
text
stringlengths 96
319k
| id
stringlengths 14
178
| metadata
dict |
|---|---|---|
#define WARP_SIZE 32
#define FULL_MASK 0xffffffff
#define OPTIMAL_THREADS 256
__global__ void index_max_cuda_kernel(
float *index_vals, // [batch_size, 32, num_block]
int *indices, // [batch_size, num_block]
float *max_vals, // [batch_size, A_num_block * 32]
float *max_vals_scatter, // [batch_size, 32, num_block]
long batch_size,
long A_num_block,
long B_num_block,
long num_block
);
__global__ void mm_to_sparse_cuda_kernel(
float *dense_A, // [batch_size, A_num_block, dim, 32]
float *dense_B, // [batch_size, B_num_block, dim, 32]
int *indices, // [batch_size, num_block]
float *sparse_C, // [batch_size, num_block, 32, 32]
long batch_size,
long A_num_block,
long B_num_block,
long dim,
long num_block
);
__global__ void sparse_dense_mm_cuda_kernel(
float *sparse_A, // [batch_size, num_block, 32, 32]
int *indices, // [batch_size, num_block]
float *dense_B, // [batch_size, B_num_block, dim, 32]
float *dense_C, // [batch_size, A_num_block, dim, 32]
long batch_size,
long A_num_block,
long B_num_block,
long dim,
long num_block
);
__global__ void reduce_sum_cuda_kernel(
float *sparse_A, // [batch_size, num_block, 32, 32]
int *indices, // [batch_size, num_block]
float *dense_C, // [batch_size, A_num_block, 32]
long batch_size,
long A_num_block,
long B_num_block,
long num_block
);
__global__ void scatter_cuda_kernel(
float *dense_A, // [batch_size, A_num_block, 32]
int *indices, // [batch_size, num_block]
float *sparse_C, // [batch_size, num_block, 32, 32]
long batch_size,
long A_num_block,
long B_num_block,
long num_block
);
| transformers/src/transformers/kernels/mra/cuda_kernel.h/0 | {
"file_path": "transformers/src/transformers/kernels/mra/cuda_kernel.h",
"repo_id": "transformers",
"token_count": 729
} |
import torch
import torch.nn as nn
from ..image_transforms import center_to_corners_format
from ..utils import is_scipy_available
from .loss_for_object_detection import (
HungarianMatcher,
ImageLoss,
_set_aux_loss,
generalized_box_iou,
sigmoid_focal_loss,
)
if is_scipy_available():
from scipy.optimize import linear_sum_assignment
class DeformableDetrHungarianMatcher(HungarianMatcher):
@torch.no_grad()
def forward(self, outputs, targets):
"""
Differences:
- out_prob = outputs["logits"].flatten(0, 1).sigmoid() instead of softmax
- class_cost uses alpha and gamma
"""
batch_size, num_queries = outputs["logits"].shape[:2]
# We flatten to compute the cost matrices in a batch
out_prob = outputs["logits"].flatten(0, 1).sigmoid() # [batch_size * num_queries, num_classes]
out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4]
# Also concat the target labels and boxes
target_ids = torch.cat([v["class_labels"] for v in targets])
target_bbox = torch.cat([v["boxes"] for v in targets])
# Compute the classification cost.
alpha = 0.25
gamma = 2.0
neg_cost_class = (1 - alpha) * (out_prob**gamma) * (-(1 - out_prob + 1e-8).log())
pos_cost_class = alpha * ((1 - out_prob) ** gamma) * (-(out_prob + 1e-8).log())
class_cost = pos_cost_class[:, target_ids] - neg_cost_class[:, target_ids]
# Compute the L1 cost between boxes
bbox_cost = torch.cdist(out_bbox, target_bbox, p=1)
# Compute the giou cost between boxes
giou_cost = -generalized_box_iou(center_to_corners_format(out_bbox), center_to_corners_format(target_bbox))
# Final cost matrix
cost_matrix = self.bbox_cost * bbox_cost + self.class_cost * class_cost + self.giou_cost * giou_cost
cost_matrix = cost_matrix.view(batch_size, num_queries, -1).cpu()
sizes = [len(v["boxes"]) for v in targets]
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(cost_matrix.split(sizes, -1))]
return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
class DeformableDetrImageLoss(ImageLoss):
def __init__(self, matcher, num_classes, focal_alpha, losses):
nn.Module.__init__(self)
self.matcher = matcher
self.num_classes = num_classes
self.focal_alpha = focal_alpha
self.losses = losses
# removed logging parameter, which was part of the original implementation
def loss_labels(self, outputs, targets, indices, num_boxes):
"""
Classification loss (Binary focal loss) targets dicts must contain the key "class_labels" containing a tensor
of dim [nb_target_boxes]
"""
if "logits" not in outputs:
raise KeyError("No logits were found in the outputs")
source_logits = outputs["logits"]
idx = self._get_source_permutation_idx(indices)
target_classes_o = torch.cat([t["class_labels"][J] for t, (_, J) in zip(targets, indices)])
target_classes = torch.full(
source_logits.shape[:2], self.num_classes, dtype=torch.int64, device=source_logits.device
)
target_classes[idx] = target_classes_o
target_classes_onehot = torch.zeros(
[source_logits.shape[0], source_logits.shape[1], source_logits.shape[2] + 1],
dtype=source_logits.dtype,
layout=source_logits.layout,
device=source_logits.device,
)
target_classes_onehot.scatter_(2, target_classes.unsqueeze(-1), 1)
target_classes_onehot = target_classes_onehot[:, :, :-1]
loss_ce = (
sigmoid_focal_loss(source_logits, target_classes_onehot, num_boxes, alpha=self.focal_alpha, gamma=2)
* source_logits.shape[1]
)
losses = {"loss_ce": loss_ce}
return losses
def DeformableDetrForSegmentationLoss(
logits, labels, device, pred_boxes, pred_masks, config, outputs_class=None, outputs_coord=None, **kwargs
):
# First: create the matcher
matcher = HungarianMatcher(class_cost=config.class_cost, bbox_cost=config.bbox_cost, giou_cost=config.giou_cost)
# Second: create the criterion
losses = ["labels", "boxes", "cardinality", "masks"]
criterion = DeformableDetrImageLoss(
matcher=matcher,
num_classes=config.num_labels,
focal_alpha=config.focal_alpha,
losses=losses,
)
criterion.to(device)
# Third: compute the losses, based on outputs and labels
outputs_loss = {}
outputs_loss["logits"] = logits
outputs_loss["pred_boxes"] = pred_boxes
outputs_loss["pred_masks"] = pred_masks
auxiliary_outputs = None
if config.auxiliary_loss:
auxiliary_outputs = _set_aux_loss(outputs_class, outputs_coord)
outputs_loss["auxiliary_outputs"] = auxiliary_outputs
loss_dict = criterion(outputs_loss, labels)
# Fourth: compute total loss, as a weighted sum of the various losses
weight_dict = {"loss_ce": 1, "loss_bbox": config.bbox_loss_coefficient}
weight_dict["loss_giou"] = config.giou_loss_coefficient
weight_dict["loss_mask"] = config.mask_loss_coefficient
weight_dict["loss_dice"] = config.dice_loss_coefficient
if config.auxiliary_loss:
aux_weight_dict = {}
for i in range(config.decoder_layers - 1):
aux_weight_dict.update({k + f"_{i}": v for k, v in weight_dict.items()})
weight_dict.update(aux_weight_dict)
loss = sum(loss_dict[k] * weight_dict[k] for k in loss_dict.keys() if k in weight_dict)
return loss, loss_dict, auxiliary_outputs
def DeformableDetrForObjectDetectionLoss(
logits, labels, device, pred_boxes, config, outputs_class=None, outputs_coord=None, **kwargs
):
# First: create the matcher
matcher = DeformableDetrHungarianMatcher(
class_cost=config.class_cost, bbox_cost=config.bbox_cost, giou_cost=config.giou_cost
)
# Second: create the criterion
losses = ["labels", "boxes", "cardinality"]
criterion = DeformableDetrImageLoss(
matcher=matcher,
num_classes=config.num_labels,
focal_alpha=config.focal_alpha,
losses=losses,
)
criterion.to(device)
# Third: compute the losses, based on outputs and labels
outputs_loss = {}
auxiliary_outputs = None
outputs_loss["logits"] = logits
outputs_loss["pred_boxes"] = pred_boxes
if config.auxiliary_loss:
auxiliary_outputs = _set_aux_loss(outputs_class, outputs_coord)
outputs_loss["auxiliary_outputs"] = auxiliary_outputs
loss_dict = criterion(outputs_loss, labels)
# Fourth: compute total loss, as a weighted sum of the various losses
weight_dict = {"loss_ce": 1, "loss_bbox": config.bbox_loss_coefficient}
weight_dict["loss_giou"] = config.giou_loss_coefficient
if config.auxiliary_loss:
aux_weight_dict = {}
for i in range(config.decoder_layers - 1):
aux_weight_dict.update({k + f"_{i}": v for k, v in weight_dict.items()})
weight_dict.update(aux_weight_dict)
loss = sum(loss_dict[k] * weight_dict[k] for k in loss_dict.keys() if k in weight_dict)
return loss, loss_dict, auxiliary_outputs
| transformers/src/transformers/loss/loss_deformable_detr.py/0 | {
"file_path": "transformers/src/transformers/loss/loss_deformable_detr.py",
"repo_id": "transformers",
"token_count": 3043
} |
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors, Facebook AI Research authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import collections
import copy
import functools
import gc
import importlib.metadata
import inspect
import itertools
import json
import os
import re
import shutil
import tempfile
import warnings
from contextlib import contextmanager
from dataclasses import dataclass
from functools import partial, wraps
from threading import Thread
from typing import Any, Callable, Dict, List, Optional, Set, Tuple, Type, TypeVar, Union
from zipfile import is_zipfile
import torch
from huggingface_hub import split_torch_state_dict_into_shards
from packaging import version
from torch import Tensor, nn
from torch.distributions import constraints
from torch.nn import CrossEntropyLoss, Identity
from torch.utils.checkpoint import checkpoint
from .activations import get_activation
from .configuration_utils import PretrainedConfig
from .dynamic_module_utils import custom_object_save
from .generation import CompileConfig, GenerationConfig, GenerationMixin
from .integrations import PeftAdapterMixin, deepspeed_config, is_deepspeed_zero3_enabled
from .integrations.flash_attention import flash_attention_forward
from .integrations.flex_attention import flex_attention_forward
from .integrations.sdpa_attention import sdpa_attention_forward
from .loss.loss_utils import LOSS_MAPPING
from .pytorch_utils import ( # noqa: F401
Conv1D,
apply_chunking_to_forward,
find_pruneable_heads_and_indices,
id_tensor_storage,
prune_conv1d_layer,
prune_layer,
prune_linear_layer,
translate_to_torch_parallel_style,
)
from .quantizers import AutoHfQuantizer, HfQuantizer
from .quantizers.quantizers_utils import get_module_from_name
from .safetensors_conversion import auto_conversion
from .utils import (
ACCELERATE_MIN_VERSION,
ADAPTER_SAFE_WEIGHTS_NAME,
ADAPTER_WEIGHTS_NAME,
CONFIG_NAME,
DUMMY_INPUTS,
FLAX_WEIGHTS_NAME,
SAFE_WEIGHTS_INDEX_NAME,
SAFE_WEIGHTS_NAME,
TF2_WEIGHTS_NAME,
TF_WEIGHTS_NAME,
WEIGHTS_INDEX_NAME,
WEIGHTS_NAME,
ContextManagers,
ModelOutput,
PushToHubMixin,
cached_file,
copy_func,
download_url,
extract_commit_hash,
has_file,
is_accelerate_available,
is_bitsandbytes_available,
is_flash_attn_2_available,
is_offline_mode,
is_optimum_available,
is_peft_available,
is_remote_url,
is_safetensors_available,
is_torch_flex_attn_available,
is_torch_greater_or_equal,
is_torch_sdpa_available,
is_torch_xla_available,
logging,
replace_return_docstrings,
strtobool,
)
from .utils.hub import create_and_tag_model_card, get_checkpoint_shard_files
from .utils.import_utils import (
ENV_VARS_TRUE_VALUES,
is_sagemaker_mp_enabled,
is_torch_fx_proxy,
is_torchdynamo_compiling,
)
from .utils.quantization_config import BitsAndBytesConfig, QuantizationMethod
XLA_USE_BF16 = os.environ.get("XLA_USE_BF16", "0").upper()
XLA_DOWNCAST_BF16 = os.environ.get("XLA_DOWNCAST_BF16", "0").upper()
if is_accelerate_available():
from accelerate import dispatch_model, infer_auto_device_map, init_empty_weights
from accelerate.hooks import add_hook_to_module
from accelerate.utils import (
check_tied_parameters_on_same_device,
extract_model_from_parallel,
find_tied_parameters,
get_balanced_memory,
get_max_memory,
load_offloaded_weights,
offload_weight,
save_offload_index,
set_module_tensor_to_device,
)
accelerate_version = version.parse(importlib.metadata.version("accelerate"))
if accelerate_version >= version.parse("0.31"):
from accelerate.utils.modeling import get_state_dict_from_offload
if is_safetensors_available():
from safetensors import safe_open
from safetensors.torch import load_file as safe_load_file
from safetensors.torch import save_file as safe_save_file
logger = logging.get_logger(__name__)
_init_weights = True
_is_quantized = False
_is_ds_init_called = False
def is_fsdp_enabled():
return (
torch.distributed.is_available()
and torch.distributed.is_initialized()
and strtobool(os.environ.get("ACCELERATE_USE_FSDP", "False")) == 1
and strtobool(os.environ.get("FSDP_CPU_RAM_EFFICIENT_LOADING", "False")) == 1
)
def is_local_dist_rank_0():
return (
torch.distributed.is_available()
and torch.distributed.is_initialized()
and int(os.environ.get("LOCAL_RANK", -1)) == 0
)
if is_sagemaker_mp_enabled():
import smdistributed.modelparallel.torch as smp
from smdistributed.modelparallel import __version__ as SMP_VERSION
IS_SAGEMAKER_MP_POST_1_10 = version.parse(SMP_VERSION) >= version.parse("1.10")
else:
IS_SAGEMAKER_MP_POST_1_10 = False
if is_peft_available():
from .utils import find_adapter_config_file
SpecificPreTrainedModelType = TypeVar("SpecificPreTrainedModelType", bound="PreTrainedModel")
TORCH_INIT_FUNCTIONS = {
"uniform_": nn.init.uniform_,
"normal_": nn.init.normal_,
"trunc_normal_": nn.init.trunc_normal_,
"constant_": nn.init.constant_,
"xavier_uniform_": nn.init.xavier_uniform_,
"xavier_normal_": nn.init.xavier_normal_,
"kaiming_uniform_": nn.init.kaiming_uniform_,
"kaiming_normal_": nn.init.kaiming_normal_,
"uniform": nn.init.uniform,
"normal": nn.init.normal,
"xavier_uniform": nn.init.xavier_uniform,
"xavier_normal": nn.init.xavier_normal,
"kaiming_uniform": nn.init.kaiming_uniform,
"kaiming_normal": nn.init.kaiming_normal,
}
@contextmanager
def no_init_weights(_enable=True):
"""
Context manager to globally disable weight initialization to speed up loading large models.
TODO(Patrick): Delete safety argument `_enable=True` at next major version. .
"""
global _init_weights
old_init_weights = _init_weights
if _enable:
_init_weights = False
def _skip_init(*args, **kwargs):
pass
# # Save the original initialization functions
for name, init_func in TORCH_INIT_FUNCTIONS.items():
setattr(torch.nn.init, name, _skip_init)
try:
yield
finally:
_init_weights = old_init_weights
if _enable:
# # Restore the original initialization functions
for name, init_func in TORCH_INIT_FUNCTIONS.items():
setattr(torch.nn.init, name, init_func)
@contextmanager
def set_quantized_state():
global _is_quantized
_is_quantized = True
try:
yield
finally:
_is_quantized = False
# Skip recursive calls to deepspeed.zero.Init to avoid pinning errors.
# This issue occurs with ZeRO stage 3 when using NVMe offloading.
# For more details, refer to issue #34429.
@contextmanager
def set_zero3_state():
global _is_ds_init_called
_is_ds_init_called = True
try:
yield
finally:
_is_ds_init_called = False
def restore_default_torch_dtype(func):
"""
Decorator to restore the default torch dtype
at the end of the function. Serves
as a backup in case calling the function raises
an error after the function has changed the default dtype but before it could restore it.
"""
@wraps(func)
def _wrapper(*args, **kwargs):
old_dtype = torch.get_default_dtype()
try:
return func(*args, **kwargs)
finally:
torch.set_default_dtype(old_dtype)
return _wrapper
def get_parameter_device(parameter: Union[nn.Module, "ModuleUtilsMixin"]):
try:
return next(parameter.parameters()).device
except StopIteration:
# For nn.DataParallel compatibility in PyTorch 1.5
def find_tensor_attributes(module: nn.Module) -> List[Tuple[str, Tensor]]:
tuples = [(k, v) for k, v in module.__dict__.items() if torch.is_tensor(v)]
return tuples
gen = parameter._named_members(get_members_fn=find_tensor_attributes)
first_tuple = next(gen)
return first_tuple[1].device
def get_first_parameter_dtype(parameter: Union[nn.Module, "ModuleUtilsMixin"]):
"""
Returns the first parameter dtype (can be non-floating) or asserts if none were found.
"""
try:
return next(parameter.parameters()).dtype
except StopIteration:
# For nn.DataParallel compatibility in PyTorch > 1.5
def find_tensor_attributes(module: nn.Module) -> List[Tuple[str, Tensor]]:
tuples = [(k, v) for k, v in module.__dict__.items() if torch.is_tensor(v)]
return tuples
gen = parameter._named_members(get_members_fn=find_tensor_attributes)
first_tuple = next(gen)
return first_tuple[1].dtype
def get_parameter_dtype(parameter: Union[nn.Module, "ModuleUtilsMixin"]):
"""
Returns the first found floating dtype in parameters if there is one, otherwise returns the last dtype it found.
"""
last_dtype = None
for t in parameter.parameters():
last_dtype = t.dtype
if t.is_floating_point():
# Adding fix for https://github.com/pytorch/xla/issues/4152
# Fixes issue where the model code passes a value that is out of range for XLA_USE_BF16=1
# and XLA_DOWNCAST_BF16=1 so the conversion would cast it to -inf
# NOTE: `is_torch_xla_available()` is checked last as it induces a graph break in torch dynamo
if XLA_USE_BF16 in ENV_VARS_TRUE_VALUES and is_torch_xla_available():
return torch.bfloat16
if XLA_DOWNCAST_BF16 in ENV_VARS_TRUE_VALUES and is_torch_xla_available():
if t.dtype == torch.float:
return torch.bfloat16
if t.dtype == torch.double:
return torch.float32
return t.dtype
if last_dtype is not None:
# if no floating dtype was found return whatever the first dtype is
return last_dtype
# For nn.DataParallel compatibility in PyTorch > 1.5
def find_tensor_attributes(module: nn.Module) -> List[Tuple[str, Tensor]]:
tuples = [(k, v) for k, v in module.__dict__.items() if torch.is_tensor(v)]
return tuples
gen = parameter._named_members(get_members_fn=find_tensor_attributes)
last_tuple = None
for tuple in gen:
last_tuple = tuple
if tuple[1].is_floating_point():
return tuple[1].dtype
if last_tuple is not None:
# fallback to the last dtype
return last_tuple[1].dtype
# fallback to buffer dtype
for t in parameter.buffers():
last_dtype = t.dtype
if t.is_floating_point():
return t.dtype
return last_dtype
def get_state_dict_float_dtype(state_dict):
"""
Returns the first found floating dtype in `state_dict` or asserts if none were found.
"""
for t in state_dict.values():
if t.is_floating_point():
return t.dtype
raise ValueError("couldn't find any floating point dtypes in state_dict")
def get_state_dict_dtype(state_dict):
"""
Returns the first found floating dtype in `state_dict` if there is one, otherwise returns the first dtype.
"""
for t in state_dict.values():
if t.is_floating_point():
return t.dtype
# if no floating dtype was found return whatever the first dtype is
else:
return next(state_dict.values()).dtype
def dtype_byte_size(dtype):
"""
Returns the size (in bytes) occupied by one parameter of type `dtype`.
Example:
```py
>>> dtype_byte_size(torch.float32)
4
```
"""
if dtype == torch.bool:
return 1 / 8
bit_search = re.search(r"[^\d](\d+)_?", str(dtype))
if bit_search is None:
raise ValueError(f"`dtype` is not a valid dtype: {dtype}.")
bit_size = int(bit_search.groups()[0])
return bit_size // 8
def check_support_param_buffer_assignment(model_to_load, state_dict, start_prefix=""):
"""
Checks if `model_to_load` supports param buffer assignment (such
as when loading in empty weights) by first checking
if the model explicitly disables it, then by ensuring that the state dict keys
are a subset of the model's parameters.
Note: We fully disable this if we are using `deepspeed`
"""
if model_to_load.device.type == "meta":
return False
if len([key for key in state_dict if key.startswith(start_prefix)]) == 0:
return False
if is_deepspeed_zero3_enabled():
return False
# Some models explicitly do not support param buffer assignment
if not getattr(model_to_load, "_supports_param_buffer_assignment", True):
logger.debug(
f"{model_to_load.__class__.__name__} does not support param buffer assignment, loading will be slower"
)
return False
# If the model does, the incoming `state_dict` and the `model_to_load` must be the same dtype
first_key = next(iter(model_to_load.state_dict().keys()))
if start_prefix + first_key in state_dict:
return state_dict[start_prefix + first_key].dtype == model_to_load.state_dict()[first_key].dtype
# For cases when the `state_dict` doesn't contain real weights to the model (`test_model_weights_reload_no_missing_tied_weights`)
return False
def load_sharded_checkpoint(model, folder, strict=True, prefer_safe=True):
"""
This is the same as
[`torch.nn.Module.load_state_dict`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html?highlight=load_state_dict#torch.nn.Module.load_state_dict)
but for a sharded checkpoint.
This load is performed efficiently: each checkpoint shard is loaded one by one in RAM and deleted after being
loaded in the model.
Args:
model (`torch.nn.Module`): The model in which to load the checkpoint.
folder (`str` or `os.PathLike`): A path to a folder containing the sharded checkpoint.
strict (`bool`, *optional`, defaults to `True`):
Whether to strictly enforce that the keys in the model state dict match the keys in the sharded checkpoint.
prefer_safe (`bool`, *optional*, defaults to `False`)
If both safetensors and PyTorch save files are present in checkpoint and `prefer_safe` is True, the
safetensors files will be loaded. Otherwise, PyTorch files are always loaded when possible.
Returns:
`NamedTuple`: A named tuple with `missing_keys` and `unexpected_keys` fields
- `missing_keys` is a list of str containing the missing keys
- `unexpected_keys` is a list of str containing the unexpected keys
"""
# Load the index
index_file = os.path.join(folder, WEIGHTS_INDEX_NAME)
safe_index_file = os.path.join(folder, SAFE_WEIGHTS_INDEX_NAME)
index_present = os.path.isfile(index_file)
safe_index_present = os.path.isfile(safe_index_file)
if not index_present and not (safe_index_present and is_safetensors_available()):
filenames = (
(WEIGHTS_INDEX_NAME, SAFE_WEIGHTS_INDEX_NAME) if is_safetensors_available() else (WEIGHTS_INDEX_NAME,)
)
raise ValueError(f"Can't find a checkpoint index ({' or '.join(filenames)}) in {folder}.")
load_safe = False
if safe_index_present:
if prefer_safe:
if is_safetensors_available():
load_safe = True # load safe due to preference
else:
logger.warning(
f"Cannot load sharded checkpoint at {folder} safely since safetensors is not installed!"
)
elif not index_present:
load_safe = True # load safe since we have no other choice
load_index = safe_index_file if load_safe else index_file
with open(load_index, "r", encoding="utf-8") as f:
index = json.load(f)
shard_files = list(set(index["weight_map"].values()))
# If strict=True, error before loading any of the state dicts.
loaded_keys = index["weight_map"].keys()
model_keys = model.state_dict().keys()
missing_keys = [key for key in model_keys if key not in loaded_keys]
unexpected_keys = [key for key in loaded_keys if key not in model_keys]
if strict and (len(missing_keys) > 0 or len(unexpected_keys) > 0):
error_message = f"Error(s) in loading state_dict for {model.__class__.__name__}"
if len(missing_keys) > 0:
str_missing_keys = ",".join([f'"{k}"' for k in missing_keys])
error_message += f"\nMissing key(s): {str_missing_keys}."
if len(unexpected_keys) > 0:
str_unexpected_keys = ",".join([f'"{k}"' for k in unexpected_keys])
error_message += f"\nMissing key(s): {str_unexpected_keys}."
raise RuntimeError(error_message)
weights_only_kwarg = {"weights_only": True}
loader = safe_load_file if load_safe else partial(torch.load, map_location="cpu", **weights_only_kwarg)
for shard_file in shard_files:
state_dict = loader(os.path.join(folder, shard_file))
model.load_state_dict(state_dict, strict=False)
# Make sure memory is freed before we load the next state dict.
del state_dict
gc.collect()
# Return the same thing as PyTorch load_state_dict function.
return torch.nn.modules.module._IncompatibleKeys(missing_keys, unexpected_keys)
def load_state_dict(
checkpoint_file: Union[str, os.PathLike],
is_quantized: bool = False,
map_location: Optional[Union[str, torch.device]] = None,
weights_only: bool = True,
):
"""
Reads a PyTorch checkpoint file, returning properly formatted errors if they arise.
"""
if checkpoint_file.endswith(".safetensors") and is_safetensors_available():
# Check format of the archive
with safe_open(checkpoint_file, framework="pt") as f:
metadata = f.metadata()
if metadata is not None and metadata.get("format") not in ["pt", "tf", "flax", "mlx"]:
raise OSError(
f"The safetensors archive passed at {checkpoint_file} does not contain the valid metadata. Make sure "
"you save your model with the `save_pretrained` method."
)
return safe_load_file(checkpoint_file)
try:
if map_location is None:
if (
(
is_deepspeed_zero3_enabled()
and torch.distributed.is_initialized()
and torch.distributed.get_rank() > 0
)
or (is_fsdp_enabled() and not is_local_dist_rank_0())
) and not is_quantized:
map_location = "meta"
else:
map_location = "cpu"
extra_args = {}
# mmap can only be used with files serialized with zipfile-based format.
if (
isinstance(checkpoint_file, str)
and map_location != "meta"
and version.parse(torch.__version__) >= version.parse("2.1.0")
and is_zipfile(checkpoint_file)
):
extra_args = {"mmap": True}
weights_only_kwarg = {"weights_only": weights_only}
return torch.load(
checkpoint_file,
map_location=map_location,
**weights_only_kwarg,
**extra_args,
)
except Exception as e:
try:
with open(checkpoint_file) as f:
if f.read(7) == "version":
raise OSError(
"You seem to have cloned a repository without having git-lfs installed. Please install "
"git-lfs and run `git lfs install` followed by `git lfs pull` in the folder "
"you cloned."
)
else:
raise ValueError(
f"Unable to locate the file {checkpoint_file} which is necessary to load this pretrained "
"model. Make sure you have saved the model properly."
) from e
except (UnicodeDecodeError, ValueError):
raise OSError(
f"Unable to load weights from pytorch checkpoint file for '{checkpoint_file}' "
f"at '{checkpoint_file}'. "
"If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True."
)
def set_initialized_submodules(model, state_dict_keys):
"""
Sets the `_is_hf_initialized` flag in all submodules of a given model when all its weights are in the loaded state
dict.
"""
state_dict_keys = set(state_dict_keys)
not_initialized_submodules = {}
for module_name, module in model.named_modules():
if module_name == "":
# When checking if the root module is loaded there's no need to prepend module_name.
module_keys = set(module.state_dict())
else:
module_keys = {f"{module_name}.{k}" for k in module.state_dict()}
if module_keys.issubset(state_dict_keys):
module._is_hf_initialized = True
else:
not_initialized_submodules[module_name] = module
return not_initialized_submodules
def _end_ptr(tensor: torch.Tensor) -> int:
# extract the end of the pointer if the tensor is a slice of a bigger tensor
if tensor.nelement():
stop = tensor.view(-1)[-1].data_ptr() + tensor.element_size()
else:
stop = tensor.data_ptr()
return stop
def _get_tied_weight_keys(module: nn.Module, prefix=""):
tied_weight_keys = []
if getattr(module, "_tied_weights_keys", None) is not None:
names = [f"{prefix}.{k}" if prefix else k for k in module._tied_weights_keys]
tied_weight_keys.extend(names)
if getattr(module, "_dynamic_tied_weights_keys", None) is not None:
names = [f"{prefix}.{k}" if prefix else k for k in module._dynamic_tied_weights_keys]
tied_weight_keys.extend(names)
for name, submodule in module.named_children():
local_prefix = f"{prefix}.{name}" if prefix else name
tied_weight_keys.extend(_get_tied_weight_keys(submodule, prefix=local_prefix))
return tied_weight_keys
def _find_disjoint(tensors: List[Set[str]], state_dict: Dict[str, torch.Tensor]) -> Tuple[List[Set[str]], List[str]]:
filtered_tensors = []
for shared in tensors:
if len(shared) < 2:
filtered_tensors.append(shared)
continue
areas = []
for name in shared:
tensor = state_dict[name]
areas.append((tensor.data_ptr(), _end_ptr(tensor), name))
areas.sort()
_, last_stop, last_name = areas[0]
filtered_tensors.append({last_name})
for start, stop, name in areas[1:]:
if start >= last_stop:
filtered_tensors.append({name})
else:
filtered_tensors[-1].add(name)
last_stop = stop
disjoint_tensors = []
shared_tensors = []
for tensors in filtered_tensors:
if len(tensors) == 1:
disjoint_tensors.append(tensors.pop())
else:
shared_tensors.append(tensors)
return shared_tensors, disjoint_tensors
def _find_identical(tensors: List[Set[str]], state_dict: Dict[str, torch.Tensor]) -> Tuple[List[Set[str]], Set[str]]:
shared_tensors = []
identical = []
for shared in tensors:
if len(shared) < 2:
continue
areas = collections.defaultdict(set)
for name in shared:
tensor = state_dict[name]
area = (tensor.device, tensor.data_ptr(), _end_ptr(tensor))
areas[area].add(name)
if len(areas) == 1:
identical.append(shared)
else:
shared_tensors.append(shared)
return shared_tensors, identical
def _load_state_dict_into_model(model_to_load, state_dict, start_prefix, assign_to_params_buffers=False):
# copy state_dict so _load_from_state_dict can modify it
metadata = getattr(state_dict, "_metadata", None)
state_dict = state_dict.copy()
if metadata is not None:
state_dict._metadata = metadata
error_msgs = []
# PyTorch's `_load_from_state_dict` does not copy parameters in a module's descendants
# so we need to apply the function recursively.
def load(module: nn.Module, state_dict, prefix="", assign_to_params_buffers=False):
local_metadata = {} if metadata is None else metadata.get(prefix[:-1], {})
local_metadata["assign_to_params_buffers"] = assign_to_params_buffers
args = (state_dict, prefix, local_metadata, True, [], [], error_msgs)
# Parameters of module and children will start with prefix. We can exit early if there are none in this
# state_dict
if len([key for key in state_dict if key.startswith(prefix)]) > 0:
if is_deepspeed_zero3_enabled():
import deepspeed
# In sharded models, each shard has only part of the full state_dict, so only gather
# parameters that are in the current state_dict.
named_parameters = dict(module.named_parameters(prefix=prefix[:-1], recurse=False))
params_to_gather = [named_parameters[k] for k in state_dict.keys() if k in named_parameters]
if len(params_to_gather) > 0:
# because zero3 puts placeholders in model params, this context
# manager gathers (unpartitions) the params of the current layer, then loads from
# the state dict and then re-partitions them again
with deepspeed.zero.GatheredParameters(params_to_gather, modifier_rank=0):
if torch.distributed.get_rank() == 0:
module._load_from_state_dict(*args)
else:
module._load_from_state_dict(*args)
for name, child in module._modules.items():
if child is not None:
load(child, state_dict, prefix + name + ".", assign_to_params_buffers)
load(model_to_load, state_dict, prefix=start_prefix, assign_to_params_buffers=assign_to_params_buffers)
# Delete `state_dict` so it could be collected by GC earlier. Note that `state_dict` is a copy of the argument, so
# it's safe to delete it.
del state_dict
return error_msgs
def find_submodule_and_param_name(model, long_key, start_prefix):
"""
A helper util to find the last sub-module and the param/buffer name. If `start_prefix` is supplied it'll be removed
from the start of the key
"""
if len(start_prefix) > 0 and long_key.startswith(start_prefix):
long_key = ".".join(long_key.split(".")[1:])
split_key = long_key.split(".")
submodule = model
while len(split_key) > 1:
if hasattr(submodule, split_key[0]):
submodule = getattr(submodule, split_key[0])
del split_key[0]
else:
submodule = None
break
if submodule == model:
submodule = None
return submodule, split_key[0]
def _move_model_to_meta(model, loaded_state_dict_keys, start_prefix):
"""
Moves `loaded_state_dict_keys` in model to meta device which frees up the memory taken by those params.
`start_prefix` is used for models which insert their name into model keys, e.g. `bert` in
`bert.pooler.dense.weight`
"""
# dematerialize param storage for keys that are going to be replaced by state_dict, by
# putting those on the meta device
for k in loaded_state_dict_keys:
submodule, param_name = find_submodule_and_param_name(model, k, start_prefix)
if submodule is not None:
# selectively switch to the meta device only those params/buffers that will
# be next replaced from state_dict. This a complex way to do p.to_("meta")
# since we have no in-place to_ for tensors.
new_val = getattr(submodule, param_name)
if isinstance(new_val, torch.nn.Parameter):
# isinstance returns False for Params on meta device, so switch after the check
new_val = torch.nn.Parameter(new_val.to("meta"))
else:
new_val = new_val.to("meta")
setattr(submodule, param_name, new_val)
def _load_state_dict_into_meta_model(
model,
state_dict,
start_prefix,
expected_keys,
device_map=None,
offload_folder=None,
offload_index=None,
state_dict_folder=None,
state_dict_index=None,
dtype=None,
hf_quantizer=None,
is_safetensors=False,
keep_in_fp32_modules=None,
unexpected_keys=None, # passing `unexpected` for cleanup from quantization items
pretrained_model_name_or_path=None, # for flagging the user when the model contains renamed keys
):
"""
This is somewhat similar to `_load_state_dict_into_model`, but deals with a model that has some or all of its
params on a `meta` device. It replaces the model params with the data from the `state_dict`, while moving the
params back to the normal device, but only for `loaded_state_dict_keys`.
`start_prefix` is used for models which insert their name into model keys, e.g. `bert` in
`bert.pooler.dense.weight`
"""
# XXX: remaining features to implement to be fully compatible with _load_state_dict_into_model
# - deepspeed zero 3 support
# - need to copy metadata if any - see _load_state_dict_into_model
# - handling error_msgs - mimicking the error handling in module._load_from_state_dict()
error_msgs = []
is_quantized = hf_quantizer is not None
is_torch_e4m3fn_available = hasattr(torch, "float8_e4m3fn")
for param_name, param in state_dict.items():
if param_name not in expected_keys:
continue
if param_name.startswith(start_prefix):
param_name = param_name[len(start_prefix) :]
module_name = param_name
set_module_kwargs = {}
# We convert floating dtypes to the `dtype` passed except for float8_e4m3fn type. We also want to keep the buffers/params
# in int/uint/bool and not cast them.
is_param_float8_e4m3fn = is_torch_e4m3fn_available and param.dtype == torch.float8_e4m3fn
if dtype is not None and torch.is_floating_point(param) and not is_param_float8_e4m3fn:
if (
keep_in_fp32_modules is not None
and any(
module_to_keep_in_fp32 in param_name.split(".") for module_to_keep_in_fp32 in keep_in_fp32_modules
)
and dtype == torch.float16
):
param = param.to(torch.float32)
# For backward compatibility with older versions of `accelerate`
# TODO: @sgugger replace this check with version check at the next `accelerate` release
if "dtype" in list(inspect.signature(set_module_tensor_to_device).parameters):
set_module_kwargs["dtype"] = torch.float32
else:
param = param.to(dtype)
# For compatibility with PyTorch load_state_dict which converts state dict dtype to existing dtype in model, and which
# uses `param.copy_(input_param)` that preserves the contiguity of the parameter in the model.
# Reference: https://github.com/pytorch/pytorch/blob/db79ceb110f6646523019a59bbd7b838f43d4a86/torch/nn/modules/module.py#L2040C29-L2040C29
old_param = model
splits = param_name.split(".")
for split in splits:
# We shouldn't hit the default value unless for quant methods like hqq that modifies expected_keys.
old_param = getattr(old_param, split, None)
if old_param is None:
break
if not isinstance(old_param, (torch.nn.Parameter, torch.Tensor)):
old_param = None
if old_param is not None:
if dtype is None:
param = param.to(old_param.dtype)
if old_param.is_contiguous():
param = param.contiguous()
set_module_kwargs["value"] = param
if device_map is None:
param_device = "cpu"
else:
# find next higher level module that is defined in device_map:
# bert.lm_head.weight -> bert.lm_head -> bert -> ''
while len(module_name) > 0 and module_name not in device_map:
module_name = ".".join(module_name.split(".")[:-1])
if module_name == "" and "" not in device_map:
# TODO: group all errors and raise at the end.
raise ValueError(f"{param_name} doesn't have any device set.")
param_device = device_map[module_name]
if param_device == "disk":
if not is_safetensors:
offload_index = offload_weight(param, param_name, offload_folder, offload_index)
elif param_device == "cpu" and state_dict_index is not None:
state_dict_index = offload_weight(param, param_name, state_dict_folder, state_dict_index)
elif (
not is_quantized
or (not hf_quantizer.requires_parameters_quantization)
or (
not hf_quantizer.check_quantized_param(
model, param, param_name, state_dict, param_device=param_device, device_map=device_map
)
)
):
if is_fsdp_enabled():
param_device = "cpu" if is_local_dist_rank_0() else "meta"
# For backward compatibility with older versions of `accelerate` and for non-quantized params
set_module_tensor_to_device(model, param_name, param_device, **set_module_kwargs)
else:
hf_quantizer.create_quantized_param(model, param, param_name, param_device, state_dict, unexpected_keys)
# For quantized modules with FSDP/DeepSpeed Stage 3, we need to quantize the parameter on the GPU
# and then cast it to CPU to avoid excessive memory usage on each GPU
# in comparison to the sharded model across GPUs.
if is_fsdp_enabled() or is_deepspeed_zero3_enabled():
module, tensor_name = get_module_from_name(model, param_name)
value = getattr(module, tensor_name)
param_to = "cpu"
if is_fsdp_enabled() and not is_local_dist_rank_0():
param_to = "meta"
val_kwargs = {}
if hasattr(module, "weight") and module.weight.__class__.__name__ == "Int8Params":
val_kwargs["requires_grad"] = False
value = type(value)(value.data.to(param_to), **val_kwargs, **value.__dict__)
setattr(module, tensor_name, value)
# TODO: consider removing used param_parts from state_dict before return
return error_msgs, offload_index, state_dict_index
def _add_variant(weights_name: str, variant: Optional[str] = None) -> str:
if variant is not None:
splits = weights_name.split(".")
splits = splits[:-1] + [variant] + splits[-1:]
weights_name = ".".join(splits)
return weights_name
class ModuleUtilsMixin:
"""
A few utilities for `torch.nn.Modules`, to be used as a mixin.
"""
@staticmethod
def _hook_rss_memory_pre_forward(module, *args, **kwargs):
try:
import psutil
except ImportError:
raise ImportError("You need to install psutil (pip install psutil) to use memory tracing.")
process = psutil.Process(os.getpid())
mem = process.memory_info()
module.mem_rss_pre_forward = mem.rss
return None
@staticmethod
def _hook_rss_memory_post_forward(module, *args, **kwargs):
try:
import psutil
except ImportError:
raise ImportError("You need to install psutil (pip install psutil) to use memory tracing.")
process = psutil.Process(os.getpid())
mem = process.memory_info()
module.mem_rss_post_forward = mem.rss
mem_rss_diff = module.mem_rss_post_forward - module.mem_rss_pre_forward
module.mem_rss_diff = mem_rss_diff + (module.mem_rss_diff if hasattr(module, "mem_rss_diff") else 0)
return None
def add_memory_hooks(self):
"""
Add a memory hook before and after each sub-module forward pass to record increase in memory consumption.
Increase in memory consumption is stored in a `mem_rss_diff` attribute for each module and can be reset to zero
with `model.reset_memory_hooks_state()`.
"""
for module in self.modules():
module.register_forward_pre_hook(self._hook_rss_memory_pre_forward)
module.register_forward_hook(self._hook_rss_memory_post_forward)
self.reset_memory_hooks_state()
def reset_memory_hooks_state(self):
"""
Reset the `mem_rss_diff` attribute of each module (see [`~modeling_utils.ModuleUtilsMixin.add_memory_hooks`]).
"""
for module in self.modules():
module.mem_rss_diff = 0
module.mem_rss_post_forward = 0
module.mem_rss_pre_forward = 0
@property
def device(self) -> torch.device:
"""
`torch.device`: The device on which the module is (assuming that all the module parameters are on the same
device).
"""
return get_parameter_device(self)
@property
def dtype(self) -> torch.dtype:
"""
`torch.dtype`: The dtype of the module (assuming that all the module parameters have the same dtype).
"""
return get_parameter_dtype(self)
def invert_attention_mask(self, encoder_attention_mask: Tensor) -> Tensor:
"""
Invert an attention mask (e.g., switches 0. and 1.).
Args:
encoder_attention_mask (`torch.Tensor`): An attention mask.
Returns:
`torch.Tensor`: The inverted attention mask.
"""
if encoder_attention_mask.dim() == 3:
encoder_extended_attention_mask = encoder_attention_mask[:, None, :, :]
if encoder_attention_mask.dim() == 2:
encoder_extended_attention_mask = encoder_attention_mask[:, None, None, :]
# T5 has a mask that can compare sequence ids, we can simulate this here with this transposition
# Cf. https://github.com/tensorflow/mesh/blob/8d2465e9bc93129b913b5ccc6a59aa97abd96ec6/mesh_tensorflow
# /transformer/transformer_layers.py#L270
# encoder_extended_attention_mask = (encoder_extended_attention_mask ==
# encoder_extended_attention_mask.transpose(-1, -2))
encoder_extended_attention_mask = encoder_extended_attention_mask.to(dtype=self.dtype) # fp16 compatibility
encoder_extended_attention_mask = (1.0 - encoder_extended_attention_mask) * torch.finfo(self.dtype).min
return encoder_extended_attention_mask
@staticmethod
def create_extended_attention_mask_for_decoder(input_shape, attention_mask, device=None):
if device is not None:
warnings.warn(
"The `device` argument is deprecated and will be removed in v5 of Transformers.", FutureWarning
)
else:
device = attention_mask.device
batch_size, seq_length = input_shape
seq_ids = torch.arange(seq_length, device=device)
causal_mask = seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <= seq_ids[None, :, None]
# in case past_key_values are used we need to add a prefix ones mask to the causal mask
# causal and attention masks must have same type with pytorch version < 1.3
causal_mask = causal_mask.to(attention_mask.dtype)
if causal_mask.shape[1] < attention_mask.shape[1]:
prefix_seq_len = attention_mask.shape[1] - causal_mask.shape[1]
causal_mask = torch.cat(
[
torch.ones((batch_size, seq_length, prefix_seq_len), device=device, dtype=causal_mask.dtype),
causal_mask,
],
axis=-1,
)
extended_attention_mask = causal_mask[:, None, :, :] * attention_mask[:, None, None, :]
return extended_attention_mask
def get_extended_attention_mask(
self, attention_mask: Tensor, input_shape: Tuple[int], device: torch.device = None, dtype: torch.float = None
) -> Tensor:
"""
Makes broadcastable attention and causal masks so that future and masked tokens are ignored.
Arguments:
attention_mask (`torch.Tensor`):
Mask with ones indicating tokens to attend to, zeros for tokens to ignore.
input_shape (`Tuple[int]`):
The shape of the input to the model.
Returns:
`torch.Tensor` The extended attention mask, with a the same dtype as `attention_mask.dtype`.
"""
if dtype is None:
dtype = self.dtype
if not (attention_mask.dim() == 2 and self.config.is_decoder):
# show warning only if it won't be shown in `create_extended_attention_mask_for_decoder`
if device is not None:
warnings.warn(
"The `device` argument is deprecated and will be removed in v5 of Transformers.", FutureWarning
)
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
if attention_mask.dim() == 3:
extended_attention_mask = attention_mask[:, None, :, :]
elif attention_mask.dim() == 2:
# Provided a padding mask of dimensions [batch_size, seq_length]
# - if the model is a decoder, apply a causal mask in addition to the padding mask
# - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder:
extended_attention_mask = ModuleUtilsMixin.create_extended_attention_mask_for_decoder(
input_shape, attention_mask, device
)
else:
extended_attention_mask = attention_mask[:, None, None, :]
else:
raise ValueError(
f"Wrong shape for input_ids (shape {input_shape}) or attention_mask (shape {attention_mask.shape})"
)
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and the dtype's smallest value for masked positions.
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
extended_attention_mask = extended_attention_mask.to(dtype=dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * torch.finfo(dtype).min
return extended_attention_mask
def get_head_mask(
self, head_mask: Optional[Tensor], num_hidden_layers: int, is_attention_chunked: bool = False
) -> Tensor:
"""
Prepare the head mask if needed.
Args:
head_mask (`torch.Tensor` with shape `[num_heads]` or `[num_hidden_layers x num_heads]`, *optional*):
The mask indicating if we should keep the heads or not (1.0 for keep, 0.0 for discard).
num_hidden_layers (`int`):
The number of hidden layers in the model.
is_attention_chunked (`bool`, *optional*, defaults to `False`):
Whether or not the attentions scores are computed by chunks or not.
Returns:
`torch.Tensor` with shape `[num_hidden_layers x batch x num_heads x seq_length x seq_length]` or list with
`[None]` for each layer.
"""
if head_mask is not None:
head_mask = self._convert_head_mask_to_5d(head_mask, num_hidden_layers)
if is_attention_chunked is True:
head_mask = head_mask.unsqueeze(-1)
else:
head_mask = [None] * num_hidden_layers
return head_mask
def _convert_head_mask_to_5d(self, head_mask, num_hidden_layers):
"""-> [num_hidden_layers x batch x num_heads x seq_length x seq_length]"""
if head_mask.dim() == 1:
head_mask = head_mask.unsqueeze(0).unsqueeze(0).unsqueeze(-1).unsqueeze(-1)
head_mask = head_mask.expand(num_hidden_layers, -1, -1, -1, -1)
elif head_mask.dim() == 2:
head_mask = head_mask.unsqueeze(1).unsqueeze(-1).unsqueeze(-1) # We can specify head_mask for each layer
assert head_mask.dim() == 5, f"head_mask.dim != 5, instead {head_mask.dim()}"
head_mask = head_mask.to(dtype=self.dtype) # switch to float if need + fp16 compatibility
return head_mask
def num_parameters(self, only_trainable: bool = False, exclude_embeddings: bool = False) -> int:
"""
Get number of (optionally, trainable or non-embeddings) parameters in the module.
Args:
only_trainable (`bool`, *optional*, defaults to `False`):
Whether or not to return only the number of trainable parameters
exclude_embeddings (`bool`, *optional*, defaults to `False`):
Whether or not to return only the number of non-embeddings parameters
Returns:
`int`: The number of parameters.
"""
if exclude_embeddings:
embedding_param_names = [
f"{name}.weight" for name, module_type in self.named_modules() if isinstance(module_type, nn.Embedding)
]
total_parameters = [
parameter for name, parameter in self.named_parameters() if name not in embedding_param_names
]
else:
total_parameters = list(self.parameters())
total_numel = []
is_loaded_in_4bit = getattr(self, "is_loaded_in_4bit", False)
if is_loaded_in_4bit:
if is_bitsandbytes_available():
import bitsandbytes as bnb
else:
raise ValueError(
"bitsandbytes is not installed but it seems that the model has been loaded in 4bit precision, something went wrong"
" make sure to install bitsandbytes with `pip install bitsandbytes`. You also need a GPU. "
)
for param in total_parameters:
if param.requires_grad or not only_trainable:
# For 4bit models, we need to multiply the number of parameters by 2 as half of the parameters are
# used for the 4bit quantization (uint8 tensors are stored)
if is_loaded_in_4bit and isinstance(param, bnb.nn.Params4bit):
if hasattr(param, "element_size"):
num_bytes = param.element_size()
elif hasattr(param, "quant_storage"):
num_bytes = param.quant_storage.itemsize
else:
num_bytes = 1
total_numel.append(param.numel() * 2 * num_bytes)
else:
total_numel.append(param.numel())
return sum(total_numel)
def estimate_tokens(self, input_dict: Dict[str, Union[torch.Tensor, Any]]) -> int:
"""
Helper function to estimate the total number of tokens from the model inputs.
Args:
inputs (`dict`): The model inputs.
Returns:
`int`: The total number of tokens.
"""
if not hasattr(self, "warnings_issued"):
self.warnings_issued = {}
if self.main_input_name in input_dict:
return input_dict[self.main_input_name].numel()
elif "estimate_tokens" not in self.warnings_issued:
logger.warning(
"Could not estimate the number of tokens of the input, floating-point operations will not be computed"
)
self.warnings_issued["estimate_tokens"] = True
return 0
def floating_point_ops(
self, input_dict: Dict[str, Union[torch.Tensor, Any]], exclude_embeddings: bool = True
) -> int:
"""
Get number of (optionally, non-embeddings) floating-point operations for the forward and backward passes of a
batch with this transformer model. Default approximation neglects the quadratic dependency on the number of
tokens (valid if `12 * d_model << sequence_length`) as laid out in [this
paper](https://arxiv.org/pdf/2001.08361.pdf) section 2.1. Should be overridden for transformers with parameter
re-use e.g. Albert or Universal Transformers, or if doing long-range modeling with very high sequence lengths.
Args:
batch_size (`int`):
The batch size for the forward pass.
sequence_length (`int`):
The number of tokens in each line of the batch.
exclude_embeddings (`bool`, *optional*, defaults to `True`):
Whether or not to count embedding and softmax operations.
Returns:
`int`: The number of floating-point operations.
"""
return 6 * self.estimate_tokens(input_dict) * self.num_parameters(exclude_embeddings=exclude_embeddings)
# TODO (joao): remove `GenerationMixin` inheritance in v4.50
class PreTrainedModel(nn.Module, ModuleUtilsMixin, GenerationMixin, PushToHubMixin, PeftAdapterMixin):
r"""
Base class for all models.
[`PreTrainedModel`] takes care of storing the configuration of the models and handles methods for loading,
downloading and saving models as well as a few methods common to all models to:
- resize the input embeddings,
- prune heads in the self-attention heads.
Class attributes (overridden by derived classes):
- **config_class** ([`PretrainedConfig`]) -- A subclass of [`PretrainedConfig`] to use as configuration class
for this model architecture.
- **load_tf_weights** (`Callable`) -- A python *method* for loading a TensorFlow checkpoint in a PyTorch model,
taking as arguments:
- **model** ([`PreTrainedModel`]) -- An instance of the model on which to load the TensorFlow checkpoint.
- **config** ([`PreTrainedConfig`]) -- An instance of the configuration associated to the model.
- **path** (`str`) -- A path to the TensorFlow checkpoint.
- **base_model_prefix** (`str`) -- A string indicating the attribute associated to the base model in derived
classes of the same architecture adding modules on top of the base model.
- **is_parallelizable** (`bool`) -- A flag indicating whether this model supports model parallelization.
- **main_input_name** (`str`) -- The name of the principal input to the model (often `input_ids` for NLP
models, `pixel_values` for vision models and `input_values` for speech models).
"""
config_class = None
base_model_prefix = ""
main_input_name = "input_ids"
model_tags = None
_auto_class = None
_no_split_modules = None
_skip_keys_device_placement = None
_keep_in_fp32_modules = None
# a list of `re` patterns of `state_dict` keys that should be removed from the list of missing
# keys we find (keys inside the model but not in the checkpoint) and avoid unnecessary warnings.
_keys_to_ignore_on_load_missing = None
# a list of `re` patterns of `state_dict` keys that should be removed from the list of
# unexpected keys we find (keys inside the checkpoint but not the model) and avoid unnecessary
# warnings.
_keys_to_ignore_on_load_unexpected = None
# a list of `state_dict` keys to ignore when saving the model (useful for keys that aren't
# trained, but which are either deterministic or tied variables)
_keys_to_ignore_on_save = None
# a list of `state_dict` keys that are potentially tied to another key in the state_dict.
_tied_weights_keys = None
is_parallelizable = False
supports_gradient_checkpointing = False
_is_stateful = False
# Flash Attention 2 support
_supports_flash_attn_2 = False
# SDPA support
_supports_sdpa = False
# Flex Attention support
_supports_flex_attn = False
# Has support for a `Cache` instance as `past_key_values`? Does it support a `StaticCache`?
_supports_cache_class = False
_supports_static_cache = False
# Has support for a `QuantoQuantizedCache` instance as `past_key_values`
_supports_quantized_cache = False
# A tensor parallel plan to be applied to the model when TP is enabled. For
# top-level models, this attribute is currently defined in respective model
# code. For base models, this attribute comes from
# `config.base_model_tp_plan` during `post_init`.
_tp_plan = None
# This flag signal that the model can be used as an efficient backend in TGI and vLLM
# In practice, it means that they support attention interface functions, fully pass the kwargs
# through all modules up to the Attention layer, can slice logits with Tensor, and have a default TP plan
_supports_attention_backend = False
@property
def dummy_inputs(self) -> Dict[str, torch.Tensor]:
"""
`Dict[str, torch.Tensor]`: Dummy inputs to do a forward pass in the network.
"""
return {"input_ids": torch.tensor(DUMMY_INPUTS)}
@property
def framework(self) -> str:
"""
:str: Identifies that this is a PyTorch model.
"""
return "pt"
def __init__(self, config: PretrainedConfig, *inputs, **kwargs):
super().__init__()
if not isinstance(config, PretrainedConfig):
raise ValueError(
f"Parameter config in `{self.__class__.__name__}(config)` should be an instance of class "
"`PretrainedConfig`. To create a model from a pretrained model use "
f"`model = {self.__class__.__name__}.from_pretrained(PRETRAINED_MODEL_NAME)`"
)
if not getattr(config, "_attn_implementation_autoset", False):
# config usually has a `torch_dtype` but we need the next line for the `no_super_init` tests
dtype = config.torch_dtype if hasattr(config, "torch_dtype") else torch.get_default_dtype()
config = self._autoset_attn_implementation(config, torch_dtype=dtype, check_device_map=False)
self.config = config
# for initialization of the loss
loss_type = self.__class__.__name__
if loss_type not in LOSS_MAPPING:
loss_groups = f"({'|'.join(LOSS_MAPPING)})"
loss_type = re.findall(loss_groups, self.__class__.__name__)
if len(loss_type) > 0:
loss_type = loss_type[0]
else:
loss_type = None
self.loss_type = loss_type
self.name_or_path = config.name_or_path
self.warnings_issued = {}
self.generation_config = GenerationConfig.from_model_config(config) if self.can_generate() else None
# Overwrite the class attribute to make it an instance attribute, so models like
# `InstructBlipForConditionalGeneration` can dynamically update it without modifying the class attribute
# when a different component (e.g. language_model) is used.
self._keep_in_fp32_modules = copy.copy(self.__class__._keep_in_fp32_modules)
def post_init(self):
"""
A method executed at the end of each Transformer model initialization, to execute code that needs the model's
modules properly initialized (such as weight initialization).
"""
self.init_weights()
self._backward_compatibility_gradient_checkpointing()
# If current model is a base model, attach `base_model_tp_plan` from config
if self.base_model is self:
self._tp_plan = self.config.base_model_tp_plan
def dequantize(self):
"""
Potentially dequantize the model in case it has been quantized by a quantization method that support
dequantization.
"""
hf_quantizer = getattr(self, "hf_quantizer", None)
if hf_quantizer is None:
raise ValueError("You need to first quantize your model in order to dequantize it")
return hf_quantizer.dequantize(self)
def _backward_compatibility_gradient_checkpointing(self):
if self.supports_gradient_checkpointing and getattr(self.config, "gradient_checkpointing", False):
self.gradient_checkpointing_enable()
# Remove the attribute now that is has been consumed, so it's no saved in the config.
delattr(self.config, "gradient_checkpointing")
def add_model_tags(self, tags: Union[List[str], str]) -> None:
r"""
Add custom tags into the model that gets pushed to the Hugging Face Hub. Will
not overwrite existing tags in the model.
Args:
tags (`Union[List[str], str]`):
The desired tags to inject in the model
Examples:
```python
from transformers import AutoModel
model = AutoModel.from_pretrained("google-bert/bert-base-cased")
model.add_model_tags(["custom", "custom-bert"])
# Push the model to your namespace with the name "my-custom-bert".
model.push_to_hub("my-custom-bert")
```
"""
if isinstance(tags, str):
tags = [tags]
if self.model_tags is None:
self.model_tags = []
for tag in tags:
if tag not in self.model_tags:
self.model_tags.append(tag)
@classmethod
@restore_default_torch_dtype
def _from_config(cls, config, **kwargs):
"""
All context managers that the model should be initialized under go here.
Args:
torch_dtype (`torch.dtype`, *optional*):
Override the default `torch.dtype` and load the model under this dtype.
"""
# when we init a model from within another model (e.g. VLMs) and dispatch on FA2
# a warning is raised that dtype should be fp16. Since we never pass dtype from within
# modeling code, we can try to infer it here same way as done in `from_pretrained`
torch_dtype = kwargs.pop("torch_dtype", config.torch_dtype)
if isinstance(torch_dtype, str):
torch_dtype = getattr(torch, torch_dtype)
use_flash_attention_2 = kwargs.pop("use_flash_attention_2", False)
# override default dtype if needed
dtype_orig = None
if torch_dtype is not None:
dtype_orig = cls._set_default_torch_dtype(torch_dtype)
config = copy.deepcopy(config) # We do not want to modify the config inplace in _from_config.
if config._attn_implementation_internal is not None:
# In this case, the config has been created with the attn_implementation set by the user, which we
# should respect.
attn_implementation = config._attn_implementation_internal
else:
attn_implementation = None
config._attn_implementation = kwargs.pop("attn_implementation", attn_implementation)
if not getattr(config, "_attn_implementation_autoset", False):
config = cls._autoset_attn_implementation(
config,
use_flash_attention_2=use_flash_attention_2,
check_device_map=False,
torch_dtype=torch_dtype,
)
if is_deepspeed_zero3_enabled() and not _is_quantized and not _is_ds_init_called:
import deepspeed
logger.info("Detected DeepSpeed ZeRO-3: activating zero.init() for this model")
# this immediately partitions the model across all gpus, to avoid the overhead in time
# and memory copying it on CPU or each GPU first
init_contexts = [deepspeed.zero.Init(config_dict_or_path=deepspeed_config()), set_zero3_state()]
with ContextManagers(init_contexts):
model = cls(config, **kwargs)
else:
model = cls(config, **kwargs)
# restore default dtype if it was modified
if dtype_orig is not None:
torch.set_default_dtype(dtype_orig)
return model
@classmethod
def _autoset_attn_implementation(
cls,
config,
use_flash_attention_2: bool = False,
torch_dtype: Optional[torch.dtype] = None,
device_map: Optional[Union[str, Dict[str, int]]] = None,
check_device_map: bool = True,
):
"""
Automatically checks and dispatches to a default attention implementation. In order of priority:
1. An implementation specified in `config._attn_implementation` (due for example to the argument attn_implementation="sdpa" in from_pretrained).
