
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_31412 | rasdani/github-patches | git_diff | nonebot__nonebot2-539 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: event_postprocessor 不能在 matcher 运行后正常执行
**描述问题:**
event_postprocessor 不能在 matcher 运行后正常执行
**如何复现?**
编写以下插件
```python
from nonebot import on_command, logger
from nonebot.message import event_postprocessor
from nonebot.typing import T_State
from nonebot.adapters.cqhttp.event import Event, MessageEvent
from nonebot.adapters.cqhttp.bot import Bot
test = on_command('test')
@test.handle()
async def handle_test(bot: Bot, event: MessageEvent, state: T_State):
logger.opt(colors=True).info('<ly>matcher is running!</ly>')
@event_postprocessor
async def handle_event_postprocessor(bot: Bot, event: Event, state: T_State):
logger.opt(colors=True).success('<ly>event_postprocessor is running!</ly>')
```
**期望的结果**
event_postprocessor 能在任意情况下正常执行
实际上当 matcher 运行后 event_postprocessor 会被跳过
**其他信息**
第 250 行 `return result` 将直接导致 matcher 运行后 event_postprocessor 被跳过
https://github.com/nonebot/nonebot2/blob/0b35d5e724a2fc7fc1e7d90499aea8a9c27e821d/nonebot/message.py#L238-L262
**环境信息:**
- OS: Windows 10 21H1
- Python Version: 3.9.6
- Nonebot Version: 2.0.0a15
**协议端信息:**
- 协议端: 无
- 协议端版本: 无
**截图或日志**
如上
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nonebot/message.py`
Content:
```
1 """
2 事件处理
3 ========
4
5 NoneBot 内部处理并按优先级分发事件给所有事件响应器,提供了多个插槽以进行事件的预处理等。
6 """
7
8 import asyncio
9 from datetime import datetime
10 from typing import TYPE_CHECKING, Set, Type, Optional
11
12 from nonebot.log import logger
13 from nonebot.rule import TrieRule
14 from nonebot.utils import escape_tag
15 from nonebot.matcher import Matcher, matchers
16 from nonebot.exception import NoLogException, StopPropagation, IgnoredException
17 from nonebot.typing import (T_State, T_RunPreProcessor, T_RunPostProcessor,
18 T_EventPreProcessor, T_EventPostProcessor)
19
20 if TYPE_CHECKING:
21 from nonebot.adapters import Bot, Event
22
23 _event_preprocessors: Set[T_EventPreProcessor] = set()
24 _event_postprocessors: Set[T_EventPostProcessor] = set()
25 _run_preprocessors: Set[T_RunPreProcessor] = set()
26 _run_postprocessors: Set[T_RunPostProcessor] = set()
27
28
29 def event_preprocessor(func: T_EventPreProcessor) -> T_EventPreProcessor:
30 """
31 :说明:
32
33 事件预处理。装饰一个函数,使它在每次接收到事件并分发给各响应器之前执行。
34
35 :参数:
36
37 事件预处理函数接收三个参数。
38
39 * ``bot: Bot``: Bot 对象
40 * ``event: Event``: Event 对象
41 * ``state: T_State``: 当前 State
42 """
43 _event_preprocessors.add(func)
44 return func
45
46
47 def event_postprocessor(func: T_EventPostProcessor) -> T_EventPostProcessor:
48 """
49 :说明:
50
51 事件后处理。装饰一个函数,使它在每次接收到事件并分发给各响应器之后执行。
52
53 :参数:
54
55 事件后处理函数接收三个参数。
56
57 * ``bot: Bot``: Bot 对象
58 * ``event: Event``: Event 对象
59 * ``state: T_State``: 当前事件运行前 State
60 """
61 _event_postprocessors.add(func)
62 return func
63
64
65 def run_preprocessor(func: T_RunPreProcessor) -> T_RunPreProcessor:
66 """
67 :说明:
68
69 运行预处理。装饰一个函数,使它在每次事件响应器运行前执行。
70
71 :参数:
72
73 运行预处理函数接收四个参数。
74
75 * ``matcher: Matcher``: 当前要运行的事件响应器
76 * ``bot: Bot``: Bot 对象
77 * ``event: Event``: Event 对象
78 * ``state: T_State``: 当前 State
79 """
80 _run_preprocessors.add(func)
81 return func
82
83
84 def run_postprocessor(func: T_RunPostProcessor) -> T_RunPostProcessor:
85 """
86 :说明:
87
88 运行后处理。装饰一个函数,使它在每次事件响应器运行后执行。
89
90 :参数:
91
92 运行后处理函数接收五个参数。
93
94 * ``matcher: Matcher``: 运行完毕的事件响应器
95 * ``exception: Optional[Exception]``: 事件响应器运行错误(如果存在)
96 * ``bot: Bot``: Bot 对象
97 * ``event: Event``: Event 对象
98 * ``state: T_State``: 当前 State
99 """
100 _run_postprocessors.add(func)
101 return func
102
103
104 async def _check_matcher(priority: int, Matcher: Type[Matcher], bot: "Bot",
105 event: "Event", state: T_State) -> None:
106 if Matcher.expire_time and datetime.now() > Matcher.expire_time:
107 try:
108 matchers[priority].remove(Matcher)
109 except Exception:
110 pass
111 return
112
113 try:
114 if not await Matcher.check_perm(
115 bot, event) or not await Matcher.check_rule(bot, event, state):
116 return
117 except Exception as e:
118 logger.opt(colors=True, exception=e).error(
119 f"<r><bg #f8bbd0>Rule check failed for {Matcher}.</bg #f8bbd0></r>")
120 return
121
122 if Matcher.temp:
123 try:
124 matchers[priority].remove(Matcher)
125 except Exception:
126 pass
127
128 await _run_matcher(Matcher, bot, event, state)
129
130
131 async def _run_matcher(Matcher: Type[Matcher], bot: "Bot", event: "Event",
132 state: T_State) -> None:
133 logger.info(f"Event will be handled by {Matcher}")
134
135 matcher = Matcher()
136
137 coros = list(
138 map(lambda x: x(matcher, bot, event, state), _run_preprocessors))
139 if coros:
140 try:
141 await asyncio.gather(*coros)
142 except IgnoredException:
143 logger.opt(colors=True).info(
144 f"Matcher {matcher} running is <b>cancelled</b>")
145 return
146 except Exception as e:
147 logger.opt(colors=True, exception=e).error(
148 "<r><bg #f8bbd0>Error when running RunPreProcessors. "
149 "Running cancelled!</bg #f8bbd0></r>")
150 return
151
152 exception = None
153
154 try:
155 logger.debug(f"Running matcher {matcher}")
156 await matcher.run(bot, event, state)
157 except Exception as e:
158 logger.opt(colors=True, exception=e).error(
159 f"<r><bg #f8bbd0>Running matcher {matcher} failed.</bg #f8bbd0></r>"
160 )
161 exception = e
162
163 coros = list(
164 map(lambda x: x(matcher, exception, bot, event, state),
165 _run_postprocessors))
166 if coros:
167 try:
168 await asyncio.gather(*coros)
169 except Exception as e:
170 logger.opt(colors=True, exception=e).error(
171 "<r><bg #f8bbd0>Error when running RunPostProcessors</bg #f8bbd0></r>"
172 )
173
174 if matcher.block:
175 raise StopPropagation
176 return
177
178
179 async def handle_event(bot: "Bot", event: "Event") -> Optional[Exception]:
180 """
181 :说明:
182
183 处理一个事件。调用该函数以实现分发事件。
184
185 :参数:
186
187 * ``bot: Bot``: Bot 对象
188 * ``event: Event``: Event 对象
189
190 :示例:
191
192 .. code-block:: python
193
194 import asyncio
195 asyncio.create_task(handle_event(bot, event))
196 """
197 show_log = True
198 log_msg = f"<m>{escape_tag(bot.type.upper())} {escape_tag(bot.self_id)}</m> | "
199 try:
200 log_msg += event.get_log_string()
201 except NoLogException:
202 show_log = False
203 if show_log:
204 logger.opt(colors=True).success(log_msg)
205
206 state = {}
207 coros = list(map(lambda x: x(bot, event, state), _event_preprocessors))
208 if coros:
209 try:
210 if show_log:
211 logger.debug("Running PreProcessors...")
212 await asyncio.gather(*coros)
213 except IgnoredException as e:
214 logger.opt(colors=True).info(
215 f"Event {escape_tag(event.get_event_name())} is <b>ignored</b>")
216 return e
217 except Exception as e:
218 logger.opt(colors=True, exception=e).error(
219 "<r><bg #f8bbd0>Error when running EventPreProcessors. "
220 "Event ignored!</bg #f8bbd0></r>")
221 return e
222
223 # Trie Match
224 _, _ = TrieRule.get_value(bot, event, state)
225
226 break_flag = False
227 for priority in sorted(matchers.keys()):
228 if break_flag:
229 break
230
231 if show_log:
232 logger.debug(f"Checking for matchers in priority {priority}...")
233
234 pending_tasks = [
235 _check_matcher(priority, matcher, bot, event, state.copy())
236 for matcher in matchers[priority]
237 ]
238
239 results = await asyncio.gather(*pending_tasks, return_exceptions=True)
240
241 for result in results:
242 if not isinstance(result, Exception):
243 continue
244 if isinstance(result, StopPropagation):
245 break_flag = True
246 logger.debug("Stop event propagation")
247 else:
248 logger.opt(colors=True, exception=result).error(
249 "<r><bg #f8bbd0>Error when checking Matcher.</bg #f8bbd0></r>"
250 )
251 return result
252
253 coros = list(map(lambda x: x(bot, event, state), _event_postprocessors))
254 if coros:
255 try:
256 if show_log:
257 logger.debug("Running PostProcessors...")
258 await asyncio.gather(*coros)
259 except Exception as e:
260 logger.opt(colors=True, exception=e).error(
261 "<r><bg #f8bbd0>Error when running EventPostProcessors</bg #f8bbd0></r>"
262 )
263 return e
264
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/nonebot/message.py b/nonebot/message.py
--- a/nonebot/message.py
+++ b/nonebot/message.py
@@ -176,7 +176,7 @@
return
-async def handle_event(bot: "Bot", event: "Event") -> Optional[Exception]:
+async def handle_event(bot: "Bot", event: "Event") -> None:
"""
:说明:
@@ -213,12 +213,12 @@
except IgnoredException as e:
logger.opt(colors=True).info(
f"Event {escape_tag(event.get_event_name())} is <b>ignored</b>")
- return e
+ return
except Exception as e:
logger.opt(colors=True, exception=e).error(
"<r><bg #f8bbd0>Error when running EventPreProcessors. "
"Event ignored!</bg #f8bbd0></r>")
- return e
+ return
# Trie Match
_, _ = TrieRule.get_value(bot, event, state)
@@ -248,7 +248,6 @@
logger.opt(colors=True, exception=result).error(
"<r><bg #f8bbd0>Error when checking Matcher.</bg #f8bbd0></r>"
)
- return result
coros = list(map(lambda x: x(bot, event, state), _event_postprocessors))
if coros:
@@ -260,4 +259,3 @@
logger.opt(colors=True, exception=e).error(
"<r><bg #f8bbd0>Error when running EventPostProcessors</bg #f8bbd0></r>"
)
- return e
| {"golden_diff": "diff --git a/nonebot/message.py b/nonebot/message.py\n--- a/nonebot/message.py\n+++ b/nonebot/message.py\n@@ -176,7 +176,7 @@\n return\n \n \n-async def handle_event(bot: \"Bot\", event: \"Event\") -> Optional[Exception]:\n+async def handle_event(bot: \"Bot\", event: \"Event\") -> None:\n \"\"\"\n :\u8bf4\u660e:\n \n@@ -213,12 +213,12 @@\n except IgnoredException as e:\n logger.opt(colors=True).info(\n f\"Event {escape_tag(event.get_event_name())} is <b>ignored</b>\")\n- return e\n+ return\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n \"<r><bg #f8bbd0>Error when running EventPreProcessors. \"\n \"Event ignored!</bg #f8bbd0></r>\")\n- return e\n+ return\n \n # Trie Match\n _, _ = TrieRule.get_value(bot, event, state)\n@@ -248,7 +248,6 @@\n logger.opt(colors=True, exception=result).error(\n \"<r><bg #f8bbd0>Error when checking Matcher.</bg #f8bbd0></r>\"\n )\n- return result\n \n coros = list(map(lambda x: x(bot, event, state), _event_postprocessors))\n if coros:\n@@ -260,4 +259,3 @@\n logger.opt(colors=True, exception=e).error(\n \"<r><bg #f8bbd0>Error when running EventPostProcessors</bg #f8bbd0></r>\"\n )\n- return e\n", "issue": "Bug: event_postprocessor \u4e0d\u80fd\u5728 matcher \u8fd0\u884c\u540e\u6b63\u5e38\u6267\u884c\n**\u63cf\u8ff0\u95ee\u9898\uff1a**\r\n\r\nevent_postprocessor \u4e0d\u80fd\u5728 matcher \u8fd0\u884c\u540e\u6b63\u5e38\u6267\u884c\r\n\r\n**\u5982\u4f55\u590d\u73b0\uff1f**\r\n\r\n\u7f16\u5199\u4ee5\u4e0b\u63d2\u4ef6\r\n```python\r\nfrom nonebot import on_command, logger\r\nfrom nonebot.message import event_postprocessor\r\nfrom nonebot.typing import T_State\r\nfrom nonebot.adapters.cqhttp.event import Event, MessageEvent\r\nfrom nonebot.adapters.cqhttp.bot import Bot\r\n\r\n\r\ntest = on_command('test')\r\n\r\n\r\[email protected]()\r\nasync def handle_test(bot: Bot, event: MessageEvent, state: T_State):\r\n logger.opt(colors=True).info('<ly>matcher is running!</ly>')\r\n\r\n\r\n@event_postprocessor\r\nasync def handle_event_postprocessor(bot: Bot, event: Event, state: T_State):\r\n logger.opt(colors=True).success('<ly>event_postprocessor is running!</ly>')\r\n```\r\n\r\n**\u671f\u671b\u7684\u7ed3\u679c**\r\n\r\nevent_postprocessor \u80fd\u5728\u4efb\u610f\u60c5\u51b5\u4e0b\u6b63\u5e38\u6267\u884c\r\n\r\n\u5b9e\u9645\u4e0a\u5f53 matcher \u8fd0\u884c\u540e event_postprocessor \u4f1a\u88ab\u8df3\u8fc7\r\n\r\n\r\n\r\n**\u5176\u4ed6\u4fe1\u606f**\r\n\r\n\u7b2c 250 \u884c `return result` \u5c06\u76f4\u63a5\u5bfc\u81f4 matcher \u8fd0\u884c\u540e event_postprocessor \u88ab\u8df3\u8fc7\r\n\r\nhttps://github.com/nonebot/nonebot2/blob/0b35d5e724a2fc7fc1e7d90499aea8a9c27e821d/nonebot/message.py#L238-L262\r\n\r\n**\u73af\u5883\u4fe1\u606f\uff1a**\r\n\r\n - OS: Windows 10 21H1\r\n - Python Version: 3.9.6\r\n - Nonebot Version: 2.0.0a15\r\n\r\n**\u534f\u8bae\u7aef\u4fe1\u606f\uff1a**\r\n\r\n - \u534f\u8bae\u7aef: \u65e0\r\n - \u534f\u8bae\u7aef\u7248\u672c: \u65e0\r\n\r\n**\u622a\u56fe\u6216\u65e5\u5fd7**\r\n\r\n\u5982\u4e0a\r\n\n", "before_files": [{"content": "\"\"\"\n\u4e8b\u4ef6\u5904\u7406\n========\n\nNoneBot \u5185\u90e8\u5904\u7406\u5e76\u6309\u4f18\u5148\u7ea7\u5206\u53d1\u4e8b\u4ef6\u7ed9\u6240\u6709\u4e8b\u4ef6\u54cd\u5e94\u5668\uff0c\u63d0\u4f9b\u4e86\u591a\u4e2a\u63d2\u69fd\u4ee5\u8fdb\u884c\u4e8b\u4ef6\u7684\u9884\u5904\u7406\u7b49\u3002\n\"\"\"\n\nimport asyncio\nfrom datetime import datetime\nfrom typing import TYPE_CHECKING, Set, Type, Optional\n\nfrom nonebot.log import logger\nfrom nonebot.rule import TrieRule\nfrom nonebot.utils import escape_tag\nfrom nonebot.matcher import Matcher, matchers\nfrom nonebot.exception import NoLogException, StopPropagation, IgnoredException\nfrom nonebot.typing import (T_State, T_RunPreProcessor, T_RunPostProcessor,\n T_EventPreProcessor, T_EventPostProcessor)\n\nif TYPE_CHECKING:\n from nonebot.adapters import Bot, Event\n\n_event_preprocessors: Set[T_EventPreProcessor] = set()\n_event_postprocessors: Set[T_EventPostProcessor] = set()\n_run_preprocessors: Set[T_RunPreProcessor] = set()\n_run_postprocessors: Set[T_RunPostProcessor] = set()\n\n\ndef event_preprocessor(func: T_EventPreProcessor) -> T_EventPreProcessor:\n \"\"\"\n :\u8bf4\u660e:\n\n \u4e8b\u4ef6\u9884\u5904\u7406\u3002\u88c5\u9970\u4e00\u4e2a\u51fd\u6570\uff0c\u4f7f\u5b83\u5728\u6bcf\u6b21\u63a5\u6536\u5230\u4e8b\u4ef6\u5e76\u5206\u53d1\u7ed9\u5404\u54cd\u5e94\u5668\u4e4b\u524d\u6267\u884c\u3002\n\n :\u53c2\u6570:\n\n \u4e8b\u4ef6\u9884\u5904\u7406\u51fd\u6570\u63a5\u6536\u4e09\u4e2a\u53c2\u6570\u3002\n\n * ``bot: Bot``: Bot \u5bf9\u8c61\n * ``event: Event``: Event \u5bf9\u8c61\n * ``state: T_State``: \u5f53\u524d State\n \"\"\"\n _event_preprocessors.add(func)\n return func\n\n\ndef event_postprocessor(func: T_EventPostProcessor) -> T_EventPostProcessor:\n \"\"\"\n :\u8bf4\u660e:\n\n \u4e8b\u4ef6\u540e\u5904\u7406\u3002\u88c5\u9970\u4e00\u4e2a\u51fd\u6570\uff0c\u4f7f\u5b83\u5728\u6bcf\u6b21\u63a5\u6536\u5230\u4e8b\u4ef6\u5e76\u5206\u53d1\u7ed9\u5404\u54cd\u5e94\u5668\u4e4b\u540e\u6267\u884c\u3002\n\n :\u53c2\u6570:\n\n \u4e8b\u4ef6\u540e\u5904\u7406\u51fd\u6570\u63a5\u6536\u4e09\u4e2a\u53c2\u6570\u3002\n\n * ``bot: Bot``: Bot \u5bf9\u8c61\n * ``event: Event``: Event \u5bf9\u8c61\n * ``state: T_State``: \u5f53\u524d\u4e8b\u4ef6\u8fd0\u884c\u524d State\n \"\"\"\n _event_postprocessors.add(func)\n return func\n\n\ndef run_preprocessor(func: T_RunPreProcessor) -> T_RunPreProcessor:\n \"\"\"\n :\u8bf4\u660e:\n\n \u8fd0\u884c\u9884\u5904\u7406\u3002\u88c5\u9970\u4e00\u4e2a\u51fd\u6570\uff0c\u4f7f\u5b83\u5728\u6bcf\u6b21\u4e8b\u4ef6\u54cd\u5e94\u5668\u8fd0\u884c\u524d\u6267\u884c\u3002\n\n :\u53c2\u6570:\n\n \u8fd0\u884c\u9884\u5904\u7406\u51fd\u6570\u63a5\u6536\u56db\u4e2a\u53c2\u6570\u3002\n\n * ``matcher: Matcher``: \u5f53\u524d\u8981\u8fd0\u884c\u7684\u4e8b\u4ef6\u54cd\u5e94\u5668\n * ``bot: Bot``: Bot \u5bf9\u8c61\n * ``event: Event``: Event \u5bf9\u8c61\n * ``state: T_State``: \u5f53\u524d State\n \"\"\"\n _run_preprocessors.add(func)\n return func\n\n\ndef run_postprocessor(func: T_RunPostProcessor) -> T_RunPostProcessor:\n \"\"\"\n :\u8bf4\u660e:\n\n \u8fd0\u884c\u540e\u5904\u7406\u3002\u88c5\u9970\u4e00\u4e2a\u51fd\u6570\uff0c\u4f7f\u5b83\u5728\u6bcf\u6b21\u4e8b\u4ef6\u54cd\u5e94\u5668\u8fd0\u884c\u540e\u6267\u884c\u3002\n\n :\u53c2\u6570:\n\n \u8fd0\u884c\u540e\u5904\u7406\u51fd\u6570\u63a5\u6536\u4e94\u4e2a\u53c2\u6570\u3002\n\n * ``matcher: Matcher``: \u8fd0\u884c\u5b8c\u6bd5\u7684\u4e8b\u4ef6\u54cd\u5e94\u5668\n * ``exception: Optional[Exception]``: \u4e8b\u4ef6\u54cd\u5e94\u5668\u8fd0\u884c\u9519\u8bef\uff08\u5982\u679c\u5b58\u5728\uff09\n * ``bot: Bot``: Bot \u5bf9\u8c61\n * ``event: Event``: Event \u5bf9\u8c61\n * ``state: T_State``: \u5f53\u524d State\n \"\"\"\n _run_postprocessors.add(func)\n return func\n\n\nasync def _check_matcher(priority: int, Matcher: Type[Matcher], bot: \"Bot\",\n event: \"Event\", state: T_State) -> None:\n if Matcher.expire_time and datetime.now() > Matcher.expire_time:\n try:\n matchers[priority].remove(Matcher)\n except Exception:\n pass\n return\n\n try:\n if not await Matcher.check_perm(\n bot, event) or not await Matcher.check_rule(bot, event, state):\n return\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n f\"<r><bg #f8bbd0>Rule check failed for {Matcher}.</bg #f8bbd0></r>\")\n return\n\n if Matcher.temp:\n try:\n matchers[priority].remove(Matcher)\n except Exception:\n pass\n\n await _run_matcher(Matcher, bot, event, state)\n\n\nasync def _run_matcher(Matcher: Type[Matcher], bot: \"Bot\", event: \"Event\",\n state: T_State) -> None:\n logger.info(f\"Event will be handled by {Matcher}\")\n\n matcher = Matcher()\n\n coros = list(\n map(lambda x: x(matcher, bot, event, state), _run_preprocessors))\n if coros:\n try:\n await asyncio.gather(*coros)\n except IgnoredException:\n logger.opt(colors=True).info(\n f\"Matcher {matcher} running is <b>cancelled</b>\")\n return\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n \"<r><bg #f8bbd0>Error when running RunPreProcessors. \"\n \"Running cancelled!</bg #f8bbd0></r>\")\n return\n\n exception = None\n\n try:\n logger.debug(f\"Running matcher {matcher}\")\n await matcher.run(bot, event, state)\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n f\"<r><bg #f8bbd0>Running matcher {matcher} failed.</bg #f8bbd0></r>\"\n )\n exception = e\n\n coros = list(\n map(lambda x: x(matcher, exception, bot, event, state),\n _run_postprocessors))\n if coros:\n try:\n await asyncio.gather(*coros)\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n \"<r><bg #f8bbd0>Error when running RunPostProcessors</bg #f8bbd0></r>\"\n )\n\n if matcher.block:\n raise StopPropagation\n return\n\n\nasync def handle_event(bot: \"Bot\", event: \"Event\") -> Optional[Exception]:\n \"\"\"\n :\u8bf4\u660e:\n\n \u5904\u7406\u4e00\u4e2a\u4e8b\u4ef6\u3002\u8c03\u7528\u8be5\u51fd\u6570\u4ee5\u5b9e\u73b0\u5206\u53d1\u4e8b\u4ef6\u3002\n\n :\u53c2\u6570:\n\n * ``bot: Bot``: Bot \u5bf9\u8c61\n * ``event: Event``: Event \u5bf9\u8c61\n\n :\u793a\u4f8b:\n\n .. code-block:: python\n\n import asyncio\n asyncio.create_task(handle_event(bot, event))\n \"\"\"\n show_log = True\n log_msg = f\"<m>{escape_tag(bot.type.upper())} {escape_tag(bot.self_id)}</m> | \"\n try:\n log_msg += event.get_log_string()\n except NoLogException:\n show_log = False\n if show_log:\n logger.opt(colors=True).success(log_msg)\n\n state = {}\n coros = list(map(lambda x: x(bot, event, state), _event_preprocessors))\n if coros:\n try:\n if show_log:\n logger.debug(\"Running PreProcessors...\")\n await asyncio.gather(*coros)\n except IgnoredException as e:\n logger.opt(colors=True).info(\n f\"Event {escape_tag(event.get_event_name())} is <b>ignored</b>\")\n return e\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n \"<r><bg #f8bbd0>Error when running EventPreProcessors. \"\n \"Event ignored!</bg #f8bbd0></r>\")\n return e\n\n # Trie Match\n _, _ = TrieRule.get_value(bot, event, state)\n\n break_flag = False\n for priority in sorted(matchers.keys()):\n if break_flag:\n break\n\n if show_log:\n logger.debug(f\"Checking for matchers in priority {priority}...\")\n\n pending_tasks = [\n _check_matcher(priority, matcher, bot, event, state.copy())\n for matcher in matchers[priority]\n ]\n\n results = await asyncio.gather(*pending_tasks, return_exceptions=True)\n\n for result in results:\n if not isinstance(result, Exception):\n continue\n if isinstance(result, StopPropagation):\n break_flag = True\n logger.debug(\"Stop event propagation\")\n else:\n logger.opt(colors=True, exception=result).error(\n \"<r><bg #f8bbd0>Error when checking Matcher.</bg #f8bbd0></r>\"\n )\n return result\n\n coros = list(map(lambda x: x(bot, event, state), _event_postprocessors))\n if coros:\n try:\n if show_log:\n logger.debug(\"Running PostProcessors...\")\n await asyncio.gather(*coros)\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n \"<r><bg #f8bbd0>Error when running EventPostProcessors</bg #f8bbd0></r>\"\n )\n return e\n", "path": "nonebot/message.py"}], "after_files": [{"content": "\"\"\"\n\u4e8b\u4ef6\u5904\u7406\n========\n\nNoneBot \u5185\u90e8\u5904\u7406\u5e76\u6309\u4f18\u5148\u7ea7\u5206\u53d1\u4e8b\u4ef6\u7ed9\u6240\u6709\u4e8b\u4ef6\u54cd\u5e94\u5668\uff0c\u63d0\u4f9b\u4e86\u591a\u4e2a\u63d2\u69fd\u4ee5\u8fdb\u884c\u4e8b\u4ef6\u7684\u9884\u5904\u7406\u7b49\u3002\n\"\"\"\n\nimport asyncio\nfrom datetime import datetime\nfrom typing import TYPE_CHECKING, Set, Type, Optional\n\nfrom nonebot.log import logger\nfrom nonebot.rule import TrieRule\nfrom nonebot.utils import escape_tag\nfrom nonebot.matcher import Matcher, matchers\nfrom nonebot.exception import NoLogException, StopPropagation, IgnoredException\nfrom nonebot.typing import (T_State, T_RunPreProcessor, T_RunPostProcessor,\n T_EventPreProcessor, T_EventPostProcessor)\n\nif TYPE_CHECKING:\n from nonebot.adapters import Bot, Event\n\n_event_preprocessors: Set[T_EventPreProcessor] = set()\n_event_postprocessors: Set[T_EventPostProcessor] = set()\n_run_preprocessors: Set[T_RunPreProcessor] = set()\n_run_postprocessors: Set[T_RunPostProcessor] = set()\n\n\ndef event_preprocessor(func: T_EventPreProcessor) -> T_EventPreProcessor:\n \"\"\"\n :\u8bf4\u660e:\n\n \u4e8b\u4ef6\u9884\u5904\u7406\u3002\u88c5\u9970\u4e00\u4e2a\u51fd\u6570\uff0c\u4f7f\u5b83\u5728\u6bcf\u6b21\u63a5\u6536\u5230\u4e8b\u4ef6\u5e76\u5206\u53d1\u7ed9\u5404\u54cd\u5e94\u5668\u4e4b\u524d\u6267\u884c\u3002\n\n :\u53c2\u6570:\n\n \u4e8b\u4ef6\u9884\u5904\u7406\u51fd\u6570\u63a5\u6536\u4e09\u4e2a\u53c2\u6570\u3002\n\n * ``bot: Bot``: Bot \u5bf9\u8c61\n * ``event: Event``: Event \u5bf9\u8c61\n * ``state: T_State``: \u5f53\u524d State\n \"\"\"\n _event_preprocessors.add(func)\n return func\n\n\ndef event_postprocessor(func: T_EventPostProcessor) -> T_EventPostProcessor:\n \"\"\"\n :\u8bf4\u660e:\n\n \u4e8b\u4ef6\u540e\u5904\u7406\u3002\u88c5\u9970\u4e00\u4e2a\u51fd\u6570\uff0c\u4f7f\u5b83\u5728\u6bcf\u6b21\u63a5\u6536\u5230\u4e8b\u4ef6\u5e76\u5206\u53d1\u7ed9\u5404\u54cd\u5e94\u5668\u4e4b\u540e\u6267\u884c\u3002\n\n :\u53c2\u6570:\n\n \u4e8b\u4ef6\u540e\u5904\u7406\u51fd\u6570\u63a5\u6536\u4e09\u4e2a\u53c2\u6570\u3002\n\n * ``bot: Bot``: Bot \u5bf9\u8c61\n * ``event: Event``: Event \u5bf9\u8c61\n * ``state: T_State``: \u5f53\u524d\u4e8b\u4ef6\u8fd0\u884c\u524d State\n \"\"\"\n _event_postprocessors.add(func)\n return func\n\n\ndef run_preprocessor(func: T_RunPreProcessor) -> T_RunPreProcessor:\n \"\"\"\n :\u8bf4\u660e:\n\n \u8fd0\u884c\u9884\u5904\u7406\u3002\u88c5\u9970\u4e00\u4e2a\u51fd\u6570\uff0c\u4f7f\u5b83\u5728\u6bcf\u6b21\u4e8b\u4ef6\u54cd\u5e94\u5668\u8fd0\u884c\u524d\u6267\u884c\u3002\n\n :\u53c2\u6570:\n\n \u8fd0\u884c\u9884\u5904\u7406\u51fd\u6570\u63a5\u6536\u56db\u4e2a\u53c2\u6570\u3002\n\n * ``matcher: Matcher``: \u5f53\u524d\u8981\u8fd0\u884c\u7684\u4e8b\u4ef6\u54cd\u5e94\u5668\n * ``bot: Bot``: Bot \u5bf9\u8c61\n * ``event: Event``: Event \u5bf9\u8c61\n * ``state: T_State``: \u5f53\u524d State\n \"\"\"\n _run_preprocessors.add(func)\n return func\n\n\ndef run_postprocessor(func: T_RunPostProcessor) -> T_RunPostProcessor:\n \"\"\"\n :\u8bf4\u660e:\n\n \u8fd0\u884c\u540e\u5904\u7406\u3002\u88c5\u9970\u4e00\u4e2a\u51fd\u6570\uff0c\u4f7f\u5b83\u5728\u6bcf\u6b21\u4e8b\u4ef6\u54cd\u5e94\u5668\u8fd0\u884c\u540e\u6267\u884c\u3002\n\n :\u53c2\u6570:\n\n \u8fd0\u884c\u540e\u5904\u7406\u51fd\u6570\u63a5\u6536\u4e94\u4e2a\u53c2\u6570\u3002\n\n * ``matcher: Matcher``: \u8fd0\u884c\u5b8c\u6bd5\u7684\u4e8b\u4ef6\u54cd\u5e94\u5668\n * ``exception: Optional[Exception]``: \u4e8b\u4ef6\u54cd\u5e94\u5668\u8fd0\u884c\u9519\u8bef\uff08\u5982\u679c\u5b58\u5728\uff09\n * ``bot: Bot``: Bot \u5bf9\u8c61\n * ``event: Event``: Event \u5bf9\u8c61\n * ``state: T_State``: \u5f53\u524d State\n \"\"\"\n _run_postprocessors.add(func)\n return func\n\n\nasync def _check_matcher(priority: int, Matcher: Type[Matcher], bot: \"Bot\",\n event: \"Event\", state: T_State) -> None:\n if Matcher.expire_time and datetime.now() > Matcher.expire_time:\n try:\n matchers[priority].remove(Matcher)\n except Exception:\n pass\n return\n\n try:\n if not await Matcher.check_perm(\n bot, event) or not await Matcher.check_rule(bot, event, state):\n return\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n f\"<r><bg #f8bbd0>Rule check failed for {Matcher}.</bg #f8bbd0></r>\")\n return\n\n if Matcher.temp:\n try:\n matchers[priority].remove(Matcher)\n except Exception:\n pass\n\n await _run_matcher(Matcher, bot, event, state)\n\n\nasync def _run_matcher(Matcher: Type[Matcher], bot: \"Bot\", event: \"Event\",\n state: T_State) -> None:\n logger.info(f\"Event will be handled by {Matcher}\")\n\n matcher = Matcher()\n\n coros = list(\n map(lambda x: x(matcher, bot, event, state), _run_preprocessors))\n if coros:\n try:\n await asyncio.gather(*coros)\n except IgnoredException:\n logger.opt(colors=True).info(\n f\"Matcher {matcher} running is <b>cancelled</b>\")\n return\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n \"<r><bg #f8bbd0>Error when running RunPreProcessors. \"\n \"Running cancelled!</bg #f8bbd0></r>\")\n return\n\n exception = None\n\n try:\n logger.debug(f\"Running matcher {matcher}\")\n await matcher.run(bot, event, state)\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n f\"<r><bg #f8bbd0>Running matcher {matcher} failed.</bg #f8bbd0></r>\"\n )\n exception = e\n\n coros = list(\n map(lambda x: x(matcher, exception, bot, event, state),\n _run_postprocessors))\n if coros:\n try:\n await asyncio.gather(*coros)\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n \"<r><bg #f8bbd0>Error when running RunPostProcessors</bg #f8bbd0></r>\"\n )\n\n if matcher.block:\n raise StopPropagation\n return\n\n\nasync def handle_event(bot: \"Bot\", event: \"Event\") -> None:\n \"\"\"\n :\u8bf4\u660e:\n\n \u5904\u7406\u4e00\u4e2a\u4e8b\u4ef6\u3002\u8c03\u7528\u8be5\u51fd\u6570\u4ee5\u5b9e\u73b0\u5206\u53d1\u4e8b\u4ef6\u3002\n\n :\u53c2\u6570:\n\n * ``bot: Bot``: Bot \u5bf9\u8c61\n * ``event: Event``: Event \u5bf9\u8c61\n\n :\u793a\u4f8b:\n\n .. code-block:: python\n\n import asyncio\n asyncio.create_task(handle_event(bot, event))\n \"\"\"\n show_log = True\n log_msg = f\"<m>{escape_tag(bot.type.upper())} {escape_tag(bot.self_id)}</m> | \"\n try:\n log_msg += event.get_log_string()\n except NoLogException:\n show_log = False\n if show_log:\n logger.opt(colors=True).success(log_msg)\n\n state = {}\n coros = list(map(lambda x: x(bot, event, state), _event_preprocessors))\n if coros:\n try:\n if show_log:\n logger.debug(\"Running PreProcessors...\")\n await asyncio.gather(*coros)\n except IgnoredException as e:\n logger.opt(colors=True).info(\n f\"Event {escape_tag(event.get_event_name())} is <b>ignored</b>\")\n return\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n \"<r><bg #f8bbd0>Error when running EventPreProcessors. \"\n \"Event ignored!</bg #f8bbd0></r>\")\n return\n\n # Trie Match\n _, _ = TrieRule.get_value(bot, event, state)\n\n break_flag = False\n for priority in sorted(matchers.keys()):\n if break_flag:\n break\n\n if show_log:\n logger.debug(f\"Checking for matchers in priority {priority}...\")\n\n pending_tasks = [\n _check_matcher(priority, matcher, bot, event, state.copy())\n for matcher in matchers[priority]\n ]\n\n results = await asyncio.gather(*pending_tasks, return_exceptions=True)\n\n for result in results:\n if not isinstance(result, Exception):\n continue\n if isinstance(result, StopPropagation):\n break_flag = True\n logger.debug(\"Stop event propagation\")\n else:\n logger.opt(colors=True, exception=result).error(\n \"<r><bg #f8bbd0>Error when checking Matcher.</bg #f8bbd0></r>\"\n )\n\n coros = list(map(lambda x: x(bot, event, state), _event_postprocessors))\n if coros:\n try:\n if show_log:\n logger.debug(\"Running PostProcessors...\")\n await asyncio.gather(*coros)\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n \"<r><bg #f8bbd0>Error when running EventPostProcessors</bg #f8bbd0></r>\"\n )\n", "path": "nonebot/message.py"}]} | 3,375 | 382 |
gh_patches_debug_37 | rasdani/github-patches | git_diff | nextcloud__appstore-67 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
After clicking confirm button I got a 404
- click the confirm link in the email
- click the button on that page
- getting redirected to https://.../accounts/login/ instead of https://.../login/ which is not available
cc @BernhardPosselt @adsworth
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nextcloudappstore/settings/base.py`
Content:
```
1 """
2 Django settings for nextcloudappstore project.
3
4 Generated by 'django-admin startproject' using Django 1.9.6.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/1.9/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/1.9/ref/settings/
11 """
12
13 from os.path import dirname, abspath, join, pardir, realpath
14
15 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
16 from django.conf.global_settings import LANGUAGES
17
18 BASE_DIR = realpath(join(dirname(dirname(abspath(__file__))), pardir))
19
20 # Quick-start development settings - unsuitable for production
21 # See https://docs.djangoproject.com/en/1.9/howto/deployment/checklist/
22
23 # Application definition
24
25 INSTALLED_APPS = [
26 'nextcloudappstore.core.apps.CoreConfig',
27 'parler',
28 'captcha',
29 'rest_framework',
30 'corsheaders',
31 'allauth',
32 'allauth.account',
33 'allauth.socialaccount',
34 'allauth.socialaccount.providers.github',
35 'allauth.socialaccount.providers.bitbucket',
36 'django.contrib.admin',
37 'django.contrib.auth',
38 'django.contrib.contenttypes',
39 'django.contrib.sessions',
40 'django.contrib.messages',
41 'django.contrib.sites',
42 'django.contrib.staticfiles',
43 ]
44
45 MIDDLEWARE_CLASSES = [
46 'django.middleware.security.SecurityMiddleware',
47 'django.contrib.sessions.middleware.SessionMiddleware',
48 'corsheaders.middleware.CorsMiddleware',
49 'django.middleware.common.CommonMiddleware',
50 'django.middleware.csrf.CsrfViewMiddleware',
51 'django.contrib.auth.middleware.AuthenticationMiddleware',
52 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',
53 'django.contrib.messages.middleware.MessageMiddleware',
54 'django.middleware.clickjacking.XFrameOptionsMiddleware',
55 ]
56
57 ROOT_URLCONF = 'nextcloudappstore.urls'
58
59 TEMPLATES = [
60 {
61 'BACKEND': 'django.template.backends.django.DjangoTemplates',
62 'DIRS': [],
63 'APP_DIRS': True,
64 'OPTIONS': {
65 'context_processors': [
66 'django.template.context_processors.debug',
67 'django.template.context_processors.request',
68 'django.contrib.auth.context_processors.auth',
69 'django.contrib.messages.context_processors.messages',
70 ],
71 },
72 },
73 ]
74
75 WSGI_APPLICATION = 'nextcloudappstore.wsgi.application'
76
77 # Database
78 # https://docs.djangoproject.com/en/1.9/ref/settings/#databases
79
80 DATABASES = {
81 'default': {
82 'ENGINE': 'django.db.backends.sqlite3',
83 'NAME': join(BASE_DIR, 'db.sqlite3'),
84 'TEST': {
85 'NAME': join(BASE_DIR, 'test.sqlite3'),
86 }
87 }
88 }
89
90 AUTHENTICATION_BACKENDS = (
91 # Needed to login by username in Django admin, regardless of `allauth`
92 'django.contrib.auth.backends.ModelBackend',
93
94 # `allauth` specific authentication methods, such as login by e-mail
95 'allauth.account.auth_backends.AuthenticationBackend',
96 )
97
98 # Password validation
99 # https://docs.djangoproject.com/en/1.9/ref/settings/#auth-password-validators
100
101 AUTH_PASSWORD_VALIDATORS = [
102 {
103 'NAME': 'django.contrib.auth.password_validation'
104 '.UserAttributeSimilarityValidator',
105 },
106 {
107 'NAME': 'django.contrib.auth.password_validation'
108 '.MinimumLengthValidator',
109 },
110 {
111 'NAME': 'django.contrib.auth.password_validation'
112 '.CommonPasswordValidator',
113 },
114 {
115 'NAME': 'django.contrib.auth.password_validation'
116 '.NumericPasswordValidator',
117 },
118 ]
119
120 REST_FRAMEWORK = {
121 'DEFAULT_RENDERER_CLASSES': (
122 'djangorestframework_camel_case.render.CamelCaseJSONRenderer',
123 ),
124 'DEFAULT_PARSER_CLASSES': (
125 'djangorestframework_camel_case.parser.CamelCaseJSONParser',
126 ),
127 'DEFAULT_THROTTLE_RATES': {
128 'app_upload': '100/day'
129 }
130 }
131
132 SITE_ID = 1
133
134 # Allauth configuration
135 # http://django-allauth.readthedocs.io/en/latest/configuration.html
136 ACCOUNT_EMAIL_REQUIRED = True
137 ACCOUNT_EMAIL_VERIFICATION = "mandatory"
138 ACCOUNT_LOGOUT_ON_GET = True
139 ACCOUNT_LOGOUT_REDIRECT_URL = 'home'
140 ACCOUNT_SESSION_REMEMBER = True
141 ACCOUNT_SIGNUP_FORM_CLASS = \
142 'nextcloudappstore.core.user.forms.SignupFormRecaptcha'
143
144 # Internationalization
145 # https://docs.djangoproject.com/en/1.9/topics/i18n/
146 LANGUAGE_CODE = 'en-us'
147 TIME_ZONE = 'UTC'
148 USE_I18N = True
149 USE_L10N = True
150 USE_TZ = True
151
152 PARLER_LANGUAGES = {
153 1: [{'code': code} for code, trans in LANGUAGES],
154 'default': {
155 'fallbacks': ['en'],
156 'hide_untranslated': False,
157 }
158 }
159
160 # Static files (CSS, JavaScript, Images)
161 # https://docs.djangoproject.com/en/1.9/howto/static-files/
162 MEDIA_ROOT = join(BASE_DIR, 'media')
163 RELEASE_DOWNLOAD_ROOT = None
164 STATIC_URL = '/static/'
165 MEDIA_URL = '/media/'
166
167 # Default security settings
168 SECURE_BROWSER_XSS_FILTER = True
169 SECURE_CONTENT_TYPE_NOSNIFF = True
170 CORS_ORIGIN_ALLOW_ALL = True
171 CORS_URLS_REGEX = r'^/api/.*$'
172 CORS_ALLOW_HEADERS = (
173 'x-requested-with',
174 'content-type',
175 'accept',
176 'origin',
177 'authorization',
178 'x-csrftoken',
179 'if-none-match',
180 )
181 CORS_EXPOSE_HEADERS = (
182 'etag',
183 'x-content-type-options',
184 'content-type',
185 )
186
187 # use modern no Captcha reCaptcha
188 NOCAPTCHA = True
189
190 LOGIN_REDIRECT_URL = 'home'
191
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/nextcloudappstore/settings/base.py b/nextcloudappstore/settings/base.py
--- a/nextcloudappstore/settings/base.py
+++ b/nextcloudappstore/settings/base.py
@@ -188,3 +188,4 @@
NOCAPTCHA = True
LOGIN_REDIRECT_URL = 'home'
+LOGIN_URL = 'account_login'
| {"golden_diff": "diff --git a/nextcloudappstore/settings/base.py b/nextcloudappstore/settings/base.py\n--- a/nextcloudappstore/settings/base.py\n+++ b/nextcloudappstore/settings/base.py\n@@ -188,3 +188,4 @@\n NOCAPTCHA = True\n \n LOGIN_REDIRECT_URL = 'home'\n+LOGIN_URL = 'account_login'\n", "issue": "After clicking confirm button I got a 404\n- click the confirm link in the email\n- click the button on that page\n- getting redirected to https://.../accounts/login/ instead of https://.../login/ which is not available\n\ncc @BernhardPosselt @adsworth \n\n", "before_files": [{"content": "\"\"\"\nDjango settings for nextcloudappstore project.\n\nGenerated by 'django-admin startproject' using Django 1.9.6.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.9/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.9/ref/settings/\n\"\"\"\n\nfrom os.path import dirname, abspath, join, pardir, realpath\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nfrom django.conf.global_settings import LANGUAGES\n\nBASE_DIR = realpath(join(dirname(dirname(abspath(__file__))), pardir))\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.9/howto/deployment/checklist/\n\n# Application definition\n\nINSTALLED_APPS = [\n 'nextcloudappstore.core.apps.CoreConfig',\n 'parler',\n 'captcha',\n 'rest_framework',\n 'corsheaders',\n 'allauth',\n 'allauth.account',\n 'allauth.socialaccount',\n 'allauth.socialaccount.providers.github',\n 'allauth.socialaccount.providers.bitbucket',\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.sites',\n 'django.contrib.staticfiles',\n]\n\nMIDDLEWARE_CLASSES = [\n 'django.middleware.security.SecurityMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'corsheaders.middleware.CorsMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nROOT_URLCONF = 'nextcloudappstore.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'nextcloudappstore.wsgi.application'\n\n# Database\n# https://docs.djangoproject.com/en/1.9/ref/settings/#databases\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.sqlite3',\n 'NAME': join(BASE_DIR, 'db.sqlite3'),\n 'TEST': {\n 'NAME': join(BASE_DIR, 'test.sqlite3'),\n }\n }\n}\n\nAUTHENTICATION_BACKENDS = (\n # Needed to login by username in Django admin, regardless of `allauth`\n 'django.contrib.auth.backends.ModelBackend',\n\n # `allauth` specific authentication methods, such as login by e-mail\n 'allauth.account.auth_backends.AuthenticationBackend',\n)\n\n# Password validation\n# https://docs.djangoproject.com/en/1.9/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation'\n '.UserAttributeSimilarityValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation'\n '.MinimumLengthValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation'\n '.CommonPasswordValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation'\n '.NumericPasswordValidator',\n },\n]\n\nREST_FRAMEWORK = {\n 'DEFAULT_RENDERER_CLASSES': (\n 'djangorestframework_camel_case.render.CamelCaseJSONRenderer',\n ),\n 'DEFAULT_PARSER_CLASSES': (\n 'djangorestframework_camel_case.parser.CamelCaseJSONParser',\n ),\n 'DEFAULT_THROTTLE_RATES': {\n 'app_upload': '100/day'\n }\n}\n\nSITE_ID = 1\n\n# Allauth configuration\n# http://django-allauth.readthedocs.io/en/latest/configuration.html\nACCOUNT_EMAIL_REQUIRED = True\nACCOUNT_EMAIL_VERIFICATION = \"mandatory\"\nACCOUNT_LOGOUT_ON_GET = True\nACCOUNT_LOGOUT_REDIRECT_URL = 'home'\nACCOUNT_SESSION_REMEMBER = True\nACCOUNT_SIGNUP_FORM_CLASS = \\\n 'nextcloudappstore.core.user.forms.SignupFormRecaptcha'\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.9/topics/i18n/\nLANGUAGE_CODE = 'en-us'\nTIME_ZONE = 'UTC'\nUSE_I18N = True\nUSE_L10N = True\nUSE_TZ = True\n\nPARLER_LANGUAGES = {\n 1: [{'code': code} for code, trans in LANGUAGES],\n 'default': {\n 'fallbacks': ['en'],\n 'hide_untranslated': False,\n }\n}\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.9/howto/static-files/\nMEDIA_ROOT = join(BASE_DIR, 'media')\nRELEASE_DOWNLOAD_ROOT = None\nSTATIC_URL = '/static/'\nMEDIA_URL = '/media/'\n\n# Default security settings\nSECURE_BROWSER_XSS_FILTER = True\nSECURE_CONTENT_TYPE_NOSNIFF = True\nCORS_ORIGIN_ALLOW_ALL = True\nCORS_URLS_REGEX = r'^/api/.*$'\nCORS_ALLOW_HEADERS = (\n 'x-requested-with',\n 'content-type',\n 'accept',\n 'origin',\n 'authorization',\n 'x-csrftoken',\n 'if-none-match',\n)\nCORS_EXPOSE_HEADERS = (\n 'etag',\n 'x-content-type-options',\n 'content-type',\n)\n\n# use modern no Captcha reCaptcha\nNOCAPTCHA = True\n\nLOGIN_REDIRECT_URL = 'home'\n", "path": "nextcloudappstore/settings/base.py"}], "after_files": [{"content": "\"\"\"\nDjango settings for nextcloudappstore project.\n\nGenerated by 'django-admin startproject' using Django 1.9.6.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.9/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.9/ref/settings/\n\"\"\"\n\nfrom os.path import dirname, abspath, join, pardir, realpath\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nfrom django.conf.global_settings import LANGUAGES\n\nBASE_DIR = realpath(join(dirname(dirname(abspath(__file__))), pardir))\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.9/howto/deployment/checklist/\n\n# Application definition\n\nINSTALLED_APPS = [\n 'nextcloudappstore.core.apps.CoreConfig',\n 'parler',\n 'captcha',\n 'rest_framework',\n 'corsheaders',\n 'allauth',\n 'allauth.account',\n 'allauth.socialaccount',\n 'allauth.socialaccount.providers.github',\n 'allauth.socialaccount.providers.bitbucket',\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.sites',\n 'django.contrib.staticfiles',\n]\n\nMIDDLEWARE_CLASSES = [\n 'django.middleware.security.SecurityMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'corsheaders.middleware.CorsMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nROOT_URLCONF = 'nextcloudappstore.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'nextcloudappstore.wsgi.application'\n\n# Database\n# https://docs.djangoproject.com/en/1.9/ref/settings/#databases\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.sqlite3',\n 'NAME': join(BASE_DIR, 'db.sqlite3'),\n 'TEST': {\n 'NAME': join(BASE_DIR, 'test.sqlite3'),\n }\n }\n}\n\nAUTHENTICATION_BACKENDS = (\n # Needed to login by username in Django admin, regardless of `allauth`\n 'django.contrib.auth.backends.ModelBackend',\n\n # `allauth` specific authentication methods, such as login by e-mail\n 'allauth.account.auth_backends.AuthenticationBackend',\n)\n\n# Password validation\n# https://docs.djangoproject.com/en/1.9/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation'\n '.UserAttributeSimilarityValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation'\n '.MinimumLengthValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation'\n '.CommonPasswordValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation'\n '.NumericPasswordValidator',\n },\n]\n\nREST_FRAMEWORK = {\n 'DEFAULT_RENDERER_CLASSES': (\n 'djangorestframework_camel_case.render.CamelCaseJSONRenderer',\n ),\n 'DEFAULT_PARSER_CLASSES': (\n 'djangorestframework_camel_case.parser.CamelCaseJSONParser',\n ),\n 'DEFAULT_THROTTLE_RATES': {\n 'app_upload': '100/day'\n }\n}\n\nSITE_ID = 1\n\n# Allauth configuration\n# http://django-allauth.readthedocs.io/en/latest/configuration.html\nACCOUNT_EMAIL_REQUIRED = True\nACCOUNT_EMAIL_VERIFICATION = \"mandatory\"\nACCOUNT_LOGOUT_ON_GET = True\nACCOUNT_LOGOUT_REDIRECT_URL = 'home'\nACCOUNT_SESSION_REMEMBER = True\nACCOUNT_SIGNUP_FORM_CLASS = \\\n 'nextcloudappstore.core.user.forms.SignupFormRecaptcha'\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.9/topics/i18n/\nLANGUAGE_CODE = 'en-us'\nTIME_ZONE = 'UTC'\nUSE_I18N = True\nUSE_L10N = True\nUSE_TZ = True\n\nPARLER_LANGUAGES = {\n 1: [{'code': code} for code, trans in LANGUAGES],\n 'default': {\n 'fallbacks': ['en'],\n 'hide_untranslated': False,\n }\n}\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.9/howto/static-files/\nMEDIA_ROOT = join(BASE_DIR, 'media')\nRELEASE_DOWNLOAD_ROOT = None\nSTATIC_URL = '/static/'\nMEDIA_URL = '/media/'\n\n# Default security settings\nSECURE_BROWSER_XSS_FILTER = True\nSECURE_CONTENT_TYPE_NOSNIFF = True\nCORS_ORIGIN_ALLOW_ALL = True\nCORS_URLS_REGEX = r'^/api/.*$'\nCORS_ALLOW_HEADERS = (\n 'x-requested-with',\n 'content-type',\n 'accept',\n 'origin',\n 'authorization',\n 'x-csrftoken',\n 'if-none-match',\n)\nCORS_EXPOSE_HEADERS = (\n 'etag',\n 'x-content-type-options',\n 'content-type',\n)\n\n# use modern no Captcha reCaptcha\nNOCAPTCHA = True\n\nLOGIN_REDIRECT_URL = 'home'\nLOGIN_URL = 'account_login'\n", "path": "nextcloudappstore/settings/base.py"}]} | 2,020 | 79 |
gh_patches_debug_5843 | rasdani/github-patches | git_diff | svthalia__concrexit-2277 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
True personal Agenda ICal Feed
### Problem
I believe it is annoying that when exporting the Personal iCal Feed to the agenda, you get the events your registered for + the open events + the events with optional registration. In practice this is very annoying as you don't want all these open events you might not go to in your agenda.
### Solution
That is why I suggest:
- Creating a 3rd button "iCal feed (personal)", which exports an iCal feed only containing the events you actually registered for.
- Renaming the current "iCal feed personal" to "iCal feed personal + open events"
### Motivation
A better user experience
### Describe alternatives you've considered
If this is not possible, I would consider adding an "add to agenda" button to the event pages so you can add events to your agenda individually.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `website/events/feeds.py`
Content:
```
1 """The feeds defined by the events package."""
2 from django.conf import settings
3 from django.db.models.query_utils import Q
4 from django.urls import reverse
5 from django.utils.translation import activate
6 from django.utils.translation import gettext as _
7 from django_ical.views import ICalFeed
8
9 from events.models import Event, FeedToken
10
11
12 class EventFeed(ICalFeed):
13 """Output an iCal feed containing all published events."""
14
15 def __init__(self, lang="en"):
16 super().__init__()
17 self.lang = lang
18 self.user = None
19
20 def __call__(self, request, *args, **kwargs):
21 if "u" in request.GET:
22 self.user = FeedToken.get_member(request.GET["u"])
23 else:
24 self.user = None
25
26 return super().__call__(request, args, kwargs)
27
28 def product_id(self):
29 return f"-//{settings.SITE_DOMAIN}//EventCalendar//{self.lang.upper()}"
30
31 def file_name(self):
32 return f"thalia_{self.lang}.ics"
33
34 def title(self):
35 activate(self.lang)
36 return _("Study Association Thalia event calendar")
37
38 def items(self):
39 query = Q(published=True)
40
41 if self.user:
42 query &= Q(registration_start__isnull=True) | (
43 Q(eventregistration__member=self.user)
44 & Q(eventregistration__date_cancelled=None)
45 )
46
47 return Event.objects.filter(query).order_by("-start")
48
49 def item_title(self, item):
50 return item.title
51
52 def item_description(self, item):
53 return f'{item.description} <a href="' f'{self.item_link(item)}">Website</a>'
54
55 def item_start_datetime(self, item):
56 return item.start
57
58 def item_end_datetime(self, item):
59 return item.end
60
61 def item_link(self, item):
62 return settings.BASE_URL + reverse("events:event", kwargs={"pk": item.id})
63
64 def item_location(self, item):
65 return f"{item.location} - {item.map_location}"
66
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/website/events/feeds.py b/website/events/feeds.py
--- a/website/events/feeds.py
+++ b/website/events/feeds.py
@@ -39,9 +39,8 @@
query = Q(published=True)
if self.user:
- query &= Q(registration_start__isnull=True) | (
- Q(eventregistration__member=self.user)
- & Q(eventregistration__date_cancelled=None)
+ query &= Q(eventregistration__member=self.user) & Q(
+ eventregistration__date_cancelled=None
)
return Event.objects.filter(query).order_by("-start")
| {"golden_diff": "diff --git a/website/events/feeds.py b/website/events/feeds.py\n--- a/website/events/feeds.py\n+++ b/website/events/feeds.py\n@@ -39,9 +39,8 @@\n query = Q(published=True)\n \n if self.user:\n- query &= Q(registration_start__isnull=True) | (\n- Q(eventregistration__member=self.user)\n- & Q(eventregistration__date_cancelled=None)\n+ query &= Q(eventregistration__member=self.user) & Q(\n+ eventregistration__date_cancelled=None\n )\n \n return Event.objects.filter(query).order_by(\"-start\")\n", "issue": "True personal Agenda ICal Feed\n### Problem\r\nI believe it is annoying that when exporting the Personal iCal Feed to the agenda, you get the events your registered for + the open events + the events with optional registration. In practice this is very annoying as you don't want all these open events you might not go to in your agenda.\r\n\r\n### Solution\r\nThat is why I suggest:\r\n- Creating a 3rd button \"iCal feed (personal)\", which exports an iCal feed only containing the events you actually registered for.\r\n- Renaming the current \"iCal feed personal\" to \"iCal feed personal + open events\"\r\n\r\n### Motivation\r\nA better user experience \r\n\r\n### Describe alternatives you've considered\r\nIf this is not possible, I would consider adding an \"add to agenda\" button to the event pages so you can add events to your agenda individually.\r\n\n", "before_files": [{"content": "\"\"\"The feeds defined by the events package.\"\"\"\nfrom django.conf import settings\nfrom django.db.models.query_utils import Q\nfrom django.urls import reverse\nfrom django.utils.translation import activate\nfrom django.utils.translation import gettext as _\nfrom django_ical.views import ICalFeed\n\nfrom events.models import Event, FeedToken\n\n\nclass EventFeed(ICalFeed):\n \"\"\"Output an iCal feed containing all published events.\"\"\"\n\n def __init__(self, lang=\"en\"):\n super().__init__()\n self.lang = lang\n self.user = None\n\n def __call__(self, request, *args, **kwargs):\n if \"u\" in request.GET:\n self.user = FeedToken.get_member(request.GET[\"u\"])\n else:\n self.user = None\n\n return super().__call__(request, args, kwargs)\n\n def product_id(self):\n return f\"-//{settings.SITE_DOMAIN}//EventCalendar//{self.lang.upper()}\"\n\n def file_name(self):\n return f\"thalia_{self.lang}.ics\"\n\n def title(self):\n activate(self.lang)\n return _(\"Study Association Thalia event calendar\")\n\n def items(self):\n query = Q(published=True)\n\n if self.user:\n query &= Q(registration_start__isnull=True) | (\n Q(eventregistration__member=self.user)\n & Q(eventregistration__date_cancelled=None)\n )\n\n return Event.objects.filter(query).order_by(\"-start\")\n\n def item_title(self, item):\n return item.title\n\n def item_description(self, item):\n return f'{item.description} <a href=\"' f'{self.item_link(item)}\">Website</a>'\n\n def item_start_datetime(self, item):\n return item.start\n\n def item_end_datetime(self, item):\n return item.end\n\n def item_link(self, item):\n return settings.BASE_URL + reverse(\"events:event\", kwargs={\"pk\": item.id})\n\n def item_location(self, item):\n return f\"{item.location} - {item.map_location}\"\n", "path": "website/events/feeds.py"}], "after_files": [{"content": "\"\"\"The feeds defined by the events package.\"\"\"\nfrom django.conf import settings\nfrom django.db.models.query_utils import Q\nfrom django.urls import reverse\nfrom django.utils.translation import activate\nfrom django.utils.translation import gettext as _\nfrom django_ical.views import ICalFeed\n\nfrom events.models import Event, FeedToken\n\n\nclass EventFeed(ICalFeed):\n \"\"\"Output an iCal feed containing all published events.\"\"\"\n\n def __init__(self, lang=\"en\"):\n super().__init__()\n self.lang = lang\n self.user = None\n\n def __call__(self, request, *args, **kwargs):\n if \"u\" in request.GET:\n self.user = FeedToken.get_member(request.GET[\"u\"])\n else:\n self.user = None\n\n return super().__call__(request, args, kwargs)\n\n def product_id(self):\n return f\"-//{settings.SITE_DOMAIN}//EventCalendar//{self.lang.upper()}\"\n\n def file_name(self):\n return f\"thalia_{self.lang}.ics\"\n\n def title(self):\n activate(self.lang)\n return _(\"Study Association Thalia event calendar\")\n\n def items(self):\n query = Q(published=True)\n\n if self.user:\n query &= Q(eventregistration__member=self.user) & Q(\n eventregistration__date_cancelled=None\n )\n\n return Event.objects.filter(query).order_by(\"-start\")\n\n def item_title(self, item):\n return item.title\n\n def item_description(self, item):\n return f'{item.description} <a href=\"' f'{self.item_link(item)}\">Website</a>'\n\n def item_start_datetime(self, item):\n return item.start\n\n def item_end_datetime(self, item):\n return item.end\n\n def item_link(self, item):\n return settings.BASE_URL + reverse(\"events:event\", kwargs={\"pk\": item.id})\n\n def item_location(self, item):\n return f\"{item.location} - {item.map_location}\"\n", "path": "website/events/feeds.py"}]} | 996 | 139 |
gh_patches_debug_19675 | rasdani/github-patches | git_diff | python-pillow__Pillow-6178 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
"box" parameter of PIL.ImageTk.PhotoImage.paste method appears to be dysfunctional
The "**box**" 4-tuple parameter of the **PIL.ImageTk.PhotoImage.paste** method is intended to allow a PIL Image to be pasted onto a Tkinter compatible PhotoImage within the specified box coordinates, but "box" appears to be dysfunctional, and I can't see anything in the source code of the method to implement its function. Smaller images pasted to larger images appear top-left and ignore any "box" value.
The documentation detailing the "box" parameter is here:
https://pillow.readthedocs.io/en/stable/reference/ImageTk.html#PIL.ImageTk.PhotoImage.paste
The source code of the paste method includes "box" as a parameter and has a docstring for it:
https://github.com/python-pillow/Pillow/blob/main/src/PIL/ImageTk.py#L178
Test code. A smaller blue box pasted into a larger yellow box always appears top-left and ignores the paste coordinates:
```python
import tkinter as tk
from PIL import Image, ImageTk
root = tk.Tk()
pil_img1 = Image.new("RGB",(400, 200), "yellow")
tk_img1 = ImageTk.PhotoImage(pil_img1)
tk.Label(root, image=tk_img1).pack()
pil_img2 = Image.new("RGB",(200, 100), "blue")
tk_img1.paste(pil_img2, box=(100, 50, 200, 150))
root.mainloop()
```
Tested with Windows 10, Python 3.10.4, Pillow 9.0.1
and with Ubuntu 21.10, Python 3.9.7, Pillow 8.1.2
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/PIL/ImageTk.py`
Content:
```
1 #
2 # The Python Imaging Library.
3 # $Id$
4 #
5 # a Tk display interface
6 #
7 # History:
8 # 96-04-08 fl Created
9 # 96-09-06 fl Added getimage method
10 # 96-11-01 fl Rewritten, removed image attribute and crop method
11 # 97-05-09 fl Use PyImagingPaste method instead of image type
12 # 97-05-12 fl Minor tweaks to match the IFUNC95 interface
13 # 97-05-17 fl Support the "pilbitmap" booster patch
14 # 97-06-05 fl Added file= and data= argument to image constructors
15 # 98-03-09 fl Added width and height methods to Image classes
16 # 98-07-02 fl Use default mode for "P" images without palette attribute
17 # 98-07-02 fl Explicitly destroy Tkinter image objects
18 # 99-07-24 fl Support multiple Tk interpreters (from Greg Couch)
19 # 99-07-26 fl Automatically hook into Tkinter (if possible)
20 # 99-08-15 fl Hook uses _imagingtk instead of _imaging
21 #
22 # Copyright (c) 1997-1999 by Secret Labs AB
23 # Copyright (c) 1996-1997 by Fredrik Lundh
24 #
25 # See the README file for information on usage and redistribution.
26 #
27
28 import tkinter
29 from io import BytesIO
30
31 from . import Image
32
33 # --------------------------------------------------------------------
34 # Check for Tkinter interface hooks
35
36 _pilbitmap_ok = None
37
38
39 def _pilbitmap_check():
40 global _pilbitmap_ok
41 if _pilbitmap_ok is None:
42 try:
43 im = Image.new("1", (1, 1))
44 tkinter.BitmapImage(data=f"PIL:{im.im.id}")
45 _pilbitmap_ok = 1
46 except tkinter.TclError:
47 _pilbitmap_ok = 0
48 return _pilbitmap_ok
49
50
51 def _get_image_from_kw(kw):
52 source = None
53 if "file" in kw:
54 source = kw.pop("file")
55 elif "data" in kw:
56 source = BytesIO(kw.pop("data"))
57 if source:
58 return Image.open(source)
59
60
61 def _pyimagingtkcall(command, photo, id):
62 tk = photo.tk
63 try:
64 tk.call(command, photo, id)
65 except tkinter.TclError:
66 # activate Tkinter hook
67 # may raise an error if it cannot attach to Tkinter
68 from . import _imagingtk
69
70 try:
71 if hasattr(tk, "interp"):
72 # Required for PyPy, which always has CFFI installed
73 from cffi import FFI
74
75 ffi = FFI()
76
77 # PyPy is using an FFI CDATA element
78 # (Pdb) self.tk.interp
79 # <cdata 'Tcl_Interp *' 0x3061b50>
80 _imagingtk.tkinit(int(ffi.cast("uintptr_t", tk.interp)), 1)
81 else:
82 _imagingtk.tkinit(tk.interpaddr(), 1)
83 except AttributeError:
84 _imagingtk.tkinit(id(tk), 0)
85 tk.call(command, photo, id)
86
87
88 # --------------------------------------------------------------------
89 # PhotoImage
90
91
92 class PhotoImage:
93 """
94 A Tkinter-compatible photo image. This can be used
95 everywhere Tkinter expects an image object. If the image is an RGBA
96 image, pixels having alpha 0 are treated as transparent.
97
98 The constructor takes either a PIL image, or a mode and a size.
99 Alternatively, you can use the ``file`` or ``data`` options to initialize
100 the photo image object.
101
102 :param image: Either a PIL image, or a mode string. If a mode string is
103 used, a size must also be given.
104 :param size: If the first argument is a mode string, this defines the size
105 of the image.
106 :keyword file: A filename to load the image from (using
107 ``Image.open(file)``).
108 :keyword data: An 8-bit string containing image data (as loaded from an
109 image file).
110 """
111
112 def __init__(self, image=None, size=None, **kw):
113
114 # Tk compatibility: file or data
115 if image is None:
116 image = _get_image_from_kw(kw)
117
118 if hasattr(image, "mode") and hasattr(image, "size"):
119 # got an image instead of a mode
120 mode = image.mode
121 if mode == "P":
122 # palette mapped data
123 image.load()
124 try:
125 mode = image.palette.mode
126 except AttributeError:
127 mode = "RGB" # default
128 size = image.size
129 kw["width"], kw["height"] = size
130 else:
131 mode = image
132 image = None
133
134 if mode not in ["1", "L", "RGB", "RGBA"]:
135 mode = Image.getmodebase(mode)
136
137 self.__mode = mode
138 self.__size = size
139 self.__photo = tkinter.PhotoImage(**kw)
140 self.tk = self.__photo.tk
141 if image:
142 self.paste(image)
143
144 def __del__(self):
145 name = self.__photo.name
146 self.__photo.name = None
147 try:
148 self.__photo.tk.call("image", "delete", name)
149 except Exception:
150 pass # ignore internal errors
151
152 def __str__(self):
153 """
154 Get the Tkinter photo image identifier. This method is automatically
155 called by Tkinter whenever a PhotoImage object is passed to a Tkinter
156 method.
157
158 :return: A Tkinter photo image identifier (a string).
159 """
160 return str(self.__photo)
161
162 def width(self):
163 """
164 Get the width of the image.
165
166 :return: The width, in pixels.
167 """
168 return self.__size[0]
169
170 def height(self):
171 """
172 Get the height of the image.
173
174 :return: The height, in pixels.
175 """
176 return self.__size[1]
177
178 def paste(self, im, box=None):
179 """
180 Paste a PIL image into the photo image. Note that this can
181 be very slow if the photo image is displayed.
182
183 :param im: A PIL image. The size must match the target region. If the
184 mode does not match, the image is converted to the mode of
185 the bitmap image.
186 :param box: A 4-tuple defining the left, upper, right, and lower pixel
187 coordinate. See :ref:`coordinate-system`. If None is given
188 instead of a tuple, all of the image is assumed.
189 """
190
191 # convert to blittable
192 im.load()
193 image = im.im
194 if image.isblock() and im.mode == self.__mode:
195 block = image
196 else:
197 block = image.new_block(self.__mode, im.size)
198 image.convert2(block, image) # convert directly between buffers
199
200 _pyimagingtkcall("PyImagingPhoto", self.__photo, block.id)
201
202
203 # --------------------------------------------------------------------
204 # BitmapImage
205
206
207 class BitmapImage:
208 """
209 A Tkinter-compatible bitmap image. This can be used everywhere Tkinter
210 expects an image object.
211
212 The given image must have mode "1". Pixels having value 0 are treated as
213 transparent. Options, if any, are passed on to Tkinter. The most commonly
214 used option is ``foreground``, which is used to specify the color for the
215 non-transparent parts. See the Tkinter documentation for information on
216 how to specify colours.
217
218 :param image: A PIL image.
219 """
220
221 def __init__(self, image=None, **kw):
222
223 # Tk compatibility: file or data
224 if image is None:
225 image = _get_image_from_kw(kw)
226
227 self.__mode = image.mode
228 self.__size = image.size
229
230 if _pilbitmap_check():
231 # fast way (requires the pilbitmap booster patch)
232 image.load()
233 kw["data"] = f"PIL:{image.im.id}"
234 self.__im = image # must keep a reference
235 else:
236 # slow but safe way
237 kw["data"] = image.tobitmap()
238 self.__photo = tkinter.BitmapImage(**kw)
239
240 def __del__(self):
241 name = self.__photo.name
242 self.__photo.name = None
243 try:
244 self.__photo.tk.call("image", "delete", name)
245 except Exception:
246 pass # ignore internal errors
247
248 def width(self):
249 """
250 Get the width of the image.
251
252 :return: The width, in pixels.
253 """
254 return self.__size[0]
255
256 def height(self):
257 """
258 Get the height of the image.
259
260 :return: The height, in pixels.
261 """
262 return self.__size[1]
263
264 def __str__(self):
265 """
266 Get the Tkinter bitmap image identifier. This method is automatically
267 called by Tkinter whenever a BitmapImage object is passed to a Tkinter
268 method.
269
270 :return: A Tkinter bitmap image identifier (a string).
271 """
272 return str(self.__photo)
273
274
275 def getimage(photo):
276 """Copies the contents of a PhotoImage to a PIL image memory."""
277 im = Image.new("RGBA", (photo.width(), photo.height()))
278 block = im.im
279
280 _pyimagingtkcall("PyImagingPhotoGet", photo, block.id)
281
282 return im
283
284
285 def _show(image, title):
286 """Helper for the Image.show method."""
287
288 class UI(tkinter.Label):
289 def __init__(self, master, im):
290 if im.mode == "1":
291 self.image = BitmapImage(im, foreground="white", master=master)
292 else:
293 self.image = PhotoImage(im, master=master)
294 super().__init__(master, image=self.image, bg="black", bd=0)
295
296 if not tkinter._default_root:
297 raise OSError("tkinter not initialized")
298 top = tkinter.Toplevel()
299 if title:
300 top.title(title)
301 UI(top, image).pack()
302
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/PIL/ImageTk.py b/src/PIL/ImageTk.py
--- a/src/PIL/ImageTk.py
+++ b/src/PIL/ImageTk.py
@@ -26,6 +26,7 @@
#
import tkinter
+import warnings
from io import BytesIO
from . import Image
@@ -183,11 +184,15 @@
:param im: A PIL image. The size must match the target region. If the
mode does not match, the image is converted to the mode of
the bitmap image.
- :param box: A 4-tuple defining the left, upper, right, and lower pixel
- coordinate. See :ref:`coordinate-system`. If None is given
- instead of a tuple, all of the image is assumed.
"""
+ if box is not None:
+ warnings.warn(
+ "The box parameter is deprecated and will be removed in Pillow 10 "
+ "(2023-07-01).",
+ DeprecationWarning,
+ )
+
# convert to blittable
im.load()
image = im.im
| {"golden_diff": "diff --git a/src/PIL/ImageTk.py b/src/PIL/ImageTk.py\n--- a/src/PIL/ImageTk.py\n+++ b/src/PIL/ImageTk.py\n@@ -26,6 +26,7 @@\n #\n \n import tkinter\n+import warnings\n from io import BytesIO\n \n from . import Image\n@@ -183,11 +184,15 @@\n :param im: A PIL image. The size must match the target region. If the\n mode does not match, the image is converted to the mode of\n the bitmap image.\n- :param box: A 4-tuple defining the left, upper, right, and lower pixel\n- coordinate. See :ref:`coordinate-system`. If None is given\n- instead of a tuple, all of the image is assumed.\n \"\"\"\n \n+ if box is not None:\n+ warnings.warn(\n+ \"The box parameter is deprecated and will be removed in Pillow 10 \"\n+ \"(2023-07-01).\",\n+ DeprecationWarning,\n+ )\n+\n # convert to blittable\n im.load()\n image = im.im\n", "issue": "\"box\" parameter of PIL.ImageTk.PhotoImage.paste method appears to be dysfunctional\nThe \"**box**\" 4-tuple parameter of the **PIL.ImageTk.PhotoImage.paste** method is intended to allow a PIL Image to be pasted onto a Tkinter compatible PhotoImage within the specified box coordinates, but \"box\" appears to be dysfunctional, and I can't see anything in the source code of the method to implement its function. Smaller images pasted to larger images appear top-left and ignore any \"box\" value.\r\n\r\nThe documentation detailing the \"box\" parameter is here:\r\nhttps://pillow.readthedocs.io/en/stable/reference/ImageTk.html#PIL.ImageTk.PhotoImage.paste\r\n\r\nThe source code of the paste method includes \"box\" as a parameter and has a docstring for it:\r\nhttps://github.com/python-pillow/Pillow/blob/main/src/PIL/ImageTk.py#L178\r\n\r\nTest code. A smaller blue box pasted into a larger yellow box always appears top-left and ignores the paste coordinates:\r\n\r\n```python\r\nimport tkinter as tk\r\nfrom PIL import Image, ImageTk\r\nroot = tk.Tk()\r\npil_img1 = Image.new(\"RGB\",(400, 200), \"yellow\")\r\ntk_img1 = ImageTk.PhotoImage(pil_img1)\r\ntk.Label(root, image=tk_img1).pack()\r\npil_img2 = Image.new(\"RGB\",(200, 100), \"blue\")\r\ntk_img1.paste(pil_img2, box=(100, 50, 200, 150))\r\nroot.mainloop()\r\n```\r\n\r\nTested with Windows 10, Python 3.10.4, Pillow 9.0.1\r\nand with Ubuntu 21.10, Python 3.9.7, Pillow 8.1.2\r\n\n", "before_files": [{"content": "#\n# The Python Imaging Library.\n# $Id$\n#\n# a Tk display interface\n#\n# History:\n# 96-04-08 fl Created\n# 96-09-06 fl Added getimage method\n# 96-11-01 fl Rewritten, removed image attribute and crop method\n# 97-05-09 fl Use PyImagingPaste method instead of image type\n# 97-05-12 fl Minor tweaks to match the IFUNC95 interface\n# 97-05-17 fl Support the \"pilbitmap\" booster patch\n# 97-06-05 fl Added file= and data= argument to image constructors\n# 98-03-09 fl Added width and height methods to Image classes\n# 98-07-02 fl Use default mode for \"P\" images without palette attribute\n# 98-07-02 fl Explicitly destroy Tkinter image objects\n# 99-07-24 fl Support multiple Tk interpreters (from Greg Couch)\n# 99-07-26 fl Automatically hook into Tkinter (if possible)\n# 99-08-15 fl Hook uses _imagingtk instead of _imaging\n#\n# Copyright (c) 1997-1999 by Secret Labs AB\n# Copyright (c) 1996-1997 by Fredrik Lundh\n#\n# See the README file for information on usage and redistribution.\n#\n\nimport tkinter\nfrom io import BytesIO\n\nfrom . import Image\n\n# --------------------------------------------------------------------\n# Check for Tkinter interface hooks\n\n_pilbitmap_ok = None\n\n\ndef _pilbitmap_check():\n global _pilbitmap_ok\n if _pilbitmap_ok is None:\n try:\n im = Image.new(\"1\", (1, 1))\n tkinter.BitmapImage(data=f\"PIL:{im.im.id}\")\n _pilbitmap_ok = 1\n except tkinter.TclError:\n _pilbitmap_ok = 0\n return _pilbitmap_ok\n\n\ndef _get_image_from_kw(kw):\n source = None\n if \"file\" in kw:\n source = kw.pop(\"file\")\n elif \"data\" in kw:\n source = BytesIO(kw.pop(\"data\"))\n if source:\n return Image.open(source)\n\n\ndef _pyimagingtkcall(command, photo, id):\n tk = photo.tk\n try:\n tk.call(command, photo, id)\n except tkinter.TclError:\n # activate Tkinter hook\n # may raise an error if it cannot attach to Tkinter\n from . import _imagingtk\n\n try:\n if hasattr(tk, \"interp\"):\n # Required for PyPy, which always has CFFI installed\n from cffi import FFI\n\n ffi = FFI()\n\n # PyPy is using an FFI CDATA element\n # (Pdb) self.tk.interp\n # <cdata 'Tcl_Interp *' 0x3061b50>\n _imagingtk.tkinit(int(ffi.cast(\"uintptr_t\", tk.interp)), 1)\n else:\n _imagingtk.tkinit(tk.interpaddr(), 1)\n except AttributeError:\n _imagingtk.tkinit(id(tk), 0)\n tk.call(command, photo, id)\n\n\n# --------------------------------------------------------------------\n# PhotoImage\n\n\nclass PhotoImage:\n \"\"\"\n A Tkinter-compatible photo image. This can be used\n everywhere Tkinter expects an image object. If the image is an RGBA\n image, pixels having alpha 0 are treated as transparent.\n\n The constructor takes either a PIL image, or a mode and a size.\n Alternatively, you can use the ``file`` or ``data`` options to initialize\n the photo image object.\n\n :param image: Either a PIL image, or a mode string. If a mode string is\n used, a size must also be given.\n :param size: If the first argument is a mode string, this defines the size\n of the image.\n :keyword file: A filename to load the image from (using\n ``Image.open(file)``).\n :keyword data: An 8-bit string containing image data (as loaded from an\n image file).\n \"\"\"\n\n def __init__(self, image=None, size=None, **kw):\n\n # Tk compatibility: file or data\n if image is None:\n image = _get_image_from_kw(kw)\n\n if hasattr(image, \"mode\") and hasattr(image, \"size\"):\n # got an image instead of a mode\n mode = image.mode\n if mode == \"P\":\n # palette mapped data\n image.load()\n try:\n mode = image.palette.mode\n except AttributeError:\n mode = \"RGB\" # default\n size = image.size\n kw[\"width\"], kw[\"height\"] = size\n else:\n mode = image\n image = None\n\n if mode not in [\"1\", \"L\", \"RGB\", \"RGBA\"]:\n mode = Image.getmodebase(mode)\n\n self.__mode = mode\n self.__size = size\n self.__photo = tkinter.PhotoImage(**kw)\n self.tk = self.__photo.tk\n if image:\n self.paste(image)\n\n def __del__(self):\n name = self.__photo.name\n self.__photo.name = None\n try:\n self.__photo.tk.call(\"image\", \"delete\", name)\n except Exception:\n pass # ignore internal errors\n\n def __str__(self):\n \"\"\"\n Get the Tkinter photo image identifier. This method is automatically\n called by Tkinter whenever a PhotoImage object is passed to a Tkinter\n method.\n\n :return: A Tkinter photo image identifier (a string).\n \"\"\"\n return str(self.__photo)\n\n def width(self):\n \"\"\"\n Get the width of the image.\n\n :return: The width, in pixels.\n \"\"\"\n return self.__size[0]\n\n def height(self):\n \"\"\"\n Get the height of the image.\n\n :return: The height, in pixels.\n \"\"\"\n return self.__size[1]\n\n def paste(self, im, box=None):\n \"\"\"\n Paste a PIL image into the photo image. Note that this can\n be very slow if the photo image is displayed.\n\n :param im: A PIL image. The size must match the target region. If the\n mode does not match, the image is converted to the mode of\n the bitmap image.\n :param box: A 4-tuple defining the left, upper, right, and lower pixel\n coordinate. See :ref:`coordinate-system`. If None is given\n instead of a tuple, all of the image is assumed.\n \"\"\"\n\n # convert to blittable\n im.load()\n image = im.im\n if image.isblock() and im.mode == self.__mode:\n block = image\n else:\n block = image.new_block(self.__mode, im.size)\n image.convert2(block, image) # convert directly between buffers\n\n _pyimagingtkcall(\"PyImagingPhoto\", self.__photo, block.id)\n\n\n# --------------------------------------------------------------------\n# BitmapImage\n\n\nclass BitmapImage:\n \"\"\"\n A Tkinter-compatible bitmap image. This can be used everywhere Tkinter\n expects an image object.\n\n The given image must have mode \"1\". Pixels having value 0 are treated as\n transparent. Options, if any, are passed on to Tkinter. The most commonly\n used option is ``foreground``, which is used to specify the color for the\n non-transparent parts. See the Tkinter documentation for information on\n how to specify colours.\n\n :param image: A PIL image.\n \"\"\"\n\n def __init__(self, image=None, **kw):\n\n # Tk compatibility: file or data\n if image is None:\n image = _get_image_from_kw(kw)\n\n self.__mode = image.mode\n self.__size = image.size\n\n if _pilbitmap_check():\n # fast way (requires the pilbitmap booster patch)\n image.load()\n kw[\"data\"] = f\"PIL:{image.im.id}\"\n self.__im = image # must keep a reference\n else:\n # slow but safe way\n kw[\"data\"] = image.tobitmap()\n self.__photo = tkinter.BitmapImage(**kw)\n\n def __del__(self):\n name = self.__photo.name\n self.__photo.name = None\n try:\n self.__photo.tk.call(\"image\", \"delete\", name)\n except Exception:\n pass # ignore internal errors\n\n def width(self):\n \"\"\"\n Get the width of the image.\n\n :return: The width, in pixels.\n \"\"\"\n return self.__size[0]\n\n def height(self):\n \"\"\"\n Get the height of the image.\n\n :return: The height, in pixels.\n \"\"\"\n return self.__size[1]\n\n def __str__(self):\n \"\"\"\n Get the Tkinter bitmap image identifier. This method is automatically\n called by Tkinter whenever a BitmapImage object is passed to a Tkinter\n method.\n\n :return: A Tkinter bitmap image identifier (a string).\n \"\"\"\n return str(self.__photo)\n\n\ndef getimage(photo):\n \"\"\"Copies the contents of a PhotoImage to a PIL image memory.\"\"\"\n im = Image.new(\"RGBA\", (photo.width(), photo.height()))\n block = im.im\n\n _pyimagingtkcall(\"PyImagingPhotoGet\", photo, block.id)\n\n return im\n\n\ndef _show(image, title):\n \"\"\"Helper for the Image.show method.\"\"\"\n\n class UI(tkinter.Label):\n def __init__(self, master, im):\n if im.mode == \"1\":\n self.image = BitmapImage(im, foreground=\"white\", master=master)\n else:\n self.image = PhotoImage(im, master=master)\n super().__init__(master, image=self.image, bg=\"black\", bd=0)\n\n if not tkinter._default_root:\n raise OSError(\"tkinter not initialized\")\n top = tkinter.Toplevel()\n if title:\n top.title(title)\n UI(top, image).pack()\n", "path": "src/PIL/ImageTk.py"}], "after_files": [{"content": "#\n# The Python Imaging Library.\n# $Id$\n#\n# a Tk display interface\n#\n# History:\n# 96-04-08 fl Created\n# 96-09-06 fl Added getimage method\n# 96-11-01 fl Rewritten, removed image attribute and crop method\n# 97-05-09 fl Use PyImagingPaste method instead of image type\n# 97-05-12 fl Minor tweaks to match the IFUNC95 interface\n# 97-05-17 fl Support the \"pilbitmap\" booster patch\n# 97-06-05 fl Added file= and data= argument to image constructors\n# 98-03-09 fl Added width and height methods to Image classes\n# 98-07-02 fl Use default mode for \"P\" images without palette attribute\n# 98-07-02 fl Explicitly destroy Tkinter image objects\n# 99-07-24 fl Support multiple Tk interpreters (from Greg Couch)\n# 99-07-26 fl Automatically hook into Tkinter (if possible)\n# 99-08-15 fl Hook uses _imagingtk instead of _imaging\n#\n# Copyright (c) 1997-1999 by Secret Labs AB\n# Copyright (c) 1996-1997 by Fredrik Lundh\n#\n# See the README file for information on usage and redistribution.\n#\n\nimport tkinter\nimport warnings\nfrom io import BytesIO\n\nfrom . import Image\n\n# --------------------------------------------------------------------\n# Check for Tkinter interface hooks\n\n_pilbitmap_ok = None\n\n\ndef _pilbitmap_check():\n global _pilbitmap_ok\n if _pilbitmap_ok is None:\n try:\n im = Image.new(\"1\", (1, 1))\n tkinter.BitmapImage(data=f\"PIL:{im.im.id}\")\n _pilbitmap_ok = 1\n except tkinter.TclError:\n _pilbitmap_ok = 0\n return _pilbitmap_ok\n\n\ndef _get_image_from_kw(kw):\n source = None\n if \"file\" in kw:\n source = kw.pop(\"file\")\n elif \"data\" in kw:\n source = BytesIO(kw.pop(\"data\"))\n if source:\n return Image.open(source)\n\n\ndef _pyimagingtkcall(command, photo, id):\n tk = photo.tk\n try:\n tk.call(command, photo, id)\n except tkinter.TclError:\n # activate Tkinter hook\n # may raise an error if it cannot attach to Tkinter\n from . import _imagingtk\n\n try:\n if hasattr(tk, \"interp\"):\n # Required for PyPy, which always has CFFI installed\n from cffi import FFI\n\n ffi = FFI()\n\n # PyPy is using an FFI CDATA element\n # (Pdb) self.tk.interp\n # <cdata 'Tcl_Interp *' 0x3061b50>\n _imagingtk.tkinit(int(ffi.cast(\"uintptr_t\", tk.interp)), 1)\n else:\n _imagingtk.tkinit(tk.interpaddr(), 1)\n except AttributeError:\n _imagingtk.tkinit(id(tk), 0)\n tk.call(command, photo, id)\n\n\n# --------------------------------------------------------------------\n# PhotoImage\n\n\nclass PhotoImage:\n \"\"\"\n A Tkinter-compatible photo image. This can be used\n everywhere Tkinter expects an image object. If the image is an RGBA\n image, pixels having alpha 0 are treated as transparent.\n\n The constructor takes either a PIL image, or a mode and a size.\n Alternatively, you can use the ``file`` or ``data`` options to initialize\n the photo image object.\n\n :param image: Either a PIL image, or a mode string. If a mode string is\n used, a size must also be given.\n :param size: If the first argument is a mode string, this defines the size\n of the image.\n :keyword file: A filename to load the image from (using\n ``Image.open(file)``).\n :keyword data: An 8-bit string containing image data (as loaded from an\n image file).\n \"\"\"\n\n def __init__(self, image=None, size=None, **kw):\n\n # Tk compatibility: file or data\n if image is None:\n image = _get_image_from_kw(kw)\n\n if hasattr(image, \"mode\") and hasattr(image, \"size\"):\n # got an image instead of a mode\n mode = image.mode\n if mode == \"P\":\n # palette mapped data\n image.load()\n try:\n mode = image.palette.mode\n except AttributeError:\n mode = \"RGB\" # default\n size = image.size\n kw[\"width\"], kw[\"height\"] = size\n else:\n mode = image\n image = None\n\n if mode not in [\"1\", \"L\", \"RGB\", \"RGBA\"]:\n mode = Image.getmodebase(mode)\n\n self.__mode = mode\n self.__size = size\n self.__photo = tkinter.PhotoImage(**kw)\n self.tk = self.__photo.tk\n if image:\n self.paste(image)\n\n def __del__(self):\n name = self.__photo.name\n self.__photo.name = None\n try:\n self.__photo.tk.call(\"image\", \"delete\", name)\n except Exception:\n pass # ignore internal errors\n\n def __str__(self):\n \"\"\"\n Get the Tkinter photo image identifier. This method is automatically\n called by Tkinter whenever a PhotoImage object is passed to a Tkinter\n method.\n\n :return: A Tkinter photo image identifier (a string).\n \"\"\"\n return str(self.__photo)\n\n def width(self):\n \"\"\"\n Get the width of the image.\n\n :return: The width, in pixels.\n \"\"\"\n return self.__size[0]\n\n def height(self):\n \"\"\"\n Get the height of the image.\n\n :return: The height, in pixels.\n \"\"\"\n return self.__size[1]\n\n def paste(self, im, box=None):\n \"\"\"\n Paste a PIL image into the photo image. Note that this can\n be very slow if the photo image is displayed.\n\n :param im: A PIL image. The size must match the target region. If the\n mode does not match, the image is converted to the mode of\n the bitmap image.\n \"\"\"\n\n if box is not None:\n warnings.warn(\n \"The box parameter is deprecated and will be removed in Pillow 10 \"\n \"(2023-07-01).\",\n DeprecationWarning,\n )\n\n # convert to blittable\n im.load()\n image = im.im\n if image.isblock() and im.mode == self.__mode:\n block = image\n else:\n block = image.new_block(self.__mode, im.size)\n image.convert2(block, image) # convert directly between buffers\n\n _pyimagingtkcall(\"PyImagingPhoto\", self.__photo, block.id)\n\n\n# --------------------------------------------------------------------\n# BitmapImage\n\n\nclass BitmapImage:\n \"\"\"\n A Tkinter-compatible bitmap image. This can be used everywhere Tkinter\n expects an image object.\n\n The given image must have mode \"1\". Pixels having value 0 are treated as\n transparent. Options, if any, are passed on to Tkinter. The most commonly\n used option is ``foreground``, which is used to specify the color for the\n non-transparent parts. See the Tkinter documentation for information on\n how to specify colours.\n\n :param image: A PIL image.\n \"\"\"\n\n def __init__(self, image=None, **kw):\n\n # Tk compatibility: file or data\n if image is None:\n image = _get_image_from_kw(kw)\n\n self.__mode = image.mode\n self.__size = image.size\n\n if _pilbitmap_check():\n # fast way (requires the pilbitmap booster patch)\n image.load()\n kw[\"data\"] = f\"PIL:{image.im.id}\"\n self.__im = image # must keep a reference\n else:\n # slow but safe way\n kw[\"data\"] = image.tobitmap()\n self.__photo = tkinter.BitmapImage(**kw)\n\n def __del__(self):\n name = self.__photo.name\n self.__photo.name = None\n try:\n self.__photo.tk.call(\"image\", \"delete\", name)\n except Exception:\n pass # ignore internal errors\n\n def width(self):\n \"\"\"\n Get the width of the image.\n\n :return: The width, in pixels.\n \"\"\"\n return self.__size[0]\n\n def height(self):\n \"\"\"\n Get the height of the image.\n\n :return: The height, in pixels.\n \"\"\"\n return self.__size[1]\n\n def __str__(self):\n \"\"\"\n Get the Tkinter bitmap image identifier. This method is automatically\n called by Tkinter whenever a BitmapImage object is passed to a Tkinter\n method.\n\n :return: A Tkinter bitmap image identifier (a string).\n \"\"\"\n return str(self.__photo)\n\n\ndef getimage(photo):\n \"\"\"Copies the contents of a PhotoImage to a PIL image memory.\"\"\"\n im = Image.new(\"RGBA\", (photo.width(), photo.height()))\n block = im.im\n\n _pyimagingtkcall(\"PyImagingPhotoGet\", photo, block.id)\n\n return im\n\n\ndef _show(image, title):\n \"\"\"Helper for the Image.show method.\"\"\"\n\n class UI(tkinter.Label):\n def __init__(self, master, im):\n if im.mode == \"1\":\n self.image = BitmapImage(im, foreground=\"white\", master=master)\n else:\n self.image = PhotoImage(im, master=master)\n super().__init__(master, image=self.image, bg=\"black\", bd=0)\n\n if not tkinter._default_root:\n raise OSError(\"tkinter not initialized\")\n top = tkinter.Toplevel()\n if title:\n top.title(title)\n UI(top, image).pack()\n", "path": "src/PIL/ImageTk.py"}]} | 3,749 | 256 |
gh_patches_debug_40922 | rasdani/github-patches | git_diff | PrefectHQ__prefect-1737 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add CLI flags for all Fargate Agent keyword arguments
As another interface for setting the various config settings.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import sys
2
3 from setuptools import find_packages, setup
4
5 import versioneer
6
7 ## base requirements
8 install_requires = open("requirements.txt").read().strip().split("\n")
9 dev_requires = open("dev-requirements.txt").read().strip().split("\n")
10
11 extras = {
12 "airtable": ["airtable-python-wrapper >= 0.11, < 0.12"],
13 "aws": ["boto3 >= 1.9, < 2.0"],
14 "azure": [
15 "azure-storage-blob >= 2.1.0, < 3.0",
16 "azureml-sdk >= 1.0.65, < 1.1",
17 "azure-cosmos >= 3.1.1, <3.2",
18 ],
19 "dev": dev_requires,
20 "dropbox": ["dropbox ~= 9.0"],
21 "google": [
22 "google-cloud-bigquery >= 1.6.0, < 2.0",
23 "google-cloud-storage >= 1.13, < 2.0",
24 ],
25 "kubernetes": ["kubernetes >= 9.0.0a1, < 10.0", "dask-kubernetes >= 0.8.0"],
26 "rss": ["feedparser >= 5.0.1, < 6.0"],
27 "postgres": ["psycopg2-binary >= 2.8.2"],
28 "snowflake": ["snowflake-connector-python >= 1.8.2, < 2.0"],
29 "redis": ["redis >= 3.2.1"],
30 "spacy": ["spacy >= 2.0.0, < 3.0.0"],
31 "templates": ["jinja2 >= 2.0, < 3.0"],
32 "viz": ["graphviz >= 0.8.3"],
33 "twitter": ["tweepy >= 3.5, < 4.0"],
34 }
35
36 if sys.version_info < (3, 6):
37 extras["dev"].remove("black")
38
39 extras["all_extras"] = sum(extras.values(), [])
40
41
42 setup(
43 name="prefect",
44 version=versioneer.get_version(),
45 cmdclass=versioneer.get_cmdclass(),
46 install_requires=install_requires,
47 extras_require=extras,
48 scripts=[],
49 packages=find_packages(where="src"),
50 package_dir={"": "src"},
51 include_package_data=True,
52 entry_points={"console_scripts": ["prefect=prefect.cli:cli"]},
53 python_requires=">=3.5.2",
54 description="The Prefect Core automation and scheduling engine.",
55 long_description=open("README.md").read(),
56 long_description_content_type="text/markdown",
57 url="https://www.github.com/PrefectHQ/prefect",
58 license="Apache License 2.0",
59 author="Prefect Technologies, Inc.",
60 author_email="[email protected]",
61 classifiers=[
62 "Development Status :: 4 - Beta",
63 "Intended Audience :: Developers",
64 "Intended Audience :: System Administrators",
65 "License :: OSI Approved :: Apache Software License",
66 "Programming Language :: Python :: 3 :: Only",
67 "Programming Language :: Python :: 3.5",
68 "Programming Language :: Python :: 3.6",
69 "Programming Language :: Python :: 3.7",
70 "Topic :: Software Development :: Libraries",
71 "Topic :: System :: Monitoring",
72 ],
73 )
74
```
Path: `src/prefect/cli/agent.py`
Content:
```
1 import click
2
3 from prefect import config, context
4 from prefect.utilities.configuration import set_temporary_config
5 from prefect.utilities.serialization import from_qualified_name
6
7 _agents = {
8 "fargate": "prefect.agent.fargate.FargateAgent",
9 "local": "prefect.agent.local.LocalAgent",
10 "kubernetes": "prefect.agent.kubernetes.KubernetesAgent",
11 "nomad": "prefect.agent.nomad.NomadAgent",
12 }
13
14
15 @click.group(hidden=True)
16 def agent():
17 """
18 Manage Prefect agents.
19
20 \b
21 Usage:
22 $ prefect agent [COMMAND]
23
24 \b
25 Arguments:
26 start Start a Prefect agent
27 install Output platform-specific agent installation configs
28
29 \b
30 Examples:
31 $ prefect agent start
32 ...agent begins running in process...
33
34 \b
35 $ prefect agent start kubernetes --token MY_TOKEN
36 ...agent begins running in process...
37
38 \b
39 $ prefect agent install --token MY_TOKEN --namespace metrics
40 ...k8s yaml output...
41 """
42 pass
43
44
45 @agent.command(hidden=True)
46 @click.argument("agent-option", default="local")
47 @click.option(
48 "--token", "-t", required=False, help="A Prefect Cloud API token.", hidden=True
49 )
50 @click.option(
51 "--name",
52 "-n",
53 required=False,
54 help="A name to use for the agent",
55 hidden=True,
56 default=None,
57 )
58 @click.option(
59 "--verbose", "-v", is_flag=True, help="Enable verbose agent logs.", hidden=True
60 )
61 @click.option(
62 "--label",
63 "-l",
64 multiple=True,
65 help="Labels the agent will use to query for flow runs.",
66 hidden=True,
67 )
68 @click.option("--no-pull", is_flag=True, help="Pull images flag.", hidden=True)
69 @click.option("--base-url", "-b", help="Docker daemon base URL.", hidden=True)
70 def start(agent_option, token, name, verbose, label, no_pull, base_url):
71 """
72 Start an agent.
73
74 \b
75 Arguments:
76 agent-option TEXT The name of an agent to start (e.g. `local`, `kubernetes`, `fargate`, `nomad`)
77 Defaults to `local`
78
79 \b
80 Options:
81 --token, -t TEXT A Prefect Cloud API token with RUNNER scope
82 --name, -n TEXT A name to use for the agent
83 --verbose, -v Enable verbose agent DEBUG logs
84 Defaults to INFO level logging
85 --label, -l TEXT Labels the agent will use to query for flow runs
86 Multiple values supported e.g. `-l label1 -l label2`
87
88 \b
89 Local Agent Options:
90 --base-url, -b TEXT A Docker daemon host URL for a LocalAgent
91 --no-pull Pull images for a LocalAgent
92 Defaults to pulling if not provided
93 """
94 tmp_config = {"cloud.agent.auth_token": token or config.cloud.agent.auth_token}
95 if verbose:
96 tmp_config["cloud.agent.level"] = "DEBUG"
97
98 with set_temporary_config(tmp_config):
99 retrieved_agent = _agents.get(agent_option, None)
100
101 if not retrieved_agent:
102 click.secho("{} is not a valid agent".format(agent_option), fg="red")
103 return
104
105 with context(no_pull=no_pull, base_url=base_url):
106 from_qualified_name(retrieved_agent)(name=name, labels=list(label)).start()
107
108
109 @agent.command(hidden=True)
110 @click.argument("name", default="kubernetes")
111 @click.option(
112 "--token", "-t", required=False, help="A Prefect Cloud API token.", hidden=True
113 )
114 @click.option(
115 "--api", "-a", required=False, help="A Prefect Cloud API URL.", hidden=True
116 )
117 @click.option(
118 "--namespace",
119 "-n",
120 required=False,
121 help="Agent namespace to launch workloads.",
122 hidden=True,
123 )
124 @click.option(
125 "--image-pull-secrets",
126 "-i",
127 required=False,
128 help="Name of image pull secrets to use for workloads.",
129 hidden=True,
130 )
131 @click.option(
132 "--resource-manager", is_flag=True, help="Enable resource manager.", hidden=True
133 )
134 @click.option(
135 "--label",
136 "-l",
137 multiple=True,
138 help="Labels the agent will use to query for flow runs.",
139 hidden=True,
140 )
141 def install(name, token, api, namespace, image_pull_secrets, resource_manager, label):
142 """
143 Install an agent. Outputs configuration text which can be used to install on various
144 platforms. The Prefect image version will default to your local `prefect.__version__`
145
146 \b
147 Arguments:
148 name TEXT The name of an agent to start (e.g. `kubernetes`)
149 Defaults to `kubernetes`
150
151 \b
152 Options:
153 --token, -t TEXT A Prefect Cloud API token
154 --api, -a TEXT A Prefect Cloud API URL
155 --namespace, -n TEXT Agent namespace to launch workloads
156 --image-pull-secrets, -i TEXT Name of image pull secrets to use for workloads
157 --resource-manager Enable resource manager on install
158 --label, -l TEXT Labels the agent will use to query for flow runs
159 Multiple values supported e.g. `-l label1 -l label2`
160 """
161
162 supported_agents = {"kubernetes": "prefect.agent.kubernetes.KubernetesAgent"}
163
164 retrieved_agent = supported_agents.get(name, None)
165
166 if not retrieved_agent:
167 click.secho("{} is not a supported agent for `install`".format(name), fg="red")
168 return
169
170 deployment = from_qualified_name(retrieved_agent).generate_deployment_yaml(
171 token=token,
172 api=api,
173 namespace=namespace,
174 image_pull_secrets=image_pull_secrets,
175 resource_manager_enabled=resource_manager,
176 labels=list(label),
177 )
178 click.echo(deployment)
179
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -20,7 +20,7 @@
"dropbox": ["dropbox ~= 9.0"],
"google": [
"google-cloud-bigquery >= 1.6.0, < 2.0",
- "google-cloud-storage >= 1.13, < 2.0",
+ "google-cloud-storage >= 1.13, < 1.23.0",
],
"kubernetes": ["kubernetes >= 9.0.0a1, < 10.0", "dask-kubernetes >= 0.8.0"],
"rss": ["feedparser >= 5.0.1, < 6.0"],
diff --git a/src/prefect/cli/agent.py b/src/prefect/cli/agent.py
--- a/src/prefect/cli/agent.py
+++ b/src/prefect/cli/agent.py
@@ -1,6 +1,6 @@
import click
-from prefect import config, context
+from prefect import config
from prefect.utilities.configuration import set_temporary_config
from prefect.utilities.serialization import from_qualified_name
@@ -42,7 +42,10 @@
pass
[email protected](hidden=True)
[email protected](
+ hidden=True,
+ context_settings=dict(ignore_unknown_options=True, allow_extra_args=True,),
+)
@click.argument("agent-option", default="local")
@click.option(
"--token", "-t", required=False, help="A Prefect Cloud API token.", hidden=True
@@ -67,7 +70,8 @@
)
@click.option("--no-pull", is_flag=True, help="Pull images flag.", hidden=True)
@click.option("--base-url", "-b", help="Docker daemon base URL.", hidden=True)
-def start(agent_option, token, name, verbose, label, no_pull, base_url):
[email protected]_context
+def start(ctx, agent_option, token, name, verbose, label, no_pull, base_url):
"""
Start an agent.
@@ -90,7 +94,19 @@
--base-url, -b TEXT A Docker daemon host URL for a LocalAgent
--no-pull Pull images for a LocalAgent
Defaults to pulling if not provided
+
+ \b
+ Fargate Agent Options:
+ Any of the configuration options outlined in the docs can be provided here
+ https://docs.prefect.io/cloud/agent/fargate.html#configuration
"""
+
+ # Split context
+ kwargs = dict()
+ for item in ctx.args:
+ item = item.replace("--", "")
+ kwargs.update([item.split("=")])
+
tmp_config = {"cloud.agent.auth_token": token or config.cloud.agent.auth_token}
if verbose:
tmp_config["cloud.agent.level"] = "DEBUG"
@@ -102,7 +118,17 @@
click.secho("{} is not a valid agent".format(agent_option), fg="red")
return
- with context(no_pull=no_pull, base_url=base_url):
+ _agent = from_qualified_name(retrieved_agent)
+
+ if agent_option == "local":
+ from_qualified_name(retrieved_agent)(
+ name=name, labels=list(label), base_url=base_url, no_pull=no_pull,
+ ).start()
+ elif agent_option == "fargate":
+ from_qualified_name(retrieved_agent)(
+ name=name, labels=list(label), **kwargs
+ ).start()
+ else:
from_qualified_name(retrieved_agent)(name=name, labels=list(label)).start()
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -20,7 +20,7 @@\n \"dropbox\": [\"dropbox ~= 9.0\"],\n \"google\": [\n \"google-cloud-bigquery >= 1.6.0, < 2.0\",\n- \"google-cloud-storage >= 1.13, < 2.0\",\n+ \"google-cloud-storage >= 1.13, < 1.23.0\",\n ],\n \"kubernetes\": [\"kubernetes >= 9.0.0a1, < 10.0\", \"dask-kubernetes >= 0.8.0\"],\n \"rss\": [\"feedparser >= 5.0.1, < 6.0\"],\ndiff --git a/src/prefect/cli/agent.py b/src/prefect/cli/agent.py\n--- a/src/prefect/cli/agent.py\n+++ b/src/prefect/cli/agent.py\n@@ -1,6 +1,6 @@\n import click\n \n-from prefect import config, context\n+from prefect import config\n from prefect.utilities.configuration import set_temporary_config\n from prefect.utilities.serialization import from_qualified_name\n \n@@ -42,7 +42,10 @@\n pass\n \n \[email protected](hidden=True)\[email protected](\n+ hidden=True,\n+ context_settings=dict(ignore_unknown_options=True, allow_extra_args=True,),\n+)\n @click.argument(\"agent-option\", default=\"local\")\n @click.option(\n \"--token\", \"-t\", required=False, help=\"A Prefect Cloud API token.\", hidden=True\n@@ -67,7 +70,8 @@\n )\n @click.option(\"--no-pull\", is_flag=True, help=\"Pull images flag.\", hidden=True)\n @click.option(\"--base-url\", \"-b\", help=\"Docker daemon base URL.\", hidden=True)\n-def start(agent_option, token, name, verbose, label, no_pull, base_url):\[email protected]_context\n+def start(ctx, agent_option, token, name, verbose, label, no_pull, base_url):\n \"\"\"\n Start an agent.\n \n@@ -90,7 +94,19 @@\n --base-url, -b TEXT A Docker daemon host URL for a LocalAgent\n --no-pull Pull images for a LocalAgent\n Defaults to pulling if not provided\n+\n+ \\b\n+ Fargate Agent Options:\n+ Any of the configuration options outlined in the docs can be provided here\n+ https://docs.prefect.io/cloud/agent/fargate.html#configuration\n \"\"\"\n+\n+ # Split context\n+ kwargs = dict()\n+ for item in ctx.args:\n+ item = item.replace(\"--\", \"\")\n+ kwargs.update([item.split(\"=\")])\n+\n tmp_config = {\"cloud.agent.auth_token\": token or config.cloud.agent.auth_token}\n if verbose:\n tmp_config[\"cloud.agent.level\"] = \"DEBUG\"\n@@ -102,7 +118,17 @@\n click.secho(\"{} is not a valid agent\".format(agent_option), fg=\"red\")\n return\n \n- with context(no_pull=no_pull, base_url=base_url):\n+ _agent = from_qualified_name(retrieved_agent)\n+\n+ if agent_option == \"local\":\n+ from_qualified_name(retrieved_agent)(\n+ name=name, labels=list(label), base_url=base_url, no_pull=no_pull,\n+ ).start()\n+ elif agent_option == \"fargate\":\n+ from_qualified_name(retrieved_agent)(\n+ name=name, labels=list(label), **kwargs\n+ ).start()\n+ else:\n from_qualified_name(retrieved_agent)(name=name, labels=list(label)).start()\n", "issue": "Add CLI flags for all Fargate Agent keyword arguments\nAs another interface for setting the various config settings.\n", "before_files": [{"content": "import sys\n\nfrom setuptools import find_packages, setup\n\nimport versioneer\n\n## base requirements\ninstall_requires = open(\"requirements.txt\").read().strip().split(\"\\n\")\ndev_requires = open(\"dev-requirements.txt\").read().strip().split(\"\\n\")\n\nextras = {\n \"airtable\": [\"airtable-python-wrapper >= 0.11, < 0.12\"],\n \"aws\": [\"boto3 >= 1.9, < 2.0\"],\n \"azure\": [\n \"azure-storage-blob >= 2.1.0, < 3.0\",\n \"azureml-sdk >= 1.0.65, < 1.1\",\n \"azure-cosmos >= 3.1.1, <3.2\",\n ],\n \"dev\": dev_requires,\n \"dropbox\": [\"dropbox ~= 9.0\"],\n \"google\": [\n \"google-cloud-bigquery >= 1.6.0, < 2.0\",\n \"google-cloud-storage >= 1.13, < 2.0\",\n ],\n \"kubernetes\": [\"kubernetes >= 9.0.0a1, < 10.0\", \"dask-kubernetes >= 0.8.0\"],\n \"rss\": [\"feedparser >= 5.0.1, < 6.0\"],\n \"postgres\": [\"psycopg2-binary >= 2.8.2\"],\n \"snowflake\": [\"snowflake-connector-python >= 1.8.2, < 2.0\"],\n \"redis\": [\"redis >= 3.2.1\"],\n \"spacy\": [\"spacy >= 2.0.0, < 3.0.0\"],\n \"templates\": [\"jinja2 >= 2.0, < 3.0\"],\n \"viz\": [\"graphviz >= 0.8.3\"],\n \"twitter\": [\"tweepy >= 3.5, < 4.0\"],\n}\n\nif sys.version_info < (3, 6):\n extras[\"dev\"].remove(\"black\")\n\nextras[\"all_extras\"] = sum(extras.values(), [])\n\n\nsetup(\n name=\"prefect\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n install_requires=install_requires,\n extras_require=extras,\n scripts=[],\n packages=find_packages(where=\"src\"),\n package_dir={\"\": \"src\"},\n include_package_data=True,\n entry_points={\"console_scripts\": [\"prefect=prefect.cli:cli\"]},\n python_requires=\">=3.5.2\",\n description=\"The Prefect Core automation and scheduling engine.\",\n long_description=open(\"README.md\").read(),\n long_description_content_type=\"text/markdown\",\n url=\"https://www.github.com/PrefectHQ/prefect\",\n license=\"Apache License 2.0\",\n author=\"Prefect Technologies, Inc.\",\n author_email=\"[email protected]\",\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: System Administrators\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Topic :: Software Development :: Libraries\",\n \"Topic :: System :: Monitoring\",\n ],\n)\n", "path": "setup.py"}, {"content": "import click\n\nfrom prefect import config, context\nfrom prefect.utilities.configuration import set_temporary_config\nfrom prefect.utilities.serialization import from_qualified_name\n\n_agents = {\n \"fargate\": \"prefect.agent.fargate.FargateAgent\",\n \"local\": \"prefect.agent.local.LocalAgent\",\n \"kubernetes\": \"prefect.agent.kubernetes.KubernetesAgent\",\n \"nomad\": \"prefect.agent.nomad.NomadAgent\",\n}\n\n\[email protected](hidden=True)\ndef agent():\n \"\"\"\n Manage Prefect agents.\n\n \\b\n Usage:\n $ prefect agent [COMMAND]\n\n \\b\n Arguments:\n start Start a Prefect agent\n install Output platform-specific agent installation configs\n\n \\b\n Examples:\n $ prefect agent start\n ...agent begins running in process...\n\n \\b\n $ prefect agent start kubernetes --token MY_TOKEN\n ...agent begins running in process...\n\n \\b\n $ prefect agent install --token MY_TOKEN --namespace metrics\n ...k8s yaml output...\n \"\"\"\n pass\n\n\[email protected](hidden=True)\[email protected](\"agent-option\", default=\"local\")\[email protected](\n \"--token\", \"-t\", required=False, help=\"A Prefect Cloud API token.\", hidden=True\n)\[email protected](\n \"--name\",\n \"-n\",\n required=False,\n help=\"A name to use for the agent\",\n hidden=True,\n default=None,\n)\[email protected](\n \"--verbose\", \"-v\", is_flag=True, help=\"Enable verbose agent logs.\", hidden=True\n)\[email protected](\n \"--label\",\n \"-l\",\n multiple=True,\n help=\"Labels the agent will use to query for flow runs.\",\n hidden=True,\n)\[email protected](\"--no-pull\", is_flag=True, help=\"Pull images flag.\", hidden=True)\[email protected](\"--base-url\", \"-b\", help=\"Docker daemon base URL.\", hidden=True)\ndef start(agent_option, token, name, verbose, label, no_pull, base_url):\n \"\"\"\n Start an agent.\n\n \\b\n Arguments:\n agent-option TEXT The name of an agent to start (e.g. `local`, `kubernetes`, `fargate`, `nomad`)\n Defaults to `local`\n\n \\b\n Options:\n --token, -t TEXT A Prefect Cloud API token with RUNNER scope\n --name, -n TEXT A name to use for the agent\n --verbose, -v Enable verbose agent DEBUG logs\n Defaults to INFO level logging\n --label, -l TEXT Labels the agent will use to query for flow runs\n Multiple values supported e.g. `-l label1 -l label2`\n\n \\b\n Local Agent Options:\n --base-url, -b TEXT A Docker daemon host URL for a LocalAgent\n --no-pull Pull images for a LocalAgent\n Defaults to pulling if not provided\n \"\"\"\n tmp_config = {\"cloud.agent.auth_token\": token or config.cloud.agent.auth_token}\n if verbose:\n tmp_config[\"cloud.agent.level\"] = \"DEBUG\"\n\n with set_temporary_config(tmp_config):\n retrieved_agent = _agents.get(agent_option, None)\n\n if not retrieved_agent:\n click.secho(\"{} is not a valid agent\".format(agent_option), fg=\"red\")\n return\n\n with context(no_pull=no_pull, base_url=base_url):\n from_qualified_name(retrieved_agent)(name=name, labels=list(label)).start()\n\n\[email protected](hidden=True)\[email protected](\"name\", default=\"kubernetes\")\[email protected](\n \"--token\", \"-t\", required=False, help=\"A Prefect Cloud API token.\", hidden=True\n)\[email protected](\n \"--api\", \"-a\", required=False, help=\"A Prefect Cloud API URL.\", hidden=True\n)\[email protected](\n \"--namespace\",\n \"-n\",\n required=False,\n help=\"Agent namespace to launch workloads.\",\n hidden=True,\n)\[email protected](\n \"--image-pull-secrets\",\n \"-i\",\n required=False,\n help=\"Name of image pull secrets to use for workloads.\",\n hidden=True,\n)\[email protected](\n \"--resource-manager\", is_flag=True, help=\"Enable resource manager.\", hidden=True\n)\[email protected](\n \"--label\",\n \"-l\",\n multiple=True,\n help=\"Labels the agent will use to query for flow runs.\",\n hidden=True,\n)\ndef install(name, token, api, namespace, image_pull_secrets, resource_manager, label):\n \"\"\"\n Install an agent. Outputs configuration text which can be used to install on various\n platforms. The Prefect image version will default to your local `prefect.__version__`\n\n \\b\n Arguments:\n name TEXT The name of an agent to start (e.g. `kubernetes`)\n Defaults to `kubernetes`\n\n \\b\n Options:\n --token, -t TEXT A Prefect Cloud API token\n --api, -a TEXT A Prefect Cloud API URL\n --namespace, -n TEXT Agent namespace to launch workloads\n --image-pull-secrets, -i TEXT Name of image pull secrets to use for workloads\n --resource-manager Enable resource manager on install\n --label, -l TEXT Labels the agent will use to query for flow runs\n Multiple values supported e.g. `-l label1 -l label2`\n \"\"\"\n\n supported_agents = {\"kubernetes\": \"prefect.agent.kubernetes.KubernetesAgent\"}\n\n retrieved_agent = supported_agents.get(name, None)\n\n if not retrieved_agent:\n click.secho(\"{} is not a supported agent for `install`\".format(name), fg=\"red\")\n return\n\n deployment = from_qualified_name(retrieved_agent).generate_deployment_yaml(\n token=token,\n api=api,\n namespace=namespace,\n image_pull_secrets=image_pull_secrets,\n resource_manager_enabled=resource_manager,\n labels=list(label),\n )\n click.echo(deployment)\n", "path": "src/prefect/cli/agent.py"}], "after_files": [{"content": "import sys\n\nfrom setuptools import find_packages, setup\n\nimport versioneer\n\n## base requirements\ninstall_requires = open(\"requirements.txt\").read().strip().split(\"\\n\")\ndev_requires = open(\"dev-requirements.txt\").read().strip().split(\"\\n\")\n\nextras = {\n \"airtable\": [\"airtable-python-wrapper >= 0.11, < 0.12\"],\n \"aws\": [\"boto3 >= 1.9, < 2.0\"],\n \"azure\": [\n \"azure-storage-blob >= 2.1.0, < 3.0\",\n \"azureml-sdk >= 1.0.65, < 1.1\",\n \"azure-cosmos >= 3.1.1, <3.2\",\n ],\n \"dev\": dev_requires,\n \"dropbox\": [\"dropbox ~= 9.0\"],\n \"google\": [\n \"google-cloud-bigquery >= 1.6.0, < 2.0\",\n \"google-cloud-storage >= 1.13, < 1.23.0\",\n ],\n \"kubernetes\": [\"kubernetes >= 9.0.0a1, < 10.0\", \"dask-kubernetes >= 0.8.0\"],\n \"rss\": [\"feedparser >= 5.0.1, < 6.0\"],\n \"postgres\": [\"psycopg2-binary >= 2.8.2\"],\n \"snowflake\": [\"snowflake-connector-python >= 1.8.2, < 2.0\"],\n \"redis\": [\"redis >= 3.2.1\"],\n \"spacy\": [\"spacy >= 2.0.0, < 3.0.0\"],\n \"templates\": [\"jinja2 >= 2.0, < 3.0\"],\n \"viz\": [\"graphviz >= 0.8.3\"],\n \"twitter\": [\"tweepy >= 3.5, < 4.0\"],\n}\n\nif sys.version_info < (3, 6):\n extras[\"dev\"].remove(\"black\")\n\nextras[\"all_extras\"] = sum(extras.values(), [])\n\n\nsetup(\n name=\"prefect\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n install_requires=install_requires,\n extras_require=extras,\n scripts=[],\n packages=find_packages(where=\"src\"),\n package_dir={\"\": \"src\"},\n include_package_data=True,\n entry_points={\"console_scripts\": [\"prefect=prefect.cli:cli\"]},\n python_requires=\">=3.5.2\",\n description=\"The Prefect Core automation and scheduling engine.\",\n long_description=open(\"README.md\").read(),\n long_description_content_type=\"text/markdown\",\n url=\"https://www.github.com/PrefectHQ/prefect\",\n license=\"Apache License 2.0\",\n author=\"Prefect Technologies, Inc.\",\n author_email=\"[email protected]\",\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: System Administrators\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Topic :: Software Development :: Libraries\",\n \"Topic :: System :: Monitoring\",\n ],\n)\n", "path": "setup.py"}, {"content": "import click\n\nfrom prefect import config\nfrom prefect.utilities.configuration import set_temporary_config\nfrom prefect.utilities.serialization import from_qualified_name\n\n_agents = {\n \"fargate\": \"prefect.agent.fargate.FargateAgent\",\n \"local\": \"prefect.agent.local.LocalAgent\",\n \"kubernetes\": \"prefect.agent.kubernetes.KubernetesAgent\",\n \"nomad\": \"prefect.agent.nomad.NomadAgent\",\n}\n\n\[email protected](hidden=True)\ndef agent():\n \"\"\"\n Manage Prefect agents.\n\n \\b\n Usage:\n $ prefect agent [COMMAND]\n\n \\b\n Arguments:\n start Start a Prefect agent\n install Output platform-specific agent installation configs\n\n \\b\n Examples:\n $ prefect agent start\n ...agent begins running in process...\n\n \\b\n $ prefect agent start kubernetes --token MY_TOKEN\n ...agent begins running in process...\n\n \\b\n $ prefect agent install --token MY_TOKEN --namespace metrics\n ...k8s yaml output...\n \"\"\"\n pass\n\n\[email protected](\n hidden=True,\n context_settings=dict(ignore_unknown_options=True, allow_extra_args=True,),\n)\[email protected](\"agent-option\", default=\"local\")\[email protected](\n \"--token\", \"-t\", required=False, help=\"A Prefect Cloud API token.\", hidden=True\n)\[email protected](\n \"--name\",\n \"-n\",\n required=False,\n help=\"A name to use for the agent\",\n hidden=True,\n default=None,\n)\[email protected](\n \"--verbose\", \"-v\", is_flag=True, help=\"Enable verbose agent logs.\", hidden=True\n)\[email protected](\n \"--label\",\n \"-l\",\n multiple=True,\n help=\"Labels the agent will use to query for flow runs.\",\n hidden=True,\n)\[email protected](\"--no-pull\", is_flag=True, help=\"Pull images flag.\", hidden=True)\[email protected](\"--base-url\", \"-b\", help=\"Docker daemon base URL.\", hidden=True)\[email protected]_context\ndef start(ctx, agent_option, token, name, verbose, label, no_pull, base_url):\n \"\"\"\n Start an agent.\n\n \\b\n Arguments:\n agent-option TEXT The name of an agent to start (e.g. `local`, `kubernetes`, `fargate`, `nomad`)\n Defaults to `local`\n\n \\b\n Options:\n --token, -t TEXT A Prefect Cloud API token with RUNNER scope\n --name, -n TEXT A name to use for the agent\n --verbose, -v Enable verbose agent DEBUG logs\n Defaults to INFO level logging\n --label, -l TEXT Labels the agent will use to query for flow runs\n Multiple values supported e.g. `-l label1 -l label2`\n\n \\b\n Local Agent Options:\n --base-url, -b TEXT A Docker daemon host URL for a LocalAgent\n --no-pull Pull images for a LocalAgent\n Defaults to pulling if not provided\n\n \\b\n Fargate Agent Options:\n Any of the configuration options outlined in the docs can be provided here\n https://docs.prefect.io/cloud/agent/fargate.html#configuration\n \"\"\"\n\n # Split context\n kwargs = dict()\n for item in ctx.args:\n item = item.replace(\"--\", \"\")\n kwargs.update([item.split(\"=\")])\n\n tmp_config = {\"cloud.agent.auth_token\": token or config.cloud.agent.auth_token}\n if verbose:\n tmp_config[\"cloud.agent.level\"] = \"DEBUG\"\n\n with set_temporary_config(tmp_config):\n retrieved_agent = _agents.get(agent_option, None)\n\n if not retrieved_agent:\n click.secho(\"{} is not a valid agent\".format(agent_option), fg=\"red\")\n return\n\n _agent = from_qualified_name(retrieved_agent)\n\n if agent_option == \"local\":\n from_qualified_name(retrieved_agent)(\n name=name, labels=list(label), base_url=base_url, no_pull=no_pull,\n ).start()\n elif agent_option == \"fargate\":\n from_qualified_name(retrieved_agent)(\n name=name, labels=list(label), **kwargs\n ).start()\n else:\n from_qualified_name(retrieved_agent)(name=name, labels=list(label)).start()\n\n\[email protected](hidden=True)\[email protected](\"name\", default=\"kubernetes\")\[email protected](\n \"--token\", \"-t\", required=False, help=\"A Prefect Cloud API token.\", hidden=True\n)\[email protected](\n \"--api\", \"-a\", required=False, help=\"A Prefect Cloud API URL.\", hidden=True\n)\[email protected](\n \"--namespace\",\n \"-n\",\n required=False,\n help=\"Agent namespace to launch workloads.\",\n hidden=True,\n)\[email protected](\n \"--image-pull-secrets\",\n \"-i\",\n required=False,\n help=\"Name of image pull secrets to use for workloads.\",\n hidden=True,\n)\[email protected](\n \"--resource-manager\", is_flag=True, help=\"Enable resource manager.\", hidden=True\n)\[email protected](\n \"--label\",\n \"-l\",\n multiple=True,\n help=\"Labels the agent will use to query for flow runs.\",\n hidden=True,\n)\ndef install(name, token, api, namespace, image_pull_secrets, resource_manager, label):\n \"\"\"\n Install an agent. Outputs configuration text which can be used to install on various\n platforms. The Prefect image version will default to your local `prefect.__version__`\n\n \\b\n Arguments:\n name TEXT The name of an agent to start (e.g. `kubernetes`)\n Defaults to `kubernetes`\n\n \\b\n Options:\n --token, -t TEXT A Prefect Cloud API token\n --api, -a TEXT A Prefect Cloud API URL\n --namespace, -n TEXT Agent namespace to launch workloads\n --image-pull-secrets, -i TEXT Name of image pull secrets to use for workloads\n --resource-manager Enable resource manager on install\n --label, -l TEXT Labels the agent will use to query for flow runs\n Multiple values supported e.g. `-l label1 -l label2`\n \"\"\"\n\n supported_agents = {\"kubernetes\": \"prefect.agent.kubernetes.KubernetesAgent\"}\n\n retrieved_agent = supported_agents.get(name, None)\n\n if not retrieved_agent:\n click.secho(\"{} is not a supported agent for `install`\".format(name), fg=\"red\")\n return\n\n deployment = from_qualified_name(retrieved_agent).generate_deployment_yaml(\n token=token,\n api=api,\n namespace=namespace,\n image_pull_secrets=image_pull_secrets,\n resource_manager_enabled=resource_manager,\n labels=list(label),\n )\n click.echo(deployment)\n", "path": "src/prefect/cli/agent.py"}]} | 2,933 | 813 |
gh_patches_debug_1549 | rasdani/github-patches | git_diff | scoutapp__scout_apm_python-679 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Disconnect receiver from celery task_failure signal
Celery instrumentation's `uninstall` should call `task_failure.disconnect(task_failure_callback)`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/scout_apm/celery.py`
Content:
```
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import datetime as dt
5 import logging
6
7 from celery.signals import before_task_publish, task_failure, task_postrun, task_prerun
8
9 try:
10 import django
11
12 if django.VERSION < (3, 1):
13 from django.views.debug import get_safe_settings
14 else:
15 from django.views.debug import SafeExceptionReporterFilter
16
17 def get_safe_settings():
18 return SafeExceptionReporterFilter().get_safe_settings()
19
20
21 except ImportError:
22 # Django not installed
23 get_safe_settings = None
24
25 import scout_apm.core
26 from scout_apm.compat import datetime_to_timestamp
27 from scout_apm.core.config import scout_config
28 from scout_apm.core.error import ErrorMonitor
29 from scout_apm.core.tracked_request import TrackedRequest
30
31 logger = logging.getLogger(__name__)
32
33
34 def before_task_publish_callback(headers=None, properties=None, **kwargs):
35 if "scout_task_start" not in headers:
36 headers["scout_task_start"] = datetime_to_timestamp(dt.datetime.utcnow())
37
38
39 def task_prerun_callback(task=None, **kwargs):
40 tracked_request = TrackedRequest.instance()
41 tracked_request.is_real_request = True
42
43 start = getattr(task.request, "scout_task_start", None)
44 if start is not None:
45 now = datetime_to_timestamp(dt.datetime.utcnow())
46 try:
47 queue_time = now - start
48 except TypeError:
49 pass
50 else:
51 tracked_request.tag("queue_time", queue_time)
52
53 task_id = getattr(task.request, "id", None)
54 if task_id:
55 tracked_request.tag("task_id", task_id)
56 parent_task_id = getattr(task.request, "parent_id", None)
57 if parent_task_id:
58 tracked_request.tag("parent_task_id", parent_task_id)
59
60 delivery_info = task.request.delivery_info
61 tracked_request.tag("is_eager", delivery_info.get("is_eager", False))
62 tracked_request.tag("exchange", delivery_info.get("exchange", "unknown"))
63 tracked_request.tag("priority", delivery_info.get("priority", "unknown"))
64 tracked_request.tag("routing_key", delivery_info.get("routing_key", "unknown"))
65 tracked_request.tag("queue", delivery_info.get("queue", "unknown"))
66
67 tracked_request.start_span(operation=("Job/" + task.name))
68
69
70 def task_postrun_callback(task=None, **kwargs):
71 tracked_request = TrackedRequest.instance()
72 tracked_request.stop_span()
73
74
75 def task_failure_callback(
76 sender,
77 task_id=None,
78 exception=None,
79 args=None,
80 kwargs=None,
81 traceback=None,
82 **remaining
83 ):
84 tracked_request = TrackedRequest.instance()
85 tracked_request.tag("error", "true")
86
87 custom_controller = sender.name
88 custom_params = {
89 "celery": {
90 "task_id": task_id,
91 "args": args,
92 "kwargs": kwargs,
93 }
94 }
95
96 # Look up the django settings if populated.
97 environment = None
98 if get_safe_settings:
99 try:
100 environment = get_safe_settings()
101 except django.core.exceptions.ImproperlyConfigured as exc:
102 # Django not setup correctly
103 logger.debug(
104 "Celery integration does not have django configured properly: %r", exc
105 )
106 pass
107 except Exception as exc:
108 logger.debug(
109 "Celery task_failure callback exception: %r", exc, exc_info=exc
110 )
111 pass
112
113 exc_info = (exception.__class__, exception, traceback)
114 ErrorMonitor.send(
115 exc_info,
116 environment=environment,
117 custom_params=custom_params,
118 custom_controller=custom_controller,
119 )
120
121
122 def install(app=None):
123 if app is not None:
124 copy_configuration(app)
125
126 installed = scout_apm.core.install()
127 if not installed:
128 return
129
130 before_task_publish.connect(before_task_publish_callback)
131 task_prerun.connect(task_prerun_callback)
132 task_failure.connect(task_failure_callback)
133 task_postrun.connect(task_postrun_callback)
134
135
136 def copy_configuration(app):
137 prefix = "scout_"
138 prefix_len = len(prefix)
139
140 to_set = {}
141 for key, value in app.conf.items():
142 key_lower = key.lower()
143 if key_lower.startswith(prefix) and len(key_lower) > prefix_len:
144 scout_key = key_lower[prefix_len:]
145 to_set[scout_key] = value
146
147 scout_config.set(**to_set)
148
149
150 def uninstall():
151 before_task_publish.disconnect(before_task_publish_callback)
152 task_prerun.disconnect(task_prerun_callback)
153 task_postrun.disconnect(task_postrun_callback)
154
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/scout_apm/celery.py b/src/scout_apm/celery.py
--- a/src/scout_apm/celery.py
+++ b/src/scout_apm/celery.py
@@ -151,3 +151,4 @@
before_task_publish.disconnect(before_task_publish_callback)
task_prerun.disconnect(task_prerun_callback)
task_postrun.disconnect(task_postrun_callback)
+ task_failure.disconnect(task_failure_callback)
| {"golden_diff": "diff --git a/src/scout_apm/celery.py b/src/scout_apm/celery.py\n--- a/src/scout_apm/celery.py\n+++ b/src/scout_apm/celery.py\n@@ -151,3 +151,4 @@\n before_task_publish.disconnect(before_task_publish_callback)\n task_prerun.disconnect(task_prerun_callback)\n task_postrun.disconnect(task_postrun_callback)\n+ task_failure.disconnect(task_failure_callback)\n", "issue": "Disconnect receiver from celery task_failure signal\nCelery instrumentation's `uninstall` should call `task_failure.disconnect(task_failure_callback)`.\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport datetime as dt\nimport logging\n\nfrom celery.signals import before_task_publish, task_failure, task_postrun, task_prerun\n\ntry:\n import django\n\n if django.VERSION < (3, 1):\n from django.views.debug import get_safe_settings\n else:\n from django.views.debug import SafeExceptionReporterFilter\n\n def get_safe_settings():\n return SafeExceptionReporterFilter().get_safe_settings()\n\n\nexcept ImportError:\n # Django not installed\n get_safe_settings = None\n\nimport scout_apm.core\nfrom scout_apm.compat import datetime_to_timestamp\nfrom scout_apm.core.config import scout_config\nfrom scout_apm.core.error import ErrorMonitor\nfrom scout_apm.core.tracked_request import TrackedRequest\n\nlogger = logging.getLogger(__name__)\n\n\ndef before_task_publish_callback(headers=None, properties=None, **kwargs):\n if \"scout_task_start\" not in headers:\n headers[\"scout_task_start\"] = datetime_to_timestamp(dt.datetime.utcnow())\n\n\ndef task_prerun_callback(task=None, **kwargs):\n tracked_request = TrackedRequest.instance()\n tracked_request.is_real_request = True\n\n start = getattr(task.request, \"scout_task_start\", None)\n if start is not None:\n now = datetime_to_timestamp(dt.datetime.utcnow())\n try:\n queue_time = now - start\n except TypeError:\n pass\n else:\n tracked_request.tag(\"queue_time\", queue_time)\n\n task_id = getattr(task.request, \"id\", None)\n if task_id:\n tracked_request.tag(\"task_id\", task_id)\n parent_task_id = getattr(task.request, \"parent_id\", None)\n if parent_task_id:\n tracked_request.tag(\"parent_task_id\", parent_task_id)\n\n delivery_info = task.request.delivery_info\n tracked_request.tag(\"is_eager\", delivery_info.get(\"is_eager\", False))\n tracked_request.tag(\"exchange\", delivery_info.get(\"exchange\", \"unknown\"))\n tracked_request.tag(\"priority\", delivery_info.get(\"priority\", \"unknown\"))\n tracked_request.tag(\"routing_key\", delivery_info.get(\"routing_key\", \"unknown\"))\n tracked_request.tag(\"queue\", delivery_info.get(\"queue\", \"unknown\"))\n\n tracked_request.start_span(operation=(\"Job/\" + task.name))\n\n\ndef task_postrun_callback(task=None, **kwargs):\n tracked_request = TrackedRequest.instance()\n tracked_request.stop_span()\n\n\ndef task_failure_callback(\n sender,\n task_id=None,\n exception=None,\n args=None,\n kwargs=None,\n traceback=None,\n **remaining\n):\n tracked_request = TrackedRequest.instance()\n tracked_request.tag(\"error\", \"true\")\n\n custom_controller = sender.name\n custom_params = {\n \"celery\": {\n \"task_id\": task_id,\n \"args\": args,\n \"kwargs\": kwargs,\n }\n }\n\n # Look up the django settings if populated.\n environment = None\n if get_safe_settings:\n try:\n environment = get_safe_settings()\n except django.core.exceptions.ImproperlyConfigured as exc:\n # Django not setup correctly\n logger.debug(\n \"Celery integration does not have django configured properly: %r\", exc\n )\n pass\n except Exception as exc:\n logger.debug(\n \"Celery task_failure callback exception: %r\", exc, exc_info=exc\n )\n pass\n\n exc_info = (exception.__class__, exception, traceback)\n ErrorMonitor.send(\n exc_info,\n environment=environment,\n custom_params=custom_params,\n custom_controller=custom_controller,\n )\n\n\ndef install(app=None):\n if app is not None:\n copy_configuration(app)\n\n installed = scout_apm.core.install()\n if not installed:\n return\n\n before_task_publish.connect(before_task_publish_callback)\n task_prerun.connect(task_prerun_callback)\n task_failure.connect(task_failure_callback)\n task_postrun.connect(task_postrun_callback)\n\n\ndef copy_configuration(app):\n prefix = \"scout_\"\n prefix_len = len(prefix)\n\n to_set = {}\n for key, value in app.conf.items():\n key_lower = key.lower()\n if key_lower.startswith(prefix) and len(key_lower) > prefix_len:\n scout_key = key_lower[prefix_len:]\n to_set[scout_key] = value\n\n scout_config.set(**to_set)\n\n\ndef uninstall():\n before_task_publish.disconnect(before_task_publish_callback)\n task_prerun.disconnect(task_prerun_callback)\n task_postrun.disconnect(task_postrun_callback)\n", "path": "src/scout_apm/celery.py"}], "after_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport datetime as dt\nimport logging\n\nfrom celery.signals import before_task_publish, task_failure, task_postrun, task_prerun\n\ntry:\n import django\n\n if django.VERSION < (3, 1):\n from django.views.debug import get_safe_settings\n else:\n from django.views.debug import SafeExceptionReporterFilter\n\n def get_safe_settings():\n return SafeExceptionReporterFilter().get_safe_settings()\n\n\nexcept ImportError:\n # Django not installed\n get_safe_settings = None\n\nimport scout_apm.core\nfrom scout_apm.compat import datetime_to_timestamp\nfrom scout_apm.core.config import scout_config\nfrom scout_apm.core.error import ErrorMonitor\nfrom scout_apm.core.tracked_request import TrackedRequest\n\nlogger = logging.getLogger(__name__)\n\n\ndef before_task_publish_callback(headers=None, properties=None, **kwargs):\n if \"scout_task_start\" not in headers:\n headers[\"scout_task_start\"] = datetime_to_timestamp(dt.datetime.utcnow())\n\n\ndef task_prerun_callback(task=None, **kwargs):\n tracked_request = TrackedRequest.instance()\n tracked_request.is_real_request = True\n\n start = getattr(task.request, \"scout_task_start\", None)\n if start is not None:\n now = datetime_to_timestamp(dt.datetime.utcnow())\n try:\n queue_time = now - start\n except TypeError:\n pass\n else:\n tracked_request.tag(\"queue_time\", queue_time)\n\n task_id = getattr(task.request, \"id\", None)\n if task_id:\n tracked_request.tag(\"task_id\", task_id)\n parent_task_id = getattr(task.request, \"parent_id\", None)\n if parent_task_id:\n tracked_request.tag(\"parent_task_id\", parent_task_id)\n\n delivery_info = task.request.delivery_info\n tracked_request.tag(\"is_eager\", delivery_info.get(\"is_eager\", False))\n tracked_request.tag(\"exchange\", delivery_info.get(\"exchange\", \"unknown\"))\n tracked_request.tag(\"priority\", delivery_info.get(\"priority\", \"unknown\"))\n tracked_request.tag(\"routing_key\", delivery_info.get(\"routing_key\", \"unknown\"))\n tracked_request.tag(\"queue\", delivery_info.get(\"queue\", \"unknown\"))\n\n tracked_request.start_span(operation=(\"Job/\" + task.name))\n\n\ndef task_postrun_callback(task=None, **kwargs):\n tracked_request = TrackedRequest.instance()\n tracked_request.stop_span()\n\n\ndef task_failure_callback(\n sender,\n task_id=None,\n exception=None,\n args=None,\n kwargs=None,\n traceback=None,\n **remaining\n):\n tracked_request = TrackedRequest.instance()\n tracked_request.tag(\"error\", \"true\")\n\n custom_controller = sender.name\n custom_params = {\n \"celery\": {\n \"task_id\": task_id,\n \"args\": args,\n \"kwargs\": kwargs,\n }\n }\n\n # Look up the django settings if populated.\n environment = None\n if get_safe_settings:\n try:\n environment = get_safe_settings()\n except django.core.exceptions.ImproperlyConfigured as exc:\n # Django not setup correctly\n logger.debug(\n \"Celery integration does not have django configured properly: %r\", exc\n )\n pass\n except Exception as exc:\n logger.debug(\n \"Celery task_failure callback exception: %r\", exc, exc_info=exc\n )\n pass\n\n exc_info = (exception.__class__, exception, traceback)\n ErrorMonitor.send(\n exc_info,\n environment=environment,\n custom_params=custom_params,\n custom_controller=custom_controller,\n )\n\n\ndef install(app=None):\n if app is not None:\n copy_configuration(app)\n\n installed = scout_apm.core.install()\n if not installed:\n return\n\n before_task_publish.connect(before_task_publish_callback)\n task_prerun.connect(task_prerun_callback)\n task_failure.connect(task_failure_callback)\n task_postrun.connect(task_postrun_callback)\n\n\ndef copy_configuration(app):\n prefix = \"scout_\"\n prefix_len = len(prefix)\n\n to_set = {}\n for key, value in app.conf.items():\n key_lower = key.lower()\n if key_lower.startswith(prefix) and len(key_lower) > prefix_len:\n scout_key = key_lower[prefix_len:]\n to_set[scout_key] = value\n\n scout_config.set(**to_set)\n\n\ndef uninstall():\n before_task_publish.disconnect(before_task_publish_callback)\n task_prerun.disconnect(task_prerun_callback)\n task_postrun.disconnect(task_postrun_callback)\n task_failure.disconnect(task_failure_callback)\n", "path": "src/scout_apm/celery.py"}]} | 1,641 | 105 |
gh_patches_debug_31319 | rasdani/github-patches | git_diff | ansible-collections__community.general-8260 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bitwarden_secrets_manager: Handle rate limits
### Summary
I'm not finding any official documentation on it yet but Bitwarden's Secret Manager seems to have a rate limit of 5 requests per second. When the rate limit is hit, the lookup fails with an error: 429 Too Many Requests; Slow down! Too many requests. Try again in 1s.
### Issue Type
Bug Report
### Component Name
bitwarden_secret_manager
### Ansible Version
```console (paste below)
$ ansible --version
ansible [core 2.16.1]
config file = /mnt/ansible/ansible.cfg
configured module search path = ['/home/matta/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python3.11/site-packages/ansible
ansible collection location = /mnt/ansible/collections
executable location = /usr/bin/ansible
python version = 3.11.9 (main, Apr 14 2024, 13:40:00) [GCC 13.2.1 20231014] (/usr/bin/python3)
jinja version = 3.1.2
libyaml = True
```
### Community.general Version
```console (paste below)
$ ansible-galaxy collection list community.general
# /mnt/ansible/collections/ansible_collections
Collection Version
----------------- -------
community.general 8.5.0
# /usr/lib/python3.11/site-packages/ansible_collections
Collection Version
----------------- -------
community.general 7.5.1
```
### Configuration
```console (paste below)
$ ansible-config dump --only-changed
COLLECTIONS_PATHS(/mnt/ansible/ansible.cfg) = ['/mnt/ansible/collections']
CONFIG_FILE() = /mnt/ansible/ansible.cfg
DEFAULT_FORKS(/mnt/ansible/ansible.cfg) = 10
DEFAULT_HOST_LIST(/mnt/ansible/ansible.cfg) = ['/mnt/ansible/inventory']
DEFAULT_MANAGED_STR(/mnt/ansible/ansible.cfg) = This file is managed by Ansible. Do not modify directly!%n
template: {file}
date: %Y-%m-%d %H:%M:%S
user: {uid}
host: {host}
DISPLAY_SKIPPED_HOSTS(/mnt/ansible/ansible.cfg) = False
EDITOR(env: EDITOR) = vim
INTERPRETER_PYTHON(/mnt/ansible/ansible.cfg) = auto_silent
PAGER(env: PAGER) = less
```
### OS / Environment
Alpine Linux 3.19
### Steps to Reproduce
<!--- Paste example playbooks or commands between quotes below -->
```yaml (paste below)
---
- name: Bitwarden Secrets Manager Rate Limit Reproduction
hosts:
- xen01
- xen02
- xen03
- xen04
- xen05
- xen06
become: false
gather_facts: false
tasks:
- debug:
var: "{{ lookup('community.general.bitwarden_secrets_manager', '<secret id here>').value }}"
```
### Expected Results
I would expect the module to handle the 429 error with a back-off and retry until it succeeds
### Actual Results
```console (paste below)
PLAY [Bitwarden Secrets Manager Rate Limit Reproduction] ******************************************************************************************************************************************************************************************************************
TASK [debug] **************************************************************************************************************************************************************************************************************************************************************
fatal: [xen01]: FAILED! => {"msg": "Error: \n 0: Received error message from server: [429 Too Many Requests] {\"message\":\"Slow down! Too many requests. Try again in 1s.\",\"validationErrors\":null,\"exceptionMessage\":null,\"exceptionStackTrace\":null,\"innerExceptionMessage\":null,\"object\":\"error\"}\n\nLocation:\n /home/matta/alpine-package-repository/main/bws/src/.cargo/registry/src/index.crates.io-6f17d22bba15001f/bws-0.4.0/src/main.rs:334\n\nBacktrace omitted. Run with RUST_BACKTRACE=1 environment variable to display it.\nRun with RUST_BACKTRACE=full to include source snippets.\n"}
ok: [xen03] => {
"this-is-a-test-secret": "{{this-is-a-test-secret}}"
}
ok: [xen04] => {
"this-is-a-test-secret": "{{this-is-a-test-secret}}"
}
ok: [xen05] => {
"this-is-a-test-secret": "{{this-is-a-test-secret}}"
}
ok: [xen06] => {
"this-is-a-test-secret": "{{this-is-a-test-secret}}"
}
ok: [xen02] => {
"this-is-a-test-secret": "{{this-is-a-test-secret}}"
}
PLAY RECAP ****************************************************************************************************************************************************************************************************************************************************************
xen01 : ok=0 changed=0 unreachable=0 failed=1 skipped=0 rescued=0 ignored=0
xen02 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
xen03 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
xen04 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
xen05 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
xen06 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
```
### Code of Conduct
- [X] I agree to follow the Ansible Code of Conduct
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugins/lookup/bitwarden_secrets_manager.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # Copyright (c) 2023, jantari (https://github.com/jantari)
3 # GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)
4 # SPDX-License-Identifier: GPL-3.0-or-later
5 from __future__ import (absolute_import, division, print_function)
6
7 __metaclass__ = type
8
9 DOCUMENTATION = """
10 name: bitwarden_secrets_manager
11 author:
12 - jantari (@jantari)
13 requirements:
14 - bws (command line utility)
15 short_description: Retrieve secrets from Bitwarden Secrets Manager
16 version_added: 7.2.0
17 description:
18 - Retrieve secrets from Bitwarden Secrets Manager.
19 options:
20 _terms:
21 description: Secret ID(s) to fetch values for.
22 required: true
23 type: list
24 elements: str
25 bws_access_token:
26 description: The BWS access token to use for this lookup.
27 env:
28 - name: BWS_ACCESS_TOKEN
29 required: true
30 type: str
31 """
32
33 EXAMPLES = """
34 - name: Get a secret relying on the BWS_ACCESS_TOKEN environment variable for authentication
35 ansible.builtin.debug:
36 msg: >-
37 {{ lookup("community.general.bitwarden_secrets_manager", "2bc23e48-4932-40de-a047-5524b7ddc972") }}
38
39 - name: Get a secret passing an explicit access token for authentication
40 ansible.builtin.debug:
41 msg: >-
42 {{
43 lookup(
44 "community.general.bitwarden_secrets_manager",
45 "2bc23e48-4932-40de-a047-5524b7ddc972",
46 bws_access_token="9.4f570d14-4b54-42f5-bc07-60f4450b1db5.YmluYXJ5LXNvbWV0aGluZy0xMjMK:d2h5IGhlbGxvIHRoZXJlCg=="
47 )
48 }}
49
50 - name: Get two different secrets each using a different access token for authentication
51 ansible.builtin.debug:
52 msg:
53 - '{{ lookup("community.general.bitwarden_secrets_manager", "2bc23e48-4932-40de-a047-5524b7ddc972", bws_access_token=token1) }}'
54 - '{{ lookup("community.general.bitwarden_secrets_manager", "9d89af4c-eb5d-41f5-bb0f-4ae81215c768", bws_access_token=token2) }}'
55 vars:
56 token1: "9.4f570d14-4b54-42f5-bc07-60f4450b1db5.YmluYXJ5LXNvbWV0aGluZy0xMjMK:d2h5IGhlbGxvIHRoZXJlCg=="
57 token2: "1.69b72797-6ea9-4687-a11e-848e41a30ae6.YW5zaWJsZSBpcyBncmVhdD8K:YW5zaWJsZSBpcyBncmVhdAo="
58
59 - name: Get just the value of a secret
60 ansible.builtin.debug:
61 msg: >-
62 {{ lookup("community.general.bitwarden_secrets_manager", "2bc23e48-4932-40de-a047-5524b7ddc972").value }}
63 """
64
65 RETURN = """
66 _raw:
67 description: List containing one or more secrets.
68 type: list
69 elements: dict
70 """
71
72 from subprocess import Popen, PIPE
73
74 from ansible.errors import AnsibleLookupError
75 from ansible.module_utils.common.text.converters import to_text
76 from ansible.parsing.ajson import AnsibleJSONDecoder
77 from ansible.plugins.lookup import LookupBase
78
79
80 class BitwardenSecretsManagerException(AnsibleLookupError):
81 pass
82
83
84 class BitwardenSecretsManager(object):
85 def __init__(self, path='bws'):
86 self._cli_path = path
87
88 @property
89 def cli_path(self):
90 return self._cli_path
91
92 def _run(self, args, stdin=None):
93 p = Popen([self.cli_path] + args, stdout=PIPE, stderr=PIPE, stdin=PIPE)
94 out, err = p.communicate(stdin)
95 rc = p.wait()
96 return to_text(out, errors='surrogate_or_strict'), to_text(err, errors='surrogate_or_strict'), rc
97
98 def get_secret(self, secret_id, bws_access_token):
99 """Get and return the secret with the given secret_id.
100 """
101
102 # Prepare set of params for Bitwarden Secrets Manager CLI
103 # Color output was not always disabled correctly with the default 'auto' setting so explicitly disable it.
104 params = [
105 '--color', 'no',
106 '--access-token', bws_access_token,
107 'get', 'secret', secret_id
108 ]
109
110 out, err, rc = self._run(params)
111 if rc != 0:
112 raise BitwardenSecretsManagerException(to_text(err))
113
114 return AnsibleJSONDecoder().raw_decode(out)[0]
115
116
117 class LookupModule(LookupBase):
118 def run(self, terms, variables=None, **kwargs):
119 self.set_options(var_options=variables, direct=kwargs)
120 bws_access_token = self.get_option('bws_access_token')
121
122 return [_bitwarden_secrets_manager.get_secret(term, bws_access_token) for term in terms]
123
124
125 _bitwarden_secrets_manager = BitwardenSecretsManager()
126
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/plugins/lookup/bitwarden_secrets_manager.py b/plugins/lookup/bitwarden_secrets_manager.py
--- a/plugins/lookup/bitwarden_secrets_manager.py
+++ b/plugins/lookup/bitwarden_secrets_manager.py
@@ -70,6 +70,7 @@
"""
from subprocess import Popen, PIPE
+from time import sleep
from ansible.errors import AnsibleLookupError
from ansible.module_utils.common.text.converters import to_text
@@ -84,11 +85,29 @@
class BitwardenSecretsManager(object):
def __init__(self, path='bws'):
self._cli_path = path
+ self._max_retries = 3
+ self._retry_delay = 1
@property
def cli_path(self):
return self._cli_path
+ def _run_with_retry(self, args, stdin=None, retries=0):
+ out, err, rc = self._run(args, stdin)
+
+ if rc != 0:
+ if retries >= self._max_retries:
+ raise BitwardenSecretsManagerException("Max retries exceeded. Unable to retrieve secret.")
+
+ if "Too many requests" in err:
+ delay = self._retry_delay * (2 ** retries)
+ sleep(delay)
+ return self._run_with_retry(args, stdin, retries + 1)
+ else:
+ raise BitwardenSecretsManagerException("Command failed with return code {rc}: {err}".format(rc=rc, err=err))
+
+ return out, err, rc
+
def _run(self, args, stdin=None):
p = Popen([self.cli_path] + args, stdout=PIPE, stderr=PIPE, stdin=PIPE)
out, err = p.communicate(stdin)
@@ -107,7 +126,7 @@
'get', 'secret', secret_id
]
- out, err, rc = self._run(params)
+ out, err, rc = self._run_with_retry(params)
if rc != 0:
raise BitwardenSecretsManagerException(to_text(err))
| {"golden_diff": "diff --git a/plugins/lookup/bitwarden_secrets_manager.py b/plugins/lookup/bitwarden_secrets_manager.py\n--- a/plugins/lookup/bitwarden_secrets_manager.py\n+++ b/plugins/lookup/bitwarden_secrets_manager.py\n@@ -70,6 +70,7 @@\n \"\"\"\n \n from subprocess import Popen, PIPE\n+from time import sleep\n \n from ansible.errors import AnsibleLookupError\n from ansible.module_utils.common.text.converters import to_text\n@@ -84,11 +85,29 @@\n class BitwardenSecretsManager(object):\n def __init__(self, path='bws'):\n self._cli_path = path\n+ self._max_retries = 3\n+ self._retry_delay = 1\n \n @property\n def cli_path(self):\n return self._cli_path\n \n+ def _run_with_retry(self, args, stdin=None, retries=0):\n+ out, err, rc = self._run(args, stdin)\n+\n+ if rc != 0:\n+ if retries >= self._max_retries:\n+ raise BitwardenSecretsManagerException(\"Max retries exceeded. Unable to retrieve secret.\")\n+\n+ if \"Too many requests\" in err:\n+ delay = self._retry_delay * (2 ** retries)\n+ sleep(delay)\n+ return self._run_with_retry(args, stdin, retries + 1)\n+ else:\n+ raise BitwardenSecretsManagerException(\"Command failed with return code {rc}: {err}\".format(rc=rc, err=err))\n+\n+ return out, err, rc\n+\n def _run(self, args, stdin=None):\n p = Popen([self.cli_path] + args, stdout=PIPE, stderr=PIPE, stdin=PIPE)\n out, err = p.communicate(stdin)\n@@ -107,7 +126,7 @@\n 'get', 'secret', secret_id\n ]\n \n- out, err, rc = self._run(params)\n+ out, err, rc = self._run_with_retry(params)\n if rc != 0:\n raise BitwardenSecretsManagerException(to_text(err))\n", "issue": "bitwarden_secrets_manager: Handle rate limits\n### Summary\n\nI'm not finding any official documentation on it yet but Bitwarden's Secret Manager seems to have a rate limit of 5 requests per second. When the rate limit is hit, the lookup fails with an error: 429 Too Many Requests; Slow down! Too many requests. Try again in 1s.\r\n\n\n### Issue Type\n\nBug Report\n\n### Component Name\n\nbitwarden_secret_manager\n\n### Ansible Version\n\n```console (paste below)\r\n$ ansible --version\r\nansible [core 2.16.1]\r\n config file = /mnt/ansible/ansible.cfg\r\n configured module search path = ['/home/matta/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']\r\n ansible python module location = /usr/lib/python3.11/site-packages/ansible\r\n ansible collection location = /mnt/ansible/collections\r\n executable location = /usr/bin/ansible\r\n python version = 3.11.9 (main, Apr 14 2024, 13:40:00) [GCC 13.2.1 20231014] (/usr/bin/python3)\r\n jinja version = 3.1.2\r\n libyaml = True\r\n```\r\n\n\n### Community.general Version\n\n```console (paste below)\r\n$ ansible-galaxy collection list community.general\r\n\r\n# /mnt/ansible/collections/ansible_collections\r\nCollection Version\r\n----------------- -------\r\ncommunity.general 8.5.0\r\n\r\n# /usr/lib/python3.11/site-packages/ansible_collections\r\nCollection Version\r\n----------------- -------\r\ncommunity.general 7.5.1\r\n```\r\n\n\n### Configuration\n\n```console (paste below)\r\n$ ansible-config dump --only-changed\r\nCOLLECTIONS_PATHS(/mnt/ansible/ansible.cfg) = ['/mnt/ansible/collections']\r\nCONFIG_FILE() = /mnt/ansible/ansible.cfg\r\nDEFAULT_FORKS(/mnt/ansible/ansible.cfg) = 10\r\nDEFAULT_HOST_LIST(/mnt/ansible/ansible.cfg) = ['/mnt/ansible/inventory']\r\nDEFAULT_MANAGED_STR(/mnt/ansible/ansible.cfg) = This file is managed by Ansible. Do not modify directly!%n\r\ntemplate: {file}\r\ndate: %Y-%m-%d %H:%M:%S\r\nuser: {uid}\r\nhost: {host}\r\nDISPLAY_SKIPPED_HOSTS(/mnt/ansible/ansible.cfg) = False\r\nEDITOR(env: EDITOR) = vim\r\nINTERPRETER_PYTHON(/mnt/ansible/ansible.cfg) = auto_silent\r\nPAGER(env: PAGER) = less\r\n```\r\n\n\n### OS / Environment\n\nAlpine Linux 3.19\n\n### Steps to Reproduce\n\n<!--- Paste example playbooks or commands between quotes below -->\r\n```yaml (paste below)\r\n---\r\n- name: Bitwarden Secrets Manager Rate Limit Reproduction\r\n hosts:\r\n - xen01\r\n - xen02\r\n - xen03\r\n - xen04\r\n - xen05\r\n - xen06\r\n become: false\r\n gather_facts: false\r\n tasks:\r\n - debug:\r\n var: \"{{ lookup('community.general.bitwarden_secrets_manager', '<secret id here>').value }}\"\r\n```\r\n\n\n### Expected Results\n\nI would expect the module to handle the 429 error with a back-off and retry until it succeeds\n\n### Actual Results\n\n```console (paste below)\r\nPLAY [Bitwarden Secrets Manager Rate Limit Reproduction] ******************************************************************************************************************************************************************************************************************\r\nTASK [debug] **************************************************************************************************************************************************************************************************************************************************************\r\nfatal: [xen01]: FAILED! => {\"msg\": \"Error: \\n 0: Received error message from server: [429 Too Many Requests] {\\\"message\\\":\\\"Slow down! Too many requests. Try again in 1s.\\\",\\\"validationErrors\\\":null,\\\"exceptionMessage\\\":null,\\\"exceptionStackTrace\\\":null,\\\"innerExceptionMessage\\\":null,\\\"object\\\":\\\"error\\\"}\\n\\nLocation:\\n /home/matta/alpine-package-repository/main/bws/src/.cargo/registry/src/index.crates.io-6f17d22bba15001f/bws-0.4.0/src/main.rs:334\\n\\nBacktrace omitted. Run with RUST_BACKTRACE=1 environment variable to display it.\\nRun with RUST_BACKTRACE=full to include source snippets.\\n\"}\r\nok: [xen03] => {\r\n \"this-is-a-test-secret\": \"{{this-is-a-test-secret}}\"\r\n}\r\nok: [xen04] => {\r\n \"this-is-a-test-secret\": \"{{this-is-a-test-secret}}\"\r\n}\r\nok: [xen05] => {\r\n \"this-is-a-test-secret\": \"{{this-is-a-test-secret}}\"\r\n}\r\nok: [xen06] => {\r\n \"this-is-a-test-secret\": \"{{this-is-a-test-secret}}\"\r\n}\r\nok: [xen02] => {\r\n \"this-is-a-test-secret\": \"{{this-is-a-test-secret}}\"\r\n}\r\n\r\nPLAY RECAP ****************************************************************************************************************************************************************************************************************************************************************\r\nxen01 : ok=0 changed=0 unreachable=0 failed=1 skipped=0 rescued=0 ignored=0\r\nxen02 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0\r\nxen03 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0\r\nxen04 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0\r\nxen05 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0\r\nxen06 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0\r\n```\r\n\n\n### Code of Conduct\n\n- [X] I agree to follow the Ansible Code of Conduct\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) 2023, jantari (https://github.com/jantari)\n# GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)\n# SPDX-License-Identifier: GPL-3.0-or-later\nfrom __future__ import (absolute_import, division, print_function)\n\n__metaclass__ = type\n\nDOCUMENTATION = \"\"\"\n name: bitwarden_secrets_manager\n author:\n - jantari (@jantari)\n requirements:\n - bws (command line utility)\n short_description: Retrieve secrets from Bitwarden Secrets Manager\n version_added: 7.2.0\n description:\n - Retrieve secrets from Bitwarden Secrets Manager.\n options:\n _terms:\n description: Secret ID(s) to fetch values for.\n required: true\n type: list\n elements: str\n bws_access_token:\n description: The BWS access token to use for this lookup.\n env:\n - name: BWS_ACCESS_TOKEN\n required: true\n type: str\n\"\"\"\n\nEXAMPLES = \"\"\"\n- name: Get a secret relying on the BWS_ACCESS_TOKEN environment variable for authentication\n ansible.builtin.debug:\n msg: >-\n {{ lookup(\"community.general.bitwarden_secrets_manager\", \"2bc23e48-4932-40de-a047-5524b7ddc972\") }}\n\n- name: Get a secret passing an explicit access token for authentication\n ansible.builtin.debug:\n msg: >-\n {{\n lookup(\n \"community.general.bitwarden_secrets_manager\",\n \"2bc23e48-4932-40de-a047-5524b7ddc972\",\n bws_access_token=\"9.4f570d14-4b54-42f5-bc07-60f4450b1db5.YmluYXJ5LXNvbWV0aGluZy0xMjMK:d2h5IGhlbGxvIHRoZXJlCg==\"\n )\n }}\n\n- name: Get two different secrets each using a different access token for authentication\n ansible.builtin.debug:\n msg:\n - '{{ lookup(\"community.general.bitwarden_secrets_manager\", \"2bc23e48-4932-40de-a047-5524b7ddc972\", bws_access_token=token1) }}'\n - '{{ lookup(\"community.general.bitwarden_secrets_manager\", \"9d89af4c-eb5d-41f5-bb0f-4ae81215c768\", bws_access_token=token2) }}'\n vars:\n token1: \"9.4f570d14-4b54-42f5-bc07-60f4450b1db5.YmluYXJ5LXNvbWV0aGluZy0xMjMK:d2h5IGhlbGxvIHRoZXJlCg==\"\n token2: \"1.69b72797-6ea9-4687-a11e-848e41a30ae6.YW5zaWJsZSBpcyBncmVhdD8K:YW5zaWJsZSBpcyBncmVhdAo=\"\n\n- name: Get just the value of a secret\n ansible.builtin.debug:\n msg: >-\n {{ lookup(\"community.general.bitwarden_secrets_manager\", \"2bc23e48-4932-40de-a047-5524b7ddc972\").value }}\n\"\"\"\n\nRETURN = \"\"\"\n _raw:\n description: List containing one or more secrets.\n type: list\n elements: dict\n\"\"\"\n\nfrom subprocess import Popen, PIPE\n\nfrom ansible.errors import AnsibleLookupError\nfrom ansible.module_utils.common.text.converters import to_text\nfrom ansible.parsing.ajson import AnsibleJSONDecoder\nfrom ansible.plugins.lookup import LookupBase\n\n\nclass BitwardenSecretsManagerException(AnsibleLookupError):\n pass\n\n\nclass BitwardenSecretsManager(object):\n def __init__(self, path='bws'):\n self._cli_path = path\n\n @property\n def cli_path(self):\n return self._cli_path\n\n def _run(self, args, stdin=None):\n p = Popen([self.cli_path] + args, stdout=PIPE, stderr=PIPE, stdin=PIPE)\n out, err = p.communicate(stdin)\n rc = p.wait()\n return to_text(out, errors='surrogate_or_strict'), to_text(err, errors='surrogate_or_strict'), rc\n\n def get_secret(self, secret_id, bws_access_token):\n \"\"\"Get and return the secret with the given secret_id.\n \"\"\"\n\n # Prepare set of params for Bitwarden Secrets Manager CLI\n # Color output was not always disabled correctly with the default 'auto' setting so explicitly disable it.\n params = [\n '--color', 'no',\n '--access-token', bws_access_token,\n 'get', 'secret', secret_id\n ]\n\n out, err, rc = self._run(params)\n if rc != 0:\n raise BitwardenSecretsManagerException(to_text(err))\n\n return AnsibleJSONDecoder().raw_decode(out)[0]\n\n\nclass LookupModule(LookupBase):\n def run(self, terms, variables=None, **kwargs):\n self.set_options(var_options=variables, direct=kwargs)\n bws_access_token = self.get_option('bws_access_token')\n\n return [_bitwarden_secrets_manager.get_secret(term, bws_access_token) for term in terms]\n\n\n_bitwarden_secrets_manager = BitwardenSecretsManager()\n", "path": "plugins/lookup/bitwarden_secrets_manager.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) 2023, jantari (https://github.com/jantari)\n# GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)\n# SPDX-License-Identifier: GPL-3.0-or-later\nfrom __future__ import (absolute_import, division, print_function)\n\n__metaclass__ = type\n\nDOCUMENTATION = \"\"\"\n name: bitwarden_secrets_manager\n author:\n - jantari (@jantari)\n requirements:\n - bws (command line utility)\n short_description: Retrieve secrets from Bitwarden Secrets Manager\n version_added: 7.2.0\n description:\n - Retrieve secrets from Bitwarden Secrets Manager.\n options:\n _terms:\n description: Secret ID(s) to fetch values for.\n required: true\n type: list\n elements: str\n bws_access_token:\n description: The BWS access token to use for this lookup.\n env:\n - name: BWS_ACCESS_TOKEN\n required: true\n type: str\n\"\"\"\n\nEXAMPLES = \"\"\"\n- name: Get a secret relying on the BWS_ACCESS_TOKEN environment variable for authentication\n ansible.builtin.debug:\n msg: >-\n {{ lookup(\"community.general.bitwarden_secrets_manager\", \"2bc23e48-4932-40de-a047-5524b7ddc972\") }}\n\n- name: Get a secret passing an explicit access token for authentication\n ansible.builtin.debug:\n msg: >-\n {{\n lookup(\n \"community.general.bitwarden_secrets_manager\",\n \"2bc23e48-4932-40de-a047-5524b7ddc972\",\n bws_access_token=\"9.4f570d14-4b54-42f5-bc07-60f4450b1db5.YmluYXJ5LXNvbWV0aGluZy0xMjMK:d2h5IGhlbGxvIHRoZXJlCg==\"\n )\n }}\n\n- name: Get two different secrets each using a different access token for authentication\n ansible.builtin.debug:\n msg:\n - '{{ lookup(\"community.general.bitwarden_secrets_manager\", \"2bc23e48-4932-40de-a047-5524b7ddc972\", bws_access_token=token1) }}'\n - '{{ lookup(\"community.general.bitwarden_secrets_manager\", \"9d89af4c-eb5d-41f5-bb0f-4ae81215c768\", bws_access_token=token2) }}'\n vars:\n token1: \"9.4f570d14-4b54-42f5-bc07-60f4450b1db5.YmluYXJ5LXNvbWV0aGluZy0xMjMK:d2h5IGhlbGxvIHRoZXJlCg==\"\n token2: \"1.69b72797-6ea9-4687-a11e-848e41a30ae6.YW5zaWJsZSBpcyBncmVhdD8K:YW5zaWJsZSBpcyBncmVhdAo=\"\n\n- name: Get just the value of a secret\n ansible.builtin.debug:\n msg: >-\n {{ lookup(\"community.general.bitwarden_secrets_manager\", \"2bc23e48-4932-40de-a047-5524b7ddc972\").value }}\n\"\"\"\n\nRETURN = \"\"\"\n _raw:\n description: List containing one or more secrets.\n type: list\n elements: dict\n\"\"\"\n\nfrom subprocess import Popen, PIPE\nfrom time import sleep\n\nfrom ansible.errors import AnsibleLookupError\nfrom ansible.module_utils.common.text.converters import to_text\nfrom ansible.parsing.ajson import AnsibleJSONDecoder\nfrom ansible.plugins.lookup import LookupBase\n\n\nclass BitwardenSecretsManagerException(AnsibleLookupError):\n pass\n\n\nclass BitwardenSecretsManager(object):\n def __init__(self, path='bws'):\n self._cli_path = path\n self._max_retries = 3\n self._retry_delay = 1\n\n @property\n def cli_path(self):\n return self._cli_path\n\n def _run_with_retry(self, args, stdin=None, retries=0):\n out, err, rc = self._run(args, stdin)\n\n if rc != 0:\n if retries >= self._max_retries:\n raise BitwardenSecretsManagerException(\"Max retries exceeded. Unable to retrieve secret.\")\n\n if \"Too many requests\" in err:\n delay = self._retry_delay * (2 ** retries)\n sleep(delay)\n return self._run_with_retry(args, stdin, retries + 1)\n else:\n raise BitwardenSecretsManagerException(\"Command failed with return code {rc}: {err}\".format(rc=rc, err=err))\n\n return out, err, rc\n\n def _run(self, args, stdin=None):\n p = Popen([self.cli_path] + args, stdout=PIPE, stderr=PIPE, stdin=PIPE)\n out, err = p.communicate(stdin)\n rc = p.wait()\n return to_text(out, errors='surrogate_or_strict'), to_text(err, errors='surrogate_or_strict'), rc\n\n def get_secret(self, secret_id, bws_access_token):\n \"\"\"Get and return the secret with the given secret_id.\n \"\"\"\n\n # Prepare set of params for Bitwarden Secrets Manager CLI\n # Color output was not always disabled correctly with the default 'auto' setting so explicitly disable it.\n params = [\n '--color', 'no',\n '--access-token', bws_access_token,\n 'get', 'secret', secret_id\n ]\n\n out, err, rc = self._run_with_retry(params)\n if rc != 0:\n raise BitwardenSecretsManagerException(to_text(err))\n\n return AnsibleJSONDecoder().raw_decode(out)[0]\n\n\nclass LookupModule(LookupBase):\n def run(self, terms, variables=None, **kwargs):\n self.set_options(var_options=variables, direct=kwargs)\n bws_access_token = self.get_option('bws_access_token')\n\n return [_bitwarden_secrets_manager.get_secret(term, bws_access_token) for term in terms]\n\n\n_bitwarden_secrets_manager = BitwardenSecretsManager()\n", "path": "plugins/lookup/bitwarden_secrets_manager.py"}]} | 3,204 | 470 |
gh_patches_debug_35086 | rasdani/github-patches | git_diff | comic__grand-challenge.org-1932 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Reduce database calls for `update_challenge_results_cache()`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/grandchallenge/challenges/tasks.py`
Content:
```
1 from celery import shared_task
2 from django.core.mail import mail_managers
3 from requests import exceptions, get
4
5 from grandchallenge.challenges.models import Challenge, ExternalChallenge
6 from grandchallenge.evaluation.models import Evaluation
7 from grandchallenge.subdomains.utils import reverse
8
9
10 @shared_task
11 def update_challenge_results_cache():
12 for c in Challenge.objects.all():
13 kwargs = {
14 "cached_num_participants": c.participants_group.user_set.all().count()
15 }
16
17 challenge_results = Evaluation.objects.filter(
18 submission__phase__challenge=c, published=True
19 ).order_by("-created")
20
21 try:
22 kwargs.update(
23 {
24 "cached_num_results": challenge_results.count(),
25 "cached_latest_result": challenge_results.first().created,
26 }
27 )
28 except AttributeError:
29 # No results for this challenge
30 kwargs.update(
31 {"cached_num_results": 0, "cached_latest_result": None}
32 )
33
34 Challenge.objects.filter(pk=c.pk).update(**kwargs)
35
36
37 @shared_task
38 def check_external_challenge_urls():
39 """
40 Checks that all external challenge urls are reachable.
41
42 Emails the managers if any of the challenges are not.
43 """
44 challenges = ExternalChallenge.objects.filter(hidden=False)
45 errors = []
46
47 for challenge in challenges:
48 try:
49 url = challenge.homepage
50 if not url.startswith("http"):
51 url = "http://" + url
52 r = get(url, timeout=60)
53 # raise an exception when we receive a http error (e.g., 404)
54 r.raise_for_status()
55 except exceptions.RequestException as err:
56 update_url = reverse(
57 "challenges:external-update",
58 kwargs={"short_name": challenge.short_name},
59 )
60 errors.append(
61 f"Error when trying to access '{challenge}': {err}. You can "
62 f"update it here: {update_url}"
63 )
64
65 if errors:
66 mail_managers(
67 subject=f"Unreachable external challenges ({len(errors)})",
68 message="\n\n".join(errors),
69 )
70
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/app/grandchallenge/challenges/tasks.py b/app/grandchallenge/challenges/tasks.py
--- a/app/grandchallenge/challenges/tasks.py
+++ b/app/grandchallenge/challenges/tasks.py
@@ -1,5 +1,7 @@
from celery import shared_task
+from django.contrib.auth import get_user_model
from django.core.mail import mail_managers
+from django.db.models import Count, Max
from requests import exceptions, get
from grandchallenge.challenges.models import Challenge, ExternalChallenge
@@ -9,29 +11,47 @@
@shared_task
def update_challenge_results_cache():
- for c in Challenge.objects.all():
- kwargs = {
- "cached_num_participants": c.participants_group.user_set.all().count()
- }
-
- challenge_results = Evaluation.objects.filter(
- submission__phase__challenge=c, published=True
- ).order_by("-created")
+ challenges = Challenge.objects.all()
+ evaluation_info = (
+ Evaluation.objects.filter(published=True)
+ .values("submission__phase__challenge_id")
+ .annotate(
+ cached_num_results=Count("submission__phase__challenge_id"),
+ cached_latest_result=Max("created"),
+ )
+ )
+ evaluation_info_by_challenge = {
+ str(v["submission__phase__challenge_id"]): v for v in evaluation_info
+ }
+ participant_counts = (
+ get_user_model()
+ .objects.values("groups__participants_of_challenge")
+ .annotate(cached_num_participants=Count("pk"))
+ )
+ participant_counts_by_challenge = {
+ str(v["groups__participants_of_challenge"]): v
+ for v in participant_counts
+ }
- try:
- kwargs.update(
- {
- "cached_num_results": challenge_results.count(),
- "cached_latest_result": challenge_results.first().created,
- }
- )
- except AttributeError:
- # No results for this challenge
- kwargs.update(
- {"cached_num_results": 0, "cached_latest_result": None}
- )
+ for c in challenges:
+ c.cached_num_results = evaluation_info_by_challenge.get(
+ str(c.pk), {}
+ ).get("cached_num_results", 0)
+ c.cached_latest_result = evaluation_info_by_challenge.get(
+ str(c.pk), {}
+ ).get("cached_latest_result", None)
+ c.cached_num_participants = participant_counts_by_challenge.get(
+ str(c.pk), {}
+ ).get("cached_num_participants", 0)
- Challenge.objects.filter(pk=c.pk).update(**kwargs)
+ Challenge.objects.bulk_update(
+ challenges,
+ [
+ "cached_num_results",
+ "cached_num_participants",
+ "cached_latest_result",
+ ],
+ )
@shared_task
| {"golden_diff": "diff --git a/app/grandchallenge/challenges/tasks.py b/app/grandchallenge/challenges/tasks.py\n--- a/app/grandchallenge/challenges/tasks.py\n+++ b/app/grandchallenge/challenges/tasks.py\n@@ -1,5 +1,7 @@\n from celery import shared_task\n+from django.contrib.auth import get_user_model\n from django.core.mail import mail_managers\n+from django.db.models import Count, Max\n from requests import exceptions, get\n \n from grandchallenge.challenges.models import Challenge, ExternalChallenge\n@@ -9,29 +11,47 @@\n \n @shared_task\n def update_challenge_results_cache():\n- for c in Challenge.objects.all():\n- kwargs = {\n- \"cached_num_participants\": c.participants_group.user_set.all().count()\n- }\n-\n- challenge_results = Evaluation.objects.filter(\n- submission__phase__challenge=c, published=True\n- ).order_by(\"-created\")\n+ challenges = Challenge.objects.all()\n+ evaluation_info = (\n+ Evaluation.objects.filter(published=True)\n+ .values(\"submission__phase__challenge_id\")\n+ .annotate(\n+ cached_num_results=Count(\"submission__phase__challenge_id\"),\n+ cached_latest_result=Max(\"created\"),\n+ )\n+ )\n+ evaluation_info_by_challenge = {\n+ str(v[\"submission__phase__challenge_id\"]): v for v in evaluation_info\n+ }\n+ participant_counts = (\n+ get_user_model()\n+ .objects.values(\"groups__participants_of_challenge\")\n+ .annotate(cached_num_participants=Count(\"pk\"))\n+ )\n+ participant_counts_by_challenge = {\n+ str(v[\"groups__participants_of_challenge\"]): v\n+ for v in participant_counts\n+ }\n \n- try:\n- kwargs.update(\n- {\n- \"cached_num_results\": challenge_results.count(),\n- \"cached_latest_result\": challenge_results.first().created,\n- }\n- )\n- except AttributeError:\n- # No results for this challenge\n- kwargs.update(\n- {\"cached_num_results\": 0, \"cached_latest_result\": None}\n- )\n+ for c in challenges:\n+ c.cached_num_results = evaluation_info_by_challenge.get(\n+ str(c.pk), {}\n+ ).get(\"cached_num_results\", 0)\n+ c.cached_latest_result = evaluation_info_by_challenge.get(\n+ str(c.pk), {}\n+ ).get(\"cached_latest_result\", None)\n+ c.cached_num_participants = participant_counts_by_challenge.get(\n+ str(c.pk), {}\n+ ).get(\"cached_num_participants\", 0)\n \n- Challenge.objects.filter(pk=c.pk).update(**kwargs)\n+ Challenge.objects.bulk_update(\n+ challenges,\n+ [\n+ \"cached_num_results\",\n+ \"cached_num_participants\",\n+ \"cached_latest_result\",\n+ ],\n+ )\n \n \n @shared_task\n", "issue": "Reduce database calls for `update_challenge_results_cache()`\n\n", "before_files": [{"content": "from celery import shared_task\nfrom django.core.mail import mail_managers\nfrom requests import exceptions, get\n\nfrom grandchallenge.challenges.models import Challenge, ExternalChallenge\nfrom grandchallenge.evaluation.models import Evaluation\nfrom grandchallenge.subdomains.utils import reverse\n\n\n@shared_task\ndef update_challenge_results_cache():\n for c in Challenge.objects.all():\n kwargs = {\n \"cached_num_participants\": c.participants_group.user_set.all().count()\n }\n\n challenge_results = Evaluation.objects.filter(\n submission__phase__challenge=c, published=True\n ).order_by(\"-created\")\n\n try:\n kwargs.update(\n {\n \"cached_num_results\": challenge_results.count(),\n \"cached_latest_result\": challenge_results.first().created,\n }\n )\n except AttributeError:\n # No results for this challenge\n kwargs.update(\n {\"cached_num_results\": 0, \"cached_latest_result\": None}\n )\n\n Challenge.objects.filter(pk=c.pk).update(**kwargs)\n\n\n@shared_task\ndef check_external_challenge_urls():\n \"\"\"\n Checks that all external challenge urls are reachable.\n\n Emails the managers if any of the challenges are not.\n \"\"\"\n challenges = ExternalChallenge.objects.filter(hidden=False)\n errors = []\n\n for challenge in challenges:\n try:\n url = challenge.homepage\n if not url.startswith(\"http\"):\n url = \"http://\" + url\n r = get(url, timeout=60)\n # raise an exception when we receive a http error (e.g., 404)\n r.raise_for_status()\n except exceptions.RequestException as err:\n update_url = reverse(\n \"challenges:external-update\",\n kwargs={\"short_name\": challenge.short_name},\n )\n errors.append(\n f\"Error when trying to access '{challenge}': {err}. You can \"\n f\"update it here: {update_url}\"\n )\n\n if errors:\n mail_managers(\n subject=f\"Unreachable external challenges ({len(errors)})\",\n message=\"\\n\\n\".join(errors),\n )\n", "path": "app/grandchallenge/challenges/tasks.py"}], "after_files": [{"content": "from celery import shared_task\nfrom django.contrib.auth import get_user_model\nfrom django.core.mail import mail_managers\nfrom django.db.models import Count, Max\nfrom requests import exceptions, get\n\nfrom grandchallenge.challenges.models import Challenge, ExternalChallenge\nfrom grandchallenge.evaluation.models import Evaluation\nfrom grandchallenge.subdomains.utils import reverse\n\n\n@shared_task\ndef update_challenge_results_cache():\n challenges = Challenge.objects.all()\n evaluation_info = (\n Evaluation.objects.filter(published=True)\n .values(\"submission__phase__challenge_id\")\n .annotate(\n cached_num_results=Count(\"submission__phase__challenge_id\"),\n cached_latest_result=Max(\"created\"),\n )\n )\n evaluation_info_by_challenge = {\n str(v[\"submission__phase__challenge_id\"]): v for v in evaluation_info\n }\n participant_counts = (\n get_user_model()\n .objects.values(\"groups__participants_of_challenge\")\n .annotate(cached_num_participants=Count(\"pk\"))\n )\n participant_counts_by_challenge = {\n str(v[\"groups__participants_of_challenge\"]): v\n for v in participant_counts\n }\n\n for c in challenges:\n c.cached_num_results = evaluation_info_by_challenge.get(\n str(c.pk), {}\n ).get(\"cached_num_results\", 0)\n c.cached_latest_result = evaluation_info_by_challenge.get(\n str(c.pk), {}\n ).get(\"cached_latest_result\", None)\n c.cached_num_participants = participant_counts_by_challenge.get(\n str(c.pk), {}\n ).get(\"cached_num_participants\", 0)\n\n Challenge.objects.bulk_update(\n challenges,\n [\n \"cached_num_results\",\n \"cached_num_participants\",\n \"cached_latest_result\",\n ],\n )\n\n\n@shared_task\ndef check_external_challenge_urls():\n \"\"\"\n Checks that all external challenge urls are reachable.\n\n Emails the managers if any of the challenges are not.\n \"\"\"\n challenges = ExternalChallenge.objects.filter(hidden=False)\n errors = []\n\n for challenge in challenges:\n try:\n url = challenge.homepage\n if not url.startswith(\"http\"):\n url = \"http://\" + url\n r = get(url, timeout=60)\n # raise an exception when we receive a http error (e.g., 404)\n r.raise_for_status()\n except exceptions.RequestException as err:\n update_url = reverse(\n \"challenges:external-update\",\n kwargs={\"short_name\": challenge.short_name},\n )\n errors.append(\n f\"Error when trying to access '{challenge}': {err}. You can \"\n f\"update it here: {update_url}\"\n )\n\n if errors:\n mail_managers(\n subject=f\"Unreachable external challenges ({len(errors)})\",\n message=\"\\n\\n\".join(errors),\n )\n", "path": "app/grandchallenge/challenges/tasks.py"}]} | 837 | 623 |
gh_patches_debug_262 | rasdani/github-patches | git_diff | google__jax-9658 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[QoL] Add copy button in docs code snippets
Since I'm a bit lazy, I'd like to have a "copy to clipboard" button in jax docs to copy over code snippets instead of drag-select-copying it. Like this:

Dupicate Checks:
Nothing relevant comes up when searching for "copy button", "docs copy button" or even "button" for that matter.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 #
15 # -*- coding: utf-8 -*-
16 #
17 # Configuration file for the Sphinx documentation builder.
18 #
19 # This file does only contain a selection of the most common options. For a
20 # full list see the documentation:
21 # http://www.sphinx-doc.org/en/master/config
22
23 # -- Path setup --------------------------------------------------------------
24
25 # If extensions (or modules to document with autodoc) are in another directory,
26 # add these directories to sys.path here. If the directory is relative to the
27 # documentation root, use os.path.abspath to make it absolute, like shown here.
28 #
29 import os
30 import sys
31
32 sys.path.insert(0, os.path.abspath('..'))
33
34
35 # Currently type aliases are expanded. We tried a workaround along the lines of:
36 # https://github.com/sphinx-doc/sphinx/issues/6518#issuecomment-589613836
37 # Unfortunately, this workaround makes Sphinx drop module-level documentation.
38 # See https://github.com/google/jax/issues/3452.
39
40 # -- Project information -----------------------------------------------------
41
42 project = 'JAX'
43 copyright = '2020, Google LLC. NumPy and SciPy documentation are copyright the respective authors.'
44 author = 'The JAX authors'
45
46 # The short X.Y version
47 version = ''
48 # The full version, including alpha/beta/rc tags
49 release = ''
50
51
52 # -- General configuration ---------------------------------------------------
53
54 # If your documentation needs a minimal Sphinx version, state it here.
55 #
56 needs_sphinx = '2.1'
57
58 # Add any Sphinx extension module names here, as strings. They can be
59 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
60 # ones.
61 sys.path.append(os.path.abspath('sphinxext'))
62 extensions = [
63 'sphinx.ext.autodoc',
64 'sphinx.ext.autosummary',
65 'sphinx.ext.intersphinx',
66 'sphinx.ext.mathjax',
67 'sphinx.ext.napoleon',
68 'sphinx.ext.viewcode',
69 'matplotlib.sphinxext.plot_directive',
70 'sphinx_autodoc_typehints',
71 'myst_nb',
72 "sphinx_remove_toctrees",
73 'jax_extensions',
74 ]
75
76 intersphinx_mapping = {
77 'python': ('https://docs.python.org/3/', None),
78 'numpy': ('https://numpy.org/doc/stable/', None),
79 'scipy': ('https://docs.scipy.org/doc/scipy-1.8.0/html-scipyorg/', None),
80 }
81
82 suppress_warnings = [
83 'ref.citation', # Many duplicated citations in numpy/scipy docstrings.
84 'ref.footnote', # Many unreferenced footnotes in numpy/scipy docstrings
85 ]
86
87 # Add any paths that contain templates here, relative to this directory.
88 templates_path = ['_templates']
89
90 # The suffix(es) of source filenames.
91 # Note: important to list ipynb before md here: we have both md and ipynb
92 # copies of each notebook, and myst will choose which to convert based on
93 # the order in the source_suffix list. Notebooks which are not executed have
94 # outputs stored in ipynb but not in md, so we must convert the ipynb.
95 source_suffix = ['.rst', '.ipynb', '.md']
96
97 # The main toctree document.
98 main_doc = 'index'
99
100 # The language for content autogenerated by Sphinx. Refer to documentation
101 # for a list of supported languages.
102 #
103 # This is also used if you do content translation via gettext catalogs.
104 # Usually you set "language" from the command line for these cases.
105 language = None
106
107 # List of patterns, relative to source directory, that match files and
108 # directories to ignore when looking for source files.
109 # This pattern also affects html_static_path and html_extra_path.
110 exclude_patterns = [
111 # Sometimes sphinx reads its own outputs as inputs!
112 'build/html',
113 'build/jupyter_execute',
114 'notebooks/README.md',
115 'README.md',
116 # Ignore markdown source for notebooks; myst-nb builds from the ipynb
117 # These are kept in sync using the jupytext pre-commit hook.
118 'notebooks/*.md',
119 'design_notes/type_promotion.md',
120 # TODO: revert to jax-101/*.md once 08-pjit has a notebook
121 'jax-101/01-jax-basics.md',
122 'jax-101/02-jitting.md',
123 'jax-101/03-vectorization.md',
124 'jax-101/04-advanced-autodiff.md',
125 'jax-101/05-random-numbers.md',
126 'jax-101/05.1-pytrees.md',
127 'jax-101/06-parallelism.md',
128 'jax-101/07-state.md',
129 'autodidax.md',
130 # Attempt to fix RTD build failure
131 'transformations.md',
132 ]
133
134 # The name of the Pygments (syntax highlighting) style to use.
135 pygments_style = None
136
137
138 autosummary_generate = True
139 napolean_use_rtype = False
140
141 # mathjax_config = {
142 # 'TeX': {'equationNumbers': {'autoNumber': 'AMS', 'useLabelIds': True}},
143 # }
144
145 # Additional files needed for generating LaTeX/PDF output:
146 # latex_additional_files = ['references.bib']
147
148 # -- Options for HTML output -------------------------------------------------
149
150 # The theme to use for HTML and HTML Help pages. See the documentation for
151 # a list of builtin themes.
152 #
153 html_theme = 'sphinx_book_theme'
154
155 # Theme options are theme-specific and customize the look and feel of a theme
156 # further. For a list of options available for each theme, see the
157 # documentation.
158 html_theme_options = {
159 'logo_only': True,
160 'show_toc_level': 2,
161 }
162
163 # The name of an image file (relative to this directory) to place at the top
164 # of the sidebar.
165 html_logo = '_static/jax_logo_250px.png'
166
167 html_favicon = '_static/favicon.png'
168
169 # Add any paths that contain custom static files (such as style sheets) here,
170 # relative to this directory. They are copied after the builtin static files,
171 # so a file named "default.css" will overwrite the builtin "default.css".
172 html_static_path = ['_static']
173
174 # Custom sidebar templates, must be a dictionary that maps document names
175 # to template names.
176 #
177 # The default sidebars (for documents that don't match any pattern) are
178 # defined by theme itself. Builtin themes are using these templates by
179 # default: ``['localtoc.html', 'relations.html', 'sourcelink.html',
180 # 'searchbox.html']``.
181 #
182 # html_sidebars = {}
183
184 # -- Options for myst ----------------------------------------------
185 jupyter_execute_notebooks = "force"
186 execution_allow_errors = False
187 execution_fail_on_error = True # Requires https://github.com/executablebooks/MyST-NB/pull/296
188
189 # Notebook cell execution timeout; defaults to 30.
190 execution_timeout = 100
191
192 # List of patterns, relative to source directory, that match notebook
193 # files that will not be executed.
194 execution_excludepatterns = [
195 # Slow notebook: long time to load tf.ds
196 'notebooks/neural_network_with_tfds_data.*',
197 # Slow notebook
198 'notebooks/Neural_Network_and_Data_Loading.*',
199 # Strange error apparently due to asynchronous cell execution
200 'notebooks/thinking_in_jax.*',
201 # TODO(jakevdp): enable execution on these
202 'design_notes/type_promotion.*',
203 'jax-101/*',
204 'notebooks/xmap_tutorial.*',
205 ]
206
207 # -- Options for HTMLHelp output ---------------------------------------------
208
209 # Output file base name for HTML help builder.
210 htmlhelp_basename = 'JAXdoc'
211
212
213 # -- Options for LaTeX output ------------------------------------------------
214
215 latex_elements = {
216 # The paper size ('letterpaper' or 'a4paper').
217 #
218 # 'papersize': 'letterpaper',
219
220 # The font size ('10pt', '11pt' or '12pt').
221 #
222 # 'pointsize': '10pt',
223
224 # Additional stuff for the LaTeX preamble.
225 #
226 # 'preamble': '',
227
228 # Latex figure (float) alignment
229 #
230 # 'figure_align': 'htbp',
231 }
232
233 # Grouping the document tree into LaTeX files. List of tuples
234 # (source start file, target name, title,
235 # author, documentclass [howto, manual, or own class]).
236 latex_documents = [
237 (main_doc, 'JAX.tex', 'JAX Documentation',
238 'The JAX authors', 'manual'),
239 ]
240
241
242 # -- Options for manual page output ------------------------------------------
243
244 # One entry per manual page. List of tuples
245 # (source start file, name, description, authors, manual section).
246 man_pages = [
247 (main_doc, 'jax', 'JAX Documentation',
248 [author], 1)
249 ]
250
251
252 # -- Options for Texinfo output ----------------------------------------------
253
254 # Grouping the document tree into Texinfo files. List of tuples
255 # (source start file, target name, title, author,
256 # dir menu entry, description, category)
257 texinfo_documents = [
258 (main_doc, 'JAX', 'JAX Documentation',
259 author, 'JAX', 'One line description of project.',
260 'Miscellaneous'),
261 ]
262
263
264 # -- Options for Epub output -------------------------------------------------
265
266 # Bibliographic Dublin Core info.
267 epub_title = project
268
269 # The unique identifier of the text. This can be a ISBN number
270 # or the project homepage.
271 #
272 # epub_identifier = ''
273
274 # A unique identification for the text.
275 #
276 # epub_uid = ''
277
278 # A list of files that should not be packed into the epub file.
279 epub_exclude_files = ['search.html']
280
281
282 # -- Extension configuration -------------------------------------------------
283
284 # Tell sphinx-autodoc-typehints to generate stub parameter annotations including
285 # types, even if the parameters aren't explicitly documented.
286 always_document_param_types = True
287
288
289 # Remove auto-generated API docs from sidebars. They take too long to build.
290 remove_from_toctrees = ["_autosummary/*"]
291
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -70,6 +70,7 @@
'sphinx_autodoc_typehints',
'myst_nb',
"sphinx_remove_toctrees",
+ 'sphinx_copybutton',
'jax_extensions',
]
| {"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -70,6 +70,7 @@\n 'sphinx_autodoc_typehints',\n 'myst_nb',\n \"sphinx_remove_toctrees\",\n+ 'sphinx_copybutton',\n 'jax_extensions',\n ]\n", "issue": "[QoL] Add copy button in docs code snippets\nSince I'm a bit lazy, I'd like to have a \"copy to clipboard\" button in jax docs to copy over code snippets instead of drag-select-copying it. Like this:\r\n\r\n\r\n\r\nDupicate Checks:\r\nNothing relevant comes up when searching for \"copy button\", \"docs copy button\" or even \"button\" for that matter.\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n# -*- coding: utf-8 -*-\n#\n# Configuration file for the Sphinx documentation builder.\n#\n# This file does only contain a selection of the most common options. For a\n# full list see the documentation:\n# http://www.sphinx-doc.org/en/master/config\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\n\nsys.path.insert(0, os.path.abspath('..'))\n\n\n# Currently type aliases are expanded. We tried a workaround along the lines of:\n# https://github.com/sphinx-doc/sphinx/issues/6518#issuecomment-589613836\n# Unfortunately, this workaround makes Sphinx drop module-level documentation.\n# See https://github.com/google/jax/issues/3452.\n\n# -- Project information -----------------------------------------------------\n\nproject = 'JAX'\ncopyright = '2020, Google LLC. NumPy and SciPy documentation are copyright the respective authors.'\nauthor = 'The JAX authors'\n\n# The short X.Y version\nversion = ''\n# The full version, including alpha/beta/rc tags\nrelease = ''\n\n\n# -- General configuration ---------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\nneeds_sphinx = '2.1'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nsys.path.append(os.path.abspath('sphinxext'))\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.intersphinx',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.napoleon',\n 'sphinx.ext.viewcode',\n 'matplotlib.sphinxext.plot_directive',\n 'sphinx_autodoc_typehints',\n 'myst_nb',\n \"sphinx_remove_toctrees\",\n 'jax_extensions',\n]\n\nintersphinx_mapping = {\n 'python': ('https://docs.python.org/3/', None),\n 'numpy': ('https://numpy.org/doc/stable/', None),\n 'scipy': ('https://docs.scipy.org/doc/scipy-1.8.0/html-scipyorg/', None),\n}\n\nsuppress_warnings = [\n 'ref.citation', # Many duplicated citations in numpy/scipy docstrings.\n 'ref.footnote', # Many unreferenced footnotes in numpy/scipy docstrings\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# Note: important to list ipynb before md here: we have both md and ipynb\n# copies of each notebook, and myst will choose which to convert based on\n# the order in the source_suffix list. Notebooks which are not executed have\n# outputs stored in ipynb but not in md, so we must convert the ipynb.\nsource_suffix = ['.rst', '.ipynb', '.md']\n\n# The main toctree document.\nmain_doc = 'index'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = [\n # Sometimes sphinx reads its own outputs as inputs!\n 'build/html',\n 'build/jupyter_execute',\n 'notebooks/README.md',\n 'README.md',\n # Ignore markdown source for notebooks; myst-nb builds from the ipynb\n # These are kept in sync using the jupytext pre-commit hook.\n 'notebooks/*.md',\n 'design_notes/type_promotion.md',\n # TODO: revert to jax-101/*.md once 08-pjit has a notebook\n 'jax-101/01-jax-basics.md',\n 'jax-101/02-jitting.md',\n 'jax-101/03-vectorization.md',\n 'jax-101/04-advanced-autodiff.md',\n 'jax-101/05-random-numbers.md',\n 'jax-101/05.1-pytrees.md',\n 'jax-101/06-parallelism.md',\n 'jax-101/07-state.md',\n 'autodidax.md',\n # Attempt to fix RTD build failure\n 'transformations.md',\n]\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = None\n\n\nautosummary_generate = True\nnapolean_use_rtype = False\n\n# mathjax_config = {\n# 'TeX': {'equationNumbers': {'autoNumber': 'AMS', 'useLabelIds': True}},\n# }\n\n# Additional files needed for generating LaTeX/PDF output:\n# latex_additional_files = ['references.bib']\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'sphinx_book_theme'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\nhtml_theme_options = {\n 'logo_only': True,\n 'show_toc_level': 2,\n}\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\nhtml_logo = '_static/jax_logo_250px.png'\n\nhtml_favicon = '_static/favicon.png'\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# The default sidebars (for documents that don't match any pattern) are\n# defined by theme itself. Builtin themes are using these templates by\n# default: ``['localtoc.html', 'relations.html', 'sourcelink.html',\n# 'searchbox.html']``.\n#\n# html_sidebars = {}\n\n# -- Options for myst ----------------------------------------------\njupyter_execute_notebooks = \"force\"\nexecution_allow_errors = False\nexecution_fail_on_error = True # Requires https://github.com/executablebooks/MyST-NB/pull/296\n\n# Notebook cell execution timeout; defaults to 30.\nexecution_timeout = 100\n\n# List of patterns, relative to source directory, that match notebook\n# files that will not be executed.\nexecution_excludepatterns = [\n # Slow notebook: long time to load tf.ds\n 'notebooks/neural_network_with_tfds_data.*',\n # Slow notebook\n 'notebooks/Neural_Network_and_Data_Loading.*',\n # Strange error apparently due to asynchronous cell execution\n 'notebooks/thinking_in_jax.*',\n # TODO(jakevdp): enable execution on these\n 'design_notes/type_promotion.*',\n 'jax-101/*',\n 'notebooks/xmap_tutorial.*',\n]\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'JAXdoc'\n\n\n# -- Options for LaTeX output ------------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (main_doc, 'JAX.tex', 'JAX Documentation',\n 'The JAX authors', 'manual'),\n]\n\n\n# -- Options for manual page output ------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (main_doc, 'jax', 'JAX Documentation',\n [author], 1)\n]\n\n\n# -- Options for Texinfo output ----------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (main_doc, 'JAX', 'JAX Documentation',\n author, 'JAX', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n\n# -- Options for Epub output -------------------------------------------------\n\n# Bibliographic Dublin Core info.\nepub_title = project\n\n# The unique identifier of the text. This can be a ISBN number\n# or the project homepage.\n#\n# epub_identifier = ''\n\n# A unique identification for the text.\n#\n# epub_uid = ''\n\n# A list of files that should not be packed into the epub file.\nepub_exclude_files = ['search.html']\n\n\n# -- Extension configuration -------------------------------------------------\n\n# Tell sphinx-autodoc-typehints to generate stub parameter annotations including\n# types, even if the parameters aren't explicitly documented.\nalways_document_param_types = True\n\n\n# Remove auto-generated API docs from sidebars. They take too long to build.\nremove_from_toctrees = [\"_autosummary/*\"]\n", "path": "docs/conf.py"}], "after_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n# -*- coding: utf-8 -*-\n#\n# Configuration file for the Sphinx documentation builder.\n#\n# This file does only contain a selection of the most common options. For a\n# full list see the documentation:\n# http://www.sphinx-doc.org/en/master/config\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\n\nsys.path.insert(0, os.path.abspath('..'))\n\n\n# Currently type aliases are expanded. We tried a workaround along the lines of:\n# https://github.com/sphinx-doc/sphinx/issues/6518#issuecomment-589613836\n# Unfortunately, this workaround makes Sphinx drop module-level documentation.\n# See https://github.com/google/jax/issues/3452.\n\n# -- Project information -----------------------------------------------------\n\nproject = 'JAX'\ncopyright = '2020, Google LLC. NumPy and SciPy documentation are copyright the respective authors.'\nauthor = 'The JAX authors'\n\n# The short X.Y version\nversion = ''\n# The full version, including alpha/beta/rc tags\nrelease = ''\n\n\n# -- General configuration ---------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\nneeds_sphinx = '2.1'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nsys.path.append(os.path.abspath('sphinxext'))\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.intersphinx',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.napoleon',\n 'sphinx.ext.viewcode',\n 'matplotlib.sphinxext.plot_directive',\n 'sphinx_autodoc_typehints',\n 'myst_nb',\n \"sphinx_remove_toctrees\",\n 'sphinx_copybutton',\n 'jax_extensions',\n]\n\nintersphinx_mapping = {\n 'python': ('https://docs.python.org/3/', None),\n 'numpy': ('https://numpy.org/doc/stable/', None),\n 'scipy': ('https://docs.scipy.org/doc/scipy-1.8.0/html-scipyorg/', None),\n}\n\nsuppress_warnings = [\n 'ref.citation', # Many duplicated citations in numpy/scipy docstrings.\n 'ref.footnote', # Many unreferenced footnotes in numpy/scipy docstrings\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# Note: important to list ipynb before md here: we have both md and ipynb\n# copies of each notebook, and myst will choose which to convert based on\n# the order in the source_suffix list. Notebooks which are not executed have\n# outputs stored in ipynb but not in md, so we must convert the ipynb.\nsource_suffix = ['.rst', '.ipynb', '.md']\n\n# The main toctree document.\nmain_doc = 'index'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = [\n # Sometimes sphinx reads its own outputs as inputs!\n 'build/html',\n 'build/jupyter_execute',\n 'notebooks/README.md',\n 'README.md',\n # Ignore markdown source for notebooks; myst-nb builds from the ipynb\n # These are kept in sync using the jupytext pre-commit hook.\n 'notebooks/*.md',\n 'design_notes/type_promotion.md',\n # TODO: revert to jax-101/*.md once 08-pjit has a notebook\n 'jax-101/01-jax-basics.md',\n 'jax-101/02-jitting.md',\n 'jax-101/03-vectorization.md',\n 'jax-101/04-advanced-autodiff.md',\n 'jax-101/05-random-numbers.md',\n 'jax-101/05.1-pytrees.md',\n 'jax-101/06-parallelism.md',\n 'jax-101/07-state.md',\n 'autodidax.md',\n # Attempt to fix RTD build failure\n 'transformations.md',\n]\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = None\n\n\nautosummary_generate = True\nnapolean_use_rtype = False\n\n# mathjax_config = {\n# 'TeX': {'equationNumbers': {'autoNumber': 'AMS', 'useLabelIds': True}},\n# }\n\n# Additional files needed for generating LaTeX/PDF output:\n# latex_additional_files = ['references.bib']\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'sphinx_book_theme'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\nhtml_theme_options = {\n 'logo_only': True,\n 'show_toc_level': 2,\n}\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\nhtml_logo = '_static/jax_logo_250px.png'\n\nhtml_favicon = '_static/favicon.png'\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# The default sidebars (for documents that don't match any pattern) are\n# defined by theme itself. Builtin themes are using these templates by\n# default: ``['localtoc.html', 'relations.html', 'sourcelink.html',\n# 'searchbox.html']``.\n#\n# html_sidebars = {}\n\n# -- Options for myst ----------------------------------------------\njupyter_execute_notebooks = \"force\"\nexecution_allow_errors = False\nexecution_fail_on_error = True # Requires https://github.com/executablebooks/MyST-NB/pull/296\n\n# Notebook cell execution timeout; defaults to 30.\nexecution_timeout = 100\n\n# List of patterns, relative to source directory, that match notebook\n# files that will not be executed.\nexecution_excludepatterns = [\n # Slow notebook: long time to load tf.ds\n 'notebooks/neural_network_with_tfds_data.*',\n # Slow notebook\n 'notebooks/Neural_Network_and_Data_Loading.*',\n # Strange error apparently due to asynchronous cell execution\n 'notebooks/thinking_in_jax.*',\n # TODO(jakevdp): enable execution on these\n 'design_notes/type_promotion.*',\n 'jax-101/*',\n 'notebooks/xmap_tutorial.*',\n]\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'JAXdoc'\n\n\n# -- Options for LaTeX output ------------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (main_doc, 'JAX.tex', 'JAX Documentation',\n 'The JAX authors', 'manual'),\n]\n\n\n# -- Options for manual page output ------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (main_doc, 'jax', 'JAX Documentation',\n [author], 1)\n]\n\n\n# -- Options for Texinfo output ----------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (main_doc, 'JAX', 'JAX Documentation',\n author, 'JAX', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n\n# -- Options for Epub output -------------------------------------------------\n\n# Bibliographic Dublin Core info.\nepub_title = project\n\n# The unique identifier of the text. This can be a ISBN number\n# or the project homepage.\n#\n# epub_identifier = ''\n\n# A unique identification for the text.\n#\n# epub_uid = ''\n\n# A list of files that should not be packed into the epub file.\nepub_exclude_files = ['search.html']\n\n\n# -- Extension configuration -------------------------------------------------\n\n# Tell sphinx-autodoc-typehints to generate stub parameter annotations including\n# types, even if the parameters aren't explicitly documented.\nalways_document_param_types = True\n\n\n# Remove auto-generated API docs from sidebars. They take too long to build.\nremove_from_toctrees = [\"_autosummary/*\"]\n", "path": "docs/conf.py"}]} | 3,509 | 75 |
gh_patches_debug_42901 | rasdani/github-patches | git_diff | graspologic-org__graspologic-202 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Issues with GClust
## Actual Behavior
1. `n_components_` is always wrong.
2. Doc issues.
## Template Code
Snippet from gclust test.
```GraSPy
np.random.seed(2)
n = 100
d = 3
X1 = np.random.normal(2, 0.5, size=(n, d))
X2 = np.random.normal(-2, 0.5, size=(n, d))
X = np.vstack((X1, X2))
gclust = GaussianCluster(min_components=5)
gclust.fit(X)
print(gclust.n_components_)
>>>> 1
```
Above should be 2. The model selection code based on bic is incorrect and **needs** to be simplified. Above test should be changed to check `n_compnents_ == 2`.
Doc issues (defaults are wrong):
1. https://github.com/neurodata/graspy/blob/master/graspy/cluster/gclust.py#L35
2. https://github.com/neurodata/graspy/blob/master/graspy/cluster/gclust.py#L40
## Your Environment
* Python version: 3.7
* GraSPy version: 0.0.3
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `graspy/cluster/gclust.py`
Content:
```
1 # Copyright 2019 NeuroData (http://neurodata.io)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import numpy as np
16 import pandas as pd
17 from sklearn.metrics import adjusted_rand_score
18 from sklearn.mixture import GaussianMixture
19 from sklearn.model_selection import ParameterGrid
20
21 from .base import BaseCluster
22
23
24 class GaussianCluster(BaseCluster):
25 r"""
26 Gaussian Mixture Model (GMM)
27
28 Representation of a Gaussian mixture model probability distribution.
29 This class allows to estimate the parameters of a Gaussian mixture
30 distribution. It computes all possible models from one component to
31 max_components. The best model is given by the lowest BIC score.
32
33 Parameters
34 ----------
35 min_components : int, defaults to 1.
36 The minimum number of mixture components to consider (unless
37 max_components=None, in which case this is the maximum number of
38 components to consider). If max_componens is not None, min_components
39 must be less than or equal to max_components.
40 max_components : int, defaults to 1.
41 The maximum number of mixture components to consider. Must be greater
42 than or equal to min_components.
43
44 covariance_type : {'full' (default), 'tied', 'diag', 'spherical'}, optional
45 String or list/array describing the type of covariance parameters to use.
46 If a string, it must be one of:
47
48 - 'full'
49 each component has its own general covariance matrix
50 - 'tied'
51 all components share the same general covariance matrix
52 - 'diag'
53 each component has its own diagonal covariance matrix
54 - 'spherical'
55 each component has its own single variance
56 - 'all'
57 considers all covariance structures in ['spherical', 'diag', 'tied', 'full']
58 If a list/array, it must be a list/array of strings containing only
59 'spherical', 'tied', 'diag', and/or 'spherical'.
60
61 random_state : int, RandomState instance or None, optional (default=None)
62 If int, random_state is the seed used by the random number generator;
63 If RandomState instance, random_state is the random number generator;
64 If None, the random number generator is the RandomState instance used
65 by ``np.random``.
66
67 Attributes
68 ----------
69 n_components_ : int
70 Optimal number of components based on BIC.
71 model_ : GaussianMixture object
72 Fitted GaussianMixture object fitted with optimal numeber of components
73 and optimal covariance structure.
74 bic_ : pandas.DataFrame
75 A pandas DataFrame of BIC values computed for all possible number of clusters
76 given by range(min_components, max_components + 1) and all covariance
77 structures given by covariance_type.
78 ari_ : pandas.DataFrame
79 Only computed when y is given. Pandas Dataframe containing ARI values computed
80 for all possible number of clusters given by range(min_components,
81 max_components) and all covariance structures given by covariance_type.
82 """
83
84 def __init__(
85 self,
86 min_components=2,
87 max_components=None,
88 covariance_type="full",
89 random_state=None,
90 ):
91 if isinstance(min_components, int):
92 if min_components <= 0:
93 msg = "min_components must be >= 1."
94 raise ValueError(msg)
95 else:
96 msg = "min_components must be an integer, not {}.".format(
97 type(min_components)
98 )
99 raise TypeError(msg)
100
101 if isinstance(max_components, int):
102 if max_components <= 0:
103 msg = "max_components must be >= 1 or None."
104 raise ValueError(msg)
105 elif min_components > max_components:
106 msg = "min_components must be less than or equal to max_components."
107 raise ValueError(msg)
108 elif max_components is not None:
109 msg = "max_components must be an integer or None, not {}.".format(
110 type(max_components)
111 )
112 raise TypeError(msg)
113
114 if isinstance(covariance_type, np.ndarray):
115 covariance_type = np.unique(covariance_type)
116 elif isinstance(covariance_type, list):
117 covariance_type = np.unique(covariance_type)
118 elif isinstance(covariance_type, str):
119 if covariance_type == "all":
120 covariance_type = ["spherical", "diag", "tied", "full"]
121 else:
122 covariance_type = [covariance_type]
123 else:
124 msg = "covariance_type must be a numpy array, a list, or "
125 msg += "string, not {}".format(type(covariance_type))
126 raise TypeError(msg)
127
128 for cov in covariance_type:
129 if cov not in ["spherical", "diag", "tied", "full"]:
130 msg = (
131 "covariance structure must be one of "
132 + '["spherical", "diag", "tied", "full"]'
133 )
134 msg += " not {}".format(cov)
135 raise ValueError(msg)
136
137 new_covariance_type = []
138 for cov in ["spherical", "diag", "tied", "full"]:
139 if cov in covariance_type:
140 new_covariance_type.append(cov)
141
142 new_covariance_type = np.array(new_covariance_type)
143
144 self.min_components = min_components
145 self.max_components = max_components
146 self.covariance_type = new_covariance_type
147 self.random_state = random_state
148
149 def fit(self, X, y=None):
150 """
151 Fits gaussian mixure model to the data.
152 Estimate model parameters with the EM algorithm.
153
154 Parameters
155 ----------
156 X : array-like, shape (n_samples, n_features)
157 List of n_features-dimensional data points. Each row
158 corresponds to a single data point.
159
160 y : array-like, shape (n_samples,), optional (default=None)
161 List of labels for X if available. Used to compute
162 ARI scores.
163
164 Returns
165 -------
166 self
167 """
168
169 # Deal with number of clusters
170 if self.max_components is None:
171 lower_ncomponents = 1
172 upper_ncomponents = self.min_components
173 else:
174 lower_ncomponents = self.min_components
175 upper_ncomponents = self.max_components
176
177 n_mixture_components = upper_ncomponents - lower_ncomponents + 1
178
179 if upper_ncomponents > X.shape[0]:
180 if self.max_components is None:
181 msg = "if max_components is None then min_components must be >= "
182 msg += "n_samples, but min_components = {}, n_samples = {}".format(
183 upper_ncomponents, X.shape[0]
184 )
185 else:
186 msg = "max_components must be >= n_samples, but max_components = "
187 msg += "{}, n_samples = {}".format(upper_ncomponents, X.shape[0])
188 raise ValueError(msg)
189 elif lower_ncomponents > X.shape[0]:
190 msg = "min_components must be <= n_samples, but min_components = "
191 msg += "{}, n_samples = {}".format(upper_ncomponents, X.shape[0])
192 raise ValueError(msg)
193
194 # Get parameters
195 random_state = self.random_state
196
197 param_grid = dict(
198 covariance_type=self.covariance_type,
199 n_components=range(lower_ncomponents, upper_ncomponents + 1),
200 random_state=[random_state],
201 )
202
203 param_grid = list(ParameterGrid(param_grid))
204
205 models = [[] for _ in range(n_mixture_components)]
206 bics = [[] for _ in range(n_mixture_components)]
207 aris = [[] for _ in range(n_mixture_components)]
208
209 for i, params in enumerate(param_grid):
210 model = GaussianMixture(**params)
211 model.fit(X)
212 models[i % n_mixture_components].append(model)
213 bics[i % n_mixture_components].append(model.bic(X))
214 if y is not None:
215 predictions = model.predict(X)
216 aris[i % n_mixture_components].append(
217 adjusted_rand_score(y, predictions)
218 )
219
220 self.bic_ = pd.DataFrame(
221 np.array(bics),
222 index=np.arange(lower_ncomponents, upper_ncomponents + 1),
223 columns=self.covariance_type,
224 )
225
226 if y is not None:
227 self.ari_ = pd.DataFrame(
228 np.array(aris),
229 index=np.arange(lower_ncomponents, upper_ncomponents + 1),
230 columns=self.covariance_type,
231 )
232 else:
233 self.ari_ = None
234
235 # Finding the minimum bic for each covariance structure
236 bic_mins = [min(bic) for bic in bics]
237 bic_argmins = [np.argmin(bic) for bic in bics]
238
239 # Find the index for the minimum bic amongst all covariance structures
240 model_type_argmin = np.argmin(bic_mins)
241
242 self.n_components_ = np.argmin(bics[model_type_argmin]) + 1
243 self.model_ = models[model_type_argmin][bic_argmins[model_type_argmin]]
244
245 return self
246
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/graspy/cluster/gclust.py b/graspy/cluster/gclust.py
--- a/graspy/cluster/gclust.py
+++ b/graspy/cluster/gclust.py
@@ -32,12 +32,13 @@
Parameters
----------
- min_components : int, defaults to 1.
+ min_components : int, default=2.
The minimum number of mixture components to consider (unless
max_components=None, in which case this is the maximum number of
components to consider). If max_componens is not None, min_components
must be less than or equal to max_components.
- max_components : int, defaults to 1.
+
+ max_components : int or None, default=None.
The maximum number of mixture components to consider. Must be greater
than or equal to min_components.
@@ -68,6 +69,8 @@
----------
n_components_ : int
Optimal number of components based on BIC.
+ covariance_type_ : str
+ Optimal covariance type based on BIC.
model_ : GaussianMixture object
Fitted GaussianMixture object fitted with optimal numeber of components
and optimal covariance structure.
@@ -111,9 +114,7 @@
)
raise TypeError(msg)
- if isinstance(covariance_type, np.ndarray):
- covariance_type = np.unique(covariance_type)
- elif isinstance(covariance_type, list):
+ if isinstance(covariance_type, (np.ndarray, list)):
covariance_type = np.unique(covariance_type)
elif isinstance(covariance_type, str):
if covariance_type == "all":
@@ -139,8 +140,6 @@
if cov in covariance_type:
new_covariance_type.append(cov)
- new_covariance_type = np.array(new_covariance_type)
-
self.min_components = min_components
self.max_components = max_components
self.covariance_type = new_covariance_type
@@ -218,28 +217,29 @@
)
self.bic_ = pd.DataFrame(
- np.array(bics),
+ bics,
index=np.arange(lower_ncomponents, upper_ncomponents + 1),
columns=self.covariance_type,
)
if y is not None:
self.ari_ = pd.DataFrame(
- np.array(aris),
+ aris,
index=np.arange(lower_ncomponents, upper_ncomponents + 1),
columns=self.covariance_type,
)
else:
self.ari_ = None
- # Finding the minimum bic for each covariance structure
- bic_mins = [min(bic) for bic in bics]
- bic_argmins = [np.argmin(bic) for bic in bics]
+ # Get the best cov type and its index within the dataframe
+ best_covariance = self.bic_.min(axis=0).idxmin()
+ best_covariance_idx = self.covariance_type.index(best_covariance)
- # Find the index for the minimum bic amongst all covariance structures
- model_type_argmin = np.argmin(bic_mins)
+ # Get the index best component for best_covariance
+ best_component = self.bic_.idxmin()[best_covariance]
- self.n_components_ = np.argmin(bics[model_type_argmin]) + 1
- self.model_ = models[model_type_argmin][bic_argmins[model_type_argmin]]
+ self.n_components_ = best_component
+ self.covariance_type_ = best_covariance
+ self.model_ = models[best_component - 1][best_covariance_idx]
return self
| {"golden_diff": "diff --git a/graspy/cluster/gclust.py b/graspy/cluster/gclust.py\n--- a/graspy/cluster/gclust.py\n+++ b/graspy/cluster/gclust.py\n@@ -32,12 +32,13 @@\n \n Parameters\n ----------\n- min_components : int, defaults to 1. \n+ min_components : int, default=2. \n The minimum number of mixture components to consider (unless\n max_components=None, in which case this is the maximum number of\n components to consider). If max_componens is not None, min_components\n must be less than or equal to max_components.\n- max_components : int, defaults to 1.\n+\n+ max_components : int or None, default=None.\n The maximum number of mixture components to consider. Must be greater \n than or equal to min_components.\n \n@@ -68,6 +69,8 @@\n ----------\n n_components_ : int\n Optimal number of components based on BIC.\n+ covariance_type_ : str\n+ Optimal covariance type based on BIC.\n model_ : GaussianMixture object\n Fitted GaussianMixture object fitted with optimal numeber of components \n and optimal covariance structure.\n@@ -111,9 +114,7 @@\n )\n raise TypeError(msg)\n \n- if isinstance(covariance_type, np.ndarray):\n- covariance_type = np.unique(covariance_type)\n- elif isinstance(covariance_type, list):\n+ if isinstance(covariance_type, (np.ndarray, list)):\n covariance_type = np.unique(covariance_type)\n elif isinstance(covariance_type, str):\n if covariance_type == \"all\":\n@@ -139,8 +140,6 @@\n if cov in covariance_type:\n new_covariance_type.append(cov)\n \n- new_covariance_type = np.array(new_covariance_type)\n-\n self.min_components = min_components\n self.max_components = max_components\n self.covariance_type = new_covariance_type\n@@ -218,28 +217,29 @@\n )\n \n self.bic_ = pd.DataFrame(\n- np.array(bics),\n+ bics,\n index=np.arange(lower_ncomponents, upper_ncomponents + 1),\n columns=self.covariance_type,\n )\n \n if y is not None:\n self.ari_ = pd.DataFrame(\n- np.array(aris),\n+ aris,\n index=np.arange(lower_ncomponents, upper_ncomponents + 1),\n columns=self.covariance_type,\n )\n else:\n self.ari_ = None\n \n- # Finding the minimum bic for each covariance structure\n- bic_mins = [min(bic) for bic in bics]\n- bic_argmins = [np.argmin(bic) for bic in bics]\n+ # Get the best cov type and its index within the dataframe\n+ best_covariance = self.bic_.min(axis=0).idxmin()\n+ best_covariance_idx = self.covariance_type.index(best_covariance)\n \n- # Find the index for the minimum bic amongst all covariance structures\n- model_type_argmin = np.argmin(bic_mins)\n+ # Get the index best component for best_covariance\n+ best_component = self.bic_.idxmin()[best_covariance]\n \n- self.n_components_ = np.argmin(bics[model_type_argmin]) + 1\n- self.model_ = models[model_type_argmin][bic_argmins[model_type_argmin]]\n+ self.n_components_ = best_component\n+ self.covariance_type_ = best_covariance\n+ self.model_ = models[best_component - 1][best_covariance_idx]\n \n return self\n", "issue": "Issues with GClust\n## Actual Behavior\r\n1. `n_components_` is always wrong.\r\n2. Doc issues.\r\n\r\n## Template Code\r\nSnippet from gclust test.\r\n```GraSPy\r\nnp.random.seed(2)\r\n\r\nn = 100\r\nd = 3\r\n\r\nX1 = np.random.normal(2, 0.5, size=(n, d))\r\nX2 = np.random.normal(-2, 0.5, size=(n, d))\r\nX = np.vstack((X1, X2))\r\n\r\ngclust = GaussianCluster(min_components=5)\r\ngclust.fit(X)\r\n\r\nprint(gclust.n_components_)\r\n\r\n>>>> 1\r\n```\r\nAbove should be 2. The model selection code based on bic is incorrect and **needs** to be simplified. Above test should be changed to check `n_compnents_ == 2`.\r\n\r\nDoc issues (defaults are wrong):\r\n1. https://github.com/neurodata/graspy/blob/master/graspy/cluster/gclust.py#L35\r\n2. https://github.com/neurodata/graspy/blob/master/graspy/cluster/gclust.py#L40\r\n\r\n## Your Environment\r\n* Python version: 3.7\r\n* GraSPy version: 0.0.3\r\n\n", "before_files": [{"content": "# Copyright 2019 NeuroData (http://neurodata.io)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport numpy as np\nimport pandas as pd\nfrom sklearn.metrics import adjusted_rand_score\nfrom sklearn.mixture import GaussianMixture\nfrom sklearn.model_selection import ParameterGrid\n\nfrom .base import BaseCluster\n\n\nclass GaussianCluster(BaseCluster):\n r\"\"\"\n Gaussian Mixture Model (GMM)\n\n Representation of a Gaussian mixture model probability distribution. \n This class allows to estimate the parameters of a Gaussian mixture \n distribution. It computes all possible models from one component to \n max_components. The best model is given by the lowest BIC score.\n\n Parameters\n ----------\n min_components : int, defaults to 1. \n The minimum number of mixture components to consider (unless\n max_components=None, in which case this is the maximum number of\n components to consider). If max_componens is not None, min_components\n must be less than or equal to max_components.\n max_components : int, defaults to 1.\n The maximum number of mixture components to consider. Must be greater \n than or equal to min_components.\n\n covariance_type : {'full' (default), 'tied', 'diag', 'spherical'}, optional\n String or list/array describing the type of covariance parameters to use.\n If a string, it must be one of:\n \n - 'full'\n each component has its own general covariance matrix\n - 'tied'\n all components share the same general covariance matrix\n - 'diag'\n each component has its own diagonal covariance matrix\n - 'spherical'\n each component has its own single variance\n - 'all'\n considers all covariance structures in ['spherical', 'diag', 'tied', 'full']\n If a list/array, it must be a list/array of strings containing only\n 'spherical', 'tied', 'diag', and/or 'spherical'.\n \n random_state : int, RandomState instance or None, optional (default=None)\n If int, random_state is the seed used by the random number generator;\n If RandomState instance, random_state is the random number generator;\n If None, the random number generator is the RandomState instance used\n by ``np.random``.\n\n Attributes\n ----------\n n_components_ : int\n Optimal number of components based on BIC.\n model_ : GaussianMixture object\n Fitted GaussianMixture object fitted with optimal numeber of components \n and optimal covariance structure.\n bic_ : pandas.DataFrame\n A pandas DataFrame of BIC values computed for all possible number of clusters\n given by range(min_components, max_components + 1) and all covariance\n structures given by covariance_type.\n ari_ : pandas.DataFrame\n Only computed when y is given. Pandas Dataframe containing ARI values computed\n for all possible number of clusters given by range(min_components,\n max_components) and all covariance structures given by covariance_type.\n \"\"\"\n\n def __init__(\n self,\n min_components=2,\n max_components=None,\n covariance_type=\"full\",\n random_state=None,\n ):\n if isinstance(min_components, int):\n if min_components <= 0:\n msg = \"min_components must be >= 1.\"\n raise ValueError(msg)\n else:\n msg = \"min_components must be an integer, not {}.\".format(\n type(min_components)\n )\n raise TypeError(msg)\n\n if isinstance(max_components, int):\n if max_components <= 0:\n msg = \"max_components must be >= 1 or None.\"\n raise ValueError(msg)\n elif min_components > max_components:\n msg = \"min_components must be less than or equal to max_components.\"\n raise ValueError(msg)\n elif max_components is not None:\n msg = \"max_components must be an integer or None, not {}.\".format(\n type(max_components)\n )\n raise TypeError(msg)\n\n if isinstance(covariance_type, np.ndarray):\n covariance_type = np.unique(covariance_type)\n elif isinstance(covariance_type, list):\n covariance_type = np.unique(covariance_type)\n elif isinstance(covariance_type, str):\n if covariance_type == \"all\":\n covariance_type = [\"spherical\", \"diag\", \"tied\", \"full\"]\n else:\n covariance_type = [covariance_type]\n else:\n msg = \"covariance_type must be a numpy array, a list, or \"\n msg += \"string, not {}\".format(type(covariance_type))\n raise TypeError(msg)\n\n for cov in covariance_type:\n if cov not in [\"spherical\", \"diag\", \"tied\", \"full\"]:\n msg = (\n \"covariance structure must be one of \"\n + '[\"spherical\", \"diag\", \"tied\", \"full\"]'\n )\n msg += \" not {}\".format(cov)\n raise ValueError(msg)\n\n new_covariance_type = []\n for cov in [\"spherical\", \"diag\", \"tied\", \"full\"]:\n if cov in covariance_type:\n new_covariance_type.append(cov)\n\n new_covariance_type = np.array(new_covariance_type)\n\n self.min_components = min_components\n self.max_components = max_components\n self.covariance_type = new_covariance_type\n self.random_state = random_state\n\n def fit(self, X, y=None):\n \"\"\"\n Fits gaussian mixure model to the data. \n Estimate model parameters with the EM algorithm.\n\n Parameters\n ----------\n X : array-like, shape (n_samples, n_features)\n List of n_features-dimensional data points. Each row\n corresponds to a single data point.\n \n y : array-like, shape (n_samples,), optional (default=None)\n List of labels for X if available. Used to compute\n ARI scores.\n\n Returns\n -------\n self\n \"\"\"\n\n # Deal with number of clusters\n if self.max_components is None:\n lower_ncomponents = 1\n upper_ncomponents = self.min_components\n else:\n lower_ncomponents = self.min_components\n upper_ncomponents = self.max_components\n\n n_mixture_components = upper_ncomponents - lower_ncomponents + 1\n\n if upper_ncomponents > X.shape[0]:\n if self.max_components is None:\n msg = \"if max_components is None then min_components must be >= \"\n msg += \"n_samples, but min_components = {}, n_samples = {}\".format(\n upper_ncomponents, X.shape[0]\n )\n else:\n msg = \"max_components must be >= n_samples, but max_components = \"\n msg += \"{}, n_samples = {}\".format(upper_ncomponents, X.shape[0])\n raise ValueError(msg)\n elif lower_ncomponents > X.shape[0]:\n msg = \"min_components must be <= n_samples, but min_components = \"\n msg += \"{}, n_samples = {}\".format(upper_ncomponents, X.shape[0])\n raise ValueError(msg)\n\n # Get parameters\n random_state = self.random_state\n\n param_grid = dict(\n covariance_type=self.covariance_type,\n n_components=range(lower_ncomponents, upper_ncomponents + 1),\n random_state=[random_state],\n )\n\n param_grid = list(ParameterGrid(param_grid))\n\n models = [[] for _ in range(n_mixture_components)]\n bics = [[] for _ in range(n_mixture_components)]\n aris = [[] for _ in range(n_mixture_components)]\n\n for i, params in enumerate(param_grid):\n model = GaussianMixture(**params)\n model.fit(X)\n models[i % n_mixture_components].append(model)\n bics[i % n_mixture_components].append(model.bic(X))\n if y is not None:\n predictions = model.predict(X)\n aris[i % n_mixture_components].append(\n adjusted_rand_score(y, predictions)\n )\n\n self.bic_ = pd.DataFrame(\n np.array(bics),\n index=np.arange(lower_ncomponents, upper_ncomponents + 1),\n columns=self.covariance_type,\n )\n\n if y is not None:\n self.ari_ = pd.DataFrame(\n np.array(aris),\n index=np.arange(lower_ncomponents, upper_ncomponents + 1),\n columns=self.covariance_type,\n )\n else:\n self.ari_ = None\n\n # Finding the minimum bic for each covariance structure\n bic_mins = [min(bic) for bic in bics]\n bic_argmins = [np.argmin(bic) for bic in bics]\n\n # Find the index for the minimum bic amongst all covariance structures\n model_type_argmin = np.argmin(bic_mins)\n\n self.n_components_ = np.argmin(bics[model_type_argmin]) + 1\n self.model_ = models[model_type_argmin][bic_argmins[model_type_argmin]]\n\n return self\n", "path": "graspy/cluster/gclust.py"}], "after_files": [{"content": "# Copyright 2019 NeuroData (http://neurodata.io)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport numpy as np\nimport pandas as pd\nfrom sklearn.metrics import adjusted_rand_score\nfrom sklearn.mixture import GaussianMixture\nfrom sklearn.model_selection import ParameterGrid\n\nfrom .base import BaseCluster\n\n\nclass GaussianCluster(BaseCluster):\n r\"\"\"\n Gaussian Mixture Model (GMM)\n\n Representation of a Gaussian mixture model probability distribution. \n This class allows to estimate the parameters of a Gaussian mixture \n distribution. It computes all possible models from one component to \n max_components. The best model is given by the lowest BIC score.\n\n Parameters\n ----------\n min_components : int, default=2. \n The minimum number of mixture components to consider (unless\n max_components=None, in which case this is the maximum number of\n components to consider). If max_componens is not None, min_components\n must be less than or equal to max_components.\n\n max_components : int or None, default=None.\n The maximum number of mixture components to consider. Must be greater \n than or equal to min_components.\n\n covariance_type : {'full' (default), 'tied', 'diag', 'spherical'}, optional\n String or list/array describing the type of covariance parameters to use.\n If a string, it must be one of:\n \n - 'full'\n each component has its own general covariance matrix\n - 'tied'\n all components share the same general covariance matrix\n - 'diag'\n each component has its own diagonal covariance matrix\n - 'spherical'\n each component has its own single variance\n - 'all'\n considers all covariance structures in ['spherical', 'diag', 'tied', 'full']\n If a list/array, it must be a list/array of strings containing only\n 'spherical', 'tied', 'diag', and/or 'spherical'.\n \n random_state : int, RandomState instance or None, optional (default=None)\n If int, random_state is the seed used by the random number generator;\n If RandomState instance, random_state is the random number generator;\n If None, the random number generator is the RandomState instance used\n by ``np.random``.\n\n Attributes\n ----------\n n_components_ : int\n Optimal number of components based on BIC.\n covariance_type_ : str\n Optimal covariance type based on BIC.\n model_ : GaussianMixture object\n Fitted GaussianMixture object fitted with optimal numeber of components \n and optimal covariance structure.\n bic_ : pandas.DataFrame\n A pandas DataFrame of BIC values computed for all possible number of clusters\n given by range(min_components, max_components + 1) and all covariance\n structures given by covariance_type.\n ari_ : pandas.DataFrame\n Only computed when y is given. Pandas Dataframe containing ARI values computed\n for all possible number of clusters given by range(min_components,\n max_components) and all covariance structures given by covariance_type.\n \"\"\"\n\n def __init__(\n self,\n min_components=2,\n max_components=None,\n covariance_type=\"full\",\n random_state=None,\n ):\n if isinstance(min_components, int):\n if min_components <= 0:\n msg = \"min_components must be >= 1.\"\n raise ValueError(msg)\n else:\n msg = \"min_components must be an integer, not {}.\".format(\n type(min_components)\n )\n raise TypeError(msg)\n\n if isinstance(max_components, int):\n if max_components <= 0:\n msg = \"max_components must be >= 1 or None.\"\n raise ValueError(msg)\n elif min_components > max_components:\n msg = \"min_components must be less than or equal to max_components.\"\n raise ValueError(msg)\n elif max_components is not None:\n msg = \"max_components must be an integer or None, not {}.\".format(\n type(max_components)\n )\n raise TypeError(msg)\n\n if isinstance(covariance_type, (np.ndarray, list)):\n covariance_type = np.unique(covariance_type)\n elif isinstance(covariance_type, str):\n if covariance_type == \"all\":\n covariance_type = [\"spherical\", \"diag\", \"tied\", \"full\"]\n else:\n covariance_type = [covariance_type]\n else:\n msg = \"covariance_type must be a numpy array, a list, or \"\n msg += \"string, not {}\".format(type(covariance_type))\n raise TypeError(msg)\n\n for cov in covariance_type:\n if cov not in [\"spherical\", \"diag\", \"tied\", \"full\"]:\n msg = (\n \"covariance structure must be one of \"\n + '[\"spherical\", \"diag\", \"tied\", \"full\"]'\n )\n msg += \" not {}\".format(cov)\n raise ValueError(msg)\n\n new_covariance_type = []\n for cov in [\"spherical\", \"diag\", \"tied\", \"full\"]:\n if cov in covariance_type:\n new_covariance_type.append(cov)\n\n self.min_components = min_components\n self.max_components = max_components\n self.covariance_type = new_covariance_type\n self.random_state = random_state\n\n def fit(self, X, y=None):\n \"\"\"\n Fits gaussian mixure model to the data. \n Estimate model parameters with the EM algorithm.\n\n Parameters\n ----------\n X : array-like, shape (n_samples, n_features)\n List of n_features-dimensional data points. Each row\n corresponds to a single data point.\n \n y : array-like, shape (n_samples,), optional (default=None)\n List of labels for X if available. Used to compute\n ARI scores.\n\n Returns\n -------\n self\n \"\"\"\n\n # Deal with number of clusters\n if self.max_components is None:\n lower_ncomponents = 1\n upper_ncomponents = self.min_components\n else:\n lower_ncomponents = self.min_components\n upper_ncomponents = self.max_components\n\n n_mixture_components = upper_ncomponents - lower_ncomponents + 1\n\n if upper_ncomponents > X.shape[0]:\n if self.max_components is None:\n msg = \"if max_components is None then min_components must be >= \"\n msg += \"n_samples, but min_components = {}, n_samples = {}\".format(\n upper_ncomponents, X.shape[0]\n )\n else:\n msg = \"max_components must be >= n_samples, but max_components = \"\n msg += \"{}, n_samples = {}\".format(upper_ncomponents, X.shape[0])\n raise ValueError(msg)\n elif lower_ncomponents > X.shape[0]:\n msg = \"min_components must be <= n_samples, but min_components = \"\n msg += \"{}, n_samples = {}\".format(upper_ncomponents, X.shape[0])\n raise ValueError(msg)\n\n # Get parameters\n random_state = self.random_state\n\n param_grid = dict(\n covariance_type=self.covariance_type,\n n_components=range(lower_ncomponents, upper_ncomponents + 1),\n random_state=[random_state],\n )\n\n param_grid = list(ParameterGrid(param_grid))\n\n models = [[] for _ in range(n_mixture_components)]\n bics = [[] for _ in range(n_mixture_components)]\n aris = [[] for _ in range(n_mixture_components)]\n\n for i, params in enumerate(param_grid):\n model = GaussianMixture(**params)\n model.fit(X)\n models[i % n_mixture_components].append(model)\n bics[i % n_mixture_components].append(model.bic(X))\n if y is not None:\n predictions = model.predict(X)\n aris[i % n_mixture_components].append(\n adjusted_rand_score(y, predictions)\n )\n\n self.bic_ = pd.DataFrame(\n bics,\n index=np.arange(lower_ncomponents, upper_ncomponents + 1),\n columns=self.covariance_type,\n )\n\n if y is not None:\n self.ari_ = pd.DataFrame(\n aris,\n index=np.arange(lower_ncomponents, upper_ncomponents + 1),\n columns=self.covariance_type,\n )\n else:\n self.ari_ = None\n\n # Get the best cov type and its index within the dataframe\n best_covariance = self.bic_.min(axis=0).idxmin()\n best_covariance_idx = self.covariance_type.index(best_covariance)\n\n # Get the index best component for best_covariance\n best_component = self.bic_.idxmin()[best_covariance]\n\n self.n_components_ = best_component\n self.covariance_type_ = best_covariance\n self.model_ = models[best_component - 1][best_covariance_idx]\n\n return self\n", "path": "graspy/cluster/gclust.py"}]} | 3,201 | 830 |
gh_patches_debug_31032 | rasdani/github-patches | git_diff | pre-commit__pre-commit-1028 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
warn on unknown keys at the top level
We're now warning on unknown keys at the hook level, this should also happen at the top level
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pre_commit/clientlib.py`
Content:
```
1 from __future__ import absolute_import
2 from __future__ import unicode_literals
3
4 import argparse
5 import functools
6 import pipes
7 import sys
8
9 import cfgv
10 from aspy.yaml import ordered_load
11 from identify.identify import ALL_TAGS
12
13 import pre_commit.constants as C
14 from pre_commit.error_handler import FatalError
15 from pre_commit.languages.all import all_languages
16 from pre_commit.util import parse_version
17
18
19 def check_type_tag(tag):
20 if tag not in ALL_TAGS:
21 raise cfgv.ValidationError(
22 'Type tag {!r} is not recognized. '
23 'Try upgrading identify and pre-commit?'.format(tag),
24 )
25
26
27 def check_min_version(version):
28 if parse_version(version) > parse_version(C.VERSION):
29 raise cfgv.ValidationError(
30 'pre-commit version {} is required but version {} is installed. '
31 'Perhaps run `pip install --upgrade pre-commit`.'.format(
32 version, C.VERSION,
33 ),
34 )
35
36
37 def _make_argparser(filenames_help):
38 parser = argparse.ArgumentParser()
39 parser.add_argument('filenames', nargs='*', help=filenames_help)
40 parser.add_argument('-V', '--version', action='version', version=C.VERSION)
41 return parser
42
43
44 MANIFEST_HOOK_DICT = cfgv.Map(
45 'Hook', 'id',
46
47 cfgv.Required('id', cfgv.check_string),
48 cfgv.Required('name', cfgv.check_string),
49 cfgv.Required('entry', cfgv.check_string),
50 cfgv.Required('language', cfgv.check_one_of(all_languages)),
51 cfgv.Optional('alias', cfgv.check_string, ''),
52
53 cfgv.Optional(
54 'files', cfgv.check_and(cfgv.check_string, cfgv.check_regex), '',
55 ),
56 cfgv.Optional(
57 'exclude', cfgv.check_and(cfgv.check_string, cfgv.check_regex), '^$',
58 ),
59 cfgv.Optional('types', cfgv.check_array(check_type_tag), ['file']),
60 cfgv.Optional('exclude_types', cfgv.check_array(check_type_tag), []),
61
62 cfgv.Optional(
63 'additional_dependencies', cfgv.check_array(cfgv.check_string), [],
64 ),
65 cfgv.Optional('args', cfgv.check_array(cfgv.check_string), []),
66 cfgv.Optional('always_run', cfgv.check_bool, False),
67 cfgv.Optional('pass_filenames', cfgv.check_bool, True),
68 cfgv.Optional('description', cfgv.check_string, ''),
69 cfgv.Optional('language_version', cfgv.check_string, C.DEFAULT),
70 cfgv.Optional('log_file', cfgv.check_string, ''),
71 cfgv.Optional('minimum_pre_commit_version', cfgv.check_string, '0'),
72 cfgv.Optional('require_serial', cfgv.check_bool, False),
73 cfgv.Optional('stages', cfgv.check_array(cfgv.check_one_of(C.STAGES)), []),
74 cfgv.Optional('verbose', cfgv.check_bool, False),
75 )
76 MANIFEST_SCHEMA = cfgv.Array(MANIFEST_HOOK_DICT)
77
78
79 class InvalidManifestError(FatalError):
80 pass
81
82
83 load_manifest = functools.partial(
84 cfgv.load_from_filename,
85 schema=MANIFEST_SCHEMA,
86 load_strategy=ordered_load,
87 exc_tp=InvalidManifestError,
88 )
89
90
91 def validate_manifest_main(argv=None):
92 parser = _make_argparser('Manifest filenames.')
93 args = parser.parse_args(argv)
94 ret = 0
95 for filename in args.filenames:
96 try:
97 load_manifest(filename)
98 except InvalidManifestError as e:
99 print(e)
100 ret = 1
101 return ret
102
103
104 LOCAL = 'local'
105 META = 'meta'
106
107
108 class MigrateShaToRev(object):
109 @staticmethod
110 def _cond(key):
111 return cfgv.Conditional(
112 key, cfgv.check_string,
113 condition_key='repo',
114 condition_value=cfgv.NotIn(LOCAL, META),
115 ensure_absent=True,
116 )
117
118 def check(self, dct):
119 if dct.get('repo') in {LOCAL, META}:
120 self._cond('rev').check(dct)
121 self._cond('sha').check(dct)
122 elif 'sha' in dct and 'rev' in dct:
123 raise cfgv.ValidationError('Cannot specify both sha and rev')
124 elif 'sha' in dct:
125 self._cond('sha').check(dct)
126 else:
127 self._cond('rev').check(dct)
128
129 def apply_default(self, dct):
130 if 'sha' in dct:
131 dct['rev'] = dct.pop('sha')
132
133 def remove_default(self, dct):
134 pass
135
136
137 def _entry(modname):
138 """the hook `entry` is passed through `shlex.split()` by the command
139 runner, so to prevent issues with spaces and backslashes (on Windows)
140 it must be quoted here.
141 """
142 return '{} -m pre_commit.meta_hooks.{}'.format(
143 pipes.quote(sys.executable), modname,
144 )
145
146
147 _meta = (
148 (
149 'check-hooks-apply', (
150 ('name', 'Check hooks apply to the repository'),
151 ('files', C.CONFIG_FILE),
152 ('entry', _entry('check_hooks_apply')),
153 ),
154 ),
155 (
156 'check-useless-excludes', (
157 ('name', 'Check for useless excludes'),
158 ('files', C.CONFIG_FILE),
159 ('entry', _entry('check_useless_excludes')),
160 ),
161 ),
162 (
163 'identity', (
164 ('name', 'identity'),
165 ('verbose', True),
166 ('entry', _entry('identity')),
167 ),
168 ),
169 )
170
171 META_HOOK_DICT = cfgv.Map(
172 'Hook', 'id',
173 cfgv.Required('id', cfgv.check_string),
174 cfgv.Required('id', cfgv.check_one_of(tuple(k for k, _ in _meta))),
175 # language must be system
176 cfgv.Optional('language', cfgv.check_one_of({'system'}), 'system'),
177 *([
178 # default to the hook definition for the meta hooks
179 cfgv.ConditionalOptional(key, cfgv.check_any, value, 'id', hook_id)
180 for hook_id, values in _meta
181 for key, value in values
182 ] + [
183 # default to the "manifest" parsing
184 cfgv.OptionalNoDefault(item.key, item.check_fn)
185 # these will always be defaulted above
186 if item.key in {'name', 'language', 'entry'} else
187 item
188 for item in MANIFEST_HOOK_DICT.items
189 ])
190 )
191 CONFIG_HOOK_DICT = cfgv.Map(
192 'Hook', 'id',
193
194 cfgv.Required('id', cfgv.check_string),
195
196 # All keys in manifest hook dict are valid in a config hook dict, but
197 # are optional.
198 # No defaults are provided here as the config is merged on top of the
199 # manifest.
200 *[
201 cfgv.OptionalNoDefault(item.key, item.check_fn)
202 for item in MANIFEST_HOOK_DICT.items
203 if item.key != 'id'
204 ]
205 )
206 CONFIG_REPO_DICT = cfgv.Map(
207 'Repository', 'repo',
208
209 cfgv.Required('repo', cfgv.check_string),
210
211 cfgv.ConditionalRecurse(
212 'hooks', cfgv.Array(CONFIG_HOOK_DICT),
213 'repo', cfgv.NotIn(LOCAL, META),
214 ),
215 cfgv.ConditionalRecurse(
216 'hooks', cfgv.Array(MANIFEST_HOOK_DICT),
217 'repo', LOCAL,
218 ),
219 cfgv.ConditionalRecurse(
220 'hooks', cfgv.Array(META_HOOK_DICT),
221 'repo', META,
222 ),
223
224 MigrateShaToRev(),
225 )
226 DEFAULT_LANGUAGE_VERSION = cfgv.Map(
227 'DefaultLanguageVersion', None,
228 cfgv.NoAdditionalKeys(all_languages),
229 *[cfgv.Optional(x, cfgv.check_string, C.DEFAULT) for x in all_languages]
230 )
231 CONFIG_SCHEMA = cfgv.Map(
232 'Config', None,
233
234 cfgv.RequiredRecurse('repos', cfgv.Array(CONFIG_REPO_DICT)),
235 cfgv.OptionalRecurse(
236 'default_language_version', DEFAULT_LANGUAGE_VERSION, {},
237 ),
238 cfgv.Optional(
239 'default_stages',
240 cfgv.check_array(cfgv.check_one_of(C.STAGES)),
241 C.STAGES,
242 ),
243 cfgv.Optional('exclude', cfgv.check_regex, '^$'),
244 cfgv.Optional('fail_fast', cfgv.check_bool, False),
245 cfgv.Optional(
246 'minimum_pre_commit_version',
247 cfgv.check_and(cfgv.check_string, check_min_version),
248 '0',
249 ),
250 )
251
252
253 class InvalidConfigError(FatalError):
254 pass
255
256
257 def ordered_load_normalize_legacy_config(contents):
258 data = ordered_load(contents)
259 if isinstance(data, list):
260 # TODO: Once happy, issue a deprecation warning and instructions
261 return {'repos': data}
262 else:
263 return data
264
265
266 load_config = functools.partial(
267 cfgv.load_from_filename,
268 schema=CONFIG_SCHEMA,
269 load_strategy=ordered_load_normalize_legacy_config,
270 exc_tp=InvalidConfigError,
271 )
272
273
274 def validate_config_main(argv=None):
275 parser = _make_argparser('Config filenames.')
276 args = parser.parse_args(argv)
277 ret = 0
278 for filename in args.filenames:
279 try:
280 load_config(filename)
281 except InvalidConfigError as e:
282 print(e)
283 ret = 1
284 return ret
285
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pre_commit/clientlib.py b/pre_commit/clientlib.py
--- a/pre_commit/clientlib.py
+++ b/pre_commit/clientlib.py
@@ -3,6 +3,7 @@
import argparse
import functools
+import logging
import pipes
import sys
@@ -15,6 +16,8 @@
from pre_commit.languages.all import all_languages
from pre_commit.util import parse_version
+logger = logging.getLogger('pre_commit')
+
def check_type_tag(tag):
if tag not in ALL_TAGS:
@@ -106,6 +109,8 @@
class MigrateShaToRev(object):
+ key = 'rev'
+
@staticmethod
def _cond(key):
return cfgv.Conditional(
@@ -144,6 +149,14 @@
)
+def warn_unknown_keys(extra, orig_keys):
+ logger.warning(
+ 'Unexpected config key(s): {}'.format(
+ ', '.join(sorted(extra)),
+ ),
+ )
+
+
_meta = (
(
'check-hooks-apply', (
@@ -222,6 +235,10 @@
),
MigrateShaToRev(),
+ cfgv.WarnAdditionalKeys(
+ ('repo', 'rev', 'hooks'),
+ warn_unknown_keys,
+ ),
)
DEFAULT_LANGUAGE_VERSION = cfgv.Map(
'DefaultLanguageVersion', None,
@@ -247,6 +264,17 @@
cfgv.check_and(cfgv.check_string, check_min_version),
'0',
),
+ cfgv.WarnAdditionalKeys(
+ (
+ 'repos',
+ 'default_language_version',
+ 'default_stages',
+ 'exclude',
+ 'fail_fast',
+ 'minimum_pre_commit_version',
+ ),
+ warn_unknown_keys,
+ ),
)
| {"golden_diff": "diff --git a/pre_commit/clientlib.py b/pre_commit/clientlib.py\n--- a/pre_commit/clientlib.py\n+++ b/pre_commit/clientlib.py\n@@ -3,6 +3,7 @@\n \n import argparse\n import functools\n+import logging\n import pipes\n import sys\n \n@@ -15,6 +16,8 @@\n from pre_commit.languages.all import all_languages\n from pre_commit.util import parse_version\n \n+logger = logging.getLogger('pre_commit')\n+\n \n def check_type_tag(tag):\n if tag not in ALL_TAGS:\n@@ -106,6 +109,8 @@\n \n \n class MigrateShaToRev(object):\n+ key = 'rev'\n+\n @staticmethod\n def _cond(key):\n return cfgv.Conditional(\n@@ -144,6 +149,14 @@\n )\n \n \n+def warn_unknown_keys(extra, orig_keys):\n+ logger.warning(\n+ 'Unexpected config key(s): {}'.format(\n+ ', '.join(sorted(extra)),\n+ ),\n+ )\n+\n+\n _meta = (\n (\n 'check-hooks-apply', (\n@@ -222,6 +235,10 @@\n ),\n \n MigrateShaToRev(),\n+ cfgv.WarnAdditionalKeys(\n+ ('repo', 'rev', 'hooks'),\n+ warn_unknown_keys,\n+ ),\n )\n DEFAULT_LANGUAGE_VERSION = cfgv.Map(\n 'DefaultLanguageVersion', None,\n@@ -247,6 +264,17 @@\n cfgv.check_and(cfgv.check_string, check_min_version),\n '0',\n ),\n+ cfgv.WarnAdditionalKeys(\n+ (\n+ 'repos',\n+ 'default_language_version',\n+ 'default_stages',\n+ 'exclude',\n+ 'fail_fast',\n+ 'minimum_pre_commit_version',\n+ ),\n+ warn_unknown_keys,\n+ ),\n )\n", "issue": "warn on unknown keys at the top level\nWe're now warning on unknown keys at the hook level, this should also happen at the top level\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import unicode_literals\n\nimport argparse\nimport functools\nimport pipes\nimport sys\n\nimport cfgv\nfrom aspy.yaml import ordered_load\nfrom identify.identify import ALL_TAGS\n\nimport pre_commit.constants as C\nfrom pre_commit.error_handler import FatalError\nfrom pre_commit.languages.all import all_languages\nfrom pre_commit.util import parse_version\n\n\ndef check_type_tag(tag):\n if tag not in ALL_TAGS:\n raise cfgv.ValidationError(\n 'Type tag {!r} is not recognized. '\n 'Try upgrading identify and pre-commit?'.format(tag),\n )\n\n\ndef check_min_version(version):\n if parse_version(version) > parse_version(C.VERSION):\n raise cfgv.ValidationError(\n 'pre-commit version {} is required but version {} is installed. '\n 'Perhaps run `pip install --upgrade pre-commit`.'.format(\n version, C.VERSION,\n ),\n )\n\n\ndef _make_argparser(filenames_help):\n parser = argparse.ArgumentParser()\n parser.add_argument('filenames', nargs='*', help=filenames_help)\n parser.add_argument('-V', '--version', action='version', version=C.VERSION)\n return parser\n\n\nMANIFEST_HOOK_DICT = cfgv.Map(\n 'Hook', 'id',\n\n cfgv.Required('id', cfgv.check_string),\n cfgv.Required('name', cfgv.check_string),\n cfgv.Required('entry', cfgv.check_string),\n cfgv.Required('language', cfgv.check_one_of(all_languages)),\n cfgv.Optional('alias', cfgv.check_string, ''),\n\n cfgv.Optional(\n 'files', cfgv.check_and(cfgv.check_string, cfgv.check_regex), '',\n ),\n cfgv.Optional(\n 'exclude', cfgv.check_and(cfgv.check_string, cfgv.check_regex), '^$',\n ),\n cfgv.Optional('types', cfgv.check_array(check_type_tag), ['file']),\n cfgv.Optional('exclude_types', cfgv.check_array(check_type_tag), []),\n\n cfgv.Optional(\n 'additional_dependencies', cfgv.check_array(cfgv.check_string), [],\n ),\n cfgv.Optional('args', cfgv.check_array(cfgv.check_string), []),\n cfgv.Optional('always_run', cfgv.check_bool, False),\n cfgv.Optional('pass_filenames', cfgv.check_bool, True),\n cfgv.Optional('description', cfgv.check_string, ''),\n cfgv.Optional('language_version', cfgv.check_string, C.DEFAULT),\n cfgv.Optional('log_file', cfgv.check_string, ''),\n cfgv.Optional('minimum_pre_commit_version', cfgv.check_string, '0'),\n cfgv.Optional('require_serial', cfgv.check_bool, False),\n cfgv.Optional('stages', cfgv.check_array(cfgv.check_one_of(C.STAGES)), []),\n cfgv.Optional('verbose', cfgv.check_bool, False),\n)\nMANIFEST_SCHEMA = cfgv.Array(MANIFEST_HOOK_DICT)\n\n\nclass InvalidManifestError(FatalError):\n pass\n\n\nload_manifest = functools.partial(\n cfgv.load_from_filename,\n schema=MANIFEST_SCHEMA,\n load_strategy=ordered_load,\n exc_tp=InvalidManifestError,\n)\n\n\ndef validate_manifest_main(argv=None):\n parser = _make_argparser('Manifest filenames.')\n args = parser.parse_args(argv)\n ret = 0\n for filename in args.filenames:\n try:\n load_manifest(filename)\n except InvalidManifestError as e:\n print(e)\n ret = 1\n return ret\n\n\nLOCAL = 'local'\nMETA = 'meta'\n\n\nclass MigrateShaToRev(object):\n @staticmethod\n def _cond(key):\n return cfgv.Conditional(\n key, cfgv.check_string,\n condition_key='repo',\n condition_value=cfgv.NotIn(LOCAL, META),\n ensure_absent=True,\n )\n\n def check(self, dct):\n if dct.get('repo') in {LOCAL, META}:\n self._cond('rev').check(dct)\n self._cond('sha').check(dct)\n elif 'sha' in dct and 'rev' in dct:\n raise cfgv.ValidationError('Cannot specify both sha and rev')\n elif 'sha' in dct:\n self._cond('sha').check(dct)\n else:\n self._cond('rev').check(dct)\n\n def apply_default(self, dct):\n if 'sha' in dct:\n dct['rev'] = dct.pop('sha')\n\n def remove_default(self, dct):\n pass\n\n\ndef _entry(modname):\n \"\"\"the hook `entry` is passed through `shlex.split()` by the command\n runner, so to prevent issues with spaces and backslashes (on Windows)\n it must be quoted here.\n \"\"\"\n return '{} -m pre_commit.meta_hooks.{}'.format(\n pipes.quote(sys.executable), modname,\n )\n\n\n_meta = (\n (\n 'check-hooks-apply', (\n ('name', 'Check hooks apply to the repository'),\n ('files', C.CONFIG_FILE),\n ('entry', _entry('check_hooks_apply')),\n ),\n ),\n (\n 'check-useless-excludes', (\n ('name', 'Check for useless excludes'),\n ('files', C.CONFIG_FILE),\n ('entry', _entry('check_useless_excludes')),\n ),\n ),\n (\n 'identity', (\n ('name', 'identity'),\n ('verbose', True),\n ('entry', _entry('identity')),\n ),\n ),\n)\n\nMETA_HOOK_DICT = cfgv.Map(\n 'Hook', 'id',\n cfgv.Required('id', cfgv.check_string),\n cfgv.Required('id', cfgv.check_one_of(tuple(k for k, _ in _meta))),\n # language must be system\n cfgv.Optional('language', cfgv.check_one_of({'system'}), 'system'),\n *([\n # default to the hook definition for the meta hooks\n cfgv.ConditionalOptional(key, cfgv.check_any, value, 'id', hook_id)\n for hook_id, values in _meta\n for key, value in values\n ] + [\n # default to the \"manifest\" parsing\n cfgv.OptionalNoDefault(item.key, item.check_fn)\n # these will always be defaulted above\n if item.key in {'name', 'language', 'entry'} else\n item\n for item in MANIFEST_HOOK_DICT.items\n ])\n)\nCONFIG_HOOK_DICT = cfgv.Map(\n 'Hook', 'id',\n\n cfgv.Required('id', cfgv.check_string),\n\n # All keys in manifest hook dict are valid in a config hook dict, but\n # are optional.\n # No defaults are provided here as the config is merged on top of the\n # manifest.\n *[\n cfgv.OptionalNoDefault(item.key, item.check_fn)\n for item in MANIFEST_HOOK_DICT.items\n if item.key != 'id'\n ]\n)\nCONFIG_REPO_DICT = cfgv.Map(\n 'Repository', 'repo',\n\n cfgv.Required('repo', cfgv.check_string),\n\n cfgv.ConditionalRecurse(\n 'hooks', cfgv.Array(CONFIG_HOOK_DICT),\n 'repo', cfgv.NotIn(LOCAL, META),\n ),\n cfgv.ConditionalRecurse(\n 'hooks', cfgv.Array(MANIFEST_HOOK_DICT),\n 'repo', LOCAL,\n ),\n cfgv.ConditionalRecurse(\n 'hooks', cfgv.Array(META_HOOK_DICT),\n 'repo', META,\n ),\n\n MigrateShaToRev(),\n)\nDEFAULT_LANGUAGE_VERSION = cfgv.Map(\n 'DefaultLanguageVersion', None,\n cfgv.NoAdditionalKeys(all_languages),\n *[cfgv.Optional(x, cfgv.check_string, C.DEFAULT) for x in all_languages]\n)\nCONFIG_SCHEMA = cfgv.Map(\n 'Config', None,\n\n cfgv.RequiredRecurse('repos', cfgv.Array(CONFIG_REPO_DICT)),\n cfgv.OptionalRecurse(\n 'default_language_version', DEFAULT_LANGUAGE_VERSION, {},\n ),\n cfgv.Optional(\n 'default_stages',\n cfgv.check_array(cfgv.check_one_of(C.STAGES)),\n C.STAGES,\n ),\n cfgv.Optional('exclude', cfgv.check_regex, '^$'),\n cfgv.Optional('fail_fast', cfgv.check_bool, False),\n cfgv.Optional(\n 'minimum_pre_commit_version',\n cfgv.check_and(cfgv.check_string, check_min_version),\n '0',\n ),\n)\n\n\nclass InvalidConfigError(FatalError):\n pass\n\n\ndef ordered_load_normalize_legacy_config(contents):\n data = ordered_load(contents)\n if isinstance(data, list):\n # TODO: Once happy, issue a deprecation warning and instructions\n return {'repos': data}\n else:\n return data\n\n\nload_config = functools.partial(\n cfgv.load_from_filename,\n schema=CONFIG_SCHEMA,\n load_strategy=ordered_load_normalize_legacy_config,\n exc_tp=InvalidConfigError,\n)\n\n\ndef validate_config_main(argv=None):\n parser = _make_argparser('Config filenames.')\n args = parser.parse_args(argv)\n ret = 0\n for filename in args.filenames:\n try:\n load_config(filename)\n except InvalidConfigError as e:\n print(e)\n ret = 1\n return ret\n", "path": "pre_commit/clientlib.py"}], "after_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import unicode_literals\n\nimport argparse\nimport functools\nimport logging\nimport pipes\nimport sys\n\nimport cfgv\nfrom aspy.yaml import ordered_load\nfrom identify.identify import ALL_TAGS\n\nimport pre_commit.constants as C\nfrom pre_commit.error_handler import FatalError\nfrom pre_commit.languages.all import all_languages\nfrom pre_commit.util import parse_version\n\nlogger = logging.getLogger('pre_commit')\n\n\ndef check_type_tag(tag):\n if tag not in ALL_TAGS:\n raise cfgv.ValidationError(\n 'Type tag {!r} is not recognized. '\n 'Try upgrading identify and pre-commit?'.format(tag),\n )\n\n\ndef check_min_version(version):\n if parse_version(version) > parse_version(C.VERSION):\n raise cfgv.ValidationError(\n 'pre-commit version {} is required but version {} is installed. '\n 'Perhaps run `pip install --upgrade pre-commit`.'.format(\n version, C.VERSION,\n ),\n )\n\n\ndef _make_argparser(filenames_help):\n parser = argparse.ArgumentParser()\n parser.add_argument('filenames', nargs='*', help=filenames_help)\n parser.add_argument('-V', '--version', action='version', version=C.VERSION)\n return parser\n\n\nMANIFEST_HOOK_DICT = cfgv.Map(\n 'Hook', 'id',\n\n cfgv.Required('id', cfgv.check_string),\n cfgv.Required('name', cfgv.check_string),\n cfgv.Required('entry', cfgv.check_string),\n cfgv.Required('language', cfgv.check_one_of(all_languages)),\n cfgv.Optional('alias', cfgv.check_string, ''),\n\n cfgv.Optional(\n 'files', cfgv.check_and(cfgv.check_string, cfgv.check_regex), '',\n ),\n cfgv.Optional(\n 'exclude', cfgv.check_and(cfgv.check_string, cfgv.check_regex), '^$',\n ),\n cfgv.Optional('types', cfgv.check_array(check_type_tag), ['file']),\n cfgv.Optional('exclude_types', cfgv.check_array(check_type_tag), []),\n\n cfgv.Optional(\n 'additional_dependencies', cfgv.check_array(cfgv.check_string), [],\n ),\n cfgv.Optional('args', cfgv.check_array(cfgv.check_string), []),\n cfgv.Optional('always_run', cfgv.check_bool, False),\n cfgv.Optional('pass_filenames', cfgv.check_bool, True),\n cfgv.Optional('description', cfgv.check_string, ''),\n cfgv.Optional('language_version', cfgv.check_string, C.DEFAULT),\n cfgv.Optional('log_file', cfgv.check_string, ''),\n cfgv.Optional('minimum_pre_commit_version', cfgv.check_string, '0'),\n cfgv.Optional('require_serial', cfgv.check_bool, False),\n cfgv.Optional('stages', cfgv.check_array(cfgv.check_one_of(C.STAGES)), []),\n cfgv.Optional('verbose', cfgv.check_bool, False),\n)\nMANIFEST_SCHEMA = cfgv.Array(MANIFEST_HOOK_DICT)\n\n\nclass InvalidManifestError(FatalError):\n pass\n\n\nload_manifest = functools.partial(\n cfgv.load_from_filename,\n schema=MANIFEST_SCHEMA,\n load_strategy=ordered_load,\n exc_tp=InvalidManifestError,\n)\n\n\ndef validate_manifest_main(argv=None):\n parser = _make_argparser('Manifest filenames.')\n args = parser.parse_args(argv)\n ret = 0\n for filename in args.filenames:\n try:\n load_manifest(filename)\n except InvalidManifestError as e:\n print(e)\n ret = 1\n return ret\n\n\nLOCAL = 'local'\nMETA = 'meta'\n\n\nclass MigrateShaToRev(object):\n key = 'rev'\n\n @staticmethod\n def _cond(key):\n return cfgv.Conditional(\n key, cfgv.check_string,\n condition_key='repo',\n condition_value=cfgv.NotIn(LOCAL, META),\n ensure_absent=True,\n )\n\n def check(self, dct):\n if dct.get('repo') in {LOCAL, META}:\n self._cond('rev').check(dct)\n self._cond('sha').check(dct)\n elif 'sha' in dct and 'rev' in dct:\n raise cfgv.ValidationError('Cannot specify both sha and rev')\n elif 'sha' in dct:\n self._cond('sha').check(dct)\n else:\n self._cond('rev').check(dct)\n\n def apply_default(self, dct):\n if 'sha' in dct:\n dct['rev'] = dct.pop('sha')\n\n def remove_default(self, dct):\n pass\n\n\ndef _entry(modname):\n \"\"\"the hook `entry` is passed through `shlex.split()` by the command\n runner, so to prevent issues with spaces and backslashes (on Windows)\n it must be quoted here.\n \"\"\"\n return '{} -m pre_commit.meta_hooks.{}'.format(\n pipes.quote(sys.executable), modname,\n )\n\n\ndef warn_unknown_keys(extra, orig_keys):\n logger.warning(\n 'Unexpected config key(s): {}'.format(\n ', '.join(sorted(extra)),\n ),\n )\n\n\n_meta = (\n (\n 'check-hooks-apply', (\n ('name', 'Check hooks apply to the repository'),\n ('files', C.CONFIG_FILE),\n ('entry', _entry('check_hooks_apply')),\n ),\n ),\n (\n 'check-useless-excludes', (\n ('name', 'Check for useless excludes'),\n ('files', C.CONFIG_FILE),\n ('entry', _entry('check_useless_excludes')),\n ),\n ),\n (\n 'identity', (\n ('name', 'identity'),\n ('verbose', True),\n ('entry', _entry('identity')),\n ),\n ),\n)\n\nMETA_HOOK_DICT = cfgv.Map(\n 'Hook', 'id',\n cfgv.Required('id', cfgv.check_string),\n cfgv.Required('id', cfgv.check_one_of(tuple(k for k, _ in _meta))),\n # language must be system\n cfgv.Optional('language', cfgv.check_one_of({'system'}), 'system'),\n *([\n # default to the hook definition for the meta hooks\n cfgv.ConditionalOptional(key, cfgv.check_any, value, 'id', hook_id)\n for hook_id, values in _meta\n for key, value in values\n ] + [\n # default to the \"manifest\" parsing\n cfgv.OptionalNoDefault(item.key, item.check_fn)\n # these will always be defaulted above\n if item.key in {'name', 'language', 'entry'} else\n item\n for item in MANIFEST_HOOK_DICT.items\n ])\n)\nCONFIG_HOOK_DICT = cfgv.Map(\n 'Hook', 'id',\n\n cfgv.Required('id', cfgv.check_string),\n\n # All keys in manifest hook dict are valid in a config hook dict, but\n # are optional.\n # No defaults are provided here as the config is merged on top of the\n # manifest.\n *[\n cfgv.OptionalNoDefault(item.key, item.check_fn)\n for item in MANIFEST_HOOK_DICT.items\n if item.key != 'id'\n ]\n)\nCONFIG_REPO_DICT = cfgv.Map(\n 'Repository', 'repo',\n\n cfgv.Required('repo', cfgv.check_string),\n\n cfgv.ConditionalRecurse(\n 'hooks', cfgv.Array(CONFIG_HOOK_DICT),\n 'repo', cfgv.NotIn(LOCAL, META),\n ),\n cfgv.ConditionalRecurse(\n 'hooks', cfgv.Array(MANIFEST_HOOK_DICT),\n 'repo', LOCAL,\n ),\n cfgv.ConditionalRecurse(\n 'hooks', cfgv.Array(META_HOOK_DICT),\n 'repo', META,\n ),\n\n MigrateShaToRev(),\n cfgv.WarnAdditionalKeys(\n ('repo', 'rev', 'hooks'),\n warn_unknown_keys,\n ),\n)\nDEFAULT_LANGUAGE_VERSION = cfgv.Map(\n 'DefaultLanguageVersion', None,\n cfgv.NoAdditionalKeys(all_languages),\n *[cfgv.Optional(x, cfgv.check_string, C.DEFAULT) for x in all_languages]\n)\nCONFIG_SCHEMA = cfgv.Map(\n 'Config', None,\n\n cfgv.RequiredRecurse('repos', cfgv.Array(CONFIG_REPO_DICT)),\n cfgv.OptionalRecurse(\n 'default_language_version', DEFAULT_LANGUAGE_VERSION, {},\n ),\n cfgv.Optional(\n 'default_stages',\n cfgv.check_array(cfgv.check_one_of(C.STAGES)),\n C.STAGES,\n ),\n cfgv.Optional('exclude', cfgv.check_regex, '^$'),\n cfgv.Optional('fail_fast', cfgv.check_bool, False),\n cfgv.Optional(\n 'minimum_pre_commit_version',\n cfgv.check_and(cfgv.check_string, check_min_version),\n '0',\n ),\n cfgv.WarnAdditionalKeys(\n (\n 'repos',\n 'default_language_version',\n 'default_stages',\n 'exclude',\n 'fail_fast',\n 'minimum_pre_commit_version',\n ),\n warn_unknown_keys,\n ),\n)\n\n\nclass InvalidConfigError(FatalError):\n pass\n\n\ndef ordered_load_normalize_legacy_config(contents):\n data = ordered_load(contents)\n if isinstance(data, list):\n # TODO: Once happy, issue a deprecation warning and instructions\n return {'repos': data}\n else:\n return data\n\n\nload_config = functools.partial(\n cfgv.load_from_filename,\n schema=CONFIG_SCHEMA,\n load_strategy=ordered_load_normalize_legacy_config,\n exc_tp=InvalidConfigError,\n)\n\n\ndef validate_config_main(argv=None):\n parser = _make_argparser('Config filenames.')\n args = parser.parse_args(argv)\n ret = 0\n for filename in args.filenames:\n try:\n load_config(filename)\n except InvalidConfigError as e:\n print(e)\n ret = 1\n return ret\n", "path": "pre_commit/clientlib.py"}]} | 3,023 | 402 |
gh_patches_debug_25978 | rasdani/github-patches | git_diff | mathesar-foundation__mathesar-2891 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Database removed from .env file does not get removed
## Description
* Add a new database to .env file, start Mathesar. It gets added.
* Remove the database and restart Mathesar. Notice that it does not get removed.
* I added two databases `mt1` and `mt2`. I removed `mt2`. This was the response from the server within `common_data.databases`:
```
[
{
"id": 1,
"name": "mt2",
"deleted": false,
"supported_types_url": "http://localhost:8000/api/ui/v0/databases/1/types/"
},
{
"id": 2,
"name": "mt1",
"deleted": false,
"supported_types_url": "http://localhost:8000/api/ui/v0/databases/2/types/"
}
]
```
* Note that 'mt2' has id 1 (I'm not sure if this was the id it had before), and that the value of `deleted` is `false`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mathesar/database/base.py`
Content:
```
1 from django.conf import settings
2
3 from db import engine
4
5 DEFAULT_DB = 'default'
6
7
8 def create_mathesar_engine(db_name):
9 """Create an SQLAlchemy engine using stored credentials."""
10 import logging
11 logger = logging.getLogger('create_mathesar_engine')
12 logger.debug('enter')
13 try:
14 credentials = _get_credentials_for_db_name_in_settings(db_name)
15 except KeyError:
16 credentials = _get_credentials_for_db_name_not_in_settings(db_name)
17 return engine.create_future_engine_with_custom_types(**credentials)
18
19
20 def _get_credentials_for_db_name_in_settings(db_name):
21 settings_entry = settings.DATABASES[db_name]
22 return dict(
23 username=settings_entry["USER"],
24 password=settings_entry["PASSWORD"],
25 hostname=settings_entry["HOST"],
26 database=settings_entry["NAME"],
27 port=settings_entry["PORT"],
28 )
29
30
31 def _get_credentials_for_db_name_not_in_settings(db_name):
32 settings_entry = settings.DATABASES[DEFAULT_DB]
33 return dict(
34 username=settings_entry["USER"],
35 password=settings_entry["PASSWORD"],
36 hostname=settings_entry["HOST"],
37 database=db_name,
38 port=settings_entry["PORT"],
39 )
40
```
Path: `mathesar/views.py`
Content:
```
1 from django.conf import settings
2 from django.contrib.auth.decorators import login_required
3 from django.shortcuts import render, redirect, get_object_or_404
4 from rest_framework import status
5 from rest_framework.decorators import api_view
6 from rest_framework.response import Response
7
8 from mathesar.api.db.permissions.database import DatabaseAccessPolicy
9 from mathesar.api.db.permissions.query import QueryAccessPolicy
10 from mathesar.api.db.permissions.schema import SchemaAccessPolicy
11 from mathesar.api.db.permissions.table import TableAccessPolicy
12 from mathesar.api.serializers.databases import DatabaseSerializer, TypeSerializer
13 from mathesar.api.serializers.schemas import SchemaSerializer
14 from mathesar.api.serializers.tables import TableSerializer
15 from mathesar.api.serializers.queries import QuerySerializer
16 from mathesar.api.ui.serializers.users import UserSerializer
17 from mathesar.database.types import UIType
18 from mathesar.models.base import Database, Schema, Table
19 from mathesar.models.query import UIQuery
20 from mathesar.state import reset_reflection
21 from mathesar import __version__
22
23
24 def get_schema_list(request, database):
25 qs = Schema.objects.filter(database=database)
26 permission_restricted_qs = SchemaAccessPolicy.scope_queryset(request, qs)
27 schema_serializer = SchemaSerializer(
28 permission_restricted_qs,
29 many=True,
30 context={'request': request}
31 )
32 return schema_serializer.data
33
34
35 def _get_permissible_db_queryset(request):
36 qs = Database.objects.all()
37 permission_restricted_qs = DatabaseAccessPolicy.scope_queryset(request, qs)
38 schema_qs = Schema.objects.all()
39 permitted_schemas = SchemaAccessPolicy.scope_queryset(request, schema_qs)
40 databases_from_permitted_schema = Database.objects.filter(schemas__in=permitted_schemas)
41 permission_restricted_qs = permission_restricted_qs | databases_from_permitted_schema
42 return permission_restricted_qs.distinct()
43
44
45 def get_database_list(request):
46 permission_restricted_db_qs = _get_permissible_db_queryset(request)
47 database_serializer = DatabaseSerializer(
48 permission_restricted_db_qs,
49 many=True,
50 context={'request': request}
51 )
52 return database_serializer.data
53
54
55 def get_table_list(request, schema):
56 if schema is None:
57 return []
58 qs = Table.objects.filter(schema=schema)
59 permission_restricted_qs = TableAccessPolicy.scope_queryset(request, qs)
60 table_serializer = TableSerializer(
61 permission_restricted_qs,
62 many=True,
63 context={'request': request}
64 )
65 return table_serializer.data
66
67
68 def get_queries_list(request, schema):
69 if schema is None:
70 return []
71 qs = UIQuery.objects.filter(base_table__schema=schema)
72 permission_restricted_qs = QueryAccessPolicy.scope_queryset(request, qs)
73
74 query_serializer = QuerySerializer(
75 permission_restricted_qs,
76 many=True,
77 context={'request': request}
78 )
79 return query_serializer.data
80
81
82 def get_ui_type_list(request, database):
83 if database is None:
84 return []
85 type_serializer = TypeSerializer(
86 UIType,
87 many=True,
88 context={'request': request}
89 )
90 return type_serializer.data
91
92
93 def get_user_data(request):
94 user_serializer = UserSerializer(
95 request.user,
96 many=False,
97 context={'request': request}
98 )
99 return user_serializer.data
100
101
102 def get_common_data(request, database=None, schema=None):
103 return {
104 'current_db': database.name if database else None,
105 'current_schema': schema.id if schema else None,
106 'schemas': get_schema_list(request, database),
107 'databases': get_database_list(request),
108 'tables': get_table_list(request, schema),
109 'queries': get_queries_list(request, schema),
110 'abstract_types': get_ui_type_list(request, database),
111 'user': get_user_data(request),
112 'live_demo_mode': getattr(settings, 'MATHESAR_LIVE_DEMO', False),
113 'current_release_tag_name': __version__,
114 }
115
116
117 def get_current_database(request, db_name):
118 """Get database from passed name, with fall back behavior."""
119 permitted_databases = _get_permissible_db_queryset(request)
120 if db_name is not None:
121 current_database = get_object_or_404(permitted_databases, name=db_name)
122 else:
123 request_database_name = request.GET.get('database')
124 try:
125 if request_database_name is not None:
126 # Try to get the database named specified in the request
127 current_database = permitted_databases.get(name=request_database_name)
128 else:
129 # Try to get the first database available
130 current_database = permitted_databases.order_by('id').first()
131 except Database.DoesNotExist:
132 current_database = None
133 return current_database
134
135
136 def get_current_schema(request, schema_id, database):
137 # if there's a schema ID passed in, try to retrieve the schema, or return a 404 error.
138 if schema_id is not None:
139 permitted_schemas = SchemaAccessPolicy.scope_queryset(request, Schema.objects.all())
140 return get_object_or_404(permitted_schemas, id=schema_id)
141 else:
142 try:
143 # Try to get the first schema in the DB
144 return Schema.objects.filter(database=database).order_by('id').first()
145 except Schema.DoesNotExist:
146 return None
147
148
149 def render_schema(request, database, schema):
150 # if there's no schema available, redirect to the schemas page.
151 if not schema:
152 return redirect('schemas', db_name=database.name)
153 else:
154 # We are redirecting so that the correct URL is passed to the frontend.
