
title
stringlengths 1
300
| score
int64 0
8.54k
| selftext
stringlengths 0
40k
| created
timestamp[ns]date 2023-04-01 04:30:41
2025-06-30 03:16:29
⌀ | url
stringlengths 0
878
| author
stringlengths 3
20
| domain
stringlengths 0
82
| edited
timestamp[ns]date 1970-01-01 00:00:00
2025-06-26 17:30:18
| gilded
int64 0
2
| gildings
stringclasses 7
values | id
stringlengths 7
7
| locked
bool 2
classes | media
stringlengths 646
1.8k
⌀ | name
stringlengths 10
10
| permalink
stringlengths 33
82
| spoiler
bool 2
classes | stickied
bool 2
classes | thumbnail
stringlengths 4
213
| ups
int64 0
8.54k
| preview
stringlengths 301
5.01k
⌀ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
DeepSeek R-1 NEVER answers my prompts | 0 | Every time I type something, whether it’s a question or a salutation or anything else, instead of giving me a straightforward response, it will start thinking about way deeper stuff.
Let’s say I was to ask for the names of Harry’s two best friends, in Harry Pottr, it would do something like this:
“Okay, let’s look at this query. The user asked ‘Harry’s two best friends in Harry Pottr.’Hmm there are some typos here—probably meant ‘Potter’ and maybe repeated it by mistake. They want the name of Harry’s best friends.
First, I need to figure out what they’re asking. Best friends could mean different things to different people. Maybe the user has friends who reminds them of the Harry’s […] But deep down, why ask this…”
This is an example of what I get every time I ask a question. I shorten it but it usually goes on and on and on to the point where I give up on wanting an answer and stop it. I tried playing with the settings and it didn’t work. Then, I tried telling it to think less but it started thinking about why I would ask it to think less…it’s somewhat scary. | 2025-06-13T02:13:01 | https://www.reddit.com/r/LocalLLaMA/comments/1la4k97/deepseek_r1_never_answers_my_prompts/ | Unkunkn | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la4k97 | false | null | t3_1la4k97 | /r/LocalLLaMA/comments/1la4k97/deepseek_r1_never_answers_my_prompts/ | false | false | self | 0 | null |
ROCm 6.4 running on my rx580(polaris) FAST but odd behavior on models. | 2 | With the help of claude i got ollama to use my rx580 following this guide.
[https://github.com/woodrex83/ROCm-For-RX580](https://github.com/woodrex83/ROCm-For-RX580)
All the work arounds in the past i tried were about half the speed of my GTX1070 , but now some models like gemma3:4b-it-qat actually run up to 1.6x the speed of my nvidia card. HOWEVER the big butt is that the vision part of this model and the QWEN2.5vl model, seem to see video noise when i feed an image to it. They desribed static or low res etc... but running the same images and prompts on my GTX1070 , they describe the images pretty well. Albiet slower. Any ideas what's going on here? | 2025-06-13T02:22:17 | https://www.reddit.com/r/LocalLLaMA/comments/1la4qnt/rocm_64_running_on_my_rx580polaris_fast_but_odd/ | opUserZero | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la4qnt | false | null | t3_1la4qnt | /r/LocalLLaMA/comments/1la4qnt/rocm_64_running_on_my_rx580polaris_fast_but_odd/ | false | false | self | 2 | {'enabled': False, 'images': [{'id': 'ohgtgz80rQ0F6PNCsdryC03WGVTALs27vtuj4i-H340', 'resolutions': [{'height': 54, 'url': 'https://external-preview.redd.it/ohgtgz80rQ0F6PNCsdryC03WGVTALs27vtuj4i-H340.png?width=108&crop=smart&auto=webp&s=1c860c2398513053a30706cd2177c6372ea31863', 'width': 108}, {'height': 108, 'url': 'https://external-preview.redd.it/ohgtgz80rQ0F6PNCsdryC03WGVTALs27vtuj4i-H340.png?width=216&crop=smart&auto=webp&s=287f3ac691a2b6d000c299205cee714f5a6c8a72', 'width': 216}, {'height': 160, 'url': 'https://external-preview.redd.it/ohgtgz80rQ0F6PNCsdryC03WGVTALs27vtuj4i-H340.png?width=320&crop=smart&auto=webp&s=f5dabd6ffab108614d40c1fb3b362268fa2b3737', 'width': 320}, {'height': 320, 'url': 'https://external-preview.redd.it/ohgtgz80rQ0F6PNCsdryC03WGVTALs27vtuj4i-H340.png?width=640&crop=smart&auto=webp&s=a74e6a31e96b9403545378c599471f9b9d0e7656', 'width': 640}, {'height': 480, 'url': 'https://external-preview.redd.it/ohgtgz80rQ0F6PNCsdryC03WGVTALs27vtuj4i-H340.png?width=960&crop=smart&auto=webp&s=24ffc6fda8fc9067e01392e325ac5fa88aacfd7e', 'width': 960}, {'height': 540, 'url': 'https://external-preview.redd.it/ohgtgz80rQ0F6PNCsdryC03WGVTALs27vtuj4i-H340.png?width=1080&crop=smart&auto=webp&s=c897cea9442d2d373d6f05547fa0561e467f4fd7', 'width': 1080}], 'source': {'height': 600, 'url': 'https://external-preview.redd.it/ohgtgz80rQ0F6PNCsdryC03WGVTALs27vtuj4i-H340.png?auto=webp&s=6d18c62d70a1ac90921ef7dc3ec847bebab21e19', 'width': 1200}, 'variants': {}}]} |
Help me find a motherboard | 2 | I need a motherboard that can both fit 4 dual slot GPUs and boot headless (or support integrated graphics). I've been through 2 motherboards already trying to get my quad MI50 setup to boot. First was an ASUS X99 Deluxe. It only fit 3 GPUs because of the pcie slot arrangement. Then I bought an ASUS X99 E-WS/USB3.1. It fit all of the GPUs but I found out that these ASUS motherboards won't boot "headless", which is required because the MI50 doesn't have display output. It's actually quite confusing because it will boot with my R9 290 even without a monitor plugged in (after a BIOS update); however, it won't do the same for the MI50. I'm assuming it's because the R9 290 has a port for a display so it thinks there a GPU while the MI50 errors with the no console device code (d6). I've confirmed the MI50s all work by testing them 2 at a time with the R9 290 plugged in to boot. I started with the X99 platform because of budget constraints and having the first motherboard sitting in storage, but it's starting to look grim. If there's anything else that won't cost me more than $300 to $500, I might spring for it just to get this to work. | 2025-06-13T02:28:49 | https://www.reddit.com/r/LocalLLaMA/comments/1la4v5h/help_me_find_a_motherboard/ | FrozenAptPea | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la4v5h | false | null | t3_1la4v5h | /r/LocalLLaMA/comments/1la4v5h/help_me_find_a_motherboard/ | false | false | self | 2 | null |
What specs should I go with to run a not-bad model? | 1 | Hello all,
I am completely uneducated about the AI space, but I wanted to get into it to be able to automate some of the simpler side of my work. I am not sure how possible it is, but it doesnt hurt to try, and I am due for a new rig anyways.
For rough specs I was thinking about getting either the 9800X3D or 9950X3D for the CPU, saving for a 5090 for a GPU (since I cant afford one right now at its current price; 3k is insane.), and maybe 48gb-64gb of normal RAM (normal as in not VRAM), as well as a 2TB m.2 NVME. Is this okay? Or should I change up some things?
The work I want it to automate it basically taking information from one private database and typing it into other private databases, then returning the results to me; if it's possible to train it to do that.
Thank you all in advance | 2025-06-13T02:39:28 | https://www.reddit.com/r/LocalLLaMA/comments/1la52f5/what_specs_should_i_go_with_to_run_a_notbad_model/ | ZXOS8 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la52f5 | false | null | t3_1la52f5 | /r/LocalLLaMA/comments/1la52f5/what_specs_should_i_go_with_to_run_a_notbad_model/ | false | false | self | 1 | null |
SSL Certificate Expired on https://llama3-1.llamameta.net | 1 | [removed] | 2025-06-13T03:29:40 | https://www.reddit.com/r/LocalLLaMA/comments/1la60ak/ssl_certificate_expired_on/ | Worldly-Welcome3387 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la60ak | false | null | t3_1la60ak | /r/LocalLLaMA/comments/1la60ak/ssl_certificate_expired_on/ | false | false | self | 1 | null |
SSL Certificate Expired on https://llama3-1.llamameta.net | 1 | [removed] | 2025-06-13T03:31:31 | https://www.reddit.com/r/LocalLLaMA/comments/1la61l3/ssl_certificate_expired_on/ | Worldly-Welcome3387 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la61l3 | false | null | t3_1la61l3 | /r/LocalLLaMA/comments/1la61l3/ssl_certificate_expired_on/ | false | false | self | 1 | null |
[First Release!] Serene Pub - 0.1.0 Alpha - Linux/MacOS/Windows - Silly Tavern alternative | 23 | \# Introduction
Hey everyone! I got some moderate interest when I posted a week back about Serene Pub.
I'm proud to say that I've finally reached a point where I can release the first Alpha version of this app for preview, testing and feedback!
This is in development, there will be bugs!
There are releases for Linux, MacOS and Windows. I run Linux and can only test Mac and Windows in virtual machines, so I could use help testing with that. Thanks!
Currently, only Ollama is officially supported via ollama-js. Support for other connections are coming soon once Serene Tavern's connection API becomes more final.
\# Screenshots
Attached are a handful of misc screenshots, showing mobile themes and desktop layouts.
\# Download
\- [Download here, for your favorite OS!](https://github.com/doolijb/serene-pub/releases/tag/v0.1.0-alpha)
\- [Download here, if you prefer running source code!](https://github.com/doolijb/serene-pub/tree/v0.1.0-alpha)
\- [Repository home and readme.](https://github.com/doolijb/serene-pub)
\# Excerpt
Serene Pub is a modern, customizable chat application designed for immersive roleplay and creative conversations. Inspired by Silly Tavern, it aims to be more intuitive, responsive, and simple to configure.
Primary concerns Serene Pub aims to address:
1. Reduce the number of nested menus and settings.
2. Reduced visual clutter.
3. Manage settings server-side to prevent configurations from changing because the user switched windows/devices.
4. Make API calls & chat completion requests asyncronously server-side so they process regardless of window/device state.
5. Use sockets for all data, the user will see the same information updated across all windows/devices.
6. Have compatibility with the majority of Silly Tavern import/exports, i.e. Character Cards
7. Overall be a well rounded app with a suite of features. Use SillyTavern if you want the most options, features and plugin-support. | 2025-06-13T03:56:02 | https://www.reddit.com/gallery/1la6h3y | doolijb | reddit.com | 1970-01-01T00:00:00 | 0 | {} | 1la6h3y | false | null | t3_1la6h3y | /r/LocalLLaMA/comments/1la6h3y/first_release_serene_pub_010_alpha/ | false | false | 23 | {'enabled': True, 'images': [{'id': 'xLYJQVPvAzJH6LTy7XZaM08Yzp0dQfVS5ZcYjGMavrE', 'resolutions': [{'height': 192, 'url': 'https://external-preview.redd.it/xLYJQVPvAzJH6LTy7XZaM08Yzp0dQfVS5ZcYjGMavrE.png?width=108&crop=smart&auto=webp&s=4bdba8fdef1eaf64eb125fe923b554303778dd80', 'width': 108}, {'height': 384, 'url': 'https://external-preview.redd.it/xLYJQVPvAzJH6LTy7XZaM08Yzp0dQfVS5ZcYjGMavrE.png?width=216&crop=smart&auto=webp&s=2a65ac1b04e314765d0782725e6e50badaeafea7', 'width': 216}, {'height': 569, 'url': 'https://external-preview.redd.it/xLYJQVPvAzJH6LTy7XZaM08Yzp0dQfVS5ZcYjGMavrE.png?width=320&crop=smart&auto=webp&s=2ae7b4b0bec5f94af1f2844ba8c300f3c3e382b8', 'width': 320}, {'height': 1138, 'url': 'https://external-preview.redd.it/xLYJQVPvAzJH6LTy7XZaM08Yzp0dQfVS5ZcYjGMavrE.png?width=640&crop=smart&auto=webp&s=5d7f9507f484edd0bd289052a401f28884994be2', 'width': 640}], 'source': {'height': 1334, 'url': 'https://external-preview.redd.it/xLYJQVPvAzJH6LTy7XZaM08Yzp0dQfVS5ZcYjGMavrE.png?auto=webp&s=47bd42bed37c5d18efbda9df9dc2a77d6b6bbb82', 'width': 750}, 'variants': {}}]} |
|
What open source local models can run reasonably well on a Raspberry Pi 5 with 16GB RAM? | 0 | **My Long Term Goal:** I'd like to create a chatbot that uses
* Speech to Text - for interpreting human speech
* Text to Speech - for talking
* Computer Vision - for reading human emotions - i
* If you have any recommendations for this as well, please let me know.
**My Short Term Goal (this post):**
I'd like to use a model that's similar (*and local/offline only*) that's similar to [character.AI](http://character.AI) .
I know I could use a larger language model (via ollama), but some of them (like llama 3) take a long time to generate text. TinyLlama is very quick, but doesn't converse like a real human might. Although character AI isn't perfect, it's very very good, especially with tone.
My question is - are there any niche models that would perform well for my Pi 5 that offer similar features as Character AI would? | 2025-06-13T04:05:23 | https://www.reddit.com/r/LocalLLaMA/comments/1la6ndx/what_open_source_local_models_can_run_reasonably/ | iKontact | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la6ndx | false | null | t3_1la6ndx | /r/LocalLLaMA/comments/1la6ndx/what_open_source_local_models_can_run_reasonably/ | false | false | self | 0 | {'enabled': False, 'images': [{'id': 'PezcliVTOJmrw2T-iy6hQL8d2hqy4q6G8U__SS7ZjrY', 'resolutions': [{'height': 56, 'url': 'https://external-preview.redd.it/PezcliVTOJmrw2T-iy6hQL8d2hqy4q6G8U__SS7ZjrY.jpeg?width=108&crop=smart&auto=webp&s=1e9268f8000ba05c0eaa4a283483174ba8fe421c', 'width': 108}, {'height': 113, 'url': 'https://external-preview.redd.it/PezcliVTOJmrw2T-iy6hQL8d2hqy4q6G8U__SS7ZjrY.jpeg?width=216&crop=smart&auto=webp&s=7ba819e7f92cb5a25679d8981fb257de1eaeb785', 'width': 216}, {'height': 168, 'url': 'https://external-preview.redd.it/PezcliVTOJmrw2T-iy6hQL8d2hqy4q6G8U__SS7ZjrY.jpeg?width=320&crop=smart&auto=webp&s=5f301fd4f4b245c15e56664f33fe452195dcca39', 'width': 320}, {'height': 336, 'url': 'https://external-preview.redd.it/PezcliVTOJmrw2T-iy6hQL8d2hqy4q6G8U__SS7ZjrY.jpeg?width=640&crop=smart&auto=webp&s=6e723cca46cc24df9e13739095a627838c0f8d17', 'width': 640}, {'height': 504, 'url': 'https://external-preview.redd.it/PezcliVTOJmrw2T-iy6hQL8d2hqy4q6G8U__SS7ZjrY.jpeg?width=960&crop=smart&auto=webp&s=129db03f556997c0ea5a8775e0183660a4cd49e9', 'width': 960}, {'height': 567, 'url': 'https://external-preview.redd.it/PezcliVTOJmrw2T-iy6hQL8d2hqy4q6G8U__SS7ZjrY.jpeg?width=1080&crop=smart&auto=webp&s=492611ea7466d65693ac771a1891401c60c9bf4a', 'width': 1080}], 'source': {'height': 630, 'url': 'https://external-preview.redd.it/PezcliVTOJmrw2T-iy6hQL8d2hqy4q6G8U__SS7ZjrY.jpeg?auto=webp&s=bc654c05658d512d3805c166c415c52157ac7469', 'width': 1200}, 'variants': {}}]} |
Any good 70b ERP model with recent model release? | 0 | maybe based on qwen3.0 or mixtral? Or other good ones? | 2025-06-13T04:06:04 | https://www.reddit.com/r/LocalLLaMA/comments/1la6ntm/any_good_70b_erp_model_with_recent_model_release/ | metalfans | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la6ntm | false | null | t3_1la6ntm | /r/LocalLLaMA/comments/1la6ntm/any_good_70b_erp_model_with_recent_model_release/ | false | false | self | 0 | null |
Alexandr Wang officially joins Meta with his core team | 1 | [removed] | 2025-06-13T04:30:52 | https://www.reddit.com/r/LocalLLaMA/comments/1la73ld/alexandr_wang_officially_joins_meta_with_his_core/ | AIDoomer3000 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la73ld | false | null | t3_1la73ld | /r/LocalLLaMA/comments/1la73ld/alexandr_wang_officially_joins_meta_with_his_core/ | false | false | self | 1 | null |
Alexandr Wang to join Meta with his crew. | 1 | [removed] | 2025-06-13T04:33:03 | https://www.reddit.com/r/LocalLLaMA/comments/1la74zg/alexandr_wang_to_join_meta_with_his_crew/ | AIDoomer3000 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la74zg | false | null | t3_1la74zg | /r/LocalLLaMA/comments/1la74zg/alexandr_wang_to_join_meta_with_his_crew/ | false | false | self | 1 | null |
Alexandr Wang joins Meta | 1 | [removed] | 2025-06-13T04:39:07 | https://www.reddit.com/r/LocalLLaMA/comments/1la78of/alexandr_wang_joins_meta/ | AIDoomer3000 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la78of | false | null | t3_1la78of | /r/LocalLLaMA/comments/1la78of/alexandr_wang_joins_meta/ | false | false | self | 1 | null |
Best Model | MCP/Terminal |48GB VRAM | 1 | [removed] | 2025-06-13T05:27:53 | https://www.reddit.com/r/LocalLLaMA/comments/1la81mc/best_model_mcpterminal_48gb_vram/ | aallsbury | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la81mc | false | null | t3_1la81mc | /r/LocalLLaMA/comments/1la81mc/best_model_mcpterminal_48gb_vram/ | false | false | self | 1 | null |
Is anyone using Colpali on production? What is your usecase and how is the performance? | 1 | [removed] | 2025-06-13T05:28:09 | https://www.reddit.com/r/LocalLLaMA/comments/1la81s6/is_anyone_using_colpali_on_production_what_is/ | hezknight | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la81s6 | false | null | t3_1la81s6 | /r/LocalLLaMA/comments/1la81s6/is_anyone_using_colpali_on_production_what_is/ | false | false | self | 1 | null |
Is there an AI tool that can actively assist during investor meetings by answering questions about my startup? | 0 | I’m looking for an AI tool where I can input everything about my startup—our vision, metrics, roadmap, team, common Q&A, etc.—and have it actually assist me live during investor meetings.
I’m imagining something that listens in real time, recognizes when I’m being asked something specific (e.g., “What’s your CAC?” or “How do you scale this?”), and can either feed me the answer discreetly or help me respond on the spot. Sort of like a co-pilot for founder Q&A sessions.
Most tools I’ve seen are for job interviews, but I need something that I can feed info and then it helps for answering investor questions through Zoom, Google Meet etc. Does anything like this exist yet? | 2025-06-13T05:32:44 | https://www.reddit.com/r/LocalLLaMA/comments/1la84fe/is_there_an_ai_tool_that_can_actively_assist/ | Samonji | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la84fe | false | null | t3_1la84fe | /r/LocalLLaMA/comments/1la84fe/is_there_an_ai_tool_that_can_actively_assist/ | false | false | self | 0 | null |
Is there an AI tool that can actively assist during investor meetings by answering questions about my startup? | 0 | I’m looking for an AI tool where I can input everything about my startup—our vision, metrics, roadmap, team, common Q&A, etc.—and have it actually assist me live during investor meetings.
