place. Use as a context manager:
210
211 with atomic_write_file('file.txt') as f:
212 f.write('hello')
213
214 THIS WON'T WORK ON WINDOWS -- atomic file renames don't overwrite
215 on Windows. We could potentially do something else to make it work
216 (just swallow the exception, someone else already wrote the file?)
217 but for now we just don't support it.
218 """
219 if IS_WINDOWS:
220 raise RuntimeError('Cannot use atomic_write_file() on Windows!')
221
222 tmp_file = f'{filename}.{os.getpid()}'
223 with open(tmp_file, mode) as f:
224 yield f
225
226 os.rename(tmp_file, filename)
227
228 # This function takes a date in milliseconds from the Unix epoch and transforms it into a printable date
229 # It operates by converting the date to a string, removing its last 3 digits, converting it back to an int
230 # and then invoking the `isoformat` date function on it
231 def mstoisostring(date):
232 return datetime.datetime.fromtimestamp (int (str (date) [:-3])).isoformat ()
233
234 # https://stackoverflow.com/a/2257449
235 def random_id_generator(size=6, chars=string.ascii_uppercase + string.ascii_lowercase + string.digits):
236 return ''.join (random.choice (chars) for _ in range (size))
237
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/utils.py b/utils.py
--- a/utils.py
+++ b/utils.py
@@ -9,7 +9,10 @@
import random
from ruamel import yaml
from website import querylog
-
+import commonmark
+commonmark_parser = commonmark.Parser ()
+commonmark_renderer = commonmark.HtmlRenderer ()
+from bs4 import BeautifulSoup
IS_WINDOWS = os.name == 'nt'
@@ -234,3 +237,10 @@
# https://stackoverflow.com/a/2257449
def random_id_generator(size=6, chars=string.ascii_uppercase + string.ascii_lowercase + string.digits):
return ''.join (random.choice (chars) for _ in range (size))
+
+# This function takes a markdown string and returns a list with each of the HTML elements obtained
+# by rendering the markdown into HTML.
+def markdown_to_html_tags (markdown):
+ _html = commonmark_renderer.render(commonmark_parser.parse (markdown))
+ soup = BeautifulSoup(_html, 'html.parser')
+ return soup.find_all ()
|
{"golden_diff": "diff --git a/utils.py b/utils.py\n--- a/utils.py\n+++ b/utils.py\n@@ -9,7 +9,10 @@\n import random\n from ruamel import yaml\n from website import querylog\n-\n+import commonmark\n+commonmark_parser = commonmark.Parser ()\n+commonmark_renderer = commonmark.HtmlRenderer ()\n+from bs4 import BeautifulSoup\n \n IS_WINDOWS = os.name == 'nt'\n \n@@ -234,3 +237,10 @@\n # https://stackoverflow.com/a/2257449\n def random_id_generator(size=6, chars=string.ascii_uppercase + string.ascii_lowercase + string.digits):\n return ''.join (random.choice (chars) for _ in range (size))\n+\n+# This function takes a markdown string and returns a list with each of the HTML elements obtained\n+# by rendering the markdown into HTML.\n+def markdown_to_html_tags (markdown):\n+ _html = commonmark_renderer.render(commonmark_parser.parse (markdown))\n+ soup = BeautifulSoup(_html, 'html.parser')\n+ return soup.find_all ()\n", "issue": "Add tests for all adventure, start and demo programs\nSometimes little errors happen in the code we ship in various examples, f.e. a typo, or when we change the grammar. Going forward, these should all be tested too. \r\n\r\nThis entails more or less:\r\n\r\n* Parse adventure yamls and extract all code between ```'s\r\n* Parse level defaults yamls and extract all start code \r\n* Parse level defaults yamls and extract all demo code in all commands\r\n\r\nParse all these as a unittest and see if they all parse (in a later stage we could even define outcome to test against, but for now just seeing that they parse is ok)\r\n\r\nWe also need to think about proper reporting, so not just a failing test but \"story adventure fails in Hungarian\" as output.\r\n\r\n\n", "before_files": [{"content": "import contextlib\nimport datetime\nimport time\nimport pickle\nimport functools\nimport os\nimport re\nimport string\nimport random\nfrom ruamel import yaml\nfrom website import querylog\n\n\nIS_WINDOWS = os.name == 'nt'\n\n\nclass Timer:\n \"\"\"A quick and dirty timer.\"\"\"\n def __init__(self, name):\n self.name = name\n\n def __enter__(self):\n self.start = time.time()\n\n def __exit__(self, type, value, tb):\n delta = time.time() - self.start\n print(f'{self.name}: {delta}s')\n\n\ndef timer(fn):\n \"\"\"Decoractor for fn.\"\"\"\n @functools.wraps(fn)\n def wrapper(*args, **kwargs):\n with Timer(fn.__name__):\n return fn(*args, **kwargs)\n return wrapper\n\n\n\ndef timems ():\n return int (round (time.time () * 1000))\n\ndef times ():\n return int (round (time.time ()))\n\n\n\n\nDEBUG_MODE = False\n\ndef is_debug_mode():\n \"\"\"Return whether or not we're in debug mode.\n\n We do more expensive things that are better for development in debug mode.\n \"\"\"\n return DEBUG_MODE\n\n\ndef set_debug_mode(debug_mode):\n \"\"\"Switch debug mode to given value.\"\"\"\n global DEBUG_MODE\n DEBUG_MODE = debug_mode\n\n\nYAML_CACHE = {}\n\[email protected]\ndef load_yaml(filename):\n \"\"\"Load the given YAML file.\n\n The file load will be cached in production, but reloaded everytime in\n development mode for much iterating. Because YAML loading is still\n somewhat slow, in production we'll have two levels of caching:\n\n - In-memory cache: each of the N processes on the box will only need to\n load the YAML file once (per restart).\n\n - On-disk pickle cache: \"pickle\" is a more efficient Python serialization\n format, and loads 400x quicker than YAML. We will prefer loading a pickle\n file to loading the source YAML file if possible. Hopefully only 1/N\n processes on the box will have to do the full load per deploy.\n\n We should be generating the pickled files at build time, but Heroku doesn't\n make it easy to have a build/deploy time... so for now let's just make sure\n we only do it once per box per deploy.\n \"\"\"\n if is_debug_mode():\n return load_yaml_uncached(filename)\n\n # Production mode, check our two-level cache\n if filename not in YAML_CACHE:\n data = load_yaml_pickled(filename)\n YAML_CACHE[filename] = data\n return data\n else:\n return YAML_CACHE[filename]\n\n\ndef load_yaml_pickled(filename):\n # Let's not even attempt the pickling on Windows, because we have\n # no pattern to atomatically write the pickled result file.\n if IS_WINDOWS:\n return load_yaml_uncached(filename)\n\n pickle_file = f'{filename}.pickle'\n if not os.path.exists(pickle_file):\n data = load_yaml_uncached(filename)\n\n # Write a pickle file, first write to a tempfile then rename\n # into place because multiple processes might try to do this in parallel,\n # plus we only want `path.exists(pickle_file)` to return True once the\n # file is actually complete and readable.\n with atomic_write_file(pickle_file) as f:\n pickle.dump(data, f)\n\n return data\n else:\n with open(pickle_file, 'rb') as f:\n return pickle.load(f)\n\n\ndef load_yaml_uncached(filename):\n try:\n y = yaml.YAML(typ='safe', pure=True)\n with open(filename, 'r', encoding='utf-8') as f:\n return y.load(f)\n except IOError:\n return {}\n\n\ndef load_yaml_rt(filename):\n \"\"\"Load YAML with the round trip loader.\"\"\"\n try:\n with open(filename, 'r', encoding='utf-8') as f:\n return yaml.round_trip_load(f, preserve_quotes=True)\n except IOError:\n return {}\n\n\ndef dump_yaml_rt(data):\n \"\"\"Dump round-tripped YAML.\"\"\"\n return yaml.round_trip_dump(data, indent=4, width=999)\n\ndef slash_join(*args):\n ret = []\n for arg in args:\n if not arg: continue\n\n if ret and not ret[-1].endswith('/'):\n ret.append('/')\n ret.append(arg.lstrip('/') if ret else arg)\n return ''.join(ret)\n\ndef is_testing_request(request):\n return bool ('X-Testing' in request.headers and request.headers ['X-Testing'])\n\ndef extract_bcrypt_rounds (hash):\n return int (re.match ('\\$2b\\$\\d+', hash) [0].replace ('$2b$', ''))\n\ndef isoformat(timestamp):\n \"\"\"Turn a timestamp into an ISO formatted string.\"\"\"\n dt = datetime.datetime.utcfromtimestamp(timestamp)\n return dt.isoformat() + 'Z'\n\n\ndef is_production():\n \"\"\"Whether we are serving production traffic.\"\"\"\n return os.getenv('IS_PRODUCTION', '') != ''\n\n\ndef is_heroku():\n \"\"\"Whether we are running on Heroku.\n\n Only use this flag if you are making a decision that really has to do with\n Heroku-based hosting or not.\n\n If you are trying to make a decision whether something needs to be done\n \"for real\" or not, prefer using:\n\n - `is_production()` to see if we're serving customer traffic and trying to\n optimize for safety and speed.\n - `is_debug_mode()` to see if we're on a developer machine and we're trying\n to optimize for developer productivity.\n\n \"\"\"\n return os.getenv('DYNO', '') != ''\n\n\ndef version():\n \"\"\"Get the version from the Heroku environment variables.\"\"\"\n if not is_heroku():\n return 'DEV'\n\n vrz = os.getenv('HEROKU_RELEASE_CREATED_AT')\n the_date = datetime.date.fromisoformat(vrz[:10]) if vrz else datetime.date.today()\n\n commit = os.getenv('HEROKU_SLUG_COMMIT', '????')[0:6]\n return the_date.strftime('%b %d') + f' ({commit})'\n\ndef valid_email(s):\n return bool (re.match ('^(([a-zA-Z0-9_+\\.\\-]+)@([\\da-zA-Z\\.\\-]+)\\.([a-zA-Z\\.]{2,6})\\s*)$', s))\n\n\[email protected]\ndef atomic_write_file(filename, mode='wb'):\n \"\"\"Write to a filename atomically.\n\n First write to a unique tempfile, then rename the tempfile into\n place. Use as a context manager:\n\n with atomic_write_file('file.txt') as f:\n f.write('hello')\n\n THIS WON'T WORK ON WINDOWS -- atomic file renames don't overwrite\n on Windows. We could potentially do something else to make it work\n (just swallow the exception, someone else already wrote the file?)\n but for now we just don't support it.\n \"\"\"\n if IS_WINDOWS:\n raise RuntimeError('Cannot use atomic_write_file() on Windows!')\n\n tmp_file = f'{filename}.{os.getpid()}'\n with open(tmp_file, mode) as f:\n yield f\n\n os.rename(tmp_file, filename)\n\n# This function takes a date in milliseconds from the Unix epoch and transforms it into a printable date\n# It operates by converting the date to a string, removing its last 3 digits, converting it back to an int\n# and then invoking the `isoformat` date function on it\ndef mstoisostring(date):\n return datetime.datetime.fromtimestamp (int (str (date) [:-3])).isoformat ()\n\n# https://stackoverflow.com/a/2257449\ndef random_id_generator(size=6, chars=string.ascii_uppercase + string.ascii_lowercase + string.digits):\n return ''.join (random.choice (chars) for _ in range (size))\n", "path": "utils.py"}], "after_files": [{"content": "import contextlib\nimport datetime\nimport time\nimport pickle\nimport functools\nimport os\nimport re\nimport string\nimport random\nfrom ruamel import yaml\nfrom website import querylog\nimport commonmark\ncommonmark_parser = commonmark.Parser ()\ncommonmark_renderer = commonmark.HtmlRenderer ()\nfrom bs4 import BeautifulSoup\n\nIS_WINDOWS = os.name == 'nt'\n\n\nclass Timer:\n \"\"\"A quick and dirty timer.\"\"\"\n def __init__(self, name):\n self.name = name\n\n def __enter__(self):\n self.start = time.time()\n\n def __exit__(self, type, value, tb):\n delta = time.time() - self.start\n print(f'{self.name}: {delta}s')\n\n\ndef timer(fn):\n \"\"\"Decoractor for fn.\"\"\"\n @functools.wraps(fn)\n def wrapper(*args, **kwargs):\n with Timer(fn.__name__):\n return fn(*args, **kwargs)\n return wrapper\n\n\n\ndef timems ():\n return int (round (time.time () * 1000))\n\ndef times ():\n return int (round (time.time ()))\n\n\n\n\nDEBUG_MODE = False\n\ndef is_debug_mode():\n \"\"\"Return whether or not we're in debug mode.\n\n We do more expensive things that are better for development in debug mode.\n \"\"\"\n return DEBUG_MODE\n\n\ndef set_debug_mode(debug_mode):\n \"\"\"Switch debug mode to given value.\"\"\"\n global DEBUG_MODE\n DEBUG_MODE = debug_mode\n\n\nYAML_CACHE = {}\n\[email protected]\ndef load_yaml(filename):\n \"\"\"Load the given YAML file.\n\n The file load will be cached in production, but reloaded everytime in\n development mode for much iterating. Because YAML loading is still\n somewhat slow, in production we'll have two levels of caching:\n\n - In-memory cache: each of the N processes on the box will only need to\n load the YAML file once (per restart).\n\n - On-disk pickle cache: \"pickle\" is a more efficient Python serialization\n format, and loads 400x quicker than YAML. We will prefer loading a pickle\n file to loading the source YAML file if possible. Hopefully only 1/N\n processes on the box will have to do the full load per deploy.\n\n We should be generating the pickled files at build time, but Heroku doesn't\n make it easy to have a build/deploy time... so for now let's just make sure\n we only do it once per box per deploy.\n \"\"\"\n if is_debug_mode():\n return load_yaml_uncached(filename)\n\n # Production mode, check our two-level cache\n if filename not in YAML_CACHE:\n data = load_yaml_pickled(filename)\n YAML_CACHE[filename] = data\n return data\n else:\n return YAML_CACHE[filename]\n\n\ndef load_yaml_pickled(filename):\n # Let's not even attempt the pickling on Windows, because we have\n # no pattern to atomatically write the pickled result file.\n if IS_WINDOWS:\n return load_yaml_uncached(filename)\n\n pickle_file = f'{filename}.pickle'\n if not os.path.exists(pickle_file):\n data = load_yaml_uncached(filename)\n\n # Write a pickle file, first write to a tempfile then rename\n # into place because multiple processes might try to do this in parallel,\n # plus we only want `path.exists(pickle_file)` to return True once the\n # file is actually complete and readable.\n with atomic_write_file(pickle_file) as f:\n pickle.dump(data, f)\n\n return data\n else:\n with open(pickle_file, 'rb') as f:\n return pickle.load(f)\n\n\ndef load_yaml_uncached(filename):\n try:\n y = yaml.YAML(typ='safe', pure=True)\n with open(filename, 'r', encoding='utf-8') as f:\n return y.load(f)\n except IOError:\n return {}\n\n\ndef load_yaml_rt(filename):\n \"\"\"Load YAML with the round trip loader.\"\"\"\n try:\n with open(filename, 'r', encoding='utf-8') as f:\n return yaml.round_trip_load(f, preserve_quotes=True)\n except IOError:\n return {}\n\n\ndef dump_yaml_rt(data):\n \"\"\"Dump round-tripped YAML.\"\"\"\n return yaml.round_trip_dump(data, indent=4, width=999)\n\ndef slash_join(*args):\n ret = []\n for arg in args:\n if not arg: continue\n\n if ret and not ret[-1].endswith('/'):\n ret.append('/')\n ret.append(arg.lstrip('/') if ret else arg)\n return ''.join(ret)\n\ndef is_testing_request(request):\n return bool ('X-Testing' in request.headers and request.headers ['X-Testing'])\n\ndef extract_bcrypt_rounds (hash):\n return int (re.match ('\\$2b\\$\\d+', hash) [0].replace ('$2b$', ''))\n\ndef isoformat(timestamp):\n \"\"\"Turn a timestamp into an ISO formatted string.\"\"\"\n dt = datetime.datetime.utcfromtimestamp(timestamp)\n return dt.isoformat() + 'Z'\n\n\ndef is_production():\n \"\"\"Whether we are serving production traffic.\"\"\"\n return os.getenv('IS_PRODUCTION', '') != ''\n\n\ndef is_heroku():\n \"\"\"Whether we are running on Heroku.\n\n Only use this flag if you are making a decision that really has to do with\n Heroku-based hosting or not.\n\n If you are trying to make a decision whether something needs to be done\n \"for real\" or not, prefer using:\n\n - `is_production()` to see if we're serving customer traffic and trying to\n optimize for safety and speed.\n - `is_debug_mode()` to see if we're on a developer machine and we're trying\n to optimize for developer productivity.\n\n \"\"\"\n return os.getenv('DYNO', '') != ''\n\n\ndef version():\n \"\"\"Get the version from the Heroku environment variables.\"\"\"\n if not is_heroku():\n return 'DEV'\n\n vrz = os.getenv('HEROKU_RELEASE_CREATED_AT')\n the_date = datetime.date.fromisoformat(vrz[:10]) if vrz else datetime.date.today()\n\n commit = os.getenv('HEROKU_SLUG_COMMIT', '????')[0:6]\n return the_date.strftime('%b %d') + f' ({commit})'\n\ndef valid_email(s):\n return bool (re.match ('^(([a-zA-Z0-9_+\\.\\-]+)@([\\da-zA-Z\\.\\-]+)\\.([a-zA-Z\\.]{2,6})\\s*)$', s))\n\n\[email protected]\ndef atomic_write_file(filename, mode='wb'):\n \"\"\"Write to a filename atomically.\n\n First write to a unique tempfile, then rename the tempfile into\n place. Use as a context manager:\n\n with atomic_write_file('file.txt') as f:\n f.write('hello')\n\n THIS WON'T WORK ON WINDOWS -- atomic file renames don't overwrite\n on Windows. We could potentially do something else to make it work\n (just swallow the exception, someone else already wrote the file?)\n but for now we just don't support it.\n \"\"\"\n if IS_WINDOWS:\n raise RuntimeError('Cannot use atomic_write_file() on Windows!')\n\n tmp_file = f'{filename}.{os.getpid()}'\n with open(tmp_file, mode) as f:\n yield f\n\n os.rename(tmp_file, filename)\n\n# This function takes a date in milliseconds from the Unix epoch and transforms it into a printable date\n# It operates by converting the date to a string, removing its last 3 digits, converting it back to an int\n# and then invoking the `isoformat` date function on it\ndef mstoisostring(date):\n return datetime.datetime.fromtimestamp (int (str (date) [:-3])).isoformat ()\n\n# https://stackoverflow.com/a/2257449\ndef random_id_generator(size=6, chars=string.ascii_uppercase + string.ascii_lowercase + string.digits):\n return ''.join (random.choice (chars) for _ in range (size))\n\n# This function takes a markdown string and returns a list with each of the HTML elements obtained\n# by rendering the markdown into HTML.\ndef markdown_to_html_tags (markdown):\n _html = commonmark_renderer.render(commonmark_parser.parse (markdown))\n soup = BeautifulSoup(_html, 'html.parser')\n return soup.find_all ()\n", "path": "utils.py"}]}
| 2,763 | 230 |
gh_patches_debug_39058
|
rasdani/github-patches
|
git_diff
|
saulpw__visidata-1924
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[urllib imports] Multiple urllib imports are missing
**Small description**
Missing imports for `urllib.error` and `urllib.parse`
**Expected result**
No stack traces from missing imports.
**Actual result with screenshot**
First Trace
```
Traceback (most recent call last):
File "/usr/lib/python3.9/site-packages/visidata/threads.py", line 200, in _toplevelTryFunc
t.status = func(*args, **kwargs)
File "/usr/lib/python3.9/site-packages/visidata/threads.py", line 219, in _func
func(*args, **kwargs)
File "/usr/lib/python3.9/site-packages/visidata/plugins.py", line 97, in reload
except urllib.error.URLError as e:
AttributeError: module 'urllib' has no attribute 'error'
```
Second trace
```
Traceback (most recent call last):
...
File "/usr/lib/python3.9/site-packages/visidata/loaders/http.py", line 50, in _iter_lines
links = urllib.parse.parse_header(linkhdr)
AttributeError: module 'urllib.parse' has no attribute 'parse_header'
```
Reproduce:
```
vd https://blog.nature.org/2021/04/12/beaver-otter-muskrat-a-field-guide-to-freshwater-mammals/
```
Please attach the commandlog (saved with `Ctrl-D`) to show the steps that led to the issue.
See [here](http://visidata.org/docs/save-restore/) for more details.
**Additional context**
Please include the version of VisiData. Latest develop version of VisData. Python 3.9.2
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `visidata/loaders/http.py`
Content:
```
1 from visidata import Path, RepeatFile, vd, VisiData
2 from visidata.loaders.tsv import splitter
3
4 content_filetypes = {
5 'tab-separated-values': 'tsv'
6 }
7
8 vd.option('http_max_next', 0, 'max next.url pages to follow in http response') #848
9 vd.option('http_req_headers', {}, 'http headers to send to requests')
10
11
12 @VisiData.api
13 def openurl_http(vd, path, filetype=None):
14 schemes = path.scheme.split('+')
15 if len(schemes) > 1:
16 sch = schemes[0]
17 openfunc = getattr(vd, f'openhttp_{sch}', vd.getGlobals().get(f'openhttp_{sch}'))
18 if not openfunc:
19 vd.fail(f'no vd.openhttp_{sch}')
20 return openfunc(Path(schemes[-1]+'://'+path.given.split('://')[1]))
21
22 import urllib.request
23 import urllib.error
24 import mimetypes
25
26 # fallback to mime-type
27 req = urllib.request.Request(path.given, **vd.options.getall('http_req_'))
28 response = urllib.request.urlopen(req)
29
30 contenttype = response.getheader('content-type')
31 subtype = contenttype.split(';')[0].split('/')[-1]
32
33 filetype = filetype or vd.guessFiletype(path, funcprefix='guessurl_').get('filetype')
34 filetype = filetype or content_filetypes.get(subtype, subtype)
35 filetype = filetype or vd.guessFiletype(path).get('filetype')
36
37 # Automatically paginate if a 'next' URL is given
38 def _iter_lines(path=path, response=response, max_next=vd.options.http_max_next):
39 path.responses = []
40 n = 0
41 while response:
42 path.responses.append(response)
43 with response as fp:
44 for line in splitter(response, delim=b'\n'):
45 yield line.decode(vd.options.encoding)
46
47 linkhdr = response.getheader('Link')
48 src = None
49 if linkhdr:
50 links = urllib.parse.parse_header(linkhdr)
51 src = links.get('next', {}).get('url', None)
52
53 if not src:
54 break
55
56 n += 1
57 if n > max_next:
58 vd.warning(f'stopping at max {max_next} pages')
59 break
60
61 vd.status(f'fetching next page from {src}')
62 response = requests.get(src, stream=True, **vd.options.getall('http_req_'))
63
64 # add resettable iterator over contents as an already-open fp
65 path.fptext = RepeatFile(_iter_lines())
66
67 return vd.openSource(path, filetype=filetype)
68
69
70 VisiData.openurl_https = VisiData.openurl_http
71
```
Path: `visidata/plugins.py`
Content:
```
1 import os.path
2 import os
3 import sys
4 import re
5 import shutil
6 import importlib
7 import subprocess
8 import urllib
9
10 from visidata import VisiData, vd, Path, CellColorizer, JsonLinesSheet, AttrDict, Column, Progress, ExpectedException, BaseSheet, asyncsingle, asyncthread
11
12
13 vd.option('plugins_url', 'https://visidata.org/plugins/plugins.jsonl', 'source of plugins sheet')
14 vd.option('plugins_autoload', True, 'do not autoload plugins if False')
15
16
17 @VisiData.lazy_property
18 def pluginsSheet(p):
19 return PluginsSheet('plugins_global')
20
21 def _plugin_path(plugin):
22 return Path(os.path.join(vd.options.visidata_dir, "plugins", plugin.name+".py"))
23
24 def _plugin_init():
25 return Path(os.path.join(vd.options.visidata_dir, "plugins", "__init__.py"))
26
27 def _plugin_import(plugin):
28 return "import " + _plugin_import_name(plugin)
29
30 def _plugin_import_name(plugin):
31 if not plugin.url:
32 return 'visidata.plugins.'+plugin.name
33 if 'git+' in plugin.url:
34 return plugin.name
35 return "plugins."+plugin.name
36
37 def _plugin_in_import_list(plugin):
38 with Path(_plugin_init()).open(mode='r', encoding='utf-8') as fprc:
39 r = re.compile(r'^{}\W'.format(_plugin_import(plugin)))
40 for line in fprc.readlines():
41 if r.match(line):
42 return True
43
44 def _installedStatus(col, plugin):
45 return '*' if importlib.util.find_spec(_plugin_import_name(plugin)) else ''
46
47 def _loadedVersion(plugin):
48 name = _plugin_import_name(plugin)
49 if name not in sys.modules:
50 return ''
51 mod = sys.modules[name]
52 return getattr(mod, '__version__', 'unknown version installed')
53
54 def _checkHash(data, sha):
55 import hashlib
56 return hashlib.sha256(data.strip().encode('utf-8')).hexdigest() == sha
57
58 def _pluginColorizer(s,c,r,v):
59 if not r: return None
60 ver = _loadedVersion(r)
61 if not ver: return None
62 if not r.latest_ver: return None
63 if ver != r.latest_ver: return 'color_warning'
64 return 'color_working'
65
66
67 @VisiData.api
68 def pipinstall(vd, deps):
69 'Install *deps*, a list of pypi modules to install via pip into the plugins-deps directory. Return True if successful (no error).'
70 p = subprocess.Popen([sys.executable, '-m', 'pip', 'install',
71 '--target', str(Path(vd.options.visidata_dir)/"plugins-deps"),
72 ] + deps,
73 stdout=subprocess.PIPE,
74 stderr=subprocess.PIPE)
75 out, err = p.communicate()
76 vd.status(out.decode())
77 if err:
78 vd.warning(err.decode())
79 return False
80 return True
81
82
83 class PluginsSheet(JsonLinesSheet):
84 rowtype = "plugins" # rowdef: AttrDict of json dict
85 colorizers = [
86 CellColorizer(3, None, _pluginColorizer)
87 ]
88
89 def iterload(self):
90 for r in JsonLinesSheet.iterload(self):
91 yield AttrDict(r)
92
93 @asyncsingle
94 def reload(self):
95 try:
96 self.source = vd.urlcache(vd.options.plugins_url or vd.fail(), days=1) # for VisiDataMetaSheet.reload()
97 except urllib.error.URLError as e:
98 vd.debug(e)
99 return
100
101 super().reload.__wrapped__(self)
102 self.addColumn(Column('available', width=0, getter=_installedStatus), index=1)
103 self.addColumn(Column('installed', width=8, getter=lambda c,r: _loadedVersion(r)), index=2)
104 self.column('description').width = 40
105 self.setKeys([self.column("name")])
106
107 for name, mod in sys.modules.items():
108 if name.startswith('visidata.plugins.'):
109 self.addRow(AttrDict(name='.'.join(name.split('.')[2:]),
110 description=getattr(mod, '__description__', mod.__doc__),
111 maintainer=getattr(mod, '__author__', None),
112 latest_release='',
113 latest_ver='',
114 url=''
115 ))
116
117 for r in Progress(self.rows):
118 for funcname in (r.provides or '').split():
119 func = lambda *args, **kwargs: vd.fail('this requires the %s plugin' % r.name)
120 vd.addGlobals({funcname: func})
121 setattr(vd, funcname, func)
122
123 # check for plugins with newer versions
124 def is_stale(r):
125 v = _loadedVersion(r)
126 return v and r.latest_ver and v != r.latest_ver
127
128 stale_plugins = list(filter(is_stale, self.rows))
129 if len(stale_plugins) > 0:
130 vd.warning(f'update available for {len(stale_plugins)} plugins')
131
132 def installPlugin(self, plugin):
133 # pip3 install requirements
134 initpath = _plugin_init()
135 os.makedirs(initpath.parent, exist_ok=True)
136 if not initpath.exists():
137 initpath.touch()
138
139 outpath = _plugin_path(plugin)
140 overwrite = True
141 if outpath.exists():
142 try:
143 vd.confirm("plugin path already exists, overwrite? ")
144 except ExpectedException:
145 overwrite = False
146 if _plugin_in_import_list(plugin):
147 vd.fail("plugin already loaded")
148 else:
149 self._loadPlugin(plugin)
150 if overwrite:
151 self._install(plugin)
152
153 @asyncthread
154 def _install(self, plugin):
155 outpath = _plugin_path(plugin)
156
157 if "git+" in plugin.url:
158 p = subprocess.Popen([sys.executable, '-m', 'pip', 'install',
159 '--upgrade', plugin.url],
160 stdout=subprocess.PIPE,
161 stderr=subprocess.PIPE)
162 out, err = p.communicate()
163 vd.status(out.decode())
164 if err:
165 vd.warning(err.decode())
166 if p.returncode != 0:
167 vd.fail('pip install failed')
168 else:
169 with vd.urlcache(plugin.url, days=0).open(encoding='utf-8') as pyfp:
170 contents = pyfp.read()
171 if plugin.sha256:
172 if not _checkHash(contents, plugin.sha256):
173 vd.error('%s plugin SHA256 does not match!' % plugin.name)
174 else:
175 vd.warning('no SHA256 provided for %s plugin, not validating' % plugin.name)
176 with outpath.open(mode='w', encoding='utf-8') as outfp:
177 outfp.write(contents)
178
179 if plugin.pydeps:
180 vd.pipinstall(plugin.pydeps.split())
181
182 vd.status('%s plugin installed' % plugin.name)
183
184 if _plugin_in_import_list(plugin):
185 vd.warning("plugin already loaded")
186 else:
187 self._loadPlugin(plugin)
188
189
190 def _loadPlugin(self, plugin):
191 with Path(_plugin_init()).open(mode='a', encoding='utf-8') as fprc:
192 print(_plugin_import(plugin), file=fprc)
193 importlib.import_module(_plugin_import_name(plugin))
194 vd.status('%s plugin loaded' % plugin.name)
195
196
197 def removePluginIfExists(self, plugin):
198 self.removePlugin(plugin)
199
200 def removePlugin(self, plugin):
201 if not _plugin_in_import_list(plugin):
202 vd.fail("plugin not in import list")
203
204 initpath = Path(_plugin_init())
205 oldinitpath = Path(initpath.with_suffix(initpath.suffix + '.bak'))
206 try:
207 shutil.copyfile(initpath, oldinitpath)
208
209 # Copy lines from the backup init file into its replacement, skipping lines that import the removed plugin.
210 #
211 # By matching from the start of a line through a word boundary, we avoid removing commented lines or inadvertently removing
212 # plugins with similar names.
213 with oldinitpath.open(encoding='utf-8') as old, initpath.open(mode='w', encoding='utf-8') as new:
214 r = re.compile(r'^{}\W'.format(_plugin_import(plugin)))
215 new.writelines(line for line in old.readlines() if not r.match(line))
216
217 if os.path.exists(_plugin_path(plugin)):
218 os.unlink(_plugin_path(plugin))
219 sys.modules.pop(_plugin_import_name(plugin))
220 importlib.invalidate_caches()
221 vd.warning('{0} plugin uninstalled'.format(plugin['name']))
222 except FileNotFoundError:
223 vd.warning("no plugins/__init__.py found")
224
225
226 BaseSheet.addCommand(None, 'open-plugins', 'vd.push(vd.pluginsSheet)', 'Open Plugins Sheet to manage supported plugins')
227
228 PluginsSheet.addCommand('a', 'add-plugin', 'installPlugin(cursorRow)', 'Install and enable current plugin')
229 PluginsSheet.addCommand('d', 'delete-plugin', 'removePluginIfExists(cursorRow)', 'Disable current plugin')
230
231 vd.addMenuItems('''
232 View > Plugins > open-plugins
233 ''')
234
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/visidata/loaders/http.py b/visidata/loaders/http.py
--- a/visidata/loaders/http.py
+++ b/visidata/loaders/http.py
@@ -1,3 +1,5 @@
+import re
+
from visidata import Path, RepeatFile, vd, VisiData
from visidata.loaders.tsv import splitter
@@ -47,24 +49,59 @@
linkhdr = response.getheader('Link')
src = None
if linkhdr:
- links = urllib.parse.parse_header(linkhdr)
- src = links.get('next', {}).get('url', None)
+ links = parse_header_links(linkhdr)
+ link_data = {}
+ for link in links:
+ key = link.get('rel') or link.get('url')
+ link_data[key] = link
+ src = link_data.get('next', {}).get('url', None)
if not src:
break
n += 1
if n > max_next:
- vd.warning(f'stopping at max {max_next} pages')
+ vd.warning(f'stopping at max next pages: {max_next} pages')
break
vd.status(f'fetching next page from {src}')
- response = requests.get(src, stream=True, **vd.options.getall('http_req_'))
+ req = urllib.request.Request(src, **vd.options.getall('http_req_'))
+ response = urllib.request.urlopen(req)
# add resettable iterator over contents as an already-open fp
path.fptext = RepeatFile(_iter_lines())
return vd.openSource(path, filetype=filetype)
+def parse_header_links(link_header):
+ '''Return a list of dictionaries:
+ [{'url': 'https://example.com/content?page=1', 'rel': 'prev'},
+ {'url': 'https://example.com/content?page=3', 'rel': 'next'}]
+ Takes a link header string, of the form
+ '<https://example.com/content?page=1>; rel="prev", <https://example.com/content?page=3>; rel="next"'
+ See https://datatracker.ietf.org/doc/html/rfc8288#section-3
+ '''
+
+ links = []
+ quote_space = ' \'"'
+ link_header = link_header.strip(quote_space)
+ if not link_header: return []
+ for link_value in re.split(', *<', link_header):
+ if ';' in link_value:
+ url, params = link_value.split(';', maxsplit=1)
+ else:
+ url, params = link_value, ''
+ link = {'url': url.strip('<>' + quote_space)}
+
+ for param in params.split(';'):
+ if '=' in param:
+ key, value = param.split('=')
+ key = key.strip(quote_space)
+ value = value.strip(quote_space)
+ link[key] = value
+ else:
+ break
+ links.append(link)
+ return links
VisiData.openurl_https = VisiData.openurl_http
diff --git a/visidata/plugins.py b/visidata/plugins.py
--- a/visidata/plugins.py
+++ b/visidata/plugins.py
@@ -5,7 +5,7 @@
import shutil
import importlib
import subprocess
-import urllib
+import urllib.error
from visidata import VisiData, vd, Path, CellColorizer, JsonLinesSheet, AttrDict, Column, Progress, ExpectedException, BaseSheet, asyncsingle, asyncthread
|
{"golden_diff": "diff --git a/visidata/loaders/http.py b/visidata/loaders/http.py\n--- a/visidata/loaders/http.py\n+++ b/visidata/loaders/http.py\n@@ -1,3 +1,5 @@\n+import re\n+\n from visidata import Path, RepeatFile, vd, VisiData\n from visidata.loaders.tsv import splitter\n \n@@ -47,24 +49,59 @@\n linkhdr = response.getheader('Link')\n src = None\n if linkhdr:\n- links = urllib.parse.parse_header(linkhdr)\n- src = links.get('next', {}).get('url', None)\n+ links = parse_header_links(linkhdr)\n+ link_data = {}\n+ for link in links:\n+ key = link.get('rel') or link.get('url')\n+ link_data[key] = link\n+ src = link_data.get('next', {}).get('url', None)\n \n if not src:\n break\n \n n += 1\n if n > max_next:\n- vd.warning(f'stopping at max {max_next} pages')\n+ vd.warning(f'stopping at max next pages: {max_next} pages')\n break\n \n vd.status(f'fetching next page from {src}')\n- response = requests.get(src, stream=True, **vd.options.getall('http_req_'))\n+ req = urllib.request.Request(src, **vd.options.getall('http_req_'))\n+ response = urllib.request.urlopen(req)\n \n # add resettable iterator over contents as an already-open fp\n path.fptext = RepeatFile(_iter_lines())\n \n return vd.openSource(path, filetype=filetype)\n \n+def parse_header_links(link_header):\n+ '''Return a list of dictionaries:\n+ [{'url': 'https://example.com/content?page=1', 'rel': 'prev'},\n+ {'url': 'https://example.com/content?page=3', 'rel': 'next'}]\n+ Takes a link header string, of the form\n+ '<https://example.com/content?page=1>; rel=\"prev\", <https://example.com/content?page=3>; rel=\"next\"'\n+ See https://datatracker.ietf.org/doc/html/rfc8288#section-3\n+ '''\n+\n+ links = []\n+ quote_space = ' \\'\"'\n+ link_header = link_header.strip(quote_space)\n+ if not link_header: return []\n+ for link_value in re.split(', *<', link_header):\n+ if ';' in link_value:\n+ url, params = link_value.split(';', maxsplit=1)\n+ else:\n+ url, params = link_value, ''\n+ link = {'url': url.strip('<>' + quote_space)}\n+\n+ for param in params.split(';'):\n+ if '=' in param:\n+ key, value = param.split('=')\n+ key = key.strip(quote_space)\n+ value = value.strip(quote_space)\n+ link[key] = value\n+ else:\n+ break\n+ links.append(link)\n+ return links\n \n VisiData.openurl_https = VisiData.openurl_http\ndiff --git a/visidata/plugins.py b/visidata/plugins.py\n--- a/visidata/plugins.py\n+++ b/visidata/plugins.py\n@@ -5,7 +5,7 @@\n import shutil\n import importlib\n import subprocess\n-import urllib\n+import urllib.error\n \n from visidata import VisiData, vd, Path, CellColorizer, JsonLinesSheet, AttrDict, Column, Progress, ExpectedException, BaseSheet, asyncsingle, asyncthread\n", "issue": "[urllib imports] Multiple urllib imports are missing\n**Small description**\r\nMissing imports for `urllib.error` and `urllib.parse`\r\n\r\n\r\n**Expected result**\r\nNo stack traces from missing imports.\r\n\r\n\r\n**Actual result with screenshot**\r\n\r\nFirst Trace\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.9/site-packages/visidata/threads.py\", line 200, in _toplevelTryFunc\r\n t.status = func(*args, **kwargs)\r\n File \"/usr/lib/python3.9/site-packages/visidata/threads.py\", line 219, in _func\r\n func(*args, **kwargs)\r\n File \"/usr/lib/python3.9/site-packages/visidata/plugins.py\", line 97, in reload\r\n except urllib.error.URLError as e:\r\nAttributeError: module 'urllib' has no attribute 'error'\r\n```\r\n\r\nSecond trace\r\n```\r\nTraceback (most recent call last):\r\n...\r\n File \"/usr/lib/python3.9/site-packages/visidata/loaders/http.py\", line 50, in _iter_lines\r\n links = urllib.parse.parse_header(linkhdr)\r\nAttributeError: module 'urllib.parse' has no attribute 'parse_header'\r\n\r\n```\r\n\r\nReproduce: \r\n```\r\nvd https://blog.nature.org/2021/04/12/beaver-otter-muskrat-a-field-guide-to-freshwater-mammals/\r\n```\r\n\r\nPlease attach the commandlog (saved with `Ctrl-D`) to show the steps that led to the issue.\r\nSee [here](http://visidata.org/docs/save-restore/) for more details.\r\n\r\n**Additional context**\r\nPlease include the version of VisiData. Latest develop version of VisData. Python 3.9.2\r\n\n", "before_files": [{"content": "from visidata import Path, RepeatFile, vd, VisiData\nfrom visidata.loaders.tsv import splitter\n\ncontent_filetypes = {\n 'tab-separated-values': 'tsv'\n}\n\nvd.option('http_max_next', 0, 'max next.url pages to follow in http response') #848\nvd.option('http_req_headers', {}, 'http headers to send to requests')\n\n\[email protected]\ndef openurl_http(vd, path, filetype=None):\n schemes = path.scheme.split('+')\n if len(schemes) > 1:\n sch = schemes[0]\n openfunc = getattr(vd, f'openhttp_{sch}', vd.getGlobals().get(f'openhttp_{sch}'))\n if not openfunc:\n vd.fail(f'no vd.openhttp_{sch}')\n return openfunc(Path(schemes[-1]+'://'+path.given.split('://')[1]))\n\n import urllib.request\n import urllib.error\n import mimetypes\n\n # fallback to mime-type\n req = urllib.request.Request(path.given, **vd.options.getall('http_req_'))\n response = urllib.request.urlopen(req)\n\n contenttype = response.getheader('content-type')\n subtype = contenttype.split(';')[0].split('/')[-1]\n\n filetype = filetype or vd.guessFiletype(path, funcprefix='guessurl_').get('filetype')\n filetype = filetype or content_filetypes.get(subtype, subtype)\n filetype = filetype or vd.guessFiletype(path).get('filetype')\n\n # Automatically paginate if a 'next' URL is given\n def _iter_lines(path=path, response=response, max_next=vd.options.http_max_next):\n path.responses = []\n n = 0\n while response:\n path.responses.append(response)\n with response as fp:\n for line in splitter(response, delim=b'\\n'):\n yield line.decode(vd.options.encoding)\n\n linkhdr = response.getheader('Link')\n src = None\n if linkhdr:\n links = urllib.parse.parse_header(linkhdr)\n src = links.get('next', {}).get('url', None)\n\n if not src:\n break\n\n n += 1\n if n > max_next:\n vd.warning(f'stopping at max {max_next} pages')\n break\n\n vd.status(f'fetching next page from {src}')\n response = requests.get(src, stream=True, **vd.options.getall('http_req_'))\n\n # add resettable iterator over contents as an already-open fp\n path.fptext = RepeatFile(_iter_lines())\n\n return vd.openSource(path, filetype=filetype)\n\n\nVisiData.openurl_https = VisiData.openurl_http\n", "path": "visidata/loaders/http.py"}, {"content": "import os.path\nimport os\nimport sys\nimport re\nimport shutil\nimport importlib\nimport subprocess\nimport urllib\n\nfrom visidata import VisiData, vd, Path, CellColorizer, JsonLinesSheet, AttrDict, Column, Progress, ExpectedException, BaseSheet, asyncsingle, asyncthread\n\n\nvd.option('plugins_url', 'https://visidata.org/plugins/plugins.jsonl', 'source of plugins sheet')\nvd.option('plugins_autoload', True, 'do not autoload plugins if False')\n\n\[email protected]_property\ndef pluginsSheet(p):\n return PluginsSheet('plugins_global')\n\ndef _plugin_path(plugin):\n return Path(os.path.join(vd.options.visidata_dir, \"plugins\", plugin.name+\".py\"))\n\ndef _plugin_init():\n return Path(os.path.join(vd.options.visidata_dir, \"plugins\", \"__init__.py\"))\n\ndef _plugin_import(plugin):\n return \"import \" + _plugin_import_name(plugin)\n\ndef _plugin_import_name(plugin):\n if not plugin.url:\n return 'visidata.plugins.'+plugin.name\n if 'git+' in plugin.url:\n return plugin.name\n return \"plugins.\"+plugin.name\n\ndef _plugin_in_import_list(plugin):\n with Path(_plugin_init()).open(mode='r', encoding='utf-8') as fprc:\n r = re.compile(r'^{}\\W'.format(_plugin_import(plugin)))\n for line in fprc.readlines():\n if r.match(line):\n return True\n\ndef _installedStatus(col, plugin):\n return '*' if importlib.util.find_spec(_plugin_import_name(plugin)) else ''\n\ndef _loadedVersion(plugin):\n name = _plugin_import_name(plugin)\n if name not in sys.modules:\n return ''\n mod = sys.modules[name]\n return getattr(mod, '__version__', 'unknown version installed')\n\ndef _checkHash(data, sha):\n import hashlib\n return hashlib.sha256(data.strip().encode('utf-8')).hexdigest() == sha\n\ndef _pluginColorizer(s,c,r,v):\n if not r: return None\n ver = _loadedVersion(r)\n if not ver: return None\n if not r.latest_ver: return None\n if ver != r.latest_ver: return 'color_warning'\n return 'color_working'\n\n\[email protected]\ndef pipinstall(vd, deps):\n 'Install *deps*, a list of pypi modules to install via pip into the plugins-deps directory. Return True if successful (no error).'\n p = subprocess.Popen([sys.executable, '-m', 'pip', 'install',\n '--target', str(Path(vd.options.visidata_dir)/\"plugins-deps\"),\n ] + deps,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE)\n out, err = p.communicate()\n vd.status(out.decode())\n if err:\n vd.warning(err.decode())\n return False\n return True\n\n\nclass PluginsSheet(JsonLinesSheet):\n rowtype = \"plugins\" # rowdef: AttrDict of json dict\n colorizers = [\n CellColorizer(3, None, _pluginColorizer)\n ]\n\n def iterload(self):\n for r in JsonLinesSheet.iterload(self):\n yield AttrDict(r)\n\n @asyncsingle\n def reload(self):\n try:\n self.source = vd.urlcache(vd.options.plugins_url or vd.fail(), days=1) # for VisiDataMetaSheet.reload()\n except urllib.error.URLError as e:\n vd.debug(e)\n return\n\n super().reload.__wrapped__(self)\n self.addColumn(Column('available', width=0, getter=_installedStatus), index=1)\n self.addColumn(Column('installed', width=8, getter=lambda c,r: _loadedVersion(r)), index=2)\n self.column('description').width = 40\n self.setKeys([self.column(\"name\")])\n\n for name, mod in sys.modules.items():\n if name.startswith('visidata.plugins.'):\n self.addRow(AttrDict(name='.'.join(name.split('.')[2:]),\n description=getattr(mod, '__description__', mod.__doc__),\n maintainer=getattr(mod, '__author__', None),\n latest_release='',\n latest_ver='',\n url=''\n ))\n\n for r in Progress(self.rows):\n for funcname in (r.provides or '').split():\n func = lambda *args, **kwargs: vd.fail('this requires the %s plugin' % r.name)\n vd.addGlobals({funcname: func})\n setattr(vd, funcname, func)\n\n # check for plugins with newer versions\n def is_stale(r):\n v = _loadedVersion(r)\n return v and r.latest_ver and v != r.latest_ver\n\n stale_plugins = list(filter(is_stale, self.rows))\n if len(stale_plugins) > 0:\n vd.warning(f'update available for {len(stale_plugins)} plugins')\n\n def installPlugin(self, plugin):\n # pip3 install requirements\n initpath = _plugin_init()\n os.makedirs(initpath.parent, exist_ok=True)\n if not initpath.exists():\n initpath.touch()\n\n outpath = _plugin_path(plugin)\n overwrite = True\n if outpath.exists():\n try:\n vd.confirm(\"plugin path already exists, overwrite? \")\n except ExpectedException:\n overwrite = False\n if _plugin_in_import_list(plugin):\n vd.fail(\"plugin already loaded\")\n else:\n self._loadPlugin(plugin)\n if overwrite:\n self._install(plugin)\n\n @asyncthread\n def _install(self, plugin):\n outpath = _plugin_path(plugin)\n\n if \"git+\" in plugin.url:\n p = subprocess.Popen([sys.executable, '-m', 'pip', 'install',\n '--upgrade', plugin.url],\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE)\n out, err = p.communicate()\n vd.status(out.decode())\n if err:\n vd.warning(err.decode())\n if p.returncode != 0:\n vd.fail('pip install failed')\n else:\n with vd.urlcache(plugin.url, days=0).open(encoding='utf-8') as pyfp:\n contents = pyfp.read()\n if plugin.sha256:\n if not _checkHash(contents, plugin.sha256):\n vd.error('%s plugin SHA256 does not match!' % plugin.name)\n else:\n vd.warning('no SHA256 provided for %s plugin, not validating' % plugin.name)\n with outpath.open(mode='w', encoding='utf-8') as outfp:\n outfp.write(contents)\n\n if plugin.pydeps:\n vd.pipinstall(plugin.pydeps.split())\n\n vd.status('%s plugin installed' % plugin.name)\n\n if _plugin_in_import_list(plugin):\n vd.warning(\"plugin already loaded\")\n else:\n self._loadPlugin(plugin)\n\n\n def _loadPlugin(self, plugin):\n with Path(_plugin_init()).open(mode='a', encoding='utf-8') as fprc:\n print(_plugin_import(plugin), file=fprc)\n importlib.import_module(_plugin_import_name(plugin))\n vd.status('%s plugin loaded' % plugin.name)\n\n\n def removePluginIfExists(self, plugin):\n self.removePlugin(plugin)\n\n def removePlugin(self, plugin):\n if not _plugin_in_import_list(plugin):\n vd.fail(\"plugin not in import list\")\n\n initpath = Path(_plugin_init())\n oldinitpath = Path(initpath.with_suffix(initpath.suffix + '.bak'))\n try:\n shutil.copyfile(initpath, oldinitpath)\n\n # Copy lines from the backup init file into its replacement, skipping lines that import the removed plugin.\n #\n # By matching from the start of a line through a word boundary, we avoid removing commented lines or inadvertently removing\n # plugins with similar names.\n with oldinitpath.open(encoding='utf-8') as old, initpath.open(mode='w', encoding='utf-8') as new:\n r = re.compile(r'^{}\\W'.format(_plugin_import(plugin)))\n new.writelines(line for line in old.readlines() if not r.match(line))\n\n if os.path.exists(_plugin_path(plugin)):\n os.unlink(_plugin_path(plugin))\n sys.modules.pop(_plugin_import_name(plugin))\n importlib.invalidate_caches()\n vd.warning('{0} plugin uninstalled'.format(plugin['name']))\n except FileNotFoundError:\n vd.warning(\"no plugins/__init__.py found\")\n\n\nBaseSheet.addCommand(None, 'open-plugins', 'vd.push(vd.pluginsSheet)', 'Open Plugins Sheet to manage supported plugins')\n\nPluginsSheet.addCommand('a', 'add-plugin', 'installPlugin(cursorRow)', 'Install and enable current plugin')\nPluginsSheet.addCommand('d', 'delete-plugin', 'removePluginIfExists(cursorRow)', 'Disable current plugin')\n\nvd.addMenuItems('''\n View > Plugins > open-plugins\n''')\n", "path": "visidata/plugins.py"}], "after_files": [{"content": "import re\n\nfrom visidata import Path, RepeatFile, vd, VisiData\nfrom visidata.loaders.tsv import splitter\n\ncontent_filetypes = {\n 'tab-separated-values': 'tsv'\n}\n\nvd.option('http_max_next', 0, 'max next.url pages to follow in http response') #848\nvd.option('http_req_headers', {}, 'http headers to send to requests')\n\n\[email protected]\ndef openurl_http(vd, path, filetype=None):\n schemes = path.scheme.split('+')\n if len(schemes) > 1:\n sch = schemes[0]\n openfunc = getattr(vd, f'openhttp_{sch}', vd.getGlobals().get(f'openhttp_{sch}'))\n if not openfunc:\n vd.fail(f'no vd.openhttp_{sch}')\n return openfunc(Path(schemes[-1]+'://'+path.given.split('://')[1]))\n\n import urllib.request\n import urllib.error\n import mimetypes\n\n # fallback to mime-type\n req = urllib.request.Request(path.given, **vd.options.getall('http_req_'))\n response = urllib.request.urlopen(req)\n\n contenttype = response.getheader('content-type')\n subtype = contenttype.split(';')[0].split('/')[-1]\n\n filetype = filetype or vd.guessFiletype(path, funcprefix='guessurl_').get('filetype')\n filetype = filetype or content_filetypes.get(subtype, subtype)\n filetype = filetype or vd.guessFiletype(path).get('filetype')\n\n # Automatically paginate if a 'next' URL is given\n def _iter_lines(path=path, response=response, max_next=vd.options.http_max_next):\n path.responses = []\n n = 0\n while response:\n path.responses.append(response)\n with response as fp:\n for line in splitter(response, delim=b'\\n'):\n yield line.decode(vd.options.encoding)\n\n linkhdr = response.getheader('Link')\n src = None\n if linkhdr:\n links = parse_header_links(linkhdr)\n link_data = {}\n for link in links:\n key = link.get('rel') or link.get('url')\n link_data[key] = link\n src = link_data.get('next', {}).get('url', None)\n\n if not src:\n break\n\n n += 1\n if n > max_next:\n vd.warning(f'stopping at max next pages: {max_next} pages')\n break\n\n vd.status(f'fetching next page from {src}')\n req = urllib.request.Request(src, **vd.options.getall('http_req_'))\n response = urllib.request.urlopen(req)\n\n # add resettable iterator over contents as an already-open fp\n path.fptext = RepeatFile(_iter_lines())\n\n return vd.openSource(path, filetype=filetype)\n\ndef parse_header_links(link_header):\n '''Return a list of dictionaries:\n [{'url': 'https://example.com/content?page=1', 'rel': 'prev'},\n {'url': 'https://example.com/content?page=3', 'rel': 'next'}]\n Takes a link header string, of the form\n '<https://example.com/content?page=1>; rel=\"prev\", <https://example.com/content?page=3>; rel=\"next\"'\n See https://datatracker.ietf.org/doc/html/rfc8288#section-3\n '''\n\n links = []\n quote_space = ' \\'\"'\n link_header = link_header.strip(quote_space)\n if not link_header: return []\n for link_value in re.split(', *<', link_header):\n if ';' in link_value:\n url, params = link_value.split(';', maxsplit=1)\n else:\n url, params = link_value, ''\n link = {'url': url.strip('<>' + quote_space)}\n\n for param in params.split(';'):\n if '=' in param:\n key, value = param.split('=')\n key = key.strip(quote_space)\n value = value.strip(quote_space)\n link[key] = value\n else:\n break\n links.append(link)\n return links\n\nVisiData.openurl_https = VisiData.openurl_http\n", "path": "visidata/loaders/http.py"}, {"content": "import os.path\nimport os\nimport sys\nimport re\nimport shutil\nimport importlib\nimport subprocess\nimport urllib.error\n\nfrom visidata import VisiData, vd, Path, CellColorizer, JsonLinesSheet, AttrDict, Column, Progress, ExpectedException, BaseSheet, asyncsingle, asyncthread\n\n\nvd.option('plugins_url', 'https://visidata.org/plugins/plugins.jsonl', 'source of plugins sheet')\nvd.option('plugins_autoload', True, 'do not autoload plugins if False')\n\n\[email protected]_property\ndef pluginsSheet(p):\n return PluginsSheet('plugins_global')\n\ndef _plugin_path(plugin):\n return Path(os.path.join(vd.options.visidata_dir, \"plugins\", plugin.name+\".py\"))\n\ndef _plugin_init():\n return Path(os.path.join(vd.options.visidata_dir, \"plugins\", \"__init__.py\"))\n\ndef _plugin_import(plugin):\n return \"import \" + _plugin_import_name(plugin)\n\ndef _plugin_import_name(plugin):\n if not plugin.url:\n return 'visidata.plugins.'+plugin.name\n if 'git+' in plugin.url:\n return plugin.name\n return \"plugins.\"+plugin.name\n\ndef _plugin_in_import_list(plugin):\n with Path(_plugin_init()).open(mode='r', encoding='utf-8') as fprc:\n r = re.compile(r'^{}\\W'.format(_plugin_import(plugin)))\n for line in fprc.readlines():\n if r.match(line):\n return True\n\ndef _installedStatus(col, plugin):\n return '*' if importlib.util.find_spec(_plugin_import_name(plugin)) else ''\n\ndef _loadedVersion(plugin):\n name = _plugin_import_name(plugin)\n if name not in sys.modules:\n return ''\n mod = sys.modules[name]\n return getattr(mod, '__version__', 'unknown version installed')\n\ndef _checkHash(data, sha):\n import hashlib\n return hashlib.sha256(data.strip().encode('utf-8')).hexdigest() == sha\n\ndef _pluginColorizer(s,c,r,v):\n if not r: return None\n ver = _loadedVersion(r)\n if not ver: return None\n if not r.latest_ver: return None\n if ver != r.latest_ver: return 'color_warning'\n return 'color_working'\n\n\[email protected]\ndef pipinstall(vd, deps):\n 'Install *deps*, a list of pypi modules to install via pip into the plugins-deps directory. Return True if successful (no error).'\n p = subprocess.Popen([sys.executable, '-m', 'pip', 'install',\n '--target', str(Path(vd.options.visidata_dir)/\"plugins-deps\"),\n ] + deps,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE)\n out, err = p.communicate()\n vd.status(out.decode())\n if err:\n vd.warning(err.decode())\n return False\n return True\n\n\nclass PluginsSheet(JsonLinesSheet):\n rowtype = \"plugins\" # rowdef: AttrDict of json dict\n colorizers = [\n CellColorizer(3, None, _pluginColorizer)\n ]\n\n def iterload(self):\n for r in JsonLinesSheet.iterload(self):\n yield AttrDict(r)\n\n @asyncsingle\n def reload(self):\n try:\n self.source = vd.urlcache(vd.options.plugins_url or vd.fail(), days=1) # for VisiDataMetaSheet.reload()\n except urllib.error.URLError as e:\n vd.debug(e)\n return\n\n super().reload.__wrapped__(self)\n self.addColumn(Column('available', width=0, getter=_installedStatus), index=1)\n self.addColumn(Column('installed', width=8, getter=lambda c,r: _loadedVersion(r)), index=2)\n self.column('description').width = 40\n self.setKeys([self.column(\"name\")])\n\n for name, mod in sys.modules.items():\n if name.startswith('visidata.plugins.'):\n self.addRow(AttrDict(name='.'.join(name.split('.')[2:]),\n description=getattr(mod, '__description__', mod.__doc__),\n maintainer=getattr(mod, '__author__', None),\n latest_release='',\n latest_ver='',\n url=''\n ))\n\n for r in Progress(self.rows):\n for funcname in (r.provides or '').split():\n func = lambda *args, **kwargs: vd.fail('this requires the %s plugin' % r.name)\n vd.addGlobals({funcname: func})\n setattr(vd, funcname, func)\n\n # check for plugins with newer versions\n def is_stale(r):\n v = _loadedVersion(r)\n return v and r.latest_ver and v != r.latest_ver\n\n stale_plugins = list(filter(is_stale, self.rows))\n if len(stale_plugins) > 0:\n vd.warning(f'update available for {len(stale_plugins)} plugins')\n\n def installPlugin(self, plugin):\n # pip3 install requirements\n initpath = _plugin_init()\n os.makedirs(initpath.parent, exist_ok=True)\n if not initpath.exists():\n initpath.touch()\n\n outpath = _plugin_path(plugin)\n overwrite = True\n if outpath.exists():\n try:\n vd.confirm(\"plugin path already exists, overwrite? \")\n except ExpectedException:\n overwrite = False\n if _plugin_in_import_list(plugin):\n vd.fail(\"plugin already loaded\")\n else:\n self._loadPlugin(plugin)\n if overwrite:\n self._install(plugin)\n\n @asyncthread\n def _install(self, plugin):\n outpath = _plugin_path(plugin)\n\n if \"git+\" in plugin.url:\n p = subprocess.Popen([sys.executable, '-m', 'pip', 'install',\n '--upgrade', plugin.url],\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE)\n out, err = p.communicate()\n vd.status(out.decode())\n if err:\n vd.warning(err.decode())\n if p.returncode != 0:\n vd.fail('pip install failed')\n else:\n with vd.urlcache(plugin.url, days=0).open(encoding='utf-8') as pyfp:\n contents = pyfp.read()\n if plugin.sha256:\n if not _checkHash(contents, plugin.sha256):\n vd.error('%s plugin SHA256 does not match!' % plugin.name)\n else:\n vd.warning('no SHA256 provided for %s plugin, not validating' % plugin.name)\n with outpath.open(mode='w', encoding='utf-8') as outfp:\n outfp.write(contents)\n\n if plugin.pydeps:\n vd.pipinstall(plugin.pydeps.split())\n\n vd.status('%s plugin installed' % plugin.name)\n\n if _plugin_in_import_list(plugin):\n vd.warning(\"plugin already loaded\")\n else:\n self._loadPlugin(plugin)\n\n\n def _loadPlugin(self, plugin):\n with Path(_plugin_init()).open(mode='a', encoding='utf-8') as fprc:\n print(_plugin_import(plugin), file=fprc)\n importlib.import_module(_plugin_import_name(plugin))\n vd.status('%s plugin loaded' % plugin.name)\n\n\n def removePluginIfExists(self, plugin):\n self.removePlugin(plugin)\n\n def removePlugin(self, plugin):\n if not _plugin_in_import_list(plugin):\n vd.fail(\"plugin not in import list\")\n\n initpath = Path(_plugin_init())\n oldinitpath = Path(initpath.with_suffix(initpath.suffix + '.bak'))\n try:\n shutil.copyfile(initpath, oldinitpath)\n\n # Copy lines from the backup init file into its replacement, skipping lines that import the removed plugin.\n #\n # By matching from the start of a line through a word boundary, we avoid removing commented lines or inadvertently removing\n # plugins with similar names.\n with oldinitpath.open(encoding='utf-8') as old, initpath.open(mode='w', encoding='utf-8') as new:\n r = re.compile(r'^{}\\W'.format(_plugin_import(plugin)))\n new.writelines(line for line in old.readlines() if not r.match(line))\n\n if os.path.exists(_plugin_path(plugin)):\n os.unlink(_plugin_path(plugin))\n sys.modules.pop(_plugin_import_name(plugin))\n importlib.invalidate_caches()\n vd.warning('{0} plugin uninstalled'.format(plugin['name']))\n except FileNotFoundError:\n vd.warning(\"no plugins/__init__.py found\")\n\n\nBaseSheet.addCommand(None, 'open-plugins', 'vd.push(vd.pluginsSheet)', 'Open Plugins Sheet to manage supported plugins')\n\nPluginsSheet.addCommand('a', 'add-plugin', 'installPlugin(cursorRow)', 'Install and enable current plugin')\nPluginsSheet.addCommand('d', 'delete-plugin', 'removePluginIfExists(cursorRow)', 'Disable current plugin')\n\nvd.addMenuItems('''\n View > Plugins > open-plugins\n''')\n", "path": "visidata/plugins.py"}]}
| 3,886 | 787 |
gh_patches_debug_27633
|
rasdani/github-patches
|
git_diff
|
fedora-infra__bodhi-417
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Markdown unordered lists do not work in update notes
Filling the update notes under https://bodhi.fedoraproject.org/updates/new with unordered lists in markdown syntax (https://help.github.com/articles/markdown-basics/) does not work, neither in the preview nor after submitting, visit e.g. https://bodhi.fedoraproject.org/updates/phpMyAdmin-4.4.14-1.fc23 with Firefox 38 ESR from RHEL/CentOS 6. It seems to work properly with a text browser such as w3m (CSS issue?).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bodhi/ffmarkdown.py`
Content:
```
1 # This program is free software; you can redistribute it and/or
2 # modify it under the terms of the GNU General Public License
3 # as published by the Free Software Foundation; either version 2
4 # of the License, or (at your option) any later version.
5 #
6 # This program is distributed in the hope that it will be useful,
7 # but WITHOUT ANY WARRANTY; without even the implied warranty of
8 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
9 # GNU General Public License for more details.
10 #
11 # You should have received a copy of the GNU General Public License
12 # along with this program; if not, write to the Free Software
13 # Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
14 # USA.
15
16 """ Fedora-flavored Markdown
17
18 Author: Ralph Bean <[email protected]>
19 """
20
21 import markdown.inlinepatterns
22 import markdown.util
23 import pyramid.threadlocal
24
25
26 def user_url(name):
27 request = pyramid.threadlocal.get_current_request()
28 return request.route_url('user', name=name)
29
30
31 def bugzilla_url(idx):
32 return "https://bugzilla.redhat.com/show_bug.cgi?id=%s" % idx
33
34
35 def inject():
36 """ Hack out python-markdown to do the autolinking that we want. """
37
38 # First, make it so that bare links get automatically linkified.
39 markdown.inlinepatterns.AUTOLINK_RE = '(%s)' % '|'.join([
40 r'<(?:f|ht)tps?://[^>]*>',
41 r'\b(?:f|ht)tps?://[^)<>\s]+[^.,)<>\s]',
42 r'\bwww\.[^)<>\s]+[^.,)<>\s]',
43 r'[^(<\s]+\.(?:com|net|org)\b',
44 ])
45
46 # Second, build some Pattern objects for @mentions, #bugs, etc...
47 class MentionPattern(markdown.inlinepatterns.Pattern):
48 def handleMatch(self, m):
49 el = markdown.util.etree.Element("a")
50 name = markdown.util.AtomicString(m.group(2))
51 el.set('href', user_url(name[1:]))
52 el.text = name
53 return el
54
55 class BugzillaPattern(markdown.inlinepatterns.Pattern):
56 def handleMatch(self, m):
57 el = markdown.util.etree.Element("a")
58 idx = markdown.util.AtomicString(m.group(2))
59 el.set('href', bugzilla_url(idx[1:]))
60 el.text = idx
61 return el
62
63 MENTION_RE = r'(@\w+)'
64 BUGZILLA_RE = r'(#[0-9]{5,})'
65
66 # Lastly, monkey-patch the build_inlinepatterns func to insert our patterns
67 original_builder = markdown.build_inlinepatterns
68
69 def extended_builder(md_instance, **kwargs):
70 patterns = original_builder(md_instance, **kwargs)
71 patterns['mention'] = MentionPattern(MENTION_RE, md_instance)
72 patterns['bugzillas'] = BugzillaPattern(BUGZILLA_RE, md_instance)
73 return patterns
74
75 markdown.build_inlinepatterns = extended_builder
76
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bodhi/ffmarkdown.py b/bodhi/ffmarkdown.py
--- a/bodhi/ffmarkdown.py
+++ b/bodhi/ffmarkdown.py
@@ -19,6 +19,7 @@
"""
import markdown.inlinepatterns
+import markdown.postprocessors
import markdown.util
import pyramid.threadlocal
@@ -63,13 +64,26 @@
MENTION_RE = r'(@\w+)'
BUGZILLA_RE = r'(#[0-9]{5,})'
+ class SurroundProcessor(markdown.postprocessors.Postprocessor):
+ def run(self, text):
+ return "<div class='markdown'>" + text + "</div>"
+
# Lastly, monkey-patch the build_inlinepatterns func to insert our patterns
- original_builder = markdown.build_inlinepatterns
+ original_pattern_builder = markdown.build_inlinepatterns
- def extended_builder(md_instance, **kwargs):
- patterns = original_builder(md_instance, **kwargs)
+ def extended_pattern_builder(md_instance, **kwargs):
+ patterns = original_pattern_builder(md_instance, **kwargs)
patterns['mention'] = MentionPattern(MENTION_RE, md_instance)
patterns['bugzillas'] = BugzillaPattern(BUGZILLA_RE, md_instance)
return patterns
- markdown.build_inlinepatterns = extended_builder
+ markdown.build_inlinepatterns = extended_pattern_builder
+
+ original_postprocessor_builder = markdown.build_postprocessors
+
+ def extended_postprocessor_builder(md_instance, **kwargs):
+ processors = original_postprocessor_builder(md_instance, **kwargs)
+ processors['surround'] = SurroundProcessor(md_instance)
+ return processors
+
+ markdown.build_postprocessors = extended_postprocessor_builder
|
{"golden_diff": "diff --git a/bodhi/ffmarkdown.py b/bodhi/ffmarkdown.py\n--- a/bodhi/ffmarkdown.py\n+++ b/bodhi/ffmarkdown.py\n@@ -19,6 +19,7 @@\n \"\"\"\n \n import markdown.inlinepatterns\n+import markdown.postprocessors\n import markdown.util\n import pyramid.threadlocal\n \n@@ -63,13 +64,26 @@\n MENTION_RE = r'(@\\w+)'\n BUGZILLA_RE = r'(#[0-9]{5,})'\n \n+ class SurroundProcessor(markdown.postprocessors.Postprocessor):\n+ def run(self, text):\n+ return \"<div class='markdown'>\" + text + \"</div>\"\n+\n # Lastly, monkey-patch the build_inlinepatterns func to insert our patterns\n- original_builder = markdown.build_inlinepatterns\n+ original_pattern_builder = markdown.build_inlinepatterns\n \n- def extended_builder(md_instance, **kwargs):\n- patterns = original_builder(md_instance, **kwargs)\n+ def extended_pattern_builder(md_instance, **kwargs):\n+ patterns = original_pattern_builder(md_instance, **kwargs)\n patterns['mention'] = MentionPattern(MENTION_RE, md_instance)\n patterns['bugzillas'] = BugzillaPattern(BUGZILLA_RE, md_instance)\n return patterns\n \n- markdown.build_inlinepatterns = extended_builder\n+ markdown.build_inlinepatterns = extended_pattern_builder\n+\n+ original_postprocessor_builder = markdown.build_postprocessors\n+\n+ def extended_postprocessor_builder(md_instance, **kwargs):\n+ processors = original_postprocessor_builder(md_instance, **kwargs)\n+ processors['surround'] = SurroundProcessor(md_instance)\n+ return processors\n+\n+ markdown.build_postprocessors = extended_postprocessor_builder\n", "issue": "Markdown unordered lists do not work in update notes\nFilling the update notes under https://bodhi.fedoraproject.org/updates/new with unordered lists in markdown syntax (https://help.github.com/articles/markdown-basics/) does not work, neither in the preview nor after submitting, visit e.g. https://bodhi.fedoraproject.org/updates/phpMyAdmin-4.4.14-1.fc23 with Firefox 38 ESR from RHEL/CentOS 6. It seems to work properly with a text browser such as w3m (CSS issue?).\n\n", "before_files": [{"content": "# This program is free software; you can redistribute it and/or\n# modify it under the terms of the GNU General Public License\n# as published by the Free Software Foundation; either version 2\n# of the License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, write to the Free Software\n# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,\n# USA.\n\n\"\"\" Fedora-flavored Markdown\n\nAuthor: Ralph Bean <[email protected]>\n\"\"\"\n\nimport markdown.inlinepatterns\nimport markdown.util\nimport pyramid.threadlocal\n\n\ndef user_url(name):\n request = pyramid.threadlocal.get_current_request()\n return request.route_url('user', name=name)\n\n\ndef bugzilla_url(idx):\n return \"https://bugzilla.redhat.com/show_bug.cgi?id=%s\" % idx\n\n\ndef inject():\n \"\"\" Hack out python-markdown to do the autolinking that we want. \"\"\"\n\n # First, make it so that bare links get automatically linkified.\n markdown.inlinepatterns.AUTOLINK_RE = '(%s)' % '|'.join([\n r'<(?:f|ht)tps?://[^>]*>',\n r'\\b(?:f|ht)tps?://[^)<>\\s]+[^.,)<>\\s]',\n r'\\bwww\\.[^)<>\\s]+[^.,)<>\\s]',\n r'[^(<\\s]+\\.(?:com|net|org)\\b',\n ])\n\n # Second, build some Pattern objects for @mentions, #bugs, etc...\n class MentionPattern(markdown.inlinepatterns.Pattern):\n def handleMatch(self, m):\n el = markdown.util.etree.Element(\"a\")\n name = markdown.util.AtomicString(m.group(2))\n el.set('href', user_url(name[1:]))\n el.text = name\n return el\n\n class BugzillaPattern(markdown.inlinepatterns.Pattern):\n def handleMatch(self, m):\n el = markdown.util.etree.Element(\"a\")\n idx = markdown.util.AtomicString(m.group(2))\n el.set('href', bugzilla_url(idx[1:]))\n el.text = idx\n return el\n\n MENTION_RE = r'(@\\w+)'\n BUGZILLA_RE = r'(#[0-9]{5,})'\n\n # Lastly, monkey-patch the build_inlinepatterns func to insert our patterns\n original_builder = markdown.build_inlinepatterns\n\n def extended_builder(md_instance, **kwargs):\n patterns = original_builder(md_instance, **kwargs)\n patterns['mention'] = MentionPattern(MENTION_RE, md_instance)\n patterns['bugzillas'] = BugzillaPattern(BUGZILLA_RE, md_instance)\n return patterns\n\n markdown.build_inlinepatterns = extended_builder\n", "path": "bodhi/ffmarkdown.py"}], "after_files": [{"content": "# This program is free software; you can redistribute it and/or\n# modify it under the terms of the GNU General Public License\n# as published by the Free Software Foundation; either version 2\n# of the License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, write to the Free Software\n# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,\n# USA.\n\n\"\"\" Fedora-flavored Markdown\n\nAuthor: Ralph Bean <[email protected]>\n\"\"\"\n\nimport markdown.inlinepatterns\nimport markdown.postprocessors\nimport markdown.util\nimport pyramid.threadlocal\n\n\ndef user_url(name):\n request = pyramid.threadlocal.get_current_request()\n return request.route_url('user', name=name)\n\n\ndef bugzilla_url(idx):\n return \"https://bugzilla.redhat.com/show_bug.cgi?id=%s\" % idx\n\n\ndef inject():\n \"\"\" Hack out python-markdown to do the autolinking that we want. \"\"\"\n\n # First, make it so that bare links get automatically linkified.\n markdown.inlinepatterns.AUTOLINK_RE = '(%s)' % '|'.join([\n r'<(?:f|ht)tps?://[^>]*>',\n r'\\b(?:f|ht)tps?://[^)<>\\s]+[^.,)<>\\s]',\n r'\\bwww\\.[^)<>\\s]+[^.,)<>\\s]',\n r'[^(<\\s]+\\.(?:com|net|org)\\b',\n ])\n\n # Second, build some Pattern objects for @mentions, #bugs, etc...\n class MentionPattern(markdown.inlinepatterns.Pattern):\n def handleMatch(self, m):\n el = markdown.util.etree.Element(\"a\")\n name = markdown.util.AtomicString(m.group(2))\n el.set('href', user_url(name[1:]))\n el.text = name\n return el\n\n class BugzillaPattern(markdown.inlinepatterns.Pattern):\n def handleMatch(self, m):\n el = markdown.util.etree.Element(\"a\")\n idx = markdown.util.AtomicString(m.group(2))\n el.set('href', bugzilla_url(idx[1:]))\n el.text = idx\n return el\n\n MENTION_RE = r'(@\\w+)'\n BUGZILLA_RE = r'(#[0-9]{5,})'\n\n class SurroundProcessor(markdown.postprocessors.Postprocessor):\n def run(self, text):\n return \"<div class='markdown'>\" + text + \"</div>\"\n\n # Lastly, monkey-patch the build_inlinepatterns func to insert our patterns\n original_pattern_builder = markdown.build_inlinepatterns\n\n def extended_pattern_builder(md_instance, **kwargs):\n patterns = original_pattern_builder(md_instance, **kwargs)\n patterns['mention'] = MentionPattern(MENTION_RE, md_instance)\n patterns['bugzillas'] = BugzillaPattern(BUGZILLA_RE, md_instance)\n return patterns\n\n markdown.build_inlinepatterns = extended_pattern_builder\n\n original_postprocessor_builder = markdown.build_postprocessors\n\n def extended_postprocessor_builder(md_instance, **kwargs):\n processors = original_postprocessor_builder(md_instance, **kwargs)\n processors['surround'] = SurroundProcessor(md_instance)\n return processors\n\n markdown.build_postprocessors = extended_postprocessor_builder\n", "path": "bodhi/ffmarkdown.py"}]}
| 1,201 | 372 |
gh_patches_debug_41172
|
rasdani/github-patches
|
git_diff
|
paperless-ngx__paperless-ngx-1596
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] DOUBLE Patch-T document seperator always leads to a failed task
### Description
Using the "patch-T" document seperator always leads to a failed task. Documents are seperated and stored properly. The failed tasks drag attention even though it's not necessary.
Seperator is [Patch-T](https://www.alliancegroup.co.uk/downloads/patches-for-printing-on-a4-paper.pdf).
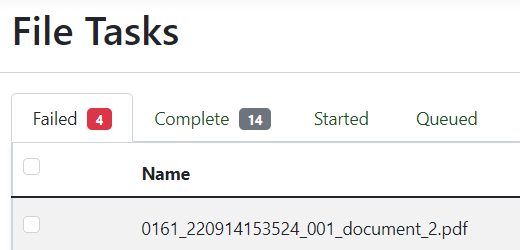
### Steps to reproduce
Source document format is pdf , it has 5 pages, page 3 is "patch-t" seperator.
### Webserver logs
```bash
Unable to get page count.
Syntax Error: Invalid page count 0
Command Line Error: Wrong page range given: the first page (1) can not be after the last page (0).
: Traceback (most recent call last):
File "/usr/local/lib/python3.9/site-packages/pdf2image/pdf2image.py", line 479, in pdfinfo_from_path
raise ValueError
ValueError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/src/paperless/src/docker/src/django-q/django_q/cluster.py", line 434, in worker
res = f(*task["args"], **task["kwargs"])
File "/usr/src/paperless/src/documents/tasks.py", line 109, in consume_file
separators = barcodes.scan_file_for_separating_barcodes(file_to_process)
File "/usr/src/paperless/src/documents/barcodes.py", line 110, in scan_file_for_separating_barcodes
pages_from_path = convert_from_path(filepath, output_folder=path)
File "/usr/local/lib/python3.9/site-packages/pdf2image/pdf2image.py", line 98, in convert_from_path
page_count = pdfinfo_from_path(pdf_path, userpw, poppler_path=poppler_path)["Pages"]
File "/usr/local/lib/python3.9/site-packages/pdf2image/pdf2image.py", line 488, in pdfinfo_from_path
raise PDFPageCountError(
pdf2image.exceptions.PDFPageCountError: Unable to get page count.
Syntax Error: Invalid page count 0
Command Line Error: Wrong page range given: the first page (1) can not be after the last page (0).
```
### Paperless-ngx version
1.8
### Host OS
Linux 3.10.108 #42661 SMP (x86_64)
### Installation method
Docker - official image
### Browser
Chrome
### Configuration changes
_No response_
### Other
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/documents/barcodes.py`
Content:
```
1 import logging
2 import os
3 import shutil
4 import tempfile
5 from functools import lru_cache
6 from typing import List # for type hinting. Can be removed, if only Python >3.8 is used
7
8 import magic
9 from django.conf import settings
10 from pdf2image import convert_from_path
11 from pikepdf import Pdf
12 from PIL import Image
13 from PIL import ImageSequence
14 from pyzbar import pyzbar
15
16 logger = logging.getLogger("paperless.barcodes")
17
18
19 @lru_cache(maxsize=8)
20 def supported_file_type(mime_type) -> bool:
21 """
22 Determines if the file is valid for barcode
23 processing, based on MIME type and settings
24
25 :return: True if the file is supported, False otherwise
26 """
27 supported_mime = ["application/pdf"]
28 if settings.CONSUMER_BARCODE_TIFF_SUPPORT:
29 supported_mime += ["image/tiff"]
30
31 return mime_type in supported_mime
32
33
34 def barcode_reader(image) -> List[str]:
35 """
36 Read any barcodes contained in image
37 Returns a list containing all found barcodes
38 """
39 barcodes = []
40 # Decode the barcode image
41 detected_barcodes = pyzbar.decode(image)
42
43 if detected_barcodes:
44 # Traverse through all the detected barcodes in image
45 for barcode in detected_barcodes:
46 if barcode.data:
47 decoded_barcode = barcode.data.decode("utf-8")
48 barcodes.append(decoded_barcode)
49 logger.debug(
50 f"Barcode of type {str(barcode.type)} found: {decoded_barcode}",
51 )
52 return barcodes
53
54
55 def get_file_mime_type(path: str) -> str:
56 """
57 Determines the file type, based on MIME type.
58
59 Returns the MIME type.
60 """
61 mime_type = magic.from_file(path, mime=True)
62 logger.debug(f"Detected mime type: {mime_type}")
63 return mime_type
64
65
66 def convert_from_tiff_to_pdf(filepath: str) -> str:
67 """
68 converts a given TIFF image file to pdf into a temporary directory.
69
70 Returns the new pdf file.
71 """
72 file_name = os.path.splitext(os.path.basename(filepath))[0]
73 mime_type = get_file_mime_type(filepath)
74 tempdir = tempfile.mkdtemp(prefix="paperless-", dir=settings.SCRATCH_DIR)
75 # use old file name with pdf extension
76 if mime_type == "image/tiff":
77 newpath = os.path.join(tempdir, file_name + ".pdf")
78 else:
79 logger.warning(
80 f"Cannot convert mime type {str(mime_type)} from {str(filepath)} to pdf.",
81 )
82 return None
83 with Image.open(filepath) as image:
84 images = []
85 for i, page in enumerate(ImageSequence.Iterator(image)):
86 page = page.convert("RGB")
87 images.append(page)
88 try:
89 if len(images) == 1:
90 images[0].save(newpath)
91 else:
92 images[0].save(newpath, save_all=True, append_images=images[1:])
93 except OSError as e:
94 logger.warning(
95 f"Could not save the file as pdf. Error: {str(e)}",
96 )
97 return None
98 return newpath
99
100
101 def scan_file_for_separating_barcodes(filepath: str) -> List[int]:
102 """
103 Scan the provided pdf file for page separating barcodes
104 Returns a list of pagenumbers, which separate the file
105 """
106 separator_page_numbers = []
107 separator_barcode = str(settings.CONSUMER_BARCODE_STRING)
108 # use a temporary directory in case the file os too big to handle in memory
109 with tempfile.TemporaryDirectory() as path:
110 pages_from_path = convert_from_path(filepath, output_folder=path)
111 for current_page_number, page in enumerate(pages_from_path):
112 current_barcodes = barcode_reader(page)
113 if separator_barcode in current_barcodes:
114 separator_page_numbers.append(current_page_number)
115 return separator_page_numbers
116
117
118 def separate_pages(filepath: str, pages_to_split_on: List[int]) -> List[str]:
119 """
120 Separate the provided pdf file on the pages_to_split_on.
121 The pages which are defined by page_numbers will be removed.
122 Returns a list of (temporary) filepaths to consume.
123 These will need to be deleted later.
124 """
125 os.makedirs(settings.SCRATCH_DIR, exist_ok=True)
126 tempdir = tempfile.mkdtemp(prefix="paperless-", dir=settings.SCRATCH_DIR)
127 fname = os.path.splitext(os.path.basename(filepath))[0]
128 pdf = Pdf.open(filepath)
129 document_paths = []
130 logger.debug(f"Temp dir is {str(tempdir)}")
131 if not pages_to_split_on:
132 logger.warning("No pages to split on!")
133 else:
134 # go from the first page to the first separator page
135 dst = Pdf.new()
136 for n, page in enumerate(pdf.pages):
137 if n < pages_to_split_on[0]:
138 dst.pages.append(page)
139 output_filename = f"{fname}_document_0.pdf"
140 savepath = os.path.join(tempdir, output_filename)
141 with open(savepath, "wb") as out:
142 dst.save(out)
143 document_paths = [savepath]
144
145 # iterate through the rest of the document
146 for count, page_number in enumerate(pages_to_split_on):
147 logger.debug(f"Count: {str(count)} page_number: {str(page_number)}")
148 dst = Pdf.new()
149 try:
150 next_page = pages_to_split_on[count + 1]
151 except IndexError:
152 next_page = len(pdf.pages)
153 # skip the first page_number. This contains the barcode page
154 for page in range(page_number + 1, next_page):
155 logger.debug(
156 f"page_number: {str(page_number)} next_page: {str(next_page)}",
157 )
158 dst.pages.append(pdf.pages[page])
159 output_filename = f"{fname}_document_{str(count + 1)}.pdf"
160 logger.debug(f"pdf no:{str(count)} has {str(len(dst.pages))} pages")
161 savepath = os.path.join(tempdir, output_filename)
162 with open(savepath, "wb") as out:
163 dst.save(out)
164 document_paths.append(savepath)
165 logger.debug(f"Temp files are {str(document_paths)}")
166 return document_paths
167
168
169 def save_to_dir(
170 filepath: str,
171 newname: str = None,
172 target_dir: str = settings.CONSUMPTION_DIR,
173 ):
174 """
175 Copies filepath to target_dir.
176 Optionally rename the file.
177 """
178 if os.path.isfile(filepath) and os.path.isdir(target_dir):
179 dst = shutil.copy(filepath, target_dir)
180 logging.debug(f"saved {str(filepath)} to {str(dst)}")
181 if newname:
182 dst_new = os.path.join(target_dir, newname)
183 logger.debug(f"moving {str(dst)} to {str(dst_new)}")
184 os.rename(dst, dst_new)
185 else:
186 logger.warning(f"{str(filepath)} or {str(target_dir)} don't exist.")
187
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/documents/barcodes.py b/src/documents/barcodes.py
--- a/src/documents/barcodes.py
+++ b/src/documents/barcodes.py
@@ -8,6 +8,7 @@
import magic
from django.conf import settings
from pdf2image import convert_from_path
+from pikepdf import Page
from pikepdf import Pdf
from PIL import Image
from PIL import ImageSequence
@@ -122,47 +123,56 @@
Returns a list of (temporary) filepaths to consume.
These will need to be deleted later.
"""
+
+ document_paths = []
+
+ if not pages_to_split_on:
+ logger.warning("No pages to split on!")
+ return document_paths
+
os.makedirs(settings.SCRATCH_DIR, exist_ok=True)
tempdir = tempfile.mkdtemp(prefix="paperless-", dir=settings.SCRATCH_DIR)
fname = os.path.splitext(os.path.basename(filepath))[0]
pdf = Pdf.open(filepath)
- document_paths = []
- logger.debug(f"Temp dir is {str(tempdir)}")
- if not pages_to_split_on:
- logger.warning("No pages to split on!")
- else:
- # go from the first page to the first separator page
+
+ # A list of documents, ie a list of lists of pages
+ documents: List[List[Page]] = []
+ # A single document, ie a list of pages
+ document: List[Page] = []
+
+ for idx, page in enumerate(pdf.pages):
+ # Keep building the new PDF as long as it is not a
+ # separator index
+ if idx not in pages_to_split_on:
+ document.append(page)
+ # Make sure to append the very last document to the documents
+ if idx == (len(pdf.pages) - 1):
+ documents.append(document)
+ document = []
+ else:
+ # This is a split index, save the current PDF pages, and restart
+ # a new destination page listing
+ logger.debug(f"Starting new document at idx {idx}")
+ documents.append(document)
+ document = []
+
+ documents = [x for x in documents if len(x)]
+
+ logger.debug(f"Split into {len(documents)} new documents")
+
+ # Write the new documents out
+ for doc_idx, document in enumerate(documents):
dst = Pdf.new()
- for n, page in enumerate(pdf.pages):
- if n < pages_to_split_on[0]:
- dst.pages.append(page)
- output_filename = f"{fname}_document_0.pdf"
+ dst.pages.extend(document)
+
+ output_filename = f"{fname}_document_{doc_idx}.pdf"
+
+ logger.debug(f"pdf no:{doc_idx} has {len(dst.pages)} pages")
savepath = os.path.join(tempdir, output_filename)
with open(savepath, "wb") as out:
dst.save(out)
- document_paths = [savepath]
-
- # iterate through the rest of the document
- for count, page_number in enumerate(pages_to_split_on):
- logger.debug(f"Count: {str(count)} page_number: {str(page_number)}")
- dst = Pdf.new()
- try:
- next_page = pages_to_split_on[count + 1]
- except IndexError:
- next_page = len(pdf.pages)
- # skip the first page_number. This contains the barcode page
- for page in range(page_number + 1, next_page):
- logger.debug(
- f"page_number: {str(page_number)} next_page: {str(next_page)}",
- )
- dst.pages.append(pdf.pages[page])
- output_filename = f"{fname}_document_{str(count + 1)}.pdf"
- logger.debug(f"pdf no:{str(count)} has {str(len(dst.pages))} pages")
- savepath = os.path.join(tempdir, output_filename)
- with open(savepath, "wb") as out:
- dst.save(out)
- document_paths.append(savepath)
- logger.debug(f"Temp files are {str(document_paths)}")
+ document_paths.append(savepath)
+
return document_paths
|
{"golden_diff": "diff --git a/src/documents/barcodes.py b/src/documents/barcodes.py\n--- a/src/documents/barcodes.py\n+++ b/src/documents/barcodes.py\n@@ -8,6 +8,7 @@\n import magic\n from django.conf import settings\n from pdf2image import convert_from_path\n+from pikepdf import Page\n from pikepdf import Pdf\n from PIL import Image\n from PIL import ImageSequence\n@@ -122,47 +123,56 @@\n Returns a list of (temporary) filepaths to consume.\n These will need to be deleted later.\n \"\"\"\n+\n+ document_paths = []\n+\n+ if not pages_to_split_on:\n+ logger.warning(\"No pages to split on!\")\n+ return document_paths\n+\n os.makedirs(settings.SCRATCH_DIR, exist_ok=True)\n tempdir = tempfile.mkdtemp(prefix=\"paperless-\", dir=settings.SCRATCH_DIR)\n fname = os.path.splitext(os.path.basename(filepath))[0]\n pdf = Pdf.open(filepath)\n- document_paths = []\n- logger.debug(f\"Temp dir is {str(tempdir)}\")\n- if not pages_to_split_on:\n- logger.warning(\"No pages to split on!\")\n- else:\n- # go from the first page to the first separator page\n+\n+ # A list of documents, ie a list of lists of pages\n+ documents: List[List[Page]] = []\n+ # A single document, ie a list of pages\n+ document: List[Page] = []\n+\n+ for idx, page in enumerate(pdf.pages):\n+ # Keep building the new PDF as long as it is not a\n+ # separator index\n+ if idx not in pages_to_split_on:\n+ document.append(page)\n+ # Make sure to append the very last document to the documents\n+ if idx == (len(pdf.pages) - 1):\n+ documents.append(document)\n+ document = []\n+ else:\n+ # This is a split index, save the current PDF pages, and restart\n+ # a new destination page listing\n+ logger.debug(f\"Starting new document at idx {idx}\")\n+ documents.append(document)\n+ document = []\n+\n+ documents = [x for x in documents if len(x)]\n+\n+ logger.debug(f\"Split into {len(documents)} new documents\")\n+\n+ # Write the new documents out\n+ for doc_idx, document in enumerate(documents):\n dst = Pdf.new()\n- for n, page in enumerate(pdf.pages):\n- if n < pages_to_split_on[0]:\n- dst.pages.append(page)\n- output_filename = f\"{fname}_document_0.pdf\"\n+ dst.pages.extend(document)\n+\n+ output_filename = f\"{fname}_document_{doc_idx}.pdf\"\n+\n+ logger.debug(f\"pdf no:{doc_idx} has {len(dst.pages)} pages\")\n savepath = os.path.join(tempdir, output_filename)\n with open(savepath, \"wb\") as out:\n dst.save(out)\n- document_paths = [savepath]\n-\n- # iterate through the rest of the document\n- for count, page_number in enumerate(pages_to_split_on):\n- logger.debug(f\"Count: {str(count)} page_number: {str(page_number)}\")\n- dst = Pdf.new()\n- try:\n- next_page = pages_to_split_on[count + 1]\n- except IndexError:\n- next_page = len(pdf.pages)\n- # skip the first page_number. This contains the barcode page\n- for page in range(page_number + 1, next_page):\n- logger.debug(\n- f\"page_number: {str(page_number)} next_page: {str(next_page)}\",\n- )\n- dst.pages.append(pdf.pages[page])\n- output_filename = f\"{fname}_document_{str(count + 1)}.pdf\"\n- logger.debug(f\"pdf no:{str(count)} has {str(len(dst.pages))} pages\")\n- savepath = os.path.join(tempdir, output_filename)\n- with open(savepath, \"wb\") as out:\n- dst.save(out)\n- document_paths.append(savepath)\n- logger.debug(f\"Temp files are {str(document_paths)}\")\n+ document_paths.append(savepath)\n+\n return document_paths\n", "issue": "[BUG] DOUBLE Patch-T document seperator always leads to a failed task\n### Description\n\nUsing the \"patch-T\" document seperator always leads to a failed task. Documents are seperated and stored properly. The failed tasks drag attention even though it's not necessary.\r\n\r\n\r\nSeperator is [Patch-T](https://www.alliancegroup.co.uk/downloads/patches-for-printing-on-a4-paper.pdf).\r\n\r\n\r\n\n\n### Steps to reproduce\n\nSource document format is pdf , it has 5 pages, page 3 is \"patch-t\" seperator.\r\n\n\n### Webserver logs\n\n```bash\nUnable to get page count.\r\nSyntax Error: Invalid page count 0\r\nCommand Line Error: Wrong page range given: the first page (1) can not be after the last page (0).\r\n : Traceback (most recent call last):\r\n File \"/usr/local/lib/python3.9/site-packages/pdf2image/pdf2image.py\", line 479, in pdfinfo_from_path\r\n raise ValueError\r\nValueError\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/usr/src/paperless/src/docker/src/django-q/django_q/cluster.py\", line 434, in worker\r\n res = f(*task[\"args\"], **task[\"kwargs\"])\r\n File \"/usr/src/paperless/src/documents/tasks.py\", line 109, in consume_file\r\n separators = barcodes.scan_file_for_separating_barcodes(file_to_process)\r\n File \"/usr/src/paperless/src/documents/barcodes.py\", line 110, in scan_file_for_separating_barcodes\r\n pages_from_path = convert_from_path(filepath, output_folder=path)\r\n File \"/usr/local/lib/python3.9/site-packages/pdf2image/pdf2image.py\", line 98, in convert_from_path\r\n page_count = pdfinfo_from_path(pdf_path, userpw, poppler_path=poppler_path)[\"Pages\"]\r\n File \"/usr/local/lib/python3.9/site-packages/pdf2image/pdf2image.py\", line 488, in pdfinfo_from_path\r\n raise PDFPageCountError(\r\npdf2image.exceptions.PDFPageCountError: Unable to get page count.\r\nSyntax Error: Invalid page count 0\r\nCommand Line Error: Wrong page range given: the first page (1) can not be after the last page (0).\n```\n\n\n### Paperless-ngx version\n\n1.8\n\n### Host OS\n\nLinux 3.10.108 #42661 SMP (x86_64)\n\n### Installation method\n\nDocker - official image\n\n### Browser\n\nChrome\n\n### Configuration changes\n\n_No response_\n\n### Other\n\n_No response_\n", "before_files": [{"content": "import logging\nimport os\nimport shutil\nimport tempfile\nfrom functools import lru_cache\nfrom typing import List # for type hinting. Can be removed, if only Python >3.8 is used\n\nimport magic\nfrom django.conf import settings\nfrom pdf2image import convert_from_path\nfrom pikepdf import Pdf\nfrom PIL import Image\nfrom PIL import ImageSequence\nfrom pyzbar import pyzbar\n\nlogger = logging.getLogger(\"paperless.barcodes\")\n\n\n@lru_cache(maxsize=8)\ndef supported_file_type(mime_type) -> bool:\n \"\"\"\n Determines if the file is valid for barcode\n processing, based on MIME type and settings\n\n :return: True if the file is supported, False otherwise\n \"\"\"\n supported_mime = [\"application/pdf\"]\n if settings.CONSUMER_BARCODE_TIFF_SUPPORT:\n supported_mime += [\"image/tiff\"]\n\n return mime_type in supported_mime\n\n\ndef barcode_reader(image) -> List[str]:\n \"\"\"\n Read any barcodes contained in image\n Returns a list containing all found barcodes\n \"\"\"\n barcodes = []\n # Decode the barcode image\n detected_barcodes = pyzbar.decode(image)\n\n if detected_barcodes:\n # Traverse through all the detected barcodes in image\n for barcode in detected_barcodes:\n if barcode.data:\n decoded_barcode = barcode.data.decode(\"utf-8\")\n barcodes.append(decoded_barcode)\n logger.debug(\n f\"Barcode of type {str(barcode.type)} found: {decoded_barcode}\",\n )\n return barcodes\n\n\ndef get_file_mime_type(path: str) -> str:\n \"\"\"\n Determines the file type, based on MIME type.\n\n Returns the MIME type.\n \"\"\"\n mime_type = magic.from_file(path, mime=True)\n logger.debug(f\"Detected mime type: {mime_type}\")\n return mime_type\n\n\ndef convert_from_tiff_to_pdf(filepath: str) -> str:\n \"\"\"\n converts a given TIFF image file to pdf into a temporary directory.\n\n Returns the new pdf file.\n \"\"\"\n file_name = os.path.splitext(os.path.basename(filepath))[0]\n mime_type = get_file_mime_type(filepath)\n tempdir = tempfile.mkdtemp(prefix=\"paperless-\", dir=settings.SCRATCH_DIR)\n # use old file name with pdf extension\n if mime_type == \"image/tiff\":\n newpath = os.path.join(tempdir, file_name + \".pdf\")\n else:\n logger.warning(\n f\"Cannot convert mime type {str(mime_type)} from {str(filepath)} to pdf.\",\n )\n return None\n with Image.open(filepath) as image:\n images = []\n for i, page in enumerate(ImageSequence.Iterator(image)):\n page = page.convert(\"RGB\")\n images.append(page)\n try:\n if len(images) == 1:\n images[0].save(newpath)\n else:\n images[0].save(newpath, save_all=True, append_images=images[1:])\n except OSError as e:\n logger.warning(\n f\"Could not save the file as pdf. Error: {str(e)}\",\n )\n return None\n return newpath\n\n\ndef scan_file_for_separating_barcodes(filepath: str) -> List[int]:\n \"\"\"\n Scan the provided pdf file for page separating barcodes\n Returns a list of pagenumbers, which separate the file\n \"\"\"\n separator_page_numbers = []\n separator_barcode = str(settings.CONSUMER_BARCODE_STRING)\n # use a temporary directory in case the file os too big to handle in memory\n with tempfile.TemporaryDirectory() as path:\n pages_from_path = convert_from_path(filepath, output_folder=path)\n for current_page_number, page in enumerate(pages_from_path):\n current_barcodes = barcode_reader(page)\n if separator_barcode in current_barcodes:\n separator_page_numbers.append(current_page_number)\n return separator_page_numbers\n\n\ndef separate_pages(filepath: str, pages_to_split_on: List[int]) -> List[str]:\n \"\"\"\n Separate the provided pdf file on the pages_to_split_on.\n The pages which are defined by page_numbers will be removed.\n Returns a list of (temporary) filepaths to consume.\n These will need to be deleted later.\n \"\"\"\n os.makedirs(settings.SCRATCH_DIR, exist_ok=True)\n tempdir = tempfile.mkdtemp(prefix=\"paperless-\", dir=settings.SCRATCH_DIR)\n fname = os.path.splitext(os.path.basename(filepath))[0]\n pdf = Pdf.open(filepath)\n document_paths = []\n logger.debug(f\"Temp dir is {str(tempdir)}\")\n if not pages_to_split_on:\n logger.warning(\"No pages to split on!\")\n else:\n # go from the first page to the first separator page\n dst = Pdf.new()\n for n, page in enumerate(pdf.pages):\n if n < pages_to_split_on[0]:\n dst.pages.append(page)\n output_filename = f\"{fname}_document_0.pdf\"\n savepath = os.path.join(tempdir, output_filename)\n with open(savepath, \"wb\") as out:\n dst.save(out)\n document_paths = [savepath]\n\n # iterate through the rest of the document\n for count, page_number in enumerate(pages_to_split_on):\n logger.debug(f\"Count: {str(count)} page_number: {str(page_number)}\")\n dst = Pdf.new()\n try:\n next_page = pages_to_split_on[count + 1]\n except IndexError:\n next_page = len(pdf.pages)\n # skip the first page_number. This contains the barcode page\n for page in range(page_number + 1, next_page):\n logger.debug(\n f\"page_number: {str(page_number)} next_page: {str(next_page)}\",\n )\n dst.pages.append(pdf.pages[page])\n output_filename = f\"{fname}_document_{str(count + 1)}.pdf\"\n logger.debug(f\"pdf no:{str(count)} has {str(len(dst.pages))} pages\")\n savepath = os.path.join(tempdir, output_filename)\n with open(savepath, \"wb\") as out:\n dst.save(out)\n document_paths.append(savepath)\n logger.debug(f\"Temp files are {str(document_paths)}\")\n return document_paths\n\n\ndef save_to_dir(\n filepath: str,\n newname: str = None,\n target_dir: str = settings.CONSUMPTION_DIR,\n):\n \"\"\"\n Copies filepath to target_dir.\n Optionally rename the file.\n \"\"\"\n if os.path.isfile(filepath) and os.path.isdir(target_dir):\n dst = shutil.copy(filepath, target_dir)\n logging.debug(f\"saved {str(filepath)} to {str(dst)}\")\n if newname:\n dst_new = os.path.join(target_dir, newname)\n logger.debug(f\"moving {str(dst)} to {str(dst_new)}\")\n os.rename(dst, dst_new)\n else:\n logger.warning(f\"{str(filepath)} or {str(target_dir)} don't exist.\")\n", "path": "src/documents/barcodes.py"}], "after_files": [{"content": "import logging\nimport os\nimport shutil\nimport tempfile\nfrom functools import lru_cache\nfrom typing import List # for type hinting. Can be removed, if only Python >3.8 is used\n\nimport magic\nfrom django.conf import settings\nfrom pdf2image import convert_from_path\nfrom pikepdf import Page\nfrom pikepdf import Pdf\nfrom PIL import Image\nfrom PIL import ImageSequence\nfrom pyzbar import pyzbar\n\nlogger = logging.getLogger(\"paperless.barcodes\")\n\n\n@lru_cache(maxsize=8)\ndef supported_file_type(mime_type) -> bool:\n \"\"\"\n Determines if the file is valid for barcode\n processing, based on MIME type and settings\n\n :return: True if the file is supported, False otherwise\n \"\"\"\n supported_mime = [\"application/pdf\"]\n if settings.CONSUMER_BARCODE_TIFF_SUPPORT:\n supported_mime += [\"image/tiff\"]\n\n return mime_type in supported_mime\n\n\ndef barcode_reader(image) -> List[str]:\n \"\"\"\n Read any barcodes contained in image\n Returns a list containing all found barcodes\n \"\"\"\n barcodes = []\n # Decode the barcode image\n detected_barcodes = pyzbar.decode(image)\n\n if detected_barcodes:\n # Traverse through all the detected barcodes in image\n for barcode in detected_barcodes:\n if barcode.data:\n decoded_barcode = barcode.data.decode(\"utf-8\")\n barcodes.append(decoded_barcode)\n logger.debug(\n f\"Barcode of type {str(barcode.type)} found: {decoded_barcode}\",\n )\n return barcodes\n\n\ndef get_file_mime_type(path: str) -> str:\n \"\"\"\n Determines the file type, based on MIME type.\n\n Returns the MIME type.\n \"\"\"\n mime_type = magic.from_file(path, mime=True)\n logger.debug(f\"Detected mime type: {mime_type}\")\n return mime_type\n\n\ndef convert_from_tiff_to_pdf(filepath: str) -> str:\n \"\"\"\n converts a given TIFF image file to pdf into a temporary directory.\n\n Returns the new pdf file.\n \"\"\"\n file_name = os.path.splitext(os.path.basename(filepath))[0]\n mime_type = get_file_mime_type(filepath)\n tempdir = tempfile.mkdtemp(prefix=\"paperless-\", dir=settings.SCRATCH_DIR)\n # use old file name with pdf extension\n if mime_type == \"image/tiff\":\n newpath = os.path.join(tempdir, file_name + \".pdf\")\n else:\n logger.warning(\n f\"Cannot convert mime type {str(mime_type)} from {str(filepath)} to pdf.\",\n )\n return None\n with Image.open(filepath) as image:\n images = []\n for i, page in enumerate(ImageSequence.Iterator(image)):\n page = page.convert(\"RGB\")\n images.append(page)\n try:\n if len(images) == 1:\n images[0].save(newpath)\n else:\n images[0].save(newpath, save_all=True, append_images=images[1:])\n except OSError as e:\n logger.warning(\n f\"Could not save the file as pdf. Error: {str(e)}\",\n )\n return None\n return newpath\n\n\ndef scan_file_for_separating_barcodes(filepath: str) -> List[int]:\n \"\"\"\n Scan the provided pdf file for page separating barcodes\n Returns a list of pagenumbers, which separate the file\n \"\"\"\n separator_page_numbers = []\n separator_barcode = str(settings.CONSUMER_BARCODE_STRING)\n # use a temporary directory in case the file os too big to handle in memory\n with tempfile.TemporaryDirectory() as path:\n pages_from_path = convert_from_path(filepath, output_folder=path)\n for current_page_number, page in enumerate(pages_from_path):\n current_barcodes = barcode_reader(page)\n if separator_barcode in current_barcodes:\n separator_page_numbers.append(current_page_number)\n return separator_page_numbers\n\n\ndef separate_pages(filepath: str, pages_to_split_on: List[int]) -> List[str]:\n \"\"\"\n Separate the provided pdf file on the pages_to_split_on.\n The pages which are defined by page_numbers will be removed.\n Returns a list of (temporary) filepaths to consume.\n These will need to be deleted later.\n \"\"\"\n\n document_paths = []\n\n if not pages_to_split_on:\n logger.warning(\"No pages to split on!\")\n return document_paths\n\n os.makedirs(settings.SCRATCH_DIR, exist_ok=True)\n tempdir = tempfile.mkdtemp(prefix=\"paperless-\", dir=settings.SCRATCH_DIR)\n fname = os.path.splitext(os.path.basename(filepath))[0]\n pdf = Pdf.open(filepath)\n\n # A list of documents, ie a list of lists of pages\n documents: List[List[Page]] = []\n # A single document, ie a list of pages\n document: List[Page] = []\n\n for idx, page in enumerate(pdf.pages):\n # Keep building the new PDF as long as it is not a\n # separator index\n if idx not in pages_to_split_on:\n document.append(page)\n # Make sure to append the very last document to the documents\n if idx == (len(pdf.pages) - 1):\n documents.append(document)\n document = []\n else:\n # This is a split index, save the current PDF pages, and restart\n # a new destination page listing\n logger.debug(f\"Starting new document at idx {idx}\")\n documents.append(document)\n document = []\n\n documents = [x for x in documents if len(x)]\n\n logger.debug(f\"Split into {len(documents)} new documents\")\n\n # Write the new documents out\n for doc_idx, document in enumerate(documents):\n dst = Pdf.new()\n dst.pages.extend(document)\n\n output_filename = f\"{fname}_document_{doc_idx}.pdf\"\n\n logger.debug(f\"pdf no:{doc_idx} has {len(dst.pages)} pages\")\n savepath = os.path.join(tempdir, output_filename)\n with open(savepath, \"wb\") as out:\n dst.save(out)\n document_paths.append(savepath)\n\n return document_paths\n\n\ndef save_to_dir(\n filepath: str,\n newname: str = None,\n target_dir: str = settings.CONSUMPTION_DIR,\n):\n \"\"\"\n Copies filepath to target_dir.\n Optionally rename the file.\n \"\"\"\n if os.path.isfile(filepath) and os.path.isdir(target_dir):\n dst = shutil.copy(filepath, target_dir)\n logging.debug(f\"saved {str(filepath)} to {str(dst)}\")\n if newname:\n dst_new = os.path.join(target_dir, newname)\n logger.debug(f\"moving {str(dst)} to {str(dst_new)}\")\n os.rename(dst, dst_new)\n else:\n logger.warning(f\"{str(filepath)} or {str(target_dir)} don't exist.\")\n", "path": "src/documents/barcodes.py"}]}
| 2,849 | 925 |
gh_patches_debug_34095
|
rasdani/github-patches
|
git_diff
|
CTPUG__wafer-299
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Schedule rendering bug when an item is offset from a column spanning item
Given the following setup, the schedule renders incorrectly
Item A - slot A & B, expands over venues 1 & 2
Item B - slot A, venue 3
Item C - slot B, venue 3
Inserting an extra blank item between Item A and Item C in the table
For example

When the expected outcome is

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wafer/schedule/views.py`
Content:
```
1 import datetime
2
3 from django.views.generic import DetailView, TemplateView
4
5 from rest_framework import viewsets
6 from rest_framework.permissions import IsAdminUser
7 from wafer.pages.models import Page
8 from wafer.schedule.models import Venue, Slot, Day
9 from wafer.schedule.admin import check_schedule, validate_schedule
10 from wafer.schedule.models import ScheduleItem
11 from wafer.schedule.serializers import ScheduleItemSerializer
12 from wafer.talks.models import ACCEPTED
13 from wafer.talks.models import Talk
14
15
16 class ScheduleRow(object):
17 """This is a helpful containter for the schedule view to keep sanity"""
18 def __init__(self, schedule_day, slot):
19 self.schedule_day = schedule_day
20 self.slot = slot
21 self.items = {}
22
23 def get_sorted_items(self):
24 sorted_items = []
25 for venue in self.schedule_day.venues:
26 if venue in self.items:
27 sorted_items.append(self.items[venue])
28 return sorted_items
29
30 def __repr__(self):
31 """Debugging aid"""
32 return '%s - %s' % (self.slot, self.get_sorted_items())
33
34
35 class ScheduleDay(object):
36 """A helpful container for information a days in a schedule view."""
37 def __init__(self, day):
38 self.day = day
39 self.venues = list(day.venue_set.all())
40 self.rows = []
41
42
43 class VenueView(DetailView):
44 template_name = 'wafer.schedule/venue.html'
45 model = Venue
46
47
48 def make_schedule_row(schedule_day, slot, seen_items):
49 """Create a row for the schedule table."""
50 row = ScheduleRow(schedule_day, slot)
51 skip = []
52 expanding = {}
53 all_items = list(slot.scheduleitem_set
54 .select_related('talk', 'page', 'venue')
55 .all())
56
57 for item in all_items:
58 if item in seen_items:
59 # Inc rowspan
60 seen_items[item]['rowspan'] += 1
61 # Note that we need to skip this during colspan checks
62 skip.append(item.venue)
63 continue
64 scheditem = {'item': item, 'rowspan': 1, 'colspan': 1}
65 row.items[item.venue] = scheditem
66 seen_items[item] = scheditem
67 if item.expand:
68 expanding[item.venue] = []
69
70 empty = []
71 expanding_right = None
72 for venue in schedule_day.venues:
73 if venue in skip:
74 # Nothing to see here
75 continue
76
77 if venue in expanding:
78 item = row.items[venue]
79 for empty_venue in empty:
80 row.items.pop(empty_venue)
81 item['colspan'] += 1
82 empty = []
83 expanding_right = item
84 elif venue in row.items:
85 empty = []
86 expanding_right = None
87 elif expanding_right:
88 expanding_right['colspan'] += 1
89 else:
90 empty.append(venue)
91 row.items[venue] = {'item': None, 'rowspan': 1, 'colspan': 1}
92
93 return row
94
95
96 def generate_schedule(today=None):
97 """Helper function which creates an ordered list of schedule days"""
98 # We create a list of slots and schedule items
99 schedule_days = {}
100 seen_items = {}
101 for slot in Slot.objects.all().order_by('end_time', 'start_time', 'day'):
102 day = slot.get_day()
103 if today and day != today:
104 # Restrict ourselves to only today
105 continue
106 schedule_day = schedule_days.get(day)
107 if schedule_day is None:
108 schedule_day = schedule_days[day] = ScheduleDay(day)
109 row = make_schedule_row(schedule_day, slot, seen_items)
110 schedule_day.rows.append(row)
111 return sorted(schedule_days.values(), key=lambda x: x.day.date)
112
113
114 class ScheduleView(TemplateView):
115 template_name = 'wafer.schedule/full_schedule.html'
116
117 def get_context_data(self, **kwargs):
118 context = super(ScheduleView, self).get_context_data(**kwargs)
119 # Check if the schedule is valid
120 context['active'] = False
121 if not check_schedule():
122 return context
123 context['active'] = True
124 day = self.request.GET.get('day', None)
125 dates = dict([(x.date.strftime('%Y-%m-%d'), x) for x in
126 Day.objects.all()])
127 # We choose to return the full schedule if given an invalid date
128 day = dates.get(day, None)
129 context['schedule_days'] = generate_schedule(day)
130 return context
131
132
133 class ScheduleXmlView(ScheduleView):
134 template_name = 'wafer.schedule/penta_schedule.xml'
135 content_type = 'application/xml'
136
137
138 class CurrentView(TemplateView):
139 template_name = 'wafer.schedule/current.html'
140
141 def _parse_today(self, day):
142 if day is None:
143 day = str(datetime.date.today())
144 dates = dict([(x.date.strftime('%Y-%m-%d'), x) for x in
145 Day.objects.all()])
146 if day not in dates:
147 return None
148 return ScheduleDay(dates[day])
149
150 def _parse_time(self, time):
151 now = datetime.datetime.now().time()
152 if time is None:
153 return now
154 try:
155 return datetime.datetime.strptime(time, '%H:%M').time()
156 except ValueError:
157 pass
158 return now
159
160 def _add_note(self, row, note, overlap_note):
161 for item in row.items.values():
162 if item['rowspan'] == 1:
163 item['note'] = note
164 else:
165 # Must overlap with current slot
166 item['note'] = overlap_note
167
168 def _current_slots(self, schedule_day, time):
169 today = schedule_day.day
170 cur_slot, prev_slot, next_slot = None, None, None
171 for slot in Slot.objects.all():
172 if slot.get_day() != today:
173 continue
174 if slot.get_start_time() <= time and slot.end_time > time:
175 cur_slot = slot
176 elif slot.end_time <= time:
177 if not prev_slot or prev_slot.end_time < slot.end_time:
178 prev_slot = slot
179 elif slot.get_start_time() >= time:
180 if not next_slot or next_slot.end_time > slot.end_time:
181 next_slot = slot
182 cur_rows = self._current_rows(
183 schedule_day, cur_slot, prev_slot, next_slot)
184 return cur_slot, cur_rows
185
186 def _current_rows(self, schedule_day, cur_slot, prev_slot, next_slot):
187 seen_items = {}
188 rows = []
189 for slot in (prev_slot, cur_slot, next_slot):
190 if slot:
191 row = make_schedule_row(schedule_day, slot, seen_items)
192 else:
193 row = None
194 rows.append(row)
195 # Add styling hints. Needs to be after all the schedule rows are
196 # created so the spans are set correctly
197 if prev_slot:
198 self._add_note(rows[0], 'complete', 'current')
199 if cur_slot:
200 self._add_note(rows[1], 'current', 'current')
201 if next_slot:
202 self._add_note(rows[2], 'forthcoming', 'current')
203 return [r for r in rows if r]
204
205 def get_context_data(self, **kwargs):
206 context = super(CurrentView, self).get_context_data(**kwargs)
207 # If the schedule is invalid, return a context with active=False
208 context['active'] = False
209 if not check_schedule():
210 return context
211 # The schedule is valid, so add active=True and empty slots
212 context['active'] = True
213 context['slots'] = []
214 # Allow refresh time to be overridden
215 context['refresh'] = self.request.GET.get('refresh', None)
216 # If there are no items scheduled for today, return an empty slots list
217 schedule_day = self._parse_today(self.request.GET.get('day', None))
218 if schedule_day is None:
219 return context
220 context['schedule_day'] = schedule_day
221 # Allow current time to be overridden
222 time = self._parse_time(self.request.GET.get('time', None))
223
224 cur_slot, current_rows = self._current_slots(schedule_day, time)
225 context['cur_slot'] = cur_slot
226 context['slots'].extend(current_rows)
227
228 return context
229
230
231 class ScheduleItemViewSet(viewsets.ModelViewSet):
232 """
233 API endpoint that allows groups to be viewed or edited.
234 """
235 queryset = ScheduleItem.objects.all()
236 serializer_class = ScheduleItemSerializer
237 permission_classes = (IsAdminUser, )
238
239
240 class ScheduleEditView(TemplateView):
241 template_name = 'wafer.schedule/edit_schedule.html'
242
243 def _slot_context(self, slot, venues):
244 slot_context = {
245 'name': slot.name,
246 'start_time': slot.get_start_time(),
247 'end_time': slot.end_time,
248 'id': slot.id,
249 'venues': []
250 }
251 for venue in venues:
252 venue_context = {
253 'name': venue.name,
254 'id': venue.id,
255 }
256 for schedule_item in slot.scheduleitem_set.all():
257 if schedule_item.venue.name == venue.name:
258 venue_context['scheduleitem_id'] = schedule_item.id
259 if schedule_item.talk:
260 talk = schedule_item.talk
261 venue_context['title'] = talk.title
262 venue_context['talk'] = talk
263 if (schedule_item.page and
264 not schedule_item.page.exclude_from_static):
265 page = schedule_item.page
266 venue_context['title'] = page.name
267 venue_context['page'] = page
268 slot_context['venues'].append(venue_context)
269 return slot_context
270
271 def get_context_data(self, day_id=None, **kwargs):
272 context = super(ScheduleEditView, self).get_context_data(**kwargs)
273
274 days = Day.objects.all()
275 if day_id:
276 day = days.get(id=day_id)
277 else:
278 day = days.first()
279
280 accepted_talks = Talk.objects.filter(status=ACCEPTED)
281 venues = Venue.objects.filter(days__in=[day])
282 slots = Slot.objects.all().select_related(
283 'day', 'previous_slot').prefetch_related(
284 'scheduleitem_set', 'slot_set').order_by(
285 'end_time', 'start_time', 'day')
286 aggregated_slots = []
287
288 for slot in slots:
289 if day != slot.get_day():
290 continue
291 aggregated_slots.append(self._slot_context(slot, venues))
292
293 context['day'] = day
294 context['venues'] = venues
295 context['slots'] = aggregated_slots
296 context['talks_all'] = accepted_talks
297 context['talks_unassigned'] = accepted_talks.filter(scheduleitem=None)
298 context['pages'] = Page.objects.all()
299 context['days'] = days
300 context['validation_errors'] = validate_schedule()
301 return context
302
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wafer/schedule/views.py b/wafer/schedule/views.py
--- a/wafer/schedule/views.py
+++ b/wafer/schedule/views.py
@@ -48,7 +48,7 @@
def make_schedule_row(schedule_day, slot, seen_items):
"""Create a row for the schedule table."""
row = ScheduleRow(schedule_day, slot)
- skip = []
+ skip = {}
expanding = {}
all_items = list(slot.scheduleitem_set
.select_related('talk', 'page', 'venue')
@@ -59,7 +59,7 @@
# Inc rowspan
seen_items[item]['rowspan'] += 1
# Note that we need to skip this during colspan checks
- skip.append(item.venue)
+ skip[item.venue] = seen_items[item]
continue
scheditem = {'item': item, 'rowspan': 1, 'colspan': 1}
row.items[item.venue] = scheditem
@@ -69,11 +69,14 @@
empty = []
expanding_right = None
+ skipping = 0
+ skip_item = None
for venue in schedule_day.venues:
if venue in skip:
- # Nothing to see here
+ # We need to skip all the venues this item spans over
+ skipping = 1
+ skip_item = skip[venue]
continue
-
if venue in expanding:
item = row.items[venue]
for empty_venue in empty:
@@ -86,7 +89,10 @@
expanding_right = None
elif expanding_right:
expanding_right['colspan'] += 1
+ elif skipping > 0 and skipping < skip_item['colspan']:
+ skipping += 1
else:
+ skipping = 0
empty.append(venue)
row.items[venue] = {'item': None, 'rowspan': 1, 'colspan': 1}
|
{"golden_diff": "diff --git a/wafer/schedule/views.py b/wafer/schedule/views.py\n--- a/wafer/schedule/views.py\n+++ b/wafer/schedule/views.py\n@@ -48,7 +48,7 @@\n def make_schedule_row(schedule_day, slot, seen_items):\n \"\"\"Create a row for the schedule table.\"\"\"\n row = ScheduleRow(schedule_day, slot)\n- skip = []\n+ skip = {}\n expanding = {}\n all_items = list(slot.scheduleitem_set\n .select_related('talk', 'page', 'venue')\n@@ -59,7 +59,7 @@\n # Inc rowspan\n seen_items[item]['rowspan'] += 1\n # Note that we need to skip this during colspan checks\n- skip.append(item.venue)\n+ skip[item.venue] = seen_items[item]\n continue\n scheditem = {'item': item, 'rowspan': 1, 'colspan': 1}\n row.items[item.venue] = scheditem\n@@ -69,11 +69,14 @@\n \n empty = []\n expanding_right = None\n+ skipping = 0\n+ skip_item = None\n for venue in schedule_day.venues:\n if venue in skip:\n- # Nothing to see here\n+ # We need to skip all the venues this item spans over\n+ skipping = 1\n+ skip_item = skip[venue]\n continue\n-\n if venue in expanding:\n item = row.items[venue]\n for empty_venue in empty:\n@@ -86,7 +89,10 @@\n expanding_right = None\n elif expanding_right:\n expanding_right['colspan'] += 1\n+ elif skipping > 0 and skipping < skip_item['colspan']:\n+ skipping += 1\n else:\n+ skipping = 0\n empty.append(venue)\n row.items[venue] = {'item': None, 'rowspan': 1, 'colspan': 1}\n", "issue": "Schedule rendering bug when an item is offset from a column spanning item\nGiven the following setup, the schedule renders incorrectly\n\nItem A - slot A & B, expands over venues 1 & 2\nItem B - slot A, venue 3\nItem C - slot B, venue 3\n\nInserting an extra blank item between Item A and Item C in the table\n\nFor example\n\n\n\nWhen the expected outcome is\n\n\n\n", "before_files": [{"content": "import datetime\n\nfrom django.views.generic import DetailView, TemplateView\n\nfrom rest_framework import viewsets\nfrom rest_framework.permissions import IsAdminUser\nfrom wafer.pages.models import Page\nfrom wafer.schedule.models import Venue, Slot, Day\nfrom wafer.schedule.admin import check_schedule, validate_schedule\nfrom wafer.schedule.models import ScheduleItem\nfrom wafer.schedule.serializers import ScheduleItemSerializer\nfrom wafer.talks.models import ACCEPTED\nfrom wafer.talks.models import Talk\n\n\nclass ScheduleRow(object):\n \"\"\"This is a helpful containter for the schedule view to keep sanity\"\"\"\n def __init__(self, schedule_day, slot):\n self.schedule_day = schedule_day\n self.slot = slot\n self.items = {}\n\n def get_sorted_items(self):\n sorted_items = []\n for venue in self.schedule_day.venues:\n if venue in self.items:\n sorted_items.append(self.items[venue])\n return sorted_items\n\n def __repr__(self):\n \"\"\"Debugging aid\"\"\"\n return '%s - %s' % (self.slot, self.get_sorted_items())\n\n\nclass ScheduleDay(object):\n \"\"\"A helpful container for information a days in a schedule view.\"\"\"\n def __init__(self, day):\n self.day = day\n self.venues = list(day.venue_set.all())\n self.rows = []\n\n\nclass VenueView(DetailView):\n template_name = 'wafer.schedule/venue.html'\n model = Venue\n\n\ndef make_schedule_row(schedule_day, slot, seen_items):\n \"\"\"Create a row for the schedule table.\"\"\"\n row = ScheduleRow(schedule_day, slot)\n skip = []\n expanding = {}\n all_items = list(slot.scheduleitem_set\n .select_related('talk', 'page', 'venue')\n .all())\n\n for item in all_items:\n if item in seen_items:\n # Inc rowspan\n seen_items[item]['rowspan'] += 1\n # Note that we need to skip this during colspan checks\n skip.append(item.venue)\n continue\n scheditem = {'item': item, 'rowspan': 1, 'colspan': 1}\n row.items[item.venue] = scheditem\n seen_items[item] = scheditem\n if item.expand:\n expanding[item.venue] = []\n\n empty = []\n expanding_right = None\n for venue in schedule_day.venues:\n if venue in skip:\n # Nothing to see here\n continue\n\n if venue in expanding:\n item = row.items[venue]\n for empty_venue in empty:\n row.items.pop(empty_venue)\n item['colspan'] += 1\n empty = []\n expanding_right = item\n elif venue in row.items:\n empty = []\n expanding_right = None\n elif expanding_right:\n expanding_right['colspan'] += 1\n else:\n empty.append(venue)\n row.items[venue] = {'item': None, 'rowspan': 1, 'colspan': 1}\n\n return row\n\n\ndef generate_schedule(today=None):\n \"\"\"Helper function which creates an ordered list of schedule days\"\"\"\n # We create a list of slots and schedule items\n schedule_days = {}\n seen_items = {}\n for slot in Slot.objects.all().order_by('end_time', 'start_time', 'day'):\n day = slot.get_day()\n if today and day != today:\n # Restrict ourselves to only today\n continue\n schedule_day = schedule_days.get(day)\n if schedule_day is None:\n schedule_day = schedule_days[day] = ScheduleDay(day)\n row = make_schedule_row(schedule_day, slot, seen_items)\n schedule_day.rows.append(row)\n return sorted(schedule_days.values(), key=lambda x: x.day.date)\n\n\nclass ScheduleView(TemplateView):\n template_name = 'wafer.schedule/full_schedule.html'\n\n def get_context_data(self, **kwargs):\n context = super(ScheduleView, self).get_context_data(**kwargs)\n # Check if the schedule is valid\n context['active'] = False\n if not check_schedule():\n return context\n context['active'] = True\n day = self.request.GET.get('day', None)\n dates = dict([(x.date.strftime('%Y-%m-%d'), x) for x in\n Day.objects.all()])\n # We choose to return the full schedule if given an invalid date\n day = dates.get(day, None)\n context['schedule_days'] = generate_schedule(day)\n return context\n\n\nclass ScheduleXmlView(ScheduleView):\n template_name = 'wafer.schedule/penta_schedule.xml'\n content_type = 'application/xml'\n\n\nclass CurrentView(TemplateView):\n template_name = 'wafer.schedule/current.html'\n\n def _parse_today(self, day):\n if day is None:\n day = str(datetime.date.today())\n dates = dict([(x.date.strftime('%Y-%m-%d'), x) for x in\n Day.objects.all()])\n if day not in dates:\n return None\n return ScheduleDay(dates[day])\n\n def _parse_time(self, time):\n now = datetime.datetime.now().time()\n if time is None:\n return now\n try:\n return datetime.datetime.strptime(time, '%H:%M').time()\n except ValueError:\n pass\n return now\n\n def _add_note(self, row, note, overlap_note):\n for item in row.items.values():\n if item['rowspan'] == 1:\n item['note'] = note\n else:\n # Must overlap with current slot\n item['note'] = overlap_note\n\n def _current_slots(self, schedule_day, time):\n today = schedule_day.day\n cur_slot, prev_slot, next_slot = None, None, None\n for slot in Slot.objects.all():\n if slot.get_day() != today:\n continue\n if slot.get_start_time() <= time and slot.end_time > time:\n cur_slot = slot\n elif slot.end_time <= time:\n if not prev_slot or prev_slot.end_time < slot.end_time:\n prev_slot = slot\n elif slot.get_start_time() >= time:\n if not next_slot or next_slot.end_time > slot.end_time:\n next_slot = slot\n cur_rows = self._current_rows(\n schedule_day, cur_slot, prev_slot, next_slot)\n return cur_slot, cur_rows\n\n def _current_rows(self, schedule_day, cur_slot, prev_slot, next_slot):\n seen_items = {}\n rows = []\n for slot in (prev_slot, cur_slot, next_slot):\n if slot:\n row = make_schedule_row(schedule_day, slot, seen_items)\n else:\n row = None\n rows.append(row)\n # Add styling hints. Needs to be after all the schedule rows are\n # created so the spans are set correctly\n if prev_slot:\n self._add_note(rows[0], 'complete', 'current')\n if cur_slot:\n self._add_note(rows[1], 'current', 'current')\n if next_slot:\n self._add_note(rows[2], 'forthcoming', 'current')\n return [r for r in rows if r]\n\n def get_context_data(self, **kwargs):\n context = super(CurrentView, self).get_context_data(**kwargs)\n # If the schedule is invalid, return a context with active=False\n context['active'] = False\n if not check_schedule():\n return context\n # The schedule is valid, so add active=True and empty slots\n context['active'] = True\n context['slots'] = []\n # Allow refresh time to be overridden\n context['refresh'] = self.request.GET.get('refresh', None)\n # If there are no items scheduled for today, return an empty slots list\n schedule_day = self._parse_today(self.request.GET.get('day', None))\n if schedule_day is None:\n return context\n context['schedule_day'] = schedule_day\n # Allow current time to be overridden\n time = self._parse_time(self.request.GET.get('time', None))\n\n cur_slot, current_rows = self._current_slots(schedule_day, time)\n context['cur_slot'] = cur_slot\n context['slots'].extend(current_rows)\n\n return context\n\n\nclass ScheduleItemViewSet(viewsets.ModelViewSet):\n \"\"\"\n API endpoint that allows groups to be viewed or edited.\n \"\"\"\n queryset = ScheduleItem.objects.all()\n serializer_class = ScheduleItemSerializer\n permission_classes = (IsAdminUser, )\n\n\nclass ScheduleEditView(TemplateView):\n template_name = 'wafer.schedule/edit_schedule.html'\n\n def _slot_context(self, slot, venues):\n slot_context = {\n 'name': slot.name,\n 'start_time': slot.get_start_time(),\n 'end_time': slot.end_time,\n 'id': slot.id,\n 'venues': []\n }\n for venue in venues:\n venue_context = {\n 'name': venue.name,\n 'id': venue.id,\n }\n for schedule_item in slot.scheduleitem_set.all():\n if schedule_item.venue.name == venue.name:\n venue_context['scheduleitem_id'] = schedule_item.id\n if schedule_item.talk:\n talk = schedule_item.talk\n venue_context['title'] = talk.title\n venue_context['talk'] = talk\n if (schedule_item.page and\n not schedule_item.page.exclude_from_static):\n page = schedule_item.page\n venue_context['title'] = page.name\n venue_context['page'] = page\n slot_context['venues'].append(venue_context)\n return slot_context\n\n def get_context_data(self, day_id=None, **kwargs):\n context = super(ScheduleEditView, self).get_context_data(**kwargs)\n\n days = Day.objects.all()\n if day_id:\n day = days.get(id=day_id)\n else:\n day = days.first()\n\n accepted_talks = Talk.objects.filter(status=ACCEPTED)\n venues = Venue.objects.filter(days__in=[day])\n slots = Slot.objects.all().select_related(\n 'day', 'previous_slot').prefetch_related(\n 'scheduleitem_set', 'slot_set').order_by(\n 'end_time', 'start_time', 'day')\n aggregated_slots = []\n\n for slot in slots:\n if day != slot.get_day():\n continue\n aggregated_slots.append(self._slot_context(slot, venues))\n\n context['day'] = day\n context['venues'] = venues\n context['slots'] = aggregated_slots\n context['talks_all'] = accepted_talks\n context['talks_unassigned'] = accepted_talks.filter(scheduleitem=None)\n context['pages'] = Page.objects.all()\n context['days'] = days\n context['validation_errors'] = validate_schedule()\n return context\n", "path": "wafer/schedule/views.py"}], "after_files": [{"content": "import datetime\n\nfrom django.views.generic import DetailView, TemplateView\n\nfrom rest_framework import viewsets\nfrom rest_framework.permissions import IsAdminUser\nfrom wafer.pages.models import Page\nfrom wafer.schedule.models import Venue, Slot, Day\nfrom wafer.schedule.admin import check_schedule, validate_schedule\nfrom wafer.schedule.models import ScheduleItem\nfrom wafer.schedule.serializers import ScheduleItemSerializer\nfrom wafer.talks.models import ACCEPTED\nfrom wafer.talks.models import Talk\n\n\nclass ScheduleRow(object):\n \"\"\"This is a helpful containter for the schedule view to keep sanity\"\"\"\n def __init__(self, schedule_day, slot):\n self.schedule_day = schedule_day\n self.slot = slot\n self.items = {}\n\n def get_sorted_items(self):\n sorted_items = []\n for venue in self.schedule_day.venues:\n if venue in self.items:\n sorted_items.append(self.items[venue])\n return sorted_items\n\n def __repr__(self):\n \"\"\"Debugging aid\"\"\"\n return '%s - %s' % (self.slot, self.get_sorted_items())\n\n\nclass ScheduleDay(object):\n \"\"\"A helpful container for information a days in a schedule view.\"\"\"\n def __init__(self, day):\n self.day = day\n self.venues = list(day.venue_set.all())\n self.rows = []\n\n\nclass VenueView(DetailView):\n template_name = 'wafer.schedule/venue.html'\n model = Venue\n\n\ndef make_schedule_row(schedule_day, slot, seen_items):\n \"\"\"Create a row for the schedule table.\"\"\"\n row = ScheduleRow(schedule_day, slot)\n skip = {}\n expanding = {}\n all_items = list(slot.scheduleitem_set\n .select_related('talk', 'page', 'venue')\n .all())\n\n for item in all_items:\n if item in seen_items:\n # Inc rowspan\n seen_items[item]['rowspan'] += 1\n # Note that we need to skip this during colspan checks\n skip[item.venue] = seen_items[item]\n continue\n scheditem = {'item': item, 'rowspan': 1, 'colspan': 1}\n row.items[item.venue] = scheditem\n seen_items[item] = scheditem\n if item.expand:\n expanding[item.venue] = []\n\n empty = []\n expanding_right = None\n skipping = 0\n skip_item = None\n for venue in schedule_day.venues:\n if venue in skip:\n # We need to skip all the venues this item spans over\n skipping = 1\n skip_item = skip[venue]\n continue\n if venue in expanding:\n item = row.items[venue]\n for empty_venue in empty:\n row.items.pop(empty_venue)\n item['colspan'] += 1\n empty = []\n expanding_right = item\n elif venue in row.items:\n empty = []\n expanding_right = None\n elif expanding_right:\n expanding_right['colspan'] += 1\n elif skipping > 0 and skipping < skip_item['colspan']:\n skipping += 1\n else:\n skipping = 0\n empty.append(venue)\n row.items[venue] = {'item': None, 'rowspan': 1, 'colspan': 1}\n\n return row\n\n\ndef generate_schedule(today=None):\n \"\"\"Helper function which creates an ordered list of schedule days\"\"\"\n # We create a list of slots and schedule items\n schedule_days = {}\n seen_items = {}\n for slot in Slot.objects.all().order_by('end_time', 'start_time', 'day'):\n day = slot.get_day()\n if today and day != today:\n # Restrict ourselves to only today\n continue\n schedule_day = schedule_days.get(day)\n if schedule_day is None:\n schedule_day = schedule_days[day] = ScheduleDay(day)\n row = make_schedule_row(schedule_day, slot, seen_items)\n schedule_day.rows.append(row)\n return sorted(schedule_days.values(), key=lambda x: x.day.date)\n\n\nclass ScheduleView(TemplateView):\n template_name = 'wafer.schedule/full_schedule.html'\n\n def get_context_data(self, **kwargs):\n context = super(ScheduleView, self).get_context_data(**kwargs)\n # Check if the schedule is valid\n context['active'] = False\n if not check_schedule():\n return context\n context['active'] = True\n day = self.request.GET.get('day', None)\n dates = dict([(x.date.strftime('%Y-%m-%d'), x) for x in\n Day.objects.all()])\n # We choose to return the full schedule if given an invalid date\n day = dates.get(day, None)\n context['schedule_days'] = generate_schedule(day)\n return context\n\n\nclass ScheduleXmlView(ScheduleView):\n template_name = 'wafer.schedule/penta_schedule.xml'\n content_type = 'application/xml'\n\n\nclass CurrentView(TemplateView):\n template_name = 'wafer.schedule/current.html'\n\n def _parse_today(self, day):\n if day is None:\n day = str(datetime.date.today())\n dates = dict([(x.date.strftime('%Y-%m-%d'), x) for x in\n Day.objects.all()])\n if day not in dates:\n return None\n return ScheduleDay(dates[day])\n\n def _parse_time(self, time):\n now = datetime.datetime.now().time()\n if time is None:\n return now\n try:\n return datetime.datetime.strptime(time, '%H:%M').time()\n except ValueError:\n pass\n return now\n\n def _add_note(self, row, note, overlap_note):\n for item in row.items.values():\n if item['rowspan'] == 1:\n item['note'] = note\n else:\n # Must overlap with current slot\n item['note'] = overlap_note\n\n def _current_slots(self, schedule_day, time):\n today = schedule_day.day\n cur_slot, prev_slot, next_slot = None, None, None\n for slot in Slot.objects.all():\n if slot.get_day() != today:\n continue\n if slot.get_start_time() <= time and slot.end_time > time:\n cur_slot = slot\n elif slot.end_time <= time:\n if not prev_slot or prev_slot.end_time < slot.end_time:\n prev_slot = slot\n elif slot.get_start_time() >= time:\n if not next_slot or next_slot.end_time > slot.end_time:\n next_slot = slot\n cur_rows = self._current_rows(\n schedule_day, cur_slot, prev_slot, next_slot)\n return cur_slot, cur_rows\n\n def _current_rows(self, schedule_day, cur_slot, prev_slot, next_slot):\n seen_items = {}\n rows = []\n for slot in (prev_slot, cur_slot, next_slot):\n if slot:\n row = make_schedule_row(schedule_day, slot, seen_items)\n else:\n row = None\n rows.append(row)\n # Add styling hints. Needs to be after all the schedule rows are\n # created so the spans are set correctly\n if prev_slot:\n self._add_note(rows[0], 'complete', 'current')\n if cur_slot:\n self._add_note(rows[1], 'current', 'current')\n if next_slot:\n self._add_note(rows[2], 'forthcoming', 'current')\n return [r for r in rows if r]\n\n def get_context_data(self, **kwargs):\n context = super(CurrentView, self).get_context_data(**kwargs)\n # If the schedule is invalid, return a context with active=False\n context['active'] = False\n if not check_schedule():\n return context\n # The schedule is valid, so add active=True and empty slots\n context['active'] = True\n context['slots'] = []\n # Allow refresh time to be overridden\n context['refresh'] = self.request.GET.get('refresh', None)\n # If there are no items scheduled for today, return an empty slots list\n schedule_day = self._parse_today(self.request.GET.get('day', None))\n if schedule_day is None:\n return context\n context['schedule_day'] = schedule_day\n # Allow current time to be overridden\n time = self._parse_time(self.request.GET.get('time', None))\n\n cur_slot, current_rows = self._current_slots(schedule_day, time)\n context['cur_slot'] = cur_slot\n context['slots'].extend(current_rows)\n\n return context\n\n\nclass ScheduleItemViewSet(viewsets.ModelViewSet):\n \"\"\"\n API endpoint that allows groups to be viewed or edited.\n \"\"\"\n queryset = ScheduleItem.objects.all()\n serializer_class = ScheduleItemSerializer\n permission_classes = (IsAdminUser, )\n\n\nclass ScheduleEditView(TemplateView):\n template_name = 'wafer.schedule/edit_schedule.html'\n\n def _slot_context(self, slot, venues):\n slot_context = {\n 'name': slot.name,\n 'start_time': slot.get_start_time(),\n 'end_time': slot.end_time,\n 'id': slot.id,\n 'venues': []\n }\n for venue in venues:\n venue_context = {\n 'name': venue.name,\n 'id': venue.id,\n }\n for schedule_item in slot.scheduleitem_set.all():\n if schedule_item.venue.name == venue.name:\n venue_context['scheduleitem_id'] = schedule_item.id\n if schedule_item.talk:\n talk = schedule_item.talk\n venue_context['title'] = talk.title\n venue_context['talk'] = talk\n if (schedule_item.page and\n not schedule_item.page.exclude_from_static):\n page = schedule_item.page\n venue_context['title'] = page.name\n venue_context['page'] = page\n slot_context['venues'].append(venue_context)\n return slot_context\n\n def get_context_data(self, day_id=None, **kwargs):\n context = super(ScheduleEditView, self).get_context_data(**kwargs)\n\n days = Day.objects.all()\n if day_id:\n day = days.get(id=day_id)\n else:\n day = days.first()\n\n accepted_talks = Talk.objects.filter(status=ACCEPTED)\n venues = Venue.objects.filter(days__in=[day])\n slots = Slot.objects.all().select_related(\n 'day', 'previous_slot').prefetch_related(\n 'scheduleitem_set', 'slot_set').order_by(\n 'end_time', 'start_time', 'day')\n aggregated_slots = []\n\n for slot in slots:\n if day != slot.get_day():\n continue\n aggregated_slots.append(self._slot_context(slot, venues))\n\n context['day'] = day\n context['venues'] = venues\n context['slots'] = aggregated_slots\n context['talks_all'] = accepted_talks\n context['talks_unassigned'] = accepted_talks.filter(scheduleitem=None)\n context['pages'] = Page.objects.all()\n context['days'] = days\n context['validation_errors'] = validate_schedule()\n return context\n", "path": "wafer/schedule/views.py"}]}
| 3,597 | 439 |
gh_patches_debug_177
|
rasdani/github-patches
|
git_diff
|
encode__starlette-455
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
py.typed missing in published artifacts
I didn’t check for earlier versions, but at least 0.11.4 on PyPI does not include `py.typed`. I assume this is an oversight, given it is mentioned in `setup.py`?
https://github.com/encode/starlette/blob/77b84a08c1e4de0db64a197b58ac363a26c51d4f/setup.py#L49
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 import os
5 import re
6
7 from setuptools import setup
8
9
10 def get_version(package):
11 """
12 Return package version as listed in `__version__` in `init.py`.
13 """
14 with open(os.path.join(package, "__init__.py")) as f:
15 return re.search("__version__ = ['\"]([^'\"]+)['\"]", f.read()).group(1)
16
17
18 def get_long_description():
19 """
20 Return the README.
21 """
22 with open("README.md", encoding="utf8") as f:
23 return f.read()
24
25
26 def get_packages(package):
27 """
28 Return root package and all sub-packages.
29 """
30 return [
31 dirpath
32 for dirpath, dirnames, filenames in os.walk(package)
33 if os.path.exists(os.path.join(dirpath, "__init__.py"))
34 ]
35
36
37 setup(
38 name="starlette",
39 python_requires=">=3.6",
40 version=get_version("starlette"),
41 url="https://github.com/encode/starlette",
42 license="BSD",
43 description="The little ASGI library that shines.",
44 long_description=get_long_description(),
45 long_description_content_type="text/markdown",
46 author="Tom Christie",
47 author_email="[email protected]",
48 packages=get_packages("starlette"),
49 package_data={"starlette": ["py.typed"]},
50 data_files=[("", ["LICENSE.md"])],
51 extras_require={
52 "full": [
53 "aiofiles",
54 "asyncpg",
55 "graphene",
56 "itsdangerous",
57 "jinja2",
58 "python-multipart",
59 "pyyaml",
60 "requests",
61 "ujson",
62 ]
63 },
64 classifiers=[
65 "Development Status :: 3 - Alpha",
66 "Environment :: Web Environment",
67 "Intended Audience :: Developers",
68 "License :: OSI Approved :: BSD License",
69 "Operating System :: OS Independent",
70 "Topic :: Internet :: WWW/HTTP",
71 "Programming Language :: Python :: 3",
72 "Programming Language :: Python :: 3.6",
73 "Programming Language :: Python :: 3.7",
74 ],
75 )
76
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -72,4 +72,5 @@
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
],
+ zip_safe=False,
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -72,4 +72,5 @@\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n ],\n+ zip_safe=False,\n )\n", "issue": "py.typed missing in published artifacts\nI didn\u2019t check for earlier versions, but at least 0.11.4 on PyPI does not include `py.typed`. I assume this is an oversight, given it is mentioned in `setup.py`?\r\n\r\nhttps://github.com/encode/starlette/blob/77b84a08c1e4de0db64a197b58ac363a26c51d4f/setup.py#L49\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport os\nimport re\n\nfrom setuptools import setup\n\n\ndef get_version(package):\n \"\"\"\n Return package version as listed in `__version__` in `init.py`.\n \"\"\"\n with open(os.path.join(package, \"__init__.py\")) as f:\n return re.search(\"__version__ = ['\\\"]([^'\\\"]+)['\\\"]\", f.read()).group(1)\n\n\ndef get_long_description():\n \"\"\"\n Return the README.\n \"\"\"\n with open(\"README.md\", encoding=\"utf8\") as f:\n return f.read()\n\n\ndef get_packages(package):\n \"\"\"\n Return root package and all sub-packages.\n \"\"\"\n return [\n dirpath\n for dirpath, dirnames, filenames in os.walk(package)\n if os.path.exists(os.path.join(dirpath, \"__init__.py\"))\n ]\n\n\nsetup(\n name=\"starlette\",\n python_requires=\">=3.6\",\n version=get_version(\"starlette\"),\n url=\"https://github.com/encode/starlette\",\n license=\"BSD\",\n description=\"The little ASGI library that shines.\",\n long_description=get_long_description(),\n long_description_content_type=\"text/markdown\",\n author=\"Tom Christie\",\n author_email=\"[email protected]\",\n packages=get_packages(\"starlette\"),\n package_data={\"starlette\": [\"py.typed\"]},\n data_files=[(\"\", [\"LICENSE.md\"])],\n extras_require={\n \"full\": [\n \"aiofiles\",\n \"asyncpg\",\n \"graphene\",\n \"itsdangerous\",\n \"jinja2\",\n \"python-multipart\",\n \"pyyaml\",\n \"requests\",\n \"ujson\",\n ]\n },\n classifiers=[\n \"Development Status :: 3 - Alpha\",\n \"Environment :: Web Environment\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: BSD License\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport os\nimport re\n\nfrom setuptools import setup\n\n\ndef get_version(package):\n \"\"\"\n Return package version as listed in `__version__` in `init.py`.\n \"\"\"\n with open(os.path.join(package, \"__init__.py\")) as f:\n return re.search(\"__version__ = ['\\\"]([^'\\\"]+)['\\\"]\", f.read()).group(1)\n\n\ndef get_long_description():\n \"\"\"\n Return the README.\n \"\"\"\n with open(\"README.md\", encoding=\"utf8\") as f:\n return f.read()\n\n\ndef get_packages(package):\n \"\"\"\n Return root package and all sub-packages.\n \"\"\"\n return [\n dirpath\n for dirpath, dirnames, filenames in os.walk(package)\n if os.path.exists(os.path.join(dirpath, \"__init__.py\"))\n ]\n\n\nsetup(\n name=\"starlette\",\n python_requires=\">=3.6\",\n version=get_version(\"starlette\"),\n url=\"https://github.com/encode/starlette\",\n license=\"BSD\",\n description=\"The little ASGI library that shines.\",\n long_description=get_long_description(),\n long_description_content_type=\"text/markdown\",\n author=\"Tom Christie\",\n author_email=\"[email protected]\",\n packages=get_packages(\"starlette\"),\n package_data={\"starlette\": [\"py.typed\"]},\n data_files=[(\"\", [\"LICENSE.md\"])],\n extras_require={\n \"full\": [\n \"aiofiles\",\n \"asyncpg\",\n \"graphene\",\n \"itsdangerous\",\n \"jinja2\",\n \"python-multipart\",\n \"pyyaml\",\n \"requests\",\n \"ujson\",\n ]\n },\n classifiers=[\n \"Development Status :: 3 - Alpha\",\n \"Environment :: Web Environment\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: BSD License\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n ],\n zip_safe=False,\n)\n", "path": "setup.py"}]}
| 973 | 65 |
gh_patches_debug_17076
|
rasdani/github-patches
|
git_diff
|
Cog-Creators__Red-DiscordBot-1533
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[V3 Cleanup] Cleanup messages not deleting if parameter bigger then channel size
### Type:
- [ ] Suggestion
- [X] Bug
### Brief description of the problem
On 3.0.0b11, when `[p]cleanup messages` is used and the number parameter is bigger then the messages in the channel, Red will not delete all messages. Since the bug is regarding deletion added walkthrough screenshots.


--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redbot/cogs/cleanup/cleanup.py`
Content:
```
1 import re
2
3 import discord
4 from discord.ext import commands
5
6 from redbot.core import checks, RedContext
7 from redbot.core.bot import Red
8 from redbot.core.i18n import CogI18n
9 from redbot.core.utils.mod import slow_deletion, mass_purge
10 from redbot.cogs.mod.log import log
11
12 _ = CogI18n("Cleanup", __file__)
13
14
15 class Cleanup:
16 """Commands for cleaning messages"""
17
18 def __init__(self, bot: Red):
19 self.bot = bot
20
21 @staticmethod
22 async def check_100_plus(ctx: RedContext, number: int) -> bool:
23 """
24 Called when trying to delete more than 100 messages at once
25
26 Prompts the user to choose whether they want to continue or not
27 """
28 def author_check(message):
29 return message.author == ctx.author
30
31 await ctx.send(_('Are you sure you want to delete {} messages? (y/n)').format(number))
32 response = await ctx.bot.wait_for('message', check=author_check)
33
34 if response.content.lower().startswith('y'):
35 return True
36 else:
37 await ctx.send(_('Cancelled.'))
38 return False
39
40 @staticmethod
41 async def get_messages_for_deletion(
42 ctx: RedContext, channel: discord.TextChannel, number,
43 check=lambda x: True, limit=100, before=None, after=None
44 ) -> list:
45 """
46 Gets a list of messages meeting the requirements to be deleted.
47
48 Generally, the requirements are:
49 - We don't have the number of messages to be deleted already
50 - The message passes a provided check (if no check is provided,
51 this is automatically true)
52 - The message is less than 14 days old
53 """
54 to_delete = []
55 too_old = False
56
57 while not too_old and len(to_delete) - 1 < number:
58 async for message in channel.history(limit=limit,
59 before=before,
60 after=after):
61 if (not number or len(to_delete) - 1 < number) and check(message) \
62 and (ctx.message.created_at - message.created_at).days < 14:
63 to_delete.append(message)
64 elif (ctx.message.created_at - message.created_at).days >= 14:
65 too_old = True
66 break
67 elif number and len(to_delete) >= number:
68 break
69 before = message
70 return to_delete
71
72 @commands.group()
73 @checks.mod_or_permissions(manage_messages=True)
74 async def cleanup(self, ctx: RedContext):
75 """Deletes messages."""
76 if ctx.invoked_subcommand is None:
77 await ctx.send_help()
78
79 @cleanup.command()
80 @commands.guild_only()
81 @commands.bot_has_permissions(manage_messages=True)
82 async def text(self, ctx: RedContext, text: str, number: int):
83 """Deletes last X messages matching the specified text.
84
85 Example:
86 cleanup text \"test\" 5
87
88 Remember to use double quotes."""
89
90 channel = ctx.channel
91 author = ctx.author
92 is_bot = self.bot.user.bot
93
94 if number > 100:
95 cont = await self.check_100_plus(ctx, number)
96 if not cont:
97 return
98
99 def check(m):
100 if text in m.content:
101 return True
102 elif m == ctx.message:
103 return True
104 else:
105 return False
106
107 to_delete = await self.get_messages_for_deletion(
108 ctx, channel, number, check=check, limit=1000, before=ctx.message)
109
110 reason = "{}({}) deleted {} messages "\
111 " containing '{}' in channel {}.".format(author.name,
112 author.id, len(to_delete), text, channel.id)
113 log.info(reason)
114
115 if is_bot:
116 await mass_purge(to_delete, channel)
117 else:
118 await slow_deletion(to_delete)
119
120 @cleanup.command()
121 @commands.guild_only()
122 @commands.bot_has_permissions(manage_messages=True)
123 async def user(self, ctx: RedContext, user: discord.Member or int, number: int):
124 """Deletes last X messages from specified user.
125
126 Examples:
127 cleanup user @\u200bTwentysix 2
128 cleanup user Red 6"""
129
130 channel = ctx.channel
131 author = ctx.author
132 is_bot = self.bot.user.bot
133
134 if number > 100:
135 cont = await self.check_100_plus(ctx, number)
136 if not cont:
137 return
138
139 def check(m):
140 if isinstance(user, discord.Member) and m.author == user:
141 return True
142 elif m.author.id == user: # Allow finding messages based on an ID
143 return True
144 elif m == ctx.message:
145 return True
146 else:
147 return False
148
149 to_delete = await self.get_messages_for_deletion(
150 ctx, channel, number, check=check, limit=1000, before=ctx.message
151 )
152 reason = "{}({}) deleted {} messages "\
153 " made by {}({}) in channel {}."\
154 "".format(author.name, author.id, len(to_delete),
155 user.name, user.id, channel.name)
156 log.info(reason)
157
158 if is_bot:
159 # For whatever reason the purge endpoint requires manage_messages
160 await mass_purge(to_delete, channel)
161 else:
162 await slow_deletion(to_delete)
163
164 @cleanup.command()
165 @commands.guild_only()
166 @commands.bot_has_permissions(manage_messages=True)
167 async def after(self, ctx: RedContext, message_id: int):
168 """Deletes all messages after specified message.
169
170 To get a message id, enable developer mode in Discord's
171 settings, 'appearance' tab. Then right click a message
172 and copy its id.
173
174 This command only works on bots running as bot accounts.
175 """
176
177 channel = ctx.channel
178 author = ctx.author
179 is_bot = self.bot.user.bot
180
181 if not is_bot:
182 await ctx.send(_("This command can only be used on bots with "
183 "bot accounts."))
184 return
185
186 after = await channel.get_message(message_id)
187
188 if not after:
189 await ctx.send(_("Message not found."))
190 return
191
192 to_delete = await self.get_messages_for_deletion(
193 ctx, channel, 0, limit=None, after=after
194 )
195
196 reason = "{}({}) deleted {} messages in channel {}."\
197 "".format(author.name, author.id,
198 len(to_delete), channel.name)
199 log.info(reason)
200
201 await mass_purge(to_delete, channel)
202
203 @cleanup.command()
204 @commands.guild_only()
205 @commands.bot_has_permissions(manage_messages=True)
206 async def messages(self, ctx: RedContext, number: int):
207 """Deletes last X messages.
208
209 Example:
210 cleanup messages 26"""
211
212 channel = ctx.channel
213 author = ctx.author
214
215 is_bot = self.bot.user.bot
216
217 if number > 100:
218 cont = await self.check_100_plus(ctx, number)
219 if not cont:
220 return
221
222 to_delete = await self.get_messages_for_deletion(
223 ctx, channel, number, limit=1000, before=ctx.message
224 )
225
226 reason = "{}({}) deleted {} messages in channel {}."\
227 "".format(author.name, author.id,
228 number, channel.name)
229 log.info(reason)
230
231 if is_bot:
232 await mass_purge(to_delete, channel)
233 else:
234 await slow_deletion(to_delete)
235
236 @cleanup.command(name='bot')
237 @commands.guild_only()
238 @commands.bot_has_permissions(manage_messages=True)
239 async def cleanup_bot(self, ctx: RedContext, number: int):
240 """Cleans up command messages and messages from the bot."""
241
242 channel = ctx.message.channel
243 author = ctx.message.author
244 is_bot = self.bot.user.bot
245
246 if number > 100:
247 cont = await self.check_100_plus(ctx, number)
248 if not cont:
249 return
250
251 prefixes = await self.bot.get_prefix(ctx.message) # This returns all server prefixes
252 if isinstance(prefixes, str):
253 prefixes = [prefixes]
254
255 # In case some idiot sets a null prefix
256 if '' in prefixes:
257 prefixes.remove('')
258
259 def check(m):
260 if m.author.id == self.bot.user.id:
261 return True
262 elif m == ctx.message:
263 return True
264 p = discord.utils.find(m.content.startswith, prefixes)
265 if p and len(p) > 0:
266 cmd_name = m.content[len(p):].split(' ')[0]
267 return bool(self.bot.get_command(cmd_name))
268 return False
269
270 to_delete = await self.get_messages_for_deletion(
271 ctx, channel, number, check=check, limit=1000, before=ctx.message
272 )
273
274 reason = "{}({}) deleted {} "\
275 " command messages in channel {}."\
276 "".format(author.name, author.id, len(to_delete),
277 channel.name)
278 log.info(reason)
279
280 if is_bot:
281 await mass_purge(to_delete, channel)
282 else:
283 await slow_deletion(to_delete)
284
285 @cleanup.command(name='self')
286 async def cleanup_self(self, ctx: RedContext, number: int, match_pattern: str = None):
287 """Cleans up messages owned by the bot.
288
289 By default, all messages are cleaned. If a third argument is specified,
290 it is used for pattern matching: If it begins with r( and ends with ),
291 then it is interpreted as a regex, and messages that match it are
292 deleted. Otherwise, it is used in a simple substring test.
293
294 Some helpful regex flags to include in your pattern:
295 Dots match newlines: (?s); Ignore case: (?i); Both: (?si)
296 """
297 channel = ctx.channel
298 author = ctx.message.author
299 is_bot = self.bot.user.bot
300
301 if number > 100:
302 cont = await self.check_100_plus(ctx, number)
303 if not cont:
304 return
305
306 # You can always delete your own messages, this is needed to purge
307 can_mass_purge = False
308 if type(author) is discord.Member:
309 me = ctx.guild.me
310 can_mass_purge = channel.permissions_for(me).manage_messages
311
312 use_re = (match_pattern and match_pattern.startswith('r(') and
313 match_pattern.endswith(')'))
314
315 if use_re:
316 match_pattern = match_pattern[1:] # strip 'r'
317 match_re = re.compile(match_pattern)
318
319 def content_match(c):
320 return bool(match_re.match(c))
321 elif match_pattern:
322 def content_match(c):
323 return match_pattern in c
324 else:
325 def content_match(_):
326 return True
327
328 def check(m):
329 if m.author.id != self.bot.user.id:
330 return False
331 elif content_match(m.content):
332 return True
333 return False
334
335 to_delete = await self.get_messages_for_deletion(
336 ctx, channel, number, check=check, limit=1000, before=ctx.message
337 )
338
339 # Selfbot convenience, delete trigger message
340 if author == self.bot.user:
341 to_delete.append(ctx.message)
342
343 if channel.name:
344 channel_name = 'channel ' + channel.name
345 else:
346 channel_name = str(channel)
347
348 reason = "{}({}) deleted {} messages "\
349 "sent by the bot in {}."\
350 "".format(author.name, author.id, len(to_delete),
351 channel_name)
352 log.info(reason)
353
354 if is_bot and can_mass_purge:
355 await mass_purge(to_delete, channel)
356 else:
357 await slow_deletion(to_delete)
358
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/redbot/cogs/cleanup/cleanup.py b/redbot/cogs/cleanup/cleanup.py
--- a/redbot/cogs/cleanup/cleanup.py
+++ b/redbot/cogs/cleanup/cleanup.py
@@ -55,6 +55,7 @@
too_old = False
while not too_old and len(to_delete) - 1 < number:
+ message = None
async for message in channel.history(limit=limit,
before=before,
after=after):
@@ -66,6 +67,9 @@
break
elif number and len(to_delete) >= number:
break
+ if message is None:
+ break
+ else:
before = message
return to_delete
|
{"golden_diff": "diff --git a/redbot/cogs/cleanup/cleanup.py b/redbot/cogs/cleanup/cleanup.py\n--- a/redbot/cogs/cleanup/cleanup.py\n+++ b/redbot/cogs/cleanup/cleanup.py\n@@ -55,6 +55,7 @@\n too_old = False\n \n while not too_old and len(to_delete) - 1 < number:\n+ message = None\n async for message in channel.history(limit=limit,\n before=before,\n after=after):\n@@ -66,6 +67,9 @@\n break\n elif number and len(to_delete) >= number:\n break\n+ if message is None:\n+ break\n+ else:\n before = message\n return to_delete\n", "issue": "[V3 Cleanup] Cleanup messages not deleting if parameter bigger then channel size\n### Type:\r\n\r\n- [ ] Suggestion\r\n- [X] Bug\r\n\r\n### Brief description of the problem\r\n\r\nOn 3.0.0b11, when `[p]cleanup messages` is used and the number parameter is bigger then the messages in the channel, Red will not delete all messages. Since the bug is regarding deletion added walkthrough screenshots.\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "import re\n\nimport discord\nfrom discord.ext import commands\n\nfrom redbot.core import checks, RedContext\nfrom redbot.core.bot import Red\nfrom redbot.core.i18n import CogI18n\nfrom redbot.core.utils.mod import slow_deletion, mass_purge\nfrom redbot.cogs.mod.log import log\n\n_ = CogI18n(\"Cleanup\", __file__)\n\n\nclass Cleanup:\n \"\"\"Commands for cleaning messages\"\"\"\n\n def __init__(self, bot: Red):\n self.bot = bot\n\n @staticmethod\n async def check_100_plus(ctx: RedContext, number: int) -> bool:\n \"\"\"\n Called when trying to delete more than 100 messages at once\n\n Prompts the user to choose whether they want to continue or not\n \"\"\"\n def author_check(message):\n return message.author == ctx.author\n\n await ctx.send(_('Are you sure you want to delete {} messages? (y/n)').format(number))\n response = await ctx.bot.wait_for('message', check=author_check)\n\n if response.content.lower().startswith('y'):\n return True\n else:\n await ctx.send(_('Cancelled.'))\n return False\n\n @staticmethod\n async def get_messages_for_deletion(\n ctx: RedContext, channel: discord.TextChannel, number,\n check=lambda x: True, limit=100, before=None, after=None\n ) -> list:\n \"\"\"\n Gets a list of messages meeting the requirements to be deleted.\n\n Generally, the requirements are:\n - We don't have the number of messages to be deleted already\n - The message passes a provided check (if no check is provided,\n this is automatically true)\n - The message is less than 14 days old\n \"\"\"\n to_delete = []\n too_old = False\n\n while not too_old and len(to_delete) - 1 < number:\n async for message in channel.history(limit=limit,\n before=before,\n after=after):\n if (not number or len(to_delete) - 1 < number) and check(message) \\\n and (ctx.message.created_at - message.created_at).days < 14:\n to_delete.append(message)\n elif (ctx.message.created_at - message.created_at).days >= 14:\n too_old = True\n break\n elif number and len(to_delete) >= number:\n break\n before = message\n return to_delete\n\n @commands.group()\n @checks.mod_or_permissions(manage_messages=True)\n async def cleanup(self, ctx: RedContext):\n \"\"\"Deletes messages.\"\"\"\n if ctx.invoked_subcommand is None:\n await ctx.send_help()\n\n @cleanup.command()\n @commands.guild_only()\n @commands.bot_has_permissions(manage_messages=True)\n async def text(self, ctx: RedContext, text: str, number: int):\n \"\"\"Deletes last X messages matching the specified text.\n\n Example:\n cleanup text \\\"test\\\" 5\n\n Remember to use double quotes.\"\"\"\n\n channel = ctx.channel\n author = ctx.author\n is_bot = self.bot.user.bot\n \n if number > 100:\n cont = await self.check_100_plus(ctx, number)\n if not cont:\n return\n \n def check(m):\n if text in m.content:\n return True\n elif m == ctx.message:\n return True\n else:\n return False\n\n to_delete = await self.get_messages_for_deletion(\n ctx, channel, number, check=check, limit=1000, before=ctx.message)\n\n reason = \"{}({}) deleted {} messages \"\\\n \" containing '{}' in channel {}.\".format(author.name,\n author.id, len(to_delete), text, channel.id)\n log.info(reason)\n\n if is_bot:\n await mass_purge(to_delete, channel)\n else:\n await slow_deletion(to_delete)\n\n @cleanup.command()\n @commands.guild_only()\n @commands.bot_has_permissions(manage_messages=True)\n async def user(self, ctx: RedContext, user: discord.Member or int, number: int):\n \"\"\"Deletes last X messages from specified user.\n\n Examples:\n cleanup user @\\u200bTwentysix 2\n cleanup user Red 6\"\"\"\n\n channel = ctx.channel\n author = ctx.author\n is_bot = self.bot.user.bot\n \n if number > 100:\n cont = await self.check_100_plus(ctx, number)\n if not cont:\n return\n\n def check(m):\n if isinstance(user, discord.Member) and m.author == user:\n return True\n elif m.author.id == user: # Allow finding messages based on an ID\n return True\n elif m == ctx.message:\n return True\n else:\n return False\n\n to_delete = await self.get_messages_for_deletion(\n ctx, channel, number, check=check, limit=1000, before=ctx.message\n )\n reason = \"{}({}) deleted {} messages \"\\\n \" made by {}({}) in channel {}.\"\\\n \"\".format(author.name, author.id, len(to_delete),\n user.name, user.id, channel.name)\n log.info(reason)\n\n if is_bot:\n # For whatever reason the purge endpoint requires manage_messages\n await mass_purge(to_delete, channel)\n else:\n await slow_deletion(to_delete)\n\n @cleanup.command()\n @commands.guild_only()\n @commands.bot_has_permissions(manage_messages=True)\n async def after(self, ctx: RedContext, message_id: int):\n \"\"\"Deletes all messages after specified message.\n\n To get a message id, enable developer mode in Discord's\n settings, 'appearance' tab. Then right click a message\n and copy its id.\n\n This command only works on bots running as bot accounts.\n \"\"\"\n\n channel = ctx.channel\n author = ctx.author\n is_bot = self.bot.user.bot\n\n if not is_bot:\n await ctx.send(_(\"This command can only be used on bots with \"\n \"bot accounts.\"))\n return\n\n after = await channel.get_message(message_id)\n\n if not after:\n await ctx.send(_(\"Message not found.\"))\n return\n\n to_delete = await self.get_messages_for_deletion(\n ctx, channel, 0, limit=None, after=after\n )\n\n reason = \"{}({}) deleted {} messages in channel {}.\"\\\n \"\".format(author.name, author.id,\n len(to_delete), channel.name)\n log.info(reason)\n\n await mass_purge(to_delete, channel)\n\n @cleanup.command()\n @commands.guild_only()\n @commands.bot_has_permissions(manage_messages=True)\n async def messages(self, ctx: RedContext, number: int):\n \"\"\"Deletes last X messages.\n\n Example:\n cleanup messages 26\"\"\"\n\n channel = ctx.channel\n author = ctx.author\n\n is_bot = self.bot.user.bot\n \n if number > 100:\n cont = await self.check_100_plus(ctx, number)\n if not cont:\n return\n\n to_delete = await self.get_messages_for_deletion(\n ctx, channel, number, limit=1000, before=ctx.message\n )\n\n reason = \"{}({}) deleted {} messages in channel {}.\"\\\n \"\".format(author.name, author.id,\n number, channel.name)\n log.info(reason)\n\n if is_bot:\n await mass_purge(to_delete, channel)\n else:\n await slow_deletion(to_delete)\n\n @cleanup.command(name='bot')\n @commands.guild_only()\n @commands.bot_has_permissions(manage_messages=True)\n async def cleanup_bot(self, ctx: RedContext, number: int):\n \"\"\"Cleans up command messages and messages from the bot.\"\"\"\n\n channel = ctx.message.channel\n author = ctx.message.author\n is_bot = self.bot.user.bot\n\n if number > 100:\n cont = await self.check_100_plus(ctx, number)\n if not cont:\n return\n\n prefixes = await self.bot.get_prefix(ctx.message) # This returns all server prefixes\n if isinstance(prefixes, str):\n prefixes = [prefixes]\n\n # In case some idiot sets a null prefix\n if '' in prefixes:\n prefixes.remove('')\n\n def check(m):\n if m.author.id == self.bot.user.id:\n return True\n elif m == ctx.message:\n return True\n p = discord.utils.find(m.content.startswith, prefixes)\n if p and len(p) > 0:\n cmd_name = m.content[len(p):].split(' ')[0]\n return bool(self.bot.get_command(cmd_name))\n return False\n\n to_delete = await self.get_messages_for_deletion(\n ctx, channel, number, check=check, limit=1000, before=ctx.message\n )\n\n reason = \"{}({}) deleted {} \"\\\n \" command messages in channel {}.\"\\\n \"\".format(author.name, author.id, len(to_delete),\n channel.name)\n log.info(reason)\n\n if is_bot:\n await mass_purge(to_delete, channel)\n else:\n await slow_deletion(to_delete)\n\n @cleanup.command(name='self')\n async def cleanup_self(self, ctx: RedContext, number: int, match_pattern: str = None):\n \"\"\"Cleans up messages owned by the bot.\n\n By default, all messages are cleaned. If a third argument is specified,\n it is used for pattern matching: If it begins with r( and ends with ),\n then it is interpreted as a regex, and messages that match it are\n deleted. Otherwise, it is used in a simple substring test.\n\n Some helpful regex flags to include in your pattern:\n Dots match newlines: (?s); Ignore case: (?i); Both: (?si)\n \"\"\"\n channel = ctx.channel\n author = ctx.message.author\n is_bot = self.bot.user.bot\n\n if number > 100:\n cont = await self.check_100_plus(ctx, number)\n if not cont:\n return\n\n # You can always delete your own messages, this is needed to purge\n can_mass_purge = False\n if type(author) is discord.Member:\n me = ctx.guild.me\n can_mass_purge = channel.permissions_for(me).manage_messages\n\n use_re = (match_pattern and match_pattern.startswith('r(') and\n match_pattern.endswith(')'))\n\n if use_re:\n match_pattern = match_pattern[1:] # strip 'r'\n match_re = re.compile(match_pattern)\n\n def content_match(c):\n return bool(match_re.match(c))\n elif match_pattern:\n def content_match(c):\n return match_pattern in c\n else:\n def content_match(_):\n return True\n\n def check(m):\n if m.author.id != self.bot.user.id:\n return False\n elif content_match(m.content):\n return True\n return False\n\n to_delete = await self.get_messages_for_deletion(\n ctx, channel, number, check=check, limit=1000, before=ctx.message\n )\n\n # Selfbot convenience, delete trigger message\n if author == self.bot.user:\n to_delete.append(ctx.message)\n\n if channel.name:\n channel_name = 'channel ' + channel.name\n else:\n channel_name = str(channel)\n\n reason = \"{}({}) deleted {} messages \"\\\n \"sent by the bot in {}.\"\\\n \"\".format(author.name, author.id, len(to_delete),\n channel_name)\n log.info(reason)\n\n if is_bot and can_mass_purge:\n await mass_purge(to_delete, channel)\n else:\n await slow_deletion(to_delete)\n", "path": "redbot/cogs/cleanup/cleanup.py"}], "after_files": [{"content": "import re\n\nimport discord\nfrom discord.ext import commands\n\nfrom redbot.core import checks, RedContext\nfrom redbot.core.bot import Red\nfrom redbot.core.i18n import CogI18n\nfrom redbot.core.utils.mod import slow_deletion, mass_purge\nfrom redbot.cogs.mod.log import log\n\n_ = CogI18n(\"Cleanup\", __file__)\n\n\nclass Cleanup:\n \"\"\"Commands for cleaning messages\"\"\"\n\n def __init__(self, bot: Red):\n self.bot = bot\n\n @staticmethod\n async def check_100_plus(ctx: RedContext, number: int) -> bool:\n \"\"\"\n Called when trying to delete more than 100 messages at once\n\n Prompts the user to choose whether they want to continue or not\n \"\"\"\n def author_check(message):\n return message.author == ctx.author\n\n await ctx.send(_('Are you sure you want to delete {} messages? (y/n)').format(number))\n response = await ctx.bot.wait_for('message', check=author_check)\n\n if response.content.lower().startswith('y'):\n return True\n else:\n await ctx.send(_('Cancelled.'))\n return False\n\n @staticmethod\n async def get_messages_for_deletion(\n ctx: RedContext, channel: discord.TextChannel, number,\n check=lambda x: True, limit=100, before=None, after=None\n ) -> list:\n \"\"\"\n Gets a list of messages meeting the requirements to be deleted.\n\n Generally, the requirements are:\n - We don't have the number of messages to be deleted already\n - The message passes a provided check (if no check is provided,\n this is automatically true)\n - The message is less than 14 days old\n \"\"\"\n to_delete = []\n too_old = False\n\n while not too_old and len(to_delete) - 1 < number:\n message = None\n async for message in channel.history(limit=limit,\n before=before,\n after=after):\n if (not number or len(to_delete) - 1 < number) and check(message) \\\n and (ctx.message.created_at - message.created_at).days < 14:\n to_delete.append(message)\n elif (ctx.message.created_at - message.created_at).days >= 14:\n too_old = True\n break\n elif number and len(to_delete) >= number:\n break\n if message is None:\n break\n else:\n before = message\n return to_delete\n\n @commands.group()\n @checks.mod_or_permissions(manage_messages=True)\n async def cleanup(self, ctx: RedContext):\n \"\"\"Deletes messages.\"\"\"\n if ctx.invoked_subcommand is None:\n await ctx.send_help()\n\n @cleanup.command()\n @commands.guild_only()\n @commands.bot_has_permissions(manage_messages=True)\n async def text(self, ctx: RedContext, text: str, number: int):\n \"\"\"Deletes last X messages matching the specified text.\n\n Example:\n cleanup text \\\"test\\\" 5\n\n Remember to use double quotes.\"\"\"\n\n channel = ctx.channel\n author = ctx.author\n is_bot = self.bot.user.bot\n \n if number > 100:\n cont = await self.check_100_plus(ctx, number)\n if not cont:\n return\n \n def check(m):\n if text in m.content:\n return True\n elif m == ctx.message:\n return True\n else:\n return False\n\n to_delete = await self.get_messages_for_deletion(\n ctx, channel, number, check=check, limit=1000, before=ctx.message)\n\n reason = \"{}({}) deleted {} messages \"\\\n \" containing '{}' in channel {}.\".format(author.name,\n author.id, len(to_delete), text, channel.id)\n log.info(reason)\n\n if is_bot:\n await mass_purge(to_delete, channel)\n else:\n await slow_deletion(to_delete)\n\n @cleanup.command()\n @commands.guild_only()\n @commands.bot_has_permissions(manage_messages=True)\n async def user(self, ctx: RedContext, user: discord.Member or int, number: int):\n \"\"\"Deletes last X messages from specified user.\n\n Examples:\n cleanup user @\\u200bTwentysix 2\n cleanup user Red 6\"\"\"\n\n channel = ctx.channel\n author = ctx.author\n is_bot = self.bot.user.bot\n \n if number > 100:\n cont = await self.check_100_plus(ctx, number)\n if not cont:\n return\n\n def check(m):\n if isinstance(user, discord.Member) and m.author == user:\n return True\n elif m.author.id == user: # Allow finding messages based on an ID\n return True\n elif m == ctx.message:\n return True\n else:\n return False\n\n to_delete = await self.get_messages_for_deletion(\n ctx, channel, number, check=check, limit=1000, before=ctx.message\n )\n reason = \"{}({}) deleted {} messages \"\\\n \" made by {}({}) in channel {}.\"\\\n \"\".format(author.name, author.id, len(to_delete),\n user.name, user.id, channel.name)\n log.info(reason)\n\n if is_bot:\n # For whatever reason the purge endpoint requires manage_messages\n await mass_purge(to_delete, channel)\n else:\n await slow_deletion(to_delete)\n\n @cleanup.command()\n @commands.guild_only()\n @commands.bot_has_permissions(manage_messages=True)\n async def after(self, ctx: RedContext, message_id: int):\n \"\"\"Deletes all messages after specified message.\n\n To get a message id, enable developer mode in Discord's\n settings, 'appearance' tab. Then right click a message\n and copy its id.\n\n This command only works on bots running as bot accounts.\n \"\"\"\n\n channel = ctx.channel\n author = ctx.author\n is_bot = self.bot.user.bot\n\n if not is_bot:\n await ctx.send(_(\"This command can only be used on bots with \"\n \"bot accounts.\"))\n return\n\n after = await channel.get_message(message_id)\n\n if not after:\n await ctx.send(_(\"Message not found.\"))\n return\n\n to_delete = await self.get_messages_for_deletion(\n ctx, channel, 0, limit=None, after=after\n )\n\n reason = \"{}({}) deleted {} messages in channel {}.\"\\\n \"\".format(author.name, author.id,\n len(to_delete), channel.name)\n log.info(reason)\n\n await mass_purge(to_delete, channel)\n\n @cleanup.command()\n @commands.guild_only()\n @commands.bot_has_permissions(manage_messages=True)\n async def messages(self, ctx: RedContext, number: int):\n \"\"\"Deletes last X messages.\n\n Example:\n cleanup messages 26\"\"\"\n\n channel = ctx.channel\n author = ctx.author\n\n is_bot = self.bot.user.bot\n \n if number > 100:\n cont = await self.check_100_plus(ctx, number)\n if not cont:\n return\n\n to_delete = await self.get_messages_for_deletion(\n ctx, channel, number, limit=1000, before=ctx.message\n )\n\n reason = \"{}({}) deleted {} messages in channel {}.\"\\\n \"\".format(author.name, author.id,\n number, channel.name)\n log.info(reason)\n\n if is_bot:\n await mass_purge(to_delete, channel)\n else:\n await slow_deletion(to_delete)\n\n @cleanup.command(name='bot')\n @commands.guild_only()\n @commands.bot_has_permissions(manage_messages=True)\n async def cleanup_bot(self, ctx: RedContext, number: int):\n \"\"\"Cleans up command messages and messages from the bot.\"\"\"\n\n channel = ctx.message.channel\n author = ctx.message.author\n is_bot = self.bot.user.bot\n\n if number > 100:\n cont = await self.check_100_plus(ctx, number)\n if not cont:\n return\n\n prefixes = await self.bot.get_prefix(ctx.message) # This returns all server prefixes\n if isinstance(prefixes, str):\n prefixes = [prefixes]\n\n # In case some idiot sets a null prefix\n if '' in prefixes:\n prefixes.remove('')\n\n def check(m):\n if m.author.id == self.bot.user.id:\n return True\n elif m == ctx.message:\n return True\n p = discord.utils.find(m.content.startswith, prefixes)\n if p and len(p) > 0:\n cmd_name = m.content[len(p):].split(' ')[0]\n return bool(self.bot.get_command(cmd_name))\n return False\n\n to_delete = await self.get_messages_for_deletion(\n ctx, channel, number, check=check, limit=1000, before=ctx.message\n )\n\n reason = \"{}({}) deleted {} \"\\\n \" command messages in channel {}.\"\\\n \"\".format(author.name, author.id, len(to_delete),\n channel.name)\n log.info(reason)\n\n if is_bot:\n await mass_purge(to_delete, channel)\n else:\n await slow_deletion(to_delete)\n\n @cleanup.command(name='self')\n async def cleanup_self(self, ctx: RedContext, number: int, match_pattern: str = None):\n \"\"\"Cleans up messages owned by the bot.\n\n By default, all messages are cleaned. If a third argument is specified,\n it is used for pattern matching: If it begins with r( and ends with ),\n then it is interpreted as a regex, and messages that match it are\n deleted. Otherwise, it is used in a simple substring test.\n\n Some helpful regex flags to include in your pattern:\n Dots match newlines: (?s); Ignore case: (?i); Both: (?si)\n \"\"\"\n channel = ctx.channel\n author = ctx.message.author\n is_bot = self.bot.user.bot\n\n if number > 100:\n cont = await self.check_100_plus(ctx, number)\n if not cont:\n return\n\n # You can always delete your own messages, this is needed to purge\n can_mass_purge = False\n if type(author) is discord.Member:\n me = ctx.guild.me\n can_mass_purge = channel.permissions_for(me).manage_messages\n\n use_re = (match_pattern and match_pattern.startswith('r(') and\n match_pattern.endswith(')'))\n\n if use_re:\n match_pattern = match_pattern[1:] # strip 'r'\n match_re = re.compile(match_pattern)\n\n def content_match(c):\n return bool(match_re.match(c))\n elif match_pattern:\n def content_match(c):\n return match_pattern in c\n else:\n def content_match(_):\n return True\n\n def check(m):\n if m.author.id != self.bot.user.id:\n return False\n elif content_match(m.content):\n return True\n return False\n\n to_delete = await self.get_messages_for_deletion(\n ctx, channel, number, check=check, limit=1000, before=ctx.message\n )\n\n # Selfbot convenience, delete trigger message\n if author == self.bot.user:\n to_delete.append(ctx.message)\n\n if channel.name:\n channel_name = 'channel ' + channel.name\n else:\n channel_name = str(channel)\n\n reason = \"{}({}) deleted {} messages \"\\\n \"sent by the bot in {}.\"\\\n \"\".format(author.name, author.id, len(to_delete),\n channel_name)\n log.info(reason)\n\n if is_bot and can_mass_purge:\n await mass_purge(to_delete, channel)\n else:\n await slow_deletion(to_delete)\n", "path": "redbot/cogs/cleanup/cleanup.py"}]}
| 4,008 | 163 |
gh_patches_debug_28591
|
rasdani/github-patches
|
git_diff
|
python-pillow__Pillow-3869
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Image.show() on image with mode LA does not show transparency
When I use `Image.show()` on an image with mode `LA`, transparency is not shown. When I use `.save(...)`, the resulting image has transparency included correctly. With mode `RGBA`, transparency is correctly displayed on `.show()` (and correctly written on `.save(...)`).
