

dataset_info:
features:
- name: __key__
dtype: string
- name: stainer
dtype: string
- name: scanner
dtype: string
- name: slide_id
dtype: string
- name: tile_id
dtype: string
- name: png
dtype: image
splits:
- name: train
num_bytes: 146324838242.894
num_examples: 1481298
download_size: 146245782502
dataset_size: 146324838242.894
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: cc-by-4.0
task_categories:
- image-feature-extraction
- image-classification
tags:
- histology
- pathology
- robustness
- webdataset
size_categories:
- 100B<n<1T
PLISM dataset
The Pathology Images of Scanners and Mobilephones (PLISM) dataset was created by (Ochi et al., 2024) for the evaluation of AI models’ robustness to inter-institutional domain shifts. All histopathological specimens used in creating the PLISM dataset were sourced from patients who were diagnosed and underwent surgery at the University of Tokyo Hospital between 1955 and 2018.
PLISM-wsi consists in a group of consecutive slides digitized under 7 different scanners and stained accross 13 H&E conditions.
Each of the 91 sample encompasses the same biological information, that is a collection of 46 TMAs (Tissue Micro Arrays) from various organs. Additional details can be found in https://p024eb.github.io/ and the original publication
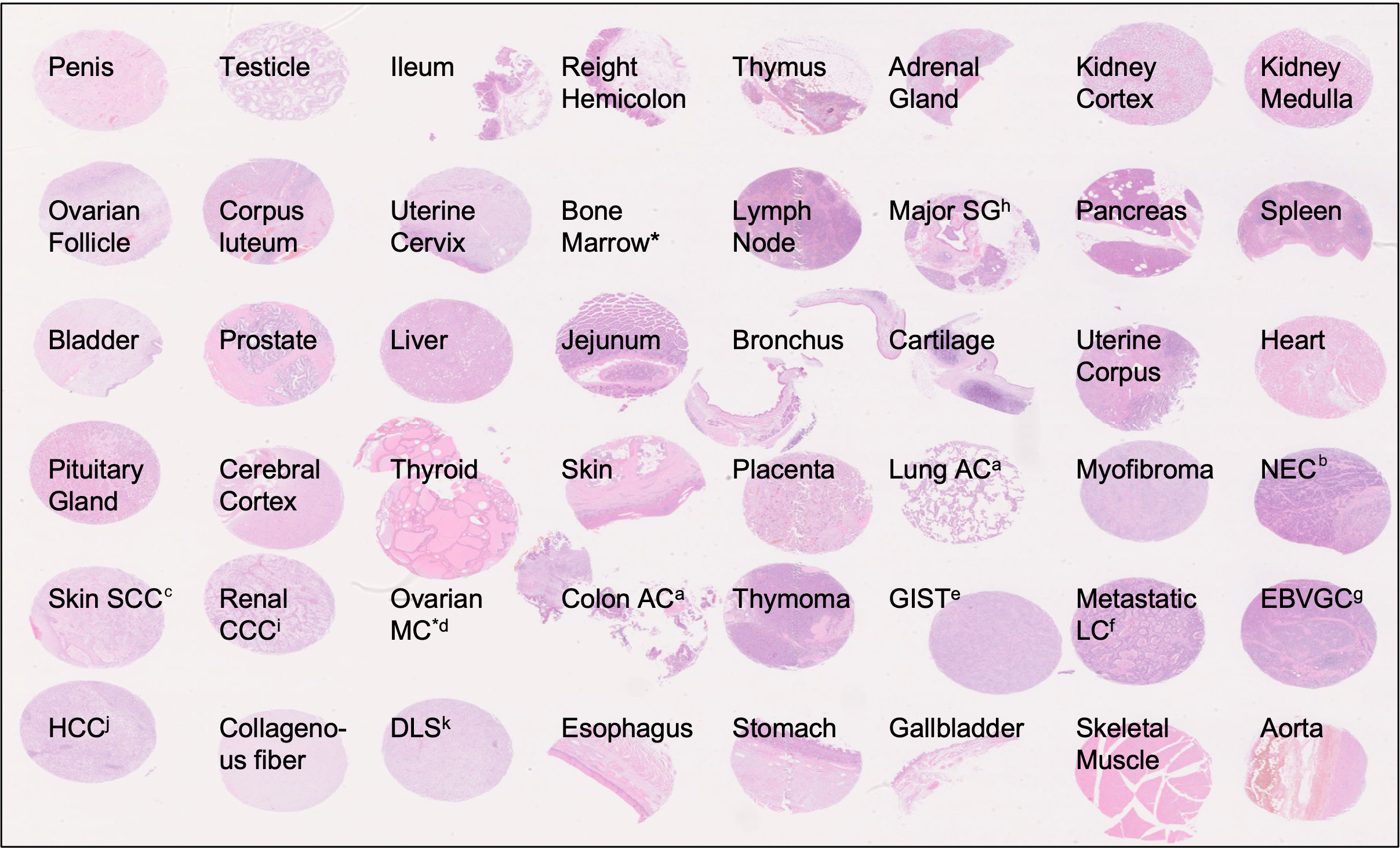
Figure 1: Tissue types included in TMA specimens of the PLISM-wsi dataset. Source: https://p024eb.github.io/ (Ochi et al., 2024)
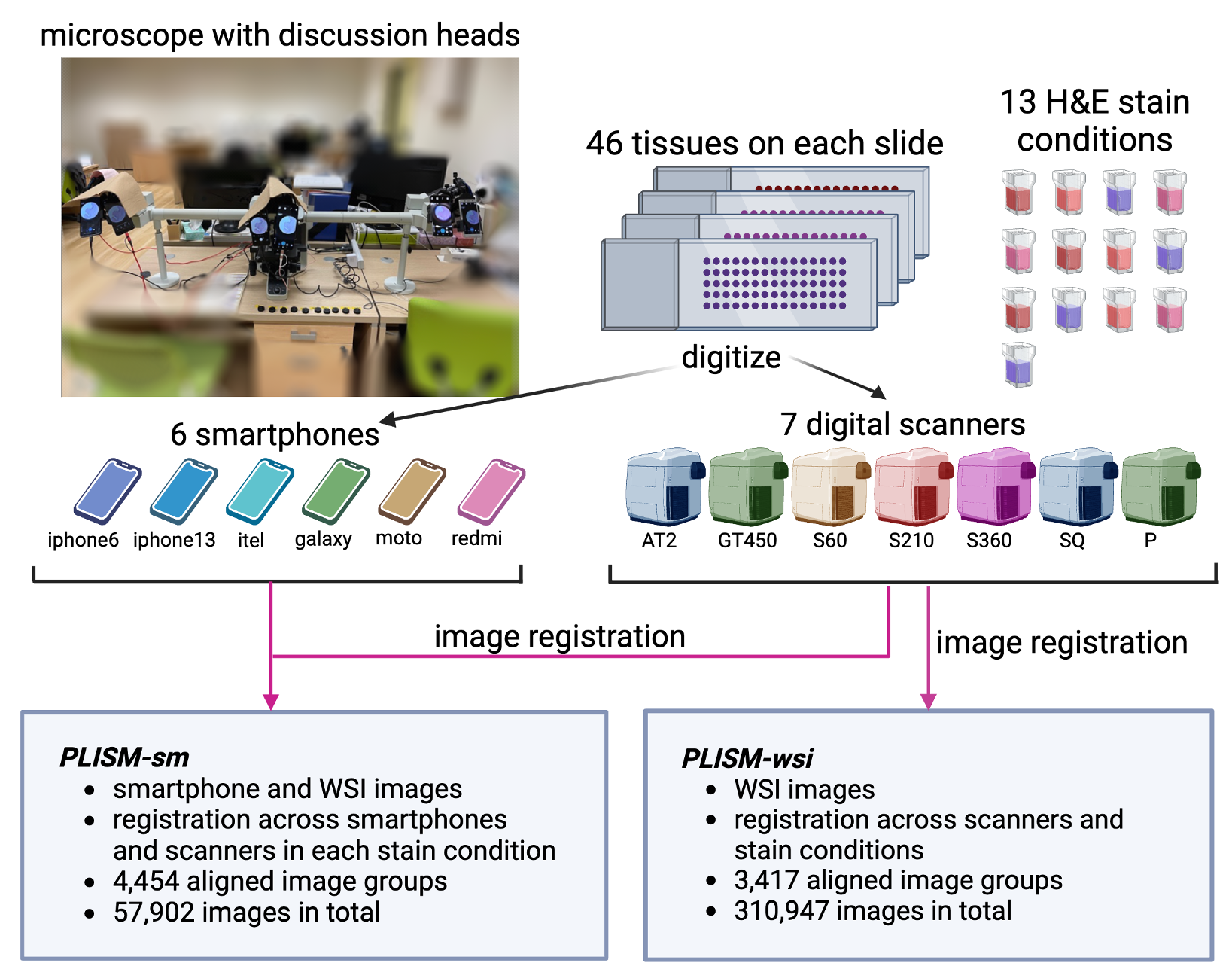
Figure 2: Digitization and staining worflow for PLISM dataset. Source: https://p024eb.github.io/ (Ochi et al., 2024)
PLISM dataset tiles
The original PLISM-wsi subset contains a total of 310,947 images.