I’m imagining something that listens in real time, recognizes when I’m being asked something specific (e.g., “What’s your CAC?” or “How do you scale this?”), and can either feed me the answer discreetly or help me respond on the spot. Sort of like a co-pilot for founder Q&A sessions.
Most tools I’ve seen are for job interviews, but I need something that I can feed info and then it helps for answering investor questions through Zoom, Google Meet etc. Does anything like this exist yet? | 2025-06-13T05:34:18 | https://www.reddit.com/r/LocalLLaMA/comments/1la859z/is_there_an_ai_tool_that_can_actively_assist/ | Samonji | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la859z | false | null | t3_1la859z | /r/LocalLLaMA/comments/1la859z/is_there_an_ai_tool_that_can_actively_assist/ | false | false | self | 0 | null |
Why Search Sucks! (But First, A Brief History) | 1 | [removed] | 2025-06-13T06:26:52 | https://youtu.be/vZVcBUnre-c | kushalgoenka | youtu.be | 1970-01-01T00:00:00 | 0 | {} | 1la8yuk | false | {'oembed': {'author_name': 'Kushal Goenka', 'author_url': 'https://www.youtube.com/@KushalGoenka', 'height': 200, 'html': '<iframe width="356" height="200" src="https://www.youtube.com/embed/vZVcBUnre-c?feature=oembed&enablejsapi=1" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" referrerpolicy="strict-origin-when-cross-origin" allowfullscreen title="Why Search Sucks! (But First, A Brief History)"></iframe>', 'provider_name': 'YouTube', 'provider_url': 'https://www.youtube.com/', 'thumbnail_height': 360, 'thumbnail_url': 'https://i.ytimg.com/vi/vZVcBUnre-c/hqdefault.jpg', 'thumbnail_width': 480, 'title': 'Why Search Sucks! (But First, A Brief History)', 'type': 'video', 'version': '1.0', 'width': 356}, 'type': 'youtube.com'} | t3_1la8yuk | /r/LocalLLaMA/comments/1la8yuk/why_search_sucks_but_first_a_brief_history/ | false | false | 1 | {'enabled': False, 'images': [{'id': 'kQ1-CKMdo6QZFdeorf2tNuFIZphNPNoLDugDK4dEZjk', 'resolutions': [{'height': 81, 'url': 'https://external-preview.redd.it/kQ1-CKMdo6QZFdeorf2tNuFIZphNPNoLDugDK4dEZjk.jpeg?width=108&crop=smart&auto=webp&s=58f0f8fb050c32318213fb63c6a00cec1cdf396c', 'width': 108}, {'height': 162, 'url': 'https://external-preview.redd.it/kQ1-CKMdo6QZFdeorf2tNuFIZphNPNoLDugDK4dEZjk.jpeg?width=216&crop=smart&auto=webp&s=1929d6d6df1c1227af108b47a64c062314b9c2ad', 'width': 216}, {'height': 240, 'url': 'https://external-preview.redd.it/kQ1-CKMdo6QZFdeorf2tNuFIZphNPNoLDugDK4dEZjk.jpeg?width=320&crop=smart&auto=webp&s=987811495a1fd3d319a94ab698bd985d2e73ee50', 'width': 320}], 'source': {'height': 360, 'url': 'https://external-preview.redd.it/kQ1-CKMdo6QZFdeorf2tNuFIZphNPNoLDugDK4dEZjk.jpeg?auto=webp&s=ada2ef276747fbc56f126e54ffba74c10feae56a', 'width': 480}, 'variants': {}}]} |
|
Llama-Server Launcher (Python with performance CUDA focus) | 105 | I wanted to share a llama-server launcher I put together for my personal use. I got tired of maintaining bash scripts and notebook files and digging through my gaggle of model folders while testing out models and turning performance. Hopefully this helps make someone else's life easier, it certainly has for me.
**Github repo:** [https://github.com/thad0ctor/llama-server-launcher](https://github.com/thad0ctor/llama-server-launcher)
**🧩 Key Features:**
* 🖥️ **Clean GUI** with tabs for:
* Basic settings (model, paths, context, batch)
* GPU/performance tuning (offload, FlashAttention, tensor split, batches, etc.)
* Chat template selection (predefined, model default, or custom Jinja2)
* Environment variables (GGML\_CUDA\_\*, custom vars)
* Config management (save/load/import/export)
* 🧠 **Auto GPU + system info** via PyTorch or manual override
* 🧾 **Model analyzer** for GGUF (layers, size, type) with fallback support
* 💾 **Script generation** (.ps1 / .sh) from your launch settings
* 🛠️ **Cross-platform:** Works on Windows/Linux (macOS untested)
**📦 Recommended Python deps:**
`torch`, `llama-cpp-python`, `psutil` (optional but useful for calculating gpu layers and selecting GPUs)
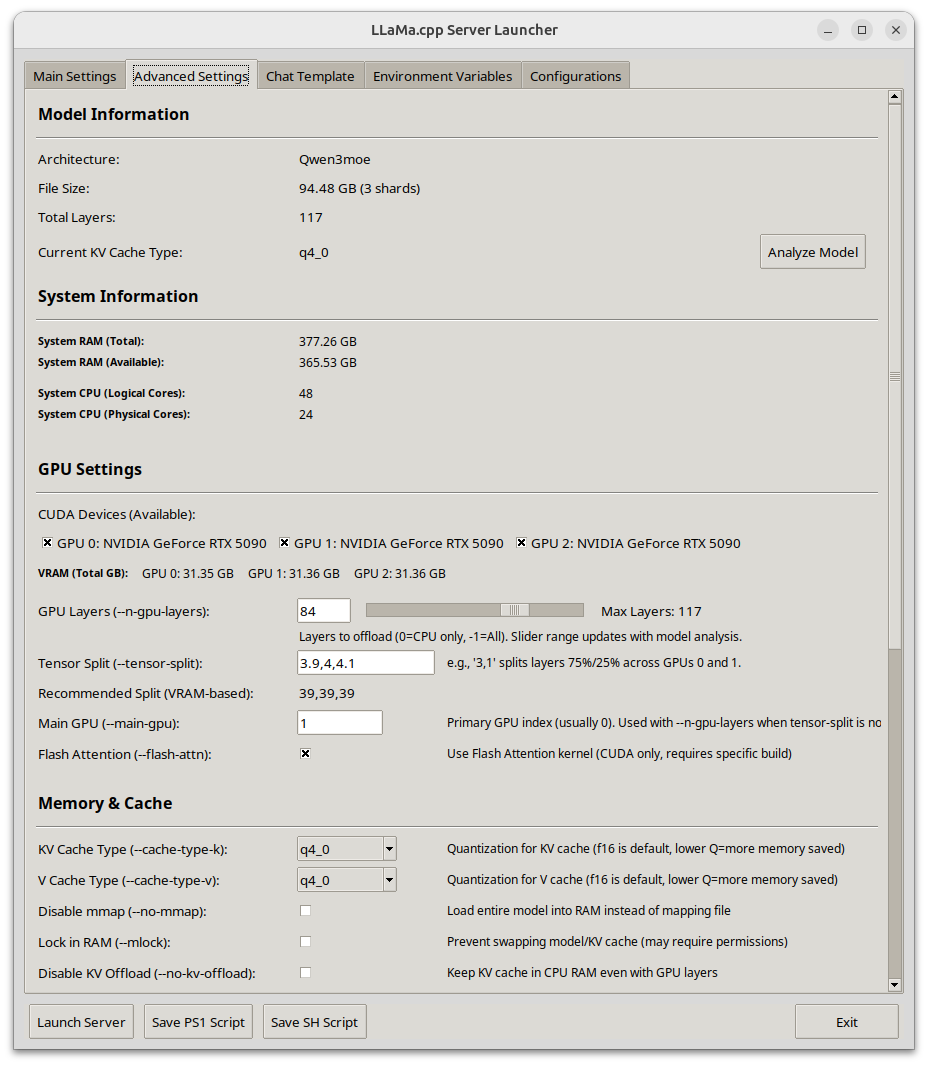
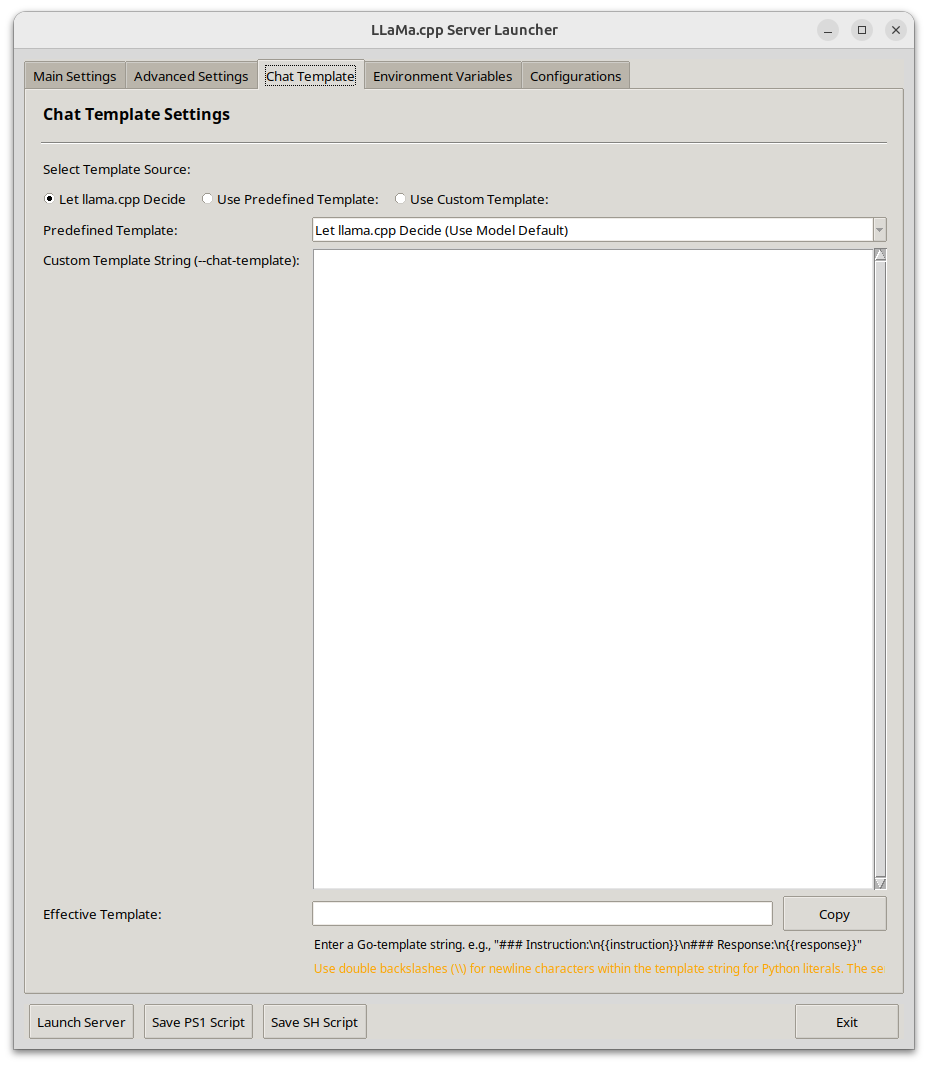
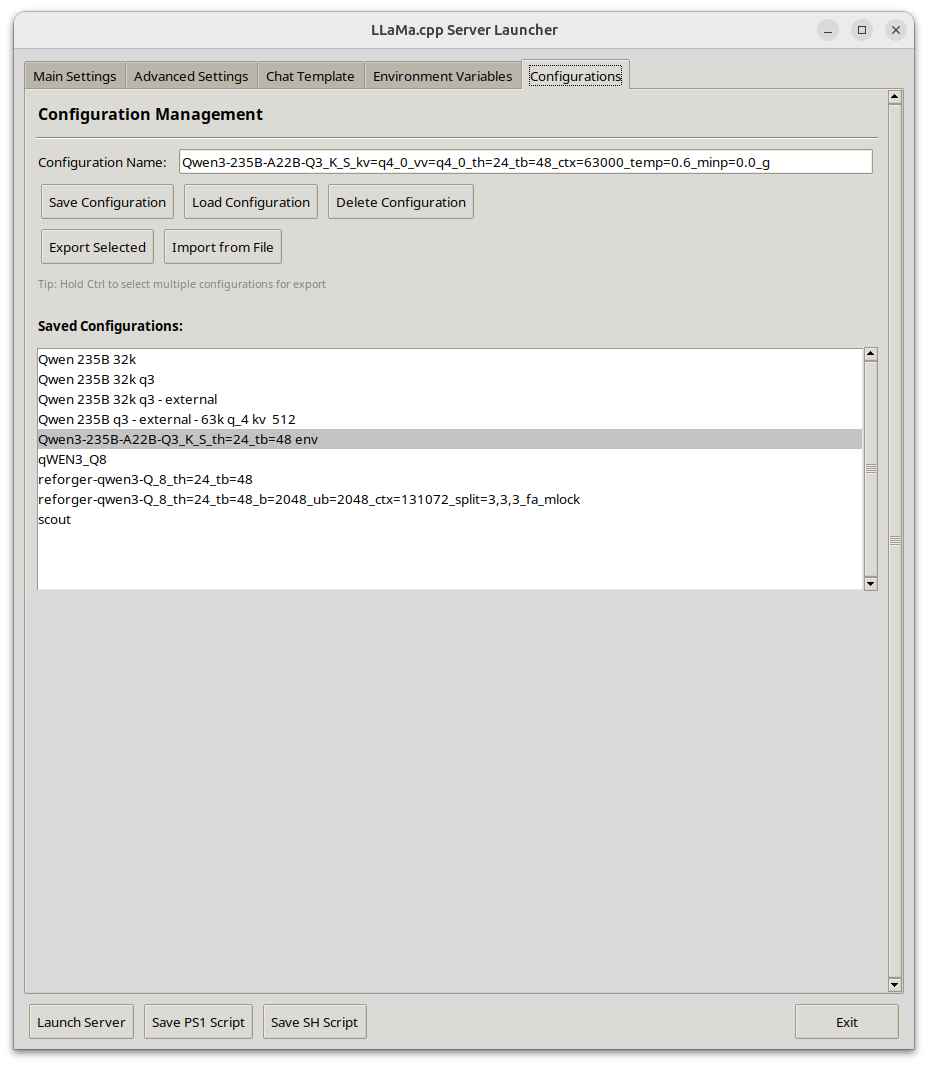
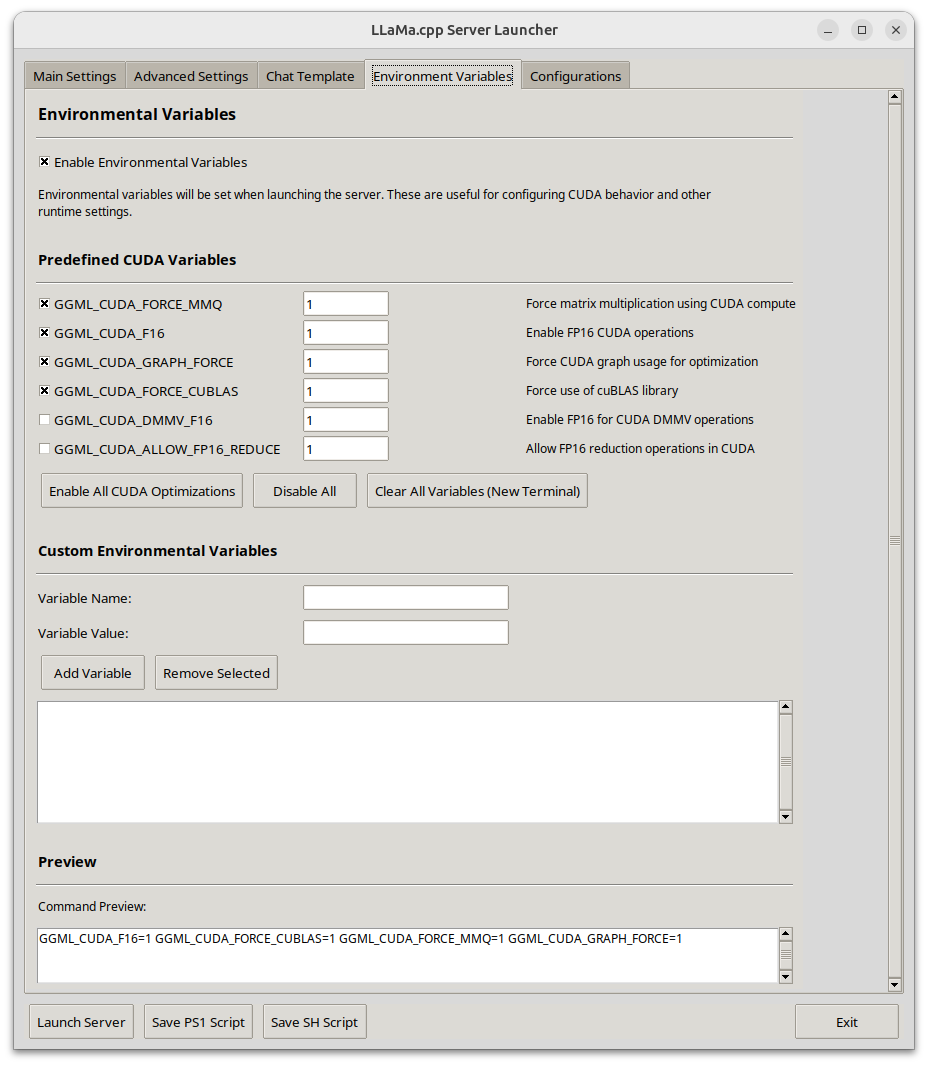
| 2025-06-13T06:31:45 | LA_rent_Aficionado | i.redd.it | 1970-01-01T00:00:00 | 0 | {} | 1la91hz | false | null | t3_1la91hz | /r/LocalLLaMA/comments/1la91hz/llamaserver_launcher_python_with_performance_cuda/ | false | false | default | 105 | {'enabled': True, 'images': [{'id': 'lwjqunrt0n6f1', 'resolutions': [{'height': 124, 'url': 'https://preview.redd.it/lwjqunrt0n6f1.png?width=108&crop=smart&auto=webp&s=51c49f9e25a337d080d25ade9a142b879e567a21', 'width': 108}, {'height': 248, 'url': 'https://preview.redd.it/lwjqunrt0n6f1.png?width=216&crop=smart&auto=webp&s=73fc95e2df2aa3a4629b57ae7c33a51c5fea2596', 'width': 216}, {'height': 367, 'url': 'https://preview.redd.it/lwjqunrt0n6f1.png?width=320&crop=smart&auto=webp&s=995493c2a8f5205b16ed73d2869d8f36f76d0c75', 'width': 320}, {'height': 735, 'url': 'https://preview.redd.it/lwjqunrt0n6f1.png?width=640&crop=smart&auto=webp&s=4334cf1869792277cb832843144b80fa08950e05', 'width': 640}], 'source': {'height': 1066, 'url': 'https://preview.redd.it/lwjqunrt0n6f1.png?auto=webp&s=cad6ca77060eab10ca0de9b7f3200c601e0a3ad8', 'width': 928}, 'variants': {}}]} |
|
🧠 MaGo AgoraAI – Multi-agent academic debate engine using Ollama + Gemma (with concept maps and dialogues) | 1 | [removed] | 2025-06-13T06:52:22 | https://www.reddit.com/r/LocalLLaMA/comments/1la9c71/mago_agoraai_multiagent_academic_debate_engine/ | Next-Lengthiness9915 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la9c71 | false | null | t3_1la9c71 | /r/LocalLLaMA/comments/1la9c71/mago_agoraai_multiagent_academic_debate_engine/ | false | false | self | 1 | null |
[Hiring] Junior Prompt Engineer | 0 | We're looking for a freelance Prompt Engineer to help us push the boundaries of what's possible with AI. We are an Italian startup that's already helping candidates land interviews at companies like Google, Stripe, and Zillow. We're a small team, moving fast, experimenting daily and we want someone who's obsessed with language, logic, and building smart systems that actually work.