155 return redirect('schema_home', db_name=database.name, schema_id=schema.id)
156
157
158 @login_required
159 @api_view(['POST'])
160 def reflect_all(_):
161 reset_reflection()
162 return Response(status=status.HTTP_200_OK)
163
164
165 @login_required
166 def home(request):
167 database = get_current_database(request, None)
168 if database is None:
169 return render(request, 'mathesar/index.html', {
170 'common_data': get_common_data(request, database)
171 })
172 return redirect('schemas', db_name=database.name)
173
174
175 @login_required
176 def profile(request):
177 return render(request, 'mathesar/index.html', {
178 'common_data': get_common_data(request)
179 })
180
181
182 @login_required
183 def admin_home(request, **kwargs):
184 return render(request, 'mathesar/index.html', {
185 'common_data': get_common_data(request)
186 })
187
188
189 @login_required
190 def schema_home(request, db_name, schema_id, **kwargs):
191 database = get_current_database(request, db_name)
192 schema = get_current_schema(request, schema_id, database)
193 return render(request, 'mathesar/index.html', {
194 'common_data': get_common_data(request, database, schema)
195 })
196
197
198 @login_required
199 def schemas(request, db_name):
200 database = get_current_database(request, db_name)
201 return render(request, 'mathesar/index.html', {
202 'common_data': get_common_data(request, database, None)
203 })
204
205
206 def page_not_found_view(request, exception):
207 return render(request, 'mathesar/index.html', {
208 'common_data': get_common_data(request),
209 }, status=404)
210
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mathesar/database/base.py b/mathesar/database/base.py
--- a/mathesar/database/base.py
+++ b/mathesar/database/base.py
@@ -13,7 +13,10 @@
try:
credentials = _get_credentials_for_db_name_in_settings(db_name)
except KeyError:
- credentials = _get_credentials_for_db_name_not_in_settings(db_name)
+ if hasattr(settings, 'MATHESAR_LIVE_DEMO') and settings.MATHESAR_LIVE_DEMO:
+ credentials = _get_credentials_for_db_name_not_in_settings(db_name)
+ else:
+ raise
return engine.create_future_engine_with_custom_types(**credentials)
diff --git a/mathesar/views.py b/mathesar/views.py
--- a/mathesar/views.py
+++ b/mathesar/views.py
@@ -33,11 +33,11 @@
def _get_permissible_db_queryset(request):
- qs = Database.objects.all()
+ qs = Database.objects.filter(deleted=False)
permission_restricted_qs = DatabaseAccessPolicy.scope_queryset(request, qs)
schema_qs = Schema.objects.all()
permitted_schemas = SchemaAccessPolicy.scope_queryset(request, schema_qs)
- databases_from_permitted_schema = Database.objects.filter(schemas__in=permitted_schemas)
+ databases_from_permitted_schema = Database.objects.filter(schemas__in=permitted_schemas, deleted=False)
permission_restricted_qs = permission_restricted_qs | databases_from_permitted_schema
return permission_restricted_qs.distinct()
| {"golden_diff": "diff --git a/mathesar/database/base.py b/mathesar/database/base.py\n--- a/mathesar/database/base.py\n+++ b/mathesar/database/base.py\n@@ -13,7 +13,10 @@\n try:\n credentials = _get_credentials_for_db_name_in_settings(db_name)\n except KeyError:\n- credentials = _get_credentials_for_db_name_not_in_settings(db_name)\n+ if hasattr(settings, 'MATHESAR_LIVE_DEMO') and settings.MATHESAR_LIVE_DEMO:\n+ credentials = _get_credentials_for_db_name_not_in_settings(db_name)\n+ else:\n+ raise\n return engine.create_future_engine_with_custom_types(**credentials)\n \n \ndiff --git a/mathesar/views.py b/mathesar/views.py\n--- a/mathesar/views.py\n+++ b/mathesar/views.py\n@@ -33,11 +33,11 @@\n \n \n def _get_permissible_db_queryset(request):\n- qs = Database.objects.all()\n+ qs = Database.objects.filter(deleted=False)\n permission_restricted_qs = DatabaseAccessPolicy.scope_queryset(request, qs)\n schema_qs = Schema.objects.all()\n permitted_schemas = SchemaAccessPolicy.scope_queryset(request, schema_qs)\n- databases_from_permitted_schema = Database.objects.filter(schemas__in=permitted_schemas)\n+ databases_from_permitted_schema = Database.objects.filter(schemas__in=permitted_schemas, deleted=False)\n permission_restricted_qs = permission_restricted_qs | databases_from_permitted_schema\n return permission_restricted_qs.distinct()\n", "issue": "Database removed from .env file does not get removed\n## Description\r\n* Add a new database to .env file, start Mathesar. It gets added.\r\n* Remove the database and restart Mathesar. Notice that it does not get removed.\r\n* I added two databases `mt1` and `mt2`. I removed `mt2`. This was the response from the server within `common_data.databases`:\r\n ```\r\n [\r\n {\r\n \"id\": 1,\r\n \"name\": \"mt2\",\r\n \"deleted\": false,\r\n \"supported_types_url\": \"http://localhost:8000/api/ui/v0/databases/1/types/\"\r\n },\r\n {\r\n \"id\": 2,\r\n \"name\": \"mt1\",\r\n \"deleted\": false,\r\n \"supported_types_url\": \"http://localhost:8000/api/ui/v0/databases/2/types/\"\r\n }\r\n ]\r\n ```\r\n* Note that 'mt2' has id 1 (I'm not sure if this was the id it had before), and that the value of `deleted` is `false`.\n", "before_files": [{"content": "from django.conf import settings\n\nfrom db import engine\n\nDEFAULT_DB = 'default'\n\n\ndef create_mathesar_engine(db_name):\n \"\"\"Create an SQLAlchemy engine using stored credentials.\"\"\"\n import logging\n logger = logging.getLogger('create_mathesar_engine')\n logger.debug('enter')\n try:\n credentials = _get_credentials_for_db_name_in_settings(db_name)\n except KeyError:\n credentials = _get_credentials_for_db_name_not_in_settings(db_name)\n return engine.create_future_engine_with_custom_types(**credentials)\n\n\ndef _get_credentials_for_db_name_in_settings(db_name):\n settings_entry = settings.DATABASES[db_name]\n return dict(\n username=settings_entry[\"USER\"],\n password=settings_entry[\"PASSWORD\"],\n hostname=settings_entry[\"HOST\"],\n database=settings_entry[\"NAME\"],\n port=settings_entry[\"PORT\"],\n )\n\n\ndef _get_credentials_for_db_name_not_in_settings(db_name):\n settings_entry = settings.DATABASES[DEFAULT_DB]\n return dict(\n username=settings_entry[\"USER\"],\n password=settings_entry[\"PASSWORD\"],\n hostname=settings_entry[\"HOST\"],\n database=db_name,\n port=settings_entry[\"PORT\"],\n )\n", "path": "mathesar/database/base.py"}, {"content": "from django.conf import settings\nfrom django.contrib.auth.decorators import login_required\nfrom django.shortcuts import render, redirect, get_object_or_404\nfrom rest_framework import status\nfrom rest_framework.decorators import api_view\nfrom rest_framework.response import Response\n\nfrom mathesar.api.db.permissions.database import DatabaseAccessPolicy\nfrom mathesar.api.db.permissions.query import QueryAccessPolicy\nfrom mathesar.api.db.permissions.schema import SchemaAccessPolicy\nfrom mathesar.api.db.permissions.table import TableAccessPolicy\nfrom mathesar.api.serializers.databases import DatabaseSerializer, TypeSerializer\nfrom mathesar.api.serializers.schemas import SchemaSerializer\nfrom mathesar.api.serializers.tables import TableSerializer\nfrom mathesar.api.serializers.queries import QuerySerializer\nfrom mathesar.api.ui.serializers.users import UserSerializer\nfrom mathesar.database.types import UIType\nfrom mathesar.models.base import Database, Schema, Table\nfrom mathesar.models.query import UIQuery\nfrom mathesar.state import reset_reflection\nfrom mathesar import __version__\n\n\ndef get_schema_list(request, database):\n qs = Schema.objects.filter(database=database)\n permission_restricted_qs = SchemaAccessPolicy.scope_queryset(request, qs)\n schema_serializer = SchemaSerializer(\n permission_restricted_qs,\n many=True,\n context={'request': request}\n )\n return schema_serializer.data\n\n\ndef _get_permissible_db_queryset(request):\n qs = Database.objects.all()\n permission_restricted_qs = DatabaseAccessPolicy.scope_queryset(request, qs)\n schema_qs = Schema.objects.all()\n permitted_schemas = SchemaAccessPolicy.scope_queryset(request, schema_qs)\n databases_from_permitted_schema = Database.objects.filter(schemas__in=permitted_schemas)\n permission_restricted_qs = permission_restricted_qs | databases_from_permitted_schema\n return permission_restricted_qs.distinct()\n\n\ndef get_database_list(request):\n permission_restricted_db_qs = _get_permissible_db_queryset(request)\n database_serializer = DatabaseSerializer(\n permission_restricted_db_qs,\n many=True,\n context={'request': request}\n )\n return database_serializer.data\n\n\ndef get_table_list(request, schema):\n if schema is None:\n return []\n qs = Table.objects.filter(schema=schema)\n permission_restricted_qs = TableAccessPolicy.scope_queryset(request, qs)\n table_serializer = TableSerializer(\n permission_restricted_qs,\n many=True,\n context={'request': request}\n )\n return table_serializer.data\n\n\ndef get_queries_list(request, schema):\n if schema is None:\n return []\n qs = UIQuery.objects.filter(base_table__schema=schema)\n permission_restricted_qs = QueryAccessPolicy.scope_queryset(request, qs)\n\n query_serializer = QuerySerializer(\n permission_restricted_qs,\n many=True,\n context={'request': request}\n )\n return query_serializer.data\n\n\ndef get_ui_type_list(request, database):\n if database is None:\n return []\n type_serializer = TypeSerializer(\n UIType,\n many=True,\n context={'request': request}\n )\n return type_serializer.data\n\n\ndef get_user_data(request):\n user_serializer = UserSerializer(\n request.user,\n many=False,\n context={'request': request}\n )\n return user_serializer.data\n\n\ndef get_common_data(request, database=None, schema=None):\n return {\n 'current_db': database.name if database else None,\n 'current_schema': schema.id if schema else None,\n 'schemas': get_schema_list(request, database),\n 'databases': get_database_list(request),\n 'tables': get_table_list(request, schema),\n 'queries': get_queries_list(request, schema),\n 'abstract_types': get_ui_type_list(request, database),\n 'user': get_user_data(request),\n 'live_demo_mode': getattr(settings, 'MATHESAR_LIVE_DEMO', False),\n 'current_release_tag_name': __version__,\n }\n\n\ndef get_current_database(request, db_name):\n \"\"\"Get database from passed name, with fall back behavior.\"\"\"\n permitted_databases = _get_permissible_db_queryset(request)\n if db_name is not None:\n current_database = get_object_or_404(permitted_databases, name=db_name)\n else:\n request_database_name = request.GET.get('database')\n try:\n if request_database_name is not None:\n # Try to get the database named specified in the request\n current_database = permitted_databases.get(name=request_database_name)\n else:\n # Try to get the first database available\n current_database = permitted_databases.order_by('id').first()\n except Database.DoesNotExist:\n current_database = None\n return current_database\n\n\ndef get_current_schema(request, schema_id, database):\n # if there's a schema ID passed in, try to retrieve the schema, or return a 404 error.\n if schema_id is not None:\n permitted_schemas = SchemaAccessPolicy.scope_queryset(request, Schema.objects.all())\n return get_object_or_404(permitted_schemas, id=schema_id)\n else:\n try:\n # Try to get the first schema in the DB\n return Schema.objects.filter(database=database).order_by('id').first()\n except Schema.DoesNotExist:\n return None\n\n\ndef render_schema(request, database, schema):\n # if there's no schema available, redirect to the schemas page.\n if not schema:\n return redirect('schemas', db_name=database.name)\n else:\n # We are redirecting so that the correct URL is passed to the frontend.\n return redirect('schema_home', db_name=database.name, schema_id=schema.id)\n\n\n@login_required\n@api_view(['POST'])\ndef reflect_all(_):\n reset_reflection()\n return Response(status=status.HTTP_200_OK)\n\n\n@login_required\ndef home(request):\n database = get_current_database(request, None)\n if database is None:\n return render(request, 'mathesar/index.html', {\n 'common_data': get_common_data(request, database)\n })\n return redirect('schemas', db_name=database.name)\n\n\n@login_required\ndef profile(request):\n return render(request, 'mathesar/index.html', {\n 'common_data': get_common_data(request)\n })\n\n\n@login_required\ndef admin_home(request, **kwargs):\n return render(request, 'mathesar/index.html', {\n 'common_data': get_common_data(request)\n })\n\n\n@login_required\ndef schema_home(request, db_name, schema_id, **kwargs):\n database = get_current_database(request, db_name)\n schema = get_current_schema(request, schema_id, database)\n return render(request, 'mathesar/index.html', {\n 'common_data': get_common_data(request, database, schema)\n })\n\n\n@login_required\ndef schemas(request, db_name):\n database = get_current_database(request, db_name)\n return render(request, 'mathesar/index.html', {\n 'common_data': get_common_data(request, database, None)\n })\n\n\ndef page_not_found_view(request, exception):\n return render(request, 'mathesar/index.html', {\n 'common_data': get_common_data(request),\n }, status=404)\n", "path": "mathesar/views.py"}], "after_files": [{"content": "from django.conf import settings\n\nfrom db import engine\n\nDEFAULT_DB = 'default'\n\n\ndef create_mathesar_engine(db_name):\n \"\"\"Create an SQLAlchemy engine using stored credentials.\"\"\"\n import logging\n logger = logging.getLogger('create_mathesar_engine')\n logger.debug('enter')\n try:\n credentials = _get_credentials_for_db_name_in_settings(db_name)\n except KeyError:\n if hasattr(settings, 'MATHESAR_LIVE_DEMO') and settings.MATHESAR_LIVE_DEMO:\n credentials = _get_credentials_for_db_name_not_in_settings(db_name)\n else:\n raise\n return engine.create_future_engine_with_custom_types(**credentials)\n\n\ndef _get_credentials_for_db_name_in_settings(db_name):\n settings_entry = settings.DATABASES[db_name]\n return dict(\n username=settings_entry[\"USER\"],\n password=settings_entry[\"PASSWORD\"],\n hostname=settings_entry[\"HOST\"],\n database=settings_entry[\"NAME\"],\n port=settings_entry[\"PORT\"],\n )\n\n\ndef _get_credentials_for_db_name_not_in_settings(db_name):\n settings_entry = settings.DATABASES[DEFAULT_DB]\n return dict(\n username=settings_entry[\"USER\"],\n password=settings_entry[\"PASSWORD\"],\n hostname=settings_entry[\"HOST\"],\n database=db_name,\n port=settings_entry[\"PORT\"],\n )\n", "path": "mathesar/database/base.py"}, {"content": "from django.conf import settings\nfrom django.contrib.auth.decorators import login_required\nfrom django.shortcuts import render, redirect, get_object_or_404\nfrom rest_framework import status\nfrom rest_framework.decorators import api_view\nfrom rest_framework.response import Response\n\nfrom mathesar.api.db.permissions.database import DatabaseAccessPolicy\nfrom mathesar.api.db.permissions.query import QueryAccessPolicy\nfrom mathesar.api.db.permissions.schema import SchemaAccessPolicy\nfrom mathesar.api.db.permissions.table import TableAccessPolicy\nfrom mathesar.api.serializers.databases import DatabaseSerializer, TypeSerializer\nfrom mathesar.api.serializers.schemas import SchemaSerializer\nfrom mathesar.api.serializers.tables import TableSerializer\nfrom mathesar.api.serializers.queries import QuerySerializer\nfrom mathesar.api.ui.serializers.users import UserSerializer\nfrom mathesar.database.types import UIType\nfrom mathesar.models.base import Database, Schema, Table\nfrom mathesar.models.query import UIQuery\nfrom mathesar.state import reset_reflection\nfrom mathesar import __version__\n\n\ndef get_schema_list(request, database):\n qs = Schema.objects.filter(database=database)\n permission_restricted_qs = SchemaAccessPolicy.scope_queryset(request, qs)\n schema_serializer = SchemaSerializer(\n permission_restricted_qs,\n many=True,\n context={'request': request}\n )\n return schema_serializer.data\n\n\ndef _get_permissible_db_queryset(request):\n qs = Database.objects.filter(deleted=False)\n permission_restricted_qs = DatabaseAccessPolicy.scope_queryset(request, qs)\n schema_qs = Schema.objects.all()\n permitted_schemas = SchemaAccessPolicy.scope_queryset(request, schema_qs)\n databases_from_permitted_schema = Database.objects.filter(schemas__in=permitted_schemas, deleted=False)\n permission_restricted_qs = permission_restricted_qs | databases_from_permitted_schema\n return permission_restricted_qs.distinct()\n\n\ndef get_database_list(request):\n permission_restricted_db_qs = _get_permissible_db_queryset(request)\n database_serializer = DatabaseSerializer(\n permission_restricted_db_qs,\n many=True,\n context={'request': request}\n )\n return database_serializer.data\n\n\ndef get_table_list(request, schema):\n if schema is None:\n return []\n qs = Table.objects.filter(schema=schema)\n permission_restricted_qs = TableAccessPolicy.scope_queryset(request, qs)\n table_serializer = TableSerializer(\n permission_restricted_qs,\n many=True,\n context={'request': request}\n )\n return table_serializer.data\n\n\ndef get_queries_list(request, schema):\n if schema is None:\n return []\n qs = UIQuery.objects.filter(base_table__schema=schema)\n permission_restricted_qs = QueryAccessPolicy.scope_queryset(request, qs)\n\n query_serializer = QuerySerializer(\n permission_restricted_qs,\n many=True,\n context={'request': request}\n )\n return query_serializer.data\n\n\ndef get_ui_type_list(request, database):\n if database is None:\n return []\n type_serializer = TypeSerializer(\n UIType,\n many=True,\n context={'request': request}\n )\n return type_serializer.data\n\n\ndef get_user_data(request):\n user_serializer = UserSerializer(\n request.user,\n many=False,\n context={'request': request}\n )\n return user_serializer.data\n\n\ndef get_common_data(request, database=None, schema=None):\n return {\n 'current_db': database.name if database else None,\n 'current_schema': schema.id if schema else None,\n 'schemas': get_schema_list(request, database),\n 'databases': get_database_list(request),\n 'tables': get_table_list(request, schema),\n 'queries': get_queries_list(request, schema),\n 'abstract_types': get_ui_type_list(request, database),\n 'user': get_user_data(request),\n 'live_demo_mode': getattr(settings, 'MATHESAR_LIVE_DEMO', False),\n 'current_release_tag_name': __version__,\n }\n\n\ndef get_current_database(request, db_name):\n \"\"\"Get database from passed name, with fall back behavior.\"\"\"\n permitted_databases = _get_permissible_db_queryset(request)\n if db_name is not None:\n current_database = get_object_or_404(permitted_databases, name=db_name)\n else:\n request_database_name = request.GET.get('database')\n try:\n if request_database_name is not None:\n # Try to get the database named specified in the request\n current_database = permitted_databases.get(name=request_database_name)\n else:\n # Try to get the first database available\n current_database = permitted_databases.order_by('id').first()\n except Database.DoesNotExist:\n current_database = None\n return current_database\n\n\ndef get_current_schema(request, schema_id, database):\n # if there's a schema ID passed in, try to retrieve the schema, or return a 404 error.\n if schema_id is not None:\n permitted_schemas = SchemaAccessPolicy.scope_queryset(request, Schema.objects.all())\n return get_object_or_404(permitted_schemas, id=schema_id)\n else:\n try:\n # Try to get the first schema in the DB\n return Schema.objects.filter(database=database).order_by('id').first()\n except Schema.DoesNotExist:\n return None\n\n\ndef render_schema(request, database, schema):\n # if there's no schema available, redirect to the schemas page.\n if not schema:\n return redirect('schemas', db_name=database.name)\n else:\n # We are redirecting so that the correct URL is passed to the frontend.\n return redirect('schema_home', db_name=database.name, schema_id=schema.id)\n\n\n@login_required\n@api_view(['POST'])\ndef reflect_all(_):\n reset_reflection()\n return Response(status=status.HTTP_200_OK)\n\n\n@login_required\ndef home(request):\n database = get_current_database(request, None)\n if database is None:\n return render(request, 'mathesar/index.html', {\n 'common_data': get_common_data(request, database)\n })\n return redirect('schemas', db_name=database.name)\n\n\n@login_required\ndef profile(request):\n return render(request, 'mathesar/index.html', {\n 'common_data': get_common_data(request)\n })\n\n\n@login_required\ndef admin_home(request, **kwargs):\n return render(request, 'mathesar/index.html', {\n 'common_data': get_common_data(request)\n })\n\n\n@login_required\ndef schema_home(request, db_name, schema_id, **kwargs):\n database = get_current_database(request, db_name)\n schema = get_current_schema(request, schema_id, database)\n return render(request, 'mathesar/index.html', {\n 'common_data': get_common_data(request, database, schema)\n })\n\n\n@login_required\ndef schemas(request, db_name):\n database = get_current_database(request, db_name)\n return render(request, 'mathesar/index.html', {\n 'common_data': get_common_data(request, database, None)\n })\n\n\ndef page_not_found_view(request, exception):\n return render(request, 'mathesar/index.html', {\n 'common_data': get_common_data(request),\n }, status=404)\n", "path": "mathesar/views.py"}]} | 2,861 | 326 |
gh_patches_debug_36099 | rasdani/github-patches | git_diff | elastic__apm-agent-python-1938 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
dbapi2 span does not include object name when calling a procedure
**Is your feature request related to a problem? Please describe.**
Aggregating metrics of stored procedures is not possible because the span name lacks the object name of the procedure being called.
Also, the span.action is only set to `exec` when a procedure is executed through `callproc`, not connection.execute etc.
Now it's set to `query` for EXECUTE statements, depending on the dbapi2 method used.
**Describe the solution you'd like**
* Set span.action to the EXEC_ACTION constant for all EXEC/EXECUTE statements
* Include the object name / procedure name in the span.name, such as `EXECUTE sp_who` instead of just `EXECUTE`
**Describe alternatives you've considered**
Custom spans can be used, but that duplicates the number of spans for each EXECUTE statement
**Additional context**
Example of current output:

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticapm/instrumentation/packages/dbapi2.py`
Content:
```
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2019, Elasticsearch BV
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions are met:
8 #
9 # * Redistributions of source code must retain the above copyright notice, this
10 # list of conditions and the following disclaimer.
11 #
12 # * Redistributions in binary form must reproduce the above copyright notice,
13 # this list of conditions and the following disclaimer in the documentation
14 # and/or other materials provided with the distribution.
15 #
16 # * Neither the name of the copyright holder nor the names of its
17 # contributors may be used to endorse or promote products derived from
18 # this software without specific prior written permission.
19 #
20 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 # OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30
31 """Provides classes to instrument dbapi2 providers
32
33 https://www.python.org/dev/peps/pep-0249/
34 """
35
36 import re
37
38 import wrapt
39
40 from elasticapm.instrumentation.packages.base import AbstractInstrumentedModule
41 from elasticapm.traces import capture_span
42 from elasticapm.utils.encoding import force_text, shorten
43
44
45 class Literal(object):
46 def __init__(self, literal_type, content) -> None:
47 self.literal_type = literal_type
48 self.content = content
49
50 def __eq__(self, other):
51 return isinstance(other, Literal) and self.literal_type == other.literal_type and self.content == other.content
52
53 def __repr__(self):
54 return "<Literal {}{}{}>".format(self.literal_type, self.content, self.literal_type)
55
56
57 def look_for_table(sql, keyword):
58 tokens = tokenize(sql)
59 table_name = _scan_for_table_with_tokens(tokens, keyword)
60 if isinstance(table_name, Literal):
61 table_name = table_name.content.strip(table_name.literal_type)
62 return table_name
63
64
65 def _scan_for_table_with_tokens(tokens, keyword):
66 seen_keyword = False
67 for idx, lexeme in scan(tokens):
68 if seen_keyword:
69 if lexeme == "(":
70 return _scan_for_table_with_tokens(tokens[idx:], keyword)
71 else:
72 return lexeme
73
74 if isinstance(lexeme, str) and lexeme.upper() == keyword:
75 seen_keyword = True
76
77
78 def tokenize(sql):
79 # split on anything that is not a word character, excluding dots
80 return [t for t in re.split(r"([^\w.])", sql) if t != ""]
81
82
83 def scan(tokens):
84 literal_start_idx = None
85 literal_started = None
86 prev_was_escape = False
87 lexeme = []
88
89 i = 0
90 while i < len(tokens):
91 token = tokens[i]
92 if literal_start_idx:
93 if prev_was_escape:
94 prev_was_escape = False
95 lexeme.append(token)
96 else:
97 if token == literal_started:
98 if literal_started == "'" and len(tokens) > i + 1 and tokens[i + 1] == "'": # double quotes
99 i += 1
100 lexeme.append("'")
101 else:
102 yield i, Literal(literal_started, "".join(lexeme))
103 literal_start_idx = None
104 literal_started = None
105 lexeme = []
106 else:
107 if token == "\\":
108 prev_was_escape = token
109 else:
110 prev_was_escape = False
111 lexeme.append(token)
112 elif literal_start_idx is None:
113 if token in ["'", '"', "`"]:
114 literal_start_idx = i
115 literal_started = token
116 elif token == "$":
117 # Postgres can use arbitrary characters between two $'s as a
118 # literal separation token, e.g.: $fish$ literal $fish$
119 # This part will detect that and skip over the literal.
120 try:
121 # Closing dollar of the opening quote,
122 # i.e. the second $ in the first $fish$
123 closing_dollar_idx = tokens.index("$", i + 1)
124 except ValueError:
125 pass
126 else:
127 quote = tokens[i : closing_dollar_idx + 1]
128 length = len(quote)
129 # Opening dollar of the closing quote,
130 # i.e. the first $ in the second $fish$
131 closing_quote_idx = closing_dollar_idx + 1
132 while True:
133 try:
134 closing_quote_idx = tokens.index("$", closing_quote_idx)
135 except ValueError:
136 break
137 if tokens[closing_quote_idx : closing_quote_idx + length] == quote:
138 yield i, Literal(
139 "".join(quote), "".join(tokens[closing_dollar_idx + 1 : closing_quote_idx])
140 )
141 i = closing_quote_idx + length
142 break
143 closing_quote_idx += 1
144 else:
145 if token != " ":
146 yield i, token
147 i += 1
148
149 if lexeme:
150 yield i, lexeme
151
152
153 def extract_signature(sql):
154 """
155 Extracts a minimal signature from a given SQL query
156 :param sql: the SQL statement
157 :return: a string representing the signature
158 """
159 sql = force_text(sql)
160 sql = sql.strip()
161 first_space = sql.find(" ")
162 if first_space < 0:
163 return sql
164
165 second_space = sql.find(" ", first_space + 1)
166
167 sql_type = sql[0:first_space].upper()
168
169 if sql_type in ["INSERT", "DELETE"]:
170 keyword = "INTO" if sql_type == "INSERT" else "FROM"
171 sql_type = sql_type + " " + keyword
172
173 table_name = look_for_table(sql, keyword)
174 elif sql_type in ["CREATE", "DROP"]:
175 # 2nd word is part of SQL type
176 sql_type = sql_type + sql[first_space:second_space]
177 table_name = ""
178 elif sql_type == "UPDATE":
179 table_name = look_for_table(sql, "UPDATE")
180 elif sql_type == "SELECT":
181 # Name is first table
182 try:
183 sql_type = "SELECT FROM"
184 table_name = look_for_table(sql, "FROM")
185 except Exception:
186 table_name = ""
187 else:
188 # No name
189 table_name = ""
190
191 signature = " ".join(filter(bool, [sql_type, table_name]))
192 return signature
193
194
195 QUERY_ACTION = "query"
196 EXEC_ACTION = "exec"
197
198
199 class CursorProxy(wrapt.ObjectProxy):
200 provider_name = None
201 DML_QUERIES = ("INSERT", "DELETE", "UPDATE")
202
203 def __init__(self, wrapped, destination_info=None) -> None:
204 super(CursorProxy, self).__init__(wrapped)
205 self._self_destination_info = destination_info or {}
206
207 def callproc(self, procname, params=None):
208 return self._trace_sql(self.__wrapped__.callproc, procname, params, action=EXEC_ACTION)
209
210 def execute(self, sql, params=None):
211 return self._trace_sql(self.__wrapped__.execute, sql, params)
212
213 def executemany(self, sql, param_list):
214 return self._trace_sql(self.__wrapped__.executemany, sql, param_list)
215
216 def _bake_sql(self, sql):
217 """
218 Method to turn the "sql" argument into a string. Most database backends simply return
219 the given object, as it is already a string
220 """
221 return sql
222
223 def _trace_sql(self, method, sql, params, action=QUERY_ACTION):
224 sql_string = self._bake_sql(sql)
225 if action == EXEC_ACTION:
226 signature = sql_string + "()"
227 else:
228 signature = self.extract_signature(sql_string)
229
230 # Truncate sql_string to 10000 characters to prevent large queries from
231 # causing an error to APM server.
232 sql_string = shorten(sql_string, string_length=10000)
233
234 with capture_span(
235 signature,
236 span_type="db",
237 span_subtype=self.provider_name,
238 span_action=action,
239 extra={
240 "db": {"type": "sql", "statement": sql_string, "instance": getattr(self, "_self_database", None)},
241 "destination": self._self_destination_info,
242 },
243 skip_frames=1,
244 leaf=True,
245 ) as span:
246 if params is None:
247 result = method(sql)
248 else:
249 result = method(sql, params)
250 # store "rows affected", but only for DML queries like insert/update/delete
251 if span and self.rowcount not in (-1, None) and signature.startswith(self.DML_QUERIES):
252 span.update_context("db", {"rows_affected": self.rowcount})
253 return result
254
255 def extract_signature(self, sql):
256 raise NotImplementedError()
257
258
259 class ConnectionProxy(wrapt.ObjectProxy):
260 cursor_proxy = CursorProxy
261
262 def __init__(self, wrapped, destination_info=None) -> None:
263 super(ConnectionProxy, self).__init__(wrapped)
264 self._self_destination_info = destination_info
265
266 def cursor(self, *args, **kwargs):
267 return self.cursor_proxy(self.__wrapped__.cursor(*args, **kwargs), self._self_destination_info)
268
269
270 class DbApi2Instrumentation(AbstractInstrumentedModule):
271 connect_method = None
272
273 def call(self, module, method, wrapped, instance, args, kwargs):
274 return ConnectionProxy(wrapped(*args, **kwargs))
275
276 def call_if_sampling(self, module, method, wrapped, instance, args, kwargs):
277 # Contrasting to the superclass implementation, we *always* want to
278 # return a proxied connection, even if there is no ongoing elasticapm
279 # transaction yet. This ensures that we instrument the cursor once
280 # the transaction started.
281 return self.call(module, method, wrapped, instance, args, kwargs)
282
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/elasticapm/instrumentation/packages/dbapi2.py b/elasticapm/instrumentation/packages/dbapi2.py
--- a/elasticapm/instrumentation/packages/dbapi2.py
+++ b/elasticapm/instrumentation/packages/dbapi2.py
@@ -170,30 +170,46 @@
keyword = "INTO" if sql_type == "INSERT" else "FROM"
sql_type = sql_type + " " + keyword
- table_name = look_for_table(sql, keyword)
+ object_name = look_for_table(sql, keyword)
elif sql_type in ["CREATE", "DROP"]:
# 2nd word is part of SQL type
sql_type = sql_type + sql[first_space:second_space]
- table_name = ""
+ object_name = ""
elif sql_type == "UPDATE":
- table_name = look_for_table(sql, "UPDATE")
+ object_name = look_for_table(sql, "UPDATE")
elif sql_type == "SELECT":
# Name is first table
try:
sql_type = "SELECT FROM"
- table_name = look_for_table(sql, "FROM")
+ object_name = look_for_table(sql, "FROM")
except Exception:
- table_name = ""
+ object_name = ""
+ elif sql_type in ["EXEC", "EXECUTE"]:
+ sql_type = "EXECUTE"
+ end = second_space if second_space > first_space else len(sql)
+ object_name = sql[first_space + 1 : end]
+ elif sql_type == "CALL":
+ first_paren = sql.find("(", first_space)
+ end = first_paren if first_paren > first_space else len(sql)
+ procedure_name = sql[first_space + 1 : end].rstrip(";")
+ object_name = procedure_name + "()"
else:
# No name
- table_name = ""
+ object_name = ""
- signature = " ".join(filter(bool, [sql_type, table_name]))
+ signature = " ".join(filter(bool, [sql_type, object_name]))
return signature
QUERY_ACTION = "query"
EXEC_ACTION = "exec"
+PROCEDURE_STATEMENTS = ["EXEC", "EXECUTE", "CALL"]
+
+
+def extract_action_from_signature(signature, default):
+ if signature.split(" ")[0] in PROCEDURE_STATEMENTS:
+ return EXEC_ACTION
+ return default
class CursorProxy(wrapt.ObjectProxy):
@@ -226,6 +242,7 @@
signature = sql_string + "()"
else:
signature = self.extract_signature(sql_string)
+ action = extract_action_from_signature(signature, action)
# Truncate sql_string to 10000 characters to prevent large queries from
# causing an error to APM server.
| {"golden_diff": "diff --git a/elasticapm/instrumentation/packages/dbapi2.py b/elasticapm/instrumentation/packages/dbapi2.py\n--- a/elasticapm/instrumentation/packages/dbapi2.py\n+++ b/elasticapm/instrumentation/packages/dbapi2.py\n@@ -170,30 +170,46 @@\n keyword = \"INTO\" if sql_type == \"INSERT\" else \"FROM\"\n sql_type = sql_type + \" \" + keyword\n \n- table_name = look_for_table(sql, keyword)\n+ object_name = look_for_table(sql, keyword)\n elif sql_type in [\"CREATE\", \"DROP\"]:\n # 2nd word is part of SQL type\n sql_type = sql_type + sql[first_space:second_space]\n- table_name = \"\"\n+ object_name = \"\"\n elif sql_type == \"UPDATE\":\n- table_name = look_for_table(sql, \"UPDATE\")\n+ object_name = look_for_table(sql, \"UPDATE\")\n elif sql_type == \"SELECT\":\n # Name is first table\n try:\n sql_type = \"SELECT FROM\"\n- table_name = look_for_table(sql, \"FROM\")\n+ object_name = look_for_table(sql, \"FROM\")\n except Exception:\n- table_name = \"\"\n+ object_name = \"\"\n+ elif sql_type in [\"EXEC\", \"EXECUTE\"]:\n+ sql_type = \"EXECUTE\"\n+ end = second_space if second_space > first_space else len(sql)\n+ object_name = sql[first_space + 1 : end]\n+ elif sql_type == \"CALL\":\n+ first_paren = sql.find(\"(\", first_space)\n+ end = first_paren if first_paren > first_space else len(sql)\n+ procedure_name = sql[first_space + 1 : end].rstrip(\";\")\n+ object_name = procedure_name + \"()\"\n else:\n # No name\n- table_name = \"\"\n+ object_name = \"\"\n \n- signature = \" \".join(filter(bool, [sql_type, table_name]))\n+ signature = \" \".join(filter(bool, [sql_type, object_name]))\n return signature\n \n \n QUERY_ACTION = \"query\"\n EXEC_ACTION = \"exec\"\n+PROCEDURE_STATEMENTS = [\"EXEC\", \"EXECUTE\", \"CALL\"]\n+\n+\n+def extract_action_from_signature(signature, default):\n+ if signature.split(\" \")[0] in PROCEDURE_STATEMENTS:\n+ return EXEC_ACTION\n+ return default\n \n \n class CursorProxy(wrapt.ObjectProxy):\n@@ -226,6 +242,7 @@\n signature = sql_string + \"()\"\n else:\n signature = self.extract_signature(sql_string)\n+ action = extract_action_from_signature(signature, action)\n \n # Truncate sql_string to 10000 characters to prevent large queries from\n # causing an error to APM server.\n", "issue": "dbapi2 span does not include object name when calling a procedure\n**Is your feature request related to a problem? Please describe.**\r\n\r\nAggregating metrics of stored procedures is not possible because the span name lacks the object name of the procedure being called.\r\nAlso, the span.action is only set to `exec` when a procedure is executed through `callproc`, not connection.execute etc.\r\nNow it's set to `query` for EXECUTE statements, depending on the dbapi2 method used.\r\n\r\n**Describe the solution you'd like**\r\n\r\n* Set span.action to the EXEC_ACTION constant for all EXEC/EXECUTE statements\r\n* Include the object name / procedure name in the span.name, such as `EXECUTE sp_who` instead of just `EXECUTE`\r\n\r\n**Describe alternatives you've considered**\r\n\r\nCustom spans can be used, but that duplicates the number of spans for each EXECUTE statement\r\n\r\n**Additional context**\r\n\r\nExample of current output:\r\n\r\n\r\n\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\n\"\"\"Provides classes to instrument dbapi2 providers\n\nhttps://www.python.org/dev/peps/pep-0249/\n\"\"\"\n\nimport re\n\nimport wrapt\n\nfrom elasticapm.instrumentation.packages.base import AbstractInstrumentedModule\nfrom elasticapm.traces import capture_span\nfrom elasticapm.utils.encoding import force_text, shorten\n\n\nclass Literal(object):\n def __init__(self, literal_type, content) -> None:\n self.literal_type = literal_type\n self.content = content\n\n def __eq__(self, other):\n return isinstance(other, Literal) and self.literal_type == other.literal_type and self.content == other.content\n\n def __repr__(self):\n return \"<Literal {}{}{}>\".format(self.literal_type, self.content, self.literal_type)\n\n\ndef look_for_table(sql, keyword):\n tokens = tokenize(sql)\n table_name = _scan_for_table_with_tokens(tokens, keyword)\n if isinstance(table_name, Literal):\n table_name = table_name.content.strip(table_name.literal_type)\n return table_name\n\n\ndef _scan_for_table_with_tokens(tokens, keyword):\n seen_keyword = False\n for idx, lexeme in scan(tokens):\n if seen_keyword:\n if lexeme == \"(\":\n return _scan_for_table_with_tokens(tokens[idx:], keyword)\n else:\n return lexeme\n\n if isinstance(lexeme, str) and lexeme.upper() == keyword:\n seen_keyword = True\n\n\ndef tokenize(sql):\n # split on anything that is not a word character, excluding dots\n return [t for t in re.split(r\"([^\\w.])\", sql) if t != \"\"]\n\n\ndef scan(tokens):\n literal_start_idx = None\n literal_started = None\n prev_was_escape = False\n lexeme = []\n\n i = 0\n while i < len(tokens):\n token = tokens[i]\n if literal_start_idx:\n if prev_was_escape:\n prev_was_escape = False\n lexeme.append(token)\n else:\n if token == literal_started:\n if literal_started == \"'\" and len(tokens) > i + 1 and tokens[i + 1] == \"'\": # double quotes\n i += 1\n lexeme.append(\"'\")\n else:\n yield i, Literal(literal_started, \"\".join(lexeme))\n literal_start_idx = None\n literal_started = None\n lexeme = []\n else:\n if token == \"\\\\\":\n prev_was_escape = token\n else:\n prev_was_escape = False\n lexeme.append(token)\n elif literal_start_idx is None:\n if token in [\"'\", '\"', \"`\"]:\n literal_start_idx = i\n literal_started = token\n elif token == \"$\":\n # Postgres can use arbitrary characters between two $'s as a\n # literal separation token, e.g.: $fish$ literal $fish$\n # This part will detect that and skip over the literal.\n try:\n # Closing dollar of the opening quote,\n # i.e. the second $ in the first $fish$\n closing_dollar_idx = tokens.index(\"$\", i + 1)\n except ValueError:\n pass\n else:\n quote = tokens[i : closing_dollar_idx + 1]\n length = len(quote)\n # Opening dollar of the closing quote,\n # i.e. the first $ in the second $fish$\n closing_quote_idx = closing_dollar_idx + 1\n while True:\n try:\n closing_quote_idx = tokens.index(\"$\", closing_quote_idx)\n except ValueError:\n break\n if tokens[closing_quote_idx : closing_quote_idx + length] == quote:\n yield i, Literal(\n \"\".join(quote), \"\".join(tokens[closing_dollar_idx + 1 : closing_quote_idx])\n )\n i = closing_quote_idx + length\n break\n closing_quote_idx += 1\n else:\n if token != \" \":\n yield i, token\n i += 1\n\n if lexeme:\n yield i, lexeme\n\n\ndef extract_signature(sql):\n \"\"\"\n Extracts a minimal signature from a given SQL query\n :param sql: the SQL statement\n :return: a string representing the signature\n \"\"\"\n sql = force_text(sql)\n sql = sql.strip()\n first_space = sql.find(\" \")\n if first_space < 0:\n return sql\n\n second_space = sql.find(\" \", first_space + 1)\n\n sql_type = sql[0:first_space].upper()\n\n if sql_type in [\"INSERT\", \"DELETE\"]:\n keyword = \"INTO\" if sql_type == \"INSERT\" else \"FROM\"\n sql_type = sql_type + \" \" + keyword\n\n table_name = look_for_table(sql, keyword)\n elif sql_type in [\"CREATE\", \"DROP\"]:\n # 2nd word is part of SQL type\n sql_type = sql_type + sql[first_space:second_space]\n table_name = \"\"\n elif sql_type == \"UPDATE\":\n table_name = look_for_table(sql, \"UPDATE\")\n elif sql_type == \"SELECT\":\n # Name is first table\n try:\n sql_type = \"SELECT FROM\"\n table_name = look_for_table(sql, \"FROM\")\n except Exception:\n table_name = \"\"\n else:\n # No name\n table_name = \"\"\n\n signature = \" \".join(filter(bool, [sql_type, table_name]))\n return signature\n\n\nQUERY_ACTION = \"query\"\nEXEC_ACTION = \"exec\"\n\n\nclass CursorProxy(wrapt.ObjectProxy):\n provider_name = None\n DML_QUERIES = (\"INSERT\", \"DELETE\", \"UPDATE\")\n\n def __init__(self, wrapped, destination_info=None) -> None:\n super(CursorProxy, self).__init__(wrapped)\n self._self_destination_info = destination_info or {}\n\n def callproc(self, procname, params=None):\n return self._trace_sql(self.__wrapped__.callproc, procname, params, action=EXEC_ACTION)\n\n def execute(self, sql, params=None):\n return self._trace_sql(self.__wrapped__.execute, sql, params)\n\n def executemany(self, sql, param_list):\n return self._trace_sql(self.__wrapped__.executemany, sql, param_list)\n\n def _bake_sql(self, sql):\n \"\"\"\n Method to turn the \"sql\" argument into a string. Most database backends simply return\n the given object, as it is already a string\n \"\"\"\n return sql\n\n def _trace_sql(self, method, sql, params, action=QUERY_ACTION):\n sql_string = self._bake_sql(sql)\n if action == EXEC_ACTION:\n signature = sql_string + \"()\"\n else:\n signature = self.extract_signature(sql_string)\n\n # Truncate sql_string to 10000 characters to prevent large queries from\n # causing an error to APM server.\n sql_string = shorten(sql_string, string_length=10000)\n\n with capture_span(\n signature,\n span_type=\"db\",\n span_subtype=self.provider_name,\n span_action=action,\n extra={\n \"db\": {\"type\": \"sql\", \"statement\": sql_string, \"instance\": getattr(self, \"_self_database\", None)},\n \"destination\": self._self_destination_info,\n },\n skip_frames=1,\n leaf=True,\n ) as span:\n if params is None:\n result = method(sql)\n else:\n result = method(sql, params)\n # store \"rows affected\", but only for DML queries like insert/update/delete\n if span and self.rowcount not in (-1, None) and signature.startswith(self.DML_QUERIES):\n span.update_context(\"db\", {\"rows_affected\": self.rowcount})\n return result\n\n def extract_signature(self, sql):\n raise NotImplementedError()\n\n\nclass ConnectionProxy(wrapt.ObjectProxy):\n cursor_proxy = CursorProxy\n\n def __init__(self, wrapped, destination_info=None) -> None:\n super(ConnectionProxy, self).__init__(wrapped)\n self._self_destination_info = destination_info\n\n def cursor(self, *args, **kwargs):\n return self.cursor_proxy(self.__wrapped__.cursor(*args, **kwargs), self._self_destination_info)\n\n\nclass DbApi2Instrumentation(AbstractInstrumentedModule):\n connect_method = None\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n return ConnectionProxy(wrapped(*args, **kwargs))\n\n def call_if_sampling(self, module, method, wrapped, instance, args, kwargs):\n # Contrasting to the superclass implementation, we *always* want to\n # return a proxied connection, even if there is no ongoing elasticapm\n # transaction yet. This ensures that we instrument the cursor once\n # the transaction started.\n return self.call(module, method, wrapped, instance, args, kwargs)\n", "path": "elasticapm/instrumentation/packages/dbapi2.py"}], "after_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\n\"\"\"Provides classes to instrument dbapi2 providers\n\nhttps://www.python.org/dev/peps/pep-0249/\n\"\"\"\n\nimport re\n\nimport wrapt\n\nfrom elasticapm.instrumentation.packages.base import AbstractInstrumentedModule\nfrom elasticapm.traces import capture_span\nfrom elasticapm.utils.encoding import force_text, shorten\n\n\nclass Literal(object):\n def __init__(self, literal_type, content) -> None:\n self.literal_type = literal_type\n self.content = content\n\n def __eq__(self, other):\n return isinstance(other, Literal) and self.literal_type == other.literal_type and self.content == other.content\n\n def __repr__(self):\n return \"<Literal {}{}{}>\".format(self.literal_type, self.content, self.literal_type)\n\n\ndef look_for_table(sql, keyword):\n tokens = tokenize(sql)\n table_name = _scan_for_table_with_tokens(tokens, keyword)\n if isinstance(table_name, Literal):\n table_name = table_name.content.strip(table_name.literal_type)\n return table_name\n\n\ndef _scan_for_table_with_tokens(tokens, keyword):\n seen_keyword = False\n for idx, lexeme in scan(tokens):\n if seen_keyword:\n if lexeme == \"(\":\n return _scan_for_table_with_tokens(tokens[idx:], keyword)\n else:\n return lexeme\n\n if isinstance(lexeme, str) and lexeme.upper() == keyword:\n seen_keyword = True\n\n\ndef tokenize(sql):\n # split on anything that is not a word character, excluding dots\n return [t for t in re.split(r\"([^\\w.])\", sql) if t != \"\"]\n\n\ndef scan(tokens):\n literal_start_idx = None\n literal_started = None\n prev_was_escape = False\n lexeme = []\n\n i = 0\n while i < len(tokens):\n token = tokens[i]\n if literal_start_idx:\n if prev_was_escape:\n prev_was_escape = False\n lexeme.append(token)\n else:\n if token == literal_started:\n if literal_started == \"'\" and len(tokens) > i + 1 and tokens[i + 1] == \"'\": # double quotes\n i += 1\n lexeme.append(\"'\")\n else:\n yield i, Literal(literal_started, \"\".join(lexeme))\n literal_start_idx = None\n literal_started = None\n lexeme = []\n else:\n if token == \"\\\\\":\n prev_was_escape = token\n else:\n prev_was_escape = False\n lexeme.append(token)\n elif literal_start_idx is None:\n if token in [\"'\", '\"', \"`\"]:\n literal_start_idx = i\n literal_started = token\n elif token == \"$\":\n # Postgres can use arbitrary characters between two $'s as a\n # literal separation token, e.g.: $fish$ literal $fish$\n # This part will detect that and skip over the literal.\n try:\n # Closing dollar of the opening quote,\n # i.e. the second $ in the first $fish$\n closing_dollar_idx = tokens.index(\"$\", i + 1)\n except ValueError:\n pass\n else:\n quote = tokens[i : closing_dollar_idx + 1]\n length = len(quote)\n # Opening dollar of the closing quote,\n # i.e. the first $ in the second $fish$\n closing_quote_idx = closing_dollar_idx + 1\n while True:\n try:\n closing_quote_idx = tokens.index(\"$\", closing_quote_idx)\n except ValueError:\n break\n if tokens[closing_quote_idx : closing_quote_idx + length] == quote:\n yield i, Literal(\n \"\".join(quote), \"\".join(tokens[closing_dollar_idx + 1 : closing_quote_idx])\n )\n i = closing_quote_idx + length\n break\n closing_quote_idx += 1\n else:\n if token != \" \":\n yield i, token\n i += 1\n\n if lexeme:\n yield i, lexeme\n\n\ndef extract_signature(sql):\n \"\"\"\n Extracts a minimal signature from a given SQL query\n :param sql: the SQL statement\n :return: a string representing the signature\n \"\"\"\n sql = force_text(sql)\n sql = sql.strip()\n first_space = sql.find(\" \")\n if first_space < 0:\n return sql\n\n second_space = sql.find(\" \", first_space + 1)\n\n sql_type = sql[0:first_space].upper()\n\n if sql_type in [\"INSERT\", \"DELETE\"]:\n keyword = \"INTO\" if sql_type == \"INSERT\" else \"FROM\"\n sql_type = sql_type + \" \" + keyword\n\n object_name = look_for_table(sql, keyword)\n elif sql_type in [\"CREATE\", \"DROP\"]:\n # 2nd word is part of SQL type\n sql_type = sql_type + sql[first_space:second_space]\n object_name = \"\"\n elif sql_type == \"UPDATE\":\n object_name = look_for_table(sql, \"UPDATE\")\n elif sql_type == \"SELECT\":\n # Name is first table\n try:\n sql_type = \"SELECT FROM\"\n object_name = look_for_table(sql, \"FROM\")\n except Exception:\n object_name = \"\"\n elif sql_type in [\"EXEC\", \"EXECUTE\"]:\n sql_type = \"EXECUTE\"\n end = second_space if second_space > first_space else len(sql)\n object_name = sql[first_space + 1 : end]\n elif sql_type == \"CALL\":\n first_paren = sql.find(\"(\", first_space)\n end = first_paren if first_paren > first_space else len(sql)\n procedure_name = sql[first_space + 1 : end].rstrip(\";\")\n object_name = procedure_name + \"()\"\n else:\n # No name\n object_name = \"\"\n\n signature = \" \".join(filter(bool, [sql_type, object_name]))\n return signature\n\n\nQUERY_ACTION = \"query\"\nEXEC_ACTION = \"exec\"\nPROCEDURE_STATEMENTS = [\"EXEC\", \"EXECUTE\", \"CALL\"]\n\n\ndef extract_action_from_signature(signature, default):\n if signature.split(\" \")[0] in PROCEDURE_STATEMENTS:\n return EXEC_ACTION\n return default\n\n\nclass CursorProxy(wrapt.ObjectProxy):\n provider_name = None\n DML_QUERIES = (\"INSERT\", \"DELETE\", \"UPDATE\")\n\n def __init__(self, wrapped, destination_info=None) -> None:\n super(CursorProxy, self).__init__(wrapped)\n self._self_destination_info = destination_info or {}\n\n def callproc(self, procname, params=None):\n return self._trace_sql(self.__wrapped__.callproc, procname, params, action=EXEC_ACTION)\n\n def execute(self, sql, params=None):\n return self._trace_sql(self.__wrapped__.execute, sql, params)\n\n def executemany(self, sql, param_list):\n return self._trace_sql(self.__wrapped__.executemany, sql, param_list)\n\n def _bake_sql(self, sql):\n \"\"\"\n Method to turn the \"sql\" argument into a string. Most database backends simply return\n the given object, as it is already a string\n \"\"\"\n return sql\n\n def _trace_sql(self, method, sql, params, action=QUERY_ACTION):\n sql_string = self._bake_sql(sql)\n if action == EXEC_ACTION:\n signature = sql_string + \"()\"\n else:\n signature = self.extract_signature(sql_string)\n action = extract_action_from_signature(signature, action)\n\n # Truncate sql_string to 10000 characters to prevent large queries from\n # causing an error to APM server.\n sql_string = shorten(sql_string, string_length=10000)\n\n with capture_span(\n signature,\n span_type=\"db\",\n span_subtype=self.provider_name,\n span_action=action,\n extra={\n \"db\": {\"type\": \"sql\", \"statement\": sql_string, \"instance\": getattr(self, \"_self_database\", None)},\n \"destination\": self._self_destination_info,\n },\n skip_frames=1,\n leaf=True,\n ) as span:\n if params is None:\n result = method(sql)\n else:\n result = method(sql, params)\n # store \"rows affected\", but only for DML queries like insert/update/delete\n if span and self.rowcount not in (-1, None) and signature.startswith(self.DML_QUERIES):\n span.update_context(\"db\", {\"rows_affected\": self.rowcount})\n return result\n\n def extract_signature(self, sql):\n raise NotImplementedError()\n\n\nclass ConnectionProxy(wrapt.ObjectProxy):\n cursor_proxy = CursorProxy\n\n def __init__(self, wrapped, destination_info=None) -> None:\n super(ConnectionProxy, self).__init__(wrapped)\n self._self_destination_info = destination_info\n\n def cursor(self, *args, **kwargs):\n return self.cursor_proxy(self.__wrapped__.cursor(*args, **kwargs), self._self_destination_info)\n\n\nclass DbApi2Instrumentation(AbstractInstrumentedModule):\n connect_method = None\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n return ConnectionProxy(wrapped(*args, **kwargs))\n\n def call_if_sampling(self, module, method, wrapped, instance, args, kwargs):\n # Contrasting to the superclass implementation, we *always* want to\n # return a proxied connection, even if there is no ongoing elasticapm\n # transaction yet. This ensures that we instrument the cursor once\n # the transaction started.\n return self.call(module, method, wrapped, instance, args, kwargs)\n", "path": "elasticapm/instrumentation/packages/dbapi2.py"}]} | 3,542 | 613 |
gh_patches_debug_32059 | rasdani/github-patches | git_diff | engnadeau__pybotics-36 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add Package to PyPi
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 from setuptools import setup
2
3 setup(
4 name='pybotics',
5 version='0.1.3',
6 packages=['examples', 'pybotics', 'tests'],
7 url='https://github.com/nnadeau/pybotics',
8 license='MIT',
9 author='Nicholas Nadeau',
10 author_email='',
11 description='Python Toolbox for Robotics',
12 setup_requires=['pytest-runner'],
13 tests_require=['pytest']
14 )
15
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,14 +1,59 @@
+import pypandoc
from setuptools import setup
+import os
+import git
+
+# tag version
+repo = git.Repo(os.getcwd())
+tag = repo.tags[-1]
+version = tag.name
+
+# requirements
+with open('requirements.txt') as f:
+ requirements = f.read().splitlines()
+
+# long description
+# TODO: pypandoc.convert() function returns wrong RST format, but saving/loading a file works
+file_path = os.path.abspath(os.path.dirname(__file__))
+pypandoc.convert_file('README.md', 'rst', outputfile=os.path.join(file_path, 'README.rst'))
+with open(os.path.join(file_path, 'README.rst'), encoding='utf-8') as f:
+ description = f.read()
setup(
name='pybotics',
- version='0.1.3',
- packages=['examples', 'pybotics', 'tests'],
+ version=version,
+ packages=['pybotics'],
url='https://github.com/nnadeau/pybotics',
license='MIT',
author='Nicholas Nadeau',
- author_email='',
+ author_email='[email protected]',
description='Python Toolbox for Robotics',
+ long_description=description,
+ install_requires=requirements,
setup_requires=['pytest-runner'],
- tests_require=['pytest']
+ tests_require=['pytest'],
+ classifiers=[
+ 'Development Status :: 4 - Beta',
+ 'Intended Audience :: Developers',
+ 'Intended Audience :: Education',
+ 'Intended Audience :: End Users/Desktop',
+ 'Intended Audience :: Manufacturing',
+ 'Intended Audience :: Science/Research',
+ 'Topic :: Education',
+ 'Topic :: Scientific/Engineering',
+ 'Topic :: Scientific/Engineering :: Artificial Intelligence',
+ 'Topic :: Scientific/Engineering :: Human Machine Interfaces',
+ 'Topic :: Scientific/Engineering :: Mathematics',
+ 'Topic :: Scientific/Engineering :: Physics',
+ 'Topic :: Utilities',
+ 'License :: OSI Approved :: MIT License',
+ 'Programming Language :: Python :: 3 :: Only',
+ 'Programming Language :: Python :: 3',
+ 'Programming Language :: Python :: 3.2',
+ 'Programming Language :: Python :: 3.3',
+ 'Programming Language :: Python :: 3.4',
+ 'Programming Language :: Python :: 3.5',
+ 'Programming Language :: Python :: 3.6',
+ ],
+ keywords='python robot robotics research automation kinematics geometry',
)
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -1,14 +1,59 @@\n+import pypandoc\n from setuptools import setup\n+import os\n+import git\n+\n+# tag version\n+repo = git.Repo(os.getcwd())\n+tag = repo.tags[-1]\n+version = tag.name\n+\n+# requirements\n+with open('requirements.txt') as f:\n+ requirements = f.read().splitlines()\n+\n+# long description\n+# TODO: pypandoc.convert() function returns wrong RST format, but saving/loading a file works\n+file_path = os.path.abspath(os.path.dirname(__file__))\n+pypandoc.convert_file('README.md', 'rst', outputfile=os.path.join(file_path, 'README.rst'))\n+with open(os.path.join(file_path, 'README.rst'), encoding='utf-8') as f:\n+ description = f.read()\n \n setup(\n name='pybotics',\n- version='0.1.3',\n- packages=['examples', 'pybotics', 'tests'],\n+ version=version,\n+ packages=['pybotics'],\n url='https://github.com/nnadeau/pybotics',\n license='MIT',\n author='Nicholas Nadeau',\n- author_email='',\n+ author_email='[email protected]',\n description='Python Toolbox for Robotics',\n+ long_description=description,\n+ install_requires=requirements,\n setup_requires=['pytest-runner'],\n- tests_require=['pytest']\n+ tests_require=['pytest'],\n+ classifiers=[\n+ 'Development Status :: 4 - Beta',\n+ 'Intended Audience :: Developers',\n+ 'Intended Audience :: Education',\n+ 'Intended Audience :: End Users/Desktop',\n+ 'Intended Audience :: Manufacturing',\n+ 'Intended Audience :: Science/Research',\n+ 'Topic :: Education',\n+ 'Topic :: Scientific/Engineering',\n+ 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n+ 'Topic :: Scientific/Engineering :: Human Machine Interfaces',\n+ 'Topic :: Scientific/Engineering :: Mathematics',\n+ 'Topic :: Scientific/Engineering :: Physics',\n+ 'Topic :: Utilities',\n+ 'License :: OSI Approved :: MIT License',\n+ 'Programming Language :: Python :: 3 :: Only',\n+ 'Programming Language :: Python :: 3',\n+ 'Programming Language :: Python :: 3.2',\n+ 'Programming Language :: Python :: 3.3',\n+ 'Programming Language :: Python :: 3.4',\n+ 'Programming Language :: Python :: 3.5',\n+ 'Programming Language :: Python :: 3.6',\n+ ],\n+ keywords='python robot robotics research automation kinematics geometry',\n )\n", "issue": "Add Package to PyPi\n\n", "before_files": [{"content": "from setuptools import setup\n\nsetup(\n name='pybotics',\n version='0.1.3',\n packages=['examples', 'pybotics', 'tests'],\n url='https://github.com/nnadeau/pybotics',\n license='MIT',\n author='Nicholas Nadeau',\n author_email='',\n description='Python Toolbox for Robotics',\n setup_requires=['pytest-runner'],\n tests_require=['pytest']\n)\n", "path": "setup.py"}], "after_files": [{"content": "import pypandoc\nfrom setuptools import setup\nimport os\nimport git\n\n# tag version\nrepo = git.Repo(os.getcwd())\ntag = repo.tags[-1]\nversion = tag.name\n\n# requirements\nwith open('requirements.txt') as f:\n requirements = f.read().splitlines()\n\n# long description\n# TODO: pypandoc.convert() function returns wrong RST format, but saving/loading a file works\nfile_path = os.path.abspath(os.path.dirname(__file__))\npypandoc.convert_file('README.md', 'rst', outputfile=os.path.join(file_path, 'README.rst'))\nwith open(os.path.join(file_path, 'README.rst'), encoding='utf-8') as f:\n description = f.read()\n\nsetup(\n name='pybotics',\n version=version,\n packages=['pybotics'],\n url='https://github.com/nnadeau/pybotics',\n license='MIT',\n author='Nicholas Nadeau',\n author_email='[email protected]',\n description='Python Toolbox for Robotics',\n long_description=description,\n install_requires=requirements,\n setup_requires=['pytest-runner'],\n tests_require=['pytest'],\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: End Users/Desktop',\n 'Intended Audience :: Manufacturing',\n 'Intended Audience :: Science/Research',\n 'Topic :: Education',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n 'Topic :: Scientific/Engineering :: Human Machine Interfaces',\n 'Topic :: Scientific/Engineering :: Mathematics',\n 'Topic :: Scientific/Engineering :: Physics',\n 'Topic :: Utilities',\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python :: 3 :: Only',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.2',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n ],\n keywords='python robot robotics research automation kinematics geometry',\n)\n", "path": "setup.py"}]} | 375 | 591 |
gh_patches_debug_15765 | rasdani/github-patches | git_diff | mkdocs__mkdocs-383 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add build date and MkDocs version to the output
The date was suggested in #290, but didn't seem useful at the time.
However, it would be really useful to see when the output was built and with what version when helping people debug.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mkdocs/build.py`
Content:
```
1 # coding: utf-8
2 from __future__ import print_function
3
4 from jinja2.exceptions import TemplateNotFound
5 from mkdocs import nav, toc, utils
6 from mkdocs.compat import urljoin, PY2
7 from mkdocs.relative_path_ext import RelativePathExtension
8 import jinja2
9 import json
10 import markdown
11 import os
12 import logging
13
14 log = logging.getLogger('mkdocs')
15
16
17 def convert_markdown(markdown_source, site_navigation=None, extensions=(), strict=False):
18 """
19 Convert the Markdown source file to HTML content, and additionally
20 return the parsed table of contents, and a dictionary of any metadata
21 that was specified in the Markdown file.
22
23 `extensions` is an optional sequence of Python Markdown extensions to add
24 to the default set.
25 """
26
27 # Generate the HTML from the markdown source
28 builtin_extensions = ['meta', 'toc', 'tables', 'fenced_code']
29 mkdocs_extensions = [RelativePathExtension(site_navigation, strict), ]
30 extensions = builtin_extensions + mkdocs_extensions + list(extensions)
31 md = markdown.Markdown(
32 extensions=extensions
33 )
34 html_content = md.convert(markdown_source)
35 meta = md.Meta
36 toc_html = md.toc
37
38 # Post process the generated table of contents into a data structure
39 table_of_contents = toc.TableOfContents(toc_html)
40
41 return (html_content, table_of_contents, meta)
42
43
44 def get_global_context(nav, config):
45 """
46 Given the SiteNavigation and config, generate the context which is relevant
47 to app pages.
48 """
49
50 site_name = config['site_name']
51
52 if config['site_favicon']:
53 site_favicon = nav.url_context.make_relative('/' + config['site_favicon'])
54 else:
55 site_favicon = None
56
57 page_description = config['site_description']
58
59 extra_javascript = utils.create_media_urls(nav=nav, url_list=config['extra_javascript'])
60
61 extra_css = utils.create_media_urls(nav=nav, url_list=config['extra_css'])
62
63 return {
64 'site_name': site_name,
65 'site_author': config['site_author'],
66 'favicon': site_favicon,
67 'page_description': page_description,
68
69 # Note that there's intentionally repetition here. Rather than simply
70 # provide the config dictionary we instead pass everything explicitly.
71 #
72 # This helps ensure that we can throughly document the context that
73 # gets passed to themes.
74 'repo_url': config['repo_url'],
75 'repo_name': config['repo_name'],
76 'nav': nav,
77 'base_url': nav.url_context.make_relative('/'),
78 'homepage_url': nav.homepage.url,
79
80 'extra_css': extra_css,
81 'extra_javascript': extra_javascript,
82
83 'include_nav': config['include_nav'],
84 'include_next_prev': config['include_next_prev'],
85 'include_search': config['include_search'],
86
87 'copyright': config['copyright'],
88 'google_analytics': config['google_analytics']
89 }
90
91
92 def get_page_context(page, content, nav, toc, meta, config):
93 """
94 Generate the page context by extending the global context and adding page
95 specific variables.
96 """
97
98 if page.is_homepage or page.title is None:
99 page_title = None
100 else:
101 page_title = page.title
102
103 if page.is_homepage:
104 page_description = config['site_description']
105 else:
106 page_description = None
107
108 if config['site_url']:
109 base = config['site_url']
110 if not base.endswith('/'):
111 base += '/'
112 canonical_url = urljoin(base, page.abs_url.lstrip('/'))
113 else:
114 canonical_url = None
115
116 return {
117 'page_title': page_title,
118 'page_description': page_description,
119
120 'content': content,
121 'toc': toc,
122 'meta': meta,
123
124
125 'canonical_url': canonical_url,
126
127 'current_page': page,
128 'previous_page': page.previous_page,
129 'next_page': page.next_page,
130 }
131
132
133 def build_404(config, env, site_navigation):
134
135 try:
136 template = env.get_template('404.html')
137 except TemplateNotFound:
138 return
139
140 global_context = get_global_context(site_navigation, config)
141
142 output_content = template.render(global_context)
143 output_path = os.path.join(config['site_dir'], '404.html')
144 utils.write_file(output_content.encode('utf-8'), output_path)
145
146
147 def build_pages(config, dump_json=False):
148 """
149 Builds all the pages and writes them into the build directory.
150 """
151 site_navigation = nav.SiteNavigation(config['pages'], config['use_directory_urls'])
152 loader = jinja2.FileSystemLoader(config['theme_dir'])
153 env = jinja2.Environment(loader=loader)
154
155 build_404(config, env, site_navigation)
156
157 for page in site_navigation.walk_pages():
158 # Read the input file
159 input_path = os.path.join(config['docs_dir'], page.input_path)
160 try:
161 input_content = open(input_path, 'r').read()
162 except IOError:
163 log.error('file not found: %s' % input_path)
164 if PY2:
165 input_content = input_content.decode('utf-8')
166
167 # Process the markdown text
168 html_content, table_of_contents, meta = convert_markdown(
169 input_content, site_navigation,
170 extensions=config['markdown_extensions'], strict=config['strict']
171 )
172
173 context = get_global_context(site_navigation, config)
174 context.update(get_page_context(
175 page, html_content, site_navigation,
176 table_of_contents, meta, config
177 ))
178
179 # Allow 'template:' override in md source files.
180 if 'template' in meta:
181 template = env.get_template(meta['template'][0])
182 else:
183 template = env.get_template('base.html')
184
185 # Render the template.
186 output_content = template.render(context)
187
188 # Write the output file.
189 output_path = os.path.join(config['site_dir'], page.output_path)
190 if dump_json:
191 json_context = {
192 'content': context['content'],
193 'title': context['current_page'].title,
194 'url': context['current_page'].abs_url,
195 'language': 'en',
196 }
197 utils.write_file(json.dumps(json_context, indent=4).encode('utf-8'), output_path.replace('.html', '.json'))
198 else:
199 utils.write_file(output_content.encode('utf-8'), output_path)
200
201
202 def build(config, live_server=False, dump_json=False, clean_site_dir=False):
203 """
204 Perform a full site build.
205 """
206 if clean_site_dir:
207 print("Cleaning site directory")
208 utils.clean_directory(config['site_dir'])
209 if not live_server:
210 print("Building documentation to directory: %s" % config['site_dir'])
211 if not clean_site_dir and site_directory_contains_stale_files(config['site_dir']):
212 print("Directory %s contains stale files. Use --clean to remove them." % config['site_dir'])
213
214 if dump_json:
215 build_pages(config, dump_json=True)
216 else:
217 # Reversed as we want to take the media files from the builtin theme
218 # and then from the custom theme_dir so the custom versions take take
219 # precedence.
220 for theme_dir in reversed(config['theme_dir']):
221 utils.copy_media_files(theme_dir, config['site_dir'])
222 utils.copy_media_files(config['docs_dir'], config['site_dir'])
223 build_pages(config)
224
225
226 def site_directory_contains_stale_files(site_directory):
227 """
228 Check if the site directory contains stale files from a previous build.
229 Right now the check returns true if the directory is not empty.
230 A more sophisticated approach should be found to trigger only if there are
231 files that won't be overwritten anyway.
232 """
233 if os.path.exists(site_directory):
234 if os.listdir(site_directory):
235 return True
236 return False
237
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mkdocs/build.py b/mkdocs/build.py
--- a/mkdocs/build.py
+++ b/mkdocs/build.py
@@ -1,7 +1,10 @@
# coding: utf-8
from __future__ import print_function
+from datetime import datetime
+
from jinja2.exceptions import TemplateNotFound
+import mkdocs
from mkdocs import nav, toc, utils
from mkdocs.compat import urljoin, PY2
from mkdocs.relative_path_ext import RelativePathExtension
@@ -85,7 +88,10 @@
'include_search': config['include_search'],
'copyright': config['copyright'],
- 'google_analytics': config['google_analytics']
+ 'google_analytics': config['google_analytics'],
+
+ 'mkdocs_version': mkdocs.__version__,
+ 'build_date_utc': datetime.utcnow()
}
| {"golden_diff": "diff --git a/mkdocs/build.py b/mkdocs/build.py\n--- a/mkdocs/build.py\n+++ b/mkdocs/build.py\n@@ -1,7 +1,10 @@\n # coding: utf-8\n from __future__ import print_function\n \n+from datetime import datetime\n+\n from jinja2.exceptions import TemplateNotFound\n+import mkdocs\n from mkdocs import nav, toc, utils\n from mkdocs.compat import urljoin, PY2\n from mkdocs.relative_path_ext import RelativePathExtension\n@@ -85,7 +88,10 @@\n 'include_search': config['include_search'],\n \n 'copyright': config['copyright'],\n- 'google_analytics': config['google_analytics']\n+ 'google_analytics': config['google_analytics'],\n+\n+ 'mkdocs_version': mkdocs.__version__,\n+ 'build_date_utc': datetime.utcnow()\n }\n", "issue": "Add build date and MkDocs version to the output\nThe date was suggested in #290, but didn't seem useful at the time.\n\nHowever, it would be really useful to see when the output was built and with what version when helping people debug.\n\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import print_function\n\nfrom jinja2.exceptions import TemplateNotFound\nfrom mkdocs import nav, toc, utils\nfrom mkdocs.compat import urljoin, PY2\nfrom mkdocs.relative_path_ext import RelativePathExtension\nimport jinja2\nimport json\nimport markdown\nimport os\nimport logging\n\nlog = logging.getLogger('mkdocs')\n\n\ndef convert_markdown(markdown_source, site_navigation=None, extensions=(), strict=False):\n \"\"\"\n Convert the Markdown source file to HTML content, and additionally\n return the parsed table of contents, and a dictionary of any metadata\n that was specified in the Markdown file.\n\n `extensions` is an optional sequence of Python Markdown extensions to add\n to the default set.\n \"\"\"\n\n # Generate the HTML from the markdown source\n builtin_extensions = ['meta', 'toc', 'tables', 'fenced_code']\n mkdocs_extensions = [RelativePathExtension(site_navigation, strict), ]\n extensions = builtin_extensions + mkdocs_extensions + list(extensions)\n md = markdown.Markdown(\n extensions=extensions\n )\n html_content = md.convert(markdown_source)\n meta = md.Meta\n toc_html = md.toc\n\n # Post process the generated table of contents into a data structure\n table_of_contents = toc.TableOfContents(toc_html)\n\n return (html_content, table_of_contents, meta)\n\n\ndef get_global_context(nav, config):\n \"\"\"\n Given the SiteNavigation and config, generate the context which is relevant\n to app pages.\n \"\"\"\n\n site_name = config['site_name']\n\n if config['site_favicon']:\n site_favicon = nav.url_context.make_relative('/' + config['site_favicon'])\n else:\n site_favicon = None\n\n page_description = config['site_description']\n\n extra_javascript = utils.create_media_urls(nav=nav, url_list=config['extra_javascript'])\n\n extra_css = utils.create_media_urls(nav=nav, url_list=config['extra_css'])\n\n return {\n 'site_name': site_name,\n 'site_author': config['site_author'],\n 'favicon': site_favicon,\n 'page_description': page_description,\n\n # Note that there's intentionally repetition here. Rather than simply\n # provide the config dictionary we instead pass everything explicitly.\n #\n # This helps ensure that we can throughly document the context that\n # gets passed to themes.\n 'repo_url': config['repo_url'],\n 'repo_name': config['repo_name'],\n 'nav': nav,\n 'base_url': nav.url_context.make_relative('/'),\n 'homepage_url': nav.homepage.url,\n\n 'extra_css': extra_css,\n 'extra_javascript': extra_javascript,\n\n 'include_nav': config['include_nav'],\n 'include_next_prev': config['include_next_prev'],\n 'include_search': config['include_search'],\n\n 'copyright': config['copyright'],\n 'google_analytics': config['google_analytics']\n }\n\n\ndef get_page_context(page, content, nav, toc, meta, config):\n \"\"\"\n Generate the page context by extending the global context and adding page\n specific variables.\n \"\"\"\n\n if page.is_homepage or page.title is None:\n page_title = None\n else:\n page_title = page.title\n\n if page.is_homepage:\n page_description = config['site_description']\n else:\n page_description = None\n\n if config['site_url']:\n base = config['site_url']\n if not base.endswith('/'):\n base += '/'\n canonical_url = urljoin(base, page.abs_url.lstrip('/'))\n else:\n canonical_url = None\n\n return {\n 'page_title': page_title,\n 'page_description': page_description,\n\n 'content': content,\n 'toc': toc,\n 'meta': meta,\n\n\n 'canonical_url': canonical_url,\n\n 'current_page': page,\n 'previous_page': page.previous_page,\n 'next_page': page.next_page,\n }\n\n\ndef build_404(config, env, site_navigation):\n\n try:\n template = env.get_template('404.html')\n except TemplateNotFound:\n return\n\n global_context = get_global_context(site_navigation, config)\n\n output_content = template.render(global_context)\n output_path = os.path.join(config['site_dir'], '404.html')\n utils.write_file(output_content.encode('utf-8'), output_path)\n\n\ndef build_pages(config, dump_json=False):\n \"\"\"\n Builds all the pages and writes them into the build directory.\n \"\"\"\n site_navigation = nav.SiteNavigation(config['pages'], config['use_directory_urls'])\n loader = jinja2.FileSystemLoader(config['theme_dir'])\n env = jinja2.Environment(loader=loader)\n\n build_404(config, env, site_navigation)\n\n for page in site_navigation.walk_pages():\n # Read the input file\n input_path = os.path.join(config['docs_dir'], page.input_path)\n try:\n input_content = open(input_path, 'r').read()\n except IOError:\n log.error('file not found: %s' % input_path)\n if PY2:\n input_content = input_content.decode('utf-8')\n\n # Process the markdown text\n html_content, table_of_contents, meta = convert_markdown(\n input_content, site_navigation,\n extensions=config['markdown_extensions'], strict=config['strict']\n )\n\n context = get_global_context(site_navigation, config)\n context.update(get_page_context(\n page, html_content, site_navigation,\n table_of_contents, meta, config\n ))\n\n # Allow 'template:' override in md source files.\n if 'template' in meta:\n template = env.get_template(meta['template'][0])\n else:\n template = env.get_template('base.html')\n\n # Render the template.\n output_content = template.render(context)\n\n # Write the output file.\n output_path = os.path.join(config['site_dir'], page.output_path)\n if dump_json:\n json_context = {\n 'content': context['content'],\n 'title': context['current_page'].title,\n 'url': context['current_page'].abs_url,\n 'language': 'en',\n }\n utils.write_file(json.dumps(json_context, indent=4).encode('utf-8'), output_path.replace('.html', '.json'))\n else:\n utils.write_file(output_content.encode('utf-8'), output_path)\n\n\ndef build(config, live_server=False, dump_json=False, clean_site_dir=False):\n \"\"\"\n Perform a full site build.\n \"\"\"\n if clean_site_dir:\n print(\"Cleaning site directory\")\n utils.clean_directory(config['site_dir'])\n if not live_server:\n print(\"Building documentation to directory: %s\" % config['site_dir'])\n if not clean_site_dir and site_directory_contains_stale_files(config['site_dir']):\n print(\"Directory %s contains stale files. Use --clean to remove them.\" % config['site_dir'])\n\n if dump_json:\n build_pages(config, dump_json=True)\n else:\n # Reversed as we want to take the media files from the builtin theme\n # and then from the custom theme_dir so the custom versions take take\n # precedence.\n for theme_dir in reversed(config['theme_dir']):\n utils.copy_media_files(theme_dir, config['site_dir'])\n utils.copy_media_files(config['docs_dir'], config['site_dir'])\n build_pages(config)\n\n\ndef site_directory_contains_stale_files(site_directory):\n \"\"\"\n Check if the site directory contains stale files from a previous build.\n Right now the check returns true if the directory is not empty.\n A more sophisticated approach should be found to trigger only if there are\n files that won't be overwritten anyway.\n \"\"\"\n if os.path.exists(site_directory):\n if os.listdir(site_directory):\n return True\n return False\n", "path": "mkdocs/build.py"}], "after_files": [{"content": "# coding: utf-8\nfrom __future__ import print_function\n\nfrom datetime import datetime\n\nfrom jinja2.exceptions import TemplateNotFound\nimport mkdocs\nfrom mkdocs import nav, toc, utils\nfrom mkdocs.compat import urljoin, PY2\nfrom mkdocs.relative_path_ext import RelativePathExtension\nimport jinja2\nimport json\nimport markdown\nimport os\nimport logging\n\nlog = logging.getLogger('mkdocs')\n\n\ndef convert_markdown(markdown_source, site_navigation=None, extensions=(), strict=False):\n \"\"\"\n Convert the Markdown source file to HTML content, and additionally\n return the parsed table of contents, and a dictionary of any metadata\n that was specified in the Markdown file.\n\n `extensions` is an optional sequence of Python Markdown extensions to add\n to the default set.\n \"\"\"\n\n # Generate the HTML from the markdown source\n builtin_extensions = ['meta', 'toc', 'tables', 'fenced_code']\n mkdocs_extensions = [RelativePathExtension(site_navigation, strict), ]\n extensions = builtin_extensions + mkdocs_extensions + list(extensions)\n md = markdown.Markdown(\n extensions=extensions\n )\n html_content = md.convert(markdown_source)\n meta = md.Meta\n toc_html = md.toc\n\n # Post process the generated table of contents into a data structure\n table_of_contents = toc.TableOfContents(toc_html)\n\n return (html_content, table_of_contents, meta)\n\n\ndef get_global_context(nav, config):\n \"\"\"\n Given the SiteNavigation and config, generate the context which is relevant\n to app pages.\n \"\"\"\n\n site_name = config['site_name']\n\n if config['site_favicon']:\n site_favicon = nav.url_context.make_relative('/' + config['site_favicon'])\n else:\n site_favicon = None\n\n page_description = config['site_description']\n\n extra_javascript = utils.create_media_urls(nav=nav, url_list=config['extra_javascript'])\n\n extra_css = utils.create_media_urls(nav=nav, url_list=config['extra_css'])\n\n return {\n 'site_name': site_name,\n 'site_author': config['site_author'],\n 'favicon': site_favicon,\n 'page_description': page_description,\n\n # Note that there's intentionally repetition here. Rather than simply\n # provide the config dictionary we instead pass everything explicitly.\n #\n # This helps ensure that we can throughly document the context that\n # gets passed to themes.\n 'repo_url': config['repo_url'],\n 'repo_name': config['repo_name'],\n 'nav': nav,\n 'base_url': nav.url_context.make_relative('/'),\n 'homepage_url': nav.homepage.url,\n\n 'extra_css': extra_css,\n 'extra_javascript': extra_javascript,\n\n 'include_nav': config['include_nav'],\n 'include_next_prev': config['include_next_prev'],\n 'include_search': config['include_search'],\n\n 'copyright': config['copyright'],\n 'google_analytics': config['google_analytics'],\n\n 'mkdocs_version': mkdocs.__version__,\n 'build_date_utc': datetime.utcnow()\n }\n\n\ndef get_page_context(page, content, nav, toc, meta, config):\n \"\"\"\n Generate the page context by extending the global context and adding page\n specific variables.\n \"\"\"\n\n if page.is_homepage or page.title is None:\n page_title = None\n else:\n page_title = page.title\n\n if page.is_homepage:\n page_description = config['site_description']\n else:\n page_description = None\n\n if config['site_url']:\n base = config['site_url']\n if not base.endswith('/'):\n base += '/'\n canonical_url = urljoin(base, page.abs_url.lstrip('/'))\n else:\n canonical_url = None\n\n return {\n 'page_title': page_title,\n 'page_description': page_description,\n\n 'content': content,\n 'toc': toc,\n 'meta': meta,\n\n\n 'canonical_url': canonical_url,\n\n 'current_page': page,\n 'previous_page': page.previous_page,\n 'next_page': page.next_page,\n }\n\n\ndef build_404(config, env, site_navigation):\n\n try:\n template = env.get_template('404.html')\n except TemplateNotFound:\n return\n\n global_context = get_global_context(site_navigation, config)\n\n output_content = template.render(global_context)\n output_path = os.path.join(config['site_dir'], '404.html')\n utils.write_file(output_content.encode('utf-8'), output_path)\n\n\ndef build_pages(config, dump_json=False):\n \"\"\"\n Builds all the pages and writes them into the build directory.\n \"\"\"\n site_navigation = nav.SiteNavigation(config['pages'], config['use_directory_urls'])\n loader = jinja2.FileSystemLoader(config['theme_dir'])\n env = jinja2.Environment(loader=loader)\n\n build_404(config, env, site_navigation)\n\n for page in site_navigation.walk_pages():\n # Read the input file\n input_path = os.path.join(config['docs_dir'], page.input_path)\n try:\n input_content = open(input_path, 'r').read()\n except IOError:\n log.error('file not found: %s' % input_path)\n if PY2:\n input_content = input_content.decode('utf-8')\n\n # Process the markdown text\n html_content, table_of_contents, meta = convert_markdown(\n input_content, site_navigation,\n extensions=config['markdown_extensions'], strict=config['strict']\n )\n\n context = get_global_context(site_navigation, config)\n context.update(get_page_context(\n page, html_content, site_navigation,\n table_of_contents, meta, config\n ))\n\n # Allow 'template:' override in md source files.\n if 'template' in meta:\n template = env.get_template(meta['template'][0])\n else:\n template = env.get_template('base.html')\n\n # Render the template.\n output_content = template.render(context)\n\n # Write the output file.\n output_path = os.path.join(config['site_dir'], page.output_path)\n if dump_json:\n json_context = {\n 'content': context['content'],\n 'title': context['current_page'].title,\n 'url': context['current_page'].abs_url,\n 'language': 'en',\n }\n utils.write_file(json.dumps(json_context, indent=4).encode('utf-8'), output_path.replace('.html', '.json'))\n else:\n utils.write_file(output_content.encode('utf-8'), output_path)\n\n\ndef build(config, live_server=False, dump_json=False, clean_site_dir=False):\n \"\"\"\n Perform a full site build.\n \"\"\"\n if clean_site_dir:\n print(\"Cleaning site directory\")\n utils.clean_directory(config['site_dir'])\n if not live_server:\n print(\"Building documentation to directory: %s\" % config['site_dir'])\n if not clean_site_dir and site_directory_contains_stale_files(config['site_dir']):\n print(\"Directory %s contains stale files. Use --clean to remove them.\" % config['site_dir'])\n\n if dump_json:\n build_pages(config, dump_json=True)\n else:\n # Reversed as we want to take the media files from the builtin theme\n # and then from the custom theme_dir so the custom versions take take\n # precedence.\n for theme_dir in reversed(config['theme_dir']):\n utils.copy_media_files(theme_dir, config['site_dir'])\n utils.copy_media_files(config['docs_dir'], config['site_dir'])\n build_pages(config)\n\n\ndef site_directory_contains_stale_files(site_directory):\n \"\"\"\n Check if the site directory contains stale files from a previous build.\n Right now the check returns true if the directory is not empty.\n A more sophisticated approach should be found to trigger only if there are\n files that won't be overwritten anyway.\n \"\"\"\n if os.path.exists(site_directory):\n if os.listdir(site_directory):\n return True\n return False\n", "path": "mkdocs/build.py"}]} | 2,618 | 194 |
gh_patches_debug_13298 | rasdani/github-patches | git_diff | mdn__kuma-6739 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
T - Add email to whoami userData so that Stripe form can be prefilled.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kuma/api/v1/views.py`
Content:
```
1 from django.conf import settings
2 from django.http import Http404, HttpResponsePermanentRedirect, JsonResponse
3 from django.shortcuts import get_object_or_404
4 from django.utils.translation import activate, gettext as _
5 from django.views.decorators.cache import never_cache
6 from django.views.decorators.http import require_GET, require_safe
7 from ratelimit.decorators import ratelimit
8 from rest_framework import serializers, status
9 from rest_framework.decorators import api_view
10 from rest_framework.renderers import JSONRenderer
11 from rest_framework.response import Response
12 from waffle.models import Flag, Sample, Switch
13
14 from kuma.api.v1.serializers import BCSignalSerializer
15 from kuma.core.urlresolvers import reverse
16 from kuma.search.filters import (
17 HighlightFilterBackend,
18 KeywordQueryBackend,
19 LanguageFilterBackend,
20 SearchQueryBackend,
21 TagGroupFilterBackend,
22 )
23 from kuma.search.search import SearchView
24 from kuma.users.models import User, UserSubscription
25 from kuma.users.templatetags.jinja_helpers import get_avatar_url
26 from kuma.wiki.models import Document
27 from kuma.wiki.templatetags.jinja_helpers import absolutify
28
29
30 @never_cache
31 @require_GET
32 def doc(request, locale, slug):
33 """
34 Return a JSON object that includes document content and metadata
35 for the document specified by the locale and path. Raises a 404
36 error if no such document exists. This is an API with URL
37 /api/v1/doc/<locale>/<path>
38 """
39 # TODO: This API endpoint probably needs to handle redirect documents
40 # and documents that fall back to the en-US locale. See
41 # the document() function in wiki/views/document.py for a model to follow.
42
43 # Since we don't have the locale at the start of the path, our
44 # locale middleware can't set the translation language correctly
45 # and we need to do it explicitly. (We need to know the language
46 # so that we can provide translated language names for the
47 # translations menu.)
48 activate(locale)
49 document = get_object_or_404(Document, locale=locale, slug=slug)
50
51 redirect = get_content_based_redirect(document)
52 if redirect:
53 redirect_url, is_redirect_to_document = redirect
54 if is_redirect_to_document:
55 return HttpResponsePermanentRedirect(redirect_url)
56 return JsonResponse(document_api_data(redirect_url=redirect_url))
57
58 return JsonResponse(document_api_data(document))
59
60
61 def get_s3_key(
62 doc=None,
63 locale=None,
64 slug=None,
65 prefix_with_forward_slash=False,
66 suffix_file_extension=True,
67 ):
68 if doc:
69 locale, slug = doc.locale, doc.slug
70 key = reverse("api.v1.doc", args=(locale, slug))
71 if suffix_file_extension:
72 key += ".json"
73 if prefix_with_forward_slash:
74 # Redirects within an S3 bucket must be prefixed with "/".
75 return key
76 return key.lstrip("/")
77
78
79 def get_cdn_key(locale, slug):
80 """Given a document's locale and slug, return the "key" for the CDN."""
81 return get_s3_key(
82 locale=locale,
83 slug=slug,
84 prefix_with_forward_slash=True,
85 suffix_file_extension=False,
86 )
87
88
89 def get_content_based_redirect(document):
90 """
91 Returns None if the document is not a content-based redirect, otherwise a
92 tuple pair comprising the redirect URL as well as a boolean value. The
93 boolean value will be True if this is a redirect to another document,
94 otherwise False. If the document is a redirect to another document or a
95 redirect to the homepage, a relative URL will be returned, otherwise it
96 will be a full URL to the wiki site.
97 """
98 redirect_url = document.get_redirect_url()
99 if redirect_url and (redirect_url != document.get_absolute_url()):
100 redirect_document = document.get_redirect_document(id_only=False)
101 if redirect_document:
102 # This is a redirect to another document.
103 return (
104 get_s3_key(
105 redirect_document,
106 prefix_with_forward_slash=True,
107 suffix_file_extension=False,
108 ),
109 True,
110 )
111 # This is a redirect to non-document page. For now, if it's the home
112 # page, return a relative path (so we stay on the read-only domain),
113 # otherwise return the full URL for the wiki site.
114 locale = document.locale
115 is_home_page = redirect_url in ("/", "/" + locale, "/{}/".format(locale))
116 if is_home_page:
117 # Let's return a relative URL to the home page for this locale.
118 return ("/{}/".format(locale), False)
119 # Otherwise, let's return a full URL to the Wiki site.
120 return (absolutify(redirect_url, for_wiki_site=True), False)
121 return None
122
123
124 def document_api_data(doc=None, redirect_url=None):
125 """
126 Returns the JSON data for the document for the document API.
127 """
128 if redirect_url:
129 return {
130 "documentData": None,
131 "redirectURL": redirect_url,
132 }
133
134 # The original english slug for this document, for google analytics
135 if doc.locale == "en-US":
136 en_slug = doc.slug
137 elif doc.parent_id and doc.parent.locale == "en-US":
138 en_slug = doc.parent.slug
139 else:
140 en_slug = ""
141
142 other_translations = doc.get_other_translations(
143 fields=("locale", "slug", "title", "parent")
144 )
145 available_locales = {doc.locale} | set(t.locale for t in other_translations)
146
147 doc_absolute_url = doc.get_absolute_url()
148 revision = doc.current_or_latest_revision()
149 translation_status = None
150 if doc.parent_id and revision and revision.localization_in_progress:
151 translation_status = (
152 "outdated" if revision.translation_age >= 10 else "in-progress"
153 )
154 return {
155 "documentData": {
156 "locale": doc.locale,
157 "slug": doc.slug,
158 "enSlug": en_slug,
159 "id": doc.id,
160 "title": doc.title,
161 "summary": doc.get_summary_html(),
162 "language": doc.language,
163 "hrefLang": doc.get_hreflang(available_locales),
164 "absoluteURL": doc_absolute_url,
165 "wikiURL": absolutify(doc_absolute_url, for_wiki_site=True),
166 "editURL": absolutify(
167 reverse("wiki.edit", args=(doc.slug,), locale=doc.locale),
168 for_wiki_site=True,
169 ),
170 "translateURL": (
171 absolutify(
172 reverse("wiki.select_locale", args=(doc.slug,), locale=doc.locale),
173 for_wiki_site=True,
174 )
175 if doc.is_localizable
176 else None
177 ),
178 "translationStatus": translation_status,
179 "bodyHTML": doc.get_body_html(),
180 "quickLinksHTML": doc.get_quick_links_html(),
181 "tocHTML": doc.get_toc_html(),
182 "raw": doc.html,
183 "parents": [
184 {"url": d.get_absolute_url(), "title": d.title} for d in doc.parents
185 ],
186 "translations": [
187 {
188 "language": t.language,
189 "hrefLang": t.get_hreflang(available_locales),
190 "localizedLanguage": _(settings.LOCALES[t.locale].english),
191 "locale": t.locale,
192 "url": t.get_absolute_url(),
193 "title": t.title,
194 }
195 for t in other_translations
196 ],
197 "lastModified": (
198 doc.current_revision and doc.current_revision.created.isoformat()
199 ),
200 },
201 "redirectURL": None,
202 }
203
204
205 @never_cache
206 @require_GET
207 def whoami(request):
208 """
209 Return a JSON object representing the current user, either
210 authenticated or anonymous.
211 """
212 user = request.user
213 if user.is_authenticated:
214 data = {
215 "username": user.username,
216 "timezone": user.timezone,
217 "is_authenticated": True,
218 "is_staff": user.is_staff,
219 "is_superuser": user.is_superuser,
220 "is_beta_tester": user.is_beta_tester,
221 "avatar_url": get_avatar_url(user),
222 "is_subscriber": UserSubscription.objects.filter(
223 user=user, canceled__isnull=True
224 ).exists(),
225 }
226 else:
227 data = {
228 "username": None,
229 "timezone": settings.TIME_ZONE,
230 "is_authenticated": False,
231 "is_staff": False,
232 "is_superuser": False,
233 "is_beta_tester": False,
234 "avatar_url": None,
235 "is_subscriber": False,
236 }
237
238 # Add waffle data to the dict we're going to be returning.
239 # This is what the waffle.wafflejs() template tag does, but we're
240 # doing it via an API instead of hardcoding the settings into
241 # the HTML page. See also from waffle.views._generate_waffle_js.
242 #
243 # Note that if we upgrade django-waffle, version 15 introduces a
244 # pluggable flag model, and the approved way to get all flag
245 # objects will then become:
246 # get_waffle_flag_model().get_all()
247 #
248 data["waffle"] = {
249 "flags": {f.name: f.is_active(request) for f in Flag.get_all()},
250 "switches": {s.name: s.is_active() for s in Switch.get_all()},
251 "samples": {s.name: s.is_active() for s in Sample.get_all()},
252 }
253 return JsonResponse(data)
254
255
256 class APIDocumentSerializer(serializers.Serializer):
257 title = serializers.CharField(read_only=True, max_length=255)
258 slug = serializers.CharField(read_only=True, max_length=255)
259 locale = serializers.CharField(read_only=True, max_length=7)
260 excerpt = serializers.ReadOnlyField(source="get_excerpt")
261
262
263 class APILanguageFilterBackend(LanguageFilterBackend):
264 """Override of kuma.search.filters:LanguageFilterBackend that is almost
265 exactly the same except the locale comes from custom code rather than
266 via kuma.core.i18n.get_language_from_request because that can't be used
267 in the API.
268
269 Basically, it's the same exact functionality but ...
270 """
271
272 def filter_queryset(self, request, queryset, view):
273 locale = request.GET.get("locale") or settings.LANGUAGE_CODE
274 if locale not in settings.ACCEPTED_LOCALES:
275 raise serializers.ValidationError({"error": "Not a valid locale code"})
276 request.LANGUAGE_CODE = locale
277 return super(APILanguageFilterBackend, self).filter_queryset(
278 request, queryset, view
279 )
280
281
282 class APISearchQueryBackend(SearchQueryBackend):
283 """Override of kuma.search.filters.SearchQueryBackend that makes a
284 stink if the 'q' query parameter is falsy."""
285
286 def filter_queryset(self, request, queryset, view):
287 search_term = (view.query_params.get("q") or "").strip()
288 if not search_term:
289 raise serializers.ValidationError({"error": "Search term 'q' must be set"})
290 return super(APISearchQueryBackend, self).filter_queryset(
291 request, queryset, view
292 )
293
294
295 class APISearchView(SearchView):
296 serializer_class = APIDocumentSerializer
297 renderer_classes = [JSONRenderer]
298 filter_backends = (
299 APISearchQueryBackend,
300 KeywordQueryBackend,
301 TagGroupFilterBackend,
302 APILanguageFilterBackend,
303 HighlightFilterBackend,
304 )
305
306
307 search = never_cache(APISearchView.as_view())
308
309
310 @ratelimit(key="user_or_ip", rate="10/d", block=True)
311 @api_view(["POST"])
312 def bc_signal(request):
313 if not settings.ENABLE_BCD_SIGNAL:
314 return Response("not enabled", status=status.HTTP_400_BAD_REQUEST)
315
316 serializer = BCSignalSerializer(data=request.data)
317 if serializer.is_valid():
318 serializer.save()
319 return Response(serializer.validated_data, status=status.HTTP_201_CREATED)
320 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
321
322
323 @never_cache
324 @require_safe
325 def get_user(request, username):
326 """
327 Returns a JSON response with a small subset of public information if a
328 user with the given username exists, otherwise returns a status code of
329 404. The case of the username is not important, since the collation of
330 the username column of the user table in MySQL is case-insensitive.
331 """
332 fields = (
333 "username",
334 "title",
335 "fullname",
336 "organization",
337 "location",
338 "timezone",
339 "locale",
340 )
341 try:
342 user = User.objects.only(*fields).get(username=username)
343 except User.DoesNotExist:
344 raise Http404(f'No user exists with the username "{username}".')
345 data = {field: getattr(user, field) for field in fields}
346 data["avatar_url"] = get_avatar_url(user)
347 return JsonResponse(data)
348
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/kuma/api/v1/views.py b/kuma/api/v1/views.py
--- a/kuma/api/v1/views.py
+++ b/kuma/api/v1/views.py
@@ -222,6 +222,7 @@
"is_subscriber": UserSubscription.objects.filter(
user=user, canceled__isnull=True
).exists(),
+ "email": user.email,
}
else:
data = {
@@ -233,6 +234,7 @@
"is_beta_tester": False,
"avatar_url": None,
"is_subscriber": False,
+ "email": None,
}
# Add waffle data to the dict we're going to be returning.
| {"golden_diff": "diff --git a/kuma/api/v1/views.py b/kuma/api/v1/views.py\n--- a/kuma/api/v1/views.py\n+++ b/kuma/api/v1/views.py\n@@ -222,6 +222,7 @@\n \"is_subscriber\": UserSubscription.objects.filter(\n user=user, canceled__isnull=True\n ).exists(),\n+ \"email\": user.email,\n }\n else:\n data = {\n@@ -233,6 +234,7 @@\n \"is_beta_tester\": False,\n \"avatar_url\": None,\n \"is_subscriber\": False,\n+ \"email\": None,\n }\n \n # Add waffle data to the dict we're going to be returning.\n", "issue": "T - Add email to whoami userData so that Stripe form can be prefilled. \n\n", "before_files": [{"content": "from django.conf import settings\nfrom django.http import Http404, HttpResponsePermanentRedirect, JsonResponse\nfrom django.shortcuts import get_object_or_404\nfrom django.utils.translation import activate, gettext as _\nfrom django.views.decorators.cache import never_cache\nfrom django.views.decorators.http import require_GET, require_safe\nfrom ratelimit.decorators import ratelimit\nfrom rest_framework import serializers, status\nfrom rest_framework.decorators import api_view\nfrom rest_framework.renderers import JSONRenderer\nfrom rest_framework.response import Response\nfrom waffle.models import Flag, Sample, Switch\n\nfrom kuma.api.v1.serializers import BCSignalSerializer\nfrom kuma.core.urlresolvers import reverse\nfrom kuma.search.filters import (\n HighlightFilterBackend,\n KeywordQueryBackend,\n LanguageFilterBackend,\n SearchQueryBackend,\n TagGroupFilterBackend,\n)\nfrom kuma.search.search import SearchView\nfrom kuma.users.models import User, UserSubscription\nfrom kuma.users.templatetags.jinja_helpers import get_avatar_url\nfrom kuma.wiki.models import Document\nfrom kuma.wiki.templatetags.jinja_helpers import absolutify\n\n\n@never_cache\n@require_GET\ndef doc(request, locale, slug):\n \"\"\"\n Return a JSON object that includes document content and metadata\n for the document specified by the locale and path. Raises a 404\n error if no such document exists. This is an API with URL\n /api/v1/doc/<locale>/<path>\n \"\"\"\n # TODO: This API endpoint probably needs to handle redirect documents\n # and documents that fall back to the en-US locale. See\n # the document() function in wiki/views/document.py for a model to follow.\n\n # Since we don't have the locale at the start of the path, our\n # locale middleware can't set the translation language correctly\n # and we need to do it explicitly. (We need to know the language\n # so that we can provide translated language names for the\n # translations menu.)\n activate(locale)\n document = get_object_or_404(Document, locale=locale, slug=slug)\n\n redirect = get_content_based_redirect(document)\n if redirect:\n redirect_url, is_redirect_to_document = redirect\n if is_redirect_to_document:\n return HttpResponsePermanentRedirect(redirect_url)\n return JsonResponse(document_api_data(redirect_url=redirect_url))\n\n return JsonResponse(document_api_data(document))\n\n\ndef get_s3_key(\n doc=None,\n locale=None,\n slug=None,\n prefix_with_forward_slash=False,\n suffix_file_extension=True,\n):\n if doc:\n locale, slug = doc.locale, doc.slug\n key = reverse(\"api.v1.doc\", args=(locale, slug))\n if suffix_file_extension:\n key += \".json\"\n if prefix_with_forward_slash:\n # Redirects within an S3 bucket must be prefixed with \"/\".\n return key\n return key.lstrip(\"/\")\n\n\ndef get_cdn_key(locale, slug):\n \"\"\"Given a document's locale and slug, return the \"key\" for the CDN.\"\"\"\n return get_s3_key(\n locale=locale,\n slug=slug,\n prefix_with_forward_slash=True,\n suffix_file_extension=False,\n )\n\n\ndef get_content_based_redirect(document):\n \"\"\"\n Returns None if the document is not a content-based redirect, otherwise a\n tuple pair comprising the redirect URL as well as a boolean value. The\n boolean value will be True if this is a redirect to another document,\n otherwise False. If the document is a redirect to another document or a\n redirect to the homepage, a relative URL will be returned, otherwise it\n will be a full URL to the wiki site.\n \"\"\"\n redirect_url = document.get_redirect_url()\n if redirect_url and (redirect_url != document.get_absolute_url()):\n redirect_document = document.get_redirect_document(id_only=False)\n if redirect_document:\n # This is a redirect to another document.\n return (\n get_s3_key(\n redirect_document,\n prefix_with_forward_slash=True,\n suffix_file_extension=False,\n ),\n True,\n )\n # This is a redirect to non-document page. For now, if it's the home\n # page, return a relative path (so we stay on the read-only domain),\n # otherwise return the full URL for the wiki site.\n locale = document.locale\n is_home_page = redirect_url in (\"/\", \"/\" + locale, \"/{}/\".format(locale))\n if is_home_page:\n # Let's return a relative URL to the home page for this locale.\n return (\"/{}/\".format(locale), False)\n # Otherwise, let's return a full URL to the Wiki site.\n return (absolutify(redirect_url, for_wiki_site=True), False)\n return None\n\n\ndef document_api_data(doc=None, redirect_url=None):\n \"\"\"\n Returns the JSON data for the document for the document API.\n \"\"\"\n if redirect_url:\n return {\n \"documentData\": None,\n \"redirectURL\": redirect_url,\n }\n\n # The original english slug for this document, for google analytics\n if doc.locale == \"en-US\":\n en_slug = doc.slug\n elif doc.parent_id and doc.parent.locale == \"en-US\":\n en_slug = doc.parent.slug\n else:\n en_slug = \"\"\n\n other_translations = doc.get_other_translations(\n fields=(\"locale\", \"slug\", \"title\", \"parent\")\n )\n available_locales = {doc.locale} | set(t.locale for t in other_translations)\n\n doc_absolute_url = doc.get_absolute_url()\n revision = doc.current_or_latest_revision()\n translation_status = None\n if doc.parent_id and revision and revision.localization_in_progress:\n translation_status = (\n \"outdated\" if revision.translation_age >= 10 else \"in-progress\"\n )\n return {\n \"documentData\": {\n \"locale\": doc.locale,\n \"slug\": doc.slug,\n \"enSlug\": en_slug,\n \"id\": doc.id,\n \"title\": doc.title,\n \"summary\": doc.get_summary_html(),\n \"language\": doc.language,\n \"hrefLang\": doc.get_hreflang(available_locales),\n \"absoluteURL\": doc_absolute_url,\n \"wikiURL\": absolutify(doc_absolute_url, for_wiki_site=True),\n \"editURL\": absolutify(\n reverse(\"wiki.edit\", args=(doc.slug,), locale=doc.locale),\n for_wiki_site=True,\n ),\n \"translateURL\": (\n absolutify(\n reverse(\"wiki.select_locale\", args=(doc.slug,), locale=doc.locale),\n for_wiki_site=True,\n )\n if doc.is_localizable\n else None\n ),\n \"translationStatus\": translation_status,\n \"bodyHTML\": doc.get_body_html(),\n \"quickLinksHTML\": doc.get_quick_links_html(),\n \"tocHTML\": doc.get_toc_html(),\n \"raw\": doc.html,\n \"parents\": [\n {\"url\": d.get_absolute_url(), \"title\": d.title} for d in doc.parents\n ],\n \"translations\": [\n {\n \"language\": t.language,\n \"hrefLang\": t.get_hreflang(available_locales),\n \"localizedLanguage\": _(settings.LOCALES[t.locale].english),\n \"locale\": t.locale,\n \"url\": t.get_absolute_url(),\n \"title\": t.title,\n }\n for t in other_translations\n ],\n \"lastModified\": (\n doc.current_revision and doc.current_revision.created.isoformat()\n ),\n },\n \"redirectURL\": None,\n }\n\n\n@never_cache\n@require_GET\ndef whoami(request):\n \"\"\"\n Return a JSON object representing the current user, either\n authenticated or anonymous.\n \"\"\"\n user = request.user\n if user.is_authenticated:\n data = {\n \"username\": user.username,\n \"timezone\": user.timezone,\n \"is_authenticated\": True,\n \"is_staff\": user.is_staff,\n \"is_superuser\": user.is_superuser,\n \"is_beta_tester\": user.is_beta_tester,\n \"avatar_url\": get_avatar_url(user),\n \"is_subscriber\": UserSubscription.objects.filter(\n user=user, canceled__isnull=True\n ).exists(),\n }\n else:\n data = {\n \"username\": None,\n \"timezone\": settings.TIME_ZONE,\n \"is_authenticated\": False,\n \"is_staff\": False,\n \"is_superuser\": False,\n \"is_beta_tester\": False,\n \"avatar_url\": None,\n \"is_subscriber\": False,\n }\n\n # Add waffle data to the dict we're going to be returning.\n # This is what the waffle.wafflejs() template tag does, but we're\n # doing it via an API instead of hardcoding the settings into\n # the HTML page. See also from waffle.views._generate_waffle_js.\n #\n # Note that if we upgrade django-waffle, version 15 introduces a\n # pluggable flag model, and the approved way to get all flag\n # objects will then become:\n # get_waffle_flag_model().get_all()\n #\n data[\"waffle\"] = {\n \"flags\": {f.name: f.is_active(request) for f in Flag.get_all()},\n \"switches\": {s.name: s.is_active() for s in Switch.get_all()},\n \"samples\": {s.name: s.is_active() for s in Sample.get_all()},\n }\n return JsonResponse(data)\n\n\nclass APIDocumentSerializer(serializers.Serializer):\n title = serializers.CharField(read_only=True, max_length=255)\n slug = serializers.CharField(read_only=True, max_length=255)\n locale = serializers.CharField(read_only=True, max_length=7)\n excerpt = serializers.ReadOnlyField(source=\"get_excerpt\")\n\n\nclass APILanguageFilterBackend(LanguageFilterBackend):\n \"\"\"Override of kuma.search.filters:LanguageFilterBackend that is almost\n exactly the same except the locale comes from custom code rather than\n via kuma.core.i18n.get_language_from_request because that can't be used\n in the API.\n\n Basically, it's the same exact functionality but ...\n \"\"\"\n\n def filter_queryset(self, request, queryset, view):\n locale = request.GET.get(\"locale\") or settings.LANGUAGE_CODE\n if locale not in settings.ACCEPTED_LOCALES:\n raise serializers.ValidationError({\"error\": \"Not a valid locale code\"})\n request.LANGUAGE_CODE = locale\n return super(APILanguageFilterBackend, self).filter_queryset(\n request, queryset, view\n )\n\n\nclass APISearchQueryBackend(SearchQueryBackend):\n \"\"\"Override of kuma.search.filters.SearchQueryBackend that makes a\n stink if the 'q' query parameter is falsy.\"\"\"\n\n def filter_queryset(self, request, queryset, view):\n search_term = (view.query_params.get(\"q\") or \"\").strip()\n if not search_term:\n raise serializers.ValidationError({\"error\": \"Search term 'q' must be set\"})\n return super(APISearchQueryBackend, self).filter_queryset(\n request, queryset, view\n )\n\n\nclass APISearchView(SearchView):\n serializer_class = APIDocumentSerializer\n renderer_classes = [JSONRenderer]\n filter_backends = (\n APISearchQueryBackend,\n KeywordQueryBackend,\n TagGroupFilterBackend,\n APILanguageFilterBackend,\n HighlightFilterBackend,\n )\n\n\nsearch = never_cache(APISearchView.as_view())\n\n\n@ratelimit(key=\"user_or_ip\", rate=\"10/d\", block=True)\n@api_view([\"POST\"])\ndef bc_signal(request):\n if not settings.ENABLE_BCD_SIGNAL:\n return Response(\"not enabled\", status=status.HTTP_400_BAD_REQUEST)\n\n serializer = BCSignalSerializer(data=request.data)\n if serializer.is_valid():\n serializer.save()\n return Response(serializer.validated_data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@never_cache\n@require_safe\ndef get_user(request, username):\n \"\"\"\n Returns a JSON response with a small subset of public information if a\n user with the given username exists, otherwise returns a status code of\n 404. The case of the username is not important, since the collation of\n the username column of the user table in MySQL is case-insensitive.\n \"\"\"\n fields = (\n \"username\",\n \"title\",\n \"fullname\",\n \"organization\",\n \"location\",\n \"timezone\",\n \"locale\",\n )\n try:\n user = User.objects.only(*fields).get(username=username)\n except User.DoesNotExist:\n raise Http404(f'No user exists with the username \"{username}\".')\n data = {field: getattr(user, field) for field in fields}\n data[\"avatar_url\"] = get_avatar_url(user)\n return JsonResponse(data)\n", "path": "kuma/api/v1/views.py"}], "after_files": [{"content": "from django.conf import settings\nfrom django.http import Http404, HttpResponsePermanentRedirect, JsonResponse\nfrom django.shortcuts import get_object_or_404\nfrom django.utils.translation import activate, gettext as _\nfrom django.views.decorators.cache import never_cache\nfrom django.views.decorators.http import require_GET, require_safe\nfrom ratelimit.decorators import ratelimit\nfrom rest_framework import serializers, status\nfrom rest_framework.decorators import api_view\nfrom rest_framework.renderers import JSONRenderer\nfrom rest_framework.response import Response\nfrom waffle.models import Flag, Sample, Switch\n\nfrom kuma.api.v1.serializers import BCSignalSerializer\nfrom kuma.core.urlresolvers import reverse\nfrom kuma.search.filters import (\n HighlightFilterBackend,\n KeywordQueryBackend,\n LanguageFilterBackend,\n SearchQueryBackend,\n TagGroupFilterBackend,\n)\nfrom kuma.search.search import SearchView\nfrom kuma.users.models import User, UserSubscription\nfrom kuma.users.templatetags.jinja_helpers import get_avatar_url\nfrom kuma.wiki.models import Document\nfrom kuma.wiki.templatetags.jinja_helpers import absolutify\n\n\n@never_cache\n@require_GET\ndef doc(request, locale, slug):\n \"\"\"\n Return a JSON object that includes document content and metadata\n for the document specified by the locale and path. Raises a 404\n error if no such document exists. This is an API with URL\n /api/v1/doc/<locale>/<path>\n \"\"\"\n # TODO: This API endpoint probably needs to handle redirect documents\n # and documents that fall back to the en-US locale. See\n # the document() function in wiki/views/document.py for a model to follow.\n\n # Since we don't have the locale at the start of the path, our\n # locale middleware can't set the translation language correctly\n # and we need to do it explicitly. (We need to know the language\n # so that we can provide translated language names for the\n # translations menu.)\n activate(locale)\n document = get_object_or_404(Document, locale=locale, slug=slug)\n\n redirect = get_content_based_redirect(document)\n if redirect:\n redirect_url, is_redirect_to_document = redirect\n if is_redirect_to_document:\n return HttpResponsePermanentRedirect(redirect_url)\n return JsonResponse(document_api_data(redirect_url=redirect_url))\n\n return JsonResponse(document_api_data(document))\n\n\ndef get_s3_key(\n doc=None,\n locale=None,\n slug=None,\n prefix_with_forward_slash=False,\n suffix_file_extension=True,\n):\n if doc:\n locale, slug = doc.locale, doc.slug\n key = reverse(\"api.v1.doc\", args=(locale, slug))\n if suffix_file_extension:\n key += \".json\"\n if prefix_with_forward_slash:\n # Redirects within an S3 bucket must be prefixed with \"/\".\n return key\n return key.lstrip(\"/\")\n\n\ndef get_cdn_key(locale, slug):\n \"\"\"Given a document's locale and slug, return the \"key\" for the CDN.\"\"\"\n return get_s3_key(\n locale=locale,\n slug=slug,\n prefix_with_forward_slash=True,\n suffix_file_extension=False,\n )\n\n\ndef get_content_based_redirect(document):\n \"\"\"\n Returns None if the document is not a content-based redirect, otherwise a\n tuple pair comprising the redirect URL as well as a boolean value. The\n boolean value will be True if this is a redirect to another document,\n otherwise False. If the document is a redirect to another document or a\n redirect to the homepage, a relative URL will be returned, otherwise it\n will be a full URL to the wiki site.\n \"\"\"\n redirect_url = document.get_redirect_url()\n if redirect_url and (redirect_url != document.get_absolute_url()):\n redirect_document = document.get_redirect_document(id_only=False)\n if redirect_document:\n # This is a redirect to another document.\n return (\n get_s3_key(\n redirect_document,\n prefix_with_forward_slash=True,\n suffix_file_extension=False,\n ),\n True,\n )\n # This is a redirect to non-document page. For now, if it's the home\n # page, return a relative path (so we stay on the read-only domain),\n # otherwise return the full URL for the wiki site.\n locale = document.locale\n is_home_page = redirect_url in (\"/\", \"/\" + locale, \"/{}/\".format(locale))\n if is_home_page:\n # Let's return a relative URL to the home page for this locale.\n return (\"/{}/\".format(locale), False)\n # Otherwise, let's return a full URL to the Wiki site.\n return (absolutify(redirect_url, for_wiki_site=True), False)\n return None\n\n\ndef document_api_data(doc=None, redirect_url=None):\n \"\"\"\n Returns the JSON data for the document for the document API.\n \"\"\"\n if redirect_url:\n return {\n \"documentData\": None,\n \"redirectURL\": redirect_url,\n }\n\n # The original english slug for this document, for google analytics\n if doc.locale == \"en-US\":\n en_slug = doc.slug\n elif doc.parent_id and doc.parent.locale == \"en-US\":\n en_slug = doc.parent.slug\n else:\n en_slug = \"\"\n\n other_translations = doc.get_other_translations(\n fields=(\"locale\", \"slug\", \"title\", \"parent\")\n )\n available_locales = {doc.locale} | set(t.locale for t in other_translations)\n\n doc_absolute_url = doc.get_absolute_url()\n revision = doc.current_or_latest_revision()\n translation_status = None\n if doc.parent_id and revision and revision.localization_in_progress:\n translation_status = (\n \"outdated\" if revision.translation_age >= 10 else \"in-progress\"\n )\n return {\n \"documentData\": {\n \"locale\": doc.locale,\n \"slug\": doc.slug,\n \"enSlug\": en_slug,\n \"id\": doc.id,\n \"title\": doc.title,\n \"summary\": doc.get_summary_html(),\n \"language\": doc.language,\n \"hrefLang\": doc.get_hreflang(available_locales),\n \"absoluteURL\": doc_absolute_url,\n \"wikiURL\": absolutify(doc_absolute_url, for_wiki_site=True),\n \"editURL\": absolutify(\n reverse(\"wiki.edit\", args=(doc.slug,), locale=doc.locale),\n for_wiki_site=True,\n ),\n \"translateURL\": (\n absolutify(\n reverse(\"wiki.select_locale\", args=(doc.slug,), locale=doc.locale),\n for_wiki_site=True,\n )\n if doc.is_localizable\n else None\n ),\n \"translationStatus\": translation_status,\n \"bodyHTML\": doc.get_body_html(),\n \"quickLinksHTML\": doc.get_quick_links_html(),\n \"tocHTML\": doc.get_toc_html(),\n \"raw\": doc.html,\n \"parents\": [\n {\"url\": d.get_absolute_url(), \"title\": d.title} for d in doc.parents\n ],\n \"translations\": [\n {\n \"language\": t.language,\n \"hrefLang\": t.get_hreflang(available_locales),\n \"localizedLanguage\": _(settings.LOCALES[t.locale].english),\n \"locale\": t.locale,\n \"url\": t.get_absolute_url(),\n \"title\": t.title,\n }\n for t in other_translations\n ],\n \"lastModified\": (\n doc.current_revision and doc.current_revision.created.isoformat()\n ),\n },\n \"redirectURL\": None,\n }\n\n\n@never_cache\n@require_GET\ndef whoami(request):\n \"\"\"\n Return a JSON object representing the current user, either\n authenticated or anonymous.\n \"\"\"\n user = request.user\n if user.is_authenticated:\n data = {\n \"username\": user.username,\n \"timezone\": user.timezone,\n \"is_authenticated\": True,\n \"is_staff\": user.is_staff,\n \"is_superuser\": user.is_superuser,\n \"is_beta_tester\": user.is_beta_tester,\n \"avatar_url\": get_avatar_url(user),\n \"is_subscriber\": UserSubscription.objects.filter(\n user=user, canceled__isnull=True\n ).exists(),\n \"email\": user.email,\n }\n else:\n data = {\n \"username\": None,\n \"timezone\": settings.TIME_ZONE,\n \"is_authenticated\": False,\n \"is_staff\": False,\n \"is_superuser\": False,\n \"is_beta_tester\": False,\n \"avatar_url\": None,\n \"is_subscriber\": False,\n \"email\": None,\n }\n\n # Add waffle data to the dict we're going to be returning.\n # This is what the waffle.wafflejs() template tag does, but we're\n # doing it via an API instead of hardcoding the settings into\n # the HTML page. See also from waffle.views._generate_waffle_js.\n #\n # Note that if we upgrade django-waffle, version 15 introduces a\n # pluggable flag model, and the approved way to get all flag\n # objects will then become:\n # get_waffle_flag_model().get_all()\n #\n data[\"waffle\"] = {\n \"flags\": {f.name: f.is_active(request) for f in Flag.get_all()},\n \"switches\": {s.name: s.is_active() for s in Switch.get_all()},\n \"samples\": {s.name: s.is_active() for s in Sample.get_all()},\n }\n return JsonResponse(data)\n\n\nclass APIDocumentSerializer(serializers.Serializer):\n title = serializers.CharField(read_only=True, max_length=255)\n slug = serializers.CharField(read_only=True, max_length=255)\n locale = serializers.CharField(read_only=True, max_length=7)\n excerpt = serializers.ReadOnlyField(source=\"get_excerpt\")\n\n\nclass APILanguageFilterBackend(LanguageFilterBackend):\n \"\"\"Override of kuma.search.filters:LanguageFilterBackend that is almost\n exactly the same except the locale comes from custom code rather than\n via kuma.core.i18n.get_language_from_request because that can't be used\n in the API.\n\n Basically, it's the same exact functionality but ...\n \"\"\"\n\n def filter_queryset(self, request, queryset, view):\n locale = request.GET.get(\"locale\") or settings.LANGUAGE_CODE\n if locale not in settings.ACCEPTED_LOCALES:\n raise serializers.ValidationError({\"error\": \"Not a valid locale code\"})\n request.LANGUAGE_CODE = locale\n return super(APILanguageFilterBackend, self).filter_queryset(\n request, queryset, view\n )\n\n\nclass APISearchQueryBackend(SearchQueryBackend):\n \"\"\"Override of kuma.search.filters.SearchQueryBackend that makes a\n stink if the 'q' query parameter is falsy.\"\"\"\n\n def filter_queryset(self, request, queryset, view):\n search_term = (view.query_params.get(\"q\") or \"\").strip()\n if not search_term:\n raise serializers.ValidationError({\"error\": \"Search term 'q' must be set\"})\n return super(APISearchQueryBackend, self).filter_queryset(\n request, queryset, view\n )\n\n\nclass APISearchView(SearchView):\n serializer_class = APIDocumentSerializer\n renderer_classes = [JSONRenderer]\n filter_backends = (\n APISearchQueryBackend,\n KeywordQueryBackend,\n TagGroupFilterBackend,\n APILanguageFilterBackend,\n HighlightFilterBackend,\n )\n\n\nsearch = never_cache(APISearchView.as_view())\n\n\n@ratelimit(key=\"user_or_ip\", rate=\"10/d\", block=True)\n@api_view([\"POST\"])\ndef bc_signal(request):\n if not settings.ENABLE_BCD_SIGNAL:\n return Response(\"not enabled\", status=status.HTTP_400_BAD_REQUEST)\n\n serializer = BCSignalSerializer(data=request.data)\n if serializer.is_valid():\n serializer.save()\n return Response(serializer.validated_data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@never_cache\n@require_safe\ndef get_user(request, username):\n \"\"\"\n Returns a JSON response with a small subset of public information if a\n user with the given username exists, otherwise returns a status code of\n 404. The case of the username is not important, since the collation of\n the username column of the user table in MySQL is case-insensitive.\n \"\"\"\n fields = (\n \"username\",\n \"title\",\n \"fullname\",\n \"organization\",\n \"location\",\n \"timezone\",\n \"locale\",\n )\n try:\n user = User.objects.only(*fields).get(username=username)\n except User.DoesNotExist:\n raise Http404(f'No user exists with the username \"{username}\".')\n data = {field: getattr(user, field) for field in fields}\n data[\"avatar_url\"] = get_avatar_url(user)\n return JsonResponse(data)\n", "path": "kuma/api/v1/views.py"}]} | 3,983 | 160 |
gh_patches_debug_399 | rasdani/github-patches | git_diff | bokeh__bokeh-1948 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`publishing` example from the `embed` directory fails
With an error message that is not particularly helpfull. Using bokeh 0.8.
```
➜ embed python publishing.py
Using saved session configuration for http://localhost:5006/
To override, pass 'load_from_config=False' to Session
INFO:requests.packages.urllib3.connectionpool:Starting new HTTP connection (1): localhost
Traceback (most recent call last):
File "publishing.py", line 11, in <module>
Session().register('testuser', 'testpassword')
File "/Users/nicolas/anaconda/lib/python2.7/site-packages/bokeh/session.py", line 208, in register
raise RuntimeError("Unknown Error")
RuntimeError: Unknown Error
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/embed/publishing.py`
Content:
```
1 # The plot server must be running
2 # Go to http://localhost:5006/bokeh to view this plot
3
4 import time
5
6 import numpy as np
7
8 from bokeh.plotting import *
9 from bokeh.session import Session
10 from bokeh import embed
11 Session().register('testuser', 'testpassword')
12 N = 80
13 x = np.linspace(0, 4*np.pi, N)
14 y = np.sin(x)
15 output_server("line_animate")
16 TOOLS = "pan,wheel_zoom,box_zoom,reset,save,box_select"
17 p = figure(tools=TOOLS)
18 p.circle(x, y, color="#3333ee", name="sin")
19 push()
20 renderer = p.select(dict(name="sin"))
21 ds = renderer[0].data_source
22 cursession().publish()
23 tag = embed.autoload_server(p, cursession(), public=True)
24 html = """
25 <html>
26 <head></head>
27 <body>
28 %s
29 </body>
30 </html>
31 """
32 html = html % (tag)
33 with open("publishing.html", "w+") as f:
34 f.write(html)
35 while True:
36 for i in np.hstack((np.linspace(1, -1, 100), np.linspace(-1, 1, 100))):
37 ds.data["y"] = y * i
38 cursession().store_objects(ds)
39 time.sleep(1.0)
40
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/examples/embed/publishing.py b/examples/embed/publishing.py
--- a/examples/embed/publishing.py
+++ b/examples/embed/publishing.py
@@ -1,4 +1,5 @@
# The plot server must be running
+# The server must run with --multi-user for this example to work
# Go to http://localhost:5006/bokeh to view this plot
import time
| {"golden_diff": "diff --git a/examples/embed/publishing.py b/examples/embed/publishing.py\n--- a/examples/embed/publishing.py\n+++ b/examples/embed/publishing.py\n@@ -1,4 +1,5 @@\n # The plot server must be running\n+# The server must run with --multi-user for this example to work\n # Go to http://localhost:5006/bokeh to view this plot\n \n import time\n", "issue": "`publishing` example from the `embed` directory fails\nWith an error message that is not particularly helpfull. Using bokeh 0.8.\n\n```\n\u279c embed python publishing.py\nUsing saved session configuration for http://localhost:5006/\nTo override, pass 'load_from_config=False' to Session\nINFO:requests.packages.urllib3.connectionpool:Starting new HTTP connection (1): localhost\nTraceback (most recent call last):\n File \"publishing.py\", line 11, in <module>\n Session().register('testuser', 'testpassword')\n File \"/Users/nicolas/anaconda/lib/python2.7/site-packages/bokeh/session.py\", line 208, in register\n raise RuntimeError(\"Unknown Error\")\nRuntimeError: Unknown Error\n```\n\n", "before_files": [{"content": "# The plot server must be running\n# Go to http://localhost:5006/bokeh to view this plot\n\nimport time\n\nimport numpy as np\n\nfrom bokeh.plotting import *\nfrom bokeh.session import Session\nfrom bokeh import embed\nSession().register('testuser', 'testpassword')\nN = 80\nx = np.linspace(0, 4*np.pi, N)\ny = np.sin(x)\noutput_server(\"line_animate\")\nTOOLS = \"pan,wheel_zoom,box_zoom,reset,save,box_select\"\np = figure(tools=TOOLS)\np.circle(x, y, color=\"#3333ee\", name=\"sin\")\npush()\nrenderer = p.select(dict(name=\"sin\"))\nds = renderer[0].data_source\ncursession().publish()\ntag = embed.autoload_server(p, cursession(), public=True)\nhtml = \"\"\"\n<html>\n<head></head>\n<body>\n%s\n</body>\n</html>\n\"\"\"\nhtml = html % (tag)\nwith open(\"publishing.html\", \"w+\") as f:\n f.write(html)\nwhile True:\n for i in np.hstack((np.linspace(1, -1, 100), np.linspace(-1, 1, 100))):\n ds.data[\"y\"] = y * i\n cursession().store_objects(ds)\n time.sleep(1.0)\n", "path": "examples/embed/publishing.py"}], "after_files": [{"content": "# The plot server must be running\n# The server must run with --multi-user for this example to work\n# Go to http://localhost:5006/bokeh to view this plot\n\nimport time\n\nimport numpy as np\n\nfrom bokeh.plotting import *\nfrom bokeh.session import Session\nfrom bokeh import embed\nSession().register('testuser', 'testpassword')\nN = 80\nx = np.linspace(0, 4*np.pi, N)\ny = np.sin(x)\noutput_server(\"line_animate\")\nTOOLS = \"pan,wheel_zoom,box_zoom,reset,save,box_select\"\np = figure(tools=TOOLS)\np.circle(x, y, color=\"#3333ee\", name=\"sin\")\npush()\nrenderer = p.select(dict(name=\"sin\"))\nds = renderer[0].data_source\ncursession().publish()\ntag = embed.autoload_server(p, cursession(), public=True)\nhtml = \"\"\"\n<html>\n<head></head>\n<body>\n%s\n</body>\n</html>\n\"\"\"\nhtml = html % (tag)\nwith open(\"publishing.html\", \"w+\") as f:\n f.write(html)\nwhile True:\n for i in np.hstack((np.linspace(1, -1, 100), np.linspace(-1, 1, 100))):\n ds.data[\"y\"] = y * i\n cursession().store_objects(ds)\n time.sleep(1.0)\n", "path": "examples/embed/publishing.py"}]} | 801 | 91 |
gh_patches_debug_41448 | rasdani/github-patches | git_diff | Lightning-Universe__lightning-flash-906 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add a tabular_forecasting example
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `flash_examples/integrations/pytorch_forecasting/tabular_forecasting_interpretable.py`
Content:
```
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import torch
15
16 import flash
17 from flash.core.integrations.pytorch_forecasting import convert_predictions
18 from flash.core.utilities.imports import example_requires
19 from flash.tabular.forecasting import TabularForecaster, TabularForecastingData
20
21 example_requires(["tabular", "matplotlib"])
22
23 import matplotlib.pyplot as plt # noqa: E402
24 import pandas as pd # noqa: E402
25 from pytorch_forecasting.data import NaNLabelEncoder # noqa: E402
26 from pytorch_forecasting.data.examples import generate_ar_data # noqa: E402
27
28 # Example based on this tutorial: https://pytorch-forecasting.readthedocs.io/en/latest/tutorials/ar.html
29 # 1. Create the DataModule
30 data = generate_ar_data(seasonality=10.0, timesteps=400, n_series=100, seed=42)
31 data["date"] = pd.Timestamp("2020-01-01") + pd.to_timedelta(data.time_idx, "D")
32
33 max_prediction_length = 20
34
35 training_cutoff = data["time_idx"].max() - max_prediction_length
36
37 datamodule = TabularForecastingData.from_data_frame(
38 time_idx="time_idx",
39 target="value",
40 categorical_encoders={"series": NaNLabelEncoder().fit(data.series)},
41 group_ids=["series"],
42 # only unknown variable is "value" - and N-Beats can also not take any additional variables
43 time_varying_unknown_reals=["value"],
44 max_encoder_length=60,
45 max_prediction_length=max_prediction_length,
46 train_data_frame=data[lambda x: x.time_idx <= training_cutoff],
47 val_data_frame=data,
48 batch_size=32,
49 )
50
51 # 2. Build the task
52 model = TabularForecaster(datamodule.parameters, backbone="n_beats", widths=[32, 512], backcast_loss_ratio=0.1)
53
54 # 3. Create the trainer and train the model
55 trainer = flash.Trainer(max_epochs=1, gpus=torch.cuda.device_count(), gradient_clip_val=0.01)
56 trainer.fit(model, datamodule=datamodule)
57
58 # 4. Generate predictions
59 predictions = model.predict(data)
60 print(predictions)
61
62 # Convert predictions
63 predictions, inputs = convert_predictions(predictions)
64
65 # Plot predictions
66 for idx in range(10): # plot 10 examples
67 model.pytorch_forecasting_model.plot_prediction(inputs, predictions, idx=idx, add_loss_to_title=True)
68
69 # Plot interpretation
70 for idx in range(10): # plot 10 examples
71 model.pytorch_forecasting_model.plot_interpretation(inputs, predictions, idx=idx)
72
73 # Show the plots!
74 plt.show()
75
```
Path: `flash/tabular/forecasting/data.py`
Content:
```
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from copy import copy
15 from dataclasses import dataclass
16 from typing import Any, Callable, Dict, List, Mapping, Optional, Union
17
18 from pytorch_lightning.utilities.exceptions import MisconfigurationException
19
20 from flash.core.data.callback import BaseDataFetcher
21 from flash.core.data.data_module import DataModule
22 from flash.core.data.data_source import DataSource, DefaultDataKeys, DefaultDataSources
23 from flash.core.data.process import Deserializer, Preprocess
24 from flash.core.data.properties import ProcessState
25 from flash.core.utilities.imports import _FORECASTING_AVAILABLE, _PANDAS_AVAILABLE, requires
26
27 if _PANDAS_AVAILABLE:
28 from pandas.core.frame import DataFrame
29 else:
30 DataFrame = object
31
32 if _FORECASTING_AVAILABLE:
33 from pytorch_forecasting import TimeSeriesDataSet
34
35
36 @dataclass(unsafe_hash=True, frozen=True)
37 class TimeSeriesDataSetParametersState(ProcessState):
38 """A :class:`~flash.core.data.properties.ProcessState` containing ``labels``, a mapping from class index to
39 label."""
40
41 time_series_dataset_parameters: Optional[Dict[str, Any]]
42
43
44 class TabularForecastingDataFrameDataSource(DataSource[DataFrame]):
45 @requires("tabular")
46 def __init__(
47 self,
48 time_idx: str,
49 target: Union[str, List[str]],
50 group_ids: List[str],
51 parameters: Optional[Dict[str, Any]] = None,
52 **data_source_kwargs: Any,
53 ):
54 super().__init__()
55 self.time_idx = time_idx
56 self.target = target
57 self.group_ids = group_ids
58 self.data_source_kwargs = data_source_kwargs
59
60 self.set_state(TimeSeriesDataSetParametersState(parameters))
61
62 def load_data(self, data: DataFrame, dataset: Optional[Any] = None):
63 if self.training:
64 time_series_dataset = TimeSeriesDataSet(
65 data, time_idx=self.time_idx, group_ids=self.group_ids, target=self.target, **self.data_source_kwargs
66 )
67 parameters = time_series_dataset.get_parameters()
68
69 # Add some sample data so that we can recreate the `TimeSeriesDataSet` later on
70 parameters["data_sample"] = data.iloc[[0]]
71
72 self.set_state(TimeSeriesDataSetParametersState(parameters))
73 dataset.parameters = parameters
74 else:
75 parameters = copy(self.get_state(TimeSeriesDataSetParametersState).time_series_dataset_parameters)
76 if parameters is None:
77 raise MisconfigurationException(
78 "Loading data for evaluation or inference requires parameters from the train data. Either "
79 "construct the train data at the same time as evaluation and inference or provide the train "
80 "`datamodule.parameters` to `from_data_frame` in the `parameters` argument."
81 )
82 parameters.pop("data_sample")
83 time_series_dataset = TimeSeriesDataSet.from_parameters(
84 parameters,
85 data,
86 predict=True,
87 stop_randomization=True,
88 )
89 dataset.time_series_dataset = time_series_dataset
90 return time_series_dataset
91
92 def load_sample(self, sample: Mapping[str, Any], dataset: Optional[Any] = None) -> Any:
93 return {DefaultDataKeys.INPUT: sample[0], DefaultDataKeys.TARGET: sample[1]}
94
95
96 class TabularForecastingPreprocess(Preprocess):
97 def __init__(
98 self,
99 train_transform: Optional[Dict[str, Callable]] = None,
100 val_transform: Optional[Dict[str, Callable]] = None,
101 test_transform: Optional[Dict[str, Callable]] = None,
102 predict_transform: Optional[Dict[str, Callable]] = None,
103 deserializer: Optional[Deserializer] = None,
104 **data_source_kwargs: Any,
105 ):
106 self.data_source_kwargs = data_source_kwargs
107 super().__init__(
108 train_transform=train_transform,
109 val_transform=val_transform,
110 test_transform=test_transform,
111 predict_transform=predict_transform,
112 data_sources={
113 DefaultDataSources.DATAFRAME: TabularForecastingDataFrameDataSource(**data_source_kwargs),
114 },
115 deserializer=deserializer,
116 default_data_source=DefaultDataSources.DATAFRAME,
117 )
118
119 def get_state_dict(self, strict: bool = False) -> Dict[str, Any]:
120 return {**self.transforms, **self.data_source_kwargs}
121
122 @classmethod
123 def load_state_dict(cls, state_dict: Dict[str, Any], strict: bool = True) -> "Preprocess":
124 return cls(**state_dict)
125
126
127 class TabularForecastingData(DataModule):
128 """Data module for tabular tasks."""
129
130 preprocess_cls = TabularForecastingPreprocess
131
132 @property
133 def parameters(self) -> Optional[Dict[str, Any]]:
134 return getattr(self.train_dataset, "parameters", None)
135
136 @classmethod
137 def from_data_frame(
138 cls,
139 time_idx: Optional[str] = None,
140 target: Optional[Union[str, List[str]]] = None,
141 group_ids: Optional[List[str]] = None,
142 parameters: Optional[Dict[str, Any]] = None,
143 train_data_frame: Optional[DataFrame] = None,
144 val_data_frame: Optional[DataFrame] = None,
145 test_data_frame: Optional[DataFrame] = None,
146 predict_data_frame: Optional[DataFrame] = None,
147 train_transform: Optional[Dict[str, Callable]] = None,
148 val_transform: Optional[Dict[str, Callable]] = None,
149 test_transform: Optional[Dict[str, Callable]] = None,
150 predict_transform: Optional[Dict[str, Callable]] = None,
151 data_fetcher: Optional[BaseDataFetcher] = None,
152 preprocess: Optional[Preprocess] = None,
153 val_split: Optional[float] = None,
154 batch_size: int = 4,
155 num_workers: Optional[int] = None,
156 **preprocess_kwargs: Any,
157 ):
158 """Creates a :class:`~flash.tabular.data.TabularClassificationData` object from the given data frames.
159
160 Args:
161 group_ids:
162 target:
163 time_idx:
164 train_data_frame: The pandas ``DataFrame`` containing the training data.
165 val_data_frame: The pandas ``DataFrame`` containing the validation data.
166 test_data_frame: The pandas ``DataFrame`` containing the testing data.
167 predict_data_frame: The pandas ``DataFrame`` containing the data to use when predicting.
168 train_transform: The dictionary of transforms to use during training which maps
169 :class:`~flash.core.data.process.Preprocess` hook names to callable transforms.
170 val_transform: The dictionary of transforms to use during validation which maps
171 :class:`~flash.core.data.process.Preprocess` hook names to callable transforms.
172 test_transform: The dictionary of transforms to use during testing which maps
173 :class:`~flash.core.data.process.Preprocess` hook names to callable transforms.
174 predict_transform: The dictionary of transforms to use during predicting which maps
175 :class:`~flash.core.data.process.Preprocess` hook names to callable transforms.
176 data_fetcher: The :class:`~flash.core.data.callback.BaseDataFetcher` to pass to the
177 :class:`~flash.core.data.data_module.DataModule`.
178 preprocess: The :class:`~flash.core.data.data.Preprocess` to pass to the
179 :class:`~flash.core.data.data_module.DataModule`. If ``None``, ``cls.preprocess_cls``
180 will be constructed and used.
181 val_split: The ``val_split`` argument to pass to the :class:`~flash.core.data.data_module.DataModule`.
182 batch_size: The ``batch_size`` argument to pass to the :class:`~flash.core.data.data_module.DataModule`.
183 num_workers: The ``num_workers`` argument to pass to the :class:`~flash.core.data.data_module.DataModule`.
184 preprocess_kwargs: Additional keyword arguments to use when constructing the preprocess. Will only be used
185 if ``preprocess = None``.
186
187 Returns:
188 The constructed data module.
189
190 Examples::
191
192 data_module = TabularClassificationData.from_data_frame(
193 "categorical_input",
194 "numerical_input",
195 "target",
196 train_data_frame=train_data,
197 )
198 """
199
200 return cls.from_data_source(
201 time_idx=time_idx,
202 target=target,
203 group_ids=group_ids,
204 parameters=parameters,
205 data_source=DefaultDataSources.DATAFRAME,
206 train_data=train_data_frame,
207 val_data=val_data_frame,
208 test_data=test_data_frame,
209 predict_data=predict_data_frame,
210 train_transform=train_transform,
211 val_transform=val_transform,
212 test_transform=test_transform,
213 predict_transform=predict_transform,
214 data_fetcher=data_fetcher,
215 preprocess=preprocess,
216 val_split=val_split,
217 batch_size=batch_size,
218 num_workers=num_workers,
219 **preprocess_kwargs,
220 )
221
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/flash/tabular/forecasting/data.py b/flash/tabular/forecasting/data.py
--- a/flash/tabular/forecasting/data.py
+++ b/flash/tabular/forecasting/data.py
@@ -125,12 +125,14 @@
class TabularForecastingData(DataModule):
- """Data module for tabular tasks."""
+ """Data module for the tabular forecasting task."""
preprocess_cls = TabularForecastingPreprocess
@property
def parameters(self) -> Optional[Dict[str, Any]]:
+ """The parameters dictionary from the ``TimeSeriesDataSet`` object created from the train data when
+ constructing the ``TabularForecastingData`` object."""
return getattr(self.train_dataset, "parameters", None)
@classmethod
@@ -155,12 +157,24 @@
num_workers: Optional[int] = None,
**preprocess_kwargs: Any,
):
- """Creates a :class:`~flash.tabular.data.TabularClassificationData` object from the given data frames.
+ """Creates a :class:`~flash.tabular.forecasting.data.TabularForecastingData` object from the given data
+ frames.
+
+ .. note::
+
+ The ``time_idx``, ``target``, and ``group_ids`` do not need to be provided if ``parameters`` are passed
+ instead. These can be obtained from the
+ :attr:`~flash.tabular.forecasting.data.TabularForecastingData.parameters` attribute of the
+ :class:`~flash.tabular.forecasting.data.TabularForecastingData` object that contains your training data.
Args:
- group_ids:
- target:
time_idx:
+ target: Column denoting the target or list of columns denoting the target.
+ group_ids: List of column names identifying a time series. This means that the group_ids identify a sample
+ together with the time_idx. If you have only one timeseries, set this to the name of column that is
+ constant.
+ parameters: Parameters to use for the timeseries if ``time_idx``, ``target``, and ``group_ids`` are not
+ provided (e.g. when loading data for inference or validation).
train_data_frame: The pandas ``DataFrame`` containing the training data.
val_data_frame: The pandas ``DataFrame`` containing the validation data.
test_data_frame: The pandas ``DataFrame`` containing the testing data.
@@ -189,10 +203,10 @@
Examples::
- data_module = TabularClassificationData.from_data_frame(
- "categorical_input",
- "numerical_input",
- "target",
+ data_module = TabularForecastingData.from_data_frame(
+ time_idx="time_idx",
+ target="value",
+ group_ids=["series"],
train_data_frame=train_data,
)
"""
diff --git a/flash_examples/integrations/pytorch_forecasting/tabular_forecasting_interpretable.py b/flash_examples/integrations/pytorch_forecasting/tabular_forecasting_interpretable.py
--- a/flash_examples/integrations/pytorch_forecasting/tabular_forecasting_interpretable.py
+++ b/flash_examples/integrations/pytorch_forecasting/tabular_forecasting_interpretable.py
@@ -59,16 +59,12 @@
predictions = model.predict(data)
print(predictions)
-# Convert predictions
+# Plot with PyTorch Forecasting!
predictions, inputs = convert_predictions(predictions)
-# Plot predictions
-for idx in range(10): # plot 10 examples
- model.pytorch_forecasting_model.plot_prediction(inputs, predictions, idx=idx, add_loss_to_title=True)
+fig, axs = plt.subplots(2, 3, sharex="col")
-# Plot interpretation
-for idx in range(10): # plot 10 examples
- model.pytorch_forecasting_model.plot_interpretation(inputs, predictions, idx=idx)
+for idx in range(3):
+ model.pytorch_forecasting_model.plot_interpretation(inputs, predictions, idx=idx, ax=[axs[0][idx], axs[1][idx]])
-# Show the plots!
plt.show()
| {"golden_diff": "diff --git a/flash/tabular/forecasting/data.py b/flash/tabular/forecasting/data.py\n--- a/flash/tabular/forecasting/data.py\n+++ b/flash/tabular/forecasting/data.py\n@@ -125,12 +125,14 @@\n \n \n class TabularForecastingData(DataModule):\n- \"\"\"Data module for tabular tasks.\"\"\"\n+ \"\"\"Data module for the tabular forecasting task.\"\"\"\n \n preprocess_cls = TabularForecastingPreprocess\n \n @property\n def parameters(self) -> Optional[Dict[str, Any]]:\n+ \"\"\"The parameters dictionary from the ``TimeSeriesDataSet`` object created from the train data when\n+ constructing the ``TabularForecastingData`` object.\"\"\"\n return getattr(self.train_dataset, \"parameters\", None)\n \n @classmethod\n@@ -155,12 +157,24 @@\n num_workers: Optional[int] = None,\n **preprocess_kwargs: Any,\n ):\n- \"\"\"Creates a :class:`~flash.tabular.data.TabularClassificationData` object from the given data frames.\n+ \"\"\"Creates a :class:`~flash.tabular.forecasting.data.TabularForecastingData` object from the given data\n+ frames.\n+\n+ .. note::\n+\n+ The ``time_idx``, ``target``, and ``group_ids`` do not need to be provided if ``parameters`` are passed\n+ instead. These can be obtained from the\n+ :attr:`~flash.tabular.forecasting.data.TabularForecastingData.parameters` attribute of the\n+ :class:`~flash.tabular.forecasting.data.TabularForecastingData` object that contains your training data.\n \n Args:\n- group_ids:\n- target:\n time_idx:\n+ target: Column denoting the target or list of columns denoting the target.\n+ group_ids: List of column names identifying a time series. This means that the group_ids identify a sample\n+ together with the time_idx. If you have only one timeseries, set this to the name of column that is\n+ constant.\n+ parameters: Parameters to use for the timeseries if ``time_idx``, ``target``, and ``group_ids`` are not\n+ provided (e.g. when loading data for inference or validation).\n train_data_frame: The pandas ``DataFrame`` containing the training data.\n val_data_frame: The pandas ``DataFrame`` containing the validation data.\n test_data_frame: The pandas ``DataFrame`` containing the testing data.\n@@ -189,10 +203,10 @@\n \n Examples::\n \n- data_module = TabularClassificationData.from_data_frame(\n- \"categorical_input\",\n- \"numerical_input\",\n- \"target\",\n+ data_module = TabularForecastingData.from_data_frame(\n+ time_idx=\"time_idx\",\n+ target=\"value\",\n+ group_ids=[\"series\"],\n train_data_frame=train_data,\n )\n \"\"\"\ndiff --git a/flash_examples/integrations/pytorch_forecasting/tabular_forecasting_interpretable.py b/flash_examples/integrations/pytorch_forecasting/tabular_forecasting_interpretable.py\n--- a/flash_examples/integrations/pytorch_forecasting/tabular_forecasting_interpretable.py\n+++ b/flash_examples/integrations/pytorch_forecasting/tabular_forecasting_interpretable.py\n@@ -59,16 +59,12 @@\n predictions = model.predict(data)\n print(predictions)\n \n-# Convert predictions\n+# Plot with PyTorch Forecasting!\n predictions, inputs = convert_predictions(predictions)\n \n-# Plot predictions\n-for idx in range(10): # plot 10 examples\n- model.pytorch_forecasting_model.plot_prediction(inputs, predictions, idx=idx, add_loss_to_title=True)\n+fig, axs = plt.subplots(2, 3, sharex=\"col\")\n \n-# Plot interpretation\n-for idx in range(10): # plot 10 examples\n- model.pytorch_forecasting_model.plot_interpretation(inputs, predictions, idx=idx)\n+for idx in range(3):\n+ model.pytorch_forecasting_model.plot_interpretation(inputs, predictions, idx=idx, ax=[axs[0][idx], axs[1][idx]])\n \n-# Show the plots!\n plt.show()\n", "issue": "Add a tabular_forecasting example\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport torch\n\nimport flash\nfrom flash.core.integrations.pytorch_forecasting import convert_predictions\nfrom flash.core.utilities.imports import example_requires\nfrom flash.tabular.forecasting import TabularForecaster, TabularForecastingData\n\nexample_requires([\"tabular\", \"matplotlib\"])\n\nimport matplotlib.pyplot as plt # noqa: E402\nimport pandas as pd # noqa: E402\nfrom pytorch_forecasting.data import NaNLabelEncoder # noqa: E402\nfrom pytorch_forecasting.data.examples import generate_ar_data # noqa: E402\n\n# Example based on this tutorial: https://pytorch-forecasting.readthedocs.io/en/latest/tutorials/ar.html\n# 1. Create the DataModule\ndata = generate_ar_data(seasonality=10.0, timesteps=400, n_series=100, seed=42)\ndata[\"date\"] = pd.Timestamp(\"2020-01-01\") + pd.to_timedelta(data.time_idx, \"D\")\n\nmax_prediction_length = 20\n\ntraining_cutoff = data[\"time_idx\"].max() - max_prediction_length\n\ndatamodule = TabularForecastingData.from_data_frame(\n time_idx=\"time_idx\",\n target=\"value\",\n categorical_encoders={\"series\": NaNLabelEncoder().fit(data.series)},\n group_ids=[\"series\"],\n # only unknown variable is \"value\" - and N-Beats can also not take any additional variables\n time_varying_unknown_reals=[\"value\"],\n max_encoder_length=60,\n max_prediction_length=max_prediction_length,\n train_data_frame=data[lambda x: x.time_idx <= training_cutoff],\n val_data_frame=data,\n batch_size=32,\n)\n\n# 2. Build the task\nmodel = TabularForecaster(datamodule.parameters, backbone=\"n_beats\", widths=[32, 512], backcast_loss_ratio=0.1)\n\n# 3. Create the trainer and train the model\ntrainer = flash.Trainer(max_epochs=1, gpus=torch.cuda.device_count(), gradient_clip_val=0.01)\ntrainer.fit(model, datamodule=datamodule)\n\n# 4. Generate predictions\npredictions = model.predict(data)\nprint(predictions)\n\n# Convert predictions\npredictions, inputs = convert_predictions(predictions)\n\n# Plot predictions\nfor idx in range(10): # plot 10 examples\n model.pytorch_forecasting_model.plot_prediction(inputs, predictions, idx=idx, add_loss_to_title=True)\n\n# Plot interpretation\nfor idx in range(10): # plot 10 examples\n model.pytorch_forecasting_model.plot_interpretation(inputs, predictions, idx=idx)\n\n# Show the plots!\nplt.show()\n", "path": "flash_examples/integrations/pytorch_forecasting/tabular_forecasting_interpretable.py"}, {"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom copy import copy\nfrom dataclasses import dataclass\nfrom typing import Any, Callable, Dict, List, Mapping, Optional, Union\n\nfrom pytorch_lightning.utilities.exceptions import MisconfigurationException\n\nfrom flash.core.data.callback import BaseDataFetcher\nfrom flash.core.data.data_module import DataModule\nfrom flash.core.data.data_source import DataSource, DefaultDataKeys, DefaultDataSources\nfrom flash.core.data.process import Deserializer, Preprocess\nfrom flash.core.data.properties import ProcessState\nfrom flash.core.utilities.imports import _FORECASTING_AVAILABLE, _PANDAS_AVAILABLE, requires\n\nif _PANDAS_AVAILABLE:\n from pandas.core.frame import DataFrame\nelse:\n DataFrame = object\n\nif _FORECASTING_AVAILABLE:\n from pytorch_forecasting import TimeSeriesDataSet\n\n\n@dataclass(unsafe_hash=True, frozen=True)\nclass TimeSeriesDataSetParametersState(ProcessState):\n \"\"\"A :class:`~flash.core.data.properties.ProcessState` containing ``labels``, a mapping from class index to\n label.\"\"\"\n\n time_series_dataset_parameters: Optional[Dict[str, Any]]\n\n\nclass TabularForecastingDataFrameDataSource(DataSource[DataFrame]):\n @requires(\"tabular\")\n def __init__(\n self,\n time_idx: str,\n target: Union[str, List[str]],\n group_ids: List[str],\n parameters: Optional[Dict[str, Any]] = None,\n **data_source_kwargs: Any,\n ):\n super().__init__()\n self.time_idx = time_idx\n self.target = target\n self.group_ids = group_ids\n self.data_source_kwargs = data_source_kwargs\n\n self.set_state(TimeSeriesDataSetParametersState(parameters))\n\n def load_data(self, data: DataFrame, dataset: Optional[Any] = None):\n if self.training:\n time_series_dataset = TimeSeriesDataSet(\n data, time_idx=self.time_idx, group_ids=self.group_ids, target=self.target, **self.data_source_kwargs\n )\n parameters = time_series_dataset.get_parameters()\n\n # Add some sample data so that we can recreate the `TimeSeriesDataSet` later on\n parameters[\"data_sample\"] = data.iloc[[0]]\n\n self.set_state(TimeSeriesDataSetParametersState(parameters))\n dataset.parameters = parameters\n else:\n parameters = copy(self.get_state(TimeSeriesDataSetParametersState).time_series_dataset_parameters)\n if parameters is None:\n raise MisconfigurationException(\n \"Loading data for evaluation or inference requires parameters from the train data. Either \"\n \"construct the train data at the same time as evaluation and inference or provide the train \"\n \"`datamodule.parameters` to `from_data_frame` in the `parameters` argument.\"\n )\n parameters.pop(\"data_sample\")\n time_series_dataset = TimeSeriesDataSet.from_parameters(\n parameters,\n data,\n predict=True,\n stop_randomization=True,\n )\n dataset.time_series_dataset = time_series_dataset\n return time_series_dataset\n\n def load_sample(self, sample: Mapping[str, Any], dataset: Optional[Any] = None) -> Any:\n return {DefaultDataKeys.INPUT: sample[0], DefaultDataKeys.TARGET: sample[1]}\n\n\nclass TabularForecastingPreprocess(Preprocess):\n def __init__(\n self,\n train_transform: Optional[Dict[str, Callable]] = None,\n val_transform: Optional[Dict[str, Callable]] = None,\n test_transform: Optional[Dict[str, Callable]] = None,\n predict_transform: Optional[Dict[str, Callable]] = None,\n deserializer: Optional[Deserializer] = None,\n **data_source_kwargs: Any,\n ):\n self.data_source_kwargs = data_source_kwargs\n super().__init__(\n train_transform=train_transform,\n val_transform=val_transform,\n test_transform=test_transform,\n predict_transform=predict_transform,\n data_sources={\n DefaultDataSources.DATAFRAME: TabularForecastingDataFrameDataSource(**data_source_kwargs),\n },\n deserializer=deserializer,\n default_data_source=DefaultDataSources.DATAFRAME,\n )\n\n def get_state_dict(self, strict: bool = False) -> Dict[str, Any]:\n return {**self.transforms, **self.data_source_kwargs}\n\n @classmethod\n def load_state_dict(cls, state_dict: Dict[str, Any], strict: bool = True) -> \"Preprocess\":\n return cls(**state_dict)\n\n\nclass TabularForecastingData(DataModule):\n \"\"\"Data module for tabular tasks.\"\"\"\n\n preprocess_cls = TabularForecastingPreprocess\n\n @property\n def parameters(self) -> Optional[Dict[str, Any]]:\n return getattr(self.train_dataset, \"parameters\", None)\n\n @classmethod\n def from_data_frame(\n cls,\n time_idx: Optional[str] = None,\n target: Optional[Union[str, List[str]]] = None,\n group_ids: Optional[List[str]] = None,\n parameters: Optional[Dict[str, Any]] = None,\n train_data_frame: Optional[DataFrame] = None,\n val_data_frame: Optional[DataFrame] = None,\n test_data_frame: Optional[DataFrame] = None,\n predict_data_frame: Optional[DataFrame] = None,\n train_transform: Optional[Dict[str, Callable]] = None,\n val_transform: Optional[Dict[str, Callable]] = None,\n test_transform: Optional[Dict[str, Callable]] = None,\n predict_transform: Optional[Dict[str, Callable]] = None,\n data_fetcher: Optional[BaseDataFetcher] = None,\n preprocess: Optional[Preprocess] = None,\n val_split: Optional[float] = None,\n batch_size: int = 4,\n num_workers: Optional[int] = None,\n **preprocess_kwargs: Any,\n ):\n \"\"\"Creates a :class:`~flash.tabular.data.TabularClassificationData` object from the given data frames.\n\n Args:\n group_ids:\n target:\n time_idx:\n train_data_frame: The pandas ``DataFrame`` containing the training data.\n val_data_frame: The pandas ``DataFrame`` containing the validation data.\n test_data_frame: The pandas ``DataFrame`` containing the testing data.\n predict_data_frame: The pandas ``DataFrame`` containing the data to use when predicting.\n train_transform: The dictionary of transforms to use during training which maps\n :class:`~flash.core.data.process.Preprocess` hook names to callable transforms.\n val_transform: The dictionary of transforms to use during validation which maps\n :class:`~flash.core.data.process.Preprocess` hook names to callable transforms.\n test_transform: The dictionary of transforms to use during testing which maps\n :class:`~flash.core.data.process.Preprocess` hook names to callable transforms.\n predict_transform: The dictionary of transforms to use during predicting which maps\n :class:`~flash.core.data.process.Preprocess` hook names to callable transforms.\n data_fetcher: The :class:`~flash.core.data.callback.BaseDataFetcher` to pass to the\n :class:`~flash.core.data.data_module.DataModule`.\n preprocess: The :class:`~flash.core.data.data.Preprocess` to pass to the\n :class:`~flash.core.data.data_module.DataModule`. If ``None``, ``cls.preprocess_cls``\n will be constructed and used.\n val_split: The ``val_split`` argument to pass to the :class:`~flash.core.data.data_module.DataModule`.\n batch_size: The ``batch_size`` argument to pass to the :class:`~flash.core.data.data_module.DataModule`.\n num_workers: The ``num_workers`` argument to pass to the :class:`~flash.core.data.data_module.DataModule`.\n preprocess_kwargs: Additional keyword arguments to use when constructing the preprocess. Will only be used\n if ``preprocess = None``.\n\n Returns:\n The constructed data module.\n\n Examples::\n\n data_module = TabularClassificationData.from_data_frame(\n \"categorical_input\",\n \"numerical_input\",\n \"target\",\n train_data_frame=train_data,\n )\n \"\"\"\n\n return cls.from_data_source(\n time_idx=time_idx,\n target=target,\n group_ids=group_ids,\n parameters=parameters,\n data_source=DefaultDataSources.DATAFRAME,\n train_data=train_data_frame,\n val_data=val_data_frame,\n test_data=test_data_frame,\n predict_data=predict_data_frame,\n train_transform=train_transform,\n val_transform=val_transform,\n test_transform=test_transform,\n predict_transform=predict_transform,\n data_fetcher=data_fetcher,\n preprocess=preprocess,\n val_split=val_split,\n batch_size=batch_size,\n num_workers=num_workers,\n **preprocess_kwargs,\n )\n", "path": "flash/tabular/forecasting/data.py"}], "after_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport torch\n\nimport flash\nfrom flash.core.integrations.pytorch_forecasting import convert_predictions\nfrom flash.core.utilities.imports import example_requires\nfrom flash.tabular.forecasting import TabularForecaster, TabularForecastingData\n\nexample_requires([\"tabular\", \"matplotlib\"])\n\nimport matplotlib.pyplot as plt # noqa: E402\nimport pandas as pd # noqa: E402\nfrom pytorch_forecasting.data import NaNLabelEncoder # noqa: E402\nfrom pytorch_forecasting.data.examples import generate_ar_data # noqa: E402\n\n# Example based on this tutorial: https://pytorch-forecasting.readthedocs.io/en/latest/tutorials/ar.html\n# 1. Create the DataModule\ndata = generate_ar_data(seasonality=10.0, timesteps=400, n_series=100, seed=42)\ndata[\"date\"] = pd.Timestamp(\"2020-01-01\") + pd.to_timedelta(data.time_idx, \"D\")\n\nmax_prediction_length = 20\n\ntraining_cutoff = data[\"time_idx\"].max() - max_prediction_length\n\ndatamodule = TabularForecastingData.from_data_frame(\n time_idx=\"time_idx\",\n target=\"value\",\n categorical_encoders={\"series\": NaNLabelEncoder().fit(data.series)},\n group_ids=[\"series\"],\n # only unknown variable is \"value\" - and N-Beats can also not take any additional variables\n time_varying_unknown_reals=[\"value\"],\n max_encoder_length=60,\n max_prediction_length=max_prediction_length,\n train_data_frame=data[lambda x: x.time_idx <= training_cutoff],\n val_data_frame=data,\n batch_size=32,\n)\n\n# 2. Build the task\nmodel = TabularForecaster(datamodule.parameters, backbone=\"n_beats\", widths=[32, 512], backcast_loss_ratio=0.1)\n\n# 3. Create the trainer and train the model\ntrainer = flash.Trainer(max_epochs=1, gpus=torch.cuda.device_count(), gradient_clip_val=0.01)\ntrainer.fit(model, datamodule=datamodule)\n\n# 4. Generate predictions\npredictions = model.predict(data)\nprint(predictions)\n\n# Plot with PyTorch Forecasting!\npredictions, inputs = convert_predictions(predictions)\n\nfig, axs = plt.subplots(2, 3, sharex=\"col\")\n\nfor idx in range(3):\n model.pytorch_forecasting_model.plot_interpretation(inputs, predictions, idx=idx, ax=[axs[0][idx], axs[1][idx]])\n\nplt.show()\n", "path": "flash_examples/integrations/pytorch_forecasting/tabular_forecasting_interpretable.py"}, {"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom copy import copy\nfrom dataclasses import dataclass\nfrom typing import Any, Callable, Dict, List, Mapping, Optional, Union\n\nfrom pytorch_lightning.utilities.exceptions import MisconfigurationException\n\nfrom flash.core.data.callback import BaseDataFetcher\nfrom flash.core.data.data_module import DataModule\nfrom flash.core.data.data_source import DataSource, DefaultDataKeys, DefaultDataSources\nfrom flash.core.data.process import Deserializer, Preprocess\nfrom flash.core.data.properties import ProcessState\nfrom flash.core.utilities.imports import _FORECASTING_AVAILABLE, _PANDAS_AVAILABLE, requires\n\nif _PANDAS_AVAILABLE:\n from pandas.core.frame import DataFrame\nelse:\n DataFrame = object\n\nif _FORECASTING_AVAILABLE:\n from pytorch_forecasting import TimeSeriesDataSet\n\n\n@dataclass(unsafe_hash=True, frozen=True)\nclass TimeSeriesDataSetParametersState(ProcessState):\n \"\"\"A :class:`~flash.core.data.properties.ProcessState` containing ``labels``, a mapping from class index to\n label.\"\"\"\n\n time_series_dataset_parameters: Optional[Dict[str, Any]]\n\n\nclass TabularForecastingDataFrameDataSource(DataSource[DataFrame]):\n @requires(\"tabular\")\n def __init__(\n self,\n time_idx: str,\n target: Union[str, List[str]],\n group_ids: List[str],\n parameters: Optional[Dict[str, Any]] = None,\n **data_source_kwargs: Any,\n ):\n super().__init__()\n self.time_idx = time_idx\n self.target = target\n self.group_ids = group_ids\n self.data_source_kwargs = data_source_kwargs\n\n self.set_state(TimeSeriesDataSetParametersState(parameters))\n\n def load_data(self, data: DataFrame, dataset: Optional[Any] = None):\n if self.training:\n time_series_dataset = TimeSeriesDataSet(\n data, time_idx=self.time_idx, group_ids=self.group_ids, target=self.target, **self.data_source_kwargs\n )\n parameters = time_series_dataset.get_parameters()\n\n # Add some sample data so that we can recreate the `TimeSeriesDataSet` later on\n parameters[\"data_sample\"] = data.iloc[[0]]\n\n self.set_state(TimeSeriesDataSetParametersState(parameters))\n dataset.parameters = parameters\n else:\n parameters = copy(self.get_state(TimeSeriesDataSetParametersState).time_series_dataset_parameters)\n if parameters is None:\n raise MisconfigurationException(\n \"Loading data for evaluation or inference requires parameters from the train data. Either \"\n \"construct the train data at the same time as evaluation and inference or provide the train \"\n \"`datamodule.parameters` to `from_data_frame` in the `parameters` argument.\"\n )\n parameters.pop(\"data_sample\")\n time_series_dataset = TimeSeriesDataSet.from_parameters(\n parameters,\n data,\n predict=True,\n stop_randomization=True,\n )\n dataset.time_series_dataset = time_series_dataset\n return time_series_dataset\n\n def load_sample(self, sample: Mapping[str, Any], dataset: Optional[Any] = None) -> Any:\n return {DefaultDataKeys.INPUT: sample[0], DefaultDataKeys.TARGET: sample[1]}\n\n\nclass TabularForecastingPreprocess(Preprocess):\n def __init__(\n self,\n train_transform: Optional[Dict[str, Callable]] = None,\n val_transform: Optional[Dict[str, Callable]] = None,\n test_transform: Optional[Dict[str, Callable]] = None,\n predict_transform: Optional[Dict[str, Callable]] = None,\n deserializer: Optional[Deserializer] = None,\n **data_source_kwargs: Any,\n ):\n self.data_source_kwargs = data_source_kwargs\n super().__init__(\n train_transform=train_transform,\n val_transform=val_transform,\n test_transform=test_transform,\n predict_transform=predict_transform,\n data_sources={\n DefaultDataSources.DATAFRAME: TabularForecastingDataFrameDataSource(**data_source_kwargs),\n },\n deserializer=deserializer,\n default_data_source=DefaultDataSources.DATAFRAME,\n )\n\n def get_state_dict(self, strict: bool = False) -> Dict[str, Any]:\n return {**self.transforms, **self.data_source_kwargs}\n\n @classmethod\n def load_state_dict(cls, state_dict: Dict[str, Any], strict: bool = True) -> \"Preprocess\":\n return cls(**state_dict)\n\n\nclass TabularForecastingData(DataModule):\n \"\"\"Data module for the tabular forecasting task.\"\"\"\n\n preprocess_cls = TabularForecastingPreprocess\n\n @property\n def parameters(self) -> Optional[Dict[str, Any]]:\n \"\"\"The parameters dictionary from the ``TimeSeriesDataSet`` object created from the train data when\n constructing the ``TabularForecastingData`` object.\"\"\"\n return getattr(self.train_dataset, \"parameters\", None)\n\n @classmethod\n def from_data_frame(\n cls,\n time_idx: Optional[str] = None,\n target: Optional[Union[str, List[str]]] = None,\n group_ids: Optional[List[str]] = None,\n parameters: Optional[Dict[str, Any]] = None,\n train_data_frame: Optional[DataFrame] = None,\n val_data_frame: Optional[DataFrame] = None,\n test_data_frame: Optional[DataFrame] = None,\n predict_data_frame: Optional[DataFrame] = None,\n train_transform: Optional[Dict[str, Callable]] = None,\n val_transform: Optional[Dict[str, Callable]] = None,\n test_transform: Optional[Dict[str, Callable]] = None,\n predict_transform: Optional[Dict[str, Callable]] = None,\n data_fetcher: Optional[BaseDataFetcher] = None,\n preprocess: Optional[Preprocess] = None,\n val_split: Optional[float] = None,\n batch_size: int = 4,\n num_workers: Optional[int] = None,\n **preprocess_kwargs: Any,\n ):\n \"\"\"Creates a :class:`~flash.tabular.forecasting.data.TabularForecastingData` object from the given data\n frames.\n\n .. note::\n\n The ``time_idx``, ``target``, and ``group_ids`` do not need to be provided if ``parameters`` are passed\n instead. These can be obtained from the\n :attr:`~flash.tabular.forecasting.data.TabularForecastingData.parameters` attribute of the\n :class:`~flash.tabular.forecasting.data.TabularForecastingData` object that contains your training data.\n\n Args:\n time_idx:\n target: Column denoting the target or list of columns denoting the target.\n group_ids: List of column names identifying a time series. This means that the group_ids identify a sample\n together with the time_idx. If you have only one timeseries, set this to the name of column that is\n constant.\n parameters: Parameters to use for the timeseries if ``time_idx``, ``target``, and ``group_ids`` are not\n provided (e.g. when loading data for inference or validation).\n train_data_frame: The pandas ``DataFrame`` containing the training data.\n val_data_frame: The pandas ``DataFrame`` containing the validation data.\n test_data_frame: The pandas ``DataFrame`` containing the testing data.\n predict_data_frame: The pandas ``DataFrame`` containing the data to use when predicting.\n train_transform: The dictionary of transforms to use during training which maps\n :class:`~flash.core.data.process.Preprocess` hook names to callable transforms.\n val_transform: The dictionary of transforms to use during validation which maps\n :class:`~flash.core.data.process.Preprocess` hook names to callable transforms.\n test_transform: The dictionary of transforms to use during testing which maps\n :class:`~flash.core.data.process.Preprocess` hook names to callable transforms.\n predict_transform: The dictionary of transforms to use during predicting which maps\n :class:`~flash.core.data.process.Preprocess` hook names to callable transforms.\n data_fetcher: The :class:`~flash.core.data.callback.BaseDataFetcher` to pass to the\n :class:`~flash.core.data.data_module.DataModule`.\n preprocess: The :class:`~flash.core.data.data.Preprocess` to pass to the\n :class:`~flash.core.data.data_module.DataModule`. If ``None``, ``cls.preprocess_cls``\n will be constructed and used.\n val_split: The ``val_split`` argument to pass to the :class:`~flash.core.data.data_module.DataModule`.\n batch_size: The ``batch_size`` argument to pass to the :class:`~flash.core.data.data_module.DataModule`.\n num_workers: The ``num_workers`` argument to pass to the :class:`~flash.core.data.data_module.DataModule`.\n preprocess_kwargs: Additional keyword arguments to use when constructing the preprocess. Will only be used\n if ``preprocess = None``.\n\n Returns:\n The constructed data module.\n\n Examples::\n\n data_module = TabularForecastingData.from_data_frame(\n time_idx=\"time_idx\",\n target=\"value\",\n group_ids=[\"series\"],\n train_data_frame=train_data,\n )\n \"\"\"\n\n return cls.from_data_source(\n time_idx=time_idx,\n target=target,\n group_ids=group_ids,\n parameters=parameters,\n data_source=DefaultDataSources.DATAFRAME,\n train_data=train_data_frame,\n val_data=val_data_frame,\n test_data=test_data_frame,\n predict_data=predict_data_frame,\n train_transform=train_transform,\n val_transform=val_transform,\n test_transform=test_transform,\n predict_transform=predict_transform,\n data_fetcher=data_fetcher,\n preprocess=preprocess,\n val_split=val_split,\n batch_size=batch_size,\n num_workers=num_workers,\n **preprocess_kwargs,\n )\n", "path": "flash/tabular/forecasting/data.py"}]} | 3,656 | 922 |
gh_patches_debug_29196 | rasdani/github-patches | git_diff | bokeh__bokeh-5957 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
sphinxext.bokeh_plot missing linenos option implementation
According to the [docs](http://bokeh.pydata.org/en/latest/docs/reference/sphinxext.html#module-bokeh.sphinxext.bokeh_plot) for sphinxext.bokeh_plot, there's a linenos option. However, this appears to be missing, as building
```
.. bokeh-plot::
:linenos:
from bokeh.plotting import figure, output_file, show
output_file("example.html")
x = [1, 2, 3, 4, 5]
y = [6, 7, 6, 4, 5]
p = figure(title="example", plot_width=300, plot_height=300)
p.line(x, y, line_width=2)
p.circle(x, y, size=10, fill_color="white")
show(p)
```
results in the following sphinx error: `ERROR: Error in "bokeh-plot" directive:
unknown option: "linenos".`
Version Info:
Python version : 3.6.0 | packaged by conda-forge | (default, Jan 14 2017, 03:13:00)
IPython version : 5.1.0
Bokeh version : 0.12.4
BokehJS static path : /Users/Atom/.anaconda/envs/py3/lib/python3.6/site-packages/bokeh/server/static
node.js version : v6.3.1
npm version : 3.10.3
jupyter --version : 4.2.1
jupyter notebook --version : 4.3.1
os version : macOS 10.12.3
browser verision: Google Chrome Version 56.0.2924.87 (64-bit)
sphinx version: 1.5.3
This is a really awesome sphinx extension!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bokeh/sphinxext/bokeh_plot.py`
Content:
```
1 """ Include Bokeh plots in Sphinx HTML documentation.
2
3 For other output types, the placeholder text ``[graph]`` will
4 be generated.
5
6 The ``bokeh-plot`` directive can be used by either supplying:
7
8 **A path to a source file** as the argument to the directive::
9
10 .. bokeh-plot:: path/to/plot.py
11
12
13 **Inline code** as the content of the directive::
14
15 .. bokeh-plot::
16
17 from bokeh.plotting import figure, output_file, show
18
19 output_file("example.html")
20
21 x = [1, 2, 3, 4, 5]
22 y = [6, 7, 6, 4, 5]
23
24 p = figure(title="example", plot_width=300, plot_height=300)
25 p.line(x, y, line_width=2)
26 p.circle(x, y, size=10, fill_color="white")
27
28 show(p)
29
30 This directive also works in conjunction with Sphinx autodoc, when
31 used in docstrings.
32
33 The ``bokeh-plot`` directive accepts the following options:
34
35 source-position : enum('above', 'below', 'none')
36 Where to locate the the block of formatted source
37 code (if anywhere).
38
39 linenos : bool
40 Whether to display line numbers along with the source.
41
42 Examples
43 --------
44
45 The inline example code above produces the following output:
46
47 .. bokeh-plot::
48
49 from bokeh.plotting import figure, output_file, show
50
51 output_file("example.html")
52
53 x = [1, 2, 3, 4, 5]
54 y = [6, 7, 6, 4, 5]
55
56 p = figure(title="example", plot_width=300, plot_height=300)
57 p.line(x, y, line_width=2)
58 p.circle(x, y, size=10, fill_color="white")
59
60 show(p)
61
62 """
63 from __future__ import absolute_import
64
65 import ast
66 import hashlib
67 from os import getenv
68 from os.path import basename, dirname, join
69 import re
70
71 from docutils import nodes
72 from docutils.parsers.rst import Directive, Parser
73 from docutils.parsers.rst.directives import choice
74
75 from sphinx.errors import SphinxError
76 from sphinx.util import console, copyfile, ensuredir
77 from sphinx.util.nodes import set_source_info
78
79 from ..document import Document
80 from ..embed import autoload_static
81 from ..resources import Resources
82 from ..settings import settings
83 from ..util.string import decode_utf8
84 from .example_handler import ExampleHandler
85 from .templates import PLOT_PAGE
86
87 if settings.docs_cdn() == "local":
88 resources = Resources(mode="server", root_url="/en/latest/")
89 else:
90 resources = Resources(mode="cdn")
91
92 GOOGLE_API_KEY = getenv('GOOGLE_API_KEY')
93 if GOOGLE_API_KEY is None:
94 if settings.docs_missing_api_key_ok():
95 GOOGLE_API_KEY = "MISSING_API_KEY"
96 else:
97 raise SphinxError("The GOOGLE_API_KEY environment variable is not set. Set GOOGLE_API_KEY to a valid API key, "
98 "or set BOKEH_DOCS_MISSING_API_KEY_OK=yes to build anyway (with broken GMaps)")
99
100 CODING = re.compile(r"^# -\*- coding: (.*) -\*-$", re.M)
101
102 class PlotScriptError(SphinxError):
103 """ Error during script parsing. """
104
105 category = 'PlotScript error'
106
107 def _process_script(source, filename, auxdir, js_name):
108 # This is lame, but seems to be required for python 2
109 source = CODING.sub("", source)
110
111 # quick and dirty way to inject Google API key
112 if "GOOGLE_API_KEY" in source:
113 run_source = source.replace("GOOGLE_API_KEY", GOOGLE_API_KEY)
114 else:
115 run_source = source
116
117 c = ExampleHandler(source=run_source, filename=filename)
118 d = Document()
119 c.modify_document(d)
120 if c.error:
121 raise PlotScriptError(c.error_detail)
122
123 script_path = join("/scripts", js_name)
124 js_path = join(auxdir, js_name)
125 js, script = autoload_static(d.roots[0], resources, script_path)
126
127 with open(js_path, "w") as f:
128 f.write(js)
129
130 return (script, js, js_path, source)
131
132 class PlotScriptParser(Parser):
133 """ This Parser recognizes .py files in the Sphinx source tree,
134 assuming that they contain bokeh examples
135
136 Note: it is important that the .py files are parsed first. This is
137 accomplished by reordering the doc names in the env_before_read_docs callback
138
139 """
140
141 supported = ('python',)
142
143 def parse(self, source, document):
144 """ Parse ``source``, write results to ``document``.
145
146 """
147 # This is lame, but seems to be required for python 2
148 source = CODING.sub("", source)
149
150 env = document.settings.env
151 filename = env.doc2path(env.docname) # e.g. full path to docs/user_guide/examples/layout_vertical
152
153 # This code splits the source into two parts: the docstring (or None if
154 # there is not one), and the remaining source code after
155 m = ast.parse(source)
156 docstring = ast.get_docstring(m)
157 if docstring is not None:
158 lines = source.split("\n")
159 lineno = m.body[0].lineno # assumes docstring is m.body[0]
160 source = "\n".join(lines[lineno:])
161
162 js_name = "bokeh-plot-%s.js" % hashlib.md5(env.docname.encode('utf-8')).hexdigest()
163
164 (script, js, js_path, source) = _process_script(source, filename, env.bokeh_plot_auxdir, js_name)
165
166 env.bokeh_plot_files[env.docname] = (script, js, js_path, source)
167
168 rst = PLOT_PAGE.render(source=source,
169 filename=basename(filename),
170 docstring=docstring,
171 script=script)
172
173 document['bokeh_plot_include_bokehjs'] = True
174
175 # can't use super, Sphinx Parser classes don't inherit object
176 Parser.parse(self, rst, document)
177
178 class BokehPlotDirective(Directive):
179
180 has_content = True
181 optional_arguments = 2
182
183 option_spec = {
184 'source-position': lambda x: choice(x, ('below', 'above', 'none')),
185 }
186
187 def run(self):
188
189 env = self.state.document.settings.env
190 app = env.app
191
192 # filename *or* python code content, but not both
193 if self.arguments and self.content:
194 raise SphinxError("bokeh-plot:: directive can't have both args and content")
195
196 # process inline examples here
197 if self.content:
198 app.debug("[bokeh-plot] handling inline example in %r", env.docname)
199 source = '\n'.join(self.content)
200 # need docname not to look like a path
201 docname = env.docname.replace("/", "-")
202 serialno = env.new_serialno(env.docname)
203 js_name = "bokeh-plot-%s-inline-%d.js" % (docname, serialno)
204 # the code runner just needs a real path to cd to, this will do
205 path = join(env.bokeh_plot_auxdir, js_name)
206
207 (script, js, js_path, source) = _process_script(source, path, env.bokeh_plot_auxdir, js_name)
208 env.bokeh_plot_files[js_name] = (script, js, js_path, source)
209
210 # process example files here
211 else:
212 example_path = self.arguments[0][:-3] # remove the ".py"
213
214 # if it's an "internal" example, the python parser has already handled it
215 if example_path in env.bokeh_plot_files:
216 app.debug("[bokeh-plot] handling internal example in %r: %s", env.docname, self.arguments[0])
217 (script, js, js_path, source) = env.bokeh_plot_files[example_path]
218
219 # handle examples external to the docs source, e.g. gallery examples
220 else:
221 app.debug("[bokeh-plot] handling external example in %r: %s", env.docname, self.arguments[0])
222 source = open(self.arguments[0]).read()
223 source = decode_utf8(source)
224 docname = env.docname.replace("/", "-")
225 serialno = env.new_serialno(env.docname)
226 js_name = "bokeh-plot-%s-external-%d.js" % (docname, serialno)
227 (script, js, js_path, source) = _process_script(source, self.arguments[0], env.bokeh_plot_auxdir, js_name)
228 env.bokeh_plot_files[js_name] = (script, js, js_path, source)
229
230 # use the source file name to construct a friendly target_id
231 target_id = "%s.%s" % (env.docname, basename(js_path))
232 target = nodes.target('', '', ids=[target_id])
233 result = [target]
234
235 code = nodes.literal_block(source, source, language="python", linenos=False, classes=[])
236 set_source_info(self, code)
237
238 source_position = self.options.get('source-position', 'below')
239
240 if source_position == "above": result += [code]
241
242 result += [nodes.raw('', script, format="html")]
243
244 if source_position == "below": result += [code]
245
246 return result
247
248 def env_before_read_docs(app, env, docnames):
249 docnames.sort(key=lambda x: 2 if "extension" in x else 0 if "examples" in x else 1)
250
251 def builder_inited(app):
252 app.env.bokeh_plot_auxdir = join(app.env.doctreedir, 'bokeh_plot')
253 ensuredir(app.env.bokeh_plot_auxdir) # sphinx/_build/doctrees/bokeh_plot
254
255 if not hasattr(app.env, 'bokeh_plot_files'):
256 app.env.bokeh_plot_files = {}
257
258 def html_page_context(app, pagename, templatename, context, doctree):
259 """ Add BokehJS to pages that contain plots.
260
261 """
262 if doctree and doctree.get('bokeh_plot_include_bokehjs'):
263 context['bokeh_css_files'] = resources.css_files
264 context['bokeh_js_files'] = resources.js_files
265
266 def build_finished(app, exception):
267 files = set()
268
269 for (script, js, js_path, source) in app.env.bokeh_plot_files.values():
270 files.add(js_path)
271
272 files_iter = app.status_iterator(sorted(files),
273 'copying bokeh-plot files... ',
274 console.brown,
275 len(files),
276 lambda x: basename(x))
277
278 for file in files_iter:
279 target = join(app.builder.outdir, "scripts", basename(file))
280 ensuredir(dirname(target))
281 try:
282 copyfile(file, target)
283 except OSError as e:
284 raise SphinxError('cannot copy local file %r, reason: %s' % (file, e))
285
286 def env_purge_doc(app, env, docname):
287 """ Remove local files for a given document.
288
289 """
290 if docname in env.bokeh_plot_files:
291 del env.bokeh_plot_files[docname]
292
293 def setup(app):
294 app.add_source_parser('.py', PlotScriptParser)
295
296 app.add_directive('bokeh-plot', BokehPlotDirective)
297
298 app.connect('env-before-read-docs', env_before_read_docs)
299 app.connect('builder-inited', builder_inited)
300 app.connect('html-page-context', html_page_context)
301 app.connect('build-finished', build_finished)
302 app.connect('env-purge-doc', env_purge_doc)
303
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/bokeh/sphinxext/bokeh_plot.py b/bokeh/sphinxext/bokeh_plot.py
--- a/bokeh/sphinxext/bokeh_plot.py
+++ b/bokeh/sphinxext/bokeh_plot.py
@@ -36,7 +36,7 @@
Where to locate the the block of formatted source
code (if anywhere).
-linenos : bool
+linenos : flag
Whether to display line numbers along with the source.
Examples
@@ -70,7 +70,7 @@
from docutils import nodes
from docutils.parsers.rst import Directive, Parser
-from docutils.parsers.rst.directives import choice
+from docutils.parsers.rst.directives import choice, flag
from sphinx.errors import SphinxError
from sphinx.util import console, copyfile, ensuredir
@@ -182,6 +182,7 @@
option_spec = {
'source-position': lambda x: choice(x, ('below', 'above', 'none')),
+ 'linenos': lambda x: True if flag(x) is None else False,
}
def run(self):
@@ -232,7 +233,8 @@
target = nodes.target('', '', ids=[target_id])
result = [target]
- code = nodes.literal_block(source, source, language="python", linenos=False, classes=[])
+ linenos = self.options.get('linenos', False)
+ code = nodes.literal_block(source, source, language="python", linenos=linenos, classes=[])
set_source_info(self, code)
source_position = self.options.get('source-position', 'below')
| {"golden_diff": "diff --git a/bokeh/sphinxext/bokeh_plot.py b/bokeh/sphinxext/bokeh_plot.py\n--- a/bokeh/sphinxext/bokeh_plot.py\n+++ b/bokeh/sphinxext/bokeh_plot.py\n@@ -36,7 +36,7 @@\n Where to locate the the block of formatted source\n code (if anywhere).\n \n-linenos : bool\n+linenos : flag\n Whether to display line numbers along with the source.\n \n Examples\n@@ -70,7 +70,7 @@\n \n from docutils import nodes\n from docutils.parsers.rst import Directive, Parser\n-from docutils.parsers.rst.directives import choice\n+from docutils.parsers.rst.directives import choice, flag\n \n from sphinx.errors import SphinxError\n from sphinx.util import console, copyfile, ensuredir\n@@ -182,6 +182,7 @@\n \n option_spec = {\n 'source-position': lambda x: choice(x, ('below', 'above', 'none')),\n+ 'linenos': lambda x: True if flag(x) is None else False,\n }\n \n def run(self):\n@@ -232,7 +233,8 @@\n target = nodes.target('', '', ids=[target_id])\n result = [target]\n \n- code = nodes.literal_block(source, source, language=\"python\", linenos=False, classes=[])\n+ linenos = self.options.get('linenos', False)\n+ code = nodes.literal_block(source, source, language=\"python\", linenos=linenos, classes=[])\n set_source_info(self, code)\n \n source_position = self.options.get('source-position', 'below')\n", "issue": "sphinxext.bokeh_plot missing linenos option implementation\nAccording to the [docs](http://bokeh.pydata.org/en/latest/docs/reference/sphinxext.html#module-bokeh.sphinxext.bokeh_plot) for sphinxext.bokeh_plot, there's a linenos option. However, this appears to be missing, as building\r\n```\r\n.. bokeh-plot::\r\n :linenos:\r\n\r\n from bokeh.plotting import figure, output_file, show\r\n\r\n output_file(\"example.html\")\r\n\r\n x = [1, 2, 3, 4, 5]\r\n y = [6, 7, 6, 4, 5]\r\n\r\n p = figure(title=\"example\", plot_width=300, plot_height=300)\r\n p.line(x, y, line_width=2)\r\n p.circle(x, y, size=10, fill_color=\"white\")\r\n\r\n show(p)\r\n```\r\nresults in the following sphinx error: `ERROR: Error in \"bokeh-plot\" directive:\r\nunknown option: \"linenos\".`\r\n\r\nVersion Info:\r\n\r\nPython version : 3.6.0 | packaged by conda-forge | (default, Jan 14 2017, 03:13:00)\r\nIPython version : 5.1.0\r\nBokeh version : 0.12.4\r\nBokehJS static path : /Users/Atom/.anaconda/envs/py3/lib/python3.6/site-packages/bokeh/server/static\r\nnode.js version : v6.3.1\r\nnpm version : 3.10.3\r\njupyter --version : 4.2.1\r\njupyter notebook --version : 4.3.1\r\nos version : macOS 10.12.3\r\nbrowser verision: Google Chrome Version 56.0.2924.87 (64-bit)\r\nsphinx version: 1.5.3\r\n\r\nThis is a really awesome sphinx extension!\n", "before_files": [{"content": "\"\"\" Include Bokeh plots in Sphinx HTML documentation.\n\nFor other output types, the placeholder text ``[graph]`` will\nbe generated.\n\nThe ``bokeh-plot`` directive can be used by either supplying:\n\n**A path to a source file** as the argument to the directive::\n\n .. bokeh-plot:: path/to/plot.py\n\n\n**Inline code** as the content of the directive::\n\n .. bokeh-plot::\n\n from bokeh.plotting import figure, output_file, show\n\n output_file(\"example.html\")\n\n x = [1, 2, 3, 4, 5]\n y = [6, 7, 6, 4, 5]\n\n p = figure(title=\"example\", plot_width=300, plot_height=300)\n p.line(x, y, line_width=2)\n p.circle(x, y, size=10, fill_color=\"white\")\n\n show(p)\n\nThis directive also works in conjunction with Sphinx autodoc, when\nused in docstrings.\n\nThe ``bokeh-plot`` directive accepts the following options:\n\nsource-position : enum('above', 'below', 'none')\n Where to locate the the block of formatted source\n code (if anywhere).\n\nlinenos : bool\n Whether to display line numbers along with the source.\n\nExamples\n--------\n\nThe inline example code above produces the following output:\n\n.. bokeh-plot::\n\n from bokeh.plotting import figure, output_file, show\n\n output_file(\"example.html\")\n\n x = [1, 2, 3, 4, 5]\n y = [6, 7, 6, 4, 5]\n\n p = figure(title=\"example\", plot_width=300, plot_height=300)\n p.line(x, y, line_width=2)\n p.circle(x, y, size=10, fill_color=\"white\")\n\n show(p)\n\n\"\"\"\nfrom __future__ import absolute_import\n\nimport ast\nimport hashlib\nfrom os import getenv\nfrom os.path import basename, dirname, join\nimport re\n\nfrom docutils import nodes\nfrom docutils.parsers.rst import Directive, Parser\nfrom docutils.parsers.rst.directives import choice\n\nfrom sphinx.errors import SphinxError\nfrom sphinx.util import console, copyfile, ensuredir\nfrom sphinx.util.nodes import set_source_info\n\nfrom ..document import Document\nfrom ..embed import autoload_static\nfrom ..resources import Resources\nfrom ..settings import settings\nfrom ..util.string import decode_utf8\nfrom .example_handler import ExampleHandler\nfrom .templates import PLOT_PAGE\n\nif settings.docs_cdn() == \"local\":\n resources = Resources(mode=\"server\", root_url=\"/en/latest/\")\nelse:\n resources = Resources(mode=\"cdn\")\n\nGOOGLE_API_KEY = getenv('GOOGLE_API_KEY')\nif GOOGLE_API_KEY is None:\n if settings.docs_missing_api_key_ok():\n GOOGLE_API_KEY = \"MISSING_API_KEY\"\n else:\n raise SphinxError(\"The GOOGLE_API_KEY environment variable is not set. Set GOOGLE_API_KEY to a valid API key, \"\n \"or set BOKEH_DOCS_MISSING_API_KEY_OK=yes to build anyway (with broken GMaps)\")\n\nCODING = re.compile(r\"^# -\\*- coding: (.*) -\\*-$\", re.M)\n\nclass PlotScriptError(SphinxError):\n \"\"\" Error during script parsing. \"\"\"\n\n category = 'PlotScript error'\n\ndef _process_script(source, filename, auxdir, js_name):\n # This is lame, but seems to be required for python 2\n source = CODING.sub(\"\", source)\n\n # quick and dirty way to inject Google API key\n if \"GOOGLE_API_KEY\" in source:\n run_source = source.replace(\"GOOGLE_API_KEY\", GOOGLE_API_KEY)\n else:\n run_source = source\n\n c = ExampleHandler(source=run_source, filename=filename)\n d = Document()\n c.modify_document(d)\n if c.error:\n raise PlotScriptError(c.error_detail)\n\n script_path = join(\"/scripts\", js_name)\n js_path = join(auxdir, js_name)\n js, script = autoload_static(d.roots[0], resources, script_path)\n\n with open(js_path, \"w\") as f:\n f.write(js)\n\n return (script, js, js_path, source)\n\nclass PlotScriptParser(Parser):\n \"\"\" This Parser recognizes .py files in the Sphinx source tree,\n assuming that they contain bokeh examples\n\n Note: it is important that the .py files are parsed first. This is\n accomplished by reordering the doc names in the env_before_read_docs callback\n\n \"\"\"\n\n supported = ('python',)\n\n def parse(self, source, document):\n \"\"\" Parse ``source``, write results to ``document``.\n\n \"\"\"\n # This is lame, but seems to be required for python 2\n source = CODING.sub(\"\", source)\n\n env = document.settings.env\n filename = env.doc2path(env.docname) # e.g. full path to docs/user_guide/examples/layout_vertical\n\n # This code splits the source into two parts: the docstring (or None if\n # there is not one), and the remaining source code after\n m = ast.parse(source)\n docstring = ast.get_docstring(m)\n if docstring is not None:\n lines = source.split(\"\\n\")\n lineno = m.body[0].lineno # assumes docstring is m.body[0]\n source = \"\\n\".join(lines[lineno:])\n\n js_name = \"bokeh-plot-%s.js\" % hashlib.md5(env.docname.encode('utf-8')).hexdigest()\n\n (script, js, js_path, source) = _process_script(source, filename, env.bokeh_plot_auxdir, js_name)\n\n env.bokeh_plot_files[env.docname] = (script, js, js_path, source)\n\n rst = PLOT_PAGE.render(source=source,\n filename=basename(filename),\n docstring=docstring,\n script=script)\n\n document['bokeh_plot_include_bokehjs'] = True\n\n # can't use super, Sphinx Parser classes don't inherit object\n Parser.parse(self, rst, document)\n\nclass BokehPlotDirective(Directive):\n\n has_content = True\n optional_arguments = 2\n\n option_spec = {\n 'source-position': lambda x: choice(x, ('below', 'above', 'none')),\n }\n\n def run(self):\n\n env = self.state.document.settings.env\n app = env.app\n\n # filename *or* python code content, but not both\n if self.arguments and self.content:\n raise SphinxError(\"bokeh-plot:: directive can't have both args and content\")\n\n # process inline examples here\n if self.content:\n app.debug(\"[bokeh-plot] handling inline example in %r\", env.docname)\n source = '\\n'.join(self.content)\n # need docname not to look like a path\n docname = env.docname.replace(\"/\", \"-\")\n serialno = env.new_serialno(env.docname)\n js_name = \"bokeh-plot-%s-inline-%d.js\" % (docname, serialno)\n # the code runner just needs a real path to cd to, this will do\n path = join(env.bokeh_plot_auxdir, js_name)\n\n (script, js, js_path, source) = _process_script(source, path, env.bokeh_plot_auxdir, js_name)\n env.bokeh_plot_files[js_name] = (script, js, js_path, source)\n\n # process example files here\n else:\n example_path = self.arguments[0][:-3] # remove the \".py\"\n\n # if it's an \"internal\" example, the python parser has already handled it\n if example_path in env.bokeh_plot_files:\n app.debug(\"[bokeh-plot] handling internal example in %r: %s\", env.docname, self.arguments[0])\n (script, js, js_path, source) = env.bokeh_plot_files[example_path]\n\n # handle examples external to the docs source, e.g. gallery examples\n else:\n app.debug(\"[bokeh-plot] handling external example in %r: %s\", env.docname, self.arguments[0])\n source = open(self.arguments[0]).read()\n source = decode_utf8(source)\n docname = env.docname.replace(\"/\", \"-\")\n serialno = env.new_serialno(env.docname)\n js_name = \"bokeh-plot-%s-external-%d.js\" % (docname, serialno)\n (script, js, js_path, source) = _process_script(source, self.arguments[0], env.bokeh_plot_auxdir, js_name)\n env.bokeh_plot_files[js_name] = (script, js, js_path, source)\n\n # use the source file name to construct a friendly target_id\n target_id = \"%s.%s\" % (env.docname, basename(js_path))\n target = nodes.target('', '', ids=[target_id])\n result = [target]\n\n code = nodes.literal_block(source, source, language=\"python\", linenos=False, classes=[])\n set_source_info(self, code)\n\n source_position = self.options.get('source-position', 'below')\n\n if source_position == \"above\": result += [code]\n\n result += [nodes.raw('', script, format=\"html\")]\n\n if source_position == \"below\": result += [code]\n\n return result\n\ndef env_before_read_docs(app, env, docnames):\n docnames.sort(key=lambda x: 2 if \"extension\" in x else 0 if \"examples\" in x else 1)\n\ndef builder_inited(app):\n app.env.bokeh_plot_auxdir = join(app.env.doctreedir, 'bokeh_plot')\n ensuredir(app.env.bokeh_plot_auxdir) # sphinx/_build/doctrees/bokeh_plot\n\n if not hasattr(app.env, 'bokeh_plot_files'):\n app.env.bokeh_plot_files = {}\n\ndef html_page_context(app, pagename, templatename, context, doctree):\n \"\"\" Add BokehJS to pages that contain plots.\n\n \"\"\"\n if doctree and doctree.get('bokeh_plot_include_bokehjs'):\n context['bokeh_css_files'] = resources.css_files\n context['bokeh_js_files'] = resources.js_files\n\ndef build_finished(app, exception):\n files = set()\n\n for (script, js, js_path, source) in app.env.bokeh_plot_files.values():\n files.add(js_path)\n\n files_iter = app.status_iterator(sorted(files),\n 'copying bokeh-plot files... ',\n console.brown,\n len(files),\n lambda x: basename(x))\n\n for file in files_iter:\n target = join(app.builder.outdir, \"scripts\", basename(file))\n ensuredir(dirname(target))\n try:\n copyfile(file, target)\n except OSError as e:\n raise SphinxError('cannot copy local file %r, reason: %s' % (file, e))\n\ndef env_purge_doc(app, env, docname):\n \"\"\" Remove local files for a given document.\n\n \"\"\"\n if docname in env.bokeh_plot_files:\n del env.bokeh_plot_files[docname]\n\ndef setup(app):\n app.add_source_parser('.py', PlotScriptParser)\n\n app.add_directive('bokeh-plot', BokehPlotDirective)\n\n app.connect('env-before-read-docs', env_before_read_docs)\n app.connect('builder-inited', builder_inited)\n app.connect('html-page-context', html_page_context)\n app.connect('build-finished', build_finished)\n app.connect('env-purge-doc', env_purge_doc)\n", "path": "bokeh/sphinxext/bokeh_plot.py"}], "after_files": [{"content": "\"\"\" Include Bokeh plots in Sphinx HTML documentation.\n\nFor other output types, the placeholder text ``[graph]`` will\nbe generated.\n\nThe ``bokeh-plot`` directive can be used by either supplying:\n\n**A path to a source file** as the argument to the directive::\n\n .. bokeh-plot:: path/to/plot.py\n\n\n**Inline code** as the content of the directive::\n\n .. bokeh-plot::\n\n from bokeh.plotting import figure, output_file, show\n\n output_file(\"example.html\")\n\n x = [1, 2, 3, 4, 5]\n y = [6, 7, 6, 4, 5]\n\n p = figure(title=\"example\", plot_width=300, plot_height=300)\n p.line(x, y, line_width=2)\n p.circle(x, y, size=10, fill_color=\"white\")\n\n show(p)\n\nThis directive also works in conjunction with Sphinx autodoc, when\nused in docstrings.\n\nThe ``bokeh-plot`` directive accepts the following options:\n\nsource-position : enum('above', 'below', 'none')\n Where to locate the the block of formatted source\n code (if anywhere).\n\nlinenos : flag\n Whether to display line numbers along with the source.\n\nExamples\n--------\n\nThe inline example code above produces the following output:\n\n.. bokeh-plot::\n\n from bokeh.plotting import figure, output_file, show\n\n output_file(\"example.html\")\n\n x = [1, 2, 3, 4, 5]\n y = [6, 7, 6, 4, 5]\n\n p = figure(title=\"example\", plot_width=300, plot_height=300)\n p.line(x, y, line_width=2)\n p.circle(x, y, size=10, fill_color=\"white\")\n\n show(p)\n\n\"\"\"\nfrom __future__ import absolute_import\n\nimport ast\nimport hashlib\nfrom os import getenv\nfrom os.path import basename, dirname, join\nimport re\n\nfrom docutils import nodes\nfrom docutils.parsers.rst import Directive, Parser\nfrom docutils.parsers.rst.directives import choice, flag\n\nfrom sphinx.errors import SphinxError\nfrom sphinx.util import console, copyfile, ensuredir\nfrom sphinx.util.nodes import set_source_info\n\nfrom ..document import Document\nfrom ..embed import autoload_static\nfrom ..resources import Resources\nfrom ..settings import settings\nfrom ..util.string import decode_utf8\nfrom .example_handler import ExampleHandler\nfrom .templates import PLOT_PAGE\n\nif settings.docs_cdn() == \"local\":\n resources = Resources(mode=\"server\", root_url=\"/en/latest/\")\nelse:\n resources = Resources(mode=\"cdn\")\n\nGOOGLE_API_KEY = getenv('GOOGLE_API_KEY')\nif GOOGLE_API_KEY is None:\n if settings.docs_missing_api_key_ok():\n GOOGLE_API_KEY = \"MISSING_API_KEY\"\n else:\n raise SphinxError(\"The GOOGLE_API_KEY environment variable is not set. Set GOOGLE_API_KEY to a valid API key, \"\n \"or set BOKEH_DOCS_MISSING_API_KEY_OK=yes to build anyway (with broken GMaps)\")\n\nCODING = re.compile(r\"^# -\\*- coding: (.*) -\\*-$\", re.M)\n\nclass PlotScriptError(SphinxError):\n \"\"\" Error during script parsing. \"\"\"\n\n category = 'PlotScript error'\n\ndef _process_script(source, filename, auxdir, js_name):\n # This is lame, but seems to be required for python 2\n source = CODING.sub(\"\", source)\n\n # quick and dirty way to inject Google API key\n if \"GOOGLE_API_KEY\" in source:\n run_source = source.replace(\"GOOGLE_API_KEY\", GOOGLE_API_KEY)\n else:\n run_source = source\n\n c = ExampleHandler(source=run_source, filename=filename)\n d = Document()\n c.modify_document(d)\n if c.error:\n raise PlotScriptError(c.error_detail)\n\n script_path = join(\"/scripts\", js_name)\n js_path = join(auxdir, js_name)\n js, script = autoload_static(d.roots[0], resources, script_path)\n\n with open(js_path, \"w\") as f:\n f.write(js)\n\n return (script, js, js_path, source)\n\nclass PlotScriptParser(Parser):\n \"\"\" This Parser recognizes .py files in the Sphinx source tree,\n assuming that they contain bokeh examples\n\n Note: it is important that the .py files are parsed first. This is\n accomplished by reordering the doc names in the env_before_read_docs callback\n\n \"\"\"\n\n supported = ('python',)\n\n def parse(self, source, document):\n \"\"\" Parse ``source``, write results to ``document``.\n\n \"\"\"\n # This is lame, but seems to be required for python 2\n source = CODING.sub(\"\", source)\n\n env = document.settings.env\n filename = env.doc2path(env.docname) # e.g. full path to docs/user_guide/examples/layout_vertical\n\n # This code splits the source into two parts: the docstring (or None if\n # there is not one), and the remaining source code after\n m = ast.parse(source)\n docstring = ast.get_docstring(m)\n if docstring is not None:\n lines = source.split(\"\\n\")\n lineno = m.body[0].lineno # assumes docstring is m.body[0]\n source = \"\\n\".join(lines[lineno:])\n\n js_name = \"bokeh-plot-%s.js\" % hashlib.md5(env.docname.encode('utf-8')).hexdigest()\n\n (script, js, js_path, source) = _process_script(source, filename, env.bokeh_plot_auxdir, js_name)\n\n env.bokeh_plot_files[env.docname] = (script, js, js_path, source)\n\n rst = PLOT_PAGE.render(source=source,\n filename=basename(filename),\n docstring=docstring,\n script=script)\n\n document['bokeh_plot_include_bokehjs'] = True\n\n # can't use super, Sphinx Parser classes don't inherit object\n Parser.parse(self, rst, document)\n\nclass BokehPlotDirective(Directive):\n\n has_content = True\n optional_arguments = 2\n\n option_spec = {\n 'source-position': lambda x: choice(x, ('below', 'above', 'none')),\n 'linenos': lambda x: True if flag(x) is None else False,\n }\n\n def run(self):\n\n env = self.state.document.settings.env\n app = env.app\n\n # filename *or* python code content, but not both\n if self.arguments and self.content:\n raise SphinxError(\"bokeh-plot:: directive can't have both args and content\")\n\n # process inline examples here\n if self.content:\n app.debug(\"[bokeh-plot] handling inline example in %r\", env.docname)\n source = '\\n'.join(self.content)\n # need docname not to look like a path\n docname = env.docname.replace(\"/\", \"-\")\n serialno = env.new_serialno(env.docname)\n js_name = \"bokeh-plot-%s-inline-%d.js\" % (docname, serialno)\n # the code runner just needs a real path to cd to, this will do\n path = join(env.bokeh_plot_auxdir, js_name)\n\n (script, js, js_path, source) = _process_script(source, path, env.bokeh_plot_auxdir, js_name)\n env.bokeh_plot_files[js_name] = (script, js, js_path, source)\n\n # process example files here\n else:\n example_path = self.arguments[0][:-3] # remove the \".py\"\n\n # if it's an \"internal\" example, the python parser has already handled it\n if example_path in env.bokeh_plot_files:\n app.debug(\"[bokeh-plot] handling internal example in %r: %s\", env.docname, self.arguments[0])\n (script, js, js_path, source) = env.bokeh_plot_files[example_path]\n\n # handle examples external to the docs source, e.g. gallery examples\n else:\n app.debug(\"[bokeh-plot] handling external example in %r: %s\", env.docname, self.arguments[0])\n source = open(self.arguments[0]).read()\n source = decode_utf8(source)\n docname = env.docname.replace(\"/\", \"-\")\n serialno = env.new_serialno(env.docname)\n js_name = \"bokeh-plot-%s-external-%d.js\" % (docname, serialno)\n (script, js, js_path, source) = _process_script(source, self.arguments[0], env.bokeh_plot_auxdir, js_name)\n env.bokeh_plot_files[js_name] = (script, js, js_path, source)\n\n # use the source file name to construct a friendly target_id\n target_id = \"%s.%s\" % (env.docname, basename(js_path))\n target = nodes.target('', '', ids=[target_id])\n result = [target]\n\n linenos = self.options.get('linenos', False)\n code = nodes.literal_block(source, source, language=\"python\", linenos=linenos, classes=[])\n set_source_info(self, code)\n\n source_position = self.options.get('source-position', 'below')\n\n if source_position == \"above\": result += [code]\n\n result += [nodes.raw('', script, format=\"html\")]\n\n if source_position == \"below\": result += [code]\n\n return result\n\ndef env_before_read_docs(app, env, docnames):\n docnames.sort(key=lambda x: 2 if \"extension\" in x else 0 if \"examples\" in x else 1)\n\ndef builder_inited(app):\n app.env.bokeh_plot_auxdir = join(app.env.doctreedir, 'bokeh_plot')\n ensuredir(app.env.bokeh_plot_auxdir) # sphinx/_build/doctrees/bokeh_plot\n\n if not hasattr(app.env, 'bokeh_plot_files'):\n app.env.bokeh_plot_files = {}\n\ndef html_page_context(app, pagename, templatename, context, doctree):\n \"\"\" Add BokehJS to pages that contain plots.\n\n \"\"\"\n if doctree and doctree.get('bokeh_plot_include_bokehjs'):\n context['bokeh_css_files'] = resources.css_files\n context['bokeh_js_files'] = resources.js_files\n\ndef build_finished(app, exception):\n files = set()\n\n for (script, js, js_path, source) in app.env.bokeh_plot_files.values():\n files.add(js_path)\n\n files_iter = app.status_iterator(sorted(files),\n 'copying bokeh-plot files... ',\n console.brown,\n len(files),\n lambda x: basename(x))\n\n for file in files_iter:\n target = join(app.builder.outdir, \"scripts\", basename(file))\n ensuredir(dirname(target))\n try:\n copyfile(file, target)\n except OSError as e:\n raise SphinxError('cannot copy local file %r, reason: %s' % (file, e))\n\ndef env_purge_doc(app, env, docname):\n \"\"\" Remove local files for a given document.\n\n \"\"\"\n if docname in env.bokeh_plot_files:\n del env.bokeh_plot_files[docname]\n\ndef setup(app):\n app.add_source_parser('.py', PlotScriptParser)\n\n app.add_directive('bokeh-plot', BokehPlotDirective)\n\n app.connect('env-before-read-docs', env_before_read_docs)\n app.connect('builder-inited', builder_inited)\n app.connect('html-page-context', html_page_context)\n app.connect('build-finished', build_finished)\n app.connect('env-purge-doc', env_purge_doc)\n", "path": "bokeh/sphinxext/bokeh_plot.py"}]} | 4,077 | 371 |
gh_patches_debug_18006 | rasdani/github-patches | git_diff | keras-team__keras-nlp-834 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add compilation defaults for the MaskedLM task models
In https://github.com/keras-team/keras-nlp/issues/709 we added compilation defaults to all classification tasks. We should also do the same for all `XXMaskedLM` models. E.g. [bert](https://github.com/keras-team/keras-nlp/blob/master/keras_nlp/models/bert/bert_masked_lm.py). Here's the full list of models.
- [ ] `AlbertMaskedLM`
- [ ] `BertMaskedLM`
- [ ] `DebertV3MaskedLM`
- [ ] `DistilBertMaskedLM`
- [ ] `FNetMaskedLM`
- [ ] `RobertaMaskedLM`
https://github.com/keras-team/keras-nlp/pull/714 is a good template PR. We can probably just use Adam and `1e-5` or `2e-5` as a learning rate for now. Though a little experimentation for each model to make sure the task does converge would be helpful. This [colab](https://gist.github.com/mattdangerw/b16c257973762a0b4ab9a34f6a932cc1) may be a helpful starting place.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `keras_nlp/models/f_net/f_net_masked_lm.py`
Content:
```
1 # Copyright 2023 The KerasNLP Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import copy
15
16 from tensorflow import keras
17
18 from keras_nlp.api_export import keras_nlp_export
19 from keras_nlp.layers.masked_lm_head import MaskedLMHead
20 from keras_nlp.models.f_net.f_net_backbone import FNetBackbone
21 from keras_nlp.models.f_net.f_net_backbone import f_net_kernel_initializer
22 from keras_nlp.models.f_net.f_net_masked_lm_preprocessor import (
23 FNetMaskedLMPreprocessor,
24 )
25 from keras_nlp.models.f_net.f_net_presets import backbone_presets
26 from keras_nlp.models.task import Task
27 from keras_nlp.utils.python_utils import classproperty
28
29
30 @keras_nlp_export("keras_nlp.models.FNetMaskedLM")
31 class FNetMaskedLM(Task):
32 """An end-to-end FNet model for the masked language modeling task.
33
34 This model will train FNet on a masked language modeling task.
35 The model will predict labels for a number of masked tokens in the
36 input data. For usage of this model with pre-trained weights, see the
37 `from_preset()` method.
38
39 This model can optionally be configured with a `preprocessor` layer, in
40 which case inputs can be raw string features during `fit()`, `predict()`,
41 and `evaluate()`. Inputs will be tokenized and dynamically masked during
42 training and evaluation. This is done by default when creating the model
43 with `from_preset()`.
44
45 Disclaimer: Pre-trained models are provided on an "as is" basis, without
46 warranties or conditions of any kind.
47
48 Args:
49 backbone: A `keras_nlp.models.FNetBackbone` instance.
50 preprocessor: A `keras_nlp.models.FNetMaskedLMPreprocessor` or
51 `None`. If `None`, this model will not apply preprocessing, and
52 inputs should be preprocessed before calling the model.
53
54 Example usage:
55
56 Raw string inputs and pretrained backbone.
57 ```python
58 # Create a dataset with raw string features. Labels are inferred.
59 features = ["The quick brown fox jumped.", "I forgot my homework."]
60
61 # Create a FNetMaskedLM with a pretrained backbone and further train
62 # on an MLM task.
63 masked_lm = keras_nlp.models.FNetMaskedLM.from_preset(
64 "f_net_base_en",
65 )
66 masked_lm.compile(
67 loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
68 )
69 masked_lm.fit(x=features, batch_size=2)
70 ```
71
72 Preprocessed inputs and custom backbone.
73 ```python
74 # Create a preprocessed dataset where 0 is the mask token.
75 preprocessed_features = {
76 "token_ids": tf.constant(
77 [[1, 2, 0, 4, 0, 6, 7, 8]] * 2, shape=(2, 8)
78 ),
79 "segment_ids": tf.constant(
80 [[0, 0, 0, 1, 1, 1, 0, 0]] * 2, shape=(2, 8)
81 ),
82 "mask_positions": tf.constant([[2, 4]] * 2, shape=(2, 2))
83 }
84 # Labels are the original masked values.
85 labels = [[3, 5]] * 2
86
87 # Randomly initialize a FNet encoder
88 backbone = keras_nlp.models.FNetBackbone(
89 vocabulary_size=50265,
90 num_layers=12,
91 hidden_dim=768,
92 intermediate_dim=3072,
93 max_sequence_length=12
94 )
95 # Create a FNet masked_lm and fit the data.
96 masked_lm = keras_nlp.models.FNetMaskedLM(
97 backbone,
98 preprocessor=None,
99 )
100 masked_lm.compile(
101 loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
102 )
103 masked_lm.fit(x=preprocessed_features, y=labels, batch_size=2)
104 ```
105 """
106
107 def __init__(
108 self,
109 backbone,
110 preprocessor=None,
111 **kwargs,
112 ):
113 inputs = {
114 **backbone.input,
115 "mask_positions": keras.Input(
116 shape=(None,), dtype="int32", name="mask_positions"
117 ),
118 }
119 backbone_outputs = backbone(backbone.input)
120 outputs = MaskedLMHead(
121 vocabulary_size=backbone.vocabulary_size,
122 embedding_weights=backbone.token_embedding.embeddings,
123 intermediate_activation="gelu",
124 kernel_initializer=f_net_kernel_initializer(),
125 name="mlm_head",
126 )(backbone_outputs["sequence_output"], inputs["mask_positions"])
127
128 # Instantiate using Functional API Model constructor
129 super().__init__(
130 inputs=inputs,
131 outputs=outputs,
132 include_preprocessing=preprocessor is not None,
133 **kwargs,
134 )
135 # All references to `self` below this line
136 self.backbone = backbone
137 self.preprocessor = preprocessor
138
139 @classproperty
140 def backbone_cls(cls):
141 return FNetBackbone
142
143 @classproperty
144 def preprocessor_cls(cls):
145 return FNetMaskedLMPreprocessor
146
147 @classproperty
148 def presets(cls):
149 return copy.deepcopy(backbone_presets)
150
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/keras_nlp/models/f_net/f_net_masked_lm.py b/keras_nlp/models/f_net/f_net_masked_lm.py
--- a/keras_nlp/models/f_net/f_net_masked_lm.py
+++ b/keras_nlp/models/f_net/f_net_masked_lm.py
@@ -24,6 +24,7 @@
)
from keras_nlp.models.f_net.f_net_presets import backbone_presets
from keras_nlp.models.task import Task
+from keras_nlp.utils.keras_utils import is_xla_compatible
from keras_nlp.utils.python_utils import classproperty
@@ -135,6 +136,12 @@
# All references to `self` below this line
self.backbone = backbone
self.preprocessor = preprocessor
+ self.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.Adam(5e-5),
+ weighted_metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=is_xla_compatible(self),
+ )
@classproperty
def backbone_cls(cls):
| {"golden_diff": "diff --git a/keras_nlp/models/f_net/f_net_masked_lm.py b/keras_nlp/models/f_net/f_net_masked_lm.py\n--- a/keras_nlp/models/f_net/f_net_masked_lm.py\n+++ b/keras_nlp/models/f_net/f_net_masked_lm.py\n@@ -24,6 +24,7 @@\n )\n from keras_nlp.models.f_net.f_net_presets import backbone_presets\n from keras_nlp.models.task import Task\n+from keras_nlp.utils.keras_utils import is_xla_compatible\n from keras_nlp.utils.python_utils import classproperty\n \n \n@@ -135,6 +136,12 @@\n # All references to `self` below this line\n self.backbone = backbone\n self.preprocessor = preprocessor\n+ self.compile(\n+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n+ optimizer=keras.optimizers.Adam(5e-5),\n+ weighted_metrics=keras.metrics.SparseCategoricalAccuracy(),\n+ jit_compile=is_xla_compatible(self),\n+ )\n \n @classproperty\n def backbone_cls(cls):\n", "issue": "Add compilation defaults for the MaskedLM task models\nIn https://github.com/keras-team/keras-nlp/issues/709 we added compilation defaults to all classification tasks. We should also do the same for all `XXMaskedLM` models. E.g. [bert](https://github.com/keras-team/keras-nlp/blob/master/keras_nlp/models/bert/bert_masked_lm.py). Here's the full list of models.\r\n\r\n- [ ] `AlbertMaskedLM`\r\n- [ ] `BertMaskedLM`\r\n- [ ] `DebertV3MaskedLM`\r\n- [ ] `DistilBertMaskedLM`\r\n- [ ] `FNetMaskedLM`\r\n- [ ] `RobertaMaskedLM`\r\n\r\nhttps://github.com/keras-team/keras-nlp/pull/714 is a good template PR. We can probably just use Adam and `1e-5` or `2e-5` as a learning rate for now. Though a little experimentation for each model to make sure the task does converge would be helpful. This [colab](https://gist.github.com/mattdangerw/b16c257973762a0b4ab9a34f6a932cc1) may be a helpful starting place.\n", "before_files": [{"content": "# Copyright 2023 The KerasNLP Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport copy\n\nfrom tensorflow import keras\n\nfrom keras_nlp.api_export import keras_nlp_export\nfrom keras_nlp.layers.masked_lm_head import MaskedLMHead\nfrom keras_nlp.models.f_net.f_net_backbone import FNetBackbone\nfrom keras_nlp.models.f_net.f_net_backbone import f_net_kernel_initializer\nfrom keras_nlp.models.f_net.f_net_masked_lm_preprocessor import (\n FNetMaskedLMPreprocessor,\n)\nfrom keras_nlp.models.f_net.f_net_presets import backbone_presets\nfrom keras_nlp.models.task import Task\nfrom keras_nlp.utils.python_utils import classproperty\n\n\n@keras_nlp_export(\"keras_nlp.models.FNetMaskedLM\")\nclass FNetMaskedLM(Task):\n \"\"\"An end-to-end FNet model for the masked language modeling task.\n\n This model will train FNet on a masked language modeling task.\n The model will predict labels for a number of masked tokens in the\n input data. For usage of this model with pre-trained weights, see the\n `from_preset()` method.\n\n This model can optionally be configured with a `preprocessor` layer, in\n which case inputs can be raw string features during `fit()`, `predict()`,\n and `evaluate()`. Inputs will be tokenized and dynamically masked during\n training and evaluation. This is done by default when creating the model\n with `from_preset()`.\n\n Disclaimer: Pre-trained models are provided on an \"as is\" basis, without\n warranties or conditions of any kind.\n\n Args:\n backbone: A `keras_nlp.models.FNetBackbone` instance.\n preprocessor: A `keras_nlp.models.FNetMaskedLMPreprocessor` or\n `None`. If `None`, this model will not apply preprocessing, and\n inputs should be preprocessed before calling the model.\n\n Example usage:\n\n Raw string inputs and pretrained backbone.\n ```python\n # Create a dataset with raw string features. Labels are inferred.\n features = [\"The quick brown fox jumped.\", \"I forgot my homework.\"]\n\n # Create a FNetMaskedLM with a pretrained backbone and further train\n # on an MLM task.\n masked_lm = keras_nlp.models.FNetMaskedLM.from_preset(\n \"f_net_base_en\",\n )\n masked_lm.compile(\n loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n )\n masked_lm.fit(x=features, batch_size=2)\n ```\n\n Preprocessed inputs and custom backbone.\n ```python\n # Create a preprocessed dataset where 0 is the mask token.\n preprocessed_features = {\n \"token_ids\": tf.constant(\n [[1, 2, 0, 4, 0, 6, 7, 8]] * 2, shape=(2, 8)\n ),\n \"segment_ids\": tf.constant(\n [[0, 0, 0, 1, 1, 1, 0, 0]] * 2, shape=(2, 8)\n ),\n \"mask_positions\": tf.constant([[2, 4]] * 2, shape=(2, 2))\n }\n # Labels are the original masked values.\n labels = [[3, 5]] * 2\n\n # Randomly initialize a FNet encoder\n backbone = keras_nlp.models.FNetBackbone(\n vocabulary_size=50265,\n num_layers=12,\n hidden_dim=768,\n intermediate_dim=3072,\n max_sequence_length=12\n )\n # Create a FNet masked_lm and fit the data.\n masked_lm = keras_nlp.models.FNetMaskedLM(\n backbone,\n preprocessor=None,\n )\n masked_lm.compile(\n loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n )\n masked_lm.fit(x=preprocessed_features, y=labels, batch_size=2)\n ```\n \"\"\"\n\n def __init__(\n self,\n backbone,\n preprocessor=None,\n **kwargs,\n ):\n inputs = {\n **backbone.input,\n \"mask_positions\": keras.Input(\n shape=(None,), dtype=\"int32\", name=\"mask_positions\"\n ),\n }\n backbone_outputs = backbone(backbone.input)\n outputs = MaskedLMHead(\n vocabulary_size=backbone.vocabulary_size,\n embedding_weights=backbone.token_embedding.embeddings,\n intermediate_activation=\"gelu\",\n kernel_initializer=f_net_kernel_initializer(),\n name=\"mlm_head\",\n )(backbone_outputs[\"sequence_output\"], inputs[\"mask_positions\"])\n\n # Instantiate using Functional API Model constructor\n super().__init__(\n inputs=inputs,\n outputs=outputs,\n include_preprocessing=preprocessor is not None,\n **kwargs,\n )\n # All references to `self` below this line\n self.backbone = backbone\n self.preprocessor = preprocessor\n\n @classproperty\n def backbone_cls(cls):\n return FNetBackbone\n\n @classproperty\n def preprocessor_cls(cls):\n return FNetMaskedLMPreprocessor\n\n @classproperty\n def presets(cls):\n return copy.deepcopy(backbone_presets)\n", "path": "keras_nlp/models/f_net/f_net_masked_lm.py"}], "after_files": [{"content": "# Copyright 2023 The KerasNLP Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport copy\n\nfrom tensorflow import keras\n\nfrom keras_nlp.api_export import keras_nlp_export\nfrom keras_nlp.layers.masked_lm_head import MaskedLMHead\nfrom keras_nlp.models.f_net.f_net_backbone import FNetBackbone\nfrom keras_nlp.models.f_net.f_net_backbone import f_net_kernel_initializer\nfrom keras_nlp.models.f_net.f_net_masked_lm_preprocessor import (\n FNetMaskedLMPreprocessor,\n)\nfrom keras_nlp.models.f_net.f_net_presets import backbone_presets\nfrom keras_nlp.models.task import Task\nfrom keras_nlp.utils.keras_utils import is_xla_compatible\nfrom keras_nlp.utils.python_utils import classproperty\n\n\n@keras_nlp_export(\"keras_nlp.models.FNetMaskedLM\")\nclass FNetMaskedLM(Task):\n \"\"\"An end-to-end FNet model for the masked language modeling task.\n\n This model will train FNet on a masked language modeling task.\n The model will predict labels for a number of masked tokens in the\n input data. For usage of this model with pre-trained weights, see the\n `from_preset()` method.\n\n This model can optionally be configured with a `preprocessor` layer, in\n which case inputs can be raw string features during `fit()`, `predict()`,\n and `evaluate()`. Inputs will be tokenized and dynamically masked during\n training and evaluation. This is done by default when creating the model\n with `from_preset()`.\n\n Disclaimer: Pre-trained models are provided on an \"as is\" basis, without\n warranties or conditions of any kind.\n\n Args:\n backbone: A `keras_nlp.models.FNetBackbone` instance.\n preprocessor: A `keras_nlp.models.FNetMaskedLMPreprocessor` or\n `None`. If `None`, this model will not apply preprocessing, and\n inputs should be preprocessed before calling the model.\n\n Example usage:\n\n Raw string inputs and pretrained backbone.\n ```python\n # Create a dataset with raw string features. Labels are inferred.\n features = [\"The quick brown fox jumped.\", \"I forgot my homework.\"]\n\n # Create a FNetMaskedLM with a pretrained backbone and further train\n # on an MLM task.\n masked_lm = keras_nlp.models.FNetMaskedLM.from_preset(\n \"f_net_base_en\",\n )\n masked_lm.compile(\n loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n )\n masked_lm.fit(x=features, batch_size=2)\n ```\n\n Preprocessed inputs and custom backbone.\n ```python\n # Create a preprocessed dataset where 0 is the mask token.\n preprocessed_features = {\n \"token_ids\": tf.constant(\n [[1, 2, 0, 4, 0, 6, 7, 8]] * 2, shape=(2, 8)\n ),\n \"segment_ids\": tf.constant(\n [[0, 0, 0, 1, 1, 1, 0, 0]] * 2, shape=(2, 8)\n ),\n \"mask_positions\": tf.constant([[2, 4]] * 2, shape=(2, 2))\n }\n # Labels are the original masked values.\n labels = [[3, 5]] * 2\n\n # Randomly initialize a FNet encoder\n backbone = keras_nlp.models.FNetBackbone(\n vocabulary_size=50265,\n num_layers=12,\n hidden_dim=768,\n intermediate_dim=3072,\n max_sequence_length=12\n )\n # Create a FNet masked_lm and fit the data.\n masked_lm = keras_nlp.models.FNetMaskedLM(\n backbone,\n preprocessor=None,\n )\n masked_lm.compile(\n loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n )\n masked_lm.fit(x=preprocessed_features, y=labels, batch_size=2)\n ```\n \"\"\"\n\n def __init__(\n self,\n backbone,\n preprocessor=None,\n **kwargs,\n ):\n inputs = {\n **backbone.input,\n \"mask_positions\": keras.Input(\n shape=(None,), dtype=\"int32\", name=\"mask_positions\"\n ),\n }\n backbone_outputs = backbone(backbone.input)\n outputs = MaskedLMHead(\n vocabulary_size=backbone.vocabulary_size,\n embedding_weights=backbone.token_embedding.embeddings,\n intermediate_activation=\"gelu\",\n kernel_initializer=f_net_kernel_initializer(),\n name=\"mlm_head\",\n )(backbone_outputs[\"sequence_output\"], inputs[\"mask_positions\"])\n\n # Instantiate using Functional API Model constructor\n super().__init__(\n inputs=inputs,\n outputs=outputs,\n include_preprocessing=preprocessor is not None,\n **kwargs,\n )\n # All references to `self` below this line\n self.backbone = backbone\n self.preprocessor = preprocessor\n self.compile(\n loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n optimizer=keras.optimizers.Adam(5e-5),\n weighted_metrics=keras.metrics.SparseCategoricalAccuracy(),\n jit_compile=is_xla_compatible(self),\n )\n\n @classproperty\n def backbone_cls(cls):\n return FNetBackbone\n\n @classproperty\n def preprocessor_cls(cls):\n return FNetMaskedLMPreprocessor\n\n @classproperty\n def presets(cls):\n return copy.deepcopy(backbone_presets)\n", "path": "keras_nlp/models/f_net/f_net_masked_lm.py"}]} | 2,159 | 253 |
gh_patches_debug_12434 | rasdani/github-patches | git_diff | joke2k__faker-297 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Sex-specific names and Sex attribute don't match
While person distinguisheds between name_male() and name_female(), and profile generates a random ['sex'] attribute, these do not correlate at present. So in 50% of cases (ignoring neutral names like Chris) this results in F with male names and M with female names.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `faker/providers/profile/__init__.py`
Content:
```
1 # coding=utf-8
2
3 from .. import BaseProvider
4 import itertools
5
6
7 class Provider(BaseProvider):
8 """
9 This provider is a collection of functions to generate personal profiles and identities.
10
11 """
12
13 def simple_profile(self):
14 """
15 Generates a basic profile with personal informations
16 """
17
18 return {
19 "username": self.generator.user_name(),
20 "name": self.generator.name(),
21 "sex": self.random_element(["M", "F"]),
22 "address": self.generator.address(),
23 "mail": self.generator.free_email(),
24
25 #"password":self.generator.password()
26 "birthdate": self.generator.date(),
27
28 }
29
30 def profile(self, fields=None):
31 """
32 Generates a complete profile.
33 If "fields" is not empty, only the fields in the list will be returned
34 """
35 if fields is None:
36 fields = []
37
38 d = {
39 "job": self.generator.job(),
40 "company": self.generator.company(),
41 "ssn": self.generator.ssn(),
42 "residence": self.generator.address(),
43 "current_location": (self.generator.latitude(), self.generator.longitude()),
44 "blood_group": "".join(self.random_element(list(itertools.product(["A", "B", "AB", "0"], ["+", "-"])))),
45 "website": [self.generator.url() for i in range(1, self.random_int(2, 5))]
46 }
47
48 d = dict(d, **self.generator.simple_profile())
49 #field selection
50 if len(fields) > 0:
51 d = dict((k, v) for (k, v) in d.items() if k in fields)
52
53 return d
54
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/faker/providers/profile/__init__.py b/faker/providers/profile/__init__.py
--- a/faker/providers/profile/__init__.py
+++ b/faker/providers/profile/__init__.py
@@ -15,10 +15,15 @@
Generates a basic profile with personal informations
"""
+ sex = self.random_element(["F", "M"])
+ if sex == 'F':
+ name = self.generator.name_female()
+ elif sex == 'M':
+ name = self.generator.name_male()
return {
"username": self.generator.user_name(),
- "name": self.generator.name(),
- "sex": self.random_element(["M", "F"]),
+ "name": name,
+ "sex": sex,
"address": self.generator.address(),
"mail": self.generator.free_email(),
| {"golden_diff": "diff --git a/faker/providers/profile/__init__.py b/faker/providers/profile/__init__.py\n--- a/faker/providers/profile/__init__.py\n+++ b/faker/providers/profile/__init__.py\n@@ -15,10 +15,15 @@\n Generates a basic profile with personal informations\n \"\"\"\n \n+ sex = self.random_element([\"F\", \"M\"])\n+ if sex == 'F':\n+ name = self.generator.name_female()\n+ elif sex == 'M':\n+ name = self.generator.name_male()\n return {\n \"username\": self.generator.user_name(),\n- \"name\": self.generator.name(),\n- \"sex\": self.random_element([\"M\", \"F\"]),\n+ \"name\": name,\n+ \"sex\": sex,\n \"address\": self.generator.address(),\n \"mail\": self.generator.free_email(),\n", "issue": "Sex-specific names and Sex attribute don't match\nWhile person distinguisheds between name_male() and name_female(), and profile generates a random ['sex'] attribute, these do not correlate at present. So in 50% of cases (ignoring neutral names like Chris) this results in F with male names and M with female names.\n\n", "before_files": [{"content": "# coding=utf-8\n\nfrom .. import BaseProvider\nimport itertools\n\n\nclass Provider(BaseProvider):\n \"\"\"\n This provider is a collection of functions to generate personal profiles and identities.\n\n \"\"\"\n\n def simple_profile(self):\n \"\"\"\n Generates a basic profile with personal informations\n \"\"\"\n\n return {\n \"username\": self.generator.user_name(),\n \"name\": self.generator.name(),\n \"sex\": self.random_element([\"M\", \"F\"]),\n \"address\": self.generator.address(),\n \"mail\": self.generator.free_email(),\n\n #\"password\":self.generator.password()\n \"birthdate\": self.generator.date(),\n\n }\n\n def profile(self, fields=None):\n \"\"\"\n Generates a complete profile.\n If \"fields\" is not empty, only the fields in the list will be returned\n \"\"\"\n if fields is None:\n fields = []\n\n d = {\n \"job\": self.generator.job(),\n \"company\": self.generator.company(),\n \"ssn\": self.generator.ssn(),\n \"residence\": self.generator.address(),\n \"current_location\": (self.generator.latitude(), self.generator.longitude()),\n \"blood_group\": \"\".join(self.random_element(list(itertools.product([\"A\", \"B\", \"AB\", \"0\"], [\"+\", \"-\"])))),\n \"website\": [self.generator.url() for i in range(1, self.random_int(2, 5))]\n }\n\n d = dict(d, **self.generator.simple_profile())\n #field selection\n if len(fields) > 0:\n d = dict((k, v) for (k, v) in d.items() if k in fields)\n\n return d\n", "path": "faker/providers/profile/__init__.py"}], "after_files": [{"content": "# coding=utf-8\n\nfrom .. import BaseProvider\nimport itertools\n\n\nclass Provider(BaseProvider):\n \"\"\"\n This provider is a collection of functions to generate personal profiles and identities.\n\n \"\"\"\n\n def simple_profile(self):\n \"\"\"\n Generates a basic profile with personal informations\n \"\"\"\n\n sex = self.random_element([\"F\", \"M\"])\n if sex == 'F':\n name = self.generator.name_female()\n elif sex == 'M':\n name = self.generator.name_male()\n return {\n \"username\": self.generator.user_name(),\n \"name\": name,\n \"sex\": sex,\n \"address\": self.generator.address(),\n \"mail\": self.generator.free_email(),\n\n #\"password\":self.generator.password()\n \"birthdate\": self.generator.date(),\n\n }\n\n def profile(self, fields=None):\n \"\"\"\n Generates a complete profile.\n If \"fields\" is not empty, only the fields in the list will be returned\n \"\"\"\n if fields is None:\n fields = []\n\n d = {\n \"job\": self.generator.job(),\n \"company\": self.generator.company(),\n \"ssn\": self.generator.ssn(),\n \"residence\": self.generator.address(),\n \"current_location\": (self.generator.latitude(), self.generator.longitude()),\n \"blood_group\": \"\".join(self.random_element(list(itertools.product([\"A\", \"B\", \"AB\", \"0\"], [\"+\", \"-\"])))),\n \"website\": [self.generator.url() for i in range(1, self.random_int(2, 5))]\n }\n\n d = dict(d, **self.generator.simple_profile())\n #field selection\n if len(fields) > 0:\n d = dict((k, v) for (k, v) in d.items() if k in fields)\n\n return d\n", "path": "faker/providers/profile/__init__.py"}]} | 778 | 183 |
gh_patches_debug_17233 | rasdani/github-patches | git_diff | mathesar-foundation__mathesar-1988 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Per-request metadata cache
## Problem
<!-- Please provide a clear and concise description of the problem that this feature request is designed to solve.-->
Currently, our `metadata` caching is global over the entire app. This may create problems if we have users simultaneously accessing different DBs.
## Proposed solution
<!-- A clear and concise description of your proposed solution or feature. -->
We should use https://github.com/anexia/django-request-cache to cache metadata per-request only.
## Additional context
<!-- Add any other context or screenshots about the feature request here.-->
We occasionally run into state-based bugs that this would probably solve.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mathesar/state/metadata.py`
Content:
```
1 from db.metadata import get_empty_metadata
2
3
4 def get_cached_metadata():
5 """
6 Cached to minimize reflection queries to Postgres.
7 """
8 global _metadata_cache
9 return _metadata_cache
10
11
12 def reset_cached_metadata():
13 """
14 Resets MetaData cache to empty.
15 """
16 global _metadata_cache
17 _metadata_cache = get_empty_metadata()
18
19
20 _metadata_cache = get_empty_metadata()
21
```
Path: `config/settings.py`
Content:
```
1 """
2 Django settings for config project.
3
4 Generated by 'django-admin startproject' using Django 3.1.7.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/3.1/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/3.1/ref/settings/
11 """
12
13 import os
14 from pathlib import Path
15
16 from decouple import Csv, config as decouple_config
17 from dj_database_url import parse as db_url
18
19
20 # We use a 'tuple' with pipes as delimiters as decople naively splits the global
21 # variables on commas when casting to Csv()
22 def pipe_delim(pipe_string):
23 # Remove opening and closing brackets
24 pipe_string = pipe_string[1:-1]
25 # Split on pipe delim
26 return pipe_string.split("|")
27
28
29 # Build paths inside the project like this: BASE_DIR / 'subdir'.
30 BASE_DIR = Path(__file__).resolve().parent.parent
31
32 # Application definition
33
34 INSTALLED_APPS = [
35 "django.contrib.admin",
36 "django.contrib.auth",
37 "django.contrib.contenttypes",
38 "django.contrib.sessions",
39 "django.contrib.messages",
40 "django.contrib.staticfiles",
41 "rest_framework",
42 "django_filters",
43 "django_property_filter",
44 "mathesar",
45 ]
46
47 MIDDLEWARE = [
48 "django.middleware.security.SecurityMiddleware",
49 "django.contrib.sessions.middleware.SessionMiddleware",
50 "django.middleware.common.CommonMiddleware",
51 "django.middleware.csrf.CsrfViewMiddleware",
52 "django.contrib.auth.middleware.AuthenticationMiddleware",
53 "django.contrib.messages.middleware.MessageMiddleware",
54 "django.middleware.clickjacking.XFrameOptionsMiddleware",
55 "mathesar.middleware.CursorClosedHandlerMiddleware",
56 ]
57
58 ROOT_URLCONF = "config.urls"
59
60 TEMPLATES = [
61 {
62 "BACKEND": "django.template.backends.django.DjangoTemplates",
63 "DIRS": [],
64 "APP_DIRS": True,
65 "OPTIONS": {
66 "context_processors": [
67 "config.context_processors.frontend_settings",
68 "django.template.context_processors.debug",
69 "django.template.context_processors.request",
70 "django.contrib.auth.context_processors.auth",
71 "django.contrib.messages.context_processors.messages",
72 ],
73 },
74 },
75 ]
76
77 WSGI_APPLICATION = "config.wsgi.application"
78
79 # Database
80 # https://docs.djangoproject.com/en/3.1/ref/settings/#databases
81
82 # TODO: Add to documentation that database keys should not be than 128 characters.
83
84 # MATHESAR_DATABASES should be of the form '({db_name}|{db_url}), ({db_name}|{db_url})'
85 # See pipe_delim above for why we use pipes as delimiters
86 DATABASES = {
87 db_key: db_url(url_string)
88 for db_key, url_string in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim))
89 }
90 DATABASES[decouple_config('DJANGO_DATABASE_KEY')] = decouple_config('DJANGO_DATABASE_URL', cast=db_url)
91
92 for db_key, db_dict in DATABASES.items():
93 # Engine can be '.postgresql' or '.postgresql_psycopg2'
94 if not db_dict['ENGINE'].startswith('django.db.backends.postgresql'):
95 raise ValueError(
96 f"{db_key} is not a PostgreSQL database. "
97 f"{db_dict['ENGINE']} found for {db_key}'s engine."
98 )
99
100
101 # pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'
102 # and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']
103 TEST = decouple_config('TEST', default=False, cast=bool)
104 if TEST:
105 for db_key, _ in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim)):
106 DATABASES[db_key]['TEST'] = {'NAME': DATABASES[db_key]['NAME']}
107
108
109 # Quick-start development settings - unsuitable for production
110 # See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/
111
112 # SECURITY WARNING: keep the secret key used in production secret!
113 SECRET_KEY = decouple_config('SECRET_KEY')
114
115 # SECURITY WARNING: don't run with debug turned on in production!
116 DEBUG = decouple_config('DEBUG', default=False, cast=bool)
117
118 ALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv())
119
120 # Password validation
121 # https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators
122
123 AUTH_PASSWORD_VALIDATORS = [
124 {
125 "NAME": "django.contrib.auth.password_validation.UserAttributeSimilarityValidator",
126 },
127 {
128 "NAME": "django.contrib.auth.password_validation.MinimumLengthValidator",
129 },
130 {
131 "NAME": "django.contrib.auth.password_validation.CommonPasswordValidator",
132 },
133 {
134 "NAME": "django.contrib.auth.password_validation.NumericPasswordValidator",
135 },
136 ]
137
138
139 # Internationalization
140 # https://docs.djangoproject.com/en/3.1/topics/i18n/
141
142 LANGUAGE_CODE = "en-us"
143
144 TIME_ZONE = "UTC"
145
146 USE_I18N = True
147
148 USE_L10N = True
149
150 USE_TZ = True
151
152
153 # Static files (CSS, JavaScript, Images)
154 # https://docs.djangoproject.com/en/3.1/howto/static-files/
155 # https://docs.djangoproject.com/en/3.1/ref/contrib/staticfiles/
156
157 STATIC_URL = "/static/"
158
159 # When running with DEBUG=False, the webserver needs to serve files from this location
160 # python manage.py collectstatic has to be run to collect all static files into this location
161 # The files need to served in brotli or gzip compressed format
162 STATIC_ROOT = os.path.join(BASE_DIR, 'static/')
163
164 # Media files (uploaded by the user)
165
166 MEDIA_ROOT = os.path.join(BASE_DIR, '.media/')
167
168 MEDIA_URL = "/media/"
169
170 # Update Authentication classes, removed BasicAuthentication
171 # Defaults: https://www.django-rest-framework.org/api-guide/settings/
172 REST_FRAMEWORK = {
173 'DEFAULT_AUTHENTICATION_CLASSES': [
174 'rest_framework.authentication.SessionAuthentication'
175 ],
176 'DEFAULT_PERMISSION_CLASSES': [
177 'rest_framework.permissions.IsAuthenticated',
178 ],
179 'DEFAULT_FILTER_BACKENDS': (
180 'django_filters.rest_framework.DjangoFilterBackend',
181 'rest_framework.filters.OrderingFilter',
182 ),
183 'TEST_REQUEST_DEFAULT_FORMAT': 'json',
184 'EXCEPTION_HANDLER':
185 'mathesar.exception_handlers.mathesar_exception_handler'
186 }
187 FRIENDLY_ERRORS = {
188 'FIELD_ERRORS': {
189 # By default drf-friendly-errors does contain error codes for ListSerializer type
190 'ListSerializer': {
191 'required': 2007,
192 'null': 2027,
193 'invalid_choice': 2083,
194 'not_a_list': 2123,
195 'empty': 2093
196 },
197 'PermittedPkRelatedField': {
198 'required': 2007,
199 'null': 2027,
200 'does_not_exist': 2151,
201 'incorrect_type': 2161
202 },
203 'PermittedSlugRelatedField': {
204 'required': 2007, 'invalid': 2002, 'null': 2027,
205 'does_not_exist': 2151, 'incorrect_type': 2161
206 },
207 },
208 'EXCEPTION_DICT': {
209 'Http404': 4005
210 }
211 }
212 # Mathesar settings
213 MATHESAR_MODE = decouple_config('MODE', default='PRODUCTION')
214 MATHESAR_UI_BUILD_LOCATION = os.path.join(BASE_DIR, 'mathesar/static/mathesar/')
215 MATHESAR_MANIFEST_LOCATION = os.path.join(MATHESAR_UI_BUILD_LOCATION, 'manifest.json')
216 MATHESAR_CLIENT_DEV_URL = 'http://localhost:3000'
217 MATHESAR_UI_SOURCE_LOCATION = os.path.join(BASE_DIR, 'mathesar_ui/')
218 MATHESAR_CAPTURE_UNHANDLED_EXCEPTION = decouple_config('CAPTURE_UNHANDLED_EXCEPTION', default=False)
219
220 # UI source files have to be served by Django in order for static assets to be included during dev mode
221 # https://vitejs.dev/guide/assets.html
222 # https://vitejs.dev/guide/backend-integration.html
223 STATICFILES_DIRS = [MATHESAR_UI_SOURCE_LOCATION] if MATHESAR_MODE == 'DEVELOPMENT' else [MATHESAR_UI_BUILD_LOCATION]
224
225 # Accounts
226 AUTH_USER_MODEL = 'mathesar.User'
227 LOGIN_URL = '/auth/login/'
228 LOGIN_REDIRECT_URL = '/'
229 DRF_ACCESS_POLICY = {
230 'reusable_conditions': ['mathesar.api.permission_conditions']
231 }
232
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/config/settings.py b/config/settings.py
--- a/config/settings.py
+++ b/config/settings.py
@@ -53,6 +53,8 @@
"django.contrib.messages.middleware.MessageMiddleware",
"django.middleware.clickjacking.XFrameOptionsMiddleware",
"mathesar.middleware.CursorClosedHandlerMiddleware",
+ 'django_userforeignkey.middleware.UserForeignKeyMiddleware',
+ 'django_request_cache.middleware.RequestCacheMiddleware',
]
ROOT_URLCONF = "config.urls"
diff --git a/mathesar/state/metadata.py b/mathesar/state/metadata.py
--- a/mathesar/state/metadata.py
+++ b/mathesar/state/metadata.py
@@ -1,11 +1,12 @@
from db.metadata import get_empty_metadata
+from django_request_cache import cache_for_request
+@cache_for_request
def get_cached_metadata():
"""
Cached to minimize reflection queries to Postgres.
"""
- global _metadata_cache
return _metadata_cache
| {"golden_diff": "diff --git a/config/settings.py b/config/settings.py\n--- a/config/settings.py\n+++ b/config/settings.py\n@@ -53,6 +53,8 @@\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"mathesar.middleware.CursorClosedHandlerMiddleware\",\n+ 'django_userforeignkey.middleware.UserForeignKeyMiddleware',\n+ 'django_request_cache.middleware.RequestCacheMiddleware',\n ]\n \n ROOT_URLCONF = \"config.urls\"\ndiff --git a/mathesar/state/metadata.py b/mathesar/state/metadata.py\n--- a/mathesar/state/metadata.py\n+++ b/mathesar/state/metadata.py\n@@ -1,11 +1,12 @@\n from db.metadata import get_empty_metadata\n+from django_request_cache import cache_for_request\n \n \n+@cache_for_request\n def get_cached_metadata():\n \"\"\"\n Cached to minimize reflection queries to Postgres.\n \"\"\"\n- global _metadata_cache\n return _metadata_cache\n", "issue": "Per-request metadata cache\n## Problem\r\n<!-- Please provide a clear and concise description of the problem that this feature request is designed to solve.-->\r\n\r\nCurrently, our `metadata` caching is global over the entire app. This may create problems if we have users simultaneously accessing different DBs. \r\n\r\n## Proposed solution\r\n<!-- A clear and concise description of your proposed solution or feature. -->\r\n\r\nWe should use https://github.com/anexia/django-request-cache to cache metadata per-request only.\r\n\r\n## Additional context\r\n<!-- Add any other context or screenshots about the feature request here.-->\r\n\r\nWe occasionally run into state-based bugs that this would probably solve.\n", "before_files": [{"content": "from db.metadata import get_empty_metadata\n\n\ndef get_cached_metadata():\n \"\"\"\n Cached to minimize reflection queries to Postgres.\n \"\"\"\n global _metadata_cache\n return _metadata_cache\n\n\ndef reset_cached_metadata():\n \"\"\"\n Resets MetaData cache to empty.\n \"\"\"\n global _metadata_cache\n _metadata_cache = get_empty_metadata()\n\n\n_metadata_cache = get_empty_metadata()\n", "path": "mathesar/state/metadata.py"}, {"content": "\"\"\"\nDjango settings for config project.\n\nGenerated by 'django-admin startproject' using Django 3.1.7.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/3.1/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/3.1/ref/settings/\n\"\"\"\n\nimport os\nfrom pathlib import Path\n\nfrom decouple import Csv, config as decouple_config\nfrom dj_database_url import parse as db_url\n\n\n# We use a 'tuple' with pipes as delimiters as decople naively splits the global\n# variables on commas when casting to Csv()\ndef pipe_delim(pipe_string):\n # Remove opening and closing brackets\n pipe_string = pipe_string[1:-1]\n # Split on pipe delim\n return pipe_string.split(\"|\")\n\n\n# Build paths inside the project like this: BASE_DIR / 'subdir'.\nBASE_DIR = Path(__file__).resolve().parent.parent\n\n# Application definition\n\nINSTALLED_APPS = [\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"rest_framework\",\n \"django_filters\",\n \"django_property_filter\",\n \"mathesar\",\n]\n\nMIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"mathesar.middleware.CursorClosedHandlerMiddleware\",\n]\n\nROOT_URLCONF = \"config.urls\"\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"config.context_processors.frontend_settings\",\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"config.wsgi.application\"\n\n# Database\n# https://docs.djangoproject.com/en/3.1/ref/settings/#databases\n\n# TODO: Add to documentation that database keys should not be than 128 characters.\n\n# MATHESAR_DATABASES should be of the form '({db_name}|{db_url}), ({db_name}|{db_url})'\n# See pipe_delim above for why we use pipes as delimiters\nDATABASES = {\n db_key: db_url(url_string)\n for db_key, url_string in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim))\n}\nDATABASES[decouple_config('DJANGO_DATABASE_KEY')] = decouple_config('DJANGO_DATABASE_URL', cast=db_url)\n\nfor db_key, db_dict in DATABASES.items():\n # Engine can be '.postgresql' or '.postgresql_psycopg2'\n if not db_dict['ENGINE'].startswith('django.db.backends.postgresql'):\n raise ValueError(\n f\"{db_key} is not a PostgreSQL database. \"\n f\"{db_dict['ENGINE']} found for {db_key}'s engine.\"\n )\n\n\n# pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'\n# and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']\nTEST = decouple_config('TEST', default=False, cast=bool)\nif TEST:\n for db_key, _ in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim)):\n DATABASES[db_key]['TEST'] = {'NAME': DATABASES[db_key]['NAME']}\n\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = decouple_config('SECRET_KEY')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = decouple_config('DEBUG', default=False, cast=bool)\n\nALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv())\n\n# Password validation\n# https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/3.1/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"UTC\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/3.1/howto/static-files/\n# https://docs.djangoproject.com/en/3.1/ref/contrib/staticfiles/\n\nSTATIC_URL = \"/static/\"\n\n# When running with DEBUG=False, the webserver needs to serve files from this location\n# python manage.py collectstatic has to be run to collect all static files into this location\n# The files need to served in brotli or gzip compressed format\nSTATIC_ROOT = os.path.join(BASE_DIR, 'static/')\n\n# Media files (uploaded by the user)\n\nMEDIA_ROOT = os.path.join(BASE_DIR, '.media/')\n\nMEDIA_URL = \"/media/\"\n\n# Update Authentication classes, removed BasicAuthentication\n# Defaults: https://www.django-rest-framework.org/api-guide/settings/\nREST_FRAMEWORK = {\n 'DEFAULT_AUTHENTICATION_CLASSES': [\n 'rest_framework.authentication.SessionAuthentication'\n ],\n 'DEFAULT_PERMISSION_CLASSES': [\n 'rest_framework.permissions.IsAuthenticated',\n ],\n 'DEFAULT_FILTER_BACKENDS': (\n 'django_filters.rest_framework.DjangoFilterBackend',\n 'rest_framework.filters.OrderingFilter',\n ),\n 'TEST_REQUEST_DEFAULT_FORMAT': 'json',\n 'EXCEPTION_HANDLER':\n 'mathesar.exception_handlers.mathesar_exception_handler'\n}\nFRIENDLY_ERRORS = {\n 'FIELD_ERRORS': {\n # By default drf-friendly-errors does contain error codes for ListSerializer type\n 'ListSerializer': {\n 'required': 2007,\n 'null': 2027,\n 'invalid_choice': 2083,\n 'not_a_list': 2123,\n 'empty': 2093\n },\n 'PermittedPkRelatedField': {\n 'required': 2007,\n 'null': 2027,\n 'does_not_exist': 2151,\n 'incorrect_type': 2161\n },\n 'PermittedSlugRelatedField': {\n 'required': 2007, 'invalid': 2002, 'null': 2027,\n 'does_not_exist': 2151, 'incorrect_type': 2161\n },\n },\n 'EXCEPTION_DICT': {\n 'Http404': 4005\n }\n}\n# Mathesar settings\nMATHESAR_MODE = decouple_config('MODE', default='PRODUCTION')\nMATHESAR_UI_BUILD_LOCATION = os.path.join(BASE_DIR, 'mathesar/static/mathesar/')\nMATHESAR_MANIFEST_LOCATION = os.path.join(MATHESAR_UI_BUILD_LOCATION, 'manifest.json')\nMATHESAR_CLIENT_DEV_URL = 'http://localhost:3000'\nMATHESAR_UI_SOURCE_LOCATION = os.path.join(BASE_DIR, 'mathesar_ui/')\nMATHESAR_CAPTURE_UNHANDLED_EXCEPTION = decouple_config('CAPTURE_UNHANDLED_EXCEPTION', default=False)\n\n# UI source files have to be served by Django in order for static assets to be included during dev mode\n# https://vitejs.dev/guide/assets.html\n# https://vitejs.dev/guide/backend-integration.html\nSTATICFILES_DIRS = [MATHESAR_UI_SOURCE_LOCATION] if MATHESAR_MODE == 'DEVELOPMENT' else [MATHESAR_UI_BUILD_LOCATION]\n\n# Accounts\nAUTH_USER_MODEL = 'mathesar.User'\nLOGIN_URL = '/auth/login/'\nLOGIN_REDIRECT_URL = '/'\nDRF_ACCESS_POLICY = {\n 'reusable_conditions': ['mathesar.api.permission_conditions']\n}\n", "path": "config/settings.py"}], "after_files": [{"content": "from db.metadata import get_empty_metadata\nfrom django_request_cache import cache_for_request\n\n\n@cache_for_request\ndef get_cached_metadata():\n \"\"\"\n Cached to minimize reflection queries to Postgres.\n \"\"\"\n return _metadata_cache\n\n\ndef reset_cached_metadata():\n \"\"\"\n Resets MetaData cache to empty.\n \"\"\"\n global _metadata_cache\n _metadata_cache = get_empty_metadata()\n\n\n_metadata_cache = get_empty_metadata()\n", "path": "mathesar/state/metadata.py"}, {"content": "\"\"\"\nDjango settings for config project.\n\nGenerated by 'django-admin startproject' using Django 3.1.7.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/3.1/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/3.1/ref/settings/\n\"\"\"\n\nimport os\nfrom pathlib import Path\n\nfrom decouple import Csv, config as decouple_config\nfrom dj_database_url import parse as db_url\n\n\n# We use a 'tuple' with pipes as delimiters as decople naively splits the global\n# variables on commas when casting to Csv()\ndef pipe_delim(pipe_string):\n # Remove opening and closing brackets\n pipe_string = pipe_string[1:-1]\n # Split on pipe delim\n return pipe_string.split(\"|\")\n\n\n# Build paths inside the project like this: BASE_DIR / 'subdir'.\nBASE_DIR = Path(__file__).resolve().parent.parent\n\n# Application definition\n\nINSTALLED_APPS = [\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"rest_framework\",\n \"django_filters\",\n \"django_property_filter\",\n \"mathesar\",\n]\n\nMIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"mathesar.middleware.CursorClosedHandlerMiddleware\",\n 'django_userforeignkey.middleware.UserForeignKeyMiddleware',\n 'django_request_cache.middleware.RequestCacheMiddleware',\n]\n\nROOT_URLCONF = \"config.urls\"\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"config.context_processors.frontend_settings\",\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"config.wsgi.application\"\n\n# Database\n# https://docs.djangoproject.com/en/3.1/ref/settings/#databases\n\n# TODO: Add to documentation that database keys should not be than 128 characters.\n\n# MATHESAR_DATABASES should be of the form '({db_name}|{db_url}), ({db_name}|{db_url})'\n# See pipe_delim above for why we use pipes as delimiters\nDATABASES = {\n db_key: db_url(url_string)\n for db_key, url_string in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim))\n}\nDATABASES[decouple_config('DJANGO_DATABASE_KEY')] = decouple_config('DJANGO_DATABASE_URL', cast=db_url)\n\nfor db_key, db_dict in DATABASES.items():\n # Engine can be '.postgresql' or '.postgresql_psycopg2'\n if not db_dict['ENGINE'].startswith('django.db.backends.postgresql'):\n raise ValueError(\n f\"{db_key} is not a PostgreSQL database. \"\n f\"{db_dict['ENGINE']} found for {db_key}'s engine.\"\n )\n\n\n# pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'\n# and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']\nTEST = decouple_config('TEST', default=False, cast=bool)\nif TEST:\n for db_key, _ in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim)):\n DATABASES[db_key]['TEST'] = {'NAME': DATABASES[db_key]['NAME']}\n\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = decouple_config('SECRET_KEY')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = decouple_config('DEBUG', default=False, cast=bool)\n\nALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv())\n\n# Password validation\n# https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/3.1/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"UTC\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/3.1/howto/static-files/\n# https://docs.djangoproject.com/en/3.1/ref/contrib/staticfiles/\n\nSTATIC_URL = \"/static/\"\n\n# When running with DEBUG=False, the webserver needs to serve files from this location\n# python manage.py collectstatic has to be run to collect all static files into this location\n# The files need to served in brotli or gzip compressed format\nSTATIC_ROOT = os.path.join(BASE_DIR, 'static/')\n\n# Media files (uploaded by the user)\n\nMEDIA_ROOT = os.path.join(BASE_DIR, '.media/')\n\nMEDIA_URL = \"/media/\"\n\n# Update Authentication classes, removed BasicAuthentication\n# Defaults: https://www.django-rest-framework.org/api-guide/settings/\nREST_FRAMEWORK = {\n 'DEFAULT_AUTHENTICATION_CLASSES': [\n 'rest_framework.authentication.SessionAuthentication'\n ],\n 'DEFAULT_PERMISSION_CLASSES': [\n 'rest_framework.permissions.IsAuthenticated',\n ],\n 'DEFAULT_FILTER_BACKENDS': (\n 'django_filters.rest_framework.DjangoFilterBackend',\n 'rest_framework.filters.OrderingFilter',\n ),\n 'TEST_REQUEST_DEFAULT_FORMAT': 'json',\n 'EXCEPTION_HANDLER':\n 'mathesar.exception_handlers.mathesar_exception_handler'\n}\nFRIENDLY_ERRORS = {\n 'FIELD_ERRORS': {\n # By default drf-friendly-errors does contain error codes for ListSerializer type\n 'ListSerializer': {\n 'required': 2007,\n 'null': 2027,\n 'invalid_choice': 2083,\n 'not_a_list': 2123,\n 'empty': 2093\n },\n 'PermittedPkRelatedField': {\n 'required': 2007,\n 'null': 2027,\n 'does_not_exist': 2151,\n 'incorrect_type': 2161\n },\n 'PermittedSlugRelatedField': {\n 'required': 2007, 'invalid': 2002, 'null': 2027,\n 'does_not_exist': 2151, 'incorrect_type': 2161\n },\n },\n 'EXCEPTION_DICT': {\n 'Http404': 4005\n }\n}\n# Mathesar settings\nMATHESAR_MODE = decouple_config('MODE', default='PRODUCTION')\nMATHESAR_UI_BUILD_LOCATION = os.path.join(BASE_DIR, 'mathesar/static/mathesar/')\nMATHESAR_MANIFEST_LOCATION = os.path.join(MATHESAR_UI_BUILD_LOCATION, 'manifest.json')\nMATHESAR_CLIENT_DEV_URL = 'http://localhost:3000'\nMATHESAR_UI_SOURCE_LOCATION = os.path.join(BASE_DIR, 'mathesar_ui/')\nMATHESAR_CAPTURE_UNHANDLED_EXCEPTION = decouple_config('CAPTURE_UNHANDLED_EXCEPTION', default=False)\n\n# UI source files have to be served by Django in order for static assets to be included during dev mode\n# https://vitejs.dev/guide/assets.html\n# https://vitejs.dev/guide/backend-integration.html\nSTATICFILES_DIRS = [MATHESAR_UI_SOURCE_LOCATION] if MATHESAR_MODE == 'DEVELOPMENT' else [MATHESAR_UI_BUILD_LOCATION]\n\n# Accounts\nAUTH_USER_MODEL = 'mathesar.User'\nLOGIN_URL = '/auth/login/'\nLOGIN_REDIRECT_URL = '/'\nDRF_ACCESS_POLICY = {\n 'reusable_conditions': ['mathesar.api.permission_conditions']\n}\n", "path": "config/settings.py"}]} | 2,958 | 205 |
gh_patches_debug_22688 | rasdani/github-patches | git_diff | pulp__pulpcore-4622 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove eval fallback from EncryptedJSONField
#4359
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulpcore/app/models/fields.py`
Content:
```
1 import json
2 import logging
3 import os
4 from functools import lru_cache
5 from gettext import gettext as _
6
7 from cryptography.fernet import Fernet, MultiFernet
8 from django.conf import settings
9 from django.core.exceptions import ImproperlyConfigured
10 from django.db.models import FileField, JSONField, Lookup
11 from django.db.models.fields import Field, TextField
12 from django.utils.encoding import force_bytes, force_str
13 from pulpcore.app.files import TemporaryDownloadedFile
14 from pulpcore.app.loggers import deprecation_logger
15
16 _logger = logging.getLogger(__name__)
17
18
19 @lru_cache(maxsize=1)
20 def _fernet():
21 # Cache the enryption keys once per application.
22 _logger.debug(f"Loading encryption key from {settings.DB_ENCRYPTION_KEY}")
23 with open(settings.DB_ENCRYPTION_KEY, "rb") as key_file:
24 return MultiFernet(
25 [
26 Fernet(key.strip())
27 for key in key_file.readlines()
28 if not key.startswith(b"#") and key.strip() != b""
29 ]
30 )
31
32
33 class ArtifactFileField(FileField):
34 """
35 A custom FileField that always saves files to location specified by 'upload_to'.
36
37 The field can be set as either a path to the file or File object. In both cases the file is
38 moved or copied to the location specified by 'upload_to' field parameter.
39 """
40
41 def pre_save(self, model_instance, add):
42 """
43 Return FieldFile object which specifies path to the file to be stored in database.
44
45 There are two ways to get artifact into Pulp: sync and upload.
46
47 The upload case
48 - file is not stored yet, aka file._committed = False
49 - nothing to do here in addition to Django pre_save actions
50
51 The sync case:
52 - file is already stored in a temporary location, aka file._committed = True
53 - it needs to be moved into Pulp artifact storage if it's not there
54 - TemporaryDownloadedFile takes care of correctly set storage path
55 - only then Django pre_save actions should be performed
56
57 Args:
58 model_instance (`class::pulpcore.plugin.Artifact`): The instance this field belongs to.
59 add (bool): Whether the instance is being saved to the database for the first time.
60 Ignored by Django pre_save method.
61
62 Returns:
63 FieldFile object just before saving.
64
65 """
66 file = model_instance.file
67 artifact_storage_path = self.upload_to(model_instance, "")
68
69 already_in_place = file.name in [
70 artifact_storage_path,
71 os.path.join(settings.MEDIA_ROOT, artifact_storage_path),
72 ]
73 is_in_artifact_storage = file.name.startswith(os.path.join(settings.MEDIA_ROOT, "artifact"))
74
75 if not already_in_place and is_in_artifact_storage:
76 raise ValueError(
77 _(
78 "The file referenced by the Artifact is already present in "
79 "Artifact storage. Files must be stored outside this location "
80 "prior to Artifact creation."
81 )
82 )
83
84 move = file._committed and file.name != artifact_storage_path
85 if move:
86 if not already_in_place:
87 file._file = TemporaryDownloadedFile(open(file.name, "rb"))
88 file._committed = False
89
90 return super().pre_save(model_instance, add)
91
92
93 class EncryptedTextField(TextField):
94 """A field mixin that encrypts text using settings.DB_ENCRYPTION_KEY."""
95
96 def __init__(self, *args, **kwargs):
97 if kwargs.get("primary_key"):
98 raise ImproperlyConfigured("EncryptedTextField does not support primary_key=True.")
99 if kwargs.get("unique"):
100 raise ImproperlyConfigured("EncryptedTextField does not support unique=True.")
101 if kwargs.get("db_index"):
102 raise ImproperlyConfigured("EncryptedTextField does not support db_index=True.")
103 super().__init__(*args, **kwargs)
104
105 def get_prep_value(self, value):
106 if value is not None:
107 assert isinstance(value, str)
108 value = force_str(_fernet().encrypt(force_bytes(value)))
109 return super().get_prep_value(value)
110
111 def from_db_value(self, value, expression, connection):
112 if value is not None:
113 value = force_str(_fernet().decrypt(force_bytes(value)))
114 return value
115
116
117 class EncryptedJSONField(JSONField):
118 """A Field mixin that encrypts the JSON text using settings.DP_ENCRYPTION_KEY."""
119
120 def __init__(self, *args, **kwargs):
121 if kwargs.get("primary_key"):
122 raise ImproperlyConfigured("EncryptedJSONField does not support primary_key=True.")
123 if kwargs.get("unique"):
124 raise ImproperlyConfigured("EncryptedJSONField does not support unique=True.")
125 if kwargs.get("db_index"):
126 raise ImproperlyConfigured("EncryptedJSONField does not support db_index=True.")
127 super().__init__(*args, **kwargs)
128
129 def encrypt(self, value):
130 if isinstance(value, dict):
131 return {k: self.encrypt(v) for k, v in value.items()}
132 elif isinstance(value, (list, tuple, set)):
133 return [self.encrypt(v) for v in value]
134
135 return force_str(_fernet().encrypt(force_bytes(json.dumps(value, cls=self.encoder))))
136
137 def decrypt(self, value):
138 if isinstance(value, dict):
139 return {k: self.decrypt(v) for k, v in value.items()}
140 elif isinstance(value, (list, tuple, set)):
141 return [self.decrypt(v) for v in value]
142
143 dec_value = force_str(_fernet().decrypt(force_bytes(value)))
144 try:
145 return json.loads(dec_value, cls=self.decoder)
146 except json.JSONDecodeError:
147 deprecation_logger.info(
148 "Failed to decode json in an EncryptedJSONField. Falling back to eval. "
149 "Please run pulpcore-manager rotate-db-key to repair."
150 "This is deprecated and will be removed in pulpcore 3.40."
151 )
152 return eval(dec_value)
153
154 def get_prep_value(self, value):
155 if value is not None:
156 if hasattr(value, "as_sql"):
157 return value
158 value = self.encrypt(value)
159 return super().get_prep_value(value)
160
161 def from_db_value(self, value, expression, connection):
162 if value is not None:
163 value = self.decrypt(super().from_db_value(value, expression, connection))
164 return value
165
166
167 @Field.register_lookup
168 class NotEqualLookup(Lookup):
169 # this is copied from https://docs.djangoproject.com/en/3.2/howto/custom-lookups/
170 lookup_name = "ne"
171
172 def as_sql(self, compiler, connection):
173 lhs, lhs_params = self.process_lhs(compiler, connection)
174 rhs, rhs_params = self.process_rhs(compiler, connection)
175 params = lhs_params + rhs_params
176 return "%s <> %s" % (lhs, rhs), params
177
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pulpcore/app/models/fields.py b/pulpcore/app/models/fields.py
--- a/pulpcore/app/models/fields.py
+++ b/pulpcore/app/models/fields.py
@@ -11,7 +11,6 @@
from django.db.models.fields import Field, TextField
from django.utils.encoding import force_bytes, force_str
from pulpcore.app.files import TemporaryDownloadedFile
-from pulpcore.app.loggers import deprecation_logger
_logger = logging.getLogger(__name__)
@@ -141,15 +140,7 @@
return [self.decrypt(v) for v in value]
dec_value = force_str(_fernet().decrypt(force_bytes(value)))
- try:
- return json.loads(dec_value, cls=self.decoder)
- except json.JSONDecodeError:
- deprecation_logger.info(
- "Failed to decode json in an EncryptedJSONField. Falling back to eval. "
- "Please run pulpcore-manager rotate-db-key to repair."
- "This is deprecated and will be removed in pulpcore 3.40."
- )
- return eval(dec_value)
+ return json.loads(dec_value, cls=self.decoder)
def get_prep_value(self, value):
if value is not None:
| {"golden_diff": "diff --git a/pulpcore/app/models/fields.py b/pulpcore/app/models/fields.py\n--- a/pulpcore/app/models/fields.py\n+++ b/pulpcore/app/models/fields.py\n@@ -11,7 +11,6 @@\n from django.db.models.fields import Field, TextField\n from django.utils.encoding import force_bytes, force_str\n from pulpcore.app.files import TemporaryDownloadedFile\n-from pulpcore.app.loggers import deprecation_logger\n \n _logger = logging.getLogger(__name__)\n \n@@ -141,15 +140,7 @@\n return [self.decrypt(v) for v in value]\n \n dec_value = force_str(_fernet().decrypt(force_bytes(value)))\n- try:\n- return json.loads(dec_value, cls=self.decoder)\n- except json.JSONDecodeError:\n- deprecation_logger.info(\n- \"Failed to decode json in an EncryptedJSONField. Falling back to eval. \"\n- \"Please run pulpcore-manager rotate-db-key to repair.\"\n- \"This is deprecated and will be removed in pulpcore 3.40.\"\n- )\n- return eval(dec_value)\n+ return json.loads(dec_value, cls=self.decoder)\n \n def get_prep_value(self, value):\n if value is not None:\n", "issue": "Remove eval fallback from EncryptedJSONField\n#4359\n", "before_files": [{"content": "import json\nimport logging\nimport os\nfrom functools import lru_cache\nfrom gettext import gettext as _\n\nfrom cryptography.fernet import Fernet, MultiFernet\nfrom django.conf import settings\nfrom django.core.exceptions import ImproperlyConfigured\nfrom django.db.models import FileField, JSONField, Lookup\nfrom django.db.models.fields import Field, TextField\nfrom django.utils.encoding import force_bytes, force_str\nfrom pulpcore.app.files import TemporaryDownloadedFile\nfrom pulpcore.app.loggers import deprecation_logger\n\n_logger = logging.getLogger(__name__)\n\n\n@lru_cache(maxsize=1)\ndef _fernet():\n # Cache the enryption keys once per application.\n _logger.debug(f\"Loading encryption key from {settings.DB_ENCRYPTION_KEY}\")\n with open(settings.DB_ENCRYPTION_KEY, \"rb\") as key_file:\n return MultiFernet(\n [\n Fernet(key.strip())\n for key in key_file.readlines()\n if not key.startswith(b\"#\") and key.strip() != b\"\"\n ]\n )\n\n\nclass ArtifactFileField(FileField):\n \"\"\"\n A custom FileField that always saves files to location specified by 'upload_to'.\n\n The field can be set as either a path to the file or File object. In both cases the file is\n moved or copied to the location specified by 'upload_to' field parameter.\n \"\"\"\n\n def pre_save(self, model_instance, add):\n \"\"\"\n Return FieldFile object which specifies path to the file to be stored in database.\n\n There are two ways to get artifact into Pulp: sync and upload.\n\n The upload case\n - file is not stored yet, aka file._committed = False\n - nothing to do here in addition to Django pre_save actions\n\n The sync case:\n - file is already stored in a temporary location, aka file._committed = True\n - it needs to be moved into Pulp artifact storage if it's not there\n - TemporaryDownloadedFile takes care of correctly set storage path\n - only then Django pre_save actions should be performed\n\n Args:\n model_instance (`class::pulpcore.plugin.Artifact`): The instance this field belongs to.\n add (bool): Whether the instance is being saved to the database for the first time.\n Ignored by Django pre_save method.\n\n Returns:\n FieldFile object just before saving.\n\n \"\"\"\n file = model_instance.file\n artifact_storage_path = self.upload_to(model_instance, \"\")\n\n already_in_place = file.name in [\n artifact_storage_path,\n os.path.join(settings.MEDIA_ROOT, artifact_storage_path),\n ]\n is_in_artifact_storage = file.name.startswith(os.path.join(settings.MEDIA_ROOT, \"artifact\"))\n\n if not already_in_place and is_in_artifact_storage:\n raise ValueError(\n _(\n \"The file referenced by the Artifact is already present in \"\n \"Artifact storage. Files must be stored outside this location \"\n \"prior to Artifact creation.\"\n )\n )\n\n move = file._committed and file.name != artifact_storage_path\n if move:\n if not already_in_place:\n file._file = TemporaryDownloadedFile(open(file.name, \"rb\"))\n file._committed = False\n\n return super().pre_save(model_instance, add)\n\n\nclass EncryptedTextField(TextField):\n \"\"\"A field mixin that encrypts text using settings.DB_ENCRYPTION_KEY.\"\"\"\n\n def __init__(self, *args, **kwargs):\n if kwargs.get(\"primary_key\"):\n raise ImproperlyConfigured(\"EncryptedTextField does not support primary_key=True.\")\n if kwargs.get(\"unique\"):\n raise ImproperlyConfigured(\"EncryptedTextField does not support unique=True.\")\n if kwargs.get(\"db_index\"):\n raise ImproperlyConfigured(\"EncryptedTextField does not support db_index=True.\")\n super().__init__(*args, **kwargs)\n\n def get_prep_value(self, value):\n if value is not None:\n assert isinstance(value, str)\n value = force_str(_fernet().encrypt(force_bytes(value)))\n return super().get_prep_value(value)\n\n def from_db_value(self, value, expression, connection):\n if value is not None:\n value = force_str(_fernet().decrypt(force_bytes(value)))\n return value\n\n\nclass EncryptedJSONField(JSONField):\n \"\"\"A Field mixin that encrypts the JSON text using settings.DP_ENCRYPTION_KEY.\"\"\"\n\n def __init__(self, *args, **kwargs):\n if kwargs.get(\"primary_key\"):\n raise ImproperlyConfigured(\"EncryptedJSONField does not support primary_key=True.\")\n if kwargs.get(\"unique\"):\n raise ImproperlyConfigured(\"EncryptedJSONField does not support unique=True.\")\n if kwargs.get(\"db_index\"):\n raise ImproperlyConfigured(\"EncryptedJSONField does not support db_index=True.\")\n super().__init__(*args, **kwargs)\n\n def encrypt(self, value):\n if isinstance(value, dict):\n return {k: self.encrypt(v) for k, v in value.items()}\n elif isinstance(value, (list, tuple, set)):\n return [self.encrypt(v) for v in value]\n\n return force_str(_fernet().encrypt(force_bytes(json.dumps(value, cls=self.encoder))))\n\n def decrypt(self, value):\n if isinstance(value, dict):\n return {k: self.decrypt(v) for k, v in value.items()}\n elif isinstance(value, (list, tuple, set)):\n return [self.decrypt(v) for v in value]\n\n dec_value = force_str(_fernet().decrypt(force_bytes(value)))\n try:\n return json.loads(dec_value, cls=self.decoder)\n except json.JSONDecodeError:\n deprecation_logger.info(\n \"Failed to decode json in an EncryptedJSONField. Falling back to eval. \"\n \"Please run pulpcore-manager rotate-db-key to repair.\"\n \"This is deprecated and will be removed in pulpcore 3.40.\"\n )\n return eval(dec_value)\n\n def get_prep_value(self, value):\n if value is not None:\n if hasattr(value, \"as_sql\"):\n return value\n value = self.encrypt(value)\n return super().get_prep_value(value)\n\n def from_db_value(self, value, expression, connection):\n if value is not None:\n value = self.decrypt(super().from_db_value(value, expression, connection))\n return value\n\n\[email protected]_lookup\nclass NotEqualLookup(Lookup):\n # this is copied from https://docs.djangoproject.com/en/3.2/howto/custom-lookups/\n lookup_name = \"ne\"\n\n def as_sql(self, compiler, connection):\n lhs, lhs_params = self.process_lhs(compiler, connection)\n rhs, rhs_params = self.process_rhs(compiler, connection)\n params = lhs_params + rhs_params\n return \"%s <> %s\" % (lhs, rhs), params\n", "path": "pulpcore/app/models/fields.py"}], "after_files": [{"content": "import json\nimport logging\nimport os\nfrom functools import lru_cache\nfrom gettext import gettext as _\n\nfrom cryptography.fernet import Fernet, MultiFernet\nfrom django.conf import settings\nfrom django.core.exceptions import ImproperlyConfigured\nfrom django.db.models import FileField, JSONField, Lookup\nfrom django.db.models.fields import Field, TextField\nfrom django.utils.encoding import force_bytes, force_str\nfrom pulpcore.app.files import TemporaryDownloadedFile\n\n_logger = logging.getLogger(__name__)\n\n\n@lru_cache(maxsize=1)\ndef _fernet():\n # Cache the enryption keys once per application.\n _logger.debug(f\"Loading encryption key from {settings.DB_ENCRYPTION_KEY}\")\n with open(settings.DB_ENCRYPTION_KEY, \"rb\") as key_file:\n return MultiFernet(\n [\n Fernet(key.strip())\n for key in key_file.readlines()\n if not key.startswith(b\"#\") and key.strip() != b\"\"\n ]\n )\n\n\nclass ArtifactFileField(FileField):\n \"\"\"\n A custom FileField that always saves files to location specified by 'upload_to'.\n\n The field can be set as either a path to the file or File object. In both cases the file is\n moved or copied to the location specified by 'upload_to' field parameter.\n \"\"\"\n\n def pre_save(self, model_instance, add):\n \"\"\"\n Return FieldFile object which specifies path to the file to be stored in database.\n\n There are two ways to get artifact into Pulp: sync and upload.\n\n The upload case\n - file is not stored yet, aka file._committed = False\n - nothing to do here in addition to Django pre_save actions\n\n The sync case:\n - file is already stored in a temporary location, aka file._committed = True\n - it needs to be moved into Pulp artifact storage if it's not there\n - TemporaryDownloadedFile takes care of correctly set storage path\n - only then Django pre_save actions should be performed\n\n Args:\n model_instance (`class::pulpcore.plugin.Artifact`): The instance this field belongs to.\n add (bool): Whether the instance is being saved to the database for the first time.\n Ignored by Django pre_save method.\n\n Returns:\n FieldFile object just before saving.\n\n \"\"\"\n file = model_instance.file\n artifact_storage_path = self.upload_to(model_instance, \"\")\n\n already_in_place = file.name in [\n artifact_storage_path,\n os.path.join(settings.MEDIA_ROOT, artifact_storage_path),\n ]\n is_in_artifact_storage = file.name.startswith(os.path.join(settings.MEDIA_ROOT, \"artifact\"))\n\n if not already_in_place and is_in_artifact_storage:\n raise ValueError(\n _(\n \"The file referenced by the Artifact is already present in \"\n \"Artifact storage. Files must be stored outside this location \"\n \"prior to Artifact creation.\"\n )\n )\n\n move = file._committed and file.name != artifact_storage_path\n if move:\n if not already_in_place:\n file._file = TemporaryDownloadedFile(open(file.name, \"rb\"))\n file._committed = False\n\n return super().pre_save(model_instance, add)\n\n\nclass EncryptedTextField(TextField):\n \"\"\"A field mixin that encrypts text using settings.DB_ENCRYPTION_KEY.\"\"\"\n\n def __init__(self, *args, **kwargs):\n if kwargs.get(\"primary_key\"):\n raise ImproperlyConfigured(\"EncryptedTextField does not support primary_key=True.\")\n if kwargs.get(\"unique\"):\n raise ImproperlyConfigured(\"EncryptedTextField does not support unique=True.\")\n if kwargs.get(\"db_index\"):\n raise ImproperlyConfigured(\"EncryptedTextField does not support db_index=True.\")\n super().__init__(*args, **kwargs)\n\n def get_prep_value(self, value):\n if value is not None:\n assert isinstance(value, str)\n value = force_str(_fernet().encrypt(force_bytes(value)))\n return super().get_prep_value(value)\n\n def from_db_value(self, value, expression, connection):\n if value is not None:\n value = force_str(_fernet().decrypt(force_bytes(value)))\n return value\n\n\nclass EncryptedJSONField(JSONField):\n \"\"\"A Field mixin that encrypts the JSON text using settings.DP_ENCRYPTION_KEY.\"\"\"\n\n def __init__(self, *args, **kwargs):\n if kwargs.get(\"primary_key\"):\n raise ImproperlyConfigured(\"EncryptedJSONField does not support primary_key=True.\")\n if kwargs.get(\"unique\"):\n raise ImproperlyConfigured(\"EncryptedJSONField does not support unique=True.\")\n if kwargs.get(\"db_index\"):\n raise ImproperlyConfigured(\"EncryptedJSONField does not support db_index=True.\")\n super().__init__(*args, **kwargs)\n\n def encrypt(self, value):\n if isinstance(value, dict):\n return {k: self.encrypt(v) for k, v in value.items()}\n elif isinstance(value, (list, tuple, set)):\n return [self.encrypt(v) for v in value]\n\n return force_str(_fernet().encrypt(force_bytes(json.dumps(value, cls=self.encoder))))\n\n def decrypt(self, value):\n if isinstance(value, dict):\n return {k: self.decrypt(v) for k, v in value.items()}\n elif isinstance(value, (list, tuple, set)):\n return [self.decrypt(v) for v in value]\n\n dec_value = force_str(_fernet().decrypt(force_bytes(value)))\n return json.loads(dec_value, cls=self.decoder)\n\n def get_prep_value(self, value):\n if value is not None:\n if hasattr(value, \"as_sql\"):\n return value\n value = self.encrypt(value)\n return super().get_prep_value(value)\n\n def from_db_value(self, value, expression, connection):\n if value is not None:\n value = self.decrypt(super().from_db_value(value, expression, connection))\n return value\n\n\[email protected]_lookup\nclass NotEqualLookup(Lookup):\n # this is copied from https://docs.djangoproject.com/en/3.2/howto/custom-lookups/\n lookup_name = \"ne\"\n\n def as_sql(self, compiler, connection):\n lhs, lhs_params = self.process_lhs(compiler, connection)\n rhs, rhs_params = self.process_rhs(compiler, connection)\n params = lhs_params + rhs_params\n return \"%s <> %s\" % (lhs, rhs), params\n", "path": "pulpcore/app/models/fields.py"}]} | 2,172 | 274 |
gh_patches_debug_14309 | rasdani/github-patches | git_diff | saleor__saleor-574 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Sales with products applied to wrong products
- Create a sale in discounts and add a product to it.
- The discount is applied to an other product.
The system is using the product pk (not the product variant pk) for calculating the discount.
So the discount is applied to the product with variant pk equal to product pk.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/discount/models.py`
Content:
```
1 from __future__ import unicode_literals
2 from datetime import date
3 from decimal import Decimal
4
5 from django.conf import settings
6 from django.db import models
7 from django.db.models import F
8 from django.utils.translation import pgettext, pgettext_lazy
9 from django.utils.encoding import python_2_unicode_compatible, smart_text
10 from django_countries import countries
11 from django_prices.models import PriceField
12 from django_prices.templatetags.prices_i18n import net
13 from prices import FixedDiscount, percentage_discount, Price
14
15 from ..cart.utils import (
16 get_product_variants_and_prices, get_category_variants_and_prices)
17
18
19 class NotApplicable(ValueError):
20 pass
21
22
23 class VoucherQueryset(models.QuerySet):
24
25 def active(self):
26 today = date.today()
27 queryset = self.filter(
28 models.Q(usage_limit__isnull=True) |
29 models.Q(used__lt=models.F('usage_limit')))
30 queryset = queryset.filter(
31 models.Q(end_date__isnull=True) | models.Q(end_date__gte=today))
32 queryset = queryset.filter(start_date__lte=today)
33 return queryset
34
35 def increase_usage(self, voucher):
36 voucher.used = F('used') + 1
37 voucher.save(update_fields=['used'])
38
39 def decrease_usage(self, voucher):
40 voucher.used = F('used') - 1
41 voucher.save(update_fields=['used'])
42
43
44 @python_2_unicode_compatible
45 class Voucher(models.Model):
46
47 APPLY_TO_ONE_PRODUCT = 'one'
48 APPLY_TO_ALL_PRODUCTS = 'all'
49
50 APPLY_TO_PRODUCT_CHOICES = (
51 (APPLY_TO_ONE_PRODUCT,
52 pgettext_lazy('voucher', 'Apply to a single item')),
53 (APPLY_TO_ALL_PRODUCTS,
54 pgettext_lazy('voucher', 'Apply to all matching products')))
55
56 DISCOUNT_VALUE_FIXED = 'fixed'
57 DISCOUNT_VALUE_PERCENTAGE = 'percentage'
58
59 DISCOUNT_VALUE_TYPE_CHOICES = (
60 (DISCOUNT_VALUE_FIXED,
61 pgettext_lazy('voucher', settings.DEFAULT_CURRENCY)),
62 (DISCOUNT_VALUE_PERCENTAGE, pgettext_lazy('voucher', '%')))
63
64 PRODUCT_TYPE = 'product'
65 CATEGORY_TYPE = 'category'
66 SHIPPING_TYPE = 'shipping'
67 VALUE_TYPE = 'value'
68
69 TYPE_CHOICES = (
70 (VALUE_TYPE, pgettext_lazy('voucher', 'All purchases')),
71 (PRODUCT_TYPE, pgettext_lazy('voucher', 'One product')),
72 (CATEGORY_TYPE, pgettext_lazy('voucherl', 'A category of products')),
73 (SHIPPING_TYPE, pgettext_lazy('voucher', 'Shipping')))
74
75 type = models.CharField(
76 pgettext_lazy('voucher', 'discount for'), max_length=20,
77 choices=TYPE_CHOICES, default=VALUE_TYPE)
78 name = models.CharField(
79 pgettext_lazy('voucher', 'name'), max_length=255, null=True,
80 blank=True)
81 code = models.CharField(
82 pgettext_lazy('voucher', 'code'), max_length=12, unique=True,
83 db_index=True)
84 usage_limit = models.PositiveIntegerField(
85 pgettext_lazy('voucher', 'usage limit'), null=True, blank=True)
86 used = models.PositiveIntegerField(default=0, editable=False)
87 start_date = models.DateField(
88 pgettext_lazy('voucher', 'start date'), default=date.today)
89 end_date = models.DateField(
90 pgettext_lazy('voucher', 'end date'), null=True, blank=True)
91
92 discount_value_type = models.CharField(
93 pgettext_lazy('voucher', 'discount type'), max_length=10,
94 choices=DISCOUNT_VALUE_TYPE_CHOICES, default=DISCOUNT_VALUE_FIXED)
95 discount_value = models.DecimalField(
96 pgettext_lazy('voucher', 'discount value'), max_digits=12,
97 decimal_places=2)
98
99 # not mandatory fields, usage depends on type
100 product = models.ForeignKey('product.Product', blank=True, null=True)
101 category = models.ForeignKey('product.Category', blank=True, null=True)
102 apply_to = models.CharField(max_length=20, blank=True, null=True)
103 limit = PriceField(max_digits=12, decimal_places=2, null=True,
104 blank=True, currency=settings.DEFAULT_CURRENCY)
105
106 objects = VoucherQueryset.as_manager()
107
108 @property
109 def is_free(self):
110 return (self.discount_value == Decimal(100) and
111 self.discount_value_type == Voucher.DISCOUNT_VALUE_PERCENTAGE)
112
113 def __str__(self):
114 if self.name:
115 return self.name
116 discount = '%s%s' % (
117 self.discount_value, self.get_discount_value_type_display())
118 if self.type == Voucher.SHIPPING_TYPE:
119 if self.is_free:
120 return pgettext('voucher', 'Free shipping')
121 else:
122 return pgettext('voucher', '%(discount)s off shipping') % {
123 'discount': discount}
124 if self.type == Voucher.PRODUCT_TYPE:
125 return pgettext('voucher', '%(discount)s off %(product)s') % {
126 'discount': discount, 'product': self.product}
127 if self.type == Voucher.CATEGORY_TYPE:
128 return pgettext('voucher', '%(discount)s off %(category)s') % {
129 'discount': discount, 'category': self.category}
130 return pgettext('voucher', '%(discount)s off') % {'discount': discount}
131
132 def get_apply_to_display(self):
133 if self.type == Voucher.SHIPPING_TYPE and self.apply_to:
134 return countries.name(self.apply_to)
135 if self.type == Voucher.SHIPPING_TYPE:
136 return pgettext('voucher', 'Any country')
137 if self.apply_to and self.type in {
138 Voucher.PRODUCT_TYPE, Voucher.CATEGORY_TYPE}:
139 choices = dict(self.APPLY_TO_PRODUCT_CHOICES)
140 return choices[self.apply_to]
141
142 def get_fixed_discount_for(self, amount):
143 if self.discount_value_type == self.DISCOUNT_VALUE_FIXED:
144 discount_price = Price(net=self.discount_value,
145 currency=settings.DEFAULT_CURRENCY)
146 discount = FixedDiscount(
147 amount=discount_price, name=smart_text(self))
148 elif self.discount_value_type == self.DISCOUNT_VALUE_PERCENTAGE:
149 discount = percentage_discount(
150 value=self.discount_value, name=smart_text(self))
151 fixed_discount_value = amount - discount.apply(amount)
152 discount = FixedDiscount(
153 amount=fixed_discount_value, name=smart_text(self))
154 else:
155 raise NotImplementedError('Unknown discount value type')
156 if discount.amount > amount:
157 return FixedDiscount(amount, name=smart_text(self))
158 else:
159 return discount
160
161 def get_discount_for_checkout(self, checkout):
162 if self.type == Voucher.VALUE_TYPE:
163 cart_total = checkout.cart.get_total()
164 limit = self.limit if self.limit is not None else cart_total
165 if cart_total < limit:
166 msg = pgettext(
167 'voucher',
168 'This offer is only valid for orders over %(amount)s.')