Registration was performed across all scanners and staining conditions using OpenCV's AKAZE (Alcantarilla et al., 2013) key-point matching algorithm.
There were 3,417 aligned image groups, with a total of 310,947 (3,417 groups × 91 WSIs) image patches of shape 512x512 at a resolution ranging from 0.22 to 0.26 µm/pixel (40x magnification).
To follow the spirit of this unique and outstanding contribution, we generated an extended version of the original tiles dataset provided by (Ochi et al. 2024) so as to ease its adoption accross the digital pathology community and serve as a reference dataset for benchmarking the robustess of foundation models to staining and scanner variations. In particular, our work differs from the original dataset in the following aspects:
• The original, non-registered WSIs were registered using Elastix (Klein et al., 2010; Shamonin et al., 2014). The reference slide was stained with GMH condition and digitized using Hamamatsu Nanozoomer S60 scanner.
• Tiles of 224x224 pixels were extracted at mpp 0.5 µm/pixel (20x magnification) using an in-house bidirectionnal U-Net (Ronneberger et al., 2015).
• All tiles from the original WSI were extracted, resulting in 16,278 tiles for each of the 91 WSIs.
In total, our dataset encompasses 1,481,298 histology tiles for a total size of 150 Gb.
For each tile, we provide the original slide id (slide_id), tile id (tile_id), stainer and scanner.
How to extract features
🎉 Check plismbench to perform the feature extraction of PLISM dataset and get run our robustness benchmark 🎉
2h30 and roughly 10 Gb storage are necessary to extract all features with a ViT-B model, 16 CPUs and 1 Nvidia T4 (16Go).
License
This dataset is licensed under CC BY 4.0 licence.
Acknowledgments
We thank PLISM dataset's authors for their unique contribution.
Third-party licenses
- PLISM dataset (Ochi et al., 2024) is distributed under CC BY 4.0 license.
- Elastix (Klein et al., 2010; Shamonin et al., 2014) is distributed under Apache 2.0 license.
How to cite
If you are using this dataset, please cite the original article (Ochi et al., 2024) and our work as follows:
APA style
Filiot, A., Dop, N., Tchita, O., Riou, A., Peeters, T., Valter, D., Scalbert, M., Saillard, C., Robin, G., & Olivier, A. (2025). Distilling foundation models for robust and efficient models in digital pathology. arXiv. https://arxiv.org/abs/2501.16239
BibTex entry
@misc{filiot2025distillingfoundationmodelsrobust,
title={Distilling foundation models for robust and efficient models in digital pathology},
author={Alexandre Filiot and Nicolas Dop and Oussama Tchita and Auriane Riou and Thomas Peeters and Daria Valter and Marin Scalbert and Charlie Saillard and Geneviève Robin and Antoine Olivier},
year={2025},
eprint={2501.16239},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2501.16239},
}
References
(Ochi et al., 2024) Ochi, M., Komura, D., Onoyama, T. et al. Registered multi-device/staining histology image dataset for domain-agnostic machine learning models. Sci Data 11, 330 (2024).
(Alcantarilla et al., 2013) Alcantarilla, P., Nuevo, J. & Bartoli, A. Fast explicit diffusion for accelerated features in nonlinear scale spaces. in Procedings of the British Machine Vision Conference 13.1–13.11 (British Machine Vision Assoc., 2013).
(Ronneberger et al., 2015) Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Convolutional networks for biomedical image segmentation. arXiv.
(Klein et al., 2010) Klein, S., Staring, M., Murphy, K., Viergever, M. A., & Pluim, J. P. W. (2010). Elastix: A toolbox for intensity-based medical image registration. IEEE Transactions on Medical Imaging, 29(1), 196–205.
(Shamonin et al., 2014) Shamonin, D. P., Bron, E. E., Lelieveldt, B. P. F., Smits, M., Klein, S., & Staring, M. (2014). Fast parallel image registration on CPU and GPU for diagnostic classification of Alzheimer's disease. Frontiers in Neuroinformatics, 7, 50.
(Filiot et al., 2025) Filiot, A., Dop, N., Tchita, O., Riou, A., Peeters, T., Valter, D., Scalbert, M., Saillard, C., Robin, G., & Olivier, A. (2025). Distilling foundation models for robust and efficient models in digital pathology. arXiv. https://arxiv.org/abs/2501.16239