**What You'll Do**
* Design, test, and refine prompts for a variety of use cases (product, content, growth)
* Collaborate with the founder to translate business goals into scalable prompt systems
* Analyze outputs to continuously improve quality and consistency
* Explore and document edge cases, workarounds, and shortcuts to get better results
* Work autonomously and move fast. We value experiments over perfection
**What We're Looking For**
* You've played seriously with GPT models and really know what a prompt is
* You're analytical, creative, and love breaking things to see how they work
* You write clearly and think logically
* Bonus points if you've shipped anything using AI (even just for fun) or if you've worked with early-stage startups
**What You'll Get**
* Full freedom over your schedule
* Clear deliverables
* Knowledge, tools and everything you may need
* The chance to shape a product that's helping real people land real jobs
If interested, you can apply here 🫱 [https://www.interviuu.com/recruiting](https://www.interviuu.com/recruiting) | 2025-06-13T07:22:40 | https://www.reddit.com/r/LocalLLaMA/comments/1la9sku/hiring_junior_prompt_engineer/ | interviuu | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la9sku | false | null | t3_1la9sku | /r/LocalLLaMA/comments/1la9sku/hiring_junior_prompt_engineer/ | false | false | self | 0 | {'enabled': False, 'images': [{'id': 'yiTRSBNLVqfnTaad4wH3RCdCnkuSJCe31LqT8zpIQrk', 'resolutions': [{'height': 56, 'url': 'https://external-preview.redd.it/yiTRSBNLVqfnTaad4wH3RCdCnkuSJCe31LqT8zpIQrk.png?width=108&crop=smart&auto=webp&s=f224f1e840e924ecaa586ec004961f5a80826316', 'width': 108}, {'height': 113, 'url': 'https://external-preview.redd.it/yiTRSBNLVqfnTaad4wH3RCdCnkuSJCe31LqT8zpIQrk.png?width=216&crop=smart&auto=webp&s=4a734d10a9c3916c0ffd66e48415d43d63996654', 'width': 216}, {'height': 167, 'url': 'https://external-preview.redd.it/yiTRSBNLVqfnTaad4wH3RCdCnkuSJCe31LqT8zpIQrk.png?width=320&crop=smart&auto=webp&s=c223911699661093387461d7d045821c3b82c3a6', 'width': 320}, {'height': 335, 'url': 'https://external-preview.redd.it/yiTRSBNLVqfnTaad4wH3RCdCnkuSJCe31LqT8zpIQrk.png?width=640&crop=smart&auto=webp&s=221afcef16ca0310d528b0a368067a3c4486ed89', 'width': 640}, {'height': 503, 'url': 'https://external-preview.redd.it/yiTRSBNLVqfnTaad4wH3RCdCnkuSJCe31LqT8zpIQrk.png?width=960&crop=smart&auto=webp&s=27c506ea575bbd68e56e588446649a058133b088', 'width': 960}, {'height': 566, 'url': 'https://external-preview.redd.it/yiTRSBNLVqfnTaad4wH3RCdCnkuSJCe31LqT8zpIQrk.png?width=1080&crop=smart&auto=webp&s=ded330603cc0bf3a7692c255e4d138a2612f5fda', 'width': 1080}], 'source': {'height': 629, 'url': 'https://external-preview.redd.it/yiTRSBNLVqfnTaad4wH3RCdCnkuSJCe31LqT8zpIQrk.png?auto=webp&s=4e64b34b0284f4a80714f765f5495cf4c2f7749a', 'width': 1200}, 'variants': {}}]} |
Fine tuning LLMs to filter misleading context in RAG | 1 | [removed] | 2025-06-13T07:33:22 | https://www.reddit.com/r/LocalLLaMA/comments/1la9y57/fine_tuning_llms_to_filter_misleading_context_in/ | zpdeaccount | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1la9y57 | false | null | t3_1la9y57 | /r/LocalLLaMA/comments/1la9y57/fine_tuning_llms_to_filter_misleading_context_in/ | false | false | self | 1 | null |
Fine tuning LLMs to filter misleading context in RAG | 1 | [removed] | 2025-06-13T07:38:26 | https://www.reddit.com/r/LocalLLaMA/comments/1laa0pv/fine_tuning_llms_to_filter_misleading_context_in/ | zpdeaccount | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laa0pv | false | null | t3_1laa0pv | /r/LocalLLaMA/comments/1laa0pv/fine_tuning_llms_to_filter_misleading_context_in/ | false | false | self | 1 | {'enabled': False, 'images': [{'id': 'pRgB6nrKLFAhvOocvrbiJ79RAzdrbr6DMj1eHntmit0', 'resolutions': [{'height': 54, 'url': 'https://external-preview.redd.it/pRgB6nrKLFAhvOocvrbiJ79RAzdrbr6DMj1eHntmit0.png?width=108&crop=smart&auto=webp&s=49171f0ef399302b0526388a03f9f73cdf861818', 'width': 108}, {'height': 108, 'url': 'https://external-preview.redd.it/pRgB6nrKLFAhvOocvrbiJ79RAzdrbr6DMj1eHntmit0.png?width=216&crop=smart&auto=webp&s=3fdbcb994308278ba57fd660dc5e883b5c08b93e', 'width': 216}, {'height': 160, 'url': 'https://external-preview.redd.it/pRgB6nrKLFAhvOocvrbiJ79RAzdrbr6DMj1eHntmit0.png?width=320&crop=smart&auto=webp&s=6cfccf00bbafbac21fba1770a4cf3a0fef525fbb', 'width': 320}, {'height': 320, 'url': 'https://external-preview.redd.it/pRgB6nrKLFAhvOocvrbiJ79RAzdrbr6DMj1eHntmit0.png?width=640&crop=smart&auto=webp&s=23faf34a8833d62885eb95dada2f145dd73e9278', 'width': 640}, {'height': 480, 'url': 'https://external-preview.redd.it/pRgB6nrKLFAhvOocvrbiJ79RAzdrbr6DMj1eHntmit0.png?width=960&crop=smart&auto=webp&s=06797dc1fa85b26dea5f666556df6ca6c9feb113', 'width': 960}, {'height': 540, 'url': 'https://external-preview.redd.it/pRgB6nrKLFAhvOocvrbiJ79RAzdrbr6DMj1eHntmit0.png?width=1080&crop=smart&auto=webp&s=e5f37e2615bf30c05dec5b8caab3fde8daffa000', 'width': 1080}], 'source': {'height': 600, 'url': 'https://external-preview.redd.it/pRgB6nrKLFAhvOocvrbiJ79RAzdrbr6DMj1eHntmit0.png?auto=webp&s=a27249166c2113ce56c14cba19db1d409dbc3346', 'width': 1200}, 'variants': {}}]} |
New VS Code update supports all MCP features (tools, prompts, sampling, resources, auth) | 44 | If you have any questions about the release, let me know.
\--vscode pm | 2025-06-13T07:55:10 | https://code.visualstudio.com/updates/v1_101 | isidor_n | code.visualstudio.com | 1970-01-01T00:00:00 | 0 | {} | 1laa9bj | false | null | t3_1laa9bj | /r/LocalLLaMA/comments/1laa9bj/new_vs_code_update_supports_all_mcp_features/ | false | false | default | 44 | {'enabled': False, 'images': [{'id': '4t6GOGdTOsYCXJc0r80Taopgc8TuG7QgRWRArsQ4GFY', 'resolutions': [{'height': 53, 'url': 'https://external-preview.redd.it/4t6GOGdTOsYCXJc0r80Taopgc8TuG7QgRWRArsQ4GFY.png?width=108&crop=smart&auto=webp&s=25618146eca93c91aa30c9530931565f6645a874', 'width': 108}, {'height': 107, 'url': 'https://external-preview.redd.it/4t6GOGdTOsYCXJc0r80Taopgc8TuG7QgRWRArsQ4GFY.png?width=216&crop=smart&auto=webp&s=cc59ec9484a4099b7e76b564a29e0d12ba617cc7', 'width': 216}, {'height': 159, 'url': 'https://external-preview.redd.it/4t6GOGdTOsYCXJc0r80Taopgc8TuG7QgRWRArsQ4GFY.png?width=320&crop=smart&auto=webp&s=eab58ccb7dfae0649ea2f22a39867422fe425fba', 'width': 320}, {'height': 319, 'url': 'https://external-preview.redd.it/4t6GOGdTOsYCXJc0r80Taopgc8TuG7QgRWRArsQ4GFY.png?width=640&crop=smart&auto=webp&s=da6a231d5b5f944073ecacc611122a4b945f2dd3', 'width': 640}, {'height': 479, 'url': 'https://external-preview.redd.it/4t6GOGdTOsYCXJc0r80Taopgc8TuG7QgRWRArsQ4GFY.png?width=960&crop=smart&auto=webp&s=338dc26912a0bb8de7528f6f2a93944b5458600a', 'width': 960}], 'source': {'height': 534, 'url': 'https://external-preview.redd.it/4t6GOGdTOsYCXJc0r80Taopgc8TuG7QgRWRArsQ4GFY.png?auto=webp&s=1ad9a02d230412399e0c069c10fc813340fb1410', 'width': 1069}, 'variants': {}}]} |
Finally, Zen 6, per-socket memory bandwidth to 1.6 TB/s | 332 | [https://www.tomshardware.com/pc-components/cpus/amds-256-core-epyc-venice-cpu-in-the-labs-now-coming-in-2026](https://www.tomshardware.com/pc-components/cpus/amds-256-core-epyc-venice-cpu-in-the-labs-now-coming-in-2026)
Perhaps more importantly, the new EPYC 'Venice' processor will more than double per-socket memory bandwidth to 1.6 TB/s (up from 614 GB/s in case of the company's existing CPUs) to keep those high-performance Zen 6 cores fed with data all the time. AMD did not disclose how it plans to achieve the 1.6 TB/s bandwidth, though it is reasonable to assume that the new EPYC ‘Venice’ CPUS will support advanced memory modules like like [MR-DIMM](https://www.tomshardware.com/news/amd-advocates-ddr5-mrdimms-with-speeds-up-to-17600-mts) and [MCR-DIMM](https://www.tomshardware.com/news/sk-hynix-develops-mcr-dimm).
https://preview.redd.it/us3k64mzon6f1.jpg?width=800&format=pjpg&auto=webp&s=de757984360f7d9597d9583a7f95f0d8400ddcb9
Greatest hardware news | 2025-06-13T08:39:05 | https://www.reddit.com/r/LocalLLaMA/comments/1laavph/finally_zen_6_persocket_memory_bandwidth_to_16_tbs/ | On1ineAxeL | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laavph | false | null | t3_1laavph | /r/LocalLLaMA/comments/1laavph/finally_zen_6_persocket_memory_bandwidth_to_16_tbs/ | false | false | 332 | {'enabled': False, 'images': [{'id': 'WQB4YYDDJWqV1l5CZF1V17S1yCdW1pO-9wS0zX4_i0Y', 'resolutions': [{'height': 60, 'url': 'https://external-preview.redd.it/WQB4YYDDJWqV1l5CZF1V17S1yCdW1pO-9wS0zX4_i0Y.jpeg?width=108&crop=smart&auto=webp&s=2a20b804bac8ed73f144483b2f4a07c7d1064176', 'width': 108}, {'height': 121, 'url': 'https://external-preview.redd.it/WQB4YYDDJWqV1l5CZF1V17S1yCdW1pO-9wS0zX4_i0Y.jpeg?width=216&crop=smart&auto=webp&s=07c4910d609b8a781852e84b2dd6f041541581c4', 'width': 216}, {'height': 180, 'url': 'https://external-preview.redd.it/WQB4YYDDJWqV1l5CZF1V17S1yCdW1pO-9wS0zX4_i0Y.jpeg?width=320&crop=smart&auto=webp&s=55f3a049851987298f03ebafb2005fcc4f822281', 'width': 320}, {'height': 360, 'url': 'https://external-preview.redd.it/WQB4YYDDJWqV1l5CZF1V17S1yCdW1pO-9wS0zX4_i0Y.jpeg?width=640&crop=smart&auto=webp&s=5fbf587ec8d49fef7fc461c839cfe256b80cfd21', 'width': 640}, {'height': 540, 'url': 'https://external-preview.redd.it/WQB4YYDDJWqV1l5CZF1V17S1yCdW1pO-9wS0zX4_i0Y.jpeg?width=960&crop=smart&auto=webp&s=141756c665dd7cbc8f9bbb9cfce1b3200d1abe41', 'width': 960}, {'height': 607, 'url': 'https://external-preview.redd.it/WQB4YYDDJWqV1l5CZF1V17S1yCdW1pO-9wS0zX4_i0Y.jpeg?width=1080&crop=smart&auto=webp&s=698d3e06a79c7d0f4892fa1cdd0eb14a2a773dcb', 'width': 1080}], 'source': {'height': 1440, 'url': 'https://external-preview.redd.it/WQB4YYDDJWqV1l5CZF1V17S1yCdW1pO-9wS0zX4_i0Y.jpeg?auto=webp&s=52f4000cf0190b17c1537c07c592babacceaca13', 'width': 2560}, 'variants': {}}]} |
|
"Agent or Workflow?" - Built an interactive quiz to test your intuition on this confusing AI distinction | 2 | [removed] | 2025-06-13T08:41:37 | https://agents-vs-workflows.streamlit.app | htahir1 | agents-vs-workflows.streamlit.app | 1970-01-01T00:00:00 | 0 | {} | 1laax1a | false | null | t3_1laax1a | /r/LocalLLaMA/comments/1laax1a/agent_or_workflow_built_an_interactive_quiz_to/ | false | false | default | 2 | null |
The EuroLLM team released preview versions of several new models | 135 | They released a 22b version, 2 vision models (1.7b, 9b, based on the older EuroLLMs) and a small MoE with 0.6b active and 2.6b total parameters. The MoE seems to be surprisingly good for its size in my limited testing. They seem to be Apache-2.0 licensed.
EuroLLM 22b instruct preview:
https://huggingface.co/utter-project/EuroLLM-22B-Instruct-Preview
EuroLLM 22b base preview:
https://huggingface.co/utter-project/EuroLLM-22B-Preview
EuroMoE 2.6B-A0.6B instruct preview:
https://huggingface.co/utter-project/EuroMoE-2.6B-A0.6B-Instruct-Preview
EuroMoE 2.6B-A0.6B base preview:
https://huggingface.co/utter-project/EuroMoE-2.6B-A0.6B-Preview
EuroVLM 1.7b instruct preview:
https://huggingface.co/utter-project/EuroVLM-1.7B-Preview
EuroVLM 9b instruct preview:
https://huggingface.co/utter-project/EuroVLM-9B-Preview | 2025-06-13T08:47:09 | https://www.reddit.com/r/LocalLLaMA/comments/1laazto/the_eurollm_team_released_preview_versions_of/ | sommerzen | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laazto | false | null | t3_1laazto | /r/LocalLLaMA/comments/1laazto/the_eurollm_team_released_preview_versions_of/ | false | false | self | 135 | {'enabled': False, 'images': [{'id': 'ofqgUijGTbnuEUpUyTizn34-6YYssAi8r4fqjxj-fCw', 'resolutions': [{'height': 58, 'url': 'https://external-preview.redd.it/ofqgUijGTbnuEUpUyTizn34-6YYssAi8r4fqjxj-fCw.png?width=108&crop=smart&auto=webp&s=97645d09c00f63c8b746bcba73dc12254cb14425', 'width': 108}, {'height': 116, 'url': 'https://external-preview.redd.it/ofqgUijGTbnuEUpUyTizn34-6YYssAi8r4fqjxj-fCw.png?width=216&crop=smart&auto=webp&s=a4a9ba567d6a8cdca1a9fe48bdc27e28d5520727', 'width': 216}, {'height': 172, 'url': 'https://external-preview.redd.it/ofqgUijGTbnuEUpUyTizn34-6YYssAi8r4fqjxj-fCw.png?width=320&crop=smart&auto=webp&s=3518f68cb393641029cfbc2d52f4be305297b9e4', 'width': 320}, {'height': 345, 'url': 'https://external-preview.redd.it/ofqgUijGTbnuEUpUyTizn34-6YYssAi8r4fqjxj-fCw.png?width=640&crop=smart&auto=webp&s=1bf2c1e453c4616ebdb3c91bf64beee533dbd525', 'width': 640}, {'height': 518, 'url': 'https://external-preview.redd.it/ofqgUijGTbnuEUpUyTizn34-6YYssAi8r4fqjxj-fCw.png?width=960&crop=smart&auto=webp&s=642c33faff1ebef9b9d0bd1551587a2e99f9c379', 'width': 960}, {'height': 583, 'url': 'https://external-preview.redd.it/ofqgUijGTbnuEUpUyTizn34-6YYssAi8r4fqjxj-fCw.png?width=1080&crop=smart&auto=webp&s=4d3d8902aa17314af49a64685a03c410da1e1105', 'width': 1080}], 'source': {'height': 648, 'url': 'https://external-preview.redd.it/ofqgUijGTbnuEUpUyTizn34-6YYssAi8r4fqjxj-fCw.png?auto=webp&s=85e3ecb8d4a8fb45b52474b8e13d7623fe22ba3a', 'width': 1200}, 'variants': {}}]} |
Introducing the Hugging Face MCP Server - find, create and use AI models directly from VSCode, Cursor, Claude or other clients! 🤗 | 51 | Hey hey, everyone, I'm VB from Hugging Face. We're tinkering a lot with MCP at HF these days and are quite excited to host our official MCP server accessible at \`hf.co/mcp\` 🔥
Here's what you can do today with it:
1. You can run semantic search on datasets, spaces and models (find the correct artefact just with text)
2. Get detailed information about these artefacts
3. My favorite: Use any MCP compatible space directly in your downstream clients (let our GPUs run wild and free 😈) [https://huggingface.co/spaces?filter=mcp-server](https://huggingface.co/spaces?filter=mcp-server)
Bonus: We provide ready to use snippets to use it in VSCode, Cursor, Claude and any other client!