2. DEPRECATED: if use_flash_attention_2 is set to `True` and `flash_attn` is available, flash attention. (`LlamaFlashAttention` for example)
3. SDPA implementation, if available and supported by the model type. (`LlamaSdpaAttention` for example)
4. The default model's implementation otherwise (`LlamaAttention` for example) .
"""
# Here we use config._attn_implementation_internal to check whether the attention implementation was explicitely set by the user.
# The property `PretrainedConfig._attn_implementation` is never `None`, for backward compatibility (always fall back on "eager").
# The `hasattr` here is used as some Transformers tests for some reason do not call PretrainedConfig __init__ (e.g. test_no_super_init_config_and_model)
requested_attn_implementation = None
if hasattr(config, "_attn_implementation_internal") and config._attn_implementation_internal is not None:
if config._attn_implementation != "flash_attention_2" and use_flash_attention_2:
raise ValueError(
f'Both attn_implementation="{config._attn_implementation}" and `use_flash_attention_2=True` were used when loading the model, which are not compatible.'
' We recommend to just use `attn_implementation="flash_attention_2"` when loading the model.'
)
if not isinstance(config._attn_implementation, dict) and config._attn_implementation not in [
"eager"
] + list(ALL_ATTENTION_FUNCTIONS.keys()):
message = f'Specified `attn_implementation="{config._attn_implementation}"` is not supported. The only possible arguments are `attn_implementation="eager"` (manual attention implementation)'
if cls._supports_flash_attn_2:
message += ', `"attn_implementation=flash_attention_2"` (implementation using flash attention 2)'
if cls._supports_sdpa:
message += ', `"attn_implementation=sdpa"` (implementation using torch.nn.functional.scaled_dot_product_attention)'
if cls._supports_flex_attn:
message += (
', `"attn_implementation=flex_attention"` (implementation using torch\'s flex_attention)'
)
raise ValueError(message + ".")
# If a config is passed with a preset attn_implementation, we skip the automatic dispatch and use the user-provided config, with hard checks that the requested attention implementation is available.
requested_attn_implementation = config._attn_implementation_internal
# Composite models consisting of several PretrainedModels have to specify attention impl as a dict
# where keys are sub-config names. But most people will specify one `str` which means that should dispatch it
# for all sub-models.
# Below we check if a config is composite and manually prepare a dict of attn impl if not already passed as a dict.
# Later each sub-module will dispatch with its own attn impl, by calling `XXXModel._from_config(config.text_config)`
# If any of sub-modules doesn't support requested attn, an error will be raised. See https://github.com/huggingface/transformers/pull/32238
for key in config.sub_configs.keys():
sub_config = getattr(config, key)
curr_attn_implementation = (
requested_attn_implementation
if not isinstance(requested_attn_implementation, dict)
else requested_attn_implementation.get(key, None)
)
sub_config._attn_implementation_internal = curr_attn_implementation
if use_flash_attention_2:
logger.warning_once(
'The model was loaded with use_flash_attention_2=True, which is deprecated and may be removed in a future release. Please use `attn_implementation="flash_attention_2"` instead.'
)
config._attn_implementation = "flash_attention_2"
if config._attn_implementation == "flash_attention_2":
cls._check_and_enable_flash_attn_2(
config,
torch_dtype=torch_dtype,
device_map=device_map,
hard_check_only=False,
check_device_map=check_device_map,
)
elif requested_attn_implementation == "flex_attention":
config = cls._check_and_enable_flex_attn(config, hard_check_only=True)
elif requested_attn_implementation in [None, "sdpa"] and not is_torch_xla_available():
# use_flash_attention_2 takes priority over SDPA, hence SDPA treated in this elif.
config = cls._check_and_enable_sdpa(
config,
hard_check_only=False if requested_attn_implementation is None else True,
)
if (
torch.version.hip is not None
and config._attn_implementation == "sdpa"
and torch.cuda.device_count() > 1
and version.parse(torch.__version__) < version.parse("2.4.1")
):
logger.warning_once(
"Using the `SDPA` attention implementation on multi-gpu setup with ROCM may lead to performance issues due to the FA backend. Disabling it to use alternative backends."
)
torch.backends.cuda.enable_flash_sdp(False)
elif requested_attn_implementation in list(ALL_ATTENTION_FUNCTIONS.keys()):
config._attn_implementation = requested_attn_implementation
elif isinstance(requested_attn_implementation, dict):
config._attn_implementation = None
else:
config._attn_implementation = "eager"
config._attn_implementation_autoset = True
return config
@classmethod
def _set_default_torch_dtype(cls, dtype: torch.dtype) -> torch.dtype:
"""
Change the default dtype and return the previous one. This is needed when wanting to instantiate the model
under specific dtype.
Args:
dtype (`torch.dtype`):
a floating dtype to set to.
Returns:
`torch.dtype`: the original `dtype` that can be used to restore `torch.set_default_dtype(dtype)` if it was
modified. If it wasn't, returns `None`.
Note `set_default_dtype` currently only works with floating-point types and asserts if for example,
`torch.int64` is passed. So if a non-float `dtype` is passed this functions will throw an exception.
"""
if not dtype.is_floating_point:
raise ValueError(
f"Can't instantiate {cls.__name__} model under dtype={dtype} since it is not a floating point dtype"
)
logger.info(f"Instantiating {cls.__name__} model under default dtype {dtype}.")
dtype_orig = torch.get_default_dtype()
torch.set_default_dtype(dtype)
return dtype_orig
@property
def base_model(self) -> nn.Module:
"""
`torch.nn.Module`: The main body of the model.
"""
return getattr(self, self.base_model_prefix, self)
@classmethod
def can_generate(cls) -> bool:
"""
Returns whether this model can generate sequences with `.generate()`.
Returns:
`bool`: Whether this model can generate sequences with `.generate()`.
"""
# Directly inherits `GenerationMixin` -> can generate
if "GenerationMixin" in str(cls.__bases__):
return True
# Model class overwrites `generate` (e.g. time series models) -> can generate
if str(cls.__name__) in str(cls.generate):
return True
# The class inherits from a class that can generate (recursive check) -> can generate
for base in cls.__bases__:
if not hasattr(base, "can_generate"):
continue
if "PreTrainedModel" not in str(base) and base.can_generate():
return True
# BC: Detects whether `prepare_inputs_for_generation` has been overwritten in the model. Prior to v4.45, this
# was how we detected whether a model could generate.
if "GenerationMixin" not in str(cls.prepare_inputs_for_generation):
logger.warning_once(
f"{cls.__name__} has generative capabilities, as `prepare_inputs_for_generation` is explicitly "
"overwritten. However, it doesn't directly inherit from `GenerationMixin`. From 👉v4.50👈 onwards, "
"`PreTrainedModel` will NOT inherit from `GenerationMixin`, and this model will lose the ability "
"to call `generate` and other related functions."
"\n - If you're using `trust_remote_code=True`, you can get rid of this warning by loading the "
"model with an auto class. See https://huggingface.co/docs/transformers/en/model_doc/auto#auto-classes"
"\n - If you are the owner of the model architecture code, please modify your model class such that "
"it inherits from `GenerationMixin` (after `PreTrainedModel`, otherwise you'll get an exception)."
"\n - If you are not the owner of the model architecture class, please contact the model code owner "
"to update it."
)
return True
# Otherwise, can't generate
return False
@classmethod
def _check_and_enable_flash_attn_2(
cls,
config,
torch_dtype: Optional[torch.dtype] = None,
device_map: Optional[Union[str, Dict[str, int]]] = None,
check_device_map: bool = True,
hard_check_only: bool = False,
) -> PretrainedConfig:
"""
Checks the availability of Flash Attention 2 and compatibility with the current model.
If all checks pass and `hard_check_only` is False, the method will set the config attribute `attn_implementation` to "flash_attention_2" so that the model can initialize the correct attention module.
"""
if not cls._supports_flash_attn_2:
raise ValueError(
f"{cls.__name__} does not support Flash Attention 2.0 yet. Please request to add support where"
f" the model is hosted, on its model hub page: https://huggingface.co/{config._name_or_path}/discussions/new"
" or in the Transformers GitHub repo: https://github.com/huggingface/transformers/issues/new"
)
if not is_flash_attn_2_available():
preface = "FlashAttention2 has been toggled on, but it cannot be used due to the following error:"
install_message = "Please refer to the documentation of https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2 to install Flash Attention 2."
if importlib.util.find_spec("flash_attn") is None:
raise ImportError(f"{preface} the package flash_attn seems to be not installed. {install_message}")
flash_attention_version = version.parse(importlib.metadata.version("flash_attn"))
if torch.version.cuda:
if flash_attention_version < version.parse("2.1.0"):
raise ImportError(
f"{preface} you need flash_attn package version to be greater or equal than 2.1.0. Detected version {flash_attention_version}. {install_message}"
)
elif not torch.cuda.is_available():
raise ValueError(
f"{preface} Flash Attention 2 is not available on CPU. Please make sure torch can access a CUDA device."
)
else:
raise ImportError(f"{preface} Flash Attention 2 is not available. {install_message}")
elif torch.version.hip:
if flash_attention_version < version.parse("2.0.4"):
raise ImportError(
f"{preface} you need flash_attn package version to be greater or equal than 2.0.4. Make sure to have that version installed - detected version {flash_attention_version}. {install_message}"
)
else:
raise ImportError(f"{preface} Flash Attention 2 is not available. {install_message}")
_is_bettertransformer = getattr(cls, "use_bettertransformer", False)
if _is_bettertransformer:
raise ValueError(
"Flash Attention 2 and BetterTransformer API are not compatible. Please make sure to disable BetterTransformers by doing model.reverse_bettertransformer()"
)
if torch_dtype is None:
logger.warning_once(
"You are attempting to use Flash Attention 2.0 without specifying a torch dtype. This might lead to unexpected behaviour"
)
elif torch_dtype is not None and torch_dtype not in [torch.float16, torch.bfloat16]:
logger.warning_once(
"Flash Attention 2.0 only supports torch.float16 and torch.bfloat16 dtypes, but"
f" the current dype in {cls.__name__} is {torch_dtype}. You should run training or inference using Automatic Mixed-Precision via the `with torch.autocast(device_type='torch_device'):` decorator,"
' or load the model with the `torch_dtype` argument. Example: `model = AutoModel.from_pretrained("openai/whisper-tiny", attn_implementation="flash_attention_2", torch_dtype=torch.float16)`'
)
# The check `torch.empty(0).device.type != "cuda"` is needed as the model may be initialized after `torch.set_default_device` has been called,
# or the model may be initialized under the context manager `with torch.device("cuda"):`.
if check_device_map and device_map is None and torch.empty(0).device.type != "cuda":
if torch.cuda.is_available():
logger.warning_once(
"You are attempting to use Flash Attention 2.0 with a model not initialized on GPU. Make sure to move the model to GPU"
" after initializing it on CPU with `model.to('cuda')`."
)
else:
raise ValueError(
"You are attempting to use Flash Attention 2.0 with a model not initialized on GPU and with no GPU available. "
"This is not supported yet. Please make sure to have access to a GPU and either initialise the model on a GPU by passing a device_map "
"or initialising the model on CPU and then moving it to GPU."
)
elif (
check_device_map
and device_map is not None
and isinstance(device_map, dict)
and ("cpu" in device_map.values() or "disk" in device_map.values())
):
raise ValueError(
"You are attempting to use Flash Attention 2.0 with a model dispatched on CPU or disk. This is not supported. Please make sure to "
"initialise the model on a GPU by passing a device_map that contains only GPU devices as keys."
)
if not hard_check_only:
config._attn_implementation = "flash_attention_2"
return config
@classmethod
def _check_and_enable_sdpa(cls, config, hard_check_only: bool = False) -> PretrainedConfig:
"""
Checks the availability of SDPA for a given model.
If all checks pass and `hard_check_only` is False, the method will set the config attribute `_attn_implementation` to "sdpa" so that the model can initialize the correct attention module.
"""
if hard_check_only:
if not cls._supports_sdpa:
raise ValueError(
f"{cls.__name__} does not support an attention implementation through torch.nn.functional.scaled_dot_product_attention yet."
" Please request the support for this architecture: https://github.com/huggingface/transformers/issues/28005. If you believe"
' this error is a bug, please open an issue in Transformers GitHub repository and load your model with the argument `attn_implementation="eager"` meanwhile. Example: `model = AutoModel.from_pretrained("openai/whisper-tiny", attn_implementation="eager")`'
)
if not is_torch_sdpa_available():
raise ImportError(
"PyTorch SDPA requirements in Transformers are not met. Please install torch>=2.1.1."
)
if not is_torch_sdpa_available() or not cls._supports_sdpa:
return config
_is_bettertransformer = getattr(cls, "use_bettertransformer", False)
if _is_bettertransformer:
return config
if not hard_check_only:
config._attn_implementation = "sdpa"
return config
@classmethod
def _check_and_enable_flex_attn(cls, config, hard_check_only: bool = False) -> PretrainedConfig:
"""
Checks the availability of Flex Attention for a given model.
If all checks pass and `hard_check_only` is False, the method will set the config attribute `_attn_implementation` to "flex_attention" so that the model can initialize the correct attention module.
"""
if hard_check_only:
if not cls._supports_flex_attn:
raise ValueError(
f"{cls.__name__} does not support an attention implementation through torch's flex_attention."
" Please request the support for this architecture: https://github.com/huggingface/transformers/issues/34809."
" If you believe this error is a bug, please open an issue in Transformers GitHub repository"
' and load your model with the argument `attn_implementation="eager"` meanwhile.'
' Example: `model = AutoModel.from_pretrained("openai/whisper-tiny", attn_implementation="eager")`'
)
if not is_torch_flex_attn_available():
raise ImportError(
"PyTorch Flex Attention requirements in Transformers are not met. Please install torch>=2.5.0."
)
if not is_torch_flex_attn_available() or not cls._supports_flex_attn:
return config
if not hard_check_only:
config._attn_implementation = "flex_attention"
return config
def enable_input_require_grads(self):
"""
Enables the gradients for the input embeddings. This is useful for fine-tuning adapter weights while keeping
the model weights fixed.
"""
def make_inputs_require_grads(module, input, output):
output.requires_grad_(True)
self._require_grads_hook = self.get_input_embeddings().register_forward_hook(make_inputs_require_grads)
def disable_input_require_grads(self):
"""
Removes the `_require_grads_hook`.
"""
self._require_grads_hook.remove()
def get_input_embeddings(self) -> nn.Module:
"""
Returns the model's input embeddings.
Returns:
`nn.Module`: A torch module mapping vocabulary to hidden states.
"""
base_model = getattr(self, self.base_model_prefix, self)
if base_model is not self:
return base_model.get_input_embeddings()
else:
raise NotImplementedError
def set_input_embeddings(self, value: nn.Module):
"""
Set model's input embeddings.
Args:
value (`nn.Module`): A module mapping vocabulary to hidden states.
"""
base_model = getattr(self, self.base_model_prefix, self)
if base_model is not self:
base_model.set_input_embeddings(value)
else:
raise NotImplementedError
def get_output_embeddings(self) -> nn.Module:
"""
Returns the model's output embeddings.
Returns:
`nn.Module`: A torch module mapping hidden states to vocabulary.
"""
return None # Overwrite for models with output embeddings
def _init_weights(self, module):
"""
Initialize the weights. This method should be overridden by derived class and is
the only initialization method that will be called when loading a checkpoint
using `from_pretrained`. Any attempt to initialize outside of this function
will be useless as the torch.nn.init function are all replaced with skip.
"""
pass
def _initialize_weights(self, module):
"""
Initialize the weights if they are not already initialized.
"""
if getattr(module, "_is_hf_initialized", False):
return
self._init_weights(module)
module._is_hf_initialized = True
def tie_weights(self):
"""
Tie the weights between the input embeddings and the output embeddings.
If the `torchscript` flag is set in the configuration, can't handle parameter sharing so we are cloning the
weights instead.
"""
if getattr(self.config.get_text_config(decoder=True), "tie_word_embeddings", True):
output_embeddings = self.get_output_embeddings()
if output_embeddings is not None:
self._tie_or_clone_weights(output_embeddings, self.get_input_embeddings())
if getattr(self.config, "is_encoder_decoder", False) and getattr(self.config, "tie_encoder_decoder", False):
if hasattr(self, self.base_model_prefix):
self = getattr(self, self.base_model_prefix)
tied_weights = self._tie_encoder_decoder_weights(
self.encoder, self.decoder, self.base_model_prefix, "encoder"
)
# Setting a dynamic variable instead of `_tied_weights_keys` because it's a class
# attributed not an instance member, therefore modifying it will modify the entire class
# Leading to issues on subsequent calls by different tests or subsequent calls.
self._dynamic_tied_weights_keys = tied_weights
for module in self.modules():
if hasattr(module, "_tie_weights"):
module._tie_weights()
@staticmethod
def _tie_encoder_decoder_weights(
encoder: nn.Module, decoder: nn.Module, base_model_prefix: str, base_encoder_name: str
):
uninitialized_encoder_weights: List[str] = []
tied_weights: List[str] = []
if decoder.__class__ != encoder.__class__:
logger.info(
f"{decoder.__class__} and {encoder.__class__} are not equal. In this case make sure that all encoder"
" weights are correctly initialized."
)
def tie_encoder_to_decoder_recursively(
decoder_pointer: nn.Module,
encoder_pointer: nn.Module,
module_name: str,
base_encoder_name: str,
uninitialized_encoder_weights: List[str],
depth=0,
total_decoder_name="",
total_encoder_name="",
):
assert isinstance(decoder_pointer, nn.Module) and isinstance(
encoder_pointer, nn.Module
), f"{decoder_pointer} and {encoder_pointer} have to be of type nn.Module"
if hasattr(decoder_pointer, "weight"):
assert hasattr(encoder_pointer, "weight")
encoder_pointer.weight = decoder_pointer.weight
tied_weights.append(f"{base_encoder_name}{total_encoder_name}.weight")
if hasattr(decoder_pointer, "bias"):
assert hasattr(encoder_pointer, "bias")
tied_weights.append(f"{base_encoder_name}{total_encoder_name}.bias")
encoder_pointer.bias = decoder_pointer.bias
return
encoder_modules = encoder_pointer._modules
decoder_modules = decoder_pointer._modules
if len(decoder_modules) > 0:
assert (
len(encoder_modules) > 0
), f"Encoder module {encoder_pointer} does not match decoder module {decoder_pointer}"
all_encoder_weights = {module_name + "/" + sub_name for sub_name in encoder_modules.keys()}
encoder_layer_pos = 0
for name, module in decoder_modules.items():
if name.isdigit():
encoder_name = str(int(name) + encoder_layer_pos)
decoder_name = name
if not isinstance(decoder_modules[decoder_name], type(encoder_modules[encoder_name])) and len(
encoder_modules
) != len(decoder_modules):
# this can happen if the name corresponds to the position in a list module list of layers
# in this case the decoder has added a cross-attention that the encoder does not have
# thus skip this step and subtract one layer pos from encoder
encoder_layer_pos -= 1
continue
elif name not in encoder_modules:
continue
elif depth > 500:
raise ValueError(
"Max depth of recursive function `tie_encoder_to_decoder` reached. It seems that there is"
" a circular dependency between two or more `nn.Modules` of your model."
)
else:
decoder_name = encoder_name = name
tie_encoder_to_decoder_recursively(
decoder_modules[decoder_name],
encoder_modules[encoder_name],
module_name + "/" + name,
base_encoder_name,
uninitialized_encoder_weights,
depth=depth + 1,
total_encoder_name=f"{total_encoder_name}.{encoder_name}",
total_decoder_name=f"{total_decoder_name}.{decoder_name}",
)
all_encoder_weights.remove(module_name + "/" + encoder_name)
uninitialized_encoder_weights += list(all_encoder_weights)
# tie weights recursively
tie_encoder_to_decoder_recursively(
decoder, encoder, base_model_prefix, base_encoder_name, uninitialized_encoder_weights
)
if len(uninitialized_encoder_weights) > 0:
logger.warning(
f"The following encoder weights were not tied to the decoder {uninitialized_encoder_weights}"
)
return tied_weights
def _tie_or_clone_weights(self, output_embeddings, input_embeddings):
"""Tie or clone module weights depending of whether we are using TorchScript or not"""
if self.config.torchscript:
output_embeddings.weight = nn.Parameter(input_embeddings.weight.clone())
else:
output_embeddings.weight = input_embeddings.weight
if getattr(output_embeddings, "bias", None) is not None:
output_embeddings.bias.data = nn.functional.pad(
output_embeddings.bias.data,
(
0,
output_embeddings.weight.shape[0] - output_embeddings.bias.shape[0],
),
"constant",
0,
)
if hasattr(output_embeddings, "out_features") and hasattr(input_embeddings, "num_embeddings"):
output_embeddings.out_features = input_embeddings.num_embeddings
def _get_no_split_modules(self, device_map: str):
"""
Get the modules of the model that should not be spit when using device_map. We iterate through the modules to
get the underlying `_no_split_modules`.
Args:
device_map (`str`):
The device map value. Options are ["auto", "balanced", "balanced_low_0", "sequential"]
Returns:
`List[str]`: List of modules that should not be split
"""
_no_split_modules = set()
modules_to_check = [self]
while len(modules_to_check) > 0:
module = modules_to_check.pop(-1)
# if the module does not appear in _no_split_modules, we also check the children
if module.__class__.__name__ not in _no_split_modules:
if isinstance(module, PreTrainedModel):
if module._no_split_modules is None:
raise ValueError(
f"{module.__class__.__name__} does not support `device_map='{device_map}'`. To implement support, the model "
"class needs to implement the `_no_split_modules` attribute."
)
else:
_no_split_modules = _no_split_modules | set(module._no_split_modules)
modules_to_check += list(module.children())
return list(_no_split_modules)
def resize_token_embeddings(
self,
new_num_tokens: Optional[int] = None,
pad_to_multiple_of: Optional[int] = None,
mean_resizing: bool = True,
) -> nn.Embedding:
"""
Resizes input token embeddings matrix of the model if `new_num_tokens != config.vocab_size`.
Takes care of tying weights embeddings afterwards if the model class has a `tie_weights()` method.
Arguments:
new_num_tokens (`int`, *optional*):
The new number of tokens in the embedding matrix. Increasing the size will add newly initialized
vectors at the end. Reducing the size will remove vectors from the end. If not provided or `None`, just
returns a pointer to the input tokens `torch.nn.Embedding` module of the model without doing anything.
pad_to_multiple_of (`int`, *optional*):
If set will pad the embedding matrix to a multiple of the provided value.If `new_num_tokens` is set to
`None` will just pad the embedding to a multiple of `pad_to_multiple_of`.
This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability
`>= 7.5` (Volta), or on TPUs which benefit from having sequence lengths be a multiple of 128. For more
details about this, or help on choosing the correct value for resizing, refer to this guide:
https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc
mean_resizing (`bool`):
Whether to initialize the added embeddings from a multivariate normal distribution that has old embeddings' mean and
covariance or to initialize them with a normal distribution that has a mean of zero and std equals `config.initializer_range`.
Setting `mean_resizing` to `True` is useful when increasing the size of the embeddings of causal language models,
where the generated tokens' probabilities won't be affected by the added embeddings because initializing the new embeddings with the
old embeddings' mean will reduce the kl-divergence between the next token probability before and after adding the new embeddings.
Refer to this article for more information: https://nlp.stanford.edu/~johnhew/vocab-expansion.html
Return:
`torch.nn.Embedding`: Pointer to the input tokens Embeddings Module of the model.
"""
model_embeds = self._resize_token_embeddings(new_num_tokens, pad_to_multiple_of, mean_resizing)
if new_num_tokens is None and pad_to_multiple_of is None:
return model_embeds
# Since we are basically resuing the same old embeddings with new weight values, gathering is required
is_quantized = hasattr(self, "hf_quantizer") and self.hf_quantizer is not None
if is_deepspeed_zero3_enabled() and not is_quantized:
import deepspeed
with deepspeed.zero.GatheredParameters(model_embeds.weight, modifier_rank=None):
vocab_size = model_embeds.weight.shape[0]
else:
vocab_size = model_embeds.weight.shape[0]
# Update base model and current model config.
self.config.get_text_config().vocab_size = vocab_size
self.vocab_size = vocab_size
# Tie weights again if needed
self.tie_weights()
return model_embeds
def _resize_token_embeddings(self, new_num_tokens, pad_to_multiple_of=None, mean_resizing=True):
old_embeddings = self.get_input_embeddings()
new_embeddings = self._get_resized_embeddings(
old_embeddings, new_num_tokens, pad_to_multiple_of, mean_resizing
)
if hasattr(old_embeddings, "_hf_hook"):
hook = old_embeddings._hf_hook
add_hook_to_module(new_embeddings, hook)
old_embeddings_requires_grad = old_embeddings.weight.requires_grad
new_embeddings.requires_grad_(old_embeddings_requires_grad)
self.set_input_embeddings(new_embeddings)
is_quantized = hasattr(self, "hf_quantizer") and self.hf_quantizer is not None
# Update new_num_tokens with the actual size of new_embeddings
if pad_to_multiple_of is not None:
if is_deepspeed_zero3_enabled() and not is_quantized:
import deepspeed
with deepspeed.zero.GatheredParameters(new_embeddings.weight, modifier_rank=None):
new_num_tokens = new_embeddings.weight.shape[0]
else:
new_num_tokens = new_embeddings.weight.shape[0]
# if word embeddings are not tied, make sure that lm head is resized as well
if (
self.get_output_embeddings() is not None
and not self.config.get_text_config(decoder=True).tie_word_embeddings
):
old_lm_head = self.get_output_embeddings()
if isinstance(old_lm_head, torch.nn.Embedding):
new_lm_head = self._get_resized_embeddings(old_lm_head, new_num_tokens, mean_resizing=mean_resizing)
else:
new_lm_head = self._get_resized_lm_head(old_lm_head, new_num_tokens, mean_resizing=mean_resizing)
if hasattr(old_lm_head, "_hf_hook"):
hook = old_lm_head._hf_hook
add_hook_to_module(new_lm_head, hook)
old_lm_head_requires_grad = old_lm_head.weight.requires_grad
new_lm_head.requires_grad_(old_lm_head_requires_grad)
self.set_output_embeddings(new_lm_head)
return self.get_input_embeddings()
def _get_resized_embeddings(
self,
old_embeddings: nn.Embedding,
new_num_tokens: Optional[int] = None,
pad_to_multiple_of: Optional[int] = None,
mean_resizing: bool = True,
) -> nn.Embedding:
"""
Build a resized Embedding Module from a provided token Embedding Module. Increasing the size will add newly
initialized vectors at the end. Reducing the size will remove vectors from the end
Args:
old_embeddings (`torch.nn.Embedding`):
Old embeddings to be resized.
new_num_tokens (`int`, *optional*):
New number of tokens in the embedding matrix.
Increasing the size will add newly initialized vectors at the end. Reducing the size will remove
vectors from the end. If not provided or `None`, just returns a pointer to the input tokens
`torch.nn.Embedding` module of the model without doing anything.
pad_to_multiple_of (`int`, *optional*):
If set will pad the embedding matrix to a multiple of the provided value. If `new_num_tokens` is set to
`None` will just pad the embedding to a multiple of `pad_to_multiple_of`.
This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability
`>= 7.5` (Volta), or on TPUs which benefit from having sequence lengths be a multiple of 128. For more
details about this, or help on choosing the correct value for resizing, refer to this guide:
https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc
mean_resizing (`bool`):
Whether to initialize the added embeddings from a multivariate normal distribution that has old embeddings' mean and
covariance or to initialize them with a normal distribution that has a mean of zero and std equals `config.initializer_range`.
Setting `mean_resizing` to `True` is useful when increasing the size of the embeddings of causal language models,
where the generated tokens' probabilities will not be affected by the added embeddings because initializing the new embeddings with the
old embeddings' mean will reduce the kl-divergence between the next token probability before and after adding the new embeddings.
Refer to this article for more information: https://nlp.stanford.edu/~johnhew/vocab-expansion.html
Return:
`torch.nn.Embedding`: Pointer to the resized Embedding Module or the old Embedding Module if
`new_num_tokens` is `None`
"""
if pad_to_multiple_of is not None:
if not isinstance(pad_to_multiple_of, int):
raise ValueError(
f"Asking to pad the embedding matrix to a multiple of `{pad_to_multiple_of}`, which is not and integer. Please make sure to pass an integer"
)
if new_num_tokens is None:
new_num_tokens = old_embeddings.weight.shape[0]
new_num_tokens = ((new_num_tokens + pad_to_multiple_of - 1) // pad_to_multiple_of) * pad_to_multiple_of
else:
logger.info(
"You are resizing the embedding layer without providing a `pad_to_multiple_of` parameter. This means that the new embedding"
f" dimension will be {new_num_tokens}. This might induce some performance reduction as *Tensor Cores* will not be available."
" For more details about this, or help on choosing the correct value for resizing, refer to this guide:"
" https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc"
)
if new_num_tokens is None:
return old_embeddings
is_quantized = hasattr(self, "hf_quantizer") and self.hf_quantizer is not None
if is_deepspeed_zero3_enabled() and not is_quantized:
import deepspeed
with deepspeed.zero.GatheredParameters(old_embeddings.weight, modifier_rank=None):
old_num_tokens, old_embedding_dim = old_embeddings.weight.size()
else:
old_num_tokens, old_embedding_dim = old_embeddings.weight.size()
if old_num_tokens == new_num_tokens and not is_deepspeed_zero3_enabled():
return old_embeddings
if not isinstance(old_embeddings, nn.Embedding):
raise TypeError(
f"Old embeddings are of type {type(old_embeddings)}, which is not an instance of {nn.Embedding}. You"
" should either use a different resize function or make sure that `old_embeddings` are an instance of"
f" {nn.Embedding}."
)
# Build new embeddings
# When using DeepSpeed ZeRO-3, we shouldn't create new embeddings with DeepSpeed init
# because the shape of the new embedding layer is used across various modeling files
# as well as to update config vocab size. Shape will be 0 when using DeepSpeed init leading
# to errors when training.
new_embeddings = nn.Embedding(
new_num_tokens,
old_embedding_dim,
device=old_embeddings.weight.device,
dtype=old_embeddings.weight.dtype,
)
if new_num_tokens > old_num_tokens and not mean_resizing:
# initialize new embeddings (in particular added tokens) with a mean of 0 and std equals `config.initializer_range`.
self._init_weights(new_embeddings)
elif new_num_tokens > old_num_tokens and mean_resizing:
# initialize new embeddings (in particular added tokens). The new embeddings will be initialized
# from a multivariate normal distribution that has old embeddings' mean and covariance.
# as described in this article: https://nlp.stanford.edu/~johnhew/vocab-expansion.html
logger.warning_once(
"The new embeddings will be initialized from a multivariate normal distribution that has old embeddings' mean and covariance. "
"As described in this article: https://nlp.stanford.edu/~johnhew/vocab-expansion.html. "
"To disable this, use `mean_resizing=False`"
)
added_num_tokens = new_num_tokens - old_num_tokens
if is_deepspeed_zero3_enabled() and not is_quantized:
import deepspeed
with deepspeed.zero.GatheredParameters([old_embeddings.weight], modifier_rank=None):
self._init_added_embeddings_weights_with_mean(
old_embeddings, new_embeddings, old_embedding_dim, old_num_tokens, added_num_tokens
)
else:
self._init_added_embeddings_weights_with_mean(
old_embeddings, new_embeddings, old_embedding_dim, old_num_tokens, added_num_tokens
)
# Copy token embeddings from the previous weights
# numbers of tokens to copy
n = min(old_num_tokens, new_num_tokens)
if is_deepspeed_zero3_enabled() and not is_quantized:
import deepspeed
params = [old_embeddings.weight, new_embeddings.weight]
with deepspeed.zero.GatheredParameters(params, modifier_rank=0):
new_embeddings.weight.data[:n, :] = old_embeddings.weight.data[:n, :]
else:
new_embeddings.weight.data[:n, :] = old_embeddings.weight.data[:n, :]
# Replace weights in old_embeddings and return to maintain the same embedding type.
# This ensures correct functionality when a Custom Embedding class is passed as input.
# The input and output embedding types remain consistent. (c.f. https://github.com/huggingface/transformers/pull/31979)
if is_deepspeed_zero3_enabled() and not is_quantized:
import deepspeed
params = [old_embeddings.weight, new_embeddings.weight]
with deepspeed.zero.GatheredParameters(params, modifier_rank=0):
old_embeddings.weight = new_embeddings.weight
old_embeddings.num_embeddings = new_embeddings.weight.data.shape[0]
# If the new number of tokens is smaller than the original `padding_idx`, the `padding_idx`
# will be set to `None` in the resized embeddings.
if old_embeddings.padding_idx is not None and (new_num_tokens - 1) < old_embeddings.padding_idx:
old_embeddings.padding_idx = None
else:
old_embeddings.weight.data = new_embeddings.weight.data
old_embeddings.num_embeddings = new_embeddings.weight.data.shape[0]
if old_embeddings.padding_idx is not None and (new_num_tokens - 1) < old_embeddings.padding_idx:
old_embeddings.padding_idx = None
return old_embeddings
def _get_resized_lm_head(
self,
old_lm_head: nn.Linear,
new_num_tokens: Optional[int] = None,
transposed: Optional[bool] = False,
mean_resizing: bool = True,
) -> nn.Linear:
"""
Build a resized Linear Module from a provided old Linear Module. Increasing the size will add newly initialized
vectors at the end. Reducing the size will remove vectors from the end
Args:
old_lm_head (`torch.nn.Linear`):
Old lm head liner layer to be resized.
new_num_tokens (`int`, *optional*):
New number of tokens in the linear matrix.
Increasing the size will add newly initialized vectors at the end. Reducing the size will remove
vectors from the end. If not provided or `None`, just returns a pointer to the input tokens
`torch.nn.Linear` module of the model without doing anything. transposed (`bool`, *optional*, defaults
to `False`): Whether `old_lm_head` is transposed or not. If True `old_lm_head.size()` is `lm_head_dim,
vocab_size` else `vocab_size, lm_head_dim`.
mean_resizing (`bool`):
Whether to initialize the added embeddings from a multivariate normal distribution that has old embeddings' mean and
covariance or to initialize them with a normal distribution that has a mean of zero and std equals `config.initializer_range`.
Setting `mean_resizing` to `True` is useful when increasing the size of the embeddings of causal language models,
where the generated tokens' probabilities will not be affected by the added embeddings because initializing the new embeddings with the
old embeddings' mean will reduce the kl-divergence between the next token probability before and after adding the new embeddings.
Refer to this article for more information: https://nlp.stanford.edu/~johnhew/vocab-expansion.html
Return:
`torch.nn.Linear`: Pointer to the resized Linear Module or the old Linear Module if `new_num_tokens` is
`None`
"""
if new_num_tokens is None:
return old_lm_head
is_quantized = hasattr(self, "hf_quantizer") and self.hf_quantizer is not None
if is_deepspeed_zero3_enabled() and not is_quantized:
import deepspeed
with deepspeed.zero.GatheredParameters(old_lm_head.weight, modifier_rank=None):
old_num_tokens, old_lm_head_dim = (
old_lm_head.weight.size() if not transposed else old_lm_head.weight.t().size()
)
else:
old_num_tokens, old_lm_head_dim = (
old_lm_head.weight.size() if not transposed else old_lm_head.weight.t().size()
)
if old_num_tokens == new_num_tokens and not is_deepspeed_zero3_enabled():
return old_lm_head
if not isinstance(old_lm_head, nn.Linear):
raise TypeError(
f"Old language model head is of type {type(old_lm_head)}, which is not an instance of {nn.Linear}. You"
" should either use a different resize function or make sure that `old_lm_head` are an instance of"
f" {nn.Linear}."
)
# Build new lm head
new_lm_head_shape = (old_lm_head_dim, new_num_tokens) if not transposed else (new_num_tokens, old_lm_head_dim)
has_new_lm_head_bias = old_lm_head.bias is not None
# When using DeepSpeed ZeRO-3, we shouldn't create new embeddings with DeepSpeed init
# because the shape of the new embedding layer is used across various modeling files
# as well as to update config vocab size. Shape will be 0 when using DeepSpeed init leading
# to errors when training.
new_lm_head = nn.Linear(
*new_lm_head_shape,
bias=has_new_lm_head_bias,
device=old_lm_head.weight.device,
dtype=old_lm_head.weight.dtype,
)
if new_num_tokens > old_num_tokens and not mean_resizing:
# initialize new embeddings (in particular added tokens) with a mean of 0 and std equals `config.initializer_range`.
self._init_weights(new_lm_head)
elif new_num_tokens > old_num_tokens and mean_resizing:
# initialize new lm_head weights (in particular added tokens). The new lm_head weights
# will be initialized from a multivariate normal distribution that has old embeddings' mean and covariance.
# as described in this article: https://nlp.stanford.edu/~johnhew/vocab-expansion.html
logger.warning_once(
"The new lm_head weights will be initialized from a multivariate normal distribution that has old embeddings' mean and covariance. "
"As described in this article: https://nlp.stanford.edu/~johnhew/vocab-expansion.html. "
"To disable this, use `mean_resizing=False`"
)
added_num_tokens = new_num_tokens - old_num_tokens
if is_deepspeed_zero3_enabled() and not is_quantized:
import deepspeed
params = [old_lm_head.weight]
if has_new_lm_head_bias:
params += [old_lm_head.bias]
with deepspeed.zero.GatheredParameters(params, modifier_rank=None):
self._init_added_lm_head_weights_with_mean(
old_lm_head, new_lm_head, old_lm_head_dim, old_num_tokens, added_num_tokens, transposed
)
if has_new_lm_head_bias:
self._init_added_lm_head_bias_with_mean(old_lm_head, new_lm_head, added_num_tokens)
else:
self._init_added_lm_head_weights_with_mean(
old_lm_head, new_lm_head, old_lm_head_dim, old_num_tokens, added_num_tokens, transposed
)
if has_new_lm_head_bias:
self._init_added_lm_head_bias_with_mean(old_lm_head, new_lm_head, added_num_tokens)
num_tokens_to_copy = min(old_num_tokens, new_num_tokens)
if is_deepspeed_zero3_enabled() and not is_quantized:
import deepspeed
params = [old_lm_head.weight, old_lm_head.bias, new_lm_head.weight, new_lm_head.bias]
with deepspeed.zero.GatheredParameters(params, modifier_rank=0):
self._copy_lm_head_original_to_resized(
new_lm_head, old_lm_head, num_tokens_to_copy, transposed, has_new_lm_head_bias
)
else:
self._copy_lm_head_original_to_resized(
new_lm_head, old_lm_head, num_tokens_to_copy, transposed, has_new_lm_head_bias
)
return new_lm_head
def _init_added_embeddings_weights_with_mean(
self, old_embeddings, new_embeddings, old_embedding_dim, old_num_tokens, added_num_tokens
):
old_embeddings_weight = old_embeddings.weight.data.to(torch.float32)
mean_embeddings = torch.mean(old_embeddings_weight, axis=0)
old_centered_embeddings = old_embeddings_weight - mean_embeddings
covariance = old_centered_embeddings.T @ old_centered_embeddings / old_num_tokens
# Check if the covariance is positive definite.
epsilon = 1e-9
is_covariance_psd = constraints.positive_definite.check(epsilon * covariance).all()
if is_covariance_psd:
# If covariances is positive definite, a distribution can be created. and we can sample new weights from it.
distribution = torch.distributions.multivariate_normal.MultivariateNormal(
mean_embeddings, covariance_matrix=epsilon * covariance
)
new_embeddings.weight.data[-1 * added_num_tokens :, :] = distribution.sample(
sample_shape=(added_num_tokens,)
).to(old_embeddings.weight.dtype)
else:
# Otherwise, just initialize with the mean. because distribtion will not be created.
new_embeddings.weight.data[-1 * added_num_tokens :, :] = (
mean_embeddings[None, :].repeat(added_num_tokens, 1).to(old_embeddings.weight.dtype)
)
def _init_added_lm_head_weights_with_mean(
self,
old_lm_head,
new_lm_head,
old_lm_head_dim,
old_num_tokens,
added_num_tokens,
transposed=False,
):
if transposed:
# Transpose to the desired shape for the function.
new_lm_head.weight.data = new_lm_head.weight.data.T
old_lm_head.weight.data = old_lm_head.weight.data.T
# The same initilization logic as Embeddings.
self._init_added_embeddings_weights_with_mean(
old_lm_head, new_lm_head, old_lm_head_dim, old_num_tokens, added_num_tokens
)
if transposed:
# Transpose again to the correct shape.
new_lm_head.weight.data = new_lm_head.weight.data.T
old_lm_head.weight.data = old_lm_head.weight.data.T
def _init_added_lm_head_bias_with_mean(self, old_lm_head, new_lm_head, added_num_tokens):
bias_mean = torch.mean(old_lm_head.bias.data, axis=0, dtype=torch.float32)
bias_std = torch.std(old_lm_head.bias.data, axis=0).to(torch.float32)
new_lm_head.bias.data[-1 * added_num_tokens :].normal_(mean=bias_mean, std=1e-9 * bias_std)
def _copy_lm_head_original_to_resized(
self, new_lm_head, old_lm_head, num_tokens_to_copy, transposed, has_new_lm_head_bias
):
# Copy old lm head weights to new lm head
if not transposed:
new_lm_head.weight.data[:num_tokens_to_copy, :] = old_lm_head.weight.data[:num_tokens_to_copy, :]
else:
new_lm_head.weight.data[:, :num_tokens_to_copy] = old_lm_head.weight.data[:, :num_tokens_to_copy]
# Copy bias weights to new lm head
if has_new_lm_head_bias:
new_lm_head.bias.data[:num_tokens_to_copy] = old_lm_head.bias.data[:num_tokens_to_copy]
def resize_position_embeddings(self, new_num_position_embeddings: int):
raise NotImplementedError(
f"`resize_position_embeddings` is not implemented for {self.__class__}`. To implement it, you should "
f"overwrite this method in the class {self.__class__} in `modeling_{self.__class__.__module__}.py`"
)
def get_position_embeddings(self) -> Union[nn.Embedding, Tuple[nn.Embedding]]:
raise NotImplementedError(
f"`get_position_embeddings` is not implemented for {self.__class__}`. To implement it, you should "
f"overwrite this method in the class {self.__class__} in `modeling_{self.__class__.__module__}.py`"
)
def init_weights(self):
"""
If needed prunes and maybe initializes weights. If using a custom `PreTrainedModel`, you need to implement any
initialization logic in `_init_weights`.
"""
# Prune heads if needed
if self.config.pruned_heads:
self.prune_heads(self.config.pruned_heads)
if _init_weights:
# Initialize weights
self.apply(self._initialize_weights)
# Tie weights should be skipped when not initializing all weights
# since from_pretrained(...) calls tie weights anyways
self.tie_weights()
def prune_heads(self, heads_to_prune: Dict[int, List[int]]):
"""
Prunes heads of the base model.
Arguments:
heads_to_prune (`Dict[int, List[int]]`):
Dictionary with keys being selected layer indices (`int`) and associated values being the list of heads
to prune in said layer (list of `int`). For instance {1: [0, 2], 2: [2, 3]} will prune heads 0 and 2 on
layer 1 and heads 2 and 3 on layer 2.
"""
# save new sets of pruned heads as union of previously stored pruned heads and newly pruned heads
for layer, heads in heads_to_prune.items():
union_heads = set(self.config.pruned_heads.get(layer, [])) | set(heads)
self.config.pruned_heads[layer] = list(union_heads) # Unfortunately we have to store it as list for JSON
self.base_model._prune_heads(heads_to_prune)
def gradient_checkpointing_enable(self, gradient_checkpointing_kwargs=None):
"""
Activates gradient checkpointing for the current model.
Note that in other frameworks this feature can be referred to as "activation checkpointing" or "checkpoint
activations".
We pass the `__call__` method of the modules instead of `forward` because `__call__` attaches all the hooks of
the module. https://discuss.pytorch.org/t/any-different-between-model-input-and-model-forward-input/3690/2
Args:
gradient_checkpointing_kwargs (dict, *optional*):
Additional keyword arguments passed along to the `torch.utils.checkpoint.checkpoint` function.
"""
if not self.supports_gradient_checkpointing:
raise ValueError(f"{self.__class__.__name__} does not support gradient checkpointing.")
if gradient_checkpointing_kwargs is None:
gradient_checkpointing_kwargs = {"use_reentrant": True}
gradient_checkpointing_func = functools.partial(checkpoint, **gradient_checkpointing_kwargs)
# For old GC format (transformers < 4.35.0) for models that live on the Hub
# we will fall back to the overwritten `_set_gradient_checkpointing` method
_is_using_old_format = "value" in inspect.signature(self._set_gradient_checkpointing).parameters
if not _is_using_old_format:
self._set_gradient_checkpointing(enable=True, gradient_checkpointing_func=gradient_checkpointing_func)
else:
self.apply(partial(self._set_gradient_checkpointing, value=True))
logger.warning(
"You are using an old version of the checkpointing format that is deprecated (We will also silently ignore `gradient_checkpointing_kwargs` in case you passed it)."
"Please update to the new format on your modeling file. To use the new format, you need to completely remove the definition of the method `_set_gradient_checkpointing` in your model."
)
if getattr(self, "_hf_peft_config_loaded", False):
# When using PEFT + gradient checkpointing + Trainer we need to make sure the input has requires_grad=True
# we do it also on PEFT: https://github.com/huggingface/peft/blob/85013987aa82aa1af3da1236b6902556ce3e483e/src/peft/peft_model.py#L334
# When training with PEFT, only LoRA layers will have requires grad set to True, but the output of frozen layers need to propagate
# the gradients to make sure the gradient flows.
self.enable_input_require_grads()
def _set_gradient_checkpointing(self, enable: bool = True, gradient_checkpointing_func: Callable = checkpoint):
is_gradient_checkpointing_set = False
# Apply it on the top-level module in case the top-level modules supports it
# for example, LongT5Stack inherits from `PreTrainedModel`.
if hasattr(self, "gradient_checkpointing"):
self._gradient_checkpointing_func = gradient_checkpointing_func
self.gradient_checkpointing = enable
is_gradient_checkpointing_set = True
for module in self.modules():
if hasattr(module, "gradient_checkpointing"):
module._gradient_checkpointing_func = gradient_checkpointing_func
module.gradient_checkpointing = enable
is_gradient_checkpointing_set = True
if not is_gradient_checkpointing_set:
raise ValueError(
f"{self.__class__.__name__} is not compatible with gradient checkpointing. Make sure all the architecture support it by setting a boolean attribute"
" `gradient_checkpointing` to modules of the model that uses checkpointing."
)
def gradient_checkpointing_disable(self):
"""
Deactivates gradient checkpointing for the current model.
Note that in other frameworks this feature can be referred to as "activation checkpointing" or "checkpoint
activations".
"""
if self.supports_gradient_checkpointing:
# For old GC format (transformers < 4.35.0) for models that live on the Hub
# we will fall back to the overwritten `_set_gradient_checkpointing` methid
_is_using_old_format = "value" in inspect.signature(self._set_gradient_checkpointing).parameters
if not _is_using_old_format:
self._set_gradient_checkpointing(enable=False)
else:
logger.warning(
"You are using an old version of the checkpointing format that is deprecated (We will also silently ignore `gradient_checkpointing_kwargs` in case you passed it)."
"Please update to the new format on your modeling file. To use the new format, you need to completely remove the definition of the method `_set_gradient_checkpointing` in your model."
)
self.apply(partial(self._set_gradient_checkpointing, value=False))
if getattr(self, "_hf_peft_config_loaded", False):
self.disable_input_require_grads()
@property
def is_gradient_checkpointing(self) -> bool:
"""
Whether gradient checkpointing is activated for this model or not.
Note that in other frameworks this feature can be referred to as "activation checkpointing" or "checkpoint
activations".
"""
return any(hasattr(m, "gradient_checkpointing") and m.gradient_checkpointing for m in self.modules())
def save_pretrained(
self,
save_directory: Union[str, os.PathLike],
is_main_process: bool = True,
state_dict: Optional[dict] = None,
save_function: Callable = torch.save,
push_to_hub: bool = False,
max_shard_size: Union[int, str] = "5GB",
safe_serialization: bool = True,
variant: Optional[str] = None,
token: Optional[Union[str, bool]] = None,
save_peft_format: bool = True,
**kwargs,
):
"""
Save a model and its configuration file to a directory, so that it can be re-loaded using the
[`~PreTrainedModel.from_pretrained`] class method.
Arguments:
save_directory (`str` or `os.PathLike`):
Directory to which to save. Will be created if it doesn't exist.
is_main_process (`bool`, *optional*, defaults to `True`):
Whether the process calling this is the main process or not. Useful when in distributed training like
TPUs and need to call this function on all processes. In this case, set `is_main_process=True` only on
the main process to avoid race conditions.
state_dict (nested dictionary of `torch.Tensor`):
The state dictionary of the model to save. Will default to `self.state_dict()`, but can be used to only
save parts of the model or if special precautions need to be taken when recovering the state dictionary
of a model (like when using model parallelism).
save_function (`Callable`):
The function to use to save the state dictionary. Useful on distributed training like TPUs when one
need to replace `torch.save` by another method.
push_to_hub (`bool`, *optional*, defaults to `False`):
Whether or not to push your model to the Hugging Face model hub after saving it. You can specify the
repository you want to push to with `repo_id` (will default to the name of `save_directory` in your
namespace).
max_shard_size (`int` or `str`, *optional*, defaults to `"5GB"`):
The maximum size for a checkpoint before being sharded. Checkpoints shard will then be each of size
lower than this size. If expressed as a string, needs to be digits followed by a unit (like `"5MB"`).
We default it to 5GB in order for models to be able to run easily on free-tier google colab instances
without CPU OOM issues.
<Tip warning={true}>
If a single weight of the model is bigger than `max_shard_size`, it will be in its own checkpoint shard
which will be bigger than `max_shard_size`.
</Tip>
safe_serialization (`bool`, *optional*, defaults to `True`):
Whether to save the model using `safetensors` or the traditional PyTorch way (that uses `pickle`).
variant (`str`, *optional*):
If specified, weights are saved in the format pytorch_model.<variant>.bin.
token (`str` or `bool`, *optional*):
The token to use as HTTP bearer authorization for remote files. If `True`, or not specified, will use
the token generated when running `huggingface-cli login` (stored in `~/.huggingface`).
save_peft_format (`bool`, *optional*, defaults to `True`):
For backward compatibility with PEFT library, in case adapter weights are attached to the model, all
keys of the state dict of adapters needs to be pre-pended with `base_model.model`. Advanced users can
disable this behaviours by setting `save_peft_format` to `False`.
kwargs (`Dict[str, Any]`, *optional*):
Additional key word arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
"""
use_auth_token = kwargs.pop("use_auth_token", None)
ignore_metadata_errors = kwargs.pop("ignore_metadata_errors", False)
if use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
FutureWarning,
)
if token is not None:
raise ValueError(
"`token` and `use_auth_token` are both specified. Please set only the argument `token`."
)
token = use_auth_token
if token is not None:
kwargs["token"] = token
_hf_peft_config_loaded = getattr(self, "_hf_peft_config_loaded", False)
hf_quantizer = getattr(self, "hf_quantizer", None)
quantization_serializable = (
hf_quantizer is not None
and isinstance(hf_quantizer, HfQuantizer)
and hf_quantizer.is_serializable(safe_serialization=safe_serialization)
)
if hf_quantizer is not None and not _hf_peft_config_loaded and not quantization_serializable:
raise ValueError(
f"The model is quantized with {hf_quantizer.quantization_config.quant_method} and is not serializable - check out the warnings from"
" the logger on the traceback to understand the reason why the quantized model is not serializable."
)
if "save_config" in kwargs:
warnings.warn(
"`save_config` is deprecated and will be removed in v5 of Transformers. Use `is_main_process` instead."
)
is_main_process = kwargs.pop("save_config")
if safe_serialization and not is_safetensors_available():
raise ImportError("`safe_serialization` requires the `safetensors library: `pip install safetensors`.")
if os.path.isfile(save_directory):
logger.error(f"Provided path ({save_directory}) should be a directory, not a file")
return
os.makedirs(save_directory, exist_ok=True)
if push_to_hub:
commit_message = kwargs.pop("commit_message", None)
repo_id = kwargs.pop("repo_id", save_directory.split(os.path.sep)[-1])
repo_id = self._create_repo(repo_id, **kwargs)
files_timestamps = self._get_files_timestamps(save_directory)
# Only save the model itself if we are using distributed training
model_to_save = unwrap_model(self)
# save the string version of dtype to the config, e.g. convert torch.float32 => "float32"
# we currently don't use this setting automatically, but may start to use with v5
dtype = get_parameter_dtype(model_to_save)
model_to_save.config.torch_dtype = str(dtype).split(".")[1]
# Attach architecture to the config
model_to_save.config.architectures = [model_to_save.__class__.__name__]
# Unset attn implementation so it can be set to another one when loading back
model_to_save.config._attn_implementation_autoset = False
# If we have a custom model, we copy the file defining it in the folder and set the attributes so it can be
# loaded from the Hub.
if self._auto_class is not None:
custom_object_save(self, save_directory, config=self.config)
# Save the config
if is_main_process:
if not _hf_peft_config_loaded:
# If the model config has set attributes that should be in the generation config, move them there.
misplaced_generation_parameters = model_to_save.config._get_non_default_generation_parameters()
if self.can_generate() and len(misplaced_generation_parameters) > 0:
warnings.warn(
"Moving the following attributes in the config to the generation config: "
f"{misplaced_generation_parameters}. You are seeing this warning because you've set "
"generation parameters in the model config, as opposed to in the generation config.",
UserWarning,
)
for param_name, param_value in misplaced_generation_parameters.items():
setattr(model_to_save.generation_config, param_name, param_value)
setattr(model_to_save.config, param_name, None)
model_to_save.config.save_pretrained(save_directory)
if self.can_generate():
model_to_save.generation_config.save_pretrained(save_directory)
if _hf_peft_config_loaded:
logger.info(
"Detected adapters on the model, saving the model in the PEFT format, only adapter weights will be saved."
)
state_dict = model_to_save.get_adapter_state_dict()
if save_peft_format:
logger.info(
"To match the expected format of the PEFT library, all keys of the state dict of adapters will be pre-pended with `base_model.model`."