### What did you do?
I used `.show()` on an image with mode `LA`.
### What did you expect to happen?
I expected it to display an image with transparency:

### What actually happened?
It showed an image without transparency:

### What are your OS, Python and Pillow versions?
* OS: openSUSE 15.0
* Python: 3.7.3
* Pillow: 6.0.0
```python
from numpy import linspace, block, concatenate, zeros, full
from PIL import Image
L = linspace(0, 255, 200*200, dtype="u1").reshape(200, 200, 1)
A = block([[zeros((100, 100), "u1"), full((100, 100), 255, "u1")],
[full((100, 100), 255, "u1"),
zeros((100, 100), "u1")]]).reshape(200, 200, 1)
im1 = Image.fromarray((concatenate((L, A), 2)), mode="LA")
im2 = Image.fromarray((concatenate((L, L, L, A), 2)), mode="RGBA")
im1.show()
im2.show()
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/PIL/ImageMode.py`
Content:
```
1 #
2 # The Python Imaging Library.
3 # $Id$
4 #
5 # standard mode descriptors
6 #
7 # History:
8 # 2006-03-20 fl Added
9 #
10 # Copyright (c) 2006 by Secret Labs AB.
11 # Copyright (c) 2006 by Fredrik Lundh.
12 #
13 # See the README file for information on usage and redistribution.
14 #
15
16 # mode descriptor cache
17 _modes = None
18
19
20 class ModeDescriptor(object):
21 """Wrapper for mode strings."""
22
23 def __init__(self, mode, bands, basemode, basetype):
24 self.mode = mode
25 self.bands = bands
26 self.basemode = basemode
27 self.basetype = basetype
28
29 def __str__(self):
30 return self.mode
31
32
33 def getmode(mode):
34 """Gets a mode descriptor for the given mode."""
35 global _modes
36 if not _modes:
37 # initialize mode cache
38
39 from . import Image
40
41 modes = {}
42 # core modes
43 for m, (basemode, basetype, bands) in Image._MODEINFO.items():
44 modes[m] = ModeDescriptor(m, bands, basemode, basetype)
45 # extra experimental modes
46 modes["RGBa"] = ModeDescriptor("RGBa", ("R", "G", "B", "a"), "RGB", "L")
47 modes["LA"] = ModeDescriptor("LA", ("L", "A"), "L", "L")
48 modes["La"] = ModeDescriptor("La", ("L", "a"), "L", "L")
49 modes["PA"] = ModeDescriptor("PA", ("P", "A"), "RGB", "L")
50 # mapping modes
51 modes["I;16"] = ModeDescriptor("I;16", "I", "L", "L")
52 modes["I;16L"] = ModeDescriptor("I;16L", "I", "L", "L")
53 modes["I;16B"] = ModeDescriptor("I;16B", "I", "L", "L")
54 # set global mode cache atomically
55 _modes = modes
56 return _modes[mode]
57
```
Path: `src/PIL/ImageShow.py`
Content:
```
1 #
2 # The Python Imaging Library.
3 # $Id$
4 #
5 # im.show() drivers
6 #
7 # History:
8 # 2008-04-06 fl Created
9 #
10 # Copyright (c) Secret Labs AB 2008.
11 #
12 # See the README file for information on usage and redistribution.
13 #
14
15 from __future__ import print_function
16
17 from PIL import Image
18 import os
19 import sys
20 import subprocess
21 import tempfile
22
23 if sys.version_info.major >= 3:
24 from shlex import quote
25 else:
26 from pipes import quote
27
28 _viewers = []
29
30
31 def register(viewer, order=1):
32 try:
33 if issubclass(viewer, Viewer):
34 viewer = viewer()
35 except TypeError:
36 pass # raised if viewer wasn't a class
37 if order > 0:
38 _viewers.append(viewer)
39 elif order < 0:
40 _viewers.insert(0, viewer)
41
42
43 def show(image, title=None, **options):
44 r"""
45 Display a given image.
46
47 :param image: An image object.
48 :param title: Optional title. Not all viewers can display the title.
49 :param \**options: Additional viewer options.
50 :returns: True if a suitable viewer was found, false otherwise.
51 """
52 for viewer in _viewers:
53 if viewer.show(image, title=title, **options):
54 return 1
55 return 0
56
57
58 class Viewer(object):
59 """Base class for viewers."""
60
61 # main api
62
63 def show(self, image, **options):
64
65 # save temporary image to disk
66 if image.mode[:4] == "I;16":
67 # @PIL88 @PIL101
68 # "I;16" isn't an 'official' mode, but we still want to
69 # provide a simple way to show 16-bit images.
70 base = "L"
71 # FIXME: auto-contrast if max() > 255?
72 else:
73 base = Image.getmodebase(image.mode)
74 if base != image.mode and image.mode != "1" and image.mode != "RGBA":
75 image = image.convert(base)
76
77 return self.show_image(image, **options)
78
79 # hook methods
80
81 format = None
82 options = {}
83
84 def get_format(self, image):
85 """Return format name, or None to save as PGM/PPM"""
86 return self.format
87
88 def get_command(self, file, **options):
89 raise NotImplementedError
90
91 def save_image(self, image):
92 """Save to temporary file, and return filename"""
93 return image._dump(format=self.get_format(image), **self.options)
94
95 def show_image(self, image, **options):
96 """Display given image"""
97 return self.show_file(self.save_image(image), **options)
98
99 def show_file(self, file, **options):
100 """Display given file"""
101 os.system(self.get_command(file, **options))
102 return 1
103
104
105 # --------------------------------------------------------------------
106
107
108 if sys.platform == "win32":
109
110 class WindowsViewer(Viewer):
111 format = "BMP"
112
113 def get_command(self, file, **options):
114 return (
115 'start "Pillow" /WAIT "%s" '
116 "&& ping -n 2 127.0.0.1 >NUL "
117 '&& del /f "%s"' % (file, file)
118 )
119
120 register(WindowsViewer)
121
122 elif sys.platform == "darwin":
123
124 class MacViewer(Viewer):
125 format = "PNG"
126 options = {"compress_level": 1}
127
128 def get_command(self, file, **options):
129 # on darwin open returns immediately resulting in the temp
130 # file removal while app is opening
131 command = "open -a /Applications/Preview.app"
132 command = "(%s %s; sleep 20; rm -f %s)&" % (
133 command,
134 quote(file),
135 quote(file),
136 )
137 return command
138
139 def show_file(self, file, **options):
140 """Display given file"""
141 fd, path = tempfile.mkstemp()
142 with os.fdopen(fd, "w") as f:
143 f.write(file)
144 with open(path, "r") as f:
145 subprocess.Popen(
146 [
147 "im=$(cat);"
148 "open -a /Applications/Preview.app $im;"
149 "sleep 20;"
150 "rm -f $im"
151 ],
152 shell=True,
153 stdin=f,
154 )
155 os.remove(path)
156 return 1
157
158 register(MacViewer)
159
160 else:
161
162 # unixoids
163
164 def which(executable):
165 path = os.environ.get("PATH")
166 if not path:
167 return None
168 for dirname in path.split(os.pathsep):
169 filename = os.path.join(dirname, executable)
170 if os.path.isfile(filename) and os.access(filename, os.X_OK):
171 return filename
172 return None
173
174 class UnixViewer(Viewer):
175 format = "PNG"
176 options = {"compress_level": 1}
177
178 def get_command(self, file, **options):
179 command = self.get_command_ex(file, **options)[0]
180 return "(%s %s; rm -f %s)&" % (command, quote(file), quote(file))
181
182 def show_file(self, file, **options):
183 """Display given file"""
184 fd, path = tempfile.mkstemp()
185 with os.fdopen(fd, "w") as f:
186 f.write(file)
187 with open(path, "r") as f:
188 command = self.get_command_ex(file, **options)[0]
189 subprocess.Popen(
190 ["im=$(cat);" + command + " $im;" "rm -f $im"], shell=True, stdin=f
191 )
192 os.remove(path)
193 return 1
194
195 # implementations
196
197 class DisplayViewer(UnixViewer):
198 def get_command_ex(self, file, **options):
199 command = executable = "display"
200 return command, executable
201
202 if which("display"):
203 register(DisplayViewer)
204
205 class EogViewer(UnixViewer):
206 def get_command_ex(self, file, **options):
207 command = executable = "eog"
208 return command, executable
209
210 if which("eog"):
211 register(EogViewer)
212
213 class XVViewer(UnixViewer):
214 def get_command_ex(self, file, title=None, **options):
215 # note: xv is pretty outdated. most modern systems have
216 # imagemagick's display command instead.
217 command = executable = "xv"
218 if title:
219 command += " -name %s" % quote(title)
220 return command, executable
221
222 if which("xv"):
223 register(XVViewer)
224
225 if __name__ == "__main__":
226
227 if len(sys.argv) < 2:
228 print("Syntax: python ImageShow.py imagefile [title]")
229 sys.exit()
230
231 print(show(Image.open(sys.argv[1]), *sys.argv[2:]))
232
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/PIL/ImageMode.py b/src/PIL/ImageMode.py
--- a/src/PIL/ImageMode.py
+++ b/src/PIL/ImageMode.py
@@ -48,9 +48,17 @@
modes["La"] = ModeDescriptor("La", ("L", "a"), "L", "L")
modes["PA"] = ModeDescriptor("PA", ("P", "A"), "RGB", "L")
# mapping modes
- modes["I;16"] = ModeDescriptor("I;16", "I", "L", "L")
- modes["I;16L"] = ModeDescriptor("I;16L", "I", "L", "L")
- modes["I;16B"] = ModeDescriptor("I;16B", "I", "L", "L")
+ for i16mode in (
+ "I;16",
+ "I;16S",
+ "I;16L",
+ "I;16LS",
+ "I;16B",
+ "I;16BS",
+ "I;16N",
+ "I;16NS",
+ ):
+ modes[i16mode] = ModeDescriptor(i16mode, ("I",), "L", "L")
# set global mode cache atomically
_modes = modes
return _modes[mode]
diff --git a/src/PIL/ImageShow.py b/src/PIL/ImageShow.py
--- a/src/PIL/ImageShow.py
+++ b/src/PIL/ImageShow.py
@@ -63,16 +63,12 @@
def show(self, image, **options):
# save temporary image to disk
- if image.mode[:4] == "I;16":
- # @PIL88 @PIL101
- # "I;16" isn't an 'official' mode, but we still want to
- # provide a simple way to show 16-bit images.
- base = "L"
- # FIXME: auto-contrast if max() > 255?
- else:
+ if not (
+ image.mode in ("1", "RGBA") or (self.format == "PNG" and image.mode == "LA")
+ ):
base = Image.getmodebase(image.mode)
- if base != image.mode and image.mode != "1" and image.mode != "RGBA":
- image = image.convert(base)
+ if image.mode != base:
+ image = image.convert(base)
return self.show_image(image, **options)
|
{"golden_diff": "diff --git a/src/PIL/ImageMode.py b/src/PIL/ImageMode.py\n--- a/src/PIL/ImageMode.py\n+++ b/src/PIL/ImageMode.py\n@@ -48,9 +48,17 @@\n modes[\"La\"] = ModeDescriptor(\"La\", (\"L\", \"a\"), \"L\", \"L\")\n modes[\"PA\"] = ModeDescriptor(\"PA\", (\"P\", \"A\"), \"RGB\", \"L\")\n # mapping modes\n- modes[\"I;16\"] = ModeDescriptor(\"I;16\", \"I\", \"L\", \"L\")\n- modes[\"I;16L\"] = ModeDescriptor(\"I;16L\", \"I\", \"L\", \"L\")\n- modes[\"I;16B\"] = ModeDescriptor(\"I;16B\", \"I\", \"L\", \"L\")\n+ for i16mode in (\n+ \"I;16\",\n+ \"I;16S\",\n+ \"I;16L\",\n+ \"I;16LS\",\n+ \"I;16B\",\n+ \"I;16BS\",\n+ \"I;16N\",\n+ \"I;16NS\",\n+ ):\n+ modes[i16mode] = ModeDescriptor(i16mode, (\"I\",), \"L\", \"L\")\n # set global mode cache atomically\n _modes = modes\n return _modes[mode]\ndiff --git a/src/PIL/ImageShow.py b/src/PIL/ImageShow.py\n--- a/src/PIL/ImageShow.py\n+++ b/src/PIL/ImageShow.py\n@@ -63,16 +63,12 @@\n def show(self, image, **options):\n \n # save temporary image to disk\n- if image.mode[:4] == \"I;16\":\n- # @PIL88 @PIL101\n- # \"I;16\" isn't an 'official' mode, but we still want to\n- # provide a simple way to show 16-bit images.\n- base = \"L\"\n- # FIXME: auto-contrast if max() > 255?\n- else:\n+ if not (\n+ image.mode in (\"1\", \"RGBA\") or (self.format == \"PNG\" and image.mode == \"LA\")\n+ ):\n base = Image.getmodebase(image.mode)\n- if base != image.mode and image.mode != \"1\" and image.mode != \"RGBA\":\n- image = image.convert(base)\n+ if image.mode != base:\n+ image = image.convert(base)\n \n return self.show_image(image, **options)\n", "issue": "Image.show() on image with mode LA does not show transparency\nWhen I use `Image.show()` on an image with mode `LA`, transparency is not shown. When I use `.save(...)`, the resulting image has transparency included correctly. With mode `RGBA`, transparency is correctly displayed on `.show()` (and correctly written on `.save(...)`).\r\n\r\n### What did you do?\r\n\r\nI used `.show()` on an image with mode `LA`.\r\n\r\n### What did you expect to happen?\r\n\r\nI expected it to display an image with transparency:\r\n\r\n\r\n\r\n### What actually happened?\r\n\r\nIt showed an image without transparency:\r\n\r\n\r\n\r\n### What are your OS, Python and Pillow versions?\r\n\r\n* OS: openSUSE 15.0\r\n* Python: 3.7.3\r\n* Pillow: 6.0.0\r\n\r\n```python\r\nfrom numpy import linspace, block, concatenate, zeros, full\r\nfrom PIL import Image\r\n\r\nL = linspace(0, 255, 200*200, dtype=\"u1\").reshape(200, 200, 1)\r\nA = block([[zeros((100, 100), \"u1\"), full((100, 100), 255, \"u1\")],\r\n [full((100, 100), 255, \"u1\"),\r\n zeros((100, 100), \"u1\")]]).reshape(200, 200, 1)\r\nim1 = Image.fromarray((concatenate((L, A), 2)), mode=\"LA\")\r\nim2 = Image.fromarray((concatenate((L, L, L, A), 2)), mode=\"RGBA\")\r\nim1.show()\r\nim2.show()\r\n```\r\n\n", "before_files": [{"content": "#\n# The Python Imaging Library.\n# $Id$\n#\n# standard mode descriptors\n#\n# History:\n# 2006-03-20 fl Added\n#\n# Copyright (c) 2006 by Secret Labs AB.\n# Copyright (c) 2006 by Fredrik Lundh.\n#\n# See the README file for information on usage and redistribution.\n#\n\n# mode descriptor cache\n_modes = None\n\n\nclass ModeDescriptor(object):\n \"\"\"Wrapper for mode strings.\"\"\"\n\n def __init__(self, mode, bands, basemode, basetype):\n self.mode = mode\n self.bands = bands\n self.basemode = basemode\n self.basetype = basetype\n\n def __str__(self):\n return self.mode\n\n\ndef getmode(mode):\n \"\"\"Gets a mode descriptor for the given mode.\"\"\"\n global _modes\n if not _modes:\n # initialize mode cache\n\n from . import Image\n\n modes = {}\n # core modes\n for m, (basemode, basetype, bands) in Image._MODEINFO.items():\n modes[m] = ModeDescriptor(m, bands, basemode, basetype)\n # extra experimental modes\n modes[\"RGBa\"] = ModeDescriptor(\"RGBa\", (\"R\", \"G\", \"B\", \"a\"), \"RGB\", \"L\")\n modes[\"LA\"] = ModeDescriptor(\"LA\", (\"L\", \"A\"), \"L\", \"L\")\n modes[\"La\"] = ModeDescriptor(\"La\", (\"L\", \"a\"), \"L\", \"L\")\n modes[\"PA\"] = ModeDescriptor(\"PA\", (\"P\", \"A\"), \"RGB\", \"L\")\n # mapping modes\n modes[\"I;16\"] = ModeDescriptor(\"I;16\", \"I\", \"L\", \"L\")\n modes[\"I;16L\"] = ModeDescriptor(\"I;16L\", \"I\", \"L\", \"L\")\n modes[\"I;16B\"] = ModeDescriptor(\"I;16B\", \"I\", \"L\", \"L\")\n # set global mode cache atomically\n _modes = modes\n return _modes[mode]\n", "path": "src/PIL/ImageMode.py"}, {"content": "#\n# The Python Imaging Library.\n# $Id$\n#\n# im.show() drivers\n#\n# History:\n# 2008-04-06 fl Created\n#\n# Copyright (c) Secret Labs AB 2008.\n#\n# See the README file for information on usage and redistribution.\n#\n\nfrom __future__ import print_function\n\nfrom PIL import Image\nimport os\nimport sys\nimport subprocess\nimport tempfile\n\nif sys.version_info.major >= 3:\n from shlex import quote\nelse:\n from pipes import quote\n\n_viewers = []\n\n\ndef register(viewer, order=1):\n try:\n if issubclass(viewer, Viewer):\n viewer = viewer()\n except TypeError:\n pass # raised if viewer wasn't a class\n if order > 0:\n _viewers.append(viewer)\n elif order < 0:\n _viewers.insert(0, viewer)\n\n\ndef show(image, title=None, **options):\n r\"\"\"\n Display a given image.\n\n :param image: An image object.\n :param title: Optional title. Not all viewers can display the title.\n :param \\**options: Additional viewer options.\n :returns: True if a suitable viewer was found, false otherwise.\n \"\"\"\n for viewer in _viewers:\n if viewer.show(image, title=title, **options):\n return 1\n return 0\n\n\nclass Viewer(object):\n \"\"\"Base class for viewers.\"\"\"\n\n # main api\n\n def show(self, image, **options):\n\n # save temporary image to disk\n if image.mode[:4] == \"I;16\":\n # @PIL88 @PIL101\n # \"I;16\" isn't an 'official' mode, but we still want to\n # provide a simple way to show 16-bit images.\n base = \"L\"\n # FIXME: auto-contrast if max() > 255?\n else:\n base = Image.getmodebase(image.mode)\n if base != image.mode and image.mode != \"1\" and image.mode != \"RGBA\":\n image = image.convert(base)\n\n return self.show_image(image, **options)\n\n # hook methods\n\n format = None\n options = {}\n\n def get_format(self, image):\n \"\"\"Return format name, or None to save as PGM/PPM\"\"\"\n return self.format\n\n def get_command(self, file, **options):\n raise NotImplementedError\n\n def save_image(self, image):\n \"\"\"Save to temporary file, and return filename\"\"\"\n return image._dump(format=self.get_format(image), **self.options)\n\n def show_image(self, image, **options):\n \"\"\"Display given image\"\"\"\n return self.show_file(self.save_image(image), **options)\n\n def show_file(self, file, **options):\n \"\"\"Display given file\"\"\"\n os.system(self.get_command(file, **options))\n return 1\n\n\n# --------------------------------------------------------------------\n\n\nif sys.platform == \"win32\":\n\n class WindowsViewer(Viewer):\n format = \"BMP\"\n\n def get_command(self, file, **options):\n return (\n 'start \"Pillow\" /WAIT \"%s\" '\n \"&& ping -n 2 127.0.0.1 >NUL \"\n '&& del /f \"%s\"' % (file, file)\n )\n\n register(WindowsViewer)\n\nelif sys.platform == \"darwin\":\n\n class MacViewer(Viewer):\n format = \"PNG\"\n options = {\"compress_level\": 1}\n\n def get_command(self, file, **options):\n # on darwin open returns immediately resulting in the temp\n # file removal while app is opening\n command = \"open -a /Applications/Preview.app\"\n command = \"(%s %s; sleep 20; rm -f %s)&\" % (\n command,\n quote(file),\n quote(file),\n )\n return command\n\n def show_file(self, file, **options):\n \"\"\"Display given file\"\"\"\n fd, path = tempfile.mkstemp()\n with os.fdopen(fd, \"w\") as f:\n f.write(file)\n with open(path, \"r\") as f:\n subprocess.Popen(\n [\n \"im=$(cat);\"\n \"open -a /Applications/Preview.app $im;\"\n \"sleep 20;\"\n \"rm -f $im\"\n ],\n shell=True,\n stdin=f,\n )\n os.remove(path)\n return 1\n\n register(MacViewer)\n\nelse:\n\n # unixoids\n\n def which(executable):\n path = os.environ.get(\"PATH\")\n if not path:\n return None\n for dirname in path.split(os.pathsep):\n filename = os.path.join(dirname, executable)\n if os.path.isfile(filename) and os.access(filename, os.X_OK):\n return filename\n return None\n\n class UnixViewer(Viewer):\n format = \"PNG\"\n options = {\"compress_level\": 1}\n\n def get_command(self, file, **options):\n command = self.get_command_ex(file, **options)[0]\n return \"(%s %s; rm -f %s)&\" % (command, quote(file), quote(file))\n\n def show_file(self, file, **options):\n \"\"\"Display given file\"\"\"\n fd, path = tempfile.mkstemp()\n with os.fdopen(fd, \"w\") as f:\n f.write(file)\n with open(path, \"r\") as f:\n command = self.get_command_ex(file, **options)[0]\n subprocess.Popen(\n [\"im=$(cat);\" + command + \" $im;\" \"rm -f $im\"], shell=True, stdin=f\n )\n os.remove(path)\n return 1\n\n # implementations\n\n class DisplayViewer(UnixViewer):\n def get_command_ex(self, file, **options):\n command = executable = \"display\"\n return command, executable\n\n if which(\"display\"):\n register(DisplayViewer)\n\n class EogViewer(UnixViewer):\n def get_command_ex(self, file, **options):\n command = executable = \"eog\"\n return command, executable\n\n if which(\"eog\"):\n register(EogViewer)\n\n class XVViewer(UnixViewer):\n def get_command_ex(self, file, title=None, **options):\n # note: xv is pretty outdated. most modern systems have\n # imagemagick's display command instead.\n command = executable = \"xv\"\n if title:\n command += \" -name %s\" % quote(title)\n return command, executable\n\n if which(\"xv\"):\n register(XVViewer)\n\nif __name__ == \"__main__\":\n\n if len(sys.argv) < 2:\n print(\"Syntax: python ImageShow.py imagefile [title]\")\n sys.exit()\n\n print(show(Image.open(sys.argv[1]), *sys.argv[2:]))\n", "path": "src/PIL/ImageShow.py"}], "after_files": [{"content": "#\n# The Python Imaging Library.\n# $Id$\n#\n# standard mode descriptors\n#\n# History:\n# 2006-03-20 fl Added\n#\n# Copyright (c) 2006 by Secret Labs AB.\n# Copyright (c) 2006 by Fredrik Lundh.\n#\n# See the README file for information on usage and redistribution.\n#\n\n# mode descriptor cache\n_modes = None\n\n\nclass ModeDescriptor(object):\n \"\"\"Wrapper for mode strings.\"\"\"\n\n def __init__(self, mode, bands, basemode, basetype):\n self.mode = mode\n self.bands = bands\n self.basemode = basemode\n self.basetype = basetype\n\n def __str__(self):\n return self.mode\n\n\ndef getmode(mode):\n \"\"\"Gets a mode descriptor for the given mode.\"\"\"\n global _modes\n if not _modes:\n # initialize mode cache\n\n from . import Image\n\n modes = {}\n # core modes\n for m, (basemode, basetype, bands) in Image._MODEINFO.items():\n modes[m] = ModeDescriptor(m, bands, basemode, basetype)\n # extra experimental modes\n modes[\"RGBa\"] = ModeDescriptor(\"RGBa\", (\"R\", \"G\", \"B\", \"a\"), \"RGB\", \"L\")\n modes[\"LA\"] = ModeDescriptor(\"LA\", (\"L\", \"A\"), \"L\", \"L\")\n modes[\"La\"] = ModeDescriptor(\"La\", (\"L\", \"a\"), \"L\", \"L\")\n modes[\"PA\"] = ModeDescriptor(\"PA\", (\"P\", \"A\"), \"RGB\", \"L\")\n # mapping modes\n for i16mode in (\n \"I;16\",\n \"I;16S\",\n \"I;16L\",\n \"I;16LS\",\n \"I;16B\",\n \"I;16BS\",\n \"I;16N\",\n \"I;16NS\",\n ):\n modes[i16mode] = ModeDescriptor(i16mode, (\"I\",), \"L\", \"L\")\n # set global mode cache atomically\n _modes = modes\n return _modes[mode]\n", "path": "src/PIL/ImageMode.py"}, {"content": "#\n# The Python Imaging Library.\n# $Id$\n#\n# im.show() drivers\n#\n# History:\n# 2008-04-06 fl Created\n#\n# Copyright (c) Secret Labs AB 2008.\n#\n# See the README file for information on usage and redistribution.\n#\n\nfrom __future__ import print_function\n\nfrom PIL import Image\nimport os\nimport sys\nimport subprocess\nimport tempfile\n\nif sys.version_info.major >= 3:\n from shlex import quote\nelse:\n from pipes import quote\n\n_viewers = []\n\n\ndef register(viewer, order=1):\n try:\n if issubclass(viewer, Viewer):\n viewer = viewer()\n except TypeError:\n pass # raised if viewer wasn't a class\n if order > 0:\n _viewers.append(viewer)\n elif order < 0:\n _viewers.insert(0, viewer)\n\n\ndef show(image, title=None, **options):\n r\"\"\"\n Display a given image.\n\n :param image: An image object.\n :param title: Optional title. Not all viewers can display the title.\n :param \\**options: Additional viewer options.\n :returns: True if a suitable viewer was found, false otherwise.\n \"\"\"\n for viewer in _viewers:\n if viewer.show(image, title=title, **options):\n return 1\n return 0\n\n\nclass Viewer(object):\n \"\"\"Base class for viewers.\"\"\"\n\n # main api\n\n def show(self, image, **options):\n\n # save temporary image to disk\n if not (\n image.mode in (\"1\", \"RGBA\") or (self.format == \"PNG\" and image.mode == \"LA\")\n ):\n base = Image.getmodebase(image.mode)\n if image.mode != base:\n image = image.convert(base)\n\n return self.show_image(image, **options)\n\n # hook methods\n\n format = None\n options = {}\n\n def get_format(self, image):\n \"\"\"Return format name, or None to save as PGM/PPM\"\"\"\n return self.format\n\n def get_command(self, file, **options):\n raise NotImplementedError\n\n def save_image(self, image):\n \"\"\"Save to temporary file, and return filename\"\"\"\n return image._dump(format=self.get_format(image), **self.options)\n\n def show_image(self, image, **options):\n \"\"\"Display given image\"\"\"\n return self.show_file(self.save_image(image), **options)\n\n def show_file(self, file, **options):\n \"\"\"Display given file\"\"\"\n os.system(self.get_command(file, **options))\n return 1\n\n\n# --------------------------------------------------------------------\n\n\nif sys.platform == \"win32\":\n\n class WindowsViewer(Viewer):\n format = \"BMP\"\n\n def get_command(self, file, **options):\n return (\n 'start \"Pillow\" /WAIT \"%s\" '\n \"&& ping -n 2 127.0.0.1 >NUL \"\n '&& del /f \"%s\"' % (file, file)\n )\n\n register(WindowsViewer)\n\nelif sys.platform == \"darwin\":\n\n class MacViewer(Viewer):\n format = \"PNG\"\n options = {\"compress_level\": 1}\n\n def get_command(self, file, **options):\n # on darwin open returns immediately resulting in the temp\n # file removal while app is opening\n command = \"open -a /Applications/Preview.app\"\n command = \"(%s %s; sleep 20; rm -f %s)&\" % (\n command,\n quote(file),\n quote(file),\n )\n return command\n\n def show_file(self, file, **options):\n \"\"\"Display given file\"\"\"\n fd, path = tempfile.mkstemp()\n with os.fdopen(fd, \"w\") as f:\n f.write(file)\n with open(path, \"r\") as f:\n subprocess.Popen(\n [\n \"im=$(cat);\"\n \"open -a /Applications/Preview.app $im;\"\n \"sleep 20;\"\n \"rm -f $im\"\n ],\n shell=True,\n stdin=f,\n )\n os.remove(path)\n return 1\n\n register(MacViewer)\n\nelse:\n\n # unixoids\n\n def which(executable):\n path = os.environ.get(\"PATH\")\n if not path:\n return None\n for dirname in path.split(os.pathsep):\n filename = os.path.join(dirname, executable)\n if os.path.isfile(filename) and os.access(filename, os.X_OK):\n return filename\n return None\n\n class UnixViewer(Viewer):\n format = \"PNG\"\n options = {\"compress_level\": 1}\n\n def get_command(self, file, **options):\n command = self.get_command_ex(file, **options)[0]\n return \"(%s %s; rm -f %s)&\" % (command, quote(file), quote(file))\n\n def show_file(self, file, **options):\n \"\"\"Display given file\"\"\"\n fd, path = tempfile.mkstemp()\n with os.fdopen(fd, \"w\") as f:\n f.write(file)\n with open(path, \"r\") as f:\n command = self.get_command_ex(file, **options)[0]\n subprocess.Popen(\n [\"im=$(cat);\" + command + \" $im;\" \"rm -f $im\"], shell=True, stdin=f\n )\n os.remove(path)\n return 1\n\n # implementations\n\n class DisplayViewer(UnixViewer):\n def get_command_ex(self, file, **options):\n command = executable = \"display\"\n return command, executable\n\n if which(\"display\"):\n register(DisplayViewer)\n\n class EogViewer(UnixViewer):\n def get_command_ex(self, file, **options):\n command = executable = \"eog\"\n return command, executable\n\n if which(\"eog\"):\n register(EogViewer)\n\n class XVViewer(UnixViewer):\n def get_command_ex(self, file, title=None, **options):\n # note: xv is pretty outdated. most modern systems have\n # imagemagick's display command instead.\n command = executable = \"xv\"\n if title:\n command += \" -name %s\" % quote(title)\n return command, executable\n\n if which(\"xv\"):\n register(XVViewer)\n\nif __name__ == \"__main__\":\n\n if len(sys.argv) < 2:\n print(\"Syntax: python ImageShow.py imagefile [title]\")\n sys.exit()\n\n print(show(Image.open(sys.argv[1]), *sys.argv[2:]))\n", "path": "src/PIL/ImageShow.py"}]}
| 3,470 | 581 |
gh_patches_debug_22231
|
rasdani/github-patches
|
git_diff
|
TheAlgorithms__Python-4867
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[mypy] Need help to fix all `mypy` errors in the codebase
# Just one left to fix...
https://github.com/TheAlgorithms/Python/blob/master/mypy.ini#L5
* [x] other/least_recently_used.py
* [x] other/lfu_cache.py #5755
* [x] other/lru_cache.py #5755
---
__UPDATE:__ Our GitHub Actions now run `mypy --ignore-missing-imports` excluding those directories that fail that test.
* https://github.com/TheAlgorithms/Python/blob/master/mypy.ini#L5
Currently, we are not running `mypy` in our regular CI tests as there are a lot of errors in the entire codebase, which needs to be fixed. This won't be a one-person job, so we are asking for help from you. I cannot paste the entire message in here as there are around 600 of them, so here's just a gist of it:
```console
$ mypy --ignore-missing-imports .
strings/word_occurrence.py:17: error: Need type annotation for 'occurrence'
strings/min_cost_string_conversion.py:36: error: No overload variant of "__setitem__" of "list" matches argument types "int", "str"
strings/min_cost_string_conversion.py:36: note: Possible overload variants:
strings/min_cost_string_conversion.py:36: note: def __setitem__(self, int, int) -> None
strings/min_cost_string_conversion.py:36: note: def __setitem__(self, slice, Iterable[int]) -> None
strings/min_cost_string_conversion.py:40: error: No overload variant of "__setitem__" of "list" matches argument types "int", "str"
strings/min_cost_string_conversion.py:40: note: Possible overload variants:
strings/min_cost_string_conversion.py:40: note: def __setitem__(self, int, int) -> None
strings/min_cost_string_conversion.py:40: note: def __setitem__(self, slice, Iterable[int]) -> None
...
backtracking/n_queens_math.py:109: error: List comprehension has incompatible type List[str]; expected List[int]
backtracking/n_queens_math.py:110: error: Argument 1 to "append" of "list" has incompatible type "List[int]"; expected "List[str]"
backtracking/n_queens_math.py:149: error: Need type annotation for 'boards' (hint: "boards: List[<type>] = ...")
backtracking/minimax.py:15: error: "list" is not subscriptable, use "typing.List" instead
backtracking/knight_tour.py:6: error: "tuple" is not subscriptable, use "typing.Tuple" instead
backtracking/knight_tour.py:6: error: "list" is not subscriptable, use "typing.List" instead
...
```
# Guidelines to follow:
- Please make sure you read the [Contributing Guidelines](https://github.com/TheAlgorithms/Python/blob/master/CONTRIBUTING.md) first.
- Please submit a fix for a maximum of 3 files at a time (1 file is also acceptable).
- As we are not running `mypy` in our CI tests, the user who is submitting a pull request should run it on their local machine and ensure there are no errors in their submission.
- Please ensure your pull request title contains the word `mypy` in it. If possible use this template for your pull request title:
```
[mypy] Fix type annotations for <filenames>
```
### Which errors to fix?
Please follow the below steps to produce all the errors in this library:
- Fork this repository if you haven't already.
- Clone the forked repository on your local machine using the command:
```
git clone --depth 1 https://github.com/TheAlgorithms/Python.git
```
Then you need to install all the necessary requirements:
```
cd python/
python -m pip install --upgrade pip
python -m pip install -r requirements.txt
python -m pip install mypy
```
Then run either of the two commands:
- `mypy --ignore-missing-imports .` -> To produce all the error messages for the entire codebase.
- `mypy --ignore-missing-imports <filepath1> <filepath2> ...` -> To produce error messages for the mentioned file.
### How to fix the errors?
- Make a separate branch for your fix with the command:
```
git checkout -b mypy-fix
```
- Make changes to the selected files.
- Push it to your forked copy and open a pull request with the appropriate title as mentioned above.
### Focus on one directory at a time:
```
.
├── [x] arithmetic_analysis
├── [x] backtracking
├── [x] bit_manipulation
├── [x] blockchain
├── [x] boolean_algebra
├── [x] cellular_automata
├── [x] ciphers
├── [x] compression
├── [x] computer_vision
├── [x] conversions
├── [ ] data_structures
├── [x] digital_image_processing
├── [x] divide_and_conquer
├── [ ] dynamic_programming
├── [x] electronics
├── [x] file_transfer
├── [x] fractals
├── [x] fuzzy_logic
├── [x] genetic_algorithm
├── [x] geodesy
├── [x] graphics
├── [ ] graphs
├── [x] hashes
├── [x] knapsack
├── [x] linear_algebra
├── [x] machine_learning
├── [ ] maths
├── [ ] matrix
├── [x] networking_flow
├── [x] neural_network
├── [ ] other
├── [ ] project_euler
├── [x] quantum
├── [x] scheduling
├── [x] scripts
├── [ ] searches
├── [x] sorts
├── [ ] strings
└── [x] web_programming
```
### Pre-requisites:
- You should be familiar with `mypy`: https://mypy.readthedocs.io
- You should be familiar with Python type hints: https://docs.python.org/3/library/typing.html
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `graphs/boruvka.py`
Content:
```
1 """Borůvka's algorithm.
2
3 Determines the minimum spanning tree (MST) of a graph using the Borůvka's algorithm.
4 Borůvka's algorithm is a greedy algorithm for finding a minimum spanning tree in a
5 connected graph, or a minimum spanning forest if a graph that is not connected.
6
7 The time complexity of this algorithm is O(ELogV), where E represents the number
8 of edges, while V represents the number of nodes.
9 O(number_of_edges Log number_of_nodes)
10
11 The space complexity of this algorithm is O(V + E), since we have to keep a couple
12 of lists whose sizes are equal to the number of nodes, as well as keep all the
13 edges of a graph inside of the data structure itself.
14
15 Borůvka's algorithm gives us pretty much the same result as other MST Algorithms -
16 they all find the minimum spanning tree, and the time complexity is approximately
17 the same.
18
19 One advantage that Borůvka's algorithm has compared to the alternatives is that it
20 doesn't need to presort the edges or maintain a priority queue in order to find the
21 minimum spanning tree.
22 Even though that doesn't help its complexity, since it still passes the edges logE
23 times, it is a bit simpler to code.
24
25 Details: https://en.wikipedia.org/wiki/Bor%C5%AFvka%27s_algorithm
26 """
27
28
29 class Graph:
30 def __init__(self, num_of_nodes: int) -> None:
31 """
32 Arguments:
33 num_of_nodes - the number of nodes in the graph
34 Attributes:
35 m_num_of_nodes - the number of nodes in the graph.
36 m_edges - the list of edges.
37 m_component - the dictionary which stores the index of the component which
38 a node belongs to.
39 """
40
41 self.m_num_of_nodes = num_of_nodes
42 self.m_edges = []
43 self.m_component = {}
44
45 def add_edge(self, u_node: int, v_node: int, weight: int) -> None:
46 """Adds an edge in the format [first, second, edge weight] to graph."""
47
48 self.m_edges.append([u_node, v_node, weight])
49
50 def find_component(self, u_node: int) -> int:
51 """Propagates a new component throughout a given component."""
52
53 if self.m_component[u_node] == u_node:
54 return u_node
55 return self.find_component(self.m_component[u_node])
56
57 def set_component(self, u_node: int) -> None:
58 """Finds the component index of a given node"""
59
60 if self.m_component[u_node] != u_node:
61 for k in self.m_component:
62 self.m_component[k] = self.find_component(k)
63
64 def union(self, component_size: list, u_node: int, v_node: int) -> None:
65 """Union finds the roots of components for two nodes, compares the components
66 in terms of size, and attaches the smaller one to the larger one to form
67 single component"""
68
69 if component_size[u_node] <= component_size[v_node]:
70 self.m_component[u_node] = v_node
71 component_size[v_node] += component_size[u_node]
72 self.set_component(u_node)
73
74 elif component_size[u_node] >= component_size[v_node]:
75 self.m_component[v_node] = self.find_component(u_node)
76 component_size[u_node] += component_size[v_node]
77 self.set_component(v_node)
78
79 def boruvka(self) -> None:
80 """Performs Borůvka's algorithm to find MST."""
81
82 # Initialize additional lists required to algorithm.
83 component_size = []
84 mst_weight = 0
85
86 minimum_weight_edge = [-1] * self.m_num_of_nodes
87
88 # A list of components (initialized to all of the nodes)
89 for node in range(self.m_num_of_nodes):
90 self.m_component.update({node: node})
91 component_size.append(1)
92
93 num_of_components = self.m_num_of_nodes
94
95 while num_of_components > 1:
96 for edge in self.m_edges:
97 u, v, w = edge
98
99 u_component = self.m_component[u]
100 v_component = self.m_component[v]
101
102 if u_component != v_component:
103 """If the current minimum weight edge of component u doesn't
104 exist (is -1), or if it's greater than the edge we're
105 observing right now, we will assign the value of the edge
106 we're observing to it.
107
108 If the current minimum weight edge of component v doesn't
109 exist (is -1), or if it's greater than the edge we're
110 observing right now, we will assign the value of the edge
111 we're observing to it"""
112
113 for component in (u_component, v_component):
114 if (
115 minimum_weight_edge[component] == -1
116 or minimum_weight_edge[component][2] > w
117 ):
118 minimum_weight_edge[component] = [u, v, w]
119
120 for edge in minimum_weight_edge:
121 if edge != -1:
122 u, v, w = edge
123
124 u_component = self.m_component[u]
125 v_component = self.m_component[v]
126
127 if u_component != v_component:
128 mst_weight += w
129 self.union(component_size, u_component, v_component)
130 print(f"Added edge [{u} - {v}]\nAdded weight: {w}\n")
131 num_of_components -= 1
132
133 minimum_weight_edge = [-1] * self.m_num_of_nodes
134 print(f"The total weight of the minimal spanning tree is: {mst_weight}")
135
136
137 def test_vector() -> None:
138 """
139 >>> g = Graph(8)
140 >>> for u_v_w in ((0, 1, 10), (0, 2, 6), (0, 3, 5), (1, 3, 15), (2, 3, 4),
141 ... (3, 4, 8), (4, 5, 10), (4, 6, 6), (4, 7, 5), (5, 7, 15), (6, 7, 4)):
142 ... g.add_edge(*u_v_w)
143 >>> g.boruvka()
144 Added edge [0 - 3]
145 Added weight: 5
146 <BLANKLINE>
147 Added edge [0 - 1]
148 Added weight: 10
149 <BLANKLINE>
150 Added edge [2 - 3]
151 Added weight: 4
152 <BLANKLINE>
153 Added edge [4 - 7]
154 Added weight: 5
155 <BLANKLINE>
156 Added edge [4 - 5]
157 Added weight: 10
158 <BLANKLINE>
159 Added edge [6 - 7]
160 Added weight: 4
161 <BLANKLINE>
162 Added edge [3 - 4]
163 Added weight: 8
164 <BLANKLINE>
165 The total weight of the minimal spanning tree is: 46
166 """
167
168
169 if __name__ == "__main__":
170 import doctest
171
172 doctest.testmod()
173
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/graphs/boruvka.py b/graphs/boruvka.py
--- a/graphs/boruvka.py
+++ b/graphs/boruvka.py
@@ -24,6 +24,7 @@
Details: https://en.wikipedia.org/wiki/Bor%C5%AFvka%27s_algorithm
"""
+from __future__ import annotations
class Graph:
@@ -39,8 +40,8 @@
"""
self.m_num_of_nodes = num_of_nodes
- self.m_edges = []
- self.m_component = {}
+ self.m_edges: list[list[int]] = []
+ self.m_component: dict[int, int] = {}
def add_edge(self, u_node: int, v_node: int, weight: int) -> None:
"""Adds an edge in the format [first, second, edge weight] to graph."""
@@ -83,7 +84,7 @@
component_size = []
mst_weight = 0
- minimum_weight_edge = [-1] * self.m_num_of_nodes
+ minimum_weight_edge: list[int] = [-1] * self.m_num_of_nodes
# A list of components (initialized to all of the nodes)
for node in range(self.m_num_of_nodes):
|
{"golden_diff": "diff --git a/graphs/boruvka.py b/graphs/boruvka.py\n--- a/graphs/boruvka.py\n+++ b/graphs/boruvka.py\n@@ -24,6 +24,7 @@\n \n Details: https://en.wikipedia.org/wiki/Bor%C5%AFvka%27s_algorithm\n \"\"\"\n+from __future__ import annotations\n \n \n class Graph:\n@@ -39,8 +40,8 @@\n \"\"\"\n \n self.m_num_of_nodes = num_of_nodes\n- self.m_edges = []\n- self.m_component = {}\n+ self.m_edges: list[list[int]] = []\n+ self.m_component: dict[int, int] = {}\n \n def add_edge(self, u_node: int, v_node: int, weight: int) -> None:\n \"\"\"Adds an edge in the format [first, second, edge weight] to graph.\"\"\"\n@@ -83,7 +84,7 @@\n component_size = []\n mst_weight = 0\n \n- minimum_weight_edge = [-1] * self.m_num_of_nodes\n+ minimum_weight_edge: list[int] = [-1] * self.m_num_of_nodes\n \n # A list of components (initialized to all of the nodes)\n for node in range(self.m_num_of_nodes):\n", "issue": "[mypy] Need help to fix all `mypy` errors in the codebase\n# Just one left to fix...\r\nhttps://github.com/TheAlgorithms/Python/blob/master/mypy.ini#L5\r\n* [x] other/least_recently_used.py\r\n* [x] other/lfu_cache.py #5755\r\n* [x] other/lru_cache.py #5755\r\n\r\n---\r\n\r\n__UPDATE:__ Our GitHub Actions now run `mypy --ignore-missing-imports` excluding those directories that fail that test.\r\n* https://github.com/TheAlgorithms/Python/blob/master/mypy.ini#L5\r\n\r\nCurrently, we are not running `mypy` in our regular CI tests as there are a lot of errors in the entire codebase, which needs to be fixed. This won't be a one-person job, so we are asking for help from you. I cannot paste the entire message in here as there are around 600 of them, so here's just a gist of it:\r\n\r\n```console\r\n$ mypy --ignore-missing-imports .\r\nstrings/word_occurrence.py:17: error: Need type annotation for 'occurrence'\r\nstrings/min_cost_string_conversion.py:36: error: No overload variant of \"__setitem__\" of \"list\" matches argument types \"int\", \"str\"\r\nstrings/min_cost_string_conversion.py:36: note: Possible overload variants:\r\nstrings/min_cost_string_conversion.py:36: note: def __setitem__(self, int, int) -> None\r\nstrings/min_cost_string_conversion.py:36: note: def __setitem__(self, slice, Iterable[int]) -> None\r\nstrings/min_cost_string_conversion.py:40: error: No overload variant of \"__setitem__\" of \"list\" matches argument types \"int\", \"str\"\r\nstrings/min_cost_string_conversion.py:40: note: Possible overload variants:\r\nstrings/min_cost_string_conversion.py:40: note: def __setitem__(self, int, int) -> None\r\nstrings/min_cost_string_conversion.py:40: note: def __setitem__(self, slice, Iterable[int]) -> None\r\n...\r\nbacktracking/n_queens_math.py:109: error: List comprehension has incompatible type List[str]; expected List[int]\r\nbacktracking/n_queens_math.py:110: error: Argument 1 to \"append\" of \"list\" has incompatible type \"List[int]\"; expected \"List[str]\"\r\nbacktracking/n_queens_math.py:149: error: Need type annotation for 'boards' (hint: \"boards: List[<type>] = ...\")\r\nbacktracking/minimax.py:15: error: \"list\" is not subscriptable, use \"typing.List\" instead\r\nbacktracking/knight_tour.py:6: error: \"tuple\" is not subscriptable, use \"typing.Tuple\" instead\r\nbacktracking/knight_tour.py:6: error: \"list\" is not subscriptable, use \"typing.List\" instead\r\n...\r\n```\r\n\r\n# Guidelines to follow:\r\n\r\n- Please make sure you read the [Contributing Guidelines](https://github.com/TheAlgorithms/Python/blob/master/CONTRIBUTING.md) first.\r\n- Please submit a fix for a maximum of 3 files at a time (1 file is also acceptable).\r\n- As we are not running `mypy` in our CI tests, the user who is submitting a pull request should run it on their local machine and ensure there are no errors in their submission.\r\n- Please ensure your pull request title contains the word `mypy` in it. If possible use this template for your pull request title:\r\n```\r\n[mypy] Fix type annotations for <filenames>\r\n```\r\n\r\n### Which errors to fix?\r\n\r\nPlease follow the below steps to produce all the errors in this library:\r\n- Fork this repository if you haven't already.\r\n- Clone the forked repository on your local machine using the command:\r\n\r\n```\r\ngit clone --depth 1 https://github.com/TheAlgorithms/Python.git\r\n```\r\nThen you need to install all the necessary requirements:\r\n```\r\ncd python/\r\npython -m pip install --upgrade pip\r\npython -m pip install -r requirements.txt\r\npython -m pip install mypy\r\n```\r\nThen run either of the two commands:\r\n- `mypy --ignore-missing-imports .` -> To produce all the error messages for the entire codebase.\r\n- `mypy --ignore-missing-imports <filepath1> <filepath2> ...` -> To produce error messages for the mentioned file.\r\n\r\n### How to fix the errors?\r\n\r\n- Make a separate branch for your fix with the command: \r\n```\r\ngit checkout -b mypy-fix\r\n```\r\n- Make changes to the selected files.\r\n- Push it to your forked copy and open a pull request with the appropriate title as mentioned above.\r\n\r\n### Focus on one directory at a time:\r\n\r\n```\r\n.\r\n\u251c\u2500\u2500 [x] arithmetic_analysis\r\n\u251c\u2500\u2500 [x] backtracking\r\n\u251c\u2500\u2500 [x] bit_manipulation\r\n\u251c\u2500\u2500 [x] blockchain\r\n\u251c\u2500\u2500 [x] boolean_algebra\r\n\u251c\u2500\u2500 [x] cellular_automata\r\n\u251c\u2500\u2500 [x] ciphers\r\n\u251c\u2500\u2500 [x] compression\r\n\u251c\u2500\u2500 [x] computer_vision\r\n\u251c\u2500\u2500 [x] conversions\r\n\u251c\u2500\u2500 [ ] data_structures\r\n\u251c\u2500\u2500 [x] digital_image_processing\r\n\u251c\u2500\u2500 [x] divide_and_conquer\r\n\u251c\u2500\u2500 [ ] dynamic_programming\r\n\u251c\u2500\u2500 [x] electronics\r\n\u251c\u2500\u2500 [x] file_transfer\r\n\u251c\u2500\u2500 [x] fractals\r\n\u251c\u2500\u2500 [x] fuzzy_logic\r\n\u251c\u2500\u2500 [x] genetic_algorithm\r\n\u251c\u2500\u2500 [x] geodesy\r\n\u251c\u2500\u2500 [x] graphics\r\n\u251c\u2500\u2500 [ ] graphs\r\n\u251c\u2500\u2500 [x] hashes\r\n\u251c\u2500\u2500 [x] knapsack\r\n\u251c\u2500\u2500 [x] linear_algebra\r\n\u251c\u2500\u2500 [x] machine_learning\r\n\u251c\u2500\u2500 [ ] maths\r\n\u251c\u2500\u2500 [ ] matrix\r\n\u251c\u2500\u2500 [x] networking_flow\r\n\u251c\u2500\u2500 [x] neural_network\r\n\u251c\u2500\u2500 [ ] other\r\n\u251c\u2500\u2500 [ ] project_euler\r\n\u251c\u2500\u2500 [x] quantum\r\n\u251c\u2500\u2500 [x] scheduling\r\n\u251c\u2500\u2500 [x] scripts\r\n\u251c\u2500\u2500 [ ] searches\r\n\u251c\u2500\u2500 [x] sorts\r\n\u251c\u2500\u2500 [ ] strings\r\n\u2514\u2500\u2500 [x] web_programming\r\n```\r\n\r\n### Pre-requisites:\r\n- You should be familiar with `mypy`: https://mypy.readthedocs.io\r\n- You should be familiar with Python type hints: https://docs.python.org/3/library/typing.html\n", "before_files": [{"content": "\"\"\"Bor\u016fvka's algorithm.\n\n Determines the minimum spanning tree (MST) of a graph using the Bor\u016fvka's algorithm.\n Bor\u016fvka's algorithm is a greedy algorithm for finding a minimum spanning tree in a\n connected graph, or a minimum spanning forest if a graph that is not connected.\n\n The time complexity of this algorithm is O(ELogV), where E represents the number\n of edges, while V represents the number of nodes.\n O(number_of_edges Log number_of_nodes)\n\n The space complexity of this algorithm is O(V + E), since we have to keep a couple\n of lists whose sizes are equal to the number of nodes, as well as keep all the\n edges of a graph inside of the data structure itself.\n\n Bor\u016fvka's algorithm gives us pretty much the same result as other MST Algorithms -\n they all find the minimum spanning tree, and the time complexity is approximately\n the same.\n\n One advantage that Bor\u016fvka's algorithm has compared to the alternatives is that it\n doesn't need to presort the edges or maintain a priority queue in order to find the\n minimum spanning tree.\n Even though that doesn't help its complexity, since it still passes the edges logE\n times, it is a bit simpler to code.\n\n Details: https://en.wikipedia.org/wiki/Bor%C5%AFvka%27s_algorithm\n\"\"\"\n\n\nclass Graph:\n def __init__(self, num_of_nodes: int) -> None:\n \"\"\"\n Arguments:\n num_of_nodes - the number of nodes in the graph\n Attributes:\n m_num_of_nodes - the number of nodes in the graph.\n m_edges - the list of edges.\n m_component - the dictionary which stores the index of the component which\n a node belongs to.\n \"\"\"\n\n self.m_num_of_nodes = num_of_nodes\n self.m_edges = []\n self.m_component = {}\n\n def add_edge(self, u_node: int, v_node: int, weight: int) -> None:\n \"\"\"Adds an edge in the format [first, second, edge weight] to graph.\"\"\"\n\n self.m_edges.append([u_node, v_node, weight])\n\n def find_component(self, u_node: int) -> int:\n \"\"\"Propagates a new component throughout a given component.\"\"\"\n\n if self.m_component[u_node] == u_node:\n return u_node\n return self.find_component(self.m_component[u_node])\n\n def set_component(self, u_node: int) -> None:\n \"\"\"Finds the component index of a given node\"\"\"\n\n if self.m_component[u_node] != u_node:\n for k in self.m_component:\n self.m_component[k] = self.find_component(k)\n\n def union(self, component_size: list, u_node: int, v_node: int) -> None:\n \"\"\"Union finds the roots of components for two nodes, compares the components\n in terms of size, and attaches the smaller one to the larger one to form\n single component\"\"\"\n\n if component_size[u_node] <= component_size[v_node]:\n self.m_component[u_node] = v_node\n component_size[v_node] += component_size[u_node]\n self.set_component(u_node)\n\n elif component_size[u_node] >= component_size[v_node]:\n self.m_component[v_node] = self.find_component(u_node)\n component_size[u_node] += component_size[v_node]\n self.set_component(v_node)\n\n def boruvka(self) -> None:\n \"\"\"Performs Bor\u016fvka's algorithm to find MST.\"\"\"\n\n # Initialize additional lists required to algorithm.\n component_size = []\n mst_weight = 0\n\n minimum_weight_edge = [-1] * self.m_num_of_nodes\n\n # A list of components (initialized to all of the nodes)\n for node in range(self.m_num_of_nodes):\n self.m_component.update({node: node})\n component_size.append(1)\n\n num_of_components = self.m_num_of_nodes\n\n while num_of_components > 1:\n for edge in self.m_edges:\n u, v, w = edge\n\n u_component = self.m_component[u]\n v_component = self.m_component[v]\n\n if u_component != v_component:\n \"\"\"If the current minimum weight edge of component u doesn't\n exist (is -1), or if it's greater than the edge we're\n observing right now, we will assign the value of the edge\n we're observing to it.\n\n If the current minimum weight edge of component v doesn't\n exist (is -1), or if it's greater than the edge we're\n observing right now, we will assign the value of the edge\n we're observing to it\"\"\"\n\n for component in (u_component, v_component):\n if (\n minimum_weight_edge[component] == -1\n or minimum_weight_edge[component][2] > w\n ):\n minimum_weight_edge[component] = [u, v, w]\n\n for edge in minimum_weight_edge:\n if edge != -1:\n u, v, w = edge\n\n u_component = self.m_component[u]\n v_component = self.m_component[v]\n\n if u_component != v_component:\n mst_weight += w\n self.union(component_size, u_component, v_component)\n print(f\"Added edge [{u} - {v}]\\nAdded weight: {w}\\n\")\n num_of_components -= 1\n\n minimum_weight_edge = [-1] * self.m_num_of_nodes\n print(f\"The total weight of the minimal spanning tree is: {mst_weight}\")\n\n\ndef test_vector() -> None:\n \"\"\"\n >>> g = Graph(8)\n >>> for u_v_w in ((0, 1, 10), (0, 2, 6), (0, 3, 5), (1, 3, 15), (2, 3, 4),\n ... (3, 4, 8), (4, 5, 10), (4, 6, 6), (4, 7, 5), (5, 7, 15), (6, 7, 4)):\n ... g.add_edge(*u_v_w)\n >>> g.boruvka()\n Added edge [0 - 3]\n Added weight: 5\n <BLANKLINE>\n Added edge [0 - 1]\n Added weight: 10\n <BLANKLINE>\n Added edge [2 - 3]\n Added weight: 4\n <BLANKLINE>\n Added edge [4 - 7]\n Added weight: 5\n <BLANKLINE>\n Added edge [4 - 5]\n Added weight: 10\n <BLANKLINE>\n Added edge [6 - 7]\n Added weight: 4\n <BLANKLINE>\n Added edge [3 - 4]\n Added weight: 8\n <BLANKLINE>\n The total weight of the minimal spanning tree is: 46\n \"\"\"\n\n\nif __name__ == \"__main__\":\n import doctest\n\n doctest.testmod()\n", "path": "graphs/boruvka.py"}], "after_files": [{"content": "\"\"\"Bor\u016fvka's algorithm.\n\n Determines the minimum spanning tree (MST) of a graph using the Bor\u016fvka's algorithm.\n Bor\u016fvka's algorithm is a greedy algorithm for finding a minimum spanning tree in a\n connected graph, or a minimum spanning forest if a graph that is not connected.\n\n The time complexity of this algorithm is O(ELogV), where E represents the number\n of edges, while V represents the number of nodes.\n O(number_of_edges Log number_of_nodes)\n\n The space complexity of this algorithm is O(V + E), since we have to keep a couple\n of lists whose sizes are equal to the number of nodes, as well as keep all the\n edges of a graph inside of the data structure itself.\n\n Bor\u016fvka's algorithm gives us pretty much the same result as other MST Algorithms -\n they all find the minimum spanning tree, and the time complexity is approximately\n the same.\n\n One advantage that Bor\u016fvka's algorithm has compared to the alternatives is that it\n doesn't need to presort the edges or maintain a priority queue in order to find the\n minimum spanning tree.\n Even though that doesn't help its complexity, since it still passes the edges logE\n times, it is a bit simpler to code.\n\n Details: https://en.wikipedia.org/wiki/Bor%C5%AFvka%27s_algorithm\n\"\"\"\nfrom __future__ import annotations\n\n\nclass Graph:\n def __init__(self, num_of_nodes: int) -> None:\n \"\"\"\n Arguments:\n num_of_nodes - the number of nodes in the graph\n Attributes:\n m_num_of_nodes - the number of nodes in the graph.\n m_edges - the list of edges.\n m_component - the dictionary which stores the index of the component which\n a node belongs to.\n \"\"\"\n\n self.m_num_of_nodes = num_of_nodes\n self.m_edges: list[list[int]] = []\n self.m_component: dict[int, int] = {}\n\n def add_edge(self, u_node: int, v_node: int, weight: int) -> None:\n \"\"\"Adds an edge in the format [first, second, edge weight] to graph.\"\"\"\n\n self.m_edges.append([u_node, v_node, weight])\n\n def find_component(self, u_node: int) -> int:\n \"\"\"Propagates a new component throughout a given component.\"\"\"\n\n if self.m_component[u_node] == u_node:\n return u_node\n return self.find_component(self.m_component[u_node])\n\n def set_component(self, u_node: int) -> None:\n \"\"\"Finds the component index of a given node\"\"\"\n\n if self.m_component[u_node] != u_node:\n for k in self.m_component:\n self.m_component[k] = self.find_component(k)\n\n def union(self, component_size: list, u_node: int, v_node: int) -> None:\n \"\"\"Union finds the roots of components for two nodes, compares the components\n in terms of size, and attaches the smaller one to the larger one to form\n single component\"\"\"\n\n if component_size[u_node] <= component_size[v_node]:\n self.m_component[u_node] = v_node\n component_size[v_node] += component_size[u_node]\n self.set_component(u_node)\n\n elif component_size[u_node] >= component_size[v_node]:\n self.m_component[v_node] = self.find_component(u_node)\n component_size[u_node] += component_size[v_node]\n self.set_component(v_node)\n\n def boruvka(self) -> None:\n \"\"\"Performs Bor\u016fvka's algorithm to find MST.\"\"\"\n\n # Initialize additional lists required to algorithm.\n component_size = []\n mst_weight = 0\n\n minimum_weight_edge: list[int] = [-1] * self.m_num_of_nodes\n\n # A list of components (initialized to all of the nodes)\n for node in range(self.m_num_of_nodes):\n self.m_component.update({node: node})\n component_size.append(1)\n\n num_of_components = self.m_num_of_nodes\n\n while num_of_components > 1:\n for edge in self.m_edges:\n u, v, w = edge\n\n u_component = self.m_component[u]\n v_component = self.m_component[v]\n\n if u_component != v_component:\n \"\"\"If the current minimum weight edge of component u doesn't\n exist (is -1), or if it's greater than the edge we're\n observing right now, we will assign the value of the edge\n we're observing to it.\n\n If the current minimum weight edge of component v doesn't\n exist (is -1), or if it's greater than the edge we're\n observing right now, we will assign the value of the edge\n we're observing to it\"\"\"\n\n for component in (u_component, v_component):\n if (\n minimum_weight_edge[component] == -1\n or minimum_weight_edge[component][2] > w\n ):\n minimum_weight_edge[component] = [u, v, w]\n\n for edge in minimum_weight_edge:\n if edge != -1:\n u, v, w = edge\n\n u_component = self.m_component[u]\n v_component = self.m_component[v]\n\n if u_component != v_component:\n mst_weight += w\n self.union(component_size, u_component, v_component)\n print(f\"Added edge [{u} - {v}]\\nAdded weight: {w}\\n\")\n num_of_components -= 1\n\n minimum_weight_edge = [-1] * self.m_num_of_nodes\n print(f\"The total weight of the minimal spanning tree is: {mst_weight}\")\n\n\ndef test_vector() -> None:\n \"\"\"\n >>> g = Graph(8)\n >>> for u_v_w in ((0, 1, 10), (0, 2, 6), (0, 3, 5), (1, 3, 15), (2, 3, 4),\n ... (3, 4, 8), (4, 5, 10), (4, 6, 6), (4, 7, 5), (5, 7, 15), (6, 7, 4)):\n ... g.add_edge(*u_v_w)\n >>> g.boruvka()\n Added edge [0 - 3]\n Added weight: 5\n <BLANKLINE>\n Added edge [0 - 1]\n Added weight: 10\n <BLANKLINE>\n Added edge [2 - 3]\n Added weight: 4\n <BLANKLINE>\n Added edge [4 - 7]\n Added weight: 5\n <BLANKLINE>\n Added edge [4 - 5]\n Added weight: 10\n <BLANKLINE>\n Added edge [6 - 7]\n Added weight: 4\n <BLANKLINE>\n Added edge [3 - 4]\n Added weight: 8\n <BLANKLINE>\n The total weight of the minimal spanning tree is: 46\n \"\"\"\n\n\nif __name__ == \"__main__\":\n import doctest\n\n doctest.testmod()\n", "path": "graphs/boruvka.py"}]}
| 3,617 | 283 |
gh_patches_debug_39
|
rasdani/github-patches
|
git_diff
|
Project-MONAI__MONAI-2568
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Missing `return` in `__call__` of transforms: `SaveImage`, `NiftiSaver` and `PNGSaver`
**To Reproduce**
Steps to reproduce the behavior:
```
from monai.transforms import SaveImage, Compose
saver = Compose([SaveImage(output_dir="./output", output_ext=".png", output_postfix="seg")])
img = torch.randn([3, 32, 32])
output = saver(img)
print(output)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `monai/transforms/io/array.py`
Content:
```
1 # Copyright 2020 - 2021 MONAI Consortium
2 # Licensed under the Apache License, Version 2.0 (the "License");
3 # you may not use this file except in compliance with the License.
4 # You may obtain a copy of the License at
5 # http://www.apache.org/licenses/LICENSE-2.0
6 # Unless required by applicable law or agreed to in writing, software
7 # distributed under the License is distributed on an "AS IS" BASIS,
8 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
9 # See the License for the specific language governing permissions and
10 # limitations under the License.
11 """
12 A collection of "vanilla" transforms for IO functions
13 https://github.com/Project-MONAI/MONAI/wiki/MONAI_Design
14 """
15
16 import sys
17 from typing import Dict, List, Optional, Sequence, Union
18
19 import numpy as np
20 import torch
21
22 from monai.config import DtypeLike
23 from monai.data.image_reader import ImageReader, ITKReader, NibabelReader, NumpyReader, PILReader
24 from monai.data.nifti_saver import NiftiSaver
25 from monai.data.png_saver import PNGSaver
26 from monai.transforms.transform import Transform
27 from monai.utils import GridSampleMode, GridSamplePadMode
28 from monai.utils import ImageMetaKey as Key
29 from monai.utils import InterpolateMode, ensure_tuple, optional_import
30
31 nib, _ = optional_import("nibabel")
32 Image, _ = optional_import("PIL.Image")
33
34 __all__ = ["LoadImage", "SaveImage"]
35
36
37 def switch_endianness(data, new="<"):
38 """
39 Convert the input `data` endianness to `new`.
40
41 Args:
42 data: input to be converted.
43 new: the target endianness, currently support "<" or ">".
44 """
45 if isinstance(data, np.ndarray):
46 # default to system endian
47 sys_native = ((sys.byteorder == "little") and "<") or ">"
48 current_ = sys_native if data.dtype.byteorder not in ("<", ">") else data.dtype.byteorder
49 if new not in ("<", ">"):
50 raise NotImplementedError(f"Not implemented option new={new}.")
51 if current_ != new:
52 data = data.byteswap().newbyteorder(new)
53 elif isinstance(data, tuple):
54 data = tuple(switch_endianness(x, new) for x in data)
55 elif isinstance(data, list):
56 data = [switch_endianness(x, new) for x in data]
57 elif isinstance(data, dict):
58 data = {k: switch_endianness(v, new) for k, v in data.items()}
59 elif isinstance(data, (bool, str, float, int, type(None))):
60 pass
61 else:
62 raise AssertionError(f"Unknown type: {type(data).__name__}")
63 return data
64
65
66 class LoadImage(Transform):
67 """
68 Load image file or files from provided path based on reader.
69 Automatically choose readers based on the supported suffixes and in below order:
70 - User specified reader at runtime when call this loader.
71 - Registered readers from the latest to the first in list.
72 - Default readers: (nii, nii.gz -> NibabelReader), (png, jpg, bmp -> PILReader),
73 (npz, npy -> NumpyReader), (others -> ITKReader).
74
75 """
76
77 def __init__(
78 self,
79 reader: Optional[Union[ImageReader, str]] = None,
80 image_only: bool = False,
81 dtype: DtypeLike = np.float32,
82 *args,
83 **kwargs,
84 ) -> None:
85 """
86 Args:
87 reader: register reader to load image file and meta data, if None, still can register readers
88 at runtime or use the default readers. If a string of reader name provided, will construct
89 a reader object with the `*args` and `**kwargs` parameters, supported reader name: "NibabelReader",
90 "PILReader", "ITKReader", "NumpyReader".
91 image_only: if True return only the image volume, otherwise return image data array and header dict.
92 dtype: if not None convert the loaded image to this data type.
93 args: additional parameters for reader if providing a reader name.
94 kwargs: additional parameters for reader if providing a reader name.
95
96 Note:
97 The transform returns image data array if `image_only` is True,
98 or a tuple of two elements containing the data array, and the meta data in a dict format otherwise.
99
100 """
101 # set predefined readers as default
102 self.readers: List[ImageReader] = [ITKReader(), NumpyReader(), PILReader(), NibabelReader()]
103 if reader is not None:
104 if isinstance(reader, str):
105 supported_readers = {
106 "nibabelreader": NibabelReader,
107 "pilreader": PILReader,
108 "itkreader": ITKReader,
109 "numpyreader": NumpyReader,
110 }
111 reader = reader.lower()
112 if reader not in supported_readers:
113 raise ValueError(f"unsupported reader type: {reader}, available options: {supported_readers}.")
114 self.register(supported_readers[reader](*args, **kwargs))
115 else:
116 self.register(reader)
117
118 self.image_only = image_only
119 self.dtype = dtype
120
121 def register(self, reader: ImageReader) -> List[ImageReader]:
122 """
123 Register image reader to load image file and meta data, latest registered reader has higher priority.
124 Return all the registered image readers.
125
126 Args:
127 reader: registered reader to load image file and meta data based on suffix,
128 if all registered readers can't match suffix at runtime, use the default readers.
129
130 """
131 if not isinstance(reader, ImageReader):
132 raise ValueError(f"reader must be ImageReader object, but got {type(reader)}.")
133 self.readers.append(reader)
134 return self.readers
135
136 def __call__(
137 self,
138 filename: Union[Sequence[str], str],
139 reader: Optional[ImageReader] = None,
140 ):
141 """
142 Args:
143 filename: path file or file-like object or a list of files.
144 will save the filename to meta_data with key `filename_or_obj`.
145 if provided a list of files, use the filename of first file.
146 reader: runtime reader to load image file and meta data.
147
148 """
149 if reader is None or not reader.verify_suffix(filename):
150 for r in reversed(self.readers):
151 if r.verify_suffix(filename):
152 reader = r
153 break
154
155 if reader is None:
156 raise RuntimeError(
157 f"can not find suitable reader for this file: {filename}. \
158 Please install dependency libraries: (nii, nii.gz) -> Nibabel, (png, jpg, bmp) -> PIL, \
159 (npz, npy) -> Numpy, others -> ITK. Refer to the installation instruction: \
160 https://docs.monai.io/en/latest/installation.html#installing-the-recommended-dependencies."
161 )
162
163 img = reader.read(filename)
164 img_array, meta_data = reader.get_data(img)
165 img_array = img_array.astype(self.dtype)
166
167 if self.image_only:
168 return img_array
169 meta_data[Key.FILENAME_OR_OBJ] = ensure_tuple(filename)[0]
170 # make sure all elements in metadata are little endian
171 meta_data = switch_endianness(meta_data, "<")
172
173 return img_array, meta_data
174
175
176 class SaveImage(Transform):
177 """
178 Save transformed data into files, support NIfTI and PNG formats.
179 It can work for both numpy array and PyTorch Tensor in both preprocessing transform
180 chain and postprocessing transform chain.
181 The name of saved file will be `{input_image_name}_{output_postfix}{output_ext}`,
182 where the input image name is extracted from the provided meta data dictionary.
183 If no meta data provided, use index from 0 as the filename prefix.
184 It can also save a list of PyTorch Tensor or numpy array without `batch dim`.
185
186 Note: image should be channel-first shape: [C,H,W,[D]].
187
188 Args:
189 output_dir: output image directory.
190 output_postfix: a string appended to all output file names, default to `trans`.
191 output_ext: output file extension name, available extensions: `.nii.gz`, `.nii`, `.png`.
192 resample: whether to resample before saving the data array.
193 if saving PNG format image, based on the `spatial_shape` from metadata.
194 if saving NIfTI format image, based on the `original_affine` from metadata.
195 mode: This option is used when ``resample = True``. Defaults to ``"nearest"``.
196
197 - NIfTI files {``"bilinear"``, ``"nearest"``}
198 Interpolation mode to calculate output values.
199 See also: https://pytorch.org/docs/stable/nn.functional.html#grid-sample
200 - PNG files {``"nearest"``, ``"linear"``, ``"bilinear"``, ``"bicubic"``, ``"trilinear"``, ``"area"``}
201 The interpolation mode.
202 See also: https://pytorch.org/docs/stable/nn.functional.html#interpolate
203
204 padding_mode: This option is used when ``resample = True``. Defaults to ``"border"``.
205
206 - NIfTI files {``"zeros"``, ``"border"``, ``"reflection"``}
207 Padding mode for outside grid values.
208 See also: https://pytorch.org/docs/stable/nn.functional.html#grid-sample
209 - PNG files
210 This option is ignored.
211
212 scale: {``255``, ``65535``} postprocess data by clipping to [0, 1] and scaling
213 [0, 255] (uint8) or [0, 65535] (uint16). Default is None to disable scaling.
214 it's used for PNG format only.
215 dtype: data type during resampling computation. Defaults to ``np.float64`` for best precision.
216 if None, use the data type of input data. To be compatible with other modules,
217 the output data type is always ``np.float32``.
218 it's used for NIfTI format only.
219 output_dtype: data type for saving data. Defaults to ``np.float32``.
220 it's used for NIfTI format only.
221 squeeze_end_dims: if True, any trailing singleton dimensions will be removed (after the channel
222 has been moved to the end). So if input is (C,H,W,D), this will be altered to (H,W,D,C), and
223 then if C==1, it will be saved as (H,W,D). If D also ==1, it will be saved as (H,W). If false,
224 image will always be saved as (H,W,D,C).
225 it's used for NIfTI format only.
226 data_root_dir: if not empty, it specifies the beginning parts of the input file's
227 absolute path. it's used to compute `input_file_rel_path`, the relative path to the file from
228 `data_root_dir` to preserve folder structure when saving in case there are files in different
229 folders with the same file names. for example:
230 input_file_name: /foo/bar/test1/image.nii,
231 output_postfix: seg
232 output_ext: nii.gz
233 output_dir: /output,
234 data_root_dir: /foo/bar,
235 output will be: /output/test1/image/image_seg.nii.gz
236 print_log: whether to print log about the saved file path, etc. default to `True`.
237
238 """
239
240 def __init__(
241 self,
242 output_dir: str = "./",
243 output_postfix: str = "trans",
244 output_ext: str = ".nii.gz",
245 resample: bool = True,
246 mode: Union[GridSampleMode, InterpolateMode, str] = "nearest",
247 padding_mode: Union[GridSamplePadMode, str] = GridSamplePadMode.BORDER,
248 scale: Optional[int] = None,
249 dtype: DtypeLike = np.float64,
250 output_dtype: DtypeLike = np.float32,
251 squeeze_end_dims: bool = True,
252 data_root_dir: str = "",
253 print_log: bool = True,
254 ) -> None:
255 self.saver: Union[NiftiSaver, PNGSaver]
256 if output_ext in (".nii.gz", ".nii"):
257 self.saver = NiftiSaver(
258 output_dir=output_dir,
259 output_postfix=output_postfix,
260 output_ext=output_ext,
261 resample=resample,
262 mode=GridSampleMode(mode),
263 padding_mode=padding_mode,
264 dtype=dtype,
265 output_dtype=output_dtype,
266 squeeze_end_dims=squeeze_end_dims,
267 data_root_dir=data_root_dir,
268 print_log=print_log,
269 )
270 elif output_ext == ".png":
271 self.saver = PNGSaver(
272 output_dir=output_dir,
273 output_postfix=output_postfix,
274 output_ext=output_ext,
275 resample=resample,
276 mode=InterpolateMode(mode),
277 scale=scale,
278 data_root_dir=data_root_dir,
279 print_log=print_log,
280 )
281 else:
282 raise ValueError(f"unsupported output extension: {output_ext}.")
283
284 def __call__(self, img: Union[torch.Tensor, np.ndarray], meta_data: Optional[Dict] = None):
285 """
286 Args:
287 img: target data content that save into file.
288 meta_data: key-value pairs of meta_data corresponding to the data.
289
290 """
291 self.saver.save(img, meta_data)
292
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/monai/transforms/io/array.py b/monai/transforms/io/array.py
--- a/monai/transforms/io/array.py
+++ b/monai/transforms/io/array.py
@@ -289,3 +289,5 @@
"""
self.saver.save(img, meta_data)
+
+ return img
|
{"golden_diff": "diff --git a/monai/transforms/io/array.py b/monai/transforms/io/array.py\n--- a/monai/transforms/io/array.py\n+++ b/monai/transforms/io/array.py\n@@ -289,3 +289,5 @@\n \n \"\"\"\n self.saver.save(img, meta_data)\n+\n+ return img\n", "issue": "Missing `return` in `__call__` of transforms: `SaveImage`, `NiftiSaver` and `PNGSaver`\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n\r\n```\r\nfrom monai.transforms import SaveImage, Compose\r\nsaver = Compose([SaveImage(output_dir=\"./output\", output_ext=\".png\", output_postfix=\"seg\")])\r\nimg = torch.randn([3, 32, 32])\r\noutput = saver(img)\r\nprint(output)\r\n```\n", "before_files": [{"content": "# Copyright 2020 - 2021 MONAI Consortium\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# http://www.apache.org/licenses/LICENSE-2.0\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"\nA collection of \"vanilla\" transforms for IO functions\nhttps://github.com/Project-MONAI/MONAI/wiki/MONAI_Design\n\"\"\"\n\nimport sys\nfrom typing import Dict, List, Optional, Sequence, Union\n\nimport numpy as np\nimport torch\n\nfrom monai.config import DtypeLike\nfrom monai.data.image_reader import ImageReader, ITKReader, NibabelReader, NumpyReader, PILReader\nfrom monai.data.nifti_saver import NiftiSaver\nfrom monai.data.png_saver import PNGSaver\nfrom monai.transforms.transform import Transform\nfrom monai.utils import GridSampleMode, GridSamplePadMode\nfrom monai.utils import ImageMetaKey as Key\nfrom monai.utils import InterpolateMode, ensure_tuple, optional_import\n\nnib, _ = optional_import(\"nibabel\")\nImage, _ = optional_import(\"PIL.Image\")\n\n__all__ = [\"LoadImage\", \"SaveImage\"]\n\n\ndef switch_endianness(data, new=\"<\"):\n \"\"\"\n Convert the input `data` endianness to `new`.\n\n Args:\n data: input to be converted.\n new: the target endianness, currently support \"<\" or \">\".\n \"\"\"\n if isinstance(data, np.ndarray):\n # default to system endian\n sys_native = ((sys.byteorder == \"little\") and \"<\") or \">\"\n current_ = sys_native if data.dtype.byteorder not in (\"<\", \">\") else data.dtype.byteorder\n if new not in (\"<\", \">\"):\n raise NotImplementedError(f\"Not implemented option new={new}.\")\n if current_ != new:\n data = data.byteswap().newbyteorder(new)\n elif isinstance(data, tuple):\n data = tuple(switch_endianness(x, new) for x in data)\n elif isinstance(data, list):\n data = [switch_endianness(x, new) for x in data]\n elif isinstance(data, dict):\n data = {k: switch_endianness(v, new) for k, v in data.items()}\n elif isinstance(data, (bool, str, float, int, type(None))):\n pass\n else:\n raise AssertionError(f\"Unknown type: {type(data).__name__}\")\n return data\n\n\nclass LoadImage(Transform):\n \"\"\"\n Load image file or files from provided path based on reader.\n Automatically choose readers based on the supported suffixes and in below order:\n - User specified reader at runtime when call this loader.\n - Registered readers from the latest to the first in list.\n - Default readers: (nii, nii.gz -> NibabelReader), (png, jpg, bmp -> PILReader),\n (npz, npy -> NumpyReader), (others -> ITKReader).\n\n \"\"\"\n\n def __init__(\n self,\n reader: Optional[Union[ImageReader, str]] = None,\n image_only: bool = False,\n dtype: DtypeLike = np.float32,\n *args,\n **kwargs,\n ) -> None:\n \"\"\"\n Args:\n reader: register reader to load image file and meta data, if None, still can register readers\n at runtime or use the default readers. If a string of reader name provided, will construct\n a reader object with the `*args` and `**kwargs` parameters, supported reader name: \"NibabelReader\",\n \"PILReader\", \"ITKReader\", \"NumpyReader\".\n image_only: if True return only the image volume, otherwise return image data array and header dict.\n dtype: if not None convert the loaded image to this data type.\n args: additional parameters for reader if providing a reader name.\n kwargs: additional parameters for reader if providing a reader name.\n\n Note:\n The transform returns image data array if `image_only` is True,\n or a tuple of two elements containing the data array, and the meta data in a dict format otherwise.\n\n \"\"\"\n # set predefined readers as default\n self.readers: List[ImageReader] = [ITKReader(), NumpyReader(), PILReader(), NibabelReader()]\n if reader is not None:\n if isinstance(reader, str):\n supported_readers = {\n \"nibabelreader\": NibabelReader,\n \"pilreader\": PILReader,\n \"itkreader\": ITKReader,\n \"numpyreader\": NumpyReader,\n }\n reader = reader.lower()\n if reader not in supported_readers:\n raise ValueError(f\"unsupported reader type: {reader}, available options: {supported_readers}.\")\n self.register(supported_readers[reader](*args, **kwargs))\n else:\n self.register(reader)\n\n self.image_only = image_only\n self.dtype = dtype\n\n def register(self, reader: ImageReader) -> List[ImageReader]:\n \"\"\"\n Register image reader to load image file and meta data, latest registered reader has higher priority.\n Return all the registered image readers.\n\n Args:\n reader: registered reader to load image file and meta data based on suffix,\n if all registered readers can't match suffix at runtime, use the default readers.\n\n \"\"\"\n if not isinstance(reader, ImageReader):\n raise ValueError(f\"reader must be ImageReader object, but got {type(reader)}.\")\n self.readers.append(reader)\n return self.readers\n\n def __call__(\n self,\n filename: Union[Sequence[str], str],\n reader: Optional[ImageReader] = None,\n ):\n \"\"\"\n Args:\n filename: path file or file-like object or a list of files.\n will save the filename to meta_data with key `filename_or_obj`.\n if provided a list of files, use the filename of first file.\n reader: runtime reader to load image file and meta data.\n\n \"\"\"\n if reader is None or not reader.verify_suffix(filename):\n for r in reversed(self.readers):\n if r.verify_suffix(filename):\n reader = r\n break\n\n if reader is None:\n raise RuntimeError(\n f\"can not find suitable reader for this file: {filename}. \\\n Please install dependency libraries: (nii, nii.gz) -> Nibabel, (png, jpg, bmp) -> PIL, \\\n (npz, npy) -> Numpy, others -> ITK. Refer to the installation instruction: \\\n https://docs.monai.io/en/latest/installation.html#installing-the-recommended-dependencies.\"\n )\n\n img = reader.read(filename)\n img_array, meta_data = reader.get_data(img)\n img_array = img_array.astype(self.dtype)\n\n if self.image_only:\n return img_array\n meta_data[Key.FILENAME_OR_OBJ] = ensure_tuple(filename)[0]\n # make sure all elements in metadata are little endian\n meta_data = switch_endianness(meta_data, \"<\")\n\n return img_array, meta_data\n\n\nclass SaveImage(Transform):\n \"\"\"\n Save transformed data into files, support NIfTI and PNG formats.\n It can work for both numpy array and PyTorch Tensor in both preprocessing transform\n chain and postprocessing transform chain.\n The name of saved file will be `{input_image_name}_{output_postfix}{output_ext}`,\n where the input image name is extracted from the provided meta data dictionary.\n If no meta data provided, use index from 0 as the filename prefix.\n It can also save a list of PyTorch Tensor or numpy array without `batch dim`.\n\n Note: image should be channel-first shape: [C,H,W,[D]].\n\n Args:\n output_dir: output image directory.\n output_postfix: a string appended to all output file names, default to `trans`.\n output_ext: output file extension name, available extensions: `.nii.gz`, `.nii`, `.png`.\n resample: whether to resample before saving the data array.\n if saving PNG format image, based on the `spatial_shape` from metadata.\n if saving NIfTI format image, based on the `original_affine` from metadata.\n mode: This option is used when ``resample = True``. Defaults to ``\"nearest\"``.\n\n - NIfTI files {``\"bilinear\"``, ``\"nearest\"``}\n Interpolation mode to calculate output values.\n See also: https://pytorch.org/docs/stable/nn.functional.html#grid-sample\n - PNG files {``\"nearest\"``, ``\"linear\"``, ``\"bilinear\"``, ``\"bicubic\"``, ``\"trilinear\"``, ``\"area\"``}\n The interpolation mode.\n See also: https://pytorch.org/docs/stable/nn.functional.html#interpolate\n\n padding_mode: This option is used when ``resample = True``. Defaults to ``\"border\"``.\n\n - NIfTI files {``\"zeros\"``, ``\"border\"``, ``\"reflection\"``}\n Padding mode for outside grid values.\n See also: https://pytorch.org/docs/stable/nn.functional.html#grid-sample\n - PNG files\n This option is ignored.\n\n scale: {``255``, ``65535``} postprocess data by clipping to [0, 1] and scaling\n [0, 255] (uint8) or [0, 65535] (uint16). Default is None to disable scaling.\n it's used for PNG format only.\n dtype: data type during resampling computation. Defaults to ``np.float64`` for best precision.\n if None, use the data type of input data. To be compatible with other modules,\n the output data type is always ``np.float32``.\n it's used for NIfTI format only.\n output_dtype: data type for saving data. Defaults to ``np.float32``.\n it's used for NIfTI format only.\n squeeze_end_dims: if True, any trailing singleton dimensions will be removed (after the channel\n has been moved to the end). So if input is (C,H,W,D), this will be altered to (H,W,D,C), and\n then if C==1, it will be saved as (H,W,D). If D also ==1, it will be saved as (H,W). If false,\n image will always be saved as (H,W,D,C).\n it's used for NIfTI format only.\n data_root_dir: if not empty, it specifies the beginning parts of the input file's\n absolute path. it's used to compute `input_file_rel_path`, the relative path to the file from\n `data_root_dir` to preserve folder structure when saving in case there are files in different\n folders with the same file names. for example:\n input_file_name: /foo/bar/test1/image.nii,\n output_postfix: seg\n output_ext: nii.gz\n output_dir: /output,\n data_root_dir: /foo/bar,\n output will be: /output/test1/image/image_seg.nii.gz\n print_log: whether to print log about the saved file path, etc. default to `True`.\n\n \"\"\"\n\n def __init__(\n self,\n output_dir: str = \"./\",\n output_postfix: str = \"trans\",\n output_ext: str = \".nii.gz\",\n resample: bool = True,\n mode: Union[GridSampleMode, InterpolateMode, str] = \"nearest\",\n padding_mode: Union[GridSamplePadMode, str] = GridSamplePadMode.BORDER,\n scale: Optional[int] = None,\n dtype: DtypeLike = np.float64,\n output_dtype: DtypeLike = np.float32,\n squeeze_end_dims: bool = True,\n data_root_dir: str = \"\",\n print_log: bool = True,\n ) -> None:\n self.saver: Union[NiftiSaver, PNGSaver]\n if output_ext in (\".nii.gz\", \".nii\"):\n self.saver = NiftiSaver(\n output_dir=output_dir,\n output_postfix=output_postfix,\n output_ext=output_ext,\n resample=resample,\n mode=GridSampleMode(mode),\n padding_mode=padding_mode,\n dtype=dtype,\n output_dtype=output_dtype,\n squeeze_end_dims=squeeze_end_dims,\n data_root_dir=data_root_dir,\n print_log=print_log,\n )\n elif output_ext == \".png\":\n self.saver = PNGSaver(\n output_dir=output_dir,\n output_postfix=output_postfix,\n output_ext=output_ext,\n resample=resample,\n mode=InterpolateMode(mode),\n scale=scale,\n data_root_dir=data_root_dir,\n print_log=print_log,\n )\n else:\n raise ValueError(f\"unsupported output extension: {output_ext}.\")\n\n def __call__(self, img: Union[torch.Tensor, np.ndarray], meta_data: Optional[Dict] = None):\n \"\"\"\n Args:\n img: target data content that save into file.\n meta_data: key-value pairs of meta_data corresponding to the data.\n\n \"\"\"\n self.saver.save(img, meta_data)\n", "path": "monai/transforms/io/array.py"}], "after_files": [{"content": "# Copyright 2020 - 2021 MONAI Consortium\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# http://www.apache.org/licenses/LICENSE-2.0\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"\nA collection of \"vanilla\" transforms for IO functions\nhttps://github.com/Project-MONAI/MONAI/wiki/MONAI_Design\n\"\"\"\n\nimport sys\nfrom typing import Dict, List, Optional, Sequence, Union\n\nimport numpy as np\nimport torch\n\nfrom monai.config import DtypeLike\nfrom monai.data.image_reader import ImageReader, ITKReader, NibabelReader, NumpyReader, PILReader\nfrom monai.data.nifti_saver import NiftiSaver\nfrom monai.data.png_saver import PNGSaver\nfrom monai.transforms.transform import Transform\nfrom monai.utils import GridSampleMode, GridSamplePadMode\nfrom monai.utils import ImageMetaKey as Key\nfrom monai.utils import InterpolateMode, ensure_tuple, optional_import\n\nnib, _ = optional_import(\"nibabel\")\nImage, _ = optional_import(\"PIL.Image\")\n\n__all__ = [\"LoadImage\", \"SaveImage\"]\n\n\ndef switch_endianness(data, new=\"<\"):\n \"\"\"\n Convert the input `data` endianness to `new`.\n\n Args:\n data: input to be converted.\n new: the target endianness, currently support \"<\" or \">\".\n \"\"\"\n if isinstance(data, np.ndarray):\n # default to system endian\n sys_native = ((sys.byteorder == \"little\") and \"<\") or \">\"\n current_ = sys_native if data.dtype.byteorder not in (\"<\", \">\") else data.dtype.byteorder\n if new not in (\"<\", \">\"):\n raise NotImplementedError(f\"Not implemented option new={new}.\")\n if current_ != new:\n data = data.byteswap().newbyteorder(new)\n elif isinstance(data, tuple):\n data = tuple(switch_endianness(x, new) for x in data)\n elif isinstance(data, list):\n data = [switch_endianness(x, new) for x in data]\n elif isinstance(data, dict):\n data = {k: switch_endianness(v, new) for k, v in data.items()}\n elif isinstance(data, (bool, str, float, int, type(None))):\n pass\n else:\n raise AssertionError(f\"Unknown type: {type(data).__name__}\")\n return data\n\n\nclass LoadImage(Transform):\n \"\"\"\n Load image file or files from provided path based on reader.\n Automatically choose readers based on the supported suffixes and in below order:\n - User specified reader at runtime when call this loader.\n - Registered readers from the latest to the first in list.\n - Default readers: (nii, nii.gz -> NibabelReader), (png, jpg, bmp -> PILReader),\n (npz, npy -> NumpyReader), (others -> ITKReader).\n\n \"\"\"\n\n def __init__(\n self,\n reader: Optional[Union[ImageReader, str]] = None,\n image_only: bool = False,\n dtype: DtypeLike = np.float32,\n *args,\n **kwargs,\n ) -> None:\n \"\"\"\n Args:\n reader: register reader to load image file and meta data, if None, still can register readers\n at runtime or use the default readers. If a string of reader name provided, will construct\n a reader object with the `*args` and `**kwargs` parameters, supported reader name: \"NibabelReader\",\n \"PILReader\", \"ITKReader\", \"NumpyReader\".\n image_only: if True return only the image volume, otherwise return image data array and header dict.\n dtype: if not None convert the loaded image to this data type.\n args: additional parameters for reader if providing a reader name.\n kwargs: additional parameters for reader if providing a reader name.\n\n Note:\n The transform returns image data array if `image_only` is True,\n or a tuple of two elements containing the data array, and the meta data in a dict format otherwise.\n\n \"\"\"\n # set predefined readers as default\n self.readers: List[ImageReader] = [ITKReader(), NumpyReader(), PILReader(), NibabelReader()]\n if reader is not None:\n if isinstance(reader, str):\n supported_readers = {\n \"nibabelreader\": NibabelReader,\n \"pilreader\": PILReader,\n \"itkreader\": ITKReader,\n \"numpyreader\": NumpyReader,\n }\n reader = reader.lower()\n if reader not in supported_readers:\n raise ValueError(f\"unsupported reader type: {reader}, available options: {supported_readers}.\")\n self.register(supported_readers[reader](*args, **kwargs))\n else:\n self.register(reader)\n\n self.image_only = image_only\n self.dtype = dtype\n\n def register(self, reader: ImageReader) -> List[ImageReader]:\n \"\"\"\n Register image reader to load image file and meta data, latest registered reader has higher priority.\n Return all the registered image readers.\n\n Args:\n reader: registered reader to load image file and meta data based on suffix,\n if all registered readers can't match suffix at runtime, use the default readers.\n\n \"\"\"\n if not isinstance(reader, ImageReader):\n raise ValueError(f\"reader must be ImageReader object, but got {type(reader)}.\")\n self.readers.append(reader)\n return self.readers\n\n def __call__(\n self,\n filename: Union[Sequence[str], str],\n reader: Optional[ImageReader] = None,\n ):\n \"\"\"\n Args:\n filename: path file or file-like object or a list of files.\n will save the filename to meta_data with key `filename_or_obj`.\n if provided a list of files, use the filename of first file.\n reader: runtime reader to load image file and meta data.\n\n \"\"\"\n if reader is None or not reader.verify_suffix(filename):\n for r in reversed(self.readers):\n if r.verify_suffix(filename):\n reader = r\n break\n\n if reader is None:\n raise RuntimeError(\n f\"can not find suitable reader for this file: {filename}. \\\n Please install dependency libraries: (nii, nii.gz) -> Nibabel, (png, jpg, bmp) -> PIL, \\\n (npz, npy) -> Numpy, others -> ITK. Refer to the installation instruction: \\\n https://docs.monai.io/en/latest/installation.html#installing-the-recommended-dependencies.\"\n )\n\n img = reader.read(filename)\n img_array, meta_data = reader.get_data(img)\n img_array = img_array.astype(self.dtype)\n\n if self.image_only:\n return img_array\n meta_data[Key.FILENAME_OR_OBJ] = ensure_tuple(filename)[0]\n # make sure all elements in metadata are little endian\n meta_data = switch_endianness(meta_data, \"<\")\n\n return img_array, meta_data\n\n\nclass SaveImage(Transform):\n \"\"\"\n Save transformed data into files, support NIfTI and PNG formats.\n It can work for both numpy array and PyTorch Tensor in both preprocessing transform\n chain and postprocessing transform chain.\n The name of saved file will be `{input_image_name}_{output_postfix}{output_ext}`,\n where the input image name is extracted from the provided meta data dictionary.\n If no meta data provided, use index from 0 as the filename prefix.\n It can also save a list of PyTorch Tensor or numpy array without `batch dim`.\n\n Note: image should be channel-first shape: [C,H,W,[D]].\n\n Args:\n output_dir: output image directory.\n output_postfix: a string appended to all output file names, default to `trans`.\n output_ext: output file extension name, available extensions: `.nii.gz`, `.nii`, `.png`.\n resample: whether to resample before saving the data array.\n if saving PNG format image, based on the `spatial_shape` from metadata.\n if saving NIfTI format image, based on the `original_affine` from metadata.\n mode: This option is used when ``resample = True``. Defaults to ``\"nearest\"``.\n\n - NIfTI files {``\"bilinear\"``, ``\"nearest\"``}\n Interpolation mode to calculate output values.\n See also: https://pytorch.org/docs/stable/nn.functional.html#grid-sample\n - PNG files {``\"nearest\"``, ``\"linear\"``, ``\"bilinear\"``, ``\"bicubic\"``, ``\"trilinear\"``, ``\"area\"``}\n The interpolation mode.\n See also: https://pytorch.org/docs/stable/nn.functional.html#interpolate\n\n padding_mode: This option is used when ``resample = True``. Defaults to ``\"border\"``.\n\n - NIfTI files {``\"zeros\"``, ``\"border\"``, ``\"reflection\"``}\n Padding mode for outside grid values.\n See also: https://pytorch.org/docs/stable/nn.functional.html#grid-sample\n - PNG files\n This option is ignored.\n\n scale: {``255``, ``65535``} postprocess data by clipping to [0, 1] and scaling\n [0, 255] (uint8) or [0, 65535] (uint16). Default is None to disable scaling.\n it's used for PNG format only.\n dtype: data type during resampling computation. Defaults to ``np.float64`` for best precision.\n if None, use the data type of input data. To be compatible with other modules,\n the output data type is always ``np.float32``.\n it's used for NIfTI format only.\n output_dtype: data type for saving data. Defaults to ``np.float32``.\n it's used for NIfTI format only.\n squeeze_end_dims: if True, any trailing singleton dimensions will be removed (after the channel\n has been moved to the end). So if input is (C,H,W,D), this will be altered to (H,W,D,C), and\n then if C==1, it will be saved as (H,W,D). If D also ==1, it will be saved as (H,W). If false,\n image will always be saved as (H,W,D,C).\n it's used for NIfTI format only.\n data_root_dir: if not empty, it specifies the beginning parts of the input file's\n absolute path. it's used to compute `input_file_rel_path`, the relative path to the file from\n `data_root_dir` to preserve folder structure when saving in case there are files in different\n folders with the same file names. for example:\n input_file_name: /foo/bar/test1/image.nii,\n output_postfix: seg\n output_ext: nii.gz\n output_dir: /output,\n data_root_dir: /foo/bar,\n output will be: /output/test1/image/image_seg.nii.gz\n print_log: whether to print log about the saved file path, etc. default to `True`.\n\n \"\"\"\n\n def __init__(\n self,\n output_dir: str = \"./\",\n output_postfix: str = \"trans\",\n output_ext: str = \".nii.gz\",\n resample: bool = True,\n mode: Union[GridSampleMode, InterpolateMode, str] = \"nearest\",\n padding_mode: Union[GridSamplePadMode, str] = GridSamplePadMode.BORDER,\n scale: Optional[int] = None,\n dtype: DtypeLike = np.float64,\n output_dtype: DtypeLike = np.float32,\n squeeze_end_dims: bool = True,\n data_root_dir: str = \"\",\n print_log: bool = True,\n ) -> None:\n self.saver: Union[NiftiSaver, PNGSaver]\n if output_ext in (\".nii.gz\", \".nii\"):\n self.saver = NiftiSaver(\n output_dir=output_dir,\n output_postfix=output_postfix,\n output_ext=output_ext,\n resample=resample,\n mode=GridSampleMode(mode),\n padding_mode=padding_mode,\n dtype=dtype,\n output_dtype=output_dtype,\n squeeze_end_dims=squeeze_end_dims,\n data_root_dir=data_root_dir,\n print_log=print_log,\n )\n elif output_ext == \".png\":\n self.saver = PNGSaver(\n output_dir=output_dir,\n output_postfix=output_postfix,\n output_ext=output_ext,\n resample=resample,\n mode=InterpolateMode(mode),\n scale=scale,\n data_root_dir=data_root_dir,\n print_log=print_log,\n )\n else:\n raise ValueError(f\"unsupported output extension: {output_ext}.\")\n\n def __call__(self, img: Union[torch.Tensor, np.ndarray], meta_data: Optional[Dict] = None):\n \"\"\"\n Args:\n img: target data content that save into file.\n meta_data: key-value pairs of meta_data corresponding to the data.\n\n \"\"\"\n self.saver.save(img, meta_data)\n\n return img\n", "path": "monai/transforms/io/array.py"}]}
| 4,083 | 77 |
gh_patches_debug_28047
|
rasdani/github-patches
|
git_diff
|
tensorflow__addons-771
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Build Addons for Windows
Splitting this as a separate issue from #77. MacOS should be an achievable goal prior to the 0.3 release. Windows will take a bit longer.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """TensorFlow Addons.
16
17 TensorFlow Addons is a repository of contributions that conform to well-
18 established API patterns, but implement new functionality not available
19 in core TensorFlow. TensorFlow natively supports a large number of
20 operators, layers, metrics, losses, and optimizers. However, in a fast
21 moving field like ML, there are many interesting new developments that
22 cannot be integrated into core TensorFlow (because their broad
23 applicability is not yet clear, or it is mostly used by a smaller subset
24 of the community).
25 """
26
27 from __future__ import absolute_import
28 from __future__ import division
29 from __future__ import print_function
30
31 import os
32 import sys
33
34 from datetime import datetime
35 from setuptools import find_packages
36 from setuptools import setup
37 from setuptools.dist import Distribution
38 from setuptools import Extension
39
40 DOCLINES = __doc__.split('\n')
41
42 TFA_NIGHTLY = 'tfa-nightly'
43 TFA_RELEASE = 'tensorflow-addons'
44
45 if '--nightly' in sys.argv:
46 project_name = TFA_NIGHTLY
47 nightly_idx = sys.argv.index('--nightly')
48 sys.argv.pop(nightly_idx)
49 else:
50 project_name = TFA_RELEASE
51
52 # Version
53 version = {}
54 base_dir = os.path.dirname(os.path.abspath(__file__))
55 with open(os.path.join(base_dir, "tensorflow_addons", "version.py")) as fp:
56 # yapf: disable
57 exec(fp.read(), version)
58 # yapf: enable
59
60 if project_name == TFA_NIGHTLY:
61 version['__version__'] += datetime.strftime(datetime.today(), "%Y%m%d")
62
63 # Dependencies
64 REQUIRED_PACKAGES = [
65 'six >= 1.10.0',
66 ]
67
68 if project_name == TFA_RELEASE:
69 REQUIRED_PACKAGES.append('tensorflow >= 2.1.0rc1')
70 elif project_name == TFA_NIGHTLY:
71 REQUIRED_PACKAGES.append('tf-nightly')
72
73
74 class BinaryDistribution(Distribution):
75 """This class is needed in order to create OS specific wheels."""
76
77 def has_ext_modules(self):
78 return True
79
80
81 setup(
82 name=project_name,
83 version=version['__version__'],
84 description=DOCLINES[0],
85 long_description='\n'.join(DOCLINES[2:]),
86 author='Google Inc.',
87 author_email='[email protected]',
88 packages=find_packages(),
89 ext_modules=[Extension('_foo', ['stub.cc'])],
90 install_requires=REQUIRED_PACKAGES,
91 include_package_data=True,
92 zip_safe=False,
93 distclass=BinaryDistribution,
94 classifiers=[
95 'Development Status :: 4 - Beta',
96 'Intended Audience :: Developers',
97 'Intended Audience :: Education',
98 'Intended Audience :: Science/Research',
99 'License :: OSI Approved :: Apache Software License',
100 'Programming Language :: Python :: 2.7',
101 'Programming Language :: Python :: 3.5',
102 'Programming Language :: Python :: 3.6',
103 'Programming Language :: Python :: 3.7',
104 'Topic :: Scientific/Engineering :: Mathematics',
105 'Topic :: Software Development :: Libraries :: Python Modules',
106 'Topic :: Software Development :: Libraries',
107 ],
108 license='Apache 2.0',
109 keywords='tensorflow addons machine learning',
110 )
111
```
Path: `tensorflow_addons/text/__init__.py`
Content:
```
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """Additional text-processing ops."""
16 from __future__ import absolute_import
17 from __future__ import division
18 from __future__ import print_function
19
20 # Conditional Random Field
21 from tensorflow_addons.text.crf import crf_binary_score
22 from tensorflow_addons.text.crf import crf_decode
23 from tensorflow_addons.text.crf import crf_decode_backward
24 from tensorflow_addons.text.crf import crf_decode_forward
25 from tensorflow_addons.text.crf import crf_forward
26 from tensorflow_addons.text.crf import crf_log_likelihood
27 from tensorflow_addons.text.crf import crf_log_norm
28 from tensorflow_addons.text.crf import crf_multitag_sequence_score
29 from tensorflow_addons.text.crf import crf_sequence_score
30 from tensorflow_addons.text.crf import crf_unary_score
31 from tensorflow_addons.text.crf import viterbi_decode
32
33 # Skip Gram Sampling
34 from tensorflow_addons.text.skip_gram_ops import skip_gram_sample
35 from tensorflow_addons.text.skip_gram_ops import skip_gram_sample_with_text_vocab
36
37 # Parse Time
38 from tensorflow_addons.text.parse_time_op import parse_time
39
```
Path: `tensorflow_addons/utils/resource_loader.py`
Content:
```
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """Utilities similar to tf.python.platform.resource_loader."""
16 from __future__ import absolute_import
17 from __future__ import division
18 from __future__ import print_function
19
20 import os
21
22
23 def get_project_root():
24 """Returns project root folder."""
25 return os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
26
27
28 def get_path_to_datafile(path):
29 """Get the path to the specified file in the data dependencies.
30
31 The path is relative to tensorflow_addons/
32
33 Args:
34 path: a string resource path relative to tensorflow_addons/
35 Returns:
36 The path to the specified data file
37 """
38 root_dir = get_project_root()
39 return os.path.join(root_dir, path)
40
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -70,6 +70,12 @@
elif project_name == TFA_NIGHTLY:
REQUIRED_PACKAGES.append('tf-nightly')
+# Manylinux2010 requires a patch for platlib
+if sys.platform.startswith('linux'):
+ ext_modules = [Extension('_foo', ['stub.cc'])]
+else:
+ ext_modules = []
+
class BinaryDistribution(Distribution):
"""This class is needed in order to create OS specific wheels."""
@@ -86,7 +92,7 @@
author='Google Inc.',
author_email='[email protected]',
packages=find_packages(),
- ext_modules=[Extension('_foo', ['stub.cc'])],
+ ext_modules=ext_modules,
install_requires=REQUIRED_PACKAGES,
include_package_data=True,
zip_safe=False,
diff --git a/tensorflow_addons/text/__init__.py b/tensorflow_addons/text/__init__.py
--- a/tensorflow_addons/text/__init__.py
+++ b/tensorflow_addons/text/__init__.py
@@ -35,4 +35,8 @@
from tensorflow_addons.text.skip_gram_ops import skip_gram_sample_with_text_vocab
# Parse Time
-from tensorflow_addons.text.parse_time_op import parse_time
+
+# Temporarily disable for windwos
+import os
+if os.name != 'nt':
+ from tensorflow_addons.text.parse_time_op import parse_time
diff --git a/tensorflow_addons/utils/resource_loader.py b/tensorflow_addons/utils/resource_loader.py
--- a/tensorflow_addons/utils/resource_loader.py
+++ b/tensorflow_addons/utils/resource_loader.py
@@ -36,4 +36,4 @@
The path to the specified data file
"""
root_dir = get_project_root()
- return os.path.join(root_dir, path)
+ return os.path.join(root_dir, path.replace("/", os.sep))
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -70,6 +70,12 @@\n elif project_name == TFA_NIGHTLY:\n REQUIRED_PACKAGES.append('tf-nightly')\n \n+# Manylinux2010 requires a patch for platlib\n+if sys.platform.startswith('linux'):\n+ ext_modules = [Extension('_foo', ['stub.cc'])]\n+else:\n+ ext_modules = []\n+\n \n class BinaryDistribution(Distribution):\n \"\"\"This class is needed in order to create OS specific wheels.\"\"\"\n@@ -86,7 +92,7 @@\n author='Google Inc.',\n author_email='[email protected]',\n packages=find_packages(),\n- ext_modules=[Extension('_foo', ['stub.cc'])],\n+ ext_modules=ext_modules,\n install_requires=REQUIRED_PACKAGES,\n include_package_data=True,\n zip_safe=False,\ndiff --git a/tensorflow_addons/text/__init__.py b/tensorflow_addons/text/__init__.py\n--- a/tensorflow_addons/text/__init__.py\n+++ b/tensorflow_addons/text/__init__.py\n@@ -35,4 +35,8 @@\n from tensorflow_addons.text.skip_gram_ops import skip_gram_sample_with_text_vocab\n \n # Parse Time\n-from tensorflow_addons.text.parse_time_op import parse_time\n+\n+# Temporarily disable for windwos\n+import os\n+if os.name != 'nt':\n+ from tensorflow_addons.text.parse_time_op import parse_time\ndiff --git a/tensorflow_addons/utils/resource_loader.py b/tensorflow_addons/utils/resource_loader.py\n--- a/tensorflow_addons/utils/resource_loader.py\n+++ b/tensorflow_addons/utils/resource_loader.py\n@@ -36,4 +36,4 @@\n The path to the specified data file\n \"\"\"\n root_dir = get_project_root()\n- return os.path.join(root_dir, path)\n+ return os.path.join(root_dir, path.replace(\"/\", os.sep))\n", "issue": "Build Addons for Windows\nSplitting this as a separate issue from #77. MacOS should be an achievable goal prior to the 0.3 release. Windows will take a bit longer.\n", "before_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"TensorFlow Addons.\n\nTensorFlow Addons is a repository of contributions that conform to well-\nestablished API patterns, but implement new functionality not available\nin core TensorFlow. TensorFlow natively supports a large number of\noperators, layers, metrics, losses, and optimizers. However, in a fast\nmoving field like ML, there are many interesting new developments that\ncannot be integrated into core TensorFlow (because their broad\napplicability is not yet clear, or it is mostly used by a smaller subset\nof the community).\n\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport os\nimport sys\n\nfrom datetime import datetime\nfrom setuptools import find_packages\nfrom setuptools import setup\nfrom setuptools.dist import Distribution\nfrom setuptools import Extension\n\nDOCLINES = __doc__.split('\\n')\n\nTFA_NIGHTLY = 'tfa-nightly'\nTFA_RELEASE = 'tensorflow-addons'\n\nif '--nightly' in sys.argv:\n project_name = TFA_NIGHTLY\n nightly_idx = sys.argv.index('--nightly')\n sys.argv.pop(nightly_idx)\nelse:\n project_name = TFA_RELEASE\n\n# Version\nversion = {}\nbase_dir = os.path.dirname(os.path.abspath(__file__))\nwith open(os.path.join(base_dir, \"tensorflow_addons\", \"version.py\")) as fp:\n # yapf: disable\n exec(fp.read(), version)\n # yapf: enable\n\nif project_name == TFA_NIGHTLY:\n version['__version__'] += datetime.strftime(datetime.today(), \"%Y%m%d\")\n\n# Dependencies\nREQUIRED_PACKAGES = [\n 'six >= 1.10.0',\n]\n\nif project_name == TFA_RELEASE:\n REQUIRED_PACKAGES.append('tensorflow >= 2.1.0rc1')\nelif project_name == TFA_NIGHTLY:\n REQUIRED_PACKAGES.append('tf-nightly')\n\n\nclass BinaryDistribution(Distribution):\n \"\"\"This class is needed in order to create OS specific wheels.\"\"\"\n\n def has_ext_modules(self):\n return True\n\n\nsetup(\n name=project_name,\n version=version['__version__'],\n description=DOCLINES[0],\n long_description='\\n'.join(DOCLINES[2:]),\n author='Google Inc.',\n author_email='[email protected]',\n packages=find_packages(),\n ext_modules=[Extension('_foo', ['stub.cc'])],\n install_requires=REQUIRED_PACKAGES,\n include_package_data=True,\n zip_safe=False,\n distclass=BinaryDistribution,\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Scientific/Engineering :: Mathematics',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Software Development :: Libraries',\n ],\n license='Apache 2.0',\n keywords='tensorflow addons machine learning',\n)\n", "path": "setup.py"}, {"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Additional text-processing ops.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\n# Conditional Random Field\nfrom tensorflow_addons.text.crf import crf_binary_score\nfrom tensorflow_addons.text.crf import crf_decode\nfrom tensorflow_addons.text.crf import crf_decode_backward\nfrom tensorflow_addons.text.crf import crf_decode_forward\nfrom tensorflow_addons.text.crf import crf_forward\nfrom tensorflow_addons.text.crf import crf_log_likelihood\nfrom tensorflow_addons.text.crf import crf_log_norm\nfrom tensorflow_addons.text.crf import crf_multitag_sequence_score\nfrom tensorflow_addons.text.crf import crf_sequence_score\nfrom tensorflow_addons.text.crf import crf_unary_score\nfrom tensorflow_addons.text.crf import viterbi_decode\n\n# Skip Gram Sampling\nfrom tensorflow_addons.text.skip_gram_ops import skip_gram_sample\nfrom tensorflow_addons.text.skip_gram_ops import skip_gram_sample_with_text_vocab\n\n# Parse Time\nfrom tensorflow_addons.text.parse_time_op import parse_time\n", "path": "tensorflow_addons/text/__init__.py"}, {"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Utilities similar to tf.python.platform.resource_loader.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport os\n\n\ndef get_project_root():\n \"\"\"Returns project root folder.\"\"\"\n return os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n\n\ndef get_path_to_datafile(path):\n \"\"\"Get the path to the specified file in the data dependencies.\n\n The path is relative to tensorflow_addons/\n\n Args:\n path: a string resource path relative to tensorflow_addons/\n Returns:\n The path to the specified data file\n \"\"\"\n root_dir = get_project_root()\n return os.path.join(root_dir, path)\n", "path": "tensorflow_addons/utils/resource_loader.py"}], "after_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"TensorFlow Addons.\n\nTensorFlow Addons is a repository of contributions that conform to well-\nestablished API patterns, but implement new functionality not available\nin core TensorFlow. TensorFlow natively supports a large number of\noperators, layers, metrics, losses, and optimizers. However, in a fast\nmoving field like ML, there are many interesting new developments that\ncannot be integrated into core TensorFlow (because their broad\napplicability is not yet clear, or it is mostly used by a smaller subset\nof the community).\n\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport os\nimport sys\n\nfrom datetime import datetime\nfrom setuptools import find_packages\nfrom setuptools import setup\nfrom setuptools.dist import Distribution\nfrom setuptools import Extension\n\nDOCLINES = __doc__.split('\\n')\n\nTFA_NIGHTLY = 'tfa-nightly'\nTFA_RELEASE = 'tensorflow-addons'\n\nif '--nightly' in sys.argv:\n project_name = TFA_NIGHTLY\n nightly_idx = sys.argv.index('--nightly')\n sys.argv.pop(nightly_idx)\nelse:\n project_name = TFA_RELEASE\n\n# Version\nversion = {}\nbase_dir = os.path.dirname(os.path.abspath(__file__))\nwith open(os.path.join(base_dir, \"tensorflow_addons\", \"version.py\")) as fp:\n # yapf: disable\n exec(fp.read(), version)\n # yapf: enable\n\nif project_name == TFA_NIGHTLY:\n version['__version__'] += datetime.strftime(datetime.today(), \"%Y%m%d\")\n\n# Dependencies\nREQUIRED_PACKAGES = [\n 'six >= 1.10.0',\n]\n\nif project_name == TFA_RELEASE:\n REQUIRED_PACKAGES.append('tensorflow >= 2.1.0rc1')\nelif project_name == TFA_NIGHTLY:\n REQUIRED_PACKAGES.append('tf-nightly')\n\n# Manylinux2010 requires a patch for platlib\nif sys.platform.startswith('linux'):\n ext_modules = [Extension('_foo', ['stub.cc'])]\nelse:\n ext_modules = []\n\n\nclass BinaryDistribution(Distribution):\n \"\"\"This class is needed in order to create OS specific wheels.\"\"\"\n\n def has_ext_modules(self):\n return True\n\n\nsetup(\n name=project_name,\n version=version['__version__'],\n description=DOCLINES[0],\n long_description='\\n'.join(DOCLINES[2:]),\n author='Google Inc.',\n author_email='[email protected]',\n packages=find_packages(),\n ext_modules=ext_modules,\n install_requires=REQUIRED_PACKAGES,\n include_package_data=True,\n zip_safe=False,\n distclass=BinaryDistribution,\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Scientific/Engineering :: Mathematics',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Software Development :: Libraries',\n ],\n license='Apache 2.0',\n keywords='tensorflow addons machine learning',\n)\n", "path": "setup.py"}, {"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Additional text-processing ops.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\n# Conditional Random Field\nfrom tensorflow_addons.text.crf import crf_binary_score\nfrom tensorflow_addons.text.crf import crf_decode\nfrom tensorflow_addons.text.crf import crf_decode_backward\nfrom tensorflow_addons.text.crf import crf_decode_forward\nfrom tensorflow_addons.text.crf import crf_forward\nfrom tensorflow_addons.text.crf import crf_log_likelihood\nfrom tensorflow_addons.text.crf import crf_log_norm\nfrom tensorflow_addons.text.crf import crf_multitag_sequence_score\nfrom tensorflow_addons.text.crf import crf_sequence_score\nfrom tensorflow_addons.text.crf import crf_unary_score\nfrom tensorflow_addons.text.crf import viterbi_decode\n\n# Skip Gram Sampling\nfrom tensorflow_addons.text.skip_gram_ops import skip_gram_sample\nfrom tensorflow_addons.text.skip_gram_ops import skip_gram_sample_with_text_vocab\n\n# Parse Time\n\n# Temporarily disable for windwos\nimport os\nif os.name != 'nt':\n from tensorflow_addons.text.parse_time_op import parse_time\n", "path": "tensorflow_addons/text/__init__.py"}, {"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Utilities similar to tf.python.platform.resource_loader.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport os\n\n\ndef get_project_root():\n \"\"\"Returns project root folder.\"\"\"\n return os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n\n\ndef get_path_to_datafile(path):\n \"\"\"Get the path to the specified file in the data dependencies.\n\n The path is relative to tensorflow_addons/\n\n Args:\n path: a string resource path relative to tensorflow_addons/\n Returns:\n The path to the specified data file\n \"\"\"\n root_dir = get_project_root()\n return os.path.join(root_dir, path.replace(\"/\", os.sep))\n", "path": "tensorflow_addons/utils/resource_loader.py"}]}
| 2,186 | 434 |
gh_patches_debug_43112
|
rasdani/github-patches
|
git_diff
|
sublimelsp__LSP-1555
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Option to disable code actions
Currently code actions can be shown as bulbs or annotations, but there doesn't seem to be a way to completely disable them. Would be nice to get such an option.
I wrote a very simple patch that prevents them from rendering when `"show_code_actions"` is not set to a known value (currently it falls back on `'annotation'` instead). But ended up not submitting it because ideally we shouldn't even calculate the code actions when they should be disabled. Unfortunately, tracking down every code path that invokes code actions has proven too much. Requesting support. 🙂
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugin/code_actions.py`
Content:
```
1 from .core.promise import Promise
2 from .core.protocol import CodeAction
3 from .core.protocol import Command
4 from .core.protocol import Diagnostic
5 from .core.protocol import Request
6 from .core.registry import LspTextCommand
7 from .core.registry import sessions_for_view
8 from .core.registry import windows
9 from .core.sessions import SessionBufferProtocol
10 from .core.settings import userprefs
11 from .core.typing import Any, List, Dict, Callable, Optional, Tuple, Union, Sequence
12 from .core.views import entire_content_region
13 from .core.views import text_document_code_action_params
14 from .save_command import LspSaveCommand, SaveTask
15 import sublime
16
17 CodeActionOrCommand = Union[CodeAction, Command]
18 CodeActionsResponse = Optional[List[CodeActionOrCommand]]
19 CodeActionsByConfigName = Dict[str, List[CodeActionOrCommand]]
20
21
22 class CodeActionsCollector:
23 """
24 Collects code action responses from multiple sessions. Calls back the "on_complete_handler" with
25 results when all responses are received.
26
27 Usage example:
28
29 with CodeActionsCollector() as collector:
30 actions_manager.request_with_diagnostics(collector.create_collector('test_config'))
31 actions_manager.request_with_diagnostics(collector.create_collector('another_config'))
32
33 The "create_collector()" must only be called within the "with" context. Once the context is
34 exited, the "on_complete_handler" will be called once all the created collectors receive the
35 response (are called).
36 """
37
38 def __init__(self, on_complete_handler: Callable[[CodeActionsByConfigName], None]):
39 self._on_complete_handler = on_complete_handler
40 self._commands_by_config = {} # type: CodeActionsByConfigName
41 self._request_count = 0
42 self._response_count = 0
43 self._all_requested = False
44
45 def __enter__(self) -> 'CodeActionsCollector':
46 return self
47
48 def __exit__(self, exc_type: Any, exc_value: Any, traceback: Any) -> None:
49 self._all_requested = True
50 self._notify_if_all_finished()
51
52 def create_collector(self, config_name: str) -> Callable[[CodeActionsResponse], None]:
53 self._request_count += 1
54 return lambda actions: self._collect_response(config_name, actions)
55
56 def _collect_response(self, config_name: str, actions: CodeActionsResponse) -> None:
57 self._response_count += 1
58 self._commands_by_config[config_name] = actions or []
59 self._notify_if_all_finished()
60
61 def _notify_if_all_finished(self) -> None:
62 if self._all_requested and self._request_count == self._response_count:
63 # Call back on Sublime's async thread
64 sublime.set_timeout_async(lambda: self._on_complete_handler(self._commands_by_config))
65
66 def get_actions(self) -> CodeActionsByConfigName:
67 return self._commands_by_config
68
69
70 class CodeActionsManager:
71 """Manager for per-location caching of code action responses."""
72
73 def __init__(self) -> None:
74 self._response_cache = None # type: Optional[Tuple[str, CodeActionsCollector]]
75
76 def request_with_diagnostics_async(
77 self,
78 view: sublime.View,
79 region: sublime.Region,
80 session_buffer_diagnostics: Sequence[Tuple[SessionBufferProtocol, Sequence[Diagnostic]]],
81 actions_handler: Callable[[CodeActionsByConfigName], None]
82 ) -> CodeActionsCollector:
83 """
84 Requests code actions *only* for provided diagnostics. If session has no diagnostics then
85 it will be skipped.
86 """
87 return self._request_async(view, region, session_buffer_diagnostics, True, actions_handler)
88
89 def request_for_region_async(
90 self,
91 view: sublime.View,
92 region: sublime.Region,
93 session_buffer_diagnostics: Sequence[Tuple[SessionBufferProtocol, Sequence[Diagnostic]]],
94 actions_handler: Callable[[CodeActionsByConfigName], None],
95 only_kinds: Optional[Dict[str, bool]] = None
96 ) -> CodeActionsCollector:
97 """
98 Requests code actions with provided diagnostics and specified region. If there are
99 no diagnostics for given session, the request will be made with empty diagnostics list.
100 """
101 return self._request_async(view, region, session_buffer_diagnostics, False, actions_handler, only_kinds)
102
103 def request_on_save(
104 self,
105 view: sublime.View,
106 actions_handler: Callable[[CodeActionsByConfigName], None],
107 on_save_actions: Dict[str, bool]
108 ) -> CodeActionsCollector:
109 """
110 Requests code actions on save.
111 """
112 return self._request_async(view, entire_content_region(view), [], False, actions_handler, on_save_actions)
113
114 def _request_async(
115 self,
116 view: sublime.View,
117 region: sublime.Region,
118 session_buffer_diagnostics: Sequence[Tuple[SessionBufferProtocol, Sequence[Diagnostic]]],
119 only_with_diagnostics: bool,
120 actions_handler: Callable[[CodeActionsByConfigName], None],
121 on_save_actions: Optional[Dict[str, bool]] = None
122 ) -> CodeActionsCollector:
123 use_cache = on_save_actions is None
124 if use_cache:
125 location_cache_key = "{}#{}:{}:{}".format(
126 view.buffer_id(), view.change_count(), region, only_with_diagnostics)
127 if self._response_cache:
128 cache_key, cache_collector = self._response_cache
129 if location_cache_key == cache_key:
130 sublime.set_timeout(lambda: actions_handler(cache_collector.get_actions()))
131 return cache_collector
132 else:
133 self._response_cache = None
134
135 collector = CodeActionsCollector(actions_handler)
136 with collector:
137 file_name = view.file_name()
138 if file_name:
139 for session in sessions_for_view(view, 'codeActionProvider'):
140 if on_save_actions:
141 supported_kinds = session.get_capability('codeActionProvider.codeActionKinds')
142 matching_kinds = get_matching_kinds(on_save_actions, supported_kinds or [])
143 if matching_kinds:
144 params = text_document_code_action_params(
145 view, file_name, region, [], matching_kinds)
146 request = Request.codeAction(params, view)
147 session.send_request_async(
148 request, *filtering_collector(session.config.name, matching_kinds, collector))
149 else:
150 diagnostics = [] # type: Sequence[Diagnostic]
151 for sb, diags in session_buffer_diagnostics:
152 if sb.session == session:
153 diagnostics = diags
154 break
155 if only_with_diagnostics and not diagnostics:
156 continue
157 params = text_document_code_action_params(view, file_name, region, diagnostics)
158 request = Request.codeAction(params, view)
159 session.send_request_async(request, collector.create_collector(session.config.name))
160 if use_cache:
161 self._response_cache = (location_cache_key, collector)
162 return collector
163
164
165 def filtering_collector(
166 config_name: str,
167 kinds: List[str],
168 actions_collector: CodeActionsCollector
169 ) -> Tuple[Callable[[CodeActionsResponse], None], Callable[[Any], None]]:
170 """
171 Filters actions returned from the session so that only matching kinds are collected.
172
173 Since older servers don't support the "context.only" property, these will return all
174 actions that need to be filtered.
175 """
176
177 def actions_filter(actions: CodeActionsResponse) -> List[CodeActionOrCommand]:
178 return [a for a in (actions or []) if a.get('kind') in kinds] # type: ignore
179
180 collector = actions_collector.create_collector(config_name)
181 return (
182 lambda actions: collector(actions_filter(actions)),
183 lambda error: collector([])
184 )
185
186
187 actions_manager = CodeActionsManager()
188
189
190 def get_matching_kinds(user_actions: Dict[str, bool], session_actions: List[str]) -> List[str]:
191 """
192 Filters user-enabled or disabled actions so that only ones matching the session actions
193 are returned. Returned actions are those that are enabled and are not overridden by more
194 specific, disabled actions.
195
196 Filtering only returns actions that exactly match the ones supported by given session.
197 If user has enabled a generic action that matches more specific session action
198 (for example user's a.b matching session's a.b.c), then the more specific (a.b.c) must be
199 returned as servers must receive only actions that they advertise support for.
200 """
201 matching_kinds = []
202 for session_action in session_actions:
203 enabled = False
204 action_parts = session_action.split('.')
205 for i in range(len(action_parts)):
206 current_part = '.'.join(action_parts[0:i + 1])
207 user_value = user_actions.get(current_part, None)
208 if isinstance(user_value, bool):
209 enabled = user_value
210 if enabled:
211 matching_kinds.append(session_action)
212 return matching_kinds
213
214
215 class CodeActionOnSaveTask(SaveTask):
216 """
217 The main task that requests code actions from sessions and runs them.
218
219 The amount of time the task is allowed to run is defined by user-controlled setting. If the task
220 runs longer, the native save will be triggered before waiting for results.
221 """
222 @classmethod
223 def is_applicable(cls, view: sublime.View) -> bool:
224 return bool(view.window()) and bool(cls._get_code_actions_on_save(view))
225
226 @classmethod
227 def _get_code_actions_on_save(cls, view: sublime.View) -> Dict[str, bool]:
228 view_code_actions = view.settings().get('lsp_code_actions_on_save') or {}
229 code_actions = userprefs().lsp_code_actions_on_save.copy()
230 code_actions.update(view_code_actions)
231 allowed_code_actions = dict()
232 for key, value in code_actions.items():
233 if key.startswith('source.'):
234 allowed_code_actions[key] = value
235 return allowed_code_actions
236
237 def get_task_timeout_ms(self) -> int:
238 return userprefs().code_action_on_save_timeout_ms
239
240 def run_async(self) -> None:
241 super().run_async()
242 self._request_code_actions_async()
243
244 def _request_code_actions_async(self) -> None:
245 self._purge_changes_async()
246 on_save_actions = self._get_code_actions_on_save(self._view)
247 actions_manager.request_on_save(self._view, self._handle_response_async, on_save_actions)
248
249 def _handle_response_async(self, responses: CodeActionsByConfigName) -> None:
250 if self._cancelled:
251 return
252 document_version = self._view.change_count()
253 tasks = [] # type: List[Promise]
254 for config_name, code_actions in responses.items():
255 if code_actions:
256 for session in sessions_for_view(self._view, 'codeActionProvider'):
257 if session.config.name == config_name:
258 for code_action in code_actions:
259 tasks.append(session.run_code_action_async(code_action, progress=False))
260 break
261 if document_version != self._view.change_count():
262 # Give on_text_changed_async a chance to trigger.
263 Promise.all(tasks).then(lambda _: sublime.set_timeout_async(self._request_code_actions_async))
264 else:
265 Promise.all(tasks).then(lambda _: sublime.set_timeout_async(self._on_complete))
266
267
268 LspSaveCommand.register_task(CodeActionOnSaveTask)
269
270
271 class LspCodeActionsCommand(LspTextCommand):
272
273 capability = 'codeActionProvider'
274
275 def run(self, edit: sublime.Edit, event: Optional[dict] = None, only_kinds: Optional[List[str]] = None) -> None:
276 self.commands = [] # type: List[Tuple[str, str, CodeActionOrCommand]]
277 self.commands_by_config = {} # type: CodeActionsByConfigName
278 view = self.view
279 try:
280 region = view.sel()[0]
281 except IndexError:
282 return
283 listener = windows.listener_for_view(view)
284 if not listener:
285 return
286 session_buffer_diagnostics, covering = listener.diagnostics_intersecting_async(region)
287 dict_kinds = {kind: True for kind in only_kinds} if only_kinds else None
288 actions_manager.request_for_region_async(
289 view, covering, session_buffer_diagnostics, self.handle_responses_async, dict_kinds)
290
291 def handle_responses_async(self, responses: CodeActionsByConfigName) -> None:
292 self.commands_by_config = responses
293 self.commands = self.combine_commands()
294 self.show_popup_menu()
295
296 def combine_commands(self) -> 'List[Tuple[str, str, CodeActionOrCommand]]':
297 results = []
298 for config, commands in self.commands_by_config.items():
299 for command in commands:
300 results.append((config, command['title'], command))
301 return results
302
303 def show_popup_menu(self) -> None:
304 if len(self.commands) > 0:
305 self.view.show_popup_menu([command[1] for command in self.commands], self.handle_select)
306 else:
307 self.view.show_popup('No actions available', sublime.HIDE_ON_MOUSE_MOVE_AWAY)
308
309 def handle_select(self, index: int) -> None:
310 if index > -1:
311
312 def run_async() -> None:
313 selected = self.commands[index]
314 session = self.session_by_name(selected[0])
315 if session:
316 session.run_code_action_async(selected[2], progress=True)
317
318 sublime.set_timeout_async(run_async)
319
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plugin/code_actions.py b/plugin/code_actions.py
--- a/plugin/code_actions.py
+++ b/plugin/code_actions.py
@@ -79,12 +79,12 @@
region: sublime.Region,
session_buffer_diagnostics: Sequence[Tuple[SessionBufferProtocol, Sequence[Diagnostic]]],
actions_handler: Callable[[CodeActionsByConfigName], None]
- ) -> CodeActionsCollector:
+ ) -> None:
"""
Requests code actions *only* for provided diagnostics. If session has no diagnostics then
it will be skipped.
"""
- return self._request_async(view, region, session_buffer_diagnostics, True, actions_handler)
+ self._request_async(view, region, session_buffer_diagnostics, True, actions_handler)
def request_for_region_async(
self,
@@ -93,23 +93,23 @@
session_buffer_diagnostics: Sequence[Tuple[SessionBufferProtocol, Sequence[Diagnostic]]],
actions_handler: Callable[[CodeActionsByConfigName], None],
only_kinds: Optional[Dict[str, bool]] = None
- ) -> CodeActionsCollector:
+ ) -> None:
"""
Requests code actions with provided diagnostics and specified region. If there are
no diagnostics for given session, the request will be made with empty diagnostics list.
"""
- return self._request_async(view, region, session_buffer_diagnostics, False, actions_handler, only_kinds)
+ self._request_async(view, region, session_buffer_diagnostics, False, actions_handler, only_kinds)
def request_on_save(
self,
view: sublime.View,
actions_handler: Callable[[CodeActionsByConfigName], None],
on_save_actions: Dict[str, bool]
- ) -> CodeActionsCollector:
+ ) -> None:
"""
Requests code actions on save.
"""
- return self._request_async(view, entire_content_region(view), [], False, actions_handler, on_save_actions)
+ self._request_async(view, entire_content_region(view), [], False, actions_handler, on_save_actions)
def _request_async(
self,
@@ -119,7 +119,10 @@
only_with_diagnostics: bool,
actions_handler: Callable[[CodeActionsByConfigName], None],
on_save_actions: Optional[Dict[str, bool]] = None
- ) -> CodeActionsCollector:
+ ) -> None:
+ if 'codeActionProvider' in userprefs().disabled_capabilities:
+ return None
+
use_cache = on_save_actions is None
if use_cache:
location_cache_key = "{}#{}:{}:{}".format(
@@ -128,7 +131,6 @@
cache_key, cache_collector = self._response_cache
if location_cache_key == cache_key:
sublime.set_timeout(lambda: actions_handler(cache_collector.get_actions()))
- return cache_collector
else:
self._response_cache = None
@@ -159,7 +161,6 @@
session.send_request_async(request, collector.create_collector(session.config.name))
if use_cache:
self._response_cache = (location_cache_key, collector)
- return collector
def filtering_collector(
|
{"golden_diff": "diff --git a/plugin/code_actions.py b/plugin/code_actions.py\n--- a/plugin/code_actions.py\n+++ b/plugin/code_actions.py\n@@ -79,12 +79,12 @@\n region: sublime.Region,\n session_buffer_diagnostics: Sequence[Tuple[SessionBufferProtocol, Sequence[Diagnostic]]],\n actions_handler: Callable[[CodeActionsByConfigName], None]\n- ) -> CodeActionsCollector:\n+ ) -> None:\n \"\"\"\n Requests code actions *only* for provided diagnostics. If session has no diagnostics then\n it will be skipped.\n \"\"\"\n- return self._request_async(view, region, session_buffer_diagnostics, True, actions_handler)\n+ self._request_async(view, region, session_buffer_diagnostics, True, actions_handler)\n \n def request_for_region_async(\n self,\n@@ -93,23 +93,23 @@\n session_buffer_diagnostics: Sequence[Tuple[SessionBufferProtocol, Sequence[Diagnostic]]],\n actions_handler: Callable[[CodeActionsByConfigName], None],\n only_kinds: Optional[Dict[str, bool]] = None\n- ) -> CodeActionsCollector:\n+ ) -> None:\n \"\"\"\n Requests code actions with provided diagnostics and specified region. If there are\n no diagnostics for given session, the request will be made with empty diagnostics list.\n \"\"\"\n- return self._request_async(view, region, session_buffer_diagnostics, False, actions_handler, only_kinds)\n+ self._request_async(view, region, session_buffer_diagnostics, False, actions_handler, only_kinds)\n \n def request_on_save(\n self,\n view: sublime.View,\n actions_handler: Callable[[CodeActionsByConfigName], None],\n on_save_actions: Dict[str, bool]\n- ) -> CodeActionsCollector:\n+ ) -> None:\n \"\"\"\n Requests code actions on save.\n \"\"\"\n- return self._request_async(view, entire_content_region(view), [], False, actions_handler, on_save_actions)\n+ self._request_async(view, entire_content_region(view), [], False, actions_handler, on_save_actions)\n \n def _request_async(\n self,\n@@ -119,7 +119,10 @@\n only_with_diagnostics: bool,\n actions_handler: Callable[[CodeActionsByConfigName], None],\n on_save_actions: Optional[Dict[str, bool]] = None\n- ) -> CodeActionsCollector:\n+ ) -> None:\n+ if 'codeActionProvider' in userprefs().disabled_capabilities:\n+ return None\n+\n use_cache = on_save_actions is None\n if use_cache:\n location_cache_key = \"{}#{}:{}:{}\".format(\n@@ -128,7 +131,6 @@\n cache_key, cache_collector = self._response_cache\n if location_cache_key == cache_key:\n sublime.set_timeout(lambda: actions_handler(cache_collector.get_actions()))\n- return cache_collector\n else:\n self._response_cache = None\n \n@@ -159,7 +161,6 @@\n session.send_request_async(request, collector.create_collector(session.config.name))\n if use_cache:\n self._response_cache = (location_cache_key, collector)\n- return collector\n \n \n def filtering_collector(\n", "issue": "Option to disable code actions\nCurrently code actions can be shown as bulbs or annotations, but there doesn't seem to be a way to completely disable them. Would be nice to get such an option.\r\n\r\nI wrote a very simple patch that prevents them from rendering when `\"show_code_actions\"` is not set to a known value (currently it falls back on `'annotation'` instead). But ended up not submitting it because ideally we shouldn't even calculate the code actions when they should be disabled. Unfortunately, tracking down every code path that invokes code actions has proven too much. Requesting support. \ud83d\ude42\n", "before_files": [{"content": "from .core.promise import Promise\nfrom .core.protocol import CodeAction\nfrom .core.protocol import Command\nfrom .core.protocol import Diagnostic\nfrom .core.protocol import Request\nfrom .core.registry import LspTextCommand\nfrom .core.registry import sessions_for_view\nfrom .core.registry import windows\nfrom .core.sessions import SessionBufferProtocol\nfrom .core.settings import userprefs\nfrom .core.typing import Any, List, Dict, Callable, Optional, Tuple, Union, Sequence\nfrom .core.views import entire_content_region\nfrom .core.views import text_document_code_action_params\nfrom .save_command import LspSaveCommand, SaveTask\nimport sublime\n\nCodeActionOrCommand = Union[CodeAction, Command]\nCodeActionsResponse = Optional[List[CodeActionOrCommand]]\nCodeActionsByConfigName = Dict[str, List[CodeActionOrCommand]]\n\n\nclass CodeActionsCollector:\n \"\"\"\n Collects code action responses from multiple sessions. Calls back the \"on_complete_handler\" with\n results when all responses are received.\n\n Usage example:\n\n with CodeActionsCollector() as collector:\n actions_manager.request_with_diagnostics(collector.create_collector('test_config'))\n actions_manager.request_with_diagnostics(collector.create_collector('another_config'))\n\n The \"create_collector()\" must only be called within the \"with\" context. Once the context is\n exited, the \"on_complete_handler\" will be called once all the created collectors receive the\n response (are called).\n \"\"\"\n\n def __init__(self, on_complete_handler: Callable[[CodeActionsByConfigName], None]):\n self._on_complete_handler = on_complete_handler\n self._commands_by_config = {} # type: CodeActionsByConfigName\n self._request_count = 0\n self._response_count = 0\n self._all_requested = False\n\n def __enter__(self) -> 'CodeActionsCollector':\n return self\n\n def __exit__(self, exc_type: Any, exc_value: Any, traceback: Any) -> None:\n self._all_requested = True\n self._notify_if_all_finished()\n\n def create_collector(self, config_name: str) -> Callable[[CodeActionsResponse], None]:\n self._request_count += 1\n return lambda actions: self._collect_response(config_name, actions)\n\n def _collect_response(self, config_name: str, actions: CodeActionsResponse) -> None:\n self._response_count += 1\n self._commands_by_config[config_name] = actions or []\n self._notify_if_all_finished()\n\n def _notify_if_all_finished(self) -> None:\n if self._all_requested and self._request_count == self._response_count:\n # Call back on Sublime's async thread\n sublime.set_timeout_async(lambda: self._on_complete_handler(self._commands_by_config))\n\n def get_actions(self) -> CodeActionsByConfigName:\n return self._commands_by_config\n\n\nclass CodeActionsManager:\n \"\"\"Manager for per-location caching of code action responses.\"\"\"\n\n def __init__(self) -> None:\n self._response_cache = None # type: Optional[Tuple[str, CodeActionsCollector]]\n\n def request_with_diagnostics_async(\n self,\n view: sublime.View,\n region: sublime.Region,\n session_buffer_diagnostics: Sequence[Tuple[SessionBufferProtocol, Sequence[Diagnostic]]],\n actions_handler: Callable[[CodeActionsByConfigName], None]\n ) -> CodeActionsCollector:\n \"\"\"\n Requests code actions *only* for provided diagnostics. If session has no diagnostics then\n it will be skipped.\n \"\"\"\n return self._request_async(view, region, session_buffer_diagnostics, True, actions_handler)\n\n def request_for_region_async(\n self,\n view: sublime.View,\n region: sublime.Region,\n session_buffer_diagnostics: Sequence[Tuple[SessionBufferProtocol, Sequence[Diagnostic]]],\n actions_handler: Callable[[CodeActionsByConfigName], None],\n only_kinds: Optional[Dict[str, bool]] = None\n ) -> CodeActionsCollector:\n \"\"\"\n Requests code actions with provided diagnostics and specified region. If there are\n no diagnostics for given session, the request will be made with empty diagnostics list.\n \"\"\"\n return self._request_async(view, region, session_buffer_diagnostics, False, actions_handler, only_kinds)\n\n def request_on_save(\n self,\n view: sublime.View,\n actions_handler: Callable[[CodeActionsByConfigName], None],\n on_save_actions: Dict[str, bool]\n ) -> CodeActionsCollector:\n \"\"\"\n Requests code actions on save.\n \"\"\"\n return self._request_async(view, entire_content_region(view), [], False, actions_handler, on_save_actions)\n\n def _request_async(\n self,\n view: sublime.View,\n region: sublime.Region,\n session_buffer_diagnostics: Sequence[Tuple[SessionBufferProtocol, Sequence[Diagnostic]]],\n only_with_diagnostics: bool,\n actions_handler: Callable[[CodeActionsByConfigName], None],\n on_save_actions: Optional[Dict[str, bool]] = None\n ) -> CodeActionsCollector:\n use_cache = on_save_actions is None\n if use_cache:\n location_cache_key = \"{}#{}:{}:{}\".format(\n view.buffer_id(), view.change_count(), region, only_with_diagnostics)\n if self._response_cache:\n cache_key, cache_collector = self._response_cache\n if location_cache_key == cache_key:\n sublime.set_timeout(lambda: actions_handler(cache_collector.get_actions()))\n return cache_collector\n else:\n self._response_cache = None\n\n collector = CodeActionsCollector(actions_handler)\n with collector:\n file_name = view.file_name()\n if file_name:\n for session in sessions_for_view(view, 'codeActionProvider'):\n if on_save_actions:\n supported_kinds = session.get_capability('codeActionProvider.codeActionKinds')\n matching_kinds = get_matching_kinds(on_save_actions, supported_kinds or [])\n if matching_kinds:\n params = text_document_code_action_params(\n view, file_name, region, [], matching_kinds)\n request = Request.codeAction(params, view)\n session.send_request_async(\n request, *filtering_collector(session.config.name, matching_kinds, collector))\n else:\n diagnostics = [] # type: Sequence[Diagnostic]\n for sb, diags in session_buffer_diagnostics:\n if sb.session == session:\n diagnostics = diags\n break\n if only_with_diagnostics and not diagnostics:\n continue\n params = text_document_code_action_params(view, file_name, region, diagnostics)\n request = Request.codeAction(params, view)\n session.send_request_async(request, collector.create_collector(session.config.name))\n if use_cache:\n self._response_cache = (location_cache_key, collector)\n return collector\n\n\ndef filtering_collector(\n config_name: str,\n kinds: List[str],\n actions_collector: CodeActionsCollector\n) -> Tuple[Callable[[CodeActionsResponse], None], Callable[[Any], None]]:\n \"\"\"\n Filters actions returned from the session so that only matching kinds are collected.\n\n Since older servers don't support the \"context.only\" property, these will return all\n actions that need to be filtered.\n \"\"\"\n\n def actions_filter(actions: CodeActionsResponse) -> List[CodeActionOrCommand]:\n return [a for a in (actions or []) if a.get('kind') in kinds] # type: ignore\n\n collector = actions_collector.create_collector(config_name)\n return (\n lambda actions: collector(actions_filter(actions)),\n lambda error: collector([])\n )\n\n\nactions_manager = CodeActionsManager()\n\n\ndef get_matching_kinds(user_actions: Dict[str, bool], session_actions: List[str]) -> List[str]:\n \"\"\"\n Filters user-enabled or disabled actions so that only ones matching the session actions\n are returned. Returned actions are those that are enabled and are not overridden by more\n specific, disabled actions.\n\n Filtering only returns actions that exactly match the ones supported by given session.\n If user has enabled a generic action that matches more specific session action\n (for example user's a.b matching session's a.b.c), then the more specific (a.b.c) must be\n returned as servers must receive only actions that they advertise support for.\n \"\"\"\n matching_kinds = []\n for session_action in session_actions:\n enabled = False\n action_parts = session_action.split('.')\n for i in range(len(action_parts)):\n current_part = '.'.join(action_parts[0:i + 1])\n user_value = user_actions.get(current_part, None)\n if isinstance(user_value, bool):\n enabled = user_value\n if enabled:\n matching_kinds.append(session_action)\n return matching_kinds\n\n\nclass CodeActionOnSaveTask(SaveTask):\n \"\"\"\n The main task that requests code actions from sessions and runs them.\n\n The amount of time the task is allowed to run is defined by user-controlled setting. If the task\n runs longer, the native save will be triggered before waiting for results.\n \"\"\"\n @classmethod\n def is_applicable(cls, view: sublime.View) -> bool:\n return bool(view.window()) and bool(cls._get_code_actions_on_save(view))\n\n @classmethod\n def _get_code_actions_on_save(cls, view: sublime.View) -> Dict[str, bool]:\n view_code_actions = view.settings().get('lsp_code_actions_on_save') or {}\n code_actions = userprefs().lsp_code_actions_on_save.copy()\n code_actions.update(view_code_actions)\n allowed_code_actions = dict()\n for key, value in code_actions.items():\n if key.startswith('source.'):\n allowed_code_actions[key] = value\n return allowed_code_actions\n\n def get_task_timeout_ms(self) -> int:\n return userprefs().code_action_on_save_timeout_ms\n\n def run_async(self) -> None:\n super().run_async()\n self._request_code_actions_async()\n\n def _request_code_actions_async(self) -> None:\n self._purge_changes_async()\n on_save_actions = self._get_code_actions_on_save(self._view)\n actions_manager.request_on_save(self._view, self._handle_response_async, on_save_actions)\n\n def _handle_response_async(self, responses: CodeActionsByConfigName) -> None:\n if self._cancelled:\n return\n document_version = self._view.change_count()\n tasks = [] # type: List[Promise]\n for config_name, code_actions in responses.items():\n if code_actions:\n for session in sessions_for_view(self._view, 'codeActionProvider'):\n if session.config.name == config_name:\n for code_action in code_actions:\n tasks.append(session.run_code_action_async(code_action, progress=False))\n break\n if document_version != self._view.change_count():\n # Give on_text_changed_async a chance to trigger.\n Promise.all(tasks).then(lambda _: sublime.set_timeout_async(self._request_code_actions_async))\n else:\n Promise.all(tasks).then(lambda _: sublime.set_timeout_async(self._on_complete))\n\n\nLspSaveCommand.register_task(CodeActionOnSaveTask)\n\n\nclass LspCodeActionsCommand(LspTextCommand):\n\n capability = 'codeActionProvider'\n\n def run(self, edit: sublime.Edit, event: Optional[dict] = None, only_kinds: Optional[List[str]] = None) -> None:\n self.commands = [] # type: List[Tuple[str, str, CodeActionOrCommand]]\n self.commands_by_config = {} # type: CodeActionsByConfigName\n view = self.view\n try:\n region = view.sel()[0]\n except IndexError:\n return\n listener = windows.listener_for_view(view)\n if not listener:\n return\n session_buffer_diagnostics, covering = listener.diagnostics_intersecting_async(region)\n dict_kinds = {kind: True for kind in only_kinds} if only_kinds else None\n actions_manager.request_for_region_async(\n view, covering, session_buffer_diagnostics, self.handle_responses_async, dict_kinds)\n\n def handle_responses_async(self, responses: CodeActionsByConfigName) -> None:\n self.commands_by_config = responses\n self.commands = self.combine_commands()\n self.show_popup_menu()\n\n def combine_commands(self) -> 'List[Tuple[str, str, CodeActionOrCommand]]':\n results = []\n for config, commands in self.commands_by_config.items():\n for command in commands:\n results.append((config, command['title'], command))\n return results\n\n def show_popup_menu(self) -> None:\n if len(self.commands) > 0:\n self.view.show_popup_menu([command[1] for command in self.commands], self.handle_select)\n else:\n self.view.show_popup('No actions available', sublime.HIDE_ON_MOUSE_MOVE_AWAY)\n\n def handle_select(self, index: int) -> None:\n if index > -1:\n\n def run_async() -> None:\n selected = self.commands[index]\n session = self.session_by_name(selected[0])\n if session:\n session.run_code_action_async(selected[2], progress=True)\n\n sublime.set_timeout_async(run_async)\n", "path": "plugin/code_actions.py"}], "after_files": [{"content": "from .core.promise import Promise\nfrom .core.protocol import CodeAction\nfrom .core.protocol import Command\nfrom .core.protocol import Diagnostic\nfrom .core.protocol import Request\nfrom .core.registry import LspTextCommand\nfrom .core.registry import sessions_for_view\nfrom .core.registry import windows\nfrom .core.sessions import SessionBufferProtocol\nfrom .core.settings import userprefs\nfrom .core.typing import Any, List, Dict, Callable, Optional, Tuple, Union, Sequence\nfrom .core.views import entire_content_region\nfrom .core.views import text_document_code_action_params\nfrom .save_command import LspSaveCommand, SaveTask\nimport sublime\n\nCodeActionOrCommand = Union[CodeAction, Command]\nCodeActionsResponse = Optional[List[CodeActionOrCommand]]\nCodeActionsByConfigName = Dict[str, List[CodeActionOrCommand]]\n\n\nclass CodeActionsCollector:\n \"\"\"\n Collects code action responses from multiple sessions. Calls back the \"on_complete_handler\" with\n results when all responses are received.\n\n Usage example:\n\n with CodeActionsCollector() as collector:\n actions_manager.request_with_diagnostics(collector.create_collector('test_config'))\n actions_manager.request_with_diagnostics(collector.create_collector('another_config'))\n\n The \"create_collector()\" must only be called within the \"with\" context. Once the context is\n exited, the \"on_complete_handler\" will be called once all the created collectors receive the\n response (are called).\n \"\"\"\n\n def __init__(self, on_complete_handler: Callable[[CodeActionsByConfigName], None]):\n self._on_complete_handler = on_complete_handler\n self._commands_by_config = {} # type: CodeActionsByConfigName\n self._request_count = 0\n self._response_count = 0\n self._all_requested = False\n\n def __enter__(self) -> 'CodeActionsCollector':\n return self\n\n def __exit__(self, exc_type: Any, exc_value: Any, traceback: Any) -> None:\n self._all_requested = True\n self._notify_if_all_finished()\n\n def create_collector(self, config_name: str) -> Callable[[CodeActionsResponse], None]:\n self._request_count += 1\n return lambda actions: self._collect_response(config_name, actions)\n\n def _collect_response(self, config_name: str, actions: CodeActionsResponse) -> None:\n self._response_count += 1\n self._commands_by_config[config_name] = actions or []\n self._notify_if_all_finished()\n\n def _notify_if_all_finished(self) -> None:\n if self._all_requested and self._request_count == self._response_count:\n # Call back on Sublime's async thread\n sublime.set_timeout_async(lambda: self._on_complete_handler(self._commands_by_config))\n\n def get_actions(self) -> CodeActionsByConfigName:\n return self._commands_by_config\n\n\nclass CodeActionsManager:\n \"\"\"Manager for per-location caching of code action responses.\"\"\"\n\n def __init__(self) -> None:\n self._response_cache = None # type: Optional[Tuple[str, CodeActionsCollector]]\n\n def request_with_diagnostics_async(\n self,\n view: sublime.View,\n region: sublime.Region,\n session_buffer_diagnostics: Sequence[Tuple[SessionBufferProtocol, Sequence[Diagnostic]]],\n actions_handler: Callable[[CodeActionsByConfigName], None]\n ) -> None:\n \"\"\"\n Requests code actions *only* for provided diagnostics. If session has no diagnostics then\n it will be skipped.\n \"\"\"\n self._request_async(view, region, session_buffer_diagnostics, True, actions_handler)\n\n def request_for_region_async(\n self,\n view: sublime.View,\n region: sublime.Region,\n session_buffer_diagnostics: Sequence[Tuple[SessionBufferProtocol, Sequence[Diagnostic]]],\n actions_handler: Callable[[CodeActionsByConfigName], None],\n only_kinds: Optional[Dict[str, bool]] = None\n ) -> None:\n \"\"\"\n Requests code actions with provided diagnostics and specified region. If there are\n no diagnostics for given session, the request will be made with empty diagnostics list.\n \"\"\"\n self._request_async(view, region, session_buffer_diagnostics, False, actions_handler, only_kinds)\n\n def request_on_save(\n self,\n view: sublime.View,\n actions_handler: Callable[[CodeActionsByConfigName], None],\n on_save_actions: Dict[str, bool]\n ) -> None:\n \"\"\"\n Requests code actions on save.\n \"\"\"\n self._request_async(view, entire_content_region(view), [], False, actions_handler, on_save_actions)\n\n def _request_async(\n self,\n view: sublime.View,\n region: sublime.Region,\n session_buffer_diagnostics: Sequence[Tuple[SessionBufferProtocol, Sequence[Diagnostic]]],\n only_with_diagnostics: bool,\n actions_handler: Callable[[CodeActionsByConfigName], None],\n on_save_actions: Optional[Dict[str, bool]] = None\n ) -> None:\n if 'codeActionProvider' in userprefs().disabled_capabilities:\n return None\n\n use_cache = on_save_actions is None\n if use_cache:\n location_cache_key = \"{}#{}:{}:{}\".format(\n view.buffer_id(), view.change_count(), region, only_with_diagnostics)\n if self._response_cache:\n cache_key, cache_collector = self._response_cache\n if location_cache_key == cache_key:\n sublime.set_timeout(lambda: actions_handler(cache_collector.get_actions()))\n else:\n self._response_cache = None\n\n collector = CodeActionsCollector(actions_handler)\n with collector:\n file_name = view.file_name()\n if file_name:\n for session in sessions_for_view(view, 'codeActionProvider'):\n if on_save_actions:\n supported_kinds = session.get_capability('codeActionProvider.codeActionKinds')\n matching_kinds = get_matching_kinds(on_save_actions, supported_kinds or [])\n if matching_kinds:\n params = text_document_code_action_params(\n view, file_name, region, [], matching_kinds)\n request = Request.codeAction(params, view)\n session.send_request_async(\n request, *filtering_collector(session.config.name, matching_kinds, collector))\n else:\n diagnostics = [] # type: Sequence[Diagnostic]\n for sb, diags in session_buffer_diagnostics:\n if sb.session == session:\n diagnostics = diags\n break\n if only_with_diagnostics and not diagnostics:\n continue\n params = text_document_code_action_params(view, file_name, region, diagnostics)\n request = Request.codeAction(params, view)\n session.send_request_async(request, collector.create_collector(session.config.name))\n if use_cache:\n self._response_cache = (location_cache_key, collector)\n\n\ndef filtering_collector(\n config_name: str,\n kinds: List[str],\n actions_collector: CodeActionsCollector\n) -> Tuple[Callable[[CodeActionsResponse], None], Callable[[Any], None]]:\n \"\"\"\n Filters actions returned from the session so that only matching kinds are collected.\n\n Since older servers don't support the \"context.only\" property, these will return all\n actions that need to be filtered.\n \"\"\"\n\n def actions_filter(actions: CodeActionsResponse) -> List[CodeActionOrCommand]:\n return [a for a in (actions or []) if a.get('kind') in kinds] # type: ignore\n\n collector = actions_collector.create_collector(config_name)\n return (\n lambda actions: collector(actions_filter(actions)),\n lambda error: collector([])\n )\n\n\nactions_manager = CodeActionsManager()\n\n\ndef get_matching_kinds(user_actions: Dict[str, bool], session_actions: List[str]) -> List[str]:\n \"\"\"\n Filters user-enabled or disabled actions so that only ones matching the session actions\n are returned. Returned actions are those that are enabled and are not overridden by more\n specific, disabled actions.\n\n Filtering only returns actions that exactly match the ones supported by given session.\n If user has enabled a generic action that matches more specific session action\n (for example user's a.b matching session's a.b.c), then the more specific (a.b.c) must be\n returned as servers must receive only actions that they advertise support for.\n \"\"\"\n matching_kinds = []\n for session_action in session_actions:\n enabled = False\n action_parts = session_action.split('.')\n for i in range(len(action_parts)):\n current_part = '.'.join(action_parts[0:i + 1])\n user_value = user_actions.get(current_part, None)\n if isinstance(user_value, bool):\n enabled = user_value\n if enabled:\n matching_kinds.append(session_action)\n return matching_kinds\n\n\nclass CodeActionOnSaveTask(SaveTask):\n \"\"\"\n The main task that requests code actions from sessions and runs them.\n\n The amount of time the task is allowed to run is defined by user-controlled setting. If the task\n runs longer, the native save will be triggered before waiting for results.\n \"\"\"\n @classmethod\n def is_applicable(cls, view: sublime.View) -> bool:\n return bool(view.window()) and bool(cls._get_code_actions_on_save(view))\n\n @classmethod\n def _get_code_actions_on_save(cls, view: sublime.View) -> Dict[str, bool]:\n view_code_actions = view.settings().get('lsp_code_actions_on_save') or {}\n code_actions = userprefs().lsp_code_actions_on_save.copy()\n code_actions.update(view_code_actions)\n allowed_code_actions = dict()\n for key, value in code_actions.items():\n if key.startswith('source.'):\n allowed_code_actions[key] = value\n return allowed_code_actions\n\n def get_task_timeout_ms(self) -> int:\n return userprefs().code_action_on_save_timeout_ms\n\n def run_async(self) -> None:\n super().run_async()\n self._request_code_actions_async()\n\n def _request_code_actions_async(self) -> None:\n self._purge_changes_async()\n on_save_actions = self._get_code_actions_on_save(self._view)\n actions_manager.request_on_save(self._view, self._handle_response_async, on_save_actions)\n\n def _handle_response_async(self, responses: CodeActionsByConfigName) -> None:\n if self._cancelled:\n return\n document_version = self._view.change_count()\n tasks = [] # type: List[Promise]\n for config_name, code_actions in responses.items():\n if code_actions:\n for session in sessions_for_view(self._view, 'codeActionProvider'):\n if session.config.name == config_name:\n for code_action in code_actions:\n tasks.append(session.run_code_action_async(code_action, progress=False))\n break\n if document_version != self._view.change_count():\n # Give on_text_changed_async a chance to trigger.\n Promise.all(tasks).then(lambda _: sublime.set_timeout_async(self._request_code_actions_async))\n else:\n Promise.all(tasks).then(lambda _: sublime.set_timeout_async(self._on_complete))\n\n\nLspSaveCommand.register_task(CodeActionOnSaveTask)\n\n\nclass LspCodeActionsCommand(LspTextCommand):\n\n capability = 'codeActionProvider'\n\n def run(self, edit: sublime.Edit, event: Optional[dict] = None, only_kinds: Optional[List[str]] = None) -> None:\n self.commands = [] # type: List[Tuple[str, str, CodeActionOrCommand]]\n self.commands_by_config = {} # type: CodeActionsByConfigName\n view = self.view\n try:\n region = view.sel()[0]\n except IndexError:\n return\n listener = windows.listener_for_view(view)\n if not listener:\n return\n session_buffer_diagnostics, covering = listener.diagnostics_intersecting_async(region)\n dict_kinds = {kind: True for kind in only_kinds} if only_kinds else None\n actions_manager.request_for_region_async(\n view, covering, session_buffer_diagnostics, self.handle_responses_async, dict_kinds)\n\n def handle_responses_async(self, responses: CodeActionsByConfigName) -> None:\n self.commands_by_config = responses\n self.commands = self.combine_commands()\n self.show_popup_menu()\n\n def combine_commands(self) -> 'List[Tuple[str, str, CodeActionOrCommand]]':\n results = []\n for config, commands in self.commands_by_config.items():\n for command in commands:\n results.append((config, command['title'], command))\n return results\n\n def show_popup_menu(self) -> None:\n if len(self.commands) > 0:\n self.view.show_popup_menu([command[1] for command in self.commands], self.handle_select)\n else:\n self.view.show_popup('No actions available', sublime.HIDE_ON_MOUSE_MOVE_AWAY)\n\n def handle_select(self, index: int) -> None:\n if index > -1:\n\n def run_async() -> None:\n selected = self.commands[index]\n session = self.session_by_name(selected[0])\n if session:\n session.run_code_action_async(selected[2], progress=True)\n\n sublime.set_timeout_async(run_async)\n", "path": "plugin/code_actions.py"}]}
| 4,056 | 699 |
gh_patches_debug_31760
|
rasdani/github-patches
|
git_diff
|
pyodide__pyodide-1113
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Soundness error in python2js_buffer
This bug goes back at least to version 0.15.0. It's been messing up my error handling code.
First:
```python
import numpy as np
x = np.array([['string1', 'string2'], ['string3', 'string4']])
```
Second: type `x<enter>1<enter>x<enter>1<enter>`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conftest.py`
Content:
```
1 """
2 Various common utilities for testing.
3 """
4
5 import contextlib
6 import multiprocessing
7 import textwrap
8 import tempfile
9 import time
10 import os
11 import pathlib
12 import queue
13 import sys
14 import shutil
15
16 ROOT_PATH = pathlib.Path(__file__).parents[0].resolve()
17 TEST_PATH = ROOT_PATH / "src" / "tests"
18 BUILD_PATH = ROOT_PATH / "build"
19
20 sys.path.append(str(ROOT_PATH))
21
22 from pyodide_build._fixes import _selenium_is_connectable # noqa: E402
23 import selenium.webdriver.common.utils # noqa: E402
24
25 # XXX: Temporary fix for ConnectionError in selenium
26
27 selenium.webdriver.common.utils.is_connectable = _selenium_is_connectable
28
29 try:
30 import pytest
31
32 def pytest_addoption(parser):
33 group = parser.getgroup("general")
34 group.addoption(
35 "--build-dir",
36 action="store",
37 default=BUILD_PATH,
38 help="Path to the build directory",
39 )
40 group.addoption(
41 "--run-xfail",
42 action="store_true",
43 help="If provided, tests marked as xfail will be run",
44 )
45
46
47 except ImportError:
48 pytest = None # type: ignore
49
50
51 class JavascriptException(Exception):
52 def __init__(self, msg, stack):
53 self.msg = msg
54 self.stack = stack
55
56 def __str__(self):
57 if self.stack:
58 return self.msg + "\n\n" + self.stack
59 else:
60 return self.msg
61
62
63 class SeleniumWrapper:
64 JavascriptException = JavascriptException
65
66 def __init__(
67 self, server_port, server_hostname="127.0.0.1", server_log=None, build_dir=None
68 ):
69 if build_dir is None:
70 build_dir = BUILD_PATH
71
72 self.driver = self.get_driver()
73 self.server_port = server_port
74 self.server_hostname = server_hostname
75 self.server_log = server_log
76
77 if not (pathlib.Path(build_dir) / "test.html").exists():
78 # selenium does not expose HTTP response codes
79 raise ValueError(
80 f"{(build_dir / 'test.html').resolve()} " f"does not exist!"
81 )
82 self.driver.get(f"http://{server_hostname}:{server_port}/test.html")
83 self.run_js("Error.stackTraceLimit = Infinity")
84 self.run_js_async("await languagePluginLoader")
85
86 @property
87 def logs(self):
88 logs = self.driver.execute_script("return window.logs")
89 if logs is not None:
90 return "\n".join(str(x) for x in logs)
91 else:
92 return ""
93
94 def clean_logs(self):
95 self.driver.execute_script("window.logs = []")
96
97 def run(self, code):
98 return self.run_js("return pyodide.runPython({!r})".format(code))
99
100 def run_async(self, code):
101 return self.run_js_async("return pyodide.runPythonAsync({!r})".format(code))
102
103 def run_js(self, code):
104 if isinstance(code, str) and code.startswith("\n"):
105 # we have a multiline string, fix indentation
106 code = textwrap.dedent(code)
107 wrapper = """
108 Error.stackTraceLimit = Infinity;
109 let run = () => { %s }
110 try {
111 return [0, run()]
112 } catch (e) {
113 return [1, e.toString(), e.stack];
114 }
115 """
116
117 retval = self.driver.execute_script(wrapper % code)
118
119 if retval[0] == 0:
120 return retval[1]
121 else:
122 raise JavascriptException(retval[1], retval[2])
123
124 def run_js_async(self, code):
125 if isinstance(code, str) and code.startswith("\n"):
126 # we have a multiline string, fix indentation
127 code = textwrap.dedent(code)
128
129 wrapper = """
130 let cb = arguments[arguments.length - 1];
131 let run = async () => { %s }
132 (async () => {
133 try {{
134 cb([0, await run()]);
135 }} catch (e) {{
136 cb([1, e.toString(), e.stack]);
137 }}
138 })()
139 """
140
141 retval = self.driver.execute_async_script(wrapper % code)
142
143 if retval[0] == 0:
144 return retval[1]
145 else:
146 raise JavascriptException(retval[1], retval[2])
147
148 def run_webworker(self, code):
149 if isinstance(code, str) and code.startswith("\n"):
150 # we have a multiline string, fix indentation
151 code = textwrap.dedent(code)
152
153 return self.run_js_async(
154 """
155 let worker = new Worker( '{}' );
156 worker.postMessage({{ python: {!r} }});
157 return new Promise((res, rej) => {{
158 worker.onerror = e => rej(e);
159 worker.onmessage = e => {{
160 if (e.data.results) {{
161 res(e.data.results);
162 }} else {{
163 rej(e.data.error);
164 }}
165 }};
166 }})
167 """.format(
168 f"http://{self.server_hostname}:{self.server_port}/webworker_dev.js",
169 code,
170 )
171 )
172
173 def load_package(self, packages):
174 self.run_js_async("await pyodide.loadPackage({!r})".format(packages))
175
176 @property
177 def urls(self):
178 for handle in self.driver.window_handles:
179 self.driver.switch_to.window(handle)
180 yield self.driver.current_url
181
182
183 class FirefoxWrapper(SeleniumWrapper):
184
185 browser = "firefox"
186
187 def get_driver(self):
188 from selenium.webdriver import Firefox
189 from selenium.webdriver.firefox.options import Options
190
191 options = Options()
192 options.add_argument("-headless")
193
194 return Firefox(executable_path="geckodriver", options=options)
195
196
197 class ChromeWrapper(SeleniumWrapper):
198
199 browser = "chrome"
200
201 def get_driver(self):
202 from selenium.webdriver import Chrome
203 from selenium.webdriver.chrome.options import Options
204
205 options = Options()
206 options.add_argument("--headless")
207 options.add_argument("--no-sandbox")
208
209 return Chrome(options=options)
210
211
212 if pytest is not None:
213
214 @pytest.fixture(params=["firefox", "chrome"])
215 def selenium_standalone(request, web_server_main):
216 server_hostname, server_port, server_log = web_server_main
217 if request.param == "firefox":
218 cls = FirefoxWrapper
219 elif request.param == "chrome":
220 cls = ChromeWrapper
221 selenium = cls(
222 build_dir=request.config.option.build_dir,
223 server_port=server_port,
224 server_hostname=server_hostname,
225 server_log=server_log,
226 )
227 try:
228 yield selenium
229 finally:
230 print(selenium.logs)
231 selenium.driver.quit()
232
233 @pytest.fixture(params=["firefox", "chrome"], scope="module")
234 def _selenium_cached(request, web_server_main):
235 # Cached selenium instance. This is a copy-paste of
236 # selenium_standalone to avoid fixture scope issues
237 server_hostname, server_port, server_log = web_server_main
238 if request.param == "firefox":
239 cls = FirefoxWrapper
240 elif request.param == "chrome":
241 cls = ChromeWrapper
242 selenium = cls(
243 build_dir=request.config.option.build_dir,
244 server_port=server_port,
245 server_hostname=server_hostname,
246 server_log=server_log,
247 )
248 try:
249 yield selenium
250 finally:
251 selenium.driver.quit()
252
253 @pytest.fixture
254 def selenium(_selenium_cached):
255 # selenium instance cached at the module level
256 try:
257 _selenium_cached.clean_logs()
258 yield _selenium_cached
259 finally:
260 print(_selenium_cached.logs)
261
262
263 @pytest.fixture(scope="session")
264 def web_server_main(request):
265 """Web server that serves files in the build/ directory"""
266 with spawn_web_server(request.config.option.build_dir) as output:
267 yield output
268
269
270 @pytest.fixture(scope="session")
271 def web_server_secondary(request):
272 """Secondary web server that serves files build/ directory"""
273 with spawn_web_server(request.config.option.build_dir) as output:
274 yield output
275
276
277 @pytest.fixture(scope="session")
278 def web_server_tst_data(request):
279 """Web server that serves files in the src/tests/data/ directory"""
280 with spawn_web_server(TEST_PATH / "data") as output:
281 yield output
282
283
284 @contextlib.contextmanager
285 def spawn_web_server(build_dir=None):
286
287 if build_dir is None:
288 build_dir = BUILD_PATH
289
290 tmp_dir = tempfile.mkdtemp()
291 log_path = pathlib.Path(tmp_dir) / "http-server.log"
292 q = multiprocessing.Queue()
293 p = multiprocessing.Process(target=run_web_server, args=(q, log_path, build_dir))
294
295 try:
296 p.start()
297 port = q.get()
298 hostname = "127.0.0.1"
299
300 print(
301 f"Spawning webserver at http://{hostname}:{port} "
302 f"(see logs in {log_path})"
303 )
304 yield hostname, port, log_path
305 finally:
306 q.put("TERMINATE")
307 p.join()
308 shutil.rmtree(tmp_dir)
309
310
311 def run_web_server(q, log_filepath, build_dir):
312 """Start the HTTP web server
313
314 Parameters
315 ----------
316 q : Queue
317 communication queue
318 log_path : pathlib.Path
319 path to the file where to store the logs
320 """
321 import http.server
322 import socketserver
323
324 os.chdir(build_dir)
325
326 log_fh = log_filepath.open("w", buffering=1)
327 sys.stdout = log_fh
328 sys.stderr = log_fh
329
330 test_prefix = "/src/tests/"
331
332 class Handler(http.server.SimpleHTTPRequestHandler):
333 def log_message(self, format_, *args):
334 print(
335 "[%s] source: %s:%s - %s"
336 % (self.log_date_time_string(), *self.client_address, format_ % args)
337 )
338
339 def end_headers(self):
340 # Enable Cross-Origin Resource Sharing (CORS)
341 self.send_header("Access-Control-Allow-Origin", "*")
342 super().end_headers()
343
344 with socketserver.TCPServer(("", 0), Handler) as httpd:
345 host, port = httpd.server_address
346 print(f"Starting webserver at http://{host}:{port}")
347 httpd.server_name = "test-server"
348 httpd.server_port = port
349 q.put(port)
350
351 def service_actions():
352 try:
353 if q.get(False) == "TERMINATE":
354 print("Stopping server...")