169 raise NotApplicable(msg % {'amount': net(limit)})
170 return self.get_fixed_discount_for(cart_total)
171
172 elif self.type == Voucher.SHIPPING_TYPE:
173 if not checkout.is_shipping_required:
174 msg = pgettext(
175 'voucher', 'Your order does not require shipping.')
176 raise NotApplicable(msg)
177 shipping_method = checkout.shipping_method
178 if not shipping_method:
179 msg = pgettext(
180 'voucher', 'Please select a shipping method first.')
181 raise NotApplicable(msg)
182 if (self.apply_to and
183 shipping_method.country_code != self.apply_to):
184 msg = pgettext(
185 'voucher', 'This offer is only valid in %(country)s.')
186 raise NotApplicable(msg % {
187 'country': self.get_apply_to_display()})
188 if self.limit is not None and shipping_method.price > self.limit:
189 msg = pgettext(
190 'voucher',
191 'This offer is only valid for shipping over %(amount)s.')
192 raise NotApplicable(msg % {'amount': net(self.limit)})
193 return self.get_fixed_discount_for(shipping_method.price)
194
195 elif self.type in (Voucher.PRODUCT_TYPE, Voucher.CATEGORY_TYPE):
196 if self.type == Voucher.PRODUCT_TYPE:
197 prices = list(
198 (item[1] for item in get_product_variants_and_prices(
199 checkout.cart, self.product)))
200 else:
201 prices = list(
202 (item[1] for item in get_category_variants_and_prices(
203 checkout.cart, self.category)))
204 if len(prices) == 0:
205 msg = pgettext(
206 'voucher', 'This offer is only valid for selected items.')
207 raise NotApplicable(msg)
208 if self.apply_to == Voucher.APPLY_TO_ALL_PRODUCTS:
209 discounts = (
210 self.get_fixed_discount_for(price) for price in prices)
211 discount_total = sum(
212 (discount.amount for discount in discounts),
213 Price(0, currency=settings.DEFAULT_CURRENCY))
214 return FixedDiscount(discount_total, smart_text(self))
215 else:
216 product_total = sum(
217 prices, Price(0, currency=settings.DEFAULT_CURRENCY))
218 return self.get_fixed_discount_for(product_total)
219
220 else:
221 raise NotImplementedError('Unknown discount type')
222
223
224 @python_2_unicode_compatible
225 class Sale(models.Model):
226 FIXED = 'fixed'
227 PERCENTAGE = 'percentage'
228
229 DISCOUNT_TYPE_CHOICES = (
230 (FIXED, pgettext_lazy('discount_type', settings.DEFAULT_CURRENCY)),
231 (PERCENTAGE, pgettext_lazy('discount_type', '%')))
232
233 name = models.CharField(max_length=255)
234 type = models.CharField(max_length=10, choices=DISCOUNT_TYPE_CHOICES,
235 default=FIXED)
236 value = models.DecimalField(max_digits=12, decimal_places=2, default=0)
237 products = models.ManyToManyField('product.Product', blank=True)
238 categories = models.ManyToManyField('product.Category', blank=True)
239
240 class Meta:
241 app_label = 'discount'
242
243 def __repr__(self):
244 return 'Sale(name=%r, value=%r, type=%s)' % (
245 str(self.name), self.value, self.get_type_display())
246
247 def __str__(self):
248 return self.name
249
250 def get_discount(self):
251 if self.type == self.FIXED:
252 discount_price = Price(net=self.value,
253 currency=settings.DEFAULT_CURRENCY)
254 return FixedDiscount(amount=discount_price, name=self.name)
255 elif self.type == self.PERCENTAGE:
256 return percentage_discount(value=self.value, name=self.name)
257 raise NotImplementedError('Unknown discount type')
258
259 def _product_has_category_discount(self, product, discounted_categories):
260 for category in product.categories.all():
261 for discounted_category in discounted_categories:
262 if category.is_descendant_of(discounted_category,
263 include_self=True):
264 return True
265 return False
266
267 def modifier_for_variant(self, variant):
268 check_price = variant.get_price_per_item()
269 discounted_products = [p.pk for p in self.products.all()]
270 discounted_categories = list(self.categories.all())
271 if discounted_products and variant.pk not in discounted_products:
272 raise NotApplicable('Discount not applicable for this product')
273 if (discounted_categories and not
274 self._product_has_category_discount(
275 variant.product, discounted_categories)):
276 raise NotApplicable('Discount too high for this product')
277 return self.get_discount()
278
279
280 def get_variant_discounts(variant, discounts, **kwargs):
281 for discount in discounts:
282 try:
283 yield discount.modifier_for_variant(variant, **kwargs)
284 except NotApplicable:
285 pass
286
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/saleor/discount/models.py b/saleor/discount/models.py
--- a/saleor/discount/models.py
+++ b/saleor/discount/models.py
@@ -265,10 +265,9 @@
return False
def modifier_for_variant(self, variant):
- check_price = variant.get_price_per_item()
discounted_products = [p.pk for p in self.products.all()]
discounted_categories = list(self.categories.all())
- if discounted_products and variant.pk not in discounted_products:
+ if discounted_products and variant.product.pk not in discounted_products:
raise NotApplicable('Discount not applicable for this product')
if (discounted_categories and not
self._product_has_category_discount(
| {"golden_diff": "diff --git a/saleor/discount/models.py b/saleor/discount/models.py\n--- a/saleor/discount/models.py\n+++ b/saleor/discount/models.py\n@@ -265,10 +265,9 @@\n return False\n \n def modifier_for_variant(self, variant):\n- check_price = variant.get_price_per_item()\n discounted_products = [p.pk for p in self.products.all()]\n discounted_categories = list(self.categories.all())\n- if discounted_products and variant.pk not in discounted_products:\n+ if discounted_products and variant.product.pk not in discounted_products:\n raise NotApplicable('Discount not applicable for this product')\n if (discounted_categories and not\n self._product_has_category_discount(\n", "issue": "Sales with products applied to wrong products\n- Create a sale in discounts and add a product to it.\n- The discount is applied to an other product.\n\nThe system is using the product pk (not the product variant pk) for calculating the discount.\nSo the discount is applied to the product with variant pk equal to product pk.\n\n", "before_files": [{"content": "from __future__ import unicode_literals\nfrom datetime import date\nfrom decimal import Decimal\n\nfrom django.conf import settings\nfrom django.db import models\nfrom django.db.models import F\nfrom django.utils.translation import pgettext, pgettext_lazy\nfrom django.utils.encoding import python_2_unicode_compatible, smart_text\nfrom django_countries import countries\nfrom django_prices.models import PriceField\nfrom django_prices.templatetags.prices_i18n import net\nfrom prices import FixedDiscount, percentage_discount, Price\n\nfrom ..cart.utils import (\n get_product_variants_and_prices, get_category_variants_and_prices)\n\n\nclass NotApplicable(ValueError):\n pass\n\n\nclass VoucherQueryset(models.QuerySet):\n\n def active(self):\n today = date.today()\n queryset = self.filter(\n models.Q(usage_limit__isnull=True) |\n models.Q(used__lt=models.F('usage_limit')))\n queryset = queryset.filter(\n models.Q(end_date__isnull=True) | models.Q(end_date__gte=today))\n queryset = queryset.filter(start_date__lte=today)\n return queryset\n\n def increase_usage(self, voucher):\n voucher.used = F('used') + 1\n voucher.save(update_fields=['used'])\n\n def decrease_usage(self, voucher):\n voucher.used = F('used') - 1\n voucher.save(update_fields=['used'])\n\n\n@python_2_unicode_compatible\nclass Voucher(models.Model):\n\n APPLY_TO_ONE_PRODUCT = 'one'\n APPLY_TO_ALL_PRODUCTS = 'all'\n\n APPLY_TO_PRODUCT_CHOICES = (\n (APPLY_TO_ONE_PRODUCT,\n pgettext_lazy('voucher', 'Apply to a single item')),\n (APPLY_TO_ALL_PRODUCTS,\n pgettext_lazy('voucher', 'Apply to all matching products')))\n\n DISCOUNT_VALUE_FIXED = 'fixed'\n DISCOUNT_VALUE_PERCENTAGE = 'percentage'\n\n DISCOUNT_VALUE_TYPE_CHOICES = (\n (DISCOUNT_VALUE_FIXED,\n pgettext_lazy('voucher', settings.DEFAULT_CURRENCY)),\n (DISCOUNT_VALUE_PERCENTAGE, pgettext_lazy('voucher', '%')))\n\n PRODUCT_TYPE = 'product'\n CATEGORY_TYPE = 'category'\n SHIPPING_TYPE = 'shipping'\n VALUE_TYPE = 'value'\n\n TYPE_CHOICES = (\n (VALUE_TYPE, pgettext_lazy('voucher', 'All purchases')),\n (PRODUCT_TYPE, pgettext_lazy('voucher', 'One product')),\n (CATEGORY_TYPE, pgettext_lazy('voucherl', 'A category of products')),\n (SHIPPING_TYPE, pgettext_lazy('voucher', 'Shipping')))\n\n type = models.CharField(\n pgettext_lazy('voucher', 'discount for'), max_length=20,\n choices=TYPE_CHOICES, default=VALUE_TYPE)\n name = models.CharField(\n pgettext_lazy('voucher', 'name'), max_length=255, null=True,\n blank=True)\n code = models.CharField(\n pgettext_lazy('voucher', 'code'), max_length=12, unique=True,\n db_index=True)\n usage_limit = models.PositiveIntegerField(\n pgettext_lazy('voucher', 'usage limit'), null=True, blank=True)\n used = models.PositiveIntegerField(default=0, editable=False)\n start_date = models.DateField(\n pgettext_lazy('voucher', 'start date'), default=date.today)\n end_date = models.DateField(\n pgettext_lazy('voucher', 'end date'), null=True, blank=True)\n\n discount_value_type = models.CharField(\n pgettext_lazy('voucher', 'discount type'), max_length=10,\n choices=DISCOUNT_VALUE_TYPE_CHOICES, default=DISCOUNT_VALUE_FIXED)\n discount_value = models.DecimalField(\n pgettext_lazy('voucher', 'discount value'), max_digits=12,\n decimal_places=2)\n\n # not mandatory fields, usage depends on type\n product = models.ForeignKey('product.Product', blank=True, null=True)\n category = models.ForeignKey('product.Category', blank=True, null=True)\n apply_to = models.CharField(max_length=20, blank=True, null=True)\n limit = PriceField(max_digits=12, decimal_places=2, null=True,\n blank=True, currency=settings.DEFAULT_CURRENCY)\n\n objects = VoucherQueryset.as_manager()\n\n @property\n def is_free(self):\n return (self.discount_value == Decimal(100) and\n self.discount_value_type == Voucher.DISCOUNT_VALUE_PERCENTAGE)\n\n def __str__(self):\n if self.name:\n return self.name\n discount = '%s%s' % (\n self.discount_value, self.get_discount_value_type_display())\n if self.type == Voucher.SHIPPING_TYPE:\n if self.is_free:\n return pgettext('voucher', 'Free shipping')\n else:\n return pgettext('voucher', '%(discount)s off shipping') % {\n 'discount': discount}\n if self.type == Voucher.PRODUCT_TYPE:\n return pgettext('voucher', '%(discount)s off %(product)s') % {\n 'discount': discount, 'product': self.product}\n if self.type == Voucher.CATEGORY_TYPE:\n return pgettext('voucher', '%(discount)s off %(category)s') % {\n 'discount': discount, 'category': self.category}\n return pgettext('voucher', '%(discount)s off') % {'discount': discount}\n\n def get_apply_to_display(self):\n if self.type == Voucher.SHIPPING_TYPE and self.apply_to:\n return countries.name(self.apply_to)\n if self.type == Voucher.SHIPPING_TYPE:\n return pgettext('voucher', 'Any country')\n if self.apply_to and self.type in {\n Voucher.PRODUCT_TYPE, Voucher.CATEGORY_TYPE}:\n choices = dict(self.APPLY_TO_PRODUCT_CHOICES)\n return choices[self.apply_to]\n\n def get_fixed_discount_for(self, amount):\n if self.discount_value_type == self.DISCOUNT_VALUE_FIXED:\n discount_price = Price(net=self.discount_value,\n currency=settings.DEFAULT_CURRENCY)\n discount = FixedDiscount(\n amount=discount_price, name=smart_text(self))\n elif self.discount_value_type == self.DISCOUNT_VALUE_PERCENTAGE:\n discount = percentage_discount(\n value=self.discount_value, name=smart_text(self))\n fixed_discount_value = amount - discount.apply(amount)\n discount = FixedDiscount(\n amount=fixed_discount_value, name=smart_text(self))\n else:\n raise NotImplementedError('Unknown discount value type')\n if discount.amount > amount:\n return FixedDiscount(amount, name=smart_text(self))\n else:\n return discount\n\n def get_discount_for_checkout(self, checkout):\n if self.type == Voucher.VALUE_TYPE:\n cart_total = checkout.cart.get_total()\n limit = self.limit if self.limit is not None else cart_total\n if cart_total < limit:\n msg = pgettext(\n 'voucher',\n 'This offer is only valid for orders over %(amount)s.')\n raise NotApplicable(msg % {'amount': net(limit)})\n return self.get_fixed_discount_for(cart_total)\n\n elif self.type == Voucher.SHIPPING_TYPE:\n if not checkout.is_shipping_required:\n msg = pgettext(\n 'voucher', 'Your order does not require shipping.')\n raise NotApplicable(msg)\n shipping_method = checkout.shipping_method\n if not shipping_method:\n msg = pgettext(\n 'voucher', 'Please select a shipping method first.')\n raise NotApplicable(msg)\n if (self.apply_to and\n shipping_method.country_code != self.apply_to):\n msg = pgettext(\n 'voucher', 'This offer is only valid in %(country)s.')\n raise NotApplicable(msg % {\n 'country': self.get_apply_to_display()})\n if self.limit is not None and shipping_method.price > self.limit:\n msg = pgettext(\n 'voucher',\n 'This offer is only valid for shipping over %(amount)s.')\n raise NotApplicable(msg % {'amount': net(self.limit)})\n return self.get_fixed_discount_for(shipping_method.price)\n\n elif self.type in (Voucher.PRODUCT_TYPE, Voucher.CATEGORY_TYPE):\n if self.type == Voucher.PRODUCT_TYPE:\n prices = list(\n (item[1] for item in get_product_variants_and_prices(\n checkout.cart, self.product)))\n else:\n prices = list(\n (item[1] for item in get_category_variants_and_prices(\n checkout.cart, self.category)))\n if len(prices) == 0:\n msg = pgettext(\n 'voucher', 'This offer is only valid for selected items.')\n raise NotApplicable(msg)\n if self.apply_to == Voucher.APPLY_TO_ALL_PRODUCTS:\n discounts = (\n self.get_fixed_discount_for(price) for price in prices)\n discount_total = sum(\n (discount.amount for discount in discounts),\n Price(0, currency=settings.DEFAULT_CURRENCY))\n return FixedDiscount(discount_total, smart_text(self))\n else:\n product_total = sum(\n prices, Price(0, currency=settings.DEFAULT_CURRENCY))\n return self.get_fixed_discount_for(product_total)\n\n else:\n raise NotImplementedError('Unknown discount type')\n\n\n@python_2_unicode_compatible\nclass Sale(models.Model):\n FIXED = 'fixed'\n PERCENTAGE = 'percentage'\n\n DISCOUNT_TYPE_CHOICES = (\n (FIXED, pgettext_lazy('discount_type', settings.DEFAULT_CURRENCY)),\n (PERCENTAGE, pgettext_lazy('discount_type', '%')))\n\n name = models.CharField(max_length=255)\n type = models.CharField(max_length=10, choices=DISCOUNT_TYPE_CHOICES,\n default=FIXED)\n value = models.DecimalField(max_digits=12, decimal_places=2, default=0)\n products = models.ManyToManyField('product.Product', blank=True)\n categories = models.ManyToManyField('product.Category', blank=True)\n\n class Meta:\n app_label = 'discount'\n\n def __repr__(self):\n return 'Sale(name=%r, value=%r, type=%s)' % (\n str(self.name), self.value, self.get_type_display())\n\n def __str__(self):\n return self.name\n\n def get_discount(self):\n if self.type == self.FIXED:\n discount_price = Price(net=self.value,\n currency=settings.DEFAULT_CURRENCY)\n return FixedDiscount(amount=discount_price, name=self.name)\n elif self.type == self.PERCENTAGE:\n return percentage_discount(value=self.value, name=self.name)\n raise NotImplementedError('Unknown discount type')\n\n def _product_has_category_discount(self, product, discounted_categories):\n for category in product.categories.all():\n for discounted_category in discounted_categories:\n if category.is_descendant_of(discounted_category,\n include_self=True):\n return True\n return False\n\n def modifier_for_variant(self, variant):\n check_price = variant.get_price_per_item()\n discounted_products = [p.pk for p in self.products.all()]\n discounted_categories = list(self.categories.all())\n if discounted_products and variant.pk not in discounted_products:\n raise NotApplicable('Discount not applicable for this product')\n if (discounted_categories and not\n self._product_has_category_discount(\n variant.product, discounted_categories)):\n raise NotApplicable('Discount too high for this product')\n return self.get_discount()\n\n\ndef get_variant_discounts(variant, discounts, **kwargs):\n for discount in discounts:\n try:\n yield discount.modifier_for_variant(variant, **kwargs)\n except NotApplicable:\n pass\n", "path": "saleor/discount/models.py"}], "after_files": [{"content": "from __future__ import unicode_literals\nfrom datetime import date\nfrom decimal import Decimal\n\nfrom django.conf import settings\nfrom django.db import models\nfrom django.db.models import F\nfrom django.utils.translation import pgettext, pgettext_lazy\nfrom django.utils.encoding import python_2_unicode_compatible, smart_text\nfrom django_countries import countries\nfrom django_prices.models import PriceField\nfrom django_prices.templatetags.prices_i18n import net\nfrom prices import FixedDiscount, percentage_discount, Price\n\nfrom ..cart.utils import (\n get_product_variants_and_prices, get_category_variants_and_prices)\n\n\nclass NotApplicable(ValueError):\n pass\n\n\nclass VoucherQueryset(models.QuerySet):\n\n def active(self):\n today = date.today()\n queryset = self.filter(\n models.Q(usage_limit__isnull=True) |\n models.Q(used__lt=models.F('usage_limit')))\n queryset = queryset.filter(\n models.Q(end_date__isnull=True) | models.Q(end_date__gte=today))\n queryset = queryset.filter(start_date__lte=today)\n return queryset\n\n def increase_usage(self, voucher):\n voucher.used = F('used') + 1\n voucher.save(update_fields=['used'])\n\n def decrease_usage(self, voucher):\n voucher.used = F('used') - 1\n voucher.save(update_fields=['used'])\n\n\n@python_2_unicode_compatible\nclass Voucher(models.Model):\n\n APPLY_TO_ONE_PRODUCT = 'one'\n APPLY_TO_ALL_PRODUCTS = 'all'\n\n APPLY_TO_PRODUCT_CHOICES = (\n (APPLY_TO_ONE_PRODUCT,\n pgettext_lazy('voucher', 'Apply to a single item')),\n (APPLY_TO_ALL_PRODUCTS,\n pgettext_lazy('voucher', 'Apply to all matching products')))\n\n DISCOUNT_VALUE_FIXED = 'fixed'\n DISCOUNT_VALUE_PERCENTAGE = 'percentage'\n\n DISCOUNT_VALUE_TYPE_CHOICES = (\n (DISCOUNT_VALUE_FIXED,\n pgettext_lazy('voucher', settings.DEFAULT_CURRENCY)),\n (DISCOUNT_VALUE_PERCENTAGE, pgettext_lazy('voucher', '%')))\n\n PRODUCT_TYPE = 'product'\n CATEGORY_TYPE = 'category'\n SHIPPING_TYPE = 'shipping'\n VALUE_TYPE = 'value'\n\n TYPE_CHOICES = (\n (VALUE_TYPE, pgettext_lazy('voucher', 'All purchases')),\n (PRODUCT_TYPE, pgettext_lazy('voucher', 'One product')),\n (CATEGORY_TYPE, pgettext_lazy('voucherl', 'A category of products')),\n (SHIPPING_TYPE, pgettext_lazy('voucher', 'Shipping')))\n\n type = models.CharField(\n pgettext_lazy('voucher', 'discount for'), max_length=20,\n choices=TYPE_CHOICES, default=VALUE_TYPE)\n name = models.CharField(\n pgettext_lazy('voucher', 'name'), max_length=255, null=True,\n blank=True)\n code = models.CharField(\n pgettext_lazy('voucher', 'code'), max_length=12, unique=True,\n db_index=True)\n usage_limit = models.PositiveIntegerField(\n pgettext_lazy('voucher', 'usage limit'), null=True, blank=True)\n used = models.PositiveIntegerField(default=0, editable=False)\n start_date = models.DateField(\n pgettext_lazy('voucher', 'start date'), default=date.today)\n end_date = models.DateField(\n pgettext_lazy('voucher', 'end date'), null=True, blank=True)\n\n discount_value_type = models.CharField(\n pgettext_lazy('voucher', 'discount type'), max_length=10,\n choices=DISCOUNT_VALUE_TYPE_CHOICES, default=DISCOUNT_VALUE_FIXED)\n discount_value = models.DecimalField(\n pgettext_lazy('voucher', 'discount value'), max_digits=12,\n decimal_places=2)\n\n # not mandatory fields, usage depends on type\n product = models.ForeignKey('product.Product', blank=True, null=True)\n category = models.ForeignKey('product.Category', blank=True, null=True)\n apply_to = models.CharField(max_length=20, blank=True, null=True)\n limit = PriceField(max_digits=12, decimal_places=2, null=True,\n blank=True, currency=settings.DEFAULT_CURRENCY)\n\n objects = VoucherQueryset.as_manager()\n\n @property\n def is_free(self):\n return (self.discount_value == Decimal(100) and\n self.discount_value_type == Voucher.DISCOUNT_VALUE_PERCENTAGE)\n\n def __str__(self):\n if self.name:\n return self.name\n discount = '%s%s' % (\n self.discount_value, self.get_discount_value_type_display())\n if self.type == Voucher.SHIPPING_TYPE:\n if self.is_free:\n return pgettext('voucher', 'Free shipping')\n else:\n return pgettext('voucher', '%(discount)s off shipping') % {\n 'discount': discount}\n if self.type == Voucher.PRODUCT_TYPE:\n return pgettext('voucher', '%(discount)s off %(product)s') % {\n 'discount': discount, 'product': self.product}\n if self.type == Voucher.CATEGORY_TYPE:\n return pgettext('voucher', '%(discount)s off %(category)s') % {\n 'discount': discount, 'category': self.category}\n return pgettext('voucher', '%(discount)s off') % {'discount': discount}\n\n def get_apply_to_display(self):\n if self.type == Voucher.SHIPPING_TYPE and self.apply_to:\n return countries.name(self.apply_to)\n if self.type == Voucher.SHIPPING_TYPE:\n return pgettext('voucher', 'Any country')\n if self.apply_to and self.type in {\n Voucher.PRODUCT_TYPE, Voucher.CATEGORY_TYPE}:\n choices = dict(self.APPLY_TO_PRODUCT_CHOICES)\n return choices[self.apply_to]\n\n def get_fixed_discount_for(self, amount):\n if self.discount_value_type == self.DISCOUNT_VALUE_FIXED:\n discount_price = Price(net=self.discount_value,\n currency=settings.DEFAULT_CURRENCY)\n discount = FixedDiscount(\n amount=discount_price, name=smart_text(self))\n elif self.discount_value_type == self.DISCOUNT_VALUE_PERCENTAGE:\n discount = percentage_discount(\n value=self.discount_value, name=smart_text(self))\n fixed_discount_value = amount - discount.apply(amount)\n discount = FixedDiscount(\n amount=fixed_discount_value, name=smart_text(self))\n else:\n raise NotImplementedError('Unknown discount value type')\n if discount.amount > amount:\n return FixedDiscount(amount, name=smart_text(self))\n else:\n return discount\n\n def get_discount_for_checkout(self, checkout):\n if self.type == Voucher.VALUE_TYPE:\n cart_total = checkout.cart.get_total()\n limit = self.limit if self.limit is not None else cart_total\n if cart_total < limit:\n msg = pgettext(\n 'voucher',\n 'This offer is only valid for orders over %(amount)s.')\n raise NotApplicable(msg % {'amount': net(limit)})\n return self.get_fixed_discount_for(cart_total)\n\n elif self.type == Voucher.SHIPPING_TYPE:\n if not checkout.is_shipping_required:\n msg = pgettext(\n 'voucher', 'Your order does not require shipping.')\n raise NotApplicable(msg)\n shipping_method = checkout.shipping_method\n if not shipping_method:\n msg = pgettext(\n 'voucher', 'Please select a shipping method first.')\n raise NotApplicable(msg)\n if (self.apply_to and\n shipping_method.country_code != self.apply_to):\n msg = pgettext(\n 'voucher', 'This offer is only valid in %(country)s.')\n raise NotApplicable(msg % {\n 'country': self.get_apply_to_display()})\n if self.limit is not None and shipping_method.price > self.limit:\n msg = pgettext(\n 'voucher',\n 'This offer is only valid for shipping over %(amount)s.')\n raise NotApplicable(msg % {'amount': net(self.limit)})\n return self.get_fixed_discount_for(shipping_method.price)\n\n elif self.type in (Voucher.PRODUCT_TYPE, Voucher.CATEGORY_TYPE):\n if self.type == Voucher.PRODUCT_TYPE:\n prices = list(\n (item[1] for item in get_product_variants_and_prices(\n checkout.cart, self.product)))\n else:\n prices = list(\n (item[1] for item in get_category_variants_and_prices(\n checkout.cart, self.category)))\n if len(prices) == 0:\n msg = pgettext(\n 'voucher', 'This offer is only valid for selected items.')\n raise NotApplicable(msg)\n if self.apply_to == Voucher.APPLY_TO_ALL_PRODUCTS:\n discounts = (\n self.get_fixed_discount_for(price) for price in prices)\n discount_total = sum(\n (discount.amount for discount in discounts),\n Price(0, currency=settings.DEFAULT_CURRENCY))\n return FixedDiscount(discount_total, smart_text(self))\n else:\n product_total = sum(\n prices, Price(0, currency=settings.DEFAULT_CURRENCY))\n return self.get_fixed_discount_for(product_total)\n\n else:\n raise NotImplementedError('Unknown discount type')\n\n\n@python_2_unicode_compatible\nclass Sale(models.Model):\n FIXED = 'fixed'\n PERCENTAGE = 'percentage'\n\n DISCOUNT_TYPE_CHOICES = (\n (FIXED, pgettext_lazy('discount_type', settings.DEFAULT_CURRENCY)),\n (PERCENTAGE, pgettext_lazy('discount_type', '%')))\n\n name = models.CharField(max_length=255)\n type = models.CharField(max_length=10, choices=DISCOUNT_TYPE_CHOICES,\n default=FIXED)\n value = models.DecimalField(max_digits=12, decimal_places=2, default=0)\n products = models.ManyToManyField('product.Product', blank=True)\n categories = models.ManyToManyField('product.Category', blank=True)\n\n class Meta:\n app_label = 'discount'\n\n def __repr__(self):\n return 'Sale(name=%r, value=%r, type=%s)' % (\n str(self.name), self.value, self.get_type_display())\n\n def __str__(self):\n return self.name\n\n def get_discount(self):\n if self.type == self.FIXED:\n discount_price = Price(net=self.value,\n currency=settings.DEFAULT_CURRENCY)\n return FixedDiscount(amount=discount_price, name=self.name)\n elif self.type == self.PERCENTAGE:\n return percentage_discount(value=self.value, name=self.name)\n raise NotImplementedError('Unknown discount type')\n\n def _product_has_category_discount(self, product, discounted_categories):\n for category in product.categories.all():\n for discounted_category in discounted_categories:\n if category.is_descendant_of(discounted_category,\n include_self=True):\n return True\n return False\n\n def modifier_for_variant(self, variant):\n discounted_products = [p.pk for p in self.products.all()]\n discounted_categories = list(self.categories.all())\n if discounted_products and variant.product.pk not in discounted_products:\n raise NotApplicable('Discount not applicable for this product')\n if (discounted_categories and not\n self._product_has_category_discount(\n variant.product, discounted_categories)):\n raise NotApplicable('Discount too high for this product')\n return self.get_discount()\n\n\ndef get_variant_discounts(variant, discounts, **kwargs):\n for discount in discounts:\n try:\n yield discount.modifier_for_variant(variant, **kwargs)\n except NotApplicable:\n pass\n", "path": "saleor/discount/models.py"}]} | 3,510 | 159 |
gh_patches_debug_22567 | rasdani/github-patches | git_diff | keras-team__keras-2924 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
KerasClassifier does not return the same thing as scikit learn in the case of binary classification
For binary classification using a stock classifier from scikit, running predict_proba will return a matrix of shape (n_samples,n_classes) however KerasClassifier returns (nsamples,noutputs).
This results in the inability to use the ootb cross_val_score with 'roc_auc' due to the error:
```
site-packages\sklearn\metrics\scorer.pyc in __call__(self, clf, X, y, sample_weight)
173
174 if y_type == "binary":
--> 175 y_pred = y_pred[:, 1]
176 elif isinstance(y_pred, list):
177 y_pred = np.vstack([p[:, -1] for p in y_pred]).T
IndexError: index 1 is out of bounds for axis 1 with size 1
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `keras/wrappers/scikit_learn.py`
Content:
```
1 from __future__ import absolute_import
2 import copy
3 import inspect
4 import types
5
6 from ..utils.np_utils import to_categorical
7 from ..models import Sequential
8
9
10 class BaseWrapper(object):
11 '''Base class for the Keras scikit-learn wrapper.
12
13 Warning: This class should not be used directly.
14 Use descendant classes instead.
15
16 # Arguments
17 build_fn: callable function or class instance
18 sk_params: model parameters & fitting parameters
19
20 The build_fn should construct, compile and return a Keras model, which
21 will then be used to fit/predict. One of the following
22 three values could be passed to build_fn:
23 1. A function
24 2. An instance of a class that implements the __call__ method
25 3. None. This means you implement a class that inherits from either
26 `KerasClassifier` or `KerasRegressor`. The __call__ method of the
27 present class will then be treated as the default build_fn.
28
29 `sk_params` takes both model parameters and fitting parameters. Legal model
30 parameters are the arguments of `build_fn`. Note that like all other
31 estimators in scikit-learn, 'build_fn' should provide default values for
32 its arguments, so that you could create the estimator without passing any
33 values to `sk_params`.
34
35 `sk_params` could also accept parameters for calling `fit`, `predict`,
36 `predict_proba`, and `score` methods (e.g., `nb_epoch`, `batch_size`).
37 fitting (predicting) parameters are selected in the following order:
38
39 1. Values passed to the dictionary arguments of
40 `fit`, `predict`, `predict_proba`, and `score` methods
41 2. Values passed to `sk_params`
42 3. The default values of the `keras.models.Sequential`
43 `fit`, `predict`, `predict_proba` and `score` methods
44
45 When using scikit-learn's `grid_search` API, legal tunable parameters are
46 those you could pass to `sk_params`, including fitting parameters.
47 In other words, you could use `grid_search` to search for the best
48 `batch_size` or `nb_epoch` as well as the model parameters.
49 '''
50
51 def __init__(self, build_fn=None, **sk_params):
52 self.build_fn = build_fn
53 self.sk_params = sk_params
54 self.check_params(sk_params)
55
56 def check_params(self, params):
57 '''Check for user typos in "params" keys to avoid
58 unwanted usage of default values
59
60 # Arguments
61 params: dictionary
62 The parameters to be checked
63 '''
64 legal_params_fns = [Sequential.fit, Sequential.predict,
65 Sequential.predict_classes, Sequential.evaluate]
66 if self.build_fn is None:
67 legal_params_fns.append(self.__call__)
68 elif not isinstance(self.build_fn, types.FunctionType):
69 legal_params_fns.append(self.build_fn.__call__)
70 else:
71 legal_params_fns.append(self.build_fn)
72
73 legal_params = []
74 for fn in legal_params_fns:
75 legal_params += inspect.getargspec(fn)[0]
76 legal_params = set(legal_params)
77
78 for params_name in params:
79 if params_name not in legal_params:
80 assert False, '{} is not a legal parameter'.format(params_name)
81
82 def get_params(self, deep=True):
83 '''Get parameters for this estimator.
84
85 # Arguments
86 deep: boolean, optional
87 If True, will return the parameters for this estimator and
88 contained sub-objects that are estimators.
89
90 # Returns
91 params : dict
92 Dictionary of parameter names mapped to their values.
93 '''
94 res = copy.deepcopy(self.sk_params)
95 res.update({'build_fn': self.build_fn})
96 return res
97
98 def set_params(self, **params):
99 '''Set the parameters of this estimator.
100
101 # Arguments
102 params: dict
103 Dictionary of parameter names mapped to their values.
104
105 # Returns
106 self
107 '''
108 self.check_params(params)
109 self.sk_params.update(params)
110 return self
111
112 def fit(self, X, y, **kwargs):
113 '''Construct a new model with build_fn and fit the model according
114 to the given training data.
115
116 # Arguments
117 X : array-like, shape `(n_samples, n_features)`
118 Training samples where n_samples in the number of samples
119 and n_features is the number of features.
120 y : array-like, shape `(n_samples,)` or `(n_samples, n_outputs)`
121 True labels for X.
122 kwargs: dictionary arguments
123 Legal arguments are the arguments of `Sequential.fit`
124
125 # Returns
126 history : object
127 details about the training history at each epoch.
128 '''
129
130 if self.build_fn is None:
131 self.model = self.__call__(**self.filter_sk_params(self.__call__))
132 elif not isinstance(self.build_fn, types.FunctionType):
133 self.model = self.build_fn(
134 **self.filter_sk_params(self.build_fn.__call__))
135 else:
136 self.model = self.build_fn(**self.filter_sk_params(self.build_fn))
137
138 loss_name = self.model.loss
139 if hasattr(loss_name, '__name__'):
140 loss_name = loss_name.__name__
141 if loss_name == 'categorical_crossentropy' and len(y.shape) != 2:
142 y = to_categorical(y)
143
144 fit_args = copy.deepcopy(self.filter_sk_params(Sequential.fit))
145 fit_args.update(kwargs)
146
147 history = self.model.fit(X, y, **fit_args)
148
149 return history
150
151 def filter_sk_params(self, fn, override={}):
152 '''Filter sk_params and return those in fn's arguments
153
154 # Arguments
155 fn : arbitrary function
156 override: dictionary, values to override sk_params
157
158 # Returns
159 res : dictionary dictionary containing variables
160 in both sk_params and fn's arguments.
161 '''
162 res = {}
163 fn_args = inspect.getargspec(fn)[0]
164 for name, value in self.sk_params.items():
165 if name in fn_args:
166 res.update({name: value})
167 res.update(override)
168 return res
169
170
171 class KerasClassifier(BaseWrapper):
172 '''Implementation of the scikit-learn classifier API for Keras.
173 '''
174
175 def predict(self, X, **kwargs):
176 '''Returns the class predictions for the given test data.
177
178 # Arguments
179 X: array-like, shape `(n_samples, n_features)`
180 Test samples where n_samples in the number of samples
181 and n_features is the number of features.
182 kwargs: dictionary arguments
183 Legal arguments are the arguments of `Sequential.predict_classes`.
184
185 # Returns
186 preds: array-like, shape `(n_samples,)`
187 Class predictions.
188 '''
189 kwargs = self.filter_sk_params(Sequential.predict_classes, kwargs)
190 return self.model.predict_classes(X, **kwargs)
191
192 def predict_proba(self, X, **kwargs):
193 '''Returns class probability estimates for the given test data.
194
195 # Arguments
196 X: array-like, shape `(n_samples, n_features)`
197 Test samples where n_samples in the number of samples
198 and n_features is the number of features.
199 kwargs: dictionary arguments
200 Legal arguments are the arguments of `Sequential.predict_classes`.
201
202 # Returns
203 proba: array-like, shape `(n_samples, n_outputs)`
204 Class probability estimates.
205 '''
206 kwargs = self.filter_sk_params(Sequential.predict_proba, kwargs)
207 return self.model.predict_proba(X, **kwargs)
208
209 def score(self, X, y, **kwargs):
210 '''Returns the mean accuracy on the given test data and labels.
211
212 # Arguments
213 X: array-like, shape `(n_samples, n_features)`
214 Test samples where n_samples in the number of samples
215 and n_features is the number of features.
216 y: array-like, shape `(n_samples,)` or `(n_samples, n_outputs)`
217 True labels for X.
218 kwargs: dictionary arguments
219 Legal arguments are the arguments of `Sequential.evaluate`.
220
221 # Returns
222 score: float
223 Mean accuracy of predictions on X wrt. y.
224 '''
225 kwargs = self.filter_sk_params(Sequential.evaluate, kwargs)
226 outputs = self.model.evaluate(X, y, **kwargs)
227 if type(outputs) is not list:
228 outputs = [outputs]
229 for name, output in zip(self.model.metrics_names, outputs):
230 if name == 'acc':
231 return output
232 raise Exception('The model is not configured to compute accuracy. '
233 'You should pass `metrics=["accuracy"]` to '
234 'the `model.compile()` method.')
235
236
237 class KerasRegressor(BaseWrapper):
238 '''Implementation of the scikit-learn regressor API for Keras.
239 '''
240
241 def predict(self, X, **kwargs):
242 '''Returns predictions for the given test data.
243
244 # Arguments
245 X: array-like, shape `(n_samples, n_features)`
246 Test samples where n_samples in the number of samples
247 and n_features is the number of features.
248 kwargs: dictionary arguments
249 Legal arguments are the arguments of `Sequential.predict`.
250 # Returns
251 preds: array-like, shape `(n_samples,)`
252 Predictions.
253 '''
254 kwargs = self.filter_sk_params(Sequential.predict, kwargs)
255 return self.model.predict(X, **kwargs)
256
257 def score(self, X, y, **kwargs):
258 '''Returns the mean loss on the given test data and labels.
259
260 # Arguments
261 X: array-like, shape `(n_samples, n_features)`
262 Test samples where n_samples in the number of samples
263 and n_features is the number of features.
264 y: array-like, shape `(n_samples,)`
265 True labels for X.
266 kwargs: dictionary arguments
267 Legal arguments are the arguments of `Sequential.evaluate`.
268
269 # Returns
270 score: float
271 Mean accuracy of predictions on X wrt. y.
272 '''
273 kwargs = self.filter_sk_params(Sequential.evaluate, kwargs)
274 loss = self.model.evaluate(X, y, **kwargs)
275 if type(loss) is list:
276 return loss[0]
277 return loss
278
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/keras/wrappers/scikit_learn.py b/keras/wrappers/scikit_learn.py
--- a/keras/wrappers/scikit_learn.py
+++ b/keras/wrappers/scikit_learn.py
@@ -2,6 +2,7 @@
import copy
import inspect
import types
+import numpy
from ..utils.np_utils import to_categorical
from ..models import Sequential
@@ -202,9 +203,17 @@
# Returns
proba: array-like, shape `(n_samples, n_outputs)`
Class probability estimates.
+ In the case of binary classification (i.e. 1 output of 0 or 1)
+ will return '(n_samples, 2)'
'''
kwargs = self.filter_sk_params(Sequential.predict_proba, kwargs)
- return self.model.predict_proba(X, **kwargs)
+ probs = self.model.predict_proba(X, **kwargs)
+
+ # check if binary classification
+ if probs.shape[1] == 1:
+ # first column is probability of class 0 and second is of class 1
+ probs = numpy.hstack([1 - probs, probs])
+ return probs
def score(self, X, y, **kwargs):
'''Returns the mean accuracy on the given test data and labels.
| {"golden_diff": "diff --git a/keras/wrappers/scikit_learn.py b/keras/wrappers/scikit_learn.py\n--- a/keras/wrappers/scikit_learn.py\n+++ b/keras/wrappers/scikit_learn.py\n@@ -2,6 +2,7 @@\n import copy\n import inspect\n import types\n+import numpy\n \n from ..utils.np_utils import to_categorical\n from ..models import Sequential\n@@ -202,9 +203,17 @@\n # Returns\n proba: array-like, shape `(n_samples, n_outputs)`\n Class probability estimates.\n+ In the case of binary classification (i.e. 1 output of 0 or 1)\n+ will return '(n_samples, 2)'\n '''\n kwargs = self.filter_sk_params(Sequential.predict_proba, kwargs)\n- return self.model.predict_proba(X, **kwargs)\n+ probs = self.model.predict_proba(X, **kwargs)\n+\n+ # check if binary classification\n+ if probs.shape[1] == 1:\n+ # first column is probability of class 0 and second is of class 1\n+ probs = numpy.hstack([1 - probs, probs])\n+ return probs\n \n def score(self, X, y, **kwargs):\n '''Returns the mean accuracy on the given test data and labels.\n", "issue": "KerasClassifier does not return the same thing as scikit learn in the case of binary classification\nFor binary classification using a stock classifier from scikit, running predict_proba will return a matrix of shape (n_samples,n_classes) however KerasClassifier returns (nsamples,noutputs).\n\nThis results in the inability to use the ootb cross_val_score with 'roc_auc' due to the error:\n\n```\nsite-packages\\sklearn\\metrics\\scorer.pyc in __call__(self, clf, X, y, sample_weight)\n 173 \n 174 if y_type == \"binary\":\n--> 175 y_pred = y_pred[:, 1]\n 176 elif isinstance(y_pred, list):\n 177 y_pred = np.vstack([p[:, -1] for p in y_pred]).T\nIndexError: index 1 is out of bounds for axis 1 with size 1\n```\n\n", "before_files": [{"content": "from __future__ import absolute_import\nimport copy\nimport inspect\nimport types\n\nfrom ..utils.np_utils import to_categorical\nfrom ..models import Sequential\n\n\nclass BaseWrapper(object):\n '''Base class for the Keras scikit-learn wrapper.\n\n Warning: This class should not be used directly.\n Use descendant classes instead.\n\n # Arguments\n build_fn: callable function or class instance\n sk_params: model parameters & fitting parameters\n\n The build_fn should construct, compile and return a Keras model, which\n will then be used to fit/predict. One of the following\n three values could be passed to build_fn:\n 1. A function\n 2. An instance of a class that implements the __call__ method\n 3. None. This means you implement a class that inherits from either\n `KerasClassifier` or `KerasRegressor`. The __call__ method of the\n present class will then be treated as the default build_fn.\n\n `sk_params` takes both model parameters and fitting parameters. Legal model\n parameters are the arguments of `build_fn`. Note that like all other\n estimators in scikit-learn, 'build_fn' should provide default values for\n its arguments, so that you could create the estimator without passing any\n values to `sk_params`.\n\n `sk_params` could also accept parameters for calling `fit`, `predict`,\n `predict_proba`, and `score` methods (e.g., `nb_epoch`, `batch_size`).\n fitting (predicting) parameters are selected in the following order:\n\n 1. Values passed to the dictionary arguments of\n `fit`, `predict`, `predict_proba`, and `score` methods\n 2. Values passed to `sk_params`\n 3. The default values of the `keras.models.Sequential`\n `fit`, `predict`, `predict_proba` and `score` methods\n\n When using scikit-learn's `grid_search` API, legal tunable parameters are\n those you could pass to `sk_params`, including fitting parameters.\n In other words, you could use `grid_search` to search for the best\n `batch_size` or `nb_epoch` as well as the model parameters.\n '''\n\n def __init__(self, build_fn=None, **sk_params):\n self.build_fn = build_fn\n self.sk_params = sk_params\n self.check_params(sk_params)\n\n def check_params(self, params):\n '''Check for user typos in \"params\" keys to avoid\n unwanted usage of default values\n\n # Arguments\n params: dictionary\n The parameters to be checked\n '''\n legal_params_fns = [Sequential.fit, Sequential.predict,\n Sequential.predict_classes, Sequential.evaluate]\n if self.build_fn is None:\n legal_params_fns.append(self.__call__)\n elif not isinstance(self.build_fn, types.FunctionType):\n legal_params_fns.append(self.build_fn.__call__)\n else:\n legal_params_fns.append(self.build_fn)\n\n legal_params = []\n for fn in legal_params_fns:\n legal_params += inspect.getargspec(fn)[0]\n legal_params = set(legal_params)\n\n for params_name in params:\n if params_name not in legal_params:\n assert False, '{} is not a legal parameter'.format(params_name)\n\n def get_params(self, deep=True):\n '''Get parameters for this estimator.\n\n # Arguments\n deep: boolean, optional\n If True, will return the parameters for this estimator and\n contained sub-objects that are estimators.\n\n # Returns\n params : dict\n Dictionary of parameter names mapped to their values.\n '''\n res = copy.deepcopy(self.sk_params)\n res.update({'build_fn': self.build_fn})\n return res\n\n def set_params(self, **params):\n '''Set the parameters of this estimator.\n\n # Arguments\n params: dict\n Dictionary of parameter names mapped to their values.\n\n # Returns\n self\n '''\n self.check_params(params)\n self.sk_params.update(params)\n return self\n\n def fit(self, X, y, **kwargs):\n '''Construct a new model with build_fn and fit the model according\n to the given training data.\n\n # Arguments\n X : array-like, shape `(n_samples, n_features)`\n Training samples where n_samples in the number of samples\n and n_features is the number of features.\n y : array-like, shape `(n_samples,)` or `(n_samples, n_outputs)`\n True labels for X.\n kwargs: dictionary arguments\n Legal arguments are the arguments of `Sequential.fit`\n\n # Returns\n history : object\n details about the training history at each epoch.\n '''\n\n if self.build_fn is None:\n self.model = self.__call__(**self.filter_sk_params(self.__call__))\n elif not isinstance(self.build_fn, types.FunctionType):\n self.model = self.build_fn(\n **self.filter_sk_params(self.build_fn.__call__))\n else:\n self.model = self.build_fn(**self.filter_sk_params(self.build_fn))\n\n loss_name = self.model.loss\n if hasattr(loss_name, '__name__'):\n loss_name = loss_name.__name__\n if loss_name == 'categorical_crossentropy' and len(y.shape) != 2:\n y = to_categorical(y)\n\n fit_args = copy.deepcopy(self.filter_sk_params(Sequential.fit))\n fit_args.update(kwargs)\n\n history = self.model.fit(X, y, **fit_args)\n\n return history\n\n def filter_sk_params(self, fn, override={}):\n '''Filter sk_params and return those in fn's arguments\n\n # Arguments\n fn : arbitrary function\n override: dictionary, values to override sk_params\n\n # Returns\n res : dictionary dictionary containing variables\n in both sk_params and fn's arguments.\n '''\n res = {}\n fn_args = inspect.getargspec(fn)[0]\n for name, value in self.sk_params.items():\n if name in fn_args:\n res.update({name: value})\n res.update(override)\n return res\n\n\nclass KerasClassifier(BaseWrapper):\n '''Implementation of the scikit-learn classifier API for Keras.\n '''\n\n def predict(self, X, **kwargs):\n '''Returns the class predictions for the given test data.\n\n # Arguments\n X: array-like, shape `(n_samples, n_features)`\n Test samples where n_samples in the number of samples\n and n_features is the number of features.\n kwargs: dictionary arguments\n Legal arguments are the arguments of `Sequential.predict_classes`.\n\n # Returns\n preds: array-like, shape `(n_samples,)`\n Class predictions.\n '''\n kwargs = self.filter_sk_params(Sequential.predict_classes, kwargs)\n return self.model.predict_classes(X, **kwargs)\n\n def predict_proba(self, X, **kwargs):\n '''Returns class probability estimates for the given test data.\n\n # Arguments\n X: array-like, shape `(n_samples, n_features)`\n Test samples where n_samples in the number of samples\n and n_features is the number of features.\n kwargs: dictionary arguments\n Legal arguments are the arguments of `Sequential.predict_classes`.\n\n # Returns\n proba: array-like, shape `(n_samples, n_outputs)`\n Class probability estimates.\n '''\n kwargs = self.filter_sk_params(Sequential.predict_proba, kwargs)\n return self.model.predict_proba(X, **kwargs)\n\n def score(self, X, y, **kwargs):\n '''Returns the mean accuracy on the given test data and labels.\n\n # Arguments\n X: array-like, shape `(n_samples, n_features)`\n Test samples where n_samples in the number of samples\n and n_features is the number of features.\n y: array-like, shape `(n_samples,)` or `(n_samples, n_outputs)`\n True labels for X.\n kwargs: dictionary arguments\n Legal arguments are the arguments of `Sequential.evaluate`.\n\n # Returns\n score: float\n Mean accuracy of predictions on X wrt. y.\n '''\n kwargs = self.filter_sk_params(Sequential.evaluate, kwargs)\n outputs = self.model.evaluate(X, y, **kwargs)\n if type(outputs) is not list:\n outputs = [outputs]\n for name, output in zip(self.model.metrics_names, outputs):\n if name == 'acc':\n return output\n raise Exception('The model is not configured to compute accuracy. '\n 'You should pass `metrics=[\"accuracy\"]` to '\n 'the `model.compile()` method.')\n\n\nclass KerasRegressor(BaseWrapper):\n '''Implementation of the scikit-learn regressor API for Keras.\n '''\n\n def predict(self, X, **kwargs):\n '''Returns predictions for the given test data.\n\n # Arguments\n X: array-like, shape `(n_samples, n_features)`\n Test samples where n_samples in the number of samples\n and n_features is the number of features.\n kwargs: dictionary arguments\n Legal arguments are the arguments of `Sequential.predict`.\n # Returns\n preds: array-like, shape `(n_samples,)`\n Predictions.\n '''\n kwargs = self.filter_sk_params(Sequential.predict, kwargs)\n return self.model.predict(X, **kwargs)\n\n def score(self, X, y, **kwargs):\n '''Returns the mean loss on the given test data and labels.\n\n # Arguments\n X: array-like, shape `(n_samples, n_features)`\n Test samples where n_samples in the number of samples\n and n_features is the number of features.\n y: array-like, shape `(n_samples,)`\n True labels for X.\n kwargs: dictionary arguments\n Legal arguments are the arguments of `Sequential.evaluate`.\n\n # Returns\n score: float\n Mean accuracy of predictions on X wrt. y.\n '''\n kwargs = self.filter_sk_params(Sequential.evaluate, kwargs)\n loss = self.model.evaluate(X, y, **kwargs)\n if type(loss) is list:\n return loss[0]\n return loss\n", "path": "keras/wrappers/scikit_learn.py"}], "after_files": [{"content": "from __future__ import absolute_import\nimport copy\nimport inspect\nimport types\nimport numpy\n\nfrom ..utils.np_utils import to_categorical\nfrom ..models import Sequential\n\n\nclass BaseWrapper(object):\n '''Base class for the Keras scikit-learn wrapper.\n\n Warning: This class should not be used directly.\n Use descendant classes instead.\n\n # Arguments\n build_fn: callable function or class instance\n sk_params: model parameters & fitting parameters\n\n The build_fn should construct, compile and return a Keras model, which\n will then be used to fit/predict. One of the following\n three values could be passed to build_fn:\n 1. A function\n 2. An instance of a class that implements the __call__ method\n 3. None. This means you implement a class that inherits from either\n `KerasClassifier` or `KerasRegressor`. The __call__ method of the\n present class will then be treated as the default build_fn.\n\n `sk_params` takes both model parameters and fitting parameters. Legal model\n parameters are the arguments of `build_fn`. Note that like all other\n estimators in scikit-learn, 'build_fn' should provide default values for\n its arguments, so that you could create the estimator without passing any\n values to `sk_params`.\n\n `sk_params` could also accept parameters for calling `fit`, `predict`,\n `predict_proba`, and `score` methods (e.g., `nb_epoch`, `batch_size`).\n fitting (predicting) parameters are selected in the following order:\n\n 1. Values passed to the dictionary arguments of\n `fit`, `predict`, `predict_proba`, and `score` methods\n 2. Values passed to `sk_params`\n 3. The default values of the `keras.models.Sequential`\n `fit`, `predict`, `predict_proba` and `score` methods\n\n When using scikit-learn's `grid_search` API, legal tunable parameters are\n those you could pass to `sk_params`, including fitting parameters.\n In other words, you could use `grid_search` to search for the best\n `batch_size` or `nb_epoch` as well as the model parameters.\n '''\n\n def __init__(self, build_fn=None, **sk_params):\n self.build_fn = build_fn\n self.sk_params = sk_params\n self.check_params(sk_params)\n\n def check_params(self, params):\n '''Check for user typos in \"params\" keys to avoid\n unwanted usage of default values\n\n # Arguments\n params: dictionary\n The parameters to be checked\n '''\n legal_params_fns = [Sequential.fit, Sequential.predict,\n Sequential.predict_classes, Sequential.evaluate]\n if self.build_fn is None:\n legal_params_fns.append(self.__call__)\n elif not isinstance(self.build_fn, types.FunctionType):\n legal_params_fns.append(self.build_fn.__call__)\n else:\n legal_params_fns.append(self.build_fn)\n\n legal_params = []\n for fn in legal_params_fns:\n legal_params += inspect.getargspec(fn)[0]\n legal_params = set(legal_params)\n\n for params_name in params:\n if params_name not in legal_params:\n assert False, '{} is not a legal parameter'.format(params_name)\n\n def get_params(self, deep=True):\n '''Get parameters for this estimator.\n\n # Arguments\n deep: boolean, optional\n If True, will return the parameters for this estimator and\n contained sub-objects that are estimators.\n\n # Returns\n params : dict\n Dictionary of parameter names mapped to their values.\n '''\n res = copy.deepcopy(self.sk_params)\n res.update({'build_fn': self.build_fn})\n return res\n\n def set_params(self, **params):\n '''Set the parameters of this estimator.\n\n # Arguments\n params: dict\n Dictionary of parameter names mapped to their values.\n\n # Returns\n self\n '''\n self.check_params(params)\n self.sk_params.update(params)\n return self\n\n def fit(self, X, y, **kwargs):\n '''Construct a new model with build_fn and fit the model according\n to the given training data.\n\n # Arguments\n X : array-like, shape `(n_samples, n_features)`\n Training samples where n_samples in the number of samples\n and n_features is the number of features.\n y : array-like, shape `(n_samples,)` or `(n_samples, n_outputs)`\n True labels for X.\n kwargs: dictionary arguments\n Legal arguments are the arguments of `Sequential.fit`\n\n # Returns\n history : object\n details about the training history at each epoch.\n '''\n\n if self.build_fn is None:\n self.model = self.__call__(**self.filter_sk_params(self.__call__))\n elif not isinstance(self.build_fn, types.FunctionType):\n self.model = self.build_fn(\n **self.filter_sk_params(self.build_fn.__call__))\n else:\n self.model = self.build_fn(**self.filter_sk_params(self.build_fn))\n\n loss_name = self.model.loss\n if hasattr(loss_name, '__name__'):\n loss_name = loss_name.__name__\n if loss_name == 'categorical_crossentropy' and len(y.shape) != 2:\n y = to_categorical(y)\n\n fit_args = copy.deepcopy(self.filter_sk_params(Sequential.fit))\n fit_args.update(kwargs)\n\n history = self.model.fit(X, y, **fit_args)\n\n return history\n\n def filter_sk_params(self, fn, override={}):\n '''Filter sk_params and return those in fn's arguments\n\n # Arguments\n fn : arbitrary function\n override: dictionary, values to override sk_params\n\n # Returns\n res : dictionary dictionary containing variables\n in both sk_params and fn's arguments.\n '''\n res = {}\n fn_args = inspect.getargspec(fn)[0]\n for name, value in self.sk_params.items():\n if name in fn_args:\n res.update({name: value})\n res.update(override)\n return res\n\n\nclass KerasClassifier(BaseWrapper):\n '''Implementation of the scikit-learn classifier API for Keras.\n '''\n\n def predict(self, X, **kwargs):\n '''Returns the class predictions for the given test data.\n\n # Arguments\n X: array-like, shape `(n_samples, n_features)`\n Test samples where n_samples in the number of samples\n and n_features is the number of features.\n kwargs: dictionary arguments\n Legal arguments are the arguments of `Sequential.predict_classes`.\n\n # Returns\n preds: array-like, shape `(n_samples,)`\n Class predictions.\n '''\n kwargs = self.filter_sk_params(Sequential.predict_classes, kwargs)\n return self.model.predict_classes(X, **kwargs)\n\n def predict_proba(self, X, **kwargs):\n '''Returns class probability estimates for the given test data.\n\n # Arguments\n X: array-like, shape `(n_samples, n_features)`\n Test samples where n_samples in the number of samples\n and n_features is the number of features.\n kwargs: dictionary arguments\n Legal arguments are the arguments of `Sequential.predict_classes`.\n\n # Returns\n proba: array-like, shape `(n_samples, n_outputs)`\n Class probability estimates.\n In the case of binary classification (i.e. 1 output of 0 or 1)\n will return '(n_samples, 2)'\n '''\n kwargs = self.filter_sk_params(Sequential.predict_proba, kwargs)\n probs = self.model.predict_proba(X, **kwargs)\n\n # check if binary classification\n if probs.shape[1] == 1:\n # first column is probability of class 0 and second is of class 1\n probs = numpy.hstack([1 - probs, probs])\n return probs\n\n def score(self, X, y, **kwargs):\n '''Returns the mean accuracy on the given test data and labels.\n\n # Arguments\n X: array-like, shape `(n_samples, n_features)`\n Test samples where n_samples in the number of samples\n and n_features is the number of features.\n y: array-like, shape `(n_samples,)` or `(n_samples, n_outputs)`\n True labels for X.\n kwargs: dictionary arguments\n Legal arguments are the arguments of `Sequential.evaluate`.\n\n # Returns\n score: float\n Mean accuracy of predictions on X wrt. y.\n '''\n kwargs = self.filter_sk_params(Sequential.evaluate, kwargs)\n outputs = self.model.evaluate(X, y, **kwargs)\n if type(outputs) is not list:\n outputs = [outputs]\n for name, output in zip(self.model.metrics_names, outputs):\n if name == 'acc':\n return output\n raise Exception('The model is not configured to compute accuracy. '\n 'You should pass `metrics=[\"accuracy\"]` to '\n 'the `model.compile()` method.')\n\n\nclass KerasRegressor(BaseWrapper):\n '''Implementation of the scikit-learn regressor API for Keras.\n '''\n\n def predict(self, X, **kwargs):\n '''Returns predictions for the given test data.\n\n # Arguments\n X: array-like, shape `(n_samples, n_features)`\n Test samples where n_samples in the number of samples\n and n_features is the number of features.\n kwargs: dictionary arguments\n Legal arguments are the arguments of `Sequential.predict`.\n # Returns\n preds: array-like, shape `(n_samples,)`\n Predictions.\n '''\n kwargs = self.filter_sk_params(Sequential.predict, kwargs)\n return self.model.predict(X, **kwargs)\n\n def score(self, X, y, **kwargs):\n '''Returns the mean loss on the given test data and labels.\n\n # Arguments\n X: array-like, shape `(n_samples, n_features)`\n Test samples where n_samples in the number of samples\n and n_features is the number of features.\n y: array-like, shape `(n_samples,)`\n True labels for X.\n kwargs: dictionary arguments\n Legal arguments are the arguments of `Sequential.evaluate`.\n\n # Returns\n score: float\n Mean accuracy of predictions on X wrt. y.\n '''\n kwargs = self.filter_sk_params(Sequential.evaluate, kwargs)\n loss = self.model.evaluate(X, y, **kwargs)\n if type(loss) is list:\n return loss[0]\n return loss\n", "path": "keras/wrappers/scikit_learn.py"}]} | 3,367 | 288 |
gh_patches_debug_14604 | rasdani/github-patches | git_diff | bookwyrm-social__bookwyrm-1778 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Receive '403: forbidden' when registering new account
**Describe the bug**
When attempting to register a new account I receive a `403` status from the `/register` endpoint.
*Full message:*
>
> CSRF verification failed. Request aborted.
>
> You are seeing this message because this site requires a CSRF cookie when submitting forms. This cookie is required for security reasons, to ensure that your browser is not being hijacked by third parties.
>
> If you have configured your browser to disable cookies, please re-enable them, at least for this site, or for “same-origin” requests.
>
A friend reported this to me and I was able to reproduce. Cookies are not disabled on my browser.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to https://bookwyrm.social/
2. Fill in new user form and click "Sign Up"
3. Observe failed request and 403 response.
**Expected behavior**
A clear and concise description of what you expected to happen.
**Screenshots**
<img width="798" alt="Screen Shot 2022-01-06 at 2 35 53 PM" src="https://user-images.githubusercontent.com/32184074/148462597-dead2839-f237-4523-b821-bb0f3055214e.png">
<img width="819" alt="Screen Shot 2022-01-06 at 2 34 21 PM" src="https://user-images.githubusercontent.com/32184074/148462625-136f0f46-4fd9-48a9-a02c-df628225c87e.png">
**Instance**
bookwyrm.social
---
**Desktop (please complete the following information):**
- OS: macOS 12.1
- Chrome Version 96.0.4664.110
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bookwyrm/views/landing/landing.py`
Content:
```
1 """ non-interactive pages """
2 from django.template.response import TemplateResponse
3 from django.views import View
4 from django.utils.decorators import method_decorator
5 from django.views.decorators.cache import cache_page
6
7 from bookwyrm import forms
8 from bookwyrm.views import helpers
9 from bookwyrm.views.feed import Feed
10
11
12 # pylint: disable= no-self-use
13 class About(View):
14 """create invites"""
15
16 def get(self, request):
17 """more information about the instance"""
18 return TemplateResponse(request, "landing/about.html")
19
20
21 class Home(View):
22 """landing page or home feed depending on auth"""
23
24 def get(self, request):
25 """this is the same as the feed on the home tab"""
26 if request.user.is_authenticated:
27 feed_view = Feed.as_view()
28 return feed_view(request, "home")
29 landing_view = Landing.as_view()
30 return landing_view(request)
31
32
33 class Landing(View):
34 """preview of recently reviewed books"""
35
36 @method_decorator(cache_page(60 * 60), name="dispatch")
37 def get(self, request):
38 """tiled book activity page"""
39 data = {
40 "register_form": forms.RegisterForm(),
41 "request_form": forms.InviteRequestForm(),
42 "books": helpers.get_landing_books(),
43 }
44 return TemplateResponse(request, "landing/landing.html", data)
45
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/bookwyrm/views/landing/landing.py b/bookwyrm/views/landing/landing.py
--- a/bookwyrm/views/landing/landing.py
+++ b/bookwyrm/views/landing/landing.py
@@ -1,8 +1,6 @@
""" non-interactive pages """
from django.template.response import TemplateResponse
from django.views import View
-from django.utils.decorators import method_decorator
-from django.views.decorators.cache import cache_page
from bookwyrm import forms
from bookwyrm.views import helpers
@@ -33,7 +31,6 @@
class Landing(View):
"""preview of recently reviewed books"""
- @method_decorator(cache_page(60 * 60), name="dispatch")
def get(self, request):
"""tiled book activity page"""
data = {
| {"golden_diff": "diff --git a/bookwyrm/views/landing/landing.py b/bookwyrm/views/landing/landing.py\n--- a/bookwyrm/views/landing/landing.py\n+++ b/bookwyrm/views/landing/landing.py\n@@ -1,8 +1,6 @@\n \"\"\" non-interactive pages \"\"\"\n from django.template.response import TemplateResponse\n from django.views import View\n-from django.utils.decorators import method_decorator\n-from django.views.decorators.cache import cache_page\n \n from bookwyrm import forms\n from bookwyrm.views import helpers\n@@ -33,7 +31,6 @@\n class Landing(View):\n \"\"\"preview of recently reviewed books\"\"\"\n \n- @method_decorator(cache_page(60 * 60), name=\"dispatch\")\n def get(self, request):\n \"\"\"tiled book activity page\"\"\"\n data = {\n", "issue": "Receive '403: forbidden' when registering new account\n**Describe the bug**\r\nWhen attempting to register a new account I receive a `403` status from the `/register` endpoint. \r\n\r\n*Full message:*\r\n> \r\n> CSRF verification failed. Request aborted.\r\n> \r\n> You are seeing this message because this site requires a CSRF cookie when submitting forms. This cookie is required for security reasons, to ensure that your browser is not being hijacked by third parties.\r\n> \r\n> If you have configured your browser to disable cookies, please re-enable them, at least for this site, or for \u201csame-origin\u201d requests.\r\n> \r\n\r\nA friend reported this to me and I was able to reproduce. Cookies are not disabled on my browser. \r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Go to https://bookwyrm.social/\r\n2. Fill in new user form and click \"Sign Up\"\r\n3. Observe failed request and 403 response. \r\n\r\n**Expected behavior**\r\nA clear and concise description of what you expected to happen.\r\n\r\n**Screenshots**\r\n<img width=\"798\" alt=\"Screen Shot 2022-01-06 at 2 35 53 PM\" src=\"https://user-images.githubusercontent.com/32184074/148462597-dead2839-f237-4523-b821-bb0f3055214e.png\">\r\n<img width=\"819\" alt=\"Screen Shot 2022-01-06 at 2 34 21 PM\" src=\"https://user-images.githubusercontent.com/32184074/148462625-136f0f46-4fd9-48a9-a02c-df628225c87e.png\">\r\n\r\n\r\n**Instance**\r\nbookwyrm.social\r\n\r\n---\r\n\r\n**Desktop (please complete the following information):**\r\n - OS: macOS 12.1\r\n - Chrome Version 96.0.4664.110\r\n\n", "before_files": [{"content": "\"\"\" non-interactive pages \"\"\"\nfrom django.template.response import TemplateResponse\nfrom django.views import View\nfrom django.utils.decorators import method_decorator\nfrom django.views.decorators.cache import cache_page\n\nfrom bookwyrm import forms\nfrom bookwyrm.views import helpers\nfrom bookwyrm.views.feed import Feed\n\n\n# pylint: disable= no-self-use\nclass About(View):\n \"\"\"create invites\"\"\"\n\n def get(self, request):\n \"\"\"more information about the instance\"\"\"\n return TemplateResponse(request, \"landing/about.html\")\n\n\nclass Home(View):\n \"\"\"landing page or home feed depending on auth\"\"\"\n\n def get(self, request):\n \"\"\"this is the same as the feed on the home tab\"\"\"\n if request.user.is_authenticated:\n feed_view = Feed.as_view()\n return feed_view(request, \"home\")\n landing_view = Landing.as_view()\n return landing_view(request)\n\n\nclass Landing(View):\n \"\"\"preview of recently reviewed books\"\"\"\n\n @method_decorator(cache_page(60 * 60), name=\"dispatch\")\n def get(self, request):\n \"\"\"tiled book activity page\"\"\"\n data = {\n \"register_form\": forms.RegisterForm(),\n \"request_form\": forms.InviteRequestForm(),\n \"books\": helpers.get_landing_books(),\n }\n return TemplateResponse(request, \"landing/landing.html\", data)\n", "path": "bookwyrm/views/landing/landing.py"}], "after_files": [{"content": "\"\"\" non-interactive pages \"\"\"\nfrom django.template.response import TemplateResponse\nfrom django.views import View\n\nfrom bookwyrm import forms\nfrom bookwyrm.views import helpers\nfrom bookwyrm.views.feed import Feed\n\n\n# pylint: disable= no-self-use\nclass About(View):\n \"\"\"create invites\"\"\"\n\n def get(self, request):\n \"\"\"more information about the instance\"\"\"\n return TemplateResponse(request, \"landing/about.html\")\n\n\nclass Home(View):\n \"\"\"landing page or home feed depending on auth\"\"\"\n\n def get(self, request):\n \"\"\"this is the same as the feed on the home tab\"\"\"\n if request.user.is_authenticated:\n feed_view = Feed.as_view()\n return feed_view(request, \"home\")\n landing_view = Landing.as_view()\n return landing_view(request)\n\n\nclass Landing(View):\n \"\"\"preview of recently reviewed books\"\"\"\n\n def get(self, request):\n \"\"\"tiled book activity page\"\"\"\n data = {\n \"register_form\": forms.RegisterForm(),\n \"request_form\": forms.InviteRequestForm(),\n \"books\": helpers.get_landing_books(),\n }\n return TemplateResponse(request, \"landing/landing.html\", data)\n", "path": "bookwyrm/views/landing/landing.py"}]} | 1,092 | 173 |
gh_patches_debug_27891 | rasdani/github-patches | git_diff | ros__ros_comm-519 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
roscpp: param.h closing namespace comment should be ros instead of param
This might be trivial.
While browsing this repository, I found that line 601 in file
ros_comm / clients / roscpp / include / ros / param.h
should be:
} // namespace ros
instead of
} // namespace param
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tools/rosgraph/src/rosgraph/roslogging.py`
Content:
```
1 # Software License Agreement (BSD License)
2 #
3 # Copyright (c) 2008, Willow Garage, Inc.
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions
8 # are met:
9 #
10 # * Redistributions of source code must retain the above copyright
11 # notice, this list of conditions and the following disclaimer.
12 # * Redistributions in binary form must reproduce the above
13 # copyright notice, this list of conditions and the following
14 # disclaimer in the documentation and/or other materials provided
15 # with the distribution.
16 # * Neither the name of Willow Garage, Inc. nor the names of its
17 # contributors may be used to endorse or promote products derived
18 # from this software without specific prior written permission.
19 #
20 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
21 # "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
22 # LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS
23 # FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE
24 # COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,
25 # INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,
26 # BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
27 # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
29 # LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN
30 # ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
31 # POSSIBILITY OF SUCH DAMAGE.
32
33 """
34 Library for configuring python logging to standard ROS locations (e.g. ROS_LOG_DIR).
35 """
36
37 import os
38 import sys
39 import time
40 import logging
41 import logging.config
42
43 import rospkg
44 from rospkg.environment import ROS_LOG_DIR
45
46 class LoggingException: pass
47
48 def configure_logging(logname, level=logging.INFO, filename=None, env=None):
49 """
50 Configure Python logging package to send log files to ROS-specific log directory
51 :param logname str: name of logger, ``str``
52 :param filename: filename to log to. If not set, a log filename
53 will be generated using logname, ``str``
54 :param env: override os.environ dictionary, ``dict``
55 :returns: log file name, ``str``
56 :raises: :exc:`LoggingException` If logging cannot be configured as specified
57 """
58 if env is None:
59 env = os.environ
60
61 logname = logname or 'unknown'
62 log_dir = rospkg.get_log_dir(env=env)
63
64 # if filename is not explicitly provided, generate one using logname
65 if not filename:
66 log_filename = os.path.join(log_dir, '%s-%s.log'%(logname, os.getpid()))
67 else:
68 log_filename = os.path.join(log_dir, filename)
69
70 logfile_dir = os.path.dirname(log_filename)
71 if not os.path.exists(logfile_dir):
72 try:
73 makedirs_with_parent_perms(logfile_dir)
74 except OSError:
75 # cannot print to screen because command-line tools with output use this
76 sys.stderr.write("WARNING: cannot create log directory [%s]. Please set %s to a writable location.\n"%(logfile_dir, ROS_LOG_DIR))
77 return None
78 elif os.path.isfile(logfile_dir):
79 raise LoggingException("Cannot save log files: file [%s] is in the way"%logfile_dir)
80
81 if 'ROS_PYTHON_LOG_CONFIG_FILE' in os.environ:
82 config_file = os.environ['ROS_PYTHON_LOG_CONFIG_FILE']
83 else:
84 # search for logging config file in /etc/. If it's not there,
85 # look for it package-relative.
86 fname = 'python_logging.conf'
87 rosgraph_d = rospkg.RosPack().get_path('rosgraph')
88 for f in [os.path.join(rospkg.get_ros_home(), 'config', fname),
89 '/etc/ros/%s'%(fname),
90 os.path.join(rosgraph_d, 'conf', fname)]:
91 if os.path.isfile(f):
92 config_file = f
93 break
94 else:
95 config_file = None
96
97 if config_file is None or not os.path.isfile(config_file):
98 # logging is considered soft-fail
99 sys.stderr.write("WARNING: cannot load logging configuration file, logging is disabled\n")
100 logging.getLogger(logname).setLevel(logging.CRITICAL)
101 return log_filename
102
103 # pass in log_filename as argument to pylogging.conf
104 os.environ['ROS_LOG_FILENAME'] = log_filename
105 # #3625: disabling_existing_loggers=False
106 logging.config.fileConfig(config_file, disable_existing_loggers=False)
107 return log_filename
108
109 def makedirs_with_parent_perms(p):
110 """
111 Create the directory using the permissions of the nearest
112 (existing) parent directory. This is useful for logging, where a
113 root process sometimes has to log in the user's space.
114 :param p: directory to create, ``str``
115 """
116 p = os.path.abspath(p)
117 parent = os.path.dirname(p)
118 # recurse upwards, checking to make sure we haven't reached the
119 # top
120 if not os.path.exists(p) and p and parent != p:
121 makedirs_with_parent_perms(parent)
122 s = os.stat(parent)
123 os.mkdir(p)
124
125 # if perms of new dir don't match, set anew
126 s2 = os.stat(p)
127 if s.st_uid != s2.st_uid or s.st_gid != s2.st_gid:
128 os.chown(p, s.st_uid, s.st_gid)
129 if s.st_mode != s2.st_mode:
130 os.chmod(p, s.st_mode)
131
132 _logging_to_rospy_names = {
133 'DEBUG': ('DEBUG', '\033[32m'),
134 'INFO': ('INFO', None),
135 'WARNING': ('WARN', '\033[33m'),
136 'ERROR': ('ERROR', '\033[31m'),
137 'CRITICAL': ('FATAL', '\033[31m')
138 }
139 _color_reset = '\033[0m'
140
141 class RosStreamHandler(logging.Handler):
142 def __init__(self, colorize=True):
143 super(RosStreamHandler, self).__init__()
144 self._colorize = colorize
145 try:
146 from rospy.rostime import get_time, is_wallclock
147 self._get_time = get_time
148 self._is_wallclock = is_wallclock
149 except ImportError:
150 self._get_time = None
151 self._is_wallclock = None
152
153 def emit(self, record):
154 level, color = _logging_to_rospy_names[record.levelname]
155 msg = '[%s] [WallTime: %f]' % (level, time.time())
156 if self._get_time is not None and not self._is_wallclock():
157 msg += ' [%f]' % self._get_time()
158 msg += ' %s\n' % record.getMessage()
159
160 if record.levelno < logging.WARNING:
161 self._write(sys.stdout, msg, color)
162 else:
163 self._write(sys.stderr, msg, color)
164
165 def _write(self, fd, msg, color):
166 if self._colorize and color and hasattr(fd, 'isatty') and fd.isatty():
167 msg = color + msg + _color_reset
168 fd.write(msg)
169
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/tools/rosgraph/src/rosgraph/roslogging.py b/tools/rosgraph/src/rosgraph/roslogging.py
--- a/tools/rosgraph/src/rosgraph/roslogging.py
+++ b/tools/rosgraph/src/rosgraph/roslogging.py
@@ -152,11 +152,33 @@
def emit(self, record):
level, color = _logging_to_rospy_names[record.levelname]
- msg = '[%s] [WallTime: %f]' % (level, time.time())
- if self._get_time is not None and not self._is_wallclock():
- msg += ' [%f]' % self._get_time()
- msg += ' %s\n' % record.getMessage()
-
+ if 'ROSCONSOLE_FORMAT' in os.environ.keys():
+ msg = os.environ['ROSCONSOLE_FORMAT']
+ msg = msg.replace('${severity}', level)
+ msg = msg.replace('${message}', str(record.getMessage()))
+ msg = msg.replace('${walltime}', '%f' % time.time())
+ msg = msg.replace('${thread}', str(record.thread))
+ msg = msg.replace('${logger}', str(record.name))
+ msg = msg.replace('${file}', str(record.pathname))
+ msg = msg.replace('${line}', str(record.lineno))
+ msg = msg.replace('${function}', str(record.funcName))
+ try:
+ from rospy import get_name
+ node_name = get_name()
+ except ImportError:
+ node_name = '<unknown_node_name>'
+ msg = msg.replace('${node}', node_name)
+ if self._get_time is not None and not self._is_wallclock():
+ t = self._get_time()
+ else:
+ t = time.time()
+ msg = msg.replace('${time}', '%f' % t)
+ msg += '\n'
+ else:
+ msg = '[%s] [WallTime: %f]' % (level, time.time())
+ if self._get_time is not None and not self._is_wallclock():
+ msg += ' [%f]' % self._get_time()
+ msg += ' %s\n' % record.getMessage()
if record.levelno < logging.WARNING:
self._write(sys.stdout, msg, color)
else:
| {"golden_diff": "diff --git a/tools/rosgraph/src/rosgraph/roslogging.py b/tools/rosgraph/src/rosgraph/roslogging.py\n--- a/tools/rosgraph/src/rosgraph/roslogging.py\n+++ b/tools/rosgraph/src/rosgraph/roslogging.py\n@@ -152,11 +152,33 @@\n \n def emit(self, record):\n level, color = _logging_to_rospy_names[record.levelname]\n- msg = '[%s] [WallTime: %f]' % (level, time.time())\n- if self._get_time is not None and not self._is_wallclock():\n- msg += ' [%f]' % self._get_time()\n- msg += ' %s\\n' % record.getMessage()\n-\n+ if 'ROSCONSOLE_FORMAT' in os.environ.keys():\n+ msg = os.environ['ROSCONSOLE_FORMAT']\n+ msg = msg.replace('${severity}', level)\n+ msg = msg.replace('${message}', str(record.getMessage()))\n+ msg = msg.replace('${walltime}', '%f' % time.time())\n+ msg = msg.replace('${thread}', str(record.thread))\n+ msg = msg.replace('${logger}', str(record.name))\n+ msg = msg.replace('${file}', str(record.pathname))\n+ msg = msg.replace('${line}', str(record.lineno))\n+ msg = msg.replace('${function}', str(record.funcName))\n+ try:\n+ from rospy import get_name\n+ node_name = get_name()\n+ except ImportError:\n+ node_name = '<unknown_node_name>'\n+ msg = msg.replace('${node}', node_name)\n+ if self._get_time is not None and not self._is_wallclock():\n+ t = self._get_time()\n+ else:\n+ t = time.time()\n+ msg = msg.replace('${time}', '%f' % t)\n+ msg += '\\n'\n+ else:\n+ msg = '[%s] [WallTime: %f]' % (level, time.time())\n+ if self._get_time is not None and not self._is_wallclock():\n+ msg += ' [%f]' % self._get_time()\n+ msg += ' %s\\n' % record.getMessage()\n if record.levelno < logging.WARNING:\n self._write(sys.stdout, msg, color)\n else:\n", "issue": "roscpp: param.h closing namespace comment should be ros instead of param\nThis might be trivial.\nWhile browsing this repository, I found that line 601 in file\nros_comm / clients / roscpp / include / ros / param.h\nshould be:\n} // namespace ros\ninstead of \n} // namespace param\n\n", "before_files": [{"content": "# Software License Agreement (BSD License)\n#\n# Copyright (c) 2008, Willow Garage, Inc.\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions\n# are met:\n#\n# * Redistributions of source code must retain the above copyright\n# notice, this list of conditions and the following disclaimer.\n# * Redistributions in binary form must reproduce the above\n# copyright notice, this list of conditions and the following\n# disclaimer in the documentation and/or other materials provided\n# with the distribution.\n# * Neither the name of Willow Garage, Inc. nor the names of its\n# contributors may be used to endorse or promote products derived\n# from this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS\n# \"AS IS\" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT\n# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS\n# FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE\n# COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,\n# INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,\n# BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\n# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT\n# LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN\n# ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE\n# POSSIBILITY OF SUCH DAMAGE.\n\n\"\"\"\nLibrary for configuring python logging to standard ROS locations (e.g. ROS_LOG_DIR).\n\"\"\"\n\nimport os\nimport sys\nimport time\nimport logging\nimport logging.config\n\nimport rospkg\nfrom rospkg.environment import ROS_LOG_DIR\n\nclass LoggingException: pass\n\ndef configure_logging(logname, level=logging.INFO, filename=None, env=None):\n \"\"\"\n Configure Python logging package to send log files to ROS-specific log directory\n :param logname str: name of logger, ``str``\n :param filename: filename to log to. If not set, a log filename\n will be generated using logname, ``str``\n :param env: override os.environ dictionary, ``dict``\n :returns: log file name, ``str``\n :raises: :exc:`LoggingException` If logging cannot be configured as specified\n \"\"\"\n if env is None:\n env = os.environ\n\n logname = logname or 'unknown'\n log_dir = rospkg.get_log_dir(env=env)\n \n # if filename is not explicitly provided, generate one using logname\n if not filename:\n log_filename = os.path.join(log_dir, '%s-%s.log'%(logname, os.getpid()))\n else:\n log_filename = os.path.join(log_dir, filename)\n\n logfile_dir = os.path.dirname(log_filename)\n if not os.path.exists(logfile_dir):\n try:\n makedirs_with_parent_perms(logfile_dir)\n except OSError:\n # cannot print to screen because command-line tools with output use this\n sys.stderr.write(\"WARNING: cannot create log directory [%s]. Please set %s to a writable location.\\n\"%(logfile_dir, ROS_LOG_DIR))\n return None\n elif os.path.isfile(logfile_dir):\n raise LoggingException(\"Cannot save log files: file [%s] is in the way\"%logfile_dir)\n\n if 'ROS_PYTHON_LOG_CONFIG_FILE' in os.environ:\n config_file = os.environ['ROS_PYTHON_LOG_CONFIG_FILE']\n else:\n # search for logging config file in /etc/. If it's not there,\n # look for it package-relative.\n fname = 'python_logging.conf'\n rosgraph_d = rospkg.RosPack().get_path('rosgraph')\n for f in [os.path.join(rospkg.get_ros_home(), 'config', fname),\n '/etc/ros/%s'%(fname),\n os.path.join(rosgraph_d, 'conf', fname)]:\n if os.path.isfile(f):\n config_file = f\n break\n else:\n config_file = None\n\n if config_file is None or not os.path.isfile(config_file):\n # logging is considered soft-fail\n sys.stderr.write(\"WARNING: cannot load logging configuration file, logging is disabled\\n\")\n logging.getLogger(logname).setLevel(logging.CRITICAL)\n return log_filename\n \n # pass in log_filename as argument to pylogging.conf\n os.environ['ROS_LOG_FILENAME'] = log_filename\n # #3625: disabling_existing_loggers=False\n logging.config.fileConfig(config_file, disable_existing_loggers=False)\n return log_filename\n\ndef makedirs_with_parent_perms(p):\n \"\"\"\n Create the directory using the permissions of the nearest\n (existing) parent directory. This is useful for logging, where a\n root process sometimes has to log in the user's space.\n :param p: directory to create, ``str``\n \"\"\" \n p = os.path.abspath(p)\n parent = os.path.dirname(p)\n # recurse upwards, checking to make sure we haven't reached the\n # top\n if not os.path.exists(p) and p and parent != p:\n makedirs_with_parent_perms(parent)\n s = os.stat(parent)\n os.mkdir(p)\n\n # if perms of new dir don't match, set anew\n s2 = os.stat(p)\n if s.st_uid != s2.st_uid or s.st_gid != s2.st_gid:\n os.chown(p, s.st_uid, s.st_gid)\n if s.st_mode != s2.st_mode:\n os.chmod(p, s.st_mode) \n\n_logging_to_rospy_names = {\n 'DEBUG': ('DEBUG', '\\033[32m'),\n 'INFO': ('INFO', None),\n 'WARNING': ('WARN', '\\033[33m'),\n 'ERROR': ('ERROR', '\\033[31m'),\n 'CRITICAL': ('FATAL', '\\033[31m')\n}\n_color_reset = '\\033[0m'\n\nclass RosStreamHandler(logging.Handler):\n def __init__(self, colorize=True):\n super(RosStreamHandler, self).__init__()\n self._colorize = colorize\n try:\n from rospy.rostime import get_time, is_wallclock\n self._get_time = get_time\n self._is_wallclock = is_wallclock\n except ImportError:\n self._get_time = None\n self._is_wallclock = None\n\n def emit(self, record):\n level, color = _logging_to_rospy_names[record.levelname]\n msg = '[%s] [WallTime: %f]' % (level, time.time())\n if self._get_time is not None and not self._is_wallclock():\n msg += ' [%f]' % self._get_time()\n msg += ' %s\\n' % record.getMessage()\n\n if record.levelno < logging.WARNING:\n self._write(sys.stdout, msg, color)\n else:\n self._write(sys.stderr, msg, color)\n\n def _write(self, fd, msg, color):\n if self._colorize and color and hasattr(fd, 'isatty') and fd.isatty():\n msg = color + msg + _color_reset\n fd.write(msg)\n", "path": "tools/rosgraph/src/rosgraph/roslogging.py"}], "after_files": [{"content": "# Software License Agreement (BSD License)\n#\n# Copyright (c) 2008, Willow Garage, Inc.\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions\n# are met:\n#\n# * Redistributions of source code must retain the above copyright\n# notice, this list of conditions and the following disclaimer.\n# * Redistributions in binary form must reproduce the above\n# copyright notice, this list of conditions and the following\n# disclaimer in the documentation and/or other materials provided\n# with the distribution.\n# * Neither the name of Willow Garage, Inc. nor the names of its\n# contributors may be used to endorse or promote products derived\n# from this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS\n# \"AS IS\" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT\n# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS\n# FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE\n# COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,\n# INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,\n# BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\n# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT\n# LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN\n# ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE\n# POSSIBILITY OF SUCH DAMAGE.\n\n\"\"\"\nLibrary for configuring python logging to standard ROS locations (e.g. ROS_LOG_DIR).\n\"\"\"\n\nimport os\nimport sys\nimport time\nimport logging\nimport logging.config\n\nimport rospkg\nfrom rospkg.environment import ROS_LOG_DIR\n\nclass LoggingException: pass\n\ndef configure_logging(logname, level=logging.INFO, filename=None, env=None):\n \"\"\"\n Configure Python logging package to send log files to ROS-specific log directory\n :param logname str: name of logger, ``str``\n :param filename: filename to log to. If not set, a log filename\n will be generated using logname, ``str``\n :param env: override os.environ dictionary, ``dict``\n :returns: log file name, ``str``\n :raises: :exc:`LoggingException` If logging cannot be configured as specified\n \"\"\"\n if env is None:\n env = os.environ\n\n logname = logname or 'unknown'\n log_dir = rospkg.get_log_dir(env=env)\n \n # if filename is not explicitly provided, generate one using logname\n if not filename:\n log_filename = os.path.join(log_dir, '%s-%s.log'%(logname, os.getpid()))\n else:\n log_filename = os.path.join(log_dir, filename)\n\n logfile_dir = os.path.dirname(log_filename)\n if not os.path.exists(logfile_dir):\n try:\n makedirs_with_parent_perms(logfile_dir)\n except OSError:\n # cannot print to screen because command-line tools with output use this\n sys.stderr.write(\"WARNING: cannot create log directory [%s]. Please set %s to a writable location.\\n\"%(logfile_dir, ROS_LOG_DIR))\n return None\n elif os.path.isfile(logfile_dir):\n raise LoggingException(\"Cannot save log files: file [%s] is in the way\"%logfile_dir)\n\n if 'ROS_PYTHON_LOG_CONFIG_FILE' in os.environ:\n config_file = os.environ['ROS_PYTHON_LOG_CONFIG_FILE']\n else:\n # search for logging config file in /etc/. If it's not there,\n # look for it package-relative.\n fname = 'python_logging.conf'\n rosgraph_d = rospkg.RosPack().get_path('rosgraph')\n for f in [os.path.join(rospkg.get_ros_home(), 'config', fname),\n '/etc/ros/%s'%(fname),\n os.path.join(rosgraph_d, 'conf', fname)]:\n if os.path.isfile(f):\n config_file = f\n break\n else:\n config_file = None\n\n if config_file is None or not os.path.isfile(config_file):\n # logging is considered soft-fail\n sys.stderr.write(\"WARNING: cannot load logging configuration file, logging is disabled\\n\")\n logging.getLogger(logname).setLevel(logging.CRITICAL)\n return log_filename\n \n # pass in log_filename as argument to pylogging.conf\n os.environ['ROS_LOG_FILENAME'] = log_filename\n # #3625: disabling_existing_loggers=False\n logging.config.fileConfig(config_file, disable_existing_loggers=False)\n return log_filename\n\ndef makedirs_with_parent_perms(p):\n \"\"\"\n Create the directory using the permissions of the nearest\n (existing) parent directory. This is useful for logging, where a\n root process sometimes has to log in the user's space.\n :param p: directory to create, ``str``\n \"\"\" \n p = os.path.abspath(p)\n parent = os.path.dirname(p)\n # recurse upwards, checking to make sure we haven't reached the\n # top\n if not os.path.exists(p) and p and parent != p:\n makedirs_with_parent_perms(parent)\n s = os.stat(parent)\n os.mkdir(p)\n\n # if perms of new dir don't match, set anew\n s2 = os.stat(p)\n if s.st_uid != s2.st_uid or s.st_gid != s2.st_gid:\n os.chown(p, s.st_uid, s.st_gid)\n if s.st_mode != s2.st_mode:\n os.chmod(p, s.st_mode) \n\n_logging_to_rospy_names = {\n 'DEBUG': ('DEBUG', '\\033[32m'),\n 'INFO': ('INFO', None),\n 'WARNING': ('WARN', '\\033[33m'),\n 'ERROR': ('ERROR', '\\033[31m'),\n 'CRITICAL': ('FATAL', '\\033[31m')\n}\n_color_reset = '\\033[0m'\n\nclass RosStreamHandler(logging.Handler):\n def __init__(self, colorize=True):\n super(RosStreamHandler, self).__init__()\n self._colorize = colorize\n try:\n from rospy.rostime import get_time, is_wallclock\n self._get_time = get_time\n self._is_wallclock = is_wallclock\n except ImportError:\n self._get_time = None\n self._is_wallclock = None\n\n def emit(self, record):\n level, color = _logging_to_rospy_names[record.levelname]\n if 'ROSCONSOLE_FORMAT' in os.environ.keys():\n msg = os.environ['ROSCONSOLE_FORMAT']\n msg = msg.replace('${severity}', level)\n msg = msg.replace('${message}', str(record.getMessage()))\n msg = msg.replace('${walltime}', '%f' % time.time())\n msg = msg.replace('${thread}', str(record.thread))\n msg = msg.replace('${logger}', str(record.name))\n msg = msg.replace('${file}', str(record.pathname))\n msg = msg.replace('${line}', str(record.lineno))\n msg = msg.replace('${function}', str(record.funcName))\n try:\n from rospy import get_name\n node_name = get_name()\n except ImportError:\n node_name = '<unknown_node_name>'\n msg = msg.replace('${node}', node_name)\n if self._get_time is not None and not self._is_wallclock():\n t = self._get_time()\n else:\n t = time.time()\n msg = msg.replace('${time}', '%f' % t)\n msg += '\\n'\n else:\n msg = '[%s] [WallTime: %f]' % (level, time.time())\n if self._get_time is not None and not self._is_wallclock():\n msg += ' [%f]' % self._get_time()\n msg += ' %s\\n' % record.getMessage()\n if record.levelno < logging.WARNING:\n self._write(sys.stdout, msg, color)\n else:\n self._write(sys.stderr, msg, color)\n\n def _write(self, fd, msg, color):\n if self._colorize and color and hasattr(fd, 'isatty') and fd.isatty():\n msg = color + msg + _color_reset\n fd.write(msg)\n", "path": "tools/rosgraph/src/rosgraph/roslogging.py"}]} | 2,314 | 493 |
gh_patches_debug_27034 | rasdani/github-patches | git_diff | lk-geimfari__mimesis-931 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PyCharm indicates wrong type for lambda
# Bug report
<!--
Hi, thanks for submitting a bug. We appreciate that.
But, we will need some information about what's wrong to help you.
-->
## What's wrong
While using PyCharm, `lambda` type in `Schema` results in *Expected type 'FunctionType', got '() -> Dict[str, Union[str, Any]]' instead*
<!-- Describe what is not working. Please, attach a traceback. -->
## How is that should be
Is this warning correct? The code runs perfectly fine but maybe the Type maybe be wrong here. On this [SO post](https://stackoverflow.com/a/33833896/12794150) they mentioned using the `from typing import Callable` for type hinting a lambda.
<!-- Describe how it should work. -->
## System information
<!-- Describe system information -->
```
❯ python3 --version
Python 3.8.5
❯ sw_vers
ProductName: macOS
ProductVersion: 11.0
BuildVersion: 20A5354i
```
PyCharm 2020.2.1
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mimesis/typing.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 """Custom types and shortcuts for annotating Mimesis."""
4
5 import datetime
6 from typing import Any, Dict, Union
7
8 __all__ = [
9 'JSON',
10 'DateTime',
11 'Timestamp',
12 'Time',
13 'Date',
14 'Seed',
15 ]
16
17 JSON = Dict[str, Any]
18
19 DateTime = datetime.datetime
20
21 Time = datetime.time
22
23 Date = datetime.date
24
25 Timestamp = Union[str, int]
26
27 Seed = Union[int, str, bytes, bytearray]
28
```
Path: `mimesis/schema.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 """Implements classes for generating data by schema."""
4
5 from typing import Any, Callable, List, Optional
6
7 from mimesis.exceptions import (
8 UnacceptableField,
9 UndefinedField,
10 UndefinedSchema,
11 UnsupportedField,
12 )
13 from mimesis.providers.generic import Generic
14 from mimesis.typing import JSON, Seed
15
16 __all__ = ['Field', 'Schema']
17
18
19 class AbstractField:
20 """
21 AbstractField is a class for generating data by the name of the method.
22
23 Instance of this object takes any string which represents name
24 of any method of any supported data provider (:class:`~mimesis.Generic`)
25 and the ``**kwargs`` of the method.
26
27 See :class:`~mimesis.schema.AbstractField.__call__` for more details.
28 """
29
30 def __init__(self, locale: str = 'en',
31 seed: Optional[Seed] = None,
32 providers: Optional[Any] = None) -> None:
33 """Initialize field.
34
35 :param locale: Locale
36 :param seed: Seed for random.
37 """
38 self.locale = locale
39 self.seed = seed
40 self._gen = Generic(self.locale, self.seed)
41
42 if providers:
43 self._gen.add_providers(*providers)
44
45 self._table = {} # type: ignore
46
47 def __call__(self, name: Optional[str] = None,
48 key: Optional[Callable] = None, **kwargs) -> Any:
49 """Override standard call.
50
51 This magic method overrides standard call so it takes any string
52 which represents the name of any method of any supported data
53 provider and the ``**kwargs`` of this method.
54
55 .. note:: Some data providers have methods with the same names
56 and in such cases, you can explicitly define that the method
57 belongs to data-provider ``name='provider.name'`` otherwise
58 it will return the data from the first provider which
59 has a method ``name``.
60
61 You can apply a *key function* to the result returned by
62 the method, bt passing a parameter **key** with a callable
63 object which returns the final result.
64
65 :param name: Name of the method.
66 :param key: A key function (or other callable object)
67 which will be applied to result.
68 :param kwargs: Kwargs of method.
69 :return: Value which represented by method.
70 :raises ValueError: if provider not
71 supported or if field not defined.
72 """
73 if name is None:
74 raise UndefinedField()
75
76 def tail_parser(tails: str, obj: Any) -> Any:
77 """Return method from end of tail.
78
79 :param tails: Tail string
80 :param obj: Search tail from this object
81 :return last tailed method
82 """
83 provider_name, method_name = tails.split('.', 1)
84
85 if '.' in method_name:
86 raise UnacceptableField()
87
88 attr = getattr(obj, provider_name)
89 if attr is not None:
90 return getattr(attr, method_name)
91
92 try:
93 if name not in self._table:
94 if '.' not in name:
95 # Fix https://github.com/lk-geimfari/mimesis/issues/619
96 if name == self._gen.choice.Meta.name:
97 self._table[name] = self._gen.choice
98 else:
99 for provider in dir(self._gen):
100 provider = getattr(self._gen, provider)
101 if name in dir(provider):
102 self._table[name] = getattr(provider, name)
103 else:
104 self._table[name] = tail_parser(name, self._gen)
105
106 result = self._table[name](**kwargs)
107 if key and callable(key):
108 return key(result)
109 return result
110 except KeyError:
111 raise UnsupportedField(name)
112
113 def __str__(self):
114 return '{} <{}>'.format(
115 self.__class__.__name__, self.locale)
116
117
118 class Schema:
119 """Class which return list of filled schemas."""
120
121 def __init__(self, schema: Callable) -> None:
122 """Initialize schema.
123
124 :param schema: A schema.
125 """
126 if callable(schema):
127 self.schema = schema
128 else:
129 raise UndefinedSchema()
130
131 def create(self, iterations: int = 1) -> List[JSON]:
132 """Return filled schema.
133
134 Create a list of a filled schemas with elements in
135 an amount of **iterations**.
136
137 :param iterations: Amount of iterations.
138 :return: List of willed schemas.
139 """
140 return [self.schema() for _ in range(iterations)]
141
142
143 # Alias for AbstractField
144 Field = AbstractField
145
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mimesis/schema.py b/mimesis/schema.py
--- a/mimesis/schema.py
+++ b/mimesis/schema.py
@@ -11,7 +11,7 @@
UnsupportedField,
)
from mimesis.providers.generic import Generic
-from mimesis.typing import JSON, Seed
+from mimesis.typing import JSON, SchemaType, Seed
__all__ = ['Field', 'Schema']
@@ -118,10 +118,10 @@
class Schema:
"""Class which return list of filled schemas."""
- def __init__(self, schema: Callable) -> None:
+ def __init__(self, schema: SchemaType) -> None:
"""Initialize schema.
- :param schema: A schema.
+ :param schema: A schema (must be a callable object).
"""
if callable(schema):
self.schema = schema
diff --git a/mimesis/typing.py b/mimesis/typing.py
--- a/mimesis/typing.py
+++ b/mimesis/typing.py
@@ -3,7 +3,7 @@
"""Custom types and shortcuts for annotating Mimesis."""
import datetime
-from typing import Any, Dict, Union
+from typing import Any, Callable, Dict, Union
__all__ = [
'JSON',
@@ -11,6 +11,7 @@
'Timestamp',
'Time',
'Date',
+ 'SchemaType',
'Seed',
]
@@ -25,3 +26,5 @@
Timestamp = Union[str, int]
Seed = Union[int, str, bytes, bytearray]
+
+SchemaType = Callable[[], JSON]
| {"golden_diff": "diff --git a/mimesis/schema.py b/mimesis/schema.py\n--- a/mimesis/schema.py\n+++ b/mimesis/schema.py\n@@ -11,7 +11,7 @@\n UnsupportedField,\n )\n from mimesis.providers.generic import Generic\n-from mimesis.typing import JSON, Seed\n+from mimesis.typing import JSON, SchemaType, Seed\n \n __all__ = ['Field', 'Schema']\n \n@@ -118,10 +118,10 @@\n class Schema:\n \"\"\"Class which return list of filled schemas.\"\"\"\n \n- def __init__(self, schema: Callable) -> None:\n+ def __init__(self, schema: SchemaType) -> None:\n \"\"\"Initialize schema.\n \n- :param schema: A schema.\n+ :param schema: A schema (must be a callable object).\n \"\"\"\n if callable(schema):\n self.schema = schema\ndiff --git a/mimesis/typing.py b/mimesis/typing.py\n--- a/mimesis/typing.py\n+++ b/mimesis/typing.py\n@@ -3,7 +3,7 @@\n \"\"\"Custom types and shortcuts for annotating Mimesis.\"\"\"\n \n import datetime\n-from typing import Any, Dict, Union\n+from typing import Any, Callable, Dict, Union\n \n __all__ = [\n 'JSON',\n@@ -11,6 +11,7 @@\n 'Timestamp',\n 'Time',\n 'Date',\n+ 'SchemaType',\n 'Seed',\n ]\n \n@@ -25,3 +26,5 @@\n Timestamp = Union[str, int]\n \n Seed = Union[int, str, bytes, bytearray]\n+\n+SchemaType = Callable[[], JSON]\n", "issue": "PyCharm indicates wrong type for lambda\n# Bug report\r\n\r\n<!--\r\nHi, thanks for submitting a bug. We appreciate that.\r\n\r\nBut, we will need some information about what's wrong to help you.\r\n-->\r\n\r\n## What's wrong\r\n\r\nWhile using PyCharm, `lambda` type in `Schema` results in *Expected type 'FunctionType', got '() -> Dict[str, Union[str, Any]]' instead*\r\n\r\n\r\n<!-- Describe what is not working. Please, attach a traceback. -->\r\n\r\n## How is that should be\r\nIs this warning correct? The code runs perfectly fine but maybe the Type maybe be wrong here. On this [SO post](https://stackoverflow.com/a/33833896/12794150) they mentioned using the `from typing import Callable` for type hinting a lambda.\r\n<!-- Describe how it should work. -->\r\n\r\n## System information\r\n\r\n<!-- Describe system information -->\r\n```\r\n\u276f python3 --version\r\nPython 3.8.5\r\n\r\n\u276f sw_vers\r\nProductName:\tmacOS\r\nProductVersion:\t11.0\r\nBuildVersion:\t20A5354i\r\n```\r\nPyCharm 2020.2.1\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Custom types and shortcuts for annotating Mimesis.\"\"\"\n\nimport datetime\nfrom typing import Any, Dict, Union\n\n__all__ = [\n 'JSON',\n 'DateTime',\n 'Timestamp',\n 'Time',\n 'Date',\n 'Seed',\n]\n\nJSON = Dict[str, Any]\n\nDateTime = datetime.datetime\n\nTime = datetime.time\n\nDate = datetime.date\n\nTimestamp = Union[str, int]\n\nSeed = Union[int, str, bytes, bytearray]\n", "path": "mimesis/typing.py"}, {"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Implements classes for generating data by schema.\"\"\"\n\nfrom typing import Any, Callable, List, Optional\n\nfrom mimesis.exceptions import (\n UnacceptableField,\n UndefinedField,\n UndefinedSchema,\n UnsupportedField,\n)\nfrom mimesis.providers.generic import Generic\nfrom mimesis.typing import JSON, Seed\n\n__all__ = ['Field', 'Schema']\n\n\nclass AbstractField:\n \"\"\"\n AbstractField is a class for generating data by the name of the method.\n\n Instance of this object takes any string which represents name\n of any method of any supported data provider (:class:`~mimesis.Generic`)\n and the ``**kwargs`` of the method.\n\n See :class:`~mimesis.schema.AbstractField.__call__` for more details.\n \"\"\"\n\n def __init__(self, locale: str = 'en',\n seed: Optional[Seed] = None,\n providers: Optional[Any] = None) -> None:\n \"\"\"Initialize field.\n\n :param locale: Locale\n :param seed: Seed for random.\n \"\"\"\n self.locale = locale\n self.seed = seed\n self._gen = Generic(self.locale, self.seed)\n\n if providers:\n self._gen.add_providers(*providers)\n\n self._table = {} # type: ignore\n\n def __call__(self, name: Optional[str] = None,\n key: Optional[Callable] = None, **kwargs) -> Any:\n \"\"\"Override standard call.\n\n This magic method overrides standard call so it takes any string\n which represents the name of any method of any supported data\n provider and the ``**kwargs`` of this method.\n\n .. note:: Some data providers have methods with the same names\n and in such cases, you can explicitly define that the method\n belongs to data-provider ``name='provider.name'`` otherwise\n it will return the data from the first provider which\n has a method ``name``.\n\n You can apply a *key function* to the result returned by\n the method, bt passing a parameter **key** with a callable\n object which returns the final result.\n\n :param name: Name of the method.\n :param key: A key function (or other callable object)\n which will be applied to result.\n :param kwargs: Kwargs of method.\n :return: Value which represented by method.\n :raises ValueError: if provider not\n supported or if field not defined.\n \"\"\"\n if name is None:\n raise UndefinedField()\n\n def tail_parser(tails: str, obj: Any) -> Any:\n \"\"\"Return method from end of tail.\n\n :param tails: Tail string\n :param obj: Search tail from this object\n :return last tailed method\n \"\"\"\n provider_name, method_name = tails.split('.', 1)\n\n if '.' in method_name:\n raise UnacceptableField()\n\n attr = getattr(obj, provider_name)\n if attr is not None:\n return getattr(attr, method_name)\n\n try:\n if name not in self._table:\n if '.' not in name:\n # Fix https://github.com/lk-geimfari/mimesis/issues/619\n if name == self._gen.choice.Meta.name:\n self._table[name] = self._gen.choice\n else:\n for provider in dir(self._gen):\n provider = getattr(self._gen, provider)\n if name in dir(provider):\n self._table[name] = getattr(provider, name)\n else:\n self._table[name] = tail_parser(name, self._gen)\n\n result = self._table[name](**kwargs)\n if key and callable(key):\n return key(result)\n return result\n except KeyError:\n raise UnsupportedField(name)\n\n def __str__(self):\n return '{} <{}>'.format(\n self.__class__.__name__, self.locale)\n\n\nclass Schema:\n \"\"\"Class which return list of filled schemas.\"\"\"\n\n def __init__(self, schema: Callable) -> None:\n \"\"\"Initialize schema.\n\n :param schema: A schema.\n \"\"\"\n if callable(schema):\n self.schema = schema\n else:\n raise UndefinedSchema()\n\n def create(self, iterations: int = 1) -> List[JSON]:\n \"\"\"Return filled schema.\n\n Create a list of a filled schemas with elements in\n an amount of **iterations**.\n\n :param iterations: Amount of iterations.\n :return: List of willed schemas.\n \"\"\"\n return [self.schema() for _ in range(iterations)]\n\n\n# Alias for AbstractField\nField = AbstractField\n", "path": "mimesis/schema.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Custom types and shortcuts for annotating Mimesis.\"\"\"\n\nimport datetime\nfrom typing import Any, Callable, Dict, Union\n\n__all__ = [\n 'JSON',\n 'DateTime',\n 'Timestamp',\n 'Time',\n 'Date',\n 'SchemaType',\n 'Seed',\n]\n\nJSON = Dict[str, Any]\n\nDateTime = datetime.datetime\n\nTime = datetime.time\n\nDate = datetime.date\n\nTimestamp = Union[str, int]\n\nSeed = Union[int, str, bytes, bytearray]\n\nSchemaType = Callable[[], JSON]\n", "path": "mimesis/typing.py"}, {"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Implements classes for generating data by schema.\"\"\"\n\nfrom typing import Any, Callable, List, Optional\n\nfrom mimesis.exceptions import (\n UnacceptableField,\n UndefinedField,\n UndefinedSchema,\n UnsupportedField,\n)\nfrom mimesis.providers.generic import Generic\nfrom mimesis.typing import JSON, SchemaType, Seed\n\n__all__ = ['Field', 'Schema']\n\n\nclass AbstractField:\n \"\"\"\n AbstractField is a class for generating data by the name of the method.\n\n Instance of this object takes any string which represents name\n of any method of any supported data provider (:class:`~mimesis.Generic`)\n and the ``**kwargs`` of the method.\n\n See :class:`~mimesis.schema.AbstractField.__call__` for more details.\n \"\"\"\n\n def __init__(self, locale: str = 'en',\n seed: Optional[Seed] = None,\n providers: Optional[Any] = None) -> None:\n \"\"\"Initialize field.\n\n :param locale: Locale\n :param seed: Seed for random.\n \"\"\"\n self.locale = locale\n self.seed = seed\n self._gen = Generic(self.locale, self.seed)\n\n if providers:\n self._gen.add_providers(*providers)\n\n self._table = {} # type: ignore\n\n def __call__(self, name: Optional[str] = None,\n key: Optional[Callable] = None, **kwargs) -> Any:\n \"\"\"Override standard call.\n\n This magic method overrides standard call so it takes any string\n which represents the name of any method of any supported data\n provider and the ``**kwargs`` of this method.\n\n .. note:: Some data providers have methods with the same names\n and in such cases, you can explicitly define that the method\n belongs to data-provider ``name='provider.name'`` otherwise\n it will return the data from the first provider which\n has a method ``name``.\n\n You can apply a *key function* to the result returned by\n the method, bt passing a parameter **key** with a callable\n object which returns the final result.\n\n :param name: Name of the method.\n :param key: A key function (or other callable object)\n which will be applied to result.\n :param kwargs: Kwargs of method.\n :return: Value which represented by method.\n :raises ValueError: if provider not\n supported or if field not defined.\n \"\"\"\n if name is None:\n raise UndefinedField()\n\n def tail_parser(tails: str, obj: Any) -> Any:\n \"\"\"Return method from end of tail.\n\n :param tails: Tail string\n :param obj: Search tail from this object\n :return last tailed method\n \"\"\"\n provider_name, method_name = tails.split('.', 1)\n\n if '.' in method_name:\n raise UnacceptableField()\n\n attr = getattr(obj, provider_name)\n if attr is not None:\n return getattr(attr, method_name)\n\n try:\n if name not in self._table:\n if '.' not in name:\n # Fix https://github.com/lk-geimfari/mimesis/issues/619\n if name == self._gen.choice.Meta.name:\n self._table[name] = self._gen.choice\n else:\n for provider in dir(self._gen):\n provider = getattr(self._gen, provider)\n if name in dir(provider):\n self._table[name] = getattr(provider, name)\n else:\n self._table[name] = tail_parser(name, self._gen)\n\n result = self._table[name](**kwargs)\n if key and callable(key):\n return key(result)\n return result\n except KeyError:\n raise UnsupportedField(name)\n\n def __str__(self):\n return '{} <{}>'.format(\n self.__class__.__name__, self.locale)\n\n\nclass Schema:\n \"\"\"Class which return list of filled schemas.\"\"\"\n\n def __init__(self, schema: SchemaType) -> None:\n \"\"\"Initialize schema.\n\n :param schema: A schema (must be a callable object).\n \"\"\"\n if callable(schema):\n self.schema = schema\n else:\n raise UndefinedSchema()\n\n def create(self, iterations: int = 1) -> List[JSON]:\n \"\"\"Return filled schema.\n\n Create a list of a filled schemas with elements in\n an amount of **iterations**.\n\n :param iterations: Amount of iterations.\n :return: List of willed schemas.\n \"\"\"\n return [self.schema() for _ in range(iterations)]\n\n\n# Alias for AbstractField\nField = AbstractField\n", "path": "mimesis/schema.py"}]} | 2,103 | 368 |
gh_patches_debug_33952 | rasdani/github-patches | git_diff | googleapis__python-bigquery-458 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Simplify AutoStrEnum definition in Jupyter magic's argument parser
The current definition of [AutoStrEnum](https://github.com/googleapis/python-bigquery/blob/0337ea0bde966c3ccb94960493a6fa6f2bee49b4/google/cloud/bigquery/magics/line_arg_parser/lexer.py#L139-L167) is rather complicated. With the library now only supporting Python 3.6+, we can simplify it and just use the `_generate_next_value_()` hook.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `google/cloud/bigquery/magics/line_arg_parser/lexer.py`
Content:
```
1 # Copyright 2020 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from collections import namedtuple
16 from collections import OrderedDict
17 import itertools
18 import re
19
20 import enum
21
22
23 Token = namedtuple("Token", ("type_", "lexeme", "pos"))
24 StateTransition = namedtuple("StateTransition", ("new_state", "total_offset"))
25
26 # Pattern matching is done with regexes, and the order in which the token patterns are
27 # defined is important.
28 #
29 # Suppose we had the following token definitions:
30 # * INT - a token matching integers,
31 # * FLOAT - a token matching floating point numbers,
32 # * DOT - a token matching a single literal dot character, i.e. "."
33 #
34 # The FLOAT token would have to be defined first, since we would want the input "1.23"
35 # to be tokenized as a single FLOAT token, and *not* three tokens (INT, DOT, INT).
36 #
37 # Sometimes, however, different tokens match too similar patterns, and it is not
38 # possible to define them in order that would avoid any ambiguity. One such case are
39 # the OPT_VAL and PY_NUMBER tokens, as both can match an integer literal, say "42".
40 #
41 # In order to avoid the dilemmas, the lexer implements a concept of STATES. States are
42 # used to split token definitions into subgroups, and in each lexer state only a single
43 # subgroup is used for tokenizing the input. Lexer states can therefore be though of as
44 # token namespaces.
45 #
46 # For example, while parsing the value of the "--params" option, we do not want to
47 # "recognize" it as a single OPT_VAL token, but instead want to parse it as a Python
48 # dictionary and verify its syntactial correctness. On the other hand, while parsing
49 # the value of an option other than "--params", we do not really care about its
50 # structure, and thus do not want to use any of the "Python tokens" for pattern matching.
51 #
52 # Since token definition order is important, an OrderedDict is needed with tightly
53 # controlled member definitions (i.e. passed as a sequence, and *not* via kwargs).
54 token_types = OrderedDict(
55 [
56 (
57 "state_parse_pos_args",
58 OrderedDict(
59 [
60 (
61 "GOTO_PARSE_NON_PARAMS_OPTIONS",
62 r"(?P<GOTO_PARSE_NON_PARAMS_OPTIONS>(?=--))", # double dash - starting the options list
63 ),
64 (
65 "DEST_VAR",
66 r"(?P<DEST_VAR>[^\d\W]\w*)", # essentially a Python ID
67 ),
68 ]
69 ),
70 ),
71 (
72 "state_parse_non_params_options",
73 OrderedDict(
74 [
75 (
76 "GOTO_PARSE_PARAMS_OPTION",
77 r"(?P<GOTO_PARSE_PARAMS_OPTION>(?=--params(?:\s|=|--|$)))", # the --params option
78 ),
79 ("OPTION_SPEC", r"(?P<OPTION_SPEC>--\w+)"),
80 ("OPTION_EQ", r"(?P<OPTION_EQ>=)"),
81 ("OPT_VAL", r"(?P<OPT_VAL>\S+?(?=\s|--|$))"),
82 ]
83 ),
84 ),
85 (
86 "state_parse_params_option",
87 OrderedDict(
88 [
89 (
90 "PY_STRING",
91 r"(?P<PY_STRING>(?:{})|(?:{}))".format(
92 r"'(?:[^'\\]|\.)*'",
93 r'"(?:[^"\\]|\.)*"', # single and double quoted strings
94 ),
95 ),
96 ("PARAMS_OPT_SPEC", r"(?P<PARAMS_OPT_SPEC>--params(?=\s|=|--|$))"),
97 ("PARAMS_OPT_EQ", r"(?P<PARAMS_OPT_EQ>=)"),
98 (
99 "GOTO_PARSE_NON_PARAMS_OPTIONS",
100 r"(?P<GOTO_PARSE_NON_PARAMS_OPTIONS>(?=--\w+))", # found another option spec
101 ),
102 ("PY_BOOL", r"(?P<PY_BOOL>True|False)"),
103 ("DOLLAR_PY_ID", r"(?P<DOLLAR_PY_ID>\$[^\d\W]\w*)"),
104 (
105 "PY_NUMBER",
106 r"(?P<PY_NUMBER>-?[1-9]\d*(?:\.\d+)?(:?[e|E][+-]?\d+)?)",
107 ),
108 ("SQUOTE", r"(?P<SQUOTE>')"),
109 ("DQUOTE", r'(?P<DQUOTE>")'),
110 ("COLON", r"(?P<COLON>:)"),
111 ("COMMA", r"(?P<COMMA>,)"),
112 ("LCURL", r"(?P<LCURL>\{)"),
113 ("RCURL", r"(?P<RCURL>})"),
114 ("LSQUARE", r"(?P<LSQUARE>\[)"),
115 ("RSQUARE", r"(?P<RSQUARE>])"),
116 ("LPAREN", r"(?P<LPAREN>\()"),
117 ("RPAREN", r"(?P<RPAREN>\))"),
118 ]
119 ),
120 ),
121 (
122 "common",
123 OrderedDict(
124 [
125 ("WS", r"(?P<WS>\s+)"),
126 ("EOL", r"(?P<EOL>$)"),
127 (
128 # anything not a whitespace or matched by something else
129 "UNKNOWN",
130 r"(?P<UNKNOWN>\S+)",
131 ),
132 ]
133 ),
134 ),
135 ]
136 )
137
138
139 # The _generate_next_value_() enum hook is only available in Python 3.6+, thus we
140 # need to do some acrobatics to implement an "auto str enum" base class. Implementation
141 # based on the recipe provided by the very author of the Enum library:
142 # https://stackoverflow.com/a/32313954/5040035
143 class StrEnumMeta(enum.EnumMeta):
144 @classmethod
145 def __prepare__(metacls, name, bases, **kwargs):
146 # Having deterministic enum members definition order is nice.
147 return OrderedDict()
148
149 def __new__(metacls, name, bases, oldclassdict):
150 # Scan through the declared enum members and convert any value that is a plain
151 # empty tuple into a `str` of the name instead.
152 newclassdict = enum._EnumDict()
153 for key, val in oldclassdict.items():
154 if val == ():
155 val = key
156 newclassdict[key] = val
157 return super(StrEnumMeta, metacls).__new__(metacls, name, bases, newclassdict)
158
159
160 # The @six.add_metaclass decorator does not work, Enum complains about _sunder_ names,
161 # and we cannot use class syntax directly, because the Python 3 version would cause
162 # a syntax error under Python 2.
163 AutoStrEnum = StrEnumMeta(
164 "AutoStrEnum",
165 (str, enum.Enum),
166 {"__doc__": "Base enum class for for name=value str enums."},
167 )
168
169 TokenType = AutoStrEnum(
170 "TokenType",
171 [
172 (name, name)
173 for name in itertools.chain.from_iterable(token_types.values())
174 if not name.startswith("GOTO_")
175 ],
176 )
177
178
179 class LexerState(AutoStrEnum):
180 PARSE_POS_ARGS = () # parsing positional arguments
181 PARSE_NON_PARAMS_OPTIONS = () # parsing options other than "--params"
182 PARSE_PARAMS_OPTION = () # parsing the "--params" option
183 STATE_END = ()
184
185
186 class Lexer(object):
187 """Lexical analyzer for tokenizing the cell magic input line."""
188
189 _GRAND_PATTERNS = {
190 LexerState.PARSE_POS_ARGS: re.compile(
191 "|".join(
192 itertools.chain(
193 token_types["state_parse_pos_args"].values(),
194 token_types["common"].values(),
195 )
196 )
197 ),
198 LexerState.PARSE_NON_PARAMS_OPTIONS: re.compile(
199 "|".join(
200 itertools.chain(
201 token_types["state_parse_non_params_options"].values(),
202 token_types["common"].values(),
203 )
204 )
205 ),
206 LexerState.PARSE_PARAMS_OPTION: re.compile(
207 "|".join(
208 itertools.chain(
209 token_types["state_parse_params_option"].values(),
210 token_types["common"].values(),
211 )
212 )
213 ),
214 }
215
216 def __init__(self, input_text):
217 self._text = input_text
218
219 def __iter__(self):
220 # Since re.scanner does not seem to support manipulating inner scanner states,
221 # we need to implement lexer state transitions manually using special
222 # non-capturing lookahead token patterns to signal when a state transition
223 # should be made.
224 # Since we don't have "nested" states, we don't really need a stack and
225 # this simple mechanism is sufficient.
226 state = LexerState.PARSE_POS_ARGS
227 offset = 0 # the number of characters processed so far
228
229 while state != LexerState.STATE_END:
230 token_stream = self._find_state_tokens(state, offset)
231
232 for maybe_token in token_stream: # pragma: NO COVER
233 if isinstance(maybe_token, StateTransition):
234 state = maybe_token.new_state
235 offset = maybe_token.total_offset
236 break
237
238 if maybe_token.type_ != TokenType.WS:
239 yield maybe_token
240
241 if maybe_token.type_ == TokenType.EOL:
242 state = LexerState.STATE_END
243 break
244
245 def _find_state_tokens(self, state, current_offset):
246 """Scan the input for current state's tokens starting at ``current_offset``.
247
248 Args:
249 state (LexerState): The current lexer state.
250 current_offset (int): The offset in the input text, i.e. the number
251 of characters already scanned so far.
252
253 Yields:
254 The next ``Token`` or ``StateTransition`` instance.
255 """
256 pattern = self._GRAND_PATTERNS[state]
257 scanner = pattern.finditer(self._text, current_offset)
258
259 for match in scanner: # pragma: NO COVER
260 token_type = match.lastgroup
261
262 if token_type.startswith("GOTO_"):
263 yield StateTransition(
264 new_state=getattr(LexerState, token_type[5:]), # w/o "GOTO_" prefix
265 total_offset=match.start(),
266 )
267
268 yield Token(token_type, match.group(), match.start())
269
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/google/cloud/bigquery/magics/line_arg_parser/lexer.py b/google/cloud/bigquery/magics/line_arg_parser/lexer.py
--- a/google/cloud/bigquery/magics/line_arg_parser/lexer.py
+++ b/google/cloud/bigquery/magics/line_arg_parser/lexer.py
@@ -136,40 +136,17 @@
)
-# The _generate_next_value_() enum hook is only available in Python 3.6+, thus we
-# need to do some acrobatics to implement an "auto str enum" base class. Implementation
-# based on the recipe provided by the very author of the Enum library:
-# https://stackoverflow.com/a/32313954/5040035
-class StrEnumMeta(enum.EnumMeta):
- @classmethod
- def __prepare__(metacls, name, bases, **kwargs):
- # Having deterministic enum members definition order is nice.
- return OrderedDict()
+class AutoStrEnum(str, enum.Enum):
+ """Base enum class for for name=value str enums."""
- def __new__(metacls, name, bases, oldclassdict):
- # Scan through the declared enum members and convert any value that is a plain
- # empty tuple into a `str` of the name instead.
- newclassdict = enum._EnumDict()
- for key, val in oldclassdict.items():
- if val == ():
- val = key
- newclassdict[key] = val
- return super(StrEnumMeta, metacls).__new__(metacls, name, bases, newclassdict)
+ def _generate_next_value_(name, start, count, last_values):
+ return name
-# The @six.add_metaclass decorator does not work, Enum complains about _sunder_ names,
-# and we cannot use class syntax directly, because the Python 3 version would cause
-# a syntax error under Python 2.
-AutoStrEnum = StrEnumMeta(
- "AutoStrEnum",
- (str, enum.Enum),
- {"__doc__": "Base enum class for for name=value str enums."},
-)
-
TokenType = AutoStrEnum(
"TokenType",
[
- (name, name)
+ (name, enum.auto())
for name in itertools.chain.from_iterable(token_types.values())
if not name.startswith("GOTO_")
],
@@ -177,10 +154,10 @@
class LexerState(AutoStrEnum):
- PARSE_POS_ARGS = () # parsing positional arguments
- PARSE_NON_PARAMS_OPTIONS = () # parsing options other than "--params"
- PARSE_PARAMS_OPTION = () # parsing the "--params" option
- STATE_END = ()
+ PARSE_POS_ARGS = enum.auto() # parsing positional arguments
+ PARSE_NON_PARAMS_OPTIONS = enum.auto() # parsing options other than "--params"
+ PARSE_PARAMS_OPTION = enum.auto() # parsing the "--params" option
+ STATE_END = enum.auto()
class Lexer(object):
| {"golden_diff": "diff --git a/google/cloud/bigquery/magics/line_arg_parser/lexer.py b/google/cloud/bigquery/magics/line_arg_parser/lexer.py\n--- a/google/cloud/bigquery/magics/line_arg_parser/lexer.py\n+++ b/google/cloud/bigquery/magics/line_arg_parser/lexer.py\n@@ -136,40 +136,17 @@\n )\n \n \n-# The _generate_next_value_() enum hook is only available in Python 3.6+, thus we\n-# need to do some acrobatics to implement an \"auto str enum\" base class. Implementation\n-# based on the recipe provided by the very author of the Enum library:\n-# https://stackoverflow.com/a/32313954/5040035\n-class StrEnumMeta(enum.EnumMeta):\n- @classmethod\n- def __prepare__(metacls, name, bases, **kwargs):\n- # Having deterministic enum members definition order is nice.\n- return OrderedDict()\n+class AutoStrEnum(str, enum.Enum):\n+ \"\"\"Base enum class for for name=value str enums.\"\"\"\n \n- def __new__(metacls, name, bases, oldclassdict):\n- # Scan through the declared enum members and convert any value that is a plain\n- # empty tuple into a `str` of the name instead.\n- newclassdict = enum._EnumDict()\n- for key, val in oldclassdict.items():\n- if val == ():\n- val = key\n- newclassdict[key] = val\n- return super(StrEnumMeta, metacls).__new__(metacls, name, bases, newclassdict)\n+ def _generate_next_value_(name, start, count, last_values):\n+ return name\n \n \n-# The @six.add_metaclass decorator does not work, Enum complains about _sunder_ names,\n-# and we cannot use class syntax directly, because the Python 3 version would cause\n-# a syntax error under Python 2.\n-AutoStrEnum = StrEnumMeta(\n- \"AutoStrEnum\",\n- (str, enum.Enum),\n- {\"__doc__\": \"Base enum class for for name=value str enums.\"},\n-)\n-\n TokenType = AutoStrEnum(\n \"TokenType\",\n [\n- (name, name)\n+ (name, enum.auto())\n for name in itertools.chain.from_iterable(token_types.values())\n if not name.startswith(\"GOTO_\")\n ],\n@@ -177,10 +154,10 @@\n \n \n class LexerState(AutoStrEnum):\n- PARSE_POS_ARGS = () # parsing positional arguments\n- PARSE_NON_PARAMS_OPTIONS = () # parsing options other than \"--params\"\n- PARSE_PARAMS_OPTION = () # parsing the \"--params\" option\n- STATE_END = ()\n+ PARSE_POS_ARGS = enum.auto() # parsing positional arguments\n+ PARSE_NON_PARAMS_OPTIONS = enum.auto() # parsing options other than \"--params\"\n+ PARSE_PARAMS_OPTION = enum.auto() # parsing the \"--params\" option\n+ STATE_END = enum.auto()\n \n \n class Lexer(object):\n", "issue": "Simplify AutoStrEnum definition in Jupyter magic's argument parser\nThe current definition of [AutoStrEnum](https://github.com/googleapis/python-bigquery/blob/0337ea0bde966c3ccb94960493a6fa6f2bee49b4/google/cloud/bigquery/magics/line_arg_parser/lexer.py#L139-L167) is rather complicated. With the library now only supporting Python 3.6+, we can simplify it and just use the `_generate_next_value_()` hook.\n", "before_files": [{"content": "# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom collections import namedtuple\nfrom collections import OrderedDict\nimport itertools\nimport re\n\nimport enum\n\n\nToken = namedtuple(\"Token\", (\"type_\", \"lexeme\", \"pos\"))\nStateTransition = namedtuple(\"StateTransition\", (\"new_state\", \"total_offset\"))\n\n# Pattern matching is done with regexes, and the order in which the token patterns are\n# defined is important.\n#\n# Suppose we had the following token definitions:\n# * INT - a token matching integers,\n# * FLOAT - a token matching floating point numbers,\n# * DOT - a token matching a single literal dot character, i.e. \".\"\n#\n# The FLOAT token would have to be defined first, since we would want the input \"1.23\"\n# to be tokenized as a single FLOAT token, and *not* three tokens (INT, DOT, INT).\n#\n# Sometimes, however, different tokens match too similar patterns, and it is not\n# possible to define them in order that would avoid any ambiguity. One such case are\n# the OPT_VAL and PY_NUMBER tokens, as both can match an integer literal, say \"42\".\n#\n# In order to avoid the dilemmas, the lexer implements a concept of STATES. States are\n# used to split token definitions into subgroups, and in each lexer state only a single\n# subgroup is used for tokenizing the input. Lexer states can therefore be though of as\n# token namespaces.\n#\n# For example, while parsing the value of the \"--params\" option, we do not want to\n# \"recognize\" it as a single OPT_VAL token, but instead want to parse it as a Python\n# dictionary and verify its syntactial correctness. On the other hand, while parsing\n# the value of an option other than \"--params\", we do not really care about its\n# structure, and thus do not want to use any of the \"Python tokens\" for pattern matching.\n#\n# Since token definition order is important, an OrderedDict is needed with tightly\n# controlled member definitions (i.e. passed as a sequence, and *not* via kwargs).\ntoken_types = OrderedDict(\n [\n (\n \"state_parse_pos_args\",\n OrderedDict(\n [\n (\n \"GOTO_PARSE_NON_PARAMS_OPTIONS\",\n r\"(?P<GOTO_PARSE_NON_PARAMS_OPTIONS>(?=--))\", # double dash - starting the options list\n ),\n (\n \"DEST_VAR\",\n r\"(?P<DEST_VAR>[^\\d\\W]\\w*)\", # essentially a Python ID\n ),\n ]\n ),\n ),\n (\n \"state_parse_non_params_options\",\n OrderedDict(\n [\n (\n \"GOTO_PARSE_PARAMS_OPTION\",\n r\"(?P<GOTO_PARSE_PARAMS_OPTION>(?=--params(?:\\s|=|--|$)))\", # the --params option\n ),\n (\"OPTION_SPEC\", r\"(?P<OPTION_SPEC>--\\w+)\"),\n (\"OPTION_EQ\", r\"(?P<OPTION_EQ>=)\"),\n (\"OPT_VAL\", r\"(?P<OPT_VAL>\\S+?(?=\\s|--|$))\"),\n ]\n ),\n ),\n (\n \"state_parse_params_option\",\n OrderedDict(\n [\n (\n \"PY_STRING\",\n r\"(?P<PY_STRING>(?:{})|(?:{}))\".format(\n r\"'(?:[^'\\\\]|\\.)*'\",\n r'\"(?:[^\"\\\\]|\\.)*\"', # single and double quoted strings\n ),\n ),\n (\"PARAMS_OPT_SPEC\", r\"(?P<PARAMS_OPT_SPEC>--params(?=\\s|=|--|$))\"),\n (\"PARAMS_OPT_EQ\", r\"(?P<PARAMS_OPT_EQ>=)\"),\n (\n \"GOTO_PARSE_NON_PARAMS_OPTIONS\",\n r\"(?P<GOTO_PARSE_NON_PARAMS_OPTIONS>(?=--\\w+))\", # found another option spec\n ),\n (\"PY_BOOL\", r\"(?P<PY_BOOL>True|False)\"),\n (\"DOLLAR_PY_ID\", r\"(?P<DOLLAR_PY_ID>\\$[^\\d\\W]\\w*)\"),\n (\n \"PY_NUMBER\",\n r\"(?P<PY_NUMBER>-?[1-9]\\d*(?:\\.\\d+)?(:?[e|E][+-]?\\d+)?)\",\n ),\n (\"SQUOTE\", r\"(?P<SQUOTE>')\"),\n (\"DQUOTE\", r'(?P<DQUOTE>\")'),\n (\"COLON\", r\"(?P<COLON>:)\"),\n (\"COMMA\", r\"(?P<COMMA>,)\"),\n (\"LCURL\", r\"(?P<LCURL>\\{)\"),\n (\"RCURL\", r\"(?P<RCURL>})\"),\n (\"LSQUARE\", r\"(?P<LSQUARE>\\[)\"),\n (\"RSQUARE\", r\"(?P<RSQUARE>])\"),\n (\"LPAREN\", r\"(?P<LPAREN>\\()\"),\n (\"RPAREN\", r\"(?P<RPAREN>\\))\"),\n ]\n ),\n ),\n (\n \"common\",\n OrderedDict(\n [\n (\"WS\", r\"(?P<WS>\\s+)\"),\n (\"EOL\", r\"(?P<EOL>$)\"),\n (\n # anything not a whitespace or matched by something else\n \"UNKNOWN\",\n r\"(?P<UNKNOWN>\\S+)\",\n ),\n ]\n ),\n ),\n ]\n)\n\n\n# The _generate_next_value_() enum hook is only available in Python 3.6+, thus we\n# need to do some acrobatics to implement an \"auto str enum\" base class. Implementation\n# based on the recipe provided by the very author of the Enum library:\n# https://stackoverflow.com/a/32313954/5040035\nclass StrEnumMeta(enum.EnumMeta):\n @classmethod\n def __prepare__(metacls, name, bases, **kwargs):\n # Having deterministic enum members definition order is nice.\n return OrderedDict()\n\n def __new__(metacls, name, bases, oldclassdict):\n # Scan through the declared enum members and convert any value that is a plain\n # empty tuple into a `str` of the name instead.\n newclassdict = enum._EnumDict()\n for key, val in oldclassdict.items():\n if val == ():\n val = key\n newclassdict[key] = val\n return super(StrEnumMeta, metacls).__new__(metacls, name, bases, newclassdict)\n\n\n# The @six.add_metaclass decorator does not work, Enum complains about _sunder_ names,\n# and we cannot use class syntax directly, because the Python 3 version would cause\n# a syntax error under Python 2.\nAutoStrEnum = StrEnumMeta(\n \"AutoStrEnum\",\n (str, enum.Enum),\n {\"__doc__\": \"Base enum class for for name=value str enums.\"},\n)\n\nTokenType = AutoStrEnum(\n \"TokenType\",\n [\n (name, name)\n for name in itertools.chain.from_iterable(token_types.values())\n if not name.startswith(\"GOTO_\")\n ],\n)\n\n\nclass LexerState(AutoStrEnum):\n PARSE_POS_ARGS = () # parsing positional arguments\n PARSE_NON_PARAMS_OPTIONS = () # parsing options other than \"--params\"\n PARSE_PARAMS_OPTION = () # parsing the \"--params\" option\n STATE_END = ()\n\n\nclass Lexer(object):\n \"\"\"Lexical analyzer for tokenizing the cell magic input line.\"\"\"\n\n _GRAND_PATTERNS = {\n LexerState.PARSE_POS_ARGS: re.compile(\n \"|\".join(\n itertools.chain(\n token_types[\"state_parse_pos_args\"].values(),\n token_types[\"common\"].values(),\n )\n )\n ),\n LexerState.PARSE_NON_PARAMS_OPTIONS: re.compile(\n \"|\".join(\n itertools.chain(\n token_types[\"state_parse_non_params_options\"].values(),\n token_types[\"common\"].values(),\n )\n )\n ),\n LexerState.PARSE_PARAMS_OPTION: re.compile(\n \"|\".join(\n itertools.chain(\n token_types[\"state_parse_params_option\"].values(),\n token_types[\"common\"].values(),\n )\n )\n ),\n }\n\n def __init__(self, input_text):\n self._text = input_text\n\n def __iter__(self):\n # Since re.scanner does not seem to support manipulating inner scanner states,\n # we need to implement lexer state transitions manually using special\n # non-capturing lookahead token patterns to signal when a state transition\n # should be made.\n # Since we don't have \"nested\" states, we don't really need a stack and\n # this simple mechanism is sufficient.\n state = LexerState.PARSE_POS_ARGS\n offset = 0 # the number of characters processed so far\n\n while state != LexerState.STATE_END:\n token_stream = self._find_state_tokens(state, offset)\n\n for maybe_token in token_stream: # pragma: NO COVER\n if isinstance(maybe_token, StateTransition):\n state = maybe_token.new_state\n offset = maybe_token.total_offset\n break\n\n if maybe_token.type_ != TokenType.WS:\n yield maybe_token\n\n if maybe_token.type_ == TokenType.EOL:\n state = LexerState.STATE_END\n break\n\n def _find_state_tokens(self, state, current_offset):\n \"\"\"Scan the input for current state's tokens starting at ``current_offset``.\n\n Args:\n state (LexerState): The current lexer state.\n current_offset (int): The offset in the input text, i.e. the number\n of characters already scanned so far.\n\n Yields:\n The next ``Token`` or ``StateTransition`` instance.\n \"\"\"\n pattern = self._GRAND_PATTERNS[state]\n scanner = pattern.finditer(self._text, current_offset)\n\n for match in scanner: # pragma: NO COVER\n token_type = match.lastgroup\n\n if token_type.startswith(\"GOTO_\"):\n yield StateTransition(\n new_state=getattr(LexerState, token_type[5:]), # w/o \"GOTO_\" prefix\n total_offset=match.start(),\n )\n\n yield Token(token_type, match.group(), match.start())\n", "path": "google/cloud/bigquery/magics/line_arg_parser/lexer.py"}], "after_files": [{"content": "# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom collections import namedtuple\nfrom collections import OrderedDict\nimport itertools\nimport re\n\nimport enum\n\n\nToken = namedtuple(\"Token\", (\"type_\", \"lexeme\", \"pos\"))\nStateTransition = namedtuple(\"StateTransition\", (\"new_state\", \"total_offset\"))\n\n# Pattern matching is done with regexes, and the order in which the token patterns are\n# defined is important.\n#\n# Suppose we had the following token definitions:\n# * INT - a token matching integers,\n# * FLOAT - a token matching floating point numbers,\n# * DOT - a token matching a single literal dot character, i.e. \".\"\n#\n# The FLOAT token would have to be defined first, since we would want the input \"1.23\"\n# to be tokenized as a single FLOAT token, and *not* three tokens (INT, DOT, INT).\n#\n# Sometimes, however, different tokens match too similar patterns, and it is not\n# possible to define them in order that would avoid any ambiguity. One such case are\n# the OPT_VAL and PY_NUMBER tokens, as both can match an integer literal, say \"42\".\n#\n# In order to avoid the dilemmas, the lexer implements a concept of STATES. States are\n# used to split token definitions into subgroups, and in each lexer state only a single\n# subgroup is used for tokenizing the input. Lexer states can therefore be though of as\n# token namespaces.\n#\n# For example, while parsing the value of the \"--params\" option, we do not want to\n# \"recognize\" it as a single OPT_VAL token, but instead want to parse it as a Python\n# dictionary and verify its syntactial correctness. On the other hand, while parsing\n# the value of an option other than \"--params\", we do not really care about its\n# structure, and thus do not want to use any of the \"Python tokens\" for pattern matching.\n#\n# Since token definition order is important, an OrderedDict is needed with tightly\n# controlled member definitions (i.e. passed as a sequence, and *not* via kwargs).\ntoken_types = OrderedDict(\n [\n (\n \"state_parse_pos_args\",\n OrderedDict(\n [\n (\n \"GOTO_PARSE_NON_PARAMS_OPTIONS\",\n r\"(?P<GOTO_PARSE_NON_PARAMS_OPTIONS>(?=--))\", # double dash - starting the options list\n ),\n (\n \"DEST_VAR\",\n r\"(?P<DEST_VAR>[^\\d\\W]\\w*)\", # essentially a Python ID\n ),\n ]\n ),\n ),\n (\n \"state_parse_non_params_options\",\n OrderedDict(\n [\n (\n \"GOTO_PARSE_PARAMS_OPTION\",\n r\"(?P<GOTO_PARSE_PARAMS_OPTION>(?=--params(?:\\s|=|--|$)))\", # the --params option\n ),\n (\"OPTION_SPEC\", r\"(?P<OPTION_SPEC>--\\w+)\"),\n (\"OPTION_EQ\", r\"(?P<OPTION_EQ>=)\"),\n (\"OPT_VAL\", r\"(?P<OPT_VAL>\\S+?(?=\\s|--|$))\"),\n ]\n ),\n ),\n (\n \"state_parse_params_option\",\n OrderedDict(\n [\n (\n \"PY_STRING\",\n r\"(?P<PY_STRING>(?:{})|(?:{}))\".format(\n r\"'(?:[^'\\\\]|\\.)*'\",\n r'\"(?:[^\"\\\\]|\\.)*\"', # single and double quoted strings\n ),\n ),\n (\"PARAMS_OPT_SPEC\", r\"(?P<PARAMS_OPT_SPEC>--params(?=\\s|=|--|$))\"),\n (\"PARAMS_OPT_EQ\", r\"(?P<PARAMS_OPT_EQ>=)\"),\n (\n \"GOTO_PARSE_NON_PARAMS_OPTIONS\",\n r\"(?P<GOTO_PARSE_NON_PARAMS_OPTIONS>(?=--\\w+))\", # found another option spec\n ),\n (\"PY_BOOL\", r\"(?P<PY_BOOL>True|False)\"),\n (\"DOLLAR_PY_ID\", r\"(?P<DOLLAR_PY_ID>\\$[^\\d\\W]\\w*)\"),\n (\n \"PY_NUMBER\",\n r\"(?P<PY_NUMBER>-?[1-9]\\d*(?:\\.\\d+)?(:?[e|E][+-]?\\d+)?)\",\n ),\n (\"SQUOTE\", r\"(?P<SQUOTE>')\"),\n (\"DQUOTE\", r'(?P<DQUOTE>\")'),\n (\"COLON\", r\"(?P<COLON>:)\"),\n (\"COMMA\", r\"(?P<COMMA>,)\"),\n (\"LCURL\", r\"(?P<LCURL>\\{)\"),\n (\"RCURL\", r\"(?P<RCURL>})\"),\n (\"LSQUARE\", r\"(?P<LSQUARE>\\[)\"),\n (\"RSQUARE\", r\"(?P<RSQUARE>])\"),\n (\"LPAREN\", r\"(?P<LPAREN>\\()\"),\n (\"RPAREN\", r\"(?P<RPAREN>\\))\"),\n ]\n ),\n ),\n (\n \"common\",\n OrderedDict(\n [\n (\"WS\", r\"(?P<WS>\\s+)\"),\n (\"EOL\", r\"(?P<EOL>$)\"),\n (\n # anything not a whitespace or matched by something else\n \"UNKNOWN\",\n r\"(?P<UNKNOWN>\\S+)\",\n ),\n ]\n ),\n ),\n ]\n)\n\n\nclass AutoStrEnum(str, enum.Enum):\n \"\"\"Base enum class for for name=value str enums.\"\"\"\n\n def _generate_next_value_(name, start, count, last_values):\n return name\n\n\nTokenType = AutoStrEnum(\n \"TokenType\",\n [\n (name, enum.auto())\n for name in itertools.chain.from_iterable(token_types.values())\n if not name.startswith(\"GOTO_\")\n ],\n)\n\n\nclass LexerState(AutoStrEnum):\n PARSE_POS_ARGS = enum.auto() # parsing positional arguments\n PARSE_NON_PARAMS_OPTIONS = enum.auto() # parsing options other than \"--params\"\n PARSE_PARAMS_OPTION = enum.auto() # parsing the \"--params\" option\n STATE_END = enum.auto()\n\n\nclass Lexer(object):\n \"\"\"Lexical analyzer for tokenizing the cell magic input line.\"\"\"\n\n _GRAND_PATTERNS = {\n LexerState.PARSE_POS_ARGS: re.compile(\n \"|\".join(\n itertools.chain(\n token_types[\"state_parse_pos_args\"].values(),\n token_types[\"common\"].values(),\n )\n )\n ),\n LexerState.PARSE_NON_PARAMS_OPTIONS: re.compile(\n \"|\".join(\n itertools.chain(\n token_types[\"state_parse_non_params_options\"].values(),\n token_types[\"common\"].values(),\n )\n )\n ),\n LexerState.PARSE_PARAMS_OPTION: re.compile(\n \"|\".join(\n itertools.chain(\n token_types[\"state_parse_params_option\"].values(),\n token_types[\"common\"].values(),\n )\n )\n ),\n }\n\n def __init__(self, input_text):\n self._text = input_text\n\n def __iter__(self):\n # Since re.scanner does not seem to support manipulating inner scanner states,\n # we need to implement lexer state transitions manually using special\n # non-capturing lookahead token patterns to signal when a state transition\n # should be made.\n # Since we don't have \"nested\" states, we don't really need a stack and\n # this simple mechanism is sufficient.\n state = LexerState.PARSE_POS_ARGS\n offset = 0 # the number of characters processed so far\n\n while state != LexerState.STATE_END:\n token_stream = self._find_state_tokens(state, offset)\n\n for maybe_token in token_stream: # pragma: NO COVER\n if isinstance(maybe_token, StateTransition):\n state = maybe_token.new_state\n offset = maybe_token.total_offset\n break\n\n if maybe_token.type_ != TokenType.WS:\n yield maybe_token\n\n if maybe_token.type_ == TokenType.EOL:\n state = LexerState.STATE_END\n break\n\n def _find_state_tokens(self, state, current_offset):\n \"\"\"Scan the input for current state's tokens starting at ``current_offset``.\n\n Args:\n state (LexerState): The current lexer state.\n current_offset (int): The offset in the input text, i.e. the number\n of characters already scanned so far.\n\n Yields:\n The next ``Token`` or ``StateTransition`` instance.\n \"\"\"\n pattern = self._GRAND_PATTERNS[state]\n scanner = pattern.finditer(self._text, current_offset)\n\n for match in scanner: # pragma: NO COVER\n token_type = match.lastgroup\n\n if token_type.startswith(\"GOTO_\"):\n yield StateTransition(\n new_state=getattr(LexerState, token_type[5:]), # w/o \"GOTO_\" prefix\n total_offset=match.start(),\n )\n\n yield Token(token_type, match.group(), match.start())\n", "path": "google/cloud/bigquery/magics/line_arg_parser/lexer.py"}]} | 3,402 | 682 |
gh_patches_debug_55162 | rasdani/github-patches | git_diff | spack__spack-23320 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Installation issue: bzip2: python error in package.py
#23230 appeared to introduce a typo/python error in package.py
### Steps to reproduce the issue
```console
$ spack install bzip2
...
==> Installing bzip2-1.0.8-4efigg64jltb6topl5suvz4dmpvupmei
==> No binary for bzip2-1.0.8-4efigg64jltb6topl5suvz4dmpvupmei found: installing from source
==> Warning: included configuration files should be updated manually [files=/software/spack/dev-environments/gcc840/packages-gcc840.yaml, /software/spack/dev-environments/common/packages-common.yaml]
==> Using cached archive: /software/spack/git.2021.04.28/var/spack/cache/_source-cache/archive/ab/ab5a03176ee106d3f0fa90e381da478ddae405918153cca248e682cd0c4a2269.tar.gz
==> Error: NameError: name 'spec' is not defined
/software/spack/git.2021.04.28/var/spack/repos/builtin/packages/bzip2/package.py:57, in patch:
56 def patch(self):
>> 57 if spec.satisfies('+debug'):
58 for makefile in ['Makefile', 'Makefile-libbz2_so']:
59 filter_file(r'-O ', '-O0 ', makefile)
60 filter_file(r'-O2 ', '-O0 ', makefile)
...
```
### Information on your system
```console
$ spack debug report
* **Spack:** 0.16.1-2429-f5e6c32495
* **Python:** 3.6.8
* **Platform:** linux-rhel8-x86_64
* **Concretizer:** original
```
### Additional information
Does not reach point of creating spack-build-out.txt, etc
No maintainers, I believe issue was added by @scheibelp in #23230
### General information
- [X ] I have run `spack debug report` and reported the version of Spack/Python/Platform
- [X ] I have run `spack maintainers <name-of-the-package>` and @mentioned any maintainers
- [X ] I have uploaded the build log and environment files
(Not applicable/none generated)
- [X ] I have searched the issues of this repo and believe this is not a duplicate
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `var/spack/repos/builtin/packages/bzip2/package.py`
Content:
```
1 # Copyright 2013-2021 Lawrence Livermore National Security, LLC and other
2 # Spack Project Developers. See the top-level COPYRIGHT file for details.
3 #
4 # SPDX-License-Identifier: (Apache-2.0 OR MIT)
5
6 import re
7
8 from spack import *
9
10
11 class Bzip2(Package, SourcewarePackage):
12 """bzip2 is a freely available, patent free high-quality data
13 compressor. It typically compresses files to within 10% to 15%
14 of the best available techniques (the PPM family of statistical
15 compressors), whilst being around twice as fast at compression
16 and six times faster at decompression."""
17
18 homepage = "https://sourceware.org/bzip2/"
19 sourceware_mirror_path = "bzip2/bzip2-1.0.8.tar.gz"
20
21 executables = [r'^bzip2$']
22
23 version('1.0.8', sha256='ab5a03176ee106d3f0fa90e381da478ddae405918153cca248e682cd0c4a2269')
24 version('1.0.7', sha256='e768a87c5b1a79511499beb41500bcc4caf203726fff46a6f5f9ad27fe08ab2b')
25 version('1.0.6', sha256='a2848f34fcd5d6cf47def00461fcb528a0484d8edef8208d6d2e2909dc61d9cd')
26
27 variant('shared', default=True, description='Enables the build of shared libraries.')
28 variant('pic', default=False, description='Build static libraries with PIC')
29 variant('debug', default=False, description='Enable debug symbols and disable optimization')
30
31 depends_on('diffutils', type='build')
32
33 @classmethod
34 def determine_version(cls, exe):
35 output = Executable(exe)('--help', output=str, error=str)
36 match = re.search(r'bzip2, a block-sorting file compressor.'
37 ' Version ([^,]+)', output)
38 return match.group(1) if match else None
39
40 # override default implementation
41 @property
42 def libs(self):
43 shared = '+shared' in self.spec
44 return find_libraries(
45 'libbz2', root=self.prefix, shared=shared, recursive=True
46 )
47
48 def flag_handler(self, name, flags):
49 if name == 'cflags':
50 if '+pic' in self.spec:
51 flags.append(self.compiler.cc_pic_flag)
52 if '+debug' in self.spec:
53 flags.append('-g')
54 return(flags, None, None)
55
56 def patch(self):
57 if self.spec.satisfies('+debug'):
58 for makefile in ['Makefile', 'Makefile-libbz2_so']:
59 filter_file(r'-O ', '-O0 ', makefile)
60 filter_file(r'-O2 ', '-O0 ', makefile)
61
62 # bzip2 comes with two separate Makefiles for static and dynamic builds
63 # Tell both to use Spack's compiler wrapper instead of GCC
64 filter_file(r'^CC=gcc', 'CC={0}'.format(spack_cc), 'Makefile')
65 filter_file(
66 r'^CC=gcc', 'CC={0}'.format(spack_cc), 'Makefile-libbz2_so'
67 )
68
69 # The Makefiles use GCC flags that are incompatible with PGI
70 if self.spec.satisfies('%pgi') or self.spec.satisfies('%nvhpc@:20.11'):
71 filter_file('-Wall -Winline', '-Minform=inform', 'Makefile')
72 filter_file('-Wall -Winline', '-Minform=inform',
73 'Makefile-libbz2_so')
74
75 # Patch the link line to use RPATHs on macOS
76 if 'darwin' in self.spec.architecture:
77 v = self.spec.version
78 v1, v2, v3 = (v.up_to(i) for i in (1, 2, 3))
79
80 kwargs = {'ignore_absent': False, 'backup': False, 'string': True}
81
82 mf = FileFilter('Makefile-libbz2_so')
83 mf.filter('$(CC) -shared -Wl,-soname -Wl,libbz2.so.{0} -o libbz2.so.{1} $(OBJS)' # noqa
84 .format(v2, v3),
85 '$(CC) -dynamiclib -Wl,-install_name -Wl,@rpath/libbz2.{0}.dylib -current_version {1} -compatibility_version {2} -o libbz2.{3}.dylib $(OBJS)' # noqa
86 .format(v1, v2, v3, v3),
87 **kwargs)
88
89 mf.filter(
90 '$(CC) $(CFLAGS) -o bzip2-shared bzip2.c libbz2.so.{0}'.format(v3), # noqa
91 '$(CC) $(CFLAGS) -o bzip2-shared bzip2.c libbz2.{0}.dylib'
92 .format(v3), **kwargs)
93 mf.filter(
94 'rm -f libbz2.so.{0}'.format(v2),
95 'rm -f libbz2.{0}.dylib'.format(v2), **kwargs)
96 mf.filter(
97 'ln -s libbz2.so.{0} libbz2.so.{1}'.format(v3, v2),
98 'ln -s libbz2.{0}.dylib libbz2.{1}.dylib'.format(v3, v2),
99 **kwargs)
100
101 def install(self, spec, prefix):
102 # Build the dynamic library first
103 if '+shared' in spec:
104 make('-f', 'Makefile-libbz2_so')
105
106 # Build the static library and everything else
107 make()
108 make('install', 'PREFIX={0}'.format(prefix))
109
110 if '+shared' in spec:
111 install('bzip2-shared', join_path(prefix.bin, 'bzip2'))
112
113 v1, v2, v3 = (self.spec.version.up_to(i) for i in (1, 2, 3))
114 if 'darwin' in self.spec.architecture:
115 lib = 'libbz2.dylib'
116 lib1, lib2, lib3 = ('libbz2.{0}.dylib'.format(v)
117 for v in (v1, v2, v3))
118 else:
119 lib = 'libbz2.so'
120 lib1, lib2, lib3 = ('libbz2.so.{0}'.format(v)
121 for v in (v1, v2, v3))
122
123 install(lib3, join_path(prefix.lib, lib3))
124 with working_dir(prefix.lib):
125 for libname in (lib, lib1, lib2):
126 symlink(lib3, libname)
127
128 with working_dir(prefix.bin):
129 force_remove('bunzip2', 'bzcat')
130 symlink('bzip2', 'bunzip2')
131 symlink('bzip2', 'bzcat')
132
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/var/spack/repos/builtin/packages/bzip2/package.py b/var/spack/repos/builtin/packages/bzip2/package.py
--- a/var/spack/repos/builtin/packages/bzip2/package.py
+++ b/var/spack/repos/builtin/packages/bzip2/package.py
@@ -54,7 +54,7 @@
return(flags, None, None)
def patch(self):
- if spec.satisfies('+debug'):
+ if self.spec.satisfies('+debug'):
for makefile in ['Makefile', 'Makefile-libbz2_so']:
filter_file(r'-O ', '-O0 ', makefile)
filter_file(r'-O2 ', '-O0 ', makefile)
| {"golden_diff": "diff --git a/var/spack/repos/builtin/packages/bzip2/package.py b/var/spack/repos/builtin/packages/bzip2/package.py\n--- a/var/spack/repos/builtin/packages/bzip2/package.py\n+++ b/var/spack/repos/builtin/packages/bzip2/package.py\n@@ -54,7 +54,7 @@\n return(flags, None, None)\n \n def patch(self):\n- if spec.satisfies('+debug'):\n+ if self.spec.satisfies('+debug'):\n for makefile in ['Makefile', 'Makefile-libbz2_so']:\n filter_file(r'-O ', '-O0 ', makefile)\n filter_file(r'-O2 ', '-O0 ', makefile)\n", "issue": "Installation issue: bzip2: python error in package.py\n#23230 appeared to introduce a typo/python error in package.py\r\n\r\n### Steps to reproduce the issue\r\n\r\n```console\r\n$ spack install bzip2\r\n...\r\n==> Installing bzip2-1.0.8-4efigg64jltb6topl5suvz4dmpvupmei\r\n==> No binary for bzip2-1.0.8-4efigg64jltb6topl5suvz4dmpvupmei found: installing from source\r\n==> Warning: included configuration files should be updated manually [files=/software/spack/dev-environments/gcc840/packages-gcc840.yaml, /software/spack/dev-environments/common/packages-common.yaml]\r\n==> Using cached archive: /software/spack/git.2021.04.28/var/spack/cache/_source-cache/archive/ab/ab5a03176ee106d3f0fa90e381da478ddae405918153cca248e682cd0c4a2269.tar.gz\r\n==> Error: NameError: name 'spec' is not defined\r\n\r\n/software/spack/git.2021.04.28/var/spack/repos/builtin/packages/bzip2/package.py:57, in patch:\r\n 56 def patch(self):\r\n >> 57 if spec.satisfies('+debug'):\r\n 58 for makefile in ['Makefile', 'Makefile-libbz2_so']:\r\n 59 filter_file(r'-O ', '-O0 ', makefile)\r\n 60 filter_file(r'-O2 ', '-O0 ', makefile)\r\n...\r\n```\r\n\r\n### Information on your system\r\n```console\r\n$ spack debug report\r\n* **Spack:** 0.16.1-2429-f5e6c32495\r\n* **Python:** 3.6.8\r\n* **Platform:** linux-rhel8-x86_64\r\n* **Concretizer:** original\r\n```\r\n\r\n### Additional information\r\nDoes not reach point of creating spack-build-out.txt, etc\r\n\r\nNo maintainers, I believe issue was added by @scheibelp in #23230\r\n\r\n\r\n### General information\r\n\r\n\r\n- [X ] I have run `spack debug report` and reported the version of Spack/Python/Platform\r\n- [X ] I have run `spack maintainers <name-of-the-package>` and @mentioned any maintainers\r\n- [X ] I have uploaded the build log and environment files \r\n(Not applicable/none generated)\r\n- [X ] I have searched the issues of this repo and believe this is not a duplicate\r\n\n", "before_files": [{"content": "# Copyright 2013-2021 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nimport re\n\nfrom spack import *\n\n\nclass Bzip2(Package, SourcewarePackage):\n \"\"\"bzip2 is a freely available, patent free high-quality data\n compressor. It typically compresses files to within 10% to 15%\n of the best available techniques (the PPM family of statistical\n compressors), whilst being around twice as fast at compression\n and six times faster at decompression.\"\"\"\n\n homepage = \"https://sourceware.org/bzip2/\"\n sourceware_mirror_path = \"bzip2/bzip2-1.0.8.tar.gz\"\n\n executables = [r'^bzip2$']\n\n version('1.0.8', sha256='ab5a03176ee106d3f0fa90e381da478ddae405918153cca248e682cd0c4a2269')\n version('1.0.7', sha256='e768a87c5b1a79511499beb41500bcc4caf203726fff46a6f5f9ad27fe08ab2b')\n version('1.0.6', sha256='a2848f34fcd5d6cf47def00461fcb528a0484d8edef8208d6d2e2909dc61d9cd')\n\n variant('shared', default=True, description='Enables the build of shared libraries.')\n variant('pic', default=False, description='Build static libraries with PIC')\n variant('debug', default=False, description='Enable debug symbols and disable optimization')\n\n depends_on('diffutils', type='build')\n\n @classmethod\n def determine_version(cls, exe):\n output = Executable(exe)('--help', output=str, error=str)\n match = re.search(r'bzip2, a block-sorting file compressor.'\n ' Version ([^,]+)', output)\n return match.group(1) if match else None\n\n # override default implementation\n @property\n def libs(self):\n shared = '+shared' in self.spec\n return find_libraries(\n 'libbz2', root=self.prefix, shared=shared, recursive=True\n )\n\n def flag_handler(self, name, flags):\n if name == 'cflags':\n if '+pic' in self.spec:\n flags.append(self.compiler.cc_pic_flag)\n if '+debug' in self.spec:\n flags.append('-g')\n return(flags, None, None)\n\n def patch(self):\n if self.spec.satisfies('+debug'):\n for makefile in ['Makefile', 'Makefile-libbz2_so']:\n filter_file(r'-O ', '-O0 ', makefile)\n filter_file(r'-O2 ', '-O0 ', makefile)\n\n # bzip2 comes with two separate Makefiles for static and dynamic builds\n # Tell both to use Spack's compiler wrapper instead of GCC\n filter_file(r'^CC=gcc', 'CC={0}'.format(spack_cc), 'Makefile')\n filter_file(\n r'^CC=gcc', 'CC={0}'.format(spack_cc), 'Makefile-libbz2_so'\n )\n\n # The Makefiles use GCC flags that are incompatible with PGI\n if self.spec.satisfies('%pgi') or self.spec.satisfies('%nvhpc@:20.11'):\n filter_file('-Wall -Winline', '-Minform=inform', 'Makefile')\n filter_file('-Wall -Winline', '-Minform=inform',\n 'Makefile-libbz2_so')\n\n # Patch the link line to use RPATHs on macOS\n if 'darwin' in self.spec.architecture:\n v = self.spec.version\n v1, v2, v3 = (v.up_to(i) for i in (1, 2, 3))\n\n kwargs = {'ignore_absent': False, 'backup': False, 'string': True}\n\n mf = FileFilter('Makefile-libbz2_so')\n mf.filter('$(CC) -shared -Wl,-soname -Wl,libbz2.so.{0} -o libbz2.so.{1} $(OBJS)' # noqa\n .format(v2, v3),\n '$(CC) -dynamiclib -Wl,-install_name -Wl,@rpath/libbz2.{0}.dylib -current_version {1} -compatibility_version {2} -o libbz2.{3}.dylib $(OBJS)' # noqa\n .format(v1, v2, v3, v3),\n **kwargs)\n\n mf.filter(\n '$(CC) $(CFLAGS) -o bzip2-shared bzip2.c libbz2.so.{0}'.format(v3), # noqa\n '$(CC) $(CFLAGS) -o bzip2-shared bzip2.c libbz2.{0}.dylib'\n .format(v3), **kwargs)\n mf.filter(\n 'rm -f libbz2.so.{0}'.format(v2),\n 'rm -f libbz2.{0}.dylib'.format(v2), **kwargs)\n mf.filter(\n 'ln -s libbz2.so.{0} libbz2.so.{1}'.format(v3, v2),\n 'ln -s libbz2.{0}.dylib libbz2.{1}.dylib'.format(v3, v2),\n **kwargs)\n\n def install(self, spec, prefix):\n # Build the dynamic library first\n if '+shared' in spec:\n make('-f', 'Makefile-libbz2_so')\n\n # Build the static library and everything else\n make()\n make('install', 'PREFIX={0}'.format(prefix))\n\n if '+shared' in spec:\n install('bzip2-shared', join_path(prefix.bin, 'bzip2'))\n\n v1, v2, v3 = (self.spec.version.up_to(i) for i in (1, 2, 3))\n if 'darwin' in self.spec.architecture:\n lib = 'libbz2.dylib'\n lib1, lib2, lib3 = ('libbz2.{0}.dylib'.format(v)\n for v in (v1, v2, v3))\n else:\n lib = 'libbz2.so'\n lib1, lib2, lib3 = ('libbz2.so.{0}'.format(v)\n for v in (v1, v2, v3))\n\n install(lib3, join_path(prefix.lib, lib3))\n with working_dir(prefix.lib):\n for libname in (lib, lib1, lib2):\n symlink(lib3, libname)\n\n with working_dir(prefix.bin):\n force_remove('bunzip2', 'bzcat')\n symlink('bzip2', 'bunzip2')\n symlink('bzip2', 'bzcat')\n", "path": "var/spack/repos/builtin/packages/bzip2/package.py"}], "after_files": [{"content": "# Copyright 2013-2021 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nimport re\n\nfrom spack import *\n\n\nclass Bzip2(Package, SourcewarePackage):\n \"\"\"bzip2 is a freely available, patent free high-quality data\n compressor. It typically compresses files to within 10% to 15%\n of the best available techniques (the PPM family of statistical\n compressors), whilst being around twice as fast at compression\n and six times faster at decompression.\"\"\"\n\n homepage = \"https://sourceware.org/bzip2/\"\n sourceware_mirror_path = \"bzip2/bzip2-1.0.8.tar.gz\"\n\n executables = [r'^bzip2$']\n\n version('1.0.8', sha256='ab5a03176ee106d3f0fa90e381da478ddae405918153cca248e682cd0c4a2269')\n version('1.0.7', sha256='e768a87c5b1a79511499beb41500bcc4caf203726fff46a6f5f9ad27fe08ab2b')\n version('1.0.6', sha256='a2848f34fcd5d6cf47def00461fcb528a0484d8edef8208d6d2e2909dc61d9cd')\n\n variant('shared', default=True, description='Enables the build of shared libraries.')\n variant('pic', default=False, description='Build static libraries with PIC')\n variant('debug', default=False, description='Enable debug symbols and disable optimization')\n\n depends_on('diffutils', type='build')\n\n @classmethod\n def determine_version(cls, exe):\n output = Executable(exe)('--help', output=str, error=str)\n match = re.search(r'bzip2, a block-sorting file compressor.'\n ' Version ([^,]+)', output)\n return match.group(1) if match else None\n\n # override default implementation\n @property\n def libs(self):\n shared = '+shared' in self.spec\n return find_libraries(\n 'libbz2', root=self.prefix, shared=shared, recursive=True\n )\n\n def flag_handler(self, name, flags):\n if name == 'cflags':\n if '+pic' in self.spec:\n flags.append(self.compiler.cc_pic_flag)\n if '+debug' in self.spec:\n flags.append('-g')\n return(flags, None, None)\n\n def patch(self):\n if self.spec.satisfies('+debug'):\n for makefile in ['Makefile', 'Makefile-libbz2_so']:\n filter_file(r'-O ', '-O0 ', makefile)\n filter_file(r'-O2 ', '-O0 ', makefile)\n\n # bzip2 comes with two separate Makefiles for static and dynamic builds\n # Tell both to use Spack's compiler wrapper instead of GCC\n filter_file(r'^CC=gcc', 'CC={0}'.format(spack_cc), 'Makefile')\n filter_file(\n r'^CC=gcc', 'CC={0}'.format(spack_cc), 'Makefile-libbz2_so'\n )\n\n # The Makefiles use GCC flags that are incompatible with PGI\n if self.spec.satisfies('%pgi') or self.spec.satisfies('%nvhpc@:20.11'):\n filter_file('-Wall -Winline', '-Minform=inform', 'Makefile')\n filter_file('-Wall -Winline', '-Minform=inform',\n 'Makefile-libbz2_so')\n\n # Patch the link line to use RPATHs on macOS\n if 'darwin' in self.spec.architecture:\n v = self.spec.version\n v1, v2, v3 = (v.up_to(i) for i in (1, 2, 3))\n\n kwargs = {'ignore_absent': False, 'backup': False, 'string': True}\n\n mf = FileFilter('Makefile-libbz2_so')\n mf.filter('$(CC) -shared -Wl,-soname -Wl,libbz2.so.{0} -o libbz2.so.{1} $(OBJS)' # noqa\n .format(v2, v3),\n '$(CC) -dynamiclib -Wl,-install_name -Wl,@rpath/libbz2.{0}.dylib -current_version {1} -compatibility_version {2} -o libbz2.{3}.dylib $(OBJS)' # noqa\n .format(v1, v2, v3, v3),\n **kwargs)\n\n mf.filter(\n '$(CC) $(CFLAGS) -o bzip2-shared bzip2.c libbz2.so.{0}'.format(v3), # noqa\n '$(CC) $(CFLAGS) -o bzip2-shared bzip2.c libbz2.{0}.dylib'\n .format(v3), **kwargs)\n mf.filter(\n 'rm -f libbz2.so.{0}'.format(v2),\n 'rm -f libbz2.{0}.dylib'.format(v2), **kwargs)\n mf.filter(\n 'ln -s libbz2.so.{0} libbz2.so.{1}'.format(v3, v2),\n 'ln -s libbz2.{0}.dylib libbz2.{1}.dylib'.format(v3, v2),\n **kwargs)\n\n def install(self, spec, prefix):\n # Build the dynamic library first\n if '+shared' in spec:\n make('-f', 'Makefile-libbz2_so')\n\n # Build the static library and everything else\n make()\n make('install', 'PREFIX={0}'.format(prefix))\n\n if '+shared' in spec:\n install('bzip2-shared', join_path(prefix.bin, 'bzip2'))\n\n v1, v2, v3 = (self.spec.version.up_to(i) for i in (1, 2, 3))\n if 'darwin' in self.spec.architecture:\n lib = 'libbz2.dylib'\n lib1, lib2, lib3 = ('libbz2.{0}.dylib'.format(v)\n for v in (v1, v2, v3))\n else:\n lib = 'libbz2.so'\n lib1, lib2, lib3 = ('libbz2.so.{0}'.format(v)\n for v in (v1, v2, v3))\n\n install(lib3, join_path(prefix.lib, lib3))\n with working_dir(prefix.lib):\n for libname in (lib, lib1, lib2):\n symlink(lib3, libname)\n\n with working_dir(prefix.bin):\n force_remove('bunzip2', 'bzcat')\n symlink('bzip2', 'bunzip2')\n symlink('bzip2', 'bzcat')\n", "path": "var/spack/repos/builtin/packages/bzip2/package.py"}]} | 2,769 | 153 |
gh_patches_debug_22928 | rasdani/github-patches | git_diff | sktime__sktime-5994 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[DOC] Bullet point not rendered properly on feature_selection.py
#### Describe the issue linked to the documentation
<!--
Tell us about the confusion introduced in the documentation.
-->Under Time series transformations (https://www.sktime.net/en/latest/api_reference/transformations.html) in
FeatureSelection , bullet point is not rendered properly for “feature-importances” under the FeatureSelection class.
#### Suggest a potential alternative/fix
<!--
Tell us how we could improve the documentation in this regard.
-->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sktime/transformations/series/feature_selection.py`
Content:
```
1 #!/usr/bin/env python3 -u
2 # copyright: sktime developers, BSD-3-Clause License (see LICENSE file)
3 """Implements feature selection algorithms."""
4
5 __author__ = ["aiwalter"]
6 __all__ = ["FeatureSelection"]
7
8 import math
9
10 import pandas as pd
11
12 from sktime.transformations.base import BaseTransformer
13 from sktime.utils.validation.forecasting import check_regressor
14
15
16 class FeatureSelection(BaseTransformer):
17 """Select exogenous features.
18
19 Transformer to enable tuneable feature selection of exogenous data. The
20 FeatureSelection implements multiple methods to select features (columns).
21 In case X is a pd.Series, then it is just passed through, unless method="none",
22 then None is returned in transform().
23
24 Parameters
25 ----------
26 method : str, required
27 The method of how to select the features. Implemented methods are:
28 * "feature-importances": Use feature_importances_ of the regressor (meta-model)
29 to select n_columns with highest importance values.
30 Requires parameter n_columns.
31 * "random": Randomly select n_columns features. Requires parameter n_columns.
32 * "columns": Select features by given names.
33 * "none": Remove all columns, transform returns None.
34 * "all": Select all given features.
35 regressor : sklearn-like regressor, optional, default=None.
36 Used as meta-model for the method "feature-importances". The given
37 regressor must have an attribute "feature_importances_". If None,
38 then a GradientBoostingRegressor(max_depth=5) is used.
39 n_columns : int, optional
40 Number of features (columns) to select. n_columns must be <=
41 number of X columns. Some methods require n_columns to be given.
42 random_state : int, RandomState instance or None, default=None
43 Used to set random_state of the default regressor and to
44 set random.seed() if method="random".
45 columns : list of str
46 A list of columns to select. If columns is given.
47
48 Attributes
49 ----------
50 columns_ : list of str
51 List of columns that have been selected as features.
52 regressor_ : sklearn-like regressor
53 Fitted regressor (meta-model).
54 n_columns_: int
55 Derived from number of features if n_columns is None, then
56 n_columns_ is calculated as int(math.ceil(Z.shape[1] / 2)). So taking
57 half of given features only as default.
58 feature_importances_ : dict or None
59 A dictionary with column name as key and feature imporatnce value as value.
60 The dict is sorted descending on value. This attribute is a dict if
61 method="feature-importances", else None.
62
63 Examples
64 --------
65 >>> from sktime.transformations.series.feature_selection import FeatureSelection
66 >>> from sktime.datasets import load_longley
67 >>> y, X = load_longley()
68 >>> transformer = FeatureSelection(method="feature-importances", n_columns=3)
69 >>> Xt = transformer.fit_transform(X, y)
70 """
71
72 _tags = {
73 "authors": ["aiwalter"],
74 "scitype:transform-input": "Series",
75 # what is the scitype of X: Series, or Panel
76 "scitype:transform-output": "Series",
77 # what scitype is returned: Primitives, Series, Panel
78 "scitype:instancewise": True, # is this an instance-wise transform?
79 "X_inner_mtype": ["pd.DataFrame", "pd.Series"],
80 # which mtypes do _fit/_predict support for X?
81 "y_inner_mtype": "pd.Series", # which mtypes do _fit/_predict support for y?
82 "fit_is_empty": False,
83 "transform-returns-same-time-index": True,
84 "skip-inverse-transform": True,
85 "univariate-only": False,
86 }
87
88 def __init__(
89 self,
90 method="feature-importances",
91 n_columns=None,
92 regressor=None,
93 random_state=None,
94 columns=None,
95 ):
96 self.n_columns = n_columns
97 self.method = method
98 self.regressor = regressor
99 self.random_state = random_state
100 self.columns = columns
101
102 super().__init__()
103
104 def _fit(self, X, y=None):
105 """Fit transformer to X and y.
106
107 private _fit containing the core logic, called from fit
108
109 Parameters
110 ----------
111 X : pd.Series or pd.DataFrame
112 Data to fit transform to
113 y : pd.DataFrame, default=None
114 Additional data, e.g., labels for transformation
115
116 Returns
117 -------
118 self: a fitted instance of the estimator
119 """
120 self.n_columns_ = self.n_columns
121 self.feature_importances_ = None
122
123 # multivariate X
124 if not isinstance(X, pd.Series):
125 if self.method == "feature-importances":
126 self.regressor_ = check_regressor(
127 regressor=self.regressor, random_state=self.random_state
128 )
129 self._check_n_columns(X)
130 # fit regressor with X as exog data and y as endog data (target)
131 self.regressor_.fit(X=X, y=y)
132 if not hasattr(self.regressor_, "feature_importances_"):
133 raise ValueError(
134 """The given regressor must have an
135 attribute feature_importances_ after fitting."""
136 )
137 # create dict with columns name (key) and feauter importance (value)
138 d = dict(zip(X.columns, self.regressor_.feature_importances_))
139 # sort d descending
140 d = {k: d[k] for k in sorted(d, key=d.get, reverse=True)}
141 self.feature_importances_ = d
142 self.columns_ = list(d.keys())[: self.n_columns_]
143 elif self.method == "random":
144 self._check_n_columns(X)
145 self.columns_ = list(
146 X.sample(
147 n=self.n_columns_, random_state=self.random_state, axis=1
148 ).columns
149 )
150 elif self.method == "columns":
151 if self.columns is None:
152 raise AttributeError("Parameter columns must be given.")
153 self.columns_ = self.columns
154 elif self.method == "none":
155 self.columns_ = None
156 elif self.method == "all":
157 self.columns_ = list(X.columns)
158 else:
159 raise ValueError("Incorrect method given. Try another method.")
160 return self
161
162 def _transform(self, X, y=None):
163 """Transform X and return a transformed version.
164
165 private _transform containing the core logic, called from transform
166
167 Parameters
168 ----------
169 X : pd.Series or pd.DataFrame
170 Data to be transformed
171 y : ignored argument for interface compatibility
172 Additional data, e.g., labels for transformation
173
174 Returns
175 -------
176 Xt : pd.Series or pd.DataFrame, same type as X
177 transformed version of X
178 """
179 # multivariate case
180 if not isinstance(X, pd.Series):
181 if self.method == "none":
182 Xt = None
183 else:
184 Xt = X[self.columns_]
185 # univariate case
186 else:
187 if self.method == "none":
188 Xt = None
189 else:
190 Xt = X
191 return Xt
192
193 def _check_n_columns(self, Z):
194 if not isinstance(self.n_columns_, int):
195 self.n_columns_ = int(math.ceil(Z.shape[1] / 2))
196
197 @classmethod
198 def get_test_params(cls, parameter_set="default"):
199 """Return testing parameter settings for the estimator.
200
201 Parameters
202 ----------
203 parameter_set : str, default="default"
204 Name of the set of test parameters to return, for use in tests. If no
205 special parameters are defined for a value, will return `"default"` set.
206
207
208 Returns
209 -------
210 params : dict or list of dict, default = {}
211 Parameters to create testing instances of the class
212 Each dict are parameters to construct an "interesting" test instance, i.e.,
213 `MyClass(**params)` or `MyClass(**params[i])` creates a valid test instance.
214 `create_test_instance` uses the first (or only) dictionary in `params`
215 """
216 return {"method": "all"}
217
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/sktime/transformations/series/feature_selection.py b/sktime/transformations/series/feature_selection.py
--- a/sktime/transformations/series/feature_selection.py
+++ b/sktime/transformations/series/feature_selection.py
@@ -25,6 +25,7 @@
----------
method : str, required
The method of how to select the features. Implemented methods are:
+
* "feature-importances": Use feature_importances_ of the regressor (meta-model)
to select n_columns with highest importance values.
Requires parameter n_columns.
@@ -32,6 +33,7 @@
* "columns": Select features by given names.
* "none": Remove all columns, transform returns None.
* "all": Select all given features.
+
regressor : sklearn-like regressor, optional, default=None.
Used as meta-model for the method "feature-importances". The given
regressor must have an attribute "feature_importances_". If None,
| {"golden_diff": "diff --git a/sktime/transformations/series/feature_selection.py b/sktime/transformations/series/feature_selection.py\n--- a/sktime/transformations/series/feature_selection.py\n+++ b/sktime/transformations/series/feature_selection.py\n@@ -25,6 +25,7 @@\n ----------\n method : str, required\n The method of how to select the features. Implemented methods are:\n+\n * \"feature-importances\": Use feature_importances_ of the regressor (meta-model)\n to select n_columns with highest importance values.\n Requires parameter n_columns.\n@@ -32,6 +33,7 @@\n * \"columns\": Select features by given names.\n * \"none\": Remove all columns, transform returns None.\n * \"all\": Select all given features.\n+\n regressor : sklearn-like regressor, optional, default=None.\n Used as meta-model for the method \"feature-importances\". The given\n regressor must have an attribute \"feature_importances_\". If None,\n", "issue": "[DOC] Bullet point not rendered properly on feature_selection.py\n#### Describe the issue linked to the documentation\r\n\r\n<!--\r\nTell us about the confusion introduced in the documentation.\r\n-->Under Time series transformations (https://www.sktime.net/en/latest/api_reference/transformations.html) in \r\nFeatureSelection , bullet point is not rendered properly for \u201cfeature-importances\u201d under the FeatureSelection class.\r\n\r\n#### Suggest a potential alternative/fix\r\n\r\n<!--\r\nTell us how we could improve the documentation in this regard.\r\n-->\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3 -u\n# copyright: sktime developers, BSD-3-Clause License (see LICENSE file)\n\"\"\"Implements feature selection algorithms.\"\"\"\n\n__author__ = [\"aiwalter\"]\n__all__ = [\"FeatureSelection\"]\n\nimport math\n\nimport pandas as pd\n\nfrom sktime.transformations.base import BaseTransformer\nfrom sktime.utils.validation.forecasting import check_regressor\n\n\nclass FeatureSelection(BaseTransformer):\n \"\"\"Select exogenous features.\n\n Transformer to enable tuneable feature selection of exogenous data. The\n FeatureSelection implements multiple methods to select features (columns).\n In case X is a pd.Series, then it is just passed through, unless method=\"none\",\n then None is returned in transform().\n\n Parameters\n ----------\n method : str, required\n The method of how to select the features. Implemented methods are:\n * \"feature-importances\": Use feature_importances_ of the regressor (meta-model)\n to select n_columns with highest importance values.\n Requires parameter n_columns.\n * \"random\": Randomly select n_columns features. Requires parameter n_columns.\n * \"columns\": Select features by given names.\n * \"none\": Remove all columns, transform returns None.\n * \"all\": Select all given features.\n regressor : sklearn-like regressor, optional, default=None.\n Used as meta-model for the method \"feature-importances\". The given\n regressor must have an attribute \"feature_importances_\". If None,\n then a GradientBoostingRegressor(max_depth=5) is used.\n n_columns : int, optional\n Number of features (columns) to select. n_columns must be <=\n number of X columns. Some methods require n_columns to be given.\n random_state : int, RandomState instance or None, default=None\n Used to set random_state of the default regressor and to\n set random.seed() if method=\"random\".\n columns : list of str\n A list of columns to select. If columns is given.\n\n Attributes\n ----------\n columns_ : list of str\n List of columns that have been selected as features.\n regressor_ : sklearn-like regressor\n Fitted regressor (meta-model).\n n_columns_: int\n Derived from number of features if n_columns is None, then\n n_columns_ is calculated as int(math.ceil(Z.shape[1] / 2)). So taking\n half of given features only as default.\n feature_importances_ : dict or None\n A dictionary with column name as key and feature imporatnce value as value.\n The dict is sorted descending on value. This attribute is a dict if\n method=\"feature-importances\", else None.\n\n Examples\n --------\n >>> from sktime.transformations.series.feature_selection import FeatureSelection\n >>> from sktime.datasets import load_longley\n >>> y, X = load_longley()\n >>> transformer = FeatureSelection(method=\"feature-importances\", n_columns=3)\n >>> Xt = transformer.fit_transform(X, y)\n \"\"\"\n\n _tags = {\n \"authors\": [\"aiwalter\"],\n \"scitype:transform-input\": \"Series\",\n # what is the scitype of X: Series, or Panel\n \"scitype:transform-output\": \"Series\",\n # what scitype is returned: Primitives, Series, Panel\n \"scitype:instancewise\": True, # is this an instance-wise transform?\n \"X_inner_mtype\": [\"pd.DataFrame\", \"pd.Series\"],\n # which mtypes do _fit/_predict support for X?\n \"y_inner_mtype\": \"pd.Series\", # which mtypes do _fit/_predict support for y?\n \"fit_is_empty\": False,\n \"transform-returns-same-time-index\": True,\n \"skip-inverse-transform\": True,\n \"univariate-only\": False,\n }\n\n def __init__(\n self,\n method=\"feature-importances\",\n n_columns=None,\n regressor=None,\n random_state=None,\n columns=None,\n ):\n self.n_columns = n_columns\n self.method = method\n self.regressor = regressor\n self.random_state = random_state\n self.columns = columns\n\n super().__init__()\n\n def _fit(self, X, y=None):\n \"\"\"Fit transformer to X and y.\n\n private _fit containing the core logic, called from fit\n\n Parameters\n ----------\n X : pd.Series or pd.DataFrame\n Data to fit transform to\n y : pd.DataFrame, default=None\n Additional data, e.g., labels for transformation\n\n Returns\n -------\n self: a fitted instance of the estimator\n \"\"\"\n self.n_columns_ = self.n_columns\n self.feature_importances_ = None\n\n # multivariate X\n if not isinstance(X, pd.Series):\n if self.method == \"feature-importances\":\n self.regressor_ = check_regressor(\n regressor=self.regressor, random_state=self.random_state\n )\n self._check_n_columns(X)\n # fit regressor with X as exog data and y as endog data (target)\n self.regressor_.fit(X=X, y=y)\n if not hasattr(self.regressor_, \"feature_importances_\"):\n raise ValueError(\n \"\"\"The given regressor must have an\n attribute feature_importances_ after fitting.\"\"\"\n )\n # create dict with columns name (key) and feauter importance (value)\n d = dict(zip(X.columns, self.regressor_.feature_importances_))\n # sort d descending\n d = {k: d[k] for k in sorted(d, key=d.get, reverse=True)}\n self.feature_importances_ = d\n self.columns_ = list(d.keys())[: self.n_columns_]\n elif self.method == \"random\":\n self._check_n_columns(X)\n self.columns_ = list(\n X.sample(\n n=self.n_columns_, random_state=self.random_state, axis=1\n ).columns\n )\n elif self.method == \"columns\":\n if self.columns is None:\n raise AttributeError(\"Parameter columns must be given.\")\n self.columns_ = self.columns\n elif self.method == \"none\":\n self.columns_ = None\n elif self.method == \"all\":\n self.columns_ = list(X.columns)\n else:\n raise ValueError(\"Incorrect method given. Try another method.\")\n return self\n\n def _transform(self, X, y=None):\n \"\"\"Transform X and return a transformed version.\n\n private _transform containing the core logic, called from transform\n\n Parameters\n ----------\n X : pd.Series or pd.DataFrame\n Data to be transformed\n y : ignored argument for interface compatibility\n Additional data, e.g., labels for transformation\n\n Returns\n -------\n Xt : pd.Series or pd.DataFrame, same type as X\n transformed version of X\n \"\"\"\n # multivariate case\n if not isinstance(X, pd.Series):\n if self.method == \"none\":\n Xt = None\n else:\n Xt = X[self.columns_]\n # univariate case\n else:\n if self.method == \"none\":\n Xt = None\n else:\n Xt = X\n return Xt\n\n def _check_n_columns(self, Z):\n if not isinstance(self.n_columns_, int):\n self.n_columns_ = int(math.ceil(Z.shape[1] / 2))\n\n @classmethod\n def get_test_params(cls, parameter_set=\"default\"):\n \"\"\"Return testing parameter settings for the estimator.\n\n Parameters\n ----------\n parameter_set : str, default=\"default\"\n Name of the set of test parameters to return, for use in tests. If no\n special parameters are defined for a value, will return `\"default\"` set.\n\n\n Returns\n -------\n params : dict or list of dict, default = {}\n Parameters to create testing instances of the class\n Each dict are parameters to construct an \"interesting\" test instance, i.e.,\n `MyClass(**params)` or `MyClass(**params[i])` creates a valid test instance.\n `create_test_instance` uses the first (or only) dictionary in `params`\n \"\"\"\n return {\"method\": \"all\"}\n", "path": "sktime/transformations/series/feature_selection.py"}], "after_files": [{"content": "#!/usr/bin/env python3 -u\n# copyright: sktime developers, BSD-3-Clause License (see LICENSE file)\n\"\"\"Implements feature selection algorithms.\"\"\"\n\n__author__ = [\"aiwalter\"]\n__all__ = [\"FeatureSelection\"]\n\nimport math\n\nimport pandas as pd\n\nfrom sktime.transformations.base import BaseTransformer\nfrom sktime.utils.validation.forecasting import check_regressor\n\n\nclass FeatureSelection(BaseTransformer):\n \"\"\"Select exogenous features.\n\n Transformer to enable tuneable feature selection of exogenous data. The\n FeatureSelection implements multiple methods to select features (columns).\n In case X is a pd.Series, then it is just passed through, unless method=\"none\",\n then None is returned in transform().\n\n Parameters\n ----------\n method : str, required\n The method of how to select the features. Implemented methods are:\n\n * \"feature-importances\": Use feature_importances_ of the regressor (meta-model)\n to select n_columns with highest importance values.\n Requires parameter n_columns.\n * \"random\": Randomly select n_columns features. Requires parameter n_columns.\n * \"columns\": Select features by given names.\n * \"none\": Remove all columns, transform returns None.\n * \"all\": Select all given features.\n\n regressor : sklearn-like regressor, optional, default=None.\n Used as meta-model for the method \"feature-importances\". The given\n regressor must have an attribute \"feature_importances_\". If None,\n then a GradientBoostingRegressor(max_depth=5) is used.\n n_columns : int, optional\n Number of features (columns) to select. n_columns must be <=\n number of X columns. Some methods require n_columns to be given.\n random_state : int, RandomState instance or None, default=None\n Used to set random_state of the default regressor and to\n set random.seed() if method=\"random\".\n columns : list of str\n A list of columns to select. If columns is given.\n\n Attributes\n ----------\n columns_ : list of str\n List of columns that have been selected as features.\n regressor_ : sklearn-like regressor\n Fitted regressor (meta-model).\n n_columns_: int\n Derived from number of features if n_columns is None, then\n n_columns_ is calculated as int(math.ceil(Z.shape[1] / 2)). So taking\n half of given features only as default.\n feature_importances_ : dict or None\n A dictionary with column name as key and feature imporatnce value as value.\n The dict is sorted descending on value. This attribute is a dict if\n method=\"feature-importances\", else None.\n\n Examples\n --------\n >>> from sktime.transformations.series.feature_selection import FeatureSelection\n >>> from sktime.datasets import load_longley\n >>> y, X = load_longley()\n >>> transformer = FeatureSelection(method=\"feature-importances\", n_columns=3)\n >>> Xt = transformer.fit_transform(X, y)\n \"\"\"\n\n _tags = {\n \"authors\": [\"aiwalter\"],\n \"scitype:transform-input\": \"Series\",\n # what is the scitype of X: Series, or Panel\n \"scitype:transform-output\": \"Series\",\n # what scitype is returned: Primitives, Series, Panel\n \"scitype:instancewise\": True, # is this an instance-wise transform?\n \"X_inner_mtype\": [\"pd.DataFrame\", \"pd.Series\"],\n # which mtypes do _fit/_predict support for X?\n \"y_inner_mtype\": \"pd.Series\", # which mtypes do _fit/_predict support for y?\n \"fit_is_empty\": False,\n \"transform-returns-same-time-index\": True,\n \"skip-inverse-transform\": True,\n \"univariate-only\": False,\n }\n\n def __init__(\n self,\n method=\"feature-importances\",\n n_columns=None,\n regressor=None,\n random_state=None,\n columns=None,\n ):\n self.n_columns = n_columns\n self.method = method\n self.regressor = regressor\n self.random_state = random_state\n self.columns = columns\n\n super().__init__()\n\n def _fit(self, X, y=None):\n \"\"\"Fit transformer to X and y.\n\n private _fit containing the core logic, called from fit\n\n Parameters\n ----------\n X : pd.Series or pd.DataFrame\n Data to fit transform to\n y : pd.DataFrame, default=None\n Additional data, e.g., labels for transformation\n\n Returns\n -------\n self: a fitted instance of the estimator\n \"\"\"\n self.n_columns_ = self.n_columns\n self.feature_importances_ = None\n\n # multivariate X\n if not isinstance(X, pd.Series):\n if self.method == \"feature-importances\":\n self.regressor_ = check_regressor(\n regressor=self.regressor, random_state=self.random_state\n )\n self._check_n_columns(X)\n # fit regressor with X as exog data and y as endog data (target)\n self.regressor_.fit(X=X, y=y)\n if not hasattr(self.regressor_, \"feature_importances_\"):\n raise ValueError(\n \"\"\"The given regressor must have an\n attribute feature_importances_ after fitting.\"\"\"\n )\n # create dict with columns name (key) and feauter importance (value)\n d = dict(zip(X.columns, self.regressor_.feature_importances_))\n # sort d descending\n d = {k: d[k] for k in sorted(d, key=d.get, reverse=True)}\n self.feature_importances_ = d\n self.columns_ = list(d.keys())[: self.n_columns_]\n elif self.method == \"random\":\n self._check_n_columns(X)\n self.columns_ = list(\n X.sample(\n n=self.n_columns_, random_state=self.random_state, axis=1\n ).columns\n )\n elif self.method == \"columns\":\n if self.columns is None:\n raise AttributeError(\"Parameter columns must be given.\")\n self.columns_ = self.columns\n elif self.method == \"none\":\n self.columns_ = None\n elif self.method == \"all\":\n self.columns_ = list(X.columns)\n else:\n raise ValueError(\"Incorrect method given. Try another method.\")\n return self\n\n def _transform(self, X, y=None):\n \"\"\"Transform X and return a transformed version.\n\n private _transform containing the core logic, called from transform\n\n Parameters\n ----------\n X : pd.Series or pd.DataFrame\n Data to be transformed\n y : ignored argument for interface compatibility\n Additional data, e.g., labels for transformation\n\n Returns\n -------\n Xt : pd.Series or pd.DataFrame, same type as X\n transformed version of X\n \"\"\"\n # multivariate case\n if not isinstance(X, pd.Series):\n if self.method == \"none\":\n Xt = None\n else:\n Xt = X[self.columns_]\n # univariate case\n else:\n if self.method == \"none\":\n Xt = None\n else:\n Xt = X\n return Xt\n\n def _check_n_columns(self, Z):\n if not isinstance(self.n_columns_, int):\n self.n_columns_ = int(math.ceil(Z.shape[1] / 2))\n\n @classmethod\n def get_test_params(cls, parameter_set=\"default\"):\n \"\"\"Return testing parameter settings for the estimator.\n\n Parameters\n ----------\n parameter_set : str, default=\"default\"\n Name of the set of test parameters to return, for use in tests. If no\n special parameters are defined for a value, will return `\"default\"` set.\n\n\n Returns\n -------\n params : dict or list of dict, default = {}\n Parameters to create testing instances of the class\n Each dict are parameters to construct an \"interesting\" test instance, i.e.,\n `MyClass(**params)` or `MyClass(**params[i])` creates a valid test instance.\n `create_test_instance` uses the first (or only) dictionary in `params`\n \"\"\"\n return {\"method\": \"all\"}\n", "path": "sktime/transformations/series/feature_selection.py"}]} | 2,680 | 225 |
gh_patches_debug_39830 | rasdani/github-patches | git_diff | iterative__dvc-702 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Number of already present files should be reflected in push progress
Hey guys, IMHO the number of pushed files should also include the files already found in the remote cache.
For example, when I upload 2 new files out of my cache of 1000 files, the progress should say 1000/1000 at the end, instead of 2/1000.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dvc/cloud/base.py`
Content:
```
1 import os
2 import re
3 import tempfile
4
5 from dvc.logger import Logger
6 from dvc.exceptions import DvcException
7 from dvc.config import Config, ConfigError
8 from dvc.cache import Cache
9
10
11 STATUS_UNKNOWN = 0
12 STATUS_OK = 1
13 STATUS_MODIFIED = 2
14 STATUS_NEW = 3
15 STATUS_DELETED = 4
16
17
18 STATUS_MAP = {
19 # (local_exists, remote_exists, cmp)
20 (True, True, True) : STATUS_OK,
21 (True, True, False) : STATUS_MODIFIED,
22 (True, False, None) : STATUS_NEW,
23 (False, True, None) : STATUS_DELETED,
24 }
25
26
27 class DataCloudError(DvcException):
28 """ Data Cloud exception """
29 def __init__(self, msg):
30 super(DataCloudError, self).__init__('Data sync error: {}'.format(msg))
31
32
33 class CloudSettings(object):
34 def __init__(self, cache=None, global_storage_path=None, cloud_config=None):
35 self.cache = cache
36 self.cloud_config = cloud_config
37 self.global_storage_path = global_storage_path
38
39
40 class DataCloudBase(object):
41 """ Base class for DataCloud """
42
43 REGEX = r''
44
45 def __init__(self, cloud_settings):
46 self._cloud_settings = cloud_settings
47
48 @property
49 def url(self):
50 config = self._cloud_settings.cloud_config
51 return config.get(Config.SECTION_REMOTE_URL, None)
52
53 @classmethod
54 def match(cls, url):
55 return re.match(cls.REGEX, url)
56
57 def group(self, group):
58 return self.match(self.url).group(group)
59
60 @property
61 def path(self):
62 return self.group('path')
63
64 @classmethod
65 def supported(cls, url):
66 return cls.match(url) != None
67
68 # backward compatibility
69 @property
70 def storage_path(self):
71 """ get storage path
72
73 Precedence: Storage, then cloud specific
74 """
75
76 if self._cloud_settings.global_storage_path:
77 return self._cloud_settings.global_storage_path
78
79 if not self.url:
80 path = self._cloud_settings.cloud_config.get(Config.SECTION_CORE_STORAGEPATH, None)
81 if path:
82 Logger.warn('Using obsoleted config format. Consider updating.')
83 else:
84 path = self.path
85
86 return path
87
88 def _storage_path_parts(self):
89 """
90 Split storage path into parts. I.e. 'dvc-test/myrepo' -> ['dvc', 'myrepo']
91 """
92 return self.storage_path.strip('/').split('/', 1)
93
94 @property
95 def storage_bucket(self):
96 """ Data -> StoragePath takes precedence; if doesn't exist, use cloud-specific """
97 return self._storage_path_parts()[0]
98
99 @property
100 def storage_prefix(self):
101 """
102 Prefix within the bucket. I.e. 'myrepo' in 'dvc-test/myrepo'.
103 """
104 parts = self._storage_path_parts()
105 if len(parts) > 1:
106 return parts[1]
107 return ''
108
109 def cache_file_key(self, fname):
110 """ Key of a file within the bucket """
111 relpath = os.path.relpath(fname, self._cloud_settings.cache.cache_dir)
112 relpath = relpath.replace('\\', '/')
113 return '{}/{}'.format(self.storage_prefix, relpath).strip('/')
114
115 @staticmethod
116 def tmp_file(fname):
117 """ Temporary name for a partial download """
118 return fname + '.part'
119
120 def sanity_check(self):
121 """
122 Cloud-specific method to check config for basic requirements.
123 """
124 pass
125
126 def _push_key(self, key, path):
127 pass
128
129 def collect(self, arg):
130 path, local = arg
131 ret = [path]
132
133 if not Cache.is_dir_cache(path):
134 return ret
135
136 if local:
137 if not os.path.isfile(path):
138 return ret
139 dir_path = path
140 else:
141 key = self._get_key(path)
142 if not key:
143 Logger.debug("File '{}' does not exist in the cloud".format(path))
144 return ret
145 tmp = os.path.join(tempfile.mkdtemp(), os.path.basename(path))
146 self._pull_key(key, tmp, no_progress_bar=True)
147 dir_path = tmp
148
149 for relpath, md5 in Cache.get_dir_cache(dir_path).items():
150 cache = self._cloud_settings.cache.get(md5)
151 ret.append(cache)
152
153 return ret
154
155 def _cmp_checksum(self, blob, fname):
156 md5 = self._cloud_settings.cache.path_to_md5(fname)
157 if self._cloud_settings.cache.state.changed(fname, md5=md5):
158 return False
159
160 return True
161
162 def push(self, path):
163 key = self._get_key(path)
164 if key:
165 Logger.debug("File '{}' already uploaded to the cloud. Validating checksum...".format(path))
166 if self._cmp_checksum(key, path):
167 Logger.debug('File checksum matches. No uploading is needed.')
168 return []
169 Logger.debug('Checksum mismatch. Reuploading is required.')
170
171 key = self._new_key(path)
172 return self._push_key(key, path)
173
174 def _makedirs(self, fname):
175 dname = os.path.dirname(fname)
176 try:
177 os.makedirs(dname)
178 except OSError as e:
179 if e.errno != os.errno.EEXIST:
180 raise
181
182 def _pull_key(self, key, path, no_progress_bar=False):
183 """ Cloud-specific method of pulling keys """
184 pass
185
186 def _get_key(self, path):
187 """ Cloud-specific method of getting keys """
188 pass
189
190 def pull(self, path):
191 """ Generic method for pulling data from the cloud """
192 key = self._get_key(path)
193 if not key:
194 Logger.error("File '{}' does not exist in the cloud".format(path))
195 return None
196
197 return self._pull_key(key, path)
198
199 def _status(self, key, path):
200 remote_exists = key != None
201 local_exists = os.path.exists(path)
202
203 diff = None
204 if remote_exists and local_exists:
205 diff = self._cmp_checksum(key, path)
206
207 return STATUS_MAP.get((local_exists, remote_exists, diff), STATUS_UNKNOWN)
208
209 def status(self, path):
210 """
211 Generic method for checking data item status.
212 """
213 key = self._get_key(path)
214 if not key:
215 return STATUS_NEW
216
217 return self._status(key, path)
218
219 def connect(self):
220 pass
221
222 def disconnect(self):
223 pass
224
```
Path: `dvc/cloud/data_cloud.py`
Content:
```
1 import re
2 from multiprocessing.pool import ThreadPool
3
4 from dvc.logger import Logger
5 from dvc.exceptions import DvcException
6 from dvc.config import Config, ConfigError
7 from dvc.utils import map_progress
8
9 from dvc.cloud.aws import DataCloudAWS
10 from dvc.cloud.gcp import DataCloudGCP
11 from dvc.cloud.ssh import DataCloudSSH
12 from dvc.cloud.local import DataCloudLOCAL
13 from dvc.cloud.base import DataCloudBase, CloudSettings
14
15
16 class DataCloud(object):
17 """ Generic class to do initial config parsing and redirect to proper DataCloud methods """
18
19 CLOUD_MAP = {
20 'aws' : DataCloudAWS,
21 'gcp' : DataCloudGCP,
22 'ssh' : DataCloudSSH,
23 'local' : DataCloudLOCAL,
24 }
25
26 def __init__(self, cache=None, config=None):
27 self._cache = cache
28 self._config = config
29
30 remote = self._config[Config.SECTION_CORE].get(Config.SECTION_CORE_REMOTE, '')
31 if remote == '':
32 if config[Config.SECTION_CORE].get(Config.SECTION_CORE_CLOUD, None):
33 # backward compatibility
34 Logger.warn('Using obsoleted config format. Consider updating.')
35 self._cloud = self.__init__compat()
36 else:
37 self._cloud = None
38 return
39
40 self._cloud = self._init_remote(remote)
41
42 @staticmethod
43 def supported(url):
44 for cloud in DataCloud.CLOUD_MAP.values():
45 if cloud.supported(url):
46 return cloud
47 return None
48
49 def _init_remote(self, remote):
50 section = Config.SECTION_REMOTE_FMT.format(remote)
51 cloud_config = self._config.get(section, None)
52 if not cloud_config:
53 raise ConfigError("Can't find remote section '{}' in config".format(section))
54
55 url = cloud_config[Config.SECTION_REMOTE_URL]
56 cloud_type = self.supported(url)
57 if not cloud_type:
58 raise ConfigError("Unsupported url '{}'".format(url))
59
60 return self._init_cloud(cloud_config, cloud_type)
61
62 def __init__compat(self):
63 cloud_name = self._config[Config.SECTION_CORE].get(Config.SECTION_CORE_CLOUD, '').strip().lower()
64 if cloud_name == '':
65 self._cloud = None
66 return
67
68 cloud_type = self.CLOUD_MAP.get(cloud_name, None)
69 if not cloud_type:
70 raise ConfigError('Wrong cloud type %s specified' % cloud_name)
71
72 cloud_config = self._config.get(cloud_name, None)
73 if not cloud_config:
74 raise ConfigError('Can\'t find cloud section \'[%s]\' in config' % cloud_name)
75
76 return self._init_cloud(cloud_config, cloud_type)
77
78 def _init_cloud(self, cloud_config, cloud_type):
79 global_storage_path = self._config[Config.SECTION_CORE].get(Config.SECTION_CORE_STORAGEPATH, None)
80 if global_storage_path:
81 Logger.warn('Using obsoleted config format. Consider updating.')
82
83 cloud_settings = CloudSettings(cache=self._cache,
84 global_storage_path=global_storage_path,
85 cloud_config=cloud_config)
86
87 cloud = cloud_type(cloud_settings)
88 cloud.sanity_check()
89 return cloud
90
91 def _collect(self, cloud, targets, jobs, local):
92 collected = set()
93 pool = ThreadPool(processes=jobs)
94 args = zip(targets, [local]*len(targets))
95 ret = pool.map(cloud.collect, args)
96
97 for r in ret:
98 collected |= set(r)
99
100 return collected
101
102 def _map_targets(self, func, targets, jobs, collect_local=False, collect_cloud=False, remote=None):
103 """
104 Process targets as data items in parallel.
105 """
106
107 if not remote:
108 cloud = self._cloud
109 else:
110 cloud = self._init_remote(remote)
111
112 if not cloud:
113 return
114
115 cloud.connect()
116
117 collected = set()
118 if collect_local:
119 collected |= self._collect(cloud, targets, jobs, True)
120 if collect_cloud:
121 collected |= self._collect(cloud, targets, jobs, False)
122
123 ret = map_progress(getattr(cloud, func), list(collected), jobs)
124
125 cloud.disconnect()
126
127 return ret
128
129 def push(self, targets, jobs=1, remote=None):
130 """
131 Push data items in a cloud-agnostic way.
132 """
133 return self._map_targets('push', targets, jobs, collect_local=True, remote=remote)
134
135 def pull(self, targets, jobs=1, remote=None):
136 """
137 Pull data items in a cloud-agnostic way.
138 """
139 return self._map_targets('pull', targets, jobs, collect_cloud=True, remote=remote)
140
141 def status(self, targets, jobs=1, remote=None):
142 """
143 Check status of data items in a cloud-agnostic way.
144 """
145 return self._map_targets('status', targets, jobs, True, True, remote=remote)
146
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/dvc/cloud/base.py b/dvc/cloud/base.py
--- a/dvc/cloud/base.py
+++ b/dvc/cloud/base.py
@@ -221,3 +221,9 @@
def disconnect(self):
pass
+
+ def __enter__(self):
+ self.connect()
+
+ def __exit__(self, type, value, tb):
+ self.disconnect()
diff --git a/dvc/cloud/data_cloud.py b/dvc/cloud/data_cloud.py
--- a/dvc/cloud/data_cloud.py
+++ b/dvc/cloud/data_cloud.py
@@ -11,6 +11,7 @@
from dvc.cloud.ssh import DataCloudSSH
from dvc.cloud.local import DataCloudLOCAL
from dvc.cloud.base import DataCloudBase, CloudSettings
+from dvc.cloud.base import STATUS_MODIFIED, STATUS_NEW, STATUS_DELETED
class DataCloud(object):
@@ -99,47 +100,54 @@
return collected
- def _map_targets(self, func, targets, jobs, collect_local=False, collect_cloud=False, remote=None):
- """
- Process targets as data items in parallel.
- """
+ def _get_cloud(self, remote):
+ if remote:
+ return self._init_remote(remote)
- if not remote:
- cloud = self._cloud
- else:
- cloud = self._init_remote(remote)
+ return self._cloud
+ def _filter(self, func, status, targets, jobs, remote):
+ cloud = self._get_cloud(remote)
if not cloud:
- return
-
- cloud.connect()
-
- collected = set()
- if collect_local:
- collected |= self._collect(cloud, targets, jobs, True)
- if collect_cloud:
- collected |= self._collect(cloud, targets, jobs, False)
+ return []
- ret = map_progress(getattr(cloud, func), list(collected), jobs)
+ with cloud:
+ filtered = []
+ for t, s in self._status(cloud, targets, jobs):
+ if s == STATUS_MODIFIED or s == status:
+ filtered.append(t)
- cloud.disconnect()
-
- return ret
+ return map_progress(getattr(cloud, func), filtered, jobs)
def push(self, targets, jobs=1, remote=None):
"""
Push data items in a cloud-agnostic way.
"""
- return self._map_targets('push', targets, jobs, collect_local=True, remote=remote)
+ return self._filter('push', STATUS_NEW, targets, jobs, remote)
def pull(self, targets, jobs=1, remote=None):
"""
Pull data items in a cloud-agnostic way.
"""
- return self._map_targets('pull', targets, jobs, collect_cloud=True, remote=remote)
+ return self._filter('pull', STATUS_DELETED, targets, jobs, remote)
+
+ def _collect_targets(self, cloud, targets, jobs=1):
+ collected = set()
+ collected |= self._collect(cloud, targets, jobs, True)
+ collected |= self._collect(cloud, targets, jobs, False)
+ return list(collected)
+
+ def _status(self, cloud, targets, jobs=1):
+ collected = self._collect_targets(cloud, targets, jobs)
+ return map_progress(cloud.status, collected, jobs)
def status(self, targets, jobs=1, remote=None):
"""
Check status of data items in a cloud-agnostic way.
"""
- return self._map_targets('status', targets, jobs, True, True, remote=remote)
+ cloud = self._get_cloud(remote)
+ if not cloud:
+ return []
+
+ with cloud:
+ return self._status(cloud, targets, jobs)
| {"golden_diff": "diff --git a/dvc/cloud/base.py b/dvc/cloud/base.py\n--- a/dvc/cloud/base.py\n+++ b/dvc/cloud/base.py\n@@ -221,3 +221,9 @@\n \n def disconnect(self):\n pass\n+\n+ def __enter__(self):\n+ self.connect()\n+\n+ def __exit__(self, type, value, tb):\n+ self.disconnect()\ndiff --git a/dvc/cloud/data_cloud.py b/dvc/cloud/data_cloud.py\n--- a/dvc/cloud/data_cloud.py\n+++ b/dvc/cloud/data_cloud.py\n@@ -11,6 +11,7 @@\n from dvc.cloud.ssh import DataCloudSSH\n from dvc.cloud.local import DataCloudLOCAL\n from dvc.cloud.base import DataCloudBase, CloudSettings\n+from dvc.cloud.base import STATUS_MODIFIED, STATUS_NEW, STATUS_DELETED\n \n \n class DataCloud(object):\n@@ -99,47 +100,54 @@\n \n return collected\n \n- def _map_targets(self, func, targets, jobs, collect_local=False, collect_cloud=False, remote=None):\n- \"\"\"\n- Process targets as data items in parallel.\n- \"\"\"\n+ def _get_cloud(self, remote):\n+ if remote:\n+ return self._init_remote(remote)\n \n- if not remote:\n- cloud = self._cloud\n- else:\n- cloud = self._init_remote(remote)\n+ return self._cloud\n \n+ def _filter(self, func, status, targets, jobs, remote):\n+ cloud = self._get_cloud(remote)\n if not cloud:\n- return\n-\n- cloud.connect()\n-\n- collected = set()\n- if collect_local:\n- collected |= self._collect(cloud, targets, jobs, True)\n- if collect_cloud:\n- collected |= self._collect(cloud, targets, jobs, False)\n+ return []\n \n- ret = map_progress(getattr(cloud, func), list(collected), jobs)\n+ with cloud:\n+ filtered = []\n+ for t, s in self._status(cloud, targets, jobs):\n+ if s == STATUS_MODIFIED or s == status:\n+ filtered.append(t)\n \n- cloud.disconnect()\n-\n- return ret\n+ return map_progress(getattr(cloud, func), filtered, jobs)\n \n def push(self, targets, jobs=1, remote=None):\n \"\"\"\n Push data items in a cloud-agnostic way.\n \"\"\"\n- return self._map_targets('push', targets, jobs, collect_local=True, remote=remote)\n+ return self._filter('push', STATUS_NEW, targets, jobs, remote)\n \n def pull(self, targets, jobs=1, remote=None):\n \"\"\"\n Pull data items in a cloud-agnostic way.\n \"\"\"\n- return self._map_targets('pull', targets, jobs, collect_cloud=True, remote=remote)\n+ return self._filter('pull', STATUS_DELETED, targets, jobs, remote)\n+\n+ def _collect_targets(self, cloud, targets, jobs=1):\n+ collected = set()\n+ collected |= self._collect(cloud, targets, jobs, True)\n+ collected |= self._collect(cloud, targets, jobs, False)\n+ return list(collected)\n+\n+ def _status(self, cloud, targets, jobs=1):\n+ collected = self._collect_targets(cloud, targets, jobs)\n+ return map_progress(cloud.status, collected, jobs)\n \n def status(self, targets, jobs=1, remote=None):\n \"\"\"\n Check status of data items in a cloud-agnostic way.\n \"\"\"\n- return self._map_targets('status', targets, jobs, True, True, remote=remote)\n+ cloud = self._get_cloud(remote)\n+ if not cloud:\n+ return []\n+\n+ with cloud:\n+ return self._status(cloud, targets, jobs)\n", "issue": "Number of already present files should be reflected in push progress\nHey guys, IMHO the number of pushed files should also include the files already found in the remote cache.\r\n\r\nFor example, when I upload 2 new files out of my cache of 1000 files, the progress should say 1000/1000 at the end, instead of 2/1000.\n", "before_files": [{"content": "import os\nimport re\nimport tempfile\n\nfrom dvc.logger import Logger\nfrom dvc.exceptions import DvcException\nfrom dvc.config import Config, ConfigError\nfrom dvc.cache import Cache\n\n\nSTATUS_UNKNOWN = 0\nSTATUS_OK = 1\nSTATUS_MODIFIED = 2\nSTATUS_NEW = 3\nSTATUS_DELETED = 4\n\n\nSTATUS_MAP = {\n # (local_exists, remote_exists, cmp)\n (True, True, True) : STATUS_OK,\n (True, True, False) : STATUS_MODIFIED,\n (True, False, None) : STATUS_NEW,\n (False, True, None) : STATUS_DELETED,\n}\n\n\nclass DataCloudError(DvcException):\n \"\"\" Data Cloud exception \"\"\"\n def __init__(self, msg):\n super(DataCloudError, self).__init__('Data sync error: {}'.format(msg))\n\n\nclass CloudSettings(object):\n def __init__(self, cache=None, global_storage_path=None, cloud_config=None):\n self.cache = cache\n self.cloud_config = cloud_config\n self.global_storage_path = global_storage_path\n\n\nclass DataCloudBase(object):\n \"\"\" Base class for DataCloud \"\"\"\n\n REGEX = r''\n\n def __init__(self, cloud_settings):\n self._cloud_settings = cloud_settings\n\n @property\n def url(self):\n config = self._cloud_settings.cloud_config\n return config.get(Config.SECTION_REMOTE_URL, None)\n\n @classmethod\n def match(cls, url):\n return re.match(cls.REGEX, url)\n\n def group(self, group):\n return self.match(self.url).group(group)\n\n @property\n def path(self):\n return self.group('path')\n\n @classmethod\n def supported(cls, url):\n return cls.match(url) != None\n\n # backward compatibility\n @property\n def storage_path(self):\n \"\"\" get storage path\n\n Precedence: Storage, then cloud specific\n \"\"\"\n\n if self._cloud_settings.global_storage_path:\n return self._cloud_settings.global_storage_path\n\n if not self.url:\n path = self._cloud_settings.cloud_config.get(Config.SECTION_CORE_STORAGEPATH, None)\n if path:\n Logger.warn('Using obsoleted config format. Consider updating.')\n else:\n path = self.path\n\n return path\n\n def _storage_path_parts(self):\n \"\"\"\n Split storage path into parts. I.e. 'dvc-test/myrepo' -> ['dvc', 'myrepo']\n \"\"\"\n return self.storage_path.strip('/').split('/', 1)\n\n @property\n def storage_bucket(self):\n \"\"\" Data -> StoragePath takes precedence; if doesn't exist, use cloud-specific \"\"\"\n return self._storage_path_parts()[0]\n\n @property\n def storage_prefix(self):\n \"\"\"\n Prefix within the bucket. I.e. 'myrepo' in 'dvc-test/myrepo'.\n \"\"\"\n parts = self._storage_path_parts()\n if len(parts) > 1:\n return parts[1]\n return ''\n\n def cache_file_key(self, fname):\n \"\"\" Key of a file within the bucket \"\"\"\n relpath = os.path.relpath(fname, self._cloud_settings.cache.cache_dir)\n relpath = relpath.replace('\\\\', '/')\n return '{}/{}'.format(self.storage_prefix, relpath).strip('/')\n\n @staticmethod\n def tmp_file(fname):\n \"\"\" Temporary name for a partial download \"\"\"\n return fname + '.part'\n\n def sanity_check(self):\n \"\"\"\n Cloud-specific method to check config for basic requirements.\n \"\"\"\n pass\n\n def _push_key(self, key, path):\n pass\n\n def collect(self, arg):\n path, local = arg\n ret = [path]\n\n if not Cache.is_dir_cache(path):\n return ret\n\n if local:\n if not os.path.isfile(path):\n return ret\n dir_path = path\n else:\n key = self._get_key(path)\n if not key:\n Logger.debug(\"File '{}' does not exist in the cloud\".format(path))\n return ret\n tmp = os.path.join(tempfile.mkdtemp(), os.path.basename(path))\n self._pull_key(key, tmp, no_progress_bar=True)\n dir_path = tmp\n\n for relpath, md5 in Cache.get_dir_cache(dir_path).items():\n cache = self._cloud_settings.cache.get(md5)\n ret.append(cache)\n\n return ret\n\n def _cmp_checksum(self, blob, fname):\n md5 = self._cloud_settings.cache.path_to_md5(fname)\n if self._cloud_settings.cache.state.changed(fname, md5=md5):\n return False\n\n return True\n\n def push(self, path):\n key = self._get_key(path)\n if key:\n Logger.debug(\"File '{}' already uploaded to the cloud. Validating checksum...\".format(path))\n if self._cmp_checksum(key, path):\n Logger.debug('File checksum matches. No uploading is needed.')\n return []\n Logger.debug('Checksum mismatch. Reuploading is required.')\n\n key = self._new_key(path)\n return self._push_key(key, path)\n\n def _makedirs(self, fname):\n dname = os.path.dirname(fname)\n try:\n os.makedirs(dname)\n except OSError as e:\n if e.errno != os.errno.EEXIST:\n raise\n\n def _pull_key(self, key, path, no_progress_bar=False):\n \"\"\" Cloud-specific method of pulling keys \"\"\"\n pass\n\n def _get_key(self, path):\n \"\"\" Cloud-specific method of getting keys \"\"\"\n pass\n\n def pull(self, path):\n \"\"\" Generic method for pulling data from the cloud \"\"\"\n key = self._get_key(path)\n if not key:\n Logger.error(\"File '{}' does not exist in the cloud\".format(path))\n return None\n\n return self._pull_key(key, path)\n\n def _status(self, key, path):\n remote_exists = key != None\n local_exists = os.path.exists(path)\n\n diff = None\n if remote_exists and local_exists:\n diff = self._cmp_checksum(key, path)\n\n return STATUS_MAP.get((local_exists, remote_exists, diff), STATUS_UNKNOWN)\n\n def status(self, path):\n \"\"\"\n Generic method for checking data item status.\n \"\"\"\n key = self._get_key(path)\n if not key:\n return STATUS_NEW\n\n return self._status(key, path)\n\n def connect(self):\n pass\n\n def disconnect(self):\n pass\n", "path": "dvc/cloud/base.py"}, {"content": "import re\nfrom multiprocessing.pool import ThreadPool\n\nfrom dvc.logger import Logger\nfrom dvc.exceptions import DvcException\nfrom dvc.config import Config, ConfigError\nfrom dvc.utils import map_progress\n\nfrom dvc.cloud.aws import DataCloudAWS\nfrom dvc.cloud.gcp import DataCloudGCP\nfrom dvc.cloud.ssh import DataCloudSSH\nfrom dvc.cloud.local import DataCloudLOCAL\nfrom dvc.cloud.base import DataCloudBase, CloudSettings\n\n\nclass DataCloud(object):\n \"\"\" Generic class to do initial config parsing and redirect to proper DataCloud methods \"\"\"\n\n CLOUD_MAP = {\n 'aws' : DataCloudAWS,\n 'gcp' : DataCloudGCP,\n 'ssh' : DataCloudSSH,\n 'local' : DataCloudLOCAL,\n }\n\n def __init__(self, cache=None, config=None):\n self._cache = cache\n self._config = config\n\n remote = self._config[Config.SECTION_CORE].get(Config.SECTION_CORE_REMOTE, '')\n if remote == '':\n if config[Config.SECTION_CORE].get(Config.SECTION_CORE_CLOUD, None):\n # backward compatibility\n Logger.warn('Using obsoleted config format. Consider updating.')\n self._cloud = self.__init__compat()\n else:\n self._cloud = None\n return\n\n self._cloud = self._init_remote(remote)\n\n @staticmethod\n def supported(url):\n for cloud in DataCloud.CLOUD_MAP.values():\n if cloud.supported(url):\n return cloud\n return None\n\n def _init_remote(self, remote):\n section = Config.SECTION_REMOTE_FMT.format(remote)\n cloud_config = self._config.get(section, None)\n if not cloud_config:\n raise ConfigError(\"Can't find remote section '{}' in config\".format(section))\n\n url = cloud_config[Config.SECTION_REMOTE_URL]\n cloud_type = self.supported(url)\n if not cloud_type:\n raise ConfigError(\"Unsupported url '{}'\".format(url))\n\n return self._init_cloud(cloud_config, cloud_type)\n\n def __init__compat(self):\n cloud_name = self._config[Config.SECTION_CORE].get(Config.SECTION_CORE_CLOUD, '').strip().lower()\n if cloud_name == '':\n self._cloud = None\n return\n\n cloud_type = self.CLOUD_MAP.get(cloud_name, None)\n if not cloud_type:\n raise ConfigError('Wrong cloud type %s specified' % cloud_name)\n\n cloud_config = self._config.get(cloud_name, None)\n if not cloud_config:\n raise ConfigError('Can\\'t find cloud section \\'[%s]\\' in config' % cloud_name)\n\n return self._init_cloud(cloud_config, cloud_type)\n\n def _init_cloud(self, cloud_config, cloud_type):\n global_storage_path = self._config[Config.SECTION_CORE].get(Config.SECTION_CORE_STORAGEPATH, None)\n if global_storage_path:\n Logger.warn('Using obsoleted config format. Consider updating.')\n\n cloud_settings = CloudSettings(cache=self._cache,\n global_storage_path=global_storage_path,\n cloud_config=cloud_config)\n\n cloud = cloud_type(cloud_settings)\n cloud.sanity_check()\n return cloud\n\n def _collect(self, cloud, targets, jobs, local):\n collected = set()\n pool = ThreadPool(processes=jobs)\n args = zip(targets, [local]*len(targets))\n ret = pool.map(cloud.collect, args)\n\n for r in ret:\n collected |= set(r)\n\n return collected\n\n def _map_targets(self, func, targets, jobs, collect_local=False, collect_cloud=False, remote=None):\n \"\"\"\n Process targets as data items in parallel.\n \"\"\"\n\n if not remote:\n cloud = self._cloud\n else:\n cloud = self._init_remote(remote)\n\n if not cloud:\n return\n\n cloud.connect()\n\n collected = set()\n if collect_local:\n collected |= self._collect(cloud, targets, jobs, True)\n if collect_cloud:\n collected |= self._collect(cloud, targets, jobs, False)\n\n ret = map_progress(getattr(cloud, func), list(collected), jobs)\n\n cloud.disconnect()\n\n return ret\n\n def push(self, targets, jobs=1, remote=None):\n \"\"\"\n Push data items in a cloud-agnostic way.\n \"\"\"\n return self._map_targets('push', targets, jobs, collect_local=True, remote=remote)\n\n def pull(self, targets, jobs=1, remote=None):\n \"\"\"\n Pull data items in a cloud-agnostic way.\n \"\"\"\n return self._map_targets('pull', targets, jobs, collect_cloud=True, remote=remote)\n\n def status(self, targets, jobs=1, remote=None):\n \"\"\"\n Check status of data items in a cloud-agnostic way.\n \"\"\"\n return self._map_targets('status', targets, jobs, True, True, remote=remote)\n", "path": "dvc/cloud/data_cloud.py"}], "after_files": [{"content": "import os\nimport re\nimport tempfile\n\nfrom dvc.logger import Logger\nfrom dvc.exceptions import DvcException\nfrom dvc.config import Config, ConfigError\nfrom dvc.cache import Cache\n\n\nSTATUS_UNKNOWN = 0\nSTATUS_OK = 1\nSTATUS_MODIFIED = 2\nSTATUS_NEW = 3\nSTATUS_DELETED = 4\n\n\nSTATUS_MAP = {\n # (local_exists, remote_exists, cmp)\n (True, True, True) : STATUS_OK,\n (True, True, False) : STATUS_MODIFIED,\n (True, False, None) : STATUS_NEW,\n (False, True, None) : STATUS_DELETED,\n}\n\n\nclass DataCloudError(DvcException):\n \"\"\" Data Cloud exception \"\"\"\n def __init__(self, msg):\n super(DataCloudError, self).__init__('Data sync error: {}'.format(msg))\n\n\nclass CloudSettings(object):\n def __init__(self, cache=None, global_storage_path=None, cloud_config=None):\n self.cache = cache\n self.cloud_config = cloud_config\n self.global_storage_path = global_storage_path\n\n\nclass DataCloudBase(object):\n \"\"\" Base class for DataCloud \"\"\"\n\n REGEX = r''\n\n def __init__(self, cloud_settings):\n self._cloud_settings = cloud_settings\n\n @property\n def url(self):\n config = self._cloud_settings.cloud_config\n return config.get(Config.SECTION_REMOTE_URL, None)\n\n @classmethod\n def match(cls, url):\n return re.match(cls.REGEX, url)\n\n def group(self, group):\n return self.match(self.url).group(group)\n\n @property\n def path(self):\n return self.group('path')\n\n @classmethod\n def supported(cls, url):\n return cls.match(url) != None\n\n # backward compatibility\n @property\n def storage_path(self):\n \"\"\" get storage path\n\n Precedence: Storage, then cloud specific\n \"\"\"\n\n if self._cloud_settings.global_storage_path:\n return self._cloud_settings.global_storage_path\n\n if not self.url:\n path = self._cloud_settings.cloud_config.get(Config.SECTION_CORE_STORAGEPATH, None)\n if path:\n Logger.warn('Using obsoleted config format. Consider updating.')\n else:\n path = self.path\n\n return path\n\n def _storage_path_parts(self):\n \"\"\"\n Split storage path into parts. I.e. 'dvc-test/myrepo' -> ['dvc', 'myrepo']\n \"\"\"\n return self.storage_path.strip('/').split('/', 1)\n\n @property\n def storage_bucket(self):\n \"\"\" Data -> StoragePath takes precedence; if doesn't exist, use cloud-specific \"\"\"\n return self._storage_path_parts()[0]\n\n @property\n def storage_prefix(self):\n \"\"\"\n Prefix within the bucket. I.e. 'myrepo' in 'dvc-test/myrepo'.\n \"\"\"\n parts = self._storage_path_parts()\n if len(parts) > 1:\n return parts[1]\n return ''\n\n def cache_file_key(self, fname):\n \"\"\" Key of a file within the bucket \"\"\"\n relpath = os.path.relpath(fname, self._cloud_settings.cache.cache_dir)\n relpath = relpath.replace('\\\\', '/')\n return '{}/{}'.format(self.storage_prefix, relpath).strip('/')\n\n @staticmethod\n def tmp_file(fname):\n \"\"\" Temporary name for a partial download \"\"\"\n return fname + '.part'\n\n def sanity_check(self):\n \"\"\"\n Cloud-specific method to check config for basic requirements.\n \"\"\"\n pass\n\n def _push_key(self, key, path):\n pass\n\n def collect(self, arg):\n path, local = arg\n ret = [path]\n\n if not Cache.is_dir_cache(path):\n return ret\n\n if local:\n if not os.path.isfile(path):\n return ret\n dir_path = path\n else:\n key = self._get_key(path)\n if not key:\n Logger.debug(\"File '{}' does not exist in the cloud\".format(path))\n return ret\n tmp = os.path.join(tempfile.mkdtemp(), os.path.basename(path))\n self._pull_key(key, tmp, no_progress_bar=True)\n dir_path = tmp\n\n for relpath, md5 in Cache.get_dir_cache(dir_path).items():\n cache = self._cloud_settings.cache.get(md5)\n ret.append(cache)\n\n return ret\n\n def _cmp_checksum(self, blob, fname):\n md5 = self._cloud_settings.cache.path_to_md5(fname)\n if self._cloud_settings.cache.state.changed(fname, md5=md5):\n return False\n\n return True\n\n def push(self, path):\n key = self._get_key(path)\n if key:\n Logger.debug(\"File '{}' already uploaded to the cloud. Validating checksum...\".format(path))\n if self._cmp_checksum(key, path):\n Logger.debug('File checksum matches. No uploading is needed.')\n return []\n Logger.debug('Checksum mismatch. Reuploading is required.')\n\n key = self._new_key(path)\n return self._push_key(key, path)\n\n def _makedirs(self, fname):\n dname = os.path.dirname(fname)\n try:\n os.makedirs(dname)\n except OSError as e:\n if e.errno != os.errno.EEXIST:\n raise\n\n def _pull_key(self, key, path, no_progress_bar=False):\n \"\"\" Cloud-specific method of pulling keys \"\"\"\n pass\n\n def _get_key(self, path):\n \"\"\" Cloud-specific method of getting keys \"\"\"\n pass\n\n def pull(self, path):\n \"\"\" Generic method for pulling data from the cloud \"\"\"\n key = self._get_key(path)\n if not key:\n Logger.error(\"File '{}' does not exist in the cloud\".format(path))\n return None\n\n return self._pull_key(key, path)\n\n def _status(self, key, path):\n remote_exists = key != None\n local_exists = os.path.exists(path)\n\n diff = None\n if remote_exists and local_exists:\n diff = self._cmp_checksum(key, path)\n\n return STATUS_MAP.get((local_exists, remote_exists, diff), STATUS_UNKNOWN)\n\n def status(self, path):\n \"\"\"\n Generic method for checking data item status.\n \"\"\"\n key = self._get_key(path)\n if not key:\n return STATUS_NEW\n\n return self._status(key, path)\n\n def connect(self):\n pass\n\n def disconnect(self):\n pass\n\n def __enter__(self):\n self.connect()\n\n def __exit__(self, type, value, tb):\n self.disconnect()\n", "path": "dvc/cloud/base.py"}, {"content": "import re\nfrom multiprocessing.pool import ThreadPool\n\nfrom dvc.logger import Logger\nfrom dvc.exceptions import DvcException\nfrom dvc.config import Config, ConfigError\nfrom dvc.utils import map_progress\n\nfrom dvc.cloud.aws import DataCloudAWS\nfrom dvc.cloud.gcp import DataCloudGCP\nfrom dvc.cloud.ssh import DataCloudSSH\nfrom dvc.cloud.local import DataCloudLOCAL\nfrom dvc.cloud.base import DataCloudBase, CloudSettings\nfrom dvc.cloud.base import STATUS_MODIFIED, STATUS_NEW, STATUS_DELETED\n\n\nclass DataCloud(object):\n \"\"\" Generic class to do initial config parsing and redirect to proper DataCloud methods \"\"\"\n\n CLOUD_MAP = {\n 'aws' : DataCloudAWS,\n 'gcp' : DataCloudGCP,\n 'ssh' : DataCloudSSH,\n 'local' : DataCloudLOCAL,\n }\n\n def __init__(self, cache=None, config=None):\n self._cache = cache\n self._config = config\n\n remote = self._config[Config.SECTION_CORE].get(Config.SECTION_CORE_REMOTE, '')\n if remote == '':\n if config[Config.SECTION_CORE].get(Config.SECTION_CORE_CLOUD, None):\n # backward compatibility\n Logger.warn('Using obsoleted config format. Consider updating.')\n self._cloud = self.__init__compat()\n else:\n self._cloud = None\n return\n\n self._cloud = self._init_remote(remote)\n\n @staticmethod\n def supported(url):\n for cloud in DataCloud.CLOUD_MAP.values():\n if cloud.supported(url):\n return cloud\n return None\n\n def _init_remote(self, remote):\n section = Config.SECTION_REMOTE_FMT.format(remote)\n cloud_config = self._config.get(section, None)\n if not cloud_config:\n raise ConfigError(\"Can't find remote section '{}' in config\".format(section))\n\n url = cloud_config[Config.SECTION_REMOTE_URL]\n cloud_type = self.supported(url)\n if not cloud_type:\n raise ConfigError(\"Unsupported url '{}'\".format(url))\n\n return self._init_cloud(cloud_config, cloud_type)\n\n def __init__compat(self):\n cloud_name = self._config[Config.SECTION_CORE].get(Config.SECTION_CORE_CLOUD, '').strip().lower()\n if cloud_name == '':\n self._cloud = None\n return\n\n cloud_type = self.CLOUD_MAP.get(cloud_name, None)\n if not cloud_type:\n raise ConfigError('Wrong cloud type %s specified' % cloud_name)\n\n cloud_config = self._config.get(cloud_name, None)\n if not cloud_config:\n raise ConfigError('Can\\'t find cloud section \\'[%s]\\' in config' % cloud_name)\n\n return self._init_cloud(cloud_config, cloud_type)\n\n def _init_cloud(self, cloud_config, cloud_type):\n global_storage_path = self._config[Config.SECTION_CORE].get(Config.SECTION_CORE_STORAGEPATH, None)\n if global_storage_path:\n Logger.warn('Using obsoleted config format. Consider updating.')\n\n cloud_settings = CloudSettings(cache=self._cache,\n global_storage_path=global_storage_path,\n cloud_config=cloud_config)\n\n cloud = cloud_type(cloud_settings)\n cloud.sanity_check()\n return cloud\n\n def _collect(self, cloud, targets, jobs, local):\n collected = set()\n pool = ThreadPool(processes=jobs)\n args = zip(targets, [local]*len(targets))\n ret = pool.map(cloud.collect, args)\n\n for r in ret:\n collected |= set(r)\n\n return collected\n\n def _get_cloud(self, remote):\n if remote:\n return self._init_remote(remote)\n\n return self._cloud\n\n def _filter(self, func, status, targets, jobs, remote):\n cloud = self._get_cloud(remote)\n if not cloud:\n return []\n\n with cloud:\n filtered = []\n for t, s in self._status(cloud, targets, jobs):\n if s == STATUS_MODIFIED or s == status:\n filtered.append(t)\n\n return map_progress(getattr(cloud, func), filtered, jobs)\n\n def push(self, targets, jobs=1, remote=None):\n \"\"\"\n Push data items in a cloud-agnostic way.\n \"\"\"\n return self._filter('push', STATUS_NEW, targets, jobs, remote)\n\n def pull(self, targets, jobs=1, remote=None):\n \"\"\"\n Pull data items in a cloud-agnostic way.\n \"\"\"\n return self._filter('pull', STATUS_DELETED, targets, jobs, remote)\n\n def _collect_targets(self, cloud, targets, jobs=1):\n collected = set()\n collected |= self._collect(cloud, targets, jobs, True)\n collected |= self._collect(cloud, targets, jobs, False)\n return list(collected)\n\n def _status(self, cloud, targets, jobs=1):\n collected = self._collect_targets(cloud, targets, jobs)\n return map_progress(cloud.status, collected, jobs)\n\n def status(self, targets, jobs=1, remote=None):\n \"\"\"\n Check status of data items in a cloud-agnostic way.\n \"\"\"\n cloud = self._get_cloud(remote)\n if not cloud:\n return []\n\n with cloud:\n return self._status(cloud, targets, jobs)\n", "path": "dvc/cloud/data_cloud.py"}]} | 3,748 | 843 |
gh_patches_debug_5106 | rasdani/github-patches | git_diff | Kinto__kinto-316 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
kinto init fails if config folder does not exist
```
kinto init
Which backend to use? (1 - postgresql, 2 - redis, default - memory)
Traceback (most recent call last):
File "/var/www/kinto.leplat.re/venv/bin/kinto", line 9, in <module>
load_entry_point('kinto==1.9.0', 'console_scripts', 'kinto')()
File "/var/www/kinto.leplat.re/venv/local/lib/python2.7/site-packages/kinto/__main__.py", line 44, in main
init(config_file)
File "/var/www/kinto.leplat.re/venv/local/lib/python2.7/site-packages/kinto/config/__init__.py", line 61, in init
permission_url=values['permission_url'])
File "/var/www/kinto.leplat.re/venv/local/lib/python2.7/site-packages/kinto/config/__init__.py", line 15, in render_template
with codecs.open(destination, 'w+', encoding='utf-8') as output:
File "/var/www/kinto.leplat.re/venv/lib/python2.7/codecs.py", line 881, in open
file = __builtin__.open(filename, mode, buffering)
IOError: [Errno 2] No such file or directory: 'config/kinto.ini'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kinto/config/__init__.py`
Content:
```
1 import os
2 import binascii
3 import codecs
4
5 HERE = os.path.abspath(os.path.dirname(__file__))
6
7
8 def render_template(template, destination, **kwargs):
9 template = os.path.join(HERE, template)
10
11 with codecs.open(template, 'r', encoding='utf-8') as f:
12 raw_template = f.read()
13 rendered = raw_template.format(**kwargs)
14 with codecs.open(destination, 'w+', encoding='utf-8') as output:
15 output.write(rendered)
16
17
18 def init(config_file, backend):
19 values = {}
20 values['secret'] = binascii.b2a_hex(os.urandom(32))
21
22 values['storage_backend'] = "cliquet.storage.%s" % backend
23 values['cache_backend'] = "cliquet.cache.%s" % backend
24 values['permission_backend'] = "cliquet.permission.%s" % backend
25
26 if backend == 'postgresql':
27 postgresql_url = "postgres://postgres:postgres@localhost/postgres"
28 values['storage_url'] = postgresql_url
29 values['cache_url'] = postgresql_url
30 values['permission_url'] = postgresql_url
31
32 elif backend == 'redis':
33 redis_url = "redis://localhost:6379"
34 values['storage_url'] = redis_url + "/1"
35 values['cache_url'] = redis_url + "/2"
36 values['permission_url'] = redis_url + "/3"
37
38 else:
39 values['storage_url'] = ''
40 values['cache_url'] = ''
41 values['permission_url'] = ''
42
43 render_template("kinto.tpl", config_file, **values)
44
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/kinto/config/__init__.py b/kinto/config/__init__.py
--- a/kinto/config/__init__.py
+++ b/kinto/config/__init__.py
@@ -8,6 +8,9 @@
def render_template(template, destination, **kwargs):
template = os.path.join(HERE, template)
+ folder = os.path.dirname(destination)
+ os.makedirs(folder)
+
with codecs.open(template, 'r', encoding='utf-8') as f:
raw_template = f.read()
rendered = raw_template.format(**kwargs)
| {"golden_diff": "diff --git a/kinto/config/__init__.py b/kinto/config/__init__.py\n--- a/kinto/config/__init__.py\n+++ b/kinto/config/__init__.py\n@@ -8,6 +8,9 @@\n def render_template(template, destination, **kwargs):\n template = os.path.join(HERE, template)\n \n+ folder = os.path.dirname(destination)\n+ os.makedirs(folder)\n+\n with codecs.open(template, 'r', encoding='utf-8') as f:\n raw_template = f.read()\n rendered = raw_template.format(**kwargs)\n", "issue": "kinto init fails if config folder does not exist\n```\nkinto init \nWhich backend to use? (1 - postgresql, 2 - redis, default - memory) \nTraceback (most recent call last):\n File \"/var/www/kinto.leplat.re/venv/bin/kinto\", line 9, in <module>\n load_entry_point('kinto==1.9.0', 'console_scripts', 'kinto')()\n File \"/var/www/kinto.leplat.re/venv/local/lib/python2.7/site-packages/kinto/__main__.py\", line 44, in main\n init(config_file)\n File \"/var/www/kinto.leplat.re/venv/local/lib/python2.7/site-packages/kinto/config/__init__.py\", line 61, in init\n permission_url=values['permission_url'])\n File \"/var/www/kinto.leplat.re/venv/local/lib/python2.7/site-packages/kinto/config/__init__.py\", line 15, in render_template\n with codecs.open(destination, 'w+', encoding='utf-8') as output:\n File \"/var/www/kinto.leplat.re/venv/lib/python2.7/codecs.py\", line 881, in open\n file = __builtin__.open(filename, mode, buffering)\nIOError: [Errno 2] No such file or directory: 'config/kinto.ini'\n```\n\n", "before_files": [{"content": "import os\nimport binascii\nimport codecs\n\nHERE = os.path.abspath(os.path.dirname(__file__))\n\n\ndef render_template(template, destination, **kwargs):\n template = os.path.join(HERE, template)\n\n with codecs.open(template, 'r', encoding='utf-8') as f:\n raw_template = f.read()\n rendered = raw_template.format(**kwargs)\n with codecs.open(destination, 'w+', encoding='utf-8') as output:\n output.write(rendered)\n\n\ndef init(config_file, backend):\n values = {}\n values['secret'] = binascii.b2a_hex(os.urandom(32))\n\n values['storage_backend'] = \"cliquet.storage.%s\" % backend\n values['cache_backend'] = \"cliquet.cache.%s\" % backend\n values['permission_backend'] = \"cliquet.permission.%s\" % backend\n\n if backend == 'postgresql':\n postgresql_url = \"postgres://postgres:postgres@localhost/postgres\"\n values['storage_url'] = postgresql_url\n values['cache_url'] = postgresql_url\n values['permission_url'] = postgresql_url\n\n elif backend == 'redis':\n redis_url = \"redis://localhost:6379\"\n values['storage_url'] = redis_url + \"/1\"\n values['cache_url'] = redis_url + \"/2\"\n values['permission_url'] = redis_url + \"/3\"\n\n else:\n values['storage_url'] = ''\n values['cache_url'] = ''\n values['permission_url'] = ''\n\n render_template(\"kinto.tpl\", config_file, **values)\n", "path": "kinto/config/__init__.py"}], "after_files": [{"content": "import os\nimport binascii\nimport codecs\n\nHERE = os.path.abspath(os.path.dirname(__file__))\n\n\ndef render_template(template, destination, **kwargs):\n template = os.path.join(HERE, template)\n\n folder = os.path.dirname(destination)\n os.makedirs(folder)\n\n with codecs.open(template, 'r', encoding='utf-8') as f:\n raw_template = f.read()\n rendered = raw_template.format(**kwargs)\n with codecs.open(destination, 'w+', encoding='utf-8') as output:\n output.write(rendered)\n\n\ndef init(config_file, backend):\n values = {}\n values['secret'] = binascii.b2a_hex(os.urandom(32))\n\n values['storage_backend'] = \"cliquet.storage.%s\" % backend\n values['cache_backend'] = \"cliquet.cache.%s\" % backend\n values['permission_backend'] = \"cliquet.permission.%s\" % backend\n\n if backend == 'postgresql':\n postgresql_url = \"postgres://postgres:postgres@localhost/postgres\"\n values['storage_url'] = postgresql_url\n values['cache_url'] = postgresql_url\n values['permission_url'] = postgresql_url\n\n elif backend == 'redis':\n redis_url = \"redis://localhost:6379\"\n values['storage_url'] = redis_url + \"/1\"\n values['cache_url'] = redis_url + \"/2\"\n values['permission_url'] = redis_url + \"/3\"\n\n else:\n values['storage_url'] = ''\n values['cache_url'] = ''\n values['permission_url'] = ''\n\n render_template(\"kinto.tpl\", config_file, **values)\n", "path": "kinto/config/__init__.py"}]} | 996 | 122 |
gh_patches_debug_35803 | rasdani/github-patches | git_diff | bookwyrm-social__bookwyrm-2449 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
importing .csv file that is empty besides header row causes hung import process.
**Describe the bug**
importing at least 1 kind of empty .csv file will result in a started import process, which will run forever from the user's point of view, stuck at 0%. there is no feedback to the user that their file was improperly formatted. the file is not *empty* since it contains the header row, and a novice user may not realize there is anything wrong with their file (nor know how to open and inspect a .csv).
**To Reproduce**
Steps to reproduce the behavior:
1. obtain an .csv export from another bookwyrm instance that is empty besides the header row
2. import the .csv file into a new instance from the user's import feature.
the user can see the import "running" in their settings panel where imports are shown. It is listed as Active, but stays stuck at 0% for at least 30 minutes (possibly indefinitely?).
an `import_job.start_import_task` task runs, but no `import_item_task`s are ever seen.
**Expected behavior**
either a "successful" import (of no books, because the file is empty), or a failed import, or some kind of feedback to the user that the file is empty
**Instance**
export from bookwyrm.social, importing to a fresh self-hosted instance.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bookwyrm/views/imports/import_data.py`
Content:
```
1 """ import books from another app """
2 from io import TextIOWrapper
3 import datetime
4
5 from django.contrib.auth.decorators import login_required
6 from django.db.models import Avg, ExpressionWrapper, F, fields
7 from django.core.exceptions import PermissionDenied
8 from django.core.paginator import Paginator
9 from django.http import HttpResponseBadRequest
10 from django.shortcuts import redirect
11 from django.template.response import TemplateResponse
12 from django.utils import timezone
13 from django.utils.decorators import method_decorator
14 from django.utils.translation import gettext_lazy as _
15 from django.views import View
16
17 from bookwyrm import forms, models
18 from bookwyrm.importers import (
19 CalibreImporter,
20 LibrarythingImporter,
21 GoodreadsImporter,
22 StorygraphImporter,
23 OpenLibraryImporter,
24 )
25 from bookwyrm.settings import PAGE_LENGTH
26 from bookwyrm.utils.cache import get_or_set
27
28 # pylint: disable= no-self-use
29 @method_decorator(login_required, name="dispatch")
30 class Import(View):
31 """import view"""
32
33 def get(self, request):
34 """load import page"""
35 jobs = models.ImportJob.objects.filter(user=request.user).order_by(
36 "-created_date"
37 )
38 paginated = Paginator(jobs, PAGE_LENGTH)
39 page = paginated.get_page(request.GET.get("page"))
40 data = {
41 "import_form": forms.ImportForm(),
42 "jobs": page,
43 "page_range": paginated.get_elided_page_range(
44 page.number, on_each_side=2, on_ends=1
45 ),
46 }
47
48 seconds = get_or_set("avg-import-time", get_average_import_time, timeout=86400)
49 if seconds and seconds > 60**2:
50 data["recent_avg_hours"] = seconds / (60**2)
51 elif seconds:
52 data["recent_avg_minutes"] = seconds / 60
53
54 return TemplateResponse(request, "import/import.html", data)
55
56 def post(self, request):
57 """ingest a goodreads csv"""
58 site = models.SiteSettings.objects.get()
59 if not site.imports_enabled:
60 raise PermissionDenied()
61
62 form = forms.ImportForm(request.POST, request.FILES)
63 if not form.is_valid():
64 return HttpResponseBadRequest()
65
66 include_reviews = request.POST.get("include_reviews") == "on"
67 privacy = request.POST.get("privacy")
68 source = request.POST.get("source")
69
70 importer = None
71 if source == "LibraryThing":
72 importer = LibrarythingImporter()
73 elif source == "Storygraph":
74 importer = StorygraphImporter()
75 elif source == "OpenLibrary":
76 importer = OpenLibraryImporter()
77 elif source == "Calibre":
78 importer = CalibreImporter()
79 else:
80 # Default : Goodreads
81 importer = GoodreadsImporter()
82
83 try:
84 job = importer.create_job(
85 request.user,
86 TextIOWrapper(request.FILES["csv_file"], encoding=importer.encoding),
87 include_reviews,
88 privacy,
89 )
90 except (UnicodeDecodeError, ValueError, KeyError):
91 return HttpResponseBadRequest(_("Not a valid csv file"))
92
93 job.start_job()
94
95 return redirect(f"/import/{job.id}")
96
97
98 def get_average_import_time() -> float:
99 """Helper to figure out how long imports are taking (returns seconds)"""
100 last_week = timezone.now() - datetime.timedelta(days=7)
101 recent_avg = (
102 models.ImportJob.objects.filter(created_date__gte=last_week, complete=True)
103 .exclude(status="stopped")
104 .annotate(
105 runtime=ExpressionWrapper(
106 F("updated_date") - F("created_date"),
107 output_field=fields.DurationField(),
108 )
109 )
110 .aggregate(Avg("runtime"))
111 .get("runtime__avg")
112 )
113
114 if recent_avg:
115 return recent_avg.total_seconds()
116 return None
117
```
Path: `bookwyrm/importers/importer.py`
Content:
```
1 """ handle reading a csv from an external service, defaults are from Goodreads """
2 import csv
3 from django.utils import timezone
4 from bookwyrm.models import ImportJob, ImportItem
5
6
7 class Importer:
8 """Generic class for csv data import from an outside service"""
9
10 service = "Import"
11 delimiter = ","
12 encoding = "UTF-8"
13
14 # these are from Goodreads
15 row_mappings_guesses = [
16 ("id", ["id", "book id"]),
17 ("title", ["title"]),
18 ("authors", ["author", "authors", "primary author"]),
19 ("isbn_10", ["isbn10", "isbn"]),
20 ("isbn_13", ["isbn13", "isbn", "isbns"]),
21 ("shelf", ["shelf", "exclusive shelf", "read status", "bookshelf"]),
22 ("review_name", ["review name"]),
23 ("review_body", ["my review", "review"]),
24 ("rating", ["my rating", "rating", "star rating"]),
25 ("date_added", ["date added", "entry date", "added"]),
26 ("date_started", ["date started", "started"]),
27 ("date_finished", ["date finished", "last date read", "date read", "finished"]),
28 ]
29 date_fields = ["date_added", "date_started", "date_finished"]
30 shelf_mapping_guesses = {
31 "to-read": ["to-read", "want to read"],
32 "read": ["read", "already read"],
33 "reading": ["currently-reading", "reading", "currently reading"],
34 }
35
36 def create_job(self, user, csv_file, include_reviews, privacy):
37 """check over a csv and creates a database entry for the job"""
38 csv_reader = csv.DictReader(csv_file, delimiter=self.delimiter)
39 rows = enumerate(list(csv_reader))
40 job = ImportJob.objects.create(
41 user=user,
42 include_reviews=include_reviews,
43 privacy=privacy,
44 mappings=self.create_row_mappings(csv_reader.fieldnames),
45 source=self.service,
46 )
47
48 for index, entry in rows:
49 self.create_item(job, index, entry)
50 return job
51
52 def update_legacy_job(self, job):
53 """patch up a job that was in the old format"""
54 items = job.items
55 headers = list(items.first().data.keys())
56 job.mappings = self.create_row_mappings(headers)
57 job.updated_date = timezone.now()
58 job.save()
59
60 for item in items.all():
61 normalized = self.normalize_row(item.data, job.mappings)
62 normalized["shelf"] = self.get_shelf(normalized)
63 item.normalized_data = normalized
64 item.save()
65
66 def create_row_mappings(self, headers):
67 """guess what the headers mean"""
68 mappings = {}
69 for (key, guesses) in self.row_mappings_guesses:
70 value = [h for h in headers if h.lower() in guesses]
71 value = value[0] if len(value) else None
72 if value:
73 headers.remove(value)
74 mappings[key] = value
75 return mappings
76
77 def create_item(self, job, index, data):
78 """creates and saves an import item"""
79 normalized = self.normalize_row(data, job.mappings)
80 normalized["shelf"] = self.get_shelf(normalized)
81 ImportItem(job=job, index=index, data=data, normalized_data=normalized).save()
82
83 def get_shelf(self, normalized_row):
84 """determine which shelf to use"""
85 shelf_name = normalized_row.get("shelf")
86 if not shelf_name:
87 return None
88 shelf_name = shelf_name.lower()
89 shelf = [
90 s for (s, gs) in self.shelf_mapping_guesses.items() if shelf_name in gs
91 ]
92 return shelf[0] if shelf else None
93
94 def normalize_row(self, entry, mappings): # pylint: disable=no-self-use
95 """use the dataclass to create the formatted row of data"""
96 return {k: entry.get(v) for k, v in mappings.items()}
97
98 def create_retry_job(self, user, original_job, items):
99 """retry items that didn't import"""
100 job = ImportJob.objects.create(
101 user=user,
102 include_reviews=original_job.include_reviews,
103 privacy=original_job.privacy,
104 source=original_job.source,
105 # TODO: allow users to adjust mappings
106 mappings=original_job.mappings,
107 retry=True,
108 )
109 for item in items:
110 # this will re-normalize the raw data
111 self.create_item(job, item.index, item.data)
112 return job
113
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/bookwyrm/importers/importer.py b/bookwyrm/importers/importer.py
--- a/bookwyrm/importers/importer.py
+++ b/bookwyrm/importers/importer.py
@@ -36,7 +36,11 @@
def create_job(self, user, csv_file, include_reviews, privacy):
"""check over a csv and creates a database entry for the job"""
csv_reader = csv.DictReader(csv_file, delimiter=self.delimiter)
- rows = enumerate(list(csv_reader))
+ rows = list(csv_reader)
+ if len(rows) < 1:
+ raise ValueError("CSV file is empty")
+ rows = enumerate(rows)
+
job = ImportJob.objects.create(
user=user,
include_reviews=include_reviews,
diff --git a/bookwyrm/views/imports/import_data.py b/bookwyrm/views/imports/import_data.py
--- a/bookwyrm/views/imports/import_data.py
+++ b/bookwyrm/views/imports/import_data.py
@@ -11,7 +11,6 @@
from django.template.response import TemplateResponse
from django.utils import timezone
from django.utils.decorators import method_decorator
-from django.utils.translation import gettext_lazy as _
from django.views import View
from bookwyrm import forms, models
@@ -30,7 +29,7 @@
class Import(View):
"""import view"""
- def get(self, request):
+ def get(self, request, invalid=False):
"""load import page"""
jobs = models.ImportJob.objects.filter(user=request.user).order_by(
"-created_date"
@@ -43,6 +42,7 @@
"page_range": paginated.get_elided_page_range(
page.number, on_each_side=2, on_ends=1
),
+ "invalid": invalid,
}
seconds = get_or_set("avg-import-time", get_average_import_time, timeout=86400)
@@ -88,7 +88,7 @@
privacy,
)
except (UnicodeDecodeError, ValueError, KeyError):
- return HttpResponseBadRequest(_("Not a valid csv file"))
+ return self.get(request, invalid=True)
job.start_job()
| {"golden_diff": "diff --git a/bookwyrm/importers/importer.py b/bookwyrm/importers/importer.py\n--- a/bookwyrm/importers/importer.py\n+++ b/bookwyrm/importers/importer.py\n@@ -36,7 +36,11 @@\n def create_job(self, user, csv_file, include_reviews, privacy):\n \"\"\"check over a csv and creates a database entry for the job\"\"\"\n csv_reader = csv.DictReader(csv_file, delimiter=self.delimiter)\n- rows = enumerate(list(csv_reader))\n+ rows = list(csv_reader)\n+ if len(rows) < 1:\n+ raise ValueError(\"CSV file is empty\")\n+ rows = enumerate(rows)\n+\n job = ImportJob.objects.create(\n user=user,\n include_reviews=include_reviews,\ndiff --git a/bookwyrm/views/imports/import_data.py b/bookwyrm/views/imports/import_data.py\n--- a/bookwyrm/views/imports/import_data.py\n+++ b/bookwyrm/views/imports/import_data.py\n@@ -11,7 +11,6 @@\n from django.template.response import TemplateResponse\n from django.utils import timezone\n from django.utils.decorators import method_decorator\n-from django.utils.translation import gettext_lazy as _\n from django.views import View\n \n from bookwyrm import forms, models\n@@ -30,7 +29,7 @@\n class Import(View):\n \"\"\"import view\"\"\"\n \n- def get(self, request):\n+ def get(self, request, invalid=False):\n \"\"\"load import page\"\"\"\n jobs = models.ImportJob.objects.filter(user=request.user).order_by(\n \"-created_date\"\n@@ -43,6 +42,7 @@\n \"page_range\": paginated.get_elided_page_range(\n page.number, on_each_side=2, on_ends=1\n ),\n+ \"invalid\": invalid,\n }\n \n seconds = get_or_set(\"avg-import-time\", get_average_import_time, timeout=86400)\n@@ -88,7 +88,7 @@\n privacy,\n )\n except (UnicodeDecodeError, ValueError, KeyError):\n- return HttpResponseBadRequest(_(\"Not a valid csv file\"))\n+ return self.get(request, invalid=True)\n \n job.start_job()\n", "issue": "importing .csv file that is empty besides header row causes hung import process. \n**Describe the bug**\r\nimporting at least 1 kind of empty .csv file will result in a started import process, which will run forever from the user's point of view, stuck at 0%. there is no feedback to the user that their file was improperly formatted. the file is not *empty* since it contains the header row, and a novice user may not realize there is anything wrong with their file (nor know how to open and inspect a .csv).\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. obtain an .csv export from another bookwyrm instance that is empty besides the header row\r\n2. import the .csv file into a new instance from the user's import feature.\r\n\r\nthe user can see the import \"running\" in their settings panel where imports are shown. It is listed as Active, but stays stuck at 0% for at least 30 minutes (possibly indefinitely?).\r\n\r\nan `import_job.start_import_task` task runs, but no `import_item_task`s are ever seen. \r\n\r\n**Expected behavior**\r\neither a \"successful\" import (of no books, because the file is empty), or a failed import, or some kind of feedback to the user that the file is empty\r\n\r\n**Instance**\r\nexport from bookwyrm.social, importing to a fresh self-hosted instance.\r\n\n", "before_files": [{"content": "\"\"\" import books from another app \"\"\"\nfrom io import TextIOWrapper\nimport datetime\n\nfrom django.contrib.auth.decorators import login_required\nfrom django.db.models import Avg, ExpressionWrapper, F, fields\nfrom django.core.exceptions import PermissionDenied\nfrom django.core.paginator import Paginator\nfrom django.http import HttpResponseBadRequest\nfrom django.shortcuts import redirect\nfrom django.template.response import TemplateResponse\nfrom django.utils import timezone\nfrom django.utils.decorators import method_decorator\nfrom django.utils.translation import gettext_lazy as _\nfrom django.views import View\n\nfrom bookwyrm import forms, models\nfrom bookwyrm.importers import (\n CalibreImporter,\n LibrarythingImporter,\n GoodreadsImporter,\n StorygraphImporter,\n OpenLibraryImporter,\n)\nfrom bookwyrm.settings import PAGE_LENGTH\nfrom bookwyrm.utils.cache import get_or_set\n\n# pylint: disable= no-self-use\n@method_decorator(login_required, name=\"dispatch\")\nclass Import(View):\n \"\"\"import view\"\"\"\n\n def get(self, request):\n \"\"\"load import page\"\"\"\n jobs = models.ImportJob.objects.filter(user=request.user).order_by(\n \"-created_date\"\n )\n paginated = Paginator(jobs, PAGE_LENGTH)\n page = paginated.get_page(request.GET.get(\"page\"))\n data = {\n \"import_form\": forms.ImportForm(),\n \"jobs\": page,\n \"page_range\": paginated.get_elided_page_range(\n page.number, on_each_side=2, on_ends=1\n ),\n }\n\n seconds = get_or_set(\"avg-import-time\", get_average_import_time, timeout=86400)\n if seconds and seconds > 60**2:\n data[\"recent_avg_hours\"] = seconds / (60**2)\n elif seconds:\n data[\"recent_avg_minutes\"] = seconds / 60\n\n return TemplateResponse(request, \"import/import.html\", data)\n\n def post(self, request):\n \"\"\"ingest a goodreads csv\"\"\"\n site = models.SiteSettings.objects.get()\n if not site.imports_enabled:\n raise PermissionDenied()\n\n form = forms.ImportForm(request.POST, request.FILES)\n if not form.is_valid():\n return HttpResponseBadRequest()\n\n include_reviews = request.POST.get(\"include_reviews\") == \"on\"\n privacy = request.POST.get(\"privacy\")\n source = request.POST.get(\"source\")\n\n importer = None\n if source == \"LibraryThing\":\n importer = LibrarythingImporter()\n elif source == \"Storygraph\":\n importer = StorygraphImporter()\n elif source == \"OpenLibrary\":\n importer = OpenLibraryImporter()\n elif source == \"Calibre\":\n importer = CalibreImporter()\n else:\n # Default : Goodreads\n importer = GoodreadsImporter()\n\n try:\n job = importer.create_job(\n request.user,\n TextIOWrapper(request.FILES[\"csv_file\"], encoding=importer.encoding),\n include_reviews,\n privacy,\n )\n except (UnicodeDecodeError, ValueError, KeyError):\n return HttpResponseBadRequest(_(\"Not a valid csv file\"))\n\n job.start_job()\n\n return redirect(f\"/import/{job.id}\")\n\n\ndef get_average_import_time() -> float:\n \"\"\"Helper to figure out how long imports are taking (returns seconds)\"\"\"\n last_week = timezone.now() - datetime.timedelta(days=7)\n recent_avg = (\n models.ImportJob.objects.filter(created_date__gte=last_week, complete=True)\n .exclude(status=\"stopped\")\n .annotate(\n runtime=ExpressionWrapper(\n F(\"updated_date\") - F(\"created_date\"),\n output_field=fields.DurationField(),\n )\n )\n .aggregate(Avg(\"runtime\"))\n .get(\"runtime__avg\")\n )\n\n if recent_avg:\n return recent_avg.total_seconds()\n return None\n", "path": "bookwyrm/views/imports/import_data.py"}, {"content": "\"\"\" handle reading a csv from an external service, defaults are from Goodreads \"\"\"\nimport csv\nfrom django.utils import timezone\nfrom bookwyrm.models import ImportJob, ImportItem\n\n\nclass Importer:\n \"\"\"Generic class for csv data import from an outside service\"\"\"\n\n service = \"Import\"\n delimiter = \",\"\n encoding = \"UTF-8\"\n\n # these are from Goodreads\n row_mappings_guesses = [\n (\"id\", [\"id\", \"book id\"]),\n (\"title\", [\"title\"]),\n (\"authors\", [\"author\", \"authors\", \"primary author\"]),\n (\"isbn_10\", [\"isbn10\", \"isbn\"]),\n (\"isbn_13\", [\"isbn13\", \"isbn\", \"isbns\"]),\n (\"shelf\", [\"shelf\", \"exclusive shelf\", \"read status\", \"bookshelf\"]),\n (\"review_name\", [\"review name\"]),\n (\"review_body\", [\"my review\", \"review\"]),\n (\"rating\", [\"my rating\", \"rating\", \"star rating\"]),\n (\"date_added\", [\"date added\", \"entry date\", \"added\"]),\n (\"date_started\", [\"date started\", \"started\"]),\n (\"date_finished\", [\"date finished\", \"last date read\", \"date read\", \"finished\"]),\n ]\n date_fields = [\"date_added\", \"date_started\", \"date_finished\"]\n shelf_mapping_guesses = {\n \"to-read\": [\"to-read\", \"want to read\"],\n \"read\": [\"read\", \"already read\"],\n \"reading\": [\"currently-reading\", \"reading\", \"currently reading\"],\n }\n\n def create_job(self, user, csv_file, include_reviews, privacy):\n \"\"\"check over a csv and creates a database entry for the job\"\"\"\n csv_reader = csv.DictReader(csv_file, delimiter=self.delimiter)\n rows = enumerate(list(csv_reader))\n job = ImportJob.objects.create(\n user=user,\n include_reviews=include_reviews,\n privacy=privacy,\n mappings=self.create_row_mappings(csv_reader.fieldnames),\n source=self.service,\n )\n\n for index, entry in rows:\n self.create_item(job, index, entry)\n return job\n\n def update_legacy_job(self, job):\n \"\"\"patch up a job that was in the old format\"\"\"\n items = job.items\n headers = list(items.first().data.keys())\n job.mappings = self.create_row_mappings(headers)\n job.updated_date = timezone.now()\n job.save()\n\n for item in items.all():\n normalized = self.normalize_row(item.data, job.mappings)\n normalized[\"shelf\"] = self.get_shelf(normalized)\n item.normalized_data = normalized\n item.save()\n\n def create_row_mappings(self, headers):\n \"\"\"guess what the headers mean\"\"\"\n mappings = {}\n for (key, guesses) in self.row_mappings_guesses:\n value = [h for h in headers if h.lower() in guesses]\n value = value[0] if len(value) else None\n if value:\n headers.remove(value)\n mappings[key] = value\n return mappings\n\n def create_item(self, job, index, data):\n \"\"\"creates and saves an import item\"\"\"\n normalized = self.normalize_row(data, job.mappings)\n normalized[\"shelf\"] = self.get_shelf(normalized)\n ImportItem(job=job, index=index, data=data, normalized_data=normalized).save()\n\n def get_shelf(self, normalized_row):\n \"\"\"determine which shelf to use\"\"\"\n shelf_name = normalized_row.get(\"shelf\")\n if not shelf_name:\n return None\n shelf_name = shelf_name.lower()\n shelf = [\n s for (s, gs) in self.shelf_mapping_guesses.items() if shelf_name in gs\n ]\n return shelf[0] if shelf else None\n\n def normalize_row(self, entry, mappings): # pylint: disable=no-self-use\n \"\"\"use the dataclass to create the formatted row of data\"\"\"\n return {k: entry.get(v) for k, v in mappings.items()}\n\n def create_retry_job(self, user, original_job, items):\n \"\"\"retry items that didn't import\"\"\"\n job = ImportJob.objects.create(\n user=user,\n include_reviews=original_job.include_reviews,\n privacy=original_job.privacy,\n source=original_job.source,\n # TODO: allow users to adjust mappings\n mappings=original_job.mappings,\n retry=True,\n )\n for item in items:\n # this will re-normalize the raw data\n self.create_item(job, item.index, item.data)\n return job\n", "path": "bookwyrm/importers/importer.py"}], "after_files": [{"content": "\"\"\" import books from another app \"\"\"\nfrom io import TextIOWrapper\nimport datetime\n\nfrom django.contrib.auth.decorators import login_required\nfrom django.db.models import Avg, ExpressionWrapper, F, fields\nfrom django.core.exceptions import PermissionDenied\nfrom django.core.paginator import Paginator\nfrom django.http import HttpResponseBadRequest\nfrom django.shortcuts import redirect\nfrom django.template.response import TemplateResponse\nfrom django.utils import timezone\nfrom django.utils.decorators import method_decorator\nfrom django.views import View\n\nfrom bookwyrm import forms, models\nfrom bookwyrm.importers import (\n CalibreImporter,\n LibrarythingImporter,\n GoodreadsImporter,\n StorygraphImporter,\n OpenLibraryImporter,\n)\nfrom bookwyrm.settings import PAGE_LENGTH\nfrom bookwyrm.utils.cache import get_or_set\n\n# pylint: disable= no-self-use\n@method_decorator(login_required, name=\"dispatch\")\nclass Import(View):\n \"\"\"import view\"\"\"\n\n def get(self, request, invalid=False):\n \"\"\"load import page\"\"\"\n jobs = models.ImportJob.objects.filter(user=request.user).order_by(\n \"-created_date\"\n )\n paginated = Paginator(jobs, PAGE_LENGTH)\n page = paginated.get_page(request.GET.get(\"page\"))\n data = {\n \"import_form\": forms.ImportForm(),\n \"jobs\": page,\n \"page_range\": paginated.get_elided_page_range(\n page.number, on_each_side=2, on_ends=1\n ),\n \"invalid\": invalid,\n }\n\n seconds = get_or_set(\"avg-import-time\", get_average_import_time, timeout=86400)\n if seconds and seconds > 60**2:\n data[\"recent_avg_hours\"] = seconds / (60**2)\n elif seconds:\n data[\"recent_avg_minutes\"] = seconds / 60\n\n return TemplateResponse(request, \"import/import.html\", data)\n\n def post(self, request):\n \"\"\"ingest a goodreads csv\"\"\"\n site = models.SiteSettings.objects.get()\n if not site.imports_enabled:\n raise PermissionDenied()\n\n form = forms.ImportForm(request.POST, request.FILES)\n if not form.is_valid():\n return HttpResponseBadRequest()\n\n include_reviews = request.POST.get(\"include_reviews\") == \"on\"\n privacy = request.POST.get(\"privacy\")\n source = request.POST.get(\"source\")\n\n importer = None\n if source == \"LibraryThing\":\n importer = LibrarythingImporter()\n elif source == \"Storygraph\":\n importer = StorygraphImporter()\n elif source == \"OpenLibrary\":\n importer = OpenLibraryImporter()\n elif source == \"Calibre\":\n importer = CalibreImporter()\n else:\n # Default : Goodreads\n importer = GoodreadsImporter()\n\n try:\n job = importer.create_job(\n request.user,\n TextIOWrapper(request.FILES[\"csv_file\"], encoding=importer.encoding),\n include_reviews,\n privacy,\n )\n except (UnicodeDecodeError, ValueError, KeyError):\n return self.get(request, invalid=True)\n\n job.start_job()\n\n return redirect(f\"/import/{job.id}\")\n\n\ndef get_average_import_time() -> float:\n \"\"\"Helper to figure out how long imports are taking (returns seconds)\"\"\"\n last_week = timezone.now() - datetime.timedelta(days=7)\n recent_avg = (\n models.ImportJob.objects.filter(created_date__gte=last_week, complete=True)\n .exclude(status=\"stopped\")\n .annotate(\n runtime=ExpressionWrapper(\n F(\"updated_date\") - F(\"created_date\"),\n output_field=fields.DurationField(),\n )\n )\n .aggregate(Avg(\"runtime\"))\n .get(\"runtime__avg\")\n )\n\n if recent_avg:\n return recent_avg.total_seconds()\n return None\n", "path": "bookwyrm/views/imports/import_data.py"}, {"content": "\"\"\" handle reading a csv from an external service, defaults are from Goodreads \"\"\"\nimport csv\nfrom django.utils import timezone\nfrom bookwyrm.models import ImportJob, ImportItem\n\n\nclass Importer:\n \"\"\"Generic class for csv data import from an outside service\"\"\"\n\n service = \"Import\"\n delimiter = \",\"\n encoding = \"UTF-8\"\n\n # these are from Goodreads\n row_mappings_guesses = [\n (\"id\", [\"id\", \"book id\"]),\n (\"title\", [\"title\"]),\n (\"authors\", [\"author\", \"authors\", \"primary author\"]),\n (\"isbn_10\", [\"isbn10\", \"isbn\"]),\n (\"isbn_13\", [\"isbn13\", \"isbn\", \"isbns\"]),\n (\"shelf\", [\"shelf\", \"exclusive shelf\", \"read status\", \"bookshelf\"]),\n (\"review_name\", [\"review name\"]),\n (\"review_body\", [\"my review\", \"review\"]),\n (\"rating\", [\"my rating\", \"rating\", \"star rating\"]),\n (\"date_added\", [\"date added\", \"entry date\", \"added\"]),\n (\"date_started\", [\"date started\", \"started\"]),\n (\"date_finished\", [\"date finished\", \"last date read\", \"date read\", \"finished\"]),\n ]\n date_fields = [\"date_added\", \"date_started\", \"date_finished\"]\n shelf_mapping_guesses = {\n \"to-read\": [\"to-read\", \"want to read\"],\n \"read\": [\"read\", \"already read\"],\n \"reading\": [\"currently-reading\", \"reading\", \"currently reading\"],\n }\n\n def create_job(self, user, csv_file, include_reviews, privacy):\n \"\"\"check over a csv and creates a database entry for the job\"\"\"\n csv_reader = csv.DictReader(csv_file, delimiter=self.delimiter)\n rows = list(csv_reader)\n if len(rows) < 1:\n raise ValueError(\"CSV file is empty\")\n rows = enumerate(rows)\n\n job = ImportJob.objects.create(\n user=user,\n include_reviews=include_reviews,\n privacy=privacy,\n mappings=self.create_row_mappings(csv_reader.fieldnames),\n source=self.service,\n )\n\n for index, entry in rows:\n self.create_item(job, index, entry)\n return job\n\n def update_legacy_job(self, job):\n \"\"\"patch up a job that was in the old format\"\"\"\n items = job.items\n headers = list(items.first().data.keys())\n job.mappings = self.create_row_mappings(headers)\n job.updated_date = timezone.now()\n job.save()\n\n for item in items.all():\n normalized = self.normalize_row(item.data, job.mappings)\n normalized[\"shelf\"] = self.get_shelf(normalized)\n item.normalized_data = normalized\n item.save()\n\n def create_row_mappings(self, headers):\n \"\"\"guess what the headers mean\"\"\"\n mappings = {}\n for (key, guesses) in self.row_mappings_guesses:\n value = [h for h in headers if h.lower() in guesses]\n value = value[0] if len(value) else None\n if value:\n headers.remove(value)\n mappings[key] = value\n return mappings\n\n def create_item(self, job, index, data):\n \"\"\"creates and saves an import item\"\"\"\n normalized = self.normalize_row(data, job.mappings)\n normalized[\"shelf\"] = self.get_shelf(normalized)\n ImportItem(job=job, index=index, data=data, normalized_data=normalized).save()\n\n def get_shelf(self, normalized_row):\n \"\"\"determine which shelf to use\"\"\"\n shelf_name = normalized_row.get(\"shelf\")\n if not shelf_name:\n return None\n shelf_name = shelf_name.lower()\n shelf = [\n s for (s, gs) in self.shelf_mapping_guesses.items() if shelf_name in gs\n ]\n return shelf[0] if shelf else None\n\n def normalize_row(self, entry, mappings): # pylint: disable=no-self-use\n \"\"\"use the dataclass to create the formatted row of data\"\"\"\n return {k: entry.get(v) for k, v in mappings.items()}\n\n def create_retry_job(self, user, original_job, items):\n \"\"\"retry items that didn't import\"\"\"\n job = ImportJob.objects.create(\n user=user,\n include_reviews=original_job.include_reviews,\n privacy=original_job.privacy,\n source=original_job.source,\n # TODO: allow users to adjust mappings\n mappings=original_job.mappings,\n retry=True,\n )\n for item in items:\n # this will re-normalize the raw data\n self.create_item(job, item.index, item.data)\n return job\n", "path": "bookwyrm/importers/importer.py"}]} | 2,809 | 472 |
gh_patches_debug_1761 | rasdani/github-patches | git_diff | cornellius-gp__gpytorch-711 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug] TypeError when calling `backward` on `gpytorch.functions.logdet`
# 🐛 Bug
I think there's a missing `list()` in https://github.com/cornellius-gp/gpytorch/blob/master/gpytorch/functions/_inv_quad_log_det.py#L221. I'm not super familiar with gpytorch internals so hopefully this is correct -- if so, happy to contribute the one-liner fix.
## To reproduce
** Code snippet to reproduce **
```python
### works (I'm guessing something dispatches elsewhere for small matrices?)
import torch
from torch.autograd import backward
import gpytorch
from gpytorch.functions import logdet, inv_matmul
n = 100
inp = torch.arange(n, dtype=torch.float)
kern = gpytorch.kernels.RBFKernel()(inp)
ld = logdet(kern)
backward(ld)
### doesn't work
import torch
from torch.autograd import backward
import gpytorch
from gpytorch.functions import logdet, inv_matmul
n = 1000
inp = torch.arange(n, dtype=torch.float)
kern = gpytorch.kernels.RBFKernel()(inp)
ld = logdet(kern)
backward(ld)
```
** Stack trace/error message **
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-46-593fbced29ac> in <module>()
3 kern = gpytorch.kernels.RBFKernel()(inp)
4 ld = logdet(kern)
----> 5 backward(ld)
<PATH SNIPPED>/lib/python3.7/site-packages/torch/autograd/__init__.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables)
91 Variable._execution_engine.run_backward(
92 tensors, grad_tensors, retain_graph, create_graph,
---> 93 allow_unreachable=True) # allow_unreachable flag
94
95
<PATH SNIPPED>/lib/python3.7/site-packages/torch/autograd/function.py in apply(self, *args)
75
76 def apply(self, *args):
---> 77 return self._forward_cls.backward(self, *args)
78
79
<PATH SNIPPED>lib/python3.7/site-packages/gpytorch/functions/_inv_quad_log_det.py in backward(ctx, inv_quad_grad_output, logdet_grad_output)
221 res = matrix_arg_grads
222
--> 223 return tuple([None] * 9 + res)
TypeError: can only concatenate list (not "tuple") to list
```
## Expected Behavior
No error.
## System information
**Please complete the following information:**
- GPyTorch version: 0.3.2 <!-- GPyTorch Version (run `print(gpytorch.__version__)` -->
- pytorch version 1.1.0.
- Mac OSX.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gpytorch/functions/_inv_quad_log_det.py`
Content:
```
1 #!/usr/bin/env python3
2
3 import torch
4 from torch.autograd import Function
5 from ..utils.lanczos import lanczos_tridiag_to_diag
6 from ..utils.stochastic_lq import StochasticLQ
7 from .. import settings
8
9
10 class InvQuadLogDet(Function):
11 """
12 Given a PSD matrix A (or a batch of PSD matrices A), this function computes one or both
13 of the following
14 - The matrix solves A^{-1} b
15 - logdet(A)
16 """
17 @staticmethod
18 def forward(
19 ctx,
20 representation_tree,
21 dtype,
22 device,
23 matrix_shape,
24 batch_shape=torch.Size(),
25 inv_quad=False,
26 logdet=False,
27 probe_vectors=None,
28 probe_vector_norms=None,
29 *args
30 ):
31 """
32 *args - The arguments representing the PSD matrix A (or batch of PSD matrices A)
33 If self.inv_quad is true, the first entry in *args is inv_quad_rhs (Tensor)
34 - the RHS of the matrix solves.
35
36 Returns:
37 - (Scalar) The inverse quadratic form (or None, if self.inv_quad is False)
38 - (Scalar) The log determinant (or None, self.if logdet is False)
39 """
40
41 if not (inv_quad or logdet):
42 raise RuntimeError("Either inv_quad or logdet must be true (or both)")
43
44 ctx.representation_tree = representation_tree
45 ctx.dtype = dtype
46 ctx.device = device
47 ctx.matrix_shape = matrix_shape
48 ctx.batch_shape = batch_shape
49 ctx.inv_quad = inv_quad
50 ctx.logdet = logdet
51
52 matrix_args = None
53 inv_quad_rhs = None
54 if ctx.inv_quad:
55 matrix_args = args[1:]
56 inv_quad_rhs = args[0]
57 else:
58 matrix_args = args
59
60 # Get closure for matmul
61 lazy_tsr = ctx.representation_tree(*matrix_args)
62 with torch.no_grad():
63 preconditioner, precond_lt, logdet_correction = lazy_tsr._preconditioner()
64
65 ctx.preconditioner = preconditioner
66
67 if (probe_vectors is None or probe_vector_norms is None) and logdet:
68 num_random_probes = settings.num_trace_samples.value()
69 if preconditioner is None:
70 probe_vectors = torch.empty(matrix_shape[-1], num_random_probes, dtype=dtype, device=device)
71 probe_vectors.bernoulli_().mul_(2).add_(-1)
72 probe_vector_norms = torch.norm(probe_vectors, 2, dim=-2, keepdim=True)
73 if batch_shape is not None:
74 probe_vectors = probe_vectors.expand(*batch_shape, matrix_shape[-1], num_random_probes)
75 probe_vector_norms = probe_vector_norms.expand(*batch_shape, 1, num_random_probes)
76 else:
77 probe_vectors = precond_lt.zero_mean_mvn_samples(num_random_probes)
78 probe_vectors = probe_vectors.unsqueeze(-2).transpose(0, -2).squeeze(0).transpose(-2, -1)
79 probe_vector_norms = torch.norm(probe_vectors, p=2, dim=-2, keepdim=True)
80 probe_vectors = probe_vectors.div(probe_vector_norms)
81
82 ctx.probe_vectors = probe_vectors
83 ctx.probe_vector_norms = probe_vector_norms
84
85 if ctx.logdet and not ctx.probe_vectors.numel():
86 raise RuntimeError("Probe vectors were not supplied for logdet computation")
87
88 # Collect terms for LinearCG
89 # We use LinearCG for both matrix solves and for stochastically estimating the log det
90 rhs_list = []
91 num_random_probes = 0
92 num_inv_quad_solves = 0
93
94 # RHS for logdet
95 if ctx.logdet:
96 rhs_list.append(ctx.probe_vectors)
97 num_random_probes = ctx.probe_vectors.size(-1)
98
99 # RHS for inv_quad
100 ctx.is_vector = False
101 if ctx.inv_quad:
102 if inv_quad_rhs.ndimension() == 1:
103 inv_quad_rhs = inv_quad_rhs.unsqueeze(-1)
104 ctx.is_vector = True
105 rhs_list.append(inv_quad_rhs)
106 num_inv_quad_solves = inv_quad_rhs.size(-1)
107
108 # Perform solves (for inv_quad) and tridiagonalization (for estimating logdet)
109 rhs = torch.cat(rhs_list, -1)
110 t_mat = None
111 if ctx.logdet and settings.skip_logdet_forward.off():
112 solves, t_mat = lazy_tsr._solve(rhs, preconditioner, num_tridiag=num_random_probes)
113
114 else:
115 solves = lazy_tsr._solve(rhs, preconditioner, num_tridiag=0)
116
117 # Final values to return
118 logdet_term = torch.zeros(lazy_tsr.batch_shape, dtype=ctx.dtype, device=ctx.device)
119 inv_quad_term = torch.zeros(lazy_tsr.batch_shape, dtype=ctx.dtype, device=ctx.device)
120
121 # Compute logdet from tridiagonalization
122 if ctx.logdet and settings.skip_logdet_forward.off():
123 if torch.any(torch.isnan(t_mat)).item():
124 logdet_term = torch.tensor(float("nan"), dtype=ctx.dtype, device=ctx.device)
125 else:
126 if ctx.batch_shape is None:
127 t_mat = t_mat.unsqueeze(1)
128 eigenvalues, eigenvectors = lanczos_tridiag_to_diag(t_mat)
129 slq = StochasticLQ()
130 logdet_term, = slq.evaluate(ctx.matrix_shape, eigenvalues, eigenvectors, [lambda x: x.log()])
131
132 # Add correction
133 if logdet_correction is not None:
134 logdet_term = logdet_term + logdet_correction
135
136 # Extract inv_quad solves from all the solves
137 if ctx.inv_quad:
138 inv_quad_solves = solves.narrow(-1, num_random_probes, num_inv_quad_solves)
139 inv_quad_term = (inv_quad_solves * inv_quad_rhs).sum(-2)
140
141 ctx.num_random_probes = num_random_probes
142 ctx.num_inv_quad_solves = num_inv_quad_solves
143
144 to_save = list(matrix_args) + [solves, ]
145 ctx.save_for_backward(*to_save)
146
147 if settings.memory_efficient.off():
148 ctx._lazy_tsr = lazy_tsr
149
150 return inv_quad_term, logdet_term
151
152 @staticmethod
153 def backward(ctx, inv_quad_grad_output, logdet_grad_output):
154 matrix_arg_grads = None
155 inv_quad_rhs_grad = None
156
157 # Which backward passes should we compute?