)
peft_state_dict = {}
for key, value in state_dict.items():
peft_state_dict[f"base_model.model.{key}"] = value
state_dict = peft_state_dict
active_adapter = self.active_adapters()
if len(active_adapter) > 1:
raise ValueError(
"Multiple active adapters detected, saving multiple active adapters is not supported yet. You can save adapters separately one by one "
"by iteratively calling `model.set_adapter(adapter_name)` then `model.save_pretrained(...)`"
)
active_adapter = active_adapter[0]
current_peft_config = self.peft_config[active_adapter]
current_peft_config.save_pretrained(save_directory)
# for offloaded modules
module_map = {}
# Save the model
if state_dict is None:
# if any model parameters are offloaded, make module map
if (
hasattr(self, "hf_device_map")
and len(set(self.hf_device_map.values())) > 1
and ("cpu" in self.hf_device_map.values() or "disk" in self.hf_device_map.values())
):
warnings.warn(
"Attempting to save a model with offloaded modules. Ensure that unallocated cpu memory exceeds the `shard_size` (5GB default)"
)
for name, module in model_to_save.named_modules():
if name == "":
continue
module_state_dict = module.state_dict()
for key in module_state_dict:
module_map[name + f".{key}"] = module
state_dict = model_to_save.state_dict()
# Translate state_dict from smp to hf if saving with smp >= 1.10
if IS_SAGEMAKER_MP_POST_1_10:
for smp_to_hf, _ in smp.state.module_manager.translate_functions:
state_dict = smp_to_hf(state_dict)
# Handle the case where some state_dict keys shouldn't be saved
if self._keys_to_ignore_on_save is not None:
for ignore_key in self._keys_to_ignore_on_save:
if ignore_key in state_dict.keys():
del state_dict[ignore_key]
# Rename state_dict keys before saving to file. Do nothing unless overriden in a particular model.
# (initially introduced with TimmWrapperModel to remove prefix and make checkpoints compatible with timm)
state_dict = self._fix_state_dict_keys_on_save(state_dict)
if safe_serialization:
# Safetensors does not allow tensor aliasing.
# We're going to remove aliases before saving
ptrs = collections.defaultdict(list)
for name, tensor in state_dict.items():
# Sometimes in the state_dict we have non-tensor objects.
# e.g. in bitsandbytes we have some `str` objects in the state_dict
if isinstance(tensor, torch.Tensor):
ptrs[id_tensor_storage(tensor)].append(name)
else:
# In the non-tensor case, fall back to the pointer of the object itself
ptrs[id(tensor)].append(name)
# These are all the pointers of shared tensors
if hasattr(self, "hf_device_map"):
# if the model has offloaded parameters, we must check using find_tied_parameters()
tied_params = find_tied_parameters(self)
if tied_params:
tied_names = tied_params[0]
shared_ptrs = {
ptr: names for ptr, names in ptrs.items() if any(name in tied_names for name in names)
}
else:
shared_ptrs = {}
else:
shared_ptrs = {ptr: names for ptr, names in ptrs.items() if len(names) > 1}
# Recursively descend to find tied weight keys
_tied_weights_keys = _get_tied_weight_keys(self)
error_names = []
to_delete_names = set()
for names in shared_ptrs.values():
# Removing the keys which are declared as known duplicates on
# load. This allows to make sure the name which is kept is consistent.
if _tied_weights_keys is not None:
found = 0
for name in sorted(names):
matches_pattern = any(re.search(pat, name) for pat in _tied_weights_keys)
if matches_pattern and name in state_dict:
found += 1
if found < len(names):
to_delete_names.add(name)
# We are entering a place where the weights and the transformers configuration do NOT match.
shared_names, disjoint_names = _find_disjoint(shared_ptrs.values(), state_dict)
# Those are actually tensor sharing but disjoint from each other, we can safely clone them
# Reloaded won't have the same property, but it shouldn't matter in any meaningful way.
for name in disjoint_names:
state_dict[name] = state_dict[name].clone()
# When not all duplicates have been cleaned, still remove those keys, but put a clear warning.
# If the link between tensors was done at runtime then `from_pretrained` will not get
# the key back leading to random tensor. A proper warning will be shown
# during reload (if applicable), but since the file is not necessarily compatible with
# the config, better show a proper warning.
shared_names, identical_names = _find_identical(shared_names, state_dict)
# delete tensors that have identical storage
for inames in identical_names:
known = inames.intersection(to_delete_names)
for name in known:
del state_dict[name]
unknown = inames.difference(to_delete_names)
if len(unknown) > 1:
error_names.append(unknown)
if shared_names:
error_names.append(set(shared_names))
if len(error_names) > 0:
raise RuntimeError(
f"The weights trying to be saved contained shared tensors {error_names} that are mismatching the transformers base configuration. Try saving using `safe_serialization=False` or remove this tensor sharing.",
)
# Shard the model if it is too big.
if not _hf_peft_config_loaded:
weights_name = SAFE_WEIGHTS_NAME if safe_serialization else WEIGHTS_NAME
weights_name = _add_variant(weights_name, variant)
else:
weights_name = ADAPTER_SAFE_WEIGHTS_NAME if safe_serialization else ADAPTER_WEIGHTS_NAME
filename_pattern = weights_name.replace(".bin", "{suffix}.bin").replace(".safetensors", "{suffix}.safetensors")
state_dict_split = split_torch_state_dict_into_shards(
state_dict, filename_pattern=filename_pattern, max_shard_size=max_shard_size
)
# Save index if sharded
index = None
if state_dict_split.is_sharded:
index = {
"metadata": state_dict_split.metadata,
"weight_map": state_dict_split.tensor_to_filename,
}
# Clean the folder from a previous save
for filename in os.listdir(save_directory):
full_filename = os.path.join(save_directory, filename)
# If we have a shard file that is not going to be replaced, we delete it, but only from the main process
# in distributed settings to avoid race conditions.
weights_no_suffix = weights_name.replace(".bin", "").replace(".safetensors", "")
# make sure that file to be deleted matches format of sharded file, e.g. pytorch_model-00001-of-00005
filename_no_suffix = filename.replace(".bin", "").replace(".safetensors", "")
reg = re.compile(r"(.*?)-\d{5}-of-\d{5}")
if (
filename.startswith(weights_no_suffix)
and os.path.isfile(full_filename)
and filename not in state_dict_split.filename_to_tensors.keys()
and is_main_process
and reg.fullmatch(filename_no_suffix) is not None
):
os.remove(full_filename)
# Save the model
filename_to_tensors = state_dict_split.filename_to_tensors.items()
if module_map:
filename_to_tensors = logging.tqdm(filename_to_tensors, desc="Saving checkpoint shards")
for shard_file, tensors in filename_to_tensors:
shard = {}
for tensor in tensors:
shard[tensor] = state_dict[tensor].contiguous()
# delete reference, see https://github.com/huggingface/transformers/pull/34890
del state_dict[tensor]
# remake shard with onloaded parameters if necessary
if module_map:
if accelerate_version < version.parse("0.31"):
raise ImportError(
f"You need accelerate version to be greater or equal than 0.31 to save models with offloaded parameters. Detected version {accelerate_version}. "
f"Please upgrade accelerate with `pip install -U accelerate`"
)
# init state_dict for this shard
shard_state_dict = {name: "" for name in shard}
for module_name in shard:
module = module_map[module_name]
# update state dict with onloaded parameters
shard_state_dict = get_state_dict_from_offload(module, module_name, shard_state_dict)
# assign shard to be the completed state dict
shard = shard_state_dict
del shard_state_dict
gc.collect()
if safe_serialization:
# At some point we will need to deal better with save_function (used for TPU and other distributed
# joyfulness), but for now this enough.
safe_save_file(shard, os.path.join(save_directory, shard_file), metadata={"format": "pt"})
else:
save_function(shard, os.path.join(save_directory, shard_file))
del state_dict
if index is None:
path_to_weights = os.path.join(save_directory, weights_name)
logger.info(f"Model weights saved in {path_to_weights}")
else:
save_index_file = SAFE_WEIGHTS_INDEX_NAME if safe_serialization else WEIGHTS_INDEX_NAME
save_index_file = os.path.join(save_directory, _add_variant(save_index_file, variant))
# Save the index as well
with open(save_index_file, "w", encoding="utf-8") as f:
content = json.dumps(index, indent=2, sort_keys=True) + "\n"
f.write(content)
logger.info(
f"The model is bigger than the maximum size per checkpoint ({max_shard_size}) and is going to be "
f"split in {len(state_dict_split.filename_to_tensors)} checkpoint shards. You can find where each parameters has been saved in the "
f"index located at {save_index_file}."
)
if push_to_hub:
# Eventually create an empty model card
model_card = create_and_tag_model_card(
repo_id, self.model_tags, token=token, ignore_metadata_errors=ignore_metadata_errors
)
# Update model card if needed:
model_card.save(os.path.join(save_directory, "README.md"))
self._upload_modified_files(
save_directory,
repo_id,
files_timestamps,
commit_message=commit_message,
token=token,
)
@wraps(PushToHubMixin.push_to_hub)
def push_to_hub(self, *args, **kwargs):
tags = self.model_tags if self.model_tags is not None else []
tags_kwargs = kwargs.get("tags", [])
if isinstance(tags_kwargs, str):
tags_kwargs = [tags_kwargs]
for tag in tags_kwargs:
if tag not in tags:
tags.append(tag)
if tags:
kwargs["tags"] = tags
return super().push_to_hub(*args, **kwargs)
def get_memory_footprint(self, return_buffers=True):
r"""
Get the memory footprint of a model. This will return the memory footprint of the current model in bytes.
Useful to benchmark the memory footprint of the current model and design some tests. Solution inspired from the
PyTorch discussions: https://discuss.pytorch.org/t/gpu-memory-that-model-uses/56822/2
Arguments:
return_buffers (`bool`, *optional*, defaults to `True`):
Whether to return the size of the buffer tensors in the computation of the memory footprint. Buffers
are tensors that do not require gradients and not registered as parameters. E.g. mean and std in batch
norm layers. Please see: https://discuss.pytorch.org/t/what-pytorch-means-by-buffers/120266/2
"""
mem = sum([param.nelement() * param.element_size() for param in self.parameters()])
if return_buffers:
mem_bufs = sum([buf.nelement() * buf.element_size() for buf in self.buffers()])
mem = mem + mem_bufs
return mem
@wraps(torch.nn.Module.cuda)
def cuda(self, *args, **kwargs):
if getattr(self, "quantization_method", None) == QuantizationMethod.HQQ:
raise ValueError("`.cuda` is not supported for HQQ-quantized models.")
# Checks if the model has been loaded in 4-bit or 8-bit with BNB
if getattr(self, "quantization_method", None) == QuantizationMethod.BITS_AND_BYTES:
if getattr(self, "is_loaded_in_8bit", False):
raise ValueError(
"Calling `cuda()` is not supported for `8-bit` quantized models. "
" Please use the model as it is, since the model has already been set to the correct devices."
)
elif version.parse(importlib.metadata.version("bitsandbytes")) < version.parse("0.43.2"):
raise ValueError(
"Calling `cuda()` is not supported for `4-bit` quantized models with the installed version of bitsandbytes. "
f"The current device is `{self.device}`. If you intended to move the model, please install bitsandbytes >= 0.43.2."
)
else:
return super().cuda(*args, **kwargs)
@wraps(torch.nn.Module.to)
def to(self, *args, **kwargs):
# For BNB/GPTQ models, we prevent users from casting the model to another dtype to restrict unwanted behaviours.
# the correct API should be to load the model with the desired dtype directly through `from_pretrained`.
dtype_present_in_args = "dtype" in kwargs
if not dtype_present_in_args:
for arg in args:
if isinstance(arg, torch.dtype):
dtype_present_in_args = True
break
if getattr(self, "quantization_method", None) == QuantizationMethod.HQQ:
raise ValueError("`.to` is not supported for HQQ-quantized models.")
# Checks if the model has been loaded in 4-bit or 8-bit with BNB
if getattr(self, "quantization_method", None) == QuantizationMethod.BITS_AND_BYTES:
if dtype_present_in_args:
raise ValueError(
"You cannot cast a bitsandbytes model in a new `dtype`. Make sure to load the model using `from_pretrained` using the"
" desired `dtype` by passing the correct `torch_dtype` argument."
)
if getattr(self, "is_loaded_in_8bit", False):
raise ValueError(
"`.to` is not supported for `8-bit` bitsandbytes models. Please use the model as it is, since the"
" model has already been set to the correct devices and casted to the correct `dtype`."
)
elif version.parse(importlib.metadata.version("bitsandbytes")) < version.parse("0.43.2"):
raise ValueError(
"Calling `to()` is not supported for `4-bit` quantized models with the installed version of bitsandbytes. "
f"The current device is `{self.device}`. If you intended to move the model, please install bitsandbytes >= 0.43.2."
)
elif getattr(self, "quantization_method", None) == QuantizationMethod.GPTQ:
if dtype_present_in_args:
raise ValueError(
"You cannot cast a GPTQ model in a new `dtype`. Make sure to load the model using `from_pretrained` using the desired"
" `dtype` by passing the correct `torch_dtype` argument."
)
return super().to(*args, **kwargs)
def half(self, *args):
# Checks if the model is quantized
if getattr(self, "is_quantized", False):
raise ValueError(
"`.half()` is not supported for quantized model. Please use the model as it is, since the"
" model has already been casted to the correct `dtype`."
)
else:
return super().half(*args)
def float(self, *args):
# Checks if the model is quantized
if getattr(self, "is_quantized", False):
raise ValueError(
"`.float()` is not supported for quantized model. Please use the model as it is, since the"
" model has already been casted to the correct `dtype`."
)
else:
return super().float(*args)
@classmethod
@restore_default_torch_dtype
def from_pretrained(
cls: Type[SpecificPreTrainedModelType],
pretrained_model_name_or_path: Optional[Union[str, os.PathLike]],
*model_args,
config: Optional[Union[PretrainedConfig, str, os.PathLike]] = None,
cache_dir: Optional[Union[str, os.PathLike]] = None,
ignore_mismatched_sizes: bool = False,
force_download: bool = False,
local_files_only: bool = False,
token: Optional[Union[str, bool]] = None,
revision: str = "main",
use_safetensors: Optional[bool] = None,
weights_only: bool = True,
**kwargs,
) -> SpecificPreTrainedModelType:
r"""
Instantiate a pretrained pytorch model from a pre-trained model configuration.
The model is set in evaluation mode by default using `model.eval()` (Dropout modules are deactivated). To train
the model, you should first set it back in training mode with `model.train()`.
The warning *Weights from XXX not initialized from pretrained model* means that the weights of XXX do not come
pretrained with the rest of the model. It is up to you to train those weights with a downstream fine-tuning
task.
The warning *Weights from XXX not used in YYY* means that the layer XXX is not used by YYY, therefore those
weights are discarded.
If model weights are the same precision as the base model (and is a supported model), weights will be lazily loaded
in using the `meta` device and brought into memory once an input is passed through that layer regardless of
`low_cpu_mem_usage`.
Parameters:
pretrained_model_name_or_path (`str` or `os.PathLike`, *optional*):
Can be either:
- A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
- A path to a *directory* containing model weights saved using
[`~PreTrainedModel.save_pretrained`], e.g., `./my_model_directory/`.
- A path or url to a *tensorflow index checkpoint file* (e.g, `./tf_model/model.ckpt.index`). In
this case, `from_tf` should be set to `True` and a configuration object should be provided as
`config` argument. This loading path is slower than converting the TensorFlow checkpoint in a
PyTorch model using the provided conversion scripts and loading the PyTorch model afterwards.
- A path or url to a model folder containing a *flax checkpoint file* in *.msgpack* format (e.g,
`./flax_model/` containing `flax_model.msgpack`). In this case, `from_flax` should be set to
`True`.
- `None` if you are both providing the configuration and state dictionary (resp. with keyword
arguments `config` and `state_dict`).
model_args (sequence of positional arguments, *optional*):
All remaining positional arguments will be passed to the underlying model's `__init__` method.
config (`Union[PretrainedConfig, str, os.PathLike]`, *optional*):
Can be either:
- an instance of a class derived from [`PretrainedConfig`],
- a string or path valid as input to [`~PretrainedConfig.from_pretrained`].
Configuration for the model to use instead of an automatically loaded configuration. Configuration can
be automatically loaded when:
- The model is a model provided by the library (loaded with the *model id* string of a pretrained
model).
- The model was saved using [`~PreTrainedModel.save_pretrained`] and is reloaded by supplying the
save directory.
- The model is loaded by supplying a local directory as `pretrained_model_name_or_path` and a
configuration JSON file named *config.json* is found in the directory.
state_dict (`Dict[str, torch.Tensor]`, *optional*):
A state dictionary to use instead of a state dictionary loaded from saved weights file.
This option can be used if you want to create a model from a pretrained configuration but load your own
weights. In this case though, you should check if using [`~PreTrainedModel.save_pretrained`] and
[`~PreTrainedModel.from_pretrained`] is not a simpler option.
cache_dir (`Union[str, os.PathLike]`, *optional*):
Path to a directory in which a downloaded pretrained model configuration should be cached if the
standard cache should not be used.
from_tf (`bool`, *optional*, defaults to `False`):
Load the model weights from a TensorFlow checkpoint save file (see docstring of
`pretrained_model_name_or_path` argument).
from_flax (`bool`, *optional*, defaults to `False`):
Load the model weights from a Flax checkpoint save file (see docstring of
`pretrained_model_name_or_path` argument).
ignore_mismatched_sizes (`bool`, *optional*, defaults to `False`):
Whether or not to raise an error if some of the weights from the checkpoint do not have the same size
as the weights of the model (if for instance, you are instantiating a model with 10 labels from a
checkpoint with 3 labels).
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
resume_download:
Deprecated and ignored. All downloads are now resumed by default when possible.
Will be removed in v5 of Transformers.
proxies (`Dict[str, str]`, *optional*):
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
output_loading_info(`bool`, *optional*, defaults to `False`):
Whether ot not to also return a dictionary containing missing keys, unexpected keys and error messages.
local_files_only(`bool`, *optional*, defaults to `False`):
Whether or not to only look at local files (i.e., do not try to download the model).
token (`str` or `bool`, *optional*):
The token to use as HTTP bearer authorization for remote files. If `True`, or not specified, will use
the token generated when running `huggingface-cli login` (stored in `~/.huggingface`).
revision (`str`, *optional*, defaults to `"main"`):
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
identifier allowed by git.
<Tip>
To test a pull request you made on the Hub, you can pass `revision="refs/pr/<pr_number>"`.
</Tip>
mirror (`str`, *optional*):
Mirror source to accelerate downloads in China. If you are from China and have an accessibility
problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
Please refer to the mirror site for more information.
_fast_init(`bool`, *optional*, defaults to `True`):
Whether or not to disable fast initialization.
<Tip warning={true}>
One should only disable *_fast_init* to ensure backwards compatibility with `transformers.__version__ <
4.6.0` for seeded model initialization. This argument will be removed at the next major version. See
[pull request 11471](https://github.com/huggingface/transformers/pull/11471) for more information.
</Tip>
attn_implementation (`str`, *optional*):
The attention implementation to use in the model (if relevant). Can be any of `"eager"` (manual implementation of the attention), `"sdpa"` (using [`F.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html)), or `"flash_attention_2"` (using [Dao-AILab/flash-attention](https://github.com/Dao-AILab/flash-attention)). By default, if available, SDPA will be used for torch>=2.1.1. The default is otherwise the manual `"eager"` implementation.
> Parameters for big model inference
low_cpu_mem_usage(`bool`, *optional*):
Tries not to use more than 1x model size in CPU memory (including peak memory) while loading the model.
Generally should be combined with a `device_map` (such as `"auto"`) for best results.
This is an experimental feature and a subject to change at any moment.
</Tip>
If the model weights are in the same precision as the model loaded in, `low_cpu_mem_usage` (without
`device_map`) is redundant and will not provide any benefit in regards to CPU memory usage. However,
this should still be enabled if you are passing in a `device_map`.
</Tip>
torch_dtype (`str` or `torch.dtype`, *optional*):
Override the default `torch.dtype` and load the model under a specific `dtype`. The different options
are:
1. `torch.float16` or `torch.bfloat16` or `torch.float`: load in a specified
`dtype`, ignoring the model's `config.torch_dtype` if one exists. If not specified
- the model will get loaded in `torch.float` (fp32).
2. `"auto"` - A `torch_dtype` entry in the `config.json` file of the model will be
attempted to be used. If this entry isn't found then next check the `dtype` of the first weight in
the checkpoint that's of a floating point type and use that as `dtype`. This will load the model
using the `dtype` it was saved in at the end of the training. It can't be used as an indicator of how
the model was trained. Since it could be trained in one of half precision dtypes, but saved in fp32.
3. A string that is a valid `torch.dtype`. E.g. "float32" loads the model in `torch.float32`, "float16" loads in `torch.float16` etc.
<Tip>
For some models the `dtype` they were trained in is unknown - you may try to check the model's paper or
reach out to the authors and ask them to add this information to the model's card and to insert the
`torch_dtype` entry in `config.json` on the hub.
</Tip>
device_map (`str` or `Dict[str, Union[int, str, torch.device]]` or `int` or `torch.device`, *optional*):
A map that specifies where each submodule should go. It doesn't need to be refined to each
parameter/buffer name, once a given module name is inside, every submodule of it will be sent to the
same device. If we only pass the device (*e.g.*, `"cpu"`, `"cuda:1"`, `"mps"`, or a GPU ordinal rank
like `1`) on which the model will be allocated, the device map will map the entire model to this
device. Passing `device_map = 0` means put the whole model on GPU 0.
To have Accelerate compute the most optimized `device_map` automatically, set `device_map="auto"`. For
more information about each option see [designing a device
map](https://hf.co/docs/accelerate/main/en/usage_guides/big_modeling#designing-a-device-map).
max_memory (`Dict`, *optional*):
A dictionary device identifier to maximum memory. Will default to the maximum memory available for each
GPU and the available CPU RAM if unset.
offload_folder (`str` or `os.PathLike`, *optional*):
If the `device_map` contains any value `"disk"`, the folder where we will offload weights.
offload_state_dict (`bool`, *optional*):
If `True`, will temporarily offload the CPU state dict to the hard drive to avoid getting out of CPU
RAM if the weight of the CPU state dict + the biggest shard of the checkpoint does not fit. Defaults to
`True` when there is some disk offload.
offload_buffers (`bool`, *optional*):
Whether or not to offload the buffers with the model parameters.
quantization_config (`Union[QuantizationConfigMixin,Dict]`, *optional*):
A dictionary of configuration parameters or a QuantizationConfigMixin object for quantization (e.g
bitsandbytes, gptq). There may be other quantization-related kwargs, including `load_in_4bit` and
`load_in_8bit`, which are parsed by QuantizationConfigParser. Supported only for bitsandbytes
quantizations and not preferred. consider inserting all such arguments into quantization_config
instead.
subfolder (`str`, *optional*, defaults to `""`):
In case the relevant files are located inside a subfolder of the model repo on huggingface.co, you can
specify the folder name here.
variant (`str`, *optional*):
If specified load weights from `variant` filename, *e.g.* pytorch_model.<variant>.bin. `variant` is
ignored when using `from_tf` or `from_flax`.
use_safetensors (`bool`, *optional*, defaults to `None`):
Whether or not to use `safetensors` checkpoints. Defaults to `None`. If not specified and `safetensors`
is not installed, it will be set to `False`.
weights_only (`bool`, *optional*, defaults to `True`):
Indicates whether unpickler should be restricted to loading only tensors, primitive types,
dictionaries and any types added via torch.serialization.add_safe_globals().
When set to False, we can load wrapper tensor subclass weights.
kwargs (remaining dictionary of keyword arguments, *optional*):
Can be used to update the configuration object (after it being loaded) and initiate the model (e.g.,
`output_attentions=True`). Behaves differently depending on whether a `config` is provided or
automatically loaded:
- If a configuration is provided with `config`, `**kwargs` will be directly passed to the
underlying model's `__init__` method (we assume all relevant updates to the configuration have
already been done)
- If a configuration is not provided, `kwargs` will be first passed to the configuration class
initialization function ([`~PretrainedConfig.from_pretrained`]). Each key of `kwargs` that
corresponds to a configuration attribute will be used to override said attribute with the
supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute
will be passed to the underlying model's `__init__` function.
<Tip>
Activate the special ["offline-mode"](https://huggingface.co/transformers/installation.html#offline-mode) to
use this method in a firewalled environment.
</Tip>
Examples:
```python
>>> from transformers import BertConfig, BertModel
>>> # Download model and configuration from huggingface.co and cache.
>>> model = BertModel.from_pretrained("google-bert/bert-base-uncased")
>>> # Model was saved using *save_pretrained('./test/saved_model/')* (for example purposes, not runnable).
>>> model = BertModel.from_pretrained("./test/saved_model/")
>>> # Update configuration during loading.
>>> model = BertModel.from_pretrained("google-bert/bert-base-uncased", output_attentions=True)
>>> assert model.config.output_attentions == True
>>> # Loading from a TF checkpoint file instead of a PyTorch model (slower, for example purposes, not runnable).
>>> config = BertConfig.from_json_file("./tf_model/my_tf_model_config.json")
>>> model = BertModel.from_pretrained("./tf_model/my_tf_checkpoint.ckpt.index", from_tf=True, config=config)
>>> # Loading from a Flax checkpoint file instead of a PyTorch model (slower)
>>> model = BertModel.from_pretrained("google-bert/bert-base-uncased", from_flax=True)
```
* `low_cpu_mem_usage` algorithm:
This is an experimental function that loads the model using ~1x model size CPU memory
Here is how it works:
1. save which state_dict keys we have
2. drop state_dict before the model is created, since the latter takes 1x model size CPU memory
3. after the model has been instantiated switch to the meta device all params/buffers that
are going to be replaced from the loaded state_dict
4. load state_dict 2nd time
5. replace the params/buffers from the state_dict
Currently, it can't handle deepspeed ZeRO stage 3 and ignores loading errors
"""
state_dict = kwargs.pop("state_dict", None)
from_tf = kwargs.pop("from_tf", False)
from_flax = kwargs.pop("from_flax", False)
resume_download = kwargs.pop("resume_download", None)
proxies = kwargs.pop("proxies", None)
output_loading_info = kwargs.pop("output_loading_info", False)
use_auth_token = kwargs.pop("use_auth_token", None)
trust_remote_code = kwargs.pop("trust_remote_code", None)
_ = kwargs.pop("mirror", None)
from_pipeline = kwargs.pop("_from_pipeline", None)
from_auto_class = kwargs.pop("_from_auto", False)
_fast_init = kwargs.pop("_fast_init", True)
torch_dtype = kwargs.pop("torch_dtype", None)
low_cpu_mem_usage = kwargs.pop("low_cpu_mem_usage", None)
device_map = kwargs.pop("device_map", None)
max_memory = kwargs.pop("max_memory", None)
offload_folder = kwargs.pop("offload_folder", None)
offload_state_dict = kwargs.pop("offload_state_dict", False)
offload_buffers = kwargs.pop("offload_buffers", False)
load_in_8bit = kwargs.pop("load_in_8bit", False)
load_in_4bit = kwargs.pop("load_in_4bit", False)
quantization_config = kwargs.pop("quantization_config", None)
subfolder = kwargs.pop("subfolder", "")
commit_hash = kwargs.pop("_commit_hash", None)
variant = kwargs.pop("variant", None)
adapter_kwargs = kwargs.pop("adapter_kwargs", {})
adapter_name = kwargs.pop("adapter_name", "default")
use_flash_attention_2 = kwargs.pop("use_flash_attention_2", False)
generation_config = kwargs.pop("generation_config", None)
gguf_file = kwargs.pop("gguf_file", None)
# Cache path to the GGUF file
gguf_path = None
tp_plan = kwargs.pop("tp_plan", None)
if tp_plan is not None and tp_plan != "auto":
# TODO: we can relax this check when we support taking tp_plan from a json file, for example.
raise ValueError(f"tp_plan supports 'auto' only for now but got {tp_plan}.")
if tp_plan is not None and device_map is not None:
raise ValueError(
"`tp_plan` and `device_map` are mutually exclusive. Choose either one for parallelization."
)
# We need to correctly dispatch the model on the current process device. The easiest way for this is to use a simple
# `device_map` pointing to the correct device. If we don't, torch will use the default device (index 0) for all
# childs processes at parallelization time, resulting in excessive memory usage on device 0 and OOMs.
# And temporarily setting the default device to current process rank result in the following error
# `torch.distributed.DistBackendError: Attempt to perform collective on tensor not on device passed to init_process_group`
tp_device = None
if tp_plan is not None:
if not torch.distributed.is_initialized():
raise ValueError("Tensor Parallel requires torch.distributed to be initialized first.")
# Detect the accelerator on the machine. If no accelerator is available, it returns CPU.
device_type = torch._C._get_accelerator().type
device_module = torch.get_device_module(device_type)
# Get device with index assuming equal number of devices per host
tp_device = torch.device(device_type, torch.distributed.get_rank() % device_module.device_count())
# This is the easiest way to dispatch to the current process device
device_map = tp_device
if is_fsdp_enabled():
low_cpu_mem_usage = True
if use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
FutureWarning,
)
if token is not None:
raise ValueError(
"`token` and `use_auth_token` are both specified. Please set only the argument `token`."
)
token = use_auth_token
if token is not None and adapter_kwargs is not None and "token" not in adapter_kwargs:
adapter_kwargs["token"] = token
if use_safetensors is None and not is_safetensors_available():
use_safetensors = False
if trust_remote_code is True:
logger.warning(
"The argument `trust_remote_code` is to be used with Auto classes. It has no effect here and is"
" ignored."
)
if gguf_file is not None and not is_accelerate_available():
raise ValueError("accelerate is required when loading a GGUF file `pip install accelerate`.")
if commit_hash is None:
if not isinstance(config, PretrainedConfig):
# We make a call to the config file first (which may be absent) to get the commit hash as soon as possible
resolved_config_file = cached_file(
pretrained_model_name_or_path,
CONFIG_NAME,
cache_dir=cache_dir,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
token=token,
revision=revision,
subfolder=subfolder,
_raise_exceptions_for_gated_repo=False,
_raise_exceptions_for_missing_entries=False,
_raise_exceptions_for_connection_errors=False,
)
commit_hash = extract_commit_hash(resolved_config_file, commit_hash)
else:
commit_hash = getattr(config, "_commit_hash", None)
if is_peft_available():
_adapter_model_path = adapter_kwargs.pop("_adapter_model_path", None)
if _adapter_model_path is None:
_adapter_model_path = find_adapter_config_file(
pretrained_model_name_or_path,
cache_dir=cache_dir,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
_commit_hash=commit_hash,
**adapter_kwargs,
)
if _adapter_model_path is not None and os.path.isfile(_adapter_model_path):
with open(_adapter_model_path, "r", encoding="utf-8") as f:
_adapter_model_path = pretrained_model_name_or_path
pretrained_model_name_or_path = json.load(f)["base_model_name_or_path"]
else:
_adapter_model_path = None
# change device_map into a map if we passed an int, a str or a torch.device
if isinstance(device_map, torch.device):
device_map = {"": device_map}
elif isinstance(device_map, str) and device_map not in ["auto", "balanced", "balanced_low_0", "sequential"]:
try:
device_map = {"": torch.device(device_map)}
except RuntimeError:
raise ValueError(
"When passing device_map as a string, the value needs to be a device name (e.g. cpu, cuda:0) or "
f"'auto', 'balanced', 'balanced_low_0', 'sequential' but found {device_map}."
)
elif isinstance(device_map, int):
if device_map < 0:
raise ValueError(
"You can't pass device_map as a negative int. If you want to put the model on the cpu, pass device_map = 'cpu' "
)
else:
device_map = {"": device_map}
if device_map is not None:
if low_cpu_mem_usage is None:
low_cpu_mem_usage = True
elif not low_cpu_mem_usage:
raise ValueError("Passing along a `device_map` requires `low_cpu_mem_usage=True`")
if low_cpu_mem_usage:
if is_deepspeed_zero3_enabled():
raise ValueError(
"DeepSpeed Zero-3 is not compatible with `low_cpu_mem_usage=True` or with passing a `device_map`."
)
elif not is_accelerate_available():
raise ImportError(
f"Using `low_cpu_mem_usage=True` or a `device_map` requires Accelerate: `pip install 'accelerate>={ACCELERATE_MIN_VERSION}'`"
)
# handling bnb config from kwargs, remove after `load_in_{4/8}bit` deprecation.
if load_in_4bit or load_in_8bit:
if quantization_config is not None:
raise ValueError(
"You can't pass `load_in_4bit`or `load_in_8bit` as a kwarg when passing "
"`quantization_config` argument at the same time."
)
# preparing BitsAndBytesConfig from kwargs
config_dict = {k: v for k, v in kwargs.items() if k in inspect.signature(BitsAndBytesConfig).parameters}
config_dict = {**config_dict, "load_in_4bit": load_in_4bit, "load_in_8bit": load_in_8bit}
quantization_config, kwargs = BitsAndBytesConfig.from_dict(
config_dict=config_dict, return_unused_kwargs=True, **kwargs
)
logger.warning(
"The `load_in_4bit` and `load_in_8bit` arguments are deprecated and will be removed in the future versions. "
"Please, pass a `BitsAndBytesConfig` object in `quantization_config` argument instead."
)
from_pt = not (from_tf | from_flax)
user_agent = {"file_type": "model", "framework": "pytorch", "from_auto_class": from_auto_class}
if from_pipeline is not None:
user_agent["using_pipeline"] = from_pipeline
if is_offline_mode() and not local_files_only:
logger.info("Offline mode: forcing local_files_only=True")
local_files_only = True
# Load config if we don't provide a configuration
if not isinstance(config, PretrainedConfig):
config_path = config if config is not None else pretrained_model_name_or_path
config, model_kwargs = cls.config_class.from_pretrained(
config_path,
cache_dir=cache_dir,
return_unused_kwargs=True,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
token=token,
revision=revision,
subfolder=subfolder,
_from_auto=from_auto_class,
_from_pipeline=from_pipeline,
**kwargs,
)
else:
# In case one passes a config to `from_pretrained` + "attn_implementation"
# override the `_attn_implementation` attribute to `attn_implementation` of the kwargs
# Please see: https://github.com/huggingface/transformers/issues/28038
# Overwrite `config._attn_implementation` by the one from the kwargs --> in auto-factory
# we pop attn_implementation from the kwargs but this handles the case where users
# passes manually the config to `from_pretrained`.
config = copy.deepcopy(config)
kwarg_attn_imp = kwargs.pop("attn_implementation", None)
if kwarg_attn_imp is not None:
config._attn_implementation = kwarg_attn_imp
model_kwargs = kwargs
pre_quantized = hasattr(config, "quantization_config")
if pre_quantized and not AutoHfQuantizer.supports_quant_method(config.quantization_config):
pre_quantized = False
if pre_quantized or quantization_config is not None:
if pre_quantized:
config.quantization_config = AutoHfQuantizer.merge_quantization_configs(
config.quantization_config, quantization_config
)
else:
config.quantization_config = quantization_config
hf_quantizer = AutoHfQuantizer.from_config(
config.quantization_config,
pre_quantized=pre_quantized,
)
else:
hf_quantizer = None
if hf_quantizer is not None:
hf_quantizer.validate_environment(
torch_dtype=torch_dtype,
from_tf=from_tf,
from_flax=from_flax,
device_map=device_map,
weights_only=weights_only,
)
torch_dtype = hf_quantizer.update_torch_dtype(torch_dtype)
device_map = hf_quantizer.update_device_map(device_map)
# In order to ensure popular quantization methods are supported. Can be disable with `disable_telemetry`
user_agent["quant"] = hf_quantizer.quantization_config.quant_method.value
# Force-set to `True` for more mem efficiency
if low_cpu_mem_usage is None:
low_cpu_mem_usage = True
logger.warning("`low_cpu_mem_usage` was None, now default to True since model is quantized.")
is_quantized = hf_quantizer is not None
# This variable will flag if we're loading a sharded checkpoint. In this case the archive file is just the
# index of the files.
is_sharded = False
sharded_metadata = None
# Load model
loading_info = None
# Keep in fp32 modules
keep_in_fp32_modules = None
use_keep_in_fp32_modules = False
if gguf_file is not None and hf_quantizer is not None:
raise ValueError(
"You cannot combine Quantization and loading a model from a GGUF file, try again by making sure you did not passed a `quantization_config` or that you did not load a quantized model from the Hub."
)
if pretrained_model_name_or_path is not None and gguf_file is None:
pretrained_model_name_or_path = str(pretrained_model_name_or_path)
is_local = os.path.isdir(pretrained_model_name_or_path)
if is_local:
if from_tf and os.path.isfile(
os.path.join(pretrained_model_name_or_path, subfolder, TF_WEIGHTS_NAME + ".index")
):
# Load from a TF 1.0 checkpoint in priority if from_tf
archive_file = os.path.join(pretrained_model_name_or_path, subfolder, TF_WEIGHTS_NAME + ".index")
elif from_tf and os.path.isfile(
os.path.join(pretrained_model_name_or_path, subfolder, TF2_WEIGHTS_NAME)
):
# Load from a TF 2.0 checkpoint in priority if from_tf
archive_file = os.path.join(pretrained_model_name_or_path, subfolder, TF2_WEIGHTS_NAME)
elif from_flax and os.path.isfile(
os.path.join(pretrained_model_name_or_path, subfolder, FLAX_WEIGHTS_NAME)
):
# Load from a Flax checkpoint in priority if from_flax
archive_file = os.path.join(pretrained_model_name_or_path, subfolder, FLAX_WEIGHTS_NAME)
elif use_safetensors is not False and os.path.isfile(
os.path.join(pretrained_model_name_or_path, subfolder, _add_variant(SAFE_WEIGHTS_NAME, variant))
):
# Load from a safetensors checkpoint
archive_file = os.path.join(
pretrained_model_name_or_path, subfolder, _add_variant(SAFE_WEIGHTS_NAME, variant)
)
elif use_safetensors is not False and os.path.isfile(
os.path.join(
pretrained_model_name_or_path, subfolder, _add_variant(SAFE_WEIGHTS_INDEX_NAME, variant)
)
):
# Load from a sharded safetensors checkpoint
archive_file = os.path.join(
pretrained_model_name_or_path, subfolder, _add_variant(SAFE_WEIGHTS_INDEX_NAME, variant)
)
is_sharded = True
elif not use_safetensors and os.path.isfile(
os.path.join(pretrained_model_name_or_path, subfolder, _add_variant(WEIGHTS_NAME, variant))
):
# Load from a PyTorch checkpoint
archive_file = os.path.join(
pretrained_model_name_or_path, subfolder, _add_variant(WEIGHTS_NAME, variant)
)
elif not use_safetensors and os.path.isfile(
os.path.join(pretrained_model_name_or_path, subfolder, _add_variant(WEIGHTS_INDEX_NAME, variant))
):
# Load from a sharded PyTorch checkpoint
archive_file = os.path.join(
pretrained_model_name_or_path, subfolder, _add_variant(WEIGHTS_INDEX_NAME, variant)
)
is_sharded = True
# At this stage we don't have a weight file so we will raise an error.
elif not use_safetensors and (
os.path.isfile(os.path.join(pretrained_model_name_or_path, subfolder, TF_WEIGHTS_NAME + ".index"))
or os.path.isfile(os.path.join(pretrained_model_name_or_path, subfolder, TF2_WEIGHTS_NAME))
):
raise EnvironmentError(
f"Error no file named {_add_variant(WEIGHTS_NAME, variant)} found in directory"
f" {pretrained_model_name_or_path} but there is a file for TensorFlow weights. Use"
" `from_tf=True` to load this model from those weights."
)
elif not use_safetensors and os.path.isfile(
os.path.join(pretrained_model_name_or_path, subfolder, FLAX_WEIGHTS_NAME)
):
raise EnvironmentError(
f"Error no file named {_add_variant(WEIGHTS_NAME, variant)} found in directory"
f" {pretrained_model_name_or_path} but there is a file for Flax weights. Use `from_flax=True`"
" to load this model from those weights."
)
elif use_safetensors:
raise EnvironmentError(
f"Error no file named {_add_variant(SAFE_WEIGHTS_NAME, variant)} found in directory"
f" {pretrained_model_name_or_path}."
)
else:
raise EnvironmentError(
f"Error no file named {_add_variant(WEIGHTS_NAME, variant)}, {_add_variant(SAFE_WEIGHTS_NAME, variant)},"
f" {TF2_WEIGHTS_NAME}, {TF_WEIGHTS_NAME + '.index'} or {FLAX_WEIGHTS_NAME} found in directory"
f" {pretrained_model_name_or_path}."
)
elif os.path.isfile(os.path.join(subfolder, pretrained_model_name_or_path)):
archive_file = pretrained_model_name_or_path
is_local = True
elif os.path.isfile(os.path.join(subfolder, pretrained_model_name_or_path + ".index")):
if not from_tf:
raise ValueError(
f"We found a TensorFlow checkpoint at {pretrained_model_name_or_path + '.index'}, please set "
"from_tf to True to load from this checkpoint."
)
archive_file = os.path.join(subfolder, pretrained_model_name_or_path + ".index")
is_local = True
elif is_remote_url(pretrained_model_name_or_path):
filename = pretrained_model_name_or_path
resolved_archive_file = download_url(pretrained_model_name_or_path)
else:
# set correct filename
if from_tf:
filename = TF2_WEIGHTS_NAME
elif from_flax:
filename = FLAX_WEIGHTS_NAME
elif use_safetensors is not False:
filename = _add_variant(SAFE_WEIGHTS_NAME, variant)
else:
filename = _add_variant(WEIGHTS_NAME, variant)
try:
# Load from URL or cache if already cached
cached_file_kwargs = {
"cache_dir": cache_dir,
"force_download": force_download,
"proxies": proxies,
"resume_download": resume_download,
"local_files_only": local_files_only,
"token": token,
"user_agent": user_agent,
"revision": revision,
"subfolder": subfolder,
"_raise_exceptions_for_gated_repo": False,
"_raise_exceptions_for_missing_entries": False,
"_commit_hash": commit_hash,
}
resolved_archive_file = cached_file(pretrained_model_name_or_path, filename, **cached_file_kwargs)
# Since we set _raise_exceptions_for_missing_entries=False, we don't get an exception but a None
# result when internet is up, the repo and revision exist, but the file does not.
if resolved_archive_file is None and filename == _add_variant(SAFE_WEIGHTS_NAME, variant):
# Maybe the checkpoint is sharded, we try to grab the index name in this case.
resolved_archive_file = cached_file(
pretrained_model_name_or_path,
_add_variant(SAFE_WEIGHTS_INDEX_NAME, variant),
**cached_file_kwargs,
)
if resolved_archive_file is not None:
is_sharded = True
elif use_safetensors:
if revision == "main":
resolved_archive_file, revision, is_sharded = auto_conversion(
pretrained_model_name_or_path, **cached_file_kwargs
)
cached_file_kwargs["revision"] = revision
if resolved_archive_file is None:
raise EnvironmentError(
f"{pretrained_model_name_or_path} does not appear to have a file named"
f" {_add_variant(SAFE_WEIGHTS_NAME, variant)} or {_add_variant(SAFE_WEIGHTS_INDEX_NAME, variant)} "
"and thus cannot be loaded with `safetensors`. Please make sure that the model has "
"been saved with `safe_serialization=True` or do not set `use_safetensors=True`."
)
else:
# This repo has no safetensors file of any kind, we switch to PyTorch.
filename = _add_variant(WEIGHTS_NAME, variant)
resolved_archive_file = cached_file(
pretrained_model_name_or_path, filename, **cached_file_kwargs
)
if resolved_archive_file is None and filename == _add_variant(WEIGHTS_NAME, variant):
# Maybe the checkpoint is sharded, we try to grab the index name in this case.
resolved_archive_file = cached_file(
pretrained_model_name_or_path,
_add_variant(WEIGHTS_INDEX_NAME, variant),
**cached_file_kwargs,
)
if resolved_archive_file is not None:
is_sharded = True
if not local_files_only and not is_offline_mode():
if resolved_archive_file is not None:
if filename in [WEIGHTS_NAME, WEIGHTS_INDEX_NAME]:
# If the PyTorch file was found, check if there is a safetensors file on the repository
# If there is no safetensors file on the repositories, start an auto conversion
safe_weights_name = SAFE_WEIGHTS_INDEX_NAME if is_sharded else SAFE_WEIGHTS_NAME
has_file_kwargs = {
"revision": revision,
"proxies": proxies,
"token": token,
"cache_dir": cache_dir,
"local_files_only": local_files_only,
}
cached_file_kwargs = {
"cache_dir": cache_dir,
"force_download": force_download,
"resume_download": resume_download,
"local_files_only": local_files_only,
"user_agent": user_agent,
"subfolder": subfolder,
"_raise_exceptions_for_gated_repo": False,
"_raise_exceptions_for_missing_entries": False,
"_commit_hash": commit_hash,
**has_file_kwargs,
}
if not has_file(pretrained_model_name_or_path, safe_weights_name, **has_file_kwargs):
Thread(
target=auto_conversion,
args=(pretrained_model_name_or_path,),
kwargs={"ignore_errors_during_conversion": True, **cached_file_kwargs},
name="Thread-auto_conversion",
).start()
else:
# Otherwise, no PyTorch file was found, maybe there is a TF or Flax model file.
# We try those to give a helpful error message.
has_file_kwargs = {
"revision": revision,
"proxies": proxies,
"token": token,
"cache_dir": cache_dir,
"local_files_only": local_files_only,
}
if has_file(pretrained_model_name_or_path, TF2_WEIGHTS_NAME, **has_file_kwargs):
raise EnvironmentError(
f"{pretrained_model_name_or_path} does not appear to have a file named"
f" {_add_variant(WEIGHTS_NAME, variant)} but there is a file for TensorFlow weights."
" Use `from_tf=True` to load this model from those weights."
)
elif has_file(pretrained_model_name_or_path, FLAX_WEIGHTS_NAME, **has_file_kwargs):
raise EnvironmentError(
f"{pretrained_model_name_or_path} does not appear to have a file named"
f" {_add_variant(WEIGHTS_NAME, variant)} but there is a file for Flax weights. Use"
" `from_flax=True` to load this model from those weights."
)
elif variant is not None and has_file(
pretrained_model_name_or_path, WEIGHTS_NAME, **has_file_kwargs
):
raise EnvironmentError(
f"{pretrained_model_name_or_path} does not appear to have a file named"
f" {_add_variant(WEIGHTS_NAME, variant)} but there is a file without the variant"
f" {variant}. Use `variant=None` to load this model from those weights."
)
else:
raise EnvironmentError(
f"{pretrained_model_name_or_path} does not appear to have a file named"
f" {_add_variant(WEIGHTS_NAME, variant)}, {_add_variant(SAFE_WEIGHTS_NAME, variant)},"
f" {TF2_WEIGHTS_NAME}, {TF_WEIGHTS_NAME} or {FLAX_WEIGHTS_NAME}."
)
except EnvironmentError:
# Raise any environment error raise by `cached_file`. It will have a helpful error message adapted
# to the original exception.
raise
except Exception as e:
# For any other exception, we throw a generic error.
raise EnvironmentError(
f"Can't load the model for '{pretrained_model_name_or_path}'. If you were trying to load it"
" from 'https://huggingface.co/models', make sure you don't have a local directory with the"
f" same name. Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a"
f" directory containing a file named {_add_variant(WEIGHTS_NAME, variant)},"
f" {TF2_WEIGHTS_NAME}, {TF_WEIGHTS_NAME} or {FLAX_WEIGHTS_NAME}."
) from e
if is_local:
logger.info(f"loading weights file {archive_file}")
resolved_archive_file = archive_file
else:
logger.info(f"loading weights file {filename} from cache at {resolved_archive_file}")
elif gguf_file:
from .modeling_gguf_pytorch_utils import load_gguf_checkpoint
# Case 1: the GGUF file is present locally
if os.path.isfile(gguf_file):
gguf_path = gguf_file
# Case 2: The GGUF path is a location on the Hub
# Load from URL or cache if already cached
else:
cached_file_kwargs = {
"cache_dir": cache_dir,
"force_download": force_download,
"proxies": proxies,
"resume_download": resume_download,
"local_files_only": local_files_only,
"token": token,
"user_agent": user_agent,
"revision": revision,
"subfolder": subfolder,
"_raise_exceptions_for_gated_repo": False,
"_raise_exceptions_for_missing_entries": False,
"_commit_hash": commit_hash,
}
gguf_path = cached_file(pretrained_model_name_or_path, gguf_file, **cached_file_kwargs)
# we need a dummy model to help rename state_dict
with torch.device("meta"):
dummy_model = cls(config)
state_dict = load_gguf_checkpoint(gguf_path, return_tensors=True, model_to_load=dummy_model)["tensors"]
resolved_archive_file = None
is_sharded = False
else:
resolved_archive_file = None
# We'll need to download and cache each checkpoint shard if the checkpoint is sharded.
if is_sharded:
# resolved_archive_file becomes a list of files that point to the different checkpoint shards in this case.
resolved_archive_file, sharded_metadata = get_checkpoint_shard_files(
pretrained_model_name_or_path,
resolved_archive_file,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
local_files_only=local_files_only,
token=token,
user_agent=user_agent,
revision=revision,
subfolder=subfolder,
_commit_hash=commit_hash,
)
if (
is_safetensors_available()
and isinstance(resolved_archive_file, str)
and resolved_archive_file.endswith(".safetensors")
):
with safe_open(resolved_archive_file, framework="pt") as f:
metadata = f.metadata()
if metadata is None:
# Assume it's a pytorch checkpoint (introduced for timm checkpoints)
pass
elif metadata.get("format") == "pt":
pass
elif metadata.get("format") == "tf":
from_tf = True
logger.info("A TensorFlow safetensors file is being loaded in a PyTorch model.")
elif metadata.get("format") == "flax":
from_flax = True
logger.info("A Flax safetensors file is being loaded in a PyTorch model.")
elif metadata.get("format") == "mlx":
# This is a mlx file, we assume weights are compatible with pt
pass
else:
raise ValueError(
f"Incompatible safetensors file. File metadata is not ['pt', 'tf', 'flax', 'mlx'] but {metadata.get('format')}"
)
from_pt = not (from_tf | from_flax)
# load pt weights early so that we know which dtype to init the model under
if from_pt:
if not is_sharded and state_dict is None:
# Time to load the checkpoint
state_dict = load_state_dict(resolved_archive_file, weights_only=weights_only)
# set dtype to instantiate the model under:
# 1. If torch_dtype is not None, we use that dtype
# 2. If torch_dtype is "auto", we auto-detect dtype from the loaded state_dict, by checking its first
# weights entry that is of a floating type - we assume all floating dtype weights are of the same dtype
# we also may have config.torch_dtype available, but we won't rely on it till v5
dtype_orig = None
if torch_dtype is not None:
if isinstance(torch_dtype, str):
if torch_dtype == "auto":
if hasattr(config, "torch_dtype") and config.torch_dtype is not None:
torch_dtype = config.torch_dtype
logger.info(f"Will use torch_dtype={torch_dtype} as defined in model's config object")
else:
if is_sharded and "dtype" in sharded_metadata:
torch_dtype = sharded_metadata["dtype"]
elif not is_sharded:
torch_dtype = get_state_dict_dtype(state_dict)
else:
one_state_dict = load_state_dict(resolved_archive_file[0], weights_only=weights_only)
torch_dtype = get_state_dict_dtype(one_state_dict)
del one_state_dict # free CPU memory
logger.info(
"Since the `torch_dtype` attribute can't be found in model's config object, "
"will use torch_dtype={torch_dtype} as derived from model's weights"
)
elif hasattr(torch, torch_dtype):
torch_dtype = getattr(torch, torch_dtype)
for sub_config_key in config.sub_configs.keys():
sub_config = getattr(config, sub_config_key)
sub_config.torch_dtype = torch_dtype
elif isinstance(torch_dtype, torch.dtype):
for sub_config_key in config.sub_configs.keys():
sub_config = getattr(config, sub_config_key)
sub_config.torch_dtype = torch_dtype
elif isinstance(torch_dtype, dict):
for key, curr_dtype in torch_dtype.items():
if hasattr(config, key):
value = getattr(config, key)
value.torch_dtype = curr_dtype
# main torch dtype for modules that aren't part of any sub-config
torch_dtype = torch_dtype.get("")
config.torch_dtype = torch_dtype
if isinstance(torch_dtype, str) and hasattr(torch, torch_dtype):
torch_dtype = getattr(torch, torch_dtype)
elif torch_dtype is None:
torch_dtype = torch.float32
else:
raise ValueError(
f"`torch_dtype` can be one of: `torch.dtype`, `'auto'`, a string of a valid `torch.dtype` or a `dict` with valid `torch_dtype` "
f"for each sub-config in composite configs, but received {torch_dtype}"
)
dtype_orig = cls._set_default_torch_dtype(torch_dtype)
else:
# set fp32 as the default dtype for BC
default_dtype = str(torch.get_default_dtype()).split(".")[-1]
config.torch_dtype = default_dtype
for key in config.sub_configs.keys():
value = getattr(config, key)
value.torch_dtype = default_dtype
# Check if `_keep_in_fp32_modules` is not None
use_keep_in_fp32_modules = (cls._keep_in_fp32_modules is not None) and (
(torch_dtype == torch.float16) or hasattr(hf_quantizer, "use_keep_in_fp32_modules")
)
if is_sharded:
loaded_state_dict_keys = sharded_metadata["all_checkpoint_keys"]
else:
loaded_state_dict_keys = list(state_dict.keys())
if (
gguf_path is None
and (low_cpu_mem_usage or (use_keep_in_fp32_modules and is_accelerate_available()))
and pretrained_model_name_or_path is not None
):
# In case some weights need to be kept in float32 and accelerate is not installed,
# we later on want to take the path where state_dict is not None, that is the one
# that do not require accelerate.
state_dict = None
config.name_or_path = pretrained_model_name_or_path
# Instantiate model.
init_contexts = [no_init_weights(_enable=_fast_init)]
if is_deepspeed_zero3_enabled() and not is_quantized and not _is_ds_init_called:
import deepspeed
logger.info("Detected DeepSpeed ZeRO-3: activating zero.init() for this model")
init_contexts = [
deepspeed.zero.Init(config_dict_or_path=deepspeed_config()),
set_zero3_state(),
] + init_contexts
elif low_cpu_mem_usage:
if not is_accelerate_available():
raise ImportError(
f"Using `low_cpu_mem_usage=True` or a `device_map` requires Accelerate: `pip install 'accelerate>={ACCELERATE_MIN_VERSION}'`"
)
init_contexts.append(init_empty_weights())
if is_deepspeed_zero3_enabled() and is_quantized:
init_contexts.append(set_quantized_state())
config = copy.deepcopy(config) # We do not want to modify the config inplace in from_pretrained.
if not getattr(config, "_attn_implementation_autoset", False):
config = cls._autoset_attn_implementation(
config, use_flash_attention_2=use_flash_attention_2, torch_dtype=torch_dtype, device_map=device_map
)
with ContextManagers(init_contexts):
# Let's make sure we don't run the init function of buffer modules
model = cls(config, *model_args, **model_kwargs)
# make sure we use the model's config since the __init__ call might have copied it
config = model.config
# Check first if we are `from_pt`
if use_keep_in_fp32_modules:
if is_accelerate_available() and not is_deepspeed_zero3_enabled():
low_cpu_mem_usage = True
keep_in_fp32_modules = model._keep_in_fp32_modules
else:
keep_in_fp32_modules = []
if hf_quantizer is not None:
hf_quantizer.preprocess_model(
model=model, device_map=device_map, keep_in_fp32_modules=keep_in_fp32_modules
)
# We store the original dtype for quantized models as we cannot easily retrieve it
# once the weights have been quantized
# Note that once you have loaded a quantized model, you can't change its dtype so this will
# remain a single source of truth
config._pre_quantization_dtype = torch_dtype
if isinstance(device_map, str):
special_dtypes = {}
if hf_quantizer is not None:
special_dtypes.update(hf_quantizer.get_special_dtypes_update(model, torch_dtype))
special_dtypes.update(
{
name: torch.float32
for name, _ in model.named_parameters()
if any(m in name for m in keep_in_fp32_modules)
}
)
target_dtype = torch_dtype
if hf_quantizer is not None:
target_dtype = hf_quantizer.adjust_target_dtype(target_dtype)
no_split_modules = model._get_no_split_modules(device_map)
if device_map not in ["auto", "balanced", "balanced_low_0", "sequential"]:
raise ValueError(
"If passing a string for `device_map`, please choose 'auto', 'balanced', 'balanced_low_0' or "
"'sequential'."
)
device_map_kwargs = {"no_split_module_classes": no_split_modules}
if "special_dtypes" in inspect.signature(infer_auto_device_map).parameters:
device_map_kwargs["special_dtypes"] = special_dtypes
elif len(special_dtypes) > 0:
logger.warning(
"This model has some weights that should be kept in higher precision, you need to upgrade "
"`accelerate` to properly deal with them (`pip install --upgrade accelerate`)."
)
if device_map != "sequential":
max_memory = get_balanced_memory(
model,
dtype=target_dtype,
low_zero=(device_map == "balanced_low_0"),
max_memory=max_memory,
**device_map_kwargs,
)
else:
max_memory = get_max_memory(max_memory)
if hf_quantizer is not None:
max_memory = hf_quantizer.adjust_max_memory(max_memory)
device_map_kwargs["max_memory"] = max_memory
# Make sure tied weights are tied before creating the device map.
model.tie_weights()
device_map = infer_auto_device_map(model, dtype=target_dtype, **device_map_kwargs)
if hf_quantizer is not None:
hf_quantizer.validate_environment(device_map=device_map)
elif device_map is not None:
model.tie_weights()
tied_params = find_tied_parameters(model)
# check if we don't have tied param in different devices
check_tied_parameters_on_same_device(tied_params, device_map)
if from_tf:
if resolved_archive_file.endswith(".index"):
# Load from a TensorFlow 1.X checkpoint - provided by original authors
model = cls.load_tf_weights(model, config, resolved_archive_file[:-6]) # Remove the '.index'
else:
# Load from our TensorFlow 2.0 checkpoints
try:
from .modeling_tf_pytorch_utils import load_tf2_checkpoint_in_pytorch_model
model, loading_info = load_tf2_checkpoint_in_pytorch_model(
model, resolved_archive_file, allow_missing_keys=True, output_loading_info=True
)
except ImportError:
logger.error(
"Loading a TensorFlow model in PyTorch, requires both PyTorch and TensorFlow to be installed."
" Please see https://pytorch.org/ and https://www.tensorflow.org/install/ for installation"
" instructions."
)
raise
elif from_flax:
try:
from .modeling_flax_pytorch_utils import load_flax_checkpoint_in_pytorch_model
model = load_flax_checkpoint_in_pytorch_model(model, resolved_archive_file)
except ImportError:
logger.error(
"Loading a Flax model in PyTorch, requires both PyTorch and Flax to be installed. Please see"
" https://pytorch.org/ and https://flax.readthedocs.io/en/latest/installation.html for"
" installation instructions."
)
raise
elif from_pt:
# restore default dtype
if dtype_orig is not None:
torch.set_default_dtype(dtype_orig)
(
model,
missing_keys,
unexpected_keys,
mismatched_keys,
offload_index,
error_msgs,
) = cls._load_pretrained_model(
model,
state_dict,
loaded_state_dict_keys, # XXX: rename?
resolved_archive_file,
pretrained_model_name_or_path,
ignore_mismatched_sizes=ignore_mismatched_sizes,
sharded_metadata=sharded_metadata,
_fast_init=_fast_init,
low_cpu_mem_usage=low_cpu_mem_usage,
device_map=device_map,
offload_folder=offload_folder,
offload_state_dict=offload_state_dict,
dtype=torch_dtype,
hf_quantizer=hf_quantizer,
keep_in_fp32_modules=keep_in_fp32_modules,
gguf_path=gguf_path,
weights_only=weights_only,
)
# make sure token embedding weights are still tied if needed
model.tie_weights()
# Set model in evaluation mode to deactivate DropOut modules by default
model.eval()
# If it is a model with generation capabilities, attempt to load the generation config
if model.can_generate() and generation_config is not None:
logger.info("The user-defined `generation_config` will be used to override the default generation config.")
model.generation_config = model.generation_config.from_dict(generation_config.to_dict())
elif model.can_generate() and pretrained_model_name_or_path is not None:
try:
model.generation_config = GenerationConfig.from_pretrained(
pretrained_model_name_or_path,
cache_dir=cache_dir,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
token=token,
revision=revision,
subfolder=subfolder,
_from_auto=from_auto_class,
_from_pipeline=from_pipeline,
**kwargs,
)
except OSError:
logger.info(
"Generation config file not found, using a generation config created from the model config."
)
pass
# Dispatch model with hooks on all devices if necessary
if device_map is not None:
device_map_kwargs = {
"device_map": device_map,
"offload_dir": offload_folder,
"offload_index": offload_index,
"offload_buffers": offload_buffers,
}
if "skip_keys" in inspect.signature(dispatch_model).parameters:
device_map_kwargs["skip_keys"] = model._skip_keys_device_placement
# For HQQ method we force-set the hooks for single GPU envs
if (
"force_hooks" in inspect.signature(dispatch_model).parameters
and hf_quantizer is not None
and hf_quantizer.quantization_config.quant_method == QuantizationMethod.HQQ
):
device_map_kwargs["force_hooks"] = True
if (
hf_quantizer is not None
and hf_quantizer.quantization_config.quant_method == QuantizationMethod.FBGEMM_FP8
and isinstance(device_map, dict)
and ("cpu" in device_map.values() or "disk" in device_map.values())
):
device_map_kwargs["offload_buffers"] = True
if not is_fsdp_enabled() and not is_deepspeed_zero3_enabled():
dispatch_model(model, **device_map_kwargs)
if hf_quantizer is not None:
hf_quantizer.postprocess_model(model, config=config)
model.hf_quantizer = hf_quantizer
if _adapter_model_path is not None:
model.load_adapter(
_adapter_model_path,
adapter_name=adapter_name,
token=token,
adapter_kwargs=adapter_kwargs,
)
if output_loading_info:
if loading_info is None:
loading_info = {
"missing_keys": missing_keys,
"unexpected_keys": unexpected_keys,
"mismatched_keys": mismatched_keys,
"error_msgs": error_msgs,
}
return model, loading_info
if tp_plan is not None:
assert tp_device is not None, "tp_device not set!"
if not model.supports_tp_plan:
raise NotImplementedError("This model does not have a tensor parallel plan.")
# Assuming sharding the model onto the world
world_size = torch.distributed.get_world_size()
device_mesh = torch.distributed.init_device_mesh(tp_device.type, (world_size,))
# Apply Tensor Parallelism
model.tensor_parallel(device_mesh)
return model
@staticmethod
def _fix_state_dict_key_on_load(key) -> Tuple[str, bool]:
"""Replace legacy parameter names with their modern equivalents. E.g. beta -> bias, gamma -> weight."""