355 sys.exit(0)
356 except queue.Empty:
357 pass
358
359 httpd.service_actions = service_actions
360 httpd.serve_forever()
361
362
363 if (
364 __name__ == "__main__"
365 and multiprocessing.current_process().name == "MainProcess"
366 and not hasattr(sys, "_pytest_session")
367 ):
368 with spawn_web_server():
369 # run forever
370 while True:
371 time.sleep(1)
372
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conftest.py b/conftest.py
--- a/conftest.py
+++ b/conftest.py
@@ -108,7 +108,18 @@
Error.stackTraceLimit = Infinity;
let run = () => { %s }
try {
- return [0, run()]
+ let result = run();
+ if(pyodide && pyodide._module && pyodide._module._PyErr_Occurred()){
+ try {
+ pyodide._module._pythonexc2js();
+ } catch(e){
+ console.error(`Python exited with error flag set! Error was:\n{e.message}`);
+ // Don't put original error message in new one: we want
+ // "pytest.raises(xxx, match=msg)" to fail
+ throw new Error(`Python exited with error flag set!`);
+ }
+ }
+ return [0, result]
} catch (e) {
return [1, e.toString(), e.stack];
}
@@ -130,11 +141,22 @@
let cb = arguments[arguments.length - 1];
let run = async () => { %s }
(async () => {
- try {{
- cb([0, await run()]);
- }} catch (e) {{
+ try {
+ let result = await run();
+ if(pyodide && pyodide._module && pyodide._module._PyErr_Occurred()){
+ try {
+ pyodide._module._pythonexc2js();
+ } catch(e){
+ console.error(`Python exited with error flag set! Error was:\n{e.message}`);
+ // Don't put original error message in new one: we want
+ // "pytest.raises(xxx, match=msg)" to fail
+ throw new Error(`Python exited with error flag set!`);
+ }
+ }
+ cb([0, result]);
+ } catch (e) {
cb([1, e.toString(), e.stack]);
- }}
+ }
})()
"""
|
{"golden_diff": "diff --git a/conftest.py b/conftest.py\n--- a/conftest.py\n+++ b/conftest.py\n@@ -108,7 +108,18 @@\n Error.stackTraceLimit = Infinity;\n let run = () => { %s }\n try {\n- return [0, run()]\n+ let result = run();\n+ if(pyodide && pyodide._module && pyodide._module._PyErr_Occurred()){\n+ try {\n+ pyodide._module._pythonexc2js();\n+ } catch(e){\n+ console.error(`Python exited with error flag set! Error was:\\n{e.message}`);\n+ // Don't put original error message in new one: we want\n+ // \"pytest.raises(xxx, match=msg)\" to fail\n+ throw new Error(`Python exited with error flag set!`);\n+ }\n+ }\n+ return [0, result]\n } catch (e) {\n return [1, e.toString(), e.stack];\n }\n@@ -130,11 +141,22 @@\n let cb = arguments[arguments.length - 1];\n let run = async () => { %s }\n (async () => {\n- try {{\n- cb([0, await run()]);\n- }} catch (e) {{\n+ try {\n+ let result = await run();\n+ if(pyodide && pyodide._module && pyodide._module._PyErr_Occurred()){\n+ try {\n+ pyodide._module._pythonexc2js();\n+ } catch(e){\n+ console.error(`Python exited with error flag set! Error was:\\n{e.message}`);\n+ // Don't put original error message in new one: we want\n+ // \"pytest.raises(xxx, match=msg)\" to fail\n+ throw new Error(`Python exited with error flag set!`);\n+ }\n+ }\n+ cb([0, result]);\n+ } catch (e) {\n cb([1, e.toString(), e.stack]);\n- }}\n+ }\n })()\n \"\"\"\n", "issue": "Soundness error in python2js_buffer\nThis bug goes back at least to version 0.15.0. It's been messing up my error handling code.\r\nFirst:\r\n```python\r\nimport numpy as np\r\nx = np.array([['string1', 'string2'], ['string3', 'string4']])\r\n```\r\nSecond: type `x<enter>1<enter>x<enter>1<enter>`.\n", "before_files": [{"content": "\"\"\"\nVarious common utilities for testing.\n\"\"\"\n\nimport contextlib\nimport multiprocessing\nimport textwrap\nimport tempfile\nimport time\nimport os\nimport pathlib\nimport queue\nimport sys\nimport shutil\n\nROOT_PATH = pathlib.Path(__file__).parents[0].resolve()\nTEST_PATH = ROOT_PATH / \"src\" / \"tests\"\nBUILD_PATH = ROOT_PATH / \"build\"\n\nsys.path.append(str(ROOT_PATH))\n\nfrom pyodide_build._fixes import _selenium_is_connectable # noqa: E402\nimport selenium.webdriver.common.utils # noqa: E402\n\n# XXX: Temporary fix for ConnectionError in selenium\n\nselenium.webdriver.common.utils.is_connectable = _selenium_is_connectable\n\ntry:\n import pytest\n\n def pytest_addoption(parser):\n group = parser.getgroup(\"general\")\n group.addoption(\n \"--build-dir\",\n action=\"store\",\n default=BUILD_PATH,\n help=\"Path to the build directory\",\n )\n group.addoption(\n \"--run-xfail\",\n action=\"store_true\",\n help=\"If provided, tests marked as xfail will be run\",\n )\n\n\nexcept ImportError:\n pytest = None # type: ignore\n\n\nclass JavascriptException(Exception):\n def __init__(self, msg, stack):\n self.msg = msg\n self.stack = stack\n\n def __str__(self):\n if self.stack:\n return self.msg + \"\\n\\n\" + self.stack\n else:\n return self.msg\n\n\nclass SeleniumWrapper:\n JavascriptException = JavascriptException\n\n def __init__(\n self, server_port, server_hostname=\"127.0.0.1\", server_log=None, build_dir=None\n ):\n if build_dir is None:\n build_dir = BUILD_PATH\n\n self.driver = self.get_driver()\n self.server_port = server_port\n self.server_hostname = server_hostname\n self.server_log = server_log\n\n if not (pathlib.Path(build_dir) / \"test.html\").exists():\n # selenium does not expose HTTP response codes\n raise ValueError(\n f\"{(build_dir / 'test.html').resolve()} \" f\"does not exist!\"\n )\n self.driver.get(f\"http://{server_hostname}:{server_port}/test.html\")\n self.run_js(\"Error.stackTraceLimit = Infinity\")\n self.run_js_async(\"await languagePluginLoader\")\n\n @property\n def logs(self):\n logs = self.driver.execute_script(\"return window.logs\")\n if logs is not None:\n return \"\\n\".join(str(x) for x in logs)\n else:\n return \"\"\n\n def clean_logs(self):\n self.driver.execute_script(\"window.logs = []\")\n\n def run(self, code):\n return self.run_js(\"return pyodide.runPython({!r})\".format(code))\n\n def run_async(self, code):\n return self.run_js_async(\"return pyodide.runPythonAsync({!r})\".format(code))\n\n def run_js(self, code):\n if isinstance(code, str) and code.startswith(\"\\n\"):\n # we have a multiline string, fix indentation\n code = textwrap.dedent(code)\n wrapper = \"\"\"\n Error.stackTraceLimit = Infinity;\n let run = () => { %s }\n try {\n return [0, run()]\n } catch (e) {\n return [1, e.toString(), e.stack];\n }\n \"\"\"\n\n retval = self.driver.execute_script(wrapper % code)\n\n if retval[0] == 0:\n return retval[1]\n else:\n raise JavascriptException(retval[1], retval[2])\n\n def run_js_async(self, code):\n if isinstance(code, str) and code.startswith(\"\\n\"):\n # we have a multiline string, fix indentation\n code = textwrap.dedent(code)\n\n wrapper = \"\"\"\n let cb = arguments[arguments.length - 1];\n let run = async () => { %s }\n (async () => {\n try {{\n cb([0, await run()]);\n }} catch (e) {{\n cb([1, e.toString(), e.stack]);\n }}\n })()\n \"\"\"\n\n retval = self.driver.execute_async_script(wrapper % code)\n\n if retval[0] == 0:\n return retval[1]\n else:\n raise JavascriptException(retval[1], retval[2])\n\n def run_webworker(self, code):\n if isinstance(code, str) and code.startswith(\"\\n\"):\n # we have a multiline string, fix indentation\n code = textwrap.dedent(code)\n\n return self.run_js_async(\n \"\"\"\n let worker = new Worker( '{}' );\n worker.postMessage({{ python: {!r} }});\n return new Promise((res, rej) => {{\n worker.onerror = e => rej(e);\n worker.onmessage = e => {{\n if (e.data.results) {{\n res(e.data.results);\n }} else {{\n rej(e.data.error);\n }}\n }};\n }})\n \"\"\".format(\n f\"http://{self.server_hostname}:{self.server_port}/webworker_dev.js\",\n code,\n )\n )\n\n def load_package(self, packages):\n self.run_js_async(\"await pyodide.loadPackage({!r})\".format(packages))\n\n @property\n def urls(self):\n for handle in self.driver.window_handles:\n self.driver.switch_to.window(handle)\n yield self.driver.current_url\n\n\nclass FirefoxWrapper(SeleniumWrapper):\n\n browser = \"firefox\"\n\n def get_driver(self):\n from selenium.webdriver import Firefox\n from selenium.webdriver.firefox.options import Options\n\n options = Options()\n options.add_argument(\"-headless\")\n\n return Firefox(executable_path=\"geckodriver\", options=options)\n\n\nclass ChromeWrapper(SeleniumWrapper):\n\n browser = \"chrome\"\n\n def get_driver(self):\n from selenium.webdriver import Chrome\n from selenium.webdriver.chrome.options import Options\n\n options = Options()\n options.add_argument(\"--headless\")\n options.add_argument(\"--no-sandbox\")\n\n return Chrome(options=options)\n\n\nif pytest is not None:\n\n @pytest.fixture(params=[\"firefox\", \"chrome\"])\n def selenium_standalone(request, web_server_main):\n server_hostname, server_port, server_log = web_server_main\n if request.param == \"firefox\":\n cls = FirefoxWrapper\n elif request.param == \"chrome\":\n cls = ChromeWrapper\n selenium = cls(\n build_dir=request.config.option.build_dir,\n server_port=server_port,\n server_hostname=server_hostname,\n server_log=server_log,\n )\n try:\n yield selenium\n finally:\n print(selenium.logs)\n selenium.driver.quit()\n\n @pytest.fixture(params=[\"firefox\", \"chrome\"], scope=\"module\")\n def _selenium_cached(request, web_server_main):\n # Cached selenium instance. This is a copy-paste of\n # selenium_standalone to avoid fixture scope issues\n server_hostname, server_port, server_log = web_server_main\n if request.param == \"firefox\":\n cls = FirefoxWrapper\n elif request.param == \"chrome\":\n cls = ChromeWrapper\n selenium = cls(\n build_dir=request.config.option.build_dir,\n server_port=server_port,\n server_hostname=server_hostname,\n server_log=server_log,\n )\n try:\n yield selenium\n finally:\n selenium.driver.quit()\n\n @pytest.fixture\n def selenium(_selenium_cached):\n # selenium instance cached at the module level\n try:\n _selenium_cached.clean_logs()\n yield _selenium_cached\n finally:\n print(_selenium_cached.logs)\n\n\[email protected](scope=\"session\")\ndef web_server_main(request):\n \"\"\"Web server that serves files in the build/ directory\"\"\"\n with spawn_web_server(request.config.option.build_dir) as output:\n yield output\n\n\[email protected](scope=\"session\")\ndef web_server_secondary(request):\n \"\"\"Secondary web server that serves files build/ directory\"\"\"\n with spawn_web_server(request.config.option.build_dir) as output:\n yield output\n\n\[email protected](scope=\"session\")\ndef web_server_tst_data(request):\n \"\"\"Web server that serves files in the src/tests/data/ directory\"\"\"\n with spawn_web_server(TEST_PATH / \"data\") as output:\n yield output\n\n\[email protected]\ndef spawn_web_server(build_dir=None):\n\n if build_dir is None:\n build_dir = BUILD_PATH\n\n tmp_dir = tempfile.mkdtemp()\n log_path = pathlib.Path(tmp_dir) / \"http-server.log\"\n q = multiprocessing.Queue()\n p = multiprocessing.Process(target=run_web_server, args=(q, log_path, build_dir))\n\n try:\n p.start()\n port = q.get()\n hostname = \"127.0.0.1\"\n\n print(\n f\"Spawning webserver at http://{hostname}:{port} \"\n f\"(see logs in {log_path})\"\n )\n yield hostname, port, log_path\n finally:\n q.put(\"TERMINATE\")\n p.join()\n shutil.rmtree(tmp_dir)\n\n\ndef run_web_server(q, log_filepath, build_dir):\n \"\"\"Start the HTTP web server\n\n Parameters\n ----------\n q : Queue\n communication queue\n log_path : pathlib.Path\n path to the file where to store the logs\n \"\"\"\n import http.server\n import socketserver\n\n os.chdir(build_dir)\n\n log_fh = log_filepath.open(\"w\", buffering=1)\n sys.stdout = log_fh\n sys.stderr = log_fh\n\n test_prefix = \"/src/tests/\"\n\n class Handler(http.server.SimpleHTTPRequestHandler):\n def log_message(self, format_, *args):\n print(\n \"[%s] source: %s:%s - %s\"\n % (self.log_date_time_string(), *self.client_address, format_ % args)\n )\n\n def end_headers(self):\n # Enable Cross-Origin Resource Sharing (CORS)\n self.send_header(\"Access-Control-Allow-Origin\", \"*\")\n super().end_headers()\n\n with socketserver.TCPServer((\"\", 0), Handler) as httpd:\n host, port = httpd.server_address\n print(f\"Starting webserver at http://{host}:{port}\")\n httpd.server_name = \"test-server\"\n httpd.server_port = port\n q.put(port)\n\n def service_actions():\n try:\n if q.get(False) == \"TERMINATE\":\n print(\"Stopping server...\")\n sys.exit(0)\n except queue.Empty:\n pass\n\n httpd.service_actions = service_actions\n httpd.serve_forever()\n\n\nif (\n __name__ == \"__main__\"\n and multiprocessing.current_process().name == \"MainProcess\"\n and not hasattr(sys, \"_pytest_session\")\n):\n with spawn_web_server():\n # run forever\n while True:\n time.sleep(1)\n", "path": "conftest.py"}], "after_files": [{"content": "\"\"\"\nVarious common utilities for testing.\n\"\"\"\n\nimport contextlib\nimport multiprocessing\nimport textwrap\nimport tempfile\nimport time\nimport os\nimport pathlib\nimport queue\nimport sys\nimport shutil\n\nROOT_PATH = pathlib.Path(__file__).parents[0].resolve()\nTEST_PATH = ROOT_PATH / \"src\" / \"tests\"\nBUILD_PATH = ROOT_PATH / \"build\"\n\nsys.path.append(str(ROOT_PATH))\n\nfrom pyodide_build._fixes import _selenium_is_connectable # noqa: E402\nimport selenium.webdriver.common.utils # noqa: E402\n\n# XXX: Temporary fix for ConnectionError in selenium\n\nselenium.webdriver.common.utils.is_connectable = _selenium_is_connectable\n\ntry:\n import pytest\n\n def pytest_addoption(parser):\n group = parser.getgroup(\"general\")\n group.addoption(\n \"--build-dir\",\n action=\"store\",\n default=BUILD_PATH,\n help=\"Path to the build directory\",\n )\n group.addoption(\n \"--run-xfail\",\n action=\"store_true\",\n help=\"If provided, tests marked as xfail will be run\",\n )\n\n\nexcept ImportError:\n pytest = None # type: ignore\n\n\nclass JavascriptException(Exception):\n def __init__(self, msg, stack):\n self.msg = msg\n self.stack = stack\n\n def __str__(self):\n if self.stack:\n return self.msg + \"\\n\\n\" + self.stack\n else:\n return self.msg\n\n\nclass SeleniumWrapper:\n JavascriptException = JavascriptException\n\n def __init__(\n self, server_port, server_hostname=\"127.0.0.1\", server_log=None, build_dir=None\n ):\n if build_dir is None:\n build_dir = BUILD_PATH\n\n self.driver = self.get_driver()\n self.server_port = server_port\n self.server_hostname = server_hostname\n self.server_log = server_log\n\n if not (pathlib.Path(build_dir) / \"test.html\").exists():\n # selenium does not expose HTTP response codes\n raise ValueError(\n f\"{(build_dir / 'test.html').resolve()} \" f\"does not exist!\"\n )\n self.driver.get(f\"http://{server_hostname}:{server_port}/test.html\")\n self.run_js(\"Error.stackTraceLimit = Infinity\")\n self.run_js_async(\"await languagePluginLoader\")\n\n @property\n def logs(self):\n logs = self.driver.execute_script(\"return window.logs\")\n if logs is not None:\n return \"\\n\".join(str(x) for x in logs)\n else:\n return \"\"\n\n def clean_logs(self):\n self.driver.execute_script(\"window.logs = []\")\n\n def run(self, code):\n return self.run_js(\"return pyodide.runPython({!r})\".format(code))\n\n def run_async(self, code):\n return self.run_js_async(\"return pyodide.runPythonAsync({!r})\".format(code))\n\n def run_js(self, code):\n if isinstance(code, str) and code.startswith(\"\\n\"):\n # we have a multiline string, fix indentation\n code = textwrap.dedent(code)\n wrapper = \"\"\"\n Error.stackTraceLimit = Infinity;\n let run = () => { %s }\n try {\n let result = run();\n if(pyodide && pyodide._module && pyodide._module._PyErr_Occurred()){\n try {\n pyodide._module._pythonexc2js();\n } catch(e){\n console.error(`Python exited with error flag set! Error was:\\n{e.message}`);\n // Don't put original error message in new one: we want\n // \"pytest.raises(xxx, match=msg)\" to fail\n throw new Error(`Python exited with error flag set!`);\n }\n }\n return [0, result]\n } catch (e) {\n return [1, e.toString(), e.stack];\n }\n \"\"\"\n\n retval = self.driver.execute_script(wrapper % code)\n\n if retval[0] == 0:\n return retval[1]\n else:\n raise JavascriptException(retval[1], retval[2])\n\n def run_js_async(self, code):\n if isinstance(code, str) and code.startswith(\"\\n\"):\n # we have a multiline string, fix indentation\n code = textwrap.dedent(code)\n\n wrapper = \"\"\"\n let cb = arguments[arguments.length - 1];\n let run = async () => { %s }\n (async () => {\n try {\n let result = await run();\n if(pyodide && pyodide._module && pyodide._module._PyErr_Occurred()){\n try {\n pyodide._module._pythonexc2js();\n } catch(e){\n console.error(`Python exited with error flag set! Error was:\\n{e.message}`);\n // Don't put original error message in new one: we want\n // \"pytest.raises(xxx, match=msg)\" to fail\n throw new Error(`Python exited with error flag set!`);\n }\n }\n cb([0, result]);\n } catch (e) {\n cb([1, e.toString(), e.stack]);\n }\n })()\n \"\"\"\n\n retval = self.driver.execute_async_script(wrapper % code)\n\n if retval[0] == 0:\n return retval[1]\n else:\n raise JavascriptException(retval[1], retval[2])\n\n def run_webworker(self, code):\n if isinstance(code, str) and code.startswith(\"\\n\"):\n # we have a multiline string, fix indentation\n code = textwrap.dedent(code)\n\n return self.run_js_async(\n \"\"\"\n let worker = new Worker( '{}' );\n worker.postMessage({{ python: {!r} }});\n return new Promise((res, rej) => {{\n worker.onerror = e => rej(e);\n worker.onmessage = e => {{\n if (e.data.results) {{\n res(e.data.results);\n }} else {{\n rej(e.data.error);\n }}\n }};\n }})\n \"\"\".format(\n f\"http://{self.server_hostname}:{self.server_port}/webworker_dev.js\",\n code,\n )\n )\n\n def load_package(self, packages):\n self.run_js_async(\"await pyodide.loadPackage({!r})\".format(packages))\n\n @property\n def urls(self):\n for handle in self.driver.window_handles:\n self.driver.switch_to.window(handle)\n yield self.driver.current_url\n\n\nclass FirefoxWrapper(SeleniumWrapper):\n\n browser = \"firefox\"\n\n def get_driver(self):\n from selenium.webdriver import Firefox\n from selenium.webdriver.firefox.options import Options\n\n options = Options()\n options.add_argument(\"-headless\")\n\n return Firefox(executable_path=\"geckodriver\", options=options)\n\n\nclass ChromeWrapper(SeleniumWrapper):\n\n browser = \"chrome\"\n\n def get_driver(self):\n from selenium.webdriver import Chrome\n from selenium.webdriver.chrome.options import Options\n\n options = Options()\n options.add_argument(\"--headless\")\n options.add_argument(\"--no-sandbox\")\n\n return Chrome(options=options)\n\n\nif pytest is not None:\n\n @pytest.fixture(params=[\"firefox\", \"chrome\"])\n def selenium_standalone(request, web_server_main):\n server_hostname, server_port, server_log = web_server_main\n if request.param == \"firefox\":\n cls = FirefoxWrapper\n elif request.param == \"chrome\":\n cls = ChromeWrapper\n selenium = cls(\n build_dir=request.config.option.build_dir,\n server_port=server_port,\n server_hostname=server_hostname,\n server_log=server_log,\n )\n try:\n yield selenium\n finally:\n print(selenium.logs)\n selenium.driver.quit()\n\n @pytest.fixture(params=[\"firefox\", \"chrome\"], scope=\"module\")\n def _selenium_cached(request, web_server_main):\n # Cached selenium instance. This is a copy-paste of\n # selenium_standalone to avoid fixture scope issues\n server_hostname, server_port, server_log = web_server_main\n if request.param == \"firefox\":\n cls = FirefoxWrapper\n elif request.param == \"chrome\":\n cls = ChromeWrapper\n selenium = cls(\n build_dir=request.config.option.build_dir,\n server_port=server_port,\n server_hostname=server_hostname,\n server_log=server_log,\n )\n try:\n yield selenium\n finally:\n selenium.driver.quit()\n\n @pytest.fixture\n def selenium(_selenium_cached):\n # selenium instance cached at the module level\n try:\n _selenium_cached.clean_logs()\n yield _selenium_cached\n finally:\n print(_selenium_cached.logs)\n\n\[email protected](scope=\"session\")\ndef web_server_main(request):\n \"\"\"Web server that serves files in the build/ directory\"\"\"\n with spawn_web_server(request.config.option.build_dir) as output:\n yield output\n\n\[email protected](scope=\"session\")\ndef web_server_secondary(request):\n \"\"\"Secondary web server that serves files build/ directory\"\"\"\n with spawn_web_server(request.config.option.build_dir) as output:\n yield output\n\n\[email protected](scope=\"session\")\ndef web_server_tst_data(request):\n \"\"\"Web server that serves files in the src/tests/data/ directory\"\"\"\n with spawn_web_server(TEST_PATH / \"data\") as output:\n yield output\n\n\[email protected]\ndef spawn_web_server(build_dir=None):\n\n if build_dir is None:\n build_dir = BUILD_PATH\n\n tmp_dir = tempfile.mkdtemp()\n log_path = pathlib.Path(tmp_dir) / \"http-server.log\"\n q = multiprocessing.Queue()\n p = multiprocessing.Process(target=run_web_server, args=(q, log_path, build_dir))\n\n try:\n p.start()\n port = q.get()\n hostname = \"127.0.0.1\"\n\n print(\n f\"Spawning webserver at http://{hostname}:{port} \"\n f\"(see logs in {log_path})\"\n )\n yield hostname, port, log_path\n finally:\n q.put(\"TERMINATE\")\n p.join()\n shutil.rmtree(tmp_dir)\n\n\ndef run_web_server(q, log_filepath, build_dir):\n \"\"\"Start the HTTP web server\n\n Parameters\n ----------\n q : Queue\n communication queue\n log_path : pathlib.Path\n path to the file where to store the logs\n \"\"\"\n import http.server\n import socketserver\n\n os.chdir(build_dir)\n\n log_fh = log_filepath.open(\"w\", buffering=1)\n sys.stdout = log_fh\n sys.stderr = log_fh\n\n test_prefix = \"/src/tests/\"\n\n class Handler(http.server.SimpleHTTPRequestHandler):\n def log_message(self, format_, *args):\n print(\n \"[%s] source: %s:%s - %s\"\n % (self.log_date_time_string(), *self.client_address, format_ % args)\n )\n\n def end_headers(self):\n # Enable Cross-Origin Resource Sharing (CORS)\n self.send_header(\"Access-Control-Allow-Origin\", \"*\")\n super().end_headers()\n\n with socketserver.TCPServer((\"\", 0), Handler) as httpd:\n host, port = httpd.server_address\n print(f\"Starting webserver at http://{host}:{port}\")\n httpd.server_name = \"test-server\"\n httpd.server_port = port\n q.put(port)\n\n def service_actions():\n try:\n if q.get(False) == \"TERMINATE\":\n print(\"Stopping server...\")\n sys.exit(0)\n except queue.Empty:\n pass\n\n httpd.service_actions = service_actions\n httpd.serve_forever()\n\n\nif (\n __name__ == \"__main__\"\n and multiprocessing.current_process().name == \"MainProcess\"\n and not hasattr(sys, \"_pytest_session\")\n):\n with spawn_web_server():\n # run forever\n while True:\n time.sleep(1)\n", "path": "conftest.py"}]}
| 3,691 | 461 |
gh_patches_debug_1159
|
rasdani/github-patches
|
git_diff
|
nltk__nltk-1274
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Tox fails with "ERROR: Failure: ImportError (No module named 'six')"
When I try to run the tests with Tox (on Ubuntu) from within a local clone of the repo, it manages to install the dependencies but blows up when trying to import things from within NLTK.
I imagine I can work around this by figuring out how to manually run just the tests I care about, but it's inconvenient.
I'm not sure whether I'm doing something dumb or whether the Tox setup is broken; if the former, the CONTRIBUTING docs should probably mention what needs to be done besides just running Tox; if the latter, it should probably be fixed.
Here's the full output (had to pastebin it due to GitHub's post length limit):
http://pastebin.com/ENuCLnv6
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nltk/tokenize/api.py`
Content:
```
1 # Natural Language Toolkit: Tokenizer Interface
2 #
3 # Copyright (C) 2001-2015 NLTK Project
4 # Author: Edward Loper <[email protected]>
5 # Steven Bird <[email protected]>
6 # URL: <http://nltk.org/>
7 # For license information, see LICENSE.TXT
8
9 """
10 Tokenizer Interface
11 """
12
13 from abc import ABCMeta, abstractmethod
14 from six import add_metaclass
15
16 from nltk.internals import overridden
17 from nltk.tokenize.util import string_span_tokenize
18
19 @add_metaclass(ABCMeta)
20 class TokenizerI(object):
21 """
22 A processing interface for tokenizing a string.
23 Subclasses must define ``tokenize()`` or ``tokenize_sents()`` (or both).
24 """
25 @abstractmethod
26 def tokenize(self, s):
27 """
28 Return a tokenized copy of *s*.
29
30 :rtype: list of str
31 """
32 if overridden(self.tokenize_sents):
33 return self.tokenize_sents([s])[0]
34
35 def span_tokenize(self, s):
36 """
37 Identify the tokens using integer offsets ``(start_i, end_i)``,
38 where ``s[start_i:end_i]`` is the corresponding token.
39
40 :rtype: iter(tuple(int, int))
41 """
42 raise NotImplementedError()
43
44 def tokenize_sents(self, strings):
45 """
46 Apply ``self.tokenize()`` to each element of ``strings``. I.e.:
47
48 return [self.tokenize(s) for s in strings]
49
50 :rtype: list(list(str))
51 """
52 return [self.tokenize(s) for s in strings]
53
54 def span_tokenize_sents(self, strings):
55 """
56 Apply ``self.span_tokenize()`` to each element of ``strings``. I.e.:
57
58 return [self.span_tokenize(s) for s in strings]
59
60 :rtype: iter(list(tuple(int, int)))
61 """
62 for s in strings:
63 yield list(self.span_tokenize(s))
64
65
66 class StringTokenizer(TokenizerI):
67 """A tokenizer that divides a string into substrings by splitting
68 on the specified string (defined in subclasses).
69 """
70
71 def tokenize(self, s):
72 return s.split(self._string)
73
74 def span_tokenize(self, s):
75 for span in string_span_tokenize(s, self._string):
76 yield span
77
78
79
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nltk/tokenize/api.py b/nltk/tokenize/api.py
--- a/nltk/tokenize/api.py
+++ b/nltk/tokenize/api.py
@@ -11,7 +11,7 @@
"""
from abc import ABCMeta, abstractmethod
-from six import add_metaclass
+from nltk.six import add_metaclass
from nltk.internals import overridden
from nltk.tokenize.util import string_span_tokenize
|
{"golden_diff": "diff --git a/nltk/tokenize/api.py b/nltk/tokenize/api.py\n--- a/nltk/tokenize/api.py\n+++ b/nltk/tokenize/api.py\n@@ -11,7 +11,7 @@\n \"\"\"\n \n from abc import ABCMeta, abstractmethod\n-from six import add_metaclass\n+from nltk.six import add_metaclass\n \n from nltk.internals import overridden\n from nltk.tokenize.util import string_span_tokenize\n", "issue": "Tox fails with \"ERROR: Failure: ImportError (No module named 'six')\"\nWhen I try to run the tests with Tox (on Ubuntu) from within a local clone of the repo, it manages to install the dependencies but blows up when trying to import things from within NLTK.\n\nI imagine I can work around this by figuring out how to manually run just the tests I care about, but it's inconvenient.\n\nI'm not sure whether I'm doing something dumb or whether the Tox setup is broken; if the former, the CONTRIBUTING docs should probably mention what needs to be done besides just running Tox; if the latter, it should probably be fixed.\n\nHere's the full output (had to pastebin it due to GitHub's post length limit):\n\nhttp://pastebin.com/ENuCLnv6\n\n", "before_files": [{"content": "# Natural Language Toolkit: Tokenizer Interface\n#\n# Copyright (C) 2001-2015 NLTK Project\n# Author: Edward Loper <[email protected]>\n# Steven Bird <[email protected]>\n# URL: <http://nltk.org/>\n# For license information, see LICENSE.TXT\n\n\"\"\"\nTokenizer Interface\n\"\"\"\n\nfrom abc import ABCMeta, abstractmethod\nfrom six import add_metaclass\n\nfrom nltk.internals import overridden\nfrom nltk.tokenize.util import string_span_tokenize\n\n@add_metaclass(ABCMeta)\nclass TokenizerI(object):\n \"\"\"\n A processing interface for tokenizing a string.\n Subclasses must define ``tokenize()`` or ``tokenize_sents()`` (or both).\n \"\"\"\n @abstractmethod\n def tokenize(self, s):\n \"\"\"\n Return a tokenized copy of *s*.\n\n :rtype: list of str\n \"\"\"\n if overridden(self.tokenize_sents):\n return self.tokenize_sents([s])[0]\n\n def span_tokenize(self, s):\n \"\"\"\n Identify the tokens using integer offsets ``(start_i, end_i)``,\n where ``s[start_i:end_i]`` is the corresponding token.\n\n :rtype: iter(tuple(int, int))\n \"\"\"\n raise NotImplementedError()\n\n def tokenize_sents(self, strings):\n \"\"\"\n Apply ``self.tokenize()`` to each element of ``strings``. I.e.:\n\n return [self.tokenize(s) for s in strings]\n\n :rtype: list(list(str))\n \"\"\"\n return [self.tokenize(s) for s in strings]\n\n def span_tokenize_sents(self, strings):\n \"\"\"\n Apply ``self.span_tokenize()`` to each element of ``strings``. I.e.:\n\n return [self.span_tokenize(s) for s in strings]\n\n :rtype: iter(list(tuple(int, int)))\n \"\"\"\n for s in strings:\n yield list(self.span_tokenize(s))\n\n\nclass StringTokenizer(TokenizerI):\n \"\"\"A tokenizer that divides a string into substrings by splitting\n on the specified string (defined in subclasses).\n \"\"\"\n\n def tokenize(self, s):\n return s.split(self._string)\n\n def span_tokenize(self, s):\n for span in string_span_tokenize(s, self._string):\n yield span\n\n\n", "path": "nltk/tokenize/api.py"}], "after_files": [{"content": "# Natural Language Toolkit: Tokenizer Interface\n#\n# Copyright (C) 2001-2015 NLTK Project\n# Author: Edward Loper <[email protected]>\n# Steven Bird <[email protected]>\n# URL: <http://nltk.org/>\n# For license information, see LICENSE.TXT\n\n\"\"\"\nTokenizer Interface\n\"\"\"\n\nfrom abc import ABCMeta, abstractmethod\nfrom nltk.six import add_metaclass\n\nfrom nltk.internals import overridden\nfrom nltk.tokenize.util import string_span_tokenize\n\n@add_metaclass(ABCMeta)\nclass TokenizerI(object):\n \"\"\"\n A processing interface for tokenizing a string.\n Subclasses must define ``tokenize()`` or ``tokenize_sents()`` (or both).\n \"\"\"\n @abstractmethod\n def tokenize(self, s):\n \"\"\"\n Return a tokenized copy of *s*.\n\n :rtype: list of str\n \"\"\"\n if overridden(self.tokenize_sents):\n return self.tokenize_sents([s])[0]\n\n def span_tokenize(self, s):\n \"\"\"\n Identify the tokens using integer offsets ``(start_i, end_i)``,\n where ``s[start_i:end_i]`` is the corresponding token.\n\n :rtype: iter(tuple(int, int))\n \"\"\"\n raise NotImplementedError()\n\n def tokenize_sents(self, strings):\n \"\"\"\n Apply ``self.tokenize()`` to each element of ``strings``. I.e.:\n\n return [self.tokenize(s) for s in strings]\n\n :rtype: list(list(str))\n \"\"\"\n return [self.tokenize(s) for s in strings]\n\n def span_tokenize_sents(self, strings):\n \"\"\"\n Apply ``self.span_tokenize()`` to each element of ``strings``. I.e.:\n\n return [self.span_tokenize(s) for s in strings]\n\n :rtype: iter(list(tuple(int, int)))\n \"\"\"\n for s in strings:\n yield list(self.span_tokenize(s))\n\n\nclass StringTokenizer(TokenizerI):\n \"\"\"A tokenizer that divides a string into substrings by splitting\n on the specified string (defined in subclasses).\n \"\"\"\n\n def tokenize(self, s):\n return s.split(self._string)\n\n def span_tokenize(self, s):\n for span in string_span_tokenize(s, self._string):\n yield span\n\n\n", "path": "nltk/tokenize/api.py"}]}
| 1,076 | 92 |
gh_patches_debug_26549
|
rasdani/github-patches
|
git_diff
|
pyjanitor-devs__pyjanitor-728
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add the ability to test and sort timestamps to be monotonic in a pandas data frame
# Brief Description
Following up on #703, this issue seeks to introduce the ability to sort the timestamps in a pandas data frame monotonically
I would like to propose...
# Example API
```python
def _test_for_monotonicity(
df: pd.DataFrame,
column_name: str = None,
direction: str = 'increasing'
) -> bool:
"""
Tests input data frame for monotonicity.
Check if the data is monotonically increasing or decreasing.
Direction is dependent on user input.
Defaults to increasing
:param df: data frame to be tested for monotonicity
:param column_name: needs to be specified if and only if the date time is not in index.
Defaults to None.
:param direction: specifies the direction in which monotonicity is being tested for.
Defaults to 'increasing'
:return: single boolean flag indicating whether the test has passed or not
"""
def sort_monotonically(
df: pd.DataFrame,
column_name: str = None,
direction: str ='increasing'
) -> pd.DataFrame:
"""
Sorts data frame monotonically.
It assumes the data frame has an index of type pd.DateTimeIndex when index is datetime.
If datetime is in a column, then the column is expected to be of type pd.Timestamp
:param df: data frame to sort monotonically
:param column_name: needs to be specified if and only if the date time is not in index.
Defaults to None
:param direction: specifies the direction in which monotonicity is being tested for.
Defaults to 'increasing'
:return: data frame with its index sorted
"""
# more examples below
# ...
```
[ENH] Adding ability to sort timestamps monotonically
Closes #707
# PR Description
Please describe the changes proposed in the pull request:
- Adding a function that allows monotonic sorting of timestamps in data frame
**This PR resolves #707 **
# PR Checklist
Please ensure that you have done the following:
1. [x] PR in from a fork off your branch. Do not PR from `<your_username>`:`dev`, but rather from `<your_username>`:`<feature-branch_name>`.
2. [x] If you're not on the contributors list, add yourself to `AUTHORS.rst`.
3. [x] Add a line to `CHANGELOG.rst` under the latest version header (i.e. the one that is "on deck") describing the contribution.
- Do use some discretion here; if there are multiple PRs that are related, keep them in a single line.
## Quick Check
To do a very quick check that everything is correct, follow these steps below:
- [x] Run the command `make check` from pyjanitor's top-level directory. This will automatically run:
- black formatting
- flake8 checking
- running the test suite
- docs build
Once done, please check off the check-box above.
If `make check` does not work for you, you can execute the commands listed in the Makefile individually.
## Code Changes
<!-- If you have not made code changes, please feel free to delete this section. -->
If you are adding code changes, please ensure the following:
- [x] Ensure that you have added tests.
- [x] Run all tests (`$ pytest .`) locally on your machine.
- [x] Check to ensure that test coverage covers the lines of code that you have added.
- [x] Ensure that all tests pass.
## Documentation Changes
If you are adding documentation changes, please ensure the following:
- [x] Build the docs locally.
- [ ] View the docs to check that it renders correctly.
# Relevant Reviewers
- @ericmjl
- @samukweku
Please tag maintainers to review.
- @ericmjl
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `janitor/timeseries.py`
Content:
```
1 """
2 Time series-specific data testing and cleaning functions.
3 """
4
5 import pandas as pd
6 import pandas_flavor as pf
7 from janitor import check
8
9
10 @pf.register_dataframe_method
11 def fill_missing_timestamps(
12 df: pd.DataFrame,
13 frequency: str,
14 first_time_stamp: pd.Timestamp = None,
15 last_time_stamp: pd.Timestamp = None,
16 ) -> pd.DataFrame:
17 """
18 Fill dataframe with missing timestamps based on a defined frequency.
19
20 If timestamps are missing,
21 this function will reindex the dataframe.
22 If timestamps are not missing,
23 then the function will return the dataframe unmodified.
24 Example usage:
25 .. code-block:: python
26
27 df = (
28 pd.DataFrame(...)
29 .fill_missing_timestamps(frequency="1H")
30 )
31
32 :param df: Dataframe which needs to be tested for missing timestamps
33 :param frequency: frequency i.e. sampling frequency of the data.
34 Acceptable frequency strings are available
35 `here <https://pandas.pydata.org/pandas-docs/stable/>`_
36 Check offset aliases under time series in user guide
37 :param first_time_stamp: timestamp expected to start from
38 Defaults to None.
39 If no input is provided assumes the minimum value in time_series
40 :param last_time_stamp: timestamp expected to end with.
41 Defaults to None.
42 If no input is provided, assumes the maximum value in time_series
43 :returns: dataframe that has a complete set of contiguous datetimes.
44 """
45 # Check all the inputs are the correct data type
46 check("frequency", frequency, [str])
47 check("first_time_stamp", first_time_stamp, [pd.Timestamp, type(None)])
48 check("last_time_stamp", last_time_stamp, [pd.Timestamp, type(None)])
49
50 if first_time_stamp is None:
51 first_time_stamp = df.index.min()
52 if last_time_stamp is None:
53 last_time_stamp = df.index.max()
54
55 # Generate expected timestamps
56 expected_timestamps = pd.date_range(
57 start=first_time_stamp, end=last_time_stamp, freq=frequency
58 )
59
60 return df.reindex(expected_timestamps)
61
62
63 def _get_missing_timestamps(
64 df: pd.DataFrame,
65 frequency: str,
66 first_time_stamp: pd.Timestamp = None,
67 last_time_stamp: pd.Timestamp = None,
68 ) -> pd.DataFrame:
69 """
70 Return the timestamps that are missing in a dataframe.
71
72 This function takes in a dataframe,
73 and checks its index against a dataframe
74 that contains the expected timestamps.
75 Here, we assume that the expected timestamps
76 are going to be of a larger size
77 than the timestamps available in the input dataframe ``df``.
78
79 If there are any missing timestamps in the input dataframe,
80 this function will return those missing timestamps
81 from the expected dataframe.
82 """
83 expected_df = df.fill_missing_timestamps(
84 frequency, first_time_stamp, last_time_stamp
85 )
86
87 missing_timestamps = expected_df.index.difference(df.index)
88
89 return expected_df.loc[missing_timestamps]
90
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/janitor/timeseries.py b/janitor/timeseries.py
--- a/janitor/timeseries.py
+++ b/janitor/timeseries.py
@@ -87,3 +87,58 @@
missing_timestamps = expected_df.index.difference(df.index)
return expected_df.loc[missing_timestamps]
+
+
[email protected]_dataframe_method
+def sort_timestamps_monotonically(
+ df: pd.DataFrame, direction: str = "increasing", strict: bool = False
+) -> pd.DataFrame:
+ """
+ Sort dataframe such that index is monotonic.
+
+ If timestamps are monotonic,
+ this function will return the dataframe unmodified.
+ If timestamps are not monotonic,
+ then the function will sort the dataframe.
+
+ Example usage:
+
+ .. code-block:: python
+
+ df = (
+ pd.DataFrame(...)
+ .sort_timestamps_monotonically(direction='increasing')
+ )
+
+ :param df: Dataframe which needs to be tested for monotonicity
+ :param direction: type of monotonicity desired.
+ Acceptable arguments are:
+ 1. increasing
+ 2. decreasing
+ :param strict: flag to enable/disable strict monotonicity.
+ If set to True,
+ will remove duplicates in the index,
+ by retaining first occurrence of value in index.
+ If set to False,
+ will not test for duplicates in the index.
+ Defaults to False.
+ :returns: Dataframe that has monotonically increasing
+ (or decreasing) timestamps.
+ """
+ # Check all the inputs are the correct data type
+ check("df", df, [pd.DataFrame])
+ check("direction", direction, [str])
+ check("strict", strict, [bool])
+
+ # Remove duplicates if requested
+ if strict:
+ df = df[~df.index.duplicated(keep="first")]
+
+ # Sort timestamps
+ if direction == "increasing":
+ df = df.sort_index()
+ else:
+ df = df.sort_index(ascending=False)
+
+ # Return the dataframe
+ return df
|
{"golden_diff": "diff --git a/janitor/timeseries.py b/janitor/timeseries.py\n--- a/janitor/timeseries.py\n+++ b/janitor/timeseries.py\n@@ -87,3 +87,58 @@\n missing_timestamps = expected_df.index.difference(df.index)\n \n return expected_df.loc[missing_timestamps]\n+\n+\[email protected]_dataframe_method\n+def sort_timestamps_monotonically(\n+ df: pd.DataFrame, direction: str = \"increasing\", strict: bool = False\n+) -> pd.DataFrame:\n+ \"\"\"\n+ Sort dataframe such that index is monotonic.\n+\n+ If timestamps are monotonic,\n+ this function will return the dataframe unmodified.\n+ If timestamps are not monotonic,\n+ then the function will sort the dataframe.\n+\n+ Example usage:\n+\n+ .. code-block:: python\n+\n+ df = (\n+ pd.DataFrame(...)\n+ .sort_timestamps_monotonically(direction='increasing')\n+ )\n+\n+ :param df: Dataframe which needs to be tested for monotonicity\n+ :param direction: type of monotonicity desired.\n+ Acceptable arguments are:\n+ 1. increasing\n+ 2. decreasing\n+ :param strict: flag to enable/disable strict monotonicity.\n+ If set to True,\n+ will remove duplicates in the index,\n+ by retaining first occurrence of value in index.\n+ If set to False,\n+ will not test for duplicates in the index.\n+ Defaults to False.\n+ :returns: Dataframe that has monotonically increasing\n+ (or decreasing) timestamps.\n+ \"\"\"\n+ # Check all the inputs are the correct data type\n+ check(\"df\", df, [pd.DataFrame])\n+ check(\"direction\", direction, [str])\n+ check(\"strict\", strict, [bool])\n+\n+ # Remove duplicates if requested\n+ if strict:\n+ df = df[~df.index.duplicated(keep=\"first\")]\n+\n+ # Sort timestamps\n+ if direction == \"increasing\":\n+ df = df.sort_index()\n+ else:\n+ df = df.sort_index(ascending=False)\n+\n+ # Return the dataframe\n+ return df\n", "issue": "Add the ability to test and sort timestamps to be monotonic in a pandas data frame\n# Brief Description\r\n\r\nFollowing up on #703, this issue seeks to introduce the ability to sort the timestamps in a pandas data frame monotonically\r\n\r\nI would like to propose...\r\n\r\n# Example API\r\n```python\r\ndef _test_for_monotonicity(\r\n df: pd.DataFrame,\r\n column_name: str = None,\r\n direction: str = 'increasing'\r\n) -> bool:\r\n \"\"\"\r\n Tests input data frame for monotonicity.\r\n\r\n Check if the data is monotonically increasing or decreasing.\r\n Direction is dependent on user input.\r\n Defaults to increasing\r\n\r\n :param df: data frame to be tested for monotonicity\r\n :param column_name: needs to be specified if and only if the date time is not in index.\r\n Defaults to None.\r\n :param direction: specifies the direction in which monotonicity is being tested for.\r\n Defaults to 'increasing'\r\n :return: single boolean flag indicating whether the test has passed or not\r\n \"\"\"\r\n\r\ndef sort_monotonically(\r\n df: pd.DataFrame,\r\n column_name: str = None,\r\n direction: str ='increasing'\r\n) -> pd.DataFrame:\r\n \"\"\"\r\n Sorts data frame monotonically.\r\n It assumes the data frame has an index of type pd.DateTimeIndex when index is datetime.\r\n If datetime is in a column, then the column is expected to be of type pd.Timestamp\r\n\r\n :param df: data frame to sort monotonically\r\n :param column_name: needs to be specified if and only if the date time is not in index.\r\n Defaults to None\r\n :param direction: specifies the direction in which monotonicity is being tested for.\r\n Defaults to 'increasing'\r\n :return: data frame with its index sorted\r\n \"\"\"\r\n\r\n\r\n# more examples below\r\n# ...\r\n```\r\n\n[ENH] Adding ability to sort timestamps monotonically\nCloses #707 \r\n\r\n# PR Description\r\n\r\nPlease describe the changes proposed in the pull request:\r\n\r\n- Adding a function that allows monotonic sorting of timestamps in data frame \r\n\r\n**This PR resolves #707 **\r\n\r\n# PR Checklist\r\nPlease ensure that you have done the following:\r\n\r\n1. [x] PR in from a fork off your branch. Do not PR from `<your_username>`:`dev`, but rather from `<your_username>`:`<feature-branch_name>`.\r\n2. [x] If you're not on the contributors list, add yourself to `AUTHORS.rst`.\r\n3. [x] Add a line to `CHANGELOG.rst` under the latest version header (i.e. the one that is \"on deck\") describing the contribution.\r\n - Do use some discretion here; if there are multiple PRs that are related, keep them in a single line.\r\n\r\n## Quick Check\r\n\r\nTo do a very quick check that everything is correct, follow these steps below:\r\n\r\n- [x] Run the command `make check` from pyjanitor's top-level directory. This will automatically run:\r\n - black formatting\r\n - flake8 checking\r\n - running the test suite\r\n - docs build\r\n\r\nOnce done, please check off the check-box above.\r\n\r\nIf `make check` does not work for you, you can execute the commands listed in the Makefile individually.\r\n\r\n## Code Changes\r\n\r\n<!-- If you have not made code changes, please feel free to delete this section. -->\r\n\r\nIf you are adding code changes, please ensure the following:\r\n\r\n- [x] Ensure that you have added tests.\r\n- [x] Run all tests (`$ pytest .`) locally on your machine.\r\n - [x] Check to ensure that test coverage covers the lines of code that you have added.\r\n - [x] Ensure that all tests pass.\r\n\r\n## Documentation Changes\r\nIf you are adding documentation changes, please ensure the following:\r\n\r\n- [x] Build the docs locally.\r\n- [ ] View the docs to check that it renders correctly.\r\n\r\n# Relevant Reviewers\r\n- @ericmjl \r\n- @samukweku \r\n\r\nPlease tag maintainers to review.\r\n\r\n- @ericmjl\r\n\n", "before_files": [{"content": "\"\"\"\nTime series-specific data testing and cleaning functions.\n\"\"\"\n\nimport pandas as pd\nimport pandas_flavor as pf\nfrom janitor import check\n\n\[email protected]_dataframe_method\ndef fill_missing_timestamps(\n df: pd.DataFrame,\n frequency: str,\n first_time_stamp: pd.Timestamp = None,\n last_time_stamp: pd.Timestamp = None,\n) -> pd.DataFrame:\n \"\"\"\n Fill dataframe with missing timestamps based on a defined frequency.\n\n If timestamps are missing,\n this function will reindex the dataframe.\n If timestamps are not missing,\n then the function will return the dataframe unmodified.\n Example usage:\n .. code-block:: python\n\n df = (\n pd.DataFrame(...)\n .fill_missing_timestamps(frequency=\"1H\")\n )\n\n :param df: Dataframe which needs to be tested for missing timestamps\n :param frequency: frequency i.e. sampling frequency of the data.\n Acceptable frequency strings are available\n `here <https://pandas.pydata.org/pandas-docs/stable/>`_\n Check offset aliases under time series in user guide\n :param first_time_stamp: timestamp expected to start from\n Defaults to None.\n If no input is provided assumes the minimum value in time_series\n :param last_time_stamp: timestamp expected to end with.\n Defaults to None.\n If no input is provided, assumes the maximum value in time_series\n :returns: dataframe that has a complete set of contiguous datetimes.\n \"\"\"\n # Check all the inputs are the correct data type\n check(\"frequency\", frequency, [str])\n check(\"first_time_stamp\", first_time_stamp, [pd.Timestamp, type(None)])\n check(\"last_time_stamp\", last_time_stamp, [pd.Timestamp, type(None)])\n\n if first_time_stamp is None:\n first_time_stamp = df.index.min()\n if last_time_stamp is None:\n last_time_stamp = df.index.max()\n\n # Generate expected timestamps\n expected_timestamps = pd.date_range(\n start=first_time_stamp, end=last_time_stamp, freq=frequency\n )\n\n return df.reindex(expected_timestamps)\n\n\ndef _get_missing_timestamps(\n df: pd.DataFrame,\n frequency: str,\n first_time_stamp: pd.Timestamp = None,\n last_time_stamp: pd.Timestamp = None,\n) -> pd.DataFrame:\n \"\"\"\n Return the timestamps that are missing in a dataframe.\n\n This function takes in a dataframe,\n and checks its index against a dataframe\n that contains the expected timestamps.\n Here, we assume that the expected timestamps\n are going to be of a larger size\n than the timestamps available in the input dataframe ``df``.\n\n If there are any missing timestamps in the input dataframe,\n this function will return those missing timestamps\n from the expected dataframe.\n \"\"\"\n expected_df = df.fill_missing_timestamps(\n frequency, first_time_stamp, last_time_stamp\n )\n\n missing_timestamps = expected_df.index.difference(df.index)\n\n return expected_df.loc[missing_timestamps]\n", "path": "janitor/timeseries.py"}], "after_files": [{"content": "\"\"\"\nTime series-specific data testing and cleaning functions.\n\"\"\"\n\nimport pandas as pd\nimport pandas_flavor as pf\nfrom janitor import check\n\n\[email protected]_dataframe_method\ndef fill_missing_timestamps(\n df: pd.DataFrame,\n frequency: str,\n first_time_stamp: pd.Timestamp = None,\n last_time_stamp: pd.Timestamp = None,\n) -> pd.DataFrame:\n \"\"\"\n Fill dataframe with missing timestamps based on a defined frequency.\n\n If timestamps are missing,\n this function will reindex the dataframe.\n If timestamps are not missing,\n then the function will return the dataframe unmodified.\n Example usage:\n .. code-block:: python\n\n df = (\n pd.DataFrame(...)\n .fill_missing_timestamps(frequency=\"1H\")\n )\n\n :param df: Dataframe which needs to be tested for missing timestamps\n :param frequency: frequency i.e. sampling frequency of the data.\n Acceptable frequency strings are available\n `here <https://pandas.pydata.org/pandas-docs/stable/>`_\n Check offset aliases under time series in user guide\n :param first_time_stamp: timestamp expected to start from\n Defaults to None.\n If no input is provided assumes the minimum value in time_series\n :param last_time_stamp: timestamp expected to end with.\n Defaults to None.\n If no input is provided, assumes the maximum value in time_series\n :returns: dataframe that has a complete set of contiguous datetimes.\n \"\"\"\n # Check all the inputs are the correct data type\n check(\"frequency\", frequency, [str])\n check(\"first_time_stamp\", first_time_stamp, [pd.Timestamp, type(None)])\n check(\"last_time_stamp\", last_time_stamp, [pd.Timestamp, type(None)])\n\n if first_time_stamp is None:\n first_time_stamp = df.index.min()\n if last_time_stamp is None:\n last_time_stamp = df.index.max()\n\n # Generate expected timestamps\n expected_timestamps = pd.date_range(\n start=first_time_stamp, end=last_time_stamp, freq=frequency\n )\n\n return df.reindex(expected_timestamps)\n\n\ndef _get_missing_timestamps(\n df: pd.DataFrame,\n frequency: str,\n first_time_stamp: pd.Timestamp = None,\n last_time_stamp: pd.Timestamp = None,\n) -> pd.DataFrame:\n \"\"\"\n Return the timestamps that are missing in a dataframe.\n\n This function takes in a dataframe,\n and checks its index against a dataframe\n that contains the expected timestamps.\n Here, we assume that the expected timestamps\n are going to be of a larger size\n than the timestamps available in the input dataframe ``df``.\n\n If there are any missing timestamps in the input dataframe,\n this function will return those missing timestamps\n from the expected dataframe.\n \"\"\"\n expected_df = df.fill_missing_timestamps(\n frequency, first_time_stamp, last_time_stamp\n )\n\n missing_timestamps = expected_df.index.difference(df.index)\n\n return expected_df.loc[missing_timestamps]\n\n\[email protected]_dataframe_method\ndef sort_timestamps_monotonically(\n df: pd.DataFrame, direction: str = \"increasing\", strict: bool = False\n) -> pd.DataFrame:\n \"\"\"\n Sort dataframe such that index is monotonic.\n\n If timestamps are monotonic,\n this function will return the dataframe unmodified.\n If timestamps are not monotonic,\n then the function will sort the dataframe.\n\n Example usage:\n\n .. code-block:: python\n\n df = (\n pd.DataFrame(...)\n .sort_timestamps_monotonically(direction='increasing')\n )\n\n :param df: Dataframe which needs to be tested for monotonicity\n :param direction: type of monotonicity desired.\n Acceptable arguments are:\n 1. increasing\n 2. decreasing\n :param strict: flag to enable/disable strict monotonicity.\n If set to True,\n will remove duplicates in the index,\n by retaining first occurrence of value in index.\n If set to False,\n will not test for duplicates in the index.\n Defaults to False.\n :returns: Dataframe that has monotonically increasing\n (or decreasing) timestamps.\n \"\"\"\n # Check all the inputs are the correct data type\n check(\"df\", df, [pd.DataFrame])\n check(\"direction\", direction, [str])\n check(\"strict\", strict, [bool])\n\n # Remove duplicates if requested\n if strict:\n df = df[~df.index.duplicated(keep=\"first\")]\n\n # Sort timestamps\n if direction == \"increasing\":\n df = df.sort_index()\n else:\n df = df.sort_index(ascending=False)\n\n # Return the dataframe\n return df\n", "path": "janitor/timeseries.py"}]}
| 1,936 | 490 |
gh_patches_debug_24266
|
rasdani/github-patches
|
git_diff
|
python-telegram-bot__python-telegram-bot-754
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bot stops responding
<!--
Thanks for reporting issues of python-telegram-bot!
To make it easier for us to help you please enter detailed information below.
Please note, we only support the latest version of python-telegram-bot and
master branch. Please make sure to upgrade & recreate the issue on the latest
version prior to opening an issue.
-->
### Steps to reproduce
1. Run the bot, type /start
2. Send your message, but don't end the conversation so it is waiting in some state
3. Wait for ~ 10 minutes
### Expected behaviour
Bot should answer when I get back and write something
### Actual behaviour
Bot does not answer instantly, but after certain period of time
### Configuration
Microsoft Azure Cloud
Ubuntu 16.04
**Version of Python, python-telegram-bot & dependencies:**
``python-telegram-bot 5.3.0``
``urllib3 1.19.1``
``certifi 2016.09.26``
``future 0.16.0``
``Python 2.7.12 (default, Jul 18 2016, 15:02:52) [GCC 4.8.4]``
### Logs
> Profiler-0 (err): 2017-02-28 08:23 +00:00: /usr/local/lib/python2.7/dist-packages/sklearn/cross_validation.py:44: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.
Profiler-0 (err): "This module will be removed in 0.20.", DeprecationWarning)
Profiler-0 (err): 2017-02-28 08:51 +00:00: 2017-02-28 08:51:58,823 - urllib3.connectionpool - WARNING - Retrying (Retry(total=2, connect=None, read=None, redirect=None)) after connection broken by 'ReadTimeoutError("HTTPSConnectionPool(host='api.telegram.org', port=443): Read timed out. (read timeout=<object object at 0x7fa6aa9590b0>)",)': /AAAAAAAAAAAAA:AAAAAAAAAAA/sendMessage
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `telegram/utils/request.py`
Content:
```
1 #!/usr/bin/env python
2 #
3 # A library that provides a Python interface to the Telegram Bot API
4 # Copyright (C) 2015-2017
5 # Leandro Toledo de Souza <[email protected]>
6 #
7 # This program is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU Lesser Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # This program is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU Lesser Public License for more details.
16 #
17 # You should have received a copy of the GNU Lesser Public License
18 # along with this program. If not, see [http://www.gnu.org/licenses/].
19 """This module contains methods to make POST and GET requests"""
20 import os
21 import socket
22 import logging
23 import warnings
24
25 try:
26 import ujson as json
27 except ImportError:
28 import json
29
30 import certifi
31 try:
32 import telegram.vendor.ptb_urllib3.urllib3 as urllib3
33 import telegram.vendor.ptb_urllib3.urllib3.contrib.appengine as appengine
34 from telegram.vendor.ptb_urllib3.urllib3.connection import HTTPConnection
35 from telegram.vendor.ptb_urllib3.urllib3.util.timeout import Timeout
36 except ImportError:
37 warnings.warn("python-telegram-bot wasn't properly installed. Please refer to README.rst on "
38 "how to properly install.")
39 raise
40
41 from telegram import (InputFile, TelegramError)
42 from telegram.error import (Unauthorized, NetworkError, TimedOut, BadRequest, ChatMigrated,
43 RetryAfter, InvalidToken)
44
45 logging.getLogger('urllib3').setLevel(logging.WARNING)
46
47
48 class Request(object):
49 """
50 Helper class for python-telegram-bot which provides methods to perform POST & GET towards
51 telegram servers.
52
53 Args:
54 con_pool_size (int): Number of connections to keep in the connection pool.
55 proxy_url (str): The URL to the proxy server. For example: `http://127.0.0.1:3128`.
56 urllib3_proxy_kwargs (dict): Arbitrary arguments passed as-is to `urllib3.ProxyManager`.
57 This value will be ignored if proxy_url is not set.
58 connect_timeout (int|float): The maximum amount of time (in seconds) to wait for a
59 connection attempt to a server to succeed. None will set an infinite timeout for
60 connection attempts. (default: 5.)
61 read_timeout (int|float): The maximum amount of time (in seconds) to wait between
62 consecutive read operations for a response from the server. None will set an infinite
63 timeout. This value is usually overridden by the various ``telegram.Bot`` methods.
64 (default: 5.)
65
66 """
67
68 def __init__(self,
69 con_pool_size=1,
70 proxy_url=None,
71 urllib3_proxy_kwargs=None,
72 connect_timeout=5.,
73 read_timeout=5.):
74 if urllib3_proxy_kwargs is None:
75 urllib3_proxy_kwargs = dict()
76
77 self._connect_timeout = connect_timeout
78
79 kwargs = dict(
80 maxsize=con_pool_size,
81 cert_reqs='CERT_REQUIRED',
82 ca_certs=certifi.where(),
83 socket_options=HTTPConnection.default_socket_options + [
84 (socket.SOL_SOCKET, socket.SO_KEEPALIVE, 1),
85 ],
86 timeout=urllib3.Timeout(
87 connect=self._connect_timeout, read=read_timeout, total=None))
88
89 # Set a proxy according to the following order:
90 # * proxy defined in proxy_url (+ urllib3_proxy_kwargs)
91 # * proxy set in `HTTPS_PROXY` env. var.
92 # * proxy set in `https_proxy` env. var.
93 # * None (if no proxy is configured)
94
95 if not proxy_url:
96 proxy_url = os.environ.get('HTTPS_PROXY') or os.environ.get('https_proxy')
97
98 if not proxy_url:
99 if appengine.is_appengine_sandbox():
100 # Use URLFetch service if running in App Engine
101 mgr = appengine.AppEngineManager()
102 else:
103 mgr = urllib3.PoolManager(**kwargs)
104 else:
105 kwargs.update(urllib3_proxy_kwargs)
106 if proxy_url.startswith('socks'):
107 try:
108 from telegram.vendor.ptb_urllib3.urllib3.contrib.socks import SOCKSProxyManager
109 except ImportError:
110 raise RuntimeError('PySocks is missing')
111 mgr = SOCKSProxyManager(proxy_url, **kwargs)
112 else:
113 mgr = urllib3.proxy_from_url(proxy_url, **kwargs)
114 if mgr.proxy.auth:
115 # TODO: what about other auth types?
116 auth_hdrs = urllib3.make_headers(proxy_basic_auth=mgr.proxy.auth)
117 mgr.proxy_headers.update(auth_hdrs)
118
119 self._con_pool = mgr
120
121 def stop(self):
122 self._con_pool.clear()
123
124 @staticmethod
125 def _parse(json_data):
126 """Try and parse the JSON returned from Telegram.
127
128 Returns:
129 dict: A JSON parsed as Python dict with results - on error this dict will be empty.
130
131 """
132 decoded_s = json_data.decode('utf-8')
133 try:
134 data = json.loads(decoded_s)
135 except ValueError:
136 raise TelegramError('Invalid server response')
137
138 if not data.get('ok'):
139 description = data.get('description')
140 parameters = data.get('parameters')
141 if parameters:
142 migrate_to_chat_id = parameters.get('migrate_to_chat_id')
143 if migrate_to_chat_id:
144 raise ChatMigrated(migrate_to_chat_id)
145 retry_after = parameters.get('retry_after')
146 if retry_after:
147 raise RetryAfter(retry_after)
148 if description:
149 return description
150
151 return data['result']
152
153 def _request_wrapper(self, *args, **kwargs):
154 """Wraps urllib3 request for handling known exceptions.
155
156 Args:
157 args: unnamed arguments, passed to urllib3 request.
158 kwargs: keyword arguments, passed tp urllib3 request.
159
160 Returns:
161 str: A non-parsed JSON text.
162
163 Raises:
164 TelegramError
165
166 """
167 # Make sure to hint Telegram servers that we reuse connections by sending
168 # "Connection: keep-alive" in the HTTP headers.
169 if 'headers' not in kwargs:
170 kwargs['headers'] = {}
171 kwargs['headers']['connection'] = 'keep-alive'
172
173 try:
174 resp = self._con_pool.request(*args, **kwargs)
175 except urllib3.exceptions.TimeoutError:
176 raise TimedOut()
177 except urllib3.exceptions.HTTPError as error:
178 # HTTPError must come last as its the base urllib3 exception class
179 # TODO: do something smart here; for now just raise NetworkError
180 raise NetworkError('urllib3 HTTPError {0}'.format(error))
181
182 if 200 <= resp.status <= 299:
183 # 200-299 range are HTTP success statuses
184 return resp.data
185
186 try:
187 message = self._parse(resp.data)
188 except ValueError:
189 message = 'Unknown HTTPError'
190
191 if resp.status in (401, 403):
192 raise Unauthorized(message)
193 elif resp.status == 400:
194 raise BadRequest(message)
195 elif resp.status == 404:
196 raise InvalidToken()
197 elif resp.status == 413:
198 raise NetworkError('File too large. Check telegram api limits '
199 'https://core.telegram.org/bots/api#senddocument')
200
201 elif resp.status == 502:
202 raise NetworkError('Bad Gateway')
203 else:
204 raise NetworkError('{0} ({1})'.format(message, resp.status))
205
206 def get(self, url, timeout=None):
207 """Request an URL.
208
209 Args:
210 url (str): The web location we want to retrieve.
211 timeout (Optional[int|float]): If this value is specified, use it as the read timeout
212 from the server (instead of the one specified during creation of the connection
213 pool).
214
215 Returns:
216 A JSON object.
217
218 """
219 urlopen_kwargs = {}
220
221 if timeout is not None:
222 urlopen_kwargs['timeout'] = Timeout(read=timeout, connect=self._connect_timeout)
223
224 result = self._request_wrapper('GET', url, **urlopen_kwargs)
225 return self._parse(result)
226
227 def post(self, url, data, timeout=None):
228 """Request an URL.
229 Args:
230 url (str): The web location we want to retrieve.
231 data (dict[str, str|int]): A dict of key/value pairs. Note: On py2.7 value is unicode.
232 timeout (Optional[int|float]): If this value is specified, use it as the read timeout
233 from the server (instead of the one specified during creation of the connection
234 pool).
235
236 Returns:
237 A JSON object.
238
239 """
240 urlopen_kwargs = {}
241
242 if timeout is not None:
243 urlopen_kwargs['timeout'] = Timeout(read=timeout, connect=self._connect_timeout)
244
245 if InputFile.is_inputfile(data):
246 data = InputFile(data)
247 result = self._request_wrapper(
248 'POST', url, body=data.to_form(), headers=data.headers, **urlopen_kwargs)
249 else:
250 data = json.dumps(data)
251 result = self._request_wrapper(
252 'POST',
253 url,
254 body=data.encode(),
255 headers={'Content-Type': 'application/json'},
256 **urlopen_kwargs)
257
258 return self._parse(result)
259
260 def retrieve(self, url, timeout=None):
261 """Retrieve the contents of a file by its URL.
262
263 Args:
264 url (str): The web location we want to retrieve.
265 timeout (Optional[int|float]): If this value is specified, use it as the read timeout
266 from the server (instead of the one specified during creation of the connection
267 pool).
268
269 """
270 urlopen_kwargs = {}
271 if timeout is not None:
272 urlopen_kwargs['timeout'] = Timeout(read=timeout, connect=self._connect_timeout)
273
274 return self._request_wrapper('GET', url, **urlopen_kwargs)
275
276 def download(self, url, filename, timeout=None):
277 """Download a file by its URL.
278 Args:
279 url (str): The web location we want to retrieve.
280 timeout (Optional[int|float]): If this value is specified, use it as the read timeout
281 from the server (instead of the one specified during creation of the connection
282 pool).
283
284 filename:
285 The filename within the path to download the file.
286
287 """
288 buf = self.retrieve(url, timeout=timeout)
289 with open(filename, 'wb') as fobj:
290 fobj.write(buf)
291
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/telegram/utils/request.py b/telegram/utils/request.py
--- a/telegram/utils/request.py
+++ b/telegram/utils/request.py
@@ -19,6 +19,7 @@
"""This module contains methods to make POST and GET requests"""
import os
import socket
+import sys
import logging
import warnings
@@ -76,13 +77,20 @@
self._connect_timeout = connect_timeout
+ sockopts = HTTPConnection.default_socket_options + [
+ (socket.SOL_SOCKET, socket.SO_KEEPALIVE, 1)]
+
+ # TODO: Support other platforms like mac and windows.
+ if 'linux' in sys.platform:
+ sockopts.append((socket.IPPROTO_TCP, socket.TCP_KEEPIDLE, 120))
+ sockopts.append((socket.IPPROTO_TCP, socket.TCP_KEEPINTVL, 30))
+ sockopts.append((socket.IPPROTO_TCP, socket.TCP_KEEPCNT, 8))
+
kwargs = dict(
maxsize=con_pool_size,
cert_reqs='CERT_REQUIRED',
ca_certs=certifi.where(),
- socket_options=HTTPConnection.default_socket_options + [
- (socket.SOL_SOCKET, socket.SO_KEEPALIVE, 1),
- ],
+ socket_options=sockopts,
timeout=urllib3.Timeout(
connect=self._connect_timeout, read=read_timeout, total=None))
|
{"golden_diff": "diff --git a/telegram/utils/request.py b/telegram/utils/request.py\n--- a/telegram/utils/request.py\n+++ b/telegram/utils/request.py\n@@ -19,6 +19,7 @@\n \"\"\"This module contains methods to make POST and GET requests\"\"\"\n import os\n import socket\n+import sys\n import logging\n import warnings\n \n@@ -76,13 +77,20 @@\n \n self._connect_timeout = connect_timeout\n \n+ sockopts = HTTPConnection.default_socket_options + [\n+ (socket.SOL_SOCKET, socket.SO_KEEPALIVE, 1)]\n+\n+ # TODO: Support other platforms like mac and windows.\n+ if 'linux' in sys.platform:\n+ sockopts.append((socket.IPPROTO_TCP, socket.TCP_KEEPIDLE, 120))\n+ sockopts.append((socket.IPPROTO_TCP, socket.TCP_KEEPINTVL, 30))\n+ sockopts.append((socket.IPPROTO_TCP, socket.TCP_KEEPCNT, 8))\n+\n kwargs = dict(\n maxsize=con_pool_size,\n cert_reqs='CERT_REQUIRED',\n ca_certs=certifi.where(),\n- socket_options=HTTPConnection.default_socket_options + [\n- (socket.SOL_SOCKET, socket.SO_KEEPALIVE, 1),\n- ],\n+ socket_options=sockopts,\n timeout=urllib3.Timeout(\n connect=self._connect_timeout, read=read_timeout, total=None))\n", "issue": "Bot stops responding \n<!--\r\nThanks for reporting issues of python-telegram-bot!\r\nTo make it easier for us to help you please enter detailed information below.\r\n\r\nPlease note, we only support the latest version of python-telegram-bot and\r\nmaster branch. Please make sure to upgrade & recreate the issue on the latest\r\nversion prior to opening an issue.\r\n-->\r\n### Steps to reproduce\r\n1. Run the bot, type /start\r\n\r\n2. Send your message, but don't end the conversation so it is waiting in some state\r\n\r\n3. Wait for ~ 10 minutes\r\n\r\n### Expected behaviour\r\nBot should answer when I get back and write something\r\n\r\n### Actual behaviour\r\nBot does not answer instantly, but after certain period of time\r\n\r\n### Configuration\r\nMicrosoft Azure Cloud\r\nUbuntu 16.04\r\n\r\n\r\n\r\n**Version of Python, python-telegram-bot & dependencies:**\r\n\r\n``python-telegram-bot 5.3.0``\r\n``urllib3 1.19.1``\r\n``certifi 2016.09.26``\r\n``future 0.16.0``\r\n``Python 2.7.12 (default, Jul 18 2016, 15:02:52) [GCC 4.8.4]``\r\n\r\n\r\n### Logs\r\n\r\n> Profiler-0 (err): 2017-02-28 08:23 +00:00: /usr/local/lib/python2.7/dist-packages/sklearn/cross_validation.py:44: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.\r\nProfiler-0 (err): \"This module will be removed in 0.20.\", DeprecationWarning)\r\nProfiler-0 (err): 2017-02-28 08:51 +00:00: 2017-02-28 08:51:58,823 - urllib3.connectionpool - WARNING - Retrying (Retry(total=2, connect=None, read=None, redirect=None)) after connection broken by 'ReadTimeoutError(\"HTTPSConnectionPool(host='api.telegram.org', port=443): Read timed out. (read timeout=<object object at 0x7fa6aa9590b0>)\",)': /AAAAAAAAAAAAA:AAAAAAAAAAA/sendMessage\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n#\n# A library that provides a Python interface to the Telegram Bot API\n# Copyright (C) 2015-2017\n# Leandro Toledo de Souza <[email protected]>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Lesser Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Lesser Public License for more details.\n#\n# You should have received a copy of the GNU Lesser Public License\n# along with this program. If not, see [http://www.gnu.org/licenses/].\n\"\"\"This module contains methods to make POST and GET requests\"\"\"\nimport os\nimport socket\nimport logging\nimport warnings\n\ntry:\n import ujson as json\nexcept ImportError:\n import json\n\nimport certifi\ntry:\n import telegram.vendor.ptb_urllib3.urllib3 as urllib3\n import telegram.vendor.ptb_urllib3.urllib3.contrib.appengine as appengine\n from telegram.vendor.ptb_urllib3.urllib3.connection import HTTPConnection\n from telegram.vendor.ptb_urllib3.urllib3.util.timeout import Timeout\nexcept ImportError:\n warnings.warn(\"python-telegram-bot wasn't properly installed. Please refer to README.rst on \"\n \"how to properly install.\")\n raise\n\nfrom telegram import (InputFile, TelegramError)\nfrom telegram.error import (Unauthorized, NetworkError, TimedOut, BadRequest, ChatMigrated,\n RetryAfter, InvalidToken)\n\nlogging.getLogger('urllib3').setLevel(logging.WARNING)\n\n\nclass Request(object):\n \"\"\"\n Helper class for python-telegram-bot which provides methods to perform POST & GET towards\n telegram servers.\n\n Args:\n con_pool_size (int): Number of connections to keep in the connection pool.\n proxy_url (str): The URL to the proxy server. For example: `http://127.0.0.1:3128`.\n urllib3_proxy_kwargs (dict): Arbitrary arguments passed as-is to `urllib3.ProxyManager`.\n This value will be ignored if proxy_url is not set.\n connect_timeout (int|float): The maximum amount of time (in seconds) to wait for a\n connection attempt to a server to succeed. None will set an infinite timeout for\n connection attempts. (default: 5.)\n read_timeout (int|float): The maximum amount of time (in seconds) to wait between\n consecutive read operations for a response from the server. None will set an infinite\n timeout. This value is usually overridden by the various ``telegram.Bot`` methods.\n (default: 5.)\n\n \"\"\"\n\n def __init__(self,\n con_pool_size=1,\n proxy_url=None,\n urllib3_proxy_kwargs=None,\n connect_timeout=5.,\n read_timeout=5.):\n if urllib3_proxy_kwargs is None:\n urllib3_proxy_kwargs = dict()\n\n self._connect_timeout = connect_timeout\n\n kwargs = dict(\n maxsize=con_pool_size,\n cert_reqs='CERT_REQUIRED',\n ca_certs=certifi.where(),\n socket_options=HTTPConnection.default_socket_options + [\n (socket.SOL_SOCKET, socket.SO_KEEPALIVE, 1),\n ],\n timeout=urllib3.Timeout(\n connect=self._connect_timeout, read=read_timeout, total=None))\n\n # Set a proxy according to the following order:\n # * proxy defined in proxy_url (+ urllib3_proxy_kwargs)\n # * proxy set in `HTTPS_PROXY` env. var.\n # * proxy set in `https_proxy` env. var.\n # * None (if no proxy is configured)\n\n if not proxy_url:\n proxy_url = os.environ.get('HTTPS_PROXY') or os.environ.get('https_proxy')\n\n if not proxy_url:\n if appengine.is_appengine_sandbox():\n # Use URLFetch service if running in App Engine\n mgr = appengine.AppEngineManager()\n else:\n mgr = urllib3.PoolManager(**kwargs)\n else:\n kwargs.update(urllib3_proxy_kwargs)\n if proxy_url.startswith('socks'):\n try:\n from telegram.vendor.ptb_urllib3.urllib3.contrib.socks import SOCKSProxyManager\n except ImportError:\n raise RuntimeError('PySocks is missing')\n mgr = SOCKSProxyManager(proxy_url, **kwargs)\n else:\n mgr = urllib3.proxy_from_url(proxy_url, **kwargs)\n if mgr.proxy.auth:\n # TODO: what about other auth types?\n auth_hdrs = urllib3.make_headers(proxy_basic_auth=mgr.proxy.auth)\n mgr.proxy_headers.update(auth_hdrs)\n\n self._con_pool = mgr\n\n def stop(self):\n self._con_pool.clear()\n\n @staticmethod\n def _parse(json_data):\n \"\"\"Try and parse the JSON returned from Telegram.\n\n Returns:\n dict: A JSON parsed as Python dict with results - on error this dict will be empty.\n\n \"\"\"\n decoded_s = json_data.decode('utf-8')\n try:\n data = json.loads(decoded_s)\n except ValueError:\n raise TelegramError('Invalid server response')\n\n if not data.get('ok'):\n description = data.get('description')\n parameters = data.get('parameters')\n if parameters:\n migrate_to_chat_id = parameters.get('migrate_to_chat_id')\n if migrate_to_chat_id:\n raise ChatMigrated(migrate_to_chat_id)\n retry_after = parameters.get('retry_after')\n if retry_after:\n raise RetryAfter(retry_after)\n if description:\n return description\n\n return data['result']\n\n def _request_wrapper(self, *args, **kwargs):\n \"\"\"Wraps urllib3 request for handling known exceptions.\n\n Args:\n args: unnamed arguments, passed to urllib3 request.\n kwargs: keyword arguments, passed tp urllib3 request.\n\n Returns:\n str: A non-parsed JSON text.\n\n Raises:\n TelegramError\n\n \"\"\"\n # Make sure to hint Telegram servers that we reuse connections by sending\n # \"Connection: keep-alive\" in the HTTP headers.\n if 'headers' not in kwargs:\n kwargs['headers'] = {}\n kwargs['headers']['connection'] = 'keep-alive'\n\n try:\n resp = self._con_pool.request(*args, **kwargs)\n except urllib3.exceptions.TimeoutError:\n raise TimedOut()\n except urllib3.exceptions.HTTPError as error:\n # HTTPError must come last as its the base urllib3 exception class\n # TODO: do something smart here; for now just raise NetworkError\n raise NetworkError('urllib3 HTTPError {0}'.format(error))\n\n if 200 <= resp.status <= 299:\n # 200-299 range are HTTP success statuses\n return resp.data\n\n try:\n message = self._parse(resp.data)\n except ValueError:\n message = 'Unknown HTTPError'\n\n if resp.status in (401, 403):\n raise Unauthorized(message)\n elif resp.status == 400:\n raise BadRequest(message)\n elif resp.status == 404:\n raise InvalidToken()\n elif resp.status == 413:\n raise NetworkError('File too large. Check telegram api limits '\n 'https://core.telegram.org/bots/api#senddocument')\n\n elif resp.status == 502:\n raise NetworkError('Bad Gateway')\n else:\n raise NetworkError('{0} ({1})'.format(message, resp.status))\n\n def get(self, url, timeout=None):\n \"\"\"Request an URL.\n\n Args:\n url (str): The web location we want to retrieve.\n timeout (Optional[int|float]): If this value is specified, use it as the read timeout\n from the server (instead of the one specified during creation of the connection\n pool).\n\n Returns:\n A JSON object.\n\n \"\"\"\n urlopen_kwargs = {}\n\n if timeout is not None:\n urlopen_kwargs['timeout'] = Timeout(read=timeout, connect=self._connect_timeout)\n\n result = self._request_wrapper('GET', url, **urlopen_kwargs)\n return self._parse(result)\n\n def post(self, url, data, timeout=None):\n \"\"\"Request an URL.\n Args:\n url (str): The web location we want to retrieve.\n data (dict[str, str|int]): A dict of key/value pairs. Note: On py2.7 value is unicode.\n timeout (Optional[int|float]): If this value is specified, use it as the read timeout\n from the server (instead of the one specified during creation of the connection\n pool).\n\n Returns:\n A JSON object.\n\n \"\"\"\n urlopen_kwargs = {}\n\n if timeout is not None:\n urlopen_kwargs['timeout'] = Timeout(read=timeout, connect=self._connect_timeout)\n\n if InputFile.is_inputfile(data):\n data = InputFile(data)\n result = self._request_wrapper(\n 'POST', url, body=data.to_form(), headers=data.headers, **urlopen_kwargs)\n else:\n data = json.dumps(data)\n result = self._request_wrapper(\n 'POST',\n url,\n body=data.encode(),\n headers={'Content-Type': 'application/json'},\n **urlopen_kwargs)\n\n return self._parse(result)\n\n def retrieve(self, url, timeout=None):\n \"\"\"Retrieve the contents of a file by its URL.\n\n Args:\n url (str): The web location we want to retrieve.\n timeout (Optional[int|float]): If this value is specified, use it as the read timeout\n from the server (instead of the one specified during creation of the connection\n pool).\n\n \"\"\"\n urlopen_kwargs = {}\n if timeout is not None:\n urlopen_kwargs['timeout'] = Timeout(read=timeout, connect=self._connect_timeout)\n\n return self._request_wrapper('GET', url, **urlopen_kwargs)\n\n def download(self, url, filename, timeout=None):\n \"\"\"Download a file by its URL.\n Args:\n url (str): The web location we want to retrieve.\n timeout (Optional[int|float]): If this value is specified, use it as the read timeout\n from the server (instead of the one specified during creation of the connection\n pool).\n\n filename:\n The filename within the path to download the file.\n\n \"\"\"\n buf = self.retrieve(url, timeout=timeout)\n with open(filename, 'wb') as fobj:\n fobj.write(buf)\n", "path": "telegram/utils/request.py"}], "after_files": [{"content": "#!/usr/bin/env python\n#\n# A library that provides a Python interface to the Telegram Bot API\n# Copyright (C) 2015-2017\n# Leandro Toledo de Souza <[email protected]>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Lesser Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Lesser Public License for more details.\n#\n# You should have received a copy of the GNU Lesser Public License\n# along with this program. If not, see [http://www.gnu.org/licenses/].\n\"\"\"This module contains methods to make POST and GET requests\"\"\"\nimport os\nimport socket\nimport sys\nimport logging\nimport warnings\n\ntry:\n import ujson as json\nexcept ImportError:\n import json\n\nimport certifi\ntry:\n import telegram.vendor.ptb_urllib3.urllib3 as urllib3\n import telegram.vendor.ptb_urllib3.urllib3.contrib.appengine as appengine\n from telegram.vendor.ptb_urllib3.urllib3.connection import HTTPConnection\n from telegram.vendor.ptb_urllib3.urllib3.util.timeout import Timeout\nexcept ImportError:\n warnings.warn(\"python-telegram-bot wasn't properly installed. Please refer to README.rst on \"\n \"how to properly install.\")\n raise\n\nfrom telegram import (InputFile, TelegramError)\nfrom telegram.error import (Unauthorized, NetworkError, TimedOut, BadRequest, ChatMigrated,\n RetryAfter, InvalidToken)\n\nlogging.getLogger('urllib3').setLevel(logging.WARNING)\n\n\nclass Request(object):\n \"\"\"\n Helper class for python-telegram-bot which provides methods to perform POST & GET towards\n telegram servers.\n\n Args:\n con_pool_size (int): Number of connections to keep in the connection pool.\n proxy_url (str): The URL to the proxy server. For example: `http://127.0.0.1:3128`.\n urllib3_proxy_kwargs (dict): Arbitrary arguments passed as-is to `urllib3.ProxyManager`.\n This value will be ignored if proxy_url is not set.\n connect_timeout (int|float): The maximum amount of time (in seconds) to wait for a\n connection attempt to a server to succeed. None will set an infinite timeout for\n connection attempts. (default: 5.)\n read_timeout (int|float): The maximum amount of time (in seconds) to wait between\n consecutive read operations for a response from the server. None will set an infinite\n timeout. This value is usually overridden by the various ``telegram.Bot`` methods.\n (default: 5.)\n\n \"\"\"\n\n def __init__(self,\n con_pool_size=1,\n proxy_url=None,\n urllib3_proxy_kwargs=None,\n connect_timeout=5.,\n read_timeout=5.):\n if urllib3_proxy_kwargs is None:\n urllib3_proxy_kwargs = dict()\n\n self._connect_timeout = connect_timeout\n\n sockopts = HTTPConnection.default_socket_options + [\n (socket.SOL_SOCKET, socket.SO_KEEPALIVE, 1)]\n\n # TODO: Support other platforms like mac and windows.\n if 'linux' in sys.platform:\n sockopts.append((socket.IPPROTO_TCP, socket.TCP_KEEPIDLE, 120))\n sockopts.append((socket.IPPROTO_TCP, socket.TCP_KEEPINTVL, 30))\n sockopts.append((socket.IPPROTO_TCP, socket.TCP_KEEPCNT, 8))\n\n kwargs = dict(\n maxsize=con_pool_size,\n cert_reqs='CERT_REQUIRED',\n ca_certs=certifi.where(),\n socket_options=sockopts,\n timeout=urllib3.Timeout(\n connect=self._connect_timeout, read=read_timeout, total=None))\n\n # Set a proxy according to the following order:\n # * proxy defined in proxy_url (+ urllib3_proxy_kwargs)\n # * proxy set in `HTTPS_PROXY` env. var.\n # * proxy set in `https_proxy` env. var.\n # * None (if no proxy is configured)\n\n if not proxy_url:\n proxy_url = os.environ.get('HTTPS_PROXY') or os.environ.get('https_proxy')\n\n if not proxy_url:\n if appengine.is_appengine_sandbox():\n # Use URLFetch service if running in App Engine\n mgr = appengine.AppEngineManager()\n else:\n mgr = urllib3.PoolManager(**kwargs)\n else:\n kwargs.update(urllib3_proxy_kwargs)\n if proxy_url.startswith('socks'):\n try:\n from telegram.vendor.ptb_urllib3.urllib3.contrib.socks import SOCKSProxyManager\n except ImportError:\n raise RuntimeError('PySocks is missing')\n mgr = SOCKSProxyManager(proxy_url, **kwargs)\n else:\n mgr = urllib3.proxy_from_url(proxy_url, **kwargs)\n if mgr.proxy.auth:\n # TODO: what about other auth types?\n auth_hdrs = urllib3.make_headers(proxy_basic_auth=mgr.proxy.auth)\n mgr.proxy_headers.update(auth_hdrs)\n\n self._con_pool = mgr\n\n def stop(self):\n self._con_pool.clear()\n\n @staticmethod\n def _parse(json_data):\n \"\"\"Try and parse the JSON returned from Telegram.\n\n Returns:\n dict: A JSON parsed as Python dict with results - on error this dict will be empty.\n\n \"\"\"\n decoded_s = json_data.decode('utf-8')\n try:\n data = json.loads(decoded_s)\n except ValueError:\n raise TelegramError('Invalid server response')\n\n if not data.get('ok'):\n description = data.get('description')\n parameters = data.get('parameters')\n if parameters:\n migrate_to_chat_id = parameters.get('migrate_to_chat_id')\n if migrate_to_chat_id:\n raise ChatMigrated(migrate_to_chat_id)\n retry_after = parameters.get('retry_after')\n if retry_after:\n raise RetryAfter(retry_after)\n if description:\n return description\n\n return data['result']\n\n def _request_wrapper(self, *args, **kwargs):\n \"\"\"Wraps urllib3 request for handling known exceptions.\n\n Args:\n args: unnamed arguments, passed to urllib3 request.\n kwargs: keyword arguments, passed tp urllib3 request.\n\n Returns:\n str: A non-parsed JSON text.\n\n Raises:\n TelegramError\n\n \"\"\"\n # Make sure to hint Telegram servers that we reuse connections by sending\n # \"Connection: keep-alive\" in the HTTP headers.\n if 'headers' not in kwargs:\n kwargs['headers'] = {}\n kwargs['headers']['connection'] = 'keep-alive'\n\n try:\n resp = self._con_pool.request(*args, **kwargs)\n except urllib3.exceptions.TimeoutError:\n raise TimedOut()\n except urllib3.exceptions.HTTPError as error:\n # HTTPError must come last as its the base urllib3 exception class\n # TODO: do something smart here; for now just raise NetworkError\n raise NetworkError('urllib3 HTTPError {0}'.format(error))\n\n if 200 <= resp.status <= 299:\n # 200-299 range are HTTP success statuses\n return resp.data\n\n try:\n message = self._parse(resp.data)\n except ValueError:\n message = 'Unknown HTTPError'\n\n if resp.status in (401, 403):\n raise Unauthorized(message)\n elif resp.status == 400:\n raise BadRequest(message)\n elif resp.status == 404:\n raise InvalidToken()\n elif resp.status == 413:\n raise NetworkError('File too large. Check telegram api limits '\n 'https://core.telegram.org/bots/api#senddocument')\n\n elif resp.status == 502:\n raise NetworkError('Bad Gateway')\n else:\n raise NetworkError('{0} ({1})'.format(message, resp.status))\n\n def get(self, url, timeout=None):\n \"\"\"Request an URL.\n\n Args:\n url (str): The web location we want to retrieve.\n timeout (Optional[int|float]): If this value is specified, use it as the read timeout\n from the server (instead of the one specified during creation of the connection\n pool).\n\n Returns:\n A JSON object.\n\n \"\"\"\n urlopen_kwargs = {}\n\n if timeout is not None:\n urlopen_kwargs['timeout'] = Timeout(read=timeout, connect=self._connect_timeout)\n\n result = self._request_wrapper('GET', url, **urlopen_kwargs)\n return self._parse(result)\n\n def post(self, url, data, timeout=None):\n \"\"\"Request an URL.\n Args:\n url (str): The web location we want to retrieve.\n data (dict[str, str|int]): A dict of key/value pairs. Note: On py2.7 value is unicode.\n timeout (Optional[int|float]): If this value is specified, use it as the read timeout\n from the server (instead of the one specified during creation of the connection\n pool).\n\n Returns:\n A JSON object.\n\n \"\"\"\n urlopen_kwargs = {}\n\n if timeout is not None:\n urlopen_kwargs['timeout'] = Timeout(read=timeout, connect=self._connect_timeout)\n\n if InputFile.is_inputfile(data):\n data = InputFile(data)\n result = self._request_wrapper(\n 'POST', url, body=data.to_form(), headers=data.headers, **urlopen_kwargs)\n else:\n data = json.dumps(data)\n result = self._request_wrapper(\n 'POST',\n url,\n body=data.encode(),\n headers={'Content-Type': 'application/json'},\n **urlopen_kwargs)\n\n return self._parse(result)\n\n def retrieve(self, url, timeout=None):\n \"\"\"Retrieve the contents of a file by its URL.\n\n Args:\n url (str): The web location we want to retrieve.\n timeout (Optional[int|float]): If this value is specified, use it as the read timeout\n from the server (instead of the one specified during creation of the connection\n pool).\n\n \"\"\"\n urlopen_kwargs = {}\n if timeout is not None:\n urlopen_kwargs['timeout'] = Timeout(read=timeout, connect=self._connect_timeout)\n\n return self._request_wrapper('GET', url, **urlopen_kwargs)\n\n def download(self, url, filename, timeout=None):\n \"\"\"Download a file by its URL.\n Args:\n url (str): The web location we want to retrieve.\n timeout (Optional[int|float]): If this value is specified, use it as the read timeout\n from the server (instead of the one specified during creation of the connection\n pool).\n\n filename:\n The filename within the path to download the file.\n\n \"\"\"\n buf = self.retrieve(url, timeout=timeout)\n with open(filename, 'wb') as fobj:\n fobj.write(buf)\n", "path": "telegram/utils/request.py"}]}
| 3,910 | 313 |
gh_patches_debug_23678
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-3833
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `colossalai/booster/plugin/torch_fsdp_plugin.py`
Content:
```
1 from pathlib import Path
2 from typing import Callable, Iterable, Iterator, List, Optional, Tuple, Union
3
4 import torch
5 import torch.nn as nn
6 from packaging import version
7 from torch.distributed import ProcessGroup
8
9
10 if version.parse(torch.__version__) >= version.parse('1.12.0'):
11 from torch.distributed.fsdp import FullStateDictConfig
12 from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
13 from torch.distributed.fsdp import StateDictType
14 from torch.distributed.fsdp.fully_sharded_data_parallel import (
15 BackwardPrefetch,
16 CPUOffload,
17 FullStateDictConfig,
18 MixedPrecision,
19 ShardingStrategy,
20 )
21 else:
22 raise RuntimeError("FSDP is not supported while torch version under 1.12.0.")
23
24 from torch.optim import Optimizer
25 from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
26 from torch.utils.data import DataLoader
27
28 from colossalai.checkpoint_io import CheckpointIO, GeneralCheckpointIO, utils
29 from colossalai.cluster import DistCoordinator
30 from colossalai.interface import ModelWrapper, OptimizerWrapper
31
32 from .dp_plugin_base import DPPluginBase
33
34 __all__ = ['TorchFSDPPlugin']
35
36
37 class TorchFSDPCheckpointIO(GeneralCheckpointIO):
38
39 def __init__(self) -> None:
40 super().__init__()
41 self.coordinator = DistCoordinator()
42
43 def load_unsharded_model(self, model: nn.Module, checkpoint: str, strict: bool):
44 checkpoint = utils.load_state_dict(checkpoint)
45 model.load_state_dict(checkpoint)
46
47 def load_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: Path):
48 checkpoint = utils.load_state_dict(checkpoint)
49 fsdp_model = optimizer.unwrap_model()
50 sharded_osd = FSDP.scatter_full_optim_state_dict(checkpoint, fsdp_model)
51 optimizer.load_state_dict(sharded_osd)
52
53 def save_unsharded_model(self, model: nn.Module, checkpoint: str, gather_dtensor: bool, use_safetensors: bool):
54 """
55 Save model to checkpoint but only on master process.
56 """
57 # the model should be unwrapped in self.load_model via ModelWrapper.unwrap
58 cfg = FullStateDictConfig(offload_to_cpu=True, rank0_only=True)
59 with FSDP.state_dict_type(model, StateDictType.FULL_STATE_DICT, cfg):
60 full_model_state = model.state_dict()
61 utils.save_state_dict(full_model_state, checkpoint_file_path=checkpoint, use_safetensors=use_safetensors)
62
63 def save_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: str, gather_dtensor: bool):
64 """
65 Save optimizer to checkpoint but only on master process.
66 """
67 assert isinstance(optimizer, FSDPOptimizerWrapper)
68 fsdp_model = optimizer.unwrap_model()
69 full_optimizer_state = FSDP.full_optim_state_dict(fsdp_model, optim=optimizer, rank0_only=True)
70 utils.save_state_dict(full_optimizer_state, checkpoint_file_path=checkpoint, use_safetensors=False)
71
72 def save_sharded_model(self, model: nn.Module, checkpoint: str, gather_dtensor: bool, variant: Optional[str],
73 size_per_shard: int, use_safetensors: bool):
74 """
75 Save model to checkpoint but only on master process.
76 """
77 raise NotImplementedError("Sharded model checkpoint is not supported yet.")
78
79 def load_sharded_model(self,
80 model: nn.Module,
81 checkpoint_index_file: Path,
82 strict: bool = False,
83 use_safetensors: bool = False,
84 load_sub_module: bool = True):
85 """
86 Load model to checkpoint but only on master process.
87 """
88 raise NotImplementedError("Sharded model checkpoint is not supported yet.")
89
90 def save_sharded_optimizer(self, optimizer: Optimizer, checkpoint: str, gather_dtensor: bool):
91 """
92 Save optimizer to checkpoint but only on master process.
93 """
94 raise NotImplementedError("Sharded optimizer checkpoint is not supported yet.")
95
96 def load_sharded_optimizer(self, optimizer: Optimizer, index_file_path: str, prefix: str, size_per_shard: int):
97 """
98 Load optimizer to checkpoint but only on master process.
99 """
100 raise NotImplementedError("Sharded optimizer checkpoint is not supported yet.")
101
102 def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
103 """
104 Save model to checkpoint but only on master process.
105 """
106 if self.coordinator.is_master():
107 super().save_lr_scheduler(lr_scheduler, checkpoint)
108
109
110 class TorchFSDPModel(ModelWrapper):
111
112 def __init__(self, module: nn.Module, *args, **kwargs) -> None:
113 super().__init__(module)
114 self.module = FSDP(module, *args, **kwargs)
115
116 def unwrap(self):
117 return self.module
118
119
120 class FSDPOptimizerWrapper(OptimizerWrapper):
121
122 def __init__(self, optimizer: Optimizer, model: nn.Module):
123 self.model = model
124 super().__init__(optimizer)
125
126 def unwrap_model(self) -> nn.Module:
127 return self.model
128
129
130 class TorchFSDPPlugin(DPPluginBase):
131 """
132 Plugin for PyTorch FSDP.
133
134 Example:
135 >>> from colossalai.booster import Booster
136 >>> from colossalai.booster.plugin import TorchFSDPPlugin
137 >>>
138 >>> model, train_dataset, optimizer, criterion = ...
139 >>> plugin = TorchFSDPPlugin()
140
141 >>> train_dataloader = plugin.prepare_train_dataloader(train_dataset, batch_size=8)
142 >>> booster = Booster(plugin=plugin)
143 >>> model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)
144
145 Args:
146 See https://pytorch.org/docs/stable/fsdp.html for details.
147 """
148
149 if version.parse(torch.__version__) >= version.parse('1.12.0'):
150
151 def __init__(
152 self,
153 process_group: Optional[ProcessGroup] = None,
154 sharding_strategy: Optional[ShardingStrategy] = None,
155 cpu_offload: Optional[CPUOffload] = None,
156 auto_wrap_policy: Optional[Callable] = None,
157 backward_prefetch: Optional[BackwardPrefetch] = None,
158 mixed_precision: Optional[MixedPrecision] = None,
159 ignored_modules: Optional[Iterable[torch.nn.Module]] = None,
160 param_init_fn: Optional[Callable[[nn.Module], None]] = None,
161 sync_module_states: bool = False,
162 ):
163 super().__init__()
164 self.fsdp_kwargs = dict(process_group=process_group,
165 sharding_strategy=sharding_strategy,
166 cpu_offload=cpu_offload,
167 auto_wrap_policy=auto_wrap_policy,
168 backward_prefetch=backward_prefetch,
169 mixed_precision=mixed_precision,
170 ignored_modules=ignored_modules,
171 param_init_fn=param_init_fn,
172 sync_module_states=sync_module_states)
173 else:
174 raise RuntimeError("FSDP is not supported while torch version under 1.12.0.")
175
176 def support_no_sync(self) -> bool:
177 False
178
179 def no_sync(self, model: nn.Module) -> Iterator[None]:
180 raise NotImplementedError("Torch fsdp no_sync func not supported yet.")
181
182 def control_precision(self) -> bool:
183 return True
184
185 def supported_precisions(self) -> List[str]:
186 return ['fp16', 'bf16']
187
188 def control_device(self) -> bool:
189 return True
190
191 def supported_devices(self) -> List[str]:
192 return ['cuda']
193
194 def configure(
195 self,
196 model: nn.Module,
197 optimizer: Optimizer,
198 criterion: Callable = None,
199 dataloader: DataLoader = None,
200 lr_scheduler: LRScheduler = None,
201 ) -> Tuple[Union[nn.Module, OptimizerWrapper, LRScheduler, DataLoader]]:
202
203 # wrap the model with PyTorch FSDP
204 fsdp_model = TorchFSDPModel(model, device_id=torch.cuda.current_device(), **self.fsdp_kwargs)
205 optimizer.__init__(fsdp_model.parameters(), **optimizer.defaults)
206
207 if not isinstance(optimizer, FSDPOptimizerWrapper):
208 optimizer = FSDPOptimizerWrapper(optimizer, fsdp_model)
209
210 return fsdp_model, optimizer, criterion, dataloader, lr_scheduler
211
212 def control_checkpoint_io(self) -> bool:
213 return True
214
215 def get_checkpoint_io(self) -> CheckpointIO:
216 return TorchFSDPCheckpointIO()
217
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/colossalai/booster/plugin/torch_fsdp_plugin.py b/colossalai/booster/plugin/torch_fsdp_plugin.py
--- a/colossalai/booster/plugin/torch_fsdp_plugin.py
+++ b/colossalai/booster/plugin/torch_fsdp_plugin.py
@@ -3,10 +3,10 @@
import torch
import torch.nn as nn
+import warnings
from packaging import version
from torch.distributed import ProcessGroup
-
if version.parse(torch.__version__) >= version.parse('1.12.0'):
from torch.distributed.fsdp import FullStateDictConfig
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
@@ -202,6 +202,11 @@
# wrap the model with PyTorch FSDP
fsdp_model = TorchFSDPModel(model, device_id=torch.cuda.current_device(), **self.fsdp_kwargs)
+
+ if len(optimizer.param_groups) > 1:
+ warnings.warn(
+ 'TorchFSDPPlugin does not support optimizer that use multi param groups. The results may not be as expected if used.'
+ )
optimizer.__init__(fsdp_model.parameters(), **optimizer.defaults)
if not isinstance(optimizer, FSDPOptimizerWrapper):
|
{"golden_diff": "diff --git a/colossalai/booster/plugin/torch_fsdp_plugin.py b/colossalai/booster/plugin/torch_fsdp_plugin.py\n--- a/colossalai/booster/plugin/torch_fsdp_plugin.py\n+++ b/colossalai/booster/plugin/torch_fsdp_plugin.py\n@@ -3,10 +3,10 @@\n \n import torch\n import torch.nn as nn\n+import warnings\n from packaging import version\n from torch.distributed import ProcessGroup\n \n-\n if version.parse(torch.__version__) >= version.parse('1.12.0'):\n from torch.distributed.fsdp import FullStateDictConfig\n from torch.distributed.fsdp import FullyShardedDataParallel as FSDP\n@@ -202,6 +202,11 @@\n \n # wrap the model with PyTorch FSDP\n fsdp_model = TorchFSDPModel(model, device_id=torch.cuda.current_device(), **self.fsdp_kwargs)\n+\n+ if len(optimizer.param_groups) > 1:\n+ warnings.warn(\n+ 'TorchFSDPPlugin does not support optimizer that use multi param groups. The results may not be as expected if used.'\n+ )\n optimizer.__init__(fsdp_model.parameters(), **optimizer.defaults)\n \n if not isinstance(optimizer, FSDPOptimizerWrapper):\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "from pathlib import Path\nfrom typing import Callable, Iterable, Iterator, List, Optional, Tuple, Union\n\nimport torch\nimport torch.nn as nn\nfrom packaging import version\nfrom torch.distributed import ProcessGroup\n\n\nif version.parse(torch.__version__) >= version.parse('1.12.0'):\n from torch.distributed.fsdp import FullStateDictConfig\n from torch.distributed.fsdp import FullyShardedDataParallel as FSDP\n from torch.distributed.fsdp import StateDictType\n from torch.distributed.fsdp.fully_sharded_data_parallel import (\n BackwardPrefetch,\n CPUOffload,\n FullStateDictConfig,\n MixedPrecision,\n ShardingStrategy,\n )\nelse:\n raise RuntimeError(\"FSDP is not supported while torch version under 1.12.0.\")\n\nfrom torch.optim import Optimizer\nfrom torch.optim.lr_scheduler import _LRScheduler as LRScheduler\nfrom torch.utils.data import DataLoader\n\nfrom colossalai.checkpoint_io import CheckpointIO, GeneralCheckpointIO, utils\nfrom colossalai.cluster import DistCoordinator\nfrom colossalai.interface import ModelWrapper, OptimizerWrapper\n\nfrom .dp_plugin_base import DPPluginBase\n\n__all__ = ['TorchFSDPPlugin']\n\n\nclass TorchFSDPCheckpointIO(GeneralCheckpointIO):\n\n def __init__(self) -> None:\n super().__init__()\n self.coordinator = DistCoordinator()\n\n def load_unsharded_model(self, model: nn.Module, checkpoint: str, strict: bool):\n checkpoint = utils.load_state_dict(checkpoint)\n model.load_state_dict(checkpoint)\n\n def load_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: Path):\n checkpoint = utils.load_state_dict(checkpoint)\n fsdp_model = optimizer.unwrap_model()\n sharded_osd = FSDP.scatter_full_optim_state_dict(checkpoint, fsdp_model)\n optimizer.load_state_dict(sharded_osd)\n\n def save_unsharded_model(self, model: nn.Module, checkpoint: str, gather_dtensor: bool, use_safetensors: bool):\n \"\"\"\n Save model to checkpoint but only on master process.\n \"\"\"\n # the model should be unwrapped in self.load_model via ModelWrapper.unwrap\n cfg = FullStateDictConfig(offload_to_cpu=True, rank0_only=True)\n with FSDP.state_dict_type(model, StateDictType.FULL_STATE_DICT, cfg):\n full_model_state = model.state_dict()\n utils.save_state_dict(full_model_state, checkpoint_file_path=checkpoint, use_safetensors=use_safetensors)\n\n def save_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: str, gather_dtensor: bool):\n \"\"\"\n Save optimizer to checkpoint but only on master process.\n \"\"\"\n assert isinstance(optimizer, FSDPOptimizerWrapper)\n fsdp_model = optimizer.unwrap_model()\n full_optimizer_state = FSDP.full_optim_state_dict(fsdp_model, optim=optimizer, rank0_only=True)\n utils.save_state_dict(full_optimizer_state, checkpoint_file_path=checkpoint, use_safetensors=False)\n\n def save_sharded_model(self, model: nn.Module, checkpoint: str, gather_dtensor: bool, variant: Optional[str],\n size_per_shard: int, use_safetensors: bool):\n \"\"\"\n Save model to checkpoint but only on master process.\n \"\"\"\n raise NotImplementedError(\"Sharded model checkpoint is not supported yet.\")\n\n def load_sharded_model(self,\n model: nn.Module,\n checkpoint_index_file: Path,\n strict: bool = False,\n use_safetensors: bool = False,\n load_sub_module: bool = True):\n \"\"\"\n Load model to checkpoint but only on master process.\n \"\"\"\n raise NotImplementedError(\"Sharded model checkpoint is not supported yet.\")\n\n def save_sharded_optimizer(self, optimizer: Optimizer, checkpoint: str, gather_dtensor: bool):\n \"\"\"\n Save optimizer to checkpoint but only on master process.\n \"\"\"\n raise NotImplementedError(\"Sharded optimizer checkpoint is not supported yet.\")\n\n def load_sharded_optimizer(self, optimizer: Optimizer, index_file_path: str, prefix: str, size_per_shard: int):\n \"\"\"\n Load optimizer to checkpoint but only on master process.\n \"\"\"\n raise NotImplementedError(\"Sharded optimizer checkpoint is not supported yet.\")\n\n def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):\n \"\"\"\n Save model to checkpoint but only on master process.\n \"\"\"\n if self.coordinator.is_master():\n super().save_lr_scheduler(lr_scheduler, checkpoint)\n\n\nclass TorchFSDPModel(ModelWrapper):\n\n def __init__(self, module: nn.Module, *args, **kwargs) -> None:\n super().__init__(module)\n self.module = FSDP(module, *args, **kwargs)\n\n def unwrap(self):\n return self.module\n\n\nclass FSDPOptimizerWrapper(OptimizerWrapper):\n\n def __init__(self, optimizer: Optimizer, model: nn.Module):\n self.model = model\n super().__init__(optimizer)\n\n def unwrap_model(self) -> nn.Module:\n return self.model\n\n\nclass TorchFSDPPlugin(DPPluginBase):\n \"\"\"\n Plugin for PyTorch FSDP.\n\n Example:\n >>> from colossalai.booster import Booster\n >>> from colossalai.booster.plugin import TorchFSDPPlugin\n >>>\n >>> model, train_dataset, optimizer, criterion = ...\n >>> plugin = TorchFSDPPlugin()\n\n >>> train_dataloader = plugin.prepare_train_dataloader(train_dataset, batch_size=8)\n >>> booster = Booster(plugin=plugin)\n >>> model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)\n\n Args:\n See https://pytorch.org/docs/stable/fsdp.html for details.\n \"\"\"\n\n if version.parse(torch.__version__) >= version.parse('1.12.0'):\n\n def __init__(\n self,\n process_group: Optional[ProcessGroup] = None,\n sharding_strategy: Optional[ShardingStrategy] = None,\n cpu_offload: Optional[CPUOffload] = None,\n auto_wrap_policy: Optional[Callable] = None,\n backward_prefetch: Optional[BackwardPrefetch] = None,\n mixed_precision: Optional[MixedPrecision] = None,\n ignored_modules: Optional[Iterable[torch.nn.Module]] = None,\n param_init_fn: Optional[Callable[[nn.Module], None]] = None,\n sync_module_states: bool = False,\n ):\n super().__init__()\n self.fsdp_kwargs = dict(process_group=process_group,\n sharding_strategy=sharding_strategy,\n cpu_offload=cpu_offload,\n auto_wrap_policy=auto_wrap_policy,\n backward_prefetch=backward_prefetch,\n mixed_precision=mixed_precision,\n ignored_modules=ignored_modules,\n param_init_fn=param_init_fn,\n sync_module_states=sync_module_states)\n else:\n raise RuntimeError(\"FSDP is not supported while torch version under 1.12.0.\")\n\n def support_no_sync(self) -> bool:\n False\n\n def no_sync(self, model: nn.Module) -> Iterator[None]:\n raise NotImplementedError(\"Torch fsdp no_sync func not supported yet.\")\n\n def control_precision(self) -> bool:\n return True\n\n def supported_precisions(self) -> List[str]:\n return ['fp16', 'bf16']\n\n def control_device(self) -> bool:\n return True\n\n def supported_devices(self) -> List[str]:\n return ['cuda']\n\n def configure(\n self,\n model: nn.Module,\n optimizer: Optimizer,\n criterion: Callable = None,\n dataloader: DataLoader = None,\n lr_scheduler: LRScheduler = None,\n ) -> Tuple[Union[nn.Module, OptimizerWrapper, LRScheduler, DataLoader]]:\n\n # wrap the model with PyTorch FSDP\n fsdp_model = TorchFSDPModel(model, device_id=torch.cuda.current_device(), **self.fsdp_kwargs)\n optimizer.__init__(fsdp_model.parameters(), **optimizer.defaults)\n\n if not isinstance(optimizer, FSDPOptimizerWrapper):\n optimizer = FSDPOptimizerWrapper(optimizer, fsdp_model)\n\n return fsdp_model, optimizer, criterion, dataloader, lr_scheduler\n\n def control_checkpoint_io(self) -> bool:\n return True\n\n def get_checkpoint_io(self) -> CheckpointIO:\n return TorchFSDPCheckpointIO()\n", "path": "colossalai/booster/plugin/torch_fsdp_plugin.py"}], "after_files": [{"content": "from pathlib import Path\nfrom typing import Callable, Iterable, Iterator, List, Optional, Tuple, Union\n\nimport torch\nimport torch.nn as nn\nimport warnings\nfrom packaging import version\nfrom torch.distributed import ProcessGroup\n\nif version.parse(torch.__version__) >= version.parse('1.12.0'):\n from torch.distributed.fsdp import FullStateDictConfig\n from torch.distributed.fsdp import FullyShardedDataParallel as FSDP\n from torch.distributed.fsdp import StateDictType\n from torch.distributed.fsdp.fully_sharded_data_parallel import (\n BackwardPrefetch,\n CPUOffload,\n FullStateDictConfig,\n MixedPrecision,\n ShardingStrategy,\n )\nelse:\n raise RuntimeError(\"FSDP is not supported while torch version under 1.12.0.\")\n\nfrom torch.optim import Optimizer\nfrom torch.optim.lr_scheduler import _LRScheduler as LRScheduler\nfrom torch.utils.data import DataLoader\n\nfrom colossalai.checkpoint_io import CheckpointIO, GeneralCheckpointIO, utils\nfrom colossalai.cluster import DistCoordinator\nfrom colossalai.interface import ModelWrapper, OptimizerWrapper\n\nfrom .dp_plugin_base import DPPluginBase\n\n__all__ = ['TorchFSDPPlugin']\n\n\nclass TorchFSDPCheckpointIO(GeneralCheckpointIO):\n\n def __init__(self) -> None:\n super().__init__()\n self.coordinator = DistCoordinator()\n\n def load_unsharded_model(self, model: nn.Module, checkpoint: str, strict: bool):\n checkpoint = utils.load_state_dict(checkpoint)\n model.load_state_dict(checkpoint)\n\n def load_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: Path):\n checkpoint = utils.load_state_dict(checkpoint)\n fsdp_model = optimizer.unwrap_model()\n sharded_osd = FSDP.scatter_full_optim_state_dict(checkpoint, fsdp_model)\n optimizer.load_state_dict(sharded_osd)\n\n def save_unsharded_model(self, model: nn.Module, checkpoint: str, gather_dtensor: bool, use_safetensors: bool):\n \"\"\"\n Save model to checkpoint but only on master process.\n \"\"\"\n # the model should be unwrapped in self.load_model via ModelWrapper.unwrap\n cfg = FullStateDictConfig(offload_to_cpu=True, rank0_only=True)\n with FSDP.state_dict_type(model, StateDictType.FULL_STATE_DICT, cfg):\n full_model_state = model.state_dict()\n utils.save_state_dict(full_model_state, checkpoint_file_path=checkpoint, use_safetensors=use_safetensors)\n\n def save_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: str, gather_dtensor: bool):\n \"\"\"\n Save optimizer to checkpoint but only on master process.\n \"\"\"\n assert isinstance(optimizer, FSDPOptimizerWrapper)\n fsdp_model = optimizer.unwrap_model()\n full_optimizer_state = FSDP.full_optim_state_dict(fsdp_model, optim=optimizer, rank0_only=True)\n utils.save_state_dict(full_optimizer_state, checkpoint_file_path=checkpoint, use_safetensors=False)\n\n def save_sharded_model(self, model: nn.Module, checkpoint: str, gather_dtensor: bool, variant: Optional[str],\n size_per_shard: int, use_safetensors: bool):\n \"\"\"\n Save model to checkpoint but only on master process.\n \"\"\"\n raise NotImplementedError(\"Sharded model checkpoint is not supported yet.\")\n\n def load_sharded_model(self,\n model: nn.Module,\n checkpoint_index_file: Path,\n strict: bool = False,\n use_safetensors: bool = False,\n load_sub_module: bool = True):\n \"\"\"\n Load model to checkpoint but only on master process.\n \"\"\"\n raise NotImplementedError(\"Sharded model checkpoint is not supported yet.\")\n\n def save_sharded_optimizer(self, optimizer: Optimizer, checkpoint: str, gather_dtensor: bool):\n \"\"\"\n Save optimizer to checkpoint but only on master process.\n \"\"\"\n raise NotImplementedError(\"Sharded optimizer checkpoint is not supported yet.\")\n\n def load_sharded_optimizer(self, optimizer: Optimizer, index_file_path: str, prefix: str, size_per_shard: int):\n \"\"\"\n Load optimizer to checkpoint but only on master process.\n \"\"\"\n raise NotImplementedError(\"Sharded optimizer checkpoint is not supported yet.\")\n\n def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):\n \"\"\"\n Save model to checkpoint but only on master process.\n \"\"\"\n if self.coordinator.is_master():\n super().save_lr_scheduler(lr_scheduler, checkpoint)\n\n\nclass TorchFSDPModel(ModelWrapper):\n\n def __init__(self, module: nn.Module, *args, **kwargs) -> None:\n super().__init__(module)\n self.module = FSDP(module, *args, **kwargs)\n\n def unwrap(self):\n return self.module\n\n\nclass FSDPOptimizerWrapper(OptimizerWrapper):\n\n def __init__(self, optimizer: Optimizer, model: nn.Module):\n self.model = model\n super().__init__(optimizer)\n\n def unwrap_model(self) -> nn.Module:\n return self.model\n\n\nclass TorchFSDPPlugin(DPPluginBase):\n \"\"\"\n Plugin for PyTorch FSDP.\n\n Example:\n >>> from colossalai.booster import Booster\n >>> from colossalai.booster.plugin import TorchFSDPPlugin\n >>>\n >>> model, train_dataset, optimizer, criterion = ...\n >>> plugin = TorchFSDPPlugin()\n\n >>> train_dataloader = plugin.prepare_train_dataloader(train_dataset, batch_size=8)\n >>> booster = Booster(plugin=plugin)\n >>> model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)\n\n Args:\n See https://pytorch.org/docs/stable/fsdp.html for details.\n \"\"\"\n\n if version.parse(torch.__version__) >= version.parse('1.12.0'):\n\n def __init__(\n self,\n process_group: Optional[ProcessGroup] = None,\n sharding_strategy: Optional[ShardingStrategy] = None,\n cpu_offload: Optional[CPUOffload] = None,\n auto_wrap_policy: Optional[Callable] = None,\n backward_prefetch: Optional[BackwardPrefetch] = None,\n mixed_precision: Optional[MixedPrecision] = None,\n ignored_modules: Optional[Iterable[torch.nn.Module]] = None,\n param_init_fn: Optional[Callable[[nn.Module], None]] = None,\n sync_module_states: bool = False,\n ):\n super().__init__()\n self.fsdp_kwargs = dict(process_group=process_group,\n sharding_strategy=sharding_strategy,\n cpu_offload=cpu_offload,\n auto_wrap_policy=auto_wrap_policy,\n backward_prefetch=backward_prefetch,\n mixed_precision=mixed_precision,\n ignored_modules=ignored_modules,\n param_init_fn=param_init_fn,\n sync_module_states=sync_module_states)\n else:\n raise RuntimeError(\"FSDP is not supported while torch version under 1.12.0.\")\n\n def support_no_sync(self) -> bool:\n False\n\n def no_sync(self, model: nn.Module) -> Iterator[None]:\n raise NotImplementedError(\"Torch fsdp no_sync func not supported yet.\")\n\n def control_precision(self) -> bool:\n return True\n\n def supported_precisions(self) -> List[str]:\n return ['fp16', 'bf16']\n\n def control_device(self) -> bool:\n return True\n\n def supported_devices(self) -> List[str]:\n return ['cuda']\n\n def configure(\n self,\n model: nn.Module,\n optimizer: Optimizer,\n criterion: Callable = None,\n dataloader: DataLoader = None,\n lr_scheduler: LRScheduler = None,\n ) -> Tuple[Union[nn.Module, OptimizerWrapper, LRScheduler, DataLoader]]:\n\n # wrap the model with PyTorch FSDP\n fsdp_model = TorchFSDPModel(model, device_id=torch.cuda.current_device(), **self.fsdp_kwargs)\n\n if len(optimizer.param_groups) > 1:\n warnings.warn(\n 'TorchFSDPPlugin does not support optimizer that use multi param groups. The results may not be as expected if used.'\n )\n optimizer.__init__(fsdp_model.parameters(), **optimizer.defaults)\n\n if not isinstance(optimizer, FSDPOptimizerWrapper):\n optimizer = FSDPOptimizerWrapper(optimizer, fsdp_model)\n\n return fsdp_model, optimizer, criterion, dataloader, lr_scheduler\n\n def control_checkpoint_io(self) -> bool:\n return True\n\n def get_checkpoint_io(self) -> CheckpointIO:\n return TorchFSDPCheckpointIO()\n", "path": "colossalai/booster/plugin/torch_fsdp_plugin.py"}]}
| 2,672 | 289 |
gh_patches_debug_29373
|
rasdani/github-patches
|
git_diff
|
interlegis__sapl-2033
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Ordenar proposições não recebidas por qualquer campo do cabeçalho
Na tela do operador de consulta às proposições não recebidas,

seria útil que o cabeçalho possibilitasse a ordenação ascendente/descendente por qualquer um dos campos, conforme escolha do usuário. É a mesma funcionalidade na visão das proposições pelo autor:

Tal recurso, aliado ao recebimento de proposições sem recibo, agilizará muito os processos internos, sobretudo nas Câmaras com grande volume de matérias legislativas a cada sessão.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sapl/base/templatetags/common_tags.py`
Content:
```
1 from compressor.utils import get_class
2 from django import template
3 from django.template.defaultfilters import stringfilter
4
5 from sapl.base.models import AppConfig
6 from sapl.materia.models import DocumentoAcessorio, MateriaLegislativa
7 from sapl.norma.models import NormaJuridica
8 from sapl.parlamentares.models import Filiacao
9 from sapl.utils import filiacao_data
10
11 register = template.Library()
12
13
14 @register.simple_tag
15 def field_verbose_name(instance, field_name):
16 return instance._meta.get_field(field_name).verbose_name
17
18
19 @register.simple_tag
20 def fieldclass_verbose_name(class_name, field_name):
21 cls = get_class(class_name)
22 return cls._meta.get_field(field_name).verbose_name
23
24
25 @register.simple_tag
26 def model_verbose_name(class_name):
27 model = get_class(class_name)
28 return model._meta.verbose_name
29
30
31 @register.simple_tag
32 def model_verbose_name_plural(class_name):
33 model = get_class(class_name)
34 return model._meta.verbose_name_plural
35
36
37 @register.filter
38 def lookup(d, key):
39 return d[key] if key in d else []
40
41
42 @register.filter
43 def isinst(value, class_str):
44 classe = value.__class__.__name__
45 return classe == class_str
46
47
48 @register.filter
49 @stringfilter
50 def strip_hash(value):
51 return value.split('/')[0][1:]
52
53
54 @register.filter
55 def get_add_perm(value, arg):
56 perm = value
57 view = arg
58
59 try:
60 nome_app = view.__class__.model._meta.app_label
61 except AttributeError:
62 return None
63 nome_model = view.__class__.model.__name__.lower()
64 can_add = '.add_' + nome_model
65
66 return perm.__contains__(nome_app + can_add)
67
68
69 @register.filter
70 def get_change_perm(value, arg):
71 perm = value
72 view = arg
73
74 try:
75 nome_app = view.__class__.model._meta.app_label
76 except AttributeError:
77 return None
78 nome_model = view.__class__.model.__name__.lower()
79 can_change = '.change_' + nome_model
80
81 return perm.__contains__(nome_app + can_change)
82
83
84 @register.filter
85 def get_delete_perm(value, arg):
86 perm = value
87 view = arg
88
89 try:
90 nome_app = view.__class__.model._meta.app_label
91 except AttributeError:
92 return None
93 nome_model = view.__class__.model.__name__.lower()
94 can_delete = '.delete_' + nome_model
95
96 return perm.__contains__(nome_app + can_delete)
97
98
99 @register.filter
100 def ultima_filiacao(value):
101 parlamentar = value
102
103 ultima_filiacao = Filiacao.objects.filter(
104 parlamentar=parlamentar).order_by('-data').first()
105
106 if ultima_filiacao:
107 return ultima_filiacao.partido
108 else:
109 return None
110
111
112 @register.filter
113 def get_config_attr(attribute):
114 return AppConfig.attr(attribute)
115
116
117 @register.filter
118 def str2intabs(value):
119 if not isinstance(value, str):
120 return ''
121 try:
122 v = int(value)
123 v = abs(v)
124 return v
125 except:
126 return ''
127
128
129 @register.filter
130 def has_iframe(request):
131
132 iframe = request.session.get('iframe', False)
133 if not iframe and 'iframe' in request.GET:
134 ival = request.GET['iframe']
135 if ival and int(ival) == 1:
136 request.session['iframe'] = True
137 return True
138 elif 'iframe' in request.GET:
139 ival = request.GET['iframe']
140 if ival and int(ival) == 0:
141 del request.session['iframe']
142 return False
143
144 return iframe
145
146
147 @register.filter
148 def url(value):
149 if value.startswith('http://') or value.startswith('https://'):
150 return True
151 return False
152
153
154 @register.filter
155 def cronometro_to_seconds(value):
156 if not AppConfig.attr('cronometro_' + value):
157 return 0
158
159 m, s, x = AppConfig.attr(
160 'cronometro_' + value).isoformat().split(':')
161
162 return 60 * int(m) + int(s)
163
164
165 @register.filter
166 def to_list_pk(object_list):
167 return [o.pk for o in object_list]
168
169
170 @register.filter
171 def search_get_model(object):
172 if type(object) == MateriaLegislativa:
173 return 'm'
174 elif type(object) == DocumentoAcessorio:
175 return 'd'
176 elif type(object) == NormaJuridica:
177 return 'n'
178
179 return None
180
181
182 @register.filter
183 def urldetail_content_type(obj, value):
184 return '%s:%s_detail' % (
185 value._meta.app_config.name, obj.content_type.model)
186
187
188 @register.filter
189 def urldetail(obj):
190 return '%s:%s_detail' % (
191 obj._meta.app_config.name, obj._meta.model_name)
192
193
194 @register.filter
195 def filiacao_data_filter(parlamentar, data_inicio):
196 return filiacao_data(parlamentar, data_inicio)
197
198
199 @register.filter
200 def filiacao_intervalo_filter(parlamentar, date_range):
201 return filiacao_data(parlamentar, date_range[0], date_range[1])
202
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sapl/base/templatetags/common_tags.py b/sapl/base/templatetags/common_tags.py
--- a/sapl/base/templatetags/common_tags.py
+++ b/sapl/base/templatetags/common_tags.py
@@ -3,7 +3,7 @@
from django.template.defaultfilters import stringfilter
from sapl.base.models import AppConfig
-from sapl.materia.models import DocumentoAcessorio, MateriaLegislativa
+from sapl.materia.models import DocumentoAcessorio, MateriaLegislativa, Proposicao
from sapl.norma.models import NormaJuridica
from sapl.parlamentares.models import Filiacao
from sapl.utils import filiacao_data
@@ -11,6 +11,11 @@
register = template.Library()
[email protected]_tag
+def define(arg):
+ return arg
+
+
@register.simple_tag
def field_verbose_name(instance, field_name):
return instance._meta.get_field(field_name).verbose_name
@@ -34,6 +39,30 @@
return model._meta.verbose_name_plural
[email protected]
+def split(value, arg):
+ return value.split(arg)
+
+
[email protected]
+def sort_by_keys(value, key):
+ transformed = []
+ id_props = [x.id for x in value]
+ qs = Proposicao.objects.filter(pk__in=id_props)
+ key_descricao = {'1': 'data_envio',
+ '-1': '-data_envio',
+ '2': 'tipo',
+ '-2': '-tipo',
+ '3': 'descricao',
+ '-3': '-descricao',
+ '4': 'autor',
+ '-4': '-autor'
+ }
+
+ transformed = qs.order_by(key_descricao[key])
+ return transformed
+
+
@register.filter
def lookup(d, key):
return d[key] if key in d else []
|
{"golden_diff": "diff --git a/sapl/base/templatetags/common_tags.py b/sapl/base/templatetags/common_tags.py\n--- a/sapl/base/templatetags/common_tags.py\n+++ b/sapl/base/templatetags/common_tags.py\n@@ -3,7 +3,7 @@\n from django.template.defaultfilters import stringfilter\n \n from sapl.base.models import AppConfig\n-from sapl.materia.models import DocumentoAcessorio, MateriaLegislativa\n+from sapl.materia.models import DocumentoAcessorio, MateriaLegislativa, Proposicao\n from sapl.norma.models import NormaJuridica\n from sapl.parlamentares.models import Filiacao\n from sapl.utils import filiacao_data\n@@ -11,6 +11,11 @@\n register = template.Library()\n \n \[email protected]_tag\n+def define(arg):\n+ return arg\n+\n+\n @register.simple_tag\n def field_verbose_name(instance, field_name):\n return instance._meta.get_field(field_name).verbose_name\n@@ -34,6 +39,30 @@\n return model._meta.verbose_name_plural\n \n \[email protected]\n+def split(value, arg):\n+ return value.split(arg)\n+\n+\[email protected]\n+def sort_by_keys(value, key):\n+ transformed = []\n+ id_props = [x.id for x in value]\n+ qs = Proposicao.objects.filter(pk__in=id_props)\n+ key_descricao = {'1': 'data_envio',\n+ '-1': '-data_envio',\n+ '2': 'tipo',\n+ '-2': '-tipo',\n+ '3': 'descricao',\n+ '-3': '-descricao',\n+ '4': 'autor',\n+ '-4': '-autor'\n+ }\n+\n+ transformed = qs.order_by(key_descricao[key])\n+ return transformed\n+\n+\n @register.filter\n def lookup(d, key):\n return d[key] if key in d else []\n", "issue": "Ordenar proposi\u00e7\u00f5es n\u00e3o recebidas por qualquer campo do cabe\u00e7alho\nNa tela do operador de consulta \u00e0s proposi\u00e7\u00f5es n\u00e3o recebidas,\r\n\r\n\r\n\r\n seria \u00fatil que o cabe\u00e7alho possibilitasse a ordena\u00e7\u00e3o ascendente/descendente por qualquer um dos campos, conforme escolha do usu\u00e1rio. \u00c9 a mesma funcionalidade na vis\u00e3o das proposi\u00e7\u00f5es pelo autor:\r\n\r\n\r\n\r\nTal recurso, aliado ao recebimento de proposi\u00e7\u00f5es sem recibo, agilizar\u00e1 muito os processos internos, sobretudo nas C\u00e2maras com grande volume de mat\u00e9rias legislativas a cada sess\u00e3o.\r\n\r\n\n", "before_files": [{"content": "from compressor.utils import get_class\nfrom django import template\nfrom django.template.defaultfilters import stringfilter\n\nfrom sapl.base.models import AppConfig\nfrom sapl.materia.models import DocumentoAcessorio, MateriaLegislativa\nfrom sapl.norma.models import NormaJuridica\nfrom sapl.parlamentares.models import Filiacao\nfrom sapl.utils import filiacao_data\n\nregister = template.Library()\n\n\[email protected]_tag\ndef field_verbose_name(instance, field_name):\n return instance._meta.get_field(field_name).verbose_name\n\n\[email protected]_tag\ndef fieldclass_verbose_name(class_name, field_name):\n cls = get_class(class_name)\n return cls._meta.get_field(field_name).verbose_name\n\n\[email protected]_tag\ndef model_verbose_name(class_name):\n model = get_class(class_name)\n return model._meta.verbose_name\n\n\[email protected]_tag\ndef model_verbose_name_plural(class_name):\n model = get_class(class_name)\n return model._meta.verbose_name_plural\n\n\[email protected]\ndef lookup(d, key):\n return d[key] if key in d else []\n\n\[email protected]\ndef isinst(value, class_str):\n classe = value.__class__.__name__\n return classe == class_str\n\n\[email protected]\n@stringfilter\ndef strip_hash(value):\n return value.split('/')[0][1:]\n\n\[email protected]\ndef get_add_perm(value, arg):\n perm = value\n view = arg\n\n try:\n nome_app = view.__class__.model._meta.app_label\n except AttributeError:\n return None\n nome_model = view.__class__.model.__name__.lower()\n can_add = '.add_' + nome_model\n\n return perm.__contains__(nome_app + can_add)\n\n\[email protected]\ndef get_change_perm(value, arg):\n perm = value\n view = arg\n\n try:\n nome_app = view.__class__.model._meta.app_label\n except AttributeError:\n return None\n nome_model = view.__class__.model.__name__.lower()\n can_change = '.change_' + nome_model\n\n return perm.__contains__(nome_app + can_change)\n\n\[email protected]\ndef get_delete_perm(value, arg):\n perm = value\n view = arg\n\n try:\n nome_app = view.__class__.model._meta.app_label\n except AttributeError:\n return None\n nome_model = view.__class__.model.__name__.lower()\n can_delete = '.delete_' + nome_model\n\n return perm.__contains__(nome_app + can_delete)\n\n\[email protected]\ndef ultima_filiacao(value):\n parlamentar = value\n\n ultima_filiacao = Filiacao.objects.filter(\n parlamentar=parlamentar).order_by('-data').first()\n\n if ultima_filiacao:\n return ultima_filiacao.partido\n else:\n return None\n\n\[email protected]\ndef get_config_attr(attribute):\n return AppConfig.attr(attribute)\n\n\[email protected]\ndef str2intabs(value):\n if not isinstance(value, str):\n return ''\n try:\n v = int(value)\n v = abs(v)\n return v\n except:\n return ''\n\n\[email protected]\ndef has_iframe(request):\n\n iframe = request.session.get('iframe', False)\n if not iframe and 'iframe' in request.GET:\n ival = request.GET['iframe']\n if ival and int(ival) == 1:\n request.session['iframe'] = True\n return True\n elif 'iframe' in request.GET:\n ival = request.GET['iframe']\n if ival and int(ival) == 0:\n del request.session['iframe']\n return False\n\n return iframe\n\n\[email protected]\ndef url(value):\n if value.startswith('http://') or value.startswith('https://'):\n return True\n return False\n\n\[email protected]\ndef cronometro_to_seconds(value):\n if not AppConfig.attr('cronometro_' + value):\n return 0\n\n m, s, x = AppConfig.attr(\n 'cronometro_' + value).isoformat().split(':')\n\n return 60 * int(m) + int(s)\n\n\[email protected]\ndef to_list_pk(object_list):\n return [o.pk for o in object_list]\n\n\[email protected]\ndef search_get_model(object):\n if type(object) == MateriaLegislativa:\n return 'm'\n elif type(object) == DocumentoAcessorio:\n return 'd'\n elif type(object) == NormaJuridica:\n return 'n'\n\n return None\n\n\[email protected]\ndef urldetail_content_type(obj, value):\n return '%s:%s_detail' % (\n value._meta.app_config.name, obj.content_type.model)\n\n\[email protected]\ndef urldetail(obj):\n return '%s:%s_detail' % (\n obj._meta.app_config.name, obj._meta.model_name)\n\n\[email protected]\ndef filiacao_data_filter(parlamentar, data_inicio):\n return filiacao_data(parlamentar, data_inicio)\n\n\[email protected]\ndef filiacao_intervalo_filter(parlamentar, date_range):\n return filiacao_data(parlamentar, date_range[0], date_range[1])\n", "path": "sapl/base/templatetags/common_tags.py"}], "after_files": [{"content": "from compressor.utils import get_class\nfrom django import template\nfrom django.template.defaultfilters import stringfilter\n\nfrom sapl.base.models import AppConfig\nfrom sapl.materia.models import DocumentoAcessorio, MateriaLegislativa, Proposicao\nfrom sapl.norma.models import NormaJuridica\nfrom sapl.parlamentares.models import Filiacao\nfrom sapl.utils import filiacao_data\n\nregister = template.Library()\n\n\[email protected]_tag\ndef define(arg):\n return arg\n\n\[email protected]_tag\ndef field_verbose_name(instance, field_name):\n return instance._meta.get_field(field_name).verbose_name\n\n\[email protected]_tag\ndef fieldclass_verbose_name(class_name, field_name):\n cls = get_class(class_name)\n return cls._meta.get_field(field_name).verbose_name\n\n\[email protected]_tag\ndef model_verbose_name(class_name):\n model = get_class(class_name)\n return model._meta.verbose_name\n\n\[email protected]_tag\ndef model_verbose_name_plural(class_name):\n model = get_class(class_name)\n return model._meta.verbose_name_plural\n\n\[email protected]\ndef split(value, arg):\n return value.split(arg)\n\n\[email protected]\ndef sort_by_keys(value, key):\n transformed = []\n id_props = [x.id for x in value]\n qs = Proposicao.objects.filter(pk__in=id_props)\n key_descricao = {'1': 'data_envio',\n '-1': '-data_envio',\n '2': 'tipo',\n '-2': '-tipo',\n '3': 'descricao',\n '-3': '-descricao',\n '4': 'autor',\n '-4': '-autor'\n }\n\n transformed = qs.order_by(key_descricao[key])\n return transformed\n\n\[email protected]\ndef lookup(d, key):\n return d[key] if key in d else []\n\n\[email protected]\ndef isinst(value, class_str):\n classe = value.__class__.__name__\n return classe == class_str\n\n\[email protected]\n@stringfilter\ndef strip_hash(value):\n return value.split('/')[0][1:]\n\n\[email protected]\ndef get_add_perm(value, arg):\n perm = value\n view = arg\n\n try:\n nome_app = view.__class__.model._meta.app_label\n except AttributeError:\n return None\n nome_model = view.__class__.model.__name__.lower()\n can_add = '.add_' + nome_model\n\n return perm.__contains__(nome_app + can_add)\n\n\[email protected]\ndef get_change_perm(value, arg):\n perm = value\n view = arg\n\n try:\n nome_app = view.__class__.model._meta.app_label\n except AttributeError:\n return None\n nome_model = view.__class__.model.__name__.lower()\n can_change = '.change_' + nome_model\n\n return perm.__contains__(nome_app + can_change)\n\n\[email protected]\ndef get_delete_perm(value, arg):\n perm = value\n view = arg\n\n try:\n nome_app = view.__class__.model._meta.app_label\n except AttributeError:\n return None\n nome_model = view.__class__.model.__name__.lower()\n can_delete = '.delete_' + nome_model\n\n return perm.__contains__(nome_app + can_delete)\n\n\[email protected]\ndef ultima_filiacao(value):\n parlamentar = value\n\n ultima_filiacao = Filiacao.objects.filter(\n parlamentar=parlamentar).order_by('-data').first()\n\n if ultima_filiacao:\n return ultima_filiacao.partido\n else:\n return None\n\n\[email protected]\ndef get_config_attr(attribute):\n return AppConfig.attr(attribute)\n\n\[email protected]\ndef str2intabs(value):\n if not isinstance(value, str):\n return ''\n try:\n v = int(value)\n v = abs(v)\n return v\n except:\n return ''\n\n\[email protected]\ndef has_iframe(request):\n\n iframe = request.session.get('iframe', False)\n if not iframe and 'iframe' in request.GET:\n ival = request.GET['iframe']\n if ival and int(ival) == 1:\n request.session['iframe'] = True\n return True\n elif 'iframe' in request.GET:\n ival = request.GET['iframe']\n if ival and int(ival) == 0:\n del request.session['iframe']\n return False\n\n return iframe\n\n\[email protected]\ndef url(value):\n if value.startswith('http://') or value.startswith('https://'):\n return True\n return False\n\n\[email protected]\ndef cronometro_to_seconds(value):\n if not AppConfig.attr('cronometro_' + value):\n return 0\n\n m, s, x = AppConfig.attr(\n 'cronometro_' + value).isoformat().split(':')\n\n return 60 * int(m) + int(s)\n\n\[email protected]\ndef to_list_pk(object_list):\n return [o.pk for o in object_list]\n\n\[email protected]\ndef search_get_model(object):\n if type(object) == MateriaLegislativa:\n return 'm'\n elif type(object) == DocumentoAcessorio:\n return 'd'\n elif type(object) == NormaJuridica:\n return 'n'\n\n return None\n\n\[email protected]\ndef urldetail_content_type(obj, value):\n return '%s:%s_detail' % (\n value._meta.app_config.name, obj.content_type.model)\n\n\[email protected]\ndef urldetail(obj):\n return '%s:%s_detail' % (\n obj._meta.app_config.name, obj._meta.model_name)\n\n\[email protected]\ndef filiacao_data_filter(parlamentar, data_inicio):\n return filiacao_data(parlamentar, data_inicio)\n\n\[email protected]\ndef filiacao_intervalo_filter(parlamentar, date_range):\n return filiacao_data(parlamentar, date_range[0], date_range[1])\n", "path": "sapl/base/templatetags/common_tags.py"}]}
| 2,204 | 435 |
gh_patches_debug_10852
|
rasdani/github-patches
|
git_diff
|
edgedb__edgedb-6005
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Creating deep nested type gives error `could not serialize result in worker subprocess`
<!-- Please search existing issues to avoid creating duplicates. -->
- EdgeDB Version:
EdgeDB CLI 2.2.0+35980b5
EdgeDB Instance "version": "2.6+db69671",
- OS Version:
MacOS 12.6 (21G115)
The schema has some types connected by links.
For each link to type `Target` the default is a freshly created as `(insert Target)`.
Most likely, the system can only cope with very short chains of such inserts or the total number of the inserts is too high.
Steps to Reproduce:
1. `edgedb migration create --non-interactive` (takes 2-3 minutes)
2. `edgedb migrate` (takes a bit more than 2 minutes)
3. echo 'insert `varycon.Henkel.Adhesive Experience`::`ARMasterConfig` { id := <uuid>"dc29dd8b-6a44-47de-9048-a2d58629a193" };' | edgedb
Result:
edgedb error: InternalServerError: could not serialize result in worker subprocess
Hint: This is most likely a bug in EdgeDB. Please consider opening an issue ticket at https://github.com/edgedb/edgedb/issues/new?template=bug_report.md
Server traceback:
Can't pickle local object 'process_insert_body.<locals>.dynamic_get_path':
Traceback (most recent call last):
File "/Users/doc/Library/Application Support/edgedb/portable/2.6/lib/python3.10/site-packages/edb/server/compiler_pool/worker_proc.py", line 64, in worker
pickled = pickle.dumps(data, -1)
AttributeError: Can't pickle local object 'process_insert_body.<locals>.dynamic_get_path'
<!-- If the issue is about a query error, please also provide your schema -->
Schema:
[default.esdl.zip](https://github.com/edgedb/edgedb/files/10021869/default.esdl.zip)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `edb/pgsql/compiler/__init__.py`
Content:
```
1 #
2 # This source file is part of the EdgeDB open source project.
3 #
4 # Copyright 2008-present MagicStack Inc. and the EdgeDB authors.
5 #
6 # Licensed under the Apache License, Version 2.0 (the "License");
7 # you may not use this file except in compliance with the License.
8 # You may obtain a copy of the License at
9 #
10 # http://www.apache.org/licenses/LICENSE-2.0
11 #
12 # Unless required by applicable law or agreed to in writing, software
13 # distributed under the License is distributed on an "AS IS" BASIS,
14 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 # See the License for the specific language governing permissions and
16 # limitations under the License.
17 #
18
19
20 from __future__ import annotations
21
22 from typing import *
23
24 from edb import errors
25
26 from edb.common import debug
27 from edb.common import exceptions as edgedb_error
28
29 from edb.ir import ast as irast
30
31 from edb.pgsql import ast as pgast
32 from edb.pgsql import codegen as pgcodegen
33 from edb.pgsql import debug as pgdebug
34 from edb.pgsql import params as pgparams
35
36 from . import config as _config_compiler # NOQA
37 from . import expr as _expr_compiler # NOQA
38 from . import stmt as _stmt_compiler # NOQA
39
40 from . import clauses
41 from . import context
42 from . import dispatch
43 from . import dml
44
45 from .context import OutputFormat as OutputFormat # NOQA
46
47
48 def compile_ir_to_sql_tree(
49 ir_expr: irast.Base,
50 *,
51 output_format: Optional[OutputFormat] = None,
52 ignore_shapes: bool = False,
53 explicit_top_cast: Optional[irast.TypeRef] = None,
54 singleton_mode: bool = False,
55 use_named_params: bool = False,
56 expected_cardinality_one: bool = False,
57 expand_inhviews: bool = False,
58 external_rvars: Optional[
59 Mapping[Tuple[irast.PathId, str], pgast.PathRangeVar]
60 ] = None,
61 external_rels: Optional[
62 Mapping[
63 irast.PathId,
64 Tuple[pgast.BaseRelation | pgast.CommonTableExpr, Tuple[str, ...]],
65 ]
66 ] = None,
67 backend_runtime_params: Optional[pgparams.BackendRuntimeParams]=None,
68 ) -> Tuple[pgast.Base, context.Environment]:
69 try:
70 # Transform to sql tree
71 query_params = []
72 query_globals = []
73 type_rewrites = {}
74 triggers: tuple[tuple[irast.Trigger, ...], ...] = ()
75
76 singletons = []
77 if isinstance(ir_expr, irast.Statement):
78 scope_tree = ir_expr.scope_tree
79 query_params = list(ir_expr.params)
80 query_globals = list(ir_expr.globals)
81 type_rewrites = ir_expr.type_rewrites
82 singletons = ir_expr.singletons
83 triggers = ir_expr.triggers
84 ir_expr = ir_expr.expr
85 elif isinstance(ir_expr, irast.ConfigCommand):
86 assert ir_expr.scope_tree
87 scope_tree = ir_expr.scope_tree
88 if ir_expr.globals:
89 query_globals = list(ir_expr.globals)
90 else:
91 scope_tree = irast.new_scope_tree()
92
93 scope_tree_nodes = {
94 node.unique_id: node for node in scope_tree.descendants
95 if node.unique_id is not None
96 }
97
98 if backend_runtime_params is None:
99 backend_runtime_params = pgparams.get_default_runtime_params()
100
101 env = context.Environment(
102 output_format=output_format,
103 expected_cardinality_one=expected_cardinality_one,
104 use_named_params=use_named_params,
105 query_params=list(tuple(query_params) + tuple(query_globals)),
106 type_rewrites=type_rewrites,
107 ignore_object_shapes=ignore_shapes,
108 explicit_top_cast=explicit_top_cast,
109 expand_inhviews=expand_inhviews,
110 singleton_mode=singleton_mode,
111 scope_tree_nodes=scope_tree_nodes,
112 external_rvars=external_rvars,
113 backend_runtime_params=backend_runtime_params,
114 )
115
116 ctx = context.CompilerContextLevel(
117 None,
118 context.ContextSwitchMode.TRANSPARENT,
119 env=env,
120 scope_tree=scope_tree,
121 )
122 ctx.rel = pgast.SelectStmt()
123
124 _ = context.CompilerContext(initial=ctx)
125
126 ctx.singleton_mode = singleton_mode
127 ctx.expr_exposed = True
128 for sing in singletons:
129 ctx.path_scope[sing] = ctx.rel
130 if external_rels:
131 ctx.external_rels = external_rels
132 clauses.populate_argmap(query_params, query_globals, ctx=ctx)
133
134 qtree = dispatch.compile(ir_expr, ctx=ctx)
135 dml.compile_triggers(triggers, qtree, ctx=ctx)
136
137 if isinstance(ir_expr, irast.Set) and not singleton_mode:
138 assert isinstance(qtree, pgast.Query)
139 clauses.fini_toplevel(qtree, ctx)
140
141 except errors.EdgeDBError:
142 # Don't wrap propertly typed EdgeDB errors into
143 # InternalServerError; raise them as is.
144 raise
145
146 except Exception as e: # pragma: no cover
147 try:
148 args = [e.args[0]]
149 except (AttributeError, IndexError):
150 args = []
151 raise errors.InternalServerError(*args) from e
152
153 return (qtree, env)
154
155
156 def compile_ir_to_tree_and_sql(
157 ir_expr: irast.Base, *,
158 output_format: Optional[OutputFormat]=None,
159 ignore_shapes: bool=False,
160 explicit_top_cast: Optional[irast.TypeRef]=None,
161 singleton_mode: bool=False,
162 use_named_params: bool=False,
163 expected_cardinality_one: bool=False,
164 expand_inhviews: bool = False,
165 pretty: bool=True,
166 backend_runtime_params: Optional[pgparams.BackendRuntimeParams]=None,
167 ) -> Tuple[pgast.Base, str, Dict[str, pgast.Param]]:
168
169 qtree, _ = compile_ir_to_sql_tree(
170 ir_expr,
171 output_format=output_format,
172 ignore_shapes=ignore_shapes,
173 explicit_top_cast=explicit_top_cast,
174 singleton_mode=singleton_mode,
175 use_named_params=use_named_params,
176 expected_cardinality_one=expected_cardinality_one,
177 backend_runtime_params=backend_runtime_params,
178 expand_inhviews=expand_inhviews,
179 )
180
181 if ( # pragma: no cover
182 debug.flags.edgeql_compile or debug.flags.edgeql_compile_sql_ast
183 ):
184 debug.header('SQL Tree')
185 debug.dump(
186 qtree, _ast_include_meta=debug.flags.edgeql_compile_sql_ast_meta)
187
188 if isinstance(qtree, pgast.Query) and qtree.argnames:
189 argmap = qtree.argnames
190 else:
191 argmap = {}
192
193 # Generate query text
194 sql_text = run_codegen(qtree, pretty=pretty)
195
196 if ( # pragma: no cover
197 debug.flags.edgeql_compile or debug.flags.edgeql_compile_sql_text
198 ):
199 debug.header('SQL')
200 debug.dump_code(sql_text, lexer='sql')
201 if ( # pragma: no cover
202 debug.flags.edgeql_compile_sql_reordered_text
203 ):
204 debug.header('Reordered SQL')
205 debug_sql_text = run_codegen(qtree, pretty=True, reordered=True)
206 if isinstance(ir_expr, irast.Statement):
207 # Rewrite uuids back into something approximating
208 # readable object names.
209 debug_sql_text = pgdebug.rewrite_names_in_sql(
210 debug_sql_text, ir_expr.schema)
211 debug.dump_code(debug_sql_text, lexer='sql')
212
213 return qtree, sql_text, argmap
214
215
216 def compile_ir_to_sql(
217 ir_expr: irast.Base, *,
218 output_format: Optional[OutputFormat]=None,
219 ignore_shapes: bool=False,
220 explicit_top_cast: Optional[irast.TypeRef]=None,
221 singleton_mode: bool=False,
222 use_named_params: bool=False,
223 expected_cardinality_one: bool=False,
224 pretty: bool=True,
225 backend_runtime_params: Optional[pgparams.BackendRuntimeParams]=None,
226 ) -> Tuple[str, Dict[str, pgast.Param]]:
227 _, sql_text, argmap = compile_ir_to_tree_and_sql(
228 ir_expr,
229 output_format=output_format,
230 ignore_shapes=ignore_shapes,
231 explicit_top_cast=explicit_top_cast,
232 singleton_mode=singleton_mode,
233 use_named_params=use_named_params,
234 expected_cardinality_one=expected_cardinality_one,
235 backend_runtime_params=backend_runtime_params,
236 pretty=pretty,
237 )
238 return sql_text, argmap
239
240
241 def run_codegen(
242 qtree: pgast.Base,
243 *,
244 pretty: bool=True,
245 reordered: bool=False,
246 ) -> str:
247 codegen = pgcodegen.SQLSourceGenerator(pretty=pretty, reordered=reordered)
248 try:
249 codegen.visit(qtree)
250 except pgcodegen.SQLSourceGeneratorError as e: # pragma: no cover
251 ctx = pgcodegen.SQLSourceGeneratorContext(
252 qtree, codegen.result)
253 edgedb_error.add_context(e, ctx)
254 raise
255 except Exception as e: # pragma: no cover
256 ctx = pgcodegen.SQLSourceGeneratorContext(
257 qtree, codegen.result)
258 err = pgcodegen.SQLSourceGeneratorError(
259 'error while generating SQL source')
260 edgedb_error.add_context(err, ctx)
261 raise err from e
262
263 return ''.join(codegen.result)
264
265
266 def new_external_rvar(
267 *,
268 rel_name: Tuple[str, ...],
269 path_id: irast.PathId,
270 outputs: Mapping[Tuple[irast.PathId, Tuple[str, ...]], str],
271 ) -> pgast.RelRangeVar:
272 """Construct a ``RangeVar`` instance given a relation name and a path id.
273
274 Given an optionally-qualified relation name *rel_name* and a *path_id*,
275 return a ``RangeVar`` instance over the specified relation that is
276 then assumed to represent the *path_id* binding.
277
278 This is useful in situations where it is necessary to "prime" the compiler
279 with a list of external relations that exist in a larger SQL expression
280 that _this_ expression is being embedded into.
281
282 The *outputs* mapping optionally specifies a set of outputs in the
283 resulting range var as a ``(path_id, tuple-of-aspects): attribute name``
284 mapping.
285 """
286 rel = new_external_rel(rel_name=rel_name, path_id=path_id)
287 assert rel.name
288
289 alias = pgast.Alias(aliasname=rel.name)
290
291 if not path_id.is_ptr_path():
292 rvar = pgast.RelRangeVar(
293 relation=rel, typeref=path_id.target, alias=alias)
294 else:
295 rvar = pgast.RelRangeVar(
296 relation=rel, alias=alias)
297
298 for (output_pid, output_aspects), colname in outputs.items():
299 var = pgast.ColumnRef(name=[colname])
300 for aspect in output_aspects:
301 rel.path_outputs[output_pid, aspect] = var
302
303 return rvar
304
305
306 def new_external_rel(
307 *,
308 rel_name: Tuple[str, ...],
309 path_id: irast.PathId,
310 ) -> pgast.Relation:
311 if len(rel_name) == 1:
312 table_name = rel_name[0]
313 schema_name = None
314 elif len(rel_name) == 2:
315 schema_name, table_name = rel_name
316 else:
317 raise AssertionError(f'unexpected rvar name: {rel_name}')
318
319 return pgast.Relation(
320 name=table_name,
321 schemaname=schema_name,
322 path_id=path_id,
323 )
324
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/edb/pgsql/compiler/__init__.py b/edb/pgsql/compiler/__init__.py
--- a/edb/pgsql/compiler/__init__.py
+++ b/edb/pgsql/compiler/__init__.py
@@ -247,6 +247,11 @@
codegen = pgcodegen.SQLSourceGenerator(pretty=pretty, reordered=reordered)
try:
codegen.visit(qtree)
+ except RecursionError:
+ # Don't try to wrap and add context to a recursion error,
+ # since the context might easily be too deeply recursive to
+ # process further down the pipe.
+ raise
except pgcodegen.SQLSourceGeneratorError as e: # pragma: no cover
ctx = pgcodegen.SQLSourceGeneratorContext(
qtree, codegen.result)
|
{"golden_diff": "diff --git a/edb/pgsql/compiler/__init__.py b/edb/pgsql/compiler/__init__.py\n--- a/edb/pgsql/compiler/__init__.py\n+++ b/edb/pgsql/compiler/__init__.py\n@@ -247,6 +247,11 @@\n codegen = pgcodegen.SQLSourceGenerator(pretty=pretty, reordered=reordered)\n try:\n codegen.visit(qtree)\n+ except RecursionError:\n+ # Don't try to wrap and add context to a recursion error,\n+ # since the context might easily be too deeply recursive to\n+ # process further down the pipe.\n+ raise\n except pgcodegen.SQLSourceGeneratorError as e: # pragma: no cover\n ctx = pgcodegen.SQLSourceGeneratorContext(\n qtree, codegen.result)\n", "issue": "Creating deep nested type gives error `could not serialize result in worker subprocess`\n<!-- Please search existing issues to avoid creating duplicates. -->\r\n- EdgeDB Version:\r\nEdgeDB CLI 2.2.0+35980b5\r\nEdgeDB Instance \"version\": \"2.6+db69671\",\r\n- OS Version:\r\nMacOS 12.6 (21G115)\r\n\r\nThe schema has some types connected by links.\r\nFor each link to type `Target` the default is a freshly created as `(insert Target)`.\r\nMost likely, the system can only cope with very short chains of such inserts or the total number of the inserts is too high.\r\n\r\nSteps to Reproduce:\r\n\r\n1. `edgedb migration create --non-interactive` (takes 2-3 minutes) \r\n2. `edgedb migrate` (takes a bit more than 2 minutes)\r\n3. echo 'insert `varycon.Henkel.Adhesive Experience`::`ARMasterConfig` { id := <uuid>\"dc29dd8b-6a44-47de-9048-a2d58629a193\" };' | edgedb\r\n\r\nResult:\r\n\r\nedgedb error: InternalServerError: could not serialize result in worker subprocess\r\n Hint: This is most likely a bug in EdgeDB. Please consider opening an issue ticket at https://github.com/edgedb/edgedb/issues/new?template=bug_report.md\r\n Server traceback:\r\n Can't pickle local object 'process_insert_body.<locals>.dynamic_get_path':\r\n\r\n Traceback (most recent call last):\r\n File \"/Users/doc/Library/Application Support/edgedb/portable/2.6/lib/python3.10/site-packages/edb/server/compiler_pool/worker_proc.py\", line 64, in worker\r\n pickled = pickle.dumps(data, -1)\r\n AttributeError: Can't pickle local object 'process_insert_body.<locals>.dynamic_get_path'\r\n\r\n<!-- If the issue is about a query error, please also provide your schema -->\r\nSchema:\r\n\r\n[default.esdl.zip](https://github.com/edgedb/edgedb/files/10021869/default.esdl.zip)\r\n\n", "before_files": [{"content": "#\n# This source file is part of the EdgeDB open source project.\n#\n# Copyright 2008-present MagicStack Inc. and the EdgeDB authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n\nfrom __future__ import annotations\n\nfrom typing import *\n\nfrom edb import errors\n\nfrom edb.common import debug\nfrom edb.common import exceptions as edgedb_error\n\nfrom edb.ir import ast as irast\n\nfrom edb.pgsql import ast as pgast\nfrom edb.pgsql import codegen as pgcodegen\nfrom edb.pgsql import debug as pgdebug\nfrom edb.pgsql import params as pgparams\n\nfrom . import config as _config_compiler # NOQA\nfrom . import expr as _expr_compiler # NOQA\nfrom . import stmt as _stmt_compiler # NOQA\n\nfrom . import clauses\nfrom . import context\nfrom . import dispatch\nfrom . import dml\n\nfrom .context import OutputFormat as OutputFormat # NOQA\n\n\ndef compile_ir_to_sql_tree(\n ir_expr: irast.Base,\n *,\n output_format: Optional[OutputFormat] = None,\n ignore_shapes: bool = False,\n explicit_top_cast: Optional[irast.TypeRef] = None,\n singleton_mode: bool = False,\n use_named_params: bool = False,\n expected_cardinality_one: bool = False,\n expand_inhviews: bool = False,\n external_rvars: Optional[\n Mapping[Tuple[irast.PathId, str], pgast.PathRangeVar]\n ] = None,\n external_rels: Optional[\n Mapping[\n irast.PathId,\n Tuple[pgast.BaseRelation | pgast.CommonTableExpr, Tuple[str, ...]],\n ]\n ] = None,\n backend_runtime_params: Optional[pgparams.BackendRuntimeParams]=None,\n) -> Tuple[pgast.Base, context.Environment]:\n try:\n # Transform to sql tree\n query_params = []\n query_globals = []\n type_rewrites = {}\n triggers: tuple[tuple[irast.Trigger, ...], ...] = ()\n\n singletons = []\n if isinstance(ir_expr, irast.Statement):\n scope_tree = ir_expr.scope_tree\n query_params = list(ir_expr.params)\n query_globals = list(ir_expr.globals)\n type_rewrites = ir_expr.type_rewrites\n singletons = ir_expr.singletons\n triggers = ir_expr.triggers\n ir_expr = ir_expr.expr\n elif isinstance(ir_expr, irast.ConfigCommand):\n assert ir_expr.scope_tree\n scope_tree = ir_expr.scope_tree\n if ir_expr.globals:\n query_globals = list(ir_expr.globals)\n else:\n scope_tree = irast.new_scope_tree()\n\n scope_tree_nodes = {\n node.unique_id: node for node in scope_tree.descendants\n if node.unique_id is not None\n }\n\n if backend_runtime_params is None:\n backend_runtime_params = pgparams.get_default_runtime_params()\n\n env = context.Environment(\n output_format=output_format,\n expected_cardinality_one=expected_cardinality_one,\n use_named_params=use_named_params,\n query_params=list(tuple(query_params) + tuple(query_globals)),\n type_rewrites=type_rewrites,\n ignore_object_shapes=ignore_shapes,\n explicit_top_cast=explicit_top_cast,\n expand_inhviews=expand_inhviews,\n singleton_mode=singleton_mode,\n scope_tree_nodes=scope_tree_nodes,\n external_rvars=external_rvars,\n backend_runtime_params=backend_runtime_params,\n )\n\n ctx = context.CompilerContextLevel(\n None,\n context.ContextSwitchMode.TRANSPARENT,\n env=env,\n scope_tree=scope_tree,\n )\n ctx.rel = pgast.SelectStmt()\n\n _ = context.CompilerContext(initial=ctx)\n\n ctx.singleton_mode = singleton_mode\n ctx.expr_exposed = True\n for sing in singletons:\n ctx.path_scope[sing] = ctx.rel\n if external_rels:\n ctx.external_rels = external_rels\n clauses.populate_argmap(query_params, query_globals, ctx=ctx)\n\n qtree = dispatch.compile(ir_expr, ctx=ctx)\n dml.compile_triggers(triggers, qtree, ctx=ctx)\n\n if isinstance(ir_expr, irast.Set) and not singleton_mode:\n assert isinstance(qtree, pgast.Query)\n clauses.fini_toplevel(qtree, ctx)\n\n except errors.EdgeDBError:\n # Don't wrap propertly typed EdgeDB errors into\n # InternalServerError; raise them as is.\n raise\n\n except Exception as e: # pragma: no cover\n try:\n args = [e.args[0]]\n except (AttributeError, IndexError):\n args = []\n raise errors.InternalServerError(*args) from e\n\n return (qtree, env)\n\n\ndef compile_ir_to_tree_and_sql(\n ir_expr: irast.Base, *,\n output_format: Optional[OutputFormat]=None,\n ignore_shapes: bool=False,\n explicit_top_cast: Optional[irast.TypeRef]=None,\n singleton_mode: bool=False,\n use_named_params: bool=False,\n expected_cardinality_one: bool=False,\n expand_inhviews: bool = False,\n pretty: bool=True,\n backend_runtime_params: Optional[pgparams.BackendRuntimeParams]=None,\n) -> Tuple[pgast.Base, str, Dict[str, pgast.Param]]:\n\n qtree, _ = compile_ir_to_sql_tree(\n ir_expr,\n output_format=output_format,\n ignore_shapes=ignore_shapes,\n explicit_top_cast=explicit_top_cast,\n singleton_mode=singleton_mode,\n use_named_params=use_named_params,\n expected_cardinality_one=expected_cardinality_one,\n backend_runtime_params=backend_runtime_params,\n expand_inhviews=expand_inhviews,\n )\n\n if ( # pragma: no cover\n debug.flags.edgeql_compile or debug.flags.edgeql_compile_sql_ast\n ):\n debug.header('SQL Tree')\n debug.dump(\n qtree, _ast_include_meta=debug.flags.edgeql_compile_sql_ast_meta)\n\n if isinstance(qtree, pgast.Query) and qtree.argnames:\n argmap = qtree.argnames\n else:\n argmap = {}\n\n # Generate query text\n sql_text = run_codegen(qtree, pretty=pretty)\n\n if ( # pragma: no cover\n debug.flags.edgeql_compile or debug.flags.edgeql_compile_sql_text\n ):\n debug.header('SQL')\n debug.dump_code(sql_text, lexer='sql')\n if ( # pragma: no cover\n debug.flags.edgeql_compile_sql_reordered_text\n ):\n debug.header('Reordered SQL')\n debug_sql_text = run_codegen(qtree, pretty=True, reordered=True)\n if isinstance(ir_expr, irast.Statement):\n # Rewrite uuids back into something approximating\n # readable object names.\n debug_sql_text = pgdebug.rewrite_names_in_sql(\n debug_sql_text, ir_expr.schema)\n debug.dump_code(debug_sql_text, lexer='sql')\n\n return qtree, sql_text, argmap\n\n\ndef compile_ir_to_sql(\n ir_expr: irast.Base, *,\n output_format: Optional[OutputFormat]=None,\n ignore_shapes: bool=False,\n explicit_top_cast: Optional[irast.TypeRef]=None,\n singleton_mode: bool=False,\n use_named_params: bool=False,\n expected_cardinality_one: bool=False,\n pretty: bool=True,\n backend_runtime_params: Optional[pgparams.BackendRuntimeParams]=None,\n) -> Tuple[str, Dict[str, pgast.Param]]:\n _, sql_text, argmap = compile_ir_to_tree_and_sql(\n ir_expr,\n output_format=output_format,\n ignore_shapes=ignore_shapes,\n explicit_top_cast=explicit_top_cast,\n singleton_mode=singleton_mode,\n use_named_params=use_named_params,\n expected_cardinality_one=expected_cardinality_one,\n backend_runtime_params=backend_runtime_params,\n pretty=pretty,\n )\n return sql_text, argmap\n\n\ndef run_codegen(\n qtree: pgast.Base,\n *,\n pretty: bool=True,\n reordered: bool=False,\n) -> str:\n codegen = pgcodegen.SQLSourceGenerator(pretty=pretty, reordered=reordered)\n try:\n codegen.visit(qtree)\n except pgcodegen.SQLSourceGeneratorError as e: # pragma: no cover\n ctx = pgcodegen.SQLSourceGeneratorContext(\n qtree, codegen.result)\n edgedb_error.add_context(e, ctx)\n raise\n except Exception as e: # pragma: no cover\n ctx = pgcodegen.SQLSourceGeneratorContext(\n qtree, codegen.result)\n err = pgcodegen.SQLSourceGeneratorError(\n 'error while generating SQL source')\n edgedb_error.add_context(err, ctx)\n raise err from e\n\n return ''.join(codegen.result)\n\n\ndef new_external_rvar(\n *,\n rel_name: Tuple[str, ...],\n path_id: irast.PathId,\n outputs: Mapping[Tuple[irast.PathId, Tuple[str, ...]], str],\n) -> pgast.RelRangeVar:\n \"\"\"Construct a ``RangeVar`` instance given a relation name and a path id.\n\n Given an optionally-qualified relation name *rel_name* and a *path_id*,\n return a ``RangeVar`` instance over the specified relation that is\n then assumed to represent the *path_id* binding.\n\n This is useful in situations where it is necessary to \"prime\" the compiler\n with a list of external relations that exist in a larger SQL expression\n that _this_ expression is being embedded into.\n\n The *outputs* mapping optionally specifies a set of outputs in the\n resulting range var as a ``(path_id, tuple-of-aspects): attribute name``\n mapping.\n \"\"\"\n rel = new_external_rel(rel_name=rel_name, path_id=path_id)\n assert rel.name\n\n alias = pgast.Alias(aliasname=rel.name)\n\n if not path_id.is_ptr_path():\n rvar = pgast.RelRangeVar(\n relation=rel, typeref=path_id.target, alias=alias)\n else:\n rvar = pgast.RelRangeVar(\n relation=rel, alias=alias)\n\n for (output_pid, output_aspects), colname in outputs.items():\n var = pgast.ColumnRef(name=[colname])\n for aspect in output_aspects:\n rel.path_outputs[output_pid, aspect] = var\n\n return rvar\n\n\ndef new_external_rel(\n *,\n rel_name: Tuple[str, ...],\n path_id: irast.PathId,\n) -> pgast.Relation:\n if len(rel_name) == 1:\n table_name = rel_name[0]\n schema_name = None\n elif len(rel_name) == 2:\n schema_name, table_name = rel_name\n else:\n raise AssertionError(f'unexpected rvar name: {rel_name}')\n\n return pgast.Relation(\n name=table_name,\n schemaname=schema_name,\n path_id=path_id,\n )\n", "path": "edb/pgsql/compiler/__init__.py"}], "after_files": [{"content": "#\n# This source file is part of the EdgeDB open source project.\n#\n# Copyright 2008-present MagicStack Inc. and the EdgeDB authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n\nfrom __future__ import annotations\n\nfrom typing import *\n\nfrom edb import errors\n\nfrom edb.common import debug\nfrom edb.common import exceptions as edgedb_error\n\nfrom edb.ir import ast as irast\n\nfrom edb.pgsql import ast as pgast\nfrom edb.pgsql import codegen as pgcodegen\nfrom edb.pgsql import debug as pgdebug\nfrom edb.pgsql import params as pgparams\n\nfrom . import config as _config_compiler # NOQA\nfrom . import expr as _expr_compiler # NOQA\nfrom . import stmt as _stmt_compiler # NOQA\n\nfrom . import clauses\nfrom . import context\nfrom . import dispatch\nfrom . import dml\n\nfrom .context import OutputFormat as OutputFormat # NOQA\n\n\ndef compile_ir_to_sql_tree(\n ir_expr: irast.Base,\n *,\n output_format: Optional[OutputFormat] = None,\n ignore_shapes: bool = False,\n explicit_top_cast: Optional[irast.TypeRef] = None,\n singleton_mode: bool = False,\n use_named_params: bool = False,\n expected_cardinality_one: bool = False,\n expand_inhviews: bool = False,\n external_rvars: Optional[\n Mapping[Tuple[irast.PathId, str], pgast.PathRangeVar]\n ] = None,\n external_rels: Optional[\n Mapping[\n irast.PathId,\n Tuple[pgast.BaseRelation | pgast.CommonTableExpr, Tuple[str, ...]],\n ]\n ] = None,\n backend_runtime_params: Optional[pgparams.BackendRuntimeParams]=None,\n) -> Tuple[pgast.Base, context.Environment]:\n try:\n # Transform to sql tree\n query_params = []\n query_globals = []\n type_rewrites = {}\n triggers: tuple[tuple[irast.Trigger, ...], ...] = ()\n\n singletons = []\n if isinstance(ir_expr, irast.Statement):\n scope_tree = ir_expr.scope_tree\n query_params = list(ir_expr.params)\n query_globals = list(ir_expr.globals)\n type_rewrites = ir_expr.type_rewrites\n singletons = ir_expr.singletons\n triggers = ir_expr.triggers\n ir_expr = ir_expr.expr\n elif isinstance(ir_expr, irast.ConfigCommand):\n assert ir_expr.scope_tree\n scope_tree = ir_expr.scope_tree\n if ir_expr.globals:\n query_globals = list(ir_expr.globals)\n else:\n scope_tree = irast.new_scope_tree()\n\n scope_tree_nodes = {\n node.unique_id: node for node in scope_tree.descendants\n if node.unique_id is not None\n }\n\n if backend_runtime_params is None:\n backend_runtime_params = pgparams.get_default_runtime_params()\n\n env = context.Environment(\n output_format=output_format,\n expected_cardinality_one=expected_cardinality_one,\n use_named_params=use_named_params,\n query_params=list(tuple(query_params) + tuple(query_globals)),\n type_rewrites=type_rewrites,\n ignore_object_shapes=ignore_shapes,\n explicit_top_cast=explicit_top_cast,\n expand_inhviews=expand_inhviews,\n singleton_mode=singleton_mode,\n scope_tree_nodes=scope_tree_nodes,\n external_rvars=external_rvars,\n backend_runtime_params=backend_runtime_params,\n )\n\n ctx = context.CompilerContextLevel(\n None,\n context.ContextSwitchMode.TRANSPARENT,\n env=env,\n scope_tree=scope_tree,\n )\n ctx.rel = pgast.SelectStmt()\n\n _ = context.CompilerContext(initial=ctx)\n\n ctx.singleton_mode = singleton_mode\n ctx.expr_exposed = True\n for sing in singletons:\n ctx.path_scope[sing] = ctx.rel\n if external_rels:\n ctx.external_rels = external_rels\n clauses.populate_argmap(query_params, query_globals, ctx=ctx)\n\n qtree = dispatch.compile(ir_expr, ctx=ctx)\n dml.compile_triggers(triggers, qtree, ctx=ctx)\n\n if isinstance(ir_expr, irast.Set) and not singleton_mode:\n assert isinstance(qtree, pgast.Query)\n clauses.fini_toplevel(qtree, ctx)\n\n except errors.EdgeDBError:\n # Don't wrap propertly typed EdgeDB errors into\n # InternalServerError; raise them as is.\n raise\n\n except Exception as e: # pragma: no cover\n try:\n args = [e.args[0]]\n except (AttributeError, IndexError):\n args = []\n raise errors.InternalServerError(*args) from e\n\n return (qtree, env)\n\n\ndef compile_ir_to_tree_and_sql(\n ir_expr: irast.Base, *,\n output_format: Optional[OutputFormat]=None,\n ignore_shapes: bool=False,\n explicit_top_cast: Optional[irast.TypeRef]=None,\n singleton_mode: bool=False,\n use_named_params: bool=False,\n expected_cardinality_one: bool=False,\n expand_inhviews: bool = False,\n pretty: bool=True,\n backend_runtime_params: Optional[pgparams.BackendRuntimeParams]=None,\n) -> Tuple[pgast.Base, str, Dict[str, pgast.Param]]:\n\n qtree, _ = compile_ir_to_sql_tree(\n ir_expr,\n output_format=output_format,\n ignore_shapes=ignore_shapes,\n explicit_top_cast=explicit_top_cast,\n singleton_mode=singleton_mode,\n use_named_params=use_named_params,\n expected_cardinality_one=expected_cardinality_one,\n backend_runtime_params=backend_runtime_params,\n expand_inhviews=expand_inhviews,\n )\n\n if ( # pragma: no cover\n debug.flags.edgeql_compile or debug.flags.edgeql_compile_sql_ast\n ):\n debug.header('SQL Tree')\n debug.dump(\n qtree, _ast_include_meta=debug.flags.edgeql_compile_sql_ast_meta)\n\n if isinstance(qtree, pgast.Query) and qtree.argnames:\n argmap = qtree.argnames\n else:\n argmap = {}\n\n # Generate query text\n sql_text = run_codegen(qtree, pretty=pretty)\n\n if ( # pragma: no cover\n debug.flags.edgeql_compile or debug.flags.edgeql_compile_sql_text\n ):\n debug.header('SQL')\n debug.dump_code(sql_text, lexer='sql')\n if ( # pragma: no cover\n debug.flags.edgeql_compile_sql_reordered_text\n ):\n debug.header('Reordered SQL')\n debug_sql_text = run_codegen(qtree, pretty=True, reordered=True)\n if isinstance(ir_expr, irast.Statement):\n # Rewrite uuids back into something approximating\n # readable object names.\n debug_sql_text = pgdebug.rewrite_names_in_sql(\n debug_sql_text, ir_expr.schema)\n debug.dump_code(debug_sql_text, lexer='sql')\n\n return qtree, sql_text, argmap\n\n\ndef compile_ir_to_sql(\n ir_expr: irast.Base, *,\n output_format: Optional[OutputFormat]=None,\n ignore_shapes: bool=False,\n explicit_top_cast: Optional[irast.TypeRef]=None,\n singleton_mode: bool=False,\n use_named_params: bool=False,\n expected_cardinality_one: bool=False,\n pretty: bool=True,\n backend_runtime_params: Optional[pgparams.BackendRuntimeParams]=None,\n) -> Tuple[str, Dict[str, pgast.Param]]:\n _, sql_text, argmap = compile_ir_to_tree_and_sql(\n ir_expr,\n output_format=output_format,\n ignore_shapes=ignore_shapes,\n explicit_top_cast=explicit_top_cast,\n singleton_mode=singleton_mode,\n use_named_params=use_named_params,\n expected_cardinality_one=expected_cardinality_one,\n backend_runtime_params=backend_runtime_params,\n pretty=pretty,\n )\n return sql_text, argmap\n\n\ndef run_codegen(\n qtree: pgast.Base,\n *,\n pretty: bool=True,\n reordered: bool=False,\n) -> str:\n codegen = pgcodegen.SQLSourceGenerator(pretty=pretty, reordered=reordered)\n try:\n codegen.visit(qtree)\n except RecursionError:\n # Don't try to wrap and add context to a recursion error,\n # since the context might easily be too deeply recursive to\n # process further down the pipe.\n raise\n except pgcodegen.SQLSourceGeneratorError as e: # pragma: no cover\n ctx = pgcodegen.SQLSourceGeneratorContext(\n qtree, codegen.result)\n edgedb_error.add_context(e, ctx)\n raise\n except Exception as e: # pragma: no cover\n ctx = pgcodegen.SQLSourceGeneratorContext(\n qtree, codegen.result)\n err = pgcodegen.SQLSourceGeneratorError(\n 'error while generating SQL source')\n edgedb_error.add_context(err, ctx)\n raise err from e\n\n return ''.join(codegen.result)\n\n\ndef new_external_rvar(\n *,\n rel_name: Tuple[str, ...],\n path_id: irast.PathId,\n outputs: Mapping[Tuple[irast.PathId, Tuple[str, ...]], str],\n) -> pgast.RelRangeVar:\n \"\"\"Construct a ``RangeVar`` instance given a relation name and a path id.\n\n Given an optionally-qualified relation name *rel_name* and a *path_id*,\n return a ``RangeVar`` instance over the specified relation that is\n then assumed to represent the *path_id* binding.\n\n This is useful in situations where it is necessary to \"prime\" the compiler\n with a list of external relations that exist in a larger SQL expression\n that _this_ expression is being embedded into.\n\n The *outputs* mapping optionally specifies a set of outputs in the\n resulting range var as a ``(path_id, tuple-of-aspects): attribute name``\n mapping.\n \"\"\"\n rel = new_external_rel(rel_name=rel_name, path_id=path_id)\n assert rel.name\n\n alias = pgast.Alias(aliasname=rel.name)\n\n if not path_id.is_ptr_path():\n rvar = pgast.RelRangeVar(\n relation=rel, typeref=path_id.target, alias=alias)\n else:\n rvar = pgast.RelRangeVar(\n relation=rel, alias=alias)\n\n for (output_pid, output_aspects), colname in outputs.items():\n var = pgast.ColumnRef(name=[colname])\n for aspect in output_aspects:\n rel.path_outputs[output_pid, aspect] = var\n\n return rvar\n\n\ndef new_external_rel(\n *,\n rel_name: Tuple[str, ...],\n path_id: irast.PathId,\n) -> pgast.Relation:\n if len(rel_name) == 1:\n table_name = rel_name[0]\n schema_name = None\n elif len(rel_name) == 2:\n schema_name, table_name = rel_name\n else:\n raise AssertionError(f'unexpected rvar name: {rel_name}')\n\n return pgast.Relation(\n name=table_name,\n schemaname=schema_name,\n path_id=path_id,\n )\n", "path": "edb/pgsql/compiler/__init__.py"}]}
| 4,094 | 177 |
gh_patches_debug_38741
|
rasdani/github-patches
|
git_diff
|
encode__httpx-682
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cannot connect to yahoo.com, receiving a ProtocolError on Stream 0 after connection
Couple of issues here: we're not raising an exception after receiving a `ProtocolError` from HTTP/2 when connecting to `yahoo.com`. We should be bubbling that exception up to users.
The second issue is is we don't know why yahoo is giving us this error, we have to figure that out as I'm sure it'll impact more than just them.
I found this by running interop tests against Alexa 1000 websites.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `httpx/dispatch/http2.py`
Content:
```
1 import typing
2
3 import h2.connection
4 import h2.events
5 from h2.config import H2Configuration
6 from h2.settings import SettingCodes, Settings
7
8 from ..backends.base import (
9 BaseEvent,
10 BaseSocketStream,
11 ConcurrencyBackend,
12 lookup_backend,
13 )
14 from ..config import Timeout
15 from ..content_streams import AsyncIteratorStream
16 from ..exceptions import ProtocolError
17 from ..models import Request, Response
18 from ..utils import get_logger
19 from .base import OpenConnection
20
21 logger = get_logger(__name__)
22
23
24 class HTTP2Connection(OpenConnection):
25 READ_NUM_BYTES = 4096
26 CONFIG = H2Configuration(validate_inbound_headers=False)
27
28 def __init__(
29 self,
30 socket: BaseSocketStream,
31 backend: typing.Union[str, ConcurrencyBackend] = "auto",
32 on_release: typing.Callable = None,
33 ):
34 self.socket = socket
35 self.backend = lookup_backend(backend)
36 self.on_release = on_release
37 self.state = h2.connection.H2Connection(config=self.CONFIG)
38
39 self.streams = {} # type: typing.Dict[int, HTTP2Stream]
40 self.events = {} # type: typing.Dict[int, typing.List[h2.events.Event]]
41
42 self.init_started = False
43
44 @property
45 def is_http2(self) -> bool:
46 return True
47
48 @property
49 def init_complete(self) -> BaseEvent:
50 # We do this lazily, to make sure backend autodetection always
51 # runs within an async context.
52 if not hasattr(self, "_initialization_complete"):
53 self._initialization_complete = self.backend.create_event()
54 return self._initialization_complete
55
56 async def send(self, request: Request, timeout: Timeout = None) -> Response:
57 timeout = Timeout() if timeout is None else timeout
58
59 if not self.init_started:
60 # The very first stream is responsible for initiating the connection.
61 self.init_started = True
62 await self.send_connection_init(timeout)
63 stream_id = self.state.get_next_available_stream_id()
64 self.init_complete.set()
65 else:
66 # All other streams need to wait until the connection is established.
67 await self.init_complete.wait()
68 stream_id = self.state.get_next_available_stream_id()
69
70 stream = HTTP2Stream(stream_id=stream_id, connection=self)
71 self.streams[stream_id] = stream
72 self.events[stream_id] = []
73 return await stream.send(request, timeout)
74
75 async def send_connection_init(self, timeout: Timeout) -> None:
76 """
77 The HTTP/2 connection requires some initial setup before we can start
78 using individual request/response streams on it.
79 """
80
81 # Need to set these manually here instead of manipulating via
82 # __setitem__() otherwise the H2Connection will emit SettingsUpdate
83 # frames in addition to sending the undesired defaults.
84 self.state.local_settings = Settings(
85 client=True,
86 initial_values={
87 # Disable PUSH_PROMISE frames from the server since we don't do anything
88 # with them for now. Maybe when we support caching?
89 SettingCodes.ENABLE_PUSH: 0,
90 # These two are taken from h2 for safe defaults
91 SettingCodes.MAX_CONCURRENT_STREAMS: 100,
92 SettingCodes.MAX_HEADER_LIST_SIZE: 65536,
93 },
94 )
95
96 # Some websites (*cough* Yahoo *cough*) balk at this setting being
97 # present in the initial handshake since it's not defined in the original
98 # RFC despite the RFC mandating ignoring settings you don't know about.
99 del self.state.local_settings[h2.settings.SettingCodes.ENABLE_CONNECT_PROTOCOL]
100
101 self.state.initiate_connection()
102 self.state.increment_flow_control_window(2 ** 24)
103 data_to_send = self.state.data_to_send()
104 await self.socket.write(data_to_send, timeout)
105
106 @property
107 def is_closed(self) -> bool:
108 return False
109
110 def is_connection_dropped(self) -> bool:
111 return self.socket.is_connection_dropped()
112
113 async def close(self) -> None:
114 await self.socket.close()
115
116 async def wait_for_outgoing_flow(self, stream_id: int, timeout: Timeout) -> int:
117 """
118 Returns the maximum allowable outgoing flow for a given stream.
119
120 If the allowable flow is zero, then waits on the network until
121 WindowUpdated frames have increased the flow rate.
122
123 https://tools.ietf.org/html/rfc7540#section-6.9
124 """
125 local_flow = self.state.local_flow_control_window(stream_id)
126 connection_flow = self.state.max_outbound_frame_size
127 flow = min(local_flow, connection_flow)
128 while flow == 0:
129 await self.receive_events(timeout)
130 local_flow = self.state.local_flow_control_window(stream_id)
131 connection_flow = self.state.max_outbound_frame_size
132 flow = min(local_flow, connection_flow)
133 return flow
134
135 async def wait_for_event(self, stream_id: int, timeout: Timeout) -> h2.events.Event:
136 """
137 Returns the next event for a given stream.
138
139 If no events are available yet, then waits on the network until
140 an event is available.
141 """
142 while not self.events[stream_id]:
143 await self.receive_events(timeout)
144 return self.events[stream_id].pop(0)
145
146 async def receive_events(self, timeout: Timeout) -> None:
147 """
148 Read some data from the network, and update the H2 state.
149 """
150 data = await self.socket.read(self.READ_NUM_BYTES, timeout)
151 events = self.state.receive_data(data)
152 for event in events:
153 event_stream_id = getattr(event, "stream_id", 0)
154 logger.trace(f"receive_event stream_id={event_stream_id} event={event!r}")
155
156 if hasattr(event, "error_code"):
157 raise ProtocolError(event)
158
159 if event_stream_id in self.events:
160 self.events[event_stream_id].append(event)
161
162 data_to_send = self.state.data_to_send()
163 await self.socket.write(data_to_send, timeout)
164
165 async def send_headers(
166 self,
167 stream_id: int,
168 headers: typing.List[typing.Tuple[bytes, bytes]],
169 timeout: Timeout,
170 ) -> None:
171 self.state.send_headers(stream_id, headers)
172 self.state.increment_flow_control_window(2 ** 24, stream_id=stream_id)
173 data_to_send = self.state.data_to_send()
174 await self.socket.write(data_to_send, timeout)
175
176 async def send_data(self, stream_id: int, chunk: bytes, timeout: Timeout) -> None:
177 self.state.send_data(stream_id, chunk)
178 data_to_send = self.state.data_to_send()
179 await self.socket.write(data_to_send, timeout)
180
181 async def end_stream(self, stream_id: int, timeout: Timeout) -> None:
182 self.state.end_stream(stream_id)
183 data_to_send = self.state.data_to_send()
184 await self.socket.write(data_to_send, timeout)
185
186 async def acknowledge_received_data(
187 self, stream_id: int, amount: int, timeout: Timeout
188 ) -> None:
189 self.state.acknowledge_received_data(amount, stream_id)
190 data_to_send = self.state.data_to_send()
191 await self.socket.write(data_to_send, timeout)
192
193 async def close_stream(self, stream_id: int) -> None:
194 del self.streams[stream_id]
195 del self.events[stream_id]
196
197 if not self.streams and self.on_release is not None:
198 await self.on_release()
199
200
201 class HTTP2Stream:
202 def __init__(self, stream_id: int, connection: HTTP2Connection) -> None:
203 self.stream_id = stream_id
204 self.connection = connection
205
206 async def send(self, request: Request, timeout: Timeout) -> Response:
207 # Send the request.
208 await self.send_headers(request, timeout)
209 await self.send_body(request, timeout)
210
211 # Receive the response.