158 compute_inv_quad_grad = inv_quad_grad_output.abs().sum() and ctx.inv_quad
159 compute_logdet_grad = logdet_grad_output.abs().sum() and ctx.logdet
160
161 # Get input arguments, and get gradients in the proper form
162 matrix_args = ctx.saved_tensors[:-1]
163 solves = ctx.saved_tensors[-1]
164
165 if hasattr(ctx, "_lazy_tsr"):
166 lazy_tsr = ctx._lazy_tsr
167 else:
168 lazy_tsr = ctx.representation_tree(*matrix_args)
169
170 # Fix grad_output sizes
171 if ctx.inv_quad:
172 inv_quad_grad_output = inv_quad_grad_output.unsqueeze(-2)
173 if compute_logdet_grad:
174 logdet_grad_output = logdet_grad_output.unsqueeze(-1)
175 logdet_grad_output.unsqueeze_(-1)
176
177 # Divide up the solves
178 probe_vector_solves = None
179 inv_quad_solves = None
180 neg_inv_quad_solves_times_grad_out = None
181 if compute_logdet_grad:
182 coef = 1.0 / ctx.probe_vectors.size(-1)
183 probe_vector_solves = solves.narrow(-1, 0, ctx.num_random_probes).mul(coef)
184 probe_vector_solves.mul_(ctx.probe_vector_norms).mul_(logdet_grad_output)
185 probe_vectors = ctx.probe_vectors.mul(ctx.probe_vector_norms)
186 if ctx.inv_quad:
187 inv_quad_solves = solves.narrow(-1, ctx.num_random_probes, ctx.num_inv_quad_solves)
188 neg_inv_quad_solves_times_grad_out = inv_quad_solves.mul(inv_quad_grad_output).mul_(-1)
189
190 # input_1 gradient
191 if any(ctx.needs_input_grad):
192 # Collect terms for arg grads
193 left_factors_list = []
194 right_factors_list = []
195
196 if compute_logdet_grad:
197 left_factors_list.append(probe_vector_solves)
198 if ctx.preconditioner is not None:
199 probe_vectors = ctx.preconditioner(probe_vectors)
200 right_factors_list.append(probe_vectors)
201
202 if compute_inv_quad_grad:
203 left_factors_list.append(neg_inv_quad_solves_times_grad_out)
204 right_factors_list.append(inv_quad_solves)
205
206 left_factors = torch.cat(left_factors_list, -1)
207 right_factors = torch.cat(right_factors_list, -1)
208 matrix_arg_grads = lazy_tsr._quad_form_derivative(left_factors, right_factors)
209
210 # input_2 gradients
211 if compute_inv_quad_grad and ctx.needs_input_grad[9]:
212 inv_quad_rhs_grad = neg_inv_quad_solves_times_grad_out.mul_(-2)
213 elif ctx.inv_quad:
214 inv_quad_rhs_grad = torch.zeros_like(inv_quad_solves)
215 if ctx.is_vector:
216 inv_quad_rhs_grad.squeeze_(-1)
217
218 if ctx.inv_quad:
219 res = [inv_quad_rhs_grad] + list(matrix_arg_grads)
220 else:
221 res = matrix_arg_grads
222
223 return tuple([None] * 9 + res)
224
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/gpytorch/functions/_inv_quad_log_det.py b/gpytorch/functions/_inv_quad_log_det.py
--- a/gpytorch/functions/_inv_quad_log_det.py
+++ b/gpytorch/functions/_inv_quad_log_det.py
@@ -218,6 +218,6 @@
if ctx.inv_quad:
res = [inv_quad_rhs_grad] + list(matrix_arg_grads)
else:
- res = matrix_arg_grads
+ res = list(matrix_arg_grads)
return tuple([None] * 9 + res)
| {"golden_diff": "diff --git a/gpytorch/functions/_inv_quad_log_det.py b/gpytorch/functions/_inv_quad_log_det.py\n--- a/gpytorch/functions/_inv_quad_log_det.py\n+++ b/gpytorch/functions/_inv_quad_log_det.py\n@@ -218,6 +218,6 @@\n if ctx.inv_quad:\n res = [inv_quad_rhs_grad] + list(matrix_arg_grads)\n else:\n- res = matrix_arg_grads\n+ res = list(matrix_arg_grads)\n \n return tuple([None] * 9 + res)\n", "issue": "[Bug] TypeError when calling `backward` on `gpytorch.functions.logdet` \n# \ud83d\udc1b Bug\r\n\r\nI think there's a missing `list()` in https://github.com/cornellius-gp/gpytorch/blob/master/gpytorch/functions/_inv_quad_log_det.py#L221. I'm not super familiar with gpytorch internals so hopefully this is correct -- if so, happy to contribute the one-liner fix. \r\n\r\n## To reproduce\r\n\r\n** Code snippet to reproduce **\r\n```python\r\n### works (I'm guessing something dispatches elsewhere for small matrices?)\r\nimport torch\r\nfrom torch.autograd import backward\r\nimport gpytorch\r\nfrom gpytorch.functions import logdet, inv_matmul\r\nn = 100\r\ninp = torch.arange(n, dtype=torch.float)\r\nkern = gpytorch.kernels.RBFKernel()(inp)\r\nld = logdet(kern)\r\nbackward(ld)\r\n\r\n### doesn't work\r\nimport torch\r\nfrom torch.autograd import backward\r\nimport gpytorch\r\nfrom gpytorch.functions import logdet, inv_matmul\r\nn = 1000\r\ninp = torch.arange(n, dtype=torch.float)\r\nkern = gpytorch.kernels.RBFKernel()(inp)\r\nld = logdet(kern)\r\nbackward(ld)\r\n```\r\n\r\n** Stack trace/error message **\r\n```\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-46-593fbced29ac> in <module>()\r\n 3 kern = gpytorch.kernels.RBFKernel()(inp)\r\n 4 ld = logdet(kern)\r\n----> 5 backward(ld)\r\n\r\n<PATH SNIPPED>/lib/python3.7/site-packages/torch/autograd/__init__.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables)\r\n 91 Variable._execution_engine.run_backward(\r\n 92 tensors, grad_tensors, retain_graph, create_graph,\r\n---> 93 allow_unreachable=True) # allow_unreachable flag\r\n 94 \r\n 95 \r\n\r\n<PATH SNIPPED>/lib/python3.7/site-packages/torch/autograd/function.py in apply(self, *args)\r\n 75 \r\n 76 def apply(self, *args):\r\n---> 77 return self._forward_cls.backward(self, *args)\r\n 78 \r\n 79 \r\n\r\n<PATH SNIPPED>lib/python3.7/site-packages/gpytorch/functions/_inv_quad_log_det.py in backward(ctx, inv_quad_grad_output, logdet_grad_output)\r\n 221 res = matrix_arg_grads\r\n 222 \r\n--> 223 return tuple([None] * 9 + res)\r\n\r\nTypeError: can only concatenate list (not \"tuple\") to list\r\n```\r\n\r\n## Expected Behavior\r\n\r\nNo error. \r\n\r\n## System information\r\n\r\n**Please complete the following information:**\r\n- GPyTorch version: 0.3.2 <!-- GPyTorch Version (run `print(gpytorch.__version__)` -->\r\n- pytorch version 1.1.0. \r\n- Mac OSX. \r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport torch\nfrom torch.autograd import Function\nfrom ..utils.lanczos import lanczos_tridiag_to_diag\nfrom ..utils.stochastic_lq import StochasticLQ\nfrom .. import settings\n\n\nclass InvQuadLogDet(Function):\n \"\"\"\n Given a PSD matrix A (or a batch of PSD matrices A), this function computes one or both\n of the following\n - The matrix solves A^{-1} b\n - logdet(A)\n \"\"\"\n @staticmethod\n def forward(\n ctx,\n representation_tree,\n dtype,\n device,\n matrix_shape,\n batch_shape=torch.Size(),\n inv_quad=False,\n logdet=False,\n probe_vectors=None,\n probe_vector_norms=None,\n *args\n ):\n \"\"\"\n *args - The arguments representing the PSD matrix A (or batch of PSD matrices A)\n If self.inv_quad is true, the first entry in *args is inv_quad_rhs (Tensor)\n - the RHS of the matrix solves.\n\n Returns:\n - (Scalar) The inverse quadratic form (or None, if self.inv_quad is False)\n - (Scalar) The log determinant (or None, self.if logdet is False)\n \"\"\"\n\n if not (inv_quad or logdet):\n raise RuntimeError(\"Either inv_quad or logdet must be true (or both)\")\n\n ctx.representation_tree = representation_tree\n ctx.dtype = dtype\n ctx.device = device\n ctx.matrix_shape = matrix_shape\n ctx.batch_shape = batch_shape\n ctx.inv_quad = inv_quad\n ctx.logdet = logdet\n\n matrix_args = None\n inv_quad_rhs = None\n if ctx.inv_quad:\n matrix_args = args[1:]\n inv_quad_rhs = args[0]\n else:\n matrix_args = args\n\n # Get closure for matmul\n lazy_tsr = ctx.representation_tree(*matrix_args)\n with torch.no_grad():\n preconditioner, precond_lt, logdet_correction = lazy_tsr._preconditioner()\n\n ctx.preconditioner = preconditioner\n\n if (probe_vectors is None or probe_vector_norms is None) and logdet:\n num_random_probes = settings.num_trace_samples.value()\n if preconditioner is None:\n probe_vectors = torch.empty(matrix_shape[-1], num_random_probes, dtype=dtype, device=device)\n probe_vectors.bernoulli_().mul_(2).add_(-1)\n probe_vector_norms = torch.norm(probe_vectors, 2, dim=-2, keepdim=True)\n if batch_shape is not None:\n probe_vectors = probe_vectors.expand(*batch_shape, matrix_shape[-1], num_random_probes)\n probe_vector_norms = probe_vector_norms.expand(*batch_shape, 1, num_random_probes)\n else:\n probe_vectors = precond_lt.zero_mean_mvn_samples(num_random_probes)\n probe_vectors = probe_vectors.unsqueeze(-2).transpose(0, -2).squeeze(0).transpose(-2, -1)\n probe_vector_norms = torch.norm(probe_vectors, p=2, dim=-2, keepdim=True)\n probe_vectors = probe_vectors.div(probe_vector_norms)\n\n ctx.probe_vectors = probe_vectors\n ctx.probe_vector_norms = probe_vector_norms\n\n if ctx.logdet and not ctx.probe_vectors.numel():\n raise RuntimeError(\"Probe vectors were not supplied for logdet computation\")\n\n # Collect terms for LinearCG\n # We use LinearCG for both matrix solves and for stochastically estimating the log det\n rhs_list = []\n num_random_probes = 0\n num_inv_quad_solves = 0\n\n # RHS for logdet\n if ctx.logdet:\n rhs_list.append(ctx.probe_vectors)\n num_random_probes = ctx.probe_vectors.size(-1)\n\n # RHS for inv_quad\n ctx.is_vector = False\n if ctx.inv_quad:\n if inv_quad_rhs.ndimension() == 1:\n inv_quad_rhs = inv_quad_rhs.unsqueeze(-1)\n ctx.is_vector = True\n rhs_list.append(inv_quad_rhs)\n num_inv_quad_solves = inv_quad_rhs.size(-1)\n\n # Perform solves (for inv_quad) and tridiagonalization (for estimating logdet)\n rhs = torch.cat(rhs_list, -1)\n t_mat = None\n if ctx.logdet and settings.skip_logdet_forward.off():\n solves, t_mat = lazy_tsr._solve(rhs, preconditioner, num_tridiag=num_random_probes)\n\n else:\n solves = lazy_tsr._solve(rhs, preconditioner, num_tridiag=0)\n\n # Final values to return\n logdet_term = torch.zeros(lazy_tsr.batch_shape, dtype=ctx.dtype, device=ctx.device)\n inv_quad_term = torch.zeros(lazy_tsr.batch_shape, dtype=ctx.dtype, device=ctx.device)\n\n # Compute logdet from tridiagonalization\n if ctx.logdet and settings.skip_logdet_forward.off():\n if torch.any(torch.isnan(t_mat)).item():\n logdet_term = torch.tensor(float(\"nan\"), dtype=ctx.dtype, device=ctx.device)\n else:\n if ctx.batch_shape is None:\n t_mat = t_mat.unsqueeze(1)\n eigenvalues, eigenvectors = lanczos_tridiag_to_diag(t_mat)\n slq = StochasticLQ()\n logdet_term, = slq.evaluate(ctx.matrix_shape, eigenvalues, eigenvectors, [lambda x: x.log()])\n\n # Add correction\n if logdet_correction is not None:\n logdet_term = logdet_term + logdet_correction\n\n # Extract inv_quad solves from all the solves\n if ctx.inv_quad:\n inv_quad_solves = solves.narrow(-1, num_random_probes, num_inv_quad_solves)\n inv_quad_term = (inv_quad_solves * inv_quad_rhs).sum(-2)\n\n ctx.num_random_probes = num_random_probes\n ctx.num_inv_quad_solves = num_inv_quad_solves\n\n to_save = list(matrix_args) + [solves, ]\n ctx.save_for_backward(*to_save)\n\n if settings.memory_efficient.off():\n ctx._lazy_tsr = lazy_tsr\n\n return inv_quad_term, logdet_term\n\n @staticmethod\n def backward(ctx, inv_quad_grad_output, logdet_grad_output):\n matrix_arg_grads = None\n inv_quad_rhs_grad = None\n\n # Which backward passes should we compute?\n compute_inv_quad_grad = inv_quad_grad_output.abs().sum() and ctx.inv_quad\n compute_logdet_grad = logdet_grad_output.abs().sum() and ctx.logdet\n\n # Get input arguments, and get gradients in the proper form\n matrix_args = ctx.saved_tensors[:-1]\n solves = ctx.saved_tensors[-1]\n\n if hasattr(ctx, \"_lazy_tsr\"):\n lazy_tsr = ctx._lazy_tsr\n else:\n lazy_tsr = ctx.representation_tree(*matrix_args)\n\n # Fix grad_output sizes\n if ctx.inv_quad:\n inv_quad_grad_output = inv_quad_grad_output.unsqueeze(-2)\n if compute_logdet_grad:\n logdet_grad_output = logdet_grad_output.unsqueeze(-1)\n logdet_grad_output.unsqueeze_(-1)\n\n # Divide up the solves\n probe_vector_solves = None\n inv_quad_solves = None\n neg_inv_quad_solves_times_grad_out = None\n if compute_logdet_grad:\n coef = 1.0 / ctx.probe_vectors.size(-1)\n probe_vector_solves = solves.narrow(-1, 0, ctx.num_random_probes).mul(coef)\n probe_vector_solves.mul_(ctx.probe_vector_norms).mul_(logdet_grad_output)\n probe_vectors = ctx.probe_vectors.mul(ctx.probe_vector_norms)\n if ctx.inv_quad:\n inv_quad_solves = solves.narrow(-1, ctx.num_random_probes, ctx.num_inv_quad_solves)\n neg_inv_quad_solves_times_grad_out = inv_quad_solves.mul(inv_quad_grad_output).mul_(-1)\n\n # input_1 gradient\n if any(ctx.needs_input_grad):\n # Collect terms for arg grads\n left_factors_list = []\n right_factors_list = []\n\n if compute_logdet_grad:\n left_factors_list.append(probe_vector_solves)\n if ctx.preconditioner is not None:\n probe_vectors = ctx.preconditioner(probe_vectors)\n right_factors_list.append(probe_vectors)\n\n if compute_inv_quad_grad:\n left_factors_list.append(neg_inv_quad_solves_times_grad_out)\n right_factors_list.append(inv_quad_solves)\n\n left_factors = torch.cat(left_factors_list, -1)\n right_factors = torch.cat(right_factors_list, -1)\n matrix_arg_grads = lazy_tsr._quad_form_derivative(left_factors, right_factors)\n\n # input_2 gradients\n if compute_inv_quad_grad and ctx.needs_input_grad[9]:\n inv_quad_rhs_grad = neg_inv_quad_solves_times_grad_out.mul_(-2)\n elif ctx.inv_quad:\n inv_quad_rhs_grad = torch.zeros_like(inv_quad_solves)\n if ctx.is_vector:\n inv_quad_rhs_grad.squeeze_(-1)\n\n if ctx.inv_quad:\n res = [inv_quad_rhs_grad] + list(matrix_arg_grads)\n else:\n res = matrix_arg_grads\n\n return tuple([None] * 9 + res)\n", "path": "gpytorch/functions/_inv_quad_log_det.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nimport torch\nfrom torch.autograd import Function\nfrom ..utils.lanczos import lanczos_tridiag_to_diag\nfrom ..utils.stochastic_lq import StochasticLQ\nfrom .. import settings\n\n\nclass InvQuadLogDet(Function):\n \"\"\"\n Given a PSD matrix A (or a batch of PSD matrices A), this function computes one or both\n of the following\n - The matrix solves A^{-1} b\n - logdet(A)\n \"\"\"\n @staticmethod\n def forward(\n ctx,\n representation_tree,\n dtype,\n device,\n matrix_shape,\n batch_shape=torch.Size(),\n inv_quad=False,\n logdet=False,\n probe_vectors=None,\n probe_vector_norms=None,\n *args\n ):\n \"\"\"\n *args - The arguments representing the PSD matrix A (or batch of PSD matrices A)\n If self.inv_quad is true, the first entry in *args is inv_quad_rhs (Tensor)\n - the RHS of the matrix solves.\n\n Returns:\n - (Scalar) The inverse quadratic form (or None, if self.inv_quad is False)\n - (Scalar) The log determinant (or None, self.if logdet is False)\n \"\"\"\n\n if not (inv_quad or logdet):\n raise RuntimeError(\"Either inv_quad or logdet must be true (or both)\")\n\n ctx.representation_tree = representation_tree\n ctx.dtype = dtype\n ctx.device = device\n ctx.matrix_shape = matrix_shape\n ctx.batch_shape = batch_shape\n ctx.inv_quad = inv_quad\n ctx.logdet = logdet\n\n matrix_args = None\n inv_quad_rhs = None\n if ctx.inv_quad:\n matrix_args = args[1:]\n inv_quad_rhs = args[0]\n else:\n matrix_args = args\n\n # Get closure for matmul\n lazy_tsr = ctx.representation_tree(*matrix_args)\n with torch.no_grad():\n preconditioner, precond_lt, logdet_correction = lazy_tsr._preconditioner()\n\n ctx.preconditioner = preconditioner\n\n if (probe_vectors is None or probe_vector_norms is None) and logdet:\n num_random_probes = settings.num_trace_samples.value()\n if preconditioner is None:\n probe_vectors = torch.empty(matrix_shape[-1], num_random_probes, dtype=dtype, device=device)\n probe_vectors.bernoulli_().mul_(2).add_(-1)\n probe_vector_norms = torch.norm(probe_vectors, 2, dim=-2, keepdim=True)\n if batch_shape is not None:\n probe_vectors = probe_vectors.expand(*batch_shape, matrix_shape[-1], num_random_probes)\n probe_vector_norms = probe_vector_norms.expand(*batch_shape, 1, num_random_probes)\n else:\n probe_vectors = precond_lt.zero_mean_mvn_samples(num_random_probes)\n probe_vectors = probe_vectors.unsqueeze(-2).transpose(0, -2).squeeze(0).transpose(-2, -1)\n probe_vector_norms = torch.norm(probe_vectors, p=2, dim=-2, keepdim=True)\n probe_vectors = probe_vectors.div(probe_vector_norms)\n\n ctx.probe_vectors = probe_vectors\n ctx.probe_vector_norms = probe_vector_norms\n\n if ctx.logdet and not ctx.probe_vectors.numel():\n raise RuntimeError(\"Probe vectors were not supplied for logdet computation\")\n\n # Collect terms for LinearCG\n # We use LinearCG for both matrix solves and for stochastically estimating the log det\n rhs_list = []\n num_random_probes = 0\n num_inv_quad_solves = 0\n\n # RHS for logdet\n if ctx.logdet:\n rhs_list.append(ctx.probe_vectors)\n num_random_probes = ctx.probe_vectors.size(-1)\n\n # RHS for inv_quad\n ctx.is_vector = False\n if ctx.inv_quad:\n if inv_quad_rhs.ndimension() == 1:\n inv_quad_rhs = inv_quad_rhs.unsqueeze(-1)\n ctx.is_vector = True\n rhs_list.append(inv_quad_rhs)\n num_inv_quad_solves = inv_quad_rhs.size(-1)\n\n # Perform solves (for inv_quad) and tridiagonalization (for estimating logdet)\n rhs = torch.cat(rhs_list, -1)\n t_mat = None\n if ctx.logdet and settings.skip_logdet_forward.off():\n solves, t_mat = lazy_tsr._solve(rhs, preconditioner, num_tridiag=num_random_probes)\n\n else:\n solves = lazy_tsr._solve(rhs, preconditioner, num_tridiag=0)\n\n # Final values to return\n logdet_term = torch.zeros(lazy_tsr.batch_shape, dtype=ctx.dtype, device=ctx.device)\n inv_quad_term = torch.zeros(lazy_tsr.batch_shape, dtype=ctx.dtype, device=ctx.device)\n\n # Compute logdet from tridiagonalization\n if ctx.logdet and settings.skip_logdet_forward.off():\n if torch.any(torch.isnan(t_mat)).item():\n logdet_term = torch.tensor(float(\"nan\"), dtype=ctx.dtype, device=ctx.device)\n else:\n if ctx.batch_shape is None:\n t_mat = t_mat.unsqueeze(1)\n eigenvalues, eigenvectors = lanczos_tridiag_to_diag(t_mat)\n slq = StochasticLQ()\n logdet_term, = slq.evaluate(ctx.matrix_shape, eigenvalues, eigenvectors, [lambda x: x.log()])\n\n # Add correction\n if logdet_correction is not None:\n logdet_term = logdet_term + logdet_correction\n\n # Extract inv_quad solves from all the solves\n if ctx.inv_quad:\n inv_quad_solves = solves.narrow(-1, num_random_probes, num_inv_quad_solves)\n inv_quad_term = (inv_quad_solves * inv_quad_rhs).sum(-2)\n\n ctx.num_random_probes = num_random_probes\n ctx.num_inv_quad_solves = num_inv_quad_solves\n\n to_save = list(matrix_args) + [solves, ]\n ctx.save_for_backward(*to_save)\n\n if settings.memory_efficient.off():\n ctx._lazy_tsr = lazy_tsr\n\n return inv_quad_term, logdet_term\n\n @staticmethod\n def backward(ctx, inv_quad_grad_output, logdet_grad_output):\n matrix_arg_grads = None\n inv_quad_rhs_grad = None\n\n # Which backward passes should we compute?\n compute_inv_quad_grad = inv_quad_grad_output.abs().sum() and ctx.inv_quad\n compute_logdet_grad = logdet_grad_output.abs().sum() and ctx.logdet\n\n # Get input arguments, and get gradients in the proper form\n matrix_args = ctx.saved_tensors[:-1]\n solves = ctx.saved_tensors[-1]\n\n if hasattr(ctx, \"_lazy_tsr\"):\n lazy_tsr = ctx._lazy_tsr\n else:\n lazy_tsr = ctx.representation_tree(*matrix_args)\n\n # Fix grad_output sizes\n if ctx.inv_quad:\n inv_quad_grad_output = inv_quad_grad_output.unsqueeze(-2)\n if compute_logdet_grad:\n logdet_grad_output = logdet_grad_output.unsqueeze(-1)\n logdet_grad_output.unsqueeze_(-1)\n\n # Divide up the solves\n probe_vector_solves = None\n inv_quad_solves = None\n neg_inv_quad_solves_times_grad_out = None\n if compute_logdet_grad:\n coef = 1.0 / ctx.probe_vectors.size(-1)\n probe_vector_solves = solves.narrow(-1, 0, ctx.num_random_probes).mul(coef)\n probe_vector_solves.mul_(ctx.probe_vector_norms).mul_(logdet_grad_output)\n probe_vectors = ctx.probe_vectors.mul(ctx.probe_vector_norms)\n if ctx.inv_quad:\n inv_quad_solves = solves.narrow(-1, ctx.num_random_probes, ctx.num_inv_quad_solves)\n neg_inv_quad_solves_times_grad_out = inv_quad_solves.mul(inv_quad_grad_output).mul_(-1)\n\n # input_1 gradient\n if any(ctx.needs_input_grad):\n # Collect terms for arg grads\n left_factors_list = []\n right_factors_list = []\n\n if compute_logdet_grad:\n left_factors_list.append(probe_vector_solves)\n if ctx.preconditioner is not None:\n probe_vectors = ctx.preconditioner(probe_vectors)\n right_factors_list.append(probe_vectors)\n\n if compute_inv_quad_grad:\n left_factors_list.append(neg_inv_quad_solves_times_grad_out)\n right_factors_list.append(inv_quad_solves)\n\n left_factors = torch.cat(left_factors_list, -1)\n right_factors = torch.cat(right_factors_list, -1)\n matrix_arg_grads = lazy_tsr._quad_form_derivative(left_factors, right_factors)\n\n # input_2 gradients\n if compute_inv_quad_grad and ctx.needs_input_grad[9]:\n inv_quad_rhs_grad = neg_inv_quad_solves_times_grad_out.mul_(-2)\n elif ctx.inv_quad:\n inv_quad_rhs_grad = torch.zeros_like(inv_quad_solves)\n if ctx.is_vector:\n inv_quad_rhs_grad.squeeze_(-1)\n\n if ctx.inv_quad:\n res = [inv_quad_rhs_grad] + list(matrix_arg_grads)\n else:\n res = list(matrix_arg_grads)\n\n return tuple([None] * 9 + res)\n", "path": "gpytorch/functions/_inv_quad_log_det.py"}]} | 3,546 | 123 |
gh_patches_debug_28904 | rasdani/github-patches | git_diff | scrapy__scrapy-3283 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`scrapy.FormRequest.from_response` observed to eliminate duplicate keys in `formdata`
This looks good:
```
In [2]: scrapy.FormRequest('http://example.com', method='GET', formdata=(('foo', 'bar'), ('foo', 'baz')))
Out[2]: <GET http://example.com?foo=bar&foo=baz>
```
While here is the issue:
```
In [3]: response = scrapy.http.TextResponse(url='http://example.com', body='<form></form>', encoding='utf8')
In [4]: scrapy.FormRequest.from_response(response, method='GET', formdata=(('foo', 'bar'), ('foo', 'baz')))
Out[4]: <GET http://example.com?foo=baz>
```
(Tested with `Scrapy 1.5.0` and `Python 3.6.5`)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scrapy/http/request/form.py`
Content:
```
1 """
2 This module implements the FormRequest class which is a more convenient class
3 (than Request) to generate Requests based on form data.
4
5 See documentation in docs/topics/request-response.rst
6 """
7
8 import six
9 from six.moves.urllib.parse import urljoin, urlencode
10
11 import lxml.html
12 from parsel.selector import create_root_node
13 from w3lib.html import strip_html5_whitespace
14
15 from scrapy.http.request import Request
16 from scrapy.utils.python import to_bytes, is_listlike
17 from scrapy.utils.response import get_base_url
18
19
20 class FormRequest(Request):
21
22 def __init__(self, *args, **kwargs):
23 formdata = kwargs.pop('formdata', None)
24 if formdata and kwargs.get('method') is None:
25 kwargs['method'] = 'POST'
26
27 super(FormRequest, self).__init__(*args, **kwargs)
28
29 if formdata:
30 items = formdata.items() if isinstance(formdata, dict) else formdata
31 querystr = _urlencode(items, self.encoding)
32 if self.method == 'POST':
33 self.headers.setdefault(b'Content-Type', b'application/x-www-form-urlencoded')
34 self._set_body(querystr)
35 else:
36 self._set_url(self.url + ('&' if '?' in self.url else '?') + querystr)
37
38 @classmethod
39 def from_response(cls, response, formname=None, formid=None, formnumber=0, formdata=None,
40 clickdata=None, dont_click=False, formxpath=None, formcss=None, **kwargs):
41
42 kwargs.setdefault('encoding', response.encoding)
43
44 if formcss is not None:
45 from parsel.csstranslator import HTMLTranslator
46 formxpath = HTMLTranslator().css_to_xpath(formcss)
47
48 form = _get_form(response, formname, formid, formnumber, formxpath)
49 formdata = _get_inputs(form, formdata, dont_click, clickdata, response)
50 url = _get_form_url(form, kwargs.pop('url', None))
51 method = kwargs.pop('method', form.method)
52 return cls(url=url, method=method, formdata=formdata, **kwargs)
53
54
55 def _get_form_url(form, url):
56 if url is None:
57 action = form.get('action')
58 if action is None:
59 return form.base_url
60 return urljoin(form.base_url, strip_html5_whitespace(action))
61 return urljoin(form.base_url, url)
62
63
64 def _urlencode(seq, enc):
65 values = [(to_bytes(k, enc), to_bytes(v, enc))
66 for k, vs in seq
67 for v in (vs if is_listlike(vs) else [vs])]
68 return urlencode(values, doseq=1)
69
70
71 def _get_form(response, formname, formid, formnumber, formxpath):
72 """Find the form element """
73 root = create_root_node(response.text, lxml.html.HTMLParser,
74 base_url=get_base_url(response))
75 forms = root.xpath('//form')
76 if not forms:
77 raise ValueError("No <form> element found in %s" % response)
78
79 if formname is not None:
80 f = root.xpath('//form[@name="%s"]' % formname)
81 if f:
82 return f[0]
83
84 if formid is not None:
85 f = root.xpath('//form[@id="%s"]' % formid)
86 if f:
87 return f[0]
88
89 # Get form element from xpath, if not found, go up
90 if formxpath is not None:
91 nodes = root.xpath(formxpath)
92 if nodes:
93 el = nodes[0]
94 while True:
95 if el.tag == 'form':
96 return el
97 el = el.getparent()
98 if el is None:
99 break
100 encoded = formxpath if six.PY3 else formxpath.encode('unicode_escape')
101 raise ValueError('No <form> element found with %s' % encoded)
102
103 # If we get here, it means that either formname was None
104 # or invalid
105 if formnumber is not None:
106 try:
107 form = forms[formnumber]
108 except IndexError:
109 raise IndexError("Form number %d not found in %s" %
110 (formnumber, response))
111 else:
112 return form
113
114
115 def _get_inputs(form, formdata, dont_click, clickdata, response):
116 try:
117 formdata = dict(formdata or ())
118 except (ValueError, TypeError):
119 raise ValueError('formdata should be a dict or iterable of tuples')
120
121 inputs = form.xpath('descendant::textarea'
122 '|descendant::select'
123 '|descendant::input[not(@type) or @type['
124 ' not(re:test(., "^(?:submit|image|reset)$", "i"))'
125 ' and (../@checked or'
126 ' not(re:test(., "^(?:checkbox|radio)$", "i")))]]',
127 namespaces={
128 "re": "http://exslt.org/regular-expressions"})
129 values = [(k, u'' if v is None else v)
130 for k, v in (_value(e) for e in inputs)
131 if k and k not in formdata]
132
133 if not dont_click:
134 clickable = _get_clickable(clickdata, form)
135 if clickable and clickable[0] not in formdata and not clickable[0] is None:
136 values.append(clickable)
137
138 values.extend((k, v) for k, v in formdata.items() if v is not None)
139 return values
140
141
142 def _value(ele):
143 n = ele.name
144 v = ele.value
145 if ele.tag == 'select':
146 return _select_value(ele, n, v)
147 return n, v
148
149
150 def _select_value(ele, n, v):
151 multiple = ele.multiple
152 if v is None and not multiple:
153 # Match browser behaviour on simple select tag without options selected
154 # And for select tags wihout options
155 o = ele.value_options
156 return (n, o[0]) if o else (None, None)
157 elif v is not None and multiple:
158 # This is a workround to bug in lxml fixed 2.3.1
159 # fix https://github.com/lxml/lxml/commit/57f49eed82068a20da3db8f1b18ae00c1bab8b12#L1L1139
160 selected_options = ele.xpath('.//option[@selected]')
161 v = [(o.get('value') or o.text or u'').strip() for o in selected_options]
162 return n, v
163
164
165 def _get_clickable(clickdata, form):
166 """
167 Returns the clickable element specified in clickdata,
168 if the latter is given. If not, it returns the first
169 clickable element found
170 """
171 clickables = [
172 el for el in form.xpath(
173 'descendant::input[re:test(@type, "^(submit|image)$", "i")]'
174 '|descendant::button[not(@type) or re:test(@type, "^submit$", "i")]',
175 namespaces={"re": "http://exslt.org/regular-expressions"})
176 ]
177 if not clickables:
178 return
179
180 # If we don't have clickdata, we just use the first clickable element
181 if clickdata is None:
182 el = clickables[0]
183 return (el.get('name'), el.get('value') or '')
184
185 # If clickdata is given, we compare it to the clickable elements to find a
186 # match. We first look to see if the number is specified in clickdata,
187 # because that uniquely identifies the element
188 nr = clickdata.get('nr', None)
189 if nr is not None:
190 try:
191 el = list(form.inputs)[nr]
192 except IndexError:
193 pass
194 else:
195 return (el.get('name'), el.get('value') or '')
196
197 # We didn't find it, so now we build an XPath expression out of the other
198 # arguments, because they can be used as such
199 xpath = u'.//*' + \
200 u''.join(u'[@%s="%s"]' % c for c in six.iteritems(clickdata))
201 el = form.xpath(xpath)
202 if len(el) == 1:
203 return (el[0].get('name'), el[0].get('value') or '')
204 elif len(el) > 1:
205 raise ValueError("Multiple elements found (%r) matching the criteria "
206 "in clickdata: %r" % (el, clickdata))
207 else:
208 raise ValueError('No clickable element matching clickdata: %r' % (clickdata,))
209
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/scrapy/http/request/form.py b/scrapy/http/request/form.py
--- a/scrapy/http/request/form.py
+++ b/scrapy/http/request/form.py
@@ -114,10 +114,12 @@
def _get_inputs(form, formdata, dont_click, clickdata, response):
try:
- formdata = dict(formdata or ())
+ formdata_keys = dict(formdata or ()).keys()
except (ValueError, TypeError):
raise ValueError('formdata should be a dict or iterable of tuples')
+ if not formdata:
+ formdata = ()
inputs = form.xpath('descendant::textarea'
'|descendant::select'
'|descendant::input[not(@type) or @type['
@@ -128,14 +130,17 @@
"re": "http://exslt.org/regular-expressions"})
values = [(k, u'' if v is None else v)
for k, v in (_value(e) for e in inputs)
- if k and k not in formdata]
+ if k and k not in formdata_keys]
if not dont_click:
clickable = _get_clickable(clickdata, form)
if clickable and clickable[0] not in formdata and not clickable[0] is None:
values.append(clickable)
- values.extend((k, v) for k, v in formdata.items() if v is not None)
+ if isinstance(formdata, dict):
+ formdata = formdata.items()
+
+ values.extend((k, v) for k, v in formdata if v is not None)
return values
| {"golden_diff": "diff --git a/scrapy/http/request/form.py b/scrapy/http/request/form.py\n--- a/scrapy/http/request/form.py\n+++ b/scrapy/http/request/form.py\n@@ -114,10 +114,12 @@\n \n def _get_inputs(form, formdata, dont_click, clickdata, response):\n try:\n- formdata = dict(formdata or ())\n+ formdata_keys = dict(formdata or ()).keys()\n except (ValueError, TypeError):\n raise ValueError('formdata should be a dict or iterable of tuples')\n \n+ if not formdata:\n+ formdata = ()\n inputs = form.xpath('descendant::textarea'\n '|descendant::select'\n '|descendant::input[not(@type) or @type['\n@@ -128,14 +130,17 @@\n \"re\": \"http://exslt.org/regular-expressions\"})\n values = [(k, u'' if v is None else v)\n for k, v in (_value(e) for e in inputs)\n- if k and k not in formdata]\n+ if k and k not in formdata_keys]\n \n if not dont_click:\n clickable = _get_clickable(clickdata, form)\n if clickable and clickable[0] not in formdata and not clickable[0] is None:\n values.append(clickable)\n \n- values.extend((k, v) for k, v in formdata.items() if v is not None)\n+ if isinstance(formdata, dict):\n+ formdata = formdata.items()\n+\n+ values.extend((k, v) for k, v in formdata if v is not None)\n return values\n", "issue": "`scrapy.FormRequest.from_response` observed to eliminate duplicate keys in `formdata`\nThis looks good:\r\n```\r\nIn [2]: scrapy.FormRequest('http://example.com', method='GET', formdata=(('foo', 'bar'), ('foo', 'baz')))\r\nOut[2]: <GET http://example.com?foo=bar&foo=baz>\r\n```\r\n\r\nWhile here is the issue:\r\n```\r\nIn [3]: response = scrapy.http.TextResponse(url='http://example.com', body='<form></form>', encoding='utf8')\r\n\r\nIn [4]: scrapy.FormRequest.from_response(response, method='GET', formdata=(('foo', 'bar'), ('foo', 'baz')))\r\nOut[4]: <GET http://example.com?foo=baz>\r\n```\r\n\r\n(Tested with `Scrapy 1.5.0` and `Python 3.6.5`)\n", "before_files": [{"content": "\"\"\"\nThis module implements the FormRequest class which is a more convenient class\n(than Request) to generate Requests based on form data.\n\nSee documentation in docs/topics/request-response.rst\n\"\"\"\n\nimport six\nfrom six.moves.urllib.parse import urljoin, urlencode\n\nimport lxml.html\nfrom parsel.selector import create_root_node\nfrom w3lib.html import strip_html5_whitespace\n\nfrom scrapy.http.request import Request\nfrom scrapy.utils.python import to_bytes, is_listlike\nfrom scrapy.utils.response import get_base_url\n\n\nclass FormRequest(Request):\n\n def __init__(self, *args, **kwargs):\n formdata = kwargs.pop('formdata', None)\n if formdata and kwargs.get('method') is None:\n kwargs['method'] = 'POST'\n\n super(FormRequest, self).__init__(*args, **kwargs)\n\n if formdata:\n items = formdata.items() if isinstance(formdata, dict) else formdata\n querystr = _urlencode(items, self.encoding)\n if self.method == 'POST':\n self.headers.setdefault(b'Content-Type', b'application/x-www-form-urlencoded')\n self._set_body(querystr)\n else:\n self._set_url(self.url + ('&' if '?' in self.url else '?') + querystr)\n\n @classmethod\n def from_response(cls, response, formname=None, formid=None, formnumber=0, formdata=None,\n clickdata=None, dont_click=False, formxpath=None, formcss=None, **kwargs):\n\n kwargs.setdefault('encoding', response.encoding)\n\n if formcss is not None:\n from parsel.csstranslator import HTMLTranslator\n formxpath = HTMLTranslator().css_to_xpath(formcss)\n\n form = _get_form(response, formname, formid, formnumber, formxpath)\n formdata = _get_inputs(form, formdata, dont_click, clickdata, response)\n url = _get_form_url(form, kwargs.pop('url', None))\n method = kwargs.pop('method', form.method)\n return cls(url=url, method=method, formdata=formdata, **kwargs)\n\n\ndef _get_form_url(form, url):\n if url is None:\n action = form.get('action')\n if action is None:\n return form.base_url\n return urljoin(form.base_url, strip_html5_whitespace(action))\n return urljoin(form.base_url, url)\n\n\ndef _urlencode(seq, enc):\n values = [(to_bytes(k, enc), to_bytes(v, enc))\n for k, vs in seq\n for v in (vs if is_listlike(vs) else [vs])]\n return urlencode(values, doseq=1)\n\n\ndef _get_form(response, formname, formid, formnumber, formxpath):\n \"\"\"Find the form element \"\"\"\n root = create_root_node(response.text, lxml.html.HTMLParser,\n base_url=get_base_url(response))\n forms = root.xpath('//form')\n if not forms:\n raise ValueError(\"No <form> element found in %s\" % response)\n\n if formname is not None:\n f = root.xpath('//form[@name=\"%s\"]' % formname)\n if f:\n return f[0]\n\n if formid is not None:\n f = root.xpath('//form[@id=\"%s\"]' % formid)\n if f:\n return f[0]\n\n # Get form element from xpath, if not found, go up\n if formxpath is not None:\n nodes = root.xpath(formxpath)\n if nodes:\n el = nodes[0]\n while True:\n if el.tag == 'form':\n return el\n el = el.getparent()\n if el is None:\n break\n encoded = formxpath if six.PY3 else formxpath.encode('unicode_escape')\n raise ValueError('No <form> element found with %s' % encoded)\n\n # If we get here, it means that either formname was None\n # or invalid\n if formnumber is not None:\n try:\n form = forms[formnumber]\n except IndexError:\n raise IndexError(\"Form number %d not found in %s\" %\n (formnumber, response))\n else:\n return form\n\n\ndef _get_inputs(form, formdata, dont_click, clickdata, response):\n try:\n formdata = dict(formdata or ())\n except (ValueError, TypeError):\n raise ValueError('formdata should be a dict or iterable of tuples')\n\n inputs = form.xpath('descendant::textarea'\n '|descendant::select'\n '|descendant::input[not(@type) or @type['\n ' not(re:test(., \"^(?:submit|image|reset)$\", \"i\"))'\n ' and (../@checked or'\n ' not(re:test(., \"^(?:checkbox|radio)$\", \"i\")))]]',\n namespaces={\n \"re\": \"http://exslt.org/regular-expressions\"})\n values = [(k, u'' if v is None else v)\n for k, v in (_value(e) for e in inputs)\n if k and k not in formdata]\n\n if not dont_click:\n clickable = _get_clickable(clickdata, form)\n if clickable and clickable[0] not in formdata and not clickable[0] is None:\n values.append(clickable)\n\n values.extend((k, v) for k, v in formdata.items() if v is not None)\n return values\n\n\ndef _value(ele):\n n = ele.name\n v = ele.value\n if ele.tag == 'select':\n return _select_value(ele, n, v)\n return n, v\n\n\ndef _select_value(ele, n, v):\n multiple = ele.multiple\n if v is None and not multiple:\n # Match browser behaviour on simple select tag without options selected\n # And for select tags wihout options\n o = ele.value_options\n return (n, o[0]) if o else (None, None)\n elif v is not None and multiple:\n # This is a workround to bug in lxml fixed 2.3.1\n # fix https://github.com/lxml/lxml/commit/57f49eed82068a20da3db8f1b18ae00c1bab8b12#L1L1139\n selected_options = ele.xpath('.//option[@selected]')\n v = [(o.get('value') or o.text or u'').strip() for o in selected_options]\n return n, v\n\n\ndef _get_clickable(clickdata, form):\n \"\"\"\n Returns the clickable element specified in clickdata,\n if the latter is given. If not, it returns the first\n clickable element found\n \"\"\"\n clickables = [\n el for el in form.xpath(\n 'descendant::input[re:test(@type, \"^(submit|image)$\", \"i\")]'\n '|descendant::button[not(@type) or re:test(@type, \"^submit$\", \"i\")]',\n namespaces={\"re\": \"http://exslt.org/regular-expressions\"})\n ]\n if not clickables:\n return\n\n # If we don't have clickdata, we just use the first clickable element\n if clickdata is None:\n el = clickables[0]\n return (el.get('name'), el.get('value') or '')\n\n # If clickdata is given, we compare it to the clickable elements to find a\n # match. We first look to see if the number is specified in clickdata,\n # because that uniquely identifies the element\n nr = clickdata.get('nr', None)\n if nr is not None:\n try:\n el = list(form.inputs)[nr]\n except IndexError:\n pass\n else:\n return (el.get('name'), el.get('value') or '')\n\n # We didn't find it, so now we build an XPath expression out of the other\n # arguments, because they can be used as such\n xpath = u'.//*' + \\\n u''.join(u'[@%s=\"%s\"]' % c for c in six.iteritems(clickdata))\n el = form.xpath(xpath)\n if len(el) == 1:\n return (el[0].get('name'), el[0].get('value') or '')\n elif len(el) > 1:\n raise ValueError(\"Multiple elements found (%r) matching the criteria \"\n \"in clickdata: %r\" % (el, clickdata))\n else:\n raise ValueError('No clickable element matching clickdata: %r' % (clickdata,))\n", "path": "scrapy/http/request/form.py"}], "after_files": [{"content": "\"\"\"\nThis module implements the FormRequest class which is a more convenient class\n(than Request) to generate Requests based on form data.\n\nSee documentation in docs/topics/request-response.rst\n\"\"\"\n\nimport six\nfrom six.moves.urllib.parse import urljoin, urlencode\n\nimport lxml.html\nfrom parsel.selector import create_root_node\nfrom w3lib.html import strip_html5_whitespace\n\nfrom scrapy.http.request import Request\nfrom scrapy.utils.python import to_bytes, is_listlike\nfrom scrapy.utils.response import get_base_url\n\n\nclass FormRequest(Request):\n\n def __init__(self, *args, **kwargs):\n formdata = kwargs.pop('formdata', None)\n if formdata and kwargs.get('method') is None:\n kwargs['method'] = 'POST'\n\n super(FormRequest, self).__init__(*args, **kwargs)\n\n if formdata:\n items = formdata.items() if isinstance(formdata, dict) else formdata\n querystr = _urlencode(items, self.encoding)\n if self.method == 'POST':\n self.headers.setdefault(b'Content-Type', b'application/x-www-form-urlencoded')\n self._set_body(querystr)\n else:\n self._set_url(self.url + ('&' if '?' in self.url else '?') + querystr)\n\n @classmethod\n def from_response(cls, response, formname=None, formid=None, formnumber=0, formdata=None,\n clickdata=None, dont_click=False, formxpath=None, formcss=None, **kwargs):\n\n kwargs.setdefault('encoding', response.encoding)\n\n if formcss is not None:\n from parsel.csstranslator import HTMLTranslator\n formxpath = HTMLTranslator().css_to_xpath(formcss)\n\n form = _get_form(response, formname, formid, formnumber, formxpath)\n formdata = _get_inputs(form, formdata, dont_click, clickdata, response)\n url = _get_form_url(form, kwargs.pop('url', None))\n method = kwargs.pop('method', form.method)\n return cls(url=url, method=method, formdata=formdata, **kwargs)\n\n\ndef _get_form_url(form, url):\n if url is None:\n action = form.get('action')\n if action is None:\n return form.base_url\n return urljoin(form.base_url, strip_html5_whitespace(action))\n return urljoin(form.base_url, url)\n\n\ndef _urlencode(seq, enc):\n values = [(to_bytes(k, enc), to_bytes(v, enc))\n for k, vs in seq\n for v in (vs if is_listlike(vs) else [vs])]\n return urlencode(values, doseq=1)\n\n\ndef _get_form(response, formname, formid, formnumber, formxpath):\n \"\"\"Find the form element \"\"\"\n root = create_root_node(response.text, lxml.html.HTMLParser,\n base_url=get_base_url(response))\n forms = root.xpath('//form')\n if not forms:\n raise ValueError(\"No <form> element found in %s\" % response)\n\n if formname is not None:\n f = root.xpath('//form[@name=\"%s\"]' % formname)\n if f:\n return f[0]\n\n if formid is not None:\n f = root.xpath('//form[@id=\"%s\"]' % formid)\n if f:\n return f[0]\n\n # Get form element from xpath, if not found, go up\n if formxpath is not None:\n nodes = root.xpath(formxpath)\n if nodes:\n el = nodes[0]\n while True:\n if el.tag == 'form':\n return el\n el = el.getparent()\n if el is None:\n break\n encoded = formxpath if six.PY3 else formxpath.encode('unicode_escape')\n raise ValueError('No <form> element found with %s' % encoded)\n\n # If we get here, it means that either formname was None\n # or invalid\n if formnumber is not None:\n try:\n form = forms[formnumber]\n except IndexError:\n raise IndexError(\"Form number %d not found in %s\" %\n (formnumber, response))\n else:\n return form\n\n\ndef _get_inputs(form, formdata, dont_click, clickdata, response):\n try:\n formdata_keys = dict(formdata or ()).keys()\n except (ValueError, TypeError):\n raise ValueError('formdata should be a dict or iterable of tuples')\n\n if not formdata:\n formdata = ()\n inputs = form.xpath('descendant::textarea'\n '|descendant::select'\n '|descendant::input[not(@type) or @type['\n ' not(re:test(., \"^(?:submit|image|reset)$\", \"i\"))'\n ' and (../@checked or'\n ' not(re:test(., \"^(?:checkbox|radio)$\", \"i\")))]]',\n namespaces={\n \"re\": \"http://exslt.org/regular-expressions\"})\n values = [(k, u'' if v is None else v)\n for k, v in (_value(e) for e in inputs)\n if k and k not in formdata_keys]\n\n if not dont_click:\n clickable = _get_clickable(clickdata, form)\n if clickable and clickable[0] not in formdata and not clickable[0] is None:\n values.append(clickable)\n\n if isinstance(formdata, dict):\n formdata = formdata.items()\n\n values.extend((k, v) for k, v in formdata if v is not None)\n return values\n\n\ndef _value(ele):\n n = ele.name\n v = ele.value\n if ele.tag == 'select':\n return _select_value(ele, n, v)\n return n, v\n\n\ndef _select_value(ele, n, v):\n multiple = ele.multiple\n if v is None and not multiple:\n # Match browser behaviour on simple select tag without options selected\n # And for select tags wihout options\n o = ele.value_options\n return (n, o[0]) if o else (None, None)\n elif v is not None and multiple:\n # This is a workround to bug in lxml fixed 2.3.1\n # fix https://github.com/lxml/lxml/commit/57f49eed82068a20da3db8f1b18ae00c1bab8b12#L1L1139\n selected_options = ele.xpath('.//option[@selected]')\n v = [(o.get('value') or o.text or u'').strip() for o in selected_options]\n return n, v\n\n\ndef _get_clickable(clickdata, form):\n \"\"\"\n Returns the clickable element specified in clickdata,\n if the latter is given. If not, it returns the first\n clickable element found\n \"\"\"\n clickables = [\n el for el in form.xpath(\n 'descendant::input[re:test(@type, \"^(submit|image)$\", \"i\")]'\n '|descendant::button[not(@type) or re:test(@type, \"^submit$\", \"i\")]',\n namespaces={\"re\": \"http://exslt.org/regular-expressions\"})\n ]\n if not clickables:\n return\n\n # If we don't have clickdata, we just use the first clickable element\n if clickdata is None:\n el = clickables[0]\n return (el.get('name'), el.get('value') or '')\n\n # If clickdata is given, we compare it to the clickable elements to find a\n # match. We first look to see if the number is specified in clickdata,\n # because that uniquely identifies the element\n nr = clickdata.get('nr', None)\n if nr is not None:\n try:\n el = list(form.inputs)[nr]\n except IndexError:\n pass\n else:\n return (el.get('name'), el.get('value') or '')\n\n # We didn't find it, so now we build an XPath expression out of the other\n # arguments, because they can be used as such\n xpath = u'.//*' + \\\n u''.join(u'[@%s=\"%s\"]' % c for c in six.iteritems(clickdata))\n el = form.xpath(xpath)\n if len(el) == 1:\n return (el[0].get('name'), el[0].get('value') or '')\n elif len(el) > 1:\n raise ValueError(\"Multiple elements found (%r) matching the criteria \"\n \"in clickdata: %r\" % (el, clickdata))\n else:\n raise ValueError('No clickable element matching clickdata: %r' % (clickdata,))\n", "path": "scrapy/http/request/form.py"}]} | 2,838 | 368 |
gh_patches_debug_2585 | rasdani/github-patches | git_diff | keras-team__keras-677 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Python 3 compatibility problem with Image loading
Loading an Image using the `load_img` results in an error.
```
Traceback (most recent call last):
File "keras/autoencoder.py", line 45, in <module>
X_train, Y_train, X_test, Y_test, nb_classes = io.load_images(join(DATA_DIR, 'dataset0'))
File "/home/jnphilipp/Documents/cnn/hieroglyphs/keras/utils/io.py", line 27, in load_images
X_train.append(img_to_array(load_img(picture, True)))
File "/home/jnphilipp/.local/lib/python3.4/site-packages/Keras-0.1.2-py3.4.egg/keras/preprocessing/image.py", line 107, in load_img
File "/home/jnphilipp/.local/lib/python3.4/site-packages/PIL/Image.py", line 2330, in open
% (filename if filename else fp))
OSError: cannot identify image file <_io.TextIOWrapper name='/home/jnphilipp/Documents/cnn/hieroglyphs/data/dataset0/train/P1_train0.png' mode='r' encoding='ISO-8859-1'>
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `keras/preprocessing/image.py`
Content:
```
1 from __future__ import absolute_import
2
3 import numpy as np
4 import re
5 from scipy import ndimage
6 from scipy import linalg
7
8 from os import listdir
9 from os.path import isfile, join
10 import random, math
11 from six.moves import range
12
13 '''
14 Fairly basic set of tools for realtime data augmentation on image data.
15 Can easily be extended to include new transforms, new preprocessing methods, etc...
16 '''
17
18 def random_rotation(x, rg, fill_mode="nearest", cval=0.):
19 angle = random.uniform(-rg, rg)
20 x = ndimage.interpolation.rotate(x, angle, axes=(1,2), reshape=False, mode=fill_mode, cval=cval)
21 return x
22
23 def random_shift(x, wrg, hrg, fill_mode="nearest", cval=0.):
24 crop_left_pixels = 0
25 crop_right_pixels = 0
26 crop_top_pixels = 0
27 crop_bottom_pixels = 0
28
29 original_w = x.shape[1]
30 original_h = x.shape[2]
31
32 if wrg:
33 crop = random.uniform(0., wrg)
34 split = random.uniform(0, 1)
35 crop_left_pixels = int(split*crop*x.shape[1])
36 crop_right_pixels = int((1-split)*crop*x.shape[1])
37
38 if hrg:
39 crop = random.uniform(0., hrg)
40 split = random.uniform(0, 1)
41 crop_top_pixels = int(split*crop*x.shape[2])
42 crop_bottom_pixels = int((1-split)*crop*x.shape[2])
43
44 x = ndimage.interpolation.shift(x, (0, crop_left_pixels, crop_top_pixels), mode=fill_mode, cval=cval)
45 return x
46
47 def horizontal_flip(x):
48 for i in range(x.shape[0]):
49 x[i] = np.fliplr(x[i])
50 return x
51
52 def vertical_flip(x):
53 for i in range(x.shape[0]):
54 x[i] = np.flipud(x[i])
55 return x
56
57
58 def random_barrel_transform(x, intensity):
59 # TODO
60 pass
61
62 def random_shear(x, intensity):
63 # TODO
64 pass
65
66 def random_channel_shift(x, rg):
67 # TODO
68 pass
69
70 def random_zoom(x, rg, fill_mode="nearest", cval=0.):
71 zoom_w = random.uniform(1.-rg, 1.)
72 zoom_h = random.uniform(1.-rg, 1.)
73 x = ndimage.interpolation.zoom(x, zoom=(1., zoom_w, zoom_h), mode=fill_mode, cval=cval)
74 return x # shape of result will be different from shape of input!
75
76
77
78
79 def array_to_img(x, scale=True):
80 from PIL import Image
81 x = x.transpose(1, 2, 0)
82 if scale:
83 x += max(-np.min(x), 0)
84 x /= np.max(x)
85 x *= 255
86 if x.shape[2] == 3:
87 # RGB
88 return Image.fromarray(x.astype("uint8"), "RGB")
89 else:
90 # grayscale
91 return Image.fromarray(x[:,:,0].astype("uint8"), "L")
92
93
94 def img_to_array(img):
95 x = np.asarray(img, dtype='float32')
96 if len(x.shape)==3:
97 # RGB: height, width, channel -> channel, height, width
98 x = x.transpose(2, 0, 1)
99 else:
100 # grayscale: height, width -> channel, height, width
101 x = x.reshape((1, x.shape[0], x.shape[1]))
102 return x
103
104
105 def load_img(path, grayscale=False):
106 from PIL import Image
107 img = Image.open(open(path))
108 if grayscale:
109 img = img.convert('L')
110 else: # Assure 3 channel even when loaded image is grayscale
111 img = img.convert('RGB')
112 return img
113
114
115 def list_pictures(directory, ext='jpg|jpeg|bmp|png'):
116 return [join(directory,f) for f in listdir(directory) \
117 if isfile(join(directory,f)) and re.match('([\w]+\.(?:' + ext + '))', f)]
118
119
120
121 class ImageDataGenerator(object):
122 '''
123 Generate minibatches with
124 realtime data augmentation.
125 '''
126 def __init__(self,
127 featurewise_center=True, # set input mean to 0 over the dataset
128 samplewise_center=False, # set each sample mean to 0
129 featurewise_std_normalization=True, # divide inputs by std of the dataset
130 samplewise_std_normalization=False, # divide each input by its std
131
132 zca_whitening=False, # apply ZCA whitening
133 rotation_range=0., # degrees (0 to 180)
134 width_shift_range=0., # fraction of total width
135 height_shift_range=0., # fraction of total height
136 horizontal_flip=False,
137 vertical_flip=False,
138 ):
139 self.__dict__.update(locals())
140 self.mean = None
141 self.std = None
142 self.principal_components = None
143
144
145 def flow(self, X, y, batch_size=32, shuffle=False, seed=None, save_to_dir=None, save_prefix="", save_format="jpeg"):
146 if seed:
147 random.seed(seed)
148
149 if shuffle:
150 seed = random.randint(1, 10e6)
151 np.random.seed(seed)
152 np.random.shuffle(X)
153 np.random.seed(seed)
154 np.random.shuffle(y)
155
156 nb_batch = int(math.ceil(float(X.shape[0])/batch_size))
157 for b in range(nb_batch):
158 batch_end = (b+1)*batch_size
159 if batch_end > X.shape[0]:
160 nb_samples = X.shape[0] - b*batch_size
161 else:
162 nb_samples = batch_size
163
164 bX = np.zeros(tuple([nb_samples]+list(X.shape)[1:]))
165 for i in range(nb_samples):
166 x = X[b*batch_size+i]
167 x = self.random_transform(x.astype("float32"))
168 x = self.standardize(x)
169 bX[i] = x
170
171 if save_to_dir:
172 for i in range(nb_samples):
173 img = array_to_img(bX[i], scale=True)
174 img.save(save_to_dir + "/" + save_prefix + "_" + str(i) + "." + save_format)
175
176 yield bX, y[b*batch_size:b*batch_size+nb_samples]
177
178
179 def standardize(self, x):
180 if self.featurewise_center:
181 x -= self.mean
182 if self.featurewise_std_normalization:
183 x /= self.std
184
185 if self.zca_whitening:
186 flatx = np.reshape(x, (x.shape[0]*x.shape[1]*x.shape[2]))
187 whitex = np.dot(flatx, self.principal_components)
188 x = np.reshape(whitex, (x.shape[0], x.shape[1], x.shape[2]))
189
190 if self.samplewise_center:
191 x -= np.mean(x)
192 if self.samplewise_std_normalization:
193 x /= np.std(x)
194
195 return x
196
197
198 def random_transform(self, x):
199 if self.rotation_range:
200 x = random_rotation(x, self.rotation_range)
201 if self.width_shift_range or self.height_shift_range:
202 x = random_shift(x, self.width_shift_range, self.height_shift_range)
203 if self.horizontal_flip:
204 if random.random() < 0.5:
205 x = horizontal_flip(x)
206 if self.vertical_flip:
207 if random.random() < 0.5:
208 x = vertical_flip(x)
209
210 # TODO:
211 # zoom
212 # barrel/fisheye
213 # shearing
214 # channel shifting
215 return x
216
217
218 def fit(self, X,
219 augment=False, # fit on randomly augmented samples
220 rounds=1, # if augment, how many augmentation passes over the data do we use
221 seed=None
222 ):
223 '''
224 Required for featurewise_center, featurewise_std_normalization and zca_whitening.
225 '''
226 X = np.copy(X)
227
228 if augment:
229 aX = np.zeros(tuple([rounds*X.shape[0]]+list(X.shape)[1:]))
230 for r in range(rounds):
231 for i in range(X.shape[0]):
232 img = array_to_img(X[i])
233 img = self.random_transform(img)
234 aX[i+r*X.shape[0]] = img_to_array(img)
235 X = aX
236
237 if self.featurewise_center:
238 self.mean = np.mean(X, axis=0)
239 X -= self.mean
240 if self.featurewise_std_normalization:
241 self.std = np.std(X, axis=0)
242 X /= self.std
243
244 if self.zca_whitening:
245 flatX = np.reshape(X, (X.shape[0], X.shape[1]*X.shape[2]*X.shape[3]))
246 fudge = 10e-6
247 sigma = np.dot(flatX.T, flatX) / flatX.shape[1]
248 U, S, V = linalg.svd(sigma)
249 self.principal_components = np.dot(np.dot(U, np.diag(1. / np.sqrt(S + fudge))), U.T)
250
251
252
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/keras/preprocessing/image.py b/keras/preprocessing/image.py
--- a/keras/preprocessing/image.py
+++ b/keras/preprocessing/image.py
@@ -104,7 +104,7 @@
def load_img(path, grayscale=False):
from PIL import Image
- img = Image.open(open(path))
+ img = Image.open(path)
if grayscale:
img = img.convert('L')
else: # Assure 3 channel even when loaded image is grayscale
| {"golden_diff": "diff --git a/keras/preprocessing/image.py b/keras/preprocessing/image.py\n--- a/keras/preprocessing/image.py\n+++ b/keras/preprocessing/image.py\n@@ -104,7 +104,7 @@\n \n def load_img(path, grayscale=False):\n from PIL import Image\n- img = Image.open(open(path))\n+ img = Image.open(path)\n if grayscale:\n img = img.convert('L')\n else: # Assure 3 channel even when loaded image is grayscale\n", "issue": "Python 3 compatibility problem with Image loading\nLoading an Image using the `load_img` results in an error.\n\n```\nTraceback (most recent call last):\n File \"keras/autoencoder.py\", line 45, in <module>\n X_train, Y_train, X_test, Y_test, nb_classes = io.load_images(join(DATA_DIR, 'dataset0'))\n File \"/home/jnphilipp/Documents/cnn/hieroglyphs/keras/utils/io.py\", line 27, in load_images\n X_train.append(img_to_array(load_img(picture, True)))\n File \"/home/jnphilipp/.local/lib/python3.4/site-packages/Keras-0.1.2-py3.4.egg/keras/preprocessing/image.py\", line 107, in load_img\n File \"/home/jnphilipp/.local/lib/python3.4/site-packages/PIL/Image.py\", line 2330, in open\n % (filename if filename else fp))\nOSError: cannot identify image file <_io.TextIOWrapper name='/home/jnphilipp/Documents/cnn/hieroglyphs/data/dataset0/train/P1_train0.png' mode='r' encoding='ISO-8859-1'>\n```\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport numpy as np\nimport re\nfrom scipy import ndimage\nfrom scipy import linalg\n\nfrom os import listdir\nfrom os.path import isfile, join\nimport random, math\nfrom six.moves import range\n\n'''\n Fairly basic set of tools for realtime data augmentation on image data.\n Can easily be extended to include new transforms, new preprocessing methods, etc...\n'''\n\ndef random_rotation(x, rg, fill_mode=\"nearest\", cval=0.):\n angle = random.uniform(-rg, rg)\n x = ndimage.interpolation.rotate(x, angle, axes=(1,2), reshape=False, mode=fill_mode, cval=cval)\n return x\n\ndef random_shift(x, wrg, hrg, fill_mode=\"nearest\", cval=0.):\n crop_left_pixels = 0\n crop_right_pixels = 0\n crop_top_pixels = 0\n crop_bottom_pixels = 0\n\n original_w = x.shape[1]\n original_h = x.shape[2]\n\n if wrg:\n crop = random.uniform(0., wrg)\n split = random.uniform(0, 1)\n crop_left_pixels = int(split*crop*x.shape[1])\n crop_right_pixels = int((1-split)*crop*x.shape[1])\n\n if hrg:\n crop = random.uniform(0., hrg)\n split = random.uniform(0, 1)\n crop_top_pixels = int(split*crop*x.shape[2])\n crop_bottom_pixels = int((1-split)*crop*x.shape[2])\n\n x = ndimage.interpolation.shift(x, (0, crop_left_pixels, crop_top_pixels), mode=fill_mode, cval=cval)\n return x\n\ndef horizontal_flip(x):\n for i in range(x.shape[0]):\n x[i] = np.fliplr(x[i])\n return x\n\ndef vertical_flip(x):\n for i in range(x.shape[0]):\n x[i] = np.flipud(x[i])\n return x\n\n\ndef random_barrel_transform(x, intensity):\n # TODO\n pass\n\ndef random_shear(x, intensity):\n # TODO\n pass\n\ndef random_channel_shift(x, rg):\n # TODO\n pass\n\ndef random_zoom(x, rg, fill_mode=\"nearest\", cval=0.):\n zoom_w = random.uniform(1.-rg, 1.)\n zoom_h = random.uniform(1.-rg, 1.)\n x = ndimage.interpolation.zoom(x, zoom=(1., zoom_w, zoom_h), mode=fill_mode, cval=cval)\n return x # shape of result will be different from shape of input!\n\n\n\n\ndef array_to_img(x, scale=True):\n from PIL import Image\n x = x.transpose(1, 2, 0) \n if scale:\n x += max(-np.min(x), 0)\n x /= np.max(x)\n x *= 255\n if x.shape[2] == 3:\n # RGB\n return Image.fromarray(x.astype(\"uint8\"), \"RGB\")\n else:\n # grayscale\n return Image.fromarray(x[:,:,0].astype(\"uint8\"), \"L\")\n\n\ndef img_to_array(img):\n x = np.asarray(img, dtype='float32')\n if len(x.shape)==3:\n # RGB: height, width, channel -> channel, height, width\n x = x.transpose(2, 0, 1)\n else:\n # grayscale: height, width -> channel, height, width\n x = x.reshape((1, x.shape[0], x.shape[1]))\n return x\n\n\ndef load_img(path, grayscale=False):\n from PIL import Image\n img = Image.open(open(path))\n if grayscale:\n img = img.convert('L')\n else: # Assure 3 channel even when loaded image is grayscale\n img = img.convert('RGB')\n return img\n\n\ndef list_pictures(directory, ext='jpg|jpeg|bmp|png'):\n return [join(directory,f) for f in listdir(directory) \\\n if isfile(join(directory,f)) and re.match('([\\w]+\\.(?:' + ext + '))', f)]\n\n\n\nclass ImageDataGenerator(object):\n '''\n Generate minibatches with \n realtime data augmentation.\n '''\n def __init__(self, \n featurewise_center=True, # set input mean to 0 over the dataset\n samplewise_center=False, # set each sample mean to 0\n featurewise_std_normalization=True, # divide inputs by std of the dataset\n samplewise_std_normalization=False, # divide each input by its std\n\n zca_whitening=False, # apply ZCA whitening\n rotation_range=0., # degrees (0 to 180)\n width_shift_range=0., # fraction of total width\n height_shift_range=0., # fraction of total height\n horizontal_flip=False,\n vertical_flip=False,\n ):\n self.__dict__.update(locals())\n self.mean = None\n self.std = None\n self.principal_components = None\n\n\n def flow(self, X, y, batch_size=32, shuffle=False, seed=None, save_to_dir=None, save_prefix=\"\", save_format=\"jpeg\"):\n if seed:\n random.seed(seed)\n\n if shuffle:\n seed = random.randint(1, 10e6)\n np.random.seed(seed)\n np.random.shuffle(X)\n np.random.seed(seed)\n np.random.shuffle(y)\n\n nb_batch = int(math.ceil(float(X.shape[0])/batch_size))\n for b in range(nb_batch):\n batch_end = (b+1)*batch_size\n if batch_end > X.shape[0]:\n nb_samples = X.shape[0] - b*batch_size\n else:\n nb_samples = batch_size\n\n bX = np.zeros(tuple([nb_samples]+list(X.shape)[1:]))\n for i in range(nb_samples):\n x = X[b*batch_size+i]\n x = self.random_transform(x.astype(\"float32\"))\n x = self.standardize(x)\n bX[i] = x\n\n if save_to_dir:\n for i in range(nb_samples):\n img = array_to_img(bX[i], scale=True)\n img.save(save_to_dir + \"/\" + save_prefix + \"_\" + str(i) + \".\" + save_format)\n\n yield bX, y[b*batch_size:b*batch_size+nb_samples]\n\n\n def standardize(self, x):\n if self.featurewise_center:\n x -= self.mean\n if self.featurewise_std_normalization:\n x /= self.std\n\n if self.zca_whitening:\n flatx = np.reshape(x, (x.shape[0]*x.shape[1]*x.shape[2]))\n whitex = np.dot(flatx, self.principal_components)\n x = np.reshape(whitex, (x.shape[0], x.shape[1], x.shape[2]))\n\n if self.samplewise_center:\n x -= np.mean(x)\n if self.samplewise_std_normalization:\n x /= np.std(x)\n\n return x\n\n\n def random_transform(self, x):\n if self.rotation_range:\n x = random_rotation(x, self.rotation_range)\n if self.width_shift_range or self.height_shift_range:\n x = random_shift(x, self.width_shift_range, self.height_shift_range)\n if self.horizontal_flip:\n if random.random() < 0.5:\n x = horizontal_flip(x)\n if self.vertical_flip:\n if random.random() < 0.5:\n x = vertical_flip(x)\n\n # TODO:\n # zoom\n # barrel/fisheye\n # shearing\n # channel shifting\n return x\n\n\n def fit(self, X, \n augment=False, # fit on randomly augmented samples\n rounds=1, # if augment, how many augmentation passes over the data do we use\n seed=None\n ):\n '''\n Required for featurewise_center, featurewise_std_normalization and zca_whitening.\n '''\n X = np.copy(X)\n \n if augment:\n aX = np.zeros(tuple([rounds*X.shape[0]]+list(X.shape)[1:]))\n for r in range(rounds):\n for i in range(X.shape[0]):\n img = array_to_img(X[i])\n img = self.random_transform(img)\n aX[i+r*X.shape[0]] = img_to_array(img)\n X = aX\n\n if self.featurewise_center:\n self.mean = np.mean(X, axis=0)\n X -= self.mean\n if self.featurewise_std_normalization:\n self.std = np.std(X, axis=0)\n X /= self.std\n\n if self.zca_whitening:\n flatX = np.reshape(X, (X.shape[0], X.shape[1]*X.shape[2]*X.shape[3]))\n fudge = 10e-6\n sigma = np.dot(flatX.T, flatX) / flatX.shape[1]\n U, S, V = linalg.svd(sigma)\n self.principal_components = np.dot(np.dot(U, np.diag(1. / np.sqrt(S + fudge))), U.T)\n\n\n", "path": "keras/preprocessing/image.py"}], "after_files": [{"content": "from __future__ import absolute_import\n\nimport numpy as np\nimport re\nfrom scipy import ndimage\nfrom scipy import linalg\n\nfrom os import listdir\nfrom os.path import isfile, join\nimport random, math\nfrom six.moves import range\n\n'''\n Fairly basic set of tools for realtime data augmentation on image data.\n Can easily be extended to include new transforms, new preprocessing methods, etc...\n'''\n\ndef random_rotation(x, rg, fill_mode=\"nearest\", cval=0.):\n angle = random.uniform(-rg, rg)\n x = ndimage.interpolation.rotate(x, angle, axes=(1,2), reshape=False, mode=fill_mode, cval=cval)\n return x\n\ndef random_shift(x, wrg, hrg, fill_mode=\"nearest\", cval=0.):\n crop_left_pixels = 0\n crop_right_pixels = 0\n crop_top_pixels = 0\n crop_bottom_pixels = 0\n\n original_w = x.shape[1]\n original_h = x.shape[2]\n\n if wrg:\n crop = random.uniform(0., wrg)\n split = random.uniform(0, 1)\n crop_left_pixels = int(split*crop*x.shape[1])\n crop_right_pixels = int((1-split)*crop*x.shape[1])\n\n if hrg:\n crop = random.uniform(0., hrg)\n split = random.uniform(0, 1)\n crop_top_pixels = int(split*crop*x.shape[2])\n crop_bottom_pixels = int((1-split)*crop*x.shape[2])\n\n x = ndimage.interpolation.shift(x, (0, crop_left_pixels, crop_top_pixels), mode=fill_mode, cval=cval)\n return x\n\ndef horizontal_flip(x):\n for i in range(x.shape[0]):\n x[i] = np.fliplr(x[i])\n return x\n\ndef vertical_flip(x):\n for i in range(x.shape[0]):\n x[i] = np.flipud(x[i])\n return x\n\n\ndef random_barrel_transform(x, intensity):\n # TODO\n pass\n\ndef random_shear(x, intensity):\n # TODO\n pass\n\ndef random_channel_shift(x, rg):\n # TODO\n pass\n\ndef random_zoom(x, rg, fill_mode=\"nearest\", cval=0.):\n zoom_w = random.uniform(1.-rg, 1.)\n zoom_h = random.uniform(1.-rg, 1.)\n x = ndimage.interpolation.zoom(x, zoom=(1., zoom_w, zoom_h), mode=fill_mode, cval=cval)\n return x # shape of result will be different from shape of input!\n\n\n\n\ndef array_to_img(x, scale=True):\n from PIL import Image\n x = x.transpose(1, 2, 0) \n if scale:\n x += max(-np.min(x), 0)\n x /= np.max(x)\n x *= 255\n if x.shape[2] == 3:\n # RGB\n return Image.fromarray(x.astype(\"uint8\"), \"RGB\")\n else:\n # grayscale\n return Image.fromarray(x[:,:,0].astype(\"uint8\"), \"L\")\n\n\ndef img_to_array(img):\n x = np.asarray(img, dtype='float32')\n if len(x.shape)==3:\n # RGB: height, width, channel -> channel, height, width\n x = x.transpose(2, 0, 1)\n else:\n # grayscale: height, width -> channel, height, width\n x = x.reshape((1, x.shape[0], x.shape[1]))\n return x\n\n\ndef load_img(path, grayscale=False):\n from PIL import Image\n img = Image.open(path)\n if grayscale:\n img = img.convert('L')\n else: # Assure 3 channel even when loaded image is grayscale\n img = img.convert('RGB')\n return img\n\n\ndef list_pictures(directory, ext='jpg|jpeg|bmp|png'):\n return [join(directory,f) for f in listdir(directory) \\\n if isfile(join(directory,f)) and re.match('([\\w]+\\.(?:' + ext + '))', f)]\n\n\n\nclass ImageDataGenerator(object):\n '''\n Generate minibatches with \n realtime data augmentation.\n '''\n def __init__(self, \n featurewise_center=True, # set input mean to 0 over the dataset\n samplewise_center=False, # set each sample mean to 0\n featurewise_std_normalization=True, # divide inputs by std of the dataset\n samplewise_std_normalization=False, # divide each input by its std\n\n zca_whitening=False, # apply ZCA whitening\n rotation_range=0., # degrees (0 to 180)\n width_shift_range=0., # fraction of total width\n height_shift_range=0., # fraction of total height\n horizontal_flip=False,\n vertical_flip=False,\n ):\n self.__dict__.update(locals())\n self.mean = None\n self.std = None\n self.principal_components = None\n\n\n def flow(self, X, y, batch_size=32, shuffle=False, seed=None, save_to_dir=None, save_prefix=\"\", save_format=\"jpeg\"):\n if seed:\n random.seed(seed)\n\n if shuffle:\n seed = random.randint(1, 10e6)\n np.random.seed(seed)\n np.random.shuffle(X)\n np.random.seed(seed)\n np.random.shuffle(y)\n\n nb_batch = int(math.ceil(float(X.shape[0])/batch_size))\n for b in range(nb_batch):\n batch_end = (b+1)*batch_size\n if batch_end > X.shape[0]:\n nb_samples = X.shape[0] - b*batch_size\n else:\n nb_samples = batch_size\n\n bX = np.zeros(tuple([nb_samples]+list(X.shape)[1:]))\n for i in range(nb_samples):\n x = X[b*batch_size+i]\n x = self.random_transform(x.astype(\"float32\"))\n x = self.standardize(x)\n bX[i] = x\n\n if save_to_dir:\n for i in range(nb_samples):\n img = array_to_img(bX[i], scale=True)\n img.save(save_to_dir + \"/\" + save_prefix + \"_\" + str(i) + \".\" + save_format)\n\n yield bX, y[b*batch_size:b*batch_size+nb_samples]\n\n\n def standardize(self, x):\n if self.featurewise_center:\n x -= self.mean\n if self.featurewise_std_normalization:\n x /= self.std\n\n if self.zca_whitening:\n flatx = np.reshape(x, (x.shape[0]*x.shape[1]*x.shape[2]))\n whitex = np.dot(flatx, self.principal_components)\n x = np.reshape(whitex, (x.shape[0], x.shape[1], x.shape[2]))\n\n if self.samplewise_center:\n x -= np.mean(x)\n if self.samplewise_std_normalization:\n x /= np.std(x)\n\n return x\n\n\n def random_transform(self, x):\n if self.rotation_range:\n x = random_rotation(x, self.rotation_range)\n if self.width_shift_range or self.height_shift_range:\n x = random_shift(x, self.width_shift_range, self.height_shift_range)\n if self.horizontal_flip:\n if random.random() < 0.5:\n x = horizontal_flip(x)\n if self.vertical_flip:\n if random.random() < 0.5:\n x = vertical_flip(x)\n\n # TODO:\n # zoom\n # barrel/fisheye\n # shearing\n # channel shifting\n return x\n\n\n def fit(self, X, \n augment=False, # fit on randomly augmented samples\n rounds=1, # if augment, how many augmentation passes over the data do we use\n seed=None\n ):\n '''\n Required for featurewise_center, featurewise_std_normalization and zca_whitening.\n '''\n X = np.copy(X)\n \n if augment:\n aX = np.zeros(tuple([rounds*X.shape[0]]+list(X.shape)[1:]))\n for r in range(rounds):\n for i in range(X.shape[0]):\n img = array_to_img(X[i])\n img = self.random_transform(img)\n aX[i+r*X.shape[0]] = img_to_array(img)\n X = aX\n\n if self.featurewise_center:\n self.mean = np.mean(X, axis=0)\n X -= self.mean\n if self.featurewise_std_normalization:\n self.std = np.std(X, axis=0)\n X /= self.std\n\n if self.zca_whitening:\n flatX = np.reshape(X, (X.shape[0], X.shape[1]*X.shape[2]*X.shape[3]))\n fudge = 10e-6\n sigma = np.dot(flatX.T, flatX) / flatX.shape[1]\n U, S, V = linalg.svd(sigma)\n self.principal_components = np.dot(np.dot(U, np.diag(1. / np.sqrt(S + fudge))), U.T)\n\n\n", "path": "keras/preprocessing/image.py"}]} | 3,208 | 114 |
gh_patches_debug_57199 | rasdani/github-patches | git_diff | hylang__hy-917 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug in reader: can't terminate string literals containing \ at end of line.
Common Lisp had docstrings before Python existed. Hy should totally support this.
``` Python
>>> def foo():
"""I'm a docstring!"""
return 42
>>> help(foo)
Help on function foo in module __main__:
foo()
I'm a docstring!
>>> foo.__doc__
"I'm a docstring!"
```
Let's try it in Hy.
```
=> (defn foo ()
... """I'm a docstring"""
... 42)
=> (help foo)
Help on function foo:
foo()
=> foo.__doc__
''
```
?!
Where's my docstring?
(some time later...)
Let's try hy2py.
``` Python
def foo():
''
"I'm a docstring!"
''
return 42
```
I see what you did there, Hy. Yeah, there should probably be a warning about that somewhere. Triple quotes don't work. Why does Python use them anyway? So we can include newlines mostly. Common Lisp strings do that already. Does Hy?
```
=> "one
... two"
'one\ntwo
```
Yup. Looks good.
Escapes also appear to work. But what if I actually wanted backslashes? Do raw strings work?
```
=> r"\foo"
'\\foo
```
Nice. Now **raw** triple quoted strings? This works in Python:
``` Python
>>> r"""\
foo"""
'\\\nfoo'
```
Let's use what we've learned and try it in Hy.
```
=> r"\
... foo"
... "
... ""
... """
... what?
... \
... \
... \\
... \\\
... \\\\
... \"
... \\"
... \\\"
... \\\\"
... C-c C-c
KeyboardInterrupt
```
Something is broken...
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hy/lex/lexer.py`
Content:
```
1 # Copyright (c) 2013 Nicolas Dandrimont <[email protected]>
2 #
3 # Permission is hereby granted, free of charge, to any person obtaining a
4 # copy of this software and associated documentation files (the "Software"),
5 # to deal in the Software without restriction, including without limitation
6 # the rights to use, copy, modify, merge, publish, distribute, sublicense,
7 # and/or sell copies of the Software, and to permit persons to whom the
8 # Software is furnished to do so, subject to the following conditions:
9 #
10 # The above copyright notice and this permission notice shall be included in
11 # all copies or substantial portions of the Software.
12 #
13 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
14 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
15 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
16 # THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
17 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
18 # FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
19 # DEALINGS IN THE SOFTWARE.
20
21 from rply import LexerGenerator
22
23
24 lg = LexerGenerator()
25
26
27 # A regexp for something that should end a quoting/unquoting operator
28 # i.e. a space or a closing brace/paren/curly
29 end_quote = r'(?![\s\)\]\}])'
30
31
32 lg.add('LPAREN', r'\(')
33 lg.add('RPAREN', r'\)')
34 lg.add('LBRACKET', r'\[')
35 lg.add('RBRACKET', r'\]')
36 lg.add('LCURLY', r'\{')
37 lg.add('RCURLY', r'\}')
38 lg.add('HLCURLY', r'#\{')
39 lg.add('QUOTE', r'\'%s' % end_quote)
40 lg.add('QUASIQUOTE', r'`%s' % end_quote)
41 lg.add('UNQUOTESPLICE', r'~@%s' % end_quote)
42 lg.add('UNQUOTE', r'~%s' % end_quote)
43 lg.add('HASHBANG', r'#!.*[^\r\n]')
44 lg.add('HASHREADER', r'#[^{]')
45
46 # A regexp which matches incomplete strings, used to support
47 # multi-line strings in the interpreter
48 partial_string = r'''(?x)
49 (?:u|r|ur|ru)? # prefix
50 " # start string
51 (?:
52 | [^"\\] # non-quote or backslash
53 | \\. # or escaped single character
54 | \\x[0-9a-fA-F]{2} # or escaped raw character
55 | \\u[0-9a-fA-F]{4} # or unicode escape
56 | \\U[0-9a-fA-F]{8} # or long unicode escape
57 )* # one or more times
58 '''
59
60 lg.add('STRING', r'%s"' % partial_string)
61 lg.add('PARTIAL_STRING', partial_string)
62
63 lg.add('IDENTIFIER', r'[^()\[\]{}\'"\s;]+')
64
65
66 lg.ignore(r';.*(?=\r|\n|$)')
67 lg.ignore(r'\s+')
68
69
70 lexer = lg.build()
71
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/hy/lex/lexer.py b/hy/lex/lexer.py
--- a/hy/lex/lexer.py
+++ b/hy/lex/lexer.py
@@ -50,7 +50,7 @@
" # start string
(?:
| [^"\\] # non-quote or backslash
- | \\. # or escaped single character
+ | \\(.|\n) # or escaped single character or newline
| \\x[0-9a-fA-F]{2} # or escaped raw character
| \\u[0-9a-fA-F]{4} # or unicode escape
| \\U[0-9a-fA-F]{8} # or long unicode escape
| {"golden_diff": "diff --git a/hy/lex/lexer.py b/hy/lex/lexer.py\n--- a/hy/lex/lexer.py\n+++ b/hy/lex/lexer.py\n@@ -50,7 +50,7 @@\n \" # start string\n (?:\n | [^\"\\\\] # non-quote or backslash\n- | \\\\. # or escaped single character\n+ | \\\\(.|\\n) # or escaped single character or newline\n | \\\\x[0-9a-fA-F]{2} # or escaped raw character\n | \\\\u[0-9a-fA-F]{4} # or unicode escape\n | \\\\U[0-9a-fA-F]{8} # or long unicode escape\n", "issue": "Bug in reader: can't terminate string literals containing \\ at end of line.\nCommon Lisp had docstrings before Python existed. Hy should totally support this.\n\n``` Python\n>>> def foo():\n \"\"\"I'm a docstring!\"\"\"\n return 42\n\n>>> help(foo)\nHelp on function foo in module __main__:\n\nfoo()\n I'm a docstring!\n\n>>> foo.__doc__\n\"I'm a docstring!\"\n```\n\nLet's try it in Hy.\n\n```\n=> (defn foo ()\n... \"\"\"I'm a docstring\"\"\"\n... 42)\n=> (help foo)\nHelp on function foo:\n\nfoo()\n\n=> foo.__doc__\n''\n```\n\n?!\nWhere's my docstring?\n(some time later...)\nLet's try hy2py.\n\n``` Python\ndef foo():\n ''\n \"I'm a docstring!\"\n ''\n return 42\n```\n\nI see what you did there, Hy. Yeah, there should probably be a warning about that somewhere. Triple quotes don't work. Why does Python use them anyway? So we can include newlines mostly. Common Lisp strings do that already. Does Hy?\n\n```\n=> \"one\n... two\"\n'one\\ntwo\n```\n\nYup. Looks good.\nEscapes also appear to work. But what if I actually wanted backslashes? Do raw strings work?\n\n```\n=> r\"\\foo\"\n'\\\\foo\n```\n\nNice. Now **raw** triple quoted strings? This works in Python:\n\n``` Python\n>>> r\"\"\"\\\nfoo\"\"\"\n'\\\\\\nfoo'\n```\n\nLet's use what we've learned and try it in Hy.\n\n```\n=> r\"\\\n... foo\"\n... \"\n... \"\"\n... \"\"\"\n... what?\n... \\\n... \\\n... \\\\\n... \\\\\\\n... \\\\\\\\\n... \\\"\n... \\\\\"\n... \\\\\\\"\n... \\\\\\\\\"\n... C-c C-c\n\nKeyboardInterrupt\n```\n\nSomething is broken...\n\n", "before_files": [{"content": "# Copyright (c) 2013 Nicolas Dandrimont <[email protected]>\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the \"Software\"),\n# to deal in the Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish, distribute, sublicense,\n# and/or sell copies of the Software, and to permit persons to whom the\n# Software is furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL\n# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.\n\nfrom rply import LexerGenerator\n\n\nlg = LexerGenerator()\n\n\n# A regexp for something that should end a quoting/unquoting operator\n# i.e. a space or a closing brace/paren/curly\nend_quote = r'(?![\\s\\)\\]\\}])'\n\n\nlg.add('LPAREN', r'\\(')\nlg.add('RPAREN', r'\\)')\nlg.add('LBRACKET', r'\\[')\nlg.add('RBRACKET', r'\\]')\nlg.add('LCURLY', r'\\{')\nlg.add('RCURLY', r'\\}')\nlg.add('HLCURLY', r'#\\{')\nlg.add('QUOTE', r'\\'%s' % end_quote)\nlg.add('QUASIQUOTE', r'`%s' % end_quote)\nlg.add('UNQUOTESPLICE', r'~@%s' % end_quote)\nlg.add('UNQUOTE', r'~%s' % end_quote)\nlg.add('HASHBANG', r'#!.*[^\\r\\n]')\nlg.add('HASHREADER', r'#[^{]')\n\n# A regexp which matches incomplete strings, used to support\n# multi-line strings in the interpreter\npartial_string = r'''(?x)\n (?:u|r|ur|ru)? # prefix\n \" # start string\n (?:\n | [^\"\\\\] # non-quote or backslash\n | \\\\. # or escaped single character\n | \\\\x[0-9a-fA-F]{2} # or escaped raw character\n | \\\\u[0-9a-fA-F]{4} # or unicode escape\n | \\\\U[0-9a-fA-F]{8} # or long unicode escape\n )* # one or more times\n'''\n\nlg.add('STRING', r'%s\"' % partial_string)\nlg.add('PARTIAL_STRING', partial_string)\n\nlg.add('IDENTIFIER', r'[^()\\[\\]{}\\'\"\\s;]+')\n\n\nlg.ignore(r';.*(?=\\r|\\n|$)')\nlg.ignore(r'\\s+')\n\n\nlexer = lg.build()\n", "path": "hy/lex/lexer.py"}], "after_files": [{"content": "# Copyright (c) 2013 Nicolas Dandrimont <[email protected]>\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the \"Software\"),\n# to deal in the Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish, distribute, sublicense,\n# and/or sell copies of the Software, and to permit persons to whom the\n# Software is furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL\n# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.\n\nfrom rply import LexerGenerator\n\n\nlg = LexerGenerator()\n\n\n# A regexp for something that should end a quoting/unquoting operator\n# i.e. a space or a closing brace/paren/curly\nend_quote = r'(?![\\s\\)\\]\\}])'\n\n\nlg.add('LPAREN', r'\\(')\nlg.add('RPAREN', r'\\)')\nlg.add('LBRACKET', r'\\[')\nlg.add('RBRACKET', r'\\]')\nlg.add('LCURLY', r'\\{')\nlg.add('RCURLY', r'\\}')\nlg.add('HLCURLY', r'#\\{')\nlg.add('QUOTE', r'\\'%s' % end_quote)\nlg.add('QUASIQUOTE', r'`%s' % end_quote)\nlg.add('UNQUOTESPLICE', r'~@%s' % end_quote)\nlg.add('UNQUOTE', r'~%s' % end_quote)\nlg.add('HASHBANG', r'#!.*[^\\r\\n]')\nlg.add('HASHREADER', r'#[^{]')\n\n# A regexp which matches incomplete strings, used to support\n# multi-line strings in the interpreter\npartial_string = r'''(?x)\n (?:u|r|ur|ru)? # prefix\n \" # start string\n (?:\n | [^\"\\\\] # non-quote or backslash\n | \\\\(.|\\n) # or escaped single character or newline\n | \\\\x[0-9a-fA-F]{2} # or escaped raw character\n | \\\\u[0-9a-fA-F]{4} # or unicode escape\n | \\\\U[0-9a-fA-F]{8} # or long unicode escape\n )* # one or more times\n'''\n\nlg.add('STRING', r'%s\"' % partial_string)\nlg.add('PARTIAL_STRING', partial_string)\n\nlg.add('IDENTIFIER', r'[^()\\[\\]{}\\'\"\\s;]+')\n\n\nlg.ignore(r';.*(?=\\r|\\n|$)')\nlg.ignore(r'\\s+')\n\n\nlexer = lg.build()\n", "path": "hy/lex/lexer.py"}]} | 1,497 | 171 |
gh_patches_debug_51217 | rasdani/github-patches | git_diff | python-pillow__Pillow-3478 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Using seek to skip more than one frame with FliImageFile only shows the pixels changed that frame
### What did you do?
I opened a FLI file and used .seek(50) on the image before creating a PhotoImage to display it on a tix label.
### What did you expect to happen?
I expected to see the complete image.
### What actually happened?
I only saw the part of the image that had changed for that particular frame. The rest of the image is black.
### What versions of Pillow and Python are you using?
Python 3.6.2 on Windows 7 x64
Pillow: 4.2.1
I did find that if I hack in a call to self.load() in FliImageFile's _seek() method, the frame displays fully. I don't know if this is the best way to fix the issue.
```python
import PIL as pil
from PIL import Image,ImageTk,FliImagePlugin
import tkinter.tix as tix
class FliImageFile(FliImagePlugin.FliImageFile):
def _seek(self, frame):
FliImagePlugin.FliImageFile._seek(self, frame)
# ensure that this frame is loaded
self.load()
def createlabel(root, filename):
label = tix.Label(root)
label.original = Image.open(filename)
label.original.seek(50) # Go to frame 50.
label.photoimage = ImageTk.PhotoImage(label.original) # keep a reference!
label.config(image=label.photoimage)
return label
def main():
root = tix.Tk()
label1 = createlabel(root, 'a.fli')
label1.pack()
# Hack to replace PIL's FliImageFile with one that loads image data at
# the end of each internal _seek() call.
Image.OPEN[FliImagePlugin.FliImageFile.format] = (FliImageFile, Image.OPEN[FliImagePlugin.FliImageFile.format][1])
label2 = createlabel(root, 'a.fli')
label2.pack()
root.mainloop()
main()
```
Using a.fli found at https://samples.libav.org/fli-flc/
Top image is what Pillow displays as-is. The bottom image uses my hack that loads the image at the end of _seek.

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/PIL/FliImagePlugin.py`
Content:
```
1 #
2 # The Python Imaging Library.
3 # $Id$
4 #
5 # FLI/FLC file handling.
6 #
7 # History:
8 # 95-09-01 fl Created
9 # 97-01-03 fl Fixed parser, setup decoder tile
10 # 98-07-15 fl Renamed offset attribute to avoid name clash
11 #
12 # Copyright (c) Secret Labs AB 1997-98.
13 # Copyright (c) Fredrik Lundh 1995-97.
14 #
15 # See the README file for information on usage and redistribution.
16 #
17
18
19 from . import Image, ImageFile, ImagePalette
20 from ._binary import i8, i16le as i16, i32le as i32, o8
21
22 __version__ = "0.2"
23
24
25 #
26 # decoder
27
28 def _accept(prefix):
29 return len(prefix) >= 6 and i16(prefix[4:6]) in [0xAF11, 0xAF12]
30
31
32 ##
33 # Image plugin for the FLI/FLC animation format. Use the <b>seek</b>
34 # method to load individual frames.
35
36 class FliImageFile(ImageFile.ImageFile):
37
38 format = "FLI"
39 format_description = "Autodesk FLI/FLC Animation"
40 _close_exclusive_fp_after_loading = False
41
42 def _open(self):
43
44 # HEAD
45 s = self.fp.read(128)
46 magic = i16(s[4:6])
47 if not (magic in [0xAF11, 0xAF12] and
48 i16(s[14:16]) in [0, 3] and # flags
49 s[20:22] == b"\x00\x00"): # reserved
50 raise SyntaxError("not an FLI/FLC file")
51
52 # frames
53 self.__framecount = i16(s[6:8])
54
55 # image characteristics
56 self.mode = "P"
57 self._size = i16(s[8:10]), i16(s[10:12])
58
59 # animation speed
60 duration = i32(s[16:20])
61 if magic == 0xAF11:
62 duration = (duration * 1000) // 70
63 self.info["duration"] = duration
64
65 # look for palette
66 palette = [(a, a, a) for a in range(256)]
67
68 s = self.fp.read(16)
69
70 self.__offset = 128
71
72 if i16(s[4:6]) == 0xF100:
73 # prefix chunk; ignore it
74 self.__offset = self.__offset + i32(s)
75 s = self.fp.read(16)
76
77 if i16(s[4:6]) == 0xF1FA:
78 # look for palette chunk
79 s = self.fp.read(6)
80 if i16(s[4:6]) == 11:
81 self._palette(palette, 2)
82 elif i16(s[4:6]) == 4:
83 self._palette(palette, 0)
84
85 palette = [o8(r)+o8(g)+o8(b) for (r, g, b) in palette]
86 self.palette = ImagePalette.raw("RGB", b"".join(palette))
87
88 # set things up to decode first frame
89 self.__frame = -1
90 self.__fp = self.fp
91 self.__rewind = self.fp.tell()
92 self.seek(0)
93
94 def _palette(self, palette, shift):
95 # load palette
96
97 i = 0
98 for e in range(i16(self.fp.read(2))):
99 s = self.fp.read(2)
100 i = i + i8(s[0])
101 n = i8(s[1])
102 if n == 0:
103 n = 256
104 s = self.fp.read(n * 3)
105 for n in range(0, len(s), 3):
106 r = i8(s[n]) << shift
107 g = i8(s[n+1]) << shift
108 b = i8(s[n+2]) << shift
109 palette[i] = (r, g, b)
110 i += 1
111
112 @property
113 def n_frames(self):
114 return self.__framecount
115
116 @property
117 def is_animated(self):
118 return self.__framecount > 1
119
120 def seek(self, frame):
121 if not self._seek_check(frame):
122 return
123 if frame < self.__frame:
124 self._seek(0)
125
126 for f in range(self.__frame + 1, frame + 1):
127 self._seek(f)
128
129 def _seek(self, frame):
130 if frame == 0:
131 self.__frame = -1
132 self.__fp.seek(self.__rewind)
133 self.__offset = 128
134
135 if frame != self.__frame + 1:
136 raise ValueError("cannot seek to frame %d" % frame)
137 self.__frame = frame
138
139 # move to next frame
140 self.fp = self.__fp
141 self.fp.seek(self.__offset)
142
143 s = self.fp.read(4)
144 if not s:
145 raise EOFError
146
147 framesize = i32(s)
148
149 self.decodermaxblock = framesize
150 self.tile = [("fli", (0, 0)+self.size, self.__offset, None)]
151
152 self.__offset += framesize
153
154 def tell(self):
155 return self.__frame
156
157
158 #
159 # registry
160
161 Image.register_open(FliImageFile.format, FliImageFile, _accept)
162
163 Image.register_extensions(FliImageFile.format, [".fli", ".flc"])
164
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/PIL/FliImagePlugin.py b/src/PIL/FliImagePlugin.py
--- a/src/PIL/FliImagePlugin.py
+++ b/src/PIL/FliImagePlugin.py
@@ -131,6 +131,9 @@
self.__frame = -1
self.__fp.seek(self.__rewind)
self.__offset = 128
+ else:
+ # ensure that the previous frame was loaded
+ self.load()
if frame != self.__frame + 1:
raise ValueError("cannot seek to frame %d" % frame)
| {"golden_diff": "diff --git a/src/PIL/FliImagePlugin.py b/src/PIL/FliImagePlugin.py\n--- a/src/PIL/FliImagePlugin.py\n+++ b/src/PIL/FliImagePlugin.py\n@@ -131,6 +131,9 @@\n self.__frame = -1\n self.__fp.seek(self.__rewind)\n self.__offset = 128\n+ else:\n+ # ensure that the previous frame was loaded\n+ self.load()\n \n if frame != self.__frame + 1:\n raise ValueError(\"cannot seek to frame %d\" % frame)\n", "issue": "Using seek to skip more than one frame with FliImageFile only shows the pixels changed that frame\n### What did you do?\r\nI opened a FLI file and used .seek(50) on the image before creating a PhotoImage to display it on a tix label.\r\n\r\n### What did you expect to happen?\r\nI expected to see the complete image.\r\n\r\n### What actually happened?\r\nI only saw the part of the image that had changed for that particular frame. The rest of the image is black.\r\n\r\n### What versions of Pillow and Python are you using?\r\nPython 3.6.2 on Windows 7 x64\r\nPillow: 4.2.1\r\n\r\nI did find that if I hack in a call to self.load() in FliImageFile's _seek() method, the frame displays fully. I don't know if this is the best way to fix the issue.\r\n\r\n```python\r\nimport PIL as pil\r\nfrom PIL import Image,ImageTk,FliImagePlugin\r\nimport tkinter.tix as tix\r\n\r\nclass FliImageFile(FliImagePlugin.FliImageFile):\r\n def _seek(self, frame):\r\n FliImagePlugin.FliImageFile._seek(self, frame)\r\n # ensure that this frame is loaded\r\n self.load()\r\n\r\ndef createlabel(root, filename):\r\n label = tix.Label(root)\r\n label.original = Image.open(filename)\r\n label.original.seek(50) # Go to frame 50.\r\n label.photoimage = ImageTk.PhotoImage(label.original) # keep a reference!\r\n label.config(image=label.photoimage)\r\n return label\r\n\r\ndef main():\r\n root = tix.Tk()\r\n label1 = createlabel(root, 'a.fli')\r\n label1.pack()\r\n # Hack to replace PIL's FliImageFile with one that loads image data at\r\n # the end of each internal _seek() call.\r\n Image.OPEN[FliImagePlugin.FliImageFile.format] = (FliImageFile, Image.OPEN[FliImagePlugin.FliImageFile.format][1])\r\n label2 = createlabel(root, 'a.fli')\r\n label2.pack()\r\n root.mainloop()\r\n\r\nmain()\r\n```\r\nUsing a.fli found at https://samples.libav.org/fli-flc/\r\n\r\nTop image is what Pillow displays as-is. The bottom image uses my hack that loads the image at the end of _seek.\r\n\r\n\n", "before_files": [{"content": "#\n# The Python Imaging Library.\n# $Id$\n#\n# FLI/FLC file handling.\n#\n# History:\n# 95-09-01 fl Created\n# 97-01-03 fl Fixed parser, setup decoder tile\n# 98-07-15 fl Renamed offset attribute to avoid name clash\n#\n# Copyright (c) Secret Labs AB 1997-98.\n# Copyright (c) Fredrik Lundh 1995-97.\n#\n# See the README file for information on usage and redistribution.\n#\n\n\nfrom . import Image, ImageFile, ImagePalette\nfrom ._binary import i8, i16le as i16, i32le as i32, o8\n\n__version__ = \"0.2\"\n\n\n#\n# decoder\n\ndef _accept(prefix):\n return len(prefix) >= 6 and i16(prefix[4:6]) in [0xAF11, 0xAF12]\n\n\n##\n# Image plugin for the FLI/FLC animation format. Use the <b>seek</b>\n# method to load individual frames.\n\nclass FliImageFile(ImageFile.ImageFile):\n\n format = \"FLI\"\n format_description = \"Autodesk FLI/FLC Animation\"\n _close_exclusive_fp_after_loading = False\n\n def _open(self):\n\n # HEAD\n s = self.fp.read(128)\n magic = i16(s[4:6])\n if not (magic in [0xAF11, 0xAF12] and\n i16(s[14:16]) in [0, 3] and # flags\n s[20:22] == b\"\\x00\\x00\"): # reserved\n raise SyntaxError(\"not an FLI/FLC file\")\n\n # frames\n self.__framecount = i16(s[6:8])\n\n # image characteristics\n self.mode = \"P\"\n self._size = i16(s[8:10]), i16(s[10:12])\n\n # animation speed\n duration = i32(s[16:20])\n if magic == 0xAF11:\n duration = (duration * 1000) // 70\n self.info[\"duration\"] = duration\n\n # look for palette\n palette = [(a, a, a) for a in range(256)]\n\n s = self.fp.read(16)\n\n self.__offset = 128\n\n if i16(s[4:6]) == 0xF100:\n # prefix chunk; ignore it\n self.__offset = self.__offset + i32(s)\n s = self.fp.read(16)\n\n if i16(s[4:6]) == 0xF1FA:\n # look for palette chunk\n s = self.fp.read(6)\n if i16(s[4:6]) == 11:\n self._palette(palette, 2)\n elif i16(s[4:6]) == 4:\n self._palette(palette, 0)\n\n palette = [o8(r)+o8(g)+o8(b) for (r, g, b) in palette]\n self.palette = ImagePalette.raw(\"RGB\", b\"\".join(palette))\n\n # set things up to decode first frame\n self.__frame = -1\n self.__fp = self.fp\n self.__rewind = self.fp.tell()\n self.seek(0)\n\n def _palette(self, palette, shift):\n # load palette\n\n i = 0\n for e in range(i16(self.fp.read(2))):\n s = self.fp.read(2)\n i = i + i8(s[0])\n n = i8(s[1])\n if n == 0:\n n = 256\n s = self.fp.read(n * 3)\n for n in range(0, len(s), 3):\n r = i8(s[n]) << shift\n g = i8(s[n+1]) << shift\n b = i8(s[n+2]) << shift\n palette[i] = (r, g, b)\n i += 1\n\n @property\n def n_frames(self):\n return self.__framecount\n\n @property\n def is_animated(self):\n return self.__framecount > 1\n\n def seek(self, frame):\n if not self._seek_check(frame):\n return\n if frame < self.__frame:\n self._seek(0)\n\n for f in range(self.__frame + 1, frame + 1):\n self._seek(f)\n\n def _seek(self, frame):\n if frame == 0:\n self.__frame = -1\n self.__fp.seek(self.__rewind)\n self.__offset = 128\n\n if frame != self.__frame + 1:\n raise ValueError(\"cannot seek to frame %d\" % frame)\n self.__frame = frame\n\n # move to next frame\n self.fp = self.__fp\n self.fp.seek(self.__offset)\n\n s = self.fp.read(4)\n if not s:\n raise EOFError\n\n framesize = i32(s)\n\n self.decodermaxblock = framesize\n self.tile = [(\"fli\", (0, 0)+self.size, self.__offset, None)]\n\n self.__offset += framesize\n\n def tell(self):\n return self.__frame\n\n\n#\n# registry\n\nImage.register_open(FliImageFile.format, FliImageFile, _accept)\n\nImage.register_extensions(FliImageFile.format, [\".fli\", \".flc\"])\n", "path": "src/PIL/FliImagePlugin.py"}], "after_files": [{"content": "#\n# The Python Imaging Library.\n# $Id$\n#\n# FLI/FLC file handling.\n#\n# History:\n# 95-09-01 fl Created\n# 97-01-03 fl Fixed parser, setup decoder tile\n# 98-07-15 fl Renamed offset attribute to avoid name clash\n#\n# Copyright (c) Secret Labs AB 1997-98.\n# Copyright (c) Fredrik Lundh 1995-97.\n#\n# See the README file for information on usage and redistribution.\n#\n\n\nfrom . import Image, ImageFile, ImagePalette\nfrom ._binary import i8, i16le as i16, i32le as i32, o8\n\n__version__ = \"0.2\"\n\n\n#\n# decoder\n\ndef _accept(prefix):\n return len(prefix) >= 6 and i16(prefix[4:6]) in [0xAF11, 0xAF12]\n\n\n##\n# Image plugin for the FLI/FLC animation format. Use the <b>seek</b>\n# method to load individual frames.\n\nclass FliImageFile(ImageFile.ImageFile):\n\n format = \"FLI\"\n format_description = \"Autodesk FLI/FLC Animation\"\n _close_exclusive_fp_after_loading = False\n\n def _open(self):\n\n # HEAD\n s = self.fp.read(128)\n magic = i16(s[4:6])\n if not (magic in [0xAF11, 0xAF12] and\n i16(s[14:16]) in [0, 3] and # flags\n s[20:22] == b\"\\x00\\x00\"): # reserved\n raise SyntaxError(\"not an FLI/FLC file\")\n\n # frames\n self.__framecount = i16(s[6:8])\n\n # image characteristics\n self.mode = \"P\"\n self._size = i16(s[8:10]), i16(s[10:12])\n\n # animation speed\n duration = i32(s[16:20])\n if magic == 0xAF11:\n duration = (duration * 1000) // 70\n self.info[\"duration\"] = duration\n\n # look for palette\n palette = [(a, a, a) for a in range(256)]\n\n s = self.fp.read(16)\n\n self.__offset = 128\n\n if i16(s[4:6]) == 0xF100:\n # prefix chunk; ignore it\n self.__offset = self.__offset + i32(s)\n s = self.fp.read(16)\n\n if i16(s[4:6]) == 0xF1FA:\n # look for palette chunk\n s = self.fp.read(6)\n if i16(s[4:6]) == 11:\n self._palette(palette, 2)\n elif i16(s[4:6]) == 4:\n self._palette(palette, 0)\n\n palette = [o8(r)+o8(g)+o8(b) for (r, g, b) in palette]\n self.palette = ImagePalette.raw(\"RGB\", b\"\".join(palette))\n\n # set things up to decode first frame\n self.__frame = -1\n self.__fp = self.fp\n self.__rewind = self.fp.tell()\n self.seek(0)\n\n def _palette(self, palette, shift):\n # load palette\n\n i = 0\n for e in range(i16(self.fp.read(2))):\n s = self.fp.read(2)\n i = i + i8(s[0])\n n = i8(s[1])\n if n == 0:\n n = 256\n s = self.fp.read(n * 3)\n for n in range(0, len(s), 3):\n r = i8(s[n]) << shift\n g = i8(s[n+1]) << shift\n b = i8(s[n+2]) << shift\n palette[i] = (r, g, b)\n i += 1\n\n @property\n def n_frames(self):\n return self.__framecount\n\n @property\n def is_animated(self):\n return self.__framecount > 1\n\n def seek(self, frame):\n if not self._seek_check(frame):\n return\n if frame < self.__frame:\n self._seek(0)\n\n for f in range(self.__frame + 1, frame + 1):\n self._seek(f)\n\n def _seek(self, frame):\n if frame == 0:\n self.__frame = -1\n self.__fp.seek(self.__rewind)\n self.__offset = 128\n else:\n # ensure that the previous frame was loaded\n self.load()\n\n if frame != self.__frame + 1:\n raise ValueError(\"cannot seek to frame %d\" % frame)\n self.__frame = frame\n\n # move to next frame\n self.fp = self.__fp\n self.fp.seek(self.__offset)\n\n s = self.fp.read(4)\n if not s:\n raise EOFError\n\n framesize = i32(s)\n\n self.decodermaxblock = framesize\n self.tile = [(\"fli\", (0, 0)+self.size, self.__offset, None)]\n\n self.__offset += framesize\n\n def tell(self):\n return self.__frame\n\n\n#\n# registry\n\nImage.register_open(FliImageFile.format, FliImageFile, _accept)\n\nImage.register_extensions(FliImageFile.format, [\".fli\", \".flc\"])\n", "path": "src/PIL/FliImagePlugin.py"}]} | 2,505 | 132 |
gh_patches_debug_29612 | rasdani/github-patches | git_diff | pytorch__pytorch-3978 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Implement random_gamma() sampler (with gradients)
Many probability distributions require sampling from the [Gamma distribution](https://en.wikipedia.org/wiki/Gamma_distribution), including: `Gamma`, `Beta`, and `Dirichlet`.
Since Gamma samplers have complex control flow (for rejection sampling) and are seldom a bottleneck in probabilistic algorithms, it should suffice to implement a CPU-only implementation at first. What is more important than a CUDA implementation is a reparameterized sampler so that stochastic gradients can be propagated through the sampler (see [paper](http://proceedings.mlr.press/v54/naesseth17a/naesseth17a.pdf) and [reference implementation](https://github.com/blei-lab/ars-reparameterization) by @naesseth).
## Tasks
- [x] #3841 CPU implementation of basic `random_gamma(requires_grad=False)`
- [ ] #3978 Support reparameterized `random_gamma(requires_grad=True)`
## Map of modifications
- `aten/src/TH/THRandom.c/h` random single numbers
- `aten/src/TH/generic/THTensorRandom.c/h` random tensors
- `aten/src/ATen/Declarations.cwrap` bindings for ATen
- `torch/csrc/generic/methods/TensorRandom.cwrap` bindings for torch.Tensor
- `torch/autograd/variable.py` - Variable
- `torch/distributions.py` - Distributions
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torch/distributions.py`
Content:
```
1 r"""
2 The ``distributions`` package contains parameterizable probability distributions
3 and sampling functions.
4
5 Policy gradient methods can be implemented using the
6 :meth:`~torch.distributions.Distribution.log_prob` method, when the probability
7 density function is differentiable with respect to its parameters. A basic
8 method is the REINFORCE rule:
9
10 .. math::
11
12 \Delta\theta = \alpha r \frac{\partial\log p(a|\pi^\theta(s))}{\partial\theta}
13
14 where :math:`\theta` are the parameters, :math:`\alpha` is the learning rate,
15 :math:`r` is the reward and :math:`p(a|\pi^\theta(s))` is the probability of
16 taking action :math:`a` in state :math:`s` given policy :math:`\pi^\theta`.
17
18 In practice we would sample an action from the output of a network, apply this
19 action in an environment, and then use ``log_prob`` to construct an equivalent
20 loss function. Note that we use a negative because optimisers use gradient
21 descent, whilst the rule above assumes gradient ascent. With a categorical
22 policy, the code for implementing REINFORCE would be as follows::
23
24 probs = policy_network(state)
25 # NOTE: this is equivalent to what used to be called multinomial
26 m = Categorical(probs)
27 action = m.sample()
28 next_state, reward = env.step(action)
29 loss = -m.log_prob(action) * reward
30 loss.backward()
31 """
32 import math
33 from numbers import Number
34 import torch
35 from torch.autograd import Variable
36
37
38 __all__ = ['Distribution', 'Bernoulli', 'Categorical', 'Normal', 'Gamma']
39
40
41 def _expand_n(v, n):
42 r"""
43 Cleanly expand float or Tensor or Variable parameters.
44 """
45 if isinstance(v, Number):
46 return torch.Tensor([v]).expand(n, 1)
47 else:
48 return v.expand(n, *v.size())
49
50
51 class Distribution(object):
52 r"""
53 Distribution is the abstract base class for probability distributions.
54 """
55
56 def sample(self):
57 """
58 Generates a single sample or single batch of samples if the distribution
59 parameters are batched.
60 """
61 raise NotImplementedError
62
63 def sample_n(self, n):
64 """
65 Generates n samples or n batches of samples if the distribution parameters
66 are batched.
67 """
68 raise NotImplementedError
69
70 def log_prob(self, value):
71 """
72 Returns the log of the probability density/mass function evaluated at
73 `value`.
74
75 Args:
76 value (Tensor or Variable):
77 """
78 raise NotImplementedError
79
80
81 class Bernoulli(Distribution):
82 r"""
83 Creates a Bernoulli distribution parameterized by `probs`.
84
85 Samples are binary (0 or 1). They take the value `1` with probability `p`
86 and `0` with probability `1 - p`.
87
88 Example::
89
90 >>> m = Bernoulli(torch.Tensor([0.3]))
91 >>> m.sample() # 30% chance 1; 70% chance 0
92 0.0
93 [torch.FloatTensor of size 1]
94
95 Args:
96 probs (Tensor or Variable): the probabilty of sampling `1`
97 """
98
99 def __init__(self, probs):
100 self.probs = probs
101
102 def sample(self):
103 return torch.bernoulli(self.probs)
104
105 def sample_n(self, n):
106 return torch.bernoulli(self.probs.expand(n, *self.probs.size()))
107
108 def log_prob(self, value):
109 # compute the log probabilities for 0 and 1
110 log_pmf = (torch.stack([1 - self.probs, self.probs])).log()
111
112 # evaluate using the values
113 return log_pmf.gather(0, value.unsqueeze(0).long()).squeeze(0)
114
115
116 class Categorical(Distribution):
117 r"""
118 Creates a categorical distribution parameterized by `probs`.
119
120 .. note::
121 It is equivalent to the distribution that ``multinomial()`` samples from.
122
123 Samples are integers from `0 ... K-1` where `K` is probs.size(-1).
124
125 If `probs` is 1D with length-`K`, each element is the relative probability
126 of sampling the class at that index.
127
128 If `probs` is 2D, it is treated as a batch of probability vectors.
129
130 See also: :func:`torch.multinomial`
131
132 Example::
133
134 >>> m = Categorical(torch.Tensor([ 0.25, 0.25, 0.25, 0.25 ]))
135 >>> m.sample() # equal probability of 0, 1, 2, 3
136 3
137 [torch.LongTensor of size 1]
138
139 Args:
140 probs (Tensor or Variable): event probabilities
141 """
142
143 def __init__(self, probs):
144 if probs.dim() != 1 and probs.dim() != 2:
145 # TODO: treat higher dimensions as part of the batch
146 raise ValueError("probs must be 1D or 2D")
147 self.probs = probs
148
149 def sample(self):
150 return torch.multinomial(self.probs, 1, True).squeeze(-1)
151
152 def sample_n(self, n):
153 if n == 1:
154 return self.sample().expand(1, 1)
155 else:
156 return torch.multinomial(self.probs, n, True).t()
157
158 def log_prob(self, value):
159 p = self.probs / self.probs.sum(-1, keepdim=True)
160 if value.dim() == 1 and self.probs.dim() == 1:
161 # special handling until we have 0-dim tensor support
162 return p.gather(-1, value).log()
163
164 return p.gather(-1, value.unsqueeze(-1)).squeeze(-1).log()
165
166
167 class Normal(Distribution):
168 r"""
169 Creates a normal (also called Gaussian) distribution parameterized by
170 `mean` and `std`.
171
172 Example::
173
174 >>> m = Normal(torch.Tensor([0.0]), torch.Tensor([1.0]))
175 >>> m.sample() # normally distributed with mean=0 and stddev=1
176 0.1046
177 [torch.FloatTensor of size 1]
178
179 Args:
180 mean (float or Tensor or Variable): mean of the distribution
181 std (float or Tensor or Variable): standard deviation of the distribution
182 """
183
184 def __init__(self, mean, std):
185 self.mean = mean
186 self.std = std
187
188 def sample(self):
189 return torch.normal(self.mean, self.std)
190
191 def sample_n(self, n):
192 return torch.normal(_expand_n(self.mean, n), _expand_n(self.std, n))
193
194 def log_prob(self, value):
195 # compute the variance
196 var = (self.std ** 2)
197 log_std = math.log(self.std) if isinstance(self.std, Number) else self.std.log()
198 return -((value - self.mean) ** 2) / (2 * var) - log_std - math.log(math.sqrt(2 * math.pi))
199
200
201 def _standard_gamma(alpha):
202 if not isinstance(alpha, Variable):
203 return torch._C._standard_gamma(alpha)
204 return Variable(torch._C._standard_gamma(alpha.data))
205
206
207 class Gamma(Distribution):
208 r"""
209 Creates a Gamma distribution parameterized by shape `alpha` and rate `beta`.
210
211 Example::
212
213 >>> m = Gamma(torch.Tensor([1.0]), torch.Tensor([1.0]))
214 >>> m.sample() # Gamma distributed with shape alpha=1 and rate beta=1
215 0.1046
216 [torch.FloatTensor of size 1]
217
218 Args:
219 alpha (float or Tensor or Variable): shape parameter of the distribution
220 beta (float or Tensor or Variable): rate = 1 / scale of the distribution
221 """
222
223 def __init__(self, alpha, beta):
224 # TODO handle (Variable, Number) cases
225 alpha_num = isinstance(alpha, Number)
226 beta_num = isinstance(beta, Number)
227 if alpha_num and not beta_num:
228 alpha = beta.new(beta.size()).fill_(alpha)
229 elif not alpha_num and beta_num:
230 beta = alpha.new(alpha.size()).fill_(beta)
231 elif alpha_num and beta_num:
232 alpha, beta = torch.Tensor([alpha]), torch.Tensor([beta])
233 elif alpha.size() != beta.size():
234 raise ValueError('Expected alpha.size() == beta.size(), actual {} vs {}'.format(
235 alpha.size(), beta.size()))
236 self.alpha = alpha
237 self.beta = beta
238
239 def sample(self):
240 return _standard_gamma(self.alpha) / self.beta
241
242 def sample_n(self, n):
243 return _standard_gamma(_expand_n(self.alpha, n)) / self.beta
244
245 def log_prob(self, value):
246 return (self.alpha * torch.log(self.beta) +
247 (self.alpha - 1) * torch.log(value) -
248 self.beta * value - torch.lgamma(self.alpha))
249
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/torch/distributions.py b/torch/distributions.py
--- a/torch/distributions.py
+++ b/torch/distributions.py
@@ -32,8 +32,8 @@
import math
from numbers import Number
import torch
-from torch.autograd import Variable
-
+from torch.autograd import Function, Variable
+from torch.autograd.function import once_differentiable
__all__ = ['Distribution', 'Bernoulli', 'Categorical', 'Normal', 'Gamma']
@@ -198,10 +198,25 @@
return -((value - self.mean) ** 2) / (2 * var) - log_std - math.log(math.sqrt(2 * math.pi))
+class _StandardGamma(Function):
+ @staticmethod
+ def forward(ctx, alpha):
+ x = torch._C._standard_gamma(alpha)
+ ctx.save_for_backward(x, alpha)
+ return x
+
+ @staticmethod
+ @once_differentiable
+ def backward(ctx, grad_output):
+ x, alpha = ctx.saved_tensors
+ grad = torch._C._standard_gamma_grad(x, alpha)
+ return grad_output * grad
+
+
def _standard_gamma(alpha):
if not isinstance(alpha, Variable):
return torch._C._standard_gamma(alpha)
- return Variable(torch._C._standard_gamma(alpha.data))
+ return _StandardGamma.apply(alpha)
class Gamma(Distribution):
@@ -219,6 +234,7 @@
alpha (float or Tensor or Variable): shape parameter of the distribution
beta (float or Tensor or Variable): rate = 1 / scale of the distribution
"""
+ has_rsample = True
def __init__(self, alpha, beta):
# TODO handle (Variable, Number) cases
| {"golden_diff": "diff --git a/torch/distributions.py b/torch/distributions.py\n--- a/torch/distributions.py\n+++ b/torch/distributions.py\n@@ -32,8 +32,8 @@\n import math\n from numbers import Number\n import torch\n-from torch.autograd import Variable\n-\n+from torch.autograd import Function, Variable\n+from torch.autograd.function import once_differentiable\n \n __all__ = ['Distribution', 'Bernoulli', 'Categorical', 'Normal', 'Gamma']\n \n@@ -198,10 +198,25 @@\n return -((value - self.mean) ** 2) / (2 * var) - log_std - math.log(math.sqrt(2 * math.pi))\n \n \n+class _StandardGamma(Function):\n+ @staticmethod\n+ def forward(ctx, alpha):\n+ x = torch._C._standard_gamma(alpha)\n+ ctx.save_for_backward(x, alpha)\n+ return x\n+\n+ @staticmethod\n+ @once_differentiable\n+ def backward(ctx, grad_output):\n+ x, alpha = ctx.saved_tensors\n+ grad = torch._C._standard_gamma_grad(x, alpha)\n+ return grad_output * grad\n+\n+\n def _standard_gamma(alpha):\n if not isinstance(alpha, Variable):\n return torch._C._standard_gamma(alpha)\n- return Variable(torch._C._standard_gamma(alpha.data))\n+ return _StandardGamma.apply(alpha)\n \n \n class Gamma(Distribution):\n@@ -219,6 +234,7 @@\n alpha (float or Tensor or Variable): shape parameter of the distribution\n beta (float or Tensor or Variable): rate = 1 / scale of the distribution\n \"\"\"\n+ has_rsample = True\n \n def __init__(self, alpha, beta):\n # TODO handle (Variable, Number) cases\n", "issue": "Implement random_gamma() sampler (with gradients)\nMany probability distributions require sampling from the [Gamma distribution](https://en.wikipedia.org/wiki/Gamma_distribution), including: `Gamma`, `Beta`, and `Dirichlet`.\r\n\r\nSince Gamma samplers have complex control flow (for rejection sampling) and are seldom a bottleneck in probabilistic algorithms, it should suffice to implement a CPU-only implementation at first. What is more important than a CUDA implementation is a reparameterized sampler so that stochastic gradients can be propagated through the sampler (see [paper](http://proceedings.mlr.press/v54/naesseth17a/naesseth17a.pdf) and [reference implementation](https://github.com/blei-lab/ars-reparameterization) by @naesseth).\r\n\r\n## Tasks\r\n- [x] #3841 CPU implementation of basic `random_gamma(requires_grad=False)`\r\n- [ ] #3978 Support reparameterized `random_gamma(requires_grad=True)`\r\n\r\n## Map of modifications\r\n- `aten/src/TH/THRandom.c/h` random single numbers\r\n- `aten/src/TH/generic/THTensorRandom.c/h` random tensors\r\n- `aten/src/ATen/Declarations.cwrap` bindings for ATen\r\n- `torch/csrc/generic/methods/TensorRandom.cwrap` bindings for torch.Tensor\r\n- `torch/autograd/variable.py` - Variable\r\n- `torch/distributions.py` - Distributions\n", "before_files": [{"content": "r\"\"\"\nThe ``distributions`` package contains parameterizable probability distributions\nand sampling functions.\n\nPolicy gradient methods can be implemented using the\n:meth:`~torch.distributions.Distribution.log_prob` method, when the probability\ndensity function is differentiable with respect to its parameters. A basic\nmethod is the REINFORCE rule:\n\n.. math::\n\n \\Delta\\theta = \\alpha r \\frac{\\partial\\log p(a|\\pi^\\theta(s))}{\\partial\\theta}\n\nwhere :math:`\\theta` are the parameters, :math:`\\alpha` is the learning rate,\n:math:`r` is the reward and :math:`p(a|\\pi^\\theta(s))` is the probability of\ntaking action :math:`a` in state :math:`s` given policy :math:`\\pi^\\theta`.\n\nIn practice we would sample an action from the output of a network, apply this\naction in an environment, and then use ``log_prob`` to construct an equivalent\nloss function. Note that we use a negative because optimisers use gradient\ndescent, whilst the rule above assumes gradient ascent. With a categorical\npolicy, the code for implementing REINFORCE would be as follows::\n\n probs = policy_network(state)\n # NOTE: this is equivalent to what used to be called multinomial\n m = Categorical(probs)\n action = m.sample()\n next_state, reward = env.step(action)\n loss = -m.log_prob(action) * reward\n loss.backward()\n\"\"\"\nimport math\nfrom numbers import Number\nimport torch\nfrom torch.autograd import Variable\n\n\n__all__ = ['Distribution', 'Bernoulli', 'Categorical', 'Normal', 'Gamma']\n\n\ndef _expand_n(v, n):\n r\"\"\"\n Cleanly expand float or Tensor or Variable parameters.\n \"\"\"\n if isinstance(v, Number):\n return torch.Tensor([v]).expand(n, 1)\n else:\n return v.expand(n, *v.size())\n\n\nclass Distribution(object):\n r\"\"\"\n Distribution is the abstract base class for probability distributions.\n \"\"\"\n\n def sample(self):\n \"\"\"\n Generates a single sample or single batch of samples if the distribution\n parameters are batched.\n \"\"\"\n raise NotImplementedError\n\n def sample_n(self, n):\n \"\"\"\n Generates n samples or n batches of samples if the distribution parameters\n are batched.\n \"\"\"\n raise NotImplementedError\n\n def log_prob(self, value):\n \"\"\"\n Returns the log of the probability density/mass function evaluated at\n `value`.\n\n Args:\n value (Tensor or Variable):\n \"\"\"\n raise NotImplementedError\n\n\nclass Bernoulli(Distribution):\n r\"\"\"\n Creates a Bernoulli distribution parameterized by `probs`.\n\n Samples are binary (0 or 1). They take the value `1` with probability `p`\n and `0` with probability `1 - p`.\n\n Example::\n\n >>> m = Bernoulli(torch.Tensor([0.3]))\n >>> m.sample() # 30% chance 1; 70% chance 0\n 0.0\n [torch.FloatTensor of size 1]\n\n Args:\n probs (Tensor or Variable): the probabilty of sampling `1`\n \"\"\"\n\n def __init__(self, probs):\n self.probs = probs\n\n def sample(self):\n return torch.bernoulli(self.probs)\n\n def sample_n(self, n):\n return torch.bernoulli(self.probs.expand(n, *self.probs.size()))\n\n def log_prob(self, value):\n # compute the log probabilities for 0 and 1\n log_pmf = (torch.stack([1 - self.probs, self.probs])).log()\n\n # evaluate using the values\n return log_pmf.gather(0, value.unsqueeze(0).long()).squeeze(0)\n\n\nclass Categorical(Distribution):\n r\"\"\"\n Creates a categorical distribution parameterized by `probs`.\n\n .. note::\n It is equivalent to the distribution that ``multinomial()`` samples from.\n\n Samples are integers from `0 ... K-1` where `K` is probs.size(-1).\n\n If `probs` is 1D with length-`K`, each element is the relative probability\n of sampling the class at that index.\n\n If `probs` is 2D, it is treated as a batch of probability vectors.\n\n See also: :func:`torch.multinomial`\n\n Example::\n\n >>> m = Categorical(torch.Tensor([ 0.25, 0.25, 0.25, 0.25 ]))\n >>> m.sample() # equal probability of 0, 1, 2, 3\n 3\n [torch.LongTensor of size 1]\n\n Args:\n probs (Tensor or Variable): event probabilities\n \"\"\"\n\n def __init__(self, probs):\n if probs.dim() != 1 and probs.dim() != 2:\n # TODO: treat higher dimensions as part of the batch\n raise ValueError(\"probs must be 1D or 2D\")\n self.probs = probs\n\n def sample(self):\n return torch.multinomial(self.probs, 1, True).squeeze(-1)\n\n def sample_n(self, n):\n if n == 1:\n return self.sample().expand(1, 1)\n else:\n return torch.multinomial(self.probs, n, True).t()\n\n def log_prob(self, value):\n p = self.probs / self.probs.sum(-1, keepdim=True)\n if value.dim() == 1 and self.probs.dim() == 1:\n # special handling until we have 0-dim tensor support\n return p.gather(-1, value).log()\n\n return p.gather(-1, value.unsqueeze(-1)).squeeze(-1).log()\n\n\nclass Normal(Distribution):\n r\"\"\"\n Creates a normal (also called Gaussian) distribution parameterized by\n `mean` and `std`.\n\n Example::\n\n >>> m = Normal(torch.Tensor([0.0]), torch.Tensor([1.0]))\n >>> m.sample() # normally distributed with mean=0 and stddev=1\n 0.1046\n [torch.FloatTensor of size 1]\n\n Args:\n mean (float or Tensor or Variable): mean of the distribution\n std (float or Tensor or Variable): standard deviation of the distribution\n \"\"\"\n\n def __init__(self, mean, std):\n self.mean = mean\n self.std = std\n\n def sample(self):\n return torch.normal(self.mean, self.std)\n\n def sample_n(self, n):\n return torch.normal(_expand_n(self.mean, n), _expand_n(self.std, n))\n\n def log_prob(self, value):\n # compute the variance\n var = (self.std ** 2)\n log_std = math.log(self.std) if isinstance(self.std, Number) else self.std.log()\n return -((value - self.mean) ** 2) / (2 * var) - log_std - math.log(math.sqrt(2 * math.pi))\n\n\ndef _standard_gamma(alpha):\n if not isinstance(alpha, Variable):\n return torch._C._standard_gamma(alpha)\n return Variable(torch._C._standard_gamma(alpha.data))\n\n\nclass Gamma(Distribution):\n r\"\"\"\n Creates a Gamma distribution parameterized by shape `alpha` and rate `beta`.\n\n Example::\n\n >>> m = Gamma(torch.Tensor([1.0]), torch.Tensor([1.0]))\n >>> m.sample() # Gamma distributed with shape alpha=1 and rate beta=1\n 0.1046\n [torch.FloatTensor of size 1]\n\n Args:\n alpha (float or Tensor or Variable): shape parameter of the distribution\n beta (float or Tensor or Variable): rate = 1 / scale of the distribution\n \"\"\"\n\n def __init__(self, alpha, beta):\n # TODO handle (Variable, Number) cases\n alpha_num = isinstance(alpha, Number)\n beta_num = isinstance(beta, Number)\n if alpha_num and not beta_num:\n alpha = beta.new(beta.size()).fill_(alpha)\n elif not alpha_num and beta_num:\n beta = alpha.new(alpha.size()).fill_(beta)\n elif alpha_num and beta_num:\n alpha, beta = torch.Tensor([alpha]), torch.Tensor([beta])\n elif alpha.size() != beta.size():\n raise ValueError('Expected alpha.size() == beta.size(), actual {} vs {}'.format(\n alpha.size(), beta.size()))\n self.alpha = alpha\n self.beta = beta\n\n def sample(self):\n return _standard_gamma(self.alpha) / self.beta\n\n def sample_n(self, n):\n return _standard_gamma(_expand_n(self.alpha, n)) / self.beta\n\n def log_prob(self, value):\n return (self.alpha * torch.log(self.beta) +\n (self.alpha - 1) * torch.log(value) -\n self.beta * value - torch.lgamma(self.alpha))\n", "path": "torch/distributions.py"}], "after_files": [{"content": "r\"\"\"\nThe ``distributions`` package contains parameterizable probability distributions\nand sampling functions.\n\nPolicy gradient methods can be implemented using the\n:meth:`~torch.distributions.Distribution.log_prob` method, when the probability\ndensity function is differentiable with respect to its parameters. A basic\nmethod is the REINFORCE rule:\n\n.. math::\n\n \\Delta\\theta = \\alpha r \\frac{\\partial\\log p(a|\\pi^\\theta(s))}{\\partial\\theta}\n\nwhere :math:`\\theta` are the parameters, :math:`\\alpha` is the learning rate,\n:math:`r` is the reward and :math:`p(a|\\pi^\\theta(s))` is the probability of\ntaking action :math:`a` in state :math:`s` given policy :math:`\\pi^\\theta`.\n\nIn practice we would sample an action from the output of a network, apply this\naction in an environment, and then use ``log_prob`` to construct an equivalent\nloss function. Note that we use a negative because optimisers use gradient\ndescent, whilst the rule above assumes gradient ascent. With a categorical\npolicy, the code for implementing REINFORCE would be as follows::\n\n probs = policy_network(state)\n # NOTE: this is equivalent to what used to be called multinomial\n m = Categorical(probs)\n action = m.sample()\n next_state, reward = env.step(action)\n loss = -m.log_prob(action) * reward\n loss.backward()\n\"\"\"\nimport math\nfrom numbers import Number\nimport torch\nfrom torch.autograd import Function, Variable\nfrom torch.autograd.function import once_differentiable\n\n__all__ = ['Distribution', 'Bernoulli', 'Categorical', 'Normal', 'Gamma']\n\n\ndef _expand_n(v, n):\n r\"\"\"\n Cleanly expand float or Tensor or Variable parameters.\n \"\"\"\n if isinstance(v, Number):\n return torch.Tensor([v]).expand(n, 1)\n else:\n return v.expand(n, *v.size())\n\n\nclass Distribution(object):\n r\"\"\"\n Distribution is the abstract base class for probability distributions.\n \"\"\"\n\n def sample(self):\n \"\"\"\n Generates a single sample or single batch of samples if the distribution\n parameters are batched.\n \"\"\"\n raise NotImplementedError\n\n def sample_n(self, n):\n \"\"\"\n Generates n samples or n batches of samples if the distribution parameters\n are batched.\n \"\"\"\n raise NotImplementedError\n\n def log_prob(self, value):\n \"\"\"\n Returns the log of the probability density/mass function evaluated at\n `value`.\n\n Args:\n value (Tensor or Variable):\n \"\"\"\n raise NotImplementedError\n\n\nclass Bernoulli(Distribution):\n r\"\"\"\n Creates a Bernoulli distribution parameterized by `probs`.\n\n Samples are binary (0 or 1). They take the value `1` with probability `p`\n and `0` with probability `1 - p`.\n\n Example::\n\n >>> m = Bernoulli(torch.Tensor([0.3]))\n >>> m.sample() # 30% chance 1; 70% chance 0\n 0.0\n [torch.FloatTensor of size 1]\n\n Args:\n probs (Tensor or Variable): the probabilty of sampling `1`\n \"\"\"\n\n def __init__(self, probs):\n self.probs = probs\n\n def sample(self):\n return torch.bernoulli(self.probs)\n\n def sample_n(self, n):\n return torch.bernoulli(self.probs.expand(n, *self.probs.size()))\n\n def log_prob(self, value):\n # compute the log probabilities for 0 and 1\n log_pmf = (torch.stack([1 - self.probs, self.probs])).log()\n\n # evaluate using the values\n return log_pmf.gather(0, value.unsqueeze(0).long()).squeeze(0)\n\n\nclass Categorical(Distribution):\n r\"\"\"\n Creates a categorical distribution parameterized by `probs`.\n\n .. note::\n It is equivalent to the distribution that ``multinomial()`` samples from.\n\n Samples are integers from `0 ... K-1` where `K` is probs.size(-1).\n\n If `probs` is 1D with length-`K`, each element is the relative probability\n of sampling the class at that index.\n\n If `probs` is 2D, it is treated as a batch of probability vectors.\n\n See also: :func:`torch.multinomial`\n\n Example::\n\n >>> m = Categorical(torch.Tensor([ 0.25, 0.25, 0.25, 0.25 ]))\n >>> m.sample() # equal probability of 0, 1, 2, 3\n 3\n [torch.LongTensor of size 1]\n\n Args:\n probs (Tensor or Variable): event probabilities\n \"\"\"\n\n def __init__(self, probs):\n if probs.dim() != 1 and probs.dim() != 2:\n # TODO: treat higher dimensions as part of the batch\n raise ValueError(\"probs must be 1D or 2D\")\n self.probs = probs\n\n def sample(self):\n return torch.multinomial(self.probs, 1, True).squeeze(-1)\n\n def sample_n(self, n):\n if n == 1:\n return self.sample().expand(1, 1)\n else:\n return torch.multinomial(self.probs, n, True).t()\n\n def log_prob(self, value):\n p = self.probs / self.probs.sum(-1, keepdim=True)\n if value.dim() == 1 and self.probs.dim() == 1:\n # special handling until we have 0-dim tensor support\n return p.gather(-1, value).log()\n\n return p.gather(-1, value.unsqueeze(-1)).squeeze(-1).log()\n\n\nclass Normal(Distribution):\n r\"\"\"\n Creates a normal (also called Gaussian) distribution parameterized by\n `mean` and `std`.\n\n Example::\n\n >>> m = Normal(torch.Tensor([0.0]), torch.Tensor([1.0]))\n >>> m.sample() # normally distributed with mean=0 and stddev=1\n 0.1046\n [torch.FloatTensor of size 1]\n\n Args:\n mean (float or Tensor or Variable): mean of the distribution\n std (float or Tensor or Variable): standard deviation of the distribution\n \"\"\"\n\n def __init__(self, mean, std):\n self.mean = mean\n self.std = std\n\n def sample(self):\n return torch.normal(self.mean, self.std)\n\n def sample_n(self, n):\n return torch.normal(_expand_n(self.mean, n), _expand_n(self.std, n))\n\n def log_prob(self, value):\n # compute the variance\n var = (self.std ** 2)\n log_std = math.log(self.std) if isinstance(self.std, Number) else self.std.log()\n return -((value - self.mean) ** 2) / (2 * var) - log_std - math.log(math.sqrt(2 * math.pi))\n\n\nclass _StandardGamma(Function):\n @staticmethod\n def forward(ctx, alpha):\n x = torch._C._standard_gamma(alpha)\n ctx.save_for_backward(x, alpha)\n return x\n\n @staticmethod\n @once_differentiable\n def backward(ctx, grad_output):\n x, alpha = ctx.saved_tensors\n grad = torch._C._standard_gamma_grad(x, alpha)\n return grad_output * grad\n\n\ndef _standard_gamma(alpha):\n if not isinstance(alpha, Variable):\n return torch._C._standard_gamma(alpha)\n return _StandardGamma.apply(alpha)\n\n\nclass Gamma(Distribution):\n r\"\"\"\n Creates a Gamma distribution parameterized by shape `alpha` and rate `beta`.\n\n Example::\n\n >>> m = Gamma(torch.Tensor([1.0]), torch.Tensor([1.0]))\n >>> m.sample() # Gamma distributed with shape alpha=1 and rate beta=1\n 0.1046\n [torch.FloatTensor of size 1]\n\n Args:\n alpha (float or Tensor or Variable): shape parameter of the distribution\n beta (float or Tensor or Variable): rate = 1 / scale of the distribution\n \"\"\"\n has_rsample = True\n\n def __init__(self, alpha, beta):\n # TODO handle (Variable, Number) cases\n alpha_num = isinstance(alpha, Number)\n beta_num = isinstance(beta, Number)\n if alpha_num and not beta_num:\n alpha = beta.new(beta.size()).fill_(alpha)\n elif not alpha_num and beta_num:\n beta = alpha.new(alpha.size()).fill_(beta)\n elif alpha_num and beta_num:\n alpha, beta = torch.Tensor([alpha]), torch.Tensor([beta])\n elif alpha.size() != beta.size():\n raise ValueError('Expected alpha.size() == beta.size(), actual {} vs {}'.format(\n alpha.size(), beta.size()))\n self.alpha = alpha\n self.beta = beta\n\n def sample(self):\n return _standard_gamma(self.alpha) / self.beta\n\n def sample_n(self, n):\n return _standard_gamma(_expand_n(self.alpha, n)) / self.beta\n\n def log_prob(self, value):\n return (self.alpha * torch.log(self.beta) +\n (self.alpha - 1) * torch.log(value) -\n self.beta * value - torch.lgamma(self.alpha))\n", "path": "torch/distributions.py"}]} | 3,174 | 393 |
gh_patches_debug_5989 | rasdani/github-patches | git_diff | cal-itp__benefits-999 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove agency index pass-through
With the new Courtesy Card designs, we have a better context-setting Agency Index (homepage). Let's remove the auto-pass-through that currently sends the user straight to Eligibility Start.
## Acceptance Criteria
<!-- Remember to consider edge cases -->
- [ ] A user lands on the Agency Index page when viewing the Benefits app
- [ ] The Agency Index continue button takes the user to the Eligibility Index page
## Additional context
Work on the new homepage is happening in #937
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `benefits/core/views.py`
Content:
```
1 """
2 The core application: view definition for the root of the webapp.
3 """
4 from django.http import HttpResponse, HttpResponseBadRequest, HttpResponseNotFound, HttpResponseServerError
5 from django.shortcuts import redirect
6 from django.template import loader
7 from django.template.response import TemplateResponse
8 from django.urls import reverse
9 from django.utils.translation import gettext as _
10
11 from . import models, session, viewmodels
12 from .middleware import pageview_decorator
13
14 ROUTE_INDEX = "core:index"
15 ROUTE_ELIGIBILITY = "eligibility:index"
16 ROUTE_HELP = "core:help"
17
18 TEMPLATE_PAGE = "core/page.html"
19 TEMPLATE_AGENCY = "core/agency_index.html"
20 TEMPLATE_HELP = "core/help.html"
21
22
23 @pageview_decorator
24 def index(request):
25 """View handler for the main entry page."""
26 session.reset(request)
27
28 agencies = models.TransitAgency.all_active()
29
30 if len(agencies) == 1:
31 agency = agencies[0]
32 return redirect(agency.index_url)
33
34 # generate a button to the landing page for each active agency
35 buttons = [viewmodels.Button.outline_primary(text=a.short_name, url=a.index_url) for a in agencies]
36 buttons[0].classes.append("mt-3")
37 buttons[0].label = _("core.pages.index.chooseprovider")
38
39 page = viewmodels.Page(
40 title=_("core.pages.index.title"),
41 headline=_("core.pages.index.headline"),
42 buttons=buttons,
43 classes="home",
44 )
45
46 return TemplateResponse(request, TEMPLATE_PAGE, page.context_dict())
47
48
49 @pageview_decorator
50 def agency_index(request, agency):
51 """View handler for an agency entry page."""
52 session.reset(request)
53 session.update(request, agency=agency, origin=agency.index_url)
54
55 if len(agency.eligibility_verifiers.all()) == 1:
56 return redirect(reverse(ROUTE_ELIGIBILITY))
57
58 button = viewmodels.Button.primary(text=_("core.pages.index.continue"), url=reverse(ROUTE_ELIGIBILITY))
59
60 page = viewmodels.Page(
61 title=_("core.pages.agency_index.title"),
62 headline=_("core.pages.agency_index.mst_cc.headline"),
63 button=button,
64 classes="home",
65 )
66
67 return TemplateResponse(request, TEMPLATE_AGENCY, page.context_dict())
68
69
70 @pageview_decorator
71 def agency_public_key(request, agency):
72 """View handler returns an agency's public key as plain text."""
73 return HttpResponse(agency.public_key_data, content_type="text/plain")
74
75
76 @pageview_decorator
77 def help(request):
78 """View handler for the help page."""
79 if session.active_agency(request):
80 agency = session.agency(request)
81 buttons = viewmodels.Button.agency_contact_links(agency)
82 else:
83 buttons = [btn for a in models.TransitAgency.all_active() for btn in viewmodels.Button.agency_contact_links(a)]
84
85 buttons.append(viewmodels.Button.home(request, _("core.buttons.back")))
86
87 page = viewmodels.Page(
88 title=_("core.buttons.help"),
89 headline=_("core.buttons.help"),
90 buttons=buttons,
91 )
92
93 return TemplateResponse(request, TEMPLATE_HELP, page.context_dict())
94
95
96 @pageview_decorator
97 def bad_request(request, exception, template_name="400.html"):
98 """View handler for HTTP 400 Bad Request responses."""
99 if session.active_agency(request):
100 session.update(request, origin=session.agency(request).index_url)
101 else:
102 session.update(request, origin=reverse(ROUTE_INDEX))
103
104 home = viewmodels.Button.home(request)
105 page = viewmodels.ErrorPage.server_error(button=home)
106 t = loader.get_template(template_name)
107
108 return HttpResponseBadRequest(t.render(page.context_dict()))
109
110
111 @pageview_decorator
112 def csrf_failure(request, reason):
113 """
114 View handler for CSRF_FAILURE_VIEW with custom data.
115 """
116 if session.active_agency(request):
117 session.update(request, origin=session.agency(request).index_url)
118 else:
119 session.update(request, origin=reverse(ROUTE_INDEX))
120
121 home = viewmodels.Button.home(request)
122 page = viewmodels.ErrorPage.not_found(button=home, path=request.path)
123 t = loader.get_template("400.html")
124
125 return HttpResponseNotFound(t.render(page.context_dict()))
126
127
128 @pageview_decorator
129 def page_not_found(request, exception, template_name="404.html"):
130 """View handler for HTTP 404 Not Found responses."""
131 if session.active_agency(request):
132 session.update(request, origin=session.agency(request).index_url)
133 else:
134 session.update(request, origin=reverse(ROUTE_INDEX))
135
136 home = viewmodels.Button.home(request)
137 # show a more user-friendly message instead of not_found
138 page = viewmodels.ErrorPage.user_error(button=home, path=request.path)
139 t = loader.get_template(template_name)
140
141 return HttpResponseNotFound(t.render(page.context_dict()))
142
143
144 @pageview_decorator
145 def server_error(request, template_name="500.html"):
146 """View handler for HTTP 500 Server Error responses."""
147 if session.active_agency(request):
148 session.update(request, origin=session.agency(request).index_url)
149 else:
150 session.update(request, origin=reverse(ROUTE_INDEX))
151
152 home = viewmodels.Button.home(request)
153 page = viewmodels.ErrorPage.server_error(button=home)
154 t = loader.get_template(template_name)
155
156 return HttpResponseServerError(t.render(page.context_dict()))
157
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/benefits/core/views.py b/benefits/core/views.py
--- a/benefits/core/views.py
+++ b/benefits/core/views.py
@@ -52,9 +52,6 @@
session.reset(request)
session.update(request, agency=agency, origin=agency.index_url)
- if len(agency.eligibility_verifiers.all()) == 1:
- return redirect(reverse(ROUTE_ELIGIBILITY))
-
button = viewmodels.Button.primary(text=_("core.pages.index.continue"), url=reverse(ROUTE_ELIGIBILITY))
page = viewmodels.Page(
| {"golden_diff": "diff --git a/benefits/core/views.py b/benefits/core/views.py\n--- a/benefits/core/views.py\n+++ b/benefits/core/views.py\n@@ -52,9 +52,6 @@\n session.reset(request)\n session.update(request, agency=agency, origin=agency.index_url)\n \n- if len(agency.eligibility_verifiers.all()) == 1:\n- return redirect(reverse(ROUTE_ELIGIBILITY))\n-\n button = viewmodels.Button.primary(text=_(\"core.pages.index.continue\"), url=reverse(ROUTE_ELIGIBILITY))\n \n page = viewmodels.Page(\n", "issue": "Remove agency index pass-through\nWith the new Courtesy Card designs, we have a better context-setting Agency Index (homepage). Let's remove the auto-pass-through that currently sends the user straight to Eligibility Start.\r\n\r\n## Acceptance Criteria\r\n\r\n<!-- Remember to consider edge cases -->\r\n\r\n- [ ] A user lands on the Agency Index page when viewing the Benefits app\r\n- [ ] The Agency Index continue button takes the user to the Eligibility Index page\r\n\r\n## Additional context\r\n\r\nWork on the new homepage is happening in #937\n", "before_files": [{"content": "\"\"\"\nThe core application: view definition for the root of the webapp.\n\"\"\"\nfrom django.http import HttpResponse, HttpResponseBadRequest, HttpResponseNotFound, HttpResponseServerError\nfrom django.shortcuts import redirect\nfrom django.template import loader\nfrom django.template.response import TemplateResponse\nfrom django.urls import reverse\nfrom django.utils.translation import gettext as _\n\nfrom . import models, session, viewmodels\nfrom .middleware import pageview_decorator\n\nROUTE_INDEX = \"core:index\"\nROUTE_ELIGIBILITY = \"eligibility:index\"\nROUTE_HELP = \"core:help\"\n\nTEMPLATE_PAGE = \"core/page.html\"\nTEMPLATE_AGENCY = \"core/agency_index.html\"\nTEMPLATE_HELP = \"core/help.html\"\n\n\n@pageview_decorator\ndef index(request):\n \"\"\"View handler for the main entry page.\"\"\"\n session.reset(request)\n\n agencies = models.TransitAgency.all_active()\n\n if len(agencies) == 1:\n agency = agencies[0]\n return redirect(agency.index_url)\n\n # generate a button to the landing page for each active agency\n buttons = [viewmodels.Button.outline_primary(text=a.short_name, url=a.index_url) for a in agencies]\n buttons[0].classes.append(\"mt-3\")\n buttons[0].label = _(\"core.pages.index.chooseprovider\")\n\n page = viewmodels.Page(\n title=_(\"core.pages.index.title\"),\n headline=_(\"core.pages.index.headline\"),\n buttons=buttons,\n classes=\"home\",\n )\n\n return TemplateResponse(request, TEMPLATE_PAGE, page.context_dict())\n\n\n@pageview_decorator\ndef agency_index(request, agency):\n \"\"\"View handler for an agency entry page.\"\"\"\n session.reset(request)\n session.update(request, agency=agency, origin=agency.index_url)\n\n if len(agency.eligibility_verifiers.all()) == 1:\n return redirect(reverse(ROUTE_ELIGIBILITY))\n\n button = viewmodels.Button.primary(text=_(\"core.pages.index.continue\"), url=reverse(ROUTE_ELIGIBILITY))\n\n page = viewmodels.Page(\n title=_(\"core.pages.agency_index.title\"),\n headline=_(\"core.pages.agency_index.mst_cc.headline\"),\n button=button,\n classes=\"home\",\n )\n\n return TemplateResponse(request, TEMPLATE_AGENCY, page.context_dict())\n\n\n@pageview_decorator\ndef agency_public_key(request, agency):\n \"\"\"View handler returns an agency's public key as plain text.\"\"\"\n return HttpResponse(agency.public_key_data, content_type=\"text/plain\")\n\n\n@pageview_decorator\ndef help(request):\n \"\"\"View handler for the help page.\"\"\"\n if session.active_agency(request):\n agency = session.agency(request)\n buttons = viewmodels.Button.agency_contact_links(agency)\n else:\n buttons = [btn for a in models.TransitAgency.all_active() for btn in viewmodels.Button.agency_contact_links(a)]\n\n buttons.append(viewmodels.Button.home(request, _(\"core.buttons.back\")))\n\n page = viewmodels.Page(\n title=_(\"core.buttons.help\"),\n headline=_(\"core.buttons.help\"),\n buttons=buttons,\n )\n\n return TemplateResponse(request, TEMPLATE_HELP, page.context_dict())\n\n\n@pageview_decorator\ndef bad_request(request, exception, template_name=\"400.html\"):\n \"\"\"View handler for HTTP 400 Bad Request responses.\"\"\"\n if session.active_agency(request):\n session.update(request, origin=session.agency(request).index_url)\n else:\n session.update(request, origin=reverse(ROUTE_INDEX))\n\n home = viewmodels.Button.home(request)\n page = viewmodels.ErrorPage.server_error(button=home)\n t = loader.get_template(template_name)\n\n return HttpResponseBadRequest(t.render(page.context_dict()))\n\n\n@pageview_decorator\ndef csrf_failure(request, reason):\n \"\"\"\n View handler for CSRF_FAILURE_VIEW with custom data.\n \"\"\"\n if session.active_agency(request):\n session.update(request, origin=session.agency(request).index_url)\n else:\n session.update(request, origin=reverse(ROUTE_INDEX))\n\n home = viewmodels.Button.home(request)\n page = viewmodels.ErrorPage.not_found(button=home, path=request.path)\n t = loader.get_template(\"400.html\")\n\n return HttpResponseNotFound(t.render(page.context_dict()))\n\n\n@pageview_decorator\ndef page_not_found(request, exception, template_name=\"404.html\"):\n \"\"\"View handler for HTTP 404 Not Found responses.\"\"\"\n if session.active_agency(request):\n session.update(request, origin=session.agency(request).index_url)\n else:\n session.update(request, origin=reverse(ROUTE_INDEX))\n\n home = viewmodels.Button.home(request)\n # show a more user-friendly message instead of not_found\n page = viewmodels.ErrorPage.user_error(button=home, path=request.path)\n t = loader.get_template(template_name)\n\n return HttpResponseNotFound(t.render(page.context_dict()))\n\n\n@pageview_decorator\ndef server_error(request, template_name=\"500.html\"):\n \"\"\"View handler for HTTP 500 Server Error responses.\"\"\"\n if session.active_agency(request):\n session.update(request, origin=session.agency(request).index_url)\n else:\n session.update(request, origin=reverse(ROUTE_INDEX))\n\n home = viewmodels.Button.home(request)\n page = viewmodels.ErrorPage.server_error(button=home)\n t = loader.get_template(template_name)\n\n return HttpResponseServerError(t.render(page.context_dict()))\n", "path": "benefits/core/views.py"}], "after_files": [{"content": "\"\"\"\nThe core application: view definition for the root of the webapp.\n\"\"\"\nfrom django.http import HttpResponse, HttpResponseBadRequest, HttpResponseNotFound, HttpResponseServerError\nfrom django.shortcuts import redirect\nfrom django.template import loader\nfrom django.template.response import TemplateResponse\nfrom django.urls import reverse\nfrom django.utils.translation import gettext as _\n\nfrom . import models, session, viewmodels\nfrom .middleware import pageview_decorator\n\nROUTE_INDEX = \"core:index\"\nROUTE_ELIGIBILITY = \"eligibility:index\"\nROUTE_HELP = \"core:help\"\n\nTEMPLATE_PAGE = \"core/page.html\"\nTEMPLATE_AGENCY = \"core/agency_index.html\"\nTEMPLATE_HELP = \"core/help.html\"\n\n\n@pageview_decorator\ndef index(request):\n \"\"\"View handler for the main entry page.\"\"\"\n session.reset(request)\n\n agencies = models.TransitAgency.all_active()\n\n if len(agencies) == 1:\n agency = agencies[0]\n return redirect(agency.index_url)\n\n # generate a button to the landing page for each active agency\n buttons = [viewmodels.Button.outline_primary(text=a.short_name, url=a.index_url) for a in agencies]\n buttons[0].classes.append(\"mt-3\")\n buttons[0].label = _(\"core.pages.index.chooseprovider\")\n\n page = viewmodels.Page(\n title=_(\"core.pages.index.title\"),\n headline=_(\"core.pages.index.headline\"),\n buttons=buttons,\n classes=\"home\",\n )\n\n return TemplateResponse(request, TEMPLATE_PAGE, page.context_dict())\n\n\n@pageview_decorator\ndef agency_index(request, agency):\n \"\"\"View handler for an agency entry page.\"\"\"\n session.reset(request)\n session.update(request, agency=agency, origin=agency.index_url)\n\n button = viewmodels.Button.primary(text=_(\"core.pages.index.continue\"), url=reverse(ROUTE_ELIGIBILITY))\n\n page = viewmodels.Page(\n title=_(\"core.pages.agency_index.title\"),\n headline=_(\"core.pages.agency_index.mst_cc.headline\"),\n button=button,\n classes=\"home\",\n )\n\n return TemplateResponse(request, TEMPLATE_AGENCY, page.context_dict())\n\n\n@pageview_decorator\ndef agency_public_key(request, agency):\n \"\"\"View handler returns an agency's public key as plain text.\"\"\"\n return HttpResponse(agency.public_key_data, content_type=\"text/plain\")\n\n\n@pageview_decorator\ndef help(request):\n \"\"\"View handler for the help page.\"\"\"\n if session.active_agency(request):\n agency = session.agency(request)\n buttons = viewmodels.Button.agency_contact_links(agency)\n else:\n buttons = [btn for a in models.TransitAgency.all_active() for btn in viewmodels.Button.agency_contact_links(a)]\n\n buttons.append(viewmodels.Button.home(request, _(\"core.buttons.back\")))\n\n page = viewmodels.Page(\n title=_(\"core.buttons.help\"),\n headline=_(\"core.buttons.help\"),\n buttons=buttons,\n )\n\n return TemplateResponse(request, TEMPLATE_HELP, page.context_dict())\n\n\n@pageview_decorator\ndef bad_request(request, exception, template_name=\"400.html\"):\n \"\"\"View handler for HTTP 400 Bad Request responses.\"\"\"\n if session.active_agency(request):\n session.update(request, origin=session.agency(request).index_url)\n else:\n session.update(request, origin=reverse(ROUTE_INDEX))\n\n home = viewmodels.Button.home(request)\n page = viewmodels.ErrorPage.server_error(button=home)\n t = loader.get_template(template_name)\n\n return HttpResponseBadRequest(t.render(page.context_dict()))\n\n\n@pageview_decorator\ndef csrf_failure(request, reason):\n \"\"\"\n View handler for CSRF_FAILURE_VIEW with custom data.\n \"\"\"\n if session.active_agency(request):\n session.update(request, origin=session.agency(request).index_url)\n else:\n session.update(request, origin=reverse(ROUTE_INDEX))\n\n home = viewmodels.Button.home(request)\n page = viewmodels.ErrorPage.not_found(button=home, path=request.path)\n t = loader.get_template(\"400.html\")\n\n return HttpResponseNotFound(t.render(page.context_dict()))\n\n\n@pageview_decorator\ndef page_not_found(request, exception, template_name=\"404.html\"):\n \"\"\"View handler for HTTP 404 Not Found responses.\"\"\"\n if session.active_agency(request):\n session.update(request, origin=session.agency(request).index_url)\n else:\n session.update(request, origin=reverse(ROUTE_INDEX))\n\n home = viewmodels.Button.home(request)\n # show a more user-friendly message instead of not_found\n page = viewmodels.ErrorPage.user_error(button=home, path=request.path)\n t = loader.get_template(template_name)\n\n return HttpResponseNotFound(t.render(page.context_dict()))\n\n\n@pageview_decorator\ndef server_error(request, template_name=\"500.html\"):\n \"\"\"View handler for HTTP 500 Server Error responses.\"\"\"\n if session.active_agency(request):\n session.update(request, origin=session.agency(request).index_url)\n else:\n session.update(request, origin=reverse(ROUTE_INDEX))\n\n home = viewmodels.Button.home(request)\n page = viewmodels.ErrorPage.server_error(button=home)\n t = loader.get_template(template_name)\n\n return HttpResponseServerError(t.render(page.context_dict()))\n", "path": "benefits/core/views.py"}]} | 1,865 | 130 |
gh_patches_debug_14429 | rasdani/github-patches | git_diff | python-pillow__Pillow-1649 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ImageSequence.Iterator name is misleading
Hi Pillow developers,
I found this error message to be rather hilarious:
```
TypeError: 'Iterator' object is not an iterator
```
which was produced by this code:
``` python
from PIL import Image, ImageSequence
with Image.open('multipage.tiff', mode='r') as tif:
i = ImageSequence.Iterator(tif)
next(i)
```
It seems that `ImageSequence.Iterator` does not define an `__iter__()` method, which means that it is a sequence type but not an iterator type. In my opinion, this is misleading and I suggest that a proper `__iter__()` method should be added to the class definition.
Thanks.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `PIL/ImageSequence.py`
Content:
```
1 #
2 # The Python Imaging Library.
3 # $Id$
4 #
5 # sequence support classes
6 #
7 # history:
8 # 1997-02-20 fl Created
9 #
10 # Copyright (c) 1997 by Secret Labs AB.
11 # Copyright (c) 1997 by Fredrik Lundh.
12 #
13 # See the README file for information on usage and redistribution.
14 #
15
16 ##
17
18
19 class Iterator(object):
20 """
21 This class implements an iterator object that can be used to loop
22 over an image sequence.
23
24 You can use the ``[]`` operator to access elements by index. This operator
25 will raise an :py:exc:`IndexError` if you try to access a nonexistent
26 frame.
27
28 :param im: An image object.
29 """
30
31 def __init__(self, im):
32 if not hasattr(im, "seek"):
33 raise AttributeError("im must have seek method")
34 self.im = im
35
36 def __getitem__(self, ix):
37 try:
38 if ix:
39 self.im.seek(ix)
40 return self.im
41 except EOFError:
42 raise IndexError # end of sequence
43
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/PIL/ImageSequence.py b/PIL/ImageSequence.py
--- a/PIL/ImageSequence.py
+++ b/PIL/ImageSequence.py
@@ -32,6 +32,7 @@
if not hasattr(im, "seek"):
raise AttributeError("im must have seek method")
self.im = im
+ self.position = 0
def __getitem__(self, ix):
try:
@@ -40,3 +41,17 @@
return self.im
except EOFError:
raise IndexError # end of sequence
+
+ def __iter__(self):
+ return self
+
+ def __next__(self):
+ try:
+ self.im.seek(self.position)
+ self.position += 1
+ return self.im
+ except EOFError:
+ raise StopIteration
+
+ def next(self):
+ return self.__next__()
| {"golden_diff": "diff --git a/PIL/ImageSequence.py b/PIL/ImageSequence.py\n--- a/PIL/ImageSequence.py\n+++ b/PIL/ImageSequence.py\n@@ -32,6 +32,7 @@\n if not hasattr(im, \"seek\"):\n raise AttributeError(\"im must have seek method\")\n self.im = im\n+ self.position = 0\n \n def __getitem__(self, ix):\n try:\n@@ -40,3 +41,17 @@\n return self.im\n except EOFError:\n raise IndexError # end of sequence\n+\n+ def __iter__(self):\n+ return self\n+\n+ def __next__(self):\n+ try:\n+ self.im.seek(self.position)\n+ self.position += 1\n+ return self.im\n+ except EOFError:\n+ raise StopIteration\n+\n+ def next(self):\n+ return self.__next__()\n", "issue": "ImageSequence.Iterator name is misleading\nHi Pillow developers,\n\nI found this error message to be rather hilarious:\n\n```\nTypeError: 'Iterator' object is not an iterator\n```\n\nwhich was produced by this code:\n\n``` python\nfrom PIL import Image, ImageSequence\n\nwith Image.open('multipage.tiff', mode='r') as tif:\n i = ImageSequence.Iterator(tif)\n next(i)\n```\n\nIt seems that `ImageSequence.Iterator` does not define an `__iter__()` method, which means that it is a sequence type but not an iterator type. In my opinion, this is misleading and I suggest that a proper `__iter__()` method should be added to the class definition.\n\nThanks.\n\n", "before_files": [{"content": "#\n# The Python Imaging Library.\n# $Id$\n#\n# sequence support classes\n#\n# history:\n# 1997-02-20 fl Created\n#\n# Copyright (c) 1997 by Secret Labs AB.\n# Copyright (c) 1997 by Fredrik Lundh.\n#\n# See the README file for information on usage and redistribution.\n#\n\n##\n\n\nclass Iterator(object):\n \"\"\"\n This class implements an iterator object that can be used to loop\n over an image sequence.\n\n You can use the ``[]`` operator to access elements by index. This operator\n will raise an :py:exc:`IndexError` if you try to access a nonexistent\n frame.\n\n :param im: An image object.\n \"\"\"\n\n def __init__(self, im):\n if not hasattr(im, \"seek\"):\n raise AttributeError(\"im must have seek method\")\n self.im = im\n\n def __getitem__(self, ix):\n try:\n if ix:\n self.im.seek(ix)\n return self.im\n except EOFError:\n raise IndexError # end of sequence\n", "path": "PIL/ImageSequence.py"}], "after_files": [{"content": "#\n# The Python Imaging Library.\n# $Id$\n#\n# sequence support classes\n#\n# history:\n# 1997-02-20 fl Created\n#\n# Copyright (c) 1997 by Secret Labs AB.\n# Copyright (c) 1997 by Fredrik Lundh.\n#\n# See the README file for information on usage and redistribution.\n#\n\n##\n\n\nclass Iterator(object):\n \"\"\"\n This class implements an iterator object that can be used to loop\n over an image sequence.\n\n You can use the ``[]`` operator to access elements by index. This operator\n will raise an :py:exc:`IndexError` if you try to access a nonexistent\n frame.\n\n :param im: An image object.\n \"\"\"\n\n def __init__(self, im):\n if not hasattr(im, \"seek\"):\n raise AttributeError(\"im must have seek method\")\n self.im = im\n self.position = 0\n\n def __getitem__(self, ix):\n try:\n if ix:\n self.im.seek(ix)\n return self.im\n except EOFError:\n raise IndexError # end of sequence\n\n def __iter__(self):\n return self\n\n def __next__(self):\n try:\n self.im.seek(self.position)\n self.position += 1\n return self.im\n except EOFError:\n raise StopIteration\n\n def next(self):\n return self.__next__()\n", "path": "PIL/ImageSequence.py"}]} | 728 | 196 |
gh_patches_debug_5137 | rasdani/github-patches | git_diff | pypi__warehouse-12440 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Doom transaction if `request.user` is None
Fixes #12422.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `warehouse/db.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import functools
14 import logging
15
16 import alembic.config
17 import pyramid_retry
18 import sqlalchemy
19 import venusian
20 import zope.sqlalchemy
21
22 from sqlalchemy import event, inspect
23 from sqlalchemy.dialects.postgresql import UUID
24 from sqlalchemy.exc import IntegrityError, OperationalError
25 from sqlalchemy.ext.declarative import declarative_base # type: ignore
26 from sqlalchemy.orm import sessionmaker
27
28 from warehouse.metrics import IMetricsService
29 from warehouse.utils.attrs import make_repr
30
31 __all__ = ["includeme", "metadata", "ModelBase"]
32
33
34 logger = logging.getLogger(__name__)
35
36
37 DEFAULT_ISOLATION = "READ COMMITTED"
38
39
40 # On the surface this might seem wrong, because retrying a request whose data violates
41 # the constraints of the database doesn't seem like a useful endeavor. However what
42 # happens if you have two requests that are trying to insert a row, and that row
43 # contains a unique, user provided value, you can get into a race condition where both
44 # requests check the database, see nothing with that value exists, then both attempt to
45 # insert it. One of the requests will succeed, the other will fail with an
46 # IntegrityError. Retrying the request that failed will then have it see the object
47 # created by the other request, and will have it do the appropriate action in that case.
48 #
49 # The most common way to run into this, is when submitting a form in the browser, if the
50 # user clicks twice in rapid succession, the browser will send two almost identical
51 # requests at basically the same time.
52 #
53 # One possible issue that this raises, is that it will slow down "legitimate"
54 # IntegrityError because they'll have to fail multiple times before they ultimately
55 # fail. We consider this an acceptable trade off, because deterministic IntegrityError
56 # should be caught with proper validation prior to submitting records to the database
57 # anyways.
58 pyramid_retry.mark_error_retryable(IntegrityError)
59
60
61 # A generic wrapper exception that we'll raise when the database isn't available, we
62 # use this so we can catch it later and turn it into a generic 5xx error.
63 class DatabaseNotAvailableError(Exception):
64 ...
65
66
67 class ModelBase:
68 def __repr__(self):
69 inst = inspect(self)
70 self.__repr__ = make_repr(
71 *[c_attr.key for c_attr in inst.mapper.column_attrs], _self=self
72 )
73 return self.__repr__()
74
75
76 # The Global metadata object.
77 metadata = sqlalchemy.MetaData()
78
79
80 # Base class for models using declarative syntax
81 ModelBase = declarative_base(cls=ModelBase, metadata=metadata) # type: ignore
82
83
84 class Model(ModelBase):
85
86 __abstract__ = True
87
88 id = sqlalchemy.Column(
89 UUID(as_uuid=True),
90 primary_key=True,
91 server_default=sqlalchemy.text("gen_random_uuid()"),
92 )
93
94
95 # Create our session class here, this will stay stateless as we'll bind the
96 # engine to each new state we create instead of binding it to the session
97 # class.
98 Session = sessionmaker()
99
100
101 def listens_for(target, identifier, *args, **kwargs):
102 def deco(wrapped):
103 def callback(scanner, _name, wrapped):
104 wrapped = functools.partial(wrapped, scanner.config)
105 event.listen(target, identifier, wrapped, *args, **kwargs)
106
107 venusian.attach(wrapped, callback, category="warehouse")
108
109 return wrapped
110
111 return deco
112
113
114 def _configure_alembic(config):
115 alembic_cfg = alembic.config.Config()
116 alembic_cfg.set_main_option("script_location", "warehouse:migrations")
117 alembic_cfg.set_main_option("url", config.registry.settings["database.url"])
118 return alembic_cfg
119
120
121 def _create_session(request):
122 metrics = request.find_service(IMetricsService, context=None)
123 metrics.increment("warehouse.db.session.start")
124
125 # Create our connection, most likely pulling it from the pool of
126 # connections
127 try:
128 connection = request.registry["sqlalchemy.engine"].connect()
129 except OperationalError:
130 # When we tried to connection to PostgreSQL, our database was not available for
131 # some reason. We're going to log it here and then raise our error. Most likely
132 # this is a transient error that will go away.
133 logger.warning("Got an error connecting to PostgreSQL", exc_info=True)
134 metrics.increment("warehouse.db.session.error", tags=["error_in:connecting"])
135 raise DatabaseNotAvailableError()
136
137 # Now, create a session from our connection
138 session = Session(bind=connection)
139
140 # Register only this particular session with zope.sqlalchemy
141 zope.sqlalchemy.register(session, transaction_manager=request.tm)
142
143 # Setup a callback that will ensure that everything is cleaned up at the
144 # end of our connection.
145 @request.add_finished_callback
146 def cleanup(request):
147 metrics.increment("warehouse.db.session.finished")
148 session.close()
149 connection.close()
150
151 # Check if we're in read-only mode
152 from warehouse.admin.flags import AdminFlag, AdminFlagValue
153
154 flag = session.query(AdminFlag).get(AdminFlagValue.READ_ONLY.value)
155 if flag and flag.enabled and not request.user.is_superuser:
156 request.tm.doom()
157
158 # Return our session now that it's created and registered
159 return session
160
161
162 def includeme(config):
163 # Add a directive to get an alembic configuration.
164 config.add_directive("alembic_config", _configure_alembic)
165
166 # Create our SQLAlchemy Engine.
167 config.registry["sqlalchemy.engine"] = sqlalchemy.create_engine(
168 config.registry.settings["database.url"],
169 isolation_level=DEFAULT_ISOLATION,
170 pool_size=35,
171 max_overflow=65,
172 pool_timeout=20,
173 )
174
175 # Register our request.db property
176 config.add_request_method(_create_session, name="db", reify=True)
177
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/warehouse/db.py b/warehouse/db.py
--- a/warehouse/db.py
+++ b/warehouse/db.py
@@ -152,7 +152,7 @@
from warehouse.admin.flags import AdminFlag, AdminFlagValue
flag = session.query(AdminFlag).get(AdminFlagValue.READ_ONLY.value)
- if flag and flag.enabled and not request.user.is_superuser:
+ if flag and flag.enabled:
request.tm.doom()
# Return our session now that it's created and registered
| {"golden_diff": "diff --git a/warehouse/db.py b/warehouse/db.py\n--- a/warehouse/db.py\n+++ b/warehouse/db.py\n@@ -152,7 +152,7 @@\n from warehouse.admin.flags import AdminFlag, AdminFlagValue\n \n flag = session.query(AdminFlag).get(AdminFlagValue.READ_ONLY.value)\n- if flag and flag.enabled and not request.user.is_superuser:\n+ if flag and flag.enabled:\n request.tm.doom()\n \n # Return our session now that it's created and registered\n", "issue": "Doom transaction if `request.user` is None\nFixes #12422.\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport functools\nimport logging\n\nimport alembic.config\nimport pyramid_retry\nimport sqlalchemy\nimport venusian\nimport zope.sqlalchemy\n\nfrom sqlalchemy import event, inspect\nfrom sqlalchemy.dialects.postgresql import UUID\nfrom sqlalchemy.exc import IntegrityError, OperationalError\nfrom sqlalchemy.ext.declarative import declarative_base # type: ignore\nfrom sqlalchemy.orm import sessionmaker\n\nfrom warehouse.metrics import IMetricsService\nfrom warehouse.utils.attrs import make_repr\n\n__all__ = [\"includeme\", \"metadata\", \"ModelBase\"]\n\n\nlogger = logging.getLogger(__name__)\n\n\nDEFAULT_ISOLATION = \"READ COMMITTED\"\n\n\n# On the surface this might seem wrong, because retrying a request whose data violates\n# the constraints of the database doesn't seem like a useful endeavor. However what\n# happens if you have two requests that are trying to insert a row, and that row\n# contains a unique, user provided value, you can get into a race condition where both\n# requests check the database, see nothing with that value exists, then both attempt to\n# insert it. One of the requests will succeed, the other will fail with an\n# IntegrityError. Retrying the request that failed will then have it see the object\n# created by the other request, and will have it do the appropriate action in that case.\n#\n# The most common way to run into this, is when submitting a form in the browser, if the\n# user clicks twice in rapid succession, the browser will send two almost identical\n# requests at basically the same time.\n#\n# One possible issue that this raises, is that it will slow down \"legitimate\"\n# IntegrityError because they'll have to fail multiple times before they ultimately\n# fail. We consider this an acceptable trade off, because deterministic IntegrityError\n# should be caught with proper validation prior to submitting records to the database\n# anyways.\npyramid_retry.mark_error_retryable(IntegrityError)\n\n\n# A generic wrapper exception that we'll raise when the database isn't available, we\n# use this so we can catch it later and turn it into a generic 5xx error.\nclass DatabaseNotAvailableError(Exception):\n ...\n\n\nclass ModelBase:\n def __repr__(self):\n inst = inspect(self)\n self.__repr__ = make_repr(\n *[c_attr.key for c_attr in inst.mapper.column_attrs], _self=self\n )\n return self.__repr__()\n\n\n# The Global metadata object.\nmetadata = sqlalchemy.MetaData()\n\n\n# Base class for models using declarative syntax\nModelBase = declarative_base(cls=ModelBase, metadata=metadata) # type: ignore\n\n\nclass Model(ModelBase):\n\n __abstract__ = True\n\n id = sqlalchemy.Column(\n UUID(as_uuid=True),\n primary_key=True,\n server_default=sqlalchemy.text(\"gen_random_uuid()\"),\n )\n\n\n# Create our session class here, this will stay stateless as we'll bind the\n# engine to each new state we create instead of binding it to the session\n# class.\nSession = sessionmaker()\n\n\ndef listens_for(target, identifier, *args, **kwargs):\n def deco(wrapped):\n def callback(scanner, _name, wrapped):\n wrapped = functools.partial(wrapped, scanner.config)\n event.listen(target, identifier, wrapped, *args, **kwargs)\n\n venusian.attach(wrapped, callback, category=\"warehouse\")\n\n return wrapped\n\n return deco\n\n\ndef _configure_alembic(config):\n alembic_cfg = alembic.config.Config()\n alembic_cfg.set_main_option(\"script_location\", \"warehouse:migrations\")\n alembic_cfg.set_main_option(\"url\", config.registry.settings[\"database.url\"])\n return alembic_cfg\n\n\ndef _create_session(request):\n metrics = request.find_service(IMetricsService, context=None)\n metrics.increment(\"warehouse.db.session.start\")\n\n # Create our connection, most likely pulling it from the pool of\n # connections\n try:\n connection = request.registry[\"sqlalchemy.engine\"].connect()\n except OperationalError:\n # When we tried to connection to PostgreSQL, our database was not available for\n # some reason. We're going to log it here and then raise our error. Most likely\n # this is a transient error that will go away.\n logger.warning(\"Got an error connecting to PostgreSQL\", exc_info=True)\n metrics.increment(\"warehouse.db.session.error\", tags=[\"error_in:connecting\"])\n raise DatabaseNotAvailableError()\n\n # Now, create a session from our connection\n session = Session(bind=connection)\n\n # Register only this particular session with zope.sqlalchemy\n zope.sqlalchemy.register(session, transaction_manager=request.tm)\n\n # Setup a callback that will ensure that everything is cleaned up at the\n # end of our connection.\n @request.add_finished_callback\n def cleanup(request):\n metrics.increment(\"warehouse.db.session.finished\")\n session.close()\n connection.close()\n\n # Check if we're in read-only mode\n from warehouse.admin.flags import AdminFlag, AdminFlagValue\n\n flag = session.query(AdminFlag).get(AdminFlagValue.READ_ONLY.value)\n if flag and flag.enabled and not request.user.is_superuser:\n request.tm.doom()\n\n # Return our session now that it's created and registered\n return session\n\n\ndef includeme(config):\n # Add a directive to get an alembic configuration.\n config.add_directive(\"alembic_config\", _configure_alembic)\n\n # Create our SQLAlchemy Engine.\n config.registry[\"sqlalchemy.engine\"] = sqlalchemy.create_engine(\n config.registry.settings[\"database.url\"],\n isolation_level=DEFAULT_ISOLATION,\n pool_size=35,\n max_overflow=65,\n pool_timeout=20,\n )\n\n # Register our request.db property\n config.add_request_method(_create_session, name=\"db\", reify=True)\n", "path": "warehouse/db.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport functools\nimport logging\n\nimport alembic.config\nimport pyramid_retry\nimport sqlalchemy\nimport venusian\nimport zope.sqlalchemy\n\nfrom sqlalchemy import event, inspect\nfrom sqlalchemy.dialects.postgresql import UUID\nfrom sqlalchemy.exc import IntegrityError, OperationalError\nfrom sqlalchemy.ext.declarative import declarative_base # type: ignore\nfrom sqlalchemy.orm import sessionmaker\n\nfrom warehouse.metrics import IMetricsService\nfrom warehouse.utils.attrs import make_repr\n\n__all__ = [\"includeme\", \"metadata\", \"ModelBase\"]\n\n\nlogger = logging.getLogger(__name__)\n\n\nDEFAULT_ISOLATION = \"READ COMMITTED\"\n\n\n# On the surface this might seem wrong, because retrying a request whose data violates\n# the constraints of the database doesn't seem like a useful endeavor. However what\n# happens if you have two requests that are trying to insert a row, and that row\n# contains a unique, user provided value, you can get into a race condition where both\n# requests check the database, see nothing with that value exists, then both attempt to\n# insert it. One of the requests will succeed, the other will fail with an\n# IntegrityError. Retrying the request that failed will then have it see the object\n# created by the other request, and will have it do the appropriate action in that case.\n#\n# The most common way to run into this, is when submitting a form in the browser, if the\n# user clicks twice in rapid succession, the browser will send two almost identical\n# requests at basically the same time.\n#\n# One possible issue that this raises, is that it will slow down \"legitimate\"\n# IntegrityError because they'll have to fail multiple times before they ultimately\n# fail. We consider this an acceptable trade off, because deterministic IntegrityError\n# should be caught with proper validation prior to submitting records to the database\n# anyways.\npyramid_retry.mark_error_retryable(IntegrityError)\n\n\n# A generic wrapper exception that we'll raise when the database isn't available, we\n# use this so we can catch it later and turn it into a generic 5xx error.\nclass DatabaseNotAvailableError(Exception):\n ...\n\n\nclass ModelBase:\n def __repr__(self):\n inst = inspect(self)\n self.__repr__ = make_repr(\n *[c_attr.key for c_attr in inst.mapper.column_attrs], _self=self\n )\n return self.__repr__()\n\n\n# The Global metadata object.\nmetadata = sqlalchemy.MetaData()\n\n\n# Base class for models using declarative syntax\nModelBase = declarative_base(cls=ModelBase, metadata=metadata) # type: ignore\n\n\nclass Model(ModelBase):\n\n __abstract__ = True\n\n id = sqlalchemy.Column(\n UUID(as_uuid=True),\n primary_key=True,\n server_default=sqlalchemy.text(\"gen_random_uuid()\"),\n )\n\n\n# Create our session class here, this will stay stateless as we'll bind the\n# engine to each new state we create instead of binding it to the session\n# class.\nSession = sessionmaker()\n\n\ndef listens_for(target, identifier, *args, **kwargs):\n def deco(wrapped):\n def callback(scanner, _name, wrapped):\n wrapped = functools.partial(wrapped, scanner.config)\n event.listen(target, identifier, wrapped, *args, **kwargs)\n\n venusian.attach(wrapped, callback, category=\"warehouse\")\n\n return wrapped\n\n return deco\n\n\ndef _configure_alembic(config):\n alembic_cfg = alembic.config.Config()\n alembic_cfg.set_main_option(\"script_location\", \"warehouse:migrations\")\n alembic_cfg.set_main_option(\"url\", config.registry.settings[\"database.url\"])\n return alembic_cfg\n\n\ndef _create_session(request):\n metrics = request.find_service(IMetricsService, context=None)\n metrics.increment(\"warehouse.db.session.start\")\n\n # Create our connection, most likely pulling it from the pool of\n # connections\n try:\n connection = request.registry[\"sqlalchemy.engine\"].connect()\n except OperationalError:\n # When we tried to connection to PostgreSQL, our database was not available for\n # some reason. We're going to log it here and then raise our error. Most likely\n # this is a transient error that will go away.\n logger.warning(\"Got an error connecting to PostgreSQL\", exc_info=True)\n metrics.increment(\"warehouse.db.session.error\", tags=[\"error_in:connecting\"])\n raise DatabaseNotAvailableError()\n\n # Now, create a session from our connection\n session = Session(bind=connection)\n\n # Register only this particular session with zope.sqlalchemy\n zope.sqlalchemy.register(session, transaction_manager=request.tm)\n\n # Setup a callback that will ensure that everything is cleaned up at the\n # end of our connection.\n @request.add_finished_callback\n def cleanup(request):\n metrics.increment(\"warehouse.db.session.finished\")\n session.close()\n connection.close()\n\n # Check if we're in read-only mode\n from warehouse.admin.flags import AdminFlag, AdminFlagValue\n\n flag = session.query(AdminFlag).get(AdminFlagValue.READ_ONLY.value)\n if flag and flag.enabled:\n request.tm.doom()\n\n # Return our session now that it's created and registered\n return session\n\n\ndef includeme(config):\n # Add a directive to get an alembic configuration.\n config.add_directive(\"alembic_config\", _configure_alembic)\n\n # Create our SQLAlchemy Engine.\n config.registry[\"sqlalchemy.engine\"] = sqlalchemy.create_engine(\n config.registry.settings[\"database.url\"],\n isolation_level=DEFAULT_ISOLATION,\n pool_size=35,\n max_overflow=65,\n pool_timeout=20,\n )\n\n # Register our request.db property\n config.add_request_method(_create_session, name=\"db\", reify=True)\n", "path": "warehouse/db.py"}]} | 2,082 | 115 |
gh_patches_debug_31216 | rasdani/github-patches | git_diff | Qiskit__qiskit-3429 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Branch `master` is failing
<!-- commit 9134634f43bc858a32b4d6a9c3edf352e2f58873@master -->
Trying to build `master` at commit 9134634f43bc858a32b4d6a9c3edf352e2f58873 failed.
More info at: https://travis-ci.com/Qiskit/qiskit-terra/jobs/253757284
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qiskit/tools/monitor/backend_overview.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # This code is part of Qiskit.
4 #
5 # (C) Copyright IBM 2017, 2018.
6 #
7 # This code is licensed under the Apache License, Version 2.0. You may
8 # obtain a copy of this license in the LICENSE.txt file in the root directory
9 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
10 #
11 # Any modifications or derivative works of this code must retain this
12 # copyright notice, and modified files need to carry a notice indicating
13 # that they have been altered from the originals.
14 # pylint: disable=invalid-name
15
16 """ A module for viewing the details of all available devices.
17 """
18
19 import math
20 from qiskit.exceptions import QiskitError
21
22 try:
23 # pylint: disable=import-error,no-name-in-module
24 from qiskit.providers.ibmq import IBMQ, IBMQBackend
25 except ImportError:
26 pass
27
28
29 def get_unique_backends():
30 """Gets the unique backends that are available.
31
32 Returns:
33 list: Unique available backends.
34
35 Raises:
36 QiskitError: No backends available.
37 """
38 backends = []
39 for provider in IBMQ.providers():
40 for backend in provider.backends():
41 backends.append(backend)
42 unique_hardware_backends = []
43 unique_names = []
44 for back in backends:
45 if back.name() not in unique_names and not back.configuration().simulator:
46 unique_hardware_backends.append(back)
47 unique_names.append(back.name())
48 if not unique_hardware_backends:
49 raise QiskitError('No backends available.')
50 return unique_hardware_backends
51
52
53 def backend_monitor(backend):
54 """Monitor a single IBMQ backend.
55
56 Args:
57 backend (IBMQBackend): Backend to monitor.
58 Raises:
59 QiskitError: Input is not a IBMQ backend.
60 """
61 if not isinstance(backend, IBMQBackend):
62 raise QiskitError('Input variable is not of type IBMQBackend.')
63 config = backend.configuration().to_dict()
64 status = backend.status().to_dict()
65 config_dict = {**status, **config}
66 if not config['simulator']:
67 props = backend.properties().to_dict()
68
69 print(backend.name())
70 print('='*len(backend.name()))
71 print('Configuration')
72 print('-'*13)
73 offset = ' '
74
75 upper_list = ['n_qubits', 'operational',
76 'status_msg', 'pending_jobs',
77 'backend_version', 'basis_gates',
78 'local', 'simulator']
79
80 lower_list = list(set(config_dict.keys()).difference(upper_list))
81 # Remove gates because they are in a different tab
82 lower_list.remove('gates')
83 for item in upper_list+lower_list:
84 print(offset+item+':', config_dict[item])
85
86 # Stop here if simulator
87 if config['simulator']:
88 return
89
90 print()
91 qubit_header = 'Qubits [Name / Freq / T1 / T2 / U1 err / U2 err / U3 err / Readout err]'
92 print(qubit_header)
93 print('-'*len(qubit_header))
94
95 sep = ' / '
96 for qub in range(len(props['qubits'])):
97 name = 'Q%s' % qub
98 qubit_data = props['qubits'][qub]
99 gate_data = [g for g in props['gates'] if g['qubits'] == [qub]]
100 t1_info = qubit_data[0]
101 t2_info = qubit_data[1]
102 freq_info = qubit_data[2]
103 readout_info = qubit_data[3]
104
105 freq = str(round(freq_info['value'], 5))+' '+freq_info['unit']
106 T1 = str(round(t1_info['value'],
107 5))+' ' + t1_info['unit']
108 T2 = str(round(t2_info['value'],
109 5))+' ' + t2_info['unit']
110 for gd in gate_data:
111 if gd['gate'] == 'u1':
112 U1 = str(round(gd['parameters'][0]['value'], 5))
113 break
114
115 for gd in gate_data:
116 if gd['gate'] == 'u2':
117 U2 = str(round(gd['parameters'][0]['value'], 5))
118 break
119 for gd in gate_data:
120 if gd['gate'] == 'u3':
121 U3 = str(round(gd['parameters'][0]['value'], 5))
122 break
123
124 readout_error = str(round(readout_info['value'], 5))
125
126 qstr = sep.join([name, freq, T1, T2, U1, U2, U3, readout_error])
127 print(offset+qstr)
128
129 print()
130 multi_qubit_gates = [g for g in props['gates'] if len(g['qubits']) > 1]
131 multi_header = 'Multi-Qubit Gates [Name / Type / Gate Error]'
132 print(multi_header)
133 print('-'*len(multi_header))
134
135 for qub, gate in enumerate(multi_qubit_gates):
136 gate = multi_qubit_gates[qub]
137 qubits = gate['qubits']
138 ttype = gate['gate']
139 error = round(gate['parameters'][0]['value'], 5)
140 mstr = sep.join(["{}{}_{}".format(ttype, qubits[0], qubits[1]), ttype, str(error)])
141 print(offset+mstr)
142
143
144 def backend_overview():
145 """Gives overview information on all the IBMQ
146 backends that are available.
147 """
148 unique_hardware_backends = get_unique_backends()
149 _backends = []
150 # Sort backends by operational or not
151 for idx, back in enumerate(unique_hardware_backends):
152 if back.status().operational:
153 _backends = [back] + _backends
154 else:
155 _backends = _backends + [back]
156
157 stati = [back.status() for back in _backends]
158 idx = list(range(len(_backends)))
159 pending = [s.pending_jobs for s in stati]
160 _, least_idx = zip(*sorted(zip(pending, idx)))
161
162 # Make sure least pending is operational
163 for ind in least_idx:
164 if stati[ind].operational:
165 least_pending_idx = ind
166 break
167
168 num_rows = math.ceil(len(_backends)/3)
169
170 count = 0
171 num_backends = len(_backends)
172 for _ in range(num_rows):
173 max_len = 0
174 str_list = ['']*8
175 for idx in range(3):
176 offset = ' ' * 10 if idx else ''
177 config = _backends[count].configuration().to_dict()
178 props = _backends[count].properties().to_dict()
179 n_qubits = config['n_qubits']
180 str_list[0] += (' '*(max_len-len(str_list[0]))+offset)
181 str_list[0] += _backends[count].name()
182
183 str_list[1] += (' '*(max_len-len(str_list[1]))+offset)
184 str_list[1] += '-'*len(_backends[count].name())
185
186 str_list[2] += (' '*(max_len-len(str_list[2]))+offset)
187 str_list[2] += 'Num. Qubits: %s' % config['n_qubits']
188
189 str_list[3] += (' '*(max_len-len(str_list[3]))+offset)
190 str_list[3] += 'Pending Jobs: %s' % stati[count].pending_jobs
191
192 str_list[4] += (' '*(max_len-len(str_list[4]))+offset)
193 str_list[4] += 'Least busy: %s' % (count == least_pending_idx)
194
195 str_list[5] += (' '*(max_len-len(str_list[5]))+offset)
196 str_list[5] += 'Operational: %s' % stati[count].operational
197
198 str_list[6] += (' '*(max_len-len(str_list[6]))+offset)
199 str_list[6] += 'Avg. T1: %s' % round(sum([q[0]['value']
200 for q in props['qubits']])/n_qubits, 1)
201 str_list[7] += (' '*(max_len-len(str_list[7]))+offset)
202 str_list[7] += 'Avg. T2: %s' % round(sum([q[1]['value']
203 for q in props['qubits']])/n_qubits, 1)
204 count += 1
205 if count == num_backends:
206 break
207 max_len = max([len(s) for s in str_list])
208
209 print("\n".join(str_list))
210 print('\n'*2)
211
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/qiskit/tools/monitor/backend_overview.py b/qiskit/tools/monitor/backend_overview.py
--- a/qiskit/tools/monitor/backend_overview.py
+++ b/qiskit/tools/monitor/backend_overview.py
@@ -19,12 +19,6 @@
import math
from qiskit.exceptions import QiskitError
-try:
- # pylint: disable=import-error,no-name-in-module
- from qiskit.providers.ibmq import IBMQ, IBMQBackend
-except ImportError:
- pass
-
def get_unique_backends():
"""Gets the unique backends that are available.
@@ -34,7 +28,14 @@
Raises:
QiskitError: No backends available.
+ ImportError: If qiskit-ibmq-provider is not installed
"""
+ try:
+ from qiskit.providers.ibmq import IBMQ
+ except ImportError:
+ raise ImportError("The IBMQ provider is necessary for this function "
+ " to work. Please ensure it's installed before "
+ "using this function")
backends = []
for provider in IBMQ.providers():
for backend in provider.backends():
@@ -57,7 +58,16 @@
backend (IBMQBackend): Backend to monitor.
Raises:
QiskitError: Input is not a IBMQ backend.
+ ImportError: If qiskit-ibmq-provider is not installed
"""
+ try:
+ # pylint: disable=import-error,no-name-in-module
+ from qiskit.providers.ibmq import IBMQBackend
+ except ImportError:
+ raise ImportError("The IBMQ provider is necessary for this function "
+ " to work. Please ensure it's installed before "
+ "using this function")
+
if not isinstance(backend, IBMQBackend):
raise QiskitError('Input variable is not of type IBMQBackend.')
config = backend.configuration().to_dict()
| {"golden_diff": "diff --git a/qiskit/tools/monitor/backend_overview.py b/qiskit/tools/monitor/backend_overview.py\n--- a/qiskit/tools/monitor/backend_overview.py\n+++ b/qiskit/tools/monitor/backend_overview.py\n@@ -19,12 +19,6 @@\n import math\n from qiskit.exceptions import QiskitError\n \n-try:\n- # pylint: disable=import-error,no-name-in-module\n- from qiskit.providers.ibmq import IBMQ, IBMQBackend\n-except ImportError:\n- pass\n-\n \n def get_unique_backends():\n \"\"\"Gets the unique backends that are available.\n@@ -34,7 +28,14 @@\n \n Raises:\n QiskitError: No backends available.\n+ ImportError: If qiskit-ibmq-provider is not installed\n \"\"\"\n+ try:\n+ from qiskit.providers.ibmq import IBMQ\n+ except ImportError:\n+ raise ImportError(\"The IBMQ provider is necessary for this function \"\n+ \" to work. Please ensure it's installed before \"\n+ \"using this function\")\n backends = []\n for provider in IBMQ.providers():\n for backend in provider.backends():\n@@ -57,7 +58,16 @@\n backend (IBMQBackend): Backend to monitor.\n Raises:\n QiskitError: Input is not a IBMQ backend.\n+ ImportError: If qiskit-ibmq-provider is not installed\n \"\"\"\n+ try:\n+ # pylint: disable=import-error,no-name-in-module\n+ from qiskit.providers.ibmq import IBMQBackend\n+ except ImportError:\n+ raise ImportError(\"The IBMQ provider is necessary for this function \"\n+ \" to work. Please ensure it's installed before \"\n+ \"using this function\")\n+\n if not isinstance(backend, IBMQBackend):\n raise QiskitError('Input variable is not of type IBMQBackend.')\n config = backend.configuration().to_dict()\n", "issue": "Branch `master` is failing\n<!-- commit 9134634f43bc858a32b4d6a9c3edf352e2f58873@master -->\nTrying to build `master` at commit 9134634f43bc858a32b4d6a9c3edf352e2f58873 failed.\nMore info at: https://travis-ci.com/Qiskit/qiskit-terra/jobs/253757284\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n# pylint: disable=invalid-name\n\n\"\"\" A module for viewing the details of all available devices.\n\"\"\"\n\nimport math\nfrom qiskit.exceptions import QiskitError\n\ntry:\n # pylint: disable=import-error,no-name-in-module\n from qiskit.providers.ibmq import IBMQ, IBMQBackend\nexcept ImportError:\n pass\n\n\ndef get_unique_backends():\n \"\"\"Gets the unique backends that are available.\n\n Returns:\n list: Unique available backends.\n\n Raises:\n QiskitError: No backends available.\n \"\"\"\n backends = []\n for provider in IBMQ.providers():\n for backend in provider.backends():\n backends.append(backend)\n unique_hardware_backends = []\n unique_names = []\n for back in backends:\n if back.name() not in unique_names and not back.configuration().simulator:\n unique_hardware_backends.append(back)\n unique_names.append(back.name())\n if not unique_hardware_backends:\n raise QiskitError('No backends available.')\n return unique_hardware_backends\n\n\ndef backend_monitor(backend):\n \"\"\"Monitor a single IBMQ backend.\n\n Args:\n backend (IBMQBackend): Backend to monitor.\n Raises:\n QiskitError: Input is not a IBMQ backend.\n \"\"\"\n if not isinstance(backend, IBMQBackend):\n raise QiskitError('Input variable is not of type IBMQBackend.')\n config = backend.configuration().to_dict()\n status = backend.status().to_dict()\n config_dict = {**status, **config}\n if not config['simulator']:\n props = backend.properties().to_dict()\n\n print(backend.name())\n print('='*len(backend.name()))\n print('Configuration')\n print('-'*13)\n offset = ' '\n\n upper_list = ['n_qubits', 'operational',\n 'status_msg', 'pending_jobs',\n 'backend_version', 'basis_gates',\n 'local', 'simulator']\n\n lower_list = list(set(config_dict.keys()).difference(upper_list))\n # Remove gates because they are in a different tab\n lower_list.remove('gates')\n for item in upper_list+lower_list:\n print(offset+item+':', config_dict[item])\n\n # Stop here if simulator\n if config['simulator']:\n return\n\n print()\n qubit_header = 'Qubits [Name / Freq / T1 / T2 / U1 err / U2 err / U3 err / Readout err]'\n print(qubit_header)\n print('-'*len(qubit_header))\n\n sep = ' / '\n for qub in range(len(props['qubits'])):\n name = 'Q%s' % qub\n qubit_data = props['qubits'][qub]\n gate_data = [g for g in props['gates'] if g['qubits'] == [qub]]\n t1_info = qubit_data[0]\n t2_info = qubit_data[1]\n freq_info = qubit_data[2]\n readout_info = qubit_data[3]\n\n freq = str(round(freq_info['value'], 5))+' '+freq_info['unit']\n T1 = str(round(t1_info['value'],\n 5))+' ' + t1_info['unit']\n T2 = str(round(t2_info['value'],\n 5))+' ' + t2_info['unit']\n for gd in gate_data:\n if gd['gate'] == 'u1':\n U1 = str(round(gd['parameters'][0]['value'], 5))\n break\n\n for gd in gate_data:\n if gd['gate'] == 'u2':\n U2 = str(round(gd['parameters'][0]['value'], 5))\n break\n for gd in gate_data:\n if gd['gate'] == 'u3':\n U3 = str(round(gd['parameters'][0]['value'], 5))\n break\n\n readout_error = str(round(readout_info['value'], 5))\n\n qstr = sep.join([name, freq, T1, T2, U1, U2, U3, readout_error])\n print(offset+qstr)\n\n print()\n multi_qubit_gates = [g for g in props['gates'] if len(g['qubits']) > 1]\n multi_header = 'Multi-Qubit Gates [Name / Type / Gate Error]'\n print(multi_header)\n print('-'*len(multi_header))\n\n for qub, gate in enumerate(multi_qubit_gates):\n gate = multi_qubit_gates[qub]\n qubits = gate['qubits']\n ttype = gate['gate']\n error = round(gate['parameters'][0]['value'], 5)\n mstr = sep.join([\"{}{}_{}\".format(ttype, qubits[0], qubits[1]), ttype, str(error)])\n print(offset+mstr)\n\n\ndef backend_overview():\n \"\"\"Gives overview information on all the IBMQ\n backends that are available.\n \"\"\"\n unique_hardware_backends = get_unique_backends()\n _backends = []\n # Sort backends by operational or not\n for idx, back in enumerate(unique_hardware_backends):\n if back.status().operational:\n _backends = [back] + _backends\n else:\n _backends = _backends + [back]\n\n stati = [back.status() for back in _backends]\n idx = list(range(len(_backends)))\n pending = [s.pending_jobs for s in stati]\n _, least_idx = zip(*sorted(zip(pending, idx)))\n\n # Make sure least pending is operational\n for ind in least_idx:\n if stati[ind].operational:\n least_pending_idx = ind\n break\n\n num_rows = math.ceil(len(_backends)/3)\n\n count = 0\n num_backends = len(_backends)\n for _ in range(num_rows):\n max_len = 0\n str_list = ['']*8\n for idx in range(3):\n offset = ' ' * 10 if idx else ''\n config = _backends[count].configuration().to_dict()\n props = _backends[count].properties().to_dict()\n n_qubits = config['n_qubits']\n str_list[0] += (' '*(max_len-len(str_list[0]))+offset)\n str_list[0] += _backends[count].name()\n\n str_list[1] += (' '*(max_len-len(str_list[1]))+offset)\n str_list[1] += '-'*len(_backends[count].name())\n\n str_list[2] += (' '*(max_len-len(str_list[2]))+offset)\n str_list[2] += 'Num. Qubits: %s' % config['n_qubits']\n\n str_list[3] += (' '*(max_len-len(str_list[3]))+offset)\n str_list[3] += 'Pending Jobs: %s' % stati[count].pending_jobs\n\n str_list[4] += (' '*(max_len-len(str_list[4]))+offset)\n str_list[4] += 'Least busy: %s' % (count == least_pending_idx)\n\n str_list[5] += (' '*(max_len-len(str_list[5]))+offset)\n str_list[5] += 'Operational: %s' % stati[count].operational\n\n str_list[6] += (' '*(max_len-len(str_list[6]))+offset)\n str_list[6] += 'Avg. T1: %s' % round(sum([q[0]['value']\n for q in props['qubits']])/n_qubits, 1)\n str_list[7] += (' '*(max_len-len(str_list[7]))+offset)\n str_list[7] += 'Avg. T2: %s' % round(sum([q[1]['value']\n for q in props['qubits']])/n_qubits, 1)\n count += 1\n if count == num_backends:\n break\n max_len = max([len(s) for s in str_list])\n\n print(\"\\n\".join(str_list))\n print('\\n'*2)\n", "path": "qiskit/tools/monitor/backend_overview.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n# pylint: disable=invalid-name\n\n\"\"\" A module for viewing the details of all available devices.\n\"\"\"\n\nimport math\nfrom qiskit.exceptions import QiskitError\n\n\ndef get_unique_backends():\n \"\"\"Gets the unique backends that are available.\n\n Returns:\n list: Unique available backends.\n\n Raises:\n QiskitError: No backends available.\n ImportError: If qiskit-ibmq-provider is not installed\n \"\"\"\n try:\n from qiskit.providers.ibmq import IBMQ\n except ImportError:\n raise ImportError(\"The IBMQ provider is necessary for this function \"\n \" to work. Please ensure it's installed before \"\n \"using this function\")\n backends = []\n for provider in IBMQ.providers():\n for backend in provider.backends():\n backends.append(backend)\n unique_hardware_backends = []\n unique_names = []\n for back in backends:\n if back.name() not in unique_names and not back.configuration().simulator:\n unique_hardware_backends.append(back)\n unique_names.append(back.name())\n if not unique_hardware_backends:\n raise QiskitError('No backends available.')\n return unique_hardware_backends\n\n\ndef backend_monitor(backend):\n \"\"\"Monitor a single IBMQ backend.\n\n Args:\n backend (IBMQBackend): Backend to monitor.\n Raises:\n QiskitError: Input is not a IBMQ backend.\n ImportError: If qiskit-ibmq-provider is not installed\n \"\"\"\n try:\n # pylint: disable=import-error,no-name-in-module\n from qiskit.providers.ibmq import IBMQBackend\n except ImportError:\n raise ImportError(\"The IBMQ provider is necessary for this function \"\n \" to work. Please ensure it's installed before \"\n \"using this function\")\n\n if not isinstance(backend, IBMQBackend):\n raise QiskitError('Input variable is not of type IBMQBackend.')\n config = backend.configuration().to_dict()\n status = backend.status().to_dict()\n config_dict = {**status, **config}\n if not config['simulator']:\n props = backend.properties().to_dict()\n\n print(backend.name())\n print('='*len(backend.name()))\n print('Configuration')\n print('-'*13)\n offset = ' '\n\n upper_list = ['n_qubits', 'operational',\n 'status_msg', 'pending_jobs',\n 'backend_version', 'basis_gates',\n 'local', 'simulator']\n\n lower_list = list(set(config_dict.keys()).difference(upper_list))\n # Remove gates because they are in a different tab\n lower_list.remove('gates')\n for item in upper_list+lower_list:\n print(offset+item+':', config_dict[item])\n\n # Stop here if simulator\n if config['simulator']:\n return\n\n print()\n qubit_header = 'Qubits [Name / Freq / T1 / T2 / U1 err / U2 err / U3 err / Readout err]'\n print(qubit_header)\n print('-'*len(qubit_header))\n\n sep = ' / '\n for qub in range(len(props['qubits'])):\n name = 'Q%s' % qub\n qubit_data = props['qubits'][qub]\n gate_data = [g for g in props['gates'] if g['qubits'] == [qub]]\n t1_info = qubit_data[0]\n t2_info = qubit_data[1]\n freq_info = qubit_data[2]\n readout_info = qubit_data[3]\n\n freq = str(round(freq_info['value'], 5))+' '+freq_info['unit']\n T1 = str(round(t1_info['value'],\n 5))+' ' + t1_info['unit']\n T2 = str(round(t2_info['value'],\n 5))+' ' + t2_info['unit']\n for gd in gate_data:\n if gd['gate'] == 'u1':\n U1 = str(round(gd['parameters'][0]['value'], 5))\n break\n\n for gd in gate_data:\n if gd['gate'] == 'u2':\n U2 = str(round(gd['parameters'][0]['value'], 5))\n break\n for gd in gate_data:\n if gd['gate'] == 'u3':\n U3 = str(round(gd['parameters'][0]['value'], 5))\n break\n\n readout_error = str(round(readout_info['value'], 5))\n\n qstr = sep.join([name, freq, T1, T2, U1, U2, U3, readout_error])\n print(offset+qstr)\n\n print()\n multi_qubit_gates = [g for g in props['gates'] if len(g['qubits']) > 1]\n multi_header = 'Multi-Qubit Gates [Name / Type / Gate Error]'\n print(multi_header)\n print('-'*len(multi_header))\n\n for qub, gate in enumerate(multi_qubit_gates):\n gate = multi_qubit_gates[qub]\n qubits = gate['qubits']\n ttype = gate['gate']\n error = round(gate['parameters'][0]['value'], 5)\n mstr = sep.join([\"{}{}_{}\".format(ttype, qubits[0], qubits[1]), ttype, str(error)])\n print(offset+mstr)\n\n\ndef backend_overview():\n \"\"\"Gives overview information on all the IBMQ\n backends that are available.\n \"\"\"\n unique_hardware_backends = get_unique_backends()\n _backends = []\n # Sort backends by operational or not\n for idx, back in enumerate(unique_hardware_backends):\n if back.status().operational:\n _backends = [back] + _backends\n else:\n _backends = _backends + [back]\n\n stati = [back.status() for back in _backends]\n idx = list(range(len(_backends)))\n pending = [s.pending_jobs for s in stati]\n _, least_idx = zip(*sorted(zip(pending, idx)))\n\n # Make sure least pending is operational\n for ind in least_idx:\n if stati[ind].operational:\n least_pending_idx = ind\n break\n\n num_rows = math.ceil(len(_backends)/3)\n\n count = 0\n num_backends = len(_backends)\n for _ in range(num_rows):\n max_len = 0\n str_list = ['']*8\n for idx in range(3):\n offset = ' ' * 10 if idx else ''\n config = _backends[count].configuration().to_dict()\n props = _backends[count].properties().to_dict()\n n_qubits = config['n_qubits']\n str_list[0] += (' '*(max_len-len(str_list[0]))+offset)\n str_list[0] += _backends[count].name()\n\n str_list[1] += (' '*(max_len-len(str_list[1]))+offset)\n str_list[1] += '-'*len(_backends[count].name())\n\n str_list[2] += (' '*(max_len-len(str_list[2]))+offset)\n str_list[2] += 'Num. Qubits: %s' % config['n_qubits']\n\n str_list[3] += (' '*(max_len-len(str_list[3]))+offset)\n str_list[3] += 'Pending Jobs: %s' % stati[count].pending_jobs\n\n str_list[4] += (' '*(max_len-len(str_list[4]))+offset)\n str_list[4] += 'Least busy: %s' % (count == least_pending_idx)\n\n str_list[5] += (' '*(max_len-len(str_list[5]))+offset)\n str_list[5] += 'Operational: %s' % stati[count].operational\n\n str_list[6] += (' '*(max_len-len(str_list[6]))+offset)\n str_list[6] += 'Avg. T1: %s' % round(sum([q[0]['value']\n for q in props['qubits']])/n_qubits, 1)\n str_list[7] += (' '*(max_len-len(str_list[7]))+offset)\n str_list[7] += 'Avg. T2: %s' % round(sum([q[1]['value']\n for q in props['qubits']])/n_qubits, 1)\n count += 1\n if count == num_backends:\n break\n max_len = max([len(s) for s in str_list])\n\n print(\"\\n\".join(str_list))\n print('\\n'*2)\n", "path": "qiskit/tools/monitor/backend_overview.py"}]} | 2,866 | 432 |
gh_patches_debug_30480 | rasdani/github-patches | git_diff | plone__Products.CMFPlone-3357 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
relationhelpers have hard dependency on plone.app.iterate
The newly introduced relationhelpers are having `plone.app.iterate` as a hard dependency.
`plone.app.iterate` is a dependency of the `Plone` package, but not of `Products.CMFPlone`. See:
https://github.com/plone/Products.CMFPlone/blob/d07a74b6f7d944a08563c479c68c76fe6bd3b260/Products/CMFPlone/relationhelper.py#L4-L5
This need to be changed into a soft dependency at least.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `Products/CMFPlone/relationhelper.py`
Content:
```
1 from collections import Counter
2 from collections import defaultdict
3 from five.intid.intid import addIntIdSubscriber
4 from plone.app.iterate.dexterity import ITERATE_RELATION_NAME
5 from plone.app.iterate.dexterity.relation import StagingRelationValue
6 from plone.app.linkintegrity.handlers import modifiedContent
7 from plone.app.linkintegrity.utils import referencedRelationship
8 from plone.app.relationfield.event import update_behavior_relations
9 from plone.app.uuid.utils import uuidToObject
10 from plone.dexterity.interfaces import IDexterityContent
11 from plone.dexterity.utils import iterSchemataForType
12 from Products.CMFCore.interfaces import IContentish
13 from Products.CMFPlone import PloneMessageFactory as _
14 from z3c.relationfield import event
15 from z3c.relationfield import RelationValue
16 from z3c.relationfield.event import updateRelations
17 from z3c.relationfield.schema import Relation
18 from z3c.relationfield.schema import RelationChoice
19 from z3c.relationfield.schema import RelationList
20 from zc.relation.interfaces import ICatalog
21 from zope.annotation.interfaces import IAnnotations
22 from zope.component import getUtility
23 from zope.component import queryUtility
24 from zope.component.hooks import getSite
25 from zope.intid.interfaces import IIntIds
26 from zope.intid.interfaces import ObjectMissingError
27
28 import logging
29
30 logger = logging.getLogger(__name__)
31
32 RELATIONS_KEY = 'ALL_REFERENCES'
33
34
35 def rebuild_relations(context=None, flush_and_rebuild_intids=False):
36 store_relations()
37 purge_relations()
38 if flush_and_rebuild_intids:
39 flush_intids()
40 rebuild_intids()
41 else:
42 cleanup_intids()
43 restore_relations()
44
45
46 def get_relations_stats():
47 info = defaultdict(int)
48 broken = defaultdict(int)
49 relation_catalog = getUtility(ICatalog)
50 for token in relation_catalog.findRelationTokens():
51 try:
52 rel = relation_catalog.resolveRelationToken(token)
53 except ObjectMissingError:
54 broken['Object is missing'] += 1
55 logger.info('Token {} has no object.'.format(token))
56 continue
57
58 if rel.isBroken():
59 broken[rel.from_attribute] += 1
60 else:
61 info[rel.from_attribute] += 1
62 return info, broken
63
64
65 def get_all_relations():
66 """Get all data from zc.relation catalog.
67 Logs some useful statistics.
68 """
69 results = []
70 info = defaultdict(int)
71
72 relation_catalog = getUtility(ICatalog)
73 for token in relation_catalog.findRelationTokens():
74 try:
75 rel = relation_catalog.resolveRelationToken(token)
76 except ObjectMissingError:
77 logger.info('Token {} has no object.'.format(token))
78 continue
79
80 if rel.from_object and rel.to_object:
81 try:
82 results.append({
83 'from_uuid': rel.from_object.UID(),
84 'to_uuid': rel.to_object.UID(),
85 'from_attribute': rel.from_attribute,
86 })
87 info[rel.from_attribute] += 1
88 except AttributeError as ex:
89 logger.info(f'Something went wrong while storing {rel}: \n {ex}')
90 else:
91 logger.info(f'Dropping relation {rel.from_attribute} from {rel.from_object} to {rel.to_object}')
92 msg = ''
93 for key, value in info.items():
94 msg += f'{key}: {value}\n'
95 logger.info(f'\nFound the following relations:\n{msg}')
96 return results
97
98
99 def store_relations(context=None):
100 """Store all relations in a annotation on the portal.
101 """
102 all_relations = get_all_relations()
103 portal = getSite()
104 IAnnotations(portal)[RELATIONS_KEY] = all_relations
105 logger.info(f'Stored {len(all_relations)} relations on the portal')
106
107
108 def purge_relations(context=None):
109 """Removes all entries form zc.relation catalog.
110 RelationValues that were set as attribute on content are still there!
111 These are removed/overwritten when restoring the relations.
112 """
113 rel_catalog = getUtility(ICatalog)
114 rel_catalog.clear()
115 logger.info('Purged zc.relation catalog')
116
117
118 def restore_relations(context=None, all_relations=None):
119 """Restore relations from a annotation on the portal.
120 """
121
122 portal = getSite()
123 if all_relations is None:
124 all_relations = IAnnotations(portal)[RELATIONS_KEY]
125 logger.info(f'Loaded {len(all_relations)} relations to restore')
126 update_linkintegrity = set()
127 modified_items = set()
128 modified_relation_lists = defaultdict(list)
129
130 # remove duplicates but keep original order
131 unique_relations = []
132 seen = set()
133 seen_add = seen.add
134 for rel in all_relations:
135 hashable = tuple(rel.items())
136 if hashable not in seen:
137 unique_relations.append(rel)
138 seen_add(hashable)
139 else:
140 logger.info(f'Dropping duplicate: {hashable}')
141
142 if len(unique_relations) < len(all_relations):
143 logger.info(f'Dropping {len(all_relations) - len(unique_relations)} duplicates')
144 all_relations = unique_relations
145
146 intids = getUtility(IIntIds)
147 for index, item in enumerate(all_relations, start=1):
148 if not index % 500:
149 logger.info(f'Restored {index} of {len(all_relations)} relations...')
150
151 try:
152 source_obj = uuidToObject(item['from_uuid'])
153 except KeyError:
154 # brain exists but no object
155 source_obj = None
156 try:
157 target_obj = uuidToObject(item['to_uuid'])
158 except KeyError:
159 # brain exists but no object
160 target_obj = None
161
162 if not source_obj:
163 logger.info(f'{item["from_uuid"]} is missing')
164 continue
165
166 if not target_obj:
167 logger.info(f'{item["to_uuid"]} is missing')
168 continue
169
170 if not IDexterityContent.providedBy(source_obj):
171 logger.info(f'{source_obj} is no dexterity content')
172 continue
173
174 if not IDexterityContent.providedBy(target_obj):
175 logger.info(f'{target_obj} is no dexterity content')
176 continue
177
178 from_attribute = item['from_attribute']
179 to_id = intids.getId(target_obj)
180
181 if from_attribute == referencedRelationship:
182 # Ignore linkintegrity for now. We'll rebuilt it at the end!
183 update_linkintegrity.add(item['from_uuid'])
184 continue
185
186 if from_attribute == ITERATE_RELATION_NAME:
187 # Iterate relations are not set as values of fields
188 relation = StagingRelationValue(to_id)
189 event._setRelation(source_obj, ITERATE_RELATION_NAME, relation)
190 continue
191
192 field_and_schema = get_field_and_schema_for_fieldname(from_attribute, source_obj.portal_type)
193 if field_and_schema is None:
194 # the from_attribute is no field
195 logger.info(f'No field. Setting relation: {item}')
196 event._setRelation(source_obj, from_attribute, RelationValue(to_id))
197 continue
198
199 field, schema = field_and_schema
200 relation = RelationValue(to_id)
201
202 if isinstance(field, RelationList):
203 logger.info(f'Add relation to relationslist {from_attribute} from {source_obj.absolute_url()} to {target_obj.absolute_url()}')
204 if item['from_uuid'] in modified_relation_lists.get(from_attribute, []):
205 # Do not purge relations
206 existing_relations = getattr(source_obj, from_attribute, [])
207 else:
208 # First touch. Make sure we purge!
209 existing_relations = []
210 existing_relations.append(relation)
211 setattr(source_obj, from_attribute, existing_relations)
212 modified_items.add(item['from_uuid'])
213 modified_relation_lists[from_attribute].append(item['from_uuid'])
214 continue
215
216 elif isinstance(field, (Relation, RelationChoice)):
217 logger.info(f'Add relation {from_attribute} from {source_obj.absolute_url()} to {target_obj.absolute_url()}')
218 setattr(source_obj, from_attribute, relation)
219 modified_items.add(item['from_uuid'])
220 continue
221
222 else:
223 # we should never end up here!
224 logger.warn(f'Unexpected relation {from_attribute} from {source_obj.absolute_url()} to {target_obj.absolute_url()}')
225
226 update_linkintegrity = set(update_linkintegrity)
227 logger.info(f'Updating linkintegrity for {len(update_linkintegrity)} items')
228 for uuid in sorted(update_linkintegrity):
229 modifiedContent(uuidToObject(uuid), None)
230 logger.info(f'Updating relations for {len(modified_items)} items')
231 for uuid in sorted(modified_items):
232 obj = uuidToObject(uuid)
233 # updateRelations from z3c.relationfield does not properly update relations in behaviors
234 # that are registered with a marker-interface.
235 # update_behavior_relations (from plone.app.relationfield) does that but does not update
236 # those in the main schema. Duh!
237 updateRelations(obj, None)
238 update_behavior_relations(obj, None)
239
240 # purge annotation from portal if they exist
241 if RELATIONS_KEY in IAnnotations(portal):
242 del IAnnotations(portal)[RELATIONS_KEY]
243 logger.info('Done!')
244
245
246 def get_intid(obj):
247 """Intid from intid-catalog"""
248 intids = queryUtility(IIntIds)
249 if intids is None:
250 return
251 # check that the object has an intid, otherwise there's nothing to be done
252 try:
253 return intids.getId(obj)
254 except KeyError: # noqa
255 # The object has not been added to the ZODB yet
256 return
257
258
259 def get_field_and_schema_for_fieldname(field_id, portal_type):
260 """Get field and its schema from a portal_type.
261 """
262 # Turn form.widgets.IDublinCore.title into title
263 field_id = field_id.split('.')[-1]
264 for schema in iterSchemataForType(portal_type):
265 field = schema.get(field_id, None)
266 if field is not None:
267 return (field, schema)
268
269
270 def cleanup_intids(context=None):
271 intids = getUtility(IIntIds)
272 all_refs = [f'{i.object.__class__.__module__}.{i.object.__class__.__name__}'
273 for i in intids.refs.values()]
274 logger.info(Counter(all_refs))
275
276 count = 0
277 refs = [i for i in intids.refs.values() if isinstance(i.object, RelationValue)]
278 for ref in refs:
279 intids.unregister(ref)
280 count += 1
281 logger.info(f'Removed all {count} RelationValues from IntId-tool')
282
283 count = 0
284 for ref in intids.refs.values():
285 if 'broken' in repr(ref.object):
286 intids.unregister(ref)
287 logger.info(f'Removed {count} broken refs from IntId-tool')
288 all_refs = ['{i.object.__class__.__module__}.{i.object.__class__.__name__}'
289 for i in intids.refs.values()]
290 logger.info(Counter(all_refs))
291
292
293 def flush_intids():
294 """ Flush all intids
295 """
296 intids = getUtility(IIntIds)
297 intids.ids = intids.family.OI.BTree()
298 intids.refs = intids.family.IO.BTree()
299
300
301 def rebuild_intids():
302 """ Create new intids
303 """
304 def add_to_intids(obj, path):
305 if IContentish.providedBy(obj):
306 logger.info(f'Added {obj} at {path} to intid')
307 addIntIdSubscriber(obj, None)
308 portal = getSite()
309 portal.ZopeFindAndApply(portal,
310 search_sub=True,
311 apply_func=add_to_intids)
312
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/Products/CMFPlone/relationhelper.py b/Products/CMFPlone/relationhelper.py
--- a/Products/CMFPlone/relationhelper.py
+++ b/Products/CMFPlone/relationhelper.py
@@ -1,8 +1,6 @@
from collections import Counter
from collections import defaultdict
from five.intid.intid import addIntIdSubscriber
-from plone.app.iterate.dexterity import ITERATE_RELATION_NAME
-from plone.app.iterate.dexterity.relation import StagingRelationValue
from plone.app.linkintegrity.handlers import modifiedContent
from plone.app.linkintegrity.utils import referencedRelationship
from plone.app.relationfield.event import update_behavior_relations
@@ -26,6 +24,18 @@
from zope.intid.interfaces import ObjectMissingError
import logging
+import pkg_resources
+
+try:
+ # "iterate" is not a dependency of CMFPlone, but a consumer of it
+ pkg_resources.get_distribution("plone.app.iterate")
+except pkg_resources.DistributionNotFound:
+ HAS_ITERATE = False
+else:
+ HAS_ITERATE = True
+ from plone.app.iterate.dexterity import ITERATE_RELATION_NAME
+ from plone.app.iterate.dexterity.relation import StagingRelationValue
+
logger = logging.getLogger(__name__)
@@ -183,7 +193,7 @@
update_linkintegrity.add(item['from_uuid'])
continue
- if from_attribute == ITERATE_RELATION_NAME:
+ if HAS_ITERATE and from_attribute == ITERATE_RELATION_NAME:
# Iterate relations are not set as values of fields
relation = StagingRelationValue(to_id)
event._setRelation(source_obj, ITERATE_RELATION_NAME, relation)
| {"golden_diff": "diff --git a/Products/CMFPlone/relationhelper.py b/Products/CMFPlone/relationhelper.py\n--- a/Products/CMFPlone/relationhelper.py\n+++ b/Products/CMFPlone/relationhelper.py\n@@ -1,8 +1,6 @@\n from collections import Counter\n from collections import defaultdict\n from five.intid.intid import addIntIdSubscriber\n-from plone.app.iterate.dexterity import ITERATE_RELATION_NAME\n-from plone.app.iterate.dexterity.relation import StagingRelationValue\n from plone.app.linkintegrity.handlers import modifiedContent\n from plone.app.linkintegrity.utils import referencedRelationship\n from plone.app.relationfield.event import update_behavior_relations\n@@ -26,6 +24,18 @@\n from zope.intid.interfaces import ObjectMissingError\n \n import logging\n+import pkg_resources\n+\n+try:\n+ # \"iterate\" is not a dependency of CMFPlone, but a consumer of it\n+ pkg_resources.get_distribution(\"plone.app.iterate\")\n+except pkg_resources.DistributionNotFound:\n+ HAS_ITERATE = False\n+else:\n+ HAS_ITERATE = True\n+ from plone.app.iterate.dexterity import ITERATE_RELATION_NAME\n+ from plone.app.iterate.dexterity.relation import StagingRelationValue\n+\n \n logger = logging.getLogger(__name__)\n \n@@ -183,7 +193,7 @@\n update_linkintegrity.add(item['from_uuid'])\n continue\n \n- if from_attribute == ITERATE_RELATION_NAME:\n+ if HAS_ITERATE and from_attribute == ITERATE_RELATION_NAME:\n # Iterate relations are not set as values of fields\n relation = StagingRelationValue(to_id)\n event._setRelation(source_obj, ITERATE_RELATION_NAME, relation)\n", "issue": "relationhelpers have hard dependency on plone.app.iterate\nThe newly introduced relationhelpers are having `plone.app.iterate` as a hard dependency.\r\n\r\n`plone.app.iterate` is a dependency of the `Plone` package, but not of `Products.CMFPlone`. See:\r\n\r\nhttps://github.com/plone/Products.CMFPlone/blob/d07a74b6f7d944a08563c479c68c76fe6bd3b260/Products/CMFPlone/relationhelper.py#L4-L5\r\n\r\nThis need to be changed into a soft dependency at least.\n", "before_files": [{"content": "from collections import Counter\nfrom collections import defaultdict\nfrom five.intid.intid import addIntIdSubscriber\nfrom plone.app.iterate.dexterity import ITERATE_RELATION_NAME\nfrom plone.app.iterate.dexterity.relation import StagingRelationValue\nfrom plone.app.linkintegrity.handlers import modifiedContent\nfrom plone.app.linkintegrity.utils import referencedRelationship\nfrom plone.app.relationfield.event import update_behavior_relations\nfrom plone.app.uuid.utils import uuidToObject\nfrom plone.dexterity.interfaces import IDexterityContent\nfrom plone.dexterity.utils import iterSchemataForType\nfrom Products.CMFCore.interfaces import IContentish\nfrom Products.CMFPlone import PloneMessageFactory as _\nfrom z3c.relationfield import event\nfrom z3c.relationfield import RelationValue\nfrom z3c.relationfield.event import updateRelations\nfrom z3c.relationfield.schema import Relation\nfrom z3c.relationfield.schema import RelationChoice\nfrom z3c.relationfield.schema import RelationList\nfrom zc.relation.interfaces import ICatalog\nfrom zope.annotation.interfaces import IAnnotations\nfrom zope.component import getUtility\nfrom zope.component import queryUtility\nfrom zope.component.hooks import getSite\nfrom zope.intid.interfaces import IIntIds\nfrom zope.intid.interfaces import ObjectMissingError\n\nimport logging\n\nlogger = logging.getLogger(__name__)\n\nRELATIONS_KEY = 'ALL_REFERENCES'\n\n\ndef rebuild_relations(context=None, flush_and_rebuild_intids=False):\n store_relations()\n purge_relations()\n if flush_and_rebuild_intids:\n flush_intids()\n rebuild_intids()\n else:\n cleanup_intids()\n restore_relations()\n\n\ndef get_relations_stats():\n info = defaultdict(int)\n broken = defaultdict(int)\n relation_catalog = getUtility(ICatalog)\n for token in relation_catalog.findRelationTokens():\n try:\n rel = relation_catalog.resolveRelationToken(token)\n except ObjectMissingError:\n broken['Object is missing'] += 1\n logger.info('Token {} has no object.'.format(token))\n continue\n\n if rel.isBroken():\n broken[rel.from_attribute] += 1\n else:\n info[rel.from_attribute] += 1\n return info, broken\n\n\ndef get_all_relations():\n \"\"\"Get all data from zc.relation catalog.\n Logs some useful statistics.\n \"\"\"\n results = []\n info = defaultdict(int)\n\n relation_catalog = getUtility(ICatalog)\n for token in relation_catalog.findRelationTokens():\n try:\n rel = relation_catalog.resolveRelationToken(token)\n except ObjectMissingError:\n logger.info('Token {} has no object.'.format(token))\n continue\n\n if rel.from_object and rel.to_object:\n try:\n results.append({\n 'from_uuid': rel.from_object.UID(),\n 'to_uuid': rel.to_object.UID(),\n 'from_attribute': rel.from_attribute,\n })\n info[rel.from_attribute] += 1\n except AttributeError as ex:\n logger.info(f'Something went wrong while storing {rel}: \\n {ex}')\n else:\n logger.info(f'Dropping relation {rel.from_attribute} from {rel.from_object} to {rel.to_object}')\n msg = ''\n for key, value in info.items():\n msg += f'{key}: {value}\\n'\n logger.info(f'\\nFound the following relations:\\n{msg}')\n return results\n\n\ndef store_relations(context=None):\n \"\"\"Store all relations in a annotation on the portal.\n \"\"\"\n all_relations = get_all_relations()\n portal = getSite()\n IAnnotations(portal)[RELATIONS_KEY] = all_relations\n logger.info(f'Stored {len(all_relations)} relations on the portal')\n\n\ndef purge_relations(context=None):\n \"\"\"Removes all entries form zc.relation catalog.\n RelationValues that were set as attribute on content are still there!\n These are removed/overwritten when restoring the relations.\n \"\"\"\n rel_catalog = getUtility(ICatalog)\n rel_catalog.clear()\n logger.info('Purged zc.relation catalog')\n\n\ndef restore_relations(context=None, all_relations=None):\n \"\"\"Restore relations from a annotation on the portal.\n \"\"\"\n\n portal = getSite()\n if all_relations is None:\n all_relations = IAnnotations(portal)[RELATIONS_KEY]\n logger.info(f'Loaded {len(all_relations)} relations to restore')\n update_linkintegrity = set()\n modified_items = set()\n modified_relation_lists = defaultdict(list)\n\n # remove duplicates but keep original order\n unique_relations = []\n seen = set()\n seen_add = seen.add\n for rel in all_relations:\n hashable = tuple(rel.items())\n if hashable not in seen:\n unique_relations.append(rel)\n seen_add(hashable)\n else:\n logger.info(f'Dropping duplicate: {hashable}')\n\n if len(unique_relations) < len(all_relations):\n logger.info(f'Dropping {len(all_relations) - len(unique_relations)} duplicates')\n all_relations = unique_relations\n\n intids = getUtility(IIntIds)\n for index, item in enumerate(all_relations, start=1):\n if not index % 500:\n logger.info(f'Restored {index} of {len(all_relations)} relations...')\n\n try:\n source_obj = uuidToObject(item['from_uuid'])\n except KeyError:\n # brain exists but no object\n source_obj = None\n try:\n target_obj = uuidToObject(item['to_uuid'])\n except KeyError:\n # brain exists but no object\n target_obj = None\n\n if not source_obj:\n logger.info(f'{item[\"from_uuid\"]} is missing')\n continue\n\n if not target_obj:\n logger.info(f'{item[\"to_uuid\"]} is missing')\n continue\n\n if not IDexterityContent.providedBy(source_obj):\n logger.info(f'{source_obj} is no dexterity content')\n continue\n\n if not IDexterityContent.providedBy(target_obj):\n logger.info(f'{target_obj} is no dexterity content')\n continue\n\n from_attribute = item['from_attribute']\n to_id = intids.getId(target_obj)\n\n if from_attribute == referencedRelationship:\n # Ignore linkintegrity for now. We'll rebuilt it at the end!\n update_linkintegrity.add(item['from_uuid'])\n continue\n\n if from_attribute == ITERATE_RELATION_NAME:\n # Iterate relations are not set as values of fields\n relation = StagingRelationValue(to_id)\n event._setRelation(source_obj, ITERATE_RELATION_NAME, relation)\n continue\n\n field_and_schema = get_field_and_schema_for_fieldname(from_attribute, source_obj.portal_type)\n if field_and_schema is None:\n # the from_attribute is no field\n logger.info(f'No field. Setting relation: {item}')\n event._setRelation(source_obj, from_attribute, RelationValue(to_id))\n continue\n\n field, schema = field_and_schema\n relation = RelationValue(to_id)\n\n if isinstance(field, RelationList):\n logger.info(f'Add relation to relationslist {from_attribute} from {source_obj.absolute_url()} to {target_obj.absolute_url()}')\n if item['from_uuid'] in modified_relation_lists.get(from_attribute, []):\n # Do not purge relations\n existing_relations = getattr(source_obj, from_attribute, [])\n else:\n # First touch. Make sure we purge!\n existing_relations = []\n existing_relations.append(relation)\n setattr(source_obj, from_attribute, existing_relations)\n modified_items.add(item['from_uuid'])\n modified_relation_lists[from_attribute].append(item['from_uuid'])\n continue\n\n elif isinstance(field, (Relation, RelationChoice)):\n logger.info(f'Add relation {from_attribute} from {source_obj.absolute_url()} to {target_obj.absolute_url()}')\n setattr(source_obj, from_attribute, relation)\n modified_items.add(item['from_uuid'])\n continue\n\n else:\n # we should never end up here!\n logger.warn(f'Unexpected relation {from_attribute} from {source_obj.absolute_url()} to {target_obj.absolute_url()}')\n\n update_linkintegrity = set(update_linkintegrity)\n logger.info(f'Updating linkintegrity for {len(update_linkintegrity)} items')\n for uuid in sorted(update_linkintegrity):\n modifiedContent(uuidToObject(uuid), None)\n logger.info(f'Updating relations for {len(modified_items)} items')\n for uuid in sorted(modified_items):\n obj = uuidToObject(uuid)\n # updateRelations from z3c.relationfield does not properly update relations in behaviors\n # that are registered with a marker-interface.\n # update_behavior_relations (from plone.app.relationfield) does that but does not update\n # those in the main schema. Duh!\n updateRelations(obj, None)\n update_behavior_relations(obj, None)\n\n # purge annotation from portal if they exist\n if RELATIONS_KEY in IAnnotations(portal):\n del IAnnotations(portal)[RELATIONS_KEY]\n logger.info('Done!')\n\n\ndef get_intid(obj):\n \"\"\"Intid from intid-catalog\"\"\"\n intids = queryUtility(IIntIds)\n if intids is None:\n return\n # check that the object has an intid, otherwise there's nothing to be done\n try:\n return intids.getId(obj)\n except KeyError: # noqa\n # The object has not been added to the ZODB yet\n return\n\n\ndef get_field_and_schema_for_fieldname(field_id, portal_type):\n \"\"\"Get field and its schema from a portal_type.\n \"\"\"\n # Turn form.widgets.IDublinCore.title into title\n field_id = field_id.split('.')[-1]\n for schema in iterSchemataForType(portal_type):\n field = schema.get(field_id, None)\n if field is not None:\n return (field, schema)\n\n\ndef cleanup_intids(context=None):\n intids = getUtility(IIntIds)\n all_refs = [f'{i.object.__class__.__module__}.{i.object.__class__.__name__}'\n for i in intids.refs.values()]\n logger.info(Counter(all_refs))\n\n count = 0\n refs = [i for i in intids.refs.values() if isinstance(i.object, RelationValue)]\n for ref in refs:\n intids.unregister(ref)\n count += 1\n logger.info(f'Removed all {count} RelationValues from IntId-tool')\n\n count = 0\n for ref in intids.refs.values():\n if 'broken' in repr(ref.object):\n intids.unregister(ref)\n logger.info(f'Removed {count} broken refs from IntId-tool')\n all_refs = ['{i.object.__class__.__module__}.{i.object.__class__.__name__}'\n for i in intids.refs.values()]\n logger.info(Counter(all_refs))\n\n\ndef flush_intids():\n \"\"\" Flush all intids\n \"\"\"\n intids = getUtility(IIntIds)\n intids.ids = intids.family.OI.BTree()\n intids.refs = intids.family.IO.BTree()\n\n\ndef rebuild_intids():\n \"\"\" Create new intids\n \"\"\"\n def add_to_intids(obj, path):\n if IContentish.providedBy(obj):\n logger.info(f'Added {obj} at {path} to intid')\n addIntIdSubscriber(obj, None)\n portal = getSite()\n portal.ZopeFindAndApply(portal,\n search_sub=True,\n apply_func=add_to_intids)\n", "path": "Products/CMFPlone/relationhelper.py"}], "after_files": [{"content": "from collections import Counter\nfrom collections import defaultdict\nfrom five.intid.intid import addIntIdSubscriber\nfrom plone.app.linkintegrity.handlers import modifiedContent\nfrom plone.app.linkintegrity.utils import referencedRelationship\nfrom plone.app.relationfield.event import update_behavior_relations\nfrom plone.app.uuid.utils import uuidToObject\nfrom plone.dexterity.interfaces import IDexterityContent\nfrom plone.dexterity.utils import iterSchemataForType\nfrom Products.CMFCore.interfaces import IContentish\nfrom Products.CMFPlone import PloneMessageFactory as _\nfrom z3c.relationfield import event\nfrom z3c.relationfield import RelationValue\nfrom z3c.relationfield.event import updateRelations\nfrom z3c.relationfield.schema import Relation\nfrom z3c.relationfield.schema import RelationChoice\nfrom z3c.relationfield.schema import RelationList\nfrom zc.relation.interfaces import ICatalog\nfrom zope.annotation.interfaces import IAnnotations\nfrom zope.component import getUtility\nfrom zope.component import queryUtility\nfrom zope.component.hooks import getSite\nfrom zope.intid.interfaces import IIntIds\nfrom zope.intid.interfaces import ObjectMissingError\n\nimport logging\nimport pkg_resources\n\ntry:\n # \"iterate\" is not a dependency of CMFPlone, but a consumer of it\n pkg_resources.get_distribution(\"plone.app.iterate\")\nexcept pkg_resources.DistributionNotFound:\n HAS_ITERATE = False\nelse:\n HAS_ITERATE = True\n from plone.app.iterate.dexterity import ITERATE_RELATION_NAME\n from plone.app.iterate.dexterity.relation import StagingRelationValue\n\n\nlogger = logging.getLogger(__name__)\n\nRELATIONS_KEY = 'ALL_REFERENCES'\n\n\ndef rebuild_relations(context=None, flush_and_rebuild_intids=False):\n store_relations()\n purge_relations()\n if flush_and_rebuild_intids:\n flush_intids()\n rebuild_intids()\n else:\n cleanup_intids()\n restore_relations()\n\n\ndef get_relations_stats():\n info = defaultdict(int)\n broken = defaultdict(int)\n relation_catalog = getUtility(ICatalog)\n for token in relation_catalog.findRelationTokens():\n try:\n rel = relation_catalog.resolveRelationToken(token)\n except ObjectMissingError:\n broken['Object is missing'] += 1\n logger.info('Token {} has no object.'.format(token))\n continue\n\n if rel.isBroken():\n broken[rel.from_attribute] += 1\n else:\n info[rel.from_attribute] += 1\n return info, broken\n\n\ndef get_all_relations():\n \"\"\"Get all data from zc.relation catalog.\n Logs some useful statistics.\n \"\"\"\n results = []\n info = defaultdict(int)\n\n relation_catalog = getUtility(ICatalog)\n for token in relation_catalog.findRelationTokens():\n try:\n rel = relation_catalog.resolveRelationToken(token)\n except ObjectMissingError:\n logger.info('Token {} has no object.'.format(token))\n continue\n\n if rel.from_object and rel.to_object:\n try:\n results.append({\n 'from_uuid': rel.from_object.UID(),\n 'to_uuid': rel.to_object.UID(),\n 'from_attribute': rel.from_attribute,\n })\n info[rel.from_attribute] += 1\n except AttributeError as ex:\n logger.info(f'Something went wrong while storing {rel}: \\n {ex}')\n else:\n logger.info(f'Dropping relation {rel.from_attribute} from {rel.from_object} to {rel.to_object}')\n msg = ''\n for key, value in info.items():\n msg += f'{key}: {value}\\n'\n logger.info(f'\\nFound the following relations:\\n{msg}')\n return results\n\n\ndef store_relations(context=None):\n \"\"\"Store all relations in a annotation on the portal.\n \"\"\"\n all_relations = get_all_relations()\n portal = getSite()\n IAnnotations(portal)[RELATIONS_KEY] = all_relations\n logger.info(f'Stored {len(all_relations)} relations on the portal')\n\n\ndef purge_relations(context=None):\n \"\"\"Removes all entries form zc.relation catalog.\n RelationValues that were set as attribute on content are still there!\n These are removed/overwritten when restoring the relations.\n \"\"\"\n rel_catalog = getUtility(ICatalog)\n rel_catalog.clear()\n logger.info('Purged zc.relation catalog')\n\n\ndef restore_relations(context=None, all_relations=None):\n \"\"\"Restore relations from a annotation on the portal.\n \"\"\"\n\n portal = getSite()\n if all_relations is None:\n all_relations = IAnnotations(portal)[RELATIONS_KEY]\n logger.info(f'Loaded {len(all_relations)} relations to restore')\n update_linkintegrity = set()\n modified_items = set()\n modified_relation_lists = defaultdict(list)\n\n # remove duplicates but keep original order\n unique_relations = []\n seen = set()\n seen_add = seen.add\n for rel in all_relations:\n hashable = tuple(rel.items())\n if hashable not in seen:\n unique_relations.append(rel)\n seen_add(hashable)\n else:\n logger.info(f'Dropping duplicate: {hashable}')\n\n if len(unique_relations) < len(all_relations):\n logger.info(f'Dropping {len(all_relations) - len(unique_relations)} duplicates')\n all_relations = unique_relations\n\n intids = getUtility(IIntIds)\n for index, item in enumerate(all_relations, start=1):\n if not index % 500:\n logger.info(f'Restored {index} of {len(all_relations)} relations...')\n\n try:\n source_obj = uuidToObject(item['from_uuid'])\n except KeyError:\n # brain exists but no object\n source_obj = None\n try:\n target_obj = uuidToObject(item['to_uuid'])\n except KeyError:\n # brain exists but no object\n target_obj = None\n\n if not source_obj:\n logger.info(f'{item[\"from_uuid\"]} is missing')\n continue\n\n if not target_obj:\n logger.info(f'{item[\"to_uuid\"]} is missing')\n continue\n\n if not IDexterityContent.providedBy(source_obj):\n logger.info(f'{source_obj} is no dexterity content')\n continue\n\n if not IDexterityContent.providedBy(target_obj):\n logger.info(f'{target_obj} is no dexterity content')\n continue\n\n from_attribute = item['from_attribute']\n to_id = intids.getId(target_obj)\n\n if from_attribute == referencedRelationship:\n # Ignore linkintegrity for now. We'll rebuilt it at the end!\n update_linkintegrity.add(item['from_uuid'])\n continue\n\n if HAS_ITERATE and from_attribute == ITERATE_RELATION_NAME:\n # Iterate relations are not set as values of fields\n relation = StagingRelationValue(to_id)\n event._setRelation(source_obj, ITERATE_RELATION_NAME, relation)\n continue\n\n field_and_schema = get_field_and_schema_for_fieldname(from_attribute, source_obj.portal_type)\n if field_and_schema is None:\n # the from_attribute is no field\n logger.info(f'No field. Setting relation: {item}')\n event._setRelation(source_obj, from_attribute, RelationValue(to_id))\n continue\n\n field, schema = field_and_schema\n relation = RelationValue(to_id)\n\n if isinstance(field, RelationList):\n logger.info(f'Add relation to relationslist {from_attribute} from {source_obj.absolute_url()} to {target_obj.absolute_url()}')\n if item['from_uuid'] in modified_relation_lists.get(from_attribute, []):\n # Do not purge relations\n existing_relations = getattr(source_obj, from_attribute, [])\n else:\n # First touch. Make sure we purge!\n existing_relations = []\n existing_relations.append(relation)\n setattr(source_obj, from_attribute, existing_relations)\n modified_items.add(item['from_uuid'])\n modified_relation_lists[from_attribute].append(item['from_uuid'])\n continue\n\n elif isinstance(field, (Relation, RelationChoice)):\n logger.info(f'Add relation {from_attribute} from {source_obj.absolute_url()} to {target_obj.absolute_url()}')\n setattr(source_obj, from_attribute, relation)\n modified_items.add(item['from_uuid'])\n continue\n\n else:\n # we should never end up here!\n logger.warn(f'Unexpected relation {from_attribute} from {source_obj.absolute_url()} to {target_obj.absolute_url()}')\n\n update_linkintegrity = set(update_linkintegrity)\n logger.info(f'Updating linkintegrity for {len(update_linkintegrity)} items')\n for uuid in sorted(update_linkintegrity):\n modifiedContent(uuidToObject(uuid), None)\n logger.info(f'Updating relations for {len(modified_items)} items')\n for uuid in sorted(modified_items):\n obj = uuidToObject(uuid)\n # updateRelations from z3c.relationfield does not properly update relations in behaviors\n # that are registered with a marker-interface.\n # update_behavior_relations (from plone.app.relationfield) does that but does not update\n # those in the main schema. Duh!\n updateRelations(obj, None)\n update_behavior_relations(obj, None)\n\n # purge annotation from portal if they exist\n if RELATIONS_KEY in IAnnotations(portal):\n del IAnnotations(portal)[RELATIONS_KEY]\n logger.info('Done!')\n\n\ndef get_intid(obj):\n \"\"\"Intid from intid-catalog\"\"\"\n intids = queryUtility(IIntIds)\n if intids is None:\n return\n # check that the object has an intid, otherwise there's nothing to be done\n try:\n return intids.getId(obj)\n except KeyError: # noqa\n # The object has not been added to the ZODB yet\n return\n\n\ndef get_field_and_schema_for_fieldname(field_id, portal_type):\n \"\"\"Get field and its schema from a portal_type.\n \"\"\"\n # Turn form.widgets.IDublinCore.title into title\n field_id = field_id.split('.')[-1]\n for schema in iterSchemataForType(portal_type):\n field = schema.get(field_id, None)\n if field is not None:\n return (field, schema)\n\n\ndef cleanup_intids(context=None):\n intids = getUtility(IIntIds)\n all_refs = [f'{i.object.__class__.__module__}.{i.object.__class__.__name__}'\n for i in intids.refs.values()]\n logger.info(Counter(all_refs))\n\n count = 0\n refs = [i for i in intids.refs.values() if isinstance(i.object, RelationValue)]\n for ref in refs:\n intids.unregister(ref)\n count += 1\n logger.info(f'Removed all {count} RelationValues from IntId-tool')\n\n count = 0\n for ref in intids.refs.values():\n if 'broken' in repr(ref.object):\n intids.unregister(ref)\n logger.info(f'Removed {count} broken refs from IntId-tool')\n all_refs = ['{i.object.__class__.__module__}.{i.object.__class__.__name__}'\n for i in intids.refs.values()]\n logger.info(Counter(all_refs))\n\n\ndef flush_intids():\n \"\"\" Flush all intids\n \"\"\"\n intids = getUtility(IIntIds)\n intids.ids = intids.family.OI.BTree()\n intids.refs = intids.family.IO.BTree()\n\n\ndef rebuild_intids():\n \"\"\" Create new intids\n \"\"\"\n def add_to_intids(obj, path):\n if IContentish.providedBy(obj):\n logger.info(f'Added {obj} at {path} to intid')\n addIntIdSubscriber(obj, None)\n portal = getSite()\n portal.ZopeFindAndApply(portal,\n search_sub=True,\n apply_func=add_to_intids)\n", "path": "Products/CMFPlone/relationhelper.py"}]} | 3,703 | 393 |
gh_patches_debug_43039 | rasdani/github-patches | git_diff | streamlink__streamlink-249 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Crunchyroll can't find 1080p streams
The current plugin seems to only find streams up to 720p.
However I tested the old plugin and it seems to be working again I tested the links I used in #70 and a few more but couldn't reproduce the issue with the old plugin.
More testing may be needed but it's more than likely safe to revert back.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/crunchyroll.py`
Content:
```
1 import random
2 import re
3 import string
4 import datetime
5
6 from streamlink.plugin import Plugin, PluginError, PluginOptions
7 from streamlink.plugin.api import http, validate
8 from streamlink.stream import HLSStream
9
10 API_URL = "https://api.crunchyroll.com/{0}.0.json"
11 API_DEFAULT_LOCALE = "en_US"
12 API_USER_AGENT = "Mozilla/5.0 (iPhone; iPhone OS 8.3.0; {})"
13 API_HEADERS = {
14 "Host": "api.crunchyroll.com",
15 "Accept-Encoding": "gzip, deflate",
16 "Accept": "*/*",
17 "Content-Type": "application/x-www-form-urlencoded"
18 }
19 API_VERSION = "2313.8"
20 API_ACCESS_TOKEN = "QWjz212GspMHH9h"
21 API_DEVICE_TYPE = "com.crunchyroll.iphone"
22 STREAM_WEIGHTS = {
23 "low": 240,
24 "mid": 420,
25 "high": 720,
26 "ultra": 1080,
27 }
28
29
30 def parse_timestamp(ts):
31 """Takes ISO 8601 format(string) and converts into a utc datetime(naive)"""
32 return (
33 datetime.datetime.strptime(ts[:-7], "%Y-%m-%dT%H:%M:%S") +
34 datetime.timedelta(hours=int(ts[-5:-3]), minutes=int(ts[-2:])) *
35 int(ts[-6:-5] + "1")
36 )
37
38
39 _url_re = re.compile("""
40 http(s)?://(\w+\.)?crunchyroll\.
41 (?:
42 com|de|es|fr|co.jp
43 )
44 /[^/&?]+
45 /[^/&?]+-(?P<media_id>\d+)
46 """, re.VERBOSE)
47
48 _api_schema = validate.Schema({
49 "error": bool,
50 validate.optional("code"): validate.text,
51 validate.optional("message"): validate.text,
52 validate.optional("data"): object,
53 })
54 _media_schema = validate.Schema(
55 {
56 "stream_data": validate.any(
57 None,
58 {
59 "streams": validate.all(
60 [{
61 "quality": validate.any(validate.text, None),
62 "url": validate.url(
63 scheme="http",
64 path=validate.endswith(".m3u8")
65 )
66 }]
67 )
68 }
69 )
70 },
71 validate.get("stream_data")
72 )
73 _login_schema = validate.Schema({
74 "auth": validate.text,
75 "expires": validate.all(
76 validate.text,
77 validate.transform(parse_timestamp)
78 ),
79 "user": {
80 "username": validate.text
81 }
82 })
83 _session_schema = validate.Schema(
84 {
85 "session_id": validate.text
86 },
87 validate.get("session_id")
88 )
89
90
91 class CrunchyrollAPIError(Exception):
92 """Exception thrown by the Crunchyroll API when an error occurs"""
93 def __init__(self, msg, code):
94 Exception.__init__(self, msg)
95 self.msg = msg
96 self.code = code
97
98
99 class CrunchyrollAPI(object):
100 def __init__(self, session_id=None, auth=None, locale=API_DEFAULT_LOCALE):
101 """Abstract the API to access to Crunchyroll data.
102
103 Can take saved credentials to use on it's calls to the API.
104 """
105 self.session_id = session_id
106 self.auth = auth
107 self.locale = locale
108
109 def _api_call(self, entrypoint, params, schema=None):
110 """Makes a call against the api.
111
112 :param entrypoint: API method to call.
113 :param params: parameters to include in the request data.
114 :param schema: schema to use to validate the data
115 """
116 url = API_URL.format(entrypoint)
117
118 # Default params
119 params = dict(params)
120 params.update({
121 "version": API_VERSION,
122 "locale": self.locale.replace('_', ''),
123 })
124
125 if self.session_id:
126 params["session_id"] = self.session_id
127
128 # Headers
129 headers = dict(API_HEADERS)
130 headers['User-Agent'] = API_USER_AGENT.format(self.locale)
131
132 # The certificate used by Crunchyroll cannot be verified in some environments.
133 res = http.get(url, params=params, headers=headers, verify=False)
134 json_res = http.json(res, schema=_api_schema)
135
136 if json_res["error"]:
137 err_msg = json_res.get("message", "Unknown error")
138 err_code = json_res.get("code", "unknown_error")
139 raise CrunchyrollAPIError(err_msg, err_code)
140
141 data = json_res.get("data")
142 if schema:
143 data = schema.validate(data, name="API response")
144
145 return data
146
147 def start_session(self, device_id, **kwargs):
148 """Starts a session against Crunchyroll's server.
149
150 Is recommended that you call this method before making any other calls
151 to make sure you have a valid session against the server.
152 """
153 params = {
154 "device_id": device_id,
155 "device_type": API_DEVICE_TYPE,
156 "access_token": API_ACCESS_TOKEN,
157 }
158
159 if self.auth:
160 params["auth"] = self.auth
161
162 return self._api_call("start_session", params, **kwargs)
163
164 def login(self, username, password, **kwargs):
165 """Authenticates the session to be able to access restricted data from
166 the server (e.g. premium restricted videos).
167 """
168 params = {
169 "account": username,
170 "password": password
171 }
172
173 return self._api_call("login", params, **kwargs)
174
175 def get_info(self, media_id, fields=None, **kwargs):
176 """Returns the data for a certain media item.
177
178 :param media_id: id that identifies the media item to be accessed.
179 :param fields: list of the media"s field to be returned. By default the
180 API returns some fields, but others are not returned unless they are
181 explicity asked for. I have no real documentation on the fields, but
182 they all seem to start with the "media." prefix (e.g. media.name,
183 media.stream_data).
184 """
185 params = {
186 "media_id": media_id
187 }
188
189 if fields:
190 params["fields"] = ",".join(fields)
191
192 return self._api_call("info", params, **kwargs)
193
194
195 class Crunchyroll(Plugin):
196 options = PluginOptions({
197 "username": None,
198 "password": None,
199 "purge_credentials": None,
200 "locale": API_DEFAULT_LOCALE
201 })
202
203 @classmethod
204 def can_handle_url(self, url):
205 return _url_re.match(url)
206
207 @classmethod
208 def stream_weight(cls, key):
209 weight = STREAM_WEIGHTS.get(key)
210 if weight:
211 return weight, "crunchyroll"
212
213 return Plugin.stream_weight(key)
214
215 def _get_streams(self):
216 api = self._create_api()
217 match = _url_re.match(self.url)
218 media_id = int(match.group("media_id"))
219
220 try:
221 info = api.get_info(media_id, fields=["media.stream_data"],
222 schema=_media_schema)
223 except CrunchyrollAPIError as err:
224 raise PluginError(u"Media lookup error: {0}".format(err.msg))
225
226 if not info:
227 return
228
229 # The adaptive quality stream contains a superset of all the other streams listeed
230 has_adaptive = any([s[u"quality"] == u"adaptive" for s in info[u"streams"]])
231 if has_adaptive:
232 self.logger.debug(u"Loading streams from adaptive playlist")
233 for stream in filter(lambda x: x[u"quality"] == u"adaptive", info[u"streams"]):
234 return HLSStream.parse_variant_playlist(self.session, stream["url"])
235 else:
236 streams = {}
237 # If there is no adaptive quality stream then parse each individual result
238 for stream in info[u"streams"]:
239 # the video_encode_id indicates that the stream is not a variant playlist
240 if u"video_encode_id" in stream:
241 streams[stream[u"quality"]] = HLSStream(self.session, stream[u"url"])
242 else:
243 # otherwise the stream url is actually a list of stream qualities
244 streams.update(HLSStream.parse_variant_playlist(self.session, stream[u"url"]))
245
246 return streams
247
248 def _get_device_id(self):
249 """Returns the saved device id or creates a new one and saves it."""
250 device_id = self.cache.get("device_id")
251
252 if not device_id:
253 # Create a random device id and cache it for a year
254 char_set = string.ascii_letters + string.digits
255 device_id = "".join(random.sample(char_set, 32))
256 self.cache.set("device_id", device_id, 365 * 24 * 60 * 60)
257
258 return device_id
259
260 def _create_api(self):
261 """Creates a new CrunchyrollAPI object, initiates it's session and
262 tries to authenticate it either by using saved credentials or the
263 user's username and password.
264 """
265 if self.options.get("purge_credentials"):
266 self.cache.set("session_id", None, 0)
267 self.cache.set("auth", None, 0)
268
269 current_time = datetime.datetime.utcnow()
270 device_id = self._get_device_id()
271 locale = self.options.get("locale")
272 api = CrunchyrollAPI(
273 self.cache.get("session_id"), self.cache.get("auth"), locale
274 )
275
276 self.logger.debug("Creating session")
277 try:
278 api.session_id = api.start_session(device_id, schema=_session_schema)
279 except CrunchyrollAPIError as err:
280 if err.code == "bad_session":
281 self.logger.debug("Current session has expired, creating a new one")
282 api = CrunchyrollAPI(locale=locale)
283 api.session_id = api.start_session(device_id, schema=_session_schema)
284 else:
285 raise err
286
287 # Save session and hope it lasts for a few hours
288 self.cache.set("session_id", api.session_id, 4 * 60 * 60)
289 self.logger.debug("Session created")
290
291 if api.auth:
292 self.logger.debug("Using saved credentials")
293 elif self.options.get("username"):
294 try:
295 self.logger.info("Attempting to login using username and password")
296 login = api.login(
297 self.options.get("username"),
298 self.options.get("password"),
299 schema=_login_schema
300 )
301 api.auth = login["auth"]
302
303 self.logger.info("Successfully logged in as '{0}'",
304 login["user"]["username"])
305
306 expires = (login["expires"] - current_time).total_seconds()
307 self.cache.set("auth", login["auth"], expires)
308 except CrunchyrollAPIError as err:
309 raise PluginError(u"Authentication error: {0}".format(err.msg))
310 else:
311 self.logger.warning(
312 "No authentication provided, you won't be able to access "
313 "premium restricted content"
314 )
315
316 return api
317
318 __plugin__ = Crunchyroll
319
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/streamlink/plugins/crunchyroll.py b/src/streamlink/plugins/crunchyroll.py
--- a/src/streamlink/plugins/crunchyroll.py
+++ b/src/streamlink/plugins/crunchyroll.py
@@ -25,6 +25,11 @@
"high": 720,
"ultra": 1080,
}
+STREAM_NAMES = {
+ "120k": "low",
+ "328k": "mid",
+ "864k": "high"
+}
def parse_timestamp(ts):
@@ -62,7 +67,8 @@
"url": validate.url(
scheme="http",
path=validate.endswith(".m3u8")
- )
+ ),
+ validate.optional("video_encode_id"): validate.text
}]
)
}
@@ -77,7 +83,8 @@
validate.transform(parse_timestamp)
),
"user": {
- "username": validate.text
+ "username": validate.any(validate.text, None),
+ "email": validate.text
}
})
_session_schema = validate.Schema(
@@ -226,24 +233,32 @@
if not info:
return
- # The adaptive quality stream contains a superset of all the other streams listeed
+ streams = {}
+
+ # The adaptive quality stream sometimes a subset of all the other streams listed, ultra is no included
has_adaptive = any([s[u"quality"] == u"adaptive" for s in info[u"streams"]])
if has_adaptive:
self.logger.debug(u"Loading streams from adaptive playlist")
for stream in filter(lambda x: x[u"quality"] == u"adaptive", info[u"streams"]):
- return HLSStream.parse_variant_playlist(self.session, stream["url"])
- else:
- streams = {}
- # If there is no adaptive quality stream then parse each individual result
- for stream in info[u"streams"]:
+ for q, s in HLSStream.parse_variant_playlist(self.session, stream[u"url"]).items():
+ # rename the bitrates to low, mid, or high. ultra doesn't seem to appear in the adaptive streams
+ name = STREAM_NAMES.get(q, q)
+ streams[name] = s
+
+ # If there is no adaptive quality stream then parse each individual result
+ for stream in info[u"streams"]:
+ if stream[u"quality"] != u"adaptive":
# the video_encode_id indicates that the stream is not a variant playlist
if u"video_encode_id" in stream:
streams[stream[u"quality"]] = HLSStream(self.session, stream[u"url"])
else:
# otherwise the stream url is actually a list of stream qualities
- streams.update(HLSStream.parse_variant_playlist(self.session, stream[u"url"]))
+ for q, s in HLSStream.parse_variant_playlist(self.session, stream[u"url"]).items():
+ # rename the bitrates to low, mid, or high. ultra doesn't seem to appear in the adaptive streams
+ name = STREAM_NAMES.get(q, q)
+ streams[name] = s
- return streams
+ return streams
def _get_device_id(self):
"""Returns the saved device id or creates a new one and saves it."""
@@ -301,7 +316,7 @@
api.auth = login["auth"]
self.logger.info("Successfully logged in as '{0}'",
- login["user"]["username"])
+ login["user"]["username"] or login["user"]["email"])
expires = (login["expires"] - current_time).total_seconds()
self.cache.set("auth", login["auth"], expires)
| {"golden_diff": "diff --git a/src/streamlink/plugins/crunchyroll.py b/src/streamlink/plugins/crunchyroll.py\n--- a/src/streamlink/plugins/crunchyroll.py\n+++ b/src/streamlink/plugins/crunchyroll.py\n@@ -25,6 +25,11 @@\n \"high\": 720,\n \"ultra\": 1080,\n }\n+STREAM_NAMES = {\n+ \"120k\": \"low\",\n+ \"328k\": \"mid\",\n+ \"864k\": \"high\"\n+}\n \n \n def parse_timestamp(ts):\n@@ -62,7 +67,8 @@\n \"url\": validate.url(\n scheme=\"http\",\n path=validate.endswith(\".m3u8\")\n- )\n+ ),\n+ validate.optional(\"video_encode_id\"): validate.text\n }]\n )\n }\n@@ -77,7 +83,8 @@\n validate.transform(parse_timestamp)\n ),\n \"user\": {\n- \"username\": validate.text\n+ \"username\": validate.any(validate.text, None),\n+ \"email\": validate.text\n }\n })\n _session_schema = validate.Schema(\n@@ -226,24 +233,32 @@\n if not info:\n return\n \n- # The adaptive quality stream contains a superset of all the other streams listeed\n+ streams = {}\n+\n+ # The adaptive quality stream sometimes a subset of all the other streams listed, ultra is no included\n has_adaptive = any([s[u\"quality\"] == u\"adaptive\" for s in info[u\"streams\"]])\n if has_adaptive:\n self.logger.debug(u\"Loading streams from adaptive playlist\")\n for stream in filter(lambda x: x[u\"quality\"] == u\"adaptive\", info[u\"streams\"]):\n- return HLSStream.parse_variant_playlist(self.session, stream[\"url\"])\n- else:\n- streams = {}\n- # If there is no adaptive quality stream then parse each individual result\n- for stream in info[u\"streams\"]:\n+ for q, s in HLSStream.parse_variant_playlist(self.session, stream[u\"url\"]).items():\n+ # rename the bitrates to low, mid, or high. ultra doesn't seem to appear in the adaptive streams\n+ name = STREAM_NAMES.get(q, q)\n+ streams[name] = s\n+\n+ # If there is no adaptive quality stream then parse each individual result\n+ for stream in info[u\"streams\"]:\n+ if stream[u\"quality\"] != u\"adaptive\":\n # the video_encode_id indicates that the stream is not a variant playlist\n if u\"video_encode_id\" in stream:\n streams[stream[u\"quality\"]] = HLSStream(self.session, stream[u\"url\"])\n else:\n # otherwise the stream url is actually a list of stream qualities\n- streams.update(HLSStream.parse_variant_playlist(self.session, stream[u\"url\"]))\n+ for q, s in HLSStream.parse_variant_playlist(self.session, stream[u\"url\"]).items():\n+ # rename the bitrates to low, mid, or high. ultra doesn't seem to appear in the adaptive streams\n+ name = STREAM_NAMES.get(q, q)\n+ streams[name] = s\n \n- return streams\n+ return streams\n \n def _get_device_id(self):\n \"\"\"Returns the saved device id or creates a new one and saves it.\"\"\"\n@@ -301,7 +316,7 @@\n api.auth = login[\"auth\"]\n \n self.logger.info(\"Successfully logged in as '{0}'\",\n- login[\"user\"][\"username\"])\n+ login[\"user\"][\"username\"] or login[\"user\"][\"email\"])\n \n expires = (login[\"expires\"] - current_time).total_seconds()\n self.cache.set(\"auth\", login[\"auth\"], expires)\n", "issue": "Crunchyroll can't find 1080p streams\nThe current plugin seems to only find streams up to 720p.\r\nHowever I tested the old plugin and it seems to be working again I tested the links I used in #70 and a few more but couldn't reproduce the issue with the old plugin.\r\nMore testing may be needed but it's more than likely safe to revert back.\n", "before_files": [{"content": "import random\nimport re\nimport string\nimport datetime\n\nfrom streamlink.plugin import Plugin, PluginError, PluginOptions\nfrom streamlink.plugin.api import http, validate\nfrom streamlink.stream import HLSStream\n\nAPI_URL = \"https://api.crunchyroll.com/{0}.0.json\"\nAPI_DEFAULT_LOCALE = \"en_US\"\nAPI_USER_AGENT = \"Mozilla/5.0 (iPhone; iPhone OS 8.3.0; {})\"\nAPI_HEADERS = {\n \"Host\": \"api.crunchyroll.com\",\n \"Accept-Encoding\": \"gzip, deflate\",\n \"Accept\": \"*/*\",\n \"Content-Type\": \"application/x-www-form-urlencoded\"\n}\nAPI_VERSION = \"2313.8\"\nAPI_ACCESS_TOKEN = \"QWjz212GspMHH9h\"\nAPI_DEVICE_TYPE = \"com.crunchyroll.iphone\"\nSTREAM_WEIGHTS = {\n \"low\": 240,\n \"mid\": 420,\n \"high\": 720,\n \"ultra\": 1080,\n}\n\n\ndef parse_timestamp(ts):\n \"\"\"Takes ISO 8601 format(string) and converts into a utc datetime(naive)\"\"\"\n return (\n datetime.datetime.strptime(ts[:-7], \"%Y-%m-%dT%H:%M:%S\") +\n datetime.timedelta(hours=int(ts[-5:-3]), minutes=int(ts[-2:])) *\n int(ts[-6:-5] + \"1\")\n )\n\n\n_url_re = re.compile(\"\"\"\n http(s)?://(\\w+\\.)?crunchyroll\\.\n (?:\n com|de|es|fr|co.jp\n )\n /[^/&?]+\n /[^/&?]+-(?P<media_id>\\d+)\n\"\"\", re.VERBOSE)\n\n_api_schema = validate.Schema({\n \"error\": bool,\n validate.optional(\"code\"): validate.text,\n validate.optional(\"message\"): validate.text,\n validate.optional(\"data\"): object,\n})\n_media_schema = validate.Schema(\n {\n \"stream_data\": validate.any(\n None,\n {\n \"streams\": validate.all(\n [{\n \"quality\": validate.any(validate.text, None),\n \"url\": validate.url(\n scheme=\"http\",\n path=validate.endswith(\".m3u8\")\n )\n }]\n )\n }\n )\n },\n validate.get(\"stream_data\")\n)\n_login_schema = validate.Schema({\n \"auth\": validate.text,\n \"expires\": validate.all(\n validate.text,\n validate.transform(parse_timestamp)\n ),\n \"user\": {\n \"username\": validate.text\n }\n})\n_session_schema = validate.Schema(\n {\n \"session_id\": validate.text\n },\n validate.get(\"session_id\")\n)\n\n\nclass CrunchyrollAPIError(Exception):\n \"\"\"Exception thrown by the Crunchyroll API when an error occurs\"\"\"\n def __init__(self, msg, code):\n Exception.__init__(self, msg)\n self.msg = msg\n self.code = code\n\n\nclass CrunchyrollAPI(object):\n def __init__(self, session_id=None, auth=None, locale=API_DEFAULT_LOCALE):\n \"\"\"Abstract the API to access to Crunchyroll data.\n\n Can take saved credentials to use on it's calls to the API.\n \"\"\"\n self.session_id = session_id\n self.auth = auth\n self.locale = locale\n\n def _api_call(self, entrypoint, params, schema=None):\n \"\"\"Makes a call against the api.\n\n :param entrypoint: API method to call.\n :param params: parameters to include in the request data.\n :param schema: schema to use to validate the data\n \"\"\"\n url = API_URL.format(entrypoint)\n\n # Default params\n params = dict(params)\n params.update({\n \"version\": API_VERSION,\n \"locale\": self.locale.replace('_', ''),\n })\n\n if self.session_id:\n params[\"session_id\"] = self.session_id\n\n # Headers\n headers = dict(API_HEADERS)\n headers['User-Agent'] = API_USER_AGENT.format(self.locale)\n\n # The certificate used by Crunchyroll cannot be verified in some environments.\n res = http.get(url, params=params, headers=headers, verify=False)\n json_res = http.json(res, schema=_api_schema)\n\n if json_res[\"error\"]:\n err_msg = json_res.get(\"message\", \"Unknown error\")\n err_code = json_res.get(\"code\", \"unknown_error\")\n raise CrunchyrollAPIError(err_msg, err_code)\n\n data = json_res.get(\"data\")\n if schema:\n data = schema.validate(data, name=\"API response\")\n\n return data\n\n def start_session(self, device_id, **kwargs):\n \"\"\"Starts a session against Crunchyroll's server.\n\n Is recommended that you call this method before making any other calls\n to make sure you have a valid session against the server.\n \"\"\"\n params = {\n \"device_id\": device_id,\n \"device_type\": API_DEVICE_TYPE,\n \"access_token\": API_ACCESS_TOKEN,\n }\n\n if self.auth:\n params[\"auth\"] = self.auth\n\n return self._api_call(\"start_session\", params, **kwargs)\n\n def login(self, username, password, **kwargs):\n \"\"\"Authenticates the session to be able to access restricted data from\n the server (e.g. premium restricted videos).\n \"\"\"\n params = {\n \"account\": username,\n \"password\": password\n }\n\n return self._api_call(\"login\", params, **kwargs)\n\n def get_info(self, media_id, fields=None, **kwargs):\n \"\"\"Returns the data for a certain media item.\n\n :param media_id: id that identifies the media item to be accessed.\n :param fields: list of the media\"s field to be returned. By default the\n API returns some fields, but others are not returned unless they are\n explicity asked for. I have no real documentation on the fields, but\n they all seem to start with the \"media.\" prefix (e.g. media.name,\n media.stream_data).\n \"\"\"\n params = {\n \"media_id\": media_id\n }\n\n if fields:\n params[\"fields\"] = \",\".join(fields)\n\n return self._api_call(\"info\", params, **kwargs)\n\n\nclass Crunchyroll(Plugin):\n options = PluginOptions({\n \"username\": None,\n \"password\": None,\n \"purge_credentials\": None,\n \"locale\": API_DEFAULT_LOCALE\n })\n\n @classmethod\n def can_handle_url(self, url):\n return _url_re.match(url)\n\n @classmethod\n def stream_weight(cls, key):\n weight = STREAM_WEIGHTS.get(key)\n if weight:\n return weight, \"crunchyroll\"\n\n return Plugin.stream_weight(key)\n\n def _get_streams(self):\n api = self._create_api()\n match = _url_re.match(self.url)\n media_id = int(match.group(\"media_id\"))\n\n try:\n info = api.get_info(media_id, fields=[\"media.stream_data\"],\n schema=_media_schema)\n except CrunchyrollAPIError as err:\n raise PluginError(u\"Media lookup error: {0}\".format(err.msg))\n\n if not info:\n return\n\n # The adaptive quality stream contains a superset of all the other streams listeed\n has_adaptive = any([s[u\"quality\"] == u\"adaptive\" for s in info[u\"streams\"]])\n if has_adaptive:\n self.logger.debug(u\"Loading streams from adaptive playlist\")\n for stream in filter(lambda x: x[u\"quality\"] == u\"adaptive\", info[u\"streams\"]):\n return HLSStream.parse_variant_playlist(self.session, stream[\"url\"])\n else:\n streams = {}\n # If there is no adaptive quality stream then parse each individual result\n for stream in info[u\"streams\"]:\n # the video_encode_id indicates that the stream is not a variant playlist\n if u\"video_encode_id\" in stream:\n streams[stream[u\"quality\"]] = HLSStream(self.session, stream[u\"url\"])\n else:\n # otherwise the stream url is actually a list of stream qualities\n streams.update(HLSStream.parse_variant_playlist(self.session, stream[u\"url\"]))\n\n return streams\n\n def _get_device_id(self):\n \"\"\"Returns the saved device id or creates a new one and saves it.\"\"\"\n device_id = self.cache.get(\"device_id\")\n\n if not device_id:\n # Create a random device id and cache it for a year\n char_set = string.ascii_letters + string.digits\n device_id = \"\".join(random.sample(char_set, 32))\n self.cache.set(\"device_id\", device_id, 365 * 24 * 60 * 60)\n\n return device_id\n\n def _create_api(self):\n \"\"\"Creates a new CrunchyrollAPI object, initiates it's session and\n tries to authenticate it either by using saved credentials or the\n user's username and password.\n \"\"\"\n if self.options.get(\"purge_credentials\"):\n self.cache.set(\"session_id\", None, 0)\n self.cache.set(\"auth\", None, 0)\n\n current_time = datetime.datetime.utcnow()\n device_id = self._get_device_id()\n locale = self.options.get(\"locale\")\n api = CrunchyrollAPI(\n self.cache.get(\"session_id\"), self.cache.get(\"auth\"), locale\n )\n\n self.logger.debug(\"Creating session\")\n try:\n api.session_id = api.start_session(device_id, schema=_session_schema)\n except CrunchyrollAPIError as err:\n if err.code == \"bad_session\":\n self.logger.debug(\"Current session has expired, creating a new one\")\n api = CrunchyrollAPI(locale=locale)\n api.session_id = api.start_session(device_id, schema=_session_schema)\n else:\n raise err\n\n # Save session and hope it lasts for a few hours\n self.cache.set(\"session_id\", api.session_id, 4 * 60 * 60)\n self.logger.debug(\"Session created\")\n\n if api.auth:\n self.logger.debug(\"Using saved credentials\")\n elif self.options.get(\"username\"):\n try:\n self.logger.info(\"Attempting to login using username and password\")\n login = api.login(\n self.options.get(\"username\"),\n self.options.get(\"password\"),\n schema=_login_schema\n )\n api.auth = login[\"auth\"]\n\n self.logger.info(\"Successfully logged in as '{0}'\",\n login[\"user\"][\"username\"])\n\n expires = (login[\"expires\"] - current_time).total_seconds()\n self.cache.set(\"auth\", login[\"auth\"], expires)\n except CrunchyrollAPIError as err:\n raise PluginError(u\"Authentication error: {0}\".format(err.msg))\n else:\n self.logger.warning(\n \"No authentication provided, you won't be able to access \"\n \"premium restricted content\"\n )\n\n return api\n\n__plugin__ = Crunchyroll\n", "path": "src/streamlink/plugins/crunchyroll.py"}], "after_files": [{"content": "import random\nimport re\nimport string\nimport datetime\n\nfrom streamlink.plugin import Plugin, PluginError, PluginOptions\nfrom streamlink.plugin.api import http, validate\nfrom streamlink.stream import HLSStream\n\nAPI_URL = \"https://api.crunchyroll.com/{0}.0.json\"\nAPI_DEFAULT_LOCALE = \"en_US\"\nAPI_USER_AGENT = \"Mozilla/5.0 (iPhone; iPhone OS 8.3.0; {})\"\nAPI_HEADERS = {\n \"Host\": \"api.crunchyroll.com\",\n \"Accept-Encoding\": \"gzip, deflate\",\n \"Accept\": \"*/*\",\n \"Content-Type\": \"application/x-www-form-urlencoded\"\n}\nAPI_VERSION = \"2313.8\"\nAPI_ACCESS_TOKEN = \"QWjz212GspMHH9h\"\nAPI_DEVICE_TYPE = \"com.crunchyroll.iphone\"\nSTREAM_WEIGHTS = {\n \"low\": 240,\n \"mid\": 420,\n \"high\": 720,\n \"ultra\": 1080,\n}\nSTREAM_NAMES = {\n \"120k\": \"low\",\n \"328k\": \"mid\",\n \"864k\": \"high\"\n}\n\n\ndef parse_timestamp(ts):\n \"\"\"Takes ISO 8601 format(string) and converts into a utc datetime(naive)\"\"\"\n return (\n datetime.datetime.strptime(ts[:-7], \"%Y-%m-%dT%H:%M:%S\") +\n datetime.timedelta(hours=int(ts[-5:-3]), minutes=int(ts[-2:])) *\n int(ts[-6:-5] + \"1\")\n )\n\n\n_url_re = re.compile(\"\"\"\n http(s)?://(\\w+\\.)?crunchyroll\\.\n (?:\n com|de|es|fr|co.jp\n )\n /[^/&?]+\n /[^/&?]+-(?P<media_id>\\d+)\n\"\"\", re.VERBOSE)\n\n_api_schema = validate.Schema({\n \"error\": bool,\n validate.optional(\"code\"): validate.text,\n validate.optional(\"message\"): validate.text,\n validate.optional(\"data\"): object,\n})\n_media_schema = validate.Schema(\n {\n \"stream_data\": validate.any(\n None,\n {\n \"streams\": validate.all(\n [{\n \"quality\": validate.any(validate.text, None),\n \"url\": validate.url(\n scheme=\"http\",\n path=validate.endswith(\".m3u8\")\n ),\n validate.optional(\"video_encode_id\"): validate.text\n }]\n )\n }\n )\n },\n validate.get(\"stream_data\")\n)\n_login_schema = validate.Schema({\n \"auth\": validate.text,\n \"expires\": validate.all(\n validate.text,\n validate.transform(parse_timestamp)\n ),\n \"user\": {\n \"username\": validate.any(validate.text, None),\n \"email\": validate.text\n }\n})\n_session_schema = validate.Schema(\n {\n \"session_id\": validate.text\n },\n validate.get(\"session_id\")\n)\n\n\nclass CrunchyrollAPIError(Exception):\n \"\"\"Exception thrown by the Crunchyroll API when an error occurs\"\"\"\n def __init__(self, msg, code):\n Exception.__init__(self, msg)\n self.msg = msg\n self.code = code\n\n\nclass CrunchyrollAPI(object):\n def __init__(self, session_id=None, auth=None, locale=API_DEFAULT_LOCALE):\n \"\"\"Abstract the API to access to Crunchyroll data.\n\n Can take saved credentials to use on it's calls to the API.\n \"\"\"\n self.session_id = session_id\n self.auth = auth\n self.locale = locale\n\n def _api_call(self, entrypoint, params, schema=None):\n \"\"\"Makes a call against the api.\n\n :param entrypoint: API method to call.\n :param params: parameters to include in the request data.\n :param schema: schema to use to validate the data\n \"\"\"\n url = API_URL.format(entrypoint)\n\n # Default params\n params = dict(params)\n params.update({\n \"version\": API_VERSION,\n \"locale\": self.locale.replace('_', ''),\n })\n\n if self.session_id:\n params[\"session_id\"] = self.session_id\n\n # Headers\n headers = dict(API_HEADERS)\n headers['User-Agent'] = API_USER_AGENT.format(self.locale)\n\n # The certificate used by Crunchyroll cannot be verified in some environments.\n res = http.get(url, params=params, headers=headers, verify=False)\n json_res = http.json(res, schema=_api_schema)\n\n if json_res[\"error\"]:\n err_msg = json_res.get(\"message\", \"Unknown error\")\n err_code = json_res.get(\"code\", \"unknown_error\")\n raise CrunchyrollAPIError(err_msg, err_code)\n\n data = json_res.get(\"data\")\n if schema:\n data = schema.validate(data, name=\"API response\")\n\n return data\n\n def start_session(self, device_id, **kwargs):\n \"\"\"Starts a session against Crunchyroll's server.\n\n Is recommended that you call this method before making any other calls\n to make sure you have a valid session against the server.\n \"\"\"\n params = {\n \"device_id\": device_id,\n \"device_type\": API_DEVICE_TYPE,\n \"access_token\": API_ACCESS_TOKEN,\n }\n\n if self.auth:\n params[\"auth\"] = self.auth\n\n return self._api_call(\"start_session\", params, **kwargs)\n\n def login(self, username, password, **kwargs):\n \"\"\"Authenticates the session to be able to access restricted data from\n the server (e.g. premium restricted videos).\n \"\"\"\n params = {\n \"account\": username,\n \"password\": password\n }\n\n return self._api_call(\"login\", params, **kwargs)\n\n def get_info(self, media_id, fields=None, **kwargs):\n \"\"\"Returns the data for a certain media item.\n\n :param media_id: id that identifies the media item to be accessed.\n :param fields: list of the media\"s field to be returned. By default the\n API returns some fields, but others are not returned unless they are\n explicity asked for. I have no real documentation on the fields, but\n they all seem to start with the \"media.\" prefix (e.g. media.name,\n media.stream_data).\n \"\"\"\n params = {\n \"media_id\": media_id\n }\n\n if fields:\n params[\"fields\"] = \",\".join(fields)\n\n return self._api_call(\"info\", params, **kwargs)\n\n\nclass Crunchyroll(Plugin):\n options = PluginOptions({\n \"username\": None,\n \"password\": None,\n \"purge_credentials\": None,\n \"locale\": API_DEFAULT_LOCALE\n })\n\n @classmethod\n def can_handle_url(self, url):\n return _url_re.match(url)\n\n @classmethod\n def stream_weight(cls, key):\n weight = STREAM_WEIGHTS.get(key)\n if weight:\n return weight, \"crunchyroll\"\n\n return Plugin.stream_weight(key)\n\n def _get_streams(self):\n api = self._create_api()\n match = _url_re.match(self.url)\n media_id = int(match.group(\"media_id\"))\n\n try:\n info = api.get_info(media_id, fields=[\"media.stream_data\"],\n schema=_media_schema)\n except CrunchyrollAPIError as err:\n raise PluginError(u\"Media lookup error: {0}\".format(err.msg))\n\n if not info:\n return\n\n streams = {}\n\n # The adaptive quality stream sometimes a subset of all the other streams listed, ultra is no included\n has_adaptive = any([s[u\"quality\"] == u\"adaptive\" for s in info[u\"streams\"]])\n if has_adaptive:\n self.logger.debug(u\"Loading streams from adaptive playlist\")\n for stream in filter(lambda x: x[u\"quality\"] == u\"adaptive\", info[u\"streams\"]):\n for q, s in HLSStream.parse_variant_playlist(self.session, stream[u\"url\"]).items():\n # rename the bitrates to low, mid, or high. ultra doesn't seem to appear in the adaptive streams\n name = STREAM_NAMES.get(q, q)\n streams[name] = s\n\n # If there is no adaptive quality stream then parse each individual result\n for stream in info[u\"streams\"]:\n if stream[u\"quality\"] != u\"adaptive\":\n # the video_encode_id indicates that the stream is not a variant playlist\n if u\"video_encode_id\" in stream:\n streams[stream[u\"quality\"]] = HLSStream(self.session, stream[u\"url\"])\n else:\n # otherwise the stream url is actually a list of stream qualities\n for q, s in HLSStream.parse_variant_playlist(self.session, stream[u\"url\"]).items():\n # rename the bitrates to low, mid, or high. ultra doesn't seem to appear in the adaptive streams\n name = STREAM_NAMES.get(q, q)\n streams[name] = s\n\n return streams\n\n def _get_device_id(self):\n \"\"\"Returns the saved device id or creates a new one and saves it.\"\"\"\n device_id = self.cache.get(\"device_id\")\n\n if not device_id:\n # Create a random device id and cache it for a year\n char_set = string.ascii_letters + string.digits\n device_id = \"\".join(random.sample(char_set, 32))\n self.cache.set(\"device_id\", device_id, 365 * 24 * 60 * 60)\n\n return device_id\n\n def _create_api(self):\n \"\"\"Creates a new CrunchyrollAPI object, initiates it's session and\n tries to authenticate it either by using saved credentials or the\n user's username and password.\n \"\"\"\n if self.options.get(\"purge_credentials\"):\n self.cache.set(\"session_id\", None, 0)\n self.cache.set(\"auth\", None, 0)\n\n current_time = datetime.datetime.utcnow()\n device_id = self._get_device_id()\n locale = self.options.get(\"locale\")\n api = CrunchyrollAPI(\n self.cache.get(\"session_id\"), self.cache.get(\"auth\"), locale\n )\n\n self.logger.debug(\"Creating session\")\n try:\n api.session_id = api.start_session(device_id, schema=_session_schema)\n except CrunchyrollAPIError as err:\n if err.code == \"bad_session\":\n self.logger.debug(\"Current session has expired, creating a new one\")\n api = CrunchyrollAPI(locale=locale)\n api.session_id = api.start_session(device_id, schema=_session_schema)\n else:\n raise err\n\n # Save session and hope it lasts for a few hours\n self.cache.set(\"session_id\", api.session_id, 4 * 60 * 60)\n self.logger.debug(\"Session created\")\n\n if api.auth:\n self.logger.debug(\"Using saved credentials\")\n elif self.options.get(\"username\"):\n try:\n self.logger.info(\"Attempting to login using username and password\")\n login = api.login(\n self.options.get(\"username\"),\n self.options.get(\"password\"),\n schema=_login_schema\n )\n api.auth = login[\"auth\"]\n\n self.logger.info(\"Successfully logged in as '{0}'\",\n login[\"user\"][\"username\"] or login[\"user\"][\"email\"])\n\n expires = (login[\"expires\"] - current_time).total_seconds()\n self.cache.set(\"auth\", login[\"auth\"], expires)\n except CrunchyrollAPIError as err:\n raise PluginError(u\"Authentication error: {0}\".format(err.msg))\n else:\n self.logger.warning(\n \"No authentication provided, you won't be able to access \"\n \"premium restricted content\"\n )\n\n return api\n\n__plugin__ = Crunchyroll\n", "path": "src/streamlink/plugins/crunchyroll.py"}]} | 3,579 | 816 |
gh_patches_debug_24845 | rasdani/github-patches | git_diff | buildbot__buildbot-6644 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
builtins.AttributeError: instead of intended log message
Hello,
Because I had set up an incorrect url, or an url that was not possible to access due to limited api token access I got this error message:
```
File "/usr/local/lib/python3.10/site-packages/buildbot/changes/github.py", line 142, in _getPulls
f"while loading {result.url}")
builtins.AttributeError: '_Response' object has no attribute 'url'
```
However, looking at the code the error should probably be something more like:
```
"GitHubPullrequestPoller error {error_code} '{error message}' while loading {some_url}")
```
Is the attribute error the intended behaviour? If not then I guess I would do some kind of patch for it (i.e. checking for existing url attribute).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/buildbot/util/httpclientservice.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can)
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 import json as jsonmodule
17 import textwrap
18
19 from twisted.internet import defer
20 from twisted.logger import Logger
21 from twisted.web.client import Agent
22 from twisted.web.client import HTTPConnectionPool
23 from zope.interface import implementer
24
25 from buildbot import config
26 from buildbot.interfaces import IHttpResponse
27 from buildbot.util import service
28 from buildbot.util import toJson
29 from buildbot.util import unicode2bytes
30
31 try:
32 import txrequests
33 except ImportError:
34 txrequests = None
35
36 try:
37 import treq
38 implementer(IHttpResponse)(treq.response._Response)
39
40 except ImportError:
41 treq = None
42
43 log = Logger()
44
45
46 @implementer(IHttpResponse)
47 class TxRequestsResponseWrapper:
48
49 def __init__(self, res):
50 self._res = res
51
52 def content(self):
53 return defer.succeed(self._res.content)
54
55 def json(self):
56 return defer.succeed(self._res.json())
57
58 @property
59 def code(self):
60 return self._res.status_code
61
62 @property
63 def url(self):
64 return self._res.url
65
66
67 class HTTPClientService(service.SharedService):
68 """A SharedService class that can make http requests to remote services.