# Rename LayerNorm beta & gamma params for some early models ported from Tensorflow (e.g. Bert)
# This rename is logged.
if key.endswith("LayerNorm.beta"):
return key.replace("LayerNorm.beta", "LayerNorm.bias"), True
if key.endswith("LayerNorm.gamma"):
return key.replace("LayerNorm.gamma", "LayerNorm.weight"), True
# Rename weight norm parametrizations to match changes across torch versions.
# Impacts a number of speech/wav2vec models. e.g. Hubert, Wav2Vec2, and others.
# This rename is not logged.
if hasattr(nn.utils.parametrizations, "weight_norm"):
if key.endswith("weight_g"):
return key.replace("weight_g", "parametrizations.weight.original0"), True
if key.endswith("weight_v"):
return key.replace("weight_v", "parametrizations.weight.original1"), True
else:
if key.endswith("parametrizations.weight.original0"):
return key.replace("parametrizations.weight.original0", "weight_g"), True
if key.endswith("parametrizations.weight.original1"):
return key.replace("parametrizations.weight.original1", "weight_v"), True
return key, False
@classmethod
def _fix_state_dict_keys_on_load(cls, state_dict):
"""Fixes state dict keys by replacing legacy parameter names with their modern equivalents.
Logs if any parameters have been renamed.
"""
renamed_keys = {}
state_dict_keys = list(state_dict.keys())
for key in state_dict_keys:
new_key, has_changed = cls._fix_state_dict_key_on_load(key)
if has_changed:
state_dict[new_key] = state_dict.pop(key)
# track gamma/beta rename for logging
if key.endswith("LayerNorm.gamma"):
renamed_keys["LayerNorm.gamma"] = (key, new_key)
elif key.endswith("LayerNorm.beta"):
renamed_keys["LayerNorm.beta"] = (key, new_key)
if renamed_keys:
warning_msg = f"A pretrained model of type `{cls.__name__}` "
warning_msg += "contains parameters that have been renamed internally (a few are listed below but more are present in the model):\n"
for old_key, new_key in renamed_keys.values():
warning_msg += f"* `{old_key}` -> `{new_key}`\n"
warning_msg += "If you are using a model from the Hub, consider submitting a PR to adjust these weights and help future users."
logger.info_once(warning_msg)
return state_dict
@staticmethod
def _fix_state_dict_key_on_save(key) -> Tuple[str, bool]:
"""
Similar to `_fix_state_dict_key_on_load` allows to define hook for state dict key renaming on model save.
Do nothing by default, but can be overridden in particular models.
"""
return key, False
def _fix_state_dict_keys_on_save(self, state_dict):
"""
Similar to `_fix_state_dict_keys_on_load` allows to define hook for state dict key renaming on model save.
Apply `_fix_state_dict_key_on_save` to all keys in `state_dict`.
"""
return {self._fix_state_dict_key_on_save(key)[0]: value for key, value in state_dict.items()}
@classmethod
def _load_pretrained_model(
cls,
model,
state_dict,
loaded_keys,
resolved_archive_file,
pretrained_model_name_or_path,
ignore_mismatched_sizes=False,
sharded_metadata=None,
_fast_init=True,
low_cpu_mem_usage=False,
device_map=None,
offload_folder=None,
offload_state_dict=None,
dtype=None,
hf_quantizer=None,
keep_in_fp32_modules=None,
gguf_path=None,
weights_only=True,
):
is_safetensors = False
is_quantized = hf_quantizer is not None
state_dict_folder = None
state_dict_index = None
if device_map is not None and "disk" in device_map.values():
archive_file = (
resolved_archive_file[0] if isinstance(resolved_archive_file, (list, tuple)) else resolved_archive_file
)
is_safetensors = archive_file.endswith(".safetensors")
if offload_folder is None and not is_safetensors:
raise ValueError(
"The current `device_map` had weights offloaded to the disk. Please provide an `offload_folder`"
" for them. Alternatively, make sure you have `safetensors` installed if the model you are using"
" offers the weights in this format."
)
if offload_folder is not None:
os.makedirs(offload_folder, exist_ok=True)
if offload_state_dict is None:
offload_state_dict = True
is_sharded_safetensors = is_safetensors and sharded_metadata is not None
# tie the model weights before retrieving the state_dict
model.tie_weights()
# Retrieve missing & unexpected_keys
model_state_dict = model.state_dict()
expected_keys = list(model_state_dict.keys())
prefix = model.base_model_prefix
if hf_quantizer is not None:
expected_keys = hf_quantizer.update_expected_keys(model, expected_keys, loaded_keys)
original_loaded_keys = loaded_keys
loaded_keys = [cls._fix_state_dict_key_on_load(key)[0] for key in loaded_keys]
if len(prefix) > 0:
has_prefix_module = any(s.startswith(prefix) for s in loaded_keys)
expects_prefix_module = any(s.startswith(prefix) for s in expected_keys)
else:
has_prefix_module = False
expects_prefix_module = False
# key re-naming operations are never done on the keys
# that are loaded, but always on the keys of the newly initialized model
remove_prefix_from_model = not has_prefix_module and expects_prefix_module
add_prefix_to_model = has_prefix_module and not expects_prefix_module
if remove_prefix_from_model:
_prefix = f"{prefix}."
expected_keys_not_prefixed = [s for s in expected_keys if not s.startswith(_prefix)]
expected_keys = [s[len(_prefix) :] if s.startswith(_prefix) else s for s in expected_keys]
elif add_prefix_to_model:
expected_keys = [".".join([prefix, s]) for s in expected_keys]
missing_keys = sorted(set(expected_keys) - set(loaded_keys))
unexpected_keys = set(loaded_keys) - set(expected_keys)
# Remove nonpersistent buffers from unexpected keys: they are not in the state dict but will be in the model
# buffers
model_buffers = {n for n, _ in model.named_buffers()}
if remove_prefix_from_model:
model_buffers = {key[len(_prefix) :] if key.startswith(_prefix) else key for key in model_buffers}
elif add_prefix_to_model:
model_buffers = {".".join([prefix, key]) for key in model_buffers}
unexpected_keys = sorted(unexpected_keys - model_buffers)
# Clean up buffer for `inv-freq` because RoPE embedding moved under base model (https://github.com/huggingface/transformers/pull/34858)
has_inv_freq_buffers = any(buffer.endswith("rotary_emb.inv_freq") for buffer in model_buffers)
if has_inv_freq_buffers:
unexpected_keys = {k for k in unexpected_keys if "rotary_emb.inv_freq" not in k}
model.tie_weights()
if device_map is None and not is_fsdp_enabled() and not is_deepspeed_zero3_enabled():
ptrs = collections.defaultdict(list)
for name, tensor in model.state_dict().items():
id_tensor = id_tensor_storage(tensor)
ptrs[id_tensor].append(name)
# These are all the pointers of shared tensors.
tied_params = [names for _, names in ptrs.items() if len(names) > 1]
else:
# id function doesn't work for meta tensor so we need this function
tied_params = find_tied_parameters(model)
for group in tied_params:
if remove_prefix_from_model:
group = [key[len(_prefix) :] if key.startswith(_prefix) else key for key in group]
elif add_prefix_to_model:
group = [".".join([prefix, key]) for key in group]
missing_in_group = [k for k in missing_keys if k in group]
if len(missing_in_group) > 0 and len(missing_in_group) < len(group):
missing_keys = [k for k in missing_keys if k not in missing_in_group]
# Some models may have keys that are not in the state by design, removing them before needlessly warning
# the user.
if cls._keys_to_ignore_on_load_missing is not None:
for pat in cls._keys_to_ignore_on_load_missing:
missing_keys = [k for k in missing_keys if re.search(pat, k) is None]
if cls._keys_to_ignore_on_load_unexpected is not None:
for pat in cls._keys_to_ignore_on_load_unexpected:
unexpected_keys = [k for k in unexpected_keys if re.search(pat, k) is None]
if hf_quantizer is not None:
missing_keys = hf_quantizer.update_missing_keys(model, missing_keys, prefix)
# retrieve weights on meta device and put them back on CPU.
# This is not ideal in terms of memory, but if we don't do that not, we can't initialize them in the next step
if low_cpu_mem_usage:
for key in missing_keys:
if key in list(model_state_dict.keys()):
key = key
elif f"{prefix}.{key}" in list(model_state_dict.keys()):
key = f"{prefix}.{key}"
elif key.startswith(prefix) and ".".join(key.split(".")[1:]) in list(model_state_dict.keys()):
key = ".".join(key.split(".")[1:])
param = model_state_dict[key]
# upcast in fp32 if any
target_dtype = dtype
if (
keep_in_fp32_modules is not None
and dtype == torch.float16
and any(
module_to_keep_in_fp32 in key.split(".") for module_to_keep_in_fp32 in keep_in_fp32_modules
)
):
target_dtype = torch.float32
if param.device == torch.device("meta"):
value = torch.empty(*param.size(), dtype=target_dtype)
if (
not is_quantized
or (getattr(hf_quantizer, "requires_parameters_quantization", False))
or not hf_quantizer.check_quantized_param(
model, param_value=value, param_name=key, state_dict={}
)
):
set_module_tensor_to_device(model, key, "cpu", value)
else:
hf_quantizer.create_quantized_param(model, value, key, "cpu", state_dict, unexpected_keys)
# retrieve uninitialized modules and initialize before maybe overriding that with the pretrained weights.
if _fast_init:
if not ignore_mismatched_sizes:
if remove_prefix_from_model:
_loaded_keys = [f"{prefix}.{k}" for k in loaded_keys]
elif add_prefix_to_model:
_loaded_keys = [k[len(prefix) + 1 :] for k in loaded_keys]
else:
_loaded_keys = loaded_keys
not_initialized_submodules = set_initialized_submodules(model, _loaded_keys)
# If we're about to tie the output embeds to the input embeds we don't need to init them
if (
hasattr(model.config.get_text_config(decoder=True), "tie_word_embeddings")
and model.config.get_text_config(decoder=True).tie_word_embeddings
):
output_embeddings = model.get_output_embeddings()
if output_embeddings is not None:
# Still need to initialize if there is a bias term since biases are not tied.
if not hasattr(output_embeddings, "bias") or output_embeddings.bias is None:
output_embeddings._is_hf_initialized = True
else:
not_initialized_submodules = dict(model.named_modules())
# This will only initialize submodules that are not marked as initialized by the line above.
if is_deepspeed_zero3_enabled() and not is_quantized:
import deepspeed
not_initialized_parameters = list(
set(
itertools.chain.from_iterable(
submodule.parameters(recurse=False) for submodule in not_initialized_submodules.values()
)
)
)
with deepspeed.zero.GatheredParameters(not_initialized_parameters, modifier_rank=0):
model.apply(model._initialize_weights)
else:
model.apply(model._initialize_weights)
# Set some modules to fp32 if any
if keep_in_fp32_modules is not None:
for name, param in model.named_parameters():
if any(module_to_keep_in_fp32 in name.split(".") for module_to_keep_in_fp32 in keep_in_fp32_modules):
# param = param.to(torch.float32) does not work here as only in the local scope.
param.data = param.data.to(torch.float32)
# Make sure we are able to load base models as well as derived models (with heads)
start_prefix = ""
model_to_load = model
if len(cls.base_model_prefix) > 0 and not hasattr(model, cls.base_model_prefix) and has_prefix_module:
start_prefix = cls.base_model_prefix + "."
if len(cls.base_model_prefix) > 0 and hasattr(model, cls.base_model_prefix) and not has_prefix_module:
model_to_load = getattr(model, cls.base_model_prefix)
base_model_expected_keys = list(model_to_load.state_dict().keys())
if any(key in expected_keys_not_prefixed and key not in base_model_expected_keys for key in loaded_keys):
raise ValueError(
"The state dictionary of the model you are trying to load is corrupted. Are you sure it was "
"properly saved?"
)
if device_map is not None:
device_map = {k.replace(f"{cls.base_model_prefix}.", ""): v for k, v in device_map.items()}
def _find_mismatched_keys(
state_dict,
model_state_dict,
loaded_keys,
original_loaded_keys,
add_prefix_to_model,
remove_prefix_from_model,
ignore_mismatched_sizes,
):
mismatched_keys = []
if ignore_mismatched_sizes:
for checkpoint_key, model_key in zip(original_loaded_keys, loaded_keys):
# If the checkpoint is sharded, we may not have the key here.
if checkpoint_key not in state_dict:
continue
if remove_prefix_from_model:
# The model key starts with `prefix` but `checkpoint_key` doesn't so we add it.
model_key = f"{prefix}.{model_key}"
elif add_prefix_to_model:
# The model key doesn't start with `prefix` but `checkpoint_key` does so we remove it.
model_key = ".".join(model_key.split(".")[1:])
if (
model_key in model_state_dict
and state_dict[checkpoint_key].shape != model_state_dict[model_key].shape
):
if (
state_dict[checkpoint_key].shape[-1] == 1
and state_dict[checkpoint_key].numel() * 2 == model_state_dict[model_key].numel()
):
# This skips size mismatches for 4-bit weights. Two 4-bit values share an 8-bit container, causing size differences.
# Without matching with module type or paramter type it seems like a practical way to detect valid 4bit weights.
pass
else:
mismatched_keys.append(
(checkpoint_key, state_dict[checkpoint_key].shape, model_state_dict[model_key].shape)
)
del state_dict[checkpoint_key]
return mismatched_keys
if resolved_archive_file is not None:
folder = os.path.sep.join(resolved_archive_file[0].split(os.path.sep)[:-1])
else:
folder = None
if device_map is not None and is_safetensors:
param_device_map = expand_device_map(device_map, original_loaded_keys, start_prefix)
str_dtype = str(dtype).replace("torch.", "") if dtype is not None else "float32"
if sharded_metadata is None:
archive_file = (
resolved_archive_file[0]
if isinstance(resolved_archive_file, (list, tuple))
else resolved_archive_file
)
weight_map = {p: archive_file for p in original_loaded_keys}
else:
weight_map = {p: os.path.join(folder, f) for p, f in sharded_metadata["weight_map"].items()}
offload_index = {
p[len(start_prefix) :]: {"safetensors_file": f, "weight_name": p, "dtype": str_dtype}
for p, f in weight_map.items()
if p.startswith(start_prefix) and param_device_map[p[len(start_prefix) :]] == "disk"
}
else:
offload_index = None
if state_dict is not None:
# Whole checkpoint
mismatched_keys = _find_mismatched_keys(
state_dict,
model_state_dict,
loaded_keys,
original_loaded_keys,
add_prefix_to_model,
remove_prefix_from_model,
ignore_mismatched_sizes,
)
# For GGUF models `state_dict` is never set to None as the state dict is always small
if gguf_path or low_cpu_mem_usage:
fixed_state_dict = cls._fix_state_dict_keys_on_load(state_dict)
error_msgs, offload_index, state_dict_index = _load_state_dict_into_meta_model(
model_to_load,
fixed_state_dict,
start_prefix,
expected_keys,
device_map=device_map,
offload_folder=offload_folder,
offload_index=offload_index,
state_dict_folder=state_dict_folder,
state_dict_index=state_dict_index,
dtype=dtype,
hf_quantizer=hf_quantizer,
is_safetensors=is_safetensors,
keep_in_fp32_modules=keep_in_fp32_modules,
unexpected_keys=unexpected_keys,
)
else:
# Sharded checkpoint or whole but low_cpu_mem_usage==True
assign_to_params_buffers = check_support_param_buffer_assignment(
model_to_load, state_dict, start_prefix
)
fixed_state_dict = cls._fix_state_dict_keys_on_load(state_dict)
error_msgs = _load_state_dict_into_model(
model_to_load, fixed_state_dict, start_prefix, assign_to_params_buffers
)
else:
# This should always be a list but, just to be sure.
if not isinstance(resolved_archive_file, list):
resolved_archive_file = [resolved_archive_file]
error_msgs = []
mismatched_keys = []
if not is_safetensors:
offload_index = {} if device_map is not None and "disk" in device_map.values() else None
if offload_state_dict:
state_dict_folder = tempfile.mkdtemp()
state_dict_index = {}
else:
state_dict_folder = None
state_dict_index = None
if is_sharded_safetensors:
disk_only_shard_files = get_disk_only_shard_files(
device_map, sharded_metadata=sharded_metadata, start_prefix=start_prefix
)
disk_only_shard_files = [os.path.join(folder, f) for f in disk_only_shard_files]
else:
disk_only_shard_files = []
if len(resolved_archive_file) > 1:
resolved_archive_file = logging.tqdm(resolved_archive_file, desc="Loading checkpoint shards")
assign_to_params_buffers = None
for shard_file in resolved_archive_file:
# Skip the load for shards that only contain disk-offloaded weights when using safetensors for the offload.
if shard_file in disk_only_shard_files:
continue
map_location = None
if (
device_map is not None
and hf_quantizer is not None
and hf_quantizer.quantization_config.quant_method == QuantizationMethod.TORCHAO
and hf_quantizer.quantization_config.quant_type == "int4_weight_only"
):
map_location = torch.device([d for d in device_map.values() if d not in ["cpu", "disk"]][0])
state_dict = load_state_dict(
shard_file, is_quantized=is_quantized, map_location=map_location, weights_only=weights_only
)
# Mistmatched keys contains tuples key/shape1/shape2 of weights in the checkpoint that have a shape not
# matching the weights in the model.
mismatched_keys += _find_mismatched_keys(
state_dict,
model_state_dict,
loaded_keys,
original_loaded_keys,
add_prefix_to_model,
remove_prefix_from_model,
ignore_mismatched_sizes,
)
if low_cpu_mem_usage:
if is_fsdp_enabled() and not is_local_dist_rank_0() and not is_quantized:
for key, param in model_to_load.state_dict().items():
if param.device == torch.device("meta"):
set_module_tensor_to_device(
model_to_load, key, "cpu", torch.empty(*param.size(), dtype=dtype)
)
else:
fixed_state_dict = cls._fix_state_dict_keys_on_load(state_dict)
new_error_msgs, offload_index, state_dict_index = _load_state_dict_into_meta_model(
model_to_load,
fixed_state_dict,
start_prefix,
expected_keys,
device_map=device_map,
offload_folder=offload_folder,
offload_index=offload_index,
state_dict_folder=state_dict_folder,
state_dict_index=state_dict_index,
dtype=dtype,
hf_quantizer=hf_quantizer,
is_safetensors=is_safetensors,
keep_in_fp32_modules=keep_in_fp32_modules,
unexpected_keys=unexpected_keys,
)
error_msgs += new_error_msgs
else:
# Sharded checkpoint or whole but low_cpu_mem_usage==True
if assign_to_params_buffers is None:
assign_to_params_buffers = check_support_param_buffer_assignment(
model_to_load, state_dict, start_prefix
)
fixed_state_dict = cls._fix_state_dict_keys_on_load(state_dict)
error_msgs += _load_state_dict_into_model(
model_to_load, fixed_state_dict, start_prefix, assign_to_params_buffers
)
# force memory release
del state_dict
gc.collect()
if offload_index is not None and len(offload_index) > 0:
if model != model_to_load:
# We need to add the prefix of the base model
prefix = cls.base_model_prefix
if not is_safetensors:
for weight_name in offload_index:
shutil.move(
os.path.join(offload_folder, f"{weight_name}.dat"),
os.path.join(offload_folder, f"{prefix}.{weight_name}.dat"),
)
offload_index = {f"{prefix}.{key}": value for key, value in offload_index.items()}
if not is_safetensors:
save_offload_index(offload_index, offload_folder)
offload_index = None
if offload_state_dict:
# Load back temporarily offloaded state dict
load_offloaded_weights(model_to_load, state_dict_index, state_dict_folder)
shutil.rmtree(state_dict_folder)
if len(error_msgs) > 0:
error_msg = "\n\t".join(error_msgs)
if "size mismatch" in error_msg:
error_msg += (
"\n\tYou may consider adding `ignore_mismatched_sizes=True` in the model `from_pretrained` method."
)
raise RuntimeError(f"Error(s) in loading state_dict for {model.__class__.__name__}:\n\t{error_msg}")
if len(unexpected_keys) > 0:
archs = [] if model.config.architectures is None else model.config.architectures
warner = logger.warning if model.__class__.__name__ in archs else logger.info
warner(
f"Some weights of the model checkpoint at {pretrained_model_name_or_path} were not used when"
f" initializing {model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are"
f" initializing {model.__class__.__name__} from the checkpoint of a model trained on another task or"
" with another architecture (e.g. initializing a BertForSequenceClassification model from a"
" BertForPreTraining model).\n- This IS NOT expected if you are initializing"
f" {model.__class__.__name__} from the checkpoint of a model that you expect to be exactly identical"
" (initializing a BertForSequenceClassification model from a BertForSequenceClassification model)."
)
else:
logger.info(f"All model checkpoint weights were used when initializing {model.__class__.__name__}.\n")
if len(missing_keys) > 0:
logger.warning(
f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
f" {pretrained_model_name_or_path} and are newly initialized: {missing_keys}\nYou should probably"
" TRAIN this model on a down-stream task to be able to use it for predictions and inference."
)
elif len(mismatched_keys) == 0:
logger.info(
f"All the weights of {model.__class__.__name__} were initialized from the model checkpoint at"
f" {pretrained_model_name_or_path}.\nIf your task is similar to the task the model of the checkpoint"
f" was trained on, you can already use {model.__class__.__name__} for predictions without further"
" training."
)
if len(mismatched_keys) > 0:
mismatched_warning = "\n".join(
[
f"- {key}: found shape {shape1} in the checkpoint and {shape2} in the model instantiated"
for key, shape1, shape2 in mismatched_keys
]
)
logger.warning(
f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
f" {pretrained_model_name_or_path} and are newly initialized because the shapes did not"
f" match:\n{mismatched_warning}\nYou should probably TRAIN this model on a down-stream task to be able"
" to use it for predictions and inference."
)
return model, missing_keys, unexpected_keys, mismatched_keys, offload_index, error_msgs
def retrieve_modules_from_names(self, names, add_prefix=False, remove_prefix=False):
module_keys = {".".join(key.split(".")[:-1]) for key in names}
# torch.nn.ParameterList is a special case where two parameter keywords
# are appended to the module name, *e.g.* bert.special_embeddings.0
module_keys = module_keys.union(
{".".join(key.split(".")[:-2]) for key in names if len(key) > 0 and key[-1].isdigit()}
)
retrieved_modules = []
# retrieve all modules that has at least one missing weight name
for name, module in self.named_modules():
if remove_prefix:
_prefix = f"{self.base_model_prefix}."
name = name[len(_prefix) :] if name.startswith(_prefix) else name
elif add_prefix:
name = ".".join([self.base_model_prefix, name]) if len(name) > 0 else self.base_model_prefix
if name in module_keys:
retrieved_modules.append(module)
return retrieved_modules
@staticmethod
def _load_pretrained_model_low_mem(
model,
loaded_state_dict_keys,
resolved_archive_file,
start_prefix="",
hf_quantizer=None,
pretrained_model_name_or_path=None,
weights_only=True,
):
"""
This is an experimental function that loads the model using ~1.x model size CPU memory
Before you call it do:
1. save which state_dict keys are available
2. drop state_dict before model is created, since the latter takes 1x model size memory
Here then we continue:
3. switch to the meta device all params/buffers that are going to be replaced from the loaded state_dict
4. load state_dict 2nd time
5. replace the params/buffers from the state_dict
Currently, it doesn't handle missing_keys, unexpected_keys, mismatched_keys. It can't handle deepspeed. To
handle bitsandbytes, needs non-empty hf_quantizer argument.
"""
_move_model_to_meta(model, loaded_state_dict_keys, start_prefix)
state_dict = load_state_dict(resolved_archive_file, weights_only=weights_only)
expected_keys = loaded_state_dict_keys # plug for missing expected_keys. TODO: replace with proper keys
fixed_state_dict = model._fix_state_dict_keys_on_load(state_dict)
error_msgs = _load_state_dict_into_meta_model(
model,
fixed_state_dict,
start_prefix,
expected_keys=expected_keys,
hf_quantizer=hf_quantizer,
)
return error_msgs
@classmethod
def register_for_auto_class(cls, auto_class="AutoModel"):
"""
Register this class with a given auto class. This should only be used for custom models as the ones in the
library are already mapped with an auto class.
<Tip warning={true}>
This API is experimental and may have some slight breaking changes in the next releases.
</Tip>
Args:
auto_class (`str` or `type`, *optional*, defaults to `"AutoModel"`):
The auto class to register this new model with.
"""
if not isinstance(auto_class, str):
auto_class = auto_class.__name__
import transformers.models.auto as auto_module
if not hasattr(auto_module, auto_class):
raise ValueError(f"{auto_class} is not a valid auto class.")
cls._auto_class = auto_class
def to_bettertransformer(self) -> "PreTrainedModel":
"""
Converts the model to use [PyTorch's native attention
implementation](https://pytorch.org/docs/stable/generated/torch.nn.MultiheadAttention.html), integrated to
Transformers through [Optimum library](https://huggingface.co/docs/optimum/bettertransformer/overview). Only a
subset of all Transformers models are supported.
PyTorch's attention fastpath allows to speed up inference through kernel fusions and the use of [nested
tensors](https://pytorch.org/docs/stable/nested.html). Detailed benchmarks can be found in [this blog
post](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2).
Returns:
[`PreTrainedModel`]: The model converted to BetterTransformer.
"""
if not is_optimum_available():
raise ImportError("The package `optimum` is required to use Better Transformer.")
from optimum.version import __version__ as optimum_version
if version.parse(optimum_version) < version.parse("1.7.0"):
raise ImportError(
f"Please install optimum>=1.7.0 to use Better Transformer. The version {optimum_version} was found."
)
from optimum.bettertransformer import BetterTransformer
return BetterTransformer.transform(self)
def reverse_bettertransformer(self):
"""
Reverts the transformation from [`~PreTrainedModel.to_bettertransformer`] so that the original modeling is
used, for example in order to save the model.
Returns:
[`PreTrainedModel`]: The model converted back to the original modeling.
"""
if not is_optimum_available():
raise ImportError("The package `optimum` is required to use Better Transformer.")
from optimum.version import __version__ as optimum_version
if version.parse(optimum_version) < version.parse("1.7.0"):
raise ImportError(
f"Please install optimum>=1.7.0 to use Better Transformer. The version {optimum_version} was found."
)
from optimum.bettertransformer import BetterTransformer
return BetterTransformer.reverse(self)
def warn_if_padding_and_no_attention_mask(self, input_ids, attention_mask):
"""
Shows a one-time warning if the input_ids appear to contain padding and no attention mask was given.
"""
# Skip the check during tracing.
if is_torch_fx_proxy(input_ids) or torch.jit.is_tracing() or is_torchdynamo_compiling():
return
if (attention_mask is not None) or (self.config.pad_token_id is None):
return
# Check only the first and last input IDs to reduce overhead.
if self.config.pad_token_id in input_ids[:, [-1, 0]]:
warn_string = (
"We strongly recommend passing in an `attention_mask` since your input_ids may be padded. See "
"https://huggingface.co/docs/transformers/troubleshooting"
"#incorrect-output-when-padding-tokens-arent-masked."
)
# If the pad token is equal to either BOS, EOS, or SEP, we do not know whether the user should use an
# attention_mask or not. In this case, we should still show a warning because this is a rare case.
if (
(self.config.bos_token_id is not None and self.config.bos_token_id == self.config.pad_token_id)
or (self.config.eos_token_id is not None and self.config.eos_token_id == self.config.pad_token_id)
or (self.config.sep_token_id is not None and self.config.sep_token_id == self.config.pad_token_id)
):
warn_string += (
f"\nYou may ignore this warning if your `pad_token_id` ({self.config.pad_token_id}) is identical "
f"to the `bos_token_id` ({self.config.bos_token_id}), `eos_token_id` ({self.config.eos_token_id}), "
f"or the `sep_token_id` ({self.config.sep_token_id}), and your input is not padded."
)
logger.warning_once(warn_string)
@property
def supports_tp_plan(self):
"""
Returns whether the model has a tensor parallelism plan.
"""
if self._tp_plan is not None:
return True
# Check if base model has a TP plan
if getattr(self.base_model, "_tp_plan", None) is not None:
return True
return False
def tensor_parallel(self, device_mesh):
"""
Tensor parallelize the model across the given device mesh.
Args:
device_mesh (`torch.distributed.DeviceMesh`):
The device mesh to use for tensor parallelism.
"""
if not is_torch_greater_or_equal("2.5"):
raise EnvironmentError("tensor parallel is only supported for `torch>=2.5`.")
# Tensor parallelize a nn.Module based on the `_tp_plan` attribute of the module.
# No op if `_tp_plan` attribute does not exist under the module.
# This is a helper function to be used with `model.apply` to recursively
# parallelize a model.
def tplize(mod: torch.nn.Module) -> None:
tp_plan = getattr(mod, "_tp_plan", None)
if tp_plan is None:
return
logger.debug(f"Applying tensor parallel to {mod.__class__.__name__}: {tp_plan}")
# In model configs, we use a neutral type (string) to specify
# parallel styles, here we translate them into torch TP types.
# Using tree_map because `tp_plan` is a dict.
tp_plan = torch.utils._pytree.tree_map(
translate_to_torch_parallel_style,
tp_plan,
)
# Apply TP to current module.
torch.distributed.tensor.parallel.parallelize_module(
mod,
device_mesh=device_mesh,
parallelize_plan=tp_plan,
)
# `apply` is a native method of `nn.Module` that recursively applies a
# function to every submodule.
self.apply(tplize)
@property
def loss_function(self):
if hasattr(self, "_loss_function"):
return self._loss_function
loss_type = getattr(self, "loss_type", None)
if loss_type is None or loss_type not in LOSS_MAPPING:
logger.warning_once(
f"`loss_type={loss_type}` was set in the config but it is unrecognised."
f"Using the default loss: `ForCausalLMLoss`."
)
loss_type = "ForCausalLM"
return LOSS_MAPPING[loss_type]
@loss_function.setter
def loss_function(self, value):
self._loss_function = value
def get_compiled_call(self, compile_config: CompileConfig):
"""Return a `torch.compile`'d version of `self.__call__`. This is useful to dynamically choose between
non-compiled/compiled `forward` during inference, especially to switch between prefill (where we don't
want to use compiled version to avoid recomputing the graph with new shapes) and iterative decoding
(where we want the speed-ups of compiled version with static shapes)."""
# Only reset it if not present or different from previous config
default_config = getattr(self.generation_config, "compile_config", CompileConfig())
if (
not hasattr(self, "_compiled_call")
or getattr(self, "_last_compile_config", default_config) != compile_config
):
self._last_compile_config = compile_config
self._compiled_call = torch.compile(self.__call__, **compile_config.to_dict())
return self._compiled_call
@classmethod
def is_backend_compatible(cls):
return cls._supports_attention_backend
PreTrainedModel.push_to_hub = copy_func(PreTrainedModel.push_to_hub)
if PreTrainedModel.push_to_hub.__doc__ is not None:
PreTrainedModel.push_to_hub.__doc__ = PreTrainedModel.push_to_hub.__doc__.format(
object="model", object_class="AutoModel", object_files="model file"
)
class PoolerStartLogits(nn.Module):
"""
Compute SQuAD start logits from sequence hidden states.
Args:
config ([`PretrainedConfig`]):
The config used by the model, will be used to grab the `hidden_size` of the model.
"""
def __init__(self, config: PretrainedConfig):
super().__init__()
self.dense = nn.Linear(config.hidden_size, 1)
def forward(
self, hidden_states: torch.FloatTensor, p_mask: Optional[torch.FloatTensor] = None
) -> torch.FloatTensor:
"""
Args:
hidden_states (`torch.FloatTensor` of shape `(batch_size, seq_len, hidden_size)`):
The final hidden states of the model.
p_mask (`torch.FloatTensor` of shape `(batch_size, seq_len)`, *optional*):
Mask for tokens at invalid position, such as query and special symbols (PAD, SEP, CLS). 1.0 means token
should be masked.
Returns:
`torch.FloatTensor`: The start logits for SQuAD.
"""
x = self.dense(hidden_states).squeeze(-1)
if p_mask is not None:
if get_parameter_dtype(self) == torch.float16:
x = x * (1 - p_mask) - 65500 * p_mask
else:
x = x * (1 - p_mask) - 1e30 * p_mask
return x
class PoolerEndLogits(nn.Module):
"""
Compute SQuAD end logits from sequence hidden states.
Args:
config ([`PretrainedConfig`]):
The config used by the model, will be used to grab the `hidden_size` of the model and the `layer_norm_eps`
to use.
"""
def __init__(self, config: PretrainedConfig):
super().__init__()
self.dense_0 = nn.Linear(config.hidden_size * 2, config.hidden_size)
self.activation = nn.Tanh()
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dense_1 = nn.Linear(config.hidden_size, 1)
def forward(
self,
hidden_states: torch.FloatTensor,
start_states: Optional[torch.FloatTensor] = None,
start_positions: Optional[torch.LongTensor] = None,
p_mask: Optional[torch.FloatTensor] = None,
) -> torch.FloatTensor:
"""
Args:
hidden_states (`torch.FloatTensor` of shape `(batch_size, seq_len, hidden_size)`):
The final hidden states of the model.
start_states (`torch.FloatTensor` of shape `(batch_size, seq_len, hidden_size)`, *optional*):
The hidden states of the first tokens for the labeled span.
start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
The position of the first token for the labeled span.
p_mask (`torch.FloatTensor` of shape `(batch_size, seq_len)`, *optional*):
Mask for tokens at invalid position, such as query and special symbols (PAD, SEP, CLS). 1.0 means token
should be masked.
<Tip>
One of `start_states` or `start_positions` should be not `None`. If both are set, `start_positions` overrides
`start_states`.
</Tip>
Returns:
`torch.FloatTensor`: The end logits for SQuAD.
"""
assert (
start_states is not None or start_positions is not None
), "One of start_states, start_positions should be not None"
if start_positions is not None:
slen, hsz = hidden_states.shape[-2:]
start_positions = start_positions[:, None, None].expand(-1, -1, hsz) # shape (bsz, 1, hsz)
start_states = hidden_states.gather(-2, start_positions) # shape (bsz, 1, hsz)
start_states = start_states.expand(-1, slen, -1) # shape (bsz, slen, hsz)
x = self.dense_0(torch.cat([hidden_states, start_states], dim=-1))
x = self.activation(x)
x = self.LayerNorm(x)
x = self.dense_1(x).squeeze(-1)
if p_mask is not None:
if get_parameter_dtype(self) == torch.float16:
x = x * (1 - p_mask) - 65500 * p_mask
else:
x = x * (1 - p_mask) - 1e30 * p_mask
return x
class PoolerAnswerClass(nn.Module):
"""
Compute SQuAD 2.0 answer class from classification and start tokens hidden states.
Args:
config ([`PretrainedConfig`]):
The config used by the model, will be used to grab the `hidden_size` of the model.
"""
def __init__(self, config):
super().__init__()
self.dense_0 = nn.Linear(config.hidden_size * 2, config.hidden_size)
self.activation = nn.Tanh()
self.dense_1 = nn.Linear(config.hidden_size, 1, bias=False)
def forward(
self,
hidden_states: torch.FloatTensor,
start_states: Optional[torch.FloatTensor] = None,
start_positions: Optional[torch.LongTensor] = None,
cls_index: Optional[torch.LongTensor] = None,
) -> torch.FloatTensor:
"""
Args:
hidden_states (`torch.FloatTensor` of shape `(batch_size, seq_len, hidden_size)`):
The final hidden states of the model.
start_states (`torch.FloatTensor` of shape `(batch_size, seq_len, hidden_size)`, *optional*):
The hidden states of the first tokens for the labeled span.
start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
The position of the first token for the labeled span.
cls_index (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Position of the CLS token for each sentence in the batch. If `None`, takes the last token.
<Tip>
One of `start_states` or `start_positions` should be not `None`. If both are set, `start_positions` overrides
`start_states`.
</Tip>
Returns:
`torch.FloatTensor`: The SQuAD 2.0 answer class.
"""
# No dependency on end_feature so that we can obtain one single `cls_logits` for each sample.
hsz = hidden_states.shape[-1]
assert (
start_states is not None or start_positions is not None
), "One of start_states, start_positions should be not None"
if start_positions is not None:
start_positions = start_positions[:, None, None].expand(-1, -1, hsz) # shape (bsz, 1, hsz)
start_states = hidden_states.gather(-2, start_positions).squeeze(-2) # shape (bsz, hsz)
if cls_index is not None:
cls_index = cls_index[:, None, None].expand(-1, -1, hsz) # shape (bsz, 1, hsz)
cls_token_state = hidden_states.gather(-2, cls_index).squeeze(-2) # shape (bsz, hsz)
else:
cls_token_state = hidden_states[:, -1, :] # shape (bsz, hsz)
x = self.dense_0(torch.cat([start_states, cls_token_state], dim=-1))
x = self.activation(x)
x = self.dense_1(x).squeeze(-1)
return x
@dataclass
class SquadHeadOutput(ModelOutput):
"""
Base class for outputs of question answering models using a [`~modeling_utils.SQuADHead`].
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned if both `start_positions` and `end_positions` are provided):
Classification loss as the sum of start token, end token (and is_impossible if provided) classification
losses.
start_top_log_probs (`torch.FloatTensor` of shape `(batch_size, config.start_n_top)`, *optional*, returned if `start_positions` or `end_positions` is not provided):
Log probabilities for the top config.start_n_top start token possibilities (beam-search).
start_top_index (`torch.LongTensor` of shape `(batch_size, config.start_n_top)`, *optional*, returned if `start_positions` or `end_positions` is not provided):
Indices for the top config.start_n_top start token possibilities (beam-search).
end_top_log_probs (`torch.FloatTensor` of shape `(batch_size, config.start_n_top * config.end_n_top)`, *optional*, returned if `start_positions` or `end_positions` is not provided):
Log probabilities for the top `config.start_n_top * config.end_n_top` end token possibilities
(beam-search).
end_top_index (`torch.LongTensor` of shape `(batch_size, config.start_n_top * config.end_n_top)`, *optional*, returned if `start_positions` or `end_positions` is not provided):
Indices for the top `config.start_n_top * config.end_n_top` end token possibilities (beam-search).
cls_logits (`torch.FloatTensor` of shape `(batch_size,)`, *optional*, returned if `start_positions` or `end_positions` is not provided):
Log probabilities for the `is_impossible` label of the answers.
"""
loss: Optional[torch.FloatTensor] = None
start_top_log_probs: Optional[torch.FloatTensor] = None
start_top_index: Optional[torch.LongTensor] = None
end_top_log_probs: Optional[torch.FloatTensor] = None
end_top_index: Optional[torch.LongTensor] = None
cls_logits: Optional[torch.FloatTensor] = None
class SQuADHead(nn.Module):
r"""
A SQuAD head inspired by XLNet.
Args:
config ([`PretrainedConfig`]):
The config used by the model, will be used to grab the `hidden_size` of the model and the `layer_norm_eps`
to use.
"""
def __init__(self, config):
super().__init__()
self.start_n_top = config.start_n_top
self.end_n_top = config.end_n_top
self.start_logits = PoolerStartLogits(config)
self.end_logits = PoolerEndLogits(config)
self.answer_class = PoolerAnswerClass(config)
@replace_return_docstrings(output_type=SquadHeadOutput, config_class=PretrainedConfig)
def forward(
self,
hidden_states: torch.FloatTensor,
start_positions: Optional[torch.LongTensor] = None,
end_positions: Optional[torch.LongTensor] = None,
cls_index: Optional[torch.LongTensor] = None,
is_impossible: Optional[torch.LongTensor] = None,
p_mask: Optional[torch.FloatTensor] = None,
return_dict: bool = False,
) -> Union[SquadHeadOutput, Tuple[torch.FloatTensor]]:
"""
Args:
hidden_states (`torch.FloatTensor` of shape `(batch_size, seq_len, hidden_size)`):
Final hidden states of the model on the sequence tokens.
start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Positions of the first token for the labeled span.
end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Positions of the last token for the labeled span.
cls_index (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Position of the CLS token for each sentence in the batch. If `None`, takes the last token.
is_impossible (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Whether the question has a possible answer in the paragraph or not.
p_mask (`torch.FloatTensor` of shape `(batch_size, seq_len)`, *optional*):
Mask for tokens at invalid position, such as query and special symbols (PAD, SEP, CLS). 1.0 means token
should be masked.
return_dict (`bool`, *optional*, defaults to `False`):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
Returns:
"""
start_logits = self.start_logits(hidden_states, p_mask=p_mask)
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, let's remove the dimension added by batch splitting
for x in (start_positions, end_positions, cls_index, is_impossible):
if x is not None and x.dim() > 1:
x.squeeze_(-1)
# during training, compute the end logits based on the ground truth of the start position
end_logits = self.end_logits(hidden_states, start_positions=start_positions, p_mask=p_mask)
loss_fct = CrossEntropyLoss()
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
if cls_index is not None and is_impossible is not None:
# Predict answerability from the representation of CLS and START
cls_logits = self.answer_class(hidden_states, start_positions=start_positions, cls_index=cls_index)
loss_fct_cls = nn.BCEWithLogitsLoss()
cls_loss = loss_fct_cls(cls_logits, is_impossible)
# note(zhiliny): by default multiply the loss by 0.5 so that the scale is comparable to start_loss and end_loss
total_loss += cls_loss * 0.5
return SquadHeadOutput(loss=total_loss) if return_dict else (total_loss,)
else:
# during inference, compute the end logits based on beam search
bsz, slen, hsz = hidden_states.size()
start_log_probs = nn.functional.softmax(start_logits, dim=-1) # shape (bsz, slen)
start_top_log_probs, start_top_index = torch.topk(
start_log_probs, self.start_n_top, dim=-1
) # shape (bsz, start_n_top)
start_top_index_exp = start_top_index.unsqueeze(-1).expand(-1, -1, hsz) # shape (bsz, start_n_top, hsz)
start_states = torch.gather(hidden_states, -2, start_top_index_exp) # shape (bsz, start_n_top, hsz)
start_states = start_states.unsqueeze(1).expand(-1, slen, -1, -1) # shape (bsz, slen, start_n_top, hsz)
hidden_states_expanded = hidden_states.unsqueeze(2).expand_as(
start_states
) # shape (bsz, slen, start_n_top, hsz)
p_mask = p_mask.unsqueeze(-1) if p_mask is not None else None
end_logits = self.end_logits(hidden_states_expanded, start_states=start_states, p_mask=p_mask)
end_log_probs = nn.functional.softmax(end_logits, dim=1) # shape (bsz, slen, start_n_top)
end_top_log_probs, end_top_index = torch.topk(
end_log_probs, self.end_n_top, dim=1
) # shape (bsz, end_n_top, start_n_top)
end_top_log_probs = end_top_log_probs.view(-1, self.start_n_top * self.end_n_top)
end_top_index = end_top_index.view(-1, self.start_n_top * self.end_n_top)
start_states = torch.einsum("blh,bl->bh", hidden_states, start_log_probs)
cls_logits = self.answer_class(hidden_states, start_states=start_states, cls_index=cls_index)
if not return_dict:
return (start_top_log_probs, start_top_index, end_top_log_probs, end_top_index, cls_logits)
else:
return SquadHeadOutput(
start_top_log_probs=start_top_log_probs,
start_top_index=start_top_index,
end_top_log_probs=end_top_log_probs,
end_top_index=end_top_index,
cls_logits=cls_logits,
)
class SequenceSummary(nn.Module):
r"""
Compute a single vector summary of a sequence hidden states.
Args:
config ([`PretrainedConfig`]):
The config used by the model. Relevant arguments in the config class of the model are (refer to the actual
config class of your model for the default values it uses):
- **summary_type** (`str`) -- The method to use to make this summary. Accepted values are:
- `"last"` -- Take the last token hidden state (like XLNet)
- `"first"` -- Take the first token hidden state (like Bert)
- `"mean"` -- Take the mean of all tokens hidden states
- `"cls_index"` -- Supply a Tensor of classification token position (GPT/GPT-2)
- `"attn"` -- Not implemented now, use multi-head attention
- **summary_use_proj** (`bool`) -- Add a projection after the vector extraction.
- **summary_proj_to_labels** (`bool`) -- If `True`, the projection outputs to `config.num_labels` classes
(otherwise to `config.hidden_size`).
- **summary_activation** (`Optional[str]`) -- Set to `"tanh"` to add a tanh activation to the output,
another string or `None` will add no activation.
- **summary_first_dropout** (`float`) -- Optional dropout probability before the projection and activation.
- **summary_last_dropout** (`float`)-- Optional dropout probability after the projection and activation.
"""
def __init__(self, config: PretrainedConfig):
super().__init__()
self.summary_type = getattr(config, "summary_type", "last")
if self.summary_type == "attn":
# We should use a standard multi-head attention module with absolute positional embedding for that.
# Cf. https://github.com/zihangdai/xlnet/blob/master/modeling.py#L253-L276
# We can probably just use the multi-head attention module of PyTorch >=1.1.0
raise NotImplementedError
self.summary = Identity()
if hasattr(config, "summary_use_proj") and config.summary_use_proj:
if hasattr(config, "summary_proj_to_labels") and config.summary_proj_to_labels and config.num_labels > 0:
num_classes = config.num_labels
else:
num_classes = config.hidden_size
self.summary = nn.Linear(config.hidden_size, num_classes)
activation_string = getattr(config, "summary_activation", None)
self.activation: Callable = get_activation(activation_string) if activation_string else Identity()
self.first_dropout = Identity()
if hasattr(config, "summary_first_dropout") and config.summary_first_dropout > 0:
self.first_dropout = nn.Dropout(config.summary_first_dropout)
self.last_dropout = Identity()
if hasattr(config, "summary_last_dropout") and config.summary_last_dropout > 0:
self.last_dropout = nn.Dropout(config.summary_last_dropout)
def forward(
self, hidden_states: torch.FloatTensor, cls_index: Optional[torch.LongTensor] = None
) -> torch.FloatTensor:
"""
Compute a single vector summary of a sequence hidden states.
Args:
hidden_states (`torch.FloatTensor` of shape `[batch_size, seq_len, hidden_size]`):
The hidden states of the last layer.
cls_index (`torch.LongTensor` of shape `[batch_size]` or `[batch_size, ...]` where ... are optional leading dimensions of `hidden_states`, *optional*):
Used if `summary_type == "cls_index"` and takes the last token of the sequence as classification token.
Returns:
`torch.FloatTensor`: The summary of the sequence hidden states.
"""
if self.summary_type == "last":
output = hidden_states[:, -1]
elif self.summary_type == "first":
output = hidden_states[:, 0]
elif self.summary_type == "mean":
output = hidden_states.mean(dim=1)
elif self.summary_type == "cls_index":
if cls_index is None:
cls_index = torch.full_like(
hidden_states[..., :1, :],
hidden_states.shape[-2] - 1,
dtype=torch.long,
)
else:
cls_index = cls_index.unsqueeze(-1).unsqueeze(-1)
cls_index = cls_index.expand((-1,) * (cls_index.dim() - 1) + (hidden_states.size(-1),))
# shape of cls_index: (bsz, XX, 1, hidden_size) where XX are optional leading dim of hidden_states
output = hidden_states.gather(-2, cls_index).squeeze(-2) # shape (bsz, XX, hidden_size)
elif self.summary_type == "attn":
raise NotImplementedError
output = self.first_dropout(output)
output = self.summary(output)
output = self.activation(output)
output = self.last_dropout(output)
return output
def unwrap_model(model: nn.Module, recursive: bool = False) -> nn.Module:
"""
Recursively unwraps a model from potential containers (as used in distributed training).
Args:
model (`torch.nn.Module`): The model to unwrap.
recursive (`bool`, *optional*, defaults to `False`):
Whether to recursively extract all cases of `module.module` from `model` as well as unwrap child sublayers
recursively, not just the top-level distributed containers.
"""
# Use accelerate implementation if available (should always be the case when using torch)
# This is for pytorch, as we also have to handle things like dynamo
if is_accelerate_available():
kwargs = {}
if recursive:
if not is_accelerate_available("0.29.0"):
raise RuntimeError(
"Setting `recursive=True` to `unwrap_model` requires `accelerate` v0.29.0. Please upgrade your version of accelerate"
)
else:
kwargs["recursive"] = recursive
return extract_model_from_parallel(model, **kwargs)
else:
# since there could be multiple levels of wrapping, unwrap recursively
if hasattr(model, "module"):
return unwrap_model(model.module)
else:
return model
def expand_device_map(device_map, param_names, start_prefix):
"""
Expand a device map to return the correspondance parameter name to device.
"""
new_device_map = {}
param_names = [p[len(start_prefix) :] for p in param_names if p.startswith(start_prefix)]
for module, device in device_map.items():
new_device_map.update(
{p: device for p in param_names if p == module or p.startswith(f"{module}.") or module == ""}
)
return new_device_map
def get_disk_only_shard_files(device_map, sharded_metadata, start_prefix):
"""
Returns the list of shard files containing only weights offloaded to disk.
"""
weight_map = {
p[len(start_prefix) :]: v for p, v in sharded_metadata["weight_map"].items() if p.startswith(start_prefix)
}
files_content = collections.defaultdict(list)
for weight_name, filename in weight_map.items():
while len(weight_name) > 0 and weight_name not in device_map:
weight_name = ".".join(weight_name.split(".")[:-1])
files_content[filename].append(device_map[weight_name])
return [fname for fname, devices in files_content.items() if set(devices) == {"disk"}]
ALL_ATTENTION_FUNCTIONS: Dict[str, Dict[str, Callable]] = {}
ALL_ATTENTION_FUNCTIONS.update(
{
"flash_attention_2": flash_attention_forward,
"flex_attention": flex_attention_forward,
"sdpa": sdpa_attention_forward,
}
)
| transformers/src/transformers/modeling_utils.py/0 | {
"file_path": "transformers/src/transformers/modeling_utils.py",
"repo_id": "transformers",
"token_count": 127749
} |
# coding=utf-8
# Copyright 2022 WenXiang ZhongzhiCheng LedellWu LiuGuang BoWenZhang and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""AltCLIP model configuration"""
from ...configuration_utils import PretrainedConfig
from ...utils import logging
logger = logging.get_logger(__name__)
class AltCLIPTextConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`AltCLIPTextModel`]. It is used to instantiate a
AltCLIP text model according to the specified arguments, defining the model architecture. Instantiating a
configuration with the defaults will yield a similar configuration to that of the AltCLIP
[BAAI/AltCLIP](https://huggingface.co/BAAI/AltCLIP) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 250002):
Vocabulary size of the AltCLIP model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`AltCLIPTextModel`].
hidden_size (`int`, *optional*, defaults to 1024):
Dimensionality of the encoder layers and the pooler layer.
num_hidden_layers (`int`, *optional*, defaults to 24):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 16):
Number of attention heads for each attention layer in the Transformer encoder.
intermediate_size (`int`, *optional*, defaults to 4096):
Dimensionality of the "intermediate" (often named feed-forward) layer in the Transformer encoder.
hidden_act (`str` or `Callable`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"silu"` and `"gelu_new"` are supported.
hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
The dropout ratio for the attention probabilities.
max_position_embeddings (`int`, *optional*, defaults to 514):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
type_vocab_size (`int`, *optional*, defaults to 1):
The vocabulary size of the `token_type_ids` passed when calling [`AltCLIPTextModel`]
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
initializer_factor (`float`, *optional*, defaults to 0.02):
A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
testing).
layer_norm_eps (`float`, *optional*, defaults to 1e-05):
The epsilon used by the layer normalization layers.
pad_token_id (`int`, *optional*, defaults to 1): The id of the *padding* token.
bos_token_id (`int`, *optional*, defaults to 0): The id of the *beginning-of-sequence* token.
eos_token_id (`Union[int, List[int]]`, *optional*, defaults to 2):
The id of the *end-of-sequence* token. Optionally, use a list to set multiple *end-of-sequence* tokens.
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
[Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
project_dim (`int`, *optional*, defaults to 768):
The dimensions of the teacher model before the mapping layer.
Examples:
```python
>>> from transformers import AltCLIPTextModel, AltCLIPTextConfig
>>> # Initializing a AltCLIPTextConfig with BAAI/AltCLIP style configuration
>>> configuration = AltCLIPTextConfig()
>>> # Initializing a AltCLIPTextModel (with random weights) from the BAAI/AltCLIP style configuration
>>> model = AltCLIPTextModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "altclip_text_model"
def __init__(
self,
vocab_size=250002,
hidden_size=1024,
num_hidden_layers=24,
num_attention_heads=16,
intermediate_size=4096,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=514,
type_vocab_size=1,
initializer_range=0.02,
initializer_factor=0.02,
layer_norm_eps=1e-05,
pad_token_id=1,
bos_token_id=0,
eos_token_id=2,
position_embedding_type="absolute",
use_cache=True,
project_dim=768,
**kwargs,
):
super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.hidden_act = hidden_act
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.initializer_range = initializer_range
self.initializer_factor = initializer_factor
self.layer_norm_eps = layer_norm_eps
self.position_embedding_type = position_embedding_type
self.use_cache = use_cache
self.project_dim = project_dim
class AltCLIPVisionConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`AltCLIPModel`]. It is used to instantiate an
AltCLIP model according to the specified arguments, defining the model architecture. Instantiating a configuration
with the defaults will yield a similar configuration to that of the AltCLIP
[BAAI/AltCLIP](https://huggingface.co/BAAI/AltCLIP) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
hidden_size (`int`, *optional*, defaults to 768):
Dimensionality of the encoder layers and the pooler layer.
intermediate_size (`int`, *optional*, defaults to 3072):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
projection_dim (`int`, *optional*, defaults to 512):
Dimensionality of text and vision projection layers.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
num_channels (`int`, *optional*, defaults to 3):
The number of input channels.
image_size (`int`, *optional*, defaults to 224):
The size (resolution) of each image.
patch_size (`int`, *optional*, defaults to 32):
The size (resolution) of each patch.
hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` `"quick_gelu"` are supported.
layer_norm_eps (`float`, *optional*, defaults to 1e-05):
The epsilon used by the layer normalization layers.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
initializer_factor (`float`, *optional*, defaults to 1.0):
A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
testing).
Example:
```python
>>> from transformers import AltCLIPVisionConfig, AltCLIPVisionModel
>>> # Initializing a AltCLIPVisionConfig with BAAI/AltCLIP style configuration
>>> configuration = AltCLIPVisionConfig()
>>> # Initializing a AltCLIPVisionModel (with random weights) from the BAAI/AltCLIP style configuration
>>> model = AltCLIPVisionModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "altclip_vision_model"
base_config_key = "vision_config"
def __init__(
self,
hidden_size=768,
intermediate_size=3072,
projection_dim=512,
num_hidden_layers=12,
num_attention_heads=12,
num_channels=3,
image_size=224,
patch_size=32,
hidden_act="quick_gelu",
layer_norm_eps=1e-5,
attention_dropout=0.0,
initializer_range=0.02,
initializer_factor=1.0,
**kwargs,
):
super().__init__(**kwargs)
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.projection_dim = projection_dim
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.num_channels = num_channels
self.patch_size = patch_size
self.image_size = image_size
self.initializer_range = initializer_range
self.initializer_factor = initializer_factor
self.attention_dropout = attention_dropout
self.layer_norm_eps = layer_norm_eps
self.hidden_act = hidden_act
class AltCLIPConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`AltCLIPModel`]. It is used to instantiate an
AltCLIP model according to the specified arguments, defining the model architecture. Instantiating a configuration
with the defaults will yield a similar configuration to that of the AltCLIP
[BAAI/AltCLIP](https://huggingface.co/BAAI/AltCLIP) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
text_config (`dict`, *optional*):
Dictionary of configuration options used to initialize [`AltCLIPTextConfig`].
vision_config (`dict`, *optional*):
Dictionary of configuration options used to initialize [`AltCLIPVisionConfig`].
projection_dim (`int`, *optional*, defaults to 768):
Dimensionality of text and vision projection layers.
logit_scale_init_value (`float`, *optional*, defaults to 2.6592):
The initial value of the *logit_scale* parameter. Default is used as per the original CLIP implementation.
kwargs (*optional*):
Dictionary of keyword arguments.
Example:
```python
>>> from transformers import AltCLIPConfig, AltCLIPModel
>>> # Initializing a AltCLIPConfig with BAAI/AltCLIP style configuration
>>> configuration = AltCLIPConfig()
>>> # Initializing a AltCLIPModel (with random weights) from the BAAI/AltCLIP style configuration
>>> model = AltCLIPModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
>>> # We can also initialize a AltCLIPConfig from a AltCLIPTextConfig and a AltCLIPVisionConfig
>>> # Initializing a AltCLIPText and AltCLIPVision configuration
>>> config_text = AltCLIPTextConfig()
>>> config_vision = AltCLIPVisionConfig()
>>> config = AltCLIPConfig.from_text_vision_configs(config_text, config_vision)
```"""
model_type = "altclip"
sub_configs = {"text_config": AltCLIPTextConfig, "vision_config": AltCLIPVisionConfig}
def __init__(
self, text_config=None, vision_config=None, projection_dim=768, logit_scale_init_value=2.6592, **kwargs
):
# If `_config_dict` exist, we use them for the backward compatibility.
# We pop out these 2 attributes before calling `super().__init__` to avoid them being saved (which causes a lot
# of confusion!).
text_config_dict = kwargs.pop("text_config_dict", None)
vision_config_dict = kwargs.pop("vision_config_dict", None)
super().__init__(**kwargs)
# Instead of simply assigning `[text|vision]_config_dict` to `[text|vision]_config`, we use the values in
# `[text|vision]_config_dict` to update the values in `[text|vision]_config`. The values should be same in most
# cases, but we don't want to break anything regarding `_config_dict` that existed before commit `8827e1b2`.
if text_config_dict is not None:
if text_config is None:
text_config = {}
# This is the complete result when using `text_config_dict`.
_text_config_dict = AltCLIPTextConfig(**text_config_dict).to_dict()
# Give a warning if the values exist in both `_text_config_dict` and `text_config` but being different.
for key, value in _text_config_dict.items():
if key in text_config and value != text_config[key] and key not in ["transformers_version"]:
# If specified in `text_config_dict`
if key in text_config_dict:
message = (
f"`{key}` is found in both `text_config_dict` and `text_config` but with different values. "
f'The value `text_config_dict["{key}"]` will be used instead.'
)
# If inferred from default argument values (just to be super careful)
else:
message = (
f"`text_config_dict` is provided which will be used to initialize `AltCLIPTextConfig`. The "
f'value `text_config["{key}"]` will be overridden.'
)
logger.info(message)
# Update all values in `text_config` with the ones in `_text_config_dict`.
text_config.update(_text_config_dict)
if vision_config_dict is not None:
if vision_config is None:
vision_config = {}
# This is the complete result when using `vision_config_dict`.
_vision_config_dict = AltCLIPVisionConfig(**vision_config_dict).to_dict()
# convert keys to string instead of integer
if "id2label" in _vision_config_dict:
_vision_config_dict["id2label"] = {
str(key): value for key, value in _vision_config_dict["id2label"].items()
}
# Give a warning if the values exist in both `_vision_config_dict` and `vision_config` but being different.
for key, value in _vision_config_dict.items():
if key in vision_config and value != vision_config[key] and key not in ["transformers_version"]:
# If specified in `vision_config_dict`
if key in vision_config_dict:
message = (
f"`{key}` is found in both `vision_config_dict` and `vision_config` but with different "
f'values. The value `vision_config_dict["{key}"]` will be used instead.'