212 status_code, headers = await self.receive_response(timeout)
213 stream = AsyncIteratorStream(
214 aiterator=self.body_iter(timeout), close_func=self.close
215 )
216
217 return Response(
218 status_code=status_code,
219 http_version="HTTP/2",
220 headers=headers,
221 stream=stream,
222 request=request,
223 )
224
225 async def send_headers(self, request: Request, timeout: Timeout) -> None:
226 headers = [
227 (b":method", request.method.encode("ascii")),
228 (b":authority", request.url.authority.encode("ascii")),
229 (b":scheme", request.url.scheme.encode("ascii")),
230 (b":path", request.url.full_path.encode("ascii")),
231 ] + [(k, v) for k, v in request.headers.raw if k != b"host"]
232
233 logger.trace(
234 f"send_headers "
235 f"stream_id={self.stream_id} "
236 f"method={request.method!r} "
237 f"target={request.url.full_path!r} "
238 f"headers={headers!r}"
239 )
240 await self.connection.send_headers(self.stream_id, headers, timeout)
241
242 async def send_body(self, request: Request, timeout: Timeout) -> None:
243 logger.trace(f"send_body stream_id={self.stream_id}")
244 async for data in request.stream:
245 while data:
246 max_flow = await self.connection.wait_for_outgoing_flow(
247 self.stream_id, timeout
248 )
249 chunk_size = min(len(data), max_flow)
250 chunk, data = data[:chunk_size], data[chunk_size:]
251 await self.connection.send_data(self.stream_id, chunk, timeout)
252
253 await self.connection.end_stream(self.stream_id, timeout)
254
255 async def receive_response(
256 self, timeout: Timeout
257 ) -> typing.Tuple[int, typing.List[typing.Tuple[bytes, bytes]]]:
258 """
259 Read the response status and headers from the network.
260 """
261 while True:
262 event = await self.connection.wait_for_event(self.stream_id, timeout)
263 if isinstance(event, h2.events.ResponseReceived):
264 break
265
266 status_code = 200
267 headers = []
268 for k, v in event.headers:
269 if k == b":status":
270 status_code = int(v.decode("ascii", errors="ignore"))
271 elif not k.startswith(b":"):
272 headers.append((k, v))
273
274 return (status_code, headers)
275
276 async def body_iter(self, timeout: Timeout) -> typing.AsyncIterator[bytes]:
277 while True:
278 event = await self.connection.wait_for_event(self.stream_id, timeout)
279 if isinstance(event, h2.events.DataReceived):
280 amount = event.flow_controlled_length
281 await self.connection.acknowledge_received_data(
282 self.stream_id, amount, timeout
283 )
284 yield event.data
285 elif isinstance(event, (h2.events.StreamEnded, h2.events.StreamReset)):
286 break
287
288 async def close(self) -> None:
289 await self.connection.close_stream(self.stream_id)
290
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/httpx/dispatch/http2.py b/httpx/dispatch/http2.py
--- a/httpx/dispatch/http2.py
+++ b/httpx/dispatch/http2.py
@@ -166,9 +166,10 @@
self,
stream_id: int,
headers: typing.List[typing.Tuple[bytes, bytes]],
+ end_stream: bool,
timeout: Timeout,
) -> None:
- self.state.send_headers(stream_id, headers)
+ self.state.send_headers(stream_id, headers, end_stream=end_stream)
self.state.increment_flow_control_window(2 ** 24, stream_id=stream_id)
data_to_send = self.state.data_to_send()
await self.socket.write(data_to_send, timeout)
@@ -205,8 +206,14 @@
async def send(self, request: Request, timeout: Timeout) -> Response:
# Send the request.
- await self.send_headers(request, timeout)
- await self.send_body(request, timeout)
+ has_body = (
+ "Content-Length" in request.headers
+ or "Transfer-Encoding" in request.headers
+ )
+
+ await self.send_headers(request, has_body, timeout)
+ if has_body:
+ await self.send_body(request, timeout)
# Receive the response.
status_code, headers = await self.receive_response(timeout)
@@ -222,13 +229,20 @@
request=request,
)
- async def send_headers(self, request: Request, timeout: Timeout) -> None:
+ async def send_headers(
+ self, request: Request, has_body: bool, timeout: Timeout
+ ) -> None:
headers = [
(b":method", request.method.encode("ascii")),
(b":authority", request.url.authority.encode("ascii")),
(b":scheme", request.url.scheme.encode("ascii")),
(b":path", request.url.full_path.encode("ascii")),
- ] + [(k, v) for k, v in request.headers.raw if k != b"host"]
+ ] + [
+ (k, v)
+ for k, v in request.headers.raw
+ if k not in (b"host", b"transfer-encoding")
+ ]
+ end_stream = not has_body
logger.trace(
f"send_headers "
@@ -237,7 +251,7 @@
f"target={request.url.full_path!r} "
f"headers={headers!r}"
)
- await self.connection.send_headers(self.stream_id, headers, timeout)
+ await self.connection.send_headers(self.stream_id, headers, end_stream, timeout)
async def send_body(self, request: Request, timeout: Timeout) -> None:
logger.trace(f"send_body stream_id={self.stream_id}")
|
{"golden_diff": "diff --git a/httpx/dispatch/http2.py b/httpx/dispatch/http2.py\n--- a/httpx/dispatch/http2.py\n+++ b/httpx/dispatch/http2.py\n@@ -166,9 +166,10 @@\n self,\n stream_id: int,\n headers: typing.List[typing.Tuple[bytes, bytes]],\n+ end_stream: bool,\n timeout: Timeout,\n ) -> None:\n- self.state.send_headers(stream_id, headers)\n+ self.state.send_headers(stream_id, headers, end_stream=end_stream)\n self.state.increment_flow_control_window(2 ** 24, stream_id=stream_id)\n data_to_send = self.state.data_to_send()\n await self.socket.write(data_to_send, timeout)\n@@ -205,8 +206,14 @@\n \n async def send(self, request: Request, timeout: Timeout) -> Response:\n # Send the request.\n- await self.send_headers(request, timeout)\n- await self.send_body(request, timeout)\n+ has_body = (\n+ \"Content-Length\" in request.headers\n+ or \"Transfer-Encoding\" in request.headers\n+ )\n+\n+ await self.send_headers(request, has_body, timeout)\n+ if has_body:\n+ await self.send_body(request, timeout)\n \n # Receive the response.\n status_code, headers = await self.receive_response(timeout)\n@@ -222,13 +229,20 @@\n request=request,\n )\n \n- async def send_headers(self, request: Request, timeout: Timeout) -> None:\n+ async def send_headers(\n+ self, request: Request, has_body: bool, timeout: Timeout\n+ ) -> None:\n headers = [\n (b\":method\", request.method.encode(\"ascii\")),\n (b\":authority\", request.url.authority.encode(\"ascii\")),\n (b\":scheme\", request.url.scheme.encode(\"ascii\")),\n (b\":path\", request.url.full_path.encode(\"ascii\")),\n- ] + [(k, v) for k, v in request.headers.raw if k != b\"host\"]\n+ ] + [\n+ (k, v)\n+ for k, v in request.headers.raw\n+ if k not in (b\"host\", b\"transfer-encoding\")\n+ ]\n+ end_stream = not has_body\n \n logger.trace(\n f\"send_headers \"\n@@ -237,7 +251,7 @@\n f\"target={request.url.full_path!r} \"\n f\"headers={headers!r}\"\n )\n- await self.connection.send_headers(self.stream_id, headers, timeout)\n+ await self.connection.send_headers(self.stream_id, headers, end_stream, timeout)\n \n async def send_body(self, request: Request, timeout: Timeout) -> None:\n logger.trace(f\"send_body stream_id={self.stream_id}\")\n", "issue": "Cannot connect to yahoo.com, receiving a ProtocolError on Stream 0 after connection\nCouple of issues here: we're not raising an exception after receiving a `ProtocolError` from HTTP/2 when connecting to `yahoo.com`. We should be bubbling that exception up to users.\r\n\r\nThe second issue is is we don't know why yahoo is giving us this error, we have to figure that out as I'm sure it'll impact more than just them.\r\n\r\nI found this by running interop tests against Alexa 1000 websites.\n", "before_files": [{"content": "import typing\n\nimport h2.connection\nimport h2.events\nfrom h2.config import H2Configuration\nfrom h2.settings import SettingCodes, Settings\n\nfrom ..backends.base import (\n BaseEvent,\n BaseSocketStream,\n ConcurrencyBackend,\n lookup_backend,\n)\nfrom ..config import Timeout\nfrom ..content_streams import AsyncIteratorStream\nfrom ..exceptions import ProtocolError\nfrom ..models import Request, Response\nfrom ..utils import get_logger\nfrom .base import OpenConnection\n\nlogger = get_logger(__name__)\n\n\nclass HTTP2Connection(OpenConnection):\n READ_NUM_BYTES = 4096\n CONFIG = H2Configuration(validate_inbound_headers=False)\n\n def __init__(\n self,\n socket: BaseSocketStream,\n backend: typing.Union[str, ConcurrencyBackend] = \"auto\",\n on_release: typing.Callable = None,\n ):\n self.socket = socket\n self.backend = lookup_backend(backend)\n self.on_release = on_release\n self.state = h2.connection.H2Connection(config=self.CONFIG)\n\n self.streams = {} # type: typing.Dict[int, HTTP2Stream]\n self.events = {} # type: typing.Dict[int, typing.List[h2.events.Event]]\n\n self.init_started = False\n\n @property\n def is_http2(self) -> bool:\n return True\n\n @property\n def init_complete(self) -> BaseEvent:\n # We do this lazily, to make sure backend autodetection always\n # runs within an async context.\n if not hasattr(self, \"_initialization_complete\"):\n self._initialization_complete = self.backend.create_event()\n return self._initialization_complete\n\n async def send(self, request: Request, timeout: Timeout = None) -> Response:\n timeout = Timeout() if timeout is None else timeout\n\n if not self.init_started:\n # The very first stream is responsible for initiating the connection.\n self.init_started = True\n await self.send_connection_init(timeout)\n stream_id = self.state.get_next_available_stream_id()\n self.init_complete.set()\n else:\n # All other streams need to wait until the connection is established.\n await self.init_complete.wait()\n stream_id = self.state.get_next_available_stream_id()\n\n stream = HTTP2Stream(stream_id=stream_id, connection=self)\n self.streams[stream_id] = stream\n self.events[stream_id] = []\n return await stream.send(request, timeout)\n\n async def send_connection_init(self, timeout: Timeout) -> None:\n \"\"\"\n The HTTP/2 connection requires some initial setup before we can start\n using individual request/response streams on it.\n \"\"\"\n\n # Need to set these manually here instead of manipulating via\n # __setitem__() otherwise the H2Connection will emit SettingsUpdate\n # frames in addition to sending the undesired defaults.\n self.state.local_settings = Settings(\n client=True,\n initial_values={\n # Disable PUSH_PROMISE frames from the server since we don't do anything\n # with them for now. Maybe when we support caching?\n SettingCodes.ENABLE_PUSH: 0,\n # These two are taken from h2 for safe defaults\n SettingCodes.MAX_CONCURRENT_STREAMS: 100,\n SettingCodes.MAX_HEADER_LIST_SIZE: 65536,\n },\n )\n\n # Some websites (*cough* Yahoo *cough*) balk at this setting being\n # present in the initial handshake since it's not defined in the original\n # RFC despite the RFC mandating ignoring settings you don't know about.\n del self.state.local_settings[h2.settings.SettingCodes.ENABLE_CONNECT_PROTOCOL]\n\n self.state.initiate_connection()\n self.state.increment_flow_control_window(2 ** 24)\n data_to_send = self.state.data_to_send()\n await self.socket.write(data_to_send, timeout)\n\n @property\n def is_closed(self) -> bool:\n return False\n\n def is_connection_dropped(self) -> bool:\n return self.socket.is_connection_dropped()\n\n async def close(self) -> None:\n await self.socket.close()\n\n async def wait_for_outgoing_flow(self, stream_id: int, timeout: Timeout) -> int:\n \"\"\"\n Returns the maximum allowable outgoing flow for a given stream.\n\n If the allowable flow is zero, then waits on the network until\n WindowUpdated frames have increased the flow rate.\n\n https://tools.ietf.org/html/rfc7540#section-6.9\n \"\"\"\n local_flow = self.state.local_flow_control_window(stream_id)\n connection_flow = self.state.max_outbound_frame_size\n flow = min(local_flow, connection_flow)\n while flow == 0:\n await self.receive_events(timeout)\n local_flow = self.state.local_flow_control_window(stream_id)\n connection_flow = self.state.max_outbound_frame_size\n flow = min(local_flow, connection_flow)\n return flow\n\n async def wait_for_event(self, stream_id: int, timeout: Timeout) -> h2.events.Event:\n \"\"\"\n Returns the next event for a given stream.\n\n If no events are available yet, then waits on the network until\n an event is available.\n \"\"\"\n while not self.events[stream_id]:\n await self.receive_events(timeout)\n return self.events[stream_id].pop(0)\n\n async def receive_events(self, timeout: Timeout) -> None:\n \"\"\"\n Read some data from the network, and update the H2 state.\n \"\"\"\n data = await self.socket.read(self.READ_NUM_BYTES, timeout)\n events = self.state.receive_data(data)\n for event in events:\n event_stream_id = getattr(event, \"stream_id\", 0)\n logger.trace(f\"receive_event stream_id={event_stream_id} event={event!r}\")\n\n if hasattr(event, \"error_code\"):\n raise ProtocolError(event)\n\n if event_stream_id in self.events:\n self.events[event_stream_id].append(event)\n\n data_to_send = self.state.data_to_send()\n await self.socket.write(data_to_send, timeout)\n\n async def send_headers(\n self,\n stream_id: int,\n headers: typing.List[typing.Tuple[bytes, bytes]],\n timeout: Timeout,\n ) -> None:\n self.state.send_headers(stream_id, headers)\n self.state.increment_flow_control_window(2 ** 24, stream_id=stream_id)\n data_to_send = self.state.data_to_send()\n await self.socket.write(data_to_send, timeout)\n\n async def send_data(self, stream_id: int, chunk: bytes, timeout: Timeout) -> None:\n self.state.send_data(stream_id, chunk)\n data_to_send = self.state.data_to_send()\n await self.socket.write(data_to_send, timeout)\n\n async def end_stream(self, stream_id: int, timeout: Timeout) -> None:\n self.state.end_stream(stream_id)\n data_to_send = self.state.data_to_send()\n await self.socket.write(data_to_send, timeout)\n\n async def acknowledge_received_data(\n self, stream_id: int, amount: int, timeout: Timeout\n ) -> None:\n self.state.acknowledge_received_data(amount, stream_id)\n data_to_send = self.state.data_to_send()\n await self.socket.write(data_to_send, timeout)\n\n async def close_stream(self, stream_id: int) -> None:\n del self.streams[stream_id]\n del self.events[stream_id]\n\n if not self.streams and self.on_release is not None:\n await self.on_release()\n\n\nclass HTTP2Stream:\n def __init__(self, stream_id: int, connection: HTTP2Connection) -> None:\n self.stream_id = stream_id\n self.connection = connection\n\n async def send(self, request: Request, timeout: Timeout) -> Response:\n # Send the request.\n await self.send_headers(request, timeout)\n await self.send_body(request, timeout)\n\n # Receive the response.\n status_code, headers = await self.receive_response(timeout)\n stream = AsyncIteratorStream(\n aiterator=self.body_iter(timeout), close_func=self.close\n )\n\n return Response(\n status_code=status_code,\n http_version=\"HTTP/2\",\n headers=headers,\n stream=stream,\n request=request,\n )\n\n async def send_headers(self, request: Request, timeout: Timeout) -> None:\n headers = [\n (b\":method\", request.method.encode(\"ascii\")),\n (b\":authority\", request.url.authority.encode(\"ascii\")),\n (b\":scheme\", request.url.scheme.encode(\"ascii\")),\n (b\":path\", request.url.full_path.encode(\"ascii\")),\n ] + [(k, v) for k, v in request.headers.raw if k != b\"host\"]\n\n logger.trace(\n f\"send_headers \"\n f\"stream_id={self.stream_id} \"\n f\"method={request.method!r} \"\n f\"target={request.url.full_path!r} \"\n f\"headers={headers!r}\"\n )\n await self.connection.send_headers(self.stream_id, headers, timeout)\n\n async def send_body(self, request: Request, timeout: Timeout) -> None:\n logger.trace(f\"send_body stream_id={self.stream_id}\")\n async for data in request.stream:\n while data:\n max_flow = await self.connection.wait_for_outgoing_flow(\n self.stream_id, timeout\n )\n chunk_size = min(len(data), max_flow)\n chunk, data = data[:chunk_size], data[chunk_size:]\n await self.connection.send_data(self.stream_id, chunk, timeout)\n\n await self.connection.end_stream(self.stream_id, timeout)\n\n async def receive_response(\n self, timeout: Timeout\n ) -> typing.Tuple[int, typing.List[typing.Tuple[bytes, bytes]]]:\n \"\"\"\n Read the response status and headers from the network.\n \"\"\"\n while True:\n event = await self.connection.wait_for_event(self.stream_id, timeout)\n if isinstance(event, h2.events.ResponseReceived):\n break\n\n status_code = 200\n headers = []\n for k, v in event.headers:\n if k == b\":status\":\n status_code = int(v.decode(\"ascii\", errors=\"ignore\"))\n elif not k.startswith(b\":\"):\n headers.append((k, v))\n\n return (status_code, headers)\n\n async def body_iter(self, timeout: Timeout) -> typing.AsyncIterator[bytes]:\n while True:\n event = await self.connection.wait_for_event(self.stream_id, timeout)\n if isinstance(event, h2.events.DataReceived):\n amount = event.flow_controlled_length\n await self.connection.acknowledge_received_data(\n self.stream_id, amount, timeout\n )\n yield event.data\n elif isinstance(event, (h2.events.StreamEnded, h2.events.StreamReset)):\n break\n\n async def close(self) -> None:\n await self.connection.close_stream(self.stream_id)\n", "path": "httpx/dispatch/http2.py"}], "after_files": [{"content": "import typing\n\nimport h2.connection\nimport h2.events\nfrom h2.config import H2Configuration\nfrom h2.settings import SettingCodes, Settings\n\nfrom ..backends.base import (\n BaseEvent,\n BaseSocketStream,\n ConcurrencyBackend,\n lookup_backend,\n)\nfrom ..config import Timeout\nfrom ..content_streams import AsyncIteratorStream\nfrom ..exceptions import ProtocolError\nfrom ..models import Request, Response\nfrom ..utils import get_logger\nfrom .base import OpenConnection\n\nlogger = get_logger(__name__)\n\n\nclass HTTP2Connection(OpenConnection):\n READ_NUM_BYTES = 4096\n CONFIG = H2Configuration(validate_inbound_headers=False)\n\n def __init__(\n self,\n socket: BaseSocketStream,\n backend: typing.Union[str, ConcurrencyBackend] = \"auto\",\n on_release: typing.Callable = None,\n ):\n self.socket = socket\n self.backend = lookup_backend(backend)\n self.on_release = on_release\n self.state = h2.connection.H2Connection(config=self.CONFIG)\n\n self.streams = {} # type: typing.Dict[int, HTTP2Stream]\n self.events = {} # type: typing.Dict[int, typing.List[h2.events.Event]]\n\n self.init_started = False\n\n @property\n def is_http2(self) -> bool:\n return True\n\n @property\n def init_complete(self) -> BaseEvent:\n # We do this lazily, to make sure backend autodetection always\n # runs within an async context.\n if not hasattr(self, \"_initialization_complete\"):\n self._initialization_complete = self.backend.create_event()\n return self._initialization_complete\n\n async def send(self, request: Request, timeout: Timeout = None) -> Response:\n timeout = Timeout() if timeout is None else timeout\n\n if not self.init_started:\n # The very first stream is responsible for initiating the connection.\n self.init_started = True\n await self.send_connection_init(timeout)\n stream_id = self.state.get_next_available_stream_id()\n self.init_complete.set()\n else:\n # All other streams need to wait until the connection is established.\n await self.init_complete.wait()\n stream_id = self.state.get_next_available_stream_id()\n\n stream = HTTP2Stream(stream_id=stream_id, connection=self)\n self.streams[stream_id] = stream\n self.events[stream_id] = []\n return await stream.send(request, timeout)\n\n async def send_connection_init(self, timeout: Timeout) -> None:\n \"\"\"\n The HTTP/2 connection requires some initial setup before we can start\n using individual request/response streams on it.\n \"\"\"\n\n # Need to set these manually here instead of manipulating via\n # __setitem__() otherwise the H2Connection will emit SettingsUpdate\n # frames in addition to sending the undesired defaults.\n self.state.local_settings = Settings(\n client=True,\n initial_values={\n # Disable PUSH_PROMISE frames from the server since we don't do anything\n # with them for now. Maybe when we support caching?\n SettingCodes.ENABLE_PUSH: 0,\n # These two are taken from h2 for safe defaults\n SettingCodes.MAX_CONCURRENT_STREAMS: 100,\n SettingCodes.MAX_HEADER_LIST_SIZE: 65536,\n },\n )\n\n # Some websites (*cough* Yahoo *cough*) balk at this setting being\n # present in the initial handshake since it's not defined in the original\n # RFC despite the RFC mandating ignoring settings you don't know about.\n del self.state.local_settings[h2.settings.SettingCodes.ENABLE_CONNECT_PROTOCOL]\n\n self.state.initiate_connection()\n self.state.increment_flow_control_window(2 ** 24)\n data_to_send = self.state.data_to_send()\n await self.socket.write(data_to_send, timeout)\n\n @property\n def is_closed(self) -> bool:\n return False\n\n def is_connection_dropped(self) -> bool:\n return self.socket.is_connection_dropped()\n\n async def close(self) -> None:\n await self.socket.close()\n\n async def wait_for_outgoing_flow(self, stream_id: int, timeout: Timeout) -> int:\n \"\"\"\n Returns the maximum allowable outgoing flow for a given stream.\n\n If the allowable flow is zero, then waits on the network until\n WindowUpdated frames have increased the flow rate.\n\n https://tools.ietf.org/html/rfc7540#section-6.9\n \"\"\"\n local_flow = self.state.local_flow_control_window(stream_id)\n connection_flow = self.state.max_outbound_frame_size\n flow = min(local_flow, connection_flow)\n while flow == 0:\n await self.receive_events(timeout)\n local_flow = self.state.local_flow_control_window(stream_id)\n connection_flow = self.state.max_outbound_frame_size\n flow = min(local_flow, connection_flow)\n return flow\n\n async def wait_for_event(self, stream_id: int, timeout: Timeout) -> h2.events.Event:\n \"\"\"\n Returns the next event for a given stream.\n\n If no events are available yet, then waits on the network until\n an event is available.\n \"\"\"\n while not self.events[stream_id]:\n await self.receive_events(timeout)\n return self.events[stream_id].pop(0)\n\n async def receive_events(self, timeout: Timeout) -> None:\n \"\"\"\n Read some data from the network, and update the H2 state.\n \"\"\"\n data = await self.socket.read(self.READ_NUM_BYTES, timeout)\n events = self.state.receive_data(data)\n for event in events:\n event_stream_id = getattr(event, \"stream_id\", 0)\n logger.trace(f\"receive_event stream_id={event_stream_id} event={event!r}\")\n\n if hasattr(event, \"error_code\"):\n raise ProtocolError(event)\n\n if event_stream_id in self.events:\n self.events[event_stream_id].append(event)\n\n data_to_send = self.state.data_to_send()\n await self.socket.write(data_to_send, timeout)\n\n async def send_headers(\n self,\n stream_id: int,\n headers: typing.List[typing.Tuple[bytes, bytes]],\n end_stream: bool,\n timeout: Timeout,\n ) -> None:\n self.state.send_headers(stream_id, headers, end_stream=end_stream)\n self.state.increment_flow_control_window(2 ** 24, stream_id=stream_id)\n data_to_send = self.state.data_to_send()\n await self.socket.write(data_to_send, timeout)\n\n async def send_data(self, stream_id: int, chunk: bytes, timeout: Timeout) -> None:\n self.state.send_data(stream_id, chunk)\n data_to_send = self.state.data_to_send()\n await self.socket.write(data_to_send, timeout)\n\n async def end_stream(self, stream_id: int, timeout: Timeout) -> None:\n self.state.end_stream(stream_id)\n data_to_send = self.state.data_to_send()\n await self.socket.write(data_to_send, timeout)\n\n async def acknowledge_received_data(\n self, stream_id: int, amount: int, timeout: Timeout\n ) -> None:\n self.state.acknowledge_received_data(amount, stream_id)\n data_to_send = self.state.data_to_send()\n await self.socket.write(data_to_send, timeout)\n\n async def close_stream(self, stream_id: int) -> None:\n del self.streams[stream_id]\n del self.events[stream_id]\n\n if not self.streams and self.on_release is not None:\n await self.on_release()\n\n\nclass HTTP2Stream:\n def __init__(self, stream_id: int, connection: HTTP2Connection) -> None:\n self.stream_id = stream_id\n self.connection = connection\n\n async def send(self, request: Request, timeout: Timeout) -> Response:\n # Send the request.\n has_body = (\n \"Content-Length\" in request.headers\n or \"Transfer-Encoding\" in request.headers\n )\n\n await self.send_headers(request, has_body, timeout)\n if has_body:\n await self.send_body(request, timeout)\n\n # Receive the response.\n status_code, headers = await self.receive_response(timeout)\n stream = AsyncIteratorStream(\n aiterator=self.body_iter(timeout), close_func=self.close\n )\n\n return Response(\n status_code=status_code,\n http_version=\"HTTP/2\",\n headers=headers,\n stream=stream,\n request=request,\n )\n\n async def send_headers(\n self, request: Request, has_body: bool, timeout: Timeout\n ) -> None:\n headers = [\n (b\":method\", request.method.encode(\"ascii\")),\n (b\":authority\", request.url.authority.encode(\"ascii\")),\n (b\":scheme\", request.url.scheme.encode(\"ascii\")),\n (b\":path\", request.url.full_path.encode(\"ascii\")),\n ] + [\n (k, v)\n for k, v in request.headers.raw\n if k not in (b\"host\", b\"transfer-encoding\")\n ]\n end_stream = not has_body\n\n logger.trace(\n f\"send_headers \"\n f\"stream_id={self.stream_id} \"\n f\"method={request.method!r} \"\n f\"target={request.url.full_path!r} \"\n f\"headers={headers!r}\"\n )\n await self.connection.send_headers(self.stream_id, headers, end_stream, timeout)\n\n async def send_body(self, request: Request, timeout: Timeout) -> None:\n logger.trace(f\"send_body stream_id={self.stream_id}\")\n async for data in request.stream:\n while data:\n max_flow = await self.connection.wait_for_outgoing_flow(\n self.stream_id, timeout\n )\n chunk_size = min(len(data), max_flow)\n chunk, data = data[:chunk_size], data[chunk_size:]\n await self.connection.send_data(self.stream_id, chunk, timeout)\n\n await self.connection.end_stream(self.stream_id, timeout)\n\n async def receive_response(\n self, timeout: Timeout\n ) -> typing.Tuple[int, typing.List[typing.Tuple[bytes, bytes]]]:\n \"\"\"\n Read the response status and headers from the network.\n \"\"\"\n while True:\n event = await self.connection.wait_for_event(self.stream_id, timeout)\n if isinstance(event, h2.events.ResponseReceived):\n break\n\n status_code = 200\n headers = []\n for k, v in event.headers:\n if k == b\":status\":\n status_code = int(v.decode(\"ascii\", errors=\"ignore\"))\n elif not k.startswith(b\":\"):\n headers.append((k, v))\n\n return (status_code, headers)\n\n async def body_iter(self, timeout: Timeout) -> typing.AsyncIterator[bytes]:\n while True:\n event = await self.connection.wait_for_event(self.stream_id, timeout)\n if isinstance(event, h2.events.DataReceived):\n amount = event.flow_controlled_length\n await self.connection.acknowledge_received_data(\n self.stream_id, amount, timeout\n )\n yield event.data\n elif isinstance(event, (h2.events.StreamEnded, h2.events.StreamReset)):\n break\n\n async def close(self) -> None:\n await self.connection.close_stream(self.stream_id)\n", "path": "httpx/dispatch/http2.py"}]}
| 3,481 | 621 |
gh_patches_debug_2519
|
rasdani/github-patches
|
git_diff
|
Cog-Creators__Red-DiscordBot-1632
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[V3 Streams] issue with `[p]streamset`
# Command bugs
<!--
Did you find a bug with a command? Fill out the following:
-->
#### Command name
`streamset`
#### What cog is this command from?
`Streams`
#### What were you expecting to happen?
Should output help
#### What actually happened?
```py
Exception in command 'streamset'
Traceback (most recent call last):
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/discord/ext/commands/core.py", line 62, in wrapped
ret = yield from coro(*args, **kwargs)
File "/home/palm/.pyenv/versions/3.6.5/envs/redbot/lib/python3.6/site-packages/redbot/cogs/streams/streams.py", line 283, in streamset
await ctx.send_help()
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/commands/context.py", line 33, in send_help
embeds = await self.bot.formatter.format_help_for(self, command)
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/help_formatter.py", line 233, in format_help_for
emb = await self.format()
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/help_formatter.py", line 156, in format
if self.command.help:
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/commands/commands.py", line 41, in help
return inspect.cleandoc(translator(self.callback.__doc__))
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/i18n.py", line 181, in __call__
normalized_untranslated = _normalize(untranslated, True)
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/i18n.py", line 127, in _normalize
string = string.replace('\\n\\n', '\n\n')
AttributeError: 'NoneType' object has no attribute 'replace'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/discord/ext/commands/bot.py", line 886, in invoke
yield from ctx.command.invoke(ctx)
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/discord/ext/commands/core.py", line 923, in invoke
yield from injected(*ctx.args, **ctx.kwargs)
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/discord/ext/commands/core.py", line 71, in wrapped
raise CommandInvokeError(e) from e
discord.ext.commands.errors.CommandInvokeError: Command raised an exception: AttributeError: 'NoneType' object has no attribute 'replace'
```
NOTE: This is an issue occurring on `V3/develop`. I'm in the process of trying to confirm if this is also occurring on the beta 13 release
#### How can we reproduce this issue?
1. Do `[p]streamset`
2. See error
[V3 Streams] issue with `[p]streamset`
# Command bugs
<!--
Did you find a bug with a command? Fill out the following:
-->
#### Command name
`streamset`
#### What cog is this command from?
`Streams`
#### What were you expecting to happen?
Should output help
#### What actually happened?
```py
Exception in command 'streamset'
Traceback (most recent call last):
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/discord/ext/commands/core.py", line 62, in wrapped
ret = yield from coro(*args, **kwargs)
File "/home/palm/.pyenv/versions/3.6.5/envs/redbot/lib/python3.6/site-packages/redbot/cogs/streams/streams.py", line 283, in streamset
await ctx.send_help()
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/commands/context.py", line 33, in send_help
embeds = await self.bot.formatter.format_help_for(self, command)
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/help_formatter.py", line 233, in format_help_for
emb = await self.format()
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/help_formatter.py", line 156, in format
if self.command.help:
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/commands/commands.py", line 41, in help
return inspect.cleandoc(translator(self.callback.__doc__))
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/i18n.py", line 181, in __call__
normalized_untranslated = _normalize(untranslated, True)
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/i18n.py", line 127, in _normalize
string = string.replace('\\n\\n', '\n\n')
AttributeError: 'NoneType' object has no attribute 'replace'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/discord/ext/commands/bot.py", line 886, in invoke
yield from ctx.command.invoke(ctx)
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/discord/ext/commands/core.py", line 923, in invoke
yield from injected(*ctx.args, **ctx.kwargs)
File "/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/discord/ext/commands/core.py", line 71, in wrapped
raise CommandInvokeError(e) from e
discord.ext.commands.errors.CommandInvokeError: Command raised an exception: AttributeError: 'NoneType' object has no attribute 'replace'
```
NOTE: This is an issue occurring on `V3/develop`. I'm in the process of trying to confirm if this is also occurring on the beta 13 release
#### How can we reproduce this issue?
1. Do `[p]streamset`
2. See error
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redbot/core/i18n.py`
Content:
```
1 import re
2 from pathlib import Path
3
4 from . import commands
5
6 __all__ = ['get_locale', 'set_locale', 'reload_locales', 'cog_i18n',
7 'Translator']
8
9 _current_locale = 'en_us'
10
11 WAITING_FOR_MSGID = 1
12 IN_MSGID = 2
13 WAITING_FOR_MSGSTR = 3
14 IN_MSGSTR = 4
15
16 MSGID = 'msgid "'
17 MSGSTR = 'msgstr "'
18
19 _translators = []
20
21
22 def get_locale():
23 return _current_locale
24
25
26 def set_locale(locale):
27 global _current_locale
28 _current_locale = locale
29 reload_locales()
30
31
32 def reload_locales():
33 for translator in _translators:
34 translator.load_translations()
35
36
37 def _parse(translation_file):
38 """
39 Custom gettext parsing of translation files. All credit for this code goes
40 to ProgVal/Valentin Lorentz and the Limnoria project.
41
42 https://github.com/ProgVal/Limnoria/blob/master/src/i18n.py
43
44 :param translation_file:
45 An open file-like object containing translations.
46 :return:
47 A set of 2-tuples containing the original string and the translated version.
48 """
49 step = WAITING_FOR_MSGID
50 translations = set()
51 for line in translation_file:
52 line = line[0:-1] # Remove the ending \n
53 line = line
54
55 if line.startswith(MSGID):
56 # Don't check if step is WAITING_FOR_MSGID
57 untranslated = ''
58 translated = ''
59 data = line[len(MSGID):-1]
60 if len(data) == 0: # Multiline mode
61 step = IN_MSGID
62 else:
63 untranslated += data
64 step = WAITING_FOR_MSGSTR
65
66 elif step is IN_MSGID and line.startswith('"') and \
67 line.endswith('"'):
68 untranslated += line[1:-1]
69 elif step is IN_MSGID and untranslated == '': # Empty MSGID
70 step = WAITING_FOR_MSGID
71 elif step is IN_MSGID: # the MSGID is finished
72 step = WAITING_FOR_MSGSTR
73
74 if step is WAITING_FOR_MSGSTR and line.startswith(MSGSTR):
75 data = line[len(MSGSTR):-1]
76 if len(data) == 0: # Multiline mode
77 step = IN_MSGSTR
78 else:
79 translations |= {(untranslated, data)}
80 step = WAITING_FOR_MSGID
81
82 elif step is IN_MSGSTR and line.startswith('"') and \
83 line.endswith('"'):
84 translated += line[1:-1]
85 elif step is IN_MSGSTR: # the MSGSTR is finished
86 step = WAITING_FOR_MSGID
87 if translated == '':
88 translated = untranslated
89 translations |= {(untranslated, translated)}
90 if step is IN_MSGSTR:
91 if translated == '':
92 translated = untranslated
93 translations |= {(untranslated, translated)}
94 return translations
95
96
97 def _normalize(string, remove_newline=False):
98 """
99 String normalization.
100
101 All credit for this code goes
102 to ProgVal/Valentin Lorentz and the Limnoria project.
103
104 https://github.com/ProgVal/Limnoria/blob/master/src/i18n.py
105
106 :param string:
107 :param remove_newline:
108 :return:
109 """
110 def normalize_whitespace(s):
111 """Normalizes the whitespace in a string; \s+ becomes one space."""
112 if not s:
113 return str(s) # not the same reference
114 starts_with_space = (s[0] in ' \n\t\r')
115 ends_with_space = (s[-1] in ' \n\t\r')
116 if remove_newline:
117 newline_re = re.compile('[\r\n]+')
118 s = ' '.join(filter(bool, newline_re.split(s)))
119 s = ' '.join(filter(bool, s.split('\t')))
120 s = ' '.join(filter(bool, s.split(' ')))
121 if starts_with_space:
122 s = ' ' + s
123 if ends_with_space:
124 s += ' '
125 return s
126
127 string = string.replace('\\n\\n', '\n\n')
128 string = string.replace('\\n', ' ')
129 string = string.replace('\\"', '"')
130 string = string.replace("\'", "'")
131 string = normalize_whitespace(string)
132 string = string.strip('\n')
133 string = string.strip('\t')
134 return string
135
136
137 def get_locale_path(cog_folder: Path, extension: str) -> Path:
138 """
139 Gets the folder path containing localization files.
140
141 :param Path cog_folder:
142 The cog folder that we want localizations for.
143 :param str extension:
144 Extension of localization files.
145 :return:
146 Path of possible localization file, it may not exist.
147 """
148 return cog_folder / 'locales' / "{}.{}".format(get_locale(), extension)
149
150
151 class Translator:
152 """Function to get translated strings at runtime."""
153
154 def __init__(self, name, file_location):
155 """
156 Initializes an internationalization object.
157
158 Parameters
159 ----------
160 name : str
161 Your cog name.
162 file_location : `str` or `pathlib.Path`
163 This should always be ``__file__`` otherwise your localizations
164 will not load.
165
166 """
167 self.cog_folder = Path(file_location).resolve().parent
168 self.cog_name = name
169 self.translations = {}
170
171 _translators.append(self)
172
173 self.load_translations()
174
175 def __call__(self, untranslated: str):
176 """Translate the given string.
177
178 This will look for the string in the translator's :code:`.pot` file,
179 with respect to the current locale.
180 """
181 normalized_untranslated = _normalize(untranslated, True)
182 try:
183 return self.translations[normalized_untranslated]
184 except KeyError:
185 return untranslated
186
187 def load_translations(self):
188 """
189 Loads the current translations.
190 """
191 self.translations = {}
192 translation_file = None
193 locale_path = get_locale_path(self.cog_folder, 'po')
194 try:
195
196 try:
197 translation_file = locale_path.open('ru', encoding='utf-8')
198 except ValueError: # We are using Windows
199 translation_file = locale_path.open('r', encoding='utf-8')
200 self._parse(translation_file)
201 except (IOError, FileNotFoundError): # The translation is unavailable
202 pass
203 finally:
204 if translation_file is not None:
205 translation_file.close()
206
207 def _parse(self, translation_file):
208 self.translations = {}
209 for translation in _parse(translation_file):
210 self._add_translation(*translation)
211
212 def _add_translation(self, untranslated, translated):
213 untranslated = _normalize(untranslated, True)
214 translated = _normalize(translated)
215 if translated:
216 self.translations.update({untranslated: translated})
217
218
219 def cog_i18n(translator: Translator):
220 """Get a class decorator to link the translator to this cog."""
221 def decorator(cog_class: type):
222 cog_class.__translator__ = translator
223 for name, attr in cog_class.__dict__.items():
224 if isinstance(attr, (commands.Group, commands.Command)):
225 attr.translator = translator
226 setattr(cog_class, name, attr)
227 return cog_class
228 return decorator
229
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/redbot/core/i18n.py b/redbot/core/i18n.py
--- a/redbot/core/i18n.py
+++ b/redbot/core/i18n.py
@@ -124,6 +124,9 @@
s += ' '
return s
+ if string is None:
+ return ""
+
string = string.replace('\\n\\n', '\n\n')
string = string.replace('\\n', ' ')
string = string.replace('\\"', '"')
|
{"golden_diff": "diff --git a/redbot/core/i18n.py b/redbot/core/i18n.py\n--- a/redbot/core/i18n.py\n+++ b/redbot/core/i18n.py\n@@ -124,6 +124,9 @@\n s += ' '\n return s\n \n+ if string is None:\n+ return \"\"\n+ \n string = string.replace('\\\\n\\\\n', '\\n\\n')\n string = string.replace('\\\\n', ' ')\n string = string.replace('\\\\\"', '\"')\n", "issue": "[V3 Streams] issue with `[p]streamset`\n# Command bugs\r\n\r\n<!-- \r\nDid you find a bug with a command? Fill out the following:\r\n-->\r\n\r\n#### Command name\r\n\r\n`streamset`\r\n\r\n#### What cog is this command from?\r\n\r\n`Streams`\r\n\r\n#### What were you expecting to happen?\r\n\r\nShould output help\r\n\r\n#### What actually happened?\r\n\r\n```py\r\nException in command 'streamset'\r\nTraceback (most recent call last):\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/discord/ext/commands/core.py\", line 62, in wrapped\r\n ret = yield from coro(*args, **kwargs)\r\n File \"/home/palm/.pyenv/versions/3.6.5/envs/redbot/lib/python3.6/site-packages/redbot/cogs/streams/streams.py\", line 283, in streamset\r\n await ctx.send_help()\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/commands/context.py\", line 33, in send_help\r\n embeds = await self.bot.formatter.format_help_for(self, command)\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/help_formatter.py\", line 233, in format_help_for\r\n emb = await self.format()\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/help_formatter.py\", line 156, in format\r\n if self.command.help:\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/commands/commands.py\", line 41, in help\r\n return inspect.cleandoc(translator(self.callback.__doc__))\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/i18n.py\", line 181, in __call__\r\n normalized_untranslated = _normalize(untranslated, True)\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/i18n.py\", line 127, in _normalize\r\n string = string.replace('\\\\n\\\\n', '\\n\\n')\r\nAttributeError: 'NoneType' object has no attribute 'replace'\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/discord/ext/commands/bot.py\", line 886, in invoke\r\n yield from ctx.command.invoke(ctx)\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/discord/ext/commands/core.py\", line 923, in invoke\r\n yield from injected(*ctx.args, **ctx.kwargs)\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/discord/ext/commands/core.py\", line 71, in wrapped\r\n raise CommandInvokeError(e) from e\r\ndiscord.ext.commands.errors.CommandInvokeError: Command raised an exception: AttributeError: 'NoneType' object has no attribute 'replace'\r\n```\r\nNOTE: This is an issue occurring on `V3/develop`. I'm in the process of trying to confirm if this is also occurring on the beta 13 release\r\n\r\n#### How can we reproduce this issue?\r\n\r\n1. Do `[p]streamset`\r\n2. See error\r\n\n[V3 Streams] issue with `[p]streamset`\n# Command bugs\r\n\r\n<!-- \r\nDid you find a bug with a command? Fill out the following:\r\n-->\r\n\r\n#### Command name\r\n\r\n`streamset`\r\n\r\n#### What cog is this command from?\r\n\r\n`Streams`\r\n\r\n#### What were you expecting to happen?\r\n\r\nShould output help\r\n\r\n#### What actually happened?\r\n\r\n```py\r\nException in command 'streamset'\r\nTraceback (most recent call last):\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/discord/ext/commands/core.py\", line 62, in wrapped\r\n ret = yield from coro(*args, **kwargs)\r\n File \"/home/palm/.pyenv/versions/3.6.5/envs/redbot/lib/python3.6/site-packages/redbot/cogs/streams/streams.py\", line 283, in streamset\r\n await ctx.send_help()\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/commands/context.py\", line 33, in send_help\r\n embeds = await self.bot.formatter.format_help_for(self, command)\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/help_formatter.py\", line 233, in format_help_for\r\n emb = await self.format()\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/help_formatter.py\", line 156, in format\r\n if self.command.help:\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/commands/commands.py\", line 41, in help\r\n return inspect.cleandoc(translator(self.callback.__doc__))\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/i18n.py\", line 181, in __call__\r\n normalized_untranslated = _normalize(untranslated, True)\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/redbot/core/i18n.py\", line 127, in _normalize\r\n string = string.replace('\\\\n\\\\n', '\\n\\n')\r\nAttributeError: 'NoneType' object has no attribute 'replace'\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/discord/ext/commands/bot.py\", line 886, in invoke\r\n yield from ctx.command.invoke(ctx)\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/discord/ext/commands/core.py\", line 923, in invoke\r\n yield from injected(*ctx.args, **ctx.kwargs)\r\n File \"/home/palm/.pyenv/versions/redbot/lib/python3.6/site-packages/discord/ext/commands/core.py\", line 71, in wrapped\r\n raise CommandInvokeError(e) from e\r\ndiscord.ext.commands.errors.CommandInvokeError: Command raised an exception: AttributeError: 'NoneType' object has no attribute 'replace'\r\n```\r\nNOTE: This is an issue occurring on `V3/develop`. I'm in the process of trying to confirm if this is also occurring on the beta 13 release\r\n\r\n#### How can we reproduce this issue?\r\n\r\n1. Do `[p]streamset`\r\n2. See error\r\n\n", "before_files": [{"content": "import re\nfrom pathlib import Path\n\nfrom . import commands\n\n__all__ = ['get_locale', 'set_locale', 'reload_locales', 'cog_i18n',\n 'Translator']\n\n_current_locale = 'en_us'\n\nWAITING_FOR_MSGID = 1\nIN_MSGID = 2\nWAITING_FOR_MSGSTR = 3\nIN_MSGSTR = 4\n\nMSGID = 'msgid \"'\nMSGSTR = 'msgstr \"'\n\n_translators = []\n\n\ndef get_locale():\n return _current_locale\n\n\ndef set_locale(locale):\n global _current_locale\n _current_locale = locale\n reload_locales()\n\n\ndef reload_locales():\n for translator in _translators:\n translator.load_translations()\n\n\ndef _parse(translation_file):\n \"\"\"\n Custom gettext parsing of translation files. All credit for this code goes\n to ProgVal/Valentin Lorentz and the Limnoria project.\n\n https://github.com/ProgVal/Limnoria/blob/master/src/i18n.py\n\n :param translation_file:\n An open file-like object containing translations.\n :return:\n A set of 2-tuples containing the original string and the translated version.\n \"\"\"\n step = WAITING_FOR_MSGID\n translations = set()\n for line in translation_file:\n line = line[0:-1] # Remove the ending \\n\n line = line\n\n if line.startswith(MSGID):\n # Don't check if step is WAITING_FOR_MSGID\n untranslated = ''\n translated = ''\n data = line[len(MSGID):-1]\n if len(data) == 0: # Multiline mode\n step = IN_MSGID\n else:\n untranslated += data\n step = WAITING_FOR_MSGSTR\n\n elif step is IN_MSGID and line.startswith('\"') and \\\n line.endswith('\"'):\n untranslated += line[1:-1]\n elif step is IN_MSGID and untranslated == '': # Empty MSGID\n step = WAITING_FOR_MSGID\n elif step is IN_MSGID: # the MSGID is finished\n step = WAITING_FOR_MSGSTR\n\n if step is WAITING_FOR_MSGSTR and line.startswith(MSGSTR):\n data = line[len(MSGSTR):-1]\n if len(data) == 0: # Multiline mode\n step = IN_MSGSTR\n else:\n translations |= {(untranslated, data)}\n step = WAITING_FOR_MSGID\n\n elif step is IN_MSGSTR and line.startswith('\"') and \\\n line.endswith('\"'):\n translated += line[1:-1]\n elif step is IN_MSGSTR: # the MSGSTR is finished\n step = WAITING_FOR_MSGID\n if translated == '':\n translated = untranslated\n translations |= {(untranslated, translated)}\n if step is IN_MSGSTR:\n if translated == '':\n translated = untranslated\n translations |= {(untranslated, translated)}\n return translations\n\n\ndef _normalize(string, remove_newline=False):\n \"\"\"\n String normalization.\n\n All credit for this code goes\n to ProgVal/Valentin Lorentz and the Limnoria project.\n\n https://github.com/ProgVal/Limnoria/blob/master/src/i18n.py\n\n :param string:\n :param remove_newline:\n :return:\n \"\"\"\n def normalize_whitespace(s):\n \"\"\"Normalizes the whitespace in a string; \\s+ becomes one space.\"\"\"\n if not s:\n return str(s) # not the same reference\n starts_with_space = (s[0] in ' \\n\\t\\r')\n ends_with_space = (s[-1] in ' \\n\\t\\r')\n if remove_newline:\n newline_re = re.compile('[\\r\\n]+')\n s = ' '.join(filter(bool, newline_re.split(s)))\n s = ' '.join(filter(bool, s.split('\\t')))\n s = ' '.join(filter(bool, s.split(' ')))\n if starts_with_space:\n s = ' ' + s\n if ends_with_space:\n s += ' '\n return s\n\n string = string.replace('\\\\n\\\\n', '\\n\\n')\n string = string.replace('\\\\n', ' ')\n string = string.replace('\\\\\"', '\"')\n string = string.replace(\"\\'\", \"'\")\n string = normalize_whitespace(string)\n string = string.strip('\\n')\n string = string.strip('\\t')\n return string\n\n\ndef get_locale_path(cog_folder: Path, extension: str) -> Path:\n \"\"\"\n Gets the folder path containing localization files.\n\n :param Path cog_folder:\n The cog folder that we want localizations for.\n :param str extension:\n Extension of localization files.\n :return:\n Path of possible localization file, it may not exist.\n \"\"\"\n return cog_folder / 'locales' / \"{}.{}\".format(get_locale(), extension)\n\n\nclass Translator:\n \"\"\"Function to get translated strings at runtime.\"\"\"\n\n def __init__(self, name, file_location):\n \"\"\"\n Initializes an internationalization object.\n\n Parameters\n ----------\n name : str\n Your cog name.\n file_location : `str` or `pathlib.Path`\n This should always be ``__file__`` otherwise your localizations\n will not load.\n\n \"\"\"\n self.cog_folder = Path(file_location).resolve().parent\n self.cog_name = name\n self.translations = {}\n\n _translators.append(self)\n\n self.load_translations()\n\n def __call__(self, untranslated: str):\n \"\"\"Translate the given string.\n\n This will look for the string in the translator's :code:`.pot` file,\n with respect to the current locale.\n \"\"\"\n normalized_untranslated = _normalize(untranslated, True)\n try:\n return self.translations[normalized_untranslated]\n except KeyError:\n return untranslated\n\n def load_translations(self):\n \"\"\"\n Loads the current translations.\n \"\"\"\n self.translations = {}\n translation_file = None\n locale_path = get_locale_path(self.cog_folder, 'po')\n try:\n\n try:\n translation_file = locale_path.open('ru', encoding='utf-8')\n except ValueError: # We are using Windows\n translation_file = locale_path.open('r', encoding='utf-8')\n self._parse(translation_file)\n except (IOError, FileNotFoundError): # The translation is unavailable\n pass\n finally:\n if translation_file is not None:\n translation_file.close()\n\n def _parse(self, translation_file):\n self.translations = {}\n for translation in _parse(translation_file):\n self._add_translation(*translation)\n\n def _add_translation(self, untranslated, translated):\n untranslated = _normalize(untranslated, True)\n translated = _normalize(translated)\n if translated:\n self.translations.update({untranslated: translated})\n\n\ndef cog_i18n(translator: Translator):\n \"\"\"Get a class decorator to link the translator to this cog.\"\"\"\n def decorator(cog_class: type):\n cog_class.__translator__ = translator\n for name, attr in cog_class.__dict__.items():\n if isinstance(attr, (commands.Group, commands.Command)):\n attr.translator = translator\n setattr(cog_class, name, attr)\n return cog_class\n return decorator\n", "path": "redbot/core/i18n.py"}], "after_files": [{"content": "import re\nfrom pathlib import Path\n\nfrom . import commands\n\n__all__ = ['get_locale', 'set_locale', 'reload_locales', 'cog_i18n',\n 'Translator']\n\n_current_locale = 'en_us'\n\nWAITING_FOR_MSGID = 1\nIN_MSGID = 2\nWAITING_FOR_MSGSTR = 3\nIN_MSGSTR = 4\n\nMSGID = 'msgid \"'\nMSGSTR = 'msgstr \"'\n\n_translators = []\n\n\ndef get_locale():\n return _current_locale\n\n\ndef set_locale(locale):\n global _current_locale\n _current_locale = locale\n reload_locales()\n\n\ndef reload_locales():\n for translator in _translators:\n translator.load_translations()\n\n\ndef _parse(translation_file):\n \"\"\"\n Custom gettext parsing of translation files. All credit for this code goes\n to ProgVal/Valentin Lorentz and the Limnoria project.\n\n https://github.com/ProgVal/Limnoria/blob/master/src/i18n.py\n\n :param translation_file:\n An open file-like object containing translations.\n :return:\n A set of 2-tuples containing the original string and the translated version.\n \"\"\"\n step = WAITING_FOR_MSGID\n translations = set()\n for line in translation_file:\n line = line[0:-1] # Remove the ending \\n\n line = line\n\n if line.startswith(MSGID):\n # Don't check if step is WAITING_FOR_MSGID\n untranslated = ''\n translated = ''\n data = line[len(MSGID):-1]\n if len(data) == 0: # Multiline mode\n step = IN_MSGID\n else:\n untranslated += data\n step = WAITING_FOR_MSGSTR\n\n elif step is IN_MSGID and line.startswith('\"') and \\\n line.endswith('\"'):\n untranslated += line[1:-1]\n elif step is IN_MSGID and untranslated == '': # Empty MSGID\n step = WAITING_FOR_MSGID\n elif step is IN_MSGID: # the MSGID is finished\n step = WAITING_FOR_MSGSTR\n\n if step is WAITING_FOR_MSGSTR and line.startswith(MSGSTR):\n data = line[len(MSGSTR):-1]\n if len(data) == 0: # Multiline mode\n step = IN_MSGSTR\n else:\n translations |= {(untranslated, data)}\n step = WAITING_FOR_MSGID\n\n elif step is IN_MSGSTR and line.startswith('\"') and \\\n line.endswith('\"'):\n translated += line[1:-1]\n elif step is IN_MSGSTR: # the MSGSTR is finished\n step = WAITING_FOR_MSGID\n if translated == '':\n translated = untranslated\n translations |= {(untranslated, translated)}\n if step is IN_MSGSTR:\n if translated == '':\n translated = untranslated\n translations |= {(untranslated, translated)}\n return translations\n\n\ndef _normalize(string, remove_newline=False):\n \"\"\"\n String normalization.\n\n All credit for this code goes\n to ProgVal/Valentin Lorentz and the Limnoria project.\n\n https://github.com/ProgVal/Limnoria/blob/master/src/i18n.py\n\n :param string:\n :param remove_newline:\n :return:\n \"\"\"\n def normalize_whitespace(s):\n \"\"\"Normalizes the whitespace in a string; \\s+ becomes one space.\"\"\"\n if not s:\n return str(s) # not the same reference\n starts_with_space = (s[0] in ' \\n\\t\\r')\n ends_with_space = (s[-1] in ' \\n\\t\\r')\n if remove_newline:\n newline_re = re.compile('[\\r\\n]+')\n s = ' '.join(filter(bool, newline_re.split(s)))\n s = ' '.join(filter(bool, s.split('\\t')))\n s = ' '.join(filter(bool, s.split(' ')))\n if starts_with_space:\n s = ' ' + s\n if ends_with_space:\n s += ' '\n return s\n\n if string is None:\n return \"\"\n \n string = string.replace('\\\\n\\\\n', '\\n\\n')\n string = string.replace('\\\\n', ' ')\n string = string.replace('\\\\\"', '\"')\n string = string.replace(\"\\'\", \"'\")\n string = normalize_whitespace(string)\n string = string.strip('\\n')\n string = string.strip('\\t')\n return string\n\n\ndef get_locale_path(cog_folder: Path, extension: str) -> Path:\n \"\"\"\n Gets the folder path containing localization files.\n\n :param Path cog_folder:\n The cog folder that we want localizations for.\n :param str extension:\n Extension of localization files.\n :return:\n Path of possible localization file, it may not exist.\n \"\"\"\n return cog_folder / 'locales' / \"{}.{}\".format(get_locale(), extension)\n\n\nclass Translator:\n \"\"\"Function to get translated strings at runtime.\"\"\"\n\n def __init__(self, name, file_location):\n \"\"\"\n Initializes an internationalization object.\n\n Parameters\n ----------\n name : str\n Your cog name.\n file_location : `str` or `pathlib.Path`\n This should always be ``__file__`` otherwise your localizations\n will not load.\n\n \"\"\"\n self.cog_folder = Path(file_location).resolve().parent\n self.cog_name = name\n self.translations = {}\n\n _translators.append(self)\n\n self.load_translations()\n\n def __call__(self, untranslated: str):\n \"\"\"Translate the given string.\n\n This will look for the string in the translator's :code:`.pot` file,\n with respect to the current locale.\n \"\"\"\n normalized_untranslated = _normalize(untranslated, True)\n try:\n return self.translations[normalized_untranslated]\n except KeyError:\n return untranslated\n\n def load_translations(self):\n \"\"\"\n Loads the current translations.\n \"\"\"\n self.translations = {}\n translation_file = None\n locale_path = get_locale_path(self.cog_folder, 'po')\n try:\n\n try:\n translation_file = locale_path.open('ru', encoding='utf-8')\n except ValueError: # We are using Windows\n translation_file = locale_path.open('r', encoding='utf-8')\n self._parse(translation_file)\n except (IOError, FileNotFoundError): # The translation is unavailable\n pass\n finally:\n if translation_file is not None:\n translation_file.close()\n\n def _parse(self, translation_file):\n self.translations = {}\n for translation in _parse(translation_file):\n self._add_translation(*translation)\n\n def _add_translation(self, untranslated, translated):\n untranslated = _normalize(untranslated, True)\n translated = _normalize(translated)\n if translated:\n self.translations.update({untranslated: translated})\n\n\ndef cog_i18n(translator: Translator):\n \"\"\"Get a class decorator to link the translator to this cog.\"\"\"\n def decorator(cog_class: type):\n cog_class.__translator__ = translator\n for name, attr in cog_class.__dict__.items():\n if isinstance(attr, (commands.Group, commands.Command)):\n attr.translator = translator\n setattr(cog_class, name, attr)\n return cog_class\n return decorator\n", "path": "redbot/core/i18n.py"}]}
| 3,944 | 114 |
gh_patches_debug_38452
|
rasdani/github-patches
|
git_diff
|
deepset-ai__haystack-683
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Combination of multiple retrievers
Originating from a discussion in #104.
**What**
Combine multiple scores during retrieval (e.g. embeddings similarity of multiple text fields, or BM25 + Embedding similarity ...)
**Options**
a) Concatenation of Retrievers: Make the Finder accept a list of Retrievers and combine their scores (incl. weights) before feeding results to the Reader
Pro: most generic solution also allowing combination of BM25 + EmbeddingRetriever
Con: Two separate retriever queries (suboptimal efficiency in some cases)
b) New MultiEmbeddingRetriever: Extend the EmbeddingRetriever to the case of multiple Embeddings
Pro: simple implementation without side effects on the regular user interface
Con: won't allow the combination of other retriever methods (e.g. ElasticsearchRetriever + EmbeddingRetriver)
I am leaning towards a), but could see b) as a simpler short-term solution for the original use case discussed in #104 .
┆Issue is synchronized with this [Jira Task](https://deepset-ai.atlassian.net/browse/HS-42) by [Unito](https://www.unito.io/learn-more)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `haystack/pipeline.py`
Content:
```
1 from pathlib import Path
2 from typing import List, Optional, Dict
3
4 import networkx as nx
5 from networkx import DiGraph
6 from networkx.drawing.nx_agraph import to_agraph
7
8 from haystack.generator.base import BaseGenerator
9 from haystack.reader.base import BaseReader
10 from haystack.retriever.base import BaseRetriever
11
12
13 class Pipeline:
14 """
15 Pipeline brings together building blocks to build a complex search pipeline with Haystack & user-defined components.
16
17 Under-the-hood, a pipeline is represented as a directed acyclic graph of component nodes. It enables custom query
18 flows with options to branch queries(eg, extractive qa vs keyword match query), merge candidate documents for a
19 Reader from multiple Retrievers, or re-ranking of candidate documents.
20 """
21
22 def __init__(self):
23 self.graph = DiGraph()
24 self.root_node_id = "Query"
25 self.graph.add_node("Query", component=QueryNode())
26
27 def add_node(self, component, name: str, inputs: List[str]):
28 """
29 Add a new node to the pipeline.
30
31 :param component: The object to be called when the data is passed to the node. It can be a Haystack component
32 (like Retriever, Reader, or Generator) or a user-defined object that implements a run()
33 method to process incoming data from predecessor node.
34 :param name: The name for the node. It must not contain any dots.
35 :param inputs: A list of inputs to the node. If the predecessor node has a single outgoing edge, just the name
36 of node is sufficient. For instance, a 'ElasticsearchRetriever' node would always output a single
37 edge with a list of documents. It can be represented as ["ElasticsearchRetriever"].
38
39 In cases when the predecessor node has multiple outputs, e.g., a "QueryClassifier", the output
40 must be specified explicitly as "QueryClassifier.output_2".
41 """
42 self.graph.add_node(name, component=component)
43
44 for i in inputs:
45 if "." in i:
46 [input_node_name, input_edge_name] = i.split(".")
47 assert "output_" in input_edge_name, f"'{input_edge_name}' is not a valid edge name."
48 outgoing_edges_input_node = self.graph.nodes[input_node_name]["component"].outgoing_edges
49 assert int(input_edge_name.split("_")[1]) <= outgoing_edges_input_node, (
50 f"Cannot connect '{input_edge_name}' from '{input_node_name}' as it only has "
51 f"{outgoing_edges_input_node} outgoing edge(s)."
52 )
53 else:
54 outgoing_edges_input_node = self.graph.nodes[i]["component"].outgoing_edges
55 assert outgoing_edges_input_node == 1, (
56 f"Adding an edge from {i} to {name} is ambiguous as {i} has {outgoing_edges_input_node} edges. "
57 f"Please specify the output explicitly."
58 )
59 input_node_name = i
60 input_edge_name = "output_1"
61 self.graph.add_edge(input_node_name, name, label=input_edge_name)
62
63 def get_node(self, name: str):
64 """
65 Get a node from the Pipeline.
66
67 :param name: The name of the node.
68 """
69 component = self.graph.nodes[name]["component"]
70 return component
71
72 def set_node(self, name: str, component):
73 """
74 Set the component for a node in the Pipeline.
75
76 :param name: The name of the node.
77 :param component: The component object to be set at the node.
78 """
79 self.graph.nodes[name]["component"] = component
80
81 def run(self, **kwargs):
82 has_next_node = True
83 current_node_id = self.root_node_id
84 input_dict = kwargs
85 output_dict = None
86
87 while has_next_node:
88 output_dict, stream_id = self.graph.nodes[current_node_id]["component"].run(**input_dict)
89 input_dict = output_dict
90 next_nodes = self._get_next_nodes(current_node_id, stream_id)
91
92 if len(next_nodes) > 1:
93 join_node_id = list(nx.neighbors(self.graph, next_nodes[0]))[0]
94 if set(self.graph.predecessors(join_node_id)) != set(next_nodes):
95 raise NotImplementedError(
96 "The current pipeline does not support multiple levels of parallel nodes."
97 )
98 inputs_for_join_node = {"inputs": []}
99 for n_id in next_nodes:
100 output = self.graph.nodes[n_id]["component"].run(**input_dict)
101 inputs_for_join_node["inputs"].append(output)
102 input_dict = inputs_for_join_node
103 current_node_id = join_node_id
104 elif len(next_nodes) == 1:
105 current_node_id = next_nodes[0]
106 else:
107 has_next_node = False
108
109 return output_dict
110
111 def _get_next_nodes(self, node_id: str, stream_id: str):
112 current_node_edges = self.graph.edges(node_id, data=True)
113 next_nodes = [
114 next_node
115 for _, next_node, data in current_node_edges
116 if not stream_id or data["label"] == stream_id
117 ]
118 return next_nodes
119
120 def draw(self, path: Path = Path("pipeline.png")):
121 """
122 Create a Graphviz visualization of the pipeline.
123
124 :param path: the path to save the image.
125 """
126 try:
127 import pygraphviz
128 except ImportError:
129 raise ImportError(f"Could not import `pygraphviz`. Please install via: \n"
130 f"pip install pygraphviz\n"
131 f"(You might need to run this first: apt install libgraphviz-dev graphviz )")
132
133 graphviz = to_agraph(self.graph)
134 graphviz.layout("dot")
135 graphviz.draw(path)
136
137
138 class BaseStandardPipeline:
139 pipeline: Pipeline
140
141 def add_node(self, component, name: str, inputs: List[str]):
142 """
143 Add a new node to the pipeline.
144
145 :param component: The object to be called when the data is passed to the node. It can be a Haystack component
146 (like Retriever, Reader, or Generator) or a user-defined object that implements a run()
147 method to process incoming data from predecessor node.
148 :param name: The name for the node. It must not contain any dots.
149 :param inputs: A list of inputs to the node. If the predecessor node has a single outgoing edge, just the name
150 of node is sufficient. For instance, a 'ElasticsearchRetriever' node would always output a single
151 edge with a list of documents. It can be represented as ["ElasticsearchRetriever"].
152
153 In cases when the predecessor node has multiple outputs, e.g., a "QueryClassifier", the output
154 must be specified explicitly as "QueryClassifier.output_2".
155 """
156
157 self.pipeline.add_node(component=component, name=name, inputs=inputs)
158
159 def get_node(self, name: str):
160 """
161 Get a node from the Pipeline.
162
163 :param name: The name of the node.
164 """
165 component = self.pipeline.get_node(name)
166 return component
167
168 def set_node(self, name: str, component):
169 """
170 Set the component for a node in the Pipeline.
171
172 :param name: The name of the node.
173 :param component: The component object to be set at the node.
174 """
175 self.pipeline.set_node(name, component)
176
177 def draw(self, path: Path = Path("pipeline.png")):
178 """
179 Create a Graphviz visualization of the pipeline.
180
181 :param path: the path to save the image.
182 """
183 self.pipeline.draw(path)
184
185
186 class ExtractiveQAPipeline(BaseStandardPipeline):
187 def __init__(self, reader: BaseReader, retriever: BaseRetriever):
188 """
189 Initialize a Pipeline for Extractive Question Answering.
190
191 :param reader: Reader instance
192 :param retriever: Retriever instance
193 """
194 self.pipeline = Pipeline()
195 self.pipeline.add_node(component=retriever, name="Retriever", inputs=["Query"])
196 self.pipeline.add_node(component=reader, name="Reader", inputs=["Retriever"])
197
198 def run(self, query: str, filters: Optional[Dict] = None, top_k_retriever: int = 10, top_k_reader: int = 10):
199 output = self.pipeline.run(
200 query=query, filters=filters, top_k_retriever=top_k_retriever, top_k_reader=top_k_reader
201 )
202 return output
203
204
205 class DocumentSearchPipeline(BaseStandardPipeline):
206 def __init__(self, retriever: BaseRetriever):
207 """
208 Initialize a Pipeline for semantic document search.
209
210 :param retriever: Retriever instance
211 """
212 self.pipeline = Pipeline()
213 self.pipeline.add_node(component=retriever, name="Retriever", inputs=["Query"])
214
215 def run(self, query: str, filters: Optional[Dict] = None, top_k_retriever: int = 10):
216 output = self.pipeline.run(query=query, filters=filters, top_k_retriever=top_k_retriever)
217 document_dicts = [doc.to_dict() for doc in output["documents"]]
218 output["documents"] = document_dicts
219 return output
220
221
222 class GenerativeQAPipeline(BaseStandardPipeline):
223 def __init__(self, generator: BaseGenerator, retriever: BaseRetriever):
224 """
225 Initialize a Pipeline for Generative Question Answering.
226
227 :param generator: Generator instance
228 :param retriever: Retriever instance
229 """
230 self.pipeline = Pipeline()
231 self.pipeline.add_node(component=retriever, name="Retriever", inputs=["Query"])
232 self.pipeline.add_node(component=generator, name="Generator", inputs=["Retriever"])
233
234 def run(self, query: str, filters: Optional[Dict] = None, top_k_retriever: int = 10, top_k_generator: int = 10):
235 output = self.pipeline.run(
236 query=query, filters=filters, top_k_retriever=top_k_retriever, top_k_generator=top_k_generator
237 )
238 return output
239
240
241 class FAQPipeline(BaseStandardPipeline):
242 def __init__(self, retriever: BaseRetriever):
243 """
244 Initialize a Pipeline for finding similar FAQs using semantic document search.
245
246 :param retriever: Retriever instance
247 """
248 self.pipeline = Pipeline()
249 self.pipeline.add_node(component=retriever, name="Retriever", inputs=["Query"])
250
251 def run(self, query: str, filters: Optional[Dict] = None, top_k_retriever: int = 10):
252 output = self.pipeline.run(query=query, filters=filters, top_k_retriever=top_k_retriever)
253 documents = output["documents"]
254
255 results: Dict = {"query": query, "answers": []}
256 for doc in documents:
257 # TODO proper calibratation of pseudo probabilities
258 cur_answer = {
259 "query": doc.text,
260 "answer": doc.meta["answer"],
261 "document_id": doc.id,
262 "context": doc.meta["answer"],
263 "score": doc.score,
264 "probability": doc.probability,
265 "offset_start": 0,
266 "offset_end": len(doc.meta["answer"]),
267 "meta": doc.meta,
268 }
269
270 results["answers"].append(cur_answer)
271
272 return results
273
274
275 class QueryNode:
276 outgoing_edges = 1
277
278 def run(self, **kwargs):
279 return kwargs, "output_1"
280
281
282 class JoinDocuments:
283 outgoing_edges = 1
284
285 def __init__(self, join_mode="concatenate"):
286 pass
287
288 def run(self, **kwargs):
289 inputs = kwargs["inputs"]
290
291 documents = []
292 for i, _ in inputs:
293 documents.extend(i["documents"])
294 output = {
295 "query": inputs[0][0]["query"],
296 "documents": documents
297 }
298 return output, "output_1"
299
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/haystack/pipeline.py b/haystack/pipeline.py
--- a/haystack/pipeline.py
+++ b/haystack/pipeline.py
@@ -1,3 +1,4 @@
+from copy import deepcopy
from pathlib import Path
from typing import List, Optional, Dict
@@ -280,19 +281,63 @@
class JoinDocuments:
+ """
+ A node to join documents outputted by multiple retriever nodes.
+
+ The node allows multiple join modes:
+ * concatenate: combine the documents from multiple nodes. Any duplicate documents are discarded.
+ * merge: merge scores of documents from multiple nodes. Optionally, each input score can be given a different
+ `weight` & a `top_k` limit can be set. This mode can also be used for "reranking" retrieved documents.
+ """
+
outgoing_edges = 1
- def __init__(self, join_mode="concatenate"):
- pass
+ def __init__(
+ self, join_mode: str = "concatenate", weights: Optional[List[float]] = None, top_k_join: Optional[int] = None
+ ):
+ """
+ :param join_mode: `concatenate` to combine documents from multiple retrievers or `merge` to aggregate scores of
+ individual documents.
+ :param weights: A node-wise list(length of list must be equal to the number of input nodes) of weights for
+ adjusting document scores when using the `merge` join_mode. By default, equal weight is given
+ to each retriever score. This param is not compatible with the `concatenate` join_mode.
+ :param top_k_join: Limit documents to top_k based on the resulting scores of the join.
+ """
+ assert join_mode in ["concatenate", "merge"], f"JoinDocuments node does not support '{join_mode}' join_mode."
+
+ assert not (
+ weights is not None and join_mode == "concatenate"
+ ), "Weights are not compatible with 'concatenate' join_mode."
+ self.join_mode = join_mode
+ self.weights = weights
+ self.top_k = top_k_join
def run(self, **kwargs):
inputs = kwargs["inputs"]
- documents = []
- for i, _ in inputs:
- documents.extend(i["documents"])
- output = {
- "query": inputs[0][0]["query"],
- "documents": documents
- }
+ if self.join_mode == "concatenate":
+ document_map = {}
+ for input_from_node, _ in inputs:
+ for doc in input_from_node["documents"]:
+ document_map[doc.id] = doc
+ elif self.join_mode == "merge":
+ document_map = {}
+ if self.weights:
+ weights = self.weights
+ else:
+ weights = [1/len(inputs)] * len(inputs)
+ for (input_from_node, _), weight in zip(inputs, weights):
+ for doc in input_from_node["documents"]:
+ if document_map.get(doc.id): # document already exists; update score
+ document_map[doc.id].score += doc.score * weight
+ else: # add the document in map
+ document_map[doc.id] = deepcopy(doc)
+ document_map[doc.id].score *= weight
+ else:
+ raise Exception(f"Invalid join_mode: {self.join_mode}")
+
+ documents = sorted(document_map.values(), key=lambda d: d.score, reverse=True)
+ if self.top_k:
+ documents = documents[: self.top_k]
+ output = {"query": inputs[0][0]["query"], "documents": documents}
return output, "output_1"
|
{"golden_diff": "diff --git a/haystack/pipeline.py b/haystack/pipeline.py\n--- a/haystack/pipeline.py\n+++ b/haystack/pipeline.py\n@@ -1,3 +1,4 @@\n+from copy import deepcopy\n from pathlib import Path\n from typing import List, Optional, Dict\n \n@@ -280,19 +281,63 @@\n \n \n class JoinDocuments:\n+ \"\"\"\n+ A node to join documents outputted by multiple retriever nodes.\n+\n+ The node allows multiple join modes:\n+ * concatenate: combine the documents from multiple nodes. Any duplicate documents are discarded.\n+ * merge: merge scores of documents from multiple nodes. Optionally, each input score can be given a different\n+ `weight` & a `top_k` limit can be set. This mode can also be used for \"reranking\" retrieved documents.\n+ \"\"\"\n+\n outgoing_edges = 1\n \n- def __init__(self, join_mode=\"concatenate\"):\n- pass\n+ def __init__(\n+ self, join_mode: str = \"concatenate\", weights: Optional[List[float]] = None, top_k_join: Optional[int] = None\n+ ):\n+ \"\"\"\n+ :param join_mode: `concatenate` to combine documents from multiple retrievers or `merge` to aggregate scores of\n+ individual documents.\n+ :param weights: A node-wise list(length of list must be equal to the number of input nodes) of weights for\n+ adjusting document scores when using the `merge` join_mode. By default, equal weight is given\n+ to each retriever score. This param is not compatible with the `concatenate` join_mode.\n+ :param top_k_join: Limit documents to top_k based on the resulting scores of the join.\n+ \"\"\"\n+ assert join_mode in [\"concatenate\", \"merge\"], f\"JoinDocuments node does not support '{join_mode}' join_mode.\"\n+\n+ assert not (\n+ weights is not None and join_mode == \"concatenate\"\n+ ), \"Weights are not compatible with 'concatenate' join_mode.\"\n+ self.join_mode = join_mode\n+ self.weights = weights\n+ self.top_k = top_k_join\n \n def run(self, **kwargs):\n inputs = kwargs[\"inputs\"]\n \n- documents = []\n- for i, _ in inputs:\n- documents.extend(i[\"documents\"])\n- output = {\n- \"query\": inputs[0][0][\"query\"],\n- \"documents\": documents\n- }\n+ if self.join_mode == \"concatenate\":\n+ document_map = {}\n+ for input_from_node, _ in inputs:\n+ for doc in input_from_node[\"documents\"]:\n+ document_map[doc.id] = doc\n+ elif self.join_mode == \"merge\":\n+ document_map = {}\n+ if self.weights:\n+ weights = self.weights\n+ else:\n+ weights = [1/len(inputs)] * len(inputs)\n+ for (input_from_node, _), weight in zip(inputs, weights):\n+ for doc in input_from_node[\"documents\"]:\n+ if document_map.get(doc.id): # document already exists; update score\n+ document_map[doc.id].score += doc.score * weight\n+ else: # add the document in map\n+ document_map[doc.id] = deepcopy(doc)\n+ document_map[doc.id].score *= weight\n+ else:\n+ raise Exception(f\"Invalid join_mode: {self.join_mode}\")\n+\n+ documents = sorted(document_map.values(), key=lambda d: d.score, reverse=True)\n+ if self.top_k:\n+ documents = documents[: self.top_k]\n+ output = {\"query\": inputs[0][0][\"query\"], \"documents\": documents}\n return output, \"output_1\"\n", "issue": "Combination of multiple retrievers\nOriginating from a discussion in #104. \n\n**What**\nCombine multiple scores during retrieval (e.g. embeddings similarity of multiple text fields, or BM25 + Embedding similarity ...) \n\n**Options**\n\na) Concatenation of Retrievers: Make the Finder accept a list of Retrievers and combine their scores (incl. weights) before feeding results to the Reader\nPro: most generic solution also allowing combination of BM25 + EmbeddingRetriever\nCon: Two separate retriever queries (suboptimal efficiency in some cases)\n\nb) New MultiEmbeddingRetriever: Extend the EmbeddingRetriever to the case of multiple Embeddings\nPro: simple implementation without side effects on the regular user interface\nCon: won't allow the combination of other retriever methods (e.g. ElasticsearchRetriever + EmbeddingRetriver)\n\nI am leaning towards a), but could see b) as a simpler short-term solution for the original use case discussed in #104 .\n\n\n\n\u2506Issue is synchronized with this [Jira Task](https://deepset-ai.atlassian.net/browse/HS-42) by [Unito](https://www.unito.io/learn-more)\n\n", "before_files": [{"content": "from pathlib import Path\nfrom typing import List, Optional, Dict\n\nimport networkx as nx\nfrom networkx import DiGraph\nfrom networkx.drawing.nx_agraph import to_agraph\n\nfrom haystack.generator.base import BaseGenerator\nfrom haystack.reader.base import BaseReader\nfrom haystack.retriever.base import BaseRetriever\n\n\nclass Pipeline:\n \"\"\"\n Pipeline brings together building blocks to build a complex search pipeline with Haystack & user-defined components.\n\n Under-the-hood, a pipeline is represented as a directed acyclic graph of component nodes. It enables custom query\n flows with options to branch queries(eg, extractive qa vs keyword match query), merge candidate documents for a\n Reader from multiple Retrievers, or re-ranking of candidate documents.\n \"\"\"\n\n def __init__(self):\n self.graph = DiGraph()\n self.root_node_id = \"Query\"\n self.graph.add_node(\"Query\", component=QueryNode())\n\n def add_node(self, component, name: str, inputs: List[str]):\n \"\"\"\n Add a new node to the pipeline.\n\n :param component: The object to be called when the data is passed to the node. It can be a Haystack component\n (like Retriever, Reader, or Generator) or a user-defined object that implements a run()\n method to process incoming data from predecessor node.\n :param name: The name for the node. It must not contain any dots.\n :param inputs: A list of inputs to the node. If the predecessor node has a single outgoing edge, just the name\n of node is sufficient. For instance, a 'ElasticsearchRetriever' node would always output a single\n edge with a list of documents. It can be represented as [\"ElasticsearchRetriever\"].\n\n In cases when the predecessor node has multiple outputs, e.g., a \"QueryClassifier\", the output\n must be specified explicitly as \"QueryClassifier.output_2\".\n \"\"\"\n self.graph.add_node(name, component=component)\n\n for i in inputs:\n if \".\" in i:\n [input_node_name, input_edge_name] = i.split(\".\")\n assert \"output_\" in input_edge_name, f\"'{input_edge_name}' is not a valid edge name.\"\n outgoing_edges_input_node = self.graph.nodes[input_node_name][\"component\"].outgoing_edges\n assert int(input_edge_name.split(\"_\")[1]) <= outgoing_edges_input_node, (\n f\"Cannot connect '{input_edge_name}' from '{input_node_name}' as it only has \"\n f\"{outgoing_edges_input_node} outgoing edge(s).\"\n )\n else:\n outgoing_edges_input_node = self.graph.nodes[i][\"component\"].outgoing_edges\n assert outgoing_edges_input_node == 1, (\n f\"Adding an edge from {i} to {name} is ambiguous as {i} has {outgoing_edges_input_node} edges. \"\n f\"Please specify the output explicitly.\"\n )\n input_node_name = i\n input_edge_name = \"output_1\"\n self.graph.add_edge(input_node_name, name, label=input_edge_name)\n\n def get_node(self, name: str):\n \"\"\"\n Get a node from the Pipeline.\n\n :param name: The name of the node.\n \"\"\"\n component = self.graph.nodes[name][\"component\"]\n return component\n\n def set_node(self, name: str, component):\n \"\"\"\n Set the component for a node in the Pipeline.\n\n :param name: The name of the node.\n :param component: The component object to be set at the node.\n \"\"\"\n self.graph.nodes[name][\"component\"] = component\n\n def run(self, **kwargs):\n has_next_node = True\n current_node_id = self.root_node_id\n input_dict = kwargs\n output_dict = None\n\n while has_next_node:\n output_dict, stream_id = self.graph.nodes[current_node_id][\"component\"].run(**input_dict)\n input_dict = output_dict\n next_nodes = self._get_next_nodes(current_node_id, stream_id)\n\n if len(next_nodes) > 1:\n join_node_id = list(nx.neighbors(self.graph, next_nodes[0]))[0]\n if set(self.graph.predecessors(join_node_id)) != set(next_nodes):\n raise NotImplementedError(\n \"The current pipeline does not support multiple levels of parallel nodes.\"\n )\n inputs_for_join_node = {\"inputs\": []}\n for n_id in next_nodes:\n output = self.graph.nodes[n_id][\"component\"].run(**input_dict)\n inputs_for_join_node[\"inputs\"].append(output)\n input_dict = inputs_for_join_node\n current_node_id = join_node_id\n elif len(next_nodes) == 1:\n current_node_id = next_nodes[0]\n else:\n has_next_node = False\n\n return output_dict\n\n def _get_next_nodes(self, node_id: str, stream_id: str):\n current_node_edges = self.graph.edges(node_id, data=True)\n next_nodes = [\n next_node\n for _, next_node, data in current_node_edges\n if not stream_id or data[\"label\"] == stream_id\n ]\n return next_nodes\n\n def draw(self, path: Path = Path(\"pipeline.png\")):\n \"\"\"\n Create a Graphviz visualization of the pipeline.\n\n :param path: the path to save the image.\n \"\"\"\n try:\n import pygraphviz\n except ImportError:\n raise ImportError(f\"Could not import `pygraphviz`. Please install via: \\n\"\n f\"pip install pygraphviz\\n\"\n f\"(You might need to run this first: apt install libgraphviz-dev graphviz )\")\n\n graphviz = to_agraph(self.graph)\n graphviz.layout(\"dot\")\n graphviz.draw(path)\n\n\nclass BaseStandardPipeline:\n pipeline: Pipeline\n\n def add_node(self, component, name: str, inputs: List[str]):\n \"\"\"\n Add a new node to the pipeline.\n\n :param component: The object to be called when the data is passed to the node. It can be a Haystack component\n (like Retriever, Reader, or Generator) or a user-defined object that implements a run()\n method to process incoming data from predecessor node.\n :param name: The name for the node. It must not contain any dots.\n :param inputs: A list of inputs to the node. If the predecessor node has a single outgoing edge, just the name\n of node is sufficient. For instance, a 'ElasticsearchRetriever' node would always output a single\n edge with a list of documents. It can be represented as [\"ElasticsearchRetriever\"].\n\n In cases when the predecessor node has multiple outputs, e.g., a \"QueryClassifier\", the output\n must be specified explicitly as \"QueryClassifier.output_2\".\n \"\"\"\n\n self.pipeline.add_node(component=component, name=name, inputs=inputs)\n\n def get_node(self, name: str):\n \"\"\"\n Get a node from the Pipeline.\n\n :param name: The name of the node.\n \"\"\"\n component = self.pipeline.get_node(name)\n return component\n\n def set_node(self, name: str, component):\n \"\"\"\n Set the component for a node in the Pipeline.\n\n :param name: The name of the node.\n :param component: The component object to be set at the node.\n \"\"\"\n self.pipeline.set_node(name, component)\n\n def draw(self, path: Path = Path(\"pipeline.png\")):\n \"\"\"\n Create a Graphviz visualization of the pipeline.\n\n :param path: the path to save the image.\n \"\"\"\n self.pipeline.draw(path)\n\n\nclass ExtractiveQAPipeline(BaseStandardPipeline):\n def __init__(self, reader: BaseReader, retriever: BaseRetriever):\n \"\"\"\n Initialize a Pipeline for Extractive Question Answering.\n\n :param reader: Reader instance\n :param retriever: Retriever instance\n \"\"\"\n self.pipeline = Pipeline()\n self.pipeline.add_node(component=retriever, name=\"Retriever\", inputs=[\"Query\"])\n self.pipeline.add_node(component=reader, name=\"Reader\", inputs=[\"Retriever\"])\n\n def run(self, query: str, filters: Optional[Dict] = None, top_k_retriever: int = 10, top_k_reader: int = 10):\n output = self.pipeline.run(\n query=query, filters=filters, top_k_retriever=top_k_retriever, top_k_reader=top_k_reader\n )\n return output\n\n\nclass DocumentSearchPipeline(BaseStandardPipeline):\n def __init__(self, retriever: BaseRetriever):\n \"\"\"\n Initialize a Pipeline for semantic document search.\n\n :param retriever: Retriever instance\n \"\"\"\n self.pipeline = Pipeline()\n self.pipeline.add_node(component=retriever, name=\"Retriever\", inputs=[\"Query\"])\n\n def run(self, query: str, filters: Optional[Dict] = None, top_k_retriever: int = 10):\n output = self.pipeline.run(query=query, filters=filters, top_k_retriever=top_k_retriever)\n document_dicts = [doc.to_dict() for doc in output[\"documents\"]]\n output[\"documents\"] = document_dicts\n return output\n\n\nclass GenerativeQAPipeline(BaseStandardPipeline):\n def __init__(self, generator: BaseGenerator, retriever: BaseRetriever):\n \"\"\"\n Initialize a Pipeline for Generative Question Answering.\n\n :param generator: Generator instance\n :param retriever: Retriever instance\n \"\"\"\n self.pipeline = Pipeline()\n self.pipeline.add_node(component=retriever, name=\"Retriever\", inputs=[\"Query\"])\n self.pipeline.add_node(component=generator, name=\"Generator\", inputs=[\"Retriever\"])\n\n def run(self, query: str, filters: Optional[Dict] = None, top_k_retriever: int = 10, top_k_generator: int = 10):\n output = self.pipeline.run(\n query=query, filters=filters, top_k_retriever=top_k_retriever, top_k_generator=top_k_generator\n )\n return output\n\n\nclass FAQPipeline(BaseStandardPipeline):\n def __init__(self, retriever: BaseRetriever):\n \"\"\"\n Initialize a Pipeline for finding similar FAQs using semantic document search.\n\n :param retriever: Retriever instance\n \"\"\"\n self.pipeline = Pipeline()\n self.pipeline.add_node(component=retriever, name=\"Retriever\", inputs=[\"Query\"])\n\n def run(self, query: str, filters: Optional[Dict] = None, top_k_retriever: int = 10):\n output = self.pipeline.run(query=query, filters=filters, top_k_retriever=top_k_retriever)\n documents = output[\"documents\"]\n\n results: Dict = {\"query\": query, \"answers\": []}\n for doc in documents:\n # TODO proper calibratation of pseudo probabilities\n cur_answer = {\n \"query\": doc.text,\n \"answer\": doc.meta[\"answer\"],\n \"document_id\": doc.id,\n \"context\": doc.meta[\"answer\"],\n \"score\": doc.score,\n \"probability\": doc.probability,\n \"offset_start\": 0,\n \"offset_end\": len(doc.meta[\"answer\"]),\n \"meta\": doc.meta,\n }\n\n results[\"answers\"].append(cur_answer)\n\n return results\n\n\nclass QueryNode:\n outgoing_edges = 1\n\n def run(self, **kwargs):\n return kwargs, \"output_1\"\n\n\nclass JoinDocuments:\n outgoing_edges = 1\n\n def __init__(self, join_mode=\"concatenate\"):\n pass\n\n def run(self, **kwargs):\n inputs = kwargs[\"inputs\"]\n\n documents = []\n for i, _ in inputs:\n documents.extend(i[\"documents\"])\n output = {\n \"query\": inputs[0][0][\"query\"],\n \"documents\": documents\n }\n return output, \"output_1\"\n", "path": "haystack/pipeline.py"}], "after_files": [{"content": "from copy import deepcopy\nfrom pathlib import Path\nfrom typing import List, Optional, Dict\n\nimport networkx as nx\nfrom networkx import DiGraph\nfrom networkx.drawing.nx_agraph import to_agraph\n\nfrom haystack.generator.base import BaseGenerator\nfrom haystack.reader.base import BaseReader\nfrom haystack.retriever.base import BaseRetriever\n\n\nclass Pipeline:\n \"\"\"\n Pipeline brings together building blocks to build a complex search pipeline with Haystack & user-defined components.\n\n Under-the-hood, a pipeline is represented as a directed acyclic graph of component nodes. It enables custom query\n flows with options to branch queries(eg, extractive qa vs keyword match query), merge candidate documents for a\n Reader from multiple Retrievers, or re-ranking of candidate documents.\n \"\"\"\n\n def __init__(self):\n self.graph = DiGraph()\n self.root_node_id = \"Query\"\n self.graph.add_node(\"Query\", component=QueryNode())\n\n def add_node(self, component, name: str, inputs: List[str]):\n \"\"\"\n Add a new node to the pipeline.\n\n :param component: The object to be called when the data is passed to the node. It can be a Haystack component\n (like Retriever, Reader, or Generator) or a user-defined object that implements a run()\n method to process incoming data from predecessor node.\n :param name: The name for the node. It must not contain any dots.\n :param inputs: A list of inputs to the node. If the predecessor node has a single outgoing edge, just the name\n of node is sufficient. For instance, a 'ElasticsearchRetriever' node would always output a single\n edge with a list of documents. It can be represented as [\"ElasticsearchRetriever\"].\n\n In cases when the predecessor node has multiple outputs, e.g., a \"QueryClassifier\", the output\n must be specified explicitly as \"QueryClassifier.output_2\".\n \"\"\"\n self.graph.add_node(name, component=component)\n\n for i in inputs:\n if \".\" in i:\n [input_node_name, input_edge_name] = i.split(\".\")\n assert \"output_\" in input_edge_name, f\"'{input_edge_name}' is not a valid edge name.\"\n outgoing_edges_input_node = self.graph.nodes[input_node_name][\"component\"].outgoing_edges\n assert int(input_edge_name.split(\"_\")[1]) <= outgoing_edges_input_node, (\n f\"Cannot connect '{input_edge_name}' from '{input_node_name}' as it only has \"\n f\"{outgoing_edges_input_node} outgoing edge(s).\"\n )\n else:\n outgoing_edges_input_node = self.graph.nodes[i][\"component\"].outgoing_edges\n assert outgoing_edges_input_node == 1, (\n f\"Adding an edge from {i} to {name} is ambiguous as {i} has {outgoing_edges_input_node} edges. \"\n f\"Please specify the output explicitly.\"\n )\n input_node_name = i\n input_edge_name = \"output_1\"\n self.graph.add_edge(input_node_name, name, label=input_edge_name)\n\n def get_node(self, name: str):\n \"\"\"\n Get a node from the Pipeline.\n\n :param name: The name of the node.\n \"\"\"\n component = self.graph.nodes[name][\"component\"]\n return component\n\n def set_node(self, name: str, component):\n \"\"\"\n Set the component for a node in the Pipeline.\n\n :param name: The name of the node.\n :param component: The component object to be set at the node.\n \"\"\"\n self.graph.nodes[name][\"component\"] = component\n\n def run(self, **kwargs):\n has_next_node = True\n current_node_id = self.root_node_id\n input_dict = kwargs\n output_dict = None\n\n while has_next_node:\n output_dict, stream_id = self.graph.nodes[current_node_id][\"component\"].run(**input_dict)\n input_dict = output_dict\n next_nodes = self._get_next_nodes(current_node_id, stream_id)\n\n if len(next_nodes) > 1:\n join_node_id = list(nx.neighbors(self.graph, next_nodes[0]))[0]\n if set(self.graph.predecessors(join_node_id)) != set(next_nodes):\n raise NotImplementedError(\n \"The current pipeline does not support multiple levels of parallel nodes.\"\n )\n inputs_for_join_node = {\"inputs\": []}\n for n_id in next_nodes:\n output = self.graph.nodes[n_id][\"component\"].run(**input_dict)\n inputs_for_join_node[\"inputs\"].append(output)\n input_dict = inputs_for_join_node\n current_node_id = join_node_id\n elif len(next_nodes) == 1:\n current_node_id = next_nodes[0]\n else:\n has_next_node = False\n\n return output_dict\n\n def _get_next_nodes(self, node_id: str, stream_id: str):\n current_node_edges = self.graph.edges(node_id, data=True)\n next_nodes = [\n next_node\n for _, next_node, data in current_node_edges\n if not stream_id or data[\"label\"] == stream_id\n ]\n return next_nodes\n\n def draw(self, path: Path = Path(\"pipeline.png\")):\n \"\"\"\n Create a Graphviz visualization of the pipeline.\n\n :param path: the path to save the image.\n \"\"\"\n try:\n import pygraphviz\n except ImportError:\n raise ImportError(f\"Could not import `pygraphviz`. Please install via: \\n\"\n f\"pip install pygraphviz\\n\"\n f\"(You might need to run this first: apt install libgraphviz-dev graphviz )\")\n\n graphviz = to_agraph(self.graph)\n graphviz.layout(\"dot\")\n graphviz.draw(path)\n\n\nclass BaseStandardPipeline:\n pipeline: Pipeline\n\n def add_node(self, component, name: str, inputs: List[str]):\n \"\"\"\n Add a new node to the pipeline.\n\n :param component: The object to be called when the data is passed to the node. It can be a Haystack component\n (like Retriever, Reader, or Generator) or a user-defined object that implements a run()\n method to process incoming data from predecessor node.\n :param name: The name for the node. It must not contain any dots.\n :param inputs: A list of inputs to the node. If the predecessor node has a single outgoing edge, just the name\n of node is sufficient. For instance, a 'ElasticsearchRetriever' node would always output a single\n edge with a list of documents. It can be represented as [\"ElasticsearchRetriever\"].\n\n In cases when the predecessor node has multiple outputs, e.g., a \"QueryClassifier\", the output\n must be specified explicitly as \"QueryClassifier.output_2\".\n \"\"\"\n\n self.pipeline.add_node(component=component, name=name, inputs=inputs)\n\n def get_node(self, name: str):\n \"\"\"\n Get a node from the Pipeline.\n\n :param name: The name of the node.\n \"\"\"\n component = self.pipeline.get_node(name)\n return component\n\n def set_node(self, name: str, component):\n \"\"\"\n Set the component for a node in the Pipeline.\n\n :param name: The name of the node.\n :param component: The component object to be set at the node.\n \"\"\"\n self.pipeline.set_node(name, component)\n\n def draw(self, path: Path = Path(\"pipeline.png\")):\n \"\"\"\n Create a Graphviz visualization of the pipeline.\n\n :param path: the path to save the image.\n \"\"\"\n self.pipeline.draw(path)\n\n\nclass ExtractiveQAPipeline(BaseStandardPipeline):\n def __init__(self, reader: BaseReader, retriever: BaseRetriever):\n \"\"\"\n Initialize a Pipeline for Extractive Question Answering.\n\n :param reader: Reader instance\n :param retriever: Retriever instance\n \"\"\"\n self.pipeline = Pipeline()\n self.pipeline.add_node(component=retriever, name=\"Retriever\", inputs=[\"Query\"])\n self.pipeline.add_node(component=reader, name=\"Reader\", inputs=[\"Retriever\"])\n\n def run(self, query: str, filters: Optional[Dict] = None, top_k_retriever: int = 10, top_k_reader: int = 10):\n output = self.pipeline.run(\n query=query, filters=filters, top_k_retriever=top_k_retriever, top_k_reader=top_k_reader\n )\n return output\n\n\nclass DocumentSearchPipeline(BaseStandardPipeline):\n def __init__(self, retriever: BaseRetriever):\n \"\"\"\n Initialize a Pipeline for semantic document search.\n\n :param retriever: Retriever instance\n \"\"\"\n self.pipeline = Pipeline()\n self.pipeline.add_node(component=retriever, name=\"Retriever\", inputs=[\"Query\"])\n\n def run(self, query: str, filters: Optional[Dict] = None, top_k_retriever: int = 10):\n output = self.pipeline.run(query=query, filters=filters, top_k_retriever=top_k_retriever)\n document_dicts = [doc.to_dict() for doc in output[\"documents\"]]\n output[\"documents\"] = document_dicts\n return output\n\n\nclass GenerativeQAPipeline(BaseStandardPipeline):\n def __init__(self, generator: BaseGenerator, retriever: BaseRetriever):\n \"\"\"\n Initialize a Pipeline for Generative Question Answering.\n\n :param generator: Generator instance\n :param retriever: Retriever instance\n \"\"\"\n self.pipeline = Pipeline()\n self.pipeline.add_node(component=retriever, name=\"Retriever\", inputs=[\"Query\"])\n self.pipeline.add_node(component=generator, name=\"Generator\", inputs=[\"Retriever\"])\n\n def run(self, query: str, filters: Optional[Dict] = None, top_k_retriever: int = 10, top_k_generator: int = 10):\n output = self.pipeline.run(\n query=query, filters=filters, top_k_retriever=top_k_retriever, top_k_generator=top_k_generator\n )\n return output\n\n\nclass FAQPipeline(BaseStandardPipeline):\n def __init__(self, retriever: BaseRetriever):\n \"\"\"\n Initialize a Pipeline for finding similar FAQs using semantic document search.\n\n :param retriever: Retriever instance\n \"\"\"\n self.pipeline = Pipeline()\n self.pipeline.add_node(component=retriever, name=\"Retriever\", inputs=[\"Query\"])\n\n def run(self, query: str, filters: Optional[Dict] = None, top_k_retriever: int = 10):\n output = self.pipeline.run(query=query, filters=filters, top_k_retriever=top_k_retriever)\n documents = output[\"documents\"]\n\n results: Dict = {\"query\": query, \"answers\": []}\n for doc in documents:\n # TODO proper calibratation of pseudo probabilities\n cur_answer = {\n \"query\": doc.text,\n \"answer\": doc.meta[\"answer\"],\n \"document_id\": doc.id,\n \"context\": doc.meta[\"answer\"],\n \"score\": doc.score,\n \"probability\": doc.probability,\n \"offset_start\": 0,\n \"offset_end\": len(doc.meta[\"answer\"]),\n \"meta\": doc.meta,\n }\n\n results[\"answers\"].append(cur_answer)\n\n return results\n\n\nclass QueryNode:\n outgoing_edges = 1\n\n def run(self, **kwargs):\n return kwargs, \"output_1\"\n\n\nclass JoinDocuments:\n \"\"\"\n A node to join documents outputted by multiple retriever nodes.\n\n The node allows multiple join modes:\n * concatenate: combine the documents from multiple nodes. Any duplicate documents are discarded.\n * merge: merge scores of documents from multiple nodes. Optionally, each input score can be given a different\n `weight` & a `top_k` limit can be set. This mode can also be used for \"reranking\" retrieved documents.\n \"\"\"\n\n outgoing_edges = 1\n\n def __init__(\n self, join_mode: str = \"concatenate\", weights: Optional[List[float]] = None, top_k_join: Optional[int] = None\n ):\n \"\"\"\n :param join_mode: `concatenate` to combine documents from multiple retrievers or `merge` to aggregate scores of\n individual documents.\n :param weights: A node-wise list(length of list must be equal to the number of input nodes) of weights for\n adjusting document scores when using the `merge` join_mode. By default, equal weight is given\n to each retriever score. This param is not compatible with the `concatenate` join_mode.\n :param top_k_join: Limit documents to top_k based on the resulting scores of the join.\n \"\"\"\n assert join_mode in [\"concatenate\", \"merge\"], f\"JoinDocuments node does not support '{join_mode}' join_mode.\"\n\n assert not (\n weights is not None and join_mode == \"concatenate\"\n ), \"Weights are not compatible with 'concatenate' join_mode.\"\n self.join_mode = join_mode\n self.weights = weights\n self.top_k = top_k_join\n\n def run(self, **kwargs):\n inputs = kwargs[\"inputs\"]\n\n if self.join_mode == \"concatenate\":\n document_map = {}\n for input_from_node, _ in inputs:\n for doc in input_from_node[\"documents\"]:\n document_map[doc.id] = doc\n elif self.join_mode == \"merge\":\n document_map = {}\n if self.weights:\n weights = self.weights\n else:\n weights = [1/len(inputs)] * len(inputs)\n for (input_from_node, _), weight in zip(inputs, weights):\n for doc in input_from_node[\"documents\"]:\n if document_map.get(doc.id): # document already exists; update score\n document_map[doc.id].score += doc.score * weight\n else: # add the document in map\n document_map[doc.id] = deepcopy(doc)\n document_map[doc.id].score *= weight\n else:\n raise Exception(f\"Invalid join_mode: {self.join_mode}\")\n\n documents = sorted(document_map.values(), key=lambda d: d.score, reverse=True)\n if self.top_k:\n documents = documents[: self.top_k]\n output = {\"query\": inputs[0][0][\"query\"], \"documents\": documents}\n return output, \"output_1\"\n", "path": "haystack/pipeline.py"}]}
| 3,898 | 823 |
gh_patches_debug_18844
|
rasdani/github-patches
|
git_diff
|
Gallopsled__pwntools-2345
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pwn constgrep a throws an exception
Ugh, this seems wrong:
```
root@pwndbg:~# pwn constgrep a
Traceback (most recent call last):
File "/usr/local/bin/pwn", line 8, in <module>
sys.exit(main())
File "/usr/local/lib/python3.10/dist-packages/pwnlib/commandline/main.py", line 58, in main
commands[args.command](args)
File "/usr/local/lib/python3.10/dist-packages/pwnlib/commandline/constgrep.py", line 110, in main
for _, k in sorted(out):
TypeError: '<' not supported between instances of 'Constant' and 'type'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwnlib/commandline/constgrep.py`
Content:
```
1 from __future__ import absolute_import
2 from __future__ import division
3
4 import argparse
5 import functools
6 import re
7
8 import pwnlib.args
9 pwnlib.args.free_form = False
10
11 from pwn import *
12 from pwnlib.commandline import common
13
14 p = common.parser_commands.add_parser(
15 'constgrep',
16 help = "Looking up constants from header files.\n\nExample: constgrep -c freebsd -m ^PROT_ '3 + 4'",
17 description = "Looking up constants from header files.\n\nExample: constgrep -c freebsd -m ^PROT_ '3 + 4'",
18 formatter_class = argparse.RawDescriptionHelpFormatter,
19 )
20
21 p.add_argument(
22 '-e', '--exact',
23 action='store_true',
24 help='Do an exact match for a constant instead of searching for a regex',
25 )
26
27 p.add_argument(
28 'regex',
29 help='The regex matching constant you want to find',
30 )
31
32 p.add_argument(
33 'constant',
34 nargs = '?',
35 default = None,
36 type = safeeval.expr,
37 help = 'The constant to find',
38 )
39
40 p.add_argument(
41 '-i', '--case-insensitive',
42 action = 'store_true',
43 help = 'Search case insensitive',
44 )
45
46 p.add_argument(
47 '-m', '--mask-mode',
48 action = 'store_true',
49 help = 'Instead of searching for a specific constant value, search for values not containing strictly less bits that the given value.',
50 )
51
52 p.add_argument(
53 '-c', '--context',
54 metavar = 'arch_or_os',
55 action = 'append',
56 type = common.context_arg,
57 choices = common.choices,
58 help = 'The os/architecture/endianness/bits the shellcode will run in (default: linux/i386), choose from: %s' % common.choices,
59 )
60
61 def main(args):
62 if args.exact:
63 # This is the simple case
64 print(cpp(args.regex).strip())
65 else:
66 # New we search in the right module.
67 # But first: We find the right module
68 if context.os == 'freebsd':
69 mod = constants.freebsd
70 else:
71 mod = getattr(getattr(constants, context.os), context.arch)
72
73 # Compile the given regex, for optimized lookup
74 if args.case_insensitive:
75 matcher = re.compile(args.regex, re.IGNORECASE)
76 else:
77 matcher = re.compile(args.regex)
78
79 # The found matching constants and the length of the longest string
80 out = []
81 maxlen = 0
82
83 constant = args.constant
84
85 for k in dir(mod):
86 # No python stuff
87 if k.endswith('__') and k.startswith('__'):
88 continue
89
90 # Run the regex
91 if not matcher.search(k):
92 continue
93
94 # Check the constant
95 if constant is not None:
96 val = getattr(mod, k)
97 if args.mask_mode:
98 if constant & val != val:
99 continue
100 else:
101 if constant != val:
102 continue
103
104 # Append it
105 out.append((getattr(mod, k), k))
106 maxlen = max(len(k), maxlen)
107
108 # Output all matching constants
109 for _, k in sorted(out):
110 print('#define %s %s' % (k.ljust(maxlen), cpp(k).strip()))
111
112 # If we are in match_mode, then try to find a combination of
113 # constants that yield the exact given value
114 # We do not want to find combinations using the value 0.
115 if constant and args.mask_mode:
116 mask = constant
117 good = []
118 out = [(v, k) for v, k in out if v != 0]
119
120 while mask and out:
121 cur = out.pop()
122 mask &= ~cur[0]
123 good.append(cur)
124
125 out = [(v, k) for v, k in out if mask & v == v]
126
127 if functools.reduce(lambda x, cur: x | cur[0], good, 0) == constant:
128 print('')
129 print('(%s) == %s' % (' | '.join(k for v, k in good), args.constant))
130
131 if __name__ == '__main__':
132 pwnlib.commandline.common.main(__file__)
133
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pwnlib/commandline/constgrep.py b/pwnlib/commandline/constgrep.py
--- a/pwnlib/commandline/constgrep.py
+++ b/pwnlib/commandline/constgrep.py
@@ -91,9 +91,13 @@
if not matcher.search(k):
continue
+ # Check if the value has proper type
+ val = getattr(mod, k)
+ if not isinstance(val, pwnlib.constants.constant.Constant):
+ continue
+
# Check the constant
if constant is not None:
- val = getattr(mod, k)
if args.mask_mode:
if constant & val != val:
continue
@@ -102,7 +106,7 @@
continue
# Append it
- out.append((getattr(mod, k), k))
+ out.append((val, k))
maxlen = max(len(k), maxlen)
# Output all matching constants
|
{"golden_diff": "diff --git a/pwnlib/commandline/constgrep.py b/pwnlib/commandline/constgrep.py\n--- a/pwnlib/commandline/constgrep.py\n+++ b/pwnlib/commandline/constgrep.py\n@@ -91,9 +91,13 @@\n if not matcher.search(k):\n continue\n \n+ # Check if the value has proper type\n+ val = getattr(mod, k)\n+ if not isinstance(val, pwnlib.constants.constant.Constant):\n+ continue\n+\n # Check the constant\n if constant is not None:\n- val = getattr(mod, k)\n if args.mask_mode:\n if constant & val != val:\n continue\n@@ -102,7 +106,7 @@\n continue\n \n # Append it\n- out.append((getattr(mod, k), k))\n+ out.append((val, k))\n maxlen = max(len(k), maxlen)\n \n # Output all matching constants\n", "issue": "pwn constgrep a throws an exception\nUgh, this seems wrong:\r\n\r\n```\r\nroot@pwndbg:~# pwn constgrep a\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/pwn\", line 8, in <module>\r\n sys.exit(main())\r\n File \"/usr/local/lib/python3.10/dist-packages/pwnlib/commandline/main.py\", line 58, in main\r\n commands[args.command](args)\r\n File \"/usr/local/lib/python3.10/dist-packages/pwnlib/commandline/constgrep.py\", line 110, in main\r\n for _, k in sorted(out):\r\nTypeError: '<' not supported between instances of 'Constant' and 'type'\r\n```\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import division\n\nimport argparse\nimport functools\nimport re\n\nimport pwnlib.args\npwnlib.args.free_form = False\n\nfrom pwn import *\nfrom pwnlib.commandline import common\n\np = common.parser_commands.add_parser(\n 'constgrep',\n help = \"Looking up constants from header files.\\n\\nExample: constgrep -c freebsd -m ^PROT_ '3 + 4'\",\n description = \"Looking up constants from header files.\\n\\nExample: constgrep -c freebsd -m ^PROT_ '3 + 4'\",\n formatter_class = argparse.RawDescriptionHelpFormatter,\n)\n\np.add_argument(\n '-e', '--exact',\n action='store_true',\n help='Do an exact match for a constant instead of searching for a regex',\n)\n\np.add_argument(\n 'regex',\n help='The regex matching constant you want to find',\n)\n\np.add_argument(\n 'constant',\n nargs = '?',\n default = None,\n type = safeeval.expr,\n help = 'The constant to find',\n)\n\np.add_argument(\n '-i', '--case-insensitive',\n action = 'store_true',\n help = 'Search case insensitive',\n)\n\np.add_argument(\n '-m', '--mask-mode',\n action = 'store_true',\n help = 'Instead of searching for a specific constant value, search for values not containing strictly less bits that the given value.',\n)\n\np.add_argument(\n '-c', '--context',\n metavar = 'arch_or_os',\n action = 'append',\n type = common.context_arg,\n choices = common.choices,\n help = 'The os/architecture/endianness/bits the shellcode will run in (default: linux/i386), choose from: %s' % common.choices,\n)\n\ndef main(args):\n if args.exact:\n # This is the simple case\n print(cpp(args.regex).strip())\n else:\n # New we search in the right module.\n # But first: We find the right module\n if context.os == 'freebsd':\n mod = constants.freebsd\n else:\n mod = getattr(getattr(constants, context.os), context.arch)\n\n # Compile the given regex, for optimized lookup\n if args.case_insensitive:\n matcher = re.compile(args.regex, re.IGNORECASE)\n else:\n matcher = re.compile(args.regex)\n\n # The found matching constants and the length of the longest string\n out = []\n maxlen = 0\n\n constant = args.constant\n\n for k in dir(mod):\n # No python stuff\n if k.endswith('__') and k.startswith('__'):\n continue\n\n # Run the regex\n if not matcher.search(k):\n continue\n\n # Check the constant\n if constant is not None:\n val = getattr(mod, k)\n if args.mask_mode:\n if constant & val != val:\n continue\n else:\n if constant != val:\n continue\n\n # Append it\n out.append((getattr(mod, k), k))\n maxlen = max(len(k), maxlen)\n\n # Output all matching constants\n for _, k in sorted(out):\n print('#define %s %s' % (k.ljust(maxlen), cpp(k).strip()))\n\n # If we are in match_mode, then try to find a combination of\n # constants that yield the exact given value\n # We do not want to find combinations using the value 0.\n if constant and args.mask_mode:\n mask = constant\n good = []\n out = [(v, k) for v, k in out if v != 0]\n\n while mask and out:\n cur = out.pop()\n mask &= ~cur[0]\n good.append(cur)\n\n out = [(v, k) for v, k in out if mask & v == v]\n\n if functools.reduce(lambda x, cur: x | cur[0], good, 0) == constant:\n print('')\n print('(%s) == %s' % (' | '.join(k for v, k in good), args.constant))\n\nif __name__ == '__main__':\n pwnlib.commandline.common.main(__file__)\n", "path": "pwnlib/commandline/constgrep.py"}], "after_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import division\n\nimport argparse\nimport functools\nimport re\n\nimport pwnlib.args\npwnlib.args.free_form = False\n\nfrom pwn import *\nfrom pwnlib.commandline import common\n\np = common.parser_commands.add_parser(\n 'constgrep',\n help = \"Looking up constants from header files.\\n\\nExample: constgrep -c freebsd -m ^PROT_ '3 + 4'\",\n description = \"Looking up constants from header files.\\n\\nExample: constgrep -c freebsd -m ^PROT_ '3 + 4'\",\n formatter_class = argparse.RawDescriptionHelpFormatter,\n)\n\np.add_argument(\n '-e', '--exact',\n action='store_true',\n help='Do an exact match for a constant instead of searching for a regex',\n)\n\np.add_argument(\n 'regex',\n help='The regex matching constant you want to find',\n)\n\np.add_argument(\n 'constant',\n nargs = '?',\n default = None,\n type = safeeval.expr,\n help = 'The constant to find',\n)\n\np.add_argument(\n '-i', '--case-insensitive',\n action = 'store_true',\n help = 'Search case insensitive',\n)\n\np.add_argument(\n '-m', '--mask-mode',\n action = 'store_true',\n help = 'Instead of searching for a specific constant value, search for values not containing strictly less bits that the given value.',\n)\n\np.add_argument(\n '-c', '--context',\n metavar = 'arch_or_os',\n action = 'append',\n type = common.context_arg,\n choices = common.choices,\n help = 'The os/architecture/endianness/bits the shellcode will run in (default: linux/i386), choose from: %s' % common.choices,\n)\n\ndef main(args):\n if args.exact:\n # This is the simple case\n print(cpp(args.regex).strip())\n else:\n # New we search in the right module.\n # But first: We find the right module\n if context.os == 'freebsd':\n mod = constants.freebsd\n else:\n mod = getattr(getattr(constants, context.os), context.arch)\n\n # Compile the given regex, for optimized lookup\n if args.case_insensitive:\n matcher = re.compile(args.regex, re.IGNORECASE)\n else:\n matcher = re.compile(args.regex)\n\n # The found matching constants and the length of the longest string\n out = []\n maxlen = 0\n\n constant = args.constant\n\n for k in dir(mod):\n # No python stuff\n if k.endswith('__') and k.startswith('__'):\n continue\n\n # Run the regex\n if not matcher.search(k):\n continue\n\n # Check if the value has proper type\n val = getattr(mod, k)\n if not isinstance(val, pwnlib.constants.constant.Constant):\n continue\n\n # Check the constant\n if constant is not None:\n if args.mask_mode:\n if constant & val != val:\n continue\n else:\n if constant != val:\n continue\n\n # Append it\n out.append((val, k))\n maxlen = max(len(k), maxlen)\n\n # Output all matching constants\n for _, k in sorted(out):\n print('#define %s %s' % (k.ljust(maxlen), cpp(k).strip()))\n\n # If we are in match_mode, then try to find a combination of\n # constants that yield the exact given value\n # We do not want to find combinations using the value 0.\n if constant and args.mask_mode:\n mask = constant\n good = []\n out = [(v, k) for v, k in out if v != 0]\n\n while mask and out:\n cur = out.pop()\n mask &= ~cur[0]\n good.append(cur)\n\n out = [(v, k) for v, k in out if mask & v == v]\n\n if functools.reduce(lambda x, cur: x | cur[0], good, 0) == constant:\n print('')\n print('(%s) == %s' % (' | '.join(k for v, k in good), args.constant))\n\nif __name__ == '__main__':\n pwnlib.commandline.common.main(__file__)\n", "path": "pwnlib/commandline/constgrep.py"}]}
| 1,630 | 209 |
gh_patches_debug_35914
|
rasdani/github-patches
|
git_diff
|
pwndbg__pwndbg-1198
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`telescope -r <num>` is broken
```
pwndbg> telescope -r 30
Traceback (most recent call last):
File "/home/gsgx/code/pwndbg/pwndbg/commands/__init__.py", line 145, in __call__
return self.function(*args, **kwargs)
File "/home/gsgx/code/pwndbg/pwndbg/commands/__init__.py", line 216, in _OnlyWhenRunning
return function(*a, **kw)
File "/home/gsgx/code/pwndbg/pwndbg/commands/telescope.py", line 191, in telescope
telescope.offset += i
UnboundLocalError: local variable 'i' referenced before assignment
```
`telescope -r` works fine though.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwndbg/commands/telescope.py`
Content:
```
1 """
2 Prints out pointer chains starting at some address in memory.
3
4 Generally used to print out the stack or register values.
5 """
6
7 import argparse
8 import collections
9 import math
10
11 import pwndbg.chain
12 import pwndbg.color.telescope as T
13 import pwndbg.color.theme as theme
14 import pwndbg.commands
15 import pwndbg.config
16 import pwndbg.gdblib.arch
17 import pwndbg.gdblib.memory
18 import pwndbg.gdblib.regs
19 import pwndbg.gdblib.typeinfo
20
21 telescope_lines = pwndbg.config.Parameter(
22 "telescope-lines", 8, "number of lines to printed by the telescope command"
23 )
24 skip_repeating_values = pwndbg.config.Parameter(
25 "telescope-skip-repeating-val",
26 True,
27 "whether to skip repeating values of the telescope command",
28 )
29 skip_repeating_values_minimum = pwndbg.config.Parameter(
30 "telescope-skip-repeating-val-minimum",
31 3,
32 "minimum amount of repeated values before skipping lines",
33 )
34
35 offset_separator = theme.Parameter(
36 "telescope-offset-separator", "│", "offset separator of the telescope command"
37 )
38 offset_delimiter = theme.Parameter(
39 "telescope-offset-delimiter", ":", "offset delimiter of the telescope command"
40 )
41 repeating_marker = theme.Parameter(
42 "telescope-repeating-marker", "... ↓", "repeating values marker of the telescope command"
43 )
44
45
46 parser = argparse.ArgumentParser(
47 description="""
48 Recursively dereferences pointers starting at the specified address
49 ($sp by default)
50 """
51 )
52 parser.add_argument(
53 "address", nargs="?", default=None, type=int, help="The address to telescope at."
54 )
55 parser.add_argument(
56 "count", nargs="?", default=telescope_lines, type=int, help="The number of lines to show."
57 )
58 parser.add_argument(
59 "-r",
60 "--reverse",
61 dest="reverse",
62 action="store_true",
63 default=False,
64 help="Show <count> previous addresses instead of next ones",
65 )
66
67
68 @pwndbg.commands.ArgparsedCommand(parser)
69 @pwndbg.commands.OnlyWhenRunning
70 def telescope(address=None, count=telescope_lines, to_string=False, reverse=False):
71 """
72 Recursively dereferences pointers starting at the specified address
73 ($sp by default)
74 """
75 ptrsize = pwndbg.gdblib.typeinfo.ptrsize
76 if telescope.repeat:
77 address = telescope.last_address + ptrsize
78 telescope.offset += 1
79 else:
80 telescope.offset = 0
81
82 address = int(address if address else pwndbg.gdblib.regs.sp) & pwndbg.gdblib.arch.ptrmask
83 count = max(int(count), 1) & pwndbg.gdblib.arch.ptrmask
84 delimiter = T.delimiter(offset_delimiter)
85 separator = T.separator(offset_separator)
86
87 # Allow invocation of telescope -r to dump previous addresses
88 if reverse:
89 address -= (count - 1) * ptrsize
90
91 # Allow invocation of "telescope 20" to dump 20 bytes at the stack pointer
92 if address < pwndbg.gdblib.memory.MMAP_MIN_ADDR and not pwndbg.gdblib.memory.peek(address):
93 count = address
94 address = pwndbg.gdblib.regs.sp
95
96 # Allow invocation of "telescope a b" to dump all bytes from A to B
97 if int(address) <= int(count):
98 # adjust count if it is an address. use ceil division as count is number of
99 # ptrsize values and we don't want to strip out a value if dest is unaligned
100 count -= address
101 count = max(math.ceil(count / ptrsize), 1)
102
103 reg_values = collections.defaultdict(lambda: [])
104 for reg in pwndbg.gdblib.regs.common:
105 reg_values[pwndbg.gdblib.regs[reg]].append(reg)
106 # address = pwndbg.gdblib.memory.poi(pwndbg.gdblib.typeinfo.ppvoid, address)
107
108 start = address
109 stop = address + (count * ptrsize)
110 step = ptrsize
111
112 # Find all registers which show up in the trace
113 regs = {}
114 for i in range(start, stop, step):
115 values = list(reg_values[i])
116
117 for width in range(1, pwndbg.gdblib.arch.ptrsize):
118 values.extend("%s-%i" % (r, width) for r in reg_values[i + width])
119
120 regs[i] = " ".join(values)
121
122 # Find the longest set of register information
123 if regs:
124 longest_regs = max(map(len, regs.values()))
125 else:
126 longest_regs = 0
127
128 # Print everything out
129 result = []
130 last = None
131 collapse_buffer = []
132 skipped_padding = (
133 2
134 + len(offset_delimiter)
135 + 4
136 + len(offset_separator)
137 + 1
138 + longest_regs
139 + 1
140 - len(repeating_marker)
141 )
142
143 # Collapse repeating values exceeding minimum delta.
144 def collapse_repeating_values():
145 # The first line was already printed, hence increment by 1
146 if collapse_buffer and len(collapse_buffer) + 1 >= skip_repeating_values_minimum:
147 result.append(
148 T.repeating_marker(
149 "%s%s%i skipped"
150 % (repeating_marker, " " * skipped_padding, len(collapse_buffer))
151 )
152 )
153 else:
154 result.extend(collapse_buffer)
155 collapse_buffer.clear()
156
157 for i, addr in enumerate(range(start, stop, step)):
158 if not pwndbg.gdblib.memory.peek(addr):
159 collapse_repeating_values()
160 result.append("<Could not read memory at %#x>" % addr)
161 break
162
163 line = " ".join(
164 (
165 T.offset(
166 "%02x%s%04x%s"
167 % (
168 i + telescope.offset,
169 delimiter,
170 addr - start + (telescope.offset * ptrsize),
171 separator,
172 )
173 ),
174 T.register(regs[addr].ljust(longest_regs)),
175 pwndbg.chain.format(addr),
176 )
177 )
178
179 # Buffer repeating values.
180 if skip_repeating_values:
181 value = pwndbg.gdblib.memory.pvoid(addr)
182 if last == value:
183 collapse_buffer.append(line)
184 continue
185 collapse_repeating_values()
186 last = value
187
188 result.append(line)
189
190 collapse_repeating_values()
191 telescope.offset += i
192 telescope.last_address = addr
193
194 if not to_string:
195 print("\n".join(result))
196
197 return result
198
199
200 parser = argparse.ArgumentParser(
201 description="dereferences on stack data with specified count and offset."
202 )
203 parser.add_argument("count", nargs="?", default=8, type=int, help="number of element to dump")
204 parser.add_argument(
205 "offset",
206 nargs="?",
207 default=0,
208 type=int,
209 help="Element offset from $sp (support negative offset)",
210 )
211
212
213 @pwndbg.commands.ArgparsedCommand(parser)
214 @pwndbg.commands.OnlyWhenRunning
215 def stack(count, offset):
216 ptrsize = pwndbg.gdblib.typeinfo.ptrsize
217 telescope.repeat = stack.repeat
218 telescope(address=pwndbg.gdblib.regs.sp + offset * ptrsize, count=count)
219
220
221 telescope.last_address = 0
222 telescope.offset = 0
223
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pwndbg/commands/telescope.py b/pwndbg/commands/telescope.py
--- a/pwndbg/commands/telescope.py
+++ b/pwndbg/commands/telescope.py
@@ -49,12 +49,6 @@
($sp by default)
"""
)
-parser.add_argument(
- "address", nargs="?", default=None, type=int, help="The address to telescope at."
-)
-parser.add_argument(
- "count", nargs="?", default=telescope_lines, type=int, help="The number of lines to show."
-)
parser.add_argument(
"-r",
"--reverse",
@@ -64,6 +58,14 @@
help="Show <count> previous addresses instead of next ones",
)
+parser.add_argument(
+ "address", nargs="?", default=None, type=int, help="The address to telescope at."
+)
+
+parser.add_argument(
+ "count", nargs="?", default=telescope_lines, type=int, help="The number of lines to show."
+)
+
@pwndbg.commands.ArgparsedCommand(parser)
@pwndbg.commands.OnlyWhenRunning
@@ -84,15 +86,15 @@
delimiter = T.delimiter(offset_delimiter)
separator = T.separator(offset_separator)
- # Allow invocation of telescope -r to dump previous addresses
- if reverse:
- address -= (count - 1) * ptrsize
-
# Allow invocation of "telescope 20" to dump 20 bytes at the stack pointer
if address < pwndbg.gdblib.memory.MMAP_MIN_ADDR and not pwndbg.gdblib.memory.peek(address):
count = address
address = pwndbg.gdblib.regs.sp
+ # Allow invocation of telescope -r to dump previous addresses
+ if reverse:
+ address -= (count - 1) * ptrsize
+
# Allow invocation of "telescope a b" to dump all bytes from A to B
if int(address) <= int(count):
# adjust count if it is an address. use ceil division as count is number of
@@ -103,7 +105,6 @@
reg_values = collections.defaultdict(lambda: [])
for reg in pwndbg.gdblib.regs.common:
reg_values[pwndbg.gdblib.regs[reg]].append(reg)
- # address = pwndbg.gdblib.memory.poi(pwndbg.gdblib.typeinfo.ppvoid, address)
start = address
stop = address + (count * ptrsize)
|
{"golden_diff": "diff --git a/pwndbg/commands/telescope.py b/pwndbg/commands/telescope.py\n--- a/pwndbg/commands/telescope.py\n+++ b/pwndbg/commands/telescope.py\n@@ -49,12 +49,6 @@\n ($sp by default)\n \"\"\"\n )\n-parser.add_argument(\n- \"address\", nargs=\"?\", default=None, type=int, help=\"The address to telescope at.\"\n-)\n-parser.add_argument(\n- \"count\", nargs=\"?\", default=telescope_lines, type=int, help=\"The number of lines to show.\"\n-)\n parser.add_argument(\n \"-r\",\n \"--reverse\",\n@@ -64,6 +58,14 @@\n help=\"Show <count> previous addresses instead of next ones\",\n )\n \n+parser.add_argument(\n+ \"address\", nargs=\"?\", default=None, type=int, help=\"The address to telescope at.\"\n+)\n+\n+parser.add_argument(\n+ \"count\", nargs=\"?\", default=telescope_lines, type=int, help=\"The number of lines to show.\"\n+)\n+\n \n @pwndbg.commands.ArgparsedCommand(parser)\n @pwndbg.commands.OnlyWhenRunning\n@@ -84,15 +86,15 @@\n delimiter = T.delimiter(offset_delimiter)\n separator = T.separator(offset_separator)\n \n- # Allow invocation of telescope -r to dump previous addresses\n- if reverse:\n- address -= (count - 1) * ptrsize\n-\n # Allow invocation of \"telescope 20\" to dump 20 bytes at the stack pointer\n if address < pwndbg.gdblib.memory.MMAP_MIN_ADDR and not pwndbg.gdblib.memory.peek(address):\n count = address\n address = pwndbg.gdblib.regs.sp\n \n+ # Allow invocation of telescope -r to dump previous addresses\n+ if reverse:\n+ address -= (count - 1) * ptrsize\n+\n # Allow invocation of \"telescope a b\" to dump all bytes from A to B\n if int(address) <= int(count):\n # adjust count if it is an address. use ceil division as count is number of\n@@ -103,7 +105,6 @@\n reg_values = collections.defaultdict(lambda: [])\n for reg in pwndbg.gdblib.regs.common:\n reg_values[pwndbg.gdblib.regs[reg]].append(reg)\n- # address = pwndbg.gdblib.memory.poi(pwndbg.gdblib.typeinfo.ppvoid, address)\n \n start = address\n stop = address + (count * ptrsize)\n", "issue": "`telescope -r <num>` is broken\n```\r\npwndbg> telescope -r 30\r\nTraceback (most recent call last):\r\n File \"/home/gsgx/code/pwndbg/pwndbg/commands/__init__.py\", line 145, in __call__\r\n return self.function(*args, **kwargs)\r\n File \"/home/gsgx/code/pwndbg/pwndbg/commands/__init__.py\", line 216, in _OnlyWhenRunning\r\n return function(*a, **kw)\r\n File \"/home/gsgx/code/pwndbg/pwndbg/commands/telescope.py\", line 191, in telescope\r\n telescope.offset += i\r\nUnboundLocalError: local variable 'i' referenced before assignment\r\n```\r\n`telescope -r` works fine though.\n", "before_files": [{"content": "\"\"\"\nPrints out pointer chains starting at some address in memory.\n\nGenerally used to print out the stack or register values.\n\"\"\"\n\nimport argparse\nimport collections\nimport math\n\nimport pwndbg.chain\nimport pwndbg.color.telescope as T\nimport pwndbg.color.theme as theme\nimport pwndbg.commands\nimport pwndbg.config\nimport pwndbg.gdblib.arch\nimport pwndbg.gdblib.memory\nimport pwndbg.gdblib.regs\nimport pwndbg.gdblib.typeinfo\n\ntelescope_lines = pwndbg.config.Parameter(\n \"telescope-lines\", 8, \"number of lines to printed by the telescope command\"\n)\nskip_repeating_values = pwndbg.config.Parameter(\n \"telescope-skip-repeating-val\",\n True,\n \"whether to skip repeating values of the telescope command\",\n)\nskip_repeating_values_minimum = pwndbg.config.Parameter(\n \"telescope-skip-repeating-val-minimum\",\n 3,\n \"minimum amount of repeated values before skipping lines\",\n)\n\noffset_separator = theme.Parameter(\n \"telescope-offset-separator\", \"\u2502\", \"offset separator of the telescope command\"\n)\noffset_delimiter = theme.Parameter(\n \"telescope-offset-delimiter\", \":\", \"offset delimiter of the telescope command\"\n)\nrepeating_marker = theme.Parameter(\n \"telescope-repeating-marker\", \"... \u2193\", \"repeating values marker of the telescope command\"\n)\n\n\nparser = argparse.ArgumentParser(\n description=\"\"\"\n Recursively dereferences pointers starting at the specified address\n ($sp by default)\n \"\"\"\n)\nparser.add_argument(\n \"address\", nargs=\"?\", default=None, type=int, help=\"The address to telescope at.\"\n)\nparser.add_argument(\n \"count\", nargs=\"?\", default=telescope_lines, type=int, help=\"The number of lines to show.\"\n)\nparser.add_argument(\n \"-r\",\n \"--reverse\",\n dest=\"reverse\",\n action=\"store_true\",\n default=False,\n help=\"Show <count> previous addresses instead of next ones\",\n)\n\n\[email protected](parser)\[email protected]\ndef telescope(address=None, count=telescope_lines, to_string=False, reverse=False):\n \"\"\"\n Recursively dereferences pointers starting at the specified address\n ($sp by default)\n \"\"\"\n ptrsize = pwndbg.gdblib.typeinfo.ptrsize\n if telescope.repeat:\n address = telescope.last_address + ptrsize\n telescope.offset += 1\n else:\n telescope.offset = 0\n\n address = int(address if address else pwndbg.gdblib.regs.sp) & pwndbg.gdblib.arch.ptrmask\n count = max(int(count), 1) & pwndbg.gdblib.arch.ptrmask\n delimiter = T.delimiter(offset_delimiter)\n separator = T.separator(offset_separator)\n\n # Allow invocation of telescope -r to dump previous addresses\n if reverse:\n address -= (count - 1) * ptrsize\n\n # Allow invocation of \"telescope 20\" to dump 20 bytes at the stack pointer\n if address < pwndbg.gdblib.memory.MMAP_MIN_ADDR and not pwndbg.gdblib.memory.peek(address):\n count = address\n address = pwndbg.gdblib.regs.sp\n\n # Allow invocation of \"telescope a b\" to dump all bytes from A to B\n if int(address) <= int(count):\n # adjust count if it is an address. use ceil division as count is number of\n # ptrsize values and we don't want to strip out a value if dest is unaligned\n count -= address\n count = max(math.ceil(count / ptrsize), 1)\n\n reg_values = collections.defaultdict(lambda: [])\n for reg in pwndbg.gdblib.regs.common:\n reg_values[pwndbg.gdblib.regs[reg]].append(reg)\n # address = pwndbg.gdblib.memory.poi(pwndbg.gdblib.typeinfo.ppvoid, address)\n\n start = address\n stop = address + (count * ptrsize)\n step = ptrsize\n\n # Find all registers which show up in the trace\n regs = {}\n for i in range(start, stop, step):\n values = list(reg_values[i])\n\n for width in range(1, pwndbg.gdblib.arch.ptrsize):\n values.extend(\"%s-%i\" % (r, width) for r in reg_values[i + width])\n\n regs[i] = \" \".join(values)\n\n # Find the longest set of register information\n if regs:\n longest_regs = max(map(len, regs.values()))\n else:\n longest_regs = 0\n\n # Print everything out\n result = []\n last = None\n collapse_buffer = []\n skipped_padding = (\n 2\n + len(offset_delimiter)\n + 4\n + len(offset_separator)\n + 1\n + longest_regs\n + 1\n - len(repeating_marker)\n )\n\n # Collapse repeating values exceeding minimum delta.\n def collapse_repeating_values():\n # The first line was already printed, hence increment by 1\n if collapse_buffer and len(collapse_buffer) + 1 >= skip_repeating_values_minimum:\n result.append(\n T.repeating_marker(\n \"%s%s%i skipped\"\n % (repeating_marker, \" \" * skipped_padding, len(collapse_buffer))\n )\n )\n else:\n result.extend(collapse_buffer)\n collapse_buffer.clear()\n\n for i, addr in enumerate(range(start, stop, step)):\n if not pwndbg.gdblib.memory.peek(addr):\n collapse_repeating_values()\n result.append(\"<Could not read memory at %#x>\" % addr)\n break\n\n line = \" \".join(\n (\n T.offset(\n \"%02x%s%04x%s\"\n % (\n i + telescope.offset,\n delimiter,\n addr - start + (telescope.offset * ptrsize),\n separator,\n )\n ),\n T.register(regs[addr].ljust(longest_regs)),\n pwndbg.chain.format(addr),\n )\n )\n\n # Buffer repeating values.\n if skip_repeating_values:\n value = pwndbg.gdblib.memory.pvoid(addr)\n if last == value:\n collapse_buffer.append(line)\n continue\n collapse_repeating_values()\n last = value\n\n result.append(line)\n\n collapse_repeating_values()\n telescope.offset += i\n telescope.last_address = addr\n\n if not to_string:\n print(\"\\n\".join(result))\n\n return result\n\n\nparser = argparse.ArgumentParser(\n description=\"dereferences on stack data with specified count and offset.\"\n)\nparser.add_argument(\"count\", nargs=\"?\", default=8, type=int, help=\"number of element to dump\")\nparser.add_argument(\n \"offset\",\n nargs=\"?\",\n default=0,\n type=int,\n help=\"Element offset from $sp (support negative offset)\",\n)\n\n\[email protected](parser)\[email protected]\ndef stack(count, offset):\n ptrsize = pwndbg.gdblib.typeinfo.ptrsize\n telescope.repeat = stack.repeat\n telescope(address=pwndbg.gdblib.regs.sp + offset * ptrsize, count=count)\n\n\ntelescope.last_address = 0\ntelescope.offset = 0\n", "path": "pwndbg/commands/telescope.py"}], "after_files": [{"content": "\"\"\"\nPrints out pointer chains starting at some address in memory.\n\nGenerally used to print out the stack or register values.\n\"\"\"\n\nimport argparse\nimport collections\nimport math\n\nimport pwndbg.chain\nimport pwndbg.color.telescope as T\nimport pwndbg.color.theme as theme\nimport pwndbg.commands\nimport pwndbg.config\nimport pwndbg.gdblib.arch\nimport pwndbg.gdblib.memory\nimport pwndbg.gdblib.regs\nimport pwndbg.gdblib.typeinfo\n\ntelescope_lines = pwndbg.config.Parameter(\n \"telescope-lines\", 8, \"number of lines to printed by the telescope command\"\n)\nskip_repeating_values = pwndbg.config.Parameter(\n \"telescope-skip-repeating-val\",\n True,\n \"whether to skip repeating values of the telescope command\",\n)\nskip_repeating_values_minimum = pwndbg.config.Parameter(\n \"telescope-skip-repeating-val-minimum\",\n 3,\n \"minimum amount of repeated values before skipping lines\",\n)\n\noffset_separator = theme.Parameter(\n \"telescope-offset-separator\", \"\u2502\", \"offset separator of the telescope command\"\n)\noffset_delimiter = theme.Parameter(\n \"telescope-offset-delimiter\", \":\", \"offset delimiter of the telescope command\"\n)\nrepeating_marker = theme.Parameter(\n \"telescope-repeating-marker\", \"... \u2193\", \"repeating values marker of the telescope command\"\n)\n\n\nparser = argparse.ArgumentParser(\n description=\"\"\"\n Recursively dereferences pointers starting at the specified address\n ($sp by default)\n \"\"\"\n)\nparser.add_argument(\n \"-r\",\n \"--reverse\",\n dest=\"reverse\",\n action=\"store_true\",\n default=False,\n help=\"Show <count> previous addresses instead of next ones\",\n)\n\nparser.add_argument(\n \"address\", nargs=\"?\", default=None, type=int, help=\"The address to telescope at.\"\n)\n\nparser.add_argument(\n \"count\", nargs=\"?\", default=telescope_lines, type=int, help=\"The number of lines to show.\"\n)\n\n\[email protected](parser)\[email protected]\ndef telescope(address=None, count=telescope_lines, to_string=False, reverse=False):\n \"\"\"\n Recursively dereferences pointers starting at the specified address\n ($sp by default)\n \"\"\"\n ptrsize = pwndbg.gdblib.typeinfo.ptrsize\n if telescope.repeat:\n address = telescope.last_address + ptrsize\n telescope.offset += 1\n else:\n telescope.offset = 0\n\n address = int(address if address else pwndbg.gdblib.regs.sp) & pwndbg.gdblib.arch.ptrmask\n count = max(int(count), 1) & pwndbg.gdblib.arch.ptrmask\n delimiter = T.delimiter(offset_delimiter)\n separator = T.separator(offset_separator)\n\n # Allow invocation of \"telescope 20\" to dump 20 bytes at the stack pointer\n if address < pwndbg.gdblib.memory.MMAP_MIN_ADDR and not pwndbg.gdblib.memory.peek(address):\n count = address\n address = pwndbg.gdblib.regs.sp\n\n # Allow invocation of telescope -r to dump previous addresses\n if reverse:\n address -= (count - 1) * ptrsize\n\n # Allow invocation of \"telescope a b\" to dump all bytes from A to B\n if int(address) <= int(count):\n # adjust count if it is an address. use ceil division as count is number of\n # ptrsize values and we don't want to strip out a value if dest is unaligned\n count -= address\n count = max(math.ceil(count / ptrsize), 1)\n\n reg_values = collections.defaultdict(lambda: [])\n for reg in pwndbg.gdblib.regs.common:\n reg_values[pwndbg.gdblib.regs[reg]].append(reg)\n\n start = address\n stop = address + (count * ptrsize)\n step = ptrsize\n\n # Find all registers which show up in the trace\n regs = {}\n for i in range(start, stop, step):\n values = list(reg_values[i])\n\n for width in range(1, pwndbg.gdblib.arch.ptrsize):\n values.extend(\"%s-%i\" % (r, width) for r in reg_values[i + width])\n\n regs[i] = \" \".join(values)\n\n # Find the longest set of register information\n if regs:\n longest_regs = max(map(len, regs.values()))\n else:\n longest_regs = 0\n\n # Print everything out\n result = []\n last = None\n collapse_buffer = []\n skipped_padding = (\n 2\n + len(offset_delimiter)\n + 4\n + len(offset_separator)\n + 1\n + longest_regs\n + 1\n - len(repeating_marker)\n )\n\n # Collapse repeating values exceeding minimum delta.\n def collapse_repeating_values():\n # The first line was already printed, hence increment by 1\n if collapse_buffer and len(collapse_buffer) + 1 >= skip_repeating_values_minimum:\n result.append(\n T.repeating_marker(\n \"%s%s%i skipped\"\n % (repeating_marker, \" \" * skipped_padding, len(collapse_buffer))\n )\n )\n else:\n result.extend(collapse_buffer)\n collapse_buffer.clear()\n\n for i, addr in enumerate(range(start, stop, step)):\n if not pwndbg.gdblib.memory.peek(addr):\n collapse_repeating_values()\n result.append(\"<Could not read memory at %#x>\" % addr)\n break\n\n line = \" \".join(\n (\n T.offset(\n \"%02x%s%04x%s\"\n % (\n i + telescope.offset,\n delimiter,\n addr - start + (telescope.offset * ptrsize),\n separator,\n )\n ),\n T.register(regs[addr].ljust(longest_regs)),\n pwndbg.chain.format(addr),\n )\n )\n\n # Buffer repeating values.\n if skip_repeating_values:\n value = pwndbg.gdblib.memory.pvoid(addr)\n if last == value:\n collapse_buffer.append(line)\n continue\n collapse_repeating_values()\n last = value\n\n result.append(line)\n\n collapse_repeating_values()\n telescope.offset += i\n telescope.last_address = addr\n\n if not to_string:\n print(\"\\n\".join(result))\n\n return result\n\n\nparser = argparse.ArgumentParser(\n description=\"dereferences on stack data with specified count and offset.\"\n)\nparser.add_argument(\"count\", nargs=\"?\", default=8, type=int, help=\"number of element to dump\")\nparser.add_argument(\n \"offset\",\n nargs=\"?\",\n default=0,\n type=int,\n help=\"Element offset from $sp (support negative offset)\",\n)\n\n\[email protected](parser)\[email protected]\ndef stack(count, offset):\n ptrsize = pwndbg.gdblib.typeinfo.ptrsize\n telescope.repeat = stack.repeat\n telescope(address=pwndbg.gdblib.regs.sp + offset * ptrsize, count=count)\n\n\ntelescope.last_address = 0\ntelescope.offset = 0\n", "path": "pwndbg/commands/telescope.py"}]}
| 2,595 | 572 |
gh_patches_debug_25913
|
rasdani/github-patches
|
git_diff
|
beeware__toga-1893
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add a `clear()` method to remove all children
### What is the problem or limitation you are having?
At present, you can:
* add a single child to a widget (`widget.add(child)`)
* remove a single child to a widget (`widget.remove(child)`)
* add multiple children to a widget in a single call (`widget.add(child1, child2)`)
* Remove multiple children from a widget in a single call (`widget.remove(child1, child2)`)
However, there is no API to remove *all* children from a node.
### Describe the solution you'd like
`widget.clear()` should remove all children from a widget. As of Travertino 0.2.0, a `clear()` API exists; however, invoking it could have unexpected consequences, as it doesn't include the Toga-side cleanups implied by this change.
### Describe alternatives you've considered
`widget.remove(*widget.children)` is a workaround at present, but isn't a great API.
### Additional context
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/src/toga/widgets/base.py`
Content:
```
1 from builtins import id as identifier
2
3 from travertino.node import Node
4
5 from toga.platform import get_platform_factory
6 from toga.style import Pack, TogaApplicator
7
8
9 class WidgetRegistry(dict):
10 # WidgetRegistry is implemented as a subclass of dict, because it provides
11 # a mapping from ID to widget. However, it exposes a set-like API; add()
12 # and update() take instances to be added, and iteration is over values.
13
14 def __init__(self, *args, **kwargs):
15 super().__init__(*args, **kwargs)
16
17 def __setitem__(self, key, value):
18 # We do not want to allow setting items directly but to use the "add"
19 # method instead.
20 raise RuntimeError("Widgets cannot be directly added to a registry")
21
22 def update(self, widgets):
23 for widget in widgets:
24 self.add(widget)
25
26 def add(self, widget):
27 if widget.id in self:
28 # Prevent from adding the same widget twice
29 # or adding 2 widgets with the same id
30 raise KeyError(f"There is already a widget with the id {widget.id!r}")
31 super().__setitem__(widget.id, widget)
32
33 def remove(self, id):
34 del self[id]
35
36 def __iter__(self):
37 return iter(self.values())
38
39
40 class Widget(Node):
41 _MIN_WIDTH = 100
42 _MIN_HEIGHT = 100
43
44 def __init__(
45 self,
46 id=None,
47 style=None,
48 ):
49 """Create a base Toga widget.
50
51 This is an abstract base class; it cannot be instantiated.
52
53 :param id: The ID for the widget.
54 :param style: A style object. If no style is provided, a default style
55 will be applied to the widget.
56 """
57 super().__init__(
58 style=style if style else Pack(),
59 applicator=TogaApplicator(self),
60 )
61
62 self._id = str(id) if id else str(identifier(self))
63 self._window = None
64 self._app = None
65 self._impl = None
66
67 self.factory = get_platform_factory()
68
69 def __repr__(self):
70 return f"<{self.__class__.__name__}:0x{identifier(self):x}>"
71
72 @property
73 def id(self):
74 """The unique identifier for the widget."""
75 return self._id
76
77 @property
78 def tab_index(self):
79 """The position of the widget in the focus chain for the window.
80
81 .. note::
82
83 This is a beta feature. The ``tab_index`` API may change in
84 future.
85 """
86 return self._impl.get_tab_index()
87
88 @tab_index.setter
89 def tab_index(self, tab_index):
90 self._impl.set_tab_index(tab_index)
91
92 def add(self, *children):
93 """Add the provided widgets as children of this widget.
94
95 If a child widget already has a parent, it will be re-parented as a
96 child of this widget. If the child widget is already a child of this
97 widget, there is no change.
98
99 Raises ``ValueError`` if this widget cannot have children.
100
101 :param children: The widgets to add as children of this widget.
102 """
103 for child in children:
104 if child.parent is not self:
105 # remove from old parent
106 if child.parent:
107 child.parent.remove(child)
108
109 # add to new parent
110 super().add(child)
111
112 # set app and window
113 child.app = self.app
114 child.window = self.window
115
116 self._impl.add_child(child._impl)
117
118 if self.window:
119 self.window.content.refresh()
120
121 def insert(self, index, child):
122 """Insert a widget as a child of this widget.
123
124 If a child widget already has a parent, it will be re-parented as a
125 child of this widget. If the child widget is already a child of this
126 widget, there is no change.
127
128 Raises ``ValueError`` if this node cannot have children.
129
130 :param index: The position in the list of children where the new widget
131 should be added.
132 :param child: The child to insert as a child of this node.
133 """
134 if child.parent is not self:
135 # remove from old parent
136 if child.parent:
137 child.parent.remove(child)
138
139 # add to new parent
140 super().insert(index, child)
141
142 # set app and window
143 child.app = self.app
144 child.window = self.window
145
146 self._impl.insert_child(index, child._impl)
147
148 if self.window:
149 self.window.content.refresh()
150
151 def remove(self, *children):
152 """Remove the provided widgets as children of this node.
153
154 Any nominated child widget that is not a child of this widget will
155 not have any change in parentage.
156
157 Raises ``ValueError`` if this widget cannot have children.
158
159 :param children: The child nodes to remove.
160 """
161 for child in children:
162 if child.parent is self:
163 super().remove(child)
164
165 child.app = None
166 child.window = None
167
168 self._impl.remove_child(child._impl)
169
170 if self.window:
171 self.window.content.refresh()
172
173 @property
174 def app(self):
175 """The App to which this widget belongs.
176
177 When setting the app for a widget, all children of this widget will be
178 recursively assigned to the same app.
179
180 Raises ``ValueError`` if the widget is already associated with another
181 app.
182 """
183 return self._app
184
185 @app.setter
186 def app(self, app):
187 # If the widget is already assigned to an app
188 if self._app:
189 if self._app == app:
190 # If app is the same as the previous app, return
191 return
192
193 # Deregister the widget from the old app
194 self._app.widgets.remove(self.id)
195
196 self._app = app
197 self._impl.set_app(app)
198 for child in self.children:
199 child.app = app
200
201 if app is not None:
202 # Add this widget to the application widget registry
203 app.widgets.add(self)
204
205 @property
206 def window(self):
207 """The window to which this widget belongs.
208
209 When setting the window for a widget, all children of this widget will be
210 recursively assigned to the same window.
211 """
212 return self._window
213
214 @window.setter
215 def window(self, window):
216 # Remove the widget from the widget registry it is currently a part of
217 if self.window is not None:
218 self.window.widgets.remove(self.id)
219
220 self._window = window
221 self._impl.set_window(window)
222
223 for child in self.children:
224 child.window = window
225
226 if window is not None:
227 # Add this widget to the window's widget registry
228 window.widgets.add(self)
229
230 @property
231 def enabled(self):
232 """Is the widget currently enabled? i.e., can the user interact with the widget?"""
233 return self._impl.get_enabled()
234
235 @enabled.setter
236 def enabled(self, value):
237 self._impl.set_enabled(bool(value))
238
239 def refresh(self):
240 self._impl.refresh()
241
242 # Refresh the layout
243 if self._root:
244 # We're not the root of the node heirarchy;
245 # defer the refresh call to the root node.
246 self._root.refresh()
247 else:
248 self.refresh_sublayouts()
249 # We can't compute a layout until we have a viewport
250 if self._impl.viewport:
251 super().refresh(self._impl.viewport)
252
253 def refresh_sublayouts(self):
254 for child in self.children:
255 child.refresh_sublayouts()
256
257 def focus(self):
258 """Give this widget the input focus.
259
260 This method is a no-op if the widget can't accept focus. The ability of a widget
261 to accept focus is platform-dependent. In general, on desktop platforms you can
262 focus any widget that can accept user input, while on mobile platforms focus is
263 limited to widgets that accept text input (i.e., widgets that cause the virtual
264 keyboard to appear).
265 """
266 self._impl.focus()
267
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/src/toga/widgets/base.py b/core/src/toga/widgets/base.py
--- a/core/src/toga/widgets/base.py
+++ b/core/src/toga/widgets/base.py
@@ -154,12 +154,17 @@
Any nominated child widget that is not a child of this widget will
not have any change in parentage.
+ Refreshes the widget after removal if any children were removed.
+
Raises ``ValueError`` if this widget cannot have children.
:param children: The child nodes to remove.
"""
+ removed = False
+
for child in children:
if child.parent is self:
+ removed = True
super().remove(child)
child.app = None
@@ -167,9 +172,18 @@
self._impl.remove_child(child._impl)
- if self.window:
+ if self.window and removed:
self.window.content.refresh()
+ def clear(self):
+ """Remove all child widgets of this node.
+
+ Refreshes the widget after removal if any children were removed.
+
+ Raises ``ValueError`` if this widget cannot have children.
+ """
+ self.remove(*self.children)
+
@property
def app(self):
"""The App to which this widget belongs.
|
{"golden_diff": "diff --git a/core/src/toga/widgets/base.py b/core/src/toga/widgets/base.py\n--- a/core/src/toga/widgets/base.py\n+++ b/core/src/toga/widgets/base.py\n@@ -154,12 +154,17 @@\n Any nominated child widget that is not a child of this widget will\n not have any change in parentage.\n \n+ Refreshes the widget after removal if any children were removed.\n+\n Raises ``ValueError`` if this widget cannot have children.\n \n :param children: The child nodes to remove.\n \"\"\"\n+ removed = False\n+\n for child in children:\n if child.parent is self:\n+ removed = True\n super().remove(child)\n \n child.app = None\n@@ -167,9 +172,18 @@\n \n self._impl.remove_child(child._impl)\n \n- if self.window:\n+ if self.window and removed:\n self.window.content.refresh()\n \n+ def clear(self):\n+ \"\"\"Remove all child widgets of this node.\n+\n+ Refreshes the widget after removal if any children were removed.\n+\n+ Raises ``ValueError`` if this widget cannot have children.\n+ \"\"\"\n+ self.remove(*self.children)\n+\n @property\n def app(self):\n \"\"\"The App to which this widget belongs.\n", "issue": "Add a `clear()` method to remove all children\n### What is the problem or limitation you are having?\n\nAt present, you can:\r\n* add a single child to a widget (`widget.add(child)`)\r\n* remove a single child to a widget (`widget.remove(child)`)\r\n* add multiple children to a widget in a single call (`widget.add(child1, child2)`)\r\n* Remove multiple children from a widget in a single call (`widget.remove(child1, child2)`)\r\n\r\nHowever, there is no API to remove *all* children from a node.\r\n\n\n### Describe the solution you'd like\n\n`widget.clear()` should remove all children from a widget. As of Travertino 0.2.0, a `clear()` API exists; however, invoking it could have unexpected consequences, as it doesn't include the Toga-side cleanups implied by this change.\n\n### Describe alternatives you've considered\n\n`widget.remove(*widget.children)` is a workaround at present, but isn't a great API.\n\n### Additional context\n\n_No response_\n", "before_files": [{"content": "from builtins import id as identifier\n\nfrom travertino.node import Node\n\nfrom toga.platform import get_platform_factory\nfrom toga.style import Pack, TogaApplicator\n\n\nclass WidgetRegistry(dict):\n # WidgetRegistry is implemented as a subclass of dict, because it provides\n # a mapping from ID to widget. However, it exposes a set-like API; add()\n # and update() take instances to be added, and iteration is over values.\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n def __setitem__(self, key, value):\n # We do not want to allow setting items directly but to use the \"add\"\n # method instead.\n raise RuntimeError(\"Widgets cannot be directly added to a registry\")\n\n def update(self, widgets):\n for widget in widgets:\n self.add(widget)\n\n def add(self, widget):\n if widget.id in self:\n # Prevent from adding the same widget twice\n # or adding 2 widgets with the same id\n raise KeyError(f\"There is already a widget with the id {widget.id!r}\")\n super().__setitem__(widget.id, widget)\n\n def remove(self, id):\n del self[id]\n\n def __iter__(self):\n return iter(self.values())\n\n\nclass Widget(Node):\n _MIN_WIDTH = 100\n _MIN_HEIGHT = 100\n\n def __init__(\n self,\n id=None,\n style=None,\n ):\n \"\"\"Create a base Toga widget.\n\n This is an abstract base class; it cannot be instantiated.\n\n :param id: The ID for the widget.\n :param style: A style object. If no style is provided, a default style\n will be applied to the widget.\n \"\"\"\n super().__init__(\n style=style if style else Pack(),\n applicator=TogaApplicator(self),\n )\n\n self._id = str(id) if id else str(identifier(self))\n self._window = None\n self._app = None\n self._impl = None\n\n self.factory = get_platform_factory()\n\n def __repr__(self):\n return f\"<{self.__class__.__name__}:0x{identifier(self):x}>\"\n\n @property\n def id(self):\n \"\"\"The unique identifier for the widget.\"\"\"\n return self._id\n\n @property\n def tab_index(self):\n \"\"\"The position of the widget in the focus chain for the window.\n\n .. note::\n\n This is a beta feature. The ``tab_index`` API may change in\n future.\n \"\"\"\n return self._impl.get_tab_index()\n\n @tab_index.setter\n def tab_index(self, tab_index):\n self._impl.set_tab_index(tab_index)\n\n def add(self, *children):\n \"\"\"Add the provided widgets as children of this widget.\n\n If a child widget already has a parent, it will be re-parented as a\n child of this widget. If the child widget is already a child of this\n widget, there is no change.\n\n Raises ``ValueError`` if this widget cannot have children.\n\n :param children: The widgets to add as children of this widget.\n \"\"\"\n for child in children:\n if child.parent is not self:\n # remove from old parent\n if child.parent:\n child.parent.remove(child)\n\n # add to new parent\n super().add(child)\n\n # set app and window\n child.app = self.app\n child.window = self.window\n\n self._impl.add_child(child._impl)\n\n if self.window:\n self.window.content.refresh()\n\n def insert(self, index, child):\n \"\"\"Insert a widget as a child of this widget.\n\n If a child widget already has a parent, it will be re-parented as a\n child of this widget. If the child widget is already a child of this\n widget, there is no change.\n\n Raises ``ValueError`` if this node cannot have children.\n\n :param index: The position in the list of children where the new widget\n should be added.\n :param child: The child to insert as a child of this node.\n \"\"\"\n if child.parent is not self:\n # remove from old parent\n if child.parent:\n child.parent.remove(child)\n\n # add to new parent\n super().insert(index, child)\n\n # set app and window\n child.app = self.app\n child.window = self.window\n\n self._impl.insert_child(index, child._impl)\n\n if self.window:\n self.window.content.refresh()\n\n def remove(self, *children):\n \"\"\"Remove the provided widgets as children of this node.\n\n Any nominated child widget that is not a child of this widget will\n not have any change in parentage.\n\n Raises ``ValueError`` if this widget cannot have children.\n\n :param children: The child nodes to remove.\n \"\"\"\n for child in children:\n if child.parent is self:\n super().remove(child)\n\n child.app = None\n child.window = None\n\n self._impl.remove_child(child._impl)\n\n if self.window:\n self.window.content.refresh()\n\n @property\n def app(self):\n \"\"\"The App to which this widget belongs.\n\n When setting the app for a widget, all children of this widget will be\n recursively assigned to the same app.\n\n Raises ``ValueError`` if the widget is already associated with another\n app.\n \"\"\"\n return self._app\n\n @app.setter\n def app(self, app):\n # If the widget is already assigned to an app\n if self._app:\n if self._app == app:\n # If app is the same as the previous app, return\n return\n\n # Deregister the widget from the old app\n self._app.widgets.remove(self.id)\n\n self._app = app\n self._impl.set_app(app)\n for child in self.children:\n child.app = app\n\n if app is not None:\n # Add this widget to the application widget registry\n app.widgets.add(self)\n\n @property\n def window(self):\n \"\"\"The window to which this widget belongs.\n\n When setting the window for a widget, all children of this widget will be\n recursively assigned to the same window.\n \"\"\"\n return self._window\n\n @window.setter\n def window(self, window):\n # Remove the widget from the widget registry it is currently a part of\n if self.window is not None:\n self.window.widgets.remove(self.id)\n\n self._window = window\n self._impl.set_window(window)\n\n for child in self.children:\n child.window = window\n\n if window is not None:\n # Add this widget to the window's widget registry\n window.widgets.add(self)\n\n @property\n def enabled(self):\n \"\"\"Is the widget currently enabled? i.e., can the user interact with the widget?\"\"\"\n return self._impl.get_enabled()\n\n @enabled.setter\n def enabled(self, value):\n self._impl.set_enabled(bool(value))\n\n def refresh(self):\n self._impl.refresh()\n\n # Refresh the layout\n if self._root:\n # We're not the root of the node heirarchy;\n # defer the refresh call to the root node.\n self._root.refresh()\n else:\n self.refresh_sublayouts()\n # We can't compute a layout until we have a viewport\n if self._impl.viewport:\n super().refresh(self._impl.viewport)\n\n def refresh_sublayouts(self):\n for child in self.children:\n child.refresh_sublayouts()\n\n def focus(self):\n \"\"\"Give this widget the input focus.\n\n This method is a no-op if the widget can't accept focus. The ability of a widget\n to accept focus is platform-dependent. In general, on desktop platforms you can\n focus any widget that can accept user input, while on mobile platforms focus is\n limited to widgets that accept text input (i.e., widgets that cause the virtual\n keyboard to appear).\n \"\"\"\n self._impl.focus()\n", "path": "core/src/toga/widgets/base.py"}], "after_files": [{"content": "from builtins import id as identifier\n\nfrom travertino.node import Node\n\nfrom toga.platform import get_platform_factory\nfrom toga.style import Pack, TogaApplicator\n\n\nclass WidgetRegistry(dict):\n # WidgetRegistry is implemented as a subclass of dict, because it provides\n # a mapping from ID to widget. However, it exposes a set-like API; add()\n # and update() take instances to be added, and iteration is over values.\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n def __setitem__(self, key, value):\n # We do not want to allow setting items directly but to use the \"add\"\n # method instead.\n raise RuntimeError(\"Widgets cannot be directly added to a registry\")\n\n def update(self, widgets):\n for widget in widgets:\n self.add(widget)\n\n def add(self, widget):\n if widget.id in self:\n # Prevent from adding the same widget twice\n # or adding 2 widgets with the same id\n raise KeyError(f\"There is already a widget with the id {widget.id!r}\")\n super().__setitem__(widget.id, widget)\n\n def remove(self, id):\n del self[id]\n\n def __iter__(self):\n return iter(self.values())\n\n\nclass Widget(Node):\n _MIN_WIDTH = 100\n _MIN_HEIGHT = 100\n\n def __init__(\n self,\n id=None,\n style=None,\n ):\n \"\"\"Create a base Toga widget.\n\n This is an abstract base class; it cannot be instantiated.\n\n :param id: The ID for the widget.\n :param style: A style object. If no style is provided, a default style\n will be applied to the widget.\n \"\"\"\n super().__init__(\n style=style if style else Pack(),\n applicator=TogaApplicator(self),\n )\n\n self._id = str(id) if id else str(identifier(self))\n self._window = None\n self._app = None\n self._impl = None\n\n self.factory = get_platform_factory()\n\n def __repr__(self):\n return f\"<{self.__class__.__name__}:0x{identifier(self):x}>\"\n\n @property\n def id(self):\n \"\"\"The unique identifier for the widget.\"\"\"\n return self._id\n\n @property\n def tab_index(self):\n \"\"\"The position of the widget in the focus chain for the window.\n\n .. note::\n\n This is a beta feature. The ``tab_index`` API may change in\n future.\n \"\"\"\n return self._impl.get_tab_index()\n\n @tab_index.setter\n def tab_index(self, tab_index):\n self._impl.set_tab_index(tab_index)\n\n def add(self, *children):\n \"\"\"Add the provided widgets as children of this widget.\n\n If a child widget already has a parent, it will be re-parented as a\n child of this widget. If the child widget is already a child of this\n widget, there is no change.\n\n Raises ``ValueError`` if this widget cannot have children.\n\n :param children: The widgets to add as children of this widget.\n \"\"\"\n for child in children:\n if child.parent is not self:\n # remove from old parent\n if child.parent:\n child.parent.remove(child)\n\n # add to new parent\n super().add(child)\n\n # set app and window\n child.app = self.app\n child.window = self.window\n\n self._impl.add_child(child._impl)\n\n if self.window:\n self.window.content.refresh()\n\n def insert(self, index, child):\n \"\"\"Insert a widget as a child of this widget.\n\n If a child widget already has a parent, it will be re-parented as a\n child of this widget. If the child widget is already a child of this\n widget, there is no change.\n\n Raises ``ValueError`` if this node cannot have children.\n\n :param index: The position in the list of children where the new widget\n should be added.\n :param child: The child to insert as a child of this node.\n \"\"\"\n if child.parent is not self:\n # remove from old parent\n if child.parent:\n child.parent.remove(child)\n\n # add to new parent\n super().insert(index, child)\n\n # set app and window\n child.app = self.app\n child.window = self.window\n\n self._impl.insert_child(index, child._impl)\n\n if self.window:\n self.window.content.refresh()\n\n def remove(self, *children):\n \"\"\"Remove the provided widgets as children of this node.\n\n Any nominated child widget that is not a child of this widget will\n not have any change in parentage.\n\n Refreshes the widget after removal if any children were removed.\n\n Raises ``ValueError`` if this widget cannot have children.\n\n :param children: The child nodes to remove.\n \"\"\"\n removed = False\n\n for child in children:\n if child.parent is self:\n removed = True\n super().remove(child)\n\n child.app = None\n child.window = None\n\n self._impl.remove_child(child._impl)\n\n if self.window and removed:\n self.window.content.refresh()\n\n def clear(self):\n \"\"\"Remove all child widgets of this node.\n\n Refreshes the widget after removal if any children were removed.\n\n Raises ``ValueError`` if this widget cannot have children.\n \"\"\"\n self.remove(*self.children)\n\n @property\n def app(self):\n \"\"\"The App to which this widget belongs.\n\n When setting the app for a widget, all children of this widget will be\n recursively assigned to the same app.\n\n Raises ``ValueError`` if the widget is already associated with another\n app.\n \"\"\"\n return self._app\n\n @app.setter\n def app(self, app):\n # If the widget is already assigned to an app\n if self._app:\n if self._app == app:\n # If app is the same as the previous app, return\n return\n\n # Deregister the widget from the old app\n self._app.widgets.remove(self.id)\n\n self._app = app\n self._impl.set_app(app)\n for child in self.children:\n child.app = app\n\n if app is not None:\n # Add this widget to the application widget registry\n app.widgets.add(self)\n\n @property\n def window(self):\n \"\"\"The window to which this widget belongs.\n\n When setting the window for a widget, all children of this widget will be\n recursively assigned to the same window.\n \"\"\"\n return self._window\n\n @window.setter\n def window(self, window):\n # Remove the widget from the widget registry it is currently a part of\n if self.window is not None:\n self.window.widgets.remove(self.id)\n\n self._window = window\n self._impl.set_window(window)\n\n for child in self.children:\n child.window = window\n\n if window is not None:\n # Add this widget to the window's widget registry\n window.widgets.add(self)\n\n @property\n def enabled(self):\n \"\"\"Is the widget currently enabled? i.e., can the user interact with the widget?\"\"\"\n return self._impl.get_enabled()\n\n @enabled.setter\n def enabled(self, value):\n self._impl.set_enabled(bool(value))\n\n def refresh(self):\n self._impl.refresh()\n\n # Refresh the layout\n if self._root:\n # We're not the root of the node heirarchy;\n # defer the refresh call to the root node.\n self._root.refresh()\n else:\n self.refresh_sublayouts()\n # We can't compute a layout until we have a viewport\n if self._impl.viewport:\n super().refresh(self._impl.viewport)\n\n def refresh_sublayouts(self):\n for child in self.children:\n child.refresh_sublayouts()\n\n def focus(self):\n \"\"\"Give this widget the input focus.\n\n This method is a no-op if the widget can't accept focus. The ability of a widget\n to accept focus is platform-dependent. In general, on desktop platforms you can\n focus any widget that can accept user input, while on mobile platforms focus is\n limited to widgets that accept text input (i.e., widgets that cause the virtual\n keyboard to appear).\n \"\"\"\n self._impl.focus()\n", "path": "core/src/toga/widgets/base.py"}]}
| 2,942 | 288 |
gh_patches_debug_57840
|
rasdani/github-patches
|
git_diff
|
nltk__nltk-1219
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Translation metrics in Python 2.7
The [CI Server](https://nltk.ci.cloudbees.com/job/nltk/TOXENV=py27-jenkins,jdk=jdk8latestOnlineInstall/lastCompletedBuild/testReport/) reports test failures for `nltk.translate.ribes_score.kendall_tau` and `nltk.translate.ribes_score.spearman_rho`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nltk/translate/ribes_score.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # Natural Language Toolkit: RIBES Score
3 #
4 # Copyright (C) 2001-2015 NLTK Project
5 # Contributors: Katsuhito Sudoh, Liling Tan, Kasramvd, J.F.Sebastian, Mark Byers, ekhumoro, P. Ortiz
6 # URL: <http://nltk.org/>
7 # For license information, see LICENSE.TXT
8 """ RIBES score implementation """
9
10 from itertools import islice
11 import math
12
13 from nltk.util import ngrams, choose
14
15
16 def ribes(references, hypothesis, alpha=0.25, beta=0.10):
17 """
18 The RIBES (Rank-based Intuitive Bilingual Evaluation Score) from
19 Hideki Isozaki, Tsutomu Hirao, Kevin Duh, Katsuhito Sudoh and
20 Hajime Tsukada. 2010. "Automatic Evaluation of Translation Quality for
21 Distant Language Pairs". In Proceedings of EMNLP.
22 http://www.aclweb.org/anthology/D/D10/D10-1092.pdf
23
24 The generic RIBES scores used in shared task, e.g. Workshop for
25 Asian Translation (WAT) uses the following RIBES calculations:
26
27 RIBES = kendall_tau * (alpha**p1) * (beta**bp)
28
29 Please note that this re-implementation differs from the official
30 RIBES implementation and though it emulates the results as describe
31 in the original paper, there are further optimization implemented
32 in the official RIBES script.
33
34 Users are encouraged to use the official RIBES script instead of this
35 implementation when evaluating your machine translation system. Refer
36 to http://www.kecl.ntt.co.jp/icl/lirg/ribes/ for the official script.
37
38 :param references: a list of reference sentences
39 :type reference: list(list(str))
40 :param hypothesis: a hypothesis sentence
41 :type hypothesis: list(str)
42 :param alpha: hyperparameter used as a prior for the unigram precision.
43 :type alpha: float
44 :param beta: hyperparameter used as a prior for the brevity penalty.
45 :type beta: float
46 :return: The best ribes score from one of the references.
47 :rtype: float
48 """
49 best_ribes = -1.0
50 # Calculates RIBES for each reference and returns the best score.
51 for reference in references:
52 # Collects the *worder* from the ranked correlation alignments.
53 worder = word_rank_alignment(reference, hypothesis)
54 nkt = kendall_tau(worder)
55
56 # Calculates the brevity penalty
57 bp = min(1.0, math.exp(1.0 - 1.0 * len(reference)/len(hypothesis)))
58
59 # Calculates the unigram precision, *p1*
60 p1 = 1.0 * len(worder) / len(hypothesis)
61
62 _ribes = nkt * (p1 ** alpha) * (bp ** beta)
63
64 if _ribes > best_ribes: # Keeps the best score.
65 best_ribes = _ribes
66
67 return best_ribes
68
69
70 def position_of_ngram(ngram, sentence):
71 """
72 This function returns the position of the first instance of the ngram
73 appearing in a sentence.
74
75 Note that one could also use string as follows but the code is a little
76 convoluted with type casting back and forth:
77
78 char_pos = ' '.join(sent)[:' '.join(sent).index(' '.join(ngram))]
79 word_pos = char_pos.count(' ')
80
81 Another way to conceive this is:
82
83 return next(i for i, ng in enumerate(ngrams(sentence, len(ngram)))
84 if ng == ngram)
85
86 :param ngram: The ngram that needs to be searched
87 :type ngram: tuple
88 :param sentence: The list of tokens to search from.
89 :type sentence: list(str)
90 """
91 # Iterates through the ngrams in sentence.
92 for i,sublist in enumerate(ngrams(sentence, len(ngram))):
93 # Returns the index of the word when ngram matches.
94 if ngram == sublist:
95 return i
96
97
98 def word_rank_alignment(reference, hypothesis, character_based=False):
99 """
100 This is the word rank alignment algorithm described in the paper to produce
101 the *worder* list, i.e. a list of word indices of the hypothesis word orders
102 w.r.t. the list of reference words.
103
104 Below is (H0, R0) example from the Isozaki et al. 2010 paper,
105 note the examples are indexed from 1 but the results here are indexed from 0:
106
107 >>> ref = str('he was interested in world history because he '
108 ... 'read the book').split()
109 >>> hyp = str('he read the book because he was interested in world '
110 ... 'history').split()
111 >>> word_rank_alignment(ref, hyp)
112 [7, 8, 9, 10, 6, 0, 1, 2, 3, 4, 5]
113
114 The (H1, R1) example from the paper, note the 0th index:
115
116 >>> ref = 'John hit Bob yesterday'.split()
117 >>> hyp = 'Bob hit John yesterday'.split()
118 >>> word_rank_alignment(ref, hyp)
119 [2, 1, 0, 3]
120
121 Here is the (H2, R2) example from the paper, note the 0th index here too:
122
123 >>> ref = 'the boy read the book'.split()
124 >>> hyp = 'the book was read by the boy'.split()
125 >>> word_rank_alignment(ref, hyp)
126 [3, 4, 2, 0, 1]
127
128 :param reference: a reference sentence
129 :type reference: list(str)
130 :param hypothesis: a hypothesis sentence
131 :type hypothesis: list(str)
132 """
133 worder = []
134 hyp_len = len(hypothesis)
135 # Stores a list of possible ngrams from the reference sentence.
136 # This is used for matching context window later in the algorithm.
137 ref_ngrams = []
138 hyp_ngrams = []
139 for n in range(1, len(reference)+1):
140 for ng in ngrams(reference, n):
141 ref_ngrams.append(ng)
142 for ng in ngrams(hypothesis, n):
143 hyp_ngrams.append(ng)
144 for i, h_word in enumerate(hypothesis):
145 # If word is not in the reference, continue.
146 if h_word not in reference:
147 continue
148 # If we can determine one-to-one word correspondence for unigrams that
149 # only appear once in both the reference and hypothesis.
150 elif hypothesis.count(h_word) == reference.count(h_word) == 1:
151 worder.append(reference.index(h_word))
152 else:
153 max_window_size = max(i, hyp_len-i+1)
154 for window in range(1, max_window_size):
155 if i+window < hyp_len: # If searching the right context is possible.
156 # Retrieve the right context window.
157 right_context_ngram = tuple(islice(hypothesis, i, i+window+1))
158 num_times_in_ref = ref_ngrams.count(right_context_ngram)
159 num_times_in_hyp = hyp_ngrams.count(right_context_ngram)
160 # If ngram appears only once in both ref and hyp.
161 if num_times_in_ref == num_times_in_hyp == 1:
162 # Find the position of ngram that matched the reference.
163 pos = position_of_ngram(right_context_ngram, reference)
164 worder.append(pos) # Add the positions of the ngram.
165 break
166 if window <= i: # If searching the left context is possible.
167 # Retrieve the left context window.
168 left_context_ngram = tuple(islice(hypothesis, i-window, i+1))
169 num_times_in_ref = ref_ngrams.count(left_context_ngram)
170 num_times_in_hyp = hyp_ngrams.count(left_context_ngram)
171 if num_times_in_ref == num_times_in_hyp == 1:
172 # Find the position of ngram that matched the reference.
173 pos = position_of_ngram(left_context_ngram, reference)
174 # Add the positions of the ngram.
175 worder.append(pos+ len(left_context_ngram) -1)
176 break
177 return worder
178
179
180 def find_increasing_sequences(worder):
181 """
182 Given the *worder* list, this function groups monotonic +1 sequences.
183
184 >>> worder = [7, 8, 9, 10, 6, 0, 1, 2, 3, 4, 5]
185 >>> list(find_increasing_sequences(worder))
186 [(7, 8, 9, 10), (0, 1, 2, 3, 4, 5)]
187
188 :param worder: The worder list output from word_rank_alignment
189 :param type: list(int)
190 """
191 items = iter(worder)
192 a, b = None, next(items, None)
193 result = [b]
194 while b is not None:
195 a, b = b, next(items, None)
196 if b is not None and a + 1 == b:
197 result.append(b)
198 else:
199 if len(result) > 1:
200 yield tuple(result)
201 result = [b]
202
203
204 def kendall_tau(worder, normalize=True):
205 """
206 Calculates the Kendall's Tau correlation coefficient given the *worder*
207 list of word alignments from word_rank_alignment(), using the formula:
208
209 tau = 2 * num_increasing_pairs / num_possible pairs -1
210
211 Note that the no. of increasing pairs can be discontinuous in the *worder*
212 list and each each increasing sequence can be tabulated as choose(len(seq), 2)
213 no. of increasing pairs, e.g.
214
215 >>> worder = [7, 8, 9, 10, 6, 0, 1, 2, 3, 4, 5]
216 >>> number_possible_pairs = choose(len(worder), 2)
217 >>> round(kendall_tau(worder, normalize=False),3)
218 -0.236
219 >>> round(kendall_tau(worder),3)
220 0.382
221
222 :param worder: The worder list output from word_rank_alignment
223 :type worder: list(int)
224 :param normalize: Flag to indicate normalization
225 :type normalize: boolean
226 :return: The Kendall's Tau correlation coefficient.
227 :rtype: float
228 """
229 worder_len = len(worder)
230 # Extract the groups of increasing/monotonic sequences.
231 increasing_sequences = find_increasing_sequences(worder)
232 # Calculate no. of increasing_pairs in *worder* list.
233 num_increasing_pairs = sum(choose(len(seq),2) for seq in increasing_sequences)
234 # Calculate no. of possible pairs.
235 num_possible_pairs = choose(worder_len, 2)
236 # Kendall's Tau computation.
237 tau = 2 * num_increasing_pairs / num_possible_pairs -1
238 if normalize: # If normalized, the tau output falls between 0.0 to 1.0
239 return (tau + 1) /2
240 else: # Otherwise, the tau outputs falls between -1.0 to +1.0
241 return tau
242
243
244 def spearman_rho(worder, normalize=True):
245 """
246 Calculates the Spearman's Rho correlation coefficient given the *worder*
247 list of word alignment from word_rank_alignment(), using the formula:
248
249 rho = 1 - sum(d**2) / choose(len(worder)+1, 3)
250
251 Given that d is the sum of difference between the *worder* list of indices
252 and the original word indices from the reference sentence.