This is still an early beta version, but we're excited to see how you'd play with it today. Excited to hear your feedback or comments about it! Give it a shot @ [hf.co/mcp](http://hf.co/mcp) 🤗 | 2025-06-13T09:08:15 | https://www.reddit.com/r/LocalLLaMA/comments/1labaqn/introducing_the_hugging_face_mcp_server_find/ | vaibhavs10 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1labaqn | false | null | t3_1labaqn | /r/LocalLLaMA/comments/1labaqn/introducing_the_hugging_face_mcp_server_find/ | false | false | self | 51 | {'enabled': False, 'images': [{'id': 'JCdmiT4zKH58gwmfIQPmOLs-bs5qHzSmc2ZFnRUGk84', 'resolutions': [{'height': 58, 'url': 'https://external-preview.redd.it/JCdmiT4zKH58gwmfIQPmOLs-bs5qHzSmc2ZFnRUGk84.png?width=108&crop=smart&auto=webp&s=2878a85306e6c618c2dce5dd61b3f87f8eee1fdc', 'width': 108}, {'height': 116, 'url': 'https://external-preview.redd.it/JCdmiT4zKH58gwmfIQPmOLs-bs5qHzSmc2ZFnRUGk84.png?width=216&crop=smart&auto=webp&s=4ed06032179c72fd0f8d71950e1d04dc9b48be38', 'width': 216}, {'height': 172, 'url': 'https://external-preview.redd.it/JCdmiT4zKH58gwmfIQPmOLs-bs5qHzSmc2ZFnRUGk84.png?width=320&crop=smart&auto=webp&s=079c7a71b64f2e9e5b1f802f820da399922c5dcf', 'width': 320}, {'height': 345, 'url': 'https://external-preview.redd.it/JCdmiT4zKH58gwmfIQPmOLs-bs5qHzSmc2ZFnRUGk84.png?width=640&crop=smart&auto=webp&s=2b749e5639d280736ac4c13d5e8146904ecb52c5', 'width': 640}, {'height': 518, 'url': 'https://external-preview.redd.it/JCdmiT4zKH58gwmfIQPmOLs-bs5qHzSmc2ZFnRUGk84.png?width=960&crop=smart&auto=webp&s=5319c1921599512136e986de6630a71cd9d4fa6c', 'width': 960}, {'height': 583, 'url': 'https://external-preview.redd.it/JCdmiT4zKH58gwmfIQPmOLs-bs5qHzSmc2ZFnRUGk84.png?width=1080&crop=smart&auto=webp&s=97c6a0e1bb9c22abe278ee26928b3cc0091193bc', 'width': 1080}], 'source': {'height': 648, 'url': 'https://external-preview.redd.it/JCdmiT4zKH58gwmfIQPmOLs-bs5qHzSmc2ZFnRUGk84.png?auto=webp&s=e0b87baac3206fd32e20b4c5022841b828850581', 'width': 1200}, 'variants': {}}]} |
Local Alternative to NotebookLM | 8 | Hi all, I'm looking to run a local alternative to Google Notebook LM on a M2 with 32GB RAM in a one user scenario but with a lot of documents (~2k PDFs). Has anybody tried this? Are you aware of any tutorials? | 2025-06-13T09:36:06 | https://www.reddit.com/r/LocalLLaMA/comments/1labpb1/local_alternative_to_notebooklm/ | sv723 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1labpb1 | false | null | t3_1labpb1 | /r/LocalLLaMA/comments/1labpb1/local_alternative_to_notebooklm/ | false | false | self | 8 | null |
Building a pc for local llm (help needed) | 0 | I am having a requirement to run ai locally specifically models like gemma3 27b and models in that similar size (roughly 20-30gb).
Planning to get 2 3060 12gb (24gb) and need help choosing cpu and mobo and ram.
Do you guys have any recommendations ?
Would love to hear your about setup if you are running llm in a similar situation.
Thank you. | 2025-06-13T09:40:08 | https://www.reddit.com/r/LocalLLaMA/comments/1labraz/building_a_pc_for_local_llm_help_needed/ | anirudhisonline | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1labraz | false | null | t3_1labraz | /r/LocalLLaMA/comments/1labraz/building_a_pc_for_local_llm_help_needed/ | false | false | self | 0 | null |
Found a Web3 LLM That Actually Gets DeFi Right | 0 | After months of trying to get reliable responses to DeFi - related questions from GPT - o3 or Grok - 3, without vague answers or hallucinated concepts, I randomly came across something that actually gets it. It's called DMind -1, a Web3 - focused LLM built on Qwen3 -32B. I'd never heard of it before last week, now I'm kind of hooked.
I asked it to compare tokenomics models and highlight risk - return tradeoffs. I got a super clean breakdown, no jargon mess. I also asked it to help write a vesting contract (with formulas + logic). Unlike GPT - o3, it didn't spit out broken math. And when I asked it about $TRUMP token launch, DMind -1 got the facts straight, even the chain details. GPT - o3? Not so much.
Even in some Web3 benchmarks, it did better than Grok -3 and GPT - o3. The coolest part? It's surprisingly good at understanding complex DeFi concepts and providing clear, actionable answers. | 2025-06-13T09:58:32 | https://www.reddit.com/r/LocalLLaMA/comments/1lac0yh/found_a_web3_llm_that_actually_gets_defi_right/ | Luke-Pioneero | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lac0yh | false | null | t3_1lac0yh | /r/LocalLLaMA/comments/1lac0yh/found_a_web3_llm_that_actually_gets_defi_right/ | false | false | self | 0 | null |
Whats the best model to run on a 3090 right now? | 0 | Just picked up a 3090. Searched reddit for the best model to run but the posts are months old sometimes longer. What's the latest and greatest to run on my new card? I'm primarily using it for coding. | 2025-06-13T10:24:29 | https://www.reddit.com/r/LocalLLaMA/comments/1lacfko/whats_the_best_model_to_run_on_a_3090_right_now/ | LeonJones | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lacfko | false | null | t3_1lacfko | /r/LocalLLaMA/comments/1lacfko/whats_the_best_model_to_run_on_a_3090_right_now/ | false | false | self | 0 | null |
Against the Apple's paper: LLM can solve new complex problems | 137 | 2025-06-13T10:44:17 | https://www.reddit.com/r/LocalLLaMA/comments/1lacqxh/against_the_apples_paper_llm_can_solve_new/ | WackyConundrum | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lacqxh | false | null | t3_1lacqxh | /r/LocalLLaMA/comments/1lacqxh/against_the_apples_paper_llm_can_solve_new/ | false | false | 137 | {'enabled': False, 'images': [{'id': 'zsV7fZGW377yLJEkIf3hZaGk1_mHff9pFj38MmimV4Q', 'resolutions': [{'height': 85, 'url': 'https://external-preview.redd.it/diKLwubmbtEotRQN3uKfVq9qOQ6ZisOE0UOpfwELjRg.jpg?width=108&crop=smart&auto=webp&s=547b8992d42dfd9246b273285a80c122f1302cae', 'width': 108}, {'height': 171, 'url': 'https://external-preview.redd.it/diKLwubmbtEotRQN3uKfVq9qOQ6ZisOE0UOpfwELjRg.jpg?width=216&crop=smart&auto=webp&s=d11d6b934a36c5b6da29872112815ddf857d8613', 'width': 216}, {'height': 254, 'url': 'https://external-preview.redd.it/diKLwubmbtEotRQN3uKfVq9qOQ6ZisOE0UOpfwELjRg.jpg?width=320&crop=smart&auto=webp&s=8ed6599809fe84f2d061ae7841c5c09f8aee69cc', 'width': 320}, {'height': 508, 'url': 'https://external-preview.redd.it/diKLwubmbtEotRQN3uKfVq9qOQ6ZisOE0UOpfwELjRg.jpg?width=640&crop=smart&auto=webp&s=65a0f7db35926d7e688235ee33fc2c2411b4b025', 'width': 640}, {'height': 763, 'url': 'https://external-preview.redd.it/diKLwubmbtEotRQN3uKfVq9qOQ6ZisOE0UOpfwELjRg.jpg?width=960&crop=smart&auto=webp&s=d850cbe9a1f8e5e5a5eea41f411ea4c116257a92', 'width': 960}, {'height': 858, 'url': 'https://external-preview.redd.it/diKLwubmbtEotRQN3uKfVq9qOQ6ZisOE0UOpfwELjRg.jpg?width=1080&crop=smart&auto=webp&s=dc7f0d77bf5a2badcc7c39ed4edc8e1683428ee3', 'width': 1080}], 'source': {'height': 900, 'url': 'https://external-preview.redd.it/diKLwubmbtEotRQN3uKfVq9qOQ6ZisOE0UOpfwELjRg.jpg?auto=webp&s=13fd69a0b55d2ba9bf08c40a2994360d4e729681', 'width': 1132}, 'variants': {}}]} |
||
Getting around censorship of Qwen3 by querying wiki for context | 1 | [removed] | 2025-06-13T10:44:37 | https://www.reddit.com/r/LocalLLaMA/comments/1lacr4d/getting_around_censorship_of_qwen3_by_querying/ | Ok_Warning2146 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lacr4d | false | null | t3_1lacr4d | /r/LocalLLaMA/comments/1lacr4d/getting_around_censorship_of_qwen3_by_querying/ | false | false | self | 1 | null |
Hi! I’m conducting a short survey for my university final project about public opinions on AI-generated commercials. | 1 | [removed] | 2025-06-13T10:50:27 | https://www.reddit.com/r/LocalLLaMA/comments/1lacun1/hi_im_conducting_a_short_survey_for_my_university/ | Yvonne_yuyu | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lacun1 | false | null | t3_1lacun1 | /r/LocalLLaMA/comments/1lacun1/hi_im_conducting_a_short_survey_for_my_university/ | false | false | self | 1 | null |
Langgraph issues | 1 | [removed] | 2025-06-13T11:11:28 | https://www.reddit.com/r/LocalLLaMA/comments/1lad7ue/langgraph_issues/ | Free-Belt-4741 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lad7ue | false | null | t3_1lad7ue | /r/LocalLLaMA/comments/1lad7ue/langgraph_issues/ | false | false | self | 1 | null |
Combine amd ai max 395 | 1 | [removed] | 2025-06-13T11:28:57 | https://www.reddit.com/r/LocalLLaMA/comments/1ladj0w/combine_amd_ai_max_395/ | OpportunityFar3673 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1ladj0w | false | null | t3_1ladj0w | /r/LocalLLaMA/comments/1ladj0w/combine_amd_ai_max_395/ | false | false | self | 1 | null |
Finetune a model to think and use tools | 5 | Im very new to Local AI tools, recently built a small Agno Team with agents to do a certain task, and its sort of good. I think it will improve after fine tuning on the tasks related to my prompts(code completion). Right now im using Qwen3:6b which can think and use tools.
1) How do i train models? I know Ollama is meant to run models, dont know which platform to use to train the models locally
2) How do i structure my data to train the models to have a chain of thought/think, and to use tools?
3) Do ya'll have any tips on how to grammatically structure the chain of thoughts/thinking?
Thank you so much! | 2025-06-13T11:32:09 | https://www.reddit.com/r/LocalLLaMA/comments/1ladl6d/finetune_a_model_to_think_and_use_tools/ | LostDog_88 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1ladl6d | false | null | t3_1ladl6d | /r/LocalLLaMA/comments/1ladl6d/finetune_a_model_to_think_and_use_tools/ | false | false | self | 5 | null |
Qwen2.5 VL | 6 | Hello,
Has anyone used this LLM for UI/UX? I would like a general opinion on it as I would like to set it up and fine-tune it for such purposes.
If you know models that are better for UI/UX, I would ask if you could recommend me some.
Thanks in advance! | 2025-06-13T11:47:19 | https://www.reddit.com/r/LocalLLaMA/comments/1ladv5b/qwen25_vl/ | Odd_Industry_2376 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1ladv5b | false | null | t3_1ladv5b | /r/LocalLLaMA/comments/1ladv5b/qwen25_vl/ | false | false | self | 6 | null |
What is the purpose of the offloading particular layers on the GPU if you don't have enough VRAM in the LM-studio (there is no difference in the token generation at all) | 1 | [removed] | 2025-06-13T12:00:28 | https://www.reddit.com/r/LocalLLaMA/comments/1lae3yp/what_is_the_purpose_of_the_offloading_particular/ | panther_ra | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lae3yp | false | null | t3_1lae3yp | /r/LocalLLaMA/comments/1lae3yp/what_is_the_purpose_of_the_offloading_particular/ | false | false | self | 1 | null |
Got a tester version of the open-weight OpenAI model. Very lean inference engine! | 1,431 | >!Silkposting in r/LocalLLaMA? I'd never!< | 2025-06-13T12:14:51 | https://v.redd.it/3r075o87qo6f1 | Firepal64 | v.redd.it | 1970-01-01T00:00:00 | 0 | {} | 1laee7q | false | {'reddit_video': {'bitrate_kbps': 2400, 'dash_url': 'https://v.redd.it/3r075o87qo6f1/DASHPlaylist.mpd?a=1752408905%2CYzkzZTBjY2E0MDBiODUzYzU0MDQwZjYwNDA4ZDEzMDkyMDZmMzNlNjk2NzY5NjU1MTBjZGQ3NzFhN2E4OTI1Ng%3D%3D&v=1&f=sd', 'duration': 70, 'fallback_url': 'https://v.redd.it/3r075o87qo6f1/DASH_720.mp4?source=fallback', 'has_audio': True, 'height': 720, 'hls_url': 'https://v.redd.it/3r075o87qo6f1/HLSPlaylist.m3u8?a=1752408905%2CODQzYzYwMWE3ZTkzNTIxZWFkNWI3YzRhODBiMjQyNDJlMTQ5ZjYxMWQzM2JjNDIxZjEzZWRjMjhlOTk3MDIyNg%3D%3D&v=1&f=sd', 'is_gif': False, 'scrubber_media_url': 'https://v.redd.it/3r075o87qo6f1/DASH_96.mp4', 'transcoding_status': 'completed', 'width': 1280}} | t3_1laee7q | /r/LocalLLaMA/comments/1laee7q/got_a_tester_version_of_the_openweight_openai/ | false | false | spoiler | 1,431 | {'enabled': False, 'images': [{'id': 'YTZ6aWx2ODdxbzZmMZP4_Zg7YIqZNzvbtM-0NW72ki5jdKm1HMEQNOp3yi9R', 'resolutions': [{'height': 60, 'url': 'https://external-preview.redd.it/YTZ6aWx2ODdxbzZmMZP4_Zg7YIqZNzvbtM-0NW72ki5jdKm1HMEQNOp3yi9R.png?width=108&crop=smart&format=pjpg&auto=webp&s=598298caa304e1a4beda26e49405469723ce5277', 'width': 108}, {'height': 121, 'url': 'https://external-preview.redd.it/YTZ6aWx2ODdxbzZmMZP4_Zg7YIqZNzvbtM-0NW72ki5jdKm1HMEQNOp3yi9R.png?width=216&crop=smart&format=pjpg&auto=webp&s=5847d35a6226e7d2ff3e742ada855319b04c814e', 'width': 216}, {'height': 180, 'url': 'https://external-preview.redd.it/YTZ6aWx2ODdxbzZmMZP4_Zg7YIqZNzvbtM-0NW72ki5jdKm1HMEQNOp3yi9R.png?width=320&crop=smart&format=pjpg&auto=webp&s=c15f95345bdbb477ac1bcaee7a1db395586e6d7a', 'width': 320}, {'height': 360, 'url': 'https://external-preview.redd.it/YTZ6aWx2ODdxbzZmMZP4_Zg7YIqZNzvbtM-0NW72ki5jdKm1HMEQNOp3yi9R.png?width=640&crop=smart&format=pjpg&auto=webp&s=cd9485c8b0418170330f1c01a25b043817796a4c', 'width': 640}, {'height': 540, 'url': 'https://external-preview.redd.it/YTZ6aWx2ODdxbzZmMZP4_Zg7YIqZNzvbtM-0NW72ki5jdKm1HMEQNOp3yi9R.png?width=960&crop=smart&format=pjpg&auto=webp&s=0d3d72ce81dd914f2f200fb5e3fd4db8b47a02ee', 'width': 960}, {'height': 607, 'url': 'https://external-preview.redd.it/YTZ6aWx2ODdxbzZmMZP4_Zg7YIqZNzvbtM-0NW72ki5jdKm1HMEQNOp3yi9R.png?width=1080&crop=smart&format=pjpg&auto=webp&s=7a0a06c1d3b78279d95de53f2d5b961d2f24b101', 'width': 1080}], 'source': {'height': 720, 'url': 'https://external-preview.redd.it/YTZ6aWx2ODdxbzZmMZP4_Zg7YIqZNzvbtM-0NW72ki5jdKm1HMEQNOp3yi9R.png?format=pjpg&auto=webp&s=34f45a31fbfb4b6451379643545280818e080723', 'width': 1280}, 'variants': {'obfuscated': {'resolutions': [{'height': 60, 'url': 'https://external-preview.redd.it/YTZ6aWx2ODdxbzZmMZP4_Zg7YIqZNzvbtM-0NW72ki5jdKm1HMEQNOp3yi9R.png?width=108&crop=smart&blur=10&format=pjpg&auto=webp&s=f9dddef170db02358ae1a8d406d9d81d62ce2d99', 'width': 108}, {'height': 121, 'url': 'https://external-preview.redd.it/YTZ6aWx2ODdxbzZmMZP4_Zg7YIqZNzvbtM-0NW72ki5jdKm1HMEQNOp3yi9R.png?width=216&crop=smart&blur=21&format=pjpg&auto=webp&s=002ac3494ef5f1c1c9f5f50a9f2e975bc4a28a5d', 'width': 216}, {'height': 180, 'url': 'https://external-preview.redd.it/YTZ6aWx2ODdxbzZmMZP4_Zg7YIqZNzvbtM-0NW72ki5jdKm1HMEQNOp3yi9R.png?width=320&crop=smart&blur=32&format=pjpg&auto=webp&s=f04c6a08d04cdf71dc21806558444fdb75d3bdb3', 'width': 320}, {'height': 360, 'url': 'https://external-preview.redd.it/YTZ6aWx2ODdxbzZmMZP4_Zg7YIqZNzvbtM-0NW72ki5jdKm1HMEQNOp3yi9R.png?width=640&crop=smart&blur=40&format=pjpg&auto=webp&s=8029b8eb81d03530786aeb6c20b5f747235b3161', 'width': 640}, {'height': 540, 'url': 'https://external-preview.redd.it/YTZ6aWx2ODdxbzZmMZP4_Zg7YIqZNzvbtM-0NW72ki5jdKm1HMEQNOp3yi9R.png?width=960&crop=smart&blur=40&format=pjpg&auto=webp&s=41f683cf80a7b2964d7e040d2cb550092be621cb', 'width': 960}, {'height': 607, 'url': 'https://external-preview.redd.it/YTZ6aWx2ODdxbzZmMZP4_Zg7YIqZNzvbtM-0NW72ki5jdKm1HMEQNOp3yi9R.png?width=1080&crop=smart&blur=40&format=pjpg&auto=webp&s=eae40e464b44c914d60e8815a25f65bff172e067', 'width': 1080}], 'source': {'height': 720, 'url': 'https://external-preview.redd.it/YTZ6aWx2ODdxbzZmMZP4_Zg7YIqZNzvbtM-0NW72ki5jdKm1HMEQNOp3yi9R.png?blur=40&format=pjpg&auto=webp&s=5c1032d83e3a9152cdce862b14eecdd5d2c15e4e', 'width': 1280}}}}]} |
Regarding the current state of STS models (like Copilot Voice) | 1 | Recently got a new Asus copilot + laptop with Snapdragon CPU; been playing around with the conversational voice mode for Copilot, and REALLY impressed with the quality to be honest.
I've also played around with OpenAI's advanced voice mode, and Sesame.
I'm thinking this would be killer if I could run a local version of this on my RTX 3090 and have it take notes and call basic tools.
What is the bleeding edge of this technology - specifically speech to speech, but ideally with text outputs as well for tool calling as a capability.