)
# If inferred from default argument values (just to be super careful)
else:
message = (
f"`vision_config_dict` is provided which will be used to initialize `AltCLIPVisionConfig`. "
f'The value `vision_config["{key}"]` will be overridden.'
)
logger.info(message)
# Update all values in `vision_config` with the ones in `_vision_config_dict`.
vision_config.update(_vision_config_dict)
if text_config is None:
text_config = {}
logger.info("`text_config` is `None`. Initializing the `AltCLIPTextConfig` with default values.")
if vision_config is None:
vision_config = {}
logger.info("`vision_config` is `None`. initializing the `AltCLIPVisionConfig` with default values.")
self.text_config = AltCLIPTextConfig(**text_config)
self.vision_config = AltCLIPVisionConfig(**vision_config)
self.projection_dim = projection_dim
self.logit_scale_init_value = logit_scale_init_value
self.initializer_factor = 1.0
@classmethod
def from_text_vision_configs(cls, text_config: AltCLIPTextConfig, vision_config: AltCLIPVisionConfig, **kwargs):
r"""
Instantiate a [`AltCLIPConfig`] (or a derived class) from altclip text model configuration and altclip vision
model configuration.
Returns:
[`AltCLIPConfig`]: An instance of a configuration object
"""
return cls(text_config=text_config.to_dict(), vision_config=vision_config.to_dict(), **kwargs)
__all__ = ["AltCLIPTextConfig", "AltCLIPVisionConfig", "AltCLIPConfig"]
| transformers/src/transformers/models/altclip/configuration_altclip.py/0 | {
"file_path": "transformers/src/transformers/models/altclip/configuration_altclip.py",
"repo_id": "transformers",
"token_count": 7354
} |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Factory function to build auto-model classes."""
import copy
import importlib
import json
import warnings
from collections import OrderedDict
from ...configuration_utils import PretrainedConfig
from ...dynamic_module_utils import get_class_from_dynamic_module, resolve_trust_remote_code
from ...utils import (
CONFIG_NAME,
cached_file,
copy_func,
extract_commit_hash,
find_adapter_config_file,
is_peft_available,
is_torch_available,
logging,
requires_backends,
)
from .configuration_auto import AutoConfig, model_type_to_module_name, replace_list_option_in_docstrings
if is_torch_available():
from ...generation import GenerationMixin
logger = logging.get_logger(__name__)
CLASS_DOCSTRING = """
This is a generic model class that will be instantiated as one of the model classes of the library when created
with the [`~BaseAutoModelClass.from_pretrained`] class method or the [`~BaseAutoModelClass.from_config`] class
method.
This class cannot be instantiated directly using `__init__()` (throws an error).
"""
FROM_CONFIG_DOCSTRING = """
Instantiates one of the model classes of the library from a configuration.
Note:
Loading a model from its configuration file does **not** load the model weights. It only affects the
model's configuration. Use [`~BaseAutoModelClass.from_pretrained`] to load the model weights.
Args:
config ([`PretrainedConfig`]):
The model class to instantiate is selected based on the configuration class:
List options
attn_implementation (`str`, *optional*):
The attention implementation to use in the model (if relevant). Can be any of `"eager"` (manual implementation of the attention), `"sdpa"` (using [`F.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html)), or `"flash_attention_2"` (using [Dao-AILab/flash-attention](https://github.com/Dao-AILab/flash-attention)). By default, if available, SDPA will be used for torch>=2.1.1. The default is otherwise the manual `"eager"` implementation.
Examples:
```python
>>> from transformers import AutoConfig, BaseAutoModelClass
>>> # Download configuration from huggingface.co and cache.
>>> config = AutoConfig.from_pretrained("checkpoint_placeholder")
>>> model = BaseAutoModelClass.from_config(config)
```
"""
FROM_PRETRAINED_TORCH_DOCSTRING = """
Instantiate one of the model classes of the library from a pretrained model.
The model class to instantiate is selected based on the `model_type` property of the config object (either
passed as an argument or loaded from `pretrained_model_name_or_path` if possible), or when it's missing, by
falling back to using pattern matching on `pretrained_model_name_or_path`:
List options
The model is set in evaluation mode by default using `model.eval()` (so for instance, dropout modules are
deactivated). To train the model, you should first set it back in training mode with `model.train()`
Args:
pretrained_model_name_or_path (`str` or `os.PathLike`):
Can be either:
- A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
- A path to a *directory* containing model weights saved using
[`~PreTrainedModel.save_pretrained`], e.g., `./my_model_directory/`.
- A path or url to a *tensorflow index checkpoint file* (e.g, `./tf_model/model.ckpt.index`). In
this case, `from_tf` should be set to `True` and a configuration object should be provided as
`config` argument. This loading path is slower than converting the TensorFlow checkpoint in a
PyTorch model using the provided conversion scripts and loading the PyTorch model afterwards.
model_args (additional positional arguments, *optional*):
Will be passed along to the underlying model `__init__()` method.
config ([`PretrainedConfig`], *optional*):
Configuration for the model to use instead of an automatically loaded configuration. Configuration can
be automatically loaded when:
- The model is a model provided by the library (loaded with the *model id* string of a pretrained
model).
- The model was saved using [`~PreTrainedModel.save_pretrained`] and is reloaded by supplying the
save directory.
- The model is loaded by supplying a local directory as `pretrained_model_name_or_path` and a
configuration JSON file named *config.json* is found in the directory.
state_dict (*Dict[str, torch.Tensor]*, *optional*):
A state dictionary to use instead of a state dictionary loaded from saved weights file.
This option can be used if you want to create a model from a pretrained configuration but load your own
weights. In this case though, you should check if using [`~PreTrainedModel.save_pretrained`] and
[`~PreTrainedModel.from_pretrained`] is not a simpler option.
cache_dir (`str` or `os.PathLike`, *optional*):
Path to a directory in which a downloaded pretrained model configuration should be cached if the
standard cache should not be used.
from_tf (`bool`, *optional*, defaults to `False`):
Load the model weights from a TensorFlow checkpoint save file (see docstring of
`pretrained_model_name_or_path` argument).
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
resume_download:
Deprecated and ignored. All downloads are now resumed by default when possible.
Will be removed in v5 of Transformers.
proxies (`Dict[str, str]`, *optional*):
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
output_loading_info(`bool`, *optional*, defaults to `False`):
Whether ot not to also return a dictionary containing missing keys, unexpected keys and error messages.
local_files_only(`bool`, *optional*, defaults to `False`):
Whether or not to only look at local files (e.g., not try downloading the model).
revision (`str`, *optional*, defaults to `"main"`):
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
identifier allowed by git.
trust_remote_code (`bool`, *optional*, defaults to `False`):
Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
should only be set to `True` for repositories you trust and in which you have read the code, as it will
execute code present on the Hub on your local machine.
code_revision (`str`, *optional*, defaults to `"main"`):
The specific revision to use for the code on the Hub, if the code leaves in a different repository than
the rest of the model. It can be a branch name, a tag name, or a commit id, since we use a git-based
system for storing models and other artifacts on huggingface.co, so `revision` can be any identifier
allowed by git.
kwargs (additional keyword arguments, *optional*):
Can be used to update the configuration object (after it being loaded) and initiate the model (e.g.,
`output_attentions=True`). Behaves differently depending on whether a `config` is provided or
automatically loaded:
- If a configuration is provided with `config`, `**kwargs` will be directly passed to the
underlying model's `__init__` method (we assume all relevant updates to the configuration have
already been done)
- If a configuration is not provided, `kwargs` will be first passed to the configuration class
initialization function ([`~PretrainedConfig.from_pretrained`]). Each key of `kwargs` that
corresponds to a configuration attribute will be used to override said attribute with the
supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute
will be passed to the underlying model's `__init__` function.
Examples:
```python
>>> from transformers import AutoConfig, BaseAutoModelClass
>>> # Download model and configuration from huggingface.co and cache.
>>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder")
>>> # Update configuration during loading
>>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder", output_attentions=True)
>>> model.config.output_attentions
True
>>> # Loading from a TF checkpoint file instead of a PyTorch model (slower)
>>> config = AutoConfig.from_pretrained("./tf_model/shortcut_placeholder_tf_model_config.json")
>>> model = BaseAutoModelClass.from_pretrained(
... "./tf_model/shortcut_placeholder_tf_checkpoint.ckpt.index", from_tf=True, config=config
... )
```
"""
FROM_PRETRAINED_TF_DOCSTRING = """
Instantiate one of the model classes of the library from a pretrained model.
The model class to instantiate is selected based on the `model_type` property of the config object (either
passed as an argument or loaded from `pretrained_model_name_or_path` if possible), or when it's missing, by
falling back to using pattern matching on `pretrained_model_name_or_path`:
List options
Args:
pretrained_model_name_or_path (`str` or `os.PathLike`):
Can be either:
- A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
- A path to a *directory* containing model weights saved using
[`~PreTrainedModel.save_pretrained`], e.g., `./my_model_directory/`.
- A path or url to a *PyTorch state_dict save file* (e.g, `./pt_model/pytorch_model.bin`). In this
case, `from_pt` should be set to `True` and a configuration object should be provided as `config`
argument. This loading path is slower than converting the PyTorch model in a TensorFlow model
using the provided conversion scripts and loading the TensorFlow model afterwards.
model_args (additional positional arguments, *optional*):
Will be passed along to the underlying model `__init__()` method.
config ([`PretrainedConfig`], *optional*):
Configuration for the model to use instead of an automatically loaded configuration. Configuration can
be automatically loaded when:
- The model is a model provided by the library (loaded with the *model id* string of a pretrained
model).
- The model was saved using [`~PreTrainedModel.save_pretrained`] and is reloaded by supplying the
save directory.
- The model is loaded by supplying a local directory as `pretrained_model_name_or_path` and a
configuration JSON file named *config.json* is found in the directory.
cache_dir (`str` or `os.PathLike`, *optional*):
Path to a directory in which a downloaded pretrained model configuration should be cached if the
standard cache should not be used.
from_pt (`bool`, *optional*, defaults to `False`):
Load the model weights from a PyTorch checkpoint save file (see docstring of
`pretrained_model_name_or_path` argument).
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
resume_download:
Deprecated and ignored. All downloads are now resumed by default when possible.
Will be removed in v5 of Transformers.
proxies (`Dict[str, str]`, *optional*):
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
output_loading_info(`bool`, *optional*, defaults to `False`):
Whether ot not to also return a dictionary containing missing keys, unexpected keys and error messages.
local_files_only(`bool`, *optional*, defaults to `False`):
Whether or not to only look at local files (e.g., not try downloading the model).
revision (`str`, *optional*, defaults to `"main"`):
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
identifier allowed by git.
trust_remote_code (`bool`, *optional*, defaults to `False`):
Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
should only be set to `True` for repositories you trust and in which you have read the code, as it will
execute code present on the Hub on your local machine.
code_revision (`str`, *optional*, defaults to `"main"`):
The specific revision to use for the code on the Hub, if the code leaves in a different repository than
the rest of the model. It can be a branch name, a tag name, or a commit id, since we use a git-based
system for storing models and other artifacts on huggingface.co, so `revision` can be any identifier
allowed by git.
kwargs (additional keyword arguments, *optional*):
Can be used to update the configuration object (after it being loaded) and initiate the model (e.g.,
`output_attentions=True`). Behaves differently depending on whether a `config` is provided or
automatically loaded:
- If a configuration is provided with `config`, `**kwargs` will be directly passed to the
underlying model's `__init__` method (we assume all relevant updates to the configuration have
already been done)
- If a configuration is not provided, `kwargs` will be first passed to the configuration class
initialization function ([`~PretrainedConfig.from_pretrained`]). Each key of `kwargs` that
corresponds to a configuration attribute will be used to override said attribute with the
supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute
will be passed to the underlying model's `__init__` function.
Examples:
```python
>>> from transformers import AutoConfig, BaseAutoModelClass
>>> # Download model and configuration from huggingface.co and cache.
>>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder")
>>> # Update configuration during loading
>>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder", output_attentions=True)
>>> model.config.output_attentions
True
>>> # Loading from a PyTorch checkpoint file instead of a TensorFlow model (slower)
>>> config = AutoConfig.from_pretrained("./pt_model/shortcut_placeholder_pt_model_config.json")
>>> model = BaseAutoModelClass.from_pretrained(
... "./pt_model/shortcut_placeholder_pytorch_model.bin", from_pt=True, config=config
... )
```
"""
FROM_PRETRAINED_FLAX_DOCSTRING = """
Instantiate one of the model classes of the library from a pretrained model.
The model class to instantiate is selected based on the `model_type` property of the config object (either
passed as an argument or loaded from `pretrained_model_name_or_path` if possible), or when it's missing, by
falling back to using pattern matching on `pretrained_model_name_or_path`:
List options
Args:
pretrained_model_name_or_path (`str` or `os.PathLike`):
Can be either:
- A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
- A path to a *directory* containing model weights saved using
[`~PreTrainedModel.save_pretrained`], e.g., `./my_model_directory/`.
- A path or url to a *PyTorch state_dict save file* (e.g, `./pt_model/pytorch_model.bin`). In this
case, `from_pt` should be set to `True` and a configuration object should be provided as `config`
argument. This loading path is slower than converting the PyTorch model in a TensorFlow model
using the provided conversion scripts and loading the TensorFlow model afterwards.
model_args (additional positional arguments, *optional*):
Will be passed along to the underlying model `__init__()` method.
config ([`PretrainedConfig`], *optional*):
Configuration for the model to use instead of an automatically loaded configuration. Configuration can
be automatically loaded when:
- The model is a model provided by the library (loaded with the *model id* string of a pretrained
model).
- The model was saved using [`~PreTrainedModel.save_pretrained`] and is reloaded by supplying the
save directory.
- The model is loaded by supplying a local directory as `pretrained_model_name_or_path` and a
configuration JSON file named *config.json* is found in the directory.
cache_dir (`str` or `os.PathLike`, *optional*):
Path to a directory in which a downloaded pretrained model configuration should be cached if the
standard cache should not be used.
from_pt (`bool`, *optional*, defaults to `False`):
Load the model weights from a PyTorch checkpoint save file (see docstring of
`pretrained_model_name_or_path` argument).
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
resume_download:
Deprecated and ignored. All downloads are now resumed by default when possible.
Will be removed in v5 of Transformers.
proxies (`Dict[str, str]`, *optional*):
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
output_loading_info(`bool`, *optional*, defaults to `False`):
Whether ot not to also return a dictionary containing missing keys, unexpected keys and error messages.
local_files_only(`bool`, *optional*, defaults to `False`):
Whether or not to only look at local files (e.g., not try downloading the model).
revision (`str`, *optional*, defaults to `"main"`):
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
identifier allowed by git.
trust_remote_code (`bool`, *optional*, defaults to `False`):
Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
should only be set to `True` for repositories you trust and in which you have read the code, as it will
execute code present on the Hub on your local machine.
code_revision (`str`, *optional*, defaults to `"main"`):
The specific revision to use for the code on the Hub, if the code leaves in a different repository than
the rest of the model. It can be a branch name, a tag name, or a commit id, since we use a git-based
system for storing models and other artifacts on huggingface.co, so `revision` can be any identifier
allowed by git.
kwargs (additional keyword arguments, *optional*):
Can be used to update the configuration object (after it being loaded) and initiate the model (e.g.,
`output_attentions=True`). Behaves differently depending on whether a `config` is provided or
automatically loaded:
- If a configuration is provided with `config`, `**kwargs` will be directly passed to the
underlying model's `__init__` method (we assume all relevant updates to the configuration have
already been done)
- If a configuration is not provided, `kwargs` will be first passed to the configuration class
initialization function ([`~PretrainedConfig.from_pretrained`]). Each key of `kwargs` that
corresponds to a configuration attribute will be used to override said attribute with the
supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute
will be passed to the underlying model's `__init__` function.
Examples:
```python
>>> from transformers import AutoConfig, BaseAutoModelClass
>>> # Download model and configuration from huggingface.co and cache.
>>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder")
>>> # Update configuration during loading
>>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder", output_attentions=True)
>>> model.config.output_attentions
True
>>> # Loading from a PyTorch checkpoint file instead of a TensorFlow model (slower)
>>> config = AutoConfig.from_pretrained("./pt_model/shortcut_placeholder_pt_model_config.json")
>>> model = BaseAutoModelClass.from_pretrained(
... "./pt_model/shortcut_placeholder_pytorch_model.bin", from_pt=True, config=config
... )
```
"""
def _get_model_class(config, model_mapping):
supported_models = model_mapping[type(config)]
if not isinstance(supported_models, (list, tuple)):
return supported_models
name_to_model = {model.__name__: model for model in supported_models}
architectures = getattr(config, "architectures", [])
for arch in architectures:
if arch in name_to_model:
return name_to_model[arch]
elif f"TF{arch}" in name_to_model:
return name_to_model[f"TF{arch}"]
elif f"Flax{arch}" in name_to_model:
return name_to_model[f"Flax{arch}"]
# If not architecture is set in the config or match the supported models, the first element of the tuple is the
# defaults.
return supported_models[0]
class _BaseAutoModelClass:
# Base class for auto models.
_model_mapping = None
def __init__(self, *args, **kwargs):
raise EnvironmentError(
f"{self.__class__.__name__} is designed to be instantiated "
f"using the `{self.__class__.__name__}.from_pretrained(pretrained_model_name_or_path)` or "
f"`{self.__class__.__name__}.from_config(config)` methods."
)
@classmethod
def from_config(cls, config, **kwargs):
trust_remote_code = kwargs.pop("trust_remote_code", None)
has_remote_code = hasattr(config, "auto_map") and cls.__name__ in config.auto_map
has_local_code = type(config) in cls._model_mapping.keys()
trust_remote_code = resolve_trust_remote_code(
trust_remote_code, config._name_or_path, has_local_code, has_remote_code
)
if has_remote_code and trust_remote_code:
class_ref = config.auto_map[cls.__name__]
if "--" in class_ref:
repo_id, class_ref = class_ref.split("--")
else:
repo_id = config.name_or_path
model_class = get_class_from_dynamic_module(class_ref, repo_id, **kwargs)
cls.register(config.__class__, model_class, exist_ok=True)
_ = kwargs.pop("code_revision", None)
model_class = add_generation_mixin_to_remote_model(model_class)
return model_class._from_config(config, **kwargs)
elif type(config) in cls._model_mapping.keys():
model_class = _get_model_class(config, cls._model_mapping)
return model_class._from_config(config, **kwargs)
raise ValueError(
f"Unrecognized configuration class {config.__class__} for this kind of AutoModel: {cls.__name__}.\n"
f"Model type should be one of {', '.join(c.__name__ for c in cls._model_mapping.keys())}."
)
@classmethod
def from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
config = kwargs.pop("config", None)
trust_remote_code = kwargs.pop("trust_remote_code", None)
kwargs["_from_auto"] = True
hub_kwargs_names = [
"cache_dir",
"force_download",
"local_files_only",
"proxies",
"resume_download",
"revision",
"subfolder",
"use_auth_token",
"token",
]
hub_kwargs = {name: kwargs.pop(name) for name in hub_kwargs_names if name in kwargs}
code_revision = kwargs.pop("code_revision", None)
commit_hash = kwargs.pop("_commit_hash", None)
adapter_kwargs = kwargs.pop("adapter_kwargs", None)
token = hub_kwargs.pop("token", None)
use_auth_token = hub_kwargs.pop("use_auth_token", None)
if use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
FutureWarning,
)
if token is not None:
raise ValueError(
"`token` and `use_auth_token` are both specified. Please set only the argument `token`."
)
token = use_auth_token
if token is not None:
hub_kwargs["token"] = token
if commit_hash is None:
if not isinstance(config, PretrainedConfig):
# We make a call to the config file first (which may be absent) to get the commit hash as soon as possible
resolved_config_file = cached_file(
pretrained_model_name_or_path,
CONFIG_NAME,
_raise_exceptions_for_gated_repo=False,
_raise_exceptions_for_missing_entries=False,
_raise_exceptions_for_connection_errors=False,
**hub_kwargs,
)
commit_hash = extract_commit_hash(resolved_config_file, commit_hash)
else:
commit_hash = getattr(config, "_commit_hash", None)
if is_peft_available():
if adapter_kwargs is None:
adapter_kwargs = {}
if token is not None:
adapter_kwargs["token"] = token
maybe_adapter_path = find_adapter_config_file(
pretrained_model_name_or_path, _commit_hash=commit_hash, **adapter_kwargs
)
if maybe_adapter_path is not None:
with open(maybe_adapter_path, "r", encoding="utf-8") as f:
adapter_config = json.load(f)
adapter_kwargs["_adapter_model_path"] = pretrained_model_name_or_path
pretrained_model_name_or_path = adapter_config["base_model_name_or_path"]
if not isinstance(config, PretrainedConfig):
kwargs_orig = copy.deepcopy(kwargs)
# ensure not to pollute the config object with torch_dtype="auto" - since it's
# meaningless in the context of the config object - torch.dtype values are acceptable
if kwargs.get("torch_dtype", None) == "auto":
_ = kwargs.pop("torch_dtype")
# to not overwrite the quantization_config if config has a quantization_config
if kwargs.get("quantization_config", None) is not None:
_ = kwargs.pop("quantization_config")
config, kwargs = AutoConfig.from_pretrained(
pretrained_model_name_or_path,
return_unused_kwargs=True,
trust_remote_code=trust_remote_code,
code_revision=code_revision,
_commit_hash=commit_hash,
**hub_kwargs,
**kwargs,
)
# if torch_dtype=auto was passed here, ensure to pass it on
if kwargs_orig.get("torch_dtype", None) == "auto":
kwargs["torch_dtype"] = "auto"
if kwargs_orig.get("quantization_config", None) is not None:
kwargs["quantization_config"] = kwargs_orig["quantization_config"]
has_remote_code = hasattr(config, "auto_map") and cls.__name__ in config.auto_map
has_local_code = type(config) in cls._model_mapping.keys()
trust_remote_code = resolve_trust_remote_code(
trust_remote_code, pretrained_model_name_or_path, has_local_code, has_remote_code
)
# Set the adapter kwargs
kwargs["adapter_kwargs"] = adapter_kwargs
if has_remote_code and trust_remote_code:
class_ref = config.auto_map[cls.__name__]
model_class = get_class_from_dynamic_module(
class_ref, pretrained_model_name_or_path, code_revision=code_revision, **hub_kwargs, **kwargs
)
_ = hub_kwargs.pop("code_revision", None)
cls.register(config.__class__, model_class, exist_ok=True)
model_class = add_generation_mixin_to_remote_model(model_class)
return model_class.from_pretrained(
pretrained_model_name_or_path, *model_args, config=config, **hub_kwargs, **kwargs
)
elif type(config) in cls._model_mapping.keys():
model_class = _get_model_class(config, cls._model_mapping)
return model_class.from_pretrained(
pretrained_model_name_or_path, *model_args, config=config, **hub_kwargs, **kwargs
)
raise ValueError(
f"Unrecognized configuration class {config.__class__} for this kind of AutoModel: {cls.__name__}.\n"
f"Model type should be one of {', '.join(c.__name__ for c in cls._model_mapping.keys())}."
)
@classmethod
def register(cls, config_class, model_class, exist_ok=False):
"""
Register a new model for this class.
Args:
config_class ([`PretrainedConfig`]):
The configuration corresponding to the model to register.
model_class ([`PreTrainedModel`]):
The model to register.
"""
if hasattr(model_class, "config_class") and model_class.config_class.__name__ != config_class.__name__:
raise ValueError(
"The model class you are passing has a `config_class` attribute that is not consistent with the "
f"config class you passed (model has {model_class.config_class} and you passed {config_class}. Fix "
"one of those so they match!"
)
cls._model_mapping.register(config_class, model_class, exist_ok=exist_ok)
class _BaseAutoBackboneClass(_BaseAutoModelClass):
# Base class for auto backbone models.
_model_mapping = None
@classmethod
def _load_timm_backbone_from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
requires_backends(cls, ["vision", "timm"])
from ...models.timm_backbone import TimmBackboneConfig
config = kwargs.pop("config", TimmBackboneConfig())
if kwargs.get("out_features", None) is not None:
raise ValueError("Cannot specify `out_features` for timm backbones")
if kwargs.get("output_loading_info", False):
raise ValueError("Cannot specify `output_loading_info=True` when loading from timm")
num_channels = kwargs.pop("num_channels", config.num_channels)
features_only = kwargs.pop("features_only", config.features_only)
use_pretrained_backbone = kwargs.pop("use_pretrained_backbone", config.use_pretrained_backbone)
out_indices = kwargs.pop("out_indices", config.out_indices)
config = TimmBackboneConfig(
backbone=pretrained_model_name_or_path,
num_channels=num_channels,
features_only=features_only,
use_pretrained_backbone=use_pretrained_backbone,
out_indices=out_indices,
)
return super().from_config(config, **kwargs)
@classmethod
def from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
use_timm_backbone = kwargs.pop("use_timm_backbone", False)
if use_timm_backbone:
return cls._load_timm_backbone_from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
return super().from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
def insert_head_doc(docstring, head_doc=""):
if len(head_doc) > 0:
return docstring.replace(
"one of the model classes of the library ",
f"one of the model classes of the library (with a {head_doc} head) ",
)
return docstring.replace(
"one of the model classes of the library ", "one of the base model classes of the library "
)
def auto_class_update(cls, checkpoint_for_example="google-bert/bert-base-cased", head_doc=""):
# Create a new class with the right name from the base class
model_mapping = cls._model_mapping
name = cls.__name__
class_docstring = insert_head_doc(CLASS_DOCSTRING, head_doc=head_doc)
cls.__doc__ = class_docstring.replace("BaseAutoModelClass", name)
# Now we need to copy and re-register `from_config` and `from_pretrained` as class methods otherwise we can't
# have a specific docstrings for them.
from_config = copy_func(_BaseAutoModelClass.from_config)
from_config_docstring = insert_head_doc(FROM_CONFIG_DOCSTRING, head_doc=head_doc)
from_config_docstring = from_config_docstring.replace("BaseAutoModelClass", name)
from_config_docstring = from_config_docstring.replace("checkpoint_placeholder", checkpoint_for_example)
from_config.__doc__ = from_config_docstring
from_config = replace_list_option_in_docstrings(model_mapping._model_mapping, use_model_types=False)(from_config)
cls.from_config = classmethod(from_config)
if name.startswith("TF"):
from_pretrained_docstring = FROM_PRETRAINED_TF_DOCSTRING
elif name.startswith("Flax"):
from_pretrained_docstring = FROM_PRETRAINED_FLAX_DOCSTRING
else:
from_pretrained_docstring = FROM_PRETRAINED_TORCH_DOCSTRING
from_pretrained = copy_func(_BaseAutoModelClass.from_pretrained)
from_pretrained_docstring = insert_head_doc(from_pretrained_docstring, head_doc=head_doc)
from_pretrained_docstring = from_pretrained_docstring.replace("BaseAutoModelClass", name)
from_pretrained_docstring = from_pretrained_docstring.replace("checkpoint_placeholder", checkpoint_for_example)
shortcut = checkpoint_for_example.split("/")[-1].split("-")[0]
from_pretrained_docstring = from_pretrained_docstring.replace("shortcut_placeholder", shortcut)
from_pretrained.__doc__ = from_pretrained_docstring
from_pretrained = replace_list_option_in_docstrings(model_mapping._model_mapping)(from_pretrained)
cls.from_pretrained = classmethod(from_pretrained)
return cls
def get_values(model_mapping):
result = []
for model in model_mapping.values():
if isinstance(model, (list, tuple)):
result += list(model)
else:
result.append(model)
return result
def getattribute_from_module(module, attr):
if attr is None:
return None
if isinstance(attr, tuple):
return tuple(getattribute_from_module(module, a) for a in attr)
if hasattr(module, attr):
return getattr(module, attr)
# Some of the mappings have entries model_type -> object of another model type. In that case we try to grab the
# object at the top level.
transformers_module = importlib.import_module("transformers")
if module != transformers_module:
try:
return getattribute_from_module(transformers_module, attr)
except ValueError:
raise ValueError(f"Could not find {attr} neither in {module} nor in {transformers_module}!")
else:
raise ValueError(f"Could not find {attr} in {transformers_module}!")
def add_generation_mixin_to_remote_model(model_class):
"""
Adds `GenerationMixin` to the inheritance of `model_class`, if `model_class` is a PyTorch model.
This function is used for backwards compatibility purposes: in v4.45, we've started a deprecation cycle to make
`PreTrainedModel` stop inheriting from `GenerationMixin`. Without this function, older models dynamically loaded
from the Hub may not have the `generate` method after we remove the inheritance.
"""
# 1. If it is not a PT model (i.e. doesn't inherit Module), do nothing
if "torch.nn.modules.module.Module" not in str(model_class.__mro__):
return model_class
# 2. If it already **directly** inherits from GenerationMixin, do nothing
if "GenerationMixin" in str(model_class.__bases__):
return model_class
# 3. Prior to v4.45, we could detect whether a model was `generate`-compatible if it had its own `generate` and/or
# `prepare_inputs_for_generation` method.
has_custom_generate = "GenerationMixin" not in str(getattr(model_class, "generate"))
has_custom_prepare_inputs = "GenerationMixin" not in str(getattr(model_class, "prepare_inputs_for_generation"))
if has_custom_generate or has_custom_prepare_inputs:
model_class_with_generation_mixin = type(
model_class.__name__, (model_class, GenerationMixin), {**model_class.__dict__}
)
return model_class_with_generation_mixin
return model_class
class _LazyAutoMapping(OrderedDict):
"""
" A mapping config to object (model or tokenizer for instance) that will load keys and values when it is accessed.
Args:
- config_mapping: The map model type to config class
- model_mapping: The map model type to model (or tokenizer) class
"""
def __init__(self, config_mapping, model_mapping):
self._config_mapping = config_mapping
self._reverse_config_mapping = {v: k for k, v in config_mapping.items()}
self._model_mapping = model_mapping
self._model_mapping._model_mapping = self
self._extra_content = {}
self._modules = {}
def __len__(self):
common_keys = set(self._config_mapping.keys()).intersection(self._model_mapping.keys())
return len(common_keys) + len(self._extra_content)
def __getitem__(self, key):
if key in self._extra_content:
return self._extra_content[key]
model_type = self._reverse_config_mapping[key.__name__]
if model_type in self._model_mapping:
model_name = self._model_mapping[model_type]
return self._load_attr_from_module(model_type, model_name)
# Maybe there was several model types associated with this config.
model_types = [k for k, v in self._config_mapping.items() if v == key.__name__]
for mtype in model_types:
if mtype in self._model_mapping:
model_name = self._model_mapping[mtype]
return self._load_attr_from_module(mtype, model_name)
raise KeyError(key)
def _load_attr_from_module(self, model_type, attr):
module_name = model_type_to_module_name(model_type)
if module_name not in self._modules:
self._modules[module_name] = importlib.import_module(f".{module_name}", "transformers.models")
return getattribute_from_module(self._modules[module_name], attr)
def keys(self):
mapping_keys = [
self._load_attr_from_module(key, name)
for key, name in self._config_mapping.items()
if key in self._model_mapping.keys()
]
return mapping_keys + list(self._extra_content.keys())
def get(self, key, default):
try:
return self.__getitem__(key)
except KeyError:
return default
def __bool__(self):
return bool(self.keys())
def values(self):
mapping_values = [
self._load_attr_from_module(key, name)
for key, name in self._model_mapping.items()
if key in self._config_mapping.keys()
]
return mapping_values + list(self._extra_content.values())
def items(self):
mapping_items = [
(
self._load_attr_from_module(key, self._config_mapping[key]),
self._load_attr_from_module(key, self._model_mapping[key]),
)
for key in self._model_mapping.keys()
if key in self._config_mapping.keys()
]
return mapping_items + list(self._extra_content.items())
def __iter__(self):
return iter(self.keys())
def __contains__(self, item):
if item in self._extra_content:
return True
if not hasattr(item, "__name__") or item.__name__ not in self._reverse_config_mapping:
return False
model_type = self._reverse_config_mapping[item.__name__]
return model_type in self._model_mapping
def register(self, key, value, exist_ok=False):
"""
Register a new model in this mapping.
"""
if hasattr(key, "__name__") and key.__name__ in self._reverse_config_mapping:
model_type = self._reverse_config_mapping[key.__name__]
if model_type in self._model_mapping.keys() and not exist_ok:
raise ValueError(f"'{key}' is already used by a Transformers model.")
self._extra_content[key] = value
| transformers/src/transformers/models/auto/auto_factory.py/0 | {
"file_path": "transformers/src/transformers/models/auto/auto_factory.py",
"repo_id": "transformers",
"token_count": 17870
} |
# coding=utf-8
# Copyright 2020 Ecole Polytechnique and the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License
"""Tokenization classes for the BARThez model."""
import os
from shutil import copyfile
from typing import Any, Dict, List, Optional, Tuple
import sentencepiece as spm
from ...tokenization_utils import AddedToken, PreTrainedTokenizer
from ...utils import logging
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model"}
SPIECE_UNDERLINE = "▁"
# TODO this class is useless. This is the most standard sentencpiece model. Let's find which one is closest and nuke this.
class BarthezTokenizer(PreTrainedTokenizer):
"""
Adapted from [`CamembertTokenizer`] and [`BartTokenizer`]. Construct a BARThez tokenizer. Based on
[SentencePiece](https://github.com/google/sentencepiece).
This tokenizer inherits from [`PreTrainedTokenizer`] which contains most of the main methods. Users should refer to
this superclass for more information regarding those methods.
Args:
vocab_file (`str`):
[SentencePiece](https://github.com/google/sentencepiece) file (generally has a *.spm* extension) that
contains the vocabulary necessary to instantiate a tokenizer.
bos_token (`str`, *optional*, defaults to `"<s>"`):
The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.
<Tip>
When building a sequence using special tokens, this is not the token that is used for the beginning of
sequence. The token used is the `cls_token`.
</Tip>
eos_token (`str`, *optional*, defaults to `"</s>"`):
The end of sequence token.
<Tip>
When building a sequence using special tokens, this is not the token that is used for the end of sequence.
The token used is the `sep_token`.
</Tip>
sep_token (`str`, *optional*, defaults to `"</s>"`):
The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for
sequence classification or for a text and a question for question answering. It is also used as the last
token of a sequence built with special tokens.
cls_token (`str`, *optional*, defaults to `"<s>"`):
The classifier token which is used when doing sequence classification (classification of the whole sequence
instead of per-token classification). It is the first token of the sequence when built with special tokens.
unk_token (`str`, *optional*, defaults to `"<unk>"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
pad_token (`str`, *optional*, defaults to `"<pad>"`):
The token used for padding, for example when batching sequences of different lengths.
mask_token (`str`, *optional*, defaults to `"<mask>"`):
The token used for masking values. This is the token used when training this model with masked language
modeling. This is the token which the model will try to predict.
sp_model_kwargs (`dict`, *optional*):
Will be passed to the `SentencePieceProcessor.__init__()` method. The [Python wrapper for
SentencePiece](https://github.com/google/sentencepiece/tree/master/python) can be used, among other things,
to set:
- `enable_sampling`: Enable subword regularization.
- `nbest_size`: Sampling parameters for unigram. Invalid for BPE-Dropout.
- `nbest_size = {0,1}`: No sampling is performed.
- `nbest_size > 1`: samples from the nbest_size results.
- `nbest_size < 0`: assuming that nbest_size is infinite and samples from the all hypothesis (lattice)
using forward-filtering-and-backward-sampling algorithm.
- `alpha`: Smoothing parameter for unigram sampling, and dropout probability of merge operations for
BPE-dropout.
Attributes:
sp_model (`SentencePieceProcessor`):
The *SentencePiece* processor that is used for every conversion (string, tokens and IDs).
"""
vocab_files_names = VOCAB_FILES_NAMES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
self,
vocab_file,
bos_token="<s>",
eos_token="</s>",
sep_token="</s>",
cls_token="<s>",
unk_token="<unk>",
pad_token="<pad>",
mask_token="<mask>",
sp_model_kwargs: Optional[Dict[str, Any]] = None,
**kwargs,
) -> None:
# Mask token behave like a normal word, i.e. include the space before it. Will have normalized=False by default this way
mask_token = AddedToken(mask_token, lstrip=True, special=True) if isinstance(mask_token, str) else mask_token
self.sp_model_kwargs = {} if sp_model_kwargs is None else sp_model_kwargs
self.vocab_file = vocab_file
self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
self.sp_model.Load(str(vocab_file))
super().__init__(
bos_token=bos_token,
eos_token=eos_token,
unk_token=unk_token,
sep_token=sep_token,
cls_token=cls_token,
pad_token=pad_token,
mask_token=mask_token,
sp_model_kwargs=self.sp_model_kwargs,
**kwargs,
)
def build_inputs_with_special_tokens(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. A BARThez sequence has the following format:
- single sequence: `<s> X </s>`
- pair of sequences: `<s> A </s></s> B </s>`
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
if token_ids_1 is None:
return [self.cls_token_id] + token_ids_0 + [self.sep_token_id]
cls = [self.cls_token_id]
sep = [self.sep_token_id]
return cls + token_ids_0 + sep + sep + token_ids_1 + sep
def get_special_tokens_mask(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
) -> List[int]:
"""
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer `prepare_for_model` method.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not the token list is already formatted with special tokens for the model.
Returns:
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
"""
if already_has_special_tokens:
return super().get_special_tokens_mask(
token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
)
if token_ids_1 is None:
return [1] + ([0] * len(token_ids_0)) + [1]
return [1] + ([0] * len(token_ids_0)) + [1, 1] + ([0] * len(token_ids_1)) + [1]
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Create a mask from the two sequences passed to be used in a sequence-pair classification task.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of zeros.
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep + sep + token_ids_1 + sep) * [0]
@property
def vocab_size(self):
return len(self.sp_model)
def get_vocab(self):
vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
vocab.update(self.added_tokens_encoder)
return vocab
def _tokenize(self, text: str) -> List[str]:
return self.sp_model.encode(text, out_type=str)
def _convert_token_to_id(self, token):
"""Converts a token (str) in an id using the vocab."""
return self.sp_model.PieceToId(token)
def _convert_id_to_token(self, index):
"""Converts an index (integer) in a token (str) using the vocab."""
return self.sp_model.IdToPiece(index)
# Copied from transformers.models.albert.tokenization_albert.AlbertTokenizer.convert_tokens_to_string
def convert_tokens_to_string(self, tokens):
"""Converts a sequence of tokens (string) in a single string."""
current_sub_tokens = []
out_string = ""
prev_is_special = False
for token in tokens:
# make sure that special tokens are not decoded using sentencepiece model
if token in self.all_special_tokens:
if not prev_is_special:
out_string += " "
out_string += self.sp_model.decode(current_sub_tokens) + token
prev_is_special = True
current_sub_tokens = []
else:
current_sub_tokens.append(token)
prev_is_special = False
out_string += self.sp_model.decode(current_sub_tokens)
return out_string.strip()
def __getstate__(self):
state = self.__dict__.copy()
state["sp_model"] = None
return state
def __setstate__(self, d):
self.__dict__ = d
# for backward compatibility
if not hasattr(self, "sp_model_kwargs"):
self.sp_model_kwargs = {}
self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
self.sp_model.Load(self.vocab_file)
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
if not os.path.isdir(save_directory):
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
return
out_vocab_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
)
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file) and os.path.isfile(self.vocab_file):
copyfile(self.vocab_file, out_vocab_file)
elif not os.path.isfile(self.vocab_file):
with open(out_vocab_file, "wb") as fi:
content_spiece_model = self.sp_model.serialized_model_proto()
fi.write(content_spiece_model)
return (out_vocab_file,)
__all__ = ["BarthezTokenizer"]
| transformers/src/transformers/models/barthez/tokenization_barthez.py/0 | {
"file_path": "transformers/src/transformers/models/barthez/tokenization_barthez.py",
"repo_id": "transformers",
"token_count": 5091
} |
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
This script converts a lm-head checkpoint from the "Token Dropping" implementation into a PyTorch-compatible BERT
model. The official implementation of "Token Dropping" can be found in the TensorFlow Models repository:
https://github.com/tensorflow/models/tree/master/official/projects/token_dropping
"""
import argparse
import tensorflow as tf
import torch
from transformers import BertConfig, BertForMaskedLM
from transformers.models.bert.modeling_bert import (
BertIntermediate,
BertLayer,
BertOutput,
BertPooler,
BertSelfAttention,
BertSelfOutput,
)
from transformers.utils import logging
logging.set_verbosity_info()
def convert_checkpoint_to_pytorch(tf_checkpoint_path: str, config_path: str, pytorch_dump_path: str):
def get_masked_lm_array(name: str):
full_name = f"masked_lm/{name}/.ATTRIBUTES/VARIABLE_VALUE"
array = tf.train.load_variable(tf_checkpoint_path, full_name)
if "kernel" in name:
array = array.transpose()
return torch.from_numpy(array)
def get_encoder_array(name: str):
full_name = f"encoder/{name}/.ATTRIBUTES/VARIABLE_VALUE"
array = tf.train.load_variable(tf_checkpoint_path, full_name)
if "kernel" in name:
array = array.transpose()
return torch.from_numpy(array)
def get_encoder_layer_array(layer_index: int, name: str):
full_name = f"encoder/_transformer_layers/{layer_index}/{name}/.ATTRIBUTES/VARIABLE_VALUE"
array = tf.train.load_variable(tf_checkpoint_path, full_name)
if "kernel" in name:
array = array.transpose()
return torch.from_numpy(array)
def get_encoder_attention_layer_array(layer_index: int, name: str, orginal_shape):
full_name = f"encoder/_transformer_layers/{layer_index}/_attention_layer/{name}/.ATTRIBUTES/VARIABLE_VALUE"
array = tf.train.load_variable(tf_checkpoint_path, full_name)
array = array.reshape(orginal_shape)
if "kernel" in name:
array = array.transpose()
return torch.from_numpy(array)
print(f"Loading model based on config from {config_path}...")
config = BertConfig.from_json_file(config_path)
model = BertForMaskedLM(config)
# Layers
for layer_index in range(0, config.num_hidden_layers):
layer: BertLayer = model.bert.encoder.layer[layer_index]
# Self-attention
self_attn: BertSelfAttention = layer.attention.self
self_attn.query.weight.data = get_encoder_attention_layer_array(
layer_index, "_query_dense/kernel", self_attn.query.weight.data.shape
)
self_attn.query.bias.data = get_encoder_attention_layer_array(
layer_index, "_query_dense/bias", self_attn.query.bias.data.shape
)
self_attn.key.weight.data = get_encoder_attention_layer_array(
layer_index, "_key_dense/kernel", self_attn.key.weight.data.shape
)
self_attn.key.bias.data = get_encoder_attention_layer_array(
layer_index, "_key_dense/bias", self_attn.key.bias.data.shape
)
self_attn.value.weight.data = get_encoder_attention_layer_array(
layer_index, "_value_dense/kernel", self_attn.value.weight.data.shape
)
self_attn.value.bias.data = get_encoder_attention_layer_array(
layer_index, "_value_dense/bias", self_attn.value.bias.data.shape
)
# Self-attention Output
self_output: BertSelfOutput = layer.attention.output
self_output.dense.weight.data = get_encoder_attention_layer_array(
layer_index, "_output_dense/kernel", self_output.dense.weight.data.shape
)
self_output.dense.bias.data = get_encoder_attention_layer_array(
layer_index, "_output_dense/bias", self_output.dense.bias.data.shape
)
self_output.LayerNorm.weight.data = get_encoder_layer_array(layer_index, "_attention_layer_norm/gamma")
self_output.LayerNorm.bias.data = get_encoder_layer_array(layer_index, "_attention_layer_norm/beta")
# Intermediate
intermediate: BertIntermediate = layer.intermediate
intermediate.dense.weight.data = get_encoder_layer_array(layer_index, "_intermediate_dense/kernel")
intermediate.dense.bias.data = get_encoder_layer_array(layer_index, "_intermediate_dense/bias")
# Output
bert_output: BertOutput = layer.output
bert_output.dense.weight.data = get_encoder_layer_array(layer_index, "_output_dense/kernel")
bert_output.dense.bias.data = get_encoder_layer_array(layer_index, "_output_dense/bias")
bert_output.LayerNorm.weight.data = get_encoder_layer_array(layer_index, "_output_layer_norm/gamma")
bert_output.LayerNorm.bias.data = get_encoder_layer_array(layer_index, "_output_layer_norm/beta")
# Embeddings
model.bert.embeddings.position_embeddings.weight.data = get_encoder_array("_position_embedding_layer/embeddings")
model.bert.embeddings.token_type_embeddings.weight.data = get_encoder_array("_type_embedding_layer/embeddings")
model.bert.embeddings.LayerNorm.weight.data = get_encoder_array("_embedding_norm_layer/gamma")
model.bert.embeddings.LayerNorm.bias.data = get_encoder_array("_embedding_norm_layer/beta")
# LM Head
lm_head = model.cls.predictions.transform
lm_head.dense.weight.data = get_masked_lm_array("dense/kernel")
lm_head.dense.bias.data = get_masked_lm_array("dense/bias")
lm_head.LayerNorm.weight.data = get_masked_lm_array("layer_norm/gamma")
lm_head.LayerNorm.bias.data = get_masked_lm_array("layer_norm/beta")
model.bert.embeddings.word_embeddings.weight.data = get_masked_lm_array("embedding_table")
# Pooling
model.bert.pooler = BertPooler(config=config)
model.bert.pooler.dense.weight.data: BertPooler = get_encoder_array("_pooler_layer/kernel")
model.bert.pooler.dense.bias.data: BertPooler = get_encoder_array("_pooler_layer/bias")
# Export final model
model.save_pretrained(pytorch_dump_path)
# Integration test - should load without any errors ;)
new_model = BertForMaskedLM.from_pretrained(pytorch_dump_path)
print(new_model.eval())
print("Model conversion was done sucessfully!")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--tf_checkpoint_path", type=str, required=True, help="Path to the TensorFlow Token Dropping checkpoint path."
)
parser.add_argument(
"--bert_config_file",
type=str,
required=True,
help="The config json file corresponding to the BERT model. This specifies the model architecture.",
)
parser.add_argument(
"--pytorch_dump_path",
type=str,
required=True,
help="Path to the output PyTorch model.",
)
args = parser.parse_args()
convert_checkpoint_to_pytorch(args.tf_checkpoint_path, args.bert_config_file, args.pytorch_dump_path)
| transformers/src/transformers/models/bert/convert_bert_token_dropping_original_tf2_checkpoint_to_pytorch.py/0 | {
"file_path": "transformers/src/transformers/models/bert/convert_bert_token_dropping_original_tf2_checkpoint_to_pytorch.py",
"repo_id": "transformers",
"token_count": 3033
} |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""BiT model configuration"""
from ...configuration_utils import PretrainedConfig
from ...utils import logging
from ...utils.backbone_utils import BackboneConfigMixin, get_aligned_output_features_output_indices
logger = logging.get_logger(__name__)
class BitConfig(BackboneConfigMixin, PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`BitModel`]. It is used to instantiate an BiT
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the BiT
[google/bit-50](https://huggingface.co/google/bit-50) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
num_channels (`int`, *optional*, defaults to 3):
The number of input channels.
embedding_size (`int`, *optional*, defaults to 64):
Dimensionality (hidden size) for the embedding layer.
hidden_sizes (`List[int]`, *optional*, defaults to `[256, 512, 1024, 2048]`):
Dimensionality (hidden size) at each stage.
depths (`List[int]`, *optional*, defaults to `[3, 4, 6, 3]`):
Depth (number of layers) for each stage.
layer_type (`str`, *optional*, defaults to `"preactivation"`):
The layer to use, it can be either `"preactivation"` or `"bottleneck"`.
hidden_act (`str`, *optional*, defaults to `"relu"`):
The non-linear activation function in each block. If string, `"gelu"`, `"relu"`, `"selu"` and `"gelu_new"`
are supported.
global_padding (`str`, *optional*):
Padding strategy to use for the convolutional layers. Can be either `"valid"`, `"same"`, or `None`.
num_groups (`int`, *optional*, defaults to 32):
Number of groups used for the `BitGroupNormActivation` layers.
drop_path_rate (`float`, *optional*, defaults to 0.0):
The drop path rate for the stochastic depth.
embedding_dynamic_padding (`bool`, *optional*, defaults to `False`):
Whether or not to make use of dynamic padding for the embedding layer.
output_stride (`int`, *optional*, defaults to 32):
The output stride of the model.
width_factor (`int`, *optional*, defaults to 1):
The width factor for the model.
out_features (`List[str]`, *optional*):
If used as backbone, list of features to output. Can be any of `"stem"`, `"stage1"`, `"stage2"`, etc.
(depending on how many stages the model has). If unset and `out_indices` is set, will default to the
corresponding stages. If unset and `out_indices` is unset, will default to the last stage. Must be in the
same order as defined in the `stage_names` attribute.
out_indices (`List[int]`, *optional*):
If used as backbone, list of indices of features to output. Can be any of 0, 1, 2, etc. (depending on how
many stages the model has). If unset and `out_features` is set, will default to the corresponding stages.
If unset and `out_features` is unset, will default to the last stage. Must be in the
same order as defined in the `stage_names` attribute.
Example:
```python
>>> from transformers import BitConfig, BitModel
>>> # Initializing a BiT bit-50 style configuration
>>> configuration = BitConfig()
>>> # Initializing a model (with random weights) from the bit-50 style configuration
>>> model = BitModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```
"""
model_type = "bit"
layer_types = ["preactivation", "bottleneck"]
supported_padding = ["SAME", "VALID"]
def __init__(
self,
num_channels=3,
embedding_size=64,
hidden_sizes=[256, 512, 1024, 2048],
depths=[3, 4, 6, 3],
layer_type="preactivation",
hidden_act="relu",
global_padding=None,
num_groups=32,
drop_path_rate=0.0,
embedding_dynamic_padding=False,
output_stride=32,
width_factor=1,
out_features=None,
out_indices=None,
**kwargs,
):
super().__init__(**kwargs)
if layer_type not in self.layer_types:
raise ValueError(f"layer_type={layer_type} is not one of {','.join(self.layer_types)}")
if global_padding is not None:
if global_padding.upper() in self.supported_padding:
global_padding = global_padding.upper()
else:
raise ValueError(f"Padding strategy {global_padding} not supported")
self.num_channels = num_channels
self.embedding_size = embedding_size
self.hidden_sizes = hidden_sizes
self.depths = depths
self.layer_type = layer_type
self.hidden_act = hidden_act
self.global_padding = global_padding
self.num_groups = num_groups
self.drop_path_rate = drop_path_rate
self.embedding_dynamic_padding = embedding_dynamic_padding
self.output_stride = output_stride
self.width_factor = width_factor
self.stage_names = ["stem"] + [f"stage{idx}" for idx in range(1, len(depths) + 1)]
self._out_features, self._out_indices = get_aligned_output_features_output_indices(
out_features=out_features, out_indices=out_indices, stage_names=self.stage_names
)
__all__ = ["BitConfig"]
| transformers/src/transformers/models/bit/configuration_bit.py/0 | {
"file_path": "transformers/src/transformers/models/bit/configuration_bit.py",
"repo_id": "transformers",
"token_count": 2362
} |
# coding=utf-8
# Copyright 2023-present NAVER Corp, The Microsoft Research Asia LayoutLM Team Authors and the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch Bros model."""
import math
from dataclasses import dataclass
from typing import List, Optional, Tuple, Union
import torch
import torch.utils.checkpoint
from torch import nn
from torch.nn import CrossEntropyLoss
from ...activations import ACT2FN
from ...modeling_outputs import (
BaseModelOutputWithPastAndCrossAttentions,
BaseModelOutputWithPoolingAndCrossAttentions,
TokenClassifierOutput,
)
from ...modeling_utils import PreTrainedModel
from ...pytorch_utils import apply_chunking_to_forward, find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import (
ModelOutput,
add_start_docstrings,
add_start_docstrings_to_model_forward,
logging,
replace_return_docstrings,
)
from .configuration_bros import BrosConfig
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "jinho8345/bros-base-uncased"
_CONFIG_FOR_DOC = "BrosConfig"
BROS_START_DOCSTRING = r"""
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`BrosConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
BROS_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`BrosProcessor`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
bbox ('torch.FloatTensor' of shape '(batch_size, num_boxes, 4)'):
Bounding box coordinates for each token in the input sequence. Each bounding box is a list of four values
(x1, y1, x2, y2), where (x1, y1) is the top left corner, and (x2, y2) is the bottom right corner of the
bounding box.
attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
bbox_first_token_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
Mask to indicate the first token of each bounding box. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~file_utils.ModelOutput`] instead of a plain tuple.
"""
@dataclass
class BrosSpadeOutput(ModelOutput):
"""
Base class for outputs of token classification models.
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided) :
Classification loss.
initial_token_logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.num_labels)`):
Classification scores for entity initial tokens (before SoftMax).
subsequent_token_logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, sequence_length+1)`):
Classification scores for entity sequence tokens (before SoftMax).
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
loss: Optional[torch.FloatTensor] = None
initial_token_logits: torch.FloatTensor = None
subsequent_token_logits: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
class BrosPositionalEmbedding1D(nn.Module):
# Reference: https://github.com/kimiyoung/transformer-xl/blob/master/pytorch/mem_transformer.py#L15
def __init__(self, config):
super(BrosPositionalEmbedding1D, self).__init__()
self.dim_bbox_sinusoid_emb_1d = config.dim_bbox_sinusoid_emb_1d
inv_freq = 1 / (
10000 ** (torch.arange(0.0, self.dim_bbox_sinusoid_emb_1d, 2.0) / self.dim_bbox_sinusoid_emb_1d)
)
self.register_buffer("inv_freq", inv_freq)
def forward(self, pos_seq: torch.Tensor) -> torch.Tensor:
seq_size = pos_seq.size()
b1, b2, b3 = seq_size
sinusoid_inp = pos_seq.view(b1, b2, b3, 1) * self.inv_freq.view(1, 1, 1, self.dim_bbox_sinusoid_emb_1d // 2)
pos_emb = torch.cat([sinusoid_inp.sin(), sinusoid_inp.cos()], dim=-1)
return pos_emb
class BrosPositionalEmbedding2D(nn.Module):
def __init__(self, config):
super(BrosPositionalEmbedding2D, self).__init__()
self.dim_bbox = config.dim_bbox
self.x_pos_emb = BrosPositionalEmbedding1D(config)
self.y_pos_emb = BrosPositionalEmbedding1D(config)
def forward(self, bbox: torch.Tensor) -> torch.Tensor:
stack = []
for i in range(self.dim_bbox):
if i % 2 == 0:
stack.append(self.x_pos_emb(bbox[..., i]))
else:
stack.append(self.y_pos_emb(bbox[..., i]))
bbox_pos_emb = torch.cat(stack, dim=-1)
return bbox_pos_emb
class BrosBboxEmbeddings(nn.Module):
def __init__(self, config):
super(BrosBboxEmbeddings, self).__init__()
self.bbox_sinusoid_emb = BrosPositionalEmbedding2D(config)
self.bbox_projection = nn.Linear(config.dim_bbox_sinusoid_emb_2d, config.dim_bbox_projection, bias=False)
def forward(self, bbox: torch.Tensor):
bbox_t = bbox.transpose(0, 1)
bbox_pos = bbox_t[None, :, :, :] - bbox_t[:, None, :, :]
bbox_pos_emb = self.bbox_sinusoid_emb(bbox_pos)
bbox_pos_emb = self.bbox_projection(bbox_pos_emb)
return bbox_pos_emb
class BrosTextEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
self.register_buffer(
"token_type_ids",
torch.zeros(
self.position_ids.size(),
dtype=torch.long,
device=self.position_ids.device,
),
persistent=False,
)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
past_key_values_length: int = 0,
) -> torch.Tensor:
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
if position_ids is None:
position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]
if token_type_ids is None:
if hasattr(self, "token_type_ids"):
buffered_token_type_ids = self.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + token_type_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
class BrosSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
f"heads ({config.num_attention_heads})"
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
self.is_decoder = config.is_decoder
def transpose_for_scores(self, x: torch.Tensor):
new_x_shape = x.size()[:-1] + (
self.num_attention_heads,
self.attention_head_size,
)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states: torch.Tensor,
bbox_pos_emb: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
output_attentions: Optional[torch.Tensor] = False,
) -> Tuple[torch.Tensor]:
mixed_query_layer = self.query(hidden_states)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
is_cross_attention = encoder_hidden_states is not None
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_layer = past_key_value[0]
value_layer = past_key_value[1]
attention_mask = encoder_attention_mask
elif is_cross_attention:
key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
attention_mask = encoder_attention_mask
elif past_key_value is not None:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
else:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_layer, value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
seq_length = hidden_states.size()[1]
position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
if self.position_embedding_type == "relative_key":
relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores
elif self.position_embedding_type == "relative_key_query":
relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
# bbox positional encoding
batch_size, n_head, seq_length, d_head = query_layer.shape
bbox_pos_emb = bbox_pos_emb.view(seq_length, seq_length, batch_size, d_head)
bbox_pos_emb = bbox_pos_emb.permute([2, 0, 1, 3])
bbox_pos_scores = torch.einsum("bnid,bijd->bnij", (query_layer, bbox_pos_emb))
attention_scores = attention_scores + bbox_pos_scores
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BrosModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
if self.is_decoder:
outputs = outputs + (past_key_value,)
return outputs
# Copied from transformers.models.bert.modeling_bert.BertSelfOutput with Bert->Bros
class BrosSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
class BrosAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.self = BrosSelfAttention(config)
self.output = BrosSelfOutput(config)
self.pruned_heads = set()
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads,
self.self.num_attention_heads,
self.self.attention_head_size,
self.pruned_heads,
)
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states: torch.Tensor,
bbox_pos_emb: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor]:
self_outputs = self.self(
hidden_states=hidden_states,
bbox_pos_emb=bbox_pos_emb,
attention_mask=attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_value=past_key_value,
output_attentions=output_attentions,
)
attention_output = self.output(self_outputs[0], hidden_states)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
# Copied from transformers.models.bert.modeling_bert.BertIntermediate with Bert->Bros
class BrosIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
class BrosOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
class BrosLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = BrosAttention(config)
self.is_decoder = config.is_decoder
self.add_cross_attention = config.add_cross_attention
if self.add_cross_attention:
if not self.is_decoder:
raise Exception(f"{self} should be used as a decoder model if cross attention is added")
self.crossattention = BrosAttention(config)
self.intermediate = BrosIntermediate(config)
self.output = BrosOutput(config)
def forward(
self,
hidden_states: torch.Tensor,
bbox_pos_emb: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor]:
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
self_attention_outputs = self.attention(
hidden_states,
bbox_pos_emb=bbox_pos_emb,
attention_mask=attention_mask,
head_mask=head_mask,
output_attentions=output_attentions,
past_key_value=self_attn_past_key_value,
)
attention_output = self_attention_outputs[0]
# if decoder, the last output is tuple of self-attn cache
if self.is_decoder:
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
else:
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
cross_attn_present_key_value = None
if self.is_decoder and encoder_hidden_states is not None:
if hasattr(self, "crossattention"):
raise Exception(
f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers by setting `config.add_cross_attention=True`"
)
# cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
cross_attention_outputs = self.crossattention(
attention_output,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
cross_attn_past_key_value,
output_attentions,
)
attention_output = cross_attention_outputs[0]
outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
# add cross-attn cache to positions 3,4 of present_key_value tuple
cross_attn_present_key_value = cross_attention_outputs[-1]
present_key_value = present_key_value + cross_attn_present_key_value
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk,
self.chunk_size_feed_forward,
self.seq_len_dim,
attention_output,
)
outputs = (layer_output,) + outputs
# if decoder, return the attn key/values as the last output
if self.is_decoder:
outputs = outputs + (present_key_value,)
return outputs
def feed_forward_chunk(self, attention_output):
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output
class BrosEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.layer = nn.ModuleList([BrosLayer(config) for _ in range(config.num_hidden_layers)])
def forward(
self,
hidden_states: torch.Tensor,
bbox_pos_emb: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = False,
output_hidden_states: Optional[bool] = False,
return_dict: Optional[bool] = True,
) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPastAndCrossAttentions]:
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
next_decoder_cache = () if use_cache else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
past_key_value = past_key_values[i] if past_key_values is not None else None
if getattr(self.config, "gradient_checkpointing", False) and self.training:
if use_cache:
logger.warning(
"`use_cache=True` is incompatible with `config.gradient_checkpointing=True`. Setting "
"`use_cache=False`..."