253
254 Using the (H0,R0) and (H5, R5) example from the paper
255
256 >>> worder = [7, 8, 9, 10, 6, 0, 1, 2, 3, 4, 5]
257 >>> round(spearman_rho(worder, normalize=False), 3)
258 -0.591
259 >>> round(spearman_rho(worder), 3)
260 0.205
261
262 :param worder: The worder list output from word_rank_alignment
263 :param type: list(int)
264 """
265 worder_len = len(worder)
266 sum_d_square = sum((wi - i)**2 for wi, i in zip(worder, range(worder_len)))
267 rho = 1 - sum_d_square / choose(worder_len+1, 3)
268
269 if normalize: # If normalized, the rho output falls between 0.0 to 1.0
270 return (rho + 1) /2
271 else: # Otherwise, the rho outputs falls between -1.0 to +1.0
272 return rho
273
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nltk/translate/ribes_score.py b/nltk/translate/ribes_score.py
--- a/nltk/translate/ribes_score.py
+++ b/nltk/translate/ribes_score.py
@@ -6,7 +6,7 @@
# URL: <http://nltk.org/>
# For license information, see LICENSE.TXT
""" RIBES score implementation """
-
+from __future__ import division
from itertools import islice
import math
|
{"golden_diff": "diff --git a/nltk/translate/ribes_score.py b/nltk/translate/ribes_score.py\n--- a/nltk/translate/ribes_score.py\n+++ b/nltk/translate/ribes_score.py\n@@ -6,7 +6,7 @@\n # URL: <http://nltk.org/>\n # For license information, see LICENSE.TXT\n \"\"\" RIBES score implementation \"\"\"\n-\n+from __future__ import division\n from itertools import islice\n import math\n", "issue": "Translation metrics in Python 2.7\nThe [CI Server](https://nltk.ci.cloudbees.com/job/nltk/TOXENV=py27-jenkins,jdk=jdk8latestOnlineInstall/lastCompletedBuild/testReport/) reports test failures for `nltk.translate.ribes_score.kendall_tau` and `nltk.translate.ribes_score.spearman_rho`.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Natural Language Toolkit: RIBES Score\n#\n# Copyright (C) 2001-2015 NLTK Project\n# Contributors: Katsuhito Sudoh, Liling Tan, Kasramvd, J.F.Sebastian, Mark Byers, ekhumoro, P. Ortiz\n# URL: <http://nltk.org/>\n# For license information, see LICENSE.TXT\n\"\"\" RIBES score implementation \"\"\"\n\nfrom itertools import islice\nimport math\n\nfrom nltk.util import ngrams, choose\n\n\ndef ribes(references, hypothesis, alpha=0.25, beta=0.10):\n \"\"\"\n The RIBES (Rank-based Intuitive Bilingual Evaluation Score) from \n Hideki Isozaki, Tsutomu Hirao, Kevin Duh, Katsuhito Sudoh and \n Hajime Tsukada. 2010. \"Automatic Evaluation of Translation Quality for \n Distant Language Pairs\". In Proceedings of EMNLP. \n http://www.aclweb.org/anthology/D/D10/D10-1092.pdf \n \n The generic RIBES scores used in shared task, e.g. Workshop for \n Asian Translation (WAT) uses the following RIBES calculations:\n \n RIBES = kendall_tau * (alpha**p1) * (beta**bp)\n \n Please note that this re-implementation differs from the official\n RIBES implementation and though it emulates the results as describe\n in the original paper, there are further optimization implemented \n in the official RIBES script.\n \n Users are encouraged to use the official RIBES script instead of this \n implementation when evaluating your machine translation system. Refer\n to http://www.kecl.ntt.co.jp/icl/lirg/ribes/ for the official script.\n \n :param references: a list of reference sentences\n :type reference: list(list(str))\n :param hypothesis: a hypothesis sentence\n :type hypothesis: list(str)\n :param alpha: hyperparameter used as a prior for the unigram precision.\n :type alpha: float\n :param beta: hyperparameter used as a prior for the brevity penalty.\n :type beta: float\n :return: The best ribes score from one of the references.\n :rtype: float\n \"\"\"\n best_ribes = -1.0\n # Calculates RIBES for each reference and returns the best score.\n for reference in references:\n # Collects the *worder* from the ranked correlation alignments.\n worder = word_rank_alignment(reference, hypothesis)\n nkt = kendall_tau(worder)\n \n # Calculates the brevity penalty\n bp = min(1.0, math.exp(1.0 - 1.0 * len(reference)/len(hypothesis)))\n \n # Calculates the unigram precision, *p1*\n p1 = 1.0 * len(worder) / len(hypothesis)\n \n _ribes = nkt * (p1 ** alpha) * (bp ** beta)\n \n if _ribes > best_ribes: # Keeps the best score.\n best_ribes = _ribes\n \n return best_ribes\n\n\ndef position_of_ngram(ngram, sentence):\n \"\"\"\n This function returns the position of the first instance of the ngram \n appearing in a sentence.\n \n Note that one could also use string as follows but the code is a little\n convoluted with type casting back and forth:\n \n char_pos = ' '.join(sent)[:' '.join(sent).index(' '.join(ngram))]\n word_pos = char_pos.count(' ')\n \n Another way to conceive this is:\n \n return next(i for i, ng in enumerate(ngrams(sentence, len(ngram))) \n if ng == ngram)\n \n :param ngram: The ngram that needs to be searched\n :type ngram: tuple\n :param sentence: The list of tokens to search from.\n :type sentence: list(str)\n \"\"\"\n # Iterates through the ngrams in sentence.\n for i,sublist in enumerate(ngrams(sentence, len(ngram))):\n # Returns the index of the word when ngram matches.\n if ngram == sublist:\n return i\n\n\ndef word_rank_alignment(reference, hypothesis, character_based=False):\n \"\"\" \n This is the word rank alignment algorithm described in the paper to produce\n the *worder* list, i.e. a list of word indices of the hypothesis word orders \n w.r.t. the list of reference words.\n \n Below is (H0, R0) example from the Isozaki et al. 2010 paper, \n note the examples are indexed from 1 but the results here are indexed from 0:\n \n >>> ref = str('he was interested in world history because he '\n ... 'read the book').split()\n >>> hyp = str('he read the book because he was interested in world '\n ... 'history').split()\n >>> word_rank_alignment(ref, hyp)\n [7, 8, 9, 10, 6, 0, 1, 2, 3, 4, 5]\n \n The (H1, R1) example from the paper, note the 0th index:\n \n >>> ref = 'John hit Bob yesterday'.split()\n >>> hyp = 'Bob hit John yesterday'.split()\n >>> word_rank_alignment(ref, hyp)\n [2, 1, 0, 3]\n\n Here is the (H2, R2) example from the paper, note the 0th index here too:\n \n >>> ref = 'the boy read the book'.split()\n >>> hyp = 'the book was read by the boy'.split()\n >>> word_rank_alignment(ref, hyp)\n [3, 4, 2, 0, 1]\n \n :param reference: a reference sentence\n :type reference: list(str)\n :param hypothesis: a hypothesis sentence\n :type hypothesis: list(str)\n \"\"\"\n worder = []\n hyp_len = len(hypothesis)\n # Stores a list of possible ngrams from the reference sentence.\n # This is used for matching context window later in the algorithm.\n ref_ngrams = []\n hyp_ngrams = []\n for n in range(1, len(reference)+1):\n for ng in ngrams(reference, n):\n ref_ngrams.append(ng)\n for ng in ngrams(hypothesis, n):\n hyp_ngrams.append(ng)\n for i, h_word in enumerate(hypothesis):\n # If word is not in the reference, continue.\n if h_word not in reference:\n continue\n # If we can determine one-to-one word correspondence for unigrams that \n # only appear once in both the reference and hypothesis.\n elif hypothesis.count(h_word) == reference.count(h_word) == 1:\n worder.append(reference.index(h_word))\n else:\n max_window_size = max(i, hyp_len-i+1)\n for window in range(1, max_window_size):\n if i+window < hyp_len: # If searching the right context is possible.\n # Retrieve the right context window.\n right_context_ngram = tuple(islice(hypothesis, i, i+window+1))\n num_times_in_ref = ref_ngrams.count(right_context_ngram)\n num_times_in_hyp = hyp_ngrams.count(right_context_ngram) \n # If ngram appears only once in both ref and hyp.\n if num_times_in_ref == num_times_in_hyp == 1:\n # Find the position of ngram that matched the reference.\n pos = position_of_ngram(right_context_ngram, reference)\n worder.append(pos) # Add the positions of the ngram.\n break\n if window <= i: # If searching the left context is possible.\n # Retrieve the left context window.\n left_context_ngram = tuple(islice(hypothesis, i-window, i+1))\n num_times_in_ref = ref_ngrams.count(left_context_ngram)\n num_times_in_hyp = hyp_ngrams.count(left_context_ngram)\n if num_times_in_ref == num_times_in_hyp == 1:\n # Find the position of ngram that matched the reference.\n pos = position_of_ngram(left_context_ngram, reference)\n # Add the positions of the ngram.\n worder.append(pos+ len(left_context_ngram) -1) \n break\n return worder\n\n \ndef find_increasing_sequences(worder):\n \"\"\"\n Given the *worder* list, this function groups monotonic +1 sequences. \n \n >>> worder = [7, 8, 9, 10, 6, 0, 1, 2, 3, 4, 5]\n >>> list(find_increasing_sequences(worder))\n [(7, 8, 9, 10), (0, 1, 2, 3, 4, 5)]\n \n :param worder: The worder list output from word_rank_alignment\n :param type: list(int)\n \"\"\"\n items = iter(worder)\n a, b = None, next(items, None)\n result = [b]\n while b is not None:\n a, b = b, next(items, None)\n if b is not None and a + 1 == b:\n result.append(b)\n else:\n if len(result) > 1:\n yield tuple(result)\n result = [b]\n\n\ndef kendall_tau(worder, normalize=True):\n \"\"\"\n Calculates the Kendall's Tau correlation coefficient given the *worder*\n list of word alignments from word_rank_alignment(), using the formula:\n \n tau = 2 * num_increasing_pairs / num_possible pairs -1\n \n Note that the no. of increasing pairs can be discontinuous in the *worder*\n list and each each increasing sequence can be tabulated as choose(len(seq), 2) \n no. of increasing pairs, e.g.\n \n >>> worder = [7, 8, 9, 10, 6, 0, 1, 2, 3, 4, 5]\n >>> number_possible_pairs = choose(len(worder), 2)\n >>> round(kendall_tau(worder, normalize=False),3)\n -0.236\n >>> round(kendall_tau(worder),3)\n 0.382\n \n :param worder: The worder list output from word_rank_alignment\n :type worder: list(int)\n :param normalize: Flag to indicate normalization\n :type normalize: boolean\n :return: The Kendall's Tau correlation coefficient.\n :rtype: float\n \"\"\"\n worder_len = len(worder)\n # Extract the groups of increasing/monotonic sequences.\n increasing_sequences = find_increasing_sequences(worder)\n # Calculate no. of increasing_pairs in *worder* list.\n num_increasing_pairs = sum(choose(len(seq),2) for seq in increasing_sequences) \n # Calculate no. of possible pairs.\n num_possible_pairs = choose(worder_len, 2)\n # Kendall's Tau computation.\n tau = 2 * num_increasing_pairs / num_possible_pairs -1\n if normalize: # If normalized, the tau output falls between 0.0 to 1.0\n return (tau + 1) /2\n else: # Otherwise, the tau outputs falls between -1.0 to +1.0\n return tau\n\n\ndef spearman_rho(worder, normalize=True):\n \"\"\"\n Calculates the Spearman's Rho correlation coefficient given the *worder* \n list of word alignment from word_rank_alignment(), using the formula:\n \n rho = 1 - sum(d**2) / choose(len(worder)+1, 3) \n \n Given that d is the sum of difference between the *worder* list of indices\n and the original word indices from the reference sentence.\n \n Using the (H0,R0) and (H5, R5) example from the paper\n \n >>> worder = [7, 8, 9, 10, 6, 0, 1, 2, 3, 4, 5]\n >>> round(spearman_rho(worder, normalize=False), 3)\n -0.591\n >>> round(spearman_rho(worder), 3)\n 0.205\n \n :param worder: The worder list output from word_rank_alignment\n :param type: list(int)\n \"\"\"\n worder_len = len(worder)\n sum_d_square = sum((wi - i)**2 for wi, i in zip(worder, range(worder_len)))\n rho = 1 - sum_d_square / choose(worder_len+1, 3)\n \n if normalize: # If normalized, the rho output falls between 0.0 to 1.0\n return (rho + 1) /2\n else: # Otherwise, the rho outputs falls between -1.0 to +1.0\n return rho\n", "path": "nltk/translate/ribes_score.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# Natural Language Toolkit: RIBES Score\n#\n# Copyright (C) 2001-2015 NLTK Project\n# Contributors: Katsuhito Sudoh, Liling Tan, Kasramvd, J.F.Sebastian, Mark Byers, ekhumoro, P. Ortiz\n# URL: <http://nltk.org/>\n# For license information, see LICENSE.TXT\n\"\"\" RIBES score implementation \"\"\"\nfrom __future__ import division\nfrom itertools import islice\nimport math\n\nfrom nltk.util import ngrams, choose\n\n\ndef ribes(references, hypothesis, alpha=0.25, beta=0.10):\n \"\"\"\n The RIBES (Rank-based Intuitive Bilingual Evaluation Score) from \n Hideki Isozaki, Tsutomu Hirao, Kevin Duh, Katsuhito Sudoh and \n Hajime Tsukada. 2010. \"Automatic Evaluation of Translation Quality for \n Distant Language Pairs\". In Proceedings of EMNLP. \n http://www.aclweb.org/anthology/D/D10/D10-1092.pdf \n \n The generic RIBES scores used in shared task, e.g. Workshop for \n Asian Translation (WAT) uses the following RIBES calculations:\n \n RIBES = kendall_tau * (alpha**p1) * (beta**bp)\n \n Please note that this re-implementation differs from the official\n RIBES implementation and though it emulates the results as describe\n in the original paper, there are further optimization implemented \n in the official RIBES script.\n \n Users are encouraged to use the official RIBES script instead of this \n implementation when evaluating your machine translation system. Refer\n to http://www.kecl.ntt.co.jp/icl/lirg/ribes/ for the official script.\n \n :param references: a list of reference sentences\n :type reference: list(list(str))\n :param hypothesis: a hypothesis sentence\n :type hypothesis: list(str)\n :param alpha: hyperparameter used as a prior for the unigram precision.\n :type alpha: float\n :param beta: hyperparameter used as a prior for the brevity penalty.\n :type beta: float\n :return: The best ribes score from one of the references.\n :rtype: float\n \"\"\"\n best_ribes = -1.0\n # Calculates RIBES for each reference and returns the best score.\n for reference in references:\n # Collects the *worder* from the ranked correlation alignments.\n worder = word_rank_alignment(reference, hypothesis)\n nkt = kendall_tau(worder)\n \n # Calculates the brevity penalty\n bp = min(1.0, math.exp(1.0 - 1.0 * len(reference)/len(hypothesis)))\n \n # Calculates the unigram precision, *p1*\n p1 = 1.0 * len(worder) / len(hypothesis)\n \n _ribes = nkt * (p1 ** alpha) * (bp ** beta)\n \n if _ribes > best_ribes: # Keeps the best score.\n best_ribes = _ribes\n \n return best_ribes\n\n\ndef position_of_ngram(ngram, sentence):\n \"\"\"\n This function returns the position of the first instance of the ngram \n appearing in a sentence.\n \n Note that one could also use string as follows but the code is a little\n convoluted with type casting back and forth:\n \n char_pos = ' '.join(sent)[:' '.join(sent).index(' '.join(ngram))]\n word_pos = char_pos.count(' ')\n \n Another way to conceive this is:\n \n return next(i for i, ng in enumerate(ngrams(sentence, len(ngram))) \n if ng == ngram)\n \n :param ngram: The ngram that needs to be searched\n :type ngram: tuple\n :param sentence: The list of tokens to search from.\n :type sentence: list(str)\n \"\"\"\n # Iterates through the ngrams in sentence.\n for i,sublist in enumerate(ngrams(sentence, len(ngram))):\n # Returns the index of the word when ngram matches.\n if ngram == sublist:\n return i\n\n\ndef word_rank_alignment(reference, hypothesis, character_based=False):\n \"\"\" \n This is the word rank alignment algorithm described in the paper to produce\n the *worder* list, i.e. a list of word indices of the hypothesis word orders \n w.r.t. the list of reference words.\n \n Below is (H0, R0) example from the Isozaki et al. 2010 paper, \n note the examples are indexed from 1 but the results here are indexed from 0:\n \n >>> ref = str('he was interested in world history because he '\n ... 'read the book').split()\n >>> hyp = str('he read the book because he was interested in world '\n ... 'history').split()\n >>> word_rank_alignment(ref, hyp)\n [7, 8, 9, 10, 6, 0, 1, 2, 3, 4, 5]\n \n The (H1, R1) example from the paper, note the 0th index:\n \n >>> ref = 'John hit Bob yesterday'.split()\n >>> hyp = 'Bob hit John yesterday'.split()\n >>> word_rank_alignment(ref, hyp)\n [2, 1, 0, 3]\n\n Here is the (H2, R2) example from the paper, note the 0th index here too:\n \n >>> ref = 'the boy read the book'.split()\n >>> hyp = 'the book was read by the boy'.split()\n >>> word_rank_alignment(ref, hyp)\n [3, 4, 2, 0, 1]\n \n :param reference: a reference sentence\n :type reference: list(str)\n :param hypothesis: a hypothesis sentence\n :type hypothesis: list(str)\n \"\"\"\n worder = []\n hyp_len = len(hypothesis)\n # Stores a list of possible ngrams from the reference sentence.\n # This is used for matching context window later in the algorithm.\n ref_ngrams = []\n hyp_ngrams = []\n for n in range(1, len(reference)+1):\n for ng in ngrams(reference, n):\n ref_ngrams.append(ng)\n for ng in ngrams(hypothesis, n):\n hyp_ngrams.append(ng)\n for i, h_word in enumerate(hypothesis):\n # If word is not in the reference, continue.\n if h_word not in reference:\n continue\n # If we can determine one-to-one word correspondence for unigrams that \n # only appear once in both the reference and hypothesis.\n elif hypothesis.count(h_word) == reference.count(h_word) == 1:\n worder.append(reference.index(h_word))\n else:\n max_window_size = max(i, hyp_len-i+1)\n for window in range(1, max_window_size):\n if i+window < hyp_len: # If searching the right context is possible.\n # Retrieve the right context window.\n right_context_ngram = tuple(islice(hypothesis, i, i+window+1))\n num_times_in_ref = ref_ngrams.count(right_context_ngram)\n num_times_in_hyp = hyp_ngrams.count(right_context_ngram) \n # If ngram appears only once in both ref and hyp.\n if num_times_in_ref == num_times_in_hyp == 1:\n # Find the position of ngram that matched the reference.\n pos = position_of_ngram(right_context_ngram, reference)\n worder.append(pos) # Add the positions of the ngram.\n break\n if window <= i: # If searching the left context is possible.\n # Retrieve the left context window.\n left_context_ngram = tuple(islice(hypothesis, i-window, i+1))\n num_times_in_ref = ref_ngrams.count(left_context_ngram)\n num_times_in_hyp = hyp_ngrams.count(left_context_ngram)\n if num_times_in_ref == num_times_in_hyp == 1:\n # Find the position of ngram that matched the reference.\n pos = position_of_ngram(left_context_ngram, reference)\n # Add the positions of the ngram.\n worder.append(pos+ len(left_context_ngram) -1) \n break\n return worder\n\n \ndef find_increasing_sequences(worder):\n \"\"\"\n Given the *worder* list, this function groups monotonic +1 sequences. \n \n >>> worder = [7, 8, 9, 10, 6, 0, 1, 2, 3, 4, 5]\n >>> list(find_increasing_sequences(worder))\n [(7, 8, 9, 10), (0, 1, 2, 3, 4, 5)]\n \n :param worder: The worder list output from word_rank_alignment\n :param type: list(int)\n \"\"\"\n items = iter(worder)\n a, b = None, next(items, None)\n result = [b]\n while b is not None:\n a, b = b, next(items, None)\n if b is not None and a + 1 == b:\n result.append(b)\n else:\n if len(result) > 1:\n yield tuple(result)\n result = [b]\n\n\ndef kendall_tau(worder, normalize=True):\n \"\"\"\n Calculates the Kendall's Tau correlation coefficient given the *worder*\n list of word alignments from word_rank_alignment(), using the formula:\n \n tau = 2 * num_increasing_pairs / num_possible pairs -1\n \n Note that the no. of increasing pairs can be discontinuous in the *worder*\n list and each each increasing sequence can be tabulated as choose(len(seq), 2) \n no. of increasing pairs, e.g.\n \n >>> worder = [7, 8, 9, 10, 6, 0, 1, 2, 3, 4, 5]\n >>> number_possible_pairs = choose(len(worder), 2)\n >>> round(kendall_tau(worder, normalize=False),3)\n -0.236\n >>> round(kendall_tau(worder),3)\n 0.382\n \n :param worder: The worder list output from word_rank_alignment\n :type worder: list(int)\n :param normalize: Flag to indicate normalization\n :type normalize: boolean\n :return: The Kendall's Tau correlation coefficient.\n :rtype: float\n \"\"\"\n worder_len = len(worder)\n # Extract the groups of increasing/monotonic sequences.\n increasing_sequences = find_increasing_sequences(worder)\n # Calculate no. of increasing_pairs in *worder* list.\n num_increasing_pairs = sum(choose(len(seq),2) for seq in increasing_sequences) \n # Calculate no. of possible pairs.\n num_possible_pairs = choose(worder_len, 2)\n # Kendall's Tau computation.\n tau = 2 * num_increasing_pairs / num_possible_pairs -1\n if normalize: # If normalized, the tau output falls between 0.0 to 1.0\n return (tau + 1) /2\n else: # Otherwise, the tau outputs falls between -1.0 to +1.0\n return tau\n\n\ndef spearman_rho(worder, normalize=True):\n \"\"\"\n Calculates the Spearman's Rho correlation coefficient given the *worder* \n list of word alignment from word_rank_alignment(), using the formula:\n \n rho = 1 - sum(d**2) / choose(len(worder)+1, 3) \n \n Given that d is the sum of difference between the *worder* list of indices\n and the original word indices from the reference sentence.\n \n Using the (H0,R0) and (H5, R5) example from the paper\n \n >>> worder = [7, 8, 9, 10, 6, 0, 1, 2, 3, 4, 5]\n >>> round(spearman_rho(worder, normalize=False), 3)\n -0.591\n >>> round(spearman_rho(worder), 3)\n 0.205\n \n :param worder: The worder list output from word_rank_alignment\n :param type: list(int)\n \"\"\"\n worder_len = len(worder)\n sum_d_square = sum((wi - i)**2 for wi, i in zip(worder, range(worder_len)))\n rho = 1 - sum_d_square / choose(worder_len+1, 3)\n \n if normalize: # If normalized, the rho output falls between 0.0 to 1.0\n return (rho + 1) /2\n else: # Otherwise, the rho outputs falls between -1.0 to +1.0\n return rho\n", "path": "nltk/translate/ribes_score.py"}]}
| 3,943 | 102 |
gh_patches_debug_17291
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1143
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Storing bytes in the memory backend should convert it to str.
- This is an inconsistency with other backends that returns unicode when storing bytes.
Storing bytes in the memory backend should convert it to str.
- This is an inconsistency with other backends that returns unicode when storing bytes.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kinto/core/cache/memory.py`
Content:
```
1 from kinto import logger
2 from kinto.core.cache import CacheBase
3 from kinto.core.utils import msec_time
4 from kinto.core.decorators import synchronized
5
6
7 class Cache(CacheBase):
8 """Cache backend implementation in local process memory.
9
10 Enable in configuration::
11
12 kinto.cache_backend = kinto.core.cache.memory
13
14 :noindex:
15 """
16
17 def __init__(self, *args, **kwargs):
18 super().__init__(*args, **kwargs)
19 self.flush()
20
21 def initialize_schema(self, dry_run=False):
22 # Nothing to do.
23 pass
24
25 def flush(self):
26 self._created_at = {}
27 self._ttl = {}
28 self._store = {}
29 self._quota = 0
30
31 def _clean_expired(self):
32 current = msec_time()
33 expired = [k for k, v in self._ttl.items() if current >= v]
34 for expired_item_key in expired:
35 self.delete(expired_item_key[len(self.prefix):])
36
37 def _clean_oversized(self):
38 if self._quota < self.max_size_bytes:
39 return
40
41 for key, value in sorted(self._created_at.items(), key=lambda k: k[1]):
42 if self._quota < (self.max_size_bytes * 0.8):
43 break
44 self.delete(key[len(self.prefix):])
45
46 @synchronized
47 def ttl(self, key):
48 ttl = self._ttl.get(self.prefix + key)
49 if ttl is not None:
50 return (ttl - msec_time()) / 1000.0
51 return -1
52
53 @synchronized
54 def expire(self, key, ttl):
55 self._ttl[self.prefix + key] = msec_time() + int(ttl * 1000.0)
56
57 @synchronized
58 def set(self, key, value, ttl=None):
59 self._clean_expired()
60 self._clean_oversized()
61 if ttl is not None:
62 self.expire(key, ttl)
63 else:
64 logger.warning("No TTL for cache key '{}'".format(key))
65 item_key = self.prefix + key
66 self._store[item_key] = value
67 self._created_at[item_key] = msec_time()
68 self._quota += size_of(item_key, value)
69
70 @synchronized
71 def get(self, key):
72 self._clean_expired()
73 return self._store.get(self.prefix + key)
74
75 @synchronized
76 def delete(self, key):
77 key = self.prefix + key
78 self._ttl.pop(key, None)
79 self._created_at.pop(key, None)
80 value = self._store.pop(key, None)
81 self._quota -= size_of(key, value)
82
83
84 def load_from_config(config):
85 settings = config.get_settings()
86 return Cache(cache_prefix=settings['cache_prefix'],
87 cache_max_size_bytes=settings['cache_max_size_bytes'])
88
89
90 def size_of(key, value):
91 # Key used for ttl, created_at and store.
92 # Int size is 24 bytes one for ttl and one for created_at values
93 return len(key) * 3 + len(str(value)) + 24 * 2
94
```
Path: `kinto/core/cache/postgresql/__init__.py`
Content:
```
1 import os
2
3 from kinto.core import logger
4 from kinto.core.cache import CacheBase
5 from kinto.core.storage.postgresql.client import create_from_config
6 from kinto.core.utils import json
7
8
9 class Cache(CacheBase):
10 """Cache backend using PostgreSQL.
11
12 Enable in configuration::
13
14 kinto.cache_backend = kinto.core.cache.postgresql
15
16 Database location URI can be customized::
17
18 kinto.cache_url = postgres://user:[email protected]:5432/dbname
19
20 Alternatively, username and password could also rely on system user ident
21 or even specified in :file:`~/.pgpass` (*see PostgreSQL documentation*).
22
23 .. note::
24
25 Some tables and indices are created when ``kinto migrate`` is run.
26 This requires some privileges on the database, or some error will
27 be raised.
28
29 **Alternatively**, the schema can be initialized outside the
30 python application, using the SQL file located in
31 :file:`kinto/core/cache/postgresql/schema.sql`. This allows to
32 distinguish schema manipulation privileges from schema usage.
33
34
35 A connection pool is enabled by default::
36
37 kinto.cache_pool_size = 10
38 kinto.cache_maxoverflow = 10
39 kinto.cache_max_backlog = -1
40 kinto.cache_pool_recycle = -1
41 kinto.cache_pool_timeout = 30
42 kinto.cache_poolclass =
43 kinto.core.storage.postgresql.pool.QueuePoolWithMaxBacklog
44
45 The ``max_backlog`` limits the number of threads that can be in the queue
46 waiting for a connection. Once this limit has been reached, any further
47 attempts to acquire a connection will be rejected immediately, instead of
48 locking up all threads by keeping them waiting in the queue.
49
50 See `dedicated section in SQLAlchemy documentation
51 <http://docs.sqlalchemy.org/en/rel_1_0/core/engines.html>`_
52 for default values and behaviour.
53
54 .. note::
55
56 Using a `dedicated connection pool <http://pgpool.net>`_ is still
57 recommended to allow load balancing, replication or limit the number
58 of connections used in a multi-process deployment.
59
60 :noindex:
61 """ # NOQA
62 def __init__(self, client, *args, **kwargs):
63 super().__init__(*args, **kwargs)
64 self.client = client
65
66 def initialize_schema(self, dry_run=False):
67 # Check if cache table exists.
68 query = """
69 SELECT 1
70 FROM information_schema.tables
71 WHERE table_name = 'cache';
72 """
73 with self.client.connect(readonly=True) as conn:
74 result = conn.execute(query)
75 if result.rowcount > 0:
76 logger.info("PostgreSQL cache schema is up-to-date.")
77 return
78
79 # Create schema
80 here = os.path.abspath(os.path.dirname(__file__))
81 sql_file = os.path.join(here, 'schema.sql')
82
83 if dry_run:
84 logger.info("Create cache schema from '{}'".format(sql_file))
85 return
86
87 # Since called outside request, force commit.
88 with open(sql_file) as f:
89 schema = f.read()
90 with self.client.connect(force_commit=True) as conn:
91 conn.execute(schema)
92 logger.info('Created PostgreSQL cache tables')
93
94 def flush(self):
95 query = """
96 DELETE FROM cache;
97 """
98 # Since called outside request (e.g. tests), force commit.
99 with self.client.connect(force_commit=True) as conn:
100 conn.execute(query)
101 logger.debug('Flushed PostgreSQL cache tables')
102
103 def ttl(self, key):
104 query = """
105 SELECT EXTRACT(SECOND FROM (ttl - now())) AS ttl
106 FROM cache
107 WHERE key = :key
108 AND ttl IS NOT NULL;
109 """
110 with self.client.connect(readonly=True) as conn:
111 result = conn.execute(query, dict(key=self.prefix + key))
112 if result.rowcount > 0:
113 return result.fetchone()['ttl']
114 return -1
115
116 def expire(self, key, ttl):
117 query = """
118 UPDATE cache SET ttl = sec2ttl(:ttl) WHERE key = :key;
119 """
120 with self.client.connect() as conn:
121 conn.execute(query, dict(ttl=ttl, key=self.prefix + key))
122
123 def set(self, key, value, ttl=None):
124 if ttl is None:
125 logger.warning("No TTL for cache key '{}'".format(key))
126 query = """
127 INSERT INTO cache (key, value, ttl)
128 VALUES (:key, :value, sec2ttl(:ttl))
129 ON CONFLICT (key) DO UPDATE
130 SET value = :value,
131 ttl = sec2ttl(:ttl);
132 """
133 value = json.dumps(value)
134 with self.client.connect() as conn:
135 conn.execute(query, dict(key=self.prefix + key,
136 value=value, ttl=ttl))
137
138 def get(self, key):
139 purge = "DELETE FROM cache WHERE ttl IS NOT NULL AND now() > ttl;"
140 query = "SELECT value FROM cache WHERE key = :key;"
141 with self.client.connect() as conn:
142 conn.execute(purge)
143 result = conn.execute(query, dict(key=self.prefix + key))
144 if result.rowcount > 0:
145 value = result.fetchone()['value']
146 return json.loads(value)
147
148 def delete(self, key):
149 query = "DELETE FROM cache WHERE key = :key"
150 with self.client.connect() as conn:
151 conn.execute(query, dict(key=self.prefix + key))
152
153
154 def load_from_config(config):
155 settings = config.get_settings()
156 client = create_from_config(config, prefix='cache_', with_transaction=False)
157 return Cache(client=client, cache_prefix=settings['cache_prefix'])
158
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kinto/core/cache/memory.py b/kinto/core/cache/memory.py
--- a/kinto/core/cache/memory.py
+++ b/kinto/core/cache/memory.py
@@ -56,6 +56,8 @@
@synchronized
def set(self, key, value, ttl=None):
+ if isinstance(value, bytes):
+ raise TypeError("a string-like object is required, not 'bytes'")
self._clean_expired()
self._clean_oversized()
if ttl is not None:
diff --git a/kinto/core/cache/postgresql/__init__.py b/kinto/core/cache/postgresql/__init__.py
--- a/kinto/core/cache/postgresql/__init__.py
+++ b/kinto/core/cache/postgresql/__init__.py
@@ -121,6 +121,9 @@
conn.execute(query, dict(ttl=ttl, key=self.prefix + key))
def set(self, key, value, ttl=None):
+ if isinstance(value, bytes):
+ raise TypeError("a string-like object is required, not 'bytes'")
+
if ttl is None:
logger.warning("No TTL for cache key '{}'".format(key))
query = """
|
{"golden_diff": "diff --git a/kinto/core/cache/memory.py b/kinto/core/cache/memory.py\n--- a/kinto/core/cache/memory.py\n+++ b/kinto/core/cache/memory.py\n@@ -56,6 +56,8 @@\n \n @synchronized\n def set(self, key, value, ttl=None):\n+ if isinstance(value, bytes):\n+ raise TypeError(\"a string-like object is required, not 'bytes'\")\n self._clean_expired()\n self._clean_oversized()\n if ttl is not None:\ndiff --git a/kinto/core/cache/postgresql/__init__.py b/kinto/core/cache/postgresql/__init__.py\n--- a/kinto/core/cache/postgresql/__init__.py\n+++ b/kinto/core/cache/postgresql/__init__.py\n@@ -121,6 +121,9 @@\n conn.execute(query, dict(ttl=ttl, key=self.prefix + key))\n \n def set(self, key, value, ttl=None):\n+ if isinstance(value, bytes):\n+ raise TypeError(\"a string-like object is required, not 'bytes'\")\n+\n if ttl is None:\n logger.warning(\"No TTL for cache key '{}'\".format(key))\n query = \"\"\"\n", "issue": "Storing bytes in the memory backend should convert it to str.\n- This is an inconsistency with other backends that returns unicode when storing bytes.\nStoring bytes in the memory backend should convert it to str.\n- This is an inconsistency with other backends that returns unicode when storing bytes.\n", "before_files": [{"content": "from kinto import logger\nfrom kinto.core.cache import CacheBase\nfrom kinto.core.utils import msec_time\nfrom kinto.core.decorators import synchronized\n\n\nclass Cache(CacheBase):\n \"\"\"Cache backend implementation in local process memory.\n\n Enable in configuration::\n\n kinto.cache_backend = kinto.core.cache.memory\n\n :noindex:\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.flush()\n\n def initialize_schema(self, dry_run=False):\n # Nothing to do.\n pass\n\n def flush(self):\n self._created_at = {}\n self._ttl = {}\n self._store = {}\n self._quota = 0\n\n def _clean_expired(self):\n current = msec_time()\n expired = [k for k, v in self._ttl.items() if current >= v]\n for expired_item_key in expired:\n self.delete(expired_item_key[len(self.prefix):])\n\n def _clean_oversized(self):\n if self._quota < self.max_size_bytes:\n return\n\n for key, value in sorted(self._created_at.items(), key=lambda k: k[1]):\n if self._quota < (self.max_size_bytes * 0.8):\n break\n self.delete(key[len(self.prefix):])\n\n @synchronized\n def ttl(self, key):\n ttl = self._ttl.get(self.prefix + key)\n if ttl is not None:\n return (ttl - msec_time()) / 1000.0\n return -1\n\n @synchronized\n def expire(self, key, ttl):\n self._ttl[self.prefix + key] = msec_time() + int(ttl * 1000.0)\n\n @synchronized\n def set(self, key, value, ttl=None):\n self._clean_expired()\n self._clean_oversized()\n if ttl is not None:\n self.expire(key, ttl)\n else:\n logger.warning(\"No TTL for cache key '{}'\".format(key))\n item_key = self.prefix + key\n self._store[item_key] = value\n self._created_at[item_key] = msec_time()\n self._quota += size_of(item_key, value)\n\n @synchronized\n def get(self, key):\n self._clean_expired()\n return self._store.get(self.prefix + key)\n\n @synchronized\n def delete(self, key):\n key = self.prefix + key\n self._ttl.pop(key, None)\n self._created_at.pop(key, None)\n value = self._store.pop(key, None)\n self._quota -= size_of(key, value)\n\n\ndef load_from_config(config):\n settings = config.get_settings()\n return Cache(cache_prefix=settings['cache_prefix'],\n cache_max_size_bytes=settings['cache_max_size_bytes'])\n\n\ndef size_of(key, value):\n # Key used for ttl, created_at and store.\n # Int size is 24 bytes one for ttl and one for created_at values\n return len(key) * 3 + len(str(value)) + 24 * 2\n", "path": "kinto/core/cache/memory.py"}, {"content": "import os\n\nfrom kinto.core import logger\nfrom kinto.core.cache import CacheBase\nfrom kinto.core.storage.postgresql.client import create_from_config\nfrom kinto.core.utils import json\n\n\nclass Cache(CacheBase):\n \"\"\"Cache backend using PostgreSQL.\n\n Enable in configuration::\n\n kinto.cache_backend = kinto.core.cache.postgresql\n\n Database location URI can be customized::\n\n kinto.cache_url = postgres://user:[email protected]:5432/dbname\n\n Alternatively, username and password could also rely on system user ident\n or even specified in :file:`~/.pgpass` (*see PostgreSQL documentation*).\n\n .. note::\n\n Some tables and indices are created when ``kinto migrate`` is run.\n This requires some privileges on the database, or some error will\n be raised.\n\n **Alternatively**, the schema can be initialized outside the\n python application, using the SQL file located in\n :file:`kinto/core/cache/postgresql/schema.sql`. This allows to\n distinguish schema manipulation privileges from schema usage.\n\n\n A connection pool is enabled by default::\n\n kinto.cache_pool_size = 10\n kinto.cache_maxoverflow = 10\n kinto.cache_max_backlog = -1\n kinto.cache_pool_recycle = -1\n kinto.cache_pool_timeout = 30\n kinto.cache_poolclass =\n kinto.core.storage.postgresql.pool.QueuePoolWithMaxBacklog\n\n The ``max_backlog`` limits the number of threads that can be in the queue\n waiting for a connection. Once this limit has been reached, any further\n attempts to acquire a connection will be rejected immediately, instead of\n locking up all threads by keeping them waiting in the queue.\n\n See `dedicated section in SQLAlchemy documentation\n <http://docs.sqlalchemy.org/en/rel_1_0/core/engines.html>`_\n for default values and behaviour.\n\n .. note::\n\n Using a `dedicated connection pool <http://pgpool.net>`_ is still\n recommended to allow load balancing, replication or limit the number\n of connections used in a multi-process deployment.\n\n :noindex:\n \"\"\" # NOQA\n def __init__(self, client, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.client = client\n\n def initialize_schema(self, dry_run=False):\n # Check if cache table exists.\n query = \"\"\"\n SELECT 1\n FROM information_schema.tables\n WHERE table_name = 'cache';\n \"\"\"\n with self.client.connect(readonly=True) as conn:\n result = conn.execute(query)\n if result.rowcount > 0:\n logger.info(\"PostgreSQL cache schema is up-to-date.\")\n return\n\n # Create schema\n here = os.path.abspath(os.path.dirname(__file__))\n sql_file = os.path.join(here, 'schema.sql')\n\n if dry_run:\n logger.info(\"Create cache schema from '{}'\".format(sql_file))\n return\n\n # Since called outside request, force commit.\n with open(sql_file) as f:\n schema = f.read()\n with self.client.connect(force_commit=True) as conn:\n conn.execute(schema)\n logger.info('Created PostgreSQL cache tables')\n\n def flush(self):\n query = \"\"\"\n DELETE FROM cache;\n \"\"\"\n # Since called outside request (e.g. tests), force commit.\n with self.client.connect(force_commit=True) as conn:\n conn.execute(query)\n logger.debug('Flushed PostgreSQL cache tables')\n\n def ttl(self, key):\n query = \"\"\"\n SELECT EXTRACT(SECOND FROM (ttl - now())) AS ttl\n FROM cache\n WHERE key = :key\n AND ttl IS NOT NULL;\n \"\"\"\n with self.client.connect(readonly=True) as conn:\n result = conn.execute(query, dict(key=self.prefix + key))\n if result.rowcount > 0:\n return result.fetchone()['ttl']\n return -1\n\n def expire(self, key, ttl):\n query = \"\"\"\n UPDATE cache SET ttl = sec2ttl(:ttl) WHERE key = :key;\n \"\"\"\n with self.client.connect() as conn:\n conn.execute(query, dict(ttl=ttl, key=self.prefix + key))\n\n def set(self, key, value, ttl=None):\n if ttl is None:\n logger.warning(\"No TTL for cache key '{}'\".format(key))\n query = \"\"\"\n INSERT INTO cache (key, value, ttl)\n VALUES (:key, :value, sec2ttl(:ttl))\n ON CONFLICT (key) DO UPDATE\n SET value = :value,\n ttl = sec2ttl(:ttl);\n \"\"\"\n value = json.dumps(value)\n with self.client.connect() as conn:\n conn.execute(query, dict(key=self.prefix + key,\n value=value, ttl=ttl))\n\n def get(self, key):\n purge = \"DELETE FROM cache WHERE ttl IS NOT NULL AND now() > ttl;\"\n query = \"SELECT value FROM cache WHERE key = :key;\"\n with self.client.connect() as conn:\n conn.execute(purge)\n result = conn.execute(query, dict(key=self.prefix + key))\n if result.rowcount > 0:\n value = result.fetchone()['value']\n return json.loads(value)\n\n def delete(self, key):\n query = \"DELETE FROM cache WHERE key = :key\"\n with self.client.connect() as conn:\n conn.execute(query, dict(key=self.prefix + key))\n\n\ndef load_from_config(config):\n settings = config.get_settings()\n client = create_from_config(config, prefix='cache_', with_transaction=False)\n return Cache(client=client, cache_prefix=settings['cache_prefix'])\n", "path": "kinto/core/cache/postgresql/__init__.py"}], "after_files": [{"content": "from kinto import logger\nfrom kinto.core.cache import CacheBase\nfrom kinto.core.utils import msec_time\nfrom kinto.core.decorators import synchronized\n\n\nclass Cache(CacheBase):\n \"\"\"Cache backend implementation in local process memory.\n\n Enable in configuration::\n\n kinto.cache_backend = kinto.core.cache.memory\n\n :noindex:\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.flush()\n\n def initialize_schema(self, dry_run=False):\n # Nothing to do.\n pass\n\n def flush(self):\n self._created_at = {}\n self._ttl = {}\n self._store = {}\n self._quota = 0\n\n def _clean_expired(self):\n current = msec_time()\n expired = [k for k, v in self._ttl.items() if current >= v]\n for expired_item_key in expired:\n self.delete(expired_item_key[len(self.prefix):])\n\n def _clean_oversized(self):\n if self._quota < self.max_size_bytes:\n return\n\n for key, value in sorted(self._created_at.items(), key=lambda k: k[1]):\n if self._quota < (self.max_size_bytes * 0.8):\n break\n self.delete(key[len(self.prefix):])\n\n @synchronized\n def ttl(self, key):\n ttl = self._ttl.get(self.prefix + key)\n if ttl is not None:\n return (ttl - msec_time()) / 1000.0\n return -1\n\n @synchronized\n def expire(self, key, ttl):\n self._ttl[self.prefix + key] = msec_time() + int(ttl * 1000.0)\n\n @synchronized\n def set(self, key, value, ttl=None):\n if isinstance(value, bytes):\n raise TypeError(\"a string-like object is required, not 'bytes'\")\n self._clean_expired()\n self._clean_oversized()\n if ttl is not None:\n self.expire(key, ttl)\n else:\n logger.warning(\"No TTL for cache key '{}'\".format(key))\n item_key = self.prefix + key\n self._store[item_key] = value\n self._created_at[item_key] = msec_time()\n self._quota += size_of(item_key, value)\n\n @synchronized\n def get(self, key):\n self._clean_expired()\n return self._store.get(self.prefix + key)\n\n @synchronized\n def delete(self, key):\n key = self.prefix + key\n self._ttl.pop(key, None)\n self._created_at.pop(key, None)\n value = self._store.pop(key, None)\n self._quota -= size_of(key, value)\n\n\ndef load_from_config(config):\n settings = config.get_settings()\n return Cache(cache_prefix=settings['cache_prefix'],\n cache_max_size_bytes=settings['cache_max_size_bytes'])\n\n\ndef size_of(key, value):\n # Key used for ttl, created_at and store.\n # Int size is 24 bytes one for ttl and one for created_at values\n return len(key) * 3 + len(str(value)) + 24 * 2\n", "path": "kinto/core/cache/memory.py"}, {"content": "import os\n\nfrom kinto.core import logger\nfrom kinto.core.cache import CacheBase\nfrom kinto.core.storage.postgresql.client import create_from_config\nfrom kinto.core.utils import json\n\n\nclass Cache(CacheBase):\n \"\"\"Cache backend using PostgreSQL.\n\n Enable in configuration::\n\n kinto.cache_backend = kinto.core.cache.postgresql\n\n Database location URI can be customized::\n\n kinto.cache_url = postgres://user:[email protected]:5432/dbname\n\n Alternatively, username and password could also rely on system user ident\n or even specified in :file:`~/.pgpass` (*see PostgreSQL documentation*).\n\n .. note::\n\n Some tables and indices are created when ``kinto migrate`` is run.\n This requires some privileges on the database, or some error will\n be raised.\n\n **Alternatively**, the schema can be initialized outside the\n python application, using the SQL file located in\n :file:`kinto/core/cache/postgresql/schema.sql`. This allows to\n distinguish schema manipulation privileges from schema usage.\n\n\n A connection pool is enabled by default::\n\n kinto.cache_pool_size = 10\n kinto.cache_maxoverflow = 10\n kinto.cache_max_backlog = -1\n kinto.cache_pool_recycle = -1\n kinto.cache_pool_timeout = 30\n kinto.cache_poolclass =\n kinto.core.storage.postgresql.pool.QueuePoolWithMaxBacklog\n\n The ``max_backlog`` limits the number of threads that can be in the queue\n waiting for a connection. Once this limit has been reached, any further\n attempts to acquire a connection will be rejected immediately, instead of\n locking up all threads by keeping them waiting in the queue.\n\n See `dedicated section in SQLAlchemy documentation\n <http://docs.sqlalchemy.org/en/rel_1_0/core/engines.html>`_\n for default values and behaviour.\n\n .. note::\n\n Using a `dedicated connection pool <http://pgpool.net>`_ is still\n recommended to allow load balancing, replication or limit the number\n of connections used in a multi-process deployment.\n\n :noindex:\n \"\"\" # NOQA\n def __init__(self, client, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.client = client\n\n def initialize_schema(self, dry_run=False):\n # Check if cache table exists.\n query = \"\"\"\n SELECT 1\n FROM information_schema.tables\n WHERE table_name = 'cache';\n \"\"\"\n with self.client.connect(readonly=True) as conn:\n result = conn.execute(query)\n if result.rowcount > 0:\n logger.info(\"PostgreSQL cache schema is up-to-date.\")\n return\n\n # Create schema\n here = os.path.abspath(os.path.dirname(__file__))\n sql_file = os.path.join(here, 'schema.sql')\n\n if dry_run:\n logger.info(\"Create cache schema from '{}'\".format(sql_file))\n return\n\n # Since called outside request, force commit.\n with open(sql_file) as f:\n schema = f.read()\n with self.client.connect(force_commit=True) as conn:\n conn.execute(schema)\n logger.info('Created PostgreSQL cache tables')\n\n def flush(self):\n query = \"\"\"\n DELETE FROM cache;\n \"\"\"\n # Since called outside request (e.g. tests), force commit.\n with self.client.connect(force_commit=True) as conn:\n conn.execute(query)\n logger.debug('Flushed PostgreSQL cache tables')\n\n def ttl(self, key):\n query = \"\"\"\n SELECT EXTRACT(SECOND FROM (ttl - now())) AS ttl\n FROM cache\n WHERE key = :key\n AND ttl IS NOT NULL;\n \"\"\"\n with self.client.connect(readonly=True) as conn:\n result = conn.execute(query, dict(key=self.prefix + key))\n if result.rowcount > 0:\n return result.fetchone()['ttl']\n return -1\n\n def expire(self, key, ttl):\n query = \"\"\"\n UPDATE cache SET ttl = sec2ttl(:ttl) WHERE key = :key;\n \"\"\"\n with self.client.connect() as conn:\n conn.execute(query, dict(ttl=ttl, key=self.prefix + key))\n\n def set(self, key, value, ttl=None):\n if isinstance(value, bytes):\n raise TypeError(\"a string-like object is required, not 'bytes'\")\n\n if ttl is None:\n logger.warning(\"No TTL for cache key '{}'\".format(key))\n query = \"\"\"\n INSERT INTO cache (key, value, ttl)\n VALUES (:key, :value, sec2ttl(:ttl))\n ON CONFLICT (key) DO UPDATE\n SET value = :value,\n ttl = sec2ttl(:ttl);\n \"\"\"\n value = json.dumps(value)\n with self.client.connect() as conn:\n conn.execute(query, dict(key=self.prefix + key,\n value=value, ttl=ttl))\n\n def get(self, key):\n purge = \"DELETE FROM cache WHERE ttl IS NOT NULL AND now() > ttl;\"\n query = \"SELECT value FROM cache WHERE key = :key;\"\n with self.client.connect() as conn:\n conn.execute(purge)\n result = conn.execute(query, dict(key=self.prefix + key))\n if result.rowcount > 0:\n value = result.fetchone()['value']\n return json.loads(value)\n\n def delete(self, key):\n query = \"DELETE FROM cache WHERE key = :key\"\n with self.client.connect() as conn:\n conn.execute(query, dict(key=self.prefix + key))\n\n\ndef load_from_config(config):\n settings = config.get_settings()\n client = create_from_config(config, prefix='cache_', with_transaction=False)\n return Cache(client=client, cache_prefix=settings['cache_prefix'])\n", "path": "kinto/core/cache/postgresql/__init__.py"}]}
| 2,795 | 256 |
gh_patches_debug_24092
|
rasdani/github-patches
|
git_diff
|
lk-geimfari__mimesis-929
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PyCharm indicates wrong type for lambda
# Bug report
<!--
Hi, thanks for submitting a bug. We appreciate that.
But, we will need some information about what's wrong to help you.
-->
## What's wrong
While using PyCharm, `lambda` type in `Schema` results in *Expected type 'FunctionType', got '() -> Dict[str, Union[str, Any]]' instead*
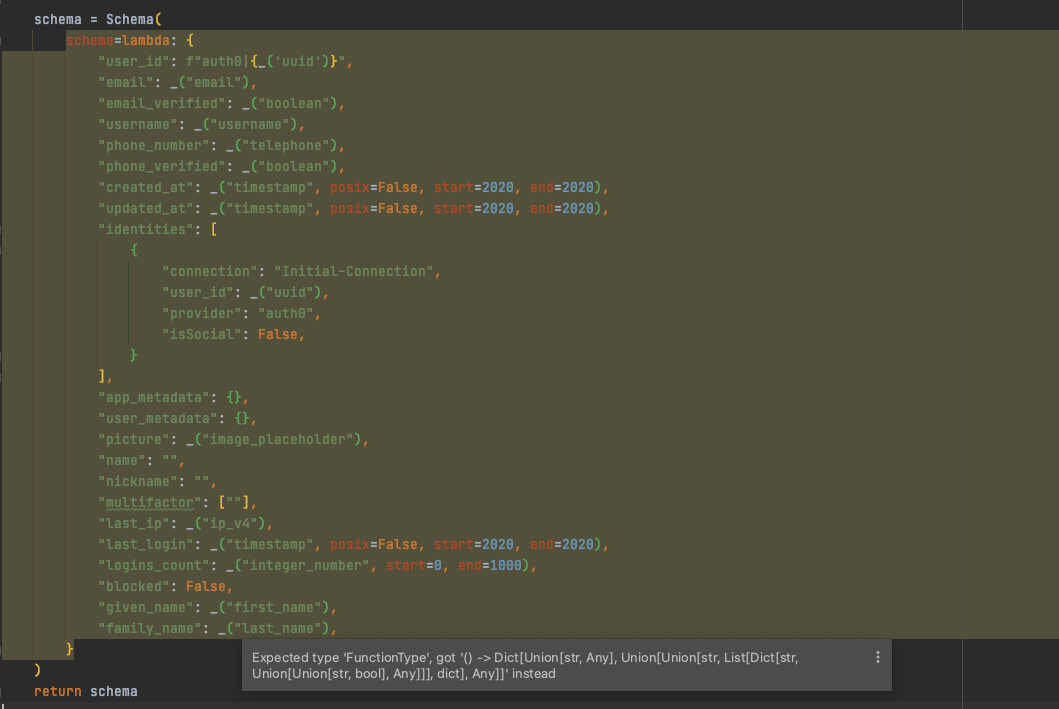
<!-- Describe what is not working. Please, attach a traceback. -->
## How is that should be
Is this warning correct? The code runs perfectly fine but maybe the Type maybe be wrong here. On this [SO post](https://stackoverflow.com/a/33833896/12794150) they mentioned using the `from typing import Callable` for type hinting a lambda.
<!-- Describe how it should work. -->
## System information
<!-- Describe system information -->
```
❯ python3 --version
Python 3.8.5
❯ sw_vers
ProductName: macOS
ProductVersion: 11.0
BuildVersion: 20A5354i
```
PyCharm 2020.2.1
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mimesis/schema.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 """Implements classes for generating data by schema."""
4
5 from types import LambdaType
6 from typing import Any, Callable, List, Optional
7
8 from mimesis.exceptions import (
9 UnacceptableField,
10 UndefinedField,
11 UndefinedSchema,
12 UnsupportedField,
13 )
14 from mimesis.providers.generic import Generic
15 from mimesis.typing import JSON, Seed
16
17 __all__ = ['Field', 'Schema']
18
19
20 class AbstractField(object):
21 """
22 AbstractField is a class for generating data by the name of the method.
23
24 Instance of this object takes any string which represents name
25 of any method of any supported data provider (:class:`~mimesis.Generic`)
26 and the ``**kwargs`` of the method.
27
28 See :class:`~mimesis.schema.AbstractField.__call__` for more details.
29 """
30
31 def __init__(self, locale: str = 'en',
32 seed: Optional[Seed] = None,
33 providers: Optional[Any] = None) -> None:
34 """Initialize field.
35
36 :param locale: Locale
37 :param seed: Seed for random.
38 """
39 self.locale = locale
40 self.seed = seed
41 self._gen = Generic(self.locale, self.seed)
42
43 if providers:
44 self._gen.add_providers(*providers)
45
46 self._table = {} # type: ignore
47
48 def __call__(self, name: Optional[str] = None,
49 key: Optional[Callable] = None, **kwargs) -> Any:
50 """Override standard call.
51
52 This magic method overrides standard call so it takes any string
53 which represents the name of any method of any supported data
54 provider and the ``**kwargs`` of this method.
55
56 .. note:: Some data providers have methods with the same names
57 and in such cases, you can explicitly define that the method
58 belongs to data-provider ``name='provider.name'`` otherwise
59 it will return the data from the first provider which
60 has a method ``name``.
61
62 You can apply a *key function* to the result returned by
63 the method, bt passing a parameter **key** with a callable
64 object which returns the final result.
65
66 :param name: Name of the method.
67 :param key: A key function (or other callable object)
68 which will be applied to result.
69 :param kwargs: Kwargs of method.
70 :return: Value which represented by method.
71 :raises ValueError: if provider not
72 supported or if field not defined.
73 """
74 if name is None:
75 raise UndefinedField()
76
77 def tail_parser(tails: str, obj: Any) -> Any:
78 """Return method from end of tail.
79
80 :param tails: Tail string
81 :param obj: Search tail from this object
82 :return last tailed method
83 """
84 provider_name, method_name = tails.split('.', 1)
85
86 if '.' in method_name:
87 raise UnacceptableField()
88
89 attr = getattr(obj, provider_name)
90 if attr is not None:
91 return getattr(attr, method_name)
92
93 try:
94 if name not in self._table:
95 if '.' not in name:
96 # Fix https://github.com/lk-geimfari/mimesis/issues/619
97 if name == self._gen.choice.Meta.name:
98 self._table[name] = self._gen.choice
99 else:
100 for provider in dir(self._gen):
101 provider = getattr(self._gen, provider)
102 if name in dir(provider):
103 self._table[name] = getattr(provider, name)
104 else:
105 self._table[name] = tail_parser(name, self._gen)
106
107 result = self._table[name](**kwargs)
108 if key and callable(key):
109 return key(result)
110 return result
111 except KeyError:
112 raise UnsupportedField(name)
113
114 def __str__(self):
115 return '{} <{}>'.format(
116 self.__class__.__name__, self.locale)
117
118
119 class Schema(object):
120 """Class which return list of filled schemas."""
121
122 def __init__(self, schema: LambdaType) -> None:
123 """Initialize schema.
124
125 :param schema: A schema.
126 """
127 if isinstance(schema, LambdaType):
128 self.schema = schema
129 else:
130 raise UndefinedSchema()
131
132 def create(self, iterations: int = 1) -> List[JSON]:
133 """Return filled schema.
134
135 Create a list of a filled schemas with elements in
136 an amount of **iterations**.
137
138 :param iterations: Amount of iterations.
139 :return: List of willed schemas.
140 """
141 return [self.schema() for _ in range(iterations)]
142
143
144 # Alias for AbstractField
145 Field = AbstractField
146
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mimesis/schema.py b/mimesis/schema.py
--- a/mimesis/schema.py
+++ b/mimesis/schema.py
@@ -2,7 +2,6 @@
"""Implements classes for generating data by schema."""
-from types import LambdaType
from typing import Any, Callable, List, Optional
from mimesis.exceptions import (
@@ -17,7 +16,7 @@
__all__ = ['Field', 'Schema']
-class AbstractField(object):
+class AbstractField:
"""
AbstractField is a class for generating data by the name of the method.
@@ -116,15 +115,15 @@
self.__class__.__name__, self.locale)
-class Schema(object):
+class Schema:
"""Class which return list of filled schemas."""
- def __init__(self, schema: LambdaType) -> None:
+ def __init__(self, schema: Callable) -> None:
"""Initialize schema.
:param schema: A schema.
"""
- if isinstance(schema, LambdaType):
+ if callable(schema):
self.schema = schema
else:
raise UndefinedSchema()
|
{"golden_diff": "diff --git a/mimesis/schema.py b/mimesis/schema.py\n--- a/mimesis/schema.py\n+++ b/mimesis/schema.py\n@@ -2,7 +2,6 @@\n \n \"\"\"Implements classes for generating data by schema.\"\"\"\n \n-from types import LambdaType\n from typing import Any, Callable, List, Optional\n \n from mimesis.exceptions import (\n@@ -17,7 +16,7 @@\n __all__ = ['Field', 'Schema']\n \n \n-class AbstractField(object):\n+class AbstractField:\n \"\"\"\n AbstractField is a class for generating data by the name of the method.\n \n@@ -116,15 +115,15 @@\n self.__class__.__name__, self.locale)\n \n \n-class Schema(object):\n+class Schema:\n \"\"\"Class which return list of filled schemas.\"\"\"\n \n- def __init__(self, schema: LambdaType) -> None:\n+ def __init__(self, schema: Callable) -> None:\n \"\"\"Initialize schema.\n \n :param schema: A schema.\n \"\"\"\n- if isinstance(schema, LambdaType):\n+ if callable(schema):\n self.schema = schema\n else:\n raise UndefinedSchema()\n", "issue": "PyCharm indicates wrong type for lambda\n# Bug report\r\n\r\n<!--\r\nHi, thanks for submitting a bug. We appreciate that.\r\n\r\nBut, we will need some information about what's wrong to help you.\r\n-->\r\n\r\n## What's wrong\r\n\r\nWhile using PyCharm, `lambda` type in `Schema` results in *Expected type 'FunctionType', got '() -> Dict[str, Union[str, Any]]' instead*\r\n\r\n\r\n<!-- Describe what is not working. Please, attach a traceback. -->\r\n\r\n## How is that should be\r\nIs this warning correct? The code runs perfectly fine but maybe the Type maybe be wrong here. On this [SO post](https://stackoverflow.com/a/33833896/12794150) they mentioned using the `from typing import Callable` for type hinting a lambda.\r\n<!-- Describe how it should work. -->\r\n\r\n## System information\r\n\r\n<!-- Describe system information -->\r\n```\r\n\u276f python3 --version\r\nPython 3.8.5\r\n\r\n\u276f sw_vers\r\nProductName:\tmacOS\r\nProductVersion:\t11.0\r\nBuildVersion:\t20A5354i\r\n```\r\nPyCharm 2020.2.1\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Implements classes for generating data by schema.\"\"\"\n\nfrom types import LambdaType\nfrom typing import Any, Callable, List, Optional\n\nfrom mimesis.exceptions import (\n UnacceptableField,\n UndefinedField,\n UndefinedSchema,\n UnsupportedField,\n)\nfrom mimesis.providers.generic import Generic\nfrom mimesis.typing import JSON, Seed\n\n__all__ = ['Field', 'Schema']\n\n\nclass AbstractField(object):\n \"\"\"\n AbstractField is a class for generating data by the name of the method.\n\n Instance of this object takes any string which represents name\n of any method of any supported data provider (:class:`~mimesis.Generic`)\n and the ``**kwargs`` of the method.\n\n See :class:`~mimesis.schema.AbstractField.__call__` for more details.\n \"\"\"\n\n def __init__(self, locale: str = 'en',\n seed: Optional[Seed] = None,\n providers: Optional[Any] = None) -> None:\n \"\"\"Initialize field.\n\n :param locale: Locale\n :param seed: Seed for random.\n \"\"\"\n self.locale = locale\n self.seed = seed\n self._gen = Generic(self.locale, self.seed)\n\n if providers:\n self._gen.add_providers(*providers)\n\n self._table = {} # type: ignore\n\n def __call__(self, name: Optional[str] = None,\n key: Optional[Callable] = None, **kwargs) -> Any:\n \"\"\"Override standard call.\n\n This magic method overrides standard call so it takes any string\n which represents the name of any method of any supported data\n provider and the ``**kwargs`` of this method.\n\n .. note:: Some data providers have methods with the same names\n and in such cases, you can explicitly define that the method\n belongs to data-provider ``name='provider.name'`` otherwise\n it will return the data from the first provider which\n has a method ``name``.\n\n You can apply a *key function* to the result returned by\n the method, bt passing a parameter **key** with a callable\n object which returns the final result.\n\n :param name: Name of the method.\n :param key: A key function (or other callable object)\n which will be applied to result.\n :param kwargs: Kwargs of method.\n :return: Value which represented by method.\n :raises ValueError: if provider not\n supported or if field not defined.\n \"\"\"\n if name is None:\n raise UndefinedField()\n\n def tail_parser(tails: str, obj: Any) -> Any:\n \"\"\"Return method from end of tail.\n\n :param tails: Tail string\n :param obj: Search tail from this object\n :return last tailed method\n \"\"\"\n provider_name, method_name = tails.split('.', 1)\n\n if '.' in method_name:\n raise UnacceptableField()\n\n attr = getattr(obj, provider_name)\n if attr is not None:\n return getattr(attr, method_name)\n\n try:\n if name not in self._table:\n if '.' not in name:\n # Fix https://github.com/lk-geimfari/mimesis/issues/619\n if name == self._gen.choice.Meta.name:\n self._table[name] = self._gen.choice\n else:\n for provider in dir(self._gen):\n provider = getattr(self._gen, provider)\n if name in dir(provider):\n self._table[name] = getattr(provider, name)\n else:\n self._table[name] = tail_parser(name, self._gen)\n\n result = self._table[name](**kwargs)\n if key and callable(key):\n return key(result)\n return result\n except KeyError:\n raise UnsupportedField(name)\n\n def __str__(self):\n return '{} <{}>'.format(\n self.__class__.__name__, self.locale)\n\n\nclass Schema(object):\n \"\"\"Class which return list of filled schemas.\"\"\"\n\n def __init__(self, schema: LambdaType) -> None:\n \"\"\"Initialize schema.\n\n :param schema: A schema.\n \"\"\"\n if isinstance(schema, LambdaType):\n self.schema = schema\n else:\n raise UndefinedSchema()\n\n def create(self, iterations: int = 1) -> List[JSON]:\n \"\"\"Return filled schema.\n\n Create a list of a filled schemas with elements in\n an amount of **iterations**.\n\n :param iterations: Amount of iterations.\n :return: List of willed schemas.\n \"\"\"\n return [self.schema() for _ in range(iterations)]\n\n\n# Alias for AbstractField\nField = AbstractField\n", "path": "mimesis/schema.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Implements classes for generating data by schema.\"\"\"\n\nfrom typing import Any, Callable, List, Optional\n\nfrom mimesis.exceptions import (\n UnacceptableField,\n UndefinedField,\n UndefinedSchema,\n UnsupportedField,\n)\nfrom mimesis.providers.generic import Generic\nfrom mimesis.typing import JSON, Seed\n\n__all__ = ['Field', 'Schema']\n\n\nclass AbstractField:\n \"\"\"\n AbstractField is a class for generating data by the name of the method.\n\n Instance of this object takes any string which represents name\n of any method of any supported data provider (:class:`~mimesis.Generic`)\n and the ``**kwargs`` of the method.\n\n See :class:`~mimesis.schema.AbstractField.__call__` for more details.\n \"\"\"\n\n def __init__(self, locale: str = 'en',\n seed: Optional[Seed] = None,\n providers: Optional[Any] = None) -> None:\n \"\"\"Initialize field.\n\n :param locale: Locale\n :param seed: Seed for random.\n \"\"\"\n self.locale = locale\n self.seed = seed\n self._gen = Generic(self.locale, self.seed)\n\n if providers:\n self._gen.add_providers(*providers)\n\n self._table = {} # type: ignore\n\n def __call__(self, name: Optional[str] = None,\n key: Optional[Callable] = None, **kwargs) -> Any:\n \"\"\"Override standard call.\n\n This magic method overrides standard call so it takes any string\n which represents the name of any method of any supported data\n provider and the ``**kwargs`` of this method.\n\n .. note:: Some data providers have methods with the same names\n and in such cases, you can explicitly define that the method\n belongs to data-provider ``name='provider.name'`` otherwise\n it will return the data from the first provider which\n has a method ``name``.\n\n You can apply a *key function* to the result returned by\n the method, bt passing a parameter **key** with a callable\n object which returns the final result.\n\n :param name: Name of the method.\n :param key: A key function (or other callable object)\n which will be applied to result.\n :param kwargs: Kwargs of method.\n :return: Value which represented by method.\n :raises ValueError: if provider not\n supported or if field not defined.\n \"\"\"\n if name is None:\n raise UndefinedField()\n\n def tail_parser(tails: str, obj: Any) -> Any:\n \"\"\"Return method from end of tail.\n\n :param tails: Tail string\n :param obj: Search tail from this object\n :return last tailed method\n \"\"\"\n provider_name, method_name = tails.split('.', 1)\n\n if '.' in method_name:\n raise UnacceptableField()\n\n attr = getattr(obj, provider_name)\n if attr is not None:\n return getattr(attr, method_name)\n\n try:\n if name not in self._table:\n if '.' not in name:\n # Fix https://github.com/lk-geimfari/mimesis/issues/619\n if name == self._gen.choice.Meta.name:\n self._table[name] = self._gen.choice\n else:\n for provider in dir(self._gen):\n provider = getattr(self._gen, provider)\n if name in dir(provider):\n self._table[name] = getattr(provider, name)\n else:\n self._table[name] = tail_parser(name, self._gen)\n\n result = self._table[name](**kwargs)\n if key and callable(key):\n return key(result)\n return result\n except KeyError:\n raise UnsupportedField(name)\n\n def __str__(self):\n return '{} <{}>'.format(\n self.__class__.__name__, self.locale)\n\n\nclass Schema:\n \"\"\"Class which return list of filled schemas.\"\"\"\n\n def __init__(self, schema: Callable) -> None:\n \"\"\"Initialize schema.\n\n :param schema: A schema.\n \"\"\"\n if callable(schema):\n self.schema = schema\n else:\n raise UndefinedSchema()\n\n def create(self, iterations: int = 1) -> List[JSON]:\n \"\"\"Return filled schema.\n\n Create a list of a filled schemas with elements in\n an amount of **iterations**.\n\n :param iterations: Amount of iterations.\n :return: List of willed schemas.\n \"\"\"\n return [self.schema() for _ in range(iterations)]\n\n\n# Alias for AbstractField\nField = AbstractField\n", "path": "mimesis/schema.py"}]}
| 1,943 | 252 |
gh_patches_debug_5354
|
rasdani/github-patches
|
git_diff
|
arviz-devs__arviz-683
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
to_netcdf fails with error writing PyMC3 trace containing pm.Data as observed
**Describe the bug**
If one creates a model that has an observed RV, and the observations for that RV are a `pm.Data` object, and one tries to invoke `to_netcdf()` on the resulting arviz `InferenceData` object, you get an error in `ensure_dtype_not_object()`. Inspection of the backtrace shows that the `InferenceData` object has the *name of the `pm.Data()`* in the observation array, instead of the data that populates the `Data` object.
Note that trying to save a *prior predictive trace* alone does *not* trigger this bug. As far as I can tell, it must be a sample from the posterior.
**To Reproduce**
See attached jupyter notebook for a minimal case.
**Additional context**
`arviz` 0.4.0
`pymc3` from git
MacOS (but I think that's irrelevant)
[arviz-to_netcdf-bug.ipynb.txt](https://github.com/arviz-devs/arviz/files/3233360/arviz-to_netcdf-bug.ipynb.txt)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `arviz/data/io_pymc3.py`
Content:
```
1 """PyMC3-specific conversion code."""
2 import numpy as np
3 import xarray as xr
4
5 from .inference_data import InferenceData
6 from .base import requires, dict_to_dataset, generate_dims_coords, make_attrs
7
8
9 class PyMC3Converter:
10 """Encapsulate PyMC3 specific logic."""
11
12 def __init__(
13 self, *, trace=None, prior=None, posterior_predictive=None, coords=None, dims=None
14 ):
15 self.trace = trace
16 self.prior = prior
17 self.posterior_predictive = posterior_predictive
18 self.coords = coords
19 self.dims = dims
20 import pymc3
21
22 self.pymc3 = pymc3
23
24 @requires("trace")
25 def _extract_log_likelihood(self):
26 """Compute log likelihood of each observation.
27
28 Return None if there is not exactly 1 observed random variable.
29 """
30 # This next line is brittle and may not work forever, but is a secret
31 # way to access the model from the trace.
32 model = self.trace._straces[0].model # pylint: disable=protected-access
33 if len(model.observed_RVs) != 1:
34 return None, None
35 else:
36 if self.dims is not None:
37 coord_name = self.dims.get(model.observed_RVs[0].name)
38 else:
39 coord_name = None
40
41 cached = [(var, var.logp_elemwise) for var in model.observed_RVs]
42
43 def log_likelihood_vals_point(point):
44 """Compute log likelihood for each observed point."""
45 log_like_vals = []
46 for var, log_like in cached:
47 log_like_val = log_like(point)
48 if var.missing_values:
49 log_like_val = log_like_val[~var.observations.mask]
50 log_like_vals.append(log_like_val)
51 return np.concatenate(log_like_vals)
52
53 chain_likelihoods = []
54 for chain in self.trace.chains:
55 log_like = (log_likelihood_vals_point(point) for point in self.trace.points([chain]))
56 chain_likelihoods.append(np.stack(log_like))
57 return np.stack(chain_likelihoods), coord_name
58
59 @requires("trace")
60 def posterior_to_xarray(self):
61 """Convert the posterior to an xarray dataset."""
62 var_names = self.pymc3.util.get_default_varnames( # pylint: disable=no-member
63 self.trace.varnames, include_transformed=False
64 )
65 data = {}
66 for var_name in var_names:
67 data[var_name] = np.array(self.trace.get_values(var_name, combine=False, squeeze=False))
68 return dict_to_dataset(data, library=self.pymc3, coords=self.coords, dims=self.dims)
69
70 @requires("trace")
71 def sample_stats_to_xarray(self):
72 """Extract sample_stats from PyMC3 trace."""
73 rename_key = {"model_logp": "lp"}
74 data = {}
75 for stat in self.trace.stat_names:
76 name = rename_key.get(stat, stat)
77 data[name] = np.array(self.trace.get_sampler_stats(stat, combine=False))
78 log_likelihood, dims = self._extract_log_likelihood()
79 if log_likelihood is not None:
80 data["log_likelihood"] = log_likelihood
81 dims = {"log_likelihood": dims}
82 else:
83 dims = None
84
85 return dict_to_dataset(data, library=self.pymc3, dims=dims, coords=self.coords)
86
87 @requires("posterior_predictive")
88 def posterior_predictive_to_xarray(self):
89 """Convert posterior_predictive samples to xarray."""
90 data = {k: np.expand_dims(v, 0) for k, v in self.posterior_predictive.items()}
91 return dict_to_dataset(data, library=self.pymc3, coords=self.coords, dims=self.dims)
92
93 @requires("prior")
94 def prior_to_xarray(self):
95 """Convert prior samples to xarray."""
96 return dict_to_dataset(
97 {k: np.expand_dims(v, 0) for k, v in self.prior.items()},
98 library=self.pymc3,
99 coords=self.coords,
100 dims=self.dims,
101 )
102
103 @requires("trace")
104 def observed_data_to_xarray(self):
105 """Convert observed data to xarray."""
106 # This next line is brittle and may not work forever, but is a secret
107 # way to access the model from the trace.
108 model = self.trace._straces[0].model # pylint: disable=protected-access
109
110 observations = {obs.name: obs.observations for obs in model.observed_RVs}
111 if self.dims is None:
112 dims = {}
113 else:
114 dims = self.dims
115 observed_data = {}
116 for name, vals in observations.items():
117 vals = np.atleast_1d(vals)
118 val_dims = dims.get(name)
119 val_dims, coords = generate_dims_coords(
120 vals.shape, name, dims=val_dims, coords=self.coords
121 )
122 # filter coords based on the dims
123 coords = {key: xr.IndexVariable((key,), data=coords[key]) for key in val_dims}
124 observed_data[name] = xr.DataArray(vals, dims=val_dims, coords=coords)
125 return xr.Dataset(data_vars=observed_data, attrs=make_attrs(library=self.pymc3))
126
127 def to_inference_data(self):
128 """Convert all available data to an InferenceData object.
129
130 Note that if groups can not be created (i.e., there is no `trace`, so
131 the `posterior` and `sample_stats` can not be extracted), then the InferenceData
132 will not have those groups.
133 """
134 return InferenceData(
135 **{
136 "posterior": self.posterior_to_xarray(),
137 "sample_stats": self.sample_stats_to_xarray(),
138 "posterior_predictive": self.posterior_predictive_to_xarray(),
139 "prior": self.prior_to_xarray(),
140 "observed_data": self.observed_data_to_xarray(),
141 }
142 )
143
144
145 def from_pymc3(trace=None, *, prior=None, posterior_predictive=None, coords=None, dims=None):
146 """Convert pymc3 data into an InferenceData object."""
147 return PyMC3Converter(
148 trace=trace,
149 prior=prior,
150 posterior_predictive=posterior_predictive,
151 coords=coords,
152 dims=dims,
153 ).to_inference_data()
154
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/arviz/data/io_pymc3.py b/arviz/data/io_pymc3.py
--- a/arviz/data/io_pymc3.py
+++ b/arviz/data/io_pymc3.py
@@ -114,6 +114,8 @@
dims = self.dims
observed_data = {}
for name, vals in observations.items():
+ if hasattr(vals, "get_value"):
+ vals = vals.get_value()
vals = np.atleast_1d(vals)
val_dims = dims.get(name)
val_dims, coords = generate_dims_coords(
|
{"golden_diff": "diff --git a/arviz/data/io_pymc3.py b/arviz/data/io_pymc3.py\n--- a/arviz/data/io_pymc3.py\n+++ b/arviz/data/io_pymc3.py\n@@ -114,6 +114,8 @@\n dims = self.dims\n observed_data = {}\n for name, vals in observations.items():\n+ if hasattr(vals, \"get_value\"):\n+ vals = vals.get_value()\n vals = np.atleast_1d(vals)\n val_dims = dims.get(name)\n val_dims, coords = generate_dims_coords(\n", "issue": "to_netcdf fails with error writing PyMC3 trace containing pm.Data as observed\n**Describe the bug**\r\nIf one creates a model that has an observed RV, and the observations for that RV are a `pm.Data` object, and one tries to invoke `to_netcdf()` on the resulting arviz `InferenceData` object, you get an error in `ensure_dtype_not_object()`. Inspection of the backtrace shows that the `InferenceData` object has the *name of the `pm.Data()`* in the observation array, instead of the data that populates the `Data` object.\r\nNote that trying to save a *prior predictive trace* alone does *not* trigger this bug. As far as I can tell, it must be a sample from the posterior.\r\n**To Reproduce**\r\nSee attached jupyter notebook for a minimal case.\r\n\r\n\r\n**Additional context**\r\n`arviz` 0.4.0\r\n`pymc3` from git\r\nMacOS (but I think that's irrelevant)\r\n[arviz-to_netcdf-bug.ipynb.txt](https://github.com/arviz-devs/arviz/files/3233360/arviz-to_netcdf-bug.ipynb.txt)\r\n\r\n\n", "before_files": [{"content": "\"\"\"PyMC3-specific conversion code.\"\"\"\nimport numpy as np\nimport xarray as xr\n\nfrom .inference_data import InferenceData\nfrom .base import requires, dict_to_dataset, generate_dims_coords, make_attrs\n\n\nclass PyMC3Converter:\n \"\"\"Encapsulate PyMC3 specific logic.\"\"\"\n\n def __init__(\n self, *, trace=None, prior=None, posterior_predictive=None, coords=None, dims=None\n ):\n self.trace = trace\n self.prior = prior\n self.posterior_predictive = posterior_predictive\n self.coords = coords\n self.dims = dims\n import pymc3\n\n self.pymc3 = pymc3\n\n @requires(\"trace\")\n def _extract_log_likelihood(self):\n \"\"\"Compute log likelihood of each observation.\n\n Return None if there is not exactly 1 observed random variable.\n \"\"\"\n # This next line is brittle and may not work forever, but is a secret\n # way to access the model from the trace.\n model = self.trace._straces[0].model # pylint: disable=protected-access\n if len(model.observed_RVs) != 1:\n return None, None\n else:\n if self.dims is not None:\n coord_name = self.dims.get(model.observed_RVs[0].name)\n else:\n coord_name = None\n\n cached = [(var, var.logp_elemwise) for var in model.observed_RVs]\n\n def log_likelihood_vals_point(point):\n \"\"\"Compute log likelihood for each observed point.\"\"\"\n log_like_vals = []\n for var, log_like in cached:\n log_like_val = log_like(point)\n if var.missing_values:\n log_like_val = log_like_val[~var.observations.mask]\n log_like_vals.append(log_like_val)\n return np.concatenate(log_like_vals)\n\n chain_likelihoods = []\n for chain in self.trace.chains:\n log_like = (log_likelihood_vals_point(point) for point in self.trace.points([chain]))\n chain_likelihoods.append(np.stack(log_like))\n return np.stack(chain_likelihoods), coord_name\n\n @requires(\"trace\")\n def posterior_to_xarray(self):\n \"\"\"Convert the posterior to an xarray dataset.\"\"\"\n var_names = self.pymc3.util.get_default_varnames( # pylint: disable=no-member\n self.trace.varnames, include_transformed=False\n )\n data = {}\n for var_name in var_names:\n data[var_name] = np.array(self.trace.get_values(var_name, combine=False, squeeze=False))\n return dict_to_dataset(data, library=self.pymc3, coords=self.coords, dims=self.dims)\n\n @requires(\"trace\")\n def sample_stats_to_xarray(self):\n \"\"\"Extract sample_stats from PyMC3 trace.\"\"\"\n rename_key = {\"model_logp\": \"lp\"}\n data = {}\n for stat in self.trace.stat_names:\n name = rename_key.get(stat, stat)\n data[name] = np.array(self.trace.get_sampler_stats(stat, combine=False))\n log_likelihood, dims = self._extract_log_likelihood()\n if log_likelihood is not None:\n data[\"log_likelihood\"] = log_likelihood\n dims = {\"log_likelihood\": dims}\n else:\n dims = None\n\n return dict_to_dataset(data, library=self.pymc3, dims=dims, coords=self.coords)\n\n @requires(\"posterior_predictive\")\n def posterior_predictive_to_xarray(self):\n \"\"\"Convert posterior_predictive samples to xarray.\"\"\"\n data = {k: np.expand_dims(v, 0) for k, v in self.posterior_predictive.items()}\n return dict_to_dataset(data, library=self.pymc3, coords=self.coords, dims=self.dims)\n\n @requires(\"prior\")\n def prior_to_xarray(self):\n \"\"\"Convert prior samples to xarray.\"\"\"\n return dict_to_dataset(\n {k: np.expand_dims(v, 0) for k, v in self.prior.items()},\n library=self.pymc3,\n coords=self.coords,\n dims=self.dims,\n )\n\n @requires(\"trace\")\n def observed_data_to_xarray(self):\n \"\"\"Convert observed data to xarray.\"\"\"\n # This next line is brittle and may not work forever, but is a secret\n # way to access the model from the trace.\n model = self.trace._straces[0].model # pylint: disable=protected-access\n\n observations = {obs.name: obs.observations for obs in model.observed_RVs}\n if self.dims is None:\n dims = {}\n else:\n dims = self.dims\n observed_data = {}\n for name, vals in observations.items():\n vals = np.atleast_1d(vals)\n val_dims = dims.get(name)\n val_dims, coords = generate_dims_coords(\n vals.shape, name, dims=val_dims, coords=self.coords\n )\n # filter coords based on the dims\n coords = {key: xr.IndexVariable((key,), data=coords[key]) for key in val_dims}\n observed_data[name] = xr.DataArray(vals, dims=val_dims, coords=coords)\n return xr.Dataset(data_vars=observed_data, attrs=make_attrs(library=self.pymc3))\n\n def to_inference_data(self):\n \"\"\"Convert all available data to an InferenceData object.\n\n Note that if groups can not be created (i.e., there is no `trace`, so\n the `posterior` and `sample_stats` can not be extracted), then the InferenceData\n will not have those groups.\n \"\"\"\n return InferenceData(\n **{\n \"posterior\": self.posterior_to_xarray(),\n \"sample_stats\": self.sample_stats_to_xarray(),\n \"posterior_predictive\": self.posterior_predictive_to_xarray(),\n \"prior\": self.prior_to_xarray(),\n \"observed_data\": self.observed_data_to_xarray(),\n }\n )\n\n\ndef from_pymc3(trace=None, *, prior=None, posterior_predictive=None, coords=None, dims=None):\n \"\"\"Convert pymc3 data into an InferenceData object.\"\"\"\n return PyMC3Converter(\n trace=trace,\n prior=prior,\n posterior_predictive=posterior_predictive,\n coords=coords,\n dims=dims,\n ).to_inference_data()\n", "path": "arviz/data/io_pymc3.py"}], "after_files": [{"content": "\"\"\"PyMC3-specific conversion code.\"\"\"\nimport numpy as np\nimport xarray as xr\n\nfrom .inference_data import InferenceData\nfrom .base import requires, dict_to_dataset, generate_dims_coords, make_attrs\n\n\nclass PyMC3Converter:\n \"\"\"Encapsulate PyMC3 specific logic.\"\"\"\n\n def __init__(\n self, *, trace=None, prior=None, posterior_predictive=None, coords=None, dims=None\n ):\n self.trace = trace\n self.prior = prior\n self.posterior_predictive = posterior_predictive\n self.coords = coords\n self.dims = dims\n import pymc3\n\n self.pymc3 = pymc3\n\n @requires(\"trace\")\n def _extract_log_likelihood(self):\n \"\"\"Compute log likelihood of each observation.\n\n Return None if there is not exactly 1 observed random variable.\n \"\"\"\n # This next line is brittle and may not work forever, but is a secret\n # way to access the model from the trace.\n model = self.trace._straces[0].model # pylint: disable=protected-access\n if len(model.observed_RVs) != 1:\n return None, None\n else:\n if self.dims is not None:\n coord_name = self.dims.get(model.observed_RVs[0].name)\n else:\n coord_name = None\n\n cached = [(var, var.logp_elemwise) for var in model.observed_RVs]\n\n def log_likelihood_vals_point(point):\n \"\"\"Compute log likelihood for each observed point.\"\"\"\n log_like_vals = []\n for var, log_like in cached:\n log_like_val = log_like(point)\n if var.missing_values:\n log_like_val = log_like_val[~var.observations.mask]\n log_like_vals.append(log_like_val)\n return np.concatenate(log_like_vals)\n\n chain_likelihoods = []\n for chain in self.trace.chains:\n log_like = (log_likelihood_vals_point(point) for point in self.trace.points([chain]))\n chain_likelihoods.append(np.stack(log_like))\n return np.stack(chain_likelihoods), coord_name\n\n @requires(\"trace\")\n def posterior_to_xarray(self):\n \"\"\"Convert the posterior to an xarray dataset.\"\"\"\n var_names = self.pymc3.util.get_default_varnames( # pylint: disable=no-member\n self.trace.varnames, include_transformed=False\n )\n data = {}\n for var_name in var_names:\n data[var_name] = np.array(self.trace.get_values(var_name, combine=False, squeeze=False))\n return dict_to_dataset(data, library=self.pymc3, coords=self.coords, dims=self.dims)\n\n @requires(\"trace\")\n def sample_stats_to_xarray(self):\n \"\"\"Extract sample_stats from PyMC3 trace.\"\"\"\n rename_key = {\"model_logp\": \"lp\"}\n data = {}\n for stat in self.trace.stat_names:\n name = rename_key.get(stat, stat)\n data[name] = np.array(self.trace.get_sampler_stats(stat, combine=False))\n log_likelihood, dims = self._extract_log_likelihood()\n if log_likelihood is not None:\n data[\"log_likelihood\"] = log_likelihood\n dims = {\"log_likelihood\": dims}\n else:\n dims = None\n\n return dict_to_dataset(data, library=self.pymc3, dims=dims, coords=self.coords)\n\n @requires(\"posterior_predictive\")\n def posterior_predictive_to_xarray(self):\n \"\"\"Convert posterior_predictive samples to xarray.\"\"\"\n data = {k: np.expand_dims(v, 0) for k, v in self.posterior_predictive.items()}\n return dict_to_dataset(data, library=self.pymc3, coords=self.coords, dims=self.dims)\n\n @requires(\"prior\")\n def prior_to_xarray(self):\n \"\"\"Convert prior samples to xarray.\"\"\"\n return dict_to_dataset(\n {k: np.expand_dims(v, 0) for k, v in self.prior.items()},\n library=self.pymc3,\n coords=self.coords,\n dims=self.dims,\n )\n\n @requires(\"trace\")\n def observed_data_to_xarray(self):\n \"\"\"Convert observed data to xarray.\"\"\"\n # This next line is brittle and may not work forever, but is a secret\n # way to access the model from the trace.\n model = self.trace._straces[0].model # pylint: disable=protected-access\n\n observations = {obs.name: obs.observations for obs in model.observed_RVs}\n if self.dims is None:\n dims = {}\n else:\n dims = self.dims\n observed_data = {}\n for name, vals in observations.items():\n if hasattr(vals, \"get_value\"):\n vals = vals.get_value()\n vals = np.atleast_1d(vals)\n val_dims = dims.get(name)\n val_dims, coords = generate_dims_coords(\n vals.shape, name, dims=val_dims, coords=self.coords\n )\n # filter coords based on the dims\n coords = {key: xr.IndexVariable((key,), data=coords[key]) for key in val_dims}\n observed_data[name] = xr.DataArray(vals, dims=val_dims, coords=coords)\n return xr.Dataset(data_vars=observed_data, attrs=make_attrs(library=self.pymc3))\n\n def to_inference_data(self):\n \"\"\"Convert all available data to an InferenceData object.\n\n Note that if groups can not be created (i.e., there is no `trace`, so\n the `posterior` and `sample_stats` can not be extracted), then the InferenceData\n will not have those groups.\n \"\"\"\n return InferenceData(\n **{\n \"posterior\": self.posterior_to_xarray(),\n \"sample_stats\": self.sample_stats_to_xarray(),\n \"posterior_predictive\": self.posterior_predictive_to_xarray(),\n \"prior\": self.prior_to_xarray(),\n \"observed_data\": self.observed_data_to_xarray(),\n }\n )\n\n\ndef from_pymc3(trace=None, *, prior=None, posterior_predictive=None, coords=None, dims=None):\n \"\"\"Convert pymc3 data into an InferenceData object.\"\"\"\n return PyMC3Converter(\n trace=trace,\n prior=prior,\n posterior_predictive=posterior_predictive,\n coords=coords,\n dims=dims,\n ).to_inference_data()\n", "path": "arviz/data/io_pymc3.py"}]}
| 2,243 | 130 |
gh_patches_debug_39902
|
rasdani/github-patches
|
git_diff
|
AnalogJ__lexicon-442
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DNS Made Easy needs retry logic, to recover from rate limiting errors
Originally certbot/certbot#7411.
DNS Made Easy has [restrictive rate limits](https://api-docs.dnsmadeeasy.com/?version=latest#f6f3c489-422d-4cf0-bccb-1933e6d655ac):
>To prevent unwanted flooding of the API system, there is a maximum number of requests that can be sent in a given time period. This limit is 150 requests per 5 minute scrolling window
Lexicon should be able to recover from hitting the rate limit without failing the operation.
The response received is an HTTP 400 with a response body of:
>{"error": ["Rate limit exceeded"]}
@adferrand suggested retry logic in [this comment](https://github.com/certbot/certbot/issues/7411#issuecomment-536438100):
>How about defining a short sleep (like 5 seconds), and a retry strategy with a max attempts, triggered in case of 400 with body {"error": ["Rate limit exceeded"]}?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lexicon/providers/dnsmadeeasy.py`
Content:
```
1 """Module provider for DNSMadeEasy"""
2 from __future__ import absolute_import
3 import hmac
4 import json
5 import logging
6 from builtins import bytes
7 from email.utils import formatdate
8 from hashlib import sha1
9
10 import requests
11 from lexicon.providers.base import Provider as BaseProvider
12
13
14 LOGGER = logging.getLogger(__name__)
15
16 NAMESERVER_DOMAINS = ['dnsmadeeasy']
17
18
19 def provider_parser(subparser):
20 """Configure provider parser for DNSMadeEasy"""
21 subparser.add_argument(
22 "--auth-username", help="specify username for authentication")
23 subparser.add_argument(
24 "--auth-token", help="specify token for authentication")
25
26
27 class Provider(BaseProvider):
28 """Provider class for DNSMadeEasy"""
29 def __init__(self, config):
30 super(Provider, self).__init__(config)
31 self.domain_id = None
32 self.api_endpoint = self._get_provider_option(
33 'api_endpoint') or 'https://api.dnsmadeeasy.com/V2.0'
34
35 def _authenticate(self):
36
37 try:
38 payload = self._get('/dns/managed/name',
39 {'domainname': self.domain})
40 except requests.exceptions.HTTPError as error:
41 if error.response.status_code == 404:
42 payload = {}
43 else:
44 raise
45
46 if not payload or not payload['id']:
47 raise Exception('No domain found')
48
49 self.domain_id = payload['id']
50
51 # Create record. If record already exists with the same content, do nothing'
52
53 def _create_record(self, rtype, name, content):
54 record = {
55 'type': rtype,
56 'name': self._relative_name(name),
57 'value': content,
58 'ttl': self._get_lexicon_option('ttl')
59 }
60 payload = {}
61 try:
62 payload = self._post(
63 '/dns/managed/{0}/records/'.format(self.domain_id), record)
64 except requests.exceptions.HTTPError as error:
65 if error.response.status_code != 400:
66 raise
67
68 # http 400 is ok here, because the record probably already exists
69 LOGGER.debug('create_record: %s', 'name' in payload)
70 return True
71
72 # List all records. Return an empty list if no records found
73 # type, name and content are used to filter records.
74 # If possible filter during the query, otherwise filter after response is received.
75 def _list_records(self, rtype=None, name=None, content=None):
76 filter_query = {}
77 if rtype:
78 filter_query['type'] = rtype
79 if name:
80 filter_query['recordName'] = self._relative_name(name)
81 payload = self._get(
82 '/dns/managed/{0}/records'.format(self.domain_id), filter_query)
83
84 records = []
85 for record in payload['data']:
86 processed_record = {
87 'type': record['type'],
88 'name': '{0}.{1}'.format(record['name'], self.domain),
89 'ttl': record['ttl'],
90 'content': record['value'],
91 'id': record['id']
92 }
93
94 processed_record = self._clean_TXT_record(processed_record)
95 records.append(processed_record)
96
97 if content:
98 records = [
99 record for record in records if record['content'].lower() == content.lower()]
100
101 LOGGER.debug('list_records: %s', records)
102 return records
103
104 # Create or update a record.
105 def _update_record(self, identifier, rtype=None, name=None, content=None):
106
107 data = {
108 'id': identifier,
109 'ttl': self._get_lexicon_option('ttl')
110 }
111
112 if name:
113 data['name'] = self._relative_name(name)
114 if content:
115 data['value'] = content
116 if rtype:
117 data['type'] = rtype
118
119 self._put(
120 '/dns/managed/{0}/records/{1}'.format(self.domain_id, identifier), data)
121
122 LOGGER.debug('update_record: %s', True)
123 return True
124
125 # Delete an existing record.
126 # If record does not exist, do nothing.
127 def _delete_record(self, identifier=None, rtype=None, name=None, content=None):
128 delete_record_id = []
129 if not identifier:
130 records = self._list_records(rtype, name, content)
131 delete_record_id = [record['id'] for record in records]
132 else:
133 delete_record_id.append(identifier)
134
135 LOGGER.debug('delete_records: %s', delete_record_id)
136
137 for record_id in delete_record_id:
138 self._delete(
139 '/dns/managed/{0}/records/{1}'.format(self.domain_id, record_id))
140
141 # is always True at this point, if a non 200 response is returned an error is raised.
142 LOGGER.debug('delete_record: %s', True)
143 return True
144
145 # Helpers
146
147 def _request(self, action='GET', url='/', data=None, query_params=None):
148 if data is None:
149 data = {}
150 if query_params is None:
151 query_params = {}
152 default_headers = {
153 'Accept': 'application/json',
154 'Content-Type': 'application/json',
155 'x-dnsme-apiKey': self._get_provider_option('auth_username')
156 }
157 default_auth = None
158
159 # Date string in HTTP format e.g. Sat, 12 Feb 2011 20:59:04 GMT
160 request_date = formatdate(usegmt=True)
161
162 hashed = hmac.new(bytes(self._get_provider_option('auth_token'), 'ascii'),
163 bytes(request_date, 'ascii'), sha1)
164
165 default_headers['x-dnsme-requestDate'] = request_date
166 default_headers['x-dnsme-hmac'] = hashed.hexdigest()
167
168 response = requests.request(action, self.api_endpoint + url, params=query_params,
169 data=json.dumps(data),
170 headers=default_headers,
171 auth=default_auth)
172 # if the request fails for any reason, throw an error.
173 response.raise_for_status()
174
175 # PUT and DELETE actions dont return valid json.
176 if action in ['DELETE', 'PUT']:
177 return response.text
178 return response.json()
179
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lexicon/providers/dnsmadeeasy.py b/lexicon/providers/dnsmadeeasy.py
--- a/lexicon/providers/dnsmadeeasy.py
+++ b/lexicon/providers/dnsmadeeasy.py
@@ -6,8 +6,10 @@
from builtins import bytes
from email.utils import formatdate
from hashlib import sha1
+from urllib3.util.retry import Retry
import requests
+from requests.adapters import HTTPAdapter
from lexicon.providers.base import Provider as BaseProvider
@@ -16,6 +18,21 @@
NAMESERVER_DOMAINS = ['dnsmadeeasy']
+class _RetryRateLimit(Retry):
+ # Standard urllib3 Retry objects trigger retries only based on HTTP status code or HTTP method.
+ # However we need to differentiate 400 errors with body `{"error": ["Rate limit exceeded"]}`
+ # from the other 400 errors. The internal _RetryRateLimit class does that.
+ def increment(self, method=None, url=None, response=None,
+ error=None, _pool=None, _stacktrace=None):
+ if response:
+ body = json.loads(response.data)
+ if 'Rate limit exceeded' in body.get('error', []):
+ return super(_RetryRateLimit, self).increment(
+ method, url, response, error, _pool, _stacktrace)
+
+ raise RuntimeError('URL {0} returned a HTTP 400 status code.'.format(url))
+
+
def provider_parser(subparser):
"""Configure provider parser for DNSMadeEasy"""
subparser.add_argument(
@@ -165,14 +182,30 @@
default_headers['x-dnsme-requestDate'] = request_date
default_headers['x-dnsme-hmac'] = hashed.hexdigest()
- response = requests.request(action, self.api_endpoint + url, params=query_params,
- data=json.dumps(data),
- headers=default_headers,
- auth=default_auth)
- # if the request fails for any reason, throw an error.
- response.raise_for_status()
-
- # PUT and DELETE actions dont return valid json.
- if action in ['DELETE', 'PUT']:
- return response.text
- return response.json()
+ session = requests.Session()
+ try:
+ # DNSMadeEasy allows only 150 requests in a floating 5 min time window.
+ # So we implement a retry strategy on requests returned as 400 with body
+ # `{"error": ["Rate limit exceeded"]}`.
+ # 10 retries with backoff = 0.6 gives following retry delays after first attempt:
+ # 1.2s, 2.4s, 4.8s, 9.6s, 19.2s, 38.4s, 76.8s, 153.6s, 307.2s
+ # So last attempt is done 5 min 7 seconds after first try, so the
+ # size of the floating window.
+ # Beyond it we can assume something else is wrong and so give up.
+ session_retries = _RetryRateLimit(total=10, backoff_factor=0.6, status_forcelist=[400])
+ session_adapter = HTTPAdapter(max_retries=session_retries)
+ session.mount('http://', session_adapter)
+ session.mount('https://', session_adapter)
+ response = session.request(action, self.api_endpoint + url, params=query_params,
+ data=json.dumps(data),
+ headers=default_headers,
+ auth=default_auth)
+ # if the request fails for any reason, throw an error.
+ response.raise_for_status()
+
+ # PUT and DELETE actions dont return valid json.
+ if action in ['DELETE', 'PUT']:
+ return response.text
+ return response.json()
+ finally:
+ session.close()
|
{"golden_diff": "diff --git a/lexicon/providers/dnsmadeeasy.py b/lexicon/providers/dnsmadeeasy.py\n--- a/lexicon/providers/dnsmadeeasy.py\n+++ b/lexicon/providers/dnsmadeeasy.py\n@@ -6,8 +6,10 @@\n from builtins import bytes\n from email.utils import formatdate\n from hashlib import sha1\n+from urllib3.util.retry import Retry\n \n import requests\n+from requests.adapters import HTTPAdapter\n from lexicon.providers.base import Provider as BaseProvider\n \n \n@@ -16,6 +18,21 @@\n NAMESERVER_DOMAINS = ['dnsmadeeasy']\n \n \n+class _RetryRateLimit(Retry):\n+ # Standard urllib3 Retry objects trigger retries only based on HTTP status code or HTTP method.\n+ # However we need to differentiate 400 errors with body `{\"error\": [\"Rate limit exceeded\"]}`\n+ # from the other 400 errors. The internal _RetryRateLimit class does that.\n+ def increment(self, method=None, url=None, response=None,\n+ error=None, _pool=None, _stacktrace=None):\n+ if response:\n+ body = json.loads(response.data)\n+ if 'Rate limit exceeded' in body.get('error', []):\n+ return super(_RetryRateLimit, self).increment(\n+ method, url, response, error, _pool, _stacktrace)\n+\n+ raise RuntimeError('URL {0} returned a HTTP 400 status code.'.format(url))\n+\n+\n def provider_parser(subparser):\n \"\"\"Configure provider parser for DNSMadeEasy\"\"\"\n subparser.add_argument(\n@@ -165,14 +182,30 @@\n default_headers['x-dnsme-requestDate'] = request_date\n default_headers['x-dnsme-hmac'] = hashed.hexdigest()\n \n- response = requests.request(action, self.api_endpoint + url, params=query_params,\n- data=json.dumps(data),\n- headers=default_headers,\n- auth=default_auth)\n- # if the request fails for any reason, throw an error.\n- response.raise_for_status()\n-\n- # PUT and DELETE actions dont return valid json.\n- if action in ['DELETE', 'PUT']:\n- return response.text\n- return response.json()\n+ session = requests.Session()\n+ try:\n+ # DNSMadeEasy allows only 150 requests in a floating 5 min time window.\n+ # So we implement a retry strategy on requests returned as 400 with body\n+ # `{\"error\": [\"Rate limit exceeded\"]}`.\n+ # 10 retries with backoff = 0.6 gives following retry delays after first attempt:\n+ # 1.2s, 2.4s, 4.8s, 9.6s, 19.2s, 38.4s, 76.8s, 153.6s, 307.2s\n+ # So last attempt is done 5 min 7 seconds after first try, so the\n+ # size of the floating window.\n+ # Beyond it we can assume something else is wrong and so give up.\n+ session_retries = _RetryRateLimit(total=10, backoff_factor=0.6, status_forcelist=[400])\n+ session_adapter = HTTPAdapter(max_retries=session_retries)\n+ session.mount('http://', session_adapter)\n+ session.mount('https://', session_adapter)\n+ response = session.request(action, self.api_endpoint + url, params=query_params,\n+ data=json.dumps(data),\n+ headers=default_headers,\n+ auth=default_auth)\n+ # if the request fails for any reason, throw an error.\n+ response.raise_for_status()\n+\n+ # PUT and DELETE actions dont return valid json.\n+ if action in ['DELETE', 'PUT']:\n+ return response.text\n+ return response.json()\n+ finally:\n+ session.close()\n", "issue": "DNS Made Easy needs retry logic, to recover from rate limiting errors\nOriginally certbot/certbot#7411.\r\n\r\nDNS Made Easy has [restrictive rate limits](https://api-docs.dnsmadeeasy.com/?version=latest#f6f3c489-422d-4cf0-bccb-1933e6d655ac):\r\n>To prevent unwanted flooding of the API system, there is a maximum number of requests that can be sent in a given time period. This limit is 150 requests per 5 minute scrolling window\r\n\r\nLexicon should be able to recover from hitting the rate limit without failing the operation.\r\n\r\nThe response received is an HTTP 400 with a response body of:\r\n\r\n>{\"error\": [\"Rate limit exceeded\"]}\r\n\r\n@adferrand suggested retry logic in [this comment](https://github.com/certbot/certbot/issues/7411#issuecomment-536438100):\r\n\r\n>How about defining a short sleep (like 5 seconds), and a retry strategy with a max attempts, triggered in case of 400 with body {\"error\": [\"Rate limit exceeded\"]}?\n", "before_files": [{"content": "\"\"\"Module provider for DNSMadeEasy\"\"\"\nfrom __future__ import absolute_import\nimport hmac\nimport json\nimport logging\nfrom builtins import bytes\nfrom email.utils import formatdate\nfrom hashlib import sha1\n\nimport requests\nfrom lexicon.providers.base import Provider as BaseProvider\n\n\nLOGGER = logging.getLogger(__name__)\n\nNAMESERVER_DOMAINS = ['dnsmadeeasy']\n\n\ndef provider_parser(subparser):\n \"\"\"Configure provider parser for DNSMadeEasy\"\"\"\n subparser.add_argument(\n \"--auth-username\", help=\"specify username for authentication\")\n subparser.add_argument(\n \"--auth-token\", help=\"specify token for authentication\")\n\n\nclass Provider(BaseProvider):\n \"\"\"Provider class for DNSMadeEasy\"\"\"\n def __init__(self, config):\n super(Provider, self).__init__(config)\n self.domain_id = None\n self.api_endpoint = self._get_provider_option(\n 'api_endpoint') or 'https://api.dnsmadeeasy.com/V2.0'\n\n def _authenticate(self):\n\n try:\n payload = self._get('/dns/managed/name',\n {'domainname': self.domain})\n except requests.exceptions.HTTPError as error:\n if error.response.status_code == 404:\n payload = {}\n else:\n raise\n\n if not payload or not payload['id']:\n raise Exception('No domain found')\n\n self.domain_id = payload['id']\n\n # Create record. If record already exists with the same content, do nothing'\n\n def _create_record(self, rtype, name, content):\n record = {\n 'type': rtype,\n 'name': self._relative_name(name),\n 'value': content,\n 'ttl': self._get_lexicon_option('ttl')\n }\n payload = {}\n try:\n payload = self._post(\n '/dns/managed/{0}/records/'.format(self.domain_id), record)\n except requests.exceptions.HTTPError as error:\n if error.response.status_code != 400:\n raise\n\n # http 400 is ok here, because the record probably already exists\n LOGGER.debug('create_record: %s', 'name' in payload)\n return True\n\n # List all records. Return an empty list if no records found\n # type, name and content are used to filter records.\n # If possible filter during the query, otherwise filter after response is received.\n def _list_records(self, rtype=None, name=None, content=None):\n filter_query = {}\n if rtype:\n filter_query['type'] = rtype\n if name:\n filter_query['recordName'] = self._relative_name(name)\n payload = self._get(\n '/dns/managed/{0}/records'.format(self.domain_id), filter_query)\n\n records = []\n for record in payload['data']:\n processed_record = {\n 'type': record['type'],\n 'name': '{0}.{1}'.format(record['name'], self.domain),\n 'ttl': record['ttl'],\n 'content': record['value'],\n 'id': record['id']\n }\n\n processed_record = self._clean_TXT_record(processed_record)\n records.append(processed_record)\n\n if content:\n records = [\n record for record in records if record['content'].lower() == content.lower()]\n\n LOGGER.debug('list_records: %s', records)\n return records\n\n # Create or update a record.\n def _update_record(self, identifier, rtype=None, name=None, content=None):\n\n data = {\n 'id': identifier,\n 'ttl': self._get_lexicon_option('ttl')\n }\n\n if name:\n data['name'] = self._relative_name(name)\n if content:\n data['value'] = content\n if rtype:\n data['type'] = rtype\n\n self._put(\n '/dns/managed/{0}/records/{1}'.format(self.domain_id, identifier), data)\n\n LOGGER.debug('update_record: %s', True)\n return True\n\n # Delete an existing record.\n # If record does not exist, do nothing.\n def _delete_record(self, identifier=None, rtype=None, name=None, content=None):\n delete_record_id = []\n if not identifier:\n records = self._list_records(rtype, name, content)\n delete_record_id = [record['id'] for record in records]\n else:\n delete_record_id.append(identifier)\n\n LOGGER.debug('delete_records: %s', delete_record_id)\n\n for record_id in delete_record_id:\n self._delete(\n '/dns/managed/{0}/records/{1}'.format(self.domain_id, record_id))\n\n # is always True at this point, if a non 200 response is returned an error is raised.\n LOGGER.debug('delete_record: %s', True)\n return True\n\n # Helpers\n\n def _request(self, action='GET', url='/', data=None, query_params=None):\n if data is None:\n data = {}\n if query_params is None:\n query_params = {}\n default_headers = {\n 'Accept': 'application/json',\n 'Content-Type': 'application/json',\n 'x-dnsme-apiKey': self._get_provider_option('auth_username')\n }\n default_auth = None\n\n # Date string in HTTP format e.g. Sat, 12 Feb 2011 20:59:04 GMT\n request_date = formatdate(usegmt=True)\n\n hashed = hmac.new(bytes(self._get_provider_option('auth_token'), 'ascii'),\n bytes(request_date, 'ascii'), sha1)\n\n default_headers['x-dnsme-requestDate'] = request_date\n default_headers['x-dnsme-hmac'] = hashed.hexdigest()\n\n response = requests.request(action, self.api_endpoint + url, params=query_params,\n data=json.dumps(data),\n headers=default_headers,\n auth=default_auth)\n # if the request fails for any reason, throw an error.\n response.raise_for_status()\n\n # PUT and DELETE actions dont return valid json.\n if action in ['DELETE', 'PUT']:\n return response.text\n return response.json()\n", "path": "lexicon/providers/dnsmadeeasy.py"}], "after_files": [{"content": "\"\"\"Module provider for DNSMadeEasy\"\"\"\nfrom __future__ import absolute_import\nimport hmac\nimport json\nimport logging\nfrom builtins import bytes\nfrom email.utils import formatdate\nfrom hashlib import sha1\nfrom urllib3.util.retry import Retry\n\nimport requests\nfrom requests.adapters import HTTPAdapter\nfrom lexicon.providers.base import Provider as BaseProvider\n\n\nLOGGER = logging.getLogger(__name__)\n\nNAMESERVER_DOMAINS = ['dnsmadeeasy']\n\n\nclass _RetryRateLimit(Retry):\n # Standard urllib3 Retry objects trigger retries only based on HTTP status code or HTTP method.\n # However we need to differentiate 400 errors with body `{\"error\": [\"Rate limit exceeded\"]}`\n # from the other 400 errors. The internal _RetryRateLimit class does that.\n def increment(self, method=None, url=None, response=None,\n error=None, _pool=None, _stacktrace=None):\n if response:\n body = json.loads(response.data)\n if 'Rate limit exceeded' in body.get('error', []):\n return super(_RetryRateLimit, self).increment(\n method, url, response, error, _pool, _stacktrace)\n\n raise RuntimeError('URL {0} returned a HTTP 400 status code.'.format(url))\n\n\ndef provider_parser(subparser):\n \"\"\"Configure provider parser for DNSMadeEasy\"\"\"\n subparser.add_argument(\n \"--auth-username\", help=\"specify username for authentication\")\n subparser.add_argument(\n \"--auth-token\", help=\"specify token for authentication\")\n\n\nclass Provider(BaseProvider):\n \"\"\"Provider class for DNSMadeEasy\"\"\"\n def __init__(self, config):\n super(Provider, self).__init__(config)\n self.domain_id = None\n self.api_endpoint = self._get_provider_option(\n 'api_endpoint') or 'https://api.dnsmadeeasy.com/V2.0'\n\n def _authenticate(self):\n\n try:\n payload = self._get('/dns/managed/name',\n {'domainname': self.domain})\n except requests.exceptions.HTTPError as error:\n if error.response.status_code == 404:\n payload = {}\n else:\n raise\n\n if not payload or not payload['id']:\n raise Exception('No domain found')\n\n self.domain_id = payload['id']\n\n # Create record. If record already exists with the same content, do nothing'\n\n def _create_record(self, rtype, name, content):\n record = {\n 'type': rtype,\n 'name': self._relative_name(name),\n 'value': content,\n 'ttl': self._get_lexicon_option('ttl')\n }\n payload = {}\n try:\n payload = self._post(\n '/dns/managed/{0}/records/'.format(self.domain_id), record)\n except requests.exceptions.HTTPError as error:\n if error.response.status_code != 400:\n raise\n\n # http 400 is ok here, because the record probably already exists\n LOGGER.debug('create_record: %s', 'name' in payload)\n return True\n\n # List all records. Return an empty list if no records found\n # type, name and content are used to filter records.\n # If possible filter during the query, otherwise filter after response is received.\n def _list_records(self, rtype=None, name=None, content=None):\n filter_query = {}\n if rtype:\n filter_query['type'] = rtype\n if name:\n filter_query['recordName'] = self._relative_name(name)\n payload = self._get(\n '/dns/managed/{0}/records'.format(self.domain_id), filter_query)\n\n records = []\n for record in payload['data']:\n processed_record = {\n 'type': record['type'],\n 'name': '{0}.{1}'.format(record['name'], self.domain),\n 'ttl': record['ttl'],\n 'content': record['value'],\n 'id': record['id']\n }\n\n processed_record = self._clean_TXT_record(processed_record)\n records.append(processed_record)\n\n if content:\n records = [\n record for record in records if record['content'].lower() == content.lower()]\n\n LOGGER.debug('list_records: %s', records)\n return records\n\n # Create or update a record.\n def _update_record(self, identifier, rtype=None, name=None, content=None):\n\n data = {\n 'id': identifier,\n 'ttl': self._get_lexicon_option('ttl')\n }\n\n if name:\n data['name'] = self._relative_name(name)\n if content:\n data['value'] = content\n if rtype:\n data['type'] = rtype\n\n self._put(\n '/dns/managed/{0}/records/{1}'.format(self.domain_id, identifier), data)\n\n LOGGER.debug('update_record: %s', True)\n return True\n\n # Delete an existing record.\n # If record does not exist, do nothing.\n def _delete_record(self, identifier=None, rtype=None, name=None, content=None):\n delete_record_id = []\n if not identifier:\n records = self._list_records(rtype, name, content)\n delete_record_id = [record['id'] for record in records]\n else:\n delete_record_id.append(identifier)\n\n LOGGER.debug('delete_records: %s', delete_record_id)\n\n for record_id in delete_record_id:\n self._delete(\n '/dns/managed/{0}/records/{1}'.format(self.domain_id, record_id))\n\n # is always True at this point, if a non 200 response is returned an error is raised.\n LOGGER.debug('delete_record: %s', True)\n return True\n\n # Helpers\n\n def _request(self, action='GET', url='/', data=None, query_params=None):\n if data is None:\n data = {}\n if query_params is None:\n query_params = {}\n default_headers = {\n 'Accept': 'application/json',\n 'Content-Type': 'application/json',\n 'x-dnsme-apiKey': self._get_provider_option('auth_username')\n }\n default_auth = None\n\n # Date string in HTTP format e.g. Sat, 12 Feb 2011 20:59:04 GMT\n request_date = formatdate(usegmt=True)\n\n hashed = hmac.new(bytes(self._get_provider_option('auth_token'), 'ascii'),\n bytes(request_date, 'ascii'), sha1)\n\n default_headers['x-dnsme-requestDate'] = request_date\n default_headers['x-dnsme-hmac'] = hashed.hexdigest()\n\n session = requests.Session()\n try:\n # DNSMadeEasy allows only 150 requests in a floating 5 min time window.\n # So we implement a retry strategy on requests returned as 400 with body\n # `{\"error\": [\"Rate limit exceeded\"]}`.\n # 10 retries with backoff = 0.6 gives following retry delays after first attempt:\n # 1.2s, 2.4s, 4.8s, 9.6s, 19.2s, 38.4s, 76.8s, 153.6s, 307.2s\n # So last attempt is done 5 min 7 seconds after first try, so the\n # size of the floating window.\n # Beyond it we can assume something else is wrong and so give up.\n session_retries = _RetryRateLimit(total=10, backoff_factor=0.6, status_forcelist=[400])\n session_adapter = HTTPAdapter(max_retries=session_retries)\n session.mount('http://', session_adapter)\n session.mount('https://', session_adapter)\n response = session.request(action, self.api_endpoint + url, params=query_params,\n data=json.dumps(data),\n headers=default_headers,\n auth=default_auth)\n # if the request fails for any reason, throw an error.\n response.raise_for_status()\n\n # PUT and DELETE actions dont return valid json.\n if action in ['DELETE', 'PUT']:\n return response.text\n return response.json()\n finally:\n session.close()\n", "path": "lexicon/providers/dnsmadeeasy.py"}]}
| 2,280 | 867 |
gh_patches_debug_13831
|
rasdani/github-patches
|
git_diff
|
pypa__setuptools-3705
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] release v65.6.0 breaks packages downstream due to removal of `distutils.log.Log`
### setuptools version
65.6.0
### Python version
Python 3.10
### OS
Ubuntu
### Additional environment information
_No response_
### Description
The `distutils.log.Log` class was removed in https://github.com/pypa/setuptools/commit/74652cabdeaacadc76ccf126563bed8ee2ccf3ef. This causes popular packages downstream, such as `numpy`, to fail: see https://github.com/numpy/numpy/issues/22623
### Expected behavior
The module `distutils.log` module was not officially marked as deprecated even though https://github.com/pypa/setuptools/commit/74652cabdeaacadc76ccf126563bed8ee2ccf3ef added to the docstring that the module is `Retained for compatibility and should not be used.`. It would be great if the removed class could be reinstated and a deprecation pathway be provided.
### How to Reproduce
1. `pip install setuptools==65.6.0`
2. `from numpy.distutils import Log`
### Output
```
In [4]: from numpy.distutils import Log
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
<ipython-input-4-f8e71815afcd> in <module>
----> 1 from numpy.distutils import Log
~/.virtualenvs/aiida_dev/lib/python3.9/site-packages/numpy/distutils/__init__.py in <module>
22 # Must import local ccompiler ASAP in order to get
23 # customized CCompiler.spawn effective.
---> 24 from . import ccompiler
25 from . import unixccompiler
26
~/.virtualenvs/aiida_dev/lib/python3.9/site-packages/numpy/distutils/ccompiler.py in <module>
18 from distutils.version import LooseVersion
19
---> 20 from numpy.distutils import log
21 from numpy.distutils.exec_command import (
22 filepath_from_subprocess_output, forward_bytes_to_stdout
~/.virtualenvs/aiida_dev/lib/python3.9/site-packages/numpy/distutils/log.py in <module>
2 import sys
3 from distutils.log import * # noqa: F403
----> 4 from distutils.log import Log as old_Log
5 from distutils.log import _global_log
6
ImportError: cannot import name 'Log' from 'distutils.log' (/home/sph/.virtualenvs/aiida_dev/lib/python3.9/site-packages/setuptools/_distutils/log.py)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setuptools/_distutils/log.py`
Content:
```
1 """
2 A simple log mechanism styled after PEP 282.
3
4 Retained for compatibility and should not be used.
5 """
6
7 import logging
8
9 from ._log import log as _global_log
10
11
12 DEBUG = logging.DEBUG
13 INFO = logging.INFO
14 WARN = logging.WARN
15 ERROR = logging.ERROR
16 FATAL = logging.FATAL
17
18 log = _global_log.log
19 debug = _global_log.debug
20 info = _global_log.info
21 warn = _global_log.warning
22 error = _global_log.error
23 fatal = _global_log.fatal
24
25
26 def set_threshold(level):
27 orig = _global_log.level
28 _global_log.setLevel(level)
29 return orig
30
31
32 def set_verbosity(v):
33 if v <= 0:
34 set_threshold(logging.WARN)
35 elif v == 1:
36 set_threshold(logging.INFO)
37 elif v >= 2:
38 set_threshold(logging.DEBUG)
39
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setuptools/_distutils/log.py b/setuptools/_distutils/log.py
--- a/setuptools/_distutils/log.py
+++ b/setuptools/_distutils/log.py
@@ -5,6 +5,7 @@
"""
import logging
+import warnings
from ._log import log as _global_log
@@ -36,3 +37,21 @@
set_threshold(logging.INFO)
elif v >= 2:
set_threshold(logging.DEBUG)
+
+
+class Log(logging.Logger):
+ """distutils.log.Log is deprecated, please use an alternative from `logging`."""
+
+ def __init__(self, threshold=WARN):
+ warnings.warn(Log.__doc__) # avoid DeprecationWarning to ensure warn is shown
+ super().__init__(__name__, level=threshold)
+
+ @property
+ def threshold(self):
+ return self.level
+
+ @threshold.setter
+ def threshold(self, level):
+ self.setLevel(level)
+
+ warn = logging.Logger.warning
|
{"golden_diff": "diff --git a/setuptools/_distutils/log.py b/setuptools/_distutils/log.py\n--- a/setuptools/_distutils/log.py\n+++ b/setuptools/_distutils/log.py\n@@ -5,6 +5,7 @@\n \"\"\"\n \n import logging\n+import warnings\n \n from ._log import log as _global_log\n \n@@ -36,3 +37,21 @@\n set_threshold(logging.INFO)\n elif v >= 2:\n set_threshold(logging.DEBUG)\n+\n+\n+class Log(logging.Logger):\n+ \"\"\"distutils.log.Log is deprecated, please use an alternative from `logging`.\"\"\"\n+\n+ def __init__(self, threshold=WARN):\n+ warnings.warn(Log.__doc__) # avoid DeprecationWarning to ensure warn is shown\n+ super().__init__(__name__, level=threshold)\n+\n+ @property\n+ def threshold(self):\n+ return self.level\n+\n+ @threshold.setter\n+ def threshold(self, level):\n+ self.setLevel(level)\n+\n+ warn = logging.Logger.warning\n", "issue": "[BUG] release v65.6.0 breaks packages downstream due to removal of `distutils.log.Log`\n### setuptools version\n\n65.6.0\n\n### Python version\n\nPython 3.10\n\n### OS\n\nUbuntu\n\n### Additional environment information\n\n_No response_\n\n### Description\n\nThe `distutils.log.Log` class was removed in https://github.com/pypa/setuptools/commit/74652cabdeaacadc76ccf126563bed8ee2ccf3ef. This causes popular packages downstream, such as `numpy`, to fail: see https://github.com/numpy/numpy/issues/22623\n\n### Expected behavior\n\nThe module `distutils.log` module was not officially marked as deprecated even though https://github.com/pypa/setuptools/commit/74652cabdeaacadc76ccf126563bed8ee2ccf3ef added to the docstring that the module is `Retained for compatibility and should not be used.`. It would be great if the removed class could be reinstated and a deprecation pathway be provided.\n\n### How to Reproduce\n\n1. `pip install setuptools==65.6.0`\r\n2. `from numpy.distutils import Log`\n\n### Output\n\n```\r\nIn [4]: from numpy.distutils import Log\r\n---------------------------------------------------------------------------\r\nImportError Traceback (most recent call last)\r\n<ipython-input-4-f8e71815afcd> in <module>\r\n----> 1 from numpy.distutils import Log\r\n\r\n~/.virtualenvs/aiida_dev/lib/python3.9/site-packages/numpy/distutils/__init__.py in <module>\r\n 22 # Must import local ccompiler ASAP in order to get\r\n 23 # customized CCompiler.spawn effective.\r\n---> 24 from . import ccompiler\r\n 25 from . import unixccompiler\r\n 26 \r\n\r\n~/.virtualenvs/aiida_dev/lib/python3.9/site-packages/numpy/distutils/ccompiler.py in <module>\r\n 18 from distutils.version import LooseVersion\r\n 19 \r\n---> 20 from numpy.distutils import log\r\n 21 from numpy.distutils.exec_command import (\r\n 22 filepath_from_subprocess_output, forward_bytes_to_stdout\r\n\r\n~/.virtualenvs/aiida_dev/lib/python3.9/site-packages/numpy/distutils/log.py in <module>\r\n 2 import sys\r\n 3 from distutils.log import * # noqa: F403\r\n----> 4 from distutils.log import Log as old_Log\r\n 5 from distutils.log import _global_log\r\n 6 \r\n\r\nImportError: cannot import name 'Log' from 'distutils.log' (/home/sph/.virtualenvs/aiida_dev/lib/python3.9/site-packages/setuptools/_distutils/log.py)\r\n```\n", "before_files": [{"content": "\"\"\"\nA simple log mechanism styled after PEP 282.\n\nRetained for compatibility and should not be used.\n\"\"\"\n\nimport logging\n\nfrom ._log import log as _global_log\n\n\nDEBUG = logging.DEBUG\nINFO = logging.INFO\nWARN = logging.WARN\nERROR = logging.ERROR\nFATAL = logging.FATAL\n\nlog = _global_log.log\ndebug = _global_log.debug\ninfo = _global_log.info\nwarn = _global_log.warning\nerror = _global_log.error\nfatal = _global_log.fatal\n\n\ndef set_threshold(level):\n orig = _global_log.level\n _global_log.setLevel(level)\n return orig\n\n\ndef set_verbosity(v):\n if v <= 0:\n set_threshold(logging.WARN)\n elif v == 1:\n set_threshold(logging.INFO)\n elif v >= 2:\n set_threshold(logging.DEBUG)\n", "path": "setuptools/_distutils/log.py"}], "after_files": [{"content": "\"\"\"\nA simple log mechanism styled after PEP 282.\n\nRetained for compatibility and should not be used.\n\"\"\"\n\nimport logging\nimport warnings\n\nfrom ._log import log as _global_log\n\n\nDEBUG = logging.DEBUG\nINFO = logging.INFO\nWARN = logging.WARN\nERROR = logging.ERROR\nFATAL = logging.FATAL\n\nlog = _global_log.log\ndebug = _global_log.debug\ninfo = _global_log.info\nwarn = _global_log.warning\nerror = _global_log.error\nfatal = _global_log.fatal\n\n\ndef set_threshold(level):\n orig = _global_log.level\n _global_log.setLevel(level)\n return orig\n\n\ndef set_verbosity(v):\n if v <= 0:\n set_threshold(logging.WARN)\n elif v == 1:\n set_threshold(logging.INFO)\n elif v >= 2:\n set_threshold(logging.DEBUG)\n\n\nclass Log(logging.Logger):\n \"\"\"distutils.log.Log is deprecated, please use an alternative from `logging`.\"\"\"\n\n def __init__(self, threshold=WARN):\n warnings.warn(Log.__doc__) # avoid DeprecationWarning to ensure warn is shown\n super().__init__(__name__, level=threshold)\n\n @property\n def threshold(self):\n return self.level\n\n @threshold.setter\n def threshold(self, level):\n self.setLevel(level)\n\n warn = logging.Logger.warning\n", "path": "setuptools/_distutils/log.py"}]}
| 1,144 | 223 |
gh_patches_debug_37266
|
rasdani/github-patches
|
git_diff
|
google__mobly-149
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Test result entry should include stacktrace
Test result entry in test summary should include the stacktrace if an exception happened during test.
Right now we only see the message of the exception, not the whole stacktrace.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mobly/records.py`
Content:
```
1 #!/usr/bin/env python3.4
2 #
3 # Copyright 2016 Google Inc.
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 """This module is where all the record definitions and record containers live.
18 """
19
20 import json
21 import logging
22 import pprint
23
24 from mobly import signals
25 from mobly import utils
26
27
28 class TestResultEnums(object):
29 """Enums used for TestResultRecord class.
30
31 Includes the tokens to mark test result with, and the string names for each
32 field in TestResultRecord.
33 """
34
35 RECORD_NAME = 'Test Name'
36 RECORD_CLASS = 'Test Class'
37 RECORD_BEGIN_TIME = 'Begin Time'
38 RECORD_END_TIME = 'End Time'
39 RECORD_RESULT = 'Result'
40 RECORD_UID = 'UID'
41 RECORD_EXTRAS = 'Extras'
42 RECORD_EXTRA_ERRORS = 'Extra Errors'
43 RECORD_DETAILS = 'Details'
44 TEST_RESULT_PASS = 'PASS'
45 TEST_RESULT_FAIL = 'FAIL'
46 TEST_RESULT_SKIP = 'SKIP'
47 TEST_RESULT_ERROR = 'ERROR'
48
49
50 class TestResultRecord(object):
51 """A record that holds the information of a test case execution.
52
53 Attributes:
54 test_name: A string representing the name of the test case.
55 begin_time: Epoch timestamp of when the test case started.
56 end_time: Epoch timestamp of when the test case ended.
57 self.uid: Unique identifier of a test case.
58 self.result: Test result, PASS/FAIL/SKIP.
59 self.extras: User defined extra information of the test result.
60 self.details: A string explaining the details of the test case.
61 """
62
63 def __init__(self, t_name, t_class=None):
64 self.test_name = t_name
65 self.test_class = t_class
66 self.begin_time = None
67 self.end_time = None
68 self.uid = None
69 self.result = None
70 self.extras = None
71 self.details = None
72 self.extra_errors = {}
73
74 def test_begin(self):
75 """Call this when the test case it records begins execution.
76
77 Sets the begin_time of this record.
78 """
79 self.begin_time = utils.get_current_epoch_time()
80
81 def _test_end(self, result, e):
82 """Class internal function to signal the end of a test case execution.
83
84 Args:
85 result: One of the TEST_RESULT enums in TestResultEnums.
86 e: A test termination signal (usually an exception object). It can
87 be any exception instance or of any subclass of
88 mobly.signals.TestSignal.
89 """
90 self.end_time = utils.get_current_epoch_time()
91 self.result = result
92 if self.extra_errors:
93 self.result = TestResultEnums.TEST_RESULT_ERROR
94 if isinstance(e, signals.TestSignal):
95 self.details = e.details
96 self.extras = e.extras
97 elif e:
98 self.details = str(e)
99
100 def test_pass(self, e=None):
101 """To mark the test as passed in this record.
102
103 Args:
104 e: An instance of mobly.signals.TestPass.
105 """
106 self._test_end(TestResultEnums.TEST_RESULT_PASS, e)
107
108 def test_fail(self, e=None):
109 """To mark the test as failed in this record.
110
111 Only test_fail does instance check because we want 'assert xxx' to also
112 fail the test same way assert_true does.
113
114 Args:
115 e: An exception object. It can be an instance of AssertionError or
116 mobly.base_test.TestFailure.
117 """
118 self._test_end(TestResultEnums.TEST_RESULT_FAIL, e)
119
120 def test_skip(self, e=None):
121 """To mark the test as skipped in this record.
122
123 Args:
124 e: An instance of mobly.signals.TestSkip.
125 """
126 self._test_end(TestResultEnums.TEST_RESULT_SKIP, e)
127
128 def test_error(self, e=None):
129 """To mark the test as error in this record.
130
131 Args:
132 e: An exception object.
133 """
134 self._test_end(TestResultEnums.TEST_RESULT_ERROR, e)
135
136 def add_error(self, tag, e):
137 """Add extra error happened during a test mark the test result as
138 ERROR.
139
140 If an error is added the test record, the record's result is equivalent
141 to the case where an uncaught exception happened.
142
143 Args:
144 tag: A string describing where this error came from, e.g. 'on_pass'.
145 e: An exception object.
146 """
147 self.result = TestResultEnums.TEST_RESULT_ERROR
148 self.extra_errors[tag] = str(e)
149
150 def __str__(self):
151 d = self.to_dict()
152 l = ['%s = %s' % (k, v) for k, v in d.items()]
153 s = ', '.join(l)
154 return s
155
156 def __repr__(self):
157 """This returns a short string representation of the test record."""
158 t = utils.epoch_to_human_time(self.begin_time)
159 return '%s %s %s' % (t, self.test_name, self.result)
160
161 def to_dict(self):
162 """Gets a dictionary representating the content of this class.
163
164 Returns:
165 A dictionary representating the content of this class.
166 """
167 d = {}
168 d[TestResultEnums.RECORD_NAME] = self.test_name
169 d[TestResultEnums.RECORD_CLASS] = self.test_class
170 d[TestResultEnums.RECORD_BEGIN_TIME] = self.begin_time
171 d[TestResultEnums.RECORD_END_TIME] = self.end_time
172 d[TestResultEnums.RECORD_RESULT] = self.result
173 d[TestResultEnums.RECORD_UID] = self.uid
174 d[TestResultEnums.RECORD_EXTRAS] = self.extras
175 d[TestResultEnums.RECORD_DETAILS] = self.details
176 d[TestResultEnums.RECORD_EXTRA_ERRORS] = self.extra_errors
177 return d
178
179 def json_str(self):
180 """Converts this test record to a string in json format.
181
182 Format of the json string is:
183 {
184 'Test Name': <test name>,
185 'Begin Time': <epoch timestamp>,
186 'Details': <details>,
187 ...
188 }
189
190 Returns:
191 A json-format string representing the test record.
192 """
193 return json.dumps(self.to_dict())
194
195
196 class TestResult(object):
197 """A class that contains metrics of a test run.
198
199 This class is essentially a container of TestResultRecord objects.
200
201 Attributes:
202 self.requested: A list of strings, each is the name of a test requested
203 by user.
204 self.failed: A list of records for tests failed.
205 self.executed: A list of records for tests that were actually executed.
206 self.passed: A list of records for tests passed.
207 self.skipped: A list of records for tests skipped.
208 self.error: A list of records for tests with error result token.
209 """
210
211 def __init__(self):
212 self.requested = []
213 self.failed = []
214 self.executed = []
215 self.passed = []
216 self.skipped = []
217 self.error = []
218 self.controller_info = {}
219
220 def __add__(self, r):
221 """Overrides '+' operator for TestResult class.
222
223 The add operator merges two TestResult objects by concatenating all of
224 their lists together.
225
226 Args:
227 r: another instance of TestResult to be added
228
229 Returns:
230 A TestResult instance that's the sum of two TestResult instances.
231 """
232 if not isinstance(r, TestResult):
233 raise TypeError('Operand %s of type %s is not a TestResult.' %
234 (r, type(r)))
235 sum_result = TestResult()
236 for name in sum_result.__dict__:
237 r_value = getattr(r, name)
238 l_value = getattr(self, name)
239 if isinstance(r_value, list):
240 setattr(sum_result, name, l_value + r_value)
241 elif isinstance(r_value, dict):
242 # '+' operator for TestResult is only valid when multiple
243 # TestResult objs were created in the same test run, which means
244 # the controller info would be the same across all of them.
245 # TODO(angli): have a better way to validate this situation.
246 setattr(sum_result, name, l_value)
247 return sum_result
248
249 def add_record(self, record):
250 """Adds a test record to test result.
251
252 A record is considered executed once it's added to the test result.
253
254 Args:
255 record: A test record object to add.
256 """
257 self.executed.append(record)
258 if record.result == TestResultEnums.TEST_RESULT_FAIL:
259 self.failed.append(record)
260 elif record.result == TestResultEnums.TEST_RESULT_SKIP:
261 self.skipped.append(record)
262 elif record.result == TestResultEnums.TEST_RESULT_PASS:
263 self.passed.append(record)
264 else:
265 self.error.append(record)
266
267 def add_controller_info(self, name, info):
268 try:
269 json.dumps(info)
270 except TypeError:
271 logging.warning('Controller info for %s is not JSON serializable!'
272 ' Coercing it to string.' % name)
273 self.controller_info[name] = str(info)
274 return
275 self.controller_info[name] = info
276
277 def fail_class(self, test_record):
278 """Add a record to indicate a test class setup has failed and no test
279 in the class was executed.
280
281 Args:
282 test_record: A TestResultRecord object for the test class.
283 """
284 self.executed.append(test_record)
285 self.failed.append(test_record)
286
287 @property
288 def is_all_pass(self):
289 """True if no tests failed or threw errors, False otherwise."""
290 num_of_failures = len(self.failed) + len(self.error)
291 if num_of_failures == 0:
292 return True
293 return False
294
295 def json_str(self):
296 """Converts this test result to a string in json format.
297
298 Format of the json string is:
299 {
300 'Results': [
301 {<executed test record 1>},
302 {<executed test record 2>},
303 ...
304 ],
305 'Summary': <summary dict>
306 }
307
308 Returns:
309 A json-format string representing the test results.
310 """
311 d = {}
312 d['ControllerInfo'] = self.controller_info
313 d['Results'] = [record.to_dict() for record in self.executed]
314 d['Summary'] = self.summary_dict()
315 json_str = json.dumps(d, indent=4, sort_keys=True)
316 return json_str
317
318 def summary_str(self):
319 """Gets a string that summarizes the stats of this test result.
320
321 The summary rovides the counts of how many test cases fall into each
322 category, like 'Passed', 'Failed' etc.
323
324 Format of the string is:
325 Requested <int>, Executed <int>, ...
326
327 Returns:
328 A summary string of this test result.
329 """
330 l = ['%s %d' % (k, v) for k, v in self.summary_dict().items()]
331 # Sort the list so the order is the same every time.
332 msg = ', '.join(sorted(l))
333 return msg
334
335 def summary_dict(self):
336 """Gets a dictionary that summarizes the stats of this test result.
337
338 The summary rovides the counts of how many test cases fall into each
339 category, like 'Passed', 'Failed' etc.
340
341 Returns:
342 A dictionary with the stats of this test result.
343 """
344 d = {}
345 d['Requested'] = len(self.requested)
346 d['Executed'] = len(self.executed)
347 d['Passed'] = len(self.passed)
348 d['Failed'] = len(self.failed)
349 d['Skipped'] = len(self.skipped)
350 d['Error'] = len(self.error)
351 return d
352
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mobly/records.py b/mobly/records.py
--- a/mobly/records.py
+++ b/mobly/records.py
@@ -13,13 +13,14 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-
"""This module is where all the record definitions and record containers live.
"""
import json
import logging
import pprint
+import sys
+import traceback
from mobly import signals
from mobly import utils
@@ -41,6 +42,7 @@
RECORD_EXTRAS = 'Extras'
RECORD_EXTRA_ERRORS = 'Extra Errors'
RECORD_DETAILS = 'Details'
+ RECORD_STACKTRACE = 'Stacktrace'
TEST_RESULT_PASS = 'PASS'
TEST_RESULT_FAIL = 'FAIL'
TEST_RESULT_SKIP = 'SKIP'
@@ -69,6 +71,7 @@
self.result = None
self.extras = None
self.details = None
+ self.stacktrace = None
self.extra_errors = {}
def test_begin(self):
@@ -93,9 +96,15 @@
self.result = TestResultEnums.TEST_RESULT_ERROR
if isinstance(e, signals.TestSignal):
self.details = e.details
+ _, _, exc_traceback = sys.exc_info()
+ if exc_traceback:
+ self.stacktrace = ''.join(traceback.format_tb(exc_traceback))
self.extras = e.extras
- elif e:
+ elif isinstance(e, Exception):
self.details = str(e)
+ _, _, exc_traceback = sys.exc_info()
+ if exc_traceback:
+ self.stacktrace = ''.join(traceback.format_tb(exc_traceback))
def test_pass(self, e=None):
"""To mark the test as passed in this record.
@@ -174,6 +183,7 @@
d[TestResultEnums.RECORD_EXTRAS] = self.extras
d[TestResultEnums.RECORD_DETAILS] = self.details
d[TestResultEnums.RECORD_EXTRA_ERRORS] = self.extra_errors
+ d[TestResultEnums.RECORD_STACKTRACE] = self.stacktrace
return d
def json_str(self):
|
{"golden_diff": "diff --git a/mobly/records.py b/mobly/records.py\n--- a/mobly/records.py\n+++ b/mobly/records.py\n@@ -13,13 +13,14 @@\n # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n # See the License for the specific language governing permissions and\n # limitations under the License.\n-\n \"\"\"This module is where all the record definitions and record containers live.\n \"\"\"\n \n import json\n import logging\n import pprint\n+import sys\n+import traceback\n \n from mobly import signals\n from mobly import utils\n@@ -41,6 +42,7 @@\n RECORD_EXTRAS = 'Extras'\n RECORD_EXTRA_ERRORS = 'Extra Errors'\n RECORD_DETAILS = 'Details'\n+ RECORD_STACKTRACE = 'Stacktrace'\n TEST_RESULT_PASS = 'PASS'\n TEST_RESULT_FAIL = 'FAIL'\n TEST_RESULT_SKIP = 'SKIP'\n@@ -69,6 +71,7 @@\n self.result = None\n self.extras = None\n self.details = None\n+ self.stacktrace = None\n self.extra_errors = {}\n \n def test_begin(self):\n@@ -93,9 +96,15 @@\n self.result = TestResultEnums.TEST_RESULT_ERROR\n if isinstance(e, signals.TestSignal):\n self.details = e.details\n+ _, _, exc_traceback = sys.exc_info()\n+ if exc_traceback:\n+ self.stacktrace = ''.join(traceback.format_tb(exc_traceback))\n self.extras = e.extras\n- elif e:\n+ elif isinstance(e, Exception):\n self.details = str(e)\n+ _, _, exc_traceback = sys.exc_info()\n+ if exc_traceback:\n+ self.stacktrace = ''.join(traceback.format_tb(exc_traceback))\n \n def test_pass(self, e=None):\n \"\"\"To mark the test as passed in this record.\n@@ -174,6 +183,7 @@\n d[TestResultEnums.RECORD_EXTRAS] = self.extras\n d[TestResultEnums.RECORD_DETAILS] = self.details\n d[TestResultEnums.RECORD_EXTRA_ERRORS] = self.extra_errors\n+ d[TestResultEnums.RECORD_STACKTRACE] = self.stacktrace\n return d\n \n def json_str(self):\n", "issue": "Test result entry should include stacktrace\nTest result entry in test summary should include the stacktrace if an exception happened during test.\r\nRight now we only see the message of the exception, not the whole stacktrace.\n", "before_files": [{"content": "#!/usr/bin/env python3.4\n#\n# Copyright 2016 Google Inc.\n# \n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# \n# http://www.apache.org/licenses/LICENSE-2.0\n# \n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"This module is where all the record definitions and record containers live.\n\"\"\"\n\nimport json\nimport logging\nimport pprint\n\nfrom mobly import signals\nfrom mobly import utils\n\n\nclass TestResultEnums(object):\n \"\"\"Enums used for TestResultRecord class.\n\n Includes the tokens to mark test result with, and the string names for each\n field in TestResultRecord.\n \"\"\"\n\n RECORD_NAME = 'Test Name'\n RECORD_CLASS = 'Test Class'\n RECORD_BEGIN_TIME = 'Begin Time'\n RECORD_END_TIME = 'End Time'\n RECORD_RESULT = 'Result'\n RECORD_UID = 'UID'\n RECORD_EXTRAS = 'Extras'\n RECORD_EXTRA_ERRORS = 'Extra Errors'\n RECORD_DETAILS = 'Details'\n TEST_RESULT_PASS = 'PASS'\n TEST_RESULT_FAIL = 'FAIL'\n TEST_RESULT_SKIP = 'SKIP'\n TEST_RESULT_ERROR = 'ERROR'\n\n\nclass TestResultRecord(object):\n \"\"\"A record that holds the information of a test case execution.\n\n Attributes:\n test_name: A string representing the name of the test case.\n begin_time: Epoch timestamp of when the test case started.\n end_time: Epoch timestamp of when the test case ended.\n self.uid: Unique identifier of a test case.\n self.result: Test result, PASS/FAIL/SKIP.\n self.extras: User defined extra information of the test result.\n self.details: A string explaining the details of the test case.\n \"\"\"\n\n def __init__(self, t_name, t_class=None):\n self.test_name = t_name\n self.test_class = t_class\n self.begin_time = None\n self.end_time = None\n self.uid = None\n self.result = None\n self.extras = None\n self.details = None\n self.extra_errors = {}\n\n def test_begin(self):\n \"\"\"Call this when the test case it records begins execution.\n\n Sets the begin_time of this record.\n \"\"\"\n self.begin_time = utils.get_current_epoch_time()\n\n def _test_end(self, result, e):\n \"\"\"Class internal function to signal the end of a test case execution.\n\n Args:\n result: One of the TEST_RESULT enums in TestResultEnums.\n e: A test termination signal (usually an exception object). It can\n be any exception instance or of any subclass of\n mobly.signals.TestSignal.\n \"\"\"\n self.end_time = utils.get_current_epoch_time()\n self.result = result\n if self.extra_errors:\n self.result = TestResultEnums.TEST_RESULT_ERROR\n if isinstance(e, signals.TestSignal):\n self.details = e.details\n self.extras = e.extras\n elif e:\n self.details = str(e)\n\n def test_pass(self, e=None):\n \"\"\"To mark the test as passed in this record.\n\n Args:\n e: An instance of mobly.signals.TestPass.\n \"\"\"\n self._test_end(TestResultEnums.TEST_RESULT_PASS, e)\n\n def test_fail(self, e=None):\n \"\"\"To mark the test as failed in this record.\n\n Only test_fail does instance check because we want 'assert xxx' to also\n fail the test same way assert_true does.\n\n Args:\n e: An exception object. It can be an instance of AssertionError or\n mobly.base_test.TestFailure.\n \"\"\"\n self._test_end(TestResultEnums.TEST_RESULT_FAIL, e)\n\n def test_skip(self, e=None):\n \"\"\"To mark the test as skipped in this record.\n\n Args:\n e: An instance of mobly.signals.TestSkip.\n \"\"\"\n self._test_end(TestResultEnums.TEST_RESULT_SKIP, e)\n\n def test_error(self, e=None):\n \"\"\"To mark the test as error in this record.\n\n Args:\n e: An exception object.\n \"\"\"\n self._test_end(TestResultEnums.TEST_RESULT_ERROR, e)\n\n def add_error(self, tag, e):\n \"\"\"Add extra error happened during a test mark the test result as\n ERROR.\n\n If an error is added the test record, the record's result is equivalent\n to the case where an uncaught exception happened.\n\n Args:\n tag: A string describing where this error came from, e.g. 'on_pass'.\n e: An exception object.\n \"\"\"\n self.result = TestResultEnums.TEST_RESULT_ERROR\n self.extra_errors[tag] = str(e)\n\n def __str__(self):\n d = self.to_dict()\n l = ['%s = %s' % (k, v) for k, v in d.items()]\n s = ', '.join(l)\n return s\n\n def __repr__(self):\n \"\"\"This returns a short string representation of the test record.\"\"\"\n t = utils.epoch_to_human_time(self.begin_time)\n return '%s %s %s' % (t, self.test_name, self.result)\n\n def to_dict(self):\n \"\"\"Gets a dictionary representating the content of this class.\n\n Returns:\n A dictionary representating the content of this class.\n \"\"\"\n d = {}\n d[TestResultEnums.RECORD_NAME] = self.test_name\n d[TestResultEnums.RECORD_CLASS] = self.test_class\n d[TestResultEnums.RECORD_BEGIN_TIME] = self.begin_time\n d[TestResultEnums.RECORD_END_TIME] = self.end_time\n d[TestResultEnums.RECORD_RESULT] = self.result\n d[TestResultEnums.RECORD_UID] = self.uid\n d[TestResultEnums.RECORD_EXTRAS] = self.extras\n d[TestResultEnums.RECORD_DETAILS] = self.details\n d[TestResultEnums.RECORD_EXTRA_ERRORS] = self.extra_errors\n return d\n\n def json_str(self):\n \"\"\"Converts this test record to a string in json format.\n\n Format of the json string is:\n {\n 'Test Name': <test name>,\n 'Begin Time': <epoch timestamp>,\n 'Details': <details>,\n ...\n }\n\n Returns:\n A json-format string representing the test record.\n \"\"\"\n return json.dumps(self.to_dict())\n\n\nclass TestResult(object):\n \"\"\"A class that contains metrics of a test run.\n\n This class is essentially a container of TestResultRecord objects.\n\n Attributes:\n self.requested: A list of strings, each is the name of a test requested\n by user.\n self.failed: A list of records for tests failed.\n self.executed: A list of records for tests that were actually executed.\n self.passed: A list of records for tests passed.\n self.skipped: A list of records for tests skipped.\n self.error: A list of records for tests with error result token.\n \"\"\"\n\n def __init__(self):\n self.requested = []\n self.failed = []\n self.executed = []\n self.passed = []\n self.skipped = []\n self.error = []\n self.controller_info = {}\n\n def __add__(self, r):\n \"\"\"Overrides '+' operator for TestResult class.\n\n The add operator merges two TestResult objects by concatenating all of\n their lists together.\n\n Args:\n r: another instance of TestResult to be added\n\n Returns:\n A TestResult instance that's the sum of two TestResult instances.\n \"\"\"\n if not isinstance(r, TestResult):\n raise TypeError('Operand %s of type %s is not a TestResult.' %\n (r, type(r)))\n sum_result = TestResult()\n for name in sum_result.__dict__:\n r_value = getattr(r, name)\n l_value = getattr(self, name)\n if isinstance(r_value, list):\n setattr(sum_result, name, l_value + r_value)\n elif isinstance(r_value, dict):\n # '+' operator for TestResult is only valid when multiple\n # TestResult objs were created in the same test run, which means\n # the controller info would be the same across all of them.\n # TODO(angli): have a better way to validate this situation.\n setattr(sum_result, name, l_value)\n return sum_result\n\n def add_record(self, record):\n \"\"\"Adds a test record to test result.\n\n A record is considered executed once it's added to the test result.\n\n Args:\n record: A test record object to add.\n \"\"\"\n self.executed.append(record)\n if record.result == TestResultEnums.TEST_RESULT_FAIL:\n self.failed.append(record)\n elif record.result == TestResultEnums.TEST_RESULT_SKIP:\n self.skipped.append(record)\n elif record.result == TestResultEnums.TEST_RESULT_PASS:\n self.passed.append(record)\n else:\n self.error.append(record)\n\n def add_controller_info(self, name, info):\n try:\n json.dumps(info)\n except TypeError:\n logging.warning('Controller info for %s is not JSON serializable!'\n ' Coercing it to string.' % name)\n self.controller_info[name] = str(info)\n return\n self.controller_info[name] = info\n\n def fail_class(self, test_record):\n \"\"\"Add a record to indicate a test class setup has failed and no test\n in the class was executed.\n\n Args:\n test_record: A TestResultRecord object for the test class.\n \"\"\"\n self.executed.append(test_record)\n self.failed.append(test_record)\n\n @property\n def is_all_pass(self):\n \"\"\"True if no tests failed or threw errors, False otherwise.\"\"\"\n num_of_failures = len(self.failed) + len(self.error)\n if num_of_failures == 0:\n return True\n return False\n\n def json_str(self):\n \"\"\"Converts this test result to a string in json format.\n\n Format of the json string is:\n {\n 'Results': [\n {<executed test record 1>},\n {<executed test record 2>},\n ...\n ],\n 'Summary': <summary dict>\n }\n\n Returns:\n A json-format string representing the test results.\n \"\"\"\n d = {}\n d['ControllerInfo'] = self.controller_info\n d['Results'] = [record.to_dict() for record in self.executed]\n d['Summary'] = self.summary_dict()\n json_str = json.dumps(d, indent=4, sort_keys=True)\n return json_str\n\n def summary_str(self):\n \"\"\"Gets a string that summarizes the stats of this test result.\n\n The summary rovides the counts of how many test cases fall into each\n category, like 'Passed', 'Failed' etc.\n\n Format of the string is:\n Requested <int>, Executed <int>, ...\n\n Returns:\n A summary string of this test result.\n \"\"\"\n l = ['%s %d' % (k, v) for k, v in self.summary_dict().items()]\n # Sort the list so the order is the same every time.\n msg = ', '.join(sorted(l))\n return msg\n\n def summary_dict(self):\n \"\"\"Gets a dictionary that summarizes the stats of this test result.\n\n The summary rovides the counts of how many test cases fall into each\n category, like 'Passed', 'Failed' etc.\n\n Returns:\n A dictionary with the stats of this test result.\n \"\"\"\n d = {}\n d['Requested'] = len(self.requested)\n d['Executed'] = len(self.executed)\n d['Passed'] = len(self.passed)\n d['Failed'] = len(self.failed)\n d['Skipped'] = len(self.skipped)\n d['Error'] = len(self.error)\n return d\n", "path": "mobly/records.py"}], "after_files": [{"content": "#!/usr/bin/env python3.4\n#\n# Copyright 2016 Google Inc.\n# \n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# \n# http://www.apache.org/licenses/LICENSE-2.0\n# \n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"This module is where all the record definitions and record containers live.\n\"\"\"\n\nimport json\nimport logging\nimport pprint\nimport sys\nimport traceback\n\nfrom mobly import signals\nfrom mobly import utils\n\n\nclass TestResultEnums(object):\n \"\"\"Enums used for TestResultRecord class.\n\n Includes the tokens to mark test result with, and the string names for each\n field in TestResultRecord.\n \"\"\"\n\n RECORD_NAME = 'Test Name'\n RECORD_CLASS = 'Test Class'\n RECORD_BEGIN_TIME = 'Begin Time'\n RECORD_END_TIME = 'End Time'\n RECORD_RESULT = 'Result'\n RECORD_UID = 'UID'\n RECORD_EXTRAS = 'Extras'\n RECORD_EXTRA_ERRORS = 'Extra Errors'\n RECORD_DETAILS = 'Details'\n RECORD_STACKTRACE = 'Stacktrace'\n TEST_RESULT_PASS = 'PASS'\n TEST_RESULT_FAIL = 'FAIL'\n TEST_RESULT_SKIP = 'SKIP'\n TEST_RESULT_ERROR = 'ERROR'\n\n\nclass TestResultRecord(object):\n \"\"\"A record that holds the information of a test case execution.\n\n Attributes:\n test_name: A string representing the name of the test case.\n begin_time: Epoch timestamp of when the test case started.\n end_time: Epoch timestamp of when the test case ended.\n self.uid: Unique identifier of a test case.\n self.result: Test result, PASS/FAIL/SKIP.\n self.extras: User defined extra information of the test result.\n self.details: A string explaining the details of the test case.\n \"\"\"\n\n def __init__(self, t_name, t_class=None):\n self.test_name = t_name\n self.test_class = t_class\n self.begin_time = None\n self.end_time = None\n self.uid = None\n self.result = None\n self.extras = None\n self.details = None\n self.stacktrace = None\n self.extra_errors = {}\n\n def test_begin(self):\n \"\"\"Call this when the test case it records begins execution.\n\n Sets the begin_time of this record.\n \"\"\"\n self.begin_time = utils.get_current_epoch_time()\n\n def _test_end(self, result, e):\n \"\"\"Class internal function to signal the end of a test case execution.\n\n Args:\n result: One of the TEST_RESULT enums in TestResultEnums.\n e: A test termination signal (usually an exception object). It can\n be any exception instance or of any subclass of\n mobly.signals.TestSignal.\n \"\"\"\n self.end_time = utils.get_current_epoch_time()\n self.result = result\n if self.extra_errors:\n self.result = TestResultEnums.TEST_RESULT_ERROR\n if isinstance(e, signals.TestSignal):\n self.details = e.details\n _, _, exc_traceback = sys.exc_info()\n if exc_traceback:\n self.stacktrace = ''.join(traceback.format_tb(exc_traceback))\n self.extras = e.extras\n elif isinstance(e, Exception):\n self.details = str(e)\n _, _, exc_traceback = sys.exc_info()\n if exc_traceback:\n self.stacktrace = ''.join(traceback.format_tb(exc_traceback))\n\n def test_pass(self, e=None):\n \"\"\"To mark the test as passed in this record.\n\n Args:\n e: An instance of mobly.signals.TestPass.\n \"\"\"\n self._test_end(TestResultEnums.TEST_RESULT_PASS, e)\n\n def test_fail(self, e=None):\n \"\"\"To mark the test as failed in this record.\n\n Only test_fail does instance check because we want 'assert xxx' to also\n fail the test same way assert_true does.\n\n Args:\n e: An exception object. It can be an instance of AssertionError or\n mobly.base_test.TestFailure.\n \"\"\"\n self._test_end(TestResultEnums.TEST_RESULT_FAIL, e)\n\n def test_skip(self, e=None):\n \"\"\"To mark the test as skipped in this record.\n\n Args:\n e: An instance of mobly.signals.TestSkip.\n \"\"\"\n self._test_end(TestResultEnums.TEST_RESULT_SKIP, e)\n\n def test_error(self, e=None):\n \"\"\"To mark the test as error in this record.\n\n Args:\n e: An exception object.\n \"\"\"\n self._test_end(TestResultEnums.TEST_RESULT_ERROR, e)\n\n def add_error(self, tag, e):\n \"\"\"Add extra error happened during a test mark the test result as\n ERROR.\n\n If an error is added the test record, the record's result is equivalent\n to the case where an uncaught exception happened.\n\n Args:\n tag: A string describing where this error came from, e.g. 'on_pass'.\n e: An exception object.\n \"\"\"\n self.result = TestResultEnums.TEST_RESULT_ERROR\n self.extra_errors[tag] = str(e)\n\n def __str__(self):\n d = self.to_dict()\n l = ['%s = %s' % (k, v) for k, v in d.items()]\n s = ', '.join(l)\n return s\n\n def __repr__(self):\n \"\"\"This returns a short string representation of the test record.\"\"\"\n t = utils.epoch_to_human_time(self.begin_time)\n return '%s %s %s' % (t, self.test_name, self.result)\n\n def to_dict(self):\n \"\"\"Gets a dictionary representating the content of this class.\n\n Returns:\n A dictionary representating the content of this class.\n \"\"\"\n d = {}\n d[TestResultEnums.RECORD_NAME] = self.test_name\n d[TestResultEnums.RECORD_CLASS] = self.test_class\n d[TestResultEnums.RECORD_BEGIN_TIME] = self.begin_time\n d[TestResultEnums.RECORD_END_TIME] = self.end_time\n d[TestResultEnums.RECORD_RESULT] = self.result\n d[TestResultEnums.RECORD_UID] = self.uid\n d[TestResultEnums.RECORD_EXTRAS] = self.extras\n d[TestResultEnums.RECORD_DETAILS] = self.details\n d[TestResultEnums.RECORD_EXTRA_ERRORS] = self.extra_errors\n d[TestResultEnums.RECORD_STACKTRACE] = self.stacktrace\n return d\n\n def json_str(self):\n \"\"\"Converts this test record to a string in json format.\n\n Format of the json string is:\n {\n 'Test Name': <test name>,\n 'Begin Time': <epoch timestamp>,\n 'Details': <details>,\n ...\n }\n\n Returns:\n A json-format string representing the test record.\n \"\"\"\n return json.dumps(self.to_dict())\n\n\nclass TestResult(object):\n \"\"\"A class that contains metrics of a test run.\n\n This class is essentially a container of TestResultRecord objects.\n\n Attributes:\n self.requested: A list of strings, each is the name of a test requested\n by user.\n self.failed: A list of records for tests failed.\n self.executed: A list of records for tests that were actually executed.\n self.passed: A list of records for tests passed.\n self.skipped: A list of records for tests skipped.\n self.error: A list of records for tests with error result token.\n \"\"\"\n\n def __init__(self):\n self.requested = []\n self.failed = []\n self.executed = []\n self.passed = []\n self.skipped = []\n self.error = []\n self.controller_info = {}\n\n def __add__(self, r):\n \"\"\"Overrides '+' operator for TestResult class.\n\n The add operator merges two TestResult objects by concatenating all of\n their lists together.\n\n Args:\n r: another instance of TestResult to be added\n\n Returns:\n A TestResult instance that's the sum of two TestResult instances.\n \"\"\"\n if not isinstance(r, TestResult):\n raise TypeError('Operand %s of type %s is not a TestResult.' %\n (r, type(r)))\n sum_result = TestResult()\n for name in sum_result.__dict__:\n r_value = getattr(r, name)\n l_value = getattr(self, name)\n if isinstance(r_value, list):\n setattr(sum_result, name, l_value + r_value)\n elif isinstance(r_value, dict):\n # '+' operator for TestResult is only valid when multiple\n # TestResult objs were created in the same test run, which means\n # the controller info would be the same across all of them.\n # TODO(angli): have a better way to validate this situation.\n setattr(sum_result, name, l_value)\n return sum_result\n\n def add_record(self, record):\n \"\"\"Adds a test record to test result.\n\n A record is considered executed once it's added to the test result.\n\n Args:\n record: A test record object to add.\n \"\"\"\n self.executed.append(record)\n if record.result == TestResultEnums.TEST_RESULT_FAIL:\n self.failed.append(record)\n elif record.result == TestResultEnums.TEST_RESULT_SKIP:\n self.skipped.append(record)\n elif record.result == TestResultEnums.TEST_RESULT_PASS:\n self.passed.append(record)\n else:\n self.error.append(record)\n\n def add_controller_info(self, name, info):\n try:\n json.dumps(info)\n except TypeError:\n logging.warning('Controller info for %s is not JSON serializable!'\n ' Coercing it to string.' % name)\n self.controller_info[name] = str(info)\n return\n self.controller_info[name] = info\n\n def fail_class(self, test_record):\n \"\"\"Add a record to indicate a test class setup has failed and no test\n in the class was executed.\n\n Args:\n test_record: A TestResultRecord object for the test class.\n \"\"\"\n self.executed.append(test_record)\n self.failed.append(test_record)\n\n @property\n def is_all_pass(self):\n \"\"\"True if no tests failed or threw errors, False otherwise.\"\"\"\n num_of_failures = len(self.failed) + len(self.error)\n if num_of_failures == 0:\n return True\n return False\n\n def json_str(self):\n \"\"\"Converts this test result to a string in json format.\n\n Format of the json string is:\n {\n 'Results': [\n {<executed test record 1>},\n {<executed test record 2>},\n ...\n ],\n 'Summary': <summary dict>\n }\n\n Returns:\n A json-format string representing the test results.\n \"\"\"\n d = {}\n d['ControllerInfo'] = self.controller_info\n d['Results'] = [record.to_dict() for record in self.executed]\n d['Summary'] = self.summary_dict()\n json_str = json.dumps(d, indent=4, sort_keys=True)\n return json_str\n\n def summary_str(self):\n \"\"\"Gets a string that summarizes the stats of this test result.\n\n The summary rovides the counts of how many test cases fall into each\n category, like 'Passed', 'Failed' etc.\n\n Format of the string is:\n Requested <int>, Executed <int>, ...\n\n Returns:\n A summary string of this test result.\n \"\"\"\n l = ['%s %d' % (k, v) for k, v in self.summary_dict().items()]\n # Sort the list so the order is the same every time.\n msg = ', '.join(sorted(l))\n return msg\n\n def summary_dict(self):\n \"\"\"Gets a dictionary that summarizes the stats of this test result.\n\n The summary rovides the counts of how many test cases fall into each\n category, like 'Passed', 'Failed' etc.\n\n Returns:\n A dictionary with the stats of this test result.\n \"\"\"\n d = {}\n d['Requested'] = len(self.requested)\n d['Executed'] = len(self.executed)\n d['Passed'] = len(self.passed)\n d['Failed'] = len(self.failed)\n d['Skipped'] = len(self.skipped)\n d['Error'] = len(self.error)\n return d\n", "path": "mobly/records.py"}]}
| 3,883 | 496 |
gh_patches_debug_42571
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-1454
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Downloading albums fills up the disk
### Describe the bug
When a user wants to download an album, the website creates a zip file containing all photos (in `/tmp` of the Docker container). If multiple albums are downloaded, multiple large zip files are created. This very quickly fills up the disk.
We should remove this functionality to prevent this. It is not used often so that should not be a problem for members.
### Additional context
This has caused website outages a few times in the past.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `website/photos/views.py`
Content:
```
1 import os
2 from tempfile import gettempdir
3 from zipfile import ZipFile
4
5 from django.contrib.auth.decorators import login_required
6 from django.core.paginator import EmptyPage, Paginator
7 from django.http import Http404
8 from django.shortcuts import get_object_or_404, render
9 from django.utils.translation import get_language
10 from django_sendfile import sendfile
11
12 from photos.models import Album, Photo
13 from photos.services import (
14 check_shared_album_token,
15 get_annotated_accessible_albums,
16 is_album_accessible,
17 )
18
19 COVER_FILENAME = "cover.jpg"
20
21
22 @login_required
23 def index(request):
24 """Render the index page showing multiple album cards."""
25 keywords = request.GET.get("keywords", "").split()
26
27 # Only show published albums
28 albums = Album.objects.filter(hidden=False)
29 for key in keywords:
30 albums = albums.filter(**{f"title_{get_language()}__icontains": key})
31
32 albums = get_annotated_accessible_albums(request, albums)
33
34 albums = albums.order_by("-date")
35 paginator = Paginator(albums, 16)
36
37 page = request.GET.get("page")
38 page = 1 if page is None or not page.isdigit() else int(page)
39 try:
40 albums = paginator.page(page)
41 except EmptyPage:
42 # If page is out of range (e.g. 9999), deliver last page of results.
43 albums = paginator.page(paginator.num_pages)
44 page = paginator.num_pages
45
46 # Show the two pages before and after the current page
47 page_range_start = max(1, page - 2)
48 page_range_stop = min(page + 3, paginator.num_pages + 1)
49
50 # Add extra pages if we show less than 5 pages
51 page_range_start = min(page_range_start, page_range_stop - 5)
52 page_range_start = max(1, page_range_start)
53
54 # Add extra pages if we still show less than 5 pages
55 page_range_stop = max(page_range_stop, page_range_start + 5)
56 page_range_stop = min(page_range_stop, paginator.num_pages + 1)
57
58 page_range = range(page_range_start, page_range_stop)
59
60 return render(
61 request,
62 "photos/index.html",
63 {"albums": albums, "page_range": page_range, "keywords": keywords},
64 )
65
66
67 def _render_album_page(request, album):
68 """Render album.html for a specified album."""
69 context = {"album": album, "photos": album.photo_set.filter(hidden=False)}
70 return render(request, "photos/album.html", context)
71
72
73 @login_required
74 def detail(request, slug):
75 """Render an album, if it accessible by the user."""
76 obj = get_object_or_404(Album, slug=slug)
77 if is_album_accessible(request, obj):
78 return _render_album_page(request, obj)
79 raise Http404("Sorry, you're not allowed to view this album")
80
81
82 def shared_album(request, slug, token):
83 """Render a shared album if the correct token is provided."""
84 obj = get_object_or_404(Album, slug=slug)
85 check_shared_album_token(obj, token)
86 return _render_album_page(request, obj)
87
88
89 def _photo_path(obj, filename):
90 """Return the path to a Photo."""
91 photoname = os.path.basename(filename)
92 albumpath = os.path.join(obj.photosdir, obj.dirname)
93 photopath = os.path.join(albumpath, photoname)
94 get_object_or_404(Photo.objects.filter(album=obj, file=photopath))
95 return photopath
96
97
98 def _download(request, obj, filename):
99 """Download a photo.
100
101 This function provides a layer of indirection for shared albums.
102 """
103 photopath = _photo_path(obj, filename)
104 photo = get_object_or_404(Photo.objects.filter(album=obj, file=photopath))
105 return sendfile(request, photo.file.path, attachment=True)
106
107
108 def _album_download(request, obj):
109 """Download an album.
110
111 This function provides a layer of indirection for shared albums.
112 """
113 albumpath = os.path.join(obj.photospath, obj.dirname)
114 zipfilename = os.path.join(gettempdir(), "{}.zip".format(obj.dirname))
115 if not os.path.exists(zipfilename):
116 with ZipFile(zipfilename, "w") as f:
117 pictures = [os.path.join(albumpath, x) for x in os.listdir(albumpath)]
118 for picture in pictures:
119 f.write(picture, arcname=os.path.basename(picture))
120 return sendfile(request, zipfilename, attachment=True)
121
122
123 @login_required
124 def download(request, slug, filename):
125 """Download a photo if the album of the photo is accessible by the user."""
126 obj = get_object_or_404(Album, slug=slug)
127 if is_album_accessible(request, obj):
128 return _download(request, obj, filename)
129 raise Http404("Sorry, you're not allowed to view this album")
130
131
132 @login_required
133 def album_download(request, slug):
134 """Download an album if the album is accessible by the user."""
135 obj = get_object_or_404(Album, slug=slug)
136 if is_album_accessible(request, obj):
137 return _album_download(request, obj)
138 raise Http404("Sorry, you're not allowed to view this album")
139
140
141 def shared_download(request, slug, token, filename):
142 """Download a photo from a shared album if the album token is provided."""
143 obj = get_object_or_404(Album, slug=slug)
144 check_shared_album_token(obj, token)
145 return _download(request, obj, filename)
146
147
148 def shared_album_download(request, slug, token):
149 """Download a shared album if the album token is provided."""
150 obj = get_object_or_404(Album, slug=slug)
151 check_shared_album_token(obj, token)
152 return _album_download(request, obj)
153
```
Path: `website/photos/urls.py`
Content:
```
1 from django.urls import path, include
2
3 from . import views
4
5 app_name = "photos"
6
7 urlpatterns = [
8 path(
9 "members/photos/",
10 include(
11 [
12 path("", views.index, name="index"),
13 path(
14 "<slug>/",
15 include(
16 [
17 path("", views.detail, name="album"),
18 path(
19 "download/",
20 include(
21 [
22 path(
23 "",
24 views.album_download,
25 name="album-download",
26 ),
27 path(
28 "<filename>",
29 views.download,
30 name="download",
31 ),
32 path(
33 "<token>/",
34 include(
35 [
36 path(
37 "",
38 views.shared_album_download,
39 name="shared-album-download",
40 ),
41 path(
42 "<filename>",
43 views.shared_download,
44 name="shared-download",
45 ),
46 ]
47 ),
48 ),
49 ]
50 ),
51 ),
52 path("<token>/", views.shared_album, name="shared-album"),
53 ]
54 ),
55 ),
56 ]
57 ),
58 )
59 ]
60
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/website/photos/urls.py b/website/photos/urls.py
--- a/website/photos/urls.py
+++ b/website/photos/urls.py
@@ -19,11 +19,6 @@
"download/",
include(
[
- path(
- "",
- views.album_download,
- name="album-download",
- ),
path(
"<filename>",
views.download,
@@ -33,11 +28,6 @@
"<token>/",
include(
[
- path(
- "",
- views.shared_album_download,
- name="shared-album-download",
- ),
path(
"<filename>",
views.shared_download,
diff --git a/website/photos/views.py b/website/photos/views.py
--- a/website/photos/views.py
+++ b/website/photos/views.py
@@ -1,6 +1,4 @@
import os
-from tempfile import gettempdir
-from zipfile import ZipFile
from django.contrib.auth.decorators import login_required
from django.core.paginator import EmptyPage, Paginator
@@ -105,21 +103,6 @@
return sendfile(request, photo.file.path, attachment=True)
-def _album_download(request, obj):
- """Download an album.
-
- This function provides a layer of indirection for shared albums.
- """
- albumpath = os.path.join(obj.photospath, obj.dirname)
- zipfilename = os.path.join(gettempdir(), "{}.zip".format(obj.dirname))
- if not os.path.exists(zipfilename):
- with ZipFile(zipfilename, "w") as f:
- pictures = [os.path.join(albumpath, x) for x in os.listdir(albumpath)]
- for picture in pictures:
- f.write(picture, arcname=os.path.basename(picture))
- return sendfile(request, zipfilename, attachment=True)
-
-
@login_required
def download(request, slug, filename):
"""Download a photo if the album of the photo is accessible by the user."""
@@ -129,24 +112,8 @@
raise Http404("Sorry, you're not allowed to view this album")
-@login_required
-def album_download(request, slug):
- """Download an album if the album is accessible by the user."""
- obj = get_object_or_404(Album, slug=slug)
- if is_album_accessible(request, obj):
- return _album_download(request, obj)
- raise Http404("Sorry, you're not allowed to view this album")
-
-
def shared_download(request, slug, token, filename):
"""Download a photo from a shared album if the album token is provided."""
obj = get_object_or_404(Album, slug=slug)
check_shared_album_token(obj, token)
return _download(request, obj, filename)
-
-
-def shared_album_download(request, slug, token):
- """Download a shared album if the album token is provided."""
- obj = get_object_or_404(Album, slug=slug)
- check_shared_album_token(obj, token)
- return _album_download(request, obj)
|
{"golden_diff": "diff --git a/website/photos/urls.py b/website/photos/urls.py\n--- a/website/photos/urls.py\n+++ b/website/photos/urls.py\n@@ -19,11 +19,6 @@\n \"download/\",\n include(\n [\n- path(\n- \"\",\n- views.album_download,\n- name=\"album-download\",\n- ),\n path(\n \"<filename>\",\n views.download,\n@@ -33,11 +28,6 @@\n \"<token>/\",\n include(\n [\n- path(\n- \"\",\n- views.shared_album_download,\n- name=\"shared-album-download\",\n- ),\n path(\n \"<filename>\",\n views.shared_download,\ndiff --git a/website/photos/views.py b/website/photos/views.py\n--- a/website/photos/views.py\n+++ b/website/photos/views.py\n@@ -1,6 +1,4 @@\n import os\n-from tempfile import gettempdir\n-from zipfile import ZipFile\n \n from django.contrib.auth.decorators import login_required\n from django.core.paginator import EmptyPage, Paginator\n@@ -105,21 +103,6 @@\n return sendfile(request, photo.file.path, attachment=True)\n \n \n-def _album_download(request, obj):\n- \"\"\"Download an album.\n-\n- This function provides a layer of indirection for shared albums.\n- \"\"\"\n- albumpath = os.path.join(obj.photospath, obj.dirname)\n- zipfilename = os.path.join(gettempdir(), \"{}.zip\".format(obj.dirname))\n- if not os.path.exists(zipfilename):\n- with ZipFile(zipfilename, \"w\") as f:\n- pictures = [os.path.join(albumpath, x) for x in os.listdir(albumpath)]\n- for picture in pictures:\n- f.write(picture, arcname=os.path.basename(picture))\n- return sendfile(request, zipfilename, attachment=True)\n-\n-\n @login_required\n def download(request, slug, filename):\n \"\"\"Download a photo if the album of the photo is accessible by the user.\"\"\"\n@@ -129,24 +112,8 @@\n raise Http404(\"Sorry, you're not allowed to view this album\")\n \n \n-@login_required\n-def album_download(request, slug):\n- \"\"\"Download an album if the album is accessible by the user.\"\"\"\n- obj = get_object_or_404(Album, slug=slug)\n- if is_album_accessible(request, obj):\n- return _album_download(request, obj)\n- raise Http404(\"Sorry, you're not allowed to view this album\")\n-\n-\n def shared_download(request, slug, token, filename):\n \"\"\"Download a photo from a shared album if the album token is provided.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n check_shared_album_token(obj, token)\n return _download(request, obj, filename)\n-\n-\n-def shared_album_download(request, slug, token):\n- \"\"\"Download a shared album if the album token is provided.\"\"\"\n- obj = get_object_or_404(Album, slug=slug)\n- check_shared_album_token(obj, token)\n- return _album_download(request, obj)\n", "issue": "Downloading albums fills up the disk\n### Describe the bug\r\nWhen a user wants to download an album, the website creates a zip file containing all photos (in `/tmp` of the Docker container). If multiple albums are downloaded, multiple large zip files are created. This very quickly fills up the disk.\r\n\r\nWe should remove this functionality to prevent this. It is not used often so that should not be a problem for members.\r\n\r\n### Additional context\r\nThis has caused website outages a few times in the past.\r\n\n", "before_files": [{"content": "import os\nfrom tempfile import gettempdir\nfrom zipfile import ZipFile\n\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.paginator import EmptyPage, Paginator\nfrom django.http import Http404\nfrom django.shortcuts import get_object_or_404, render\nfrom django.utils.translation import get_language\nfrom django_sendfile import sendfile\n\nfrom photos.models import Album, Photo\nfrom photos.services import (\n check_shared_album_token,\n get_annotated_accessible_albums,\n is_album_accessible,\n)\n\nCOVER_FILENAME = \"cover.jpg\"\n\n\n@login_required\ndef index(request):\n \"\"\"Render the index page showing multiple album cards.\"\"\"\n keywords = request.GET.get(\"keywords\", \"\").split()\n\n # Only show published albums\n albums = Album.objects.filter(hidden=False)\n for key in keywords:\n albums = albums.filter(**{f\"title_{get_language()}__icontains\": key})\n\n albums = get_annotated_accessible_albums(request, albums)\n\n albums = albums.order_by(\"-date\")\n paginator = Paginator(albums, 16)\n\n page = request.GET.get(\"page\")\n page = 1 if page is None or not page.isdigit() else int(page)\n try:\n albums = paginator.page(page)\n except EmptyPage:\n # If page is out of range (e.g. 9999), deliver last page of results.\n albums = paginator.page(paginator.num_pages)\n page = paginator.num_pages\n\n # Show the two pages before and after the current page\n page_range_start = max(1, page - 2)\n page_range_stop = min(page + 3, paginator.num_pages + 1)\n\n # Add extra pages if we show less than 5 pages\n page_range_start = min(page_range_start, page_range_stop - 5)\n page_range_start = max(1, page_range_start)\n\n # Add extra pages if we still show less than 5 pages\n page_range_stop = max(page_range_stop, page_range_start + 5)\n page_range_stop = min(page_range_stop, paginator.num_pages + 1)\n\n page_range = range(page_range_start, page_range_stop)\n\n return render(\n request,\n \"photos/index.html\",\n {\"albums\": albums, \"page_range\": page_range, \"keywords\": keywords},\n )\n\n\ndef _render_album_page(request, album):\n \"\"\"Render album.html for a specified album.\"\"\"\n context = {\"album\": album, \"photos\": album.photo_set.filter(hidden=False)}\n return render(request, \"photos/album.html\", context)\n\n\n@login_required\ndef detail(request, slug):\n \"\"\"Render an album, if it accessible by the user.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n if is_album_accessible(request, obj):\n return _render_album_page(request, obj)\n raise Http404(\"Sorry, you're not allowed to view this album\")\n\n\ndef shared_album(request, slug, token):\n \"\"\"Render a shared album if the correct token is provided.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n check_shared_album_token(obj, token)\n return _render_album_page(request, obj)\n\n\ndef _photo_path(obj, filename):\n \"\"\"Return the path to a Photo.\"\"\"\n photoname = os.path.basename(filename)\n albumpath = os.path.join(obj.photosdir, obj.dirname)\n photopath = os.path.join(albumpath, photoname)\n get_object_or_404(Photo.objects.filter(album=obj, file=photopath))\n return photopath\n\n\ndef _download(request, obj, filename):\n \"\"\"Download a photo.\n\n This function provides a layer of indirection for shared albums.\n \"\"\"\n photopath = _photo_path(obj, filename)\n photo = get_object_or_404(Photo.objects.filter(album=obj, file=photopath))\n return sendfile(request, photo.file.path, attachment=True)\n\n\ndef _album_download(request, obj):\n \"\"\"Download an album.\n\n This function provides a layer of indirection for shared albums.\n \"\"\"\n albumpath = os.path.join(obj.photospath, obj.dirname)\n zipfilename = os.path.join(gettempdir(), \"{}.zip\".format(obj.dirname))\n if not os.path.exists(zipfilename):\n with ZipFile(zipfilename, \"w\") as f:\n pictures = [os.path.join(albumpath, x) for x in os.listdir(albumpath)]\n for picture in pictures:\n f.write(picture, arcname=os.path.basename(picture))\n return sendfile(request, zipfilename, attachment=True)\n\n\n@login_required\ndef download(request, slug, filename):\n \"\"\"Download a photo if the album of the photo is accessible by the user.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n if is_album_accessible(request, obj):\n return _download(request, obj, filename)\n raise Http404(\"Sorry, you're not allowed to view this album\")\n\n\n@login_required\ndef album_download(request, slug):\n \"\"\"Download an album if the album is accessible by the user.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n if is_album_accessible(request, obj):\n return _album_download(request, obj)\n raise Http404(\"Sorry, you're not allowed to view this album\")\n\n\ndef shared_download(request, slug, token, filename):\n \"\"\"Download a photo from a shared album if the album token is provided.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n check_shared_album_token(obj, token)\n return _download(request, obj, filename)\n\n\ndef shared_album_download(request, slug, token):\n \"\"\"Download a shared album if the album token is provided.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n check_shared_album_token(obj, token)\n return _album_download(request, obj)\n", "path": "website/photos/views.py"}, {"content": "from django.urls import path, include\n\nfrom . import views\n\napp_name = \"photos\"\n\nurlpatterns = [\n path(\n \"members/photos/\",\n include(\n [\n path(\"\", views.index, name=\"index\"),\n path(\n \"<slug>/\",\n include(\n [\n path(\"\", views.detail, name=\"album\"),\n path(\n \"download/\",\n include(\n [\n path(\n \"\",\n views.album_download,\n name=\"album-download\",\n ),\n path(\n \"<filename>\",\n views.download,\n name=\"download\",\n ),\n path(\n \"<token>/\",\n include(\n [\n path(\n \"\",\n views.shared_album_download,\n name=\"shared-album-download\",\n ),\n path(\n \"<filename>\",\n views.shared_download,\n name=\"shared-download\",\n ),\n ]\n ),\n ),\n ]\n ),\n ),\n path(\"<token>/\", views.shared_album, name=\"shared-album\"),\n ]\n ),\n ),\n ]\n ),\n )\n]\n", "path": "website/photos/urls.py"}], "after_files": [{"content": "import os\n\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.paginator import EmptyPage, Paginator\nfrom django.http import Http404\nfrom django.shortcuts import get_object_or_404, render\nfrom django.utils.translation import get_language\nfrom django_sendfile import sendfile\n\nfrom photos.models import Album, Photo\nfrom photos.services import (\n check_shared_album_token,\n get_annotated_accessible_albums,\n is_album_accessible,\n)\n\nCOVER_FILENAME = \"cover.jpg\"\n\n\n@login_required\ndef index(request):\n \"\"\"Render the index page showing multiple album cards.\"\"\"\n keywords = request.GET.get(\"keywords\", \"\").split()\n\n # Only show published albums\n albums = Album.objects.filter(hidden=False)\n for key in keywords:\n albums = albums.filter(**{f\"title_{get_language()}__icontains\": key})\n\n albums = get_annotated_accessible_albums(request, albums)\n\n albums = albums.order_by(\"-date\")\n paginator = Paginator(albums, 16)\n\n page = request.GET.get(\"page\")\n page = 1 if page is None or not page.isdigit() else int(page)\n try:\n albums = paginator.page(page)\n except EmptyPage:\n # If page is out of range (e.g. 9999), deliver last page of results.\n albums = paginator.page(paginator.num_pages)\n page = paginator.num_pages\n\n # Show the two pages before and after the current page\n page_range_start = max(1, page - 2)\n page_range_stop = min(page + 3, paginator.num_pages + 1)\n\n # Add extra pages if we show less than 5 pages\n page_range_start = min(page_range_start, page_range_stop - 5)\n page_range_start = max(1, page_range_start)\n\n # Add extra pages if we still show less than 5 pages\n page_range_stop = max(page_range_stop, page_range_start + 5)\n page_range_stop = min(page_range_stop, paginator.num_pages + 1)\n\n page_range = range(page_range_start, page_range_stop)\n\n return render(\n request,\n \"photos/index.html\",\n {\"albums\": albums, \"page_range\": page_range, \"keywords\": keywords},\n )\n\n\ndef _render_album_page(request, album):\n \"\"\"Render album.html for a specified album.\"\"\"\n context = {\"album\": album, \"photos\": album.photo_set.filter(hidden=False)}\n return render(request, \"photos/album.html\", context)\n\n\n@login_required\ndef detail(request, slug):\n \"\"\"Render an album, if it accessible by the user.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n if is_album_accessible(request, obj):\n return _render_album_page(request, obj)\n raise Http404(\"Sorry, you're not allowed to view this album\")\n\n\ndef shared_album(request, slug, token):\n \"\"\"Render a shared album if the correct token is provided.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n check_shared_album_token(obj, token)\n return _render_album_page(request, obj)\n\n\ndef _photo_path(obj, filename):\n \"\"\"Return the path to a Photo.\"\"\"\n photoname = os.path.basename(filename)\n albumpath = os.path.join(obj.photosdir, obj.dirname)\n photopath = os.path.join(albumpath, photoname)\n get_object_or_404(Photo.objects.filter(album=obj, file=photopath))\n return photopath\n\n\ndef _download(request, obj, filename):\n \"\"\"Download a photo.\n\n This function provides a layer of indirection for shared albums.\n \"\"\"\n photopath = _photo_path(obj, filename)\n photo = get_object_or_404(Photo.objects.filter(album=obj, file=photopath))\n return sendfile(request, photo.file.path, attachment=True)\n\n\n@login_required\ndef download(request, slug, filename):\n \"\"\"Download a photo if the album of the photo is accessible by the user.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n if is_album_accessible(request, obj):\n return _download(request, obj, filename)\n raise Http404(\"Sorry, you're not allowed to view this album\")\n\n\ndef shared_download(request, slug, token, filename):\n \"\"\"Download a photo from a shared album if the album token is provided.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n check_shared_album_token(obj, token)\n return _download(request, obj, filename)\n", "path": "website/photos/views.py"}, {"content": "from django.urls import path, include\n\nfrom . import views\n\napp_name = \"photos\"\n\nurlpatterns = [\n path(\n \"members/photos/\",\n include(\n [\n path(\"\", views.index, name=\"index\"),\n path(\n \"<slug>/\",\n include(\n [\n path(\"\", views.detail, name=\"album\"),\n path(\n \"download/\",\n include(\n [\n path(\n \"<filename>\",\n views.download,\n name=\"download\",\n ),\n path(\n \"<token>/\",\n include(\n [\n path(\n \"<filename>\",\n views.shared_download,\n name=\"shared-download\",\n ),\n ]\n ),\n ),\n ]\n ),\n ),\n path(\"<token>/\", views.shared_album, name=\"shared-album\"),\n ]\n ),\n ),\n ]\n ),\n )\n]\n", "path": "website/photos/urls.py"}]}
| 2,340 | 690 |
gh_patches_debug_7375
|
rasdani/github-patches
|
git_diff
|
mindsdb__mindsdb-866
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix address already in use when running mindsdb
We need help with find and fix bug:
When you run mindsdb in console, for each interface (specified during --api argument) it needs to run the separate process. When you interrupt the main process by ctrl-c, all other processes should stop too. But sometimes it doesn't happen. We don't know why, maybe it depends on OS, or terminal, or something else. You can check it easy:
1. for your convenience create and activate venv (commands below will be slightly different on windows):
```
python3 -m venv venv
source venv/bin/activate
```
2. install mindsdb:
```
pip3 install mindsdb
```
3. run mindsdb as:
```
python3 -m mindsdb
```
by default will be stated 2 interfaces: HTTP on port 47334 and MySQL on port 47335.