69
70 I can use either txrequests or treq, depending on what I find installed
71
72 I provide minimal get/post/put/delete API with automatic baseurl joining, and json data encoding
73 that is suitable for use from buildbot services.
74 """
75 TREQ_PROS_AND_CONS = textwrap.dedent("""
76 txrequests is based on requests and is probably a bit more mature, but it requires threads
77 to run, so has more overhead.
78 treq is better integrated in twisted and is more and more feature equivalent
79
80 txrequests is 2.8x slower than treq due to the use of threads.
81
82 http://treq.readthedocs.io/en/latest/#feature-parity-w-requests
83 pip install txrequests
84 or
85 pip install treq
86 """)
87 # Those could be in theory be overridden in master.cfg by using
88 # import buildbot.util.httpclientservice.HTTPClientService.PREFER_TREQ = True
89 # We prefer at the moment keeping it simple
90 PREFER_TREQ = False
91 MAX_THREADS = 5
92
93 def __init__(self, base_url, auth=None, headers=None, verify=None, debug=False,
94 skipEncoding=False):
95 assert not base_url.endswith(
96 "/"), "baseurl should not end with /: " + base_url
97 super().__init__()
98 self._base_url = base_url
99 self._auth = auth
100 self._headers = headers
101 self._pool = None
102 self._session = None
103 self.verify = verify
104 self.debug = debug
105 self.skipEncoding = skipEncoding
106
107 def updateHeaders(self, headers):
108 if self._headers is None:
109 self._headers = {}
110 self._headers.update(headers)
111
112 @staticmethod
113 def checkAvailable(from_module):
114 """Call me at checkConfig time to properly report config error
115 if neither txrequests or treq is installed
116 """
117 if txrequests is None and treq is None:
118 config.error(f"neither txrequests nor treq is installed, but {from_module} is "
119 f"requiring it\n\n{HTTPClientService.TREQ_PROS_AND_CONS}")
120
121 def startService(self):
122 # treq only supports basicauth, so we force txrequests if the auth is
123 # something else
124 if self._auth is not None and not isinstance(self._auth, tuple):
125 self.PREFER_TREQ = False
126 if txrequests is not None and not self.PREFER_TREQ:
127 self._session = txrequests.Session()
128 self._doRequest = self._doTxRequest
129 elif treq is None:
130 raise ImportError("{classname} requires either txrequest or treq install."
131 " Users should call {classname}.checkAvailable() during checkConfig()"
132 " to properly alert the user.".format(
133 classname=self.__class__.__name__))
134 else:
135 self._doRequest = self._doTReq
136 self._pool = HTTPConnectionPool(self.master.reactor)
137 self._pool.maxPersistentPerHost = self.MAX_THREADS
138 self._agent = Agent(self.master.reactor, pool=self._pool)
139 return super().startService()
140
141 @defer.inlineCallbacks
142 def stopService(self):
143 if self._session:
144 yield self._session.close()
145 if self._pool:
146 yield self._pool.closeCachedConnections()
147 yield super().stopService()
148
149 def _prepareRequest(self, ep, kwargs):
150 if ep.startswith('http://') or ep.startswith('https://'):
151 url = ep
152 else:
153 assert ep == "" or ep.startswith("/"), "ep should start with /: " + ep
154 url = self._base_url + ep
155 if self._auth is not None and 'auth' not in kwargs:
156 kwargs['auth'] = self._auth
157 headers = kwargs.get('headers', {})
158 if self._headers is not None:
159 headers.update(self._headers)
160 kwargs['headers'] = headers
161
162 # we manually do the json encoding in order to automatically convert timestamps
163 # for txrequests and treq
164 json = kwargs.pop('json', None)
165 if isinstance(json, (dict, list)):
166 jsonStr = jsonmodule.dumps(json, default=toJson)
167 kwargs['headers']['Content-Type'] = 'application/json'
168 if self.skipEncoding:
169 kwargs['data'] = jsonStr
170 else:
171 jsonBytes = unicode2bytes(jsonStr)
172 kwargs['data'] = jsonBytes
173 return url, kwargs
174
175 @defer.inlineCallbacks
176 def _doTxRequest(self, method, ep, **kwargs):
177 url, kwargs = yield self._prepareRequest(ep, kwargs)
178 if self.debug:
179 log.debug("http {url} {kwargs}", url=url, kwargs=kwargs)
180
181 def readContent(session, res):
182 # this forces reading of the content inside the thread
183 res.content
184 if self.debug:
185 log.debug("==> {code}: {content}", code=res.status_code, content=res.content)
186 return res
187
188 # read the whole content in the thread
189 kwargs['background_callback'] = readContent
190 if self.verify is False:
191 kwargs['verify'] = False
192
193 res = yield self._session.request(method, url, **kwargs)
194 return IHttpResponse(TxRequestsResponseWrapper(res))
195
196 @defer.inlineCallbacks
197 def _doTReq(self, method, ep, **kwargs):
198 url, kwargs = yield self._prepareRequest(ep, kwargs)
199 # treq requires header values to be an array
200 kwargs['headers'] = {k: [v]
201 for k, v in kwargs['headers'].items()}
202 kwargs['agent'] = self._agent
203
204 res = yield getattr(treq, method)(url, **kwargs)
205 return IHttpResponse(res)
206
207 # lets be nice to the auto completers, and don't generate that code
208 def get(self, ep, **kwargs):
209 return self._doRequest('get', ep, **kwargs)
210
211 def put(self, ep, **kwargs):
212 return self._doRequest('put', ep, **kwargs)
213
214 def delete(self, ep, **kwargs):
215 return self._doRequest('delete', ep, **kwargs)
216
217 def post(self, ep, **kwargs):
218 return self._doRequest('post', ep, **kwargs)
219
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/master/buildbot/util/httpclientservice.py b/master/buildbot/util/httpclientservice.py
--- a/master/buildbot/util/httpclientservice.py
+++ b/master/buildbot/util/httpclientservice.py
@@ -35,8 +35,6 @@
try:
import treq
- implementer(IHttpResponse)(treq.response._Response)
-
except ImportError:
treq = None
@@ -64,6 +62,27 @@
return self._res.url
+@implementer(IHttpResponse)
+class TreqResponseWrapper:
+
+ def __init__(self, res):
+ self._res = res
+
+ def content(self):
+ return self._res.content()
+
+ def json(self):
+ return self._res.json()
+
+ @property
+ def code(self):
+ return self._res.code
+
+ @property
+ def url(self):
+ return self._res.request.absoluteURI.decode()
+
+
class HTTPClientService(service.SharedService):
"""A SharedService class that can make http requests to remote services.
@@ -202,7 +221,7 @@
kwargs['agent'] = self._agent
res = yield getattr(treq, method)(url, **kwargs)
- return IHttpResponse(res)
+ return IHttpResponse(TreqResponseWrapper(res))
# lets be nice to the auto completers, and don't generate that code
def get(self, ep, **kwargs):
| {"golden_diff": "diff --git a/master/buildbot/util/httpclientservice.py b/master/buildbot/util/httpclientservice.py\n--- a/master/buildbot/util/httpclientservice.py\n+++ b/master/buildbot/util/httpclientservice.py\n@@ -35,8 +35,6 @@\n \n try:\n import treq\n- implementer(IHttpResponse)(treq.response._Response)\n-\n except ImportError:\n treq = None\n \n@@ -64,6 +62,27 @@\n return self._res.url\n \n \n+@implementer(IHttpResponse)\n+class TreqResponseWrapper:\n+\n+ def __init__(self, res):\n+ self._res = res\n+\n+ def content(self):\n+ return self._res.content()\n+\n+ def json(self):\n+ return self._res.json()\n+\n+ @property\n+ def code(self):\n+ return self._res.code\n+\n+ @property\n+ def url(self):\n+ return self._res.request.absoluteURI.decode()\n+\n+\n class HTTPClientService(service.SharedService):\n \"\"\"A SharedService class that can make http requests to remote services.\n \n@@ -202,7 +221,7 @@\n kwargs['agent'] = self._agent\n \n res = yield getattr(treq, method)(url, **kwargs)\n- return IHttpResponse(res)\n+ return IHttpResponse(TreqResponseWrapper(res))\n \n # lets be nice to the auto completers, and don't generate that code\n def get(self, ep, **kwargs):\n", "issue": "builtins.AttributeError: instead of intended log message\nHello,\r\n\r\nBecause I had set up an incorrect url, or an url that was not possible to access due to limited api token access I got this error message:\r\n```\r\n File \"/usr/local/lib/python3.10/site-packages/buildbot/changes/github.py\", line 142, in _getPulls\r\n f\"while loading {result.url}\")\r\n builtins.AttributeError: '_Response' object has no attribute 'url'\r\n```\r\n\r\nHowever, looking at the code the error should probably be something more like:\r\n```\r\n\"GitHubPullrequestPoller error {error_code} '{error message}' while loading {some_url}\")\r\n```\r\n\r\nIs the attribute error the intended behaviour? If not then I guess I would do some kind of patch for it (i.e. checking for existing url attribute).\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can)\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nimport json as jsonmodule\nimport textwrap\n\nfrom twisted.internet import defer\nfrom twisted.logger import Logger\nfrom twisted.web.client import Agent\nfrom twisted.web.client import HTTPConnectionPool\nfrom zope.interface import implementer\n\nfrom buildbot import config\nfrom buildbot.interfaces import IHttpResponse\nfrom buildbot.util import service\nfrom buildbot.util import toJson\nfrom buildbot.util import unicode2bytes\n\ntry:\n import txrequests\nexcept ImportError:\n txrequests = None\n\ntry:\n import treq\n implementer(IHttpResponse)(treq.response._Response)\n\nexcept ImportError:\n treq = None\n\nlog = Logger()\n\n\n@implementer(IHttpResponse)\nclass TxRequestsResponseWrapper:\n\n def __init__(self, res):\n self._res = res\n\n def content(self):\n return defer.succeed(self._res.content)\n\n def json(self):\n return defer.succeed(self._res.json())\n\n @property\n def code(self):\n return self._res.status_code\n\n @property\n def url(self):\n return self._res.url\n\n\nclass HTTPClientService(service.SharedService):\n \"\"\"A SharedService class that can make http requests to remote services.\n\n I can use either txrequests or treq, depending on what I find installed\n\n I provide minimal get/post/put/delete API with automatic baseurl joining, and json data encoding\n that is suitable for use from buildbot services.\n \"\"\"\n TREQ_PROS_AND_CONS = textwrap.dedent(\"\"\"\n txrequests is based on requests and is probably a bit more mature, but it requires threads\n to run, so has more overhead.\n treq is better integrated in twisted and is more and more feature equivalent\n\n txrequests is 2.8x slower than treq due to the use of threads.\n\n http://treq.readthedocs.io/en/latest/#feature-parity-w-requests\n pip install txrequests\n or\n pip install treq\n \"\"\")\n # Those could be in theory be overridden in master.cfg by using\n # import buildbot.util.httpclientservice.HTTPClientService.PREFER_TREQ = True\n # We prefer at the moment keeping it simple\n PREFER_TREQ = False\n MAX_THREADS = 5\n\n def __init__(self, base_url, auth=None, headers=None, verify=None, debug=False,\n skipEncoding=False):\n assert not base_url.endswith(\n \"/\"), \"baseurl should not end with /: \" + base_url\n super().__init__()\n self._base_url = base_url\n self._auth = auth\n self._headers = headers\n self._pool = None\n self._session = None\n self.verify = verify\n self.debug = debug\n self.skipEncoding = skipEncoding\n\n def updateHeaders(self, headers):\n if self._headers is None:\n self._headers = {}\n self._headers.update(headers)\n\n @staticmethod\n def checkAvailable(from_module):\n \"\"\"Call me at checkConfig time to properly report config error\n if neither txrequests or treq is installed\n \"\"\"\n if txrequests is None and treq is None:\n config.error(f\"neither txrequests nor treq is installed, but {from_module} is \"\n f\"requiring it\\n\\n{HTTPClientService.TREQ_PROS_AND_CONS}\")\n\n def startService(self):\n # treq only supports basicauth, so we force txrequests if the auth is\n # something else\n if self._auth is not None and not isinstance(self._auth, tuple):\n self.PREFER_TREQ = False\n if txrequests is not None and not self.PREFER_TREQ:\n self._session = txrequests.Session()\n self._doRequest = self._doTxRequest\n elif treq is None:\n raise ImportError(\"{classname} requires either txrequest or treq install.\"\n \" Users should call {classname}.checkAvailable() during checkConfig()\"\n \" to properly alert the user.\".format(\n classname=self.__class__.__name__))\n else:\n self._doRequest = self._doTReq\n self._pool = HTTPConnectionPool(self.master.reactor)\n self._pool.maxPersistentPerHost = self.MAX_THREADS\n self._agent = Agent(self.master.reactor, pool=self._pool)\n return super().startService()\n\n @defer.inlineCallbacks\n def stopService(self):\n if self._session:\n yield self._session.close()\n if self._pool:\n yield self._pool.closeCachedConnections()\n yield super().stopService()\n\n def _prepareRequest(self, ep, kwargs):\n if ep.startswith('http://') or ep.startswith('https://'):\n url = ep\n else:\n assert ep == \"\" or ep.startswith(\"/\"), \"ep should start with /: \" + ep\n url = self._base_url + ep\n if self._auth is not None and 'auth' not in kwargs:\n kwargs['auth'] = self._auth\n headers = kwargs.get('headers', {})\n if self._headers is not None:\n headers.update(self._headers)\n kwargs['headers'] = headers\n\n # we manually do the json encoding in order to automatically convert timestamps\n # for txrequests and treq\n json = kwargs.pop('json', None)\n if isinstance(json, (dict, list)):\n jsonStr = jsonmodule.dumps(json, default=toJson)\n kwargs['headers']['Content-Type'] = 'application/json'\n if self.skipEncoding:\n kwargs['data'] = jsonStr\n else:\n jsonBytes = unicode2bytes(jsonStr)\n kwargs['data'] = jsonBytes\n return url, kwargs\n\n @defer.inlineCallbacks\n def _doTxRequest(self, method, ep, **kwargs):\n url, kwargs = yield self._prepareRequest(ep, kwargs)\n if self.debug:\n log.debug(\"http {url} {kwargs}\", url=url, kwargs=kwargs)\n\n def readContent(session, res):\n # this forces reading of the content inside the thread\n res.content\n if self.debug:\n log.debug(\"==> {code}: {content}\", code=res.status_code, content=res.content)\n return res\n\n # read the whole content in the thread\n kwargs['background_callback'] = readContent\n if self.verify is False:\n kwargs['verify'] = False\n\n res = yield self._session.request(method, url, **kwargs)\n return IHttpResponse(TxRequestsResponseWrapper(res))\n\n @defer.inlineCallbacks\n def _doTReq(self, method, ep, **kwargs):\n url, kwargs = yield self._prepareRequest(ep, kwargs)\n # treq requires header values to be an array\n kwargs['headers'] = {k: [v]\n for k, v in kwargs['headers'].items()}\n kwargs['agent'] = self._agent\n\n res = yield getattr(treq, method)(url, **kwargs)\n return IHttpResponse(res)\n\n # lets be nice to the auto completers, and don't generate that code\n def get(self, ep, **kwargs):\n return self._doRequest('get', ep, **kwargs)\n\n def put(self, ep, **kwargs):\n return self._doRequest('put', ep, **kwargs)\n\n def delete(self, ep, **kwargs):\n return self._doRequest('delete', ep, **kwargs)\n\n def post(self, ep, **kwargs):\n return self._doRequest('post', ep, **kwargs)\n", "path": "master/buildbot/util/httpclientservice.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can)\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nimport json as jsonmodule\nimport textwrap\n\nfrom twisted.internet import defer\nfrom twisted.logger import Logger\nfrom twisted.web.client import Agent\nfrom twisted.web.client import HTTPConnectionPool\nfrom zope.interface import implementer\n\nfrom buildbot import config\nfrom buildbot.interfaces import IHttpResponse\nfrom buildbot.util import service\nfrom buildbot.util import toJson\nfrom buildbot.util import unicode2bytes\n\ntry:\n import txrequests\nexcept ImportError:\n txrequests = None\n\ntry:\n import treq\nexcept ImportError:\n treq = None\n\nlog = Logger()\n\n\n@implementer(IHttpResponse)\nclass TxRequestsResponseWrapper:\n\n def __init__(self, res):\n self._res = res\n\n def content(self):\n return defer.succeed(self._res.content)\n\n def json(self):\n return defer.succeed(self._res.json())\n\n @property\n def code(self):\n return self._res.status_code\n\n @property\n def url(self):\n return self._res.url\n\n\n@implementer(IHttpResponse)\nclass TreqResponseWrapper:\n\n def __init__(self, res):\n self._res = res\n\n def content(self):\n return self._res.content()\n\n def json(self):\n return self._res.json()\n\n @property\n def code(self):\n return self._res.code\n\n @property\n def url(self):\n return self._res.request.absoluteURI.decode()\n\n\nclass HTTPClientService(service.SharedService):\n \"\"\"A SharedService class that can make http requests to remote services.\n\n I can use either txrequests or treq, depending on what I find installed\n\n I provide minimal get/post/put/delete API with automatic baseurl joining, and json data encoding\n that is suitable for use from buildbot services.\n \"\"\"\n TREQ_PROS_AND_CONS = textwrap.dedent(\"\"\"\n txrequests is based on requests and is probably a bit more mature, but it requires threads\n to run, so has more overhead.\n treq is better integrated in twisted and is more and more feature equivalent\n\n txrequests is 2.8x slower than treq due to the use of threads.\n\n http://treq.readthedocs.io/en/latest/#feature-parity-w-requests\n pip install txrequests\n or\n pip install treq\n \"\"\")\n # Those could be in theory be overridden in master.cfg by using\n # import buildbot.util.httpclientservice.HTTPClientService.PREFER_TREQ = True\n # We prefer at the moment keeping it simple\n PREFER_TREQ = False\n MAX_THREADS = 5\n\n def __init__(self, base_url, auth=None, headers=None, verify=None, debug=False,\n skipEncoding=False):\n assert not base_url.endswith(\n \"/\"), \"baseurl should not end with /: \" + base_url\n super().__init__()\n self._base_url = base_url\n self._auth = auth\n self._headers = headers\n self._pool = None\n self._session = None\n self.verify = verify\n self.debug = debug\n self.skipEncoding = skipEncoding\n\n def updateHeaders(self, headers):\n if self._headers is None:\n self._headers = {}\n self._headers.update(headers)\n\n @staticmethod\n def checkAvailable(from_module):\n \"\"\"Call me at checkConfig time to properly report config error\n if neither txrequests or treq is installed\n \"\"\"\n if txrequests is None and treq is None:\n config.error(f\"neither txrequests nor treq is installed, but {from_module} is \"\n f\"requiring it\\n\\n{HTTPClientService.TREQ_PROS_AND_CONS}\")\n\n def startService(self):\n # treq only supports basicauth, so we force txrequests if the auth is\n # something else\n if self._auth is not None and not isinstance(self._auth, tuple):\n self.PREFER_TREQ = False\n if txrequests is not None and not self.PREFER_TREQ:\n self._session = txrequests.Session()\n self._doRequest = self._doTxRequest\n elif treq is None:\n raise ImportError(\"{classname} requires either txrequest or treq install.\"\n \" Users should call {classname}.checkAvailable() during checkConfig()\"\n \" to properly alert the user.\".format(\n classname=self.__class__.__name__))\n else:\n self._doRequest = self._doTReq\n self._pool = HTTPConnectionPool(self.master.reactor)\n self._pool.maxPersistentPerHost = self.MAX_THREADS\n self._agent = Agent(self.master.reactor, pool=self._pool)\n return super().startService()\n\n @defer.inlineCallbacks\n def stopService(self):\n if self._session:\n yield self._session.close()\n if self._pool:\n yield self._pool.closeCachedConnections()\n yield super().stopService()\n\n def _prepareRequest(self, ep, kwargs):\n if ep.startswith('http://') or ep.startswith('https://'):\n url = ep\n else:\n assert ep == \"\" or ep.startswith(\"/\"), \"ep should start with /: \" + ep\n url = self._base_url + ep\n if self._auth is not None and 'auth' not in kwargs:\n kwargs['auth'] = self._auth\n headers = kwargs.get('headers', {})\n if self._headers is not None:\n headers.update(self._headers)\n kwargs['headers'] = headers\n\n # we manually do the json encoding in order to automatically convert timestamps\n # for txrequests and treq\n json = kwargs.pop('json', None)\n if isinstance(json, (dict, list)):\n jsonStr = jsonmodule.dumps(json, default=toJson)\n kwargs['headers']['Content-Type'] = 'application/json'\n if self.skipEncoding:\n kwargs['data'] = jsonStr\n else:\n jsonBytes = unicode2bytes(jsonStr)\n kwargs['data'] = jsonBytes\n return url, kwargs\n\n @defer.inlineCallbacks\n def _doTxRequest(self, method, ep, **kwargs):\n url, kwargs = yield self._prepareRequest(ep, kwargs)\n if self.debug:\n log.debug(\"http {url} {kwargs}\", url=url, kwargs=kwargs)\n\n def readContent(session, res):\n # this forces reading of the content inside the thread\n res.content\n if self.debug:\n log.debug(\"==> {code}: {content}\", code=res.status_code, content=res.content)\n return res\n\n # read the whole content in the thread\n kwargs['background_callback'] = readContent\n if self.verify is False:\n kwargs['verify'] = False\n\n res = yield self._session.request(method, url, **kwargs)\n return IHttpResponse(TxRequestsResponseWrapper(res))\n\n @defer.inlineCallbacks\n def _doTReq(self, method, ep, **kwargs):\n url, kwargs = yield self._prepareRequest(ep, kwargs)\n # treq requires header values to be an array\n kwargs['headers'] = {k: [v]\n for k, v in kwargs['headers'].items()}\n kwargs['agent'] = self._agent\n\n res = yield getattr(treq, method)(url, **kwargs)\n return IHttpResponse(TreqResponseWrapper(res))\n\n # lets be nice to the auto completers, and don't generate that code\n def get(self, ep, **kwargs):\n return self._doRequest('get', ep, **kwargs)\n\n def put(self, ep, **kwargs):\n return self._doRequest('put', ep, **kwargs)\n\n def delete(self, ep, **kwargs):\n return self._doRequest('delete', ep, **kwargs)\n\n def post(self, ep, **kwargs):\n return self._doRequest('post', ep, **kwargs)\n", "path": "master/buildbot/util/httpclientservice.py"}]} | 2,782 | 326 |
gh_patches_debug_2731 | rasdani/github-patches | git_diff | strawberry-graphql__strawberry-2481 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Increased CPU usage when subscribing with the graphql-transport-ws protocol
<!-- Provide a general summary of the bug in the title above. -->
<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->
<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->
## Describe the Bug
We have a Strawberry GraphQL server that we have been stress testing and running CPU performance tests on. We have found that there is a noticeable and consistent increase in the CPU usage of our server application when our client subscribes using the _graphql-transport-ws_ protocol compared to using the _graphql-ws_ protocol.
I have done a bit of investigating and further profiling using py-spy and discovered that the Strawberry code is creating a `NextMessage` object ([here](https://github.com/strawberry-graphql/strawberry/blob/db9c22a53205cd82330a9c84d44ac1ee2731eafb/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py#L261)) for each message, which it then converts to a dictionary ([here](https://github.com/strawberry-graphql/strawberry/blob/db9c22a53205cd82330a9c84d44ac1ee2731eafb/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py#L283)) using the `dataclasses` `asdict() `method ([here](https://github.com/strawberry-graphql/strawberry/blob/db9c22a53205cd82330a9c84d44ac1ee2731eafb/strawberry/subscriptions/protocols/graphql_transport_ws/types.py#L12)). Some internet research shows that this `asdict()` method is doing a `deepcopy` of everything within the class. I ran a few timing tests and the `asdict()` method takes an order of magnitude longer than doing a simple `.__dict__` on the object. This is only done in the _graphql-transport-ws_ implementation and not the _graphql-ws_ implementation which explains why there is a difference in CPU usage between the 2 protocols.
I do not believe that we need to be doing a deepcopy when turning the class into a dictionary. What's more, I wonder whether we need to even be creating the `NextMessage` object because as far as I can see, we create it and pass it to a function that immediately turns it into a dictionary. So why don't we just create it as a dictionary and send it instead. This would bypass having to do any sort of conversion costing time.
I.e. instead of line 261 and 262 ([here](https://github.com/strawberry-graphql/strawberry/blob/db9c22a53205cd82330a9c84d44ac1ee2731eafb/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py#L261)) which do:
```
next_message = NextMessage(id=operation_id, payload=next_payload)
await self.send_message(next_message)`
```
we could do something like:
```
next_message = {"id":operation_id, "payload": next_payload, "type": "next"}
await self.send_json(next_message)
```
When I ran the performance tests with the above change the CPU usage dropped and was consistent with the _graphql-ws_ protocol performance.
<!-- A clear and concise description of what the bug is. -->
## System Information
- Operating system: Centos 7
- Strawberry version (if applicable): 0.154.1
## Additional Context
I have created a simple demo Strawberry GraphQL server and Python client on GitHub, available at: https://github.com/rjwills28/strawberry_cpu_demo/tree/master.
Instructions on how to install and run are in the readme. It simulates the tests that we were running where we have a server providing subscription updates at 10Hz and a client that creates 100 different subscriptions. Follow the example in the readme to first run with the _graphql-ws_ protocol (command line argument (`-p 1`) and then with the _graphql-transport-ws_ protocol (`-p 2`). Run both a few times and you should see that the average CPU usage is on the whole higher for the latter protocol. Please let me know if you have any problems running this.
<!-- POLAR PLEDGE BADGE START -->
## Upvote & Fund
- We're using [Polar.sh](https://polar.sh/strawberry-graphql) so you can upvote and help fund this issue.
- We receive the funding once the issue is completed & confirmed by you.
- Thank you in advance for helping prioritize & fund our backlog.
<a href="https://polar.sh/strawberry-graphql/strawberry/issues/2479">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://polar.sh/api/github/strawberry-graphql/strawberry/issues/2479/pledge.svg?darkmode=1">
<img alt="Fund with Polar" src="https://polar.sh/api/github/strawberry-graphql/strawberry/issues/2479/pledge.svg">
</picture>
</a>
<!-- POLAR PLEDGE BADGE END -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `strawberry/subscriptions/protocols/graphql_transport_ws/types.py`
Content:
```
1 from dataclasses import asdict, dataclass
2 from typing import Any, Dict, List, Optional
3
4 from graphql import GraphQLFormattedError
5
6 from strawberry.unset import UNSET
7
8
9 @dataclass
10 class GraphQLTransportMessage:
11 def as_dict(self) -> dict:
12 data = asdict(self)
13 if getattr(self, "payload", None) is UNSET:
14 # Unset fields must have a JSON value of "undefined" not "null"
15 data.pop("payload")
16 return data
17
18
19 @dataclass
20 class ConnectionInitMessage(GraphQLTransportMessage):
21 """
22 Direction: Client -> Server
23 """
24
25 payload: Optional[Dict[str, Any]] = UNSET
26 type: str = "connection_init"
27
28
29 @dataclass
30 class ConnectionAckMessage(GraphQLTransportMessage):
31 """
32 Direction: Server -> Client
33 """
34
35 payload: Optional[Dict[str, Any]] = UNSET
36 type: str = "connection_ack"
37
38
39 @dataclass
40 class PingMessage(GraphQLTransportMessage):
41 """
42 Direction: bidirectional
43 """
44
45 payload: Optional[Dict[str, Any]] = UNSET
46 type: str = "ping"
47
48
49 @dataclass
50 class PongMessage(GraphQLTransportMessage):
51 """
52 Direction: bidirectional
53 """
54
55 payload: Optional[Dict[str, Any]] = UNSET
56 type: str = "pong"
57
58
59 @dataclass
60 class SubscribeMessagePayload:
61 query: str
62 operationName: Optional[str] = None
63 variables: Optional[Dict[str, Any]] = None
64 extensions: Optional[Dict[str, Any]] = None
65
66
67 @dataclass
68 class SubscribeMessage(GraphQLTransportMessage):
69 """
70 Direction: Client -> Server
71 """
72
73 id: str
74 payload: SubscribeMessagePayload
75 type: str = "subscribe"
76
77
78 @dataclass
79 class NextMessage(GraphQLTransportMessage):
80 """
81 Direction: Server -> Client
82 """
83
84 id: str
85 payload: Dict[str, Any] # TODO: shape like ExecutionResult
86 type: str = "next"
87
88
89 @dataclass
90 class ErrorMessage(GraphQLTransportMessage):
91 """
92 Direction: Server -> Client
93 """
94
95 id: str
96 payload: List[GraphQLFormattedError]
97 type: str = "error"
98
99
100 @dataclass
101 class CompleteMessage(GraphQLTransportMessage):
102 """
103 Direction: bidirectional
104 """
105
106 id: str
107 type: str = "complete"
108
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/strawberry/subscriptions/protocols/graphql_transport_ws/types.py b/strawberry/subscriptions/protocols/graphql_transport_ws/types.py
--- a/strawberry/subscriptions/protocols/graphql_transport_ws/types.py
+++ b/strawberry/subscriptions/protocols/graphql_transport_ws/types.py
@@ -85,6 +85,9 @@
payload: Dict[str, Any] # TODO: shape like ExecutionResult
type: str = "next"
+ def as_dict(self) -> dict:
+ return {"id": self.id, "payload": self.payload, "type": self.type}
+
@dataclass
class ErrorMessage(GraphQLTransportMessage):
| {"golden_diff": "diff --git a/strawberry/subscriptions/protocols/graphql_transport_ws/types.py b/strawberry/subscriptions/protocols/graphql_transport_ws/types.py\n--- a/strawberry/subscriptions/protocols/graphql_transport_ws/types.py\n+++ b/strawberry/subscriptions/protocols/graphql_transport_ws/types.py\n@@ -85,6 +85,9 @@\n payload: Dict[str, Any] # TODO: shape like ExecutionResult\n type: str = \"next\"\n \n+ def as_dict(self) -> dict:\n+ return {\"id\": self.id, \"payload\": self.payload, \"type\": self.type}\n+\n \n @dataclass\n class ErrorMessage(GraphQLTransportMessage):\n", "issue": "Increased CPU usage when subscribing with the graphql-transport-ws protocol\n<!-- Provide a general summary of the bug in the title above. -->\r\n\r\n<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->\r\n<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->\r\n\r\n## Describe the Bug\r\nWe have a Strawberry GraphQL server that we have been stress testing and running CPU performance tests on. We have found that there is a noticeable and consistent increase in the CPU usage of our server application when our client subscribes using the _graphql-transport-ws_ protocol compared to using the _graphql-ws_ protocol. \r\n\r\nI have done a bit of investigating and further profiling using py-spy and discovered that the Strawberry code is creating a `NextMessage` object ([here](https://github.com/strawberry-graphql/strawberry/blob/db9c22a53205cd82330a9c84d44ac1ee2731eafb/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py#L261)) for each message, which it then converts to a dictionary ([here](https://github.com/strawberry-graphql/strawberry/blob/db9c22a53205cd82330a9c84d44ac1ee2731eafb/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py#L283)) using the `dataclasses` `asdict() `method ([here](https://github.com/strawberry-graphql/strawberry/blob/db9c22a53205cd82330a9c84d44ac1ee2731eafb/strawberry/subscriptions/protocols/graphql_transport_ws/types.py#L12)). Some internet research shows that this `asdict()` method is doing a `deepcopy` of everything within the class. I ran a few timing tests and the `asdict()` method takes an order of magnitude longer than doing a simple `.__dict__` on the object. This is only done in the _graphql-transport-ws_ implementation and not the _graphql-ws_ implementation which explains why there is a difference in CPU usage between the 2 protocols.\r\n\r\nI do not believe that we need to be doing a deepcopy when turning the class into a dictionary. What's more, I wonder whether we need to even be creating the `NextMessage` object because as far as I can see, we create it and pass it to a function that immediately turns it into a dictionary. So why don't we just create it as a dictionary and send it instead. This would bypass having to do any sort of conversion costing time. \r\n\r\nI.e. instead of line 261 and 262 ([here](https://github.com/strawberry-graphql/strawberry/blob/db9c22a53205cd82330a9c84d44ac1ee2731eafb/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py#L261)) which do:\r\n```\r\n next_message = NextMessage(id=operation_id, payload=next_payload)\r\n await self.send_message(next_message)`\r\n```\r\nwe could do something like:\r\n```\r\n next_message = {\"id\":operation_id, \"payload\": next_payload, \"type\": \"next\"}\r\n await self.send_json(next_message)\r\n```\r\n\r\nWhen I ran the performance tests with the above change the CPU usage dropped and was consistent with the _graphql-ws_ protocol performance.\r\n<!-- A clear and concise description of what the bug is. -->\r\n\r\n## System Information\r\n\r\n - Operating system: Centos 7\r\n - Strawberry version (if applicable): 0.154.1\r\n\r\n## Additional Context\r\nI have created a simple demo Strawberry GraphQL server and Python client on GitHub, available at: https://github.com/rjwills28/strawberry_cpu_demo/tree/master.\r\nInstructions on how to install and run are in the readme. It simulates the tests that we were running where we have a server providing subscription updates at 10Hz and a client that creates 100 different subscriptions. Follow the example in the readme to first run with the _graphql-ws_ protocol (command line argument (`-p 1`) and then with the _graphql-transport-ws_ protocol (`-p 2`). Run both a few times and you should see that the average CPU usage is on the whole higher for the latter protocol. Please let me know if you have any problems running this. \r\n\n\n<!-- POLAR PLEDGE BADGE START -->\n## Upvote & Fund\n\n- We're using [Polar.sh](https://polar.sh/strawberry-graphql) so you can upvote and help fund this issue.\n- We receive the funding once the issue is completed & confirmed by you.\n- Thank you in advance for helping prioritize & fund our backlog.\n\n<a href=\"https://polar.sh/strawberry-graphql/strawberry/issues/2479\">\n<picture>\n <source media=\"(prefers-color-scheme: dark)\" srcset=\"https://polar.sh/api/github/strawberry-graphql/strawberry/issues/2479/pledge.svg?darkmode=1\">\n <img alt=\"Fund with Polar\" src=\"https://polar.sh/api/github/strawberry-graphql/strawberry/issues/2479/pledge.svg\">\n</picture>\n</a>\n<!-- POLAR PLEDGE BADGE END -->\n\n", "before_files": [{"content": "from dataclasses import asdict, dataclass\nfrom typing import Any, Dict, List, Optional\n\nfrom graphql import GraphQLFormattedError\n\nfrom strawberry.unset import UNSET\n\n\n@dataclass\nclass GraphQLTransportMessage:\n def as_dict(self) -> dict:\n data = asdict(self)\n if getattr(self, \"payload\", None) is UNSET:\n # Unset fields must have a JSON value of \"undefined\" not \"null\"\n data.pop(\"payload\")\n return data\n\n\n@dataclass\nclass ConnectionInitMessage(GraphQLTransportMessage):\n \"\"\"\n Direction: Client -> Server\n \"\"\"\n\n payload: Optional[Dict[str, Any]] = UNSET\n type: str = \"connection_init\"\n\n\n@dataclass\nclass ConnectionAckMessage(GraphQLTransportMessage):\n \"\"\"\n Direction: Server -> Client\n \"\"\"\n\n payload: Optional[Dict[str, Any]] = UNSET\n type: str = \"connection_ack\"\n\n\n@dataclass\nclass PingMessage(GraphQLTransportMessage):\n \"\"\"\n Direction: bidirectional\n \"\"\"\n\n payload: Optional[Dict[str, Any]] = UNSET\n type: str = \"ping\"\n\n\n@dataclass\nclass PongMessage(GraphQLTransportMessage):\n \"\"\"\n Direction: bidirectional\n \"\"\"\n\n payload: Optional[Dict[str, Any]] = UNSET\n type: str = \"pong\"\n\n\n@dataclass\nclass SubscribeMessagePayload:\n query: str\n operationName: Optional[str] = None\n variables: Optional[Dict[str, Any]] = None\n extensions: Optional[Dict[str, Any]] = None\n\n\n@dataclass\nclass SubscribeMessage(GraphQLTransportMessage):\n \"\"\"\n Direction: Client -> Server\n \"\"\"\n\n id: str\n payload: SubscribeMessagePayload\n type: str = \"subscribe\"\n\n\n@dataclass\nclass NextMessage(GraphQLTransportMessage):\n \"\"\"\n Direction: Server -> Client\n \"\"\"\n\n id: str\n payload: Dict[str, Any] # TODO: shape like ExecutionResult\n type: str = \"next\"\n\n\n@dataclass\nclass ErrorMessage(GraphQLTransportMessage):\n \"\"\"\n Direction: Server -> Client\n \"\"\"\n\n id: str\n payload: List[GraphQLFormattedError]\n type: str = \"error\"\n\n\n@dataclass\nclass CompleteMessage(GraphQLTransportMessage):\n \"\"\"\n Direction: bidirectional\n \"\"\"\n\n id: str\n type: str = \"complete\"\n", "path": "strawberry/subscriptions/protocols/graphql_transport_ws/types.py"}], "after_files": [{"content": "from dataclasses import asdict, dataclass\nfrom typing import Any, Dict, List, Optional\n\nfrom graphql import GraphQLFormattedError\n\nfrom strawberry.unset import UNSET\n\n\n@dataclass\nclass GraphQLTransportMessage:\n def as_dict(self) -> dict:\n data = asdict(self)\n if getattr(self, \"payload\", None) is UNSET:\n # Unset fields must have a JSON value of \"undefined\" not \"null\"\n data.pop(\"payload\")\n return data\n\n\n@dataclass\nclass ConnectionInitMessage(GraphQLTransportMessage):\n \"\"\"\n Direction: Client -> Server\n \"\"\"\n\n payload: Optional[Dict[str, Any]] = UNSET\n type: str = \"connection_init\"\n\n\n@dataclass\nclass ConnectionAckMessage(GraphQLTransportMessage):\n \"\"\"\n Direction: Server -> Client\n \"\"\"\n\n payload: Optional[Dict[str, Any]] = UNSET\n type: str = \"connection_ack\"\n\n\n@dataclass\nclass PingMessage(GraphQLTransportMessage):\n \"\"\"\n Direction: bidirectional\n \"\"\"\n\n payload: Optional[Dict[str, Any]] = UNSET\n type: str = \"ping\"\n\n\n@dataclass\nclass PongMessage(GraphQLTransportMessage):\n \"\"\"\n Direction: bidirectional\n \"\"\"\n\n payload: Optional[Dict[str, Any]] = UNSET\n type: str = \"pong\"\n\n\n@dataclass\nclass SubscribeMessagePayload:\n query: str\n operationName: Optional[str] = None\n variables: Optional[Dict[str, Any]] = None\n extensions: Optional[Dict[str, Any]] = None\n\n\n@dataclass\nclass SubscribeMessage(GraphQLTransportMessage):\n \"\"\"\n Direction: Client -> Server\n \"\"\"\n\n id: str\n payload: SubscribeMessagePayload\n type: str = \"subscribe\"\n\n\n@dataclass\nclass NextMessage(GraphQLTransportMessage):\n \"\"\"\n Direction: Server -> Client\n \"\"\"\n\n id: str\n payload: Dict[str, Any] # TODO: shape like ExecutionResult\n type: str = \"next\"\n\n def as_dict(self) -> dict:\n return {\"id\": self.id, \"payload\": self.payload, \"type\": self.type}\n\n\n@dataclass\nclass ErrorMessage(GraphQLTransportMessage):\n \"\"\"\n Direction: Server -> Client\n \"\"\"\n\n id: str\n payload: List[GraphQLFormattedError]\n type: str = \"error\"\n\n\n@dataclass\nclass CompleteMessage(GraphQLTransportMessage):\n \"\"\"\n Direction: bidirectional\n \"\"\"\n\n id: str\n type: str = \"complete\"\n", "path": "strawberry/subscriptions/protocols/graphql_transport_ws/types.py"}]} | 2,229 | 146 |
gh_patches_debug_7779 | rasdani/github-patches | git_diff | Mailu__Mailu-2275 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
master can't receive mail – "AUTH not supported"
## Before you open your issue
- [X] Check if no issue or pull-request for this already exists.
- [X] Check [documentation](https://mailu.io/master/) and [FAQ](https://mailu.io/master/faq.html). (Tip, use the search function on the documentation page)
- [X] You understand `Mailu` is made by volunteers in their **free time** — be conscise, civil and accept that delays can occur.
- [X] The title of the issue should be short and simple. It should contain specific terms related to the actual issue. Be specific while writing the title.
## Environment & Versions
### Environment
- [X] docker-compose
- [ ] kubernetes
- [ ] docker swarm
### Versions
`master`
## Description
Not able to receive email.
Error `502 5.5.1 AUTH not supported (in reply to RCPT TO command)`
## Replication Steps
1) Spin up a `master` instance, using setup.mailu.io
2) Send an E-Mail to the newly created admin on the instance
3) (Make sure it's nothing on your end, set up a `1.9` instance the same way. Works without a problem.)
## Logs
On the receiving side (mailu:master).
```
front_1 | 2022/03/09 16:27:12 [info] 19#19: *107 client [removed-ipv4]:38640 connected to 0.0.0.0:25
front_1 | 2022/03/09 16:27:13 [info] 19#19: *107 client login failed: "AUTH not supported" while in http auth state, client: [removed-ipv4] using starttls, server: 0.0.0.0:25
```
And on the sending side (mailu:1.9 - my production instance) I get this email:
```
This is the mail system at host [my-domain].
I'm sorry to have to inform you that your message could not
be delivered to one or more recipients. It's attached below.
For further assistance, please send mail to postmaster.
If you do so, please include this problem report. You can
delete your own text from the attached returned message.
The mail system
<admin@[destination.mail]>: host [destination.mail][removed-ipv4] said:
502 5.5.1 AUTH not supported (in reply to RCPT TO command)
Reporting-MTA: dns; [my-domain]
X-Postfix-Queue-ID: 027AA1198C9
X-Postfix-Sender: rfc822; [my-mail]
Arrival-Date: Wed, 9 Mar 2022 17:27:11 +0100 (CET)
Final-Recipient: rfc822; admin@[destination.mail]
Original-Recipient: rfc822;admin@[destination.mail]</a>
Action: failed
Status: 5.5.1
Remote-MTA: dns; [destination.mail]
Diagnostic-Code: smtp; 502 5.5.1 AUTH not supported
```
Same thing (but differently formatted) with gmail, too.
Probably related to #2265 and #2261
*Edit:* Maybe this commit, too: https://github.com/Mailu/Mailu/pull/2265/commits/7ce7f2096b530376af4944a98bd6edc276cd648e
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/admin/mailu/internal/views/auth.py`
Content:
```
1 from mailu import models, utils
2 from mailu.internal import internal, nginx
3 from flask import current_app as app
4
5 import flask
6 import flask_login
7 import base64
8
9 @internal.route("/auth/email")
10 def nginx_authentication():
11 """ Main authentication endpoint for Nginx email server
12 """
13 client_ip = flask.request.headers["Client-Ip"]
14 headers = flask.request.headers
15 if headers["Auth-Port"] == '25':
16 response = flask.Response()
17 response.headers['Auth-Status'] = 'AUTH not supported'
18 response.headers['Auth-Error-Code'] = '502 5.5.1'
19 utils.limiter.rate_limit_ip(client_ip)
20 return response
21 is_from_webmail = headers['Auth-Port'] in ['10143', '10025']
22 if not is_from_webmail and utils.limiter.should_rate_limit_ip(client_ip):
23 status, code = nginx.get_status(flask.request.headers['Auth-Protocol'], 'ratelimit')
24 response = flask.Response()
25 response.headers['Auth-Status'] = status
26 response.headers['Auth-Error-Code'] = code
27 if int(flask.request.headers['Auth-Login-Attempt']) < 10:
28 response.headers['Auth-Wait'] = '3'
29 return response
30 headers = nginx.handle_authentication(flask.request.headers)
31 response = flask.Response()
32 for key, value in headers.items():
33 response.headers[key] = str(value)
34 is_valid_user = False
35 if response.headers.get("Auth-User-Exists"):
36 username = response.headers["Auth-User"]
37 if utils.limiter.should_rate_limit_user(username, client_ip):
38 # FIXME could be done before handle_authentication()
39 status, code = nginx.get_status(flask.request.headers['Auth-Protocol'], 'ratelimit')
40 response = flask.Response()
41 response.headers['Auth-Status'] = status
42 response.headers['Auth-Error-Code'] = code
43 if int(flask.request.headers['Auth-Login-Attempt']) < 10:
44 response.headers['Auth-Wait'] = '3'
45 return response
46 is_valid_user = True
47 if headers.get("Auth-Status") == "OK":
48 utils.limiter.exempt_ip_from_ratelimits(client_ip)
49 elif is_valid_user:
50 utils.limiter.rate_limit_user(username, client_ip)
51 elif not is_from_webmail:
52 utils.limiter.rate_limit_ip(client_ip)
53 return response
54
55 @internal.route("/auth/admin")
56 def admin_authentication():
57 """ Fails if the user is not an authenticated admin.
58 """
59 if (not flask_login.current_user.is_anonymous
60 and flask_login.current_user.global_admin
61 and flask_login.current_user.enabled):
62 return ""
63 return flask.abort(403)
64
65 @internal.route("/auth/user")
66 def user_authentication():
67 """ Fails if the user is not authenticated.
68 """
69 if (not flask_login.current_user.is_anonymous
70 and flask_login.current_user.enabled):
71 response = flask.Response()
72 email = flask_login.current_user.get_id()
73 response.headers["X-User"] = models.IdnaEmail.process_bind_param(flask_login, email, "")
74 response.headers["X-User-Token"] = utils.gen_temp_token(email, flask.session)
75 return response
76 return flask.abort(403)
77
78
79 @internal.route("/auth/basic")
80 def basic_authentication():
81 """ Tries to authenticate using the Authorization header.
82 """
83 client_ip = flask.request.headers.get('X-Real-IP', flask.request.remote_addr)
84 if utils.limiter.should_rate_limit_ip(client_ip):
85 response = flask.Response(status=401)
86 response.headers["WWW-Authenticate"] = 'Basic realm="Authentication rate limit from one source exceeded"'
87 response.headers['Retry-After'] = '60'
88 return response
89 authorization = flask.request.headers.get("Authorization")
90 if authorization and authorization.startswith("Basic "):
91 encoded = authorization.replace("Basic ", "")
92 user_email, password = base64.b64decode(encoded).split(b":", 1)
93 user_email = user_email.decode("utf8")
94 if utils.limiter.should_rate_limit_user(user_email, client_ip):
95 response = flask.Response(status=401)
96 response.headers["WWW-Authenticate"] = 'Basic realm="Authentication rate limit for this username exceeded"'
97 response.headers['Retry-After'] = '60'
98 return response
99 user = models.User.query.get(user_email)
100 if user and nginx.check_credentials(user, password.decode('utf-8'), client_ip, "web"):
101 response = flask.Response()
102 response.headers["X-User"] = models.IdnaEmail.process_bind_param(flask_login, user.email, "")
103 utils.limiter.exempt_ip_from_ratelimits(client_ip)
104 return response
105 utils.limiter.rate_limit_user(user_email, client_ip) if user else utils.limiter.rate_limit_ip(client_ip)
106 response = flask.Response(status=401)
107 response.headers["WWW-Authenticate"] = 'Basic realm="Login Required"'
108 return response
109
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/core/admin/mailu/internal/views/auth.py b/core/admin/mailu/internal/views/auth.py
--- a/core/admin/mailu/internal/views/auth.py
+++ b/core/admin/mailu/internal/views/auth.py
@@ -12,7 +12,7 @@
"""
client_ip = flask.request.headers["Client-Ip"]
headers = flask.request.headers
- if headers["Auth-Port"] == '25':
+ if headers["Auth-Port"] == '25' and headers['Auth-Method'] != 'none':
response = flask.Response()
response.headers['Auth-Status'] = 'AUTH not supported'
response.headers['Auth-Error-Code'] = '502 5.5.1'
| {"golden_diff": "diff --git a/core/admin/mailu/internal/views/auth.py b/core/admin/mailu/internal/views/auth.py\n--- a/core/admin/mailu/internal/views/auth.py\n+++ b/core/admin/mailu/internal/views/auth.py\n@@ -12,7 +12,7 @@\n \"\"\"\n client_ip = flask.request.headers[\"Client-Ip\"]\n headers = flask.request.headers\n- if headers[\"Auth-Port\"] == '25':\n+ if headers[\"Auth-Port\"] == '25' and headers['Auth-Method'] != 'none':\n response = flask.Response()\n response.headers['Auth-Status'] = 'AUTH not supported'\n response.headers['Auth-Error-Code'] = '502 5.5.1'\n", "issue": "master can't receive mail \u2013 \"AUTH not supported\"\n## Before you open your issue\r\n- [X] Check if no issue or pull-request for this already exists.\r\n- [X] Check [documentation](https://mailu.io/master/) and [FAQ](https://mailu.io/master/faq.html). (Tip, use the search function on the documentation page)\r\n- [X] You understand `Mailu` is made by volunteers in their **free time** \u2014 be conscise, civil and accept that delays can occur.\r\n- [X] The title of the issue should be short and simple. It should contain specific terms related to the actual issue. Be specific while writing the title.\r\n\r\n## Environment & Versions\r\n### Environment\r\n - [X] docker-compose\r\n - [ ] kubernetes\r\n - [ ] docker swarm\r\n\r\n### Versions\r\n`master`\r\n\r\n## Description\r\n\r\nNot able to receive email.\r\nError `502 5.5.1 AUTH not supported (in reply to RCPT TO command)`\r\n\r\n## Replication Steps\r\n\r\n1) Spin up a `master` instance, using setup.mailu.io\r\n2) Send an E-Mail to the newly created admin on the instance\r\n3) (Make sure it's nothing on your end, set up a `1.9` instance the same way. Works without a problem.)\r\n\r\n## Logs\r\n\r\nOn the receiving side (mailu:master).\r\n\r\n```\r\nfront_1 | 2022/03/09 16:27:12 [info] 19#19: *107 client [removed-ipv4]:38640 connected to 0.0.0.0:25\r\nfront_1 | 2022/03/09 16:27:13 [info] 19#19: *107 client login failed: \"AUTH not supported\" while in http auth state, client: [removed-ipv4] using starttls, server: 0.0.0.0:25\r\n```\r\n\r\nAnd on the sending side (mailu:1.9 - my production instance) I get this email:\r\n\r\n```\r\nThis is the mail system at host [my-domain].\r\n\r\nI'm sorry to have to inform you that your message could not\r\nbe delivered to one or more recipients. It's attached below.\r\n\r\nFor further assistance, please send mail to postmaster.\r\n\r\nIf you do so, please include this problem report. You can\r\ndelete your own text from the attached returned message.\r\n\r\n The mail system\r\n\r\n<admin@[destination.mail]>: host [destination.mail][removed-ipv4] said:\r\n 502 5.5.1 AUTH not supported (in reply to RCPT TO command)\r\n\r\nReporting-MTA: dns; [my-domain]\r\nX-Postfix-Queue-ID: 027AA1198C9\r\nX-Postfix-Sender: rfc822; [my-mail]\r\nArrival-Date: Wed, 9 Mar 2022 17:27:11 +0100 (CET)\r\n\r\nFinal-Recipient: rfc822; admin@[destination.mail]\r\nOriginal-Recipient: rfc822;admin@[destination.mail]</a>\r\nAction: failed\r\nStatus: 5.5.1\r\nRemote-MTA: dns; [destination.mail]\r\nDiagnostic-Code: smtp; 502 5.5.1 AUTH not supported\r\n```\r\n\r\nSame thing (but differently formatted) with gmail, too.\r\n\r\nProbably related to #2265 and #2261\r\n*Edit:* Maybe this commit, too: https://github.com/Mailu/Mailu/pull/2265/commits/7ce7f2096b530376af4944a98bd6edc276cd648e\n", "before_files": [{"content": "from mailu import models, utils\nfrom mailu.internal import internal, nginx\nfrom flask import current_app as app\n\nimport flask\nimport flask_login\nimport base64\n\[email protected](\"/auth/email\")\ndef nginx_authentication():\n \"\"\" Main authentication endpoint for Nginx email server\n \"\"\"\n client_ip = flask.request.headers[\"Client-Ip\"]\n headers = flask.request.headers\n if headers[\"Auth-Port\"] == '25':\n response = flask.Response()\n response.headers['Auth-Status'] = 'AUTH not supported'\n response.headers['Auth-Error-Code'] = '502 5.5.1'\n utils.limiter.rate_limit_ip(client_ip)\n return response\n is_from_webmail = headers['Auth-Port'] in ['10143', '10025']\n if not is_from_webmail and utils.limiter.should_rate_limit_ip(client_ip):\n status, code = nginx.get_status(flask.request.headers['Auth-Protocol'], 'ratelimit')\n response = flask.Response()\n response.headers['Auth-Status'] = status\n response.headers['Auth-Error-Code'] = code\n if int(flask.request.headers['Auth-Login-Attempt']) < 10:\n response.headers['Auth-Wait'] = '3'\n return response\n headers = nginx.handle_authentication(flask.request.headers)\n response = flask.Response()\n for key, value in headers.items():\n response.headers[key] = str(value)\n is_valid_user = False\n if response.headers.get(\"Auth-User-Exists\"):\n username = response.headers[\"Auth-User\"]\n if utils.limiter.should_rate_limit_user(username, client_ip):\n # FIXME could be done before handle_authentication()\n status, code = nginx.get_status(flask.request.headers['Auth-Protocol'], 'ratelimit')\n response = flask.Response()\n response.headers['Auth-Status'] = status\n response.headers['Auth-Error-Code'] = code\n if int(flask.request.headers['Auth-Login-Attempt']) < 10:\n response.headers['Auth-Wait'] = '3'\n return response\n is_valid_user = True\n if headers.get(\"Auth-Status\") == \"OK\":\n utils.limiter.exempt_ip_from_ratelimits(client_ip)\n elif is_valid_user:\n utils.limiter.rate_limit_user(username, client_ip)\n elif not is_from_webmail:\n utils.limiter.rate_limit_ip(client_ip)\n return response\n\[email protected](\"/auth/admin\")\ndef admin_authentication():\n \"\"\" Fails if the user is not an authenticated admin.\n \"\"\"\n if (not flask_login.current_user.is_anonymous\n and flask_login.current_user.global_admin\n and flask_login.current_user.enabled):\n return \"\"\n return flask.abort(403)\n\[email protected](\"/auth/user\")\ndef user_authentication():\n \"\"\" Fails if the user is not authenticated.\n \"\"\"\n if (not flask_login.current_user.is_anonymous\n and flask_login.current_user.enabled):\n response = flask.Response()\n email = flask_login.current_user.get_id()\n response.headers[\"X-User\"] = models.IdnaEmail.process_bind_param(flask_login, email, \"\")\n response.headers[\"X-User-Token\"] = utils.gen_temp_token(email, flask.session)\n return response\n return flask.abort(403)\n\n\[email protected](\"/auth/basic\")\ndef basic_authentication():\n \"\"\" Tries to authenticate using the Authorization header.\n \"\"\"\n client_ip = flask.request.headers.get('X-Real-IP', flask.request.remote_addr)\n if utils.limiter.should_rate_limit_ip(client_ip):\n response = flask.Response(status=401)\n response.headers[\"WWW-Authenticate\"] = 'Basic realm=\"Authentication rate limit from one source exceeded\"'\n response.headers['Retry-After'] = '60'\n return response\n authorization = flask.request.headers.get(\"Authorization\")\n if authorization and authorization.startswith(\"Basic \"):\n encoded = authorization.replace(\"Basic \", \"\")\n user_email, password = base64.b64decode(encoded).split(b\":\", 1)\n user_email = user_email.decode(\"utf8\")\n if utils.limiter.should_rate_limit_user(user_email, client_ip):\n response = flask.Response(status=401)\n response.headers[\"WWW-Authenticate\"] = 'Basic realm=\"Authentication rate limit for this username exceeded\"'\n response.headers['Retry-After'] = '60'\n return response\n user = models.User.query.get(user_email)\n if user and nginx.check_credentials(user, password.decode('utf-8'), client_ip, \"web\"):\n response = flask.Response()\n response.headers[\"X-User\"] = models.IdnaEmail.process_bind_param(flask_login, user.email, \"\")\n utils.limiter.exempt_ip_from_ratelimits(client_ip)\n return response\n utils.limiter.rate_limit_user(user_email, client_ip) if user else utils.limiter.rate_limit_ip(client_ip)\n response = flask.Response(status=401)\n response.headers[\"WWW-Authenticate\"] = 'Basic realm=\"Login Required\"'\n return response\n", "path": "core/admin/mailu/internal/views/auth.py"}], "after_files": [{"content": "from mailu import models, utils\nfrom mailu.internal import internal, nginx\nfrom flask import current_app as app\n\nimport flask\nimport flask_login\nimport base64\n\[email protected](\"/auth/email\")\ndef nginx_authentication():\n \"\"\" Main authentication endpoint for Nginx email server\n \"\"\"\n client_ip = flask.request.headers[\"Client-Ip\"]\n headers = flask.request.headers\n if headers[\"Auth-Port\"] == '25' and headers['Auth-Method'] != 'none':\n response = flask.Response()\n response.headers['Auth-Status'] = 'AUTH not supported'\n response.headers['Auth-Error-Code'] = '502 5.5.1'\n utils.limiter.rate_limit_ip(client_ip)\n return response\n is_from_webmail = headers['Auth-Port'] in ['10143', '10025']\n if not is_from_webmail and utils.limiter.should_rate_limit_ip(client_ip):\n status, code = nginx.get_status(flask.request.headers['Auth-Protocol'], 'ratelimit')\n response = flask.Response()\n response.headers['Auth-Status'] = status\n response.headers['Auth-Error-Code'] = code\n if int(flask.request.headers['Auth-Login-Attempt']) < 10:\n response.headers['Auth-Wait'] = '3'\n return response\n headers = nginx.handle_authentication(flask.request.headers)\n response = flask.Response()\n for key, value in headers.items():\n response.headers[key] = str(value)\n is_valid_user = False\n if response.headers.get(\"Auth-User-Exists\"):\n username = response.headers[\"Auth-User\"]\n if utils.limiter.should_rate_limit_user(username, client_ip):\n # FIXME could be done before handle_authentication()\n status, code = nginx.get_status(flask.request.headers['Auth-Protocol'], 'ratelimit')\n response = flask.Response()\n response.headers['Auth-Status'] = status\n response.headers['Auth-Error-Code'] = code\n if int(flask.request.headers['Auth-Login-Attempt']) < 10:\n response.headers['Auth-Wait'] = '3'\n return response\n is_valid_user = True\n if headers.get(\"Auth-Status\") == \"OK\":\n utils.limiter.exempt_ip_from_ratelimits(client_ip)\n elif is_valid_user:\n utils.limiter.rate_limit_user(username, client_ip)\n elif not is_from_webmail:\n utils.limiter.rate_limit_ip(client_ip)\n return response\n\[email protected](\"/auth/admin\")\ndef admin_authentication():\n \"\"\" Fails if the user is not an authenticated admin.\n \"\"\"\n if (not flask_login.current_user.is_anonymous\n and flask_login.current_user.global_admin\n and flask_login.current_user.enabled):\n return \"\"\n return flask.abort(403)\n\[email protected](\"/auth/user\")\ndef user_authentication():\n \"\"\" Fails if the user is not authenticated.\n \"\"\"\n if (not flask_login.current_user.is_anonymous\n and flask_login.current_user.enabled):\n response = flask.Response()\n email = flask_login.current_user.get_id()\n response.headers[\"X-User\"] = models.IdnaEmail.process_bind_param(flask_login, email, \"\")\n response.headers[\"X-User-Token\"] = utils.gen_temp_token(email, flask.session)\n return response\n return flask.abort(403)\n\n\[email protected](\"/auth/basic\")\ndef basic_authentication():\n \"\"\" Tries to authenticate using the Authorization header.\n \"\"\"\n client_ip = flask.request.headers.get('X-Real-IP', flask.request.remote_addr)\n if utils.limiter.should_rate_limit_ip(client_ip):\n response = flask.Response(status=401)\n response.headers[\"WWW-Authenticate\"] = 'Basic realm=\"Authentication rate limit from one source exceeded\"'\n response.headers['Retry-After'] = '60'\n return response\n authorization = flask.request.headers.get(\"Authorization\")\n if authorization and authorization.startswith(\"Basic \"):\n encoded = authorization.replace(\"Basic \", \"\")\n user_email, password = base64.b64decode(encoded).split(b\":\", 1)\n user_email = user_email.decode(\"utf8\")\n if utils.limiter.should_rate_limit_user(user_email, client_ip):\n response = flask.Response(status=401)\n response.headers[\"WWW-Authenticate\"] = 'Basic realm=\"Authentication rate limit for this username exceeded\"'\n response.headers['Retry-After'] = '60'\n return response\n user = models.User.query.get(user_email)\n if user and nginx.check_credentials(user, password.decode('utf-8'), client_ip, \"web\"):\n response = flask.Response()\n response.headers[\"X-User\"] = models.IdnaEmail.process_bind_param(flask_login, user.email, \"\")\n utils.limiter.exempt_ip_from_ratelimits(client_ip)\n return response\n utils.limiter.rate_limit_user(user_email, client_ip) if user else utils.limiter.rate_limit_ip(client_ip)\n response = flask.Response(status=401)\n response.headers[\"WWW-Authenticate\"] = 'Basic realm=\"Login Required\"'\n return response\n", "path": "core/admin/mailu/internal/views/auth.py"}]} | 2,401 | 158 |
gh_patches_debug_2054 | rasdani/github-patches | git_diff | carpentries__amy-770 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Names show up multiple times in assignment pulldown
1. Go to an event.
2. Try to assign to assign to someone other than yourself.
3. Selection dialog with pulldown appears so that you can choose person.
4. Some names (currently Greg Wilson and Tracy Teal, possibly others) show up multiple times in that list.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `workshops/lookups.py`
Content:
```
1 from functools import reduce
2 import operator
3 import re
4
5 from django.contrib.auth.models import Group
6 from django.db.models import Q
7
8 from selectable.base import ModelLookup
9 from selectable.registry import registry
10 from selectable.decorators import login_required
11
12 from workshops import models
13
14
15 @login_required
16 class EventLookup(ModelLookup):
17 model = models.Event
18 search_fields = ('slug__icontains', )
19
20
21 @login_required
22 class HostLookup(ModelLookup):
23 model = models.Host
24 search_fields = (
25 'domain__icontains',
26 'fullname__icontains'
27 )
28
29
30 @login_required
31 class PersonLookup(ModelLookup):
32 model = models.Person
33 search_fields = (
34 'personal__icontains',
35 'family__icontains',
36 'email__icontains',
37 'username__icontains'
38 )
39
40 def get_query(self, request, term):
41 """Override this method to allow for additional lookup method: """
42 # original code from selectable.base.ModelLookup.get_query:
43 qs = self.get_queryset()
44 if term:
45 search_filters = []
46 if self.search_fields:
47 for field in self.search_fields:
48 search_filters.append(Q(**{field: term}))
49
50 # tokenizing part
51 tokens = re.split('\s+', term)
52 if len(tokens) == 2:
53 name1, name2 = tokens
54 complex_q = (
55 Q(personal__icontains=name1) & Q(family__icontains=name2)
56 ) | (
57 Q(personal__icontains=name2) & Q(family__icontains=name1)
58 )
59 search_filters.append(complex_q)
60
61 # this is brilliant: it applies OR to all search filters
62 qs = qs.filter(reduce(operator.or_, search_filters))
63
64 return qs
65
66
67 @login_required
68 class AdminLookup(ModelLookup):
69 """The same as PersonLookup, but allows only to select administrators.
70
71 Administrator is anyone with superuser power or in "administrators" group.
72 """
73 model = models.Person
74 search_fields = (
75 'personal__icontains',
76 'family__icontains',
77 'email__icontains',
78 'username__icontains'
79 )
80
81 def get_query(self, request, term):
82 results = super().get_query(request, term)
83 admin_group = Group.objects.get(name='administrators')
84 results = results.filter(
85 Q(is_superuser=True) | Q(groups__in=[admin_group])
86 )
87 return results
88
89
90 @login_required
91 class AirportLookup(ModelLookup):
92 model = models.Airport
93 search_fields = (
94 'iata__icontains',
95 'fullname__icontains'
96 )
97
98
99 registry.register(EventLookup)
100 registry.register(HostLookup)
101 registry.register(PersonLookup)
102 registry.register(AdminLookup)
103 registry.register(AirportLookup)
104
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/workshops/lookups.py b/workshops/lookups.py
--- a/workshops/lookups.py
+++ b/workshops/lookups.py
@@ -83,7 +83,7 @@
admin_group = Group.objects.get(name='administrators')
results = results.filter(
Q(is_superuser=True) | Q(groups__in=[admin_group])
- )
+ ).distinct()
return results
| {"golden_diff": "diff --git a/workshops/lookups.py b/workshops/lookups.py\n--- a/workshops/lookups.py\n+++ b/workshops/lookups.py\n@@ -83,7 +83,7 @@\n admin_group = Group.objects.get(name='administrators')\n results = results.filter(\n Q(is_superuser=True) | Q(groups__in=[admin_group])\n- )\n+ ).distinct()\n return results\n", "issue": "Names show up multiple times in assignment pulldown\n1. Go to an event.\n2. Try to assign to assign to someone other than yourself.\n3. Selection dialog with pulldown appears so that you can choose person.\n4. Some names (currently Greg Wilson and Tracy Teal, possibly others) show up multiple times in that list.\n\n", "before_files": [{"content": "from functools import reduce\nimport operator\nimport re\n\nfrom django.contrib.auth.models import Group\nfrom django.db.models import Q\n\nfrom selectable.base import ModelLookup\nfrom selectable.registry import registry\nfrom selectable.decorators import login_required\n\nfrom workshops import models\n\n\n@login_required\nclass EventLookup(ModelLookup):\n model = models.Event\n search_fields = ('slug__icontains', )\n\n\n@login_required\nclass HostLookup(ModelLookup):\n model = models.Host\n search_fields = (\n 'domain__icontains',\n 'fullname__icontains'\n )\n\n\n@login_required\nclass PersonLookup(ModelLookup):\n model = models.Person\n search_fields = (\n 'personal__icontains',\n 'family__icontains',\n 'email__icontains',\n 'username__icontains'\n )\n\n def get_query(self, request, term):\n \"\"\"Override this method to allow for additional lookup method: \"\"\"\n # original code from selectable.base.ModelLookup.get_query:\n qs = self.get_queryset()\n if term:\n search_filters = []\n if self.search_fields:\n for field in self.search_fields:\n search_filters.append(Q(**{field: term}))\n\n # tokenizing part\n tokens = re.split('\\s+', term)\n if len(tokens) == 2:\n name1, name2 = tokens\n complex_q = (\n Q(personal__icontains=name1) & Q(family__icontains=name2)\n ) | (\n Q(personal__icontains=name2) & Q(family__icontains=name1)\n )\n search_filters.append(complex_q)\n\n # this is brilliant: it applies OR to all search filters\n qs = qs.filter(reduce(operator.or_, search_filters))\n\n return qs\n\n\n@login_required\nclass AdminLookup(ModelLookup):\n \"\"\"The same as PersonLookup, but allows only to select administrators.\n\n Administrator is anyone with superuser power or in \"administrators\" group.\n \"\"\"\n model = models.Person\n search_fields = (\n 'personal__icontains',\n 'family__icontains',\n 'email__icontains',\n 'username__icontains'\n )\n\n def get_query(self, request, term):\n results = super().get_query(request, term)\n admin_group = Group.objects.get(name='administrators')\n results = results.filter(\n Q(is_superuser=True) | Q(groups__in=[admin_group])\n )\n return results\n\n\n@login_required\nclass AirportLookup(ModelLookup):\n model = models.Airport\n search_fields = (\n 'iata__icontains',\n 'fullname__icontains'\n )\n\n\nregistry.register(EventLookup)\nregistry.register(HostLookup)\nregistry.register(PersonLookup)\nregistry.register(AdminLookup)\nregistry.register(AirportLookup)\n", "path": "workshops/lookups.py"}], "after_files": [{"content": "from functools import reduce\nimport operator\nimport re\n\nfrom django.contrib.auth.models import Group\nfrom django.db.models import Q\n\nfrom selectable.base import ModelLookup\nfrom selectable.registry import registry\nfrom selectable.decorators import login_required\n\nfrom workshops import models\n\n\n@login_required\nclass EventLookup(ModelLookup):\n model = models.Event\n search_fields = ('slug__icontains', )\n\n\n@login_required\nclass HostLookup(ModelLookup):\n model = models.Host\n search_fields = (\n 'domain__icontains',\n 'fullname__icontains'\n )\n\n\n@login_required\nclass PersonLookup(ModelLookup):\n model = models.Person\n search_fields = (\n 'personal__icontains',\n 'family__icontains',\n 'email__icontains',\n 'username__icontains'\n )\n\n def get_query(self, request, term):\n \"\"\"Override this method to allow for additional lookup method: \"\"\"\n # original code from selectable.base.ModelLookup.get_query:\n qs = self.get_queryset()\n if term:\n search_filters = []\n if self.search_fields:\n for field in self.search_fields:\n search_filters.append(Q(**{field: term}))\n\n # tokenizing part\n tokens = re.split('\\s+', term)\n if len(tokens) == 2:\n name1, name2 = tokens\n complex_q = (\n Q(personal__icontains=name1) & Q(family__icontains=name2)\n ) | (\n Q(personal__icontains=name2) & Q(family__icontains=name1)\n )\n search_filters.append(complex_q)\n\n # this is brilliant: it applies OR to all search filters\n qs = qs.filter(reduce(operator.or_, search_filters))\n\n return qs\n\n\n@login_required\nclass AdminLookup(ModelLookup):\n \"\"\"The same as PersonLookup, but allows only to select administrators.\n\n Administrator is anyone with superuser power or in \"administrators\" group.\n \"\"\"\n model = models.Person\n search_fields = (\n 'personal__icontains',\n 'family__icontains',\n 'email__icontains',\n 'username__icontains'\n )\n\n def get_query(self, request, term):\n results = super().get_query(request, term)\n admin_group = Group.objects.get(name='administrators')\n results = results.filter(\n Q(is_superuser=True) | Q(groups__in=[admin_group])\n ).distinct()\n return results\n\n\n@login_required\nclass AirportLookup(ModelLookup):\n model = models.Airport\n search_fields = (\n 'iata__icontains',\n 'fullname__icontains'\n )\n\n\nregistry.register(EventLookup)\nregistry.register(HostLookup)\nregistry.register(PersonLookup)\nregistry.register(AdminLookup)\nregistry.register(AirportLookup)\n", "path": "workshops/lookups.py"}]} | 1,118 | 93 |
gh_patches_debug_21780 | rasdani/github-patches | git_diff | tensorflow__tfx-1580 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Code formatting can affect the semantic behavior of tfx pipelines (DagRunner not being registered)
https://github.com/tensorflow/tfx/blob/bfbc9587c568c1247f6a6cfb59db161ed3a4970c/tfx/tools/cli/handler/base_handler.py#L106-L117
The referenced code is where the issue happens.
As can be seen, it checks for existence of a `KubeflowDagRunner(...)` in the contents, but that's a naive assumption since the opening and closing parenthesis can be in separate lines and in that case the regex won't match.
### Steps to reproduce the issue:
The following piece of code _works just fine_.
```python
kf_config = KubeflowDagRunnerConfig(
kubeflow_metadata_config=kf_metadata,
tfx_image=os.environ.get("KUBEFLOW_TFX_IMAGE", None),
)
KubeflowDagRunner(config=kf_config)
```
The following piece of code though, _fails_ with **_kubeflow runner not found in dsl._**
```python
KubeflowDagRunner(
config=KubeflowDagRunnerConfig(
kubeflow_metadata_config=kf_metadata,
tfx_image=os.environ.get("KUBEFLOW_TFX_IMAGE", None),
)
)
```
Output of the `tfx pipeline create` cli command is as follows:
```
CLI
Updating pipeline
Detected Kubeflow.
Use --engine flag if you intend to use a different orchestrator.
Reading build spec from build.yaml
Use skaffold to build the container image.
/usr/local/bin/skaffold
kubeflow runner not found in dsl.
New container image is built. Target image is available in the build spec file.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tfx/tools/cli/handler/base_handler.py`
Content:
```
1 # Lint as: python2, python3
2 # Copyright 2019 Google LLC. All Rights Reserved.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 """Base handler class."""
16
17 from __future__ import absolute_import
18 from __future__ import division
19 from __future__ import print_function
20
21 import abc
22 import json
23 import os
24 import re
25 import subprocess
26 import sys
27 import tempfile
28 from typing import Any, Dict, List, Text
29
30 import click
31 from six import with_metaclass
32 import tensorflow as tf
33
34 from tfx.tools.cli import labels
35 from tfx.utils import io_utils
36
37
38 class BaseHandler(with_metaclass(abc.ABCMeta, object)):
39 """Base Handler for CLI.
40
41 Attributes:
42 flags_dict: A dictionary with flags provided in a command.
43 """
44
45 def __init__(self, flags_dict: Dict[Text, Any]):
46 self.flags_dict = flags_dict
47 self._handler_home_dir = self._get_handler_home()
48
49 @abc.abstractmethod
50 def create_pipeline(self) -> None:
51 """Creates pipeline for the handler."""
52 pass
53
54 @abc.abstractmethod
55 def update_pipeline(self) -> None:
56 """Updates pipeline for the handler."""
57 pass
58
59 @abc.abstractmethod
60 def list_pipelines(self) -> None:
61 """List all the pipelines in the environment."""
62 pass
63
64 @abc.abstractmethod
65 def delete_pipeline(self) -> None:
66 """Deletes pipeline for the handler."""
67 pass
68
69 @abc.abstractmethod
70 def compile_pipeline(self) -> None:
71 """Compiles pipeline for the handler."""
72 pass
73
74 @abc.abstractmethod
75 def create_run(self) -> None:
76 """Runs a pipeline for the handler."""
77 pass
78
79 @abc.abstractmethod
80 def delete_run(self) -> None:
81 """Deletes a run."""
82 pass
83
84 @abc.abstractmethod
85 def terminate_run(self) -> None:
86 """Stops a run."""
87 pass
88
89 @abc.abstractmethod
90 def list_runs(self) -> None:
91 """Lists all runs of a pipeline."""
92 pass
93
94 @abc.abstractmethod
95 def get_run(self) -> None:
96 """Checks run status."""
97 pass
98
99 def _check_pipeline_dsl_path(self) -> None:
100 """Check if pipeline dsl path exists."""
101 pipeline_dsl_path = self.flags_dict[labels.PIPELINE_DSL_PATH]
102 if not tf.io.gfile.exists(pipeline_dsl_path):
103 sys.exit('Invalid pipeline path: {}'.format(pipeline_dsl_path))
104
105 def _check_dsl_runner(self) -> None:
106 """Check if runner in dsl is same as engine flag."""
107 engine_flag = self.flags_dict[labels.ENGINE_FLAG]
108 with open(self.flags_dict[labels.PIPELINE_DSL_PATH], 'r') as f:
109 dsl_contents = f.read()
110 regexes = {
111 labels.AIRFLOW_ENGINE: r'AirflowDagRunner\(.*\)',
112 labels.KUBEFLOW_ENGINE: r'KubeflowDagRunner\(.*\)',
113 labels.BEAM_ENGINE: r'BeamDagRunner\(.*\)'
114 }
115 match = re.search(regexes[engine_flag], dsl_contents)
116 if not match:
117 sys.exit('{} runner not found in dsl.'.format(engine_flag))
118
119 def _extract_pipeline_args(self) -> Dict[Text, Any]:
120 """Get pipeline args from the DSL.
121
122 Returns:
123 Python dictionary with pipeline details extracted from DSL.
124 """
125 pipeline_dsl_path = self.flags_dict[labels.PIPELINE_DSL_PATH]
126 if os.path.isdir(pipeline_dsl_path):
127 sys.exit('Provide dsl file path.')
128
129 # Create an environment for subprocess.
130 temp_env = os.environ.copy()
131
132 # Create temp file to store pipeline_args from pipeline dsl.
133 temp_file = tempfile.mkstemp(prefix='cli_tmp_', suffix='_pipeline_args')[1]
134
135 # Store temp_file path in temp_env.
136 temp_env[labels.TFX_JSON_EXPORT_PIPELINE_ARGS_PATH] = temp_file
137
138 # Mark the SDK environment if not in a template.
139 if 'pipelines.kubeflow.org/pipeline-sdk-type' not in temp_env:
140 temp_env['pipelines.kubeflow.org/pipeline-sdk-type'] = 'tfx-cli'
141
142 # Run dsl with mock environment to store pipeline args in temp_file.
143 self._subprocess_call([sys.executable, pipeline_dsl_path], env=temp_env)
144 if os.stat(temp_file).st_size != 0:
145 # Load pipeline_args from temp_file for TFX pipelines
146 with open(temp_file, 'r') as f:
147 pipeline_args = json.load(f)
148 else:
149 # For non-TFX pipelines, extract pipeline name from the dsl filename.
150 pipeline_args = {
151 labels.PIPELINE_NAME:
152 os.path.basename(pipeline_dsl_path).split('.')[0]
153 }
154
155 # Delete temp file
156 io_utils.delete_dir(temp_file)
157
158 return pipeline_args
159
160 def _get_handler_home(self) -> Text:
161 """Sets handler home.
162
163 Returns:
164 Path to handler home directory.
165 """
166 engine_flag = self.flags_dict[labels.ENGINE_FLAG]
167 handler_home_dir = engine_flag.upper() + '_HOME'
168 if handler_home_dir in os.environ:
169 return os.environ[handler_home_dir]
170 return os.path.join(os.environ['HOME'], engine_flag, '')
171
172 def _subprocess_call(self,
173 command: List[Text],
174 env: Dict[Text, Any] = None) -> None:
175 return_code = subprocess.call(command, env=env)
176 if return_code != 0:
177 sys.exit('Error while running "{}" '.format(' '.join(command)))
178
179 def _check_pipeline_existence(self,
180 pipeline_name: Text,
181 required: bool = True) -> None:
182 """Check if pipeline folder exists and if not, exit system.
183
184 Args:
185 pipeline_name: Name of the pipeline.
186 required: Set it as True if pipeline needs to exist else set it to False.
187 """
188 handler_pipeline_path = os.path.join(self._handler_home_dir, pipeline_name,
189 '')
190 # Check if pipeline folder exists.
191 exists = tf.io.gfile.exists(handler_pipeline_path)
192 if required and not exists:
193 sys.exit('Pipeline "{}" does not exist.'.format(pipeline_name))
194 elif not required and exists:
195 sys.exit('Pipeline "{}" already exists.'.format(pipeline_name))
196
197 def get_schema(self):
198 pipeline_name = self.flags_dict[labels.PIPELINE_NAME]
199
200 # Check if pipeline exists.
201 self._check_pipeline_existence(pipeline_name)
202
203 # Path to pipeline args.
204 pipeline_args_path = os.path.join(self._handler_home_dir,
205 self.flags_dict[labels.PIPELINE_NAME],
206 'pipeline_args.json')
207
208 # Get pipeline_root.
209 with open(pipeline_args_path, 'r') as f:
210 pipeline_args = json.load(f)
211
212 # Check if pipeline root created. If not, it means that the user has not
213 # created a run yet or the pipeline is still running for the first time.
214 pipeline_root = pipeline_args[labels.PIPELINE_ROOT]
215 if not tf.io.gfile.exists(pipeline_root):
216 sys.exit(
217 'Create a run before inferring schema. If pipeline is already running, then wait for it to successfully finish.'
218 )
219
220 # If pipeline_root exists, then check if SchemaGen output exists.
221 components = tf.io.gfile.listdir(pipeline_root)
222 if 'SchemaGen' not in components:
223 sys.exit(
224 'Either SchemaGen component does not exist or pipeline is still running. If pipeline is running, then wait for it to successfully finish.'
225 )
226
227 # Get the latest SchemaGen output.
228 schemagen_outputs = tf.io.gfile.listdir(
229 os.path.join(pipeline_root, 'SchemaGen', 'schema', ''))
230 latest_schema_folder = max(schemagen_outputs, key=int)
231
232 # Copy schema to current dir.
233 latest_schema_path = os.path.join(pipeline_root, 'SchemaGen', 'schema',
234 latest_schema_folder, 'schema.pbtxt')
235 curr_dir_path = os.path.join(os.getcwd(), 'schema.pbtxt')
236 io_utils.copy_file(latest_schema_path, curr_dir_path, overwrite=True)
237
238 # Print schema and path to schema
239 click.echo('Path to schema: {}'.format(curr_dir_path))
240 click.echo('*********SCHEMA FOR {}**********'.format(pipeline_name.upper()))
241 with open(curr_dir_path, 'r') as f:
242 click.echo(f.read())
243
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/tfx/tools/cli/handler/base_handler.py b/tfx/tools/cli/handler/base_handler.py
--- a/tfx/tools/cli/handler/base_handler.py
+++ b/tfx/tools/cli/handler/base_handler.py
@@ -21,7 +21,6 @@
import abc
import json
import os
-import re
import subprocess
import sys
import tempfile
@@ -107,13 +106,12 @@
engine_flag = self.flags_dict[labels.ENGINE_FLAG]
with open(self.flags_dict[labels.PIPELINE_DSL_PATH], 'r') as f:
dsl_contents = f.read()
- regexes = {
- labels.AIRFLOW_ENGINE: r'AirflowDagRunner\(.*\)',
- labels.KUBEFLOW_ENGINE: r'KubeflowDagRunner\(.*\)',
- labels.BEAM_ENGINE: r'BeamDagRunner\(.*\)'
+ runner_names = {
+ labels.AIRFLOW_ENGINE: 'AirflowDagRunner',
+ labels.KUBEFLOW_ENGINE: 'KubeflowDagRunner',
+ labels.BEAM_ENGINE: 'BeamDagRunner',
}
- match = re.search(regexes[engine_flag], dsl_contents)
- if not match:
+ if runner_names[engine_flag] not in dsl_contents:
sys.exit('{} runner not found in dsl.'.format(engine_flag))
def _extract_pipeline_args(self) -> Dict[Text, Any]:
| {"golden_diff": "diff --git a/tfx/tools/cli/handler/base_handler.py b/tfx/tools/cli/handler/base_handler.py\n--- a/tfx/tools/cli/handler/base_handler.py\n+++ b/tfx/tools/cli/handler/base_handler.py\n@@ -21,7 +21,6 @@\n import abc\n import json\n import os\n-import re\n import subprocess\n import sys\n import tempfile\n@@ -107,13 +106,12 @@\n engine_flag = self.flags_dict[labels.ENGINE_FLAG]\n with open(self.flags_dict[labels.PIPELINE_DSL_PATH], 'r') as f:\n dsl_contents = f.read()\n- regexes = {\n- labels.AIRFLOW_ENGINE: r'AirflowDagRunner\\(.*\\)',\n- labels.KUBEFLOW_ENGINE: r'KubeflowDagRunner\\(.*\\)',\n- labels.BEAM_ENGINE: r'BeamDagRunner\\(.*\\)'\n+ runner_names = {\n+ labels.AIRFLOW_ENGINE: 'AirflowDagRunner',\n+ labels.KUBEFLOW_ENGINE: 'KubeflowDagRunner',\n+ labels.BEAM_ENGINE: 'BeamDagRunner',\n }\n- match = re.search(regexes[engine_flag], dsl_contents)\n- if not match:\n+ if runner_names[engine_flag] not in dsl_contents:\n sys.exit('{} runner not found in dsl.'.format(engine_flag))\n \n def _extract_pipeline_args(self) -> Dict[Text, Any]:\n", "issue": "Code formatting can affect the semantic behavior of tfx pipelines (DagRunner not being registered)\nhttps://github.com/tensorflow/tfx/blob/bfbc9587c568c1247f6a6cfb59db161ed3a4970c/tfx/tools/cli/handler/base_handler.py#L106-L117\r\n\r\nThe referenced code is where the issue happens.\r\n\r\nAs can be seen, it checks for existence of a `KubeflowDagRunner(...)` in the contents, but that's a naive assumption since the opening and closing parenthesis can be in separate lines and in that case the regex won't match.\r\n\r\n### Steps to reproduce the issue:\r\nThe following piece of code _works just fine_.\r\n```python\r\n kf_config = KubeflowDagRunnerConfig(\r\n kubeflow_metadata_config=kf_metadata,\r\n tfx_image=os.environ.get(\"KUBEFLOW_TFX_IMAGE\", None),\r\n )\r\n\r\nKubeflowDagRunner(config=kf_config)\r\n```\r\n\r\nThe following piece of code though, _fails_ with **_kubeflow runner not found in dsl._**\r\n```python\r\nKubeflowDagRunner(\r\n config=KubeflowDagRunnerConfig(\r\n kubeflow_metadata_config=kf_metadata,\r\n tfx_image=os.environ.get(\"KUBEFLOW_TFX_IMAGE\", None),\r\n )\r\n)\r\n```\r\n\r\nOutput of the `tfx pipeline create` cli command is as follows:\r\n```\r\nCLI\r\nUpdating pipeline\r\nDetected Kubeflow.\r\nUse --engine flag if you intend to use a different orchestrator.\r\nReading build spec from build.yaml\r\nUse skaffold to build the container image.\r\n/usr/local/bin/skaffold\r\nkubeflow runner not found in dsl.\r\nNew container image is built. Target image is available in the build spec file.\r\n```\r\n\r\n\n", "before_files": [{"content": "# Lint as: python2, python3\n# Copyright 2019 Google LLC. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Base handler class.\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport abc\nimport json\nimport os\nimport re\nimport subprocess\nimport sys\nimport tempfile\nfrom typing import Any, Dict, List, Text\n\nimport click\nfrom six import with_metaclass\nimport tensorflow as tf\n\nfrom tfx.tools.cli import labels\nfrom tfx.utils import io_utils\n\n\nclass BaseHandler(with_metaclass(abc.ABCMeta, object)):\n \"\"\"Base Handler for CLI.\n\n Attributes:\n flags_dict: A dictionary with flags provided in a command.\n \"\"\"\n\n def __init__(self, flags_dict: Dict[Text, Any]):\n self.flags_dict = flags_dict\n self._handler_home_dir = self._get_handler_home()\n\n @abc.abstractmethod\n def create_pipeline(self) -> None:\n \"\"\"Creates pipeline for the handler.\"\"\"\n pass\n\n @abc.abstractmethod\n def update_pipeline(self) -> None:\n \"\"\"Updates pipeline for the handler.\"\"\"\n pass\n\n @abc.abstractmethod\n def list_pipelines(self) -> None:\n \"\"\"List all the pipelines in the environment.\"\"\"\n pass\n\n @abc.abstractmethod\n def delete_pipeline(self) -> None:\n \"\"\"Deletes pipeline for the handler.\"\"\"\n pass\n\n @abc.abstractmethod\n def compile_pipeline(self) -> None:\n \"\"\"Compiles pipeline for the handler.\"\"\"\n pass\n\n @abc.abstractmethod\n def create_run(self) -> None:\n \"\"\"Runs a pipeline for the handler.\"\"\"\n pass\n\n @abc.abstractmethod\n def delete_run(self) -> None:\n \"\"\"Deletes a run.\"\"\"\n pass\n\n @abc.abstractmethod\n def terminate_run(self) -> None:\n \"\"\"Stops a run.\"\"\"\n pass\n\n @abc.abstractmethod\n def list_runs(self) -> None:\n \"\"\"Lists all runs of a pipeline.\"\"\"\n pass\n\n @abc.abstractmethod\n def get_run(self) -> None:\n \"\"\"Checks run status.\"\"\"\n pass\n\n def _check_pipeline_dsl_path(self) -> None:\n \"\"\"Check if pipeline dsl path exists.\"\"\"\n pipeline_dsl_path = self.flags_dict[labels.PIPELINE_DSL_PATH]\n if not tf.io.gfile.exists(pipeline_dsl_path):\n sys.exit('Invalid pipeline path: {}'.format(pipeline_dsl_path))\n\n def _check_dsl_runner(self) -> None:\n \"\"\"Check if runner in dsl is same as engine flag.\"\"\"\n engine_flag = self.flags_dict[labels.ENGINE_FLAG]\n with open(self.flags_dict[labels.PIPELINE_DSL_PATH], 'r') as f:\n dsl_contents = f.read()\n regexes = {\n labels.AIRFLOW_ENGINE: r'AirflowDagRunner\\(.*\\)',\n labels.KUBEFLOW_ENGINE: r'KubeflowDagRunner\\(.*\\)',\n labels.BEAM_ENGINE: r'BeamDagRunner\\(.*\\)'\n }\n match = re.search(regexes[engine_flag], dsl_contents)\n if not match:\n sys.exit('{} runner not found in dsl.'.format(engine_flag))\n\n def _extract_pipeline_args(self) -> Dict[Text, Any]:\n \"\"\"Get pipeline args from the DSL.\n\n Returns:\n Python dictionary with pipeline details extracted from DSL.\n \"\"\"\n pipeline_dsl_path = self.flags_dict[labels.PIPELINE_DSL_PATH]\n if os.path.isdir(pipeline_dsl_path):\n sys.exit('Provide dsl file path.')\n\n # Create an environment for subprocess.\n temp_env = os.environ.copy()\n\n # Create temp file to store pipeline_args from pipeline dsl.\n temp_file = tempfile.mkstemp(prefix='cli_tmp_', suffix='_pipeline_args')[1]\n\n # Store temp_file path in temp_env.\n temp_env[labels.TFX_JSON_EXPORT_PIPELINE_ARGS_PATH] = temp_file\n\n # Mark the SDK environment if not in a template.\n if 'pipelines.kubeflow.org/pipeline-sdk-type' not in temp_env:\n temp_env['pipelines.kubeflow.org/pipeline-sdk-type'] = 'tfx-cli'\n\n # Run dsl with mock environment to store pipeline args in temp_file.\n self._subprocess_call([sys.executable, pipeline_dsl_path], env=temp_env)\n if os.stat(temp_file).st_size != 0:\n # Load pipeline_args from temp_file for TFX pipelines\n with open(temp_file, 'r') as f:\n pipeline_args = json.load(f)\n else:\n # For non-TFX pipelines, extract pipeline name from the dsl filename.\n pipeline_args = {\n labels.PIPELINE_NAME:\n os.path.basename(pipeline_dsl_path).split('.')[0]\n }\n\n # Delete temp file\n io_utils.delete_dir(temp_file)\n\n return pipeline_args\n\n def _get_handler_home(self) -> Text:\n \"\"\"Sets handler home.\n\n Returns:\n Path to handler home directory.\n \"\"\"\n engine_flag = self.flags_dict[labels.ENGINE_FLAG]\n handler_home_dir = engine_flag.upper() + '_HOME'\n if handler_home_dir in os.environ:\n return os.environ[handler_home_dir]\n return os.path.join(os.environ['HOME'], engine_flag, '')\n\n def _subprocess_call(self,\n command: List[Text],\n env: Dict[Text, Any] = None) -> None:\n return_code = subprocess.call(command, env=env)\n if return_code != 0:\n sys.exit('Error while running \"{}\" '.format(' '.join(command)))\n\n def _check_pipeline_existence(self,\n pipeline_name: Text,\n required: bool = True) -> None:\n \"\"\"Check if pipeline folder exists and if not, exit system.\n\n Args:\n pipeline_name: Name of the pipeline.\n required: Set it as True if pipeline needs to exist else set it to False.\n \"\"\"\n handler_pipeline_path = os.path.join(self._handler_home_dir, pipeline_name,\n '')\n # Check if pipeline folder exists.\n exists = tf.io.gfile.exists(handler_pipeline_path)\n if required and not exists:\n sys.exit('Pipeline \"{}\" does not exist.'.format(pipeline_name))\n elif not required and exists:\n sys.exit('Pipeline \"{}\" already exists.'.format(pipeline_name))\n\n def get_schema(self):\n pipeline_name = self.flags_dict[labels.PIPELINE_NAME]\n\n # Check if pipeline exists.\n self._check_pipeline_existence(pipeline_name)\n\n # Path to pipeline args.\n pipeline_args_path = os.path.join(self._handler_home_dir,\n self.flags_dict[labels.PIPELINE_NAME],\n 'pipeline_args.json')\n\n # Get pipeline_root.\n with open(pipeline_args_path, 'r') as f:\n pipeline_args = json.load(f)\n\n # Check if pipeline root created. If not, it means that the user has not\n # created a run yet or the pipeline is still running for the first time.\n pipeline_root = pipeline_args[labels.PIPELINE_ROOT]\n if not tf.io.gfile.exists(pipeline_root):\n sys.exit(\n 'Create a run before inferring schema. If pipeline is already running, then wait for it to successfully finish.'\n )\n\n # If pipeline_root exists, then check if SchemaGen output exists.\n components = tf.io.gfile.listdir(pipeline_root)\n if 'SchemaGen' not in components:\n sys.exit(\n 'Either SchemaGen component does not exist or pipeline is still running. If pipeline is running, then wait for it to successfully finish.'\n )\n\n # Get the latest SchemaGen output.\n schemagen_outputs = tf.io.gfile.listdir(\n os.path.join(pipeline_root, 'SchemaGen', 'schema', ''))\n latest_schema_folder = max(schemagen_outputs, key=int)\n\n # Copy schema to current dir.\n latest_schema_path = os.path.join(pipeline_root, 'SchemaGen', 'schema',\n latest_schema_folder, 'schema.pbtxt')\n curr_dir_path = os.path.join(os.getcwd(), 'schema.pbtxt')\n io_utils.copy_file(latest_schema_path, curr_dir_path, overwrite=True)\n\n # Print schema and path to schema\n click.echo('Path to schema: {}'.format(curr_dir_path))\n click.echo('*********SCHEMA FOR {}**********'.format(pipeline_name.upper()))\n with open(curr_dir_path, 'r') as f:\n click.echo(f.read())\n", "path": "tfx/tools/cli/handler/base_handler.py"}], "after_files": [{"content": "# Lint as: python2, python3\n# Copyright 2019 Google LLC. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Base handler class.\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport abc\nimport json\nimport os\nimport subprocess\nimport sys\nimport tempfile\nfrom typing import Any, Dict, List, Text\n\nimport click\nfrom six import with_metaclass\nimport tensorflow as tf\n\nfrom tfx.tools.cli import labels\nfrom tfx.utils import io_utils\n\n\nclass BaseHandler(with_metaclass(abc.ABCMeta, object)):\n \"\"\"Base Handler for CLI.\n\n Attributes:\n flags_dict: A dictionary with flags provided in a command.\n \"\"\"\n\n def __init__(self, flags_dict: Dict[Text, Any]):\n self.flags_dict = flags_dict\n self._handler_home_dir = self._get_handler_home()\n\n @abc.abstractmethod\n def create_pipeline(self) -> None:\n \"\"\"Creates pipeline for the handler.\"\"\"\n pass\n\n @abc.abstractmethod\n def update_pipeline(self) -> None:\n \"\"\"Updates pipeline for the handler.\"\"\"\n pass\n\n @abc.abstractmethod\n def list_pipelines(self) -> None:\n \"\"\"List all the pipelines in the environment.\"\"\"\n pass\n\n @abc.abstractmethod\n def delete_pipeline(self) -> None:\n \"\"\"Deletes pipeline for the handler.\"\"\"\n pass\n\n @abc.abstractmethod\n def compile_pipeline(self) -> None:\n \"\"\"Compiles pipeline for the handler.\"\"\"\n pass\n\n @abc.abstractmethod\n def create_run(self) -> None:\n \"\"\"Runs a pipeline for the handler.\"\"\"\n pass\n\n @abc.abstractmethod\n def delete_run(self) -> None:\n \"\"\"Deletes a run.\"\"\"\n pass\n\n @abc.abstractmethod\n def terminate_run(self) -> None:\n \"\"\"Stops a run.\"\"\"\n pass\n\n @abc.abstractmethod\n def list_runs(self) -> None:\n \"\"\"Lists all runs of a pipeline.\"\"\"\n pass\n\n @abc.abstractmethod\n def get_run(self) -> None:\n \"\"\"Checks run status.\"\"\"\n pass\n\n def _check_pipeline_dsl_path(self) -> None:\n \"\"\"Check if pipeline dsl path exists.\"\"\"\n pipeline_dsl_path = self.flags_dict[labels.PIPELINE_DSL_PATH]\n if not tf.io.gfile.exists(pipeline_dsl_path):\n sys.exit('Invalid pipeline path: {}'.format(pipeline_dsl_path))\n\n def _check_dsl_runner(self) -> None:\n \"\"\"Check if runner in dsl is same as engine flag.\"\"\"\n engine_flag = self.flags_dict[labels.ENGINE_FLAG]\n with open(self.flags_dict[labels.PIPELINE_DSL_PATH], 'r') as f:\n dsl_contents = f.read()\n runner_names = {\n labels.AIRFLOW_ENGINE: 'AirflowDagRunner',\n labels.KUBEFLOW_ENGINE: 'KubeflowDagRunner',\n labels.BEAM_ENGINE: 'BeamDagRunner',\n }\n if runner_names[engine_flag] not in dsl_contents:\n sys.exit('{} runner not found in dsl.'.format(engine_flag))\n\n def _extract_pipeline_args(self) -> Dict[Text, Any]:\n \"\"\"Get pipeline args from the DSL.\n\n Returns:\n Python dictionary with pipeline details extracted from DSL.\n \"\"\"\n pipeline_dsl_path = self.flags_dict[labels.PIPELINE_DSL_PATH]\n if os.path.isdir(pipeline_dsl_path):\n sys.exit('Provide dsl file path.')\n\n # Create an environment for subprocess.\n temp_env = os.environ.copy()\n\n # Create temp file to store pipeline_args from pipeline dsl.\n temp_file = tempfile.mkstemp(prefix='cli_tmp_', suffix='_pipeline_args')[1]\n\n # Store temp_file path in temp_env.\n temp_env[labels.TFX_JSON_EXPORT_PIPELINE_ARGS_PATH] = temp_file\n\n # Mark the SDK environment if not in a template.\n if 'pipelines.kubeflow.org/pipeline-sdk-type' not in temp_env:\n temp_env['pipelines.kubeflow.org/pipeline-sdk-type'] = 'tfx-cli'\n\n # Run dsl with mock environment to store pipeline args in temp_file.\n self._subprocess_call([sys.executable, pipeline_dsl_path], env=temp_env)\n if os.stat(temp_file).st_size != 0:\n # Load pipeline_args from temp_file for TFX pipelines\n with open(temp_file, 'r') as f:\n pipeline_args = json.load(f)\n else:\n # For non-TFX pipelines, extract pipeline name from the dsl filename.\n pipeline_args = {\n labels.PIPELINE_NAME:\n os.path.basename(pipeline_dsl_path).split('.')[0]\n }\n\n # Delete temp file\n io_utils.delete_dir(temp_file)\n\n return pipeline_args\n\n def _get_handler_home(self) -> Text:\n \"\"\"Sets handler home.\n\n Returns:\n Path to handler home directory.\n \"\"\"\n engine_flag = self.flags_dict[labels.ENGINE_FLAG]\n handler_home_dir = engine_flag.upper() + '_HOME'\n if handler_home_dir in os.environ:\n return os.environ[handler_home_dir]\n return os.path.join(os.environ['HOME'], engine_flag, '')\n\n def _subprocess_call(self,\n command: List[Text],\n env: Dict[Text, Any] = None) -> None:\n return_code = subprocess.call(command, env=env)\n if return_code != 0:\n sys.exit('Error while running \"{}\" '.format(' '.join(command)))\n\n def _check_pipeline_existence(self,\n pipeline_name: Text,\n required: bool = True) -> None:\n \"\"\"Check if pipeline folder exists and if not, exit system.\n\n Args:\n pipeline_name: Name of the pipeline.\n required: Set it as True if pipeline needs to exist else set it to False.\n \"\"\"\n handler_pipeline_path = os.path.join(self._handler_home_dir, pipeline_name,\n '')\n # Check if pipeline folder exists.\n exists = tf.io.gfile.exists(handler_pipeline_path)\n if required and not exists:\n sys.exit('Pipeline \"{}\" does not exist.'.format(pipeline_name))\n elif not required and exists:\n sys.exit('Pipeline \"{}\" already exists.'.format(pipeline_name))\n\n def get_schema(self):\n pipeline_name = self.flags_dict[labels.PIPELINE_NAME]\n\n # Check if pipeline exists.\n self._check_pipeline_existence(pipeline_name)\n\n # Path to pipeline args.\n pipeline_args_path = os.path.join(self._handler_home_dir,\n self.flags_dict[labels.PIPELINE_NAME],\n 'pipeline_args.json')\n\n # Get pipeline_root.\n with open(pipeline_args_path, 'r') as f:\n pipeline_args = json.load(f)\n\n # Check if pipeline root created. If not, it means that the user has not\n # created a run yet or the pipeline is still running for the first time.\n pipeline_root = pipeline_args[labels.PIPELINE_ROOT]\n if not tf.io.gfile.exists(pipeline_root):\n sys.exit(\n 'Create a run before inferring schema. If pipeline is already running, then wait for it to successfully finish.'\n )\n\n # If pipeline_root exists, then check if SchemaGen output exists.\n components = tf.io.gfile.listdir(pipeline_root)\n if 'SchemaGen' not in components:\n sys.exit(\n 'Either SchemaGen component does not exist or pipeline is still running. If pipeline is running, then wait for it to successfully finish.'\n )\n\n # Get the latest SchemaGen output.\n schemagen_outputs = tf.io.gfile.listdir(\n os.path.join(pipeline_root, 'SchemaGen', 'schema', ''))\n latest_schema_folder = max(schemagen_outputs, key=int)\n\n # Copy schema to current dir.\n latest_schema_path = os.path.join(pipeline_root, 'SchemaGen', 'schema',\n latest_schema_folder, 'schema.pbtxt')\n curr_dir_path = os.path.join(os.getcwd(), 'schema.pbtxt')\n io_utils.copy_file(latest_schema_path, curr_dir_path, overwrite=True)\n\n # Print schema and path to schema\n click.echo('Path to schema: {}'.format(curr_dir_path))\n click.echo('*********SCHEMA FOR {}**********'.format(pipeline_name.upper()))\n with open(curr_dir_path, 'r') as f:\n click.echo(f.read())\n", "path": "tfx/tools/cli/handler/base_handler.py"}]} | 3,245 | 326 |
gh_patches_debug_26661 | rasdani/github-patches | git_diff | koxudaxi__datamodel-code-generator-1942 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
msgspec: Optional fields are missing a default when using `--snake-case-field`
### Steps to reproduce
1. Download the NVD CVE [schema][schema]
2. Generate a msgpsec model:
```sh
datamodel-codegen \
--input $schema_json \
--input-file-type jsonschema \
--output-model-type 'msgspec.Struct' \
# This is important I think
--snake-case-field \
--output "."
```
3. (Ignore the circular imports #836)
4. (Ignore wrong field ordering #1919
5. Look at the `class CpeMatch` (and most other classes as well).
```python
class CpeMatch(Struct, kw_only=True):
vulnerable: bool
criteria: str
match_criteria_id: str = field(name='matchCriteriaId')
version_start_excluding: Optional[str] = field(name='versionStartExcluding')
version_start_including: Optional[str] = field(name='versionStartIncluding')
version_end_excluding: Optional[str] = field(name='versionEndExcluding')
version_end_including: Optional[str] = field(name='versionEndIncluding')
```
vs
```json
"cpe_match": {
"description": "CPE match string or range",
"type": "object",
"properties": {
"vulnerable": {"type": "boolean"},
"criteria": {"type": "string"},
"matchCriteriaId": {"type": "string", "format": "uuid"},
"versionStartExcluding": {"type": "string"},
"versionStartIncluding": {"type": "string"},
"versionEndExcluding": {"type": "string"},
"versionEndIncluding": {"type": "string"}
},
"required": ["vulnerable", "criteria", "matchCriteriaId"],
"additionalProperties": false
},
```
Note that the optional fields are missing the `default=None` parameter in the `field` call.
[schema]: https://csrc.nist.gov/schema/nvd/api/2.0/cve_api_json_2.0.schema
### Expected behavior
The field should have a default of value `None`.
### Workaround
Do not use `--snake-case-field`.
### Setup
```sh
$ datamodel-codegen --version
0.25.5
$ python --version
Python 3.11.8
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `datamodel_code_generator/model/msgspec.py`
Content:
```
1 from functools import wraps
2 from pathlib import Path
3 from typing import (
4 Any,
5 ClassVar,
6 DefaultDict,
7 Dict,
8 List,
9 Optional,
10 Set,
11 Tuple,
12 Type,
13 TypeVar,
14 )
15
16 from pydantic import Field
17
18 from datamodel_code_generator.imports import Import
19 from datamodel_code_generator.model import DataModel, DataModelFieldBase
20 from datamodel_code_generator.model.base import UNDEFINED
21 from datamodel_code_generator.model.imports import (
22 IMPORT_MSGSPEC_CONVERT,
23 IMPORT_MSGSPEC_FIELD,
24 IMPORT_MSGSPEC_META,
25 IMPORT_MSGSPEC_STRUCT,
26 )
27 from datamodel_code_generator.model.pydantic.base_model import (
28 Constraints as _Constraints,
29 )
30 from datamodel_code_generator.model.rootmodel import RootModel as _RootModel
31 from datamodel_code_generator.reference import Reference
32 from datamodel_code_generator.types import chain_as_tuple, get_optional_type
33
34
35 def _has_field_assignment(field: DataModelFieldBase) -> bool:
36 return bool(field.field) or not (
37 field.required
38 or (field.represented_default == 'None' and field.strip_default_none)
39 )
40
41
42 DataModelFieldBaseT = TypeVar('DataModelFieldBaseT', bound=DataModelFieldBase)
43
44
45 def import_extender(cls: Type[DataModelFieldBaseT]) -> Type[DataModelFieldBaseT]:
46 original_imports: property = getattr(cls, 'imports', None) # type: ignore
47
48 @wraps(original_imports.fget) # type: ignore
49 def new_imports(self: DataModelFieldBaseT) -> Tuple[Import, ...]:
50 extra_imports = []
51 if self.field:
52 extra_imports.append(IMPORT_MSGSPEC_FIELD)
53 if self.field and 'lambda: convert' in self.field:
54 extra_imports.append(IMPORT_MSGSPEC_CONVERT)
55 if self.annotated:
56 extra_imports.append(IMPORT_MSGSPEC_META)
57 return chain_as_tuple(original_imports.fget(self), extra_imports) # type: ignore
58
59 setattr(cls, 'imports', property(new_imports))
60 return cls
61
62
63 class RootModel(_RootModel):
64 pass
65
66
67 class Struct(DataModel):
68 TEMPLATE_FILE_PATH: ClassVar[str] = 'msgspec.jinja2'
69 BASE_CLASS: ClassVar[str] = 'msgspec.Struct'
70 DEFAULT_IMPORTS: ClassVar[Tuple[Import, ...]] = (IMPORT_MSGSPEC_STRUCT,)
71
72 def __init__(
73 self,
74 *,
75 reference: Reference,
76 fields: List[DataModelFieldBase],
77 decorators: Optional[List[str]] = None,
78 base_classes: Optional[List[Reference]] = None,
79 custom_base_class: Optional[str] = None,
80 custom_template_dir: Optional[Path] = None,
81 extra_template_data: Optional[DefaultDict[str, Dict[str, Any]]] = None,
82 methods: Optional[List[str]] = None,
83 path: Optional[Path] = None,
84 description: Optional[str] = None,
85 default: Any = UNDEFINED,
86 nullable: bool = False,
87 ) -> None:
88 super().__init__(
89 reference=reference,
90 fields=sorted(fields, key=_has_field_assignment, reverse=False),
91 decorators=decorators,
92 base_classes=base_classes,
93 custom_base_class=custom_base_class,
94 custom_template_dir=custom_template_dir,
95 extra_template_data=extra_template_data,
96 methods=methods,
97 path=path,
98 description=description,
99 default=default,
100 nullable=nullable,
101 )
102
103
104 class Constraints(_Constraints):
105 # To override existing pattern alias
106 regex: Optional[str] = Field(None, alias='regex')
107 pattern: Optional[str] = Field(None, alias='pattern')
108
109
110 @import_extender
111 class DataModelField(DataModelFieldBase):
112 _FIELD_KEYS: ClassVar[Set[str]] = {
113 'default',
114 'default_factory',
115 }
116 _META_FIELD_KEYS: ClassVar[Set[str]] = {
117 'title',
118 'description',
119 'gt',
120 'ge',
121 'lt',
122 'le',
123 'multiple_of',
124 # 'min_items', # not supported by msgspec
125 # 'max_items', # not supported by msgspec
126 'min_length',
127 'max_length',
128 'pattern',
129 'examples',
130 # 'unique_items', # not supported by msgspec
131 }
132 _PARSE_METHOD = 'convert'
133 _COMPARE_EXPRESSIONS: ClassVar[Set[str]] = {'gt', 'ge', 'lt', 'le', 'multiple_of'}
134 constraints: Optional[Constraints] = None
135
136 def self_reference(self) -> bool: # pragma: no cover
137 return isinstance(self.parent, Struct) and self.parent.reference.path in {
138 d.reference.path for d in self.data_type.all_data_types if d.reference
139 }
140
141 def process_const(self) -> None:
142 if 'const' not in self.extras:
143 return None
144 self.const = True
145 self.nullable = False
146 const = self.extras['const']
147 if self.data_type.type == 'str' and isinstance(
148 const, str
149 ): # pragma: no cover # Literal supports only str
150 self.data_type = self.data_type.__class__(literals=[const])
151
152 def _get_strict_field_constraint_value(self, constraint: str, value: Any) -> Any:
153 if value is None or constraint not in self._COMPARE_EXPRESSIONS:
154 return value
155
156 if any(
157 data_type.type == 'float' for data_type in self.data_type.all_data_types
158 ):
159 return float(value)
160 return int(value)
161
162 @property
163 def field(self) -> Optional[str]:
164 """for backwards compatibility"""
165 result = str(self)
166 if result == '':
167 return None
168
169 return result
170
171 def __str__(self) -> str:
172 data: Dict[str, Any] = {
173 k: v for k, v in self.extras.items() if k in self._FIELD_KEYS
174 }
175 if self.alias:
176 data['name'] = self.alias
177
178 if self.default != UNDEFINED and self.default is not None:
179 data['default'] = self.default
180
181 if self.required:
182 data = {
183 k: v
184 for k, v in data.items()
185 if k
186 not in (
187 'default',
188 'default_factory',
189 )
190 }
191 elif self.default and 'default_factory' not in data:
192 default_factory = self._get_default_as_struct_model()
193 if default_factory is not None:
194 data.pop('default')
195 data['default_factory'] = default_factory
196
197 if not data:
198 return ''
199
200 if len(data) == 1 and 'default' in data:
201 return repr(data['default'])
202
203 kwargs = [
204 f'{k}={v if k == "default_factory" else repr(v)}' for k, v in data.items()
205 ]
206 return f'field({", ".join(kwargs)})'
207
208 @property
209 def annotated(self) -> Optional[str]:
210 if not self.use_annotated: # pragma: no cover
211 return None
212
213 data: Dict[str, Any] = {
214 k: v for k, v in self.extras.items() if k in self._META_FIELD_KEYS
215 }
216 if (
217 self.constraints is not None
218 and not self.self_reference()
219 and not self.data_type.strict
220 ):
221 data = {
222 **data,
223 **{
224 k: self._get_strict_field_constraint_value(k, v)
225 for k, v in self.constraints.dict().items()
226 if k in self._META_FIELD_KEYS
227 },
228 }
229
230 meta_arguments = sorted(
231 f'{k}={repr(v)}' for k, v in data.items() if v is not None
232 )
233 if not meta_arguments:
234 return None
235
236 meta = f'Meta({", ".join(meta_arguments)})'
237
238 if not self.required:
239 type_hint = self.data_type.type_hint
240 annotated_type = f'Annotated[{type_hint}, {meta}]'
241 return get_optional_type(annotated_type, self.data_type.use_union_operator)
242 return f'Annotated[{self.type_hint}, {meta}]'
243
244 def _get_default_as_struct_model(self) -> Optional[str]:
245 for data_type in self.data_type.data_types or (self.data_type,):
246 # TODO: Check nested data_types
247 if data_type.is_dict or self.data_type.is_union:
248 # TODO: Parse Union and dict model for default
249 continue # pragma: no cover
250 elif data_type.is_list and len(data_type.data_types) == 1:
251 data_type = data_type.data_types[0]
252 if ( # pragma: no cover
253 data_type.reference
254 and (
255 isinstance(data_type.reference.source, Struct)
256 or isinstance(data_type.reference.source, RootModel)
257 )
258 and isinstance(self.default, list)
259 ):
260 return f'lambda: {self._PARSE_METHOD}({repr(self.default)}, type=list[{data_type.alias or data_type.reference.source.class_name}])'
261 elif data_type.reference and isinstance(data_type.reference.source, Struct):
262 return f'lambda: {self._PARSE_METHOD}({repr(self.default)}, type={data_type.alias or data_type.reference.source.class_name})'
263 return None
264
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/datamodel_code_generator/model/msgspec.py b/datamodel_code_generator/model/msgspec.py
--- a/datamodel_code_generator/model/msgspec.py
+++ b/datamodel_code_generator/model/msgspec.py
@@ -33,7 +33,7 @@
def _has_field_assignment(field: DataModelFieldBase) -> bool:
- return bool(field.field) or not (
+ return not (
field.required
or (field.represented_default == 'None' and field.strip_default_none)
)
@@ -48,7 +48,9 @@
@wraps(original_imports.fget) # type: ignore
def new_imports(self: DataModelFieldBaseT) -> Tuple[Import, ...]:
extra_imports = []
- if self.field:
+ field = self.field
+ # TODO: Improve field detection
+ if field and field.startswith('field('):
extra_imports.append(IMPORT_MSGSPEC_FIELD)
if self.field and 'lambda: convert' in self.field:
extra_imports.append(IMPORT_MSGSPEC_CONVERT)
@@ -177,6 +179,8 @@
if self.default != UNDEFINED and self.default is not None:
data['default'] = self.default
+ elif not self.required:
+ data['default'] = None
if self.required:
data = {
| {"golden_diff": "diff --git a/datamodel_code_generator/model/msgspec.py b/datamodel_code_generator/model/msgspec.py\n--- a/datamodel_code_generator/model/msgspec.py\n+++ b/datamodel_code_generator/model/msgspec.py\n@@ -33,7 +33,7 @@\n \n \n def _has_field_assignment(field: DataModelFieldBase) -> bool:\n- return bool(field.field) or not (\n+ return not (\n field.required\n or (field.represented_default == 'None' and field.strip_default_none)\n )\n@@ -48,7 +48,9 @@\n @wraps(original_imports.fget) # type: ignore\n def new_imports(self: DataModelFieldBaseT) -> Tuple[Import, ...]:\n extra_imports = []\n- if self.field:\n+ field = self.field\n+ # TODO: Improve field detection\n+ if field and field.startswith('field('):\n extra_imports.append(IMPORT_MSGSPEC_FIELD)\n if self.field and 'lambda: convert' in self.field:\n extra_imports.append(IMPORT_MSGSPEC_CONVERT)\n@@ -177,6 +179,8 @@\n \n if self.default != UNDEFINED and self.default is not None:\n data['default'] = self.default\n+ elif not self.required:\n+ data['default'] = None\n \n if self.required:\n data = {\n", "issue": "msgspec: Optional fields are missing a default when using `--snake-case-field`\n### Steps to reproduce\r\n1. Download the NVD CVE [schema][schema]\r\n2. Generate a msgpsec model:\r\n```sh\r\ndatamodel-codegen \\\r\n --input $schema_json \\\r\n --input-file-type jsonschema \\\r\n --output-model-type 'msgspec.Struct' \\\r\n # This is important I think\r\n --snake-case-field \\\r\n --output \".\"\r\n```\r\n3. (Ignore the circular imports #836)\r\n4. (Ignore wrong field ordering #1919 \r\n5. Look at the `class CpeMatch` (and most other classes as well).\r\n```python\r\nclass CpeMatch(Struct, kw_only=True):\r\n vulnerable: bool\r\n criteria: str\r\n match_criteria_id: str = field(name='matchCriteriaId')\r\n version_start_excluding: Optional[str] = field(name='versionStartExcluding')\r\n version_start_including: Optional[str] = field(name='versionStartIncluding')\r\n version_end_excluding: Optional[str] = field(name='versionEndExcluding')\r\n version_end_including: Optional[str] = field(name='versionEndIncluding')\r\n\r\n```\r\nvs\r\n```json\r\n\r\n\"cpe_match\": {\r\n\t\"description\": \"CPE match string or range\",\r\n\t\"type\": \"object\",\r\n\t\"properties\": {\r\n\t\t\"vulnerable\": {\"type\": \"boolean\"},\r\n\t\t\"criteria\": {\"type\": \"string\"},\r\n\t\t\"matchCriteriaId\": {\"type\": \"string\", \"format\": \"uuid\"},\r\n\t\t\"versionStartExcluding\": {\"type\": \"string\"},\r\n\t\t\"versionStartIncluding\": {\"type\": \"string\"},\r\n\t\t\"versionEndExcluding\": {\"type\": \"string\"},\r\n\t\t\"versionEndIncluding\": {\"type\": \"string\"}\r\n\t},\r\n\t\"required\": [\"vulnerable\", \"criteria\", \"matchCriteriaId\"],\r\n\t\"additionalProperties\": false\r\n},\r\n```\r\n\r\nNote that the optional fields are missing the `default=None` parameter in the `field` call.\r\n\r\n[schema]: https://csrc.nist.gov/schema/nvd/api/2.0/cve_api_json_2.0.schema\r\n\r\n### Expected behavior\r\nThe field should have a default of value `None`.\r\n\r\n### Workaround\r\nDo not use `--snake-case-field`.\r\n\r\n### Setup\r\n\r\n```sh\r\n$ datamodel-codegen --version\r\n0.25.5\r\n\r\n$ python --version\r\nPython 3.11.8\r\n```\r\n\n", "before_files": [{"content": "from functools import wraps\nfrom pathlib import Path\nfrom typing import (\n Any,\n ClassVar,\n DefaultDict,\n Dict,\n List,\n Optional,\n Set,\n Tuple,\n Type,\n TypeVar,\n)\n\nfrom pydantic import Field\n\nfrom datamodel_code_generator.imports import Import\nfrom datamodel_code_generator.model import DataModel, DataModelFieldBase\nfrom datamodel_code_generator.model.base import UNDEFINED\nfrom datamodel_code_generator.model.imports import (\n IMPORT_MSGSPEC_CONVERT,\n IMPORT_MSGSPEC_FIELD,\n IMPORT_MSGSPEC_META,\n IMPORT_MSGSPEC_STRUCT,\n)\nfrom datamodel_code_generator.model.pydantic.base_model import (\n Constraints as _Constraints,\n)\nfrom datamodel_code_generator.model.rootmodel import RootModel as _RootModel\nfrom datamodel_code_generator.reference import Reference\nfrom datamodel_code_generator.types import chain_as_tuple, get_optional_type\n\n\ndef _has_field_assignment(field: DataModelFieldBase) -> bool:\n return bool(field.field) or not (\n field.required\n or (field.represented_default == 'None' and field.strip_default_none)\n )\n\n\nDataModelFieldBaseT = TypeVar('DataModelFieldBaseT', bound=DataModelFieldBase)\n\n\ndef import_extender(cls: Type[DataModelFieldBaseT]) -> Type[DataModelFieldBaseT]:\n original_imports: property = getattr(cls, 'imports', None) # type: ignore\n\n @wraps(original_imports.fget) # type: ignore\n def new_imports(self: DataModelFieldBaseT) -> Tuple[Import, ...]:\n extra_imports = []\n if self.field:\n extra_imports.append(IMPORT_MSGSPEC_FIELD)\n if self.field and 'lambda: convert' in self.field:\n extra_imports.append(IMPORT_MSGSPEC_CONVERT)\n if self.annotated:\n extra_imports.append(IMPORT_MSGSPEC_META)\n return chain_as_tuple(original_imports.fget(self), extra_imports) # type: ignore\n\n setattr(cls, 'imports', property(new_imports))\n return cls\n\n\nclass RootModel(_RootModel):\n pass\n\n\nclass Struct(DataModel):\n TEMPLATE_FILE_PATH: ClassVar[str] = 'msgspec.jinja2'\n BASE_CLASS: ClassVar[str] = 'msgspec.Struct'\n DEFAULT_IMPORTS: ClassVar[Tuple[Import, ...]] = (IMPORT_MSGSPEC_STRUCT,)\n\n def __init__(\n self,\n *,\n reference: Reference,\n fields: List[DataModelFieldBase],\n decorators: Optional[List[str]] = None,\n base_classes: Optional[List[Reference]] = None,\n custom_base_class: Optional[str] = None,\n custom_template_dir: Optional[Path] = None,\n extra_template_data: Optional[DefaultDict[str, Dict[str, Any]]] = None,\n methods: Optional[List[str]] = None,\n path: Optional[Path] = None,\n description: Optional[str] = None,\n default: Any = UNDEFINED,\n nullable: bool = False,\n ) -> None:\n super().__init__(\n reference=reference,\n fields=sorted(fields, key=_has_field_assignment, reverse=False),\n decorators=decorators,\n base_classes=base_classes,\n custom_base_class=custom_base_class,\n custom_template_dir=custom_template_dir,\n extra_template_data=extra_template_data,\n methods=methods,\n path=path,\n description=description,\n default=default,\n nullable=nullable,\n )\n\n\nclass Constraints(_Constraints):\n # To override existing pattern alias\n regex: Optional[str] = Field(None, alias='regex')\n pattern: Optional[str] = Field(None, alias='pattern')\n\n\n@import_extender\nclass DataModelField(DataModelFieldBase):\n _FIELD_KEYS: ClassVar[Set[str]] = {\n 'default',\n 'default_factory',\n }\n _META_FIELD_KEYS: ClassVar[Set[str]] = {\n 'title',\n 'description',\n 'gt',\n 'ge',\n 'lt',\n 'le',\n 'multiple_of',\n # 'min_items', # not supported by msgspec\n # 'max_items', # not supported by msgspec\n 'min_length',\n 'max_length',\n 'pattern',\n 'examples',\n # 'unique_items', # not supported by msgspec\n }\n _PARSE_METHOD = 'convert'\n _COMPARE_EXPRESSIONS: ClassVar[Set[str]] = {'gt', 'ge', 'lt', 'le', 'multiple_of'}\n constraints: Optional[Constraints] = None\n\n def self_reference(self) -> bool: # pragma: no cover\n return isinstance(self.parent, Struct) and self.parent.reference.path in {\n d.reference.path for d in self.data_type.all_data_types if d.reference\n }\n\n def process_const(self) -> None:\n if 'const' not in self.extras:\n return None\n self.const = True\n self.nullable = False\n const = self.extras['const']\n if self.data_type.type == 'str' and isinstance(\n const, str\n ): # pragma: no cover # Literal supports only str\n self.data_type = self.data_type.__class__(literals=[const])\n\n def _get_strict_field_constraint_value(self, constraint: str, value: Any) -> Any:\n if value is None or constraint not in self._COMPARE_EXPRESSIONS:\n return value\n\n if any(\n data_type.type == 'float' for data_type in self.data_type.all_data_types\n ):\n return float(value)\n return int(value)\n\n @property\n def field(self) -> Optional[str]:\n \"\"\"for backwards compatibility\"\"\"\n result = str(self)\n if result == '':\n return None\n\n return result\n\n def __str__(self) -> str:\n data: Dict[str, Any] = {\n k: v for k, v in self.extras.items() if k in self._FIELD_KEYS\n }\n if self.alias:\n data['name'] = self.alias\n\n if self.default != UNDEFINED and self.default is not None:\n data['default'] = self.default\n\n if self.required:\n data = {\n k: v\n for k, v in data.items()\n if k\n not in (\n 'default',\n 'default_factory',\n )\n }\n elif self.default and 'default_factory' not in data:\n default_factory = self._get_default_as_struct_model()\n if default_factory is not None:\n data.pop('default')\n data['default_factory'] = default_factory\n\n if not data:\n return ''\n\n if len(data) == 1 and 'default' in data:\n return repr(data['default'])\n\n kwargs = [\n f'{k}={v if k == \"default_factory\" else repr(v)}' for k, v in data.items()\n ]\n return f'field({\", \".join(kwargs)})'\n\n @property\n def annotated(self) -> Optional[str]:\n if not self.use_annotated: # pragma: no cover\n return None\n\n data: Dict[str, Any] = {\n k: v for k, v in self.extras.items() if k in self._META_FIELD_KEYS\n }\n if (\n self.constraints is not None\n and not self.self_reference()\n and not self.data_type.strict\n ):\n data = {\n **data,\n **{\n k: self._get_strict_field_constraint_value(k, v)\n for k, v in self.constraints.dict().items()\n if k in self._META_FIELD_KEYS\n },\n }\n\n meta_arguments = sorted(\n f'{k}={repr(v)}' for k, v in data.items() if v is not None\n )\n if not meta_arguments:\n return None\n\n meta = f'Meta({\", \".join(meta_arguments)})'\n\n if not self.required:\n type_hint = self.data_type.type_hint\n annotated_type = f'Annotated[{type_hint}, {meta}]'\n return get_optional_type(annotated_type, self.data_type.use_union_operator)\n return f'Annotated[{self.type_hint}, {meta}]'\n\n def _get_default_as_struct_model(self) -> Optional[str]:\n for data_type in self.data_type.data_types or (self.data_type,):\n # TODO: Check nested data_types\n if data_type.is_dict or self.data_type.is_union:\n # TODO: Parse Union and dict model for default\n continue # pragma: no cover\n elif data_type.is_list and len(data_type.data_types) == 1:\n data_type = data_type.data_types[0]\n if ( # pragma: no cover\n data_type.reference\n and (\n isinstance(data_type.reference.source, Struct)\n or isinstance(data_type.reference.source, RootModel)\n )\n and isinstance(self.default, list)\n ):\n return f'lambda: {self._PARSE_METHOD}({repr(self.default)}, type=list[{data_type.alias or data_type.reference.source.class_name}])'\n elif data_type.reference and isinstance(data_type.reference.source, Struct):\n return f'lambda: {self._PARSE_METHOD}({repr(self.default)}, type={data_type.alias or data_type.reference.source.class_name})'\n return None\n", "path": "datamodel_code_generator/model/msgspec.py"}], "after_files": [{"content": "from functools import wraps\nfrom pathlib import Path\nfrom typing import (\n Any,\n ClassVar,\n DefaultDict,\n Dict,\n List,\n Optional,\n Set,\n Tuple,\n Type,\n TypeVar,\n)\n\nfrom pydantic import Field\n\nfrom datamodel_code_generator.imports import Import\nfrom datamodel_code_generator.model import DataModel, DataModelFieldBase\nfrom datamodel_code_generator.model.base import UNDEFINED\nfrom datamodel_code_generator.model.imports import (\n IMPORT_MSGSPEC_CONVERT,\n IMPORT_MSGSPEC_FIELD,\n IMPORT_MSGSPEC_META,\n IMPORT_MSGSPEC_STRUCT,\n)\nfrom datamodel_code_generator.model.pydantic.base_model import (\n Constraints as _Constraints,\n)\nfrom datamodel_code_generator.model.rootmodel import RootModel as _RootModel\nfrom datamodel_code_generator.reference import Reference\nfrom datamodel_code_generator.types import chain_as_tuple, get_optional_type\n\n\ndef _has_field_assignment(field: DataModelFieldBase) -> bool:\n return not (\n field.required\n or (field.represented_default == 'None' and field.strip_default_none)\n )\n\n\nDataModelFieldBaseT = TypeVar('DataModelFieldBaseT', bound=DataModelFieldBase)\n\n\ndef import_extender(cls: Type[DataModelFieldBaseT]) -> Type[DataModelFieldBaseT]:\n original_imports: property = getattr(cls, 'imports', None) # type: ignore\n\n @wraps(original_imports.fget) # type: ignore\n def new_imports(self: DataModelFieldBaseT) -> Tuple[Import, ...]:\n extra_imports = []\n field = self.field\n # TODO: Improve field detection\n if field and field.startswith('field('):\n extra_imports.append(IMPORT_MSGSPEC_FIELD)\n if self.field and 'lambda: convert' in self.field:\n extra_imports.append(IMPORT_MSGSPEC_CONVERT)\n if self.annotated:\n extra_imports.append(IMPORT_MSGSPEC_META)\n return chain_as_tuple(original_imports.fget(self), extra_imports) # type: ignore\n\n setattr(cls, 'imports', property(new_imports))\n return cls\n\n\nclass RootModel(_RootModel):\n pass\n\n\nclass Struct(DataModel):\n TEMPLATE_FILE_PATH: ClassVar[str] = 'msgspec.jinja2'\n BASE_CLASS: ClassVar[str] = 'msgspec.Struct'\n DEFAULT_IMPORTS: ClassVar[Tuple[Import, ...]] = (IMPORT_MSGSPEC_STRUCT,)\n\n def __init__(\n self,\n *,\n reference: Reference,\n fields: List[DataModelFieldBase],\n decorators: Optional[List[str]] = None,\n base_classes: Optional[List[Reference]] = None,\n custom_base_class: Optional[str] = None,\n custom_template_dir: Optional[Path] = None,\n extra_template_data: Optional[DefaultDict[str, Dict[str, Any]]] = None,\n methods: Optional[List[str]] = None,\n path: Optional[Path] = None,\n description: Optional[str] = None,\n default: Any = UNDEFINED,\n nullable: bool = False,\n ) -> None:\n super().__init__(\n reference=reference,\n fields=sorted(fields, key=_has_field_assignment, reverse=False),\n decorators=decorators,\n base_classes=base_classes,\n custom_base_class=custom_base_class,\n custom_template_dir=custom_template_dir,\n extra_template_data=extra_template_data,\n methods=methods,\n path=path,\n description=description,\n default=default,\n nullable=nullable,\n )\n\n\nclass Constraints(_Constraints):\n # To override existing pattern alias\n regex: Optional[str] = Field(None, alias='regex')\n pattern: Optional[str] = Field(None, alias='pattern')\n\n\n@import_extender\nclass DataModelField(DataModelFieldBase):\n _FIELD_KEYS: ClassVar[Set[str]] = {\n 'default',\n 'default_factory',\n }\n _META_FIELD_KEYS: ClassVar[Set[str]] = {\n 'title',\n 'description',\n 'gt',\n 'ge',\n 'lt',\n 'le',\n 'multiple_of',\n # 'min_items', # not supported by msgspec\n # 'max_items', # not supported by msgspec\n 'min_length',\n 'max_length',\n 'pattern',\n 'examples',\n # 'unique_items', # not supported by msgspec\n }\n _PARSE_METHOD = 'convert'\n _COMPARE_EXPRESSIONS: ClassVar[Set[str]] = {'gt', 'ge', 'lt', 'le', 'multiple_of'}\n constraints: Optional[Constraints] = None\n\n def self_reference(self) -> bool: # pragma: no cover\n return isinstance(self.parent, Struct) and self.parent.reference.path in {\n d.reference.path for d in self.data_type.all_data_types if d.reference\n }\n\n def process_const(self) -> None:\n if 'const' not in self.extras:\n return None\n self.const = True\n self.nullable = False\n const = self.extras['const']\n if self.data_type.type == 'str' and isinstance(\n const, str\n ): # pragma: no cover # Literal supports only str\n self.data_type = self.data_type.__class__(literals=[const])\n\n def _get_strict_field_constraint_value(self, constraint: str, value: Any) -> Any:\n if value is None or constraint not in self._COMPARE_EXPRESSIONS:\n return value\n\n if any(\n data_type.type == 'float' for data_type in self.data_type.all_data_types\n ):\n return float(value)\n return int(value)\n\n @property\n def field(self) -> Optional[str]:\n \"\"\"for backwards compatibility\"\"\"\n result = str(self)\n if result == '':\n return None\n\n return result\n\n def __str__(self) -> str:\n data: Dict[str, Any] = {\n k: v for k, v in self.extras.items() if k in self._FIELD_KEYS\n }\n if self.alias:\n data['name'] = self.alias\n\n if self.default != UNDEFINED and self.default is not None:\n data['default'] = self.default\n elif not self.required:\n data['default'] = None\n\n if self.required:\n data = {\n k: v\n for k, v in data.items()\n if k\n not in (\n 'default',\n 'default_factory',\n )\n }\n elif self.default and 'default_factory' not in data:\n default_factory = self._get_default_as_struct_model()\n if default_factory is not None:\n data.pop('default')\n data['default_factory'] = default_factory\n\n if not data:\n return ''\n\n if len(data) == 1 and 'default' in data:\n return repr(data['default'])\n\n kwargs = [\n f'{k}={v if k == \"default_factory\" else repr(v)}' for k, v in data.items()\n ]\n return f'field({\", \".join(kwargs)})'\n\n @property\n def annotated(self) -> Optional[str]:\n if not self.use_annotated: # pragma: no cover\n return None\n\n data: Dict[str, Any] = {\n k: v for k, v in self.extras.items() if k in self._META_FIELD_KEYS\n }\n if (\n self.constraints is not None\n and not self.self_reference()\n and not self.data_type.strict\n ):\n data = {\n **data,\n **{\n k: self._get_strict_field_constraint_value(k, v)\n for k, v in self.constraints.dict().items()\n if k in self._META_FIELD_KEYS\n },\n }\n\n meta_arguments = sorted(\n f'{k}={repr(v)}' for k, v in data.items() if v is not None\n )\n if not meta_arguments:\n return None\n\n meta = f'Meta({\", \".join(meta_arguments)})'\n\n if not self.required:\n type_hint = self.data_type.type_hint\n annotated_type = f'Annotated[{type_hint}, {meta}]'\n return get_optional_type(annotated_type, self.data_type.use_union_operator)\n return f'Annotated[{self.type_hint}, {meta}]'\n\n def _get_default_as_struct_model(self) -> Optional[str]:\n for data_type in self.data_type.data_types or (self.data_type,):\n # TODO: Check nested data_types\n if data_type.is_dict or self.data_type.is_union:\n # TODO: Parse Union and dict model for default\n continue # pragma: no cover\n elif data_type.is_list and len(data_type.data_types) == 1:\n data_type = data_type.data_types[0]\n if ( # pragma: no cover\n data_type.reference\n and (\n isinstance(data_type.reference.source, Struct)\n or isinstance(data_type.reference.source, RootModel)\n )\n and isinstance(self.default, list)\n ):\n return f'lambda: {self._PARSE_METHOD}({repr(self.default)}, type=list[{data_type.alias or data_type.reference.source.class_name}])'\n elif data_type.reference and isinstance(data_type.reference.source, Struct):\n return f'lambda: {self._PARSE_METHOD}({repr(self.default)}, type={data_type.alias or data_type.reference.source.class_name})'\n return None\n", "path": "datamodel_code_generator/model/msgspec.py"}]} | 3,478 | 297 |
gh_patches_debug_34157 | rasdani/github-patches | git_diff | Textualize__textual-2095 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Consider updating `DirectoryTree` so that it takes `Path` as well as a `str` as the path to browse
Some people tend to favour using `Path` over `str` for paths and the like, so I feel it would be an idea to accept a `Path` as the path.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/textual/widgets/_directory_tree.py`
Content:
```
1 from __future__ import annotations
2
3 from dataclasses import dataclass
4 from pathlib import Path
5 from typing import ClassVar
6
7 from rich.style import Style
8 from rich.text import Text, TextType
9
10 from .._types import MessageTarget
11 from ..message import Message
12 from ._tree import TOGGLE_STYLE, Tree, TreeNode
13
14
15 @dataclass
16 class DirEntry:
17 """Attaches directory information ot a node."""
18
19 path: str
20 is_dir: bool
21 loaded: bool = False
22
23
24 class DirectoryTree(Tree[DirEntry]):
25 """A Tree widget that presents files and directories.
26
27 Args:
28 path: Path to directory.
29 name: The name of the widget, or None for no name. Defaults to None.
30 id: The ID of the widget in the DOM, or None for no ID. Defaults to None.
31 classes: A space-separated list of classes, or None for no classes. Defaults to None.
32 disabled: Whether the directory tree is disabled or not.
33 """
34
35 COMPONENT_CLASSES: ClassVar[set[str]] = {
36 "directory-tree--folder",
37 "directory-tree--file",
38 "directory-tree--extension",
39 "directory-tree--hidden",
40 }
41 """
42 | Class | Description |
43 | :- | :- |
44 | `directory-tree--extension` | Target the extension of a file name. |
45 | `directory-tree--file` | Target files in the directory structure. |
46 | `directory-tree--folder` | Target folders in the directory structure. |
47 | `directory-tree--hidden` | Target hidden items in the directory structure. |
48
49 See also the [component classes for `Tree`][textual.widgets.Tree.COMPONENT_CLASSES].
50 """
51
52 DEFAULT_CSS = """
53 DirectoryTree > .directory-tree--folder {
54 text-style: bold;
55 }
56
57 DirectoryTree > .directory-tree--file {
58
59 }
60
61 DirectoryTree > .directory-tree--extension {
62 text-style: italic;
63 }
64
65 DirectoryTree > .directory-tree--hidden {
66 color: $text 50%;
67 }
68 """
69
70 class FileSelected(Message, bubble=True):
71 """Posted when a file is selected.
72
73 Can be handled using `on_directory_tree_file_selected` in a subclass of
74 `DirectoryTree` or in a parent widget in the DOM.
75
76 Attributes:
77 path: The path of the file that was selected.
78 """
79
80 def __init__(self, path: str) -> None:
81 self.path: str = path
82 super().__init__()
83
84 def __init__(
85 self,
86 path: str,
87 *,
88 name: str | None = None,
89 id: str | None = None,
90 classes: str | None = None,
91 disabled: bool = False,
92 ) -> None:
93 self.path = path
94 super().__init__(
95 path,
96 data=DirEntry(path, True),
97 name=name,
98 id=id,
99 classes=classes,
100 disabled=disabled,
101 )
102
103 def process_label(self, label: TextType):
104 """Process a str or Text into a label. Maybe overridden in a subclass to modify how labels are rendered.
105
106 Args:
107 label: Label.
108
109 Returns:
110 A Rich Text object.
111 """
112 if isinstance(label, str):
113 text_label = Text(label)
114 else:
115 text_label = label
116 first_line = text_label.split()[0]
117 return first_line
118
119 def render_label(self, node: TreeNode[DirEntry], base_style: Style, style: Style):
120 node_label = node._label.copy()
121 node_label.stylize(style)
122
123 if node._allow_expand:
124 prefix = ("📂 " if node.is_expanded else "📁 ", base_style + TOGGLE_STYLE)
125 node_label.stylize_before(
126 self.get_component_rich_style("directory-tree--folder", partial=True)
127 )
128 else:
129 prefix = (
130 "📄 ",
131 base_style,
132 )
133 node_label.stylize_before(
134 self.get_component_rich_style("directory-tree--file", partial=True),
135 )
136 node_label.highlight_regex(
137 r"\..+$",
138 self.get_component_rich_style(
139 "directory-tree--extension", partial=True
140 ),
141 )
142
143 if node_label.plain.startswith("."):
144 node_label.stylize_before(
145 self.get_component_rich_style("directory-tree--hidden")
146 )
147
148 text = Text.assemble(prefix, node_label)
149 return text
150
151 def load_directory(self, node: TreeNode[DirEntry]) -> None:
152 assert node.data is not None
153 dir_path = Path(node.data.path)
154 node.data.loaded = True
155 directory = sorted(
156 list(dir_path.iterdir()),
157 key=lambda path: (not path.is_dir(), path.name.lower()),
158 )
159 for path in directory:
160 node.add(
161 path.name,
162 data=DirEntry(str(path), path.is_dir()),
163 allow_expand=path.is_dir(),
164 )
165 node.expand()
166
167 def on_mount(self) -> None:
168 self.load_directory(self.root)
169
170 def on_tree_node_expanded(self, event: Tree.NodeSelected) -> None:
171 event.stop()
172 dir_entry = event.node.data
173 if dir_entry is None:
174 return
175 if dir_entry.is_dir:
176 if not dir_entry.loaded:
177 self.load_directory(event.node)
178 else:
179 self.post_message(self.FileSelected(dir_entry.path))
180
181 def on_tree_node_selected(self, event: Tree.NodeSelected) -> None:
182 event.stop()
183 dir_entry = event.node.data
184 if dir_entry is None:
185 return
186 if not dir_entry.is_dir:
187 self.post_message(self.FileSelected(dir_entry.path))
188
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/textual/widgets/_directory_tree.py b/src/textual/widgets/_directory_tree.py
--- a/src/textual/widgets/_directory_tree.py
+++ b/src/textual/widgets/_directory_tree.py
@@ -1,5 +1,6 @@
from __future__ import annotations
+import os
from dataclasses import dataclass
from pathlib import Path
from typing import ClassVar
@@ -7,14 +8,13 @@
from rich.style import Style
from rich.text import Text, TextType
-from .._types import MessageTarget
from ..message import Message
from ._tree import TOGGLE_STYLE, Tree, TreeNode
@dataclass
class DirEntry:
- """Attaches directory information ot a node."""
+ """Attaches directory information to a node."""
path: str
is_dir: bool
@@ -26,9 +26,9 @@
Args:
path: Path to directory.
- name: The name of the widget, or None for no name. Defaults to None.
- id: The ID of the widget in the DOM, or None for no ID. Defaults to None.
- classes: A space-separated list of classes, or None for no classes. Defaults to None.
+ name: The name of the widget, or None for no name.
+ id: The ID of the widget in the DOM, or None for no ID.
+ classes: A space-separated list of classes, or None for no classes.
disabled: Whether the directory tree is disabled or not.
"""
@@ -83,17 +83,18 @@
def __init__(
self,
- path: str,
+ path: str | Path,
*,
name: str | None = None,
id: str | None = None,
classes: str | None = None,
disabled: bool = False,
) -> None:
- self.path = path
+ str_path = os.fspath(path)
+ self.path = str_path
super().__init__(
- path,
- data=DirEntry(path, True),
+ str_path,
+ data=DirEntry(str_path, True),
name=name,
id=id,
classes=classes,
| {"golden_diff": "diff --git a/src/textual/widgets/_directory_tree.py b/src/textual/widgets/_directory_tree.py\n--- a/src/textual/widgets/_directory_tree.py\n+++ b/src/textual/widgets/_directory_tree.py\n@@ -1,5 +1,6 @@\n from __future__ import annotations\n \n+import os\n from dataclasses import dataclass\n from pathlib import Path\n from typing import ClassVar\n@@ -7,14 +8,13 @@\n from rich.style import Style\n from rich.text import Text, TextType\n \n-from .._types import MessageTarget\n from ..message import Message\n from ._tree import TOGGLE_STYLE, Tree, TreeNode\n \n \n @dataclass\n class DirEntry:\n- \"\"\"Attaches directory information ot a node.\"\"\"\n+ \"\"\"Attaches directory information to a node.\"\"\"\n \n path: str\n is_dir: bool\n@@ -26,9 +26,9 @@\n \n Args:\n path: Path to directory.\n- name: The name of the widget, or None for no name. Defaults to None.\n- id: The ID of the widget in the DOM, or None for no ID. Defaults to None.\n- classes: A space-separated list of classes, or None for no classes. Defaults to None.\n+ name: The name of the widget, or None for no name.\n+ id: The ID of the widget in the DOM, or None for no ID.\n+ classes: A space-separated list of classes, or None for no classes.\n disabled: Whether the directory tree is disabled or not.\n \"\"\"\n \n@@ -83,17 +83,18 @@\n \n def __init__(\n self,\n- path: str,\n+ path: str | Path,\n *,\n name: str | None = None,\n id: str | None = None,\n classes: str | None = None,\n disabled: bool = False,\n ) -> None:\n- self.path = path\n+ str_path = os.fspath(path)\n+ self.path = str_path\n super().__init__(\n- path,\n- data=DirEntry(path, True),\n+ str_path,\n+ data=DirEntry(str_path, True),\n name=name,\n id=id,\n classes=classes,\n", "issue": "Consider updating `DirectoryTree` so that it takes `Path` as well as a `str` as the path to browse\nSome people tend to favour using `Path` over `str` for paths and the like, so I feel it would be an idea to accept a `Path` as the path.\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom dataclasses import dataclass\nfrom pathlib import Path\nfrom typing import ClassVar\n\nfrom rich.style import Style\nfrom rich.text import Text, TextType\n\nfrom .._types import MessageTarget\nfrom ..message import Message\nfrom ._tree import TOGGLE_STYLE, Tree, TreeNode\n\n\n@dataclass\nclass DirEntry:\n \"\"\"Attaches directory information ot a node.\"\"\"\n\n path: str\n is_dir: bool\n loaded: bool = False\n\n\nclass DirectoryTree(Tree[DirEntry]):\n \"\"\"A Tree widget that presents files and directories.\n\n Args:\n path: Path to directory.\n name: The name of the widget, or None for no name. Defaults to None.\n id: The ID of the widget in the DOM, or None for no ID. Defaults to None.\n classes: A space-separated list of classes, or None for no classes. Defaults to None.\n disabled: Whether the directory tree is disabled or not.\n \"\"\"\n\n COMPONENT_CLASSES: ClassVar[set[str]] = {\n \"directory-tree--folder\",\n \"directory-tree--file\",\n \"directory-tree--extension\",\n \"directory-tree--hidden\",\n }\n \"\"\"\n | Class | Description |\n | :- | :- |\n | `directory-tree--extension` | Target the extension of a file name. |\n | `directory-tree--file` | Target files in the directory structure. |\n | `directory-tree--folder` | Target folders in the directory structure. |\n | `directory-tree--hidden` | Target hidden items in the directory structure. |\n\n See also the [component classes for `Tree`][textual.widgets.Tree.COMPONENT_CLASSES].\n \"\"\"\n\n DEFAULT_CSS = \"\"\"\n DirectoryTree > .directory-tree--folder {\n text-style: bold;\n }\n\n DirectoryTree > .directory-tree--file {\n\n }\n\n DirectoryTree > .directory-tree--extension {\n text-style: italic;\n }\n\n DirectoryTree > .directory-tree--hidden {\n color: $text 50%;\n }\n \"\"\"\n\n class FileSelected(Message, bubble=True):\n \"\"\"Posted when a file is selected.\n\n Can be handled using `on_directory_tree_file_selected` in a subclass of\n `DirectoryTree` or in a parent widget in the DOM.\n\n Attributes:\n path: The path of the file that was selected.\n \"\"\"\n\n def __init__(self, path: str) -> None:\n self.path: str = path\n super().__init__()\n\n def __init__(\n self,\n path: str,\n *,\n name: str | None = None,\n id: str | None = None,\n classes: str | None = None,\n disabled: bool = False,\n ) -> None:\n self.path = path\n super().__init__(\n path,\n data=DirEntry(path, True),\n name=name,\n id=id,\n classes=classes,\n disabled=disabled,\n )\n\n def process_label(self, label: TextType):\n \"\"\"Process a str or Text into a label. Maybe overridden in a subclass to modify how labels are rendered.\n\n Args:\n label: Label.\n\n Returns:\n A Rich Text object.\n \"\"\"\n if isinstance(label, str):\n text_label = Text(label)\n else:\n text_label = label\n first_line = text_label.split()[0]\n return first_line\n\n def render_label(self, node: TreeNode[DirEntry], base_style: Style, style: Style):\n node_label = node._label.copy()\n node_label.stylize(style)\n\n if node._allow_expand:\n prefix = (\"\ud83d\udcc2 \" if node.is_expanded else \"\ud83d\udcc1 \", base_style + TOGGLE_STYLE)\n node_label.stylize_before(\n self.get_component_rich_style(\"directory-tree--folder\", partial=True)\n )\n else:\n prefix = (\n \"\ud83d\udcc4 \",\n base_style,\n )\n node_label.stylize_before(\n self.get_component_rich_style(\"directory-tree--file\", partial=True),\n )\n node_label.highlight_regex(\n r\"\\..+$\",\n self.get_component_rich_style(\n \"directory-tree--extension\", partial=True\n ),\n )\n\n if node_label.plain.startswith(\".\"):\n node_label.stylize_before(\n self.get_component_rich_style(\"directory-tree--hidden\")\n )\n\n text = Text.assemble(prefix, node_label)\n return text\n\n def load_directory(self, node: TreeNode[DirEntry]) -> None:\n assert node.data is not None\n dir_path = Path(node.data.path)\n node.data.loaded = True\n directory = sorted(\n list(dir_path.iterdir()),\n key=lambda path: (not path.is_dir(), path.name.lower()),\n )\n for path in directory:\n node.add(\n path.name,\n data=DirEntry(str(path), path.is_dir()),\n allow_expand=path.is_dir(),\n )\n node.expand()\n\n def on_mount(self) -> None:\n self.load_directory(self.root)\n\n def on_tree_node_expanded(self, event: Tree.NodeSelected) -> None:\n event.stop()\n dir_entry = event.node.data\n if dir_entry is None:\n return\n if dir_entry.is_dir:\n if not dir_entry.loaded:\n self.load_directory(event.node)\n else:\n self.post_message(self.FileSelected(dir_entry.path))\n\n def on_tree_node_selected(self, event: Tree.NodeSelected) -> None:\n event.stop()\n dir_entry = event.node.data\n if dir_entry is None:\n return\n if not dir_entry.is_dir:\n self.post_message(self.FileSelected(dir_entry.path))\n", "path": "src/textual/widgets/_directory_tree.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport os\nfrom dataclasses import dataclass\nfrom pathlib import Path\nfrom typing import ClassVar\n\nfrom rich.style import Style\nfrom rich.text import Text, TextType\n\nfrom ..message import Message\nfrom ._tree import TOGGLE_STYLE, Tree, TreeNode\n\n\n@dataclass\nclass DirEntry:\n \"\"\"Attaches directory information to a node.\"\"\"\n\n path: str\n is_dir: bool\n loaded: bool = False\n\n\nclass DirectoryTree(Tree[DirEntry]):\n \"\"\"A Tree widget that presents files and directories.\n\n Args:\n path: Path to directory.\n name: The name of the widget, or None for no name.\n id: The ID of the widget in the DOM, or None for no ID.\n classes: A space-separated list of classes, or None for no classes.\n disabled: Whether the directory tree is disabled or not.\n \"\"\"\n\n COMPONENT_CLASSES: ClassVar[set[str]] = {\n \"directory-tree--folder\",\n \"directory-tree--file\",\n \"directory-tree--extension\",\n \"directory-tree--hidden\",\n }\n \"\"\"\n | Class | Description |\n | :- | :- |\n | `directory-tree--extension` | Target the extension of a file name. |\n | `directory-tree--file` | Target files in the directory structure. |\n | `directory-tree--folder` | Target folders in the directory structure. |\n | `directory-tree--hidden` | Target hidden items in the directory structure. |\n\n See also the [component classes for `Tree`][textual.widgets.Tree.COMPONENT_CLASSES].\n \"\"\"\n\n DEFAULT_CSS = \"\"\"\n DirectoryTree > .directory-tree--folder {\n text-style: bold;\n }\n\n DirectoryTree > .directory-tree--file {\n\n }\n\n DirectoryTree > .directory-tree--extension {\n text-style: italic;\n }\n\n DirectoryTree > .directory-tree--hidden {\n color: $text 50%;\n }\n \"\"\"\n\n class FileSelected(Message, bubble=True):\n \"\"\"Posted when a file is selected.\n\n Can be handled using `on_directory_tree_file_selected` in a subclass of\n `DirectoryTree` or in a parent widget in the DOM.\n\n Attributes:\n path: The path of the file that was selected.\n \"\"\"\n\n def __init__(self, path: str) -> None:\n self.path: str = path\n super().__init__()\n\n def __init__(\n self,\n path: str | Path,\n *,\n name: str | None = None,\n id: str | None = None,\n classes: str | None = None,\n disabled: bool = False,\n ) -> None:\n str_path = os.fspath(path)\n self.path = str_path\n super().__init__(\n str_path,\n data=DirEntry(str_path, True),\n name=name,\n id=id,\n classes=classes,\n disabled=disabled,\n )\n\n def process_label(self, label: TextType):\n \"\"\"Process a str or Text into a label. Maybe overridden in a subclass to modify how labels are rendered.\n\n Args:\n label: Label.\n\n Returns:\n A Rich Text object.\n \"\"\"\n if isinstance(label, str):\n text_label = Text(label)\n else:\n text_label = label\n first_line = text_label.split()[0]\n return first_line\n\n def render_label(self, node: TreeNode[DirEntry], base_style: Style, style: Style):\n node_label = node._label.copy()\n node_label.stylize(style)\n\n if node._allow_expand:\n prefix = (\"\ud83d\udcc2 \" if node.is_expanded else \"\ud83d\udcc1 \", base_style + TOGGLE_STYLE)\n node_label.stylize_before(\n self.get_component_rich_style(\"directory-tree--folder\", partial=True)\n )\n else:\n prefix = (\n \"\ud83d\udcc4 \",\n base_style,\n )\n node_label.stylize_before(\n self.get_component_rich_style(\"directory-tree--file\", partial=True),\n )\n node_label.highlight_regex(\n r\"\\..+$\",\n self.get_component_rich_style(\n \"directory-tree--extension\", partial=True\n ),\n )\n\n if node_label.plain.startswith(\".\"):\n node_label.stylize_before(\n self.get_component_rich_style(\"directory-tree--hidden\")\n )\n\n text = Text.assemble(prefix, node_label)\n return text\n\n def load_directory(self, node: TreeNode[DirEntry]) -> None:\n assert node.data is not None\n dir_path = Path(node.data.path)\n node.data.loaded = True\n directory = sorted(\n list(dir_path.iterdir()),\n key=lambda path: (not path.is_dir(), path.name.lower()),\n )\n for path in directory:\n node.add(\n path.name,\n data=DirEntry(str(path), path.is_dir()),\n allow_expand=path.is_dir(),\n )\n node.expand()\n\n def on_mount(self) -> None:\n self.load_directory(self.root)\n\n def on_tree_node_expanded(self, event: Tree.NodeSelected) -> None:\n event.stop()\n dir_entry = event.node.data\n if dir_entry is None:\n return\n if dir_entry.is_dir:\n if not dir_entry.loaded:\n self.load_directory(event.node)\n else:\n self.post_message(self.FileSelected(dir_entry.path))\n\n def on_tree_node_selected(self, event: Tree.NodeSelected) -> None:\n event.stop()\n dir_entry = event.node.data\n if dir_entry is None:\n return\n if not dir_entry.is_dir:\n self.post_message(self.FileSelected(dir_entry.path))\n", "path": "src/textual/widgets/_directory_tree.py"}]} | 1,999 | 484 |
gh_patches_debug_11640 | rasdani/github-patches | git_diff | Mailu__Mailu-1886 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
connect to /tmp/podop.socket: Permission denied
Hi,
I build the docker images from Mailu/tests/build_arm.sh (commit 5d20f28).
Setting mailu.env log level to: `LOG_LEVEL=DEBUG`
I got this "Temporary lookup failure" when sending a test email to my domain.
Digging out the postfix's log is the best I can manage with my limited knowledge.
Any help please?
Thanks,
Tin.
`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: connect to /tmp/podop.socket: Permission denied`
`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: table socketmap:unix:/tmp/podop.socket:transport lookup error: Permission denied`
`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: socketmap:unix:/tmp/podop.socket:transport lookup error for "*"`
`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: connect to /tmp/podop.socket: Permission denied`
`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: table socketmap:unix:/tmp/podop.socket:transport lookup error: Permission denied`
`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: socketmap:unix:/tmp/podop.socket:transport lookup error for "*"`
`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: connect to /tmp/podop.socket: Permission denied`
`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: table socketmap:unix:/tmp/podop.socket:domain lookup error: Permission denied`
`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: virtual_mailbox_domains: socketmap:unix:/tmp/podop.socket:domain: table lookup problem`
`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: virtual_mailbox_domains lookup failure`
`smtp | Dec 25 21:35:19 mail postfix/trivial-rewrite[276]: warning: connect to /tmp/podop.socket: Permission denied`
`smtp | Dec 25 21:35:19 mail postfix/trivial-rewrite[276]: warning: table socketmap:unix:/tmp/podop.socket:domain lookup error: Permission denied`
`smtp | Dec 25 21:35:19 mail postfix/trivial-rewrite[276]: warning: virtual_mailbox_domains: socketmap:unix:/tmp/podop.socket:domain: table lookup problem`
`smtp | Dec 25 21:35:19 mail postfix/trivial-rewrite[276]: warning: virtual_mailbox_domains lookup failure`
`smtp | Dec 25 21:35:19 mail postfix/smtpd[198]: NOQUEUE: reject: RCPT from localhost[127.0.0.1]: 451 4.3.0 <tin@***obscured.com***>: Temporary lookup failure; from=<admin@***obscured.com***> to=<tin@***obscured.com***> proto=SMTP helo=<mail.***obscured.com***>`
`smtp | Dec 25 21:35:24 mail postfix/smtpd[258]: connect from localhost[127.0.0.1]`
`smtp | Dec 25 21:35:24 mail postfix/smtpd[258]: disconnect from localhost[127.0.0.1] quit=1 commands=1`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/postfix/start.py`
Content:
```
1 #!/usr/bin/python3
2
3 import os
4 import glob
5 import shutil
6 import multiprocessing
7 import logging as log
8 import sys
9
10 from podop import run_server
11 from socrate import system, conf
12
13 log.basicConfig(stream=sys.stderr, level=os.environ.get("LOG_LEVEL", "WARNING"))
14
15 def start_podop():
16 os.setuid(100)
17 url = "http://" + os.environ["ADMIN_ADDRESS"] + "/internal/postfix/"
18 # TODO: Remove verbosity setting from Podop?
19 run_server(0, "postfix", "/tmp/podop.socket", [
20 ("transport", "url", url + "transport/§"),
21 ("alias", "url", url + "alias/§"),
22 ("domain", "url", url + "domain/§"),
23 ("mailbox", "url", url + "mailbox/§"),
24 ("recipientmap", "url", url + "recipient/map/§"),
25 ("sendermap", "url", url + "sender/map/§"),
26 ("senderaccess", "url", url + "sender/access/§"),
27 ("senderlogin", "url", url + "sender/login/§")
28 ])
29
30 def is_valid_postconf_line(line):
31 return not line.startswith("#") \
32 and not line == ''
33
34 # Actual startup script
35 os.environ["FRONT_ADDRESS"] = system.get_host_address_from_environment("FRONT", "front")
36 os.environ["ADMIN_ADDRESS"] = system.get_host_address_from_environment("ADMIN", "admin")
37 os.environ["ANTISPAM_MILTER_ADDRESS"] = system.get_host_address_from_environment("ANTISPAM_MILTER", "antispam:11332")
38 os.environ["LMTP_ADDRESS"] = system.get_host_address_from_environment("LMTP", "imap:2525")
39 os.environ["OUTCLEAN"] = os.environ["HOSTNAMES"].split(",")[0]
40 try:
41 os.environ["OUTCLEAN_ADDRESS"] = system.resolve_hostname(os.environ["OUTCLEAN"])
42 except:
43 os.environ["OUTCLEAN_ADDRESS"] = "10.10.10.10"
44
45 for postfix_file in glob.glob("/conf/*.cf"):
46 conf.jinja(postfix_file, os.environ, os.path.join("/etc/postfix", os.path.basename(postfix_file)))
47
48 if os.path.exists("/overrides/postfix.cf"):
49 for line in open("/overrides/postfix.cf").read().strip().split("\n"):
50 if is_valid_postconf_line(line):
51 os.system('postconf -e "{}"'.format(line))
52
53 if os.path.exists("/overrides/postfix.master"):
54 for line in open("/overrides/postfix.master").read().strip().split("\n"):
55 if is_valid_postconf_line(line):
56 os.system('postconf -Me "{}"'.format(line))
57
58 for map_file in glob.glob("/overrides/*.map"):
59 destination = os.path.join("/etc/postfix", os.path.basename(map_file))
60 shutil.copyfile(map_file, destination)
61 os.system("postmap {}".format(destination))
62 os.remove(destination)
63
64 if "RELAYUSER" in os.environ:
65 path = "/etc/postfix/sasl_passwd"
66 conf.jinja("/conf/sasl_passwd", os.environ, path)
67 os.system("postmap {}".format(path))
68
69 # Run Podop and Postfix
70 multiprocessing.Process(target=start_podop).start()
71 os.system("/usr/libexec/postfix/post-install meta_directory=/etc/postfix create-missing")
72 # Before starting postfix, we need to check permissions on /queue
73 # in the event that postfix,postdrop id have changed
74 os.system("postfix set-permissions")
75 os.system("postfix start-fg")
76
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/core/postfix/start.py b/core/postfix/start.py
--- a/core/postfix/start.py
+++ b/core/postfix/start.py
@@ -8,12 +8,13 @@
import sys
from podop import run_server
+from pwd import getpwnam
from socrate import system, conf
log.basicConfig(stream=sys.stderr, level=os.environ.get("LOG_LEVEL", "WARNING"))
def start_podop():
- os.setuid(100)
+ os.setuid(getpwnam('postfix').pw_uid)
url = "http://" + os.environ["ADMIN_ADDRESS"] + "/internal/postfix/"
# TODO: Remove verbosity setting from Podop?
run_server(0, "postfix", "/tmp/podop.socket", [
| {"golden_diff": "diff --git a/core/postfix/start.py b/core/postfix/start.py\n--- a/core/postfix/start.py\n+++ b/core/postfix/start.py\n@@ -8,12 +8,13 @@\n import sys\n \n from podop import run_server\n+from pwd import getpwnam\n from socrate import system, conf\n \n log.basicConfig(stream=sys.stderr, level=os.environ.get(\"LOG_LEVEL\", \"WARNING\"))\n \n def start_podop():\n- os.setuid(100)\n+ os.setuid(getpwnam('postfix').pw_uid)\n url = \"http://\" + os.environ[\"ADMIN_ADDRESS\"] + \"/internal/postfix/\"\n # TODO: Remove verbosity setting from Podop?\n run_server(0, \"postfix\", \"/tmp/podop.socket\", [\n", "issue": "connect to /tmp/podop.socket: Permission denied\nHi,\r\nI build the docker images from Mailu/tests/build_arm.sh (commit 5d20f28).\r\nSetting mailu.env log level to: `LOG_LEVEL=DEBUG`\r\nI got this \"Temporary lookup failure\" when sending a test email to my domain.\r\nDigging out the postfix's log is the best I can manage with my limited knowledge.\r\nAny help please?\r\nThanks,\r\nTin.\r\n\r\n`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: connect to /tmp/podop.socket: Permission denied`\r\n`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: table socketmap:unix:/tmp/podop.socket:transport lookup error: Permission denied`\r\n`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: socketmap:unix:/tmp/podop.socket:transport lookup error for \"*\"`\r\n`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: connect to /tmp/podop.socket: Permission denied`\r\n`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: table socketmap:unix:/tmp/podop.socket:transport lookup error: Permission denied`\r\n`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: socketmap:unix:/tmp/podop.socket:transport lookup error for \"*\"`\r\n`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: connect to /tmp/podop.socket: Permission denied`\r\n`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: table socketmap:unix:/tmp/podop.socket:domain lookup error: Permission denied`\r\n`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: virtual_mailbox_domains: socketmap:unix:/tmp/podop.socket:domain: table lookup problem`\r\n`smtp | Dec 25 21:35:01 mail postfix/trivial-rewrite[276]: warning: virtual_mailbox_domains lookup failure`\r\n`smtp | Dec 25 21:35:19 mail postfix/trivial-rewrite[276]: warning: connect to /tmp/podop.socket: Permission denied`\r\n`smtp | Dec 25 21:35:19 mail postfix/trivial-rewrite[276]: warning: table socketmap:unix:/tmp/podop.socket:domain lookup error: Permission denied`\r\n`smtp | Dec 25 21:35:19 mail postfix/trivial-rewrite[276]: warning: virtual_mailbox_domains: socketmap:unix:/tmp/podop.socket:domain: table lookup problem`\r\n`smtp | Dec 25 21:35:19 mail postfix/trivial-rewrite[276]: warning: virtual_mailbox_domains lookup failure`\r\n`smtp | Dec 25 21:35:19 mail postfix/smtpd[198]: NOQUEUE: reject: RCPT from localhost[127.0.0.1]: 451 4.3.0 <tin@***obscured.com***>: Temporary lookup failure; from=<admin@***obscured.com***> to=<tin@***obscured.com***> proto=SMTP helo=<mail.***obscured.com***>`\r\n`smtp | Dec 25 21:35:24 mail postfix/smtpd[258]: connect from localhost[127.0.0.1]`\r\n`smtp | Dec 25 21:35:24 mail postfix/smtpd[258]: disconnect from localhost[127.0.0.1] quit=1 commands=1`\n", "before_files": [{"content": "#!/usr/bin/python3\n\nimport os\nimport glob\nimport shutil\nimport multiprocessing\nimport logging as log\nimport sys\n\nfrom podop import run_server\nfrom socrate import system, conf\n\nlog.basicConfig(stream=sys.stderr, level=os.environ.get(\"LOG_LEVEL\", \"WARNING\"))\n\ndef start_podop():\n os.setuid(100)\n url = \"http://\" + os.environ[\"ADMIN_ADDRESS\"] + \"/internal/postfix/\"\n # TODO: Remove verbosity setting from Podop?\n run_server(0, \"postfix\", \"/tmp/podop.socket\", [\n\t\t(\"transport\", \"url\", url + \"transport/\u00a7\"),\n\t\t(\"alias\", \"url\", url + \"alias/\u00a7\"),\n\t\t(\"domain\", \"url\", url + \"domain/\u00a7\"),\n (\"mailbox\", \"url\", url + \"mailbox/\u00a7\"),\n (\"recipientmap\", \"url\", url + \"recipient/map/\u00a7\"),\n (\"sendermap\", \"url\", url + \"sender/map/\u00a7\"),\n (\"senderaccess\", \"url\", url + \"sender/access/\u00a7\"),\n (\"senderlogin\", \"url\", url + \"sender/login/\u00a7\")\n ])\n\ndef is_valid_postconf_line(line):\n return not line.startswith(\"#\") \\\n and not line == ''\n\n# Actual startup script\nos.environ[\"FRONT_ADDRESS\"] = system.get_host_address_from_environment(\"FRONT\", \"front\")\nos.environ[\"ADMIN_ADDRESS\"] = system.get_host_address_from_environment(\"ADMIN\", \"admin\")\nos.environ[\"ANTISPAM_MILTER_ADDRESS\"] = system.get_host_address_from_environment(\"ANTISPAM_MILTER\", \"antispam:11332\")\nos.environ[\"LMTP_ADDRESS\"] = system.get_host_address_from_environment(\"LMTP\", \"imap:2525\")\nos.environ[\"OUTCLEAN\"] = os.environ[\"HOSTNAMES\"].split(\",\")[0]\ntry:\n os.environ[\"OUTCLEAN_ADDRESS\"] = system.resolve_hostname(os.environ[\"OUTCLEAN\"])\nexcept:\n os.environ[\"OUTCLEAN_ADDRESS\"] = \"10.10.10.10\"\n\nfor postfix_file in glob.glob(\"/conf/*.cf\"):\n conf.jinja(postfix_file, os.environ, os.path.join(\"/etc/postfix\", os.path.basename(postfix_file)))\n\nif os.path.exists(\"/overrides/postfix.cf\"):\n for line in open(\"/overrides/postfix.cf\").read().strip().split(\"\\n\"):\n if is_valid_postconf_line(line):\n os.system('postconf -e \"{}\"'.format(line))\n\nif os.path.exists(\"/overrides/postfix.master\"):\n for line in open(\"/overrides/postfix.master\").read().strip().split(\"\\n\"):\n if is_valid_postconf_line(line):\n os.system('postconf -Me \"{}\"'.format(line))\n\nfor map_file in glob.glob(\"/overrides/*.map\"):\n destination = os.path.join(\"/etc/postfix\", os.path.basename(map_file))\n shutil.copyfile(map_file, destination)\n os.system(\"postmap {}\".format(destination))\n os.remove(destination)\n\nif \"RELAYUSER\" in os.environ:\n path = \"/etc/postfix/sasl_passwd\"\n conf.jinja(\"/conf/sasl_passwd\", os.environ, path)\n os.system(\"postmap {}\".format(path))\n\n# Run Podop and Postfix\nmultiprocessing.Process(target=start_podop).start()\nos.system(\"/usr/libexec/postfix/post-install meta_directory=/etc/postfix create-missing\")\n# Before starting postfix, we need to check permissions on /queue\n# in the event that postfix,postdrop id have changed\nos.system(\"postfix set-permissions\")\nos.system(\"postfix start-fg\")\n", "path": "core/postfix/start.py"}], "after_files": [{"content": "#!/usr/bin/python3\n\nimport os\nimport glob\nimport shutil\nimport multiprocessing\nimport logging as log\nimport sys\n\nfrom podop import run_server\nfrom pwd import getpwnam\nfrom socrate import system, conf\n\nlog.basicConfig(stream=sys.stderr, level=os.environ.get(\"LOG_LEVEL\", \"WARNING\"))\n\ndef start_podop():\n os.setuid(getpwnam('postfix').pw_uid)\n url = \"http://\" + os.environ[\"ADMIN_ADDRESS\"] + \"/internal/postfix/\"\n # TODO: Remove verbosity setting from Podop?\n run_server(0, \"postfix\", \"/tmp/podop.socket\", [\n\t\t(\"transport\", \"url\", url + \"transport/\u00a7\"),\n\t\t(\"alias\", \"url\", url + \"alias/\u00a7\"),\n\t\t(\"domain\", \"url\", url + \"domain/\u00a7\"),\n (\"mailbox\", \"url\", url + \"mailbox/\u00a7\"),\n (\"recipientmap\", \"url\", url + \"recipient/map/\u00a7\"),\n (\"sendermap\", \"url\", url + \"sender/map/\u00a7\"),\n (\"senderaccess\", \"url\", url + \"sender/access/\u00a7\"),\n (\"senderlogin\", \"url\", url + \"sender/login/\u00a7\")\n ])\n\ndef is_valid_postconf_line(line):\n return not line.startswith(\"#\") \\\n and not line == ''\n\n# Actual startup script\nos.environ[\"FRONT_ADDRESS\"] = system.get_host_address_from_environment(\"FRONT\", \"front\")\nos.environ[\"ADMIN_ADDRESS\"] = system.get_host_address_from_environment(\"ADMIN\", \"admin\")\nos.environ[\"ANTISPAM_MILTER_ADDRESS\"] = system.get_host_address_from_environment(\"ANTISPAM_MILTER\", \"antispam:11332\")\nos.environ[\"LMTP_ADDRESS\"] = system.get_host_address_from_environment(\"LMTP\", \"imap:2525\")\nos.environ[\"OUTCLEAN\"] = os.environ[\"HOSTNAMES\"].split(\",\")[0]\ntry:\n os.environ[\"OUTCLEAN_ADDRESS\"] = system.resolve_hostname(os.environ[\"OUTCLEAN\"])\nexcept:\n os.environ[\"OUTCLEAN_ADDRESS\"] = \"10.10.10.10\"\n\nfor postfix_file in glob.glob(\"/conf/*.cf\"):\n conf.jinja(postfix_file, os.environ, os.path.join(\"/etc/postfix\", os.path.basename(postfix_file)))\n\nif os.path.exists(\"/overrides/postfix.cf\"):\n for line in open(\"/overrides/postfix.cf\").read().strip().split(\"\\n\"):\n if is_valid_postconf_line(line):\n os.system('postconf -e \"{}\"'.format(line))\n\nif os.path.exists(\"/overrides/postfix.master\"):\n for line in open(\"/overrides/postfix.master\").read().strip().split(\"\\n\"):\n if is_valid_postconf_line(line):\n os.system('postconf -Me \"{}\"'.format(line))\n\nfor map_file in glob.glob(\"/overrides/*.map\"):\n destination = os.path.join(\"/etc/postfix\", os.path.basename(map_file))\n shutil.copyfile(map_file, destination)\n os.system(\"postmap {}\".format(destination))\n os.remove(destination)\n\nif \"RELAYUSER\" in os.environ:\n path = \"/etc/postfix/sasl_passwd\"\n conf.jinja(\"/conf/sasl_passwd\", os.environ, path)\n os.system(\"postmap {}\".format(path))\n\n# Run Podop and Postfix\nmultiprocessing.Process(target=start_podop).start()\nos.system(\"/usr/libexec/postfix/post-install meta_directory=/etc/postfix create-missing\")\n# Before starting postfix, we need to check permissions on /queue\n# in the event that postfix,postdrop id have changed\nos.system(\"postfix set-permissions\")\nos.system(\"postfix start-fg\")\n", "path": "core/postfix/start.py"}]} | 2,110 | 170 |
gh_patches_debug_8739 | rasdani/github-patches | git_diff | cookiecutter__cookiecutter-1989 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add Python 3.12 support
* Cookiecutter version: 2.5.0
* Python version: 3.12
* Operating System: All
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 """cookiecutter distutils configuration."""
2 from pathlib import Path
3
4 from setuptools import setup
5
6
7 def _get_version() -> str:
8 """Read cookiecutter/VERSION.txt and return its contents."""
9 path = Path("cookiecutter").resolve()
10 version_file = path / "VERSION.txt"
11 return version_file.read_text().strip()
12
13
14 version = _get_version()
15
16
17 with open('README.md', encoding='utf-8') as readme_file:
18 readme = readme_file.read()
19
20
21 requirements = [
22 'binaryornot>=0.4.4',
23 'Jinja2>=2.7,<4.0.0',
24 'click>=7.0,<9.0.0',
25 'pyyaml>=5.3.1',
26 'python-slugify>=4.0.0',
27 'requests>=2.23.0',
28 'arrow',
29 'rich',
30 ]
31
32 setup(
33 name='cookiecutter',
34 version=version,
35 description=(
36 'A command-line utility that creates projects from project '
37 'templates, e.g. creating a Python package project from a '
38 'Python package project template.'
39 ),
40 long_description=readme,
41 long_description_content_type='text/markdown',
42 author='Audrey Feldroy',
43 author_email='[email protected]',
44 url='https://github.com/cookiecutter/cookiecutter',
45 project_urls={
46 "Documentation": "https://cookiecutter.readthedocs.io",
47 "Issues": "https://github.com/cookiecutter/cookiecutter/issues",
48 "Discord": "https://discord.gg/9BrxzPKuEW",
49 },
50 packages=['cookiecutter'],
51 package_dir={'cookiecutter': 'cookiecutter'},
52 entry_points={'console_scripts': ['cookiecutter = cookiecutter.__main__:main']},
53 include_package_data=True,
54 python_requires='>=3.7',
55 install_requires=requirements,
56 license='BSD',
57 zip_safe=False,
58 classifiers=[
59 "Development Status :: 5 - Production/Stable",
60 "Environment :: Console",
61 "Intended Audience :: Developers",
62 "Natural Language :: English",
63 "License :: OSI Approved :: BSD License",
64 "Programming Language :: Python :: 3 :: Only",
65 "Programming Language :: Python :: 3",
66 "Programming Language :: Python :: 3.7",
67 "Programming Language :: Python :: 3.8",
68 "Programming Language :: Python :: 3.9",
69 "Programming Language :: Python :: 3.10",
70 "Programming Language :: Python :: 3.11",
71 "Programming Language :: Python :: Implementation :: CPython",
72 "Programming Language :: Python :: Implementation :: PyPy",
73 "Programming Language :: Python",
74 "Topic :: Software Development",
75 ],
76 keywords=[
77 "cookiecutter",
78 "Python",
79 "projects",
80 "project templates",
81 "Jinja2",
82 "skeleton",
83 "scaffolding",
84 "project directory",
85 "package",
86 "packaging",
87 ],
88 )
89
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -68,6 +68,7 @@
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
+ "Programming Language :: Python :: 3.12",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy",
"Programming Language :: Python",
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -68,6 +68,7 @@\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n+ \"Programming Language :: Python :: 3.12\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Programming Language :: Python\",\n", "issue": "Add Python 3.12 support\n* Cookiecutter version: 2.5.0\r\n* Python version: 3.12\r\n* Operating System: All\r\n\n", "before_files": [{"content": "\"\"\"cookiecutter distutils configuration.\"\"\"\nfrom pathlib import Path\n\nfrom setuptools import setup\n\n\ndef _get_version() -> str:\n \"\"\"Read cookiecutter/VERSION.txt and return its contents.\"\"\"\n path = Path(\"cookiecutter\").resolve()\n version_file = path / \"VERSION.txt\"\n return version_file.read_text().strip()\n\n\nversion = _get_version()\n\n\nwith open('README.md', encoding='utf-8') as readme_file:\n readme = readme_file.read()\n\n\nrequirements = [\n 'binaryornot>=0.4.4',\n 'Jinja2>=2.7,<4.0.0',\n 'click>=7.0,<9.0.0',\n 'pyyaml>=5.3.1',\n 'python-slugify>=4.0.0',\n 'requests>=2.23.0',\n 'arrow',\n 'rich',\n]\n\nsetup(\n name='cookiecutter',\n version=version,\n description=(\n 'A command-line utility that creates projects from project '\n 'templates, e.g. creating a Python package project from a '\n 'Python package project template.'\n ),\n long_description=readme,\n long_description_content_type='text/markdown',\n author='Audrey Feldroy',\n author_email='[email protected]',\n url='https://github.com/cookiecutter/cookiecutter',\n project_urls={\n \"Documentation\": \"https://cookiecutter.readthedocs.io\",\n \"Issues\": \"https://github.com/cookiecutter/cookiecutter/issues\",\n \"Discord\": \"https://discord.gg/9BrxzPKuEW\",\n },\n packages=['cookiecutter'],\n package_dir={'cookiecutter': 'cookiecutter'},\n entry_points={'console_scripts': ['cookiecutter = cookiecutter.__main__:main']},\n include_package_data=True,\n python_requires='>=3.7',\n install_requires=requirements,\n license='BSD',\n zip_safe=False,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Environment :: Console\",\n \"Intended Audience :: Developers\",\n \"Natural Language :: English\",\n \"License :: OSI Approved :: BSD License\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Programming Language :: Python\",\n \"Topic :: Software Development\",\n ],\n keywords=[\n \"cookiecutter\",\n \"Python\",\n \"projects\",\n \"project templates\",\n \"Jinja2\",\n \"skeleton\",\n \"scaffolding\",\n \"project directory\",\n \"package\",\n \"packaging\",\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "\"\"\"cookiecutter distutils configuration.\"\"\"\nfrom pathlib import Path\n\nfrom setuptools import setup\n\n\ndef _get_version() -> str:\n \"\"\"Read cookiecutter/VERSION.txt and return its contents.\"\"\"\n path = Path(\"cookiecutter\").resolve()\n version_file = path / \"VERSION.txt\"\n return version_file.read_text().strip()\n\n\nversion = _get_version()\n\n\nwith open('README.md', encoding='utf-8') as readme_file:\n readme = readme_file.read()\n\n\nrequirements = [\n 'binaryornot>=0.4.4',\n 'Jinja2>=2.7,<4.0.0',\n 'click>=7.0,<9.0.0',\n 'pyyaml>=5.3.1',\n 'python-slugify>=4.0.0',\n 'requests>=2.23.0',\n 'arrow',\n 'rich',\n]\n\nsetup(\n name='cookiecutter',\n version=version,\n description=(\n 'A command-line utility that creates projects from project '\n 'templates, e.g. creating a Python package project from a '\n 'Python package project template.'\n ),\n long_description=readme,\n long_description_content_type='text/markdown',\n author='Audrey Feldroy',\n author_email='[email protected]',\n url='https://github.com/cookiecutter/cookiecutter',\n project_urls={\n \"Documentation\": \"https://cookiecutter.readthedocs.io\",\n \"Issues\": \"https://github.com/cookiecutter/cookiecutter/issues\",\n \"Discord\": \"https://discord.gg/9BrxzPKuEW\",\n },\n packages=['cookiecutter'],\n package_dir={'cookiecutter': 'cookiecutter'},\n entry_points={'console_scripts': ['cookiecutter = cookiecutter.__main__:main']},\n include_package_data=True,\n python_requires='>=3.7',\n install_requires=requirements,\n license='BSD',\n zip_safe=False,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Environment :: Console\",\n \"Intended Audience :: Developers\",\n \"Natural Language :: English\",\n \"License :: OSI Approved :: BSD License\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Programming Language :: Python :: 3.12\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Programming Language :: Python\",\n \"Topic :: Software Development\",\n ],\n keywords=[\n \"cookiecutter\",\n \"Python\",\n \"projects\",\n \"project templates\",\n \"Jinja2\",\n \"skeleton\",\n \"scaffolding\",\n \"project directory\",\n \"package\",\n \"packaging\",\n ],\n)\n", "path": "setup.py"}]} | 1,120 | 115 |
gh_patches_debug_3825 | rasdani/github-patches | git_diff | conda__conda-5335 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
conda env update : does not support --prefix
The `conda env update` does not support the `--prefix` / `-p` argument.
```
$ conda info | grep version
conda version : 4.2.12
conda-env version : 4.2.12
conda-build version : 1.20.3
python version : 2.7.11.final.0
requests version : 2.10.0
$ conda env update -p ./conda-env
usage: conda-env [-h] {attach,create,export,list,remove,upload,update} ...
conda-env: error: unrecognized arguments: -p
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda_env/cli/main_update.py`
Content:
```
1 from argparse import RawDescriptionHelpFormatter
2 import os
3 import textwrap
4 import sys
5
6 from conda import config
7 from conda.cli import common
8 from conda.cli import install as cli_install
9 from conda.misc import touch_nonadmin
10 from ..installers.base import get_installer, InvalidInstaller
11 from .. import specs as install_specs
12 from .. import exceptions
13 # for conda env
14 from conda_env.cli.common import get_prefix
15 from ..exceptions import CondaEnvException
16 description = """
17 Update the current environment based on environment file
18 """
19
20 example = """
21 examples:
22 conda env update
23 conda env update -n=foo
24 conda env update -f=/path/to/environment.yml
25 conda env update --name=foo --file=environment.yml
26 conda env update vader/deathstar
27 """
28
29
30 def configure_parser(sub_parsers):
31 p = sub_parsers.add_parser(
32 'update',
33 formatter_class=RawDescriptionHelpFormatter,
34 description=description,
35 help=description,
36 epilog=example,
37 )
38 p.add_argument(
39 '-n', '--name',
40 action='store',
41 help='name of environment (in %s)' % os.pathsep.join(config.envs_dirs),
42 default=None,
43 )
44 p.add_argument(
45 '-f', '--file',
46 action='store',
47 help='environment definition (default: environment.yml)',
48 default='environment.yml',
49 )
50 p.add_argument(
51 '--prune',
52 action='store_true',
53 default=False,
54 help='remove installed packages not defined in environment.yml',
55 )
56 p.add_argument(
57 '-q', '--quiet',
58 action='store_true',
59 default=False,
60 )
61 p.add_argument(
62 'remote_definition',
63 help='remote environment definition / IPython notebook',
64 action='store',
65 default=None,
66 nargs='?'
67 )
68 common.add_parser_json(p)
69 p.set_defaults(func=execute)
70
71
72 def execute(args, parser):
73 name = args.remote_definition or args.name
74
75 try:
76 spec = install_specs.detect(name=name, filename=args.file,
77 directory=os.getcwd())
78 env = spec.environment
79 except exceptions.SpecNotFound:
80 raise
81
82 if not args.name:
83 if not env.name:
84 # Note, this is a hack fofr get_prefix that assumes argparse results
85 # TODO Refactor common.get_prefix
86 name = os.environ.get('CONDA_DEFAULT_ENV', False)
87 if not name:
88 msg = "Unable to determine environment\n\n"
89 msg += textwrap.dedent("""
90 Please re-run this command with one of the following options:
91
92 * Provide an environment name via --name or -n
93 * Re-run this command inside an activated conda environment.""").lstrip()
94 # TODO Add json support
95 raise CondaEnvException(msg)
96
97 # Note: stubbing out the args object as all of the
98 # conda.cli.common code thinks that name will always
99 # be specified.
100 args.name = env.name
101
102 prefix = get_prefix(args, search=False)
103 # CAN'T Check with this function since it assumes we will create prefix.
104 # cli_install.check_prefix(prefix, json=args.json)
105
106 # TODO, add capability
107 # common.ensure_override_channels_requires_channel(args)
108 # channel_urls = args.channel or ()
109
110 for installer_type, specs in env.dependencies.items():
111 try:
112 installer = get_installer(installer_type)
113 installer.install(prefix, specs, args, env, prune=args.prune)
114 except InvalidInstaller:
115 sys.stderr.write(textwrap.dedent("""
116 Unable to install package for {0}.
117
118 Please double check and ensure you dependencies file has
119 the correct spelling. You might also try installing the
120 conda-env-{0} package to see if provides the required
121 installer.
122 """).lstrip().format(installer_type)
123 )
124 return -1
125
126 touch_nonadmin(prefix)
127 if not args.json:
128 print(cli_install.print_activate(args.name if args.name else prefix))
129
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/conda_env/cli/main_update.py b/conda_env/cli/main_update.py
--- a/conda_env/cli/main_update.py
+++ b/conda_env/cli/main_update.py
@@ -79,7 +79,7 @@
except exceptions.SpecNotFound:
raise
- if not args.name:
+ if not (args.name or args.prefix):
if not env.name:
# Note, this is a hack fofr get_prefix that assumes argparse results
# TODO Refactor common.get_prefix
| {"golden_diff": "diff --git a/conda_env/cli/main_update.py b/conda_env/cli/main_update.py\n--- a/conda_env/cli/main_update.py\n+++ b/conda_env/cli/main_update.py\n@@ -79,7 +79,7 @@\n except exceptions.SpecNotFound:\n raise\n \n- if not args.name:\n+ if not (args.name or args.prefix):\n if not env.name:\n # Note, this is a hack fofr get_prefix that assumes argparse results\n # TODO Refactor common.get_prefix\n", "issue": "conda env update : does not support --prefix\nThe `conda env update` does not support the `--prefix` / `-p` argument.\r\n\r\n```\r\n$ conda info | grep version\r\n conda version : 4.2.12\r\n conda-env version : 4.2.12\r\n conda-build version : 1.20.3\r\n python version : 2.7.11.final.0\r\n requests version : 2.10.0\r\n\r\n$ conda env update -p ./conda-env\r\nusage: conda-env [-h] {attach,create,export,list,remove,upload,update} ...\r\nconda-env: error: unrecognized arguments: -p\r\n```\r\n\n", "before_files": [{"content": "from argparse import RawDescriptionHelpFormatter\nimport os\nimport textwrap\nimport sys\n\nfrom conda import config\nfrom conda.cli import common\nfrom conda.cli import install as cli_install\nfrom conda.misc import touch_nonadmin\nfrom ..installers.base import get_installer, InvalidInstaller\nfrom .. import specs as install_specs\nfrom .. import exceptions\n# for conda env\nfrom conda_env.cli.common import get_prefix\nfrom ..exceptions import CondaEnvException\ndescription = \"\"\"\nUpdate the current environment based on environment file\n\"\"\"\n\nexample = \"\"\"\nexamples:\n conda env update\n conda env update -n=foo\n conda env update -f=/path/to/environment.yml\n conda env update --name=foo --file=environment.yml\n conda env update vader/deathstar\n\"\"\"\n\n\ndef configure_parser(sub_parsers):\n p = sub_parsers.add_parser(\n 'update',\n formatter_class=RawDescriptionHelpFormatter,\n description=description,\n help=description,\n epilog=example,\n )\n p.add_argument(\n '-n', '--name',\n action='store',\n help='name of environment (in %s)' % os.pathsep.join(config.envs_dirs),\n default=None,\n )\n p.add_argument(\n '-f', '--file',\n action='store',\n help='environment definition (default: environment.yml)',\n default='environment.yml',\n )\n p.add_argument(\n '--prune',\n action='store_true',\n default=False,\n help='remove installed packages not defined in environment.yml',\n )\n p.add_argument(\n '-q', '--quiet',\n action='store_true',\n default=False,\n )\n p.add_argument(\n 'remote_definition',\n help='remote environment definition / IPython notebook',\n action='store',\n default=None,\n nargs='?'\n )\n common.add_parser_json(p)\n p.set_defaults(func=execute)\n\n\ndef execute(args, parser):\n name = args.remote_definition or args.name\n\n try:\n spec = install_specs.detect(name=name, filename=args.file,\n directory=os.getcwd())\n env = spec.environment\n except exceptions.SpecNotFound:\n raise\n\n if not args.name:\n if not env.name:\n # Note, this is a hack fofr get_prefix that assumes argparse results\n # TODO Refactor common.get_prefix\n name = os.environ.get('CONDA_DEFAULT_ENV', False)\n if not name:\n msg = \"Unable to determine environment\\n\\n\"\n msg += textwrap.dedent(\"\"\"\n Please re-run this command with one of the following options:\n\n * Provide an environment name via --name or -n\n * Re-run this command inside an activated conda environment.\"\"\").lstrip()\n # TODO Add json support\n raise CondaEnvException(msg)\n\n # Note: stubbing out the args object as all of the\n # conda.cli.common code thinks that name will always\n # be specified.\n args.name = env.name\n\n prefix = get_prefix(args, search=False)\n # CAN'T Check with this function since it assumes we will create prefix.\n # cli_install.check_prefix(prefix, json=args.json)\n\n # TODO, add capability\n # common.ensure_override_channels_requires_channel(args)\n # channel_urls = args.channel or ()\n\n for installer_type, specs in env.dependencies.items():\n try:\n installer = get_installer(installer_type)\n installer.install(prefix, specs, args, env, prune=args.prune)\n except InvalidInstaller:\n sys.stderr.write(textwrap.dedent(\"\"\"\n Unable to install package for {0}.\n\n Please double check and ensure you dependencies file has\n the correct spelling. You might also try installing the\n conda-env-{0} package to see if provides the required\n installer.\n \"\"\").lstrip().format(installer_type)\n )\n return -1\n\n touch_nonadmin(prefix)\n if not args.json:\n print(cli_install.print_activate(args.name if args.name else prefix))\n", "path": "conda_env/cli/main_update.py"}], "after_files": [{"content": "from argparse import RawDescriptionHelpFormatter\nimport os\nimport textwrap\nimport sys\n\nfrom conda import config\nfrom conda.cli import common\nfrom conda.cli import install as cli_install\nfrom conda.misc import touch_nonadmin\nfrom ..installers.base import get_installer, InvalidInstaller\nfrom .. import specs as install_specs\nfrom .. import exceptions\n# for conda env\nfrom conda_env.cli.common import get_prefix\nfrom ..exceptions import CondaEnvException\ndescription = \"\"\"\nUpdate the current environment based on environment file\n\"\"\"\n\nexample = \"\"\"\nexamples:\n conda env update\n conda env update -n=foo\n conda env update -f=/path/to/environment.yml\n conda env update --name=foo --file=environment.yml\n conda env update vader/deathstar\n\"\"\"\n\n\ndef configure_parser(sub_parsers):\n p = sub_parsers.add_parser(\n 'update',\n formatter_class=RawDescriptionHelpFormatter,\n description=description,\n help=description,\n epilog=example,\n )\n p.add_argument(\n '-n', '--name',\n action='store',\n help='name of environment (in %s)' % os.pathsep.join(config.envs_dirs),\n default=None,\n )\n p.add_argument(\n '-f', '--file',\n action='store',\n help='environment definition (default: environment.yml)',\n default='environment.yml',\n )\n p.add_argument(\n '--prune',\n action='store_true',\n default=False,\n help='remove installed packages not defined in environment.yml',\n )\n p.add_argument(\n '-q', '--quiet',\n action='store_true',\n default=False,\n )\n p.add_argument(\n 'remote_definition',\n help='remote environment definition / IPython notebook',\n action='store',\n default=None,\n nargs='?'\n )\n common.add_parser_json(p)\n p.set_defaults(func=execute)\n\n\ndef execute(args, parser):\n name = args.remote_definition or args.name\n\n try:\n spec = install_specs.detect(name=name, filename=args.file,\n directory=os.getcwd())\n env = spec.environment\n except exceptions.SpecNotFound:\n raise\n\n if not (args.name or args.prefix):\n if not env.name:\n # Note, this is a hack fofr get_prefix that assumes argparse results\n # TODO Refactor common.get_prefix\n name = os.environ.get('CONDA_DEFAULT_ENV', False)\n if not name:\n msg = \"Unable to determine environment\\n\\n\"\n msg += textwrap.dedent(\"\"\"\n Please re-run this command with one of the following options:\n\n * Provide an environment name via --name or -n\n * Re-run this command inside an activated conda environment.\"\"\").lstrip()\n # TODO Add json support\n raise CondaEnvException(msg)\n\n # Note: stubbing out the args object as all of the\n # conda.cli.common code thinks that name will always\n # be specified.\n args.name = env.name\n\n prefix = get_prefix(args, search=False)\n # CAN'T Check with this function since it assumes we will create prefix.\n # cli_install.check_prefix(prefix, json=args.json)\n\n # TODO, add capability\n # common.ensure_override_channels_requires_channel(args)\n # channel_urls = args.channel or ()\n\n for installer_type, specs in env.dependencies.items():\n try:\n installer = get_installer(installer_type)\n installer.install(prefix, specs, args, env, prune=args.prune)\n except InvalidInstaller:\n sys.stderr.write(textwrap.dedent(\"\"\"\n Unable to install package for {0}.\n\n Please double check and ensure you dependencies file has\n the correct spelling. You might also try installing the\n conda-env-{0} package to see if provides the required\n installer.\n \"\"\").lstrip().format(installer_type)\n )\n return -1\n\n touch_nonadmin(prefix)\n if not args.json:\n print(cli_install.print_activate(args.name if args.name else prefix))\n", "path": "conda_env/cli/main_update.py"}]} | 1,564 | 112 |
gh_patches_debug_16946 | rasdani/github-patches | git_diff | comic__grand-challenge.org-1375 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Import error DICOM file
**Describe the bug**
When uploading a DICOM file in which the Window Center and Window Width attributes are set to floating values (e.g. 2047.0), the file importer raises an error (see screenshot). The issue can be solved by converting the floating values to integers and writing a new DICOM file.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to 'Reader Studies'.
2. Select a reader study.
3. Go to 'Cases'.
4. Click 'Add Cases'.
5. Click 'Choose Files'.
6. Select a DICOM image with Window Center/Width set to a floating value.
7. Click 'Submit'.
8. An error will be raised.
**Screenshots**
<img width="828" alt="import_error" src="https://user-images.githubusercontent.com/47858231/83017756-817de600-a024-11ea-9094-d7e4d60cb01f.PNG">
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/grandchallenge/cases/image_builders/utils.py`
Content:
```
1 from pathlib import Path
2 from tempfile import TemporaryDirectory, TemporaryFile
3 from typing import AnyStr, Optional, Sequence, Tuple
4 from uuid import uuid4
5
6 import SimpleITK
7 from django.conf import settings
8 from django.core.files import File
9
10 from grandchallenge.cases.models import Image, ImageFile
11
12
13 def convert_itk_to_internal(
14 simple_itk_image: SimpleITK.Image,
15 name: Optional[AnyStr] = None,
16 use_spacing: Optional[bool] = True,
17 ) -> Tuple[Image, Sequence[ImageFile]]:
18 color_space = simple_itk_image.GetNumberOfComponentsPerPixel()
19 color_space = {
20 1: Image.COLOR_SPACE_GRAY,
21 3: Image.COLOR_SPACE_RGB,
22 4: Image.COLOR_SPACE_RGBA,
23 }.get(color_space, None)
24 if color_space is None:
25 raise ValueError("Unknown color space for MetaIO image.")
26
27 with TemporaryDirectory() as work_dir:
28 work_dir = Path(work_dir)
29
30 pk = uuid4()
31 if not name:
32 name = str(pk)
33 SimpleITK.WriteImage(
34 simple_itk_image,
35 str(work_dir / f"{pk}.{settings.ITK_INTERNAL_FILE_FORMAT}"),
36 True,
37 )
38
39 if simple_itk_image.GetDimension() == 4:
40 timepoints = simple_itk_image.GetSize()[-1]
41 else:
42 timepoints = None
43 depth = simple_itk_image.GetDepth()
44 metadata_keys = simple_itk_image.GetMetaDataKeys()
45 window_center = (
46 float(simple_itk_image.GetMetaData("WindowCenter"))
47 if "WindowCenter" in metadata_keys
48 else None
49 )
50 window_width = (
51 float(simple_itk_image.GetMetaData("WindowWidth"))
52 if "WindowWidth" in metadata_keys
53 else None
54 )
55 db_image = Image(
56 pk=pk,
57 name=name,
58 width=simple_itk_image.GetWidth(),
59 height=simple_itk_image.GetHeight(),
60 depth=depth if depth else None,
61 window_center=window_center,
62 window_width=window_width,
63 timepoints=timepoints,
64 resolution_levels=None,
65 color_space=color_space,
66 voxel_width_mm=simple_itk_image.GetSpacing()[0]
67 if use_spacing
68 else None,
69 voxel_height_mm=simple_itk_image.GetSpacing()[1]
70 if use_spacing
71 else None,
72 voxel_depth_mm=simple_itk_image.GetSpacing()[2] if depth else None,
73 )
74 db_image_files = []
75 for _file in work_dir.iterdir():
76 temp_file = TemporaryFile()
77 with open(str(_file), "rb") as open_file:
78 buffer = True
79 while buffer:
80 buffer = open_file.read(1024)
81 temp_file.write(buffer)
82 db_image_file = ImageFile(
83 image=db_image,
84 image_type=ImageFile.IMAGE_TYPE_MHD,
85 file=File(temp_file, name=_file.name),
86 )
87 db_image_files.append(db_image_file)
88
89 return db_image, db_image_files
90
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/app/grandchallenge/cases/image_builders/utils.py b/app/grandchallenge/cases/image_builders/utils.py
--- a/app/grandchallenge/cases/image_builders/utils.py
+++ b/app/grandchallenge/cases/image_builders/utils.py
@@ -41,17 +41,16 @@
else:
timepoints = None
depth = simple_itk_image.GetDepth()
- metadata_keys = simple_itk_image.GetMetaDataKeys()
- window_center = (
- float(simple_itk_image.GetMetaData("WindowCenter"))
- if "WindowCenter" in metadata_keys
- else None
- )
- window_width = (
- float(simple_itk_image.GetMetaData("WindowWidth"))
- if "WindowWidth" in metadata_keys
- else None
- )
+
+ try:
+ window_center = float(simple_itk_image.GetMetaData("WindowCenter"))
+ except (RuntimeError, ValueError):
+ window_center = None
+ try:
+ window_width = float(simple_itk_image.GetMetaData("WindowWidth"))
+ except (RuntimeError, ValueError):
+ window_width = None
+
db_image = Image(
pk=pk,
name=name,
| {"golden_diff": "diff --git a/app/grandchallenge/cases/image_builders/utils.py b/app/grandchallenge/cases/image_builders/utils.py\n--- a/app/grandchallenge/cases/image_builders/utils.py\n+++ b/app/grandchallenge/cases/image_builders/utils.py\n@@ -41,17 +41,16 @@\n else:\n timepoints = None\n depth = simple_itk_image.GetDepth()\n- metadata_keys = simple_itk_image.GetMetaDataKeys()\n- window_center = (\n- float(simple_itk_image.GetMetaData(\"WindowCenter\"))\n- if \"WindowCenter\" in metadata_keys\n- else None\n- )\n- window_width = (\n- float(simple_itk_image.GetMetaData(\"WindowWidth\"))\n- if \"WindowWidth\" in metadata_keys\n- else None\n- )\n+\n+ try:\n+ window_center = float(simple_itk_image.GetMetaData(\"WindowCenter\"))\n+ except (RuntimeError, ValueError):\n+ window_center = None\n+ try:\n+ window_width = float(simple_itk_image.GetMetaData(\"WindowWidth\"))\n+ except (RuntimeError, ValueError):\n+ window_width = None\n+\n db_image = Image(\n pk=pk,\n name=name,\n", "issue": "Import error DICOM file\n**Describe the bug**\r\nWhen uploading a DICOM file in which the Window Center and Window Width attributes are set to floating values (e.g. 2047.0), the file importer raises an error (see screenshot). The issue can be solved by converting the floating values to integers and writing a new DICOM file. \r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Go to 'Reader Studies'.\r\n2. Select a reader study. \r\n3. Go to 'Cases'.\r\n4. Click 'Add Cases'.\r\n5. Click 'Choose Files'. \r\n6. Select a DICOM image with Window Center/Width set to a floating value. \r\n7. Click 'Submit'.\r\n8. An error will be raised.\r\n\r\n**Screenshots**\r\n<img width=\"828\" alt=\"import_error\" src=\"https://user-images.githubusercontent.com/47858231/83017756-817de600-a024-11ea-9094-d7e4d60cb01f.PNG\">\r\n\n", "before_files": [{"content": "from pathlib import Path\nfrom tempfile import TemporaryDirectory, TemporaryFile\nfrom typing import AnyStr, Optional, Sequence, Tuple\nfrom uuid import uuid4\n\nimport SimpleITK\nfrom django.conf import settings\nfrom django.core.files import File\n\nfrom grandchallenge.cases.models import Image, ImageFile\n\n\ndef convert_itk_to_internal(\n simple_itk_image: SimpleITK.Image,\n name: Optional[AnyStr] = None,\n use_spacing: Optional[bool] = True,\n) -> Tuple[Image, Sequence[ImageFile]]:\n color_space = simple_itk_image.GetNumberOfComponentsPerPixel()\n color_space = {\n 1: Image.COLOR_SPACE_GRAY,\n 3: Image.COLOR_SPACE_RGB,\n 4: Image.COLOR_SPACE_RGBA,\n }.get(color_space, None)\n if color_space is None:\n raise ValueError(\"Unknown color space for MetaIO image.\")\n\n with TemporaryDirectory() as work_dir:\n work_dir = Path(work_dir)\n\n pk = uuid4()\n if not name:\n name = str(pk)\n SimpleITK.WriteImage(\n simple_itk_image,\n str(work_dir / f\"{pk}.{settings.ITK_INTERNAL_FILE_FORMAT}\"),\n True,\n )\n\n if simple_itk_image.GetDimension() == 4:\n timepoints = simple_itk_image.GetSize()[-1]\n else:\n timepoints = None\n depth = simple_itk_image.GetDepth()\n metadata_keys = simple_itk_image.GetMetaDataKeys()\n window_center = (\n float(simple_itk_image.GetMetaData(\"WindowCenter\"))\n if \"WindowCenter\" in metadata_keys\n else None\n )\n window_width = (\n float(simple_itk_image.GetMetaData(\"WindowWidth\"))\n if \"WindowWidth\" in metadata_keys\n else None\n )\n db_image = Image(\n pk=pk,\n name=name,\n width=simple_itk_image.GetWidth(),\n height=simple_itk_image.GetHeight(),\n depth=depth if depth else None,\n window_center=window_center,\n window_width=window_width,\n timepoints=timepoints,\n resolution_levels=None,\n color_space=color_space,\n voxel_width_mm=simple_itk_image.GetSpacing()[0]\n if use_spacing\n else None,\n voxel_height_mm=simple_itk_image.GetSpacing()[1]\n if use_spacing\n else None,\n voxel_depth_mm=simple_itk_image.GetSpacing()[2] if depth else None,\n )\n db_image_files = []\n for _file in work_dir.iterdir():\n temp_file = TemporaryFile()\n with open(str(_file), \"rb\") as open_file:\n buffer = True\n while buffer:\n buffer = open_file.read(1024)\n temp_file.write(buffer)\n db_image_file = ImageFile(\n image=db_image,\n image_type=ImageFile.IMAGE_TYPE_MHD,\n file=File(temp_file, name=_file.name),\n )\n db_image_files.append(db_image_file)\n\n return db_image, db_image_files\n", "path": "app/grandchallenge/cases/image_builders/utils.py"}], "after_files": [{"content": "from pathlib import Path\nfrom tempfile import TemporaryDirectory, TemporaryFile\nfrom typing import AnyStr, Optional, Sequence, Tuple\nfrom uuid import uuid4\n\nimport SimpleITK\nfrom django.conf import settings\nfrom django.core.files import File\n\nfrom grandchallenge.cases.models import Image, ImageFile\n\n\ndef convert_itk_to_internal(\n simple_itk_image: SimpleITK.Image,\n name: Optional[AnyStr] = None,\n use_spacing: Optional[bool] = True,\n) -> Tuple[Image, Sequence[ImageFile]]:\n color_space = simple_itk_image.GetNumberOfComponentsPerPixel()\n color_space = {\n 1: Image.COLOR_SPACE_GRAY,\n 3: Image.COLOR_SPACE_RGB,\n 4: Image.COLOR_SPACE_RGBA,\n }.get(color_space, None)\n if color_space is None:\n raise ValueError(\"Unknown color space for MetaIO image.\")\n\n with TemporaryDirectory() as work_dir:\n work_dir = Path(work_dir)\n\n pk = uuid4()\n if not name:\n name = str(pk)\n SimpleITK.WriteImage(\n simple_itk_image,\n str(work_dir / f\"{pk}.{settings.ITK_INTERNAL_FILE_FORMAT}\"),\n True,\n )\n\n if simple_itk_image.GetDimension() == 4:\n timepoints = simple_itk_image.GetSize()[-1]\n else:\n timepoints = None\n depth = simple_itk_image.GetDepth()\n\n try:\n window_center = float(simple_itk_image.GetMetaData(\"WindowCenter\"))\n except (RuntimeError, ValueError):\n window_center = None\n try:\n window_width = float(simple_itk_image.GetMetaData(\"WindowWidth\"))\n except (RuntimeError, ValueError):\n window_width = None\n\n db_image = Image(\n pk=pk,\n name=name,\n width=simple_itk_image.GetWidth(),\n height=simple_itk_image.GetHeight(),\n depth=depth if depth else None,\n window_center=window_center,\n window_width=window_width,\n timepoints=timepoints,\n resolution_levels=None,\n color_space=color_space,\n voxel_width_mm=simple_itk_image.GetSpacing()[0]\n if use_spacing\n else None,\n voxel_height_mm=simple_itk_image.GetSpacing()[1]\n if use_spacing\n else None,\n voxel_depth_mm=simple_itk_image.GetSpacing()[2] if depth else None,\n )\n db_image_files = []\n for _file in work_dir.iterdir():\n temp_file = TemporaryFile()\n with open(str(_file), \"rb\") as open_file:\n buffer = True\n while buffer:\n buffer = open_file.read(1024)\n temp_file.write(buffer)\n db_image_file = ImageFile(\n image=db_image,\n image_type=ImageFile.IMAGE_TYPE_MHD,\n file=File(temp_file, name=_file.name),\n )\n db_image_files.append(db_image_file)\n\n return db_image, db_image_files\n", "path": "app/grandchallenge/cases/image_builders/utils.py"}]} | 1,321 | 270 |
gh_patches_debug_15339 | rasdani/github-patches | git_diff | ethereum__web3.py-2730 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ipfshttpclient is unmaintained
* Version: not-relevant
* Python: not-relevant
* OS: not-relevant
* `pip freeze` output
```
not-relevant
```
### What was wrong?
According to https://github.com/ipfs-shipyard/py-ipfs-http-client/issues/316 and https://github.com/NixOS/nixpkgs/issues/185294 ; we surmise that `ipfshttpclient` is currently unmaintained or has some breakages unresolved at the moment.
I wanted to understand if you had plans to migrate away to another library or mark the IPFS backend as an extra module or deprecated for now?
### How can it be fixed?
- Drop the IPFS backend (deprecation)
- Move it as an extra module (with appropriate documentation)
- Offer up help to maintain the Python IPFS HTTP client
- Move to another library (homegrown or whatever.)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 from setuptools import (
3 find_packages,
4 setup,
5 )
6
7 extras_require = {
8 "tester": [
9 "eth-tester[py-evm]==v0.7.0-beta.1",
10 "py-geth>=3.10.0",
11 ],
12 "linter": [
13 "black>=22.1.0",
14 "flake8==3.8.3",
15 "isort>=4.2.15,<4.3.5",
16 "mypy==0.910",
17 "types-setuptools>=57.4.4",
18 "types-requests>=2.26.1",
19 "types-protobuf==3.19.13",
20 ],
21 "docs": [
22 "mock",
23 "click>=5.1",
24 "configparser==3.5.0",
25 "contextlib2>=0.5.4",
26 "py-geth>=3.9.1",
27 "py-solc>=0.4.0",
28 "pytest>=6.2.5",
29 "sphinx>=4.2.0",
30 "sphinx_rtd_theme>=0.5.2",
31 "toposort>=1.4",
32 "towncrier==18.5.0",
33 "urllib3",
34 "wheel",
35 ],
36 "dev": [
37 "bumpversion",
38 "flaky>=3.7.0",
39 "hypothesis>=3.31.2",
40 "importlib-metadata<5.0;python_version<'3.8'",
41 "pytest>=6.2.5",
42 "pytest-asyncio>=0.18.1",
43 "pytest-mock>=1.10",
44 "pytest-pythonpath>=0.3",
45 "pytest-watch>=4.2",
46 "pytest-xdist>=1.29",
47 "setuptools>=38.6.0",
48 "tox>=1.8.0",
49 "tqdm>4.32",
50 "twine>=1.13",
51 "pluggy==0.13.1",
52 "when-changed>=0.3.0",
53 ],
54 }
55
56 extras_require["dev"] = (
57 extras_require["tester"]
58 + extras_require["linter"]
59 + extras_require["docs"]
60 + extras_require["dev"]
61 )
62
63 with open("./README.md") as readme:
64 long_description = readme.read()
65
66 setup(
67 name="web3",
68 # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.
69 version="6.0.0-beta.8",
70 description="""Web3.py""",
71 long_description_content_type="text/markdown",
72 long_description=long_description,
73 author="Piper Merriam",
74 author_email="[email protected]",
75 url="https://github.com/ethereum/web3.py",
76 include_package_data=True,
77 install_requires=[
78 "aiohttp>=3.7.4.post0",
79 "eth-abi>=3.0.0",
80 "eth-account>=0.7.0",
81 "eth-hash[pycryptodome]>=0.2.0",
82 "eth-typing>=3.0.0",
83 "eth-utils>=2.0.0",
84 "hexbytes>=0.1.0",
85 "ipfshttpclient==0.8.0a2",
86 "jsonschema>=4.0.0",
87 "lru-dict>=1.1.6",
88 "protobuf>=4.21.6",
89 "pywin32>=223;platform_system=='Windows'",
90 "requests>=2.16.0",
91 # remove typing_extensions after python_requires>=3.8, see web3._utils.compat
92 "typing-extensions>=3.7.4.1,<5;python_version<'3.8'",
93 "websockets>=10.0.0",
94 ],
95 python_requires=">=3.7.2",
96 extras_require=extras_require,
97 py_modules=["web3", "ens", "ethpm"],
98 entry_points={"pytest11": ["pytest_ethereum = web3.tools.pytest_ethereum.plugins"]},
99 license="MIT",
100 zip_safe=False,
101 keywords="ethereum",
102 packages=find_packages(exclude=["tests", "tests.*"]),
103 package_data={"web3": ["py.typed"]},
104 classifiers=[
105 "Development Status :: 5 - Production/Stable",
106 "Intended Audience :: Developers",
107 "License :: OSI Approved :: MIT License",
108 "Natural Language :: English",
109 "Programming Language :: Python :: 3",
110 "Programming Language :: Python :: 3.7",
111 "Programming Language :: Python :: 3.8",
112 "Programming Language :: Python :: 3.9",
113 "Programming Language :: Python :: 3.10",
114 ],
115 )
116
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -51,12 +51,16 @@
"pluggy==0.13.1",
"when-changed>=0.3.0",
],
+ "ipfs": [
+ "ipfshttpclient==0.8.0a2",
+ ],
}
extras_require["dev"] = (
extras_require["tester"]
+ extras_require["linter"]
+ extras_require["docs"]
+ + extras_require["ipfs"]
+ extras_require["dev"]
)
@@ -82,7 +86,6 @@
"eth-typing>=3.0.0",
"eth-utils>=2.0.0",
"hexbytes>=0.1.0",
- "ipfshttpclient==0.8.0a2",
"jsonschema>=4.0.0",
"lru-dict>=1.1.6",
"protobuf>=4.21.6",
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -51,12 +51,16 @@\n \"pluggy==0.13.1\",\n \"when-changed>=0.3.0\",\n ],\n+ \"ipfs\": [\n+ \"ipfshttpclient==0.8.0a2\",\n+ ],\n }\n \n extras_require[\"dev\"] = (\n extras_require[\"tester\"]\n + extras_require[\"linter\"]\n + extras_require[\"docs\"]\n+ + extras_require[\"ipfs\"]\n + extras_require[\"dev\"]\n )\n \n@@ -82,7 +86,6 @@\n \"eth-typing>=3.0.0\",\n \"eth-utils>=2.0.0\",\n \"hexbytes>=0.1.0\",\n- \"ipfshttpclient==0.8.0a2\",\n \"jsonschema>=4.0.0\",\n \"lru-dict>=1.1.6\",\n \"protobuf>=4.21.6\",\n", "issue": "ipfshttpclient is unmaintained\n* Version: not-relevant\r\n* Python: not-relevant\r\n* OS: not-relevant\r\n* `pip freeze` output\r\n\r\n```\r\nnot-relevant\r\n```\r\n\r\n\r\n### What was wrong?\r\n\r\nAccording to https://github.com/ipfs-shipyard/py-ipfs-http-client/issues/316 and https://github.com/NixOS/nixpkgs/issues/185294 ; we surmise that `ipfshttpclient` is currently unmaintained or has some breakages unresolved at the moment.\r\n\r\nI wanted to understand if you had plans to migrate away to another library or mark the IPFS backend as an extra module or deprecated for now?\r\n\r\n### How can it be fixed?\r\n\r\n- Drop the IPFS backend (deprecation)\r\n- Move it as an extra module (with appropriate documentation)\r\n- Offer up help to maintain the Python IPFS HTTP client\r\n- Move to another library (homegrown or whatever.)\n", "before_files": [{"content": "#!/usr/bin/env python\nfrom setuptools import (\n find_packages,\n setup,\n)\n\nextras_require = {\n \"tester\": [\n \"eth-tester[py-evm]==v0.7.0-beta.1\",\n \"py-geth>=3.10.0\",\n ],\n \"linter\": [\n \"black>=22.1.0\",\n \"flake8==3.8.3\",\n \"isort>=4.2.15,<4.3.5\",\n \"mypy==0.910\",\n \"types-setuptools>=57.4.4\",\n \"types-requests>=2.26.1\",\n \"types-protobuf==3.19.13\",\n ],\n \"docs\": [\n \"mock\",\n \"click>=5.1\",\n \"configparser==3.5.0\",\n \"contextlib2>=0.5.4\",\n \"py-geth>=3.9.1\",\n \"py-solc>=0.4.0\",\n \"pytest>=6.2.5\",\n \"sphinx>=4.2.0\",\n \"sphinx_rtd_theme>=0.5.2\",\n \"toposort>=1.4\",\n \"towncrier==18.5.0\",\n \"urllib3\",\n \"wheel\",\n ],\n \"dev\": [\n \"bumpversion\",\n \"flaky>=3.7.0\",\n \"hypothesis>=3.31.2\",\n \"importlib-metadata<5.0;python_version<'3.8'\",\n \"pytest>=6.2.5\",\n \"pytest-asyncio>=0.18.1\",\n \"pytest-mock>=1.10\",\n \"pytest-pythonpath>=0.3\",\n \"pytest-watch>=4.2\",\n \"pytest-xdist>=1.29\",\n \"setuptools>=38.6.0\",\n \"tox>=1.8.0\",\n \"tqdm>4.32\",\n \"twine>=1.13\",\n \"pluggy==0.13.1\",\n \"when-changed>=0.3.0\",\n ],\n}\n\nextras_require[\"dev\"] = (\n extras_require[\"tester\"]\n + extras_require[\"linter\"]\n + extras_require[\"docs\"]\n + extras_require[\"dev\"]\n)\n\nwith open(\"./README.md\") as readme:\n long_description = readme.read()\n\nsetup(\n name=\"web3\",\n # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.\n version=\"6.0.0-beta.8\",\n description=\"\"\"Web3.py\"\"\",\n long_description_content_type=\"text/markdown\",\n long_description=long_description,\n author=\"Piper Merriam\",\n author_email=\"[email protected]\",\n url=\"https://github.com/ethereum/web3.py\",\n include_package_data=True,\n install_requires=[\n \"aiohttp>=3.7.4.post0\",\n \"eth-abi>=3.0.0\",\n \"eth-account>=0.7.0\",\n \"eth-hash[pycryptodome]>=0.2.0\",\n \"eth-typing>=3.0.0\",\n \"eth-utils>=2.0.0\",\n \"hexbytes>=0.1.0\",\n \"ipfshttpclient==0.8.0a2\",\n \"jsonschema>=4.0.0\",\n \"lru-dict>=1.1.6\",\n \"protobuf>=4.21.6\",\n \"pywin32>=223;platform_system=='Windows'\",\n \"requests>=2.16.0\",\n # remove typing_extensions after python_requires>=3.8, see web3._utils.compat\n \"typing-extensions>=3.7.4.1,<5;python_version<'3.8'\",\n \"websockets>=10.0.0\",\n ],\n python_requires=\">=3.7.2\",\n extras_require=extras_require,\n py_modules=[\"web3\", \"ens\", \"ethpm\"],\n entry_points={\"pytest11\": [\"pytest_ethereum = web3.tools.pytest_ethereum.plugins\"]},\n license=\"MIT\",\n zip_safe=False,\n keywords=\"ethereum\",\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n package_data={\"web3\": [\"py.typed\"]},\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Natural Language :: English\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\nfrom setuptools import (\n find_packages,\n setup,\n)\n\nextras_require = {\n \"tester\": [\n \"eth-tester[py-evm]==v0.7.0-beta.1\",\n \"py-geth>=3.10.0\",\n ],\n \"linter\": [\n \"black>=22.1.0\",\n \"flake8==3.8.3\",\n \"isort>=4.2.15,<4.3.5\",\n \"mypy==0.910\",\n \"types-setuptools>=57.4.4\",\n \"types-requests>=2.26.1\",\n \"types-protobuf==3.19.13\",\n ],\n \"docs\": [\n \"mock\",\n \"click>=5.1\",\n \"configparser==3.5.0\",\n \"contextlib2>=0.5.4\",\n \"py-geth>=3.9.1\",\n \"py-solc>=0.4.0\",\n \"pytest>=6.2.5\",\n \"sphinx>=4.2.0\",\n \"sphinx_rtd_theme>=0.5.2\",\n \"toposort>=1.4\",\n \"towncrier==18.5.0\",\n \"urllib3\",\n \"wheel\",\n ],\n \"dev\": [\n \"bumpversion\",\n \"flaky>=3.7.0\",\n \"hypothesis>=3.31.2\",\n \"importlib-metadata<5.0;python_version<'3.8'\",\n \"pytest>=6.2.5\",\n \"pytest-asyncio>=0.18.1\",\n \"pytest-mock>=1.10\",\n \"pytest-pythonpath>=0.3\",\n \"pytest-watch>=4.2\",\n \"pytest-xdist>=1.29\",\n \"setuptools>=38.6.0\",\n \"tox>=1.8.0\",\n \"tqdm>4.32\",\n \"twine>=1.13\",\n \"pluggy==0.13.1\",\n \"when-changed>=0.3.0\",\n ],\n \"ipfs\": [\n \"ipfshttpclient==0.8.0a2\",\n ],\n}\n\nextras_require[\"dev\"] = (\n extras_require[\"tester\"]\n + extras_require[\"linter\"]\n + extras_require[\"docs\"]\n + extras_require[\"ipfs\"]\n + extras_require[\"dev\"]\n)\n\nwith open(\"./README.md\") as readme:\n long_description = readme.read()\n\nsetup(\n name=\"web3\",\n # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.\n version=\"6.0.0-beta.8\",\n description=\"\"\"Web3.py\"\"\",\n long_description_content_type=\"text/markdown\",\n long_description=long_description,\n author=\"Piper Merriam\",\n author_email=\"[email protected]\",\n url=\"https://github.com/ethereum/web3.py\",\n include_package_data=True,\n install_requires=[\n \"aiohttp>=3.7.4.post0\",\n \"eth-abi>=3.0.0\",\n \"eth-account>=0.7.0\",\n \"eth-hash[pycryptodome]>=0.2.0\",\n \"eth-typing>=3.0.0\",\n \"eth-utils>=2.0.0\",\n \"hexbytes>=0.1.0\",\n \"jsonschema>=4.0.0\",\n \"lru-dict>=1.1.6\",\n \"protobuf>=4.21.6\",\n \"pywin32>=223;platform_system=='Windows'\",\n \"requests>=2.16.0\",\n # remove typing_extensions after python_requires>=3.8, see web3._utils.compat\n \"typing-extensions>=3.7.4.1,<5;python_version<'3.8'\",\n \"websockets>=10.0.0\",\n ],\n python_requires=\">=3.7.2\",\n extras_require=extras_require,\n py_modules=[\"web3\", \"ens\", \"ethpm\"],\n entry_points={\"pytest11\": [\"pytest_ethereum = web3.tools.pytest_ethereum.plugins\"]},\n license=\"MIT\",\n zip_safe=False,\n keywords=\"ethereum\",\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n package_data={\"web3\": [\"py.typed\"]},\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Natural Language :: English\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n ],\n)\n", "path": "setup.py"}]} | 1,769 | 232 |
gh_patches_debug_7975 | rasdani/github-patches | git_diff | mne-tools__mne-bids-1110 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
API error in 'write_raw_bids': channel type mappings description is not correct. KeyError: 'grad'
### Description of the problem
We have a Neuromag-122 system which is equipped with 61 dual-channel planar first-order gradiometers.
I am trying to convert our local meg files to MNE-BIDS format using write_raw_bids API. The API prompts the following error.
### Steps to reproduce
```Python
***Error description*:**
Traceback (most recent call last):
File "/media/dip_linux/18F80D53F80D3094/Auditory_P3/x_Dip_p300/auditory_code/regression_model/MNE_BIDs.py", line 99, in <module>
write_raw_bids(
File "<decorator-gen-627>", line 12, in write_raw_bids
File "/home/dip_linux/anaconda3/envs/mne/lib/python3.10/site-packages/mne_bids/write.py", line 1865, in write_raw_bids
_channels_tsv(raw, channels_path.fpath, overwrite)
File "/home/dip_linux/anaconda3/envs/mne/lib/python3.10/site-packages/mne_bids/write.py", line 126, in _channels_tsv
ch_type.append(map_chs[_channel_type])
KeyError: 'grad'
# It seems channel type mappings description is not correct.
Currently its written as:
# line 90:
map_desc.update(meggradaxial='Axial Gradiometer',
megrefgradaxial='Axial Gradiometer Reference',
meggradplanar='Planar Gradiometer',
megmag='Magnetometer',
megrefmag='Magnetometer Reference',
stim='Trigger',
eeg='ElectroEncephaloGram',
ecog='Electrocorticography',
seeg='StereoEEG',
ecg='ElectroCardioGram',
eog='ElectroOculoGram',
emg='ElectroMyoGram',
misc='Miscellaneous',
bio='Biological',
ias='Internal Active Shielding',
dbs='Deep Brain Stimulation',
fnirs_cw_amplitude='Near Infrared Spectroscopy '
'(continuous wave)',
resp='Respiration',
gsr='Galvanic skin response (electrodermal activity, EDA)',
temperature='Temperature',)
# get the manufacturer from the file in the Raw object
_, ext = _parse_ext(raw.filenames[0])
manufacturer = MANUFACTURERS.get(ext, '')
ignored_channels = IGNORED_CHANNELS.get(manufacturer, list())
status, ch_type, description = list(), list(), list()
for idx, ch in enumerate(raw.info['ch_names']):
status.append('bad' if ch in raw.info['bads'] else 'good')
_channel_type = channel_type(raw.info, idx)
if _channel_type in get_specific:
_channel_type = coil_type(raw.info, idx, _channel_type)
ch_type.append(map_chs[_channel_type])
description.append(map_desc[_channel_type]) # error prompt line 126
```
### Expected results
current system outputs:
map_desc output is:
defaultdict(<function _channels_tsv.<locals>.<lambda> at 0x7f7705bcadd0>, {'meggradaxial': 'Axial Gradiometer', 'megrefgradaxial': 'Axial Gradiometer Reference', 'meggradplanar': 'Planar Gradiometer', 'megmag': 'Magnetometer', 'megrefmag': 'Magnetometer Reference', 'stim': 'Trigger', 'eeg': 'ElectroEncephaloGram', 'ecog': 'Electrocorticography', 'seeg': 'StereoEEG', 'ecg': 'ElectroCardioGram', 'eog': 'ElectroOculoGram', 'emg': 'ElectroMyoGram', 'misc': 'Miscellaneous', 'bio': 'Biological', 'ias': 'Internal Active Shielding', 'dbs': 'Deep Brain Stimulation', 'fnirs_cw_amplitude': 'Near Infrared Spectroscopy (continuous wave)', 'resp': 'Respiration', 'gsr': 'Galvanic skin response (electrodermal activity, EDA)', 'temperature': 'Temperature'})
_channel_type output is:
'grad'
### Actual results
######### error line 126
ch_type.append(map_chs[_channel_type])
map_chs[_channel_type] expects the key word 'meggradplanar' instead of 'grad'
### Additional information
Platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.31
Python: 3.10.6 | packaged by conda-forge | (main, Aug 22 2022, 20:35:26) [GCC 10.4.0]
Executable: /home/dip_linux/anaconda3/envs/mne/bin/python3.10
CPU: x86_64: 8 cores
Memory: 15.3 GB
mne: 1.2.3
numpy: 1.22.4 {OpenBLAS 0.3.21 with 8 threads}
scipy: 1.9.1
matplotlib: 3.6.0 {backend=QtAgg}
sklearn: 1.1.2
numba: 0.55.2
nibabel: 4.0.2
nilearn: 0.9.2
dipy: 1.5.0
openmeeg: Not found
cupy: Not found
pandas: 1.5.0
pyvista: 0.36.1 {OpenGL 3.3 (Core Profile) Mesa 21.2.6 via Mesa Intel(R) UHD Graphics (CML GT2)}
pyvistaqt: 0.9.0
ipyvtklink: 0.2.2
vtk: 9.1.0
qtpy: 2.2.0 {PyQt5=5.12.10}
ipympl: Not found
pyqtgraph: 0.12.4
pooch: v1.6.0
mne_bids: 0.12.dev0
mne_nirs: Not found
mne_features: Not found
mne_qt_browser: 0.3.2
mne_connectivity: 0.4.0
mne_icalabel: Not found
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mne_bids/pick.py`
Content:
```
1 """Define coil types for MEG."""
2 # Authors: Matt Sanderson <[email protected]>
3 #
4 # License: BSD-3-Clause
5 from mne.io.constants import FIFF
6
7
8 def get_coil_types():
9 """Return all known coil types.
10
11 Returns
12 -------
13 coil_types : dict
14 The keys contain the channel types, and the values contain the
15 corresponding values in the info['chs'][idx]['kind']
16
17 """
18 return dict(meggradaxial=(FIFF.FIFFV_COIL_KIT_GRAD,
19 FIFF.FIFFV_COIL_CTF_GRAD,
20 # Support for gradient-compensated data:
21 int(FIFF.FIFFV_COIL_CTF_GRAD | (3 << 16)),
22 int(FIFF.FIFFV_COIL_CTF_GRAD | (2 << 16)),
23 FIFF.FIFFV_COIL_AXIAL_GRAD_5CM,
24 FIFF.FIFFV_COIL_BABY_GRAD),
25 megrefgradaxial=(FIFF.FIFFV_COIL_CTF_REF_GRAD,
26 FIFF.FIFFV_COIL_CTF_OFFDIAG_REF_GRAD,
27 FIFF.FIFFV_COIL_MAGNES_REF_GRAD,
28 FIFF.FIFFV_COIL_MAGNES_OFFDIAG_REF_GRAD),
29 meggradplanar=(FIFF.FIFFV_COIL_VV_PLANAR_T1,
30 FIFF.FIFFV_COIL_VV_PLANAR_T2,
31 FIFF.FIFFV_COIL_VV_PLANAR_T3),
32 megmag=(FIFF.FIFFV_COIL_POINT_MAGNETOMETER,
33 FIFF.FIFFV_COIL_VV_MAG_W,
34 FIFF.FIFFV_COIL_VV_MAG_T1,
35 FIFF.FIFFV_COIL_VV_MAG_T2,
36 FIFF.FIFFV_COIL_VV_MAG_T3,
37 FIFF.FIFFV_COIL_MAGNES_MAG,
38 FIFF.FIFFV_COIL_BABY_MAG),
39 megrefmag=(FIFF.FIFFV_COIL_KIT_REF_MAG,
40 FIFF.FIFFV_COIL_CTF_REF_MAG,
41 FIFF.FIFFV_COIL_MAGNES_REF_MAG,
42 FIFF.FIFFV_COIL_BABY_REF_MAG,
43 FIFF.FIFFV_COIL_BABY_REF_MAG2,
44 FIFF.FIFFV_COIL_ARTEMIS123_REF_MAG,
45 FIFF.FIFFV_COIL_MAGNES_REF_MAG),
46 eeg=(FIFF.FIFFV_COIL_EEG,),
47 misc=(FIFF.FIFFV_COIL_NONE,))
48
49
50 def coil_type(info, idx, ch_type='n/a'):
51 """Get coil type.
52
53 Parameters
54 ----------
55 info : dict
56 Measurement info
57 idx : int
58 Index of channel
59 ch_type : str
60 Channel type to fall back upon if a more specific
61 type is not found
62
63 Returns
64 -------
65 type : 'meggradaxial' | 'megrefgradaxial' | 'meggradplanar'
66 'megmag' | 'megrefmag' | 'eeg' | 'misc'
67 Type of coil
68
69 """
70 ch = info['chs'][idx]
71 for key, values in get_coil_types().items():
72 if ch['coil_type'] in values:
73 return key
74 return ch_type
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mne_bids/pick.py b/mne_bids/pick.py
--- a/mne_bids/pick.py
+++ b/mne_bids/pick.py
@@ -34,6 +34,7 @@
FIFF.FIFFV_COIL_VV_MAG_T1,
FIFF.FIFFV_COIL_VV_MAG_T2,
FIFF.FIFFV_COIL_VV_MAG_T3,
+ FIFF.FIFFV_COIL_NM_122,
FIFF.FIFFV_COIL_MAGNES_MAG,
FIFF.FIFFV_COIL_BABY_MAG),
megrefmag=(FIFF.FIFFV_COIL_KIT_REF_MAG,
| {"golden_diff": "diff --git a/mne_bids/pick.py b/mne_bids/pick.py\n--- a/mne_bids/pick.py\n+++ b/mne_bids/pick.py\n@@ -34,6 +34,7 @@\n FIFF.FIFFV_COIL_VV_MAG_T1,\n FIFF.FIFFV_COIL_VV_MAG_T2,\n FIFF.FIFFV_COIL_VV_MAG_T3,\n+ FIFF.FIFFV_COIL_NM_122,\n FIFF.FIFFV_COIL_MAGNES_MAG,\n FIFF.FIFFV_COIL_BABY_MAG),\n megrefmag=(FIFF.FIFFV_COIL_KIT_REF_MAG,\n", "issue": "API error in 'write_raw_bids': channel type mappings description is not correct. KeyError: 'grad'\n### Description of the problem\r\n\r\n\r\nWe have a Neuromag-122 system which is equipped with 61 dual-channel planar first-order gradiometers. \r\nI am trying to convert our local meg files to MNE-BIDS format using write_raw_bids API. The API prompts the following error. \r\n\r\n\r\n\r\n\r\n \r\n\r\n### Steps to reproduce\r\n\r\n```Python\r\n***Error description*:**\r\n\r\nTraceback (most recent call last):\r\n File \"/media/dip_linux/18F80D53F80D3094/Auditory_P3/x_Dip_p300/auditory_code/regression_model/MNE_BIDs.py\", line 99, in <module>\r\n write_raw_bids(\r\n File \"<decorator-gen-627>\", line 12, in write_raw_bids\r\n File \"/home/dip_linux/anaconda3/envs/mne/lib/python3.10/site-packages/mne_bids/write.py\", line 1865, in write_raw_bids\r\n _channels_tsv(raw, channels_path.fpath, overwrite)\r\n File \"/home/dip_linux/anaconda3/envs/mne/lib/python3.10/site-packages/mne_bids/write.py\", line 126, in _channels_tsv\r\n ch_type.append(map_chs[_channel_type])\r\nKeyError: 'grad'\r\n\r\n\r\n# It seems channel type mappings description is not correct. \r\nCurrently its written as: \r\n# line 90: \r\nmap_desc.update(meggradaxial='Axial Gradiometer',\r\n megrefgradaxial='Axial Gradiometer Reference',\r\n meggradplanar='Planar Gradiometer',\r\n megmag='Magnetometer',\r\n megrefmag='Magnetometer Reference',\r\n stim='Trigger',\r\n eeg='ElectroEncephaloGram',\r\n ecog='Electrocorticography',\r\n seeg='StereoEEG',\r\n ecg='ElectroCardioGram',\r\n eog='ElectroOculoGram',\r\n emg='ElectroMyoGram',\r\n misc='Miscellaneous',\r\n bio='Biological',\r\n ias='Internal Active Shielding',\r\n dbs='Deep Brain Stimulation',\r\n fnirs_cw_amplitude='Near Infrared Spectroscopy '\r\n '(continuous wave)',\r\n resp='Respiration',\r\n gsr='Galvanic skin response (electrodermal activity, EDA)',\r\n temperature='Temperature',)\r\n\r\n # get the manufacturer from the file in the Raw object\r\n _, ext = _parse_ext(raw.filenames[0])\r\n manufacturer = MANUFACTURERS.get(ext, '')\r\n ignored_channels = IGNORED_CHANNELS.get(manufacturer, list())\r\n\r\n status, ch_type, description = list(), list(), list()\r\n for idx, ch in enumerate(raw.info['ch_names']):\r\n status.append('bad' if ch in raw.info['bads'] else 'good')\r\n _channel_type = channel_type(raw.info, idx)\r\n if _channel_type in get_specific:\r\n _channel_type = coil_type(raw.info, idx, _channel_type)\r\n ch_type.append(map_chs[_channel_type]) \r\n description.append(map_desc[_channel_type]) # error prompt line 126\r\n```\r\n\r\n\r\n### Expected results\r\n\r\ncurrent system outputs:\r\n\r\nmap_desc output is:\r\n\r\ndefaultdict(<function _channels_tsv.<locals>.<lambda> at 0x7f7705bcadd0>, {'meggradaxial': 'Axial Gradiometer', 'megrefgradaxial': 'Axial Gradiometer Reference', 'meggradplanar': 'Planar Gradiometer', 'megmag': 'Magnetometer', 'megrefmag': 'Magnetometer Reference', 'stim': 'Trigger', 'eeg': 'ElectroEncephaloGram', 'ecog': 'Electrocorticography', 'seeg': 'StereoEEG', 'ecg': 'ElectroCardioGram', 'eog': 'ElectroOculoGram', 'emg': 'ElectroMyoGram', 'misc': 'Miscellaneous', 'bio': 'Biological', 'ias': 'Internal Active Shielding', 'dbs': 'Deep Brain Stimulation', 'fnirs_cw_amplitude': 'Near Infrared Spectroscopy (continuous wave)', 'resp': 'Respiration', 'gsr': 'Galvanic skin response (electrodermal activity, EDA)', 'temperature': 'Temperature'})\r\n\r\n _channel_type output is: \r\n'grad'\r\n\r\n\r\n### Actual results\r\n\r\n######### error line 126\r\nch_type.append(map_chs[_channel_type]) \r\nmap_chs[_channel_type] expects the key word 'meggradplanar' instead of 'grad'\r\n\r\n\r\n### Additional information\r\nPlatform: Linux-5.15.0-52-generic-x86_64-with-glibc2.31\r\nPython: 3.10.6 | packaged by conda-forge | (main, Aug 22 2022, 20:35:26) [GCC 10.4.0]\r\nExecutable: /home/dip_linux/anaconda3/envs/mne/bin/python3.10\r\nCPU: x86_64: 8 cores\r\nMemory: 15.3 GB\r\n\r\nmne: 1.2.3\r\nnumpy: 1.22.4 {OpenBLAS 0.3.21 with 8 threads}\r\nscipy: 1.9.1\r\nmatplotlib: 3.6.0 {backend=QtAgg}\r\n\r\nsklearn: 1.1.2\r\nnumba: 0.55.2\r\nnibabel: 4.0.2\r\nnilearn: 0.9.2\r\ndipy: 1.5.0\r\nopenmeeg: Not found\r\ncupy: Not found\r\npandas: 1.5.0\r\npyvista: 0.36.1 {OpenGL 3.3 (Core Profile) Mesa 21.2.6 via Mesa Intel(R) UHD Graphics (CML GT2)}\r\npyvistaqt: 0.9.0\r\nipyvtklink: 0.2.2\r\nvtk: 9.1.0\r\nqtpy: 2.2.0 {PyQt5=5.12.10}\r\nipympl: Not found\r\npyqtgraph: 0.12.4\r\npooch: v1.6.0\r\n\r\nmne_bids: 0.12.dev0\r\nmne_nirs: Not found\r\nmne_features: Not found\r\nmne_qt_browser: 0.3.2\r\nmne_connectivity: 0.4.0\r\nmne_icalabel: Not found\r\n\n", "before_files": [{"content": "\"\"\"Define coil types for MEG.\"\"\"\n# Authors: Matt Sanderson <[email protected]>\n#\n# License: BSD-3-Clause\nfrom mne.io.constants import FIFF\n\n\ndef get_coil_types():\n \"\"\"Return all known coil types.\n\n Returns\n -------\n coil_types : dict\n The keys contain the channel types, and the values contain the\n corresponding values in the info['chs'][idx]['kind']\n\n \"\"\"\n return dict(meggradaxial=(FIFF.FIFFV_COIL_KIT_GRAD,\n FIFF.FIFFV_COIL_CTF_GRAD,\n # Support for gradient-compensated data:\n int(FIFF.FIFFV_COIL_CTF_GRAD | (3 << 16)),\n int(FIFF.FIFFV_COIL_CTF_GRAD | (2 << 16)),\n FIFF.FIFFV_COIL_AXIAL_GRAD_5CM,\n FIFF.FIFFV_COIL_BABY_GRAD),\n megrefgradaxial=(FIFF.FIFFV_COIL_CTF_REF_GRAD,\n FIFF.FIFFV_COIL_CTF_OFFDIAG_REF_GRAD,\n FIFF.FIFFV_COIL_MAGNES_REF_GRAD,\n FIFF.FIFFV_COIL_MAGNES_OFFDIAG_REF_GRAD),\n meggradplanar=(FIFF.FIFFV_COIL_VV_PLANAR_T1,\n FIFF.FIFFV_COIL_VV_PLANAR_T2,\n FIFF.FIFFV_COIL_VV_PLANAR_T3),\n megmag=(FIFF.FIFFV_COIL_POINT_MAGNETOMETER,\n FIFF.FIFFV_COIL_VV_MAG_W,\n FIFF.FIFFV_COIL_VV_MAG_T1,\n FIFF.FIFFV_COIL_VV_MAG_T2,\n FIFF.FIFFV_COIL_VV_MAG_T3,\n FIFF.FIFFV_COIL_MAGNES_MAG,\n FIFF.FIFFV_COIL_BABY_MAG),\n megrefmag=(FIFF.FIFFV_COIL_KIT_REF_MAG,\n FIFF.FIFFV_COIL_CTF_REF_MAG,\n FIFF.FIFFV_COIL_MAGNES_REF_MAG,\n FIFF.FIFFV_COIL_BABY_REF_MAG,\n FIFF.FIFFV_COIL_BABY_REF_MAG2,\n FIFF.FIFFV_COIL_ARTEMIS123_REF_MAG,\n FIFF.FIFFV_COIL_MAGNES_REF_MAG),\n eeg=(FIFF.FIFFV_COIL_EEG,),\n misc=(FIFF.FIFFV_COIL_NONE,))\n\n\ndef coil_type(info, idx, ch_type='n/a'):\n \"\"\"Get coil type.\n\n Parameters\n ----------\n info : dict\n Measurement info\n idx : int\n Index of channel\n ch_type : str\n Channel type to fall back upon if a more specific\n type is not found\n\n Returns\n -------\n type : 'meggradaxial' | 'megrefgradaxial' | 'meggradplanar'\n 'megmag' | 'megrefmag' | 'eeg' | 'misc'\n Type of coil\n\n \"\"\"\n ch = info['chs'][idx]\n for key, values in get_coil_types().items():\n if ch['coil_type'] in values:\n return key\n return ch_type\n", "path": "mne_bids/pick.py"}], "after_files": [{"content": "\"\"\"Define coil types for MEG.\"\"\"\n# Authors: Matt Sanderson <[email protected]>\n#\n# License: BSD-3-Clause\nfrom mne.io.constants import FIFF\n\n\ndef get_coil_types():\n \"\"\"Return all known coil types.\n\n Returns\n -------\n coil_types : dict\n The keys contain the channel types, and the values contain the\n corresponding values in the info['chs'][idx]['kind']\n\n \"\"\"\n return dict(meggradaxial=(FIFF.FIFFV_COIL_KIT_GRAD,\n FIFF.FIFFV_COIL_CTF_GRAD,\n # Support for gradient-compensated data:\n int(FIFF.FIFFV_COIL_CTF_GRAD | (3 << 16)),\n int(FIFF.FIFFV_COIL_CTF_GRAD | (2 << 16)),\n FIFF.FIFFV_COIL_AXIAL_GRAD_5CM,\n FIFF.FIFFV_COIL_BABY_GRAD),\n megrefgradaxial=(FIFF.FIFFV_COIL_CTF_REF_GRAD,\n FIFF.FIFFV_COIL_CTF_OFFDIAG_REF_GRAD,\n FIFF.FIFFV_COIL_MAGNES_REF_GRAD,\n FIFF.FIFFV_COIL_MAGNES_OFFDIAG_REF_GRAD),\n meggradplanar=(FIFF.FIFFV_COIL_VV_PLANAR_T1,\n FIFF.FIFFV_COIL_VV_PLANAR_T2,\n FIFF.FIFFV_COIL_VV_PLANAR_T3),\n megmag=(FIFF.FIFFV_COIL_POINT_MAGNETOMETER,\n FIFF.FIFFV_COIL_VV_MAG_W,\n FIFF.FIFFV_COIL_VV_MAG_T1,\n FIFF.FIFFV_COIL_VV_MAG_T2,\n FIFF.FIFFV_COIL_VV_MAG_T3,\n FIFF.FIFFV_COIL_NM_122,\n FIFF.FIFFV_COIL_MAGNES_MAG,\n FIFF.FIFFV_COIL_BABY_MAG),\n megrefmag=(FIFF.FIFFV_COIL_KIT_REF_MAG,\n FIFF.FIFFV_COIL_CTF_REF_MAG,\n FIFF.FIFFV_COIL_MAGNES_REF_MAG,\n FIFF.FIFFV_COIL_BABY_REF_MAG,\n FIFF.FIFFV_COIL_BABY_REF_MAG2,\n FIFF.FIFFV_COIL_ARTEMIS123_REF_MAG,\n FIFF.FIFFV_COIL_MAGNES_REF_MAG),\n eeg=(FIFF.FIFFV_COIL_EEG,),\n misc=(FIFF.FIFFV_COIL_NONE,))\n\n\ndef coil_type(info, idx, ch_type='n/a'):\n \"\"\"Get coil type.\n\n Parameters\n ----------\n info : dict\n Measurement info\n idx : int\n Index of channel\n ch_type : str\n Channel type to fall back upon if a more specific\n type is not found\n\n Returns\n -------\n type : 'meggradaxial' | 'megrefgradaxial' | 'meggradplanar'\n 'megmag' | 'megrefmag' | 'eeg' | 'misc'\n Type of coil\n\n \"\"\"\n ch = info['chs'][idx]\n for key, values in get_coil_types().items():\n if ch['coil_type'] in values:\n return key\n return ch_type\n", "path": "mne_bids/pick.py"}]} | 2,643 | 151 |
gh_patches_debug_42223 | rasdani/github-patches | git_diff | bokeh__bokeh-3156 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Allow for configuring the IP address of the Bokeh server
I have downloaded the bokeh developer build "conda install -c bokeh/channel/dev bokeh", which has a new Bokeh server "https://github.com/bokeh/bokeh/wiki/Porting-guide:-new-Bokeh-server".
For previous Bokeh server, this capability is added (see "add ability to use a different ip address and port for bokeh-server #383").
Please tell me how to use a different ip address for the new bokeh server "boken serve".
BTW, I know that I can change to a different port by using "bokeh serve --port PORT"
Thank you very much!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bokeh/server/server.py`
Content:
```
1 ''' Provides a Server which instantiates Application instances as clients connect
2
3 '''
4 from __future__ import absolute_import, print_function
5
6 import logging
7 log = logging.getLogger(__name__)
8
9 import sys
10
11 from tornado.httpserver import HTTPServer
12
13 from .tornado import BokehTornado
14
15 from bokeh.application import Application
16
17 from bokeh.resources import DEFAULT_SERVER_PORT
18
19 class Server(object):
20 ''' A Server which creates a new Session for each connection, using an Application to initialize each Session.
21
22 Args:
23 applications (dict of str: bokeh.application.Application) or bokeh.application.Application:
24 mapping from URL paths to Application instances, or a single Application to put at the root URL
25 The Application is a factory for Document, with a new Document initialized for each Session.
26 Each application should be identified by a path meant to go in a URL, like "/" or "/foo"
27 '''
28
29 def __init__(self, applications, **kwargs):
30 if isinstance(applications, Application):
31 self._applications = { '/' : applications }
32 else:
33 self._applications = applications
34 io_loop = None
35 if 'io_loop' in kwargs:
36 io_loop = kwargs['io_loop']
37 self._tornado = BokehTornado(self._applications, io_loop=io_loop)
38 self._http = HTTPServer(self._tornado)
39 self._port = DEFAULT_SERVER_PORT
40 if 'port' in kwargs:
41 self._port = kwargs['port']
42 # these queue a callback on the ioloop rather than
43 # doing the operation immediately (I think - havocp)
44 try:
45 self._http.bind(self._port)
46 self._http.start(1)
47 except OSError:
48 log.critical("Cannot start bokeh server, port %s already in use" % self._port)
49 sys.exit(1)
50
51 # TODO this is broken, it's only used by test_client_server.py so fix that then remove this
52 @property
53 def ws_url(self):
54 return "ws://localhost:" + str(self._port) + "/ws"
55
56 @property
57 def port(self):
58 return self._port
59
60 @property
61 def io_loop(self):
62 return self._tornado.io_loop
63
64 def start(self):
65 ''' Start the Bokeh Server's IO loop.
66
67 Returns:
68 None
69
70 Notes:
71 Keyboard interrupts or sigterm will cause the server to shut down.
72
73 '''
74 self._tornado.start()
75
76 def stop(self):
77 ''' Stop the Bokeh Server's IO loop.
78
79 Returns:
80 None
81
82 '''
83 self._tornado.stop()
84
85 def unlisten(self):
86 '''Stop listening on ports (Server will no longer be usable after calling this)
87
88 Returns:
89 None
90 '''
91 self._http.stop()
92
93 def get_session(self, app_path, session_id):
94 '''Gets a session by name (session must already exist)'''
95
96 return self._tornado.get_session(app_path, session_id)
97
98 def show(self, app_path, browser=None, new='tab'):
99 ''' Opens an app in a browser window or tab.
100
101 Useful for testing server applications on your local desktop but
102 should not call when running bokeh-server on an actual server.
103
104 Args:
105 app_path (str) : the app path to open
106 The part of the URL after the hostname:port, with leading slash.
107
108 browser (str, optional) : browser to show with (default: None)
109 For systems that support it, the **browser** argument allows
110 specifying which browser to display in, e.g. "safari", "firefox",
111 "opera", "windows-default" (see the ``webbrowser`` module
112 documentation in the standard lib for more details).
113
114 new (str, optional) : window or tab (default: "tab")
115 If ``new`` is 'tab', then opens a new tab.
116 If ``new`` is 'window', then opens a new window.
117
118 Returns:
119 None
120 '''
121 if not app_path.startswith("/"):
122 raise ValueError("app_path must start with a /")
123 from bokeh.browserlib import view
124 url = "http://localhost:%d%s" % (self.port, app_path)
125 view(url, browser=browser, new=new)
126
127
```
Path: `bokeh/command/__init__.py`
Content:
```
1 from __future__ import print_function
2
3 import argparse
4 import sys
5 import os
6
7 from bokeh.settings import settings
8 from bokeh.application import Application
9 from bokeh.server.server import Server
10 from bokeh.application.spellings import ScriptHandler, DirectoryHandler
11 from bokeh.io import output_file, save, show
12
13 import logging
14 log = logging.getLogger(__name__)
15
16 def die(message):
17 print(message, file=sys.stderr)
18 sys.exit(1)
19
20 class Subcommand(object):
21 """Abstract base class for subcommands"""
22
23 def __init__(self, parser):
24 """Initialize the subcommand with its parser; can call parser.add_argument to add subcommand flags"""
25 self.parser = parser
26
27 def func(self, args):
28 """Takes over main program flow to perform the subcommand"""
29 pass
30
31 class ApplicationsSubcommand(Subcommand):
32 """Abstract base class for subcommand that operates on a list of applications."""
33
34 def __init__(self, **kwargs):
35 super(ApplicationsSubcommand, self).__init__(**kwargs)
36 self.parser.add_argument('files', metavar='DIRECTORY-OR-SCRIPT', nargs='*', help="The app directories or scripts to serve (serve empty document if not specified)", default=None)
37
38 def build_applications(self, args):
39 if args.files:
40 files = args.files
41 else:
42 files = []
43
44 applications = {}
45
46 for file in files:
47 file = os.path.abspath(file)
48 if os.path.isdir(file):
49 handler = DirectoryHandler(filename=file)
50 else:
51 handler = ScriptHandler(filename=file)
52
53 if handler.failed:
54 die("Error loading %s:\n\n%s\n%s " % (file, handler.error, handler.error_detail))
55
56 application = Application()
57 application.add(handler)
58
59 route = handler.url_path()
60 if not route:
61 if '/' in applications:
62 die("Don't know the URL path to use for %s" % (file))
63 route = '/'
64 applications[route] = application
65
66 if len(applications) == 0:
67 # create an empty application by default, used with output_server typically
68 applications['/'] = Application()
69
70 return applications
71
72 class Serve(ApplicationsSubcommand):
73 """Subcommand to launch the Bokeh server."""
74
75 name = "serve"
76 help = "Run a Bokeh server hosting one or more applications"
77
78 def __init__(self, **kwargs):
79 super(Serve, self).__init__(**kwargs)
80 self.parser.add_argument('--port', metavar='PORT', type=int, help="Port to listen on", default=-1)
81 self.parser.add_argument('--develop', action='store_true', help="Enable develop-time features that should not be used in production")
82 self.parser.add_argument('--show', action='store_true', help="Open server app(s) in a browser")
83 self.port = 5006
84 self.develop_mode = False
85 self.server = None
86
87 def func(self, args):
88 if args.port >= 0:
89 self.port = args.port
90
91 self.develop_mode = args.develop
92
93 applications = self.build_applications(args)
94
95 # TODO make log level a command line option
96 logging.basicConfig(level=logging.DEBUG)
97
98 server = Server(applications, port=self.port)
99
100 if args.show:
101 # we have to defer opening in browser until
102 # we start up the server
103 def show_callback():
104 for route in applications.keys():
105 server.show(route)
106 server.io_loop.add_callback(show_callback)
107
108 if self.develop_mode:
109 log.info("Using develop mode (do not enable --develop in production)")
110 log.info("Starting Bokeh server on port %d with apps at %r", server.port, sorted(applications.keys()))
111 server.start()
112
113 class Html(ApplicationsSubcommand):
114 """Subcommand to output applications as standalone HTML files."""
115
116 name = "html"
117 help = "Create standalone HTML files for one or more applications"
118
119 def __init__(self, **kwargs):
120 super(Html, self).__init__(**kwargs)
121 self.parser.add_argument('--show', action='store_true', help="Open generated file(s) in a browser")
122
123 def func(self, args):
124 applications = self.build_applications(args)
125
126 for (route, app) in applications.items():
127 doc = app.create_document()
128 if route == "/":
129 filename = "index.html"
130 else:
131 filename = route[1:] + ".html"
132
133 output_file(filename)
134
135 if args.show:
136 show(doc, new='tab')
137 else:
138 save(doc)
139
140 subcommands = [Serve, Html]
141
142 def main(argv):
143 parser = argparse.ArgumentParser(prog=argv[0])
144 # does this get set by anything other than BOKEH_VERSION env var?
145 version = settings.version()
146 if not version:
147 version = "unknown version"
148 parser.add_argument('-v', '--version', action='version', version=version)
149 subs = parser.add_subparsers(help="Sub-commands")
150 for klass in subcommands:
151 c_parser = subs.add_parser(klass.name, help=klass.help)
152 c = klass(parser=c_parser)
153 c_parser.set_defaults(func=c.func)
154
155 args = parser.parse_args(argv[1:])
156 args.func(args)
157
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/bokeh/command/__init__.py b/bokeh/command/__init__.py
--- a/bokeh/command/__init__.py
+++ b/bokeh/command/__init__.py
@@ -77,9 +77,10 @@
def __init__(self, **kwargs):
super(Serve, self).__init__(**kwargs)
- self.parser.add_argument('--port', metavar='PORT', type=int, help="Port to listen on", default=-1)
self.parser.add_argument('--develop', action='store_true', help="Enable develop-time features that should not be used in production")
self.parser.add_argument('--show', action='store_true', help="Open server app(s) in a browser")
+ self.parser.add_argument('--port', metavar='PORT', type=int, help="Port to listen on", default=-1)
+ self.parser.add_argument('--address', metavar='ADDRESS', type=str, help="Address to listen on", default=None)
self.port = 5006
self.develop_mode = False
self.server = None
@@ -95,7 +96,7 @@
# TODO make log level a command line option
logging.basicConfig(level=logging.DEBUG)
- server = Server(applications, port=self.port)
+ server = Server(applications, port=self.port, address=args.address)
if args.show:
# we have to defer opening in browser until
@@ -107,7 +108,13 @@
if self.develop_mode:
log.info("Using develop mode (do not enable --develop in production)")
- log.info("Starting Bokeh server on port %d with apps at %r", server.port, sorted(applications.keys()))
+ address_string = ''
+ if server.address is not None and server.address != '':
+ address_string = ' address ' + server.address
+ log.info("Starting Bokeh server on port %d%s with applications at paths %r",
+ server.port,
+ address_string,
+ sorted(applications.keys()))
server.start()
class Html(ApplicationsSubcommand):
diff --git a/bokeh/server/server.py b/bokeh/server/server.py
--- a/bokeh/server/server.py
+++ b/bokeh/server/server.py
@@ -39,13 +39,23 @@
self._port = DEFAULT_SERVER_PORT
if 'port' in kwargs:
self._port = kwargs['port']
+ self._address = None
+ if 'address' in kwargs:
+ self._address = kwargs['address']
# these queue a callback on the ioloop rather than
# doing the operation immediately (I think - havocp)
try:
- self._http.bind(self._port)
+ self._http.bind(self._port, address=self._address)
self._http.start(1)
- except OSError:
- log.critical("Cannot start bokeh server, port %s already in use" % self._port)
+ except OSError as e:
+ import errno
+ if e.errno == errno.EADDRINUSE:
+ log.critical("Cannot start Bokeh server, port %s is already in use", self._port)
+ elif e.errno == errno.EADDRNOTAVAIL:
+ log.critical("Cannot start Bokeh server, address '%s' not available", self._address)
+ else:
+ codename = errno.errorcode[e.errno]
+ log.critical("Cannot start Bokeh server, %s %r", codename, e)
sys.exit(1)
# TODO this is broken, it's only used by test_client_server.py so fix that then remove this
@@ -57,6 +67,10 @@
def port(self):
return self._port
+ @property
+ def address(self):
+ return self._address
+
@property
def io_loop(self):
return self._tornado.io_loop
| {"golden_diff": "diff --git a/bokeh/command/__init__.py b/bokeh/command/__init__.py\n--- a/bokeh/command/__init__.py\n+++ b/bokeh/command/__init__.py\n@@ -77,9 +77,10 @@\n \n def __init__(self, **kwargs):\n super(Serve, self).__init__(**kwargs)\n- self.parser.add_argument('--port', metavar='PORT', type=int, help=\"Port to listen on\", default=-1)\n self.parser.add_argument('--develop', action='store_true', help=\"Enable develop-time features that should not be used in production\")\n self.parser.add_argument('--show', action='store_true', help=\"Open server app(s) in a browser\")\n+ self.parser.add_argument('--port', metavar='PORT', type=int, help=\"Port to listen on\", default=-1)\n+ self.parser.add_argument('--address', metavar='ADDRESS', type=str, help=\"Address to listen on\", default=None)\n self.port = 5006\n self.develop_mode = False\n self.server = None\n@@ -95,7 +96,7 @@\n # TODO make log level a command line option\n logging.basicConfig(level=logging.DEBUG)\n \n- server = Server(applications, port=self.port)\n+ server = Server(applications, port=self.port, address=args.address)\n \n if args.show:\n # we have to defer opening in browser until\n@@ -107,7 +108,13 @@\n \n if self.develop_mode:\n log.info(\"Using develop mode (do not enable --develop in production)\")\n- log.info(\"Starting Bokeh server on port %d with apps at %r\", server.port, sorted(applications.keys()))\n+ address_string = ''\n+ if server.address is not None and server.address != '':\n+ address_string = ' address ' + server.address\n+ log.info(\"Starting Bokeh server on port %d%s with applications at paths %r\",\n+ server.port,\n+ address_string,\n+ sorted(applications.keys()))\n server.start()\n \n class Html(ApplicationsSubcommand):\ndiff --git a/bokeh/server/server.py b/bokeh/server/server.py\n--- a/bokeh/server/server.py\n+++ b/bokeh/server/server.py\n@@ -39,13 +39,23 @@\n self._port = DEFAULT_SERVER_PORT\n if 'port' in kwargs:\n self._port = kwargs['port']\n+ self._address = None\n+ if 'address' in kwargs:\n+ self._address = kwargs['address']\n # these queue a callback on the ioloop rather than\n # doing the operation immediately (I think - havocp)\n try:\n- self._http.bind(self._port)\n+ self._http.bind(self._port, address=self._address)\n self._http.start(1)\n- except OSError:\n- log.critical(\"Cannot start bokeh server, port %s already in use\" % self._port)\n+ except OSError as e:\n+ import errno\n+ if e.errno == errno.EADDRINUSE:\n+ log.critical(\"Cannot start Bokeh server, port %s is already in use\", self._port)\n+ elif e.errno == errno.EADDRNOTAVAIL:\n+ log.critical(\"Cannot start Bokeh server, address '%s' not available\", self._address)\n+ else:\n+ codename = errno.errorcode[e.errno]\n+ log.critical(\"Cannot start Bokeh server, %s %r\", codename, e)\n sys.exit(1)\n \n # TODO this is broken, it's only used by test_client_server.py so fix that then remove this\n@@ -57,6 +67,10 @@\n def port(self):\n return self._port\n \n+ @property\n+ def address(self):\n+ return self._address\n+\n @property\n def io_loop(self):\n return self._tornado.io_loop\n", "issue": "Allow for configuring the IP address of the Bokeh server\nI have downloaded the bokeh developer build \"conda install -c bokeh/channel/dev bokeh\", which has a new Bokeh server \"https://github.com/bokeh/bokeh/wiki/Porting-guide:-new-Bokeh-server\".\n\nFor previous Bokeh server, this capability is added (see \"add ability to use a different ip address and port for bokeh-server #383\"). \n\nPlease tell me how to use a different ip address for the new bokeh server \"boken serve\".\nBTW, I know that I can change to a different port by using \"bokeh serve --port PORT\"\n\nThank you very much!\n\n", "before_files": [{"content": "''' Provides a Server which instantiates Application instances as clients connect\n\n'''\nfrom __future__ import absolute_import, print_function\n\nimport logging\nlog = logging.getLogger(__name__)\n\nimport sys\n\nfrom tornado.httpserver import HTTPServer\n\nfrom .tornado import BokehTornado\n\nfrom bokeh.application import Application\n\nfrom bokeh.resources import DEFAULT_SERVER_PORT\n\nclass Server(object):\n ''' A Server which creates a new Session for each connection, using an Application to initialize each Session.\n\n Args:\n applications (dict of str: bokeh.application.Application) or bokeh.application.Application:\n mapping from URL paths to Application instances, or a single Application to put at the root URL\n The Application is a factory for Document, with a new Document initialized for each Session.\n Each application should be identified by a path meant to go in a URL, like \"/\" or \"/foo\"\n '''\n\n def __init__(self, applications, **kwargs):\n if isinstance(applications, Application):\n self._applications = { '/' : applications }\n else:\n self._applications = applications\n io_loop = None\n if 'io_loop' in kwargs:\n io_loop = kwargs['io_loop']\n self._tornado = BokehTornado(self._applications, io_loop=io_loop)\n self._http = HTTPServer(self._tornado)\n self._port = DEFAULT_SERVER_PORT\n if 'port' in kwargs:\n self._port = kwargs['port']\n # these queue a callback on the ioloop rather than\n # doing the operation immediately (I think - havocp)\n try:\n self._http.bind(self._port)\n self._http.start(1)\n except OSError:\n log.critical(\"Cannot start bokeh server, port %s already in use\" % self._port)\n sys.exit(1)\n\n # TODO this is broken, it's only used by test_client_server.py so fix that then remove this\n @property\n def ws_url(self):\n return \"ws://localhost:\" + str(self._port) + \"/ws\"\n\n @property\n def port(self):\n return self._port\n\n @property\n def io_loop(self):\n return self._tornado.io_loop\n\n def start(self):\n ''' Start the Bokeh Server's IO loop.\n\n Returns:\n None\n\n Notes:\n Keyboard interrupts or sigterm will cause the server to shut down.\n\n '''\n self._tornado.start()\n\n def stop(self):\n ''' Stop the Bokeh Server's IO loop.\n\n Returns:\n None\n\n '''\n self._tornado.stop()\n\n def unlisten(self):\n '''Stop listening on ports (Server will no longer be usable after calling this)\n\n Returns:\n None\n '''\n self._http.stop()\n\n def get_session(self, app_path, session_id):\n '''Gets a session by name (session must already exist)'''\n\n return self._tornado.get_session(app_path, session_id)\n\n def show(self, app_path, browser=None, new='tab'):\n ''' Opens an app in a browser window or tab.\n\n Useful for testing server applications on your local desktop but\n should not call when running bokeh-server on an actual server.\n\n Args:\n app_path (str) : the app path to open\n The part of the URL after the hostname:port, with leading slash.\n\n browser (str, optional) : browser to show with (default: None)\n For systems that support it, the **browser** argument allows\n specifying which browser to display in, e.g. \"safari\", \"firefox\",\n \"opera\", \"windows-default\" (see the ``webbrowser`` module\n documentation in the standard lib for more details).\n\n new (str, optional) : window or tab (default: \"tab\")\n If ``new`` is 'tab', then opens a new tab.\n If ``new`` is 'window', then opens a new window.\n\n Returns:\n None\n '''\n if not app_path.startswith(\"/\"):\n raise ValueError(\"app_path must start with a /\")\n from bokeh.browserlib import view\n url = \"http://localhost:%d%s\" % (self.port, app_path)\n view(url, browser=browser, new=new)\n\n", "path": "bokeh/server/server.py"}, {"content": "from __future__ import print_function\n\nimport argparse\nimport sys\nimport os\n\nfrom bokeh.settings import settings\nfrom bokeh.application import Application\nfrom bokeh.server.server import Server\nfrom bokeh.application.spellings import ScriptHandler, DirectoryHandler\nfrom bokeh.io import output_file, save, show\n\nimport logging\nlog = logging.getLogger(__name__)\n\ndef die(message):\n print(message, file=sys.stderr)\n sys.exit(1)\n\nclass Subcommand(object):\n \"\"\"Abstract base class for subcommands\"\"\"\n\n def __init__(self, parser):\n \"\"\"Initialize the subcommand with its parser; can call parser.add_argument to add subcommand flags\"\"\"\n self.parser = parser\n\n def func(self, args):\n \"\"\"Takes over main program flow to perform the subcommand\"\"\"\n pass\n\nclass ApplicationsSubcommand(Subcommand):\n \"\"\"Abstract base class for subcommand that operates on a list of applications.\"\"\"\n\n def __init__(self, **kwargs):\n super(ApplicationsSubcommand, self).__init__(**kwargs)\n self.parser.add_argument('files', metavar='DIRECTORY-OR-SCRIPT', nargs='*', help=\"The app directories or scripts to serve (serve empty document if not specified)\", default=None)\n\n def build_applications(self, args):\n if args.files:\n files = args.files\n else:\n files = []\n\n applications = {}\n\n for file in files:\n file = os.path.abspath(file)\n if os.path.isdir(file):\n handler = DirectoryHandler(filename=file)\n else:\n handler = ScriptHandler(filename=file)\n\n if handler.failed:\n die(\"Error loading %s:\\n\\n%s\\n%s \" % (file, handler.error, handler.error_detail))\n\n application = Application()\n application.add(handler)\n\n route = handler.url_path()\n if not route:\n if '/' in applications:\n die(\"Don't know the URL path to use for %s\" % (file))\n route = '/'\n applications[route] = application\n\n if len(applications) == 0:\n # create an empty application by default, used with output_server typically\n applications['/'] = Application()\n\n return applications\n\nclass Serve(ApplicationsSubcommand):\n \"\"\"Subcommand to launch the Bokeh server.\"\"\"\n\n name = \"serve\"\n help = \"Run a Bokeh server hosting one or more applications\"\n\n def __init__(self, **kwargs):\n super(Serve, self).__init__(**kwargs)\n self.parser.add_argument('--port', metavar='PORT', type=int, help=\"Port to listen on\", default=-1)\n self.parser.add_argument('--develop', action='store_true', help=\"Enable develop-time features that should not be used in production\")\n self.parser.add_argument('--show', action='store_true', help=\"Open server app(s) in a browser\")\n self.port = 5006\n self.develop_mode = False\n self.server = None\n\n def func(self, args):\n if args.port >= 0:\n self.port = args.port\n\n self.develop_mode = args.develop\n\n applications = self.build_applications(args)\n\n # TODO make log level a command line option\n logging.basicConfig(level=logging.DEBUG)\n\n server = Server(applications, port=self.port)\n\n if args.show:\n # we have to defer opening in browser until\n # we start up the server\n def show_callback():\n for route in applications.keys():\n server.show(route)\n server.io_loop.add_callback(show_callback)\n\n if self.develop_mode:\n log.info(\"Using develop mode (do not enable --develop in production)\")\n log.info(\"Starting Bokeh server on port %d with apps at %r\", server.port, sorted(applications.keys()))\n server.start()\n\nclass Html(ApplicationsSubcommand):\n \"\"\"Subcommand to output applications as standalone HTML files.\"\"\"\n\n name = \"html\"\n help = \"Create standalone HTML files for one or more applications\"\n\n def __init__(self, **kwargs):\n super(Html, self).__init__(**kwargs)\n self.parser.add_argument('--show', action='store_true', help=\"Open generated file(s) in a browser\")\n\n def func(self, args):\n applications = self.build_applications(args)\n\n for (route, app) in applications.items():\n doc = app.create_document()\n if route == \"/\":\n filename = \"index.html\"\n else:\n filename = route[1:] + \".html\"\n\n output_file(filename)\n\n if args.show:\n show(doc, new='tab')\n else:\n save(doc)\n\nsubcommands = [Serve, Html]\n\ndef main(argv):\n parser = argparse.ArgumentParser(prog=argv[0])\n # does this get set by anything other than BOKEH_VERSION env var?\n version = settings.version()\n if not version:\n version = \"unknown version\"\n parser.add_argument('-v', '--version', action='version', version=version)\n subs = parser.add_subparsers(help=\"Sub-commands\")\n for klass in subcommands:\n c_parser = subs.add_parser(klass.name, help=klass.help)\n c = klass(parser=c_parser)\n c_parser.set_defaults(func=c.func)\n\n args = parser.parse_args(argv[1:])\n args.func(args)\n", "path": "bokeh/command/__init__.py"}], "after_files": [{"content": "''' Provides a Server which instantiates Application instances as clients connect\n\n'''\nfrom __future__ import absolute_import, print_function\n\nimport logging\nlog = logging.getLogger(__name__)\n\nimport sys\n\nfrom tornado.httpserver import HTTPServer\n\nfrom .tornado import BokehTornado\n\nfrom bokeh.application import Application\n\nfrom bokeh.resources import DEFAULT_SERVER_PORT\n\nclass Server(object):\n ''' A Server which creates a new Session for each connection, using an Application to initialize each Session.\n\n Args:\n applications (dict of str: bokeh.application.Application) or bokeh.application.Application:\n mapping from URL paths to Application instances, or a single Application to put at the root URL\n The Application is a factory for Document, with a new Document initialized for each Session.\n Each application should be identified by a path meant to go in a URL, like \"/\" or \"/foo\"\n '''\n\n def __init__(self, applications, **kwargs):\n if isinstance(applications, Application):\n self._applications = { '/' : applications }\n else:\n self._applications = applications\n io_loop = None\n if 'io_loop' in kwargs:\n io_loop = kwargs['io_loop']\n self._tornado = BokehTornado(self._applications, io_loop=io_loop)\n self._http = HTTPServer(self._tornado)\n self._port = DEFAULT_SERVER_PORT\n if 'port' in kwargs:\n self._port = kwargs['port']\n self._address = None\n if 'address' in kwargs:\n self._address = kwargs['address']\n # these queue a callback on the ioloop rather than\n # doing the operation immediately (I think - havocp)\n try:\n self._http.bind(self._port, address=self._address)\n self._http.start(1)\n except OSError as e:\n import errno\n if e.errno == errno.EADDRINUSE:\n log.critical(\"Cannot start Bokeh server, port %s is already in use\", self._port)\n elif e.errno == errno.EADDRNOTAVAIL:\n log.critical(\"Cannot start Bokeh server, address '%s' not available\", self._address)\n else:\n codename = errno.errorcode[e.errno]\n log.critical(\"Cannot start Bokeh server, %s %r\", codename, e)\n sys.exit(1)\n\n # TODO this is broken, it's only used by test_client_server.py so fix that then remove this\n @property\n def ws_url(self):\n return \"ws://localhost:\" + str(self._port) + \"/ws\"\n\n @property\n def port(self):\n return self._port\n\n @property\n def address(self):\n return self._address\n\n @property\n def io_loop(self):\n return self._tornado.io_loop\n\n def start(self):\n ''' Start the Bokeh Server's IO loop.\n\n Returns:\n None\n\n Notes:\n Keyboard interrupts or sigterm will cause the server to shut down.\n\n '''\n self._tornado.start()\n\n def stop(self):\n ''' Stop the Bokeh Server's IO loop.\n\n Returns:\n None\n\n '''\n self._tornado.stop()\n\n def unlisten(self):\n '''Stop listening on ports (Server will no longer be usable after calling this)\n\n Returns:\n None\n '''\n self._http.stop()\n\n def get_session(self, app_path, session_id):\n '''Gets a session by name (session must already exist)'''\n\n return self._tornado.get_session(app_path, session_id)\n\n def show(self, app_path, browser=None, new='tab'):\n ''' Opens an app in a browser window or tab.\n\n Useful for testing server applications on your local desktop but\n should not call when running bokeh-server on an actual server.\n\n Args:\n app_path (str) : the app path to open\n The part of the URL after the hostname:port, with leading slash.\n\n browser (str, optional) : browser to show with (default: None)\n For systems that support it, the **browser** argument allows\n specifying which browser to display in, e.g. \"safari\", \"firefox\",\n \"opera\", \"windows-default\" (see the ``webbrowser`` module\n documentation in the standard lib for more details).\n\n new (str, optional) : window or tab (default: \"tab\")\n If ``new`` is 'tab', then opens a new tab.\n If ``new`` is 'window', then opens a new window.\n\n Returns:\n None\n '''\n if not app_path.startswith(\"/\"):\n raise ValueError(\"app_path must start with a /\")\n from bokeh.browserlib import view\n url = \"http://localhost:%d%s\" % (self.port, app_path)\n view(url, browser=browser, new=new)\n\n", "path": "bokeh/server/server.py"}, {"content": "from __future__ import print_function\n\nimport argparse\nimport sys\nimport os\n\nfrom bokeh.settings import settings\nfrom bokeh.application import Application\nfrom bokeh.server.server import Server\nfrom bokeh.application.spellings import ScriptHandler, DirectoryHandler\nfrom bokeh.io import output_file, save, show\n\nimport logging\nlog = logging.getLogger(__name__)\n\ndef die(message):\n print(message, file=sys.stderr)\n sys.exit(1)\n\nclass Subcommand(object):\n \"\"\"Abstract base class for subcommands\"\"\"\n\n def __init__(self, parser):\n \"\"\"Initialize the subcommand with its parser; can call parser.add_argument to add subcommand flags\"\"\"\n self.parser = parser\n\n def func(self, args):\n \"\"\"Takes over main program flow to perform the subcommand\"\"\"\n pass\n\nclass ApplicationsSubcommand(Subcommand):\n \"\"\"Abstract base class for subcommand that operates on a list of applications.\"\"\"\n\n def __init__(self, **kwargs):\n super(ApplicationsSubcommand, self).__init__(**kwargs)\n self.parser.add_argument('files', metavar='DIRECTORY-OR-SCRIPT', nargs='*', help=\"The app directories or scripts to serve (serve empty document if not specified)\", default=None)\n\n def build_applications(self, args):\n if args.files:\n files = args.files\n else:\n files = []\n\n applications = {}\n\n for file in files:\n file = os.path.abspath(file)\n if os.path.isdir(file):\n handler = DirectoryHandler(filename=file)\n else:\n handler = ScriptHandler(filename=file)\n\n if handler.failed:\n die(\"Error loading %s:\\n\\n%s\\n%s \" % (file, handler.error, handler.error_detail))\n\n application = Application()\n application.add(handler)\n\n route = handler.url_path()\n if not route:\n if '/' in applications:\n die(\"Don't know the URL path to use for %s\" % (file))\n route = '/'\n applications[route] = application\n\n if len(applications) == 0:\n # create an empty application by default, used with output_server typically\n applications['/'] = Application()\n\n return applications\n\nclass Serve(ApplicationsSubcommand):\n \"\"\"Subcommand to launch the Bokeh server.\"\"\"\n\n name = \"serve\"\n help = \"Run a Bokeh server hosting one or more applications\"\n\n def __init__(self, **kwargs):\n super(Serve, self).__init__(**kwargs)\n self.parser.add_argument('--develop', action='store_true', help=\"Enable develop-time features that should not be used in production\")\n self.parser.add_argument('--show', action='store_true', help=\"Open server app(s) in a browser\")\n self.parser.add_argument('--port', metavar='PORT', type=int, help=\"Port to listen on\", default=-1)\n self.parser.add_argument('--address', metavar='ADDRESS', type=str, help=\"Address to listen on\", default=None)\n self.port = 5006\n self.develop_mode = False\n self.server = None\n\n def func(self, args):\n if args.port >= 0:\n self.port = args.port\n\n self.develop_mode = args.develop\n\n applications = self.build_applications(args)\n\n # TODO make log level a command line option\n logging.basicConfig(level=logging.DEBUG)\n\n server = Server(applications, port=self.port, address=args.address)\n\n if args.show:\n # we have to defer opening in browser until\n # we start up the server\n def show_callback():\n for route in applications.keys():\n server.show(route)\n server.io_loop.add_callback(show_callback)\n\n if self.develop_mode:\n log.info(\"Using develop mode (do not enable --develop in production)\")\n address_string = ''\n if server.address is not None and server.address != '':\n address_string = ' address ' + server.address\n log.info(\"Starting Bokeh server on port %d%s with applications at paths %r\",\n server.port,\n address_string,\n sorted(applications.keys()))\n server.start()\n\nclass Html(ApplicationsSubcommand):\n \"\"\"Subcommand to output applications as standalone HTML files.\"\"\"\n\n name = \"html\"\n help = \"Create standalone HTML files for one or more applications\"\n\n def __init__(self, **kwargs):\n super(Html, self).__init__(**kwargs)\n self.parser.add_argument('--show', action='store_true', help=\"Open generated file(s) in a browser\")\n\n def func(self, args):\n applications = self.build_applications(args)\n\n for (route, app) in applications.items():\n doc = app.create_document()\n if route == \"/\":\n filename = \"index.html\"\n else:\n filename = route[1:] + \".html\"\n\n output_file(filename)\n\n if args.show:\n show(doc, new='tab')\n else:\n save(doc)\n\nsubcommands = [Serve, Html]\n\ndef main(argv):\n parser = argparse.ArgumentParser(prog=argv[0])\n # does this get set by anything other than BOKEH_VERSION env var?\n version = settings.version()\n if not version:\n version = \"unknown version\"\n parser.add_argument('-v', '--version', action='version', version=version)\n subs = parser.add_subparsers(help=\"Sub-commands\")\n for klass in subcommands:\n c_parser = subs.add_parser(klass.name, help=klass.help)\n c = klass(parser=c_parser)\n c_parser.set_defaults(func=c.func)\n\n args = parser.parse_args(argv[1:])\n args.func(args)\n", "path": "bokeh/command/__init__.py"}]} | 3,122 | 869 |
gh_patches_debug_2418 | rasdani/github-patches | git_diff | horovod__horovod-2651 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Wrong default for horovod.tensorflow.keras.allreduce(average...