)
use_cache = False
layer_outputs = self._gradient_checkpointing_func(
layer_module.__call__,
hidden_states,
bbox_pos_emb,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
output_attentions,
)
else:
layer_outputs = layer_module(
hidden_states=hidden_states,
bbox_pos_emb=bbox_pos_emb,
attention_mask=attention_mask,
head_mask=layer_head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_value=past_key_value,
output_attentions=output_attentions,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[-1],)
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if self.config.add_cross_attention:
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [
hidden_states,
next_decoder_cache,
all_hidden_states,
all_self_attentions,
all_cross_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
# Copied from transformers.models.bert.modeling_bert.BertPooler with Bert->Bros
class BrosPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
class BrosRelationExtractor(nn.Module):
def __init__(self, config):
super().__init__()
self.n_relations = config.n_relations
self.backbone_hidden_size = config.hidden_size
self.head_hidden_size = config.hidden_size
self.classifier_dropout_prob = config.classifier_dropout_prob
self.drop = nn.Dropout(self.classifier_dropout_prob)
self.query = nn.Linear(self.backbone_hidden_size, self.n_relations * self.head_hidden_size)
self.key = nn.Linear(self.backbone_hidden_size, self.n_relations * self.head_hidden_size)
self.dummy_node = nn.Parameter(torch.zeros(1, self.backbone_hidden_size))
def forward(self, query_layer: torch.Tensor, key_layer: torch.Tensor):
query_layer = self.query(self.drop(query_layer))
dummy_vec = self.dummy_node.unsqueeze(0).repeat(1, key_layer.size(1), 1)
key_layer = torch.cat([key_layer, dummy_vec], axis=0)
key_layer = self.key(self.drop(key_layer))
query_layer = query_layer.view(
query_layer.size(0), query_layer.size(1), self.n_relations, self.head_hidden_size
)
key_layer = key_layer.view(key_layer.size(0), key_layer.size(1), self.n_relations, self.head_hidden_size)
relation_score = torch.matmul(
query_layer.permute(2, 1, 0, 3), key_layer.permute(2, 1, 3, 0)
) # equivalent to torch.einsum("ibnd,jbnd->nbij", (query_layer, key_layer))
return relation_score
class BrosPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = BrosConfig
base_model_prefix = "bros"
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, nn.Linear):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
@add_start_docstrings(
"The bare Bros Model transformer outputting raw hidden-states without any specific head on top.",
BROS_START_DOCSTRING,
)
class BrosModel(BrosPreTrainedModel):
def __init__(self, config, add_pooling_layer=True):
super().__init__(config)
self.config = config
self.embeddings = BrosTextEmbeddings(config)
self.bbox_embeddings = BrosBboxEmbeddings(config)
self.encoder = BrosEncoder(config)
self.pooler = BrosPooler(config) if add_pooling_layer else None
self.init_weights()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward(BROS_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=BaseModelOutputWithPoolingAndCrossAttentions, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
bbox: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPoolingAndCrossAttentions]:
r"""
Returns:
Examples:
```python
>>> import torch
>>> from transformers import BrosProcessor, BrosModel
>>> processor = BrosProcessor.from_pretrained("jinho8345/bros-base-uncased")
>>> model = BrosModel.from_pretrained("jinho8345/bros-base-uncased")
>>> encoding = processor("Hello, my dog is cute", add_special_tokens=False, return_tensors="pt")
>>> bbox = torch.tensor([[[0, 0, 1, 1]]]).repeat(1, encoding["input_ids"].shape[-1], 1)
>>> encoding["bbox"] = bbox
>>> outputs = model(**encoding)
>>> last_hidden_states = outputs.last_hidden_state
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if self.config.is_decoder:
use_cache = use_cache if use_cache is not None else self.config.use_cache
else:
use_cache = False
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if bbox is None:
raise ValueError("You have to specify bbox")
batch_size, seq_length = input_shape
device = input_ids.device if input_ids is not None else inputs_embeds.device
# past_key_values_length
past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
if attention_mask is None:
attention_mask = torch.ones(input_shape, device=device)
if token_type_ids is None:
if hasattr(self.embeddings, "token_type_ids"):
buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape, device)
# If a 2D or 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder and encoder_hidden_states is not None:
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
else:
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
token_type_ids=token_type_ids,
inputs_embeds=inputs_embeds,
past_key_values_length=past_key_values_length,
)
# if bbox has 2 points (4 float tensors) per token, convert it to 4 points (8 float tensors) per token
if bbox.shape[-1] == 4:
bbox = bbox[:, :, [0, 1, 2, 1, 2, 3, 0, 3]]
scaled_bbox = bbox * self.config.bbox_scale
bbox_position_embeddings = self.bbox_embeddings(scaled_bbox)
encoder_outputs = self.encoder(
embedding_output,
bbox_pos_emb=bbox_position_embeddings,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
@add_start_docstrings(
"""
Bros Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
Named-Entity-Recognition (NER) tasks.
""",
BROS_START_DOCSTRING,
)
class BrosForTokenClassification(BrosPreTrainedModel):
_keys_to_ignore_on_load_unexpected = [r"pooler"]
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.bros = BrosModel(config)
classifier_dropout = (
config.classifier_dropout if hasattr(config, "classifier_dropout") else config.hidden_dropout_prob
)
self.dropout = nn.Dropout(classifier_dropout)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
@add_start_docstrings_to_model_forward(BROS_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=TokenClassifierOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
bbox: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
bbox_first_token_mask: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], TokenClassifierOutput]:
r"""
Returns:
Examples:
```python
>>> import torch
>>> from transformers import BrosProcessor, BrosForTokenClassification
>>> processor = BrosProcessor.from_pretrained("jinho8345/bros-base-uncased")
>>> model = BrosForTokenClassification.from_pretrained("jinho8345/bros-base-uncased")
>>> encoding = processor("Hello, my dog is cute", add_special_tokens=False, return_tensors="pt")
>>> bbox = torch.tensor([[[0, 0, 1, 1]]]).repeat(1, encoding["input_ids"].shape[-1], 1)
>>> encoding["bbox"] = bbox
>>> outputs = model(**encoding)
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.bros(
input_ids,
bbox=bbox,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
if bbox_first_token_mask is not None:
bbox_first_token_mask = bbox_first_token_mask.view(-1)
loss = loss_fct(
logits.view(-1, self.num_labels)[bbox_first_token_mask], labels.view(-1)[bbox_first_token_mask]
)
else:
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
Bros Model with a token classification head on top (initial_token_layers and subsequent_token_layer on top of the
hidden-states output) e.g. for Named-Entity-Recognition (NER) tasks. The initial_token_classifier is used to
predict the first token of each entity, and the subsequent_token_classifier is used to predict the subsequent
tokens within an entity. Compared to BrosForTokenClassification, this model is more robust to serialization errors
since it predicts next token from one token.
""",
BROS_START_DOCSTRING,
)
class BrosSpadeEEForTokenClassification(BrosPreTrainedModel):
_keys_to_ignore_on_load_unexpected = [r"pooler"]
def __init__(self, config):
super().__init__(config)
self.config = config
self.num_labels = config.num_labels
self.n_relations = config.n_relations
self.backbone_hidden_size = config.hidden_size
self.bros = BrosModel(config)
classifier_dropout = (
config.classifier_dropout if hasattr(config, "classifier_dropout") else config.hidden_dropout_prob
)
# Initial token classification for Entity Extraction (NER)
self.initial_token_classifier = nn.Sequential(
nn.Dropout(classifier_dropout),
nn.Linear(config.hidden_size, config.hidden_size),
nn.Dropout(classifier_dropout),
nn.Linear(config.hidden_size, config.num_labels),
)
# Subsequent token classification for Entity Extraction (NER)
self.subsequent_token_classifier = BrosRelationExtractor(config)
self.init_weights()
@add_start_docstrings_to_model_forward(BROS_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=BrosSpadeOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
bbox: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
bbox_first_token_mask: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
initial_token_labels: Optional[torch.Tensor] = None,
subsequent_token_labels: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], BrosSpadeOutput]:
r"""
Returns:
Examples:
```python
>>> import torch
>>> from transformers import BrosProcessor, BrosSpadeEEForTokenClassification
>>> processor = BrosProcessor.from_pretrained("jinho8345/bros-base-uncased")
>>> model = BrosSpadeEEForTokenClassification.from_pretrained("jinho8345/bros-base-uncased")
>>> encoding = processor("Hello, my dog is cute", add_special_tokens=False, return_tensors="pt")
>>> bbox = torch.tensor([[[0, 0, 1, 1]]]).repeat(1, encoding["input_ids"].shape[-1], 1)
>>> encoding["bbox"] = bbox
>>> outputs = model(**encoding)
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.bros(
input_ids=input_ids,
bbox=bbox,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
last_hidden_states = outputs[0]
last_hidden_states = last_hidden_states.transpose(0, 1).contiguous()
initial_token_logits = self.initial_token_classifier(last_hidden_states).transpose(0, 1).contiguous()
subsequent_token_logits = self.subsequent_token_classifier(last_hidden_states, last_hidden_states).squeeze(0)
# make subsequent token (sequence token classification) mask
inv_attention_mask = 1 - attention_mask
batch_size, max_seq_length = inv_attention_mask.shape
device = inv_attention_mask.device
invalid_token_mask = torch.cat([inv_attention_mask, torch.zeros([batch_size, 1]).to(device)], axis=1).bool()
subsequent_token_logits = subsequent_token_logits.masked_fill(
invalid_token_mask[:, None, :], torch.finfo(subsequent_token_logits.dtype).min
)
self_token_mask = torch.eye(max_seq_length, max_seq_length + 1).to(device).bool()
subsequent_token_logits = subsequent_token_logits.masked_fill(
self_token_mask[None, :, :], torch.finfo(subsequent_token_logits.dtype).min
)
subsequent_token_mask = attention_mask.view(-1).bool()
loss = None
if initial_token_labels is not None and subsequent_token_labels is not None:
loss_fct = CrossEntropyLoss()
# get initial token loss
initial_token_labels = initial_token_labels.view(-1)
if bbox_first_token_mask is not None:
bbox_first_token_mask = bbox_first_token_mask.view(-1)
initial_token_loss = loss_fct(
initial_token_logits.view(-1, self.num_labels)[bbox_first_token_mask],
initial_token_labels[bbox_first_token_mask],
)
else:
initial_token_loss = loss_fct(initial_token_logits.view(-1, self.num_labels), initial_token_labels)
subsequent_token_labels = subsequent_token_labels.view(-1)
subsequent_token_loss = loss_fct(
subsequent_token_logits.view(-1, max_seq_length + 1)[subsequent_token_mask],
subsequent_token_labels[subsequent_token_mask],
)
loss = initial_token_loss + subsequent_token_loss
if not return_dict:
output = (initial_token_logits, subsequent_token_logits) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return BrosSpadeOutput(
loss=loss,
initial_token_logits=initial_token_logits,
subsequent_token_logits=subsequent_token_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
Bros Model with a token classification head on top (a entity_linker layer on top of the hidden-states output) e.g.
for Entity-Linking. The entity_linker is used to predict intra-entity links (one entity to another entity).
""",
BROS_START_DOCSTRING,
)
class BrosSpadeELForTokenClassification(BrosPreTrainedModel):
_keys_to_ignore_on_load_unexpected = [r"pooler"]
def __init__(self, config):
super().__init__(config)
self.config = config
self.num_labels = config.num_labels
self.n_relations = config.n_relations
self.backbone_hidden_size = config.hidden_size
self.bros = BrosModel(config)
(config.classifier_dropout if hasattr(config, "classifier_dropout") else config.hidden_dropout_prob)
self.entity_linker = BrosRelationExtractor(config)
self.init_weights()
@add_start_docstrings_to_model_forward(BROS_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=TokenClassifierOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
bbox: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
bbox_first_token_mask: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], TokenClassifierOutput]:
r"""
Returns:
Examples:
```python
>>> import torch
>>> from transformers import BrosProcessor, BrosSpadeELForTokenClassification
>>> processor = BrosProcessor.from_pretrained("jinho8345/bros-base-uncased")
>>> model = BrosSpadeELForTokenClassification.from_pretrained("jinho8345/bros-base-uncased")
>>> encoding = processor("Hello, my dog is cute", add_special_tokens=False, return_tensors="pt")
>>> bbox = torch.tensor([[[0, 0, 1, 1]]]).repeat(1, encoding["input_ids"].shape[-1], 1)
>>> encoding["bbox"] = bbox
>>> outputs = model(**encoding)
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.bros(
input_ids=input_ids,
bbox=bbox,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
last_hidden_states = outputs[0]
last_hidden_states = last_hidden_states.transpose(0, 1).contiguous()
logits = self.entity_linker(last_hidden_states, last_hidden_states).squeeze(0)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
batch_size, max_seq_length = attention_mask.shape
device = attention_mask.device
self_token_mask = torch.eye(max_seq_length, max_seq_length + 1).to(device).bool()
mask = bbox_first_token_mask.view(-1)
bbox_first_token_mask = torch.cat(
[
~bbox_first_token_mask,
torch.zeros([batch_size, 1], dtype=torch.bool).to(device),
],
axis=1,
)
logits = logits.masked_fill(bbox_first_token_mask[:, None, :], torch.finfo(logits.dtype).min)
logits = logits.masked_fill(self_token_mask[None, :, :], torch.finfo(logits.dtype).min)
loss = loss_fct(logits.view(-1, max_seq_length + 1)[mask], labels.view(-1)[mask])
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
__all__ = [
"BrosPreTrainedModel",
"BrosModel",
"BrosForTokenClassification",
"BrosSpadeEEForTokenClassification",
"BrosSpadeELForTokenClassification",
]
| transformers/src/transformers/models/bros/modeling_bros.py/0 | {
"file_path": "transformers/src/transformers/models/bros/modeling_bros.py",
"repo_id": "transformers",
"token_count": 25097
} |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Feature extractor class for CLAP."""
import copy
from typing import Any, Dict, List, Optional, Union
import numpy as np
import torch
from ...audio_utils import mel_filter_bank, spectrogram, window_function
from ...feature_extraction_sequence_utils import SequenceFeatureExtractor
from ...feature_extraction_utils import BatchFeature
from ...utils import TensorType, logging
logger = logging.get_logger(__name__)
class ClapFeatureExtractor(SequenceFeatureExtractor):
r"""
Constructs a CLAP feature extractor.
This feature extractor inherits from [`~feature_extraction_sequence_utils.SequenceFeatureExtractor`] which contains
most of the main methods. Users should refer to this superclass for more information regarding those methods.
This class extracts mel-filter bank features from raw speech using a custom numpy implementation of the *Short Time
Fourier Transform* (STFT) which should match pytorch's `torch.stft` equivalent.
Args:
feature_size (`int`, *optional*, defaults to 64):
The feature dimension of the extracted Mel spectrograms. This corresponds to the number of mel filters
(`n_mels`).
sampling_rate (`int`, *optional*, defaults to 48000):
The sampling rate at which the audio files should be digitalized expressed in hertz (Hz). This only serves
to warn users if the audio fed to the feature extractor does not have the same sampling rate.
hop_length (`int`,*optional*, defaults to 480):
Length of the overlaping windows for the STFT used to obtain the Mel Spectrogram. The audio will be split
in smaller `frames` with a step of `hop_length` between each frame.
max_length_s (`int`, *optional*, defaults to 10):
The maximum input length of the model in seconds. This is used to pad the audio.
fft_window_size (`int`, *optional*, defaults to 1024):
Size of the window (in samples) on which the Fourier transform is applied. This controls the frequency
resolution of the spectrogram. 400 means that the fourrier transform is computed on windows of 400 samples.
padding_value (`float`, *optional*, defaults to 0.0):
Padding value used to pad the audio. Should correspond to silences.
return_attention_mask (`bool`, *optional*, defaults to `False`):
Whether or not the model should return the attention masks coresponding to the input.
frequency_min (`float`, *optional*, defaults to 0):
The lowest frequency of interest. The STFT will not be computed for values below this.
frequency_max (`float`, *optional*, defaults to 14000):
The highest frequency of interest. The STFT will not be computed for values above this.
top_db (`float`, *optional*):
The highest decibel value used to convert the mel spectrogram to the log scale. For more details see the
`audio_utils.power_to_db` function
truncation (`str`, *optional*, defaults to `"fusion"`):
Truncation pattern for long audio inputs. Two patterns are available:
- `fusion` will use `_random_mel_fusion`, which stacks 3 random crops from the mel spectrogram and a
downsampled version of the entire mel spectrogram.
If `config.fusion` is set to True, shorter audios also need to to return 4 mels, which will just be a copy
of the original mel obtained from the padded audio.
- `rand_trunc` will select a random crop of the mel spectrogram.
padding (`str`, *optional*, defaults to `"repeatpad"`):
Padding pattern for shorter audio inputs. Three patterns were originally implemented:
- `repeatpad`: the audio is repeated, and then padded to fit the `max_length`.
- `repeat`: the audio is repeated and then cut to fit the `max_length`
- `pad`: the audio is padded.
"""
model_input_names = ["input_features", "is_longer"]
def __init__(
self,
feature_size=64,
sampling_rate=48_000,
hop_length=480,
max_length_s=10,
fft_window_size=1024,
padding_value=0.0,
return_attention_mask=False, # pad inputs to max length with silence token (zero) and no attention mask
frequency_min: float = 0,
frequency_max: float = 14_000,
top_db: int = None,
truncation: str = "fusion",
padding: str = "repeatpad",
**kwargs,
):
super().__init__(
feature_size=feature_size,
sampling_rate=sampling_rate,
padding_value=padding_value,
return_attention_mask=return_attention_mask,
**kwargs,
)
self.top_db = top_db
self.truncation = truncation
self.padding = padding
self.fft_window_size = fft_window_size
self.nb_frequency_bins = (fft_window_size >> 1) + 1
self.hop_length = hop_length
self.max_length_s = max_length_s
self.nb_max_samples = max_length_s * sampling_rate
self.sampling_rate = sampling_rate
self.frequency_min = frequency_min
self.frequency_max = frequency_max
self.mel_filters = mel_filter_bank(
num_frequency_bins=self.nb_frequency_bins,
num_mel_filters=feature_size,
min_frequency=frequency_min,
max_frequency=frequency_max,
sampling_rate=sampling_rate,
norm=None,
mel_scale="htk",
)
self.mel_filters_slaney = mel_filter_bank(
num_frequency_bins=self.nb_frequency_bins,
num_mel_filters=feature_size,
min_frequency=frequency_min,
max_frequency=frequency_max,
sampling_rate=sampling_rate,
norm="slaney",
mel_scale="slaney",
)
def to_dict(self) -> Dict[str, Any]:
"""
Serializes this instance to a Python dictionary.
Returns:
`Dict[str, Any]`: Dictionary of all the attributes that make up this configuration instance, excpet for the
mel filter banks, which do not need to be saved or printed as they are too long.
"""
output = copy.deepcopy(self.__dict__)
output["feature_extractor_type"] = self.__class__.__name__
if "mel_filters" in output:
del output["mel_filters"]
if "mel_filters_slaney" in output:
del output["mel_filters_slaney"]
return output
def _np_extract_fbank_features(self, waveform: np.array, mel_filters: Optional[np.array] = None) -> np.ndarray:
"""
Compute the log-mel spectrogram of the provided `waveform` using the Hann window. In CLAP, two different filter
banks are used depending on the truncation pattern:
- `self.mel_filters`: they correspond to the default parameters of `torchaudio` which can be obtained from
calling `torchaudio.transforms.MelSpectrogram().mel_scale.fb`. These filters are used when `truncation`
is set to `"fusion"`.
- `self.mel_filteres_slaney` : they correspond to the default parameters of `librosa` which used
`librosa.filters.mel` when computing the mel spectrogram. These filters were only used in the original
implementation when the truncation mode is not `"fusion"`.
"""
log_mel_spectrogram = spectrogram(
waveform,
window_function(self.fft_window_size, "hann"),
frame_length=self.fft_window_size,
hop_length=self.hop_length,
power=2.0,
mel_filters=mel_filters,
log_mel="dB",
)
return log_mel_spectrogram.T
def _random_mel_fusion(self, mel, total_frames, chunk_frames):
ranges = np.array_split(list(range(0, total_frames - chunk_frames + 1)), 3)
if len(ranges[1]) == 0:
# if the audio is too short, we just use the first chunk
ranges[1] = [0]
if len(ranges[2]) == 0:
# if the audio is too short, we just use the first chunk
ranges[2] = [0]
# randomly choose index for each part
idx_front = np.random.choice(ranges[0])
idx_middle = np.random.choice(ranges[1])
idx_back = np.random.choice(ranges[2])
mel_chunk_front = mel[idx_front : idx_front + chunk_frames, :]
mel_chunk_middle = mel[idx_middle : idx_middle + chunk_frames, :]
mel_chunk_back = mel[idx_back : idx_back + chunk_frames, :]
mel = torch.tensor(mel[None, None, :])
mel_shrink = torch.nn.functional.interpolate(
mel, size=[chunk_frames, 64], mode="bilinear", align_corners=False
)
mel_shrink = mel_shrink[0][0].numpy()
mel_fusion = np.stack([mel_shrink, mel_chunk_front, mel_chunk_middle, mel_chunk_back], axis=0)
return mel_fusion
def _get_input_mel(self, waveform: np.array, max_length, truncation, padding) -> np.array:
"""
Extracts the mel spectrogram and prepares it for the mode based on the `truncation` and `padding` arguments.
Four different path are possible:
- `truncation="fusion"` and the length of the waveform is greater than the max length: the mel spectrogram
will be computed on the entire audio. 3 random crops and a dowsampled version of the full mel spectrogram
are then stacked together. They will later be used for `feature_fusion`.
- `truncation="rand_trunc"` and the length of the waveform is smaller than the max length: the audio is
padded based on `padding`.
- `truncation="fusion"` and the length of the waveform is smaller than the max length: the audio is padded
based on `padding`, and is repeated `4` times.
- `truncation="rand_trunc"` and the length of the waveform is greater than the max length: the mel
spectrogram will be computed on a random crop of the waveform.
"""
if waveform.shape[0] > max_length:
if truncation == "rand_trunc":
longer = True
# random crop to max_length (for compatibility) -> this should be handled by self.pad
overflow = len(waveform) - max_length
idx = np.random.randint(0, overflow + 1)
waveform = waveform[idx : idx + max_length]
input_mel = self._np_extract_fbank_features(waveform, self.mel_filters_slaney)[None, :]
elif truncation == "fusion":
mel = self._np_extract_fbank_features(waveform, self.mel_filters)
chunk_frames = max_length // self.hop_length + 1 # the +1 related to how the spectrogram is computed
total_frames = mel.shape[0]
if chunk_frames == total_frames:
# there is a corner case where the audio length is larger than max_length but smaller than max_length+hop_length.
# In this case, we just use the whole audio.
input_mel = np.stack([mel, mel, mel, mel], axis=0)
longer = False
else:
input_mel = self._random_mel_fusion(mel, total_frames, chunk_frames)
longer = True
else:
raise NotImplementedError(f"data_truncating {truncation} not implemented")
else:
longer = False
# only use repeat as a new possible value for padding. you repeat the audio before applying the usual max_length padding
if waveform.shape[0] < max_length:
if padding == "repeat":
n_repeat = int(max_length / len(waveform))
waveform = np.tile(waveform, n_repeat + 1)[:max_length]
if padding == "repeatpad":
n_repeat = int(max_length / len(waveform))
waveform = np.tile(waveform, n_repeat)
waveform = np.pad(waveform, (0, max_length - waveform.shape[0]), mode="constant", constant_values=0)
if truncation == "fusion":
input_mel = self._np_extract_fbank_features(waveform, self.mel_filters)
input_mel = np.stack([input_mel, input_mel, input_mel, input_mel], axis=0)
else:
input_mel = self._np_extract_fbank_features(waveform, self.mel_filters_slaney)[None, :]
return input_mel, longer
def __call__(
self,
raw_speech: Union[np.ndarray, List[float], List[np.ndarray], List[List[float]]],
truncation: str = None,
padding: Optional[str] = None,
max_length: Optional[int] = None,
sampling_rate: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
**kwargs,
) -> BatchFeature:
"""
Main method to featurize and prepare for the model one or several sequence(s).
Args:
raw_speech (`np.ndarray`, `List[float]`, `List[np.ndarray]`, `List[List[float]]`):
The sequence or batch of sequences to be padded. Each sequence can be a numpy array, a list of float
values, a list of numpy arrays or a list of list of float values. Must be mono channel audio, not
stereo, i.e. single float per timestep.
truncation (`str`, *optional*):
Truncation pattern for long audio inputs. Two patterns are available:
- `fusion` will use `_random_mel_fusion`, which stacks 3 random crops from the mel spectrogram and
a downsampled version of the entire mel spectrogram.
If `config.fusion` is set to True, shorter audios also need to to return 4 mels, which will just be a
copy of the original mel obtained from the padded audio.
- `rand_trunc` will select a random crop of the mel spectrogram.
padding (`str`, *optional*):
Padding pattern for shorter audio inputs. Three patterns were originally implemented:
- `repeatpad`: the audio is repeated, and then padded to fit the `max_length`.
- `repeat`: the audio is repeated and then cut to fit the `max_length`
- `pad`: the audio is padded.
return_tensors (`str` or [`~utils.TensorType`], *optional*):
If set, will return tensors instead of list of python integers. Acceptable values are:
- `'tf'`: Return TensorFlow `tf.constant` objects.
- `'pt'`: Return PyTorch `torch.np.array` objects.
- `'np'`: Return Numpy `np.ndarray` objects.
sampling_rate (`int`, *optional*):
The sampling rate at which the `raw_speech` input was sampled. It is strongly recommended to pass
`sampling_rate` at the forward call to prevent silent errors and allow automatic speech recognition
pipeline.
"""
truncation = truncation if truncation is not None else self.truncation
padding = padding if padding else self.padding
if sampling_rate is not None:
if sampling_rate != self.sampling_rate:
raise ValueError(
f"The model corresponding to this feature extractor: {self.__class__.__name__} was trained using a"
f" sampling rate of {self.sampling_rate}. Please make sure that the provided `raw_speech` input"
f" was sampled with {self.sampling_rate} and not {sampling_rate}."
)
else:
logger.warning(
"It is strongly recommended to pass the `sampling_rate` argument to this function. "
"Failing to do so can result in silent errors that might be hard to debug."
)
is_batched_numpy = isinstance(raw_speech, np.ndarray) and len(raw_speech.shape) > 1
if is_batched_numpy and len(raw_speech.shape) > 2:
raise ValueError(f"Only mono-channel audio is supported for input to {self}")
is_batched = is_batched_numpy or (
isinstance(raw_speech, (list, tuple)) and (isinstance(raw_speech[0], (np.ndarray, tuple, list)))
)
if is_batched:
raw_speech = [np.asarray(speech, dtype=np.float64) for speech in raw_speech]
elif not is_batched and not isinstance(raw_speech, np.ndarray):
raw_speech = np.asarray(raw_speech, dtype=np.float64)
elif isinstance(raw_speech, np.ndarray) and raw_speech.dtype is np.dtype(np.float64):
raw_speech = raw_speech.astype(np.float64)
# always return batch
if not is_batched:
raw_speech = [np.asarray(raw_speech)]
# convert to mel spectrogram, truncate and pad if needed.
padded_inputs = [
self._get_input_mel(waveform, max_length if max_length else self.nb_max_samples, truncation, padding)
for waveform in raw_speech
]
input_mel = []
is_longer = []
for mel, longer in padded_inputs:
input_mel.append(mel)
is_longer.append(longer)
if truncation == "fusion" and sum(is_longer) == 0:
# if no audio is longer than 10s, then randomly select one audio to be longer
rand_idx = np.random.randint(0, len(input_mel))
is_longer[rand_idx] = True
if isinstance(input_mel[0], List):
input_mel = [np.asarray(feature, dtype=np.float64) for feature in input_mel]
# is_longer is a list of bool
is_longer = [[longer] for longer in is_longer]
input_features = {"input_features": input_mel, "is_longer": is_longer}
input_features = BatchFeature(input_features)
if return_tensors is not None:
input_features = input_features.convert_to_tensors(return_tensors)
return input_features
__all__ = ["ClapFeatureExtractor"]
| transformers/src/transformers/models/clap/feature_extraction_clap.py/0 | {
"file_path": "transformers/src/transformers/models/clap/feature_extraction_clap.py",
"repo_id": "transformers",
"token_count": 7787
} |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""CLIPSeg model configuration"""
from ...configuration_utils import PretrainedConfig
from ...utils import logging
logger = logging.get_logger(__name__)
class CLIPSegTextConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`CLIPSegModel`]. It is used to instantiate an
CLIPSeg model according to the specified arguments, defining the model architecture. Instantiating a configuration
with the defaults will yield a similar configuration to that of the CLIPSeg
[CIDAS/clipseg-rd64](https://huggingface.co/CIDAS/clipseg-rd64) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 49408):
Vocabulary size of the CLIPSeg text model. Defines the number of different tokens that can be represented
by the `inputs_ids` passed when calling [`CLIPSegModel`].
hidden_size (`int`, *optional*, defaults to 512):
Dimensionality of the encoder layers and the pooler layer.
intermediate_size (`int`, *optional*, defaults to 2048):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 8):
Number of attention heads for each attention layer in the Transformer encoder.
max_position_embeddings (`int`, *optional*, defaults to 77):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` `"quick_gelu"` are supported.
layer_norm_eps (`float`, *optional*, defaults to 1e-05):
The epsilon used by the layer normalization layers.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
initializer_factor (`float`, *optional*, defaults to 1.0):
A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
testing).
pad_token_id (`int`, *optional*, defaults to 1):
Padding token id.
bos_token_id (`int`, *optional*, defaults to 49406):
Beginning of stream token id.
eos_token_id (`int`, *optional*, defaults to 49407):
End of stream token id.
Example:
```python
>>> from transformers import CLIPSegTextConfig, CLIPSegTextModel
>>> # Initializing a CLIPSegTextConfig with CIDAS/clipseg-rd64 style configuration
>>> configuration = CLIPSegTextConfig()
>>> # Initializing a CLIPSegTextModel (with random weights) from the CIDAS/clipseg-rd64 style configuration
>>> model = CLIPSegTextModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "clipseg_text_model"
base_config_key = "text_config"
def __init__(
self,
vocab_size=49408,
hidden_size=512,
intermediate_size=2048,
num_hidden_layers=12,
num_attention_heads=8,
max_position_embeddings=77,
hidden_act="quick_gelu",
layer_norm_eps=1e-5,
attention_dropout=0.0,
initializer_range=0.02,
initializer_factor=1.0,
pad_token_id=1,
bos_token_id=49406,
eos_token_id=49407,
**kwargs,
):
super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.max_position_embeddings = max_position_embeddings
self.layer_norm_eps = layer_norm_eps
self.hidden_act = hidden_act
self.initializer_range = initializer_range
self.initializer_factor = initializer_factor
self.attention_dropout = attention_dropout
class CLIPSegVisionConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`CLIPSegModel`]. It is used to instantiate an
CLIPSeg model according to the specified arguments, defining the model architecture. Instantiating a configuration
with the defaults will yield a similar configuration to that of the CLIPSeg
[CIDAS/clipseg-rd64](https://huggingface.co/CIDAS/clipseg-rd64) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
hidden_size (`int`, *optional*, defaults to 768):
Dimensionality of the encoder layers and the pooler layer.
intermediate_size (`int`, *optional*, defaults to 3072):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
num_channels (`int`, *optional*, defaults to 3):
The number of input channels.
image_size (`int`, *optional*, defaults to 224):
The size (resolution) of each image.
patch_size (`int`, *optional*, defaults to 32):
The size (resolution) of each patch.
hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` `"quick_gelu"` are supported.
layer_norm_eps (`float`, *optional*, defaults to 1e-05):
The epsilon used by the layer normalization layers.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
initializer_factor (`float`, *optional*, defaults to 1.0):
A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
testing).
Example:
```python
>>> from transformers import CLIPSegVisionConfig, CLIPSegVisionModel
>>> # Initializing a CLIPSegVisionConfig with CIDAS/clipseg-rd64 style configuration
>>> configuration = CLIPSegVisionConfig()
>>> # Initializing a CLIPSegVisionModel (with random weights) from the CIDAS/clipseg-rd64 style configuration
>>> model = CLIPSegVisionModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "clipseg_vision_model"
base_config_key = "vision_config"
def __init__(
self,
hidden_size=768,
intermediate_size=3072,
num_hidden_layers=12,
num_attention_heads=12,
num_channels=3,
image_size=224,
patch_size=32,
hidden_act="quick_gelu",
layer_norm_eps=1e-5,
attention_dropout=0.0,
initializer_range=0.02,
initializer_factor=1.0,
**kwargs,
):
super().__init__(**kwargs)
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.num_channels = num_channels
self.patch_size = patch_size
self.image_size = image_size
self.initializer_range = initializer_range
self.initializer_factor = initializer_factor
self.attention_dropout = attention_dropout
self.layer_norm_eps = layer_norm_eps
self.hidden_act = hidden_act
class CLIPSegConfig(PretrainedConfig):
r"""
[`CLIPSegConfig`] is the configuration class to store the configuration of a [`CLIPSegModel`]. It is used to
instantiate a CLIPSeg model according to the specified arguments, defining the text model and vision model configs.
Instantiating a configuration with the defaults will yield a similar configuration to that of the CLIPSeg
[CIDAS/clipseg-rd64](https://huggingface.co/CIDAS/clipseg-rd64) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
text_config (`dict`, *optional*):
Dictionary of configuration options used to initialize [`CLIPSegTextConfig`].
vision_config (`dict`, *optional*):
Dictionary of configuration options used to initialize [`CLIPSegVisionConfig`].
projection_dim (`int`, *optional*, defaults to 512):
Dimensionality of text and vision projection layers.
logit_scale_init_value (`float`, *optional*, defaults to 2.6592):
The initial value of the *logit_scale* parameter. Default is used as per the original CLIPSeg implementation.
extract_layers (`List[int]`, *optional*, defaults to `[3, 6, 9]`):
Layers to extract when forwarding the query image through the frozen visual backbone of CLIP.
reduce_dim (`int`, *optional*, defaults to 64):
Dimensionality to reduce the CLIP vision embedding.
decoder_num_attention_heads (`int`, *optional*, defaults to 4):
Number of attention heads in the decoder of CLIPSeg.
decoder_attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
decoder_hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` `"quick_gelu"` are supported.
decoder_intermediate_size (`int`, *optional*, defaults to 2048):
Dimensionality of the "intermediate" (i.e., feed-forward) layers in the Transformer decoder.
conditional_layer (`int`, *optional*, defaults to 0):
The layer to use of the Transformer encoder whose activations will be combined with the condition
embeddings using FiLM (Feature-wise Linear Modulation). If 0, the last layer is used.
use_complex_transposed_convolution (`bool`, *optional*, defaults to `False`):
Whether to use a more complex transposed convolution in the decoder, enabling more fine-grained
segmentation.
kwargs (*optional*):
Dictionary of keyword arguments.
Example:
```python
>>> from transformers import CLIPSegConfig, CLIPSegModel
>>> # Initializing a CLIPSegConfig with CIDAS/clipseg-rd64 style configuration
>>> configuration = CLIPSegConfig()
>>> # Initializing a CLIPSegModel (with random weights) from the CIDAS/clipseg-rd64 style configuration
>>> model = CLIPSegModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
>>> # We can also initialize a CLIPSegConfig from a CLIPSegTextConfig and a CLIPSegVisionConfig
>>> # Initializing a CLIPSegText and CLIPSegVision configuration
>>> config_text = CLIPSegTextConfig()
>>> config_vision = CLIPSegVisionConfig()
>>> config = CLIPSegConfig.from_text_vision_configs(config_text, config_vision)
```"""
model_type = "clipseg"
sub_configs = {"text_config": CLIPSegTextConfig, "vision_config": CLIPSegVisionConfig}
def __init__(
self,
text_config=None,
vision_config=None,
projection_dim=512,
logit_scale_init_value=2.6592,
extract_layers=[3, 6, 9],
reduce_dim=64,
decoder_num_attention_heads=4,
decoder_attention_dropout=0.0,
decoder_hidden_act="quick_gelu",
decoder_intermediate_size=2048,
conditional_layer=0,
use_complex_transposed_convolution=False,
**kwargs,
):
# If `_config_dict` exist, we use them for the backward compatibility.
# We pop out these 2 attributes before calling `super().__init__` to avoid them being saved (which causes a lot
# of confusion!).
text_config_dict = kwargs.pop("text_config_dict", None)
vision_config_dict = kwargs.pop("vision_config_dict", None)
super().__init__(**kwargs)
# Instead of simply assigning `[text|vision]_config_dict` to `[text|vision]_config`, we use the values in
# `[text|vision]_config_dict` to update the values in `[text|vision]_config`. The values should be same in most
# cases, but we don't want to break anything regarding `_config_dict` that existed before commit `8827e1b2`.
if text_config_dict is not None:
if text_config is None:
text_config = {}
# This is the complete result when using `text_config_dict`.
_text_config_dict = CLIPSegTextConfig(**text_config_dict).to_dict()
# Give a warning if the values exist in both `_text_config_dict` and `text_config` but being different.
for key, value in _text_config_dict.items():
if key in text_config and value != text_config[key] and key not in ["transformers_version"]:
# If specified in `text_config_dict`
if key in text_config_dict:
message = (
f"`{key}` is found in both `text_config_dict` and `text_config` but with different values. "
f'The value `text_config_dict["{key}"]` will be used instead.'
)
# If inferred from default argument values (just to be super careful)
else:
message = (
f"`text_config_dict` is provided which will be used to initialize `CLIPSegTextConfig`. The "
f'value `text_config["{key}"]` will be overridden.'
)
logger.info(message)
# Update all values in `text_config` with the ones in `_text_config_dict`.
text_config.update(_text_config_dict)
if vision_config_dict is not None:
if vision_config is None:
vision_config = {}
# This is the complete result when using `vision_config_dict`.
_vision_config_dict = CLIPSegVisionConfig(**vision_config_dict).to_dict()
# convert keys to string instead of integer
if "id2label" in _vision_config_dict:
_vision_config_dict["id2label"] = {
str(key): value for key, value in _vision_config_dict["id2label"].items()
}
# Give a warning if the values exist in both `_vision_config_dict` and `vision_config` but being different.
for key, value in _vision_config_dict.items():
if key in vision_config and value != vision_config[key] and key not in ["transformers_version"]:
# If specified in `vision_config_dict`
if key in vision_config_dict:
message = (
f"`{key}` is found in both `vision_config_dict` and `vision_config` but with different "
f'values. The value `vision_config_dict["{key}"]` will be used instead.'
)
# If inferred from default argument values (just to be super careful)
else:
message = (
f"`vision_config_dict` is provided which will be used to initialize `CLIPSegVisionConfig`. "
f'The value `vision_config["{key}"]` will be overridden.'
)
logger.info(message)
# Update all values in `vision_config` with the ones in `_vision_config_dict`.
vision_config.update(_vision_config_dict)
if text_config is None:
text_config = {}
logger.info("`text_config` is `None`. Initializing the `CLIPSegTextConfig` with default values.")
if vision_config is None:
vision_config = {}
logger.info("`vision_config` is `None`. initializing the `CLIPSegVisionConfig` with default values.")
self.text_config = CLIPSegTextConfig(**text_config)
self.vision_config = CLIPSegVisionConfig(**vision_config)
self.projection_dim = projection_dim
self.logit_scale_init_value = logit_scale_init_value
self.extract_layers = extract_layers
self.reduce_dim = reduce_dim
self.decoder_num_attention_heads = decoder_num_attention_heads
self.decoder_attention_dropout = decoder_attention_dropout
self.decoder_hidden_act = decoder_hidden_act
self.decoder_intermediate_size = decoder_intermediate_size
self.conditional_layer = conditional_layer
self.initializer_factor = 1.0
self.use_complex_transposed_convolution = use_complex_transposed_convolution
@classmethod
def from_text_vision_configs(cls, text_config: CLIPSegTextConfig, vision_config: CLIPSegVisionConfig, **kwargs):
r"""
Instantiate a [`CLIPSegConfig`] (or a derived class) from clipseg text model configuration and clipseg vision
model configuration.
Returns:
[`CLIPSegConfig`]: An instance of a configuration object
"""
return cls(text_config=text_config.to_dict(), vision_config=vision_config.to_dict(), **kwargs)
__all__ = ["CLIPSegConfig", "CLIPSegTextConfig", "CLIPSegVisionConfig"]
| transformers/src/transformers/models/clipseg/configuration_clipseg.py/0 | {
"file_path": "transformers/src/transformers/models/clipseg/configuration_clipseg.py",
"repo_id": "transformers",
"token_count": 7548
} |
# coding=utf-8
# Copyright 2022 Salesforce authors, The EleutherAI, and HuggingFace Teams. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""CodeGen model configuration"""
from collections import OrderedDict
from typing import Any, List, Mapping, Optional
from ... import PreTrainedTokenizer, TensorType, is_torch_available
from ...configuration_utils import PretrainedConfig
from ...onnx import OnnxConfigWithPast, PatchingSpec
from ...utils import logging
logger = logging.get_logger(__name__)
class CodeGenConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`CodeGenModel`]. It is used to instantiate a
CodeGen model according to the specified arguments, defining the model architecture. Instantiating a configuration
with the defaults will yield a similar configuration to that of the CodeGen
[Salesforce/codegen-2B-mono](https://huggingface.co/Salesforce/codegen-2B-mono) architecture. Configuration objects
inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the documentation from
[`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 50400):
Vocabulary size of the CodeGen model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`CodeGenModel`].
n_positions (`int`, *optional*, defaults to 2048):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
n_ctx (`int`, *optional*, defaults to 2048):
This attribute is used in `CodeGenModel.__init__` without any real effect.
n_embd (`int`, *optional*, defaults to 4096):
Dimensionality of the embeddings and hidden states.
n_layer (`int`, *optional*, defaults to 28):
Number of hidden layers in the Transformer encoder.
n_head (`int`, *optional*, defaults to 16):
Number of attention heads for each attention layer in the Transformer encoder.
rotary_dim (`int`, *optional*, defaults to 64):
Number of dimensions in the embedding that Rotary Position Embedding is applied to.
n_inner (`int`, *optional*):
Dimensionality of the inner feed-forward layers. `None` will set it to 4 times n_embd
activation_function (`str`, *optional*, defaults to `"gelu_new"`):
Activation function, to be selected in the list `["relu", "silu", "gelu", "tanh", "gelu_new"]`.
resid_pdrop (`float`, *optional*, defaults to 0.0):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
embd_pdrop (`int`, *optional*, defaults to 0.0):
The dropout ratio for the embeddings.
attn_pdrop (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention.
layer_norm_epsilon (`float`, *optional*, defaults to 1e-05):
The epsilon to use in the layer normalization layers.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models).
bos_token_id (`int`, *optional*, defaults to 50256):
Beginning of stream token id.
eos_token_id (`int`, *optional*, defaults to 50256):
End of stream token id.
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
Whether the model's input and output word embeddings should be tied. Note that this is only relevant if the
model has a output word embedding layer.
Example:
```python
>>> from transformers import CodeGenConfig, CodeGenModel
>>> # Initializing a CodeGen 6B configuration
>>> configuration = CodeGenConfig()
>>> # Initializing a model (with random weights) from the configuration
>>> model = CodeGenModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "codegen"
attribute_map = {
"max_position_embeddings": "n_positions",
"hidden_size": "n_embd",
"num_attention_heads": "n_head",
"num_hidden_layers": "n_layer",
}
def __init__(
self,
vocab_size=50400,
n_positions=2048,
n_ctx=2048,
n_embd=4096,
n_layer=28,
n_head=16,
rotary_dim=64,
n_inner=None,
activation_function="gelu_new",
resid_pdrop=0.0,
embd_pdrop=0.0,
attn_pdrop=0.0,
layer_norm_epsilon=1e-5,
initializer_range=0.02,
use_cache=True,
bos_token_id=50256,
eos_token_id=50256,
tie_word_embeddings=False,
**kwargs,
):
self.vocab_size = vocab_size
self.n_ctx = n_ctx
self.n_positions = n_positions
self.n_embd = n_embd
self.n_layer = n_layer
self.n_head = n_head
self.n_inner = n_inner
self.rotary_dim = rotary_dim
self.activation_function = activation_function
self.resid_pdrop = resid_pdrop
self.embd_pdrop = embd_pdrop
self.attn_pdrop = attn_pdrop
self.layer_norm_epsilon = layer_norm_epsilon
self.initializer_range = initializer_range
self.use_cache = use_cache
self.bos_token_id = bos_token_id
self.eos_token_id = eos_token_id
super().__init__(
bos_token_id=bos_token_id, eos_token_id=eos_token_id, tie_word_embeddings=tie_word_embeddings, **kwargs
)
# Copied from transformers.models.gpt2.configuration_gpt2.GPT2OnnxConfig
class CodeGenOnnxConfig(OnnxConfigWithPast):
def __init__(
self,
config: PretrainedConfig,
task: str = "default",
patching_specs: List[PatchingSpec] = None,
use_past: bool = False,
):
super().__init__(config, task=task, patching_specs=patching_specs, use_past=use_past)
if not getattr(self._config, "pad_token_id", None):
# TODO: how to do that better?
self._config.pad_token_id = 0
@property
def inputs(self) -> Mapping[str, Mapping[int, str]]:
common_inputs = OrderedDict({"input_ids": {0: "batch", 1: "sequence"}})
if self.use_past:
self.fill_with_past_key_values_(common_inputs, direction="inputs")
common_inputs["attention_mask"] = {0: "batch", 1: "past_sequence + sequence"}
else:
common_inputs["attention_mask"] = {0: "batch", 1: "sequence"}
return common_inputs
@property
def num_layers(self) -> int:
return self._config.n_layer
@property
def num_attention_heads(self) -> int:
return self._config.n_head
def generate_dummy_inputs(
self,
tokenizer: PreTrainedTokenizer,
batch_size: int = -1,
seq_length: int = -1,
is_pair: bool = False,
framework: Optional[TensorType] = None,
) -> Mapping[str, Any]:
common_inputs = super(OnnxConfigWithPast, self).generate_dummy_inputs(
tokenizer, batch_size=batch_size, seq_length=seq_length, is_pair=is_pair, framework=framework
)
# We need to order the input in the way they appears in the forward()
ordered_inputs = OrderedDict({"input_ids": common_inputs["input_ids"]})
# Need to add the past_keys
if self.use_past:
if not is_torch_available():
raise ValueError("Cannot generate dummy past_keys inputs without PyTorch installed.")
else:
import torch
batch, seqlen = common_inputs["input_ids"].shape
# Not using the same length for past_key_values
past_key_values_length = seqlen + 2
past_shape = (
batch,
self.num_attention_heads,
past_key_values_length,
self._config.hidden_size // self.num_attention_heads,
)
ordered_inputs["past_key_values"] = [
(torch.zeros(past_shape), torch.zeros(past_shape)) for _ in range(self.num_layers)
]
ordered_inputs["attention_mask"] = common_inputs["attention_mask"]
if self.use_past:
mask_dtype = ordered_inputs["attention_mask"].dtype
ordered_inputs["attention_mask"] = torch.cat(
[ordered_inputs["attention_mask"], torch.ones(batch, past_key_values_length, dtype=mask_dtype)], dim=1
)
return ordered_inputs
@property
def default_onnx_opset(self) -> int:
return 13
__all__ = ["CodeGenConfig", "CodeGenOnnxConfig"]
| transformers/src/transformers/models/codegen/configuration_codegen.py/0 | {
"file_path": "transformers/src/transformers/models/codegen/configuration_codegen.py",
"repo_id": "transformers",
"token_count": 3936
} |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch ColPali model"""
from dataclasses import dataclass
from typing import List, Optional, Tuple, Union
import torch
from torch import nn
from transformers import AutoModelForImageTextToText
from ...cache_utils import Cache
from ...modeling_utils import PreTrainedModel
from ...utils import (
ModelOutput,
add_start_docstrings,
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
from .configuration_colpali import ColPaliConfig
_CONFIG_FOR_DOC = "ColPaliConfig"
COLPALI_START_DOCSTRING = r"""
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`ColPaliConfig`]):
Model configuration class with all the parameters of the model. Initializing with a config file does not
load the weights associated with the model, only the configuration. Check out the
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
@add_start_docstrings(
"The bare ColPali model outputting raw hidden-states without any specific head on top.",
COLPALI_START_DOCSTRING,
)
class ColPaliPreTrainedModel(PreTrainedModel):
config_class = ColPaliConfig
base_model_prefix = "model"
_no_split_modules = []
def _init_weights(self, module):
std = (
self.config.initializer_range
if hasattr(self.config, "initializer_range")
else self.config.vlm_config.text_config.initializer_range
)
if isinstance(module, (nn.Linear, nn.Conv2d)):
module.weight.data.normal_(mean=0.0, std=std)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=std)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
@dataclass
class ColPaliForRetrievalOutput(ModelOutput):
"""
Base class for ColPali embeddings output.
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
Language modeling loss (for next-token prediction).
embeddings (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
The embeddings of the model.
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
`(batch_size, num_heads, sequence_length, embed_size_per_head)`)
Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
`past_key_values` input) to speed up sequential decoding.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
image_hidden_states (`torch.FloatTensor`, *optional*):
A `torch.FloatTensor` of size `(batch_size, num_images, sequence_length, hidden_size)`.
image_hidden_states of the model produced by the vision encoder after projecting last hidden state.
"""
loss: Optional[torch.FloatTensor] = None
embeddings: torch.Tensor = None
past_key_values: Optional[Union[List[torch.FloatTensor], Cache]] = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
image_hidden_states: Optional[torch.FloatTensor] = None
COLPALI_FOR_RETRIEVAL_INPUT_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, image_size, image_size)):
The tensors corresponding to the input images. Pixel values can be obtained using
[`AutoImageProcessor`]. See [`SiglipImageProcessor.__call__`] for details ([]`PaliGemmaProcessor`] uses
[`SiglipImageProcessor`] for processing images). If none, ColPali will only process text (query embeddings).
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
kwargs (`Dict[str, Any]`, *optional*):
Additional key word arguments passed along to the vlm backbone model.
"""
@add_start_docstrings(
"""
In our proposed ColPali approach, we leverage VLMs to construct efficient multi-vector embeddings directly
from document images (“screenshots”) for document retrieval. We train the model to maximize the similarity
between these document embeddings and the corresponding query embeddings, using the late interaction method
introduced in ColBERT.
Using ColPali removes the need for potentially complex and brittle layout recognition and OCR pipelines with a
single model that can take into account both the textual and visual content (layout, charts, etc.) of a document.
"""
)
class ColPaliForRetrieval(ColPaliPreTrainedModel):
def __init__(self, config: ColPaliConfig):
super().__init__(config)
self.config = config
self.vocab_size = config.vlm_config.text_config.vocab_size
vlm = AutoModelForImageTextToText.from_config(config.vlm_config)
if vlm.language_model._tied_weights_keys is not None:
self._tied_weights_keys = [f"vlm.language_model.{k}" for k in vlm.language_model._tied_weights_keys]
self.vlm = vlm
self.embedding_dim = self.config.embedding_dim
self.embedding_proj_layer = nn.Linear(
self.config.vlm_config.text_config.hidden_size,
self.embedding_dim,
)
self.post_init()
@add_start_docstrings_to_model_forward(COLPALI_FOR_RETRIEVAL_INPUT_DOCSTRING)
@replace_return_docstrings(output_type=ColPaliForRetrievalOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: torch.LongTensor = None,
pixel_values: torch.FloatTensor = None,
attention_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
**kwargs,
) -> Union[Tuple, ColPaliForRetrievalOutput]:
r"""
Returns:
"""
if "pixel_values" in kwargs:
kwargs["pixel_values"] = kwargs["pixel_values"].to(dtype=self.dtype)
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.vlm(
input_ids=input_ids,
attention_mask=attention_mask,
pixel_values=pixel_values,
output_hidden_states=True,
return_dict=return_dict,
output_attentions=output_attentions,
**kwargs,
)
last_hidden_states = outputs.hidden_states[-1] # (batch_size, sequence_length, hidden_size)
embeddings = self.embedding_proj_layer(last_hidden_states) # (batch_size, sequence_length, dim)
# L2 normalization
embeddings = embeddings / embeddings.norm(dim=-1, keepdim=True) # (batch_size, sequence_length, dim)
embeddings = embeddings * attention_mask.unsqueeze(-1) # (batch_size, sequence_length, dim)
loss = None
if not return_dict:
output = (embeddings,) + outputs[2:]
output[2] = output[2] if output_hidden_states is not None else None
output[-1] = (outputs.image_hidden_states if pixel_values is not None else None,)
return (loss,) + output if loss is not None else output
return ColPaliForRetrievalOutput(
loss=loss,
embeddings=embeddings,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states if output_hidden_states else None,
attentions=outputs.attentions,
image_hidden_states=outputs.image_hidden_states if pixel_values is not None else None,
)
def get_input_embeddings(self):
return self.vlm.language_model.get_input_embeddings()
def set_input_embeddings(self, value):
self.vlm.language_model.set_input_embeddings(value)
def get_output_embeddings(self):
return self.vlm.language_model.get_output_embeddings()
def set_output_embeddings(self, new_embeddings):
self.vlm.language_model.set_output_embeddings(new_embeddings)
def set_decoder(self, decoder):
self.vlm.language_model.set_decoder(decoder)
def get_decoder(self):
return self.vlm.language_model.get_decoder()
def tie_weights(self):
return self.vlm.language_model.tie_weights()
def resize_token_embeddings(
self,
new_num_tokens: Optional[int] = None,
pad_to_multiple_of: Optional[int] = None,
mean_resizing: bool = True,
) -> nn.Embedding:
model_embeds = self.vlm.language_model.resize_token_embeddings(
new_num_tokens=new_num_tokens,
pad_to_multiple_of=pad_to_multiple_of,
mean_resizing=mean_resizing,
)
self.config.vlm_config.text_config.vocab_size = model_embeds.num_embeddings
self.config.vlm_config.vocab_size = model_embeds.num_embeddings
self.vlm.vocab_size = model_embeds.num_embeddings
self.vocab_size = model_embeds.num_embeddings
return model_embeds
__all__ = [
"ColPaliForRetrieval",
"ColPaliForRetrievalOutput",
"ColPaliPreTrainedModel",
]
| transformers/src/transformers/models/colpali/modeling_colpali.py/0 | {
"file_path": "transformers/src/transformers/models/colpali/modeling_colpali.py",
"repo_id": "transformers",
"token_count": 5298
} |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Convert DAB-DETR checkpoints."""
import argparse
import gc
import json
import re
from pathlib import Path
import torch
from huggingface_hub import hf_hub_download
from transformers import ConditionalDetrImageProcessor, DabDetrConfig, DabDetrForObjectDetection
from transformers.utils import logging
logging.set_verbosity_info()
logger = logging.get_logger(__name__)
ORIGINAL_TO_CONVERTED_KEY_MAPPING = {
# convolutional projection + query embeddings + layernorm of decoder + class and bounding box heads
# for dab-DETR, also convert reference point head and query scale MLP
r"input_proj\.(bias|weight)": r"input_projection.\1",
r"refpoint_embed\.weight": r"query_refpoint_embeddings.weight",
r"class_embed\.(bias|weight)": r"class_embed.\1",
# negative lookbehind because of the overlap
r"(?<!transformer\.decoder\.)bbox_embed\.layers\.(\d+)\.(bias|weight)": r"bbox_predictor.layers.\1.\2",
r"transformer\.encoder\.query_scale\.layers\.(\d+)\.(bias|weight)": r"encoder.query_scale.layers.\1.\2",
r"transformer\.decoder\.bbox_embed\.layers\.(\d+)\.(bias|weight)": r"decoder.bbox_embed.layers.\1.\2",
r"transformer\.decoder\.norm\.(bias|weight)": r"decoder.layernorm.\1",
r"transformer\.decoder\.ref_point_head\.layers\.(\d+)\.(bias|weight)": r"decoder.ref_point_head.layers.\1.\2",
r"transformer\.decoder\.ref_anchor_head\.layers\.(\d+)\.(bias|weight)": r"decoder.ref_anchor_head.layers.\1.\2",
r"transformer\.decoder\.query_scale\.layers\.(\d+)\.(bias|weight)": r"decoder.query_scale.layers.\1.\2",
r"transformer\.decoder\.layers\.0\.ca_qpos_proj\.(bias|weight)": r"decoder.layers.0.cross_attn.cross_attn_query_pos_proj.\1",
# encoder layers: output projection, 2 feedforward neural networks and 2 layernorms + activation function
# output projection
r"transformer\.encoder\.layers\.(\d+)\.self_attn\.out_proj\.(bias|weight)": r"encoder.layers.\1.self_attn.out_proj.\2",
# FFN layers
r"transformer\.encoder\.layers\.(\d+)\.linear(\d)\.(bias|weight)": r"encoder.layers.\1.fc\2.\3",
# normalization layers
# nm1
r"transformer\.encoder\.layers\.(\d+)\.norm1\.(bias|weight)": r"encoder.layers.\1.self_attn_layer_norm.\2",
# nm2
r"transformer\.encoder\.layers\.(\d+)\.norm2\.(bias|weight)": r"encoder.layers.\1.final_layer_norm.\2",
# activation function weight
r"transformer\.encoder\.layers\.(\d+)\.activation\.weight": r"encoder.layers.\1.activation_fn.weight",
#########################################################################################################################################
# decoder layers: 2 times output projection, 2 feedforward neural networks and 3 layernorms + activiation function weight
r"transformer\.decoder\.layers\.(\d+)\.self_attn\.out_proj\.(bias|weight)": r"decoder.layers.\1.self_attn.self_attn.output_proj.\2",
r"transformer\.decoder\.layers\.(\d+)\.cross_attn\.out_proj\.(bias|weight)": r"decoder.layers.\1.cross_attn.cross_attn.output_proj.\2",
# FFNs
r"transformer\.decoder\.layers\.(\d+)\.linear(\d)\.(bias|weight)": r"decoder.layers.\1.mlp.fc\2.\3",
# nm1
r"transformer\.decoder\.layers\.(\d+)\.norm1\.(bias|weight)": r"decoder.layers.\1.self_attn.self_attn_layer_norm.\2",
# nm2
r"transformer\.decoder\.layers\.(\d+)\.norm2\.(bias|weight)": r"decoder.layers.\1.cross_attn.cross_attn_layer_norm.\2",
# nm3
r"transformer\.decoder\.layers\.(\d+)\.norm3\.(bias|weight)": r"decoder.layers.\1.mlp.final_layer_norm.\2",
# activation function weight
r"transformer\.decoder\.layers\.(\d+)\.activation\.weight": r"decoder.layers.\1.mlp.activation_fn.weight",
# q, k, v projections and biases in self-attention in decoder
r"transformer\.decoder\.layers\.(\d+)\.sa_qcontent_proj\.(bias|weight)": r"decoder.layers.\1.self_attn.self_attn_query_content_proj.\2",
r"transformer\.decoder\.layers\.(\d+)\.sa_kcontent_proj\.(bias|weight)": r"decoder.layers.\1.self_attn.self_attn_key_content_proj.\2",
r"transformer\.decoder\.layers\.(\d+)\.sa_qpos_proj\.(bias|weight)": r"decoder.layers.\1.self_attn.self_attn_query_pos_proj.\2",
r"transformer\.decoder\.layers\.(\d+)\.sa_kpos_proj\.(bias|weight)": r"decoder.layers.\1.self_attn.self_attn_key_pos_proj.\2",
r"transformer\.decoder\.layers\.(\d+)\.sa_v_proj\.(bias|weight)": r"decoder.layers.\1.self_attn.self_attn_value_proj.\2",
# q, k, v projections in cross-attention in decoder
r"transformer\.decoder\.layers\.(\d+)\.ca_qcontent_proj\.(bias|weight)": r"decoder.layers.\1.cross_attn.cross_attn_query_content_proj.\2",
r"transformer\.decoder\.layers\.(\d+)\.ca_kcontent_proj\.(bias|weight)": r"decoder.layers.\1.cross_attn.cross_attn_key_content_proj.\2",
r"transformer\.decoder\.layers\.(\d+)\.ca_kpos_proj\.(bias|weight)": r"decoder.layers.\1.cross_attn.cross_attn_key_pos_proj.\2",
r"transformer\.decoder\.layers\.(\d+)\.ca_v_proj\.(bias|weight)": r"decoder.layers.\1.cross_attn.cross_attn_value_proj.\2",
r"transformer\.decoder\.layers\.(\d+)\.ca_qpos_sine_proj\.(bias|weight)": r"decoder.layers.\1.cross_attn.cross_attn_query_pos_sine_proj.\2",
}
# Copied from transformers.models.mllama.convert_mllama_weights_to_hf.convert_old_keys_to_new_keys
def convert_old_keys_to_new_keys(state_dict_keys: dict = None):
"""
This function should be applied only once, on the concatenated keys to efficiently rename using
the key mappings.