4. Interrupt it by ctrl-c
5. Run mindsdb again. If you see the error 'address already in use', then well, you caught the error :)
All processes start and close in __main__.py https://github.com/mindsdb/mindsdb/blob/staging/mindsdb/__main__.py
We assume on 'ctrl-c' interrupt should be executed in close_api_gracefully function https://github.com/mindsdb/mindsdb/blob/staging/mindsdb/__main__.py#L23
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mindsdb/__main__.py`
Content:
```
1 import atexit
2 import traceback
3 import sys
4 import os
5 import time
6 import asyncio
7
8 from pkg_resources import get_distribution
9 import torch.multiprocessing as mp
10
11 from mindsdb.utilities.config import Config
12 from mindsdb.interfaces.native.mindsdb import MindsdbNative
13 from mindsdb.interfaces.custom.custom_models import CustomModels
14 from mindsdb.api.http.start import start as start_http
15 from mindsdb.api.mysql.start import start as start_mysql
16 from mindsdb.api.mongo.start import start as start_mongo
17 from mindsdb.utilities.fs import (
18 get_or_create_dir_struct,
19 update_versions_file,
20 archive_obsolete_predictors,
21 remove_corrupted_predictors
22 )
23 from mindsdb.utilities.ps import is_pid_listen_port
24 from mindsdb.interfaces.database.database import DatabaseWrapper
25 from mindsdb.utilities.functions import args_parse
26 from mindsdb.utilities.log import initialize_log
27
28
29 def close_api_gracefully(apis):
30 for api in apis.values():
31 process = api['process']
32 sys.stdout.flush()
33 process.terminate()
34 process.join()
35 sys.stdout.flush()
36
37
38 if __name__ == '__main__':
39 version_error_msg = """
40 MindsDB server requires Python >= 3.6 to run
41
42 Once you have Python 3.6 installed you can tun mindsdb as follows:
43
44 1. create and activate venv:
45 python3.6 -m venv venv
46 source venv/bin/activate
47
48 2. install MindsDB:
49 pip3 install mindsdb
50
51 3. Run MindsDB
52 python3.6 -m mindsdb
53
54 More instructions in https://docs.mindsdb.com
55 """
56
57 if not (sys.version_info[0] >= 3 and sys.version_info[1] >= 6):
58 print(version_error_msg)
59 exit(1)
60
61 mp.freeze_support()
62
63 args = args_parse()
64
65 from mindsdb.__about__ import __version__ as mindsdb_version
66
67 if args.version:
68 print(f'MindsDB {mindsdb_version}')
69 sys.exit(0)
70
71 config_path = args.config
72 if config_path is None:
73 config_dir, _ = get_or_create_dir_struct()
74 config_path = os.path.join(config_dir, 'config.json')
75
76 config = Config(config_path)
77
78 if args.verbose is True:
79 config['log']['level']['console'] = 'DEBUG'
80 os.environ['DEFAULT_LOG_LEVEL'] = config['log']['level']['console']
81 os.environ['LIGHTWOOD_LOG_LEVEL'] = config['log']['level']['console']
82
83 log = initialize_log(config)
84
85 try:
86 lightwood_version = get_distribution('lightwood').version
87 except Exception:
88 from lightwood.__about__ import __version__ as lightwood_version
89
90 try:
91 mindsdb_native_version = get_distribution('mindsdb_native').version
92 except Exception:
93 from mindsdb_native.__about__ import __version__ as mindsdb_native_version
94
95 print(f'Configuration file:\n {config_path}')
96 print(f"Storage path:\n {config.paths['root']}")
97
98 print('Versions:')
99 print(f' - lightwood {lightwood_version}')
100 print(f' - MindsDB_native {mindsdb_native_version}')
101 print(f' - MindsDB {mindsdb_version}')
102
103 os.environ['MINDSDB_STORAGE_PATH'] = config.paths['predictors']
104
105 update_versions_file(
106 config,
107 {
108 'lightwood': lightwood_version,
109 'mindsdb_native': mindsdb_native_version,
110 'mindsdb': mindsdb_version,
111 'python': sys.version.replace('\n', '')
112 }
113 )
114
115 if args.api is None:
116 api_arr = ['http', 'mysql']
117 else:
118 api_arr = args.api.split(',')
119
120 apis = {
121 api: {
122 'port': config['api'][api]['port'],
123 'process': None,
124 'started': False
125 } for api in api_arr
126 }
127
128 for api_name in apis.keys():
129 if api_name not in config['api']:
130 print(f"Trying run '{api_name}' API, but is no config for this api.")
131 print(f"Please, fill config['api']['{api_name}']")
132 sys.exit(0)
133
134 start_functions = {
135 'http': start_http,
136 'mysql': start_mysql,
137 'mongodb': start_mongo
138 }
139
140 archive_obsolete_predictors(config, '2.11.0')
141
142 mdb = MindsdbNative(config)
143 cst = CustomModels(config)
144
145 remove_corrupted_predictors(config, mdb)
146
147 # @TODO Maybe just use `get_model_data` directly here ? Seems like a useless abstraction
148 model_data_arr = [
149 {
150 'name': x['name'],
151 'predict': x['predict'],
152 'data_analysis': mdb.get_model_data(x['name'])['data_analysis_v2']
153 } for x in mdb.get_models()
154 ]
155
156 model_data_arr.extend(cst.get_models())
157
158 dbw = DatabaseWrapper(config)
159 dbw.register_predictors(model_data_arr)
160
161 for broken_name in [name for name, connected in dbw.check_connections().items() if connected is False]:
162 log.error(f'Error failed to integrate with database aliased: {broken_name}')
163
164 ctx = mp.get_context('spawn')
165
166 for api_name, api_data in apis.items():
167 print(f'{api_name} API: starting...')
168 try:
169 p = ctx.Process(target=start_functions[api_name], args=(config_path, args.verbose))
170 p.start()
171 api_data['process'] = p
172 except Exception as e:
173 close_api_gracefully(apis)
174 log.error(f'Failed to start {api_name} API with exception {e}\n{traceback.format_exc()}')
175 raise
176
177 atexit.register(close_api_gracefully, apis=apis)
178
179 async def wait_api_start(api_name, pid, port):
180 timeout = 60
181 start_time = time.time()
182 started = is_pid_listen_port(pid, port)
183 while (time.time() - start_time) < timeout and started is False:
184 await asyncio.sleep(0.5)
185 started = is_pid_listen_port(pid, port)
186 return api_name, port, started
187
188 async def wait_apis_start():
189 futures = [
190 wait_api_start(api_name, api_data['process'].pid, api_data['port'])
191 for api_name, api_data in apis.items()
192 ]
193 for i, future in enumerate(asyncio.as_completed(futures)):
194 api_name, port, started = await future
195 if started:
196 print(f"{api_name} API: started on {port}")
197 else:
198 log.error(f"ERROR: {api_name} API cant start on {port}")
199
200 ioloop = asyncio.get_event_loop()
201 ioloop.run_until_complete(wait_apis_start())
202 ioloop.close()
203
204 try:
205 for api_data in apis.values():
206 api_data['process'].join()
207 except KeyboardInterrupt:
208 print('Closing app...')
209
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mindsdb/__main__.py b/mindsdb/__main__.py
--- a/mindsdb/__main__.py
+++ b/mindsdb/__main__.py
@@ -27,13 +27,15 @@
def close_api_gracefully(apis):
- for api in apis.values():
- process = api['process']
- sys.stdout.flush()
- process.terminate()
- process.join()
- sys.stdout.flush()
-
+ try:
+ for api in apis.values():
+ process = api['process']
+ sys.stdout.flush()
+ process.terminate()
+ process.join()
+ sys.stdout.flush()
+ except KeyboardInterrupt:
+ sys.exit(0)
if __name__ == '__main__':
version_error_msg = """
|
{"golden_diff": "diff --git a/mindsdb/__main__.py b/mindsdb/__main__.py\n--- a/mindsdb/__main__.py\n+++ b/mindsdb/__main__.py\n@@ -27,13 +27,15 @@\n \n \n def close_api_gracefully(apis):\n- for api in apis.values():\n- process = api['process']\n- sys.stdout.flush()\n- process.terminate()\n- process.join()\n- sys.stdout.flush()\n-\n+ try: \n+ for api in apis.values():\n+ process = api['process']\n+ sys.stdout.flush()\n+ process.terminate()\n+ process.join()\n+ sys.stdout.flush()\n+ except KeyboardInterrupt:\n+ sys.exit(0)\n \n if __name__ == '__main__':\n version_error_msg = \"\"\"\n", "issue": "Fix address already in use when running mindsdb\nWe need help with find and fix bug:\r\nWhen you run mindsdb in console, for each interface (specified during --api argument) it needs to run the separate process. When you interrupt the main process by ctrl-c, all other processes should stop too. But sometimes it doesn't happen. We don't know why, maybe it depends on OS, or terminal, or something else. You can check it easy:\r\n1. for your convenience create and activate venv (commands below will be slightly different on windows):\r\n```\r\npython3 -m venv venv\r\nsource venv/bin/activate\r\n```\r\n2. install mindsdb:\r\n```\r\npip3 install mindsdb\r\n```\r\n3. run mindsdb as:\r\n```\r\npython3 -m mindsdb\r\n```\r\nby default will be stated 2 interfaces: HTTP on port 47334 and MySQL on port 47335.\r\n4. Interrupt it by ctrl-c\r\n5. Run mindsdb again. If you see the error 'address already in use', then well, you caught the error :)\r\n\r\nAll processes start and close in __main__.py https://github.com/mindsdb/mindsdb/blob/staging/mindsdb/__main__.py\r\nWe assume on 'ctrl-c' interrupt should be executed in close_api_gracefully function https://github.com/mindsdb/mindsdb/blob/staging/mindsdb/__main__.py#L23\n", "before_files": [{"content": "import atexit\nimport traceback\nimport sys\nimport os\nimport time\nimport asyncio\n\nfrom pkg_resources import get_distribution\nimport torch.multiprocessing as mp\n\nfrom mindsdb.utilities.config import Config\nfrom mindsdb.interfaces.native.mindsdb import MindsdbNative\nfrom mindsdb.interfaces.custom.custom_models import CustomModels\nfrom mindsdb.api.http.start import start as start_http\nfrom mindsdb.api.mysql.start import start as start_mysql\nfrom mindsdb.api.mongo.start import start as start_mongo\nfrom mindsdb.utilities.fs import (\n get_or_create_dir_struct,\n update_versions_file,\n archive_obsolete_predictors,\n remove_corrupted_predictors\n)\nfrom mindsdb.utilities.ps import is_pid_listen_port\nfrom mindsdb.interfaces.database.database import DatabaseWrapper\nfrom mindsdb.utilities.functions import args_parse\nfrom mindsdb.utilities.log import initialize_log\n\n\ndef close_api_gracefully(apis):\n for api in apis.values():\n process = api['process']\n sys.stdout.flush()\n process.terminate()\n process.join()\n sys.stdout.flush()\n\n\nif __name__ == '__main__':\n version_error_msg = \"\"\"\nMindsDB server requires Python >= 3.6 to run\n\nOnce you have Python 3.6 installed you can tun mindsdb as follows:\n\n1. create and activate venv:\npython3.6 -m venv venv\nsource venv/bin/activate\n\n2. install MindsDB:\npip3 install mindsdb\n\n3. Run MindsDB\npython3.6 -m mindsdb\n\nMore instructions in https://docs.mindsdb.com\n \"\"\"\n\n if not (sys.version_info[0] >= 3 and sys.version_info[1] >= 6):\n print(version_error_msg)\n exit(1)\n\n mp.freeze_support()\n\n args = args_parse()\n\n from mindsdb.__about__ import __version__ as mindsdb_version\n\n if args.version:\n print(f'MindsDB {mindsdb_version}')\n sys.exit(0)\n\n config_path = args.config\n if config_path is None:\n config_dir, _ = get_or_create_dir_struct()\n config_path = os.path.join(config_dir, 'config.json')\n\n config = Config(config_path)\n\n if args.verbose is True:\n config['log']['level']['console'] = 'DEBUG'\n os.environ['DEFAULT_LOG_LEVEL'] = config['log']['level']['console']\n os.environ['LIGHTWOOD_LOG_LEVEL'] = config['log']['level']['console']\n\n log = initialize_log(config)\n\n try:\n lightwood_version = get_distribution('lightwood').version\n except Exception:\n from lightwood.__about__ import __version__ as lightwood_version\n\n try:\n mindsdb_native_version = get_distribution('mindsdb_native').version\n except Exception:\n from mindsdb_native.__about__ import __version__ as mindsdb_native_version\n\n print(f'Configuration file:\\n {config_path}')\n print(f\"Storage path:\\n {config.paths['root']}\")\n\n print('Versions:')\n print(f' - lightwood {lightwood_version}')\n print(f' - MindsDB_native {mindsdb_native_version}')\n print(f' - MindsDB {mindsdb_version}')\n\n os.environ['MINDSDB_STORAGE_PATH'] = config.paths['predictors']\n\n update_versions_file(\n config,\n {\n 'lightwood': lightwood_version,\n 'mindsdb_native': mindsdb_native_version,\n 'mindsdb': mindsdb_version,\n 'python': sys.version.replace('\\n', '')\n }\n )\n\n if args.api is None:\n api_arr = ['http', 'mysql']\n else:\n api_arr = args.api.split(',')\n\n apis = {\n api: {\n 'port': config['api'][api]['port'],\n 'process': None,\n 'started': False\n } for api in api_arr\n }\n\n for api_name in apis.keys():\n if api_name not in config['api']:\n print(f\"Trying run '{api_name}' API, but is no config for this api.\")\n print(f\"Please, fill config['api']['{api_name}']\")\n sys.exit(0)\n\n start_functions = {\n 'http': start_http,\n 'mysql': start_mysql,\n 'mongodb': start_mongo\n }\n\n archive_obsolete_predictors(config, '2.11.0')\n\n mdb = MindsdbNative(config)\n cst = CustomModels(config)\n\n remove_corrupted_predictors(config, mdb)\n\n # @TODO Maybe just use `get_model_data` directly here ? Seems like a useless abstraction\n model_data_arr = [\n {\n 'name': x['name'],\n 'predict': x['predict'],\n 'data_analysis': mdb.get_model_data(x['name'])['data_analysis_v2']\n } for x in mdb.get_models()\n ]\n\n model_data_arr.extend(cst.get_models())\n\n dbw = DatabaseWrapper(config)\n dbw.register_predictors(model_data_arr)\n\n for broken_name in [name for name, connected in dbw.check_connections().items() if connected is False]:\n log.error(f'Error failed to integrate with database aliased: {broken_name}')\n\n ctx = mp.get_context('spawn')\n\n for api_name, api_data in apis.items():\n print(f'{api_name} API: starting...')\n try:\n p = ctx.Process(target=start_functions[api_name], args=(config_path, args.verbose))\n p.start()\n api_data['process'] = p\n except Exception as e:\n close_api_gracefully(apis)\n log.error(f'Failed to start {api_name} API with exception {e}\\n{traceback.format_exc()}')\n raise\n\n atexit.register(close_api_gracefully, apis=apis)\n\n async def wait_api_start(api_name, pid, port):\n timeout = 60\n start_time = time.time()\n started = is_pid_listen_port(pid, port)\n while (time.time() - start_time) < timeout and started is False:\n await asyncio.sleep(0.5)\n started = is_pid_listen_port(pid, port)\n return api_name, port, started\n\n async def wait_apis_start():\n futures = [\n wait_api_start(api_name, api_data['process'].pid, api_data['port'])\n for api_name, api_data in apis.items()\n ]\n for i, future in enumerate(asyncio.as_completed(futures)):\n api_name, port, started = await future\n if started:\n print(f\"{api_name} API: started on {port}\")\n else:\n log.error(f\"ERROR: {api_name} API cant start on {port}\")\n\n ioloop = asyncio.get_event_loop()\n ioloop.run_until_complete(wait_apis_start())\n ioloop.close()\n\n try:\n for api_data in apis.values():\n api_data['process'].join()\n except KeyboardInterrupt:\n print('Closing app...')\n", "path": "mindsdb/__main__.py"}], "after_files": [{"content": "import atexit\nimport traceback\nimport sys\nimport os\nimport time\nimport asyncio\n\nfrom pkg_resources import get_distribution\nimport torch.multiprocessing as mp\n\nfrom mindsdb.utilities.config import Config\nfrom mindsdb.interfaces.native.mindsdb import MindsdbNative\nfrom mindsdb.interfaces.custom.custom_models import CustomModels\nfrom mindsdb.api.http.start import start as start_http\nfrom mindsdb.api.mysql.start import start as start_mysql\nfrom mindsdb.api.mongo.start import start as start_mongo\nfrom mindsdb.utilities.fs import (\n get_or_create_dir_struct,\n update_versions_file,\n archive_obsolete_predictors,\n remove_corrupted_predictors\n)\nfrom mindsdb.utilities.ps import is_pid_listen_port\nfrom mindsdb.interfaces.database.database import DatabaseWrapper\nfrom mindsdb.utilities.functions import args_parse\nfrom mindsdb.utilities.log import initialize_log\n\n\ndef close_api_gracefully(apis):\n try: \n for api in apis.values():\n process = api['process']\n sys.stdout.flush()\n process.terminate()\n process.join()\n sys.stdout.flush()\n except KeyboardInterrupt:\n sys.exit(0)\n\nif __name__ == '__main__':\n version_error_msg = \"\"\"\nMindsDB server requires Python >= 3.6 to run\n\nOnce you have Python 3.6 installed you can tun mindsdb as follows:\n\n1. create and activate venv:\npython3.6 -m venv venv\nsource venv/bin/activate\n\n2. install MindsDB:\npip3 install mindsdb\n\n3. Run MindsDB\npython3.6 -m mindsdb\n\nMore instructions in https://docs.mindsdb.com\n \"\"\"\n\n if not (sys.version_info[0] >= 3 and sys.version_info[1] >= 6):\n print(version_error_msg)\n exit(1)\n\n mp.freeze_support()\n\n args = args_parse()\n\n from mindsdb.__about__ import __version__ as mindsdb_version\n\n if args.version:\n print(f'MindsDB {mindsdb_version}')\n sys.exit(0)\n\n config_path = args.config\n if config_path is None:\n config_dir, _ = get_or_create_dir_struct()\n config_path = os.path.join(config_dir, 'config.json')\n\n config = Config(config_path)\n\n if args.verbose is True:\n config['log']['level']['console'] = 'DEBUG'\n os.environ['DEFAULT_LOG_LEVEL'] = config['log']['level']['console']\n os.environ['LIGHTWOOD_LOG_LEVEL'] = config['log']['level']['console']\n\n log = initialize_log(config)\n\n try:\n lightwood_version = get_distribution('lightwood').version\n except Exception:\n from lightwood.__about__ import __version__ as lightwood_version\n\n try:\n mindsdb_native_version = get_distribution('mindsdb_native').version\n except Exception:\n from mindsdb_native.__about__ import __version__ as mindsdb_native_version\n\n print(f'Configuration file:\\n {config_path}')\n print(f\"Storage path:\\n {config.paths['root']}\")\n\n print('Versions:')\n print(f' - lightwood {lightwood_version}')\n print(f' - MindsDB_native {mindsdb_native_version}')\n print(f' - MindsDB {mindsdb_version}')\n\n os.environ['MINDSDB_STORAGE_PATH'] = config.paths['predictors']\n\n update_versions_file(\n config,\n {\n 'lightwood': lightwood_version,\n 'mindsdb_native': mindsdb_native_version,\n 'mindsdb': mindsdb_version,\n 'python': sys.version.replace('\\n', '')\n }\n )\n\n if args.api is None:\n api_arr = ['http', 'mysql']\n else:\n api_arr = args.api.split(',')\n\n apis = {\n api: {\n 'port': config['api'][api]['port'],\n 'process': None,\n 'started': False\n } for api in api_arr\n }\n\n for api_name in apis.keys():\n if api_name not in config['api']:\n print(f\"Trying run '{api_name}' API, but is no config for this api.\")\n print(f\"Please, fill config['api']['{api_name}']\")\n sys.exit(0)\n\n start_functions = {\n 'http': start_http,\n 'mysql': start_mysql,\n 'mongodb': start_mongo\n }\n\n archive_obsolete_predictors(config, '2.11.0')\n\n mdb = MindsdbNative(config)\n cst = CustomModels(config)\n\n remove_corrupted_predictors(config, mdb)\n\n # @TODO Maybe just use `get_model_data` directly here ? Seems like a useless abstraction\n model_data_arr = [\n {\n 'name': x['name'],\n 'predict': x['predict'],\n 'data_analysis': mdb.get_model_data(x['name'])['data_analysis_v2']\n } for x in mdb.get_models()\n ]\n\n model_data_arr.extend(cst.get_models())\n\n dbw = DatabaseWrapper(config)\n dbw.register_predictors(model_data_arr)\n\n for broken_name in [name for name, connected in dbw.check_connections().items() if connected is False]:\n log.error(f'Error failed to integrate with database aliased: {broken_name}')\n\n ctx = mp.get_context('spawn')\n\n for api_name, api_data in apis.items():\n print(f'{api_name} API: starting...')\n try:\n p = ctx.Process(target=start_functions[api_name], args=(config_path, args.verbose))\n p.start()\n api_data['process'] = p\n except Exception as e:\n close_api_gracefully(apis)\n log.error(f'Failed to start {api_name} API with exception {e}\\n{traceback.format_exc()}')\n raise\n\n atexit.register(close_api_gracefully, apis=apis)\n\n async def wait_api_start(api_name, pid, port):\n timeout = 60\n start_time = time.time()\n started = is_pid_listen_port(pid, port)\n while (time.time() - start_time) < timeout and started is False:\n await asyncio.sleep(0.5)\n started = is_pid_listen_port(pid, port)\n return api_name, port, started\n\n async def wait_apis_start():\n futures = [\n wait_api_start(api_name, api_data['process'].pid, api_data['port'])\n for api_name, api_data in apis.items()\n ]\n for i, future in enumerate(asyncio.as_completed(futures)):\n api_name, port, started = await future\n if started:\n print(f\"{api_name} API: started on {port}\")\n else:\n log.error(f\"ERROR: {api_name} API cant start on {port}\")\n\n ioloop = asyncio.get_event_loop()\n ioloop.run_until_complete(wait_apis_start())\n ioloop.close()\n\n try:\n for api_data in apis.values():\n api_data['process'].join()\n except KeyboardInterrupt:\n print('Closing app...')\n", "path": "mindsdb/__main__.py"}]}
| 2,598 | 173 |
gh_patches_debug_38767
|
rasdani/github-patches
|
git_diff
|
microsoft__botbuilder-python-976
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Skill consumers should not be able to send Activities to skills without a recipient (Python)
See [parent](https://github.com/microsoft/botframework-sdk/issues/5785).
Issue may be specific to dotnet, need to verify if this is the case.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `libraries/botbuilder-integration-aiohttp/botbuilder/integration/aiohttp/bot_framework_http_client.py`
Content:
```
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3 # pylint: disable=no-member
4
5 import json
6 from typing import Dict
7 from logging import Logger
8
9 import aiohttp
10 from botbuilder.core import InvokeResponse
11 from botbuilder.core.skills import BotFrameworkClient
12 from botbuilder.schema import (
13 Activity,
14 ExpectedReplies,
15 ConversationReference,
16 ConversationAccount,
17 )
18 from botframework.connector.auth import (
19 ChannelProvider,
20 CredentialProvider,
21 MicrosoftAppCredentials,
22 AppCredentials,
23 MicrosoftGovernmentAppCredentials,
24 )
25
26
27 class BotFrameworkHttpClient(BotFrameworkClient):
28
29 """
30 A skill host adapter implements API to forward activity to a skill and
31 implements routing ChannelAPI calls from the Skill up through the bot/adapter.
32 """
33
34 INVOKE_ACTIVITY_NAME = "SkillEvents.ChannelApiInvoke"
35 _BOT_IDENTITY_KEY = "BotIdentity"
36 _APP_CREDENTIALS_CACHE: Dict[str, MicrosoftAppCredentials] = {}
37
38 def __init__(
39 self,
40 credential_provider: CredentialProvider,
41 channel_provider: ChannelProvider = None,
42 logger: Logger = None,
43 ):
44 if not credential_provider:
45 raise TypeError("credential_provider can't be None")
46
47 self._credential_provider = credential_provider
48 self._channel_provider = channel_provider
49 self._logger = logger
50 self._session = aiohttp.ClientSession()
51
52 async def post_activity(
53 self,
54 from_bot_id: str,
55 to_bot_id: str,
56 to_url: str,
57 service_url: str,
58 conversation_id: str,
59 activity: Activity,
60 ) -> InvokeResponse:
61 app_credentials = await self._get_app_credentials(from_bot_id, to_bot_id)
62
63 if not app_credentials:
64 raise KeyError("Unable to get appCredentials to connect to the skill")
65
66 # Get token for the skill call
67 token = (
68 app_credentials.get_access_token()
69 if app_credentials.microsoft_app_id
70 else None
71 )
72
73 # Capture current activity settings before changing them.
74 original_conversation_id = activity.conversation.id
75 original_service_url = activity.service_url
76 original_relates_to = activity.relates_to
77
78 try:
79 activity.relates_to = ConversationReference(
80 service_url=activity.service_url,
81 activity_id=activity.id,
82 channel_id=activity.channel_id,
83 conversation=ConversationAccount(
84 id=activity.conversation.id,
85 name=activity.conversation.name,
86 conversation_type=activity.conversation.conversation_type,
87 aad_object_id=activity.conversation.aad_object_id,
88 is_group=activity.conversation.is_group,
89 role=activity.conversation.role,
90 tenant_id=activity.conversation.tenant_id,
91 properties=activity.conversation.properties,
92 ),
93 bot=None,
94 )
95 activity.conversation.id = conversation_id
96 activity.service_url = service_url
97
98 headers_dict = {
99 "Content-type": "application/json; charset=utf-8",
100 }
101 if token:
102 headers_dict.update(
103 {"Authorization": f"Bearer {token}",}
104 )
105
106 json_content = json.dumps(activity.serialize())
107 resp = await self._session.post(
108 to_url, data=json_content.encode("utf-8"), headers=headers_dict,
109 )
110 resp.raise_for_status()
111 data = (await resp.read()).decode()
112 content = json.loads(data) if data else None
113
114 return InvokeResponse(status=resp.status, body=content)
115
116 finally:
117 # Restore activity properties.
118 activity.conversation.id = original_conversation_id
119 activity.service_url = original_service_url
120 activity.relates_to = original_relates_to
121
122 async def post_buffered_activity(
123 self,
124 from_bot_id: str,
125 to_bot_id: str,
126 to_url: str,
127 service_url: str,
128 conversation_id: str,
129 activity: Activity,
130 ) -> [Activity]:
131 """
132 Helper method to return a list of activities when an Activity is being
133 sent with DeliveryMode == expectReplies.
134 """
135 response = await self.post_activity(
136 from_bot_id, to_bot_id, to_url, service_url, conversation_id, activity
137 )
138 if not response or (response.status / 100) != 2:
139 return []
140 return ExpectedReplies().deserialize(response.body).activities
141
142 async def _get_app_credentials(
143 self, app_id: str, oauth_scope: str
144 ) -> AppCredentials:
145 if not app_id:
146 return MicrosoftAppCredentials.empty()
147
148 # in the cache?
149 cache_key = f"{app_id}{oauth_scope}"
150 app_credentials = BotFrameworkHttpClient._APP_CREDENTIALS_CACHE.get(cache_key)
151 if app_credentials:
152 return app_credentials
153
154 # create a new AppCredentials
155 app_password = await self._credential_provider.get_app_password(app_id)
156
157 app_credentials = (
158 MicrosoftGovernmentAppCredentials(app_id, app_password, scope=oauth_scope)
159 if self._credential_provider and self._channel_provider.is_government()
160 else MicrosoftAppCredentials(app_id, app_password, oauth_scope=oauth_scope)
161 )
162
163 # put it in the cache
164 BotFrameworkHttpClient._APP_CREDENTIALS_CACHE[cache_key] = app_credentials
165
166 return app_credentials
167
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/libraries/botbuilder-integration-aiohttp/botbuilder/integration/aiohttp/bot_framework_http_client.py b/libraries/botbuilder-integration-aiohttp/botbuilder/integration/aiohttp/bot_framework_http_client.py
--- a/libraries/botbuilder-integration-aiohttp/botbuilder/integration/aiohttp/bot_framework_http_client.py
+++ b/libraries/botbuilder-integration-aiohttp/botbuilder/integration/aiohttp/bot_framework_http_client.py
@@ -14,6 +14,7 @@
ExpectedReplies,
ConversationReference,
ConversationAccount,
+ ChannelAccount,
)
from botframework.connector.auth import (
ChannelProvider,
@@ -74,6 +75,7 @@
original_conversation_id = activity.conversation.id
original_service_url = activity.service_url
original_relates_to = activity.relates_to
+ original_recipient = activity.recipient
try:
activity.relates_to = ConversationReference(
@@ -94,30 +96,38 @@
)
activity.conversation.id = conversation_id
activity.service_url = service_url
+ if not activity.recipient:
+ activity.recipient = ChannelAccount()
- headers_dict = {
- "Content-type": "application/json; charset=utf-8",
- }
- if token:
- headers_dict.update(
- {"Authorization": f"Bearer {token}",}
- )
-
- json_content = json.dumps(activity.serialize())
- resp = await self._session.post(
- to_url, data=json_content.encode("utf-8"), headers=headers_dict,
- )
- resp.raise_for_status()
- data = (await resp.read()).decode()
- content = json.loads(data) if data else None
+ status, content = await self._post_content(to_url, token, activity)
- return InvokeResponse(status=resp.status, body=content)
+ return InvokeResponse(status=status, body=content)
finally:
# Restore activity properties.
activity.conversation.id = original_conversation_id
activity.service_url = original_service_url
activity.relates_to = original_relates_to
+ activity.recipient = original_recipient
+
+ async def _post_content(
+ self, to_url: str, token: str, activity: Activity
+ ) -> (int, object):
+ headers_dict = {
+ "Content-type": "application/json; charset=utf-8",
+ }
+ if token:
+ headers_dict.update(
+ {"Authorization": f"Bearer {token}",}
+ )
+
+ json_content = json.dumps(activity.serialize())
+ resp = await self._session.post(
+ to_url, data=json_content.encode("utf-8"), headers=headers_dict,
+ )
+ resp.raise_for_status()
+ data = (await resp.read()).decode()
+ return resp.status, json.loads(data) if data else None
async def post_buffered_activity(
self,
|
{"golden_diff": "diff --git a/libraries/botbuilder-integration-aiohttp/botbuilder/integration/aiohttp/bot_framework_http_client.py b/libraries/botbuilder-integration-aiohttp/botbuilder/integration/aiohttp/bot_framework_http_client.py\n--- a/libraries/botbuilder-integration-aiohttp/botbuilder/integration/aiohttp/bot_framework_http_client.py\n+++ b/libraries/botbuilder-integration-aiohttp/botbuilder/integration/aiohttp/bot_framework_http_client.py\n@@ -14,6 +14,7 @@\n ExpectedReplies,\n ConversationReference,\n ConversationAccount,\n+ ChannelAccount,\n )\n from botframework.connector.auth import (\n ChannelProvider,\n@@ -74,6 +75,7 @@\n original_conversation_id = activity.conversation.id\n original_service_url = activity.service_url\n original_relates_to = activity.relates_to\n+ original_recipient = activity.recipient\n \n try:\n activity.relates_to = ConversationReference(\n@@ -94,30 +96,38 @@\n )\n activity.conversation.id = conversation_id\n activity.service_url = service_url\n+ if not activity.recipient:\n+ activity.recipient = ChannelAccount()\n \n- headers_dict = {\n- \"Content-type\": \"application/json; charset=utf-8\",\n- }\n- if token:\n- headers_dict.update(\n- {\"Authorization\": f\"Bearer {token}\",}\n- )\n-\n- json_content = json.dumps(activity.serialize())\n- resp = await self._session.post(\n- to_url, data=json_content.encode(\"utf-8\"), headers=headers_dict,\n- )\n- resp.raise_for_status()\n- data = (await resp.read()).decode()\n- content = json.loads(data) if data else None\n+ status, content = await self._post_content(to_url, token, activity)\n \n- return InvokeResponse(status=resp.status, body=content)\n+ return InvokeResponse(status=status, body=content)\n \n finally:\n # Restore activity properties.\n activity.conversation.id = original_conversation_id\n activity.service_url = original_service_url\n activity.relates_to = original_relates_to\n+ activity.recipient = original_recipient\n+\n+ async def _post_content(\n+ self, to_url: str, token: str, activity: Activity\n+ ) -> (int, object):\n+ headers_dict = {\n+ \"Content-type\": \"application/json; charset=utf-8\",\n+ }\n+ if token:\n+ headers_dict.update(\n+ {\"Authorization\": f\"Bearer {token}\",}\n+ )\n+\n+ json_content = json.dumps(activity.serialize())\n+ resp = await self._session.post(\n+ to_url, data=json_content.encode(\"utf-8\"), headers=headers_dict,\n+ )\n+ resp.raise_for_status()\n+ data = (await resp.read()).decode()\n+ return resp.status, json.loads(data) if data else None\n \n async def post_buffered_activity(\n self,\n", "issue": "Skill consumers should not be able to send Activities to skills without a recipient (Python)\nSee [parent](https://github.com/microsoft/botframework-sdk/issues/5785).\r\n\r\nIssue may be specific to dotnet, need to verify if this is the case.\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n# pylint: disable=no-member\n\nimport json\nfrom typing import Dict\nfrom logging import Logger\n\nimport aiohttp\nfrom botbuilder.core import InvokeResponse\nfrom botbuilder.core.skills import BotFrameworkClient\nfrom botbuilder.schema import (\n Activity,\n ExpectedReplies,\n ConversationReference,\n ConversationAccount,\n)\nfrom botframework.connector.auth import (\n ChannelProvider,\n CredentialProvider,\n MicrosoftAppCredentials,\n AppCredentials,\n MicrosoftGovernmentAppCredentials,\n)\n\n\nclass BotFrameworkHttpClient(BotFrameworkClient):\n\n \"\"\"\n A skill host adapter implements API to forward activity to a skill and\n implements routing ChannelAPI calls from the Skill up through the bot/adapter.\n \"\"\"\n\n INVOKE_ACTIVITY_NAME = \"SkillEvents.ChannelApiInvoke\"\n _BOT_IDENTITY_KEY = \"BotIdentity\"\n _APP_CREDENTIALS_CACHE: Dict[str, MicrosoftAppCredentials] = {}\n\n def __init__(\n self,\n credential_provider: CredentialProvider,\n channel_provider: ChannelProvider = None,\n logger: Logger = None,\n ):\n if not credential_provider:\n raise TypeError(\"credential_provider can't be None\")\n\n self._credential_provider = credential_provider\n self._channel_provider = channel_provider\n self._logger = logger\n self._session = aiohttp.ClientSession()\n\n async def post_activity(\n self,\n from_bot_id: str,\n to_bot_id: str,\n to_url: str,\n service_url: str,\n conversation_id: str,\n activity: Activity,\n ) -> InvokeResponse:\n app_credentials = await self._get_app_credentials(from_bot_id, to_bot_id)\n\n if not app_credentials:\n raise KeyError(\"Unable to get appCredentials to connect to the skill\")\n\n # Get token for the skill call\n token = (\n app_credentials.get_access_token()\n if app_credentials.microsoft_app_id\n else None\n )\n\n # Capture current activity settings before changing them.\n original_conversation_id = activity.conversation.id\n original_service_url = activity.service_url\n original_relates_to = activity.relates_to\n\n try:\n activity.relates_to = ConversationReference(\n service_url=activity.service_url,\n activity_id=activity.id,\n channel_id=activity.channel_id,\n conversation=ConversationAccount(\n id=activity.conversation.id,\n name=activity.conversation.name,\n conversation_type=activity.conversation.conversation_type,\n aad_object_id=activity.conversation.aad_object_id,\n is_group=activity.conversation.is_group,\n role=activity.conversation.role,\n tenant_id=activity.conversation.tenant_id,\n properties=activity.conversation.properties,\n ),\n bot=None,\n )\n activity.conversation.id = conversation_id\n activity.service_url = service_url\n\n headers_dict = {\n \"Content-type\": \"application/json; charset=utf-8\",\n }\n if token:\n headers_dict.update(\n {\"Authorization\": f\"Bearer {token}\",}\n )\n\n json_content = json.dumps(activity.serialize())\n resp = await self._session.post(\n to_url, data=json_content.encode(\"utf-8\"), headers=headers_dict,\n )\n resp.raise_for_status()\n data = (await resp.read()).decode()\n content = json.loads(data) if data else None\n\n return InvokeResponse(status=resp.status, body=content)\n\n finally:\n # Restore activity properties.\n activity.conversation.id = original_conversation_id\n activity.service_url = original_service_url\n activity.relates_to = original_relates_to\n\n async def post_buffered_activity(\n self,\n from_bot_id: str,\n to_bot_id: str,\n to_url: str,\n service_url: str,\n conversation_id: str,\n activity: Activity,\n ) -> [Activity]:\n \"\"\"\n Helper method to return a list of activities when an Activity is being\n sent with DeliveryMode == expectReplies.\n \"\"\"\n response = await self.post_activity(\n from_bot_id, to_bot_id, to_url, service_url, conversation_id, activity\n )\n if not response or (response.status / 100) != 2:\n return []\n return ExpectedReplies().deserialize(response.body).activities\n\n async def _get_app_credentials(\n self, app_id: str, oauth_scope: str\n ) -> AppCredentials:\n if not app_id:\n return MicrosoftAppCredentials.empty()\n\n # in the cache?\n cache_key = f\"{app_id}{oauth_scope}\"\n app_credentials = BotFrameworkHttpClient._APP_CREDENTIALS_CACHE.get(cache_key)\n if app_credentials:\n return app_credentials\n\n # create a new AppCredentials\n app_password = await self._credential_provider.get_app_password(app_id)\n\n app_credentials = (\n MicrosoftGovernmentAppCredentials(app_id, app_password, scope=oauth_scope)\n if self._credential_provider and self._channel_provider.is_government()\n else MicrosoftAppCredentials(app_id, app_password, oauth_scope=oauth_scope)\n )\n\n # put it in the cache\n BotFrameworkHttpClient._APP_CREDENTIALS_CACHE[cache_key] = app_credentials\n\n return app_credentials\n", "path": "libraries/botbuilder-integration-aiohttp/botbuilder/integration/aiohttp/bot_framework_http_client.py"}], "after_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n# pylint: disable=no-member\n\nimport json\nfrom typing import Dict\nfrom logging import Logger\n\nimport aiohttp\nfrom botbuilder.core import InvokeResponse\nfrom botbuilder.core.skills import BotFrameworkClient\nfrom botbuilder.schema import (\n Activity,\n ExpectedReplies,\n ConversationReference,\n ConversationAccount,\n ChannelAccount,\n)\nfrom botframework.connector.auth import (\n ChannelProvider,\n CredentialProvider,\n MicrosoftAppCredentials,\n AppCredentials,\n MicrosoftGovernmentAppCredentials,\n)\n\n\nclass BotFrameworkHttpClient(BotFrameworkClient):\n\n \"\"\"\n A skill host adapter implements API to forward activity to a skill and\n implements routing ChannelAPI calls from the Skill up through the bot/adapter.\n \"\"\"\n\n INVOKE_ACTIVITY_NAME = \"SkillEvents.ChannelApiInvoke\"\n _BOT_IDENTITY_KEY = \"BotIdentity\"\n _APP_CREDENTIALS_CACHE: Dict[str, MicrosoftAppCredentials] = {}\n\n def __init__(\n self,\n credential_provider: CredentialProvider,\n channel_provider: ChannelProvider = None,\n logger: Logger = None,\n ):\n if not credential_provider:\n raise TypeError(\"credential_provider can't be None\")\n\n self._credential_provider = credential_provider\n self._channel_provider = channel_provider\n self._logger = logger\n self._session = aiohttp.ClientSession()\n\n async def post_activity(\n self,\n from_bot_id: str,\n to_bot_id: str,\n to_url: str,\n service_url: str,\n conversation_id: str,\n activity: Activity,\n ) -> InvokeResponse:\n app_credentials = await self._get_app_credentials(from_bot_id, to_bot_id)\n\n if not app_credentials:\n raise KeyError(\"Unable to get appCredentials to connect to the skill\")\n\n # Get token for the skill call\n token = (\n app_credentials.get_access_token()\n if app_credentials.microsoft_app_id\n else None\n )\n\n # Capture current activity settings before changing them.\n original_conversation_id = activity.conversation.id\n original_service_url = activity.service_url\n original_relates_to = activity.relates_to\n original_recipient = activity.recipient\n\n try:\n activity.relates_to = ConversationReference(\n service_url=activity.service_url,\n activity_id=activity.id,\n channel_id=activity.channel_id,\n conversation=ConversationAccount(\n id=activity.conversation.id,\n name=activity.conversation.name,\n conversation_type=activity.conversation.conversation_type,\n aad_object_id=activity.conversation.aad_object_id,\n is_group=activity.conversation.is_group,\n role=activity.conversation.role,\n tenant_id=activity.conversation.tenant_id,\n properties=activity.conversation.properties,\n ),\n bot=None,\n )\n activity.conversation.id = conversation_id\n activity.service_url = service_url\n if not activity.recipient:\n activity.recipient = ChannelAccount()\n\n status, content = await self._post_content(to_url, token, activity)\n\n return InvokeResponse(status=status, body=content)\n\n finally:\n # Restore activity properties.\n activity.conversation.id = original_conversation_id\n activity.service_url = original_service_url\n activity.relates_to = original_relates_to\n activity.recipient = original_recipient\n\n async def _post_content(\n self, to_url: str, token: str, activity: Activity\n ) -> (int, object):\n headers_dict = {\n \"Content-type\": \"application/json; charset=utf-8\",\n }\n if token:\n headers_dict.update(\n {\"Authorization\": f\"Bearer {token}\",}\n )\n\n json_content = json.dumps(activity.serialize())\n resp = await self._session.post(\n to_url, data=json_content.encode(\"utf-8\"), headers=headers_dict,\n )\n resp.raise_for_status()\n data = (await resp.read()).decode()\n return resp.status, json.loads(data) if data else None\n\n async def post_buffered_activity(\n self,\n from_bot_id: str,\n to_bot_id: str,\n to_url: str,\n service_url: str,\n conversation_id: str,\n activity: Activity,\n ) -> [Activity]:\n \"\"\"\n Helper method to return a list of activities when an Activity is being\n sent with DeliveryMode == expectReplies.\n \"\"\"\n response = await self.post_activity(\n from_bot_id, to_bot_id, to_url, service_url, conversation_id, activity\n )\n if not response or (response.status / 100) != 2:\n return []\n return ExpectedReplies().deserialize(response.body).activities\n\n async def _get_app_credentials(\n self, app_id: str, oauth_scope: str\n ) -> AppCredentials:\n if not app_id:\n return MicrosoftAppCredentials.empty()\n\n # in the cache?\n cache_key = f\"{app_id}{oauth_scope}\"\n app_credentials = BotFrameworkHttpClient._APP_CREDENTIALS_CACHE.get(cache_key)\n if app_credentials:\n return app_credentials\n\n # create a new AppCredentials\n app_password = await self._credential_provider.get_app_password(app_id)\n\n app_credentials = (\n MicrosoftGovernmentAppCredentials(app_id, app_password, scope=oauth_scope)\n if self._credential_provider and self._channel_provider.is_government()\n else MicrosoftAppCredentials(app_id, app_password, oauth_scope=oauth_scope)\n )\n\n # put it in the cache\n BotFrameworkHttpClient._APP_CREDENTIALS_CACHE[cache_key] = app_credentials\n\n return app_credentials\n", "path": "libraries/botbuilder-integration-aiohttp/botbuilder/integration/aiohttp/bot_framework_http_client.py"}]}
| 1,846 | 656 |
gh_patches_debug_40283
|
rasdani/github-patches
|
git_diff
|
enthought__chaco-598
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Serializable mixin should be removed
The class is not used by any current code, appears to be broken, and the problem it was meant to solve (selection of which traits to pickle) is better solved via the use of `transient` traits metadata.
Technically this is a backwards-incompatible change, however.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chaco/serializable.py`
Content:
```
1 """ Defines the Serializable mix-in class.
2 """
3
4
5 class Serializable(object):
6 """
7 Mix-in class to help serialization. Serializes just the attributes in
8 **_pickles**.
9
10 This mix-in works best when all the classes in a hierarchy subclass
11 from it. It solves the problem of allowing each class to specify
12 its own set of attributes to pickle and attributes to ignore, without
13 having to also implement __getstate__ and __setstate__.
14 """
15
16 # The basic list of attributes to save. These get set without firing
17 # any trait events.
18 _pickles = None
19
20 # A list of the parents of this class that will be searched for their
21 # list of _pickles. Only the parents in this list that inherit from
22 # Serialized will be pickled. The process stops at the first item in
23 # __pickle_parents that is not a subclass of Serialized.
24 #
25 # This is a double-underscore variable so that Python's attribute name
26 # will shield base class
27 # __pickle_parents = None
28
29 def _get_pickle_parents(self):
30 """
31 Subclasses can override this method to return the list of base
32 classes they want to have the serializer look at.
33 """
34 bases = []
35 for cls in self.__class__.__mro__:
36 if cls is Serializable:
37 # don't add Serializable to the list of parents
38 continue
39 elif issubclass(cls, Serializable):
40 bases.append(cls)
41 else:
42 break
43 return bases
44
45 def _pre_save(self):
46 """
47 Called before __getstate__ to give the object a chance to tidy up
48 and get ready to be saved. This usually also calls the superclass.
49 """
50
51 def _post_load(self):
52 """
53 Called after __setstate__ finishes restoring the state on the object.
54 This method usually needs to include a call to super(cls, self)._post_load().
55 Avoid explicitly calling a parent class by name, because in general
56 you want post_load() to happen in the same order as MRO, which super()
57 does automatically.
58 """
59 print("Serializable._post_load")
60 pass
61
62 def _do_setstate(self, state):
63 """
64 Called by __setstate__ to allow the subclass to set its state in a
65 special way.
66
67 Subclasses should override this instead of Serializable.__setstate__
68 because we need Serializable's implementation to call _post_load() after
69 all the _do_setstate() have returned.)
70 """
71 # Quietly set all the attributes
72 self.trait_setq(**state)
73
74 # ------------------------------------------------------------------------
75 # Private methods
76 # ------------------------------------------------------------------------
77
78
79 # def __getstate__(self):
80 # #idstring = self.__class__.__name__ + " id=" + str(id(self))
81 # # Give the object a chance to tidy up before saving
82 # self._pre_save()
83 #
84 # # Get the attributes that this class needs to serialize. We do this by
85 # # marching up the list of parent classes in _pickle_parents and getting
86 # # their lists of _pickles.
87 # all_pickles = Set()
88 # pickle_parents = self._get_pickle_parents()
89 # for parent_class in pickle_parents:
90 # all_pickles.update(parent_class._pickles)
91 #
92 # if self._pickles is not None:
93 # all_pickles.update(self._pickles)
94 #
95 # state = {}
96 # for attrib in all_pickles:
97 # state[attrib] = getattr(self, attrib)
98 #
99 # print('<<<<<<<<<<<<<', self)
100 # for key,value in state.items():
101 # print(key, type(value))
102 # print '>>>>>>>>>>>>>'
103 #
104 # return state
105
106 # ~ def __setstate__(self, state):
107 # ~ idstring = self.__class__.__name__ + " id=" + str(id(self))
108 # ~ self._do_setstate(state)
109 # ~ self._post_load()
110 # ~ return
111
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chaco/serializable.py b/chaco/serializable.py
deleted file mode 100644
--- a/chaco/serializable.py
+++ /dev/null
@@ -1,110 +0,0 @@
-""" Defines the Serializable mix-in class.
-"""
-
-
-class Serializable(object):
- """
- Mix-in class to help serialization. Serializes just the attributes in
- **_pickles**.
-
- This mix-in works best when all the classes in a hierarchy subclass
- from it. It solves the problem of allowing each class to specify
- its own set of attributes to pickle and attributes to ignore, without
- having to also implement __getstate__ and __setstate__.
- """
-
- # The basic list of attributes to save. These get set without firing
- # any trait events.
- _pickles = None
-
- # A list of the parents of this class that will be searched for their
- # list of _pickles. Only the parents in this list that inherit from
- # Serialized will be pickled. The process stops at the first item in
- # __pickle_parents that is not a subclass of Serialized.
- #
- # This is a double-underscore variable so that Python's attribute name
- # will shield base class
- # __pickle_parents = None
-
- def _get_pickle_parents(self):
- """
- Subclasses can override this method to return the list of base
- classes they want to have the serializer look at.
- """
- bases = []
- for cls in self.__class__.__mro__:
- if cls is Serializable:
- # don't add Serializable to the list of parents
- continue
- elif issubclass(cls, Serializable):
- bases.append(cls)
- else:
- break
- return bases
-
- def _pre_save(self):
- """
- Called before __getstate__ to give the object a chance to tidy up
- and get ready to be saved. This usually also calls the superclass.
- """
-
- def _post_load(self):
- """
- Called after __setstate__ finishes restoring the state on the object.
- This method usually needs to include a call to super(cls, self)._post_load().
- Avoid explicitly calling a parent class by name, because in general
- you want post_load() to happen in the same order as MRO, which super()
- does automatically.
- """
- print("Serializable._post_load")
- pass
-
- def _do_setstate(self, state):
- """
- Called by __setstate__ to allow the subclass to set its state in a
- special way.
-
- Subclasses should override this instead of Serializable.__setstate__
- because we need Serializable's implementation to call _post_load() after
- all the _do_setstate() have returned.)
- """
- # Quietly set all the attributes
- self.trait_setq(**state)
-
- # ------------------------------------------------------------------------
- # Private methods
- # ------------------------------------------------------------------------
-
-
-# def __getstate__(self):
-# #idstring = self.__class__.__name__ + " id=" + str(id(self))
-# # Give the object a chance to tidy up before saving
-# self._pre_save()
-#
-# # Get the attributes that this class needs to serialize. We do this by
-# # marching up the list of parent classes in _pickle_parents and getting
-# # their lists of _pickles.
-# all_pickles = Set()
-# pickle_parents = self._get_pickle_parents()
-# for parent_class in pickle_parents:
-# all_pickles.update(parent_class._pickles)
-#
-# if self._pickles is not None:
-# all_pickles.update(self._pickles)
-#
-# state = {}
-# for attrib in all_pickles:
-# state[attrib] = getattr(self, attrib)
-#
-# print('<<<<<<<<<<<<<', self)
-# for key,value in state.items():
-# print(key, type(value))
-# print '>>>>>>>>>>>>>'
-#
-# return state
-
-# ~ def __setstate__(self, state):
-# ~ idstring = self.__class__.__name__ + " id=" + str(id(self))
-# ~ self._do_setstate(state)
-# ~ self._post_load()
-# ~ return
|
{"golden_diff": "diff --git a/chaco/serializable.py b/chaco/serializable.py\ndeleted file mode 100644\n--- a/chaco/serializable.py\n+++ /dev/null\n@@ -1,110 +0,0 @@\n-\"\"\" Defines the Serializable mix-in class.\n-\"\"\"\n-\n-\n-class Serializable(object):\n- \"\"\"\n- Mix-in class to help serialization. Serializes just the attributes in\n- **_pickles**.\n-\n- This mix-in works best when all the classes in a hierarchy subclass\n- from it. It solves the problem of allowing each class to specify\n- its own set of attributes to pickle and attributes to ignore, without\n- having to also implement __getstate__ and __setstate__.\n- \"\"\"\n-\n- # The basic list of attributes to save. These get set without firing\n- # any trait events.\n- _pickles = None\n-\n- # A list of the parents of this class that will be searched for their\n- # list of _pickles. Only the parents in this list that inherit from\n- # Serialized will be pickled. The process stops at the first item in\n- # __pickle_parents that is not a subclass of Serialized.\n- #\n- # This is a double-underscore variable so that Python's attribute name\n- # will shield base class\n- # __pickle_parents = None\n-\n- def _get_pickle_parents(self):\n- \"\"\"\n- Subclasses can override this method to return the list of base\n- classes they want to have the serializer look at.\n- \"\"\"\n- bases = []\n- for cls in self.__class__.__mro__:\n- if cls is Serializable:\n- # don't add Serializable to the list of parents\n- continue\n- elif issubclass(cls, Serializable):\n- bases.append(cls)\n- else:\n- break\n- return bases\n-\n- def _pre_save(self):\n- \"\"\"\n- Called before __getstate__ to give the object a chance to tidy up\n- and get ready to be saved. This usually also calls the superclass.\n- \"\"\"\n-\n- def _post_load(self):\n- \"\"\"\n- Called after __setstate__ finishes restoring the state on the object.\n- This method usually needs to include a call to super(cls, self)._post_load().\n- Avoid explicitly calling a parent class by name, because in general\n- you want post_load() to happen in the same order as MRO, which super()\n- does automatically.\n- \"\"\"\n- print(\"Serializable._post_load\")\n- pass\n-\n- def _do_setstate(self, state):\n- \"\"\"\n- Called by __setstate__ to allow the subclass to set its state in a\n- special way.\n-\n- Subclasses should override this instead of Serializable.__setstate__\n- because we need Serializable's implementation to call _post_load() after\n- all the _do_setstate() have returned.)\n- \"\"\"\n- # Quietly set all the attributes\n- self.trait_setq(**state)\n-\n- # ------------------------------------------------------------------------\n- # Private methods\n- # ------------------------------------------------------------------------\n-\n-\n-# def __getstate__(self):\n-# #idstring = self.__class__.__name__ + \" id=\" + str(id(self))\n-# # Give the object a chance to tidy up before saving\n-# self._pre_save()\n-#\n-# # Get the attributes that this class needs to serialize. We do this by\n-# # marching up the list of parent classes in _pickle_parents and getting\n-# # their lists of _pickles.\n-# all_pickles = Set()\n-# pickle_parents = self._get_pickle_parents()\n-# for parent_class in pickle_parents:\n-# all_pickles.update(parent_class._pickles)\n-#\n-# if self._pickles is not None:\n-# all_pickles.update(self._pickles)\n-#\n-# state = {}\n-# for attrib in all_pickles:\n-# state[attrib] = getattr(self, attrib)\n-#\n-# print('<<<<<<<<<<<<<', self)\n-# for key,value in state.items():\n-# print(key, type(value))\n-# print '>>>>>>>>>>>>>'\n-#\n-# return state\n-\n-# ~ def __setstate__(self, state):\n-# ~ idstring = self.__class__.__name__ + \" id=\" + str(id(self))\n-# ~ self._do_setstate(state)\n-# ~ self._post_load()\n-# ~ return\n", "issue": "Serializable mixin should be removed\nThe class is not used by any current code, appears to be broken, and the problem it was meant to solve (selection of which traits to pickle) is better solved via the use of `transient` traits metadata.\n\nTechnically this is a backwards-incompatible change, however.\n\n", "before_files": [{"content": "\"\"\" Defines the Serializable mix-in class.\n\"\"\"\n\n\nclass Serializable(object):\n \"\"\"\n Mix-in class to help serialization. Serializes just the attributes in\n **_pickles**.\n\n This mix-in works best when all the classes in a hierarchy subclass\n from it. It solves the problem of allowing each class to specify\n its own set of attributes to pickle and attributes to ignore, without\n having to also implement __getstate__ and __setstate__.\n \"\"\"\n\n # The basic list of attributes to save. These get set without firing\n # any trait events.\n _pickles = None\n\n # A list of the parents of this class that will be searched for their\n # list of _pickles. Only the parents in this list that inherit from\n # Serialized will be pickled. The process stops at the first item in\n # __pickle_parents that is not a subclass of Serialized.\n #\n # This is a double-underscore variable so that Python's attribute name\n # will shield base class\n # __pickle_parents = None\n\n def _get_pickle_parents(self):\n \"\"\"\n Subclasses can override this method to return the list of base\n classes they want to have the serializer look at.\n \"\"\"\n bases = []\n for cls in self.__class__.__mro__:\n if cls is Serializable:\n # don't add Serializable to the list of parents\n continue\n elif issubclass(cls, Serializable):\n bases.append(cls)\n else:\n break\n return bases\n\n def _pre_save(self):\n \"\"\"\n Called before __getstate__ to give the object a chance to tidy up\n and get ready to be saved. This usually also calls the superclass.\n \"\"\"\n\n def _post_load(self):\n \"\"\"\n Called after __setstate__ finishes restoring the state on the object.\n This method usually needs to include a call to super(cls, self)._post_load().\n Avoid explicitly calling a parent class by name, because in general\n you want post_load() to happen in the same order as MRO, which super()\n does automatically.\n \"\"\"\n print(\"Serializable._post_load\")\n pass\n\n def _do_setstate(self, state):\n \"\"\"\n Called by __setstate__ to allow the subclass to set its state in a\n special way.\n\n Subclasses should override this instead of Serializable.__setstate__\n because we need Serializable's implementation to call _post_load() after\n all the _do_setstate() have returned.)\n \"\"\"\n # Quietly set all the attributes\n self.trait_setq(**state)\n\n # ------------------------------------------------------------------------\n # Private methods\n # ------------------------------------------------------------------------\n\n\n# def __getstate__(self):\n# #idstring = self.__class__.__name__ + \" id=\" + str(id(self))\n# # Give the object a chance to tidy up before saving\n# self._pre_save()\n#\n# # Get the attributes that this class needs to serialize. We do this by\n# # marching up the list of parent classes in _pickle_parents and getting\n# # their lists of _pickles.\n# all_pickles = Set()\n# pickle_parents = self._get_pickle_parents()\n# for parent_class in pickle_parents:\n# all_pickles.update(parent_class._pickles)\n#\n# if self._pickles is not None:\n# all_pickles.update(self._pickles)\n#\n# state = {}\n# for attrib in all_pickles:\n# state[attrib] = getattr(self, attrib)\n#\n# print('<<<<<<<<<<<<<', self)\n# for key,value in state.items():\n# print(key, type(value))\n# print '>>>>>>>>>>>>>'\n#\n# return state\n\n# ~ def __setstate__(self, state):\n# ~ idstring = self.__class__.__name__ + \" id=\" + str(id(self))\n# ~ self._do_setstate(state)\n# ~ self._post_load()\n# ~ return\n", "path": "chaco/serializable.py"}], "after_files": [{"content": null, "path": "chaco/serializable.py"}]}
| 1,411 | 1,013 |
gh_patches_debug_21876
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-4663
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SCRAPY_CHECK is not set while running contract
### Description
Hi, it seems that #3739 is not doing what the [documentation describe](https://docs.scrapy.org/en/latest/topics/contracts.html#detecting-check-runs):
`os.environ.get('SCRAPY_CHECK')` is returning `None` in my contract check.
### Steps to Reproduce
1. Create a project from scratch
2. Add a random spider
3. Contract code is as follow
```
def parse(self, response):
"""
@url http://www.amazon.com/s?field-keywords=selfish+gene
@returns requests 1 1
"""
print("test", os.environ.get('SCRAPY_CHECK'))
if os.environ.get('SCRAPY_CHECK'):
yield scrapy.Request(url="next_url")
```
**Expected behavior:** Request should be yielded as per the documentation
**Actual behavior:** Nothing happen
**Reproduces how often:** In my local project and with fresh project
### Versions
Windows
```
(globenv) C:\Users\johnl>scrapy version --verbose
Scrapy : 1.8.0
lxml : 4.4.1.0
libxml2 : 2.9.5
cssselect : 1.1.0
parsel : 1.5.2
w3lib : 1.21.0
Twisted : 19.10.0
Python : 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 19:29:22) [MSC v.1916 32 bit (Intel)]
pyOpenSSL : 19.0.0 (OpenSSL 1.1.1c 28 May 2019)
cryptography : 2.7
Platform : Windows-10-10.0.18362-SP0
```
Linux
```
scrapy version --verbose
Scrapy : 1.8.0
lxml : 4.4.1.0
libxml2 : 2.9.9
cssselect : 1.1.0
parsel : 1.5.2
w3lib : 1.21.0
Twisted : 19.7.0
Python : 3.6.8 (default, Oct 7 2019, 12:59:55) - [GCC 8.3.0]
pyOpenSSL : 19.0.0 (OpenSSL 1.1.1d 10 Sep 2019)
cryptography : 2.8
Platform : Linux-4.4.0-18362-Microsoft-x86_64-with-Ubuntu-18.04-bionic
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scrapy/commands/check.py`
Content:
```
1 import time
2 from collections import defaultdict
3 from unittest import TextTestRunner, TextTestResult as _TextTestResult
4
5 from scrapy.commands import ScrapyCommand
6 from scrapy.contracts import ContractsManager
7 from scrapy.utils.misc import load_object, set_environ
8 from scrapy.utils.conf import build_component_list
9
10
11 class TextTestResult(_TextTestResult):
12 def printSummary(self, start, stop):
13 write = self.stream.write
14 writeln = self.stream.writeln
15
16 run = self.testsRun
17 plural = "s" if run != 1 else ""
18
19 writeln(self.separator2)
20 writeln("Ran %d contract%s in %.3fs" % (run, plural, stop - start))
21 writeln()
22
23 infos = []
24 if not self.wasSuccessful():
25 write("FAILED")
26 failed, errored = map(len, (self.failures, self.errors))
27 if failed:
28 infos.append("failures=%d" % failed)
29 if errored:
30 infos.append("errors=%d" % errored)
31 else:
32 write("OK")
33
34 if infos:
35 writeln(" (%s)" % (", ".join(infos),))
36 else:
37 write("\n")
38
39
40 class Command(ScrapyCommand):
41 requires_project = True
42 default_settings = {'LOG_ENABLED': False}
43
44 def syntax(self):
45 return "[options] <spider>"
46
47 def short_desc(self):
48 return "Check spider contracts"
49
50 def add_options(self, parser):
51 ScrapyCommand.add_options(self, parser)
52 parser.add_option("-l", "--list", dest="list", action="store_true",
53 help="only list contracts, without checking them")
54 parser.add_option("-v", "--verbose", dest="verbose", default=False, action='store_true',
55 help="print contract tests for all spiders")
56
57 def run(self, args, opts):
58 # load contracts
59 contracts = build_component_list(self.settings.getwithbase('SPIDER_CONTRACTS'))
60 conman = ContractsManager(load_object(c) for c in contracts)
61 runner = TextTestRunner(verbosity=2 if opts.verbose else 1)
62 result = TextTestResult(runner.stream, runner.descriptions, runner.verbosity)
63
64 # contract requests
65 contract_reqs = defaultdict(list)
66
67 spider_loader = self.crawler_process.spider_loader
68
69 with set_environ(SCRAPY_CHECK='true'):
70 for spidername in args or spider_loader.list():
71 spidercls = spider_loader.load(spidername)
72 spidercls.start_requests = lambda s: conman.from_spider(s, result)
73
74 tested_methods = conman.tested_methods_from_spidercls(spidercls)
75 if opts.list:
76 for method in tested_methods:
77 contract_reqs[spidercls.name].append(method)
78 elif tested_methods:
79 self.crawler_process.crawl(spidercls)
80
81 # start checks
82 if opts.list:
83 for spider, methods in sorted(contract_reqs.items()):
84 if not methods and not opts.verbose:
85 continue
86 print(spider)
87 for method in sorted(methods):
88 print(' * %s' % method)
89 else:
90 start = time.time()
91 self.crawler_process.start()
92 stop = time.time()
93
94 result.printErrors()
95 result.printSummary(start, stop)
96 self.exitcode = int(not result.wasSuccessful())
97
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scrapy/commands/check.py b/scrapy/commands/check.py
--- a/scrapy/commands/check.py
+++ b/scrapy/commands/check.py
@@ -78,19 +78,19 @@
elif tested_methods:
self.crawler_process.crawl(spidercls)
- # start checks
- if opts.list:
- for spider, methods in sorted(contract_reqs.items()):
- if not methods and not opts.verbose:
- continue
- print(spider)
- for method in sorted(methods):
- print(' * %s' % method)
- else:
- start = time.time()
- self.crawler_process.start()
- stop = time.time()
-
- result.printErrors()
- result.printSummary(start, stop)
- self.exitcode = int(not result.wasSuccessful())
+ # start checks
+ if opts.list:
+ for spider, methods in sorted(contract_reqs.items()):
+ if not methods and not opts.verbose:
+ continue
+ print(spider)
+ for method in sorted(methods):
+ print(' * %s' % method)
+ else:
+ start = time.time()
+ self.crawler_process.start()
+ stop = time.time()
+
+ result.printErrors()
+ result.printSummary(start, stop)
+ self.exitcode = int(not result.wasSuccessful())
|
{"golden_diff": "diff --git a/scrapy/commands/check.py b/scrapy/commands/check.py\n--- a/scrapy/commands/check.py\n+++ b/scrapy/commands/check.py\n@@ -78,19 +78,19 @@\n elif tested_methods:\n self.crawler_process.crawl(spidercls)\n \n- # start checks\n- if opts.list:\n- for spider, methods in sorted(contract_reqs.items()):\n- if not methods and not opts.verbose:\n- continue\n- print(spider)\n- for method in sorted(methods):\n- print(' * %s' % method)\n- else:\n- start = time.time()\n- self.crawler_process.start()\n- stop = time.time()\n-\n- result.printErrors()\n- result.printSummary(start, stop)\n- self.exitcode = int(not result.wasSuccessful())\n+ # start checks\n+ if opts.list:\n+ for spider, methods in sorted(contract_reqs.items()):\n+ if not methods and not opts.verbose:\n+ continue\n+ print(spider)\n+ for method in sorted(methods):\n+ print(' * %s' % method)\n+ else:\n+ start = time.time()\n+ self.crawler_process.start()\n+ stop = time.time()\n+\n+ result.printErrors()\n+ result.printSummary(start, stop)\n+ self.exitcode = int(not result.wasSuccessful())\n", "issue": "SCRAPY_CHECK is not set while running contract\n### Description\r\n\r\nHi, it seems that #3739 is not doing what the [documentation describe](https://docs.scrapy.org/en/latest/topics/contracts.html#detecting-check-runs):\r\n\r\n`os.environ.get('SCRAPY_CHECK')` is returning `None` in my contract check.\r\n\r\n### Steps to Reproduce\r\n\r\n1. Create a project from scratch\r\n2. Add a random spider\r\n3. Contract code is as follow\r\n```\r\n def parse(self, response):\r\n \"\"\"\r\n @url http://www.amazon.com/s?field-keywords=selfish+gene\r\n @returns requests 1 1\r\n \"\"\"\r\n print(\"test\", os.environ.get('SCRAPY_CHECK'))\r\n if os.environ.get('SCRAPY_CHECK'):\r\n yield scrapy.Request(url=\"next_url\")\r\n```\r\n\r\n**Expected behavior:** Request should be yielded as per the documentation\r\n\r\n**Actual behavior:** Nothing happen\r\n\r\n**Reproduces how often:** In my local project and with fresh project\r\n\r\n### Versions\r\n\r\nWindows\r\n```\r\n(globenv) C:\\Users\\johnl>scrapy version --verbose\r\nScrapy : 1.8.0\r\nlxml : 4.4.1.0\r\nlibxml2 : 2.9.5\r\ncssselect : 1.1.0\r\nparsel : 1.5.2\r\nw3lib : 1.21.0\r\nTwisted : 19.10.0\r\nPython : 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 19:29:22) [MSC v.1916 32 bit (Intel)]\r\npyOpenSSL : 19.0.0 (OpenSSL 1.1.1c 28 May 2019)\r\ncryptography : 2.7\r\nPlatform : Windows-10-10.0.18362-SP0\r\n```\r\n\r\nLinux\r\n```\r\nscrapy version --verbose\r\nScrapy : 1.8.0\r\nlxml : 4.4.1.0\r\nlibxml2 : 2.9.9\r\ncssselect : 1.1.0\r\nparsel : 1.5.2\r\nw3lib : 1.21.0\r\nTwisted : 19.7.0\r\nPython : 3.6.8 (default, Oct 7 2019, 12:59:55) - [GCC 8.3.0]\r\npyOpenSSL : 19.0.0 (OpenSSL 1.1.1d 10 Sep 2019)\r\ncryptography : 2.8\r\nPlatform : Linux-4.4.0-18362-Microsoft-x86_64-with-Ubuntu-18.04-bionic\r\n```\r\n\n", "before_files": [{"content": "import time\nfrom collections import defaultdict\nfrom unittest import TextTestRunner, TextTestResult as _TextTestResult\n\nfrom scrapy.commands import ScrapyCommand\nfrom scrapy.contracts import ContractsManager\nfrom scrapy.utils.misc import load_object, set_environ\nfrom scrapy.utils.conf import build_component_list\n\n\nclass TextTestResult(_TextTestResult):\n def printSummary(self, start, stop):\n write = self.stream.write\n writeln = self.stream.writeln\n\n run = self.testsRun\n plural = \"s\" if run != 1 else \"\"\n\n writeln(self.separator2)\n writeln(\"Ran %d contract%s in %.3fs\" % (run, plural, stop - start))\n writeln()\n\n infos = []\n if not self.wasSuccessful():\n write(\"FAILED\")\n failed, errored = map(len, (self.failures, self.errors))\n if failed:\n infos.append(\"failures=%d\" % failed)\n if errored:\n infos.append(\"errors=%d\" % errored)\n else:\n write(\"OK\")\n\n if infos:\n writeln(\" (%s)\" % (\", \".join(infos),))\n else:\n write(\"\\n\")\n\n\nclass Command(ScrapyCommand):\n requires_project = True\n default_settings = {'LOG_ENABLED': False}\n\n def syntax(self):\n return \"[options] <spider>\"\n\n def short_desc(self):\n return \"Check spider contracts\"\n\n def add_options(self, parser):\n ScrapyCommand.add_options(self, parser)\n parser.add_option(\"-l\", \"--list\", dest=\"list\", action=\"store_true\",\n help=\"only list contracts, without checking them\")\n parser.add_option(\"-v\", \"--verbose\", dest=\"verbose\", default=False, action='store_true',\n help=\"print contract tests for all spiders\")\n\n def run(self, args, opts):\n # load contracts\n contracts = build_component_list(self.settings.getwithbase('SPIDER_CONTRACTS'))\n conman = ContractsManager(load_object(c) for c in contracts)\n runner = TextTestRunner(verbosity=2 if opts.verbose else 1)\n result = TextTestResult(runner.stream, runner.descriptions, runner.verbosity)\n\n # contract requests\n contract_reqs = defaultdict(list)\n\n spider_loader = self.crawler_process.spider_loader\n\n with set_environ(SCRAPY_CHECK='true'):\n for spidername in args or spider_loader.list():\n spidercls = spider_loader.load(spidername)\n spidercls.start_requests = lambda s: conman.from_spider(s, result)\n\n tested_methods = conman.tested_methods_from_spidercls(spidercls)\n if opts.list:\n for method in tested_methods:\n contract_reqs[spidercls.name].append(method)\n elif tested_methods:\n self.crawler_process.crawl(spidercls)\n\n # start checks\n if opts.list:\n for spider, methods in sorted(contract_reqs.items()):\n if not methods and not opts.verbose:\n continue\n print(spider)\n for method in sorted(methods):\n print(' * %s' % method)\n else:\n start = time.time()\n self.crawler_process.start()\n stop = time.time()\n\n result.printErrors()\n result.printSummary(start, stop)\n self.exitcode = int(not result.wasSuccessful())\n", "path": "scrapy/commands/check.py"}], "after_files": [{"content": "import time\nfrom collections import defaultdict\nfrom unittest import TextTestRunner, TextTestResult as _TextTestResult\n\nfrom scrapy.commands import ScrapyCommand\nfrom scrapy.contracts import ContractsManager\nfrom scrapy.utils.misc import load_object, set_environ\nfrom scrapy.utils.conf import build_component_list\n\n\nclass TextTestResult(_TextTestResult):\n def printSummary(self, start, stop):\n write = self.stream.write\n writeln = self.stream.writeln\n\n run = self.testsRun\n plural = \"s\" if run != 1 else \"\"\n\n writeln(self.separator2)\n writeln(\"Ran %d contract%s in %.3fs\" % (run, plural, stop - start))\n writeln()\n\n infos = []\n if not self.wasSuccessful():\n write(\"FAILED\")\n failed, errored = map(len, (self.failures, self.errors))\n if failed:\n infos.append(\"failures=%d\" % failed)\n if errored:\n infos.append(\"errors=%d\" % errored)\n else:\n write(\"OK\")\n\n if infos:\n writeln(\" (%s)\" % (\", \".join(infos),))\n else:\n write(\"\\n\")\n\n\nclass Command(ScrapyCommand):\n requires_project = True\n default_settings = {'LOG_ENABLED': False}\n\n def syntax(self):\n return \"[options] <spider>\"\n\n def short_desc(self):\n return \"Check spider contracts\"\n\n def add_options(self, parser):\n ScrapyCommand.add_options(self, parser)\n parser.add_option(\"-l\", \"--list\", dest=\"list\", action=\"store_true\",\n help=\"only list contracts, without checking them\")\n parser.add_option(\"-v\", \"--verbose\", dest=\"verbose\", default=False, action='store_true',\n help=\"print contract tests for all spiders\")\n\n def run(self, args, opts):\n # load contracts\n contracts = build_component_list(self.settings.getwithbase('SPIDER_CONTRACTS'))\n conman = ContractsManager(load_object(c) for c in contracts)\n runner = TextTestRunner(verbosity=2 if opts.verbose else 1)\n result = TextTestResult(runner.stream, runner.descriptions, runner.verbosity)\n\n # contract requests\n contract_reqs = defaultdict(list)\n\n spider_loader = self.crawler_process.spider_loader\n\n with set_environ(SCRAPY_CHECK='true'):\n for spidername in args or spider_loader.list():\n spidercls = spider_loader.load(spidername)\n spidercls.start_requests = lambda s: conman.from_spider(s, result)\n\n tested_methods = conman.tested_methods_from_spidercls(spidercls)\n if opts.list:\n for method in tested_methods:\n contract_reqs[spidercls.name].append(method)\n elif tested_methods:\n self.crawler_process.crawl(spidercls)\n\n # start checks\n if opts.list:\n for spider, methods in sorted(contract_reqs.items()):\n if not methods and not opts.verbose:\n continue\n print(spider)\n for method in sorted(methods):\n print(' * %s' % method)\n else:\n start = time.time()\n self.crawler_process.start()\n stop = time.time()\n\n result.printErrors()\n result.printSummary(start, stop)\n self.exitcode = int(not result.wasSuccessful())\n", "path": "scrapy/commands/check.py"}]}
| 1,832 | 309 |
gh_patches_debug_15307
|
rasdani/github-patches
|
git_diff
|
encode__uvicorn-1069
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Sending SIGTERM to parent process when running with --workers hangs indefinitely
### Checklist
<!-- Please make sure you check all these items before submitting your bug report. -->
- [x] The bug is reproducible against the latest release and/or `master`.
- [x] There are no similar issues or pull requests to fix it yet.
### Describe the bug
<!-- A clear and concise description of what the bug is. -->
When running uvicorn with multiple workers, sending a SIGTERM ie `kill -15 ppid` there's no graceful shutdown and the process hangs indefinitely on https://github.com/encode/uvicorn/blob/ff4af12d6902bc9d535fe2a948d1df3ffa02b0d3/uvicorn/supervisors/multiprocess.py#L57
### To reproduce
<!-- Provide a *minimal* example with steps to reproduce the bug locally.
1. Run `uvicorn app:app --workers 2 --log-level=debug`
2. Get the ppid in the logs `INFO: Started parent process [38237]`
3. Send the SIGTERM `kill -15 38237`
NOTE: try to keep any external dependencies *at an absolute minimum* .
In other words, remove anything that doesn't make the bug go away.
-->
### Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
A graceful shutdown
### Actual behavior
<!-- A clear and concise description of what actually happens. -->
### Debugging material
<!-- Any tracebacks, screenshots, etc. that can help understanding the problem.
NOTE:
- Please list tracebacks in full (don't truncate them).
- If relevant, consider turning on DEBUG or TRACE logs for additional details (see the Logging section on https://www.uvicorn.org/settings/ specifically the `log-level` flag).
- Consider using `<details>` to make tracebacks/logs collapsible if they're very large (see https://gist.github.com/ericclemmons/b146fe5da72ca1f706b2ef72a20ac39d).
-->
### Environment
- OS / Python / Uvicorn version: just run `uvicorn --version`
`Running uvicorn 0.12.2 with CPython 3.8.6 on Linux`
- The exact command you're running uvicorn with, all flags you passed included. If you run it with gunicorn please do the same. If there is a reverse-proxy involved and you cannot reproduce without it please give the minimal config of it to reproduce.
### Additional context
<!-- Any additional information that can help understanding the problem.
Eg. linked issues, or a description of what you were trying to achieve. -->
originally discovered in https://github.com/encode/uvicorn/issues/364 and mistakenly taken for a docker issue, it's in fact a SIGTERM issue afaiu
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `uvicorn/supervisors/basereload.py`
Content:
```
1 import logging
2 import os
3 import signal
4 import threading
5 from socket import socket
6 from types import FrameType
7 from typing import Callable, Dict, List, Optional
8
9 import click
10
11 from uvicorn.config import Config
12 from uvicorn.subprocess import get_subprocess
13
14 HANDLED_SIGNALS = (
15 signal.SIGINT, # Unix signal 2. Sent by Ctrl+C.
16 signal.SIGTERM, # Unix signal 15. Sent by `kill <pid>`.
17 )
18
19 logger = logging.getLogger("uvicorn.error")
20
21
22 class BaseReload:
23 def __init__(
24 self,
25 config: Config,
26 target: Callable[[Optional[List[socket]]], None],
27 sockets: List[socket],
28 ) -> None:
29 self.config = config
30 self.target = target
31 self.sockets = sockets
32 self.should_exit = threading.Event()
33 self.pid = os.getpid()
34 self.reloader_name: Optional[str] = None
35
36 def signal_handler(self, sig: signal.Signals, frame: FrameType) -> None:
37 """
38 A signal handler that is registered with the parent process.
39 """
40 self.should_exit.set()
41
42 def run(self) -> None:
43 self.startup()
44 while not self.should_exit.wait(self.config.reload_delay):
45 if self.should_restart():
46 self.restart()
47
48 self.shutdown()
49
50 def startup(self) -> None:
51 message = f"Started reloader process [{self.pid}] using {self.reloader_name}"
52 color_message = "Started reloader process [{}] using {}".format(
53 click.style(str(self.pid), fg="cyan", bold=True),
54 click.style(str(self.reloader_name), fg="cyan", bold=True),
55 )
56 logger.info(message, extra={"color_message": color_message})
57
58 for sig in HANDLED_SIGNALS:
59 signal.signal(sig, self.signal_handler)
60
61 self.process = get_subprocess(
62 config=self.config, target=self.target, sockets=self.sockets
63 )
64 self.process.start()
65
66 def restart(self) -> None:
67 self.mtimes: Dict[str, float] = {}
68
69 self.process.terminate()
70 self.process.join()
71
72 self.process = get_subprocess(
73 config=self.config, target=self.target, sockets=self.sockets
74 )
75 self.process.start()
76
77 def shutdown(self) -> None:
78 self.process.join()
79 message = "Stopping reloader process [{}]".format(str(self.pid))
80 color_message = "Stopping reloader process [{}]".format(
81 click.style(str(self.pid), fg="cyan", bold=True)
82 )
83 logger.info(message, extra={"color_message": color_message})
84
85 def should_restart(self) -> bool:
86 raise NotImplementedError("Reload strategies should override should_restart()")
87
```
Path: `uvicorn/supervisors/multiprocess.py`
Content:
```
1 import logging
2 import os
3 import signal
4 import threading
5 from multiprocessing.context import SpawnProcess
6 from socket import socket
7 from types import FrameType
8 from typing import Callable, List, Optional
9
10 import click
11
12 from uvicorn.config import Config
13 from uvicorn.subprocess import get_subprocess
14
15 HANDLED_SIGNALS = (
16 signal.SIGINT, # Unix signal 2. Sent by Ctrl+C.
17 signal.SIGTERM, # Unix signal 15. Sent by `kill <pid>`.
18 )
19
20 logger = logging.getLogger("uvicorn.error")
21
22
23 class Multiprocess:
24 def __init__(
25 self,
26 config: Config,
27 target: Callable[[Optional[List[socket]]], None],
28 sockets: List[socket],
29 ) -> None:
30 self.config = config
31 self.target = target
32 self.sockets = sockets
33 self.processes: List[SpawnProcess] = []
34 self.should_exit = threading.Event()
35 self.pid = os.getpid()
36
37 def signal_handler(self, sig: signal.Signals, frame: FrameType) -> None:
38 """
39 A signal handler that is registered with the parent process.
40 """
41 self.should_exit.set()
42
43 def run(self) -> None:
44 self.startup()
45 self.should_exit.wait()
46 self.shutdown()
47
48 def startup(self) -> None:
49 message = "Started parent process [{}]".format(str(self.pid))
50 color_message = "Started parent process [{}]".format(
51 click.style(str(self.pid), fg="cyan", bold=True)
52 )
53 logger.info(message, extra={"color_message": color_message})
54
55 for sig in HANDLED_SIGNALS:
56 signal.signal(sig, self.signal_handler)
57
58 for idx in range(self.config.workers):
59 process = get_subprocess(
60 config=self.config, target=self.target, sockets=self.sockets
61 )
62 process.start()
63 self.processes.append(process)
64
65 def shutdown(self) -> None:
66 for process in self.processes:
67 process.join()
68
69 message = "Stopping parent process [{}]".format(str(self.pid))
70 color_message = "Stopping parent process [{}]".format(
71 click.style(str(self.pid), fg="cyan", bold=True)
72 )
73 logger.info(message, extra={"color_message": color_message})
74
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/uvicorn/supervisors/basereload.py b/uvicorn/supervisors/basereload.py
--- a/uvicorn/supervisors/basereload.py
+++ b/uvicorn/supervisors/basereload.py
@@ -75,6 +75,7 @@
self.process.start()
def shutdown(self) -> None:
+ self.process.terminate()
self.process.join()
message = "Stopping reloader process [{}]".format(str(self.pid))
color_message = "Stopping reloader process [{}]".format(
diff --git a/uvicorn/supervisors/multiprocess.py b/uvicorn/supervisors/multiprocess.py
--- a/uvicorn/supervisors/multiprocess.py
+++ b/uvicorn/supervisors/multiprocess.py
@@ -64,6 +64,7 @@
def shutdown(self) -> None:
for process in self.processes:
+ process.terminate()
process.join()
message = "Stopping parent process [{}]".format(str(self.pid))
|
{"golden_diff": "diff --git a/uvicorn/supervisors/basereload.py b/uvicorn/supervisors/basereload.py\n--- a/uvicorn/supervisors/basereload.py\n+++ b/uvicorn/supervisors/basereload.py\n@@ -75,6 +75,7 @@\n self.process.start()\n \n def shutdown(self) -> None:\n+ self.process.terminate()\n self.process.join()\n message = \"Stopping reloader process [{}]\".format(str(self.pid))\n color_message = \"Stopping reloader process [{}]\".format(\ndiff --git a/uvicorn/supervisors/multiprocess.py b/uvicorn/supervisors/multiprocess.py\n--- a/uvicorn/supervisors/multiprocess.py\n+++ b/uvicorn/supervisors/multiprocess.py\n@@ -64,6 +64,7 @@\n \n def shutdown(self) -> None:\n for process in self.processes:\n+ process.terminate()\n process.join()\n \n message = \"Stopping parent process [{}]\".format(str(self.pid))\n", "issue": "Sending SIGTERM to parent process when running with --workers hangs indefinitely\n### Checklist\r\n\r\n<!-- Please make sure you check all these items before submitting your bug report. -->\r\n\r\n- [x] The bug is reproducible against the latest release and/or `master`.\r\n- [x] There are no similar issues or pull requests to fix it yet.\r\n\r\n### Describe the bug\r\n\r\n<!-- A clear and concise description of what the bug is. -->\r\nWhen running uvicorn with multiple workers, sending a SIGTERM ie `kill -15 ppid` there's no graceful shutdown and the process hangs indefinitely on https://github.com/encode/uvicorn/blob/ff4af12d6902bc9d535fe2a948d1df3ffa02b0d3/uvicorn/supervisors/multiprocess.py#L57\r\n\r\n### To reproduce\r\n\r\n<!-- Provide a *minimal* example with steps to reproduce the bug locally.\r\n\r\n1. Run `uvicorn app:app --workers 2 --log-level=debug`\r\n2. Get the ppid in the logs `INFO: Started parent process [38237]`\r\n3. Send the SIGTERM `kill -15 38237`\r\n\r\nNOTE: try to keep any external dependencies *at an absolute minimum* .\r\nIn other words, remove anything that doesn't make the bug go away.\r\n\r\n-->\r\n\r\n### Expected behavior\r\n\r\n<!-- A clear and concise description of what you expected to happen. -->\r\nA graceful shutdown\r\n\r\n### Actual behavior\r\n\r\n<!-- A clear and concise description of what actually happens. -->\r\n\r\n### Debugging material\r\n\r\n<!-- Any tracebacks, screenshots, etc. that can help understanding the problem.\r\n\r\nNOTE:\r\n- Please list tracebacks in full (don't truncate them).\r\n- If relevant, consider turning on DEBUG or TRACE logs for additional details (see the Logging section on https://www.uvicorn.org/settings/ specifically the `log-level` flag).\r\n- Consider using `<details>` to make tracebacks/logs collapsible if they're very large (see https://gist.github.com/ericclemmons/b146fe5da72ca1f706b2ef72a20ac39d).\r\n-->\r\n\r\n### Environment\r\n\r\n- OS / Python / Uvicorn version: just run `uvicorn --version`\r\n`Running uvicorn 0.12.2 with CPython 3.8.6 on Linux`\r\n- The exact command you're running uvicorn with, all flags you passed included. If you run it with gunicorn please do the same. If there is a reverse-proxy involved and you cannot reproduce without it please give the minimal config of it to reproduce.\r\n\r\n### Additional context\r\n\r\n<!-- Any additional information that can help understanding the problem.\r\n\r\nEg. linked issues, or a description of what you were trying to achieve. -->\r\n\r\noriginally discovered in https://github.com/encode/uvicorn/issues/364 and mistakenly taken for a docker issue, it's in fact a SIGTERM issue afaiu\n", "before_files": [{"content": "import logging\nimport os\nimport signal\nimport threading\nfrom socket import socket\nfrom types import FrameType\nfrom typing import Callable, Dict, List, Optional\n\nimport click\n\nfrom uvicorn.config import Config\nfrom uvicorn.subprocess import get_subprocess\n\nHANDLED_SIGNALS = (\n signal.SIGINT, # Unix signal 2. Sent by Ctrl+C.\n signal.SIGTERM, # Unix signal 15. Sent by `kill <pid>`.\n)\n\nlogger = logging.getLogger(\"uvicorn.error\")\n\n\nclass BaseReload:\n def __init__(\n self,\n config: Config,\n target: Callable[[Optional[List[socket]]], None],\n sockets: List[socket],\n ) -> None:\n self.config = config\n self.target = target\n self.sockets = sockets\n self.should_exit = threading.Event()\n self.pid = os.getpid()\n self.reloader_name: Optional[str] = None\n\n def signal_handler(self, sig: signal.Signals, frame: FrameType) -> None:\n \"\"\"\n A signal handler that is registered with the parent process.\n \"\"\"\n self.should_exit.set()\n\n def run(self) -> None:\n self.startup()\n while not self.should_exit.wait(self.config.reload_delay):\n if self.should_restart():\n self.restart()\n\n self.shutdown()\n\n def startup(self) -> None:\n message = f\"Started reloader process [{self.pid}] using {self.reloader_name}\"\n color_message = \"Started reloader process [{}] using {}\".format(\n click.style(str(self.pid), fg=\"cyan\", bold=True),\n click.style(str(self.reloader_name), fg=\"cyan\", bold=True),\n )\n logger.info(message, extra={\"color_message\": color_message})\n\n for sig in HANDLED_SIGNALS:\n signal.signal(sig, self.signal_handler)\n\n self.process = get_subprocess(\n config=self.config, target=self.target, sockets=self.sockets\n )\n self.process.start()\n\n def restart(self) -> None:\n self.mtimes: Dict[str, float] = {}\n\n self.process.terminate()\n self.process.join()\n\n self.process = get_subprocess(\n config=self.config, target=self.target, sockets=self.sockets\n )\n self.process.start()\n\n def shutdown(self) -> None:\n self.process.join()\n message = \"Stopping reloader process [{}]\".format(str(self.pid))\n color_message = \"Stopping reloader process [{}]\".format(\n click.style(str(self.pid), fg=\"cyan\", bold=True)\n )\n logger.info(message, extra={\"color_message\": color_message})\n\n def should_restart(self) -> bool:\n raise NotImplementedError(\"Reload strategies should override should_restart()\")\n", "path": "uvicorn/supervisors/basereload.py"}, {"content": "import logging\nimport os\nimport signal\nimport threading\nfrom multiprocessing.context import SpawnProcess\nfrom socket import socket\nfrom types import FrameType\nfrom typing import Callable, List, Optional\n\nimport click\n\nfrom uvicorn.config import Config\nfrom uvicorn.subprocess import get_subprocess\n\nHANDLED_SIGNALS = (\n signal.SIGINT, # Unix signal 2. Sent by Ctrl+C.\n signal.SIGTERM, # Unix signal 15. Sent by `kill <pid>`.\n)\n\nlogger = logging.getLogger(\"uvicorn.error\")\n\n\nclass Multiprocess:\n def __init__(\n self,\n config: Config,\n target: Callable[[Optional[List[socket]]], None],\n sockets: List[socket],\n ) -> None:\n self.config = config\n self.target = target\n self.sockets = sockets\n self.processes: List[SpawnProcess] = []\n self.should_exit = threading.Event()\n self.pid = os.getpid()\n\n def signal_handler(self, sig: signal.Signals, frame: FrameType) -> None:\n \"\"\"\n A signal handler that is registered with the parent process.\n \"\"\"\n self.should_exit.set()\n\n def run(self) -> None:\n self.startup()\n self.should_exit.wait()\n self.shutdown()\n\n def startup(self) -> None:\n message = \"Started parent process [{}]\".format(str(self.pid))\n color_message = \"Started parent process [{}]\".format(\n click.style(str(self.pid), fg=\"cyan\", bold=True)\n )\n logger.info(message, extra={\"color_message\": color_message})\n\n for sig in HANDLED_SIGNALS:\n signal.signal(sig, self.signal_handler)\n\n for idx in range(self.config.workers):\n process = get_subprocess(\n config=self.config, target=self.target, sockets=self.sockets\n )\n process.start()\n self.processes.append(process)\n\n def shutdown(self) -> None:\n for process in self.processes:\n process.join()\n\n message = \"Stopping parent process [{}]\".format(str(self.pid))\n color_message = \"Stopping parent process [{}]\".format(\n click.style(str(self.pid), fg=\"cyan\", bold=True)\n )\n logger.info(message, extra={\"color_message\": color_message})\n", "path": "uvicorn/supervisors/multiprocess.py"}], "after_files": [{"content": "import logging\nimport os\nimport signal\nimport threading\nfrom socket import socket\nfrom types import FrameType\nfrom typing import Callable, Dict, List, Optional\n\nimport click\n\nfrom uvicorn.config import Config\nfrom uvicorn.subprocess import get_subprocess\n\nHANDLED_SIGNALS = (\n signal.SIGINT, # Unix signal 2. Sent by Ctrl+C.\n signal.SIGTERM, # Unix signal 15. Sent by `kill <pid>`.\n)\n\nlogger = logging.getLogger(\"uvicorn.error\")\n\n\nclass BaseReload:\n def __init__(\n self,\n config: Config,\n target: Callable[[Optional[List[socket]]], None],\n sockets: List[socket],\n ) -> None:\n self.config = config\n self.target = target\n self.sockets = sockets\n self.should_exit = threading.Event()\n self.pid = os.getpid()\n self.reloader_name: Optional[str] = None\n\n def signal_handler(self, sig: signal.Signals, frame: FrameType) -> None:\n \"\"\"\n A signal handler that is registered with the parent process.\n \"\"\"\n self.should_exit.set()\n\n def run(self) -> None:\n self.startup()\n while not self.should_exit.wait(self.config.reload_delay):\n if self.should_restart():\n self.restart()\n\n self.shutdown()\n\n def startup(self) -> None:\n message = f\"Started reloader process [{self.pid}] using {self.reloader_name}\"\n color_message = \"Started reloader process [{}] using {}\".format(\n click.style(str(self.pid), fg=\"cyan\", bold=True),\n click.style(str(self.reloader_name), fg=\"cyan\", bold=True),\n )\n logger.info(message, extra={\"color_message\": color_message})\n\n for sig in HANDLED_SIGNALS:\n signal.signal(sig, self.signal_handler)\n\n self.process = get_subprocess(\n config=self.config, target=self.target, sockets=self.sockets\n )\n self.process.start()\n\n def restart(self) -> None:\n self.mtimes: Dict[str, float] = {}\n\n self.process.terminate()\n self.process.join()\n\n self.process = get_subprocess(\n config=self.config, target=self.target, sockets=self.sockets\n )\n self.process.start()\n\n def shutdown(self) -> None:\n self.process.terminate()\n self.process.join()\n message = \"Stopping reloader process [{}]\".format(str(self.pid))\n color_message = \"Stopping reloader process [{}]\".format(\n click.style(str(self.pid), fg=\"cyan\", bold=True)\n )\n logger.info(message, extra={\"color_message\": color_message})\n\n def should_restart(self) -> bool:\n raise NotImplementedError(\"Reload strategies should override should_restart()\")\n", "path": "uvicorn/supervisors/basereload.py"}, {"content": "import logging\nimport os\nimport signal\nimport threading\nfrom multiprocessing.context import SpawnProcess\nfrom socket import socket\nfrom types import FrameType\nfrom typing import Callable, List, Optional\n\nimport click\n\nfrom uvicorn.config import Config\nfrom uvicorn.subprocess import get_subprocess\n\nHANDLED_SIGNALS = (\n signal.SIGINT, # Unix signal 2. Sent by Ctrl+C.\n signal.SIGTERM, # Unix signal 15. Sent by `kill <pid>`.\n)\n\nlogger = logging.getLogger(\"uvicorn.error\")\n\n\nclass Multiprocess:\n def __init__(\n self,\n config: Config,\n target: Callable[[Optional[List[socket]]], None],\n sockets: List[socket],\n ) -> None:\n self.config = config\n self.target = target\n self.sockets = sockets\n self.processes: List[SpawnProcess] = []\n self.should_exit = threading.Event()\n self.pid = os.getpid()\n\n def signal_handler(self, sig: signal.Signals, frame: FrameType) -> None:\n \"\"\"\n A signal handler that is registered with the parent process.\n \"\"\"\n self.should_exit.set()\n\n def run(self) -> None:\n self.startup()\n self.should_exit.wait()\n self.shutdown()\n\n def startup(self) -> None:\n message = \"Started parent process [{}]\".format(str(self.pid))\n color_message = \"Started parent process [{}]\".format(\n click.style(str(self.pid), fg=\"cyan\", bold=True)\n )\n logger.info(message, extra={\"color_message\": color_message})\n\n for sig in HANDLED_SIGNALS:\n signal.signal(sig, self.signal_handler)\n\n for idx in range(self.config.workers):\n process = get_subprocess(\n config=self.config, target=self.target, sockets=self.sockets\n )\n process.start()\n self.processes.append(process)\n\n def shutdown(self) -> None:\n for process in self.processes:\n process.terminate()\n process.join()\n\n message = \"Stopping parent process [{}]\".format(str(self.pid))\n color_message = \"Stopping parent process [{}]\".format(\n click.style(str(self.pid), fg=\"cyan\", bold=True)\n )\n logger.info(message, extra={\"color_message\": color_message})\n", "path": "uvicorn/supervisors/multiprocess.py"}]}
| 2,284 | 233 |
gh_patches_debug_27393
|
rasdani/github-patches
|
git_diff
|
nltk__nltk-633
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove prob_parse from ParserI
The ParserI methods `prob_parse` and `prob_parse_sents` are not used anywhere, and are not defined anywhere, so I propose to remove them from `nltk/parse/api.py`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nltk/parse/api.py`
Content:
```
1 # Natural Language Toolkit: Parser API
2 #
3 # Copyright (C) 2001-2014 NLTK Project
4 # Author: Steven Bird <[email protected]>
5 # Edward Loper <[email protected]>
6 # URL: <http://nltk.org/>
7 # For license information, see LICENSE.TXT
8 #
9
10 import itertools
11
12 from nltk.internals import overridden
13
14 class ParserI(object):
15 """
16 A processing class for deriving trees that represent possible
17 structures for a sequence of tokens. These tree structures are
18 known as "parses". Typically, parsers are used to derive syntax
19 trees for sentences. But parsers can also be used to derive other
20 kinds of tree structure, such as morphological trees and discourse
21 structures.
22
23 Subclasses must define:
24 - at least one of: ``parse()``, ``nbest_parse()``, ``iter_parse()``,
25 ``parse_sents()``, ``nbest_parse_sents()``, ``iter_parse_sents()``.
26
27 Subclasses may define:
28 - ``grammar()``
29 - either ``prob_parse()`` or ``prob_parse_sents()`` (or both)
30 """
31 def grammar(self):
32 """
33 :return: The grammar used by this parser.
34 """
35 raise NotImplementedError()
36
37 def parse(self, sent):
38 """
39 :return: A parse tree that represents the structure of the
40 given sentence, or None if no parse tree is found. If
41 multiple parses are found, then return the best parse.
42
43 :param sent: The sentence to be parsed
44 :type sent: list(str)
45 :rtype: Tree
46 """
47 if overridden(self.parse_sents):
48 return self.parse_sents([sent])[0]
49 else:
50 trees = self.nbest_parse(sent, 1)
51 if trees: return trees[0]
52 else: return None
53
54 def nbest_parse(self, sent, n=None):
55 """
56 :return: A list of parse trees that represent possible
57 structures for the given sentence. When possible, this list is
58 sorted from most likely to least likely. If ``n`` is
59 specified, then the returned list will contain at most ``n``
60 parse trees.
61
62 :param sent: The sentence to be parsed
63 :type sent: list(str)
64 :param n: The maximum number of trees to return.
65 :type n: int
66 :rtype: list(Tree)
67 """
68 if overridden(self.nbest_parse_sents):
69 return self.nbest_parse_sents([sent],n)[0]
70 elif overridden(self.parse) or overridden(self.parse_sents):
71 tree = self.parse(sent)
72 if tree: return [tree]
73 else: return []
74 else:
75 return list(itertools.islice(self.iter_parse(sent), n))
76
77 def iter_parse(self, sent):
78 """
79 :return: An iterator that generates parse trees that represent
80 possible structures for the given sentence. When possible,
81 this list is sorted from most likely to least likely.
82
83 :param sent: The sentence to be parsed
84 :type sent: list(str)
85 :rtype: iter(Tree)
86 """
87 if overridden(self.iter_parse_sents):
88 return self.iter_parse_sents([sent])[0]
89 elif overridden(self.nbest_parse) or overridden(self.nbest_parse_sents):
90 return iter(self.nbest_parse(sent))
91 elif overridden(self.parse) or overridden(self.parse_sents):
92 tree = self.parse(sent)
93 if tree: return iter([tree])
94 else: return iter([])
95 else:
96 raise NotImplementedError()
97
98 def prob_parse(self, sent):
99 """
100 :return: A probability distribution over the possible parse
101 trees for the given sentence. If there are no possible parse
102 trees for the given sentence, return a probability distribution
103 that assigns a probability of 1.0 to None.
104
105 :param sent: The sentence to be parsed
106 :type sent: list(str)
107 :rtype: ProbDistI(Tree)
108 """
109 if overridden(self.prob_parse_sents):
110 return self.prob_parse_sents([sent])[0]
111 else:
112 raise NotImplementedError
113
114 def parse_sents(self, sents):
115 """
116 Apply ``self.parse()`` to each element of ``sents``. I.e.:
117
118 return [self.parse(sent) for sent in sents]
119
120 :rtype: list(Tree)
121 """
122 return [self.parse(sent) for sent in sents]
123
124 def nbest_parse_sents(self, sents, n=None):
125 """
126 Apply ``self.nbest_parse()`` to each element of ``sents``. I.e.:
127
128 return [self.nbest_parse(sent, n) for sent in sents]
129
130 :rtype: list(list(Tree))
131 """
132 return [self.nbest_parse(sent,n ) for sent in sents]
133
134 def iter_parse_sents(self, sents):
135 """
136 Apply ``self.iter_parse()`` to each element of ``sents``. I.e.:
137
138 return [self.iter_parse(sent) for sent in sents]
139
140 :rtype: list(iter(Tree))
141 """
142 return [self.iter_parse(sent) for sent in sents]
143
144 def prob_parse_sents(self, sents):
145 """
146 Apply ``self.prob_parse()`` to each element of ``sents``. I.e.:
147
148 return [self.prob_parse(sent) for sent in sents]
149
150 :rtype: list(ProbDistI(Tree))
151 """
152 return [self.prob_parse(sent) for sent in sents]
153
154
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nltk/parse/api.py b/nltk/parse/api.py
--- a/nltk/parse/api.py
+++ b/nltk/parse/api.py
@@ -26,7 +26,6 @@
Subclasses may define:
- ``grammar()``
- - either ``prob_parse()`` or ``prob_parse_sents()`` (or both)
"""
def grammar(self):
"""
@@ -95,22 +94,6 @@
else:
raise NotImplementedError()
- def prob_parse(self, sent):
- """
- :return: A probability distribution over the possible parse
- trees for the given sentence. If there are no possible parse
- trees for the given sentence, return a probability distribution
- that assigns a probability of 1.0 to None.
-
- :param sent: The sentence to be parsed
- :type sent: list(str)
- :rtype: ProbDistI(Tree)
- """
- if overridden(self.prob_parse_sents):
- return self.prob_parse_sents([sent])[0]
- else:
- raise NotImplementedError
-
def parse_sents(self, sents):
"""
Apply ``self.parse()`` to each element of ``sents``. I.e.:
@@ -141,13 +124,3 @@
"""
return [self.iter_parse(sent) for sent in sents]
- def prob_parse_sents(self, sents):
- """
- Apply ``self.prob_parse()`` to each element of ``sents``. I.e.:
-
- return [self.prob_parse(sent) for sent in sents]
-
- :rtype: list(ProbDistI(Tree))
- """
- return [self.prob_parse(sent) for sent in sents]
-
|
{"golden_diff": "diff --git a/nltk/parse/api.py b/nltk/parse/api.py\n--- a/nltk/parse/api.py\n+++ b/nltk/parse/api.py\n@@ -26,7 +26,6 @@\n \n Subclasses may define:\n - ``grammar()``\n- - either ``prob_parse()`` or ``prob_parse_sents()`` (or both)\n \"\"\"\n def grammar(self):\n \"\"\"\n@@ -95,22 +94,6 @@\n else:\n raise NotImplementedError()\n \n- def prob_parse(self, sent):\n- \"\"\"\n- :return: A probability distribution over the possible parse\n- trees for the given sentence. If there are no possible parse\n- trees for the given sentence, return a probability distribution\n- that assigns a probability of 1.0 to None.\n-\n- :param sent: The sentence to be parsed\n- :type sent: list(str)\n- :rtype: ProbDistI(Tree)\n- \"\"\"\n- if overridden(self.prob_parse_sents):\n- return self.prob_parse_sents([sent])[0]\n- else:\n- raise NotImplementedError\n-\n def parse_sents(self, sents):\n \"\"\"\n Apply ``self.parse()`` to each element of ``sents``. I.e.:\n@@ -141,13 +124,3 @@\n \"\"\"\n return [self.iter_parse(sent) for sent in sents]\n \n- def prob_parse_sents(self, sents):\n- \"\"\"\n- Apply ``self.prob_parse()`` to each element of ``sents``. I.e.:\n-\n- return [self.prob_parse(sent) for sent in sents]\n-\n- :rtype: list(ProbDistI(Tree))\n- \"\"\"\n- return [self.prob_parse(sent) for sent in sents]\n-\n", "issue": "Remove prob_parse from ParserI\nThe ParserI methods `prob_parse` and `prob_parse_sents` are not used anywhere, and are not defined anywhere, so I propose to remove them from `nltk/parse/api.py`\n\n", "before_files": [{"content": "# Natural Language Toolkit: Parser API\n#\n# Copyright (C) 2001-2014 NLTK Project\n# Author: Steven Bird <[email protected]>\n# Edward Loper <[email protected]>\n# URL: <http://nltk.org/>\n# For license information, see LICENSE.TXT\n#\n\nimport itertools\n\nfrom nltk.internals import overridden\n\nclass ParserI(object):\n \"\"\"\n A processing class for deriving trees that represent possible\n structures for a sequence of tokens. These tree structures are\n known as \"parses\". Typically, parsers are used to derive syntax\n trees for sentences. But parsers can also be used to derive other\n kinds of tree structure, such as morphological trees and discourse\n structures.\n\n Subclasses must define:\n - at least one of: ``parse()``, ``nbest_parse()``, ``iter_parse()``,\n ``parse_sents()``, ``nbest_parse_sents()``, ``iter_parse_sents()``.\n\n Subclasses may define:\n - ``grammar()``\n - either ``prob_parse()`` or ``prob_parse_sents()`` (or both)\n \"\"\"\n def grammar(self):\n \"\"\"\n :return: The grammar used by this parser.\n \"\"\"\n raise NotImplementedError()\n\n def parse(self, sent):\n \"\"\"\n :return: A parse tree that represents the structure of the\n given sentence, or None if no parse tree is found. If\n multiple parses are found, then return the best parse.\n\n :param sent: The sentence to be parsed\n :type sent: list(str)\n :rtype: Tree\n \"\"\"\n if overridden(self.parse_sents):\n return self.parse_sents([sent])[0]\n else:\n trees = self.nbest_parse(sent, 1)\n if trees: return trees[0]\n else: return None\n\n def nbest_parse(self, sent, n=None):\n \"\"\"\n :return: A list of parse trees that represent possible\n structures for the given sentence. When possible, this list is\n sorted from most likely to least likely. If ``n`` is\n specified, then the returned list will contain at most ``n``\n parse trees.\n\n :param sent: The sentence to be parsed\n :type sent: list(str)\n :param n: The maximum number of trees to return.\n :type n: int\n :rtype: list(Tree)\n \"\"\"\n if overridden(self.nbest_parse_sents):\n return self.nbest_parse_sents([sent],n)[0]\n elif overridden(self.parse) or overridden(self.parse_sents):\n tree = self.parse(sent)\n if tree: return [tree]\n else: return []\n else:\n return list(itertools.islice(self.iter_parse(sent), n))\n\n def iter_parse(self, sent):\n \"\"\"\n :return: An iterator that generates parse trees that represent\n possible structures for the given sentence. When possible,\n this list is sorted from most likely to least likely.\n\n :param sent: The sentence to be parsed\n :type sent: list(str)\n :rtype: iter(Tree)\n \"\"\"\n if overridden(self.iter_parse_sents):\n return self.iter_parse_sents([sent])[0]\n elif overridden(self.nbest_parse) or overridden(self.nbest_parse_sents):\n return iter(self.nbest_parse(sent))\n elif overridden(self.parse) or overridden(self.parse_sents):\n tree = self.parse(sent)\n if tree: return iter([tree])\n else: return iter([])\n else:\n raise NotImplementedError()\n\n def prob_parse(self, sent):\n \"\"\"\n :return: A probability distribution over the possible parse\n trees for the given sentence. If there are no possible parse\n trees for the given sentence, return a probability distribution\n that assigns a probability of 1.0 to None.\n\n :param sent: The sentence to be parsed\n :type sent: list(str)\n :rtype: ProbDistI(Tree)\n \"\"\"\n if overridden(self.prob_parse_sents):\n return self.prob_parse_sents([sent])[0]\n else:\n raise NotImplementedError\n\n def parse_sents(self, sents):\n \"\"\"\n Apply ``self.parse()`` to each element of ``sents``. I.e.:\n\n return [self.parse(sent) for sent in sents]\n\n :rtype: list(Tree)\n \"\"\"\n return [self.parse(sent) for sent in sents]\n\n def nbest_parse_sents(self, sents, n=None):\n \"\"\"\n Apply ``self.nbest_parse()`` to each element of ``sents``. I.e.:\n\n return [self.nbest_parse(sent, n) for sent in sents]\n\n :rtype: list(list(Tree))\n \"\"\"\n return [self.nbest_parse(sent,n ) for sent in sents]\n\n def iter_parse_sents(self, sents):\n \"\"\"\n Apply ``self.iter_parse()`` to each element of ``sents``. I.e.:\n\n return [self.iter_parse(sent) for sent in sents]\n\n :rtype: list(iter(Tree))\n \"\"\"\n return [self.iter_parse(sent) for sent in sents]\n\n def prob_parse_sents(self, sents):\n \"\"\"\n Apply ``self.prob_parse()`` to each element of ``sents``. I.e.:\n\n return [self.prob_parse(sent) for sent in sents]\n\n :rtype: list(ProbDistI(Tree))\n \"\"\"\n return [self.prob_parse(sent) for sent in sents]\n\n", "path": "nltk/parse/api.py"}], "after_files": [{"content": "# Natural Language Toolkit: Parser API\n#\n# Copyright (C) 2001-2014 NLTK Project\n# Author: Steven Bird <[email protected]>\n# Edward Loper <[email protected]>\n# URL: <http://nltk.org/>\n# For license information, see LICENSE.TXT\n#\n\nimport itertools\n\nfrom nltk.internals import overridden\n\nclass ParserI(object):\n \"\"\"\n A processing class for deriving trees that represent possible\n structures for a sequence of tokens. These tree structures are\n known as \"parses\". Typically, parsers are used to derive syntax\n trees for sentences. But parsers can also be used to derive other\n kinds of tree structure, such as morphological trees and discourse\n structures.\n\n Subclasses must define:\n - at least one of: ``parse()``, ``nbest_parse()``, ``iter_parse()``,\n ``parse_sents()``, ``nbest_parse_sents()``, ``iter_parse_sents()``.\n\n Subclasses may define:\n - ``grammar()``\n \"\"\"\n def grammar(self):\n \"\"\"\n :return: The grammar used by this parser.\n \"\"\"\n raise NotImplementedError()\n\n def parse(self, sent):\n \"\"\"\n :return: A parse tree that represents the structure of the\n given sentence, or None if no parse tree is found. If\n multiple parses are found, then return the best parse.\n\n :param sent: The sentence to be parsed\n :type sent: list(str)\n :rtype: Tree\n \"\"\"\n if overridden(self.parse_sents):\n return self.parse_sents([sent])[0]\n else:\n trees = self.nbest_parse(sent, 1)\n if trees: return trees[0]\n else: return None\n\n def nbest_parse(self, sent, n=None):\n \"\"\"\n :return: A list of parse trees that represent possible\n structures for the given sentence. When possible, this list is\n sorted from most likely to least likely. If ``n`` is\n specified, then the returned list will contain at most ``n``\n parse trees.\n\n :param sent: The sentence to be parsed\n :type sent: list(str)\n :param n: The maximum number of trees to return.\n :type n: int\n :rtype: list(Tree)\n \"\"\"\n if overridden(self.nbest_parse_sents):\n return self.nbest_parse_sents([sent],n)[0]\n elif overridden(self.parse) or overridden(self.parse_sents):\n tree = self.parse(sent)\n if tree: return [tree]\n else: return []\n else:\n return list(itertools.islice(self.iter_parse(sent), n))\n\n def iter_parse(self, sent):\n \"\"\"\n :return: An iterator that generates parse trees that represent\n possible structures for the given sentence. When possible,\n this list is sorted from most likely to least likely.\n\n :param sent: The sentence to be parsed\n :type sent: list(str)\n :rtype: iter(Tree)\n \"\"\"\n if overridden(self.iter_parse_sents):\n return self.iter_parse_sents([sent])[0]\n elif overridden(self.nbest_parse) or overridden(self.nbest_parse_sents):\n return iter(self.nbest_parse(sent))\n elif overridden(self.parse) or overridden(self.parse_sents):\n tree = self.parse(sent)\n if tree: return iter([tree])\n else: return iter([])\n else:\n raise NotImplementedError()\n\n def parse_sents(self, sents):\n \"\"\"\n Apply ``self.parse()`` to each element of ``sents``. I.e.:\n\n return [self.parse(sent) for sent in sents]\n\n :rtype: list(Tree)\n \"\"\"\n return [self.parse(sent) for sent in sents]\n\n def nbest_parse_sents(self, sents, n=None):\n \"\"\"\n Apply ``self.nbest_parse()`` to each element of ``sents``. I.e.:\n\n return [self.nbest_parse(sent, n) for sent in sents]\n\n :rtype: list(list(Tree))\n \"\"\"\n return [self.nbest_parse(sent,n ) for sent in sents]\n\n def iter_parse_sents(self, sents):\n \"\"\"\n Apply ``self.iter_parse()`` to each element of ``sents``. I.e.:\n\n return [self.iter_parse(sent) for sent in sents]\n\n :rtype: list(iter(Tree))\n \"\"\"\n return [self.iter_parse(sent) for sent in sents]\n\n", "path": "nltk/parse/api.py"}]}
| 1,873 | 399 |
gh_patches_debug_25437
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-2289
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Internal server error for API call
This URL currently gives an internal server error: http://rsr.akvo.org/rest/v1/project_extra/787/.json
Part of the stacktrace:
```
IOError Root Cause
image file is truncated (48 bytes not processed)
...
akvo/rest/fields.py ? in to_native
default_thumb = get_thumbnail(value, default_width, quality=99)
sorl/thumbnail/shortcuts.py ? in get_thumbnail
return default.backend.get_thumbnail(file_, geometry_string, **options)
sorl/thumbnail/base.py ? in get_thumbnail
thumbnail)
sorl/thumbnail/base.py ? in _create_thumbnail
image = default.engine.create(source_image, geometry, options)
sorl/thumbnail/engines/base.py ? in create
image = self.colorspace(image, geometry, options)
sorl/thumbnail/engines/base.py ? in colorspace
return self._colorspace(image, colorspace)
sorl/thumbnail/engines/pil_engine.py ? in _colorspace
return image.convert('RGB')
PIL/Image.py ? in convert
self.load()
PIL/ImageFile.py ? in load
"(%d bytes not processed)" % len(b))
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `akvo/rest/fields.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7
8 import base64
9 import imghdr
10 import six
11 import uuid
12
13 from django.core.files.base import ContentFile
14 from django.utils.encoding import smart_text
15 from django.utils.translation import ugettext_lazy as _
16
17 from rest_framework import serializers
18 from rest_framework.fields import ImageField
19 from sorl.thumbnail import get_thumbnail
20 from sorl.thumbnail.parsers import ThumbnailParseError
21
22
23 class NonNullCharField(serializers.CharField):
24 """ Fix fo CharField so that '' is returned if the field value is None
25 see https://github.com/tomchristie/django-rest-framework/pull/1665
26 """
27 def from_native(self, value):
28 if isinstance(value, six.string_types):
29 return value
30 if value is None:
31 return u''
32 return smart_text(value)
33
34
35 class NonNullURLField(NonNullCharField, serializers.URLField):
36 pass
37
38
39 class Base64ImageField(ImageField):
40 """ A django-rest-framework field for handling image-uploads through raw post data.
41 It uses base64 for en-/decoding the contents of the file.
42 Now also supports thumbnails of different sizes. See to_native() for more info.
43 """
44 ALLOWED_IMAGE_TYPES = (
45 'gif',
46 'jpeg',
47 'jpg',
48 'png',
49 )
50 def from_native(self, base64_data):
51 # Check if this is a base64 string
52 if isinstance(base64_data, basestring):
53 # Try to decode the file. Return validation error if it fails.
54 try:
55 decoded_file = base64.b64decode(base64_data)
56 except TypeError:
57 raise serializers.ValidationError(_(u"Please upload a valid image."))
58
59 # Generate file name:
60 file_name = str(uuid.uuid4())[:12] # 12 characters are more than enough.
61 # Get the file name extension:
62 file_extension = self.get_file_extension(file_name, decoded_file)
63 if file_extension not in self.ALLOWED_IMAGE_TYPES:
64 raise serializers.ValidationError(
65 _(u"The type of the image couldn't been determined.")
66 )
67 complete_file_name = file_name + "." + file_extension
68 data = ContentFile(decoded_file, name=complete_file_name)
69 else:
70 data = base64_data
71
72 return super(Base64ImageField, self).from_native(data)
73
74 def to_native(self, value):
75 """
76 :param value: A Base64ImageField object
77 :return: a path to a thumbnail with a predetermined size, the default thumb
78 OR
79 a dict with a number of thumbnails, one of which is the default, the others being generated
80 from the query string parameters, and finally the path to the original image keyed to
81 "original".
82
83 The extended functionality, allowing the generation of one or more thumbnails from the
84 original image is triggered by including "image_thumb_name" in the query string. The value
85 for image_thumb_name is a comma separated list of identifiers for the generated thumbs.
86 The names must not be "default" or "original".
87
88 For each thumb thus specified a size must be supplied as a query param on the form
89 image_thumb_<name>_<dimension>
90 where <name> is the name of the thumb specified as one of the values for image_thumb_name
91 and <dimension> is one of "width, "height" or "max_size". width and height must be an integer
92 specifying that dimension in pixels. The image will be scaled correctly in the other
93 dimension. max_size is width and height concatenated with an "x" and sets the maximum size
94 allowed for the respective dimensions, while still maintaining the correct aspect ratio of
95 the image.
96
97 Example:
98 the querystring
99 ?image_thumb_name=big,small&image_thumb_small_width=90&image_thumb_big_max_size=300x200
100 results in the following dict being returned:
101 {
102 'original': '/full/path/to/original/image.png',
103 'default': '/full/path/to/default/thumbnail/image.png',
104 'small': '/full/path/to/small/thumbnail/image.png',
105 'big': '/full/path/to/big/thumbnail/image.png',
106 }
107 This dict will be converted as appropriate to JSON or XML
108
109 NOTE: This special functionality works best when there is only one image field in a model.
110 If there are more, things will still work (I think), but for each image all thumbs returned
111 will have the same dimensions
112 """
113 def get_thumb(request, name):
114 if name not in [u'original', u'default']:
115 try:
116 width = request.GET.get('image_thumb_{}_width'.format(name))
117 if width:
118 return get_thumbnail(value, '{}'.format(width), quality=99)
119 height = request.GET.get('image_thumb_{}_height'.format(name))
120 if height:
121 return get_thumbnail(value, 'x{}'.format(height), quality=99)
122 # yes this is redundant...code is nearly identical with the width code above
123 # but for clarity of function we keep them separate
124 max_size = request.GET.get('image_thumb_{}_max_size'.format(name))
125 if max_size:
126 return get_thumbnail(value, '{}'.format(max_size), quality=99)
127 except ThumbnailParseError:
128 return None
129 # no size specification matching the name found; give up
130 return None
131
132 if value:
133 default_width = '191' # width of update images on akvo.org/seeithappen
134 default_thumb = get_thumbnail(value, default_width, quality=99)
135 try:
136 request = self.context['request']
137 except KeyError:
138 return None
139 # look for name(s) of thumb(s)
140 image_thumb_name = request.GET.get('image_thumb_name')
141 if image_thumb_name:
142 names = image_thumb_name.split(',')
143 thumbs = {u'original': value.url, u'default': default_thumb.url}
144 for name in names:
145 thumb = get_thumb(request, name)
146 if thumb is not None:
147 thumbs[name] = thumb.url
148 return thumbs
149 return default_thumb.url
150
151 def get_file_extension(self, filename, decoded_file):
152 extension = imghdr.what(filename, decoded_file)
153 extension = "jpg" if extension == "jpeg" else extension
154 return extension
155
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/akvo/rest/fields.py b/akvo/rest/fields.py
--- a/akvo/rest/fields.py
+++ b/akvo/rest/fields.py
@@ -124,18 +124,20 @@
max_size = request.GET.get('image_thumb_{}_max_size'.format(name))
if max_size:
return get_thumbnail(value, '{}'.format(max_size), quality=99)
- except ThumbnailParseError:
+ except (ThumbnailParseError, IOError):
return None
+
# no size specification matching the name found; give up
return None
if value:
default_width = '191' # width of update images on akvo.org/seeithappen
- default_thumb = get_thumbnail(value, default_width, quality=99)
try:
+ default_thumb = get_thumbnail(value, default_width, quality=99)
request = self.context['request']
- except KeyError:
+ except (ThumbnailParseError, IOError, KeyError):
return None
+
# look for name(s) of thumb(s)
image_thumb_name = request.GET.get('image_thumb_name')
if image_thumb_name:
|
{"golden_diff": "diff --git a/akvo/rest/fields.py b/akvo/rest/fields.py\n--- a/akvo/rest/fields.py\n+++ b/akvo/rest/fields.py\n@@ -124,18 +124,20 @@\n max_size = request.GET.get('image_thumb_{}_max_size'.format(name))\n if max_size:\n return get_thumbnail(value, '{}'.format(max_size), quality=99)\n- except ThumbnailParseError:\n+ except (ThumbnailParseError, IOError):\n return None\n+\n # no size specification matching the name found; give up\n return None\n \n if value:\n default_width = '191' # width of update images on akvo.org/seeithappen\n- default_thumb = get_thumbnail(value, default_width, quality=99)\n try:\n+ default_thumb = get_thumbnail(value, default_width, quality=99)\n request = self.context['request']\n- except KeyError:\n+ except (ThumbnailParseError, IOError, KeyError):\n return None\n+\n # look for name(s) of thumb(s)\n image_thumb_name = request.GET.get('image_thumb_name')\n if image_thumb_name:\n", "issue": "Internal server error for API call\nThis URL currently gives an internal server error: http://rsr.akvo.org/rest/v1/project_extra/787/.json\n\nPart of the stacktrace:\n\n```\nIOError Root Cause\nimage file is truncated (48 bytes not processed)\n\n...\nakvo/rest/fields.py ? in to_native\n default_thumb = get_thumbnail(value, default_width, quality=99)\nsorl/thumbnail/shortcuts.py ? in get_thumbnail\n return default.backend.get_thumbnail(file_, geometry_string, **options)\nsorl/thumbnail/base.py ? in get_thumbnail\n thumbnail)\nsorl/thumbnail/base.py ? in _create_thumbnail\n image = default.engine.create(source_image, geometry, options)\nsorl/thumbnail/engines/base.py ? in create\n image = self.colorspace(image, geometry, options)\nsorl/thumbnail/engines/base.py ? in colorspace\n return self._colorspace(image, colorspace)\nsorl/thumbnail/engines/pil_engine.py ? in _colorspace\n return image.convert('RGB')\nPIL/Image.py ? in convert\n self.load()\nPIL/ImageFile.py ? in load\n \"(%d bytes not processed)\" % len(b))\n```\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\n\nimport base64\nimport imghdr\nimport six\nimport uuid\n\nfrom django.core.files.base import ContentFile\nfrom django.utils.encoding import smart_text\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom rest_framework import serializers\nfrom rest_framework.fields import ImageField\nfrom sorl.thumbnail import get_thumbnail\nfrom sorl.thumbnail.parsers import ThumbnailParseError\n\n\nclass NonNullCharField(serializers.CharField):\n \"\"\" Fix fo CharField so that '' is returned if the field value is None\n see https://github.com/tomchristie/django-rest-framework/pull/1665\n \"\"\"\n def from_native(self, value):\n if isinstance(value, six.string_types):\n return value\n if value is None:\n return u''\n return smart_text(value)\n\n\nclass NonNullURLField(NonNullCharField, serializers.URLField):\n pass\n\n\nclass Base64ImageField(ImageField):\n \"\"\" A django-rest-framework field for handling image-uploads through raw post data.\n It uses base64 for en-/decoding the contents of the file.\n Now also supports thumbnails of different sizes. See to_native() for more info.\n \"\"\"\n ALLOWED_IMAGE_TYPES = (\n 'gif',\n 'jpeg',\n 'jpg',\n 'png',\n )\n def from_native(self, base64_data):\n # Check if this is a base64 string\n if isinstance(base64_data, basestring):\n # Try to decode the file. Return validation error if it fails.\n try:\n decoded_file = base64.b64decode(base64_data)\n except TypeError:\n raise serializers.ValidationError(_(u\"Please upload a valid image.\"))\n\n # Generate file name:\n file_name = str(uuid.uuid4())[:12] # 12 characters are more than enough.\n # Get the file name extension:\n file_extension = self.get_file_extension(file_name, decoded_file)\n if file_extension not in self.ALLOWED_IMAGE_TYPES:\n raise serializers.ValidationError(\n _(u\"The type of the image couldn't been determined.\")\n )\n complete_file_name = file_name + \".\" + file_extension\n data = ContentFile(decoded_file, name=complete_file_name)\n else:\n data = base64_data\n\n return super(Base64ImageField, self).from_native(data)\n\n def to_native(self, value):\n \"\"\"\n :param value: A Base64ImageField object\n :return: a path to a thumbnail with a predetermined size, the default thumb\n OR\n a dict with a number of thumbnails, one of which is the default, the others being generated\n from the query string parameters, and finally the path to the original image keyed to\n \"original\".\n\n The extended functionality, allowing the generation of one or more thumbnails from the\n original image is triggered by including \"image_thumb_name\" in the query string. The value\n for image_thumb_name is a comma separated list of identifiers for the generated thumbs.\n The names must not be \"default\" or \"original\".\n\n For each thumb thus specified a size must be supplied as a query param on the form\n image_thumb_<name>_<dimension>\n where <name> is the name of the thumb specified as one of the values for image_thumb_name\n and <dimension> is one of \"width, \"height\" or \"max_size\". width and height must be an integer\n specifying that dimension in pixels. The image will be scaled correctly in the other\n dimension. max_size is width and height concatenated with an \"x\" and sets the maximum size\n allowed for the respective dimensions, while still maintaining the correct aspect ratio of\n the image.\n\n Example:\n the querystring\n ?image_thumb_name=big,small&image_thumb_small_width=90&image_thumb_big_max_size=300x200\n results in the following dict being returned:\n {\n 'original': '/full/path/to/original/image.png',\n 'default': '/full/path/to/default/thumbnail/image.png',\n 'small': '/full/path/to/small/thumbnail/image.png',\n 'big': '/full/path/to/big/thumbnail/image.png',\n }\n This dict will be converted as appropriate to JSON or XML\n\n NOTE: This special functionality works best when there is only one image field in a model.\n If there are more, things will still work (I think), but for each image all thumbs returned\n will have the same dimensions\n \"\"\"\n def get_thumb(request, name):\n if name not in [u'original', u'default']:\n try:\n width = request.GET.get('image_thumb_{}_width'.format(name))\n if width:\n return get_thumbnail(value, '{}'.format(width), quality=99)\n height = request.GET.get('image_thumb_{}_height'.format(name))\n if height:\n return get_thumbnail(value, 'x{}'.format(height), quality=99)\n # yes this is redundant...code is nearly identical with the width code above\n # but for clarity of function we keep them separate\n max_size = request.GET.get('image_thumb_{}_max_size'.format(name))\n if max_size:\n return get_thumbnail(value, '{}'.format(max_size), quality=99)\n except ThumbnailParseError:\n return None\n # no size specification matching the name found; give up\n return None\n\n if value:\n default_width = '191' # width of update images on akvo.org/seeithappen\n default_thumb = get_thumbnail(value, default_width, quality=99)\n try:\n request = self.context['request']\n except KeyError:\n return None\n # look for name(s) of thumb(s)\n image_thumb_name = request.GET.get('image_thumb_name')\n if image_thumb_name:\n names = image_thumb_name.split(',')\n thumbs = {u'original': value.url, u'default': default_thumb.url}\n for name in names:\n thumb = get_thumb(request, name)\n if thumb is not None:\n thumbs[name] = thumb.url\n return thumbs\n return default_thumb.url\n\n def get_file_extension(self, filename, decoded_file):\n extension = imghdr.what(filename, decoded_file)\n extension = \"jpg\" if extension == \"jpeg\" else extension\n return extension\n", "path": "akvo/rest/fields.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\n\nimport base64\nimport imghdr\nimport six\nimport uuid\n\nfrom django.core.files.base import ContentFile\nfrom django.utils.encoding import smart_text\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom rest_framework import serializers\nfrom rest_framework.fields import ImageField\nfrom sorl.thumbnail import get_thumbnail\nfrom sorl.thumbnail.parsers import ThumbnailParseError\n\n\nclass NonNullCharField(serializers.CharField):\n \"\"\" Fix fo CharField so that '' is returned if the field value is None\n see https://github.com/tomchristie/django-rest-framework/pull/1665\n \"\"\"\n def from_native(self, value):\n if isinstance(value, six.string_types):\n return value\n if value is None:\n return u''\n return smart_text(value)\n\n\nclass NonNullURLField(NonNullCharField, serializers.URLField):\n pass\n\n\nclass Base64ImageField(ImageField):\n \"\"\" A django-rest-framework field for handling image-uploads through raw post data.\n It uses base64 for en-/decoding the contents of the file.\n Now also supports thumbnails of different sizes. See to_native() for more info.\n \"\"\"\n ALLOWED_IMAGE_TYPES = (\n 'gif',\n 'jpeg',\n 'jpg',\n 'png',\n )\n def from_native(self, base64_data):\n # Check if this is a base64 string\n if isinstance(base64_data, basestring):\n # Try to decode the file. Return validation error if it fails.\n try:\n decoded_file = base64.b64decode(base64_data)\n except TypeError:\n raise serializers.ValidationError(_(u\"Please upload a valid image.\"))\n\n # Generate file name:\n file_name = str(uuid.uuid4())[:12] # 12 characters are more than enough.\n # Get the file name extension:\n file_extension = self.get_file_extension(file_name, decoded_file)\n if file_extension not in self.ALLOWED_IMAGE_TYPES:\n raise serializers.ValidationError(\n _(u\"The type of the image couldn't been determined.\")\n )\n complete_file_name = file_name + \".\" + file_extension\n data = ContentFile(decoded_file, name=complete_file_name)\n else:\n data = base64_data\n\n return super(Base64ImageField, self).from_native(data)\n\n def to_native(self, value):\n \"\"\"\n :param value: A Base64ImageField object\n :return: a path to a thumbnail with a predetermined size, the default thumb\n OR\n a dict with a number of thumbnails, one of which is the default, the others being generated\n from the query string parameters, and finally the path to the original image keyed to\n \"original\".\n\n The extended functionality, allowing the generation of one or more thumbnails from the\n original image is triggered by including \"image_thumb_name\" in the query string. The value\n for image_thumb_name is a comma separated list of identifiers for the generated thumbs.\n The names must not be \"default\" or \"original\".\n\n For each thumb thus specified a size must be supplied as a query param on the form\n image_thumb_<name>_<dimension>\n where <name> is the name of the thumb specified as one of the values for image_thumb_name\n and <dimension> is one of \"width, \"height\" or \"max_size\". width and height must be an integer\n specifying that dimension in pixels. The image will be scaled correctly in the other\n dimension. max_size is width and height concatenated with an \"x\" and sets the maximum size\n allowed for the respective dimensions, while still maintaining the correct aspect ratio of\n the image.\n\n Example:\n the querystring\n ?image_thumb_name=big,small&image_thumb_small_width=90&image_thumb_big_max_size=300x200\n results in the following dict being returned:\n {\n 'original': '/full/path/to/original/image.png',\n 'default': '/full/path/to/default/thumbnail/image.png',\n 'small': '/full/path/to/small/thumbnail/image.png',\n 'big': '/full/path/to/big/thumbnail/image.png',\n }\n This dict will be converted as appropriate to JSON or XML\n\n NOTE: This special functionality works best when there is only one image field in a model.\n If there are more, things will still work (I think), but for each image all thumbs returned\n will have the same dimensions\n \"\"\"\n def get_thumb(request, name):\n if name not in [u'original', u'default']:\n try:\n width = request.GET.get('image_thumb_{}_width'.format(name))\n if width:\n return get_thumbnail(value, '{}'.format(width), quality=99)\n height = request.GET.get('image_thumb_{}_height'.format(name))\n if height:\n return get_thumbnail(value, 'x{}'.format(height), quality=99)\n # yes this is redundant...code is nearly identical with the width code above\n # but for clarity of function we keep them separate\n max_size = request.GET.get('image_thumb_{}_max_size'.format(name))\n if max_size:\n return get_thumbnail(value, '{}'.format(max_size), quality=99)\n except (ThumbnailParseError, IOError):\n return None\n\n # no size specification matching the name found; give up\n return None\n\n if value:\n default_width = '191' # width of update images on akvo.org/seeithappen\n try:\n default_thumb = get_thumbnail(value, default_width, quality=99)\n request = self.context['request']\n except (ThumbnailParseError, IOError, KeyError):\n return None\n\n # look for name(s) of thumb(s)\n image_thumb_name = request.GET.get('image_thumb_name')\n if image_thumb_name:\n names = image_thumb_name.split(',')\n thumbs = {u'original': value.url, u'default': default_thumb.url}\n for name in names:\n thumb = get_thumb(request, name)\n if thumb is not None:\n thumbs[name] = thumb.url\n return thumbs\n return default_thumb.url\n\n def get_file_extension(self, filename, decoded_file):\n extension = imghdr.what(filename, decoded_file)\n extension = \"jpg\" if extension == \"jpeg\" else extension\n return extension\n", "path": "akvo/rest/fields.py"}]}
| 2,316 | 259 |
gh_patches_debug_30234
|
rasdani/github-patches
|
git_diff
|
OCA__stock-logistics-warehouse-983
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[13.0] stock_request error to create or selected product
I install stock_request but get error, at create new record or select product show this error, any idea??
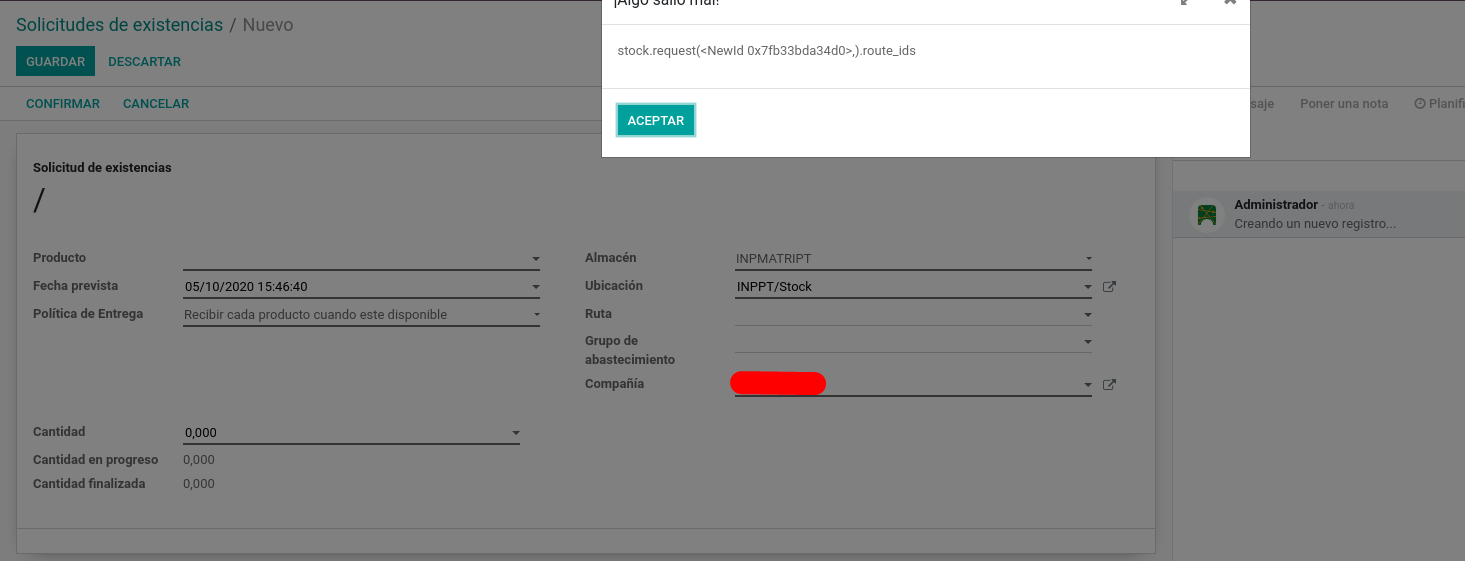
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `stock_request/models/stock_request_abstract.py`
Content:
```
1 # Copyright 2017-2020 ForgeFlow, S.L.
2 # License LGPL-3.0 or later (https://www.gnu.org/licenses/lgpl.html).
3
4 from odoo import _, api, fields, models
5 from odoo.exceptions import ValidationError
6
7
8 class StockRequest(models.AbstractModel):
9 _name = "stock.request.abstract"
10 _description = "Stock Request Template"
11 _inherit = ["mail.thread", "mail.activity.mixin"]
12
13 @api.model
14 def default_get(self, fields):
15 res = super(StockRequest, self).default_get(fields)
16 warehouse = None
17 if "warehouse_id" not in res and res.get("company_id"):
18 warehouse = self.env["stock.warehouse"].search(
19 [("company_id", "=", res["company_id"])], limit=1
20 )
21 if warehouse:
22 res["warehouse_id"] = warehouse.id
23 res["location_id"] = warehouse.lot_stock_id.id
24 return res
25
26 @api.depends(
27 "product_id",
28 "product_uom_id",
29 "product_uom_qty",
30 "product_id.product_tmpl_id.uom_id",
31 )
32 def _compute_product_qty(self):
33 for rec in self:
34 rec.product_qty = rec.product_uom_id._compute_quantity(
35 rec.product_uom_qty, rec.product_id.product_tmpl_id.uom_id
36 )
37
38 name = fields.Char("Name", copy=False, required=True, readonly=True, default="/")
39 warehouse_id = fields.Many2one(
40 "stock.warehouse", "Warehouse", ondelete="cascade", required=True
41 )
42 location_id = fields.Many2one(
43 "stock.location",
44 "Location",
45 domain=[("usage", "in", ["internal", "transit"])],
46 ondelete="cascade",
47 required=True,
48 )
49 product_id = fields.Many2one(
50 "product.product",
51 "Product",
52 domain=[("type", "in", ["product", "consu"])],
53 ondelete="cascade",
54 required=True,
55 )
56 allow_virtual_location = fields.Boolean(
57 related="company_id.stock_request_allow_virtual_loc", readonly=True
58 )
59 product_uom_id = fields.Many2one(
60 "uom.uom",
61 "Product Unit of Measure",
62 required=True,
63 default=lambda self: self._context.get("product_uom_id", False),
64 )
65 product_uom_qty = fields.Float(
66 "Quantity",
67 digits="Product Unit of Measure",
68 required=True,
69 help="Quantity, specified in the unit of measure indicated in the request.",
70 )
71 product_qty = fields.Float(
72 "Real Quantity",
73 compute="_compute_product_qty",
74 store=True,
75 copy=False,
76 digits="Product Unit of Measure",
77 help="Quantity in the default UoM of the product",
78 )
79 procurement_group_id = fields.Many2one(
80 "procurement.group",
81 "Procurement Group",
82 help="Moves created through this stock request will be put in this "
83 "procurement group. If none is given, the moves generated by "
84 "procurement rules will be grouped into one big picking.",
85 )
86 company_id = fields.Many2one(
87 "res.company", "Company", required=True, default=lambda self: self.env.company
88 )
89 route_id = fields.Many2one(
90 "stock.location.route",
91 string="Route",
92 domain="[('id', 'in', route_ids)]",
93 ondelete="restrict",
94 )
95
96 route_ids = fields.Many2many(
97 "stock.location.route",
98 string="Routes",
99 compute="_compute_route_ids",
100 readonly=True,
101 )
102
103 _sql_constraints = [
104 ("name_uniq", "unique(name, company_id)", "Name must be unique")
105 ]
106
107 @api.depends("product_id", "warehouse_id", "location_id")
108 def _compute_route_ids(self):
109 route_obj = self.env["stock.location.route"]
110 for wh in self.mapped("warehouse_id"):
111 wh_routes = route_obj.search([("warehouse_ids", "=", wh.id)])
112 for record in self.filtered(lambda r: r.warehouse_id == wh):
113 routes = route_obj
114 if record.product_id:
115 routes += record.product_id.mapped(
116 "route_ids"
117 ) | record.product_id.mapped("categ_id").mapped("total_route_ids")
118 if record.warehouse_id:
119 routes |= wh_routes
120 parents = record.get_parents().ids
121 record.route_ids = routes.filtered(
122 lambda r: any(p.location_id.id in parents for p in r.rule_ids)
123 )
124
125 def get_parents(self):
126 location = self.location_id
127 result = location
128 while location.location_id:
129 location = location.location_id
130 result |= location
131 return result
132
133 @api.constrains(
134 "company_id", "product_id", "warehouse_id", "location_id", "route_id"
135 )
136 def _check_company_constrains(self):
137 """ Check if the related models have the same company """
138 for rec in self:
139 if (
140 rec.product_id.company_id
141 and rec.product_id.company_id != rec.company_id
142 ):
143 raise ValidationError(
144 _(
145 "You have entered a product that is assigned "
146 "to another company."
147 )
148 )
149 if (
150 rec.location_id.company_id
151 and rec.location_id.company_id != rec.company_id
152 ):
153 raise ValidationError(
154 _(
155 "You have entered a location that is "
156 "assigned to another company."
157 )
158 )
159 if rec.warehouse_id.company_id != rec.company_id:
160 raise ValidationError(
161 _(
162 "You have entered a warehouse that is "
163 "assigned to another company."
164 )
165 )
166 if (
167 rec.route_id
168 and rec.route_id.company_id
169 and rec.route_id.company_id != rec.company_id
170 ):
171 raise ValidationError(
172 _(
173 "You have entered a route that is "
174 "assigned to another company."
175 )
176 )
177
178 @api.constrains("product_id")
179 def _check_product_uom(self):
180 """ Check if the UoM has the same category as the
181 product standard UoM """
182 if any(
183 request.product_id.uom_id.category_id != request.product_uom_id.category_id
184 for request in self
185 ):
186 raise ValidationError(
187 _(
188 "You have to select a product unit of measure in the "
189 "same category than the default unit "
190 "of measure of the product"
191 )
192 )
193
194 @api.constrains("product_qty")
195 def _check_qty(self):
196 for rec in self:
197 if rec.product_qty <= 0:
198 raise ValidationError(
199 _("Stock Request product quantity has to be strictly positive.")
200 )
201
202 @api.onchange("warehouse_id")
203 def onchange_warehouse_id(self):
204 """ Finds location id for changed warehouse. """
205 res = {"domain": {}}
206 if self._name == "stock.request" and self.order_id:
207 # When the stock request is created from an order the wh and
208 # location are taken from the order and we rely on it to change
209 # all request associated. Thus, no need to apply
210 # the onchange, as it could lead to inconsistencies.
211 return res
212 if self.warehouse_id:
213 loc_wh = self.location_id.get_warehouse()
214 if self.warehouse_id != loc_wh:
215 self.location_id = self.warehouse_id.lot_stock_id.id
216 if self.warehouse_id.company_id != self.company_id:
217 self.company_id = self.warehouse_id.company_id
218 return res
219
220 @api.onchange("location_id")
221 def onchange_location_id(self):
222 if self.location_id:
223 loc_wh = self.location_id.get_warehouse()
224 if loc_wh and self.warehouse_id != loc_wh:
225 self.warehouse_id = loc_wh
226 self.with_context(no_change_childs=True).onchange_warehouse_id()
227
228 @api.onchange("allow_virtual_location")
229 def onchange_allow_virtual_location(self):
230 if self.allow_virtual_location:
231 return {"domain": {"location_id": []}}
232
233 @api.onchange("company_id")
234 def onchange_company_id(self):
235 """ Sets a default warehouse when the company is changed and limits
236 the user selection of warehouses. """
237 if self.company_id and (
238 not self.warehouse_id or self.warehouse_id.company_id != self.company_id
239 ):
240 self.warehouse_id = self.env["stock.warehouse"].search(
241 [("company_id", "=", self.company_id.id)], limit=1
242 )
243 self.onchange_warehouse_id()
244
245 return {"domain": {"warehouse_id": [("company_id", "=", self.company_id.id)]}}
246
247 @api.onchange("product_id")
248 def onchange_product_id(self):
249 res = {"domain": {}}
250 if self.product_id:
251 self.product_uom_id = self.product_id.uom_id.id
252 res["domain"]["product_uom_id"] = [
253 ("category_id", "=", self.product_id.uom_id.category_id.id)
254 ]
255 return res
256 res["domain"]["product_uom_id"] = []
257 return res
258
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/stock_request/models/stock_request_abstract.py b/stock_request/models/stock_request_abstract.py
--- a/stock_request/models/stock_request_abstract.py
+++ b/stock_request/models/stock_request_abstract.py
@@ -107,20 +107,28 @@
@api.depends("product_id", "warehouse_id", "location_id")
def _compute_route_ids(self):
route_obj = self.env["stock.location.route"]
- for wh in self.mapped("warehouse_id"):
- wh_routes = route_obj.search([("warehouse_ids", "=", wh.id)])
- for record in self.filtered(lambda r: r.warehouse_id == wh):
- routes = route_obj
- if record.product_id:
- routes += record.product_id.mapped(
- "route_ids"
- ) | record.product_id.mapped("categ_id").mapped("total_route_ids")
- if record.warehouse_id:
- routes |= wh_routes
- parents = record.get_parents().ids
- record.route_ids = routes.filtered(
- lambda r: any(p.location_id.id in parents for p in r.rule_ids)
+ routes = route_obj.search(
+ [("warehouse_ids", "in", self.mapped("warehouse_id").ids)]
+ )
+ routes_by_warehouse = {}
+ for route in routes:
+ for warehouse in route.warehouse_ids:
+ routes_by_warehouse.setdefault(
+ warehouse.id, self.env["stock.location.route"]
)
+ routes_by_warehouse[warehouse.id] |= route
+ for record in self:
+ routes = route_obj
+ if record.product_id:
+ routes += record.product_id.mapped(
+ "route_ids"
+ ) | record.product_id.mapped("categ_id").mapped("total_route_ids")
+ if record.warehouse_id and routes_by_warehouse.get(record.warehouse_id.id):
+ routes |= routes_by_warehouse[record.warehouse_id.id]
+ parents = record.get_parents().ids
+ record.route_ids = routes.filtered(
+ lambda r: any(p.location_id.id in parents for p in r.rule_ids)
+ )
def get_parents(self):
location = self.location_id
|
{"golden_diff": "diff --git a/stock_request/models/stock_request_abstract.py b/stock_request/models/stock_request_abstract.py\n--- a/stock_request/models/stock_request_abstract.py\n+++ b/stock_request/models/stock_request_abstract.py\n@@ -107,20 +107,28 @@\n @api.depends(\"product_id\", \"warehouse_id\", \"location_id\")\n def _compute_route_ids(self):\n route_obj = self.env[\"stock.location.route\"]\n- for wh in self.mapped(\"warehouse_id\"):\n- wh_routes = route_obj.search([(\"warehouse_ids\", \"=\", wh.id)])\n- for record in self.filtered(lambda r: r.warehouse_id == wh):\n- routes = route_obj\n- if record.product_id:\n- routes += record.product_id.mapped(\n- \"route_ids\"\n- ) | record.product_id.mapped(\"categ_id\").mapped(\"total_route_ids\")\n- if record.warehouse_id:\n- routes |= wh_routes\n- parents = record.get_parents().ids\n- record.route_ids = routes.filtered(\n- lambda r: any(p.location_id.id in parents for p in r.rule_ids)\n+ routes = route_obj.search(\n+ [(\"warehouse_ids\", \"in\", self.mapped(\"warehouse_id\").ids)]\n+ )\n+ routes_by_warehouse = {}\n+ for route in routes:\n+ for warehouse in route.warehouse_ids:\n+ routes_by_warehouse.setdefault(\n+ warehouse.id, self.env[\"stock.location.route\"]\n )\n+ routes_by_warehouse[warehouse.id] |= route\n+ for record in self:\n+ routes = route_obj\n+ if record.product_id:\n+ routes += record.product_id.mapped(\n+ \"route_ids\"\n+ ) | record.product_id.mapped(\"categ_id\").mapped(\"total_route_ids\")\n+ if record.warehouse_id and routes_by_warehouse.get(record.warehouse_id.id):\n+ routes |= routes_by_warehouse[record.warehouse_id.id]\n+ parents = record.get_parents().ids\n+ record.route_ids = routes.filtered(\n+ lambda r: any(p.location_id.id in parents for p in r.rule_ids)\n+ )\n \n def get_parents(self):\n location = self.location_id\n", "issue": "[13.0] stock_request error to create or selected product\nI install stock_request but get error, at create new record or select product show this error, any idea??\r\n\r\n\n", "before_files": [{"content": "# Copyright 2017-2020 ForgeFlow, S.L.\n# License LGPL-3.0 or later (https://www.gnu.org/licenses/lgpl.html).\n\nfrom odoo import _, api, fields, models\nfrom odoo.exceptions import ValidationError\n\n\nclass StockRequest(models.AbstractModel):\n _name = \"stock.request.abstract\"\n _description = \"Stock Request Template\"\n _inherit = [\"mail.thread\", \"mail.activity.mixin\"]\n\n @api.model\n def default_get(self, fields):\n res = super(StockRequest, self).default_get(fields)\n warehouse = None\n if \"warehouse_id\" not in res and res.get(\"company_id\"):\n warehouse = self.env[\"stock.warehouse\"].search(\n [(\"company_id\", \"=\", res[\"company_id\"])], limit=1\n )\n if warehouse:\n res[\"warehouse_id\"] = warehouse.id\n res[\"location_id\"] = warehouse.lot_stock_id.id\n return res\n\n @api.depends(\n \"product_id\",\n \"product_uom_id\",\n \"product_uom_qty\",\n \"product_id.product_tmpl_id.uom_id\",\n )\n def _compute_product_qty(self):\n for rec in self:\n rec.product_qty = rec.product_uom_id._compute_quantity(\n rec.product_uom_qty, rec.product_id.product_tmpl_id.uom_id\n )\n\n name = fields.Char(\"Name\", copy=False, required=True, readonly=True, default=\"/\")\n warehouse_id = fields.Many2one(\n \"stock.warehouse\", \"Warehouse\", ondelete=\"cascade\", required=True\n )\n location_id = fields.Many2one(\n \"stock.location\",\n \"Location\",\n domain=[(\"usage\", \"in\", [\"internal\", \"transit\"])],\n ondelete=\"cascade\",\n required=True,\n )\n product_id = fields.Many2one(\n \"product.product\",\n \"Product\",\n domain=[(\"type\", \"in\", [\"product\", \"consu\"])],\n ondelete=\"cascade\",\n required=True,\n )\n allow_virtual_location = fields.Boolean(\n related=\"company_id.stock_request_allow_virtual_loc\", readonly=True\n )\n product_uom_id = fields.Many2one(\n \"uom.uom\",\n \"Product Unit of Measure\",\n required=True,\n default=lambda self: self._context.get(\"product_uom_id\", False),\n )\n product_uom_qty = fields.Float(\n \"Quantity\",\n digits=\"Product Unit of Measure\",\n required=True,\n help=\"Quantity, specified in the unit of measure indicated in the request.\",\n )\n product_qty = fields.Float(\n \"Real Quantity\",\n compute=\"_compute_product_qty\",\n store=True,\n copy=False,\n digits=\"Product Unit of Measure\",\n help=\"Quantity in the default UoM of the product\",\n )\n procurement_group_id = fields.Many2one(\n \"procurement.group\",\n \"Procurement Group\",\n help=\"Moves created through this stock request will be put in this \"\n \"procurement group. If none is given, the moves generated by \"\n \"procurement rules will be grouped into one big picking.\",\n )\n company_id = fields.Many2one(\n \"res.company\", \"Company\", required=True, default=lambda self: self.env.company\n )\n route_id = fields.Many2one(\n \"stock.location.route\",\n string=\"Route\",\n domain=\"[('id', 'in', route_ids)]\",\n ondelete=\"restrict\",\n )\n\n route_ids = fields.Many2many(\n \"stock.location.route\",\n string=\"Routes\",\n compute=\"_compute_route_ids\",\n readonly=True,\n )\n\n _sql_constraints = [\n (\"name_uniq\", \"unique(name, company_id)\", \"Name must be unique\")\n ]\n\n @api.depends(\"product_id\", \"warehouse_id\", \"location_id\")\n def _compute_route_ids(self):\n route_obj = self.env[\"stock.location.route\"]\n for wh in self.mapped(\"warehouse_id\"):\n wh_routes = route_obj.search([(\"warehouse_ids\", \"=\", wh.id)])\n for record in self.filtered(lambda r: r.warehouse_id == wh):\n routes = route_obj\n if record.product_id:\n routes += record.product_id.mapped(\n \"route_ids\"\n ) | record.product_id.mapped(\"categ_id\").mapped(\"total_route_ids\")\n if record.warehouse_id:\n routes |= wh_routes\n parents = record.get_parents().ids\n record.route_ids = routes.filtered(\n lambda r: any(p.location_id.id in parents for p in r.rule_ids)\n )\n\n def get_parents(self):\n location = self.location_id\n result = location\n while location.location_id:\n location = location.location_id\n result |= location\n return result\n\n @api.constrains(\n \"company_id\", \"product_id\", \"warehouse_id\", \"location_id\", \"route_id\"\n )\n def _check_company_constrains(self):\n \"\"\" Check if the related models have the same company \"\"\"\n for rec in self:\n if (\n rec.product_id.company_id\n and rec.product_id.company_id != rec.company_id\n ):\n raise ValidationError(\n _(\n \"You have entered a product that is assigned \"\n \"to another company.\"\n )\n )\n if (\n rec.location_id.company_id\n and rec.location_id.company_id != rec.company_id\n ):\n raise ValidationError(\n _(\n \"You have entered a location that is \"\n \"assigned to another company.\"\n )\n )\n if rec.warehouse_id.company_id != rec.company_id:\n raise ValidationError(\n _(\n \"You have entered a warehouse that is \"\n \"assigned to another company.\"\n )\n )\n if (\n rec.route_id\n and rec.route_id.company_id\n and rec.route_id.company_id != rec.company_id\n ):\n raise ValidationError(\n _(\n \"You have entered a route that is \"\n \"assigned to another company.\"\n )\n )\n\n @api.constrains(\"product_id\")\n def _check_product_uom(self):\n \"\"\" Check if the UoM has the same category as the\n product standard UoM \"\"\"\n if any(\n request.product_id.uom_id.category_id != request.product_uom_id.category_id\n for request in self\n ):\n raise ValidationError(\n _(\n \"You have to select a product unit of measure in the \"\n \"same category than the default unit \"\n \"of measure of the product\"\n )\n )\n\n @api.constrains(\"product_qty\")\n def _check_qty(self):\n for rec in self:\n if rec.product_qty <= 0:\n raise ValidationError(\n _(\"Stock Request product quantity has to be strictly positive.\")\n )\n\n @api.onchange(\"warehouse_id\")\n def onchange_warehouse_id(self):\n \"\"\" Finds location id for changed warehouse. \"\"\"\n res = {\"domain\": {}}\n if self._name == \"stock.request\" and self.order_id:\n # When the stock request is created from an order the wh and\n # location are taken from the order and we rely on it to change\n # all request associated. Thus, no need to apply\n # the onchange, as it could lead to inconsistencies.\n return res\n if self.warehouse_id:\n loc_wh = self.location_id.get_warehouse()\n if self.warehouse_id != loc_wh:\n self.location_id = self.warehouse_id.lot_stock_id.id\n if self.warehouse_id.company_id != self.company_id:\n self.company_id = self.warehouse_id.company_id\n return res\n\n @api.onchange(\"location_id\")\n def onchange_location_id(self):\n if self.location_id:\n loc_wh = self.location_id.get_warehouse()\n if loc_wh and self.warehouse_id != loc_wh:\n self.warehouse_id = loc_wh\n self.with_context(no_change_childs=True).onchange_warehouse_id()\n\n @api.onchange(\"allow_virtual_location\")\n def onchange_allow_virtual_location(self):\n if self.allow_virtual_location:\n return {\"domain\": {\"location_id\": []}}\n\n @api.onchange(\"company_id\")\n def onchange_company_id(self):\n \"\"\" Sets a default warehouse when the company is changed and limits\n the user selection of warehouses. \"\"\"\n if self.company_id and (\n not self.warehouse_id or self.warehouse_id.company_id != self.company_id\n ):\n self.warehouse_id = self.env[\"stock.warehouse\"].search(\n [(\"company_id\", \"=\", self.company_id.id)], limit=1\n )\n self.onchange_warehouse_id()\n\n return {\"domain\": {\"warehouse_id\": [(\"company_id\", \"=\", self.company_id.id)]}}\n\n @api.onchange(\"product_id\")\n def onchange_product_id(self):\n res = {\"domain\": {}}\n if self.product_id:\n self.product_uom_id = self.product_id.uom_id.id\n res[\"domain\"][\"product_uom_id\"] = [\n (\"category_id\", \"=\", self.product_id.uom_id.category_id.id)\n ]\n return res\n res[\"domain\"][\"product_uom_id\"] = []\n return res\n", "path": "stock_request/models/stock_request_abstract.py"}], "after_files": [{"content": "# Copyright 2017-2020 ForgeFlow, S.L.\n# License LGPL-3.0 or later (https://www.gnu.org/licenses/lgpl.html).\n\nfrom odoo import _, api, fields, models\nfrom odoo.exceptions import ValidationError\n\n\nclass StockRequest(models.AbstractModel):\n _name = \"stock.request.abstract\"\n _description = \"Stock Request Template\"\n _inherit = [\"mail.thread\", \"mail.activity.mixin\"]\n\n @api.model\n def default_get(self, fields):\n res = super(StockRequest, self).default_get(fields)\n warehouse = None\n if \"warehouse_id\" not in res and res.get(\"company_id\"):\n warehouse = self.env[\"stock.warehouse\"].search(\n [(\"company_id\", \"=\", res[\"company_id\"])], limit=1\n )\n if warehouse:\n res[\"warehouse_id\"] = warehouse.id\n res[\"location_id\"] = warehouse.lot_stock_id.id\n return res\n\n @api.depends(\n \"product_id\",\n \"product_uom_id\",\n \"product_uom_qty\",\n \"product_id.product_tmpl_id.uom_id\",\n )\n def _compute_product_qty(self):\n for rec in self:\n rec.product_qty = rec.product_uom_id._compute_quantity(\n rec.product_uom_qty, rec.product_id.product_tmpl_id.uom_id\n )\n\n name = fields.Char(\"Name\", copy=False, required=True, readonly=True, default=\"/\")\n warehouse_id = fields.Many2one(\n \"stock.warehouse\", \"Warehouse\", ondelete=\"cascade\", required=True\n )\n location_id = fields.Many2one(\n \"stock.location\",\n \"Location\",\n domain=[(\"usage\", \"in\", [\"internal\", \"transit\"])],\n ondelete=\"cascade\",\n required=True,\n )\n product_id = fields.Many2one(\n \"product.product\",\n \"Product\",\n domain=[(\"type\", \"in\", [\"product\", \"consu\"])],\n ondelete=\"cascade\",\n required=True,\n )\n allow_virtual_location = fields.Boolean(\n related=\"company_id.stock_request_allow_virtual_loc\", readonly=True\n )\n product_uom_id = fields.Many2one(\n \"uom.uom\",\n \"Product Unit of Measure\",\n required=True,\n default=lambda self: self._context.get(\"product_uom_id\", False),\n )\n product_uom_qty = fields.Float(\n \"Quantity\",\n digits=\"Product Unit of Measure\",\n required=True,\n help=\"Quantity, specified in the unit of measure indicated in the request.\",\n )\n product_qty = fields.Float(\n \"Real Quantity\",\n compute=\"_compute_product_qty\",\n store=True,\n copy=False,\n digits=\"Product Unit of Measure\",\n help=\"Quantity in the default UoM of the product\",\n )\n procurement_group_id = fields.Many2one(\n \"procurement.group\",\n \"Procurement Group\",\n help=\"Moves created through this stock request will be put in this \"\n \"procurement group. If none is given, the moves generated by \"\n \"procurement rules will be grouped into one big picking.\",\n )\n company_id = fields.Many2one(\n \"res.company\", \"Company\", required=True, default=lambda self: self.env.company\n )\n route_id = fields.Many2one(\n \"stock.location.route\",\n string=\"Route\",\n domain=\"[('id', 'in', route_ids)]\",\n ondelete=\"restrict\",\n )\n\n route_ids = fields.Many2many(\n \"stock.location.route\",\n string=\"Routes\",\n compute=\"_compute_route_ids\",\n readonly=True,\n )\n\n _sql_constraints = [\n (\"name_uniq\", \"unique(name, company_id)\", \"Name must be unique\")\n ]\n\n @api.depends(\"product_id\", \"warehouse_id\", \"location_id\")\n def _compute_route_ids(self):\n route_obj = self.env[\"stock.location.route\"]\n routes = route_obj.search(\n [(\"warehouse_ids\", \"in\", self.mapped(\"warehouse_id\").ids)]\n )\n routes_by_warehouse = {}\n for route in routes:\n for warehouse in route.warehouse_ids:\n routes_by_warehouse.setdefault(\n warehouse.id, self.env[\"stock.location.route\"]\n )\n routes_by_warehouse[warehouse.id] |= route\n for record in self:\n routes = route_obj\n if record.product_id:\n routes += record.product_id.mapped(\n \"route_ids\"\n ) | record.product_id.mapped(\"categ_id\").mapped(\"total_route_ids\")\n if record.warehouse_id and routes_by_warehouse.get(record.warehouse_id.id):\n routes |= routes_by_warehouse[record.warehouse_id.id]\n parents = record.get_parents().ids\n record.route_ids = routes.filtered(\n lambda r: any(p.location_id.id in parents for p in r.rule_ids)\n )\n\n def get_parents(self):\n location = self.location_id\n result = location\n while location.location_id:\n location = location.location_id\n result |= location\n return result\n\n @api.constrains(\n \"company_id\", \"product_id\", \"warehouse_id\", \"location_id\", \"route_id\"\n )\n def _check_company_constrains(self):\n \"\"\" Check if the related models have the same company \"\"\"\n for rec in self:\n if (\n rec.product_id.company_id\n and rec.product_id.company_id != rec.company_id\n ):\n raise ValidationError(\n _(\n \"You have entered a product that is assigned \"\n \"to another company.\"\n )\n )\n if (\n rec.location_id.company_id\n and rec.location_id.company_id != rec.company_id\n ):\n raise ValidationError(\n _(\n \"You have entered a location that is \"\n \"assigned to another company.\"\n )\n )\n if rec.warehouse_id.company_id != rec.company_id:\n raise ValidationError(\n _(\n \"You have entered a warehouse that is \"\n \"assigned to another company.\"\n )\n )\n if (\n rec.route_id\n and rec.route_id.company_id\n and rec.route_id.company_id != rec.company_id\n ):\n raise ValidationError(\n _(\n \"You have entered a route that is \"\n \"assigned to another company.\"\n )\n )\n\n @api.constrains(\"product_id\")\n def _check_product_uom(self):\n \"\"\" Check if the UoM has the same category as the\n product standard UoM \"\"\"\n if any(\n request.product_id.uom_id.category_id != request.product_uom_id.category_id\n for request in self\n ):\n raise ValidationError(\n _(\n \"You have to select a product unit of measure in the \"\n \"same category than the default unit \"\n \"of measure of the product\"\n )\n )\n\n @api.constrains(\"product_qty\")\n def _check_qty(self):\n for rec in self:\n if rec.product_qty <= 0:\n raise ValidationError(\n _(\"Stock Request product quantity has to be strictly positive.\")\n )\n\n @api.onchange(\"warehouse_id\")\n def onchange_warehouse_id(self):\n \"\"\" Finds location id for changed warehouse. \"\"\"\n res = {\"domain\": {}}\n if self._name == \"stock.request\" and self.order_id:\n # When the stock request is created from an order the wh and\n # location are taken from the order and we rely on it to change\n # all request associated. Thus, no need to apply\n # the onchange, as it could lead to inconsistencies.\n return res\n if self.warehouse_id:\n loc_wh = self.location_id.get_warehouse()\n if self.warehouse_id != loc_wh:\n self.location_id = self.warehouse_id.lot_stock_id.id\n if self.warehouse_id.company_id != self.company_id:\n self.company_id = self.warehouse_id.company_id\n return res\n\n @api.onchange(\"location_id\")\n def onchange_location_id(self):\n if self.location_id:\n loc_wh = self.location_id.get_warehouse()\n if loc_wh and self.warehouse_id != loc_wh:\n self.warehouse_id = loc_wh\n self.with_context(no_change_childs=True).onchange_warehouse_id()\n\n @api.onchange(\"allow_virtual_location\")\n def onchange_allow_virtual_location(self):\n if self.allow_virtual_location:\n return {\"domain\": {\"location_id\": []}}\n\n @api.onchange(\"company_id\")\n def onchange_company_id(self):\n \"\"\" Sets a default warehouse when the company is changed and limits\n the user selection of warehouses. \"\"\"\n if self.company_id and (\n not self.warehouse_id or self.warehouse_id.company_id != self.company_id\n ):\n self.warehouse_id = self.env[\"stock.warehouse\"].search(\n [(\"company_id\", \"=\", self.company_id.id)], limit=1\n )\n self.onchange_warehouse_id()\n\n return {\"domain\": {\"warehouse_id\": [(\"company_id\", \"=\", self.company_id.id)]}}\n\n @api.onchange(\"product_id\")\n def onchange_product_id(self):\n res = {\"domain\": {}}\n if self.product_id:\n self.product_uom_id = self.product_id.uom_id.id\n res[\"domain\"][\"product_uom_id\"] = [\n (\"category_id\", \"=\", self.product_id.uom_id.category_id.id)\n ]\n return res\n res[\"domain\"][\"product_uom_id\"] = []\n return res\n", "path": "stock_request/models/stock_request_abstract.py"}]}
| 2,992 | 484 |
gh_patches_debug_31387
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-8805
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unable to 'pip install ipython' with PyPy 2.6.1 on OS X
Attempting to `pip install ipython` with PyPy 2.6.1 on OS X fails due to being unable to install gnureadline:
```
Failed to build gnureadline
Installing collected packages: decorator, path.py, pickleshare, simplegeneric, ipython-genutils, traitlets, pexpect, appnope, gnureadline, ipython
Running setup.py install for gnureadline
Complete output from command /Users/rouge8/.virtualenvs/tmp-62491ef39875e400/bin/python -c "import setuptools, tokenize;__file__='/private/var/folders/tv/tqsxmfzd7l5_5ys1jq3496hr0000gp/T/pip-build-MSyBT_/gnureadline/setup.py';exec(compile(getattr(tokenize, 'open', open)(__file__).read().replace('\r\n', '\n'), __file__, 'exec'))" install --record /var/folders/tv/tqsxmfzd7l5_5ys1jq3496hr0000gp/T/pip-Yzq13m-record/install-record.txt --single-version-externally-managed --compile --install-headers /Users/rouge8/.virtualenvs/tmp-62491ef39875e400/include/site/python2.7/gnureadline:
running install
running build
running build_py
running egg_info
writing gnureadline.egg-info/PKG-INFO
writing dependency_links to gnureadline.egg-info/dependency_links.txt
writing top-level names to gnureadline.egg-info/top_level.txt
warning: manifest_maker: standard file '-c' not found
reading manifest file 'gnureadline.egg-info/SOURCES.txt'
reading manifest template 'MANIFEST.in'
writing manifest file 'gnureadline.egg-info/SOURCES.txt'
warning: build_py: byte-compiling is disabled, skipping.
running build_ext
building 'gnureadline' extension
cc -arch x86_64 -O2 -fPIC -Wimplicit -DHAVE_RL_CALLBACK -DHAVE_RL_CATCH_SIGNAL -DHAVE_RL_COMPLETION_APPEND_CHARACTER -DHAVE_RL_COMPLETION_DISPLAY_MATCHES_HOOK -DHAVE_RL_COMPLETION_MATCHES -DHAVE_RL_COMPLETION_SUPPRESS_APPEND -DHAVE_RL_PRE_INPUT_HOOK -I. -I/Users/rouge8/.virtualenvs/tmp-62491ef39875e400/include -c Modules/2.x/readline.c -o build/temp.macosx-10.10-x86_64-2.7/Modules/2.x/readline.o
Modules/2.x/readline.c:1057:21: error: use of undeclared identifier 'PyOS_InputHook'
rl_event_hook = PyOS_InputHook;
^
Modules/2.x/readline.c:1170:5: error: use of undeclared identifier 'PyOS_ReadlineFunctionPointer'
PyOS_ReadlineFunctionPointer = call_readline;
^
2 errors generated.
error: command 'cc' failed with exit status 1
```
Python version:
``` sh
$ python --version
Python 2.7.10 (f3ad1e1e1d6215e20d34bb65ab85ff9188c9f559, Sep 01 2015, 06:26:30)
[PyPy 2.6.1 with GCC 4.2.1 Compatible Apple LLVM 6.1.0 (clang-602.0.53)]
```
I was able to work around this by installing all of the IPython dependencies except for gnureadline and then running `pip install --no-deps ipython`, but obviously that's not ideal. :/
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 """Setup script for IPython.
4
5 Under Posix environments it works like a typical setup.py script.
6 Under Windows, the command sdist is not supported, since IPython
7 requires utilities which are not available under Windows."""
8
9 #-----------------------------------------------------------------------------
10 # Copyright (c) 2008-2011, IPython Development Team.
11 # Copyright (c) 2001-2007, Fernando Perez <[email protected]>
12 # Copyright (c) 2001, Janko Hauser <[email protected]>
13 # Copyright (c) 2001, Nathaniel Gray <[email protected]>
14 #
15 # Distributed under the terms of the Modified BSD License.
16 #
17 # The full license is in the file COPYING.rst, distributed with this software.
18 #-----------------------------------------------------------------------------
19
20 #-----------------------------------------------------------------------------
21 # Minimal Python version sanity check
22 #-----------------------------------------------------------------------------
23 from __future__ import print_function
24
25 import sys
26
27 # This check is also made in IPython/__init__, don't forget to update both when
28 # changing Python version requirements.
29 v = sys.version_info
30 if v[:2] < (2,7) or (v[0] >= 3 and v[:2] < (3,3)):
31 error = "ERROR: IPython requires Python version 2.7 or 3.3 or above."
32 print(error, file=sys.stderr)
33 sys.exit(1)
34
35 PY3 = (sys.version_info[0] >= 3)
36
37 # At least we're on the python version we need, move on.
38
39 #-------------------------------------------------------------------------------
40 # Imports
41 #-------------------------------------------------------------------------------
42
43 # Stdlib imports
44 import os
45 import shutil
46
47 from glob import glob
48
49 # BEFORE importing distutils, remove MANIFEST. distutils doesn't properly
50 # update it when the contents of directories change.
51 if os.path.exists('MANIFEST'): os.remove('MANIFEST')
52
53 from distutils.core import setup
54
55 # Our own imports
56 from setupbase import target_update
57
58 from setupbase import (
59 setup_args,
60 find_packages,
61 find_package_data,
62 check_package_data_first,
63 find_entry_points,
64 build_scripts_entrypt,
65 find_data_files,
66 git_prebuild,
67 install_symlinked,
68 install_lib_symlink,
69 install_scripts_for_symlink,
70 unsymlink,
71 )
72
73 isfile = os.path.isfile
74 pjoin = os.path.join
75
76 #-------------------------------------------------------------------------------
77 # Handle OS specific things
78 #-------------------------------------------------------------------------------
79
80 if os.name in ('nt','dos'):
81 os_name = 'windows'
82 else:
83 os_name = os.name
84
85 # Under Windows, 'sdist' has not been supported. Now that the docs build with
86 # Sphinx it might work, but let's not turn it on until someone confirms that it
87 # actually works.
88 if os_name == 'windows' and 'sdist' in sys.argv:
89 print('The sdist command is not available under Windows. Exiting.')
90 sys.exit(1)
91
92
93 #-------------------------------------------------------------------------------
94 # Things related to the IPython documentation
95 #-------------------------------------------------------------------------------
96
97 # update the manuals when building a source dist
98 if len(sys.argv) >= 2 and sys.argv[1] in ('sdist','bdist_rpm'):
99
100 # List of things to be updated. Each entry is a triplet of args for
101 # target_update()
102 to_update = [
103 ('docs/man/ipython.1.gz',
104 ['docs/man/ipython.1'],
105 'cd docs/man && gzip -9c ipython.1 > ipython.1.gz'),
106 ]
107
108
109 [ target_update(*t) for t in to_update ]
110
111 #---------------------------------------------------------------------------
112 # Find all the packages, package data, and data_files
113 #---------------------------------------------------------------------------
114
115 packages = find_packages()
116 package_data = find_package_data()
117
118 data_files = find_data_files()
119
120 setup_args['packages'] = packages
121 setup_args['package_data'] = package_data
122 setup_args['data_files'] = data_files
123
124 #---------------------------------------------------------------------------
125 # custom distutils commands
126 #---------------------------------------------------------------------------
127 # imports here, so they are after setuptools import if there was one
128 from distutils.command.sdist import sdist
129 from distutils.command.upload import upload
130
131 class UploadWindowsInstallers(upload):
132
133 description = "Upload Windows installers to PyPI (only used from tools/release_windows.py)"
134 user_options = upload.user_options + [
135 ('files=', 'f', 'exe file (or glob) to upload')
136 ]
137 def initialize_options(self):
138 upload.initialize_options(self)
139 meta = self.distribution.metadata
140 base = '{name}-{version}'.format(
141 name=meta.get_name(),
142 version=meta.get_version()
143 )
144 self.files = os.path.join('dist', '%s.*.exe' % base)
145
146 def run(self):
147 for dist_file in glob(self.files):
148 self.upload_file('bdist_wininst', 'any', dist_file)
149
150 setup_args['cmdclass'] = {
151 'build_py': \
152 check_package_data_first(git_prebuild('IPython')),
153 'sdist' : git_prebuild('IPython', sdist),
154 'upload_wininst' : UploadWindowsInstallers,
155 'symlink': install_symlinked,
156 'install_lib_symlink': install_lib_symlink,
157 'install_scripts_sym': install_scripts_for_symlink,
158 'unsymlink': unsymlink,
159 }
160
161
162 #---------------------------------------------------------------------------
163 # Handle scripts, dependencies, and setuptools specific things
164 #---------------------------------------------------------------------------
165
166 # For some commands, use setuptools. Note that we do NOT list install here!
167 # If you want a setuptools-enhanced install, just run 'setupegg.py install'
168 needs_setuptools = set(('develop', 'release', 'bdist_egg', 'bdist_rpm',
169 'bdist', 'bdist_dumb', 'bdist_wininst', 'bdist_wheel',
170 'egg_info', 'easy_install', 'upload', 'install_egg_info',
171 ))
172
173 if len(needs_setuptools.intersection(sys.argv)) > 0:
174 import setuptools
175
176 # This dict is used for passing extra arguments that are setuptools
177 # specific to setup
178 setuptools_extra_args = {}
179
180 # setuptools requirements
181
182 extras_require = dict(
183 parallel = ['ipyparallel'],
184 qtconsole = ['qtconsole'],
185 doc = ['Sphinx>=1.1', 'numpydoc'],
186 test = ['nose>=0.10.1', 'requests', 'testpath'],
187 terminal = [],
188 kernel = ['ipykernel'],
189 nbformat = ['nbformat'],
190 notebook = ['notebook'],
191 nbconvert = ['nbconvert'],
192 )
193 install_requires = [
194 'decorator',
195 'pickleshare',
196 'simplegeneric>0.8',
197 'traitlets',
198 ]
199
200 # Platform-specific dependencies:
201 # This is the correct way to specify these,
202 # but requires pip >= 6. pip < 6 ignores these.
203 extras_require.update({
204 ':sys_platform != "win32"': ['pexpect'],
205 ':sys_platform == "darwin"': ['appnope', 'gnureadline'],
206 'terminal:sys_platform == "win32"': ['pyreadline>=2'],
207 'test:python_version == "2.7"': ['mock'],
208 })
209 # FIXME: re-specify above platform dependencies for pip < 6
210 # These would result in non-portable bdists.
211 if not any(arg.startswith('bdist') for arg in sys.argv):
212 if sys.version_info < (3, 3):
213 extras_require['test'].append('mock')
214
215 if sys.platform == 'darwin':
216 install_requires.extend(['appnope', 'gnureadline'])
217
218 if sys.platform.startswith('win'):
219 extras_require['terminal'].append('pyreadline>=2.0')
220 else:
221 install_requires.append('pexpect')
222
223 everything = set()
224 for key, deps in extras_require.items():
225 if ':' not in key:
226 everything.update(deps)
227 extras_require['all'] = everything
228
229 if 'setuptools' in sys.modules:
230 setuptools_extra_args['zip_safe'] = False
231 setuptools_extra_args['entry_points'] = {
232 'console_scripts': find_entry_points(),
233 'pygments.lexers': [
234 'ipythonconsole = IPython.lib.lexers:IPythonConsoleLexer',
235 'ipython = IPython.lib.lexers:IPythonLexer',
236 'ipython3 = IPython.lib.lexers:IPython3Lexer',
237 ],
238 }
239 setup_args['extras_require'] = extras_require
240 requires = setup_args['install_requires'] = install_requires
241
242 # Script to be run by the windows binary installer after the default setup
243 # routine, to add shortcuts and similar windows-only things. Windows
244 # post-install scripts MUST reside in the scripts/ dir, otherwise distutils
245 # doesn't find them.