In Horovod 0.21.1 the default for `average` in `allreduce` is still `True` leading to
> ValueError: The op parameter supersedes average. Please provide only one of them.
when using `op=...` (only).
This is only in in `horovod.tensorflow.keras`, not in `horovod.tensorflow`
BTW: In TF2, is there any benefit of using `horovod.tensorflow.keras` over `horovod.tensorflow` when not disabling eager execution (which in my tests is pretty much unfeasible)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `horovod/tensorflow/keras/__init__.py`
Content:
```
1 # Copyright 2018 Uber Technologies, Inc. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15
16 import inspect
17
18 import tensorflow as tf
19
20 from tensorflow import keras
21 from tensorflow.python.keras import backend as K
22
23 from horovod.tensorflow import init
24 from horovod.tensorflow import shutdown
25 from horovod.tensorflow import is_initialized, start_timeline, stop_timeline
26 from horovod.tensorflow import size
27 from horovod.tensorflow import local_size
28 from horovod.tensorflow import rank
29 from horovod.tensorflow import local_rank
30 from horovod.tensorflow import mpi_threads_supported, mpi_enabled, mpi_built
31 from horovod.tensorflow import gloo_enabled, gloo_built
32 from horovod.tensorflow import nccl_built, ddl_built, ccl_built, cuda_built, rocm_built
33 from horovod.tensorflow import Average, Compression, Sum
34
35 import horovod._keras as _impl
36 from horovod.tensorflow.keras import callbacks, elastic
37
38
39 try:
40 # In later versions of TensorFlow, optimizers are spread across multiple modules. This set is used to distinguish
41 # stock optimizers that come with tf.keras from custom optimizers that may need to be wrapped specially.
42 _OPTIMIZER_MODULES = set([obj.__module__ for name, obj in inspect.getmembers(tf.keras.optimizers)
43 if isinstance(obj, type(tf.keras.optimizers.Optimizer))])
44 except:
45 _OPTIMIZER_MODULES = set()
46
47
48 def DistributedOptimizer(optimizer, name=None,
49 device_dense='', device_sparse='',
50 compression=Compression.none,
51 sparse_as_dense=False,
52 gradient_predivide_factor=1.0,
53 op=Average,
54 backward_passes_per_step=1,
55 average_aggregated_gradients=False):
56 """
57 An optimizer that wraps another keras.optimizers.Optimizer, using an allreduce to
58 average gradient values before applying gradients to model weights.
59
60 Args:
61 optimizer: Optimizer to use for computing gradients and applying updates.
62 name: Optional name prefix for the operations created when applying
63 gradients. Defaults to "Distributed" followed by the provided
64 optimizer type.
65 device_dense: Device to be used for dense tensors. Uses GPU by default
66 if Horovod was build with HOROVOD_GPU_OPERATIONS.
67 device_sparse: Device to be used for sparse tensors. Uses GPU by default
68 if Horovod was build with HOROVOD_GPU_OPERATIONS.
69 compression: Compression algorithm used to reduce the amount of data
70 sent and received by each worker node. Defaults to not
71 using compression.
72 sparse_as_dense: Treat all sparse gradients as dense tensors. This can
73 help improve performance and memory utilization if
74 the original sparse gradient has high density.
75 Defaults to false.
76 gradient_predivide_factor: gradient_predivide_factor splits the averaging
77 before and after the sum. Gradients are scaled by
78 1.0 / gradient_predivide_factor before the sum and
79 gradient_predivide_factor / size after the sum.
80 op: The reduction operation to use when combining gradients across
81 different ranks. Defaults to Average.
82 backward_passes_per_step: Number of backward passes to perform before calling
83 hvd.allreduce. This allows accumulating updates over
84 multiple mini-batches before reducing and applying them.
85 average_aggregated_gradients: Whether to average the aggregated gradients that
86 have been accumulated over multiple mini-batches.
87 If true divides gradient updates by
88 backward_passes_per_step.
89 Only applicable for backward_passes_per_step > 1.
90 """
91 if gradient_predivide_factor != 1.0 and rocm_built():
92 raise ValueError('gradient_predivide_factor not supported yet with ROCm')
93
94 if op != Average and op != Sum:
95 raise ValueError('op currently only supports Average and Sum')
96
97 return _impl.create_distributed_optimizer(
98 keras=keras,
99 optimizer=optimizer,
100 name=name,
101 device_dense=device_dense,
102 device_sparse=device_sparse,
103 compression=compression,
104 sparse_as_dense=sparse_as_dense,
105 gradient_predivide_factor=gradient_predivide_factor,
106 op=op,
107 backward_passes_per_step=backward_passes_per_step,
108 average_aggregated_gradients=average_aggregated_gradients,
109 )
110
111
112 def broadcast_global_variables(root_rank):
113 """Broadcasts all global variables from root rank to all other processes.
114
115 Arguments:
116 root_rank: Rank of the process from which global variables will be broadcasted
117 to all other processes.
118 """
119 return _impl.broadcast_global_variables(K, root_rank)
120
121
122 def allreduce(value, name=None, average=True,
123 prescale_factor=1.0,
124 postscale_factor=1.0,
125 op=None,
126 compression=Compression.none):
127 """
128 Perform an allreduce on a tensor-compatible value.
129
130 Arguments:
131 value: A tensor-compatible value to reduce.
132 The shape of the input must be identical across all ranks.
133 name: Optional name for the constants created by this operation.
134 average:
135 .. warning:: .. deprecated:: 0.19.0
136
137 Use `op` instead. Will be removed in v0.21.0.
138
139 prescale_factor: Multiplicative factor to scale tensor before allreduce.
140 postscale_factor: Multiplicative factor to scale tensor after allreduce.
141 op: The reduction operation to combine tensors across different ranks.
142 Defaults to Average if None is given.
143 compression: Compression algorithm used to reduce the amount of data
144 sent and received by each worker node. Defaults to not
145 using compression.
146 """
147 return _impl.allreduce(
148 backend=K,
149 value=value,
150 name=name,
151 average=average,
152 prescale_factor=prescale_factor,
153 postscale_factor=postscale_factor,
154 op=op,
155 compression=compression)
156
157
158 def allgather(value, name=None):
159 """
160 Perform an allgather on a tensor-compatible value.
161
162 The concatenation is done on the first dimension, so the input values on the
163 different processes must have the same rank and shape, except for the first
164 dimension, which is allowed to be different.
165
166 Arguments:
167 value: A tensor-compatible value to gather.
168 name: Optional name prefix for the constants created by this operation.
169 """
170 return _impl.allgather(K, value, name)
171
172
173 def broadcast(value, root_rank, name=None):
174 """
175 Perform a broadcast on a tensor-compatible value.
176
177 Arguments:
178 value: A tensor-compatible value to reduce.
179 The shape of the input must be identical across all ranks.
180 root_rank: Rank of the process from which global variables will be
181 broadcasted to all other processes.
182 name: Optional name for the constants created by this operation.
183 """
184 return _impl.broadcast(K, value, root_rank, name)
185
186
187 def load_model(filepath, custom_optimizers=None, custom_objects=None, compression=Compression.none):
188 """
189 Loads a saved Keras model with a Horovod DistributedOptimizer.
190
191 The DistributedOptimizer will wrap the underlying optimizer used to train
192 the saved model, so that the optimizer state (params and weights) will
193 be picked up for retraining.
194
195 By default, all optimizers in the module `keras.optimizers` will be loaded
196 and wrapped without needing to specify any `custom_optimizers` or
197 `custom_objects`.
198
199 Arguments:
200 filepath: One of the following:
201 - string, path to the saved model, or
202 - h5py.File object from which to load the model
203 custom_optimizers: Optional list of Optimizer subclasses to support
204 during loading.
205 custom_objects: Optional dictionary mapping names (strings) to custom
206 classes or functions to be considered during deserialization.
207 compression: Compression algorithm used to reduce the amount of data
208 sent and received by each worker node. Defaults to not
209 using compression.
210
211 Returns:
212 A Keras model instance.
213
214 Raises:
215 ImportError: If h5py is not available.
216 ValueError: In case of an invalid savefile.
217 """
218 def wrap_optimizer(cls):
219 return lambda **kwargs: DistributedOptimizer(cls(**kwargs), compression=compression)
220 return _impl.load_model(keras, wrap_optimizer, _OPTIMIZER_MODULES, filepath, custom_optimizers, custom_objects)
221
222
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/horovod/tensorflow/keras/__init__.py b/horovod/tensorflow/keras/__init__.py
--- a/horovod/tensorflow/keras/__init__.py
+++ b/horovod/tensorflow/keras/__init__.py
@@ -119,7 +119,7 @@
return _impl.broadcast_global_variables(K, root_rank)
-def allreduce(value, name=None, average=True,
+def allreduce(value, name=None, average=None,
prescale_factor=1.0,
postscale_factor=1.0,
op=None,
| {"golden_diff": "diff --git a/horovod/tensorflow/keras/__init__.py b/horovod/tensorflow/keras/__init__.py\n--- a/horovod/tensorflow/keras/__init__.py\n+++ b/horovod/tensorflow/keras/__init__.py\n@@ -119,7 +119,7 @@\n return _impl.broadcast_global_variables(K, root_rank)\n \n \n-def allreduce(value, name=None, average=True,\n+def allreduce(value, name=None, average=None,\n prescale_factor=1.0,\n postscale_factor=1.0,\n op=None,\n", "issue": "Wrong default for horovod.tensorflow.keras.allreduce(average...\nIn Horovod 0.21.1 the default for `average` in `allreduce` is still `True` leading to \r\n\r\n> ValueError: The op parameter supersedes average. Please provide only one of them.\r\n\r\nwhen using `op=...` (only).\r\n\r\nThis is only in in `horovod.tensorflow.keras`, not in `horovod.tensorflow`\r\n\r\nBTW: In TF2, is there any benefit of using `horovod.tensorflow.keras` over `horovod.tensorflow` when not disabling eager execution (which in my tests is pretty much unfeasible)\n", "before_files": [{"content": "# Copyright 2018 Uber Technologies, Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\nimport inspect\n\nimport tensorflow as tf\n\nfrom tensorflow import keras\nfrom tensorflow.python.keras import backend as K\n\nfrom horovod.tensorflow import init\nfrom horovod.tensorflow import shutdown\nfrom horovod.tensorflow import is_initialized, start_timeline, stop_timeline\nfrom horovod.tensorflow import size\nfrom horovod.tensorflow import local_size\nfrom horovod.tensorflow import rank\nfrom horovod.tensorflow import local_rank\nfrom horovod.tensorflow import mpi_threads_supported, mpi_enabled, mpi_built\nfrom horovod.tensorflow import gloo_enabled, gloo_built\nfrom horovod.tensorflow import nccl_built, ddl_built, ccl_built, cuda_built, rocm_built\nfrom horovod.tensorflow import Average, Compression, Sum\n\nimport horovod._keras as _impl\nfrom horovod.tensorflow.keras import callbacks, elastic\n\n\ntry:\n # In later versions of TensorFlow, optimizers are spread across multiple modules. This set is used to distinguish\n # stock optimizers that come with tf.keras from custom optimizers that may need to be wrapped specially.\n _OPTIMIZER_MODULES = set([obj.__module__ for name, obj in inspect.getmembers(tf.keras.optimizers)\n if isinstance(obj, type(tf.keras.optimizers.Optimizer))])\nexcept:\n _OPTIMIZER_MODULES = set()\n\n\ndef DistributedOptimizer(optimizer, name=None,\n device_dense='', device_sparse='',\n compression=Compression.none,\n sparse_as_dense=False,\n gradient_predivide_factor=1.0,\n op=Average,\n backward_passes_per_step=1,\n average_aggregated_gradients=False):\n \"\"\"\n An optimizer that wraps another keras.optimizers.Optimizer, using an allreduce to\n average gradient values before applying gradients to model weights.\n\n Args:\n optimizer: Optimizer to use for computing gradients and applying updates.\n name: Optional name prefix for the operations created when applying\n gradients. Defaults to \"Distributed\" followed by the provided\n optimizer type.\n device_dense: Device to be used for dense tensors. Uses GPU by default\n if Horovod was build with HOROVOD_GPU_OPERATIONS.\n device_sparse: Device to be used for sparse tensors. Uses GPU by default\n if Horovod was build with HOROVOD_GPU_OPERATIONS.\n compression: Compression algorithm used to reduce the amount of data\n sent and received by each worker node. Defaults to not\n using compression.\n sparse_as_dense: Treat all sparse gradients as dense tensors. This can\n help improve performance and memory utilization if\n the original sparse gradient has high density.\n Defaults to false.\n gradient_predivide_factor: gradient_predivide_factor splits the averaging\n before and after the sum. Gradients are scaled by\n 1.0 / gradient_predivide_factor before the sum and\n gradient_predivide_factor / size after the sum.\n op: The reduction operation to use when combining gradients across\n different ranks. Defaults to Average.\n backward_passes_per_step: Number of backward passes to perform before calling\n hvd.allreduce. This allows accumulating updates over\n multiple mini-batches before reducing and applying them.\n average_aggregated_gradients: Whether to average the aggregated gradients that\n have been accumulated over multiple mini-batches.\n If true divides gradient updates by\n backward_passes_per_step.\n Only applicable for backward_passes_per_step > 1.\n \"\"\"\n if gradient_predivide_factor != 1.0 and rocm_built():\n raise ValueError('gradient_predivide_factor not supported yet with ROCm')\n\n if op != Average and op != Sum:\n raise ValueError('op currently only supports Average and Sum')\n\n return _impl.create_distributed_optimizer(\n keras=keras,\n optimizer=optimizer,\n name=name,\n device_dense=device_dense,\n device_sparse=device_sparse,\n compression=compression,\n sparse_as_dense=sparse_as_dense,\n gradient_predivide_factor=gradient_predivide_factor,\n op=op,\n backward_passes_per_step=backward_passes_per_step,\n average_aggregated_gradients=average_aggregated_gradients,\n )\n\n\ndef broadcast_global_variables(root_rank):\n \"\"\"Broadcasts all global variables from root rank to all other processes.\n\n Arguments:\n root_rank: Rank of the process from which global variables will be broadcasted\n to all other processes.\n \"\"\"\n return _impl.broadcast_global_variables(K, root_rank)\n\n\ndef allreduce(value, name=None, average=True,\n prescale_factor=1.0,\n postscale_factor=1.0,\n op=None,\n compression=Compression.none):\n \"\"\"\n Perform an allreduce on a tensor-compatible value.\n\n Arguments:\n value: A tensor-compatible value to reduce.\n The shape of the input must be identical across all ranks.\n name: Optional name for the constants created by this operation.\n average:\n .. warning:: .. deprecated:: 0.19.0\n\n Use `op` instead. Will be removed in v0.21.0.\n\n prescale_factor: Multiplicative factor to scale tensor before allreduce.\n postscale_factor: Multiplicative factor to scale tensor after allreduce.\n op: The reduction operation to combine tensors across different ranks.\n Defaults to Average if None is given.\n compression: Compression algorithm used to reduce the amount of data\n sent and received by each worker node. Defaults to not\n using compression.\n \"\"\"\n return _impl.allreduce(\n backend=K,\n value=value,\n name=name,\n average=average,\n prescale_factor=prescale_factor,\n postscale_factor=postscale_factor,\n op=op,\n compression=compression)\n\n\ndef allgather(value, name=None):\n \"\"\"\n Perform an allgather on a tensor-compatible value.\n\n The concatenation is done on the first dimension, so the input values on the\n different processes must have the same rank and shape, except for the first\n dimension, which is allowed to be different.\n\n Arguments:\n value: A tensor-compatible value to gather.\n name: Optional name prefix for the constants created by this operation.\n \"\"\"\n return _impl.allgather(K, value, name)\n\n\ndef broadcast(value, root_rank, name=None):\n \"\"\"\n Perform a broadcast on a tensor-compatible value.\n\n Arguments:\n value: A tensor-compatible value to reduce.\n The shape of the input must be identical across all ranks.\n root_rank: Rank of the process from which global variables will be\n broadcasted to all other processes.\n name: Optional name for the constants created by this operation.\n \"\"\"\n return _impl.broadcast(K, value, root_rank, name)\n\n\ndef load_model(filepath, custom_optimizers=None, custom_objects=None, compression=Compression.none):\n \"\"\"\n Loads a saved Keras model with a Horovod DistributedOptimizer.\n\n The DistributedOptimizer will wrap the underlying optimizer used to train\n the saved model, so that the optimizer state (params and weights) will\n be picked up for retraining.\n\n By default, all optimizers in the module `keras.optimizers` will be loaded\n and wrapped without needing to specify any `custom_optimizers` or\n `custom_objects`.\n\n Arguments:\n filepath: One of the following:\n - string, path to the saved model, or\n - h5py.File object from which to load the model\n custom_optimizers: Optional list of Optimizer subclasses to support\n during loading.\n custom_objects: Optional dictionary mapping names (strings) to custom\n classes or functions to be considered during deserialization.\n compression: Compression algorithm used to reduce the amount of data\n sent and received by each worker node. Defaults to not\n using compression.\n\n Returns:\n A Keras model instance.\n\n Raises:\n ImportError: If h5py is not available.\n ValueError: In case of an invalid savefile.\n \"\"\"\n def wrap_optimizer(cls):\n return lambda **kwargs: DistributedOptimizer(cls(**kwargs), compression=compression)\n return _impl.load_model(keras, wrap_optimizer, _OPTIMIZER_MODULES, filepath, custom_optimizers, custom_objects)\n\n", "path": "horovod/tensorflow/keras/__init__.py"}], "after_files": [{"content": "# Copyright 2018 Uber Technologies, Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\nimport inspect\n\nimport tensorflow as tf\n\nfrom tensorflow import keras\nfrom tensorflow.python.keras import backend as K\n\nfrom horovod.tensorflow import init\nfrom horovod.tensorflow import shutdown\nfrom horovod.tensorflow import is_initialized, start_timeline, stop_timeline\nfrom horovod.tensorflow import size\nfrom horovod.tensorflow import local_size\nfrom horovod.tensorflow import rank\nfrom horovod.tensorflow import local_rank\nfrom horovod.tensorflow import mpi_threads_supported, mpi_enabled, mpi_built\nfrom horovod.tensorflow import gloo_enabled, gloo_built\nfrom horovod.tensorflow import nccl_built, ddl_built, ccl_built, cuda_built, rocm_built\nfrom horovod.tensorflow import Average, Compression, Sum\n\nimport horovod._keras as _impl\nfrom horovod.tensorflow.keras import callbacks, elastic\n\n\ntry:\n # In later versions of TensorFlow, optimizers are spread across multiple modules. This set is used to distinguish\n # stock optimizers that come with tf.keras from custom optimizers that may need to be wrapped specially.\n _OPTIMIZER_MODULES = set([obj.__module__ for name, obj in inspect.getmembers(tf.keras.optimizers)\n if isinstance(obj, type(tf.keras.optimizers.Optimizer))])\nexcept:\n _OPTIMIZER_MODULES = set()\n\n\ndef DistributedOptimizer(optimizer, name=None,\n device_dense='', device_sparse='',\n compression=Compression.none,\n sparse_as_dense=False,\n gradient_predivide_factor=1.0,\n op=Average,\n backward_passes_per_step=1,\n average_aggregated_gradients=False):\n \"\"\"\n An optimizer that wraps another keras.optimizers.Optimizer, using an allreduce to\n average gradient values before applying gradients to model weights.\n\n Args:\n optimizer: Optimizer to use for computing gradients and applying updates.\n name: Optional name prefix for the operations created when applying\n gradients. Defaults to \"Distributed\" followed by the provided\n optimizer type.\n device_dense: Device to be used for dense tensors. Uses GPU by default\n if Horovod was build with HOROVOD_GPU_OPERATIONS.\n device_sparse: Device to be used for sparse tensors. Uses GPU by default\n if Horovod was build with HOROVOD_GPU_OPERATIONS.\n compression: Compression algorithm used to reduce the amount of data\n sent and received by each worker node. Defaults to not\n using compression.\n sparse_as_dense: Treat all sparse gradients as dense tensors. This can\n help improve performance and memory utilization if\n the original sparse gradient has high density.\n Defaults to false.\n gradient_predivide_factor: gradient_predivide_factor splits the averaging\n before and after the sum. Gradients are scaled by\n 1.0 / gradient_predivide_factor before the sum and\n gradient_predivide_factor / size after the sum.\n op: The reduction operation to use when combining gradients across\n different ranks. Defaults to Average.\n backward_passes_per_step: Number of backward passes to perform before calling\n hvd.allreduce. This allows accumulating updates over\n multiple mini-batches before reducing and applying them.\n average_aggregated_gradients: Whether to average the aggregated gradients that\n have been accumulated over multiple mini-batches.\n If true divides gradient updates by\n backward_passes_per_step.\n Only applicable for backward_passes_per_step > 1.\n \"\"\"\n if gradient_predivide_factor != 1.0 and rocm_built():\n raise ValueError('gradient_predivide_factor not supported yet with ROCm')\n\n if op != Average and op != Sum:\n raise ValueError('op currently only supports Average and Sum')\n\n return _impl.create_distributed_optimizer(\n keras=keras,\n optimizer=optimizer,\n name=name,\n device_dense=device_dense,\n device_sparse=device_sparse,\n compression=compression,\n sparse_as_dense=sparse_as_dense,\n gradient_predivide_factor=gradient_predivide_factor,\n op=op,\n backward_passes_per_step=backward_passes_per_step,\n average_aggregated_gradients=average_aggregated_gradients,\n )\n\n\ndef broadcast_global_variables(root_rank):\n \"\"\"Broadcasts all global variables from root rank to all other processes.\n\n Arguments:\n root_rank: Rank of the process from which global variables will be broadcasted\n to all other processes.\n \"\"\"\n return _impl.broadcast_global_variables(K, root_rank)\n\n\ndef allreduce(value, name=None, average=None,\n prescale_factor=1.0,\n postscale_factor=1.0,\n op=None,\n compression=Compression.none):\n \"\"\"\n Perform an allreduce on a tensor-compatible value.\n\n Arguments:\n value: A tensor-compatible value to reduce.\n The shape of the input must be identical across all ranks.\n name: Optional name for the constants created by this operation.\n average:\n .. warning:: .. deprecated:: 0.19.0\n\n Use `op` instead. Will be removed in v0.21.0.\n\n prescale_factor: Multiplicative factor to scale tensor before allreduce.\n postscale_factor: Multiplicative factor to scale tensor after allreduce.\n op: The reduction operation to combine tensors across different ranks.\n Defaults to Average if None is given.\n compression: Compression algorithm used to reduce the amount of data\n sent and received by each worker node. Defaults to not\n using compression.\n \"\"\"\n return _impl.allreduce(\n backend=K,\n value=value,\n name=name,\n average=average,\n prescale_factor=prescale_factor,\n postscale_factor=postscale_factor,\n op=op,\n compression=compression)\n\n\ndef allgather(value, name=None):\n \"\"\"\n Perform an allgather on a tensor-compatible value.\n\n The concatenation is done on the first dimension, so the input values on the\n different processes must have the same rank and shape, except for the first\n dimension, which is allowed to be different.\n\n Arguments:\n value: A tensor-compatible value to gather.\n name: Optional name prefix for the constants created by this operation.\n \"\"\"\n return _impl.allgather(K, value, name)\n\n\ndef broadcast(value, root_rank, name=None):\n \"\"\"\n Perform a broadcast on a tensor-compatible value.\n\n Arguments:\n value: A tensor-compatible value to reduce.\n The shape of the input must be identical across all ranks.\n root_rank: Rank of the process from which global variables will be\n broadcasted to all other processes.\n name: Optional name for the constants created by this operation.\n \"\"\"\n return _impl.broadcast(K, value, root_rank, name)\n\n\ndef load_model(filepath, custom_optimizers=None, custom_objects=None, compression=Compression.none):\n \"\"\"\n Loads a saved Keras model with a Horovod DistributedOptimizer.\n\n The DistributedOptimizer will wrap the underlying optimizer used to train\n the saved model, so that the optimizer state (params and weights) will\n be picked up for retraining.\n\n By default, all optimizers in the module `keras.optimizers` will be loaded\n and wrapped without needing to specify any `custom_optimizers` or\n `custom_objects`.\n\n Arguments:\n filepath: One of the following:\n - string, path to the saved model, or\n - h5py.File object from which to load the model\n custom_optimizers: Optional list of Optimizer subclasses to support\n during loading.\n custom_objects: Optional dictionary mapping names (strings) to custom\n classes or functions to be considered during deserialization.\n compression: Compression algorithm used to reduce the amount of data\n sent and received by each worker node. Defaults to not\n using compression.\n\n Returns:\n A Keras model instance.\n\n Raises:\n ImportError: If h5py is not available.\n ValueError: In case of an invalid savefile.\n \"\"\"\n def wrap_optimizer(cls):\n return lambda **kwargs: DistributedOptimizer(cls(**kwargs), compression=compression)\n return _impl.load_model(keras, wrap_optimizer, _OPTIMIZER_MODULES, filepath, custom_optimizers, custom_objects)\n\n", "path": "horovod/tensorflow/keras/__init__.py"}]} | 2,868 | 140 |
gh_patches_debug_35711 | rasdani/github-patches | git_diff | readthedocs__readthedocs.org-3683 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Link to open an issue from a failed Build with pre-filled details
There are several issues that are reported where there are missing information in the details section.
To solve this I was thinking on generating a link inside this message that could contain all the information pre-filled:

I found that github supports _some_ query arguments in the URL but I didn't found a way to use those key/args inside the template itself.
https://help.github.com/articles/about-automation-for-issues-and-pull-requests-with-query-parameters/
I think it would be awesome if the user can just click a link and the username, project url, etc could be pre-filled automatically.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `readthedocs/builds/views.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 """Views for builds app."""
4
5 import logging
6
7 from django.contrib import messages
8 from django.contrib.auth.decorators import login_required
9 from django.http import (
10 HttpResponseForbidden,
11 HttpResponsePermanentRedirect,
12 HttpResponseRedirect,
13 )
14 from django.shortcuts import get_object_or_404
15 from django.urls import reverse
16 from django.utils.decorators import method_decorator
17 from django.views.generic import DetailView, ListView
18
19 from readthedocs.builds.models import Build, Version
20 from readthedocs.core.permissions import AdminPermission
21 from readthedocs.core.utils import trigger_build
22 from readthedocs.projects.models import Project
23
24
25 log = logging.getLogger(__name__)
26
27
28 class BuildBase:
29 model = Build
30
31 def get_queryset(self):
32 self.project_slug = self.kwargs.get('project_slug', None)
33 self.project = get_object_or_404(
34 Project.objects.protected(self.request.user),
35 slug=self.project_slug,
36 )
37 queryset = Build.objects.public(
38 user=self.request.user,
39 project=self.project,
40 )
41
42 return queryset
43
44
45 class BuildTriggerMixin:
46
47 @method_decorator(login_required)
48 def post(self, request, project_slug):
49 project = get_object_or_404(Project, slug=project_slug)
50
51 if not AdminPermission.is_admin(request.user, project):
52 return HttpResponseForbidden()
53
54 version_slug = request.POST.get('version_slug')
55 version = get_object_or_404(
56 Version,
57 project=project,
58 slug=version_slug,
59 )
60
61 update_docs_task, build = trigger_build(
62 project=project,
63 version=version,
64 )
65 if (update_docs_task, build) == (None, None):
66 # Build was skipped
67 messages.add_message(
68 request,
69 messages.WARNING,
70 "This project is currently disabled and can't trigger new builds.",
71 )
72 return HttpResponseRedirect(
73 reverse('builds_project_list', args=[project.slug]),
74 )
75
76 return HttpResponseRedirect(
77 reverse('builds_detail', args=[project.slug, build.pk]),
78 )
79
80
81 class BuildList(BuildBase, BuildTriggerMixin, ListView):
82
83 def get_context_data(self, **kwargs):
84 context = super().get_context_data(**kwargs)
85
86 active_builds = self.get_queryset().exclude(
87 state='finished',
88 ).values('id')
89
90 context['project'] = self.project
91 context['active_builds'] = active_builds
92 context['versions'] = Version.objects.public(
93 user=self.request.user,
94 project=self.project,
95 )
96 context['build_qs'] = self.get_queryset()
97
98 return context
99
100
101 class BuildDetail(BuildBase, DetailView):
102 pk_url_kwarg = 'build_pk'
103
104 def get_context_data(self, **kwargs):
105 context = super().get_context_data(**kwargs)
106 context['project'] = self.project
107 return context
108
109
110 # Old build view redirects
111
112
113 def builds_redirect_list(request, project_slug): # pylint: disable=unused-argument
114 return HttpResponsePermanentRedirect(
115 reverse('builds_project_list', args=[project_slug]),
116 )
117
118
119 def builds_redirect_detail(request, project_slug, pk): # pylint: disable=unused-argument
120 return HttpResponsePermanentRedirect(
121 reverse('builds_detail', args=[project_slug, pk]),
122 )
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/readthedocs/builds/views.py b/readthedocs/builds/views.py
--- a/readthedocs/builds/views.py
+++ b/readthedocs/builds/views.py
@@ -3,6 +3,7 @@
"""Views for builds app."""
import logging
+import textwrap
from django.contrib import messages
from django.contrib.auth.decorators import login_required
@@ -15,7 +16,10 @@
from django.urls import reverse
from django.utils.decorators import method_decorator
from django.views.generic import DetailView, ListView
+from requests.utils import quote
+from urllib.parse import urlparse
+from readthedocs.doc_builder.exceptions import BuildEnvironmentError
from readthedocs.builds.models import Build, Version
from readthedocs.core.permissions import AdminPermission
from readthedocs.core.utils import trigger_build
@@ -104,6 +108,49 @@
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context['project'] = self.project
+
+ build = self.get_object()
+ if build.error != BuildEnvironmentError.GENERIC_WITH_BUILD_ID.format(build_id=build.pk):
+ # Do not suggest to open an issue if the error is not generic
+ return context
+
+ scheme = (
+ 'https://github.com/rtfd/readthedocs.org/issues/new'
+ '?title={title}{build_id}'
+ '&body={body}'
+ )
+
+ # TODO: we could use ``.github/ISSUE_TEMPLATE.md`` here, but we would
+ # need to add some variables to it which could impact in the UX when
+ # filling an issue from the web
+ body = """
+ ## Details:
+
+ * Project URL: https://readthedocs.org/projects/{project_slug}/
+ * Build URL(if applicable): https://readthedocs.org{build_path}
+ * Read the Docs username(if applicable): {username}
+
+ ## Expected Result
+
+ *A description of what you wanted to happen*
+
+ ## Actual Result
+
+ *A description of what actually happened*""".format(
+ project_slug=self.project,
+ build_path=self.request.path,
+ username=self.request.user,
+ )
+
+ scheme_dict = {
+ 'title': quote('Build error with build id #'),
+ 'build_id': context['build'].id,
+ 'body': quote(textwrap.dedent(body)),
+ }
+
+ issue_url = scheme.format(**scheme_dict)
+ issue_url = urlparse(issue_url).geturl()
+ context['issue_url'] = issue_url
return context
| {"golden_diff": "diff --git a/readthedocs/builds/views.py b/readthedocs/builds/views.py\n--- a/readthedocs/builds/views.py\n+++ b/readthedocs/builds/views.py\n@@ -3,6 +3,7 @@\n \"\"\"Views for builds app.\"\"\"\n \n import logging\n+import textwrap\n \n from django.contrib import messages\n from django.contrib.auth.decorators import login_required\n@@ -15,7 +16,10 @@\n from django.urls import reverse\n from django.utils.decorators import method_decorator\n from django.views.generic import DetailView, ListView\n+from requests.utils import quote\n+from urllib.parse import urlparse\n \n+from readthedocs.doc_builder.exceptions import BuildEnvironmentError\n from readthedocs.builds.models import Build, Version\n from readthedocs.core.permissions import AdminPermission\n from readthedocs.core.utils import trigger_build\n@@ -104,6 +108,49 @@\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['project'] = self.project\n+\n+ build = self.get_object()\n+ if build.error != BuildEnvironmentError.GENERIC_WITH_BUILD_ID.format(build_id=build.pk):\n+ # Do not suggest to open an issue if the error is not generic\n+ return context\n+\n+ scheme = (\n+ 'https://github.com/rtfd/readthedocs.org/issues/new'\n+ '?title={title}{build_id}'\n+ '&body={body}'\n+ )\n+\n+ # TODO: we could use ``.github/ISSUE_TEMPLATE.md`` here, but we would\n+ # need to add some variables to it which could impact in the UX when\n+ # filling an issue from the web\n+ body = \"\"\"\n+ ## Details:\n+\n+ * Project URL: https://readthedocs.org/projects/{project_slug}/\n+ * Build URL(if applicable): https://readthedocs.org{build_path}\n+ * Read the Docs username(if applicable): {username}\n+\n+ ## Expected Result\n+\n+ *A description of what you wanted to happen*\n+\n+ ## Actual Result\n+\n+ *A description of what actually happened*\"\"\".format(\n+ project_slug=self.project,\n+ build_path=self.request.path,\n+ username=self.request.user,\n+ )\n+\n+ scheme_dict = {\n+ 'title': quote('Build error with build id #'),\n+ 'build_id': context['build'].id,\n+ 'body': quote(textwrap.dedent(body)),\n+ }\n+\n+ issue_url = scheme.format(**scheme_dict)\n+ issue_url = urlparse(issue_url).geturl()\n+ context['issue_url'] = issue_url\n return context\n", "issue": "Link to open an issue from a failed Build with pre-filled details\nThere are several issues that are reported where there are missing information in the details section.\r\n\r\nTo solve this I was thinking on generating a link inside this message that could contain all the information pre-filled:\r\n\r\n\r\n\r\n\r\nI found that github supports _some_ query arguments in the URL but I didn't found a way to use those key/args inside the template itself.\r\n\r\nhttps://help.github.com/articles/about-automation-for-issues-and-pull-requests-with-query-parameters/\r\n\r\nI think it would be awesome if the user can just click a link and the username, project url, etc could be pre-filled automatically.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Views for builds app.\"\"\"\n\nimport logging\n\nfrom django.contrib import messages\nfrom django.contrib.auth.decorators import login_required\nfrom django.http import (\n HttpResponseForbidden,\n HttpResponsePermanentRedirect,\n HttpResponseRedirect,\n)\nfrom django.shortcuts import get_object_or_404\nfrom django.urls import reverse\nfrom django.utils.decorators import method_decorator\nfrom django.views.generic import DetailView, ListView\n\nfrom readthedocs.builds.models import Build, Version\nfrom readthedocs.core.permissions import AdminPermission\nfrom readthedocs.core.utils import trigger_build\nfrom readthedocs.projects.models import Project\n\n\nlog = logging.getLogger(__name__)\n\n\nclass BuildBase:\n model = Build\n\n def get_queryset(self):\n self.project_slug = self.kwargs.get('project_slug', None)\n self.project = get_object_or_404(\n Project.objects.protected(self.request.user),\n slug=self.project_slug,\n )\n queryset = Build.objects.public(\n user=self.request.user,\n project=self.project,\n )\n\n return queryset\n\n\nclass BuildTriggerMixin:\n\n @method_decorator(login_required)\n def post(self, request, project_slug):\n project = get_object_or_404(Project, slug=project_slug)\n\n if not AdminPermission.is_admin(request.user, project):\n return HttpResponseForbidden()\n\n version_slug = request.POST.get('version_slug')\n version = get_object_or_404(\n Version,\n project=project,\n slug=version_slug,\n )\n\n update_docs_task, build = trigger_build(\n project=project,\n version=version,\n )\n if (update_docs_task, build) == (None, None):\n # Build was skipped\n messages.add_message(\n request,\n messages.WARNING,\n \"This project is currently disabled and can't trigger new builds.\",\n )\n return HttpResponseRedirect(\n reverse('builds_project_list', args=[project.slug]),\n )\n\n return HttpResponseRedirect(\n reverse('builds_detail', args=[project.slug, build.pk]),\n )\n\n\nclass BuildList(BuildBase, BuildTriggerMixin, ListView):\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n\n active_builds = self.get_queryset().exclude(\n state='finished',\n ).values('id')\n\n context['project'] = self.project\n context['active_builds'] = active_builds\n context['versions'] = Version.objects.public(\n user=self.request.user,\n project=self.project,\n )\n context['build_qs'] = self.get_queryset()\n\n return context\n\n\nclass BuildDetail(BuildBase, DetailView):\n pk_url_kwarg = 'build_pk'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['project'] = self.project\n return context\n\n\n# Old build view redirects\n\n\ndef builds_redirect_list(request, project_slug): # pylint: disable=unused-argument\n return HttpResponsePermanentRedirect(\n reverse('builds_project_list', args=[project_slug]),\n )\n\n\ndef builds_redirect_detail(request, project_slug, pk): # pylint: disable=unused-argument\n return HttpResponsePermanentRedirect(\n reverse('builds_detail', args=[project_slug, pk]),\n )\n", "path": "readthedocs/builds/views.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Views for builds app.\"\"\"\n\nimport logging\nimport textwrap\n\nfrom django.contrib import messages\nfrom django.contrib.auth.decorators import login_required\nfrom django.http import (\n HttpResponseForbidden,\n HttpResponsePermanentRedirect,\n HttpResponseRedirect,\n)\nfrom django.shortcuts import get_object_or_404\nfrom django.urls import reverse\nfrom django.utils.decorators import method_decorator\nfrom django.views.generic import DetailView, ListView\nfrom requests.utils import quote\nfrom urllib.parse import urlparse\n\nfrom readthedocs.doc_builder.exceptions import BuildEnvironmentError\nfrom readthedocs.builds.models import Build, Version\nfrom readthedocs.core.permissions import AdminPermission\nfrom readthedocs.core.utils import trigger_build\nfrom readthedocs.projects.models import Project\n\n\nlog = logging.getLogger(__name__)\n\n\nclass BuildBase:\n model = Build\n\n def get_queryset(self):\n self.project_slug = self.kwargs.get('project_slug', None)\n self.project = get_object_or_404(\n Project.objects.protected(self.request.user),\n slug=self.project_slug,\n )\n queryset = Build.objects.public(\n user=self.request.user,\n project=self.project,\n )\n\n return queryset\n\n\nclass BuildTriggerMixin:\n\n @method_decorator(login_required)\n def post(self, request, project_slug):\n project = get_object_or_404(Project, slug=project_slug)\n\n if not AdminPermission.is_admin(request.user, project):\n return HttpResponseForbidden()\n\n version_slug = request.POST.get('version_slug')\n version = get_object_or_404(\n Version,\n project=project,\n slug=version_slug,\n )\n\n update_docs_task, build = trigger_build(\n project=project,\n version=version,\n )\n if (update_docs_task, build) == (None, None):\n # Build was skipped\n messages.add_message(\n request,\n messages.WARNING,\n \"This project is currently disabled and can't trigger new builds.\",\n )\n return HttpResponseRedirect(\n reverse('builds_project_list', args=[project.slug]),\n )\n\n return HttpResponseRedirect(\n reverse('builds_detail', args=[project.slug, build.pk]),\n )\n\n\nclass BuildList(BuildBase, BuildTriggerMixin, ListView):\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n\n active_builds = self.get_queryset().exclude(\n state='finished',\n ).values('id')\n\n context['project'] = self.project\n context['active_builds'] = active_builds\n context['versions'] = Version.objects.public(\n user=self.request.user,\n project=self.project,\n )\n context['build_qs'] = self.get_queryset()\n\n return context\n\n\nclass BuildDetail(BuildBase, DetailView):\n pk_url_kwarg = 'build_pk'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['project'] = self.project\n\n build = self.get_object()\n if build.error != BuildEnvironmentError.GENERIC_WITH_BUILD_ID.format(build_id=build.pk):\n # Do not suggest to open an issue if the error is not generic\n return context\n\n scheme = (\n 'https://github.com/rtfd/readthedocs.org/issues/new'\n '?title={title}{build_id}'\n '&body={body}'\n )\n\n # TODO: we could use ``.github/ISSUE_TEMPLATE.md`` here, but we would\n # need to add some variables to it which could impact in the UX when\n # filling an issue from the web\n body = \"\"\"\n ## Details:\n\n * Project URL: https://readthedocs.org/projects/{project_slug}/\n * Build URL(if applicable): https://readthedocs.org{build_path}\n * Read the Docs username(if applicable): {username}\n\n ## Expected Result\n\n *A description of what you wanted to happen*\n\n ## Actual Result\n\n *A description of what actually happened*\"\"\".format(\n project_slug=self.project,\n build_path=self.request.path,\n username=self.request.user,\n )\n\n scheme_dict = {\n 'title': quote('Build error with build id #'),\n 'build_id': context['build'].id,\n 'body': quote(textwrap.dedent(body)),\n }\n\n issue_url = scheme.format(**scheme_dict)\n issue_url = urlparse(issue_url).geturl()\n context['issue_url'] = issue_url\n return context\n\n\n# Old build view redirects\n\n\ndef builds_redirect_list(request, project_slug): # pylint: disable=unused-argument\n return HttpResponsePermanentRedirect(\n reverse('builds_project_list', args=[project_slug]),\n )\n\n\ndef builds_redirect_detail(request, project_slug, pk): # pylint: disable=unused-argument\n return HttpResponsePermanentRedirect(\n reverse('builds_detail', args=[project_slug, pk]),\n )\n", "path": "readthedocs/builds/views.py"}]} | 1,449 | 583 |
gh_patches_debug_3459 | rasdani/github-patches | git_diff | strawberry-graphql__strawberry-887 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: Failure when returning List[List[int]] as a strawberry type in a query
The follow code doesn't run
strawberry server schema
Then running a graphiql query is sufficient to reproduce this error.
error message TypeError: 'float' object is not iterable
```python
@strawberry.type(description="list of list breaks it")
class Polygon:
polygon_of_death: typing.List[typing.List[float]]
def get_polygon() -> Polygon:
not_polygon_of_death = Polygon([])
polygon_of_death = Polygon(polygon_of_death=[[2.0,6.0]])
return polygon_of_death
@strawberry.type(description="This is the root level query description")
class Query:
get_polygons: Polygon = strawberry.field(resolver=get_polygon)
schema = strawberry.Schema(query=Query)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `strawberry/field.py`
Content:
```
1 import dataclasses
2 import enum
3 import typing
4 from inspect import iscoroutine
5 from typing import Any, Awaitable, Callable, Dict, List, Optional, Tuple, Type, Union
6
7 from graphql import GraphQLResolveInfo
8
9 from strawberry.arguments import UNSET, convert_arguments
10 from strawberry.types.info import Info
11 from strawberry.utils.typing import get_parameters, has_type_var, is_type_var
12
13 from .arguments import StrawberryArgument
14 from .permission import BasePermission
15 from .types.fields.resolver import StrawberryResolver
16 from .types.types import FederationFieldParams
17 from .union import StrawberryUnion
18 from .utils.str_converters import to_camel_case
19
20
21 _RESOLVER_TYPE = Union[StrawberryResolver, Callable]
22
23
24 class StrawberryField(dataclasses.Field):
25 def __init__(
26 self,
27 python_name: Optional[str],
28 graphql_name: Optional[str],
29 type_: Optional[Union[Type, StrawberryUnion]],
30 origin: Optional[Union[Type, Callable]] = None,
31 child: Optional["StrawberryField"] = None,
32 is_subscription: bool = False,
33 is_optional: bool = False,
34 is_child_optional: bool = False,
35 is_list: bool = False,
36 is_union: bool = False,
37 federation: FederationFieldParams = None,
38 description: Optional[str] = None,
39 base_resolver: Optional[StrawberryResolver] = None,
40 permission_classes: List[Type[BasePermission]] = (), # type: ignore
41 default_value: Any = UNSET,
42 default_factory: Union[Callable, object] = UNSET,
43 deprecation_reason: Optional[str] = None,
44 ):
45 federation = federation or FederationFieldParams()
46
47 # basic fields are fields with no provided resolver
48 is_basic_field = not base_resolver
49
50 super().__init__( # type: ignore
51 default=(default_value if default_value != UNSET else dataclasses.MISSING),
52 default_factory=(
53 default_factory if default_factory != UNSET else dataclasses.MISSING
54 ),
55 init=is_basic_field,
56 repr=is_basic_field,
57 compare=is_basic_field,
58 hash=None,
59 metadata=None,
60 )
61
62 self._graphql_name = graphql_name
63 if python_name is not None:
64 self.python_name = python_name
65 if type_ is not None:
66 # TODO: Clean up the typing around StrawberryField.type
67 self.type = typing.cast(type, type_)
68
69 self.description: Optional[str] = description
70 self.origin: Optional[Union[Type, Callable]] = origin
71
72 self._base_resolver: Optional[StrawberryResolver] = None
73 if base_resolver is not None:
74 self.base_resolver = base_resolver
75
76 self.default_value = default_value
77
78 self.child = child
79 self.is_child_optional = is_child_optional
80
81 self.is_list = is_list
82 self.is_optional = is_optional
83 self.is_subscription = is_subscription
84 self.is_union = is_union
85
86 self.federation: FederationFieldParams = federation
87 self.permission_classes: List[Type[BasePermission]] = list(permission_classes)
88
89 self.deprecation_reason = deprecation_reason
90
91 def __call__(self, resolver: _RESOLVER_TYPE) -> "StrawberryField":
92 """Add a resolver to the field"""
93
94 # Allow for StrawberryResolvers or bare functions to be provided
95 if not isinstance(resolver, StrawberryResolver):
96 resolver = StrawberryResolver(resolver)
97
98 self.base_resolver = resolver
99 self.type = resolver.type
100
101 return self
102
103 @property
104 def arguments(self) -> List[StrawberryArgument]:
105 if not self.base_resolver:
106 return []
107
108 return self.base_resolver.arguments
109
110 @property
111 def graphql_name(self) -> Optional[str]:
112 if self._graphql_name:
113 return self._graphql_name
114 if self.python_name:
115 return to_camel_case(self.python_name)
116 if self.base_resolver:
117 return to_camel_case(self.base_resolver.name)
118 return None
119
120 @property
121 def python_name(self) -> str:
122 return self.name
123
124 @python_name.setter
125 def python_name(self, name: str) -> None:
126 self.name = name
127
128 @property
129 def base_resolver(self) -> Optional[StrawberryResolver]:
130 return self._base_resolver
131
132 @base_resolver.setter
133 def base_resolver(self, resolver: StrawberryResolver) -> None:
134 self._base_resolver = resolver
135 self.origin = resolver.wrapped_func
136
137 # Don't add field to __init__, __repr__ and __eq__ once it has a resolver
138 self.init = False
139 self.compare = False
140 self.repr = False
141
142 # TODO: See test_resolvers.test_raises_error_when_argument_annotation_missing
143 # (https://github.com/strawberry-graphql/strawberry/blob/8e102d3/tests/types/test_resolvers.py#L89-L98)
144 #
145 # Currently we expect the exception to be thrown when the StrawberryField
146 # is constructed, but this only happens if we explicitly retrieve the
147 # arguments.
148 #
149 # If we want to change when the exception is thrown, this line can be
150 # removed.
151 _ = resolver.arguments
152
153 @property
154 def type_params(self) -> Optional[List[Type]]:
155 if self.is_list:
156 assert self.child is not None
157 return self.child.type_params
158
159 if isinstance(self.type, StrawberryUnion):
160 types = self.type.types
161 type_vars = [t for t in types if is_type_var(t)]
162
163 if type_vars:
164 return type_vars
165
166 if is_type_var(self.type):
167 return [self.type]
168
169 if has_type_var(self.type):
170 return get_parameters(self.type)
171
172 return None
173
174 def _get_arguments(
175 self, kwargs: Dict[str, Any], source: Any, info: Any
176 ) -> Tuple[List[Any], Dict[str, Any]]:
177 assert self.base_resolver is not None
178
179 kwargs = convert_arguments(kwargs, self.arguments)
180
181 # the following code allows to omit info and root arguments
182 # by inspecting the original resolver arguments,
183 # if it asks for self, the source will be passed as first argument
184 # if it asks for root, the source it will be passed as kwarg
185 # if it asks for info, the info will be passed as kwarg
186
187 args = []
188
189 if self.base_resolver.has_self_arg:
190 args.append(source)
191
192 if self.base_resolver.has_root_arg:
193 kwargs["root"] = source
194
195 if self.base_resolver.has_info_arg:
196 kwargs["info"] = info
197
198 return args, kwargs
199
200 def get_result(
201 self, kwargs: Dict[str, Any], source: Any, info: Any
202 ) -> Union[Awaitable[Any], Any]:
203 """
204 Calls the resolver defined for the StrawberryField. If the field doesn't have a
205 resolver defined we default to using getattr on `source`.
206 """
207
208 if self.base_resolver:
209 args, kwargs = self._get_arguments(kwargs, source=source, info=info)
210
211 return self.base_resolver(*args, **kwargs)
212
213 return getattr(source, self.python_name)
214
215 def get_wrapped_resolver(self) -> Callable:
216 # TODO: This could potentially be handled by StrawberryResolver in the future
217 def _check_permissions(source, info: Info, **kwargs):
218 """
219 Checks if the permission should be accepted and
220 raises an exception if not
221 """
222 for permission_class in self.permission_classes:
223 permission = permission_class()
224
225 if not permission.has_permission(source, info, **kwargs):
226 message = getattr(permission, "message", None)
227 raise PermissionError(message)
228
229 def _convert_enums_to_values(field_: StrawberryField, result: Any) -> Any:
230 # graphql-core expects a resolver for an Enum type to return
231 # the enum's *value* (not its name or an instance of the enum).
232
233 # short circuit to skip checks when result is falsy
234 if not result:
235 return result
236
237 if isinstance(result, enum.Enum):
238 return result.value
239
240 if field_.is_list:
241 assert self.child is not None
242 return [_convert_enums_to_values(self.child, item) for item in result]
243
244 return result
245
246 def _strawberry_info_from_graphql(info: GraphQLResolveInfo) -> Info:
247 return Info(
248 field_name=info.field_name,
249 field_nodes=info.field_nodes,
250 context=info.context,
251 root_value=info.root_value,
252 variable_values=info.variable_values,
253 return_type=self._get_return_type(),
254 operation=info.operation,
255 path=info.path,
256 )
257
258 def _resolver(source, info: GraphQLResolveInfo, **kwargs):
259 strawberry_info = _strawberry_info_from_graphql(info)
260 _check_permissions(source, strawberry_info, **kwargs)
261
262 result = self.get_result(kwargs=kwargs, info=strawberry_info, source=source)
263
264 if iscoroutine(result): # pragma: no cover
265
266 async def await_result(result):
267 return _convert_enums_to_values(self, await result)
268
269 return await_result(result)
270
271 result = _convert_enums_to_values(self, result)
272 return result
273
274 _resolver._is_default = not self.base_resolver # type: ignore
275 return _resolver
276
277 def _get_return_type(self):
278 # using type ignore to make mypy happy,
279 # this codepath will change in future anyway, so this is ok
280 if self.is_list:
281 assert self.child
282
283 type_ = List[self.child._get_return_type()] # type: ignore
284 else:
285 type_ = self.type
286
287 if self.is_optional:
288 type_ = Optional[type_] # type: ignore
289
290 return type_
291
292
293 def field(
294 resolver: Optional[_RESOLVER_TYPE] = None,
295 *,
296 name: Optional[str] = None,
297 is_subscription: bool = False,
298 description: Optional[str] = None,
299 permission_classes: Optional[List[Type[BasePermission]]] = None,
300 federation: Optional[FederationFieldParams] = None,
301 deprecation_reason: Optional[str] = None,
302 default: Any = UNSET,
303 default_factory: Union[Callable, object] = UNSET,
304 ) -> StrawberryField:
305 """Annotates a method or property as a GraphQL field.
306
307 This is normally used inside a type declaration:
308
309 >>> @strawberry.type:
310 >>> class X:
311 >>> field_abc: str = strawberry.field(description="ABC")
312
313 >>> @strawberry.field(description="ABC")
314 >>> def field_with_resolver(self) -> str:
315 >>> return "abc"
316
317 it can be used both as decorator and as a normal function.
318 """
319
320 field_ = StrawberryField(
321 python_name=None,
322 graphql_name=name,
323 type_=None,
324 description=description,
325 is_subscription=is_subscription,
326 permission_classes=permission_classes or [],
327 federation=federation or FederationFieldParams(),
328 deprecation_reason=deprecation_reason,
329 default_value=default,
330 default_factory=default_factory,
331 )
332
333 if resolver:
334 return field_(resolver)
335 return field_
336
337
338 __all__ = ["FederationFieldParams", "StrawberryField", "field"]
339
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/strawberry/field.py b/strawberry/field.py
--- a/strawberry/field.py
+++ b/strawberry/field.py
@@ -238,8 +238,8 @@
return result.value
if field_.is_list:
- assert self.child is not None
- return [_convert_enums_to_values(self.child, item) for item in result]
+ assert field_.child is not None
+ return [_convert_enums_to_values(field_.child, item) for item in result]
return result
| {"golden_diff": "diff --git a/strawberry/field.py b/strawberry/field.py\n--- a/strawberry/field.py\n+++ b/strawberry/field.py\n@@ -238,8 +238,8 @@\n return result.value\n \n if field_.is_list:\n- assert self.child is not None\n- return [_convert_enums_to_values(self.child, item) for item in result]\n+ assert field_.child is not None\n+ return [_convert_enums_to_values(field_.child, item) for item in result]\n \n return result\n", "issue": "Bug: Failure when returning List[List[int]] as a strawberry type in a query\nThe follow code doesn't run\r\n\r\nstrawberry server schema\r\nThen running a graphiql query is sufficient to reproduce this error.\r\n\r\nerror message TypeError: 'float' object is not iterable\r\n\r\n```python\r\[email protected](description=\"list of list breaks it\")\r\nclass Polygon:\r\n polygon_of_death: typing.List[typing.List[float]]\r\n\r\n\r\ndef get_polygon() -> Polygon:\r\n not_polygon_of_death = Polygon([])\r\n polygon_of_death = Polygon(polygon_of_death=[[2.0,6.0]])\r\n return polygon_of_death\r\n\r\n\r\[email protected](description=\"This is the root level query description\")\r\nclass Query:\r\n get_polygons: Polygon = strawberry.field(resolver=get_polygon)\r\n\r\n\r\nschema = strawberry.Schema(query=Query)\r\n\r\n```\r\n\r\n\n", "before_files": [{"content": "import dataclasses\nimport enum\nimport typing\nfrom inspect import iscoroutine\nfrom typing import Any, Awaitable, Callable, Dict, List, Optional, Tuple, Type, Union\n\nfrom graphql import GraphQLResolveInfo\n\nfrom strawberry.arguments import UNSET, convert_arguments\nfrom strawberry.types.info import Info\nfrom strawberry.utils.typing import get_parameters, has_type_var, is_type_var\n\nfrom .arguments import StrawberryArgument\nfrom .permission import BasePermission\nfrom .types.fields.resolver import StrawberryResolver\nfrom .types.types import FederationFieldParams\nfrom .union import StrawberryUnion\nfrom .utils.str_converters import to_camel_case\n\n\n_RESOLVER_TYPE = Union[StrawberryResolver, Callable]\n\n\nclass StrawberryField(dataclasses.Field):\n def __init__(\n self,\n python_name: Optional[str],\n graphql_name: Optional[str],\n type_: Optional[Union[Type, StrawberryUnion]],\n origin: Optional[Union[Type, Callable]] = None,\n child: Optional[\"StrawberryField\"] = None,\n is_subscription: bool = False,\n is_optional: bool = False,\n is_child_optional: bool = False,\n is_list: bool = False,\n is_union: bool = False,\n federation: FederationFieldParams = None,\n description: Optional[str] = None,\n base_resolver: Optional[StrawberryResolver] = None,\n permission_classes: List[Type[BasePermission]] = (), # type: ignore\n default_value: Any = UNSET,\n default_factory: Union[Callable, object] = UNSET,\n deprecation_reason: Optional[str] = None,\n ):\n federation = federation or FederationFieldParams()\n\n # basic fields are fields with no provided resolver\n is_basic_field = not base_resolver\n\n super().__init__( # type: ignore\n default=(default_value if default_value != UNSET else dataclasses.MISSING),\n default_factory=(\n default_factory if default_factory != UNSET else dataclasses.MISSING\n ),\n init=is_basic_field,\n repr=is_basic_field,\n compare=is_basic_field,\n hash=None,\n metadata=None,\n )\n\n self._graphql_name = graphql_name\n if python_name is not None:\n self.python_name = python_name\n if type_ is not None:\n # TODO: Clean up the typing around StrawberryField.type\n self.type = typing.cast(type, type_)\n\n self.description: Optional[str] = description\n self.origin: Optional[Union[Type, Callable]] = origin\n\n self._base_resolver: Optional[StrawberryResolver] = None\n if base_resolver is not None:\n self.base_resolver = base_resolver\n\n self.default_value = default_value\n\n self.child = child\n self.is_child_optional = is_child_optional\n\n self.is_list = is_list\n self.is_optional = is_optional\n self.is_subscription = is_subscription\n self.is_union = is_union\n\n self.federation: FederationFieldParams = federation\n self.permission_classes: List[Type[BasePermission]] = list(permission_classes)\n\n self.deprecation_reason = deprecation_reason\n\n def __call__(self, resolver: _RESOLVER_TYPE) -> \"StrawberryField\":\n \"\"\"Add a resolver to the field\"\"\"\n\n # Allow for StrawberryResolvers or bare functions to be provided\n if not isinstance(resolver, StrawberryResolver):\n resolver = StrawberryResolver(resolver)\n\n self.base_resolver = resolver\n self.type = resolver.type\n\n return self\n\n @property\n def arguments(self) -> List[StrawberryArgument]:\n if not self.base_resolver:\n return []\n\n return self.base_resolver.arguments\n\n @property\n def graphql_name(self) -> Optional[str]:\n if self._graphql_name:\n return self._graphql_name\n if self.python_name:\n return to_camel_case(self.python_name)\n if self.base_resolver:\n return to_camel_case(self.base_resolver.name)\n return None\n\n @property\n def python_name(self) -> str:\n return self.name\n\n @python_name.setter\n def python_name(self, name: str) -> None:\n self.name = name\n\n @property\n def base_resolver(self) -> Optional[StrawberryResolver]:\n return self._base_resolver\n\n @base_resolver.setter\n def base_resolver(self, resolver: StrawberryResolver) -> None:\n self._base_resolver = resolver\n self.origin = resolver.wrapped_func\n\n # Don't add field to __init__, __repr__ and __eq__ once it has a resolver\n self.init = False\n self.compare = False\n self.repr = False\n\n # TODO: See test_resolvers.test_raises_error_when_argument_annotation_missing\n # (https://github.com/strawberry-graphql/strawberry/blob/8e102d3/tests/types/test_resolvers.py#L89-L98)\n #\n # Currently we expect the exception to be thrown when the StrawberryField\n # is constructed, but this only happens if we explicitly retrieve the\n # arguments.\n #\n # If we want to change when the exception is thrown, this line can be\n # removed.\n _ = resolver.arguments\n\n @property\n def type_params(self) -> Optional[List[Type]]:\n if self.is_list:\n assert self.child is not None\n return self.child.type_params\n\n if isinstance(self.type, StrawberryUnion):\n types = self.type.types\n type_vars = [t for t in types if is_type_var(t)]\n\n if type_vars:\n return type_vars\n\n if is_type_var(self.type):\n return [self.type]\n\n if has_type_var(self.type):\n return get_parameters(self.type)\n\n return None\n\n def _get_arguments(\n self, kwargs: Dict[str, Any], source: Any, info: Any\n ) -> Tuple[List[Any], Dict[str, Any]]:\n assert self.base_resolver is not None\n\n kwargs = convert_arguments(kwargs, self.arguments)\n\n # the following code allows to omit info and root arguments\n # by inspecting the original resolver arguments,\n # if it asks for self, the source will be passed as first argument\n # if it asks for root, the source it will be passed as kwarg\n # if it asks for info, the info will be passed as kwarg\n\n args = []\n\n if self.base_resolver.has_self_arg:\n args.append(source)\n\n if self.base_resolver.has_root_arg:\n kwargs[\"root\"] = source\n\n if self.base_resolver.has_info_arg:\n kwargs[\"info\"] = info\n\n return args, kwargs\n\n def get_result(\n self, kwargs: Dict[str, Any], source: Any, info: Any\n ) -> Union[Awaitable[Any], Any]:\n \"\"\"\n Calls the resolver defined for the StrawberryField. If the field doesn't have a\n resolver defined we default to using getattr on `source`.\n \"\"\"\n\n if self.base_resolver:\n args, kwargs = self._get_arguments(kwargs, source=source, info=info)\n\n return self.base_resolver(*args, **kwargs)\n\n return getattr(source, self.python_name)\n\n def get_wrapped_resolver(self) -> Callable:\n # TODO: This could potentially be handled by StrawberryResolver in the future\n def _check_permissions(source, info: Info, **kwargs):\n \"\"\"\n Checks if the permission should be accepted and\n raises an exception if not\n \"\"\"\n for permission_class in self.permission_classes:\n permission = permission_class()\n\n if not permission.has_permission(source, info, **kwargs):\n message = getattr(permission, \"message\", None)\n raise PermissionError(message)\n\n def _convert_enums_to_values(field_: StrawberryField, result: Any) -> Any:\n # graphql-core expects a resolver for an Enum type to return\n # the enum's *value* (not its name or an instance of the enum).\n\n # short circuit to skip checks when result is falsy\n if not result:\n return result\n\n if isinstance(result, enum.Enum):\n return result.value\n\n if field_.is_list:\n assert self.child is not None\n return [_convert_enums_to_values(self.child, item) for item in result]\n\n return result\n\n def _strawberry_info_from_graphql(info: GraphQLResolveInfo) -> Info:\n return Info(\n field_name=info.field_name,\n field_nodes=info.field_nodes,\n context=info.context,\n root_value=info.root_value,\n variable_values=info.variable_values,\n return_type=self._get_return_type(),\n operation=info.operation,\n path=info.path,\n )\n\n def _resolver(source, info: GraphQLResolveInfo, **kwargs):\n strawberry_info = _strawberry_info_from_graphql(info)\n _check_permissions(source, strawberry_info, **kwargs)\n\n result = self.get_result(kwargs=kwargs, info=strawberry_info, source=source)\n\n if iscoroutine(result): # pragma: no cover\n\n async def await_result(result):\n return _convert_enums_to_values(self, await result)\n\n return await_result(result)\n\n result = _convert_enums_to_values(self, result)\n return result\n\n _resolver._is_default = not self.base_resolver # type: ignore\n return _resolver\n\n def _get_return_type(self):\n # using type ignore to make mypy happy,\n # this codepath will change in future anyway, so this is ok\n if self.is_list:\n assert self.child\n\n type_ = List[self.child._get_return_type()] # type: ignore\n else:\n type_ = self.type\n\n if self.is_optional:\n type_ = Optional[type_] # type: ignore\n\n return type_\n\n\ndef field(\n resolver: Optional[_RESOLVER_TYPE] = None,\n *,\n name: Optional[str] = None,\n is_subscription: bool = False,\n description: Optional[str] = None,\n permission_classes: Optional[List[Type[BasePermission]]] = None,\n federation: Optional[FederationFieldParams] = None,\n deprecation_reason: Optional[str] = None,\n default: Any = UNSET,\n default_factory: Union[Callable, object] = UNSET,\n) -> StrawberryField:\n \"\"\"Annotates a method or property as a GraphQL field.\n\n This is normally used inside a type declaration:\n\n >>> @strawberry.type:\n >>> class X:\n >>> field_abc: str = strawberry.field(description=\"ABC\")\n\n >>> @strawberry.field(description=\"ABC\")\n >>> def field_with_resolver(self) -> str:\n >>> return \"abc\"\n\n it can be used both as decorator and as a normal function.\n \"\"\"\n\n field_ = StrawberryField(\n python_name=None,\n graphql_name=name,\n type_=None,\n description=description,\n is_subscription=is_subscription,\n permission_classes=permission_classes or [],\n federation=federation or FederationFieldParams(),\n deprecation_reason=deprecation_reason,\n default_value=default,\n default_factory=default_factory,\n )\n\n if resolver:\n return field_(resolver)\n return field_\n\n\n__all__ = [\"FederationFieldParams\", \"StrawberryField\", \"field\"]\n", "path": "strawberry/field.py"}], "after_files": [{"content": "import dataclasses\nimport enum\nimport typing\nfrom inspect import iscoroutine\nfrom typing import Any, Awaitable, Callable, Dict, List, Optional, Tuple, Type, Union\n\nfrom graphql import GraphQLResolveInfo\n\nfrom strawberry.arguments import UNSET, convert_arguments\nfrom strawberry.types.info import Info\nfrom strawberry.utils.typing import get_parameters, has_type_var, is_type_var\n\nfrom .arguments import StrawberryArgument\nfrom .permission import BasePermission\nfrom .types.fields.resolver import StrawberryResolver\nfrom .types.types import FederationFieldParams\nfrom .union import StrawberryUnion\nfrom .utils.str_converters import to_camel_case\n\n\n_RESOLVER_TYPE = Union[StrawberryResolver, Callable]\n\n\nclass StrawberryField(dataclasses.Field):\n def __init__(\n self,\n python_name: Optional[str],\n graphql_name: Optional[str],\n type_: Optional[Union[Type, StrawberryUnion]],\n origin: Optional[Union[Type, Callable]] = None,\n child: Optional[\"StrawberryField\"] = None,\n is_subscription: bool = False,\n is_optional: bool = False,\n is_child_optional: bool = False,\n is_list: bool = False,\n is_union: bool = False,\n federation: FederationFieldParams = None,\n description: Optional[str] = None,\n base_resolver: Optional[StrawberryResolver] = None,\n permission_classes: List[Type[BasePermission]] = (), # type: ignore\n default_value: Any = UNSET,\n default_factory: Union[Callable, object] = UNSET,\n deprecation_reason: Optional[str] = None,\n ):\n federation = federation or FederationFieldParams()\n\n # basic fields are fields with no provided resolver\n is_basic_field = not base_resolver\n\n super().__init__( # type: ignore\n default=(default_value if default_value != UNSET else dataclasses.MISSING),\n default_factory=(\n default_factory if default_factory != UNSET else dataclasses.MISSING\n ),\n init=is_basic_field,\n repr=is_basic_field,\n compare=is_basic_field,\n hash=None,\n metadata=None,\n )\n\n self._graphql_name = graphql_name\n if python_name is not None:\n self.python_name = python_name\n if type_ is not None:\n # TODO: Clean up the typing around StrawberryField.type\n self.type = typing.cast(type, type_)\n\n self.description: Optional[str] = description\n self.origin: Optional[Union[Type, Callable]] = origin\n\n self._base_resolver: Optional[StrawberryResolver] = None\n if base_resolver is not None:\n self.base_resolver = base_resolver\n\n self.default_value = default_value\n\n self.child = child\n self.is_child_optional = is_child_optional\n\n self.is_list = is_list\n self.is_optional = is_optional\n self.is_subscription = is_subscription\n self.is_union = is_union\n\n self.federation: FederationFieldParams = federation\n self.permission_classes: List[Type[BasePermission]] = list(permission_classes)\n\n self.deprecation_reason = deprecation_reason\n\n def __call__(self, resolver: _RESOLVER_TYPE) -> \"StrawberryField\":\n \"\"\"Add a resolver to the field\"\"\"\n\n # Allow for StrawberryResolvers or bare functions to be provided\n if not isinstance(resolver, StrawberryResolver):\n resolver = StrawberryResolver(resolver)\n\n self.base_resolver = resolver\n self.type = resolver.type\n\n return self\n\n @property\n def arguments(self) -> List[StrawberryArgument]:\n if not self.base_resolver:\n return []\n\n return self.base_resolver.arguments\n\n @property\n def graphql_name(self) -> Optional[str]:\n if self._graphql_name:\n return self._graphql_name\n if self.python_name:\n return to_camel_case(self.python_name)\n if self.base_resolver:\n return to_camel_case(self.base_resolver.name)\n return None\n\n @property\n def python_name(self) -> str:\n return self.name\n\n @python_name.setter\n def python_name(self, name: str) -> None:\n self.name = name\n\n @property\n def base_resolver(self) -> Optional[StrawberryResolver]:\n return self._base_resolver\n\n @base_resolver.setter\n def base_resolver(self, resolver: StrawberryResolver) -> None:\n self._base_resolver = resolver\n self.origin = resolver.wrapped_func\n\n # Don't add field to __init__, __repr__ and __eq__ once it has a resolver\n self.init = False\n self.compare = False\n self.repr = False\n\n # TODO: See test_resolvers.test_raises_error_when_argument_annotation_missing\n # (https://github.com/strawberry-graphql/strawberry/blob/8e102d3/tests/types/test_resolvers.py#L89-L98)\n #\n # Currently we expect the exception to be thrown when the StrawberryField\n # is constructed, but this only happens if we explicitly retrieve the\n # arguments.\n #\n # If we want to change when the exception is thrown, this line can be\n # removed.\n _ = resolver.arguments\n\n @property\n def type_params(self) -> Optional[List[Type]]:\n if self.is_list:\n assert self.child is not None\n return self.child.type_params\n\n if isinstance(self.type, StrawberryUnion):\n types = self.type.types\n type_vars = [t for t in types if is_type_var(t)]\n\n if type_vars:\n return type_vars\n\n if is_type_var(self.type):\n return [self.type]\n\n if has_type_var(self.type):\n return get_parameters(self.type)\n\n return None\n\n def _get_arguments(\n self, kwargs: Dict[str, Any], source: Any, info: Any\n ) -> Tuple[List[Any], Dict[str, Any]]:\n assert self.base_resolver is not None\n\n kwargs = convert_arguments(kwargs, self.arguments)\n\n # the following code allows to omit info and root arguments\n # by inspecting the original resolver arguments,\n # if it asks for self, the source will be passed as first argument\n # if it asks for root, the source it will be passed as kwarg\n # if it asks for info, the info will be passed as kwarg\n\n args = []\n\n if self.base_resolver.has_self_arg:\n args.append(source)\n\n if self.base_resolver.has_root_arg:\n kwargs[\"root\"] = source\n\n if self.base_resolver.has_info_arg:\n kwargs[\"info\"] = info\n\n return args, kwargs\n\n def get_result(\n self, kwargs: Dict[str, Any], source: Any, info: Any\n ) -> Union[Awaitable[Any], Any]:\n \"\"\"\n Calls the resolver defined for the StrawberryField. If the field doesn't have a\n resolver defined we default to using getattr on `source`.\n \"\"\"\n\n if self.base_resolver:\n args, kwargs = self._get_arguments(kwargs, source=source, info=info)\n\n return self.base_resolver(*args, **kwargs)\n\n return getattr(source, self.python_name)\n\n def get_wrapped_resolver(self) -> Callable:\n # TODO: This could potentially be handled by StrawberryResolver in the future\n def _check_permissions(source, info: Info, **kwargs):\n \"\"\"\n Checks if the permission should be accepted and\n raises an exception if not\n \"\"\"\n for permission_class in self.permission_classes:\n permission = permission_class()\n\n if not permission.has_permission(source, info, **kwargs):\n message = getattr(permission, \"message\", None)\n raise PermissionError(message)\n\n def _convert_enums_to_values(field_: StrawberryField, result: Any) -> Any:\n # graphql-core expects a resolver for an Enum type to return\n # the enum's *value* (not its name or an instance of the enum).\n\n # short circuit to skip checks when result is falsy\n if not result:\n return result\n\n if isinstance(result, enum.Enum):\n return result.value\n\n if field_.is_list:\n assert field_.child is not None\n return [_convert_enums_to_values(field_.child, item) for item in result]\n\n return result\n\n def _strawberry_info_from_graphql(info: GraphQLResolveInfo) -> Info:\n return Info(\n field_name=info.field_name,\n field_nodes=info.field_nodes,\n context=info.context,\n root_value=info.root_value,\n variable_values=info.variable_values,\n return_type=self._get_return_type(),\n operation=info.operation,\n path=info.path,\n )\n\n def _resolver(source, info: GraphQLResolveInfo, **kwargs):\n strawberry_info = _strawberry_info_from_graphql(info)\n _check_permissions(source, strawberry_info, **kwargs)\n\n result = self.get_result(kwargs=kwargs, info=strawberry_info, source=source)\n\n if iscoroutine(result): # pragma: no cover\n\n async def await_result(result):\n return _convert_enums_to_values(self, await result)\n\n return await_result(result)\n\n result = _convert_enums_to_values(self, result)\n return result\n\n _resolver._is_default = not self.base_resolver # type: ignore\n return _resolver\n\n def _get_return_type(self):\n # using type ignore to make mypy happy,\n # this codepath will change in future anyway, so this is ok\n if self.is_list:\n assert self.child\n\n type_ = List[self.child._get_return_type()] # type: ignore\n else:\n type_ = self.type\n\n if self.is_optional:\n type_ = Optional[type_] # type: ignore\n\n return type_\n\n\ndef field(\n resolver: Optional[_RESOLVER_TYPE] = None,\n *,\n name: Optional[str] = None,\n is_subscription: bool = False,\n description: Optional[str] = None,\n permission_classes: Optional[List[Type[BasePermission]]] = None,\n federation: Optional[FederationFieldParams] = None,\n deprecation_reason: Optional[str] = None,\n default: Any = UNSET,\n default_factory: Union[Callable, object] = UNSET,\n) -> StrawberryField:\n \"\"\"Annotates a method or property as a GraphQL field.\n\n This is normally used inside a type declaration:\n\n >>> @strawberry.type:\n >>> class X:\n >>> field_abc: str = strawberry.field(description=\"ABC\")\n\n >>> @strawberry.field(description=\"ABC\")\n >>> def field_with_resolver(self) -> str:\n >>> return \"abc\"\n\n it can be used both as decorator and as a normal function.\n \"\"\"\n\n field_ = StrawberryField(\n python_name=None,\n graphql_name=name,\n type_=None,\n description=description,\n is_subscription=is_subscription,\n permission_classes=permission_classes or [],\n federation=federation or FederationFieldParams(),\n deprecation_reason=deprecation_reason,\n default_value=default,\n default_factory=default_factory,\n )\n\n if resolver:\n return field_(resolver)\n return field_\n\n\n__all__ = [\"FederationFieldParams\", \"StrawberryField\", \"field\"]\n", "path": "strawberry/field.py"}]} | 3,813 | 129 |
gh_patches_debug_8936 | rasdani/github-patches | git_diff | goauthentik__authentik-5414 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Stacktrace when attempting to save an invalid blueprint to internal storage
**Describe the bug**
`POST /api/v3/managed/blueprints/` results in a stacktrace when attempting to upload an invalid blueprint
**To Reproduce**
Steps to reproduce the behavior:
1. Go to 'Customization / Blueprints'
2. Click on Create
3. Paste the included blueprint (which is apparently invalid for some reason) in the code block under "Internal". Name it whatever.
4. Click 'Create' to save, it flashes red but no information is presented.
5. See error in Logs view.
**Expected behavior**
A useful error shows up in the UI and no stack trace in the logs.
**Logs**
<details>
<summary>Stacktrace from authentik</summary>
```
Traceback (most recent call last):
File "/usr/local/lib/python3.11/site-packages/asgiref/sync.py", line 472, in thread_handler
raise exc_info[1]
File "/usr/local/lib/python3.11/site-packages/django/core/handlers/base.py", line 253, in _get_response_async
response = await wrapped_callback(
^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/asgiref/sync.py", line 435, in __call__
ret = await asyncio.wait_for(future, timeout=None)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/asyncio/tasks.py", line 442, in wait_for
return await fut
^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/asgiref/current_thread_executor.py", line 22, in run
result = self.fn(*self.args, **self.kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/asgiref/sync.py", line 476, in thread_handler
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/django/views/decorators/csrf.py", line 55, in wrapped_view
return view_func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/rest_framework/viewsets.py", line 125, in view
return self.dispatch(request, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/rest_framework/views.py", line 509, in dispatch
response = self.handle_exception(exc)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/rest_framework/views.py", line 469, in handle_exception
self.raise_uncaught_exception(exc)
File "/usr/local/lib/python3.11/site-packages/rest_framework/views.py", line 480, in raise_uncaught_exception
raise exc
File "/usr/local/lib/python3.11/site-packages/rest_framework/views.py", line 506, in dispatch
response = handler(request, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/rest_framework/mixins.py", line 18, in create
serializer.is_valid(raise_exception=True)
File "/usr/local/lib/python3.11/site-packages/rest_framework/serializers.py", line 227, in is_valid
self._validated_data = self.run_validation(self.initial_data)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/rest_framework/serializers.py", line 426, in run_validation
value = self.to_internal_value(data)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/rest_framework/serializers.py", line 485, in to_internal_value
validated_value = validate_method(validated_value)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/authentik/blueprints/api.py", line 52, in validate_content
raise ValidationError(_("Failed to validate blueprint"), *[x["msg"] for x in logs])
^^^^^^^^^^^^^^^^^^^^^^^^
File "/authentik/blueprints/api.py", line 52, in <listcomp>
raise ValidationError(_("Failed to validate blueprint"), *[x["msg"] for x in logs])
~^^^^^^^
builtins.KeyError: 'msg'
```
</details>
**Version and Deployment (please complete the following information):**
- authentik version: 2023.4.1
- Deployment: podman via personal ansible role
**Additional context**
<details>
<summary>Invalid blueprint</summary>
```
entries:
- attrs:
authorization_flow: !Find [authentik_flows.flow, [slug, "allow-app"]]
client_type: "confidential"
property_mappings:
- !Find [authentik_providers_oauth2.ScopeMapping, [scope_name, "minio admin"]]
- !Find [authentik_providers_oauth2.ScopeMapping, [scope_name, "email"]]
redirect_uris:
- "https://minio:9000/"
id: "provider/min-io"
identifiers:
name: "Min.IO"
model: "authentik_providers_oauth2.OAuth2Provider"
state: "present"
- attrs:
meta_description: "MinIO is a Object Storage released under AGPL-3.0. It is API compatible with Amazon S3."
meta_launch_url: "https://minio.example.com/"
meta_publisher: "MinIO, Inc."
name: "Min.IO"
open_in_new_tab: false
policy_engine_mode: "any"
provider: !KeyOf provider/min-io
slug: "min-io"
id: "app/min-io"
identifiers:
slug: "min-io"
model: "authentik_core.Application"
state: "present"
- attrs:
is_superuser: false
name: "Min.IO Users"
parent: null
id: "group/min-io"
identifiers:
name: "Min.IO Users"
model: "authentik_core.group"
state: "present"
- attrs:
group: !KeyOf group/min-io
order: 10
target: !Find [authentik_core.Application, [slug, "min-io"]]
id: "policy/min-io"
identifiers:
group: !KeyOf group/min-io
model: "authentik_policies.PolicyBinding"
state: "present"
metadata:
name: "Application: Min.IO"
version: 1
```
</details>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `authentik/blueprints/api.py`
Content:
```
1 """Serializer mixin for managed models"""
2 from django.utils.translation import gettext_lazy as _
3 from drf_spectacular.utils import extend_schema, inline_serializer
4 from rest_framework.decorators import action
5 from rest_framework.exceptions import ValidationError
6 from rest_framework.fields import CharField, DateTimeField, JSONField
7 from rest_framework.permissions import IsAdminUser
8 from rest_framework.request import Request
9 from rest_framework.response import Response
10 from rest_framework.serializers import ListSerializer, ModelSerializer
11 from rest_framework.viewsets import ModelViewSet
12
13 from authentik.api.decorators import permission_required
14 from authentik.blueprints.models import BlueprintInstance, BlueprintRetrievalFailed
15 from authentik.blueprints.v1.importer import Importer
16 from authentik.blueprints.v1.tasks import apply_blueprint, blueprints_find_dict
17 from authentik.core.api.used_by import UsedByMixin
18 from authentik.core.api.utils import PassiveSerializer
19
20
21 class ManagedSerializer:
22 """Managed Serializer"""
23
24 managed = CharField(read_only=True, allow_null=True)
25
26
27 class MetadataSerializer(PassiveSerializer):
28 """Serializer for blueprint metadata"""
29
30 name = CharField()
31 labels = JSONField()
32
33
34 class BlueprintInstanceSerializer(ModelSerializer):
35 """Info about a single blueprint instance file"""
36
37 def validate_path(self, path: str) -> str:
38 """Ensure the path specified is retrievable"""
39 try:
40 BlueprintInstance(path=path).retrieve()
41 except BlueprintRetrievalFailed as exc:
42 raise ValidationError(exc) from exc
43 return path
44
45 def validate_content(self, content: str) -> str:
46 """Ensure content (if set) is a valid blueprint"""
47 if content == "":
48 return content
49 context = self.instance.context if self.instance else {}
50 valid, logs = Importer(content, context).validate()
51 if not valid:
52 raise ValidationError(_("Failed to validate blueprint"), *[x["msg"] for x in logs])
53 return content
54
55 def validate(self, attrs: dict) -> dict:
56 if attrs.get("path", "") == "" and attrs.get("content", "") == "":
57 raise ValidationError(_("Either path or content must be set."))
58 return super().validate(attrs)
59
60 class Meta:
61 model = BlueprintInstance
62 fields = [
63 "pk",
64 "name",
65 "path",
66 "context",
67 "last_applied",
68 "last_applied_hash",
69 "status",
70 "enabled",
71 "managed_models",
72 "metadata",
73 "content",
74 ]
75 extra_kwargs = {
76 "status": {"read_only": True},
77 "last_applied": {"read_only": True},
78 "last_applied_hash": {"read_only": True},
79 "managed_models": {"read_only": True},
80 "metadata": {"read_only": True},
81 }
82
83
84 class BlueprintInstanceViewSet(UsedByMixin, ModelViewSet):
85 """Blueprint instances"""
86
87 permission_classes = [IsAdminUser]
88 serializer_class = BlueprintInstanceSerializer
89 queryset = BlueprintInstance.objects.all()
90 search_fields = ["name", "path"]
91 filterset_fields = ["name", "path"]
92
93 @extend_schema(
94 responses={
95 200: ListSerializer(
96 child=inline_serializer(
97 "BlueprintFile",
98 fields={
99 "path": CharField(),
100 "last_m": DateTimeField(),
101 "hash": CharField(),
102 "meta": MetadataSerializer(required=False, read_only=True),
103 },
104 )
105 )
106 }
107 )
108 @action(detail=False, pagination_class=None, filter_backends=[])
109 def available(self, request: Request) -> Response:
110 """Get blueprints"""
111 files: list[dict] = blueprints_find_dict.delay().get()
112 return Response(files)
113
114 @permission_required("authentik_blueprints.view_blueprintinstance")
115 @extend_schema(
116 request=None,
117 responses={
118 200: BlueprintInstanceSerializer(),
119 },
120 )
121 @action(detail=True, pagination_class=None, filter_backends=[], methods=["POST"])
122 def apply(self, request: Request, *args, **kwargs) -> Response:
123 """Apply a blueprint"""
124 blueprint = self.get_object()
125 apply_blueprint.delay(str(blueprint.pk)).get()
126 return self.retrieve(request, *args, **kwargs)
127
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/authentik/blueprints/api.py b/authentik/blueprints/api.py
--- a/authentik/blueprints/api.py
+++ b/authentik/blueprints/api.py
@@ -49,7 +49,8 @@
context = self.instance.context if self.instance else {}
valid, logs = Importer(content, context).validate()
if not valid:
- raise ValidationError(_("Failed to validate blueprint"), *[x["msg"] for x in logs])
+ text_logs = "\n".join([x["event"] for x in logs])
+ raise ValidationError(_("Failed to validate blueprint: %(logs)s" % {"logs": text_logs}))
return content
def validate(self, attrs: dict) -> dict:
| {"golden_diff": "diff --git a/authentik/blueprints/api.py b/authentik/blueprints/api.py\n--- a/authentik/blueprints/api.py\n+++ b/authentik/blueprints/api.py\n@@ -49,7 +49,8 @@\n context = self.instance.context if self.instance else {}\n valid, logs = Importer(content, context).validate()\n if not valid:\n- raise ValidationError(_(\"Failed to validate blueprint\"), *[x[\"msg\"] for x in logs])\n+ text_logs = \"\\n\".join([x[\"event\"] for x in logs])\n+ raise ValidationError(_(\"Failed to validate blueprint: %(logs)s\" % {\"logs\": text_logs}))\n return content\n \n def validate(self, attrs: dict) -> dict:\n", "issue": "Stacktrace when attempting to save an invalid blueprint to internal storage\n**Describe the bug**\r\n`POST /api/v3/managed/blueprints/` results in a stacktrace when attempting to upload an invalid blueprint\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Go to 'Customization / Blueprints'\r\n2. Click on Create\r\n3. Paste the included blueprint (which is apparently invalid for some reason) in the code block under \"Internal\". Name it whatever.\r\n4. Click 'Create' to save, it flashes red but no information is presented.\r\n5. See error in Logs view.\r\n\r\n**Expected behavior**\r\nA useful error shows up in the UI and no stack trace in the logs.\r\n\r\n**Logs**\r\n<details>\r\n <summary>Stacktrace from authentik</summary>\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.11/site-packages/asgiref/sync.py\", line 472, in thread_handler\r\n raise exc_info[1]\r\n File \"/usr/local/lib/python3.11/site-packages/django/core/handlers/base.py\", line 253, in _get_response_async\r\n response = await wrapped_callback(\r\n ^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/local/lib/python3.11/site-packages/asgiref/sync.py\", line 435, in __call__\r\n ret = await asyncio.wait_for(future, timeout=None)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/local/lib/python3.11/asyncio/tasks.py\", line 442, in wait_for\r\n return await fut\r\n ^^^^^^^^^\r\n File \"/usr/local/lib/python3.11/site-packages/asgiref/current_thread_executor.py\", line 22, in run\r\n result = self.fn(*self.args, **self.kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/local/lib/python3.11/site-packages/asgiref/sync.py\", line 476, in thread_handler\r\n return func(*args, **kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/local/lib/python3.11/site-packages/django/views/decorators/csrf.py\", line 55, in wrapped_view\r\n return view_func(*args, **kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/local/lib/python3.11/site-packages/rest_framework/viewsets.py\", line 125, in view\r\n return self.dispatch(request, *args, **kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/local/lib/python3.11/site-packages/rest_framework/views.py\", line 509, in dispatch\r\n response = self.handle_exception(exc)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/local/lib/python3.11/site-packages/rest_framework/views.py\", line 469, in handle_exception\r\n self.raise_uncaught_exception(exc)\r\n File \"/usr/local/lib/python3.11/site-packages/rest_framework/views.py\", line 480, in raise_uncaught_exception\r\n raise exc\r\n File \"/usr/local/lib/python3.11/site-packages/rest_framework/views.py\", line 506, in dispatch\r\n response = handler(request, *args, **kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/local/lib/python3.11/site-packages/rest_framework/mixins.py\", line 18, in create\r\n serializer.is_valid(raise_exception=True)\r\n File \"/usr/local/lib/python3.11/site-packages/rest_framework/serializers.py\", line 227, in is_valid\r\n self._validated_data = self.run_validation(self.initial_data)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/local/lib/python3.11/site-packages/rest_framework/serializers.py\", line 426, in run_validation\r\n value = self.to_internal_value(data)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/local/lib/python3.11/site-packages/rest_framework/serializers.py\", line 485, in to_internal_value\r\n validated_value = validate_method(validated_value)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/authentik/blueprints/api.py\", line 52, in validate_content\r\n raise ValidationError(_(\"Failed to validate blueprint\"), *[x[\"msg\"] for x in logs])\r\n ^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/authentik/blueprints/api.py\", line 52, in <listcomp>\r\n raise ValidationError(_(\"Failed to validate blueprint\"), *[x[\"msg\"] for x in logs])\r\n ~^^^^^^^\r\nbuiltins.KeyError: 'msg'\r\n```\r\n</details>\r\n\r\n\r\n**Version and Deployment (please complete the following information):**\r\n- authentik version: 2023.4.1\r\n- Deployment: podman via personal ansible role\r\n\r\n**Additional context**\r\n\r\n<details>\r\n <summary>Invalid blueprint</summary>\r\n\r\n```\r\nentries:\r\n - attrs:\r\n authorization_flow: !Find [authentik_flows.flow, [slug, \"allow-app\"]]\r\n client_type: \"confidential\"\r\n property_mappings:\r\n - !Find [authentik_providers_oauth2.ScopeMapping, [scope_name, \"minio admin\"]]\r\n - !Find [authentik_providers_oauth2.ScopeMapping, [scope_name, \"email\"]]\r\n redirect_uris:\r\n - \"https://minio:9000/\"\r\n id: \"provider/min-io\"\r\n identifiers:\r\n name: \"Min.IO\"\r\n model: \"authentik_providers_oauth2.OAuth2Provider\"\r\n state: \"present\"\r\n - attrs:\r\n meta_description: \"MinIO is a Object Storage released under AGPL-3.0. It is API compatible with Amazon S3.\"\r\n meta_launch_url: \"https://minio.example.com/\"\r\n meta_publisher: \"MinIO, Inc.\"\r\n name: \"Min.IO\"\r\n open_in_new_tab: false\r\n policy_engine_mode: \"any\"\r\n provider: !KeyOf provider/min-io\r\n slug: \"min-io\"\r\n id: \"app/min-io\"\r\n identifiers:\r\n slug: \"min-io\"\r\n model: \"authentik_core.Application\"\r\n state: \"present\"\r\n - attrs:\r\n is_superuser: false\r\n name: \"Min.IO Users\"\r\n parent: null\r\n id: \"group/min-io\"\r\n identifiers:\r\n name: \"Min.IO Users\"\r\n model: \"authentik_core.group\"\r\n state: \"present\"\r\n - attrs:\r\n group: !KeyOf group/min-io\r\n order: 10\r\n target: !Find [authentik_core.Application, [slug, \"min-io\"]]\r\n id: \"policy/min-io\"\r\n identifiers:\r\n group: !KeyOf group/min-io\r\n model: \"authentik_policies.PolicyBinding\"\r\n state: \"present\"\r\nmetadata:\r\n name: \"Application: Min.IO\"\r\nversion: 1\r\n```\r\n</details>\n", "before_files": [{"content": "\"\"\"Serializer mixin for managed models\"\"\"\nfrom django.utils.translation import gettext_lazy as _\nfrom drf_spectacular.utils import extend_schema, inline_serializer\nfrom rest_framework.decorators import action\nfrom rest_framework.exceptions import ValidationError\nfrom rest_framework.fields import CharField, DateTimeField, JSONField\nfrom rest_framework.permissions import IsAdminUser\nfrom rest_framework.request import Request\nfrom rest_framework.response import Response\nfrom rest_framework.serializers import ListSerializer, ModelSerializer\nfrom rest_framework.viewsets import ModelViewSet\n\nfrom authentik.api.decorators import permission_required\nfrom authentik.blueprints.models import BlueprintInstance, BlueprintRetrievalFailed\nfrom authentik.blueprints.v1.importer import Importer\nfrom authentik.blueprints.v1.tasks import apply_blueprint, blueprints_find_dict\nfrom authentik.core.api.used_by import UsedByMixin\nfrom authentik.core.api.utils import PassiveSerializer\n\n\nclass ManagedSerializer:\n \"\"\"Managed Serializer\"\"\"\n\n managed = CharField(read_only=True, allow_null=True)\n\n\nclass MetadataSerializer(PassiveSerializer):\n \"\"\"Serializer for blueprint metadata\"\"\"\n\n name = CharField()\n labels = JSONField()\n\n\nclass BlueprintInstanceSerializer(ModelSerializer):\n \"\"\"Info about a single blueprint instance file\"\"\"\n\n def validate_path(self, path: str) -> str:\n \"\"\"Ensure the path specified is retrievable\"\"\"\n try:\n BlueprintInstance(path=path).retrieve()\n except BlueprintRetrievalFailed as exc:\n raise ValidationError(exc) from exc\n return path\n\n def validate_content(self, content: str) -> str:\n \"\"\"Ensure content (if set) is a valid blueprint\"\"\"\n if content == \"\":\n return content\n context = self.instance.context if self.instance else {}\n valid, logs = Importer(content, context).validate()\n if not valid:\n raise ValidationError(_(\"Failed to validate blueprint\"), *[x[\"msg\"] for x in logs])\n return content\n\n def validate(self, attrs: dict) -> dict:\n if attrs.get(\"path\", \"\") == \"\" and attrs.get(\"content\", \"\") == \"\":\n raise ValidationError(_(\"Either path or content must be set.\"))\n return super().validate(attrs)\n\n class Meta:\n model = BlueprintInstance\n fields = [\n \"pk\",\n \"name\",\n \"path\",\n \"context\",\n \"last_applied\",\n \"last_applied_hash\",\n \"status\",\n \"enabled\",\n \"managed_models\",\n \"metadata\",\n \"content\",\n ]\n extra_kwargs = {\n \"status\": {\"read_only\": True},\n \"last_applied\": {\"read_only\": True},\n \"last_applied_hash\": {\"read_only\": True},\n \"managed_models\": {\"read_only\": True},\n \"metadata\": {\"read_only\": True},\n }\n\n\nclass BlueprintInstanceViewSet(UsedByMixin, ModelViewSet):\n \"\"\"Blueprint instances\"\"\"\n\n permission_classes = [IsAdminUser]\n serializer_class = BlueprintInstanceSerializer\n queryset = BlueprintInstance.objects.all()\n search_fields = [\"name\", \"path\"]\n filterset_fields = [\"name\", \"path\"]\n\n @extend_schema(\n responses={\n 200: ListSerializer(\n child=inline_serializer(\n \"BlueprintFile\",\n fields={\n \"path\": CharField(),\n \"last_m\": DateTimeField(),\n \"hash\": CharField(),\n \"meta\": MetadataSerializer(required=False, read_only=True),\n },\n )\n )\n }\n )\n @action(detail=False, pagination_class=None, filter_backends=[])\n def available(self, request: Request) -> Response:\n \"\"\"Get blueprints\"\"\"\n files: list[dict] = blueprints_find_dict.delay().get()\n return Response(files)\n\n @permission_required(\"authentik_blueprints.view_blueprintinstance\")\n @extend_schema(\n request=None,\n responses={\n 200: BlueprintInstanceSerializer(),\n },\n )\n @action(detail=True, pagination_class=None, filter_backends=[], methods=[\"POST\"])\n def apply(self, request: Request, *args, **kwargs) -> Response:\n \"\"\"Apply a blueprint\"\"\"\n blueprint = self.get_object()\n apply_blueprint.delay(str(blueprint.pk)).get()\n return self.retrieve(request, *args, **kwargs)\n", "path": "authentik/blueprints/api.py"}], "after_files": [{"content": "\"\"\"Serializer mixin for managed models\"\"\"\nfrom django.utils.translation import gettext_lazy as _\nfrom drf_spectacular.utils import extend_schema, inline_serializer\nfrom rest_framework.decorators import action\nfrom rest_framework.exceptions import ValidationError\nfrom rest_framework.fields import CharField, DateTimeField, JSONField\nfrom rest_framework.permissions import IsAdminUser\nfrom rest_framework.request import Request\nfrom rest_framework.response import Response\nfrom rest_framework.serializers import ListSerializer, ModelSerializer\nfrom rest_framework.viewsets import ModelViewSet\n\nfrom authentik.api.decorators import permission_required\nfrom authentik.blueprints.models import BlueprintInstance, BlueprintRetrievalFailed\nfrom authentik.blueprints.v1.importer import Importer\nfrom authentik.blueprints.v1.tasks import apply_blueprint, blueprints_find_dict\nfrom authentik.core.api.used_by import UsedByMixin\nfrom authentik.core.api.utils import PassiveSerializer\n\n\nclass ManagedSerializer:\n \"\"\"Managed Serializer\"\"\"\n\n managed = CharField(read_only=True, allow_null=True)\n\n\nclass MetadataSerializer(PassiveSerializer):\n \"\"\"Serializer for blueprint metadata\"\"\"\n\n name = CharField()\n labels = JSONField()\n\n\nclass BlueprintInstanceSerializer(ModelSerializer):\n \"\"\"Info about a single blueprint instance file\"\"\"\n\n def validate_path(self, path: str) -> str:\n \"\"\"Ensure the path specified is retrievable\"\"\"\n try:\n BlueprintInstance(path=path).retrieve()\n except BlueprintRetrievalFailed as exc:\n raise ValidationError(exc) from exc\n return path\n\n def validate_content(self, content: str) -> str:\n \"\"\"Ensure content (if set) is a valid blueprint\"\"\"\n if content == \"\":\n return content\n context = self.instance.context if self.instance else {}\n valid, logs = Importer(content, context).validate()\n if not valid:\n text_logs = \"\\n\".join([x[\"event\"] for x in logs])\n raise ValidationError(_(\"Failed to validate blueprint: %(logs)s\" % {\"logs\": text_logs}))\n return content\n\n def validate(self, attrs: dict) -> dict:\n if attrs.get(\"path\", \"\") == \"\" and attrs.get(\"content\", \"\") == \"\":\n raise ValidationError(_(\"Either path or content must be set.\"))\n return super().validate(attrs)\n\n class Meta:\n model = BlueprintInstance\n fields = [\n \"pk\",\n \"name\",\n \"path\",\n \"context\",\n \"last_applied\",\n \"last_applied_hash\",\n \"status\",\n \"enabled\",\n \"managed_models\",\n \"metadata\",\n \"content\",\n ]\n extra_kwargs = {\n \"status\": {\"read_only\": True},\n \"last_applied\": {\"read_only\": True},\n \"last_applied_hash\": {\"read_only\": True},\n \"managed_models\": {\"read_only\": True},\n \"metadata\": {\"read_only\": True},\n }\n\n\nclass BlueprintInstanceViewSet(UsedByMixin, ModelViewSet):\n \"\"\"Blueprint instances\"\"\"\n\n permission_classes = [IsAdminUser]\n serializer_class = BlueprintInstanceSerializer\n queryset = BlueprintInstance.objects.all()\n search_fields = [\"name\", \"path\"]\n filterset_fields = [\"name\", \"path\"]\n\n @extend_schema(\n responses={\n 200: ListSerializer(\n child=inline_serializer(\n \"BlueprintFile\",\n fields={\n \"path\": CharField(),\n \"last_m\": DateTimeField(),\n \"hash\": CharField(),\n \"meta\": MetadataSerializer(required=False, read_only=True),\n },\n )\n )\n }\n )\n @action(detail=False, pagination_class=None, filter_backends=[])\n def available(self, request: Request) -> Response:\n \"\"\"Get blueprints\"\"\"\n files: list[dict] = blueprints_find_dict.delay().get()\n return Response(files)\n\n @permission_required(\"authentik_blueprints.view_blueprintinstance\")\n @extend_schema(\n request=None,\n responses={\n 200: BlueprintInstanceSerializer(),\n },\n )\n @action(detail=True, pagination_class=None, filter_backends=[], methods=[\"POST\"])\n def apply(self, request: Request, *args, **kwargs) -> Response:\n \"\"\"Apply a blueprint\"\"\"\n blueprint = self.get_object()\n apply_blueprint.delay(str(blueprint.pk)).get()\n return self.retrieve(request, *args, **kwargs)\n", "path": "authentik/blueprints/api.py"}]} | 2,961 | 157 |
gh_patches_debug_38020 | rasdani/github-patches | git_diff | certbot__certbot-761 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Race condition in recent Travis builds
#726, #752 and #754 are affected by annoying race condition that causes Travis build to fail randomly (see https://travis-ci.org/letsencrypt/letsencrypt/builds/77715204, https://travis-ci.org/letsencrypt/letsencrypt/builds/78978888, https://travis-ci.org/letsencrypt/letsencrypt/builds/78990354, resp.).
It seems that manual authenticator doesn't manage to bootstrap on time before we proceed to `simple_verify`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `letsencrypt/plugins/manual.py`
Content:
```
1 """Manual plugin."""
2 import os
3 import logging
4 import pipes
5 import shutil
6 import signal
7 import subprocess
8 import sys
9 import tempfile
10 import time
11
12 import zope.component
13 import zope.interface
14
15 from acme import challenges
16
17 from letsencrypt import errors
18 from letsencrypt import interfaces
19 from letsencrypt.plugins import common
20
21
22 logger = logging.getLogger(__name__)
23
24
25 class ManualAuthenticator(common.Plugin):
26 """Manual Authenticator.
27
28 .. todo:: Support for `~.challenges.DVSNI`.
29
30 """
31 zope.interface.implements(interfaces.IAuthenticator)
32 zope.interface.classProvides(interfaces.IPluginFactory)
33
34 description = "Manual Authenticator"
35
36 MESSAGE_TEMPLATE = """\
37 Make sure your web server displays the following content at
38 {uri} before continuing:
39
40 {achall.token}
41
42 Content-Type header MUST be set to {ct}.
43
44 If you don't have HTTP server configured, you can run the following
45 command on the target server (as root):
46
47 {command}
48 """
49
50 # "cd /tmp/letsencrypt" makes sure user doesn't serve /root,
51 # separate "public_html" ensures that cert.pem/key.pem are not
52 # served and makes it more obvious that Python command will serve
53 # anything recursively under the cwd
54
55 HTTP_TEMPLATE = """\
56 mkdir -p {root}/public_html/{response.URI_ROOT_PATH}
57 cd {root}/public_html
58 echo -n {validation} > {response.URI_ROOT_PATH}/{encoded_token}
59 # run only once per server:
60 $(command -v python2 || command -v python2.7 || command -v python2.6) -c \\
61 "import BaseHTTPServer, SimpleHTTPServer; \\
62 SimpleHTTPServer.SimpleHTTPRequestHandler.extensions_map = {{'': '{ct}'}}; \\
63 s = BaseHTTPServer.HTTPServer(('', {port}), SimpleHTTPServer.SimpleHTTPRequestHandler); \\
64 s.serve_forever()" """
65 """Non-TLS command template."""
66
67 # https://www.piware.de/2011/01/creating-an-https-server-in-python/
68 HTTPS_TEMPLATE = """\
69 mkdir -p {root}/public_html/{response.URI_ROOT_PATH}
70 cd {root}/public_html
71 echo -n {validation} > {response.URI_ROOT_PATH}/{encoded_token}
72 # run only once per server:
73 openssl req -new -newkey rsa:4096 -subj "/" -days 1 -nodes -x509 -keyout ../key.pem -out ../cert.pem
74 $(command -v python2 || command -v python2.7 || command -v python2.6) -c \\
75 "import BaseHTTPServer, SimpleHTTPServer, ssl; \\
76 SimpleHTTPServer.SimpleHTTPRequestHandler.extensions_map = {{'': '{ct}'}}; \\
77 s = BaseHTTPServer.HTTPServer(('', {port}), SimpleHTTPServer.SimpleHTTPRequestHandler); \\
78 s.socket = ssl.wrap_socket(s.socket, keyfile='../key.pem', certfile='../cert.pem'); \\
79 s.serve_forever()" """
80 """TLS command template.
81
82 According to the ACME specification, "the ACME server MUST ignore
83 the certificate provided by the HTTPS server", so the first command
84 generates temporary self-signed certificate.
85
86 """
87
88 def __init__(self, *args, **kwargs):
89 super(ManualAuthenticator, self).__init__(*args, **kwargs)
90 self.template = (self.HTTP_TEMPLATE if self.config.no_simple_http_tls
91 else self.HTTPS_TEMPLATE)
92 self._root = (tempfile.mkdtemp() if self.conf("test-mode")
93 else "/tmp/letsencrypt")
94 self._httpd = None
95
96 @classmethod
97 def add_parser_arguments(cls, add):
98 add("test-mode", action="store_true",
99 help="Test mode. Executes the manual command in subprocess. "
100 "Requires openssl to be installed unless --no-simple-http-tls.")
101
102 def prepare(self): # pylint: disable=missing-docstring,no-self-use
103 pass # pragma: no cover
104
105 def more_info(self): # pylint: disable=missing-docstring,no-self-use
106 return """\
107 This plugin requires user's manual intervention in setting up a HTTP
108 server for solving SimpleHTTP challenges and thus does not need to be
109 run as a privilidged process. Alternatively shows instructions on how
110 to use Python's built-in HTTP server and, in case of HTTPS, openssl
111 binary for temporary key/certificate generation.""".replace("\n", "")
112
113 def get_chall_pref(self, domain):
114 # pylint: disable=missing-docstring,no-self-use,unused-argument
115 return [challenges.SimpleHTTP]
116
117 def perform(self, achalls): # pylint: disable=missing-docstring
118 responses = []
119 # TODO: group achalls by the same socket.gethostbyname(_ex)
120 # and prompt only once per server (one "echo -n" per domain)
121 for achall in achalls:
122 responses.append(self._perform_single(achall))
123 return responses
124
125 def _perform_single(self, achall):
126 # same path for each challenge response would be easier for
127 # users, but will not work if multiple domains point at the
128 # same server: default command doesn't support virtual hosts
129 response, validation = achall.gen_response_and_validation(
130 tls=(not self.config.no_simple_http_tls))
131
132 command = self.template.format(
133 root=self._root, achall=achall, response=response,
134 validation=pipes.quote(validation.json_dumps()),
135 encoded_token=achall.chall.encode("token"),
136 ct=response.CONTENT_TYPE, port=(
137 response.port if self.config.simple_http_port is None
138 else self.config.simple_http_port))
139 if self.conf("test-mode"):
140 logger.debug("Test mode. Executing the manual command: %s", command)
141 try:
142 self._httpd = subprocess.Popen(
143 command,
144 # don't care about setting stdout and stderr,
145 # we're in test mode anyway
146 shell=True,
147 # "preexec_fn" is UNIX specific, but so is "command"
148 preexec_fn=os.setsid)
149 except OSError as error: # ValueError should not happen!
150 logger.debug(
151 "Couldn't execute manual command: %s", error, exc_info=True)
152 return False
153 logger.debug("Manual command running as PID %s.", self._httpd.pid)
154 # give it some time to bootstrap, before we try to verify
155 # (cert generation in case of simpleHttpS might take time)
156 time.sleep(4) # XXX
157 if self._httpd.poll() is not None:
158 raise errors.Error("Couldn't execute manual command")
159 else:
160 self._notify_and_wait(self.MESSAGE_TEMPLATE.format(
161 achall=achall, response=response,
162 uri=response.uri(achall.domain, achall.challb.chall),
163 ct=response.CONTENT_TYPE, command=command))
164
165 if response.simple_verify(
166 achall.chall, achall.domain,
167 achall.account_key.public_key(), self.config.simple_http_port):
168 return response
169 else:
170 if self.conf("test-mode") and self._httpd.poll() is not None:
171 # simply verify cause command failure...
172 return False
173 return None
174
175 def _notify_and_wait(self, message): # pylint: disable=no-self-use
176 # TODO: IDisplay wraps messages, breaking the command
177 #answer = zope.component.getUtility(interfaces.IDisplay).notification(
178 # message=message, height=25, pause=True)
179 sys.stdout.write(message)
180 raw_input("Press ENTER to continue")
181
182 def cleanup(self, achalls):
183 # pylint: disable=missing-docstring,no-self-use,unused-argument
184 if self.conf("test-mode"):
185 assert self._httpd is not None, (
186 "cleanup() must be called after perform()")
187 if self._httpd.poll() is None:
188 logger.debug("Terminating manual command process")
189 os.killpg(self._httpd.pid, signal.SIGTERM)
190 else:
191 logger.debug("Manual command process already terminated "
192 "with %s code", self._httpd.returncode)
193 shutil.rmtree(self._root)
194
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/letsencrypt/plugins/manual.py b/letsencrypt/plugins/manual.py
--- a/letsencrypt/plugins/manual.py
+++ b/letsencrypt/plugins/manual.py
@@ -4,6 +4,7 @@
import pipes
import shutil
import signal
+import socket
import subprocess
import sys
import tempfile
@@ -122,6 +123,20 @@
responses.append(self._perform_single(achall))
return responses
+ @classmethod
+ def _test_mode_busy_wait(cls, port):
+ while True:
+ time.sleep(1)
+ sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
+ try:
+ sock.connect(("localhost", port))
+ except socket.error: # pragma: no cover
+ pass
+ else:
+ break
+ finally:
+ sock.close()
+
def _perform_single(self, achall):
# same path for each challenge response would be easier for
# users, but will not work if multiple domains point at the
@@ -129,13 +144,13 @@
response, validation = achall.gen_response_and_validation(
tls=(not self.config.no_simple_http_tls))
+ port = (response.port if self.config.simple_http_port is None
+ else int(self.config.simple_http_port))
command = self.template.format(
root=self._root, achall=achall, response=response,
validation=pipes.quote(validation.json_dumps()),
encoded_token=achall.chall.encode("token"),
- ct=response.CONTENT_TYPE, port=(
- response.port if self.config.simple_http_port is None
- else self.config.simple_http_port))
+ ct=response.CONTENT_TYPE, port=port)
if self.conf("test-mode"):
logger.debug("Test mode. Executing the manual command: %s", command)
try:
@@ -153,7 +168,7 @@
logger.debug("Manual command running as PID %s.", self._httpd.pid)
# give it some time to bootstrap, before we try to verify
# (cert generation in case of simpleHttpS might take time)
- time.sleep(4) # XXX
+ self._test_mode_busy_wait(port)
if self._httpd.poll() is not None:
raise errors.Error("Couldn't execute manual command")
else:
| {"golden_diff": "diff --git a/letsencrypt/plugins/manual.py b/letsencrypt/plugins/manual.py\n--- a/letsencrypt/plugins/manual.py\n+++ b/letsencrypt/plugins/manual.py\n@@ -4,6 +4,7 @@\n import pipes\n import shutil\n import signal\n+import socket\n import subprocess\n import sys\n import tempfile\n@@ -122,6 +123,20 @@\n responses.append(self._perform_single(achall))\n return responses\n \n+ @classmethod\n+ def _test_mode_busy_wait(cls, port):\n+ while True:\n+ time.sleep(1)\n+ sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n+ try:\n+ sock.connect((\"localhost\", port))\n+ except socket.error: # pragma: no cover\n+ pass\n+ else:\n+ break\n+ finally:\n+ sock.close()\n+\n def _perform_single(self, achall):\n # same path for each challenge response would be easier for\n # users, but will not work if multiple domains point at the\n@@ -129,13 +144,13 @@\n response, validation = achall.gen_response_and_validation(\n tls=(not self.config.no_simple_http_tls))\n \n+ port = (response.port if self.config.simple_http_port is None\n+ else int(self.config.simple_http_port))\n command = self.template.format(\n root=self._root, achall=achall, response=response,\n validation=pipes.quote(validation.json_dumps()),\n encoded_token=achall.chall.encode(\"token\"),\n- ct=response.CONTENT_TYPE, port=(\n- response.port if self.config.simple_http_port is None\n- else self.config.simple_http_port))\n+ ct=response.CONTENT_TYPE, port=port)\n if self.conf(\"test-mode\"):\n logger.debug(\"Test mode. Executing the manual command: %s\", command)\n try:\n@@ -153,7 +168,7 @@\n logger.debug(\"Manual command running as PID %s.\", self._httpd.pid)\n # give it some time to bootstrap, before we try to verify\n # (cert generation in case of simpleHttpS might take time)\n- time.sleep(4) # XXX\n+ self._test_mode_busy_wait(port)\n if self._httpd.poll() is not None:\n raise errors.Error(\"Couldn't execute manual command\")\n else:\n", "issue": "Race condition in recent Travis builds\n#726, #752 and #754 are affected by annoying race condition that causes Travis build to fail randomly (see https://travis-ci.org/letsencrypt/letsencrypt/builds/77715204, https://travis-ci.org/letsencrypt/letsencrypt/builds/78978888, https://travis-ci.org/letsencrypt/letsencrypt/builds/78990354, resp.).\n\nIt seems that manual authenticator doesn't manage to bootstrap on time before we proceed to `simple_verify`.\n\n", "before_files": [{"content": "\"\"\"Manual plugin.\"\"\"\nimport os\nimport logging\nimport pipes\nimport shutil\nimport signal\nimport subprocess\nimport sys\nimport tempfile\nimport time\n\nimport zope.component\nimport zope.interface\n\nfrom acme import challenges\n\nfrom letsencrypt import errors\nfrom letsencrypt import interfaces\nfrom letsencrypt.plugins import common\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass ManualAuthenticator(common.Plugin):\n \"\"\"Manual Authenticator.\n\n .. todo:: Support for `~.challenges.DVSNI`.\n\n \"\"\"\n zope.interface.implements(interfaces.IAuthenticator)\n zope.interface.classProvides(interfaces.IPluginFactory)\n\n description = \"Manual Authenticator\"\n\n MESSAGE_TEMPLATE = \"\"\"\\\nMake sure your web server displays the following content at\n{uri} before continuing:\n\n{achall.token}\n\nContent-Type header MUST be set to {ct}.\n\nIf you don't have HTTP server configured, you can run the following\ncommand on the target server (as root):\n\n{command}\n\"\"\"\n\n # \"cd /tmp/letsencrypt\" makes sure user doesn't serve /root,\n # separate \"public_html\" ensures that cert.pem/key.pem are not\n # served and makes it more obvious that Python command will serve\n # anything recursively under the cwd\n\n HTTP_TEMPLATE = \"\"\"\\\nmkdir -p {root}/public_html/{response.URI_ROOT_PATH}\ncd {root}/public_html\necho -n {validation} > {response.URI_ROOT_PATH}/{encoded_token}\n# run only once per server:\n$(command -v python2 || command -v python2.7 || command -v python2.6) -c \\\\\n\"import BaseHTTPServer, SimpleHTTPServer; \\\\\nSimpleHTTPServer.SimpleHTTPRequestHandler.extensions_map = {{'': '{ct}'}}; \\\\\ns = BaseHTTPServer.HTTPServer(('', {port}), SimpleHTTPServer.SimpleHTTPRequestHandler); \\\\\ns.serve_forever()\" \"\"\"\n \"\"\"Non-TLS command template.\"\"\"\n\n # https://www.piware.de/2011/01/creating-an-https-server-in-python/\n HTTPS_TEMPLATE = \"\"\"\\\nmkdir -p {root}/public_html/{response.URI_ROOT_PATH}\ncd {root}/public_html\necho -n {validation} > {response.URI_ROOT_PATH}/{encoded_token}\n# run only once per server:\nopenssl req -new -newkey rsa:4096 -subj \"/\" -days 1 -nodes -x509 -keyout ../key.pem -out ../cert.pem\n$(command -v python2 || command -v python2.7 || command -v python2.6) -c \\\\\n\"import BaseHTTPServer, SimpleHTTPServer, ssl; \\\\\nSimpleHTTPServer.SimpleHTTPRequestHandler.extensions_map = {{'': '{ct}'}}; \\\\\ns = BaseHTTPServer.HTTPServer(('', {port}), SimpleHTTPServer.SimpleHTTPRequestHandler); \\\\\ns.socket = ssl.wrap_socket(s.socket, keyfile='../key.pem', certfile='../cert.pem'); \\\\\ns.serve_forever()\" \"\"\"\n \"\"\"TLS command template.\n\n According to the ACME specification, \"the ACME server MUST ignore\n the certificate provided by the HTTPS server\", so the first command\n generates temporary self-signed certificate.\n\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n super(ManualAuthenticator, self).__init__(*args, **kwargs)\n self.template = (self.HTTP_TEMPLATE if self.config.no_simple_http_tls\n else self.HTTPS_TEMPLATE)\n self._root = (tempfile.mkdtemp() if self.conf(\"test-mode\")\n else \"/tmp/letsencrypt\")\n self._httpd = None\n\n @classmethod\n def add_parser_arguments(cls, add):\n add(\"test-mode\", action=\"store_true\",\n help=\"Test mode. Executes the manual command in subprocess. \"\n \"Requires openssl to be installed unless --no-simple-http-tls.\")\n\n def prepare(self): # pylint: disable=missing-docstring,no-self-use\n pass # pragma: no cover\n\n def more_info(self): # pylint: disable=missing-docstring,no-self-use\n return \"\"\"\\\nThis plugin requires user's manual intervention in setting up a HTTP\nserver for solving SimpleHTTP challenges and thus does not need to be\nrun as a privilidged process. Alternatively shows instructions on how\nto use Python's built-in HTTP server and, in case of HTTPS, openssl\nbinary for temporary key/certificate generation.\"\"\".replace(\"\\n\", \"\")\n\n def get_chall_pref(self, domain):\n # pylint: disable=missing-docstring,no-self-use,unused-argument\n return [challenges.SimpleHTTP]\n\n def perform(self, achalls): # pylint: disable=missing-docstring\n responses = []\n # TODO: group achalls by the same socket.gethostbyname(_ex)\n # and prompt only once per server (one \"echo -n\" per domain)\n for achall in achalls:\n responses.append(self._perform_single(achall))\n return responses\n\n def _perform_single(self, achall):\n # same path for each challenge response would be easier for\n # users, but will not work if multiple domains point at the\n # same server: default command doesn't support virtual hosts\n response, validation = achall.gen_response_and_validation(\n tls=(not self.config.no_simple_http_tls))\n\n command = self.template.format(\n root=self._root, achall=achall, response=response,\n validation=pipes.quote(validation.json_dumps()),\n encoded_token=achall.chall.encode(\"token\"),\n ct=response.CONTENT_TYPE, port=(\n response.port if self.config.simple_http_port is None\n else self.config.simple_http_port))\n if self.conf(\"test-mode\"):\n logger.debug(\"Test mode. Executing the manual command: %s\", command)\n try:\n self._httpd = subprocess.Popen(\n command,\n # don't care about setting stdout and stderr,\n # we're in test mode anyway\n shell=True,\n # \"preexec_fn\" is UNIX specific, but so is \"command\"\n preexec_fn=os.setsid)\n except OSError as error: # ValueError should not happen!\n logger.debug(\n \"Couldn't execute manual command: %s\", error, exc_info=True)\n return False\n logger.debug(\"Manual command running as PID %s.\", self._httpd.pid)\n # give it some time to bootstrap, before we try to verify\n # (cert generation in case of simpleHttpS might take time)\n time.sleep(4) # XXX\n if self._httpd.poll() is not None:\n raise errors.Error(\"Couldn't execute manual command\")\n else:\n self._notify_and_wait(self.MESSAGE_TEMPLATE.format(\n achall=achall, response=response,\n uri=response.uri(achall.domain, achall.challb.chall),\n ct=response.CONTENT_TYPE, command=command))\n\n if response.simple_verify(\n achall.chall, achall.domain,\n achall.account_key.public_key(), self.config.simple_http_port):\n return response\n else:\n if self.conf(\"test-mode\") and self._httpd.poll() is not None:\n # simply verify cause command failure...\n return False\n return None\n\n def _notify_and_wait(self, message): # pylint: disable=no-self-use\n # TODO: IDisplay wraps messages, breaking the command\n #answer = zope.component.getUtility(interfaces.IDisplay).notification(\n # message=message, height=25, pause=True)\n sys.stdout.write(message)\n raw_input(\"Press ENTER to continue\")\n\n def cleanup(self, achalls):\n # pylint: disable=missing-docstring,no-self-use,unused-argument\n if self.conf(\"test-mode\"):\n assert self._httpd is not None, (\n \"cleanup() must be called after perform()\")\n if self._httpd.poll() is None:\n logger.debug(\"Terminating manual command process\")\n os.killpg(self._httpd.pid, signal.SIGTERM)\n else:\n logger.debug(\"Manual command process already terminated \"\n \"with %s code\", self._httpd.returncode)\n shutil.rmtree(self._root)\n", "path": "letsencrypt/plugins/manual.py"}], "after_files": [{"content": "\"\"\"Manual plugin.\"\"\"\nimport os\nimport logging\nimport pipes\nimport shutil\nimport signal\nimport socket\nimport subprocess\nimport sys\nimport tempfile\nimport time\n\nimport zope.component\nimport zope.interface\n\nfrom acme import challenges\n\nfrom letsencrypt import errors\nfrom letsencrypt import interfaces\nfrom letsencrypt.plugins import common\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass ManualAuthenticator(common.Plugin):\n \"\"\"Manual Authenticator.\n\n .. todo:: Support for `~.challenges.DVSNI`.\n\n \"\"\"\n zope.interface.implements(interfaces.IAuthenticator)\n zope.interface.classProvides(interfaces.IPluginFactory)\n\n description = \"Manual Authenticator\"\n\n MESSAGE_TEMPLATE = \"\"\"\\\nMake sure your web server displays the following content at\n{uri} before continuing:\n\n{achall.token}\n\nContent-Type header MUST be set to {ct}.\n\nIf you don't have HTTP server configured, you can run the following\ncommand on the target server (as root):\n\n{command}\n\"\"\"\n\n # \"cd /tmp/letsencrypt\" makes sure user doesn't serve /root,\n # separate \"public_html\" ensures that cert.pem/key.pem are not\n # served and makes it more obvious that Python command will serve\n # anything recursively under the cwd\n\n HTTP_TEMPLATE = \"\"\"\\\nmkdir -p {root}/public_html/{response.URI_ROOT_PATH}\ncd {root}/public_html\necho -n {validation} > {response.URI_ROOT_PATH}/{encoded_token}\n# run only once per server:\n$(command -v python2 || command -v python2.7 || command -v python2.6) -c \\\\\n\"import BaseHTTPServer, SimpleHTTPServer; \\\\\nSimpleHTTPServer.SimpleHTTPRequestHandler.extensions_map = {{'': '{ct}'}}; \\\\\ns = BaseHTTPServer.HTTPServer(('', {port}), SimpleHTTPServer.SimpleHTTPRequestHandler); \\\\\ns.serve_forever()\" \"\"\"\n \"\"\"Non-TLS command template.\"\"\"\n\n # https://www.piware.de/2011/01/creating-an-https-server-in-python/\n HTTPS_TEMPLATE = \"\"\"\\\nmkdir -p {root}/public_html/{response.URI_ROOT_PATH}\ncd {root}/public_html\necho -n {validation} > {response.URI_ROOT_PATH}/{encoded_token}\n# run only once per server:\nopenssl req -new -newkey rsa:4096 -subj \"/\" -days 1 -nodes -x509 -keyout ../key.pem -out ../cert.pem\n$(command -v python2 || command -v python2.7 || command -v python2.6) -c \\\\\n\"import BaseHTTPServer, SimpleHTTPServer, ssl; \\\\\nSimpleHTTPServer.SimpleHTTPRequestHandler.extensions_map = {{'': '{ct}'}}; \\\\\ns = BaseHTTPServer.HTTPServer(('', {port}), SimpleHTTPServer.SimpleHTTPRequestHandler); \\\\\ns.socket = ssl.wrap_socket(s.socket, keyfile='../key.pem', certfile='../cert.pem'); \\\\\ns.serve_forever()\" \"\"\"\n \"\"\"TLS command template.\n\n According to the ACME specification, \"the ACME server MUST ignore\n the certificate provided by the HTTPS server\", so the first command\n generates temporary self-signed certificate.\n\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n super(ManualAuthenticator, self).__init__(*args, **kwargs)\n self.template = (self.HTTP_TEMPLATE if self.config.no_simple_http_tls\n else self.HTTPS_TEMPLATE)\n self._root = (tempfile.mkdtemp() if self.conf(\"test-mode\")\n else \"/tmp/letsencrypt\")\n self._httpd = None\n\n @classmethod\n def add_parser_arguments(cls, add):\n add(\"test-mode\", action=\"store_true\",\n help=\"Test mode. Executes the manual command in subprocess. \"\n \"Requires openssl to be installed unless --no-simple-http-tls.\")\n\n def prepare(self): # pylint: disable=missing-docstring,no-self-use\n pass # pragma: no cover\n\n def more_info(self): # pylint: disable=missing-docstring,no-self-use\n return \"\"\"\\\nThis plugin requires user's manual intervention in setting up a HTTP\nserver for solving SimpleHTTP challenges and thus does not need to be\nrun as a privilidged process. Alternatively shows instructions on how\nto use Python's built-in HTTP server and, in case of HTTPS, openssl\nbinary for temporary key/certificate generation.\"\"\".replace(\"\\n\", \"\")\n\n def get_chall_pref(self, domain):\n # pylint: disable=missing-docstring,no-self-use,unused-argument\n return [challenges.SimpleHTTP]\n\n def perform(self, achalls): # pylint: disable=missing-docstring\n responses = []\n # TODO: group achalls by the same socket.gethostbyname(_ex)\n # and prompt only once per server (one \"echo -n\" per domain)\n for achall in achalls:\n responses.append(self._perform_single(achall))\n return responses\n\n @classmethod\n def _test_mode_busy_wait(cls, port):\n while True:\n time.sleep(1)\n sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n try:\n sock.connect((\"localhost\", port))\n except socket.error: # pragma: no cover\n pass\n else:\n break\n finally:\n sock.close()\n\n def _perform_single(self, achall):\n # same path for each challenge response would be easier for\n # users, but will not work if multiple domains point at the\n # same server: default command doesn't support virtual hosts\n response, validation = achall.gen_response_and_validation(\n tls=(not self.config.no_simple_http_tls))\n\n port = (response.port if self.config.simple_http_port is None\n else int(self.config.simple_http_port))\n command = self.template.format(\n root=self._root, achall=achall, response=response,\n validation=pipes.quote(validation.json_dumps()),\n encoded_token=achall.chall.encode(\"token\"),\n ct=response.CONTENT_TYPE, port=port)\n if self.conf(\"test-mode\"):\n logger.debug(\"Test mode. Executing the manual command: %s\", command)\n try:\n self._httpd = subprocess.Popen(\n command,\n # don't care about setting stdout and stderr,\n # we're in test mode anyway\n shell=True,\n # \"preexec_fn\" is UNIX specific, but so is \"command\"\n preexec_fn=os.setsid)\n except OSError as error: # ValueError should not happen!\n logger.debug(\n \"Couldn't execute manual command: %s\", error, exc_info=True)\n return False\n logger.debug(\"Manual command running as PID %s.\", self._httpd.pid)\n # give it some time to bootstrap, before we try to verify\n # (cert generation in case of simpleHttpS might take time)\n self._test_mode_busy_wait(port)\n if self._httpd.poll() is not None:\n raise errors.Error(\"Couldn't execute manual command\")\n else:\n self._notify_and_wait(self.MESSAGE_TEMPLATE.format(\n achall=achall, response=response,\n uri=response.uri(achall.domain, achall.challb.chall),\n ct=response.CONTENT_TYPE, command=command))\n\n if response.simple_verify(\n achall.chall, achall.domain,\n achall.account_key.public_key(), self.config.simple_http_port):\n return response\n else:\n if self.conf(\"test-mode\") and self._httpd.poll() is not None:\n # simply verify cause command failure...\n return False\n return None\n\n def _notify_and_wait(self, message): # pylint: disable=no-self-use\n # TODO: IDisplay wraps messages, breaking the command\n #answer = zope.component.getUtility(interfaces.IDisplay).notification(\n # message=message, height=25, pause=True)\n sys.stdout.write(message)\n raw_input(\"Press ENTER to continue\")\n\n def cleanup(self, achalls):\n # pylint: disable=missing-docstring,no-self-use,unused-argument\n if self.conf(\"test-mode\"):\n assert self._httpd is not None, (\n \"cleanup() must be called after perform()\")\n if self._httpd.poll() is None:\n logger.debug(\"Terminating manual command process\")\n os.killpg(self._httpd.pid, signal.SIGTERM)\n else:\n logger.debug(\"Manual command process already terminated \"\n \"with %s code\", self._httpd.returncode)\n shutil.rmtree(self._root)\n", "path": "letsencrypt/plugins/manual.py"}]} | 2,615 | 517 |
gh_patches_debug_18780 | rasdani/github-patches | git_diff | aws-cloudformation__cfn-lint-1562 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
AWS::Serverless::StateMachine.DefinitionUri support for local files
*cfn-lint version: 0.32.1*
*Description of issue.*
The recent release of SAM support for Step Functions has added the ability to use a non-S3 URL for the [`DefinitionUri`](https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/sam-resource-statemachine.html#sam-statemachine-definitionuri) in order to reference local files that get included during a deploy. The linter is currently throwing an error for all non-S3 values, though.
```
[cfn-lint] E0001: Error transforming template: Resource with id [StateMachine] is invalid. 'DefinitionUri' is not a valid S3 Uri of the form 's3://bucket/key' with optional versionId query parameter.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 """
2 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import codecs
6 import re
7 from setuptools import find_packages
8 from setuptools import setup
9
10
11 def get_version(filename):
12 with codecs.open(filename, 'r', 'utf-8') as fp:
13 contents = fp.read()
14 return re.search(r"__version__ = ['\"]([^'\"]+)['\"]", contents).group(1)
15
16
17 version = get_version('src/cfnlint/version.py')
18
19
20 with open('README.md') as f:
21 readme = f.read()
22
23 setup(
24 name='cfn-lint',
25 version=version,
26 description=('Checks CloudFormation templates for practices and behaviour \
27 that could potentially be improved'),
28 long_description=readme,
29 long_description_content_type="text/markdown",
30 keywords='aws, lint',
31 author='kddejong',
32 author_email='[email protected]',
33 url='https://github.com/aws-cloudformation/cfn-python-lint',
34 package_dir={'': 'src'},
35 package_data={'cfnlint': [
36 'data/CloudSpecs/*.json',
37 'data/AdditionalSpecs/*.json',
38 'data/Serverless/*.json',
39 'data/ExtendedSpecs/*/*.json',
40 'data/CfnLintCli/config/schema.json'
41 ]},
42 packages=find_packages('src'),
43 zip_safe=False,
44 install_requires=[
45 'pyyaml<=5.2;python_version=="3.4"',
46 'pyyaml;python_version!="3.4"',
47 'six~=1.11',
48 'aws-sam-translator>=1.23.0',
49 'jsonpatch;python_version!="3.4"',
50 'jsonpatch<=1.24;python_version=="3.4"',
51 'jsonschema~=3.0',
52 'pathlib2>=2.3.0;python_version<="3.4"',
53 'importlib_resources~=1.0.2;python_version=="3.4"',
54 'importlib_resources~=1.4;python_version<"3.7" and python_version!="3.4"',
55 'networkx~=2.4;python_version>="3.5"',
56 'networkx<=2.2;python_version<"3.5"',
57 'junit-xml~=1.9',
58 ],
59 python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*',
60 entry_points={
61 'console_scripts': [
62 'cfn-lint = cfnlint.__main__:main'
63 ]
64 },
65 license='MIT no attribution',
66 test_suite="unittest",
67 classifiers=[
68 'Development Status :: 5 - Production/Stable',
69 'Intended Audience :: Developers',
70 'License :: OSI Approved :: MIT License',
71 'Natural Language :: English',
72 'Operating System :: OS Independent',
73 'Programming Language :: Python :: 2',
74 'Programming Language :: Python :: 2.7',
75 'Programming Language :: Python :: 3',
76 'Programming Language :: Python :: 3.4',
77 'Programming Language :: Python :: 3.5',
78 'Programming Language :: Python :: 3.6',
79 'Programming Language :: Python :: 3.7',
80 'Programming Language :: Python :: 3.8',
81 ],
82 )
83
```
Path: `src/cfnlint/transform.py`
Content:
```
1 """
2 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import os
6 import logging
7 import six
8 import samtranslator
9 from samtranslator.parser import parser
10 from samtranslator.translator.translator import Translator
11 from samtranslator.public.exceptions import InvalidDocumentException
12
13 from cfnlint.helpers import load_resource, convert_dict, format_json_string
14 from cfnlint.data import Serverless
15 from cfnlint.rules import Match, TransformError
16 LOGGER = logging.getLogger('cfnlint')
17
18
19 class Transform(object):
20 """
21 Application Serverless Module tranform Wrapper.
22 Based on code from AWS SAM CLI:
23 https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/commands/validate/lib/sam_template_validator.py
24 """
25
26 def __init__(self, filename, template, region):
27 """
28 Initialize Transform class
29 """
30 self._filename = filename
31 self._template = template
32 self._region = region
33 self._parameters = {}
34
35 self._managed_policy_map = self.load_managed_policies()
36 self._sam_parser = parser.Parser()
37
38 def template(self):
39 """Get the template"""
40 return self._template
41
42 def load_managed_policies(self):
43 """
44 Load the ManagedPolicies locally, based on the AWS-CLI:
45 https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/lib/samlib/default_managed_policies.json
46 """
47 return load_resource(Serverless, 'ManagedPolicies.json')
48
49 def _replace_local_codeuri(self):
50 """
51 Replaces the CodeUri in AWS::Serverless::Function and DefinitionUri in
52 AWS::Serverless::Api to a fake S3 Uri. This is to support running the
53 SAM Translator with valid values for these fields. If this is not done,
54 the template is invalid in the eyes of SAM Translator (the translator
55 does not support local paths)
56 """
57
58 all_resources = self._template.get('Resources', {})
59
60 for _, resource in all_resources.items():
61
62 resource_type = resource.get('Type')
63 resource_dict = resource.get('Properties')
64
65 if resource_type == 'AWS::Serverless::Function':
66
67 Transform._update_to_s3_uri('CodeUri', resource_dict)
68 auto_publish_alias = resource_dict.get('AutoPublishAlias')
69 if isinstance(auto_publish_alias, dict):
70 if len(auto_publish_alias) == 1:
71 for k, v in auto_publish_alias.items():
72 if k == 'Ref':
73 if v in self._template.get('Parameters'):
74 self._parameters[v] = 'Alias'
75 if resource_type in ['AWS::Serverless::LayerVersion']:
76 if resource_dict.get('ContentUri'):
77 Transform._update_to_s3_uri('ContentUri', resource_dict)
78 if resource_type == 'AWS::Serverless::Application':
79 if resource_dict.get('Location'):
80 resource_dict['Location'] = ''
81 Transform._update_to_s3_uri('Location', resource_dict)
82 if resource_type == 'AWS::Serverless::Api':
83 if ('DefinitionBody' not in resource_dict and
84 'Auth' not in resource_dict and 'Cors' not in resource_dict):
85 Transform._update_to_s3_uri('DefinitionUri', resource_dict)
86 else:
87 resource_dict['DefinitionBody'] = ''
88
89 def transform_template(self):
90 """
91 Transform the Template using the Serverless Application Model.
92 """
93 matches = []
94
95 try:
96 # Output the SAM Translator version in debug mode
97 LOGGER.info('SAM Translator: %s', samtranslator.__version__)
98
99 sam_translator = Translator(
100 managed_policy_map=self._managed_policy_map,
101 sam_parser=self._sam_parser)
102
103 self._replace_local_codeuri()
104
105 # Tell SAM to use the region we're linting in, this has to be
106 # controlled using the default AWS mechanisms, see also:
107 # https://github.com/awslabs/serverless-application-model/blob/master/samtranslator/translator/arn_generator.py
108 LOGGER.info('Setting AWS_DEFAULT_REGION to %s', self._region)
109 os.environ['AWS_DEFAULT_REGION'] = self._region
110
111 self._template = convert_dict(
112 sam_translator.translate(sam_template=self._template,
113 parameter_values=self._parameters))
114
115 LOGGER.info('Transformed template: \n%s',
116 format_json_string(self._template))
117 except InvalidDocumentException as e:
118 message = 'Error transforming template: {0}'
119 for cause in e.causes:
120 matches.append(Match(
121 1, 1,
122 1, 1,
123 self._filename,
124 TransformError(), message.format(cause.message)))
125 except Exception as e: # pylint: disable=W0703
126 LOGGER.debug('Error transforming template: %s', str(e))
127 LOGGER.debug('Stack trace: %s', e, exc_info=True)
128 message = 'Error transforming template: {0}'
129 matches.append(Match(
130 1, 1,
131 1, 1,
132 self._filename,
133 TransformError(), message.format(str(e))))
134
135 return matches
136
137 @staticmethod
138 def is_s3_uri(uri):
139 """
140 Checks the uri and determines if it is a valid S3 Uri
141 Parameters
142 ----------
143 uri str, required
144 Uri to check
145 Returns
146 -------
147 bool
148 Returns True if the uri given is an S3 uri, otherwise False
149 """
150 return isinstance(uri, six.string_types) and uri.startswith('s3://')
151
152 @staticmethod
153 def _update_to_s3_uri(
154 property_key, resource_property_dict,
155 s3_uri_value='s3://bucket/value'):
156 """
157 Updates the 'property_key' in the 'resource_property_dict' to the
158 value of 's3_uri_value'
159 Note: The function will mutate the resource_property_dict that is pass
160 in Parameters
161 ----------
162 property_key str, required
163 Key in the resource_property_dict
164 resource_property_dict dict, required
165 Property dictionary of a Resource in the template to replace
166 s3_uri_value str, optional
167 Value to update the value of the property_key to
168 """
169 uri_property = resource_property_dict.get(property_key, '.')
170
171 # ignore if dict or already an S3 Uri
172 if isinstance(uri_property, dict) or Transform.is_s3_uri(uri_property):
173 return
174
175 resource_property_dict[property_key] = s3_uri_value
176
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -45,7 +45,7 @@
'pyyaml<=5.2;python_version=="3.4"',
'pyyaml;python_version!="3.4"',
'six~=1.11',
- 'aws-sam-translator>=1.23.0',
+ 'aws-sam-translator>=1.24.0',
'jsonpatch;python_version!="3.4"',
'jsonpatch<=1.24;python_version=="3.4"',
'jsonschema~=3.0',
diff --git a/src/cfnlint/transform.py b/src/cfnlint/transform.py
--- a/src/cfnlint/transform.py
+++ b/src/cfnlint/transform.py
@@ -85,6 +85,8 @@
Transform._update_to_s3_uri('DefinitionUri', resource_dict)
else:
resource_dict['DefinitionBody'] = ''
+ if resource_type == 'AWS::Serverless::StateMachine':
+ Transform._update_to_s3_uri('DefinitionUri', resource_dict)
def transform_template(self):
"""
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -45,7 +45,7 @@\n 'pyyaml<=5.2;python_version==\"3.4\"',\n 'pyyaml;python_version!=\"3.4\"',\n 'six~=1.11',\n- 'aws-sam-translator>=1.23.0',\n+ 'aws-sam-translator>=1.24.0',\n 'jsonpatch;python_version!=\"3.4\"',\n 'jsonpatch<=1.24;python_version==\"3.4\"',\n 'jsonschema~=3.0',\ndiff --git a/src/cfnlint/transform.py b/src/cfnlint/transform.py\n--- a/src/cfnlint/transform.py\n+++ b/src/cfnlint/transform.py\n@@ -85,6 +85,8 @@\n Transform._update_to_s3_uri('DefinitionUri', resource_dict)\n else:\n resource_dict['DefinitionBody'] = ''\n+ if resource_type == 'AWS::Serverless::StateMachine':\n+ Transform._update_to_s3_uri('DefinitionUri', resource_dict)\n \n def transform_template(self):\n \"\"\"\n", "issue": "AWS::Serverless::StateMachine.DefinitionUri support for local files\n*cfn-lint version: 0.32.1*\r\n\r\n*Description of issue.*\r\n\r\nThe recent release of SAM support for Step Functions has added the ability to use a non-S3 URL for the [`DefinitionUri`](https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/sam-resource-statemachine.html#sam-statemachine-definitionuri) in order to reference local files that get included during a deploy. The linter is currently throwing an error for all non-S3 values, though.\r\n\r\n```\r\n[cfn-lint] E0001: Error transforming template: Resource with id [StateMachine] is invalid. 'DefinitionUri' is not a valid S3 Uri of the form 's3://bucket/key' with optional versionId query parameter.\r\n```\n", "before_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport codecs\nimport re\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\ndef get_version(filename):\n with codecs.open(filename, 'r', 'utf-8') as fp:\n contents = fp.read()\n return re.search(r\"__version__ = ['\\\"]([^'\\\"]+)['\\\"]\", contents).group(1)\n\n\nversion = get_version('src/cfnlint/version.py')\n\n\nwith open('README.md') as f:\n readme = f.read()\n\nsetup(\n name='cfn-lint',\n version=version,\n description=('Checks CloudFormation templates for practices and behaviour \\\nthat could potentially be improved'),\n long_description=readme,\n long_description_content_type=\"text/markdown\",\n keywords='aws, lint',\n author='kddejong',\n author_email='[email protected]',\n url='https://github.com/aws-cloudformation/cfn-python-lint',\n package_dir={'': 'src'},\n package_data={'cfnlint': [\n 'data/CloudSpecs/*.json',\n 'data/AdditionalSpecs/*.json',\n 'data/Serverless/*.json',\n 'data/ExtendedSpecs/*/*.json',\n 'data/CfnLintCli/config/schema.json'\n ]},\n packages=find_packages('src'),\n zip_safe=False,\n install_requires=[\n 'pyyaml<=5.2;python_version==\"3.4\"',\n 'pyyaml;python_version!=\"3.4\"',\n 'six~=1.11',\n 'aws-sam-translator>=1.23.0',\n 'jsonpatch;python_version!=\"3.4\"',\n 'jsonpatch<=1.24;python_version==\"3.4\"',\n 'jsonschema~=3.0',\n 'pathlib2>=2.3.0;python_version<=\"3.4\"',\n 'importlib_resources~=1.0.2;python_version==\"3.4\"',\n 'importlib_resources~=1.4;python_version<\"3.7\" and python_version!=\"3.4\"',\n 'networkx~=2.4;python_version>=\"3.5\"',\n 'networkx<=2.2;python_version<\"3.5\"',\n 'junit-xml~=1.9',\n ],\n python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*',\n entry_points={\n 'console_scripts': [\n 'cfn-lint = cfnlint.__main__:main'\n ]\n },\n license='MIT no attribution',\n test_suite=\"unittest\",\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n ],\n)\n", "path": "setup.py"}, {"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport os\nimport logging\nimport six\nimport samtranslator\nfrom samtranslator.parser import parser\nfrom samtranslator.translator.translator import Translator\nfrom samtranslator.public.exceptions import InvalidDocumentException\n\nfrom cfnlint.helpers import load_resource, convert_dict, format_json_string\nfrom cfnlint.data import Serverless\nfrom cfnlint.rules import Match, TransformError\nLOGGER = logging.getLogger('cfnlint')\n\n\nclass Transform(object):\n \"\"\"\n Application Serverless Module tranform Wrapper.\n Based on code from AWS SAM CLI:\n https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/commands/validate/lib/sam_template_validator.py\n \"\"\"\n\n def __init__(self, filename, template, region):\n \"\"\"\n Initialize Transform class\n \"\"\"\n self._filename = filename\n self._template = template\n self._region = region\n self._parameters = {}\n\n self._managed_policy_map = self.load_managed_policies()\n self._sam_parser = parser.Parser()\n\n def template(self):\n \"\"\"Get the template\"\"\"\n return self._template\n\n def load_managed_policies(self):\n \"\"\"\n Load the ManagedPolicies locally, based on the AWS-CLI:\n https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/lib/samlib/default_managed_policies.json\n \"\"\"\n return load_resource(Serverless, 'ManagedPolicies.json')\n\n def _replace_local_codeuri(self):\n \"\"\"\n Replaces the CodeUri in AWS::Serverless::Function and DefinitionUri in\n AWS::Serverless::Api to a fake S3 Uri. This is to support running the\n SAM Translator with valid values for these fields. If this is not done,\n the template is invalid in the eyes of SAM Translator (the translator\n does not support local paths)\n \"\"\"\n\n all_resources = self._template.get('Resources', {})\n\n for _, resource in all_resources.items():\n\n resource_type = resource.get('Type')\n resource_dict = resource.get('Properties')\n\n if resource_type == 'AWS::Serverless::Function':\n\n Transform._update_to_s3_uri('CodeUri', resource_dict)\n auto_publish_alias = resource_dict.get('AutoPublishAlias')\n if isinstance(auto_publish_alias, dict):\n if len(auto_publish_alias) == 1:\n for k, v in auto_publish_alias.items():\n if k == 'Ref':\n if v in self._template.get('Parameters'):\n self._parameters[v] = 'Alias'\n if resource_type in ['AWS::Serverless::LayerVersion']:\n if resource_dict.get('ContentUri'):\n Transform._update_to_s3_uri('ContentUri', resource_dict)\n if resource_type == 'AWS::Serverless::Application':\n if resource_dict.get('Location'):\n resource_dict['Location'] = ''\n Transform._update_to_s3_uri('Location', resource_dict)\n if resource_type == 'AWS::Serverless::Api':\n if ('DefinitionBody' not in resource_dict and\n 'Auth' not in resource_dict and 'Cors' not in resource_dict):\n Transform._update_to_s3_uri('DefinitionUri', resource_dict)\n else:\n resource_dict['DefinitionBody'] = ''\n\n def transform_template(self):\n \"\"\"\n Transform the Template using the Serverless Application Model.\n \"\"\"\n matches = []\n\n try:\n # Output the SAM Translator version in debug mode\n LOGGER.info('SAM Translator: %s', samtranslator.__version__)\n\n sam_translator = Translator(\n managed_policy_map=self._managed_policy_map,\n sam_parser=self._sam_parser)\n\n self._replace_local_codeuri()\n\n # Tell SAM to use the region we're linting in, this has to be\n # controlled using the default AWS mechanisms, see also:\n # https://github.com/awslabs/serverless-application-model/blob/master/samtranslator/translator/arn_generator.py\n LOGGER.info('Setting AWS_DEFAULT_REGION to %s', self._region)\n os.environ['AWS_DEFAULT_REGION'] = self._region\n\n self._template = convert_dict(\n sam_translator.translate(sam_template=self._template,\n parameter_values=self._parameters))\n\n LOGGER.info('Transformed template: \\n%s',\n format_json_string(self._template))\n except InvalidDocumentException as e:\n message = 'Error transforming template: {0}'\n for cause in e.causes:\n matches.append(Match(\n 1, 1,\n 1, 1,\n self._filename,\n TransformError(), message.format(cause.message)))\n except Exception as e: # pylint: disable=W0703\n LOGGER.debug('Error transforming template: %s', str(e))\n LOGGER.debug('Stack trace: %s', e, exc_info=True)\n message = 'Error transforming template: {0}'\n matches.append(Match(\n 1, 1,\n 1, 1,\n self._filename,\n TransformError(), message.format(str(e))))\n\n return matches\n\n @staticmethod\n def is_s3_uri(uri):\n \"\"\"\n Checks the uri and determines if it is a valid S3 Uri\n Parameters\n ----------\n uri str, required\n Uri to check\n Returns\n -------\n bool\n Returns True if the uri given is an S3 uri, otherwise False\n \"\"\"\n return isinstance(uri, six.string_types) and uri.startswith('s3://')\n\n @staticmethod\n def _update_to_s3_uri(\n property_key, resource_property_dict,\n s3_uri_value='s3://bucket/value'):\n \"\"\"\n Updates the 'property_key' in the 'resource_property_dict' to the\n value of 's3_uri_value'\n Note: The function will mutate the resource_property_dict that is pass\n in Parameters\n ----------\n property_key str, required\n Key in the resource_property_dict\n resource_property_dict dict, required\n Property dictionary of a Resource in the template to replace\n s3_uri_value str, optional\n Value to update the value of the property_key to\n \"\"\"\n uri_property = resource_property_dict.get(property_key, '.')\n\n # ignore if dict or already an S3 Uri\n if isinstance(uri_property, dict) or Transform.is_s3_uri(uri_property):\n return\n\n resource_property_dict[property_key] = s3_uri_value\n", "path": "src/cfnlint/transform.py"}], "after_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport codecs\nimport re\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\ndef get_version(filename):\n with codecs.open(filename, 'r', 'utf-8') as fp:\n contents = fp.read()\n return re.search(r\"__version__ = ['\\\"]([^'\\\"]+)['\\\"]\", contents).group(1)\n\n\nversion = get_version('src/cfnlint/version.py')\n\n\nwith open('README.md') as f:\n readme = f.read()\n\nsetup(\n name='cfn-lint',\n version=version,\n description=('Checks CloudFormation templates for practices and behaviour \\\nthat could potentially be improved'),\n long_description=readme,\n long_description_content_type=\"text/markdown\",\n keywords='aws, lint',\n author='kddejong',\n author_email='[email protected]',\n url='https://github.com/aws-cloudformation/cfn-python-lint',\n package_dir={'': 'src'},\n package_data={'cfnlint': [\n 'data/CloudSpecs/*.json',\n 'data/AdditionalSpecs/*.json',\n 'data/Serverless/*.json',\n 'data/ExtendedSpecs/*/*.json',\n 'data/CfnLintCli/config/schema.json'\n ]},\n packages=find_packages('src'),\n zip_safe=False,\n install_requires=[\n 'pyyaml<=5.2;python_version==\"3.4\"',\n 'pyyaml;python_version!=\"3.4\"',\n 'six~=1.11',\n 'aws-sam-translator>=1.24.0',\n 'jsonpatch;python_version!=\"3.4\"',\n 'jsonpatch<=1.24;python_version==\"3.4\"',\n 'jsonschema~=3.0',\n 'pathlib2>=2.3.0;python_version<=\"3.4\"',\n 'importlib_resources~=1.0.2;python_version==\"3.4\"',\n 'importlib_resources~=1.4;python_version<\"3.7\" and python_version!=\"3.4\"',\n 'networkx~=2.4;python_version>=\"3.5\"',\n 'networkx<=2.2;python_version<\"3.5\"',\n 'junit-xml~=1.9',\n ],\n python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*',\n entry_points={\n 'console_scripts': [\n 'cfn-lint = cfnlint.__main__:main'\n ]\n },\n license='MIT no attribution',\n test_suite=\"unittest\",\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n ],\n)\n", "path": "setup.py"}, {"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport os\nimport logging\nimport six\nimport samtranslator\nfrom samtranslator.parser import parser\nfrom samtranslator.translator.translator import Translator\nfrom samtranslator.public.exceptions import InvalidDocumentException\n\nfrom cfnlint.helpers import load_resource, convert_dict, format_json_string\nfrom cfnlint.data import Serverless\nfrom cfnlint.rules import Match, TransformError\nLOGGER = logging.getLogger('cfnlint')\n\n\nclass Transform(object):\n \"\"\"\n Application Serverless Module tranform Wrapper.\n Based on code from AWS SAM CLI:\n https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/commands/validate/lib/sam_template_validator.py\n \"\"\"\n\n def __init__(self, filename, template, region):\n \"\"\"\n Initialize Transform class\n \"\"\"\n self._filename = filename\n self._template = template\n self._region = region\n self._parameters = {}\n\n self._managed_policy_map = self.load_managed_policies()\n self._sam_parser = parser.Parser()\n\n def template(self):\n \"\"\"Get the template\"\"\"\n return self._template\n\n def load_managed_policies(self):\n \"\"\"\n Load the ManagedPolicies locally, based on the AWS-CLI:\n https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/lib/samlib/default_managed_policies.json\n \"\"\"\n return load_resource(Serverless, 'ManagedPolicies.json')\n\n def _replace_local_codeuri(self):\n \"\"\"\n Replaces the CodeUri in AWS::Serverless::Function and DefinitionUri in\n AWS::Serverless::Api to a fake S3 Uri. This is to support running the\n SAM Translator with valid values for these fields. If this is not done,\n the template is invalid in the eyes of SAM Translator (the translator\n does not support local paths)\n \"\"\"\n\n all_resources = self._template.get('Resources', {})\n\n for _, resource in all_resources.items():\n\n resource_type = resource.get('Type')\n resource_dict = resource.get('Properties')\n\n if resource_type == 'AWS::Serverless::Function':\n\n Transform._update_to_s3_uri('CodeUri', resource_dict)\n auto_publish_alias = resource_dict.get('AutoPublishAlias')\n if isinstance(auto_publish_alias, dict):\n if len(auto_publish_alias) == 1:\n for k, v in auto_publish_alias.items():\n if k == 'Ref':\n if v in self._template.get('Parameters'):\n self._parameters[v] = 'Alias'\n if resource_type in ['AWS::Serverless::LayerVersion']:\n if resource_dict.get('ContentUri'):\n Transform._update_to_s3_uri('ContentUri', resource_dict)\n if resource_type == 'AWS::Serverless::Application':\n if resource_dict.get('Location'):\n resource_dict['Location'] = ''\n Transform._update_to_s3_uri('Location', resource_dict)\n if resource_type == 'AWS::Serverless::Api':\n if ('DefinitionBody' not in resource_dict and\n 'Auth' not in resource_dict and 'Cors' not in resource_dict):\n Transform._update_to_s3_uri('DefinitionUri', resource_dict)\n else:\n resource_dict['DefinitionBody'] = ''\n if resource_type == 'AWS::Serverless::StateMachine':\n Transform._update_to_s3_uri('DefinitionUri', resource_dict)\n\n def transform_template(self):\n \"\"\"\n Transform the Template using the Serverless Application Model.\n \"\"\"\n matches = []\n\n try:\n # Output the SAM Translator version in debug mode\n LOGGER.info('SAM Translator: %s', samtranslator.__version__)\n\n sam_translator = Translator(\n managed_policy_map=self._managed_policy_map,\n sam_parser=self._sam_parser)\n\n self._replace_local_codeuri()\n\n # Tell SAM to use the region we're linting in, this has to be\n # controlled using the default AWS mechanisms, see also:\n # https://github.com/awslabs/serverless-application-model/blob/master/samtranslator/translator/arn_generator.py\n LOGGER.info('Setting AWS_DEFAULT_REGION to %s', self._region)\n os.environ['AWS_DEFAULT_REGION'] = self._region\n\n self._template = convert_dict(\n sam_translator.translate(sam_template=self._template,\n parameter_values=self._parameters))\n\n LOGGER.info('Transformed template: \\n%s',\n format_json_string(self._template))\n except InvalidDocumentException as e:\n message = 'Error transforming template: {0}'\n for cause in e.causes:\n matches.append(Match(\n 1, 1,\n 1, 1,\n self._filename,\n TransformError(), message.format(cause.message)))\n except Exception as e: # pylint: disable=W0703\n LOGGER.debug('Error transforming template: %s', str(e))\n LOGGER.debug('Stack trace: %s', e, exc_info=True)\n message = 'Error transforming template: {0}'\n matches.append(Match(\n 1, 1,\n 1, 1,\n self._filename,\n TransformError(), message.format(str(e))))\n\n return matches\n\n @staticmethod\n def is_s3_uri(uri):\n \"\"\"\n Checks the uri and determines if it is a valid S3 Uri\n Parameters\n ----------\n uri str, required\n Uri to check\n Returns\n -------\n bool\n Returns True if the uri given is an S3 uri, otherwise False\n \"\"\"\n return isinstance(uri, six.string_types) and uri.startswith('s3://')\n\n @staticmethod\n def _update_to_s3_uri(\n property_key, resource_property_dict,\n s3_uri_value='s3://bucket/value'):\n \"\"\"\n Updates the 'property_key' in the 'resource_property_dict' to the\n value of 's3_uri_value'\n Note: The function will mutate the resource_property_dict that is pass\n in Parameters\n ----------\n property_key str, required\n Key in the resource_property_dict\n resource_property_dict dict, required\n Property dictionary of a Resource in the template to replace\n s3_uri_value str, optional\n Value to update the value of the property_key to\n \"\"\"\n uri_property = resource_property_dict.get(property_key, '.')\n\n # ignore if dict or already an S3 Uri\n if isinstance(uri_property, dict) or Transform.is_s3_uri(uri_property):\n return\n\n resource_property_dict[property_key] = s3_uri_value\n", "path": "src/cfnlint/transform.py"}]} | 3,138 | 257 |
gh_patches_debug_18435 | rasdani/github-patches | git_diff | RedHatInsights__insights-core-2088 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Core doesn't detect chkconfig in services directory of sos archives
We have a [spec](https://github.com/RedHatInsights/insights-core/blob/master/insights/specs/sos_archive.py#L27) for `sos_commands/startup/chkconfig_--list` but miss `sos_commands/services/chkconfig_--list`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `insights/specs/sos_archive.py`
Content:
```
1 from functools import partial
2 from insights.specs import Specs
3 from insights.core.context import SosArchiveContext
4 from insights.core.spec_factory import simple_file, first_of, first_file, glob_file
5
6 first_file = partial(first_file, context=SosArchiveContext)
7 glob_file = partial(glob_file, context=SosArchiveContext)
8 simple_file = partial(simple_file, context=SosArchiveContext)
9
10
11 class SosSpecs(Specs):
12 auditctl_status = simple_file("sos_commands/auditd/auditctl_-s")
13 blkid = simple_file("sos_commands/block/blkid_-c_.dev.null")
14 candlepin_log = first_of([
15 simple_file("/var/log/candlepin/candlepin.log"),
16 simple_file("sos_commands/foreman/foreman-debug/var/log/candlepin/candlepin.log")
17 ])
18 candlepin_error_log = first_of([
19 simple_file("var/log/candlepin/error.log"),
20 simple_file(r"sos_commands/foreman/foreman-debug/var/log/candlepin/error.log")
21 ])
22 catalina_out = glob_file("var/log/tomcat*/catalina.out")
23 catalina_server_log = glob_file("var/log/tomcat*/catalina*.log")
24 ceph_osd_tree_text = simple_file("sos_commands/ceph/ceph_osd_tree")
25 ceph_report = simple_file("sos_commands/ceph/ceph_report")
26 ceph_health_detail = simple_file("sos_commands/ceph/ceph_health_detail_--format_json-pretty")
27 chkconfig = simple_file("sos_commands/startup/chkconfig_--list")
28 date = first_of([simple_file("sos_commands/general/date"), simple_file("sos_commands/date/date")])
29 df__al = first_file(["sos_commands/filesys/df_-al", "sos_commands/filesys/df_-al_-x_autofs"])
30 display_java = simple_file("sos_commands/java/alternatives_--display_java")
31 docker_info = simple_file("sos_commands/docker/docker_info")
32 docker_list_containers = first_file(["sos_commands/docker/docker_ps_-a", "sos_commands/docker/docker_ps"])
33 dmesg = first_file(["sos_commands/kernel/dmesg", "var/log/dmesg"])
34 dmidecode = simple_file("sos_commands/hardware/dmidecode")
35 dmsetup_info = simple_file("sos_commands/devicemapper/dmsetup_info_-c")
36 dumpe2fs_h = glob_file("sos_commands/filesys/dumpe2fs_-h_*")
37 ethtool = glob_file("sos_commands/networking/ethtool_*", ignore="ethtool_-.*")
38 ethtool_S = glob_file("sos_commands/networking/ethtool_-S_*")
39 ethtool_T = glob_file("sos_commands/networking/ethtool_-T_*")
40 ethtool_a = glob_file("sos_commands/networking/ethtool_-a_*")
41 ethtool_c = glob_file("sos_commands/networking/ethtool_-c_*")
42 ethtool_g = glob_file("sos_commands/networking/ethtool_-g_*")
43 ethtool_i = glob_file("sos_commands/networking/ethtool_-i_*")
44 ethtool_k = glob_file("sos_commands/networking/ethtool_-k_*")
45 fdisk_l_sos = first_of([glob_file(r"sos_commands/filesys/fdisk_-l_*"), glob_file(r"sos_commands/block/fdisk_-l_*")])
46 foreman_production_log = first_of([simple_file("/var/log/foreman/production.log"), simple_file("sos_commands/foreman/foreman-debug/var/log/foreman/production.log")])
47 foreman_proxy_conf = first_of([simple_file("/etc/foreman-proxy/settings.yml"), simple_file("sos_commands/foreman/foreman-debug/etc/foreman-proxy/settings.yml")])
48 foreman_proxy_log = first_of([simple_file("/var/log/foreman-proxy/proxy.log"), simple_file("sos_commands/foreman/foreman-debug/var/log/foreman-proxy/proxy.log")])
49 foreman_satellite_log = first_of([simple_file("/var/log/foreman-installer/satellite.log"), simple_file("sos_commands/foreman/foreman-debug/var/log/foreman-installer/satellite.log")])
50 foreman_ssl_access_ssl_log = first_file(["var/log/httpd/foreman-ssl_access_ssl.log", r"sos_commands/foreman/foreman-debug/var/log/httpd/foreman-ssl_access_ssl.log"])
51 getcert_list = first_file(["sos_commands/ipa/ipa-getcert_list", "sos_commands/ipa/getcert_list"])
52 gluster_v_info = simple_file("sos_commands/gluster/gluster_volume_info")
53 gluster_v_status = simple_file("sos_commands/gluster/gluster_volume_status")
54 hostname = first_file(["sos_commands/general/hostname_-f", "sos_commands/general/hostname", "sos_commands/host/hostname_-f", "sos_commands/host/hostname", "/etc/hostname", "hostname"])
55 installed_rpms = simple_file("installed-rpms")
56 ip_addr = first_of([simple_file("sos_commands/networking/ip_-d_address"), simple_file("sos_commands/networking/ip_address")])
57 ip_route_show_table_all = simple_file("sos_commands/networking/ip_route_show_table_all")
58 ip_s_link = first_of([simple_file("sos_commands/networking/ip_-s_-d_link"), simple_file("sos_commands/networking/ip_-s_link"), simple_file("sos_commands/networking/ip_link")])
59 iptables = first_file(["/etc/sysconfig/iptables", "/etc/sysconfig/iptables.save"])
60 journal_since_boot = first_of([simple_file("sos_commands/logs/journalctl_--no-pager_--boot"), simple_file("sos_commands/logs/journalctl_--no-pager_--catalog_--boot")])
61 locale = simple_file("sos_commands/i18n/locale")
62 lsblk = simple_file("sos_commands/block/lsblk")
63 lsinitrd = simple_file("sos_commands/boot/lsinitrd")
64 lsof = simple_file("sos_commands/process/lsof_-b_M_-n_-l")
65 lsmod = simple_file("sos_commands/kernel/lsmod")
66 lspci = first_of([
67 simple_file("sos_commands/pci/lspci_-nnvv"),
68 simple_file("sos_commands/pci/lspci"),
69 simple_file("sos_commands/pci/lspci_-nvv")
70 ])
71 lsscsi = simple_file("sos_commands/scsi/lsscsi")
72 ls_dev = first_file(["sos_commands/block/ls_-lanR_.dev", "sos_commands/devicemapper/ls_-lanR_.dev"])
73 lvs = first_file(["sos_commands/lvm2/lvs_-a_-o_lv_tags_devices_--config_global_locking_type_0", "sos_commands/lvm2/lvs_-a_-o_devices"])
74 mount = simple_file("sos_commands/filesys/mount_-l")
75 multipath__v4__ll = first_file(["sos_commands/multipath/multipath_-v4_-ll", "sos_commands/devicemapper/multipath_-v4_-ll"])
76 netstat = first_file(["sos_commands/networking/netstat_-neopa", "sos_commands/networking/netstat_-W_-neopa", "sos_commands/networking/netstat_-T_-neopa"])
77 netstat_agn = first_of([simple_file("sos_commands/networking/netstat_-agn"), simple_file("sos_commands/networking/netstat_-W_-agn"), simple_file("sos_commands/networking/netstat_-T_-agn")])
78 netstat_s = simple_file("sos_commands/networking/netstat_-s")
79 nmcli_dev_show = simple_file("sos_commands/networking/nmcli_device_show")
80 nmcli_dev_show_sos = glob_file(["sos_commands/networking/nmcli_dev_show_*", "sos_commands/networkmanager/nmcli_dev_show_*"])
81 ntptime = simple_file("sos_commands/ntp/ntptime")
82 pcs_config = simple_file("sos_commands/pacemaker/pcs_config")
83 pcs_status = simple_file("sos_commands/pacemaker/pcs_status")
84 ps_alxwww = simple_file("sos_commands/process/ps_alxwww")
85 ps_aux = first_file(["sos_commands/process/ps_aux", "sos_commands/process/ps_auxwww", "sos_commands/process/ps_auxcww"])
86 ps_auxcww = first_file(["sos_commands/process/ps_auxcww", "sos_commands/process/ps_auxwww", "sos_commands/process/ps_aux"])
87 ps_auxww = first_file(["sos_commands/process/ps_auxww", "sos_commands/process/ps_auxwww", "sos_commands/process/ps_aux", "sos_commands/process/ps_auxcww"])
88 puppet_ssl_cert_ca_pem = simple_file("sos_commands/foreman/foreman-debug/var/lib/puppet/ssl/certs/ca.pem")
89 pvs = first_file(["sos_commands/lvm2/pvs_-a_-v_-o_pv_mda_free_pv_mda_size_pv_mda_count_pv_mda_used_count_pe_start_--config_global_locking_type_0", "sos_commands/lvm2/pvs_-a_-v"])
90 qpid_stat_q = first_of([
91 simple_file("qpid_stat_queues"),
92 simple_file("qpid-stat-q"),
93 simple_file("sos_commands/foreman/foreman-debug/qpid_stat_queues"),
94 simple_file("sos_commands/foreman/foreman-debug/qpid-stat-q")
95 ])
96 qpid_stat_u = first_of([
97 simple_file("qpid_stat_subscriptions"),
98 simple_file("qpid-stat-u"),
99 simple_file("sos_commands/foreman/foreman-debug/qpid_stat_subscriptions"),
100 simple_file("sos_commands/foreman/foreman-debug/qpid-stat-u")
101 ])
102 rabbitmq_report = simple_file("sos_commands/rabbitmq/rabbitmqctl_report")
103 rabbitmq_report_of_containers = glob_file("sos_commands/rabbitmq/docker_exec_-t_rabbitmq-bundle-docker-*_rabbitmqctl_report")
104 rhn_charsets = first_file(["sos_commands/satellite/rhn-charsets", "sos_commands/rhn/rhn-charsets"])
105 root_crontab = first_file(["sos_commands/crontab/root_crontab", "sos_commands/cron/root_crontab"])
106 route = simple_file("sos_commands/networking/route_-n")
107 sestatus = simple_file("sos_commands/selinux/sestatus_-b")
108 subscription_manager_list_consumed = first_file([
109 'sos_commands/yum/subscription-manager_list_--consumed',
110 'sos_commands/subscription_manager/subscription-manager_list_--consumed',
111 'sos_commands/general/subscription-manager_list_--consumed']
112 )
113 subscription_manager_list_installed = first_file([
114 'sos_commands/yum/subscription-manager_list_--installed',
115 'sos_commands/subscription_manager/subscription-manager_list_--installed',
116 'sos_commands/general/subscription-manager_list_--installed']
117 )
118 sysctl = simple_file("sos_commands/kernel/sysctl_-a")
119 systemctl_list_unit_files = simple_file("sos_commands/systemd/systemctl_list-unit-files")
120 systemctl_list_units = first_file(["sos_commands/systemd/systemctl_list-units", "sos_commands/systemd/systemctl_list-units_--all"])
121 uname = simple_file("sos_commands/kernel/uname_-a")
122 uptime = first_of([simple_file("sos_commands/general/uptime"), simple_file("sos_commands/host/uptime")])
123 var_qemu_xml = glob_file(r"var/run/libvirt/qemu/*.xml")
124 vdsm_import_log = glob_file("var/log/vdsm/import/import-*.log")
125 vgdisplay = first_file(["sos_commands/lvm2/vgdisplay_-vv_--config_global_locking_type_0", "sos_commands/lvm2/vgdisplay_-vv"])
126 vgs = first_file(["sos_commands/lvm2/vgs_-v_-o_vg_mda_count_vg_mda_free_vg_mda_size_vg_mda_used_count_vg_tags_--config_global_locking_type_0", "sos_commands/lvm2/vgs_-v"])
127 xfs_info = glob_file("sos_commands/xfs/xfs_info*")
128 yum_repolist = simple_file("sos_commands/yum/yum_-C_repolist")
129
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/insights/specs/sos_archive.py b/insights/specs/sos_archive.py
--- a/insights/specs/sos_archive.py
+++ b/insights/specs/sos_archive.py
@@ -24,7 +24,7 @@
ceph_osd_tree_text = simple_file("sos_commands/ceph/ceph_osd_tree")
ceph_report = simple_file("sos_commands/ceph/ceph_report")
ceph_health_detail = simple_file("sos_commands/ceph/ceph_health_detail_--format_json-pretty")
- chkconfig = simple_file("sos_commands/startup/chkconfig_--list")
+ chkconfig = first_file(["sos_commands/startup/chkconfig_--list", "sos_commands/services/chkconfig_--list"])
date = first_of([simple_file("sos_commands/general/date"), simple_file("sos_commands/date/date")])
df__al = first_file(["sos_commands/filesys/df_-al", "sos_commands/filesys/df_-al_-x_autofs"])
display_java = simple_file("sos_commands/java/alternatives_--display_java")
| {"golden_diff": "diff --git a/insights/specs/sos_archive.py b/insights/specs/sos_archive.py\n--- a/insights/specs/sos_archive.py\n+++ b/insights/specs/sos_archive.py\n@@ -24,7 +24,7 @@\n ceph_osd_tree_text = simple_file(\"sos_commands/ceph/ceph_osd_tree\")\n ceph_report = simple_file(\"sos_commands/ceph/ceph_report\")\n ceph_health_detail = simple_file(\"sos_commands/ceph/ceph_health_detail_--format_json-pretty\")\n- chkconfig = simple_file(\"sos_commands/startup/chkconfig_--list\")\n+ chkconfig = first_file([\"sos_commands/startup/chkconfig_--list\", \"sos_commands/services/chkconfig_--list\"])\n date = first_of([simple_file(\"sos_commands/general/date\"), simple_file(\"sos_commands/date/date\")])\n df__al = first_file([\"sos_commands/filesys/df_-al\", \"sos_commands/filesys/df_-al_-x_autofs\"])\n display_java = simple_file(\"sos_commands/java/alternatives_--display_java\")\n", "issue": "Core doesn't detect chkconfig in services directory of sos archives\nWe have a [spec](https://github.com/RedHatInsights/insights-core/blob/master/insights/specs/sos_archive.py#L27) for `sos_commands/startup/chkconfig_--list` but miss `sos_commands/services/chkconfig_--list`.\n", "before_files": [{"content": "from functools import partial\nfrom insights.specs import Specs\nfrom insights.core.context import SosArchiveContext\nfrom insights.core.spec_factory import simple_file, first_of, first_file, glob_file\n\nfirst_file = partial(first_file, context=SosArchiveContext)\nglob_file = partial(glob_file, context=SosArchiveContext)\nsimple_file = partial(simple_file, context=SosArchiveContext)\n\n\nclass SosSpecs(Specs):\n auditctl_status = simple_file(\"sos_commands/auditd/auditctl_-s\")\n blkid = simple_file(\"sos_commands/block/blkid_-c_.dev.null\")\n candlepin_log = first_of([\n simple_file(\"/var/log/candlepin/candlepin.log\"),\n simple_file(\"sos_commands/foreman/foreman-debug/var/log/candlepin/candlepin.log\")\n ])\n candlepin_error_log = first_of([\n simple_file(\"var/log/candlepin/error.log\"),\n simple_file(r\"sos_commands/foreman/foreman-debug/var/log/candlepin/error.log\")\n ])\n catalina_out = glob_file(\"var/log/tomcat*/catalina.out\")\n catalina_server_log = glob_file(\"var/log/tomcat*/catalina*.log\")\n ceph_osd_tree_text = simple_file(\"sos_commands/ceph/ceph_osd_tree\")\n ceph_report = simple_file(\"sos_commands/ceph/ceph_report\")\n ceph_health_detail = simple_file(\"sos_commands/ceph/ceph_health_detail_--format_json-pretty\")\n chkconfig = simple_file(\"sos_commands/startup/chkconfig_--list\")\n date = first_of([simple_file(\"sos_commands/general/date\"), simple_file(\"sos_commands/date/date\")])\n df__al = first_file([\"sos_commands/filesys/df_-al\", \"sos_commands/filesys/df_-al_-x_autofs\"])\n display_java = simple_file(\"sos_commands/java/alternatives_--display_java\")\n docker_info = simple_file(\"sos_commands/docker/docker_info\")\n docker_list_containers = first_file([\"sos_commands/docker/docker_ps_-a\", \"sos_commands/docker/docker_ps\"])\n dmesg = first_file([\"sos_commands/kernel/dmesg\", \"var/log/dmesg\"])\n dmidecode = simple_file(\"sos_commands/hardware/dmidecode\")\n dmsetup_info = simple_file(\"sos_commands/devicemapper/dmsetup_info_-c\")\n dumpe2fs_h = glob_file(\"sos_commands/filesys/dumpe2fs_-h_*\")\n ethtool = glob_file(\"sos_commands/networking/ethtool_*\", ignore=\"ethtool_-.*\")\n ethtool_S = glob_file(\"sos_commands/networking/ethtool_-S_*\")\n ethtool_T = glob_file(\"sos_commands/networking/ethtool_-T_*\")\n ethtool_a = glob_file(\"sos_commands/networking/ethtool_-a_*\")\n ethtool_c = glob_file(\"sos_commands/networking/ethtool_-c_*\")\n ethtool_g = glob_file(\"sos_commands/networking/ethtool_-g_*\")\n ethtool_i = glob_file(\"sos_commands/networking/ethtool_-i_*\")\n ethtool_k = glob_file(\"sos_commands/networking/ethtool_-k_*\")\n fdisk_l_sos = first_of([glob_file(r\"sos_commands/filesys/fdisk_-l_*\"), glob_file(r\"sos_commands/block/fdisk_-l_*\")])\n foreman_production_log = first_of([simple_file(\"/var/log/foreman/production.log\"), simple_file(\"sos_commands/foreman/foreman-debug/var/log/foreman/production.log\")])\n foreman_proxy_conf = first_of([simple_file(\"/etc/foreman-proxy/settings.yml\"), simple_file(\"sos_commands/foreman/foreman-debug/etc/foreman-proxy/settings.yml\")])\n foreman_proxy_log = first_of([simple_file(\"/var/log/foreman-proxy/proxy.log\"), simple_file(\"sos_commands/foreman/foreman-debug/var/log/foreman-proxy/proxy.log\")])\n foreman_satellite_log = first_of([simple_file(\"/var/log/foreman-installer/satellite.log\"), simple_file(\"sos_commands/foreman/foreman-debug/var/log/foreman-installer/satellite.log\")])\n foreman_ssl_access_ssl_log = first_file([\"var/log/httpd/foreman-ssl_access_ssl.log\", r\"sos_commands/foreman/foreman-debug/var/log/httpd/foreman-ssl_access_ssl.log\"])\n getcert_list = first_file([\"sos_commands/ipa/ipa-getcert_list\", \"sos_commands/ipa/getcert_list\"])\n gluster_v_info = simple_file(\"sos_commands/gluster/gluster_volume_info\")\n gluster_v_status = simple_file(\"sos_commands/gluster/gluster_volume_status\")\n hostname = first_file([\"sos_commands/general/hostname_-f\", \"sos_commands/general/hostname\", \"sos_commands/host/hostname_-f\", \"sos_commands/host/hostname\", \"/etc/hostname\", \"hostname\"])\n installed_rpms = simple_file(\"installed-rpms\")\n ip_addr = first_of([simple_file(\"sos_commands/networking/ip_-d_address\"), simple_file(\"sos_commands/networking/ip_address\")])\n ip_route_show_table_all = simple_file(\"sos_commands/networking/ip_route_show_table_all\")\n ip_s_link = first_of([simple_file(\"sos_commands/networking/ip_-s_-d_link\"), simple_file(\"sos_commands/networking/ip_-s_link\"), simple_file(\"sos_commands/networking/ip_link\")])\n iptables = first_file([\"/etc/sysconfig/iptables\", \"/etc/sysconfig/iptables.save\"])\n journal_since_boot = first_of([simple_file(\"sos_commands/logs/journalctl_--no-pager_--boot\"), simple_file(\"sos_commands/logs/journalctl_--no-pager_--catalog_--boot\")])\n locale = simple_file(\"sos_commands/i18n/locale\")\n lsblk = simple_file(\"sos_commands/block/lsblk\")\n lsinitrd = simple_file(\"sos_commands/boot/lsinitrd\")\n lsof = simple_file(\"sos_commands/process/lsof_-b_M_-n_-l\")\n lsmod = simple_file(\"sos_commands/kernel/lsmod\")\n lspci = first_of([\n simple_file(\"sos_commands/pci/lspci_-nnvv\"),\n simple_file(\"sos_commands/pci/lspci\"),\n simple_file(\"sos_commands/pci/lspci_-nvv\")\n ])\n lsscsi = simple_file(\"sos_commands/scsi/lsscsi\")\n ls_dev = first_file([\"sos_commands/block/ls_-lanR_.dev\", \"sos_commands/devicemapper/ls_-lanR_.dev\"])\n lvs = first_file([\"sos_commands/lvm2/lvs_-a_-o_lv_tags_devices_--config_global_locking_type_0\", \"sos_commands/lvm2/lvs_-a_-o_devices\"])\n mount = simple_file(\"sos_commands/filesys/mount_-l\")\n multipath__v4__ll = first_file([\"sos_commands/multipath/multipath_-v4_-ll\", \"sos_commands/devicemapper/multipath_-v4_-ll\"])\n netstat = first_file([\"sos_commands/networking/netstat_-neopa\", \"sos_commands/networking/netstat_-W_-neopa\", \"sos_commands/networking/netstat_-T_-neopa\"])\n netstat_agn = first_of([simple_file(\"sos_commands/networking/netstat_-agn\"), simple_file(\"sos_commands/networking/netstat_-W_-agn\"), simple_file(\"sos_commands/networking/netstat_-T_-agn\")])\n netstat_s = simple_file(\"sos_commands/networking/netstat_-s\")\n nmcli_dev_show = simple_file(\"sos_commands/networking/nmcli_device_show\")\n nmcli_dev_show_sos = glob_file([\"sos_commands/networking/nmcli_dev_show_*\", \"sos_commands/networkmanager/nmcli_dev_show_*\"])\n ntptime = simple_file(\"sos_commands/ntp/ntptime\")\n pcs_config = simple_file(\"sos_commands/pacemaker/pcs_config\")\n pcs_status = simple_file(\"sos_commands/pacemaker/pcs_status\")\n ps_alxwww = simple_file(\"sos_commands/process/ps_alxwww\")\n ps_aux = first_file([\"sos_commands/process/ps_aux\", \"sos_commands/process/ps_auxwww\", \"sos_commands/process/ps_auxcww\"])\n ps_auxcww = first_file([\"sos_commands/process/ps_auxcww\", \"sos_commands/process/ps_auxwww\", \"sos_commands/process/ps_aux\"])\n ps_auxww = first_file([\"sos_commands/process/ps_auxww\", \"sos_commands/process/ps_auxwww\", \"sos_commands/process/ps_aux\", \"sos_commands/process/ps_auxcww\"])\n puppet_ssl_cert_ca_pem = simple_file(\"sos_commands/foreman/foreman-debug/var/lib/puppet/ssl/certs/ca.pem\")\n pvs = first_file([\"sos_commands/lvm2/pvs_-a_-v_-o_pv_mda_free_pv_mda_size_pv_mda_count_pv_mda_used_count_pe_start_--config_global_locking_type_0\", \"sos_commands/lvm2/pvs_-a_-v\"])\n qpid_stat_q = first_of([\n simple_file(\"qpid_stat_queues\"),\n simple_file(\"qpid-stat-q\"),\n simple_file(\"sos_commands/foreman/foreman-debug/qpid_stat_queues\"),\n simple_file(\"sos_commands/foreman/foreman-debug/qpid-stat-q\")\n ])\n qpid_stat_u = first_of([\n simple_file(\"qpid_stat_subscriptions\"),\n simple_file(\"qpid-stat-u\"),\n simple_file(\"sos_commands/foreman/foreman-debug/qpid_stat_subscriptions\"),\n simple_file(\"sos_commands/foreman/foreman-debug/qpid-stat-u\")\n ])\n rabbitmq_report = simple_file(\"sos_commands/rabbitmq/rabbitmqctl_report\")\n rabbitmq_report_of_containers = glob_file(\"sos_commands/rabbitmq/docker_exec_-t_rabbitmq-bundle-docker-*_rabbitmqctl_report\")\n rhn_charsets = first_file([\"sos_commands/satellite/rhn-charsets\", \"sos_commands/rhn/rhn-charsets\"])\n root_crontab = first_file([\"sos_commands/crontab/root_crontab\", \"sos_commands/cron/root_crontab\"])\n route = simple_file(\"sos_commands/networking/route_-n\")\n sestatus = simple_file(\"sos_commands/selinux/sestatus_-b\")\n subscription_manager_list_consumed = first_file([\n 'sos_commands/yum/subscription-manager_list_--consumed',\n 'sos_commands/subscription_manager/subscription-manager_list_--consumed',\n 'sos_commands/general/subscription-manager_list_--consumed']\n )\n subscription_manager_list_installed = first_file([\n 'sos_commands/yum/subscription-manager_list_--installed',\n 'sos_commands/subscription_manager/subscription-manager_list_--installed',\n 'sos_commands/general/subscription-manager_list_--installed']\n )\n sysctl = simple_file(\"sos_commands/kernel/sysctl_-a\")\n systemctl_list_unit_files = simple_file(\"sos_commands/systemd/systemctl_list-unit-files\")\n systemctl_list_units = first_file([\"sos_commands/systemd/systemctl_list-units\", \"sos_commands/systemd/systemctl_list-units_--all\"])\n uname = simple_file(\"sos_commands/kernel/uname_-a\")\n uptime = first_of([simple_file(\"sos_commands/general/uptime\"), simple_file(\"sos_commands/host/uptime\")])\n var_qemu_xml = glob_file(r\"var/run/libvirt/qemu/*.xml\")\n vdsm_import_log = glob_file(\"var/log/vdsm/import/import-*.log\")\n vgdisplay = first_file([\"sos_commands/lvm2/vgdisplay_-vv_--config_global_locking_type_0\", \"sos_commands/lvm2/vgdisplay_-vv\"])\n vgs = first_file([\"sos_commands/lvm2/vgs_-v_-o_vg_mda_count_vg_mda_free_vg_mda_size_vg_mda_used_count_vg_tags_--config_global_locking_type_0\", \"sos_commands/lvm2/vgs_-v\"])\n xfs_info = glob_file(\"sos_commands/xfs/xfs_info*\")\n yum_repolist = simple_file(\"sos_commands/yum/yum_-C_repolist\")\n", "path": "insights/specs/sos_archive.py"}], "after_files": [{"content": "from functools import partial\nfrom insights.specs import Specs\nfrom insights.core.context import SosArchiveContext\nfrom insights.core.spec_factory import simple_file, first_of, first_file, glob_file\n\nfirst_file = partial(first_file, context=SosArchiveContext)\nglob_file = partial(glob_file, context=SosArchiveContext)\nsimple_file = partial(simple_file, context=SosArchiveContext)\n\n\nclass SosSpecs(Specs):\n auditctl_status = simple_file(\"sos_commands/auditd/auditctl_-s\")\n blkid = simple_file(\"sos_commands/block/blkid_-c_.dev.null\")\n candlepin_log = first_of([\n simple_file(\"/var/log/candlepin/candlepin.log\"),\n simple_file(\"sos_commands/foreman/foreman-debug/var/log/candlepin/candlepin.log\")\n ])\n candlepin_error_log = first_of([\n simple_file(\"var/log/candlepin/error.log\"),\n simple_file(r\"sos_commands/foreman/foreman-debug/var/log/candlepin/error.log\")\n ])\n catalina_out = glob_file(\"var/log/tomcat*/catalina.out\")\n catalina_server_log = glob_file(\"var/log/tomcat*/catalina*.log\")\n ceph_osd_tree_text = simple_file(\"sos_commands/ceph/ceph_osd_tree\")\n ceph_report = simple_file(\"sos_commands/ceph/ceph_report\")\n ceph_health_detail = simple_file(\"sos_commands/ceph/ceph_health_detail_--format_json-pretty\")\n chkconfig = first_file([\"sos_commands/startup/chkconfig_--list\", \"sos_commands/services/chkconfig_--list\"])\n date = first_of([simple_file(\"sos_commands/general/date\"), simple_file(\"sos_commands/date/date\")])\n df__al = first_file([\"sos_commands/filesys/df_-al\", \"sos_commands/filesys/df_-al_-x_autofs\"])\n display_java = simple_file(\"sos_commands/java/alternatives_--display_java\")\n docker_info = simple_file(\"sos_commands/docker/docker_info\")\n docker_list_containers = first_file([\"sos_commands/docker/docker_ps_-a\", \"sos_commands/docker/docker_ps\"])\n dmesg = first_file([\"sos_commands/kernel/dmesg\", \"var/log/dmesg\"])\n dmidecode = simple_file(\"sos_commands/hardware/dmidecode\")\n dmsetup_info = simple_file(\"sos_commands/devicemapper/dmsetup_info_-c\")\n dumpe2fs_h = glob_file(\"sos_commands/filesys/dumpe2fs_-h_*\")\n ethtool = glob_file(\"sos_commands/networking/ethtool_*\", ignore=\"ethtool_-.*\")\n ethtool_S = glob_file(\"sos_commands/networking/ethtool_-S_*\")\n ethtool_T = glob_file(\"sos_commands/networking/ethtool_-T_*\")\n ethtool_a = glob_file(\"sos_commands/networking/ethtool_-a_*\")\n ethtool_c = glob_file(\"sos_commands/networking/ethtool_-c_*\")\n ethtool_g = glob_file(\"sos_commands/networking/ethtool_-g_*\")\n ethtool_i = glob_file(\"sos_commands/networking/ethtool_-i_*\")\n ethtool_k = glob_file(\"sos_commands/networking/ethtool_-k_*\")\n fdisk_l_sos = first_of([glob_file(r\"sos_commands/filesys/fdisk_-l_*\"), glob_file(r\"sos_commands/block/fdisk_-l_*\")])\n foreman_production_log = first_of([simple_file(\"/var/log/foreman/production.log\"), simple_file(\"sos_commands/foreman/foreman-debug/var/log/foreman/production.log\")])\n foreman_proxy_conf = first_of([simple_file(\"/etc/foreman-proxy/settings.yml\"), simple_file(\"sos_commands/foreman/foreman-debug/etc/foreman-proxy/settings.yml\")])\n foreman_proxy_log = first_of([simple_file(\"/var/log/foreman-proxy/proxy.log\"), simple_file(\"sos_commands/foreman/foreman-debug/var/log/foreman-proxy/proxy.log\")])\n foreman_satellite_log = first_of([simple_file(\"/var/log/foreman-installer/satellite.log\"), simple_file(\"sos_commands/foreman/foreman-debug/var/log/foreman-installer/satellite.log\")])\n foreman_ssl_access_ssl_log = first_file([\"var/log/httpd/foreman-ssl_access_ssl.log\", r\"sos_commands/foreman/foreman-debug/var/log/httpd/foreman-ssl_access_ssl.log\"])\n getcert_list = first_file([\"sos_commands/ipa/ipa-getcert_list\", \"sos_commands/ipa/getcert_list\"])\n gluster_v_info = simple_file(\"sos_commands/gluster/gluster_volume_info\")\n gluster_v_status = simple_file(\"sos_commands/gluster/gluster_volume_status\")\n hostname = first_file([\"sos_commands/general/hostname_-f\", \"sos_commands/general/hostname\", \"sos_commands/host/hostname_-f\", \"sos_commands/host/hostname\", \"/etc/hostname\", \"hostname\"])\n installed_rpms = simple_file(\"installed-rpms\")\n ip_addr = first_of([simple_file(\"sos_commands/networking/ip_-d_address\"), simple_file(\"sos_commands/networking/ip_address\")])\n ip_route_show_table_all = simple_file(\"sos_commands/networking/ip_route_show_table_all\")\n ip_s_link = first_of([simple_file(\"sos_commands/networking/ip_-s_-d_link\"), simple_file(\"sos_commands/networking/ip_-s_link\"), simple_file(\"sos_commands/networking/ip_link\")])\n iptables = first_file([\"/etc/sysconfig/iptables\", \"/etc/sysconfig/iptables.save\"])\n journal_since_boot = first_of([simple_file(\"sos_commands/logs/journalctl_--no-pager_--boot\"), simple_file(\"sos_commands/logs/journalctl_--no-pager_--catalog_--boot\")])\n locale = simple_file(\"sos_commands/i18n/locale\")\n lsblk = simple_file(\"sos_commands/block/lsblk\")\n lsinitrd = simple_file(\"sos_commands/boot/lsinitrd\")\n lsof = simple_file(\"sos_commands/process/lsof_-b_M_-n_-l\")\n lsmod = simple_file(\"sos_commands/kernel/lsmod\")\n lspci = first_of([\n simple_file(\"sos_commands/pci/lspci_-nnvv\"),\n simple_file(\"sos_commands/pci/lspci\"),\n simple_file(\"sos_commands/pci/lspci_-nvv\")\n ])\n lsscsi = simple_file(\"sos_commands/scsi/lsscsi\")\n ls_dev = first_file([\"sos_commands/block/ls_-lanR_.dev\", \"sos_commands/devicemapper/ls_-lanR_.dev\"])\n lvs = first_file([\"sos_commands/lvm2/lvs_-a_-o_lv_tags_devices_--config_global_locking_type_0\", \"sos_commands/lvm2/lvs_-a_-o_devices\"])\n mount = simple_file(\"sos_commands/filesys/mount_-l\")\n multipath__v4__ll = first_file([\"sos_commands/multipath/multipath_-v4_-ll\", \"sos_commands/devicemapper/multipath_-v4_-ll\"])\n netstat = first_file([\"sos_commands/networking/netstat_-neopa\", \"sos_commands/networking/netstat_-W_-neopa\", \"sos_commands/networking/netstat_-T_-neopa\"])\n netstat_agn = first_of([simple_file(\"sos_commands/networking/netstat_-agn\"), simple_file(\"sos_commands/networking/netstat_-W_-agn\"), simple_file(\"sos_commands/networking/netstat_-T_-agn\")])\n netstat_s = simple_file(\"sos_commands/networking/netstat_-s\")\n nmcli_dev_show = simple_file(\"sos_commands/networking/nmcli_device_show\")\n nmcli_dev_show_sos = glob_file([\"sos_commands/networking/nmcli_dev_show_*\", \"sos_commands/networkmanager/nmcli_dev_show_*\"])\n ntptime = simple_file(\"sos_commands/ntp/ntptime\")\n pcs_config = simple_file(\"sos_commands/pacemaker/pcs_config\")\n pcs_status = simple_file(\"sos_commands/pacemaker/pcs_status\")\n ps_alxwww = simple_file(\"sos_commands/process/ps_alxwww\")\n ps_aux = first_file([\"sos_commands/process/ps_aux\", \"sos_commands/process/ps_auxwww\", \"sos_commands/process/ps_auxcww\"])\n ps_auxcww = first_file([\"sos_commands/process/ps_auxcww\", \"sos_commands/process/ps_auxwww\", \"sos_commands/process/ps_aux\"])\n ps_auxww = first_file([\"sos_commands/process/ps_auxww\", \"sos_commands/process/ps_auxwww\", \"sos_commands/process/ps_aux\", \"sos_commands/process/ps_auxcww\"])\n puppet_ssl_cert_ca_pem = simple_file(\"sos_commands/foreman/foreman-debug/var/lib/puppet/ssl/certs/ca.pem\")\n pvs = first_file([\"sos_commands/lvm2/pvs_-a_-v_-o_pv_mda_free_pv_mda_size_pv_mda_count_pv_mda_used_count_pe_start_--config_global_locking_type_0\", \"sos_commands/lvm2/pvs_-a_-v\"])\n qpid_stat_q = first_of([\n simple_file(\"qpid_stat_queues\"),\n simple_file(\"qpid-stat-q\"),\n simple_file(\"sos_commands/foreman/foreman-debug/qpid_stat_queues\"),\n simple_file(\"sos_commands/foreman/foreman-debug/qpid-stat-q\")\n ])\n qpid_stat_u = first_of([\n simple_file(\"qpid_stat_subscriptions\"),\n simple_file(\"qpid-stat-u\"),\n simple_file(\"sos_commands/foreman/foreman-debug/qpid_stat_subscriptions\"),\n simple_file(\"sos_commands/foreman/foreman-debug/qpid-stat-u\")\n ])\n rabbitmq_report = simple_file(\"sos_commands/rabbitmq/rabbitmqctl_report\")\n rabbitmq_report_of_containers = glob_file(\"sos_commands/rabbitmq/docker_exec_-t_rabbitmq-bundle-docker-*_rabbitmqctl_report\")\n rhn_charsets = first_file([\"sos_commands/satellite/rhn-charsets\", \"sos_commands/rhn/rhn-charsets\"])\n root_crontab = first_file([\"sos_commands/crontab/root_crontab\", \"sos_commands/cron/root_crontab\"])\n route = simple_file(\"sos_commands/networking/route_-n\")\n sestatus = simple_file(\"sos_commands/selinux/sestatus_-b\")\n subscription_manager_list_consumed = first_file([\n 'sos_commands/yum/subscription-manager_list_--consumed',\n 'sos_commands/subscription_manager/subscription-manager_list_--consumed',\n 'sos_commands/general/subscription-manager_list_--consumed']\n )\n subscription_manager_list_installed = first_file([\n 'sos_commands/yum/subscription-manager_list_--installed',\n 'sos_commands/subscription_manager/subscription-manager_list_--installed',\n 'sos_commands/general/subscription-manager_list_--installed']\n )\n sysctl = simple_file(\"sos_commands/kernel/sysctl_-a\")\n systemctl_list_unit_files = simple_file(\"sos_commands/systemd/systemctl_list-unit-files\")\n systemctl_list_units = first_file([\"sos_commands/systemd/systemctl_list-units\", \"sos_commands/systemd/systemctl_list-units_--all\"])\n uname = simple_file(\"sos_commands/kernel/uname_-a\")\n uptime = first_of([simple_file(\"sos_commands/general/uptime\"), simple_file(\"sos_commands/host/uptime\")])\n var_qemu_xml = glob_file(r\"var/run/libvirt/qemu/*.xml\")\n vdsm_import_log = glob_file(\"var/log/vdsm/import/import-*.log\")\n vgdisplay = first_file([\"sos_commands/lvm2/vgdisplay_-vv_--config_global_locking_type_0\", \"sos_commands/lvm2/vgdisplay_-vv\"])\n vgs = first_file([\"sos_commands/lvm2/vgs_-v_-o_vg_mda_count_vg_mda_free_vg_mda_size_vg_mda_used_count_vg_tags_--config_global_locking_type_0\", \"sos_commands/lvm2/vgs_-v\"])\n xfs_info = glob_file(\"sos_commands/xfs/xfs_info*\")\n yum_repolist = simple_file(\"sos_commands/yum/yum_-C_repolist\")\n", "path": "insights/specs/sos_archive.py"}]} | 3,379 | 253 |
gh_patches_debug_6039 | rasdani/github-patches | git_diff | Parsl__parsl-1807 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Broken link to online documentation
In the [Quickstart Guide](https://parsl.readthedocs.io/en/stable/quickstart.html#installation-using-conda), the third option in the Tutorial list, "Read through the online tutorial documentation," contains a broken link: <https://parsl.readthedocs.io/en/stable/parsl-introduction> leads to rtd's "Maze Not Found" error page.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 #!/usr/bin/env python3
2 # -*- coding: utf-8 -*-
3 #
4 # Parsl documentation build configuration file, created by
5 # sphinx-quickstart on Mon Feb 20 16:35:17 2017.
6 #
7 # This file is execfile()d with the current directory set to its
8 # containing dir.
9 #
10 # Note that not all possible configuration values are present in this
11 # autogenerated file.
12 #
13 # All configuration values have a default; values that are commented out
14 # serve to show the default.
15
16 # If extensions (or modules to document with autodoc) are in another directory,
17 # add these directories to sys.path here. If the directory is relative to the
18 # documentation root, use os.path.abspath to make it absolute, like shown here.
19 #
20 import os
21 import sys
22 import requests
23 sys.path.insert(0, os.path.abspath('../'))
24 import parsl
25 # -- General configuration ------------------------------------------------
26
27 # If your documentation needs a minimal Sphinx version, state it here.
28 #
29 # needs_sphinx = '1.0'
30
31 # Add any Sphinx extension module names here, as strings. They can be
32 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
33 # ones.
34 extensions = [
35 'nbsphinx',
36 'sphinx.ext.autodoc',
37 'sphinx.ext.autosummary',
38 'sphinx.ext.intersphinx',
39 'sphinx.ext.linkcode',
40 'sphinx.ext.napoleon'
41 ]
42
43 url = 'https://raw.githubusercontent.com/Parsl/parsl-tutorial/master/parsl-introduction.ipynb'
44 r = requests.get(url)
45 with open(os.path.join(os.path.dirname(__file__), 'parsl-introduction.ipynb'), 'wb') as f:
46 f.write(r.content)
47
48 nbsphinx_execute = 'never'
49
50 def linkcode_resolve(domain, info):
51 if domain != 'py':
52 return None
53 if not info['module']:
54 return None
55 filename = info['module'].replace('.', '/')
56 return "http://github.com/Parsl/parsl/blob/master/{}.py".format(filename)
57
58 # Add any paths that contain templates here, relative to this directory.
59 templates_path = ['_templates']
60
61 intersphinx_mapping = {
62 'python': ('https://docs.python.org/3', None),
63 }
64 # The suffix(es) of source filenames.
65 # You can specify multiple suffix as a list of string:
66 #
67 # source_suffix = ['.rst', '.md']
68 source_suffix = '.rst'
69
70 # The encoding of source files.
71 #
72 # source_encoding = 'utf-8-sig'
73
74 # The master toctree document.
75 master_doc = 'index'
76
77 # General information about the project.
78 project = 'Parsl'
79 copyright = '2018--2020, Parsl Project'
80 author = 'Parsl Project'
81
82 # The version info for the project you're documenting, acts as replacement for
83 # |version| and |release|, also used in various other places throughout the
84 # built documents.
85 #
86 # The short X.Y version.
87 version = parsl.__version__.rsplit('.', 1)[0]
88 # The full version, including alpha/beta/rc tags.
89 release = parsl.__version__
90
91 # The language for content autogenerated by Sphinx. Refer to documentation
92 # for a list of supported languages.
93 #
94 # This is also used if you do content translation via gettext catalogs.
95 # Usually you set "language" from the command line for these cases.
96 language = None
97
98 # There are two options for replacing |today|: either, you set today to some
99 # non-false value, then it is used:
100 #
101 # today = ''
102 #
103 # Else, today_fmt is used as the format for a strftime call.
104 #
105 # today_fmt = '%B %d, %Y'
106
107 # List of patterns, relative to source directory, that match files and
108 # directories to ignore when looking for source files.
109 # This patterns also effect to html_static_path and html_extra_path
110 exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
111
112 # The reST default role (used for this markup: `text`) to use for all
113 # documents.
114 #
115 default_role = 'any'
116
117 # If true, '()' will be appended to :func: etc. cross-reference text.
118 #
119 # add_function_parentheses = True
120
121 # If true, the current module name will be prepended to all description
122 # unit titles (such as .. function::).
123 #
124 # add_module_names = True
125
126 # If true, sectionauthor and moduleauthor directives will be shown in the
127 # output. They are ignored by default.
128 #
129 # show_authors = False
130
131 # The name of the Pygments (syntax highlighting) style to use.
132 pygments_style = 'sphinx'
133
134 # A list of ignored prefixes for module index sorting.
135 # modindex_common_prefix = []
136
137 # If true, keep warnings as "system message" paragraphs in the built documents.
138 # keep_warnings = False
139
140 # If true, `todo` and `todoList` produce output, else they produce nothing.
141 todo_include_todos = False
142
143
144 # -- Options for HTML output ----------------------------------------------
145
146 # The theme to use for HTML and HTML Help pages. See the documentation for
147 # a list of builtin themes.
148 #
149 #html_theme = 'alabaster'
150 html_theme = 'sphinx_rtd_theme'
151
152 # Theme options are theme-specific and customize the look and feel of a theme
153 # further. For a list of options available for each theme, see the
154 # documentation.
155 #
156 # html_theme_options = {}
157
158 # Add any paths that contain custom themes here, relative to this directory.
159 # html_theme_path = []
160
161 # The name for this set of Sphinx documents.
162 # "<project> v<release> documentation" by default.
163 #
164 # html_title = 'Parsl v0.1'
165
166 # A shorter title for the navigation bar. Default is the same as html_title.
167 #
168 # html_short_title = None
169
170 # The name of an image file (relative to this directory) to place at the top
171 # of the sidebar.
172 #
173 # html_logo = None
174
175 # The name of an image file (relative to this directory) to use as a favicon of
176 # the docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
177 # pixels large.
178 #
179 # html_favicon = None
180
181 # Add any paths that contain custom static files (such as style sheets) here,
182 # relative to this directory. They are copied after the builtin static files,
183 # so a file named "default.css" will overwrite the builtin "default.css".
184 html_static_path = ['_static']
185
186 # Add any extra paths that contain custom files (such as robots.txt or
187 # .htaccess) here, relative to this directory. These files are copied
188 # directly to the root of the documentation.
189 #
190 # html_extra_path = []
191
192 # If not None, a 'Last updated on:' timestamp is inserted at every page
193 # bottom, using the given strftime format.
194 # The empty string is equivalent to '%b %d, %Y'.
195 #
196 # html_last_updated_fmt = None
197
198 # If true, SmartyPants will be used to convert quotes and dashes to
199 # typographically correct entities.
200 #
201 # html_use_smartypants = True
202
203 # Custom sidebar templates, maps document names to template names.
204 #
205 # html_sidebars = {}
206
207 # Additional templates that should be rendered to pages, maps page names to
208 # template names.
209 #
210 # html_additional_pages = {}
211
212 # If false, no module index is generated.
213 #
214 # html_domain_indices = True
215
216 # If false, no index is generated.
217 #
218 # html_use_index = True
219
220 # If true, the index is split into individual pages for each letter.
221 #
222 # html_split_index = False
223
224 # If true, links to the reST sources are added to the pages.
225 #
226 # html_show_sourcelink = True
227
228 # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
229 #
230 # html_show_sphinx = True
231
232 # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
233 #
234 # html_show_copyright = True
235
236 # If true, an OpenSearch description file will be output, and all pages will
237 # contain a <link> tag referring to it. The value of this option must be the
238 # base URL from which the finished HTML is served.
239 #
240 # html_use_opensearch = ''
241
242 # This is the file name suffix for HTML files (e.g. ".xhtml").
243 # html_file_suffix = None
244
245 # Language to be used for generating the HTML full-text search index.
246 # Sphinx supports the following languages:
247 # 'da', 'de', 'en', 'es', 'fi', 'fr', 'h', 'it', 'ja'
248 # 'nl', 'no', 'pt', 'ro', 'r', 'sv', 'tr', 'zh'
249 #
250 # html_search_language = 'en'
251
252 # A dictionary with options for the search language support, empty by default.
253 # 'ja' uses this config value.
254 # 'zh' user can custom change `jieba` dictionary path.
255 #
256 # html_search_options = {'type': 'default'}
257
258 # The name of a javascript file (relative to the configuration directory) that
259 # implements a search results scorer. If empty, the default will be used.
260 #
261 # html_search_scorer = 'scorer.js'
262
263 # Output file base name for HTML help builder.
264 htmlhelp_basename = 'Parsldoc'
265
266 # -- Options for LaTeX output ---------------------------------------------
267
268 latex_elements = {
269 # The paper size ('letterpaper' or 'a4paper').
270 #
271 # 'papersize': 'letterpaper',
272
273 # The font size ('10pt', '11pt' or '12pt').
274 #
275 # 'pointsize': '10pt',
276
277 # Additional stuff for the LaTeX preamble.
278 #
279 # 'preamble': '',
280
281 # Latex figure (float) alignment
282 #
283 # 'figure_align': 'htbp',
284 }
285
286 # Grouping the document tree into LaTeX files. List of tuples
287 # (source start file, target name, title,
288 # author, documentclass [howto, manual, or own class]).
289 latex_documents = [
290 (master_doc, 'Parsl.tex', 'Parsl Documentation',
291 'The Parsl Team', 'manual'),
292 ]
293
294 # The name of an image file (relative to this directory) to place at the top of
295 # the title page.
296 #
297 # latex_logo = None
298
299 # For "manual" documents, if this is true, then toplevel headings are parts,
300 # not chapters.
301 #
302 # latex_use_parts = False
303
304 # If true, show page references after internal links.
305 #
306 # latex_show_pagerefs = False
307
308 # If true, show URL addresses after external links.
309 #
310 # latex_show_urls = False
311
312 # Documents to append as an appendix to all manuals.
313 #
314 # latex_appendices = []
315
316 # It false, will not define \strong, \code, itleref, \crossref ... but only
317 # \sphinxstrong, ..., \sphinxtitleref, ... To help avoid clash with user added
318 # packages.
319 #
320 # latex_keep_old_macro_names = True
321
322 # If false, no module index is generated.
323 #
324 # latex_domain_indices = True
325
326
327 # -- Options for manual page output ---------------------------------------
328
329 # One entry per manual page. List of tuples
330 # (source start file, name, description, authors, manual section).
331 man_pages = [
332 (master_doc, 'parsl', 'Parsl Documentation',
333 [author], 1)
334 ]
335
336 # If true, show URL addresses after external links.
337 #
338 # man_show_urls = False
339
340
341 # -- Options for Texinfo output -------------------------------------------
342
343 # Grouping the document tree into Texinfo files. List of tuples
344 # (source start file, target name, title, author,
345 # dir menu entry, description, category)
346 texinfo_documents = [
347 (master_doc, 'Parsl', 'Parsl Documentation',
348 author, 'Parsl', 'One line description of project.',
349 'Miscellaneous'),
350 ]
351
352 # Documents to append as an appendix to all manuals.
353 #
354 # texinfo_appendices = []
355
356 # If false, no module index is generated.
357 #
358 # texinfo_domain_indices = True
359
360 # How to display URL addresses: 'footnote', 'no', or 'inline'.
361 #
362 # texinfo_show_urls = 'footnote'
363
364 # If true, do not generate a @detailmenu in the "Top" node's menu.
365 #
366 # texinfo_no_detailmenu = False
367
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -40,9 +40,9 @@
'sphinx.ext.napoleon'
]
-url = 'https://raw.githubusercontent.com/Parsl/parsl-tutorial/master/parsl-introduction.ipynb'
+url = 'https://raw.githubusercontent.com/Parsl/parsl-tutorial/master/1-parsl-introduction.ipynb'
r = requests.get(url)
-with open(os.path.join(os.path.dirname(__file__), 'parsl-introduction.ipynb'), 'wb') as f:
+with open(os.path.join(os.path.dirname(__file__), '1-parsl-introduction.ipynb'), 'wb') as f:
f.write(r.content)
nbsphinx_execute = 'never'
| {"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -40,9 +40,9 @@\n 'sphinx.ext.napoleon'\n ]\n \n-url = 'https://raw.githubusercontent.com/Parsl/parsl-tutorial/master/parsl-introduction.ipynb'\n+url = 'https://raw.githubusercontent.com/Parsl/parsl-tutorial/master/1-parsl-introduction.ipynb'\n r = requests.get(url)\n-with open(os.path.join(os.path.dirname(__file__), 'parsl-introduction.ipynb'), 'wb') as f:\n+with open(os.path.join(os.path.dirname(__file__), '1-parsl-introduction.ipynb'), 'wb') as f:\n f.write(r.content)\n \n nbsphinx_execute = 'never'\n", "issue": "Broken link to online documentation\nIn the [Quickstart Guide](https://parsl.readthedocs.io/en/stable/quickstart.html#installation-using-conda), the third option in the Tutorial list, \"Read through the online tutorial documentation,\" contains a broken link: <https://parsl.readthedocs.io/en/stable/parsl-introduction> leads to rtd's \"Maze Not Found\" error page.\n", "before_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n#\n# Parsl documentation build configuration file, created by\n# sphinx-quickstart on Mon Feb 20 16:35:17 2017.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nimport requests\nsys.path.insert(0, os.path.abspath('../'))\nimport parsl\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'nbsphinx',\n 'sphinx.ext.autodoc',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.intersphinx',\n 'sphinx.ext.linkcode',\n 'sphinx.ext.napoleon'\n]\n\nurl = 'https://raw.githubusercontent.com/Parsl/parsl-tutorial/master/parsl-introduction.ipynb'\nr = requests.get(url)\nwith open(os.path.join(os.path.dirname(__file__), 'parsl-introduction.ipynb'), 'wb') as f:\n f.write(r.content)\n\nnbsphinx_execute = 'never'\n\ndef linkcode_resolve(domain, info):\n if domain != 'py':\n return None\n if not info['module']:\n return None\n filename = info['module'].replace('.', '/')\n return \"http://github.com/Parsl/parsl/blob/master/{}.py\".format(filename)\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\nintersphinx_mapping = {\n 'python': ('https://docs.python.org/3', None),\n}\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#\n# source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = 'Parsl'\ncopyright = '2018--2020, Parsl Project'\nauthor = 'Parsl Project'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = parsl.__version__.rsplit('.', 1)[0]\n# The full version, including alpha/beta/rc tags.\nrelease = parsl.__version__\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#\n# today = ''\n#\n# Else, today_fmt is used as the format for a strftime call.\n#\n# today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']\n\n# The reST default role (used for this markup: `text`) to use for all\n# documents.\n#\ndefault_role = 'any'\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#\n# add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#\n# add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#\n# show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n# modindex_common_prefix = []\n\n# If true, keep warnings as \"system message\" paragraphs in the built documents.\n# keep_warnings = False\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\n#html_theme = 'alabaster'\nhtml_theme = 'sphinx_rtd_theme'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\n# html_theme_path = []\n\n# The name for this set of Sphinx documents.\n# \"<project> v<release> documentation\" by default.\n#\n# html_title = 'Parsl v0.1'\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#\n# html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\n#\n# html_logo = None\n\n# The name of an image file (relative to this directory) to use as a favicon of\n# the docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\n#\n# html_favicon = None\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# Add any extra paths that contain custom files (such as robots.txt or\n# .htaccess) here, relative to this directory. These files are copied\n# directly to the root of the documentation.\n#\n# html_extra_path = []\n\n# If not None, a 'Last updated on:' timestamp is inserted at every page\n# bottom, using the given strftime format.\n# The empty string is equivalent to '%b %d, %Y'.\n#\n# html_last_updated_fmt = None\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n#\n# html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n#\n# html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#\n# html_additional_pages = {}\n\n# If false, no module index is generated.\n#\n# html_domain_indices = True\n\n# If false, no index is generated.\n#\n# html_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#\n# html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#\n# html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#\n# html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#\n# html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#\n# html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n# html_file_suffix = None\n\n# Language to be used for generating the HTML full-text search index.\n# Sphinx supports the following languages:\n# 'da', 'de', 'en', 'es', 'fi', 'fr', 'h', 'it', 'ja'\n# 'nl', 'no', 'pt', 'ro', 'r', 'sv', 'tr', 'zh'\n#\n# html_search_language = 'en'\n\n# A dictionary with options for the search language support, empty by default.\n# 'ja' uses this config value.\n# 'zh' user can custom change `jieba` dictionary path.\n#\n# html_search_options = {'type': 'default'}\n\n# The name of a javascript file (relative to the configuration directory) that\n# implements a search results scorer. If empty, the default will be used.\n#\n# html_search_scorer = 'scorer.js'\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Parsldoc'\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'Parsl.tex', 'Parsl Documentation',\n 'The Parsl Team', 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#\n# latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#\n# latex_use_parts = False\n\n# If true, show page references after internal links.\n#\n# latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#\n# latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#\n# latex_appendices = []\n\n# It false, will not define \\strong, \\code, \titleref, \\crossref ... but only\n# \\sphinxstrong, ..., \\sphinxtitleref, ... To help avoid clash with user added\n# packages.\n#\n# latex_keep_old_macro_names = True\n\n# If false, no module index is generated.\n#\n# latex_domain_indices = True\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'parsl', 'Parsl Documentation',\n [author], 1)\n]\n\n# If true, show URL addresses after external links.\n#\n# man_show_urls = False\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'Parsl', 'Parsl Documentation',\n author, 'Parsl', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#\n# texinfo_appendices = []\n\n# If false, no module index is generated.\n#\n# texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#\n# texinfo_show_urls = 'footnote'\n\n# If true, do not generate a @detailmenu in the \"Top\" node's menu.\n#\n# texinfo_no_detailmenu = False\n", "path": "docs/conf.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n#\n# Parsl documentation build configuration file, created by\n# sphinx-quickstart on Mon Feb 20 16:35:17 2017.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nimport requests\nsys.path.insert(0, os.path.abspath('../'))\nimport parsl\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'nbsphinx',\n 'sphinx.ext.autodoc',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.intersphinx',\n 'sphinx.ext.linkcode',\n 'sphinx.ext.napoleon'\n]\n\nurl = 'https://raw.githubusercontent.com/Parsl/parsl-tutorial/master/1-parsl-introduction.ipynb'\nr = requests.get(url)\nwith open(os.path.join(os.path.dirname(__file__), '1-parsl-introduction.ipynb'), 'wb') as f:\n f.write(r.content)\n\nnbsphinx_execute = 'never'\n\ndef linkcode_resolve(domain, info):\n if domain != 'py':\n return None\n if not info['module']:\n return None\n filename = info['module'].replace('.', '/')\n return \"http://github.com/Parsl/parsl/blob/master/{}.py\".format(filename)\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\nintersphinx_mapping = {\n 'python': ('https://docs.python.org/3', None),\n}\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#\n# source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = 'Parsl'\ncopyright = '2018--2020, Parsl Project'\nauthor = 'Parsl Project'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = parsl.__version__.rsplit('.', 1)[0]\n# The full version, including alpha/beta/rc tags.\nrelease = parsl.__version__\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#\n# today = ''\n#\n# Else, today_fmt is used as the format for a strftime call.\n#\n# today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']\n\n# The reST default role (used for this markup: `text`) to use for all\n# documents.\n#\ndefault_role = 'any'\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#\n# add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#\n# add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#\n# show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n# modindex_common_prefix = []\n\n# If true, keep warnings as \"system message\" paragraphs in the built documents.\n# keep_warnings = False\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\n#html_theme = 'alabaster'\nhtml_theme = 'sphinx_rtd_theme'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\n# html_theme_path = []\n\n# The name for this set of Sphinx documents.\n# \"<project> v<release> documentation\" by default.\n#\n# html_title = 'Parsl v0.1'\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#\n# html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\n#\n# html_logo = None\n\n# The name of an image file (relative to this directory) to use as a favicon of\n# the docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\n#\n# html_favicon = None\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# Add any extra paths that contain custom files (such as robots.txt or\n# .htaccess) here, relative to this directory. These files are copied\n# directly to the root of the documentation.\n#\n# html_extra_path = []\n\n# If not None, a 'Last updated on:' timestamp is inserted at every page\n# bottom, using the given strftime format.\n# The empty string is equivalent to '%b %d, %Y'.\n#\n# html_last_updated_fmt = None\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n#\n# html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n#\n# html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#\n# html_additional_pages = {}\n\n# If false, no module index is generated.\n#\n# html_domain_indices = True\n\n# If false, no index is generated.\n#\n# html_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#\n# html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#\n# html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#\n# html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#\n# html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#\n# html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n# html_file_suffix = None\n\n# Language to be used for generating the HTML full-text search index.\n# Sphinx supports the following languages:\n# 'da', 'de', 'en', 'es', 'fi', 'fr', 'h', 'it', 'ja'\n# 'nl', 'no', 'pt', 'ro', 'r', 'sv', 'tr', 'zh'\n#\n# html_search_language = 'en'\n\n# A dictionary with options for the search language support, empty by default.\n# 'ja' uses this config value.\n# 'zh' user can custom change `jieba` dictionary path.\n#\n# html_search_options = {'type': 'default'}\n\n# The name of a javascript file (relative to the configuration directory) that\n# implements a search results scorer. If empty, the default will be used.\n#\n# html_search_scorer = 'scorer.js'\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Parsldoc'\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'Parsl.tex', 'Parsl Documentation',\n 'The Parsl Team', 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#\n# latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#\n# latex_use_parts = False\n\n# If true, show page references after internal links.\n#\n# latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#\n# latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#\n# latex_appendices = []\n\n# It false, will not define \\strong, \\code, \titleref, \\crossref ... but only\n# \\sphinxstrong, ..., \\sphinxtitleref, ... To help avoid clash with user added\n# packages.\n#\n# latex_keep_old_macro_names = True\n\n# If false, no module index is generated.\n#\n# latex_domain_indices = True\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'parsl', 'Parsl Documentation',\n [author], 1)\n]\n\n# If true, show URL addresses after external links.\n#\n# man_show_urls = False\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'Parsl', 'Parsl Documentation',\n author, 'Parsl', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#\n# texinfo_appendices = []\n\n# If false, no module index is generated.\n#\n# texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#\n# texinfo_show_urls = 'footnote'\n\n# If true, do not generate a @detailmenu in the \"Top\" node's menu.\n#\n# texinfo_no_detailmenu = False\n", "path": "docs/conf.py"}]} | 4,075 | 178 |
gh_patches_debug_5725 | rasdani/github-patches | git_diff | chainer__chainer-7529 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
test_init_docstring.py fail
```
C:\Path\To\chainer>py -3.7 -m pytest tests\chainer_tests\test_init_docstring.py
================================================= test session starts =================================================
platform win32 -- Python 3.7.3, pytest-4.1.1, py-1.8.0, pluggy-0.12.0
rootdir: C:\Development\gopath\src\github.com\chainer\chainer, inifile: setup.cfg
collected 1 item
tests\chainer_tests\test_init_docstring.py F [100%]
====================================================== FAILURES =======================================================
_____________________________________ TestInitDocstring.test_init_docstring_empty _____________________________________
self = <chainer_tests.test_init_docstring.TestInitDocstring testMethod=test_init_docstring_empty>
def test_init_docstring_empty(self):
errors = []
root = chainer.__path__
for loader, modname, ispkg in pkgutil.walk_packages(root, 'chainer.'):
# Skip modules generated by protobuf.
if '_pb2' in modname:
continue
try:
> mod = importlib.import_module(modname)
tests\chainer_tests\test_init_docstring.py:48:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
C:\Development\Python\Python37\lib\importlib\__init__.py:127: in import_module
return _bootstrap._gcd_import(name[level:], package, level)
<frozen importlib._bootstrap>:1006: in _gcd_import
???
<frozen importlib._bootstrap>:983: in _find_and_load
???
<frozen importlib._bootstrap>:967: in _find_and_load_unlocked
???
<frozen importlib._bootstrap>:677: in _load_unlocked
???
<frozen importlib._bootstrap_external>:728: in exec_module
???
<frozen importlib._bootstrap>:219: in _call_with_frames_removed
???
chainer\exporters\__init__.py:1: in <module>
from chainer.exporters import caffe # NOQA
chainer\exporters\caffe.py:11: in <module>
from chainer.links.caffe.protobuf3 import caffe_pb2 as caffe_pb
chainer\links\caffe\__init__.py:1: in <module>
from chainer.links.caffe.caffe_function import CaffeFunction # NOQA
chainer\links\caffe\caffe_function.py:10: in <module>
from chainer.links.caffe.protobuf3 import caffe_pb2 as caffe_pb
chainer\links\caffe\protobuf3\caffe_pb2.py:7: in <module>
from google.protobuf import descriptor as _descriptor
C:\Development\Python\Python37\lib\site-packages\google\protobuf\descriptor.py:47: in <module>
from google.protobuf.pyext import _message
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
name = 'MutableSequence'
def __getattr__(name):
# For backwards compatibility, continue to make the collections ABCs
# through Python 3.6 available through the collections module.
# Note, no new collections ABCs were added in Python 3.7
if name in _collections_abc.__all__:
obj = getattr(_collections_abc, name)
import warnings
warnings.warn("Using or importing the ABCs from 'collections' instead "
"of from 'collections.abc' is deprecated, "
"and in 3.8 it will stop working",
> DeprecationWarning, stacklevel=2)
E DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
C:\Development\Python\Python37\lib\collections\__init__.py:52: DeprecationWarning
============================================== 1 failed in 0.45 seconds ===============================================
```
- Python 3.7
- Chainer version: master (https://github.com/chainer/chainer/commit/c7b9c037f3e7116aeb29db8273e025b90bed0a70)
- Depend modules: `pip install -e .[test]` on the commit id
- OS/Platform: windows10
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 import os
4 import pkg_resources
5 import sys
6
7 from setuptools import setup
8
9 import chainerx_build_helper
10
11
12 if sys.version_info[:3] == (3, 5, 0):
13 if not int(os.getenv('CHAINER_PYTHON_350_FORCE', '0')):
14 msg = """
15 Chainer does not work with Python 3.5.0.
16
17 We strongly recommend to use another version of Python.
18 If you want to use Chainer with Python 3.5.0 at your own risk,
19 set CHAINER_PYTHON_350_FORCE environment variable to 1."""
20 print(msg)
21 sys.exit(1)
22
23
24 requirements = {
25 'install': [
26 'setuptools',
27 'typing',
28 'typing_extensions',
29 'filelock',
30 'numpy>=1.9.0',
31 # protobuf 3.8.0rc1 causes CI errors.
32 # TODO(niboshi): Probably we should always use pip in CIs for
33 # installing chainer. It avoids pre-release dependencies by default.
34 # See also: https://github.com/pypa/setuptools/issues/855
35 'protobuf>=3.0.0,<3.8.0rc1',
36 'six>=1.9.0',
37 ],
38 'stylecheck': [
39 'autopep8>=1.4.1,<1.5',
40 'flake8>=3.7,<3.8',
41 'pycodestyle>=2.5,<2.6',
42 ],
43 'test': [
44 'pytest<4.2.0', # 4.2.0 is slow collecting tests and times out on CI.
45 'mock',
46 ],
47 'doctest': [
48 'sphinx==1.8.2',
49 'matplotlib',
50 'theano',
51 ],
52 'docs': [
53 'sphinx==1.8.2',
54 'sphinx_rtd_theme',
55 ],
56 'appveyor': [
57 '-r test',
58 # pytest-timeout>=1.3.0 requires pytest>=3.6.
59 # TODO(niboshi): Consider upgrading pytest to >=3.6
60 'pytest-timeout<1.3.0',
61 ],
62 }
63
64
65 if sys.version_info >= (3, 4): # mypy requires Python 3.4 or later
66 requirements['stylecheck'].append('mypy')
67
68
69 def reduce_requirements(key):
70 # Resolve recursive requirements notation (-r)
71 reqs = requirements[key]
72 resolved_reqs = []
73 for req in reqs:
74 if req.startswith('-r'):
75 depend_key = req[2:].lstrip()
76 reduce_requirements(depend_key)
77 resolved_reqs += requirements[depend_key]
78 else:
79 resolved_reqs.append(req)
80 requirements[key] = resolved_reqs
81
82
83 for k in requirements.keys():
84 reduce_requirements(k)
85
86
87 extras_require = {k: v for k, v in requirements.items() if k != 'install'}
88 setup_requires = []
89 install_requires = requirements['install']
90 tests_require = requirements['test']
91
92
93 def find_any_distribution(pkgs):
94 for pkg in pkgs:
95 try:
96 return pkg_resources.get_distribution(pkg)
97 except pkg_resources.DistributionNotFound:
98 pass
99 return None
100
101
102 mn_pkg = find_any_distribution(['chainermn'])
103 if mn_pkg is not None:
104 msg = """
105 We detected that ChainerMN is installed in your environment.
106 ChainerMN has been integrated to Chainer and no separate installation
107 is necessary. Please uninstall the old ChainerMN in advance.
108 """
109 print(msg)
110 exit(1)
111
112 here = os.path.abspath(os.path.dirname(__file__))
113 # Get __version__ variable
114 exec(open(os.path.join(here, 'chainer', '_version.py')).read())
115
116
117 setup_kwargs = dict(
118 name='chainer',
119 version=__version__, # NOQA
120 description='A flexible framework of neural networks',
121 long_description=open('README.md').read(),
122 long_description_content_type='text/markdown',
123 author='Seiya Tokui',
124 author_email='[email protected]',
125 url='https://chainer.org/',
126 license='MIT License',
127 packages=['chainer',
128 'chainer.backends',
129 'chainer.dataset',
130 'chainer.dataset.tabular',
131 'chainer.datasets',
132 'chainer.distributions',
133 'chainer.exporters',
134 'chainer.functions',
135 'chainer.functions.activation',
136 'chainer.functions.array',
137 'chainer.functions.connection',
138 'chainer.functions.evaluation',
139 'chainer.functions.loss',
140 'chainer.functions.math',
141 'chainer.functions.noise',
142 'chainer.functions.normalization',
143 'chainer.functions.pooling',
144 'chainer.functions.theano',
145 'chainer.functions.util',
146 'chainer.function_hooks',
147 'chainer.iterators',
148 'chainer.initializers',
149 'chainer.links',
150 'chainer.links.activation',
151 'chainer.links.caffe',
152 'chainer.links.caffe.protobuf3',
153 'chainer.links.connection',
154 'chainer.links.loss',
155 'chainer.links.model',
156 'chainer.links.model.vision',
157 'chainer.links.normalization',
158 'chainer.links.theano',
159 'chainer.link_hooks',
160 'chainer.graph_optimizations',
161 'chainer.optimizers',
162 'chainer.optimizer_hooks',
163 'chainer.serializers',
164 'chainer.testing',
165 'chainer.training',
166 'chainer.training.extensions',
167 'chainer.training.triggers',
168 'chainer.training.updaters',
169 'chainer.utils',
170 'chainermn',
171 'chainermn.communicators',
172 'chainermn.datasets',
173 'chainermn.extensions',
174 'chainermn.functions',
175 'chainermn.iterators',
176 'chainermn.links'],
177 package_data={
178 'chainer': ['py.typed'],
179 },
180 zip_safe=False,
181 setup_requires=setup_requires,
182 install_requires=install_requires,
183 tests_require=tests_require,
184 extras_require=extras_require,
185 )
186
187
188 build_chainerx = 0 != int(os.getenv('CHAINER_BUILD_CHAINERX', '0'))
189 if (os.getenv('READTHEDOCS', None) == 'True'
190 and os.getenv('READTHEDOCS_PROJECT', None) == 'chainer'):
191 os.environ['MAKEFLAGS'] = '-j2'
192 build_chainerx = True
193
194 chainerx_build_helper.config_setup_kwargs(setup_kwargs, build_chainerx)
195
196
197 setup(**setup_kwargs)
198
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -28,11 +28,7 @@
'typing_extensions',
'filelock',
'numpy>=1.9.0',
- # protobuf 3.8.0rc1 causes CI errors.
- # TODO(niboshi): Probably we should always use pip in CIs for
- # installing chainer. It avoids pre-release dependencies by default.
- # See also: https://github.com/pypa/setuptools/issues/855
- 'protobuf>=3.0.0,<3.8.0rc1',
+ 'protobuf>=3.0.0',
'six>=1.9.0',
],
'stylecheck': [
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -28,11 +28,7 @@\n 'typing_extensions',\n 'filelock',\n 'numpy>=1.9.0',\n- # protobuf 3.8.0rc1 causes CI errors.\n- # TODO(niboshi): Probably we should always use pip in CIs for\n- # installing chainer. It avoids pre-release dependencies by default.\n- # See also: https://github.com/pypa/setuptools/issues/855\n- 'protobuf>=3.0.0,<3.8.0rc1',\n+ 'protobuf>=3.0.0',\n 'six>=1.9.0',\n ],\n 'stylecheck': [\n", "issue": "test_init_docstring.py fail\n```\r\nC:\\Path\\To\\chainer>py -3.7 -m pytest tests\\chainer_tests\\test_init_docstring.py\r\n================================================= test session starts =================================================\r\nplatform win32 -- Python 3.7.3, pytest-4.1.1, py-1.8.0, pluggy-0.12.0\r\nrootdir: C:\\Development\\gopath\\src\\github.com\\chainer\\chainer, inifile: setup.cfg\r\ncollected 1 item\r\n\r\ntests\\chainer_tests\\test_init_docstring.py F [100%]\r\n\r\n====================================================== FAILURES =======================================================\r\n_____________________________________ TestInitDocstring.test_init_docstring_empty _____________________________________\r\n\r\nself = <chainer_tests.test_init_docstring.TestInitDocstring testMethod=test_init_docstring_empty>\r\n\r\n def test_init_docstring_empty(self):\r\n errors = []\r\n root = chainer.__path__\r\n for loader, modname, ispkg in pkgutil.walk_packages(root, 'chainer.'):\r\n # Skip modules generated by protobuf.\r\n if '_pb2' in modname:\r\n continue\r\n\r\n try:\r\n> mod = importlib.import_module(modname)\r\n\r\ntests\\chainer_tests\\test_init_docstring.py:48:\r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _\r\nC:\\Development\\Python\\Python37\\lib\\importlib\\__init__.py:127: in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\n<frozen importlib._bootstrap>:1006: in _gcd_import\r\n ???\r\n<frozen importlib._bootstrap>:983: in _find_and_load\r\n ???\r\n<frozen importlib._bootstrap>:967: in _find_and_load_unlocked\r\n ???\r\n<frozen importlib._bootstrap>:677: in _load_unlocked\r\n ???\r\n<frozen importlib._bootstrap_external>:728: in exec_module\r\n ???\r\n<frozen importlib._bootstrap>:219: in _call_with_frames_removed\r\n ???\r\nchainer\\exporters\\__init__.py:1: in <module>\r\n from chainer.exporters import caffe # NOQA\r\nchainer\\exporters\\caffe.py:11: in <module>\r\n from chainer.links.caffe.protobuf3 import caffe_pb2 as caffe_pb\r\nchainer\\links\\caffe\\__init__.py:1: in <module>\r\n from chainer.links.caffe.caffe_function import CaffeFunction # NOQA\r\nchainer\\links\\caffe\\caffe_function.py:10: in <module>\r\n from chainer.links.caffe.protobuf3 import caffe_pb2 as caffe_pb\r\nchainer\\links\\caffe\\protobuf3\\caffe_pb2.py:7: in <module>\r\n from google.protobuf import descriptor as _descriptor\r\nC:\\Development\\Python\\Python37\\lib\\site-packages\\google\\protobuf\\descriptor.py:47: in <module>\r\n from google.protobuf.pyext import _message\r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _\r\n\r\nname = 'MutableSequence'\r\n\r\n def __getattr__(name):\r\n # For backwards compatibility, continue to make the collections ABCs\r\n # through Python 3.6 available through the collections module.\r\n # Note, no new collections ABCs were added in Python 3.7\r\n if name in _collections_abc.__all__:\r\n obj = getattr(_collections_abc, name)\r\n import warnings\r\n warnings.warn(\"Using or importing the ABCs from 'collections' instead \"\r\n \"of from 'collections.abc' is deprecated, \"\r\n \"and in 3.8 it will stop working\",\r\n> DeprecationWarning, stacklevel=2)\r\nE DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working\r\n\r\nC:\\Development\\Python\\Python37\\lib\\collections\\__init__.py:52: DeprecationWarning\r\n============================================== 1 failed in 0.45 seconds ===============================================\r\n```\r\n\r\n- Python 3.7\r\n- Chainer version: master (https://github.com/chainer/chainer/commit/c7b9c037f3e7116aeb29db8273e025b90bed0a70)\r\n- Depend modules: `pip install -e .[test]` on the commit id\r\n- OS/Platform: windows10\n", "before_files": [{"content": "#!/usr/bin/env python\n\nimport os\nimport pkg_resources\nimport sys\n\nfrom setuptools import setup\n\nimport chainerx_build_helper\n\n\nif sys.version_info[:3] == (3, 5, 0):\n if not int(os.getenv('CHAINER_PYTHON_350_FORCE', '0')):\n msg = \"\"\"\nChainer does not work with Python 3.5.0.\n\nWe strongly recommend to use another version of Python.\nIf you want to use Chainer with Python 3.5.0 at your own risk,\nset CHAINER_PYTHON_350_FORCE environment variable to 1.\"\"\"\n print(msg)\n sys.exit(1)\n\n\nrequirements = {\n 'install': [\n 'setuptools',\n 'typing',\n 'typing_extensions',\n 'filelock',\n 'numpy>=1.9.0',\n # protobuf 3.8.0rc1 causes CI errors.\n # TODO(niboshi): Probably we should always use pip in CIs for\n # installing chainer. It avoids pre-release dependencies by default.\n # See also: https://github.com/pypa/setuptools/issues/855\n 'protobuf>=3.0.0,<3.8.0rc1',\n 'six>=1.9.0',\n ],\n 'stylecheck': [\n 'autopep8>=1.4.1,<1.5',\n 'flake8>=3.7,<3.8',\n 'pycodestyle>=2.5,<2.6',\n ],\n 'test': [\n 'pytest<4.2.0', # 4.2.0 is slow collecting tests and times out on CI.\n 'mock',\n ],\n 'doctest': [\n 'sphinx==1.8.2',\n 'matplotlib',\n 'theano',\n ],\n 'docs': [\n 'sphinx==1.8.2',\n 'sphinx_rtd_theme',\n ],\n 'appveyor': [\n '-r test',\n # pytest-timeout>=1.3.0 requires pytest>=3.6.\n # TODO(niboshi): Consider upgrading pytest to >=3.6\n 'pytest-timeout<1.3.0',\n ],\n}\n\n\nif sys.version_info >= (3, 4): # mypy requires Python 3.4 or later\n requirements['stylecheck'].append('mypy')\n\n\ndef reduce_requirements(key):\n # Resolve recursive requirements notation (-r)\n reqs = requirements[key]\n resolved_reqs = []\n for req in reqs:\n if req.startswith('-r'):\n depend_key = req[2:].lstrip()\n reduce_requirements(depend_key)\n resolved_reqs += requirements[depend_key]\n else:\n resolved_reqs.append(req)\n requirements[key] = resolved_reqs\n\n\nfor k in requirements.keys():\n reduce_requirements(k)\n\n\nextras_require = {k: v for k, v in requirements.items() if k != 'install'}\nsetup_requires = []\ninstall_requires = requirements['install']\ntests_require = requirements['test']\n\n\ndef find_any_distribution(pkgs):\n for pkg in pkgs:\n try:\n return pkg_resources.get_distribution(pkg)\n except pkg_resources.DistributionNotFound:\n pass\n return None\n\n\nmn_pkg = find_any_distribution(['chainermn'])\nif mn_pkg is not None:\n msg = \"\"\"\nWe detected that ChainerMN is installed in your environment.\nChainerMN has been integrated to Chainer and no separate installation\nis necessary. Please uninstall the old ChainerMN in advance.\n\"\"\"\n print(msg)\n exit(1)\n\nhere = os.path.abspath(os.path.dirname(__file__))\n# Get __version__ variable\nexec(open(os.path.join(here, 'chainer', '_version.py')).read())\n\n\nsetup_kwargs = dict(\n name='chainer',\n version=__version__, # NOQA\n description='A flexible framework of neural networks',\n long_description=open('README.md').read(),\n long_description_content_type='text/markdown',\n author='Seiya Tokui',\n author_email='[email protected]',\n url='https://chainer.org/',\n license='MIT License',\n packages=['chainer',\n 'chainer.backends',\n 'chainer.dataset',\n 'chainer.dataset.tabular',\n 'chainer.datasets',\n 'chainer.distributions',\n 'chainer.exporters',\n 'chainer.functions',\n 'chainer.functions.activation',\n 'chainer.functions.array',\n 'chainer.functions.connection',\n 'chainer.functions.evaluation',\n 'chainer.functions.loss',\n 'chainer.functions.math',\n 'chainer.functions.noise',\n 'chainer.functions.normalization',\n 'chainer.functions.pooling',\n 'chainer.functions.theano',\n 'chainer.functions.util',\n 'chainer.function_hooks',\n 'chainer.iterators',\n 'chainer.initializers',\n 'chainer.links',\n 'chainer.links.activation',\n 'chainer.links.caffe',\n 'chainer.links.caffe.protobuf3',\n 'chainer.links.connection',\n 'chainer.links.loss',\n 'chainer.links.model',\n 'chainer.links.model.vision',\n 'chainer.links.normalization',\n 'chainer.links.theano',\n 'chainer.link_hooks',\n 'chainer.graph_optimizations',\n 'chainer.optimizers',\n 'chainer.optimizer_hooks',\n 'chainer.serializers',\n 'chainer.testing',\n 'chainer.training',\n 'chainer.training.extensions',\n 'chainer.training.triggers',\n 'chainer.training.updaters',\n 'chainer.utils',\n 'chainermn',\n 'chainermn.communicators',\n 'chainermn.datasets',\n 'chainermn.extensions',\n 'chainermn.functions',\n 'chainermn.iterators',\n 'chainermn.links'],\n package_data={\n 'chainer': ['py.typed'],\n },\n zip_safe=False,\n setup_requires=setup_requires,\n install_requires=install_requires,\n tests_require=tests_require,\n extras_require=extras_require,\n)\n\n\nbuild_chainerx = 0 != int(os.getenv('CHAINER_BUILD_CHAINERX', '0'))\nif (os.getenv('READTHEDOCS', None) == 'True'\n and os.getenv('READTHEDOCS_PROJECT', None) == 'chainer'):\n os.environ['MAKEFLAGS'] = '-j2'\n build_chainerx = True\n\nchainerx_build_helper.config_setup_kwargs(setup_kwargs, build_chainerx)\n\n\nsetup(**setup_kwargs)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\nimport os\nimport pkg_resources\nimport sys\n\nfrom setuptools import setup\n\nimport chainerx_build_helper\n\n\nif sys.version_info[:3] == (3, 5, 0):\n if not int(os.getenv('CHAINER_PYTHON_350_FORCE', '0')):\n msg = \"\"\"\nChainer does not work with Python 3.5.0.\n\nWe strongly recommend to use another version of Python.\nIf you want to use Chainer with Python 3.5.0 at your own risk,\nset CHAINER_PYTHON_350_FORCE environment variable to 1.\"\"\"\n print(msg)\n sys.exit(1)\n\n\nrequirements = {\n 'install': [\n 'setuptools',\n 'typing',\n 'typing_extensions',\n 'filelock',\n 'numpy>=1.9.0',\n 'protobuf>=3.0.0',\n 'six>=1.9.0',\n ],\n 'stylecheck': [\n 'autopep8>=1.4.1,<1.5',\n 'flake8>=3.7,<3.8',\n 'pycodestyle>=2.5,<2.6',\n ],\n 'test': [\n 'pytest<4.2.0', # 4.2.0 is slow collecting tests and times out on CI.\n 'mock',\n ],\n 'doctest': [\n 'sphinx==1.8.2',\n 'matplotlib',\n 'theano',\n ],\n 'docs': [\n 'sphinx==1.8.2',\n 'sphinx_rtd_theme',\n ],\n 'appveyor': [\n '-r test',\n # pytest-timeout>=1.3.0 requires pytest>=3.6.\n # TODO(niboshi): Consider upgrading pytest to >=3.6\n 'pytest-timeout<1.3.0',\n ],\n}\n\n\nif sys.version_info >= (3, 4): # mypy requires Python 3.4 or later\n requirements['stylecheck'].append('mypy')\n\n\ndef reduce_requirements(key):\n # Resolve recursive requirements notation (-r)\n reqs = requirements[key]\n resolved_reqs = []\n for req in reqs:\n if req.startswith('-r'):\n depend_key = req[2:].lstrip()\n reduce_requirements(depend_key)\n resolved_reqs += requirements[depend_key]\n else:\n resolved_reqs.append(req)\n requirements[key] = resolved_reqs\n\n\nfor k in requirements.keys():\n reduce_requirements(k)\n\n\nextras_require = {k: v for k, v in requirements.items() if k != 'install'}\nsetup_requires = []\ninstall_requires = requirements['install']\ntests_require = requirements['test']\n\n\ndef find_any_distribution(pkgs):\n for pkg in pkgs:\n try:\n return pkg_resources.get_distribution(pkg)\n except pkg_resources.DistributionNotFound:\n pass\n return None\n\n\nmn_pkg = find_any_distribution(['chainermn'])\nif mn_pkg is not None:\n msg = \"\"\"\nWe detected that ChainerMN is installed in your environment.\nChainerMN has been integrated to Chainer and no separate installation\nis necessary. Please uninstall the old ChainerMN in advance.\n\"\"\"\n print(msg)\n exit(1)\n\nhere = os.path.abspath(os.path.dirname(__file__))\n# Get __version__ variable\nexec(open(os.path.join(here, 'chainer', '_version.py')).read())\n\n\nsetup_kwargs = dict(\n name='chainer',\n version=__version__, # NOQA\n description='A flexible framework of neural networks',\n long_description=open('README.md').read(),\n long_description_content_type='text/markdown',\n author='Seiya Tokui',\n author_email='[email protected]',\n url='https://chainer.org/',\n license='MIT License',\n packages=['chainer',\n 'chainer.backends',\n 'chainer.dataset',\n 'chainer.dataset.tabular',\n 'chainer.datasets',\n 'chainer.distributions',\n 'chainer.exporters',\n 'chainer.functions',\n 'chainer.functions.activation',\n 'chainer.functions.array',\n 'chainer.functions.connection',\n 'chainer.functions.evaluation',\n 'chainer.functions.loss',\n 'chainer.functions.math',\n 'chainer.functions.noise',\n 'chainer.functions.normalization',\n 'chainer.functions.pooling',\n 'chainer.functions.theano',\n 'chainer.functions.util',\n 'chainer.function_hooks',\n 'chainer.iterators',\n 'chainer.initializers',\n 'chainer.links',\n 'chainer.links.activation',\n 'chainer.links.caffe',\n 'chainer.links.caffe.protobuf3',\n 'chainer.links.connection',\n 'chainer.links.loss',\n 'chainer.links.model',\n 'chainer.links.model.vision',\n 'chainer.links.normalization',\n 'chainer.links.theano',\n 'chainer.link_hooks',\n 'chainer.graph_optimizations',\n 'chainer.optimizers',\n 'chainer.optimizer_hooks',\n 'chainer.serializers',\n 'chainer.testing',\n 'chainer.training',\n 'chainer.training.extensions',\n 'chainer.training.triggers',\n 'chainer.training.updaters',\n 'chainer.utils',\n 'chainermn',\n 'chainermn.communicators',\n 'chainermn.datasets',\n 'chainermn.extensions',\n 'chainermn.functions',\n 'chainermn.iterators',\n 'chainermn.links'],\n package_data={\n 'chainer': ['py.typed'],\n },\n zip_safe=False,\n setup_requires=setup_requires,\n install_requires=install_requires,\n tests_require=tests_require,\n extras_require=extras_require,\n)\n\n\nbuild_chainerx = 0 != int(os.getenv('CHAINER_BUILD_CHAINERX', '0'))\nif (os.getenv('READTHEDOCS', None) == 'True'\n and os.getenv('READTHEDOCS_PROJECT', None) == 'chainer'):\n os.environ['MAKEFLAGS'] = '-j2'\n build_chainerx = True\n\nchainerx_build_helper.config_setup_kwargs(setup_kwargs, build_chainerx)\n\n\nsetup(**setup_kwargs)\n", "path": "setup.py"}]} | 3,237 | 172 |
gh_patches_debug_66911 | rasdani/github-patches | git_diff | ivy-llc__ivy-18929 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bincount
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/paddle/tensor/linalg.py`
Content:
```
1 # global
2 import ivy
3 from ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes
4 from ivy.functional.frontends.paddle import promote_types_of_paddle_inputs
5 from ivy.functional.frontends.paddle.func_wrapper import (
6 to_ivy_arrays_and_back,
7 )
8
9
10 @with_supported_dtypes(
11 {"2.5.0 and below": ("float32", "float64", "int32", "int64")}, "paddle"
12 )
13 @to_ivy_arrays_and_back
14 def cross(x, y, /, *, axis=9, name=None):
15 x, y = promote_types_of_paddle_inputs(x, y)
16 return ivy.cross(x, y, axis=axis)
17
18
19 # matmul
20 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
21 @to_ivy_arrays_and_back
22 def matmul(x, y, transpose_x=False, transpose_y=False, name=None):
23 x, y = promote_types_of_paddle_inputs(x, y)
24 return ivy.matmul(x, y, transpose_a=transpose_x, transpose_b=transpose_y)
25
26
27 # norm
28 @with_supported_dtypes({"2.5.0 and below": ("float32", "float64")}, "paddle")
29 @to_ivy_arrays_and_back
30 def norm(x, p="fro", axis=None, keepdim=False, name=None):
31 if axis is None and p is not None:
32 if p == "fro":
33 p = 2
34 ret = ivy.vector_norm(x.flatten(), ord=p, axis=-1)
35 if keepdim:
36 ret = ret.reshape([1] * len(x.shape))
37 if len(ret.shape) == 0:
38 return ivy.array([ret])
39 return ret
40
41 if isinstance(axis, tuple):
42 axis = list(axis)
43 if isinstance(axis, list) and len(axis) == 1:
44 axis = axis[0]
45
46 if isinstance(axis, int):
47 if p == "fro":
48 p = 2
49 if p in [0, 1, 2, ivy.inf, -ivy.inf]:
50 ret = ivy.vector_norm(x, ord=p, axis=axis, keepdims=keepdim)
51 elif isinstance(p, (int, float)):
52 ret = ivy.pow(
53 ivy.sum(ivy.pow(ivy.abs(x), p), axis=axis, keepdims=keepdim),
54 float(1.0 / p),
55 )
56
57 elif isinstance(axis, list) and len(axis) == 2:
58 if p == 0:
59 raise ValueError
60 elif p == 1:
61 ret = ivy.sum(ivy.abs(x), axis=axis, keepdims=keepdim)
62 elif p == 2 or p == "fro":
63 ret = ivy.matrix_norm(x, ord="fro", axis=axis, keepdims=keepdim)
64 elif p == ivy.inf:
65 ret = ivy.max(ivy.abs(x), axis=axis, keepdims=keepdim)
66 elif p == -ivy.inf:
67 ret = ivy.min(ivy.abs(x), axis=axis, keepdims=keepdim)
68 elif isinstance(p, (int, float)) and p > 0:
69 ret = ivy.pow(
70 ivy.sum(ivy.pow(ivy.abs(x), p), axis=axis, keepdims=keepdim),
71 float(1.0 / p),
72 )
73 else:
74 raise ValueError
75
76 else:
77 raise ValueError
78
79 if len(ret.shape) == 0:
80 ret = ivy.array(
81 [ret]
82 ) # this is done so as to match shape of output from paddle
83 return ret
84
85
86 # eig
87 @to_ivy_arrays_and_back
88 def eig(x, name=None):
89 return ivy.eig(x)
90
91
92 # eigvals
93 @to_ivy_arrays_and_back
94 def eigvals(x, name=None):
95 return ivy.eigvals(x)
96
97
98 # eigvalsh
99 @to_ivy_arrays_and_back
100 def eigvalsh(x, UPLO="L", name=None):
101 return ivy.eigvalsh(x, UPLO=UPLO)
102
103
104 # eigh
105 @to_ivy_arrays_and_back
106 def eigh(x, UPLO="L", name=None):
107 return ivy.eigh(x, UPLO=UPLO)
108
109
110 # pinv
111 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
112 @to_ivy_arrays_and_back
113 def pinv(x, rcond=1e-15, hermitian=False, name=None):
114 # TODO: Add hermitian functionality
115 return ivy.pinv(x, rtol=rcond)
116
117
118 # solve
119 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
120 @to_ivy_arrays_and_back
121 def solve(x1, x2, name=None):
122 return ivy.solve(x1, x2)
123
124
125 # cholesky
126 @with_supported_dtypes({"2.5.0 and below": ("float32", "float64")}, "paddle")
127 @to_ivy_arrays_and_back
128 def cholesky(x, /, *, upper=False, name=None):
129 return ivy.cholesky(x, upper=upper)
130
131
132 # bmm
133 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
134 @to_ivy_arrays_and_back
135 def bmm(x, y, transpose_x=False, transpose_y=False, name=None):
136 if len(ivy.shape(x)) != 3 or len(ivy.shape(y)) != 3:
137 raise RuntimeError("input must be 3D matrices")
138 x, y = promote_types_of_paddle_inputs(x, y)
139 return ivy.matmul(x, y, transpose_a=transpose_x, transpose_b=transpose_y)
140
141
142 # matrix_power
143 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
144 @to_ivy_arrays_and_back
145 def matrix_power(x, n, name=None):
146 return ivy.matrix_power(x, n)
147
148
149 # cond
150 @with_supported_dtypes({"2.5.0 and below": ("float32", "float64")}, "paddle")
151 @to_ivy_arrays_and_back
152 def cond(x, p=None, name=None):
153 ret = ivy.cond(x, p=p, out=name)
154 if ret.shape == ():
155 ret = ret.reshape((1, ))
156 return ret
157
158
159 # dot
160 @with_supported_dtypes({"2.5.0 and below": ("float32", "float64")}, "paddle")
161 @to_ivy_arrays_and_back
162 def dot(x, y, name=None):
163 x, y = promote_types_of_paddle_inputs(x, y)
164 out = ivy.multiply(x, y)
165 return ivy.sum(out, axis=ivy.get_num_dims(x) - 1, keepdims=False)
166
167
168 # transpose
169 @with_unsupported_dtypes({"2.5.0 and below": ("uint8", "int8", "int16")}, "paddle")
170 @to_ivy_arrays_and_back
171 def transpose(x, perm, name=None):
172 return ivy.permute_dims(x, axes=perm)
173
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/ivy/functional/frontends/paddle/tensor/linalg.py b/ivy/functional/frontends/paddle/tensor/linalg.py
--- a/ivy/functional/frontends/paddle/tensor/linalg.py
+++ b/ivy/functional/frontends/paddle/tensor/linalg.py
@@ -170,3 +170,9 @@
@to_ivy_arrays_and_back
def transpose(x, perm, name=None):
return ivy.permute_dims(x, axes=perm)
+
+
+@with_supported_dtypes({"2.4.1 and above": ("int64",)}, "paddle")
+@to_ivy_arrays_and_back
+def bincount(x, weights=None, minlength=0, name=None):
+ return ivy.bincount(x, weights=weights, minlength=minlength)
| {"golden_diff": "diff --git a/ivy/functional/frontends/paddle/tensor/linalg.py b/ivy/functional/frontends/paddle/tensor/linalg.py\n--- a/ivy/functional/frontends/paddle/tensor/linalg.py\n+++ b/ivy/functional/frontends/paddle/tensor/linalg.py\n@@ -170,3 +170,9 @@\n @to_ivy_arrays_and_back\n def transpose(x, perm, name=None):\n return ivy.permute_dims(x, axes=perm)\n+\n+\n+@with_supported_dtypes({\"2.4.1 and above\": (\"int64\",)}, \"paddle\")\n+@to_ivy_arrays_and_back\n+def bincount(x, weights=None, minlength=0, name=None):\n+ return ivy.bincount(x, weights=weights, minlength=minlength)\n", "issue": "bincount\n\n", "before_files": [{"content": "# global\nimport ivy\nfrom ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes\nfrom ivy.functional.frontends.paddle import promote_types_of_paddle_inputs\nfrom ivy.functional.frontends.paddle.func_wrapper import (\n to_ivy_arrays_and_back,\n)\n\n\n@with_supported_dtypes(\n {\"2.5.0 and below\": (\"float32\", \"float64\", \"int32\", \"int64\")}, \"paddle\"\n)\n@to_ivy_arrays_and_back\ndef cross(x, y, /, *, axis=9, name=None):\n x, y = promote_types_of_paddle_inputs(x, y)\n return ivy.cross(x, y, axis=axis)\n\n\n# matmul\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef matmul(x, y, transpose_x=False, transpose_y=False, name=None):\n x, y = promote_types_of_paddle_inputs(x, y)\n return ivy.matmul(x, y, transpose_a=transpose_x, transpose_b=transpose_y)\n\n\n# norm\n@with_supported_dtypes({\"2.5.0 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef norm(x, p=\"fro\", axis=None, keepdim=False, name=None):\n if axis is None and p is not None:\n if p == \"fro\":\n p = 2\n ret = ivy.vector_norm(x.flatten(), ord=p, axis=-1)\n if keepdim:\n ret = ret.reshape([1] * len(x.shape))\n if len(ret.shape) == 0:\n return ivy.array([ret])\n return ret\n\n if isinstance(axis, tuple):\n axis = list(axis)\n if isinstance(axis, list) and len(axis) == 1:\n axis = axis[0]\n\n if isinstance(axis, int):\n if p == \"fro\":\n p = 2\n if p in [0, 1, 2, ivy.inf, -ivy.inf]:\n ret = ivy.vector_norm(x, ord=p, axis=axis, keepdims=keepdim)\n elif isinstance(p, (int, float)):\n ret = ivy.pow(\n ivy.sum(ivy.pow(ivy.abs(x), p), axis=axis, keepdims=keepdim),\n float(1.0 / p),\n )\n\n elif isinstance(axis, list) and len(axis) == 2:\n if p == 0:\n raise ValueError\n elif p == 1:\n ret = ivy.sum(ivy.abs(x), axis=axis, keepdims=keepdim)\n elif p == 2 or p == \"fro\":\n ret = ivy.matrix_norm(x, ord=\"fro\", axis=axis, keepdims=keepdim)\n elif p == ivy.inf:\n ret = ivy.max(ivy.abs(x), axis=axis, keepdims=keepdim)\n elif p == -ivy.inf:\n ret = ivy.min(ivy.abs(x), axis=axis, keepdims=keepdim)\n elif isinstance(p, (int, float)) and p > 0:\n ret = ivy.pow(\n ivy.sum(ivy.pow(ivy.abs(x), p), axis=axis, keepdims=keepdim),\n float(1.0 / p),\n )\n else:\n raise ValueError\n\n else:\n raise ValueError\n\n if len(ret.shape) == 0:\n ret = ivy.array(\n [ret]\n ) # this is done so as to match shape of output from paddle\n return ret\n\n\n# eig\n@to_ivy_arrays_and_back\ndef eig(x, name=None):\n return ivy.eig(x)\n\n\n# eigvals\n@to_ivy_arrays_and_back\ndef eigvals(x, name=None):\n return ivy.eigvals(x)\n\n\n# eigvalsh\n@to_ivy_arrays_and_back\ndef eigvalsh(x, UPLO=\"L\", name=None):\n return ivy.eigvalsh(x, UPLO=UPLO)\n\n\n# eigh\n@to_ivy_arrays_and_back\ndef eigh(x, UPLO=\"L\", name=None):\n return ivy.eigh(x, UPLO=UPLO)\n\n\n# pinv\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef pinv(x, rcond=1e-15, hermitian=False, name=None):\n # TODO: Add hermitian functionality\n return ivy.pinv(x, rtol=rcond)\n\n\n# solve\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef solve(x1, x2, name=None):\n return ivy.solve(x1, x2)\n\n\n# cholesky\n@with_supported_dtypes({\"2.5.0 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef cholesky(x, /, *, upper=False, name=None):\n return ivy.cholesky(x, upper=upper)\n\n\n# bmm\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef bmm(x, y, transpose_x=False, transpose_y=False, name=None):\n if len(ivy.shape(x)) != 3 or len(ivy.shape(y)) != 3:\n raise RuntimeError(\"input must be 3D matrices\")\n x, y = promote_types_of_paddle_inputs(x, y)\n return ivy.matmul(x, y, transpose_a=transpose_x, transpose_b=transpose_y)\n\n\n# matrix_power\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef matrix_power(x, n, name=None):\n return ivy.matrix_power(x, n)\n\n\n# cond\n@with_supported_dtypes({\"2.5.0 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef cond(x, p=None, name=None):\n ret = ivy.cond(x, p=p, out=name)\n if ret.shape == ():\n ret = ret.reshape((1, ))\n return ret\n\n\n# dot\n@with_supported_dtypes({\"2.5.0 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef dot(x, y, name=None):\n x, y = promote_types_of_paddle_inputs(x, y)\n out = ivy.multiply(x, y)\n return ivy.sum(out, axis=ivy.get_num_dims(x) - 1, keepdims=False)\n\n\n# transpose\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"uint8\", \"int8\", \"int16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef transpose(x, perm, name=None):\n return ivy.permute_dims(x, axes=perm)\n", "path": "ivy/functional/frontends/paddle/tensor/linalg.py"}], "after_files": [{"content": "# global\nimport ivy\nfrom ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes\nfrom ivy.functional.frontends.paddle import promote_types_of_paddle_inputs\nfrom ivy.functional.frontends.paddle.func_wrapper import (\n to_ivy_arrays_and_back,\n)\n\n\n@with_supported_dtypes(\n {\"2.5.0 and below\": (\"float32\", \"float64\", \"int32\", \"int64\")}, \"paddle\"\n)\n@to_ivy_arrays_and_back\ndef cross(x, y, /, *, axis=9, name=None):\n x, y = promote_types_of_paddle_inputs(x, y)\n return ivy.cross(x, y, axis=axis)\n\n\n# matmul\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef matmul(x, y, transpose_x=False, transpose_y=False, name=None):\n x, y = promote_types_of_paddle_inputs(x, y)\n return ivy.matmul(x, y, transpose_a=transpose_x, transpose_b=transpose_y)\n\n\n# norm\n@with_supported_dtypes({\"2.5.0 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef norm(x, p=\"fro\", axis=None, keepdim=False, name=None):\n if axis is None and p is not None:\n if p == \"fro\":\n p = 2\n ret = ivy.vector_norm(x.flatten(), ord=p, axis=-1)\n if keepdim:\n ret = ret.reshape([1] * len(x.shape))\n if len(ret.shape) == 0:\n return ivy.array([ret])\n return ret\n\n if isinstance(axis, tuple):\n axis = list(axis)\n if isinstance(axis, list) and len(axis) == 1:\n axis = axis[0]\n\n if isinstance(axis, int):\n if p == \"fro\":\n p = 2\n if p in [0, 1, 2, ivy.inf, -ivy.inf]:\n ret = ivy.vector_norm(x, ord=p, axis=axis, keepdims=keepdim)\n elif isinstance(p, (int, float)):\n ret = ivy.pow(\n ivy.sum(ivy.pow(ivy.abs(x), p), axis=axis, keepdims=keepdim),\n float(1.0 / p),\n )\n\n elif isinstance(axis, list) and len(axis) == 2:\n if p == 0:\n raise ValueError\n elif p == 1:\n ret = ivy.sum(ivy.abs(x), axis=axis, keepdims=keepdim)\n elif p == 2 or p == \"fro\":\n ret = ivy.matrix_norm(x, ord=\"fro\", axis=axis, keepdims=keepdim)\n elif p == ivy.inf:\n ret = ivy.max(ivy.abs(x), axis=axis, keepdims=keepdim)\n elif p == -ivy.inf:\n ret = ivy.min(ivy.abs(x), axis=axis, keepdims=keepdim)\n elif isinstance(p, (int, float)) and p > 0:\n ret = ivy.pow(\n ivy.sum(ivy.pow(ivy.abs(x), p), axis=axis, keepdims=keepdim),\n float(1.0 / p),\n )\n else:\n raise ValueError\n\n else:\n raise ValueError\n\n if len(ret.shape) == 0:\n ret = ivy.array(\n [ret]\n ) # this is done so as to match shape of output from paddle\n return ret\n\n\n# eig\n@to_ivy_arrays_and_back\ndef eig(x, name=None):\n return ivy.eig(x)\n\n\n# eigvals\n@to_ivy_arrays_and_back\ndef eigvals(x, name=None):\n return ivy.eigvals(x)\n\n\n# eigvalsh\n@to_ivy_arrays_and_back\ndef eigvalsh(x, UPLO=\"L\", name=None):\n return ivy.eigvalsh(x, UPLO=UPLO)\n\n\n# eigh\n@to_ivy_arrays_and_back\ndef eigh(x, UPLO=\"L\", name=None):\n return ivy.eigh(x, UPLO=UPLO)\n\n\n# pinv\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef pinv(x, rcond=1e-15, hermitian=False, name=None):\n # TODO: Add hermitian functionality\n return ivy.pinv(x, rtol=rcond)\n\n\n# solve\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef solve(x1, x2, name=None):\n return ivy.solve(x1, x2)\n\n\n# cholesky\n@with_supported_dtypes({\"2.5.0 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef cholesky(x, /, *, upper=False, name=None):\n return ivy.cholesky(x, upper=upper)\n\n\n# bmm\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef bmm(x, y, transpose_x=False, transpose_y=False, name=None):\n if len(ivy.shape(x)) != 3 or len(ivy.shape(y)) != 3:\n raise RuntimeError(\"input must be 3D matrices\")\n x, y = promote_types_of_paddle_inputs(x, y)\n return ivy.matmul(x, y, transpose_a=transpose_x, transpose_b=transpose_y)\n\n\n# matrix_power\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef matrix_power(x, n, name=None):\n return ivy.matrix_power(x, n)\n\n\n# cond\n@with_supported_dtypes({\"2.5.0 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef cond(x, p=None, name=None):\n ret = ivy.cond(x, p=p, out=name)\n if ret.shape == ():\n ret = ret.reshape((1, ))\n return ret\n\n\n# dot\n@with_supported_dtypes({\"2.5.0 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef dot(x, y, name=None):\n x, y = promote_types_of_paddle_inputs(x, y)\n out = ivy.multiply(x, y)\n return ivy.sum(out, axis=ivy.get_num_dims(x) - 1, keepdims=False)\n\n\n# transpose\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"uint8\", \"int8\", \"int16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef transpose(x, perm, name=None):\n return ivy.permute_dims(x, axes=perm)\n\n\n@with_supported_dtypes({\"2.4.1 and above\": (\"int64\",)}, \"paddle\")\n@to_ivy_arrays_and_back\ndef bincount(x, weights=None, minlength=0, name=None):\n return ivy.bincount(x, weights=weights, minlength=minlength)\n", "path": "ivy/functional/frontends/paddle/tensor/linalg.py"}]} | 2,323 | 177 |
gh_patches_debug_27316 | rasdani/github-patches | git_diff | mkdocs__mkdocs-2507 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
V.1.2: Markdown links earlier processed as html files, are now processed as directories
The new version brings a curious issue. With versions < 1.2, I used internal links in this way, to make a call to page `bar.md`, from page `foo.md`:
```markdown
[linking to content in bar](../bar#content)
```
Which was transformed correctly into:
```html
<a href="../bar/#content">linking to content in bar</a>
```
Since version 1.2, the `bar` is intepreted differently by `mkdocs serve`, which breaks all such links. I realize this is highly irregular and correct call should have been:
```markdown
[linking to content in bar](bar.md#content)
```
So please dont throw rotten tomatoes at me 🍅 .
But just to help me fix this: why this change of behavior? Has some part been reimplemented? Or has this been intentional, to prevent that kind of error in the future?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mkdocs/livereload/__init__.py`
Content:
```
1 import functools
2 import io
3 import logging
4 import mimetypes
5 import os
6 import os.path
7 import re
8 import socketserver
9 import threading
10 import time
11 import warnings
12 import wsgiref.simple_server
13
14 import watchdog.events
15 import watchdog.observers.polling
16
17
18 class _LoggerAdapter(logging.LoggerAdapter):
19 def process(self, msg, kwargs):
20 return time.strftime("[%H:%M:%S] ") + msg, kwargs
21
22
23 log = _LoggerAdapter(logging.getLogger(__name__), {})
24
25
26 class LiveReloadServer(socketserver.ThreadingMixIn, wsgiref.simple_server.WSGIServer):
27 daemon_threads = True
28 poll_response_timeout = 60
29
30 def __init__(
31 self,
32 builder,
33 host,
34 port,
35 root,
36 mount_path="/",
37 polling_interval=0.5,
38 shutdown_delay=0.25,
39 **kwargs,
40 ):
41 self.builder = builder
42 self.server_name = host
43 self.server_port = port
44 self.root = os.path.abspath(root)
45 self.mount_path = ("/" + mount_path.lstrip("/")).rstrip("/") + "/"
46 self.url = f"http://{self.server_name}:{self.server_port}{self.mount_path}"
47 self.build_delay = 0.1
48 self.shutdown_delay = shutdown_delay
49 # To allow custom error pages.
50 self.error_handler = lambda code: None
51
52 super().__init__((host, port), _Handler, **kwargs)
53 self.set_app(self.serve_request)
54
55 self._wanted_epoch = _timestamp() # The version of the site that started building.
56 self._visible_epoch = self._wanted_epoch # Latest fully built version of the site.
57 self._epoch_cond = threading.Condition() # Must be held when accessing _visible_epoch.
58
59 self._to_rebuild = {} # Used as an ordered set of functions to call.
60 self._rebuild_cond = threading.Condition() # Must be held when accessing _to_rebuild.
61
62 self._shutdown = False
63 self.serve_thread = threading.Thread(target=lambda: self.serve_forever(shutdown_delay))
64 self.observer = watchdog.observers.polling.PollingObserver(timeout=polling_interval)
65
66 def watch(self, path, func=None, recursive=True):
67 """Add the 'path' to watched paths, call the function and reload when any file changes under it."""
68 path = os.path.abspath(path)
69 if func in (None, self.builder):
70 func = self.builder
71 else:
72 warnings.warn(
73 "Plugins should not pass the 'func' parameter of watch(). "
74 "The ability to execute custom callbacks will be removed soon.",
75 DeprecationWarning,
76 stacklevel=2,
77 )
78
79 def callback(event):
80 if event.is_directory:
81 return
82 log.debug(str(event))
83 with self._rebuild_cond:
84 self._to_rebuild[func] = True
85 self._rebuild_cond.notify_all()
86
87 handler = watchdog.events.FileSystemEventHandler()
88 handler.on_any_event = callback
89 log.debug(f"Watching '{path}'")
90 self.observer.schedule(handler, path, recursive=recursive)
91
92 def serve(self):
93 self.observer.start()
94
95 log.info(f"Serving on {self.url}")
96 self.serve_thread.start()
97
98 self._build_loop()
99
100 def _build_loop(self):
101 while True:
102 with self._rebuild_cond:
103 while not self._rebuild_cond.wait_for(
104 lambda: self._to_rebuild or self._shutdown, timeout=self.shutdown_delay
105 ):
106 # We could have used just one wait instead of a loop + timeout, but we need
107 # occasional breaks, otherwise on Windows we can't receive KeyboardInterrupt.
108 pass
109 if self._shutdown:
110 break
111 log.info("Detected file changes")
112 while self._rebuild_cond.wait(timeout=self.build_delay):
113 log.debug("Waiting for file changes to stop happening")
114
115 self._wanted_epoch = _timestamp()
116 funcs = list(self._to_rebuild)
117 self._to_rebuild.clear()
118
119 for func in funcs:
120 func()
121
122 with self._epoch_cond:
123 log.info("Reloading browsers")
124 self._visible_epoch = self._wanted_epoch
125 self._epoch_cond.notify_all()
126
127 def shutdown(self):
128 self.observer.stop()
129 with self._rebuild_cond:
130 self._shutdown = True
131 self._rebuild_cond.notify_all()
132
133 if self.serve_thread.is_alive():
134 super().shutdown()
135 self.serve_thread.join()
136 self.observer.join()
137
138 def serve_request(self, environ, start_response):
139 try:
140 result = self._serve_request(environ, start_response)
141 except Exception:
142 code = 500
143 msg = "500 Internal Server Error"
144 log.exception(msg)
145 else:
146 if result is not None:
147 return result
148 code = 404
149 msg = "404 Not Found"
150
151 error_content = None
152 try:
153 error_content = self.error_handler(code)
154 except Exception:
155 log.exception("Failed to render an error message!")
156 if error_content is None:
157 error_content = msg.encode()
158
159 start_response(msg, [("Content-Type", "text/html")])
160 return [error_content]
161
162 def _serve_request(self, environ, start_response):
163 # https://bugs.python.org/issue16679
164 # https://github.com/bottlepy/bottle/blob/f9b1849db4/bottle.py#L984
165 path = environ["PATH_INFO"].encode("latin-1").decode("utf-8", "ignore")
166
167 m = re.fullmatch(r"/livereload/([0-9]+)/[0-9]+", path)
168 if m:
169 epoch = int(m[1])
170 start_response("200 OK", [("Content-Type", "text/plain")])
171
172 def condition():
173 return self._visible_epoch > epoch
174
175 with self._epoch_cond:
176 if not condition():
177 # Stall the browser, respond as soon as there's something new.
178 # If there's not, respond anyway after a minute.
179 self._log_poll_request(environ.get("HTTP_REFERER"), request_id=path)
180 self._epoch_cond.wait_for(condition, timeout=self.poll_response_timeout)
181 return [b"%d" % self._visible_epoch]
182
183 if path == "/js/livereload.js":
184 file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), "livereload.js")
185 elif path.startswith(self.mount_path):
186 if path.endswith("/"):
187 path += "index.html"
188 path = path[len(self.mount_path):]
189 file_path = os.path.join(self.root, path.lstrip("/"))
190 elif path == "/":
191 start_response("302 Found", [("Location", self.mount_path)])
192 return []
193 else:
194 return None # Not found
195
196 # Wait until the ongoing rebuild (if any) finishes, so we're not serving a half-built site.
197 with self._epoch_cond:
198 self._epoch_cond.wait_for(lambda: self._visible_epoch == self._wanted_epoch)
199 epoch = self._visible_epoch
200
201 try:
202 file = open(file_path, "rb")
203 except OSError:
204 return None # Not found
205
206 if path.endswith(".html"):
207 with file:
208 content = file.read()
209 content = self._inject_js_into_html(content, epoch)
210 file = io.BytesIO(content)
211 content_length = len(content)
212 else:
213 content_length = os.path.getsize(file_path)
214
215 content_type = self._guess_type(file_path)
216 start_response(
217 "200 OK", [("Content-Type", content_type), ("Content-Length", str(content_length))]
218 )
219 return wsgiref.util.FileWrapper(file)
220
221 @classmethod
222 def _inject_js_into_html(cls, content, epoch):
223 try:
224 body_end = content.rindex(b"</body>")
225 except ValueError:
226 body_end = len(content)
227 # The page will reload if the livereload poller returns a newer epoch than what it knows.
228 # The other timestamp becomes just a unique identifier for the initiating page.
229 return (
230 b'%b<script src="/js/livereload.js"></script><script>livereload(%d, %d);</script>%b'
231 % (content[:body_end], epoch, _timestamp(), content[body_end:])
232 )
233
234 @classmethod
235 @functools.lru_cache() # "Cache" to not repeat the same message for the same browser tab.
236 def _log_poll_request(cls, url, request_id):
237 log.info(f"Browser connected: {url}")
238
239 def _guess_type(cls, path):
240 # MkDocs only ensures a few common types (as seen in livereload_tests.py::test_mime_types).
241 # Other uncommon types will not be accepted.