"""
output_dict = {}
if state_dict_keys is not None:
old_text = "\n".join(state_dict_keys)
new_text = old_text
for pattern, replacement in ORIGINAL_TO_CONVERTED_KEY_MAPPING.items():
if replacement is None:
new_text = re.sub(pattern, "", new_text) # an empty line
continue
new_text = re.sub(pattern, replacement, new_text)
output_dict = dict(zip(old_text.split("\n"), new_text.split("\n")))
return output_dict
def write_image_processor(model_name, pytorch_dump_folder_path, push_to_hub):
logger.info("Converting image processor...")
format = "coco_detection"
image_processor = ConditionalDetrImageProcessor(format=format)
Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
image_processor.save_pretrained(pytorch_dump_folder_path)
if push_to_hub:
image_processor.push_to_hub(repo_id=model_name, commit_message="Add new image processor")
@torch.no_grad()
def write_model(model_name, pretrained_model_weights_path, pytorch_dump_folder_path, push_to_hub):
# load modified config. Why? After loading the default config, the backbone kwargs are already set.
if "dc5" in model_name:
config = DabDetrConfig(dilation=True)
else:
# load default config
config = DabDetrConfig()
# set other attributes
if "dab-detr-resnet-50-dc5" == model_name:
config.temperature_height = 10
config.temperature_width = 10
if "fixxy" in model_name:
config.random_refpoints_xy = True
if "pat3" in model_name:
config.num_patterns = 3
# only when the number of patterns (num_patterns parameter in config) are more than 0 like r50-pat3 or r50dc5-pat3
ORIGINAL_TO_CONVERTED_KEY_MAPPING.update({r"transformer.patterns.weight": r"patterns.weight"})
config.num_labels = 91
repo_id = "huggingface/label-files"
filename = "coco-detection-id2label.json"
id2label = json.load(open(hf_hub_download(repo_id, filename, repo_type="dataset"), "r"))
id2label = {int(k): v for k, v in id2label.items()}
config.id2label = id2label
config.label2id = {v: k for k, v in id2label.items()}
# load original model from local path
loaded = torch.load(pretrained_model_weights_path, map_location=torch.device("cpu"))["model"]
# Renaming the original model state dictionary to HF compatibile
all_keys = list(loaded.keys())
new_keys = convert_old_keys_to_new_keys(all_keys)
state_dict = {}
for key in all_keys:
if "backbone.0.body" in key:
new_key = key.replace("backbone.0.body", "backbone.conv_encoder.model._backbone")
state_dict[new_key] = loaded[key]
# Q, K, V encoder values mapping
elif re.search("self_attn.in_proj_(weight|bias)", key):
# Dynamically find the layer number
pattern = r"layers\.(\d+)\.self_attn\.in_proj_(weight|bias)"
match = re.search(pattern, key)
if match:
layer_num = match.group(1)
else:
raise ValueError(f"Pattern not found in key: {key}")
in_proj_value = loaded.pop(key)
if "weight" in key:
state_dict[f"encoder.layers.{layer_num}.self_attn.q_proj.weight"] = in_proj_value[:256, :]
state_dict[f"encoder.layers.{layer_num}.self_attn.k_proj.weight"] = in_proj_value[256:512, :]
state_dict[f"encoder.layers.{layer_num}.self_attn.v_proj.weight"] = in_proj_value[-256:, :]
elif "bias" in key:
state_dict[f"encoder.layers.{layer_num}.self_attn.q_proj.bias"] = in_proj_value[:256]
state_dict[f"encoder.layers.{layer_num}.self_attn.k_proj.bias"] = in_proj_value[256:512]
state_dict[f"encoder.layers.{layer_num}.self_attn.v_proj.bias"] = in_proj_value[-256:]
else:
new_key = new_keys[key]
state_dict[new_key] = loaded[key]
del loaded
gc.collect()
# important: we need to prepend a prefix to each of the base model keys as the head models use different attributes for them
prefix = "model."
for key in state_dict.copy().keys():
if not key.startswith("class_embed") and not key.startswith("bbox_predictor"):
val = state_dict.pop(key)
state_dict[prefix + key] = val
# finally, create HuggingFace model and load state dict
model = DabDetrForObjectDetection(config)
model.load_state_dict(state_dict)
model.eval()
logger.info(f"Saving PyTorch model to {pytorch_dump_folder_path}...")
Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
model.save_pretrained(pytorch_dump_folder_path)
if push_to_hub:
model.push_to_hub(repo_id=model_name, commit_message="Add new model")
def convert_dab_detr_checkpoint(model_name, pretrained_model_weights_path, pytorch_dump_folder_path, push_to_hub):
logger.info("Converting image processor...")
write_image_processor(model_name, pytorch_dump_folder_path, push_to_hub)
logger.info(f"Converting model {model_name}...")
write_model(model_name, pretrained_model_weights_path, pytorch_dump_folder_path, push_to_hub)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_name",
default="dab-detr-resnet-50",
type=str,
help="Name of the DAB_DETR model you'd like to convert.",
)
parser.add_argument(
"--pretrained_model_weights_path",
default="modelzoo/R50/checkpoint.pth",
type=str,
help="The path of the original model weights like: modelzoo/checkpoint.pth",
)
parser.add_argument(
"--pytorch_dump_folder_path", default="DAB_DETR", type=str, help="Path to the folder to output PyTorch model."
)
parser.add_argument(
"--push_to_hub",
default=True,
type=bool,
help="Whether to upload the converted weights and image processor config to the HuggingFace model profile. Default is set to false.",
)
args = parser.parse_args()
convert_dab_detr_checkpoint(
args.model_name, args.pretrained_model_weights_path, args.pytorch_dump_folder_path, args.push_to_hub
)
| transformers/src/transformers/models/dab_detr/convert_dab_detr_original_pytorch_checkpoint_to_pytorch.py/0 | {
"file_path": "transformers/src/transformers/models/dab_detr/convert_dab_detr_original_pytorch_checkpoint_to_pytorch.py",
"repo_id": "transformers",
"token_count": 5154
} |
# coding=utf-8
# Copyright 2022 Meta Platforms and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch Data2VecVision model."""
import collections.abc
import math
from dataclasses import dataclass
from typing import List, Optional, Tuple, Union
import torch
import torch.utils.checkpoint
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from ...activations import ACT2FN
from ...modeling_outputs import (
BaseModelOutput,
BaseModelOutputWithPooling,
ImageClassifierOutput,
SemanticSegmenterOutput,
)
from ...modeling_utils import PreTrainedModel
from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import (
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
logging,
replace_return_docstrings,
torch_int,
)
from .configuration_data2vec_vision import Data2VecVisionConfig
logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "Data2VecVisionConfig"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/data2vec-vision-base"
_EXPECTED_OUTPUT_SHAPE = [1, 197, 768]
# Image classification docstring
_IMAGE_CLASS_CHECKPOINT = "facebook/data2vec-vision-base-ft1k"
_IMAGE_CLASS_EXPECTED_OUTPUT = "remote control, remote"
@dataclass
# Copied from transformers.models.beit.modeling_beit.BeitModelOutputWithPooling with Beit->Data2VecVision
class Data2VecVisionModelOutputWithPooling(BaseModelOutputWithPooling):
"""
Class for outputs of [`Data2VecVisionModel`].
Args:
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
pooler_output (`torch.FloatTensor` of shape `(batch_size, hidden_size)`):
Average of the last layer hidden states of the patch tokens (excluding the *[CLS]* token) if
*config.use_mean_pooling* is set to True. If set to False, then the final hidden state of the *[CLS]* token
will be returned.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
# Copied from transformers.models.beit.modeling_beit.drop_path
def drop_path(input: torch.Tensor, drop_prob: float = 0.0, training: bool = False) -> torch.Tensor:
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
Comment by Ross Wightman: This is the same as the DropConnect impl I created for EfficientNet, etc networks,
however, the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for changing the
layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use 'survival rate' as the
argument.
"""
if drop_prob == 0.0 or not training:
return input
keep_prob = 1 - drop_prob
shape = (input.shape[0],) + (1,) * (input.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=input.dtype, device=input.device)
random_tensor.floor_() # binarize
output = input.div(keep_prob) * random_tensor
return output
# Copied from transformers.models.beit.modeling_beit.BeitDropPath with Beit->Data2VecVision
class Data2VecVisionDropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
def __init__(self, drop_prob: Optional[float] = None) -> None:
super().__init__()
self.drop_prob = drop_prob
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
return drop_path(hidden_states, self.drop_prob, self.training)
def extra_repr(self) -> str:
return "p={}".format(self.drop_prob)
# Copied from transformers.models.beit.modeling_beit.BeitEmbeddings with Beit->Data2VecVision
class Data2VecVisionEmbeddings(nn.Module):
"""
Construct the CLS token, position and patch embeddings. Optionally, also the mask token.
"""
def __init__(self, config: Data2VecVisionConfig) -> None:
super().__init__()
self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
if config.use_mask_token:
self.mask_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
else:
self.mask_token = None
self.patch_embeddings = Data2VecVisionPatchEmbeddings(config)
self.patch_size = config.patch_size
self.image_size = (
config.image_size
if isinstance(config.image_size, collections.abc.Iterable)
else (config.image_size, config.image_size)
)
num_patches = self.patch_embeddings.num_patches
if config.use_absolute_position_embeddings:
self.position_embeddings = nn.Parameter(torch.zeros(1, num_patches + 1, config.hidden_size))
else:
self.position_embeddings = None
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# Copied from transformers.models.vit.modeling_vit.ViTEmbeddings.interpolate_pos_encoding
def interpolate_pos_encoding(self, embeddings: torch.Tensor, height: int, width: int) -> torch.Tensor:
"""
This method allows to interpolate the pre-trained position encodings, to be able to use the model on higher resolution
images. This method is also adapted to support torch.jit tracing.
Adapted from:
- https://github.com/facebookresearch/dino/blob/de9ee3df6cf39fac952ab558447af1fa1365362a/vision_transformer.py#L174-L194, and
- https://github.com/facebookresearch/dinov2/blob/e1277af2ba9496fbadf7aec6eba56e8d882d1e35/dinov2/models/vision_transformer.py#L179-L211
"""
num_patches = embeddings.shape[1] - 1
num_positions = self.position_embeddings.shape[1] - 1
# always interpolate when tracing to ensure the exported model works for dynamic input shapes
if not torch.jit.is_tracing() and num_patches == num_positions and height == width:
return self.position_embeddings
class_pos_embed = self.position_embeddings[:, :1]
patch_pos_embed = self.position_embeddings[:, 1:]
dim = embeddings.shape[-1]
new_height = height // self.patch_size
new_width = width // self.patch_size
sqrt_num_positions = torch_int(num_positions**0.5)
patch_pos_embed = patch_pos_embed.reshape(1, sqrt_num_positions, sqrt_num_positions, dim)
patch_pos_embed = patch_pos_embed.permute(0, 3, 1, 2)
patch_pos_embed = nn.functional.interpolate(
patch_pos_embed,
size=(new_height, new_width),
mode="bicubic",
align_corners=False,
)
patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
return torch.cat((class_pos_embed, patch_pos_embed), dim=1)
def forward(
self,
pixel_values: torch.Tensor,
bool_masked_pos: Optional[torch.BoolTensor] = None,
interpolate_pos_encoding: bool = False,
) -> torch.Tensor:
_, _, height, width = pixel_values.shape
embeddings, (patch_height, patch_width) = self.patch_embeddings(
pixel_values, self.position_embeddings[:, 1:, :] if self.position_embeddings is not None else None
)
batch_size, seq_len, _ = embeddings.size()
if bool_masked_pos is not None:
mask_tokens = self.mask_token.expand(batch_size, seq_len, -1)
# replace the masked visual tokens by mask_tokens
w = bool_masked_pos.unsqueeze(-1).type_as(mask_tokens)
embeddings = embeddings * (1 - w) + mask_tokens * w
cls_tokens = self.cls_token.expand(batch_size, -1, -1)
if self.position_embeddings is not None:
if interpolate_pos_encoding:
cls_tokens = cls_tokens + self.interpolate_pos_encoding(embeddings, height, width)
else:
cls_tokens = cls_tokens + self.position_embeddings[:, :1, :]
embeddings = torch.cat((cls_tokens, embeddings), dim=1)
embeddings = self.dropout(embeddings)
return embeddings, (patch_height, patch_width)
# Copied from transformers.models.beit.modeling_beit.BeitPatchEmbeddings with Beit->Data2VecVision
class Data2VecVisionPatchEmbeddings(nn.Module):
"""
This class turns `pixel_values` of shape `(batch_size, num_channels, height, width)` into the initial
`hidden_states` (patch embeddings) of shape `(batch_size, seq_length, hidden_size)` to be consumed by a
Transformer.
"""
def __init__(self, config):
super().__init__()
image_size, patch_size = config.image_size, config.patch_size
num_channels, hidden_size = config.num_channels, config.hidden_size
image_size = image_size if isinstance(image_size, collections.abc.Iterable) else (image_size, image_size)
patch_size = patch_size if isinstance(patch_size, collections.abc.Iterable) else (patch_size, patch_size)
num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
patch_shape = (image_size[0] // patch_size[0], image_size[1] // patch_size[1])
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.num_patches = num_patches
self.patch_shape = patch_shape
self.projection = nn.Conv2d(num_channels, hidden_size, kernel_size=patch_size, stride=patch_size)
def forward(
self,
pixel_values: torch.Tensor,
position_embedding: Optional[torch.Tensor] = None,
) -> torch.Tensor:
batch_size, num_channels, height, width = pixel_values.shape
if num_channels != self.num_channels:
raise ValueError(
"Make sure that the channel dimension of the pixel values match with the one set in the configuration."
)
embeddings = self.projection(pixel_values)
patch_height, patch_width = embeddings.shape[2], embeddings.shape[3]
if position_embedding is not None:
# interpolate the position embedding to the corresponding size
position_embedding = position_embedding.view(1, self.patch_shape[0], self.patch_shape[1], -1).permute(
0, 3, 1, 2
)
position_embedding = nn.functional.interpolate(
position_embedding, size=(patch_height, patch_width), mode="bicubic"
)
embeddings = embeddings + position_embedding
embeddings = embeddings.flatten(2).transpose(1, 2)
return embeddings, (patch_height, patch_width)
# Copied from transformers.models.beit.modeling_beit.BeitSelfAttention with Beit->Data2VecVision
class Data2VecVisionSelfAttention(nn.Module):
def __init__(self, config: Data2VecVisionConfig, window_size: Optional[tuple] = None) -> None:
super().__init__()
self.config = config
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
f"heads {config.num_attention_heads}."
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size, bias=False)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
if window_size:
self.relative_position_bias = Data2VecVisionRelativePositionBias(config, window_size=window_size)
else:
self.relative_position_bias = None
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states: torch.Tensor,
head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
relative_position_bias: Optional["Data2VecVisionRelativePositionBias"] = None,
interpolate_pos_encoding: bool = False,
resolution: Optional[Tuple[int]] = None,
) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
mixed_query_layer = self.query(hidden_states)
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
# Add relative position bias if present.
if self.relative_position_bias is not None:
height, width = resolution
window_size = (height // self.config.patch_size, width // self.config.patch_size)
attention_scores = attention_scores + self.relative_position_bias(
window_size, interpolate_pos_encoding, dim_size=hidden_states.shape[1]
)
# Add shared relative position bias if provided.
if relative_position_bias is not None:
attention_scores = attention_scores + relative_position_bias
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
return outputs
# Copied from transformers.models.beit.modeling_beit.BeitSdpaSelfAttention with Beit->Data2VecVision
class Data2VecVisionSdpaSelfAttention(Data2VecVisionSelfAttention):
def forward(
self,
hidden_states: torch.Tensor,
head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
relative_position_bias: Optional["Data2VecVisionRelativePositionBias"] = None,
interpolate_pos_encoding: bool = False,
resolution: Optional[Tuple[int]] = None,
) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
if output_attentions or head_mask is not None:
logger.warning_once(
"`Data2VecVisionSdpaSelfAttention` is used but `torch.nn.functional.scaled_dot_product_attention` does not "
"support `output_attentions=True` or `head_mask`. Falling back to the manual attention implementation, "
"but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. "
'This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
)
return super().forward(
hidden_states=hidden_states,
head_mask=head_mask,
output_attentions=output_attentions,
relative_position_bias=relative_position_bias,
interpolate_pos_encoding=interpolate_pos_encoding,
resolution=resolution,
)
mixed_query_layer = self.query(hidden_states)
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
attn_bias = None
if self.relative_position_bias is not None:
height, width = resolution
window_size = (height // self.config.patch_size, width // self.config.patch_size)
attn_bias = self.relative_position_bias(
window_size, interpolate_pos_encoding, dim_size=hidden_states.shape[1]
)
# Add shared relative position bias if provided.
if relative_position_bias is not None:
if attn_bias is None:
attn_bias = relative_position_bias
else:
attn_bias += relative_position_bias
scaling = 1 / math.sqrt(self.attention_head_size)
context_layer = torch.nn.functional.scaled_dot_product_attention(
query_layer,
key_layer,
value_layer,
attn_mask=attn_bias,
dropout_p=self.config.attention_probs_dropout_prob if self.training else 0.0,
is_causal=False,
scale=scaling,
)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
return context_layer, None
# Copied from transformers.models.beit.modeling_beit.BeitSelfOutput with Beit->Data2VecVision
class Data2VecVisionSelfOutput(nn.Module):
"""
The residual connection is defined in Data2VecVisionLayer instead of here (as is the case with other models), due to the
layernorm applied before each block.
"""
def __init__(self, config: Data2VecVisionConfig) -> None:
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor, gamma=None) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
return hidden_states
DATA2VEC_VISION_SELF_ATTENTION_CLASSES = {
"eager": Data2VecVisionSelfAttention,
"sdpa": Data2VecVisionSdpaSelfAttention,
}
# Copied from tests.models.beit.modeling_beit.BeitAttention with Beit->Data2VecVision, BEIT->DATA2VEC_VISION
class Data2VecVisionAttention(nn.Module):
def __init__(self, config: Data2VecVisionConfig, window_size: Optional[tuple] = None) -> None:
super().__init__()
self.attention = DATA2VEC_VISION_SELF_ATTENTION_CLASSES[config._attn_implementation](
config, window_size=window_size
)
self.output = Data2VecVisionSelfOutput(config)
self.pruned_heads = set()
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.attention.num_attention_heads, self.attention.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.attention.query = prune_linear_layer(self.attention.query, index)
self.attention.key = prune_linear_layer(self.attention.key, index)
self.attention.value = prune_linear_layer(self.attention.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.attention.num_attention_heads = self.attention.num_attention_heads - len(heads)
self.attention.all_head_size = self.attention.attention_head_size * self.attention.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states: torch.Tensor,
head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
relative_position_bias: Optional["Data2VecVisionRelativePositionBias"] = None,
interpolate_pos_encoding: bool = False,
resolution: Optional[Tuple[int]] = None,
) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
self_outputs = self.attention(
hidden_states, head_mask, output_attentions, relative_position_bias, interpolate_pos_encoding, resolution
)
attention_output = self.output(self_outputs[0], hidden_states)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
# Copied from transformers.models.beit.modeling_beit.BeitIntermediate with Beit->Data2VecVision
class Data2VecVisionIntermediate(nn.Module):
def __init__(self, config: Data2VecVisionConfig) -> None:
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
# Copied from transformers.models.beit.modeling_beit.BeitOutput with Beit->Data2VecVision
class Data2VecVisionOutput(nn.Module):
def __init__(self, config: Data2VecVisionConfig) -> None:
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
return hidden_states
# Copied from transformers.models.beit.modeling_beit.BeitLayer with Beit->Data2VecVision,BEiT->Data2VecVision
class Data2VecVisionLayer(nn.Module):
"""This corresponds to the Block class in the timm implementation."""
def __init__(
self, config: Data2VecVisionConfig, window_size: Optional[tuple] = None, drop_path_rate: float = 0.0
) -> None:
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = Data2VecVisionAttention(config, window_size=window_size)
self.intermediate = Data2VecVisionIntermediate(config)
self.output = Data2VecVisionOutput(config)
self.layernorm_before = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.drop_path = Data2VecVisionDropPath(drop_path_rate) if drop_path_rate > 0.0 else nn.Identity()
self.layernorm_after = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
init_values = config.layer_scale_init_value
if init_values > 0:
self.lambda_1 = nn.Parameter(init_values * torch.ones((config.hidden_size)), requires_grad=True)
self.lambda_2 = nn.Parameter(init_values * torch.ones((config.hidden_size)), requires_grad=True)
else:
self.lambda_1, self.lambda_2 = None, None
def forward(
self,
hidden_states: torch.Tensor,
head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
relative_position_bias: Optional["Data2VecVisionRelativePositionBias"] = None,
interpolate_pos_encoding: bool = False,
resolution: Optional[Tuple[int]] = None,
) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
self_attention_outputs = self.attention(
self.layernorm_before(hidden_states), # in Data2VecVision, layernorm is applied before self-attention
head_mask,
output_attentions=output_attentions,
relative_position_bias=relative_position_bias,
interpolate_pos_encoding=interpolate_pos_encoding,
resolution=resolution,
)
attention_output = self_attention_outputs[0]
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
# apply lambda_1 if present
if self.lambda_1 is not None:
attention_output = self.lambda_1 * attention_output
# first residual connection
hidden_states = self.drop_path(attention_output) + hidden_states
# in Data2VecVision, layernorm is also applied after self-attention
layer_output = self.layernorm_after(hidden_states)
layer_output = self.intermediate(layer_output)
layer_output = self.output(layer_output)
if self.lambda_2 is not None:
layer_output = self.lambda_2 * layer_output
# second residual connection
layer_output = self.drop_path(layer_output) + hidden_states
outputs = (layer_output,) + outputs
return outputs
# Copied from transformers.models.beit.modeling_beit.BeitRelativePositionBias with Beit->Data2VecVision
class Data2VecVisionRelativePositionBias(nn.Module):
def __init__(self, config: Data2VecVisionConfig, window_size: tuple) -> None:
super().__init__()
self.window_size = window_size
self.num_relative_distance = (2 * window_size[0] - 1) * (2 * window_size[1] - 1) + 3
self.relative_position_bias_table = nn.Parameter(
torch.zeros(self.num_relative_distance, config.num_attention_heads)
) # 2*Wh-1 * 2*Ww-1, nH
# cls to token & token 2 cls & cls to cls
self.relative_position_indices = {}
def generate_relative_position_index(self, window_size: Tuple[int, int]) -> torch.Tensor:
"""
This method creates the relative position index, modified to support arbitrary window sizes,
as introduced in [MiDaS v3.1](https://arxiv.org/abs/2307.14460).
"""
num_relative_distance = (2 * window_size[0] - 1) * (2 * window_size[1] - 1) + 3
# cls to token & token 2 cls & cls to cls
# get pair-wise relative position index for each token inside the window
window_area = window_size[0] * window_size[1]
grid = torch.meshgrid(torch.arange(window_size[0]), torch.arange(window_size[1]), indexing="ij")
coords = torch.stack(grid) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += window_size[1] - 1
relative_coords[:, :, 0] *= 2 * window_size[1] - 1
relative_position_index = torch.zeros(size=(window_area + 1,) * 2, dtype=relative_coords.dtype)
relative_position_index[1:, 1:] = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
relative_position_index[0, 0:] = num_relative_distance - 3
relative_position_index[0:, 0] = num_relative_distance - 2
relative_position_index[0, 0] = num_relative_distance - 1
return relative_position_index
def forward(self, window_size, interpolate_pos_encoding: bool = False, dim_size=None) -> torch.Tensor:
"""
Modification of timm.models.beit.py: Attention._get_rel_pos_bias to support arbitrary window sizes.
"""
old_height = 2 * self.window_size[0] - 1
old_width = 2 * self.window_size[1] - 1
new_height = 2 * window_size[0] - 1
new_width = 2 * window_size[1] - 1
old_relative_position_bias_table = self.relative_position_bias_table
old_num_relative_distance = self.num_relative_distance
new_num_relative_distance = new_height * new_width + 3
old_sub_table = old_relative_position_bias_table[: old_num_relative_distance - 3]
old_sub_table = old_sub_table.reshape(1, old_width, old_height, -1).permute(0, 3, 1, 2)
new_sub_table = nn.functional.interpolate(
old_sub_table, size=(torch_int(new_height), torch_int(new_width)), mode="bilinear"
)
new_sub_table = new_sub_table.permute(0, 2, 3, 1).reshape(new_num_relative_distance - 3, -1)
new_relative_position_bias_table = torch.cat(
[new_sub_table, old_relative_position_bias_table[old_num_relative_distance - 3 :]]
)
key = window_size
if key not in self.relative_position_indices.keys():
self.relative_position_indices[key] = self.generate_relative_position_index(window_size)
relative_position_bias = new_relative_position_bias_table[self.relative_position_indices[key].view(-1)]
# patch_size*num_patches_height, patch_size*num_patches_width, num_attention_heads
relative_position_bias = relative_position_bias.view(
window_size[0] * window_size[1] + 1, window_size[0] * window_size[1] + 1, -1
)
# num_attention_heads, patch_size*num_patches_width, patch_size*num_patches_height
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
if interpolate_pos_encoding:
relative_position_bias = nn.functional.interpolate(
relative_position_bias.unsqueeze(1),
size=(dim_size, dim_size),
mode="bilinear",
align_corners=False,
).squeeze(1)
return relative_position_bias.unsqueeze(0)
# Copied from transformers.models.beit.modeling_beit.BeitEncoder with Beit->Data2VecVision
class Data2VecVisionEncoder(nn.Module):
def __init__(self, config: Data2VecVisionConfig, window_size: Optional[tuple] = None) -> None:
super().__init__()
self.config = config
if config.use_shared_relative_position_bias:
self.relative_position_bias = Data2VecVisionRelativePositionBias(config, window_size=window_size)
else:
self.relative_position_bias = None
# stochastic depth decay rule
dpr = [x.item() for x in torch.linspace(0, config.drop_path_rate, config.num_hidden_layers)]
self.layer = nn.ModuleList(
[
Data2VecVisionLayer(
config,
window_size=window_size if config.use_relative_position_bias else None,
drop_path_rate=dpr[i],
)
for i in range(config.num_hidden_layers)
]
)
self.gradient_checkpointing = False
def forward(
self,
hidden_states: torch.Tensor,
head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
output_hidden_states: bool = False,
interpolate_pos_encoding: bool = False,
resolution: Optional[Tuple[int]] = None,
return_dict: bool = True,
) -> Union[tuple, BaseModelOutput]:
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
layer_module.__call__,
hidden_states,
layer_head_mask,
output_attentions,
)
else:
height, width = resolution
window_size = (height // self.config.patch_size, width // self.config.patch_size)
relative_position_bias = (
self.relative_position_bias(
window_size, interpolate_pos_encoding=interpolate_pos_encoding, dim_size=hidden_states.shape[1]
)
if self.relative_position_bias is not None
else None
)
layer_outputs = layer_module(
hidden_states,
layer_head_mask,
output_attentions,
relative_position_bias,
interpolate_pos_encoding,
resolution,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
# Copied from transformers.models.beit.modeling_beit.BeitPreTrainedModel with Beit->Data2VecVision,beit->data2vec_vision
class Data2VecVisionPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = Data2VecVisionConfig
base_model_prefix = "data2vec_vision"
main_input_name = "pixel_values"
supports_gradient_checkpointing = True
_no_split_modules = ["Data2VecVisionLayer"]
_keys_to_ignore_on_load_unexpected = [r".*relative_position_index.*"]
_supports_sdpa = True
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, (nn.Linear, nn.Conv2d, nn.ConvTranspose2d)):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
DATA2VEC_VISION_START_DOCSTRING = r"""
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
Parameters:
config ([`Data2VecVisionConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
DATA2VEC_VISION_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
[`BeitImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
interpolate_pos_encoding (`bool`, *optional*, defaults to `False`):
Whether to interpolate the pre-trained position encodings.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
@add_start_docstrings(
"The bare Data2VecVision Model transformer outputting raw hidden-states without any specific head on top.",
DATA2VEC_VISION_START_DOCSTRING,
)
# Copied from transformers.models.beit.modeling_beit.BeitModel with BEIT->DATA2VEC_VISION,Beit->Data2VecVision,True->False
class Data2VecVisionModel(Data2VecVisionPreTrainedModel):
def __init__(self, config: Data2VecVisionConfig, add_pooling_layer: bool = False) -> None:
super().__init__(config)
self.config = config
self.embeddings = Data2VecVisionEmbeddings(config)
self.encoder = Data2VecVisionEncoder(config, window_size=self.embeddings.patch_embeddings.patch_shape)
self.layernorm = (
nn.Identity() if config.use_mean_pooling else nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
)
self.pooler = Data2VecVisionPooler(config) if add_pooling_layer else None
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.embeddings.patch_embeddings
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward(DATA2VEC_VISION_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=Data2VecVisionModelOutputWithPooling,
config_class=_CONFIG_FOR_DOC,
modality="vision",
expected_output=_EXPECTED_OUTPUT_SHAPE,
)
def forward(
self,
pixel_values: torch.Tensor,
bool_masked_pos: Optional[torch.BoolTensor] = None,
head_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
interpolate_pos_encoding: bool = False,
return_dict: Optional[bool] = None,
) -> Union[tuple, Data2VecVisionModelOutputWithPooling]:
r"""
bool_masked_pos (`torch.BoolTensor` of shape `(batch_size, num_patches)`, *optional*):
Boolean masked positions. Indicates which patches are masked (1) and which aren't (0).
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output, _ = self.embeddings(
pixel_values, bool_masked_pos=bool_masked_pos, interpolate_pos_encoding=interpolate_pos_encoding
)
resolution = pixel_values.shape[2:]
encoder_outputs = self.encoder(
embedding_output,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
resolution=resolution,
return_dict=return_dict,
interpolate_pos_encoding=interpolate_pos_encoding,
)
sequence_output = encoder_outputs[0]
sequence_output = self.layernorm(sequence_output)
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
if not return_dict:
head_outputs = (sequence_output, pooled_output) if pooled_output is not None else (sequence_output,)
return head_outputs + encoder_outputs[1:]
return Data2VecVisionModelOutputWithPooling(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
# Copied from transformers.models.beit.modeling_beit.BeitPooler with Beit->Data2VecVision
class Data2VecVisionPooler(nn.Module):
def __init__(self, config: Data2VecVisionConfig) -> None:
super().__init__()
self.layernorm = (
nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps) if config.use_mean_pooling else None
)
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
if self.layernorm is not None:
# Mean pool the final hidden states of the patch tokens
patch_tokens = hidden_states[:, 1:, :]
pooled_output = self.layernorm(patch_tokens.mean(1))
else:
# Pool by simply taking the final hidden state of the [CLS] token
pooled_output = hidden_states[:, 0]
return pooled_output
@add_start_docstrings(
"""
Data2VecVision Model transformer with an image classification head on top (a linear layer on top of the average of
the final hidden states of the patch tokens) e.g. for ImageNet.
""",
DATA2VEC_VISION_START_DOCSTRING,
)
# Copied from transformers.models.beit.modeling_beit.BeitForImageClassification with BEIT->DATA2VEC_VISION,Beit->Data2VecVision,beit->data2vec_vision
class Data2VecVisionForImageClassification(Data2VecVisionPreTrainedModel):
def __init__(self, config: Data2VecVisionConfig) -> None:
super().__init__(config)
self.num_labels = config.num_labels
self.data2vec_vision = Data2VecVisionModel(config, add_pooling_layer=True)
# Classifier head
self.classifier = nn.Linear(config.hidden_size, config.num_labels) if config.num_labels > 0 else nn.Identity()
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(DATA2VEC_VISION_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_IMAGE_CLASS_CHECKPOINT,
output_type=ImageClassifierOutput,
config_class=_CONFIG_FOR_DOC,
expected_output=_IMAGE_CLASS_EXPECTED_OUTPUT,
)
def forward(
self,
pixel_values: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
interpolate_pos_encoding: bool = False,
return_dict: Optional[bool] = None,
) -> Union[tuple, ImageClassifierOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the image classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.data2vec_vision(
pixel_values,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
interpolate_pos_encoding=interpolate_pos_encoding,
return_dict=return_dict,
)
pooled_output = outputs.pooler_output if return_dict else outputs[1]
logits = self.classifier(pooled_output)
loss = None
if labels is not None:
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return ImageClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
# Copied from transformers.models.beit.modeling_beit.BeitConvModule with Beit->Data2VecVision
class Data2VecVisionConvModule(nn.Module):
"""
A convolutional block that bundles conv/norm/activation layers. This block simplifies the usage of convolution
layers, which are commonly used with a norm layer (e.g., BatchNorm) and activation layer (e.g., ReLU).
Based on OpenMMLab's implementation, found in https://github.com/open-mmlab/mmsegmentation.
"""
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: Union[int, Tuple[int, int]],
padding: Union[int, Tuple[int, int], str] = 0,
bias: bool = False,
dilation: Union[int, Tuple[int, int]] = 1,
) -> None:
super().__init__()
self.conv = nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
padding=padding,
bias=bias,
dilation=dilation,
)
self.bn = nn.BatchNorm2d(out_channels)
self.activation = nn.ReLU()
def forward(self, input: torch.Tensor) -> torch.Tensor:
output = self.conv(input)
output = self.bn(output)
output = self.activation(output)
return output
# Copied from transformers.models.beit.modeling_beit.BeitPyramidPoolingBlock with Beit->Data2VecVision
class Data2VecVisionPyramidPoolingBlock(nn.Module):
def __init__(self, pool_scale: int, in_channels: int, channels: int) -> None:
super().__init__()
self.layers = [
nn.AdaptiveAvgPool2d(pool_scale),
Data2VecVisionConvModule(in_channels, channels, kernel_size=1),
]
for i, layer in enumerate(self.layers):
self.add_module(str(i), layer)
def forward(self, input: torch.Tensor) -> torch.Tensor:
hidden_state = input
for layer in self.layers:
hidden_state = layer(hidden_state)
return hidden_state
# Copied from transformers.models.beit.modeling_beit.BeitPyramidPoolingModule with Beit->Data2VecVision
class Data2VecVisionPyramidPoolingModule(nn.Module):
"""
Pyramid Pooling Module (PPM) used in PSPNet.
Args:
pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
Module.
in_channels (int): Input channels.
channels (int): Channels after modules, before conv_seg.
align_corners (bool): align_corners argument of F.interpolate.
Based on OpenMMLab's implementation, found in https://github.com/open-mmlab/mmsegmentation.
"""
def __init__(self, pool_scales: Tuple[int, ...], in_channels: int, channels: int, align_corners: bool) -> None:
super().__init__()
self.pool_scales = pool_scales
self.align_corners = align_corners
self.in_channels = in_channels
self.channels = channels
self.blocks = []
for i, pool_scale in enumerate(pool_scales):
block = Data2VecVisionPyramidPoolingBlock(
pool_scale=pool_scale, in_channels=in_channels, channels=channels
)
self.blocks.append(block)
self.add_module(str(i), block)
def forward(self, x: torch.Tensor) -> List[torch.Tensor]:
ppm_outs = []
for ppm in self.blocks:
ppm_out = ppm(x)
upsampled_ppm_out = nn.functional.interpolate(
ppm_out, size=x.size()[2:], mode="bilinear", align_corners=self.align_corners
)
ppm_outs.append(upsampled_ppm_out)
return ppm_outs
# Copied from transformers.models.beit.modeling_beit.BeitUperHead with Beit->Data2VecVision
class Data2VecVisionUperHead(nn.Module):
"""
Unified Perceptual Parsing for Scene Understanding. This head is the implementation of
[UPerNet](https://arxiv.org/abs/1807.10221).
Based on OpenMMLab's implementation, found in https://github.com/open-mmlab/mmsegmentation.
"""
def __init__(self, config: Data2VecVisionConfig) -> None:
super().__init__()
self.pool_scales = config.pool_scales # e.g. (1, 2, 3, 6)
self.in_channels = [config.hidden_size] * 4 # e.g. [768, 768, 768, 768]
self.channels = config.hidden_size
self.align_corners = False
self.classifier = nn.Conv2d(self.channels, config.num_labels, kernel_size=1)
# PSP Module
self.psp_modules = Data2VecVisionPyramidPoolingModule(
self.pool_scales,
self.in_channels[-1],
self.channels,
align_corners=self.align_corners,
)
self.bottleneck = Data2VecVisionConvModule(
self.in_channels[-1] + len(self.pool_scales) * self.channels,
self.channels,
kernel_size=3,
padding=1,
)
# FPN Module
self.lateral_convs = nn.ModuleList()
self.fpn_convs = nn.ModuleList()
for in_channels in self.in_channels[:-1]: # skip the top layer
l_conv = Data2VecVisionConvModule(in_channels, self.channels, kernel_size=1)
fpn_conv = Data2VecVisionConvModule(self.channels, self.channels, kernel_size=3, padding=1)
self.lateral_convs.append(l_conv)
self.fpn_convs.append(fpn_conv)
self.fpn_bottleneck = Data2VecVisionConvModule(
len(self.in_channels) * self.channels,
self.channels,
kernel_size=3,
padding=1,
)
def psp_forward(self, inputs):
x = inputs[-1]
psp_outs = [x]
psp_outs.extend(self.psp_modules(x))
psp_outs = torch.cat(psp_outs, dim=1)
output = self.bottleneck(psp_outs)
return output
def forward(self, encoder_hidden_states: torch.Tensor) -> torch.Tensor:
# build laterals
laterals = [lateral_conv(encoder_hidden_states[i]) for i, lateral_conv in enumerate(self.lateral_convs)]
laterals.append(self.psp_forward(encoder_hidden_states))
# build top-down path
used_backbone_levels = len(laterals)
for i in range(used_backbone_levels - 1, 0, -1):
prev_shape = laterals[i - 1].shape[2:]
laterals[i - 1] = laterals[i - 1] + nn.functional.interpolate(
laterals[i], size=prev_shape, mode="bilinear", align_corners=self.align_corners
)
# build outputs
fpn_outs = [self.fpn_convs[i](laterals[i]) for i in range(used_backbone_levels - 1)]
# append psp feature
fpn_outs.append(laterals[-1])
for i in range(used_backbone_levels - 1, 0, -1):
fpn_outs[i] = nn.functional.interpolate(
fpn_outs[i], size=fpn_outs[0].shape[2:], mode="bilinear", align_corners=self.align_corners
)
fpn_outs = torch.cat(fpn_outs, dim=1)
output = self.fpn_bottleneck(fpn_outs)
output = self.classifier(output)
return output
# Copied from transformers.models.beit.modeling_beit.BeitFCNHead with Beit->Data2VecVision
class Data2VecVisionFCNHead(nn.Module):
"""
Fully Convolution Networks for Semantic Segmentation. This head is implemented of
[FCNNet](https://arxiv.org/abs/1411.4038>).
Args:
config (Data2VecVisionConfig): Configuration.
in_channels
kernel_size (int): The kernel size for convs in the head. Default: 3.
dilation (int): The dilation rate for convs in the head. Default: 1.
Based on OpenMMLab's implementation, found in https://github.com/open-mmlab/mmsegmentation.
"""
def __init__(
self,
config: Data2VecVisionConfig,
in_index: int = 2,
kernel_size: int = 3,
dilation: Union[int, Tuple[int, int]] = 1,
) -> None:
super().__init__()
self.in_channels = config.hidden_size
self.channels = config.auxiliary_channels
self.num_convs = config.auxiliary_num_convs
self.concat_input = config.auxiliary_concat_input
self.in_index = in_index
conv_padding = (kernel_size // 2) * dilation
convs = []
convs.append(
Data2VecVisionConvModule(
self.in_channels, self.channels, kernel_size=kernel_size, padding=conv_padding, dilation=dilation
)
)
for i in range(self.num_convs - 1):
convs.append(
Data2VecVisionConvModule(
self.channels, self.channels, kernel_size=kernel_size, padding=conv_padding, dilation=dilation
)
)
if self.num_convs == 0:
self.convs = nn.Identity()
else:
self.convs = nn.Sequential(*convs)
if self.concat_input:
self.conv_cat = Data2VecVisionConvModule(
self.in_channels + self.channels, self.channels, kernel_size=kernel_size, padding=kernel_size // 2
)
self.classifier = nn.Conv2d(self.channels, config.num_labels, kernel_size=1)
def forward(self, encoder_hidden_states: torch.Tensor) -> torch.Tensor:
# just take the relevant feature maps
hidden_states = encoder_hidden_states[self.in_index]
output = self.convs(hidden_states)
if self.concat_input:
output = self.conv_cat(torch.cat([hidden_states, output], dim=1))
output = self.classifier(output)
return output
@add_start_docstrings(
"""
Data2VecVision Model transformer with a semantic segmentation head on top e.g. for ADE20k, CityScapes.
""",
DATA2VEC_VISION_START_DOCSTRING,
)
# Copied from transformers.models.beit.modeling_beit.BeitForSemanticSegmentation with BEIT->DATA2VEC_VISION,Beit->Data2VecVision,microsoft/beit-base-finetuned-ade-640-640->facebook/data2vec-vision-base,beit->data2vec_vision
class Data2VecVisionForSemanticSegmentation(Data2VecVisionPreTrainedModel):
def __init__(self, config: Data2VecVisionConfig) -> None:
super().__init__(config)
self.num_labels = config.num_labels
self.data2vec_vision = Data2VecVisionModel(config, add_pooling_layer=False)
# FPNs
if len(self.config.out_indices) != 4:
raise ValueError(
"Data2VecVisionForSemanticSegmentation requires config.out_indices to be a list of 4 integers, "
"specifying which features to use from the backbone. One can use [3, 5, 7, 11] in case of "
"a base-sized architecture."
)
self.fpn1 = nn.Sequential(
nn.ConvTranspose2d(config.hidden_size, config.hidden_size, kernel_size=2, stride=2),
nn.BatchNorm2d(config.hidden_size),
nn.GELU(),
nn.ConvTranspose2d(config.hidden_size, config.hidden_size, kernel_size=2, stride=2),
)
self.fpn2 = nn.Sequential(
nn.ConvTranspose2d(config.hidden_size, config.hidden_size, kernel_size=2, stride=2),
)
self.fpn3 = nn.Identity()
self.fpn4 = nn.MaxPool2d(kernel_size=2, stride=2)
# Semantic segmentation head(s)
self.decode_head = Data2VecVisionUperHead(config)
self.auxiliary_head = Data2VecVisionFCNHead(config) if config.use_auxiliary_head else None
# Initialize weights and apply final processing
self.post_init()
def compute_loss(self, logits, auxiliary_logits, labels):
# upsample logits to the images' original size
upsampled_logits = nn.functional.interpolate(
logits, size=labels.shape[-2:], mode="bilinear", align_corners=False
)
if auxiliary_logits is not None:
upsampled_auxiliary_logits = nn.functional.interpolate(
auxiliary_logits, size=labels.shape[-2:], mode="bilinear", align_corners=False
)
# compute weighted loss
loss_fct = CrossEntropyLoss(ignore_index=self.config.semantic_loss_ignore_index)
main_loss = loss_fct(upsampled_logits, labels)
loss = main_loss
if auxiliary_logits is not None:
auxiliary_loss = loss_fct(upsampled_auxiliary_logits, labels)
loss += self.config.auxiliary_loss_weight * auxiliary_loss
return loss
@add_start_docstrings_to_model_forward(DATA2VEC_VISION_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=SemanticSegmenterOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
pixel_values: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
interpolate_pos_encoding: bool = False,
return_dict: Optional[bool] = None,
) -> Union[tuple, SemanticSegmenterOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Ground truth semantic segmentation maps for computing the loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels > 1`, a classification loss is computed (Cross-Entropy).
Returns:
Examples:
```python
>>> from transformers import AutoImageProcessor, Data2VecVisionForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("facebook/data2vec-vision-base")
>>> model = Data2VecVisionForSemanticSegmentation.from_pretrained("facebook/data2vec-vision-base")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # logits are of shape (batch_size, num_labels, height, width)
>>> logits = outputs.logits
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
if labels is not None and self.config.num_labels == 1:
raise ValueError("The number of labels should be greater than one")
outputs = self.data2vec_vision(
pixel_values,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=True, # we need the intermediate hidden states
interpolate_pos_encoding=interpolate_pos_encoding,
return_dict=return_dict,
)
encoder_hidden_states = outputs.hidden_states if return_dict else outputs[1]
# only keep certain features, and reshape
# note that we do +1 as the encoder_hidden_states also includes the initial embeddings
features = [feature for idx, feature in enumerate(encoder_hidden_states) if idx + 1 in self.config.out_indices]
batch_size = pixel_values.shape[0]
patch_resolution = self.config.image_size // self.config.patch_size
features = [
x[:, 1:, :].permute(0, 2, 1).reshape(batch_size, -1, patch_resolution, patch_resolution) for x in features
]
# apply FPNs
ops = [self.fpn1, self.fpn2, self.fpn3, self.fpn4]
for i in range(len(features)):
features[i] = ops[i](features[i])
logits = self.decode_head(features)
auxiliary_logits = None
if self.auxiliary_head is not None:
auxiliary_logits = self.auxiliary_head(features)
loss = None
if labels is not None:
loss = self.compute_loss(logits, auxiliary_logits, labels)
if not return_dict:
if output_hidden_states:
output = (logits,) + outputs[1:]
else:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return SemanticSegmenterOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states if output_hidden_states else None,
attentions=outputs.attentions,
)
__all__ = [
"Data2VecVisionForImageClassification",
"Data2VecVisionForSemanticSegmentation",
"Data2VecVisionModel",
"Data2VecVisionPreTrainedModel",
]
| transformers/src/transformers/models/data2vec/modeling_data2vec_vision.py/0 | {
"file_path": "transformers/src/transformers/models/data2vec/modeling_data2vec_vision.py",
"repo_id": "transformers",
"token_count": 27191
} |
# coding=utf-8
# Copyright 2020 Microsoft and the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Fast Tokenization class for model DeBERTa."""
import os
from shutil import copyfile
from typing import Optional, Tuple
from ...file_utils import is_sentencepiece_available
from ...tokenization_utils_fast import PreTrainedTokenizerFast
from ...utils import logging
if is_sentencepiece_available():
from .tokenization_deberta_v2 import DebertaV2Tokenizer
else:
DebertaV2Tokenizer = None
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "spm.model", "tokenizer_file": "tokenizer.json"}
class DebertaV2TokenizerFast(PreTrainedTokenizerFast):
r"""
Constructs a DeBERTa-v2 fast tokenizer. Based on [SentencePiece](https://github.com/google/sentencepiece).
Args:
vocab_file (`str`):
[SentencePiece](https://github.com/google/sentencepiece) file (generally has a *.spm* extension) that
contains the vocabulary necessary to instantiate a tokenizer.
do_lower_case (`bool`, *optional*, defaults to `False`):
Whether or not to lowercase the input when tokenizing.
bos_token (`string`, *optional*, defaults to `"[CLS]"`):
The beginning of sequence token that was used during pre-training. Can be used a sequence classifier token.
When building a sequence using special tokens, this is not the token that is used for the beginning of
sequence. The token used is the `cls_token`.
eos_token (`string`, *optional*, defaults to `"[SEP]"`):
The end of sequence token. When building a sequence using special tokens, this is not the token that is
used for the end of sequence. The token used is the `sep_token`.
unk_token (`str`, *optional*, defaults to `"[UNK]"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
sep_token (`str`, *optional*, defaults to `"[SEP]"`):
The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for
sequence classification or for a text and a question for question answering. It is also used as the last
token of a sequence built with special tokens.
pad_token (`str`, *optional*, defaults to `"[PAD]"`):
The token used for padding, for example when batching sequences of different lengths.
cls_token (`str`, *optional*, defaults to `"[CLS]"`):
The classifier token which is used when doing sequence classification (classification of the whole sequence
instead of per-token classification). It is the first token of the sequence when built with special tokens.
mask_token (`str`, *optional*, defaults to `"[MASK]"`):
The token used for masking values. This is the token used when training this model with masked language
modeling. This is the token which the model will try to predict.
sp_model_kwargs (`dict`, *optional*):
Will be passed to the `SentencePieceProcessor.__init__()` method. The [Python wrapper for
SentencePiece](https://github.com/google/sentencepiece/tree/master/python) can be used, among other things,
to set:
- `enable_sampling`: Enable subword regularization.
- `nbest_size`: Sampling parameters for unigram. Invalid for BPE-Dropout.
- `nbest_size = {0,1}`: No sampling is performed.
- `nbest_size > 1`: samples from the nbest_size results.
- `nbest_size < 0`: assuming that nbest_size is infinite and samples from the all hypothesis (lattice)
using forward-filtering-and-backward-sampling algorithm.
- `alpha`: Smoothing parameter for unigram sampling, and dropout probability of merge operations for
BPE-dropout.
"""
vocab_files_names = VOCAB_FILES_NAMES
slow_tokenizer_class = DebertaV2Tokenizer
def __init__(
self,
vocab_file=None,
tokenizer_file=None,
do_lower_case=False,
split_by_punct=False,
bos_token="[CLS]",
eos_token="[SEP]",
unk_token="[UNK]",
sep_token="[SEP]",
pad_token="[PAD]",
cls_token="[CLS]",
mask_token="[MASK]",
**kwargs,
) -> None:
super().__init__(
vocab_file,
tokenizer_file=tokenizer_file,
do_lower_case=do_lower_case,
bos_token=bos_token,
eos_token=eos_token,
unk_token=unk_token,
sep_token=sep_token,
pad_token=pad_token,
cls_token=cls_token,
mask_token=mask_token,
split_by_punct=split_by_punct,
**kwargs,
)
self.do_lower_case = do_lower_case
self.split_by_punct = split_by_punct
self.vocab_file = vocab_file
@property
def can_save_slow_tokenizer(self) -> bool:
return os.path.isfile(self.vocab_file) if self.vocab_file else False
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. A DeBERTa sequence has the following format:
- single sequence: [CLS] X [SEP]
- pair of sequences: [CLS] A [SEP] B [SEP]
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
if token_ids_1 is None:
return [self.cls_token_id] + token_ids_0 + [self.sep_token_id]
cls = [self.cls_token_id]
sep = [self.sep_token_id]
return cls + token_ids_0 + sep + token_ids_1 + sep
def get_special_tokens_mask(self, token_ids_0, token_ids_1=None, already_has_special_tokens=False):
"""
Retrieves sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer `prepare_for_model` or `encode_plus` methods.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not the token list is already formatted with special tokens for the model.
Returns:
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
"""
if already_has_special_tokens:
return super().get_special_tokens_mask(
token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
)
if token_ids_1 is not None:
return [1] + ([0] * len(token_ids_0)) + [1] + ([0] * len(token_ids_1)) + [1]
return [1] + ([0] * len(token_ids_0)) + [1]
def create_token_type_ids_from_sequences(self, token_ids_0, token_ids_1=None):
"""
Create a mask from the two sequences passed to be used in a sequence-pair classification task. A DeBERTa
sequence pair mask has the following format:
```
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
```
If `token_ids_1` is `None`, this method only returns the first portion of the mask (0s).
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [token type IDs](../glossary#token-type-ids) according to the given sequence(s).
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep) * [0] + len(token_ids_1 + sep) * [1]
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
if not self.can_save_slow_tokenizer:
raise ValueError(
"Your fast tokenizer does not have the necessary information to save the vocabulary for a slow "
"tokenizer."
)
if not os.path.isdir(save_directory):
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
return
out_vocab_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
)
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file):
copyfile(self.vocab_file, out_vocab_file)
return (out_vocab_file,)
__all__ = ["DebertaV2TokenizerFast"]
| transformers/src/transformers/models/deberta_v2/tokenization_deberta_v2_fast.py/0 | {
"file_path": "transformers/src/transformers/models/deberta_v2/tokenization_deberta_v2_fast.py",
"repo_id": "transformers",
"token_count": 4079
} |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Convert EfficientFormer checkpoints from the original repository.
URL: https://github.com/snap-research/EfficientFormer
"""
import argparse
import re
from pathlib import Path
import requests
import torch
from PIL import Image
from torchvision.transforms import CenterCrop, Compose, Normalize, Resize, ToTensor
from transformers import (
EfficientFormerConfig,
EfficientFormerForImageClassificationWithTeacher,
EfficientFormerImageProcessor,
)
from transformers.image_utils import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD, PILImageResampling
def rename_key(old_name, num_meta4D_last_stage):
new_name = old_name
if "patch_embed" in old_name:
_, layer, param = old_name.split(".")
if layer == "0":
new_name = old_name.replace("0", "convolution1")
elif layer == "1":
new_name = old_name.replace("1", "batchnorm_before")
elif layer == "3":
new_name = old_name.replace("3", "convolution2")
else:
new_name = old_name.replace("4", "batchnorm_after")
if "network" in old_name and re.search(r"\d\.\d", old_name):
two_digit_num = r"\b\d{2}\b"
if bool(re.search(two_digit_num, old_name)):
match = re.search(r"\d\.\d\d.", old_name).group()
else:
match = re.search(r"\d\.\d.", old_name).group()
if int(match[0]) < 6:
trimmed_name = old_name.replace(match, "")
trimmed_name = trimmed_name.replace("network", match[0] + ".meta4D_layers.blocks." + match[2:-1])
new_name = "intermediate_stages." + trimmed_name
else:
trimmed_name = old_name.replace(match, "")
if int(match[2]) < num_meta4D_last_stage:
trimmed_name = trimmed_name.replace("network", "meta4D_layers.blocks." + match[2])
else:
layer_index = str(int(match[2]) - num_meta4D_last_stage)
trimmed_name = trimmed_name.replace("network", "meta3D_layers.blocks." + layer_index)
if "norm1" in old_name:
trimmed_name = trimmed_name.replace("norm1", "layernorm1")
elif "norm2" in old_name:
trimmed_name = trimmed_name.replace("norm2", "layernorm2")
elif "fc1" in old_name:
trimmed_name = trimmed_name.replace("fc1", "linear_in")
elif "fc2" in old_name:
trimmed_name = trimmed_name.replace("fc2", "linear_out")
new_name = "last_stage." + trimmed_name
elif "network" in old_name and re.search(r".\d.", old_name):
new_name = old_name.replace("network", "intermediate_stages")
if "fc" in new_name:
new_name = new_name.replace("fc", "convolution")
elif ("norm1" in new_name) and ("layernorm1" not in new_name):
new_name = new_name.replace("norm1", "batchnorm_before")
elif ("norm2" in new_name) and ("layernorm2" not in new_name):
new_name = new_name.replace("norm2", "batchnorm_after")
if "proj" in new_name:
new_name = new_name.replace("proj", "projection")
if "dist_head" in new_name:
new_name = new_name.replace("dist_head", "distillation_classifier")
elif "head" in new_name:
new_name = new_name.replace("head", "classifier")
elif "patch_embed" in new_name:
new_name = "efficientformer." + new_name
elif new_name == "norm.weight" or new_name == "norm.bias":
new_name = new_name.replace("norm", "layernorm")
new_name = "efficientformer." + new_name
else:
new_name = "efficientformer.encoder." + new_name
return new_name
def convert_torch_checkpoint(checkpoint, num_meta4D_last_stage):
for key in checkpoint.copy().keys():
val = checkpoint.pop(key)
checkpoint[rename_key(key, num_meta4D_last_stage)] = val
return checkpoint
# We will verify our results on a COCO image
def prepare_img():
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
return image
def convert_efficientformer_checkpoint(
checkpoint_path: Path, efficientformer_config_file: Path, pytorch_dump_path: Path, push_to_hub: bool
):
orig_state_dict = torch.load(checkpoint_path, map_location="cpu")["model"]
config = EfficientFormerConfig.from_json_file(efficientformer_config_file)
model = EfficientFormerForImageClassificationWithTeacher(config)
model_name = "_".join(checkpoint_path.split("/")[-1].split(".")[0].split("_")[:-1])
num_meta4D_last_stage = config.depths[-1] - config.num_meta3d_blocks + 1
new_state_dict = convert_torch_checkpoint(orig_state_dict, num_meta4D_last_stage)
model.load_state_dict(new_state_dict)
model.eval()
pillow_resamplings = {
"bilinear": PILImageResampling.BILINEAR,
"bicubic": PILImageResampling.BICUBIC,
"nearest": PILImageResampling.NEAREST,
}
# prepare image
image = prepare_img()
image_size = 256
crop_size = 224
processor = EfficientFormerImageProcessor(
size={"shortest_edge": image_size},
crop_size={"height": crop_size, "width": crop_size},
resample=pillow_resamplings["bicubic"],
)
pixel_values = processor(images=image, return_tensors="pt").pixel_values
# original processing pipeline
image_transforms = Compose(
[
Resize(image_size, interpolation=pillow_resamplings["bicubic"]),
CenterCrop(crop_size),
ToTensor(),
Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD),
]
)
original_pixel_values = image_transforms(image).unsqueeze(0)
assert torch.allclose(original_pixel_values, pixel_values)
outputs = model(pixel_values)
logits = outputs.logits
expected_shape = (1, 1000)
if "l1" in model_name:
expected_logits = torch.Tensor(
[-0.1312, 0.4353, -1.0499, -0.5124, 0.4183, -0.6793, -1.3777, -0.0893, -0.7358, -2.4328]
)
assert torch.allclose(logits[0, :10], expected_logits, atol=1e-3)
assert logits.shape == expected_shape
elif "l3" in model_name:
expected_logits = torch.Tensor(
[-1.3150, -1.5456, -1.2556, -0.8496, -0.7127, -0.7897, -0.9728, -0.3052, 0.3751, -0.3127]
)
assert torch.allclose(logits[0, :10], expected_logits, atol=1e-3)
assert logits.shape == expected_shape
elif "l7" in model_name:
expected_logits = torch.Tensor(
[-1.0283, -1.4131, -0.5644, -1.3115, -0.5785, -1.2049, -0.7528, 0.1992, -0.3822, -0.0878]
)
assert logits.shape == expected_shape
else:
raise ValueError(
f"Unknown model checkpoint: {checkpoint_path}. Supported version of efficientformer are l1, l3 and l7"
)
# Save Checkpoints
Path(pytorch_dump_path).mkdir(exist_ok=True)
model.save_pretrained(pytorch_dump_path)
print(f"Checkpoint successfuly converted. Model saved at {pytorch_dump_path}")
processor.save_pretrained(pytorch_dump_path)
print(f"Processor successfuly saved at {pytorch_dump_path}")
if push_to_hub:
print("Pushing model to the hub...")
model.push_to_hub(
repo_id=f"Bearnardd/{pytorch_dump_path}",
commit_message="Add model",
use_temp_dir=True,
)
processor.push_to_hub(
repo_id=f"Bearnardd/{pytorch_dump_path}",
commit_message="Add image processor",
use_temp_dir=True,
)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--pytorch_model_path",
default=None,
type=str,
required=True,
help="Path to EfficientFormer pytorch checkpoint.",
)
parser.add_argument(
"--config_file",
default=None,
type=str,
required=True,
help="The json file for EfficientFormer model config.",
)
parser.add_argument(
"--pytorch_dump_path", default=None, type=str, required=True, help="Path to the output PyTorch model."