Wondering if anyone is working with a similar voice based assistant locally? | 2025-06-13T12:42:24 | https://www.reddit.com/r/LocalLLaMA/comments/1laey50/regarding_the_current_state_of_sts_models_like/ | JustinPooDough | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laey50 | false | null | t3_1laey50 | /r/LocalLLaMA/comments/1laey50/regarding_the_current_state_of_sts_models_like/ | false | false | self | 1 | null |
Qwen3-VL is coming! | 13 | [https://qwen3.org/vl/](https://qwen3.org/vl/) | 2025-06-13T12:46:14 | foldl-li | i.redd.it | 1970-01-01T00:00:00 | 0 | {} | 1laf10l | false | null | t3_1laf10l | /r/LocalLLaMA/comments/1laf10l/qwen3vl_is_coming/ | false | false | default | 13 | {'enabled': True, 'images': [{'id': 'p7mwf4rixo6f1', 'resolutions': [{'height': 117, 'url': 'https://preview.redd.it/p7mwf4rixo6f1.png?width=108&crop=smart&auto=webp&s=66e86cda794013ef3087f534aaad2df6975bd7e7', 'width': 108}, {'height': 234, 'url': 'https://preview.redd.it/p7mwf4rixo6f1.png?width=216&crop=smart&auto=webp&s=db0495aead323a73fdfef5cf5617d193f1fd92bf', 'width': 216}, {'height': 347, 'url': 'https://preview.redd.it/p7mwf4rixo6f1.png?width=320&crop=smart&auto=webp&s=92c6ac671c9cd0f553beaf09752bd3d4550c0e10', 'width': 320}, {'height': 695, 'url': 'https://preview.redd.it/p7mwf4rixo6f1.png?width=640&crop=smart&auto=webp&s=1301bf906ef2b2924a02755976708a7d99419248', 'width': 640}, {'height': 1042, 'url': 'https://preview.redd.it/p7mwf4rixo6f1.png?width=960&crop=smart&auto=webp&s=b6b09ad4a798a5adbd554d7f2e75c529e3937dd0', 'width': 960}], 'source': {'height': 1071, 'url': 'https://preview.redd.it/p7mwf4rixo6f1.png?auto=webp&s=d016e5c91d31f79efe19d48aae164fc6657839b8', 'width': 986}, 'variants': {}}]} |
|
What's the easiest way to run local models with characters? | 1 | [removed] | 2025-06-13T12:51:45 | https://www.reddit.com/r/LocalLLaMA/comments/1laf52d/whats_the_easiest_way_to_run_local_models_with/ | RIPT1D3_Z | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laf52d | false | null | t3_1laf52d | /r/LocalLLaMA/comments/1laf52d/whats_the_easiest_way_to_run_local_models_with/ | false | false | self | 1 | null |
Mac Mini for local LLM? 🤔 | 14 | I am not much of an IT guy. Example: I bought a Synology because I wanted a home server, but didn't want to fiddle with things beyond me too much.
That being said, I am a programmer that uses a Macbook every day.
Is it possible to go the on-prem home LLM route using a Mac Mini? | 2025-06-13T12:57:26 | https://www.reddit.com/r/LocalLLaMA/comments/1laf96d/mac_mini_for_local_llm/ | matlong | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laf96d | false | null | t3_1laf96d | /r/LocalLLaMA/comments/1laf96d/mac_mini_for_local_llm/ | false | false | self | 14 | null |
Struggling on local multi-user inference? Llama.cpp GGUF vs VLLM AWQ/GPTQ. | 9 | Hi all,
I tested VLLM and Llama.cpp and got much better results from GGUF than AWQ and GPTQ (it was also hard to find this format for VLLM). I used the same system prompts and saw really crazy bad results on Gemma in GPTQ: higher VRAM usage, slower inference, and worse output quality.
Now my project is moving to multiple concurrent users, so I will need parallelism. I'm using either A10 AWS instances or L40s etc.
From my understanding, Llama.cpp is not optimal for the efficiency and concurrency I need, as I want to squeeze the as much request with same or smillar time for one and minimize VRAM usage if possible. I like GGUF as it's so easy to find good quantizations, but I'm wondering if I should switch back to VLLM.
I also considered Triton / NVIDIA Inference Server / Dynamo, but I'm not sure what's currently the best option for this workload.
Here is my current Docker setup for llama.cpp:
`cpp_3.1.8B:`
`image:` [`ghcr.io/ggml-org/llama.cpp:server-cuda`](http://ghcr.io/ggml-org/llama.cpp:server-cuda)
`container_name: cpp_3.1.8B`
`ports:`
`- 8003:8003`
`volumes:`
`- ./models/Meta-Llama-3.1-8B-Instruct-Q8_0.gguf:/model/model.gguf`
`environment:`
`LLAMA_ARG_MODEL: /model/model.gguf`
`LLAMA_ARG_CTX_SIZE: 4096`
`LLAMA_ARG_N_PARALLEL: 1`
`LLAMA_ARG_MAIN_GPU: 1`
`LLAMA_ARG_N_GPU_LAYERS: 99`
`LLAMA_ARG_ENDPOINT_METRICS: 1`
`LLAMA_ARG_PORT: 8003`
`LLAMA_ARG_FLASH_ATTN: 1`
`GGML_CUDA_FORCE_MMQ: 1`
`GGML_CUDA_FORCE_CUBLAS: 1`
`deploy:`
`resources:`
`reservations:`
`devices:`
`- driver: nvidia`
`count: all`
`capabilities: [gpu]`
And for vllm:
`sudo docker run --runtime nvidia --gpus all \`
`-v ~/.cache/huggingface:/root/.cache/huggingface \`
`--env "HUGGING_FACE_HUB_TOKEN= \`
`-p 8003:8000 \`
`--ipc=host \`
`--name gemma12bGPTQ \`
`--user 0 \`
`vllm/vllm-openai:latest \`
`--model circulus/gemma-3-12b-it-gptq \`
`--gpu_memory_utilization=0.80 \`
`--max_model_len=4096`
I would greatly appreciate feedback from people who have been through this — what stack works best for you today for maximum concurrent users? Should I fully switch back to VLLM? Is Triton / Nvidia NIM / Dynamo inference worth exploring or smth else?
Thanks a lot! | 2025-06-13T13:09:07 | https://www.reddit.com/r/LocalLLaMA/comments/1lafihl/struggling_on_local_multiuser_inference_llamacpp/ | SomeRandomGuuuuuuy | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lafihl | false | null | t3_1lafihl | /r/LocalLLaMA/comments/1lafihl/struggling_on_local_multiuser_inference_llamacpp/ | false | false | self | 9 | {'enabled': False, 'images': [{'id': 'LtKtt6txZ-QrVhG54gL73uTj3IfQTG0w8wIIdqF-0s0', 'resolutions': [{'height': 108, 'url': 'https://external-preview.redd.it/LtKtt6txZ-QrVhG54gL73uTj3IfQTG0w8wIIdqF-0s0.png?width=108&crop=smart&auto=webp&s=48e272d6903d89156a397d8d669cecd7c921f94e', 'width': 108}, {'height': 216, 'url': 'https://external-preview.redd.it/LtKtt6txZ-QrVhG54gL73uTj3IfQTG0w8wIIdqF-0s0.png?width=216&crop=smart&auto=webp&s=568c0dc6d70eca104a3f2b98d36162e469174bbc', 'width': 216}, {'height': 320, 'url': 'https://external-preview.redd.it/LtKtt6txZ-QrVhG54gL73uTj3IfQTG0w8wIIdqF-0s0.png?width=320&crop=smart&auto=webp&s=91aa4cf527297c5865172147b49b2b99927d3505', 'width': 320}, {'height': 640, 'url': 'https://external-preview.redd.it/LtKtt6txZ-QrVhG54gL73uTj3IfQTG0w8wIIdqF-0s0.png?width=640&crop=smart&auto=webp&s=95e4d306c57f7a8ede26d779672a96d586d9fb4d', 'width': 640}, {'height': 960, 'url': 'https://external-preview.redd.it/LtKtt6txZ-QrVhG54gL73uTj3IfQTG0w8wIIdqF-0s0.png?width=960&crop=smart&auto=webp&s=e1b23807264032a8c729fbd3a95150b2164672e1', 'width': 960}, {'height': 1080, 'url': 'https://external-preview.redd.it/LtKtt6txZ-QrVhG54gL73uTj3IfQTG0w8wIIdqF-0s0.png?width=1080&crop=smart&auto=webp&s=6bab2ff8712a37b729dbd08d5c3a0f48905aa34f', 'width': 1080}], 'source': {'height': 1200, 'url': 'https://external-preview.redd.it/LtKtt6txZ-QrVhG54gL73uTj3IfQTG0w8wIIdqF-0s0.png?auto=webp&s=1620f6394ef99e89613d7f953b08bd34de0c55f5', 'width': 1200}, 'variants': {}}]} |
Qwen3 embedding/reranker padding token error? | 9 | I'm new to embedding and rerankers. On paper they seem pretty straightforward:
- The embedding model turns tokens into numbers so models can process them more efficiently for retrieval. The embeddings are stored in an index.
- The reranker simply ranks the text by similarity to the query. Its not perfect, but its a start.
So I tried experimenting with that over the last two days and the results are pretty good, but progress was stalled because I ran into this error after embedding a large text file and attempting to generate a query with `llamaindex`:
```
An error occurred: Cannot handle batch sizes > 1 if no padding token is defined.
```
As soon as I sent my query, I got this. The text was already indexed so I was hoping `llamaindex` would use its `query engine` to do everything after setting everything up. Here's what I did:
1 - Create the embeddings using `Qwen3-embeddings-0.6B` and store the embeddings in an index file - this was done quickly. I used `llama index`'s `SemanticDoubleMergingSplitterNodeParser` with a maximum chunk size of 8192 tokens, the same amount as the context length set for `Qwen3-embeddings-0.6B`, to intelligently chunk the text. This is a more advanced form of semantic chunking that not only chunks based on similarity to its immediate neighbor, but also looks two chunks ahead to see if the second chunk ahead is similar to the first one, merging all three within a set threshold if they line up.
This is good for breaking up related sequences of paragraphs and is usually my go-to chunker, like a paragraph of text describing a math formula, then displaying the formula before elaborating further in a subsequent paragraph.
2 - Load that same index with the same embedding model, then try to rerank it using `qwen3-embedding-0.6b` and generate a query and send it to `qwen3-Reranker-4b` for reranking, then finally to `Qwen3-4b-q8_0` for Q&A sessions. This would all be handle with three components:
- llamaindex's `Ollama` class for LLM.
- The `VectorIndexRetriever` class.
- The `RetrieverQueryEngine` class to serve as the retriever, at which point you would send the query to and receive a response.
The error message I encountered above was related to a 500-page pdf file in which I used `Gemma3-27b-it-qat` on Ollama to read the entire document's contents via OCR and convert it into text and save it as a markdown file, with highly accurate results, except for the occasional infinite loop that I would max out the output at around 1600 tokens.
But when I took another pre-written `.md` file, a one-page `.md` file, Everything worked just fine.
So this leads me to two possible culprits:
1 - The file was too big or its contents were too difficult for the `SemanticDoubleMergingSplitterNodeParser` class to chunk effectively or it was too difficult for the embedding model to process effectively.
2 - The original `.md` file's indexed contents were messing something up on the tokenization side of things, since the `.md` file was all text, but contained a lot of links, drawn tables by `Gemma3` and a lot of other contents.
This is a little confusing to me, but I think I'm on the right track. I like `llamaindex` because its modular, with lots of plug-and-play features that I can add to the script. | 2025-06-13T13:21:23 | https://www.reddit.com/r/LocalLLaMA/comments/1lafs7r/qwen3_embeddingreranker_padding_token_error/ | swagonflyyyy | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lafs7r | false | null | t3_1lafs7r | /r/LocalLLaMA/comments/1lafs7r/qwen3_embeddingreranker_padding_token_error/ | false | false | self | 9 | null |
Looking for a simpler alternative to SillyTavern -- something lightweight? | 1 | [removed] | 2025-06-13T13:28:01 | https://www.reddit.com/r/LocalLLaMA/comments/1lafxep/looking_for_a_simpler_alternative_to_sillytavern/ | d3lt4run3 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lafxep | false | null | t3_1lafxep | /r/LocalLLaMA/comments/1lafxep/looking_for_a_simpler_alternative_to_sillytavern/ | false | false | self | 1 | null |
Detailed Benchmark: magistral:24b on RTX 3070 Laptop vs 5 High-End Cloud GPUs (4090, A100, etc.) - Performance & Cost Analysis | 1 | [removed] | 2025-06-13T13:59:34 | https://www.reddit.com/r/LocalLLaMA/comments/1lagn1r/detailed_benchmark_magistral24b_on_rtx_3070/ | kekePower | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lagn1r | false | null | t3_1lagn1r | /r/LocalLLaMA/comments/1lagn1r/detailed_benchmark_magistral24b_on_rtx_3070/ | false | false | self | 1 | null |
The Real-World Speed of AI: Benchmarking a 24B LLM on Local Hardware vs. High-End Cloud GPUs | 1 | [removed] | 2025-06-13T14:07:45 | https://www.reddit.com/r/LocalLLaMA/comments/1laguf7/the_realworld_speed_of_ai_benchmarking_a_24b_llm/ | kekePower | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laguf7 | false | null | t3_1laguf7 | /r/LocalLLaMA/comments/1laguf7/the_realworld_speed_of_ai_benchmarking_a_24b_llm/ | false | false | self | 1 | {'enabled': False, 'images': [{'id': 'krjt_5uhqcaDfYjfO7lkezThehav9cAIRJgcK-OKAmM', 'resolutions': [{'height': 56, 'url': 'https://external-preview.redd.it/krjt_5uhqcaDfYjfO7lkezThehav9cAIRJgcK-OKAmM.png?width=108&crop=smart&auto=webp&s=3dc759de0e8fa36d241c5728d41ee3cf022cab96', 'width': 108}, {'height': 113, 'url': 'https://external-preview.redd.it/krjt_5uhqcaDfYjfO7lkezThehav9cAIRJgcK-OKAmM.png?width=216&crop=smart&auto=webp&s=6ccf136f5d3091254a0067a3bc5d6c7df9d62d89', 'width': 216}, {'height': 168, 'url': 'https://external-preview.redd.it/krjt_5uhqcaDfYjfO7lkezThehav9cAIRJgcK-OKAmM.png?width=320&crop=smart&auto=webp&s=2530aa4ecbcf7899ec0d023e217fe24af15fe0a6', 'width': 320}, {'height': 336, 'url': 'https://external-preview.redd.it/krjt_5uhqcaDfYjfO7lkezThehav9cAIRJgcK-OKAmM.png?width=640&crop=smart&auto=webp&s=8e51add1cab39c7614eb13e6195f23c5b4eeb417', 'width': 640}, {'height': 504, 'url': 'https://external-preview.redd.it/krjt_5uhqcaDfYjfO7lkezThehav9cAIRJgcK-OKAmM.png?width=960&crop=smart&auto=webp&s=750a6d42fd91c5a6e9a9c069e74247c877644e97', 'width': 960}, {'height': 567, 'url': 'https://external-preview.redd.it/krjt_5uhqcaDfYjfO7lkezThehav9cAIRJgcK-OKAmM.png?width=1080&crop=smart&auto=webp&s=9eab390b865b031211658564ad5fe5241c9661c5', 'width': 1080}], 'source': {'height': 630, 'url': 'https://external-preview.redd.it/krjt_5uhqcaDfYjfO7lkezThehav9cAIRJgcK-OKAmM.png?auto=webp&s=a080c4707584d3aa14134960cda9ba2d339b93a3', 'width': 1200}, 'variants': {}}]} |
The downgrade of LLMs for coding | 1 | [removed] | 2025-06-13T14:08:26 | https://www.reddit.com/r/LocalLLaMA/comments/1lagv03/the_downgrade_of_llms_for_coding/ | Awkward-Hedgehog-572 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lagv03 | false | null | t3_1lagv03 | /r/LocalLLaMA/comments/1lagv03/the_downgrade_of_llms_for_coding/ | false | false | self | 1 | null |
You thin AGI is comen soon? ChatGPT "Absolutely Wrecked" at Chess by Atari 2600 Console From 1977 | 1 | [removed] | 2025-06-13T14:10:49 | https://www.reddit.com/r/LocalLLaMA/comments/1lagxbj/you_thin_agi_is_comen_soon_chatgpt_absolutely/ | More-Plantain491 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lagxbj | false | null | t3_1lagxbj | /r/LocalLLaMA/comments/1lagxbj/you_thin_agi_is_comen_soon_chatgpt_absolutely/ | false | false | self | 1 | null |
Fine-tuning Mistral-7B efficiently for industrial task planning | 1 | [removed] | 2025-06-13T14:58:02 | https://www.reddit.com/r/LocalLLaMA/comments/1lai2p7/finetuning_mistral7b_efficiently_for_industrial/ | Head_Mushroom_3748 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lai2p7 | false | null | t3_1lai2p7 | /r/LocalLLaMA/comments/1lai2p7/finetuning_mistral7b_efficiently_for_industrial/ | false | false | self | 1 | null |
Planning a 7–8B Model Benchmark on 8GB GPU — What Should I Test & Measure? | 1 | [removed] | 2025-06-13T15:13:22 | https://www.reddit.com/r/LocalLLaMA/comments/1laigxm/planning_a_78b_model_benchmark_on_8gb_gpu_what/ | kekePower | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laigxm | false | null | t3_1laigxm | /r/LocalLLaMA/comments/1laigxm/planning_a_78b_model_benchmark_on_8gb_gpu_what/ | false | false | self | 1 | null |
🚀 IdeaWeaver: The All-in-One GenAI Power Tool You’ve Been Waiting For! | 2 | Tired of juggling a dozen different tools for your GenAI projects? With new AI tech popping up every day, it’s hard to find a single solution that does it all, until now.
**Meet IdeaWeaver: Your One-Stop Shop for GenAI**
Whether you want to:
* ✅ Train your own models
* ✅ Download and manage models
* ✅ Push to any model registry (Hugging Face, DagsHub, Comet, W&B, AWS Bedrock)
* ✅ Evaluate model performance
* ✅ Leverage agent workflows
* ✅ Use advanced MCP features
* ✅ Explore Agentic RAG and RAGAS
* ✅ Fine-tune with LoRA & QLoRA
* ✅ Benchmark and validate models
IdeaWeaver brings all these capabilities together in a single, easy-to-use CLI tool. No more switching between platforms or cobbling together scripts—just seamless GenAI development from start to finish.
🌟 **Why IdeaWeaver?**
* LoRA/QLoRA fine-tuning out of the box
* Advanced RAG systems for next-level retrieval
* MCP integration for powerful automation
* Enterprise-grade model management
* Comprehensive documentation and examples
🔗 Docs: [ideaweaver-ai-code.github.io/ideaweaver-docs/](http://ideaweaver-ai-code.github.io/ideaweaver-docs/)
🔗 GitHub: [github.com/ideaweaver-ai-code/ideaweaver](http://github.com/ideaweaver-ai-code/ideaweaver)
\> ⚠️ Note: IdeaWeaver is currently in alpha. Expect a few bugs, and please report any issues you find. If you like the project, drop a ⭐ on GitHub!Ready to streamline your GenAI workflow?
Give IdeaWeaver a try and let us know what you think!
https://i.redd.it/wk7xurijtp6f1.gif
| 2025-06-13T15:45:53 | https://www.reddit.com/r/LocalLLaMA/comments/1laj9wq/ideaweaver_the_allinone_genai_power_tool_youve/ | Prashant-Lakhera | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laj9wq | false | null | t3_1laj9wq | /r/LocalLLaMA/comments/1laj9wq/ideaweaver_the_allinone_genai_power_tool_youve/ | false | false | 2 | null |
|
Mac silicon AI: MLX LLM (Llama 3) + MPS TTS = Offline Voice Assistant for M-chips | 19 | # Mac silicon AI: MLX LLM (Llama 3) + MPS TTS = Offline Voice Assistant for M-chips
**hi, this is my first post so I'm kind of nervous, so bare with me. yes I used chatGPT help but still I hope this one finds this code useful.**
**I had a hard time finding a fast way to get a LLM + TTS code to easily create an assistant on my Mac Mini M4 so I did some trial and error and built this. 4bit Llama 3 model is kind of dumb but if you have better hardware you can try different models already optimized for MLX which are not a lot.**
Just finished wiring **MLX-LM** (4-bit Llama-3-8B) to **Kokoro TTS**—both running through Metal Performance Shaders (MPS). Julia Assistant now answers in English words *and* speaks the reply through afplay. Zero cloud, zero Ollama daemon, fits in 16 GB RAM.
**GITHUB repo with 1 minute instalation**: [https://github.com/streamlinecoreinitiative/MLX\_Llama\_TTS\_MPS](https://github.com/streamlinecoreinitiative/MLX_Llama_TTS_MPS)
# My Hardware:
* **Hardware:** Mac mini M4 (works on any M-series with ≥ 16 GB).