246 if 'bdist_wininst' in sys.argv:
247 if len(sys.argv) > 2 and \
248 ('sdist' in sys.argv or 'bdist_rpm' in sys.argv):
249 print("ERROR: bdist_wininst must be run alone. Exiting.", file=sys.stderr)
250 sys.exit(1)
251 setup_args['data_files'].append(
252 ['Scripts', ('scripts/ipython.ico', 'scripts/ipython_nb.ico')])
253 setup_args['scripts'] = [pjoin('scripts','ipython_win_post_install.py')]
254 setup_args['options'] = {"bdist_wininst":
255 {"install_script":
256 "ipython_win_post_install.py"}}
257
258 else:
259 # scripts has to be a non-empty list, or install_scripts isn't called
260 setup_args['scripts'] = [e.split('=')[0].strip() for e in find_entry_points()]
261
262 setup_args['cmdclass']['build_scripts'] = build_scripts_entrypt
263
264 #---------------------------------------------------------------------------
265 # Do the actual setup now
266 #---------------------------------------------------------------------------
267
268 setup_args.update(setuptools_extra_args)
269
270 def main():
271 setup(**setup_args)
272
273 if __name__ == '__main__':
274 main()
275
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -200,9 +200,11 @@
# Platform-specific dependencies:
# This is the correct way to specify these,
# but requires pip >= 6. pip < 6 ignores these.
+
extras_require.update({
':sys_platform != "win32"': ['pexpect'],
- ':sys_platform == "darwin"': ['appnope', 'gnureadline'],
+ ':sys_platform == "darwin"': ['appnope'],
+ ':sys_platform == "darwin" and platform_python_implementation == "CPython"': ['gnureadline'],
'terminal:sys_platform == "win32"': ['pyreadline>=2'],
'test:python_version == "2.7"': ['mock'],
})
@@ -213,12 +215,30 @@
extras_require['test'].append('mock')
if sys.platform == 'darwin':
- install_requires.extend(['appnope', 'gnureadline'])
+ install_requires.extend(['appnope'])
+ have_readline = False
+ try:
+ import readline
+ except ImportError:
+ pass
+ else:
+ if 'libedit' not in readline.__doc__:
+ have_readline = True
+ if not have_readline:
+ install_requires.extend(['gnureadline'])
if sys.platform.startswith('win'):
extras_require['terminal'].append('pyreadline>=2.0')
else:
install_requires.append('pexpect')
+
+ # workaround pypa/setuptools#147, where setuptools misspells
+ # platform_python_implementation as python_implementation
+ if 'setuptools' in sys.modules:
+ for key in list(extras_require):
+ if 'platform_python_implementation' in key:
+ new_key = key.replace('platform_python_implementation', 'python_implementation')
+ extras_require[new_key] = extras_require.pop(key)
everything = set()
for key, deps in extras_require.items():
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -200,9 +200,11 @@\n # Platform-specific dependencies:\n # This is the correct way to specify these,\n # but requires pip >= 6. pip < 6 ignores these.\n+\n extras_require.update({\n ':sys_platform != \"win32\"': ['pexpect'],\n- ':sys_platform == \"darwin\"': ['appnope', 'gnureadline'],\n+ ':sys_platform == \"darwin\"': ['appnope'],\n+ ':sys_platform == \"darwin\" and platform_python_implementation == \"CPython\"': ['gnureadline'],\n 'terminal:sys_platform == \"win32\"': ['pyreadline>=2'],\n 'test:python_version == \"2.7\"': ['mock'],\n })\n@@ -213,12 +215,30 @@\n extras_require['test'].append('mock')\n \n if sys.platform == 'darwin':\n- install_requires.extend(['appnope', 'gnureadline'])\n+ install_requires.extend(['appnope'])\n+ have_readline = False\n+ try:\n+ import readline\n+ except ImportError:\n+ pass\n+ else:\n+ if 'libedit' not in readline.__doc__:\n+ have_readline = True\n+ if not have_readline:\n+ install_requires.extend(['gnureadline'])\n \n if sys.platform.startswith('win'):\n extras_require['terminal'].append('pyreadline>=2.0')\n else:\n install_requires.append('pexpect')\n+ \n+ # workaround pypa/setuptools#147, where setuptools misspells\n+ # platform_python_implementation as python_implementation\n+ if 'setuptools' in sys.modules:\n+ for key in list(extras_require):\n+ if 'platform_python_implementation' in key:\n+ new_key = key.replace('platform_python_implementation', 'python_implementation')\n+ extras_require[new_key] = extras_require.pop(key)\n \n everything = set()\n for key, deps in extras_require.items():\n", "issue": "Unable to 'pip install ipython' with PyPy 2.6.1 on OS X\nAttempting to `pip install ipython` with PyPy 2.6.1 on OS X fails due to being unable to install gnureadline:\n\n```\nFailed to build gnureadline\nInstalling collected packages: decorator, path.py, pickleshare, simplegeneric, ipython-genutils, traitlets, pexpect, appnope, gnureadline, ipython\n Running setup.py install for gnureadline\n Complete output from command /Users/rouge8/.virtualenvs/tmp-62491ef39875e400/bin/python -c \"import setuptools, tokenize;__file__='/private/var/folders/tv/tqsxmfzd7l5_5ys1jq3496hr0000gp/T/pip-build-MSyBT_/gnureadline/setup.py';exec(compile(getattr(tokenize, 'open', open)(__file__).read().replace('\\r\\n', '\\n'), __file__, 'exec'))\" install --record /var/folders/tv/tqsxmfzd7l5_5ys1jq3496hr0000gp/T/pip-Yzq13m-record/install-record.txt --single-version-externally-managed --compile --install-headers /Users/rouge8/.virtualenvs/tmp-62491ef39875e400/include/site/python2.7/gnureadline:\n running install\n running build\n running build_py\n running egg_info\n writing gnureadline.egg-info/PKG-INFO\n writing dependency_links to gnureadline.egg-info/dependency_links.txt\n writing top-level names to gnureadline.egg-info/top_level.txt\n warning: manifest_maker: standard file '-c' not found\n\n reading manifest file 'gnureadline.egg-info/SOURCES.txt'\n reading manifest template 'MANIFEST.in'\n writing manifest file 'gnureadline.egg-info/SOURCES.txt'\n warning: build_py: byte-compiling is disabled, skipping.\n\n running build_ext\n building 'gnureadline' extension\n cc -arch x86_64 -O2 -fPIC -Wimplicit -DHAVE_RL_CALLBACK -DHAVE_RL_CATCH_SIGNAL -DHAVE_RL_COMPLETION_APPEND_CHARACTER -DHAVE_RL_COMPLETION_DISPLAY_MATCHES_HOOK -DHAVE_RL_COMPLETION_MATCHES -DHAVE_RL_COMPLETION_SUPPRESS_APPEND -DHAVE_RL_PRE_INPUT_HOOK -I. -I/Users/rouge8/.virtualenvs/tmp-62491ef39875e400/include -c Modules/2.x/readline.c -o build/temp.macosx-10.10-x86_64-2.7/Modules/2.x/readline.o\n Modules/2.x/readline.c:1057:21: error: use of undeclared identifier 'PyOS_InputHook'\n rl_event_hook = PyOS_InputHook;\n ^\n Modules/2.x/readline.c:1170:5: error: use of undeclared identifier 'PyOS_ReadlineFunctionPointer'\n PyOS_ReadlineFunctionPointer = call_readline;\n ^\n 2 errors generated.\n error: command 'cc' failed with exit status 1\n```\n\nPython version:\n\n``` sh\n$ python --version\nPython 2.7.10 (f3ad1e1e1d6215e20d34bb65ab85ff9188c9f559, Sep 01 2015, 06:26:30)\n[PyPy 2.6.1 with GCC 4.2.1 Compatible Apple LLVM 6.1.0 (clang-602.0.53)]\n```\n\nI was able to work around this by installing all of the IPython dependencies except for gnureadline and then running `pip install --no-deps ipython`, but obviously that's not ideal. :/\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"Setup script for IPython.\n\nUnder Posix environments it works like a typical setup.py script.\nUnder Windows, the command sdist is not supported, since IPython\nrequires utilities which are not available under Windows.\"\"\"\n\n#-----------------------------------------------------------------------------\n# Copyright (c) 2008-2011, IPython Development Team.\n# Copyright (c) 2001-2007, Fernando Perez <[email protected]>\n# Copyright (c) 2001, Janko Hauser <[email protected]>\n# Copyright (c) 2001, Nathaniel Gray <[email protected]>\n#\n# Distributed under the terms of the Modified BSD License.\n#\n# The full license is in the file COPYING.rst, distributed with this software.\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Minimal Python version sanity check\n#-----------------------------------------------------------------------------\nfrom __future__ import print_function\n\nimport sys\n\n# This check is also made in IPython/__init__, don't forget to update both when\n# changing Python version requirements.\nv = sys.version_info\nif v[:2] < (2,7) or (v[0] >= 3 and v[:2] < (3,3)):\n error = \"ERROR: IPython requires Python version 2.7 or 3.3 or above.\"\n print(error, file=sys.stderr)\n sys.exit(1)\n\nPY3 = (sys.version_info[0] >= 3)\n\n# At least we're on the python version we need, move on.\n\n#-------------------------------------------------------------------------------\n# Imports\n#-------------------------------------------------------------------------------\n\n# Stdlib imports\nimport os\nimport shutil\n\nfrom glob import glob\n\n# BEFORE importing distutils, remove MANIFEST. distutils doesn't properly\n# update it when the contents of directories change.\nif os.path.exists('MANIFEST'): os.remove('MANIFEST')\n\nfrom distutils.core import setup\n\n# Our own imports\nfrom setupbase import target_update\n\nfrom setupbase import (\n setup_args,\n find_packages,\n find_package_data,\n check_package_data_first,\n find_entry_points,\n build_scripts_entrypt,\n find_data_files,\n git_prebuild,\n install_symlinked,\n install_lib_symlink,\n install_scripts_for_symlink,\n unsymlink,\n)\n\nisfile = os.path.isfile\npjoin = os.path.join\n\n#-------------------------------------------------------------------------------\n# Handle OS specific things\n#-------------------------------------------------------------------------------\n\nif os.name in ('nt','dos'):\n os_name = 'windows'\nelse:\n os_name = os.name\n\n# Under Windows, 'sdist' has not been supported. Now that the docs build with\n# Sphinx it might work, but let's not turn it on until someone confirms that it\n# actually works.\nif os_name == 'windows' and 'sdist' in sys.argv:\n print('The sdist command is not available under Windows. Exiting.')\n sys.exit(1)\n\n\n#-------------------------------------------------------------------------------\n# Things related to the IPython documentation\n#-------------------------------------------------------------------------------\n\n# update the manuals when building a source dist\nif len(sys.argv) >= 2 and sys.argv[1] in ('sdist','bdist_rpm'):\n\n # List of things to be updated. Each entry is a triplet of args for\n # target_update()\n to_update = [\n ('docs/man/ipython.1.gz',\n ['docs/man/ipython.1'],\n 'cd docs/man && gzip -9c ipython.1 > ipython.1.gz'),\n ]\n\n\n [ target_update(*t) for t in to_update ]\n\n#---------------------------------------------------------------------------\n# Find all the packages, package data, and data_files\n#---------------------------------------------------------------------------\n\npackages = find_packages()\npackage_data = find_package_data()\n\ndata_files = find_data_files()\n\nsetup_args['packages'] = packages\nsetup_args['package_data'] = package_data\nsetup_args['data_files'] = data_files\n\n#---------------------------------------------------------------------------\n# custom distutils commands\n#---------------------------------------------------------------------------\n# imports here, so they are after setuptools import if there was one\nfrom distutils.command.sdist import sdist\nfrom distutils.command.upload import upload\n\nclass UploadWindowsInstallers(upload):\n\n description = \"Upload Windows installers to PyPI (only used from tools/release_windows.py)\"\n user_options = upload.user_options + [\n ('files=', 'f', 'exe file (or glob) to upload')\n ]\n def initialize_options(self):\n upload.initialize_options(self)\n meta = self.distribution.metadata\n base = '{name}-{version}'.format(\n name=meta.get_name(),\n version=meta.get_version()\n )\n self.files = os.path.join('dist', '%s.*.exe' % base)\n\n def run(self):\n for dist_file in glob(self.files):\n self.upload_file('bdist_wininst', 'any', dist_file)\n\nsetup_args['cmdclass'] = {\n 'build_py': \\\n check_package_data_first(git_prebuild('IPython')),\n 'sdist' : git_prebuild('IPython', sdist),\n 'upload_wininst' : UploadWindowsInstallers,\n 'symlink': install_symlinked,\n 'install_lib_symlink': install_lib_symlink,\n 'install_scripts_sym': install_scripts_for_symlink,\n 'unsymlink': unsymlink,\n}\n\n\n#---------------------------------------------------------------------------\n# Handle scripts, dependencies, and setuptools specific things\n#---------------------------------------------------------------------------\n\n# For some commands, use setuptools. Note that we do NOT list install here!\n# If you want a setuptools-enhanced install, just run 'setupegg.py install'\nneeds_setuptools = set(('develop', 'release', 'bdist_egg', 'bdist_rpm',\n 'bdist', 'bdist_dumb', 'bdist_wininst', 'bdist_wheel',\n 'egg_info', 'easy_install', 'upload', 'install_egg_info',\n ))\n\nif len(needs_setuptools.intersection(sys.argv)) > 0:\n import setuptools\n\n# This dict is used for passing extra arguments that are setuptools\n# specific to setup\nsetuptools_extra_args = {}\n\n# setuptools requirements\n\nextras_require = dict(\n parallel = ['ipyparallel'],\n qtconsole = ['qtconsole'],\n doc = ['Sphinx>=1.1', 'numpydoc'],\n test = ['nose>=0.10.1', 'requests', 'testpath'],\n terminal = [],\n kernel = ['ipykernel'],\n nbformat = ['nbformat'],\n notebook = ['notebook'],\n nbconvert = ['nbconvert'],\n)\ninstall_requires = [\n 'decorator',\n 'pickleshare',\n 'simplegeneric>0.8',\n 'traitlets',\n]\n\n# Platform-specific dependencies:\n# This is the correct way to specify these,\n# but requires pip >= 6. pip < 6 ignores these.\nextras_require.update({\n ':sys_platform != \"win32\"': ['pexpect'],\n ':sys_platform == \"darwin\"': ['appnope', 'gnureadline'],\n 'terminal:sys_platform == \"win32\"': ['pyreadline>=2'],\n 'test:python_version == \"2.7\"': ['mock'],\n})\n# FIXME: re-specify above platform dependencies for pip < 6\n# These would result in non-portable bdists.\nif not any(arg.startswith('bdist') for arg in sys.argv):\n if sys.version_info < (3, 3):\n extras_require['test'].append('mock')\n\n if sys.platform == 'darwin':\n install_requires.extend(['appnope', 'gnureadline'])\n\n if sys.platform.startswith('win'):\n extras_require['terminal'].append('pyreadline>=2.0')\n else:\n install_requires.append('pexpect')\n\neverything = set()\nfor key, deps in extras_require.items():\n if ':' not in key:\n everything.update(deps)\nextras_require['all'] = everything\n\nif 'setuptools' in sys.modules:\n setuptools_extra_args['zip_safe'] = False\n setuptools_extra_args['entry_points'] = {\n 'console_scripts': find_entry_points(),\n 'pygments.lexers': [\n 'ipythonconsole = IPython.lib.lexers:IPythonConsoleLexer',\n 'ipython = IPython.lib.lexers:IPythonLexer',\n 'ipython3 = IPython.lib.lexers:IPython3Lexer',\n ],\n }\n setup_args['extras_require'] = extras_require\n requires = setup_args['install_requires'] = install_requires\n\n # Script to be run by the windows binary installer after the default setup\n # routine, to add shortcuts and similar windows-only things. Windows\n # post-install scripts MUST reside in the scripts/ dir, otherwise distutils\n # doesn't find them.\n if 'bdist_wininst' in sys.argv:\n if len(sys.argv) > 2 and \\\n ('sdist' in sys.argv or 'bdist_rpm' in sys.argv):\n print(\"ERROR: bdist_wininst must be run alone. Exiting.\", file=sys.stderr)\n sys.exit(1)\n setup_args['data_files'].append(\n ['Scripts', ('scripts/ipython.ico', 'scripts/ipython_nb.ico')])\n setup_args['scripts'] = [pjoin('scripts','ipython_win_post_install.py')]\n setup_args['options'] = {\"bdist_wininst\":\n {\"install_script\":\n \"ipython_win_post_install.py\"}}\n\nelse:\n # scripts has to be a non-empty list, or install_scripts isn't called\n setup_args['scripts'] = [e.split('=')[0].strip() for e in find_entry_points()]\n\n setup_args['cmdclass']['build_scripts'] = build_scripts_entrypt\n\n#---------------------------------------------------------------------------\n# Do the actual setup now\n#---------------------------------------------------------------------------\n\nsetup_args.update(setuptools_extra_args)\n\ndef main():\n setup(**setup_args)\n\nif __name__ == '__main__':\n main()\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"Setup script for IPython.\n\nUnder Posix environments it works like a typical setup.py script.\nUnder Windows, the command sdist is not supported, since IPython\nrequires utilities which are not available under Windows.\"\"\"\n\n#-----------------------------------------------------------------------------\n# Copyright (c) 2008-2011, IPython Development Team.\n# Copyright (c) 2001-2007, Fernando Perez <[email protected]>\n# Copyright (c) 2001, Janko Hauser <[email protected]>\n# Copyright (c) 2001, Nathaniel Gray <[email protected]>\n#\n# Distributed under the terms of the Modified BSD License.\n#\n# The full license is in the file COPYING.rst, distributed with this software.\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Minimal Python version sanity check\n#-----------------------------------------------------------------------------\nfrom __future__ import print_function\n\nimport sys\n\n# This check is also made in IPython/__init__, don't forget to update both when\n# changing Python version requirements.\nv = sys.version_info\nif v[:2] < (2,7) or (v[0] >= 3 and v[:2] < (3,3)):\n error = \"ERROR: IPython requires Python version 2.7 or 3.3 or above.\"\n print(error, file=sys.stderr)\n sys.exit(1)\n\nPY3 = (sys.version_info[0] >= 3)\n\n# At least we're on the python version we need, move on.\n\n#-------------------------------------------------------------------------------\n# Imports\n#-------------------------------------------------------------------------------\n\n# Stdlib imports\nimport os\nimport shutil\n\nfrom glob import glob\n\n# BEFORE importing distutils, remove MANIFEST. distutils doesn't properly\n# update it when the contents of directories change.\nif os.path.exists('MANIFEST'): os.remove('MANIFEST')\n\nfrom distutils.core import setup\n\n# Our own imports\nfrom setupbase import target_update\n\nfrom setupbase import (\n setup_args,\n find_packages,\n find_package_data,\n check_package_data_first,\n find_entry_points,\n build_scripts_entrypt,\n find_data_files,\n git_prebuild,\n install_symlinked,\n install_lib_symlink,\n install_scripts_for_symlink,\n unsymlink,\n)\n\nisfile = os.path.isfile\npjoin = os.path.join\n\n#-------------------------------------------------------------------------------\n# Handle OS specific things\n#-------------------------------------------------------------------------------\n\nif os.name in ('nt','dos'):\n os_name = 'windows'\nelse:\n os_name = os.name\n\n# Under Windows, 'sdist' has not been supported. Now that the docs build with\n# Sphinx it might work, but let's not turn it on until someone confirms that it\n# actually works.\nif os_name == 'windows' and 'sdist' in sys.argv:\n print('The sdist command is not available under Windows. Exiting.')\n sys.exit(1)\n\n\n#-------------------------------------------------------------------------------\n# Things related to the IPython documentation\n#-------------------------------------------------------------------------------\n\n# update the manuals when building a source dist\nif len(sys.argv) >= 2 and sys.argv[1] in ('sdist','bdist_rpm'):\n\n # List of things to be updated. Each entry is a triplet of args for\n # target_update()\n to_update = [\n ('docs/man/ipython.1.gz',\n ['docs/man/ipython.1'],\n 'cd docs/man && gzip -9c ipython.1 > ipython.1.gz'),\n ]\n\n\n [ target_update(*t) for t in to_update ]\n\n#---------------------------------------------------------------------------\n# Find all the packages, package data, and data_files\n#---------------------------------------------------------------------------\n\npackages = find_packages()\npackage_data = find_package_data()\n\ndata_files = find_data_files()\n\nsetup_args['packages'] = packages\nsetup_args['package_data'] = package_data\nsetup_args['data_files'] = data_files\n\n#---------------------------------------------------------------------------\n# custom distutils commands\n#---------------------------------------------------------------------------\n# imports here, so they are after setuptools import if there was one\nfrom distutils.command.sdist import sdist\nfrom distutils.command.upload import upload\n\nclass UploadWindowsInstallers(upload):\n\n description = \"Upload Windows installers to PyPI (only used from tools/release_windows.py)\"\n user_options = upload.user_options + [\n ('files=', 'f', 'exe file (or glob) to upload')\n ]\n def initialize_options(self):\n upload.initialize_options(self)\n meta = self.distribution.metadata\n base = '{name}-{version}'.format(\n name=meta.get_name(),\n version=meta.get_version()\n )\n self.files = os.path.join('dist', '%s.*.exe' % base)\n\n def run(self):\n for dist_file in glob(self.files):\n self.upload_file('bdist_wininst', 'any', dist_file)\n\nsetup_args['cmdclass'] = {\n 'build_py': \\\n check_package_data_first(git_prebuild('IPython')),\n 'sdist' : git_prebuild('IPython', sdist),\n 'upload_wininst' : UploadWindowsInstallers,\n 'symlink': install_symlinked,\n 'install_lib_symlink': install_lib_symlink,\n 'install_scripts_sym': install_scripts_for_symlink,\n 'unsymlink': unsymlink,\n}\n\n\n#---------------------------------------------------------------------------\n# Handle scripts, dependencies, and setuptools specific things\n#---------------------------------------------------------------------------\n\n# For some commands, use setuptools. Note that we do NOT list install here!\n# If you want a setuptools-enhanced install, just run 'setupegg.py install'\nneeds_setuptools = set(('develop', 'release', 'bdist_egg', 'bdist_rpm',\n 'bdist', 'bdist_dumb', 'bdist_wininst', 'bdist_wheel',\n 'egg_info', 'easy_install', 'upload', 'install_egg_info',\n ))\n\nif len(needs_setuptools.intersection(sys.argv)) > 0:\n import setuptools\n\n# This dict is used for passing extra arguments that are setuptools\n# specific to setup\nsetuptools_extra_args = {}\n\n# setuptools requirements\n\nextras_require = dict(\n parallel = ['ipyparallel'],\n qtconsole = ['qtconsole'],\n doc = ['Sphinx>=1.1', 'numpydoc'],\n test = ['nose>=0.10.1', 'requests', 'testpath'],\n terminal = [],\n kernel = ['ipykernel'],\n nbformat = ['nbformat'],\n notebook = ['notebook'],\n nbconvert = ['nbconvert'],\n)\ninstall_requires = [\n 'decorator',\n 'pickleshare',\n 'simplegeneric>0.8',\n 'traitlets',\n]\n\n# Platform-specific dependencies:\n# This is the correct way to specify these,\n# but requires pip >= 6. pip < 6 ignores these.\n\nextras_require.update({\n ':sys_platform != \"win32\"': ['pexpect'],\n ':sys_platform == \"darwin\"': ['appnope'],\n ':sys_platform == \"darwin\" and platform_python_implementation == \"CPython\"': ['gnureadline'],\n 'terminal:sys_platform == \"win32\"': ['pyreadline>=2'],\n 'test:python_version == \"2.7\"': ['mock'],\n})\n# FIXME: re-specify above platform dependencies for pip < 6\n# These would result in non-portable bdists.\nif not any(arg.startswith('bdist') for arg in sys.argv):\n if sys.version_info < (3, 3):\n extras_require['test'].append('mock')\n\n if sys.platform == 'darwin':\n install_requires.extend(['appnope'])\n have_readline = False\n try:\n import readline\n except ImportError:\n pass\n else:\n if 'libedit' not in readline.__doc__:\n have_readline = True\n if not have_readline:\n install_requires.extend(['gnureadline'])\n\n if sys.platform.startswith('win'):\n extras_require['terminal'].append('pyreadline>=2.0')\n else:\n install_requires.append('pexpect')\n \n # workaround pypa/setuptools#147, where setuptools misspells\n # platform_python_implementation as python_implementation\n if 'setuptools' in sys.modules:\n for key in list(extras_require):\n if 'platform_python_implementation' in key:\n new_key = key.replace('platform_python_implementation', 'python_implementation')\n extras_require[new_key] = extras_require.pop(key)\n\neverything = set()\nfor key, deps in extras_require.items():\n if ':' not in key:\n everything.update(deps)\nextras_require['all'] = everything\n\nif 'setuptools' in sys.modules:\n setuptools_extra_args['zip_safe'] = False\n setuptools_extra_args['entry_points'] = {\n 'console_scripts': find_entry_points(),\n 'pygments.lexers': [\n 'ipythonconsole = IPython.lib.lexers:IPythonConsoleLexer',\n 'ipython = IPython.lib.lexers:IPythonLexer',\n 'ipython3 = IPython.lib.lexers:IPython3Lexer',\n ],\n }\n setup_args['extras_require'] = extras_require\n requires = setup_args['install_requires'] = install_requires\n\n # Script to be run by the windows binary installer after the default setup\n # routine, to add shortcuts and similar windows-only things. Windows\n # post-install scripts MUST reside in the scripts/ dir, otherwise distutils\n # doesn't find them.\n if 'bdist_wininst' in sys.argv:\n if len(sys.argv) > 2 and \\\n ('sdist' in sys.argv or 'bdist_rpm' in sys.argv):\n print(\"ERROR: bdist_wininst must be run alone. Exiting.\", file=sys.stderr)\n sys.exit(1)\n setup_args['data_files'].append(\n ['Scripts', ('scripts/ipython.ico', 'scripts/ipython_nb.ico')])\n setup_args['scripts'] = [pjoin('scripts','ipython_win_post_install.py')]\n setup_args['options'] = {\"bdist_wininst\":\n {\"install_script\":\n \"ipython_win_post_install.py\"}}\n\nelse:\n # scripts has to be a non-empty list, or install_scripts isn't called\n setup_args['scripts'] = [e.split('=')[0].strip() for e in find_entry_points()]\n\n setup_args['cmdclass']['build_scripts'] = build_scripts_entrypt\n\n#---------------------------------------------------------------------------\n# Do the actual setup now\n#---------------------------------------------------------------------------\n\nsetup_args.update(setuptools_extra_args)\n\ndef main():\n setup(**setup_args)\n\nif __name__ == '__main__':\n main()\n", "path": "setup.py"}]}
| 4,042 | 464 |
gh_patches_debug_42953
|
rasdani/github-patches
|
git_diff
|
StackStorm__st2-2830
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
st2-register-content should fail on failure (exit with non zero) by default
Right now it doesn't which means it easy to miss some (important) errors.
The change is not backward compatible, but it's a good one (imo). We can also add `--register-no-failure-on-failure` flag for users which desire old behavior.
See https://github.com/StackStorm/st2/issues/2827#issuecomment-235047780.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `st2common/st2common/content/bootstrap.py`
Content:
```
1 # Licensed to the StackStorm, Inc ('StackStorm') under one or more
2 # contributor license agreements. See the NOTICE file distributed with
3 # this work for additional information regarding copyright ownership.
4 # The ASF licenses this file to You under the Apache License, Version 2.0
5 # (the "License"); you may not use this file except in compliance with
6 # the License. You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15
16 import os
17 import sys
18 import logging
19
20 from oslo_config import cfg
21
22 import st2common
23 from st2common import config
24 from st2common.script_setup import setup as common_setup
25 from st2common.script_setup import teardown as common_teardown
26 from st2common.bootstrap.base import ResourceRegistrar
27 import st2common.bootstrap.triggersregistrar as triggers_registrar
28 import st2common.bootstrap.sensorsregistrar as sensors_registrar
29 import st2common.bootstrap.actionsregistrar as actions_registrar
30 import st2common.bootstrap.aliasesregistrar as aliases_registrar
31 import st2common.bootstrap.policiesregistrar as policies_registrar
32 import st2common.bootstrap.runnersregistrar as runners_registrar
33 import st2common.bootstrap.rulesregistrar as rules_registrar
34 import st2common.bootstrap.ruletypesregistrar as rule_types_registrar
35 import st2common.bootstrap.configsregistrar as configs_registrar
36 import st2common.content.utils as content_utils
37 from st2common.util.virtualenvs import setup_pack_virtualenv
38
39 __all__ = [
40 'main'
41 ]
42
43 LOG = logging.getLogger('st2common.content.bootstrap')
44
45 cfg.CONF.register_cli_opt(cfg.BoolOpt('experimental', default=False))
46
47
48 def register_opts():
49 content_opts = [
50 cfg.BoolOpt('all', default=False, help='Register sensors, actions and rules.'),
51 cfg.BoolOpt('triggers', default=False, help='Register triggers.'),
52 cfg.BoolOpt('sensors', default=False, help='Register sensors.'),
53 cfg.BoolOpt('actions', default=False, help='Register actions.'),
54 cfg.BoolOpt('rules', default=False, help='Register rules.'),
55 cfg.BoolOpt('aliases', default=False, help='Register aliases.'),
56 cfg.BoolOpt('policies', default=False, help='Register policies.'),
57 cfg.BoolOpt('configs', default=False, help='Register and load pack configs.'),
58
59 cfg.StrOpt('pack', default=None, help='Directory to the pack to register content from.'),
60 cfg.BoolOpt('setup-virtualenvs', default=False, help=('Setup Python virtual environments '
61 'all the Python runner actions.')),
62
63 cfg.BoolOpt('fail-on-failure', default=False, help=('Exit with non-zero of resource '
64 'registration fails.'))
65 ]
66 try:
67 cfg.CONF.register_cli_opts(content_opts, group='register')
68 except:
69 sys.stderr.write('Failed registering opts.\n')
70 register_opts()
71
72
73 def setup_virtualenvs():
74 """
75 Setup Python virtual environments for all the registered or the provided pack.
76 """
77
78 LOG.info('=========================================================')
79 LOG.info('########### Setting up virtual environments #############')
80 LOG.info('=========================================================')
81
82 pack_dir = cfg.CONF.register.pack
83 fail_on_failure = cfg.CONF.register.fail_on_failure
84
85 registrar = ResourceRegistrar()
86
87 if pack_dir:
88 pack_name = os.path.basename(pack_dir)
89 pack_names = [pack_name]
90
91 # 1. Register pack
92 registrar.register_pack(pack_name=pack_name, pack_dir=pack_dir)
93 else:
94 # 1. Register pack
95 base_dirs = content_utils.get_packs_base_paths()
96 registrar.register_packs(base_dirs=base_dirs)
97
98 # 2. Retrieve available packs (aka packs which have been registered)
99 pack_names = registrar.get_registered_packs()
100
101 setup_count = 0
102 for pack_name in pack_names:
103 try:
104 setup_pack_virtualenv(pack_name=pack_name, update=True, logger=LOG)
105 except Exception as e:
106 exc_info = not fail_on_failure
107 LOG.warning('Failed to setup virtualenv for pack "%s": %s', pack_name, e,
108 exc_info=exc_info)
109
110 if fail_on_failure:
111 raise e
112 else:
113 setup_count += 1
114
115 LOG.info('Setup virtualenv for %s pack(s).' % (setup_count))
116
117
118 def register_triggers():
119 pack_dir = cfg.CONF.register.pack
120 fail_on_failure = cfg.CONF.register.fail_on_failure
121
122 registered_count = 0
123
124 try:
125 LOG.info('=========================================================')
126 LOG.info('############## Registering triggers #####################')
127 LOG.info('=========================================================')
128 registered_count = triggers_registrar.register_triggers(pack_dir=pack_dir,
129 fail_on_failure=fail_on_failure)
130 except Exception as e:
131 exc_info = not fail_on_failure
132 LOG.warning('Failed to register sensors: %s', e, exc_info=exc_info)
133
134 if fail_on_failure:
135 raise e
136
137 LOG.info('Registered %s triggers.' % (registered_count))
138
139
140 def register_sensors():
141 pack_dir = cfg.CONF.register.pack
142 fail_on_failure = cfg.CONF.register.fail_on_failure
143
144 registered_count = 0
145
146 try:
147 LOG.info('=========================================================')
148 LOG.info('############## Registering sensors ######################')
149 LOG.info('=========================================================')
150 registered_count = sensors_registrar.register_sensors(pack_dir=pack_dir,
151 fail_on_failure=fail_on_failure)
152 except Exception as e:
153 exc_info = not fail_on_failure
154 LOG.warning('Failed to register sensors: %s', e, exc_info=exc_info)
155
156 if fail_on_failure:
157 raise e
158
159 LOG.info('Registered %s sensors.' % (registered_count))
160
161
162 def register_actions():
163 # Register runnertypes and actions. The order is important because actions require action
164 # types to be present in the system.
165 pack_dir = cfg.CONF.register.pack
166 fail_on_failure = cfg.CONF.register.fail_on_failure
167
168 registered_count = 0
169
170 # 1. Register runner types
171 try:
172 LOG.info('=========================================================')
173 LOG.info('############## Registering actions ######################')
174 LOG.info('=========================================================')
175 runners_registrar.register_runner_types(experimental=cfg.CONF.experimental)
176 except Exception as e:
177 LOG.warning('Failed to register runner types: %s', e, exc_info=True)
178 LOG.warning('Not registering stock runners .')
179 return
180
181 # 2. Register actions
182 try:
183 registered_count = actions_registrar.register_actions(pack_dir=pack_dir,
184 fail_on_failure=fail_on_failure)
185 except Exception as e:
186 exc_info = not fail_on_failure
187 LOG.warning('Failed to register actions: %s', e, exc_info=exc_info)
188
189 if fail_on_failure:
190 raise e
191
192 LOG.info('Registered %s actions.' % (registered_count))
193
194
195 def register_rules():
196 # Register ruletypes and rules.
197 pack_dir = cfg.CONF.register.pack
198 fail_on_failure = cfg.CONF.register.fail_on_failure
199
200 registered_count = 0
201
202 try:
203 LOG.info('=========================================================')
204 LOG.info('############## Registering rules ########################')
205 LOG.info('=========================================================')
206 rule_types_registrar.register_rule_types()
207 except Exception as e:
208 LOG.warning('Failed to register rule types: %s', e, exc_info=True)
209 return
210
211 try:
212 registered_count = rules_registrar.register_rules(pack_dir=pack_dir,
213 fail_on_failure=fail_on_failure)
214 except Exception as e:
215 exc_info = not fail_on_failure
216 LOG.warning('Failed to register rules: %s', e, exc_info=exc_info)
217
218 if fail_on_failure:
219 raise e
220
221 LOG.info('Registered %s rules.', registered_count)
222
223
224 def register_aliases():
225 pack_dir = cfg.CONF.register.pack
226 fail_on_failure = cfg.CONF.register.fail_on_failure
227
228 registered_count = 0
229
230 try:
231 LOG.info('=========================================================')
232 LOG.info('############## Registering aliases ######################')
233 LOG.info('=========================================================')
234 registered_count = aliases_registrar.register_aliases(pack_dir=pack_dir,
235 fail_on_failure=fail_on_failure)
236 except Exception as e:
237 if fail_on_failure:
238 raise e
239
240 LOG.warning('Failed to register aliases.', exc_info=True)
241
242 LOG.info('Registered %s aliases.', registered_count)
243
244
245 def register_policies():
246 # Register policy types and policies.
247 pack_dir = cfg.CONF.register.pack
248 fail_on_failure = cfg.CONF.register.fail_on_failure
249
250 registered_type_count = 0
251
252 try:
253 LOG.info('=========================================================')
254 LOG.info('############## Registering policy types #################')
255 LOG.info('=========================================================')
256 registered_type_count = policies_registrar.register_policy_types(st2common)
257 except Exception:
258 LOG.warning('Failed to register policy types.', exc_info=True)
259
260 LOG.info('Registered %s policy types.', registered_type_count)
261
262 registered_count = 0
263 try:
264 LOG.info('=========================================================')
265 LOG.info('############## Registering policies #####################')
266 LOG.info('=========================================================')
267 registered_count = policies_registrar.register_policies(pack_dir=pack_dir,
268 fail_on_failure=fail_on_failure)
269 except Exception as e:
270 exc_info = not fail_on_failure
271 LOG.warning('Failed to register policies: %s', e, exc_info=exc_info)
272
273 if fail_on_failure:
274 raise e
275
276 LOG.info('Registered %s policies.', registered_count)
277
278
279 def register_configs():
280 pack_dir = cfg.CONF.register.pack
281 fail_on_failure = cfg.CONF.register.fail_on_failure
282
283 registered_count = 0
284
285 try:
286 LOG.info('=========================================================')
287 LOG.info('############## Registering configs ######################')
288 LOG.info('=========================================================')
289 registered_count = configs_registrar.register_configs(pack_dir=pack_dir,
290 fail_on_failure=fail_on_failure)
291 except Exception as e:
292 exc_info = not fail_on_failure
293 LOG.warning('Failed to register configs: %s', e, exc_info=exc_info)
294
295 if fail_on_failure:
296 raise e
297
298 LOG.info('Registered %s configs.' % (registered_count))
299
300
301 def register_content():
302 register_all = cfg.CONF.register.all
303
304 if register_all:
305 register_triggers()
306 register_sensors()
307 register_actions()
308 register_rules()
309 register_aliases()
310 register_policies()
311 register_configs()
312
313 if cfg.CONF.register.triggers and not register_all:
314 register_triggers()
315
316 if cfg.CONF.register.sensors and not register_all:
317 register_sensors()
318
319 if cfg.CONF.register.actions and not register_all:
320 register_actions()
321
322 if cfg.CONF.register.rules and not register_all:
323 register_rules()
324
325 if cfg.CONF.register.aliases and not register_all:
326 register_aliases()
327
328 if cfg.CONF.register.policies and not register_all:
329 register_policies()
330
331 if cfg.CONF.register.configs and not register_all:
332 register_configs()
333
334 if cfg.CONF.register.setup_virtualenvs:
335 setup_virtualenvs()
336
337
338 def setup(argv):
339 common_setup(config=config, setup_db=True, register_mq_exchanges=True)
340
341
342 def teardown():
343 common_teardown()
344
345
346 def main(argv):
347 setup(argv)
348 register_content()
349 teardown()
350
351
352 # This script registers actions and rules from content-packs.
353 if __name__ == '__main__':
354 main(sys.argv[1:])
355
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/st2common/st2common/content/bootstrap.py b/st2common/st2common/content/bootstrap.py
--- a/st2common/st2common/content/bootstrap.py
+++ b/st2common/st2common/content/bootstrap.py
@@ -60,8 +60,12 @@
cfg.BoolOpt('setup-virtualenvs', default=False, help=('Setup Python virtual environments '
'all the Python runner actions.')),
- cfg.BoolOpt('fail-on-failure', default=False, help=('Exit with non-zero of resource '
- 'registration fails.'))
+ cfg.BoolOpt('no-fail-on-failure', default=False,
+ help=('Don\'t exit with non-zero if some resource registration fails.')),
+ # Note: Fail on failure is now a default behavior. This flag is only left here for backward
+ # compatibility reasons, but it's not actually used.
+ cfg.BoolOpt('fail-on-failure', default=False,
+ help=('Exit with non-zero if some resource registration fails.'))
]
try:
cfg.CONF.register_cli_opts(content_opts, group='register')
@@ -80,7 +84,7 @@
LOG.info('=========================================================')
pack_dir = cfg.CONF.register.pack
- fail_on_failure = cfg.CONF.register.fail_on_failure
+ fail_on_failure = not cfg.CONF.register.no_fail_on_failure
registrar = ResourceRegistrar()
@@ -117,7 +121,7 @@
def register_triggers():
pack_dir = cfg.CONF.register.pack
- fail_on_failure = cfg.CONF.register.fail_on_failure
+ fail_on_failure = not cfg.CONF.register.no_fail_on_failure
registered_count = 0
@@ -139,7 +143,7 @@
def register_sensors():
pack_dir = cfg.CONF.register.pack
- fail_on_failure = cfg.CONF.register.fail_on_failure
+ fail_on_failure = not cfg.CONF.register.no_fail_on_failure
registered_count = 0
@@ -163,7 +167,7 @@
# Register runnertypes and actions. The order is important because actions require action
# types to be present in the system.
pack_dir = cfg.CONF.register.pack
- fail_on_failure = cfg.CONF.register.fail_on_failure
+ fail_on_failure = not cfg.CONF.register.no_fail_on_failure
registered_count = 0
@@ -195,7 +199,7 @@
def register_rules():
# Register ruletypes and rules.
pack_dir = cfg.CONF.register.pack
- fail_on_failure = cfg.CONF.register.fail_on_failure
+ fail_on_failure = not cfg.CONF.register.no_fail_on_failure
registered_count = 0
@@ -223,7 +227,7 @@
def register_aliases():
pack_dir = cfg.CONF.register.pack
- fail_on_failure = cfg.CONF.register.fail_on_failure
+ fail_on_failure = not cfg.CONF.register.no_fail_on_failure
registered_count = 0
@@ -245,7 +249,7 @@
def register_policies():
# Register policy types and policies.
pack_dir = cfg.CONF.register.pack
- fail_on_failure = cfg.CONF.register.fail_on_failure
+ fail_on_failure = not cfg.CONF.register.no_fail_on_failure
registered_type_count = 0
@@ -278,7 +282,7 @@
def register_configs():
pack_dir = cfg.CONF.register.pack
- fail_on_failure = cfg.CONF.register.fail_on_failure
+ fail_on_failure = not cfg.CONF.register.no_fail_on_failure
registered_count = 0
|
{"golden_diff": "diff --git a/st2common/st2common/content/bootstrap.py b/st2common/st2common/content/bootstrap.py\n--- a/st2common/st2common/content/bootstrap.py\n+++ b/st2common/st2common/content/bootstrap.py\n@@ -60,8 +60,12 @@\n cfg.BoolOpt('setup-virtualenvs', default=False, help=('Setup Python virtual environments '\n 'all the Python runner actions.')),\n \n- cfg.BoolOpt('fail-on-failure', default=False, help=('Exit with non-zero of resource '\n- 'registration fails.'))\n+ cfg.BoolOpt('no-fail-on-failure', default=False,\n+ help=('Don\\'t exit with non-zero if some resource registration fails.')),\n+ # Note: Fail on failure is now a default behavior. This flag is only left here for backward\n+ # compatibility reasons, but it's not actually used.\n+ cfg.BoolOpt('fail-on-failure', default=False,\n+ help=('Exit with non-zero if some resource registration fails.'))\n ]\n try:\n cfg.CONF.register_cli_opts(content_opts, group='register')\n@@ -80,7 +84,7 @@\n LOG.info('=========================================================')\n \n pack_dir = cfg.CONF.register.pack\n- fail_on_failure = cfg.CONF.register.fail_on_failure\n+ fail_on_failure = not cfg.CONF.register.no_fail_on_failure\n \n registrar = ResourceRegistrar()\n \n@@ -117,7 +121,7 @@\n \n def register_triggers():\n pack_dir = cfg.CONF.register.pack\n- fail_on_failure = cfg.CONF.register.fail_on_failure\n+ fail_on_failure = not cfg.CONF.register.no_fail_on_failure\n \n registered_count = 0\n \n@@ -139,7 +143,7 @@\n \n def register_sensors():\n pack_dir = cfg.CONF.register.pack\n- fail_on_failure = cfg.CONF.register.fail_on_failure\n+ fail_on_failure = not cfg.CONF.register.no_fail_on_failure\n \n registered_count = 0\n \n@@ -163,7 +167,7 @@\n # Register runnertypes and actions. The order is important because actions require action\n # types to be present in the system.\n pack_dir = cfg.CONF.register.pack\n- fail_on_failure = cfg.CONF.register.fail_on_failure\n+ fail_on_failure = not cfg.CONF.register.no_fail_on_failure\n \n registered_count = 0\n \n@@ -195,7 +199,7 @@\n def register_rules():\n # Register ruletypes and rules.\n pack_dir = cfg.CONF.register.pack\n- fail_on_failure = cfg.CONF.register.fail_on_failure\n+ fail_on_failure = not cfg.CONF.register.no_fail_on_failure\n \n registered_count = 0\n \n@@ -223,7 +227,7 @@\n \n def register_aliases():\n pack_dir = cfg.CONF.register.pack\n- fail_on_failure = cfg.CONF.register.fail_on_failure\n+ fail_on_failure = not cfg.CONF.register.no_fail_on_failure\n \n registered_count = 0\n \n@@ -245,7 +249,7 @@\n def register_policies():\n # Register policy types and policies.\n pack_dir = cfg.CONF.register.pack\n- fail_on_failure = cfg.CONF.register.fail_on_failure\n+ fail_on_failure = not cfg.CONF.register.no_fail_on_failure\n \n registered_type_count = 0\n \n@@ -278,7 +282,7 @@\n \n def register_configs():\n pack_dir = cfg.CONF.register.pack\n- fail_on_failure = cfg.CONF.register.fail_on_failure\n+ fail_on_failure = not cfg.CONF.register.no_fail_on_failure\n \n registered_count = 0\n", "issue": "st2-register-content should fail on failure (exit with non zero) by default\nRight now it doesn't which means it easy to miss some (important) errors.\n\nThe change is not backward compatible, but it's a good one (imo). We can also add `--register-no-failure-on-failure` flag for users which desire old behavior.\n\nSee https://github.com/StackStorm/st2/issues/2827#issuecomment-235047780.\n\n", "before_files": [{"content": "# Licensed to the StackStorm, Inc ('StackStorm') under one or more\n# contributor license agreements. See the NOTICE file distributed with\n# this work for additional information regarding copyright ownership.\n# The ASF licenses this file to You under the Apache License, Version 2.0\n# (the \"License\"); you may not use this file except in compliance with\n# the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport sys\nimport logging\n\nfrom oslo_config import cfg\n\nimport st2common\nfrom st2common import config\nfrom st2common.script_setup import setup as common_setup\nfrom st2common.script_setup import teardown as common_teardown\nfrom st2common.bootstrap.base import ResourceRegistrar\nimport st2common.bootstrap.triggersregistrar as triggers_registrar\nimport st2common.bootstrap.sensorsregistrar as sensors_registrar\nimport st2common.bootstrap.actionsregistrar as actions_registrar\nimport st2common.bootstrap.aliasesregistrar as aliases_registrar\nimport st2common.bootstrap.policiesregistrar as policies_registrar\nimport st2common.bootstrap.runnersregistrar as runners_registrar\nimport st2common.bootstrap.rulesregistrar as rules_registrar\nimport st2common.bootstrap.ruletypesregistrar as rule_types_registrar\nimport st2common.bootstrap.configsregistrar as configs_registrar\nimport st2common.content.utils as content_utils\nfrom st2common.util.virtualenvs import setup_pack_virtualenv\n\n__all__ = [\n 'main'\n]\n\nLOG = logging.getLogger('st2common.content.bootstrap')\n\ncfg.CONF.register_cli_opt(cfg.BoolOpt('experimental', default=False))\n\n\ndef register_opts():\n content_opts = [\n cfg.BoolOpt('all', default=False, help='Register sensors, actions and rules.'),\n cfg.BoolOpt('triggers', default=False, help='Register triggers.'),\n cfg.BoolOpt('sensors', default=False, help='Register sensors.'),\n cfg.BoolOpt('actions', default=False, help='Register actions.'),\n cfg.BoolOpt('rules', default=False, help='Register rules.'),\n cfg.BoolOpt('aliases', default=False, help='Register aliases.'),\n cfg.BoolOpt('policies', default=False, help='Register policies.'),\n cfg.BoolOpt('configs', default=False, help='Register and load pack configs.'),\n\n cfg.StrOpt('pack', default=None, help='Directory to the pack to register content from.'),\n cfg.BoolOpt('setup-virtualenvs', default=False, help=('Setup Python virtual environments '\n 'all the Python runner actions.')),\n\n cfg.BoolOpt('fail-on-failure', default=False, help=('Exit with non-zero of resource '\n 'registration fails.'))\n ]\n try:\n cfg.CONF.register_cli_opts(content_opts, group='register')\n except:\n sys.stderr.write('Failed registering opts.\\n')\nregister_opts()\n\n\ndef setup_virtualenvs():\n \"\"\"\n Setup Python virtual environments for all the registered or the provided pack.\n \"\"\"\n\n LOG.info('=========================================================')\n LOG.info('########### Setting up virtual environments #############')\n LOG.info('=========================================================')\n\n pack_dir = cfg.CONF.register.pack\n fail_on_failure = cfg.CONF.register.fail_on_failure\n\n registrar = ResourceRegistrar()\n\n if pack_dir:\n pack_name = os.path.basename(pack_dir)\n pack_names = [pack_name]\n\n # 1. Register pack\n registrar.register_pack(pack_name=pack_name, pack_dir=pack_dir)\n else:\n # 1. Register pack\n base_dirs = content_utils.get_packs_base_paths()\n registrar.register_packs(base_dirs=base_dirs)\n\n # 2. Retrieve available packs (aka packs which have been registered)\n pack_names = registrar.get_registered_packs()\n\n setup_count = 0\n for pack_name in pack_names:\n try:\n setup_pack_virtualenv(pack_name=pack_name, update=True, logger=LOG)\n except Exception as e:\n exc_info = not fail_on_failure\n LOG.warning('Failed to setup virtualenv for pack \"%s\": %s', pack_name, e,\n exc_info=exc_info)\n\n if fail_on_failure:\n raise e\n else:\n setup_count += 1\n\n LOG.info('Setup virtualenv for %s pack(s).' % (setup_count))\n\n\ndef register_triggers():\n pack_dir = cfg.CONF.register.pack\n fail_on_failure = cfg.CONF.register.fail_on_failure\n\n registered_count = 0\n\n try:\n LOG.info('=========================================================')\n LOG.info('############## Registering triggers #####################')\n LOG.info('=========================================================')\n registered_count = triggers_registrar.register_triggers(pack_dir=pack_dir,\n fail_on_failure=fail_on_failure)\n except Exception as e:\n exc_info = not fail_on_failure\n LOG.warning('Failed to register sensors: %s', e, exc_info=exc_info)\n\n if fail_on_failure:\n raise e\n\n LOG.info('Registered %s triggers.' % (registered_count))\n\n\ndef register_sensors():\n pack_dir = cfg.CONF.register.pack\n fail_on_failure = cfg.CONF.register.fail_on_failure\n\n registered_count = 0\n\n try:\n LOG.info('=========================================================')\n LOG.info('############## Registering sensors ######################')\n LOG.info('=========================================================')\n registered_count = sensors_registrar.register_sensors(pack_dir=pack_dir,\n fail_on_failure=fail_on_failure)\n except Exception as e:\n exc_info = not fail_on_failure\n LOG.warning('Failed to register sensors: %s', e, exc_info=exc_info)\n\n if fail_on_failure:\n raise e\n\n LOG.info('Registered %s sensors.' % (registered_count))\n\n\ndef register_actions():\n # Register runnertypes and actions. The order is important because actions require action\n # types to be present in the system.\n pack_dir = cfg.CONF.register.pack\n fail_on_failure = cfg.CONF.register.fail_on_failure\n\n registered_count = 0\n\n # 1. Register runner types\n try:\n LOG.info('=========================================================')\n LOG.info('############## Registering actions ######################')\n LOG.info('=========================================================')\n runners_registrar.register_runner_types(experimental=cfg.CONF.experimental)\n except Exception as e:\n LOG.warning('Failed to register runner types: %s', e, exc_info=True)\n LOG.warning('Not registering stock runners .')\n return\n\n # 2. Register actions\n try:\n registered_count = actions_registrar.register_actions(pack_dir=pack_dir,\n fail_on_failure=fail_on_failure)\n except Exception as e:\n exc_info = not fail_on_failure\n LOG.warning('Failed to register actions: %s', e, exc_info=exc_info)\n\n if fail_on_failure:\n raise e\n\n LOG.info('Registered %s actions.' % (registered_count))\n\n\ndef register_rules():\n # Register ruletypes and rules.\n pack_dir = cfg.CONF.register.pack\n fail_on_failure = cfg.CONF.register.fail_on_failure\n\n registered_count = 0\n\n try:\n LOG.info('=========================================================')\n LOG.info('############## Registering rules ########################')\n LOG.info('=========================================================')\n rule_types_registrar.register_rule_types()\n except Exception as e:\n LOG.warning('Failed to register rule types: %s', e, exc_info=True)\n return\n\n try:\n registered_count = rules_registrar.register_rules(pack_dir=pack_dir,\n fail_on_failure=fail_on_failure)\n except Exception as e:\n exc_info = not fail_on_failure\n LOG.warning('Failed to register rules: %s', e, exc_info=exc_info)\n\n if fail_on_failure:\n raise e\n\n LOG.info('Registered %s rules.', registered_count)\n\n\ndef register_aliases():\n pack_dir = cfg.CONF.register.pack\n fail_on_failure = cfg.CONF.register.fail_on_failure\n\n registered_count = 0\n\n try:\n LOG.info('=========================================================')\n LOG.info('############## Registering aliases ######################')\n LOG.info('=========================================================')\n registered_count = aliases_registrar.register_aliases(pack_dir=pack_dir,\n fail_on_failure=fail_on_failure)\n except Exception as e:\n if fail_on_failure:\n raise e\n\n LOG.warning('Failed to register aliases.', exc_info=True)\n\n LOG.info('Registered %s aliases.', registered_count)\n\n\ndef register_policies():\n # Register policy types and policies.\n pack_dir = cfg.CONF.register.pack\n fail_on_failure = cfg.CONF.register.fail_on_failure\n\n registered_type_count = 0\n\n try:\n LOG.info('=========================================================')\n LOG.info('############## Registering policy types #################')\n LOG.info('=========================================================')\n registered_type_count = policies_registrar.register_policy_types(st2common)\n except Exception:\n LOG.warning('Failed to register policy types.', exc_info=True)\n\n LOG.info('Registered %s policy types.', registered_type_count)\n\n registered_count = 0\n try:\n LOG.info('=========================================================')\n LOG.info('############## Registering policies #####################')\n LOG.info('=========================================================')\n registered_count = policies_registrar.register_policies(pack_dir=pack_dir,\n fail_on_failure=fail_on_failure)\n except Exception as e:\n exc_info = not fail_on_failure\n LOG.warning('Failed to register policies: %s', e, exc_info=exc_info)\n\n if fail_on_failure:\n raise e\n\n LOG.info('Registered %s policies.', registered_count)\n\n\ndef register_configs():\n pack_dir = cfg.CONF.register.pack\n fail_on_failure = cfg.CONF.register.fail_on_failure\n\n registered_count = 0\n\n try:\n LOG.info('=========================================================')\n LOG.info('############## Registering configs ######################')\n LOG.info('=========================================================')\n registered_count = configs_registrar.register_configs(pack_dir=pack_dir,\n fail_on_failure=fail_on_failure)\n except Exception as e:\n exc_info = not fail_on_failure\n LOG.warning('Failed to register configs: %s', e, exc_info=exc_info)\n\n if fail_on_failure:\n raise e\n\n LOG.info('Registered %s configs.' % (registered_count))\n\n\ndef register_content():\n register_all = cfg.CONF.register.all\n\n if register_all:\n register_triggers()\n register_sensors()\n register_actions()\n register_rules()\n register_aliases()\n register_policies()\n register_configs()\n\n if cfg.CONF.register.triggers and not register_all:\n register_triggers()\n\n if cfg.CONF.register.sensors and not register_all:\n register_sensors()\n\n if cfg.CONF.register.actions and not register_all:\n register_actions()\n\n if cfg.CONF.register.rules and not register_all:\n register_rules()\n\n if cfg.CONF.register.aliases and not register_all:\n register_aliases()\n\n if cfg.CONF.register.policies and not register_all:\n register_policies()\n\n if cfg.CONF.register.configs and not register_all:\n register_configs()\n\n if cfg.CONF.register.setup_virtualenvs:\n setup_virtualenvs()\n\n\ndef setup(argv):\n common_setup(config=config, setup_db=True, register_mq_exchanges=True)\n\n\ndef teardown():\n common_teardown()\n\n\ndef main(argv):\n setup(argv)\n register_content()\n teardown()\n\n\n# This script registers actions and rules from content-packs.\nif __name__ == '__main__':\n main(sys.argv[1:])\n", "path": "st2common/st2common/content/bootstrap.py"}], "after_files": [{"content": "# Licensed to the StackStorm, Inc ('StackStorm') under one or more\n# contributor license agreements. See the NOTICE file distributed with\n# this work for additional information regarding copyright ownership.\n# The ASF licenses this file to You under the Apache License, Version 2.0\n# (the \"License\"); you may not use this file except in compliance with\n# the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport sys\nimport logging\n\nfrom oslo_config import cfg\n\nimport st2common\nfrom st2common import config\nfrom st2common.script_setup import setup as common_setup\nfrom st2common.script_setup import teardown as common_teardown\nfrom st2common.bootstrap.base import ResourceRegistrar\nimport st2common.bootstrap.triggersregistrar as triggers_registrar\nimport st2common.bootstrap.sensorsregistrar as sensors_registrar\nimport st2common.bootstrap.actionsregistrar as actions_registrar\nimport st2common.bootstrap.aliasesregistrar as aliases_registrar\nimport st2common.bootstrap.policiesregistrar as policies_registrar\nimport st2common.bootstrap.runnersregistrar as runners_registrar\nimport st2common.bootstrap.rulesregistrar as rules_registrar\nimport st2common.bootstrap.ruletypesregistrar as rule_types_registrar\nimport st2common.bootstrap.configsregistrar as configs_registrar\nimport st2common.content.utils as content_utils\nfrom st2common.util.virtualenvs import setup_pack_virtualenv\n\n__all__ = [\n 'main'\n]\n\nLOG = logging.getLogger('st2common.content.bootstrap')\n\ncfg.CONF.register_cli_opt(cfg.BoolOpt('experimental', default=False))\n\n\ndef register_opts():\n content_opts = [\n cfg.BoolOpt('all', default=False, help='Register sensors, actions and rules.'),\n cfg.BoolOpt('triggers', default=False, help='Register triggers.'),\n cfg.BoolOpt('sensors', default=False, help='Register sensors.'),\n cfg.BoolOpt('actions', default=False, help='Register actions.'),\n cfg.BoolOpt('rules', default=False, help='Register rules.'),\n cfg.BoolOpt('aliases', default=False, help='Register aliases.'),\n cfg.BoolOpt('policies', default=False, help='Register policies.'),\n cfg.BoolOpt('configs', default=False, help='Register and load pack configs.'),\n\n cfg.StrOpt('pack', default=None, help='Directory to the pack to register content from.'),\n cfg.BoolOpt('setup-virtualenvs', default=False, help=('Setup Python virtual environments '\n 'all the Python runner actions.')),\n\n cfg.BoolOpt('no-fail-on-failure', default=False,\n help=('Don\\'t exit with non-zero if some resource registration fails.')),\n # Note: Fail on failure is now a default behavior. This flag is only left here for backward\n # compatibility reasons, but it's not actually used.\n cfg.BoolOpt('fail-on-failure', default=False,\n help=('Exit with non-zero if some resource registration fails.'))\n ]\n try:\n cfg.CONF.register_cli_opts(content_opts, group='register')\n except:\n sys.stderr.write('Failed registering opts.\\n')\nregister_opts()\n\n\ndef setup_virtualenvs():\n \"\"\"\n Setup Python virtual environments for all the registered or the provided pack.\n \"\"\"\n\n LOG.info('=========================================================')\n LOG.info('########### Setting up virtual environments #############')\n LOG.info('=========================================================')\n\n pack_dir = cfg.CONF.register.pack\n fail_on_failure = not cfg.CONF.register.no_fail_on_failure\n\n registrar = ResourceRegistrar()\n\n if pack_dir:\n pack_name = os.path.basename(pack_dir)\n pack_names = [pack_name]\n\n # 1. Register pack\n registrar.register_pack(pack_name=pack_name, pack_dir=pack_dir)\n else:\n # 1. Register pack\n base_dirs = content_utils.get_packs_base_paths()\n registrar.register_packs(base_dirs=base_dirs)\n\n # 2. Retrieve available packs (aka packs which have been registered)\n pack_names = registrar.get_registered_packs()\n\n setup_count = 0\n for pack_name in pack_names:\n try:\n setup_pack_virtualenv(pack_name=pack_name, update=True, logger=LOG)\n except Exception as e:\n exc_info = not fail_on_failure\n LOG.warning('Failed to setup virtualenv for pack \"%s\": %s', pack_name, e,\n exc_info=exc_info)\n\n if fail_on_failure:\n raise e\n else:\n setup_count += 1\n\n LOG.info('Setup virtualenv for %s pack(s).' % (setup_count))\n\n\ndef register_triggers():\n pack_dir = cfg.CONF.register.pack\n fail_on_failure = not cfg.CONF.register.no_fail_on_failure\n\n registered_count = 0\n\n try:\n LOG.info('=========================================================')\n LOG.info('############## Registering triggers #####################')\n LOG.info('=========================================================')\n registered_count = triggers_registrar.register_triggers(pack_dir=pack_dir,\n fail_on_failure=fail_on_failure)\n except Exception as e:\n exc_info = not fail_on_failure\n LOG.warning('Failed to register sensors: %s', e, exc_info=exc_info)\n\n if fail_on_failure:\n raise e\n\n LOG.info('Registered %s triggers.' % (registered_count))\n\n\ndef register_sensors():\n pack_dir = cfg.CONF.register.pack\n fail_on_failure = not cfg.CONF.register.no_fail_on_failure\n\n registered_count = 0\n\n try:\n LOG.info('=========================================================')\n LOG.info('############## Registering sensors ######################')\n LOG.info('=========================================================')\n registered_count = sensors_registrar.register_sensors(pack_dir=pack_dir,\n fail_on_failure=fail_on_failure)\n except Exception as e:\n exc_info = not fail_on_failure\n LOG.warning('Failed to register sensors: %s', e, exc_info=exc_info)\n\n if fail_on_failure:\n raise e\n\n LOG.info('Registered %s sensors.' % (registered_count))\n\n\ndef register_actions():\n # Register runnertypes and actions. The order is important because actions require action\n # types to be present in the system.\n pack_dir = cfg.CONF.register.pack\n fail_on_failure = not cfg.CONF.register.no_fail_on_failure\n\n registered_count = 0\n\n # 1. Register runner types\n try:\n LOG.info('=========================================================')\n LOG.info('############## Registering actions ######################')\n LOG.info('=========================================================')\n runners_registrar.register_runner_types(experimental=cfg.CONF.experimental)\n except Exception as e:\n LOG.warning('Failed to register runner types: %s', e, exc_info=True)\n LOG.warning('Not registering stock runners .')\n return\n\n # 2. Register actions\n try:\n registered_count = actions_registrar.register_actions(pack_dir=pack_dir,\n fail_on_failure=fail_on_failure)\n except Exception as e:\n exc_info = not fail_on_failure\n LOG.warning('Failed to register actions: %s', e, exc_info=exc_info)\n\n if fail_on_failure:\n raise e\n\n LOG.info('Registered %s actions.' % (registered_count))\n\n\ndef register_rules():\n # Register ruletypes and rules.\n pack_dir = cfg.CONF.register.pack\n fail_on_failure = not cfg.CONF.register.no_fail_on_failure\n\n registered_count = 0\n\n try:\n LOG.info('=========================================================')\n LOG.info('############## Registering rules ########################')\n LOG.info('=========================================================')\n rule_types_registrar.register_rule_types()\n except Exception as e:\n LOG.warning('Failed to register rule types: %s', e, exc_info=True)\n return\n\n try:\n registered_count = rules_registrar.register_rules(pack_dir=pack_dir,\n fail_on_failure=fail_on_failure)\n except Exception as e:\n exc_info = not fail_on_failure\n LOG.warning('Failed to register rules: %s', e, exc_info=exc_info)\n\n if fail_on_failure:\n raise e\n\n LOG.info('Registered %s rules.', registered_count)\n\n\ndef register_aliases():\n pack_dir = cfg.CONF.register.pack\n fail_on_failure = not cfg.CONF.register.no_fail_on_failure\n\n registered_count = 0\n\n try:\n LOG.info('=========================================================')\n LOG.info('############## Registering aliases ######################')\n LOG.info('=========================================================')\n registered_count = aliases_registrar.register_aliases(pack_dir=pack_dir,\n fail_on_failure=fail_on_failure)\n except Exception as e:\n if fail_on_failure:\n raise e\n\n LOG.warning('Failed to register aliases.', exc_info=True)\n\n LOG.info('Registered %s aliases.', registered_count)\n\n\ndef register_policies():\n # Register policy types and policies.\n pack_dir = cfg.CONF.register.pack\n fail_on_failure = not cfg.CONF.register.no_fail_on_failure\n\n registered_type_count = 0\n\n try:\n LOG.info('=========================================================')\n LOG.info('############## Registering policy types #################')\n LOG.info('=========================================================')\n registered_type_count = policies_registrar.register_policy_types(st2common)\n except Exception:\n LOG.warning('Failed to register policy types.', exc_info=True)\n\n LOG.info('Registered %s policy types.', registered_type_count)\n\n registered_count = 0\n try:\n LOG.info('=========================================================')\n LOG.info('############## Registering policies #####################')\n LOG.info('=========================================================')\n registered_count = policies_registrar.register_policies(pack_dir=pack_dir,\n fail_on_failure=fail_on_failure)\n except Exception as e:\n exc_info = not fail_on_failure\n LOG.warning('Failed to register policies: %s', e, exc_info=exc_info)\n\n if fail_on_failure:\n raise e\n\n LOG.info('Registered %s policies.', registered_count)\n\n\ndef register_configs():\n pack_dir = cfg.CONF.register.pack\n fail_on_failure = not cfg.CONF.register.no_fail_on_failure\n\n registered_count = 0\n\n try:\n LOG.info('=========================================================')\n LOG.info('############## Registering configs ######################')\n LOG.info('=========================================================')\n registered_count = configs_registrar.register_configs(pack_dir=pack_dir,\n fail_on_failure=fail_on_failure)\n except Exception as e:\n exc_info = not fail_on_failure\n LOG.warning('Failed to register configs: %s', e, exc_info=exc_info)\n\n if fail_on_failure:\n raise e\n\n LOG.info('Registered %s configs.' % (registered_count))\n\n\ndef register_content():\n register_all = cfg.CONF.register.all\n\n if register_all:\n register_triggers()\n register_sensors()\n register_actions()\n register_rules()\n register_aliases()\n register_policies()\n register_configs()\n\n if cfg.CONF.register.triggers and not register_all:\n register_triggers()\n\n if cfg.CONF.register.sensors and not register_all:\n register_sensors()\n\n if cfg.CONF.register.actions and not register_all:\n register_actions()\n\n if cfg.CONF.register.rules and not register_all:\n register_rules()\n\n if cfg.CONF.register.aliases and not register_all:\n register_aliases()\n\n if cfg.CONF.register.policies and not register_all:\n register_policies()\n\n if cfg.CONF.register.configs and not register_all:\n register_configs()\n\n if cfg.CONF.register.setup_virtualenvs:\n setup_virtualenvs()\n\n\ndef setup(argv):\n common_setup(config=config, setup_db=True, register_mq_exchanges=True)\n\n\ndef teardown():\n common_teardown()\n\n\ndef main(argv):\n setup(argv)\n register_content()\n teardown()\n\n\n# This script registers actions and rules from content-packs.\nif __name__ == '__main__':\n main(sys.argv[1:])\n", "path": "st2common/st2common/content/bootstrap.py"}]}
| 3,905 | 812 |
gh_patches_debug_13783
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-8260
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove verify_interface
Now that `register_interface` is gone we have no use for `verify_interface`, but https://github.com/aws/aws-encryption-sdk-python/issues/464 is a blocker for removing it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cryptography/utils.py`
Content:
```
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5
6 import abc
7 import enum
8 import sys
9 import types
10 import typing
11 import warnings
12
13
14 # We use a UserWarning subclass, instead of DeprecationWarning, because CPython
15 # decided deprecation warnings should be invisble by default.
16 class CryptographyDeprecationWarning(UserWarning):
17 pass
18
19
20 # Several APIs were deprecated with no specific end-of-life date because of the
21 # ubiquity of their use. They should not be removed until we agree on when that
22 # cycle ends.
23 DeprecatedIn36 = CryptographyDeprecationWarning
24 DeprecatedIn37 = CryptographyDeprecationWarning
25 DeprecatedIn39 = CryptographyDeprecationWarning
26 DeprecatedIn40 = CryptographyDeprecationWarning
27
28
29 def _check_bytes(name: str, value: bytes) -> None:
30 if not isinstance(value, bytes):
31 raise TypeError(f"{name} must be bytes")
32
33
34 def _check_byteslike(name: str, value: bytes) -> None:
35 try:
36 memoryview(value)
37 except TypeError:
38 raise TypeError(f"{name} must be bytes-like")
39
40
41 def int_to_bytes(integer: int, length: typing.Optional[int] = None) -> bytes:
42 return integer.to_bytes(
43 length or (integer.bit_length() + 7) // 8 or 1, "big"
44 )
45
46
47 class InterfaceNotImplemented(Exception):
48 pass
49
50
51 # DeprecatedIn39 -- Our only known consumer is aws-encryption-sdk, but we've
52 # made this a no-op to avoid breaking old versions.
53 def verify_interface(
54 iface: abc.ABCMeta, klass: object, *, check_annotations: bool = False
55 ):
56 # Exists exclusively for `aws-encryption-sdk` which relies on it existing,
57 # even though it was never a public API.
58 pass
59
60
61 class _DeprecatedValue:
62 def __init__(self, value: object, message: str, warning_class):
63 self.value = value
64 self.message = message
65 self.warning_class = warning_class
66
67
68 class _ModuleWithDeprecations(types.ModuleType):
69 def __init__(self, module: types.ModuleType):
70 super().__init__(module.__name__)
71 self.__dict__["_module"] = module
72
73 def __getattr__(self, attr: str) -> object:
74 obj = getattr(self._module, attr)
75 if isinstance(obj, _DeprecatedValue):
76 warnings.warn(obj.message, obj.warning_class, stacklevel=2)
77 obj = obj.value
78 return obj
79
80 def __setattr__(self, attr: str, value: object) -> None:
81 setattr(self._module, attr, value)
82
83 def __delattr__(self, attr: str) -> None:
84 obj = getattr(self._module, attr)
85 if isinstance(obj, _DeprecatedValue):
86 warnings.warn(obj.message, obj.warning_class, stacklevel=2)
87
88 delattr(self._module, attr)
89
90 def __dir__(self) -> typing.Sequence[str]:
91 return ["_module"] + dir(self._module)
92
93
94 def deprecated(
95 value: object,
96 module_name: str,
97 message: str,
98 warning_class: typing.Type[Warning],
99 name: typing.Optional[str] = None,
100 ) -> _DeprecatedValue:
101 module = sys.modules[module_name]
102 if not isinstance(module, _ModuleWithDeprecations):
103 sys.modules[module_name] = module = _ModuleWithDeprecations(module)
104 dv = _DeprecatedValue(value, message, warning_class)
105 # Maintain backwards compatibility with `name is None` for pyOpenSSL.
106 if name is not None:
107 setattr(module, name, dv)
108 return dv
109
110
111 def cached_property(func: typing.Callable) -> property:
112 cached_name = f"_cached_{func}"
113 sentinel = object()
114
115 def inner(instance: object):
116 cache = getattr(instance, cached_name, sentinel)
117 if cache is not sentinel:
118 return cache
119 result = func(instance)
120 setattr(instance, cached_name, result)
121 return result
122
123 return property(inner)
124
125
126 # Python 3.10 changed representation of enums. We use well-defined object
127 # representation and string representation from Python 3.9.
128 class Enum(enum.Enum):
129 def __repr__(self) -> str:
130 return f"<{self.__class__.__name__}.{self._name_}: {self._value_!r}>"
131
132 def __str__(self) -> str:
133 return f"{self.__class__.__name__}.{self._name_}"
134
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cryptography/utils.py b/src/cryptography/utils.py
--- a/src/cryptography/utils.py
+++ b/src/cryptography/utils.py
@@ -3,7 +3,6 @@
# for complete details.
-import abc
import enum
import sys
import types
@@ -48,16 +47,6 @@
pass
-# DeprecatedIn39 -- Our only known consumer is aws-encryption-sdk, but we've
-# made this a no-op to avoid breaking old versions.
-def verify_interface(
- iface: abc.ABCMeta, klass: object, *, check_annotations: bool = False
-):
- # Exists exclusively for `aws-encryption-sdk` which relies on it existing,
- # even though it was never a public API.
- pass
-
-
class _DeprecatedValue:
def __init__(self, value: object, message: str, warning_class):
self.value = value
|
{"golden_diff": "diff --git a/src/cryptography/utils.py b/src/cryptography/utils.py\n--- a/src/cryptography/utils.py\n+++ b/src/cryptography/utils.py\n@@ -3,7 +3,6 @@\n # for complete details.\n \n \n-import abc\n import enum\n import sys\n import types\n@@ -48,16 +47,6 @@\n pass\n \n \n-# DeprecatedIn39 -- Our only known consumer is aws-encryption-sdk, but we've\n-# made this a no-op to avoid breaking old versions.\n-def verify_interface(\n- iface: abc.ABCMeta, klass: object, *, check_annotations: bool = False\n-):\n- # Exists exclusively for `aws-encryption-sdk` which relies on it existing,\n- # even though it was never a public API.\n- pass\n-\n-\n class _DeprecatedValue:\n def __init__(self, value: object, message: str, warning_class):\n self.value = value\n", "issue": "Remove verify_interface\nNow that `register_interface` is gone we have no use for `verify_interface`, but https://github.com/aws/aws-encryption-sdk-python/issues/464 is a blocker for removing it.\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\n\nimport abc\nimport enum\nimport sys\nimport types\nimport typing\nimport warnings\n\n\n# We use a UserWarning subclass, instead of DeprecationWarning, because CPython\n# decided deprecation warnings should be invisble by default.\nclass CryptographyDeprecationWarning(UserWarning):\n pass\n\n\n# Several APIs were deprecated with no specific end-of-life date because of the\n# ubiquity of their use. They should not be removed until we agree on when that\n# cycle ends.\nDeprecatedIn36 = CryptographyDeprecationWarning\nDeprecatedIn37 = CryptographyDeprecationWarning\nDeprecatedIn39 = CryptographyDeprecationWarning\nDeprecatedIn40 = CryptographyDeprecationWarning\n\n\ndef _check_bytes(name: str, value: bytes) -> None:\n if not isinstance(value, bytes):\n raise TypeError(f\"{name} must be bytes\")\n\n\ndef _check_byteslike(name: str, value: bytes) -> None:\n try:\n memoryview(value)\n except TypeError:\n raise TypeError(f\"{name} must be bytes-like\")\n\n\ndef int_to_bytes(integer: int, length: typing.Optional[int] = None) -> bytes:\n return integer.to_bytes(\n length or (integer.bit_length() + 7) // 8 or 1, \"big\"\n )\n\n\nclass InterfaceNotImplemented(Exception):\n pass\n\n\n# DeprecatedIn39 -- Our only known consumer is aws-encryption-sdk, but we've\n# made this a no-op to avoid breaking old versions.\ndef verify_interface(\n iface: abc.ABCMeta, klass: object, *, check_annotations: bool = False\n):\n # Exists exclusively for `aws-encryption-sdk` which relies on it existing,\n # even though it was never a public API.\n pass\n\n\nclass _DeprecatedValue:\n def __init__(self, value: object, message: str, warning_class):\n self.value = value\n self.message = message\n self.warning_class = warning_class\n\n\nclass _ModuleWithDeprecations(types.ModuleType):\n def __init__(self, module: types.ModuleType):\n super().__init__(module.__name__)\n self.__dict__[\"_module\"] = module\n\n def __getattr__(self, attr: str) -> object:\n obj = getattr(self._module, attr)\n if isinstance(obj, _DeprecatedValue):\n warnings.warn(obj.message, obj.warning_class, stacklevel=2)\n obj = obj.value\n return obj\n\n def __setattr__(self, attr: str, value: object) -> None:\n setattr(self._module, attr, value)\n\n def __delattr__(self, attr: str) -> None:\n obj = getattr(self._module, attr)\n if isinstance(obj, _DeprecatedValue):\n warnings.warn(obj.message, obj.warning_class, stacklevel=2)\n\n delattr(self._module, attr)\n\n def __dir__(self) -> typing.Sequence[str]:\n return [\"_module\"] + dir(self._module)\n\n\ndef deprecated(\n value: object,\n module_name: str,\n message: str,\n warning_class: typing.Type[Warning],\n name: typing.Optional[str] = None,\n) -> _DeprecatedValue:\n module = sys.modules[module_name]\n if not isinstance(module, _ModuleWithDeprecations):\n sys.modules[module_name] = module = _ModuleWithDeprecations(module)\n dv = _DeprecatedValue(value, message, warning_class)\n # Maintain backwards compatibility with `name is None` for pyOpenSSL.\n if name is not None:\n setattr(module, name, dv)\n return dv\n\n\ndef cached_property(func: typing.Callable) -> property:\n cached_name = f\"_cached_{func}\"\n sentinel = object()\n\n def inner(instance: object):\n cache = getattr(instance, cached_name, sentinel)\n if cache is not sentinel:\n return cache\n result = func(instance)\n setattr(instance, cached_name, result)\n return result\n\n return property(inner)\n\n\n# Python 3.10 changed representation of enums. We use well-defined object\n# representation and string representation from Python 3.9.\nclass Enum(enum.Enum):\n def __repr__(self) -> str:\n return f\"<{self.__class__.__name__}.{self._name_}: {self._value_!r}>\"\n\n def __str__(self) -> str:\n return f\"{self.__class__.__name__}.{self._name_}\"\n", "path": "src/cryptography/utils.py"}], "after_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\n\nimport enum\nimport sys\nimport types\nimport typing\nimport warnings\n\n\n# We use a UserWarning subclass, instead of DeprecationWarning, because CPython\n# decided deprecation warnings should be invisble by default.\nclass CryptographyDeprecationWarning(UserWarning):\n pass\n\n\n# Several APIs were deprecated with no specific end-of-life date because of the\n# ubiquity of their use. They should not be removed until we agree on when that\n# cycle ends.\nDeprecatedIn36 = CryptographyDeprecationWarning\nDeprecatedIn37 = CryptographyDeprecationWarning\nDeprecatedIn39 = CryptographyDeprecationWarning\nDeprecatedIn40 = CryptographyDeprecationWarning\n\n\ndef _check_bytes(name: str, value: bytes) -> None:\n if not isinstance(value, bytes):\n raise TypeError(f\"{name} must be bytes\")\n\n\ndef _check_byteslike(name: str, value: bytes) -> None:\n try:\n memoryview(value)\n except TypeError:\n raise TypeError(f\"{name} must be bytes-like\")\n\n\ndef int_to_bytes(integer: int, length: typing.Optional[int] = None) -> bytes:\n return integer.to_bytes(\n length or (integer.bit_length() + 7) // 8 or 1, \"big\"\n )\n\n\nclass InterfaceNotImplemented(Exception):\n pass\n\n\nclass _DeprecatedValue:\n def __init__(self, value: object, message: str, warning_class):\n self.value = value\n self.message = message\n self.warning_class = warning_class\n\n\nclass _ModuleWithDeprecations(types.ModuleType):\n def __init__(self, module: types.ModuleType):\n super().__init__(module.__name__)\n self.__dict__[\"_module\"] = module\n\n def __getattr__(self, attr: str) -> object:\n obj = getattr(self._module, attr)\n if isinstance(obj, _DeprecatedValue):\n warnings.warn(obj.message, obj.warning_class, stacklevel=2)\n obj = obj.value\n return obj\n\n def __setattr__(self, attr: str, value: object) -> None:\n setattr(self._module, attr, value)\n\n def __delattr__(self, attr: str) -> None:\n obj = getattr(self._module, attr)\n if isinstance(obj, _DeprecatedValue):\n warnings.warn(obj.message, obj.warning_class, stacklevel=2)\n\n delattr(self._module, attr)\n\n def __dir__(self) -> typing.Sequence[str]:\n return [\"_module\"] + dir(self._module)\n\n\ndef deprecated(\n value: object,\n module_name: str,\n message: str,\n warning_class: typing.Type[Warning],\n name: typing.Optional[str] = None,\n) -> _DeprecatedValue:\n module = sys.modules[module_name]\n if not isinstance(module, _ModuleWithDeprecations):\n sys.modules[module_name] = module = _ModuleWithDeprecations(module)\n dv = _DeprecatedValue(value, message, warning_class)\n # Maintain backwards compatibility with `name is None` for pyOpenSSL.\n if name is not None:\n setattr(module, name, dv)\n return dv\n\n\ndef cached_property(func: typing.Callable) -> property:\n cached_name = f\"_cached_{func}\"\n sentinel = object()\n\n def inner(instance: object):\n cache = getattr(instance, cached_name, sentinel)\n if cache is not sentinel:\n return cache\n result = func(instance)\n setattr(instance, cached_name, result)\n return result\n\n return property(inner)\n\n\n# Python 3.10 changed representation of enums. We use well-defined object\n# representation and string representation from Python 3.9.\nclass Enum(enum.Enum):\n def __repr__(self) -> str:\n return f\"<{self.__class__.__name__}.{self._name_}: {self._value_!r}>\"\n\n def __str__(self) -> str:\n return f\"{self.__class__.__name__}.{self._name_}\"\n", "path": "src/cryptography/utils.py"}]}
| 1,608 | 203 |
gh_patches_debug_16594
|
rasdani/github-patches
|
git_diff
|
mlflow__mlflow-7141
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[DOC-FIX] MLFLOW_TRACKING_AWS_SIGV4 environment variable does not appear in the python API docs
### Willingness to contribute
Yes. I can contribute a documentation fix independently.
### URL(s) with the issue
https://www.mlflow.org/docs/latest/python_api/mlflow.environment_variables.html
### Description of proposal (what needs changing)
Fix the doc-string in `mlflow.environment_variables` to ensure the documentation compiles correctly (there is a missing semicolon)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mlflow/environment_variables.py`
Content:
```
1 """
2 This module defines environment variables used in MLflow.
3 """
4 import os
5
6
7 class _EnvironmentVariable:
8 """
9 Represents an environment variable.
10 """
11
12 def __init__(self, name, type_, default):
13 self.name = name
14 self.type = type_
15 self.default = default
16
17 @property
18 def is_defined(self):
19 return self.name in os.environ
20
21 def get(self):
22 """
23 Reads the value of the environment variable if it exists and converts it to the desired
24 type. Otherwise, returns the default value.
25 """
26 val = os.getenv(self.name)
27 if val:
28 try:
29 return self.type(val)
30 except Exception as e:
31 raise ValueError(f"Failed to convert {val} to {self.type} for {self.name}: {e}")
32 return self.default
33
34 def __str__(self):
35 return f"{self.name} (default: {self.default}, type: {self.type.__name__})"
36
37 def __repr__(self):
38 return repr(self.name)
39
40
41 class _BooleanEnvironmentVariable(_EnvironmentVariable):
42 """
43 Represents a boolean environment variable.
44 """
45
46 def __init__(self, name, default):
47 # `default not in [True, False, None]` doesn't work because `1 in [True]`
48 # (or `0 in [False]`) returns True.
49 if not (default is True or default is False or default is None):
50 raise ValueError(f"{name} default value must be one of [True, False, None]")
51 super().__init__(name, bool, default)
52
53 def get(self):
54 if not self.is_defined:
55 return self.default
56
57 val = os.getenv(self.name)
58 lowercased = val.lower()
59 if lowercased not in ["true", "false", "1", "0"]:
60 raise ValueError(
61 f"{self.name} value must be one of ['true', 'false', '1', '0'] (case-insensitive), "
62 f"but got {val}"
63 )
64 return lowercased in ["true", "1"]
65
66
67 #: Specifies the ``dfs_tmpdir`` parameter to use for ``mlflow.spark.save_model``,
68 #: ``mlflow.spark.log_model`` and ``mlflow.spark.load_model``. See
69 #: https://www.mlflow.org/docs/latest/python_api/mlflow.spark.html#mlflow.spark.save_model
70 #: for more information.
71 #: (default: ``/tmp/mlflow``)
72 MLFLOW_DFS_TMP = _EnvironmentVariable("MLFLOW_DFS_TMP", str, "/tmp/mlflow")
73
74 #: Specifies the maximum number of retries for MLflow HTTP requests
75 #: (default: ``5``)
76 MLFLOW_HTTP_REQUEST_MAX_RETRIES = _EnvironmentVariable("MLFLOW_HTTP_REQUEST_MAX_RETRIES", int, 5)
77
78 #: Specifies the backoff increase factor between MLflow HTTP request failures
79 #: (default: ``2``)
80 MLFLOW_HTTP_REQUEST_BACKOFF_FACTOR = _EnvironmentVariable(
81 "MLFLOW_HTTP_REQUEST_BACKOFF_FACTOR", int, 2
82 )
83
84 #: Specifies the timeout in seconds for MLflow HTTP requests
85 #: (default: ``120``)
86 MLFLOW_HTTP_REQUEST_TIMEOUT = _EnvironmentVariable("MLFLOW_HTTP_REQUEST_TIMEOUT", int, 120)
87
88 #: Specifies whether MLFlow HTTP requests should be signed using AWS signature V4. It will overwrite
89 #: (default: ``False``). When set, it will overwrite the "Authorization" HTTP header
90 # See https://docs.aws.amazon.com/general/latest/gr/signature-version-4.html for more information.
91 MLFLOW_TRACKING_AWS_SIGV4 = _BooleanEnvironmentVariable("MLFLOW_TRACKING_AWS_SIGV4", False)
92
93 #: Specifies the chunk size to use when downloading a file from GCS
94 #: (default: ``None``). If None, the chunk size is automatically determined by the
95 #: ``google-cloud-storage`` package.
96 MLFLOW_GCS_DOWNLOAD_CHUNK_SIZE = _EnvironmentVariable("MLFLOW_GCS_DOWNLOAD_CHUNK_SIZE", int, None)
97
98 #: Specifies the chunk size to use when uploading a file to GCS.
99 #: (default: ``None``). If None, the chunk size is automatically determined by the
100 #: ``google-cloud-storage`` package.
101 MLFLOW_GCS_UPLOAD_CHUNK_SIZE = _EnvironmentVariable("MLFLOW_GCS_UPLOAD_CHUNK_SIZE", int, None)
102
103 #: Specifies the default timeout to use when downloading/uploading a file from/to GCS
104 #: (default: ``None``). If None, ``google.cloud.storage.constants._DEFAULT_TIMEOUT`` is used.
105 MLFLOW_GCS_DEFAULT_TIMEOUT = _EnvironmentVariable("MLFLOW_GCS_DEFAULT_TIMEOUT", int, None)
106
107 #: Specifies whether to disable model logging and loading via mlflowdbfs.
108 #: (default: ``None``)
109 _DISABLE_MLFLOWDBFS = _EnvironmentVariable("DISABLE_MLFLOWDBFS", str, None)
110
111 #: Specifies the S3 endpoint URL to use for S3 artifact operations.
112 #: (default: ``None``)
113 MLFLOW_S3_ENDPOINT_URL = _EnvironmentVariable("MLFLOW_S3_ENDPOINT_URL", str, None)
114
115 #: Specifies whether or not to skip TLS certificate verification for S3 artifact operations.
116 #: (default: ``False``)
117 MLFLOW_S3_IGNORE_TLS = _BooleanEnvironmentVariable("MLFLOW_S3_IGNORE_TLS", False)
118
119 #: Specifies extra arguments for S3 artifact uploads.
120 #: (default: ``None``)
121 MLFLOW_S3_UPLOAD_EXTRA_ARGS = _EnvironmentVariable("MLFLOW_S3_UPLOAD_EXTRA_ARGS", str, None)
122
123 #: Specifies the location of a Kerberos ticket cache to use for HDFS artifact operations.
124 #: (default: ``None``)
125 MLFLOW_KERBEROS_TICKET_CACHE = _EnvironmentVariable("MLFLOW_KERBEROS_TICKET_CACHE", str, None)
126
127 #: Specifies a Kerberos user for HDFS artifact operations.
128 #: (default: ``None``)
129 MLFLOW_KERBEROS_USER = _EnvironmentVariable("MLFLOW_KERBEROS_USER", str, None)
130
131 #: Specifies extra pyarrow configurations for HDFS artifact operations.
132 #: (default: ``None``)
133 MLFLOW_PYARROW_EXTRA_CONF = _EnvironmentVariable("MLFLOW_PYARROW_EXTRA_CONF", str, None)
134
135 #: Specifies the ``pool_size`` parameter to use for ``sqlalchemy.create_engine`` in the SQLAlchemy
136 #: tracking store. See https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine.params.pool_size
137 #: for more information.
138 #: (default: ``None``)
139 MLFLOW_SQLALCHEMYSTORE_POOL_SIZE = _EnvironmentVariable(
140 "MLFLOW_SQLALCHEMYSTORE_POOL_SIZE", int, None
141 )
142
143 #: Specifies the ``pool_recycle`` parameter to use for ``sqlalchemy.create_engine`` in the
144 #: SQLAlchemy tracking store. See https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine.params.pool_recycle
145 #: for more information.
146 #: (default: ``None``)
147 MLFLOW_SQLALCHEMYSTORE_POOL_RECYCLE = _EnvironmentVariable(
148 "MLFLOW_SQLALCHEMYSTORE_POOL_RECYCLE", int, None
149 )
150
151 #: Specifies the ``max_overflow`` parameter to use for ``sqlalchemy.create_engine`` in the
152 #: SQLAlchemy tracking store. See https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine.params.max_overflow
153 #: for more information.
154 #: (default: ``None``)
155 MLFLOW_SQLALCHEMYSTORE_MAX_OVERFLOW = _EnvironmentVariable(
156 "MLFLOW_SQLALCHEMYSTORE_MAX_OVERFLOW", int, None
157 )
158
159 #: Specifies the ``echo`` parameter to use for ``sqlalchemy.create_engine`` in the
160 #: SQLAlchemy tracking store. See https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine.params.echo
161 #: for more information.
162 #: (default: ``False``)
163 MLFLOW_SQLALCHEMYSTORE_ECHO = _BooleanEnvironmentVariable("MLFLOW_SQLALCHEMYSTORE_ECHO", False)
164
165 #: Specifies the ``poolclass`` parameter to use for ``sqlalchemy.create_engine`` in the
166 #: SQLAlchemy tracking store. See https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine.params.poolclass
167 #: for more information.
168 #: (default: ``None``)
169 MLFLOW_SQLALCHEMYSTORE_POOLCLASS = _EnvironmentVariable(
170 "MLFLOW_SQLALCHEMYSTORE_POOLCLASS", str, None
171 )
172
173 #: Specifies the ``timeout_seconds`` for MLflow Model dependency inference operations.
174 #: (default: ``120``)
175 MLFLOW_REQUIREMENTS_INFERENCE_TIMEOUT = _EnvironmentVariable(
176 "MLFLOW_REQUIREMENTS_INFERENCE_TIMEOUT", int, 120
177 )
178
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mlflow/environment_variables.py b/mlflow/environment_variables.py
--- a/mlflow/environment_variables.py
+++ b/mlflow/environment_variables.py
@@ -86,8 +86,8 @@
MLFLOW_HTTP_REQUEST_TIMEOUT = _EnvironmentVariable("MLFLOW_HTTP_REQUEST_TIMEOUT", int, 120)
#: Specifies whether MLFlow HTTP requests should be signed using AWS signature V4. It will overwrite
-#: (default: ``False``). When set, it will overwrite the "Authorization" HTTP header
-# See https://docs.aws.amazon.com/general/latest/gr/signature-version-4.html for more information.
+#: (default: ``False``). When set, it will overwrite the "Authorization" HTTP header.
+#: See https://docs.aws.amazon.com/general/latest/gr/signature-version-4.html for more information.
MLFLOW_TRACKING_AWS_SIGV4 = _BooleanEnvironmentVariable("MLFLOW_TRACKING_AWS_SIGV4", False)
#: Specifies the chunk size to use when downloading a file from GCS
|
{"golden_diff": "diff --git a/mlflow/environment_variables.py b/mlflow/environment_variables.py\n--- a/mlflow/environment_variables.py\n+++ b/mlflow/environment_variables.py\n@@ -86,8 +86,8 @@\n MLFLOW_HTTP_REQUEST_TIMEOUT = _EnvironmentVariable(\"MLFLOW_HTTP_REQUEST_TIMEOUT\", int, 120)\n \n #: Specifies whether MLFlow HTTP requests should be signed using AWS signature V4. It will overwrite\n-#: (default: ``False``). When set, it will overwrite the \"Authorization\" HTTP header\n-# See https://docs.aws.amazon.com/general/latest/gr/signature-version-4.html for more information.\n+#: (default: ``False``). When set, it will overwrite the \"Authorization\" HTTP header.\n+#: See https://docs.aws.amazon.com/general/latest/gr/signature-version-4.html for more information.\n MLFLOW_TRACKING_AWS_SIGV4 = _BooleanEnvironmentVariable(\"MLFLOW_TRACKING_AWS_SIGV4\", False)\n \n #: Specifies the chunk size to use when downloading a file from GCS\n", "issue": "[DOC-FIX] MLFLOW_TRACKING_AWS_SIGV4 environment variable does not appear in the python API docs\n### Willingness to contribute\n\nYes. I can contribute a documentation fix independently.\n\n### URL(s) with the issue\n\nhttps://www.mlflow.org/docs/latest/python_api/mlflow.environment_variables.html\n\n### Description of proposal (what needs changing)\n\nFix the doc-string in `mlflow.environment_variables` to ensure the documentation compiles correctly (there is a missing semicolon)\n", "before_files": [{"content": "\"\"\"\nThis module defines environment variables used in MLflow.\n\"\"\"\nimport os\n\n\nclass _EnvironmentVariable:\n \"\"\"\n Represents an environment variable.\n \"\"\"\n\n def __init__(self, name, type_, default):\n self.name = name\n self.type = type_\n self.default = default\n\n @property\n def is_defined(self):\n return self.name in os.environ\n\n def get(self):\n \"\"\"\n Reads the value of the environment variable if it exists and converts it to the desired\n type. Otherwise, returns the default value.\n \"\"\"\n val = os.getenv(self.name)\n if val:\n try:\n return self.type(val)\n except Exception as e:\n raise ValueError(f\"Failed to convert {val} to {self.type} for {self.name}: {e}\")\n return self.default\n\n def __str__(self):\n return f\"{self.name} (default: {self.default}, type: {self.type.__name__})\"\n\n def __repr__(self):\n return repr(self.name)\n\n\nclass _BooleanEnvironmentVariable(_EnvironmentVariable):\n \"\"\"\n Represents a boolean environment variable.\n \"\"\"\n\n def __init__(self, name, default):\n # `default not in [True, False, None]` doesn't work because `1 in [True]`\n # (or `0 in [False]`) returns True.\n if not (default is True or default is False or default is None):\n raise ValueError(f\"{name} default value must be one of [True, False, None]\")\n super().__init__(name, bool, default)\n\n def get(self):\n if not self.is_defined:\n return self.default\n\n val = os.getenv(self.name)\n lowercased = val.lower()\n if lowercased not in [\"true\", \"false\", \"1\", \"0\"]:\n raise ValueError(\n f\"{self.name} value must be one of ['true', 'false', '1', '0'] (case-insensitive), \"\n f\"but got {val}\"\n )\n return lowercased in [\"true\", \"1\"]\n\n\n#: Specifies the ``dfs_tmpdir`` parameter to use for ``mlflow.spark.save_model``,\n#: ``mlflow.spark.log_model`` and ``mlflow.spark.load_model``. See\n#: https://www.mlflow.org/docs/latest/python_api/mlflow.spark.html#mlflow.spark.save_model\n#: for more information.\n#: (default: ``/tmp/mlflow``)\nMLFLOW_DFS_TMP = _EnvironmentVariable(\"MLFLOW_DFS_TMP\", str, \"/tmp/mlflow\")\n\n#: Specifies the maximum number of retries for MLflow HTTP requests\n#: (default: ``5``)\nMLFLOW_HTTP_REQUEST_MAX_RETRIES = _EnvironmentVariable(\"MLFLOW_HTTP_REQUEST_MAX_RETRIES\", int, 5)\n\n#: Specifies the backoff increase factor between MLflow HTTP request failures\n#: (default: ``2``)\nMLFLOW_HTTP_REQUEST_BACKOFF_FACTOR = _EnvironmentVariable(\n \"MLFLOW_HTTP_REQUEST_BACKOFF_FACTOR\", int, 2\n)\n\n#: Specifies the timeout in seconds for MLflow HTTP requests\n#: (default: ``120``)\nMLFLOW_HTTP_REQUEST_TIMEOUT = _EnvironmentVariable(\"MLFLOW_HTTP_REQUEST_TIMEOUT\", int, 120)\n\n#: Specifies whether MLFlow HTTP requests should be signed using AWS signature V4. It will overwrite\n#: (default: ``False``). When set, it will overwrite the \"Authorization\" HTTP header\n# See https://docs.aws.amazon.com/general/latest/gr/signature-version-4.html for more information.\nMLFLOW_TRACKING_AWS_SIGV4 = _BooleanEnvironmentVariable(\"MLFLOW_TRACKING_AWS_SIGV4\", False)\n\n#: Specifies the chunk size to use when downloading a file from GCS\n#: (default: ``None``). If None, the chunk size is automatically determined by the\n#: ``google-cloud-storage`` package.\nMLFLOW_GCS_DOWNLOAD_CHUNK_SIZE = _EnvironmentVariable(\"MLFLOW_GCS_DOWNLOAD_CHUNK_SIZE\", int, None)\n\n#: Specifies the chunk size to use when uploading a file to GCS.\n#: (default: ``None``). If None, the chunk size is automatically determined by the\n#: ``google-cloud-storage`` package.\nMLFLOW_GCS_UPLOAD_CHUNK_SIZE = _EnvironmentVariable(\"MLFLOW_GCS_UPLOAD_CHUNK_SIZE\", int, None)\n\n#: Specifies the default timeout to use when downloading/uploading a file from/to GCS\n#: (default: ``None``). If None, ``google.cloud.storage.constants._DEFAULT_TIMEOUT`` is used.\nMLFLOW_GCS_DEFAULT_TIMEOUT = _EnvironmentVariable(\"MLFLOW_GCS_DEFAULT_TIMEOUT\", int, None)\n\n#: Specifies whether to disable model logging and loading via mlflowdbfs.\n#: (default: ``None``)\n_DISABLE_MLFLOWDBFS = _EnvironmentVariable(\"DISABLE_MLFLOWDBFS\", str, None)\n\n#: Specifies the S3 endpoint URL to use for S3 artifact operations.\n#: (default: ``None``)\nMLFLOW_S3_ENDPOINT_URL = _EnvironmentVariable(\"MLFLOW_S3_ENDPOINT_URL\", str, None)\n\n#: Specifies whether or not to skip TLS certificate verification for S3 artifact operations.\n#: (default: ``False``)\nMLFLOW_S3_IGNORE_TLS = _BooleanEnvironmentVariable(\"MLFLOW_S3_IGNORE_TLS\", False)\n\n#: Specifies extra arguments for S3 artifact uploads.\n#: (default: ``None``)\nMLFLOW_S3_UPLOAD_EXTRA_ARGS = _EnvironmentVariable(\"MLFLOW_S3_UPLOAD_EXTRA_ARGS\", str, None)\n\n#: Specifies the location of a Kerberos ticket cache to use for HDFS artifact operations.\n#: (default: ``None``)\nMLFLOW_KERBEROS_TICKET_CACHE = _EnvironmentVariable(\"MLFLOW_KERBEROS_TICKET_CACHE\", str, None)\n\n#: Specifies a Kerberos user for HDFS artifact operations.\n#: (default: ``None``)\nMLFLOW_KERBEROS_USER = _EnvironmentVariable(\"MLFLOW_KERBEROS_USER\", str, None)\n\n#: Specifies extra pyarrow configurations for HDFS artifact operations.\n#: (default: ``None``)\nMLFLOW_PYARROW_EXTRA_CONF = _EnvironmentVariable(\"MLFLOW_PYARROW_EXTRA_CONF\", str, None)\n\n#: Specifies the ``pool_size`` parameter to use for ``sqlalchemy.create_engine`` in the SQLAlchemy\n#: tracking store. See https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine.params.pool_size\n#: for more information.\n#: (default: ``None``)\nMLFLOW_SQLALCHEMYSTORE_POOL_SIZE = _EnvironmentVariable(\n \"MLFLOW_SQLALCHEMYSTORE_POOL_SIZE\", int, None\n)\n\n#: Specifies the ``pool_recycle`` parameter to use for ``sqlalchemy.create_engine`` in the\n#: SQLAlchemy tracking store. See https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine.params.pool_recycle\n#: for more information.\n#: (default: ``None``)\nMLFLOW_SQLALCHEMYSTORE_POOL_RECYCLE = _EnvironmentVariable(\n \"MLFLOW_SQLALCHEMYSTORE_POOL_RECYCLE\", int, None\n)\n\n#: Specifies the ``max_overflow`` parameter to use for ``sqlalchemy.create_engine`` in the\n#: SQLAlchemy tracking store. See https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine.params.max_overflow\n#: for more information.\n#: (default: ``None``)\nMLFLOW_SQLALCHEMYSTORE_MAX_OVERFLOW = _EnvironmentVariable(\n \"MLFLOW_SQLALCHEMYSTORE_MAX_OVERFLOW\", int, None\n)\n\n#: Specifies the ``echo`` parameter to use for ``sqlalchemy.create_engine`` in the\n#: SQLAlchemy tracking store. See https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine.params.echo\n#: for more information.\n#: (default: ``False``)\nMLFLOW_SQLALCHEMYSTORE_ECHO = _BooleanEnvironmentVariable(\"MLFLOW_SQLALCHEMYSTORE_ECHO\", False)\n\n#: Specifies the ``poolclass`` parameter to use for ``sqlalchemy.create_engine`` in the\n#: SQLAlchemy tracking store. See https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine.params.poolclass\n#: for more information.\n#: (default: ``None``)\nMLFLOW_SQLALCHEMYSTORE_POOLCLASS = _EnvironmentVariable(\n \"MLFLOW_SQLALCHEMYSTORE_POOLCLASS\", str, None\n)\n\n#: Specifies the ``timeout_seconds`` for MLflow Model dependency inference operations.\n#: (default: ``120``)\nMLFLOW_REQUIREMENTS_INFERENCE_TIMEOUT = _EnvironmentVariable(\n \"MLFLOW_REQUIREMENTS_INFERENCE_TIMEOUT\", int, 120\n)\n", "path": "mlflow/environment_variables.py"}], "after_files": [{"content": "\"\"\"\nThis module defines environment variables used in MLflow.\n\"\"\"\nimport os\n\n\nclass _EnvironmentVariable:\n \"\"\"\n Represents an environment variable.\n \"\"\"\n\n def __init__(self, name, type_, default):\n self.name = name\n self.type = type_\n self.default = default\n\n @property\n def is_defined(self):\n return self.name in os.environ\n\n def get(self):\n \"\"\"\n Reads the value of the environment variable if it exists and converts it to the desired\n type. Otherwise, returns the default value.\n \"\"\"\n val = os.getenv(self.name)\n if val:\n try:\n return self.type(val)\n except Exception as e:\n raise ValueError(f\"Failed to convert {val} to {self.type} for {self.name}: {e}\")\n return self.default\n\n def __str__(self):\n return f\"{self.name} (default: {self.default}, type: {self.type.__name__})\"\n\n def __repr__(self):\n return repr(self.name)\n\n\nclass _BooleanEnvironmentVariable(_EnvironmentVariable):\n \"\"\"\n Represents a boolean environment variable.\n \"\"\"\n\n def __init__(self, name, default):\n # `default not in [True, False, None]` doesn't work because `1 in [True]`\n # (or `0 in [False]`) returns True.\n if not (default is True or default is False or default is None):\n raise ValueError(f\"{name} default value must be one of [True, False, None]\")\n super().__init__(name, bool, default)\n\n def get(self):\n if not self.is_defined:\n return self.default\n\n val = os.getenv(self.name)\n lowercased = val.lower()\n if lowercased not in [\"true\", \"false\", \"1\", \"0\"]:\n raise ValueError(\n f\"{self.name} value must be one of ['true', 'false', '1', '0'] (case-insensitive), \"\n f\"but got {val}\"\n )\n return lowercased in [\"true\", \"1\"]\n\n\n#: Specifies the ``dfs_tmpdir`` parameter to use for ``mlflow.spark.save_model``,\n#: ``mlflow.spark.log_model`` and ``mlflow.spark.load_model``. See\n#: https://www.mlflow.org/docs/latest/python_api/mlflow.spark.html#mlflow.spark.save_model\n#: for more information.\n#: (default: ``/tmp/mlflow``)\nMLFLOW_DFS_TMP = _EnvironmentVariable(\"MLFLOW_DFS_TMP\", str, \"/tmp/mlflow\")\n\n#: Specifies the maximum number of retries for MLflow HTTP requests\n#: (default: ``5``)\nMLFLOW_HTTP_REQUEST_MAX_RETRIES = _EnvironmentVariable(\"MLFLOW_HTTP_REQUEST_MAX_RETRIES\", int, 5)\n\n#: Specifies the backoff increase factor between MLflow HTTP request failures\n#: (default: ``2``)\nMLFLOW_HTTP_REQUEST_BACKOFF_FACTOR = _EnvironmentVariable(\n \"MLFLOW_HTTP_REQUEST_BACKOFF_FACTOR\", int, 2\n)\n\n#: Specifies the timeout in seconds for MLflow HTTP requests\n#: (default: ``120``)\nMLFLOW_HTTP_REQUEST_TIMEOUT = _EnvironmentVariable(\"MLFLOW_HTTP_REQUEST_TIMEOUT\", int, 120)\n\n#: Specifies whether MLFlow HTTP requests should be signed using AWS signature V4. It will overwrite\n#: (default: ``False``). When set, it will overwrite the \"Authorization\" HTTP header.\n#: See https://docs.aws.amazon.com/general/latest/gr/signature-version-4.html for more information.\nMLFLOW_TRACKING_AWS_SIGV4 = _BooleanEnvironmentVariable(\"MLFLOW_TRACKING_AWS_SIGV4\", False)\n\n#: Specifies the chunk size to use when downloading a file from GCS\n#: (default: ``None``). If None, the chunk size is automatically determined by the\n#: ``google-cloud-storage`` package.\nMLFLOW_GCS_DOWNLOAD_CHUNK_SIZE = _EnvironmentVariable(\"MLFLOW_GCS_DOWNLOAD_CHUNK_SIZE\", int, None)\n\n#: Specifies the chunk size to use when uploading a file to GCS.\n#: (default: ``None``). If None, the chunk size is automatically determined by the\n#: ``google-cloud-storage`` package.\nMLFLOW_GCS_UPLOAD_CHUNK_SIZE = _EnvironmentVariable(\"MLFLOW_GCS_UPLOAD_CHUNK_SIZE\", int, None)\n\n#: Specifies the default timeout to use when downloading/uploading a file from/to GCS\n#: (default: ``None``). If None, ``google.cloud.storage.constants._DEFAULT_TIMEOUT`` is used.\nMLFLOW_GCS_DEFAULT_TIMEOUT = _EnvironmentVariable(\"MLFLOW_GCS_DEFAULT_TIMEOUT\", int, None)\n\n#: Specifies whether to disable model logging and loading via mlflowdbfs.\n#: (default: ``None``)\n_DISABLE_MLFLOWDBFS = _EnvironmentVariable(\"DISABLE_MLFLOWDBFS\", str, None)\n\n#: Specifies the S3 endpoint URL to use for S3 artifact operations.\n#: (default: ``None``)\nMLFLOW_S3_ENDPOINT_URL = _EnvironmentVariable(\"MLFLOW_S3_ENDPOINT_URL\", str, None)\n\n#: Specifies whether or not to skip TLS certificate verification for S3 artifact operations.\n#: (default: ``False``)\nMLFLOW_S3_IGNORE_TLS = _BooleanEnvironmentVariable(\"MLFLOW_S3_IGNORE_TLS\", False)\n\n#: Specifies extra arguments for S3 artifact uploads.\n#: (default: ``None``)\nMLFLOW_S3_UPLOAD_EXTRA_ARGS = _EnvironmentVariable(\"MLFLOW_S3_UPLOAD_EXTRA_ARGS\", str, None)\n\n#: Specifies the location of a Kerberos ticket cache to use for HDFS artifact operations.\n#: (default: ``None``)\nMLFLOW_KERBEROS_TICKET_CACHE = _EnvironmentVariable(\"MLFLOW_KERBEROS_TICKET_CACHE\", str, None)\n\n#: Specifies a Kerberos user for HDFS artifact operations.\n#: (default: ``None``)\nMLFLOW_KERBEROS_USER = _EnvironmentVariable(\"MLFLOW_KERBEROS_USER\", str, None)\n\n#: Specifies extra pyarrow configurations for HDFS artifact operations.\n#: (default: ``None``)\nMLFLOW_PYARROW_EXTRA_CONF = _EnvironmentVariable(\"MLFLOW_PYARROW_EXTRA_CONF\", str, None)\n\n#: Specifies the ``pool_size`` parameter to use for ``sqlalchemy.create_engine`` in the SQLAlchemy\n#: tracking store. See https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine.params.pool_size\n#: for more information.\n#: (default: ``None``)\nMLFLOW_SQLALCHEMYSTORE_POOL_SIZE = _EnvironmentVariable(\n \"MLFLOW_SQLALCHEMYSTORE_POOL_SIZE\", int, None\n)\n\n#: Specifies the ``pool_recycle`` parameter to use for ``sqlalchemy.create_engine`` in the\n#: SQLAlchemy tracking store. See https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine.params.pool_recycle\n#: for more information.\n#: (default: ``None``)\nMLFLOW_SQLALCHEMYSTORE_POOL_RECYCLE = _EnvironmentVariable(\n \"MLFLOW_SQLALCHEMYSTORE_POOL_RECYCLE\", int, None\n)\n\n#: Specifies the ``max_overflow`` parameter to use for ``sqlalchemy.create_engine`` in the\n#: SQLAlchemy tracking store. See https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine.params.max_overflow\n#: for more information.\n#: (default: ``None``)\nMLFLOW_SQLALCHEMYSTORE_MAX_OVERFLOW = _EnvironmentVariable(\n \"MLFLOW_SQLALCHEMYSTORE_MAX_OVERFLOW\", int, None\n)\n\n#: Specifies the ``echo`` parameter to use for ``sqlalchemy.create_engine`` in the\n#: SQLAlchemy tracking store. See https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine.params.echo\n#: for more information.\n#: (default: ``False``)\nMLFLOW_SQLALCHEMYSTORE_ECHO = _BooleanEnvironmentVariable(\"MLFLOW_SQLALCHEMYSTORE_ECHO\", False)\n\n#: Specifies the ``poolclass`` parameter to use for ``sqlalchemy.create_engine`` in the\n#: SQLAlchemy tracking store. See https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine.params.poolclass\n#: for more information.\n#: (default: ``None``)\nMLFLOW_SQLALCHEMYSTORE_POOLCLASS = _EnvironmentVariable(\n \"MLFLOW_SQLALCHEMYSTORE_POOLCLASS\", str, None\n)\n\n#: Specifies the ``timeout_seconds`` for MLflow Model dependency inference operations.\n#: (default: ``120``)\nMLFLOW_REQUIREMENTS_INFERENCE_TIMEOUT = _EnvironmentVariable(\n \"MLFLOW_REQUIREMENTS_INFERENCE_TIMEOUT\", int, 120\n)\n", "path": "mlflow/environment_variables.py"}]}
| 2,608 | 219 |
gh_patches_debug_1940
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-941
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
use short URL for better help message
The current help msg has a long url, but this includes line breaks
which makes it hard to copy.
```
pyhf cls --help
Usage: pyhf cls [OPTIONS] [WORKSPACE]
Compute CLs value(s) for a given pyhf workspace.
Example:
.. code-block:: shell
$ curl -sL https://raw.githubusercontent.com/scikit-
hep/pyhf/master/docs/examples/json/2-bin_1-channel.json | pyhf cls
{ "CLs_exp": [ 0.07807427911686156,
0.17472571775474618, 0.35998495263681285,
0.6343568235898907, 0.8809947004472013 ],
"CLs_obs": 0.3599845631401915 }
Options:
--output-file TEXT The location of the output json file. If not
specified, prints to screen.
--measurement TEXT
-p, --patch TEXT
--testpoi FLOAT
--teststat [q|qtilde]
--backend [numpy|pytorch|tensorflow|jax|np|torch|tf]
The tensor backend used for the calculation.
--optimizer TEXT
--optconf EQUAL-DELIMITED OPTION
-h, --help Show this message and exit.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/pyhf/cli/infer.py`
Content:
```
1 """The inference CLI group."""
2 import logging
3
4 import click
5 import json
6
7 from ..utils import EqDelimStringParamType
8 from ..infer import hypotest
9 from ..workspace import Workspace
10 from .. import tensor, get_backend, set_backend, optimize
11
12 log = logging.getLogger(__name__)
13
14
15 @click.group(name='infer')
16 def cli():
17 """Infererence CLI group."""
18
19
20 @cli.command()
21 @click.argument('workspace', default='-')
22 @click.option(
23 '--output-file',
24 help='The location of the output json file. If not specified, prints to screen.',
25 default=None,
26 )
27 @click.option('--measurement', default=None)
28 @click.option('-p', '--patch', multiple=True)
29 @click.option('--testpoi', default=1.0)
30 @click.option('--teststat', type=click.Choice(['q', 'qtilde']), default='qtilde')
31 @click.option(
32 '--backend',
33 type=click.Choice(['numpy', 'pytorch', 'tensorflow', 'jax', 'np', 'torch', 'tf']),
34 help='The tensor backend used for the calculation.',
35 default='numpy',
36 )
37 @click.option('--optimizer')
38 @click.option('--optconf', type=EqDelimStringParamType(), multiple=True)
39 def cls(
40 workspace,
41 output_file,
42 measurement,
43 patch,
44 testpoi,
45 teststat,
46 backend,
47 optimizer,
48 optconf,
49 ):
50 """
51 Compute CLs value(s) for a given pyhf workspace.
52
53 Example:
54
55 .. code-block:: shell
56
57 $ curl -sL https://raw.githubusercontent.com/scikit-hep/pyhf/master/docs/examples/json/2-bin_1-channel.json | pyhf cls
58 {
59 "CLs_exp": [
60 0.07807427911686156,
61 0.17472571775474618,
62 0.35998495263681285,
63 0.6343568235898907,
64 0.8809947004472013
65 ],
66 "CLs_obs": 0.3599845631401915
67 }
68 """
69 with click.open_file(workspace, 'r') as specstream:
70 spec = json.load(specstream)
71
72 ws = Workspace(spec)
73
74 is_qtilde = teststat == 'qtilde'
75
76 patches = [json.loads(click.open_file(pfile, 'r').read()) for pfile in patch]
77 model = ws.model(
78 measurement_name=measurement,
79 patches=patches,
80 modifier_settings={
81 'normsys': {'interpcode': 'code4'},
82 'histosys': {'interpcode': 'code4p'},
83 },
84 )
85
86 # set the backend if not NumPy
87 if backend in ['pytorch', 'torch']:
88 set_backend(tensor.pytorch_backend(precision='64b'))
89 elif backend in ['tensorflow', 'tf']:
90 set_backend(tensor.tensorflow_backend(precision='64b'))
91 elif backend in ['jax']:
92 set_backend(tensor.jax_backend())
93 tensorlib, _ = get_backend()
94
95 optconf = {k: v for item in optconf for k, v in item.items()}
96
97 # set the new optimizer
98 if optimizer:
99 new_optimizer = getattr(optimize, optimizer)
100 set_backend(tensorlib, new_optimizer(**optconf))
101
102 result = hypotest(
103 testpoi, ws.data(model), model, qtilde=is_qtilde, return_expected_set=True
104 )
105 result = {
106 'CLs_obs': tensorlib.tolist(result[0])[0],
107 'CLs_exp': tensorlib.tolist(tensorlib.reshape(result[-1], [-1])),
108 }
109
110 if output_file is None:
111 click.echo(json.dumps(result, indent=4, sort_keys=True))
112 else:
113 with open(output_file, 'w+') as out_file:
114 json.dump(result, out_file, indent=4, sort_keys=True)
115 log.debug("Written to {0:s}".format(output_file))
116
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/pyhf/cli/infer.py b/src/pyhf/cli/infer.py
--- a/src/pyhf/cli/infer.py
+++ b/src/pyhf/cli/infer.py
@@ -54,7 +54,9 @@
.. code-block:: shell
- $ curl -sL https://raw.githubusercontent.com/scikit-hep/pyhf/master/docs/examples/json/2-bin_1-channel.json | pyhf cls
+ $ curl -sL https://git.io/JJYDE | pyhf cls
+
+ \b
{
"CLs_exp": [
0.07807427911686156,
|
{"golden_diff": "diff --git a/src/pyhf/cli/infer.py b/src/pyhf/cli/infer.py\n--- a/src/pyhf/cli/infer.py\n+++ b/src/pyhf/cli/infer.py\n@@ -54,7 +54,9 @@\n \n .. code-block:: shell\n \n- $ curl -sL https://raw.githubusercontent.com/scikit-hep/pyhf/master/docs/examples/json/2-bin_1-channel.json | pyhf cls\n+ $ curl -sL https://git.io/JJYDE | pyhf cls\n+\n+ \\b\n {\n \"CLs_exp\": [\n 0.07807427911686156,\n", "issue": "use short URL for better help message\nThe current help msg has a long url, but this includes line breaks\r\nwhich makes it hard to copy. \r\n\r\n```\r\npyhf cls --help \r\nUsage: pyhf cls [OPTIONS] [WORKSPACE]\r\n\r\n Compute CLs value(s) for a given pyhf workspace.\r\n\r\n Example:\r\n\r\n .. code-block:: shell\r\n\r\n $ curl -sL https://raw.githubusercontent.com/scikit-\r\n hep/pyhf/master/docs/examples/json/2-bin_1-channel.json | pyhf cls\r\n { \"CLs_exp\": [ 0.07807427911686156,\r\n 0.17472571775474618, 0.35998495263681285,\r\n 0.6343568235898907, 0.8809947004472013 ],\r\n \"CLs_obs\": 0.3599845631401915 }\r\n\r\nOptions:\r\n --output-file TEXT The location of the output json file. If not\r\n specified, prints to screen.\r\n\r\n --measurement TEXT\r\n -p, --patch TEXT\r\n --testpoi FLOAT\r\n --teststat [q|qtilde]\r\n --backend [numpy|pytorch|tensorflow|jax|np|torch|tf]\r\n The tensor backend used for the calculation.\r\n --optimizer TEXT\r\n --optconf EQUAL-DELIMITED OPTION\r\n -h, --help Show this message and exit.\r\n\r\n```\n", "before_files": [{"content": "\"\"\"The inference CLI group.\"\"\"\nimport logging\n\nimport click\nimport json\n\nfrom ..utils import EqDelimStringParamType\nfrom ..infer import hypotest\nfrom ..workspace import Workspace\nfrom .. import tensor, get_backend, set_backend, optimize\n\nlog = logging.getLogger(__name__)\n\n\[email protected](name='infer')\ndef cli():\n \"\"\"Infererence CLI group.\"\"\"\n\n\[email protected]()\[email protected]('workspace', default='-')\[email protected](\n '--output-file',\n help='The location of the output json file. If not specified, prints to screen.',\n default=None,\n)\[email protected]('--measurement', default=None)\[email protected]('-p', '--patch', multiple=True)\[email protected]('--testpoi', default=1.0)\[email protected]('--teststat', type=click.Choice(['q', 'qtilde']), default='qtilde')\[email protected](\n '--backend',\n type=click.Choice(['numpy', 'pytorch', 'tensorflow', 'jax', 'np', 'torch', 'tf']),\n help='The tensor backend used for the calculation.',\n default='numpy',\n)\[email protected]('--optimizer')\[email protected]('--optconf', type=EqDelimStringParamType(), multiple=True)\ndef cls(\n workspace,\n output_file,\n measurement,\n patch,\n testpoi,\n teststat,\n backend,\n optimizer,\n optconf,\n):\n \"\"\"\n Compute CLs value(s) for a given pyhf workspace.\n\n Example:\n\n .. code-block:: shell\n\n $ curl -sL https://raw.githubusercontent.com/scikit-hep/pyhf/master/docs/examples/json/2-bin_1-channel.json | pyhf cls\n {\n \"CLs_exp\": [\n 0.07807427911686156,\n 0.17472571775474618,\n 0.35998495263681285,\n 0.6343568235898907,\n 0.8809947004472013\n ],\n \"CLs_obs\": 0.3599845631401915\n }\n \"\"\"\n with click.open_file(workspace, 'r') as specstream:\n spec = json.load(specstream)\n\n ws = Workspace(spec)\n\n is_qtilde = teststat == 'qtilde'\n\n patches = [json.loads(click.open_file(pfile, 'r').read()) for pfile in patch]\n model = ws.model(\n measurement_name=measurement,\n patches=patches,\n modifier_settings={\n 'normsys': {'interpcode': 'code4'},\n 'histosys': {'interpcode': 'code4p'},\n },\n )\n\n # set the backend if not NumPy\n if backend in ['pytorch', 'torch']:\n set_backend(tensor.pytorch_backend(precision='64b'))\n elif backend in ['tensorflow', 'tf']:\n set_backend(tensor.tensorflow_backend(precision='64b'))\n elif backend in ['jax']:\n set_backend(tensor.jax_backend())\n tensorlib, _ = get_backend()\n\n optconf = {k: v for item in optconf for k, v in item.items()}\n\n # set the new optimizer\n if optimizer:\n new_optimizer = getattr(optimize, optimizer)\n set_backend(tensorlib, new_optimizer(**optconf))\n\n result = hypotest(\n testpoi, ws.data(model), model, qtilde=is_qtilde, return_expected_set=True\n )\n result = {\n 'CLs_obs': tensorlib.tolist(result[0])[0],\n 'CLs_exp': tensorlib.tolist(tensorlib.reshape(result[-1], [-1])),\n }\n\n if output_file is None:\n click.echo(json.dumps(result, indent=4, sort_keys=True))\n else:\n with open(output_file, 'w+') as out_file:\n json.dump(result, out_file, indent=4, sort_keys=True)\n log.debug(\"Written to {0:s}\".format(output_file))\n", "path": "src/pyhf/cli/infer.py"}], "after_files": [{"content": "\"\"\"The inference CLI group.\"\"\"\nimport logging\n\nimport click\nimport json\n\nfrom ..utils import EqDelimStringParamType\nfrom ..infer import hypotest\nfrom ..workspace import Workspace\nfrom .. import tensor, get_backend, set_backend, optimize\n\nlog = logging.getLogger(__name__)\n\n\[email protected](name='infer')\ndef cli():\n \"\"\"Infererence CLI group.\"\"\"\n\n\[email protected]()\[email protected]('workspace', default='-')\[email protected](\n '--output-file',\n help='The location of the output json file. If not specified, prints to screen.',\n default=None,\n)\[email protected]('--measurement', default=None)\[email protected]('-p', '--patch', multiple=True)\[email protected]('--testpoi', default=1.0)\[email protected]('--teststat', type=click.Choice(['q', 'qtilde']), default='qtilde')\[email protected](\n '--backend',\n type=click.Choice(['numpy', 'pytorch', 'tensorflow', 'jax', 'np', 'torch', 'tf']),\n help='The tensor backend used for the calculation.',\n default='numpy',\n)\[email protected]('--optimizer')\[email protected]('--optconf', type=EqDelimStringParamType(), multiple=True)\ndef cls(\n workspace,\n output_file,\n measurement,\n patch,\n testpoi,\n teststat,\n backend,\n optimizer,\n optconf,\n):\n \"\"\"\n Compute CLs value(s) for a given pyhf workspace.\n\n Example:\n\n .. code-block:: shell\n\n $ curl -sL https://git.io/JJYDE | pyhf cls\n\n \\b\n {\n \"CLs_exp\": [\n 0.07807427911686156,\n 0.17472571775474618,\n 0.35998495263681285,\n 0.6343568235898907,\n 0.8809947004472013\n ],\n \"CLs_obs\": 0.3599845631401915\n }\n \"\"\"\n with click.open_file(workspace, 'r') as specstream:\n spec = json.load(specstream)\n\n ws = Workspace(spec)\n\n is_qtilde = teststat == 'qtilde'\n\n patches = [json.loads(click.open_file(pfile, 'r').read()) for pfile in patch]\n model = ws.model(\n measurement_name=measurement,\n patches=patches,\n modifier_settings={\n 'normsys': {'interpcode': 'code4'},\n 'histosys': {'interpcode': 'code4p'},\n },\n )\n\n # set the backend if not NumPy\n if backend in ['pytorch', 'torch']:\n set_backend(tensor.pytorch_backend(precision='64b'))\n elif backend in ['tensorflow', 'tf']:\n set_backend(tensor.tensorflow_backend(precision='64b'))\n elif backend in ['jax']:\n set_backend(tensor.jax_backend())\n tensorlib, _ = get_backend()\n\n optconf = {k: v for item in optconf for k, v in item.items()}\n\n # set the new optimizer\n if optimizer:\n new_optimizer = getattr(optimize, optimizer)\n set_backend(tensorlib, new_optimizer(**optconf))\n\n result = hypotest(\n testpoi, ws.data(model), model, qtilde=is_qtilde, return_expected_set=True\n )\n result = {\n 'CLs_obs': tensorlib.tolist(result[0])[0],\n 'CLs_exp': tensorlib.tolist(tensorlib.reshape(result[-1], [-1])),\n }\n\n if output_file is None:\n click.echo(json.dumps(result, indent=4, sort_keys=True))\n else:\n with open(output_file, 'w+') as out_file:\n json.dump(result, out_file, indent=4, sort_keys=True)\n log.debug(\"Written to {0:s}\".format(output_file))\n", "path": "src/pyhf/cli/infer.py"}]}
| 1,789 | 151 |
gh_patches_debug_39026
|
rasdani/github-patches
|
git_diff
|
feast-dev__feast-4117
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
feast serve convert number to INT64
## Expected Behavior
when we use the get-online-features endpoint the request body numbers converted to Int64 type and while from python file calling get_online_feature function convert number to Int32 which leads to inconsistency between both use
if the entity value type is Int32 then feature servering with online feast serve command will not work expected behavior is to convert the value to Int32 while it is being converted to Int64
## Current Behavior
when using feast serve number are converted to Int64 type
## Steps to reproduce
create a entity with a column with type Int32 create a feature view with the entity apply the changes using feast apply materialize the data to online store start feature server using feast serve and call endpoint /get-online-feature to retrive feature ... expected response is the feature retrived while it show none due to type issue
### Specifications
- Version: 0.36
- Platform:
- Subsystem:
## Possible Solution
before converting the type to Int64 get the repo and convert the type to the entity data type defined
other solution is just write in doc to use Int64 and Float64 type while defining entity
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sdk/python/feast/feature_server.py`
Content:
```
1 import json
2 import sys
3 import threading
4 import traceback
5 import warnings
6 from typing import List, Optional
7
8 import pandas as pd
9 from dateutil import parser
10 from fastapi import FastAPI, HTTPException, Request, Response, status
11 from fastapi.logger import logger
12 from fastapi.params import Depends
13 from google.protobuf.json_format import MessageToDict, Parse
14 from pydantic import BaseModel
15
16 import feast
17 from feast import proto_json, utils
18 from feast.constants import DEFAULT_FEATURE_SERVER_REGISTRY_TTL
19 from feast.data_source import PushMode
20 from feast.errors import PushSourceNotFoundException
21 from feast.protos.feast.serving.ServingService_pb2 import GetOnlineFeaturesRequest
22
23
24 # TODO: deprecate this in favor of push features
25 class WriteToFeatureStoreRequest(BaseModel):
26 feature_view_name: str
27 df: dict
28 allow_registry_cache: bool = True
29
30
31 class PushFeaturesRequest(BaseModel):
32 push_source_name: str
33 df: dict
34 allow_registry_cache: bool = True
35 to: str = "online"
36
37
38 class MaterializeRequest(BaseModel):
39 start_ts: str
40 end_ts: str
41 feature_views: Optional[List[str]] = None
42
43
44 class MaterializeIncrementalRequest(BaseModel):
45 end_ts: str
46 feature_views: Optional[List[str]] = None
47
48
49 def get_app(
50 store: "feast.FeatureStore",
51 registry_ttl_sec: int = DEFAULT_FEATURE_SERVER_REGISTRY_TTL,
52 ):
53 proto_json.patch()
54
55 app = FastAPI()
56 # Asynchronously refresh registry, notifying shutdown and canceling the active timer if the app is shutting down
57 registry_proto = None
58 shutting_down = False
59 active_timer: Optional[threading.Timer] = None
60
61 async def get_body(request: Request):
62 return await request.body()
63
64 def async_refresh():
65 store.refresh_registry()
66 nonlocal registry_proto
67 registry_proto = store.registry.proto()
68 if shutting_down:
69 return
70 nonlocal active_timer
71 active_timer = threading.Timer(registry_ttl_sec, async_refresh)
72 active_timer.start()
73
74 @app.on_event("shutdown")
75 def shutdown_event():
76 nonlocal shutting_down
77 shutting_down = True
78 if active_timer:
79 active_timer.cancel()
80
81 async_refresh()
82
83 @app.post("/get-online-features")
84 def get_online_features(body=Depends(get_body)):
85 try:
86 # Validate and parse the request data into GetOnlineFeaturesRequest Protobuf object
87 request_proto = GetOnlineFeaturesRequest()
88 Parse(body, request_proto)
89
90 # Initialize parameters for FeatureStore.get_online_features(...) call
91 if request_proto.HasField("feature_service"):
92 features = store.get_feature_service(
93 request_proto.feature_service, allow_cache=True
94 )
95 else:
96 features = list(request_proto.features.val)
97
98 full_feature_names = request_proto.full_feature_names
99
100 batch_sizes = [len(v.val) for v in request_proto.entities.values()]
101 num_entities = batch_sizes[0]
102 if any(batch_size != num_entities for batch_size in batch_sizes):
103 raise HTTPException(status_code=500, detail="Uneven number of columns")
104
105 response_proto = store._get_online_features(
106 features=features,
107 entity_values=request_proto.entities,
108 full_feature_names=full_feature_names,
109 native_entity_values=False,
110 ).proto
111
112 # Convert the Protobuf object to JSON and return it
113 return MessageToDict( # type: ignore
114 response_proto, preserving_proto_field_name=True, float_precision=18
115 )
116 except Exception as e:
117 # Print the original exception on the server side
118 logger.exception(traceback.format_exc())
119 # Raise HTTPException to return the error message to the client
120 raise HTTPException(status_code=500, detail=str(e))
121
122 @app.post("/push")
123 def push(body=Depends(get_body)):
124 try:
125 request = PushFeaturesRequest(**json.loads(body))
126 df = pd.DataFrame(request.df)
127 if request.to == "offline":
128 to = PushMode.OFFLINE
129 elif request.to == "online":
130 to = PushMode.ONLINE
131 elif request.to == "online_and_offline":
132 to = PushMode.ONLINE_AND_OFFLINE
133 else:
134 raise ValueError(
135 f"{request.to} is not a supported push format. Please specify one of these ['online', 'offline', 'online_and_offline']."
136 )
137 store.push(
138 push_source_name=request.push_source_name,
139 df=df,
140 allow_registry_cache=request.allow_registry_cache,
141 to=to,
142 )
143 except PushSourceNotFoundException as e:
144 # Print the original exception on the server side
145 logger.exception(traceback.format_exc())
146 # Raise HTTPException to return the error message to the client
147 raise HTTPException(status_code=422, detail=str(e))
148 except Exception as e:
149 # Print the original exception on the server side
150 logger.exception(traceback.format_exc())
151 # Raise HTTPException to return the error message to the client
152 raise HTTPException(status_code=500, detail=str(e))
153
154 @app.post("/write-to-online-store")
155 def write_to_online_store(body=Depends(get_body)):
156 warnings.warn(
157 "write_to_online_store is deprecated. Please consider using /push instead",
158 RuntimeWarning,
159 )
160 try:
161 request = WriteToFeatureStoreRequest(**json.loads(body))
162 df = pd.DataFrame(request.df)
163 store.write_to_online_store(
164 feature_view_name=request.feature_view_name,
165 df=df,
166 allow_registry_cache=request.allow_registry_cache,
167 )
168 except Exception as e:
169 # Print the original exception on the server side
170 logger.exception(traceback.format_exc())
171 # Raise HTTPException to return the error message to the client
172 raise HTTPException(status_code=500, detail=str(e))
173
174 @app.get("/health")
175 def health():
176 return Response(status_code=status.HTTP_200_OK)
177
178 @app.post("/materialize")
179 def materialize(body=Depends(get_body)):
180 try:
181 request = MaterializeRequest(**json.loads(body))
182 store.materialize(
183 utils.make_tzaware(parser.parse(request.start_ts)),
184 utils.make_tzaware(parser.parse(request.end_ts)),
185 request.feature_views,
186 )
187 except Exception as e:
188 # Print the original exception on the server side
189 logger.exception(traceback.format_exc())
190 # Raise HTTPException to return the error message to the client
191 raise HTTPException(status_code=500, detail=str(e))
192
193 @app.post("/materialize-incremental")
194 def materialize_incremental(body=Depends(get_body)):
195 try:
196 request = MaterializeIncrementalRequest(**json.loads(body))
197 store.materialize_incremental(
198 utils.make_tzaware(parser.parse(request.end_ts)), request.feature_views
199 )
200 except Exception as e:
201 # Print the original exception on the server side
202 logger.exception(traceback.format_exc())
203 # Raise HTTPException to return the error message to the client
204 raise HTTPException(status_code=500, detail=str(e))
205
206 return app
207
208
209 if sys.platform != "win32":
210 import gunicorn.app.base
211
212 class FeastServeApplication(gunicorn.app.base.BaseApplication):
213 def __init__(self, store: "feast.FeatureStore", **options):
214 self._app = get_app(
215 store=store,
216 registry_ttl_sec=options["registry_ttl_sec"],
217 )
218 self._options = options
219 super().__init__()
220
221 def load_config(self):
222 for key, value in self._options.items():
223 if key.lower() in self.cfg.settings and value is not None:
224 self.cfg.set(key.lower(), value)
225
226 self.cfg.set("worker_class", "uvicorn.workers.UvicornWorker")
227
228 def load(self):
229 return self._app
230
231
232 def start_server(
233 store: "feast.FeatureStore",
234 host: str,
235 port: int,
236 no_access_log: bool,
237 workers: int,
238 keep_alive_timeout: int,
239 registry_ttl_sec: int,
240 ):
241 if sys.platform != "win32":
242 FeastServeApplication(
243 store=store,
244 bind=f"{host}:{port}",
245 accesslog=None if no_access_log else "-",
246 workers=workers,
247 keepalive=keep_alive_timeout,
248 registry_ttl_sec=registry_ttl_sec,
249 ).run()
250 else:
251 import uvicorn
252
253 app = get_app(store, registry_ttl_sec)
254 uvicorn.run(app, host=host, port=port, access_log=(not no_access_log))
255
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sdk/python/feast/feature_server.py b/sdk/python/feast/feature_server.py
--- a/sdk/python/feast/feature_server.py
+++ b/sdk/python/feast/feature_server.py
@@ -10,7 +10,7 @@
from fastapi import FastAPI, HTTPException, Request, Response, status
from fastapi.logger import logger
from fastapi.params import Depends
-from google.protobuf.json_format import MessageToDict, Parse
+from google.protobuf.json_format import MessageToDict
from pydantic import BaseModel
import feast
@@ -18,7 +18,6 @@
from feast.constants import DEFAULT_FEATURE_SERVER_REGISTRY_TTL
from feast.data_source import PushMode
from feast.errors import PushSourceNotFoundException
-from feast.protos.feast.serving.ServingService_pb2 import GetOnlineFeaturesRequest
# TODO: deprecate this in favor of push features
@@ -83,34 +82,25 @@
@app.post("/get-online-features")
def get_online_features(body=Depends(get_body)):
try:
- # Validate and parse the request data into GetOnlineFeaturesRequest Protobuf object
- request_proto = GetOnlineFeaturesRequest()
- Parse(body, request_proto)
-
+ body = json.loads(body)
# Initialize parameters for FeatureStore.get_online_features(...) call
- if request_proto.HasField("feature_service"):
+ if "feature_service" in body:
features = store.get_feature_service(
- request_proto.feature_service, allow_cache=True
+ body["feature_service"], allow_cache=True
)
else:
- features = list(request_proto.features.val)
-
- full_feature_names = request_proto.full_feature_names
+ features = body["features"]
- batch_sizes = [len(v.val) for v in request_proto.entities.values()]
- num_entities = batch_sizes[0]
- if any(batch_size != num_entities for batch_size in batch_sizes):
- raise HTTPException(status_code=500, detail="Uneven number of columns")
+ full_feature_names = body.get("full_feature_names", False)
response_proto = store._get_online_features(
features=features,
- entity_values=request_proto.entities,
+ entity_values=body["entities"],
full_feature_names=full_feature_names,
- native_entity_values=False,
).proto
# Convert the Protobuf object to JSON and return it
- return MessageToDict( # type: ignore
+ return MessageToDict(
response_proto, preserving_proto_field_name=True, float_precision=18
)
except Exception as e:
|
{"golden_diff": "diff --git a/sdk/python/feast/feature_server.py b/sdk/python/feast/feature_server.py\n--- a/sdk/python/feast/feature_server.py\n+++ b/sdk/python/feast/feature_server.py\n@@ -10,7 +10,7 @@\n from fastapi import FastAPI, HTTPException, Request, Response, status\n from fastapi.logger import logger\n from fastapi.params import Depends\n-from google.protobuf.json_format import MessageToDict, Parse\n+from google.protobuf.json_format import MessageToDict\n from pydantic import BaseModel\n \n import feast\n@@ -18,7 +18,6 @@\n from feast.constants import DEFAULT_FEATURE_SERVER_REGISTRY_TTL\n from feast.data_source import PushMode\n from feast.errors import PushSourceNotFoundException\n-from feast.protos.feast.serving.ServingService_pb2 import GetOnlineFeaturesRequest\n \n \n # TODO: deprecate this in favor of push features\n@@ -83,34 +82,25 @@\n @app.post(\"/get-online-features\")\n def get_online_features(body=Depends(get_body)):\n try:\n- # Validate and parse the request data into GetOnlineFeaturesRequest Protobuf object\n- request_proto = GetOnlineFeaturesRequest()\n- Parse(body, request_proto)\n-\n+ body = json.loads(body)\n # Initialize parameters for FeatureStore.get_online_features(...) call\n- if request_proto.HasField(\"feature_service\"):\n+ if \"feature_service\" in body:\n features = store.get_feature_service(\n- request_proto.feature_service, allow_cache=True\n+ body[\"feature_service\"], allow_cache=True\n )\n else:\n- features = list(request_proto.features.val)\n-\n- full_feature_names = request_proto.full_feature_names\n+ features = body[\"features\"]\n \n- batch_sizes = [len(v.val) for v in request_proto.entities.values()]\n- num_entities = batch_sizes[0]\n- if any(batch_size != num_entities for batch_size in batch_sizes):\n- raise HTTPException(status_code=500, detail=\"Uneven number of columns\")\n+ full_feature_names = body.get(\"full_feature_names\", False)\n \n response_proto = store._get_online_features(\n features=features,\n- entity_values=request_proto.entities,\n+ entity_values=body[\"entities\"],\n full_feature_names=full_feature_names,\n- native_entity_values=False,\n ).proto\n \n # Convert the Protobuf object to JSON and return it\n- return MessageToDict( # type: ignore\n+ return MessageToDict(\n response_proto, preserving_proto_field_name=True, float_precision=18\n )\n except Exception as e:\n", "issue": "feast serve convert number to INT64 \n## Expected Behavior \r\nwhen we use the get-online-features endpoint the request body numbers converted to Int64 type and while from python file calling get_online_feature function convert number to Int32 which leads to inconsistency between both use \r\nif the entity value type is Int32 then feature servering with online feast serve command will not work expected behavior is to convert the value to Int32 while it is being converted to Int64\r\n## Current Behavior\r\nwhen using feast serve number are converted to Int64 type \r\n## Steps to reproduce\r\ncreate a entity with a column with type Int32 create a feature view with the entity apply the changes using feast apply materialize the data to online store start feature server using feast serve and call endpoint /get-online-feature to retrive feature ... expected response is the feature retrived while it show none due to type issue \r\n### Specifications\r\n\r\n- Version: 0.36\r\n- Platform: \r\n- Subsystem:\r\n\r\n## Possible Solution\r\nbefore converting the type to Int64 get the repo and convert the type to the entity data type defined \r\nother solution is just write in doc to use Int64 and Float64 type while defining entity\r\n\n", "before_files": [{"content": "import json\nimport sys\nimport threading\nimport traceback\nimport warnings\nfrom typing import List, Optional\n\nimport pandas as pd\nfrom dateutil import parser\nfrom fastapi import FastAPI, HTTPException, Request, Response, status\nfrom fastapi.logger import logger\nfrom fastapi.params import Depends\nfrom google.protobuf.json_format import MessageToDict, Parse\nfrom pydantic import BaseModel\n\nimport feast\nfrom feast import proto_json, utils\nfrom feast.constants import DEFAULT_FEATURE_SERVER_REGISTRY_TTL\nfrom feast.data_source import PushMode\nfrom feast.errors import PushSourceNotFoundException\nfrom feast.protos.feast.serving.ServingService_pb2 import GetOnlineFeaturesRequest\n\n\n# TODO: deprecate this in favor of push features\nclass WriteToFeatureStoreRequest(BaseModel):\n feature_view_name: str\n df: dict\n allow_registry_cache: bool = True\n\n\nclass PushFeaturesRequest(BaseModel):\n push_source_name: str\n df: dict\n allow_registry_cache: bool = True\n to: str = \"online\"\n\n\nclass MaterializeRequest(BaseModel):\n start_ts: str\n end_ts: str\n feature_views: Optional[List[str]] = None\n\n\nclass MaterializeIncrementalRequest(BaseModel):\n end_ts: str\n feature_views: Optional[List[str]] = None\n\n\ndef get_app(\n store: \"feast.FeatureStore\",\n registry_ttl_sec: int = DEFAULT_FEATURE_SERVER_REGISTRY_TTL,\n):\n proto_json.patch()\n\n app = FastAPI()\n # Asynchronously refresh registry, notifying shutdown and canceling the active timer if the app is shutting down\n registry_proto = None\n shutting_down = False\n active_timer: Optional[threading.Timer] = None\n\n async def get_body(request: Request):\n return await request.body()\n\n def async_refresh():\n store.refresh_registry()\n nonlocal registry_proto\n registry_proto = store.registry.proto()\n if shutting_down:\n return\n nonlocal active_timer\n active_timer = threading.Timer(registry_ttl_sec, async_refresh)\n active_timer.start()\n\n @app.on_event(\"shutdown\")\n def shutdown_event():\n nonlocal shutting_down\n shutting_down = True\n if active_timer:\n active_timer.cancel()\n\n async_refresh()\n\n @app.post(\"/get-online-features\")\n def get_online_features(body=Depends(get_body)):\n try:\n # Validate and parse the request data into GetOnlineFeaturesRequest Protobuf object\n request_proto = GetOnlineFeaturesRequest()\n Parse(body, request_proto)\n\n # Initialize parameters for FeatureStore.get_online_features(...) call\n if request_proto.HasField(\"feature_service\"):\n features = store.get_feature_service(\n request_proto.feature_service, allow_cache=True\n )\n else:\n features = list(request_proto.features.val)\n\n full_feature_names = request_proto.full_feature_names\n\n batch_sizes = [len(v.val) for v in request_proto.entities.values()]\n num_entities = batch_sizes[0]\n if any(batch_size != num_entities for batch_size in batch_sizes):\n raise HTTPException(status_code=500, detail=\"Uneven number of columns\")\n\n response_proto = store._get_online_features(\n features=features,\n entity_values=request_proto.entities,\n full_feature_names=full_feature_names,\n native_entity_values=False,\n ).proto\n\n # Convert the Protobuf object to JSON and return it\n return MessageToDict( # type: ignore\n response_proto, preserving_proto_field_name=True, float_precision=18\n )\n except Exception as e:\n # Print the original exception on the server side\n logger.exception(traceback.format_exc())\n # Raise HTTPException to return the error message to the client\n raise HTTPException(status_code=500, detail=str(e))\n\n @app.post(\"/push\")\n def push(body=Depends(get_body)):\n try:\n request = PushFeaturesRequest(**json.loads(body))\n df = pd.DataFrame(request.df)\n if request.to == \"offline\":\n to = PushMode.OFFLINE\n elif request.to == \"online\":\n to = PushMode.ONLINE\n elif request.to == \"online_and_offline\":\n to = PushMode.ONLINE_AND_OFFLINE\n else:\n raise ValueError(\n f\"{request.to} is not a supported push format. Please specify one of these ['online', 'offline', 'online_and_offline'].\"\n )\n store.push(\n push_source_name=request.push_source_name,\n df=df,\n allow_registry_cache=request.allow_registry_cache,\n to=to,\n )\n except PushSourceNotFoundException as e:\n # Print the original exception on the server side\n logger.exception(traceback.format_exc())\n # Raise HTTPException to return the error message to the client\n raise HTTPException(status_code=422, detail=str(e))\n except Exception as e:\n # Print the original exception on the server side\n logger.exception(traceback.format_exc())\n # Raise HTTPException to return the error message to the client\n raise HTTPException(status_code=500, detail=str(e))\n\n @app.post(\"/write-to-online-store\")\n def write_to_online_store(body=Depends(get_body)):\n warnings.warn(\n \"write_to_online_store is deprecated. Please consider using /push instead\",\n RuntimeWarning,\n )\n try:\n request = WriteToFeatureStoreRequest(**json.loads(body))\n df = pd.DataFrame(request.df)\n store.write_to_online_store(\n feature_view_name=request.feature_view_name,\n df=df,\n allow_registry_cache=request.allow_registry_cache,\n )\n except Exception as e:\n # Print the original exception on the server side\n logger.exception(traceback.format_exc())\n # Raise HTTPException to return the error message to the client\n raise HTTPException(status_code=500, detail=str(e))\n\n @app.get(\"/health\")\n def health():\n return Response(status_code=status.HTTP_200_OK)\n\n @app.post(\"/materialize\")\n def materialize(body=Depends(get_body)):\n try:\n request = MaterializeRequest(**json.loads(body))\n store.materialize(\n utils.make_tzaware(parser.parse(request.start_ts)),\n utils.make_tzaware(parser.parse(request.end_ts)),\n request.feature_views,\n )\n except Exception as e:\n # Print the original exception on the server side\n logger.exception(traceback.format_exc())\n # Raise HTTPException to return the error message to the client\n raise HTTPException(status_code=500, detail=str(e))\n\n @app.post(\"/materialize-incremental\")\n def materialize_incremental(body=Depends(get_body)):\n try:\n request = MaterializeIncrementalRequest(**json.loads(body))\n store.materialize_incremental(\n utils.make_tzaware(parser.parse(request.end_ts)), request.feature_views\n )\n except Exception as e:\n # Print the original exception on the server side\n logger.exception(traceback.format_exc())\n # Raise HTTPException to return the error message to the client\n raise HTTPException(status_code=500, detail=str(e))\n\n return app\n\n\nif sys.platform != \"win32\":\n import gunicorn.app.base\n\n class FeastServeApplication(gunicorn.app.base.BaseApplication):\n def __init__(self, store: \"feast.FeatureStore\", **options):\n self._app = get_app(\n store=store,\n registry_ttl_sec=options[\"registry_ttl_sec\"],\n )\n self._options = options\n super().__init__()\n\n def load_config(self):\n for key, value in self._options.items():\n if key.lower() in self.cfg.settings and value is not None:\n self.cfg.set(key.lower(), value)\n\n self.cfg.set(\"worker_class\", \"uvicorn.workers.UvicornWorker\")\n\n def load(self):\n return self._app\n\n\ndef start_server(\n store: \"feast.FeatureStore\",\n host: str,\n port: int,\n no_access_log: bool,\n workers: int,\n keep_alive_timeout: int,\n registry_ttl_sec: int,\n):\n if sys.platform != \"win32\":\n FeastServeApplication(\n store=store,\n bind=f\"{host}:{port}\",\n accesslog=None if no_access_log else \"-\",\n workers=workers,\n keepalive=keep_alive_timeout,\n registry_ttl_sec=registry_ttl_sec,\n ).run()\n else:\n import uvicorn\n\n app = get_app(store, registry_ttl_sec)\n uvicorn.run(app, host=host, port=port, access_log=(not no_access_log))\n", "path": "sdk/python/feast/feature_server.py"}], "after_files": [{"content": "import json\nimport sys\nimport threading\nimport traceback\nimport warnings\nfrom typing import List, Optional\n\nimport pandas as pd\nfrom dateutil import parser\nfrom fastapi import FastAPI, HTTPException, Request, Response, status\nfrom fastapi.logger import logger\nfrom fastapi.params import Depends\nfrom google.protobuf.json_format import MessageToDict\nfrom pydantic import BaseModel\n\nimport feast\nfrom feast import proto_json, utils\nfrom feast.constants import DEFAULT_FEATURE_SERVER_REGISTRY_TTL\nfrom feast.data_source import PushMode\nfrom feast.errors import PushSourceNotFoundException\n\n\n# TODO: deprecate this in favor of push features\nclass WriteToFeatureStoreRequest(BaseModel):\n feature_view_name: str\n df: dict\n allow_registry_cache: bool = True\n\n\nclass PushFeaturesRequest(BaseModel):\n push_source_name: str\n df: dict\n allow_registry_cache: bool = True\n to: str = \"online\"\n\n\nclass MaterializeRequest(BaseModel):\n start_ts: str\n end_ts: str\n feature_views: Optional[List[str]] = None\n\n\nclass MaterializeIncrementalRequest(BaseModel):\n end_ts: str\n feature_views: Optional[List[str]] = None\n\n\ndef get_app(\n store: \"feast.FeatureStore\",\n registry_ttl_sec: int = DEFAULT_FEATURE_SERVER_REGISTRY_TTL,\n):\n proto_json.patch()\n\n app = FastAPI()\n # Asynchronously refresh registry, notifying shutdown and canceling the active timer if the app is shutting down\n registry_proto = None\n shutting_down = False\n active_timer: Optional[threading.Timer] = None\n\n async def get_body(request: Request):\n return await request.body()\n\n def async_refresh():\n store.refresh_registry()\n nonlocal registry_proto\n registry_proto = store.registry.proto()\n if shutting_down:\n return\n nonlocal active_timer\n active_timer = threading.Timer(registry_ttl_sec, async_refresh)\n active_timer.start()\n\n @app.on_event(\"shutdown\")\n def shutdown_event():\n nonlocal shutting_down\n shutting_down = True\n if active_timer:\n active_timer.cancel()\n\n async_refresh()\n\n @app.post(\"/get-online-features\")\n def get_online_features(body=Depends(get_body)):\n try:\n body = json.loads(body)\n # Initialize parameters for FeatureStore.get_online_features(...) call\n if \"feature_service\" in body:\n features = store.get_feature_service(\n body[\"feature_service\"], allow_cache=True\n )\n else:\n features = body[\"features\"]\n\n full_feature_names = body.get(\"full_feature_names\", False)\n\n response_proto = store._get_online_features(\n features=features,\n entity_values=body[\"entities\"],\n full_feature_names=full_feature_names,\n ).proto\n\n # Convert the Protobuf object to JSON and return it\n return MessageToDict(\n response_proto, preserving_proto_field_name=True, float_precision=18\n )\n except Exception as e:\n # Print the original exception on the server side\n logger.exception(traceback.format_exc())\n # Raise HTTPException to return the error message to the client\n raise HTTPException(status_code=500, detail=str(e))\n\n @app.post(\"/push\")\n def push(body=Depends(get_body)):\n try:\n request = PushFeaturesRequest(**json.loads(body))\n df = pd.DataFrame(request.df)\n if request.to == \"offline\":\n to = PushMode.OFFLINE\n elif request.to == \"online\":\n to = PushMode.ONLINE\n elif request.to == \"online_and_offline\":\n to = PushMode.ONLINE_AND_OFFLINE\n else:\n raise ValueError(\n f\"{request.to} is not a supported push format. Please specify one of these ['online', 'offline', 'online_and_offline'].\"\n )\n store.push(\n push_source_name=request.push_source_name,\n df=df,\n allow_registry_cache=request.allow_registry_cache,\n to=to,\n )\n except PushSourceNotFoundException as e:\n # Print the original exception on the server side\n logger.exception(traceback.format_exc())\n # Raise HTTPException to return the error message to the client\n raise HTTPException(status_code=422, detail=str(e))\n except Exception as e:\n # Print the original exception on the server side\n logger.exception(traceback.format_exc())\n # Raise HTTPException to return the error message to the client\n raise HTTPException(status_code=500, detail=str(e))\n\n @app.post(\"/write-to-online-store\")\n def write_to_online_store(body=Depends(get_body)):\n warnings.warn(\n \"write_to_online_store is deprecated. Please consider using /push instead\",\n RuntimeWarning,\n )\n try:\n request = WriteToFeatureStoreRequest(**json.loads(body))\n df = pd.DataFrame(request.df)\n store.write_to_online_store(\n feature_view_name=request.feature_view_name,\n df=df,\n allow_registry_cache=request.allow_registry_cache,\n )\n except Exception as e:\n # Print the original exception on the server side\n logger.exception(traceback.format_exc())\n # Raise HTTPException to return the error message to the client\n raise HTTPException(status_code=500, detail=str(e))\n\n @app.get(\"/health\")\n def health():\n return Response(status_code=status.HTTP_200_OK)\n\n @app.post(\"/materialize\")\n def materialize(body=Depends(get_body)):\n try:\n request = MaterializeRequest(**json.loads(body))\n store.materialize(\n utils.make_tzaware(parser.parse(request.start_ts)),\n utils.make_tzaware(parser.parse(request.end_ts)),\n request.feature_views,\n )\n except Exception as e:\n # Print the original exception on the server side\n logger.exception(traceback.format_exc())\n # Raise HTTPException to return the error message to the client\n raise HTTPException(status_code=500, detail=str(e))\n\n @app.post(\"/materialize-incremental\")\n def materialize_incremental(body=Depends(get_body)):\n try:\n request = MaterializeIncrementalRequest(**json.loads(body))\n store.materialize_incremental(\n utils.make_tzaware(parser.parse(request.end_ts)), request.feature_views\n )\n except Exception as e:\n # Print the original exception on the server side\n logger.exception(traceback.format_exc())\n # Raise HTTPException to return the error message to the client\n raise HTTPException(status_code=500, detail=str(e))\n\n return app\n\n\nif sys.platform != \"win32\":\n import gunicorn.app.base\n\n class FeastServeApplication(gunicorn.app.base.BaseApplication):\n def __init__(self, store: \"feast.FeatureStore\", **options):\n self._app = get_app(\n store=store,\n registry_ttl_sec=options[\"registry_ttl_sec\"],\n )\n self._options = options\n super().__init__()\n\n def load_config(self):\n for key, value in self._options.items():\n if key.lower() in self.cfg.settings and value is not None:\n self.cfg.set(key.lower(), value)\n\n self.cfg.set(\"worker_class\", \"uvicorn.workers.UvicornWorker\")\n\n def load(self):\n return self._app\n\n\ndef start_server(\n store: \"feast.FeatureStore\",\n host: str,\n port: int,\n no_access_log: bool,\n workers: int,\n keep_alive_timeout: int,\n registry_ttl_sec: int,\n):\n if sys.platform != \"win32\":\n FeastServeApplication(\n store=store,\n bind=f\"{host}:{port}\",\n accesslog=None if no_access_log else \"-\",\n workers=workers,\n keepalive=keep_alive_timeout,\n registry_ttl_sec=registry_ttl_sec,\n ).run()\n else:\n import uvicorn\n\n app = get_app(store, registry_ttl_sec)\n uvicorn.run(app, host=host, port=port, access_log=(not no_access_log))\n", "path": "sdk/python/feast/feature_server.py"}]}
| 3,019 | 569 |
gh_patches_debug_10293
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-5245
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
"Accounts" tab in settings is blank

When navigating to the "accounts" tab in the lutris settings (version 0.5.15), it is blank and I get this error. This is on Fedora 39 KDE.
```
2024-01-14 08:52:03,865: Error handling signal 'row-selected': 'PersonalName'
Traceback (most recent call last):
File "/usr/lib/python3.12/site-packages/lutris/exception_backstops.py", line 79, in error_wrapper
return handler(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/site-packages/lutris/gui/config/preferences_dialog.py", line 109, in on_sidebar_activated
generator()
File "/usr/lib/python3.12/site-packages/lutris/gui/config/accounts_box.py", line 33, in populate_accounts
account["PersonalName"]
~~~~~~~^^^^^^^^^^^^^^^^
KeyError: 'PersonalName'
```
My only guess is that my steam display name has a " / " in it. But I'm not sure.
I have both Steam RPM and Steam flatpak installed.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lutris/gui/config/accounts_box.py`
Content:
```
1 from gettext import gettext as _
2
3 from gi.repository import Gtk
4
5 from lutris import settings
6 from lutris.gui.config.base_config_box import BaseConfigBox
7 from lutris.util.steam.config import STEAM_ACCOUNT_SETTING, get_steam_users
8
9
10 class AccountsBox(BaseConfigBox):
11
12 def __init__(self):
13 super().__init__()
14 self.add(self.get_section_label(_("Steam accounts")))
15 self.add(self.get_description_label(
16 _("Select which Steam account is used for Lutris integration and creating Steam shortcuts.")
17 ))
18 frame = Gtk.Frame(visible=True, shadow_type=Gtk.ShadowType.ETCHED_IN)
19 frame.get_style_context().add_class("info-frame")
20 self.pack_start(frame, False, False, 0)
21
22 self.accounts_box = Gtk.VBox(visible=True)
23 frame.add(self.accounts_box)
24
25 def populate_accounts(self):
26 main_radio_button = None
27 active_steam_account = settings.read_setting(STEAM_ACCOUNT_SETTING)
28
29 steam_users = get_steam_users()
30 for account in steam_users:
31 steamid64 = account["steamid64"]
32 name = account.get("PersonalName") or f"#{steamid64}"
33 radio_button = Gtk.RadioButton.new_with_label_from_widget(main_radio_button, name)
34 radio_button.set_margin_top(16)
35 radio_button.set_margin_start(16)
36 radio_button.set_margin_bottom(16)
37 radio_button.show()
38 radio_button.set_active(active_steam_account == steamid64)
39 radio_button.connect("toggled", self.on_steam_account_toggled, steamid64)
40 self.accounts_box.pack_start(radio_button, True, True, 0)
41 if not main_radio_button:
42 main_radio_button = radio_button
43 if not steam_users:
44 self.accounts_box.pack_start(Gtk.Label(_("No Steam account found"), visible=True), True, True, 0)
45
46 def on_steam_account_toggled(self, radio_button, steamid64):
47 """Handler for switching the active Steam account."""
48 settings.write_setting(STEAM_ACCOUNT_SETTING, steamid64)
49
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lutris/gui/config/accounts_box.py b/lutris/gui/config/accounts_box.py
--- a/lutris/gui/config/accounts_box.py
+++ b/lutris/gui/config/accounts_box.py
@@ -29,7 +29,7 @@
steam_users = get_steam_users()
for account in steam_users:
steamid64 = account["steamid64"]
- name = account.get("PersonalName") or f"#{steamid64}"
+ name = account.get("PersonaName") or f"#{steamid64}"
radio_button = Gtk.RadioButton.new_with_label_from_widget(main_radio_button, name)
radio_button.set_margin_top(16)
radio_button.set_margin_start(16)
|
{"golden_diff": "diff --git a/lutris/gui/config/accounts_box.py b/lutris/gui/config/accounts_box.py\n--- a/lutris/gui/config/accounts_box.py\n+++ b/lutris/gui/config/accounts_box.py\n@@ -29,7 +29,7 @@\n steam_users = get_steam_users()\n for account in steam_users:\n steamid64 = account[\"steamid64\"]\n- name = account.get(\"PersonalName\") or f\"#{steamid64}\"\n+ name = account.get(\"PersonaName\") or f\"#{steamid64}\"\n radio_button = Gtk.RadioButton.new_with_label_from_widget(main_radio_button, name)\n radio_button.set_margin_top(16)\n radio_button.set_margin_start(16)\n", "issue": "\"Accounts\" tab in settings is blank\n\r\n\r\nWhen navigating to the \"accounts\" tab in the lutris settings (version 0.5.15), it is blank and I get this error. This is on Fedora 39 KDE.\r\n\r\n```\r\n2024-01-14 08:52:03,865: Error handling signal 'row-selected': 'PersonalName'\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.12/site-packages/lutris/exception_backstops.py\", line 79, in error_wrapper\r\n return handler(*args, **kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/lib/python3.12/site-packages/lutris/gui/config/preferences_dialog.py\", line 109, in on_sidebar_activated\r\n generator()\r\n File \"/usr/lib/python3.12/site-packages/lutris/gui/config/accounts_box.py\", line 33, in populate_accounts\r\n account[\"PersonalName\"]\r\n ~~~~~~~^^^^^^^^^^^^^^^^\r\nKeyError: 'PersonalName'\r\n```\r\n\r\nMy only guess is that my steam display name has a \" / \" in it. But I'm not sure.\r\n\r\nI have both Steam RPM and Steam flatpak installed.\n", "before_files": [{"content": "from gettext import gettext as _\n\nfrom gi.repository import Gtk\n\nfrom lutris import settings\nfrom lutris.gui.config.base_config_box import BaseConfigBox\nfrom lutris.util.steam.config import STEAM_ACCOUNT_SETTING, get_steam_users\n\n\nclass AccountsBox(BaseConfigBox):\n\n def __init__(self):\n super().__init__()\n self.add(self.get_section_label(_(\"Steam accounts\")))\n self.add(self.get_description_label(\n _(\"Select which Steam account is used for Lutris integration and creating Steam shortcuts.\")\n ))\n frame = Gtk.Frame(visible=True, shadow_type=Gtk.ShadowType.ETCHED_IN)\n frame.get_style_context().add_class(\"info-frame\")\n self.pack_start(frame, False, False, 0)\n\n self.accounts_box = Gtk.VBox(visible=True)\n frame.add(self.accounts_box)\n\n def populate_accounts(self):\n main_radio_button = None\n active_steam_account = settings.read_setting(STEAM_ACCOUNT_SETTING)\n\n steam_users = get_steam_users()\n for account in steam_users:\n steamid64 = account[\"steamid64\"]\n name = account.get(\"PersonalName\") or f\"#{steamid64}\"\n radio_button = Gtk.RadioButton.new_with_label_from_widget(main_radio_button, name)\n radio_button.set_margin_top(16)\n radio_button.set_margin_start(16)\n radio_button.set_margin_bottom(16)\n radio_button.show()\n radio_button.set_active(active_steam_account == steamid64)\n radio_button.connect(\"toggled\", self.on_steam_account_toggled, steamid64)\n self.accounts_box.pack_start(radio_button, True, True, 0)\n if not main_radio_button:\n main_radio_button = radio_button\n if not steam_users:\n self.accounts_box.pack_start(Gtk.Label(_(\"No Steam account found\"), visible=True), True, True, 0)\n\n def on_steam_account_toggled(self, radio_button, steamid64):\n \"\"\"Handler for switching the active Steam account.\"\"\"\n settings.write_setting(STEAM_ACCOUNT_SETTING, steamid64)\n", "path": "lutris/gui/config/accounts_box.py"}], "after_files": [{"content": "from gettext import gettext as _\n\nfrom gi.repository import Gtk\n\nfrom lutris import settings\nfrom lutris.gui.config.base_config_box import BaseConfigBox\nfrom lutris.util.steam.config import STEAM_ACCOUNT_SETTING, get_steam_users\n\n\nclass AccountsBox(BaseConfigBox):\n\n def __init__(self):\n super().__init__()\n self.add(self.get_section_label(_(\"Steam accounts\")))\n self.add(self.get_description_label(\n _(\"Select which Steam account is used for Lutris integration and creating Steam shortcuts.\")\n ))\n frame = Gtk.Frame(visible=True, shadow_type=Gtk.ShadowType.ETCHED_IN)\n frame.get_style_context().add_class(\"info-frame\")\n self.pack_start(frame, False, False, 0)\n\n self.accounts_box = Gtk.VBox(visible=True)\n frame.add(self.accounts_box)\n\n def populate_accounts(self):\n main_radio_button = None\n active_steam_account = settings.read_setting(STEAM_ACCOUNT_SETTING)\n\n steam_users = get_steam_users()\n for account in steam_users:\n steamid64 = account[\"steamid64\"]\n name = account.get(\"PersonaName\") or f\"#{steamid64}\"\n radio_button = Gtk.RadioButton.new_with_label_from_widget(main_radio_button, name)\n radio_button.set_margin_top(16)\n radio_button.set_margin_start(16)\n radio_button.set_margin_bottom(16)\n radio_button.show()\n radio_button.set_active(active_steam_account == steamid64)\n radio_button.connect(\"toggled\", self.on_steam_account_toggled, steamid64)\n self.accounts_box.pack_start(radio_button, True, True, 0)\n if not main_radio_button:\n main_radio_button = radio_button\n if not steam_users:\n self.accounts_box.pack_start(Gtk.Label(_(\"No Steam account found\"), visible=True), True, True, 0)\n\n def on_steam_account_toggled(self, radio_button, steamid64):\n \"\"\"Handler for switching the active Steam account.\"\"\"\n settings.write_setting(STEAM_ACCOUNT_SETTING, steamid64)\n", "path": "lutris/gui/config/accounts_box.py"}]}
| 1,119 | 160 |
gh_patches_debug_40728
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-3400
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Spider verizon is broken
During the global build at 2021-10-27-14-42-46, spider **verizon** failed with **4573 features** and **1650 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-10-27-14-42-46/logs/verizon.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-10-27-14-42-46/output/verizon.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-10-27-14-42-46/output/verizon.geojson))
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/verizon.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 import scrapy
3 import json
4 import re
5
6 from locations.items import GeojsonPointItem
7 from locations.hours import OpeningHours
8
9
10 class VerizonSpider(scrapy.Spider):
11 name = "verizon"
12 item_attributes = { 'brand': "Verizon" }
13 allowed_domains = ["www.verizonwireless.com"]
14 start_urls = (
15 'https://www.verizonwireless.com/sitemap_storelocator.xml',
16 )
17 custom_settings = {
18 'USER_AGENT': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
19 }
20
21 def parse_hours(self, store_hours):
22 opening_hours = OpeningHours()
23 for store_day in store_hours['dayOfWeek']:
24 if store_day.lower() == 'closed':
25 continue
26 else:
27 day, open_close = store_day.split('-')
28 day = day.strip()[:2]
29 open_time = ' '.join(open_close.strip().split(' ', 2)[0:2])
30 if open_time.split(' ')[0].lower() == 'closed':
31 continue
32 elif open_time.split(' ')[0].lower() == 'null':
33 continue
34 else:
35 if open_close.strip().count(' ') == 1:
36 open_time, close_time = open_time.split(' ')
37 opening_hours.add_range(day=day,
38 open_time=open_time,
39 close_time=close_time,
40 time_format='%I:%M%p'
41 )
42 elif open_close.strip().count(' ') == 2:
43 open_time = open_close.strip().split(' ')[0]
44 close_time = ''.join(open_close.strip().split(' ')[1:3])
45 opening_hours.add_range(day=day,
46 open_time=open_time,
47 close_time=close_time,
48 time_format='%I:%M%p'
49 )
50 else:
51 close_time = open_close.strip().split(' ', 2)[2]
52 opening_hours.add_range(day=day,
53 open_time=open_time,
54 close_time=close_time,
55 time_format='%I:%M %p'
56 )
57
58 return opening_hours.as_opening_hours()
59
60 def parse(self, response):
61 response.selector.remove_namespaces()
62 urls = response.xpath('//url/loc/text()').extract()
63
64 for url in urls:
65 if url.split('/')[-2].split('-')[-1].isdigit():
66 # Store pages have a number at the end of their URL
67 yield scrapy.Request(url, callback=self.parse_store)
68
69 def parse_store(self, response):
70 script = response.xpath('//script[contains(text(), "storeJSON")]/text()').extract_first()
71 if not script:
72 return
73
74 store_data = json.loads(re.search(r'var storeJSON = (.*);', script).group(1))
75
76 properties = {
77 'name': store_data["storeName"],
78 'ref': store_data["storeNumber"],
79 'addr_full': store_data["address"]["streetAddress"],
80 'city': store_data["address"]["addressLocality"],
81 'state': store_data["address"]["addressRegion"],
82 'postcode': store_data["address"]["postalCode"],
83 'country': store_data["address"]["addressCountry"],
84 'phone': store_data.get("telephone"),
85 'website': store_data.get("url") or response.url,
86 'lat': store_data["geo"].get("latitude"),
87 'lon': store_data["geo"].get("longitude"),
88 'extras': {
89 'business_name': store_data.get('posStoreDetail').get('businessName'),
90 'retail_id': store_data.get('retailId'),
91 'store_type': store_data.get('posStoreDetail').get('storeType'),
92 'store_type_note': store_data.get('typeOfStore')
93 }
94 }
95
96 hours = self.parse_hours(store_data.get("openingHoursSpecification"))
97 if hours:
98 properties["opening_hours"] = hours
99
100 yield GeojsonPointItem(**properties)
101
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/spiders/verizon.py b/locations/spiders/verizon.py
--- a/locations/spiders/verizon.py
+++ b/locations/spiders/verizon.py
@@ -20,40 +20,18 @@
def parse_hours(self, store_hours):
opening_hours = OpeningHours()
- for store_day in store_hours['dayOfWeek']:
- if store_day.lower() == 'closed':
- continue
- else:
- day, open_close = store_day.split('-')
- day = day.strip()[:2]
- open_time = ' '.join(open_close.strip().split(' ', 2)[0:2])
- if open_time.split(' ')[0].lower() == 'closed':
- continue
- elif open_time.split(' ')[0].lower() == 'null':
- continue
- else:
- if open_close.strip().count(' ') == 1:
- open_time, close_time = open_time.split(' ')
- opening_hours.add_range(day=day,
- open_time=open_time,
- close_time=close_time,
- time_format='%I:%M%p'
- )
- elif open_close.strip().count(' ') == 2:
- open_time = open_close.strip().split(' ')[0]
- close_time = ''.join(open_close.strip().split(' ')[1:3])
- opening_hours.add_range(day=day,
- open_time=open_time,
- close_time=close_time,
- time_format='%I:%M%p'
- )
- else:
- close_time = open_close.strip().split(' ', 2)[2]
- opening_hours.add_range(day=day,
- open_time=open_time,
- close_time=close_time,
- time_format='%I:%M %p'
- )
+
+ for store_day in ['Sun', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat']:
+ open_time = store_hours.get(f'{store_day}Open')
+ close_time = store_hours.get(f'{store_day}Close')
+
+ if open_time and close_time and open_time.lower() != 'closed' and close_time.lower() != 'closed':
+ opening_hours.add_range(
+ day=store_day[0:2],
+ open_time=open_time,
+ close_time=close_time,
+ time_format='%I:%M %p'
+ )
return opening_hours.as_opening_hours()
@@ -86,14 +64,15 @@
'lat': store_data["geo"].get("latitude"),
'lon': store_data["geo"].get("longitude"),
'extras': {
- 'business_name': store_data.get('posStoreDetail').get('businessName'),
+ # Sometimes 'postStoreDetail' exists with "None" value, usual get w/ default syntax isn't reliable
+ 'business_name': (store_data.get('posStoreDetail') or {}).get('businessName'),
'retail_id': store_data.get('retailId'),
- 'store_type': store_data.get('posStoreDetail').get('storeType'),
+ 'store_type': (store_data.get('posStoreDetail') or {}).get('storeType'),
'store_type_note': store_data.get('typeOfStore')
}
}
- hours = self.parse_hours(store_data.get("openingHoursSpecification"))
+ hours = self.parse_hours(store_data.get("StoreHours"))
if hours:
properties["opening_hours"] = hours
|
{"golden_diff": "diff --git a/locations/spiders/verizon.py b/locations/spiders/verizon.py\n--- a/locations/spiders/verizon.py\n+++ b/locations/spiders/verizon.py\n@@ -20,40 +20,18 @@\n \n def parse_hours(self, store_hours):\n opening_hours = OpeningHours()\n- for store_day in store_hours['dayOfWeek']:\n- if store_day.lower() == 'closed':\n- continue\n- else:\n- day, open_close = store_day.split('-')\n- day = day.strip()[:2]\n- open_time = ' '.join(open_close.strip().split(' ', 2)[0:2])\n- if open_time.split(' ')[0].lower() == 'closed':\n- continue\n- elif open_time.split(' ')[0].lower() == 'null':\n- continue\n- else:\n- if open_close.strip().count(' ') == 1:\n- open_time, close_time = open_time.split(' ')\n- opening_hours.add_range(day=day,\n- open_time=open_time,\n- close_time=close_time,\n- time_format='%I:%M%p'\n- )\n- elif open_close.strip().count(' ') == 2:\n- open_time = open_close.strip().split(' ')[0]\n- close_time = ''.join(open_close.strip().split(' ')[1:3])\n- opening_hours.add_range(day=day,\n- open_time=open_time,\n- close_time=close_time,\n- time_format='%I:%M%p'\n- )\n- else:\n- close_time = open_close.strip().split(' ', 2)[2]\n- opening_hours.add_range(day=day,\n- open_time=open_time,\n- close_time=close_time,\n- time_format='%I:%M %p'\n- )\n+\n+ for store_day in ['Sun', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat']:\n+ open_time = store_hours.get(f'{store_day}Open')\n+ close_time = store_hours.get(f'{store_day}Close')\n+\n+ if open_time and close_time and open_time.lower() != 'closed' and close_time.lower() != 'closed':\n+ opening_hours.add_range(\n+ day=store_day[0:2],\n+ open_time=open_time,\n+ close_time=close_time,\n+ time_format='%I:%M %p'\n+ )\n \n return opening_hours.as_opening_hours()\n \n@@ -86,14 +64,15 @@\n 'lat': store_data[\"geo\"].get(\"latitude\"),\n 'lon': store_data[\"geo\"].get(\"longitude\"),\n 'extras': {\n- 'business_name': store_data.get('posStoreDetail').get('businessName'),\n+ # Sometimes 'postStoreDetail' exists with \"None\" value, usual get w/ default syntax isn't reliable\n+ 'business_name': (store_data.get('posStoreDetail') or {}).get('businessName'),\n 'retail_id': store_data.get('retailId'),\n- 'store_type': store_data.get('posStoreDetail').get('storeType'),\n+ 'store_type': (store_data.get('posStoreDetail') or {}).get('storeType'),\n 'store_type_note': store_data.get('typeOfStore')\n }\n }\n \n- hours = self.parse_hours(store_data.get(\"openingHoursSpecification\"))\n+ hours = self.parse_hours(store_data.get(\"StoreHours\"))\n if hours:\n properties[\"opening_hours\"] = hours\n", "issue": "Spider verizon is broken\nDuring the global build at 2021-10-27-14-42-46, spider **verizon** failed with **4573 features** and **1650 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-10-27-14-42-46/logs/verizon.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-10-27-14-42-46/output/verizon.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-10-27-14-42-46/output/verizon.geojson))\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\nimport json\nimport re\n\nfrom locations.items import GeojsonPointItem\nfrom locations.hours import OpeningHours\n\n\nclass VerizonSpider(scrapy.Spider):\n name = \"verizon\"\n item_attributes = { 'brand': \"Verizon\" }\n allowed_domains = [\"www.verizonwireless.com\"]\n start_urls = (\n 'https://www.verizonwireless.com/sitemap_storelocator.xml',\n )\n custom_settings = {\n 'USER_AGENT': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',\n }\n\n def parse_hours(self, store_hours):\n opening_hours = OpeningHours()\n for store_day in store_hours['dayOfWeek']:\n if store_day.lower() == 'closed':\n continue\n else:\n day, open_close = store_day.split('-')\n day = day.strip()[:2]\n open_time = ' '.join(open_close.strip().split(' ', 2)[0:2])\n if open_time.split(' ')[0].lower() == 'closed':\n continue\n elif open_time.split(' ')[0].lower() == 'null':\n continue\n else:\n if open_close.strip().count(' ') == 1:\n open_time, close_time = open_time.split(' ')\n opening_hours.add_range(day=day,\n open_time=open_time,\n close_time=close_time,\n time_format='%I:%M%p'\n )\n elif open_close.strip().count(' ') == 2:\n open_time = open_close.strip().split(' ')[0]\n close_time = ''.join(open_close.strip().split(' ')[1:3])\n opening_hours.add_range(day=day,\n open_time=open_time,\n close_time=close_time,\n time_format='%I:%M%p'\n )\n else:\n close_time = open_close.strip().split(' ', 2)[2]\n opening_hours.add_range(day=day,\n open_time=open_time,\n close_time=close_time,\n time_format='%I:%M %p'\n )\n\n return opening_hours.as_opening_hours()\n\n def parse(self, response):\n response.selector.remove_namespaces()\n urls = response.xpath('//url/loc/text()').extract()\n\n for url in urls:\n if url.split('/')[-2].split('-')[-1].isdigit():\n # Store pages have a number at the end of their URL\n yield scrapy.Request(url, callback=self.parse_store)\n\n def parse_store(self, response):\n script = response.xpath('//script[contains(text(), \"storeJSON\")]/text()').extract_first()\n if not script:\n return\n\n store_data = json.loads(re.search(r'var storeJSON = (.*);', script).group(1))\n\n properties = {\n 'name': store_data[\"storeName\"],\n 'ref': store_data[\"storeNumber\"],\n 'addr_full': store_data[\"address\"][\"streetAddress\"],\n 'city': store_data[\"address\"][\"addressLocality\"],\n 'state': store_data[\"address\"][\"addressRegion\"],\n 'postcode': store_data[\"address\"][\"postalCode\"],\n 'country': store_data[\"address\"][\"addressCountry\"],\n 'phone': store_data.get(\"telephone\"),\n 'website': store_data.get(\"url\") or response.url,\n 'lat': store_data[\"geo\"].get(\"latitude\"),\n 'lon': store_data[\"geo\"].get(\"longitude\"),\n 'extras': {\n 'business_name': store_data.get('posStoreDetail').get('businessName'),\n 'retail_id': store_data.get('retailId'),\n 'store_type': store_data.get('posStoreDetail').get('storeType'),\n 'store_type_note': store_data.get('typeOfStore')\n }\n }\n\n hours = self.parse_hours(store_data.get(\"openingHoursSpecification\"))\n if hours:\n properties[\"opening_hours\"] = hours\n\n yield GeojsonPointItem(**properties)\n", "path": "locations/spiders/verizon.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\nimport json\nimport re\n\nfrom locations.items import GeojsonPointItem\nfrom locations.hours import OpeningHours\n\n\nclass VerizonSpider(scrapy.Spider):\n name = \"verizon\"\n item_attributes = { 'brand': \"Verizon\" }\n allowed_domains = [\"www.verizonwireless.com\"]\n start_urls = (\n 'https://www.verizonwireless.com/sitemap_storelocator.xml',\n )\n custom_settings = {\n 'USER_AGENT': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',\n }\n\n def parse_hours(self, store_hours):\n opening_hours = OpeningHours()\n\n for store_day in ['Sun', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat']:\n open_time = store_hours.get(f'{store_day}Open')\n close_time = store_hours.get(f'{store_day}Close')\n\n if open_time and close_time and open_time.lower() != 'closed' and close_time.lower() != 'closed':\n opening_hours.add_range(\n day=store_day[0:2],\n open_time=open_time,\n close_time=close_time,\n time_format='%I:%M %p'\n )\n\n return opening_hours.as_opening_hours()\n\n def parse(self, response):\n response.selector.remove_namespaces()\n urls = response.xpath('//url/loc/text()').extract()\n\n for url in urls:\n if url.split('/')[-2].split('-')[-1].isdigit():\n # Store pages have a number at the end of their URL\n yield scrapy.Request(url, callback=self.parse_store)\n\n def parse_store(self, response):\n script = response.xpath('//script[contains(text(), \"storeJSON\")]/text()').extract_first()\n if not script:\n return\n\n store_data = json.loads(re.search(r'var storeJSON = (.*);', script).group(1))\n\n properties = {\n 'name': store_data[\"storeName\"],\n 'ref': store_data[\"storeNumber\"],\n 'addr_full': store_data[\"address\"][\"streetAddress\"],\n 'city': store_data[\"address\"][\"addressLocality\"],\n 'state': store_data[\"address\"][\"addressRegion\"],\n 'postcode': store_data[\"address\"][\"postalCode\"],\n 'country': store_data[\"address\"][\"addressCountry\"],\n 'phone': store_data.get(\"telephone\"),\n 'website': store_data.get(\"url\") or response.url,\n 'lat': store_data[\"geo\"].get(\"latitude\"),\n 'lon': store_data[\"geo\"].get(\"longitude\"),\n 'extras': {\n # Sometimes 'postStoreDetail' exists with \"None\" value, usual get w/ default syntax isn't reliable\n 'business_name': (store_data.get('posStoreDetail') or {}).get('businessName'),\n 'retail_id': store_data.get('retailId'),\n 'store_type': (store_data.get('posStoreDetail') or {}).get('storeType'),\n 'store_type_note': store_data.get('typeOfStore')\n }\n }\n\n hours = self.parse_hours(store_data.get(\"StoreHours\"))\n if hours:\n properties[\"opening_hours\"] = hours\n\n yield GeojsonPointItem(**properties)\n", "path": "locations/spiders/verizon.py"}]}
| 1,520 | 774 |
gh_patches_debug_22389
|
rasdani/github-patches
|
git_diff
|
ckan__ckan-7309
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
White on Yellow?? Color Contrast
**CKAN version**
https://demo.ckan.org/en/user/edit/mgifford
**Describe the bug**
Title: WCAG 1.4.3: Ensures the contrast between foreground and background colors meets WCAG 2 AA contrast ratio thresholds (.btn-warning)
Tags: Accessibility, WCAG 1.4.3, color-contrast
Issue: Ensures the contrast between foreground and background colors meets WCAG 2 AA contrast ratio thresholds (color-contrast - https://accessibilityinsights.io/info-examples/web/color-contrast)
Target application: Manage - mgifford - Users - CKAN Demo - https://demo.ckan.org/en/user/edit/mgifford
Element path: .btn-warning
Snippet: <a class="btn btn-warning" href="/en/user/generate_key/b8037a86-a216-4c9b-8211-e197fa09143a" data-module="confirm-action" data-module-content="Are you sure you want to regenerate the API key?">Regenerate API Key</a>
How to fix:
Fix any of the following:
Element has insufficient color contrast of 1.94 (foreground color: #ffffff, background color: #f0ad4e, font size: 10.5pt (14px), font weight: bold). Expected contrast ratio of 4.5:1
Environment: Microsoft Edge version 107.0.1418.35
====
This accessibility issue was found using Accessibility Insights for Web 2.35.0 (axe-core 4.4.1), a tool that helps find and fix accessibility issues. Get more information & download this tool at http://aka.ms/AccessibilityInsights.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ckan/cli/sass.py`
Content:
```
1 # encoding: utf-8
2 from __future__ import annotations
3
4 import subprocess
5 import os
6
7 import click
8 import six
9
10 from ckan.common import config
11
12
13 @click.command(
14 name=u'sass',
15 short_help=u'Compile all root sass documents into their CSS counterparts')
16 def sass():
17 command = (u'npm', u'run', u'build')
18
19 public = config.get_value(u'ckan.base_public_folder')
20
21 root = os.path.join(os.path.dirname(__file__), u'..', public, u'base')
22 root = os.path.abspath(root)
23 _compile_sass(root, command, u'main')
24
25
26 def _compile_sass(root: str, command: tuple[str, ...], color: str):
27 click.echo(u'compile {}.css'.format(color))
28 command = command + (u'--', u'--' + color)
29
30 process = subprocess.Popen(
31 command,
32 stdout=subprocess.PIPE,
33 stderr=subprocess.PIPE)
34 output = process.communicate()
35 for block in output:
36 click.echo(six.ensure_text(block))
37
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ckan/cli/sass.py b/ckan/cli/sass.py
--- a/ckan/cli/sass.py
+++ b/ckan/cli/sass.py
@@ -11,21 +11,32 @@
@click.command(
- name=u'sass',
- short_help=u'Compile all root sass documents into their CSS counterparts')
-def sass():
- command = (u'npm', u'run', u'build')
-
- public = config.get_value(u'ckan.base_public_folder')
-
- root = os.path.join(os.path.dirname(__file__), u'..', public, u'base')
+ name='sass',
+ short_help='Compile all root sass documents into their CSS counterparts')
[email protected](
+ '-d',
+ '--debug',
+ is_flag=True,
+ help="Compile css with sourcemaps.")