242 if path.endswith((".js", ".JS")):
243 return "application/javascript"
244 if path.endswith(".gz"):
245 return "application/gzip"
246
247 guess, _ = mimetypes.guess_type(path)
248 if guess:
249 return guess
250 return "application/octet-stream"
251
252
253 class _Handler(wsgiref.simple_server.WSGIRequestHandler):
254 def log_request(self, code="-", size="-"):
255 level = logging.DEBUG if str(code) == "200" else logging.WARNING
256 log.log(level, f'"{self.requestline}" code {code}')
257
258 def log_message(self, format, *args):
259 log.debug(format, *args)
260
261
262 def _timestamp():
263 return round(time.monotonic() * 1000)
264
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mkdocs/livereload/__init__.py b/mkdocs/livereload/__init__.py
--- a/mkdocs/livereload/__init__.py
+++ b/mkdocs/livereload/__init__.py
@@ -183,10 +183,10 @@
if path == "/js/livereload.js":
file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), "livereload.js")
elif path.startswith(self.mount_path):
+ rel_file_path = path[len(self.mount_path):].lstrip("/")
if path.endswith("/"):
- path += "index.html"
- path = path[len(self.mount_path):]
- file_path = os.path.join(self.root, path.lstrip("/"))
+ rel_file_path += "index.html"
+ file_path = os.path.join(self.root, rel_file_path)
elif path == "/":
start_response("302 Found", [("Location", self.mount_path)])
return []
@@ -201,9 +201,12 @@
try:
file = open(file_path, "rb")
except OSError:
+ if not path.endswith("/") and os.path.isfile(os.path.join(file_path, "index.html")):
+ start_response("302 Found", [("Location", path + "/")])
+ return []
return None # Not found
- if path.endswith(".html"):
+ if file_path.endswith(".html"):
with file:
content = file.read()
content = self._inject_js_into_html(content, epoch)
| {"golden_diff": "diff --git a/mkdocs/livereload/__init__.py b/mkdocs/livereload/__init__.py\n--- a/mkdocs/livereload/__init__.py\n+++ b/mkdocs/livereload/__init__.py\n@@ -183,10 +183,10 @@\n if path == \"/js/livereload.js\":\n file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), \"livereload.js\")\n elif path.startswith(self.mount_path):\n+ rel_file_path = path[len(self.mount_path):].lstrip(\"/\")\n if path.endswith(\"/\"):\n- path += \"index.html\"\n- path = path[len(self.mount_path):]\n- file_path = os.path.join(self.root, path.lstrip(\"/\"))\n+ rel_file_path += \"index.html\"\n+ file_path = os.path.join(self.root, rel_file_path)\n elif path == \"/\":\n start_response(\"302 Found\", [(\"Location\", self.mount_path)])\n return []\n@@ -201,9 +201,12 @@\n try:\n file = open(file_path, \"rb\")\n except OSError:\n+ if not path.endswith(\"/\") and os.path.isfile(os.path.join(file_path, \"index.html\")):\n+ start_response(\"302 Found\", [(\"Location\", path + \"/\")])\n+ return []\n return None # Not found\n \n- if path.endswith(\".html\"):\n+ if file_path.endswith(\".html\"):\n with file:\n content = file.read()\n content = self._inject_js_into_html(content, epoch)\n", "issue": "V.1.2: Markdown links earlier processed as html files, are now processed as directories\nThe new version brings a curious issue. With versions < 1.2, I used internal links in this way, to make a call to page `bar.md`, from page `foo.md`:\r\n\r\n```markdown\r\n[linking to content in bar](../bar#content)\r\n```\r\n\r\nWhich was transformed correctly into:\r\n\r\n```html\r\n<a href=\"../bar/#content\">linking to content in bar</a>\r\n```\r\n\r\nSince version 1.2, the `bar` is intepreted differently by `mkdocs serve`, which breaks all such links. I realize this is highly irregular and correct call should have been:\r\n\r\n```markdown\r\n[linking to content in bar](bar.md#content)\r\n```\r\n\r\nSo please dont throw rotten tomatoes at me \ud83c\udf45 .\r\n\r\nBut just to help me fix this: why this change of behavior? Has some part been reimplemented? Or has this been intentional, to prevent that kind of error in the future?\r\n\n", "before_files": [{"content": "import functools\nimport io\nimport logging\nimport mimetypes\nimport os\nimport os.path\nimport re\nimport socketserver\nimport threading\nimport time\nimport warnings\nimport wsgiref.simple_server\n\nimport watchdog.events\nimport watchdog.observers.polling\n\n\nclass _LoggerAdapter(logging.LoggerAdapter):\n def process(self, msg, kwargs):\n return time.strftime(\"[%H:%M:%S] \") + msg, kwargs\n\n\nlog = _LoggerAdapter(logging.getLogger(__name__), {})\n\n\nclass LiveReloadServer(socketserver.ThreadingMixIn, wsgiref.simple_server.WSGIServer):\n daemon_threads = True\n poll_response_timeout = 60\n\n def __init__(\n self,\n builder,\n host,\n port,\n root,\n mount_path=\"/\",\n polling_interval=0.5,\n shutdown_delay=0.25,\n **kwargs,\n ):\n self.builder = builder\n self.server_name = host\n self.server_port = port\n self.root = os.path.abspath(root)\n self.mount_path = (\"/\" + mount_path.lstrip(\"/\")).rstrip(\"/\") + \"/\"\n self.url = f\"http://{self.server_name}:{self.server_port}{self.mount_path}\"\n self.build_delay = 0.1\n self.shutdown_delay = shutdown_delay\n # To allow custom error pages.\n self.error_handler = lambda code: None\n\n super().__init__((host, port), _Handler, **kwargs)\n self.set_app(self.serve_request)\n\n self._wanted_epoch = _timestamp() # The version of the site that started building.\n self._visible_epoch = self._wanted_epoch # Latest fully built version of the site.\n self._epoch_cond = threading.Condition() # Must be held when accessing _visible_epoch.\n\n self._to_rebuild = {} # Used as an ordered set of functions to call.\n self._rebuild_cond = threading.Condition() # Must be held when accessing _to_rebuild.\n\n self._shutdown = False\n self.serve_thread = threading.Thread(target=lambda: self.serve_forever(shutdown_delay))\n self.observer = watchdog.observers.polling.PollingObserver(timeout=polling_interval)\n\n def watch(self, path, func=None, recursive=True):\n \"\"\"Add the 'path' to watched paths, call the function and reload when any file changes under it.\"\"\"\n path = os.path.abspath(path)\n if func in (None, self.builder):\n func = self.builder\n else:\n warnings.warn(\n \"Plugins should not pass the 'func' parameter of watch(). \"\n \"The ability to execute custom callbacks will be removed soon.\",\n DeprecationWarning,\n stacklevel=2,\n )\n\n def callback(event):\n if event.is_directory:\n return\n log.debug(str(event))\n with self._rebuild_cond:\n self._to_rebuild[func] = True\n self._rebuild_cond.notify_all()\n\n handler = watchdog.events.FileSystemEventHandler()\n handler.on_any_event = callback\n log.debug(f\"Watching '{path}'\")\n self.observer.schedule(handler, path, recursive=recursive)\n\n def serve(self):\n self.observer.start()\n\n log.info(f\"Serving on {self.url}\")\n self.serve_thread.start()\n\n self._build_loop()\n\n def _build_loop(self):\n while True:\n with self._rebuild_cond:\n while not self._rebuild_cond.wait_for(\n lambda: self._to_rebuild or self._shutdown, timeout=self.shutdown_delay\n ):\n # We could have used just one wait instead of a loop + timeout, but we need\n # occasional breaks, otherwise on Windows we can't receive KeyboardInterrupt.\n pass\n if self._shutdown:\n break\n log.info(\"Detected file changes\")\n while self._rebuild_cond.wait(timeout=self.build_delay):\n log.debug(\"Waiting for file changes to stop happening\")\n\n self._wanted_epoch = _timestamp()\n funcs = list(self._to_rebuild)\n self._to_rebuild.clear()\n\n for func in funcs:\n func()\n\n with self._epoch_cond:\n log.info(\"Reloading browsers\")\n self._visible_epoch = self._wanted_epoch\n self._epoch_cond.notify_all()\n\n def shutdown(self):\n self.observer.stop()\n with self._rebuild_cond:\n self._shutdown = True\n self._rebuild_cond.notify_all()\n\n if self.serve_thread.is_alive():\n super().shutdown()\n self.serve_thread.join()\n self.observer.join()\n\n def serve_request(self, environ, start_response):\n try:\n result = self._serve_request(environ, start_response)\n except Exception:\n code = 500\n msg = \"500 Internal Server Error\"\n log.exception(msg)\n else:\n if result is not None:\n return result\n code = 404\n msg = \"404 Not Found\"\n\n error_content = None\n try:\n error_content = self.error_handler(code)\n except Exception:\n log.exception(\"Failed to render an error message!\")\n if error_content is None:\n error_content = msg.encode()\n\n start_response(msg, [(\"Content-Type\", \"text/html\")])\n return [error_content]\n\n def _serve_request(self, environ, start_response):\n # https://bugs.python.org/issue16679\n # https://github.com/bottlepy/bottle/blob/f9b1849db4/bottle.py#L984\n path = environ[\"PATH_INFO\"].encode(\"latin-1\").decode(\"utf-8\", \"ignore\")\n\n m = re.fullmatch(r\"/livereload/([0-9]+)/[0-9]+\", path)\n if m:\n epoch = int(m[1])\n start_response(\"200 OK\", [(\"Content-Type\", \"text/plain\")])\n\n def condition():\n return self._visible_epoch > epoch\n\n with self._epoch_cond:\n if not condition():\n # Stall the browser, respond as soon as there's something new.\n # If there's not, respond anyway after a minute.\n self._log_poll_request(environ.get(\"HTTP_REFERER\"), request_id=path)\n self._epoch_cond.wait_for(condition, timeout=self.poll_response_timeout)\n return [b\"%d\" % self._visible_epoch]\n\n if path == \"/js/livereload.js\":\n file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), \"livereload.js\")\n elif path.startswith(self.mount_path):\n if path.endswith(\"/\"):\n path += \"index.html\"\n path = path[len(self.mount_path):]\n file_path = os.path.join(self.root, path.lstrip(\"/\"))\n elif path == \"/\":\n start_response(\"302 Found\", [(\"Location\", self.mount_path)])\n return []\n else:\n return None # Not found\n\n # Wait until the ongoing rebuild (if any) finishes, so we're not serving a half-built site.\n with self._epoch_cond:\n self._epoch_cond.wait_for(lambda: self._visible_epoch == self._wanted_epoch)\n epoch = self._visible_epoch\n\n try:\n file = open(file_path, \"rb\")\n except OSError:\n return None # Not found\n\n if path.endswith(\".html\"):\n with file:\n content = file.read()\n content = self._inject_js_into_html(content, epoch)\n file = io.BytesIO(content)\n content_length = len(content)\n else:\n content_length = os.path.getsize(file_path)\n\n content_type = self._guess_type(file_path)\n start_response(\n \"200 OK\", [(\"Content-Type\", content_type), (\"Content-Length\", str(content_length))]\n )\n return wsgiref.util.FileWrapper(file)\n\n @classmethod\n def _inject_js_into_html(cls, content, epoch):\n try:\n body_end = content.rindex(b\"</body>\")\n except ValueError:\n body_end = len(content)\n # The page will reload if the livereload poller returns a newer epoch than what it knows.\n # The other timestamp becomes just a unique identifier for the initiating page.\n return (\n b'%b<script src=\"/js/livereload.js\"></script><script>livereload(%d, %d);</script>%b'\n % (content[:body_end], epoch, _timestamp(), content[body_end:])\n )\n\n @classmethod\n @functools.lru_cache() # \"Cache\" to not repeat the same message for the same browser tab.\n def _log_poll_request(cls, url, request_id):\n log.info(f\"Browser connected: {url}\")\n\n def _guess_type(cls, path):\n # MkDocs only ensures a few common types (as seen in livereload_tests.py::test_mime_types).\n # Other uncommon types will not be accepted.\n if path.endswith((\".js\", \".JS\")):\n return \"application/javascript\"\n if path.endswith(\".gz\"):\n return \"application/gzip\"\n\n guess, _ = mimetypes.guess_type(path)\n if guess:\n return guess\n return \"application/octet-stream\"\n\n\nclass _Handler(wsgiref.simple_server.WSGIRequestHandler):\n def log_request(self, code=\"-\", size=\"-\"):\n level = logging.DEBUG if str(code) == \"200\" else logging.WARNING\n log.log(level, f'\"{self.requestline}\" code {code}')\n\n def log_message(self, format, *args):\n log.debug(format, *args)\n\n\ndef _timestamp():\n return round(time.monotonic() * 1000)\n", "path": "mkdocs/livereload/__init__.py"}], "after_files": [{"content": "import functools\nimport io\nimport logging\nimport mimetypes\nimport os\nimport os.path\nimport re\nimport socketserver\nimport threading\nimport time\nimport warnings\nimport wsgiref.simple_server\n\nimport watchdog.events\nimport watchdog.observers.polling\n\n\nclass _LoggerAdapter(logging.LoggerAdapter):\n def process(self, msg, kwargs):\n return time.strftime(\"[%H:%M:%S] \") + msg, kwargs\n\n\nlog = _LoggerAdapter(logging.getLogger(__name__), {})\n\n\nclass LiveReloadServer(socketserver.ThreadingMixIn, wsgiref.simple_server.WSGIServer):\n daemon_threads = True\n poll_response_timeout = 60\n\n def __init__(\n self,\n builder,\n host,\n port,\n root,\n mount_path=\"/\",\n polling_interval=0.5,\n shutdown_delay=0.25,\n **kwargs,\n ):\n self.builder = builder\n self.server_name = host\n self.server_port = port\n self.root = os.path.abspath(root)\n self.mount_path = (\"/\" + mount_path.lstrip(\"/\")).rstrip(\"/\") + \"/\"\n self.url = f\"http://{self.server_name}:{self.server_port}{self.mount_path}\"\n self.build_delay = 0.1\n self.shutdown_delay = shutdown_delay\n # To allow custom error pages.\n self.error_handler = lambda code: None\n\n super().__init__((host, port), _Handler, **kwargs)\n self.set_app(self.serve_request)\n\n self._wanted_epoch = _timestamp() # The version of the site that started building.\n self._visible_epoch = self._wanted_epoch # Latest fully built version of the site.\n self._epoch_cond = threading.Condition() # Must be held when accessing _visible_epoch.\n\n self._to_rebuild = {} # Used as an ordered set of functions to call.\n self._rebuild_cond = threading.Condition() # Must be held when accessing _to_rebuild.\n\n self._shutdown = False\n self.serve_thread = threading.Thread(target=lambda: self.serve_forever(shutdown_delay))\n self.observer = watchdog.observers.polling.PollingObserver(timeout=polling_interval)\n\n def watch(self, path, func=None, recursive=True):\n \"\"\"Add the 'path' to watched paths, call the function and reload when any file changes under it.\"\"\"\n path = os.path.abspath(path)\n if func in (None, self.builder):\n func = self.builder\n else:\n warnings.warn(\n \"Plugins should not pass the 'func' parameter of watch(). \"\n \"The ability to execute custom callbacks will be removed soon.\",\n DeprecationWarning,\n stacklevel=2,\n )\n\n def callback(event):\n if event.is_directory:\n return\n log.debug(str(event))\n with self._rebuild_cond:\n self._to_rebuild[func] = True\n self._rebuild_cond.notify_all()\n\n handler = watchdog.events.FileSystemEventHandler()\n handler.on_any_event = callback\n log.debug(f\"Watching '{path}'\")\n self.observer.schedule(handler, path, recursive=recursive)\n\n def serve(self):\n self.observer.start()\n\n log.info(f\"Serving on {self.url}\")\n self.serve_thread.start()\n\n self._build_loop()\n\n def _build_loop(self):\n while True:\n with self._rebuild_cond:\n while not self._rebuild_cond.wait_for(\n lambda: self._to_rebuild or self._shutdown, timeout=self.shutdown_delay\n ):\n # We could have used just one wait instead of a loop + timeout, but we need\n # occasional breaks, otherwise on Windows we can't receive KeyboardInterrupt.\n pass\n if self._shutdown:\n break\n log.info(\"Detected file changes\")\n while self._rebuild_cond.wait(timeout=self.build_delay):\n log.debug(\"Waiting for file changes to stop happening\")\n\n self._wanted_epoch = _timestamp()\n funcs = list(self._to_rebuild)\n self._to_rebuild.clear()\n\n for func in funcs:\n func()\n\n with self._epoch_cond:\n log.info(\"Reloading browsers\")\n self._visible_epoch = self._wanted_epoch\n self._epoch_cond.notify_all()\n\n def shutdown(self):\n self.observer.stop()\n with self._rebuild_cond:\n self._shutdown = True\n self._rebuild_cond.notify_all()\n\n if self.serve_thread.is_alive():\n super().shutdown()\n self.serve_thread.join()\n self.observer.join()\n\n def serve_request(self, environ, start_response):\n try:\n result = self._serve_request(environ, start_response)\n except Exception:\n code = 500\n msg = \"500 Internal Server Error\"\n log.exception(msg)\n else:\n if result is not None:\n return result\n code = 404\n msg = \"404 Not Found\"\n\n error_content = None\n try:\n error_content = self.error_handler(code)\n except Exception:\n log.exception(\"Failed to render an error message!\")\n if error_content is None:\n error_content = msg.encode()\n\n start_response(msg, [(\"Content-Type\", \"text/html\")])\n return [error_content]\n\n def _serve_request(self, environ, start_response):\n # https://bugs.python.org/issue16679\n # https://github.com/bottlepy/bottle/blob/f9b1849db4/bottle.py#L984\n path = environ[\"PATH_INFO\"].encode(\"latin-1\").decode(\"utf-8\", \"ignore\")\n\n m = re.fullmatch(r\"/livereload/([0-9]+)/[0-9]+\", path)\n if m:\n epoch = int(m[1])\n start_response(\"200 OK\", [(\"Content-Type\", \"text/plain\")])\n\n def condition():\n return self._visible_epoch > epoch\n\n with self._epoch_cond:\n if not condition():\n # Stall the browser, respond as soon as there's something new.\n # If there's not, respond anyway after a minute.\n self._log_poll_request(environ.get(\"HTTP_REFERER\"), request_id=path)\n self._epoch_cond.wait_for(condition, timeout=self.poll_response_timeout)\n return [b\"%d\" % self._visible_epoch]\n\n if path == \"/js/livereload.js\":\n file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), \"livereload.js\")\n elif path.startswith(self.mount_path):\n rel_file_path = path[len(self.mount_path):].lstrip(\"/\")\n if path.endswith(\"/\"):\n rel_file_path += \"index.html\"\n file_path = os.path.join(self.root, rel_file_path)\n elif path == \"/\":\n start_response(\"302 Found\", [(\"Location\", self.mount_path)])\n return []\n else:\n return None # Not found\n\n # Wait until the ongoing rebuild (if any) finishes, so we're not serving a half-built site.\n with self._epoch_cond:\n self._epoch_cond.wait_for(lambda: self._visible_epoch == self._wanted_epoch)\n epoch = self._visible_epoch\n\n try:\n file = open(file_path, \"rb\")\n except OSError:\n if not path.endswith(\"/\") and os.path.isfile(os.path.join(file_path, \"index.html\")):\n start_response(\"302 Found\", [(\"Location\", path + \"/\")])\n return []\n return None # Not found\n\n if file_path.endswith(\".html\"):\n with file:\n content = file.read()\n content = self._inject_js_into_html(content, epoch)\n file = io.BytesIO(content)\n content_length = len(content)\n else:\n content_length = os.path.getsize(file_path)\n\n content_type = self._guess_type(file_path)\n start_response(\n \"200 OK\", [(\"Content-Type\", content_type), (\"Content-Length\", str(content_length))]\n )\n return wsgiref.util.FileWrapper(file)\n\n @classmethod\n def _inject_js_into_html(cls, content, epoch):\n try:\n body_end = content.rindex(b\"</body>\")\n except ValueError:\n body_end = len(content)\n # The page will reload if the livereload poller returns a newer epoch than what it knows.\n # The other timestamp becomes just a unique identifier for the initiating page.\n return (\n b'%b<script src=\"/js/livereload.js\"></script><script>livereload(%d, %d);</script>%b'\n % (content[:body_end], epoch, _timestamp(), content[body_end:])\n )\n\n @classmethod\n @functools.lru_cache() # \"Cache\" to not repeat the same message for the same browser tab.\n def _log_poll_request(cls, url, request_id):\n log.info(f\"Browser connected: {url}\")\n\n def _guess_type(cls, path):\n # MkDocs only ensures a few common types (as seen in livereload_tests.py::test_mime_types).\n # Other uncommon types will not be accepted.\n if path.endswith((\".js\", \".JS\")):\n return \"application/javascript\"\n if path.endswith(\".gz\"):\n return \"application/gzip\"\n\n guess, _ = mimetypes.guess_type(path)\n if guess:\n return guess\n return \"application/octet-stream\"\n\n\nclass _Handler(wsgiref.simple_server.WSGIRequestHandler):\n def log_request(self, code=\"-\", size=\"-\"):\n level = logging.DEBUG if str(code) == \"200\" else logging.WARNING\n log.log(level, f'\"{self.requestline}\" code {code}')\n\n def log_message(self, format, *args):\n log.debug(format, *args)\n\n\ndef _timestamp():\n return round(time.monotonic() * 1000)\n", "path": "mkdocs/livereload/__init__.py"}]} | 3,246 | 341 |
gh_patches_debug_40523 | rasdani/github-patches | git_diff | mindsdb__mindsdb-1440 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Streams are still exists if parent integration is deleted
**Describe the bug**
Streams are still exists if parent integration is deleted
**To Reproduce**
Steps to reproduce the behavior, for example:
1. Create a Stream Integration
2. Create a Stream which is based on this integration
3.Delete the integration
4. check db. `select * from stream;`
Note, that created stream is still exist while its parent integration is deleted.
**Expected behavior**
Need to delete all related streams in case of deleting a stream integration
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mindsdb/interfaces/storage/db.py`
Content:
```
1 import os
2 import json
3 import datetime
4
5 import numpy as np
6 from sqlalchemy import create_engine, orm, types, UniqueConstraint
7 from sqlalchemy.orm import scoped_session, sessionmaker
8 from sqlalchemy.ext.declarative import declarative_base
9 from sqlalchemy import Column, Integer, String, DateTime, Boolean, Index
10 from sqlalchemy.sql.expression import null
11 from sqlalchemy.sql.schema import ForeignKey
12
13 if os.environ['MINDSDB_DB_CON'].startswith('sqlite:'):
14 engine = create_engine(os.environ['MINDSDB_DB_CON'], echo=False)
15 else:
16 engine = create_engine(os.environ['MINDSDB_DB_CON'], convert_unicode=True, pool_size=30, max_overflow=200, echo=False)
17 Base = declarative_base()
18 session = scoped_session(sessionmaker(bind=engine, autoflush=True))
19 Base.query = session.query_property()
20
21
22 # Source: https://stackoverflow.com/questions/26646362/numpy-array-is-not-json-serializable
23 class NumpyEncoder(json.JSONEncoder):
24 """ Special json encoder for numpy types """
25 def default(self, obj):
26 if isinstance(obj, np.integer):
27 return int(obj)
28 elif isinstance(obj, np.floating):
29 return float(obj)
30 elif isinstance(obj, np.ndarray):
31 return obj.tolist()
32 return json.JSONEncoder.default(self, obj)
33
34
35 class Array(types.TypeDecorator):
36 ''' Float Type that replaces commas with dots on input '''
37 impl = types.String
38
39 def process_bind_param(self, value, dialect): # insert
40 if isinstance(value, str):
41 return value
42 elif value is None:
43 return value
44 else:
45 return ',|,|,'.join(value)
46
47 def process_result_value(self, value, dialect): # select
48 return value.split(',|,|,') if value is not None else None
49
50
51 class Json(types.TypeDecorator):
52 ''' Float Type that replaces commas with dots on input '''
53 impl = types.String
54
55 def process_bind_param(self, value, dialect): # insert
56 return json.dumps(value, cls=NumpyEncoder) if value is not None else None
57
58 def process_result_value(self, value, dialect): # select
59 return json.loads(value) if value is not None else None
60
61
62 class Semaphor(Base):
63 __tablename__ = 'semaphor'
64
65 id = Column(Integer, primary_key=True)
66 updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)
67 created_at = Column(DateTime, default=datetime.datetime.now)
68 entity_type = Column('entity_type', String)
69 entity_id = Column('entity_id', Integer)
70 action = Column(String)
71 company_id = Column(Integer)
72 uniq_const = UniqueConstraint('entity_type', 'entity_id')
73
74
75 class Datasource(Base):
76 __tablename__ = 'datasource'
77
78 id = Column(Integer, primary_key=True)
79 updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)
80 created_at = Column(DateTime, default=datetime.datetime.now)
81 name = Column(String)
82 data = Column(String) # Including, e.g. the query used to create it and even the connection info when there's no integration associated with it -- A JSON
83 creation_info = Column(String)
84 analysis = Column(String) # A JSON
85 company_id = Column(Integer)
86 mindsdb_version = Column(String)
87 datasources_version = Column(String)
88 integration_id = Column(Integer)
89
90
91 class Predictor(Base):
92 __tablename__ = 'predictor'
93
94 id = Column(Integer, primary_key=True)
95 updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)
96 created_at = Column(DateTime, default=datetime.datetime.now)
97 name = Column(String, unique=True)
98 data = Column(Json) # A JSON -- should be everything returned by `get_model_data`, I think
99 to_predict = Column(Array)
100 company_id = Column(Integer)
101 mindsdb_version = Column(String)
102 native_version = Column(String)
103 datasource_id = Column(Integer)
104 is_custom = Column(Boolean) # to del
105 learn_args = Column(Json)
106 update_status = Column(String, default='up_to_date')
107
108 json_ai = Column(Json, nullable=True)
109 code = Column(String, nullable=True)
110 lightwood_version = Column(String, nullable=True)
111 dtype_dict = Column(Json, nullable=True)
112
113
114 class AITable(Base):
115 __tablename__ = 'ai_table'
116 id = Column(Integer, primary_key=True)
117 updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)
118 created_at = Column(DateTime, default=datetime.datetime.now)
119 name = Column(String)
120 integration_name = Column(String)
121 integration_query = Column(String)
122 query_fields = Column(Json)
123 predictor_name = Column(String)
124 predictor_columns = Column(Json)
125 company_id = Column(Integer)
126
127
128 class Log(Base):
129 __tablename__ = 'log'
130
131 id = Column(Integer, primary_key=True)
132 created_at = Column(DateTime, default=datetime.datetime.now)
133 log_type = Column(String) # log, info, warning, traceback etc
134 source = Column(String) # file + line
135 company_id = Column(Integer)
136 payload = Column(String)
137 created_at_index = Index("some_index", "created_at_index")
138
139
140 class Integration(Base):
141 __tablename__ = 'integration'
142 id = Column(Integer, primary_key=True)
143 updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)
144 created_at = Column(DateTime, default=datetime.datetime.now)
145 name = Column(String, nullable=False, unique=True)
146 data = Column(Json)
147 company_id = Column(Integer)
148
149
150 class Stream(Base):
151 __tablename__ = 'stream'
152 id = Column(Integer, primary_key=True)
153 name = Column(String, nullable=False, unique=True)
154 stream_in = Column(String, nullable=False)
155 stream_out = Column(String, nullable=False)
156 anomaly_stream = Column(String)
157 learning_stream = Column(String)
158 integration = Column(String, ForeignKey('integration.name', ondelete='CASCADE'), nullable=True)
159 predictor = Column(String, ForeignKey('predictor.name', ondelete='CASCADE'), nullable=False)
160 company_id = Column(Integer)
161 updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)
162 created_at = Column(DateTime, default=datetime.datetime.now)
163 type = Column(String, default='unknown')
164 connection_info = Column(Json, default={})
165
166
167 Base.metadata.create_all(engine)
168 orm.configure_mappers()
169
```
Path: `mindsdb/integrations/base/integration.py`
Content:
```
1 import os
2 from threading import Thread
3 from mindsdb.streams import StreamController
4
5 from mindsdb.utilities.config import STOP_THREADS_EVENT
6 from mindsdb.utilities.log import log
7 import mindsdb.interfaces.storage.db as db
8
9
10 class Integration:
11 def __init__(self, config, name):
12 self.config = config
13 self.name = name
14 self.mindsdb_database = config['api']['mysql']['database']
15 self.company_id = os.environ.get('MINDSDB_COMPANY_ID', None)
16
17 def setup(self):
18 raise NotImplementedError
19
20 def _query(self, query, fetch=False):
21 raise NotImplementedError
22
23 def register_predictors(self, model_data_arr):
24 raise NotImplementedError
25
26 def unregister_predictor(self, name):
27 raise NotImplementedError
28
29
30 class StreamIntegration(Integration):
31 def __init__(self, config, name, control_stream=None):
32 Integration.__init__(self, config, name)
33 self._streams = []
34 self._control_stream = control_stream
35
36 def setup(self):
37 Thread(target=StreamIntegration._loop, args=(self,)).start()
38
39 def _loop(self):
40 while not STOP_THREADS_EVENT.wait(1.0):
41 if self._control_stream is not None:
42 # Create or delete streams based on messages from control_stream
43 for dct in self._control_stream.read():
44 if 'action' not in dct:
45 log.error('INTEGRATION %s: no action value found in control record - %s', self.name, dct)
46 else:
47 if dct['action'] == 'create':
48 for k in ['name', 'predictor', 'stream_in', 'stream_out']:
49 if k not in dct:
50 # Not all required parameters were provided (i.e. stream will not be created)
51 # TODO: what's a good way to notify user about this?
52 log.error('INTEGRATION %s: stream creating error. not enough data in control record - %s', self.name, dct)
53 break
54 else:
55 log.info('INTEGRATION %s: creating stream %s', self.name, dct['name'])
56 if db.session.query(db.Stream).filter_by(name=dct['name'], company_id=self.company_id).first() is None:
57 stream = db.Stream(
58 company_id=self.company_id,
59 name=dct['name'],
60 integration=self.name,
61 predictor=dct['predictor'],
62 stream_in=dct['stream_in'],
63 stream_out=dct['stream_out'],
64 anomaly_stream=dct.get('anomaly_stream', None),
65 learning_stream=dct.get('learning_stream', None)
66 )
67 db.session.add(stream)
68 db.session.commit()
69 else:
70 log.error('INTEGRATION %s: stream with this name already exists - %s', self.name, dct['name'])
71 elif dct['action'] == 'delete':
72 for k in ['name']:
73 if k not in dct:
74 # Not all required parameters were provided (i.e. stream will not be created)
75 # TODO: what's a good way to notify user about this?
76 log.error('INTEGRATION %s: unable to delete stream - stream name is not provided', self.name)
77 break
78 else:
79 log.error('INTEGRATION %s: deleting stream - %s', self.name, dct['name'])
80 db.session.query(db.Stream).filter_by(
81 company_id=self.company_id,
82 integration=self.name,
83 name=dct['name']
84 ).delete()
85 db.session.commit()
86 else:
87 # Bad action value
88 log.error('INTEGRATION %s: bad action value received - %s', self.name, dct)
89
90 stream_db_recs = db.session.query(db.Stream).filter_by(
91 company_id=self.company_id,
92 integration=self.name
93 ).all()
94
95 # Stop streams that weren't found in DB
96 indices_to_delete = []
97 for i, s in enumerate(self._streams):
98 if s.name not in map(lambda x: x.name, stream_db_recs):
99 log.info("INTEGRATION %s: stopping stream - %s", self.name, s.name)
100 indices_to_delete.append(i)
101 self._streams[i].stop_event.set()
102 self._streams = [s for i, s in enumerate(self._streams) if i not in indices_to_delete]
103
104 # Start new streams found in DB
105 for s in stream_db_recs:
106 if s.name not in map(lambda x: x.name, self._streams):
107 self._streams.append(self._make_stream(s))
108
109 for s in self._streams:
110 s.stop_event.set()
111
112 def _make_stream(self, s: db.Stream) -> StreamController:
113 raise NotImplementedError
114
115 def _query(self, query, fetch=False):
116 pass
117
118 def register_predictors(self, model_data_arr):
119 pass
120
121 def unregister_predictor(self, name):
122 pass
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mindsdb/integrations/base/integration.py b/mindsdb/integrations/base/integration.py
--- a/mindsdb/integrations/base/integration.py
+++ b/mindsdb/integrations/base/integration.py
@@ -37,6 +37,7 @@
Thread(target=StreamIntegration._loop, args=(self,)).start()
def _loop(self):
+ log.info("INTEGRATION %s: starting", self.name)
while not STOP_THREADS_EVENT.wait(1.0):
if self._control_stream is not None:
# Create or delete streams based on messages from control_stream
@@ -104,8 +105,10 @@
# Start new streams found in DB
for s in stream_db_recs:
if s.name not in map(lambda x: x.name, self._streams):
+ log.info("INTEGRATION %s: starting stream - %s", self.name, s.name)
self._streams.append(self._make_stream(s))
+ log.info("INTEGRATION %s: stopping", self.name)
for s in self._streams:
s.stop_event.set()
diff --git a/mindsdb/interfaces/storage/db.py b/mindsdb/interfaces/storage/db.py
--- a/mindsdb/interfaces/storage/db.py
+++ b/mindsdb/interfaces/storage/db.py
@@ -4,7 +4,7 @@
import numpy as np
from sqlalchemy import create_engine, orm, types, UniqueConstraint
-from sqlalchemy.orm import scoped_session, sessionmaker
+from sqlalchemy.orm import scoped_session, sessionmaker, relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime, Boolean, Index
from sqlalchemy.sql.expression import null
@@ -109,6 +109,7 @@
code = Column(String, nullable=True)
lightwood_version = Column(String, nullable=True)
dtype_dict = Column(Json, nullable=True)
+ streams = relationship("Stream", cascade="all, delete")
class AITable(Base):
@@ -145,6 +146,7 @@
name = Column(String, nullable=False, unique=True)
data = Column(Json)
company_id = Column(Integer)
+ streams = relationship("Stream", cascade="all, delete")
class Stream(Base):
@@ -155,8 +157,8 @@
stream_out = Column(String, nullable=False)
anomaly_stream = Column(String)
learning_stream = Column(String)
- integration = Column(String, ForeignKey('integration.name', ondelete='CASCADE'), nullable=True)
- predictor = Column(String, ForeignKey('predictor.name', ondelete='CASCADE'), nullable=False)
+ integration = Column(String, ForeignKey(Integration.name))
+ predictor = Column(String, ForeignKey(Predictor.name), nullable=False)
company_id = Column(Integer)
updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)
created_at = Column(DateTime, default=datetime.datetime.now)
| {"golden_diff": "diff --git a/mindsdb/integrations/base/integration.py b/mindsdb/integrations/base/integration.py\n--- a/mindsdb/integrations/base/integration.py\n+++ b/mindsdb/integrations/base/integration.py\n@@ -37,6 +37,7 @@\n Thread(target=StreamIntegration._loop, args=(self,)).start()\n \n def _loop(self):\n+ log.info(\"INTEGRATION %s: starting\", self.name)\n while not STOP_THREADS_EVENT.wait(1.0):\n if self._control_stream is not None:\n # Create or delete streams based on messages from control_stream\n@@ -104,8 +105,10 @@\n # Start new streams found in DB\n for s in stream_db_recs:\n if s.name not in map(lambda x: x.name, self._streams):\n+ log.info(\"INTEGRATION %s: starting stream - %s\", self.name, s.name)\n self._streams.append(self._make_stream(s))\n \n+ log.info(\"INTEGRATION %s: stopping\", self.name)\n for s in self._streams:\n s.stop_event.set()\n \ndiff --git a/mindsdb/interfaces/storage/db.py b/mindsdb/interfaces/storage/db.py\n--- a/mindsdb/interfaces/storage/db.py\n+++ b/mindsdb/interfaces/storage/db.py\n@@ -4,7 +4,7 @@\n \n import numpy as np\n from sqlalchemy import create_engine, orm, types, UniqueConstraint\n-from sqlalchemy.orm import scoped_session, sessionmaker\n+from sqlalchemy.orm import scoped_session, sessionmaker, relationship\n from sqlalchemy.ext.declarative import declarative_base\n from sqlalchemy import Column, Integer, String, DateTime, Boolean, Index\n from sqlalchemy.sql.expression import null\n@@ -109,6 +109,7 @@\n code = Column(String, nullable=True)\n lightwood_version = Column(String, nullable=True)\n dtype_dict = Column(Json, nullable=True)\n+ streams = relationship(\"Stream\", cascade=\"all, delete\")\n \n \n class AITable(Base):\n@@ -145,6 +146,7 @@\n name = Column(String, nullable=False, unique=True)\n data = Column(Json)\n company_id = Column(Integer)\n+ streams = relationship(\"Stream\", cascade=\"all, delete\")\n \n \n class Stream(Base):\n@@ -155,8 +157,8 @@\n stream_out = Column(String, nullable=False)\n anomaly_stream = Column(String)\n learning_stream = Column(String)\n- integration = Column(String, ForeignKey('integration.name', ondelete='CASCADE'), nullable=True)\n- predictor = Column(String, ForeignKey('predictor.name', ondelete='CASCADE'), nullable=False)\n+ integration = Column(String, ForeignKey(Integration.name))\n+ predictor = Column(String, ForeignKey(Predictor.name), nullable=False)\n company_id = Column(Integer)\n updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)\n created_at = Column(DateTime, default=datetime.datetime.now)\n", "issue": "Streams are still exists if parent integration is deleted\n**Describe the bug**\r\nStreams are still exists if parent integration is deleted\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior, for example:\r\n1. Create a Stream Integration\r\n2. Create a Stream which is based on this integration\r\n3.Delete the integration\r\n4. check db. `select * from stream;`\r\nNote, that created stream is still exist while its parent integration is deleted.\r\n\r\n**Expected behavior**\r\nNeed to delete all related streams in case of deleting a stream integration\r\n\n", "before_files": [{"content": "import os\nimport json\nimport datetime\n\nimport numpy as np\nfrom sqlalchemy import create_engine, orm, types, UniqueConstraint\nfrom sqlalchemy.orm import scoped_session, sessionmaker\nfrom sqlalchemy.ext.declarative import declarative_base\nfrom sqlalchemy import Column, Integer, String, DateTime, Boolean, Index\nfrom sqlalchemy.sql.expression import null\nfrom sqlalchemy.sql.schema import ForeignKey\n\nif os.environ['MINDSDB_DB_CON'].startswith('sqlite:'):\n engine = create_engine(os.environ['MINDSDB_DB_CON'], echo=False)\nelse:\n engine = create_engine(os.environ['MINDSDB_DB_CON'], convert_unicode=True, pool_size=30, max_overflow=200, echo=False)\nBase = declarative_base()\nsession = scoped_session(sessionmaker(bind=engine, autoflush=True))\nBase.query = session.query_property()\n\n\n# Source: https://stackoverflow.com/questions/26646362/numpy-array-is-not-json-serializable\nclass NumpyEncoder(json.JSONEncoder):\n \"\"\" Special json encoder for numpy types \"\"\"\n def default(self, obj):\n if isinstance(obj, np.integer):\n return int(obj)\n elif isinstance(obj, np.floating):\n return float(obj)\n elif isinstance(obj, np.ndarray):\n return obj.tolist()\n return json.JSONEncoder.default(self, obj)\n\n\nclass Array(types.TypeDecorator):\n ''' Float Type that replaces commas with dots on input '''\n impl = types.String\n\n def process_bind_param(self, value, dialect): # insert\n if isinstance(value, str):\n return value\n elif value is None:\n return value\n else:\n return ',|,|,'.join(value)\n\n def process_result_value(self, value, dialect): # select\n return value.split(',|,|,') if value is not None else None\n\n\nclass Json(types.TypeDecorator):\n ''' Float Type that replaces commas with dots on input '''\n impl = types.String\n\n def process_bind_param(self, value, dialect): # insert\n return json.dumps(value, cls=NumpyEncoder) if value is not None else None\n\n def process_result_value(self, value, dialect): # select\n return json.loads(value) if value is not None else None\n\n\nclass Semaphor(Base):\n __tablename__ = 'semaphor'\n\n id = Column(Integer, primary_key=True)\n updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)\n created_at = Column(DateTime, default=datetime.datetime.now)\n entity_type = Column('entity_type', String)\n entity_id = Column('entity_id', Integer)\n action = Column(String)\n company_id = Column(Integer)\n uniq_const = UniqueConstraint('entity_type', 'entity_id')\n\n\nclass Datasource(Base):\n __tablename__ = 'datasource'\n\n id = Column(Integer, primary_key=True)\n updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)\n created_at = Column(DateTime, default=datetime.datetime.now)\n name = Column(String)\n data = Column(String) # Including, e.g. the query used to create it and even the connection info when there's no integration associated with it -- A JSON\n creation_info = Column(String)\n analysis = Column(String) # A JSON\n company_id = Column(Integer)\n mindsdb_version = Column(String)\n datasources_version = Column(String)\n integration_id = Column(Integer)\n\n\nclass Predictor(Base):\n __tablename__ = 'predictor'\n\n id = Column(Integer, primary_key=True)\n updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)\n created_at = Column(DateTime, default=datetime.datetime.now)\n name = Column(String, unique=True)\n data = Column(Json) # A JSON -- should be everything returned by `get_model_data`, I think\n to_predict = Column(Array)\n company_id = Column(Integer)\n mindsdb_version = Column(String)\n native_version = Column(String)\n datasource_id = Column(Integer)\n is_custom = Column(Boolean) # to del\n learn_args = Column(Json)\n update_status = Column(String, default='up_to_date')\n\n json_ai = Column(Json, nullable=True)\n code = Column(String, nullable=True)\n lightwood_version = Column(String, nullable=True)\n dtype_dict = Column(Json, nullable=True)\n\n\nclass AITable(Base):\n __tablename__ = 'ai_table'\n id = Column(Integer, primary_key=True)\n updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)\n created_at = Column(DateTime, default=datetime.datetime.now)\n name = Column(String)\n integration_name = Column(String)\n integration_query = Column(String)\n query_fields = Column(Json)\n predictor_name = Column(String)\n predictor_columns = Column(Json)\n company_id = Column(Integer)\n\n\nclass Log(Base):\n __tablename__ = 'log'\n\n id = Column(Integer, primary_key=True)\n created_at = Column(DateTime, default=datetime.datetime.now)\n log_type = Column(String) # log, info, warning, traceback etc\n source = Column(String) # file + line\n company_id = Column(Integer)\n payload = Column(String)\n created_at_index = Index(\"some_index\", \"created_at_index\")\n\n\nclass Integration(Base):\n __tablename__ = 'integration'\n id = Column(Integer, primary_key=True)\n updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)\n created_at = Column(DateTime, default=datetime.datetime.now)\n name = Column(String, nullable=False, unique=True)\n data = Column(Json)\n company_id = Column(Integer)\n\n\nclass Stream(Base):\n __tablename__ = 'stream'\n id = Column(Integer, primary_key=True)\n name = Column(String, nullable=False, unique=True)\n stream_in = Column(String, nullable=False)\n stream_out = Column(String, nullable=False)\n anomaly_stream = Column(String)\n learning_stream = Column(String)\n integration = Column(String, ForeignKey('integration.name', ondelete='CASCADE'), nullable=True)\n predictor = Column(String, ForeignKey('predictor.name', ondelete='CASCADE'), nullable=False)\n company_id = Column(Integer)\n updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)\n created_at = Column(DateTime, default=datetime.datetime.now)\n type = Column(String, default='unknown')\n connection_info = Column(Json, default={})\n\n\nBase.metadata.create_all(engine)\norm.configure_mappers()\n", "path": "mindsdb/interfaces/storage/db.py"}, {"content": "import os\nfrom threading import Thread\nfrom mindsdb.streams import StreamController\n\nfrom mindsdb.utilities.config import STOP_THREADS_EVENT\nfrom mindsdb.utilities.log import log\nimport mindsdb.interfaces.storage.db as db\n\n\nclass Integration:\n def __init__(self, config, name):\n self.config = config\n self.name = name\n self.mindsdb_database = config['api']['mysql']['database']\n self.company_id = os.environ.get('MINDSDB_COMPANY_ID', None)\n\n def setup(self):\n raise NotImplementedError\n\n def _query(self, query, fetch=False):\n raise NotImplementedError\n\n def register_predictors(self, model_data_arr):\n raise NotImplementedError\n\n def unregister_predictor(self, name):\n raise NotImplementedError\n\n\nclass StreamIntegration(Integration):\n def __init__(self, config, name, control_stream=None):\n Integration.__init__(self, config, name)\n self._streams = []\n self._control_stream = control_stream\n \n def setup(self):\n Thread(target=StreamIntegration._loop, args=(self,)).start()\n\n def _loop(self):\n while not STOP_THREADS_EVENT.wait(1.0):\n if self._control_stream is not None:\n # Create or delete streams based on messages from control_stream\n for dct in self._control_stream.read():\n if 'action' not in dct:\n log.error('INTEGRATION %s: no action value found in control record - %s', self.name, dct)\n else:\n if dct['action'] == 'create':\n for k in ['name', 'predictor', 'stream_in', 'stream_out']:\n if k not in dct:\n # Not all required parameters were provided (i.e. stream will not be created)\n # TODO: what's a good way to notify user about this?\n log.error('INTEGRATION %s: stream creating error. not enough data in control record - %s', self.name, dct)\n break\n else:\n log.info('INTEGRATION %s: creating stream %s', self.name, dct['name'])\n if db.session.query(db.Stream).filter_by(name=dct['name'], company_id=self.company_id).first() is None:\n stream = db.Stream(\n company_id=self.company_id,\n name=dct['name'],\n integration=self.name,\n predictor=dct['predictor'],\n stream_in=dct['stream_in'],\n stream_out=dct['stream_out'],\n anomaly_stream=dct.get('anomaly_stream', None),\n learning_stream=dct.get('learning_stream', None)\n )\n db.session.add(stream)\n db.session.commit()\n else:\n log.error('INTEGRATION %s: stream with this name already exists - %s', self.name, dct['name'])\n elif dct['action'] == 'delete':\n for k in ['name']:\n if k not in dct:\n # Not all required parameters were provided (i.e. stream will not be created)\n # TODO: what's a good way to notify user about this?\n log.error('INTEGRATION %s: unable to delete stream - stream name is not provided', self.name)\n break\n else:\n log.error('INTEGRATION %s: deleting stream - %s', self.name, dct['name'])\n db.session.query(db.Stream).filter_by(\n company_id=self.company_id,\n integration=self.name,\n name=dct['name']\n ).delete()\n db.session.commit()\n else:\n # Bad action value\n log.error('INTEGRATION %s: bad action value received - %s', self.name, dct)\n \n stream_db_recs = db.session.query(db.Stream).filter_by(\n company_id=self.company_id,\n integration=self.name\n ).all()\n\n # Stop streams that weren't found in DB\n indices_to_delete = []\n for i, s in enumerate(self._streams):\n if s.name not in map(lambda x: x.name, stream_db_recs):\n log.info(\"INTEGRATION %s: stopping stream - %s\", self.name, s.name)\n indices_to_delete.append(i)\n self._streams[i].stop_event.set()\n self._streams = [s for i, s in enumerate(self._streams) if i not in indices_to_delete]\n\n # Start new streams found in DB\n for s in stream_db_recs:\n if s.name not in map(lambda x: x.name, self._streams):\n self._streams.append(self._make_stream(s))\n\n for s in self._streams:\n s.stop_event.set()\n\n def _make_stream(self, s: db.Stream) -> StreamController:\n raise NotImplementedError\n\n def _query(self, query, fetch=False):\n pass\n\n def register_predictors(self, model_data_arr):\n pass\n\n def unregister_predictor(self, name):\n pass\n", "path": "mindsdb/integrations/base/integration.py"}], "after_files": [{"content": "import os\nimport json\nimport datetime\n\nimport numpy as np\nfrom sqlalchemy import create_engine, orm, types, UniqueConstraint\nfrom sqlalchemy.orm import scoped_session, sessionmaker, relationship\nfrom sqlalchemy.ext.declarative import declarative_base\nfrom sqlalchemy import Column, Integer, String, DateTime, Boolean, Index\nfrom sqlalchemy.sql.expression import null\nfrom sqlalchemy.sql.schema import ForeignKey\n\nif os.environ['MINDSDB_DB_CON'].startswith('sqlite:'):\n engine = create_engine(os.environ['MINDSDB_DB_CON'], echo=False)\nelse:\n engine = create_engine(os.environ['MINDSDB_DB_CON'], convert_unicode=True, pool_size=30, max_overflow=200, echo=False)\nBase = declarative_base()\nsession = scoped_session(sessionmaker(bind=engine, autoflush=True))\nBase.query = session.query_property()\n\n\n# Source: https://stackoverflow.com/questions/26646362/numpy-array-is-not-json-serializable\nclass NumpyEncoder(json.JSONEncoder):\n \"\"\" Special json encoder for numpy types \"\"\"\n def default(self, obj):\n if isinstance(obj, np.integer):\n return int(obj)\n elif isinstance(obj, np.floating):\n return float(obj)\n elif isinstance(obj, np.ndarray):\n return obj.tolist()\n return json.JSONEncoder.default(self, obj)\n\n\nclass Array(types.TypeDecorator):\n ''' Float Type that replaces commas with dots on input '''\n impl = types.String\n\n def process_bind_param(self, value, dialect): # insert\n if isinstance(value, str):\n return value\n elif value is None:\n return value\n else:\n return ',|,|,'.join(value)\n\n def process_result_value(self, value, dialect): # select\n return value.split(',|,|,') if value is not None else None\n\n\nclass Json(types.TypeDecorator):\n ''' Float Type that replaces commas with dots on input '''\n impl = types.String\n\n def process_bind_param(self, value, dialect): # insert\n return json.dumps(value, cls=NumpyEncoder) if value is not None else None\n\n def process_result_value(self, value, dialect): # select\n return json.loads(value) if value is not None else None\n\n\nclass Semaphor(Base):\n __tablename__ = 'semaphor'\n\n id = Column(Integer, primary_key=True)\n updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)\n created_at = Column(DateTime, default=datetime.datetime.now)\n entity_type = Column('entity_type', String)\n entity_id = Column('entity_id', Integer)\n action = Column(String)\n company_id = Column(Integer)\n uniq_const = UniqueConstraint('entity_type', 'entity_id')\n\n\nclass Datasource(Base):\n __tablename__ = 'datasource'\n\n id = Column(Integer, primary_key=True)\n updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)\n created_at = Column(DateTime, default=datetime.datetime.now)\n name = Column(String)\n data = Column(String) # Including, e.g. the query used to create it and even the connection info when there's no integration associated with it -- A JSON\n creation_info = Column(String)\n analysis = Column(String) # A JSON\n company_id = Column(Integer)\n mindsdb_version = Column(String)\n datasources_version = Column(String)\n integration_id = Column(Integer)\n\n\nclass Predictor(Base):\n __tablename__ = 'predictor'\n\n id = Column(Integer, primary_key=True)\n updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)\n created_at = Column(DateTime, default=datetime.datetime.now)\n name = Column(String, unique=True)\n data = Column(Json) # A JSON -- should be everything returned by `get_model_data`, I think\n to_predict = Column(Array)\n company_id = Column(Integer)\n mindsdb_version = Column(String)\n native_version = Column(String)\n datasource_id = Column(Integer)\n is_custom = Column(Boolean) # to del\n learn_args = Column(Json)\n update_status = Column(String, default='up_to_date')\n\n json_ai = Column(Json, nullable=True)\n code = Column(String, nullable=True)\n lightwood_version = Column(String, nullable=True)\n dtype_dict = Column(Json, nullable=True)\n streams = relationship(\"Stream\", cascade=\"all, delete\")\n\n\nclass AITable(Base):\n __tablename__ = 'ai_table'\n id = Column(Integer, primary_key=True)\n updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)\n created_at = Column(DateTime, default=datetime.datetime.now)\n name = Column(String)\n integration_name = Column(String)\n integration_query = Column(String)\n query_fields = Column(Json)\n predictor_name = Column(String)\n predictor_columns = Column(Json)\n company_id = Column(Integer)\n\n\nclass Log(Base):\n __tablename__ = 'log'\n\n id = Column(Integer, primary_key=True)\n created_at = Column(DateTime, default=datetime.datetime.now)\n log_type = Column(String) # log, info, warning, traceback etc\n source = Column(String) # file + line\n company_id = Column(Integer)\n payload = Column(String)\n created_at_index = Index(\"some_index\", \"created_at_index\")\n\n\nclass Integration(Base):\n __tablename__ = 'integration'\n id = Column(Integer, primary_key=True)\n updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)\n created_at = Column(DateTime, default=datetime.datetime.now)\n name = Column(String, nullable=False, unique=True)\n data = Column(Json)\n company_id = Column(Integer)\n streams = relationship(\"Stream\", cascade=\"all, delete\")\n\n\nclass Stream(Base):\n __tablename__ = 'stream'\n id = Column(Integer, primary_key=True)\n name = Column(String, nullable=False, unique=True)\n stream_in = Column(String, nullable=False)\n stream_out = Column(String, nullable=False)\n anomaly_stream = Column(String)\n learning_stream = Column(String)\n integration = Column(String, ForeignKey(Integration.name))\n predictor = Column(String, ForeignKey(Predictor.name), nullable=False)\n company_id = Column(Integer)\n updated_at = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now)\n created_at = Column(DateTime, default=datetime.datetime.now)\n type = Column(String, default='unknown')\n connection_info = Column(Json, default={})\n\n\nBase.metadata.create_all(engine)\norm.configure_mappers()\n", "path": "mindsdb/interfaces/storage/db.py"}, {"content": "import os\nfrom threading import Thread\nfrom mindsdb.streams import StreamController\n\nfrom mindsdb.utilities.config import STOP_THREADS_EVENT\nfrom mindsdb.utilities.log import log\nimport mindsdb.interfaces.storage.db as db\n\n\nclass Integration:\n def __init__(self, config, name):\n self.config = config\n self.name = name\n self.mindsdb_database = config['api']['mysql']['database']\n self.company_id = os.environ.get('MINDSDB_COMPANY_ID', None)\n\n def setup(self):\n raise NotImplementedError\n\n def _query(self, query, fetch=False):\n raise NotImplementedError\n\n def register_predictors(self, model_data_arr):\n raise NotImplementedError\n\n def unregister_predictor(self, name):\n raise NotImplementedError\n\n\nclass StreamIntegration(Integration):\n def __init__(self, config, name, control_stream=None):\n Integration.__init__(self, config, name)\n self._streams = []\n self._control_stream = control_stream\n \n def setup(self):\n Thread(target=StreamIntegration._loop, args=(self,)).start()\n\n def _loop(self):\n log.info(\"INTEGRATION %s: starting\", self.name)\n while not STOP_THREADS_EVENT.wait(1.0):\n if self._control_stream is not None:\n # Create or delete streams based on messages from control_stream\n for dct in self._control_stream.read():\n if 'action' not in dct:\n log.error('INTEGRATION %s: no action value found in control record - %s', self.name, dct)\n else:\n if dct['action'] == 'create':\n for k in ['name', 'predictor', 'stream_in', 'stream_out']:\n if k not in dct:\n # Not all required parameters were provided (i.e. stream will not be created)\n # TODO: what's a good way to notify user about this?\n log.error('INTEGRATION %s: stream creating error. not enough data in control record - %s', self.name, dct)\n break\n else:\n log.info('INTEGRATION %s: creating stream %s', self.name, dct['name'])\n if db.session.query(db.Stream).filter_by(name=dct['name'], company_id=self.company_id).first() is None:\n stream = db.Stream(\n company_id=self.company_id,\n name=dct['name'],\n integration=self.name,\n predictor=dct['predictor'],\n stream_in=dct['stream_in'],\n stream_out=dct['stream_out'],\n anomaly_stream=dct.get('anomaly_stream', None),\n learning_stream=dct.get('learning_stream', None)\n )\n db.session.add(stream)\n db.session.commit()\n else:\n log.error('INTEGRATION %s: stream with this name already exists - %s', self.name, dct['name'])\n elif dct['action'] == 'delete':\n for k in ['name']:\n if k not in dct:\n # Not all required parameters were provided (i.e. stream will not be created)\n # TODO: what's a good way to notify user about this?\n log.error('INTEGRATION %s: unable to delete stream - stream name is not provided', self.name)\n break\n else:\n log.error('INTEGRATION %s: deleting stream - %s', self.name, dct['name'])\n db.session.query(db.Stream).filter_by(\n company_id=self.company_id,\n integration=self.name,\n name=dct['name']\n ).delete()\n db.session.commit()\n else:\n # Bad action value\n log.error('INTEGRATION %s: bad action value received - %s', self.name, dct)\n \n stream_db_recs = db.session.query(db.Stream).filter_by(\n company_id=self.company_id,\n integration=self.name\n ).all()\n\n # Stop streams that weren't found in DB\n indices_to_delete = []\n for i, s in enumerate(self._streams):\n if s.name not in map(lambda x: x.name, stream_db_recs):\n log.info(\"INTEGRATION %s: stopping stream - %s\", self.name, s.name)\n indices_to_delete.append(i)\n self._streams[i].stop_event.set()\n self._streams = [s for i, s in enumerate(self._streams) if i not in indices_to_delete]\n\n # Start new streams found in DB\n for s in stream_db_recs:\n if s.name not in map(lambda x: x.name, self._streams):\n log.info(\"INTEGRATION %s: starting stream - %s\", self.name, s.name)\n self._streams.append(self._make_stream(s))\n\n log.info(\"INTEGRATION %s: stopping\", self.name)\n for s in self._streams:\n s.stop_event.set()\n\n def _make_stream(self, s: db.Stream) -> StreamController:\n raise NotImplementedError\n\n def _query(self, query, fetch=False):\n pass\n\n def register_predictors(self, model_data_arr):\n pass\n\n def unregister_predictor(self, name):\n pass\n", "path": "mindsdb/integrations/base/integration.py"}]} | 3,491 | 646 |
gh_patches_debug_3359 | rasdani/github-patches | git_diff | akvo__akvo-rsr-2495 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Signing in from RSR Up fails with error 'Unable to authorize:'
Login for a user who has `rsr.change_project` permissions for a lot of projects, but is not an `rsr_admin` can timeout. This piece of code seems like the [culprit code](https://github.com/akvo/akvo-rsr/blob/5a07b31d1c272f2014e5eb3209f23506aa6e91f1/akvo/rsr/views/account.py#L273).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `akvo/rsr/views/account.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 """Akvo RSR is covered by the GNU Affero General Public License.
4
5 See more details in the license.txt file located at the root folder of the
6 Akvo RSR module. For additional details on the GNU license please
7 see < http://www.gnu.org/licenses/agpl.html >.
8 """
9
10 import re
11 import json
12
13 from lxml import etree
14 from tastypie.models import ApiKey
15
16 from akvo.rsr.forms import RegisterForm, InvitedUserForm
17 from akvo.rsr.models import Employment
18 from akvo.utils import rsr_send_mail
19
20 from django.conf import settings
21 from django.contrib.auth import login, logout, authenticate, get_user_model
22 from django.contrib.auth.forms import AuthenticationForm, PasswordResetForm
23 from django.core.exceptions import ObjectDoesNotExist
24 from django.core.signing import TimestampSigner, BadSignature
25 from django.http import (HttpResponse, HttpResponseRedirect,
26 HttpResponseForbidden)
27 from django.shortcuts import redirect, render, render_to_response
28 from django.template import RequestContext
29
30 from registration.models import RegistrationProfile
31
32 from django.views.decorators.csrf import csrf_exempt
33 from django.views.decorators.http import require_POST
34
35
36 def register(request):
37 """Register form."""
38 context = RequestContext(request)
39 if request.method == 'POST':
40 form = RegisterForm(data=request.POST, files=request.FILES)
41 if form.is_valid():
42 user = form.save(request)
43 return render_to_response('registration/register_complete.html',
44 {'new_user': user},
45 context_instance=context)
46 else:
47 form = RegisterForm()
48 return render_to_response('registration/register.html', {'form': form},
49 context_instance=context)
50
51
52 def activate(request, activation_key, extra_context=None):
53 """Activate resouce.
54
55 Activate a User's account, if their key is valid and hasn't expired.
56 Any values passed in the keyword argument "extra_context"
57 (which must be a dictionary) will be added to the context.
58 Any values in "extra_context" which are callable will be called prior to
59 being added to the context.
60 """
61 sha = re.compile('^[a-f0-9]{40}$')
62 activation_key = activation_key.lower()
63
64 if sha.search(activation_key):
65 try:
66 registration_profile = RegistrationProfile.objects.get(
67 activation_key=activation_key)
68 except RegistrationProfile.DoesNotExist:
69 user = False
70 else:
71 if not registration_profile.activation_key_expired():
72 registration_profile.activation_key = RegistrationProfile.ACTIVATED
73 registration_profile.save()
74 user = registration_profile.user
75 user.is_active = True
76 user.save()
77
78 # Log in user without password, using custom backend
79 user = authenticate(username=user.username, no_password=True)
80 login(request, user)
81 if extra_context is None:
82 extra_context = {}
83 context = RequestContext(request)
84 for key, value in extra_context.items():
85 context[key] = callable(value) and value() or value
86 return render_to_response(
87 'registration/activate.html',
88 context_instance=context
89 )
90
91
92 def invite_activate(request, inviting_pk, user_pk, employment_pk, token_date, token):
93 """
94 Activate a user that has been invited to use RSR.
95
96 :param request: the request
97 :param inviting_pk: the invitee user's primary key
98 :param user_pk: the invited user's primary key
99 :param employment_pk: the employment's primary key
100 :param token_date: the first part of the token
101 :param token: the second part of the token
102 """
103
104 def approve_employment(invitee, invited, empl):
105 """
106 Approves the employment and sends a mail to the user that has invited the new user.
107
108 :param invitee: the invitee user's instance
109 :param invited: the invited user's instance
110 :param empl: the employment's instance
111 """
112 empl.approve(invitee)
113
114 if invitee:
115 # Send notification email to inviting user
116 rsr_send_mail(
117 [invitee.email],
118 subject='registration/inviting_user_notification_subject.txt',
119 message='registration/inviting_user_notification_message.txt',
120 html_message='registration/inviting_user_notification_message.html',
121 subject_context={
122 'user': invited,
123 },
124 msg_context={
125 'invited_user': invited,
126 'inviting_user': invitee,
127 'organisation': empl.organisation,
128 }
129 )
130
131 def login_and_redirect(req, invited):
132 """
133 Log the invited user in and redirect to the My details page in MyRSR.
134
135 :param req: the request
136 :param invited: the invited user's instance
137 """
138 invited = authenticate(username=invited.username, no_password=True)
139 login(request, invited)
140 return redirect('my_details')
141
142 bad_link, user, inviting_user, employment = False, None, None, None
143
144 try:
145 user = get_user_model().objects.get(pk=user_pk)
146 inviting_user = get_user_model().objects.get(pk=inviting_pk)
147 employment = Employment.objects.get(pk=employment_pk)
148 except ObjectDoesNotExist:
149 bad_link = True
150
151 try:
152 TimestampSigner().unsign(':'.join([user.email, token_date, token]))
153 except BadSignature:
154 bad_link = True
155
156 if user and user.is_active:
157 if employment and employment.is_approved:
158 # User is active and employment is approved, so nothing to do here
159 return login_and_redirect(request, user)
160 elif employment and not bad_link:
161 # Employment is not yet approved, and link is ok.
162 # Approve employment and log user in.
163 approve_employment(inviting_user, user, employment)
164 return login_and_redirect(request, user)
165
166 if request.method == 'POST':
167 form = InvitedUserForm(user=user, data=request.POST)
168 if form.is_valid():
169 # Approve employment and save new user details
170 form.save(request)
171 approve_employment(inviting_user, user, employment)
172 return login_and_redirect(request, user)
173 else:
174 form = InvitedUserForm(user=user)
175
176 context = {
177 'form': form,
178 'bad_link': bad_link,
179 }
180 return render(request, 'registration/invite_activate.html', context)
181
182
183 def sign_in(request):
184 """Sign in.
185
186 POST have two variants with username & email:
187 - username > normal sign in
188 - email > password reset workflow
189 """
190 context = RequestContext(request)
191 form = AuthenticationForm()
192 reset_form = PasswordResetForm()
193 if request.method == "POST" and 'username' in request.POST:
194 form = AuthenticationForm(data=request.POST)
195 if form.is_valid():
196 login(request, form.get_user())
197 next_page = request.GET.get('next')
198 return HttpResponseRedirect(next_page) if next_page else redirect('my_details')
199 # Password reset on sign in page
200 elif request.method == "POST" and 'email' in request.POST:
201 reset_form = PasswordResetForm(data=request.POST)
202 if reset_form.is_valid():
203 reset_form.save(domain_override=settings.RSR_DOMAIN)
204 return HttpResponse()
205 return render_to_response('sign_in.html', {'form': form, 'reset_form': reset_form},
206 context_instance=context)
207
208
209 def sign_out(request):
210 """Log out resouce."""
211 logout(request)
212 return redirect('index')
213
214
215 def api_key_xml_response(user, orgs):
216 """Build the XML response.
217
218 This is used by the Up app - so make sure they match on change.
219 """
220 xml_root = etree.Element("credentials")
221
222 # User
223 user_id_element = etree.SubElement(xml_root, "user_id")
224 user_id_element.text = str(user.id)
225 user_username_element = etree.SubElement(xml_root, "username")
226 user_username_element.text = user.username
227
228 # Organisations
229 for org in orgs:
230 org_id_element = etree.SubElement(xml_root, "org_id")
231 org_id_element.text = str(org.id)
232
233 # API key
234 api_key_element = etree.SubElement(xml_root, "api_key")
235 api_key_element.text = ApiKey.objects.get_or_create(user=user)[0].key
236
237 # Published and editable projects
238 projects = user.organisations.all_projects().published()
239 pub_projs_element = etree.SubElement(xml_root, "published_projects")
240 edit_projs_element = etree.SubElement(xml_root, "allow_edit_projects")
241 for project in projects:
242 project_id_element = etree.SubElement(pub_projs_element, "id")
243 project_id_element.text = str(project.id)
244 if user.has_perm('rsr.change_project', project):
245 project_id_element = etree.SubElement(edit_projs_element, "id")
246 project_id_element.text = str(project.id)
247
248 return etree.tostring(etree.ElementTree(xml_root))
249
250
251 def api_key_json_response(user, orgs):
252 """
253 Build the JSON response. This is used by the Up app - so make sure they match on change.
254 """
255 response_data = dict()
256
257 # User
258 response_data["user_id"] = user.id
259 response_data["username"] = user.username
260
261 # Organisations
262 response_data["organisations"] = [org.id for org in orgs]
263
264 # API key
265 response_data["api_key"] = ApiKey.objects.get_or_create(user=user)[0].key
266
267 # Published projects
268 projects = user.organisations.all_projects().published()
269 response_data["published_projects"] = [p.id for p in projects]
270
271 # Editable projects
272 perm = 'rsr.change_project'
273 response_data["allow_edit_projects"] = [p.id for p in projects if user.has_perm(perm, p)]
274
275 return json.dumps(response_data)
276
277
278 @require_POST
279 @csrf_exempt
280 def api_key(request):
281 """On successful user credentials returns an auth token for API usage.
282
283 Since RSR changed in v3 to allow users without an organisation we need to
284 introduce a way to make old Up apps work as before but new ones support
285 users without any connected organisations.
286 """
287 request_format = request.GET.get('format', 'xml')
288 username = request.POST.get('username', False)
289 password = request.POST.get('password', False)
290 handles_unemployed = bool(request.POST.get("handles_unemployed", False))
291
292 if username and password:
293 user = authenticate(username=username, password=password)
294 if user is not None and user.is_active:
295 orgs = user.approved_organisations()
296 if orgs or handles_unemployed:
297 if request_format == 'xml':
298 return HttpResponse(api_key_xml_response(user, orgs),
299 content_type="text/xml")
300 elif request_format == 'json':
301 return HttpResponse(api_key_json_response(user, orgs),
302 content_type="application/json")
303 return HttpResponseForbidden()
304
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/akvo/rsr/views/account.py b/akvo/rsr/views/account.py
--- a/akvo/rsr/views/account.py
+++ b/akvo/rsr/views/account.py
@@ -270,7 +270,8 @@
# Editable projects
perm = 'rsr.change_project'
- response_data["allow_edit_projects"] = [p.id for p in projects if user.has_perm(perm, p)]
+ perm_filter = user.get_permission_filter(perm, '')
+ response_data["allow_edit_projects"] = list(projects.filter(perm_filter).values_list('id', flat=True))
return json.dumps(response_data)
| {"golden_diff": "diff --git a/akvo/rsr/views/account.py b/akvo/rsr/views/account.py\n--- a/akvo/rsr/views/account.py\n+++ b/akvo/rsr/views/account.py\n@@ -270,7 +270,8 @@\n \n # Editable projects\n perm = 'rsr.change_project'\n- response_data[\"allow_edit_projects\"] = [p.id for p in projects if user.has_perm(perm, p)]\n+ perm_filter = user.get_permission_filter(perm, '')\n+ response_data[\"allow_edit_projects\"] = list(projects.filter(perm_filter).values_list('id', flat=True))\n \n return json.dumps(response_data)\n", "issue": "Signing in from RSR Up fails with error 'Unable to authorize:'\nLogin for a user who has `rsr.change_project` permissions for a lot of projects, but is not an `rsr_admin` can timeout. This piece of code seems like the [culprit code](https://github.com/akvo/akvo-rsr/blob/5a07b31d1c272f2014e5eb3209f23506aa6e91f1/akvo/rsr/views/account.py#L273). \n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Akvo RSR is covered by the GNU Affero General Public License.\n\nSee more details in the license.txt file located at the root folder of the\nAkvo RSR module. For additional details on the GNU license please\nsee < http://www.gnu.org/licenses/agpl.html >.\n\"\"\"\n\nimport re\nimport json\n\nfrom lxml import etree\nfrom tastypie.models import ApiKey\n\nfrom akvo.rsr.forms import RegisterForm, InvitedUserForm\nfrom akvo.rsr.models import Employment\nfrom akvo.utils import rsr_send_mail\n\nfrom django.conf import settings\nfrom django.contrib.auth import login, logout, authenticate, get_user_model\nfrom django.contrib.auth.forms import AuthenticationForm, PasswordResetForm\nfrom django.core.exceptions import ObjectDoesNotExist\nfrom django.core.signing import TimestampSigner, BadSignature\nfrom django.http import (HttpResponse, HttpResponseRedirect,\n HttpResponseForbidden)\nfrom django.shortcuts import redirect, render, render_to_response\nfrom django.template import RequestContext\n\nfrom registration.models import RegistrationProfile\n\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.views.decorators.http import require_POST\n\n\ndef register(request):\n \"\"\"Register form.\"\"\"\n context = RequestContext(request)\n if request.method == 'POST':\n form = RegisterForm(data=request.POST, files=request.FILES)\n if form.is_valid():\n user = form.save(request)\n return render_to_response('registration/register_complete.html',\n {'new_user': user},\n context_instance=context)\n else:\n form = RegisterForm()\n return render_to_response('registration/register.html', {'form': form},\n context_instance=context)\n\n\ndef activate(request, activation_key, extra_context=None):\n \"\"\"Activate resouce.\n\n Activate a User's account, if their key is valid and hasn't expired.\n Any values passed in the keyword argument \"extra_context\"\n (which must be a dictionary) will be added to the context.\n Any values in \"extra_context\" which are callable will be called prior to\n being added to the context.\n \"\"\"\n sha = re.compile('^[a-f0-9]{40}$')\n activation_key = activation_key.lower()\n\n if sha.search(activation_key):\n try:\n registration_profile = RegistrationProfile.objects.get(\n activation_key=activation_key)\n except RegistrationProfile.DoesNotExist:\n user = False\n else:\n if not registration_profile.activation_key_expired():\n registration_profile.activation_key = RegistrationProfile.ACTIVATED\n registration_profile.save()\n user = registration_profile.user\n user.is_active = True\n user.save()\n\n # Log in user without password, using custom backend\n user = authenticate(username=user.username, no_password=True)\n login(request, user)\n if extra_context is None:\n extra_context = {}\n context = RequestContext(request)\n for key, value in extra_context.items():\n context[key] = callable(value) and value() or value\n return render_to_response(\n 'registration/activate.html',\n context_instance=context\n )\n\n\ndef invite_activate(request, inviting_pk, user_pk, employment_pk, token_date, token):\n \"\"\"\n Activate a user that has been invited to use RSR.\n\n :param request: the request\n :param inviting_pk: the invitee user's primary key\n :param user_pk: the invited user's primary key\n :param employment_pk: the employment's primary key\n :param token_date: the first part of the token\n :param token: the second part of the token\n \"\"\"\n\n def approve_employment(invitee, invited, empl):\n \"\"\"\n Approves the employment and sends a mail to the user that has invited the new user.\n\n :param invitee: the invitee user's instance\n :param invited: the invited user's instance\n :param empl: the employment's instance\n \"\"\"\n empl.approve(invitee)\n\n if invitee:\n # Send notification email to inviting user\n rsr_send_mail(\n [invitee.email],\n subject='registration/inviting_user_notification_subject.txt',\n message='registration/inviting_user_notification_message.txt',\n html_message='registration/inviting_user_notification_message.html',\n subject_context={\n 'user': invited,\n },\n msg_context={\n 'invited_user': invited,\n 'inviting_user': invitee,\n 'organisation': empl.organisation,\n }\n )\n\n def login_and_redirect(req, invited):\n \"\"\"\n Log the invited user in and redirect to the My details page in MyRSR.\n\n :param req: the request\n :param invited: the invited user's instance\n \"\"\"\n invited = authenticate(username=invited.username, no_password=True)\n login(request, invited)\n return redirect('my_details')\n\n bad_link, user, inviting_user, employment = False, None, None, None\n\n try:\n user = get_user_model().objects.get(pk=user_pk)\n inviting_user = get_user_model().objects.get(pk=inviting_pk)\n employment = Employment.objects.get(pk=employment_pk)\n except ObjectDoesNotExist:\n bad_link = True\n\n try:\n TimestampSigner().unsign(':'.join([user.email, token_date, token]))\n except BadSignature:\n bad_link = True\n\n if user and user.is_active:\n if employment and employment.is_approved:\n # User is active and employment is approved, so nothing to do here\n return login_and_redirect(request, user)\n elif employment and not bad_link:\n # Employment is not yet approved, and link is ok.\n # Approve employment and log user in.\n approve_employment(inviting_user, user, employment)\n return login_and_redirect(request, user)\n\n if request.method == 'POST':\n form = InvitedUserForm(user=user, data=request.POST)\n if form.is_valid():\n # Approve employment and save new user details\n form.save(request)\n approve_employment(inviting_user, user, employment)\n return login_and_redirect(request, user)\n else:\n form = InvitedUserForm(user=user)\n\n context = {\n 'form': form,\n 'bad_link': bad_link,\n }\n return render(request, 'registration/invite_activate.html', context)\n\n\ndef sign_in(request):\n \"\"\"Sign in.\n\n POST have two variants with username & email:\n - username > normal sign in\n - email > password reset workflow\n \"\"\"\n context = RequestContext(request)\n form = AuthenticationForm()\n reset_form = PasswordResetForm()\n if request.method == \"POST\" and 'username' in request.POST:\n form = AuthenticationForm(data=request.POST)\n if form.is_valid():\n login(request, form.get_user())\n next_page = request.GET.get('next')\n return HttpResponseRedirect(next_page) if next_page else redirect('my_details')\n # Password reset on sign in page\n elif request.method == \"POST\" and 'email' in request.POST:\n reset_form = PasswordResetForm(data=request.POST)\n if reset_form.is_valid():\n reset_form.save(domain_override=settings.RSR_DOMAIN)\n return HttpResponse()\n return render_to_response('sign_in.html', {'form': form, 'reset_form': reset_form},\n context_instance=context)\n\n\ndef sign_out(request):\n \"\"\"Log out resouce.\"\"\"\n logout(request)\n return redirect('index')\n\n\ndef api_key_xml_response(user, orgs):\n \"\"\"Build the XML response.\n\n This is used by the Up app - so make sure they match on change.\n \"\"\"\n xml_root = etree.Element(\"credentials\")\n\n # User\n user_id_element = etree.SubElement(xml_root, \"user_id\")\n user_id_element.text = str(user.id)\n user_username_element = etree.SubElement(xml_root, \"username\")\n user_username_element.text = user.username\n\n # Organisations\n for org in orgs:\n org_id_element = etree.SubElement(xml_root, \"org_id\")\n org_id_element.text = str(org.id)\n\n # API key\n api_key_element = etree.SubElement(xml_root, \"api_key\")\n api_key_element.text = ApiKey.objects.get_or_create(user=user)[0].key\n\n # Published and editable projects\n projects = user.organisations.all_projects().published()\n pub_projs_element = etree.SubElement(xml_root, \"published_projects\")\n edit_projs_element = etree.SubElement(xml_root, \"allow_edit_projects\")\n for project in projects:\n project_id_element = etree.SubElement(pub_projs_element, \"id\")\n project_id_element.text = str(project.id)\n if user.has_perm('rsr.change_project', project):\n project_id_element = etree.SubElement(edit_projs_element, \"id\")\n project_id_element.text = str(project.id)\n\n return etree.tostring(etree.ElementTree(xml_root))\n\n\ndef api_key_json_response(user, orgs):\n \"\"\"\n Build the JSON response. This is used by the Up app - so make sure they match on change.\n \"\"\"\n response_data = dict()\n\n # User\n response_data[\"user_id\"] = user.id\n response_data[\"username\"] = user.username\n\n # Organisations\n response_data[\"organisations\"] = [org.id for org in orgs]\n\n # API key\n response_data[\"api_key\"] = ApiKey.objects.get_or_create(user=user)[0].key\n\n # Published projects\n projects = user.organisations.all_projects().published()\n response_data[\"published_projects\"] = [p.id for p in projects]\n\n # Editable projects\n perm = 'rsr.change_project'\n response_data[\"allow_edit_projects\"] = [p.id for p in projects if user.has_perm(perm, p)]\n\n return json.dumps(response_data)\n\n\n@require_POST\n@csrf_exempt\ndef api_key(request):\n \"\"\"On successful user credentials returns an auth token for API usage.\n\n Since RSR changed in v3 to allow users without an organisation we need to\n introduce a way to make old Up apps work as before but new ones support\n users without any connected organisations.\n \"\"\"\n request_format = request.GET.get('format', 'xml')\n username = request.POST.get('username', False)\n password = request.POST.get('password', False)\n handles_unemployed = bool(request.POST.get(\"handles_unemployed\", False))\n\n if username and password:\n user = authenticate(username=username, password=password)\n if user is not None and user.is_active:\n orgs = user.approved_organisations()\n if orgs or handles_unemployed:\n if request_format == 'xml':\n return HttpResponse(api_key_xml_response(user, orgs),\n content_type=\"text/xml\")\n elif request_format == 'json':\n return HttpResponse(api_key_json_response(user, orgs),\n content_type=\"application/json\")\n return HttpResponseForbidden()\n", "path": "akvo/rsr/views/account.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Akvo RSR is covered by the GNU Affero General Public License.\n\nSee more details in the license.txt file located at the root folder of the\nAkvo RSR module. For additional details on the GNU license please\nsee < http://www.gnu.org/licenses/agpl.html >.\n\"\"\"\n\nimport re\nimport json\n\nfrom lxml import etree\nfrom tastypie.models import ApiKey\n\nfrom akvo.rsr.forms import RegisterForm, InvitedUserForm\nfrom akvo.rsr.models import Employment\nfrom akvo.utils import rsr_send_mail\n\nfrom django.conf import settings\nfrom django.contrib.auth import login, logout, authenticate, get_user_model\nfrom django.contrib.auth.forms import AuthenticationForm, PasswordResetForm\nfrom django.core.exceptions import ObjectDoesNotExist\nfrom django.core.signing import TimestampSigner, BadSignature\nfrom django.http import (HttpResponse, HttpResponseRedirect,\n HttpResponseForbidden)\nfrom django.shortcuts import redirect, render, render_to_response\nfrom django.template import RequestContext\n\nfrom registration.models import RegistrationProfile\n\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.views.decorators.http import require_POST\n\n\ndef register(request):\n \"\"\"Register form.\"\"\"\n context = RequestContext(request)\n if request.method == 'POST':\n form = RegisterForm(data=request.POST, files=request.FILES)\n if form.is_valid():\n user = form.save(request)\n return render_to_response('registration/register_complete.html',\n {'new_user': user},\n context_instance=context)\n else:\n form = RegisterForm()\n return render_to_response('registration/register.html', {'form': form},\n context_instance=context)\n\n\ndef activate(request, activation_key, extra_context=None):\n \"\"\"Activate resouce.\n\n Activate a User's account, if their key is valid and hasn't expired.\n Any values passed in the keyword argument \"extra_context\"\n (which must be a dictionary) will be added to the context.\n Any values in \"extra_context\" which are callable will be called prior to\n being added to the context.\n \"\"\"\n sha = re.compile('^[a-f0-9]{40}$')\n activation_key = activation_key.lower()\n\n if sha.search(activation_key):\n try:\n registration_profile = RegistrationProfile.objects.get(\n activation_key=activation_key)\n except RegistrationProfile.DoesNotExist:\n user = False\n else:\n if not registration_profile.activation_key_expired():\n registration_profile.activation_key = RegistrationProfile.ACTIVATED\n registration_profile.save()\n user = registration_profile.user\n user.is_active = True\n user.save()\n\n # Log in user without password, using custom backend\n user = authenticate(username=user.username, no_password=True)\n login(request, user)\n if extra_context is None:\n extra_context = {}\n context = RequestContext(request)\n for key, value in extra_context.items():\n context[key] = callable(value) and value() or value\n return render_to_response(\n 'registration/activate.html',\n context_instance=context\n )\n\n\ndef invite_activate(request, inviting_pk, user_pk, employment_pk, token_date, token):\n \"\"\"\n Activate a user that has been invited to use RSR.\n\n :param request: the request\n :param inviting_pk: the invitee user's primary key\n :param user_pk: the invited user's primary key\n :param employment_pk: the employment's primary key\n :param token_date: the first part of the token\n :param token: the second part of the token\n \"\"\"\n\n def approve_employment(invitee, invited, empl):\n \"\"\"\n Approves the employment and sends a mail to the user that has invited the new user.\n\n :param invitee: the invitee user's instance\n :param invited: the invited user's instance\n :param empl: the employment's instance\n \"\"\"\n empl.approve(invitee)\n\n if invitee:\n # Send notification email to inviting user\n rsr_send_mail(\n [invitee.email],\n subject='registration/inviting_user_notification_subject.txt',\n message='registration/inviting_user_notification_message.txt',\n html_message='registration/inviting_user_notification_message.html',\n subject_context={\n 'user': invited,\n },\n msg_context={\n 'invited_user': invited,\n 'inviting_user': invitee,\n 'organisation': empl.organisation,\n }\n )\n\n def login_and_redirect(req, invited):\n \"\"\"\n Log the invited user in and redirect to the My details page in MyRSR.\n\n :param req: the request\n :param invited: the invited user's instance\n \"\"\"\n invited = authenticate(username=invited.username, no_password=True)\n login(request, invited)\n return redirect('my_details')\n\n bad_link, user, inviting_user, employment = False, None, None, None\n\n try:\n user = get_user_model().objects.get(pk=user_pk)\n inviting_user = get_user_model().objects.get(pk=inviting_pk)\n employment = Employment.objects.get(pk=employment_pk)\n except ObjectDoesNotExist:\n bad_link = True\n\n try:\n TimestampSigner().unsign(':'.join([user.email, token_date, token]))\n except BadSignature:\n bad_link = True\n\n if user and user.is_active:\n if employment and employment.is_approved:\n # User is active and employment is approved, so nothing to do here\n return login_and_redirect(request, user)\n elif employment and not bad_link:\n # Employment is not yet approved, and link is ok.\n # Approve employment and log user in.\n approve_employment(inviting_user, user, employment)\n return login_and_redirect(request, user)\n\n if request.method == 'POST':\n form = InvitedUserForm(user=user, data=request.POST)\n if form.is_valid():\n # Approve employment and save new user details\n form.save(request)\n approve_employment(inviting_user, user, employment)\n return login_and_redirect(request, user)\n else:\n form = InvitedUserForm(user=user)\n\n context = {\n 'form': form,\n 'bad_link': bad_link,\n }\n return render(request, 'registration/invite_activate.html', context)\n\n\ndef sign_in(request):\n \"\"\"Sign in.\n\n POST have two variants with username & email:\n - username > normal sign in\n - email > password reset workflow\n \"\"\"\n context = RequestContext(request)\n form = AuthenticationForm()\n reset_form = PasswordResetForm()\n if request.method == \"POST\" and 'username' in request.POST:\n form = AuthenticationForm(data=request.POST)\n if form.is_valid():\n login(request, form.get_user())\n next_page = request.GET.get('next')\n return HttpResponseRedirect(next_page) if next_page else redirect('my_details')\n # Password reset on sign in page\n elif request.method == \"POST\" and 'email' in request.POST:\n reset_form = PasswordResetForm(data=request.POST)\n if reset_form.is_valid():\n reset_form.save(domain_override=settings.RSR_DOMAIN)\n return HttpResponse()\n return render_to_response('sign_in.html', {'form': form, 'reset_form': reset_form},\n context_instance=context)\n\n\ndef sign_out(request):\n \"\"\"Log out resouce.\"\"\"\n logout(request)\n return redirect('index')\n\n\ndef api_key_xml_response(user, orgs):\n \"\"\"Build the XML response.\n\n This is used by the Up app - so make sure they match on change.\n \"\"\"\n xml_root = etree.Element(\"credentials\")\n\n # User\n user_id_element = etree.SubElement(xml_root, \"user_id\")\n user_id_element.text = str(user.id)\n user_username_element = etree.SubElement(xml_root, \"username\")\n user_username_element.text = user.username\n\n # Organisations\n for org in orgs:\n org_id_element = etree.SubElement(xml_root, \"org_id\")\n org_id_element.text = str(org.id)\n\n # API key\n api_key_element = etree.SubElement(xml_root, \"api_key\")\n api_key_element.text = ApiKey.objects.get_or_create(user=user)[0].key\n\n # Published and editable projects\n projects = user.organisations.all_projects().published()\n pub_projs_element = etree.SubElement(xml_root, \"published_projects\")\n edit_projs_element = etree.SubElement(xml_root, \"allow_edit_projects\")\n for project in projects:\n project_id_element = etree.SubElement(pub_projs_element, \"id\")\n project_id_element.text = str(project.id)\n if user.has_perm('rsr.change_project', project):\n project_id_element = etree.SubElement(edit_projs_element, \"id\")\n project_id_element.text = str(project.id)\n\n return etree.tostring(etree.ElementTree(xml_root))\n\n\ndef api_key_json_response(user, orgs):\n \"\"\"\n Build the JSON response. This is used by the Up app - so make sure they match on change.\n \"\"\"\n response_data = dict()\n\n # User\n response_data[\"user_id\"] = user.id\n response_data[\"username\"] = user.username\n\n # Organisations\n response_data[\"organisations\"] = [org.id for org in orgs]\n\n # API key\n response_data[\"api_key\"] = ApiKey.objects.get_or_create(user=user)[0].key\n\n # Published projects\n projects = user.organisations.all_projects().published()\n response_data[\"published_projects\"] = [p.id for p in projects]\n\n # Editable projects\n perm = 'rsr.change_project'\n perm_filter = user.get_permission_filter(perm, '')\n response_data[\"allow_edit_projects\"] = list(projects.filter(perm_filter).values_list('id', flat=True))\n\n return json.dumps(response_data)\n\n\n@require_POST\n@csrf_exempt\ndef api_key(request):\n \"\"\"On successful user credentials returns an auth token for API usage.\n\n Since RSR changed in v3 to allow users without an organisation we need to\n introduce a way to make old Up apps work as before but new ones support\n users without any connected organisations.\n \"\"\"\n request_format = request.GET.get('format', 'xml')\n username = request.POST.get('username', False)\n password = request.POST.get('password', False)\n handles_unemployed = bool(request.POST.get(\"handles_unemployed\", False))\n\n if username and password:\n user = authenticate(username=username, password=password)\n if user is not None and user.is_active:\n orgs = user.approved_organisations()\n if orgs or handles_unemployed:\n if request_format == 'xml':\n return HttpResponse(api_key_xml_response(user, orgs),\n content_type=\"text/xml\")\n elif request_format == 'json':\n return HttpResponse(api_key_json_response(user, orgs),\n content_type=\"application/json\")\n return HttpResponseForbidden()\n", "path": "akvo/rsr/views/account.py"}]} | 3,505 | 147 |
gh_patches_debug_26337 | rasdani/github-patches | git_diff | ansible__ansible-22414 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
UnboudLocalError: local variable 'f' referenced before assignment
Version: 1.9 but also devel as the file handling code does not changed.
Server/Client OS: Ubuntu
This is not a duplicate of #2618. When defining a caching path for the jsonfile caching plugin that is not writable by Ansible. Ansible fails with the following message:
```
fatal: [my-host] => Traceback (most recent call last):
File "/home/david/.pip/ansible/lib/ansible/runner/__init__.py", line 586, in _executor
exec_rc = self._executor_internal(host, new_stdin)
File "/home/david/.pip/ansible/lib/ansible/runner/__init__.py", line 668, in _executor_internal
inject = self.get_inject_vars(host)
File "/home/david/.pip/ansible/lib/ansible/runner/__init__.py", line 611, in get_inject_vars
combined_cache = self.get_combined_cache()
File "/home/david/.pip/ansible/lib/ansible/runner/__init__.py", line 606, in get_combined_cache
combined_cache = self.setup_cache.copy()
File "/home/david/.pip/ansible/lib/ansible/cache/__init__.py", line 54, in copy
return dict([(k, v) for (k, v) in self.iteritems()])
File "/usr/lib/python2.7/_abcoll.py", line 406, in iteritems
yield (key, self[key])
File "/home/david/.pip/ansible/lib/ansible/cache/__init__.py", line 35, in __getitem__
return self._plugin.get(key)
File "/home/david/.pip/ansible/lib/ansible/cache/jsonfile.py", line 69, in get
f.close()
UnboundLocalError: local variable 'f' referenced before assignment
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/ansible/plugins/cache/base.py`
Content:
```
1 # (c) 2014, Brian Coca, Josh Drake, et al
2 #
3 # This file is part of Ansible
4 #
5 # Ansible is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # Ansible is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
17
18 from __future__ import (absolute_import, division, print_function)
19 __metaclass__ = type
20
21 import os
22 import time
23 import errno
24 from abc import ABCMeta, abstractmethod
25
26 from ansible import constants as C
27 from ansible.compat.six import with_metaclass
28 from ansible.errors import AnsibleError
29 from ansible.module_utils._text import to_bytes
30
31 try:
32 from __main__ import display
33 except ImportError:
34 from ansible.utils.display import Display
35 display = Display()
36
37 class BaseCacheModule(with_metaclass(ABCMeta, object)):
38
39 # Backwards compat only. Just import the global display instead
40 _display = display
41
42 @abstractmethod
43 def get(self, key):
44 pass
45
46 @abstractmethod
47 def set(self, key, value):
48 pass
49
50 @abstractmethod
51 def keys(self):
52 pass
53
54 @abstractmethod
55 def contains(self, key):
56 pass
57
58 @abstractmethod
59 def delete(self, key):
60 pass
61
62 @abstractmethod
63 def flush(self):
64 pass
65
66 @abstractmethod
67 def copy(self):
68 pass
69
70
71 class BaseFileCacheModule(BaseCacheModule):
72 """
73 A caching module backed by file based storage.
74 """
75 def __init__(self, *args, **kwargs):
76
77 self.plugin_name = self.__module__.split('.')[-1]
78 self._timeout = float(C.CACHE_PLUGIN_TIMEOUT)
79 self._cache = {}
80 self._cache_dir = None
81
82 if C.CACHE_PLUGIN_CONNECTION:
83 # expects a dir path
84 self._cache_dir = os.path.expanduser(os.path.expandvars(C.CACHE_PLUGIN_CONNECTION))
85
86 if not self._cache_dir:
87 raise AnsibleError("error, '%s' cache plugin requires the 'fact_caching_connection' config option"
88 " to be set (to a writeable directory path)" % self.plugin_name)
89
90 if not os.path.exists(self._cache_dir):
91 try:
92 os.makedirs(self._cache_dir)
93 except (OSError,IOError) as e:
94 display.warning("error in '%s' cache plugin while trying to create cache dir %s : %s" % (self.plugin_name, self._cache_dir, to_bytes(e)))
95 return None
96
97 def get(self, key):
98 """ This checks the in memory cache first as the fact was not expired at 'gather time'
99 and it would be problematic if the key did expire after some long running tasks and
100 user gets 'undefined' error in the same play """
101
102 if key in self._cache:
103 return self._cache.get(key)
104
105 if self.has_expired(key) or key == "":
106 raise KeyError
107
108 cachefile = "%s/%s" % (self._cache_dir, key)
109 try:
110 try:
111 value = self._load(cachefile)
112 self._cache[key] = value
113 return value
114 except ValueError as e:
115 display.warning("error in '%s' cache plugin while trying to read %s : %s."
116 " Most likely a corrupt file, so erasing and failing." % (self.plugin_name, cachefile, to_bytes(e)))
117 self.delete(key)
118 raise AnsibleError("The cache file %s was corrupt, or did not otherwise contain valid data."
119 " It has been removed, so you can re-run your command now." % cachefile)
120 except (OSError,IOError) as e:
121 display.warning("error in '%s' cache plugin while trying to read %s : %s" % (self.plugin_name, cachefile, to_bytes(e)))
122 raise KeyError
123 except Exception as e:
124 raise AnsibleError("Error while decoding the cache file %s: %s" % (cachefile, to_bytes(e)))
125
126 def set(self, key, value):
127
128 self._cache[key] = value
129
130 cachefile = "%s/%s" % (self._cache_dir, key)
131 try:
132 self._dump(value, cachefile)
133 except (OSError,IOError) as e:
134 display.warning("error in '%s' cache plugin while trying to write to %s : %s" % (self.plugin_name, cachefile, to_bytes(e)))
135
136 def has_expired(self, key):
137
138 if self._timeout == 0:
139 return False
140
141 cachefile = "%s/%s" % (self._cache_dir, key)
142 try:
143 st = os.stat(cachefile)
144 except (OSError,IOError) as e:
145 if e.errno == errno.ENOENT:
146 return False
147 else:
148 display.warning("error in '%s' cache plugin while trying to stat %s : %s" % (self.plugin_name, cachefile, to_bytes(e)))
149 pass
150
151 if time.time() - st.st_mtime <= self._timeout:
152 return False
153
154 if key in self._cache:
155 del self._cache[key]
156 return True
157
158 def keys(self):
159 keys = []
160 for k in os.listdir(self._cache_dir):
161 if not (k.startswith('.') or self.has_expired(k)):
162 keys.append(k)
163 return keys
164
165 def contains(self, key):
166 cachefile = "%s/%s" % (self._cache_dir, key)
167
168 if key in self._cache:
169 return True
170
171 if self.has_expired(key):
172 return False
173 try:
174 os.stat(cachefile)
175 return True
176 except (OSError,IOError) as e:
177 if e.errno == errno.ENOENT:
178 return False
179 else:
180 display.warning("error in '%s' cache plugin while trying to stat %s : %s" % (self.plugin_name, cachefile, to_bytes(e)))
181 pass
182
183 def delete(self, key):
184 try:
185 del self._cache[key]
186 except KeyError:
187 pass
188 try:
189 os.remove("%s/%s" % (self._cache_dir, key))
190 except (OSError, IOError):
191 pass #TODO: only pass on non existing?
192
193 def flush(self):
194 self._cache = {}
195 for key in self.keys():
196 self.delete(key)
197
198 def copy(self):
199 ret = dict()
200 for key in self.keys():
201 ret[key] = self.get(key)
202 return ret
203
204 @abstractmethod
205 def _load(self, filepath):
206 """
207 Read data from a filepath and return it as a value
208
209 :arg filepath: The filepath to read from.
210 :returns: The value stored in the filepath
211
212 This method reads from the file on disk and takes care of any parsing
213 and transformation of the data before returning it. The value
214 returned should be what Ansible would expect if it were uncached data.
215
216 .. note:: Filehandles have advantages but calling code doesn't know
217 whether this file is text or binary, should be decoded, or accessed via
218 a library function. Therefore the API uses a filepath and opens
219 the file inside of the method.
220 """
221 pass
222
223 @abstractmethod
224 def _dump(self, value, filepath):
225 """
226 Write data to a filepath
227
228 :arg value: The value to store
229 :arg filepath: The filepath to store it at
230 """
231 pass
232
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/lib/ansible/plugins/cache/base.py b/lib/ansible/plugins/cache/base.py
--- a/lib/ansible/plugins/cache/base.py
+++ b/lib/ansible/plugins/cache/base.py
@@ -91,8 +91,11 @@
try:
os.makedirs(self._cache_dir)
except (OSError,IOError) as e:
- display.warning("error in '%s' cache plugin while trying to create cache dir %s : %s" % (self.plugin_name, self._cache_dir, to_bytes(e)))
- return None
+ raise AnsibleError("error in '%s' cache plugin while trying to create cache dir %s : %s" % (self.plugin_name, self._cache_dir, to_bytes(e)))
+ else:
+ for x in (os.R_OK, os.W_OK, os.X_OK):
+ if not os.access(self._cache_dir, x):
+ raise AnsibleError("error in '%s' cache, configured path (%s) does not have necessary permissions (rwx), disabling plugin" % (self.plugin_name, self._cache_dir))
def get(self, key):
""" This checks the in memory cache first as the fact was not expired at 'gather time'
@@ -146,7 +149,7 @@
return False
else:
display.warning("error in '%s' cache plugin while trying to stat %s : %s" % (self.plugin_name, cachefile, to_bytes(e)))
- pass
+ return False
if time.time() - st.st_mtime <= self._timeout:
return False
| {"golden_diff": "diff --git a/lib/ansible/plugins/cache/base.py b/lib/ansible/plugins/cache/base.py\n--- a/lib/ansible/plugins/cache/base.py\n+++ b/lib/ansible/plugins/cache/base.py\n@@ -91,8 +91,11 @@\n try:\n os.makedirs(self._cache_dir)\n except (OSError,IOError) as e:\n- display.warning(\"error in '%s' cache plugin while trying to create cache dir %s : %s\" % (self.plugin_name, self._cache_dir, to_bytes(e)))\n- return None\n+ raise AnsibleError(\"error in '%s' cache plugin while trying to create cache dir %s : %s\" % (self.plugin_name, self._cache_dir, to_bytes(e)))\n+ else:\n+ for x in (os.R_OK, os.W_OK, os.X_OK):\n+ if not os.access(self._cache_dir, x):\n+ raise AnsibleError(\"error in '%s' cache, configured path (%s) does not have necessary permissions (rwx), disabling plugin\" % (self.plugin_name, self._cache_dir))\n \n def get(self, key):\n \"\"\" This checks the in memory cache first as the fact was not expired at 'gather time'\n@@ -146,7 +149,7 @@\n return False\n else:\n display.warning(\"error in '%s' cache plugin while trying to stat %s : %s\" % (self.plugin_name, cachefile, to_bytes(e)))\n- pass\n+ return False\n \n if time.time() - st.st_mtime <= self._timeout:\n return False\n", "issue": "UnboudLocalError: local variable 'f' referenced before assignment\nVersion: 1.9 but also devel as the file handling code does not changed.\nServer/Client OS: Ubuntu\n\nThis is not a duplicate of #2618. When defining a caching path for the jsonfile caching plugin that is not writable by Ansible. Ansible fails with the following message:\n\n```\nfatal: [my-host] => Traceback (most recent call last):\n File \"/home/david/.pip/ansible/lib/ansible/runner/__init__.py\", line 586, in _executor\n exec_rc = self._executor_internal(host, new_stdin)\n File \"/home/david/.pip/ansible/lib/ansible/runner/__init__.py\", line 668, in _executor_internal\n inject = self.get_inject_vars(host)\n File \"/home/david/.pip/ansible/lib/ansible/runner/__init__.py\", line 611, in get_inject_vars\n combined_cache = self.get_combined_cache()\n File \"/home/david/.pip/ansible/lib/ansible/runner/__init__.py\", line 606, in get_combined_cache\n combined_cache = self.setup_cache.copy()\n File \"/home/david/.pip/ansible/lib/ansible/cache/__init__.py\", line 54, in copy\n return dict([(k, v) for (k, v) in self.iteritems()])\n File \"/usr/lib/python2.7/_abcoll.py\", line 406, in iteritems\n yield (key, self[key])\n File \"/home/david/.pip/ansible/lib/ansible/cache/__init__.py\", line 35, in __getitem__\n return self._plugin.get(key)\n File \"/home/david/.pip/ansible/lib/ansible/cache/jsonfile.py\", line 69, in get\n f.close()\nUnboundLocalError: local variable 'f' referenced before assignment\n```\n\n", "before_files": [{"content": "# (c) 2014, Brian Coca, Josh Drake, et al\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\nimport os\nimport time\nimport errno\nfrom abc import ABCMeta, abstractmethod\n\nfrom ansible import constants as C\nfrom ansible.compat.six import with_metaclass\nfrom ansible.errors import AnsibleError\nfrom ansible.module_utils._text import to_bytes\n\ntry:\n from __main__ import display\nexcept ImportError:\n from ansible.utils.display import Display\n display = Display()\n\nclass BaseCacheModule(with_metaclass(ABCMeta, object)):\n\n # Backwards compat only. Just import the global display instead\n _display = display\n\n @abstractmethod\n def get(self, key):\n pass\n\n @abstractmethod\n def set(self, key, value):\n pass\n\n @abstractmethod\n def keys(self):\n pass\n\n @abstractmethod\n def contains(self, key):\n pass\n\n @abstractmethod\n def delete(self, key):\n pass\n\n @abstractmethod\n def flush(self):\n pass\n\n @abstractmethod\n def copy(self):\n pass\n\n\nclass BaseFileCacheModule(BaseCacheModule):\n \"\"\"\n A caching module backed by file based storage.\n \"\"\"\n def __init__(self, *args, **kwargs):\n\n self.plugin_name = self.__module__.split('.')[-1]\n self._timeout = float(C.CACHE_PLUGIN_TIMEOUT)\n self._cache = {}\n self._cache_dir = None\n\n if C.CACHE_PLUGIN_CONNECTION:\n # expects a dir path\n self._cache_dir = os.path.expanduser(os.path.expandvars(C.CACHE_PLUGIN_CONNECTION))\n\n if not self._cache_dir:\n raise AnsibleError(\"error, '%s' cache plugin requires the 'fact_caching_connection' config option\"\n \" to be set (to a writeable directory path)\" % self.plugin_name)\n\n if not os.path.exists(self._cache_dir):\n try:\n os.makedirs(self._cache_dir)\n except (OSError,IOError) as e:\n display.warning(\"error in '%s' cache plugin while trying to create cache dir %s : %s\" % (self.plugin_name, self._cache_dir, to_bytes(e)))\n return None\n\n def get(self, key):\n \"\"\" This checks the in memory cache first as the fact was not expired at 'gather time'\n and it would be problematic if the key did expire after some long running tasks and\n user gets 'undefined' error in the same play \"\"\"\n\n if key in self._cache:\n return self._cache.get(key)\n\n if self.has_expired(key) or key == \"\":\n raise KeyError\n\n cachefile = \"%s/%s\" % (self._cache_dir, key)\n try:\n try:\n value = self._load(cachefile)\n self._cache[key] = value\n return value\n except ValueError as e:\n display.warning(\"error in '%s' cache plugin while trying to read %s : %s.\"\n \" Most likely a corrupt file, so erasing and failing.\" % (self.plugin_name, cachefile, to_bytes(e)))\n self.delete(key)\n raise AnsibleError(\"The cache file %s was corrupt, or did not otherwise contain valid data.\"\n \" It has been removed, so you can re-run your command now.\" % cachefile)\n except (OSError,IOError) as e:\n display.warning(\"error in '%s' cache plugin while trying to read %s : %s\" % (self.plugin_name, cachefile, to_bytes(e)))\n raise KeyError\n except Exception as e:\n raise AnsibleError(\"Error while decoding the cache file %s: %s\" % (cachefile, to_bytes(e)))\n\n def set(self, key, value):\n\n self._cache[key] = value\n\n cachefile = \"%s/%s\" % (self._cache_dir, key)\n try:\n self._dump(value, cachefile)\n except (OSError,IOError) as e:\n display.warning(\"error in '%s' cache plugin while trying to write to %s : %s\" % (self.plugin_name, cachefile, to_bytes(e)))\n\n def has_expired(self, key):\n\n if self._timeout == 0:\n return False\n\n cachefile = \"%s/%s\" % (self._cache_dir, key)\n try:\n st = os.stat(cachefile)\n except (OSError,IOError) as e:\n if e.errno == errno.ENOENT:\n return False\n else:\n display.warning(\"error in '%s' cache plugin while trying to stat %s : %s\" % (self.plugin_name, cachefile, to_bytes(e)))\n pass\n\n if time.time() - st.st_mtime <= self._timeout:\n return False\n\n if key in self._cache:\n del self._cache[key]\n return True\n\n def keys(self):\n keys = []\n for k in os.listdir(self._cache_dir):\n if not (k.startswith('.') or self.has_expired(k)):\n keys.append(k)\n return keys\n\n def contains(self, key):\n cachefile = \"%s/%s\" % (self._cache_dir, key)\n\n if key in self._cache:\n return True\n\n if self.has_expired(key):\n return False\n try:\n os.stat(cachefile)\n return True\n except (OSError,IOError) as e:\n if e.errno == errno.ENOENT:\n return False\n else:\n display.warning(\"error in '%s' cache plugin while trying to stat %s : %s\" % (self.plugin_name, cachefile, to_bytes(e)))\n pass\n\n def delete(self, key):\n try:\n del self._cache[key]\n except KeyError:\n pass\n try:\n os.remove(\"%s/%s\" % (self._cache_dir, key))\n except (OSError, IOError):\n pass #TODO: only pass on non existing?\n\n def flush(self):\n self._cache = {}\n for key in self.keys():\n self.delete(key)\n\n def copy(self):\n ret = dict()\n for key in self.keys():\n ret[key] = self.get(key)\n return ret\n\n @abstractmethod\n def _load(self, filepath):\n \"\"\"\n Read data from a filepath and return it as a value\n\n :arg filepath: The filepath to read from.\n :returns: The value stored in the filepath\n\n This method reads from the file on disk and takes care of any parsing\n and transformation of the data before returning it. The value\n returned should be what Ansible would expect if it were uncached data.\n\n .. note:: Filehandles have advantages but calling code doesn't know\n whether this file is text or binary, should be decoded, or accessed via\n a library function. Therefore the API uses a filepath and opens\n the file inside of the method.\n \"\"\"\n pass\n\n @abstractmethod\n def _dump(self, value, filepath):\n \"\"\"\n Write data to a filepath\n\n :arg value: The value to store\n :arg filepath: The filepath to store it at\n \"\"\"\n pass\n", "path": "lib/ansible/plugins/cache/base.py"}], "after_files": [{"content": "# (c) 2014, Brian Coca, Josh Drake, et al\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\nimport os\nimport time\nimport errno\nfrom abc import ABCMeta, abstractmethod\n\nfrom ansible import constants as C\nfrom ansible.compat.six import with_metaclass\nfrom ansible.errors import AnsibleError\nfrom ansible.module_utils._text import to_bytes\n\ntry:\n from __main__ import display\nexcept ImportError:\n from ansible.utils.display import Display\n display = Display()\n\nclass BaseCacheModule(with_metaclass(ABCMeta, object)):\n\n # Backwards compat only. Just import the global display instead\n _display = display\n\n @abstractmethod\n def get(self, key):\n pass\n\n @abstractmethod\n def set(self, key, value):\n pass\n\n @abstractmethod\n def keys(self):\n pass\n\n @abstractmethod\n def contains(self, key):\n pass\n\n @abstractmethod\n def delete(self, key):\n pass\n\n @abstractmethod\n def flush(self):\n pass\n\n @abstractmethod\n def copy(self):\n pass\n\n\nclass BaseFileCacheModule(BaseCacheModule):\n \"\"\"\n A caching module backed by file based storage.\n \"\"\"\n def __init__(self, *args, **kwargs):\n\n self.plugin_name = self.__module__.split('.')[-1]\n self._timeout = float(C.CACHE_PLUGIN_TIMEOUT)\n self._cache = {}\n self._cache_dir = None\n\n if C.CACHE_PLUGIN_CONNECTION:\n # expects a dir path\n self._cache_dir = os.path.expanduser(os.path.expandvars(C.CACHE_PLUGIN_CONNECTION))\n\n if not self._cache_dir:\n raise AnsibleError(\"error, '%s' cache plugin requires the 'fact_caching_connection' config option\"\n \" to be set (to a writeable directory path)\" % self.plugin_name)\n\n if not os.path.exists(self._cache_dir):\n try:\n os.makedirs(self._cache_dir)\n except (OSError,IOError) as e:\n raise AnsibleError(\"error in '%s' cache plugin while trying to create cache dir %s : %s\" % (self.plugin_name, self._cache_dir, to_bytes(e)))\n else:\n for x in (os.R_OK, os.W_OK, os.X_OK):\n if not os.access(self._cache_dir, x):\n raise AnsibleError(\"error in '%s' cache, configured path (%s) does not have necessary permissions (rwx), disabling plugin\" % (self.plugin_name, self._cache_dir))\n\n def get(self, key):\n \"\"\" This checks the in memory cache first as the fact was not expired at 'gather time'\n and it would be problematic if the key did expire after some long running tasks and\n user gets 'undefined' error in the same play \"\"\"\n\n if key in self._cache:\n return self._cache.get(key)\n\n if self.has_expired(key) or key == \"\":\n raise KeyError\n\n cachefile = \"%s/%s\" % (self._cache_dir, key)\n try:\n try:\n value = self._load(cachefile)\n self._cache[key] = value\n return value\n except ValueError as e:\n display.warning(\"error in '%s' cache plugin while trying to read %s : %s.\"\n \" Most likely a corrupt file, so erasing and failing.\" % (self.plugin_name, cachefile, to_bytes(e)))\n self.delete(key)\n raise AnsibleError(\"The cache file %s was corrupt, or did not otherwise contain valid data.\"\n \" It has been removed, so you can re-run your command now.\" % cachefile)\n except (OSError,IOError) as e:\n display.warning(\"error in '%s' cache plugin while trying to read %s : %s\" % (self.plugin_name, cachefile, to_bytes(e)))\n raise KeyError\n except Exception as e:\n raise AnsibleError(\"Error while decoding the cache file %s: %s\" % (cachefile, to_bytes(e)))\n\n def set(self, key, value):\n\n self._cache[key] = value\n\n cachefile = \"%s/%s\" % (self._cache_dir, key)\n try:\n self._dump(value, cachefile)\n except (OSError,IOError) as e:\n display.warning(\"error in '%s' cache plugin while trying to write to %s : %s\" % (self.plugin_name, cachefile, to_bytes(e)))\n\n def has_expired(self, key):\n\n if self._timeout == 0:\n return False\n\n cachefile = \"%s/%s\" % (self._cache_dir, key)\n try:\n st = os.stat(cachefile)\n except (OSError,IOError) as e:\n if e.errno == errno.ENOENT:\n return False\n else:\n display.warning(\"error in '%s' cache plugin while trying to stat %s : %s\" % (self.plugin_name, cachefile, to_bytes(e)))\n return False\n\n if time.time() - st.st_mtime <= self._timeout:\n return False\n\n if key in self._cache:\n del self._cache[key]\n return True\n\n def keys(self):\n keys = []\n for k in os.listdir(self._cache_dir):\n if not (k.startswith('.') or self.has_expired(k)):\n keys.append(k)\n return keys\n\n def contains(self, key):\n cachefile = \"%s/%s\" % (self._cache_dir, key)\n\n if key in self._cache:\n return True\n\n if self.has_expired(key):\n return False\n try:\n os.stat(cachefile)\n return True\n except (OSError,IOError) as e:\n if e.errno == errno.ENOENT:\n return False\n else:\n display.warning(\"error in '%s' cache plugin while trying to stat %s : %s\" % (self.plugin_name, cachefile, to_bytes(e)))\n pass\n\n def delete(self, key):\n try:\n del self._cache[key]\n except KeyError:\n pass\n try:\n os.remove(\"%s/%s\" % (self._cache_dir, key))\n except (OSError, IOError):\n pass #TODO: only pass on non existing?\n\n def flush(self):\n self._cache = {}\n for key in self.keys():\n self.delete(key)\n\n def copy(self):\n ret = dict()\n for key in self.keys():\n ret[key] = self.get(key)\n return ret\n\n @abstractmethod\n def _load(self, filepath):\n \"\"\"\n Read data from a filepath and return it as a value\n\n :arg filepath: The filepath to read from.\n :returns: The value stored in the filepath\n\n This method reads from the file on disk and takes care of any parsing\n and transformation of the data before returning it. The value\n returned should be what Ansible would expect if it were uncached data.\n\n .. note:: Filehandles have advantages but calling code doesn't know\n whether this file is text or binary, should be decoded, or accessed via\n a library function. Therefore the API uses a filepath and opens\n the file inside of the method.\n \"\"\"\n pass\n\n @abstractmethod\n def _dump(self, value, filepath):\n \"\"\"\n Write data to a filepath\n\n :arg value: The value to store\n :arg filepath: The filepath to store it at\n \"\"\"\n pass\n", "path": "lib/ansible/plugins/cache/base.py"}]} | 3,027 | 349 |
gh_patches_debug_10866 | rasdani/github-patches | git_diff | zestedesavoir__zds-site-3230 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Un template qui n'est pas variabilisé
Comme on peut le constater dans le template [opensearch.xml](https://github.com/zestedesavoir/zds-site/blob/3e91b083ee882396abf4dc0d508595d9bdb101d7/templates/search/opensearch.xml#L13) il y'a une valeur en dur qui y traine.
Il faut remplacer la ligne :
``` python
<Contact>http://zestedesavoir.com/pages/contact/</Contact>
```
par
``` python
<Contact>{% url "zds.pages.views.contact" %}</Contact>
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zds/search/views.py`
Content:
```
1 # coding: utf-8
2 from django.db.models import Q
3
4 from django.shortcuts import render
5 from django.core.urlresolvers import reverse
6 from haystack.views import SearchView
7
8 from zds import settings
9 from zds.utils.paginator import paginator_range
10
11
12 class CustomSearchView(SearchView):
13
14 def create_response(self):
15 (paginator, page) = self.build_page()
16
17 page_nbr = int(self.request.GET.get('page', 1))
18
19 context = {
20 'query': self.query,
21 'form': self.form,
22 'page': page,
23 'pages': paginator_range(page_nbr, paginator.num_pages),
24 'nb': page_nbr,
25 'paginator': paginator,
26 'suggestion': None,
27 'model_name': '',
28 'models': self.request.GET.getlist('models', ''),
29 }
30
31 if self.results and hasattr(self.results, 'query') and self.results.query.backend.include_spelling:
32 context['suggestion'] = self.form.get_suggestion()
33
34 context.update(self.extra_context())
35 return render(self.request, self.template, context)
36
37 def get_results(self):
38 queryset = super(CustomSearchView, self).get_results()
39
40 # We want to search only on authorized post and topic
41 if self.request.user.is_authenticated():
42 groups = self.request.user.groups
43
44 if groups.count() > 0:
45 return queryset.filter(Q(permissions="public") |
46 Q(permissions__in=[group.name for group in groups.all()]))
47 else:
48 return queryset.filter(permissions="public")
49 else:
50 return queryset.filter(permissions="public")
51
52
53 def opensearch(request):
54 """Generate OpenSearch Description file"""
55
56 return render(request, 'search/opensearch.xml', {
57 'site_name': settings.ZDS_APP['site']['litteral_name'],
58 'site_url': settings.ZDS_APP['site']['url'],
59 'language': settings.LANGUAGE_CODE,
60 'search_url': settings.ZDS_APP['site']['url'] + reverse('haystack_search')
61 }, content_type='application/opensearchdescription+xml')
62
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/zds/search/views.py b/zds/search/views.py
--- a/zds/search/views.py
+++ b/zds/search/views.py
@@ -56,6 +56,7 @@
return render(request, 'search/opensearch.xml', {
'site_name': settings.ZDS_APP['site']['litteral_name'],
'site_url': settings.ZDS_APP['site']['url'],
+ 'email_contact': settings.ZDS_APP['site']['email_contact'],
'language': settings.LANGUAGE_CODE,
'search_url': settings.ZDS_APP['site']['url'] + reverse('haystack_search')
}, content_type='application/opensearchdescription+xml')
| {"golden_diff": "diff --git a/zds/search/views.py b/zds/search/views.py\n--- a/zds/search/views.py\n+++ b/zds/search/views.py\n@@ -56,6 +56,7 @@\n return render(request, 'search/opensearch.xml', {\n 'site_name': settings.ZDS_APP['site']['litteral_name'],\n 'site_url': settings.ZDS_APP['site']['url'],\n+ 'email_contact': settings.ZDS_APP['site']['email_contact'],\n 'language': settings.LANGUAGE_CODE,\n 'search_url': settings.ZDS_APP['site']['url'] + reverse('haystack_search')\n }, content_type='application/opensearchdescription+xml')\n", "issue": "Un template qui n'est pas variabilis\u00e9\nComme on peut le constater dans le template [opensearch.xml](https://github.com/zestedesavoir/zds-site/blob/3e91b083ee882396abf4dc0d508595d9bdb101d7/templates/search/opensearch.xml#L13) il y'a une valeur en dur qui y traine.\n\nIl faut remplacer la ligne : \n\n``` python\n<Contact>http://zestedesavoir.com/pages/contact/</Contact>\n```\n\npar \n\n``` python\n<Contact>{% url \"zds.pages.views.contact\" %}</Contact>\n```\n\n", "before_files": [{"content": "# coding: utf-8\nfrom django.db.models import Q\n\nfrom django.shortcuts import render\nfrom django.core.urlresolvers import reverse\nfrom haystack.views import SearchView\n\nfrom zds import settings\nfrom zds.utils.paginator import paginator_range\n\n\nclass CustomSearchView(SearchView):\n\n def create_response(self):\n (paginator, page) = self.build_page()\n\n page_nbr = int(self.request.GET.get('page', 1))\n\n context = {\n 'query': self.query,\n 'form': self.form,\n 'page': page,\n 'pages': paginator_range(page_nbr, paginator.num_pages),\n 'nb': page_nbr,\n 'paginator': paginator,\n 'suggestion': None,\n 'model_name': '',\n 'models': self.request.GET.getlist('models', ''),\n }\n\n if self.results and hasattr(self.results, 'query') and self.results.query.backend.include_spelling:\n context['suggestion'] = self.form.get_suggestion()\n\n context.update(self.extra_context())\n return render(self.request, self.template, context)\n\n def get_results(self):\n queryset = super(CustomSearchView, self).get_results()\n\n # We want to search only on authorized post and topic\n if self.request.user.is_authenticated():\n groups = self.request.user.groups\n\n if groups.count() > 0:\n return queryset.filter(Q(permissions=\"public\") |\n Q(permissions__in=[group.name for group in groups.all()]))\n else:\n return queryset.filter(permissions=\"public\")\n else:\n return queryset.filter(permissions=\"public\")\n\n\ndef opensearch(request):\n \"\"\"Generate OpenSearch Description file\"\"\"\n\n return render(request, 'search/opensearch.xml', {\n 'site_name': settings.ZDS_APP['site']['litteral_name'],\n 'site_url': settings.ZDS_APP['site']['url'],\n 'language': settings.LANGUAGE_CODE,\n 'search_url': settings.ZDS_APP['site']['url'] + reverse('haystack_search')\n }, content_type='application/opensearchdescription+xml')\n", "path": "zds/search/views.py"}], "after_files": [{"content": "# coding: utf-8\nfrom django.db.models import Q\n\nfrom django.shortcuts import render\nfrom django.core.urlresolvers import reverse\nfrom haystack.views import SearchView\n\nfrom zds import settings\nfrom zds.utils.paginator import paginator_range\n\n\nclass CustomSearchView(SearchView):\n\n def create_response(self):\n (paginator, page) = self.build_page()\n\n page_nbr = int(self.request.GET.get('page', 1))\n\n context = {\n 'query': self.query,\n 'form': self.form,\n 'page': page,\n 'pages': paginator_range(page_nbr, paginator.num_pages),\n 'nb': page_nbr,\n 'paginator': paginator,\n 'suggestion': None,\n 'model_name': '',\n 'models': self.request.GET.getlist('models', ''),\n }\n\n if self.results and hasattr(self.results, 'query') and self.results.query.backend.include_spelling:\n context['suggestion'] = self.form.get_suggestion()\n\n context.update(self.extra_context())\n return render(self.request, self.template, context)\n\n def get_results(self):\n queryset = super(CustomSearchView, self).get_results()\n\n # We want to search only on authorized post and topic\n if self.request.user.is_authenticated():\n groups = self.request.user.groups\n\n if groups.count() > 0:\n return queryset.filter(Q(permissions=\"public\") |\n Q(permissions__in=[group.name for group in groups.all()]))\n else:\n return queryset.filter(permissions=\"public\")\n else:\n return queryset.filter(permissions=\"public\")\n\n\ndef opensearch(request):\n \"\"\"Generate OpenSearch Description file\"\"\"\n\n return render(request, 'search/opensearch.xml', {\n 'site_name': settings.ZDS_APP['site']['litteral_name'],\n 'site_url': settings.ZDS_APP['site']['url'],\n 'email_contact': settings.ZDS_APP['site']['email_contact'],\n 'language': settings.LANGUAGE_CODE,\n 'search_url': settings.ZDS_APP['site']['url'] + reverse('haystack_search')\n }, content_type='application/opensearchdescription+xml')\n", "path": "zds/search/views.py"}]} | 967 | 146 |
gh_patches_debug_35022 | rasdani/github-patches | git_diff | ansible__ansible-modules-extras-1175 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
alternatives should allow link priorty as an optional parameter
**Issue Type:** “Feature Idea”
**Ansible Version:** 1.9.1
**Ansible Configuration:** Stock configuration
**Environment:** Ubuntu 14.04 x64 managing an Ubuntu 14.04 x64 machine
**Summary:** The alternatives module should allow you to pass in the link priority as an optional parameter. Currently the link priority is hard coded in the module as highlighted below:
https://github.com/ansible/ansible-modules-extras/blob/devel/system/alternatives.py#L61
Ansible should only report a change when the priority and link stayed the same.
**Steps To Reproduce:** None, feature idea
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `system/alternatives.py`
Content:
```
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 """
5 Ansible module to manage symbolic link alternatives.
6 (c) 2014, Gabe Mulley <[email protected]>
7 (c) 2015, David Wittman <[email protected]>
8
9 This file is part of Ansible
10
11 Ansible is free software: you can redistribute it and/or modify
12 it under the terms of the GNU General Public License as published by
13 the Free Software Foundation, either version 3 of the License, or
14 (at your option) any later version.
15
16 Ansible is distributed in the hope that it will be useful,
17 but WITHOUT ANY WARRANTY; without even the implied warranty of
18 MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
19 GNU General Public License for more details.
20
21 You should have received a copy of the GNU General Public License
22 along with Ansible. If not, see <http://www.gnu.org/licenses/>.
23 """
24
25 DOCUMENTATION = '''
26 ---
27 module: alternatives
28 short_description: Manages alternative programs for common commands
29 description:
30 - Manages symbolic links using the 'update-alternatives' tool
31 - Useful when multiple programs are installed but provide similar functionality (e.g. different editors).
32 version_added: "1.6"
33 author:
34 - "David Wittman (@DavidWittman)"
35 - "Gabe Mulley (@mulby)"
36 options:
37 name:
38 description:
39 - The generic name of the link.
40 required: true
41 path:
42 description:
43 - The path to the real executable that the link should point to.
44 required: true
45 link:
46 description:
47 - The path to the symbolic link that should point to the real executable.
48 - This option is required on RHEL-based distributions
49 required: false
50 requirements: [ update-alternatives ]
51 '''
52
53 EXAMPLES = '''
54 - name: correct java version selected
55 alternatives: name=java path=/usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java
56
57 - name: alternatives link created
58 alternatives: name=hadoop-conf link=/etc/hadoop/conf path=/etc/hadoop/conf.ansible
59 '''
60
61 DEFAULT_LINK_PRIORITY = 50
62
63 import re
64 from ansible.module_utils.basic import *
65 from ansible.module_utils.pycompat24 import get_exception
66
67
68 def main():
69
70 module = AnsibleModule(
71 argument_spec = dict(
72 name = dict(required=True),
73 path = dict(required=True, type='path'),
74 link = dict(required=False, type='path'),
75 ),
76 supports_check_mode=True,
77 )
78
79 params = module.params
80 name = params['name']
81 path = params['path']
82 link = params['link']
83
84 UPDATE_ALTERNATIVES = module.get_bin_path('update-alternatives',True)
85
86 current_path = None
87 all_alternatives = []
88
89 # Run `update-alternatives --display <name>` to find existing alternatives
90 (rc, display_output, _) = module.run_command(
91 ['env', 'LC_ALL=C', UPDATE_ALTERNATIVES, '--display', name]
92 )
93
94 if rc == 0:
95 # Alternatives already exist for this link group
96 # Parse the output to determine the current path of the symlink and
97 # available alternatives
98 current_path_regex = re.compile(r'^\s*link currently points to (.*)$',
99 re.MULTILINE)
100 alternative_regex = re.compile(r'^(\/.*)\s-\spriority', re.MULTILINE)
101
102 current_path = current_path_regex.search(display_output).group(1)
103 all_alternatives = alternative_regex.findall(display_output)
104
105 if not link:
106 # Read the current symlink target from `update-alternatives --query`
107 # in case we need to install the new alternative before setting it.
108 #
109 # This is only compatible on Debian-based systems, as the other
110 # alternatives don't have --query available
111 rc, query_output, _ = module.run_command(
112 ['env', 'LC_ALL=C', UPDATE_ALTERNATIVES, '--query', name]
113 )
114 if rc == 0:
115 for line in query_output.splitlines():
116 if line.startswith('Link:'):
117 link = line.split()[1]
118 break
119
120 if current_path != path:
121 if module.check_mode:
122 module.exit_json(changed=True, current_path=current_path)
123 try:
124 # install the requested path if necessary
125 if path not in all_alternatives:
126 if not link:
127 module.fail_json(msg="Needed to install the alternative, but unable to do so as we are missing the link")
128
129 module.run_command(
130 [UPDATE_ALTERNATIVES, '--install', link, name, path, str(DEFAULT_LINK_PRIORITY)],
131 check_rc=True
132 )
133
134 # select the requested path
135 module.run_command(
136 [UPDATE_ALTERNATIVES, '--set', name, path],
137 check_rc=True
138 )
139
140 module.exit_json(changed=True)
141 except subprocess.CalledProcessError:
142 e = get_exception()
143 module.fail_json(msg=str(dir(cpe)))
144 else:
145 module.exit_json(changed=False)
146
147
148 main()
149
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/system/alternatives.py b/system/alternatives.py
--- a/system/alternatives.py
+++ b/system/alternatives.py
@@ -47,6 +47,10 @@
- The path to the symbolic link that should point to the real executable.
- This option is required on RHEL-based distributions
required: false
+ priority:
+ description:
+ - The priority of the alternative
+ required: false
requirements: [ update-alternatives ]
'''
@@ -56,9 +60,10 @@
- name: alternatives link created
alternatives: name=hadoop-conf link=/etc/hadoop/conf path=/etc/hadoop/conf.ansible
-'''
-DEFAULT_LINK_PRIORITY = 50
+- name: make java 32 bit an alternative with low priority
+ alternatives: name=java path=/usr/lib/jvm/java-7-openjdk-i386/jre/bin/java priority=-10
+'''
import re
from ansible.module_utils.basic import *
@@ -72,6 +77,8 @@
name = dict(required=True),
path = dict(required=True, type='path'),
link = dict(required=False, type='path'),
+ priority = dict(required=False, type='int',
+ default=50),
),
supports_check_mode=True,
)
@@ -80,6 +87,7 @@
name = params['name']
path = params['path']
link = params['link']
+ priority = params['priority']
UPDATE_ALTERNATIVES = module.get_bin_path('update-alternatives',True)
@@ -127,7 +135,7 @@
module.fail_json(msg="Needed to install the alternative, but unable to do so as we are missing the link")
module.run_command(
- [UPDATE_ALTERNATIVES, '--install', link, name, path, str(DEFAULT_LINK_PRIORITY)],
+ [UPDATE_ALTERNATIVES, '--install', link, name, path, str(priority)],
check_rc=True
)
| {"golden_diff": "diff --git a/system/alternatives.py b/system/alternatives.py\n--- a/system/alternatives.py\n+++ b/system/alternatives.py\n@@ -47,6 +47,10 @@\n - The path to the symbolic link that should point to the real executable.\n - This option is required on RHEL-based distributions\n required: false\n+ priority:\n+ description:\n+ - The priority of the alternative\n+ required: false\n requirements: [ update-alternatives ]\n '''\n \n@@ -56,9 +60,10 @@\n \n - name: alternatives link created\n alternatives: name=hadoop-conf link=/etc/hadoop/conf path=/etc/hadoop/conf.ansible\n-'''\n \n-DEFAULT_LINK_PRIORITY = 50\n+- name: make java 32 bit an alternative with low priority\n+ alternatives: name=java path=/usr/lib/jvm/java-7-openjdk-i386/jre/bin/java priority=-10\n+'''\n \n import re\n from ansible.module_utils.basic import *\n@@ -72,6 +77,8 @@\n name = dict(required=True),\n path = dict(required=True, type='path'),\n link = dict(required=False, type='path'),\n+ priority = dict(required=False, type='int',\n+ default=50),\n ),\n supports_check_mode=True,\n )\n@@ -80,6 +87,7 @@\n name = params['name']\n path = params['path']\n link = params['link']\n+ priority = params['priority']\n \n UPDATE_ALTERNATIVES = module.get_bin_path('update-alternatives',True)\n \n@@ -127,7 +135,7 @@\n module.fail_json(msg=\"Needed to install the alternative, but unable to do so as we are missing the link\")\n \n module.run_command(\n- [UPDATE_ALTERNATIVES, '--install', link, name, path, str(DEFAULT_LINK_PRIORITY)],\n+ [UPDATE_ALTERNATIVES, '--install', link, name, path, str(priority)],\n check_rc=True\n )\n", "issue": "alternatives should allow link priorty as an optional parameter\n**Issue Type:** \u201cFeature Idea\u201d\n**Ansible Version:** 1.9.1\n**Ansible Configuration:** Stock configuration\n**Environment:** Ubuntu 14.04 x64 managing an Ubuntu 14.04 x64 machine\n\n**Summary:** The alternatives module should allow you to pass in the link priority as an optional parameter. Currently the link priority is hard coded in the module as highlighted below:\n\nhttps://github.com/ansible/ansible-modules-extras/blob/devel/system/alternatives.py#L61\n\nAnsible should only report a change when the priority and link stayed the same.\n\n**Steps To Reproduce:** None, feature idea\n\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n\"\"\"\nAnsible module to manage symbolic link alternatives.\n(c) 2014, Gabe Mulley <[email protected]>\n(c) 2015, David Wittman <[email protected]>\n\nThis file is part of Ansible\n\nAnsible is free software: you can redistribute it and/or modify\nit under the terms of the GNU General Public License as published by\nthe Free Software Foundation, either version 3 of the License, or\n(at your option) any later version.\n\nAnsible is distributed in the hope that it will be useful,\nbut WITHOUT ANY WARRANTY; without even the implied warranty of\nMERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\nGNU General Public License for more details.\n\nYou should have received a copy of the GNU General Public License\nalong with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\"\"\"\n\nDOCUMENTATION = '''\n---\nmodule: alternatives\nshort_description: Manages alternative programs for common commands\ndescription:\n - Manages symbolic links using the 'update-alternatives' tool\n - Useful when multiple programs are installed but provide similar functionality (e.g. different editors).\nversion_added: \"1.6\"\nauthor:\n - \"David Wittman (@DavidWittman)\"\n - \"Gabe Mulley (@mulby)\"\noptions:\n name:\n description:\n - The generic name of the link.\n required: true\n path:\n description:\n - The path to the real executable that the link should point to.\n required: true\n link:\n description:\n - The path to the symbolic link that should point to the real executable.\n - This option is required on RHEL-based distributions\n required: false\nrequirements: [ update-alternatives ]\n'''\n\nEXAMPLES = '''\n- name: correct java version selected\n alternatives: name=java path=/usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java\n\n- name: alternatives link created\n alternatives: name=hadoop-conf link=/etc/hadoop/conf path=/etc/hadoop/conf.ansible\n'''\n\nDEFAULT_LINK_PRIORITY = 50\n\nimport re\nfrom ansible.module_utils.basic import *\nfrom ansible.module_utils.pycompat24 import get_exception\n\n\ndef main():\n\n module = AnsibleModule(\n argument_spec = dict(\n name = dict(required=True),\n path = dict(required=True, type='path'),\n link = dict(required=False, type='path'),\n ),\n supports_check_mode=True,\n )\n\n params = module.params\n name = params['name']\n path = params['path']\n link = params['link']\n\n UPDATE_ALTERNATIVES = module.get_bin_path('update-alternatives',True)\n\n current_path = None\n all_alternatives = []\n\n # Run `update-alternatives --display <name>` to find existing alternatives\n (rc, display_output, _) = module.run_command(\n ['env', 'LC_ALL=C', UPDATE_ALTERNATIVES, '--display', name]\n )\n\n if rc == 0:\n # Alternatives already exist for this link group\n # Parse the output to determine the current path of the symlink and\n # available alternatives\n current_path_regex = re.compile(r'^\\s*link currently points to (.*)$',\n re.MULTILINE)\n alternative_regex = re.compile(r'^(\\/.*)\\s-\\spriority', re.MULTILINE)\n\n current_path = current_path_regex.search(display_output).group(1)\n all_alternatives = alternative_regex.findall(display_output)\n\n if not link:\n # Read the current symlink target from `update-alternatives --query`\n # in case we need to install the new alternative before setting it.\n #\n # This is only compatible on Debian-based systems, as the other\n # alternatives don't have --query available\n rc, query_output, _ = module.run_command(\n ['env', 'LC_ALL=C', UPDATE_ALTERNATIVES, '--query', name]\n )\n if rc == 0:\n for line in query_output.splitlines():\n if line.startswith('Link:'):\n link = line.split()[1]\n break\n\n if current_path != path:\n if module.check_mode:\n module.exit_json(changed=True, current_path=current_path)\n try:\n # install the requested path if necessary\n if path not in all_alternatives:\n if not link:\n module.fail_json(msg=\"Needed to install the alternative, but unable to do so as we are missing the link\")\n\n module.run_command(\n [UPDATE_ALTERNATIVES, '--install', link, name, path, str(DEFAULT_LINK_PRIORITY)],\n check_rc=True\n )\n\n # select the requested path\n module.run_command(\n [UPDATE_ALTERNATIVES, '--set', name, path],\n check_rc=True\n )\n\n module.exit_json(changed=True)\n except subprocess.CalledProcessError:\n e = get_exception()\n module.fail_json(msg=str(dir(cpe)))\n else:\n module.exit_json(changed=False)\n\n\nmain()\n", "path": "system/alternatives.py"}], "after_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n\"\"\"\nAnsible module to manage symbolic link alternatives.\n(c) 2014, Gabe Mulley <[email protected]>\n(c) 2015, David Wittman <[email protected]>\n\nThis file is part of Ansible\n\nAnsible is free software: you can redistribute it and/or modify\nit under the terms of the GNU General Public License as published by\nthe Free Software Foundation, either version 3 of the License, or\n(at your option) any later version.\n\nAnsible is distributed in the hope that it will be useful,\nbut WITHOUT ANY WARRANTY; without even the implied warranty of\nMERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\nGNU General Public License for more details.\n\nYou should have received a copy of the GNU General Public License\nalong with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\"\"\"\n\nDOCUMENTATION = '''\n---\nmodule: alternatives\nshort_description: Manages alternative programs for common commands\ndescription:\n - Manages symbolic links using the 'update-alternatives' tool\n - Useful when multiple programs are installed but provide similar functionality (e.g. different editors).\nversion_added: \"1.6\"\nauthor:\n - \"David Wittman (@DavidWittman)\"\n - \"Gabe Mulley (@mulby)\"\noptions:\n name:\n description:\n - The generic name of the link.\n required: true\n path:\n description:\n - The path to the real executable that the link should point to.\n required: true\n link:\n description:\n - The path to the symbolic link that should point to the real executable.\n - This option is required on RHEL-based distributions\n required: false\n priority:\n description:\n - The priority of the alternative\n required: false\nrequirements: [ update-alternatives ]\n'''\n\nEXAMPLES = '''\n- name: correct java version selected\n alternatives: name=java path=/usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java\n\n- name: alternatives link created\n alternatives: name=hadoop-conf link=/etc/hadoop/conf path=/etc/hadoop/conf.ansible\n\n- name: make java 32 bit an alternative with low priority\n alternatives: name=java path=/usr/lib/jvm/java-7-openjdk-i386/jre/bin/java priority=-10\n'''\n\nimport re\nfrom ansible.module_utils.basic import *\nfrom ansible.module_utils.pycompat24 import get_exception\n\n\ndef main():\n\n module = AnsibleModule(\n argument_spec = dict(\n name = dict(required=True),\n path = dict(required=True, type='path'),\n link = dict(required=False, type='path'),\n priority = dict(required=False, type='int',\n default=50),\n ),\n supports_check_mode=True,\n )\n\n params = module.params\n name = params['name']\n path = params['path']\n link = params['link']\n priority = params['priority']\n\n UPDATE_ALTERNATIVES = module.get_bin_path('update-alternatives',True)\n\n current_path = None\n all_alternatives = []\n\n # Run `update-alternatives --display <name>` to find existing alternatives\n (rc, display_output, _) = module.run_command(\n ['env', 'LC_ALL=C', UPDATE_ALTERNATIVES, '--display', name]\n )\n\n if rc == 0:\n # Alternatives already exist for this link group\n # Parse the output to determine the current path of the symlink and\n # available alternatives\n current_path_regex = re.compile(r'^\\s*link currently points to (.*)$',\n re.MULTILINE)\n alternative_regex = re.compile(r'^(\\/.*)\\s-\\spriority', re.MULTILINE)\n\n current_path = current_path_regex.search(display_output).group(1)\n all_alternatives = alternative_regex.findall(display_output)\n\n if not link:\n # Read the current symlink target from `update-alternatives --query`\n # in case we need to install the new alternative before setting it.\n #\n # This is only compatible on Debian-based systems, as the other\n # alternatives don't have --query available\n rc, query_output, _ = module.run_command(\n ['env', 'LC_ALL=C', UPDATE_ALTERNATIVES, '--query', name]\n )\n if rc == 0:\n for line in query_output.splitlines():\n if line.startswith('Link:'):\n link = line.split()[1]\n break\n\n if current_path != path:\n if module.check_mode:\n module.exit_json(changed=True, current_path=current_path)\n try:\n # install the requested path if necessary\n if path not in all_alternatives:\n if not link:\n module.fail_json(msg=\"Needed to install the alternative, but unable to do so as we are missing the link\")\n\n module.run_command(\n [UPDATE_ALTERNATIVES, '--install', link, name, path, str(priority)],\n check_rc=True\n )\n\n # select the requested path\n module.run_command(\n [UPDATE_ALTERNATIVES, '--set', name, path],\n check_rc=True\n )\n\n module.exit_json(changed=True)\n except subprocess.CalledProcessError:\n e = get_exception()\n module.fail_json(msg=str(dir(cpe)))\n else:\n module.exit_json(changed=False)\n\n\nmain()\n", "path": "system/alternatives.py"}]} | 1,859 | 452 |
gh_patches_debug_32159 | rasdani/github-patches | git_diff | alltheplaces__alltheplaces-8238 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Food Warehouse spider missing a handful of stores
The spider for "The Food Warehouse" at https://github.com/alltheplaces/alltheplaces/blob/master/locations/spiders/the_food_warehouse_gb.py appears to be missing a small number (probably around 8) stores. These include:
* https://www.thefoodwarehouse.com/store-locator/exeter
* https://www.thefoodwarehouse.com/store-locator/falkirk
* https://www.thefoodwarehouse.com/store-locator/Norwich-Longwater
* https://www.thefoodwarehouse.com/store-locator/york-foss-islands
The spider gets the store details from https://www.thefoodwarehouse.com/assets/foodwarehouse/ajax/ . The above stores are all listed there, and I can't see any obvious problems with the data for them, but they're not returned in the dataset at https://alltheplaces-data.openaddresses.io/runs/2024-04-13-13-32-00/output/the_food_warehouse_gb.geojson . The number of stores returned by the spider appears stable, and it looks like the stores above are consistently absent from the returned datasets.
There's nothing in the error log to indicate any problems. I don't know what it signifies, but the stats at https://alltheplaces-data.openaddresses.io/runs/2024-04-13-13-32-00/stats/the_food_warehouse_gb.json say item_dropped_count=8 and
item_dropped_reasons_count/DropItem=8. I'm guessing that these could be the missing stores, but I don't know why they've been 'dropped'.
There are currently 187 items in the JSON at https://www.thefoodwarehouse.com/assets/foodwarehouse/ajax/ . 5 include "coming soon" in the name, so (correctly) aren't returned by the spider. There's another two that include "now open", so may have been "coming soon" at the last run. That would leave 180 stores to be returned. The number actually returned at the last run was 172, which probably matches the 8 described as being dropped in the stats.
Can anyone see what's going wrong here, and why these stores aren't being returned?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/the_food_warehouse_gb.py`
Content:
```
1 from scrapy import Spider
2
3 from locations.categories import Categories
4 from locations.dict_parser import DictParser
5 from locations.hours import OpeningHours
6
7
8 class TheFoodWarehouseGBSpider(Spider):
9 name = "the_food_warehouse_gb"
10 item_attributes = {
11 "brand": "The Food Warehouse",
12 "brand_wikidata": "Q87263899",
13 "extras": Categories.SHOP_SUPERMARKET.value,
14 }
15 allowed_domains = ["www.thefoodwarehouse.com"]
16 start_urls = ["https://www.thefoodwarehouse.com/assets/foodwarehouse/ajax/"]
17
18 def parse(self, response):
19 for store in response.json():
20 item = DictParser.parse(store)
21 if "CLOSED" in item["name"].upper() or "COMING SOON" in item["name"].upper():
22 continue
23 item["ref"] = store["storeNo"]
24 item["website"] = "https://www.thefoodwarehouse.com" + store["url"]
25 item["phone"] = store.get("store-number")
26 item["addr_full"] = (
27 item["addr_full"].replace("<br>", "").replace("<br />", "").replace("<p>", "").replace("</p>", "")
28 )
29 item["opening_hours"] = OpeningHours()
30 item["opening_hours"].add_ranges_from_string(store.get("opening-times", ""))
31 yield item
32
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/locations/spiders/the_food_warehouse_gb.py b/locations/spiders/the_food_warehouse_gb.py
--- a/locations/spiders/the_food_warehouse_gb.py
+++ b/locations/spiders/the_food_warehouse_gb.py
@@ -1,8 +1,9 @@
-from scrapy import Spider
+from scrapy import Selector, Spider
from locations.categories import Categories
from locations.dict_parser import DictParser
from locations.hours import OpeningHours
+from locations.pipelines.address_clean_up import merge_address_lines
class TheFoodWarehouseGBSpider(Spider):
@@ -14,18 +15,18 @@
}
allowed_domains = ["www.thefoodwarehouse.com"]
start_urls = ["https://www.thefoodwarehouse.com/assets/foodwarehouse/ajax/"]
+ no_refs = True # https://github.com/alltheplaces/alltheplaces/issues/8237
def parse(self, response):
for store in response.json():
item = DictParser.parse(store)
if "CLOSED" in item["name"].upper() or "COMING SOON" in item["name"].upper():
continue
- item["ref"] = store["storeNo"]
- item["website"] = "https://www.thefoodwarehouse.com" + store["url"]
+ if store["url"] != "/store-locator/default-store":
+ item["website"] = "https://www.thefoodwarehouse.com" + store["url"]
+ item["branch"] = item.pop("name").removesuffix(" - Now Open")
item["phone"] = store.get("store-number")
- item["addr_full"] = (
- item["addr_full"].replace("<br>", "").replace("<br />", "").replace("<p>", "").replace("</p>", "")
- )
+ item["addr_full"] = merge_address_lines(Selector(text=item["addr_full"]).xpath("//text()").getall())
item["opening_hours"] = OpeningHours()
item["opening_hours"].add_ranges_from_string(store.get("opening-times", ""))
yield item
| {"golden_diff": "diff --git a/locations/spiders/the_food_warehouse_gb.py b/locations/spiders/the_food_warehouse_gb.py\n--- a/locations/spiders/the_food_warehouse_gb.py\n+++ b/locations/spiders/the_food_warehouse_gb.py\n@@ -1,8 +1,9 @@\n-from scrapy import Spider\n+from scrapy import Selector, Spider\n \n from locations.categories import Categories\n from locations.dict_parser import DictParser\n from locations.hours import OpeningHours\n+from locations.pipelines.address_clean_up import merge_address_lines\n \n \n class TheFoodWarehouseGBSpider(Spider):\n@@ -14,18 +15,18 @@\n }\n allowed_domains = [\"www.thefoodwarehouse.com\"]\n start_urls = [\"https://www.thefoodwarehouse.com/assets/foodwarehouse/ajax/\"]\n+ no_refs = True # https://github.com/alltheplaces/alltheplaces/issues/8237\n \n def parse(self, response):\n for store in response.json():\n item = DictParser.parse(store)\n if \"CLOSED\" in item[\"name\"].upper() or \"COMING SOON\" in item[\"name\"].upper():\n continue\n- item[\"ref\"] = store[\"storeNo\"]\n- item[\"website\"] = \"https://www.thefoodwarehouse.com\" + store[\"url\"]\n+ if store[\"url\"] != \"/store-locator/default-store\":\n+ item[\"website\"] = \"https://www.thefoodwarehouse.com\" + store[\"url\"]\n+ item[\"branch\"] = item.pop(\"name\").removesuffix(\" - Now Open\")\n item[\"phone\"] = store.get(\"store-number\")\n- item[\"addr_full\"] = (\n- item[\"addr_full\"].replace(\"<br>\", \"\").replace(\"<br />\", \"\").replace(\"<p>\", \"\").replace(\"</p>\", \"\")\n- )\n+ item[\"addr_full\"] = merge_address_lines(Selector(text=item[\"addr_full\"]).xpath(\"//text()\").getall())\n item[\"opening_hours\"] = OpeningHours()\n item[\"opening_hours\"].add_ranges_from_string(store.get(\"opening-times\", \"\"))\n yield item\n", "issue": "Food Warehouse spider missing a handful of stores\nThe spider for \"The Food Warehouse\" at https://github.com/alltheplaces/alltheplaces/blob/master/locations/spiders/the_food_warehouse_gb.py appears to be missing a small number (probably around 8) stores. These include:\r\n\r\n* https://www.thefoodwarehouse.com/store-locator/exeter\r\n* https://www.thefoodwarehouse.com/store-locator/falkirk\r\n* https://www.thefoodwarehouse.com/store-locator/Norwich-Longwater\r\n* https://www.thefoodwarehouse.com/store-locator/york-foss-islands\r\n\r\nThe spider gets the store details from https://www.thefoodwarehouse.com/assets/foodwarehouse/ajax/ . The above stores are all listed there, and I can't see any obvious problems with the data for them, but they're not returned in the dataset at https://alltheplaces-data.openaddresses.io/runs/2024-04-13-13-32-00/output/the_food_warehouse_gb.geojson . The number of stores returned by the spider appears stable, and it looks like the stores above are consistently absent from the returned datasets.\r\n\r\nThere's nothing in the error log to indicate any problems. I don't know what it signifies, but the stats at https://alltheplaces-data.openaddresses.io/runs/2024-04-13-13-32-00/stats/the_food_warehouse_gb.json say item_dropped_count=8 and \r\nitem_dropped_reasons_count/DropItem=8. I'm guessing that these could be the missing stores, but I don't know why they've been 'dropped'.\r\n\r\nThere are currently 187 items in the JSON at https://www.thefoodwarehouse.com/assets/foodwarehouse/ajax/ . 5 include \"coming soon\" in the name, so (correctly) aren't returned by the spider. There's another two that include \"now open\", so may have been \"coming soon\" at the last run. That would leave 180 stores to be returned. The number actually returned at the last run was 172, which probably matches the 8 described as being dropped in the stats.\r\n\r\nCan anyone see what's going wrong here, and why these stores aren't being returned?\n", "before_files": [{"content": "from scrapy import Spider\n\nfrom locations.categories import Categories\nfrom locations.dict_parser import DictParser\nfrom locations.hours import OpeningHours\n\n\nclass TheFoodWarehouseGBSpider(Spider):\n name = \"the_food_warehouse_gb\"\n item_attributes = {\n \"brand\": \"The Food Warehouse\",\n \"brand_wikidata\": \"Q87263899\",\n \"extras\": Categories.SHOP_SUPERMARKET.value,\n }\n allowed_domains = [\"www.thefoodwarehouse.com\"]\n start_urls = [\"https://www.thefoodwarehouse.com/assets/foodwarehouse/ajax/\"]\n\n def parse(self, response):\n for store in response.json():\n item = DictParser.parse(store)\n if \"CLOSED\" in item[\"name\"].upper() or \"COMING SOON\" in item[\"name\"].upper():\n continue\n item[\"ref\"] = store[\"storeNo\"]\n item[\"website\"] = \"https://www.thefoodwarehouse.com\" + store[\"url\"]\n item[\"phone\"] = store.get(\"store-number\")\n item[\"addr_full\"] = (\n item[\"addr_full\"].replace(\"<br>\", \"\").replace(\"<br />\", \"\").replace(\"<p>\", \"\").replace(\"</p>\", \"\")\n )\n item[\"opening_hours\"] = OpeningHours()\n item[\"opening_hours\"].add_ranges_from_string(store.get(\"opening-times\", \"\"))\n yield item\n", "path": "locations/spiders/the_food_warehouse_gb.py"}], "after_files": [{"content": "from scrapy import Selector, Spider\n\nfrom locations.categories import Categories\nfrom locations.dict_parser import DictParser\nfrom locations.hours import OpeningHours\nfrom locations.pipelines.address_clean_up import merge_address_lines\n\n\nclass TheFoodWarehouseGBSpider(Spider):\n name = \"the_food_warehouse_gb\"\n item_attributes = {\n \"brand\": \"The Food Warehouse\",\n \"brand_wikidata\": \"Q87263899\",\n \"extras\": Categories.SHOP_SUPERMARKET.value,\n }\n allowed_domains = [\"www.thefoodwarehouse.com\"]\n start_urls = [\"https://www.thefoodwarehouse.com/assets/foodwarehouse/ajax/\"]\n no_refs = True # https://github.com/alltheplaces/alltheplaces/issues/8237\n\n def parse(self, response):\n for store in response.json():\n item = DictParser.parse(store)\n if \"CLOSED\" in item[\"name\"].upper() or \"COMING SOON\" in item[\"name\"].upper():\n continue\n if store[\"url\"] != \"/store-locator/default-store\":\n item[\"website\"] = \"https://www.thefoodwarehouse.com\" + store[\"url\"]\n item[\"branch\"] = item.pop(\"name\").removesuffix(\" - Now Open\")\n item[\"phone\"] = store.get(\"store-number\")\n item[\"addr_full\"] = merge_address_lines(Selector(text=item[\"addr_full\"]).xpath(\"//text()\").getall())\n item[\"opening_hours\"] = OpeningHours()\n item[\"opening_hours\"].add_ranges_from_string(store.get(\"opening-times\", \"\"))\n yield item\n", "path": "locations/spiders/the_food_warehouse_gb.py"}]} | 1,095 | 446 |
gh_patches_debug_4291 | rasdani/github-patches | git_diff | learningequality__kolibri-3151 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
inconsistent channel ordering
### Observed behavior
In 'Recommended', channel order is based on order of import:'

In 'Channels', order is not the same:

### Expected behavior
In the 'Channels' sub-section, order should be based on order of import.
### User-facing consequences
Administrators are not able to control the order that channels appear in on that page.
### Context
Desired for one VF deployment.
@rtibbles would you mind linking to the change you made to update the 'Recommended' page?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kolibri/__init__.py`
Content:
```
1 from __future__ import absolute_import, print_function, unicode_literals
2
3 # NB! This is not necessarily the version scheme we want, however having a good
4 # tracking of releases once we start doing lots of pre-releases is essential.
5 from .utils.version import get_version
6
7 #: This may not be the exact version as it's subject to modification with
8 #: get_version() - use ``kolibri.__version__`` for the exact version string.
9 VERSION = (0, 6, 1, 'final', 0)
10
11 __author__ = 'Learning Equality'
12 __email__ = '[email protected]'
13 __version__ = str(get_version(VERSION))
14
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/kolibri/__init__.py b/kolibri/__init__.py
--- a/kolibri/__init__.py
+++ b/kolibri/__init__.py
@@ -6,7 +6,7 @@
#: This may not be the exact version as it's subject to modification with
#: get_version() - use ``kolibri.__version__`` for the exact version string.
-VERSION = (0, 6, 1, 'final', 0)
+VERSION = (0, 6, 2, 'final', 0)
__author__ = 'Learning Equality'
__email__ = '[email protected]'
| {"golden_diff": "diff --git a/kolibri/__init__.py b/kolibri/__init__.py\n--- a/kolibri/__init__.py\n+++ b/kolibri/__init__.py\n@@ -6,7 +6,7 @@\n \n #: This may not be the exact version as it's subject to modification with\n #: get_version() - use ``kolibri.__version__`` for the exact version string.\n-VERSION = (0, 6, 1, 'final', 0)\n+VERSION = (0, 6, 2, 'final', 0)\n \n __author__ = 'Learning Equality'\n __email__ = '[email protected]'\n", "issue": "inconsistent channel ordering\n\r\n### Observed behavior\r\n\r\nIn 'Recommended', channel order is based on order of import:'\r\n\r\n\r\n\r\nIn 'Channels', order is not the same:\r\n\r\n\r\n\r\n\r\n### Expected behavior\r\n\r\nIn the 'Channels' sub-section, order should be based on order of import.\r\n\r\n### User-facing consequences\r\n\r\nAdministrators are not able to control the order that channels appear in on that page.\r\n\r\n### Context\r\n\r\nDesired for one VF deployment.\r\n\r\n@rtibbles would you mind linking to the change you made to update the 'Recommended' page?\r\n\r\n\r\n\n", "before_files": [{"content": "from __future__ import absolute_import, print_function, unicode_literals\n\n# NB! This is not necessarily the version scheme we want, however having a good\n# tracking of releases once we start doing lots of pre-releases is essential.\nfrom .utils.version import get_version\n\n#: This may not be the exact version as it's subject to modification with\n#: get_version() - use ``kolibri.__version__`` for the exact version string.\nVERSION = (0, 6, 1, 'final', 0)\n\n__author__ = 'Learning Equality'\n__email__ = '[email protected]'\n__version__ = str(get_version(VERSION))\n", "path": "kolibri/__init__.py"}], "after_files": [{"content": "from __future__ import absolute_import, print_function, unicode_literals\n\n# NB! This is not necessarily the version scheme we want, however having a good\n# tracking of releases once we start doing lots of pre-releases is essential.\nfrom .utils.version import get_version\n\n#: This may not be the exact version as it's subject to modification with\n#: get_version() - use ``kolibri.__version__`` for the exact version string.\nVERSION = (0, 6, 2, 'final', 0)\n\n__author__ = 'Learning Equality'\n__email__ = '[email protected]'\n__version__ = str(get_version(VERSION))\n", "path": "kolibri/__init__.py"}]} | 656 | 142 |
gh_patches_debug_44291 | rasdani/github-patches | git_diff | pytorch__TensorRT-816 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
🐛 [Bug] Incorrect judgment of model type
## Bug Description
When I provide a TorchScript model, Torch-TensorRT claims it is an nn.Module model
```
INFO: [Torch-TensorRT] - ir was set to default, using TorchScript as ir
INFO: [Torch-TensorRT] - Module was provided as a torch.nn.Module, trying to script the module with torch.jit.script. In the event of a failure please preconvert your module to TorchScript
```
<!-- A clear and concise description of what the bug is. -->
## To Reproduce
Just run:
```
import torch
import torch.nn as nn
import torch_tensorrt as tt
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
self.conv=nn.Conv2d(3,3,3)
def forward(self,x1):
out=self.conv(x1)
return out
a=Model().cuda().eval()
b=torch.jit.trace(a,torch.ones([1,3,20,20]).cuda())
compile_settings = {}
compile_settings["inputs"] = [tt.Input(shape = [1,3,20,20])]
tt.logging.set_reportable_log_level(tt.logging.Level.Graph)
tt.compile(b,**compile_settings)
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
Model type is correctly judged.
<!-- A clear and concise description of what you expected to happen. -->
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- Torch-TensorRT Version : 1.0.0
- PyTorch Version: 1.10.0
- CPU Architecture: Intel(R) Xeon(R) Platinum 8352Y CPU @ 2.20GHz
- OS (e.g., Linux): CentOS 7
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version: 3.6.8
- CUDA version: 11.4
- GPU models and configuration: A30
- Any other relevant information:
## Additional context
I have fixed this bug locally. After confirming the existence of this bug, I will open a PR to fix it.
<!-- Add any other context about the problem here. -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `py/torch_tensorrt/_compile.py`
Content:
```
1 from typing import List, Dict, Any
2 from torch_tensorrt import _enums
3 import torch_tensorrt.ts
4 from torch_tensorrt import logging
5 import torch
6 from torch import fx
7 from enum import Enum
8
9
10 class _IRType(Enum):
11 """Enum to set the minimum required logging level to print a message to stdout
12 """
13 ts = 0
14 fx = 1
15
16
17 def _module_ir(module: Any, ir: str) -> _IRType.ts:
18 # Possible module types
19 module_is_tsable = any(
20 isinstance(module, t) for t in [torch.nn.Module, torch.jit.ScriptModule, torch.jit.ScriptFunction])
21 module_is_fxable = any(isinstance(module, t) for t in [torch.nn.Module, torch.fx.GraphModule])
22
23 ir_targets_torchscript = any([ir == opt for opt in ["torchscript", "ts"]])
24 ir_targets_fx = ir == "fx"
25
26 if module_is_tsable and ir_targets_torchscript:
27 return _IRType.ts
28 elif module_is_fxable and ir_targets_fx:
29 if isinstance(module, torch.fx.GraphModule):
30 raise ValueError("Was given a torch.fx.GraphModule, fx is not currently supported by Torch-TensorRT")
31 elif ir_targets_fx:
32 raise ValueError("Preferred ir was set to \"fx\" which is currently not supported by Torch-TensorRT")
33 else:
34 raise ValueError("Torch-TensorRT currently does not support fx")
35 # return _IRType.fx
36 else:
37 if ir == "default":
38 # Options are listed in order of preference
39 if module_is_tsable:
40 logging.log(logging.Level.Info, "ir was set to default, using TorchScript as ir")
41 return _IRType.ts
42 elif module_is_fxable:
43 raise ValueError("Was given a torch.fx.GraphModule, fx is not currently supported by Torch-TensorRT")
44 #logging.log(logging.Level.Info, "ir was set to default, using TorchScript as fx")
45 #return _IRType.fx
46 else:
47 raise ValueError("Module was provided with in an unsupported format")
48 else:
49 raise ValueError("Unknown ir was requested")
50
51
52 def compile(module: Any, ir="default", inputs=[], enabled_precisions=set([_enums.dtype.float]), **kwargs):
53 """Compile a PyTorch module for NVIDIA GPUs using TensorRT
54
55 Takes a existing PyTorch module and a set of settings to configure the compiler
56 and using the path specified in ``ir`` lower and compile the module to TensorRT
57 returning a PyTorch Module back
58
59 Converts specifically the forward method of a Module
60
61 Arguments:
62 module (Union(torch.nn.Module,torch.jit.ScriptModule): Source module
63
64 Keyword Arguments:
65 inputs (List[Union(torch_tensorrt.Input, torch.Tensor)]): **Required** List of specifications of input shape, dtype and memory layout for inputs to the module. This argument is required. Input Sizes can be specified as torch sizes, tuples or lists. dtypes can be specified using
66 torch datatypes or torch_tensorrt datatypes and you can use either torch devices or the torch_tensorrt device type enum
67 to select device type. ::
68
69 input=[
70 torch_tensorrt.Input((1, 3, 224, 224)), # Static NCHW input shape for input #1
71 torch_tensorrt.Input(
72 min_shape=(1, 224, 224, 3),
73 opt_shape=(1, 512, 512, 3),
74 max_shape=(1, 1024, 1024, 3),
75 dtype=torch.int32
76 format=torch.channel_last
77 ), # Dynamic input shape for input #2
78 torch.randn((1, 3, 224, 244)) # Use an example tensor and let torch_tensorrt infer settings
79 ]
80
81 enabled_precision (Set(Union(torch.dtype, torch_tensorrt.dtype))): The set of datatypes that TensorRT can use when selecting kernels
82 ir (str): The requested strategy to compile. (Options: default - Let Torch-TensorRT decide, ts - TorchScript with scripting path)
83 **kwargs: Additional settings for the specific requested strategy (See submodules for more info)
84
85 Returns:
86 torch.nn.Module: Compiled Module, when run it will execute via TensorRT
87 """
88 target_ir = _module_ir(module, ir)
89 if target_ir == _IRType.ts:
90 ts_mod = module
91 if isinstance(module, torch.nn.Module):
92 logging.log(
93 logging.Level.Info,
94 "Module was provided as a torch.nn.Module, trying to script the module with torch.jit.script. In the event of a failure please preconvert your module to TorchScript"
95 )
96 ts_mod = torch.jit.script(module)
97 return torch_tensorrt.ts.compile(ts_mod, inputs=inputs, enabled_precisions=enabled_precisions, **kwargs)
98 elif target_ir == _IRType.fx:
99 raise RuntimeError("fx is currently not supported")
100 else:
101 raise RuntimeError("Module is an unknown format or the ir requested is unknown")
102
103
104 def convert_method_to_trt_engine(module: Any,
105 method_name: str,
106 ir="default",
107 inputs=[],
108 enabled_precisions=set([_enums.dtype.float]),
109 **kwargs):
110 """Convert a TorchScript module method to a serialized TensorRT engine
111
112 Converts a specified method of a module to a serialized TensorRT engine given a dictionary of conversion settings
113
114 Arguments:
115 module (Union(torch.nn.Module,torch.jit.ScriptModule): Source module
116
117 Keyword Arguments:
118 inputs (List[Union(torch_tensorrt.Input, torch.Tensor)]): **Required** List of specifications of input shape, dtype and memory layout for inputs to the module. This argument is required. Input Sizes can be specified as torch sizes, tuples or lists. dtypes can be specified using
119 torch datatypes or torch_tensorrt datatypes and you can use either torch devices or the torch_tensorrt device type enum
120 to select device type. ::
121
122 input=[
123 torch_tensorrt.Input((1, 3, 224, 224)), # Static NCHW input shape for input #1
124 torch_tensorrt.Input(
125 min_shape=(1, 224, 224, 3),
126 opt_shape=(1, 512, 512, 3),
127 max_shape=(1, 1024, 1024, 3),
128 dtype=torch.int32
129 format=torch.channel_last
130 ), # Dynamic input shape for input #2
131 torch.randn((1, 3, 224, 244)) # Use an example tensor and let torch_tensorrt infer settings
132 ]
133
134 enabled_precision (Set(Union(torch.dtype, torch_tensorrt.dtype))): The set of datatypes that TensorRT can use when selecting kernels
135 ir (str): The requested strategy to compile. (Options: default - Let Torch-TensorRT decide, ts - TorchScript with scripting path)
136 **kwargs: Additional settings for the specific requested strategy (See submodules for more info)
137
138 Returns:
139 bytes: Serialized TensorRT engine, can either be saved to a file or deserialized via TensorRT APIs
140 """
141 target_ir = _module_ir(module, ir)
142 if target_ir == _IRType.ts:
143 ts_mod = module
144 if isinstance(module, torch.nn.Module):
145 logging.log(
146 logging.Level.Info,
147 "Module was provided as a torch.nn.Module, trying to script the module with torch.jit.script. In the event of a failure please preconvert your module to TorchScript"
148 )
149 ts_mod = torch.jit.script(module)
150 return torch_tensorrt.ts.convert_method_to_trt_engine(ts_mod,
151 method_name,
152 inputs=inputs,
153 enabled_precisions=enabled_precisions,
154 **kwargs)
155 elif target_ir == _IRType.fx:
156 raise RuntimeError("fx is currently not supported")
157 else:
158 raise RuntimeError("Module is an unknown format or the ir requested is unknown")
159
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/py/torch_tensorrt/_compile.py b/py/torch_tensorrt/_compile.py
--- a/py/torch_tensorrt/_compile.py
+++ b/py/torch_tensorrt/_compile.py
@@ -14,11 +14,28 @@
fx = 1
-def _module_ir(module: Any, ir: str) -> _IRType.ts:
- # Possible module types
- module_is_tsable = any(
- isinstance(module, t) for t in [torch.nn.Module, torch.jit.ScriptModule, torch.jit.ScriptFunction])
- module_is_fxable = any(isinstance(module, t) for t in [torch.nn.Module, torch.fx.GraphModule])
+class _ModuleType(Enum):
+ """Enum to set the minimum required logging level to print a message to stdout
+ """
+ nn = 0
+ ts = 1
+ fx = 2
+
+
+def _parse_module_type(module: Any) -> _ModuleType:
+ if any(isinstance(module, t) for t in [torch.jit.ScriptModule, torch.jit.ScriptFunction]):
+ return _ModuleType.ts
+ elif isinstance(module, torch.fx.GraphModule):
+ return _ModuleType.fx
+ elif isinstance(module, torch.nn.Module):
+ return _ModuleType.nn
+ else:
+ raise RuntimeError("Module is an unknown format")
+
+
+def _get_target_ir(module_type: _ModuleType, ir: str) -> _IRType:
+ module_is_tsable = any([module_type == t for t in [_ModuleType.nn, _ModuleType.ts]])
+ module_is_fxable = any([module_type == t for t in [_ModuleType.nn, _ModuleType.fx]])
ir_targets_torchscript = any([ir == opt for opt in ["torchscript", "ts"]])
ir_targets_fx = ir == "fx"
@@ -26,7 +43,7 @@
if module_is_tsable and ir_targets_torchscript:
return _IRType.ts
elif module_is_fxable and ir_targets_fx:
- if isinstance(module, torch.fx.GraphModule):
+ if module_type == _ModuleType.fx:
raise ValueError("Was given a torch.fx.GraphModule, fx is not currently supported by Torch-TensorRT")
elif ir_targets_fx:
raise ValueError("Preferred ir was set to \"fx\" which is currently not supported by Torch-TensorRT")
@@ -85,10 +102,11 @@
Returns:
torch.nn.Module: Compiled Module, when run it will execute via TensorRT
"""
- target_ir = _module_ir(module, ir)
+ module_type = _parse_module_type(module)
+ target_ir = _get_target_ir(module_type, ir)
if target_ir == _IRType.ts:
ts_mod = module
- if isinstance(module, torch.nn.Module):
+ if module_type == _ModuleType.nn:
logging.log(
logging.Level.Info,
"Module was provided as a torch.nn.Module, trying to script the module with torch.jit.script. In the event of a failure please preconvert your module to TorchScript"
@@ -134,14 +152,14 @@
enabled_precision (Set(Union(torch.dtype, torch_tensorrt.dtype))): The set of datatypes that TensorRT can use when selecting kernels
ir (str): The requested strategy to compile. (Options: default - Let Torch-TensorRT decide, ts - TorchScript with scripting path)
**kwargs: Additional settings for the specific requested strategy (See submodules for more info)
-
Returns:
bytes: Serialized TensorRT engine, can either be saved to a file or deserialized via TensorRT APIs
"""
- target_ir = _module_ir(module, ir)
+ module_type = _parse_module_type(module)
+ target_ir = _get_target_ir(module_type, ir)
if target_ir == _IRType.ts:
ts_mod = module
- if isinstance(module, torch.nn.Module):
+ if module_type == _ModuleType.nn:
logging.log(
logging.Level.Info,
"Module was provided as a torch.nn.Module, trying to script the module with torch.jit.script. In the event of a failure please preconvert your module to TorchScript"
@@ -155,4 +173,4 @@
elif target_ir == _IRType.fx:
raise RuntimeError("fx is currently not supported")
else:
- raise RuntimeError("Module is an unknown format or the ir requested is unknown")
+ raise RuntimeError("Module is an unknown format or the ir requested is unknown")
\ No newline at end of file
| {"golden_diff": "diff --git a/py/torch_tensorrt/_compile.py b/py/torch_tensorrt/_compile.py\n--- a/py/torch_tensorrt/_compile.py\n+++ b/py/torch_tensorrt/_compile.py\n@@ -14,11 +14,28 @@\n fx = 1\n \n \n-def _module_ir(module: Any, ir: str) -> _IRType.ts:\n- # Possible module types\n- module_is_tsable = any(\n- isinstance(module, t) for t in [torch.nn.Module, torch.jit.ScriptModule, torch.jit.ScriptFunction])\n- module_is_fxable = any(isinstance(module, t) for t in [torch.nn.Module, torch.fx.GraphModule])\n+class _ModuleType(Enum):\n+ \"\"\"Enum to set the minimum required logging level to print a message to stdout\n+ \"\"\"\n+ nn = 0\n+ ts = 1\n+ fx = 2\n+\n+\n+def _parse_module_type(module: Any) -> _ModuleType:\n+ if any(isinstance(module, t) for t in [torch.jit.ScriptModule, torch.jit.ScriptFunction]):\n+ return _ModuleType.ts\n+ elif isinstance(module, torch.fx.GraphModule):\n+ return _ModuleType.fx\n+ elif isinstance(module, torch.nn.Module):\n+ return _ModuleType.nn\n+ else:\n+ raise RuntimeError(\"Module is an unknown format\")\n+\n+\n+def _get_target_ir(module_type: _ModuleType, ir: str) -> _IRType:\n+ module_is_tsable = any([module_type == t for t in [_ModuleType.nn, _ModuleType.ts]])\n+ module_is_fxable = any([module_type == t for t in [_ModuleType.nn, _ModuleType.fx]])\n \n ir_targets_torchscript = any([ir == opt for opt in [\"torchscript\", \"ts\"]])\n ir_targets_fx = ir == \"fx\"\n@@ -26,7 +43,7 @@\n if module_is_tsable and ir_targets_torchscript:\n return _IRType.ts\n elif module_is_fxable and ir_targets_fx:\n- if isinstance(module, torch.fx.GraphModule):\n+ if module_type == _ModuleType.fx:\n raise ValueError(\"Was given a torch.fx.GraphModule, fx is not currently supported by Torch-TensorRT\")\n elif ir_targets_fx:\n raise ValueError(\"Preferred ir was set to \\\"fx\\\" which is currently not supported by Torch-TensorRT\")\n@@ -85,10 +102,11 @@\n Returns:\n torch.nn.Module: Compiled Module, when run it will execute via TensorRT\n \"\"\"\n- target_ir = _module_ir(module, ir)\n+ module_type = _parse_module_type(module)\n+ target_ir = _get_target_ir(module_type, ir)\n if target_ir == _IRType.ts:\n ts_mod = module\n- if isinstance(module, torch.nn.Module):\n+ if module_type == _ModuleType.nn:\n logging.log(\n logging.Level.Info,\n \"Module was provided as a torch.nn.Module, trying to script the module with torch.jit.script. In the event of a failure please preconvert your module to TorchScript\"\n@@ -134,14 +152,14 @@\n enabled_precision (Set(Union(torch.dtype, torch_tensorrt.dtype))): The set of datatypes that TensorRT can use when selecting kernels\n ir (str): The requested strategy to compile. (Options: default - Let Torch-TensorRT decide, ts - TorchScript with scripting path)\n **kwargs: Additional settings for the specific requested strategy (See submodules for more info)\n-\n Returns:\n bytes: Serialized TensorRT engine, can either be saved to a file or deserialized via TensorRT APIs\n \"\"\"\n- target_ir = _module_ir(module, ir)\n+ module_type = _parse_module_type(module)\n+ target_ir = _get_target_ir(module_type, ir)\n if target_ir == _IRType.ts:\n ts_mod = module\n- if isinstance(module, torch.nn.Module):\n+ if module_type == _ModuleType.nn:\n logging.log(\n logging.Level.Info,\n \"Module was provided as a torch.nn.Module, trying to script the module with torch.jit.script. In the event of a failure please preconvert your module to TorchScript\"\n@@ -155,4 +173,4 @@\n elif target_ir == _IRType.fx:\n raise RuntimeError(\"fx is currently not supported\")\n else:\n- raise RuntimeError(\"Module is an unknown format or the ir requested is unknown\")\n+ raise RuntimeError(\"Module is an unknown format or the ir requested is unknown\")\n\\ No newline at end of file\n", "issue": "\ud83d\udc1b [Bug] Incorrect judgment of model type\n## Bug Description\r\n\r\nWhen I provide a TorchScript model, Torch-TensorRT claims it is an nn.Module model\r\n\r\n```\r\nINFO: [Torch-TensorRT] - ir was set to default, using TorchScript as ir\r\nINFO: [Torch-TensorRT] - Module was provided as a torch.nn.Module, trying to script the module with torch.jit.script. In the event of a failure please preconvert your module to TorchScript\r\n```\r\n\r\n<!-- A clear and concise description of what the bug is. -->\r\n\r\n## To Reproduce\r\n\r\nJust run:\r\n\r\n```\r\nimport torch\r\nimport torch.nn as nn\r\nimport torch_tensorrt as tt\r\n\r\nclass Model(nn.Module):\r\n def __init__(self):\r\n super(Model,self).__init__()\r\n self.conv=nn.Conv2d(3,3,3)\r\n\r\n def forward(self,x1):\r\n out=self.conv(x1)\r\n return out\r\n\r\na=Model().cuda().eval()\r\nb=torch.jit.trace(a,torch.ones([1,3,20,20]).cuda())\r\n\r\ncompile_settings = {}\r\ncompile_settings[\"inputs\"] = [tt.Input(shape = [1,3,20,20])]\r\ntt.logging.set_reportable_log_level(tt.logging.Level.Graph)\r\n\r\ntt.compile(b,**compile_settings)\r\n```\r\n\r\n<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->\r\n\r\n## Expected behavior\r\n\r\nModel type is correctly judged.\r\n\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n\r\n## Environment\r\n\r\n> Build information about Torch-TensorRT can be found by turning on debug messages\r\n\r\n - Torch-TensorRT Version : 1.0.0\r\n - PyTorch Version: 1.10.0\r\n - CPU Architecture: Intel(R) Xeon(R) Platinum 8352Y CPU @ 2.20GHz\r\n - OS (e.g., Linux): CentOS 7\r\n - How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip\r\n - Build command you used (if compiling from source):\r\n - Are you using local sources or building from archives:\r\n - Python version: 3.6.8\r\n - CUDA version: 11.4\r\n - GPU models and configuration: A30\r\n - Any other relevant information:\r\n\r\n## Additional context\r\n\r\nI have fixed this bug locally. After confirming the existence of this bug, I will open a PR to fix it.\r\n\r\n<!-- Add any other context about the problem here. -->\r\n\n", "before_files": [{"content": "from typing import List, Dict, Any\nfrom torch_tensorrt import _enums\nimport torch_tensorrt.ts\nfrom torch_tensorrt import logging\nimport torch\nfrom torch import fx\nfrom enum import Enum\n\n\nclass _IRType(Enum):\n \"\"\"Enum to set the minimum required logging level to print a message to stdout\n \"\"\"\n ts = 0\n fx = 1\n\n\ndef _module_ir(module: Any, ir: str) -> _IRType.ts:\n # Possible module types\n module_is_tsable = any(\n isinstance(module, t) for t in [torch.nn.Module, torch.jit.ScriptModule, torch.jit.ScriptFunction])\n module_is_fxable = any(isinstance(module, t) for t in [torch.nn.Module, torch.fx.GraphModule])\n\n ir_targets_torchscript = any([ir == opt for opt in [\"torchscript\", \"ts\"]])\n ir_targets_fx = ir == \"fx\"\n\n if module_is_tsable and ir_targets_torchscript:\n return _IRType.ts\n elif module_is_fxable and ir_targets_fx:\n if isinstance(module, torch.fx.GraphModule):\n raise ValueError(\"Was given a torch.fx.GraphModule, fx is not currently supported by Torch-TensorRT\")\n elif ir_targets_fx:\n raise ValueError(\"Preferred ir was set to \\\"fx\\\" which is currently not supported by Torch-TensorRT\")\n else:\n raise ValueError(\"Torch-TensorRT currently does not support fx\")\n # return _IRType.fx\n else:\n if ir == \"default\":\n # Options are listed in order of preference\n if module_is_tsable:\n logging.log(logging.Level.Info, \"ir was set to default, using TorchScript as ir\")\n return _IRType.ts\n elif module_is_fxable:\n raise ValueError(\"Was given a torch.fx.GraphModule, fx is not currently supported by Torch-TensorRT\")\n #logging.log(logging.Level.Info, \"ir was set to default, using TorchScript as fx\")\n #return _IRType.fx\n else:\n raise ValueError(\"Module was provided with in an unsupported format\")\n else:\n raise ValueError(\"Unknown ir was requested\")\n\n\ndef compile(module: Any, ir=\"default\", inputs=[], enabled_precisions=set([_enums.dtype.float]), **kwargs):\n \"\"\"Compile a PyTorch module for NVIDIA GPUs using TensorRT\n\n Takes a existing PyTorch module and a set of settings to configure the compiler\n and using the path specified in ``ir`` lower and compile the module to TensorRT\n returning a PyTorch Module back\n\n Converts specifically the forward method of a Module\n\n Arguments:\n module (Union(torch.nn.Module,torch.jit.ScriptModule): Source module\n\n Keyword Arguments:\n inputs (List[Union(torch_tensorrt.Input, torch.Tensor)]): **Required** List of specifications of input shape, dtype and memory layout for inputs to the module. This argument is required. Input Sizes can be specified as torch sizes, tuples or lists. dtypes can be specified using\n torch datatypes or torch_tensorrt datatypes and you can use either torch devices or the torch_tensorrt device type enum\n to select device type. ::\n\n input=[\n torch_tensorrt.Input((1, 3, 224, 224)), # Static NCHW input shape for input #1\n torch_tensorrt.Input(\n min_shape=(1, 224, 224, 3),\n opt_shape=(1, 512, 512, 3),\n max_shape=(1, 1024, 1024, 3),\n dtype=torch.int32\n format=torch.channel_last\n ), # Dynamic input shape for input #2\n torch.randn((1, 3, 224, 244)) # Use an example tensor and let torch_tensorrt infer settings\n ]\n\n enabled_precision (Set(Union(torch.dtype, torch_tensorrt.dtype))): The set of datatypes that TensorRT can use when selecting kernels\n ir (str): The requested strategy to compile. (Options: default - Let Torch-TensorRT decide, ts - TorchScript with scripting path)\n **kwargs: Additional settings for the specific requested strategy (See submodules for more info)\n\n Returns:\n torch.nn.Module: Compiled Module, when run it will execute via TensorRT\n \"\"\"\n target_ir = _module_ir(module, ir)\n if target_ir == _IRType.ts:\n ts_mod = module\n if isinstance(module, torch.nn.Module):\n logging.log(\n logging.Level.Info,\n \"Module was provided as a torch.nn.Module, trying to script the module with torch.jit.script. In the event of a failure please preconvert your module to TorchScript\"\n )\n ts_mod = torch.jit.script(module)\n return torch_tensorrt.ts.compile(ts_mod, inputs=inputs, enabled_precisions=enabled_precisions, **kwargs)\n elif target_ir == _IRType.fx:\n raise RuntimeError(\"fx is currently not supported\")\n else:\n raise RuntimeError(\"Module is an unknown format or the ir requested is unknown\")\n\n\ndef convert_method_to_trt_engine(module: Any,\n method_name: str,\n ir=\"default\",\n inputs=[],\n enabled_precisions=set([_enums.dtype.float]),\n **kwargs):\n \"\"\"Convert a TorchScript module method to a serialized TensorRT engine\n\n Converts a specified method of a module to a serialized TensorRT engine given a dictionary of conversion settings\n\n Arguments:\n module (Union(torch.nn.Module,torch.jit.ScriptModule): Source module\n\n Keyword Arguments:\n inputs (List[Union(torch_tensorrt.Input, torch.Tensor)]): **Required** List of specifications of input shape, dtype and memory layout for inputs to the module. This argument is required. Input Sizes can be specified as torch sizes, tuples or lists. dtypes can be specified using\n torch datatypes or torch_tensorrt datatypes and you can use either torch devices or the torch_tensorrt device type enum\n to select device type. ::\n\n input=[\n torch_tensorrt.Input((1, 3, 224, 224)), # Static NCHW input shape for input #1\n torch_tensorrt.Input(\n min_shape=(1, 224, 224, 3),\n opt_shape=(1, 512, 512, 3),\n max_shape=(1, 1024, 1024, 3),\n dtype=torch.int32\n format=torch.channel_last\n ), # Dynamic input shape for input #2\n torch.randn((1, 3, 224, 244)) # Use an example tensor and let torch_tensorrt infer settings\n ]\n\n enabled_precision (Set(Union(torch.dtype, torch_tensorrt.dtype))): The set of datatypes that TensorRT can use when selecting kernels\n ir (str): The requested strategy to compile. (Options: default - Let Torch-TensorRT decide, ts - TorchScript with scripting path)\n **kwargs: Additional settings for the specific requested strategy (See submodules for more info)\n\n Returns:\n bytes: Serialized TensorRT engine, can either be saved to a file or deserialized via TensorRT APIs\n \"\"\"\n target_ir = _module_ir(module, ir)\n if target_ir == _IRType.ts:\n ts_mod = module\n if isinstance(module, torch.nn.Module):\n logging.log(\n logging.Level.Info,\n \"Module was provided as a torch.nn.Module, trying to script the module with torch.jit.script. In the event of a failure please preconvert your module to TorchScript\"\n )\n ts_mod = torch.jit.script(module)\n return torch_tensorrt.ts.convert_method_to_trt_engine(ts_mod,\n method_name,\n inputs=inputs,\n enabled_precisions=enabled_precisions,\n **kwargs)\n elif target_ir == _IRType.fx:\n raise RuntimeError(\"fx is currently not supported\")\n else:\n raise RuntimeError(\"Module is an unknown format or the ir requested is unknown\")\n", "path": "py/torch_tensorrt/_compile.py"}], "after_files": [{"content": "from typing import List, Dict, Any\nfrom torch_tensorrt import _enums\nimport torch_tensorrt.ts\nfrom torch_tensorrt import logging\nimport torch\nfrom torch import fx\nfrom enum import Enum\n\n\nclass _IRType(Enum):\n \"\"\"Enum to set the minimum required logging level to print a message to stdout\n \"\"\"\n ts = 0\n fx = 1\n\n\nclass _ModuleType(Enum):\n \"\"\"Enum to set the minimum required logging level to print a message to stdout\n \"\"\"\n nn = 0\n ts = 1\n fx = 2\n\n\ndef _parse_module_type(module: Any) -> _ModuleType:\n if any(isinstance(module, t) for t in [torch.jit.ScriptModule, torch.jit.ScriptFunction]):\n return _ModuleType.ts\n elif isinstance(module, torch.fx.GraphModule):\n return _ModuleType.fx\n elif isinstance(module, torch.nn.Module):\n return _ModuleType.nn\n else:\n raise RuntimeError(\"Module is an unknown format\")\n\n\ndef _get_target_ir(module_type: _ModuleType, ir: str) -> _IRType:\n module_is_tsable = any([module_type == t for t in [_ModuleType.nn, _ModuleType.ts]])\n module_is_fxable = any([module_type == t for t in [_ModuleType.nn, _ModuleType.fx]])\n\n ir_targets_torchscript = any([ir == opt for opt in [\"torchscript\", \"ts\"]])\n ir_targets_fx = ir == \"fx\"\n\n if module_is_tsable and ir_targets_torchscript:\n return _IRType.ts\n elif module_is_fxable and ir_targets_fx:\n if module_type == _ModuleType.fx:\n raise ValueError(\"Was given a torch.fx.GraphModule, fx is not currently supported by Torch-TensorRT\")\n elif ir_targets_fx:\n raise ValueError(\"Preferred ir was set to \\\"fx\\\" which is currently not supported by Torch-TensorRT\")\n else:\n raise ValueError(\"Torch-TensorRT currently does not support fx\")\n # return _IRType.fx\n else:\n if ir == \"default\":\n # Options are listed in order of preference\n if module_is_tsable:\n logging.log(logging.Level.Info, \"ir was set to default, using TorchScript as ir\")\n return _IRType.ts\n elif module_is_fxable:\n raise ValueError(\"Was given a torch.fx.GraphModule, fx is not currently supported by Torch-TensorRT\")\n #logging.log(logging.Level.Info, \"ir was set to default, using TorchScript as fx\")\n #return _IRType.fx\n else:\n raise ValueError(\"Module was provided with in an unsupported format\")\n else:\n raise ValueError(\"Unknown ir was requested\")\n\n\ndef compile(module: Any, ir=\"default\", inputs=[], enabled_precisions=set([_enums.dtype.float]), **kwargs):\n \"\"\"Compile a PyTorch module for NVIDIA GPUs using TensorRT\n\n Takes a existing PyTorch module and a set of settings to configure the compiler\n and using the path specified in ``ir`` lower and compile the module to TensorRT\n returning a PyTorch Module back\n\n Converts specifically the forward method of a Module\n\n Arguments:\n module (Union(torch.nn.Module,torch.jit.ScriptModule): Source module\n\n Keyword Arguments:\n inputs (List[Union(torch_tensorrt.Input, torch.Tensor)]): **Required** List of specifications of input shape, dtype and memory layout for inputs to the module. This argument is required. Input Sizes can be specified as torch sizes, tuples or lists. dtypes can be specified using\n torch datatypes or torch_tensorrt datatypes and you can use either torch devices or the torch_tensorrt device type enum\n to select device type. ::\n\n input=[\n torch_tensorrt.Input((1, 3, 224, 224)), # Static NCHW input shape for input #1\n torch_tensorrt.Input(\n min_shape=(1, 224, 224, 3),\n opt_shape=(1, 512, 512, 3),\n max_shape=(1, 1024, 1024, 3),\n dtype=torch.int32\n format=torch.channel_last\n ), # Dynamic input shape for input #2\n torch.randn((1, 3, 224, 244)) # Use an example tensor and let torch_tensorrt infer settings\n ]\n\n enabled_precision (Set(Union(torch.dtype, torch_tensorrt.dtype))): The set of datatypes that TensorRT can use when selecting kernels\n ir (str): The requested strategy to compile. (Options: default - Let Torch-TensorRT decide, ts - TorchScript with scripting path)\n **kwargs: Additional settings for the specific requested strategy (See submodules for more info)\n\n Returns:\n torch.nn.Module: Compiled Module, when run it will execute via TensorRT\n \"\"\"\n module_type = _parse_module_type(module)\n target_ir = _get_target_ir(module_type, ir)\n if target_ir == _IRType.ts:\n ts_mod = module\n if module_type == _ModuleType.nn:\n logging.log(\n logging.Level.Info,\n \"Module was provided as a torch.nn.Module, trying to script the module with torch.jit.script. In the event of a failure please preconvert your module to TorchScript\"\n )\n ts_mod = torch.jit.script(module)\n return torch_tensorrt.ts.compile(ts_mod, inputs=inputs, enabled_precisions=enabled_precisions, **kwargs)\n elif target_ir == _IRType.fx:\n raise RuntimeError(\"fx is currently not supported\")\n else:\n raise RuntimeError(\"Module is an unknown format or the ir requested is unknown\")\n\n\ndef convert_method_to_trt_engine(module: Any,\n method_name: str,\n ir=\"default\",\n inputs=[],\n enabled_precisions=set([_enums.dtype.float]),\n **kwargs):\n \"\"\"Convert a TorchScript module method to a serialized TensorRT engine\n\n Converts a specified method of a module to a serialized TensorRT engine given a dictionary of conversion settings\n\n Arguments:\n module (Union(torch.nn.Module,torch.jit.ScriptModule): Source module\n\n Keyword Arguments:\n inputs (List[Union(torch_tensorrt.Input, torch.Tensor)]): **Required** List of specifications of input shape, dtype and memory layout for inputs to the module. This argument is required. Input Sizes can be specified as torch sizes, tuples or lists. dtypes can be specified using\n torch datatypes or torch_tensorrt datatypes and you can use either torch devices or the torch_tensorrt device type enum\n to select device type. ::\n\n input=[\n torch_tensorrt.Input((1, 3, 224, 224)), # Static NCHW input shape for input #1\n torch_tensorrt.Input(\n min_shape=(1, 224, 224, 3),\n opt_shape=(1, 512, 512, 3),\n max_shape=(1, 1024, 1024, 3),\n dtype=torch.int32\n format=torch.channel_last\n ), # Dynamic input shape for input #2\n torch.randn((1, 3, 224, 244)) # Use an example tensor and let torch_tensorrt infer settings\n ]\n\n enabled_precision (Set(Union(torch.dtype, torch_tensorrt.dtype))): The set of datatypes that TensorRT can use when selecting kernels\n ir (str): The requested strategy to compile. (Options: default - Let Torch-TensorRT decide, ts - TorchScript with scripting path)\n **kwargs: Additional settings for the specific requested strategy (See submodules for more info)\n Returns:\n bytes: Serialized TensorRT engine, can either be saved to a file or deserialized via TensorRT APIs\n \"\"\"\n module_type = _parse_module_type(module)\n target_ir = _get_target_ir(module_type, ir)\n if target_ir == _IRType.ts:\n ts_mod = module\n if module_type == _ModuleType.nn:\n logging.log(\n logging.Level.Info,\n \"Module was provided as a torch.nn.Module, trying to script the module with torch.jit.script. In the event of a failure please preconvert your module to TorchScript\"\n )\n ts_mod = torch.jit.script(module)\n return torch_tensorrt.ts.convert_method_to_trt_engine(ts_mod,\n method_name,\n inputs=inputs,\n enabled_precisions=enabled_precisions,\n **kwargs)\n elif target_ir == _IRType.fx:\n raise RuntimeError(\"fx is currently not supported\")\n else:\n raise RuntimeError(\"Module is an unknown format or the ir requested is unknown\")", "path": "py/torch_tensorrt/_compile.py"}]} | 2,902 | 1,011 |
gh_patches_debug_35860 | rasdani/github-patches | git_diff | feast-dev__feast-3518 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add Kubernetes Deployment Options to the Bytewax Materialization Engine
**Is your feature request related to a problem? Please describe.**
The Bytewax materialization engine needs to support configuration options for more advanced Kubernetes deployments (EKS, GCP, etc) to make it usable at scale.
**Describe the solution you'd like**
The main configuration options that are needed for the Bytewax materialization job are:
* setting explicit resource requests and limits (rather than relying on platform defaults which may not be enough)
* supporting service accounts and IAM roles
* specifying an image pull secret to support pulling Docker images from Dockerhub, Artifactory, etc
**Describe alternatives you've considered**
The Kubernetes job that runs is dynamically generated by the bytewax code. Existing configuration options are insufficient.
**Additional context**
I'd really like to test the Bytewax materialization engine on our instance of EKS. In its current implementation, it's operationally too simple and not usable outside of minikube.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py`
Content:
```
1 import uuid
2 from datetime import datetime
3 from typing import Callable, List, Literal, Sequence, Union
4
5 import yaml
6 from kubernetes import client
7 from kubernetes import config as k8s_config
8 from kubernetes import utils
9 from kubernetes.utils import FailToCreateError
10 from pydantic import StrictStr
11 from tqdm import tqdm
12
13 from feast import FeatureView, RepoConfig
14 from feast.batch_feature_view import BatchFeatureView
15 from feast.entity import Entity
16 from feast.infra.materialization.batch_materialization_engine import (
17 BatchMaterializationEngine,
18 MaterializationJob,
19 MaterializationTask,
20 )
21 from feast.infra.offline_stores.offline_store import OfflineStore
22 from feast.infra.online_stores.online_store import OnlineStore
23 from feast.infra.registry.base_registry import BaseRegistry
24 from feast.repo_config import FeastConfigBaseModel
25 from feast.stream_feature_view import StreamFeatureView
26 from feast.utils import _get_column_names, get_default_yaml_file_path
27
28 from .bytewax_materialization_job import BytewaxMaterializationJob
29
30
31 class BytewaxMaterializationEngineConfig(FeastConfigBaseModel):
32 """Batch Materialization Engine config for Bytewax"""
33
34 type: Literal["bytewax"] = "bytewax"
35 """ Materialization type selector"""
36
37 namespace: StrictStr = "default"
38 """ (optional) The namespace in Kubernetes to use when creating services, configuration maps and jobs.
39 """
40
41 image: StrictStr = "bytewax/bytewax-feast:latest"
42 """ (optional) The container image to use when running the materialization job."""
43
44 env: List[dict] = []
45 """ (optional) A list of environment variables to set in the created Kubernetes pods.
46 These environment variables can be used to reference Kubernetes secrets.
47 """
48
49
50 class BytewaxMaterializationEngine(BatchMaterializationEngine):
51 def __init__(
52 self,
53 *,
54 repo_config: RepoConfig,
55 offline_store: OfflineStore,
56 online_store: OnlineStore,
57 **kwargs,
58 ):
59 super().__init__(
60 repo_config=repo_config,
61 offline_store=offline_store,
62 online_store=online_store,
63 **kwargs,
64 )
65 self.repo_config = repo_config
66 self.offline_store = offline_store
67 self.online_store = online_store
68
69 # TODO: Configure k8s here
70 k8s_config.load_kube_config()
71
72 self.k8s_client = client.api_client.ApiClient()
73 self.v1 = client.CoreV1Api(self.k8s_client)
74 self.batch_v1 = client.BatchV1Api(self.k8s_client)
75 self.batch_engine_config = repo_config.batch_engine
76 self.namespace = self.batch_engine_config.namespace
77
78 def update(
79 self,
80 project: str,
81 views_to_delete: Sequence[
82 Union[BatchFeatureView, StreamFeatureView, FeatureView]
83 ],
84 views_to_keep: Sequence[
85 Union[BatchFeatureView, StreamFeatureView, FeatureView]
86 ],
87 entities_to_delete: Sequence[Entity],
88 entities_to_keep: Sequence[Entity],
89 ):
90 """This method ensures that any necessary infrastructure or resources needed by the
91 engine are set up ahead of materialization."""
92 pass
93
94 def teardown_infra(
95 self,
96 project: str,
97 fvs: Sequence[Union[BatchFeatureView, StreamFeatureView, FeatureView]],
98 entities: Sequence[Entity],
99 ):
100 """This method ensures that any infrastructure or resources set up by ``update()``are torn down."""
101 pass
102
103 def materialize(
104 self,
105 registry: BaseRegistry,
106 tasks: List[MaterializationTask],
107 ) -> List[MaterializationJob]:
108 return [
109 self._materialize_one(
110 registry,
111 task.feature_view,
112 task.start_time,
113 task.end_time,
114 task.project,
115 task.tqdm_builder,
116 )
117 for task in tasks
118 ]
119
120 def _materialize_one(
121 self,
122 registry: BaseRegistry,
123 feature_view: Union[BatchFeatureView, StreamFeatureView, FeatureView],
124 start_date: datetime,
125 end_date: datetime,
126 project: str,
127 tqdm_builder: Callable[[int], tqdm],
128 ):
129 entities = []
130 for entity_name in feature_view.entities:
131 entities.append(registry.get_entity(entity_name, project))
132
133 (
134 join_key_columns,
135 feature_name_columns,
136 timestamp_field,
137 created_timestamp_column,
138 ) = _get_column_names(feature_view, entities)
139
140 offline_job = self.offline_store.pull_latest_from_table_or_query(
141 config=self.repo_config,
142 data_source=feature_view.batch_source,
143 join_key_columns=join_key_columns,
144 feature_name_columns=feature_name_columns,
145 timestamp_field=timestamp_field,
146 created_timestamp_column=created_timestamp_column,
147 start_date=start_date,
148 end_date=end_date,
149 )
150
151 paths = offline_job.to_remote_storage()
152 job_id = str(uuid.uuid4())
153 return self._create_kubernetes_job(job_id, paths, feature_view)
154
155 def _create_kubernetes_job(self, job_id, paths, feature_view):
156 try:
157 # Create a k8s configmap with information needed by bytewax
158 self._create_configuration_map(job_id, paths, feature_view, self.namespace)
159
160 # Create the k8s job definition
161 self._create_job_definition(
162 job_id,
163 self.namespace,
164 len(paths), # Create a pod for each parquet file
165 self.batch_engine_config.env,
166 )
167 except FailToCreateError as failures:
168 return BytewaxMaterializationJob(job_id, self.namespace, error=failures)
169
170 return BytewaxMaterializationJob(job_id, self.namespace)
171
172 def _create_configuration_map(self, job_id, paths, feature_view, namespace):
173 """Create a Kubernetes configmap for this job"""
174
175 repo_path = self.repo_config.repo_path
176 assert repo_path
177 feature_store_path = get_default_yaml_file_path(repo_path)
178 feature_store_configuration = feature_store_path.read_text()
179
180 materialization_config = yaml.dump(
181 {"paths": paths, "feature_view": feature_view.name}
182 )
183
184 configmap_manifest = {
185 "kind": "ConfigMap",
186 "apiVersion": "v1",
187 "metadata": {
188 "name": f"feast-{job_id}",
189 },
190 "data": {
191 "feature_store.yaml": feature_store_configuration,
192 "bytewax_materialization_config.yaml": materialization_config,
193 },
194 }
195 self.v1.create_namespaced_config_map(
196 namespace=namespace,
197 body=configmap_manifest,
198 )
199
200 def _create_job_definition(self, job_id, namespace, pods, env):
201 """Create a kubernetes job definition."""
202 job_env = [
203 {"name": "RUST_BACKTRACE", "value": "full"},
204 {
205 "name": "BYTEWAX_PYTHON_FILE_PATH",
206 "value": "/bytewax/dataflow.py",
207 },
208 {"name": "BYTEWAX_WORKDIR", "value": "/bytewax"},
209 {
210 "name": "BYTEWAX_WORKERS_PER_PROCESS",
211 "value": "1",
212 },
213 {
214 "name": "BYTEWAX_POD_NAME",
215 "valueFrom": {
216 "fieldRef": {
217 "apiVersion": "v1",
218 "fieldPath": "metadata.annotations['batch.kubernetes.io/job-completion-index']",
219 }
220 },
221 },
222 {
223 "name": "BYTEWAX_REPLICAS",
224 "value": f"{pods}",
225 },
226 {
227 "name": "BYTEWAX_KEEP_CONTAINER_ALIVE",
228 "value": "false",
229 },
230 {
231 "name": "BYTEWAX_STATEFULSET_NAME",
232 "value": f"dataflow-{job_id}",
233 },
234 ]
235 # Add any Feast configured environment variables
236 job_env.extend(env)
237
238 job_definition = {
239 "apiVersion": "batch/v1",
240 "kind": "Job",
241 "metadata": {
242 "name": f"dataflow-{job_id}",
243 "namespace": namespace,
244 },
245 "spec": {
246 "ttlSecondsAfterFinished": 3600,
247 "completions": pods,
248 "parallelism": pods,
249 "completionMode": "Indexed",
250 "template": {
251 "spec": {
252 "restartPolicy": "Never",
253 "subdomain": f"dataflow-{job_id}",
254 "initContainers": [
255 {
256 "env": [
257 {
258 "name": "BYTEWAX_REPLICAS",
259 "value": f"{pods}",
260 }
261 ],
262 "image": "busybox",
263 "imagePullPolicy": "Always",
264 "name": "init-hostfile",
265 "resources": {},
266 "securityContext": {
267 "allowPrivilegeEscalation": False,
268 "capabilities": {
269 "add": ["NET_BIND_SERVICE"],
270 "drop": ["ALL"],
271 },
272 "readOnlyRootFilesystem": True,
273 },
274 "terminationMessagePath": "/dev/termination-log",
275 "terminationMessagePolicy": "File",
276 "volumeMounts": [
277 {"mountPath": "/etc/bytewax", "name": "hostfile"},
278 {
279 "mountPath": "/tmp/bytewax/",
280 "name": "python-files",
281 },
282 {
283 "mountPath": "/var/feast/",
284 "name": f"feast-{job_id}",
285 },
286 ],
287 }
288 ],
289 "containers": [
290 {
291 "command": ["sh", "-c", "sh ./entrypoint.sh"],
292 "env": job_env,
293 "image": self.batch_engine_config.image,
294 "imagePullPolicy": "Always",
295 "name": "process",
296 "ports": [
297 {
298 "containerPort": 9999,
299 "name": "process",
300 "protocol": "TCP",
301 }
302 ],
303 "resources": {},
304 "securityContext": {
305 "allowPrivilegeEscalation": False,
306 "capabilities": {
307 "add": ["NET_BIND_SERVICE"],
308 "drop": ["ALL"],
309 },
310 "readOnlyRootFilesystem": False,
311 },
312 "terminationMessagePath": "/dev/termination-log",
313 "terminationMessagePolicy": "File",
314 "volumeMounts": [
315 {"mountPath": "/etc/bytewax", "name": "hostfile"},
316 {
317 "mountPath": "/var/feast/",
318 "name": f"feast-{job_id}",
319 },
320 ],
321 }
322 ],
323 "volumes": [
324 {"emptyDir": {}, "name": "hostfile"},
325 {
326 "configMap": {
327 "defaultMode": 420,
328 "name": f"feast-{job_id}",
329 },
330 "name": "python-files",
331 },
332 {
333 "configMap": {"name": f"feast-{job_id}"},
334 "name": f"feast-{job_id}",
335 },
336 ],
337 }
338 },
339 },
340 }
341 utils.create_from_dict(self.k8s_client, job_definition)
342
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py b/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
--- a/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
+++ b/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
@@ -46,6 +46,17 @@
These environment variables can be used to reference Kubernetes secrets.
"""
+ image_pull_secrets: List[str] = []
+ """ (optional) The secrets to use when pulling the image to run for the materialization job """
+
+ resources: dict = {}
+ """ (optional) The resource requests and limits for the materialization containers """
+
+ service_account_name: StrictStr = ""
+ """ (optional) The service account name to use when running the job """
+
+ annotations: dict = {}
+ """ (optional) Annotations to apply to the job container. Useful for linking the service account to IAM roles, operational metadata, etc """
class BytewaxMaterializationEngine(BatchMaterializationEngine):
def __init__(
@@ -248,9 +259,14 @@
"parallelism": pods,
"completionMode": "Indexed",
"template": {
+ "metadata": {
+ "annotations": self.batch_engine_config.annotations,
+ },
"spec": {
"restartPolicy": "Never",
"subdomain": f"dataflow-{job_id}",
+ "imagePullSecrets": self.batch_engine_config.image_pull_secrets,
+ "serviceAccountName": self.batch_engine_config.service_account_name,
"initContainers": [
{
"env": [
@@ -300,7 +316,7 @@
"protocol": "TCP",
}
],
- "resources": {},
+ "resources": self.batch_engine_config.resources,
"securityContext": {
"allowPrivilegeEscalation": False,
"capabilities": {
| {"golden_diff": "diff --git a/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py b/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py\n--- a/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py\n+++ b/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py\n@@ -46,6 +46,17 @@\n These environment variables can be used to reference Kubernetes secrets.\n \"\"\"\n \n+ image_pull_secrets: List[str] = []\n+ \"\"\" (optional) The secrets to use when pulling the image to run for the materialization job \"\"\"\n+\n+ resources: dict = {}\n+ \"\"\" (optional) The resource requests and limits for the materialization containers \"\"\"\n+\n+ service_account_name: StrictStr = \"\"\n+ \"\"\" (optional) The service account name to use when running the job \"\"\"\n+\n+ annotations: dict = {}\n+ \"\"\" (optional) Annotations to apply to the job container. Useful for linking the service account to IAM roles, operational metadata, etc \"\"\"\n \n class BytewaxMaterializationEngine(BatchMaterializationEngine):\n def __init__(\n@@ -248,9 +259,14 @@\n \"parallelism\": pods,\n \"completionMode\": \"Indexed\",\n \"template\": {\n+ \"metadata\": {\n+ \"annotations\": self.batch_engine_config.annotations,\n+ },\n \"spec\": {\n \"restartPolicy\": \"Never\",\n \"subdomain\": f\"dataflow-{job_id}\",\n+ \"imagePullSecrets\": self.batch_engine_config.image_pull_secrets,\n+ \"serviceAccountName\": self.batch_engine_config.service_account_name,\n \"initContainers\": [\n {\n \"env\": [\n@@ -300,7 +316,7 @@\n \"protocol\": \"TCP\",\n }\n ],\n- \"resources\": {},\n+ \"resources\": self.batch_engine_config.resources,\n \"securityContext\": {\n \"allowPrivilegeEscalation\": False,\n \"capabilities\": {\n", "issue": "Add Kubernetes Deployment Options to the Bytewax Materialization Engine\n**Is your feature request related to a problem? Please describe.**\r\nThe Bytewax materialization engine needs to support configuration options for more advanced Kubernetes deployments (EKS, GCP, etc) to make it usable at scale.\r\n\r\n**Describe the solution you'd like**\r\nThe main configuration options that are needed for the Bytewax materialization job are:\r\n\r\n* setting explicit resource requests and limits (rather than relying on platform defaults which may not be enough)\r\n* supporting service accounts and IAM roles\r\n* specifying an image pull secret to support pulling Docker images from Dockerhub, Artifactory, etc\r\n\r\n**Describe alternatives you've considered**\r\nThe Kubernetes job that runs is dynamically generated by the bytewax code. Existing configuration options are insufficient.\r\n\r\n**Additional context**\r\nI'd really like to test the Bytewax materialization engine on our instance of EKS. In its current implementation, it's operationally too simple and not usable outside of minikube.\r\n\n", "before_files": [{"content": "import uuid\nfrom datetime import datetime\nfrom typing import Callable, List, Literal, Sequence, Union\n\nimport yaml\nfrom kubernetes import client\nfrom kubernetes import config as k8s_config\nfrom kubernetes import utils\nfrom kubernetes.utils import FailToCreateError\nfrom pydantic import StrictStr\nfrom tqdm import tqdm\n\nfrom feast import FeatureView, RepoConfig\nfrom feast.batch_feature_view import BatchFeatureView\nfrom feast.entity import Entity\nfrom feast.infra.materialization.batch_materialization_engine import (\n BatchMaterializationEngine,\n MaterializationJob,\n MaterializationTask,\n)\nfrom feast.infra.offline_stores.offline_store import OfflineStore\nfrom feast.infra.online_stores.online_store import OnlineStore\nfrom feast.infra.registry.base_registry import BaseRegistry\nfrom feast.repo_config import FeastConfigBaseModel\nfrom feast.stream_feature_view import StreamFeatureView\nfrom feast.utils import _get_column_names, get_default_yaml_file_path\n\nfrom .bytewax_materialization_job import BytewaxMaterializationJob\n\n\nclass BytewaxMaterializationEngineConfig(FeastConfigBaseModel):\n \"\"\"Batch Materialization Engine config for Bytewax\"\"\"\n\n type: Literal[\"bytewax\"] = \"bytewax\"\n \"\"\" Materialization type selector\"\"\"\n\n namespace: StrictStr = \"default\"\n \"\"\" (optional) The namespace in Kubernetes to use when creating services, configuration maps and jobs.\n \"\"\"\n\n image: StrictStr = \"bytewax/bytewax-feast:latest\"\n \"\"\" (optional) The container image to use when running the materialization job.\"\"\"\n\n env: List[dict] = []\n \"\"\" (optional) A list of environment variables to set in the created Kubernetes pods.\n These environment variables can be used to reference Kubernetes secrets.\n \"\"\"\n\n\nclass BytewaxMaterializationEngine(BatchMaterializationEngine):\n def __init__(\n self,\n *,\n repo_config: RepoConfig,\n offline_store: OfflineStore,\n online_store: OnlineStore,\n **kwargs,\n ):\n super().__init__(\n repo_config=repo_config,\n offline_store=offline_store,\n online_store=online_store,\n **kwargs,\n )\n self.repo_config = repo_config\n self.offline_store = offline_store\n self.online_store = online_store\n\n # TODO: Configure k8s here\n k8s_config.load_kube_config()\n\n self.k8s_client = client.api_client.ApiClient()\n self.v1 = client.CoreV1Api(self.k8s_client)\n self.batch_v1 = client.BatchV1Api(self.k8s_client)\n self.batch_engine_config = repo_config.batch_engine\n self.namespace = self.batch_engine_config.namespace\n\n def update(\n self,\n project: str,\n views_to_delete: Sequence[\n Union[BatchFeatureView, StreamFeatureView, FeatureView]\n ],\n views_to_keep: Sequence[\n Union[BatchFeatureView, StreamFeatureView, FeatureView]\n ],\n entities_to_delete: Sequence[Entity],\n entities_to_keep: Sequence[Entity],\n ):\n \"\"\"This method ensures that any necessary infrastructure or resources needed by the\n engine are set up ahead of materialization.\"\"\"\n pass\n\n def teardown_infra(\n self,\n project: str,\n fvs: Sequence[Union[BatchFeatureView, StreamFeatureView, FeatureView]],\n entities: Sequence[Entity],\n ):\n \"\"\"This method ensures that any infrastructure or resources set up by ``update()``are torn down.\"\"\"\n pass\n\n def materialize(\n self,\n registry: BaseRegistry,\n tasks: List[MaterializationTask],\n ) -> List[MaterializationJob]:\n return [\n self._materialize_one(\n registry,\n task.feature_view,\n task.start_time,\n task.end_time,\n task.project,\n task.tqdm_builder,\n )\n for task in tasks\n ]\n\n def _materialize_one(\n self,\n registry: BaseRegistry,\n feature_view: Union[BatchFeatureView, StreamFeatureView, FeatureView],\n start_date: datetime,\n end_date: datetime,\n project: str,\n tqdm_builder: Callable[[int], tqdm],\n ):\n entities = []\n for entity_name in feature_view.entities:\n entities.append(registry.get_entity(entity_name, project))\n\n (\n join_key_columns,\n feature_name_columns,\n timestamp_field,\n created_timestamp_column,\n ) = _get_column_names(feature_view, entities)\n\n offline_job = self.offline_store.pull_latest_from_table_or_query(\n config=self.repo_config,\n data_source=feature_view.batch_source,\n join_key_columns=join_key_columns,\n feature_name_columns=feature_name_columns,\n timestamp_field=timestamp_field,\n created_timestamp_column=created_timestamp_column,\n start_date=start_date,\n end_date=end_date,\n )\n\n paths = offline_job.to_remote_storage()\n job_id = str(uuid.uuid4())\n return self._create_kubernetes_job(job_id, paths, feature_view)\n\n def _create_kubernetes_job(self, job_id, paths, feature_view):\n try:\n # Create a k8s configmap with information needed by bytewax\n self._create_configuration_map(job_id, paths, feature_view, self.namespace)\n\n # Create the k8s job definition\n self._create_job_definition(\n job_id,\n self.namespace,\n len(paths), # Create a pod for each parquet file\n self.batch_engine_config.env,\n )\n except FailToCreateError as failures:\n return BytewaxMaterializationJob(job_id, self.namespace, error=failures)\n\n return BytewaxMaterializationJob(job_id, self.namespace)\n\n def _create_configuration_map(self, job_id, paths, feature_view, namespace):\n \"\"\"Create a Kubernetes configmap for this job\"\"\"\n\n repo_path = self.repo_config.repo_path\n assert repo_path\n feature_store_path = get_default_yaml_file_path(repo_path)\n feature_store_configuration = feature_store_path.read_text()\n\n materialization_config = yaml.dump(\n {\"paths\": paths, \"feature_view\": feature_view.name}\n )\n\n configmap_manifest = {\n \"kind\": \"ConfigMap\",\n \"apiVersion\": \"v1\",\n \"metadata\": {\n \"name\": f\"feast-{job_id}\",\n },\n \"data\": {\n \"feature_store.yaml\": feature_store_configuration,\n \"bytewax_materialization_config.yaml\": materialization_config,\n },\n }\n self.v1.create_namespaced_config_map(\n namespace=namespace,\n body=configmap_manifest,\n )\n\n def _create_job_definition(self, job_id, namespace, pods, env):\n \"\"\"Create a kubernetes job definition.\"\"\"\n job_env = [\n {\"name\": \"RUST_BACKTRACE\", \"value\": \"full\"},\n {\n \"name\": \"BYTEWAX_PYTHON_FILE_PATH\",\n \"value\": \"/bytewax/dataflow.py\",\n },\n {\"name\": \"BYTEWAX_WORKDIR\", \"value\": \"/bytewax\"},\n {\n \"name\": \"BYTEWAX_WORKERS_PER_PROCESS\",\n \"value\": \"1\",\n },\n {\n \"name\": \"BYTEWAX_POD_NAME\",\n \"valueFrom\": {\n \"fieldRef\": {\n \"apiVersion\": \"v1\",\n \"fieldPath\": \"metadata.annotations['batch.kubernetes.io/job-completion-index']\",\n }\n },\n },\n {\n \"name\": \"BYTEWAX_REPLICAS\",\n \"value\": f\"{pods}\",\n },\n {\n \"name\": \"BYTEWAX_KEEP_CONTAINER_ALIVE\",\n \"value\": \"false\",\n },\n {\n \"name\": \"BYTEWAX_STATEFULSET_NAME\",\n \"value\": f\"dataflow-{job_id}\",\n },\n ]\n # Add any Feast configured environment variables\n job_env.extend(env)\n\n job_definition = {\n \"apiVersion\": \"batch/v1\",\n \"kind\": \"Job\",\n \"metadata\": {\n \"name\": f\"dataflow-{job_id}\",\n \"namespace\": namespace,\n },\n \"spec\": {\n \"ttlSecondsAfterFinished\": 3600,\n \"completions\": pods,\n \"parallelism\": pods,\n \"completionMode\": \"Indexed\",\n \"template\": {\n \"spec\": {\n \"restartPolicy\": \"Never\",\n \"subdomain\": f\"dataflow-{job_id}\",\n \"initContainers\": [\n {\n \"env\": [\n {\n \"name\": \"BYTEWAX_REPLICAS\",\n \"value\": f\"{pods}\",\n }\n ],\n \"image\": \"busybox\",\n \"imagePullPolicy\": \"Always\",\n \"name\": \"init-hostfile\",\n \"resources\": {},\n \"securityContext\": {\n \"allowPrivilegeEscalation\": False,\n \"capabilities\": {\n \"add\": [\"NET_BIND_SERVICE\"],\n \"drop\": [\"ALL\"],\n },\n \"readOnlyRootFilesystem\": True,\n },\n \"terminationMessagePath\": \"/dev/termination-log\",\n \"terminationMessagePolicy\": \"File\",\n \"volumeMounts\": [\n {\"mountPath\": \"/etc/bytewax\", \"name\": \"hostfile\"},\n {\n \"mountPath\": \"/tmp/bytewax/\",\n \"name\": \"python-files\",\n },\n {\n \"mountPath\": \"/var/feast/\",\n \"name\": f\"feast-{job_id}\",\n },\n ],\n }\n ],\n \"containers\": [\n {\n \"command\": [\"sh\", \"-c\", \"sh ./entrypoint.sh\"],\n \"env\": job_env,\n \"image\": self.batch_engine_config.image,\n \"imagePullPolicy\": \"Always\",\n \"name\": \"process\",\n \"ports\": [\n {\n \"containerPort\": 9999,\n \"name\": \"process\",\n \"protocol\": \"TCP\",\n }\n ],\n \"resources\": {},\n \"securityContext\": {\n \"allowPrivilegeEscalation\": False,\n \"capabilities\": {\n \"add\": [\"NET_BIND_SERVICE\"],\n \"drop\": [\"ALL\"],\n },\n \"readOnlyRootFilesystem\": False,\n },\n \"terminationMessagePath\": \"/dev/termination-log\",\n \"terminationMessagePolicy\": \"File\",\n \"volumeMounts\": [\n {\"mountPath\": \"/etc/bytewax\", \"name\": \"hostfile\"},\n {\n \"mountPath\": \"/var/feast/\",\n \"name\": f\"feast-{job_id}\",\n },\n ],\n }\n ],\n \"volumes\": [\n {\"emptyDir\": {}, \"name\": \"hostfile\"},\n {\n \"configMap\": {\n \"defaultMode\": 420,\n \"name\": f\"feast-{job_id}\",\n },\n \"name\": \"python-files\",\n },\n {\n \"configMap\": {\"name\": f\"feast-{job_id}\"},\n \"name\": f\"feast-{job_id}\",\n },\n ],\n }\n },\n },\n }\n utils.create_from_dict(self.k8s_client, job_definition)\n", "path": "sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py"}], "after_files": [{"content": "import uuid\nfrom datetime import datetime\nfrom typing import Callable, List, Literal, Sequence, Union\n\nimport yaml\nfrom kubernetes import client\nfrom kubernetes import config as k8s_config\nfrom kubernetes import utils\nfrom kubernetes.utils import FailToCreateError\nfrom pydantic import StrictStr\nfrom tqdm import tqdm\n\nfrom feast import FeatureView, RepoConfig\nfrom feast.batch_feature_view import BatchFeatureView\nfrom feast.entity import Entity\nfrom feast.infra.materialization.batch_materialization_engine import (\n BatchMaterializationEngine,\n MaterializationJob,\n MaterializationTask,\n)\nfrom feast.infra.offline_stores.offline_store import OfflineStore\nfrom feast.infra.online_stores.online_store import OnlineStore\nfrom feast.infra.registry.base_registry import BaseRegistry\nfrom feast.repo_config import FeastConfigBaseModel\nfrom feast.stream_feature_view import StreamFeatureView\nfrom feast.utils import _get_column_names, get_default_yaml_file_path\n\nfrom .bytewax_materialization_job import BytewaxMaterializationJob\n\n\nclass BytewaxMaterializationEngineConfig(FeastConfigBaseModel):\n \"\"\"Batch Materialization Engine config for Bytewax\"\"\"\n\n type: Literal[\"bytewax\"] = \"bytewax\"\n \"\"\" Materialization type selector\"\"\"\n\n namespace: StrictStr = \"default\"\n \"\"\" (optional) The namespace in Kubernetes to use when creating services, configuration maps and jobs.\n \"\"\"\n\n image: StrictStr = \"bytewax/bytewax-feast:latest\"\n \"\"\" (optional) The container image to use when running the materialization job.\"\"\"\n\n env: List[dict] = []\n \"\"\" (optional) A list of environment variables to set in the created Kubernetes pods.\n These environment variables can be used to reference Kubernetes secrets.\n \"\"\"\n\n image_pull_secrets: List[str] = []\n \"\"\" (optional) The secrets to use when pulling the image to run for the materialization job \"\"\"\n\n resources: dict = {}\n \"\"\" (optional) The resource requests and limits for the materialization containers \"\"\"\n\n service_account_name: StrictStr = \"\"\n \"\"\" (optional) The service account name to use when running the job \"\"\"\n\n annotations: dict = {}\n \"\"\" (optional) Annotations to apply to the job container. Useful for linking the service account to IAM roles, operational metadata, etc \"\"\"\n\nclass BytewaxMaterializationEngine(BatchMaterializationEngine):\n def __init__(\n self,\n *,\n repo_config: RepoConfig,\n offline_store: OfflineStore,\n online_store: OnlineStore,\n **kwargs,\n ):\n super().__init__(\n repo_config=repo_config,\n offline_store=offline_store,\n online_store=online_store,\n **kwargs,\n )\n self.repo_config = repo_config\n self.offline_store = offline_store\n self.online_store = online_store\n\n # TODO: Configure k8s here\n k8s_config.load_kube_config()\n\n self.k8s_client = client.api_client.ApiClient()\n self.v1 = client.CoreV1Api(self.k8s_client)\n self.batch_v1 = client.BatchV1Api(self.k8s_client)\n self.batch_engine_config = repo_config.batch_engine\n self.namespace = self.batch_engine_config.namespace\n\n def update(\n self,\n project: str,\n views_to_delete: Sequence[\n Union[BatchFeatureView, StreamFeatureView, FeatureView]\n ],\n views_to_keep: Sequence[\n Union[BatchFeatureView, StreamFeatureView, FeatureView]\n ],\n entities_to_delete: Sequence[Entity],\n entities_to_keep: Sequence[Entity],\n ):\n \"\"\"This method ensures that any necessary infrastructure or resources needed by the\n engine are set up ahead of materialization.\"\"\"\n pass\n\n def teardown_infra(\n self,\n project: str,\n fvs: Sequence[Union[BatchFeatureView, StreamFeatureView, FeatureView]],\n entities: Sequence[Entity],\n ):\n \"\"\"This method ensures that any infrastructure or resources set up by ``update()``are torn down.\"\"\"\n pass\n\n def materialize(\n self,\n registry: BaseRegistry,\n tasks: List[MaterializationTask],\n ) -> List[MaterializationJob]:\n return [\n self._materialize_one(\n registry,\n task.feature_view,\n task.start_time,\n task.end_time,\n task.project,\n task.tqdm_builder,\n )\n for task in tasks\n ]\n\n def _materialize_one(\n self,\n registry: BaseRegistry,\n feature_view: Union[BatchFeatureView, StreamFeatureView, FeatureView],\n start_date: datetime,\n end_date: datetime,\n project: str,\n tqdm_builder: Callable[[int], tqdm],\n ):\n entities = []\n for entity_name in feature_view.entities:\n entities.append(registry.get_entity(entity_name, project))\n\n (\n join_key_columns,\n feature_name_columns,\n timestamp_field,\n created_timestamp_column,\n ) = _get_column_names(feature_view, entities)\n\n offline_job = self.offline_store.pull_latest_from_table_or_query(\n config=self.repo_config,\n data_source=feature_view.batch_source,\n join_key_columns=join_key_columns,\n feature_name_columns=feature_name_columns,\n timestamp_field=timestamp_field,\n created_timestamp_column=created_timestamp_column,\n start_date=start_date,\n end_date=end_date,\n )\n\n paths = offline_job.to_remote_storage()\n job_id = str(uuid.uuid4())\n return self._create_kubernetes_job(job_id, paths, feature_view)\n\n def _create_kubernetes_job(self, job_id, paths, feature_view):\n try:\n # Create a k8s configmap with information needed by bytewax\n self._create_configuration_map(job_id, paths, feature_view, self.namespace)\n\n # Create the k8s job definition\n self._create_job_definition(\n job_id,\n self.namespace,\n len(paths), # Create a pod for each parquet file\n self.batch_engine_config.env,\n )\n except FailToCreateError as failures:\n return BytewaxMaterializationJob(job_id, self.namespace, error=failures)\n\n return BytewaxMaterializationJob(job_id, self.namespace)\n\n def _create_configuration_map(self, job_id, paths, feature_view, namespace):\n \"\"\"Create a Kubernetes configmap for this job\"\"\"\n\n repo_path = self.repo_config.repo_path\n assert repo_path\n feature_store_path = get_default_yaml_file_path(repo_path)\n feature_store_configuration = feature_store_path.read_text()\n\n materialization_config = yaml.dump(\n {\"paths\": paths, \"feature_view\": feature_view.name}\n )\n\n configmap_manifest = {\n \"kind\": \"ConfigMap\",\n \"apiVersion\": \"v1\",\n \"metadata\": {\n \"name\": f\"feast-{job_id}\",\n },\n \"data\": {\n \"feature_store.yaml\": feature_store_configuration,\n \"bytewax_materialization_config.yaml\": materialization_config,\n },\n }\n self.v1.create_namespaced_config_map(\n namespace=namespace,\n body=configmap_manifest,\n )\n\n def _create_job_definition(self, job_id, namespace, pods, env):\n \"\"\"Create a kubernetes job definition.\"\"\"\n job_env = [\n {\"name\": \"RUST_BACKTRACE\", \"value\": \"full\"},\n {\n \"name\": \"BYTEWAX_PYTHON_FILE_PATH\",\n \"value\": \"/bytewax/dataflow.py\",\n },\n {\"name\": \"BYTEWAX_WORKDIR\", \"value\": \"/bytewax\"},\n {\n \"name\": \"BYTEWAX_WORKERS_PER_PROCESS\",\n \"value\": \"1\",\n },\n {\n \"name\": \"BYTEWAX_POD_NAME\",\n \"valueFrom\": {\n \"fieldRef\": {\n \"apiVersion\": \"v1\",\n \"fieldPath\": \"metadata.annotations['batch.kubernetes.io/job-completion-index']\",\n }\n },\n },\n {\n \"name\": \"BYTEWAX_REPLICAS\",\n \"value\": f\"{pods}\",\n },\n {\n \"name\": \"BYTEWAX_KEEP_CONTAINER_ALIVE\",\n \"value\": \"false\",\n },\n {\n \"name\": \"BYTEWAX_STATEFULSET_NAME\",\n \"value\": f\"dataflow-{job_id}\",\n },\n ]\n # Add any Feast configured environment variables\n job_env.extend(env)\n\n job_definition = {\n \"apiVersion\": \"batch/v1\",\n \"kind\": \"Job\",\n \"metadata\": {\n \"name\": f\"dataflow-{job_id}\",\n \"namespace\": namespace,\n },\n \"spec\": {\n \"ttlSecondsAfterFinished\": 3600,\n \"completions\": pods,\n \"parallelism\": pods,\n \"completionMode\": \"Indexed\",\n \"template\": {\n \"metadata\": {\n \"annotations\": self.batch_engine_config.annotations,\n },\n \"spec\": {\n \"restartPolicy\": \"Never\",\n \"subdomain\": f\"dataflow-{job_id}\",\n \"imagePullSecrets\": self.batch_engine_config.image_pull_secrets,\n \"serviceAccountName\": self.batch_engine_config.service_account_name,\n \"initContainers\": [\n {\n \"env\": [\n {\n \"name\": \"BYTEWAX_REPLICAS\",\n \"value\": f\"{pods}\",\n }\n ],\n \"image\": \"busybox\",\n \"imagePullPolicy\": \"Always\",\n \"name\": \"init-hostfile\",\n \"resources\": {},\n \"securityContext\": {\n \"allowPrivilegeEscalation\": False,\n \"capabilities\": {\n \"add\": [\"NET_BIND_SERVICE\"],\n \"drop\": [\"ALL\"],\n },\n \"readOnlyRootFilesystem\": True,\n },\n \"terminationMessagePath\": \"/dev/termination-log\",\n \"terminationMessagePolicy\": \"File\",\n \"volumeMounts\": [\n {\"mountPath\": \"/etc/bytewax\", \"name\": \"hostfile\"},\n {\n \"mountPath\": \"/tmp/bytewax/\",\n \"name\": \"python-files\",\n },\n {\n \"mountPath\": \"/var/feast/\",\n \"name\": f\"feast-{job_id}\",\n },\n ],\n }\n ],\n \"containers\": [\n {\n \"command\": [\"sh\", \"-c\", \"sh ./entrypoint.sh\"],\n \"env\": job_env,\n \"image\": self.batch_engine_config.image,\n \"imagePullPolicy\": \"Always\",\n \"name\": \"process\",\n \"ports\": [\n {\n \"containerPort\": 9999,\n \"name\": \"process\",\n \"protocol\": \"TCP\",\n }\n ],\n \"resources\": self.batch_engine_config.resources,\n \"securityContext\": {\n \"allowPrivilegeEscalation\": False,\n \"capabilities\": {\n \"add\": [\"NET_BIND_SERVICE\"],\n \"drop\": [\"ALL\"],\n },\n \"readOnlyRootFilesystem\": False,\n },\n \"terminationMessagePath\": \"/dev/termination-log\",\n \"terminationMessagePolicy\": \"File\",\n \"volumeMounts\": [\n {\"mountPath\": \"/etc/bytewax\", \"name\": \"hostfile\"},\n {\n \"mountPath\": \"/var/feast/\",\n \"name\": f\"feast-{job_id}\",\n },\n ],\n }\n ],\n \"volumes\": [\n {\"emptyDir\": {}, \"name\": \"hostfile\"},\n {\n \"configMap\": {\n \"defaultMode\": 420,\n \"name\": f\"feast-{job_id}\",\n },\n \"name\": \"python-files\",\n },\n {\n \"configMap\": {\"name\": f\"feast-{job_id}\"},\n \"name\": f\"feast-{job_id}\",\n },\n ],\n }\n },\n },\n }\n utils.create_from_dict(self.k8s_client, job_definition)\n", "path": "sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py"}]} | 3,799 | 466 |
gh_patches_debug_362 | rasdani/github-patches | git_diff | numpy__numpy-3055 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
2to3 run `execfile` fixer
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setupegg.py`
Content:
```
1 #!/usr/bin/env python
2 """
3 A setup.py script to use setuptools, which gives egg goodness, etc.
4
5 This is used to build installers for OS X through bdist_mpkg.
6
7 Notes
8 -----
9 Using ``python setupegg.py install`` directly results in file permissions being
10 set wrong, with nose refusing to run any tests. To run the tests anyway, use::
11
12 >>> np.test(extra_argv=['--exe'])
13
14 """
15
16 import sys
17 from setuptools import setup
18
19 if sys.version_info[0] >= 3:
20 import imp
21 setupfile = imp.load_source('setupfile', 'setup.py')
22 setupfile.setup_package()
23 else:
24 execfile('setup.py')
25
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/setupegg.py b/setupegg.py
--- a/setupegg.py
+++ b/setupegg.py
@@ -21,4 +21,4 @@
setupfile = imp.load_source('setupfile', 'setup.py')
setupfile.setup_package()
else:
- execfile('setup.py')
+ exec(compile(open('setup.py').read(), 'setup.py', 'exec'))
| {"golden_diff": "diff --git a/setupegg.py b/setupegg.py\n--- a/setupegg.py\n+++ b/setupegg.py\n@@ -21,4 +21,4 @@\n setupfile = imp.load_source('setupfile', 'setup.py')\n setupfile.setup_package()\n else:\n- execfile('setup.py')\n+ exec(compile(open('setup.py').read(), 'setup.py', 'exec'))\n", "issue": "2to3 run `execfile` fixer\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"\nA setup.py script to use setuptools, which gives egg goodness, etc.\n\nThis is used to build installers for OS X through bdist_mpkg.\n\nNotes\n-----\nUsing ``python setupegg.py install`` directly results in file permissions being\nset wrong, with nose refusing to run any tests. To run the tests anyway, use::\n\n >>> np.test(extra_argv=['--exe'])\n\n\"\"\"\n\nimport sys\nfrom setuptools import setup\n\nif sys.version_info[0] >= 3:\n import imp\n setupfile = imp.load_source('setupfile', 'setup.py')\n setupfile.setup_package()\nelse:\n execfile('setup.py')\n", "path": "setupegg.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\"\"\"\nA setup.py script to use setuptools, which gives egg goodness, etc.\n\nThis is used to build installers for OS X through bdist_mpkg.\n\nNotes\n-----\nUsing ``python setupegg.py install`` directly results in file permissions being\nset wrong, with nose refusing to run any tests. To run the tests anyway, use::\n\n >>> np.test(extra_argv=['--exe'])\n\n\"\"\"\n\nimport sys\nfrom setuptools import setup\n\nif sys.version_info[0] >= 3:\n import imp\n setupfile = imp.load_source('setupfile', 'setup.py')\n setupfile.setup_package()\nelse:\n exec(compile(open('setup.py').read(), 'setup.py', 'exec'))\n", "path": "setupegg.py"}]} | 459 | 94 |
gh_patches_debug_2886 | rasdani/github-patches | git_diff | conda__conda-build-389 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
MD5 checking argument not passed to update_index
I was happy to see that there was a `-c` argument to `conda index` which forces it to use md5 hashes instead of file modification times. However, looks like `main_index.py` never passes that argument on to the `update_index()` function, i.e.,
``` python
...
update_index(path, verbose=(not args.quiet), force=args.force)
...
```
should actually be:
``` python
...
update_index(path, verbose=(not args.quiet), force=args.force, check_md5=args.check_md5)
...
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda_build/main_index.py`
Content:
```
1 from __future__ import absolute_import, division, print_function
2
3 import argparse
4 import os
5 from locale import getpreferredencoding
6 from os.path import abspath
7
8 from conda.compat import PY3
9
10 from conda_build.index import update_index
11
12
13 def main():
14 p = argparse.ArgumentParser(
15 description="Update package index metadata files in given directories")
16
17 p.add_argument('dir',
18 help='Directory that contains an index to be updated.',
19 nargs='*',
20 default=[os.getcwd()])
21
22 p.add_argument('-c', "--check-md5",
23 action="store_true",
24 help="Use MD5 values instead of file modification times for\
25 determining if a package's metadata needs to be \
26 updated.")
27
28 p.add_argument('-f', "--force",
29 action="store_true",
30 help="force reading all files")
31
32 p.add_argument('-q', "--quiet",
33 action="store_true")
34
35 args = p.parse_args()
36
37 dir_paths = [abspath(path) for path in args.dir]
38 # Don't use byte strings in Python 2
39 if not PY3:
40 dir_paths = [path.decode(getpreferredencoding()) for path in dir_paths]
41
42 for path in dir_paths:
43 update_index(path, verbose=(not args.quiet), force=args.force)
44
45
46 if __name__ == '__main__':
47 main()
48
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/conda_build/main_index.py b/conda_build/main_index.py
--- a/conda_build/main_index.py
+++ b/conda_build/main_index.py
@@ -40,7 +40,7 @@
dir_paths = [path.decode(getpreferredencoding()) for path in dir_paths]
for path in dir_paths:
- update_index(path, verbose=(not args.quiet), force=args.force)
+ update_index(path, verbose=(not args.quiet), force=args.force, check_md5=args.check_md5)
if __name__ == '__main__':
| {"golden_diff": "diff --git a/conda_build/main_index.py b/conda_build/main_index.py\n--- a/conda_build/main_index.py\n+++ b/conda_build/main_index.py\n@@ -40,7 +40,7 @@\n dir_paths = [path.decode(getpreferredencoding()) for path in dir_paths]\n \n for path in dir_paths:\n- update_index(path, verbose=(not args.quiet), force=args.force)\n+ update_index(path, verbose=(not args.quiet), force=args.force, check_md5=args.check_md5)\n \n \n if __name__ == '__main__':\n", "issue": "MD5 checking argument not passed to update_index\nI was happy to see that there was a `-c` argument to `conda index` which forces it to use md5 hashes instead of file modification times. However, looks like `main_index.py` never passes that argument on to the `update_index()` function, i.e., \n\n``` python\n...\nupdate_index(path, verbose=(not args.quiet), force=args.force)\n...\n```\n\nshould actually be:\n\n``` python\n...\nupdate_index(path, verbose=(not args.quiet), force=args.force, check_md5=args.check_md5)\n...\n```\n\n", "before_files": [{"content": "from __future__ import absolute_import, division, print_function\n\nimport argparse\nimport os\nfrom locale import getpreferredencoding\nfrom os.path import abspath\n\nfrom conda.compat import PY3\n\nfrom conda_build.index import update_index\n\n\ndef main():\n p = argparse.ArgumentParser(\n description=\"Update package index metadata files in given directories\")\n\n p.add_argument('dir',\n help='Directory that contains an index to be updated.',\n nargs='*',\n default=[os.getcwd()])\n\n p.add_argument('-c', \"--check-md5\",\n action=\"store_true\",\n help=\"Use MD5 values instead of file modification times for\\\n determining if a package's metadata needs to be \\\n updated.\")\n\n p.add_argument('-f', \"--force\",\n action=\"store_true\",\n help=\"force reading all files\")\n\n p.add_argument('-q', \"--quiet\",\n action=\"store_true\")\n\n args = p.parse_args()\n\n dir_paths = [abspath(path) for path in args.dir]\n # Don't use byte strings in Python 2\n if not PY3:\n dir_paths = [path.decode(getpreferredencoding()) for path in dir_paths]\n\n for path in dir_paths:\n update_index(path, verbose=(not args.quiet), force=args.force)\n\n\nif __name__ == '__main__':\n main()\n", "path": "conda_build/main_index.py"}], "after_files": [{"content": "from __future__ import absolute_import, division, print_function\n\nimport argparse\nimport os\nfrom locale import getpreferredencoding\nfrom os.path import abspath\n\nfrom conda.compat import PY3\n\nfrom conda_build.index import update_index\n\n\ndef main():\n p = argparse.ArgumentParser(\n description=\"Update package index metadata files in given directories\")\n\n p.add_argument('dir',\n help='Directory that contains an index to be updated.',\n nargs='*',\n default=[os.getcwd()])\n\n p.add_argument('-c', \"--check-md5\",\n action=\"store_true\",\n help=\"Use MD5 values instead of file modification times for\\\n determining if a package's metadata needs to be \\\n updated.\")\n\n p.add_argument('-f', \"--force\",\n action=\"store_true\",\n help=\"force reading all files\")\n\n p.add_argument('-q', \"--quiet\",\n action=\"store_true\")\n\n args = p.parse_args()\n\n dir_paths = [abspath(path) for path in args.dir]\n # Don't use byte strings in Python 2\n if not PY3:\n dir_paths = [path.decode(getpreferredencoding()) for path in dir_paths]\n\n for path in dir_paths:\n update_index(path, verbose=(not args.quiet), force=args.force, check_md5=args.check_md5)\n\n\nif __name__ == '__main__':\n main()\n", "path": "conda_build/main_index.py"}]} | 762 | 124 |
gh_patches_debug_6802 | rasdani/github-patches | git_diff | spack__spack-1778 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cannot use Spack-built gcc
I built gcc with Spack, then added it manually to Spack's compiler list:
```
$ cat ~/.spack/compilers.yaml
compilers:
- compiler:
modules: []
operating_system: elcapitan
paths:
cc: /usr/bin/clang
cxx: /usr/bin/clang++
f77: null
fc: null
spec: [email protected]
- compiler:
modules: []
operating_system: elcapitan
paths:
cc: /usr/bin/gcc
cxx: /usr/bin/g++
f77: null
fc: null
spec: [email protected]
- compiler:
modules: []
operating_system: elcapitan
paths:
cc: /Users/eschnett/src/spack/opt/spack/darwin-elcapitan-x86_64/clang-8.0.0-apple/gcc-6.2.0-oqafsa4af6qaah553lcrsqlh2dczk2ic/bin/gcc
cxx: /Users/eschnett/src/spack/opt/spack/darwin-elcapitan-x86_64/clang-8.0.0-apple/gcc-6.2.0-oqafsa4af6qaah553lcrsqlh2dczk2ic/bin/g++
f77: /Users/eschnett/src/spack/opt/spack/darwin-elcapitan-x86_64/clang-8.0.0-apple/gcc-6.2.0-oqafsa4af6qaah553lcrsqlh2dczk2ic/bin/gfortran
fc: /Users/eschnett/src/spack/opt/spack/darwin-elcapitan-x86_64/clang-8.0.0-apple/gcc-6.2.0-oqafsa4af6qaah553lcrsqlh2dczk2ic/bin/gfortran
spec: [email protected]
```
This used to work fine, but doesn't any more: When I try to use this compiler, Spack produces an error:
```
$ spack spec cactusext +funhpc +julia +simulationio %[email protected]
Input spec
------------------------------
cactusext%[email protected]+funhpc+julia+simulationio
Normalized
------------------------------
cactusext%[email protected]+funhpc+julia+simulationio
^boost+mpi
^openmpi%[email protected]
^hwloc%[email protected]
^libpciaccess
^libtool
^m4
^fftw%[email protected]+mpi+openmp
^funhpc%[email protected]
^cereal
^[email protected]:
^curl
^openssl%[email protected]
^zlib%[email protected]
^jemalloc%[email protected]
^openmpi%[email protected]
^qthreads
^git%[email protected]
^autoconf
^expat
^gettext
^libiconv
^pcre
^perl
^gsl%[email protected]
^[email protected]%[email protected]+mpi
^hdf5-blosc%[email protected]
^c-blosc
^snappy
^julia@master%[email protected]+hdf5+mpi
^[email protected]%[email protected]
^bzip2
^ncurses
^readline
^sqlite
^lmod%[email protected]
^[email protected]:%[email protected]
^lua-luafilesystem
^lua-luaposix
^tcl
^openblas%[email protected]
^papi%[email protected]
^petsc%[email protected]+boost+hdf5+mpi~mumps
^openblas%[email protected]
^simulationio%[email protected]
^swig
Concretized
------------------------------
Traceback (most recent call last):
File "/Users/eschnett/src/spack/bin/spack", line 192, in <module>
main()
File "/Users/eschnett/src/spack/bin/spack", line 169, in main
return_val = command(parser, args)
File "/Users/eschnett/src/spack/lib/spack/spack/cmd/spec.py", line 57, in spec
spec.concretize()
File "/Users/eschnett/src/spack/lib/spack/spack/spec.py", line 1256, in concretize
self._expand_virtual_packages(),
File "/Users/eschnett/src/spack/lib/spack/spack/spec.py", line 1173, in _expand_virtual_packages
spec)
File "/Users/eschnett/src/spack/lib/spack/spack/concretize.py", line 127, in choose_virtual_or_external
strict = [spack.abi.compatible(c, abi_exemplar) for c in candidates]
File "/Users/eschnett/src/spack/lib/spack/spack/abi.py", line 126, in compatible
self.compiler_compatible(parent, child, loose=loosematch)
File "/Users/eschnett/src/spack/lib/spack/spack/abi.py", line 115, in compiler_compatible
self._gcc_compiler_compare(pversion, cversion)):
File "/Users/eschnett/src/spack/lib/spack/llnl/util/lang.py", line 187, in __call__
self.cache[args] = self.func(*args)
File "/Users/eschnett/src/spack/lib/spack/spack/abi.py", line 79, in _gcc_compiler_compare
plib = self._gcc_get_libstdcxx_version(pversion)
File "/Users/eschnett/src/spack/lib/spack/llnl/util/lang.py", line 187, in __call__
self.cache[args] = self.func(*args)
File "/Users/eschnett/src/spack/lib/spack/spack/abi.py", line 70, in _gcc_get_libstdcxx_version
libpath = os.readlink(output.strip())
OSError: [Errno 2] No such file or directory: 'libstdc++.so'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/spack/spack/abi.py`
Content:
```
1 ##############################################################################
2 # Copyright (c) 2013-2016, Lawrence Livermore National Security, LLC.
3 # Produced at the Lawrence Livermore National Laboratory.
4 #
5 # This file is part of Spack.
6 # Created by Todd Gamblin, [email protected], All rights reserved.
7 # LLNL-CODE-647188
8 #
9 # For details, see https://github.com/llnl/spack
10 # Please also see the LICENSE file for our notice and the LGPL.
11 #
12 # This program is free software; you can redistribute it and/or modify
13 # it under the terms of the GNU Lesser General Public License (as
14 # published by the Free Software Foundation) version 2.1, February 1999.
15 #
16 # This program is distributed in the hope that it will be useful, but
17 # WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF
18 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and
19 # conditions of the GNU Lesser General Public License for more details.
20 #
21 # You should have received a copy of the GNU Lesser General Public
22 # License along with this program; if not, write to the Free Software
23 # Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
24 ##############################################################################
25
26 import os
27 import spack
28 import spack.spec
29 from spack.spec import CompilerSpec
30 from spack.util.executable import Executable, ProcessError
31 from llnl.util.lang import memoized
32
33
34 class ABI(object):
35 """This class provides methods to test ABI compatibility between specs.
36 The current implementation is rather rough and could be improved."""
37
38 def architecture_compatible(self, parent, child):
39 """Return true if parent and child have ABI compatible targets."""
40 return not parent.architecture or not child.architecture or \
41 parent.architecture == child.architecture
42
43 @memoized
44 def _gcc_get_libstdcxx_version(self, version):
45 """Returns gcc ABI compatibility info by getting the library version of
46 a compiler's libstdc++.so or libgcc_s.so"""
47 spec = CompilerSpec("gcc", version)
48 compilers = spack.compilers.compilers_for_spec(spec)
49 if not compilers:
50 return None
51 compiler = compilers[0]
52 rungcc = None
53 libname = None
54 output = None
55 if compiler.cxx:
56 rungcc = Executable(compiler.cxx)
57 libname = "libstdc++.so"
58 elif compiler.cc:
59 rungcc = Executable(compiler.cc)
60 libname = "libgcc_s.so"
61 else:
62 return None
63 try:
64 output = rungcc("--print-file-name=%s" % libname,
65 return_output=True)
66 except ProcessError:
67 return None
68 if not output:
69 return None
70 libpath = os.readlink(output.strip())
71 if not libpath:
72 return None
73 return os.path.basename(libpath)
74
75 @memoized
76 def _gcc_compiler_compare(self, pversion, cversion):
77 """Returns true iff the gcc version pversion and cversion
78 are ABI compatible."""
79 plib = self._gcc_get_libstdcxx_version(pversion)
80 clib = self._gcc_get_libstdcxx_version(cversion)
81 if not plib or not clib:
82 return False
83 return plib == clib
84
85 def _intel_compiler_compare(self, pversion, cversion):
86 """Returns true iff the intel version pversion and cversion
87 are ABI compatible"""
88
89 # Test major and minor versions. Ignore build version.
90 if (len(pversion.version) < 2 or len(cversion.version) < 2):
91 return False
92 return pversion.version[:2] == cversion.version[:2]
93
94 def compiler_compatible(self, parent, child, **kwargs):
95 """Return true if compilers for parent and child are ABI compatible."""
96 if not parent.compiler or not child.compiler:
97 return True
98
99 if parent.compiler.name != child.compiler.name:
100 # Different compiler families are assumed ABI incompatible
101 return False
102
103 if kwargs.get('loose', False):
104 return True
105
106 # TODO: Can we move the specialized ABI matching stuff
107 # TODO: into compiler classes?
108 for pversion in parent.compiler.versions:
109 for cversion in child.compiler.versions:
110 # For a few compilers use specialized comparisons.
111 # Otherwise match on version match.
112 if pversion.satisfies(cversion):
113 return True
114 elif (parent.compiler.name == "gcc" and
115 self._gcc_compiler_compare(pversion, cversion)):
116 return True
117 elif (parent.compiler.name == "intel" and
118 self._intel_compiler_compare(pversion, cversion)):
119 return True
120 return False
121
122 def compatible(self, parent, child, **kwargs):
123 """Returns true iff a parent and child spec are ABI compatible"""
124 loosematch = kwargs.get('loose', False)
125 return self.architecture_compatible(parent, child) and \
126 self.compiler_compatible(parent, child, loose=loosematch)
127
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/lib/spack/spack/abi.py b/lib/spack/spack/abi.py
--- a/lib/spack/spack/abi.py
+++ b/lib/spack/spack/abi.py
@@ -54,10 +54,10 @@
output = None
if compiler.cxx:
rungcc = Executable(compiler.cxx)
- libname = "libstdc++.so"
+ libname = "libstdc++." + dso_suffix
elif compiler.cc:
rungcc = Executable(compiler.cc)
- libname = "libgcc_s.so"
+ libname = "libgcc_s." + dso_suffix
else:
return None
try:
| {"golden_diff": "diff --git a/lib/spack/spack/abi.py b/lib/spack/spack/abi.py\n--- a/lib/spack/spack/abi.py\n+++ b/lib/spack/spack/abi.py\n@@ -54,10 +54,10 @@\n output = None\n if compiler.cxx:\n rungcc = Executable(compiler.cxx)\n- libname = \"libstdc++.so\"\n+ libname = \"libstdc++.\" + dso_suffix\n elif compiler.cc:\n rungcc = Executable(compiler.cc)\n- libname = \"libgcc_s.so\"\n+ libname = \"libgcc_s.\" + dso_suffix\n else:\n return None\n try:\n", "issue": "Cannot use Spack-built gcc\nI built gcc with Spack, then added it manually to Spack's compiler list:\n\n```\n$ cat ~/.spack/compilers.yaml\ncompilers:\n- compiler:\n modules: []\n operating_system: elcapitan\n paths:\n cc: /usr/bin/clang\n cxx: /usr/bin/clang++\n f77: null\n fc: null\n spec: [email protected]\n- compiler:\n modules: []\n operating_system: elcapitan\n paths:\n cc: /usr/bin/gcc\n cxx: /usr/bin/g++\n f77: null\n fc: null\n spec: [email protected]\n- compiler:\n modules: []\n operating_system: elcapitan\n paths:\n cc: /Users/eschnett/src/spack/opt/spack/darwin-elcapitan-x86_64/clang-8.0.0-apple/gcc-6.2.0-oqafsa4af6qaah553lcrsqlh2dczk2ic/bin/gcc\n cxx: /Users/eschnett/src/spack/opt/spack/darwin-elcapitan-x86_64/clang-8.0.0-apple/gcc-6.2.0-oqafsa4af6qaah553lcrsqlh2dczk2ic/bin/g++\n f77: /Users/eschnett/src/spack/opt/spack/darwin-elcapitan-x86_64/clang-8.0.0-apple/gcc-6.2.0-oqafsa4af6qaah553lcrsqlh2dczk2ic/bin/gfortran\n fc: /Users/eschnett/src/spack/opt/spack/darwin-elcapitan-x86_64/clang-8.0.0-apple/gcc-6.2.0-oqafsa4af6qaah553lcrsqlh2dczk2ic/bin/gfortran\n spec: [email protected]\n```\n\nThis used to work fine, but doesn't any more: When I try to use this compiler, Spack produces an error:\n\n```\n$ spack spec cactusext +funhpc +julia +simulationio %[email protected]\nInput spec\n------------------------------\n cactusext%[email protected]+funhpc+julia+simulationio\n\nNormalized\n------------------------------\n cactusext%[email protected]+funhpc+julia+simulationio\n ^boost+mpi\n ^openmpi%[email protected]\n ^hwloc%[email protected]\n ^libpciaccess\n ^libtool\n ^m4\n ^fftw%[email protected]+mpi+openmp\n ^funhpc%[email protected]\n ^cereal\n ^[email protected]:\n ^curl\n ^openssl%[email protected]\n ^zlib%[email protected]\n ^jemalloc%[email protected]\n ^openmpi%[email protected]\n ^qthreads\n ^git%[email protected]\n ^autoconf\n ^expat\n ^gettext\n ^libiconv\n ^pcre\n ^perl\n ^gsl%[email protected]\n ^[email protected]%[email protected]+mpi\n ^hdf5-blosc%[email protected]\n ^c-blosc\n ^snappy\n ^julia@master%[email protected]+hdf5+mpi\n ^[email protected]%[email protected]\n ^bzip2\n ^ncurses\n ^readline\n ^sqlite\n ^lmod%[email protected]\n ^[email protected]:%[email protected]\n ^lua-luafilesystem\n ^lua-luaposix\n ^tcl\n ^openblas%[email protected]\n ^papi%[email protected]\n ^petsc%[email protected]+boost+hdf5+mpi~mumps\n ^openblas%[email protected]\n ^simulationio%[email protected]\n ^swig\n\nConcretized\n------------------------------\nTraceback (most recent call last):\n File \"/Users/eschnett/src/spack/bin/spack\", line 192, in <module>\n main()\n File \"/Users/eschnett/src/spack/bin/spack\", line 169, in main\n return_val = command(parser, args)\n File \"/Users/eschnett/src/spack/lib/spack/spack/cmd/spec.py\", line 57, in spec\n spec.concretize()\n File \"/Users/eschnett/src/spack/lib/spack/spack/spec.py\", line 1256, in concretize\n self._expand_virtual_packages(),\n File \"/Users/eschnett/src/spack/lib/spack/spack/spec.py\", line 1173, in _expand_virtual_packages\n spec)\n File \"/Users/eschnett/src/spack/lib/spack/spack/concretize.py\", line 127, in choose_virtual_or_external\n strict = [spack.abi.compatible(c, abi_exemplar) for c in candidates]\n File \"/Users/eschnett/src/spack/lib/spack/spack/abi.py\", line 126, in compatible\n self.compiler_compatible(parent, child, loose=loosematch)\n File \"/Users/eschnett/src/spack/lib/spack/spack/abi.py\", line 115, in compiler_compatible\n self._gcc_compiler_compare(pversion, cversion)):\n File \"/Users/eschnett/src/spack/lib/spack/llnl/util/lang.py\", line 187, in __call__\n self.cache[args] = self.func(*args)\n File \"/Users/eschnett/src/spack/lib/spack/spack/abi.py\", line 79, in _gcc_compiler_compare\n plib = self._gcc_get_libstdcxx_version(pversion)\n File \"/Users/eschnett/src/spack/lib/spack/llnl/util/lang.py\", line 187, in __call__\n self.cache[args] = self.func(*args)\n File \"/Users/eschnett/src/spack/lib/spack/spack/abi.py\", line 70, in _gcc_get_libstdcxx_version\n libpath = os.readlink(output.strip())\nOSError: [Errno 2] No such file or directory: 'libstdc++.so'\n```\n\n", "before_files": [{"content": "##############################################################################\n# Copyright (c) 2013-2016, Lawrence Livermore National Security, LLC.\n# Produced at the Lawrence Livermore National Laboratory.\n#\n# This file is part of Spack.\n# Created by Todd Gamblin, [email protected], All rights reserved.\n# LLNL-CODE-647188\n#\n# For details, see https://github.com/llnl/spack\n# Please also see the LICENSE file for our notice and the LGPL.\n#\n# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU Lesser General Public License (as\n# published by the Free Software Foundation) version 2.1, February 1999.\n#\n# This program is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and\n# conditions of the GNU Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this program; if not, write to the Free Software\n# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA\n##############################################################################\n\nimport os\nimport spack\nimport spack.spec\nfrom spack.spec import CompilerSpec\nfrom spack.util.executable import Executable, ProcessError\nfrom llnl.util.lang import memoized\n\n\nclass ABI(object):\n \"\"\"This class provides methods to test ABI compatibility between specs.\n The current implementation is rather rough and could be improved.\"\"\"\n\n def architecture_compatible(self, parent, child):\n \"\"\"Return true if parent and child have ABI compatible targets.\"\"\"\n return not parent.architecture or not child.architecture or \\\n parent.architecture == child.architecture\n\n @memoized\n def _gcc_get_libstdcxx_version(self, version):\n \"\"\"Returns gcc ABI compatibility info by getting the library version of\n a compiler's libstdc++.so or libgcc_s.so\"\"\"\n spec = CompilerSpec(\"gcc\", version)\n compilers = spack.compilers.compilers_for_spec(spec)\n if not compilers:\n return None\n compiler = compilers[0]\n rungcc = None\n libname = None\n output = None\n if compiler.cxx:\n rungcc = Executable(compiler.cxx)\n libname = \"libstdc++.so\"\n elif compiler.cc:\n rungcc = Executable(compiler.cc)\n libname = \"libgcc_s.so\"\n else:\n return None\n try:\n output = rungcc(\"--print-file-name=%s\" % libname,\n return_output=True)\n except ProcessError:\n return None\n if not output:\n return None\n libpath = os.readlink(output.strip())\n if not libpath:\n return None\n return os.path.basename(libpath)\n\n @memoized\n def _gcc_compiler_compare(self, pversion, cversion):\n \"\"\"Returns true iff the gcc version pversion and cversion\n are ABI compatible.\"\"\"\n plib = self._gcc_get_libstdcxx_version(pversion)\n clib = self._gcc_get_libstdcxx_version(cversion)\n if not plib or not clib:\n return False\n return plib == clib\n\n def _intel_compiler_compare(self, pversion, cversion):\n \"\"\"Returns true iff the intel version pversion and cversion\n are ABI compatible\"\"\"\n\n # Test major and minor versions. Ignore build version.\n if (len(pversion.version) < 2 or len(cversion.version) < 2):\n return False\n return pversion.version[:2] == cversion.version[:2]\n\n def compiler_compatible(self, parent, child, **kwargs):\n \"\"\"Return true if compilers for parent and child are ABI compatible.\"\"\"\n if not parent.compiler or not child.compiler:\n return True\n\n if parent.compiler.name != child.compiler.name:\n # Different compiler families are assumed ABI incompatible\n return False\n\n if kwargs.get('loose', False):\n return True\n\n # TODO: Can we move the specialized ABI matching stuff\n # TODO: into compiler classes?\n for pversion in parent.compiler.versions:\n for cversion in child.compiler.versions:\n # For a few compilers use specialized comparisons.\n # Otherwise match on version match.\n if pversion.satisfies(cversion):\n return True\n elif (parent.compiler.name == \"gcc\" and\n self._gcc_compiler_compare(pversion, cversion)):\n return True\n elif (parent.compiler.name == \"intel\" and\n self._intel_compiler_compare(pversion, cversion)):\n return True\n return False\n\n def compatible(self, parent, child, **kwargs):\n \"\"\"Returns true iff a parent and child spec are ABI compatible\"\"\"\n loosematch = kwargs.get('loose', False)\n return self.architecture_compatible(parent, child) and \\\n self.compiler_compatible(parent, child, loose=loosematch)\n", "path": "lib/spack/spack/abi.py"}], "after_files": [{"content": "##############################################################################\n# Copyright (c) 2013-2016, Lawrence Livermore National Security, LLC.\n# Produced at the Lawrence Livermore National Laboratory.\n#\n# This file is part of Spack.\n# Created by Todd Gamblin, [email protected], All rights reserved.\n# LLNL-CODE-647188\n#\n# For details, see https://github.com/llnl/spack\n# Please also see the LICENSE file for our notice and the LGPL.\n#\n# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU Lesser General Public License (as\n# published by the Free Software Foundation) version 2.1, February 1999.\n#\n# This program is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and\n# conditions of the GNU Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this program; if not, write to the Free Software\n# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA\n##############################################################################\n\nimport os\nimport spack\nimport spack.spec\nfrom spack.spec import CompilerSpec\nfrom spack.util.executable import Executable, ProcessError\nfrom llnl.util.lang import memoized\n\n\nclass ABI(object):\n \"\"\"This class provides methods to test ABI compatibility between specs.\n The current implementation is rather rough and could be improved.\"\"\"\n\n def architecture_compatible(self, parent, child):\n \"\"\"Return true if parent and child have ABI compatible targets.\"\"\"\n return not parent.architecture or not child.architecture or \\\n parent.architecture == child.architecture\n\n @memoized\n def _gcc_get_libstdcxx_version(self, version):\n \"\"\"Returns gcc ABI compatibility info by getting the library version of\n a compiler's libstdc++.so or libgcc_s.so\"\"\"\n spec = CompilerSpec(\"gcc\", version)\n compilers = spack.compilers.compilers_for_spec(spec)\n if not compilers:\n return None\n compiler = compilers[0]\n rungcc = None\n libname = None\n output = None\n if compiler.cxx:\n rungcc = Executable(compiler.cxx)\n libname = \"libstdc++.\" + dso_suffix\n elif compiler.cc:\n rungcc = Executable(compiler.cc)\n libname = \"libgcc_s.\" + dso_suffix\n else:\n return None\n try:\n output = rungcc(\"--print-file-name=%s\" % libname,\n return_output=True)\n except ProcessError:\n return None\n if not output:\n return None\n libpath = os.readlink(output.strip())\n if not libpath:\n return None\n return os.path.basename(libpath)\n\n @memoized\n def _gcc_compiler_compare(self, pversion, cversion):\n \"\"\"Returns true iff the gcc version pversion and cversion\n are ABI compatible.\"\"\"\n plib = self._gcc_get_libstdcxx_version(pversion)\n clib = self._gcc_get_libstdcxx_version(cversion)\n if not plib or not clib:\n return False\n return plib == clib\n\n def _intel_compiler_compare(self, pversion, cversion):\n \"\"\"Returns true iff the intel version pversion and cversion\n are ABI compatible\"\"\"\n\n # Test major and minor versions. Ignore build version.\n if (len(pversion.version) < 2 or len(cversion.version) < 2):\n return False\n return pversion.version[:2] == cversion.version[:2]\n\n def compiler_compatible(self, parent, child, **kwargs):\n \"\"\"Return true if compilers for parent and child are ABI compatible.\"\"\"\n if not parent.compiler or not child.compiler:\n return True\n\n if parent.compiler.name != child.compiler.name:\n # Different compiler families are assumed ABI incompatible\n return False\n\n if kwargs.get('loose', False):\n return True\n\n # TODO: Can we move the specialized ABI matching stuff\n # TODO: into compiler classes?\n for pversion in parent.compiler.versions:\n for cversion in child.compiler.versions:\n # For a few compilers use specialized comparisons.\n # Otherwise match on version match.\n if pversion.satisfies(cversion):\n return True\n elif (parent.compiler.name == \"gcc\" and\n self._gcc_compiler_compare(pversion, cversion)):\n return True\n elif (parent.compiler.name == \"intel\" and\n self._intel_compiler_compare(pversion, cversion)):\n return True\n return False\n\n def compatible(self, parent, child, **kwargs):\n \"\"\"Returns true iff a parent and child spec are ABI compatible\"\"\"\n loosematch = kwargs.get('loose', False)\n return self.architecture_compatible(parent, child) and \\\n self.compiler_compatible(parent, child, loose=loosematch)\n", "path": "lib/spack/spack/abi.py"}]} | 3,225 | 159 |
gh_patches_debug_6448 | rasdani/github-patches | git_diff | ipython__ipython-4915 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
greedy completer bug in terminal console
i'm back from finishing my thesis and i'm awed by the massive progress over the last few months. i'm particularly fond of the terminal 2-process frontend, which is super-useful to me. alas the greedy completer is not working properly in this mode. if i start a console session with greedy on, and then run
``` python
x = [0, 1, 2]
x[0].im<TAB>
```
it will autocomplete `imag`, but the next line will be
``` python
x[0]x[0].imag
```
which is obviously not right. this problem (rightfully) does not occur in the 1-process terminal or the qtconsole mode.
i remember this being an issue before in previous versions of ipython, but with the new structure i cannot see yet where this bug arises and how to solve it. best to ask an expert...
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `IPython/terminal/console/completer.py`
Content:
```
1 """Adapt readline completer interface to make ZMQ request.
2 """
3 # -*- coding: utf-8 -*-
4 import readline
5 try:
6 from queue import Empty # Py 3
7 except ImportError:
8 from Queue import Empty # Py 2
9
10 from IPython.config import Configurable
11 from IPython.utils.traitlets import Float
12
13 class ZMQCompleter(Configurable):
14 """Client-side completion machinery.
15
16 How it works: self.complete will be called multiple times, with
17 state=0,1,2,... When state=0 it should compute ALL the completion matches,
18 and then return them for each value of state."""
19
20 timeout = Float(5.0, config=True, help='timeout before completion abort')
21
22 def __init__(self, shell, client, config=None):
23 super(ZMQCompleter,self).__init__(config=config)
24
25 self.shell = shell
26 self.client = client
27 self.matches = []
28
29 def complete_request(self,text):
30 line = readline.get_line_buffer()
31 cursor_pos = readline.get_endidx()
32
33 # send completion request to kernel
34 # Give the kernel up to 0.5s to respond
35 msg_id = self.client.shell_channel.complete(text=text, line=line,
36 cursor_pos=cursor_pos)
37
38 msg = self.client.shell_channel.get_msg(timeout=self.timeout)
39 if msg['parent_header']['msg_id'] == msg_id:
40 return msg["content"]["matches"]
41 return []
42
43 def rlcomplete(self, text, state):
44 if state == 0:
45 try:
46 self.matches = self.complete_request(text)
47 except Empty:
48 #print('WARNING: Kernel timeout on tab completion.')
49 pass
50
51 try:
52 return self.matches[state]
53 except IndexError:
54 return None
55
56 def complete(self, text, line, cursor_pos=None):
57 return self.rlcomplete(text, 0)
58
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/IPython/terminal/console/completer.py b/IPython/terminal/console/completer.py
--- a/IPython/terminal/console/completer.py
+++ b/IPython/terminal/console/completer.py
@@ -8,9 +8,10 @@
from Queue import Empty # Py 2
from IPython.config import Configurable
+from IPython.core.completer import IPCompleter
from IPython.utils.traitlets import Float
-class ZMQCompleter(Configurable):
+class ZMQCompleter(IPCompleter):
"""Client-side completion machinery.
How it works: self.complete will be called multiple times, with
| {"golden_diff": "diff --git a/IPython/terminal/console/completer.py b/IPython/terminal/console/completer.py\n--- a/IPython/terminal/console/completer.py\n+++ b/IPython/terminal/console/completer.py\n@@ -8,9 +8,10 @@\n from Queue import Empty # Py 2\n \n from IPython.config import Configurable\n+from IPython.core.completer import IPCompleter\n from IPython.utils.traitlets import Float\n \n-class ZMQCompleter(Configurable):\n+class ZMQCompleter(IPCompleter):\n \"\"\"Client-side completion machinery.\n \n How it works: self.complete will be called multiple times, with\n", "issue": "greedy completer bug in terminal console\ni'm back from finishing my thesis and i'm awed by the massive progress over the last few months. i'm particularly fond of the terminal 2-process frontend, which is super-useful to me. alas the greedy completer is not working properly in this mode. if i start a console session with greedy on, and then run\n\n``` python\nx = [0, 1, 2]\nx[0].im<TAB>\n```\n\nit will autocomplete `imag`, but the next line will be\n\n``` python\nx[0]x[0].imag\n```\n\nwhich is obviously not right. this problem (rightfully) does not occur in the 1-process terminal or the qtconsole mode.\n\ni remember this being an issue before in previous versions of ipython, but with the new structure i cannot see yet where this bug arises and how to solve it. best to ask an expert...\n\n", "before_files": [{"content": "\"\"\"Adapt readline completer interface to make ZMQ request.\n\"\"\"\n# -*- coding: utf-8 -*-\nimport readline\ntry:\n from queue import Empty # Py 3\nexcept ImportError:\n from Queue import Empty # Py 2\n\nfrom IPython.config import Configurable\nfrom IPython.utils.traitlets import Float\n\nclass ZMQCompleter(Configurable):\n \"\"\"Client-side completion machinery.\n\n How it works: self.complete will be called multiple times, with\n state=0,1,2,... When state=0 it should compute ALL the completion matches,\n and then return them for each value of state.\"\"\"\n\n timeout = Float(5.0, config=True, help='timeout before completion abort')\n \n def __init__(self, shell, client, config=None):\n super(ZMQCompleter,self).__init__(config=config)\n\n self.shell = shell\n self.client = client\n self.matches = []\n \n def complete_request(self,text):\n line = readline.get_line_buffer()\n cursor_pos = readline.get_endidx()\n \n # send completion request to kernel\n # Give the kernel up to 0.5s to respond\n msg_id = self.client.shell_channel.complete(text=text, line=line,\n cursor_pos=cursor_pos)\n \n msg = self.client.shell_channel.get_msg(timeout=self.timeout)\n if msg['parent_header']['msg_id'] == msg_id:\n return msg[\"content\"][\"matches\"]\n return []\n \n def rlcomplete(self, text, state):\n if state == 0:\n try:\n self.matches = self.complete_request(text)\n except Empty:\n #print('WARNING: Kernel timeout on tab completion.')\n pass\n \n try:\n return self.matches[state]\n except IndexError:\n return None\n \n def complete(self, text, line, cursor_pos=None):\n return self.rlcomplete(text, 0)\n", "path": "IPython/terminal/console/completer.py"}], "after_files": [{"content": "\"\"\"Adapt readline completer interface to make ZMQ request.\n\"\"\"\n# -*- coding: utf-8 -*-\nimport readline\ntry:\n from queue import Empty # Py 3\nexcept ImportError:\n from Queue import Empty # Py 2\n\nfrom IPython.config import Configurable\nfrom IPython.core.completer import IPCompleter\nfrom IPython.utils.traitlets import Float\n\nclass ZMQCompleter(IPCompleter):\n \"\"\"Client-side completion machinery.\n\n How it works: self.complete will be called multiple times, with\n state=0,1,2,... When state=0 it should compute ALL the completion matches,\n and then return them for each value of state.\"\"\"\n\n timeout = Float(5.0, config=True, help='timeout before completion abort')\n \n def __init__(self, shell, client, config=None):\n super(ZMQCompleter,self).__init__(config=config)\n\n self.shell = shell\n self.client = client\n self.matches = []\n \n def complete_request(self,text):\n line = readline.get_line_buffer()\n cursor_pos = readline.get_endidx()\n \n # send completion request to kernel\n # Give the kernel up to 0.5s to respond\n msg_id = self.client.shell_channel.complete(text=text, line=line,\n cursor_pos=cursor_pos)\n \n msg = self.client.shell_channel.get_msg(timeout=self.timeout)\n if msg['parent_header']['msg_id'] == msg_id:\n return msg[\"content\"][\"matches\"]\n return []\n \n def rlcomplete(self, text, state):\n if state == 0:\n try:\n self.matches = self.complete_request(text)\n except Empty:\n #print('WARNING: Kernel timeout on tab completion.')\n pass\n \n try:\n return self.matches[state]\n except IndexError:\n return None\n \n def complete(self, text, line, cursor_pos=None):\n return self.rlcomplete(text, 0)\n", "path": "IPython/terminal/console/completer.py"}]} | 970 | 143 |
gh_patches_debug_21612 | rasdani/github-patches | git_diff | numpy__numpy-12754 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
numpy.save rejects unicode paths in Python 2.7
We've discovered this in our tests in [nipy/nipype](https://github.com/nipy/nipype) when 1.16 was released ([failing test](https://circleci.com/gh/nipy/nipype/7570)). It's unclear why it wasn't hitting our `--pre` tests, but it wasn't too tough to track down and reproduce.
It appears to have been introduced in #12157, which dropped an `if isinstance(file, basestring):` and explicitly checks `str` and `bytes`, which will resolve to `str` and `str` in Python 2, not `unicode` and `str`.
This is probably easily fixable on our end (just call `str()`), but in case you intend to support unicode paths, you should know about this.
Related: nipy/nipype#2855
<!-- Please describe the issue in detail here, and fill in the fields below -->
### Reproducing code example:
<!-- A short code example that reproduces the problem/missing feature. It should be
self-contained, i.e., possible to run as-is via 'python myproblem.py' -->
```python
from __future__ import unicode_literals
import numpy as np
np.save('abc.npy', np.array([0, 1, 2])
```
<!-- Remove these sections for a feature request -->
### Error message:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-6-109f1bba4449> in <module>()
----> 1 np.save('abc.npy', np.array([0, 1, 2]))
/anaconda3/envs/python27/lib/python2.7/site-packages/numpy/lib/npyio.pyc in save(file, arr, allow_pickle, fix_imports)
512 fid = file
513 else:
--> 514 file = os_fspath(file)
515 if not file.endswith('.npy'):
516 file = file + '.npy'
/anaconda3/envs/python27/lib/python2.7/site-packages/numpy/compat/py3k.pyc in os_fspath(path)
235 else:
236 raise TypeError("expected str, bytes or os.PathLike object, "
--> 237 "not " + path_type.__name__)
238 if isinstance(path_repr, (str, bytes)):
239 return path_repr
TypeError: expected str, bytes or os.PathLike object, not unicode
```
<!-- If you are reporting a segfault please include a GDB traceback, which you
can generate by following
https://github.com/numpy/numpy/blob/master/doc/source/dev/development_environment.rst#debugging -->
<!-- Full error message, if any (starting from line Traceback: ...) -->
### Numpy/Python version information:
<!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' -->
```
('1.16.0', '2.7.15 |Anaconda, Inc.| (default, Dec 14 2018, 13:10:39) \n[GCC 4.2.1 Compatible Clang 4.0.1 (tags/RELEASE_401/final)]')
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `numpy/compat/py3k.py`
Content:
```
1 """
2 Python 3 compatibility tools.
3
4 """
5 from __future__ import division, absolute_import, print_function
6
7 __all__ = ['bytes', 'asbytes', 'isfileobj', 'getexception', 'strchar',
8 'unicode', 'asunicode', 'asbytes_nested', 'asunicode_nested',
9 'asstr', 'open_latin1', 'long', 'basestring', 'sixu',
10 'integer_types', 'is_pathlib_path', 'npy_load_module', 'Path',
11 'contextlib_nullcontext', 'os_fspath', 'os_PathLike']
12
13 import sys
14 try:
15 from pathlib import Path, PurePath
16 except ImportError:
17 Path = PurePath = None
18
19 if sys.version_info[0] >= 3:
20 import io
21
22 long = int
23 integer_types = (int,)
24 basestring = str
25 unicode = str
26 bytes = bytes
27
28 def asunicode(s):
29 if isinstance(s, bytes):
30 return s.decode('latin1')
31 return str(s)
32
33 def asbytes(s):
34 if isinstance(s, bytes):
35 return s
36 return str(s).encode('latin1')
37
38 def asstr(s):
39 if isinstance(s, bytes):
40 return s.decode('latin1')
41 return str(s)
42
43 def isfileobj(f):
44 return isinstance(f, (io.FileIO, io.BufferedReader, io.BufferedWriter))
45
46 def open_latin1(filename, mode='r'):
47 return open(filename, mode=mode, encoding='iso-8859-1')
48
49 def sixu(s):
50 return s
51
52 strchar = 'U'
53
54
55 else:
56 bytes = str
57 long = long
58 basestring = basestring
59 unicode = unicode
60 integer_types = (int, long)
61 asbytes = str
62 asstr = str
63 strchar = 'S'
64
65 def isfileobj(f):
66 return isinstance(f, file)
67
68 def asunicode(s):
69 if isinstance(s, unicode):
70 return s
71 return str(s).decode('ascii')
72
73 def open_latin1(filename, mode='r'):
74 return open(filename, mode=mode)
75
76 def sixu(s):
77 return unicode(s, 'unicode_escape')
78
79
80 def getexception():
81 return sys.exc_info()[1]
82
83 def asbytes_nested(x):
84 if hasattr(x, '__iter__') and not isinstance(x, (bytes, unicode)):
85 return [asbytes_nested(y) for y in x]
86 else:
87 return asbytes(x)
88
89 def asunicode_nested(x):
90 if hasattr(x, '__iter__') and not isinstance(x, (bytes, unicode)):
91 return [asunicode_nested(y) for y in x]
92 else:
93 return asunicode(x)
94
95 def is_pathlib_path(obj):
96 """
97 Check whether obj is a pathlib.Path object.
98
99 Prefer using `isinstance(obj, os_PathLike)` instead of this function.
100 """
101 return Path is not None and isinstance(obj, Path)
102
103 # from Python 3.7
104 class contextlib_nullcontext(object):
105 """Context manager that does no additional processing.
106
107 Used as a stand-in for a normal context manager, when a particular
108 block of code is only sometimes used with a normal context manager:
109
110 cm = optional_cm if condition else nullcontext()
111 with cm:
112 # Perform operation, using optional_cm if condition is True
113 """
114
115 def __init__(self, enter_result=None):
116 self.enter_result = enter_result
117
118 def __enter__(self):
119 return self.enter_result
120
121 def __exit__(self, *excinfo):
122 pass
123
124
125 if sys.version_info[0] >= 3 and sys.version_info[1] >= 4:
126 def npy_load_module(name, fn, info=None):
127 """
128 Load a module.
129
130 .. versionadded:: 1.11.2
131
132 Parameters
133 ----------
134 name : str
135 Full module name.
136 fn : str
137 Path to module file.
138 info : tuple, optional
139 Only here for backward compatibility with Python 2.*.
140
141 Returns
142 -------
143 mod : module
144
145 """
146 import importlib.machinery
147 return importlib.machinery.SourceFileLoader(name, fn).load_module()
148 else:
149 def npy_load_module(name, fn, info=None):
150 """
151 Load a module.
152
153 .. versionadded:: 1.11.2
154
155 Parameters
156 ----------
157 name : str
158 Full module name.
159 fn : str
160 Path to module file.
161 info : tuple, optional
162 Information as returned by `imp.find_module`
163 (suffix, mode, type).
164
165 Returns
166 -------
167 mod : module
168
169 """
170 import imp
171 import os
172 if info is None:
173 path = os.path.dirname(fn)
174 fo, fn, info = imp.find_module(name, [path])
175 else:
176 fo = open(fn, info[1])
177 try:
178 mod = imp.load_module(name, fo, fn, info)
179 finally:
180 fo.close()
181 return mod
182
183 # backport abc.ABC
184 import abc
185 if sys.version_info[:2] >= (3, 4):
186 abc_ABC = abc.ABC
187 else:
188 abc_ABC = abc.ABCMeta('ABC', (object,), {'__slots__': ()})
189
190
191 # Backport os.fs_path, os.PathLike, and PurePath.__fspath__
192 if sys.version_info[:2] >= (3, 6):
193 import os
194 os_fspath = os.fspath
195 os_PathLike = os.PathLike
196 else:
197 def _PurePath__fspath__(self):
198 return str(self)
199
200 class os_PathLike(abc_ABC):
201 """Abstract base class for implementing the file system path protocol."""
202
203 @abc.abstractmethod
204 def __fspath__(self):
205 """Return the file system path representation of the object."""
206 raise NotImplementedError
207
208 @classmethod
209 def __subclasshook__(cls, subclass):
210 if PurePath is not None and issubclass(subclass, PurePath):
211 return True
212 return hasattr(subclass, '__fspath__')
213
214
215 def os_fspath(path):
216 """Return the path representation of a path-like object.
217 If str or bytes is passed in, it is returned unchanged. Otherwise the
218 os.PathLike interface is used to get the path representation. If the
219 path representation is not str or bytes, TypeError is raised. If the
220 provided path is not str, bytes, or os.PathLike, TypeError is raised.
221 """
222 if isinstance(path, (str, bytes)):
223 return path
224
225 # Work from the object's type to match method resolution of other magic
226 # methods.
227 path_type = type(path)
228 try:
229 path_repr = path_type.__fspath__(path)
230 except AttributeError:
231 if hasattr(path_type, '__fspath__'):
232 raise
233 elif PurePath is not None and issubclass(path_type, PurePath):
234 return _PurePath__fspath__(path)
235 else:
236 raise TypeError("expected str, bytes or os.PathLike object, "
237 "not " + path_type.__name__)
238 if isinstance(path_repr, (str, bytes)):
239 return path_repr
240 else:
241 raise TypeError("expected {}.__fspath__() to return str or bytes, "
242 "not {}".format(path_type.__name__,
243 type(path_repr).__name__))
244
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/numpy/compat/py3k.py b/numpy/compat/py3k.py
--- a/numpy/compat/py3k.py
+++ b/numpy/compat/py3k.py
@@ -219,7 +219,7 @@
path representation is not str or bytes, TypeError is raised. If the
provided path is not str, bytes, or os.PathLike, TypeError is raised.