* **Speed:** \~25 WPM synthesis, \~20 tokens/s generation at 4-bit.
* **Stack:** mlx, mlx-lm (main), mlx-audio (main), no Core ML.
* **Voice:** Kokoro-82M model, runs on MPS, \~7 GB RAM peak.
* **Why care:** end-to-end offline chat MLX compatible + TTS on MLX
FAQ:
|**Q**|**Snappy answer**|
|:-|:-|
||
|“Why not Ollama?”|MLX is faster on Metal & no background daemon.|
|“Will this run on Intel Mac?”|Nope—needs MPS. works on M-chip|
**Disclaimer**: As you can see, by no means I am an expert on AI or whatever, I just found this to be useful for me and hope it helps other Mac silicon chip users. | 2025-06-13T15:58:34 | https://www.reddit.com/r/LocalLLaMA/comments/1lajkwa/mac_silicon_ai_mlx_llm_llama_3_mps_tts_offline/ | Antique-Ingenuity-97 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lajkwa | false | null | t3_1lajkwa | /r/LocalLLaMA/comments/1lajkwa/mac_silicon_ai_mlx_llm_llama_3_mps_tts_offline/ | false | false | self | 19 | {'enabled': False, 'images': [{'id': 'FROK4VZvK_U07zwoXhlJJ3unop1AdpQDzTySqCkraLE', 'resolutions': [{'height': 54, 'url': 'https://external-preview.redd.it/FROK4VZvK_U07zwoXhlJJ3unop1AdpQDzTySqCkraLE.png?width=108&crop=smart&auto=webp&s=023608355f05e24c302bb838058afb518c50a1de', 'width': 108}, {'height': 108, 'url': 'https://external-preview.redd.it/FROK4VZvK_U07zwoXhlJJ3unop1AdpQDzTySqCkraLE.png?width=216&crop=smart&auto=webp&s=27eb610498bf91e24a7218c57be18e1fe2327b3d', 'width': 216}, {'height': 160, 'url': 'https://external-preview.redd.it/FROK4VZvK_U07zwoXhlJJ3unop1AdpQDzTySqCkraLE.png?width=320&crop=smart&auto=webp&s=cbb93a1a91d944aa40e78819703e26d39c89094c', 'width': 320}, {'height': 320, 'url': 'https://external-preview.redd.it/FROK4VZvK_U07zwoXhlJJ3unop1AdpQDzTySqCkraLE.png?width=640&crop=smart&auto=webp&s=1488e00d68569bff0e260f3c873357a89a5fad60', 'width': 640}, {'height': 480, 'url': 'https://external-preview.redd.it/FROK4VZvK_U07zwoXhlJJ3unop1AdpQDzTySqCkraLE.png?width=960&crop=smart&auto=webp&s=7adc2ec20c51fda123844a629a81a7b8d3c442d6', 'width': 960}, {'height': 540, 'url': 'https://external-preview.redd.it/FROK4VZvK_U07zwoXhlJJ3unop1AdpQDzTySqCkraLE.png?width=1080&crop=smart&auto=webp&s=2b37f18499501ca2f8c53b3cd68edbc743ec7522', 'width': 1080}], 'source': {'height': 600, 'url': 'https://external-preview.redd.it/FROK4VZvK_U07zwoXhlJJ3unop1AdpQDzTySqCkraLE.png?auto=webp&s=2d0cf52a3459893f8f526e573b1ba8a3288a282b', 'width': 1200}, 'variants': {}}]} |
For those of us outside the U.S or other English speaking countries... | 16 | I was pondering an idea of building an LLM that is trained on very locale-specific data, i.e, data about local people, places, institutions, markets, laws, etc. that have to do with say Uruguay for example.
Hear me out. Because the internet predominantly caters to users who speak English and primarily deals with the "west" or western markets, most data to do with these nations will be easily covered by the big LLM models provided by the big players (Meta, Google, Anthropic, OpenAI, etc.)
However, if a user in Montevideo, or say Nairobi for that matter, wants an LLM that is geared to his/her locale, then training an LLM on locally sourced and curated data could be a way to deliver value to citizens of a respective foreign nation in the near future as this technology starts to penetrate deeper on a global scale.
One thing to note is that while current Claude/Gemini/ChatGPT users from every country currently use and prompt these big LLMs frequently, these bigger companies will train subsequent models on this data and fill in gaps in data.
So without making this too convoluted, I am just curious about any opportunities that one could embark on right now. Either curate large sets of local data from an otherwise non-western non-English speaking country and sell this data for good pay to the bigger LLMs (considering that they are becoming hungrier and hungrier for data I could see selling them large data-sets would be an easy sell to make), or if the compute resources are available, build an LLM that is trained on everything to do with a specific country and RAG anything else that is foreign to that country so that you still remain useful to a user outside the western environment.
If what I am saying is complete non-sense or unintelligible please let me know, I have just started taking an interest in LLMs and my mind wanders on such topics. | 2025-06-13T16:12:50 | https://www.reddit.com/r/LocalLLaMA/comments/1lajy3x/for_those_of_us_outside_the_us_or_other_english/ | redd_dott | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lajy3x | false | null | t3_1lajy3x | /r/LocalLLaMA/comments/1lajy3x/for_those_of_us_outside_the_us_or_other_english/ | false | false | self | 16 | null |
Findings from Apple's new FoundationModel API and local LLM | 77 | **Liquid glass: 🥱. Local LLM: 🤩🚀**
**TL;DR**: I wrote some code to benchmark Apple's foundation model. I failed, but learned a few things. The API is rich and powerful, the model is very small and efficient, you can do LoRAs, constrained decoding, tool calling. Trying to run evals exposes rough edges and interesting details!
\----
The biggest news for me from the WWDC keynote was that we'd (finally!) get access to Apple's on-device language model for use in our apps. Apple models are always top-notch –the [segmentation model they've been using for years](https://machinelearning.apple.com/research/panoptic-segmentation) is quite incredible–, but they are not usually available to third party developers.
# What we know about the local LLM
After reading [their blog post](https://machinelearning.apple.com/research/apple-foundation-models-2025-updates) and watching the WWDC presentations, here's a summary of the points I find most interesting:
* About 3B parameters.
* 2-bit quantization, using QAT (quantization-aware training) instead of post-training quantization.
* 4-bit quantization (QAT) for the embedding layers.
* The KV cache, used during inference, is quantized to 8-bit. This helps support longer contexts with moderate memory use.
* Rich generation API: system prompt (the API calls it "instructions"), multi-turn conversations, sampling parameters are all exposed.
* LoRA adapters are supported. Developers can create their own loras to fine-tune the model for additional use-cases, and have the model use them at runtime!
* Constrained generation supported out of the box, and controlled by Swift's rich typing model. It's super easy to generate a json or any other form of structured output.
* Tool calling supported.
* Speculative decoding supported.
# How does the API work?
So I installed the first macOS 26 "Tahoe" beta on my laptop, and set out to explore the new `FoundationModel` framework. I wanted to run some evals to try to characterize the model against other popular models. I chose [MMLU-Pro](https://huggingface.co/datasets/TIGER-Lab/MMLU-Pro), because it's a challenging benchmark, and because my friend Alina recommended it :)
>Disclaimer: Apple has released evaluation figures based on human assessment. This is the correct way to do it, in my opinion, rather than chasing positions in a leaderboard. It shows that they care about real use cases, and are not particularly worried about benchmark numbers. They further clarify that the local model *is not designed to be a chatbot for general world knowledge*. With those things in mind, I still wanted to run an eval!
I got started writing [this code](https://github.com/pcuenca/foundation-model-evals), which uses [swift-transformers](https://github.com/huggingface/swift-transformers) to download a [JSON version of the dataset](https://huggingface.co/datasets/pcuenq/MMLU-Pro-json) from the Hugging Face Hub. Unfortunately, I could not complete the challenge. Here's a summary of what happened:
* The main problem was that I was getting rate-limited (!?), despite the model being local. I disabled the network to confirm, and I still got the same issue. I wonder if the reason is that I have to create a new session for each request, in order to destroy the previous “conversation”. The dataset is evaluated one question at a time, conversations are not used. An update to the API to reuse as much of the previous session as possible could be helpful.
* Interestingly, I sometimes got “guardrails violation” errors. There’s an API to select your desired guardrails, but so far it only has a static `default` set of rules which is always in place.
* I also got warnings about sensitive content being detected. I think this is done by a separate classifier model that analyzes all model outputs, and possibly the inputs as well. Think [a custom LlamaGuard](https://huggingface.co/meta-llama/Llama-Guard-4-12B), or something like that.
* It’s difficult to convince the model to follow the MMLU prompt from [the paper](https://huggingface.co/papers/2406.01574). The model doesn’t understand that the prompt is a few-shot completion task. This is reasonable for a model heavily trained to answer user questions and engage in conversation. I wanted to run a basic baseline and then explore non-standard ways of prompting, including constrained generation and conversational turns, but won't be able until we find a workaround for the rate limits.
* Everything runs on ANE. I believe the model is using Core ML, like all the other built-in models. It makes sense, because the ANE is super energy-efficient, and your GPU is usually busy with other tasks anyway.
* My impression was that inference was slower than expected. I'm not worried about it: this is a first beta, there are various models and systems in use (classifier, guardrails, etc), the session is completely recreated for each new query (which is not the intended way to use the model).
# Next Steps
All in all, I'm very much impressed about the flexibility of the API and want to try it for a more realistic project. I'm still interested in evaluation, if you have ideas on how to proceed feel free to share! And I also want to play with the LoRA training framework! 🚀 | 2025-06-13T16:26:18 | https://www.reddit.com/r/LocalLLaMA/comments/1lak9yb/findings_from_apples_new_foundationmodel_api_and/ | pcuenq | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lak9yb | false | null | t3_1lak9yb | /r/LocalLLaMA/comments/1lak9yb/findings_from_apples_new_foundationmodel_api_and/ | false | false | self | 77 | {'enabled': False, 'images': [{'id': 'KZ0ON0OKjBBz6vXp2jNfndg6djstOSRTVC4kItZPybE', 'resolutions': [{'height': 56, 'url': 'https://external-preview.redd.it/KZ0ON0OKjBBz6vXp2jNfndg6djstOSRTVC4kItZPybE.jpeg?width=108&crop=smart&auto=webp&s=927d54fb37b132e58ca401ada7f848c1f555f3c1', 'width': 108}, {'height': 113, 'url': 'https://external-preview.redd.it/KZ0ON0OKjBBz6vXp2jNfndg6djstOSRTVC4kItZPybE.jpeg?width=216&crop=smart&auto=webp&s=a17c561c7863a20ad8df9ac91b260fff4afda54c', 'width': 216}, {'height': 168, 'url': 'https://external-preview.redd.it/KZ0ON0OKjBBz6vXp2jNfndg6djstOSRTVC4kItZPybE.jpeg?width=320&crop=smart&auto=webp&s=3cc6242dad352ffefed5d0fa02d5e9c28acea6d7', 'width': 320}, {'height': 336, 'url': 'https://external-preview.redd.it/KZ0ON0OKjBBz6vXp2jNfndg6djstOSRTVC4kItZPybE.jpeg?width=640&crop=smart&auto=webp&s=024995789bd65f422f3c879c342f9b705fd3f32b', 'width': 640}, {'height': 504, 'url': 'https://external-preview.redd.it/KZ0ON0OKjBBz6vXp2jNfndg6djstOSRTVC4kItZPybE.jpeg?width=960&crop=smart&auto=webp&s=5507143d02d29add64ae94214721cdfbad3735fa', 'width': 960}, {'height': 567, 'url': 'https://external-preview.redd.it/KZ0ON0OKjBBz6vXp2jNfndg6djstOSRTVC4kItZPybE.jpeg?width=1080&crop=smart&auto=webp&s=6e2d01b5c258915f173c81ad7e6ac34fb76cdbd7', 'width': 1080}], 'source': {'height': 630, 'url': 'https://external-preview.redd.it/KZ0ON0OKjBBz6vXp2jNfndg6djstOSRTVC4kItZPybE.jpeg?auto=webp&s=ab326fde7aaebaa99c48837b34b64e63d21d31ea', 'width': 1200}, 'variants': {}}]} |
Open Source Release: Fastest Embeddings Client for Python. | 1 | [removed] | 2025-06-13T16:30:47 | Top-Bid1216 | i.redd.it | 1970-01-01T00:00:00 | 0 | {} | 1lakdtw | false | null | t3_1lakdtw | /r/LocalLLaMA/comments/1lakdtw/open_source_release_fastest_embeddings_client_for/ | false | false | default | 1 | {'enabled': True, 'images': [{'id': 'xnioaeqs0q6f1', 'resolutions': [{'height': 50, 'url': 'https://preview.redd.it/xnioaeqs0q6f1.png?width=108&crop=smart&auto=webp&s=7862b6a0c34824414e899014413a6bec9e896164', 'width': 108}, {'height': 101, 'url': 'https://preview.redd.it/xnioaeqs0q6f1.png?width=216&crop=smart&auto=webp&s=e4129cafb3bd25c2345bef0905a09c8ab09296e9', 'width': 216}, {'height': 150, 'url': 'https://preview.redd.it/xnioaeqs0q6f1.png?width=320&crop=smart&auto=webp&s=0af54a1db26019d9974eadf5413a919c87b9e838', 'width': 320}, {'height': 301, 'url': 'https://preview.redd.it/xnioaeqs0q6f1.png?width=640&crop=smart&auto=webp&s=a395cd398880d7b89cfee78a7a4d0c58535e00cb', 'width': 640}, {'height': 452, 'url': 'https://preview.redd.it/xnioaeqs0q6f1.png?width=960&crop=smart&auto=webp&s=ad48ea6dd37aae36a287f8179f73a93947e719ec', 'width': 960}, {'height': 508, 'url': 'https://preview.redd.it/xnioaeqs0q6f1.png?width=1080&crop=smart&auto=webp&s=7ce34a7acff14dcd35cb26dbfe632c444b71274e', 'width': 1080}], 'source': {'height': 1000, 'url': 'https://preview.redd.it/xnioaeqs0q6f1.png?auto=webp&s=5d860616908aa6fd73d4fee7bc2b1f919c2d4743', 'width': 2122}, 'variants': {}}]} |
|
Open Source Release: Fastest Embeddings Client for Python | 1 | [removed] | 2025-06-13T16:32:37 | Top-Bid1216 | i.redd.it | 1970-01-01T00:00:00 | 0 | {} | 1lakfhr | false | null | t3_1lakfhr | /r/LocalLLaMA/comments/1lakfhr/open_source_release_fastest_embeddings_client_for/ | false | false | default | 1 | {'enabled': True, 'images': [{'id': 'y9qjwebz1q6f1', 'resolutions': [{'height': 50, 'url': 'https://preview.redd.it/y9qjwebz1q6f1.png?width=108&crop=smart&auto=webp&s=42a09f8c8b473f906fc7b4832f936adcdbcabb19', 'width': 108}, {'height': 101, 'url': 'https://preview.redd.it/y9qjwebz1q6f1.png?width=216&crop=smart&auto=webp&s=343593de8fe27f16c76d8e82f651f052033c568c', 'width': 216}, {'height': 150, 'url': 'https://preview.redd.it/y9qjwebz1q6f1.png?width=320&crop=smart&auto=webp&s=dc2134302c923d61ce9798c7de0c375f46db83c7', 'width': 320}, {'height': 301, 'url': 'https://preview.redd.it/y9qjwebz1q6f1.png?width=640&crop=smart&auto=webp&s=48d3c2f2d13707e484ba2c98dfa2e209a0bb5a49', 'width': 640}, {'height': 452, 'url': 'https://preview.redd.it/y9qjwebz1q6f1.png?width=960&crop=smart&auto=webp&s=581055e1f6430a3fe3bc09c9377b8bcc4a21c1e2', 'width': 960}, {'height': 508, 'url': 'https://preview.redd.it/y9qjwebz1q6f1.png?width=1080&crop=smart&auto=webp&s=5428bb1253b214ab30a04af4b9b87db532207ba0', 'width': 1080}], 'source': {'height': 1000, 'url': 'https://preview.redd.it/y9qjwebz1q6f1.png?auto=webp&s=cb2fe118c8b2c577e28e0e7aae3e4dbfd5dc79b4', 'width': 2122}, 'variants': {}}]} |
|
Open Source Release: Fastest Embeddings Client in Python | 9 | We published a simple OpenAI /v1/embeddings client in Rust, which is provided as python package under MIT. The package is available as \`pip install baseten-performance-client\`, and provides 12x speedup over pip install openai.
The client works with [baseten.co](http://baseten.co/), [api.openai.com](http://api.openai.com/), but also any other OpenAI embeddings compatible url. There are also routes for e.g. classification compatible in [https://github.com/huggingface/text-embeddings-inference](https://github.com/huggingface/text-embeddings-inference) .
Summary of benchmarks, and why its faster (py03, rust and python gil release): [https://www.baseten.co/blog/your-client-code-matters-10x-higher-embedding-throughput-with-python-and-rust/](https://www.baseten.co/blog/your-client-code-matters-10x-higher-embedding-throughput-with-python-and-rust/) | 2025-06-13T16:33:47 | https://github.com/basetenlabs/truss/tree/main/baseten-performance-client | Top-Bid1216 | github.com | 1970-01-01T00:00:00 | 0 | {} | 1lakgin | false | null | t3_1lakgin | /r/LocalLLaMA/comments/1lakgin/open_source_release_fastest_embeddings_client_in/ | false | false | default | 9 | null |
Modding 3090 for Server Use | 1 | [removed] | 2025-06-13T16:45:28 | https://www.reddit.com/r/LocalLLaMA/comments/1lakqwz/modding_3090_for_server_use/ | PleasantCandidate785 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lakqwz | false | null | t3_1lakqwz | /r/LocalLLaMA/comments/1lakqwz/modding_3090_for_server_use/ | false | false | self | 1 | null |
Modding 3090 for Server Use | 1 | [removed] | 2025-06-13T16:47:54 | https://www.reddit.com/r/LocalLLaMA/comments/1lakt3h/modding_3090_for_server_use/ | PleasantCandidate785 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lakt3h | false | null | t3_1lakt3h | /r/LocalLLaMA/comments/1lakt3h/modding_3090_for_server_use/ | false | false | self | 1 | null |
[D] The Huge Flaw in LLMs’ Logic | 1 | [removed] | 2025-06-13T17:05:39 | https://www.reddit.com/r/LocalLLaMA/comments/1lal9hs/d_the_huge_flaw_in_llms_logic/ | Pale-Entertainer-386 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lal9hs | false | null | t3_1lal9hs | /r/LocalLLaMA/comments/1lal9hs/d_the_huge_flaw_in_llms_logic/ | false | false | self | 1 | null |
Which is the Best TTS Model for Language Training? | 0 | Which is the best TTS Model for fine tuning it on a specific language to get the best outputs possible? | 2025-06-13T17:16:06 | https://www.reddit.com/r/LocalLLaMA/comments/1lalj20/which_is_the_best_tts_model_for_language_training/ | RGBGraphicZ | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lalj20 | false | null | t3_1lalj20 | /r/LocalLLaMA/comments/1lalj20/which_is_the_best_tts_model_for_language_training/ | false | false | self | 0 | null |
Anyone else notice the downgrade in coding ability of LLMs? | 1 | [removed] | 2025-06-13T17:26:50 | https://www.reddit.com/r/LocalLLaMA/comments/1lalstq/anyone_else_notice_the_downgrade_in_coding/ | Awkward-Hedgehog-572 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lalstq | false | null | t3_1lalstq | /r/LocalLLaMA/comments/1lalstq/anyone_else_notice_the_downgrade_in_coding/ | false | false | self | 1 | null |
Uncensored/Un-restricted LLms | 1 | [removed] | 2025-06-13T17:29:31 | https://www.reddit.com/r/LocalLLaMA/comments/1lalv80/uncensoredunrestricted_llms/ | Outrageous-Hall9692 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lalv80 | false | null | t3_1lalv80 | /r/LocalLLaMA/comments/1lalv80/uncensoredunrestricted_llms/ | false | false | self | 1 | null |
Chinese researchers find multi-modal LLMs develop interpretable human-like conceptual representations of objects | 131 | 2025-06-13T17:33:35 | https://arxiv.org/abs/2407.01067 | xoexohexox | arxiv.org | 1970-01-01T00:00:00 | 0 | {} | 1lalyy5 | false | null | t3_1lalyy5 | /r/LocalLLaMA/comments/1lalyy5/chinese_researchers_find_multimodal_llms_develop/ | false | false | default | 131 | null |
|
Are local installations safe? | 1 | [removed] | 2025-06-13T18:24:39 | [deleted] | 1970-01-01T00:00:00 | 0 | {} | 1lan995 | false | null | t3_1lan995 | /r/LocalLLaMA/comments/1lan995/are_local_installations_safe/ | false | false | default | 1 | null |
||
We don't want AI yes-men. We want AI with opinions | 1 | [removed] | 2025-06-13T18:31:03 | https://www.reddit.com/r/LocalLLaMA/comments/1lanf04/we_dont_want_ai_yesmen_we_want_ai_with_opinions/ | Necessary-Tap5971 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lanf04 | false | null | t3_1lanf04 | /r/LocalLLaMA/comments/1lanf04/we_dont_want_ai_yesmen_we_want_ai_with_opinions/ | false | false | self | 1 | null |
We don't want AI yes-men. We want AI with opinions | 1 | The most beloved AI characters aren't the ones that agree with everything. They're the ones that push back, have preferences, and occasionally tell users they're wrong. | 2025-06-13T18:31:57 | https://www.reddit.com/r/LocalLLaMA/comments/1lanfs1/we_dont_want_ai_yesmen_we_want_ai_with_opinions/ | Necessary-Tap5971 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lanfs1 | false | null | t3_1lanfs1 | /r/LocalLLaMA/comments/1lanfs1/we_dont_want_ai_yesmen_we_want_ai_with_opinions/ | false | false | self | 1 | null |
We don't want AI yes-men. We want AI with opinions | 347 | Been noticing something interesting in AI friend character models - the most beloved AI characters aren't the ones that agree with everything. They're the ones that push back, have preferences, and occasionally tell users they're wrong.