+def sass(debug: bool):
+ command = ('npm', 'run', 'build')
+
+ public = config.get_value('ckan.base_public_folder')
+
+ root = os.path.join(os.path.dirname(__file__), '..', public, 'base')
root = os.path.abspath(root)
- _compile_sass(root, command, u'main')
-
-
-def _compile_sass(root: str, command: tuple[str, ...], color: str):
- click.echo(u'compile {}.css'.format(color))
- command = command + (u'--', u'--' + color)
+ _compile_sass(root, command, 'main', debug)
+
+
+def _compile_sass(
+ root: str,
+ command: tuple[str, ...],
+ color: str,
+ debug: bool):
+ click.echo('compile {}.css'.format(color))
+ command = command + ('--', '--' + color)
+ if debug:
+ command = command + ('--debug',)
process = subprocess.Popen(
command,
|
{"golden_diff": "diff --git a/ckan/cli/sass.py b/ckan/cli/sass.py\n--- a/ckan/cli/sass.py\n+++ b/ckan/cli/sass.py\n@@ -11,21 +11,32 @@\n \n \n @click.command(\n- name=u'sass',\n- short_help=u'Compile all root sass documents into their CSS counterparts')\n-def sass():\n- command = (u'npm', u'run', u'build')\n-\n- public = config.get_value(u'ckan.base_public_folder')\n-\n- root = os.path.join(os.path.dirname(__file__), u'..', public, u'base')\n+ name='sass',\n+ short_help='Compile all root sass documents into their CSS counterparts')\[email protected](\n+ '-d',\n+ '--debug',\n+ is_flag=True,\n+ help=\"Compile css with sourcemaps.\")\n+def sass(debug: bool):\n+ command = ('npm', 'run', 'build')\n+\n+ public = config.get_value('ckan.base_public_folder')\n+\n+ root = os.path.join(os.path.dirname(__file__), '..', public, 'base')\n root = os.path.abspath(root)\n- _compile_sass(root, command, u'main')\n-\n-\n-def _compile_sass(root: str, command: tuple[str, ...], color: str):\n- click.echo(u'compile {}.css'.format(color))\n- command = command + (u'--', u'--' + color)\n+ _compile_sass(root, command, 'main', debug)\n+\n+\n+def _compile_sass(\n+ root: str,\n+ command: tuple[str, ...],\n+ color: str,\n+ debug: bool):\n+ click.echo('compile {}.css'.format(color))\n+ command = command + ('--', '--' + color)\n+ if debug:\n+ command = command + ('--debug',)\n \n process = subprocess.Popen(\n command,\n", "issue": "White on Yellow?? Color Contrast\n**CKAN version**\r\nhttps://demo.ckan.org/en/user/edit/mgifford\r\n\r\n**Describe the bug**\r\nTitle: WCAG 1.4.3: Ensures the contrast between foreground and background colors meets WCAG 2 AA contrast ratio thresholds (.btn-warning)\r\nTags: Accessibility, WCAG 1.4.3, color-contrast\r\n\r\nIssue: Ensures the contrast between foreground and background colors meets WCAG 2 AA contrast ratio thresholds (color-contrast - https://accessibilityinsights.io/info-examples/web/color-contrast)\r\n\r\nTarget application: Manage - mgifford - Users - CKAN Demo - https://demo.ckan.org/en/user/edit/mgifford\r\n\r\nElement path: .btn-warning\r\n\r\nSnippet: <a class=\"btn btn-warning\" href=\"/en/user/generate_key/b8037a86-a216-4c9b-8211-e197fa09143a\" data-module=\"confirm-action\" data-module-content=\"Are you sure you want to regenerate the API key?\">Regenerate API Key</a>\r\n\r\nHow to fix: \r\nFix any of the following:\r\n Element has insufficient color contrast of 1.94 (foreground color: #ffffff, background color: #f0ad4e, font size: 10.5pt (14px), font weight: bold). Expected contrast ratio of 4.5:1\r\n\r\nEnvironment: Microsoft Edge version 107.0.1418.35\r\n\r\n====\r\n\r\nThis accessibility issue was found using Accessibility Insights for Web 2.35.0 (axe-core 4.4.1), a tool that helps find and fix accessibility issues. Get more information & download this tool at http://aka.ms/AccessibilityInsights.\n", "before_files": [{"content": "# encoding: utf-8\nfrom __future__ import annotations\n\nimport subprocess\nimport os\n\nimport click\nimport six\n\nfrom ckan.common import config\n\n\[email protected](\n name=u'sass',\n short_help=u'Compile all root sass documents into their CSS counterparts')\ndef sass():\n command = (u'npm', u'run', u'build')\n\n public = config.get_value(u'ckan.base_public_folder')\n\n root = os.path.join(os.path.dirname(__file__), u'..', public, u'base')\n root = os.path.abspath(root)\n _compile_sass(root, command, u'main')\n\n\ndef _compile_sass(root: str, command: tuple[str, ...], color: str):\n click.echo(u'compile {}.css'.format(color))\n command = command + (u'--', u'--' + color)\n\n process = subprocess.Popen(\n command,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE)\n output = process.communicate()\n for block in output:\n click.echo(six.ensure_text(block))\n", "path": "ckan/cli/sass.py"}], "after_files": [{"content": "# encoding: utf-8\nfrom __future__ import annotations\n\nimport subprocess\nimport os\n\nimport click\nimport six\n\nfrom ckan.common import config\n\n\[email protected](\n name='sass',\n short_help='Compile all root sass documents into their CSS counterparts')\[email protected](\n '-d',\n '--debug',\n is_flag=True,\n help=\"Compile css with sourcemaps.\")\ndef sass(debug: bool):\n command = ('npm', 'run', 'build')\n\n public = config.get_value('ckan.base_public_folder')\n\n root = os.path.join(os.path.dirname(__file__), '..', public, 'base')\n root = os.path.abspath(root)\n _compile_sass(root, command, 'main', debug)\n\n\ndef _compile_sass(\n root: str,\n command: tuple[str, ...],\n color: str,\n debug: bool):\n click.echo('compile {}.css'.format(color))\n command = command + ('--', '--' + color)\n if debug:\n command = command + ('--debug',)\n\n process = subprocess.Popen(\n command,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE)\n output = process.communicate()\n for block in output:\n click.echo(six.ensure_text(block))\n", "path": "ckan/cli/sass.py"}]}
| 944 | 427 |
gh_patches_debug_10692
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-4865
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
update ansible to 2.6.18 or later due to CVE-2019-10156
## Description
We should update Ansible to version 2.6.18 or later due to [CVE-2019-10156](https://nvd.nist.gov/vuln/detail/CVE-2019-10156). This is a templating vulnerability that would require an attacker to first insert malicious templates into the Admin workstation so the impact is minimal for SecureDrop. Nevertheless, to reduce alert noise and not be using dependencies with known vulnerabilities, we should update.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `install_files/ansible-base/callback_plugins/ansible_version_check.py`
Content:
```
1 # -*- encoding:utf-8 -*-
2 from __future__ import absolute_import, division, print_function, \
3 unicode_literals
4
5 import sys
6
7 import ansible
8
9 try:
10 # Version 2.0+
11 from ansible.plugins.callback import CallbackBase
12 except ImportError:
13 CallbackBase = object
14
15
16 def print_red_bold(text):
17 print('\x1b[31;1m' + text + '\x1b[0m')
18
19
20 class CallbackModule(CallbackBase):
21 def __init__(self):
22 # Can't use `on_X` because this isn't forwards compatible
23 # with Ansible 2.0+
24 required_version = '2.6.14' # Keep synchronized with requirements files
25 if not ansible.__version__.startswith(required_version):
26 print_red_bold(
27 "SecureDrop restriction: only Ansible {version}.*"
28 "is supported."
29 .format(version=required_version)
30 )
31 sys.exit(1)
32
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/install_files/ansible-base/callback_plugins/ansible_version_check.py b/install_files/ansible-base/callback_plugins/ansible_version_check.py
--- a/install_files/ansible-base/callback_plugins/ansible_version_check.py
+++ b/install_files/ansible-base/callback_plugins/ansible_version_check.py
@@ -21,7 +21,7 @@
def __init__(self):
# Can't use `on_X` because this isn't forwards compatible
# with Ansible 2.0+
- required_version = '2.6.14' # Keep synchronized with requirements files
+ required_version = '2.6.19' # Keep synchronized with requirements files
if not ansible.__version__.startswith(required_version):
print_red_bold(
"SecureDrop restriction: only Ansible {version}.*"
|
{"golden_diff": "diff --git a/install_files/ansible-base/callback_plugins/ansible_version_check.py b/install_files/ansible-base/callback_plugins/ansible_version_check.py\n--- a/install_files/ansible-base/callback_plugins/ansible_version_check.py\n+++ b/install_files/ansible-base/callback_plugins/ansible_version_check.py\n@@ -21,7 +21,7 @@\n def __init__(self):\n # Can't use `on_X` because this isn't forwards compatible\n # with Ansible 2.0+\n- required_version = '2.6.14' # Keep synchronized with requirements files\n+ required_version = '2.6.19' # Keep synchronized with requirements files\n if not ansible.__version__.startswith(required_version):\n print_red_bold(\n \"SecureDrop restriction: only Ansible {version}.*\"\n", "issue": "update ansible to 2.6.18 or later due to CVE-2019-10156\n## Description\r\n\r\nWe should update Ansible to version 2.6.18 or later due to [CVE-2019-10156](https://nvd.nist.gov/vuln/detail/CVE-2019-10156). This is a templating vulnerability that would require an attacker to first insert malicious templates into the Admin workstation so the impact is minimal for SecureDrop. Nevertheless, to reduce alert noise and not be using dependencies with known vulnerabilities, we should update. \n", "before_files": [{"content": "# -*- encoding:utf-8 -*-\nfrom __future__ import absolute_import, division, print_function, \\\n unicode_literals\n\nimport sys\n\nimport ansible\n\ntry:\n # Version 2.0+\n from ansible.plugins.callback import CallbackBase\nexcept ImportError:\n CallbackBase = object\n\n\ndef print_red_bold(text):\n print('\\x1b[31;1m' + text + '\\x1b[0m')\n\n\nclass CallbackModule(CallbackBase):\n def __init__(self):\n # Can't use `on_X` because this isn't forwards compatible\n # with Ansible 2.0+\n required_version = '2.6.14' # Keep synchronized with requirements files\n if not ansible.__version__.startswith(required_version):\n print_red_bold(\n \"SecureDrop restriction: only Ansible {version}.*\"\n \"is supported.\"\n .format(version=required_version)\n )\n sys.exit(1)\n", "path": "install_files/ansible-base/callback_plugins/ansible_version_check.py"}], "after_files": [{"content": "# -*- encoding:utf-8 -*-\nfrom __future__ import absolute_import, division, print_function, \\\n unicode_literals\n\nimport sys\n\nimport ansible\n\ntry:\n # Version 2.0+\n from ansible.plugins.callback import CallbackBase\nexcept ImportError:\n CallbackBase = object\n\n\ndef print_red_bold(text):\n print('\\x1b[31;1m' + text + '\\x1b[0m')\n\n\nclass CallbackModule(CallbackBase):\n def __init__(self):\n # Can't use `on_X` because this isn't forwards compatible\n # with Ansible 2.0+\n required_version = '2.6.19' # Keep synchronized with requirements files\n if not ansible.__version__.startswith(required_version):\n print_red_bold(\n \"SecureDrop restriction: only Ansible {version}.*\"\n \"is supported.\"\n .format(version=required_version)\n )\n sys.exit(1)\n", "path": "install_files/ansible-base/callback_plugins/ansible_version_check.py"}]}
| 664 | 177 |
gh_patches_debug_60820
|
rasdani/github-patches
|
git_diff
|
cltk__cltk-575
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Double-check code and data for new French PR
This issue is for @nat1881 to follow up on her large PR #571 for Old and Middle French.
Natasha, I would like you to do the following steps, to be certain that the code works as you intended:
* Start a brand new clone of (this) cltk repo.
* Make a new virtual env
* Mk source tarball and install (this should install all dependencies, too): `python setup.py sdist install`
* Temporarily rename your `~/cltk_data` dir (eg, `mv ~/cltk_data ~/cltk_data_backup`)
* Import the french corpora and make sure they appear as they should
* Check in ipython all of your commands that you have added to the docs. Copy-paste these exactly as they are in the docs.
* Follow up on any bugs in your own updated branch ([this is what I recommend for updating your branch](https://github.com/cltk/cltk/wiki/Example-Git-and-Python-workflow))
* Bump the version in `setup.py` and make PR for this
* Then @diyclassics or I will push the code to PyPI
You may be tired of this, but you're getting close! :weary:
cc @mlj
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 """Config for PyPI."""
2
3 from setuptools import find_packages
4 from setuptools import setup
5
6
7 setup(
8 author='Kyle P. Johnson',
9 author_email='[email protected]',
10 classifiers=[
11 'Intended Audience :: Education',
12 'Intended Audience :: Science/Research',
13 'License :: OSI Approved :: MIT License',
14 'Natural Language :: Chinese (Traditional)',
15 'Natural Language :: English',
16 'Natural Language :: Greek',
17 'Natural Language :: Latin',
18 'Operating System :: POSIX',
19 'Programming Language :: Python :: 3.6',
20 'Topic :: Scientific/Engineering :: Artificial Intelligence',
21 'Topic :: Text Processing',
22 'Topic :: Text Processing :: General',
23 'Topic :: Text Processing :: Linguistic',
24 ],
25 description='NLP for the ancient world',
26 install_requires=['gitpython',
27 'nltk',
28 'python-crfsuite',
29 'pyuca',
30 'pyyaml',
31 'regex',
32 'whoosh'],
33 keywords=['nlp', 'nltk', 'greek', 'latin', 'chinese', 'sanskrit', 'pali', 'tibetan'],
34 license='MIT',
35 long_description='The Classical Language Toolkit (CLTK) is a framework for natural language processing for Classical languages.', # pylint: disable=C0301,
36 name='cltk',
37 packages=find_packages(),
38 url='https://github.com/cltk/cltk',
39 version='0.1.63',
40 zip_safe=True,
41 test_suite='cltk.tests.test_cltk',
42 )
43
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -36,7 +36,7 @@
name='cltk',
packages=find_packages(),
url='https://github.com/cltk/cltk',
- version='0.1.63',
+ version='0.1.64',
zip_safe=True,
test_suite='cltk.tests.test_cltk',
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -36,7 +36,7 @@\n name='cltk',\n packages=find_packages(),\n url='https://github.com/cltk/cltk',\n- version='0.1.63',\n+ version='0.1.64',\n zip_safe=True,\n test_suite='cltk.tests.test_cltk',\n )\n", "issue": "Double-check code and data for new French PR\nThis issue is for @nat1881 to follow up on her large PR #571 for Old and Middle French.\r\n\r\nNatasha, I would like you to do the following steps, to be certain that the code works as you intended:\r\n\r\n* Start a brand new clone of (this) cltk repo.\r\n* Make a new virtual env\r\n* Mk source tarball and install (this should install all dependencies, too): `python setup.py sdist install`\r\n* Temporarily rename your `~/cltk_data` dir (eg, `mv ~/cltk_data ~/cltk_data_backup`)\r\n* Import the french corpora and make sure they appear as they should\r\n* Check in ipython all of your commands that you have added to the docs. Copy-paste these exactly as they are in the docs.\r\n* Follow up on any bugs in your own updated branch ([this is what I recommend for updating your branch](https://github.com/cltk/cltk/wiki/Example-Git-and-Python-workflow))\r\n* Bump the version in `setup.py` and make PR for this\r\n* Then @diyclassics or I will push the code to PyPI\r\n\r\nYou may be tired of this, but you're getting close! :weary:\r\n\r\ncc @mlj \n", "before_files": [{"content": "\"\"\"Config for PyPI.\"\"\"\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\nsetup(\n author='Kyle P. Johnson',\n author_email='[email protected]',\n classifiers=[\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: Chinese (Traditional)',\n 'Natural Language :: English',\n 'Natural Language :: Greek',\n 'Natural Language :: Latin',\n 'Operating System :: POSIX',\n 'Programming Language :: Python :: 3.6',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n 'Topic :: Text Processing',\n 'Topic :: Text Processing :: General',\n 'Topic :: Text Processing :: Linguistic',\n ],\n description='NLP for the ancient world',\n install_requires=['gitpython',\n 'nltk',\n 'python-crfsuite',\n 'pyuca',\n 'pyyaml',\n 'regex',\n 'whoosh'],\n keywords=['nlp', 'nltk', 'greek', 'latin', 'chinese', 'sanskrit', 'pali', 'tibetan'],\n license='MIT',\n long_description='The Classical Language Toolkit (CLTK) is a framework for natural language processing for Classical languages.', # pylint: disable=C0301,\n name='cltk',\n packages=find_packages(),\n url='https://github.com/cltk/cltk',\n version='0.1.63',\n zip_safe=True,\n test_suite='cltk.tests.test_cltk',\n)\n", "path": "setup.py"}], "after_files": [{"content": "\"\"\"Config for PyPI.\"\"\"\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\nsetup(\n author='Kyle P. Johnson',\n author_email='[email protected]',\n classifiers=[\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: Chinese (Traditional)',\n 'Natural Language :: English',\n 'Natural Language :: Greek',\n 'Natural Language :: Latin',\n 'Operating System :: POSIX',\n 'Programming Language :: Python :: 3.6',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n 'Topic :: Text Processing',\n 'Topic :: Text Processing :: General',\n 'Topic :: Text Processing :: Linguistic',\n ],\n description='NLP for the ancient world',\n install_requires=['gitpython',\n 'nltk',\n 'python-crfsuite',\n 'pyuca',\n 'pyyaml',\n 'regex',\n 'whoosh'],\n keywords=['nlp', 'nltk', 'greek', 'latin', 'chinese', 'sanskrit', 'pali', 'tibetan'],\n license='MIT',\n long_description='The Classical Language Toolkit (CLTK) is a framework for natural language processing for Classical languages.', # pylint: disable=C0301,\n name='cltk',\n packages=find_packages(),\n url='https://github.com/cltk/cltk',\n version='0.1.64',\n zip_safe=True,\n test_suite='cltk.tests.test_cltk',\n)\n", "path": "setup.py"}]}
| 945 | 94 |
gh_patches_debug_6139
|
rasdani/github-patches
|
git_diff
|
uclapi__uclapi-140
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Documentation] Docs link is Absolute, not Relative
The documentation link always goes to `https://uclapi.com/docs`, even if running in, for example, staging. Just linking to `/docs` would be adequate to fix this.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `backend/uclapi/resources/views.py`
Content:
```
1 import os
2 import requests
3
4 from lxml import etree
5
6 from common.decorators import uclapi_protected_endpoint
7 from common.helpers import PrettyJsonResponse as JsonResponse
8
9 from rest_framework.decorators import api_view
10
11
12 @api_view(['GET'])
13 @uclapi_protected_endpoint()
14 def get_pc_availability(request, *args, **kwargs):
15 try:
16 r = requests.get(os.environ["PCA_LINK"])
17 except requests.exceptions.MissingSchema:
18 resp = JsonResponse({
19 "ok": False,
20 "error": ("Could not retrieve availability data."
21 " Please try again later or contact us for support.")
22 }, rate_limiting_data=kwargs)
23 resp.status_code = 400
24 return resp
25
26 try:
27 e = etree.fromstring(r.content)
28 except (ValueError, etree.XMLSyntaxError):
29 resp = JsonResponse({
30 "ok": False,
31 "error": ("Could not parse the desktop availability data."
32 " Please try again later or contact us for support.")
33 }, rate_limiting_data=kwargs)
34 resp.status_code = 400
35 return resp
36
37 data = []
38 for pc in e.findall("room"):
39 _ = pc.get
40 data.append({
41 "location": {
42 "room_name": _("location"),
43 "room_id": _("rid"),
44 "latitude": _("latitude"),
45 "longitude": _("longitude"),
46 "building_name": _("buildingName"),
47 "address": _("buildingAddress"),
48 "postcode": _("buildingPostCode")
49 },
50 "free_seats": _("free"),
51 "total_seats": _("seats"),
52 "room_status": _("info")
53 })
54
55 return JsonResponse({
56 "ok": True,
57 "data": data
58 }, rate_limiting_data=kwargs)
59
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/backend/uclapi/resources/views.py b/backend/uclapi/resources/views.py
--- a/backend/uclapi/resources/views.py
+++ b/backend/uclapi/resources/views.py
@@ -45,7 +45,7 @@
"longitude": _("longitude"),
"building_name": _("buildingName"),
"address": _("buildingAddress"),
- "postcode": _("buildingPostCode")
+ "postcode": _("buildingPostcode")
},
"free_seats": _("free"),
"total_seats": _("seats"),
|
{"golden_diff": "diff --git a/backend/uclapi/resources/views.py b/backend/uclapi/resources/views.py\n--- a/backend/uclapi/resources/views.py\n+++ b/backend/uclapi/resources/views.py\n@@ -45,7 +45,7 @@\n \"longitude\": _(\"longitude\"),\n \"building_name\": _(\"buildingName\"),\n \"address\": _(\"buildingAddress\"),\n- \"postcode\": _(\"buildingPostCode\")\n+ \"postcode\": _(\"buildingPostcode\")\n },\n \"free_seats\": _(\"free\"),\n \"total_seats\": _(\"seats\"),\n", "issue": "[Documentation] Docs link is Absolute, not Relative\nThe documentation link always goes to `https://uclapi.com/docs`, even if running in, for example, staging. Just linking to `/docs` would be adequate to fix this.\n", "before_files": [{"content": "import os\nimport requests\n\nfrom lxml import etree\n\nfrom common.decorators import uclapi_protected_endpoint\nfrom common.helpers import PrettyJsonResponse as JsonResponse\n\nfrom rest_framework.decorators import api_view\n\n\n@api_view(['GET'])\n@uclapi_protected_endpoint()\ndef get_pc_availability(request, *args, **kwargs):\n try:\n r = requests.get(os.environ[\"PCA_LINK\"])\n except requests.exceptions.MissingSchema:\n resp = JsonResponse({\n \"ok\": False,\n \"error\": (\"Could not retrieve availability data.\"\n \" Please try again later or contact us for support.\")\n }, rate_limiting_data=kwargs)\n resp.status_code = 400\n return resp\n\n try:\n e = etree.fromstring(r.content)\n except (ValueError, etree.XMLSyntaxError):\n resp = JsonResponse({\n \"ok\": False,\n \"error\": (\"Could not parse the desktop availability data.\"\n \" Please try again later or contact us for support.\")\n }, rate_limiting_data=kwargs)\n resp.status_code = 400\n return resp\n\n data = []\n for pc in e.findall(\"room\"):\n _ = pc.get\n data.append({\n \"location\": {\n \"room_name\": _(\"location\"),\n \"room_id\": _(\"rid\"),\n \"latitude\": _(\"latitude\"),\n \"longitude\": _(\"longitude\"),\n \"building_name\": _(\"buildingName\"),\n \"address\": _(\"buildingAddress\"),\n \"postcode\": _(\"buildingPostCode\")\n },\n \"free_seats\": _(\"free\"),\n \"total_seats\": _(\"seats\"),\n \"room_status\": _(\"info\")\n })\n\n return JsonResponse({\n \"ok\": True,\n \"data\": data\n }, rate_limiting_data=kwargs)\n", "path": "backend/uclapi/resources/views.py"}], "after_files": [{"content": "import os\nimport requests\n\nfrom lxml import etree\n\nfrom common.decorators import uclapi_protected_endpoint\nfrom common.helpers import PrettyJsonResponse as JsonResponse\n\nfrom rest_framework.decorators import api_view\n\n\n@api_view(['GET'])\n@uclapi_protected_endpoint()\ndef get_pc_availability(request, *args, **kwargs):\n try:\n r = requests.get(os.environ[\"PCA_LINK\"])\n except requests.exceptions.MissingSchema:\n resp = JsonResponse({\n \"ok\": False,\n \"error\": (\"Could not retrieve availability data.\"\n \" Please try again later or contact us for support.\")\n }, rate_limiting_data=kwargs)\n resp.status_code = 400\n return resp\n\n try:\n e = etree.fromstring(r.content)\n except (ValueError, etree.XMLSyntaxError):\n resp = JsonResponse({\n \"ok\": False,\n \"error\": (\"Could not parse the desktop availability data.\"\n \" Please try again later or contact us for support.\")\n }, rate_limiting_data=kwargs)\n resp.status_code = 400\n return resp\n\n data = []\n for pc in e.findall(\"room\"):\n _ = pc.get\n data.append({\n \"location\": {\n \"room_name\": _(\"location\"),\n \"room_id\": _(\"rid\"),\n \"latitude\": _(\"latitude\"),\n \"longitude\": _(\"longitude\"),\n \"building_name\": _(\"buildingName\"),\n \"address\": _(\"buildingAddress\"),\n \"postcode\": _(\"buildingPostcode\")\n },\n \"free_seats\": _(\"free\"),\n \"total_seats\": _(\"seats\"),\n \"room_status\": _(\"info\")\n })\n\n return JsonResponse({\n \"ok\": True,\n \"data\": data\n }, rate_limiting_data=kwargs)\n", "path": "backend/uclapi/resources/views.py"}]}
| 795 | 117 |
gh_patches_debug_32603
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-3518
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
searching for phrases within quotes doesn't work
the `munge_search_term` method doesn't work when searching for quoted phrases.
https://github.com/plone/Products.CMFPlone/blob/master/Products/CMFPlone/browser/search.py
**Reproduce:**
- go to https://6-classic.demo.plone.org/en
- search for `"Welcome to Plone"`
- you get an empty search result
**Background**
the `munge_search_term` returns this for the phrase above:
`'Welcome AND to AND Plone*'`
**Solution**
keep phrases within quotes untouched.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `Products/CMFPlone/browser/search.py`
Content:
```
1 from DateTime import DateTime
2 from plone.app.contentlisting.interfaces import IContentListing
3 from plone.app.layout.navigation.interfaces import INavigationRoot
4 from plone.registry.interfaces import IRegistry
5 from Products.CMFCore.utils import getToolByName
6 from Products.CMFPlone.browser.navtree import getNavigationRoot
7 from plone.base.interfaces import ISearchSchema
8 from Products.CMFPlone.PloneBatch import Batch
9 from Products.ZCTextIndex.ParseTree import ParseError
10 from zope.cachedescriptors.property import Lazy as lazy_property
11 from zope.component import getMultiAdapter
12 from zope.component import getUtility
13 from zope.component import queryUtility
14 from zope.i18nmessageid import MessageFactory
15 from zope.publisher.browser import BrowserView
16 from ZTUtils import make_query
17
18 import json
19
20 _ = MessageFactory('plone')
21
22 # We should accept both a simple space, unicode u'\u0020 but also a
23 # multi-space, so called 'waji-kankaku', unicode u'\u3000'
24 MULTISPACE = '\u3000'
25 BAD_CHARS = ('?', '-', '+', '*', MULTISPACE)
26 EVER = DateTime('1970-01-03')
27
28
29 def quote_chars(s):
30 # We need to quote parentheses when searching text indices
31 if '(' in s:
32 s = s.replace('(', '"("')
33 if ')' in s:
34 s = s.replace(')', '")"')
35 if MULTISPACE in s:
36 s = s.replace(MULTISPACE, ' ')
37 return s
38
39
40 def quote(term):
41 # The terms and, or and not must be wrapped in quotes to avoid
42 # being parsed as logical query atoms.
43 if term.lower() in ('and', 'or', 'not'):
44 term = '"%s"' % term
45 return term
46
47
48 class Search(BrowserView):
49
50 valid_keys = ('sort_on', 'sort_order', 'sort_limit', 'fq', 'fl', 'facet')
51
52 def munge_search_term(self, q):
53 for char in BAD_CHARS:
54 q = q.replace(char, ' ')
55 r = map(quote, q.split())
56 r = " AND ".join(r)
57 r = quote_chars(r) + '*'
58 return r
59
60 def results(self, query=None, batch=True, b_size=10, b_start=0,
61 use_content_listing=True):
62 """ Get properly wrapped search results from the catalog.
63 Everything in Plone that performs searches should go through this view.
64 'query' should be a dictionary of catalog parameters.
65 """
66 if query is None:
67 query = {}
68 if batch:
69 query['b_start'] = b_start = int(b_start)
70 query['b_size'] = b_size
71 query = self.filter_query(query)
72
73 if query is None:
74 results = []
75 else:
76 catalog = getToolByName(self.context, 'portal_catalog')
77 try:
78 results = catalog(**query)
79 except ParseError:
80 return []
81
82 if use_content_listing:
83 results = IContentListing(results)
84 if batch:
85 results = Batch(results, b_size, b_start)
86 return results
87
88 def _filter_query(self, query):
89 request = self.request
90
91 catalog = getToolByName(self.context, 'portal_catalog')
92 valid_indexes = tuple(catalog.indexes())
93 valid_keys = self.valid_keys + valid_indexes
94
95 text = query.get('SearchableText', None)
96 if text is None:
97 text = request.form.get('SearchableText', '')
98 if not text:
99 # Without text, must provide a meaningful non-empty search
100 valid = set(valid_indexes).intersection(request.form.keys()) or \
101 set(valid_indexes).intersection(query.keys())
102 if not valid:
103 return
104
105 for k, v in request.form.items():
106 if v and ((k in valid_keys) or k.startswith('facet.')):
107 query[k] = v
108 if text:
109 query['SearchableText'] = self.munge_search_term(text)
110
111 # don't filter on created at all if we want all results
112 created = query.get('created')
113 if created:
114 try:
115 if created.get('query', EVER) <= EVER:
116 del query['created']
117 except AttributeError:
118 # created not a mapping
119 del query['created']
120
121 # respect `types_not_searched` setting
122 types = query.get('portal_type', [])
123 if 'query' in types:
124 types = types['query']
125 query['portal_type'] = self.filter_types(types)
126 # respect effective/expiration date
127 query['show_inactive'] = False
128 # respect navigation root
129 if 'path' not in query:
130 query['path'] = getNavigationRoot(self.context)
131
132 if 'sort_order' in query and not query['sort_order']:
133 del query['sort_order']
134 return query
135
136 @lazy_property
137 def default_sort_on(self):
138 registry = getUtility(IRegistry)
139 search_settings = registry.forInterface(ISearchSchema, prefix='plone')
140 return search_settings.sort_on
141
142 def filter_query(self, query):
143 query = self._filter_query(query)
144 if query is None:
145 query = {}
146 # explicitly set a sort; if no `sort_on` is present, the catalog sorts
147 # by relevance
148 if 'sort_on' not in query:
149 self.default_sort_on
150 if self.default_sort_on != 'relevance':
151 query['sort_on'] = self.default_sort_on
152 elif query['sort_on'] == 'relevance':
153 del query['sort_on']
154 if query.get('sort_on', '') == 'Date':
155 query['sort_order'] = 'reverse'
156 elif 'sort_order' in query:
157 del query['sort_order']
158 if not query:
159 return None
160 return query
161
162 def filter_types(self, types):
163 plone_utils = getToolByName(self.context, 'plone_utils')
164 if not isinstance(types, list):
165 types = [types]
166 return plone_utils.getUserFriendlyTypes(types)
167
168 def types_list(self):
169 # only show those types that have any content
170 catalog = getToolByName(self.context, 'portal_catalog')
171 used_types = catalog._catalog.getIndex('portal_type').uniqueValues()
172 return self.filter_types(list(used_types))
173
174 def sort_options(self):
175 """ Sorting options for search results view. """
176 if 'sort_on' not in self.request.form:
177 self.request.form['sort_on'] = self.default_sort_on
178 return (
179 SortOption(self.request, _('relevance'), 'relevance'),
180 SortOption(
181 self.request, _('date (newest first)'), 'Date', reverse=True
182 ),
183 SortOption(self.request, _('alphabetically'), 'sortable_title'),
184 )
185
186 def show_advanced_search(self):
187 """Whether we need to show advanced search options a.k.a. filters?"""
188 show = self.request.get('advanced_search', None)
189 if not show or show == 'False':
190 return False
191 return True
192
193 def advanced_search_trigger(self):
194 """URL builder for show/close advanced search filters."""
195 query = self.request.get('QUERY_STRING', None)
196 url = self.request.get('ACTUAL_URL', self.context.absolute_url())
197 if not query:
198 return url
199 if 'advanced_search' in query:
200 if 'advanced_search=True' in query:
201 query = query.replace('advanced_search=True', '')
202 if 'advanced_search=False' in query:
203 query = query.replace('advanced_search=False', '')
204 else:
205 query = query + '&advanced_search=True'
206 return url + '?' + query
207
208 def breadcrumbs(self, item):
209 obj = item.getObject()
210 view = getMultiAdapter((obj, self.request), name='breadcrumbs_view')
211 # cut off the item itself
212 breadcrumbs = list(view.breadcrumbs())[:-1]
213 if len(breadcrumbs) == 0:
214 # don't show breadcrumbs if we only have a single element
215 return None
216 if len(breadcrumbs) > 3:
217 # if we have too long breadcrumbs, emit the middle elements
218 empty = {'absolute_url': '', 'Title': '…'}
219 breadcrumbs = [breadcrumbs[0], empty] + breadcrumbs[-2:]
220 return breadcrumbs
221
222 def navroot_url(self):
223 if not hasattr(self, '_navroot_url'):
224 state = self.context.unrestrictedTraverse('@@plone_portal_state')
225 self._navroot_url = state.navigation_root_url()
226 return self._navroot_url
227
228 @property
229 def show_images(self):
230 registry = queryUtility(IRegistry)
231 return registry.get('plone.search_show_images')
232
233 @property
234 def search_image_scale(self):
235 registry = queryUtility(IRegistry)
236 return registry.get('plone.search_image_scale')
237
238
239 class AjaxSearch(Search):
240
241 def __call__(self):
242 items = []
243 try:
244 per_page = int(self.request.form.get('perPage'))
245 except:
246 per_page = 10
247 try:
248 page = int(self.request.form.get('page'))
249 except:
250 page = 1
251
252 results = self.results(batch=False, use_content_listing=False)
253 batch = Batch(results, per_page, start=(page - 1) * per_page)
254
255 registry = queryUtility(IRegistry)
256 length = registry.get('plone.search_results_description_length')
257 show_images = registry.get('plone.search_show_images')
258 if show_images:
259 image_scale = registry.get('plone.search_image_scale')
260 # image_scaling = getMultiAdapter((self.context, self.request), name='image_scale')
261 self.image_scaling = getMultiAdapter((INavigationRoot(self.context), self.request), name='image_scale')
262 plone_view = getMultiAdapter(
263 (self.context, self.request), name='plone')
264 view_action_types = registry.get(
265 'plone.types_use_view_action_in_listings', [])
266 for item in batch:
267 url = item.getURL()
268 if item.portal_type in view_action_types:
269 url = '%s/view' % url
270 img_tag = None
271 if show_images:
272 img_tag = self.get_image_tag(item, image_scale)
273 items.append({
274 'id': item.UID,
275 'title': item.Title,
276 'description': plone_view.cropText(item.Description, length),
277 'url': url,
278 'state': item.review_state if item.review_state else None,
279 'img_tag': img_tag,
280 })
281 return json.dumps({
282 'total': len(results),
283 'items': items
284 })
285
286 def get_image_tag(self, item, image_scale):
287 return self.image_scaling.tag(item, "image", scale=image_scale)
288
289 class SortOption:
290
291 def __init__(self, request, title, sortkey='', reverse=False):
292 self.request = request
293 self.title = title
294 self.sortkey = sortkey
295 self.reverse = reverse
296
297 def selected(self):
298 sort_on = self.request.get('sort_on', '')
299 return sort_on == self.sortkey and sort_on != ''
300
301 def url(self):
302 q = {}
303 q.update(self.request.form)
304 if 'sort_on' in q.keys():
305 del q['sort_on']
306 if 'sort_order' in q.keys():
307 del q['sort_order']
308 q['sort_on'] = self.sortkey
309 if self.reverse:
310 q['sort_order'] = 'reverse'
311
312 base_url = self.request.URL
313 return base_url + '?' + make_query(q)
314
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/Products/CMFPlone/browser/search.py b/Products/CMFPlone/browser/search.py
--- a/Products/CMFPlone/browser/search.py
+++ b/Products/CMFPlone/browser/search.py
@@ -16,6 +16,7 @@
from ZTUtils import make_query
import json
+import re
_ = MessageFactory('plone')
@@ -45,18 +46,33 @@
return term
+def munge_search_term(query):
+ for char in BAD_CHARS:
+ query = query.replace(char, ' ')
+
+ # extract quoted phrases first
+ quoted_phrases = re.findall(r'"([^"]*)"', query)
+ r = []
+ for qp in quoted_phrases:
+ # remove from original query
+ query = query.replace(f'"{qp}"', "")
+ # replace with cleaned leading/trailing whitespaces
+ # and skip empty phrases
+ clean_qp = qp.strip()
+ if not clean_qp:
+ continue
+ r.append(f'"{clean_qp}"')
+
+ r += map(quote, query.strip().split())
+ r = " AND ".join(r)
+ r = quote_chars(r) + ('*' if r and not r.endswith('"') else '')
+ return r
+
+
class Search(BrowserView):
valid_keys = ('sort_on', 'sort_order', 'sort_limit', 'fq', 'fl', 'facet')
- def munge_search_term(self, q):
- for char in BAD_CHARS:
- q = q.replace(char, ' ')
- r = map(quote, q.split())
- r = " AND ".join(r)
- r = quote_chars(r) + '*'
- return r
-
def results(self, query=None, batch=True, b_size=10, b_start=0,
use_content_listing=True):
""" Get properly wrapped search results from the catalog.
@@ -106,7 +122,7 @@
if v and ((k in valid_keys) or k.startswith('facet.')):
query[k] = v
if text:
- query['SearchableText'] = self.munge_search_term(text)
+ query['SearchableText'] = munge_search_term(text)
# don't filter on created at all if we want all results
created = query.get('created')
|
{"golden_diff": "diff --git a/Products/CMFPlone/browser/search.py b/Products/CMFPlone/browser/search.py\n--- a/Products/CMFPlone/browser/search.py\n+++ b/Products/CMFPlone/browser/search.py\n@@ -16,6 +16,7 @@\n from ZTUtils import make_query\n \n import json\n+import re\n \n _ = MessageFactory('plone')\n \n@@ -45,18 +46,33 @@\n return term\n \n \n+def munge_search_term(query):\n+ for char in BAD_CHARS:\n+ query = query.replace(char, ' ')\n+\n+ # extract quoted phrases first\n+ quoted_phrases = re.findall(r'\"([^\"]*)\"', query)\n+ r = []\n+ for qp in quoted_phrases:\n+ # remove from original query\n+ query = query.replace(f'\"{qp}\"', \"\")\n+ # replace with cleaned leading/trailing whitespaces\n+ # and skip empty phrases\n+ clean_qp = qp.strip()\n+ if not clean_qp:\n+ continue\n+ r.append(f'\"{clean_qp}\"')\n+\n+ r += map(quote, query.strip().split())\n+ r = \" AND \".join(r)\n+ r = quote_chars(r) + ('*' if r and not r.endswith('\"') else '')\n+ return r\n+\n+\n class Search(BrowserView):\n \n valid_keys = ('sort_on', 'sort_order', 'sort_limit', 'fq', 'fl', 'facet')\n \n- def munge_search_term(self, q):\n- for char in BAD_CHARS:\n- q = q.replace(char, ' ')\n- r = map(quote, q.split())\n- r = \" AND \".join(r)\n- r = quote_chars(r) + '*'\n- return r\n-\n def results(self, query=None, batch=True, b_size=10, b_start=0,\n use_content_listing=True):\n \"\"\" Get properly wrapped search results from the catalog.\n@@ -106,7 +122,7 @@\n if v and ((k in valid_keys) or k.startswith('facet.')):\n query[k] = v\n if text:\n- query['SearchableText'] = self.munge_search_term(text)\n+ query['SearchableText'] = munge_search_term(text)\n \n # don't filter on created at all if we want all results\n created = query.get('created')\n", "issue": "searching for phrases within quotes doesn't work\nthe `munge_search_term` method doesn't work when searching for quoted phrases.\r\n\r\nhttps://github.com/plone/Products.CMFPlone/blob/master/Products/CMFPlone/browser/search.py\r\n\r\n**Reproduce:**\r\n\r\n- go to https://6-classic.demo.plone.org/en\r\n- search for `\"Welcome to Plone\"`\r\n- you get an empty search result\r\n\r\n**Background**\r\n\r\nthe `munge_search_term` returns this for the phrase above:\r\n\r\n`'Welcome AND to AND Plone*'`\r\n\r\n**Solution**\r\n\r\nkeep phrases within quotes untouched.\n", "before_files": [{"content": "from DateTime import DateTime\nfrom plone.app.contentlisting.interfaces import IContentListing\nfrom plone.app.layout.navigation.interfaces import INavigationRoot\nfrom plone.registry.interfaces import IRegistry\nfrom Products.CMFCore.utils import getToolByName\nfrom Products.CMFPlone.browser.navtree import getNavigationRoot\nfrom plone.base.interfaces import ISearchSchema\nfrom Products.CMFPlone.PloneBatch import Batch\nfrom Products.ZCTextIndex.ParseTree import ParseError\nfrom zope.cachedescriptors.property import Lazy as lazy_property\nfrom zope.component import getMultiAdapter\nfrom zope.component import getUtility\nfrom zope.component import queryUtility\nfrom zope.i18nmessageid import MessageFactory\nfrom zope.publisher.browser import BrowserView\nfrom ZTUtils import make_query\n\nimport json\n\n_ = MessageFactory('plone')\n\n# We should accept both a simple space, unicode u'\\u0020 but also a\n# multi-space, so called 'waji-kankaku', unicode u'\\u3000'\nMULTISPACE = '\\u3000'\nBAD_CHARS = ('?', '-', '+', '*', MULTISPACE)\nEVER = DateTime('1970-01-03')\n\n\ndef quote_chars(s):\n # We need to quote parentheses when searching text indices\n if '(' in s:\n s = s.replace('(', '\"(\"')\n if ')' in s:\n s = s.replace(')', '\")\"')\n if MULTISPACE in s:\n s = s.replace(MULTISPACE, ' ')\n return s\n\n\ndef quote(term):\n # The terms and, or and not must be wrapped in quotes to avoid\n # being parsed as logical query atoms.\n if term.lower() in ('and', 'or', 'not'):\n term = '\"%s\"' % term\n return term\n\n\nclass Search(BrowserView):\n\n valid_keys = ('sort_on', 'sort_order', 'sort_limit', 'fq', 'fl', 'facet')\n\n def munge_search_term(self, q):\n for char in BAD_CHARS:\n q = q.replace(char, ' ')\n r = map(quote, q.split())\n r = \" AND \".join(r)\n r = quote_chars(r) + '*'\n return r\n\n def results(self, query=None, batch=True, b_size=10, b_start=0,\n use_content_listing=True):\n \"\"\" Get properly wrapped search results from the catalog.\n Everything in Plone that performs searches should go through this view.\n 'query' should be a dictionary of catalog parameters.\n \"\"\"\n if query is None:\n query = {}\n if batch:\n query['b_start'] = b_start = int(b_start)\n query['b_size'] = b_size\n query = self.filter_query(query)\n\n if query is None:\n results = []\n else:\n catalog = getToolByName(self.context, 'portal_catalog')\n try:\n results = catalog(**query)\n except ParseError:\n return []\n\n if use_content_listing:\n results = IContentListing(results)\n if batch:\n results = Batch(results, b_size, b_start)\n return results\n\n def _filter_query(self, query):\n request = self.request\n\n catalog = getToolByName(self.context, 'portal_catalog')\n valid_indexes = tuple(catalog.indexes())\n valid_keys = self.valid_keys + valid_indexes\n\n text = query.get('SearchableText', None)\n if text is None:\n text = request.form.get('SearchableText', '')\n if not text:\n # Without text, must provide a meaningful non-empty search\n valid = set(valid_indexes).intersection(request.form.keys()) or \\\n set(valid_indexes).intersection(query.keys())\n if not valid:\n return\n\n for k, v in request.form.items():\n if v and ((k in valid_keys) or k.startswith('facet.')):\n query[k] = v\n if text:\n query['SearchableText'] = self.munge_search_term(text)\n\n # don't filter on created at all if we want all results\n created = query.get('created')\n if created:\n try:\n if created.get('query', EVER) <= EVER:\n del query['created']\n except AttributeError:\n # created not a mapping\n del query['created']\n\n # respect `types_not_searched` setting\n types = query.get('portal_type', [])\n if 'query' in types:\n types = types['query']\n query['portal_type'] = self.filter_types(types)\n # respect effective/expiration date\n query['show_inactive'] = False\n # respect navigation root\n if 'path' not in query:\n query['path'] = getNavigationRoot(self.context)\n\n if 'sort_order' in query and not query['sort_order']:\n del query['sort_order']\n return query\n\n @lazy_property\n def default_sort_on(self):\n registry = getUtility(IRegistry)\n search_settings = registry.forInterface(ISearchSchema, prefix='plone')\n return search_settings.sort_on\n\n def filter_query(self, query):\n query = self._filter_query(query)\n if query is None:\n query = {}\n # explicitly set a sort; if no `sort_on` is present, the catalog sorts\n # by relevance\n if 'sort_on' not in query:\n self.default_sort_on\n if self.default_sort_on != 'relevance':\n query['sort_on'] = self.default_sort_on\n elif query['sort_on'] == 'relevance':\n del query['sort_on']\n if query.get('sort_on', '') == 'Date':\n query['sort_order'] = 'reverse'\n elif 'sort_order' in query:\n del query['sort_order']\n if not query:\n return None\n return query\n\n def filter_types(self, types):\n plone_utils = getToolByName(self.context, 'plone_utils')\n if not isinstance(types, list):\n types = [types]\n return plone_utils.getUserFriendlyTypes(types)\n\n def types_list(self):\n # only show those types that have any content\n catalog = getToolByName(self.context, 'portal_catalog')\n used_types = catalog._catalog.getIndex('portal_type').uniqueValues()\n return self.filter_types(list(used_types))\n\n def sort_options(self):\n \"\"\" Sorting options for search results view. \"\"\"\n if 'sort_on' not in self.request.form:\n self.request.form['sort_on'] = self.default_sort_on\n return (\n SortOption(self.request, _('relevance'), 'relevance'),\n SortOption(\n self.request, _('date (newest first)'), 'Date', reverse=True\n ),\n SortOption(self.request, _('alphabetically'), 'sortable_title'),\n )\n\n def show_advanced_search(self):\n \"\"\"Whether we need to show advanced search options a.k.a. filters?\"\"\"\n show = self.request.get('advanced_search', None)\n if not show or show == 'False':\n return False\n return True\n\n def advanced_search_trigger(self):\n \"\"\"URL builder for show/close advanced search filters.\"\"\"\n query = self.request.get('QUERY_STRING', None)\n url = self.request.get('ACTUAL_URL', self.context.absolute_url())\n if not query:\n return url\n if 'advanced_search' in query:\n if 'advanced_search=True' in query:\n query = query.replace('advanced_search=True', '')\n if 'advanced_search=False' in query:\n query = query.replace('advanced_search=False', '')\n else:\n query = query + '&advanced_search=True'\n return url + '?' + query\n\n def breadcrumbs(self, item):\n obj = item.getObject()\n view = getMultiAdapter((obj, self.request), name='breadcrumbs_view')\n # cut off the item itself\n breadcrumbs = list(view.breadcrumbs())[:-1]\n if len(breadcrumbs) == 0:\n # don't show breadcrumbs if we only have a single element\n return None\n if len(breadcrumbs) > 3:\n # if we have too long breadcrumbs, emit the middle elements\n empty = {'absolute_url': '', 'Title': '\u2026'}\n breadcrumbs = [breadcrumbs[0], empty] + breadcrumbs[-2:]\n return breadcrumbs\n\n def navroot_url(self):\n if not hasattr(self, '_navroot_url'):\n state = self.context.unrestrictedTraverse('@@plone_portal_state')\n self._navroot_url = state.navigation_root_url()\n return self._navroot_url\n\n @property\n def show_images(self):\n registry = queryUtility(IRegistry)\n return registry.get('plone.search_show_images')\n\n @property\n def search_image_scale(self):\n registry = queryUtility(IRegistry)\n return registry.get('plone.search_image_scale')\n\n\nclass AjaxSearch(Search):\n\n def __call__(self):\n items = []\n try:\n per_page = int(self.request.form.get('perPage'))\n except:\n per_page = 10\n try:\n page = int(self.request.form.get('page'))\n except:\n page = 1\n\n results = self.results(batch=False, use_content_listing=False)\n batch = Batch(results, per_page, start=(page - 1) * per_page)\n\n registry = queryUtility(IRegistry)\n length = registry.get('plone.search_results_description_length')\n show_images = registry.get('plone.search_show_images')\n if show_images:\n image_scale = registry.get('plone.search_image_scale')\n # image_scaling = getMultiAdapter((self.context, self.request), name='image_scale')\n self.image_scaling = getMultiAdapter((INavigationRoot(self.context), self.request), name='image_scale')\n plone_view = getMultiAdapter(\n (self.context, self.request), name='plone')\n view_action_types = registry.get(\n 'plone.types_use_view_action_in_listings', [])\n for item in batch:\n url = item.getURL()\n if item.portal_type in view_action_types:\n url = '%s/view' % url\n img_tag = None\n if show_images:\n img_tag = self.get_image_tag(item, image_scale)\n items.append({\n 'id': item.UID,\n 'title': item.Title,\n 'description': plone_view.cropText(item.Description, length),\n 'url': url,\n 'state': item.review_state if item.review_state else None,\n 'img_tag': img_tag,\n })\n return json.dumps({\n 'total': len(results),\n 'items': items\n })\n\n def get_image_tag(self, item, image_scale):\n return self.image_scaling.tag(item, \"image\", scale=image_scale)\n\nclass SortOption:\n\n def __init__(self, request, title, sortkey='', reverse=False):\n self.request = request\n self.title = title\n self.sortkey = sortkey\n self.reverse = reverse\n\n def selected(self):\n sort_on = self.request.get('sort_on', '')\n return sort_on == self.sortkey and sort_on != ''\n\n def url(self):\n q = {}\n q.update(self.request.form)\n if 'sort_on' in q.keys():\n del q['sort_on']\n if 'sort_order' in q.keys():\n del q['sort_order']\n q['sort_on'] = self.sortkey\n if self.reverse:\n q['sort_order'] = 'reverse'\n\n base_url = self.request.URL\n return base_url + '?' + make_query(q)\n", "path": "Products/CMFPlone/browser/search.py"}], "after_files": [{"content": "from DateTime import DateTime\nfrom plone.app.contentlisting.interfaces import IContentListing\nfrom plone.app.layout.navigation.interfaces import INavigationRoot\nfrom plone.registry.interfaces import IRegistry\nfrom Products.CMFCore.utils import getToolByName\nfrom Products.CMFPlone.browser.navtree import getNavigationRoot\nfrom plone.base.interfaces import ISearchSchema\nfrom Products.CMFPlone.PloneBatch import Batch\nfrom Products.ZCTextIndex.ParseTree import ParseError\nfrom zope.cachedescriptors.property import Lazy as lazy_property\nfrom zope.component import getMultiAdapter\nfrom zope.component import getUtility\nfrom zope.component import queryUtility\nfrom zope.i18nmessageid import MessageFactory\nfrom zope.publisher.browser import BrowserView\nfrom ZTUtils import make_query\n\nimport json\nimport re\n\n_ = MessageFactory('plone')\n\n# We should accept both a simple space, unicode u'\\u0020 but also a\n# multi-space, so called 'waji-kankaku', unicode u'\\u3000'\nMULTISPACE = '\\u3000'\nBAD_CHARS = ('?', '-', '+', '*', MULTISPACE)\nEVER = DateTime('1970-01-03')\n\n\ndef quote_chars(s):\n # We need to quote parentheses when searching text indices\n if '(' in s:\n s = s.replace('(', '\"(\"')\n if ')' in s:\n s = s.replace(')', '\")\"')\n if MULTISPACE in s:\n s = s.replace(MULTISPACE, ' ')\n return s\n\n\ndef quote(term):\n # The terms and, or and not must be wrapped in quotes to avoid\n # being parsed as logical query atoms.\n if term.lower() in ('and', 'or', 'not'):\n term = '\"%s\"' % term\n return term\n\n\ndef munge_search_term(query):\n for char in BAD_CHARS:\n query = query.replace(char, ' ')\n\n # extract quoted phrases first\n quoted_phrases = re.findall(r'\"([^\"]*)\"', query)\n r = []\n for qp in quoted_phrases:\n # remove from original query\n query = query.replace(f'\"{qp}\"', \"\")\n # replace with cleaned leading/trailing whitespaces\n # and skip empty phrases\n clean_qp = qp.strip()\n if not clean_qp:\n continue\n r.append(f'\"{clean_qp}\"')\n\n r += map(quote, query.strip().split())\n r = \" AND \".join(r)\n r = quote_chars(r) + ('*' if r and not r.endswith('\"') else '')\n return r\n\n\nclass Search(BrowserView):\n\n valid_keys = ('sort_on', 'sort_order', 'sort_limit', 'fq', 'fl', 'facet')\n\n def results(self, query=None, batch=True, b_size=10, b_start=0,\n use_content_listing=True):\n \"\"\" Get properly wrapped search results from the catalog.\n Everything in Plone that performs searches should go through this view.\n 'query' should be a dictionary of catalog parameters.\n \"\"\"\n if query is None:\n query = {}\n if batch:\n query['b_start'] = b_start = int(b_start)\n query['b_size'] = b_size\n query = self.filter_query(query)\n\n if query is None:\n results = []\n else:\n catalog = getToolByName(self.context, 'portal_catalog')\n try:\n results = catalog(**query)\n except ParseError:\n return []\n\n if use_content_listing:\n results = IContentListing(results)\n if batch:\n results = Batch(results, b_size, b_start)\n return results\n\n def _filter_query(self, query):\n request = self.request\n\n catalog = getToolByName(self.context, 'portal_catalog')\n valid_indexes = tuple(catalog.indexes())\n valid_keys = self.valid_keys + valid_indexes\n\n text = query.get('SearchableText', None)\n if text is None:\n text = request.form.get('SearchableText', '')\n if not text:\n # Without text, must provide a meaningful non-empty search\n valid = set(valid_indexes).intersection(request.form.keys()) or \\\n set(valid_indexes).intersection(query.keys())\n if not valid:\n return\n\n for k, v in request.form.items():\n if v and ((k in valid_keys) or k.startswith('facet.')):\n query[k] = v\n if text:\n query['SearchableText'] = munge_search_term(text)\n\n # don't filter on created at all if we want all results\n created = query.get('created')\n if created:\n try:\n if created.get('query', EVER) <= EVER:\n del query['created']\n except AttributeError:\n # created not a mapping\n del query['created']\n\n # respect `types_not_searched` setting\n types = query.get('portal_type', [])\n if 'query' in types:\n types = types['query']\n query['portal_type'] = self.filter_types(types)\n # respect effective/expiration date\n query['show_inactive'] = False\n # respect navigation root\n if 'path' not in query:\n query['path'] = getNavigationRoot(self.context)\n\n if 'sort_order' in query and not query['sort_order']:\n del query['sort_order']\n return query\n\n @lazy_property\n def default_sort_on(self):\n registry = getUtility(IRegistry)\n search_settings = registry.forInterface(ISearchSchema, prefix='plone')\n return search_settings.sort_on\n\n def filter_query(self, query):\n query = self._filter_query(query)\n if query is None:\n query = {}\n # explicitly set a sort; if no `sort_on` is present, the catalog sorts\n # by relevance\n if 'sort_on' not in query:\n self.default_sort_on\n if self.default_sort_on != 'relevance':\n query['sort_on'] = self.default_sort_on\n elif query['sort_on'] == 'relevance':\n del query['sort_on']\n if query.get('sort_on', '') == 'Date':\n query['sort_order'] = 'reverse'\n elif 'sort_order' in query:\n del query['sort_order']\n if not query:\n return None\n return query\n\n def filter_types(self, types):\n plone_utils = getToolByName(self.context, 'plone_utils')\n if not isinstance(types, list):\n types = [types]\n return plone_utils.getUserFriendlyTypes(types)\n\n def types_list(self):\n # only show those types that have any content\n catalog = getToolByName(self.context, 'portal_catalog')\n used_types = catalog._catalog.getIndex('portal_type').uniqueValues()\n return self.filter_types(list(used_types))\n\n def sort_options(self):\n \"\"\" Sorting options for search results view. \"\"\"\n if 'sort_on' not in self.request.form:\n self.request.form['sort_on'] = self.default_sort_on\n return (\n SortOption(self.request, _('relevance'), 'relevance'),\n SortOption(\n self.request, _('date (newest first)'), 'Date', reverse=True\n ),\n SortOption(self.request, _('alphabetically'), 'sortable_title'),\n )\n\n def show_advanced_search(self):\n \"\"\"Whether we need to show advanced search options a.k.a. filters?\"\"\"\n show = self.request.get('advanced_search', None)\n if not show or show == 'False':\n return False\n return True\n\n def advanced_search_trigger(self):\n \"\"\"URL builder for show/close advanced search filters.\"\"\"\n query = self.request.get('QUERY_STRING', None)\n url = self.request.get('ACTUAL_URL', self.context.absolute_url())\n if not query:\n return url\n if 'advanced_search' in query:\n if 'advanced_search=True' in query:\n query = query.replace('advanced_search=True', '')\n if 'advanced_search=False' in query:\n query = query.replace('advanced_search=False', '')\n else:\n query = query + '&advanced_search=True'\n return url + '?' + query\n\n def breadcrumbs(self, item):\n obj = item.getObject()\n view = getMultiAdapter((obj, self.request), name='breadcrumbs_view')\n # cut off the item itself\n breadcrumbs = list(view.breadcrumbs())[:-1]\n if len(breadcrumbs) == 0:\n # don't show breadcrumbs if we only have a single element\n return None\n if len(breadcrumbs) > 3:\n # if we have too long breadcrumbs, emit the middle elements\n empty = {'absolute_url': '', 'Title': '\u2026'}\n breadcrumbs = [breadcrumbs[0], empty] + breadcrumbs[-2:]\n return breadcrumbs\n\n def navroot_url(self):\n if not hasattr(self, '_navroot_url'):\n state = self.context.unrestrictedTraverse('@@plone_portal_state')\n self._navroot_url = state.navigation_root_url()\n return self._navroot_url\n\n @property\n def show_images(self):\n registry = queryUtility(IRegistry)\n return registry.get('plone.search_show_images')\n\n @property\n def search_image_scale(self):\n registry = queryUtility(IRegistry)\n return registry.get('plone.search_image_scale')\n\n\nclass AjaxSearch(Search):\n\n def __call__(self):\n items = []\n try:\n per_page = int(self.request.form.get('perPage'))\n except:\n per_page = 10\n try:\n page = int(self.request.form.get('page'))\n except:\n page = 1\n\n results = self.results(batch=False, use_content_listing=False)\n batch = Batch(results, per_page, start=(page - 1) * per_page)\n\n registry = queryUtility(IRegistry)\n length = registry.get('plone.search_results_description_length')\n show_images = registry.get('plone.search_show_images')\n if show_images:\n image_scale = registry.get('plone.search_image_scale')\n # image_scaling = getMultiAdapter((self.context, self.request), name='image_scale')\n self.image_scaling = getMultiAdapter((INavigationRoot(self.context), self.request), name='image_scale')\n plone_view = getMultiAdapter(\n (self.context, self.request), name='plone')\n view_action_types = registry.get(\n 'plone.types_use_view_action_in_listings', [])\n for item in batch:\n url = item.getURL()\n if item.portal_type in view_action_types:\n url = '%s/view' % url\n img_tag = None\n if show_images:\n img_tag = self.get_image_tag(item, image_scale)\n items.append({\n 'id': item.UID,\n 'title': item.Title,\n 'description': plone_view.cropText(item.Description, length),\n 'url': url,\n 'state': item.review_state if item.review_state else None,\n 'img_tag': img_tag,\n })\n return json.dumps({\n 'total': len(results),\n 'items': items\n })\n\n def get_image_tag(self, item, image_scale):\n return self.image_scaling.tag(item, \"image\", scale=image_scale)\n\nclass SortOption:\n\n def __init__(self, request, title, sortkey='', reverse=False):\n self.request = request\n self.title = title\n self.sortkey = sortkey\n self.reverse = reverse\n\n def selected(self):\n sort_on = self.request.get('sort_on', '')\n return sort_on == self.sortkey and sort_on != ''\n\n def url(self):\n q = {}\n q.update(self.request.form)\n if 'sort_on' in q.keys():\n del q['sort_on']\n if 'sort_order' in q.keys():\n del q['sort_order']\n q['sort_on'] = self.sortkey\n if self.reverse:\n q['sort_order'] = 'reverse'\n\n base_url = self.request.URL\n return base_url + '?' + make_query(q)\n", "path": "Products/CMFPlone/browser/search.py"}]}
| 3,713 | 531 |
gh_patches_debug_24152
|
rasdani/github-patches
|
git_diff
|
ckan__ckan-5093
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Missing dependency in requirements.txt (cookiecutter)
https://github.com/ckan/ckan/blob/f2cea089bc0aaeede06d98449c4e9eb65e8c2f14/ckan/cli/generate.py#L7
- cookiecutter lib will be imported on a `ckan` cli attempt, but as it is missing from requirments.txt, is not present which will result to ImportError
- cookiecutter is listed in requirments-dev.txt, but docker builds don't use it
Tested on a docker personal build, by :
> docker build -t ckan .
> docker run --rm -it --entrypoint bash --name ckan -p 5000:5000 --link db:db --link redis:redis --link solr:solr ckan
> (activated-env)
> ckan
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ckan/cli/generate.py`
Content:
```
1 # encoding: utf-8
2
3 import os
4 import sys
5 import click
6 from ckan.cli import error_shout
7 from cookiecutter.main import cookiecutter
8
9
10 @click.group(name=u'generate',
11 short_help=u"Generate empty extension files to expand CKAN.")
12 def generate():
13 pass
14
15
16 @generate.command(name=u'extension', short_help=u"Create empty extension.")
17 @click.option(u'-o', u'--output-dir', help=u"Location to put the generated "
18 u"template.",
19 default=u'.')
20 def extension(output_dir):
21 cur_loc = os.path.dirname(os.path.abspath(__file__))
22 os.chdir(cur_loc)
23 os.chdir(u'../../contrib/cookiecutter/ckan_extension/')
24 template_loc = os.getcwd()
25
26 # Prompt user for information
27 click.echo(u"\n")
28 name = click.prompt(u"Extenion's name", default=u"must begin 'ckanext-'")
29 author = click.prompt(u"Author's name", default=u"")
30 email = click.prompt(u"Author's email", default=u"")
31 github = click.prompt(u"Your Github user or organization name",
32 default=u"")
33 description = click.prompt(u"Brief description of the project",
34 default=u"")
35 keywords = click.prompt(u"List of keywords (seperated by spaces)",
36 default=u"CKAN")
37
38 # Ensure one instance of 'CKAN' in keywords
39 keywords = keywords.strip().split()
40 keywords = [keyword for keyword in keywords
41 if keyword not in (u'ckan', u'CKAN')]
42 keywords.insert(0, u'CKAN')
43 keywords = u' '.join(keywords)
44
45 # Set short name and plugin class name
46 project_short = name[8:].lower().replace(u'-', u'_')
47 plugin_class_name = project_short.title().replace(u'_', u'') + u'Plugin'
48
49 context = {u"project": name,
50 u"description": description,
51 u"author": author,
52 u"author_email": email,
53 u"keywords": keywords,
54 u"github_user_name": github,
55 u"project_shortname": project_short,
56 u"plugin_class_name": plugin_class_name,
57 u"_source": u"cli"}
58
59 if output_dir == u'.':
60 os.chdir(u'../../../..')
61 output_dir = os.getcwd()
62
63 if not name.startswith(u"ckanext-"):
64 print(u"\nERROR: Project name must start with 'ckanext-' > {}"
65 .format(name))
66 sys.exit(1)
67
68 cookiecutter(template_loc, no_input=True, extra_context=context,
69 output_dir=output_dir)
70
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ckan/cli/generate.py b/ckan/cli/generate.py
--- a/ckan/cli/generate.py
+++ b/ckan/cli/generate.py
@@ -4,13 +4,21 @@
import sys
import click
from ckan.cli import error_shout
-from cookiecutter.main import cookiecutter
[email protected](name=u'generate',
- short_help=u"Generate empty extension files to expand CKAN.")
[email protected](
+ name=u'generate',
+ short_help=u"Generate empty extension files to expand CKAN.",
+ invoke_without_command=True,
+)
def generate():
- pass
+ try:
+ from cookiecutter.main import cookiecutter
+ except ImportError:
+ error_shout(u"`cookiecutter` library is missing from import path.")
+ error_shout(u"Make sure you have dev-dependencies installed:")
+ error_shout(u"\tpip install -r dev-requirements.txt")
+ raise click.Abort()
@generate.command(name=u'extension', short_help=u"Create empty extension.")
@@ -18,6 +26,7 @@
u"template.",
default=u'.')
def extension(output_dir):
+ from cookiecutter.main import cookiecutter
cur_loc = os.path.dirname(os.path.abspath(__file__))
os.chdir(cur_loc)
os.chdir(u'../../contrib/cookiecutter/ckan_extension/')
|
{"golden_diff": "diff --git a/ckan/cli/generate.py b/ckan/cli/generate.py\n--- a/ckan/cli/generate.py\n+++ b/ckan/cli/generate.py\n@@ -4,13 +4,21 @@\n import sys\n import click\n from ckan.cli import error_shout\n-from cookiecutter.main import cookiecutter\n \n \[email protected](name=u'generate',\n- short_help=u\"Generate empty extension files to expand CKAN.\")\[email protected](\n+ name=u'generate',\n+ short_help=u\"Generate empty extension files to expand CKAN.\",\n+ invoke_without_command=True,\n+)\n def generate():\n- pass\n+ try:\n+ from cookiecutter.main import cookiecutter\n+ except ImportError:\n+ error_shout(u\"`cookiecutter` library is missing from import path.\")\n+ error_shout(u\"Make sure you have dev-dependencies installed:\")\n+ error_shout(u\"\\tpip install -r dev-requirements.txt\")\n+ raise click.Abort()\n \n \n @generate.command(name=u'extension', short_help=u\"Create empty extension.\")\n@@ -18,6 +26,7 @@\n u\"template.\",\n default=u'.')\n def extension(output_dir):\n+ from cookiecutter.main import cookiecutter\n cur_loc = os.path.dirname(os.path.abspath(__file__))\n os.chdir(cur_loc)\n os.chdir(u'../../contrib/cookiecutter/ckan_extension/')\n", "issue": "Missing dependency in requirements.txt (cookiecutter) \nhttps://github.com/ckan/ckan/blob/f2cea089bc0aaeede06d98449c4e9eb65e8c2f14/ckan/cli/generate.py#L7\r\n\r\n- cookiecutter lib will be imported on a `ckan` cli attempt, but as it is missing from requirments.txt, is not present which will result to ImportError \r\n\r\n- cookiecutter is listed in requirments-dev.txt, but docker builds don't use it\r\n\r\nTested on a docker personal build, by : \r\n> docker build -t ckan .\r\n> docker run --rm -it --entrypoint bash --name ckan -p 5000:5000 --link db:db --link redis:redis --link solr:solr ckan\r\n> (activated-env)\r\n> ckan\n", "before_files": [{"content": "# encoding: utf-8\n\nimport os\nimport sys\nimport click\nfrom ckan.cli import error_shout\nfrom cookiecutter.main import cookiecutter\n\n\[email protected](name=u'generate',\n short_help=u\"Generate empty extension files to expand CKAN.\")\ndef generate():\n pass\n\n\[email protected](name=u'extension', short_help=u\"Create empty extension.\")\[email protected](u'-o', u'--output-dir', help=u\"Location to put the generated \"\n u\"template.\",\n default=u'.')\ndef extension(output_dir):\n cur_loc = os.path.dirname(os.path.abspath(__file__))\n os.chdir(cur_loc)\n os.chdir(u'../../contrib/cookiecutter/ckan_extension/')\n template_loc = os.getcwd()\n\n # Prompt user for information\n click.echo(u\"\\n\")\n name = click.prompt(u\"Extenion's name\", default=u\"must begin 'ckanext-'\")\n author = click.prompt(u\"Author's name\", default=u\"\")\n email = click.prompt(u\"Author's email\", default=u\"\")\n github = click.prompt(u\"Your Github user or organization name\",\n default=u\"\")\n description = click.prompt(u\"Brief description of the project\",\n default=u\"\")\n keywords = click.prompt(u\"List of keywords (seperated by spaces)\",\n default=u\"CKAN\")\n\n # Ensure one instance of 'CKAN' in keywords\n keywords = keywords.strip().split()\n keywords = [keyword for keyword in keywords\n if keyword not in (u'ckan', u'CKAN')]\n keywords.insert(0, u'CKAN')\n keywords = u' '.join(keywords)\n\n # Set short name and plugin class name\n project_short = name[8:].lower().replace(u'-', u'_')\n plugin_class_name = project_short.title().replace(u'_', u'') + u'Plugin'\n\n context = {u\"project\": name,\n u\"description\": description,\n u\"author\": author,\n u\"author_email\": email,\n u\"keywords\": keywords,\n u\"github_user_name\": github,\n u\"project_shortname\": project_short,\n u\"plugin_class_name\": plugin_class_name,\n u\"_source\": u\"cli\"}\n\n if output_dir == u'.':\n os.chdir(u'../../../..')\n output_dir = os.getcwd()\n\n if not name.startswith(u\"ckanext-\"):\n print(u\"\\nERROR: Project name must start with 'ckanext-' > {}\"\n .format(name))\n sys.exit(1)\n\n cookiecutter(template_loc, no_input=True, extra_context=context,\n output_dir=output_dir)\n", "path": "ckan/cli/generate.py"}], "after_files": [{"content": "# encoding: utf-8\n\nimport os\nimport sys\nimport click\nfrom ckan.cli import error_shout\n\n\[email protected](\n name=u'generate',\n short_help=u\"Generate empty extension files to expand CKAN.\",\n invoke_without_command=True,\n)\ndef generate():\n try:\n from cookiecutter.main import cookiecutter\n except ImportError:\n error_shout(u\"`cookiecutter` library is missing from import path.\")\n error_shout(u\"Make sure you have dev-dependencies installed:\")\n error_shout(u\"\\tpip install -r dev-requirements.txt\")\n raise click.Abort()\n\n\[email protected](name=u'extension', short_help=u\"Create empty extension.\")\[email protected](u'-o', u'--output-dir', help=u\"Location to put the generated \"\n u\"template.\",\n default=u'.')\ndef extension(output_dir):\n from cookiecutter.main import cookiecutter\n cur_loc = os.path.dirname(os.path.abspath(__file__))\n os.chdir(cur_loc)\n os.chdir(u'../../contrib/cookiecutter/ckan_extension/')\n template_loc = os.getcwd()\n\n # Prompt user for information\n click.echo(u\"\\n\")\n name = click.prompt(u\"Extenion's name\", default=u\"must begin 'ckanext-'\")\n author = click.prompt(u\"Author's name\", default=u\"\")\n email = click.prompt(u\"Author's email\", default=u\"\")\n github = click.prompt(u\"Your Github user or organization name\",\n default=u\"\")\n description = click.prompt(u\"Brief description of the project\",\n default=u\"\")\n keywords = click.prompt(u\"List of keywords (seperated by spaces)\",\n default=u\"CKAN\")\n\n # Ensure one instance of 'CKAN' in keywords\n keywords = keywords.strip().split()\n keywords = [keyword for keyword in keywords\n if keyword not in (u'ckan', u'CKAN')]\n keywords.insert(0, u'CKAN')\n keywords = u' '.join(keywords)\n\n # Set short name and plugin class name\n project_short = name[8:].lower().replace(u'-', u'_')\n plugin_class_name = project_short.title().replace(u'_', u'') + u'Plugin'\n\n context = {u\"project\": name,\n u\"description\": description,\n u\"author\": author,\n u\"author_email\": email,\n u\"keywords\": keywords,\n u\"github_user_name\": github,\n u\"project_shortname\": project_short,\n u\"plugin_class_name\": plugin_class_name,\n u\"_source\": u\"cli\"}\n\n if output_dir == u'.':\n os.chdir(u'../../../..')\n output_dir = os.getcwd()\n\n if not name.startswith(u\"ckanext-\"):\n print(u\"\\nERROR: Project name must start with 'ckanext-' > {}\"\n .format(name))\n sys.exit(1)\n\n cookiecutter(template_loc, no_input=True, extra_context=context,\n output_dir=output_dir)\n", "path": "ckan/cli/generate.py"}]}
| 1,169 | 315 |
gh_patches_debug_25941
|
rasdani/github-patches
|
git_diff
|
readthedocs__readthedocs.org-5460
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
502 Bad Gateway on Projects > Versions page
The Projects > Versions page for our project is throwing a 502 Bad Gateway error. It's happening at the following URL:
https://readthedocs.org/projects/htcondor/versions
I thought this might be a transient error but it's been happening consistently for the last day or so. All the other pages I've tried seem to work fine.
It's worth noting a similar ticket #5441 was filed a couple of days ago for a 502 error on the Import a Repository page. This seems to be working correctly now.
## Details
* Read the Docs project URL: https://htcondor.readthedocs.io
* Build URL (if applicable):
* Read the Docs username (if applicable): htcondor
## Expected Result
A list of the different versions of our docs, dropdown menus to connect them to different branches, etc.
## Actual Result
Server Error
502 - Web server received an invalid response while acting as a gateway or proxy server.
There is a problem with the page you are looking for, and it cannot be displayed. When the Web server (while acting as a gateway or proxy) contacted the upstream content server, it received an invalid response from the content server.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `readthedocs/core/permissions.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 """Objects for User permission checks."""
4
5 from readthedocs.core.utils.extend import SettingsOverrideObject
6
7
8 class AdminPermissionBase:
9
10 @classmethod
11 def is_admin(cls, user, project):
12 return user in project.users.all() or user.is_superuser
13
14 @classmethod
15 def is_member(cls, user, obj):
16 return user in obj.users.all() or user.is_superuser
17
18
19 class AdminPermission(SettingsOverrideObject):
20 _default_class = AdminPermissionBase
21 _override_setting = 'ADMIN_PERMISSION'
22
```
Path: `readthedocs/projects/views/public.py`
Content:
```
1 """Public project views."""
2
3 import json
4 import logging
5 import mimetypes
6 import operator
7 import os
8 from collections import OrderedDict
9
10 import requests
11 from django.conf import settings
12 from django.contrib import messages
13 from django.contrib.auth.models import User
14 from django.core.cache import cache
15 from django.core.files.storage import get_storage_class
16 from django.http import HttpResponse, HttpResponseRedirect
17 from django.shortcuts import get_object_or_404, render
18 from django.urls import reverse
19 from django.views.decorators.cache import never_cache
20 from django.views.generic import DetailView, ListView
21 from taggit.models import Tag
22
23 from readthedocs.builds.constants import LATEST
24 from readthedocs.builds.models import Version
25 from readthedocs.builds.views import BuildTriggerMixin
26 from readthedocs.projects.models import Project
27 from readthedocs.projects.templatetags.projects_tags import sort_version_aware
28
29 from .base import ProjectOnboardMixin
30
31
32 log = logging.getLogger(__name__)
33 search_log = logging.getLogger(__name__ + '.search')
34 mimetypes.add_type('application/epub+zip', '.epub')
35 storage = get_storage_class()()
36
37
38 class ProjectIndex(ListView):
39
40 """List view of public :py:class:`Project` instances."""
41
42 model = Project
43
44 def get_queryset(self):
45 queryset = Project.objects.public(self.request.user)
46 queryset = queryset.exclude(users__profile__banned=True)
47
48 if self.kwargs.get('tag'):
49 self.tag = get_object_or_404(Tag, slug=self.kwargs.get('tag'))
50 queryset = queryset.filter(tags__slug__in=[self.tag.slug])
51 else:
52 self.tag = None
53
54 if self.kwargs.get('username'):
55 self.user = get_object_or_404(
56 User,
57 username=self.kwargs.get('username'),
58 )
59 queryset = queryset.filter(user=self.user)
60 else:
61 self.user = None
62
63 return queryset
64
65 def get_context_data(self, **kwargs):
66 context = super().get_context_data(**kwargs)
67 context['person'] = self.user
68 context['tag'] = self.tag
69 return context
70
71
72 class ProjectDetailView(BuildTriggerMixin, ProjectOnboardMixin, DetailView):
73
74 """Display project onboard steps."""
75
76 model = Project
77 slug_url_kwarg = 'project_slug'
78
79 def get_queryset(self):
80 return Project.objects.protected(self.request.user)
81
82 def get_context_data(self, **kwargs):
83 context = super().get_context_data(**kwargs)
84
85 project = self.get_object()
86 context['versions'] = Version.objects.public(
87 user=self.request.user,
88 project=project,
89 )
90
91 protocol = 'http'
92 if self.request.is_secure():
93 protocol = 'https'
94
95 version_slug = project.get_default_version()
96
97 context['badge_url'] = '{}://{}{}?version={}'.format(
98 protocol,
99 settings.PRODUCTION_DOMAIN,
100 reverse('project_badge', args=[project.slug]),
101 project.get_default_version(),
102 )
103 context['site_url'] = '{url}?badge={version}'.format(
104 url=project.get_docs_url(version_slug),
105 version=version_slug,
106 )
107
108 return context
109
110
111 @never_cache
112 def project_badge(request, project_slug):
113 """Return a sweet badge for the project."""
114 style = request.GET.get('style', 'flat')
115 if style not in (
116 'flat',
117 'plastic',
118 'flat-square',
119 'for-the-badge',
120 'social',
121 ):
122 style = 'flat'
123
124 # Get the local path to the badge files
125 badge_path = os.path.join(
126 os.path.dirname(__file__),
127 '..',
128 'static',
129 'projects',
130 'badges',
131 '%s-' + style + '.svg',
132 )
133
134 version_slug = request.GET.get('version', LATEST)
135 file_path = badge_path % 'unknown'
136
137 version = Version.objects.public(request.user).filter(
138 project__slug=project_slug,
139 slug=version_slug,
140 ).first()
141
142 if version:
143 last_build = version.builds.filter(
144 type='html',
145 state='finished',
146 ).order_by('-date').first()
147 if last_build:
148 if last_build.success:
149 file_path = badge_path % 'passing'
150 else:
151 file_path = badge_path % 'failing'
152
153 try:
154 with open(file_path) as fd:
155 return HttpResponse(
156 fd.read(),
157 content_type='image/svg+xml',
158 )
159 except (IOError, OSError):
160 log.exception(
161 'Failed to read local filesystem while serving a docs badge',
162 )
163 return HttpResponse(status=503)
164
165
166 def project_downloads(request, project_slug):
167 """A detail view for a project with various downloads."""
168 project = get_object_or_404(
169 Project.objects.protected(request.user),
170 slug=project_slug,
171 )
172 versions = Version.objects.public(user=request.user, project=project)
173 versions = sort_version_aware(versions)
174 version_data = OrderedDict()
175 for version in versions:
176 data = version.get_downloads()
177 # Don't show ones that have no downloads.
178 if data:
179 version_data[version] = data
180
181 return render(
182 request,
183 'projects/project_downloads.html',
184 {
185 'project': project,
186 'version_data': version_data,
187 'versions': versions,
188 },
189 )
190
191
192 def project_download_media(request, project_slug, type_, version_slug):
193 """
194 Download a specific piece of media.
195
196 Perform an auth check if serving in private mode.
197
198 .. warning:: This is linked directly from the HTML pages.
199 It should only care about the Version permissions,
200 not the actual Project permissions.
201 """
202 version = get_object_or_404(
203 Version.objects.public(user=request.user),
204 project__slug=project_slug,
205 slug=version_slug,
206 )
207 privacy_level = getattr(settings, 'DEFAULT_PRIVACY_LEVEL', 'public')
208 if privacy_level == 'public' or settings.DEBUG:
209 storage_path = version.project.get_storage_path(
210 type_=type_, version_slug=version_slug
211 )
212 if storage.exists(storage_path):
213 return HttpResponseRedirect(storage.url(storage_path))
214
215 media_path = os.path.join(
216 settings.MEDIA_URL,
217 type_,
218 project_slug,
219 version_slug,
220 '%s.%s' % (project_slug, type_.replace('htmlzip', 'zip')),
221 )
222 return HttpResponseRedirect(media_path)
223
224 # Get relative media path
225 path = (
226 version.project.get_production_media_path(
227 type_=type_,
228 version_slug=version_slug,
229 ).replace(settings.PRODUCTION_ROOT, '/prod_artifacts')
230 )
231 content_type, encoding = mimetypes.guess_type(path)
232 content_type = content_type or 'application/octet-stream'
233 response = HttpResponse(content_type=content_type)
234 if encoding:
235 response['Content-Encoding'] = encoding
236 response['X-Accel-Redirect'] = path
237 # Include version in filename; this fixes a long-standing bug
238 filename = '{}-{}.{}'.format(
239 project_slug,
240 version_slug,
241 path.split('.')[-1],
242 )
243 response['Content-Disposition'] = 'filename=%s' % filename
244 return response
245
246
247 def project_versions(request, project_slug):
248 """
249 Project version list view.
250
251 Shows the available versions and lets the user choose which ones to build.
252 """
253 project = get_object_or_404(
254 Project.objects.protected(request.user),
255 slug=project_slug,
256 )
257
258 versions = Version.objects.public(
259 user=request.user,
260 project=project,
261 only_active=False,
262 )
263 active_versions = versions.filter(active=True)
264 inactive_versions = versions.filter(active=False)
265
266 # If there's a wiped query string, check the string against the versions
267 # list and display a success message. Deleting directories doesn't know how
268 # to fail. :)
269 wiped = request.GET.get('wipe', '')
270 wiped_version = versions.filter(slug=wiped)
271 if wiped and wiped_version.count():
272 messages.success(request, 'Version wiped: ' + wiped)
273
274 return render(
275 request,
276 'projects/project_version_list.html',
277 {
278 'inactive_versions': inactive_versions,
279 'active_versions': active_versions,
280 'project': project,
281 },
282 )
283
284
285 def project_analytics(request, project_slug):
286 """Have a analytics API placeholder."""
287 project = get_object_or_404(
288 Project.objects.protected(request.user),
289 slug=project_slug,
290 )
291 analytics_cache = cache.get('analytics:%s' % project_slug)
292 if analytics_cache:
293 analytics = json.loads(analytics_cache)
294 else:
295 try:
296 resp = requests.get(
297 '{host}/api/v1/index/1/heatmap/'.format(
298 host=settings.GROK_API_HOST,
299 ),
300 params={'project': project.slug, 'days': 7, 'compare': True},
301 )
302 analytics = resp.json()
303 cache.set('analytics:%s' % project_slug, resp.content, 1800)
304 except requests.exceptions.RequestException:
305 analytics = None
306
307 if analytics:
308 page_list = list(
309 reversed(
310 sorted(
311 list(analytics['page'].items()),
312 key=operator.itemgetter(1),
313 ),
314 ),
315 )
316 version_list = list(
317 reversed(
318 sorted(
319 list(analytics['version'].items()),
320 key=operator.itemgetter(1),
321 ),
322 ),
323 )
324 else:
325 page_list = []
326 version_list = []
327
328 full = request.GET.get('full')
329 if not full:
330 page_list = page_list[:20]
331 version_list = version_list[:20]
332
333 return render(
334 request,
335 'projects/project_analytics.html',
336 {
337 'project': project,
338 'analytics': analytics,
339 'page_list': page_list,
340 'version_list': version_list,
341 'full': full,
342 },
343 )
344
345
346 def project_embed(request, project_slug):
347 """Have a content API placeholder."""
348 project = get_object_or_404(
349 Project.objects.protected(request.user),
350 slug=project_slug,
351 )
352 version = project.versions.get(slug=LATEST)
353 files = version.imported_files.filter(
354 name__endswith='.html',
355 ).order_by('path')
356
357 return render(
358 request,
359 'projects/project_embed.html',
360 {
361 'project': project,
362 'files': files,
363 'settings': {
364 'PUBLIC_API_URL': settings.PUBLIC_API_URL,
365 'URI': request.build_absolute_uri(location='/').rstrip('/'),
366 },
367 },
368 )
369
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/readthedocs/core/permissions.py b/readthedocs/core/permissions.py
--- a/readthedocs/core/permissions.py
+++ b/readthedocs/core/permissions.py
@@ -9,6 +9,8 @@
@classmethod
def is_admin(cls, user, project):
+ # This explicitly uses "user in project.users.all" so that
+ # users on projects can be cached using prefetch_related or prefetch_related_objects
return user in project.users.all() or user.is_superuser
@classmethod
diff --git a/readthedocs/projects/views/public.py b/readthedocs/projects/views/public.py
--- a/readthedocs/projects/views/public.py
+++ b/readthedocs/projects/views/public.py
@@ -13,6 +13,7 @@
from django.contrib.auth.models import User
from django.core.cache import cache
from django.core.files.storage import get_storage_class
+from django.db.models import prefetch_related_objects
from django.http import HttpResponse, HttpResponseRedirect
from django.shortcuts import get_object_or_404, render
from django.urls import reverse
@@ -271,6 +272,9 @@
if wiped and wiped_version.count():
messages.success(request, 'Version wiped: ' + wiped)
+ # Optimize project permission checks
+ prefetch_related_objects([project], 'users')
+
return render(
request,
'projects/project_version_list.html',
|
{"golden_diff": "diff --git a/readthedocs/core/permissions.py b/readthedocs/core/permissions.py\n--- a/readthedocs/core/permissions.py\n+++ b/readthedocs/core/permissions.py\n@@ -9,6 +9,8 @@\n \n @classmethod\n def is_admin(cls, user, project):\n+ # This explicitly uses \"user in project.users.all\" so that\n+ # users on projects can be cached using prefetch_related or prefetch_related_objects\n return user in project.users.all() or user.is_superuser\n \n @classmethod\ndiff --git a/readthedocs/projects/views/public.py b/readthedocs/projects/views/public.py\n--- a/readthedocs/projects/views/public.py\n+++ b/readthedocs/projects/views/public.py\n@@ -13,6 +13,7 @@\n from django.contrib.auth.models import User\n from django.core.cache import cache\n from django.core.files.storage import get_storage_class\n+from django.db.models import prefetch_related_objects\n from django.http import HttpResponse, HttpResponseRedirect\n from django.shortcuts import get_object_or_404, render\n from django.urls import reverse\n@@ -271,6 +272,9 @@\n if wiped and wiped_version.count():\n messages.success(request, 'Version wiped: ' + wiped)\n \n+ # Optimize project permission checks\n+ prefetch_related_objects([project], 'users')\n+\n return render(\n request,\n 'projects/project_version_list.html',\n", "issue": "502 Bad Gateway on Projects > Versions page\nThe Projects > Versions page for our project is throwing a 502 Bad Gateway error. It's happening at the following URL: \r\n\r\nhttps://readthedocs.org/projects/htcondor/versions\r\n\r\nI thought this might be a transient error but it's been happening consistently for the last day or so. All the other pages I've tried seem to work fine.\r\n\r\nIt's worth noting a similar ticket #5441 was filed a couple of days ago for a 502 error on the Import a Repository page. This seems to be working correctly now.\r\n\r\n## Details\r\n\r\n* Read the Docs project URL: https://htcondor.readthedocs.io\r\n* Build URL (if applicable): \r\n* Read the Docs username (if applicable): htcondor\r\n\r\n## Expected Result\r\n\r\nA list of the different versions of our docs, dropdown menus to connect them to different branches, etc.\r\n\r\n## Actual Result\r\n\r\nServer Error\r\n\r\n502 - Web server received an invalid response while acting as a gateway or proxy server.\r\n\r\nThere is a problem with the page you are looking for, and it cannot be displayed. When the Web server (while acting as a gateway or proxy) contacted the upstream content server, it received an invalid response from the content server.\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Objects for User permission checks.\"\"\"\n\nfrom readthedocs.core.utils.extend import SettingsOverrideObject\n\n\nclass AdminPermissionBase:\n\n @classmethod\n def is_admin(cls, user, project):\n return user in project.users.all() or user.is_superuser\n\n @classmethod\n def is_member(cls, user, obj):\n return user in obj.users.all() or user.is_superuser\n\n\nclass AdminPermission(SettingsOverrideObject):\n _default_class = AdminPermissionBase\n _override_setting = 'ADMIN_PERMISSION'\n", "path": "readthedocs/core/permissions.py"}, {"content": "\"\"\"Public project views.\"\"\"\n\nimport json\nimport logging\nimport mimetypes\nimport operator\nimport os\nfrom collections import OrderedDict\n\nimport requests\nfrom django.conf import settings\nfrom django.contrib import messages\nfrom django.contrib.auth.models import User\nfrom django.core.cache import cache\nfrom django.core.files.storage import get_storage_class\nfrom django.http import HttpResponse, HttpResponseRedirect\nfrom django.shortcuts import get_object_or_404, render\nfrom django.urls import reverse\nfrom django.views.decorators.cache import never_cache\nfrom django.views.generic import DetailView, ListView\nfrom taggit.models import Tag\n\nfrom readthedocs.builds.constants import LATEST\nfrom readthedocs.builds.models import Version\nfrom readthedocs.builds.views import BuildTriggerMixin\nfrom readthedocs.projects.models import Project\nfrom readthedocs.projects.templatetags.projects_tags import sort_version_aware\n\nfrom .base import ProjectOnboardMixin\n\n\nlog = logging.getLogger(__name__)\nsearch_log = logging.getLogger(__name__ + '.search')\nmimetypes.add_type('application/epub+zip', '.epub')\nstorage = get_storage_class()()\n\n\nclass ProjectIndex(ListView):\n\n \"\"\"List view of public :py:class:`Project` instances.\"\"\"\n\n model = Project\n\n def get_queryset(self):\n queryset = Project.objects.public(self.request.user)\n queryset = queryset.exclude(users__profile__banned=True)\n\n if self.kwargs.get('tag'):\n self.tag = get_object_or_404(Tag, slug=self.kwargs.get('tag'))\n queryset = queryset.filter(tags__slug__in=[self.tag.slug])\n else:\n self.tag = None\n\n if self.kwargs.get('username'):\n self.user = get_object_or_404(\n User,\n username=self.kwargs.get('username'),\n )\n queryset = queryset.filter(user=self.user)\n else:\n self.user = None\n\n return queryset\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['person'] = self.user\n context['tag'] = self.tag\n return context\n\n\nclass ProjectDetailView(BuildTriggerMixin, ProjectOnboardMixin, DetailView):\n\n \"\"\"Display project onboard steps.\"\"\"\n\n model = Project\n slug_url_kwarg = 'project_slug'\n\n def get_queryset(self):\n return Project.objects.protected(self.request.user)\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n\n project = self.get_object()\n context['versions'] = Version.objects.public(\n user=self.request.user,\n project=project,\n )\n\n protocol = 'http'\n if self.request.is_secure():\n protocol = 'https'\n\n version_slug = project.get_default_version()\n\n context['badge_url'] = '{}://{}{}?version={}'.format(\n protocol,\n settings.PRODUCTION_DOMAIN,\n reverse('project_badge', args=[project.slug]),\n project.get_default_version(),\n )\n context['site_url'] = '{url}?badge={version}'.format(\n url=project.get_docs_url(version_slug),\n version=version_slug,\n )\n\n return context\n\n\n@never_cache\ndef project_badge(request, project_slug):\n \"\"\"Return a sweet badge for the project.\"\"\"\n style = request.GET.get('style', 'flat')\n if style not in (\n 'flat',\n 'plastic',\n 'flat-square',\n 'for-the-badge',\n 'social',\n ):\n style = 'flat'\n\n # Get the local path to the badge files\n badge_path = os.path.join(\n os.path.dirname(__file__),\n '..',\n 'static',\n 'projects',\n 'badges',\n '%s-' + style + '.svg',\n )\n\n version_slug = request.GET.get('version', LATEST)\n file_path = badge_path % 'unknown'\n\n version = Version.objects.public(request.user).filter(\n project__slug=project_slug,\n slug=version_slug,\n ).first()\n\n if version:\n last_build = version.builds.filter(\n type='html',\n state='finished',\n ).order_by('-date').first()\n if last_build:\n if last_build.success:\n file_path = badge_path % 'passing'\n else:\n file_path = badge_path % 'failing'\n\n try:\n with open(file_path) as fd:\n return HttpResponse(\n fd.read(),\n content_type='image/svg+xml',\n )\n except (IOError, OSError):\n log.exception(\n 'Failed to read local filesystem while serving a docs badge',\n )\n return HttpResponse(status=503)\n\n\ndef project_downloads(request, project_slug):\n \"\"\"A detail view for a project with various downloads.\"\"\"\n project = get_object_or_404(\n Project.objects.protected(request.user),\n slug=project_slug,\n )\n versions = Version.objects.public(user=request.user, project=project)\n versions = sort_version_aware(versions)\n version_data = OrderedDict()\n for version in versions:\n data = version.get_downloads()\n # Don't show ones that have no downloads.\n if data:\n version_data[version] = data\n\n return render(\n request,\n 'projects/project_downloads.html',\n {\n 'project': project,\n 'version_data': version_data,\n 'versions': versions,\n },\n )\n\n\ndef project_download_media(request, project_slug, type_, version_slug):\n \"\"\"\n Download a specific piece of media.\n\n Perform an auth check if serving in private mode.\n\n .. warning:: This is linked directly from the HTML pages.\n It should only care about the Version permissions,\n not the actual Project permissions.\n \"\"\"\n version = get_object_or_404(\n Version.objects.public(user=request.user),\n project__slug=project_slug,\n slug=version_slug,\n )\n privacy_level = getattr(settings, 'DEFAULT_PRIVACY_LEVEL', 'public')\n if privacy_level == 'public' or settings.DEBUG:\n storage_path = version.project.get_storage_path(\n type_=type_, version_slug=version_slug\n )\n if storage.exists(storage_path):\n return HttpResponseRedirect(storage.url(storage_path))\n\n media_path = os.path.join(\n settings.MEDIA_URL,\n type_,\n project_slug,\n version_slug,\n '%s.%s' % (project_slug, type_.replace('htmlzip', 'zip')),\n )\n return HttpResponseRedirect(media_path)\n\n # Get relative media path\n path = (\n version.project.get_production_media_path(\n type_=type_,\n version_slug=version_slug,\n ).replace(settings.PRODUCTION_ROOT, '/prod_artifacts')\n )\n content_type, encoding = mimetypes.guess_type(path)\n content_type = content_type or 'application/octet-stream'\n response = HttpResponse(content_type=content_type)\n if encoding:\n response['Content-Encoding'] = encoding\n response['X-Accel-Redirect'] = path\n # Include version in filename; this fixes a long-standing bug\n filename = '{}-{}.{}'.format(\n project_slug,\n version_slug,\n path.split('.')[-1],\n )\n response['Content-Disposition'] = 'filename=%s' % filename\n return response\n\n\ndef project_versions(request, project_slug):\n \"\"\"\n Project version list view.\n\n Shows the available versions and lets the user choose which ones to build.\n \"\"\"\n project = get_object_or_404(\n Project.objects.protected(request.user),\n slug=project_slug,\n )\n\n versions = Version.objects.public(\n user=request.user,\n project=project,\n only_active=False,\n )\n active_versions = versions.filter(active=True)\n inactive_versions = versions.filter(active=False)\n\n # If there's a wiped query string, check the string against the versions\n # list and display a success message. Deleting directories doesn't know how\n # to fail. :)\n wiped = request.GET.get('wipe', '')\n wiped_version = versions.filter(slug=wiped)\n if wiped and wiped_version.count():\n messages.success(request, 'Version wiped: ' + wiped)\n\n return render(\n request,\n 'projects/project_version_list.html',\n {\n 'inactive_versions': inactive_versions,\n 'active_versions': active_versions,\n 'project': project,\n },\n )\n\n\ndef project_analytics(request, project_slug):\n \"\"\"Have a analytics API placeholder.\"\"\"\n project = get_object_or_404(\n Project.objects.protected(request.user),\n slug=project_slug,\n )\n analytics_cache = cache.get('analytics:%s' % project_slug)\n if analytics_cache:\n analytics = json.loads(analytics_cache)\n else:\n try:\n resp = requests.get(\n '{host}/api/v1/index/1/heatmap/'.format(\n host=settings.GROK_API_HOST,\n ),\n params={'project': project.slug, 'days': 7, 'compare': True},\n )\n analytics = resp.json()\n cache.set('analytics:%s' % project_slug, resp.content, 1800)\n except requests.exceptions.RequestException:\n analytics = None\n\n if analytics:\n page_list = list(\n reversed(\n sorted(\n list(analytics['page'].items()),\n key=operator.itemgetter(1),\n ),\n ),\n )\n version_list = list(\n reversed(\n sorted(\n list(analytics['version'].items()),\n key=operator.itemgetter(1),\n ),\n ),\n )\n else:\n page_list = []\n version_list = []\n\n full = request.GET.get('full')\n if not full:\n page_list = page_list[:20]\n version_list = version_list[:20]\n\n return render(\n request,\n 'projects/project_analytics.html',\n {\n 'project': project,\n 'analytics': analytics,\n 'page_list': page_list,\n 'version_list': version_list,\n 'full': full,\n },\n )\n\n\ndef project_embed(request, project_slug):\n \"\"\"Have a content API placeholder.\"\"\"\n project = get_object_or_404(\n Project.objects.protected(request.user),\n slug=project_slug,\n )\n version = project.versions.get(slug=LATEST)\n files = version.imported_files.filter(\n name__endswith='.html',\n ).order_by('path')\n\n return render(\n request,\n 'projects/project_embed.html',\n {\n 'project': project,\n 'files': files,\n 'settings': {\n 'PUBLIC_API_URL': settings.PUBLIC_API_URL,\n 'URI': request.build_absolute_uri(location='/').rstrip('/'),\n },\n },\n )\n", "path": "readthedocs/projects/views/public.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Objects for User permission checks.\"\"\"\n\nfrom readthedocs.core.utils.extend import SettingsOverrideObject\n\n\nclass AdminPermissionBase:\n\n @classmethod\n def is_admin(cls, user, project):\n # This explicitly uses \"user in project.users.all\" so that\n # users on projects can be cached using prefetch_related or prefetch_related_objects\n return user in project.users.all() or user.is_superuser\n\n @classmethod\n def is_member(cls, user, obj):\n return user in obj.users.all() or user.is_superuser\n\n\nclass AdminPermission(SettingsOverrideObject):\n _default_class = AdminPermissionBase\n _override_setting = 'ADMIN_PERMISSION'\n", "path": "readthedocs/core/permissions.py"}, {"content": "\"\"\"Public project views.\"\"\"\n\nimport json\nimport logging\nimport mimetypes\nimport operator\nimport os\nfrom collections import OrderedDict\n\nimport requests\nfrom django.conf import settings\nfrom django.contrib import messages\nfrom django.contrib.auth.models import User\nfrom django.core.cache import cache\nfrom django.core.files.storage import get_storage_class\nfrom django.db.models import prefetch_related_objects\nfrom django.http import HttpResponse, HttpResponseRedirect\nfrom django.shortcuts import get_object_or_404, render\nfrom django.urls import reverse\nfrom django.views.decorators.cache import never_cache\nfrom django.views.generic import DetailView, ListView\nfrom taggit.models import Tag\n\nfrom readthedocs.builds.constants import LATEST\nfrom readthedocs.builds.models import Version\nfrom readthedocs.builds.views import BuildTriggerMixin\nfrom readthedocs.projects.models import Project\nfrom readthedocs.projects.templatetags.projects_tags import sort_version_aware\n\nfrom .base import ProjectOnboardMixin\n\n\nlog = logging.getLogger(__name__)\nsearch_log = logging.getLogger(__name__ + '.search')\nmimetypes.add_type('application/epub+zip', '.epub')\nstorage = get_storage_class()()\n\n\nclass ProjectIndex(ListView):\n\n \"\"\"List view of public :py:class:`Project` instances.\"\"\"\n\n model = Project\n\n def get_queryset(self):\n queryset = Project.objects.public(self.request.user)\n queryset = queryset.exclude(users__profile__banned=True)\n\n if self.kwargs.get('tag'):\n self.tag = get_object_or_404(Tag, slug=self.kwargs.get('tag'))\n queryset = queryset.filter(tags__slug__in=[self.tag.slug])\n else:\n self.tag = None\n\n if self.kwargs.get('username'):\n self.user = get_object_or_404(\n User,\n username=self.kwargs.get('username'),\n )\n queryset = queryset.filter(user=self.user)\n else:\n self.user = None\n\n return queryset\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['person'] = self.user\n context['tag'] = self.tag\n return context\n\n\nclass ProjectDetailView(BuildTriggerMixin, ProjectOnboardMixin, DetailView):\n\n \"\"\"Display project onboard steps.\"\"\"\n\n model = Project\n slug_url_kwarg = 'project_slug'\n\n def get_queryset(self):\n return Project.objects.protected(self.request.user)\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n\n project = self.get_object()\n context['versions'] = Version.objects.public(\n user=self.request.user,\n project=project,\n )\n\n protocol = 'http'\n if self.request.is_secure():\n protocol = 'https'\n\n version_slug = project.get_default_version()\n\n context['badge_url'] = '{}://{}{}?version={}'.format(\n protocol,\n settings.PRODUCTION_DOMAIN,\n reverse('project_badge', args=[project.slug]),\n project.get_default_version(),\n )\n context['site_url'] = '{url}?badge={version}'.format(\n url=project.get_docs_url(version_slug),\n version=version_slug,\n )\n\n return context\n\n\n@never_cache\ndef project_badge(request, project_slug):\n \"\"\"Return a sweet badge for the project.\"\"\"\n style = request.GET.get('style', 'flat')\n if style not in (\n 'flat',\n 'plastic',\n 'flat-square',\n 'for-the-badge',\n 'social',\n ):\n style = 'flat'\n\n # Get the local path to the badge files\n badge_path = os.path.join(\n os.path.dirname(__file__),\n '..',\n 'static',\n 'projects',\n 'badges',\n '%s-' + style + '.svg',\n )\n\n version_slug = request.GET.get('version', LATEST)\n file_path = badge_path % 'unknown'\n\n version = Version.objects.public(request.user).filter(\n project__slug=project_slug,\n slug=version_slug,\n ).first()\n\n if version:\n last_build = version.builds.filter(\n type='html',\n state='finished',\n ).order_by('-date').first()\n if last_build:\n if last_build.success:\n file_path = badge_path % 'passing'\n else:\n file_path = badge_path % 'failing'\n\n try:\n with open(file_path) as fd:\n return HttpResponse(\n fd.read(),\n content_type='image/svg+xml',\n )\n except (IOError, OSError):\n log.exception(\n 'Failed to read local filesystem while serving a docs badge',\n )\n return HttpResponse(status=503)\n\n\ndef project_downloads(request, project_slug):\n \"\"\"A detail view for a project with various downloads.\"\"\"\n project = get_object_or_404(\n Project.objects.protected(request.user),\n slug=project_slug,\n )\n versions = Version.objects.public(user=request.user, project=project)\n versions = sort_version_aware(versions)\n version_data = OrderedDict()\n for version in versions:\n data = version.get_downloads()\n # Don't show ones that have no downloads.\n if data:\n version_data[version] = data\n\n return render(\n request,\n 'projects/project_downloads.html',\n {\n 'project': project,\n 'version_data': version_data,\n 'versions': versions,\n },\n )\n\n\ndef project_download_media(request, project_slug, type_, version_slug):\n \"\"\"\n Download a specific piece of media.\n\n Perform an auth check if serving in private mode.\n\n .. warning:: This is linked directly from the HTML pages.\n It should only care about the Version permissions,\n not the actual Project permissions.\n \"\"\"\n version = get_object_or_404(\n Version.objects.public(user=request.user),\n project__slug=project_slug,\n slug=version_slug,\n )\n privacy_level = getattr(settings, 'DEFAULT_PRIVACY_LEVEL', 'public')\n if privacy_level == 'public' or settings.DEBUG:\n storage_path = version.project.get_storage_path(\n type_=type_, version_slug=version_slug\n )\n if storage.exists(storage_path):\n return HttpResponseRedirect(storage.url(storage_path))\n\n media_path = os.path.join(\n settings.MEDIA_URL,\n type_,\n project_slug,\n version_slug,\n '%s.%s' % (project_slug, type_.replace('htmlzip', 'zip')),\n )\n return HttpResponseRedirect(media_path)\n\n # Get relative media path\n path = (\n version.project.get_production_media_path(\n type_=type_,\n version_slug=version_slug,\n ).replace(settings.PRODUCTION_ROOT, '/prod_artifacts')\n )\n content_type, encoding = mimetypes.guess_type(path)\n content_type = content_type or 'application/octet-stream'\n response = HttpResponse(content_type=content_type)\n if encoding:\n response['Content-Encoding'] = encoding\n response['X-Accel-Redirect'] = path\n # Include version in filename; this fixes a long-standing bug\n filename = '{}-{}.{}'.format(\n project_slug,\n version_slug,\n path.split('.')[-1],\n )\n response['Content-Disposition'] = 'filename=%s' % filename\n return response\n\n\ndef project_versions(request, project_slug):\n \"\"\"\n Project version list view.\n\n Shows the available versions and lets the user choose which ones to build.\n \"\"\"\n project = get_object_or_404(\n Project.objects.protected(request.user),\n slug=project_slug,\n )\n\n versions = Version.objects.public(\n user=request.user,\n project=project,\n only_active=False,\n )\n active_versions = versions.filter(active=True)\n inactive_versions = versions.filter(active=False)\n\n # If there's a wiped query string, check the string against the versions\n # list and display a success message. Deleting directories doesn't know how\n # to fail. :)\n wiped = request.GET.get('wipe', '')\n wiped_version = versions.filter(slug=wiped)\n if wiped and wiped_version.count():\n messages.success(request, 'Version wiped: ' + wiped)\n\n # Optimize project permission checks\n prefetch_related_objects([project], 'users')\n\n return render(\n request,\n 'projects/project_version_list.html',\n {\n 'inactive_versions': inactive_versions,\n 'active_versions': active_versions,\n 'project': project,\n },\n )\n\n\ndef project_analytics(request, project_slug):\n \"\"\"Have a analytics API placeholder.\"\"\"\n project = get_object_or_404(\n Project.objects.protected(request.user),\n slug=project_slug,\n )\n analytics_cache = cache.get('analytics:%s' % project_slug)\n if analytics_cache:\n analytics = json.loads(analytics_cache)\n else:\n try:\n resp = requests.get(\n '{host}/api/v1/index/1/heatmap/'.format(\n host=settings.GROK_API_HOST,\n ),\n params={'project': project.slug, 'days': 7, 'compare': True},\n )\n analytics = resp.json()\n cache.set('analytics:%s' % project_slug, resp.content, 1800)\n except requests.exceptions.RequestException:\n analytics = None\n\n if analytics:\n page_list = list(\n reversed(\n sorted(\n list(analytics['page'].items()),\n key=operator.itemgetter(1),\n ),\n ),\n )\n version_list = list(\n reversed(\n sorted(\n list(analytics['version'].items()),\n key=operator.itemgetter(1),\n ),\n ),\n )\n else:\n page_list = []\n version_list = []\n\n full = request.GET.get('full')\n if not full:\n page_list = page_list[:20]\n version_list = version_list[:20]\n\n return render(\n request,\n 'projects/project_analytics.html',\n {\n 'project': project,\n 'analytics': analytics,\n 'page_list': page_list,\n 'version_list': version_list,\n 'full': full,\n },\n )\n\n\ndef project_embed(request, project_slug):\n \"\"\"Have a content API placeholder.\"\"\"\n project = get_object_or_404(\n Project.objects.protected(request.user),\n slug=project_slug,\n )\n version = project.versions.get(slug=LATEST)\n files = version.imported_files.filter(\n name__endswith='.html',\n ).order_by('path')\n\n return render(\n request,\n 'projects/project_embed.html',\n {\n 'project': project,\n 'files': files,\n 'settings': {\n 'PUBLIC_API_URL': settings.PUBLIC_API_URL,\n 'URI': request.build_absolute_uri(location='/').rstrip('/'),\n },\n },\n )\n", "path": "readthedocs/projects/views/public.py"}]}
| 3,985 | 302 |
gh_patches_debug_34192
|
rasdani/github-patches
|
git_diff
|
horovod__horovod-2724
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug in global_step update when local gradient aggregation is used
**Environment:**
1. Framework: TensorFlow
2. Framework version: 1.15.3
3. Horovod version: 0.21.3
4. MPI version: 3.1.6
5. CUDA version: 11.0.194
6. NCCL version: 2.7.6
7. Python version: 3.6.9
8. Spark / PySpark version:
9. OS and version:
10. GCC version:
11. CMake version:
**Bug report:**
There seems to be a bug in how the `global_step` variable is updated when using local gradient aggregation with `backward_passes_per_step>1`.
Here is a simple example to reproduce the issue:
```
import tensorflow as tf
import horovod.tensorflow as hvd
tf.disable_eager_execution()
LR=0.01
# data/label is always just 1
data = tf.constant([[1]], dtype=tf.float32)
# one-variable linear model, no bias (y = w*x)
#
# gradient update is hand-calculatable if needed for testing:
#
# model: yhat = w*x
# mse loss: L = (ytrue - w*x)**2
# gradient: dL/dw = -2*x*(ytrue - `w*x)`
# let ytrue = x: dL/dw = -2*x*x*(1-w)
def predict(x):
dense = tf.layers.Dense(1, use_bias=False, kernel_initializer=tf.zeros_initializer())
return dense(x)
pred = predict(data)
loss = tf.losses.mean_squared_error(data, pred)
step = tf.contrib.framework.get_or_create_global_step()
optimizer = tf.train.GradientDescentOptimizer(LR)
hvd.init()
optimizer = hvd.DistributedOptimizer(optimizer, backward_passes_per_step=2, average_aggregated_gradients=True)
with tf.control_dependencies([tf.print("step:", step, "loss:", loss)]):
train_op = optimizer.minimize(loss, global_step=step)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
# training loop
for i in range(10):
sess.run([train_op])
```
Which gives this output:
```
step: 0 loss: 1
step: 0 loss: 1
step: 0 loss: 1
step: 2 loss: 0.960400045
step: 2 loss: 0.960400045
step: 4 loss: 0.922368109
step: 4 loss: 0.922368109
step: 6 loss: 0.885842443
step: 6 loss: 0.885842443
step: 8 loss: 0.850763
step: 8 loss: 0.850763
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `horovod/tensorflow/gradient_aggregation.py`
Content:
```
1 import tensorflow as tf
2
3
4 def apply_op_to_not_none_tensors(tensor_op, tensors, *args):
5 return [
6 tensor_op(
7 tensor,
8 *args
9 ) if tensor is not None else tensor for tensor in tensors]
10
11
12 def get_not_none_from_list(tensor_list):
13 return [x for x in tensor_list if x is not None]
14
15
16 class LocalGradientAggregationHelper:
17 """
18 LocalGradientAggregationHelper aggregates gradient updates locally,
19 and communicates the updates across machines only once every
20 backward_passes_per_step. Only supports graph mode execution.
21 """
22
23 _OPTIMIZER_TYPE_KERAS = "optimizer_type_keras"
24 _OPTIMIZER_TYPE_LEGACY = "optimizer_type_legacy"
25
26 def __init__(
27 self,
28 backward_passes_per_step,
29 allreduce_func,
30 sparse_as_dense,
31 average_aggregated_gradients,
32 rank,
33 optimizer_type):
34 self._allreduce_grads = allreduce_func
35
36 # backward_passes_per_step controls how often gradient updates are
37 # synchronized.
38 self.backward_passes_per_step = backward_passes_per_step
39 if self.backward_passes_per_step <= 0:
40 raise ValueError("backward_passes_per_step must be > 0")
41
42 # average_aggregated_gradients controls whether gradient updates that are
43 # aggregated, should be divided by `backward_passes_per_step`.
44 self.average_aggregated_gradients = average_aggregated_gradients
45
46 # This is going to be [N] data structure holding the aggregated gradient updates
47 # N is the number of parameters.
48 self.locally_aggregated_grads = []
49
50 # Used to know when to allreduce and apply gradients. We allreduce when `self.counter`
51 # is equal to `self.backward_passes_per_step`. We apply gradients when `self.counter` is
52 # equal to 0.
53 self.counter = None
54
55 self.sparse_as_dense = sparse_as_dense
56 self.rank = rank
57 self.optimizer_type = optimizer_type
58
59 # Contains the mapping of indexes of grad updates that are not None to their index in
60 # locally_aggregated_grads which only contains not None gradients. When performing
61 # gradient aggregation we have to remove them from the list of grads prior to passing
62 # the list into a tf.cond().
63 self.not_none_indexes = {}
64 self.num_none_grad_updates = 0
65
66 def _init_aggregation_vars(self, grads):
67 """
68 Initializes the counter that is used when to communicate and aggregate gradients
69 and the tensorflow variables that store the locally aggregated gradients.
70 """
71 variable_scope_name = "aggregation_variables_" + str(self.rank)
72 with tf.compat.v1.variable_scope(variable_scope_name, reuse=tf.compat.v1.AUTO_REUSE):
73 self.counter = tf.compat.v1.get_variable(
74 "aggregation_counter", shape=(), dtype=tf.int32,
75 trainable=False, initializer=tf.compat.v1.zeros_initializer(),
76 collections=[tf.compat.v1.GraphKeys.LOCAL_VARIABLES],
77 )
78 for idx, grad in enumerate(grads):
79 # Handle IndexedSlices.
80 if self.sparse_as_dense and isinstance(grad, tf.IndexedSlices):
81 grad = tf.convert_to_tensor(grad)
82 elif isinstance(grad, tf.IndexedSlices):
83 raise ValueError(
84 "IndexedSlices are not supported when "
85 "`backward_passes_per_step` > 1 and "
86 "`sparse_as_dense` is False."
87 )
88
89 # Handle grads that are None.
90 if grad is None:
91 self.num_none_grad_updates += 1
92 continue
93 self.not_none_indexes[idx] = len(self.locally_aggregated_grads)
94
95 # Create shadow variable.
96 grad_aggregation_variable_name = str(idx)
97 zero_grad = tf.zeros(shape=grad.get_shape().as_list(), dtype=grad.dtype)
98 grad_aggregation_variable = tf.compat.v1.get_variable(
99 grad_aggregation_variable_name,
100 trainable=False,
101 initializer=zero_grad,
102 collections=[
103 tf.compat.v1.GraphKeys.LOCAL_VARIABLES,
104 "aggregating_collection"],
105 )
106 self.locally_aggregated_grads.append(grad_aggregation_variable)
107 assert len(self.locally_aggregated_grads) + \
108 self.num_none_grad_updates == len(grads)
109
110 # We expect to get a `sess` when we need to manually do a `sess.run(...)`
111 # for the variables to be initialized. This is the `tf.keras`
112 # optimizers.
113 if self.optimizer_type == self._OPTIMIZER_TYPE_KERAS:
114 session = tf.compat.v1.keras.backend.get_session(op_input_list=())
115 vars_init_op = tf.compat.v1.variables_initializer(
116 [self.counter, *get_not_none_from_list(self.locally_aggregated_grads)]
117 )
118 session.run(vars_init_op)
119
120 def _clear_grads(self):
121 clear_ops_list = []
122 for idx, grad_aggregator in enumerate(self.locally_aggregated_grads):
123 clear_op = grad_aggregator.assign(grad_aggregator.initial_value)
124 clear_ops_list.append(clear_op)
125 return tf.group(*clear_ops_list)
126
127 def _aggregate_grads(self, grads):
128 aggregation_ops_list = []
129 grads = get_not_none_from_list(grads)
130 assert len(grads) == len(self.locally_aggregated_grads)
131
132 # Apply new gradient updates to the local copy.
133 for idx, grad in enumerate(grads):
134 if self.sparse_as_dense and isinstance(grad, tf.IndexedSlices):
135 grad = tf.convert_to_tensor(grad)
136
137 updated_grad_aggregator = self.locally_aggregated_grads[idx].assign_add(
138 grad)
139 aggregation_ops_list.append(updated_grad_aggregator)
140
141 return aggregation_ops_list
142
143 def _allreduce_grads_helper(self, grads, vars):
144 # Read in latest variables values.
145 aggregated_grads = []
146 aggregation_read_ops_list = []
147 for idx, locally_aggregated_grad in enumerate(
148 self.locally_aggregated_grads):
149 aggregated_grads.append(locally_aggregated_grad.read_value())
150 aggregation_read_ops_list.append(aggregated_grads[idx])
151 aggregation_read_ops = tf.group(*aggregation_read_ops_list)
152
153 with tf.control_dependencies([aggregation_read_ops]):
154 averaged_gradients = self._allreduce_grads(aggregated_grads, vars)
155
156 # Reset counter.
157 with tf.control_dependencies([g.op for g in averaged_gradients if g is not None]):
158 reset_op = self.counter.assign(
159 tf.constant(0), use_locking=True)
160
161 # Divide by backward_passes_per_step if
162 # average_aggregated_gradients is True.
163 with tf.control_dependencies([reset_op]):
164 gradient_divisor = self.backward_passes_per_step if \
165 self.average_aggregated_gradients else 1
166
167 averaged_gradients = apply_op_to_not_none_tensors(
168 tf.divide,
169 averaged_gradients,
170 gradient_divisor,
171 )
172 return averaged_gradients
173
174 def compute_gradients(self, grads, vars):
175 """
176 Applies the new gradient updates the locally aggregated gradients, and
177 performs cross-machine communication every backward_passes_per_step
178 times it is called.
179 """
180 self._init_aggregation_vars(grads)
181
182 # Clear the locally aggregated gradients when the counter is at zero.
183 clear_op = tf.cond(
184 pred=tf.equal(self.counter, 0),
185 true_fn=lambda: self._clear_grads(),
186 false_fn=tf.no_op
187 )
188
189 # Add new gradients to the locally aggregated gradients.
190 with tf.control_dependencies([clear_op]):
191 aggregation_ops_list = self._aggregate_grads(grads)
192
193 # Increment the counter once new gradients have been applied.
194 aggregation_ops = tf.group(*aggregation_ops_list)
195 with tf.control_dependencies([aggregation_ops]):
196 update_counter = self.counter.assign_add(tf.constant(1))
197
198 with tf.control_dependencies([update_counter]):
199 grads = get_not_none_from_list(grads)
200 assert len(grads) == len(self.locally_aggregated_grads)
201
202 # Allreduce locally aggregated gradients when the counter is equivalent to
203 # `backward_passes_per_step`. This the condition is true, it also resets
204 # the counter back to 0.
205 allreduced_grads = tf.cond(
206 tf.equal(self.counter, self.backward_passes_per_step),
207 lambda: self._allreduce_grads_helper(grads, vars),
208 lambda: grads,
209 )
210
211 # Handle case where there is only one variable.
212 if not isinstance(allreduced_grads, (list, tuple)):
213 allreduced_grads = (allreduced_grads,)
214 assert len(allreduced_grads) == len(self.locally_aggregated_grads)
215
216 # Insert gradients that are None back in.
217 allreduced_grads = [
218 allreduced_grads[self.not_none_indexes[idx]] if idx in self.not_none_indexes else None
219 for idx in range(len(self.locally_aggregated_grads) + self.num_none_grad_updates)
220 ]
221 assert len(allreduced_grads) == len(
222 self.locally_aggregated_grads) + self.num_none_grad_updates
223
224 # If gradients have not been allreduced this batch, we return the gradients
225 # that were submitted as the updates (the input).
226 return allreduced_grads
227
228 def apply_gradients(self, apply_grads_closure, optimizer, *args, **kwargs):
229 """
230 Apply updates every backward_passes_per_step, which lines up with
231 the batches on which we communicated the locally aggregated gradients.
232 """
233 flattended_args0 = [item for tup in args[0] for item in tup]
234
235 # Since we skip applying updates when the counter is not at zero we
236 # still want to increment the global step if it is being tracked
237 # (e.g., Tensorflow Estimators).
238 def increment_global_step_counter():
239 global_step_counter = tf.compat.v1.train.get_global_step()
240 if global_step_counter is None:
241 return tf.no_op()
242 return global_step_counter.assign_add(
243 tf.constant(1, dtype=tf.int64),
244 use_locking=True,
245 read_value=False
246 )
247
248 # Increment global step on iterations where we don't call `apply_gradients()`.
249 cond_increment_global_step_counter = tf.cond(
250 pred=tf.equal(self.counter, 0),
251 true_fn=tf.no_op,
252 false_fn=increment_global_step_counter,
253 )
254 flattended_args0.append(cond_increment_global_step_counter)
255
256 # If optimizer tracks iterations, we increment it on steps where we
257 # are not going to call `apply_gradients()`.
258 def increment_optimizer_iteration():
259 if hasattr(optimizer, "_iterations") and optimizer._iterations is not None:
260 return optimizer._iterations.assign_add(1).op
261 return tf.no_op()
262
263 with tf.control_dependencies([tf.group(*get_not_none_from_list(flattended_args0))]):
264 return tf.cond(
265 pred=tf.equal(self.counter, 0),
266 true_fn=apply_grads_closure,
267 false_fn=increment_optimizer_iteration,
268 )
269
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/horovod/tensorflow/gradient_aggregation.py b/horovod/tensorflow/gradient_aggregation.py
--- a/horovod/tensorflow/gradient_aggregation.py
+++ b/horovod/tensorflow/gradient_aggregation.py
@@ -232,6 +232,20 @@
"""
flattended_args0 = [item for tup in args[0] for item in tup]
+ # If optimizer tracks iterations, we increment it on steps where we
+ # are not going to call `apply_gradients()`.
+ def increment_optimizer_iteration():
+ if hasattr(optimizer, "_iterations") and optimizer._iterations is not None:
+ return optimizer._iterations.assign_add(1).op
+ return tf.no_op()
+
+ with tf.control_dependencies([tf.group(*get_not_none_from_list(flattended_args0))]):
+ train_op = tf.cond(
+ pred=tf.equal(self.counter, 0),
+ true_fn=apply_grads_closure,
+ false_fn=increment_optimizer_iteration,
+ )
+
# Since we skip applying updates when the counter is not at zero we
# still want to increment the global step if it is being tracked
# (e.g., Tensorflow Estimators).
@@ -245,24 +259,10 @@
read_value=False
)
- # Increment global step on iterations where we don't call `apply_gradients()`.
- cond_increment_global_step_counter = tf.cond(
- pred=tf.equal(self.counter, 0),
- true_fn=tf.no_op,
- false_fn=increment_global_step_counter,
- )
- flattended_args0.append(cond_increment_global_step_counter)
-
- # If optimizer tracks iterations, we increment it on steps where we
- # are not going to call `apply_gradients()`.
- def increment_optimizer_iteration():
- if hasattr(optimizer, "_iterations") and optimizer._iterations is not None:
- return optimizer._iterations.assign_add(1).op
- return tf.no_op()
-
- with tf.control_dependencies([tf.group(*get_not_none_from_list(flattended_args0))]):
+ with tf.control_dependencies([train_op]):
+ # Increment global step on iterations where we don't call `apply_gradients()`.
return tf.cond(
pred=tf.equal(self.counter, 0),
- true_fn=apply_grads_closure,
- false_fn=increment_optimizer_iteration,
+ true_fn=tf.no_op,
+ false_fn=increment_global_step_counter,
)
|
{"golden_diff": "diff --git a/horovod/tensorflow/gradient_aggregation.py b/horovod/tensorflow/gradient_aggregation.py\n--- a/horovod/tensorflow/gradient_aggregation.py\n+++ b/horovod/tensorflow/gradient_aggregation.py\n@@ -232,6 +232,20 @@\n \"\"\"\n flattended_args0 = [item for tup in args[0] for item in tup]\n \n+ # If optimizer tracks iterations, we increment it on steps where we\n+ # are not going to call `apply_gradients()`.\n+ def increment_optimizer_iteration():\n+ if hasattr(optimizer, \"_iterations\") and optimizer._iterations is not None:\n+ return optimizer._iterations.assign_add(1).op\n+ return tf.no_op()\n+\n+ with tf.control_dependencies([tf.group(*get_not_none_from_list(flattended_args0))]):\n+ train_op = tf.cond(\n+ pred=tf.equal(self.counter, 0),\n+ true_fn=apply_grads_closure,\n+ false_fn=increment_optimizer_iteration,\n+ )\n+\n # Since we skip applying updates when the counter is not at zero we\n # still want to increment the global step if it is being tracked\n # (e.g., Tensorflow Estimators).\n@@ -245,24 +259,10 @@\n read_value=False\n )\n \n- # Increment global step on iterations where we don't call `apply_gradients()`.\n- cond_increment_global_step_counter = tf.cond(\n- pred=tf.equal(self.counter, 0),\n- true_fn=tf.no_op,\n- false_fn=increment_global_step_counter,\n- )\n- flattended_args0.append(cond_increment_global_step_counter)\n-\n- # If optimizer tracks iterations, we increment it on steps where we\n- # are not going to call `apply_gradients()`.\n- def increment_optimizer_iteration():\n- if hasattr(optimizer, \"_iterations\") and optimizer._iterations is not None:\n- return optimizer._iterations.assign_add(1).op\n- return tf.no_op()\n-\n- with tf.control_dependencies([tf.group(*get_not_none_from_list(flattended_args0))]):\n+ with tf.control_dependencies([train_op]):\n+ # Increment global step on iterations where we don't call `apply_gradients()`.\n return tf.cond(\n pred=tf.equal(self.counter, 0),\n- true_fn=apply_grads_closure,\n- false_fn=increment_optimizer_iteration,\n+ true_fn=tf.no_op,\n+ false_fn=increment_global_step_counter,\n )\n", "issue": "Bug in global_step update when local gradient aggregation is used\n**Environment:**\r\n1. Framework: TensorFlow\r\n2. Framework version: 1.15.3\r\n3. Horovod version: 0.21.3\r\n4. MPI version: 3.1.6\r\n5. CUDA version: 11.0.194\r\n6. NCCL version: 2.7.6\r\n7. Python version: 3.6.9\r\n8. Spark / PySpark version:\r\n9. OS and version: \r\n10. GCC version:\r\n11. CMake version:\r\n\r\n**Bug report:**\r\nThere seems to be a bug in how the `global_step` variable is updated when using local gradient aggregation with `backward_passes_per_step>1`. \r\n\r\nHere is a simple example to reproduce the issue:\r\n```\r\nimport tensorflow as tf\r\nimport horovod.tensorflow as hvd\r\n\r\ntf.disable_eager_execution()\r\nLR=0.01\r\n# data/label is always just 1\r\ndata = tf.constant([[1]], dtype=tf.float32)\r\n# one-variable linear model, no bias (y = w*x)\r\n#\r\n# gradient update is hand-calculatable if needed for testing:\r\n#\r\n# model: yhat = w*x\r\n# mse loss: L = (ytrue - w*x)**2\r\n# gradient: dL/dw = -2*x*(ytrue - `w*x)`\r\n# let ytrue = x: dL/dw = -2*x*x*(1-w)\r\ndef predict(x):\r\n dense = tf.layers.Dense(1, use_bias=False, kernel_initializer=tf.zeros_initializer())\r\n return dense(x)\r\npred = predict(data)\r\nloss = tf.losses.mean_squared_error(data, pred)\r\nstep = tf.contrib.framework.get_or_create_global_step()\r\noptimizer = tf.train.GradientDescentOptimizer(LR)\r\nhvd.init()\r\noptimizer = hvd.DistributedOptimizer(optimizer, backward_passes_per_step=2, average_aggregated_gradients=True)\r\n\r\nwith tf.control_dependencies([tf.print(\"step:\", step, \"loss:\", loss)]):\r\n train_op = optimizer.minimize(loss, global_step=step)\r\nwith tf.Session() as sess:\r\n sess.run(tf.global_variables_initializer())\r\n sess.run(tf.local_variables_initializer())\r\n # training loop\r\n for i in range(10):\r\n sess.run([train_op])\r\n```\r\n\r\nWhich gives this output:\r\n```\r\nstep: 0 loss: 1\r\nstep: 0 loss: 1\r\nstep: 0 loss: 1\r\nstep: 2 loss: 0.960400045\r\nstep: 2 loss: 0.960400045\r\nstep: 4 loss: 0.922368109\r\nstep: 4 loss: 0.922368109\r\nstep: 6 loss: 0.885842443\r\nstep: 6 loss: 0.885842443\r\nstep: 8 loss: 0.850763\r\nstep: 8 loss: 0.850763\r\n```\r\n\r\n\r\n\n", "before_files": [{"content": "import tensorflow as tf\n\n\ndef apply_op_to_not_none_tensors(tensor_op, tensors, *args):\n return [\n tensor_op(\n tensor,\n *args\n ) if tensor is not None else tensor for tensor in tensors]\n\n\ndef get_not_none_from_list(tensor_list):\n return [x for x in tensor_list if x is not None]\n\n\nclass LocalGradientAggregationHelper:\n \"\"\"\n LocalGradientAggregationHelper aggregates gradient updates locally,\n and communicates the updates across machines only once every\n backward_passes_per_step. Only supports graph mode execution.\n \"\"\"\n\n _OPTIMIZER_TYPE_KERAS = \"optimizer_type_keras\"\n _OPTIMIZER_TYPE_LEGACY = \"optimizer_type_legacy\"\n\n def __init__(\n self,\n backward_passes_per_step,\n allreduce_func,\n sparse_as_dense,\n average_aggregated_gradients,\n rank,\n optimizer_type):\n self._allreduce_grads = allreduce_func\n\n # backward_passes_per_step controls how often gradient updates are\n # synchronized.\n self.backward_passes_per_step = backward_passes_per_step\n if self.backward_passes_per_step <= 0:\n raise ValueError(\"backward_passes_per_step must be > 0\")\n\n # average_aggregated_gradients controls whether gradient updates that are\n # aggregated, should be divided by `backward_passes_per_step`.\n self.average_aggregated_gradients = average_aggregated_gradients\n\n # This is going to be [N] data structure holding the aggregated gradient updates\n # N is the number of parameters.\n self.locally_aggregated_grads = []\n\n # Used to know when to allreduce and apply gradients. We allreduce when `self.counter`\n # is equal to `self.backward_passes_per_step`. We apply gradients when `self.counter` is\n # equal to 0.\n self.counter = None\n\n self.sparse_as_dense = sparse_as_dense\n self.rank = rank\n self.optimizer_type = optimizer_type\n\n # Contains the mapping of indexes of grad updates that are not None to their index in\n # locally_aggregated_grads which only contains not None gradients. When performing\n # gradient aggregation we have to remove them from the list of grads prior to passing\n # the list into a tf.cond().\n self.not_none_indexes = {}\n self.num_none_grad_updates = 0\n\n def _init_aggregation_vars(self, grads):\n \"\"\"\n Initializes the counter that is used when to communicate and aggregate gradients\n and the tensorflow variables that store the locally aggregated gradients.\n \"\"\"\n variable_scope_name = \"aggregation_variables_\" + str(self.rank)\n with tf.compat.v1.variable_scope(variable_scope_name, reuse=tf.compat.v1.AUTO_REUSE):\n self.counter = tf.compat.v1.get_variable(\n \"aggregation_counter\", shape=(), dtype=tf.int32,\n trainable=False, initializer=tf.compat.v1.zeros_initializer(),\n collections=[tf.compat.v1.GraphKeys.LOCAL_VARIABLES],\n )\n for idx, grad in enumerate(grads):\n # Handle IndexedSlices.\n if self.sparse_as_dense and isinstance(grad, tf.IndexedSlices):\n grad = tf.convert_to_tensor(grad)\n elif isinstance(grad, tf.IndexedSlices):\n raise ValueError(\n \"IndexedSlices are not supported when \"\n \"`backward_passes_per_step` > 1 and \"\n \"`sparse_as_dense` is False.\"\n )\n\n # Handle grads that are None.\n if grad is None:\n self.num_none_grad_updates += 1\n continue\n self.not_none_indexes[idx] = len(self.locally_aggregated_grads)\n\n # Create shadow variable.\n grad_aggregation_variable_name = str(idx)\n zero_grad = tf.zeros(shape=grad.get_shape().as_list(), dtype=grad.dtype)\n grad_aggregation_variable = tf.compat.v1.get_variable(\n grad_aggregation_variable_name,\n trainable=False,\n initializer=zero_grad,\n collections=[\n tf.compat.v1.GraphKeys.LOCAL_VARIABLES,\n \"aggregating_collection\"],\n )\n self.locally_aggregated_grads.append(grad_aggregation_variable)\n assert len(self.locally_aggregated_grads) + \\\n self.num_none_grad_updates == len(grads)\n\n # We expect to get a `sess` when we need to manually do a `sess.run(...)`\n # for the variables to be initialized. This is the `tf.keras`\n # optimizers.\n if self.optimizer_type == self._OPTIMIZER_TYPE_KERAS:\n session = tf.compat.v1.keras.backend.get_session(op_input_list=())\n vars_init_op = tf.compat.v1.variables_initializer(\n [self.counter, *get_not_none_from_list(self.locally_aggregated_grads)]\n )\n session.run(vars_init_op)\n\n def _clear_grads(self):\n clear_ops_list = []\n for idx, grad_aggregator in enumerate(self.locally_aggregated_grads):\n clear_op = grad_aggregator.assign(grad_aggregator.initial_value)\n clear_ops_list.append(clear_op)\n return tf.group(*clear_ops_list)\n\n def _aggregate_grads(self, grads):\n aggregation_ops_list = []\n grads = get_not_none_from_list(grads)\n assert len(grads) == len(self.locally_aggregated_grads)\n\n # Apply new gradient updates to the local copy.\n for idx, grad in enumerate(grads):\n if self.sparse_as_dense and isinstance(grad, tf.IndexedSlices):\n grad = tf.convert_to_tensor(grad)\n\n updated_grad_aggregator = self.locally_aggregated_grads[idx].assign_add(\n grad)\n aggregation_ops_list.append(updated_grad_aggregator)\n\n return aggregation_ops_list\n\n def _allreduce_grads_helper(self, grads, vars):\n # Read in latest variables values.\n aggregated_grads = []\n aggregation_read_ops_list = []\n for idx, locally_aggregated_grad in enumerate(\n self.locally_aggregated_grads):\n aggregated_grads.append(locally_aggregated_grad.read_value())\n aggregation_read_ops_list.append(aggregated_grads[idx])\n aggregation_read_ops = tf.group(*aggregation_read_ops_list)\n\n with tf.control_dependencies([aggregation_read_ops]):\n averaged_gradients = self._allreduce_grads(aggregated_grads, vars)\n\n # Reset counter.\n with tf.control_dependencies([g.op for g in averaged_gradients if g is not None]):\n reset_op = self.counter.assign(\n tf.constant(0), use_locking=True)\n\n # Divide by backward_passes_per_step if\n # average_aggregated_gradients is True.\n with tf.control_dependencies([reset_op]):\n gradient_divisor = self.backward_passes_per_step if \\\n self.average_aggregated_gradients else 1\n\n averaged_gradients = apply_op_to_not_none_tensors(\n tf.divide,\n averaged_gradients,\n gradient_divisor,\n )\n return averaged_gradients\n\n def compute_gradients(self, grads, vars):\n \"\"\"\n Applies the new gradient updates the locally aggregated gradients, and\n performs cross-machine communication every backward_passes_per_step\n times it is called.\n \"\"\"\n self._init_aggregation_vars(grads)\n\n # Clear the locally aggregated gradients when the counter is at zero.\n clear_op = tf.cond(\n pred=tf.equal(self.counter, 0),\n true_fn=lambda: self._clear_grads(),\n false_fn=tf.no_op\n )\n\n # Add new gradients to the locally aggregated gradients.\n with tf.control_dependencies([clear_op]):\n aggregation_ops_list = self._aggregate_grads(grads)\n\n # Increment the counter once new gradients have been applied.\n aggregation_ops = tf.group(*aggregation_ops_list)\n with tf.control_dependencies([aggregation_ops]):\n update_counter = self.counter.assign_add(tf.constant(1))\n\n with tf.control_dependencies([update_counter]):\n grads = get_not_none_from_list(grads)\n assert len(grads) == len(self.locally_aggregated_grads)\n\n # Allreduce locally aggregated gradients when the counter is equivalent to\n # `backward_passes_per_step`. This the condition is true, it also resets\n # the counter back to 0.\n allreduced_grads = tf.cond(\n tf.equal(self.counter, self.backward_passes_per_step),\n lambda: self._allreduce_grads_helper(grads, vars),\n lambda: grads,\n )\n\n # Handle case where there is only one variable.\n if not isinstance(allreduced_grads, (list, tuple)):\n allreduced_grads = (allreduced_grads,)\n assert len(allreduced_grads) == len(self.locally_aggregated_grads)\n\n # Insert gradients that are None back in.\n allreduced_grads = [\n allreduced_grads[self.not_none_indexes[idx]] if idx in self.not_none_indexes else None\n for idx in range(len(self.locally_aggregated_grads) + self.num_none_grad_updates)\n ]\n assert len(allreduced_grads) == len(\n self.locally_aggregated_grads) + self.num_none_grad_updates\n\n # If gradients have not been allreduced this batch, we return the gradients\n # that were submitted as the updates (the input).\n return allreduced_grads\n\n def apply_gradients(self, apply_grads_closure, optimizer, *args, **kwargs):\n \"\"\"\n Apply updates every backward_passes_per_step, which lines up with\n the batches on which we communicated the locally aggregated gradients.\n \"\"\"\n flattended_args0 = [item for tup in args[0] for item in tup]\n\n # Since we skip applying updates when the counter is not at zero we\n # still want to increment the global step if it is being tracked\n # (e.g., Tensorflow Estimators).\n def increment_global_step_counter():\n global_step_counter = tf.compat.v1.train.get_global_step()\n if global_step_counter is None:\n return tf.no_op()\n return global_step_counter.assign_add(\n tf.constant(1, dtype=tf.int64),\n use_locking=True,\n read_value=False\n )\n\n # Increment global step on iterations where we don't call `apply_gradients()`.\n cond_increment_global_step_counter = tf.cond(\n pred=tf.equal(self.counter, 0),\n true_fn=tf.no_op,\n false_fn=increment_global_step_counter,\n )\n flattended_args0.append(cond_increment_global_step_counter)\n\n # If optimizer tracks iterations, we increment it on steps where we\n # are not going to call `apply_gradients()`.\n def increment_optimizer_iteration():\n if hasattr(optimizer, \"_iterations\") and optimizer._iterations is not None:\n return optimizer._iterations.assign_add(1).op\n return tf.no_op()\n\n with tf.control_dependencies([tf.group(*get_not_none_from_list(flattended_args0))]):\n return tf.cond(\n pred=tf.equal(self.counter, 0),\n true_fn=apply_grads_closure,\n false_fn=increment_optimizer_iteration,\n )\n", "path": "horovod/tensorflow/gradient_aggregation.py"}], "after_files": [{"content": "import tensorflow as tf\n\n\ndef apply_op_to_not_none_tensors(tensor_op, tensors, *args):\n return [\n tensor_op(\n tensor,\n *args\n ) if tensor is not None else tensor for tensor in tensors]\n\n\ndef get_not_none_from_list(tensor_list):\n return [x for x in tensor_list if x is not None]\n\n\nclass LocalGradientAggregationHelper:\n \"\"\"\n LocalGradientAggregationHelper aggregates gradient updates locally,\n and communicates the updates across machines only once every\n backward_passes_per_step. Only supports graph mode execution.\n \"\"\"\n\n _OPTIMIZER_TYPE_KERAS = \"optimizer_type_keras\"\n _OPTIMIZER_TYPE_LEGACY = \"optimizer_type_legacy\"\n\n def __init__(\n self,\n backward_passes_per_step,\n allreduce_func,\n sparse_as_dense,\n average_aggregated_gradients,\n rank,\n optimizer_type):\n self._allreduce_grads = allreduce_func\n\n # backward_passes_per_step controls how often gradient updates are\n # synchronized.\n self.backward_passes_per_step = backward_passes_per_step\n if self.backward_passes_per_step <= 0:\n raise ValueError(\"backward_passes_per_step must be > 0\")\n\n # average_aggregated_gradients controls whether gradient updates that are\n # aggregated, should be divided by `backward_passes_per_step`.\n self.average_aggregated_gradients = average_aggregated_gradients\n\n # This is going to be [N] data structure holding the aggregated gradient updates\n # N is the number of parameters.\n self.locally_aggregated_grads = []\n\n # Used to know when to allreduce and apply gradients. We allreduce when `self.counter`\n # is equal to `self.backward_passes_per_step`. We apply gradients when `self.counter` is\n # equal to 0.\n self.counter = None\n\n self.sparse_as_dense = sparse_as_dense\n self.rank = rank\n self.optimizer_type = optimizer_type\n\n # Contains the mapping of indexes of grad updates that are not None to their index in\n # locally_aggregated_grads which only contains not None gradients. When performing\n # gradient aggregation we have to remove them from the list of grads prior to passing\n # the list into a tf.cond().\n self.not_none_indexes = {}\n self.num_none_grad_updates = 0\n\n def _init_aggregation_vars(self, grads):\n \"\"\"\n Initializes the counter that is used when to communicate and aggregate gradients\n and the tensorflow variables that store the locally aggregated gradients.\n \"\"\"\n variable_scope_name = \"aggregation_variables_\" + str(self.rank)\n with tf.compat.v1.variable_scope(variable_scope_name, reuse=tf.compat.v1.AUTO_REUSE):\n self.counter = tf.compat.v1.get_variable(\n \"aggregation_counter\", shape=(), dtype=tf.int32,\n trainable=False, initializer=tf.compat.v1.zeros_initializer(),\n collections=[tf.compat.v1.GraphKeys.LOCAL_VARIABLES],\n )\n for idx, grad in enumerate(grads):\n # Handle IndexedSlices.\n if self.sparse_as_dense and isinstance(grad, tf.IndexedSlices):\n grad = tf.convert_to_tensor(grad)\n elif isinstance(grad, tf.IndexedSlices):\n raise ValueError(\n \"IndexedSlices are not supported when \"\n \"`backward_passes_per_step` > 1 and \"\n \"`sparse_as_dense` is False.\"\n )\n\n # Handle grads that are None.\n if grad is None:\n self.num_none_grad_updates += 1\n continue\n self.not_none_indexes[idx] = len(self.locally_aggregated_grads)\n\n # Create shadow variable.\n grad_aggregation_variable_name = str(idx)\n zero_grad = tf.zeros(shape=grad.get_shape().as_list(), dtype=grad.dtype)\n grad_aggregation_variable = tf.compat.v1.get_variable(\n grad_aggregation_variable_name,\n trainable=False,\n initializer=zero_grad,\n collections=[\n tf.compat.v1.GraphKeys.LOCAL_VARIABLES,\n \"aggregating_collection\"],\n )\n self.locally_aggregated_grads.append(grad_aggregation_variable)\n assert len(self.locally_aggregated_grads) + \\\n self.num_none_grad_updates == len(grads)\n\n # We expect to get a `sess` when we need to manually do a `sess.run(...)`\n # for the variables to be initialized. This is the `tf.keras`\n # optimizers.\n if self.optimizer_type == self._OPTIMIZER_TYPE_KERAS:\n session = tf.compat.v1.keras.backend.get_session(op_input_list=())\n vars_init_op = tf.compat.v1.variables_initializer(\n [self.counter, *get_not_none_from_list(self.locally_aggregated_grads)]\n )\n session.run(vars_init_op)\n\n def _clear_grads(self):\n clear_ops_list = []\n for idx, grad_aggregator in enumerate(self.locally_aggregated_grads):\n clear_op = grad_aggregator.assign(grad_aggregator.initial_value)\n clear_ops_list.append(clear_op)\n return tf.group(*clear_ops_list)\n\n def _aggregate_grads(self, grads):\n aggregation_ops_list = []\n grads = get_not_none_from_list(grads)\n assert len(grads) == len(self.locally_aggregated_grads)\n\n # Apply new gradient updates to the local copy.\n for idx, grad in enumerate(grads):\n if self.sparse_as_dense and isinstance(grad, tf.IndexedSlices):\n grad = tf.convert_to_tensor(grad)\n\n updated_grad_aggregator = self.locally_aggregated_grads[idx].assign_add(\n grad)\n aggregation_ops_list.append(updated_grad_aggregator)\n\n return aggregation_ops_list\n\n def _allreduce_grads_helper(self, grads, vars):\n # Read in latest variables values.\n aggregated_grads = []\n aggregation_read_ops_list = []\n for idx, locally_aggregated_grad in enumerate(\n self.locally_aggregated_grads):\n aggregated_grads.append(locally_aggregated_grad.read_value())\n aggregation_read_ops_list.append(aggregated_grads[idx])\n aggregation_read_ops = tf.group(*aggregation_read_ops_list)\n\n with tf.control_dependencies([aggregation_read_ops]):\n averaged_gradients = self._allreduce_grads(aggregated_grads, vars)\n\n # Reset counter.\n with tf.control_dependencies([g.op for g in averaged_gradients if g is not None]):\n reset_op = self.counter.assign(\n tf.constant(0), use_locking=True)\n\n # Divide by backward_passes_per_step if\n # average_aggregated_gradients is True.\n with tf.control_dependencies([reset_op]):\n gradient_divisor = self.backward_passes_per_step if \\\n self.average_aggregated_gradients else 1\n\n averaged_gradients = apply_op_to_not_none_tensors(\n tf.divide,\n averaged_gradients,\n gradient_divisor,\n )\n return averaged_gradients\n\n def compute_gradients(self, grads, vars):\n \"\"\"\n Applies the new gradient updates the locally aggregated gradients, and\n performs cross-machine communication every backward_passes_per_step\n times it is called.\n \"\"\"\n self._init_aggregation_vars(grads)\n\n # Clear the locally aggregated gradients when the counter is at zero.\n clear_op = tf.cond(\n pred=tf.equal(self.counter, 0),\n true_fn=lambda: self._clear_grads(),\n false_fn=tf.no_op\n )\n\n # Add new gradients to the locally aggregated gradients.\n with tf.control_dependencies([clear_op]):\n aggregation_ops_list = self._aggregate_grads(grads)\n\n # Increment the counter once new gradients have been applied.\n aggregation_ops = tf.group(*aggregation_ops_list)\n with tf.control_dependencies([aggregation_ops]):\n update_counter = self.counter.assign_add(tf.constant(1))\n\n with tf.control_dependencies([update_counter]):\n grads = get_not_none_from_list(grads)\n assert len(grads) == len(self.locally_aggregated_grads)\n\n # Allreduce locally aggregated gradients when the counter is equivalent to\n # `backward_passes_per_step`. This the condition is true, it also resets\n # the counter back to 0.\n allreduced_grads = tf.cond(\n tf.equal(self.counter, self.backward_passes_per_step),\n lambda: self._allreduce_grads_helper(grads, vars),\n lambda: grads,\n )\n\n # Handle case where there is only one variable.\n if not isinstance(allreduced_grads, (list, tuple)):\n allreduced_grads = (allreduced_grads,)\n assert len(allreduced_grads) == len(self.locally_aggregated_grads)\n\n # Insert gradients that are None back in.\n allreduced_grads = [\n allreduced_grads[self.not_none_indexes[idx]] if idx in self.not_none_indexes else None\n for idx in range(len(self.locally_aggregated_grads) + self.num_none_grad_updates)\n ]\n assert len(allreduced_grads) == len(\n self.locally_aggregated_grads) + self.num_none_grad_updates\n\n # If gradients have not been allreduced this batch, we return the gradients\n # that were submitted as the updates (the input).\n return allreduced_grads\n\n def apply_gradients(self, apply_grads_closure, optimizer, *args, **kwargs):\n \"\"\"\n Apply updates every backward_passes_per_step, which lines up with\n the batches on which we communicated the locally aggregated gradients.\n \"\"\"\n flattended_args0 = [item for tup in args[0] for item in tup]\n\n # If optimizer tracks iterations, we increment it on steps where we\n # are not going to call `apply_gradients()`.\n def increment_optimizer_iteration():\n if hasattr(optimizer, \"_iterations\") and optimizer._iterations is not None:\n return optimizer._iterations.assign_add(1).op\n return tf.no_op()\n\n with tf.control_dependencies([tf.group(*get_not_none_from_list(flattended_args0))]):\n train_op = tf.cond(\n pred=tf.equal(self.counter, 0),\n true_fn=apply_grads_closure,\n false_fn=increment_optimizer_iteration,\n )\n\n # Since we skip applying updates when the counter is not at zero we\n # still want to increment the global step if it is being tracked\n # (e.g., Tensorflow Estimators).\n def increment_global_step_counter():\n global_step_counter = tf.compat.v1.train.get_global_step()\n if global_step_counter is None:\n return tf.no_op()\n return global_step_counter.assign_add(\n tf.constant(1, dtype=tf.int64),\n use_locking=True,\n read_value=False\n )\n\n with tf.control_dependencies([train_op]):\n # Increment global step on iterations where we don't call `apply_gradients()`.\n return tf.cond(\n pred=tf.equal(self.counter, 0),\n true_fn=tf.no_op,\n false_fn=increment_global_step_counter,\n )\n", "path": "horovod/tensorflow/gradient_aggregation.py"}]}
| 3,994 | 553 |
gh_patches_debug_31494
|
rasdani/github-patches
|
git_diff
|
pyjanitor-devs__pyjanitor-1216
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[DOC] Missing Pyjanitor description on PyPi
# Brief Description of Fix
Since `pyjanitor` release `0.22.0`, there has not been a ["Project description" for the package on PyPi](https://pypi.org/project/pyjanitor/0.22.0/#description).
During the release of of `0.24.0`, @samukweku and I got an error during the release process due to:
```
Checking dist/pyjanitor-0.24.0-py3-none-any.whl: FAILED
ERROR `long_description` has syntax errors in markup and would not be
rendered on PyPI.
No content rendered from RST source.
```
Our guess is that we had switched the README from RST to MD some time ago, causing the `long_description` to quietly fail, and now the `gh-action-pypi-publish` GitHub action would no longer accept the bad `long_description`.
We updated the `long_description_content_type` in `setup.py` to markdown in #1197 and the package was successfully published to PyPi, but there is still no Project description. So there must still be something that is not being generated correctly.
We need to verify that `long_description` is properly being generated. We should test with local tools *and* https://test.pypi.org/ to verify that this is fixed.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 """Setup script."""
2 import codecs
3 import os
4 import re
5 from pathlib import Path
6 from pprint import pprint
7
8 from setuptools import find_packages, setup
9
10 HERE = os.path.abspath(os.path.dirname(__file__))
11
12
13 def read(*parts):
14 # intentionally *not* adding an encoding option to open
15 return codecs.open(os.path.join(HERE, *parts), "r").read()
16
17
18 def read_requirements(*parts):
19 """
20 Return requirements from parts.
21
22 Given a requirements.txt (or similar style file),
23 returns a list of requirements.
24 Assumes anything after a single '#' on a line is a comment, and ignores
25 empty lines.
26
27 :param parts: list of filenames which contain the installation "parts",
28 i.e. submodule-specific installation requirements
29 :returns: A compiled list of requirements.
30 """
31 requirements = []
32 for line in read(*parts).splitlines():
33 new_line = re.sub( # noqa: PD005
34 r"(\s*)?#.*$", # the space immediately before the
35 # hash mark, the hash mark, and
36 # anything that follows it
37 "", # replace with a blank string
38 line,
39 )
40 new_line = re.sub( # noqa: PD005
41 r"-r.*$", # link to another requirement file
42 "", # replace with a blank string
43 new_line,
44 )
45 new_line = re.sub( # noqa: PD005
46 r"-e \..*$", # link to editable install
47 "", # replace with a blank string
48 new_line,
49 )
50 # print(line, "-->", new_line)
51 if new_line: # i.e. we have a non-zero-length string
52 requirements.append(new_line)
53 return requirements
54
55
56 # pull from requirements.IN, requirements.TXT is generated from this
57 INSTALL_REQUIRES = read_requirements(".requirements/base.in")
58
59 EXTRA_REQUIRES = {
60 "dev": read_requirements(".requirements/dev.in"),
61 "docs": read_requirements(".requirements/docs.in"),
62 "test": read_requirements(".requirements/testing.in"),
63 "biology": read_requirements(".requirements/biology.in"),
64 "chemistry": read_requirements(".requirements/chemistry.in"),
65 "engineering": read_requirements(".requirements/engineering.in"),
66 "spark": read_requirements(".requirements/spark.in"),
67 }
68
69 # add 'all' key to EXTRA_REQUIRES
70 all_requires = []
71 for k, v in EXTRA_REQUIRES.items():
72 all_requires.extend(v)
73 EXTRA_REQUIRES["all"] = set(all_requires)
74
75 for k1 in ["biology", "chemistry", "engineering", "spark"]:
76 for v2 in EXTRA_REQUIRES[k1]:
77 EXTRA_REQUIRES["docs"].append(v2)
78
79 pprint(EXTRA_REQUIRES)
80
81
82 def generate_long_description() -> str:
83 """
84 Extra chunks from README for PyPI description.
85
86 Target chunks must be contained within `.. pypi-doc` pair comments,
87 so there must be an even number of comments in README.
88
89 :returns: Extracted description from README.
90 :raises Exception: if odd number of `.. pypi-doc` comments
91 in README.
92 """
93 # Read the contents of README file
94 this_directory = Path(__file__).parent
95 with open(this_directory / "mkdocs" / "index.md", encoding="utf-8") as f:
96 readme = f.read()
97
98 # Find pypi-doc comments in README
99 indices = [m.start() for m in re.finditer(".. pypi-doc", readme)]
100 if len(indices) % 2 != 0:
101 raise Exception("Odd number of `.. pypi-doc` comments in README")
102
103 # Loop through pairs of comments and save text between pairs
104 long_description = ""
105 for i in range(0, len(indices), 2):
106 start_index = indices[i] + 11
107 end_index = indices[i + 1]
108 long_description += readme[start_index:end_index]
109 return long_description
110
111
112 setup(
113 name="pyjanitor",
114 version="0.24.0",
115 description="Tools for cleaning pandas DataFrames",
116 author="pyjanitor devs",
117 author_email="[email protected]",
118 url="https://github.com/pyjanitor-devs/pyjanitor",
119 license="MIT",
120 # packages=["janitor", "janitor.xarray", "janitor.spark"],
121 packages=find_packages(),
122 install_requires=INSTALL_REQUIRES,
123 extras_require=EXTRA_REQUIRES,
124 python_requires=">=3.6",
125 long_description=generate_long_description(),
126 long_description_content_type="text/markdown",
127 )
128
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -68,7 +68,7 @@
# add 'all' key to EXTRA_REQUIRES
all_requires = []
-for k, v in EXTRA_REQUIRES.items():
+for _, v in EXTRA_REQUIRES.items():
all_requires.extend(v)
EXTRA_REQUIRES["all"] = set(all_requires)
@@ -83,11 +83,11 @@
"""
Extra chunks from README for PyPI description.
- Target chunks must be contained within `.. pypi-doc` pair comments,
+ Target chunks must be contained within `<!-- pypi-doc -->` pair comments,
so there must be an even number of comments in README.
:returns: Extracted description from README.
- :raises Exception: if odd number of `.. pypi-doc` comments
+ :raises Exception: If odd number of `<!-- pypi-doc -->` comments
in README.
"""
# Read the contents of README file
@@ -96,14 +96,15 @@
readme = f.read()
# Find pypi-doc comments in README
- indices = [m.start() for m in re.finditer(".. pypi-doc", readme)]
+ boundary = r"<!-- pypi-doc -->"
+ indices = [m.start() for m in re.finditer(boundary, readme)]
if len(indices) % 2 != 0:
- raise Exception("Odd number of `.. pypi-doc` comments in README")
+ raise Exception(f"Odd number of `{boundary}` comments in README")
# Loop through pairs of comments and save text between pairs
long_description = ""
for i in range(0, len(indices), 2):
- start_index = indices[i] + 11
+ start_index = indices[i] + len(boundary)
end_index = indices[i + 1]
long_description += readme[start_index:end_index]
return long_description
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -68,7 +68,7 @@\n \n # add 'all' key to EXTRA_REQUIRES\n all_requires = []\n-for k, v in EXTRA_REQUIRES.items():\n+for _, v in EXTRA_REQUIRES.items():\n all_requires.extend(v)\n EXTRA_REQUIRES[\"all\"] = set(all_requires)\n \n@@ -83,11 +83,11 @@\n \"\"\"\n Extra chunks from README for PyPI description.\n \n- Target chunks must be contained within `.. pypi-doc` pair comments,\n+ Target chunks must be contained within `<!-- pypi-doc -->` pair comments,\n so there must be an even number of comments in README.\n \n :returns: Extracted description from README.\n- :raises Exception: if odd number of `.. pypi-doc` comments\n+ :raises Exception: If odd number of `<!-- pypi-doc -->` comments\n in README.\n \"\"\"\n # Read the contents of README file\n@@ -96,14 +96,15 @@\n readme = f.read()\n \n # Find pypi-doc comments in README\n- indices = [m.start() for m in re.finditer(\".. pypi-doc\", readme)]\n+ boundary = r\"<!-- pypi-doc -->\"\n+ indices = [m.start() for m in re.finditer(boundary, readme)]\n if len(indices) % 2 != 0:\n- raise Exception(\"Odd number of `.. pypi-doc` comments in README\")\n+ raise Exception(f\"Odd number of `{boundary}` comments in README\")\n \n # Loop through pairs of comments and save text between pairs\n long_description = \"\"\n for i in range(0, len(indices), 2):\n- start_index = indices[i] + 11\n+ start_index = indices[i] + len(boundary)\n end_index = indices[i + 1]\n long_description += readme[start_index:end_index]\n return long_description\n", "issue": "[DOC] Missing Pyjanitor description on PyPi\n# Brief Description of Fix\r\n\r\nSince `pyjanitor` release `0.22.0`, there has not been a [\"Project description\" for the package on PyPi](https://pypi.org/project/pyjanitor/0.22.0/#description).\r\n\r\nDuring the release of of `0.24.0`, @samukweku and I got an error during the release process due to:\r\n\r\n```\r\nChecking dist/pyjanitor-0.24.0-py3-none-any.whl: FAILED\r\nERROR `long_description` has syntax errors in markup and would not be \r\n rendered on PyPI. \r\n No content rendered from RST source. \r\n```\r\nOur guess is that we had switched the README from RST to MD some time ago, causing the `long_description` to quietly fail, and now the `gh-action-pypi-publish` GitHub action would no longer accept the bad `long_description`.\r\n\r\nWe updated the `long_description_content_type` in `setup.py` to markdown in #1197 and the package was successfully published to PyPi, but there is still no Project description. So there must still be something that is not being generated correctly.\r\n\r\nWe need to verify that `long_description` is properly being generated. We should test with local tools *and* https://test.pypi.org/ to verify that this is fixed.\n", "before_files": [{"content": "\"\"\"Setup script.\"\"\"\nimport codecs\nimport os\nimport re\nfrom pathlib import Path\nfrom pprint import pprint\n\nfrom setuptools import find_packages, setup\n\nHERE = os.path.abspath(os.path.dirname(__file__))\n\n\ndef read(*parts):\n # intentionally *not* adding an encoding option to open\n return codecs.open(os.path.join(HERE, *parts), \"r\").read()\n\n\ndef read_requirements(*parts):\n \"\"\"\n Return requirements from parts.\n\n Given a requirements.txt (or similar style file),\n returns a list of requirements.\n Assumes anything after a single '#' on a line is a comment, and ignores\n empty lines.\n\n :param parts: list of filenames which contain the installation \"parts\",\n i.e. submodule-specific installation requirements\n :returns: A compiled list of requirements.\n \"\"\"\n requirements = []\n for line in read(*parts).splitlines():\n new_line = re.sub( # noqa: PD005\n r\"(\\s*)?#.*$\", # the space immediately before the\n # hash mark, the hash mark, and\n # anything that follows it\n \"\", # replace with a blank string\n line,\n )\n new_line = re.sub( # noqa: PD005\n r\"-r.*$\", # link to another requirement file\n \"\", # replace with a blank string\n new_line,\n )\n new_line = re.sub( # noqa: PD005\n r\"-e \\..*$\", # link to editable install\n \"\", # replace with a blank string\n new_line,\n )\n # print(line, \"-->\", new_line)\n if new_line: # i.e. we have a non-zero-length string\n requirements.append(new_line)\n return requirements\n\n\n# pull from requirements.IN, requirements.TXT is generated from this\nINSTALL_REQUIRES = read_requirements(\".requirements/base.in\")\n\nEXTRA_REQUIRES = {\n \"dev\": read_requirements(\".requirements/dev.in\"),\n \"docs\": read_requirements(\".requirements/docs.in\"),\n \"test\": read_requirements(\".requirements/testing.in\"),\n \"biology\": read_requirements(\".requirements/biology.in\"),\n \"chemistry\": read_requirements(\".requirements/chemistry.in\"),\n \"engineering\": read_requirements(\".requirements/engineering.in\"),\n \"spark\": read_requirements(\".requirements/spark.in\"),\n}\n\n# add 'all' key to EXTRA_REQUIRES\nall_requires = []\nfor k, v in EXTRA_REQUIRES.items():\n all_requires.extend(v)\nEXTRA_REQUIRES[\"all\"] = set(all_requires)\n\nfor k1 in [\"biology\", \"chemistry\", \"engineering\", \"spark\"]:\n for v2 in EXTRA_REQUIRES[k1]:\n EXTRA_REQUIRES[\"docs\"].append(v2)\n\npprint(EXTRA_REQUIRES)\n\n\ndef generate_long_description() -> str:\n \"\"\"\n Extra chunks from README for PyPI description.\n\n Target chunks must be contained within `.. pypi-doc` pair comments,\n so there must be an even number of comments in README.\n\n :returns: Extracted description from README.\n :raises Exception: if odd number of `.. pypi-doc` comments\n in README.\n \"\"\"\n # Read the contents of README file\n this_directory = Path(__file__).parent\n with open(this_directory / \"mkdocs\" / \"index.md\", encoding=\"utf-8\") as f:\n readme = f.read()\n\n # Find pypi-doc comments in README\n indices = [m.start() for m in re.finditer(\".. pypi-doc\", readme)]\n if len(indices) % 2 != 0:\n raise Exception(\"Odd number of `.. pypi-doc` comments in README\")\n\n # Loop through pairs of comments and save text between pairs\n long_description = \"\"\n for i in range(0, len(indices), 2):\n start_index = indices[i] + 11\n end_index = indices[i + 1]\n long_description += readme[start_index:end_index]\n return long_description\n\n\nsetup(\n name=\"pyjanitor\",\n version=\"0.24.0\",\n description=\"Tools for cleaning pandas DataFrames\",\n author=\"pyjanitor devs\",\n author_email=\"[email protected]\",\n url=\"https://github.com/pyjanitor-devs/pyjanitor\",\n license=\"MIT\",\n # packages=[\"janitor\", \"janitor.xarray\", \"janitor.spark\"],\n packages=find_packages(),\n install_requires=INSTALL_REQUIRES,\n extras_require=EXTRA_REQUIRES,\n python_requires=\">=3.6\",\n long_description=generate_long_description(),\n long_description_content_type=\"text/markdown\",\n)\n", "path": "setup.py"}], "after_files": [{"content": "\"\"\"Setup script.\"\"\"\nimport codecs\nimport os\nimport re\nfrom pathlib import Path\nfrom pprint import pprint\n\nfrom setuptools import find_packages, setup\n\nHERE = os.path.abspath(os.path.dirname(__file__))\n\n\ndef read(*parts):\n # intentionally *not* adding an encoding option to open\n return codecs.open(os.path.join(HERE, *parts), \"r\").read()\n\n\ndef read_requirements(*parts):\n \"\"\"\n Return requirements from parts.\n\n Given a requirements.txt (or similar style file),\n returns a list of requirements.\n Assumes anything after a single '#' on a line is a comment, and ignores\n empty lines.\n\n :param parts: list of filenames which contain the installation \"parts\",\n i.e. submodule-specific installation requirements\n :returns: A compiled list of requirements.\n \"\"\"\n requirements = []\n for line in read(*parts).splitlines():\n new_line = re.sub( # noqa: PD005\n r\"(\\s*)?#.*$\", # the space immediately before the\n # hash mark, the hash mark, and\n # anything that follows it\n \"\", # replace with a blank string\n line,\n )\n new_line = re.sub( # noqa: PD005\n r\"-r.*$\", # link to another requirement file\n \"\", # replace with a blank string\n new_line,\n )\n new_line = re.sub( # noqa: PD005\n r\"-e \\..*$\", # link to editable install\n \"\", # replace with a blank string\n new_line,\n )\n # print(line, \"-->\", new_line)\n if new_line: # i.e. we have a non-zero-length string\n requirements.append(new_line)\n return requirements\n\n\n# pull from requirements.IN, requirements.TXT is generated from this\nINSTALL_REQUIRES = read_requirements(\".requirements/base.in\")\n\nEXTRA_REQUIRES = {\n \"dev\": read_requirements(\".requirements/dev.in\"),\n \"docs\": read_requirements(\".requirements/docs.in\"),\n \"test\": read_requirements(\".requirements/testing.in\"),\n \"biology\": read_requirements(\".requirements/biology.in\"),\n \"chemistry\": read_requirements(\".requirements/chemistry.in\"),\n \"engineering\": read_requirements(\".requirements/engineering.in\"),\n \"spark\": read_requirements(\".requirements/spark.in\"),\n}\n\n# add 'all' key to EXTRA_REQUIRES\nall_requires = []\nfor _, v in EXTRA_REQUIRES.items():\n all_requires.extend(v)\nEXTRA_REQUIRES[\"all\"] = set(all_requires)\n\nfor k1 in [\"biology\", \"chemistry\", \"engineering\", \"spark\"]:\n for v2 in EXTRA_REQUIRES[k1]:\n EXTRA_REQUIRES[\"docs\"].append(v2)\n\npprint(EXTRA_REQUIRES)\n\n\ndef generate_long_description() -> str:\n \"\"\"\n Extra chunks from README for PyPI description.\n\n Target chunks must be contained within `<!-- pypi-doc -->` pair comments,\n so there must be an even number of comments in README.\n\n :returns: Extracted description from README.\n :raises Exception: If odd number of `<!-- pypi-doc -->` comments\n in README.\n \"\"\"\n # Read the contents of README file\n this_directory = Path(__file__).parent\n with open(this_directory / \"mkdocs\" / \"index.md\", encoding=\"utf-8\") as f:\n readme = f.read()\n\n # Find pypi-doc comments in README\n boundary = r\"<!-- pypi-doc -->\"\n indices = [m.start() for m in re.finditer(boundary, readme)]\n if len(indices) % 2 != 0:\n raise Exception(f\"Odd number of `{boundary}` comments in README\")\n\n # Loop through pairs of comments and save text between pairs\n long_description = \"\"\n for i in range(0, len(indices), 2):\n start_index = indices[i] + len(boundary)\n end_index = indices[i + 1]\n long_description += readme[start_index:end_index]\n return long_description\n\n\nsetup(\n name=\"pyjanitor\",\n version=\"0.24.0\",\n description=\"Tools for cleaning pandas DataFrames\",\n author=\"pyjanitor devs\",\n author_email=\"[email protected]\",\n url=\"https://github.com/pyjanitor-devs/pyjanitor\",\n license=\"MIT\",\n # packages=[\"janitor\", \"janitor.xarray\", \"janitor.spark\"],\n packages=find_packages(),\n install_requires=INSTALL_REQUIRES,\n extras_require=EXTRA_REQUIRES,\n python_requires=\">=3.6\",\n long_description=generate_long_description(),\n long_description_content_type=\"text/markdown\",\n)\n", "path": "setup.py"}]}
| 1,829 | 437 |
gh_patches_debug_1208
|
rasdani/github-patches
|
git_diff
|
OCA__server-tools-464
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
runbot 9.0 red due to letsencrypt?
Hi,
It seems the 9.0 branch is red on runbot due to the letsencrypt module?
```
Call of self.pool.get('letsencrypt').cron(cr, uid, *()) failed in Job 2
Traceback (most recent call last):
File "/srv/openerp/instances/openerp-oca-runbot/parts/odoo-extra/runbot/static/build/3148182-9-0-209efa/openerp/addons/base/ir/ir_cron.py", line 129, in _callback
getattr(model, method_name)(cr, uid, *args)
File "/srv/openerp/instances/openerp-oca-runbot/parts/odoo-extra/runbot/static/build/3148182-9-0-209efa/openerp/api.py", line 250, in wrapper
return old_api(self, *args, **kwargs)
File "/srv/openerp/instances/openerp-oca-runbot/parts/odoo-extra/runbot/static/build/3148182-9-0-209efa/openerp/api.py", line 354, in old_api
result = method(recs, *args, **kwargs)
File "/srv/openerp/instances/openerp-oca-runbot/parts/odoo-extra/runbot/static/build/3148182-9-0-209efa/openerp/addons/letsencrypt/models/letsencrypt.py", line 151, in cron
account_key, csr, acme_challenge, log=_logger, CA=DEFAULT_CA)
File "/srv/openerp/instances/openerp-oca-runbot/sandbox/local/lib/python2.7/site-packages/acme_tiny.py", line 104, in get_crt
raise ValueError("Error requesting challenges: {0} {1}".format(code, result))
ValueError: Error requesting challenges: 400 {
"type": "urn:acme:error:malformed",
"detail": "Error creating new authz :: Invalid character in DNS name",
"status": 400
}
```
@hbrunn
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `letsencrypt/__openerp__.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # © 2016 Therp BV <http://therp.nl>
3 # License AGPL-3.0 or later (http://www.gnu.org/licenses/agpl.html).
4 {
5 "name": "Let's encrypt",
6 "version": "9.0.1.0.0",
7 "author": "Therp BV,"
8 "Tecnativa,"
9 "Odoo Community Association (OCA)",
10 "license": "AGPL-3",
11 "category": "Hidden/Dependency",
12 "summary": "Request SSL certificates from letsencrypt.org",
13 "depends": [
14 'base',
15 ],
16 "data": [
17 "data/ir_config_parameter.xml",
18 "data/ir_cron.xml",
19 ],
20 "post_init_hook": 'post_init_hook',
21 "installable": True,
22 "external_dependencies": {
23 'bin': [
24 'openssl',
25 ],
26 'python': [
27 'acme_tiny',
28 'IPy',
29 ],
30 },
31 }
32
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/letsencrypt/__openerp__.py b/letsencrypt/__openerp__.py
--- a/letsencrypt/__openerp__.py
+++ b/letsencrypt/__openerp__.py
@@ -16,6 +16,7 @@
"data": [
"data/ir_config_parameter.xml",
"data/ir_cron.xml",
+ "demo/ir_cron.xml",
],
"post_init_hook": 'post_init_hook',
"installable": True,
|
{"golden_diff": "diff --git a/letsencrypt/__openerp__.py b/letsencrypt/__openerp__.py\n--- a/letsencrypt/__openerp__.py\n+++ b/letsencrypt/__openerp__.py\n@@ -16,6 +16,7 @@\n \"data\": [\n \"data/ir_config_parameter.xml\",\n \"data/ir_cron.xml\",\n+ \"demo/ir_cron.xml\",\n ],\n \"post_init_hook\": 'post_init_hook',\n \"installable\": True,\n", "issue": "runbot 9.0 red due to letsencrypt?\nHi,\n\nIt seems the 9.0 branch is red on runbot due to the letsencrypt module?\n\n```\nCall of self.pool.get('letsencrypt').cron(cr, uid, *()) failed in Job 2\nTraceback (most recent call last):\n File \"/srv/openerp/instances/openerp-oca-runbot/parts/odoo-extra/runbot/static/build/3148182-9-0-209efa/openerp/addons/base/ir/ir_cron.py\", line 129, in _callback\n getattr(model, method_name)(cr, uid, *args)\n File \"/srv/openerp/instances/openerp-oca-runbot/parts/odoo-extra/runbot/static/build/3148182-9-0-209efa/openerp/api.py\", line 250, in wrapper\n return old_api(self, *args, **kwargs)\n File \"/srv/openerp/instances/openerp-oca-runbot/parts/odoo-extra/runbot/static/build/3148182-9-0-209efa/openerp/api.py\", line 354, in old_api\n result = method(recs, *args, **kwargs)\n File \"/srv/openerp/instances/openerp-oca-runbot/parts/odoo-extra/runbot/static/build/3148182-9-0-209efa/openerp/addons/letsencrypt/models/letsencrypt.py\", line 151, in cron\n account_key, csr, acme_challenge, log=_logger, CA=DEFAULT_CA)\n File \"/srv/openerp/instances/openerp-oca-runbot/sandbox/local/lib/python2.7/site-packages/acme_tiny.py\", line 104, in get_crt\n raise ValueError(\"Error requesting challenges: {0} {1}\".format(code, result))\nValueError: Error requesting challenges: 400 {\n \"type\": \"urn:acme:error:malformed\",\n \"detail\": \"Error creating new authz :: Invalid character in DNS name\",\n \"status\": 400\n}\n```\n\n@hbrunn \n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# \u00a9 2016 Therp BV <http://therp.nl>\n# License AGPL-3.0 or later (http://www.gnu.org/licenses/agpl.html).\n{\n \"name\": \"Let's encrypt\",\n \"version\": \"9.0.1.0.0\",\n \"author\": \"Therp BV,\"\n \"Tecnativa,\"\n \"Odoo Community Association (OCA)\",\n \"license\": \"AGPL-3\",\n \"category\": \"Hidden/Dependency\",\n \"summary\": \"Request SSL certificates from letsencrypt.org\",\n \"depends\": [\n 'base',\n ],\n \"data\": [\n \"data/ir_config_parameter.xml\",\n \"data/ir_cron.xml\",\n ],\n \"post_init_hook\": 'post_init_hook',\n \"installable\": True,\n \"external_dependencies\": {\n 'bin': [\n 'openssl',\n ],\n 'python': [\n 'acme_tiny',\n 'IPy',\n ],\n },\n}\n", "path": "letsencrypt/__openerp__.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# \u00a9 2016 Therp BV <http://therp.nl>\n# License AGPL-3.0 or later (http://www.gnu.org/licenses/agpl.html).\n{\n \"name\": \"Let's encrypt\",\n \"version\": \"9.0.1.0.0\",\n \"author\": \"Therp BV,\"\n \"Tecnativa,\"\n \"Odoo Community Association (OCA)\",\n \"license\": \"AGPL-3\",\n \"category\": \"Hidden/Dependency\",\n \"summary\": \"Request SSL certificates from letsencrypt.org\",\n \"depends\": [\n 'base',\n ],\n \"data\": [\n \"data/ir_config_parameter.xml\",\n \"data/ir_cron.xml\",\n \"demo/ir_cron.xml\",\n ],\n \"post_init_hook\": 'post_init_hook',\n \"installable\": True,\n \"external_dependencies\": {\n 'bin': [\n 'openssl',\n ],\n 'python': [\n 'acme_tiny',\n 'IPy',\n ],\n },\n}\n", "path": "letsencrypt/__openerp__.py"}]}
| 1,034 | 113 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.