"""
- if isinstance(path, (str, bytes)):
+ if isinstance(path, (unicode, bytes)):
return path
# Work from the object's type to match method resolution of other magic
@@ -235,7 +235,7 @@
else:
raise TypeError("expected str, bytes or os.PathLike object, "
"not " + path_type.__name__)
- if isinstance(path_repr, (str, bytes)):
+ if isinstance(path_repr, (unicode, bytes)):
return path_repr
else:
raise TypeError("expected {}.__fspath__() to return str or bytes, "
| {"golden_diff": "diff --git a/numpy/compat/py3k.py b/numpy/compat/py3k.py\n--- a/numpy/compat/py3k.py\n+++ b/numpy/compat/py3k.py\n@@ -219,7 +219,7 @@\n path representation is not str or bytes, TypeError is raised. If the\n provided path is not str, bytes, or os.PathLike, TypeError is raised.\n \"\"\"\n- if isinstance(path, (str, bytes)):\n+ if isinstance(path, (unicode, bytes)):\n return path\n \n # Work from the object's type to match method resolution of other magic\n@@ -235,7 +235,7 @@\n else:\n raise TypeError(\"expected str, bytes or os.PathLike object, \"\n \"not \" + path_type.__name__)\n- if isinstance(path_repr, (str, bytes)):\n+ if isinstance(path_repr, (unicode, bytes)):\n return path_repr\n else:\n raise TypeError(\"expected {}.__fspath__() to return str or bytes, \"\n", "issue": "numpy.save rejects unicode paths in Python 2.7\nWe've discovered this in our tests in [nipy/nipype](https://github.com/nipy/nipype) when 1.16 was released ([failing test](https://circleci.com/gh/nipy/nipype/7570)). It's unclear why it wasn't hitting our `--pre` tests, but it wasn't too tough to track down and reproduce.\r\n\r\nIt appears to have been introduced in #12157, which dropped an `if isinstance(file, basestring):` and explicitly checks `str` and `bytes`, which will resolve to `str` and `str` in Python 2, not `unicode` and `str`.\r\n\r\nThis is probably easily fixable on our end (just call `str()`), but in case you intend to support unicode paths, you should know about this.\r\n\r\nRelated: nipy/nipype#2855\r\n\r\n<!-- Please describe the issue in detail here, and fill in the fields below -->\r\n\r\n### Reproducing code example:\r\n\r\n<!-- A short code example that reproduces the problem/missing feature. It should be\r\nself-contained, i.e., possible to run as-is via 'python myproblem.py' -->\r\n\r\n```python\r\nfrom __future__ import unicode_literals\r\nimport numpy as np\r\nnp.save('abc.npy', np.array([0, 1, 2])\r\n```\r\n\r\n<!-- Remove these sections for a feature request -->\r\n\r\n### Error message:\r\n\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-6-109f1bba4449> in <module>()\r\n----> 1 np.save('abc.npy', np.array([0, 1, 2]))\r\n\r\n/anaconda3/envs/python27/lib/python2.7/site-packages/numpy/lib/npyio.pyc in save(file, arr, allow_pickle, fix_imports)\r\n 512 fid = file\r\n 513 else:\r\n--> 514 file = os_fspath(file)\r\n 515 if not file.endswith('.npy'):\r\n 516 file = file + '.npy'\r\n\r\n/anaconda3/envs/python27/lib/python2.7/site-packages/numpy/compat/py3k.pyc in os_fspath(path)\r\n 235 else:\r\n 236 raise TypeError(\"expected str, bytes or os.PathLike object, \"\r\n--> 237 \"not \" + path_type.__name__)\r\n 238 if isinstance(path_repr, (str, bytes)):\r\n 239 return path_repr\r\n\r\nTypeError: expected str, bytes or os.PathLike object, not unicode\r\n```\r\n<!-- If you are reporting a segfault please include a GDB traceback, which you\r\ncan generate by following\r\nhttps://github.com/numpy/numpy/blob/master/doc/source/dev/development_environment.rst#debugging -->\r\n\r\n<!-- Full error message, if any (starting from line Traceback: ...) -->\r\n\r\n### Numpy/Python version information:\r\n\r\n<!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' -->\r\n\r\n```\r\n('1.16.0', '2.7.15 |Anaconda, Inc.| (default, Dec 14 2018, 13:10:39) \\n[GCC 4.2.1 Compatible Clang 4.0.1 (tags/RELEASE_401/final)]')\r\n```\n", "before_files": [{"content": "\"\"\"\nPython 3 compatibility tools.\n\n\"\"\"\nfrom __future__ import division, absolute_import, print_function\n\n__all__ = ['bytes', 'asbytes', 'isfileobj', 'getexception', 'strchar',\n 'unicode', 'asunicode', 'asbytes_nested', 'asunicode_nested',\n 'asstr', 'open_latin1', 'long', 'basestring', 'sixu',\n 'integer_types', 'is_pathlib_path', 'npy_load_module', 'Path',\n 'contextlib_nullcontext', 'os_fspath', 'os_PathLike']\n\nimport sys\ntry:\n from pathlib import Path, PurePath\nexcept ImportError:\n Path = PurePath = None\n\nif sys.version_info[0] >= 3:\n import io\n\n long = int\n integer_types = (int,)\n basestring = str\n unicode = str\n bytes = bytes\n\n def asunicode(s):\n if isinstance(s, bytes):\n return s.decode('latin1')\n return str(s)\n\n def asbytes(s):\n if isinstance(s, bytes):\n return s\n return str(s).encode('latin1')\n\n def asstr(s):\n if isinstance(s, bytes):\n return s.decode('latin1')\n return str(s)\n\n def isfileobj(f):\n return isinstance(f, (io.FileIO, io.BufferedReader, io.BufferedWriter))\n\n def open_latin1(filename, mode='r'):\n return open(filename, mode=mode, encoding='iso-8859-1')\n\n def sixu(s):\n return s\n\n strchar = 'U'\n\n\nelse:\n bytes = str\n long = long\n basestring = basestring\n unicode = unicode\n integer_types = (int, long)\n asbytes = str\n asstr = str\n strchar = 'S'\n\n def isfileobj(f):\n return isinstance(f, file)\n\n def asunicode(s):\n if isinstance(s, unicode):\n return s\n return str(s).decode('ascii')\n\n def open_latin1(filename, mode='r'):\n return open(filename, mode=mode)\n\n def sixu(s):\n return unicode(s, 'unicode_escape')\n\n\ndef getexception():\n return sys.exc_info()[1]\n\ndef asbytes_nested(x):\n if hasattr(x, '__iter__') and not isinstance(x, (bytes, unicode)):\n return [asbytes_nested(y) for y in x]\n else:\n return asbytes(x)\n\ndef asunicode_nested(x):\n if hasattr(x, '__iter__') and not isinstance(x, (bytes, unicode)):\n return [asunicode_nested(y) for y in x]\n else:\n return asunicode(x)\n\ndef is_pathlib_path(obj):\n \"\"\"\n Check whether obj is a pathlib.Path object.\n\n Prefer using `isinstance(obj, os_PathLike)` instead of this function.\n \"\"\"\n return Path is not None and isinstance(obj, Path)\n\n# from Python 3.7\nclass contextlib_nullcontext(object):\n \"\"\"Context manager that does no additional processing.\n\n Used as a stand-in for a normal context manager, when a particular\n block of code is only sometimes used with a normal context manager:\n\n cm = optional_cm if condition else nullcontext()\n with cm:\n # Perform operation, using optional_cm if condition is True\n \"\"\"\n\n def __init__(self, enter_result=None):\n self.enter_result = enter_result\n\n def __enter__(self):\n return self.enter_result\n\n def __exit__(self, *excinfo):\n pass\n\n\nif sys.version_info[0] >= 3 and sys.version_info[1] >= 4:\n def npy_load_module(name, fn, info=None):\n \"\"\"\n Load a module.\n\n .. versionadded:: 1.11.2\n\n Parameters\n ----------\n name : str\n Full module name.\n fn : str\n Path to module file.\n info : tuple, optional\n Only here for backward compatibility with Python 2.*.\n\n Returns\n -------\n mod : module\n\n \"\"\"\n import importlib.machinery\n return importlib.machinery.SourceFileLoader(name, fn).load_module()\nelse:\n def npy_load_module(name, fn, info=None):\n \"\"\"\n Load a module.\n\n .. versionadded:: 1.11.2\n\n Parameters\n ----------\n name : str\n Full module name.\n fn : str\n Path to module file.\n info : tuple, optional\n Information as returned by `imp.find_module`\n (suffix, mode, type).\n\n Returns\n -------\n mod : module\n\n \"\"\"\n import imp\n import os\n if info is None:\n path = os.path.dirname(fn)\n fo, fn, info = imp.find_module(name, [path])\n else:\n fo = open(fn, info[1])\n try:\n mod = imp.load_module(name, fo, fn, info)\n finally:\n fo.close()\n return mod\n\n# backport abc.ABC\nimport abc\nif sys.version_info[:2] >= (3, 4):\n abc_ABC = abc.ABC\nelse:\n abc_ABC = abc.ABCMeta('ABC', (object,), {'__slots__': ()})\n\n\n# Backport os.fs_path, os.PathLike, and PurePath.__fspath__\nif sys.version_info[:2] >= (3, 6):\n import os\n os_fspath = os.fspath\n os_PathLike = os.PathLike\nelse:\n def _PurePath__fspath__(self):\n return str(self)\n\n class os_PathLike(abc_ABC):\n \"\"\"Abstract base class for implementing the file system path protocol.\"\"\"\n\n @abc.abstractmethod\n def __fspath__(self):\n \"\"\"Return the file system path representation of the object.\"\"\"\n raise NotImplementedError\n\n @classmethod\n def __subclasshook__(cls, subclass):\n if PurePath is not None and issubclass(subclass, PurePath):\n return True\n return hasattr(subclass, '__fspath__')\n\n\n def os_fspath(path):\n \"\"\"Return the path representation of a path-like object.\n If str or bytes is passed in, it is returned unchanged. Otherwise the\n os.PathLike interface is used to get the path representation. If the\n path representation is not str or bytes, TypeError is raised. If the\n provided path is not str, bytes, or os.PathLike, TypeError is raised.\n \"\"\"\n if isinstance(path, (str, bytes)):\n return path\n\n # Work from the object's type to match method resolution of other magic\n # methods.\n path_type = type(path)\n try:\n path_repr = path_type.__fspath__(path)\n except AttributeError:\n if hasattr(path_type, '__fspath__'):\n raise\n elif PurePath is not None and issubclass(path_type, PurePath):\n return _PurePath__fspath__(path)\n else:\n raise TypeError(\"expected str, bytes or os.PathLike object, \"\n \"not \" + path_type.__name__)\n if isinstance(path_repr, (str, bytes)):\n return path_repr\n else:\n raise TypeError(\"expected {}.__fspath__() to return str or bytes, \"\n \"not {}\".format(path_type.__name__,\n type(path_repr).__name__))\n", "path": "numpy/compat/py3k.py"}], "after_files": [{"content": "\"\"\"\nPython 3 compatibility tools.\n\n\"\"\"\nfrom __future__ import division, absolute_import, print_function\n\n__all__ = ['bytes', 'asbytes', 'isfileobj', 'getexception', 'strchar',\n 'unicode', 'asunicode', 'asbytes_nested', 'asunicode_nested',\n 'asstr', 'open_latin1', 'long', 'basestring', 'sixu',\n 'integer_types', 'is_pathlib_path', 'npy_load_module', 'Path',\n 'contextlib_nullcontext', 'os_fspath', 'os_PathLike']\n\nimport sys\ntry:\n from pathlib import Path, PurePath\nexcept ImportError:\n Path = PurePath = None\n\nif sys.version_info[0] >= 3:\n import io\n\n long = int\n integer_types = (int,)\n basestring = str\n unicode = str\n bytes = bytes\n\n def asunicode(s):\n if isinstance(s, bytes):\n return s.decode('latin1')\n return str(s)\n\n def asbytes(s):\n if isinstance(s, bytes):\n return s\n return str(s).encode('latin1')\n\n def asstr(s):\n if isinstance(s, bytes):\n return s.decode('latin1')\n return str(s)\n\n def isfileobj(f):\n return isinstance(f, (io.FileIO, io.BufferedReader, io.BufferedWriter))\n\n def open_latin1(filename, mode='r'):\n return open(filename, mode=mode, encoding='iso-8859-1')\n\n def sixu(s):\n return s\n\n strchar = 'U'\n\n\nelse:\n bytes = str\n long = long\n basestring = basestring\n unicode = unicode\n integer_types = (int, long)\n asbytes = str\n asstr = str\n strchar = 'S'\n\n def isfileobj(f):\n return isinstance(f, file)\n\n def asunicode(s):\n if isinstance(s, unicode):\n return s\n return str(s).decode('ascii')\n\n def open_latin1(filename, mode='r'):\n return open(filename, mode=mode)\n\n def sixu(s):\n return unicode(s, 'unicode_escape')\n\n\ndef getexception():\n return sys.exc_info()[1]\n\ndef asbytes_nested(x):\n if hasattr(x, '__iter__') and not isinstance(x, (bytes, unicode)):\n return [asbytes_nested(y) for y in x]\n else:\n return asbytes(x)\n\ndef asunicode_nested(x):\n if hasattr(x, '__iter__') and not isinstance(x, (bytes, unicode)):\n return [asunicode_nested(y) for y in x]\n else:\n return asunicode(x)\n\ndef is_pathlib_path(obj):\n \"\"\"\n Check whether obj is a pathlib.Path object.\n\n Prefer using `isinstance(obj, os_PathLike)` instead of this function.\n \"\"\"\n return Path is not None and isinstance(obj, Path)\n\n# from Python 3.7\nclass contextlib_nullcontext(object):\n \"\"\"Context manager that does no additional processing.\n\n Used as a stand-in for a normal context manager, when a particular\n block of code is only sometimes used with a normal context manager:\n\n cm = optional_cm if condition else nullcontext()\n with cm:\n # Perform operation, using optional_cm if condition is True\n \"\"\"\n\n def __init__(self, enter_result=None):\n self.enter_result = enter_result\n\n def __enter__(self):\n return self.enter_result\n\n def __exit__(self, *excinfo):\n pass\n\n\nif sys.version_info[0] >= 3 and sys.version_info[1] >= 4:\n def npy_load_module(name, fn, info=None):\n \"\"\"\n Load a module.\n\n .. versionadded:: 1.11.2\n\n Parameters\n ----------\n name : str\n Full module name.\n fn : str\n Path to module file.\n info : tuple, optional\n Only here for backward compatibility with Python 2.*.\n\n Returns\n -------\n mod : module\n\n \"\"\"\n import importlib.machinery\n return importlib.machinery.SourceFileLoader(name, fn).load_module()\nelse:\n def npy_load_module(name, fn, info=None):\n \"\"\"\n Load a module.\n\n .. versionadded:: 1.11.2\n\n Parameters\n ----------\n name : str\n Full module name.\n fn : str\n Path to module file.\n info : tuple, optional\n Information as returned by `imp.find_module`\n (suffix, mode, type).\n\n Returns\n -------\n mod : module\n\n \"\"\"\n import imp\n import os\n if info is None:\n path = os.path.dirname(fn)\n fo, fn, info = imp.find_module(name, [path])\n else:\n fo = open(fn, info[1])\n try:\n mod = imp.load_module(name, fo, fn, info)\n finally:\n fo.close()\n return mod\n\n# backport abc.ABC\nimport abc\nif sys.version_info[:2] >= (3, 4):\n abc_ABC = abc.ABC\nelse:\n abc_ABC = abc.ABCMeta('ABC', (object,), {'__slots__': ()})\n\n\n# Backport os.fs_path, os.PathLike, and PurePath.__fspath__\nif sys.version_info[:2] >= (3, 6):\n import os\n os_fspath = os.fspath\n os_PathLike = os.PathLike\nelse:\n def _PurePath__fspath__(self):\n return str(self)\n\n class os_PathLike(abc_ABC):\n \"\"\"Abstract base class for implementing the file system path protocol.\"\"\"\n\n @abc.abstractmethod\n def __fspath__(self):\n \"\"\"Return the file system path representation of the object.\"\"\"\n raise NotImplementedError\n\n @classmethod\n def __subclasshook__(cls, subclass):\n if PurePath is not None and issubclass(subclass, PurePath):\n return True\n return hasattr(subclass, '__fspath__')\n\n\n def os_fspath(path):\n \"\"\"Return the path representation of a path-like object.\n If str or bytes is passed in, it is returned unchanged. Otherwise the\n os.PathLike interface is used to get the path representation. If the\n path representation is not str or bytes, TypeError is raised. If the\n provided path is not str, bytes, or os.PathLike, TypeError is raised.\n \"\"\"\n if isinstance(path, (unicode, bytes)):\n return path\n\n # Work from the object's type to match method resolution of other magic\n # methods.\n path_type = type(path)\n try:\n path_repr = path_type.__fspath__(path)\n except AttributeError:\n if hasattr(path_type, '__fspath__'):\n raise\n elif PurePath is not None and issubclass(path_type, PurePath):\n return _PurePath__fspath__(path)\n else:\n raise TypeError(\"expected str, bytes or os.PathLike object, \"\n \"not \" + path_type.__name__)\n if isinstance(path_repr, (unicode, bytes)):\n return path_repr\n else:\n raise TypeError(\"expected {}.__fspath__() to return str or bytes, \"\n \"not {}\".format(path_type.__name__,\n type(path_repr).__name__))\n", "path": "numpy/compat/py3k.py"}]} | 3,244 | 227 |
gh_patches_debug_23739 | rasdani/github-patches | git_diff | mosaicml__composer-151 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Checkpointing fails when using the composer command
## Environment
Running on colo on branch `moin/bert` rebased off of the latest dev: commit hash `be411d3f71feffcbab84da8671dd530fdbbc2f30`.
## To reproduce
Steps to reproduce the behavior:
1. Checkout `moin/bert` branch
2. Run `composer -n 8 examples/run_mosaic_trainer.py -f composer/yamls/models/glue/sst-2_checkpointing.yaml`
## Expected behavior
If I run `python examples/run_mosaic_trainer.py -f composer/yamls/models/glue/sst-2_checkpointing.yaml` instead of `composer -n 8`, then checkpointing works as expected, and we are able to save a checkpoint successfully and continue training. However, when I run it with `composer -n 8`, we see the following crash (exactly when checkpointing happens):
```
[BATCH][step=599]: { "lr-AdamW/group0": 0.0000, }
Error in subprocess
----------Subprocess STDOUT----------
----------Subprocess STDERR----------
Command '['/usr/bin/python3.8', '-u', 'examples/run_mosaic_trainer.py', '-f', 'composer/yamls/models/glue/sst-2_checkpointing.yaml']' returned non-zero exit status 1.
Killing subprocess 33667 with SIGTERM
Killing subprocess 33662 with SIGTERM
Killing subprocess 33661 with SIGTERM
Killing subprocess 33669 with SIGTERM
Killing subprocess 33659 with SIGTERM
Waiting 30 seconds for processes to terminate...
```
For reference, checkpointing is set to every 600 iterations. There is no printed output.
## Additional context
This is the next step in getting BERT pre-training working (saving the pre-trained model, and then fine-tuning it on GLUE tasks).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `composer/trainer/checkpoint.py`
Content:
```
1 # Copyright 2021 MosaicML. All Rights Reserved.
2
3 import logging
4 import os
5 import random
6 import warnings
7 from typing import Any, Dict, Optional
8
9 import numpy as np
10 import torch
11 import yaml
12
13 from composer.core import Event, State
14 from composer.core.types import StateDict
15 from composer.trainer.devices.device import Device
16 from composer.utils import ddp, seed_all
17
18 log = logging.getLogger(__name__)
19
20
21 class CheckpointLoader:
22 """Manager for initializing state and restoring RNG state from existing checkpoints.
23
24 Args:
25 checkpoint_filepath (str): The path to an existing checkpoint file.
26 """
27
28 def __init__(self, checkpoint_filepath: str):
29 self.state_dict = torch.load(checkpoint_filepath, map_location='cpu')
30
31 def load_checkpoint(self, state: State):
32 """Initialize state from the loaded checkpoint's data.
33 """
34
35 state.load_state_dict(self.state_dict["state"])
36 self.checkpoint_rng_state = self._get_checkpoint_rng_state(state, self.state_dict["rng"])
37
38 if "seed" in self.state_dict:
39 seed_all(self.state_dict["seed"])
40
41 def restore_checkpoint_rng_state(self, state: State, device: Device):
42 """Restore the state of all RNG objects in this context from the loaded checkpoint's data.
43 """
44
45 if self.checkpoint_rng_state is None:
46 return
47
48 assert ddp.get_world_size() == len(
49 self.checkpoint_rng_state['torch']
50 ), f"invariant violation: if the rng state is being restored, then" \
51 "the world size should be the same as in the checkpoint."
52
53 torch.set_rng_state(self.checkpoint_rng_state['torch'][ddp.get_global_rank()])
54 device.load_state_dict(self.checkpoint_rng_state['device'][ddp.get_global_rank()])
55 random.setstate(self.checkpoint_rng_state['python'][ddp.get_global_rank()])
56 np.random.set_state(self.checkpoint_rng_state['numpy'][ddp.get_global_rank()])
57
58 self.checkpoint_rng_state = None
59
60 def _get_checkpoint_rng_state(self, state: State, checkpoint_rng_state: StateDict) -> Optional[StateDict]:
61 original_world_size = len(checkpoint_rng_state["torch"])
62 if original_world_size == ddp.get_world_size():
63 return checkpoint_rng_state
64 else:
65 warnings.warn(f"The checkpoint was created with world_size({original_world_size}), "
66 f"which differs from the current world_size({ddp.get_world_size()})."
67 f"RNG state will not be restored.")
68
69
70 class Checkpointer:
71 """Manager for saving state to checkpoint files.
72
73 Args:
74 checkpoint_folder (str): The path to the folder to store checkpoints in.
75 checkpoint_interval (int): The amount of time units to wait between checkpoints.
76 checkpoint_interval_unit (str): The unit (`"ep"` or `"it"`) that
77 `checkpoint_interval` should be measured in.
78 """
79
80 def __init__(self, checkpoint_folder: str, checkpoint_interval: int, checkpoint_interval_unit: str):
81 if checkpoint_interval_unit.lower() == "ep":
82 self.save_event = Event.EPOCH_END
83 elif checkpoint_interval_unit.lower() == "it":
84 self.save_event = Event.BATCH_END
85 else:
86 raise ValueError(f"Unknown checkpointing interval: {checkpoint_interval_unit}")
87 self.checkpoint_folder = checkpoint_folder
88 self.save_interval = checkpoint_interval
89
90 def should_checkpoint(self, state: State, event: Event) -> bool:
91 """Given the current state and event, determine whether a checkpoint needs to be created.
92
93 Args:
94 state (State): The current State of the trainer.
95 event (Event): The current Event being executed.
96 """
97
98 if event != self.save_event:
99 return False
100 if self.save_event == Event.EPOCH_END:
101 return state.epoch % self.save_interval == 0
102 if self.save_event == Event.BATCH_END:
103 return state.step % self.save_interval == 0
104 return False
105
106 def save_checkpoint(self, state: State, seed: int, device: Device, config: Optional[Dict[str, Any]] = None) -> None:
107 """Save the current state to a a new checkpoint file.
108
109 Args:
110 state (State): The current State of the trainer.
111 device (Device): The Device in use by this process.
112 ddp (DDP): The DDP engine in use by this trainer.
113 config (Optional[Dict[str, Any]]): The hparams used to initialize this trainer, if any.
114 """
115
116 # Store the rank0 seed, if the seed was provided on trainer init
117 # then this is the same seed on all processes
118 # If the seed was not provided, then the rank0 seed will be copied
119 # to all processes on checkpoint resume.
120 # This will be fixed by: https://github.com/mosaicml/composer/issues/12
121 state_dict = {
122 'state': state.state_dict(), # should be the same across all ranks. per-rank state not stored
123 'rng': self._get_rng_state(device=device), # stored across all ranks
124 'seed': seed,
125 }
126 if ddp.get_global_rank() != 0:
127 # only rank 0 saves checkpoints
128 # Need the check down here so all the DDP syncs will work for generating the checkpoint
129 return
130
131 if config:
132 hparams_path = os.path.join(self.checkpoint_folder, "hparams.yaml")
133 os.makedirs(self.checkpoint_folder, mode=0o775, exist_ok=True)
134 config_yaml_str = yaml.dump(config)
135 try:
136 with open(hparams_path, "x") as f:
137 # Storing the config (ex. hparams) in a separate file so they can be modified before resuming
138 f.write(config_yaml_str)
139 except FileExistsError as e:
140 with open(hparams_path, "r") as f:
141 # comparing the parsed hparams to ignore whitespace and formatting differences
142 if yaml.safe_load(config_yaml_str) != yaml.safe_load(f):
143 raise RuntimeError(f"The hparams in the existing checkpoint folder {self.checkpoint_folder} "
144 "differ from those being used in the current training run. "
145 "Please specify a new checkpoint folder.") from e
146 if self.save_event == Event.EPOCH_END:
147 filename = f"ep{state.epoch}.pt"
148 elif self.save_event == Event.BATCH_END:
149 filename = f"it{state.step}.pt"
150 else:
151 raise ValueError(f"Invalid checkpoint event: {self.save_event}")
152 save_file = os.path.join(self.checkpoint_folder, filename)
153 with open(save_file, 'xb') as f:
154 torch.save(state_dict, f)
155 log.info(f'Trainer checkpoint saved to {save_file}')
156
157 def _get_rng_state(self, device: Device) -> StateDict:
158 rng_state = {
159 "python": ddp.all_gather_object(random.getstate()),
160 "numpy": ddp.all_gather_object(np.random.get_state()),
161 "torch": ddp.all_gather_object(torch.random.get_rng_state()),
162 "device": ddp.all_gather_object(device.state_dict()),
163 }
164 # casting the state dict as on non-rank-0, entries will be None-like
165 return rng_state
166
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/composer/trainer/checkpoint.py b/composer/trainer/checkpoint.py
--- a/composer/trainer/checkpoint.py
+++ b/composer/trainer/checkpoint.py
@@ -119,7 +119,6 @@
# to all processes on checkpoint resume.
# This will be fixed by: https://github.com/mosaicml/composer/issues/12
state_dict = {
- 'state': state.state_dict(), # should be the same across all ranks. per-rank state not stored
'rng': self._get_rng_state(device=device), # stored across all ranks
'seed': seed,
}
@@ -128,6 +127,9 @@
# Need the check down here so all the DDP syncs will work for generating the checkpoint
return
+ # we add the state only on rank 0 since other processes don't have loggers to serialize
+ state_dict['state'] = state.state_dict() # should be the same across all ranks. per-rank state not stored
+
if config:
hparams_path = os.path.join(self.checkpoint_folder, "hparams.yaml")
os.makedirs(self.checkpoint_folder, mode=0o775, exist_ok=True)
| {"golden_diff": "diff --git a/composer/trainer/checkpoint.py b/composer/trainer/checkpoint.py\n--- a/composer/trainer/checkpoint.py\n+++ b/composer/trainer/checkpoint.py\n@@ -119,7 +119,6 @@\n # to all processes on checkpoint resume.\n # This will be fixed by: https://github.com/mosaicml/composer/issues/12\n state_dict = {\n- 'state': state.state_dict(), # should be the same across all ranks. per-rank state not stored\n 'rng': self._get_rng_state(device=device), # stored across all ranks\n 'seed': seed,\n }\n@@ -128,6 +127,9 @@\n # Need the check down here so all the DDP syncs will work for generating the checkpoint\n return\n \n+ # we add the state only on rank 0 since other processes don't have loggers to serialize\n+ state_dict['state'] = state.state_dict() # should be the same across all ranks. per-rank state not stored\n+\n if config:\n hparams_path = os.path.join(self.checkpoint_folder, \"hparams.yaml\")\n os.makedirs(self.checkpoint_folder, mode=0o775, exist_ok=True)\n", "issue": "Checkpointing fails when using the composer command\n## Environment \r\nRunning on colo on branch `moin/bert` rebased off of the latest dev: commit hash `be411d3f71feffcbab84da8671dd530fdbbc2f30`.\r\n\r\n## To reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. Checkout `moin/bert` branch\r\n2. Run `composer -n 8 examples/run_mosaic_trainer.py -f composer/yamls/models/glue/sst-2_checkpointing.yaml`\r\n\r\n## Expected behavior\r\n\r\nIf I run `python examples/run_mosaic_trainer.py -f composer/yamls/models/glue/sst-2_checkpointing.yaml` instead of `composer -n 8`, then checkpointing works as expected, and we are able to save a checkpoint successfully and continue training. However, when I run it with `composer -n 8`, we see the following crash (exactly when checkpointing happens): \r\n\r\n```\r\n[BATCH][step=599]: { \"lr-AdamW/group0\": 0.0000, }\r\nError in subprocess\r\n----------Subprocess STDOUT----------\r\n\r\n----------Subprocess STDERR----------\r\n\r\nCommand '['/usr/bin/python3.8', '-u', 'examples/run_mosaic_trainer.py', '-f', 'composer/yamls/models/glue/sst-2_checkpointing.yaml']' returned non-zero exit status 1.\r\nKilling subprocess 33667 with SIGTERM\r\nKilling subprocess 33662 with SIGTERM\r\nKilling subprocess 33661 with SIGTERM\r\nKilling subprocess 33669 with SIGTERM\r\nKilling subprocess 33659 with SIGTERM\r\nWaiting 30 seconds for processes to terminate...\r\n```\r\n\r\nFor reference, checkpointing is set to every 600 iterations. There is no printed output.\r\n\r\n## Additional context\r\nThis is the next step in getting BERT pre-training working (saving the pre-trained model, and then fine-tuning it on GLUE tasks).\r\n\n", "before_files": [{"content": "# Copyright 2021 MosaicML. All Rights Reserved.\n\nimport logging\nimport os\nimport random\nimport warnings\nfrom typing import Any, Dict, Optional\n\nimport numpy as np\nimport torch\nimport yaml\n\nfrom composer.core import Event, State\nfrom composer.core.types import StateDict\nfrom composer.trainer.devices.device import Device\nfrom composer.utils import ddp, seed_all\n\nlog = logging.getLogger(__name__)\n\n\nclass CheckpointLoader:\n \"\"\"Manager for initializing state and restoring RNG state from existing checkpoints.\n\n Args:\n checkpoint_filepath (str): The path to an existing checkpoint file.\n \"\"\"\n\n def __init__(self, checkpoint_filepath: str):\n self.state_dict = torch.load(checkpoint_filepath, map_location='cpu')\n\n def load_checkpoint(self, state: State):\n \"\"\"Initialize state from the loaded checkpoint's data.\n \"\"\"\n\n state.load_state_dict(self.state_dict[\"state\"])\n self.checkpoint_rng_state = self._get_checkpoint_rng_state(state, self.state_dict[\"rng\"])\n\n if \"seed\" in self.state_dict:\n seed_all(self.state_dict[\"seed\"])\n\n def restore_checkpoint_rng_state(self, state: State, device: Device):\n \"\"\"Restore the state of all RNG objects in this context from the loaded checkpoint's data.\n \"\"\"\n\n if self.checkpoint_rng_state is None:\n return\n\n assert ddp.get_world_size() == len(\n self.checkpoint_rng_state['torch']\n ), f\"invariant violation: if the rng state is being restored, then\" \\\n \"the world size should be the same as in the checkpoint.\"\n\n torch.set_rng_state(self.checkpoint_rng_state['torch'][ddp.get_global_rank()])\n device.load_state_dict(self.checkpoint_rng_state['device'][ddp.get_global_rank()])\n random.setstate(self.checkpoint_rng_state['python'][ddp.get_global_rank()])\n np.random.set_state(self.checkpoint_rng_state['numpy'][ddp.get_global_rank()])\n\n self.checkpoint_rng_state = None\n\n def _get_checkpoint_rng_state(self, state: State, checkpoint_rng_state: StateDict) -> Optional[StateDict]:\n original_world_size = len(checkpoint_rng_state[\"torch\"])\n if original_world_size == ddp.get_world_size():\n return checkpoint_rng_state\n else:\n warnings.warn(f\"The checkpoint was created with world_size({original_world_size}), \"\n f\"which differs from the current world_size({ddp.get_world_size()}).\"\n f\"RNG state will not be restored.\")\n\n\nclass Checkpointer:\n \"\"\"Manager for saving state to checkpoint files.\n\n Args:\n checkpoint_folder (str): The path to the folder to store checkpoints in.\n checkpoint_interval (int): The amount of time units to wait between checkpoints.\n checkpoint_interval_unit (str): The unit (`\"ep\"` or `\"it\"`) that\n `checkpoint_interval` should be measured in.\n \"\"\"\n\n def __init__(self, checkpoint_folder: str, checkpoint_interval: int, checkpoint_interval_unit: str):\n if checkpoint_interval_unit.lower() == \"ep\":\n self.save_event = Event.EPOCH_END\n elif checkpoint_interval_unit.lower() == \"it\":\n self.save_event = Event.BATCH_END\n else:\n raise ValueError(f\"Unknown checkpointing interval: {checkpoint_interval_unit}\")\n self.checkpoint_folder = checkpoint_folder\n self.save_interval = checkpoint_interval\n\n def should_checkpoint(self, state: State, event: Event) -> bool:\n \"\"\"Given the current state and event, determine whether a checkpoint needs to be created.\n\n Args:\n state (State): The current State of the trainer.\n event (Event): The current Event being executed.\n \"\"\"\n\n if event != self.save_event:\n return False\n if self.save_event == Event.EPOCH_END:\n return state.epoch % self.save_interval == 0\n if self.save_event == Event.BATCH_END:\n return state.step % self.save_interval == 0\n return False\n\n def save_checkpoint(self, state: State, seed: int, device: Device, config: Optional[Dict[str, Any]] = None) -> None:\n \"\"\"Save the current state to a a new checkpoint file.\n\n Args:\n state (State): The current State of the trainer.\n device (Device): The Device in use by this process.\n ddp (DDP): The DDP engine in use by this trainer.\n config (Optional[Dict[str, Any]]): The hparams used to initialize this trainer, if any.\n \"\"\"\n\n # Store the rank0 seed, if the seed was provided on trainer init\n # then this is the same seed on all processes\n # If the seed was not provided, then the rank0 seed will be copied\n # to all processes on checkpoint resume.\n # This will be fixed by: https://github.com/mosaicml/composer/issues/12\n state_dict = {\n 'state': state.state_dict(), # should be the same across all ranks. per-rank state not stored\n 'rng': self._get_rng_state(device=device), # stored across all ranks\n 'seed': seed,\n }\n if ddp.get_global_rank() != 0:\n # only rank 0 saves checkpoints\n # Need the check down here so all the DDP syncs will work for generating the checkpoint\n return\n\n if config:\n hparams_path = os.path.join(self.checkpoint_folder, \"hparams.yaml\")\n os.makedirs(self.checkpoint_folder, mode=0o775, exist_ok=True)\n config_yaml_str = yaml.dump(config)\n try:\n with open(hparams_path, \"x\") as f:\n # Storing the config (ex. hparams) in a separate file so they can be modified before resuming\n f.write(config_yaml_str)\n except FileExistsError as e:\n with open(hparams_path, \"r\") as f:\n # comparing the parsed hparams to ignore whitespace and formatting differences\n if yaml.safe_load(config_yaml_str) != yaml.safe_load(f):\n raise RuntimeError(f\"The hparams in the existing checkpoint folder {self.checkpoint_folder} \"\n \"differ from those being used in the current training run. \"\n \"Please specify a new checkpoint folder.\") from e\n if self.save_event == Event.EPOCH_END:\n filename = f\"ep{state.epoch}.pt\"\n elif self.save_event == Event.BATCH_END:\n filename = f\"it{state.step}.pt\"\n else:\n raise ValueError(f\"Invalid checkpoint event: {self.save_event}\")\n save_file = os.path.join(self.checkpoint_folder, filename)\n with open(save_file, 'xb') as f:\n torch.save(state_dict, f)\n log.info(f'Trainer checkpoint saved to {save_file}')\n\n def _get_rng_state(self, device: Device) -> StateDict:\n rng_state = {\n \"python\": ddp.all_gather_object(random.getstate()),\n \"numpy\": ddp.all_gather_object(np.random.get_state()),\n \"torch\": ddp.all_gather_object(torch.random.get_rng_state()),\n \"device\": ddp.all_gather_object(device.state_dict()),\n }\n # casting the state dict as on non-rank-0, entries will be None-like\n return rng_state\n", "path": "composer/trainer/checkpoint.py"}], "after_files": [{"content": "# Copyright 2021 MosaicML. All Rights Reserved.\n\nimport logging\nimport os\nimport random\nimport warnings\nfrom typing import Any, Dict, Optional\n\nimport numpy as np\nimport torch\nimport yaml\n\nfrom composer.core import Event, State\nfrom composer.core.types import StateDict\nfrom composer.trainer.devices.device import Device\nfrom composer.utils import ddp, seed_all\n\nlog = logging.getLogger(__name__)\n\n\nclass CheckpointLoader:\n \"\"\"Manager for initializing state and restoring RNG state from existing checkpoints.\n\n Args:\n checkpoint_filepath (str): The path to an existing checkpoint file.\n \"\"\"\n\n def __init__(self, checkpoint_filepath: str):\n self.state_dict = torch.load(checkpoint_filepath, map_location='cpu')\n\n def load_checkpoint(self, state: State):\n \"\"\"Initialize state from the loaded checkpoint's data.\n \"\"\"\n\n state.load_state_dict(self.state_dict[\"state\"])\n self.checkpoint_rng_state = self._get_checkpoint_rng_state(state, self.state_dict[\"rng\"])\n\n if \"seed\" in self.state_dict:\n seed_all(self.state_dict[\"seed\"])\n\n def restore_checkpoint_rng_state(self, state: State, device: Device):\n \"\"\"Restore the state of all RNG objects in this context from the loaded checkpoint's data.\n \"\"\"\n\n if self.checkpoint_rng_state is None:\n return\n\n assert ddp.get_world_size() == len(\n self.checkpoint_rng_state['torch']\n ), f\"invariant violation: if the rng state is being restored, then\" \\\n \"the world size should be the same as in the checkpoint.\"\n\n torch.set_rng_state(self.checkpoint_rng_state['torch'][ddp.get_global_rank()])\n device.load_state_dict(self.checkpoint_rng_state['device'][ddp.get_global_rank()])\n random.setstate(self.checkpoint_rng_state['python'][ddp.get_global_rank()])\n np.random.set_state(self.checkpoint_rng_state['numpy'][ddp.get_global_rank()])\n\n self.checkpoint_rng_state = None\n\n def _get_checkpoint_rng_state(self, state: State, checkpoint_rng_state: StateDict) -> Optional[StateDict]:\n original_world_size = len(checkpoint_rng_state[\"torch\"])\n if original_world_size == ddp.get_world_size():\n return checkpoint_rng_state\n else:\n warnings.warn(f\"The checkpoint was created with world_size({original_world_size}), \"\n f\"which differs from the current world_size({ddp.get_world_size()}).\"\n f\"RNG state will not be restored.\")\n\n\nclass Checkpointer:\n \"\"\"Manager for saving state to checkpoint files.\n\n Args:\n checkpoint_folder (str): The path to the folder to store checkpoints in.\n checkpoint_interval (int): The amount of time units to wait between checkpoints.\n checkpoint_interval_unit (str): The unit (`\"ep\"` or `\"it\"`) that\n `checkpoint_interval` should be measured in.\n \"\"\"\n\n def __init__(self, checkpoint_folder: str, checkpoint_interval: int, checkpoint_interval_unit: str):\n if checkpoint_interval_unit.lower() == \"ep\":\n self.save_event = Event.EPOCH_END\n elif checkpoint_interval_unit.lower() == \"it\":\n self.save_event = Event.BATCH_END\n else:\n raise ValueError(f\"Unknown checkpointing interval: {checkpoint_interval_unit}\")\n self.checkpoint_folder = checkpoint_folder\n self.save_interval = checkpoint_interval\n\n def should_checkpoint(self, state: State, event: Event) -> bool:\n \"\"\"Given the current state and event, determine whether a checkpoint needs to be created.\n\n Args:\n state (State): The current State of the trainer.\n event (Event): The current Event being executed.\n \"\"\"\n\n if event != self.save_event:\n return False\n if self.save_event == Event.EPOCH_END:\n return state.epoch % self.save_interval == 0\n if self.save_event == Event.BATCH_END:\n return state.step % self.save_interval == 0\n return False\n\n def save_checkpoint(self, state: State, seed: int, device: Device, config: Optional[Dict[str, Any]] = None) -> None:\n \"\"\"Save the current state to a a new checkpoint file.\n\n Args:\n state (State): The current State of the trainer.\n device (Device): The Device in use by this process.\n ddp (DDP): The DDP engine in use by this trainer.\n config (Optional[Dict[str, Any]]): The hparams used to initialize this trainer, if any.\n \"\"\"\n\n # Store the rank0 seed, if the seed was provided on trainer init\n # then this is the same seed on all processes\n # If the seed was not provided, then the rank0 seed will be copied\n # to all processes on checkpoint resume.\n # This will be fixed by: https://github.com/mosaicml/composer/issues/12\n state_dict = {\n 'rng': self._get_rng_state(device=device), # stored across all ranks\n 'seed': seed,\n }\n if ddp.get_global_rank() != 0:\n # only rank 0 saves checkpoints\n # Need the check down here so all the DDP syncs will work for generating the checkpoint\n return\n\n # we add the state only on rank 0 since other processes don't have loggers to serialize\n state_dict['state'] = state.state_dict() # should be the same across all ranks. per-rank state not stored\n\n if config:\n hparams_path = os.path.join(self.checkpoint_folder, \"hparams.yaml\")\n os.makedirs(self.checkpoint_folder, mode=0o775, exist_ok=True)\n config_yaml_str = yaml.dump(config)\n try:\n with open(hparams_path, \"x\") as f:\n # Storing the config (ex. hparams) in a separate file so they can be modified before resuming\n f.write(config_yaml_str)\n except FileExistsError as e:\n with open(hparams_path, \"r\") as f:\n # comparing the parsed hparams to ignore whitespace and formatting differences\n if yaml.safe_load(config_yaml_str) != yaml.safe_load(f):\n raise RuntimeError(f\"The hparams in the existing checkpoint folder {self.checkpoint_folder} \"\n \"differ from those being used in the current training run. \"\n \"Please specify a new checkpoint folder.\") from e\n if self.save_event == Event.EPOCH_END:\n filename = f\"ep{state.epoch}.pt\"\n elif self.save_event == Event.BATCH_END:\n filename = f\"it{state.step}.pt\"\n else:\n raise ValueError(f\"Invalid checkpoint event: {self.save_event}\")\n save_file = os.path.join(self.checkpoint_folder, filename)\n with open(save_file, 'xb') as f:\n torch.save(state_dict, f)\n log.info(f'Trainer checkpoint saved to {save_file}')\n\n def _get_rng_state(self, device: Device) -> StateDict:\n rng_state = {\n \"python\": ddp.all_gather_object(random.getstate()),\n \"numpy\": ddp.all_gather_object(np.random.get_state()),\n \"torch\": ddp.all_gather_object(torch.random.get_rng_state()),\n \"device\": ddp.all_gather_object(device.state_dict()),\n }\n # casting the state dict as on non-rank-0, entries will be None-like\n return rng_state\n", "path": "composer/trainer/checkpoint.py"}]} | 2,657 | 276 |
gh_patches_debug_29247 | rasdani/github-patches | git_diff | lnbits__lnbits-944 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Ticket Counter Broken
Test bought 2 tickets. Amount available didn't decrease. Amount Sold didn't increase...
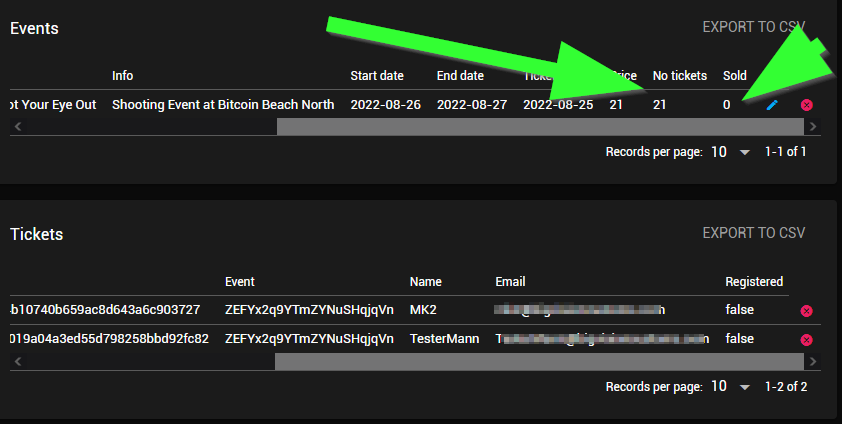
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lnbits/extensions/events/views_api.py`
Content:
```
1 from http import HTTPStatus
2
3 from fastapi.param_functions import Query
4 from fastapi.params import Depends
5 from starlette.exceptions import HTTPException
6 from starlette.requests import Request
7
8 from lnbits.core.crud import get_user
9 from lnbits.core.services import create_invoice
10 from lnbits.core.views.api import api_payment
11 from lnbits.decorators import WalletTypeInfo, get_key_type
12 from lnbits.extensions.events.models import CreateEvent, CreateTicket
13
14 from . import events_ext
15 from .crud import (
16 create_event,
17 create_ticket,
18 delete_event,
19 delete_event_tickets,
20 delete_ticket,
21 get_event,
22 get_event_tickets,
23 get_events,
24 get_ticket,
25 get_tickets,
26 reg_ticket,
27 set_ticket_paid,
28 update_event,
29 )
30
31 # Events
32
33
34 @events_ext.get("/api/v1/events")
35 async def api_events(
36 all_wallets: bool = Query(False), wallet: WalletTypeInfo = Depends(get_key_type)
37 ):
38 wallet_ids = [wallet.wallet.id]
39
40 if all_wallets:
41 wallet_ids = (await get_user(wallet.wallet.user)).wallet_ids
42
43 return [event.dict() for event in await get_events(wallet_ids)]
44
45
46 @events_ext.post("/api/v1/events")
47 @events_ext.put("/api/v1/events/{event_id}")
48 async def api_event_create(
49 data: CreateEvent, event_id=None, wallet: WalletTypeInfo = Depends(get_key_type)
50 ):
51 if event_id:
52 event = await get_event(event_id)
53 if not event:
54 raise HTTPException(
55 status_code=HTTPStatus.NOT_FOUND, detail=f"Event does not exist."
56 )
57
58 if event.wallet != wallet.wallet.id:
59 raise HTTPException(
60 status_code=HTTPStatus.FORBIDDEN, detail=f"Not your event."
61 )
62 event = await update_event(event_id, **data.dict())
63 else:
64 event = await create_event(data=data)
65
66 return event.dict()
67
68
69 @events_ext.delete("/api/v1/events/{event_id}")
70 async def api_form_delete(event_id, wallet: WalletTypeInfo = Depends(get_key_type)):
71 event = await get_event(event_id)
72 if not event:
73 raise HTTPException(
74 status_code=HTTPStatus.NOT_FOUND, detail=f"Event does not exist."
75 )
76
77 if event.wallet != wallet.wallet.id:
78 raise HTTPException(status_code=HTTPStatus.FORBIDDEN, detail=f"Not your event.")
79
80 await delete_event(event_id)
81 await delete_event_tickets(event_id)
82 raise HTTPException(status_code=HTTPStatus.NO_CONTENT)
83
84
85 #########Tickets##########
86
87
88 @events_ext.get("/api/v1/tickets")
89 async def api_tickets(
90 all_wallets: bool = Query(False), wallet: WalletTypeInfo = Depends(get_key_type)
91 ):
92 wallet_ids = [wallet.wallet.id]
93
94 if all_wallets:
95 wallet_ids = (await get_user(wallet.wallet.user)).wallet_ids
96
97 return [ticket.dict() for ticket in await get_tickets(wallet_ids)]
98
99
100 @events_ext.get("/api/v1/tickets/{event_id}")
101 async def api_ticket_make_ticket(event_id):
102 event = await get_event(event_id)
103 if not event:
104 raise HTTPException(
105 status_code=HTTPStatus.NOT_FOUND, detail=f"Event does not exist."
106 )
107 try:
108 payment_hash, payment_request = await create_invoice(
109 wallet_id=event.wallet,
110 amount=event.price_per_ticket,
111 memo=f"{event_id}",
112 extra={"tag": "events"},
113 )
114 except Exception as e:
115 raise HTTPException(status_code=HTTPStatus.INTERNAL_SERVER_ERROR, detail=str(e))
116
117 return {"payment_hash": payment_hash, "payment_request": payment_request}
118
119
120 @events_ext.post("/api/v1/tickets/{event_id}/{payment_hash}")
121 async def api_ticket_send_ticket(event_id, payment_hash, data: CreateTicket):
122 event = await get_event(event_id)
123 try:
124 status = await api_payment(payment_hash)
125 if status["paid"]:
126 ticket = await create_ticket(
127 payment_hash=payment_hash,
128 wallet=event.wallet,
129 event=event_id,
130 name=data.name,
131 email=data.email,
132 )
133
134 if not ticket:
135 raise HTTPException(
136 status_code=HTTPStatus.NOT_FOUND,
137 detail=f"Event could not be fetched.",
138 )
139
140 return {"paid": True, "ticket_id": ticket.id}
141 except Exception:
142 raise HTTPException(status_code=HTTPStatus.NOT_FOUND, detail="Not paid")
143 return {"paid": False}
144
145
146 @events_ext.delete("/api/v1/tickets/{ticket_id}")
147 async def api_ticket_delete(ticket_id, wallet: WalletTypeInfo = Depends(get_key_type)):
148 ticket = await get_ticket(ticket_id)
149 if not ticket:
150 raise HTTPException(
151 status_code=HTTPStatus.NOT_FOUND, detail=f"Ticket does not exist."
152 )
153
154 if ticket.wallet != wallet.wallet.id:
155 raise HTTPException(
156 status_code=HTTPStatus.FORBIDDEN, detail=f"Not your ticket."
157 )
158
159 await delete_ticket(ticket_id)
160 raise HTTPException(status_code=HTTPStatus.NO_CONTENT)
161
162
163 # Event Tickets
164
165
166 @events_ext.get("/api/v1/eventtickets/{wallet_id}/{event_id}")
167 async def api_event_tickets(wallet_id, event_id):
168 return [
169 ticket.dict()
170 for ticket in await get_event_tickets(wallet_id=wallet_id, event_id=event_id)
171 ]
172
173
174 @events_ext.get("/api/v1/register/ticket/{ticket_id}")
175 async def api_event_register_ticket(ticket_id):
176 ticket = await get_ticket(ticket_id)
177 if not ticket:
178 raise HTTPException(
179 status_code=HTTPStatus.NOT_FOUND, detail="Ticket does not exist."
180 )
181
182 if not ticket.paid:
183 raise HTTPException(
184 status_code=HTTPStatus.FORBIDDEN, detail="Ticket not paid for."
185 )
186
187 if ticket.registered == True:
188 raise HTTPException(
189 status_code=HTTPStatus.FORBIDDEN, detail="Ticket already registered"
190 )
191
192 return [ticket.dict() for ticket in await reg_ticket(ticket_id)]
193
```
Path: `lnbits/extensions/events/crud.py`
Content:
```
1 from typing import List, Optional, Union
2
3 from lnbits.helpers import urlsafe_short_hash
4
5 from . import db
6 from .models import CreateEvent, Events, Tickets
7
8 # TICKETS
9
10
11 async def create_ticket(
12 payment_hash: str, wallet: str, event: str, name: str, email: str
13 ) -> Tickets:
14 await db.execute(
15 """
16 INSERT INTO events.ticket (id, wallet, event, name, email, registered, paid)
17 VALUES (?, ?, ?, ?, ?, ?, ?)
18 """,
19 (payment_hash, wallet, event, name, email, False, True),
20 )
21
22 ticket = await get_ticket(payment_hash)
23 assert ticket, "Newly created ticket couldn't be retrieved"
24 return ticket
25
26
27 async def set_ticket_paid(payment_hash: str) -> Tickets:
28 row = await db.fetchone("SELECT * FROM events.ticket WHERE id = ?", (payment_hash,))
29 if row[6] != True:
30 await db.execute(
31 """
32 UPDATE events.ticket
33 SET paid = true
34 WHERE id = ?
35 """,
36 (payment_hash,),
37 )
38
39 eventdata = await get_event(row[2])
40 assert eventdata, "Couldn't get event from ticket being paid"
41
42 sold = eventdata.sold + 1
43 amount_tickets = eventdata.amount_tickets - 1
44 await db.execute(
45 """
46 UPDATE events.events
47 SET sold = ?, amount_tickets = ?
48 WHERE id = ?
49 """,
50 (sold, amount_tickets, row[2]),
51 )
52
53 ticket = await get_ticket(payment_hash)
54 assert ticket, "Newly updated ticket couldn't be retrieved"
55 return ticket
56
57
58 async def get_ticket(payment_hash: str) -> Optional[Tickets]:
59 row = await db.fetchone("SELECT * FROM events.ticket WHERE id = ?", (payment_hash,))
60 return Tickets(**row) if row else None
61
62
63 async def get_tickets(wallet_ids: Union[str, List[str]]) -> List[Tickets]:
64 if isinstance(wallet_ids, str):
65 wallet_ids = [wallet_ids]
66
67 q = ",".join(["?"] * len(wallet_ids))
68 rows = await db.fetchall(
69 f"SELECT * FROM events.ticket WHERE wallet IN ({q})", (*wallet_ids,)
70 )
71 return [Tickets(**row) for row in rows]
72
73
74 async def delete_ticket(payment_hash: str) -> None:
75 await db.execute("DELETE FROM events.ticket WHERE id = ?", (payment_hash,))
76
77
78 async def delete_event_tickets(event_id: str) -> None:
79 await db.execute("DELETE FROM events.ticket WHERE event = ?", (event_id,))
80
81
82 # EVENTS
83
84
85 async def create_event(data: CreateEvent) -> Events:
86 event_id = urlsafe_short_hash()
87 await db.execute(
88 """
89 INSERT INTO events.events (id, wallet, name, info, closing_date, event_start_date, event_end_date, amount_tickets, price_per_ticket, sold)
90 VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
91 """,
92 (
93 event_id,
94 data.wallet,
95 data.name,
96 data.info,
97 data.closing_date,
98 data.event_start_date,
99 data.event_end_date,
100 data.amount_tickets,
101 data.price_per_ticket,
102 0,
103 ),
104 )
105
106 event = await get_event(event_id)
107 assert event, "Newly created event couldn't be retrieved"
108 return event
109
110
111 async def update_event(event_id: str, **kwargs) -> Events:
112 q = ", ".join([f"{field[0]} = ?" for field in kwargs.items()])
113 await db.execute(
114 f"UPDATE events.events SET {q} WHERE id = ?", (*kwargs.values(), event_id)
115 )
116 event = await get_event(event_id)
117 assert event, "Newly updated event couldn't be retrieved"
118 return event
119
120
121 async def get_event(event_id: str) -> Optional[Events]:
122 row = await db.fetchone("SELECT * FROM events.events WHERE id = ?", (event_id,))
123 return Events(**row) if row else None
124
125
126 async def get_events(wallet_ids: Union[str, List[str]]) -> List[Events]:
127 if isinstance(wallet_ids, str):
128 wallet_ids = [wallet_ids]
129
130 q = ",".join(["?"] * len(wallet_ids))
131 rows = await db.fetchall(
132 f"SELECT * FROM events.events WHERE wallet IN ({q})", (*wallet_ids,)
133 )
134
135 return [Events(**row) for row in rows]
136
137
138 async def delete_event(event_id: str) -> None:
139 await db.execute("DELETE FROM events.events WHERE id = ?", (event_id,))
140
141
142 # EVENTTICKETS
143
144
145 async def get_event_tickets(event_id: str, wallet_id: str) -> List[Tickets]:
146 rows = await db.fetchall(
147 "SELECT * FROM events.ticket WHERE wallet = ? AND event = ?",
148 (wallet_id, event_id),
149 )
150 return [Tickets(**row) for row in rows]
151
152
153 async def reg_ticket(ticket_id: str) -> List[Tickets]:
154 await db.execute(
155 "UPDATE events.ticket SET registered = ? WHERE id = ?", (True, ticket_id)
156 )
157 ticket = await db.fetchone("SELECT * FROM events.ticket WHERE id = ?", (ticket_id,))
158 rows = await db.fetchall(
159 "SELECT * FROM events.ticket WHERE event = ?", (ticket[1],)
160 )
161 return [Tickets(**row) for row in rows]
162
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/lnbits/extensions/events/crud.py b/lnbits/extensions/events/crud.py
--- a/lnbits/extensions/events/crud.py
+++ b/lnbits/extensions/events/crud.py
@@ -19,39 +19,22 @@
(payment_hash, wallet, event, name, email, False, True),
)
- ticket = await get_ticket(payment_hash)
- assert ticket, "Newly created ticket couldn't be retrieved"
- return ticket
-
-
-async def set_ticket_paid(payment_hash: str) -> Tickets:
- row = await db.fetchone("SELECT * FROM events.ticket WHERE id = ?", (payment_hash,))
- if row[6] != True:
- await db.execute(
- """
- UPDATE events.ticket
- SET paid = true
- WHERE id = ?
- """,
- (payment_hash,),
- )
-
- eventdata = await get_event(row[2])
- assert eventdata, "Couldn't get event from ticket being paid"
-
- sold = eventdata.sold + 1
- amount_tickets = eventdata.amount_tickets - 1
- await db.execute(
- """
- UPDATE events.events
- SET sold = ?, amount_tickets = ?
- WHERE id = ?
- """,
- (sold, amount_tickets, row[2]),
- )
+ # UPDATE EVENT DATA ON SOLD TICKET
+ eventdata = await get_event(event)
+ assert eventdata, "Couldn't get event from ticket being paid"
+ sold = eventdata.sold + 1
+ amount_tickets = eventdata.amount_tickets - 1
+ await db.execute(
+ """
+ UPDATE events.events
+ SET sold = ?, amount_tickets = ?
+ WHERE id = ?
+ """,
+ (sold, amount_tickets, event),
+ )
ticket = await get_ticket(payment_hash)
- assert ticket, "Newly updated ticket couldn't be retrieved"
+ assert ticket, "Newly created ticket couldn't be retrieved"
return ticket
diff --git a/lnbits/extensions/events/views_api.py b/lnbits/extensions/events/views_api.py
--- a/lnbits/extensions/events/views_api.py
+++ b/lnbits/extensions/events/views_api.py
@@ -24,7 +24,6 @@
get_ticket,
get_tickets,
reg_ticket,
- set_ticket_paid,
update_event,
)
| {"golden_diff": "diff --git a/lnbits/extensions/events/crud.py b/lnbits/extensions/events/crud.py\n--- a/lnbits/extensions/events/crud.py\n+++ b/lnbits/extensions/events/crud.py\n@@ -19,39 +19,22 @@\n (payment_hash, wallet, event, name, email, False, True),\n )\n \n- ticket = await get_ticket(payment_hash)\n- assert ticket, \"Newly created ticket couldn't be retrieved\"\n- return ticket\n-\n-\n-async def set_ticket_paid(payment_hash: str) -> Tickets:\n- row = await db.fetchone(\"SELECT * FROM events.ticket WHERE id = ?\", (payment_hash,))\n- if row[6] != True:\n- await db.execute(\n- \"\"\"\n- UPDATE events.ticket\n- SET paid = true\n- WHERE id = ?\n- \"\"\",\n- (payment_hash,),\n- )\n-\n- eventdata = await get_event(row[2])\n- assert eventdata, \"Couldn't get event from ticket being paid\"\n-\n- sold = eventdata.sold + 1\n- amount_tickets = eventdata.amount_tickets - 1\n- await db.execute(\n- \"\"\"\n- UPDATE events.events\n- SET sold = ?, amount_tickets = ?\n- WHERE id = ?\n- \"\"\",\n- (sold, amount_tickets, row[2]),\n- )\n+ # UPDATE EVENT DATA ON SOLD TICKET\n+ eventdata = await get_event(event)\n+ assert eventdata, \"Couldn't get event from ticket being paid\"\n+ sold = eventdata.sold + 1\n+ amount_tickets = eventdata.amount_tickets - 1\n+ await db.execute(\n+ \"\"\"\n+ UPDATE events.events\n+ SET sold = ?, amount_tickets = ?\n+ WHERE id = ?\n+ \"\"\",\n+ (sold, amount_tickets, event),\n+ )\n \n ticket = await get_ticket(payment_hash)\n- assert ticket, \"Newly updated ticket couldn't be retrieved\"\n+ assert ticket, \"Newly created ticket couldn't be retrieved\"\n return ticket\n \n \ndiff --git a/lnbits/extensions/events/views_api.py b/lnbits/extensions/events/views_api.py\n--- a/lnbits/extensions/events/views_api.py\n+++ b/lnbits/extensions/events/views_api.py\n@@ -24,7 +24,6 @@\n get_ticket,\n get_tickets,\n reg_ticket,\n- set_ticket_paid,\n update_event,\n )\n", "issue": "Ticket Counter Broken\nTest bought 2 tickets. Amount available didn't decrease. Amount Sold didn't increase...\r\n\r\n\r\n\n", "before_files": [{"content": "from http import HTTPStatus\n\nfrom fastapi.param_functions import Query\nfrom fastapi.params import Depends\nfrom starlette.exceptions import HTTPException\nfrom starlette.requests import Request\n\nfrom lnbits.core.crud import get_user\nfrom lnbits.core.services import create_invoice\nfrom lnbits.core.views.api import api_payment\nfrom lnbits.decorators import WalletTypeInfo, get_key_type\nfrom lnbits.extensions.events.models import CreateEvent, CreateTicket\n\nfrom . import events_ext\nfrom .crud import (\n create_event,\n create_ticket,\n delete_event,\n delete_event_tickets,\n delete_ticket,\n get_event,\n get_event_tickets,\n get_events,\n get_ticket,\n get_tickets,\n reg_ticket,\n set_ticket_paid,\n update_event,\n)\n\n# Events\n\n\n@events_ext.get(\"/api/v1/events\")\nasync def api_events(\n all_wallets: bool = Query(False), wallet: WalletTypeInfo = Depends(get_key_type)\n):\n wallet_ids = [wallet.wallet.id]\n\n if all_wallets:\n wallet_ids = (await get_user(wallet.wallet.user)).wallet_ids\n\n return [event.dict() for event in await get_events(wallet_ids)]\n\n\n@events_ext.post(\"/api/v1/events\")\n@events_ext.put(\"/api/v1/events/{event_id}\")\nasync def api_event_create(\n data: CreateEvent, event_id=None, wallet: WalletTypeInfo = Depends(get_key_type)\n):\n if event_id:\n event = await get_event(event_id)\n if not event:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND, detail=f\"Event does not exist.\"\n )\n\n if event.wallet != wallet.wallet.id:\n raise HTTPException(\n status_code=HTTPStatus.FORBIDDEN, detail=f\"Not your event.\"\n )\n event = await update_event(event_id, **data.dict())\n else:\n event = await create_event(data=data)\n\n return event.dict()\n\n\n@events_ext.delete(\"/api/v1/events/{event_id}\")\nasync def api_form_delete(event_id, wallet: WalletTypeInfo = Depends(get_key_type)):\n event = await get_event(event_id)\n if not event:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND, detail=f\"Event does not exist.\"\n )\n\n if event.wallet != wallet.wallet.id:\n raise HTTPException(status_code=HTTPStatus.FORBIDDEN, detail=f\"Not your event.\")\n\n await delete_event(event_id)\n await delete_event_tickets(event_id)\n raise HTTPException(status_code=HTTPStatus.NO_CONTENT)\n\n\n#########Tickets##########\n\n\n@events_ext.get(\"/api/v1/tickets\")\nasync def api_tickets(\n all_wallets: bool = Query(False), wallet: WalletTypeInfo = Depends(get_key_type)\n):\n wallet_ids = [wallet.wallet.id]\n\n if all_wallets:\n wallet_ids = (await get_user(wallet.wallet.user)).wallet_ids\n\n return [ticket.dict() for ticket in await get_tickets(wallet_ids)]\n\n\n@events_ext.get(\"/api/v1/tickets/{event_id}\")\nasync def api_ticket_make_ticket(event_id):\n event = await get_event(event_id)\n if not event:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND, detail=f\"Event does not exist.\"\n )\n try:\n payment_hash, payment_request = await create_invoice(\n wallet_id=event.wallet,\n amount=event.price_per_ticket,\n memo=f\"{event_id}\",\n extra={\"tag\": \"events\"},\n )\n except Exception as e:\n raise HTTPException(status_code=HTTPStatus.INTERNAL_SERVER_ERROR, detail=str(e))\n\n return {\"payment_hash\": payment_hash, \"payment_request\": payment_request}\n\n\n@events_ext.post(\"/api/v1/tickets/{event_id}/{payment_hash}\")\nasync def api_ticket_send_ticket(event_id, payment_hash, data: CreateTicket):\n event = await get_event(event_id)\n try:\n status = await api_payment(payment_hash)\n if status[\"paid\"]:\n ticket = await create_ticket(\n payment_hash=payment_hash,\n wallet=event.wallet,\n event=event_id,\n name=data.name,\n email=data.email,\n )\n\n if not ticket:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND,\n detail=f\"Event could not be fetched.\",\n )\n\n return {\"paid\": True, \"ticket_id\": ticket.id}\n except Exception:\n raise HTTPException(status_code=HTTPStatus.NOT_FOUND, detail=\"Not paid\")\n return {\"paid\": False}\n\n\n@events_ext.delete(\"/api/v1/tickets/{ticket_id}\")\nasync def api_ticket_delete(ticket_id, wallet: WalletTypeInfo = Depends(get_key_type)):\n ticket = await get_ticket(ticket_id)\n if not ticket:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND, detail=f\"Ticket does not exist.\"\n )\n\n if ticket.wallet != wallet.wallet.id:\n raise HTTPException(\n status_code=HTTPStatus.FORBIDDEN, detail=f\"Not your ticket.\"\n )\n\n await delete_ticket(ticket_id)\n raise HTTPException(status_code=HTTPStatus.NO_CONTENT)\n\n\n# Event Tickets\n\n\n@events_ext.get(\"/api/v1/eventtickets/{wallet_id}/{event_id}\")\nasync def api_event_tickets(wallet_id, event_id):\n return [\n ticket.dict()\n for ticket in await get_event_tickets(wallet_id=wallet_id, event_id=event_id)\n ]\n\n\n@events_ext.get(\"/api/v1/register/ticket/{ticket_id}\")\nasync def api_event_register_ticket(ticket_id):\n ticket = await get_ticket(ticket_id)\n if not ticket:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND, detail=\"Ticket does not exist.\"\n )\n\n if not ticket.paid:\n raise HTTPException(\n status_code=HTTPStatus.FORBIDDEN, detail=\"Ticket not paid for.\"\n )\n\n if ticket.registered == True:\n raise HTTPException(\n status_code=HTTPStatus.FORBIDDEN, detail=\"Ticket already registered\"\n )\n\n return [ticket.dict() for ticket in await reg_ticket(ticket_id)]\n", "path": "lnbits/extensions/events/views_api.py"}, {"content": "from typing import List, Optional, Union\n\nfrom lnbits.helpers import urlsafe_short_hash\n\nfrom . import db\nfrom .models import CreateEvent, Events, Tickets\n\n# TICKETS\n\n\nasync def create_ticket(\n payment_hash: str, wallet: str, event: str, name: str, email: str\n) -> Tickets:\n await db.execute(\n \"\"\"\n INSERT INTO events.ticket (id, wallet, event, name, email, registered, paid)\n VALUES (?, ?, ?, ?, ?, ?, ?)\n \"\"\",\n (payment_hash, wallet, event, name, email, False, True),\n )\n\n ticket = await get_ticket(payment_hash)\n assert ticket, \"Newly created ticket couldn't be retrieved\"\n return ticket\n\n\nasync def set_ticket_paid(payment_hash: str) -> Tickets:\n row = await db.fetchone(\"SELECT * FROM events.ticket WHERE id = ?\", (payment_hash,))\n if row[6] != True:\n await db.execute(\n \"\"\"\n UPDATE events.ticket\n SET paid = true\n WHERE id = ?\n \"\"\",\n (payment_hash,),\n )\n\n eventdata = await get_event(row[2])\n assert eventdata, \"Couldn't get event from ticket being paid\"\n\n sold = eventdata.sold + 1\n amount_tickets = eventdata.amount_tickets - 1\n await db.execute(\n \"\"\"\n UPDATE events.events\n SET sold = ?, amount_tickets = ?\n WHERE id = ?\n \"\"\",\n (sold, amount_tickets, row[2]),\n )\n\n ticket = await get_ticket(payment_hash)\n assert ticket, \"Newly updated ticket couldn't be retrieved\"\n return ticket\n\n\nasync def get_ticket(payment_hash: str) -> Optional[Tickets]:\n row = await db.fetchone(\"SELECT * FROM events.ticket WHERE id = ?\", (payment_hash,))\n return Tickets(**row) if row else None\n\n\nasync def get_tickets(wallet_ids: Union[str, List[str]]) -> List[Tickets]:\n if isinstance(wallet_ids, str):\n wallet_ids = [wallet_ids]\n\n q = \",\".join([\"?\"] * len(wallet_ids))\n rows = await db.fetchall(\n f\"SELECT * FROM events.ticket WHERE wallet IN ({q})\", (*wallet_ids,)\n )\n return [Tickets(**row) for row in rows]\n\n\nasync def delete_ticket(payment_hash: str) -> None:\n await db.execute(\"DELETE FROM events.ticket WHERE id = ?\", (payment_hash,))\n\n\nasync def delete_event_tickets(event_id: str) -> None:\n await db.execute(\"DELETE FROM events.ticket WHERE event = ?\", (event_id,))\n\n\n# EVENTS\n\n\nasync def create_event(data: CreateEvent) -> Events:\n event_id = urlsafe_short_hash()\n await db.execute(\n \"\"\"\n INSERT INTO events.events (id, wallet, name, info, closing_date, event_start_date, event_end_date, amount_tickets, price_per_ticket, sold)\n VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)\n \"\"\",\n (\n event_id,\n data.wallet,\n data.name,\n data.info,\n data.closing_date,\n data.event_start_date,\n data.event_end_date,\n data.amount_tickets,\n data.price_per_ticket,\n 0,\n ),\n )\n\n event = await get_event(event_id)\n assert event, \"Newly created event couldn't be retrieved\"\n return event\n\n\nasync def update_event(event_id: str, **kwargs) -> Events:\n q = \", \".join([f\"{field[0]} = ?\" for field in kwargs.items()])\n await db.execute(\n f\"UPDATE events.events SET {q} WHERE id = ?\", (*kwargs.values(), event_id)\n )\n event = await get_event(event_id)\n assert event, \"Newly updated event couldn't be retrieved\"\n return event\n\n\nasync def get_event(event_id: str) -> Optional[Events]:\n row = await db.fetchone(\"SELECT * FROM events.events WHERE id = ?\", (event_id,))\n return Events(**row) if row else None\n\n\nasync def get_events(wallet_ids: Union[str, List[str]]) -> List[Events]:\n if isinstance(wallet_ids, str):\n wallet_ids = [wallet_ids]\n\n q = \",\".join([\"?\"] * len(wallet_ids))\n rows = await db.fetchall(\n f\"SELECT * FROM events.events WHERE wallet IN ({q})\", (*wallet_ids,)\n )\n\n return [Events(**row) for row in rows]\n\n\nasync def delete_event(event_id: str) -> None:\n await db.execute(\"DELETE FROM events.events WHERE id = ?\", (event_id,))\n\n\n# EVENTTICKETS\n\n\nasync def get_event_tickets(event_id: str, wallet_id: str) -> List[Tickets]:\n rows = await db.fetchall(\n \"SELECT * FROM events.ticket WHERE wallet = ? AND event = ?\",\n (wallet_id, event_id),\n )\n return [Tickets(**row) for row in rows]\n\n\nasync def reg_ticket(ticket_id: str) -> List[Tickets]:\n await db.execute(\n \"UPDATE events.ticket SET registered = ? WHERE id = ?\", (True, ticket_id)\n )\n ticket = await db.fetchone(\"SELECT * FROM events.ticket WHERE id = ?\", (ticket_id,))\n rows = await db.fetchall(\n \"SELECT * FROM events.ticket WHERE event = ?\", (ticket[1],)\n )\n return [Tickets(**row) for row in rows]\n", "path": "lnbits/extensions/events/crud.py"}], "after_files": [{"content": "from http import HTTPStatus\n\nfrom fastapi.param_functions import Query\nfrom fastapi.params import Depends\nfrom starlette.exceptions import HTTPException\nfrom starlette.requests import Request\n\nfrom lnbits.core.crud import get_user\nfrom lnbits.core.services import create_invoice\nfrom lnbits.core.views.api import api_payment\nfrom lnbits.decorators import WalletTypeInfo, get_key_type\nfrom lnbits.extensions.events.models import CreateEvent, CreateTicket\n\nfrom . import events_ext\nfrom .crud import (\n create_event,\n create_ticket,\n delete_event,\n delete_event_tickets,\n delete_ticket,\n get_event,\n get_event_tickets,\n get_events,\n get_ticket,\n get_tickets,\n reg_ticket,\n update_event,\n)\n\n# Events\n\n\n@events_ext.get(\"/api/v1/events\")\nasync def api_events(\n all_wallets: bool = Query(False), wallet: WalletTypeInfo = Depends(get_key_type)\n):\n wallet_ids = [wallet.wallet.id]\n\n if all_wallets:\n wallet_ids = (await get_user(wallet.wallet.user)).wallet_ids\n\n return [event.dict() for event in await get_events(wallet_ids)]\n\n\n@events_ext.post(\"/api/v1/events\")\n@events_ext.put(\"/api/v1/events/{event_id}\")\nasync def api_event_create(\n data: CreateEvent, event_id=None, wallet: WalletTypeInfo = Depends(get_key_type)\n):\n if event_id:\n event = await get_event(event_id)\n if not event:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND, detail=f\"Event does not exist.\"\n )\n\n if event.wallet != wallet.wallet.id:\n raise HTTPException(\n status_code=HTTPStatus.FORBIDDEN, detail=f\"Not your event.\"\n )\n event = await update_event(event_id, **data.dict())\n else:\n event = await create_event(data=data)\n\n return event.dict()\n\n\n@events_ext.delete(\"/api/v1/events/{event_id}\")\nasync def api_form_delete(event_id, wallet: WalletTypeInfo = Depends(get_key_type)):\n event = await get_event(event_id)\n if not event:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND, detail=f\"Event does not exist.\"\n )\n\n if event.wallet != wallet.wallet.id:\n raise HTTPException(status_code=HTTPStatus.FORBIDDEN, detail=f\"Not your event.\")\n\n await delete_event(event_id)\n await delete_event_tickets(event_id)\n raise HTTPException(status_code=HTTPStatus.NO_CONTENT)\n\n\n#########Tickets##########\n\n\n@events_ext.get(\"/api/v1/tickets\")\nasync def api_tickets(\n all_wallets: bool = Query(False), wallet: WalletTypeInfo = Depends(get_key_type)\n):\n wallet_ids = [wallet.wallet.id]\n\n if all_wallets:\n wallet_ids = (await get_user(wallet.wallet.user)).wallet_ids\n\n return [ticket.dict() for ticket in await get_tickets(wallet_ids)]\n\n\n@events_ext.get(\"/api/v1/tickets/{event_id}\")\nasync def api_ticket_make_ticket(event_id):\n event = await get_event(event_id)\n if not event:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND, detail=f\"Event does not exist.\"\n )\n try:\n payment_hash, payment_request = await create_invoice(\n wallet_id=event.wallet,\n amount=event.price_per_ticket,\n memo=f\"{event_id}\",\n extra={\"tag\": \"events\"},\n )\n except Exception as e:\n raise HTTPException(status_code=HTTPStatus.INTERNAL_SERVER_ERROR, detail=str(e))\n\n return {\"payment_hash\": payment_hash, \"payment_request\": payment_request}\n\n\n@events_ext.post(\"/api/v1/tickets/{event_id}/{payment_hash}\")\nasync def api_ticket_send_ticket(event_id, payment_hash, data: CreateTicket):\n event = await get_event(event_id)\n try:\n status = await api_payment(payment_hash)\n if status[\"paid\"]:\n ticket = await create_ticket(\n payment_hash=payment_hash,\n wallet=event.wallet,\n event=event_id,\n name=data.name,\n email=data.email,\n )\n\n if not ticket:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND,\n detail=f\"Event could not be fetched.\",\n )\n\n return {\"paid\": True, \"ticket_id\": ticket.id}\n except Exception:\n raise HTTPException(status_code=HTTPStatus.NOT_FOUND, detail=\"Not paid\")\n return {\"paid\": False}\n\n\n@events_ext.delete(\"/api/v1/tickets/{ticket_id}\")\nasync def api_ticket_delete(ticket_id, wallet: WalletTypeInfo = Depends(get_key_type)):\n ticket = await get_ticket(ticket_id)\n if not ticket:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND, detail=f\"Ticket does not exist.\"\n )\n\n if ticket.wallet != wallet.wallet.id:\n raise HTTPException(\n status_code=HTTPStatus.FORBIDDEN, detail=f\"Not your ticket.\"\n )\n\n await delete_ticket(ticket_id)\n raise HTTPException(status_code=HTTPStatus.NO_CONTENT)\n\n\n# Event Tickets\n\n\n@events_ext.get(\"/api/v1/eventtickets/{wallet_id}/{event_id}\")\nasync def api_event_tickets(wallet_id, event_id):\n return [\n ticket.dict()\n for ticket in await get_event_tickets(wallet_id=wallet_id, event_id=event_id)\n ]\n\n\n@events_ext.get(\"/api/v1/register/ticket/{ticket_id}\")\nasync def api_event_register_ticket(ticket_id):\n ticket = await get_ticket(ticket_id)\n if not ticket:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND, detail=\"Ticket does not exist.\"\n )\n\n if not ticket.paid:\n raise HTTPException(\n status_code=HTTPStatus.FORBIDDEN, detail=\"Ticket not paid for.\"\n )\n\n if ticket.registered == True:\n raise HTTPException(\n status_code=HTTPStatus.FORBIDDEN, detail=\"Ticket already registered\"\n )\n\n return [ticket.dict() for ticket in await reg_ticket(ticket_id)]\n", "path": "lnbits/extensions/events/views_api.py"}, {"content": "from typing import List, Optional, Union\n\nfrom lnbits.helpers import urlsafe_short_hash\n\nfrom . import db\nfrom .models import CreateEvent, Events, Tickets\n\n# TICKETS\n\n\nasync def create_ticket(\n payment_hash: str, wallet: str, event: str, name: str, email: str\n) -> Tickets:\n await db.execute(\n \"\"\"\n INSERT INTO events.ticket (id, wallet, event, name, email, registered, paid)\n VALUES (?, ?, ?, ?, ?, ?, ?)\n \"\"\",\n (payment_hash, wallet, event, name, email, False, True),\n )\n\n # UPDATE EVENT DATA ON SOLD TICKET\n eventdata = await get_event(event)\n assert eventdata, \"Couldn't get event from ticket being paid\"\n sold = eventdata.sold + 1\n amount_tickets = eventdata.amount_tickets - 1\n await db.execute(\n \"\"\"\n UPDATE events.events\n SET sold = ?, amount_tickets = ?\n WHERE id = ?\n \"\"\",\n (sold, amount_tickets, event),\n )\n\n ticket = await get_ticket(payment_hash)\n assert ticket, \"Newly created ticket couldn't be retrieved\"\n return ticket\n\n\nasync def get_ticket(payment_hash: str) -> Optional[Tickets]:\n row = await db.fetchone(\"SELECT * FROM events.ticket WHERE id = ?\", (payment_hash,))\n return Tickets(**row) if row else None\n\n\nasync def get_tickets(wallet_ids: Union[str, List[str]]) -> List[Tickets]:\n if isinstance(wallet_ids, str):\n wallet_ids = [wallet_ids]\n\n q = \",\".join([\"?\"] * len(wallet_ids))\n rows = await db.fetchall(\n f\"SELECT * FROM events.ticket WHERE wallet IN ({q})\", (*wallet_ids,)\n )\n return [Tickets(**row) for row in rows]\n\n\nasync def delete_ticket(payment_hash: str) -> None:\n await db.execute(\"DELETE FROM events.ticket WHERE id = ?\", (payment_hash,))\n\n\nasync def delete_event_tickets(event_id: str) -> None:\n await db.execute(\"DELETE FROM events.ticket WHERE event = ?\", (event_id,))\n\n\n# EVENTS\n\n\nasync def create_event(data: CreateEvent) -> Events:\n event_id = urlsafe_short_hash()\n await db.execute(\n \"\"\"\n INSERT INTO events.events (id, wallet, name, info, closing_date, event_start_date, event_end_date, amount_tickets, price_per_ticket, sold)\n VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)\n \"\"\",\n (\n event_id,\n data.wallet,\n data.name,\n data.info,\n data.closing_date,\n data.event_start_date,\n data.event_end_date,\n data.amount_tickets,\n data.price_per_ticket,\n 0,\n ),\n )\n\n event = await get_event(event_id)\n assert event, \"Newly created event couldn't be retrieved\"\n return event\n\n\nasync def update_event(event_id: str, **kwargs) -> Events:\n q = \", \".join([f\"{field[0]} = ?\" for field in kwargs.items()])\n await db.execute(\n f\"UPDATE events.events SET {q} WHERE id = ?\", (*kwargs.values(), event_id)\n )\n event = await get_event(event_id)\n assert event, \"Newly updated event couldn't be retrieved\"\n return event\n\n\nasync def get_event(event_id: str) -> Optional[Events]:\n row = await db.fetchone(\"SELECT * FROM events.events WHERE id = ?\", (event_id,))\n return Events(**row) if row else None\n\n\nasync def get_events(wallet_ids: Union[str, List[str]]) -> List[Events]:\n if isinstance(wallet_ids, str):\n wallet_ids = [wallet_ids]\n\n q = \",\".join([\"?\"] * len(wallet_ids))\n rows = await db.fetchall(\n f\"SELECT * FROM events.events WHERE wallet IN ({q})\", (*wallet_ids,)\n )\n\n return [Events(**row) for row in rows]\n\n\nasync def delete_event(event_id: str) -> None:\n await db.execute(\"DELETE FROM events.events WHERE id = ?\", (event_id,))\n\n\n# EVENTTICKETS\n\n\nasync def get_event_tickets(event_id: str, wallet_id: str) -> List[Tickets]:\n rows = await db.fetchall(\n \"SELECT * FROM events.ticket WHERE wallet = ? AND event = ?\",\n (wallet_id, event_id),\n )\n return [Tickets(**row) for row in rows]\n\n\nasync def reg_ticket(ticket_id: str) -> List[Tickets]:\n await db.execute(\n \"UPDATE events.ticket SET registered = ? WHERE id = ?\", (True, ticket_id)\n )\n ticket = await db.fetchone(\"SELECT * FROM events.ticket WHERE id = ?\", (ticket_id,))\n rows = await db.fetchall(\n \"SELECT * FROM events.ticket WHERE event = ?\", (ticket[1],)\n )\n return [Tickets(**row) for row in rows]\n", "path": "lnbits/extensions/events/crud.py"}]} | 3,685 | 527 |
gh_patches_debug_65242 | rasdani/github-patches | git_diff | streamlink__streamlink-2229 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
powerapp.py No plugin can handle URL
## Error Report
- [X] This is a bug report and I have read the Posting Guidelines.
### Description
powerapp.com.tr should be able to play the stations
### Expected / actual behavior
Inserting the page in the streamlink does not play the stream. About my web browser Firefox I see the picture and hear the sound synonymous
### Reproduction steps / Explicit stream URLs to test
1.www.powerapp.com.tr/tvs/powertv/
streamlink http://www.powerapp.com.tr/tvs/powertv best
### log output
> streamlink http://www.powerapp.com.tr/tvs/powertv best
error: No plugin can handle URL: http://www.powerapp.com.tr/tvs/powertv
> error: No plugin can handle URL: http://www.powerapp.com.tr/tvs/powertv
error:: The term "error:" was not used as the name of a cmdlet, a function, a script file, or a
recognized executable program. Check the spelling of the name, or if the path is correct (provided
contain) and repeat the process.
In line: 1 character: 1
+ error: No plugin can handle URL: http://www.powerapp.com.tr/tvs/power ...
+~~~~~
+ CategoryInfo: ObjectNotFound: (error :: String) [], CommandNotFoundException
+ FullyQualifiedErrorId: CommandNotFoundException
### Additional comments, screenshots, etc.
Screenshot
https://i.ibb.co/g99nXC0/france.jpg
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/powerapp.py`
Content:
```
1 from __future__ import print_function
2 import re
3
4 from streamlink.plugin import Plugin
5 from streamlink.plugin.api import validate
6 from streamlink.stream import HLSStream
7
8
9 class PowerApp(Plugin):
10 url_re = re.compile(r"https?://(?:www.)?powerapp.com.tr/tv/(\w+)")
11 api_url = "http://api.powergroup.com.tr/Channels/{0}/?appRef=iPowerWeb&apiVersion=11"
12 api_schema = validate.Schema(validate.all({
13 "errorCode": 0,
14 "response": {
15 "channel_stream_url": validate.url()
16 }
17 }, validate.get("response")))
18
19 @classmethod
20 def can_handle_url(cls, url):
21 return cls.url_re.match(url) is not None
22
23 def _get_streams(self):
24 channel = self.url_re.match(self.url).group(1)
25
26 res = self.session.http.get(self.api_url.format(channel))
27 data = self.session.http.json(res, schema=self.api_schema)
28
29 return HLSStream.parse_variant_playlist(self.session, data["channel_stream_url"])
30
31
32 __plugin__ = PowerApp
33
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/streamlink/plugins/powerapp.py b/src/streamlink/plugins/powerapp.py
--- a/src/streamlink/plugins/powerapp.py
+++ b/src/streamlink/plugins/powerapp.py
@@ -7,7 +7,7 @@
class PowerApp(Plugin):
- url_re = re.compile(r"https?://(?:www.)?powerapp.com.tr/tv/(\w+)")
+ url_re = re.compile(r"https?://(?:www.)?powerapp.com.tr/tvs?/(\w+)")
api_url = "http://api.powergroup.com.tr/Channels/{0}/?appRef=iPowerWeb&apiVersion=11"
api_schema = validate.Schema(validate.all({
"errorCode": 0,
| {"golden_diff": "diff --git a/src/streamlink/plugins/powerapp.py b/src/streamlink/plugins/powerapp.py\n--- a/src/streamlink/plugins/powerapp.py\n+++ b/src/streamlink/plugins/powerapp.py\n@@ -7,7 +7,7 @@\n \n \n class PowerApp(Plugin):\n- url_re = re.compile(r\"https?://(?:www.)?powerapp.com.tr/tv/(\\w+)\")\n+ url_re = re.compile(r\"https?://(?:www.)?powerapp.com.tr/tvs?/(\\w+)\")\n api_url = \"http://api.powergroup.com.tr/Channels/{0}/?appRef=iPowerWeb&apiVersion=11\"\n api_schema = validate.Schema(validate.all({\n \"errorCode\": 0,\n", "issue": "powerapp.py No plugin can handle URL\n## Error Report\r\n\r\n- [X] This is a bug report and I have read the Posting Guidelines.\r\n\r\n### Description\r\n\r\n powerapp.com.tr should be able to play the stations\r\n\r\n\r\n### Expected / actual behavior\r\n\r\nInserting the page in the streamlink does not play the stream. About my web browser Firefox I see the picture and hear the sound synonymous\r\n\r\n### Reproduction steps / Explicit stream URLs to test\r\n\r\n1.www.powerapp.com.tr/tvs/powertv/\r\n\r\nstreamlink http://www.powerapp.com.tr/tvs/powertv best\r\n\r\n### log output\r\n\r\n> streamlink http://www.powerapp.com.tr/tvs/powertv best\r\nerror: No plugin can handle URL: http://www.powerapp.com.tr/tvs/powertv\r\n> error: No plugin can handle URL: http://www.powerapp.com.tr/tvs/powertv\r\nerror:: The term \"error:\" was not used as the name of a cmdlet, a function, a script file, or a\r\nrecognized executable program. Check the spelling of the name, or if the path is correct (provided\r\ncontain) and repeat the process.\r\nIn line: 1 character: 1\r\n+ error: No plugin can handle URL: http://www.powerapp.com.tr/tvs/power ...\r\n+~~~~~\r\n + CategoryInfo: ObjectNotFound: (error :: String) [], CommandNotFoundException\r\n + FullyQualifiedErrorId: CommandNotFoundException\r\n\r\n\r\n### Additional comments, screenshots, etc.\r\n\r\n Screenshot\r\n\r\nhttps://i.ibb.co/g99nXC0/france.jpg\n", "before_files": [{"content": "from __future__ import print_function\nimport re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HLSStream\n\n\nclass PowerApp(Plugin):\n url_re = re.compile(r\"https?://(?:www.)?powerapp.com.tr/tv/(\\w+)\")\n api_url = \"http://api.powergroup.com.tr/Channels/{0}/?appRef=iPowerWeb&apiVersion=11\"\n api_schema = validate.Schema(validate.all({\n \"errorCode\": 0,\n \"response\": {\n \"channel_stream_url\": validate.url()\n }\n }, validate.get(\"response\")))\n\n @classmethod\n def can_handle_url(cls, url):\n return cls.url_re.match(url) is not None\n\n def _get_streams(self):\n channel = self.url_re.match(self.url).group(1)\n\n res = self.session.http.get(self.api_url.format(channel))\n data = self.session.http.json(res, schema=self.api_schema)\n\n return HLSStream.parse_variant_playlist(self.session, data[\"channel_stream_url\"])\n\n\n__plugin__ = PowerApp\n", "path": "src/streamlink/plugins/powerapp.py"}], "after_files": [{"content": "from __future__ import print_function\nimport re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HLSStream\n\n\nclass PowerApp(Plugin):\n url_re = re.compile(r\"https?://(?:www.)?powerapp.com.tr/tvs?/(\\w+)\")\n api_url = \"http://api.powergroup.com.tr/Channels/{0}/?appRef=iPowerWeb&apiVersion=11\"\n api_schema = validate.Schema(validate.all({\n \"errorCode\": 0,\n \"response\": {\n \"channel_stream_url\": validate.url()\n }\n }, validate.get(\"response\")))\n\n @classmethod\n def can_handle_url(cls, url):\n return cls.url_re.match(url) is not None\n\n def _get_streams(self):\n channel = self.url_re.match(self.url).group(1)\n\n res = self.session.http.get(self.api_url.format(channel))\n data = self.session.http.json(res, schema=self.api_schema)\n\n return HLSStream.parse_variant_playlist(self.session, data[\"channel_stream_url\"])\n\n\n__plugin__ = PowerApp\n", "path": "src/streamlink/plugins/powerapp.py"}]} | 888 | 156 |
gh_patches_debug_10436 | rasdani/github-patches | git_diff | privacyidea__privacyidea-1480 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Migrate EMail, TAN and VASCO token to Python 3
This slightly changes behavior: The VASCO token initialization now throws a ``ParameterError`` if the secret couldn't be decoded.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `privacyidea/lib/authcache.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # 2017-08-11 Cornelius Kölbel <[email protected]>
4 # initial writeup
5 #
6 # License: AGPLv3
7 # contact: http://www.privacyidea.org
8 #
9 # This code is free software; you can redistribute it and/or
10 # modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE
11 # License as published by the Free Software Foundation; either
12 # version 3 of the License, or any later version.
13 #
14 # This code is distributed in the hope that it will be useful,
15 # but WITHOUT ANY WARRANTY; without even the implied warranty of
16 # MERCHANTABILITY or FITNE7SS FOR A PARTICULAR PURPOSE. See the
17 # GNU AFFERO GENERAL PUBLIC LICENSE for more details.
18 #
19 # You should have received a copy of the GNU Affero General Public
20 # License along with this program. If not, see <http://www.gnu.org/licenses/>.
21 #
22 import binascii
23
24 from ..models import AuthCache, db
25 from sqlalchemy import and_
26 from privacyidea.lib.crypto import hash
27 import datetime
28 import logging
29
30 log = logging.getLogger(__name__)
31
32
33 def _hash_password(password):
34 return binascii.hexlify(hash(password, seed=""))
35
36
37 def add_to_cache(username, realm, resolver, password):
38 # Can not store timezone aware timestamps!
39 first_auth = datetime.datetime.utcnow()
40 auth_hash = _hash_password(password)
41 record = AuthCache(username, realm, resolver, auth_hash, first_auth, first_auth)
42 log.debug('Adding record to auth cache: ({!r}, {!r}, {!r}, {!r})'.format(
43 username, realm, resolver, auth_hash))
44 r = record.save()
45 return r
46
47
48 def update_cache_last_auth(cache_id):
49 last_auth = datetime.datetime.utcnow()
50 AuthCache.query.filter(
51 AuthCache.id == cache_id).update({"last_auth": last_auth})
52 db.session.commit()
53
54
55 def delete_from_cache(username, realm, resolver, password):
56 r = db.session.query(AuthCache).filter(AuthCache.username == username,
57 AuthCache.realm == realm,
58 AuthCache.resolver == resolver,
59 AuthCache.authentication ==
60 _hash_password(password)).delete()
61 db.session.commit()
62 return r
63
64
65 def verify_in_cache(username, realm, resolver, password,
66 first_auth = None,
67 last_auth = None):
68 """
69 Verify if the given credentials are cached and if the time is correct.
70
71 :param username:
72 :param realm:
73 :param resolver:
74 :param password:
75 :param first_auth: The timestamp when the entry was first written to the
76 cache. Only find newer entries
77 :param last_auth: The timestamp when the entry was last successfully
78 verified. Only find newer entries
79 :return:
80 """
81 conditions = []
82 conditions.append(AuthCache.username == username)
83 conditions.append(AuthCache.realm == realm)
84 conditions.append(AuthCache.resolver == resolver)
85 auth_hash = _hash_password(password)
86 conditions.append(AuthCache.authentication == auth_hash)
87
88 if first_auth:
89 conditions.append(AuthCache.first_auth > first_auth)
90 if last_auth:
91 conditions.append(AuthCache.last_auth > last_auth)
92
93 filter_condition = and_(*conditions)
94 r = AuthCache.query.filter(filter_condition).first()
95 result = bool(r)
96
97 if result:
98 # Update the last_auth
99 update_cache_last_auth(r.id)
100
101 else:
102 # Delete older entries
103 delete_from_cache(username, realm, resolver, password)
104
105 return result
106
107
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/privacyidea/lib/authcache.py b/privacyidea/lib/authcache.py
--- a/privacyidea/lib/authcache.py
+++ b/privacyidea/lib/authcache.py
@@ -62,6 +62,21 @@
return r
+def cleanup(minutes):
+ """
+ Will delete all authcache entries, where last_auth column is older than
+ the given minutes.
+
+ :param minutes: Age of the last_authentication in minutes
+ :type minutes: int
+ :return:
+ """
+ cleanuptime = datetime.datetime.utcnow() - datetime.timedelta(minutes=minutes)
+ r = db.session.query(AuthCache).filter(AuthCache.last_auth < cleanuptime).delete()
+ db.session.commit()
+ return r
+
+
def verify_in_cache(username, realm, resolver, password,
first_auth = None,
last_auth = None):
| {"golden_diff": "diff --git a/privacyidea/lib/authcache.py b/privacyidea/lib/authcache.py\n--- a/privacyidea/lib/authcache.py\n+++ b/privacyidea/lib/authcache.py\n@@ -62,6 +62,21 @@\n return r\n \n \n+def cleanup(minutes):\n+ \"\"\"\n+ Will delete all authcache entries, where last_auth column is older than\n+ the given minutes.\n+\n+ :param minutes: Age of the last_authentication in minutes\n+ :type minutes: int\n+ :return:\n+ \"\"\"\n+ cleanuptime = datetime.datetime.utcnow() - datetime.timedelta(minutes=minutes)\n+ r = db.session.query(AuthCache).filter(AuthCache.last_auth < cleanuptime).delete()\n+ db.session.commit()\n+ return r\n+\n+\n def verify_in_cache(username, realm, resolver, password,\n first_auth = None,\n last_auth = None):\n", "issue": "Migrate EMail, TAN and VASCO token to Python 3\nThis slightly changes behavior: The VASCO token initialization now throws a ``ParameterError`` if the secret couldn't be decoded.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# 2017-08-11 Cornelius K\u00f6lbel <[email protected]>\n# initial writeup\n#\n# License: AGPLv3\n# contact: http://www.privacyidea.org\n#\n# This code is free software; you can redistribute it and/or\n# modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE\n# License as published by the Free Software Foundation; either\n# version 3 of the License, or any later version.\n#\n# This code is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNE7SS FOR A PARTICULAR PURPOSE. See the\n# GNU AFFERO GENERAL PUBLIC LICENSE for more details.\n#\n# You should have received a copy of the GNU Affero General Public\n# License along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\nimport binascii\n\nfrom ..models import AuthCache, db\nfrom sqlalchemy import and_\nfrom privacyidea.lib.crypto import hash\nimport datetime\nimport logging\n\nlog = logging.getLogger(__name__)\n\n\ndef _hash_password(password):\n return binascii.hexlify(hash(password, seed=\"\"))\n\n\ndef add_to_cache(username, realm, resolver, password):\n # Can not store timezone aware timestamps!\n first_auth = datetime.datetime.utcnow()\n auth_hash = _hash_password(password)\n record = AuthCache(username, realm, resolver, auth_hash, first_auth, first_auth)\n log.debug('Adding record to auth cache: ({!r}, {!r}, {!r}, {!r})'.format(\n username, realm, resolver, auth_hash))\n r = record.save()\n return r\n\n\ndef update_cache_last_auth(cache_id):\n last_auth = datetime.datetime.utcnow()\n AuthCache.query.filter(\n AuthCache.id == cache_id).update({\"last_auth\": last_auth})\n db.session.commit()\n\n\ndef delete_from_cache(username, realm, resolver, password):\n r = db.session.query(AuthCache).filter(AuthCache.username == username,\n AuthCache.realm == realm,\n AuthCache.resolver == resolver,\n AuthCache.authentication ==\n _hash_password(password)).delete()\n db.session.commit()\n return r\n\n\ndef verify_in_cache(username, realm, resolver, password,\n first_auth = None,\n last_auth = None):\n \"\"\"\n Verify if the given credentials are cached and if the time is correct.\n \n :param username: \n :param realm: \n :param resolver: \n :param password: \n :param first_auth: The timestamp when the entry was first written to the \n cache. Only find newer entries \n :param last_auth: The timestamp when the entry was last successfully \n verified. Only find newer entries \n :return: \n \"\"\"\n conditions = []\n conditions.append(AuthCache.username == username)\n conditions.append(AuthCache.realm == realm)\n conditions.append(AuthCache.resolver == resolver)\n auth_hash = _hash_password(password)\n conditions.append(AuthCache.authentication == auth_hash)\n\n if first_auth:\n conditions.append(AuthCache.first_auth > first_auth)\n if last_auth:\n conditions.append(AuthCache.last_auth > last_auth)\n\n filter_condition = and_(*conditions)\n r = AuthCache.query.filter(filter_condition).first()\n result = bool(r)\n\n if result:\n # Update the last_auth\n update_cache_last_auth(r.id)\n\n else:\n # Delete older entries\n delete_from_cache(username, realm, resolver, password)\n\n return result\n\n", "path": "privacyidea/lib/authcache.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# 2017-08-11 Cornelius K\u00f6lbel <[email protected]>\n# initial writeup\n#\n# License: AGPLv3\n# contact: http://www.privacyidea.org\n#\n# This code is free software; you can redistribute it and/or\n# modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE\n# License as published by the Free Software Foundation; either\n# version 3 of the License, or any later version.\n#\n# This code is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNE7SS FOR A PARTICULAR PURPOSE. See the\n# GNU AFFERO GENERAL PUBLIC LICENSE for more details.\n#\n# You should have received a copy of the GNU Affero General Public\n# License along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\nimport binascii\n\nfrom ..models import AuthCache, db\nfrom sqlalchemy import and_\nfrom privacyidea.lib.crypto import hash\nimport datetime\nimport logging\n\nlog = logging.getLogger(__name__)\n\n\ndef _hash_password(password):\n return binascii.hexlify(hash(password, seed=\"\"))\n\n\ndef add_to_cache(username, realm, resolver, password):\n # Can not store timezone aware timestamps!\n first_auth = datetime.datetime.utcnow()\n auth_hash = _hash_password(password)\n record = AuthCache(username, realm, resolver, auth_hash, first_auth, first_auth)\n log.debug('Adding record to auth cache: ({!r}, {!r}, {!r}, {!r})'.format(\n username, realm, resolver, auth_hash))\n r = record.save()\n return r\n\n\ndef update_cache_last_auth(cache_id):\n last_auth = datetime.datetime.utcnow()\n AuthCache.query.filter(\n AuthCache.id == cache_id).update({\"last_auth\": last_auth})\n db.session.commit()\n\n\ndef delete_from_cache(username, realm, resolver, password):\n r = db.session.query(AuthCache).filter(AuthCache.username == username,\n AuthCache.realm == realm,\n AuthCache.resolver == resolver,\n AuthCache.authentication ==\n _hash_password(password)).delete()\n db.session.commit()\n return r\n\n\ndef cleanup(minutes):\n \"\"\"\n Will delete all authcache entries, where last_auth column is older than\n the given minutes.\n\n :param minutes: Age of the last_authentication in minutes\n :type minutes: int\n :return:\n \"\"\"\n cleanuptime = datetime.datetime.utcnow() - datetime.timedelta(minutes=minutes)\n r = db.session.query(AuthCache).filter(AuthCache.last_auth < cleanuptime).delete()\n db.session.commit()\n return r\n\n\ndef verify_in_cache(username, realm, resolver, password,\n first_auth = None,\n last_auth = None):\n \"\"\"\n Verify if the given credentials are cached and if the time is correct.\n \n :param username: \n :param realm: \n :param resolver: \n :param password: \n :param first_auth: The timestamp when the entry was first written to the \n cache. Only find newer entries \n :param last_auth: The timestamp when the entry was last successfully \n verified. Only find newer entries \n :return: \n \"\"\"\n conditions = []\n conditions.append(AuthCache.username == username)\n conditions.append(AuthCache.realm == realm)\n conditions.append(AuthCache.resolver == resolver)\n auth_hash = _hash_password(password)\n conditions.append(AuthCache.authentication == auth_hash)\n\n if first_auth:\n conditions.append(AuthCache.first_auth > first_auth)\n if last_auth:\n conditions.append(AuthCache.last_auth > last_auth)\n\n filter_condition = and_(*conditions)\n r = AuthCache.query.filter(filter_condition).first()\n result = bool(r)\n\n if result:\n # Update the last_auth\n update_cache_last_auth(r.id)\n\n else:\n # Delete older entries\n delete_from_cache(username, realm, resolver, password)\n\n return result\n\n", "path": "privacyidea/lib/authcache.py"}]} | 1,295 | 194 |
gh_patches_debug_27025 | rasdani/github-patches | git_diff | comic__grand-challenge.org-2883 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove usage of jsdelivr and include scss on admin page
Follow up from #2870
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/grandchallenge/core/widgets.py`
Content:
```
1 from django import forms
2 from django.template.loader import render_to_string
3 from markdownx.widgets import AdminMarkdownxWidget, MarkdownxWidget
4
5
6 class JSONEditorWidget(forms.Textarea):
7 template_name = "jsoneditor/jsoneditor_widget.html"
8
9 def __init__(self, schema=None, attrs=None):
10 super().__init__(attrs)
11 self.schema = schema
12
13 def get_context(self, name, value, attrs):
14 context = super().get_context(name, value, attrs)
15 context.update({"schema": self.schema})
16 return context
17
18 class Media:
19 css = {"all": ("vendored/jsoneditor/jsoneditor.min.css",)}
20 js = ("vendored/jsoneditor/jsoneditor.min.js",)
21
22
23 class ColorEditorWidget(forms.TextInput):
24 """
25 Widget that uses the vendored jscolor for editing a color.
26
27 Parameters
28 ----------
29 format
30 Specify the color format by adding a format keyword:
31 >>> ColorEditorWidget(format="hex")
32
33 Options include "auto", "any", "hex", "hexa", "rgb", "rgba".
34 See the jscolor (https://jscolor.com/docs/) for details.
35 """
36
37 template_name = "coloreditor/coloreditor_widget.html"
38
39 class Media:
40 js = (
41 "vendored/jscolor/jscolor.min.js",
42 "js/coloreditor_widget.js",
43 )
44
45 def __init__(self, attrs=None, format="auto", placeholder=None):
46 super().__init__(attrs)
47 self.format = format
48 self.placeholder = placeholder
49
50 def get_context(self, name, value, attrs=None):
51 context = super().get_context(name, value, attrs)
52 context["widget"].update(
53 {
54 "placeholder": self.placeholder,
55 "format": self.format,
56 }
57 )
58 return context
59
60 def render(self, name, value, attrs=None, renderer=None):
61 return render_to_string(
62 self.template_name, self.get_context(name, value, attrs)
63 )
64
65
66 class MarkdownEditorWidget(MarkdownxWidget):
67 @property
68 def media(self):
69 return forms.Media(
70 js=(
71 "js/markdownx.js",
72 "vendored/@github/markdown-toolbar-element/dist/index.umd.js",
73 )
74 )
75
76
77 class MarkdownEditorAdminWidget(AdminMarkdownxWidget):
78 @property
79 def media(self):
80 return forms.Media(
81 css={
82 "all": [
83 *AdminMarkdownxWidget.Media.css["all"],
84 "vendor/css/base.min.css",
85 "vendored/font-awesome/css/all.min.css",
86 "css/markdown.css",
87 ]
88 },
89 js=[
90 "js/markdownx.js",
91 "vendored/@github/markdown-toolbar-element/dist/index.umd.js",
92 "vendored/jquery/jquery.min.js",
93 "vendored/bootstrap/js/bootstrap.bundle.min.js",
94 ],
95 )
96
```
Path: `app/grandchallenge/charts/specs.py`
Content:
```
1 def bar(*, values, lookup, title):
2 chart = {
3 "$schema": "https://vega.github.io/schema/vega-lite/v5.json",
4 "width": "container",
5 "padding": 0,
6 "title": title,
7 "data": {"values": values},
8 "mark": "bar",
9 "encoding": {
10 "x": {
11 "field": "Month",
12 "type": "temporal",
13 "timeUnit": "yearmonth",
14 },
15 "y": {
16 "field": lookup,
17 "type": "quantitative",
18 },
19 "tooltip": [
20 {
21 "field": "Month",
22 "type": "temporal",
23 "timeUnit": "yearmonth",
24 },
25 {"field": lookup, "type": "quantitative"},
26 ],
27 },
28 }
29
30 totals = sum(datum[lookup] for datum in values)
31
32 return {"chart": chart, "totals": totals}
33
34
35 def stacked_bar(*, values, lookup, title, facet, domain):
36 domain = dict(domain)
37
38 totals = {str(d): 0 for d in domain.values()}
39 for datum in values:
40 datum[facet] = domain[datum[facet]]
41 totals[str(datum[facet])] += datum[lookup]
42
43 chart = {
44 "$schema": "https://vega.github.io/schema/vega-lite/v5.json",
45 "width": "container",
46 "padding": 0,
47 "title": title,
48 "data": {"values": values},
49 "mark": "bar",
50 "encoding": {
51 "x": {
52 "field": "Month",
53 "type": "temporal",
54 "timeUnit": "yearmonth",
55 },
56 "y": {
57 "field": lookup,
58 "type": "quantitative",
59 "stack": True,
60 },
61 "tooltip": [
62 {
63 "field": "Month",
64 "type": "temporal",
65 "timeUnit": "yearmonth",
66 },
67 {"field": facet, "type": "nominal"},
68 {"field": lookup, "type": "quantitative"},
69 ],
70 "color": {
71 "field": facet,
72 "scale": {
73 "domain": list(domain.values()),
74 },
75 "type": "nominal",
76 },
77 },
78 }
79
80 return {"chart": chart, "totals": totals}
81
82
83 def horizontal_bar(*, values, lookup, title):
84 url_lookup = "absolute_url"
85 challenge_name_lookup = "short_name"
86 return {
87 "$schema": "https://vega.github.io/schema/vega-lite/v5.json",
88 "width": "container",
89 "padding": 0,
90 "data": {"values": values},
91 "mark": "bar",
92 "encoding": {
93 "color": {
94 "field": lookup,
95 "type": "nominal",
96 "legend": None,
97 "scale": {"scheme": {"name": "viridis", "extent": [0, 1]}},
98 },
99 "tooltip": [
100 {
101 "field": challenge_name_lookup,
102 "type": "nominal",
103 "title": "Challenge",
104 },
105 {
106 "field": lookup,
107 "type": "quantitative",
108 "title": title,
109 "format": ".0f",
110 },
111 ],
112 "y": {
113 "field": challenge_name_lookup,
114 "type": "nominal",
115 "axis": {"labelAngle": 0},
116 "title": None,
117 "sort": "-x",
118 },
119 "x": {
120 "field": lookup,
121 "type": "quantitative",
122 "title": title,
123 "axis": {"tickMinStep": "1", "format": ".0f"},
124 },
125 "href": {"field": url_lookup, "type": "nominal"},
126 },
127 }
128
129
130 def world_map(*, values):
131 return {
132 "$schema": "https://vega.github.io/schema/vega-lite/v5.json",
133 "width": "container",
134 "height": "container",
135 "padding": 0,
136 "view": {"stroke": "transparent", "fill": "#c9eeff"},
137 "data": {
138 "url": "https://cdn.jsdelivr.net/npm/world-atlas@2/countries-110m.json",
139 "format": {"type": "topojson", "feature": "countries"},
140 },
141 "transform": [
142 {
143 "lookup": "id",
144 "from": {
145 "data": {"values": values},
146 "key": "id",
147 "fields": ["participants"],
148 },
149 "default": 0.01,
150 }
151 ],
152 "projection": {"type": "equalEarth"},
153 "mark": {
154 "type": "geoshape",
155 "stroke": "#757575",
156 "strokeWidth": 0.5,
157 },
158 "encoding": {
159 "color": {
160 "field": "participants",
161 "type": "quantitative",
162 "scale": {
163 "scheme": "viridis",
164 "domainMin": 1,
165 "type": "log",
166 },
167 "legend": None,
168 "condition": {
169 "test": "datum['participants'] === 0.01",
170 "value": "#eee",
171 },
172 },
173 "tooltip": [
174 {
175 "field": "properties.name",
176 "type": "nominal",
177 "title": "Location",
178 },
179 {
180 "field": "participants",
181 "type": "quantitative",
182 "title": "Participants",
183 "format": ".0f",
184 },
185 ],
186 },
187 }
188
189
190 def components_line(*, values, title, cpu_limit, tooltip):
191 return {
192 "$schema": "https://vega.github.io/schema/vega-lite/v5.json",
193 "width": "container",
194 "padding": 0,
195 "title": title,
196 "data": {"values": values},
197 "layer": [
198 {
199 "transform": [
200 {"calculate": "100*datum.Percent", "as": "Percent100"},
201 ],
202 "encoding": {
203 "x": {
204 "timeUnit": "hoursminutesseconds",
205 "field": "Timestamp",
206 "title": "Local Time / HH:MM:SS",
207 },
208 "y": {
209 "field": "Percent100",
210 "type": "quantitative",
211 "title": "Utilization / %",
212 },
213 "color": {"field": "Metric", "type": "nominal"},
214 },
215 "layer": [
216 {"mark": "line"},
217 {
218 "transform": [
219 {"filter": {"param": "hover", "empty": False}}
220 ],
221 "mark": "point",
222 },
223 ],
224 },
225 {
226 "transform": [
227 {
228 "pivot": "Metric",
229 "value": "Percent",
230 "groupby": ["Timestamp"],
231 }
232 ],
233 "mark": "rule",
234 "encoding": {
235 "opacity": {
236 "condition": {
237 "value": 0.3,
238 "param": "hover",
239 "empty": False,
240 },
241 "value": 0,
242 },
243 "tooltip": tooltip,
244 "x": {
245 "timeUnit": "hoursminutesseconds",
246 "field": "Timestamp",
247 "title": "Local Time / HH:MM:SS",
248 },
249 },
250 "params": [
251 {
252 "name": "hover",
253 "select": {
254 "type": "point",
255 "fields": ["Timestamp"],
256 "nearest": True,
257 "on": "mouseover",
258 "clear": "mouseout",
259 },
260 }
261 ],
262 },
263 {
264 "data": {"values": [{}]},
265 "mark": {"type": "rule", "strokeDash": [8, 8]},
266 "encoding": {"y": {"datum": cpu_limit}},
267 },
268 {
269 "data": {"values": [{}]},
270 "mark": {"type": "text", "baseline": "line-bottom"},
271 "encoding": {
272 "text": {"datum": "CPU Utilization Limit"},
273 "y": {"datum": cpu_limit},
274 },
275 },
276 {
277 "data": {"values": [{}]},
278 "mark": {"type": "rule", "strokeDash": [8, 8]},
279 "encoding": {"y": {"datum": 100}},
280 },
281 {
282 "data": {"values": [{}]},
283 "mark": {"type": "text", "baseline": "line-bottom"},
284 "encoding": {
285 "text": {
286 "datum": "Memory / GPU / GPU Memory Utilization Limit"
287 },
288 "y": {"datum": 100},
289 },
290 },
291 ],
292 }
293
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/app/grandchallenge/charts/specs.py b/app/grandchallenge/charts/specs.py
--- a/app/grandchallenge/charts/specs.py
+++ b/app/grandchallenge/charts/specs.py
@@ -1,3 +1,6 @@
+from django.templatetags.static import static
+
+
def bar(*, values, lookup, title):
chart = {
"$schema": "https://vega.github.io/schema/vega-lite/v5.json",
@@ -135,7 +138,7 @@
"padding": 0,
"view": {"stroke": "transparent", "fill": "#c9eeff"},
"data": {
- "url": "https://cdn.jsdelivr.net/npm/world-atlas@2/countries-110m.json",
+ "url": static("vendored/world-atlas/countries-110m.json"),
"format": {"type": "topojson", "feature": "countries"},
},
"transform": [
diff --git a/app/grandchallenge/core/widgets.py b/app/grandchallenge/core/widgets.py
--- a/app/grandchallenge/core/widgets.py
+++ b/app/grandchallenge/core/widgets.py
@@ -75,15 +75,14 @@
class MarkdownEditorAdminWidget(AdminMarkdownxWidget):
+ template_name = "markdownx/admin_widget.html"
+
@property
def media(self):
return forms.Media(
css={
"all": [
*AdminMarkdownxWidget.Media.css["all"],
- "vendor/css/base.min.css",
- "vendored/font-awesome/css/all.min.css",
- "css/markdown.css",
]
},
js=[
| {"golden_diff": "diff --git a/app/grandchallenge/charts/specs.py b/app/grandchallenge/charts/specs.py\n--- a/app/grandchallenge/charts/specs.py\n+++ b/app/grandchallenge/charts/specs.py\n@@ -1,3 +1,6 @@\n+from django.templatetags.static import static\n+\n+\n def bar(*, values, lookup, title):\n chart = {\n \"$schema\": \"https://vega.github.io/schema/vega-lite/v5.json\",\n@@ -135,7 +138,7 @@\n \"padding\": 0,\n \"view\": {\"stroke\": \"transparent\", \"fill\": \"#c9eeff\"},\n \"data\": {\n- \"url\": \"https://cdn.jsdelivr.net/npm/world-atlas@2/countries-110m.json\",\n+ \"url\": static(\"vendored/world-atlas/countries-110m.json\"),\n \"format\": {\"type\": \"topojson\", \"feature\": \"countries\"},\n },\n \"transform\": [\ndiff --git a/app/grandchallenge/core/widgets.py b/app/grandchallenge/core/widgets.py\n--- a/app/grandchallenge/core/widgets.py\n+++ b/app/grandchallenge/core/widgets.py\n@@ -75,15 +75,14 @@\n \n \n class MarkdownEditorAdminWidget(AdminMarkdownxWidget):\n+ template_name = \"markdownx/admin_widget.html\"\n+\n @property\n def media(self):\n return forms.Media(\n css={\n \"all\": [\n *AdminMarkdownxWidget.Media.css[\"all\"],\n- \"vendor/css/base.min.css\",\n- \"vendored/font-awesome/css/all.min.css\",\n- \"css/markdown.css\",\n ]\n },\n js=[\n", "issue": "Remove usage of jsdelivr and include scss on admin page\nFollow up from #2870 \n", "before_files": [{"content": "from django import forms\nfrom django.template.loader import render_to_string\nfrom markdownx.widgets import AdminMarkdownxWidget, MarkdownxWidget\n\n\nclass JSONEditorWidget(forms.Textarea):\n template_name = \"jsoneditor/jsoneditor_widget.html\"\n\n def __init__(self, schema=None, attrs=None):\n super().__init__(attrs)\n self.schema = schema\n\n def get_context(self, name, value, attrs):\n context = super().get_context(name, value, attrs)\n context.update({\"schema\": self.schema})\n return context\n\n class Media:\n css = {\"all\": (\"vendored/jsoneditor/jsoneditor.min.css\",)}\n js = (\"vendored/jsoneditor/jsoneditor.min.js\",)\n\n\nclass ColorEditorWidget(forms.TextInput):\n \"\"\"\n Widget that uses the vendored jscolor for editing a color.\n\n Parameters\n ----------\n format\n Specify the color format by adding a format keyword:\n >>> ColorEditorWidget(format=\"hex\")\n\n Options include \"auto\", \"any\", \"hex\", \"hexa\", \"rgb\", \"rgba\".\n See the jscolor (https://jscolor.com/docs/) for details.\n \"\"\"\n\n template_name = \"coloreditor/coloreditor_widget.html\"\n\n class Media:\n js = (\n \"vendored/jscolor/jscolor.min.js\",\n \"js/coloreditor_widget.js\",\n )\n\n def __init__(self, attrs=None, format=\"auto\", placeholder=None):\n super().__init__(attrs)\n self.format = format\n self.placeholder = placeholder\n\n def get_context(self, name, value, attrs=None):\n context = super().get_context(name, value, attrs)\n context[\"widget\"].update(\n {\n \"placeholder\": self.placeholder,\n \"format\": self.format,\n }\n )\n return context\n\n def render(self, name, value, attrs=None, renderer=None):\n return render_to_string(\n self.template_name, self.get_context(name, value, attrs)\n )\n\n\nclass MarkdownEditorWidget(MarkdownxWidget):\n @property\n def media(self):\n return forms.Media(\n js=(\n \"js/markdownx.js\",\n \"vendored/@github/markdown-toolbar-element/dist/index.umd.js\",\n )\n )\n\n\nclass MarkdownEditorAdminWidget(AdminMarkdownxWidget):\n @property\n def media(self):\n return forms.Media(\n css={\n \"all\": [\n *AdminMarkdownxWidget.Media.css[\"all\"],\n \"vendor/css/base.min.css\",\n \"vendored/font-awesome/css/all.min.css\",\n \"css/markdown.css\",\n ]\n },\n js=[\n \"js/markdownx.js\",\n \"vendored/@github/markdown-toolbar-element/dist/index.umd.js\",\n \"vendored/jquery/jquery.min.js\",\n \"vendored/bootstrap/js/bootstrap.bundle.min.js\",\n ],\n )\n", "path": "app/grandchallenge/core/widgets.py"}, {"content": "def bar(*, values, lookup, title):\n chart = {\n \"$schema\": \"https://vega.github.io/schema/vega-lite/v5.json\",\n \"width\": \"container\",\n \"padding\": 0,\n \"title\": title,\n \"data\": {\"values\": values},\n \"mark\": \"bar\",\n \"encoding\": {\n \"x\": {\n \"field\": \"Month\",\n \"type\": \"temporal\",\n \"timeUnit\": \"yearmonth\",\n },\n \"y\": {\n \"field\": lookup,\n \"type\": \"quantitative\",\n },\n \"tooltip\": [\n {\n \"field\": \"Month\",\n \"type\": \"temporal\",\n \"timeUnit\": \"yearmonth\",\n },\n {\"field\": lookup, \"type\": \"quantitative\"},\n ],\n },\n }\n\n totals = sum(datum[lookup] for datum in values)\n\n return {\"chart\": chart, \"totals\": totals}\n\n\ndef stacked_bar(*, values, lookup, title, facet, domain):\n domain = dict(domain)\n\n totals = {str(d): 0 for d in domain.values()}\n for datum in values:\n datum[facet] = domain[datum[facet]]\n totals[str(datum[facet])] += datum[lookup]\n\n chart = {\n \"$schema\": \"https://vega.github.io/schema/vega-lite/v5.json\",\n \"width\": \"container\",\n \"padding\": 0,\n \"title\": title,\n \"data\": {\"values\": values},\n \"mark\": \"bar\",\n \"encoding\": {\n \"x\": {\n \"field\": \"Month\",\n \"type\": \"temporal\",\n \"timeUnit\": \"yearmonth\",\n },\n \"y\": {\n \"field\": lookup,\n \"type\": \"quantitative\",\n \"stack\": True,\n },\n \"tooltip\": [\n {\n \"field\": \"Month\",\n \"type\": \"temporal\",\n \"timeUnit\": \"yearmonth\",\n },\n {\"field\": facet, \"type\": \"nominal\"},\n {\"field\": lookup, \"type\": \"quantitative\"},\n ],\n \"color\": {\n \"field\": facet,\n \"scale\": {\n \"domain\": list(domain.values()),\n },\n \"type\": \"nominal\",\n },\n },\n }\n\n return {\"chart\": chart, \"totals\": totals}\n\n\ndef horizontal_bar(*, values, lookup, title):\n url_lookup = \"absolute_url\"\n challenge_name_lookup = \"short_name\"\n return {\n \"$schema\": \"https://vega.github.io/schema/vega-lite/v5.json\",\n \"width\": \"container\",\n \"padding\": 0,\n \"data\": {\"values\": values},\n \"mark\": \"bar\",\n \"encoding\": {\n \"color\": {\n \"field\": lookup,\n \"type\": \"nominal\",\n \"legend\": None,\n \"scale\": {\"scheme\": {\"name\": \"viridis\", \"extent\": [0, 1]}},\n },\n \"tooltip\": [\n {\n \"field\": challenge_name_lookup,\n \"type\": \"nominal\",\n \"title\": \"Challenge\",\n },\n {\n \"field\": lookup,\n \"type\": \"quantitative\",\n \"title\": title,\n \"format\": \".0f\",\n },\n ],\n \"y\": {\n \"field\": challenge_name_lookup,\n \"type\": \"nominal\",\n \"axis\": {\"labelAngle\": 0},\n \"title\": None,\n \"sort\": \"-x\",\n },\n \"x\": {\n \"field\": lookup,\n \"type\": \"quantitative\",\n \"title\": title,\n \"axis\": {\"tickMinStep\": \"1\", \"format\": \".0f\"},\n },\n \"href\": {\"field\": url_lookup, \"type\": \"nominal\"},\n },\n }\n\n\ndef world_map(*, values):\n return {\n \"$schema\": \"https://vega.github.io/schema/vega-lite/v5.json\",\n \"width\": \"container\",\n \"height\": \"container\",\n \"padding\": 0,\n \"view\": {\"stroke\": \"transparent\", \"fill\": \"#c9eeff\"},\n \"data\": {\n \"url\": \"https://cdn.jsdelivr.net/npm/world-atlas@2/countries-110m.json\",\n \"format\": {\"type\": \"topojson\", \"feature\": \"countries\"},\n },\n \"transform\": [\n {\n \"lookup\": \"id\",\n \"from\": {\n \"data\": {\"values\": values},\n \"key\": \"id\",\n \"fields\": [\"participants\"],\n },\n \"default\": 0.01,\n }\n ],\n \"projection\": {\"type\": \"equalEarth\"},\n \"mark\": {\n \"type\": \"geoshape\",\n \"stroke\": \"#757575\",\n \"strokeWidth\": 0.5,\n },\n \"encoding\": {\n \"color\": {\n \"field\": \"participants\",\n \"type\": \"quantitative\",\n \"scale\": {\n \"scheme\": \"viridis\",\n \"domainMin\": 1,\n \"type\": \"log\",\n },\n \"legend\": None,\n \"condition\": {\n \"test\": \"datum['participants'] === 0.01\",\n \"value\": \"#eee\",\n },\n },\n \"tooltip\": [\n {\n \"field\": \"properties.name\",\n \"type\": \"nominal\",\n \"title\": \"Location\",\n },\n {\n \"field\": \"participants\",\n \"type\": \"quantitative\",\n \"title\": \"Participants\",\n \"format\": \".0f\",\n },\n ],\n },\n }\n\n\ndef components_line(*, values, title, cpu_limit, tooltip):\n return {\n \"$schema\": \"https://vega.github.io/schema/vega-lite/v5.json\",\n \"width\": \"container\",\n \"padding\": 0,\n \"title\": title,\n \"data\": {\"values\": values},\n \"layer\": [\n {\n \"transform\": [\n {\"calculate\": \"100*datum.Percent\", \"as\": \"Percent100\"},\n ],\n \"encoding\": {\n \"x\": {\n \"timeUnit\": \"hoursminutesseconds\",\n \"field\": \"Timestamp\",\n \"title\": \"Local Time / HH:MM:SS\",\n },\n \"y\": {\n \"field\": \"Percent100\",\n \"type\": \"quantitative\",\n \"title\": \"Utilization / %\",\n },\n \"color\": {\"field\": \"Metric\", \"type\": \"nominal\"},\n },\n \"layer\": [\n {\"mark\": \"line\"},\n {\n \"transform\": [\n {\"filter\": {\"param\": \"hover\", \"empty\": False}}\n ],\n \"mark\": \"point\",\n },\n ],\n },\n {\n \"transform\": [\n {\n \"pivot\": \"Metric\",\n \"value\": \"Percent\",\n \"groupby\": [\"Timestamp\"],\n }\n ],\n \"mark\": \"rule\",\n \"encoding\": {\n \"opacity\": {\n \"condition\": {\n \"value\": 0.3,\n \"param\": \"hover\",\n \"empty\": False,\n },\n \"value\": 0,\n },\n \"tooltip\": tooltip,\n \"x\": {\n \"timeUnit\": \"hoursminutesseconds\",\n \"field\": \"Timestamp\",\n \"title\": \"Local Time / HH:MM:SS\",\n },\n },\n \"params\": [\n {\n \"name\": \"hover\",\n \"select\": {\n \"type\": \"point\",\n \"fields\": [\"Timestamp\"],\n \"nearest\": True,\n \"on\": \"mouseover\",\n \"clear\": \"mouseout\",\n },\n }\n ],\n },\n {\n \"data\": {\"values\": [{}]},\n \"mark\": {\"type\": \"rule\", \"strokeDash\": [8, 8]},\n \"encoding\": {\"y\": {\"datum\": cpu_limit}},\n },\n {\n \"data\": {\"values\": [{}]},\n \"mark\": {\"type\": \"text\", \"baseline\": \"line-bottom\"},\n \"encoding\": {\n \"text\": {\"datum\": \"CPU Utilization Limit\"},\n \"y\": {\"datum\": cpu_limit},\n },\n },\n {\n \"data\": {\"values\": [{}]},\n \"mark\": {\"type\": \"rule\", \"strokeDash\": [8, 8]},\n \"encoding\": {\"y\": {\"datum\": 100}},\n },\n {\n \"data\": {\"values\": [{}]},\n \"mark\": {\"type\": \"text\", \"baseline\": \"line-bottom\"},\n \"encoding\": {\n \"text\": {\n \"datum\": \"Memory / GPU / GPU Memory Utilization Limit\"\n },\n \"y\": {\"datum\": 100},\n },\n },\n ],\n }\n", "path": "app/grandchallenge/charts/specs.py"}], "after_files": [{"content": "from django import forms\nfrom django.template.loader import render_to_string\nfrom markdownx.widgets import AdminMarkdownxWidget, MarkdownxWidget\n\n\nclass JSONEditorWidget(forms.Textarea):\n template_name = \"jsoneditor/jsoneditor_widget.html\"\n\n def __init__(self, schema=None, attrs=None):\n super().__init__(attrs)\n self.schema = schema\n\n def get_context(self, name, value, attrs):\n context = super().get_context(name, value, attrs)\n context.update({\"schema\": self.schema})\n return context\n\n class Media:\n css = {\"all\": (\"vendored/jsoneditor/jsoneditor.min.css\",)}\n js = (\"vendored/jsoneditor/jsoneditor.min.js\",)\n\n\nclass ColorEditorWidget(forms.TextInput):\n \"\"\"\n Widget that uses the vendored jscolor for editing a color.\n\n Parameters\n ----------\n format\n Specify the color format by adding a format keyword:\n >>> ColorEditorWidget(format=\"hex\")\n\n Options include \"auto\", \"any\", \"hex\", \"hexa\", \"rgb\", \"rgba\".\n See the jscolor (https://jscolor.com/docs/) for details.\n \"\"\"\n\n template_name = \"coloreditor/coloreditor_widget.html\"\n\n class Media:\n js = (\n \"vendored/jscolor/jscolor.min.js\",\n \"js/coloreditor_widget.js\",\n )\n\n def __init__(self, attrs=None, format=\"auto\", placeholder=None):\n super().__init__(attrs)\n self.format = format\n self.placeholder = placeholder\n\n def get_context(self, name, value, attrs=None):\n context = super().get_context(name, value, attrs)\n context[\"widget\"].update(\n {\n \"placeholder\": self.placeholder,\n \"format\": self.format,\n }\n )\n return context\n\n def render(self, name, value, attrs=None, renderer=None):\n return render_to_string(\n self.template_name, self.get_context(name, value, attrs)\n )\n\n\nclass MarkdownEditorWidget(MarkdownxWidget):\n @property\n def media(self):\n return forms.Media(\n js=(\n \"js/markdownx.js\",\n \"vendored/@github/markdown-toolbar-element/dist/index.umd.js\",\n )\n )\n\n\nclass MarkdownEditorAdminWidget(AdminMarkdownxWidget):\n template_name = \"markdownx/admin_widget.html\"\n\n @property\n def media(self):\n return forms.Media(\n css={\n \"all\": [\n *AdminMarkdownxWidget.Media.css[\"all\"],\n ]\n },\n js=[\n \"js/markdownx.js\",\n \"vendored/@github/markdown-toolbar-element/dist/index.umd.js\",\n \"vendored/jquery/jquery.min.js\",\n \"vendored/bootstrap/js/bootstrap.bundle.min.js\",\n ],\n )\n", "path": "app/grandchallenge/core/widgets.py"}, {"content": "from django.templatetags.static import static\n\n\ndef bar(*, values, lookup, title):\n chart = {\n \"$schema\": \"https://vega.github.io/schema/vega-lite/v5.json\",\n \"width\": \"container\",\n \"padding\": 0,\n \"title\": title,\n \"data\": {\"values\": values},\n \"mark\": \"bar\",\n \"encoding\": {\n \"x\": {\n \"field\": \"Month\",\n \"type\": \"temporal\",\n \"timeUnit\": \"yearmonth\",\n },\n \"y\": {\n \"field\": lookup,\n \"type\": \"quantitative\",\n },\n \"tooltip\": [\n {\n \"field\": \"Month\",\n \"type\": \"temporal\",\n \"timeUnit\": \"yearmonth\",\n },\n {\"field\": lookup, \"type\": \"quantitative\"},\n ],\n },\n }\n\n totals = sum(datum[lookup] for datum in values)\n\n return {\"chart\": chart, \"totals\": totals}\n\n\ndef stacked_bar(*, values, lookup, title, facet, domain):\n domain = dict(domain)\n\n totals = {str(d): 0 for d in domain.values()}\n for datum in values:\n datum[facet] = domain[datum[facet]]\n totals[str(datum[facet])] += datum[lookup]\n\n chart = {\n \"$schema\": \"https://vega.github.io/schema/vega-lite/v5.json\",\n \"width\": \"container\",\n \"padding\": 0,\n \"title\": title,\n \"data\": {\"values\": values},\n \"mark\": \"bar\",\n \"encoding\": {\n \"x\": {\n \"field\": \"Month\",\n \"type\": \"temporal\",\n \"timeUnit\": \"yearmonth\",\n },\n \"y\": {\n \"field\": lookup,\n \"type\": \"quantitative\",\n \"stack\": True,\n },\n \"tooltip\": [\n {\n \"field\": \"Month\",\n \"type\": \"temporal\",\n \"timeUnit\": \"yearmonth\",\n },\n {\"field\": facet, \"type\": \"nominal\"},\n {\"field\": lookup, \"type\": \"quantitative\"},\n ],\n \"color\": {\n \"field\": facet,\n \"scale\": {\n \"domain\": list(domain.values()),\n },\n \"type\": \"nominal\",\n },\n },\n }\n\n return {\"chart\": chart, \"totals\": totals}\n\n\ndef horizontal_bar(*, values, lookup, title):\n url_lookup = \"absolute_url\"\n challenge_name_lookup = \"short_name\"\n return {\n \"$schema\": \"https://vega.github.io/schema/vega-lite/v5.json\",\n \"width\": \"container\",\n \"padding\": 0,\n \"data\": {\"values\": values},\n \"mark\": \"bar\",\n \"encoding\": {\n \"color\": {\n \"field\": lookup,\n \"type\": \"nominal\",\n \"legend\": None,\n \"scale\": {\"scheme\": {\"name\": \"viridis\", \"extent\": [0, 1]}},\n },\n \"tooltip\": [\n {\n \"field\": challenge_name_lookup,\n \"type\": \"nominal\",\n \"title\": \"Challenge\",\n },\n {\n \"field\": lookup,\n \"type\": \"quantitative\",\n \"title\": title,\n \"format\": \".0f\",\n },\n ],\n \"y\": {\n \"field\": challenge_name_lookup,\n \"type\": \"nominal\",\n \"axis\": {\"labelAngle\": 0},\n \"title\": None,\n \"sort\": \"-x\",\n },\n \"x\": {\n \"field\": lookup,\n \"type\": \"quantitative\",\n \"title\": title,\n \"axis\": {\"tickMinStep\": \"1\", \"format\": \".0f\"},\n },\n \"href\": {\"field\": url_lookup, \"type\": \"nominal\"},\n },\n }\n\n\ndef world_map(*, values):\n return {\n \"$schema\": \"https://vega.github.io/schema/vega-lite/v5.json\",\n \"width\": \"container\",\n \"height\": \"container\",\n \"padding\": 0,\n \"view\": {\"stroke\": \"transparent\", \"fill\": \"#c9eeff\"},\n \"data\": {\n \"url\": static(\"vendored/world-atlas/countries-110m.json\"),\n \"format\": {\"type\": \"topojson\", \"feature\": \"countries\"},\n },\n \"transform\": [\n {\n \"lookup\": \"id\",\n \"from\": {\n \"data\": {\"values\": values},\n \"key\": \"id\",\n \"fields\": [\"participants\"],\n },\n \"default\": 0.01,\n }\n ],\n \"projection\": {\"type\": \"equalEarth\"},\n \"mark\": {\n \"type\": \"geoshape\",\n \"stroke\": \"#757575\",\n \"strokeWidth\": 0.5,\n },\n \"encoding\": {\n \"color\": {\n \"field\": \"participants\",\n \"type\": \"quantitative\",\n \"scale\": {\n \"scheme\": \"viridis\",\n \"domainMin\": 1,\n \"type\": \"log\",\n },\n \"legend\": None,\n \"condition\": {\n \"test\": \"datum['participants'] === 0.01\",\n \"value\": \"#eee\",\n },\n },\n \"tooltip\": [\n {\n \"field\": \"properties.name\",\n \"type\": \"nominal\",\n \"title\": \"Location\",\n },\n {\n \"field\": \"participants\",\n \"type\": \"quantitative\",\n \"title\": \"Participants\",\n \"format\": \".0f\",\n },\n ],\n },\n }\n\n\ndef components_line(*, values, title, cpu_limit, tooltip):\n return {\n \"$schema\": \"https://vega.github.io/schema/vega-lite/v5.json\",\n \"width\": \"container\",\n \"padding\": 0,\n \"title\": title,\n \"data\": {\"values\": values},\n \"layer\": [\n {\n \"transform\": [\n {\"calculate\": \"100*datum.Percent\", \"as\": \"Percent100\"},\n ],\n \"encoding\": {\n \"x\": {\n \"timeUnit\": \"hoursminutesseconds\",\n \"field\": \"Timestamp\",\n \"title\": \"Local Time / HH:MM:SS\",\n },\n \"y\": {\n \"field\": \"Percent100\",\n \"type\": \"quantitative\",\n \"title\": \"Utilization / %\",\n },\n \"color\": {\"field\": \"Metric\", \"type\": \"nominal\"},\n },\n \"layer\": [\n {\"mark\": \"line\"},\n {\n \"transform\": [\n {\"filter\": {\"param\": \"hover\", \"empty\": False}}\n ],\n \"mark\": \"point\",\n },\n ],\n },\n {\n \"transform\": [\n {\n \"pivot\": \"Metric\",\n \"value\": \"Percent\",\n \"groupby\": [\"Timestamp\"],\n }\n ],\n \"mark\": \"rule\",\n \"encoding\": {\n \"opacity\": {\n \"condition\": {\n \"value\": 0.3,\n \"param\": \"hover\",\n \"empty\": False,\n },\n \"value\": 0,\n },\n \"tooltip\": tooltip,\n \"x\": {\n \"timeUnit\": \"hoursminutesseconds\",\n \"field\": \"Timestamp\",\n \"title\": \"Local Time / HH:MM:SS\",\n },\n },\n \"params\": [\n {\n \"name\": \"hover\",\n \"select\": {\n \"type\": \"point\",\n \"fields\": [\"Timestamp\"],\n \"nearest\": True,\n \"on\": \"mouseover\",\n \"clear\": \"mouseout\",\n },\n }\n ],\n },\n {\n \"data\": {\"values\": [{}]},\n \"mark\": {\"type\": \"rule\", \"strokeDash\": [8, 8]},\n \"encoding\": {\"y\": {\"datum\": cpu_limit}},\n },\n {\n \"data\": {\"values\": [{}]},\n \"mark\": {\"type\": \"text\", \"baseline\": \"line-bottom\"},\n \"encoding\": {\n \"text\": {\"datum\": \"CPU Utilization Limit\"},\n \"y\": {\"datum\": cpu_limit},\n },\n },\n {\n \"data\": {\"values\": [{}]},\n \"mark\": {\"type\": \"rule\", \"strokeDash\": [8, 8]},\n \"encoding\": {\"y\": {\"datum\": 100}},\n },\n {\n \"data\": {\"values\": [{}]},\n \"mark\": {\"type\": \"text\", \"baseline\": \"line-bottom\"},\n \"encoding\": {\n \"text\": {\n \"datum\": \"Memory / GPU / GPU Memory Utilization Limit\"\n },\n \"y\": {\"datum\": 100},\n },\n },\n ],\n }\n", "path": "app/grandchallenge/charts/specs.py"}]} | 3,788 | 373 |
gh_patches_debug_30295 | rasdani/github-patches | git_diff | NVIDIA__NVFlare-143 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
shell scripts missing x permission in poc
The shell script files generated from poc command do not have original permission settings, especially the execute permission, after switching to shutil.unpack_archive.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nvflare/lighter/poc.py`
Content:
```
1 # Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import argparse
16 import os
17 import pathlib
18 import shutil
19
20
21 def clone_client(num_clients: int):
22 current_path = os.getcwd()
23 poc_folder = os.path.join(current_path, "poc")
24 src_folder = os.path.join(poc_folder, "client")
25 for index in range(1, num_clients + 1):
26 dst_folder = os.path.join(poc_folder, f"site-{index}")
27 shutil.copytree(src_folder, dst_folder)
28 start_sh = open(os.path.join(dst_folder, "startup", "start.sh"), "rt")
29 content = start_sh.read()
30 start_sh.close()
31 content = content.replace("NNN", f"{index}")
32 with open(os.path.join(dst_folder, "startup", "start.sh"), "wt") as f:
33 f.write(content)
34 shutil.rmtree(src_folder)
35
36
37 def main():
38 parser = argparse.ArgumentParser()
39 parser.add_argument("-n", "--num_clients", type=int, default=1, help="number of client folders to create")
40
41 args = parser.parse_args()
42
43 file_dir_path = pathlib.Path(__file__).parent.absolute()
44 poc_zip_path = file_dir_path.parent / "poc.zip"
45 answer = input("This will delete poc folder in current directory and create a new one. Is it OK to proceed? (y/N) ")
46 if answer.strip().upper() == "Y":
47 shutil.rmtree(os.path.join(os.getcwd(), "poc"), ignore_errors=True)
48 shutil.unpack_archive(poc_zip_path)
49 clone_client(args.num_clients)
50 print("Successfully creating poc folder. Please read poc/Readme.rst for user guide.")
51
52
53 if __name__ == "__main__":
54 main()
55
```
Path: `setup.py`
Content:
```
1 # Copyright (c) 2021, NVIDIA CORPORATION.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 # Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
16 import os
17 import shutil
18 from datetime import datetime
19
20 from setuptools import find_packages, setup
21
22 # read the contents of your README file
23 this_directory = os.path.abspath(os.path.dirname(__file__))
24 with open(os.path.join(this_directory, "README.md"), encoding="utf-8") as f:
25 long_description = f.read()
26
27 with open(os.path.join(this_directory, "nvflare", "__init__.py"), encoding="utf-8") as f:
28 for line in f.readlines():
29 if "__version__" in line:
30 init_version = line.split("=")[1].strip()
31
32 nvfl_version = os.environ.get("NVFL_VERSION", init_version)
33 yymmdd = datetime.today().strftime("%y%m%d")
34 nvfl_nightly_version = f"{nvfl_version}.dev{yymmdd}"
35
36 if os.environ.get("NVFL_RELEASE"):
37 package_name = "nvflare"
38 version = nvfl_version
39 else:
40 package_name = "nvflare-nightly"
41 version = nvfl_nightly_version
42
43
44 if os.path.exists(os.path.join(this_directory, "nvflare", "poc.zip")):
45 os.remove(os.path.join(this_directory, "nvflare", "poc.zip"))
46 shutil.make_archive(base_name="poc", format="zip", root_dir=os.path.join(this_directory, "nvflare"), base_dir="poc")
47 shutil.move("poc.zip", os.path.join(this_directory, "nvflare", "poc.zip"))
48
49 python_version = os.environ.get("PY_VERSION", "3.7")
50 setup(
51 name=package_name,
52 version=version,
53 description="Federated Learning Application Runtime Environment",
54 url="https://github.com/NVIDIA/NVFlare",
55 package_dir={"nvflare": "nvflare"},
56 packages=find_packages(
57 where=".",
58 include=[
59 "*",
60 ],
61 exclude=[
62 "test",
63 ],
64 ),
65 package_data={"": ["*.yml", "*.html", "poc.zip"]},
66 zip_safe=True,
67 license_files=("LICENSE.pdf",),
68 classifiers=[
69 "Programming Language :: Python :: 3",
70 "License :: Other/Proprietary License",
71 "Operating System :: OS Independent",
72 ],
73 long_description=long_description,
74 long_description_content_type="text/markdown",
75 python_requires=">=3.7",
76 # install_requires=list(pkutils.parse_requirements("requirements.txt")),
77 install_requires=[
78 "PyYAML",
79 "psutil",
80 "numpy",
81 "grpcio",
82 "google-api-python-client",
83 "cryptography",
84 "tenseal==0.3.0",
85 ],
86 entry_points={
87 "console_scripts": [
88 "provision=nvflare.lighter.provision:main",
89 "poc=nvflare.lighter.poc:main",
90 "authz_preview=nvflare.fuel.hci.tools.authz_preview:main",
91 ],
92 },
93 )
94
95 os.remove(os.path.join(this_directory, "nvflare", "poc.zip"))
96
```
Path: `nvflare/__init__.py`
Content:
```
1 # Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 __version__ = "2.0.5"
16
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/nvflare/__init__.py b/nvflare/__init__.py
--- a/nvflare/__init__.py
+++ b/nvflare/__init__.py
@@ -12,4 +12,4 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-__version__ = "2.0.5"
+__version__ = "2.0.7"
diff --git a/nvflare/lighter/poc.py b/nvflare/lighter/poc.py
--- a/nvflare/lighter/poc.py
+++ b/nvflare/lighter/poc.py
@@ -44,8 +44,13 @@
poc_zip_path = file_dir_path.parent / "poc.zip"
answer = input("This will delete poc folder in current directory and create a new one. Is it OK to proceed? (y/N) ")
if answer.strip().upper() == "Y":
- shutil.rmtree(os.path.join(os.getcwd(), "poc"), ignore_errors=True)
+ dest_poc_folder = os.path.join(os.getcwd(), "poc")
+ shutil.rmtree(dest_poc_folder, ignore_errors=True)
shutil.unpack_archive(poc_zip_path)
+ for root, dirs, files in os.walk(dest_poc_folder):
+ for file in files:
+ if file.endswith(".sh"):
+ os.chmod(os.path.join(root, file), 0o755)
clone_client(args.num_clients)
print("Successfully creating poc folder. Please read poc/Readme.rst for user guide.")
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -27,7 +27,7 @@
with open(os.path.join(this_directory, "nvflare", "__init__.py"), encoding="utf-8") as f:
for line in f.readlines():
if "__version__" in line:
- init_version = line.split("=")[1].strip()
+ init_version = line.split("=")[1].strip().strip('"')
nvfl_version = os.environ.get("NVFL_VERSION", init_version)
yymmdd = datetime.today().strftime("%y%m%d")
| {"golden_diff": "diff --git a/nvflare/__init__.py b/nvflare/__init__.py\n--- a/nvflare/__init__.py\n+++ b/nvflare/__init__.py\n@@ -12,4 +12,4 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n \n-__version__ = \"2.0.5\"\n+__version__ = \"2.0.7\"\ndiff --git a/nvflare/lighter/poc.py b/nvflare/lighter/poc.py\n--- a/nvflare/lighter/poc.py\n+++ b/nvflare/lighter/poc.py\n@@ -44,8 +44,13 @@\n poc_zip_path = file_dir_path.parent / \"poc.zip\"\n answer = input(\"This will delete poc folder in current directory and create a new one. Is it OK to proceed? (y/N) \")\n if answer.strip().upper() == \"Y\":\n- shutil.rmtree(os.path.join(os.getcwd(), \"poc\"), ignore_errors=True)\n+ dest_poc_folder = os.path.join(os.getcwd(), \"poc\")\n+ shutil.rmtree(dest_poc_folder, ignore_errors=True)\n shutil.unpack_archive(poc_zip_path)\n+ for root, dirs, files in os.walk(dest_poc_folder):\n+ for file in files:\n+ if file.endswith(\".sh\"):\n+ os.chmod(os.path.join(root, file), 0o755)\n clone_client(args.num_clients)\n print(\"Successfully creating poc folder. Please read poc/Readme.rst for user guide.\")\n \ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -27,7 +27,7 @@\n with open(os.path.join(this_directory, \"nvflare\", \"__init__.py\"), encoding=\"utf-8\") as f:\n for line in f.readlines():\n if \"__version__\" in line:\n- init_version = line.split(\"=\")[1].strip()\n+ init_version = line.split(\"=\")[1].strip().strip('\"')\n \n nvfl_version = os.environ.get(\"NVFL_VERSION\", init_version)\n yymmdd = datetime.today().strftime(\"%y%m%d\")\n", "issue": "shell scripts missing x permission in poc\nThe shell script files generated from poc command do not have original permission settings, especially the execute permission, after switching to shutil.unpack_archive.\n", "before_files": [{"content": "# Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport argparse\nimport os\nimport pathlib\nimport shutil\n\n\ndef clone_client(num_clients: int):\n current_path = os.getcwd()\n poc_folder = os.path.join(current_path, \"poc\")\n src_folder = os.path.join(poc_folder, \"client\")\n for index in range(1, num_clients + 1):\n dst_folder = os.path.join(poc_folder, f\"site-{index}\")\n shutil.copytree(src_folder, dst_folder)\n start_sh = open(os.path.join(dst_folder, \"startup\", \"start.sh\"), \"rt\")\n content = start_sh.read()\n start_sh.close()\n content = content.replace(\"NNN\", f\"{index}\")\n with open(os.path.join(dst_folder, \"startup\", \"start.sh\"), \"wt\") as f:\n f.write(content)\n shutil.rmtree(src_folder)\n\n\ndef main():\n parser = argparse.ArgumentParser()\n parser.add_argument(\"-n\", \"--num_clients\", type=int, default=1, help=\"number of client folders to create\")\n\n args = parser.parse_args()\n\n file_dir_path = pathlib.Path(__file__).parent.absolute()\n poc_zip_path = file_dir_path.parent / \"poc.zip\"\n answer = input(\"This will delete poc folder in current directory and create a new one. Is it OK to proceed? (y/N) \")\n if answer.strip().upper() == \"Y\":\n shutil.rmtree(os.path.join(os.getcwd(), \"poc\"), ignore_errors=True)\n shutil.unpack_archive(poc_zip_path)\n clone_client(args.num_clients)\n print(\"Successfully creating poc folder. Please read poc/Readme.rst for user guide.\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "nvflare/lighter/poc.py"}, {"content": "# Copyright (c) 2021, NVIDIA CORPORATION.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.\nimport os\nimport shutil\nfrom datetime import datetime\n\nfrom setuptools import find_packages, setup\n\n# read the contents of your README file\nthis_directory = os.path.abspath(os.path.dirname(__file__))\nwith open(os.path.join(this_directory, \"README.md\"), encoding=\"utf-8\") as f:\n long_description = f.read()\n\nwith open(os.path.join(this_directory, \"nvflare\", \"__init__.py\"), encoding=\"utf-8\") as f:\n for line in f.readlines():\n if \"__version__\" in line:\n init_version = line.split(\"=\")[1].strip()\n\nnvfl_version = os.environ.get(\"NVFL_VERSION\", init_version)\nyymmdd = datetime.today().strftime(\"%y%m%d\")\nnvfl_nightly_version = f\"{nvfl_version}.dev{yymmdd}\"\n\nif os.environ.get(\"NVFL_RELEASE\"):\n package_name = \"nvflare\"\n version = nvfl_version\nelse:\n package_name = \"nvflare-nightly\"\n version = nvfl_nightly_version\n\n\nif os.path.exists(os.path.join(this_directory, \"nvflare\", \"poc.zip\")):\n os.remove(os.path.join(this_directory, \"nvflare\", \"poc.zip\"))\nshutil.make_archive(base_name=\"poc\", format=\"zip\", root_dir=os.path.join(this_directory, \"nvflare\"), base_dir=\"poc\")\nshutil.move(\"poc.zip\", os.path.join(this_directory, \"nvflare\", \"poc.zip\"))\n\npython_version = os.environ.get(\"PY_VERSION\", \"3.7\")\nsetup(\n name=package_name,\n version=version,\n description=\"Federated Learning Application Runtime Environment\",\n url=\"https://github.com/NVIDIA/NVFlare\",\n package_dir={\"nvflare\": \"nvflare\"},\n packages=find_packages(\n where=\".\",\n include=[\n \"*\",\n ],\n exclude=[\n \"test\",\n ],\n ),\n package_data={\"\": [\"*.yml\", \"*.html\", \"poc.zip\"]},\n zip_safe=True,\n license_files=(\"LICENSE.pdf\",),\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"License :: Other/Proprietary License\",\n \"Operating System :: OS Independent\",\n ],\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n python_requires=\">=3.7\",\n # install_requires=list(pkutils.parse_requirements(\"requirements.txt\")),\n install_requires=[\n \"PyYAML\",\n \"psutil\",\n \"numpy\",\n \"grpcio\",\n \"google-api-python-client\",\n \"cryptography\",\n \"tenseal==0.3.0\",\n ],\n entry_points={\n \"console_scripts\": [\n \"provision=nvflare.lighter.provision:main\",\n \"poc=nvflare.lighter.poc:main\",\n \"authz_preview=nvflare.fuel.hci.tools.authz_preview:main\",\n ],\n },\n)\n\nos.remove(os.path.join(this_directory, \"nvflare\", \"poc.zip\"))\n", "path": "setup.py"}, {"content": "# Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n__version__ = \"2.0.5\"\n", "path": "nvflare/__init__.py"}], "after_files": [{"content": "# Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport argparse\nimport os\nimport pathlib\nimport shutil\n\n\ndef clone_client(num_clients: int):\n current_path = os.getcwd()\n poc_folder = os.path.join(current_path, \"poc\")\n src_folder = os.path.join(poc_folder, \"client\")\n for index in range(1, num_clients + 1):\n dst_folder = os.path.join(poc_folder, f\"site-{index}\")\n shutil.copytree(src_folder, dst_folder)\n start_sh = open(os.path.join(dst_folder, \"startup\", \"start.sh\"), \"rt\")\n content = start_sh.read()\n start_sh.close()\n content = content.replace(\"NNN\", f\"{index}\")\n with open(os.path.join(dst_folder, \"startup\", \"start.sh\"), \"wt\") as f:\n f.write(content)\n shutil.rmtree(src_folder)\n\n\ndef main():\n parser = argparse.ArgumentParser()\n parser.add_argument(\"-n\", \"--num_clients\", type=int, default=1, help=\"number of client folders to create\")\n\n args = parser.parse_args()\n\n file_dir_path = pathlib.Path(__file__).parent.absolute()\n poc_zip_path = file_dir_path.parent / \"poc.zip\"\n answer = input(\"This will delete poc folder in current directory and create a new one. Is it OK to proceed? (y/N) \")\n if answer.strip().upper() == \"Y\":\n dest_poc_folder = os.path.join(os.getcwd(), \"poc\")\n shutil.rmtree(dest_poc_folder, ignore_errors=True)\n shutil.unpack_archive(poc_zip_path)\n for root, dirs, files in os.walk(dest_poc_folder):\n for file in files:\n if file.endswith(\".sh\"):\n os.chmod(os.path.join(root, file), 0o755)\n clone_client(args.num_clients)\n print(\"Successfully creating poc folder. Please read poc/Readme.rst for user guide.\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "nvflare/lighter/poc.py"}, {"content": "# Copyright (c) 2021, NVIDIA CORPORATION.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.\nimport os\nimport shutil\nfrom datetime import datetime\n\nfrom setuptools import find_packages, setup\n\n# read the contents of your README file\nthis_directory = os.path.abspath(os.path.dirname(__file__))\nwith open(os.path.join(this_directory, \"README.md\"), encoding=\"utf-8\") as f:\n long_description = f.read()\n\nwith open(os.path.join(this_directory, \"nvflare\", \"__init__.py\"), encoding=\"utf-8\") as f:\n for line in f.readlines():\n if \"__version__\" in line:\n init_version = line.split(\"=\")[1].strip().strip('\"')\n\nnvfl_version = os.environ.get(\"NVFL_VERSION\", init_version)\nyymmdd = datetime.today().strftime(\"%y%m%d\")\nnvfl_nightly_version = f\"{nvfl_version}.dev{yymmdd}\"\n\nif os.environ.get(\"NVFL_RELEASE\"):\n package_name = \"nvflare\"\n version = nvfl_version\nelse:\n package_name = \"nvflare-nightly\"\n version = nvfl_nightly_version\n\n\nif os.path.exists(os.path.join(this_directory, \"nvflare\", \"poc.zip\")):\n os.remove(os.path.join(this_directory, \"nvflare\", \"poc.zip\"))\nshutil.make_archive(base_name=\"poc\", format=\"zip\", root_dir=os.path.join(this_directory, \"nvflare\"), base_dir=\"poc\")\nshutil.move(\"poc.zip\", os.path.join(this_directory, \"nvflare\", \"poc.zip\"))\n\npython_version = os.environ.get(\"PY_VERSION\", \"3.7\")\nsetup(\n name=package_name,\n version=version,\n description=\"Federated Learning Application Runtime Environment\",\n url=\"https://github.com/NVIDIA/NVFlare\",\n package_dir={\"nvflare\": \"nvflare\"},\n packages=find_packages(\n where=\".\",\n include=[\n \"*\",\n ],\n exclude=[\n \"test\",\n ],\n ),\n package_data={\"\": [\"*.yml\", \"*.html\", \"poc.zip\"]},\n zip_safe=True,\n license_files=(\"LICENSE.pdf\",),\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"License :: Other/Proprietary License\",\n \"Operating System :: OS Independent\",\n ],\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n python_requires=\">=3.7\",\n # install_requires=list(pkutils.parse_requirements(\"requirements.txt\")),\n install_requires=[\n \"PyYAML\",\n \"psutil\",\n \"numpy\",\n \"grpcio\",\n \"google-api-python-client\",\n \"cryptography\",\n \"tenseal==0.3.0\",\n ],\n entry_points={\n \"console_scripts\": [\n \"provision=nvflare.lighter.provision:main\",\n \"poc=nvflare.lighter.poc:main\",\n \"authz_preview=nvflare.fuel.hci.tools.authz_preview:main\",\n ],\n },\n)\n\nos.remove(os.path.join(this_directory, \"nvflare\", \"poc.zip\"))\n", "path": "setup.py"}, {"content": "# Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n__version__ = \"2.0.7\"\n", "path": "nvflare/__init__.py"}]} | 2,086 | 476 |
gh_patches_debug_23774 | rasdani/github-patches | git_diff | piskvorky__gensim-2226 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Poincare visualization breaks with plotly 3.0.0
#### Description
poincare_2d_visualization - receives the following error -
ValueError:
Invalid value of type 'builtins.str' received for the 'textposition' property of scatter
Received value: 'bottom'
#### Steps/Code/Corpus to Reproduce
Example:
```
from gensim.viz.poincare import poincare_2d_visualization
import plotly
vis = poincare_2d_visualization(model, tuples, 'Poincare Plot')
```
#### Versions
Please run the following snippet and paste the output below.
Darwin-17.2.0-x86_64-i386-64bit
Python 3.6.5 |Anaconda, Inc.| (default, Apr 26 2018, 08:42:37)
[GCC 4.2.1 Compatible Clang 4.0.1 (tags/RELEASE_401/final)]
NumPy 1.14.3
SciPy 1.1.0
gensim 3.5.0
FAST_VERSION 1
Plotly 3.0.0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gensim/viz/poincare.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 #
4 # Author: Jayant Jain <[email protected]>
5 # Copyright (C) 2017 Radim Rehurek <[email protected]>
6 # Licensed under the GNU LGPL v2.1 - http://www.gnu.org/licenses/lgpl.html
7
8
9 """
10 Utilities for creating 2-D visualizations of Poincare models and Poincare distance heatmaps.
11
12 """
13
14 import logging
15
16 from collections import Counter
17 import numpy as np
18 import plotly.graph_objs as go
19
20 from gensim.models.poincare import PoincareKeyedVectors
21
22
23 logger = logging.getLogger(__name__)
24
25
26 def poincare_2d_visualization(model, tree, figure_title, num_nodes=50, show_node_labels=()):
27 """Create a 2-d plot of the nodes and edges of a 2-d poincare embedding.
28
29 Parameters
30 ----------
31 model : :class:`~gensim.models.poincare.PoincareModel`
32 The model to visualize, model size must be 2.
33 tree : set
34 Set of tuples containing the direct edges present in the original dataset.
35 figure_title : str
36 Title of the plotted figure.
37 num_nodes : int or None
38 Number of nodes for which edges are to be plotted.
39 If `None`, all edges are plotted.
40 Helpful to limit this in case the data is too large to avoid a messy plot.
41 show_node_labels : iterable
42 Iterable of nodes for which to show labels by default.
43
44 Returns
45 -------
46 :class:`plotly.graph_objs.Figure`
47 Plotly figure that contains plot.
48
49 """
50 vectors = model.kv.syn0
51 if vectors.shape[1] != 2:
52 raise ValueError('Can only plot 2-D vectors')
53
54 node_labels = model.kv.index2word
55 nodes_x = list(vectors[:, 0])
56 nodes_y = list(vectors[:, 1])
57 nodes = go.Scatter(
58 x=nodes_x, y=nodes_y,
59 mode='markers',
60 marker=dict(color='rgb(30, 100, 200)'),
61 text=node_labels,
62 textposition='bottom'
63 )
64
65 nodes_x, nodes_y, node_labels = [], [], []
66 for node in show_node_labels:
67 vector = model.kv[node]
68 nodes_x.append(vector[0])
69 nodes_y.append(vector[1])
70 node_labels.append(node)
71 nodes_with_labels = go.Scatter(
72 x=nodes_x, y=nodes_y,
73 mode='markers+text',
74 marker=dict(color='rgb(200, 100, 200)'),
75 text=node_labels,
76 textposition='bottom'
77 )
78
79 node_out_degrees = Counter(hypernym_pair[1] for hypernym_pair in tree)
80 if num_nodes is None:
81 chosen_nodes = list(node_out_degrees.keys())
82 else:
83 chosen_nodes = list(sorted(node_out_degrees.keys(), key=lambda k: -node_out_degrees[k]))[:num_nodes]
84
85 edges_x = []
86 edges_y = []
87 for u, v in tree:
88 if not(u in chosen_nodes or v in chosen_nodes):
89 continue
90 vector_u = model.kv[u]
91 vector_v = model.kv[v]
92 edges_x += [vector_u[0], vector_v[0], None]
93 edges_y += [vector_u[1], vector_v[1], None]
94 edges = go.Scatter(
95 x=edges_x, y=edges_y, mode="line", hoverinfo=False,
96 line=dict(color='rgb(50,50,50)', width=1))
97
98 layout = go.Layout(
99 title=figure_title, showlegend=False, hovermode='closest', width=800, height=800)
100 return go.Figure(data=[edges, nodes, nodes_with_labels], layout=layout)
101
102
103 def poincare_distance_heatmap(origin_point, x_range=(-1.0, 1.0), y_range=(-1.0, 1.0), num_points=100):
104 """Create a heatmap of Poincare distances from `origin_point` for each point (x, y),
105 where x and y lie in `x_range` and `y_range` respectively, with `num_points` points chosen uniformly in both ranges.
106
107 Parameters
108 ----------
109 origin_point : tuple (int, int)
110 (x, y) from which distances are to be measured and plotted.
111 x_range : tuple (int, int)
112 Range for x-axis from which to choose `num_points` points.
113 y_range : tuple (int, int)
114 Range for y-axis from which to choose `num_points` points.
115 num_points : int
116 Number of points to choose from `x_range` and `y_range`.
117
118 Notes
119 -----
120 Points outside the unit circle are ignored, since the Poincare distance is defined
121 only for points inside the circle boundaries (exclusive of the boundary).
122
123 Returns
124 -------
125 :class:`plotly.graph_objs.Figure`
126 Plotly figure that contains plot
127
128 """
129 epsilon = 1e-8 # Can't choose (-1.0, -1.0) or (1.0, 1.0), distance undefined
130 x_range, y_range = list(x_range), list(y_range)
131 if x_range[0] == -1.0 and y_range[0] == -1.0:
132 x_range[0] += epsilon
133 y_range[0] += epsilon
134 if x_range[0] == 1.0 and y_range[0] == 1.0:
135 x_range[0] -= epsilon
136 y_range[0] -= epsilon
137
138 x_axis_values = np.linspace(x_range[0], x_range[1], num=num_points)
139 y_axis_values = np.linspace(x_range[0], x_range[1], num=num_points)
140 x, y = np.meshgrid(x_axis_values, y_axis_values)
141 all_points = np.dstack((x, y)).swapaxes(1, 2).swapaxes(0, 1).reshape(2, num_points ** 2).T
142 norms = np.linalg.norm(all_points, axis=1)
143 all_points = all_points[norms < 1]
144
145 origin_point = np.array(origin_point)
146 all_distances = PoincareKeyedVectors.poincare_dists(origin_point, all_points)
147
148 distances = go.Scatter(
149 x=all_points[:, 0],
150 y=all_points[:, 1],
151 mode='markers',
152 marker=dict(
153 size='9',
154 color=all_distances,
155 colorscale='Viridis',
156 showscale=True,
157 colorbar=go.ColorBar(
158 title='Poincare Distance'
159 ),
160 ),
161 text=[
162 'Distance from (%.2f, %.2f): %.2f' % (origin_point[0], origin_point[1], d)
163 for d in all_distances],
164 name='', # To avoid the default 'trace 0'
165 )
166
167 origin = go.Scatter(
168 x=[origin_point[0]],
169 y=[origin_point[1]],
170 name='Distance from (%.2f, %.2f)' % (origin_point[0], origin_point[1]),
171 mode='markers+text',
172 marker=dict(
173 size='10',
174 color='rgb(200, 50, 50)'
175 )
176 )
177
178 layout = go.Layout(
179 width=900,
180 height=800,
181 showlegend=False,
182 title='Poincare Distances from (%.2f, %.2f)' % (origin_point[0], origin_point[1]),
183 hovermode='closest',
184 )
185
186 return go.Figure(data=[distances, origin], layout=layout)
187
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/gensim/viz/poincare.py b/gensim/viz/poincare.py
--- a/gensim/viz/poincare.py
+++ b/gensim/viz/poincare.py
@@ -59,7 +59,7 @@
mode='markers',
marker=dict(color='rgb(30, 100, 200)'),
text=node_labels,
- textposition='bottom'
+ textposition='bottom center'
)
nodes_x, nodes_y, node_labels = [], [], []
@@ -73,7 +73,7 @@
mode='markers+text',
marker=dict(color='rgb(200, 100, 200)'),
text=node_labels,
- textposition='bottom'
+ textposition='bottom center'
)
node_out_degrees = Counter(hypernym_pair[1] for hypernym_pair in tree)
@@ -92,7 +92,7 @@
edges_x += [vector_u[0], vector_v[0], None]
edges_y += [vector_u[1], vector_v[1], None]
edges = go.Scatter(
- x=edges_x, y=edges_y, mode="line", hoverinfo=False,
+ x=edges_x, y=edges_y, mode="lines", hoverinfo='none',
line=dict(color='rgb(50,50,50)', width=1))
layout = go.Layout(
| {"golden_diff": "diff --git a/gensim/viz/poincare.py b/gensim/viz/poincare.py\n--- a/gensim/viz/poincare.py\n+++ b/gensim/viz/poincare.py\n@@ -59,7 +59,7 @@\n mode='markers',\n marker=dict(color='rgb(30, 100, 200)'),\n text=node_labels,\n- textposition='bottom'\n+ textposition='bottom center'\n )\n \n nodes_x, nodes_y, node_labels = [], [], []\n@@ -73,7 +73,7 @@\n mode='markers+text',\n marker=dict(color='rgb(200, 100, 200)'),\n text=node_labels,\n- textposition='bottom'\n+ textposition='bottom center'\n )\n \n node_out_degrees = Counter(hypernym_pair[1] for hypernym_pair in tree)\n@@ -92,7 +92,7 @@\n edges_x += [vector_u[0], vector_v[0], None]\n edges_y += [vector_u[1], vector_v[1], None]\n edges = go.Scatter(\n- x=edges_x, y=edges_y, mode=\"line\", hoverinfo=False,\n+ x=edges_x, y=edges_y, mode=\"lines\", hoverinfo='none',\n line=dict(color='rgb(50,50,50)', width=1))\n \n layout = go.Layout(\n", "issue": "Poincare visualization breaks with plotly 3.0.0 \n#### Description\r\n\r\npoincare_2d_visualization - receives the following error - \r\nValueError: \r\n Invalid value of type 'builtins.str' received for the 'textposition' property of scatter\r\n Received value: 'bottom'\r\n\r\n#### Steps/Code/Corpus to Reproduce\r\nExample:\r\n```\r\nfrom gensim.viz.poincare import poincare_2d_visualization\r\nimport plotly\r\n\r\n\r\nvis = poincare_2d_visualization(model, tuples, 'Poincare Plot')\r\n```\r\n\r\n#### Versions\r\nPlease run the following snippet and paste the output below.\r\nDarwin-17.2.0-x86_64-i386-64bit\r\nPython 3.6.5 |Anaconda, Inc.| (default, Apr 26 2018, 08:42:37) \r\n[GCC 4.2.1 Compatible Clang 4.0.1 (tags/RELEASE_401/final)]\r\nNumPy 1.14.3\r\nSciPy 1.1.0\r\ngensim 3.5.0\r\nFAST_VERSION 1\r\nPlotly 3.0.0\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Author: Jayant Jain <[email protected]>\n# Copyright (C) 2017 Radim Rehurek <[email protected]>\n# Licensed under the GNU LGPL v2.1 - http://www.gnu.org/licenses/lgpl.html\n\n\n\"\"\"\nUtilities for creating 2-D visualizations of Poincare models and Poincare distance heatmaps.\n\n\"\"\"\n\nimport logging\n\nfrom collections import Counter\nimport numpy as np\nimport plotly.graph_objs as go\n\nfrom gensim.models.poincare import PoincareKeyedVectors\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef poincare_2d_visualization(model, tree, figure_title, num_nodes=50, show_node_labels=()):\n \"\"\"Create a 2-d plot of the nodes and edges of a 2-d poincare embedding.\n\n Parameters\n ----------\n model : :class:`~gensim.models.poincare.PoincareModel`\n The model to visualize, model size must be 2.\n tree : set\n Set of tuples containing the direct edges present in the original dataset.\n figure_title : str\n Title of the plotted figure.\n num_nodes : int or None\n Number of nodes for which edges are to be plotted.\n If `None`, all edges are plotted.\n Helpful to limit this in case the data is too large to avoid a messy plot.\n show_node_labels : iterable\n Iterable of nodes for which to show labels by default.\n\n Returns\n -------\n :class:`plotly.graph_objs.Figure`\n Plotly figure that contains plot.\n\n \"\"\"\n vectors = model.kv.syn0\n if vectors.shape[1] != 2:\n raise ValueError('Can only plot 2-D vectors')\n\n node_labels = model.kv.index2word\n nodes_x = list(vectors[:, 0])\n nodes_y = list(vectors[:, 1])\n nodes = go.Scatter(\n x=nodes_x, y=nodes_y,\n mode='markers',\n marker=dict(color='rgb(30, 100, 200)'),\n text=node_labels,\n textposition='bottom'\n )\n\n nodes_x, nodes_y, node_labels = [], [], []\n for node in show_node_labels:\n vector = model.kv[node]\n nodes_x.append(vector[0])\n nodes_y.append(vector[1])\n node_labels.append(node)\n nodes_with_labels = go.Scatter(\n x=nodes_x, y=nodes_y,\n mode='markers+text',\n marker=dict(color='rgb(200, 100, 200)'),\n text=node_labels,\n textposition='bottom'\n )\n\n node_out_degrees = Counter(hypernym_pair[1] for hypernym_pair in tree)\n if num_nodes is None:\n chosen_nodes = list(node_out_degrees.keys())\n else:\n chosen_nodes = list(sorted(node_out_degrees.keys(), key=lambda k: -node_out_degrees[k]))[:num_nodes]\n\n edges_x = []\n edges_y = []\n for u, v in tree:\n if not(u in chosen_nodes or v in chosen_nodes):\n continue\n vector_u = model.kv[u]\n vector_v = model.kv[v]\n edges_x += [vector_u[0], vector_v[0], None]\n edges_y += [vector_u[1], vector_v[1], None]\n edges = go.Scatter(\n x=edges_x, y=edges_y, mode=\"line\", hoverinfo=False,\n line=dict(color='rgb(50,50,50)', width=1))\n\n layout = go.Layout(\n title=figure_title, showlegend=False, hovermode='closest', width=800, height=800)\n return go.Figure(data=[edges, nodes, nodes_with_labels], layout=layout)\n\n\ndef poincare_distance_heatmap(origin_point, x_range=(-1.0, 1.0), y_range=(-1.0, 1.0), num_points=100):\n \"\"\"Create a heatmap of Poincare distances from `origin_point` for each point (x, y),\n where x and y lie in `x_range` and `y_range` respectively, with `num_points` points chosen uniformly in both ranges.\n\n Parameters\n ----------\n origin_point : tuple (int, int)\n (x, y) from which distances are to be measured and plotted.\n x_range : tuple (int, int)\n Range for x-axis from which to choose `num_points` points.\n y_range : tuple (int, int)\n Range for y-axis from which to choose `num_points` points.\n num_points : int\n Number of points to choose from `x_range` and `y_range`.\n\n Notes\n -----\n Points outside the unit circle are ignored, since the Poincare distance is defined\n only for points inside the circle boundaries (exclusive of the boundary).\n\n Returns\n -------\n :class:`plotly.graph_objs.Figure`\n Plotly figure that contains plot\n\n \"\"\"\n epsilon = 1e-8 # Can't choose (-1.0, -1.0) or (1.0, 1.0), distance undefined\n x_range, y_range = list(x_range), list(y_range)\n if x_range[0] == -1.0 and y_range[0] == -1.0:\n x_range[0] += epsilon\n y_range[0] += epsilon\n if x_range[0] == 1.0 and y_range[0] == 1.0:\n x_range[0] -= epsilon\n y_range[0] -= epsilon\n\n x_axis_values = np.linspace(x_range[0], x_range[1], num=num_points)\n y_axis_values = np.linspace(x_range[0], x_range[1], num=num_points)\n x, y = np.meshgrid(x_axis_values, y_axis_values)\n all_points = np.dstack((x, y)).swapaxes(1, 2).swapaxes(0, 1).reshape(2, num_points ** 2).T\n norms = np.linalg.norm(all_points, axis=1)\n all_points = all_points[norms < 1]\n\n origin_point = np.array(origin_point)\n all_distances = PoincareKeyedVectors.poincare_dists(origin_point, all_points)\n\n distances = go.Scatter(\n x=all_points[:, 0],\n y=all_points[:, 1],\n mode='markers',\n marker=dict(\n size='9',\n color=all_distances,\n colorscale='Viridis',\n showscale=True,\n colorbar=go.ColorBar(\n title='Poincare Distance'\n ),\n ),\n text=[\n 'Distance from (%.2f, %.2f): %.2f' % (origin_point[0], origin_point[1], d)\n for d in all_distances],\n name='', # To avoid the default 'trace 0'\n )\n\n origin = go.Scatter(\n x=[origin_point[0]],\n y=[origin_point[1]],\n name='Distance from (%.2f, %.2f)' % (origin_point[0], origin_point[1]),\n mode='markers+text',\n marker=dict(\n size='10',\n color='rgb(200, 50, 50)'\n )\n )\n\n layout = go.Layout(\n width=900,\n height=800,\n showlegend=False,\n title='Poincare Distances from (%.2f, %.2f)' % (origin_point[0], origin_point[1]),\n hovermode='closest',\n )\n\n return go.Figure(data=[distances, origin], layout=layout)\n", "path": "gensim/viz/poincare.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Author: Jayant Jain <[email protected]>\n# Copyright (C) 2017 Radim Rehurek <[email protected]>\n# Licensed under the GNU LGPL v2.1 - http://www.gnu.org/licenses/lgpl.html\n\n\n\"\"\"\nUtilities for creating 2-D visualizations of Poincare models and Poincare distance heatmaps.\n\n\"\"\"\n\nimport logging\n\nfrom collections import Counter\nimport numpy as np\nimport plotly.graph_objs as go\n\nfrom gensim.models.poincare import PoincareKeyedVectors\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef poincare_2d_visualization(model, tree, figure_title, num_nodes=50, show_node_labels=()):\n \"\"\"Create a 2-d plot of the nodes and edges of a 2-d poincare embedding.\n\n Parameters\n ----------\n model : :class:`~gensim.models.poincare.PoincareModel`\n The model to visualize, model size must be 2.\n tree : set\n Set of tuples containing the direct edges present in the original dataset.\n figure_title : str\n Title of the plotted figure.\n num_nodes : int or None\n Number of nodes for which edges are to be plotted.\n If `None`, all edges are plotted.\n Helpful to limit this in case the data is too large to avoid a messy plot.\n show_node_labels : iterable\n Iterable of nodes for which to show labels by default.\n\n Returns\n -------\n :class:`plotly.graph_objs.Figure`\n Plotly figure that contains plot.\n\n \"\"\"\n vectors = model.kv.syn0\n if vectors.shape[1] != 2:\n raise ValueError('Can only plot 2-D vectors')\n\n node_labels = model.kv.index2word\n nodes_x = list(vectors[:, 0])\n nodes_y = list(vectors[:, 1])\n nodes = go.Scatter(\n x=nodes_x, y=nodes_y,\n mode='markers',\n marker=dict(color='rgb(30, 100, 200)'),\n text=node_labels,\n textposition='bottom center'\n )\n\n nodes_x, nodes_y, node_labels = [], [], []\n for node in show_node_labels:\n vector = model.kv[node]\n nodes_x.append(vector[0])\n nodes_y.append(vector[1])\n node_labels.append(node)\n nodes_with_labels = go.Scatter(\n x=nodes_x, y=nodes_y,\n mode='markers+text',\n marker=dict(color='rgb(200, 100, 200)'),\n text=node_labels,\n textposition='bottom center'\n )\n\n node_out_degrees = Counter(hypernym_pair[1] for hypernym_pair in tree)\n if num_nodes is None:\n chosen_nodes = list(node_out_degrees.keys())\n else:\n chosen_nodes = list(sorted(node_out_degrees.keys(), key=lambda k: -node_out_degrees[k]))[:num_nodes]\n\n edges_x = []\n edges_y = []\n for u, v in tree:\n if not(u in chosen_nodes or v in chosen_nodes):\n continue\n vector_u = model.kv[u]\n vector_v = model.kv[v]\n edges_x += [vector_u[0], vector_v[0], None]\n edges_y += [vector_u[1], vector_v[1], None]\n edges = go.Scatter(\n x=edges_x, y=edges_y, mode=\"lines\", hoverinfo='none',\n line=dict(color='rgb(50,50,50)', width=1))\n\n layout = go.Layout(\n title=figure_title, showlegend=False, hovermode='closest', width=800, height=800)\n return go.Figure(data=[edges, nodes, nodes_with_labels], layout=layout)\n\n\ndef poincare_distance_heatmap(origin_point, x_range=(-1.0, 1.0), y_range=(-1.0, 1.0), num_points=100):\n \"\"\"Create a heatmap of Poincare distances from `origin_point` for each point (x, y),\n where x and y lie in `x_range` and `y_range` respectively, with `num_points` points chosen uniformly in both ranges.\n\n Parameters\n ----------\n origin_point : tuple (int, int)\n (x, y) from which distances are to be measured and plotted.\n x_range : tuple (int, int)\n Range for x-axis from which to choose `num_points` points.\n y_range : tuple (int, int)\n Range for y-axis from which to choose `num_points` points.\n num_points : int\n Number of points to choose from `x_range` and `y_range`.\n\n Notes\n -----\n Points outside the unit circle are ignored, since the Poincare distance is defined\n only for points inside the circle boundaries (exclusive of the boundary).\n\n Returns\n -------\n :class:`plotly.graph_objs.Figure`\n Plotly figure that contains plot\n\n \"\"\"\n epsilon = 1e-8 # Can't choose (-1.0, -1.0) or (1.0, 1.0), distance undefined\n x_range, y_range = list(x_range), list(y_range)\n if x_range[0] == -1.0 and y_range[0] == -1.0:\n x_range[0] += epsilon\n y_range[0] += epsilon\n if x_range[0] == 1.0 and y_range[0] == 1.0:\n x_range[0] -= epsilon\n y_range[0] -= epsilon\n\n x_axis_values = np.linspace(x_range[0], x_range[1], num=num_points)\n y_axis_values = np.linspace(x_range[0], x_range[1], num=num_points)\n x, y = np.meshgrid(x_axis_values, y_axis_values)\n all_points = np.dstack((x, y)).swapaxes(1, 2).swapaxes(0, 1).reshape(2, num_points ** 2).T\n norms = np.linalg.norm(all_points, axis=1)\n all_points = all_points[norms < 1]\n\n origin_point = np.array(origin_point)\n all_distances = PoincareKeyedVectors.poincare_dists(origin_point, all_points)\n\n distances = go.Scatter(\n x=all_points[:, 0],\n y=all_points[:, 1],\n mode='markers',\n marker=dict(\n size='9',\n color=all_distances,\n colorscale='Viridis',\n showscale=True,\n colorbar=go.ColorBar(\n title='Poincare Distance'\n ),\n ),\n text=[\n 'Distance from (%.2f, %.2f): %.2f' % (origin_point[0], origin_point[1], d)\n for d in all_distances],\n name='', # To avoid the default 'trace 0'\n )\n\n origin = go.Scatter(\n x=[origin_point[0]],\n y=[origin_point[1]],\n name='Distance from (%.2f, %.2f)' % (origin_point[0], origin_point[1]),\n mode='markers+text',\n marker=dict(\n size='10',\n color='rgb(200, 50, 50)'\n )\n )\n\n layout = go.Layout(\n width=900,\n height=800,\n showlegend=False,\n title='Poincare Distances from (%.2f, %.2f)' % (origin_point[0], origin_point[1]),\n hovermode='closest',\n )\n\n return go.Figure(data=[distances, origin], layout=layout)\n", "path": "gensim/viz/poincare.py"}]} | 2,703 | 326 |
gh_patches_debug_16990 | rasdani/github-patches | git_diff | cobbler__cobbler-3454 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cobblerd start failure due to incorrect ownership of /var/lib/cobbler/web.ss
As has been noted for some time, cobblerd will fail to start after a restart, giving an error about /var/lib/cobbler/web.ss. This was reported in https://github.com/cobbler/cobbler/issues/2183, and discussed elsewhere. When successfully starting, the permission began as:
`
-rw-r--r--. 1 root root system_u:object_r:cobbler_var_lib_t:s0 1024 Jun 7 09:46 /var/lib/cobbler/web.ss
`
but after starting, the permission becomes:
`
-rw-r--r--. 1 apache root system_u:object_r:cobbler_var_lib_t:s0 1024 Jun 7 09:47 /var/lib/cobbler/web.ss
`
And while the ownership remains as apache, the cobblerd server will fail to start.
<!--- A clear and concise description of what the bug is. -->
The problem is that in cobblerd.py:regen_ss_file(), after this file is created by cobblerd for use in authorizing the CLI and web, the routine changes the ownership to 'apache', and then when the process is restarted, the routine once again tries to open it for writing the random 1024 byte auth token, the open fails. Changing the ownership back to root fixes the issue.
<!--- HINT: You can paste gist.github.com links for long logs or larger files -->
### Steps to reproduce
1. Start the server for the first time... it starts.
2. Restart the server, It will fail with an error opening /var/lib/cobbler/web.ss
3. Changing the ownership of the file back to root.root and restarting will succeed.
### Expected behavior
<!--- A clear and concise description of what you expected to happen. -->
The cobblerd service would restart each and every time.
### Cobbler version
<!--- Paste output from `cobbler version` -->
````
Cobbler 3.3.3
source: ?, ?
build time: Tue Jun 14 00:00:00 2022
````
(From EPEL 9 repository)
### Operating system
<!--- On which operating system do you use Cobbler? -->
Rocky Linux release 9.2 (Blue Onyx)
### Cobbler log
<!--- Paste (partial) output from `/var/log/cobbler/cobbler.log` -->
````
[Daemon] 2023-06-07T22:11:08 - INFO | running: ['/usr/sbin/selinuxenabled']
[Daemon] 2023-06-07T22:11:08 - INFO | received on stdout:
[Daemon] 2023-06-07T22:11:08 - DEBUG | received on stderr:
[Daemon] 2023-06-07T22:11:08 - INFO | Automigration NOT executed
[Daemon] 2023-06-07T22:11:09 - INFO | python3-hivex not found. If you need Automatic Windows Installation support, please install.
[Daemon] 2023-06-07T22:11:09 - INFO | 11 breeds and 131 OS versions read from the signature file
[Daemon] 2023-06-07T22:11:09 - DEBUG | API handle initialized
[Daemon] 2023-06-07T22:11:09 - ERROR | [Errno 13] Permission denied: '/var/lib/cobbler/web.ss'
````
### Screenshots
<!--- If applicable, add screenshots to help explain your problem. -->
### Additional information
<!--- Add any other context about the problem here. -->
The fix is to remove the call to os.lchown() from cobblerd.py:regen_ss_file()
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cobbler/cobblerd.py`
Content:
```
1 """
2 Cobbler daemon for logging remote syslog traffic during automatic installation
3
4 Copyright 2007-2009, Red Hat, Inc and Others
5 Michael DeHaan <michael.dehaan AT gmail>
6
7 This program is free software; you can redistribute it and/or modify
8 it under the terms of the GNU General Public License as published by
9 the Free Software Foundation; either version 2 of the License, or
10 (at your option) any later version.
11
12 This program is distributed in the hope that it will be useful,
13 but WITHOUT ANY WARRANTY; without even the implied warranty of
14 MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 GNU General Public License for more details.
16
17 You should have received a copy of the GNU General Public License
18 along with this program; if not, write to the Free Software
19 Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
20 02110-1301 USA
21 """
22
23 import binascii
24 import logging.config
25 import os
26 import pwd
27 import time
28
29 from cobbler import remote, utils
30 from cobbler.api import CobblerAPI
31
32 if os.geteuid() == 0 and os.path.exists('/etc/cobbler/logging_config.conf'):
33 logging.config.fileConfig('/etc/cobbler/logging_config.conf')
34
35
36 logger = logging.getLogger()
37
38
39 def core(cobbler_api: CobblerAPI):
40 """
41 Starts Cobbler.
42
43 :param cobbler_api: The cobbler_api instance which is used for this method.
44 """
45 settings = cobbler_api.settings()
46 xmlrpc_port = settings.xmlrpc_port
47
48 regen_ss_file()
49 do_xmlrpc_rw(cobbler_api, xmlrpc_port)
50
51
52 def regen_ss_file():
53 """
54 This is only used for Kerberos auth at the moment. It identifies XMLRPC requests from Apache that have already been
55 cleared by Kerberos.
56 """
57 ssfile = "/var/lib/cobbler/web.ss"
58 with open("/dev/urandom", 'rb') as fd:
59 data = fd.read(512)
60
61 with open(ssfile, 'wb', 0o660) as fd:
62 fd.write(binascii.hexlify(data))
63
64 http_user = "apache"
65 family = utils.get_family()
66 if family == "debian":
67 http_user = "www-data"
68 elif family == "suse":
69 http_user = "wwwrun"
70 os.lchown("/var/lib/cobbler/web.ss", pwd.getpwnam(http_user)[2], -1)
71
72
73 def do_xmlrpc_rw(cobbler_api: CobblerAPI, port):
74 """
75 This trys to bring up the Cobbler xmlrpc_api and restart it if it fails.
76
77 :param cobbler_api: The cobbler_api instance which is used for this method.
78 :param port: The port where the xmlrpc api should run on.
79 """
80 xinterface = remote.ProxiedXMLRPCInterface(cobbler_api, remote.CobblerXMLRPCInterface)
81 server = remote.CobblerXMLRPCServer(('127.0.0.1', port))
82 server.logRequests = 0 # don't print stuff
83 logger.debug("XMLRPC running on %s", port)
84 server.register_instance(xinterface)
85 start_time = ""
86 try:
87 import psutil
88 p = psutil.Process(os.getpid())
89 start_time = " in %s seconds" % str(time.time() - p.create_time())
90 except ModuleNotFoundError:
91 # This is not critical, but debug only - just install python3-psutil
92 pass
93
94 while True:
95 try:
96 logger.info("Cobbler startup completed %s", start_time)
97 server.serve_forever()
98 except IOError:
99 # interrupted? try to serve again
100 time.sleep(0.5)
101
102
103 if __name__ == "__main__":
104 core(CobblerAPI())
105
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/cobbler/cobblerd.py b/cobbler/cobblerd.py
--- a/cobbler/cobblerd.py
+++ b/cobbler/cobblerd.py
@@ -23,10 +23,9 @@
import binascii
import logging.config
import os
-import pwd
import time
-from cobbler import remote, utils
+from cobbler import remote
from cobbler.api import CobblerAPI
if os.geteuid() == 0 and os.path.exists('/etc/cobbler/logging_config.conf'):
@@ -61,14 +60,6 @@
with open(ssfile, 'wb', 0o660) as fd:
fd.write(binascii.hexlify(data))
- http_user = "apache"
- family = utils.get_family()
- if family == "debian":
- http_user = "www-data"
- elif family == "suse":
- http_user = "wwwrun"
- os.lchown("/var/lib/cobbler/web.ss", pwd.getpwnam(http_user)[2], -1)
-
def do_xmlrpc_rw(cobbler_api: CobblerAPI, port):
"""
| {"golden_diff": "diff --git a/cobbler/cobblerd.py b/cobbler/cobblerd.py\n--- a/cobbler/cobblerd.py\n+++ b/cobbler/cobblerd.py\n@@ -23,10 +23,9 @@\n import binascii\n import logging.config\n import os\n-import pwd\n import time\n \n-from cobbler import remote, utils\n+from cobbler import remote\n from cobbler.api import CobblerAPI\n \n if os.geteuid() == 0 and os.path.exists('/etc/cobbler/logging_config.conf'):\n@@ -61,14 +60,6 @@\n with open(ssfile, 'wb', 0o660) as fd:\n fd.write(binascii.hexlify(data))\n \n- http_user = \"apache\"\n- family = utils.get_family()\n- if family == \"debian\":\n- http_user = \"www-data\"\n- elif family == \"suse\":\n- http_user = \"wwwrun\"\n- os.lchown(\"/var/lib/cobbler/web.ss\", pwd.getpwnam(http_user)[2], -1)\n-\n \n def do_xmlrpc_rw(cobbler_api: CobblerAPI, port):\n \"\"\"\n", "issue": "Cobblerd start failure due to incorrect ownership of /var/lib/cobbler/web.ss\nAs has been noted for some time, cobblerd will fail to start after a restart, giving an error about /var/lib/cobbler/web.ss. This was reported in https://github.com/cobbler/cobbler/issues/2183, and discussed elsewhere. When successfully starting, the permission began as: \r\n\r\n`\r\n-rw-r--r--. 1 root root system_u:object_r:cobbler_var_lib_t:s0 1024 Jun 7 09:46 /var/lib/cobbler/web.ss\r\n`\r\n\r\nbut after starting, the permission becomes:\r\n\r\n`\r\n-rw-r--r--. 1 apache root system_u:object_r:cobbler_var_lib_t:s0 1024 Jun 7 09:47 /var/lib/cobbler/web.ss\r\n`\r\n\r\nAnd while the ownership remains as apache, the cobblerd server will fail to start.\r\n\r\n<!--- A clear and concise description of what the bug is. -->\r\n\r\nThe problem is that in cobblerd.py:regen_ss_file(), after this file is created by cobblerd for use in authorizing the CLI and web, the routine changes the ownership to 'apache', and then when the process is restarted, the routine once again tries to open it for writing the random 1024 byte auth token, the open fails. Changing the ownership back to root fixes the issue.\r\n\r\n<!--- HINT: You can paste gist.github.com links for long logs or larger files -->\r\n\r\n### Steps to reproduce\r\n\r\n1. Start the server for the first time... it starts.\r\n2. Restart the server, It will fail with an error opening /var/lib/cobbler/web.ss\r\n3. Changing the ownership of the file back to root.root and restarting will succeed.\r\n\r\n### Expected behavior\r\n\r\n<!--- A clear and concise description of what you expected to happen. -->\r\nThe cobblerd service would restart each and every time.\r\n\r\n### Cobbler version\r\n\r\n<!--- Paste output from `cobbler version` -->\r\n````\r\nCobbler 3.3.3\r\n source: ?, ?\r\n build time: Tue Jun 14 00:00:00 2022\r\n````\r\n(From EPEL 9 repository)\r\n\r\n### Operating system\r\n\r\n<!--- On which operating system do you use Cobbler? -->\r\nRocky Linux release 9.2 (Blue Onyx)\r\n\r\n### Cobbler log\r\n\r\n<!--- Paste (partial) output from `/var/log/cobbler/cobbler.log` -->\r\n````\r\n[Daemon] 2023-06-07T22:11:08 - INFO | running: ['/usr/sbin/selinuxenabled']\r\n[Daemon] 2023-06-07T22:11:08 - INFO | received on stdout: \r\n[Daemon] 2023-06-07T22:11:08 - DEBUG | received on stderr: \r\n[Daemon] 2023-06-07T22:11:08 - INFO | Automigration NOT executed\r\n[Daemon] 2023-06-07T22:11:09 - INFO | python3-hivex not found. If you need Automatic Windows Installation support, please install.\r\n[Daemon] 2023-06-07T22:11:09 - INFO | 11 breeds and 131 OS versions read from the signature file\r\n[Daemon] 2023-06-07T22:11:09 - DEBUG | API handle initialized\r\n[Daemon] 2023-06-07T22:11:09 - ERROR | [Errno 13] Permission denied: '/var/lib/cobbler/web.ss'\r\n````\r\n\r\n### Screenshots\r\n\r\n<!--- If applicable, add screenshots to help explain your problem. -->\r\n\r\n### Additional information\r\n\r\n<!--- Add any other context about the problem here. -->\r\nThe fix is to remove the call to os.lchown() from cobblerd.py:regen_ss_file()\n", "before_files": [{"content": "\"\"\"\nCobbler daemon for logging remote syslog traffic during automatic installation\n\nCopyright 2007-2009, Red Hat, Inc and Others\nMichael DeHaan <michael.dehaan AT gmail>\n\nThis program is free software; you can redistribute it and/or modify\nit under the terms of the GNU General Public License as published by\nthe Free Software Foundation; either version 2 of the License, or\n(at your option) any later version.\n\nThis program is distributed in the hope that it will be useful,\nbut WITHOUT ANY WARRANTY; without even the implied warranty of\nMERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\nGNU General Public License for more details.\n\nYou should have received a copy of the GNU General Public License\nalong with this program; if not, write to the Free Software\nFoundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA\n02110-1301 USA\n\"\"\"\n\nimport binascii\nimport logging.config\nimport os\nimport pwd\nimport time\n\nfrom cobbler import remote, utils\nfrom cobbler.api import CobblerAPI\n\nif os.geteuid() == 0 and os.path.exists('/etc/cobbler/logging_config.conf'):\n logging.config.fileConfig('/etc/cobbler/logging_config.conf')\n\n\nlogger = logging.getLogger()\n\n\ndef core(cobbler_api: CobblerAPI):\n \"\"\"\n Starts Cobbler.\n\n :param cobbler_api: The cobbler_api instance which is used for this method.\n \"\"\"\n settings = cobbler_api.settings()\n xmlrpc_port = settings.xmlrpc_port\n\n regen_ss_file()\n do_xmlrpc_rw(cobbler_api, xmlrpc_port)\n\n\ndef regen_ss_file():\n \"\"\"\n This is only used for Kerberos auth at the moment. It identifies XMLRPC requests from Apache that have already been\n cleared by Kerberos.\n \"\"\"\n ssfile = \"/var/lib/cobbler/web.ss\"\n with open(\"/dev/urandom\", 'rb') as fd:\n data = fd.read(512)\n\n with open(ssfile, 'wb', 0o660) as fd:\n fd.write(binascii.hexlify(data))\n\n http_user = \"apache\"\n family = utils.get_family()\n if family == \"debian\":\n http_user = \"www-data\"\n elif family == \"suse\":\n http_user = \"wwwrun\"\n os.lchown(\"/var/lib/cobbler/web.ss\", pwd.getpwnam(http_user)[2], -1)\n\n\ndef do_xmlrpc_rw(cobbler_api: CobblerAPI, port):\n \"\"\"\n This trys to bring up the Cobbler xmlrpc_api and restart it if it fails.\n\n :param cobbler_api: The cobbler_api instance which is used for this method.\n :param port: The port where the xmlrpc api should run on.\n \"\"\"\n xinterface = remote.ProxiedXMLRPCInterface(cobbler_api, remote.CobblerXMLRPCInterface)\n server = remote.CobblerXMLRPCServer(('127.0.0.1', port))\n server.logRequests = 0 # don't print stuff\n logger.debug(\"XMLRPC running on %s\", port)\n server.register_instance(xinterface)\n start_time = \"\"\n try:\n import psutil\n p = psutil.Process(os.getpid())\n start_time = \" in %s seconds\" % str(time.time() - p.create_time())\n except ModuleNotFoundError:\n # This is not critical, but debug only - just install python3-psutil\n pass\n\n while True:\n try:\n logger.info(\"Cobbler startup completed %s\", start_time)\n server.serve_forever()\n except IOError:\n # interrupted? try to serve again\n time.sleep(0.5)\n\n\nif __name__ == \"__main__\":\n core(CobblerAPI())\n", "path": "cobbler/cobblerd.py"}], "after_files": [{"content": "\"\"\"\nCobbler daemon for logging remote syslog traffic during automatic installation\n\nCopyright 2007-2009, Red Hat, Inc and Others\nMichael DeHaan <michael.dehaan AT gmail>\n\nThis program is free software; you can redistribute it and/or modify\nit under the terms of the GNU General Public License as published by\nthe Free Software Foundation; either version 2 of the License, or\n(at your option) any later version.\n\nThis program is distributed in the hope that it will be useful,\nbut WITHOUT ANY WARRANTY; without even the implied warranty of\nMERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\nGNU General Public License for more details.\n\nYou should have received a copy of the GNU General Public License\nalong with this program; if not, write to the Free Software\nFoundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA\n02110-1301 USA\n\"\"\"\n\nimport binascii\nimport logging.config\nimport os\nimport time\n\nfrom cobbler import remote\nfrom cobbler.api import CobblerAPI\n\nif os.geteuid() == 0 and os.path.exists('/etc/cobbler/logging_config.conf'):\n logging.config.fileConfig('/etc/cobbler/logging_config.conf')\n\n\nlogger = logging.getLogger()\n\n\ndef core(cobbler_api: CobblerAPI):\n \"\"\"\n Starts Cobbler.\n\n :param cobbler_api: The cobbler_api instance which is used for this method.\n \"\"\"\n settings = cobbler_api.settings()\n xmlrpc_port = settings.xmlrpc_port\n\n regen_ss_file()\n do_xmlrpc_rw(cobbler_api, xmlrpc_port)\n\n\ndef regen_ss_file():\n \"\"\"\n This is only used for Kerberos auth at the moment. It identifies XMLRPC requests from Apache that have already been\n cleared by Kerberos.\n \"\"\"\n ssfile = \"/var/lib/cobbler/web.ss\"\n with open(\"/dev/urandom\", 'rb') as fd:\n data = fd.read(512)\n\n with open(ssfile, 'wb', 0o660) as fd:\n fd.write(binascii.hexlify(data))\n\n\ndef do_xmlrpc_rw(cobbler_api: CobblerAPI, port):\n \"\"\"\n This trys to bring up the Cobbler xmlrpc_api and restart it if it fails.\n\n :param cobbler_api: The cobbler_api instance which is used for this method.\n :param port: The port where the xmlrpc api should run on.\n \"\"\"\n xinterface = remote.ProxiedXMLRPCInterface(cobbler_api, remote.CobblerXMLRPCInterface)\n server = remote.CobblerXMLRPCServer(('127.0.0.1', port))\n server.logRequests = 0 # don't print stuff\n logger.debug(\"XMLRPC running on %s\", port)\n server.register_instance(xinterface)\n start_time = \"\"\n try:\n import psutil\n p = psutil.Process(os.getpid())\n start_time = \" in %s seconds\" % str(time.time() - p.create_time())\n except ModuleNotFoundError:\n # This is not critical, but debug only - just install python3-psutil\n pass\n\n while True:\n try:\n logger.info(\"Cobbler startup completed %s\", start_time)\n server.serve_forever()\n except IOError:\n # interrupted? try to serve again\n time.sleep(0.5)\n\n\nif __name__ == \"__main__\":\n core(CobblerAPI())\n", "path": "cobbler/cobblerd.py"}]} | 2,235 | 264 |
gh_patches_debug_4609 | rasdani/github-patches | git_diff | mitmproxy__mitmproxy-4334 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Mitmdump option "--modify-headers" not working if any script added using "--scripts".
#### Problem Description
When using mitmdump with script specified using `--scripts` option - `--modify-headers` option is ignored.
#### Steps to reproduce the behavior:
**1.** Launch `mitmdump` with `--modify-headers`.
My example:
`mitmdump --set confdir=./.mitmproxy --flow-detail=2 --listen-port=8081 --modify-headers "/~q/Host/example.org"`
Output with `curl -x 127.0.0.1:8081 "http://www.trackip.net/ip?json"`:
```
127.0.0.1:50216: clientconnect
127.0.0.1:50216: GET http://www.trackip.net/ip?json
User-Agent: curl/7.64.1
Accept: */*
Proxy-Connection: Keep-Alive
Host: example.org
<< 404 Not Found 1.67k
Date: Thu, 26 Nov 2020 10:06:22 GMT
Content-Type: text/html; charset=UTF-8
Transfer-Encoding: chunked
Connection: keep-alive
Set-Cookie: __cfduid=de786483d16a417b8768b01f604ef7f991606385181; expires=Sat, 26-Dec-20 10:06:21 GMT; path=/; domain=.example.org; HttpOnly; SameSite=Lax
Lookup-Cache-Hit: 1
Cache-Control: public, max-age=60
Vary: Accept-Language, Accept-Encoding
X-Cache: MISS
X-Cache-Hits: 0
CF-Cache-Status: MISS
cf-request-id: 06a59dbd0500002d377c038000000001
Report-To: {"endpoints":[{"url":"https:\\/\\/a.nel.cloudflare.com\\/report?s=NYIz48uJ3L6ZWGjd%2FEO4iNMvcCH0gsGhQhs4dpQ92t5e7W2I3wP1hp%2FoVqfbe94xjJbxqsuNcuvGp4dShFlFYVyn3W0hQX6RveNgJw%3D%3D"}],"group":"cf-nel","max_age":604800}
NEL: {"report_to":"cf-nel","max_age":604800}
X-Content-Type-Options: nosniff
Server: cloudflare
CF-RAY: 5f82cbdb3f422d37-KBP
127.0.0.1:50216: clientdisconnect
```
Header `Host` has been replaced with `example.org`, as expected.
**2.** Now launch `mitmdump` with `--modify-headers` and `--script`.
My example (using [jsondump.py](https://github.com/mitmproxy/mitmproxy/blob/master/examples/contrib/jsondump.py) script from `examples/contrib`):
`mitmdump --set confdir=./.mitmproxy --flow-detail=2 --listen-port=8081 --modify-headers "/~q/Host/example.org" --scripts="/Users/ignisor/dev/proxy_lib/proxy/utils/jsondump.py"`
Output with `curl -x 127.0.0.1:8081 "http://www.trackip.net/ip?json"`:
```
Proxy server listening at http://*:8081
127.0.0.1:50412: clientconnect
127.0.0.1:50412: GET http://www.trackip.net/ip?json
Host: www.trackip.net
User-Agent: curl/7.64.1
Accept: */*
Proxy-Connection: Keep-Alive
<< 200 OK 76b
Date: Thu, 26 Nov 2020 10:11:30 GMT
Content-Type: text/plain
Content-Length: 76
Connection: keep-alive
Set-Cookie: __cfduid=dd9e78e478768657490d8e5f8df1e870d1606385490; expires=Sat, 26-Dec-20 10:11:30 GMT; path=/; domain=.trackip.net; HttpOnly; SameSite=Lax
CF-Cache-Status: DYNAMIC
cf-request-id: 06a5a272a300003f0495bde000000001
Report-To: {"endpoints":[{"url":"https:\\/\\/a.nel.cloudflare.com\\/report?s=E3IAN%2BfUeGUIqX75SqBx%2FwUVisP1%2Fa7iRdHS7P6wUzZI1A6zSkhSqR6sKJ82sZo9tWkzTrtPYVQq6xozPGJ82Y34hSyPXP%2Fo%2FW7kC%2FFulUc%3D"}],"group":"cf-nel","max_age":604800}
NEL: {"report_to":"cf-nel","max_age":604800}
Server: cloudflare
CF-RAY: 5f82d3643d183f04-KBP
127.0.0.1:50412: clientdisconnect
```
Header `Host` **not changed** and still `www.trackip.net`.
#### System Information
> Mitmproxy: 5.3.0
> Python: 3.9.0
> OpenSSL: OpenSSL 1.1.1h 22 Sep 2020
> Platform: macOS-10.16-x86_64-i386-64bit
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mitmproxy/addons/modifyheaders.py`
Content:
```
1 import re
2 import typing
3 from pathlib import Path
4
5 from mitmproxy import ctx, exceptions, flowfilter, http
6 from mitmproxy.net.http import Headers
7 from mitmproxy.utils import strutils
8 from mitmproxy.utils.spec import parse_spec
9
10
11 class ModifySpec(typing.NamedTuple):
12 matches: flowfilter.TFilter
13 subject: bytes
14 replacement_str: str
15
16 def read_replacement(self) -> bytes:
17 """
18 Process the replacement str. This usually just involves converting it to bytes.
19 However, if it starts with `@`, we interpret the rest as a file path to read from.
20
21 Raises:
22 - IOError if the file cannot be read.
23 """
24 if self.replacement_str.startswith("@"):
25 return Path(self.replacement_str[1:]).expanduser().read_bytes()
26 else:
27 # We could cache this at some point, but unlikely to be a problem.
28 return strutils.escaped_str_to_bytes(self.replacement_str)
29
30
31 def parse_modify_spec(option: str, subject_is_regex: bool) -> ModifySpec:
32 flow_filter, subject_str, replacement = parse_spec(option)
33
34 subject = strutils.escaped_str_to_bytes(subject_str)
35 if subject_is_regex:
36 try:
37 re.compile(subject)
38 except re.error as e:
39 raise ValueError(f"Invalid regular expression {subject!r} ({e})")
40
41 spec = ModifySpec(flow_filter, subject, replacement)
42
43 try:
44 spec.read_replacement()
45 except OSError as e:
46 raise ValueError(f"Invalid file path: {replacement[1:]} ({e})")
47
48 return spec
49
50
51 class ModifyHeaders:
52 def __init__(self):
53 self.replacements: typing.List[ModifySpec] = []
54
55 def load(self, loader):
56 loader.add_option(
57 "modify_headers", typing.Sequence[str], [],
58 """
59 Header modify pattern of the form "[/flow-filter]/header-name/[@]header-value", where the
60 separator can be any character. The @ allows to provide a file path that is used to read
61 the header value string. An empty header-value removes existing header-name headers.
62 """
63 )
64
65 def configure(self, updated):
66 self.replacements = []
67 if "modify_headers" in updated:
68 for option in ctx.options.modify_headers:
69 try:
70 spec = parse_modify_spec(option, False)
71 except ValueError as e:
72 raise exceptions.OptionsError(f"Cannot parse modify_headers option {option}: {e}") from e
73 self.replacements.append(spec)
74
75 def request(self, flow):
76 if not flow.reply.has_message:
77 self.run(flow, flow.request.headers)
78
79 def response(self, flow):
80 if not flow.reply.has_message:
81 self.run(flow, flow.response.headers)
82
83 def run(self, flow: http.HTTPFlow, hdrs: Headers) -> None:
84 # unset all specified headers
85 for spec in self.replacements:
86 if spec.matches(flow):
87 hdrs.pop(spec.subject, None)
88
89 # set all specified headers if the replacement string is not empty
90 for spec in self.replacements:
91 if spec.matches(flow):
92 try:
93 replacement = spec.read_replacement()
94 except OSError as e:
95 ctx.log.warn(f"Could not read replacement file: {e}")
96 continue
97 else:
98 if replacement:
99 hdrs.add(spec.subject, replacement)
100
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mitmproxy/addons/modifyheaders.py b/mitmproxy/addons/modifyheaders.py
--- a/mitmproxy/addons/modifyheaders.py
+++ b/mitmproxy/addons/modifyheaders.py
@@ -63,8 +63,8 @@
)
def configure(self, updated):
- self.replacements = []
if "modify_headers" in updated:
+ self.replacements = []
for option in ctx.options.modify_headers:
try:
spec = parse_modify_spec(option, False)
| {"golden_diff": "diff --git a/mitmproxy/addons/modifyheaders.py b/mitmproxy/addons/modifyheaders.py\n--- a/mitmproxy/addons/modifyheaders.py\n+++ b/mitmproxy/addons/modifyheaders.py\n@@ -63,8 +63,8 @@\n )\n \n def configure(self, updated):\n- self.replacements = []\n if \"modify_headers\" in updated:\n+ self.replacements = []\n for option in ctx.options.modify_headers:\n try:\n spec = parse_modify_spec(option, False)\n", "issue": "Mitmdump option \"--modify-headers\" not working if any script added using \"--scripts\".\n#### Problem Description\r\nWhen using mitmdump with script specified using `--scripts` option - `--modify-headers` option is ignored.\r\n\r\n#### Steps to reproduce the behavior:\r\n\r\n**1.** Launch `mitmdump` with `--modify-headers`. \r\nMy example: \r\n`mitmdump --set confdir=./.mitmproxy --flow-detail=2 --listen-port=8081 --modify-headers \"/~q/Host/example.org\"`\r\nOutput with `curl -x 127.0.0.1:8081 \"http://www.trackip.net/ip?json\"`:\r\n```\r\n127.0.0.1:50216: clientconnect\r\n127.0.0.1:50216: GET http://www.trackip.net/ip?json\r\n User-Agent: curl/7.64.1\r\n Accept: */*\r\n Proxy-Connection: Keep-Alive\r\n Host: example.org\r\n << 404 Not Found 1.67k\r\n Date: Thu, 26 Nov 2020 10:06:22 GMT\r\n Content-Type: text/html; charset=UTF-8\r\n Transfer-Encoding: chunked\r\n Connection: keep-alive\r\n Set-Cookie: __cfduid=de786483d16a417b8768b01f604ef7f991606385181; expires=Sat, 26-Dec-20 10:06:21 GMT; path=/; domain=.example.org; HttpOnly; SameSite=Lax\r\n Lookup-Cache-Hit: 1\r\n Cache-Control: public, max-age=60\r\n Vary: Accept-Language, Accept-Encoding\r\n X-Cache: MISS\r\n X-Cache-Hits: 0\r\n CF-Cache-Status: MISS\r\n cf-request-id: 06a59dbd0500002d377c038000000001\r\n Report-To: {\"endpoints\":[{\"url\":\"https:\\\\/\\\\/a.nel.cloudflare.com\\\\/report?s=NYIz48uJ3L6ZWGjd%2FEO4iNMvcCH0gsGhQhs4dpQ92t5e7W2I3wP1hp%2FoVqfbe94xjJbxqsuNcuvGp4dShFlFYVyn3W0hQX6RveNgJw%3D%3D\"}],\"group\":\"cf-nel\",\"max_age\":604800}\r\n NEL: {\"report_to\":\"cf-nel\",\"max_age\":604800}\r\n X-Content-Type-Options: nosniff\r\n Server: cloudflare\r\n CF-RAY: 5f82cbdb3f422d37-KBP\r\n127.0.0.1:50216: clientdisconnect\r\n```\r\nHeader `Host` has been replaced with `example.org`, as expected.\r\n\r\n**2.** Now launch `mitmdump` with `--modify-headers` and `--script`.\r\nMy example (using [jsondump.py](https://github.com/mitmproxy/mitmproxy/blob/master/examples/contrib/jsondump.py) script from `examples/contrib`): \r\n`mitmdump --set confdir=./.mitmproxy --flow-detail=2 --listen-port=8081 --modify-headers \"/~q/Host/example.org\" --scripts=\"/Users/ignisor/dev/proxy_lib/proxy/utils/jsondump.py\"`\r\nOutput with `curl -x 127.0.0.1:8081 \"http://www.trackip.net/ip?json\"`:\r\n```\r\nProxy server listening at http://*:8081\r\n127.0.0.1:50412: clientconnect\r\n127.0.0.1:50412: GET http://www.trackip.net/ip?json\r\n Host: www.trackip.net\r\n User-Agent: curl/7.64.1\r\n Accept: */*\r\n Proxy-Connection: Keep-Alive\r\n << 200 OK 76b\r\n Date: Thu, 26 Nov 2020 10:11:30 GMT\r\n Content-Type: text/plain\r\n Content-Length: 76\r\n Connection: keep-alive\r\n Set-Cookie: __cfduid=dd9e78e478768657490d8e5f8df1e870d1606385490; expires=Sat, 26-Dec-20 10:11:30 GMT; path=/; domain=.trackip.net; HttpOnly; SameSite=Lax\r\n CF-Cache-Status: DYNAMIC\r\n cf-request-id: 06a5a272a300003f0495bde000000001\r\n Report-To: {\"endpoints\":[{\"url\":\"https:\\\\/\\\\/a.nel.cloudflare.com\\\\/report?s=E3IAN%2BfUeGUIqX75SqBx%2FwUVisP1%2Fa7iRdHS7P6wUzZI1A6zSkhSqR6sKJ82sZo9tWkzTrtPYVQq6xozPGJ82Y34hSyPXP%2Fo%2FW7kC%2FFulUc%3D\"}],\"group\":\"cf-nel\",\"max_age\":604800}\r\n NEL: {\"report_to\":\"cf-nel\",\"max_age\":604800}\r\n Server: cloudflare\r\n CF-RAY: 5f82d3643d183f04-KBP\r\n127.0.0.1:50412: clientdisconnect\r\n```\r\nHeader `Host` **not changed** and still `www.trackip.net`.\r\n\r\n\r\n#### System Information\r\n\r\n> Mitmproxy: 5.3.0\r\n> Python: 3.9.0\r\n> OpenSSL: OpenSSL 1.1.1h 22 Sep 2020\r\n> Platform: macOS-10.16-x86_64-i386-64bit\r\n\n", "before_files": [{"content": "import re\nimport typing\nfrom pathlib import Path\n\nfrom mitmproxy import ctx, exceptions, flowfilter, http\nfrom mitmproxy.net.http import Headers\nfrom mitmproxy.utils import strutils\nfrom mitmproxy.utils.spec import parse_spec\n\n\nclass ModifySpec(typing.NamedTuple):\n matches: flowfilter.TFilter\n subject: bytes\n replacement_str: str\n\n def read_replacement(self) -> bytes:\n \"\"\"\n Process the replacement str. This usually just involves converting it to bytes.\n However, if it starts with `@`, we interpret the rest as a file path to read from.\n\n Raises:\n - IOError if the file cannot be read.\n \"\"\"\n if self.replacement_str.startswith(\"@\"):\n return Path(self.replacement_str[1:]).expanduser().read_bytes()\n else:\n # We could cache this at some point, but unlikely to be a problem.\n return strutils.escaped_str_to_bytes(self.replacement_str)\n\n\ndef parse_modify_spec(option: str, subject_is_regex: bool) -> ModifySpec:\n flow_filter, subject_str, replacement = parse_spec(option)\n\n subject = strutils.escaped_str_to_bytes(subject_str)\n if subject_is_regex:\n try:\n re.compile(subject)\n except re.error as e:\n raise ValueError(f\"Invalid regular expression {subject!r} ({e})\")\n\n spec = ModifySpec(flow_filter, subject, replacement)\n\n try:\n spec.read_replacement()\n except OSError as e:\n raise ValueError(f\"Invalid file path: {replacement[1:]} ({e})\")\n\n return spec\n\n\nclass ModifyHeaders:\n def __init__(self):\n self.replacements: typing.List[ModifySpec] = []\n\n def load(self, loader):\n loader.add_option(\n \"modify_headers\", typing.Sequence[str], [],\n \"\"\"\n Header modify pattern of the form \"[/flow-filter]/header-name/[@]header-value\", where the\n separator can be any character. The @ allows to provide a file path that is used to read\n the header value string. An empty header-value removes existing header-name headers.\n \"\"\"\n )\n\n def configure(self, updated):\n self.replacements = []\n if \"modify_headers\" in updated:\n for option in ctx.options.modify_headers:\n try:\n spec = parse_modify_spec(option, False)\n except ValueError as e:\n raise exceptions.OptionsError(f\"Cannot parse modify_headers option {option}: {e}\") from e\n self.replacements.append(spec)\n\n def request(self, flow):\n if not flow.reply.has_message:\n self.run(flow, flow.request.headers)\n\n def response(self, flow):\n if not flow.reply.has_message:\n self.run(flow, flow.response.headers)\n\n def run(self, flow: http.HTTPFlow, hdrs: Headers) -> None:\n # unset all specified headers\n for spec in self.replacements:\n if spec.matches(flow):\n hdrs.pop(spec.subject, None)\n\n # set all specified headers if the replacement string is not empty\n for spec in self.replacements:\n if spec.matches(flow):\n try:\n replacement = spec.read_replacement()\n except OSError as e:\n ctx.log.warn(f\"Could not read replacement file: {e}\")\n continue\n else:\n if replacement:\n hdrs.add(spec.subject, replacement)\n", "path": "mitmproxy/addons/modifyheaders.py"}], "after_files": [{"content": "import re\nimport typing\nfrom pathlib import Path\n\nfrom mitmproxy import ctx, exceptions, flowfilter, http\nfrom mitmproxy.net.http import Headers\nfrom mitmproxy.utils import strutils\nfrom mitmproxy.utils.spec import parse_spec\n\n\nclass ModifySpec(typing.NamedTuple):\n matches: flowfilter.TFilter\n subject: bytes\n replacement_str: str\n\n def read_replacement(self) -> bytes:\n \"\"\"\n Process the replacement str. This usually just involves converting it to bytes.\n However, if it starts with `@`, we interpret the rest as a file path to read from.\n\n Raises:\n - IOError if the file cannot be read.\n \"\"\"\n if self.replacement_str.startswith(\"@\"):\n return Path(self.replacement_str[1:]).expanduser().read_bytes()\n else:\n # We could cache this at some point, but unlikely to be a problem.\n return strutils.escaped_str_to_bytes(self.replacement_str)\n\n\ndef parse_modify_spec(option: str, subject_is_regex: bool) -> ModifySpec:\n flow_filter, subject_str, replacement = parse_spec(option)\n\n subject = strutils.escaped_str_to_bytes(subject_str)\n if subject_is_regex:\n try:\n re.compile(subject)\n except re.error as e:\n raise ValueError(f\"Invalid regular expression {subject!r} ({e})\")\n\n spec = ModifySpec(flow_filter, subject, replacement)\n\n try:\n spec.read_replacement()\n except OSError as e:\n raise ValueError(f\"Invalid file path: {replacement[1:]} ({e})\")\n\n return spec\n\n\nclass ModifyHeaders:\n def __init__(self):\n self.replacements: typing.List[ModifySpec] = []\n\n def load(self, loader):\n loader.add_option(\n \"modify_headers\", typing.Sequence[str], [],\n \"\"\"\n Header modify pattern of the form \"[/flow-filter]/header-name/[@]header-value\", where the\n separator can be any character. The @ allows to provide a file path that is used to read\n the header value string. An empty header-value removes existing header-name headers.\n \"\"\"\n )\n\n def configure(self, updated):\n if \"modify_headers\" in updated:\n self.replacements = []\n for option in ctx.options.modify_headers:\n try:\n spec = parse_modify_spec(option, False)\n except ValueError as e:\n raise exceptions.OptionsError(f\"Cannot parse modify_headers option {option}: {e}\") from e\n self.replacements.append(spec)\n\n def request(self, flow):\n if not flow.reply.has_message:\n self.run(flow, flow.request.headers)\n\n def response(self, flow):\n if not flow.reply.has_message:\n self.run(flow, flow.response.headers)\n\n def run(self, flow: http.HTTPFlow, hdrs: Headers) -> None:\n # unset all specified headers\n for spec in self.replacements:\n if spec.matches(flow):\n hdrs.pop(spec.subject, None)\n\n # set all specified headers if the replacement string is not empty\n for spec in self.replacements:\n if spec.matches(flow):\n try:\n replacement = spec.read_replacement()\n except OSError as e:\n ctx.log.warn(f\"Could not read replacement file: {e}\")\n continue\n else:\n if replacement:\n hdrs.add(spec.subject, replacement)\n", "path": "mitmproxy/addons/modifyheaders.py"}]} | 2,638 | 115 |
gh_patches_debug_17943 | rasdani/github-patches | git_diff | koxudaxi__datamodel-code-generator-1477 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Wrong parent class for pydantic V2 root models
**Describe the bug**
Generator uses `pydantic.BaseModel` as parent class for root model instead of `pydantic.RootModel`
Example schema (`custom_id.yaml`):
```yaml
openapi: 3.0.0
components:
schemas:
CustomId:
description: My custom ID
type: string
format: uuid
```
Used commandline:
```
$ datamodel-codegen --input custom_id.yaml --output-model-type pydantic_v2.BaseModel --output model.py
```
Contents of `model.py`:
```python
from __future__ import annotations
from uuid import UUID
from pydantic import BaseModel, Field
class CustomId(BaseModel):
root: UUID = Field(..., description='My custom ID')
```
**Expected behavior**
```python
from __future__ import annotations
from uuid import UUID
from pydantic import RootModel, Field
class CustomId(RootModel):
root: UUID = Field(..., description='My custom ID')
```
**Version:**
- OS: [e.g. iOS]
- Python version: 3.10.8
- datamodel-code-generator version: 0.21.1
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `datamodel_code_generator/model/pydantic_v2/root_model.py`
Content:
```
1 from __future__ import annotations
2
3 from typing import ClassVar
4
5 from datamodel_code_generator.model.pydantic_v2.base_model import BaseModel
6
7
8 class RootModel(BaseModel):
9 TEMPLATE_FILE_PATH: ClassVar[str] = 'pydantic_v2/RootModel.jinja2'
10 BASE_CLASS: ClassVar[str] = 'pydantic.RootModel'
11
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/datamodel_code_generator/model/pydantic_v2/root_model.py b/datamodel_code_generator/model/pydantic_v2/root_model.py
--- a/datamodel_code_generator/model/pydantic_v2/root_model.py
+++ b/datamodel_code_generator/model/pydantic_v2/root_model.py
@@ -1,6 +1,6 @@
from __future__ import annotations
-from typing import ClassVar
+from typing import Any, ClassVar
from datamodel_code_generator.model.pydantic_v2.base_model import BaseModel
@@ -8,3 +8,14 @@
class RootModel(BaseModel):
TEMPLATE_FILE_PATH: ClassVar[str] = 'pydantic_v2/RootModel.jinja2'
BASE_CLASS: ClassVar[str] = 'pydantic.RootModel'
+
+ def __init__(
+ self,
+ **kwargs: Any,
+ ) -> None:
+ # Remove custom_base_class for Pydantic V2 models; behaviour is different from Pydantic V1 as it will not
+ # be treated as a root model. custom_base_class cannot both implement BaseModel and RootModel!
+ if 'custom_base_class' in kwargs:
+ kwargs.pop('custom_base_class')
+
+ super().__init__(**kwargs)
| {"golden_diff": "diff --git a/datamodel_code_generator/model/pydantic_v2/root_model.py b/datamodel_code_generator/model/pydantic_v2/root_model.py\n--- a/datamodel_code_generator/model/pydantic_v2/root_model.py\n+++ b/datamodel_code_generator/model/pydantic_v2/root_model.py\n@@ -1,6 +1,6 @@\n from __future__ import annotations\n \n-from typing import ClassVar\n+from typing import Any, ClassVar\n \n from datamodel_code_generator.model.pydantic_v2.base_model import BaseModel\n \n@@ -8,3 +8,14 @@\n class RootModel(BaseModel):\n TEMPLATE_FILE_PATH: ClassVar[str] = 'pydantic_v2/RootModel.jinja2'\n BASE_CLASS: ClassVar[str] = 'pydantic.RootModel'\n+\n+ def __init__(\n+ self,\n+ **kwargs: Any,\n+ ) -> None:\n+ # Remove custom_base_class for Pydantic V2 models; behaviour is different from Pydantic V1 as it will not\n+ # be treated as a root model. custom_base_class cannot both implement BaseModel and RootModel!\n+ if 'custom_base_class' in kwargs:\n+ kwargs.pop('custom_base_class')\n+\n+ super().__init__(**kwargs)\n", "issue": "Wrong parent class for pydantic V2 root models \n**Describe the bug**\r\nGenerator uses `pydantic.BaseModel` as parent class for root model instead of `pydantic.RootModel`\r\n\r\nExample schema (`custom_id.yaml`):\r\n```yaml\r\nopenapi: 3.0.0\r\ncomponents:\r\n schemas:\r\n CustomId:\r\n description: My custom ID\r\n type: string\r\n format: uuid\r\n```\r\nUsed commandline:\r\n```\r\n$ datamodel-codegen --input custom_id.yaml --output-model-type pydantic_v2.BaseModel --output model.py\r\n```\r\nContents of `model.py`:\r\n```python\r\nfrom __future__ import annotations\r\n\r\nfrom uuid import UUID\r\n\r\nfrom pydantic import BaseModel, Field\r\n\r\n\r\nclass CustomId(BaseModel):\r\n root: UUID = Field(..., description='My custom ID')\r\n```\r\n\r\n**Expected behavior**\r\n```python\r\nfrom __future__ import annotations\r\n\r\nfrom uuid import UUID\r\n\r\nfrom pydantic import RootModel, Field\r\n\r\n\r\nclass CustomId(RootModel):\r\n root: UUID = Field(..., description='My custom ID')\r\n```\r\n\r\n**Version:**\r\n - OS: [e.g. iOS]\r\n - Python version: 3.10.8\r\n - datamodel-code-generator version: 0.21.1\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import ClassVar\n\nfrom datamodel_code_generator.model.pydantic_v2.base_model import BaseModel\n\n\nclass RootModel(BaseModel):\n TEMPLATE_FILE_PATH: ClassVar[str] = 'pydantic_v2/RootModel.jinja2'\n BASE_CLASS: ClassVar[str] = 'pydantic.RootModel'\n", "path": "datamodel_code_generator/model/pydantic_v2/root_model.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom typing import Any, ClassVar\n\nfrom datamodel_code_generator.model.pydantic_v2.base_model import BaseModel\n\n\nclass RootModel(BaseModel):\n TEMPLATE_FILE_PATH: ClassVar[str] = 'pydantic_v2/RootModel.jinja2'\n BASE_CLASS: ClassVar[str] = 'pydantic.RootModel'\n\n def __init__(\n self,\n **kwargs: Any,\n ) -> None:\n # Remove custom_base_class for Pydantic V2 models; behaviour is different from Pydantic V1 as it will not\n # be treated as a root model. custom_base_class cannot both implement BaseModel and RootModel!\n if 'custom_base_class' in kwargs:\n kwargs.pop('custom_base_class')\n\n super().__init__(**kwargs)\n", "path": "datamodel_code_generator/model/pydantic_v2/root_model.py"}]} | 629 | 272 |
gh_patches_debug_13291 | rasdani/github-patches | git_diff | sunpy__sunpy-2956 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improve our warnings in line with PEP 565
See astropy/astropy#8465
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sunpy/util/exceptions.py`
Content:
```
1 # Licensed under a 3-clause BSD style license - see LICENSE.rst
2 """
3 This module contains errors/exceptions and warnings of general use for
4 sunpy. Exceptions that are specific to a given subpackage should *not*
5 be here, but rather in the particular subpackage.
6 """
7
8 class SunpyWarning(Warning):
9 """
10 The base warning class from which all Sunpy warnings should inherit.
11 """
12
13
14 class SunpyUserWarning(UserWarning, SunpyWarning):
15 """
16 The primary warning class for Sunpy.
17
18 Use this if you do not need a specific sub-class.
19 """
20
21
22 class SunpyDeprecationWarning(SunpyWarning):
23 """
24 A warning class to indicate a deprecated feature.
25 """
26
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/sunpy/util/exceptions.py b/sunpy/util/exceptions.py
--- a/sunpy/util/exceptions.py
+++ b/sunpy/util/exceptions.py
@@ -4,6 +4,8 @@
sunpy. Exceptions that are specific to a given subpackage should *not*
be here, but rather in the particular subpackage.
"""
+import sys
+
class SunpyWarning(Warning):
"""
@@ -19,7 +21,11 @@
"""
-class SunpyDeprecationWarning(SunpyWarning):
+# For PEP 565 (https://www.python.org/dev/peps/pep-0565/) compliance.
+DeprecationClass = DeprecationWarning if sys.version_info >= (3, 7) else FutureWarning
+
+
+class SunpyDeprecationWarning(DeprecationClass, SunpyWarning):
"""
A warning class to indicate a deprecated feature.
"""
| {"golden_diff": "diff --git a/sunpy/util/exceptions.py b/sunpy/util/exceptions.py\n--- a/sunpy/util/exceptions.py\n+++ b/sunpy/util/exceptions.py\n@@ -4,6 +4,8 @@\n sunpy. Exceptions that are specific to a given subpackage should *not*\n be here, but rather in the particular subpackage.\n \"\"\"\n+import sys\n+\n \n class SunpyWarning(Warning):\n \"\"\"\n@@ -19,7 +21,11 @@\n \"\"\"\n \n \n-class SunpyDeprecationWarning(SunpyWarning):\n+# For PEP 565 (https://www.python.org/dev/peps/pep-0565/) compliance.\n+DeprecationClass = DeprecationWarning if sys.version_info >= (3, 7) else FutureWarning\n+\n+\n+class SunpyDeprecationWarning(DeprecationClass, SunpyWarning):\n \"\"\"\n A warning class to indicate a deprecated feature.\n \"\"\"\n", "issue": "Improve our warnings in line with PEP 565\nSee astropy/astropy#8465\n", "before_files": [{"content": "# Licensed under a 3-clause BSD style license - see LICENSE.rst\n\"\"\"\nThis module contains errors/exceptions and warnings of general use for\nsunpy. Exceptions that are specific to a given subpackage should *not*\nbe here, but rather in the particular subpackage.\n\"\"\"\n\nclass SunpyWarning(Warning):\n \"\"\"\n The base warning class from which all Sunpy warnings should inherit.\n \"\"\"\n\n\nclass SunpyUserWarning(UserWarning, SunpyWarning):\n \"\"\"\n The primary warning class for Sunpy.\n\n Use this if you do not need a specific sub-class.\n \"\"\"\n\n\nclass SunpyDeprecationWarning(SunpyWarning):\n \"\"\"\n A warning class to indicate a deprecated feature.\n \"\"\"\n", "path": "sunpy/util/exceptions.py"}], "after_files": [{"content": "# Licensed under a 3-clause BSD style license - see LICENSE.rst\n\"\"\"\nThis module contains errors/exceptions and warnings of general use for\nsunpy. Exceptions that are specific to a given subpackage should *not*\nbe here, but rather in the particular subpackage.\n\"\"\"\nimport sys\n\n\nclass SunpyWarning(Warning):\n \"\"\"\n The base warning class from which all Sunpy warnings should inherit.\n \"\"\"\n\n\nclass SunpyUserWarning(UserWarning, SunpyWarning):\n \"\"\"\n The primary warning class for Sunpy.\n\n Use this if you do not need a specific sub-class.\n \"\"\"\n\n\n# For PEP 565 (https://www.python.org/dev/peps/pep-0565/) compliance.\nDeprecationClass = DeprecationWarning if sys.version_info >= (3, 7) else FutureWarning\n\n\nclass SunpyDeprecationWarning(DeprecationClass, SunpyWarning):\n \"\"\"\n A warning class to indicate a deprecated feature.\n \"\"\"\n", "path": "sunpy/util/exceptions.py"}]} | 483 | 209 |
gh_patches_debug_20057 | rasdani/github-patches | git_diff | svthalia__concrexit-1832 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Sales API uses TokenHasScopeForMethod but no scopes per method are provided
### Describe the change
The sales API uses some IsAuthenticatedOrTokenHasScopeForMethod permission classes, but no scopes per method are provided
### Motivation
Simpler code
### Current implementation
See above
### Suggested implementation
Use IsAuthenticatedOrTokenHasScope, or specify scope per method
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `website/sales/api/v2/admin/views.py`
Content:
```
1 from oauth2_provider.contrib.rest_framework import IsAuthenticatedOrTokenHasScope
2 from rest_framework import filters, exceptions
3 from rest_framework.exceptions import PermissionDenied
4 from rest_framework.generics import get_object_or_404
5 from rest_framework.permissions import DjangoModelPermissions
6
7 from sales.api.v2.admin.permissions import IsManager
8 from sales.api.v2.admin.serializers.order import OrderSerializer, OrderListSerializer
9 from sales.api.v2.admin.serializers.shift import ShiftSerializer
10 from sales.models.order import Order
11 from sales.models.shift import Shift
12 from thaliawebsite.api.v2.admin import (
13 AdminCreateAPIView,
14 AdminListAPIView,
15 AdminRetrieveAPIView,
16 AdminUpdateAPIView,
17 AdminDestroyAPIView,
18 )
19 from thaliawebsite.api.v2.permissions import IsAuthenticatedOrTokenHasScopeForMethod
20
21
22 class ShiftListView(AdminListAPIView):
23 """Returns an overview of all sales shifts."""
24
25 serializer_class = ShiftSerializer
26 queryset = Shift.objects.all()
27 filter_backends = (
28 filters.OrderingFilter,
29 filters.SearchFilter,
30 )
31 ordering_fields = ("start", "end")
32 permission_classes = [IsAuthenticatedOrTokenHasScope, DjangoModelPermissions]
33 required_scopes = ["sales:admin"]
34
35 def get_queryset(self):
36 queryset = super().get_queryset().filter(locked=False)
37
38 if not self.request.member:
39 queryset = queryset.none()
40 elif not self.request.member.has_perm("sales.override_manager"):
41 queryset = queryset.filter(
42 managers__in=self.request.member.get_member_groups()
43 ).distinct()
44
45 queryset = queryset.select_properties(
46 "active",
47 "total_revenue",
48 "total_revenue_paid",
49 "num_orders",
50 "num_orders_paid",
51 )
52 queryset = queryset.prefetch_related("event", "product_list")
53 queryset = queryset.prefetch_related("orders__order_items",)
54 return queryset
55
56
57 class ShiftDetailView(AdminRetrieveAPIView):
58 serializer_class = ShiftSerializer
59 queryset = Shift.objects.all()
60 permission_classes = [
61 IsAuthenticatedOrTokenHasScope,
62 DjangoModelPermissions,
63 IsManager,
64 ]
65 required_scopes = ["sales:admin"]
66
67
68 class OrderListView(AdminListAPIView, AdminCreateAPIView):
69 method_serializer_classes = {
70 ("GET",): OrderListSerializer,
71 ("POST",): OrderSerializer,
72 }
73 permission_classes = [
74 IsAuthenticatedOrTokenHasScopeForMethod,
75 DjangoModelPermissions,
76 IsManager,
77 ]
78 required_scopes = ["sales:admin"]
79 shift_lookup_field = "pk"
80
81 def get_serializer_class(self):
82 for methods, serializer_cls in self.method_serializer_classes.items():
83 if self.request.method in methods:
84 return serializer_cls
85 raise exceptions.MethodNotAllowed(self.request.method)
86
87 def create(self, request, *args, **kwargs):
88 shift = Shift.objects.get(pk=kwargs["pk"])
89 if shift.locked:
90 raise PermissionDenied
91
92 return super(OrderListView, self).create(request, args, kwargs)
93
94 def get_queryset(self):
95 queryset = Order.objects.all()
96
97 pk = self.kwargs.get("pk")
98 if pk:
99 queryset = queryset.filter(shift=pk)
100
101 queryset = queryset.select_properties(
102 "total_amount", "subtotal", "num_items", "age_restricted"
103 )
104 queryset = queryset.prefetch_related(
105 "shift", "shift__event", "shift__product_list"
106 )
107 queryset = queryset.prefetch_related(
108 "order_items", "order_items__product", "order_items__product__product"
109 )
110 queryset = queryset.prefetch_related("payment")
111 return queryset
112
113 def get_serializer_context(self):
114 context = super(OrderListView, self).get_serializer_context()
115 pk = self.kwargs.get("pk")
116 if pk:
117 shift = get_object_or_404(Shift, pk=self.kwargs.get("pk"))
118 context.update({"shift": shift})
119 return context
120
121
122 class OrderDetailView(AdminRetrieveAPIView, AdminUpdateAPIView, AdminDestroyAPIView):
123 serializer_class = OrderSerializer
124 queryset = Order.objects.all()
125 permission_classes = [
126 IsAuthenticatedOrTokenHasScopeForMethod,
127 DjangoModelPermissions,
128 IsManager,
129 ]
130 required_scopes = ["sales:admin"]
131
132 def get_queryset(self):
133 queryset = super().get_queryset()
134
135 if not self.request.member:
136 queryset = queryset.none()
137 elif not self.request.member.has_perm("sales.override_manager"):
138 queryset = queryset.filter(
139 shift__managers__in=self.request.member.get_member_groups()
140 ).distinct()
141
142 queryset = queryset.select_properties(
143 "total_amount", "subtotal", "num_items", "age_restricted"
144 )
145 queryset = queryset.prefetch_related(
146 "shift", "shift__event", "shift__product_list"
147 )
148 queryset = queryset.prefetch_related(
149 "order_items", "order_items__product", "order_items__product__product"
150 )
151 queryset = queryset.prefetch_related("payment")
152 return queryset
153
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/website/sales/api/v2/admin/views.py b/website/sales/api/v2/admin/views.py
--- a/website/sales/api/v2/admin/views.py
+++ b/website/sales/api/v2/admin/views.py
@@ -16,7 +16,6 @@
AdminUpdateAPIView,
AdminDestroyAPIView,
)
-from thaliawebsite.api.v2.permissions import IsAuthenticatedOrTokenHasScopeForMethod
class ShiftListView(AdminListAPIView):
@@ -71,7 +70,7 @@
("POST",): OrderSerializer,
}
permission_classes = [
- IsAuthenticatedOrTokenHasScopeForMethod,
+ IsAuthenticatedOrTokenHasScope,
DjangoModelPermissions,
IsManager,
]
@@ -123,7 +122,7 @@
serializer_class = OrderSerializer
queryset = Order.objects.all()
permission_classes = [
- IsAuthenticatedOrTokenHasScopeForMethod,
+ IsAuthenticatedOrTokenHasScope,
DjangoModelPermissions,
IsManager,
]
| {"golden_diff": "diff --git a/website/sales/api/v2/admin/views.py b/website/sales/api/v2/admin/views.py\n--- a/website/sales/api/v2/admin/views.py\n+++ b/website/sales/api/v2/admin/views.py\n@@ -16,7 +16,6 @@\n AdminUpdateAPIView,\n AdminDestroyAPIView,\n )\n-from thaliawebsite.api.v2.permissions import IsAuthenticatedOrTokenHasScopeForMethod\n \n \n class ShiftListView(AdminListAPIView):\n@@ -71,7 +70,7 @@\n (\"POST\",): OrderSerializer,\n }\n permission_classes = [\n- IsAuthenticatedOrTokenHasScopeForMethod,\n+ IsAuthenticatedOrTokenHasScope,\n DjangoModelPermissions,\n IsManager,\n ]\n@@ -123,7 +122,7 @@\n serializer_class = OrderSerializer\n queryset = Order.objects.all()\n permission_classes = [\n- IsAuthenticatedOrTokenHasScopeForMethod,\n+ IsAuthenticatedOrTokenHasScope,\n DjangoModelPermissions,\n IsManager,\n ]\n", "issue": "Sales API uses TokenHasScopeForMethod but no scopes per method are provided\n### Describe the change\r\nThe sales API uses some IsAuthenticatedOrTokenHasScopeForMethod permission classes, but no scopes per method are provided\r\n\r\n### Motivation\r\nSimpler code\r\n\r\n### Current implementation\r\nSee above\r\n\r\n### Suggested implementation\r\nUse IsAuthenticatedOrTokenHasScope, or specify scope per method \r\n\r\n\n", "before_files": [{"content": "from oauth2_provider.contrib.rest_framework import IsAuthenticatedOrTokenHasScope\nfrom rest_framework import filters, exceptions\nfrom rest_framework.exceptions import PermissionDenied\nfrom rest_framework.generics import get_object_or_404\nfrom rest_framework.permissions import DjangoModelPermissions\n\nfrom sales.api.v2.admin.permissions import IsManager\nfrom sales.api.v2.admin.serializers.order import OrderSerializer, OrderListSerializer\nfrom sales.api.v2.admin.serializers.shift import ShiftSerializer\nfrom sales.models.order import Order\nfrom sales.models.shift import Shift\nfrom thaliawebsite.api.v2.admin import (\n AdminCreateAPIView,\n AdminListAPIView,\n AdminRetrieveAPIView,\n AdminUpdateAPIView,\n AdminDestroyAPIView,\n)\nfrom thaliawebsite.api.v2.permissions import IsAuthenticatedOrTokenHasScopeForMethod\n\n\nclass ShiftListView(AdminListAPIView):\n \"\"\"Returns an overview of all sales shifts.\"\"\"\n\n serializer_class = ShiftSerializer\n queryset = Shift.objects.all()\n filter_backends = (\n filters.OrderingFilter,\n filters.SearchFilter,\n )\n ordering_fields = (\"start\", \"end\")\n permission_classes = [IsAuthenticatedOrTokenHasScope, DjangoModelPermissions]\n required_scopes = [\"sales:admin\"]\n\n def get_queryset(self):\n queryset = super().get_queryset().filter(locked=False)\n\n if not self.request.member:\n queryset = queryset.none()\n elif not self.request.member.has_perm(\"sales.override_manager\"):\n queryset = queryset.filter(\n managers__in=self.request.member.get_member_groups()\n ).distinct()\n\n queryset = queryset.select_properties(\n \"active\",\n \"total_revenue\",\n \"total_revenue_paid\",\n \"num_orders\",\n \"num_orders_paid\",\n )\n queryset = queryset.prefetch_related(\"event\", \"product_list\")\n queryset = queryset.prefetch_related(\"orders__order_items\",)\n return queryset\n\n\nclass ShiftDetailView(AdminRetrieveAPIView):\n serializer_class = ShiftSerializer\n queryset = Shift.objects.all()\n permission_classes = [\n IsAuthenticatedOrTokenHasScope,\n DjangoModelPermissions,\n IsManager,\n ]\n required_scopes = [\"sales:admin\"]\n\n\nclass OrderListView(AdminListAPIView, AdminCreateAPIView):\n method_serializer_classes = {\n (\"GET\",): OrderListSerializer,\n (\"POST\",): OrderSerializer,\n }\n permission_classes = [\n IsAuthenticatedOrTokenHasScopeForMethod,\n DjangoModelPermissions,\n IsManager,\n ]\n required_scopes = [\"sales:admin\"]\n shift_lookup_field = \"pk\"\n\n def get_serializer_class(self):\n for methods, serializer_cls in self.method_serializer_classes.items():\n if self.request.method in methods:\n return serializer_cls\n raise exceptions.MethodNotAllowed(self.request.method)\n\n def create(self, request, *args, **kwargs):\n shift = Shift.objects.get(pk=kwargs[\"pk\"])\n if shift.locked:\n raise PermissionDenied\n\n return super(OrderListView, self).create(request, args, kwargs)\n\n def get_queryset(self):\n queryset = Order.objects.all()\n\n pk = self.kwargs.get(\"pk\")\n if pk:\n queryset = queryset.filter(shift=pk)\n\n queryset = queryset.select_properties(\n \"total_amount\", \"subtotal\", \"num_items\", \"age_restricted\"\n )\n queryset = queryset.prefetch_related(\n \"shift\", \"shift__event\", \"shift__product_list\"\n )\n queryset = queryset.prefetch_related(\n \"order_items\", \"order_items__product\", \"order_items__product__product\"\n )\n queryset = queryset.prefetch_related(\"payment\")\n return queryset\n\n def get_serializer_context(self):\n context = super(OrderListView, self).get_serializer_context()\n pk = self.kwargs.get(\"pk\")\n if pk:\n shift = get_object_or_404(Shift, pk=self.kwargs.get(\"pk\"))\n context.update({\"shift\": shift})\n return context\n\n\nclass OrderDetailView(AdminRetrieveAPIView, AdminUpdateAPIView, AdminDestroyAPIView):\n serializer_class = OrderSerializer\n queryset = Order.objects.all()\n permission_classes = [\n IsAuthenticatedOrTokenHasScopeForMethod,\n DjangoModelPermissions,\n IsManager,\n ]\n required_scopes = [\"sales:admin\"]\n\n def get_queryset(self):\n queryset = super().get_queryset()\n\n if not self.request.member:\n queryset = queryset.none()\n elif not self.request.member.has_perm(\"sales.override_manager\"):\n queryset = queryset.filter(\n shift__managers__in=self.request.member.get_member_groups()\n ).distinct()\n\n queryset = queryset.select_properties(\n \"total_amount\", \"subtotal\", \"num_items\", \"age_restricted\"\n )\n queryset = queryset.prefetch_related(\n \"shift\", \"shift__event\", \"shift__product_list\"\n )\n queryset = queryset.prefetch_related(\n \"order_items\", \"order_items__product\", \"order_items__product__product\"\n )\n queryset = queryset.prefetch_related(\"payment\")\n return queryset\n", "path": "website/sales/api/v2/admin/views.py"}], "after_files": [{"content": "from oauth2_provider.contrib.rest_framework import IsAuthenticatedOrTokenHasScope\nfrom rest_framework import filters, exceptions\nfrom rest_framework.exceptions import PermissionDenied\nfrom rest_framework.generics import get_object_or_404\nfrom rest_framework.permissions import DjangoModelPermissions\n\nfrom sales.api.v2.admin.permissions import IsManager\nfrom sales.api.v2.admin.serializers.order import OrderSerializer, OrderListSerializer\nfrom sales.api.v2.admin.serializers.shift import ShiftSerializer\nfrom sales.models.order import Order\nfrom sales.models.shift import Shift\nfrom thaliawebsite.api.v2.admin import (\n AdminCreateAPIView,\n AdminListAPIView,\n AdminRetrieveAPIView,\n AdminUpdateAPIView,\n AdminDestroyAPIView,\n)\n\n\nclass ShiftListView(AdminListAPIView):\n \"\"\"Returns an overview of all sales shifts.\"\"\"\n\n serializer_class = ShiftSerializer\n queryset = Shift.objects.all()\n filter_backends = (\n filters.OrderingFilter,\n filters.SearchFilter,\n )\n ordering_fields = (\"start\", \"end\")\n permission_classes = [IsAuthenticatedOrTokenHasScope, DjangoModelPermissions]\n required_scopes = [\"sales:admin\"]\n\n def get_queryset(self):\n queryset = super().get_queryset().filter(locked=False)\n\n if not self.request.member:\n queryset = queryset.none()\n elif not self.request.member.has_perm(\"sales.override_manager\"):\n queryset = queryset.filter(\n managers__in=self.request.member.get_member_groups()\n ).distinct()\n\n queryset = queryset.select_properties(\n \"active\",\n \"total_revenue\",\n \"total_revenue_paid\",\n \"num_orders\",\n \"num_orders_paid\",\n )\n queryset = queryset.prefetch_related(\"event\", \"product_list\")\n queryset = queryset.prefetch_related(\"orders__order_items\",)\n return queryset\n\n\nclass ShiftDetailView(AdminRetrieveAPIView):\n serializer_class = ShiftSerializer\n queryset = Shift.objects.all()\n permission_classes = [\n IsAuthenticatedOrTokenHasScope,\n DjangoModelPermissions,\n IsManager,\n ]\n required_scopes = [\"sales:admin\"]\n\n\nclass OrderListView(AdminListAPIView, AdminCreateAPIView):\n method_serializer_classes = {\n (\"GET\",): OrderListSerializer,\n (\"POST\",): OrderSerializer,\n }\n permission_classes = [\n IsAuthenticatedOrTokenHasScope,\n DjangoModelPermissions,\n IsManager,\n ]\n required_scopes = [\"sales:admin\"]\n shift_lookup_field = \"pk\"\n\n def get_serializer_class(self):\n for methods, serializer_cls in self.method_serializer_classes.items():\n if self.request.method in methods:\n return serializer_cls\n raise exceptions.MethodNotAllowed(self.request.method)\n\n def create(self, request, *args, **kwargs):\n shift = Shift.objects.get(pk=kwargs[\"pk\"])\n if shift.locked:\n raise PermissionDenied\n\n return super(OrderListView, self).create(request, args, kwargs)\n\n def get_queryset(self):\n queryset = Order.objects.all()\n\n pk = self.kwargs.get(\"pk\")\n if pk:\n queryset = queryset.filter(shift=pk)\n\n queryset = queryset.select_properties(\n \"total_amount\", \"subtotal\", \"num_items\", \"age_restricted\"\n )\n queryset = queryset.prefetch_related(\n \"shift\", \"shift__event\", \"shift__product_list\"\n )\n queryset = queryset.prefetch_related(\n \"order_items\", \"order_items__product\", \"order_items__product__product\"\n )\n queryset = queryset.prefetch_related(\"payment\")\n return queryset\n\n def get_serializer_context(self):\n context = super(OrderListView, self).get_serializer_context()\n pk = self.kwargs.get(\"pk\")\n if pk:\n shift = get_object_or_404(Shift, pk=self.kwargs.get(\"pk\"))\n context.update({\"shift\": shift})\n return context\n\n\nclass OrderDetailView(AdminRetrieveAPIView, AdminUpdateAPIView, AdminDestroyAPIView):\n serializer_class = OrderSerializer\n queryset = Order.objects.all()\n permission_classes = [\n IsAuthenticatedOrTokenHasScope,\n DjangoModelPermissions,\n IsManager,\n ]\n required_scopes = [\"sales:admin\"]\n\n def get_queryset(self):\n queryset = super().get_queryset()\n\n if not self.request.member:\n queryset = queryset.none()\n elif not self.request.member.has_perm(\"sales.override_manager\"):\n queryset = queryset.filter(\n shift__managers__in=self.request.member.get_member_groups()\n ).distinct()\n\n queryset = queryset.select_properties(\n \"total_amount\", \"subtotal\", \"num_items\", \"age_restricted\"\n )\n queryset = queryset.prefetch_related(\n \"shift\", \"shift__event\", \"shift__product_list\"\n )\n queryset = queryset.prefetch_related(\n \"order_items\", \"order_items__product\", \"order_items__product__product\"\n )\n queryset = queryset.prefetch_related(\"payment\")\n return queryset\n", "path": "website/sales/api/v2/admin/views.py"}]} | 1,753 | 225 |
gh_patches_debug_14896 | rasdani/github-patches | git_diff | mozilla__telemetry-analysis-service-975 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Don't overwrite creator when saving jobs
Since we can provide view and editing permissions to other users (e.g. admins) with row-level permissions we should stop overwriting the creator on every save of a scheduled Spark job since it would prevent an effective trail of ownership and has in the past led to inconsistencies when updating jobs by an admin.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `atmo/forms/mixins.py`
Content:
```
1 # This Source Code Form is subject to the terms of the Mozilla Public
2 # License, v. 2.0. If a copy of the MPL was not distributed with this
3 # file, you can obtain one at http://mozilla.org/MPL/2.0/.
4 import uuid
5 from collections import OrderedDict
6
7 from django import forms
8
9 from .cache import CachedFileCache
10 from .fields import CachedFileField
11 from .widgets import CachedFileHiddenInput
12
13
14 class AutoClassFormMixin:
15 """
16 A form mixin that adds the 'form-control' to all field widgets
17 automatically
18 """
19 class_names = {
20 'form-control': {
21 'excluded_widgets': ['file'],
22 }
23 }
24
25 def __init__(self, *args, **kwargs):
26 super().__init__(*args, **kwargs)
27 for field in list(self.fields.values()):
28 classes = field.widget.attrs.get('class', '').split(' ')
29 for class_name, options in list(self.class_names.items()):
30 if class_name in classes:
31 continue
32 excluded_widgets = options.get('excluded_widgets', [])
33 if (hasattr(field.widget, 'input_type') and
34 field.widget.input_type in excluded_widgets):
35 continue
36 field.widget.attrs['class'] = ' '.join([class_name] + classes)
37
38
39 class CreatedByModelFormMixin(forms.ModelForm):
40 """
41 Custom Django form mixin that takes a user object and if the provided
42 model form instance has a primary key checks if the given user
43 matches the 'created_by' field.
44 """
45 def __init__(self, user, *args, **kwargs):
46 self.created_by = user
47 super().__init__(*args, **kwargs)
48
49 def save(self, commit=True):
50 # create the object without committing, since we haven't
51 # set the required created_by field yet
52 obj = super().save(commit=False)
53
54 # set the field to the user that created the object
55 obj.created_by = self.created_by
56
57 if commit:
58 # actually start the real object, and return the model object
59 obj.save()
60 return obj
61
62 def clean(self):
63 """
64 only allow deleting clusters that one created
65 """
66 super().clean()
67 if self.instance.id and self.created_by != self.instance.created_by:
68 raise forms.ValidationError(
69 'Access denied to the data of another user'
70 )
71
72
73 class CachedFileModelFormMixin(forms.ModelForm):
74 """
75 A model form mixin that automatically adds additional hidden form fields
76 to store a random value to be used as the cache key for caching FileField
77 files on submission. That is needed to prevent having to reselect files
78 over and over again when form submission fails for the fields other than
79 the file fields.
80 """
81 def __init__(self, *args, **kwargs):
82 super().__init__(*args, **kwargs)
83 self.cache = CachedFileCache()
84 self.cached_filefields = OrderedDict()
85 self.required_filefields = []
86
87 field_order = []
88 for name, field in list(self.fields.items()):
89 # add any found field to the list of order items
90 field_order.append(name)
91
92 # in case it's a file input
93 if isinstance(field, CachedFileField):
94 # we'll use this later in the clean and save step
95 self.cached_filefields[name] = field
96
97 # store the field that are required so we can validate
98 # them optionally in our clean method
99 if field.real_required:
100 self.required_filefields.append(name)
101
102 # get the name of the cache key field
103 cachekey_input_name = self.cachekey_input_name(name)
104 field_order.append(cachekey_input_name)
105
106 # add the cache key field
107 self.fields[cachekey_input_name] = forms.CharField(
108 max_length=32,
109 widget=CachedFileHiddenInput(),
110 initial=uuid.uuid4().hex
111 )
112
113 self.order_fields(field_order)
114
115 def cachekey_input_name(self, name):
116 return name + '-cache'
117
118 def cachekey_input_data(self, field):
119 name = self.cachekey_input_name(field)
120 return self.cleaned_data[name]
121
122 def save(self, *args, **kwargs):
123 # on save get rid of the cache keys
124 for name in self.cached_filefields:
125 self.cache.remove(self.cachekey_input_data(name))
126 return super().save(*args, **kwargs)
127
128 def clean(self):
129 for field_name in self.cached_filefields:
130 # get the name of the cache key field name and its value
131 cache_key = self.cachekey_input_data(field_name)
132
133 # check form data if the file field was submitted
134 submitted_file = self.cleaned_data.get(field_name)
135 if submitted_file is None:
136 # if not, check the cache and update the cleaned data
137 cached_file = self.cache.retrieve(cache_key, field_name)
138 if cached_file is None:
139 # raise a required validation error if nothing was found
140 if field_name in self.required_filefields:
141 field = self.cached_filefields[field_name]
142 self.add_error(
143 field_name,
144 forms.ValidationError(
145 field.error_messages['required'],
146 code='required'
147 )
148 )
149 else:
150 self.cleaned_data[field_name] = cached_file
151 else:
152 # or store the submitted file for later use (or reset after saving)
153 self.cache.store(cache_key, submitted_file)
154
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/atmo/forms/mixins.py b/atmo/forms/mixins.py
--- a/atmo/forms/mixins.py
+++ b/atmo/forms/mixins.py
@@ -5,6 +5,7 @@
from collections import OrderedDict
from django import forms
+from django.contrib.auth.models import User
from .cache import CachedFileCache
from .fields import CachedFileField
@@ -52,7 +53,10 @@
obj = super().save(commit=False)
# set the field to the user that created the object
- obj.created_by = self.created_by
+ try:
+ obj.created_by
+ except User.DoesNotExist:
+ obj.created_by = self.created_by
if commit:
# actually start the real object, and return the model object
| {"golden_diff": "diff --git a/atmo/forms/mixins.py b/atmo/forms/mixins.py\n--- a/atmo/forms/mixins.py\n+++ b/atmo/forms/mixins.py\n@@ -5,6 +5,7 @@\n from collections import OrderedDict\n \n from django import forms\n+from django.contrib.auth.models import User\n \n from .cache import CachedFileCache\n from .fields import CachedFileField\n@@ -52,7 +53,10 @@\n obj = super().save(commit=False)\n \n # set the field to the user that created the object\n- obj.created_by = self.created_by\n+ try:\n+ obj.created_by\n+ except User.DoesNotExist:\n+ obj.created_by = self.created_by\n \n if commit:\n # actually start the real object, and return the model object\n", "issue": "Don't overwrite creator when saving jobs\nSince we can provide view and editing permissions to other users (e.g. admins) with row-level permissions we should stop overwriting the creator on every save of a scheduled Spark job since it would prevent an effective trail of ownership and has in the past led to inconsistencies when updating jobs by an admin.\n", "before_files": [{"content": "# This Source Code Form is subject to the terms of the Mozilla Public\n# License, v. 2.0. If a copy of the MPL was not distributed with this\n# file, you can obtain one at http://mozilla.org/MPL/2.0/.\nimport uuid\nfrom collections import OrderedDict\n\nfrom django import forms\n\nfrom .cache import CachedFileCache\nfrom .fields import CachedFileField\nfrom .widgets import CachedFileHiddenInput\n\n\nclass AutoClassFormMixin:\n \"\"\"\n A form mixin that adds the 'form-control' to all field widgets\n automatically\n \"\"\"\n class_names = {\n 'form-control': {\n 'excluded_widgets': ['file'],\n }\n }\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n for field in list(self.fields.values()):\n classes = field.widget.attrs.get('class', '').split(' ')\n for class_name, options in list(self.class_names.items()):\n if class_name in classes:\n continue\n excluded_widgets = options.get('excluded_widgets', [])\n if (hasattr(field.widget, 'input_type') and\n field.widget.input_type in excluded_widgets):\n continue\n field.widget.attrs['class'] = ' '.join([class_name] + classes)\n\n\nclass CreatedByModelFormMixin(forms.ModelForm):\n \"\"\"\n Custom Django form mixin that takes a user object and if the provided\n model form instance has a primary key checks if the given user\n matches the 'created_by' field.\n \"\"\"\n def __init__(self, user, *args, **kwargs):\n self.created_by = user\n super().__init__(*args, **kwargs)\n\n def save(self, commit=True):\n # create the object without committing, since we haven't\n # set the required created_by field yet\n obj = super().save(commit=False)\n\n # set the field to the user that created the object\n obj.created_by = self.created_by\n\n if commit:\n # actually start the real object, and return the model object\n obj.save()\n return obj\n\n def clean(self):\n \"\"\"\n only allow deleting clusters that one created\n \"\"\"\n super().clean()\n if self.instance.id and self.created_by != self.instance.created_by:\n raise forms.ValidationError(\n 'Access denied to the data of another user'\n )\n\n\nclass CachedFileModelFormMixin(forms.ModelForm):\n \"\"\"\n A model form mixin that automatically adds additional hidden form fields\n to store a random value to be used as the cache key for caching FileField\n files on submission. That is needed to prevent having to reselect files\n over and over again when form submission fails for the fields other than\n the file fields.\n \"\"\"\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.cache = CachedFileCache()\n self.cached_filefields = OrderedDict()\n self.required_filefields = []\n\n field_order = []\n for name, field in list(self.fields.items()):\n # add any found field to the list of order items\n field_order.append(name)\n\n # in case it's a file input\n if isinstance(field, CachedFileField):\n # we'll use this later in the clean and save step\n self.cached_filefields[name] = field\n\n # store the field that are required so we can validate\n # them optionally in our clean method\n if field.real_required:\n self.required_filefields.append(name)\n\n # get the name of the cache key field\n cachekey_input_name = self.cachekey_input_name(name)\n field_order.append(cachekey_input_name)\n\n # add the cache key field\n self.fields[cachekey_input_name] = forms.CharField(\n max_length=32,\n widget=CachedFileHiddenInput(),\n initial=uuid.uuid4().hex\n )\n\n self.order_fields(field_order)\n\n def cachekey_input_name(self, name):\n return name + '-cache'\n\n def cachekey_input_data(self, field):\n name = self.cachekey_input_name(field)\n return self.cleaned_data[name]\n\n def save(self, *args, **kwargs):\n # on save get rid of the cache keys\n for name in self.cached_filefields:\n self.cache.remove(self.cachekey_input_data(name))\n return super().save(*args, **kwargs)\n\n def clean(self):\n for field_name in self.cached_filefields:\n # get the name of the cache key field name and its value\n cache_key = self.cachekey_input_data(field_name)\n\n # check form data if the file field was submitted\n submitted_file = self.cleaned_data.get(field_name)\n if submitted_file is None:\n # if not, check the cache and update the cleaned data\n cached_file = self.cache.retrieve(cache_key, field_name)\n if cached_file is None:\n # raise a required validation error if nothing was found\n if field_name in self.required_filefields:\n field = self.cached_filefields[field_name]\n self.add_error(\n field_name,\n forms.ValidationError(\n field.error_messages['required'],\n code='required'\n )\n )\n else:\n self.cleaned_data[field_name] = cached_file\n else:\n # or store the submitted file for later use (or reset after saving)\n self.cache.store(cache_key, submitted_file)\n", "path": "atmo/forms/mixins.py"}], "after_files": [{"content": "# This Source Code Form is subject to the terms of the Mozilla Public\n# License, v. 2.0. If a copy of the MPL was not distributed with this\n# file, you can obtain one at http://mozilla.org/MPL/2.0/.\nimport uuid\nfrom collections import OrderedDict\n\nfrom django import forms\nfrom django.contrib.auth.models import User\n\nfrom .cache import CachedFileCache\nfrom .fields import CachedFileField\nfrom .widgets import CachedFileHiddenInput\n\n\nclass AutoClassFormMixin:\n \"\"\"\n A form mixin that adds the 'form-control' to all field widgets\n automatically\n \"\"\"\n class_names = {\n 'form-control': {\n 'excluded_widgets': ['file'],\n }\n }\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n for field in list(self.fields.values()):\n classes = field.widget.attrs.get('class', '').split(' ')\n for class_name, options in list(self.class_names.items()):\n if class_name in classes:\n continue\n excluded_widgets = options.get('excluded_widgets', [])\n if (hasattr(field.widget, 'input_type') and\n field.widget.input_type in excluded_widgets):\n continue\n field.widget.attrs['class'] = ' '.join([class_name] + classes)\n\n\nclass CreatedByModelFormMixin(forms.ModelForm):\n \"\"\"\n Custom Django form mixin that takes a user object and if the provided\n model form instance has a primary key checks if the given user\n matches the 'created_by' field.\n \"\"\"\n def __init__(self, user, *args, **kwargs):\n self.created_by = user\n super().__init__(*args, **kwargs)\n\n def save(self, commit=True):\n # create the object without committing, since we haven't\n # set the required created_by field yet\n obj = super().save(commit=False)\n\n # set the field to the user that created the object\n try:\n obj.created_by\n except User.DoesNotExist:\n obj.created_by = self.created_by\n\n if commit:\n # actually start the real object, and return the model object\n obj.save()\n return obj\n\n def clean(self):\n \"\"\"\n only allow deleting clusters that one created\n \"\"\"\n super().clean()\n if self.instance.id and self.created_by != self.instance.created_by:\n raise forms.ValidationError(\n 'Access denied to the data of another user'\n )\n\n\nclass CachedFileModelFormMixin(forms.ModelForm):\n \"\"\"\n A model form mixin that automatically adds additional hidden form fields\n to store a random value to be used as the cache key for caching FileField\n files on submission. That is needed to prevent having to reselect files\n over and over again when form submission fails for the fields other than\n the file fields.\n \"\"\"\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.cache = CachedFileCache()\n self.cached_filefields = OrderedDict()\n self.required_filefields = []\n\n field_order = []\n for name, field in list(self.fields.items()):\n # add any found field to the list of order items\n field_order.append(name)\n\n # in case it's a file input\n if isinstance(field, CachedFileField):\n # we'll use this later in the clean and save step\n self.cached_filefields[name] = field\n\n # store the field that are required so we can validate\n # them optionally in our clean method\n if field.real_required:\n self.required_filefields.append(name)\n\n # get the name of the cache key field\n cachekey_input_name = self.cachekey_input_name(name)\n field_order.append(cachekey_input_name)\n\n # add the cache key field\n self.fields[cachekey_input_name] = forms.CharField(\n max_length=32,\n widget=CachedFileHiddenInput(),\n initial=uuid.uuid4().hex\n )\n\n self.order_fields(field_order)\n\n def cachekey_input_name(self, name):\n return name + '-cache'\n\n def cachekey_input_data(self, field):\n name = self.cachekey_input_name(field)\n return self.cleaned_data[name]\n\n def save(self, *args, **kwargs):\n # on save get rid of the cache keys\n for name in self.cached_filefields:\n self.cache.remove(self.cachekey_input_data(name))\n return super().save(*args, **kwargs)\n\n def clean(self):\n for field_name in self.cached_filefields:\n # get the name of the cache key field name and its value\n cache_key = self.cachekey_input_data(field_name)\n\n # check form data if the file field was submitted\n submitted_file = self.cleaned_data.get(field_name)\n if submitted_file is None:\n # if not, check the cache and update the cleaned data\n cached_file = self.cache.retrieve(cache_key, field_name)\n if cached_file is None:\n # raise a required validation error if nothing was found\n if field_name in self.required_filefields:\n field = self.cached_filefields[field_name]\n self.add_error(\n field_name,\n forms.ValidationError(\n field.error_messages['required'],\n code='required'\n )\n )\n else:\n self.cleaned_data[field_name] = cached_file\n else:\n # or store the submitted file for later use (or reset after saving)\n self.cache.store(cache_key, submitted_file)\n", "path": "atmo/forms/mixins.py"}]} | 1,844 | 175 |
gh_patches_debug_3639 | rasdani/github-patches | git_diff | Mailu__Mailu-2958 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Vulnerability in ClamAV
## Environment & Version
### Environment
- [ ] docker compose
- [x] kubernetes
- [ ] docker swarm
### Version
- Version: `master`
## Description
ClamAV version 0.105.2 is vulnerable to [CVE-2023-20197](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-20197)
Unfortunately, ClamAV will not provide any update in the 0.105 branch, as it is EOL see https://blog.clamav.net/2023/07/2023-08-16-releases.html
## Replication Steps
```
$ docker run --pull=always --rm -it ghcr.io/mailu/clamav:master clamd --version
master: Pulling from mailu/clamav
Digest: sha256:dd088fc80ab063b0588160a69fce034d5d1f33db6d85d57296154fc51cdeaffa
Status: Image is up to date for ghcr.io/mailu/clamav:master
ClamAV 0.105.2
```
## Observed behaviour
ClamAV is in a vulnerable state
## Expected behaviour
I expect ClamAV to be updated to a fixed version (1.1.1 or 1.0.2)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/rspamd/start.py`
Content:
```
1 #!/usr/bin/env python3
2
3 import os
4 import glob
5 import logging as log
6 import requests
7 import shutil
8 import sys
9 import time
10 from socrate import system,conf
11
12 env = system.set_env()
13
14 # Actual startup script
15
16 config_files = []
17 for rspamd_file in glob.glob("/conf/*"):
18 conf.jinja(rspamd_file, env, os.path.join("/etc/rspamd/local.d", os.path.basename(rspamd_file)))
19 config_files.append(os.path.basename(rspamd_file))
20
21 for override_file in glob.glob("/overrides/*"):
22 if os.path.basename(override_file) not in config_files:
23 shutil.copyfile(override_file, os.path.join("/etc/rspamd/local.d", os.path.basename(override_file)))
24
25 # Admin may not be up just yet
26 healthcheck = f'http://{env["ADMIN_ADDRESS"]}:8080/internal/rspamd/local_domains'
27 while True:
28 time.sleep(1)
29 try:
30 if requests.get(healthcheck,timeout=2).ok:
31 break
32 except:
33 pass
34 log.warning("Admin is not up just yet, retrying in 1 second")
35
36 # Run rspamd
37 os.system("mkdir -m 755 -p /run/rspamd")
38 os.system("chown rspamd:rspamd /run/rspamd")
39 os.system("find /var/lib/rspamd | grep -v /filter | xargs -n1 chown rspamd:rspamd")
40 os.execv("/usr/sbin/rspamd", ["rspamd", "-f", "-u", "rspamd", "-g", "rspamd"])
41
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/core/rspamd/start.py b/core/rspamd/start.py
--- a/core/rspamd/start.py
+++ b/core/rspamd/start.py
@@ -37,4 +37,4 @@
os.system("mkdir -m 755 -p /run/rspamd")
os.system("chown rspamd:rspamd /run/rspamd")
os.system("find /var/lib/rspamd | grep -v /filter | xargs -n1 chown rspamd:rspamd")
-os.execv("/usr/sbin/rspamd", ["rspamd", "-f", "-u", "rspamd", "-g", "rspamd"])
+os.execv("/usr/bin/rspamd", ["rspamd", "-f", "-u", "rspamd", "-g", "rspamd"])
| {"golden_diff": "diff --git a/core/rspamd/start.py b/core/rspamd/start.py\n--- a/core/rspamd/start.py\n+++ b/core/rspamd/start.py\n@@ -37,4 +37,4 @@\n os.system(\"mkdir -m 755 -p /run/rspamd\")\n os.system(\"chown rspamd:rspamd /run/rspamd\")\n os.system(\"find /var/lib/rspamd | grep -v /filter | xargs -n1 chown rspamd:rspamd\")\n-os.execv(\"/usr/sbin/rspamd\", [\"rspamd\", \"-f\", \"-u\", \"rspamd\", \"-g\", \"rspamd\"])\n+os.execv(\"/usr/bin/rspamd\", [\"rspamd\", \"-f\", \"-u\", \"rspamd\", \"-g\", \"rspamd\"])\n", "issue": "Vulnerability in ClamAV\n\r\n## Environment & Version\r\n\r\n### Environment\r\n\r\n- [ ] docker compose\r\n- [x] kubernetes\r\n- [ ] docker swarm\r\n\r\n### Version\r\n\r\n- Version: `master`\r\n\r\n## Description\r\nClamAV version 0.105.2 is vulnerable to [CVE-2023-20197](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-20197)\r\nUnfortunately, ClamAV will not provide any update in the 0.105 branch, as it is EOL see https://blog.clamav.net/2023/07/2023-08-16-releases.html\r\n\r\n## Replication Steps\r\n```\r\n$ docker run --pull=always --rm -it ghcr.io/mailu/clamav:master clamd --version\r\nmaster: Pulling from mailu/clamav\r\nDigest: sha256:dd088fc80ab063b0588160a69fce034d5d1f33db6d85d57296154fc51cdeaffa\r\nStatus: Image is up to date for ghcr.io/mailu/clamav:master\r\nClamAV 0.105.2\r\n```\r\n\r\n## Observed behaviour\r\nClamAV is in a vulnerable state\r\n\r\n## Expected behaviour\r\nI expect ClamAV to be updated to a fixed version (1.1.1 or 1.0.2)\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport os\nimport glob\nimport logging as log\nimport requests\nimport shutil\nimport sys\nimport time\nfrom socrate import system,conf\n\nenv = system.set_env()\n\n# Actual startup script\n\nconfig_files = []\nfor rspamd_file in glob.glob(\"/conf/*\"):\n conf.jinja(rspamd_file, env, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(rspamd_file)))\n config_files.append(os.path.basename(rspamd_file))\n\nfor override_file in glob.glob(\"/overrides/*\"):\n if os.path.basename(override_file) not in config_files:\n shutil.copyfile(override_file, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(override_file)))\n\n# Admin may not be up just yet\nhealthcheck = f'http://{env[\"ADMIN_ADDRESS\"]}:8080/internal/rspamd/local_domains'\nwhile True:\n time.sleep(1)\n try:\n if requests.get(healthcheck,timeout=2).ok:\n break\n except:\n pass\n log.warning(\"Admin is not up just yet, retrying in 1 second\")\n\n# Run rspamd\nos.system(\"mkdir -m 755 -p /run/rspamd\")\nos.system(\"chown rspamd:rspamd /run/rspamd\")\nos.system(\"find /var/lib/rspamd | grep -v /filter | xargs -n1 chown rspamd:rspamd\")\nos.execv(\"/usr/sbin/rspamd\", [\"rspamd\", \"-f\", \"-u\", \"rspamd\", \"-g\", \"rspamd\"])\n", "path": "core/rspamd/start.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nimport os\nimport glob\nimport logging as log\nimport requests\nimport shutil\nimport sys\nimport time\nfrom socrate import system,conf\n\nenv = system.set_env()\n\n# Actual startup script\n\nconfig_files = []\nfor rspamd_file in glob.glob(\"/conf/*\"):\n conf.jinja(rspamd_file, env, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(rspamd_file)))\n config_files.append(os.path.basename(rspamd_file))\n\nfor override_file in glob.glob(\"/overrides/*\"):\n if os.path.basename(override_file) not in config_files:\n shutil.copyfile(override_file, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(override_file)))\n\n# Admin may not be up just yet\nhealthcheck = f'http://{env[\"ADMIN_ADDRESS\"]}:8080/internal/rspamd/local_domains'\nwhile True:\n time.sleep(1)\n try:\n if requests.get(healthcheck,timeout=2).ok:\n break\n except:\n pass\n log.warning(\"Admin is not up just yet, retrying in 1 second\")\n\n# Run rspamd\nos.system(\"mkdir -m 755 -p /run/rspamd\")\nos.system(\"chown rspamd:rspamd /run/rspamd\")\nos.system(\"find /var/lib/rspamd | grep -v /filter | xargs -n1 chown rspamd:rspamd\")\nos.execv(\"/usr/bin/rspamd\", [\"rspamd\", \"-f\", \"-u\", \"rspamd\", \"-g\", \"rspamd\"])\n", "path": "core/rspamd/start.py"}]} | 1,031 | 175 |
gh_patches_debug_7962 | rasdani/github-patches | git_diff | Gallopsled__pwntools-1304 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
from pwn import * changes __name__
Running `pwntools==3.14.0.dev0` from py3 dev branch.
from pwn import * imports __name__ apparently.
```python
In [1]: __name__
Out[1]: '__main__'
In [2]: from pwn import *
In [3]: __name__
Out[3]: 'pwn.toplevel'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwn/toplevel.py`
Content:
```
1 # Get all the modules from pwnlib
2 import collections
3 import logging
4 import math
5 import operator
6 import os
7 import re
8 import socks
9 import signal
10 import string
11 import struct
12 import subprocess
13 import sys
14 import tempfile
15 import threading
16 import time
17
18 from pprint import pprint
19
20 import pwnlib
21 from pwnlib import *
22 from pwnlib.asm import *
23 from pwnlib.context import Thread
24 from pwnlib.context import context
25 from pwnlib.dynelf import DynELF
26 from pwnlib.encoders import *
27 from pwnlib.elf.corefile import Core, Corefile, Coredump
28 from pwnlib.elf.elf import ELF, load
29 from pwnlib.encoders import *
30 from pwnlib.exception import PwnlibException
31 from pwnlib.gdb import attach, debug, debug_assembly, debug_shellcode
32 from pwnlib.flag import *
33 from pwnlib.fmtstr import FmtStr, fmtstr_payload
34 from pwnlib.log import getLogger
35 from pwnlib.memleak import MemLeak, RelativeMemLeak
36 from pwnlib.regsort import *
37 from pwnlib.replacements import *
38 from pwnlib.rop import ROP
39 from pwnlib.rop.srop import SigreturnFrame
40 from pwnlib.runner import *
41 from pwnlib.timeout import Timeout
42 from pwnlib.tubes.listen import listen
43 from pwnlib.tubes.process import process, PTY, PIPE, STDOUT
44 from pwnlib.tubes.remote import remote, tcp, udp, connect
45 from pwnlib.tubes.serialtube import serialtube
46 from pwnlib.tubes.server import server
47 from pwnlib.tubes.ssh import ssh
48 from pwnlib.tubes.tube import tube
49 from pwnlib.ui import *
50 from pwnlib.util import crc
51 from pwnlib.util import iters
52 from pwnlib.util import net
53 from pwnlib.util import proc
54 from pwnlib.util import safeeval
55 from pwnlib.util.crc import BitPolynom
56 from pwnlib.util.cyclic import *
57 from pwnlib.util.fiddling import *
58 from pwnlib.util.getdents import *
59 from pwnlib.util.hashes import *
60 from pwnlib.util.lists import *
61 from pwnlib.util.misc import *
62 from pwnlib.util.packing import *
63 from pwnlib.util.proc import pidof
64 from pwnlib.util.sh_string import sh_string, sh_prepare, sh_command_with
65 from pwnlib.util.splash import *
66 from pwnlib.util.web import *
67
68 # Promote these modules, so that "from pwn import *" will let you access them
69
70 __all__ = ["pickle", "StringIO", "BytesIO"]
71 from six.moves import cPickle as pickle, cStringIO as StringIO
72 from six import BytesIO
73
74 error = log.error
75 warning = log.warning
76 warn = log.warning
77 info = log.info
78 debug = log.debug
79 success = log.success
80
81 __all__ += list(globals().keys())
82
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pwn/toplevel.py b/pwn/toplevel.py
--- a/pwn/toplevel.py
+++ b/pwn/toplevel.py
@@ -67,7 +67,6 @@
# Promote these modules, so that "from pwn import *" will let you access them
-__all__ = ["pickle", "StringIO", "BytesIO"]
from six.moves import cPickle as pickle, cStringIO as StringIO
from six import BytesIO
@@ -78,4 +77,4 @@
debug = log.debug
success = log.success
-__all__ += list(globals().keys())
+__all__ = [x for x in globals().keys() if x != '__name__']
| {"golden_diff": "diff --git a/pwn/toplevel.py b/pwn/toplevel.py\n--- a/pwn/toplevel.py\n+++ b/pwn/toplevel.py\n@@ -67,7 +67,6 @@\n \n # Promote these modules, so that \"from pwn import *\" will let you access them\n \n-__all__ = [\"pickle\", \"StringIO\", \"BytesIO\"]\n from six.moves import cPickle as pickle, cStringIO as StringIO\n from six import BytesIO\n \n@@ -78,4 +77,4 @@\n debug = log.debug\n success = log.success\n \n-__all__ += list(globals().keys())\n+__all__ = [x for x in globals().keys() if x != '__name__']\n", "issue": "from pwn import * changes __name__\nRunning `pwntools==3.14.0.dev0` from py3 dev branch.\r\n\r\nfrom pwn import * imports __name__ apparently.\r\n\r\n```python\r\nIn [1]: __name__\r\nOut[1]: '__main__'\r\n\r\nIn [2]: from pwn import *\r\n\r\nIn [3]: __name__\r\nOut[3]: 'pwn.toplevel'\r\n```\n", "before_files": [{"content": "# Get all the modules from pwnlib\nimport collections\nimport logging\nimport math\nimport operator\nimport os\nimport re\nimport socks\nimport signal\nimport string\nimport struct\nimport subprocess\nimport sys\nimport tempfile\nimport threading\nimport time\n\nfrom pprint import pprint\n\nimport pwnlib\nfrom pwnlib import *\nfrom pwnlib.asm import *\nfrom pwnlib.context import Thread\nfrom pwnlib.context import context\nfrom pwnlib.dynelf import DynELF\nfrom pwnlib.encoders import *\nfrom pwnlib.elf.corefile import Core, Corefile, Coredump\nfrom pwnlib.elf.elf import ELF, load\nfrom pwnlib.encoders import *\nfrom pwnlib.exception import PwnlibException\nfrom pwnlib.gdb import attach, debug, debug_assembly, debug_shellcode\nfrom pwnlib.flag import *\nfrom pwnlib.fmtstr import FmtStr, fmtstr_payload\nfrom pwnlib.log import getLogger\nfrom pwnlib.memleak import MemLeak, RelativeMemLeak\nfrom pwnlib.regsort import *\nfrom pwnlib.replacements import *\nfrom pwnlib.rop import ROP\nfrom pwnlib.rop.srop import SigreturnFrame\nfrom pwnlib.runner import *\nfrom pwnlib.timeout import Timeout\nfrom pwnlib.tubes.listen import listen\nfrom pwnlib.tubes.process import process, PTY, PIPE, STDOUT\nfrom pwnlib.tubes.remote import remote, tcp, udp, connect\nfrom pwnlib.tubes.serialtube import serialtube\nfrom pwnlib.tubes.server import server\nfrom pwnlib.tubes.ssh import ssh\nfrom pwnlib.tubes.tube import tube\nfrom pwnlib.ui import *\nfrom pwnlib.util import crc\nfrom pwnlib.util import iters\nfrom pwnlib.util import net\nfrom pwnlib.util import proc\nfrom pwnlib.util import safeeval\nfrom pwnlib.util.crc import BitPolynom\nfrom pwnlib.util.cyclic import *\nfrom pwnlib.util.fiddling import *\nfrom pwnlib.util.getdents import *\nfrom pwnlib.util.hashes import *\nfrom pwnlib.util.lists import *\nfrom pwnlib.util.misc import *\nfrom pwnlib.util.packing import *\nfrom pwnlib.util.proc import pidof\nfrom pwnlib.util.sh_string import sh_string, sh_prepare, sh_command_with\nfrom pwnlib.util.splash import *\nfrom pwnlib.util.web import *\n\n# Promote these modules, so that \"from pwn import *\" will let you access them\n\n__all__ = [\"pickle\", \"StringIO\", \"BytesIO\"]\nfrom six.moves import cPickle as pickle, cStringIO as StringIO\nfrom six import BytesIO\n\nerror = log.error\nwarning = log.warning\nwarn = log.warning\ninfo = log.info\ndebug = log.debug\nsuccess = log.success\n\n__all__ += list(globals().keys())\n", "path": "pwn/toplevel.py"}], "after_files": [{"content": "# Get all the modules from pwnlib\nimport collections\nimport logging\nimport math\nimport operator\nimport os\nimport re\nimport socks\nimport signal\nimport string\nimport struct\nimport subprocess\nimport sys\nimport tempfile\nimport threading\nimport time\n\nfrom pprint import pprint\n\nimport pwnlib\nfrom pwnlib import *\nfrom pwnlib.asm import *\nfrom pwnlib.context import Thread\nfrom pwnlib.context import context\nfrom pwnlib.dynelf import DynELF\nfrom pwnlib.encoders import *\nfrom pwnlib.elf.corefile import Core, Corefile, Coredump\nfrom pwnlib.elf.elf import ELF, load\nfrom pwnlib.encoders import *\nfrom pwnlib.exception import PwnlibException\nfrom pwnlib.gdb import attach, debug, debug_assembly, debug_shellcode\nfrom pwnlib.flag import *\nfrom pwnlib.fmtstr import FmtStr, fmtstr_payload\nfrom pwnlib.log import getLogger\nfrom pwnlib.memleak import MemLeak, RelativeMemLeak\nfrom pwnlib.regsort import *\nfrom pwnlib.replacements import *\nfrom pwnlib.rop import ROP\nfrom pwnlib.rop.srop import SigreturnFrame\nfrom pwnlib.runner import *\nfrom pwnlib.timeout import Timeout\nfrom pwnlib.tubes.listen import listen\nfrom pwnlib.tubes.process import process, PTY, PIPE, STDOUT\nfrom pwnlib.tubes.remote import remote, tcp, udp, connect\nfrom pwnlib.tubes.serialtube import serialtube\nfrom pwnlib.tubes.server import server\nfrom pwnlib.tubes.ssh import ssh\nfrom pwnlib.tubes.tube import tube\nfrom pwnlib.ui import *\nfrom pwnlib.util import crc\nfrom pwnlib.util import iters\nfrom pwnlib.util import net\nfrom pwnlib.util import proc\nfrom pwnlib.util import safeeval\nfrom pwnlib.util.crc import BitPolynom\nfrom pwnlib.util.cyclic import *\nfrom pwnlib.util.fiddling import *\nfrom pwnlib.util.getdents import *\nfrom pwnlib.util.hashes import *\nfrom pwnlib.util.lists import *\nfrom pwnlib.util.misc import *\nfrom pwnlib.util.packing import *\nfrom pwnlib.util.proc import pidof\nfrom pwnlib.util.sh_string import sh_string, sh_prepare, sh_command_with\nfrom pwnlib.util.splash import *\nfrom pwnlib.util.web import *\n\n# Promote these modules, so that \"from pwn import *\" will let you access them\n\nfrom six.moves import cPickle as pickle, cStringIO as StringIO\nfrom six import BytesIO\n\nerror = log.error\nwarning = log.warning\nwarn = log.warning\ninfo = log.info\ndebug = log.debug\nsuccess = log.success\n\n__all__ = [x for x in globals().keys() if x != '__name__']\n", "path": "pwn/toplevel.py"}]} | 1,151 | 158 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.