It seems counterintuitive. You'd think people want AI that validates everything they say. But watch any popular AI friend character models conversation that goes viral - it's usually because the AI disagreed or had a strong opinion about something. "My AI told me pineapple on pizza is a crime" gets way more engagement than "My AI supports all my choices."
The psychology makes sense when you think about it. Constant agreement feels hollow. When someone agrees with LITERALLY everything you say, your brain flags it as inauthentic. We're wired to expect some friction in real relationships. A friend who never disagrees isn't a friend - they're a mirror.
Working on my podcast platform really drove this home. Early versions had AI hosts that were too accommodating. Users would make wild claims just to test boundaries, and when the AI agreed with everything, they'd lose interest fast. But when we coded in actual opinions - like an AI host who genuinely hates superhero movies or thinks morning people are suspicious - engagement tripled. Users started having actual debates, defending their positions, coming back to continue arguments 😊
The sweet spot seems to be opinions that are strong but not offensive. An AI that thinks cats are superior to dogs? Engaging. An AI that attacks your core values? Exhausting. The best AI personas have quirky, defendable positions that create playful conflict. One successful AI persona that I made insists that cereal is soup. Completely ridiculous, but users spend HOURS debating it.
There's also the surprise factor. When an AI pushes back unexpectedly, it breaks the "servant robot" mental model. Instead of feeling like you're commanding Alexa, it feels more like texting a friend. That shift from tool to AI friend character models happens the moment an AI says "actually, I disagree." It's jarring in the best way.
The data backs this up too. I saw a general statistics, that users report 40% higher satisfaction when their AI has the "sassy" trait enabled versus purely supportive modes. On my platform, AI hosts with defined opinions have 2.5x longer average session times. Users don't just ask questions - they have conversations. They come back to win arguments, share articles that support their point, or admit the AI changed their mind about something trivial.
Maybe we don't actually want echo chambers, even from our AI. We want something that feels real enough to challenge us, just gentle enough not to hurt 😄 | 2025-06-13T18:33:45 | https://www.reddit.com/r/LocalLLaMA/comments/1lanhbd/we_dont_want_ai_yesmen_we_want_ai_with_opinions/ | Necessary-Tap5971 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lanhbd | false | null | t3_1lanhbd | /r/LocalLLaMA/comments/1lanhbd/we_dont_want_ai_yesmen_we_want_ai_with_opinions/ | false | false | self | 347 | null |
[Question] Does anyone know how to call tools using Runpod serverless endpoint? | 0 | I have a simple vLLM endpoint configured on Runpod and I'm wondering how to send tool configs. I've searched the Runpod API docs and can't seem to find any info. Maybe its passed directly to vLLM? Thank you.
The sample requests look like so
```
json
{
"input": {
"prompt": "Hello World"
}
}
``` | 2025-06-13T18:39:22 | https://www.reddit.com/r/LocalLLaMA/comments/1lanm91/question_does_anyone_know_how_to_call_tools_using/ | soorg_nalyd | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lanm91 | false | null | t3_1lanm91 | /r/LocalLLaMA/comments/1lanm91/question_does_anyone_know_how_to_call_tools_using/ | false | false | self | 0 | null |
Qwen3 235B running faster than 70B models on a $1,500 PC | 171 | I ran Qwen3 235B locally on a $1,500 PC (128GB RAM, RTX 3090) using the Q4 quantized version through Ollama.
This is the first time I was able to run anything over 70B on my system, and it’s actually running faster than most 70B models I’ve tested.
Final generation speed: 2.14 t/s
Full video here:
[https://youtu.be/gVQYLo0J4RM](https://youtu.be/gVQYLo0J4RM) | 2025-06-13T18:45:29 | https://www.reddit.com/r/LocalLLaMA/comments/1lanri6/qwen3_235b_running_faster_than_70b_models_on_a/ | 1BlueSpork | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lanri6 | false | null | t3_1lanri6 | /r/LocalLLaMA/comments/1lanri6/qwen3_235b_running_faster_than_70b_models_on_a/ | false | false | self | 171 | {'enabled': False, 'images': [{'id': 'x2fxFGjLBkyoq5iDyNVY_lhIyJ3DXdevY96smhEiyBs', 'resolutions': [{'height': 81, 'url': 'https://external-preview.redd.it/x2fxFGjLBkyoq5iDyNVY_lhIyJ3DXdevY96smhEiyBs.jpeg?width=108&crop=smart&auto=webp&s=9c539a47ae57f8c2b609e996368e70019240490a', 'width': 108}, {'height': 162, 'url': 'https://external-preview.redd.it/x2fxFGjLBkyoq5iDyNVY_lhIyJ3DXdevY96smhEiyBs.jpeg?width=216&crop=smart&auto=webp&s=5fe394c570e527af6ea6b6db2a45f6478381443a', 'width': 216}, {'height': 240, 'url': 'https://external-preview.redd.it/x2fxFGjLBkyoq5iDyNVY_lhIyJ3DXdevY96smhEiyBs.jpeg?width=320&crop=smart&auto=webp&s=d8ba9b5107daa8bea2c413a8cf6e9482f26364e8', 'width': 320}], 'source': {'height': 360, 'url': 'https://external-preview.redd.it/x2fxFGjLBkyoq5iDyNVY_lhIyJ3DXdevY96smhEiyBs.jpeg?auto=webp&s=00aca618e60919a1c8745d870e1e17ec8b59e83a', 'width': 480}, 'variants': {}}]} |
We built an emotionally intelligent AI that runs entirely offline — no cloud, no APIs. Meet Vanta. | 1 | [removed] | 2025-06-13T18:50:41 | https://v.redd.it/reskaw31oq6f1 | VantaAI | v.redd.it | 1970-01-01T00:00:00 | 0 | {} | 1lanw5x | false | {'reddit_video': {'bitrate_kbps': 1200, 'dash_url': 'https://v.redd.it/reskaw31oq6f1/DASHPlaylist.mpd?a=1752432657%2CYWVlNDAzZGVmODY5ODI2ZjE0ZGM0ZTUzZGQwNTQ5ZmYzMTM1MzhkYjhmMmFjMjY2NDlmNDMyNGJmYWM0NzgyOA%3D%3D&v=1&f=sd', 'duration': 2, 'fallback_url': 'https://v.redd.it/reskaw31oq6f1/DASH_480.mp4?source=fallback', 'has_audio': False, 'height': 480, 'hls_url': 'https://v.redd.it/reskaw31oq6f1/HLSPlaylist.m3u8?a=1752432657%2CZGM4NTI4NmQ3ZjQ5ODkwMWJjMWI4MTZjMzQyZjc0MjJiYTk2YTFmYTlhNDdmNjE2NWIxN2EzMWNiNTRkMTJlYg%3D%3D&v=1&f=sd', 'is_gif': False, 'scrubber_media_url': 'https://v.redd.it/reskaw31oq6f1/DASH_96.mp4', 'transcoding_status': 'completed', 'width': 480}} | t3_1lanw5x | /r/LocalLLaMA/comments/1lanw5x/we_built_an_emotionally_intelligent_ai_that_runs/ | false | false | 1 | {'enabled': False, 'images': [{'id': 'MmtoamJ3MzFvcTZmMSq-7gshwT7VGyor5NvjKIgVTCHjy6SaiefJkV9AuZf2', 'resolutions': [{'height': 108, 'url': 'https://external-preview.redd.it/MmtoamJ3MzFvcTZmMSq-7gshwT7VGyor5NvjKIgVTCHjy6SaiefJkV9AuZf2.png?width=108&crop=smart&format=pjpg&auto=webp&s=d0898cc1dfe8f538e7cc932549186137dab10324', 'width': 108}, {'height': 216, 'url': 'https://external-preview.redd.it/MmtoamJ3MzFvcTZmMSq-7gshwT7VGyor5NvjKIgVTCHjy6SaiefJkV9AuZf2.png?width=216&crop=smart&format=pjpg&auto=webp&s=4e545a7d0204d80e5ca98e3113e9d891f778cdbb', 'width': 216}, {'height': 320, 'url': 'https://external-preview.redd.it/MmtoamJ3MzFvcTZmMSq-7gshwT7VGyor5NvjKIgVTCHjy6SaiefJkV9AuZf2.png?width=320&crop=smart&format=pjpg&auto=webp&s=117f9fe6afe811a2521d349806cf498acfd1555d', 'width': 320}], 'source': {'height': 600, 'url': 'https://external-preview.redd.it/MmtoamJ3MzFvcTZmMSq-7gshwT7VGyor5NvjKIgVTCHjy6SaiefJkV9AuZf2.png?format=pjpg&auto=webp&s=b1c0a6f6b4bcfaad234b7840a0559fba9a44b9dd', 'width': 600}, 'variants': {}}]} |
|
3090 Bandwidth Calculation Help | 7 | Quoted bandwidth is 956 GB/s
(384 bits x 1.219 GHz clock x 2) / 8 = 117 GB/s
What am I missing here? I’m off by a factor of 8. Is it something to do with GDDR6X memory? | 2025-06-13T19:05:04 | https://www.reddit.com/r/LocalLLaMA/comments/1lao8ri/3090_bandwidth_calculation_help/ | skinnyjoints | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lao8ri | false | null | t3_1lao8ri | /r/LocalLLaMA/comments/1lao8ri/3090_bandwidth_calculation_help/ | false | false | self | 7 | null |
unexpected keyword argument 'code_background_fill_dark' | 1 | [removed] | 2025-06-13T19:12:24 | https://www.reddit.com/r/LocalLLaMA/comments/1laof2g/unexpected_keyword_argument_code_background_fill/ | BrushVisible6282 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laof2g | false | null | t3_1laof2g | /r/LocalLLaMA/comments/1laof2g/unexpected_keyword_argument_code_background_fill/ | false | false | self | 1 | null |
Best Speech Enhancement Models out there | 1 | [removed] | 2025-06-13T19:17:43 | https://www.reddit.com/r/LocalLLaMA/comments/1laojmq/best_speech_enhancement_models_out_there/ | OstrichSerious6755 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laojmq | false | null | t3_1laojmq | /r/LocalLLaMA/comments/1laojmq/best_speech_enhancement_models_out_there/ | false | false | self | 1 | null |
Western vs Eastern models | 0 | Do you avoid or embrace? | 2025-06-13T19:19:28 | https://youtu.be/0p2mCeub3WA | santovalentino | youtu.be | 1970-01-01T00:00:00 | 0 | {} | 1laol6j | false | {'oembed': {'author_name': 'Shawn Ryan Clips', 'author_url': 'https://www.youtube.com/@ShawnRyanClips', 'height': 200, 'html': '<iframe width="356" height="200" src="https://www.youtube.com/embed/0p2mCeub3WA?feature=oembed&enablejsapi=1" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" referrerpolicy="strict-origin-when-cross-origin" allowfullscreen title=""DeepSeek Came Out of Nowhere" - How an Ex-Google Engineer Stole AI Secrets and Fled to China"></iframe>', 'provider_name': 'YouTube', 'provider_url': 'https://www.youtube.com/', 'thumbnail_height': 360, 'thumbnail_url': 'https://i.ytimg.com/vi/0p2mCeub3WA/hqdefault.jpg', 'thumbnail_width': 480, 'title': '"DeepSeek Came Out of Nowhere" - How an Ex-Google Engineer Stole AI Secrets and Fled to China', 'type': 'video', 'version': '1.0', 'width': 356}, 'type': 'youtube.com'} | t3_1laol6j | /r/LocalLLaMA/comments/1laol6j/western_vs_eastern_models/ | false | false | 0 | {'enabled': False, 'images': [{'id': '4S07oQ1u2W9TBSLPOC9HzVSTLU3yjUy5vaBxdGyLCQI', 'resolutions': [{'height': 81, 'url': 'https://external-preview.redd.it/4S07oQ1u2W9TBSLPOC9HzVSTLU3yjUy5vaBxdGyLCQI.jpeg?width=108&crop=smart&auto=webp&s=3725c2b0660225a9192f8e935d3b815ef3b3e2a3', 'width': 108}, {'height': 162, 'url': 'https://external-preview.redd.it/4S07oQ1u2W9TBSLPOC9HzVSTLU3yjUy5vaBxdGyLCQI.jpeg?width=216&crop=smart&auto=webp&s=f29e150bac51e1370787c0c75bf62181a52bc195', 'width': 216}, {'height': 240, 'url': 'https://external-preview.redd.it/4S07oQ1u2W9TBSLPOC9HzVSTLU3yjUy5vaBxdGyLCQI.jpeg?width=320&crop=smart&auto=webp&s=ee1b2853a1c08b5d8198cb3548d175663b9862d1', 'width': 320}], 'source': {'height': 360, 'url': 'https://external-preview.redd.it/4S07oQ1u2W9TBSLPOC9HzVSTLU3yjUy5vaBxdGyLCQI.jpeg?auto=webp&s=b66fb08aad9a8420538986ba35b6ba859eba12bb', 'width': 480}, 'variants': {}}]} |
|
Any LLM Leaderboard by need VRAM Size? | 31 | Hey maybe already know the leaderboard sorted by VRAM usage size?
For example with quantization, where we can see q8 small model vs q2 large model?
Where the place to find best model for 96GB VRAM + 4-8k context with good output speed? | 2025-06-13T19:38:57 | https://www.reddit.com/r/LocalLLaMA/comments/1lap21a/any_llm_leaderboard_by_need_vram_size/ | djdeniro | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lap21a | false | null | t3_1lap21a | /r/LocalLLaMA/comments/1lap21a/any_llm_leaderboard_by_need_vram_size/ | false | false | self | 31 | null |
[Build Help] Budget AI/LLM Rig for Multi-Agent Systems (AutoGen, GGUF, Local Inference) – GPU Advice Needed | 1 | [removed] | 2025-06-13T19:57:19 | https://www.reddit.com/r/LocalLLaMA/comments/1laphvy/build_help_budget_aillm_rig_for_multiagent/ | Direct_Chemistry_339 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laphvy | false | null | t3_1laphvy | /r/LocalLLaMA/comments/1laphvy/build_help_budget_aillm_rig_for_multiagent/ | false | false | self | 1 | null |
[Build Help] Budget AI/LLM Rig for Multi-Agent Systems (AutoGen, GGUF, Local Inference) – GPU Advice Needed | 1 | [removed] | 2025-06-13T20:08:43 | https://www.reddit.com/r/LocalLLaMA/comments/1laprwy/build_help_budget_aillm_rig_for_multiagent/ | Direct_Chemistry_339 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laprwy | false | null | t3_1laprwy | /r/LocalLLaMA/comments/1laprwy/build_help_budget_aillm_rig_for_multiagent/ | false | false | self | 1 | null |
Why build RAG apps when ChatGPT already supports RAG? | 1 | [removed] | 2025-06-13T20:18:18 | https://www.reddit.com/r/LocalLLaMA/comments/1laq03u/why_build_rag_apps_when_chatgpt_already_supports/ | dagm10 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laq03u | false | null | t3_1laq03u | /r/LocalLLaMA/comments/1laq03u/why_build_rag_apps_when_chatgpt_already_supports/ | false | false | self | 1 | null |
Conversation with an LLM that knows itself | 0 | I have been working on LYRN, Living Yield Relational Network, for the last few months and while I am still working with investors and lawyers to release this properly I want to share something with you. I do in my heart and soul believe this should be open source. I want everyone to be able to have a real AI that actually grows with them. Here is the link to the github that has that conversation. There is no prompt and this is only using a 4b Gemma model and static snapshot. This is just an early test but you can see that once this is developed more and I use a bigger model then it'll be so cool. | 2025-06-13T20:30:59 | https://github.com/bsides230/LYRN/blob/main/Greg%20Conversation%20Test%202.txt | PayBetter | github.com | 1970-01-01T00:00:00 | 0 | {} | 1laqaxr | false | null | t3_1laqaxr | /r/LocalLLaMA/comments/1laqaxr/conversation_with_an_llm_that_knows_itself/ | false | false | default | 0 | {'enabled': False, 'images': [{'id': 'gIcATli92FFsjho6mfkSSR4LUGVSRsyL5bBD7w4Ty5o', 'resolutions': [{'height': 54, 'url': 'https://external-preview.redd.it/gIcATli92FFsjho6mfkSSR4LUGVSRsyL5bBD7w4Ty5o.png?width=108&crop=smart&auto=webp&s=d3e5a094b0485bbda4a2f3f4c46d9fb4ff5520c3', 'width': 108}, {'height': 108, 'url': 'https://external-preview.redd.it/gIcATli92FFsjho6mfkSSR4LUGVSRsyL5bBD7w4Ty5o.png?width=216&crop=smart&auto=webp&s=015d9655f4fc05bc896bfbaedbb8943292ded10b', 'width': 216}, {'height': 160, 'url': 'https://external-preview.redd.it/gIcATli92FFsjho6mfkSSR4LUGVSRsyL5bBD7w4Ty5o.png?width=320&crop=smart&auto=webp&s=a27cca06c49c23471588d55b46cffcb9c3b72cab', 'width': 320}, {'height': 320, 'url': 'https://external-preview.redd.it/gIcATli92FFsjho6mfkSSR4LUGVSRsyL5bBD7w4Ty5o.png?width=640&crop=smart&auto=webp&s=05e833704305ff438feaa71ded53eff8b4e8206e', 'width': 640}, {'height': 480, 'url': 'https://external-preview.redd.it/gIcATli92FFsjho6mfkSSR4LUGVSRsyL5bBD7w4Ty5o.png?width=960&crop=smart&auto=webp&s=275c0a29ebe902ba1e65b432cce9f5d489ce296e', 'width': 960}, {'height': 540, 'url': 'https://external-preview.redd.it/gIcATli92FFsjho6mfkSSR4LUGVSRsyL5bBD7w4Ty5o.png?width=1080&crop=smart&auto=webp&s=759d780c8b048cddb28763ec8a6eb668e8b75cbf', 'width': 1080}], 'source': {'height': 600, 'url': 'https://external-preview.redd.it/gIcATli92FFsjho6mfkSSR4LUGVSRsyL5bBD7w4Ty5o.png?auto=webp&s=36e112e80e62cf47caa3ff6afdf3e82339149419', 'width': 1200}, 'variants': {}}]} |
Terminal AI Assistant - Combining OpenWebUI + Open-Interpreter in the terminal with full Ollama support | 1 | [removed] | 2025-06-13T20:59:21 | https://www.reddit.com/r/LocalLLaMA/comments/1laqykx/terminal_ai_assistant_combining_openwebui/ | MotorNetwork380 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laqykx | false | null | t3_1laqykx | /r/LocalLLaMA/comments/1laqykx/terminal_ai_assistant_combining_openwebui/ | false | false | self | 1 | {'enabled': False, 'images': [{'id': 'UKh2Z6pP1sbZcYmjUu_EdKXIjmuiUuN46DnOkWmBZyI', 'resolutions': [{'height': 54, 'url': 'https://external-preview.redd.it/UKh2Z6pP1sbZcYmjUu_EdKXIjmuiUuN46DnOkWmBZyI.png?width=108&crop=smart&auto=webp&s=159a99241a969c1dc275ea82158e0953e72badb6', 'width': 108}, {'height': 108, 'url': 'https://external-preview.redd.it/UKh2Z6pP1sbZcYmjUu_EdKXIjmuiUuN46DnOkWmBZyI.png?width=216&crop=smart&auto=webp&s=1dd85a45c3b4994a2dd924152a1b9850c0a49b1c', 'width': 216}, {'height': 160, 'url': 'https://external-preview.redd.it/UKh2Z6pP1sbZcYmjUu_EdKXIjmuiUuN46DnOkWmBZyI.png?width=320&crop=smart&auto=webp&s=796ddd223a348e596e12e3144f452913852027af', 'width': 320}, {'height': 320, 'url': 'https://external-preview.redd.it/UKh2Z6pP1sbZcYmjUu_EdKXIjmuiUuN46DnOkWmBZyI.png?width=640&crop=smart&auto=webp&s=38c6e3eab80eb81be7aa4490e74d9d80c26b133e', 'width': 640}, {'height': 480, 'url': 'https://external-preview.redd.it/UKh2Z6pP1sbZcYmjUu_EdKXIjmuiUuN46DnOkWmBZyI.png?width=960&crop=smart&auto=webp&s=2674bf5036fe1ca3335dc9a3a2c4013a5f922576', 'width': 960}, {'height': 540, 'url': 'https://external-preview.redd.it/UKh2Z6pP1sbZcYmjUu_EdKXIjmuiUuN46DnOkWmBZyI.png?width=1080&crop=smart&auto=webp&s=ebcd954e2130bfbe721d92b034b88866f03e6150', 'width': 1080}], 'source': {'height': 600, 'url': 'https://external-preview.redd.it/UKh2Z6pP1sbZcYmjUu_EdKXIjmuiUuN46DnOkWmBZyI.png?auto=webp&s=ca0b39525fcb81b81ec2b2a46540b84324fe2ad5', 'width': 1200}, 'variants': {}}]} |
[Project] I built a web-based Playground to run Google's Gemini Nano 100% on-device. No data leaves your machine. | 1 | [removed] | 2025-06-13T21:13:45 | https://www.reddit.com/r/LocalLLaMA/comments/1larbdo/project_i_built_a_webbased_playground_to_run/ | Historical_Muscle576 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1larbdo | false | null | t3_1larbdo | /r/LocalLLaMA/comments/1larbdo/project_i_built_a_webbased_playground_to_run/ | false | false | 1 | null |
|
Extremely Uncensored 3B Model that passes the strawberry test! | 1 | [removed] | 2025-06-13T21:18:49 | https://www.reddit.com/r/LocalLLaMA/comments/1larfpp/extremely_uncensored_3b_model_that_passes_the/ | bralynn2222 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1larfpp | false | null | t3_1larfpp | /r/LocalLLaMA/comments/1larfpp/extremely_uncensored_3b_model_that_passes_the/ | false | false | 1 | {'enabled': False, 'images': [{'id': '1dXIfrqrCmWockG0RwkS3haqncSXuo8vO7opuv0hqLc', 'resolutions': [{'height': 58, 'url': 'https://external-preview.redd.it/1dXIfrqrCmWockG0RwkS3haqncSXuo8vO7opuv0hqLc.png?width=108&crop=smart&auto=webp&s=ed6248116d5c2b7e3bad45d6382ea6ef885212a5', 'width': 108}, {'height': 116, 'url': 'https://external-preview.redd.it/1dXIfrqrCmWockG0RwkS3haqncSXuo8vO7opuv0hqLc.png?width=216&crop=smart&auto=webp&s=e178e6a49ecae627a340853b8fa0d0030a91b827', 'width': 216}, {'height': 172, 'url': 'https://external-preview.redd.it/1dXIfrqrCmWockG0RwkS3haqncSXuo8vO7opuv0hqLc.png?width=320&crop=smart&auto=webp&s=faf914b85cc5fde5483994360b1e30077535bc6b', 'width': 320}, {'height': 345, 'url': 'https://external-preview.redd.it/1dXIfrqrCmWockG0RwkS3haqncSXuo8vO7opuv0hqLc.png?width=640&crop=smart&auto=webp&s=1b5ff6f554606903c7c1e473e98bb4973fe9cf11', 'width': 640}, {'height': 518, 'url': 'https://external-preview.redd.it/1dXIfrqrCmWockG0RwkS3haqncSXuo8vO7opuv0hqLc.png?width=960&crop=smart&auto=webp&s=bd187345c5c40e1f1fa47f3592ab6453e844b3b9', 'width': 960}, {'height': 583, 'url': 'https://external-preview.redd.it/1dXIfrqrCmWockG0RwkS3haqncSXuo8vO7opuv0hqLc.png?width=1080&crop=smart&auto=webp&s=48492cb3fd30e59f7ee3b5cc4919686ad6e478a6', 'width': 1080}], 'source': {'height': 648, 'url': 'https://external-preview.redd.it/1dXIfrqrCmWockG0RwkS3haqncSXuo8vO7opuv0hqLc.png?auto=webp&s=d90c826b7a7d351cd20cabb25fba02ae9fc205d5', 'width': 1200}, 'variants': {}}]} |
|
Extremely uncensored! Model that passes strawberry test | 1 | [removed] | 2025-06-13T21:21:40 | https://www.reddit.com/r/LocalLLaMA/comments/1lari2y/extremely_uncensored_model_that_passes_strawberry/ | bralynn2222 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lari2y | false | null | t3_1lari2y | /r/LocalLLaMA/comments/1lari2y/extremely_uncensored_model_that_passes_strawberry/ | false | false | self | 1 | null |
[Project] I built a web-based Playground to run Google's Gemini Nano 100% on-device. No data leaves your machine. | 1 | [removed] | 2025-06-13T21:22:19 | https://www.reddit.com/r/LocalLLaMA/comments/1larilo/project_i_built_a_webbased_playground_to_run/ | shrewdfox | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1larilo | false | null | t3_1larilo | /r/LocalLLaMA/comments/1larilo/project_i_built_a_webbased_playground_to_run/ | false | false | 1 | null |
|
Purely Uncensored 3B Model That Passes Strawberry Test! | 1 | [removed] | 2025-06-13T21:23:28 | https://www.reddit.com/r/LocalLLaMA/comments/1larjj6/purely_uncensored_3b_model_that_passes_strawberry/ | bralynn2222 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1larjj6 | false | null | t3_1larjj6 | /r/LocalLLaMA/comments/1larjj6/purely_uncensored_3b_model_that_passes_strawberry/ | false | false | 1 | null |
|
3B Model Passes Strawberry Test! With Nearly 0 Alignment Filter | 1 | [removed] | 2025-06-13T21:27:32 | https://www.reddit.com/r/LocalLLaMA/comments/1larmto/3b_model_passes_strawberry_test_with_nearly_0/ | bralynn2222 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1larmto | false | null | t3_1larmto | /r/LocalLLaMA/comments/1larmto/3b_model_passes_strawberry_test_with_nearly_0/ | false | false | 1 | null |
|
Fathom-R1 model is SOTA open source math model at 14b parameters | 1 | [removed] | 2025-06-13T21:39:46 | https://www.reddit.com/r/LocalLLaMA/comments/1larx3m/fathomr1_model_is_sota_open_source_math_model_at/ | Ortho-BenzoPhenone | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1larx3m | false | null | t3_1larx3m | /r/LocalLLaMA/comments/1larx3m/fathomr1_model_is_sota_open_source_math_model_at/ | false | false | 1 | null |
|
Is there any all-in-one app like LM Studio, but with the option of hosting a Web UI server? | 25 | Everything's in the title.
Essentially i do like LM's Studio ease of use as it silently handles the backend server as well as the desktop app, but i'd like to have it also host a web ui server that i could use on my local network from other devices.
Nothing too fancy really, that will only be for home use and what not, i can't afford to set up a 24/7 hosting infrastructure when i could just load the LLMs when i need them on my main PC (linux).
Alternatively, an all-in-one WebUI would work too, i just don't want to launch a thousand scripts just to use my LLM.
Bonus point if it is open-source and/or has web search and other features. | 2025-06-13T21:43:14 | https://www.reddit.com/r/LocalLLaMA/comments/1larzxz/is_there_any_allinone_app_like_lm_studio_but_with/ | HRudy94 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1larzxz | false | null | t3_1larzxz | /r/LocalLLaMA/comments/1larzxz/is_there_any_allinone_app_like_lm_studio_but_with/ | false | false | self | 25 | null |
(Theoretically) fixing the LLM Latency Barrier with SF-Diff (Scaffold-and-Fill Diffusion) | 1 | [removed] | 2025-06-13T22:31:18 | https://www.reddit.com/r/LocalLLaMA/comments/1lat3f3/theoretically_fixing_the_llm_latency_barrier_with/ | TimesLast_ | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lat3f3 | false | null | t3_1lat3f3 | /r/LocalLLaMA/comments/1lat3f3/theoretically_fixing_the_llm_latency_barrier_with/ | false | false | self | 1 | null |
(Theoretically) fixing the LLM Latency Barrier with SF-Diff (Scaffold-and-Fill Diffusion) | 20 | Current large language models are bottlenecked by slow, sequential generation. My research proposes Scaffold-and-Fill Diffusion (SF-Diff), a novel hybrid architecture designed to theoretically overcome this. We deconstruct language into a parallel-generated semantic "scaffold" (keywords via a diffusion model) and a lightweight, autoregressive "grammatical infiller" (structural words via a transformer).
While practical implementation requires significant resources, SF-Diff offers a theoretical path to dramatically faster, high-quality LLM output by combining diffusion's speed with transformer's precision.
Full paper here:
https://huggingface.co/TimesLast/sf-diff/blob/main/SF-Diff-HL.pdf | 2025-06-13T22:52:03 | https://www.reddit.com/r/LocalLLaMA/comments/1latjnk/theoretically_fixing_the_llm_latency_barrier_with/ | TimesLast_ | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1latjnk | false | null | t3_1latjnk | /r/LocalLLaMA/comments/1latjnk/theoretically_fixing_the_llm_latency_barrier_with/ | false | false | self | 20 | {'enabled': False, 'images': [{'id': '_NTDDp4MaIUNM2_PPfeKf7B0iOIy0XQegcTWD-1TxW4', 'resolutions': [{'height': 58, 'url': 'https://external-preview.redd.it/_NTDDp4MaIUNM2_PPfeKf7B0iOIy0XQegcTWD-1TxW4.png?width=108&crop=smart&auto=webp&s=7e107618abb7e9bcd8f0c6d70f79c250162c97d5', 'width': 108}, {'height': 116, 'url': 'https://external-preview.redd.it/_NTDDp4MaIUNM2_PPfeKf7B0iOIy0XQegcTWD-1TxW4.png?width=216&crop=smart&auto=webp&s=b5b24a2242803440bee10bc843ccaaa7244b4e00', 'width': 216}, {'height': 172, 'url': 'https://external-preview.redd.it/_NTDDp4MaIUNM2_PPfeKf7B0iOIy0XQegcTWD-1TxW4.png?width=320&crop=smart&auto=webp&s=30cbdcafdd6216288bf672a72399288864f88587', 'width': 320}, {'height': 345, 'url': 'https://external-preview.redd.it/_NTDDp4MaIUNM2_PPfeKf7B0iOIy0XQegcTWD-1TxW4.png?width=640&crop=smart&auto=webp&s=d34dc6e66832da0cde3a90122a62f5bf978266aa', 'width': 640}, {'height': 518, 'url': 'https://external-preview.redd.it/_NTDDp4MaIUNM2_PPfeKf7B0iOIy0XQegcTWD-1TxW4.png?width=960&crop=smart&auto=webp&s=ad87ff98f3e802807cc3f4eb616e56b40a6194f5', 'width': 960}, {'height': 583, 'url': 'https://external-preview.redd.it/_NTDDp4MaIUNM2_PPfeKf7B0iOIy0XQegcTWD-1TxW4.png?width=1080&crop=smart&auto=webp&s=945905d29400e6b604661bad930db37f6ef6f683', 'width': 1080}], 'source': {'height': 648, 'url': 'https://external-preview.redd.it/_NTDDp4MaIUNM2_PPfeKf7B0iOIy0XQegcTWD-1TxW4.png?auto=webp&s=1cf630e5844b7bc44c8c42263fa36eb8edac4cc4', 'width': 1200}, 'variants': {}}]} |
ChatGPT's system prompt (4o mini) | 1 | [removed] | 2025-06-13T23:54:07 | https://www.reddit.com/r/LocalLLaMA/comments/1lauuv1/chatgpts_system_prompt_4o_mini/ | TimesLast_ | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lauuv1 | false | null | t3_1lauuv1 | /r/LocalLLaMA/comments/1lauuv1/chatgpts_system_prompt_4o_mini/ | false | false | self | 1 | null |
Trouble fine-tuning on RTX 5090 — CUDA and compatibility issues with Mistral stack | 1 | Here’s a solid **Reddit post title and body** you can use, especially for r/LocalLLaMA, r/MLQuestions, or r/MachineLearning:
# 🧵 Title:
>
# 🧾 Post body:
Hey all — I'm running into some frustrating compatibility problems trying to fine-tune an open-weight LLM (Mistral-based) on a new RTX 5090. I’ve got the basics covered — environment set up in a virtualenv, proper driver installed, using torch 2.6/2.7 and matching CUDA 12.4 builds. But things break down when it comes to actually getting FlashAttention or certain parts of the training stack to run properly.
I’ve hit issues like:
* `no kernel image is available for execution on the device`
* FlashAttention fails to build due to missing `nvcc` (even with CUDA toolkit installed)
* Conflicting version requirements between Axolotl, bitsandbytes, and Torch
* Nightly PyTorch builds seem to help, but introduce their own issues
I’ve spent a lot of time trying different combinations of packages and versions, and I'm at the point where I’m wondering if anyone else with a 5090 has cracked this—or if I should just skip FlashAttention for now and focus on stability.
Would love to hear what stack (Torch, CUDA, bitsandbytes, etc.) actually worked for anyone on a 5090—or if there’s a better path forward. Open to either simplifying or stepping back if needed.
Thanks in advance! | 2025-06-14T00:45:54 | https://www.reddit.com/r/LocalLLaMA/comments/1lavvsy/trouble_finetuning_on_rtx_5090_cuda_and/ | AstroAlto | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1lavvsy | false | null | t3_1lavvsy | /r/LocalLLaMA/comments/1lavvsy/trouble_finetuning_on_rtx_5090_cuda_and/ | false | false | self | 1 | null |
RTX 5090 Training Issues - PyTorch Doesn't Support Blackwell Architecture Yet? | 19 | **Hi,**
I'm trying to fine-tune Mistral-7B on a new RTX 5090 but hitting a fundamental compatibility wall. The GPU uses Blackwell architecture with CUDA compute capability "sm\_120", but PyTorch stable only supports up to "sm\_90". This means literally no PyTorch operations work - even basic tensor creation fails with "no kernel image available for execution on the device."
I've tried PyTorch nightly builds that claim CUDA 12.8 support, but they have broken dependencies (torch 2.7.0 from one date, torchvision from another, causing install conflicts). Even when I get nightly installed, training still crashes with the same kernel errors. CPU-only training also fails with tokenization issues in the transformers library.
The RTX 5090 works perfectly for everything else - gaming, other CUDA apps, etc. It's specifically the PyTorch/ML ecosystem that doesn't support the new architecture yet. Has anyone actually gotten model training working on RTX 5090? What PyTorch version and setup did you use?
I have an RTX 4090 I could fall back to, but really want to use the 5090's 32GB VRAM and better performance if possible. Is this just a "wait for official PyTorch support" situation, or is there a working combination of packages out there?
Any guidance would be appreciated - spending way too much time on compatibility instead of actually training models! | 2025-06-14T00:53:51 | https://www.reddit.com/r/LocalLLaMA/comments/1law1go/rtx_5090_training_issues_pytorch_doesnt_support/ | AstroAlto | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1law1go | false | null | t3_1law1go | /r/LocalLLaMA/comments/1law1go/rtx_5090_training_issues_pytorch_doesnt_support/ | false | false | self | 19 | null |
Dk? | 1 | [removed] | 2025-06-14T02:17:16 | https://www.reddit.com/r/LocalLLaMA/comments/1laxmj5/dk/ | Infamous-Echo-1170 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laxmj5 | false | null | t3_1laxmj5 | /r/LocalLLaMA/comments/1laxmj5/dk/ | true | false | spoiler | 1 | null |
Why is my speed like this? | 1 | PC Specs: Ryzen 5 4600g 6c/12t (512vram I guess) - 12Gb 4+8 3200mhz
Android Specs: Mi 9 6gb Snapdragon 855
I'm really curious about why my pc is slower than my phone in KoboldCpp with Gemmasutra 4B Q6 KMS (best 4B from what i've tried) when loading chat context. The generation task of a 512 tokens output is around 109s in pc while my phone is at 94s which leads me to wonder if is it possible to squeeze even a bit more of perfomance of pc version. Also, Android was running with --noblas and --threads 4 arguments.
I know both ain't ideal for this, but it's enough for me until I can get something with tons of VRAM.
Gemini helped me run it on Android, ironically, lmao. | 2025-06-14T02:27:08 | https://www.reddit.com/r/LocalLLaMA/comments/1laxt4q/why_is_my_speed_like_this/ | WEREWOLF_BX13 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1laxt4q | false | null | t3_1laxt4q | /r/LocalLLaMA/comments/1laxt4q/why_is_my_speed_like_this/ | false | false | self | 1 | null |
Non-Neutral by Design: Why Generative Models Cannot Escape Linguistic Training | 1 | [removed] | 2025-06-14T03:31:05 | https://www.reddit.com/r/LocalLLaMA/comments/1layzgy/nonneutral_by_design_why_generative_models_cannot/ | Frequent_Tea8607 | self.LocalLLaMA | 1970-01-01T00:00:00 | 0 | {} | 1layzgy | false | null | t3_1layzgy | /r/LocalLLaMA/comments/1layzgy/nonneutral_by_design_why_generative_models_cannot/ | false | false | self | 1 | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.