)
parser.add_argument("--push_to_hub", action="store_true", help="Push model and image processor to the hub")
parser.add_argument(
"--no-push_to_hub",
dest="push_to_hub",
action="store_false",
help="Do not push model and image processor to the hub",
)
parser.set_defaults(push_to_hub=True)
args = parser.parse_args()
convert_efficientformer_checkpoint(
checkpoint_path=args.pytorch_model_path,
efficientformer_config_file=args.config_file,
pytorch_dump_path=args.pytorch_dump_path,
push_to_hub=args.push_to_hub,
)
| transformers/src/transformers/models/deprecated/efficientformer/convert_efficientformer_original_pytorch_checkpoint_to_pytorch.py/0 | {
"file_path": "transformers/src/transformers/models/deprecated/efficientformer/convert_efficientformer_original_pytorch_checkpoint_to_pytorch.py",
"repo_id": "transformers",
"token_count": 4066
} |
# coding=utf-8
# Copyright 2022 Microsoft, clefourrier and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Graphormer model configuration"""
from ....configuration_utils import PretrainedConfig
from ....utils import logging
logger = logging.get_logger(__name__)
class GraphormerConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`~GraphormerModel`]. It is used to instantiate an
Graphormer model according to the specified arguments, defining the model architecture. Instantiating a
configuration with the defaults will yield a similar configuration to that of the Graphormer
[graphormer-base-pcqm4mv1](https://huggingface.co/graphormer-base-pcqm4mv1) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
num_classes (`int`, *optional*, defaults to 1):
Number of target classes or labels, set to n for binary classification of n tasks.
num_atoms (`int`, *optional*, defaults to 512*9):
Number of node types in the graphs.
num_edges (`int`, *optional*, defaults to 512*3):
Number of edges types in the graph.
num_in_degree (`int`, *optional*, defaults to 512):
Number of in degrees types in the input graphs.
num_out_degree (`int`, *optional*, defaults to 512):
Number of out degrees types in the input graphs.
num_edge_dis (`int`, *optional*, defaults to 128):
Number of edge dis in the input graphs.
multi_hop_max_dist (`int`, *optional*, defaults to 20):
Maximum distance of multi hop edges between two nodes.
spatial_pos_max (`int`, *optional*, defaults to 1024):
Maximum distance between nodes in the graph attention bias matrices, used during preprocessing and
collation.
edge_type (`str`, *optional*, defaults to multihop):
Type of edge relation chosen.
max_nodes (`int`, *optional*, defaults to 512):
Maximum number of nodes which can be parsed for the input graphs.
share_input_output_embed (`bool`, *optional*, defaults to `False`):
Shares the embedding layer between encoder and decoder - careful, True is not implemented.
num_layers (`int`, *optional*, defaults to 12):
Number of layers.
embedding_dim (`int`, *optional*, defaults to 768):
Dimension of the embedding layer in encoder.
ffn_embedding_dim (`int`, *optional*, defaults to 768):
Dimension of the "intermediate" (often named feed-forward) layer in encoder.
num_attention_heads (`int`, *optional*, defaults to 32):
Number of attention heads in the encoder.
self_attention (`bool`, *optional*, defaults to `True`):
Model is self attentive (False not implemented).
activation_function (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"silu"` and `"gelu_new"` are supported.
dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for the attention weights.
activation_dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for the activation of the linear transformer layer.
layerdrop (`float`, *optional*, defaults to 0.0):
The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
for more details.
bias (`bool`, *optional*, defaults to `True`):
Uses bias in the attention module - unsupported at the moment.
embed_scale(`float`, *optional*, defaults to None):
Scaling factor for the node embeddings.
num_trans_layers_to_freeze (`int`, *optional*, defaults to 0):
Number of transformer layers to freeze.
encoder_normalize_before (`bool`, *optional*, defaults to `False`):
Normalize features before encoding the graph.
pre_layernorm (`bool`, *optional*, defaults to `False`):
Apply layernorm before self attention and the feed forward network. Without this, post layernorm will be
used.
apply_graphormer_init (`bool`, *optional*, defaults to `False`):
Apply a custom graphormer initialisation to the model before training.
freeze_embeddings (`bool`, *optional*, defaults to `False`):
Freeze the embedding layer, or train it along the model.
encoder_normalize_before (`bool`, *optional*, defaults to `False`):
Apply the layer norm before each encoder block.
q_noise (`float`, *optional*, defaults to 0.0):
Amount of quantization noise (see "Training with Quantization Noise for Extreme Model Compression"). (For
more detail, see fairseq's documentation on quant_noise).
qn_block_size (`int`, *optional*, defaults to 8):
Size of the blocks for subsequent quantization with iPQ (see q_noise).
kdim (`int`, *optional*, defaults to None):
Dimension of the key in the attention, if different from the other values.
vdim (`int`, *optional*, defaults to None):
Dimension of the value in the attention, if different from the other values.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models).
traceable (`bool`, *optional*, defaults to `False`):
Changes return value of the encoder's inner_state to stacked tensors.
Example:
```python
>>> from transformers import GraphormerForGraphClassification, GraphormerConfig
>>> # Initializing a Graphormer graphormer-base-pcqm4mv2 style configuration
>>> configuration = GraphormerConfig()
>>> # Initializing a model from the graphormer-base-pcqm4mv1 style configuration
>>> model = GraphormerForGraphClassification(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```
"""
model_type = "graphormer"
keys_to_ignore_at_inference = ["past_key_values"]
def __init__(
self,
num_classes: int = 1,
num_atoms: int = 512 * 9,
num_edges: int = 512 * 3,
num_in_degree: int = 512,
num_out_degree: int = 512,
num_spatial: int = 512,
num_edge_dis: int = 128,
multi_hop_max_dist: int = 5, # sometimes is 20
spatial_pos_max: int = 1024,
edge_type: str = "multi_hop",
max_nodes: int = 512,
share_input_output_embed: bool = False,
num_hidden_layers: int = 12,
embedding_dim: int = 768,
ffn_embedding_dim: int = 768,
num_attention_heads: int = 32,
dropout: float = 0.1,
attention_dropout: float = 0.1,
activation_dropout: float = 0.1,
layerdrop: float = 0.0,
encoder_normalize_before: bool = False,
pre_layernorm: bool = False,
apply_graphormer_init: bool = False,
activation_fn: str = "gelu",
embed_scale: float = None,
freeze_embeddings: bool = False,
num_trans_layers_to_freeze: int = 0,
traceable: bool = False,
q_noise: float = 0.0,
qn_block_size: int = 8,
kdim: int = None,
vdim: int = None,
bias: bool = True,
self_attention: bool = True,
pad_token_id=0,
bos_token_id=1,
eos_token_id=2,
**kwargs,
):
self.num_classes = num_classes
self.num_atoms = num_atoms
self.num_in_degree = num_in_degree
self.num_out_degree = num_out_degree
self.num_edges = num_edges
self.num_spatial = num_spatial
self.num_edge_dis = num_edge_dis
self.edge_type = edge_type
self.multi_hop_max_dist = multi_hop_max_dist
self.spatial_pos_max = spatial_pos_max
self.max_nodes = max_nodes
self.num_hidden_layers = num_hidden_layers
self.embedding_dim = embedding_dim
self.hidden_size = embedding_dim
self.ffn_embedding_dim = ffn_embedding_dim
self.num_attention_heads = num_attention_heads
self.dropout = dropout
self.attention_dropout = attention_dropout
self.activation_dropout = activation_dropout
self.layerdrop = layerdrop
self.encoder_normalize_before = encoder_normalize_before
self.pre_layernorm = pre_layernorm
self.apply_graphormer_init = apply_graphormer_init
self.activation_fn = activation_fn
self.embed_scale = embed_scale
self.freeze_embeddings = freeze_embeddings
self.num_trans_layers_to_freeze = num_trans_layers_to_freeze
self.share_input_output_embed = share_input_output_embed
self.traceable = traceable
self.q_noise = q_noise
self.qn_block_size = qn_block_size
# These parameters are here for future extensions
# atm, the model only supports self attention
self.kdim = kdim
self.vdim = vdim
self.self_attention = self_attention
self.bias = bias
super().__init__(
pad_token_id=pad_token_id,
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
**kwargs,
)
| transformers/src/transformers/models/deprecated/graphormer/configuration_graphormer.py/0 | {
"file_path": "transformers/src/transformers/models/deprecated/graphormer/configuration_graphormer.py",
"repo_id": "transformers",
"token_count": 4097
} |
# coding=utf-8
# Copyright 2022 The REALM authors and The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""REALM model configuration."""
from ....configuration_utils import PretrainedConfig
from ....utils import logging
logger = logging.get_logger(__name__)
class RealmConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of
1. [`RealmEmbedder`]
2. [`RealmScorer`]
3. [`RealmKnowledgeAugEncoder`]
4. [`RealmRetriever`]
5. [`RealmReader`]
6. [`RealmForOpenQA`]
It is used to instantiate an REALM model according to the specified arguments, defining the model architecture.
Instantiating a configuration with the defaults will yield a similar configuration to that of the REALM
[google/realm-cc-news-pretrained-embedder](https://huggingface.co/google/realm-cc-news-pretrained-embedder)
architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 30522):
Vocabulary size of the REALM model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`RealmEmbedder`], [`RealmScorer`], [`RealmKnowledgeAugEncoder`], or
[`RealmReader`].
hidden_size (`int`, *optional*, defaults to 768):
Dimension of the encoder layers and the pooler layer.
retriever_proj_size (`int`, *optional*, defaults to 128):
Dimension of the retriever(embedder) projection.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
num_candidates (`int`, *optional*, defaults to 8):
Number of candidates inputted to the RealmScorer or RealmKnowledgeAugEncoder.
intermediate_size (`int`, *optional*, defaults to 3072):
Dimension of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
hidden_act (`str` or `function`, *optional*, defaults to `"gelu_new"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` are supported.
hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
The dropout ratio for the attention probabilities.
max_position_embeddings (`int`, *optional*, defaults to 512):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
type_vocab_size (`int`, *optional*, defaults to 2):
The vocabulary size of the `token_type_ids` passed when calling [`RealmEmbedder`], [`RealmScorer`],
[`RealmKnowledgeAugEncoder`], or [`RealmReader`].
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (`float`, *optional*, defaults to 1e-12):
The epsilon used by the layer normalization layers.
span_hidden_size (`int`, *optional*, defaults to 256):
Dimension of the reader's spans.
max_span_width (`int`, *optional*, defaults to 10):
Max span width of the reader.
reader_layer_norm_eps (`float`, *optional*, defaults to 1e-3):
The epsilon used by the reader's layer normalization layers.
reader_beam_size (`int`, *optional*, defaults to 5):
Beam size of the reader.
reader_seq_len (`int`, *optional*, defaults to 288+32):
Maximum sequence length of the reader.
num_block_records (`int`, *optional*, defaults to 13353718):
Number of block records.
searcher_beam_size (`int`, *optional*, defaults to 5000):
Beam size of the searcher. Note that when eval mode is enabled, *searcher_beam_size* will be the same as
*reader_beam_size*.
Example:
```python
>>> from transformers import RealmConfig, RealmEmbedder
>>> # Initializing a REALM realm-cc-news-pretrained-* style configuration
>>> configuration = RealmConfig()
>>> # Initializing a model (with random weights) from the google/realm-cc-news-pretrained-embedder style configuration
>>> model = RealmEmbedder(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "realm"
def __init__(
self,
vocab_size=30522,
hidden_size=768,
retriever_proj_size=128,
num_hidden_layers=12,
num_attention_heads=12,
num_candidates=8,
intermediate_size=3072,
hidden_act="gelu_new",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=2,
initializer_range=0.02,
layer_norm_eps=1e-12,
span_hidden_size=256,
max_span_width=10,
reader_layer_norm_eps=1e-3,
reader_beam_size=5,
reader_seq_len=320, # 288 + 32
num_block_records=13353718,
searcher_beam_size=5000,
pad_token_id=1,
bos_token_id=0,
eos_token_id=2,
**kwargs,
):
super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
# Common config
self.vocab_size = vocab_size
self.max_position_embeddings = max_position_embeddings
self.hidden_size = hidden_size
self.retriever_proj_size = retriever_proj_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.num_candidates = num_candidates
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.initializer_range = initializer_range
self.type_vocab_size = type_vocab_size
self.layer_norm_eps = layer_norm_eps
# Reader config
self.span_hidden_size = span_hidden_size
self.max_span_width = max_span_width
self.reader_layer_norm_eps = reader_layer_norm_eps
self.reader_beam_size = reader_beam_size
self.reader_seq_len = reader_seq_len
# Retrieval config
self.num_block_records = num_block_records
self.searcher_beam_size = searcher_beam_size
| transformers/src/transformers/models/deprecated/realm/configuration_realm.py/0 | {
"file_path": "transformers/src/transformers/models/deprecated/realm/configuration_realm.py",
"repo_id": "transformers",
"token_count": 2947
} |
# coding=utf-8
# Copyright 2022 Microsoft Research and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tokenization classes for TAPEX."""
import json
import os
import random
from functools import lru_cache
from typing import Dict, List, Optional, Tuple, Union
import regex as re
from ....file_utils import ExplicitEnum, PaddingStrategy, TensorType, add_end_docstrings, is_pandas_available
from ....tokenization_utils import AddedToken, PreTrainedTokenizer
from ....tokenization_utils_base import ENCODE_KWARGS_DOCSTRING, BatchEncoding, TextInput, TruncationStrategy
from ....utils import logging
if is_pandas_available():
import pandas as pd
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt"}
class TapexTruncationStrategy(ExplicitEnum):
"""
Possible values for the `truncation` argument in [`~TapasTokenizer.__call__`]. Useful for tab-completion in an IDE.
"""
DROP_ROWS_TO_FIT = "drop_rows_to_fit"
TAPEX_ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING = r"""
add_special_tokens (`bool`, *optional*, defaults to `True`):
Whether or not to encode the sequences with the special tokens relative to their model.
padding (`bool`, `str` or [`~file_utils.PaddingStrategy`], *optional*, defaults to `False`):
Activates and controls padding. Accepts the following values:
- `True` or `'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
- `'max_length'`: Pad to a maximum length specified with the argument `max_length` or to the maximum
acceptable input length for the model if that argument is not provided.
- `False` or `'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of different
lengths).
truncation (`bool`, `str`, [`TapexTruncationStrategy`] or [`~tokenization_utils_base.TruncationStrategy`],
*optional*, defaults to `False`):
Activates and controls truncation. Accepts the following values:
- `'drop_rows_to_fit'`: Truncate to a maximum length specified with the argument `max_length` or to the
maximum acceptable input length for the model if that argument is not provided. This will truncate
row by row, removing rows from the table.
- `True` or `'longest_first'`: Truncate to a maximum length specified with the argument `max_length` or
to the maximum acceptable input length for the model if that argument is not provided. This will
truncate token by token, removing a token from the longest sequence in the pair if a pair of
sequences (or a batch of pairs) is provided.
- `'only_first'`: Truncate to a maximum length specified with the argument `max_length` or to the
maximum acceptable input length for the model if that argument is not provided. This will only
truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.
- `'only_second'`: Truncate to a maximum length specified with the argument `max_length` or to the
maximum acceptable input length for the model if that argument is not provided. This will only
truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.
- `False` or `'do_not_truncate'` (default): No truncation (i.e., can output batch with sequence lengths
greater than the model maximum admissible input size).
max_length (`int`, *optional*):
Controls the maximum length to use by one of the truncation/padding parameters. If left unset or set to
`None`, this will use the predefined model maximum length if a maximum length is required by one of the
truncation/padding parameters. If the model has no specific maximum input length (like XLNet)
truncation/padding to a maximum length will be deactivated.
stride (`int`, *optional*, defaults to 0):
If set to a number along with `max_length`, the overflowing tokens returned when
`return_overflowing_tokens=True` will contain some tokens from the end of the truncated sequence
returned to provide some overlap between truncated and overflowing sequences. The value of this
argument defines the number of overlapping tokens.
pad_to_multiple_of (`int`, *optional*):
If set will pad the sequence to a multiple of the provided value. This is especially useful to enable
the use of Tensor Cores on NVIDIA hardware with compute capability `>= 7.5` (Volta).
return_tensors (`str` or [`~file_utils.TensorType`], *optional*):
If set, will return tensors instead of list of python integers. Acceptable values are:
- `'tf'`: Return TensorFlow `tf.constant` objects.
- `'pt'`: Return PyTorch `torch.Tensor` objects.
- `'np'`: Return Numpy `np.ndarray` objects.
"""
@lru_cache()
def bytes_to_unicode():
"""
Returns list of utf-8 byte and a mapping to unicode strings. We specifically avoids mapping to whitespace/control
characters the bpe code barfs on. The reversible bpe codes work on unicode strings. This means you need a large #
of unicode characters in your vocab if you want to avoid UNKs. When you're at something like a 10B token dataset
you end up needing around 5K for decent coverage. This is a significant percentage of your normal, say, 32K bpe
vocab. To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
"""
bs = (
list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1))
)
cs = bs[:]
n = 0
for b in range(2**8):
if b not in bs:
bs.append(b)
cs.append(2**8 + n)
n += 1
cs = [chr(n) for n in cs]
return dict(zip(bs, cs))
def get_pairs(word):
"""
Return set of symbol pairs in a word. Word is represented as tuple of symbols (symbols being variable-length
strings).
"""
pairs = set()
prev_char = word[0]
for char in word[1:]:
pairs.add((prev_char, char))
prev_char = char
return pairs
class IndexedRowTableLinearize:
"""
FORMAT: col: col1 | col2 | col 3 row 1 : val1 | val2 | val3 row 2 : ...
"""
def process_table(self, table_content: Dict):
"""
Given a table, TableLinearize aims at converting it into a flatten sequence with special symbols.
"""
assert "header" in table_content and "rows" in table_content, self.PROMPT_MESSAGE
# process header
table_str = self.process_header(table_content["header"]) + " "
# process rows
for i, row_example in enumerate(table_content["rows"]):
# NOTE: the row should start from row 1 instead of 0
table_str += self.process_row(row_example, row_index=i + 1) + " "
return table_str.strip()
def process_header(self, headers: List):
"""
Given a list of headers, TableLinearize aims at converting it into a flatten sequence with special symbols.
"""
return "col : " + " | ".join(headers)
def process_row(self, row: List, row_index: int):
"""
Given a row, TableLinearize aims at converting it into a flatten sequence with special symbols.
"""
row_str = ""
row_cell_values = []
for cell_value in row:
if isinstance(cell_value, int):
row_cell_values.append(str(cell_value))
else:
row_cell_values.append(cell_value)
row_str += " | ".join(row_cell_values)
return "row " + str(row_index) + " : " + row_str
class TapexTokenizer(PreTrainedTokenizer):
r"""
Construct a TAPEX tokenizer. Based on byte-level Byte-Pair-Encoding (BPE).
This tokenizer can be used to flatten one or more table(s) and concatenate them with one or more related sentences
to be used by TAPEX models. The format that the TAPEX tokenizer creates is the following:
sentence col: col1 | col2 | col 3 row 1 : val1 | val2 | val3 row 2 : ...
The tokenizer supports a single table + single query, a single table and multiple queries (in which case the table
will be duplicated for every query), a single query and multiple tables (in which case the query will be duplicated
for every table), and multiple tables and queries. In other words, you can provide a batch of tables + questions to
the tokenizer for instance to prepare them for the model.
Tokenization itself is based on the BPE algorithm. It is identical to the one used by BART, RoBERTa and GPT-2.
This tokenizer inherits from [`PreTrainedTokenizer`] which contains most of the main methods. Users should refer to
this superclass for more information regarding those methods.
Args:
vocab_file (`str`):
Path to the vocabulary file.
merges_file (`str`):
Path to the merges file.
do_lower_case (`bool`, *optional*, defaults to `True`):
Whether or not to lowercase the input when tokenizing.
errors (`str`, *optional*, defaults to `"replace"`):
Paradigm to follow when decoding bytes to UTF-8. See
[bytes.decode](https://docs.python.org/3/library/stdtypes.html#bytes.decode) for more information.
bos_token (`str`, *optional*, defaults to `"<s>"`):
The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.
<Tip>
When building a sequence using special tokens, this is not the token that is used for the beginning of
sequence. The token used is the `cls_token`.
</Tip>
eos_token (`str`, *optional*, defaults to `"</s>"`):
The end of sequence token.
<Tip>
When building a sequence using special tokens, this is not the token that is used for the end of sequence.
The token used is the `sep_token`.
</Tip>
sep_token (`str`, *optional*, defaults to `"</s>"`):
The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for
sequence classification or for a text and a question for question answering. It is also used as the last
token of a sequence built with special tokens.
cls_token (`str`, *optional*, defaults to `"<s>"`):
The classifier token which is used when doing sequence classification (classification of the whole sequence
instead of per-token classification). It is the first token of the sequence when built with special tokens.
unk_token (`str`, *optional*, defaults to `"<unk>"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
pad_token (`str`, *optional*, defaults to `"<pad>"`):
The token used for padding, for example when batching sequences of different lengths.
mask_token (`str`, *optional*, defaults to `"<mask>"`):
The token used for masking values. This is the token used when training this model with masked language
modeling. This is the token which the model will try to predict.
add_prefix_space (`bool`, *optional*, defaults to `False`):
Whether or not to add an initial space to the input. This allows to treat the leading word just as any
other word. (BART tokenizer detect beginning of words by the preceding space).
max_cell_length (`int`, *optional*, defaults to 15):
Maximum number of characters per cell when linearizing a table. If this number is exceeded, truncation
takes place.
"""
vocab_files_names = VOCAB_FILES_NAMES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
self,
vocab_file,
merges_file,
do_lower_case=True,
errors="replace",
bos_token="<s>",
eos_token="</s>",
sep_token="</s>",
cls_token="<s>",
unk_token="<unk>",
pad_token="<pad>",
mask_token="<mask>",
add_prefix_space=False,
max_cell_length=15,
**kwargs,
):
bos_token = AddedToken(bos_token, lstrip=False, rstrip=False) if isinstance(bos_token, str) else bos_token
eos_token = AddedToken(eos_token, lstrip=False, rstrip=False) if isinstance(eos_token, str) else eos_token
sep_token = AddedToken(sep_token, lstrip=False, rstrip=False) if isinstance(sep_token, str) else sep_token
cls_token = AddedToken(cls_token, lstrip=False, rstrip=False) if isinstance(cls_token, str) else cls_token
unk_token = AddedToken(unk_token, lstrip=False, rstrip=False) if isinstance(unk_token, str) else unk_token
pad_token = AddedToken(pad_token, lstrip=False, rstrip=False) if isinstance(pad_token, str) else pad_token
# Mask token behave like a normal word, i.e. include the space before it
mask_token = AddedToken(mask_token, lstrip=True, rstrip=False) if isinstance(mask_token, str) else mask_token
with open(vocab_file, encoding="utf-8") as vocab_handle:
self.encoder = json.load(vocab_handle)
self.decoder = {v: k for k, v in self.encoder.items()}
self.errors = errors # how to handle errors in decoding
self.byte_encoder = bytes_to_unicode()
self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
with open(merges_file, encoding="utf-8") as merges_handle:
bpe_merges = merges_handle.read().split("\n")[1:-1]
bpe_merges = [tuple(merge.split()) for merge in bpe_merges]
self.bpe_ranks = dict(zip(bpe_merges, range(len(bpe_merges))))
self.cache = {}
self.add_prefix_space = add_prefix_space
self.do_lower_case = do_lower_case
# Should have added re.IGNORECASE so BPE merges can happen for capitalized versions of contractions
self.pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")
# additional properties
super().__init__(
vocab_file=vocab_file,
merges_file=merges_file,
do_lower_case=do_lower_case,
errors=errors,
bos_token=bos_token,
eos_token=eos_token,
unk_token=unk_token,
sep_token=sep_token,
cls_token=cls_token,
pad_token=pad_token,
mask_token=mask_token,
add_prefix_space=add_prefix_space,
max_cell_length=max_cell_length,
**kwargs,
)
self.max_cell_length = max_cell_length
self.table_linearize = IndexedRowTableLinearize()
def build_inputs_with_special_tokens(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. A TAPEX sequence has the following format:
- single sequence: `<s> X </s>`
- pair of sequences: `<s> A </s></s> B </s>`
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
if token_ids_1 is None:
return [self.cls_token_id] + token_ids_0 + [self.sep_token_id]
cls = [self.cls_token_id]
sep = [self.sep_token_id]
return cls + token_ids_0 + sep + sep + token_ids_1 + sep
def get_special_tokens_mask(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
) -> List[int]:
"""
Args:
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer `prepare_for_model` method.
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not the token list is already formatted with special tokens for the model.
Returns:
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
"""
if already_has_special_tokens:
return super().get_special_tokens_mask(
token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
)
if token_ids_1 is None:
return [1] + ([0] * len(token_ids_0)) + [1]
return [1] + ([0] * len(token_ids_0)) + [1, 1] + ([0] * len(token_ids_1)) + [1]
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Args:
Create a mask from the two sequences passed to be used in a sequence-pair classification task. TAPEX does not:
make use of token type ids, therefore a list of zeros is returned.
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of zeros.
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep + sep + token_ids_1 + sep) * [0]
def prepare_for_tokenization(self, text, is_split_into_words=False, **kwargs):
add_prefix_space = kwargs.pop("add_prefix_space", self.add_prefix_space)
if (is_split_into_words or add_prefix_space) and (len(text) > 0 and not text[0].isspace()):
text = " " + text
return (text, kwargs)
@property
def vocab_size(self):
return len(self.encoder)
def get_vocab(self):
return dict(self.encoder, **self.added_tokens_encoder)
def bpe(self, token):
if token in self.cache:
return self.cache[token]
word = tuple(token)
pairs = get_pairs(word)
if not pairs:
return token
while True:
bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float("inf")))
if bigram not in self.bpe_ranks:
break
first, second = bigram
new_word = []
i = 0
while i < len(word):
try:
j = word.index(first, i)
except ValueError:
new_word.extend(word[i:])
break
else:
new_word.extend(word[i:j])
i = j
if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
new_word.append(first + second)
i += 2
else:
new_word.append(word[i])
i += 1
new_word = tuple(new_word)
word = new_word
if len(word) == 1:
break
else:
pairs = get_pairs(word)
word = " ".join(word)
self.cache[token] = word
return word
def _tokenize(self, text):
"""Tokenize a string."""
bpe_tokens = []
for token in re.findall(self.pat, text):
token = "".join(
self.byte_encoder[b] for b in token.encode("utf-8")
) # Maps all our bytes to unicode strings, avoiding control tokens of the BPE (spaces in our case)
bpe_tokens.extend(bpe_token for bpe_token in self.bpe(token).split(" "))
return bpe_tokens
def _convert_token_to_id(self, token):
"""Converts a token (str) in an id using the vocab."""
return self.encoder.get(token, self.encoder.get(self.unk_token))
def _convert_id_to_token(self, index):
"""Converts an index (integer) in a token (str) using the vocab."""
return self.decoder.get(index)
def convert_tokens_to_string(self, tokens):
"""Converts a sequence of tokens (string) in a single string."""
text = "".join(tokens)
text = bytearray([self.byte_decoder[c] for c in text]).decode("utf-8", errors=self.errors)
return text
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
if not os.path.isdir(save_directory):
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
return
vocab_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
)
merge_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["merges_file"]
)
with open(vocab_file, "w", encoding="utf-8") as f:
f.write(json.dumps(self.encoder, indent=2, sort_keys=True, ensure_ascii=False) + "\n")
index = 0
with open(merge_file, "w", encoding="utf-8") as writer:
writer.write("#version: 0.2\n")
for bpe_tokens, token_index in sorted(self.bpe_ranks.items(), key=lambda kv: kv[1]):
if index != token_index:
logger.warning(
f"Saving vocabulary to {merge_file}: BPE merge indices are not consecutive."
" Please check that the tokenizer is not corrupted!"
)
index = token_index
writer.write(" ".join(bpe_tokens) + "\n")
index += 1
return vocab_file, merge_file
@add_end_docstrings(ENCODE_KWARGS_DOCSTRING, TAPEX_ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING)
def __call__(
self,
table: Union["pd.DataFrame", List["pd.DataFrame"]] = None,
query: Optional[Union[TextInput, List[TextInput]]] = None,
answer: Union[str, List[str]] = None,
add_special_tokens: bool = True,
padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str, TruncationStrategy] = None,
max_length: Optional[int] = None,
stride: int = 0,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_offsets_mapping: bool = False,
return_length: bool = False,
verbose: bool = True,
**kwargs,
) -> BatchEncoding:
"""
Main method to tokenize and prepare for the model one or several table-sequence pair(s).
Args:
table (`pd.DataFrame`, `List[pd.DataFrame]`):
Table(s) containing tabular data.
query (`str` or `List[str]`, *optional*):
Sentence or batch of sentences related to one or more table(s) to be encoded. Note that the number of
sentences must match the number of tables.
answer (`str` or `List[str]`, *optional*):
Optionally, the corresponding answer to the questions as supervision.
"""
if table is not None:
return self.source_call_func(
table=table,
query=query,
answer=answer,
add_special_tokens=add_special_tokens,
padding=padding,
truncation=truncation,
max_length=max_length,
stride=stride,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors=return_tensors,
return_token_type_ids=return_token_type_ids,
return_attention_mask=return_attention_mask,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_offsets_mapping=return_offsets_mapping,
return_length=return_length,
verbose=verbose,
**kwargs,
)
elif answer is not None:
return self.target_call_func(
answer=answer,
add_special_tokens=add_special_tokens,
padding=padding,
truncation=truncation,
max_length=max_length,
stride=stride,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors=return_tensors,
return_token_type_ids=return_token_type_ids,
return_attention_mask=return_attention_mask,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_offsets_mapping=return_offsets_mapping,
return_length=return_length,
verbose=verbose,
**kwargs,
)
else:
raise ValueError("You need to provide either a `table` or an `answer`.")
def source_call_func(
self,
table: Union["pd.DataFrame", List["pd.DataFrame"]],
query: Optional[Union[TextInput, List[TextInput]]] = None,
answer: Union[str, List[str]] = None,
add_special_tokens: bool = True,
padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str, TruncationStrategy] = None,
max_length: Optional[int] = None,
stride: int = 0,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_offsets_mapping: bool = False,
return_length: bool = False,
verbose: bool = True,
**kwargs,
) -> BatchEncoding:
# Input type checking for clearer error
valid_table = False
valid_query = False
# Check that table have a valid type
if isinstance(table, pd.DataFrame):
valid_table = True
elif isinstance(table, (list, tuple)) and isinstance(table[0], pd.DataFrame):
valid_table = True
# Check that query have a valid type
if query is None or isinstance(query, str):
valid_query = True
elif isinstance(query, (list, tuple)):
if len(query) == 0 or isinstance(query[0], str):
valid_query = True
if not valid_table:
raise ValueError(
"table input must of type `pd.DataFrame` (single example), `List[pd.DataFrame]` (batch of examples). "
)
if not valid_query:
raise ValueError("query input must of type `str` (single example), `List[str]` (batch of examples). ")
is_batched = isinstance(table, (list, tuple)) or isinstance(query, (list, tuple))
if is_batched:
return self.batch_encode_plus(
table=table,
query=query,
answer=answer,
add_special_tokens=add_special_tokens,
padding=padding,
truncation=truncation,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors=return_tensors,
return_token_type_ids=return_token_type_ids,
return_attention_mask=return_attention_mask,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_offsets_mapping=return_offsets_mapping,
return_length=return_length,
verbose=verbose,
**kwargs,
)
else:
return self.encode_plus(
table=table,
query=query,
answer=answer,
add_special_tokens=add_special_tokens,
padding=padding,
truncation=truncation,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors=return_tensors,
return_token_type_ids=return_token_type_ids,
return_attention_mask=return_attention_mask,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_offsets_mapping=return_offsets_mapping,
return_length=return_length,
verbose=verbose,
**kwargs,
)
@add_end_docstrings(ENCODE_KWARGS_DOCSTRING, TAPEX_ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING)
def batch_encode_plus(
self,
table: Union["pd.DataFrame", List["pd.DataFrame"]],
query: Optional[List[TextInput]] = None,
answer: List[str] = None,
add_special_tokens: bool = True,
padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str] = None,
max_length: Optional[int] = None,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_offsets_mapping: bool = False,
return_length: bool = False,
verbose: bool = True,
**kwargs,
) -> BatchEncoding:
"""
<Tip warning={true}>
This method is deprecated, `__call__` should be used instead.
</Tip>
"""
# Backward compatibility for 'truncation_strategy', 'pad_to_max_length'
padding_strategy, truncation_strategy, max_length, kwargs = self._get_padding_truncation_strategies(
padding=padding,
truncation=truncation,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
verbose=verbose,
**kwargs,
)
return self._batch_encode_plus(
table=table,
query=query,
answer=answer,
add_special_tokens=add_special_tokens,
padding_strategy=padding_strategy,
truncation_strategy=truncation_strategy,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors=return_tensors,
return_token_type_ids=return_token_type_ids,
return_attention_mask=return_attention_mask,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_offsets_mapping=return_offsets_mapping,
return_length=return_length,
verbose=verbose,
**kwargs,
)
def _batch_encode_plus(
self,
table: Union["pd.DataFrame", List["pd.DataFrame"]],
query: Optional[List[TextInput]] = None,
answer: Optional[List[str]] = None,
add_special_tokens: bool = True,
padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
truncation_strategy: TruncationStrategy = TruncationStrategy.DO_NOT_TRUNCATE,
max_length: Optional[int] = None,
stride: int = 0,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_offsets_mapping: bool = False,
return_length: bool = False,
verbose: bool = True,
**kwargs,
) -> BatchEncoding:
if return_offsets_mapping:
raise NotImplementedError(
"return_offset_mapping is not available when using Python tokenizers. "
"To use this feature, change your tokenizer to one deriving from "
"transformers.PreTrainedTokenizerFast."
)
if isinstance(table, pd.DataFrame) and isinstance(query, (list, tuple)):
# single table, many queries case
# duplicate table for every query
table = [table] * len(query)
if isinstance(table, (list, tuple)) and isinstance(query, str):
# many tables, single query case
# duplicate query for every table
query = [query] * len(table)
batch_outputs = self._batch_prepare_for_model(
table=table,
query=query,
answer=answer,
add_special_tokens=add_special_tokens,
padding_strategy=padding_strategy,
truncation_strategy=truncation_strategy,
max_length=max_length,
stride=stride,
pad_to_multiple_of=pad_to_multiple_of,
return_attention_mask=return_attention_mask,
return_token_type_ids=return_token_type_ids,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_length=return_length,
return_tensors=return_tensors,
verbose=verbose,
)
return BatchEncoding(batch_outputs)
@add_end_docstrings(ENCODE_KWARGS_DOCSTRING, TAPEX_ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING)
def _batch_prepare_for_model(
self,
table: Union["pd.DataFrame", List["pd.DataFrame"]],
query: Optional[Union[TextInput, List[TextInput]]] = None,
answer: Optional[Union[str, List[str]]] = None,
add_special_tokens: bool = True,
padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
truncation_strategy: TruncationStrategy = TruncationStrategy.DO_NOT_TRUNCATE,
max_length: Optional[int] = None,
stride: int = 0,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[str] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_length: bool = False,
verbose: bool = True,
) -> BatchEncoding:
"""
This method adds special tokens, truncates sequences if overflowing while taking into account the special
tokens and manages a moving window (with user defined stride) for overflowing tokens.
"""
batch_outputs = {}
if answer is None:
answer = [None] * len(table)
for _table, _query, _answer in zip(table, query, answer):
text = self.prepare_table_query(
_table, _query, _answer, truncation_strategy=truncation_strategy, max_length=max_length
)
if self.do_lower_case:
text = text.lower()
tokens = self.tokenize(text)
outputs = self.prepare_for_model(
ids=self.convert_tokens_to_ids(tokens),
add_special_tokens=add_special_tokens,
padding=PaddingStrategy.DO_NOT_PAD.value, # we pad in batch afterwards
truncation=truncation_strategy.value,
max_length=max_length,
stride=stride,
pad_to_multiple_of=None, # we pad in batch afterwards
return_attention_mask=False, # we pad in batch afterwards
return_token_type_ids=return_token_type_ids,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_length=return_length,
return_tensors=None, # We convert the whole batch to tensors at the end
prepend_batch_axis=False,
verbose=verbose,
)
for key, value in outputs.items():
if key not in batch_outputs:
batch_outputs[key] = []
batch_outputs[key].append(value)
batch_outputs = self.pad(
batch_outputs,
padding=padding_strategy.value,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_attention_mask=return_attention_mask,
)
batch_outputs = BatchEncoding(batch_outputs, tensor_type=return_tensors)
return batch_outputs
@add_end_docstrings(ENCODE_KWARGS_DOCSTRING)
def encode(
self,
table: "pd.DataFrame",
query: Optional[TextInput] = None,
answer: Optional[str] = None,
add_special_tokens: bool = True,
padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str, TruncationStrategy, TapexTruncationStrategy] = None,
max_length: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
**kwargs,
) -> List[int]:
"""
Prepare a table, a string and possible answer for the model. This method does not return token type IDs,
attention masks, etc. which are necessary for the model to work correctly. Use this method if you want to build
your processing on your own, otherwise refer to `__call__`.
"""
encoded_inputs = self.encode_plus(
table,
query=query,
answer=answer,
add_special_tokens=add_special_tokens,
padding=padding,
truncation=truncation,
max_length=max_length,
return_tensors=return_tensors,
**kwargs,
)
return encoded_inputs["input_ids"]
@add_end_docstrings(ENCODE_KWARGS_DOCSTRING, TAPEX_ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING)
def encode_plus(
self,
table: "pd.DataFrame",
query: Optional[TextInput] = None,
answer: Optional[str] = None,
add_special_tokens: bool = True,
padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str] = None,
max_length: Optional[int] = None,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_special_tokens_mask: bool = False,
return_offsets_mapping: bool = False,
return_length: bool = False,
verbose: bool = True,
**kwargs,
) -> BatchEncoding:
# Backward compatibility for 'truncation_strategy', 'pad_to_max_length'
padding_strategy, truncation_strategy, max_length, kwargs = self._get_padding_truncation_strategies(
padding=padding,
truncation=truncation,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
verbose=verbose,
**kwargs,
)
return self._encode_plus(
table=table,
query=query,
answer=answer,
add_special_tokens=add_special_tokens,
padding_strategy=padding_strategy,
truncation_strategy=truncation_strategy,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors=return_tensors,
return_token_type_ids=return_token_type_ids,
return_attention_mask=return_attention_mask,
return_special_tokens_mask=return_special_tokens_mask,
return_offsets_mapping=return_offsets_mapping,
return_length=return_length,
verbose=verbose,
**kwargs,
)
def _encode_plus(
self,
table: "pd.DataFrame",
query: Optional[TextInput] = None,
answer: Optional[str] = None,
add_special_tokens: bool = True,
padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
truncation_strategy: TruncationStrategy = TruncationStrategy.DO_NOT_TRUNCATE,
max_length: Optional[int] = None,
stride: int = 0,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_offsets_mapping: bool = False,
return_length: bool = False,
verbose: bool = True,
**kwargs,
) -> BatchEncoding:
if return_offsets_mapping:
raise NotImplementedError(
"return_offset_mapping is not available when using Python tokenizers. "
"To use this feature, change your tokenizer to one deriving from "
"transformers.PreTrainedTokenizerFast. "
"More information on available tokenizers at "
"https://github.com/huggingface/transformers/pull/2674"
)
text = self.prepare_table_query(
table, query, answer, truncation_strategy=truncation_strategy, max_length=max_length
)
# if necessary, perform lower case
if self.do_lower_case:
text = text.lower()
tokens = self.tokenize(text)
return self.prepare_for_model(
ids=self.convert_tokens_to_ids(tokens),
add_special_tokens=add_special_tokens,
padding=padding_strategy.value,
truncation=truncation_strategy.value,
max_length=max_length,
stride=stride,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors=return_tensors,
prepend_batch_axis=True,
return_attention_mask=return_attention_mask,
return_token_type_ids=return_token_type_ids,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_length=return_length,
verbose=verbose,
)
def target_call_func(
self,
answer: Union[str, List[str]],
add_special_tokens: bool = True,
padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str, TruncationStrategy] = None,
max_length: Optional[int] = None,
stride: int = 0,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_offsets_mapping: bool = False,
return_length: bool = False,
verbose: bool = True,
**kwargs,
) -> BatchEncoding:
"""
The method tokenizes and prepares the answer label for the model.
Args:
answer (`str` or `List[str]`):
Corresponding answer supervision to the queries for training the model.
"""
is_batched = isinstance(answer, (list, tuple))
if is_batched:
return self.target_batch_encode_plus(
answer=answer,
add_special_tokens=add_special_tokens,
padding=padding,
truncation=truncation,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors=return_tensors,
return_token_type_ids=return_token_type_ids,
return_attention_mask=return_attention_mask,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_offsets_mapping=return_offsets_mapping,
return_length=return_length,
verbose=verbose,
**kwargs,
)
else:
return self.target_encode_plus(
answer=answer,
add_special_tokens=add_special_tokens,
padding=padding,
truncation=truncation,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors=return_tensors,
return_token_type_ids=return_token_type_ids,
return_attention_mask=return_attention_mask,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_offsets_mapping=return_offsets_mapping,
return_length=return_length,
verbose=verbose,
**kwargs,
)
def target_batch_encode_plus(
self,
answer: List[str],
add_special_tokens: bool = True,
padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str] = None,
max_length: Optional[int] = None,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_offsets_mapping: bool = False,
return_length: bool = False,
verbose: bool = True,
**kwargs,
) -> BatchEncoding:
"""
Prepare answer strings for the model.
Args:
answer `List[str]`:
Corresponding answer supervision to the queries for training the model.
"""
# Backward compatibility for 'truncation_strategy', 'pad_to_max_length'
padding_strategy, truncation_strategy, max_length, kwargs = self._get_padding_truncation_strategies(
padding=padding,
truncation=truncation,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
verbose=verbose,
**kwargs,
)
return self._target_batch_encode_plus(
answer=answer,
add_special_tokens=add_special_tokens,
padding_strategy=padding_strategy,
truncation_strategy=truncation_strategy,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors=return_tensors,
return_token_type_ids=return_token_type_ids,
return_attention_mask=return_attention_mask,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_offsets_mapping=return_offsets_mapping,
return_length=return_length,
verbose=verbose,
**kwargs,
)
def _target_batch_encode_plus(
self,
answer: List[str],
add_special_tokens: bool = True,
padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
truncation_strategy: TruncationStrategy = TruncationStrategy.DO_NOT_TRUNCATE,
max_length: Optional[int] = None,
stride: int = 0,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_offsets_mapping: bool = False,
return_length: bool = False,
verbose: bool = True,
**kwargs,
) -> BatchEncoding:
batch_outputs = {}
for text in answer:
if self.do_lower_case:
text = text.lower()
tokens = self.tokenize(text)
outputs = self.prepare_for_model(
ids=self.convert_tokens_to_ids(tokens),
add_special_tokens=add_special_tokens,
padding=PaddingStrategy.DO_NOT_PAD.value, # we pad in batch afterwards
truncation=truncation_strategy.value,
max_length=max_length,
stride=stride,
pad_to_multiple_of=None, # we pad in batch afterwards
return_attention_mask=False, # we pad in batch afterwards
return_token_type_ids=return_token_type_ids,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_length=return_length,
return_tensors=None, # We convert the whole batch to tensors at the end
prepend_batch_axis=False,
verbose=verbose,
)
for key, value in outputs.items():
if key not in batch_outputs:
batch_outputs[key] = []
batch_outputs[key].append(value)
batch_outputs = self.pad(
batch_outputs,
padding=padding_strategy.value,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_attention_mask=return_attention_mask,
)
batch_outputs = BatchEncoding(batch_outputs, tensor_type=return_tensors)
return BatchEncoding(batch_outputs)
def target_encode(
self,
answer: str,
add_special_tokens: bool = True,
padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str, TruncationStrategy, TapexTruncationStrategy] = None,
max_length: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
**kwargs,
) -> List[int]:
"""
Prepare the answer string for the model. This method does not return token type IDs, attention masks, etc.
which are necessary for the model to work correctly. Use this method if you want to build your processing on
your own, otherwise refer to `__call__`.
Args:
answer `str`:
Corresponding answer supervision to the queries for training the model
"""
encoded_outputs = self.target_encode_plus(
answer=answer,
add_special_tokens=add_special_tokens,
padding=padding,
truncation=truncation,
max_length=max_length,
return_tensors=return_tensors,
**kwargs,
)
return encoded_outputs["input_ids"]
def target_encode_plus(
self,
answer: str,
add_special_tokens: bool = True,
padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str] = None,
max_length: Optional[int] = None,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_special_tokens_mask: bool = False,
return_offsets_mapping: bool = False,
return_length: bool = False,
verbose: bool = True,
**kwargs,
) -> BatchEncoding:
"""
Prepare a answer string for the model.
Args:
answer `str`:
Corresponding answer supervision to the queries for training the model.
"""
# Backward compatibility for 'truncation_strategy', 'pad_to_max_length'
padding_strategy, truncation_strategy, max_length, kwargs = self._get_padding_truncation_strategies(
padding=padding,
truncation=truncation,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
verbose=verbose,
**kwargs,
)
return self._target_encode_plus(
answer=answer,
add_special_tokens=add_special_tokens,
padding_strategy=padding_strategy,
truncation_strategy=truncation_strategy,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors=return_tensors,
return_token_type_ids=return_token_type_ids,
return_attention_mask=return_attention_mask,
return_special_tokens_mask=return_special_tokens_mask,
return_offsets_mapping=return_offsets_mapping,
return_length=return_length,
verbose=verbose,
**kwargs,
)
def _target_encode_plus(
self,
answer: str,
add_special_tokens: bool = True,
padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
truncation_strategy: TruncationStrategy = TruncationStrategy.DO_NOT_TRUNCATE,
max_length: Optional[int] = None,
stride: int = 0,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_offsets_mapping: bool = False,
return_length: bool = False,
verbose: bool = True,
**kwargs,
) -> BatchEncoding:
if return_offsets_mapping:
raise NotImplementedError(
"return_offset_mapping is not available when using Python tokenizers. "
"To use this feature, change your tokenizer to one deriving from "
"transformers.PreTrainedTokenizerFast. "
"More information on available tokenizers at "
"https://github.com/huggingface/transformers/pull/2674"
)
text = answer
# if necessary, perform lower case
if self.do_lower_case:
text = text.lower()
tokens = self.tokenize(text)
return self.prepare_for_model(
ids=self.convert_tokens_to_ids(tokens),
add_special_tokens=add_special_tokens,
padding=padding_strategy.value,
truncation=truncation_strategy.value,
max_length=max_length,
stride=stride,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors=return_tensors,
prepend_batch_axis=True,
return_attention_mask=return_attention_mask,
return_token_type_ids=return_token_type_ids,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_length=return_length,
verbose=verbose,
)
def prepare_table_query(
self,
table,
query,
answer=None,
truncation_strategy=Union[str, TruncationStrategy, TapexTruncationStrategy],
max_length=None,
):
"""
This method can be used to linearize a table and add a corresponding query.
Optionally, it also handles truncation of the table (cells).
An answer can be provided for more precise truncation.
"""
if not table.empty:
# step 1: create table dictionary
table_content = {"header": list(table.columns), "rows": [list(row.values) for i, row in table.iterrows()]}
# step 2: modify table internally
# always truncate table cells based on self.max_cell_length
# optionally truncate rows if truncation_strategy is set to it
self.truncate_table_cells(table_content, query, answer)
if truncation_strategy == TapexTruncationStrategy.DROP_ROWS_TO_FIT:
self.truncate_table_rows(table_content, query, answer, max_length=max_length)
# step 3: linearize table
linear_table = self.table_linearize.process_table(table_content)
else:
linear_table = ""
if linear_table == "":
logger.warning(
"You provide an empty table, or all cells contain much tokens (e.g., >= 1024 tokens). "
+ f"Please carefully check the corresponding table with the query : {query}."
)
if query == "":
logger.warning("You provide nothing to query with respect to the table.")
# step 4: concatenate query with linear_table
separator = " " if query and linear_table else ""
joint_input = (query + separator + linear_table) if query else linear_table
return joint_input
def truncate_table_cells(self, table_content: Dict, question: str, answer: List):
# TODO (Qian): is it possible to revert the original cell if it is in the final answer?
cell_mapping = {}
for row in table_content["rows"]:
for i, cell in enumerate(row):
truncate_cell = self.truncate_cell(cell)
if truncate_cell is not None:
cell_mapping[cell] = truncate_cell
row[i] = truncate_cell
# modify the answer list
if answer is not None:
for i, case in enumerate(answer):
if case in cell_mapping.keys():
answer[i] = cell_mapping[case]
def truncate_cell(self, cell_value):
# do not process on these cases
if isinstance(cell_value, int) or isinstance(cell_value, float):
return cell_value
if cell_value.strip() != "":
try_tokens = self.tokenize(cell_value)
if len(try_tokens) >= self.max_cell_length:
retain_tokens = try_tokens[: self.max_cell_length]
retain_cell_value = self.convert_tokens_to_string(retain_tokens)
return retain_cell_value
else:
return None
else:
return cell_value
def truncate_table_rows(
self, table_content: Dict, question: str, answer: Optional[Union[str, List[str]]] = None, max_length=None
):
"""
Args:
table_content:
{"header": xxx, "rows": xxx, "id" (Optionally): xxx}
question:
natural language sentence
answer:
if for training, is the supervision; otherwise will be empty
"""
delete_ratio, remain_token_len = self.estimate_delete_ratio(table_content, question, max_length)
# randomly delete unrelated rows
self.delete_unrelated_rows(table_content, question, answer, delete_ratio)
# guarantee the result < max_length
maximum_keep_rows = 0
for ind, row_example in enumerate(table_content["rows"]):
value_string = self.table_linearize.process_row(row_example, ind + 1)
value_token_len = len(self.tokenize(value_string))
# over the size limit, and take action
if value_token_len > remain_token_len:
break
remain_token_len -= value_token_len
maximum_keep_rows += 1
del table_content["rows"][maximum_keep_rows:]
def estimate_delete_ratio(self, table_content: Dict, question: str, max_length=None):
if "header" not in table_content or "rows" not in table_content:
raise ValueError("The table content should contain both 'header' and 'rows' keys.")
# calculate the tokens of header, special tokens will only be pre-prepended into question
question_tokens = self.tokenize(question, add_special_tokens=True)
# calculate the tokens of header
header_string = self.table_linearize.process_header(table_content["header"])
header_tokens = self.tokenize(header_string, add_special_tokens=False)
# split all cell values into tokens and see how many can be accommodated
used_token_len = len(question_tokens) + len(header_tokens)
# remaining token space for rows
remain_token_len = max_length - used_token_len
value_string = ""
for _, row_example in enumerate(table_content["rows"]):
# use a general index to roughly estimate the overall token len
value_string += self.table_linearize.process_row(row_example, 100) + " "
value_token_len = len(self.tokenize(value_string))
if value_token_len < remain_token_len:
# no row will be deleted
return 0.0, remain_token_len
else:
# calc a roughly delete rate
return 1.0 - remain_token_len / value_token_len, remain_token_len
def delete_unrelated_rows(self, table_content: Dict, question: str, answer: List, delete_ratio: float):
"""
The argument answer is used only during training.
"""
truncated_unrelated_indices = []
related_indices = []
if answer is None or len(answer) == 0:
answer_set = set()
else:
answer_set = {ans_ex.lower() for ans_ex in answer}
# add question key words into answer set
if question is not None:
answer_set.update(question.split())
question_set = set(question.strip("?!.,").split(" "))
row_max_len = len(table_content["rows"])
for _row_idx, row in enumerate(table_content["rows"]):
lower_row = {str(cell).lower() for cell in row}
if len(lower_row & answer_set) == 0 and len(lower_row & question_set) == 0:
truncated_unrelated_indices.append(_row_idx)
else:
# add neighbours to preserve information aggressively
related_indices.extend([_row_idx - 2, _row_idx - 1, _row_idx, _row_idx + 1, _row_idx + 2])
# remove the neighbours
truncated_unrelated_indices = [
_row_idx for _row_idx in truncated_unrelated_indices if _row_idx not in related_indices
]
# select some cases to drop
drop_items = min(len(truncated_unrelated_indices), int(len(table_content["rows"]) * delete_ratio))
drop_row_indices = random.choices(truncated_unrelated_indices, k=drop_items)
for _row_idx in reversed(range(row_max_len)):
if _row_idx in drop_row_indices:
del table_content["rows"][_row_idx]
# only when the drop ratio is too large, logging for warning.
if "id" in table_content and len(drop_row_indices) > 0:
logger.warning("Delete {:.2f} rows in table {}".format(len(drop_row_indices), table_content["id"]))
| transformers/src/transformers/models/deprecated/tapex/tokenization_tapex.py/0 | {
"file_path": "transformers/src/transformers/models/deprecated/tapex/tokenization_tapex.py",
"repo_id": "transformers",
"token_count": 29313
} |
# coding=utf-8
# Copyright 2019-present, the HuggingFace Inc. team, The Google AI Language Team and Facebook, Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""DistilBERT model configuration"""
from collections import OrderedDict
from typing import Mapping
from ...configuration_utils import PretrainedConfig
from ...onnx import OnnxConfig
from ...utils import logging
logger = logging.get_logger(__name__)
class DistilBertConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`DistilBertModel`] or a [`TFDistilBertModel`]. It
is used to instantiate a DistilBERT model according to the specified arguments, defining the model architecture.
Instantiating a configuration with the defaults will yield a similar configuration to that of the DistilBERT
[distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 30522):
Vocabulary size of the DistilBERT model. Defines the number of different tokens that can be represented by
the `inputs_ids` passed when calling [`DistilBertModel`] or [`TFDistilBertModel`].
max_position_embeddings (`int`, *optional*, defaults to 512):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
sinusoidal_pos_embds (`boolean`, *optional*, defaults to `False`):
Whether to use sinusoidal positional embeddings.
n_layers (`int`, *optional*, defaults to 6):
Number of hidden layers in the Transformer encoder.
n_heads (`int`, *optional*, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
dim (`int`, *optional*, defaults to 768):
Dimensionality of the encoder layers and the pooler layer.
hidden_dim (`int`, *optional*, defaults to 3072):
The size of the "intermediate" (often named feed-forward) layer in the Transformer encoder.
dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_dropout (`float`, *optional*, defaults to 0.1):
The dropout ratio for the attention probabilities.
activation (`str` or `Callable`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"silu"` and `"gelu_new"` are supported.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
qa_dropout (`float`, *optional*, defaults to 0.1):
The dropout probabilities used in the question answering model [`DistilBertForQuestionAnswering`].
seq_classif_dropout (`float`, *optional*, defaults to 0.2):
The dropout probabilities used in the sequence classification and the multiple choice model
[`DistilBertForSequenceClassification`].
Examples:
```python
>>> from transformers import DistilBertConfig, DistilBertModel
>>> # Initializing a DistilBERT configuration
>>> configuration = DistilBertConfig()
>>> # Initializing a model (with random weights) from the configuration
>>> model = DistilBertModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "distilbert"
attribute_map = {
"hidden_size": "dim",
"num_attention_heads": "n_heads",
"num_hidden_layers": "n_layers",
}
def __init__(
self,
vocab_size=30522,
max_position_embeddings=512,
sinusoidal_pos_embds=False,
n_layers=6,
n_heads=12,
dim=768,
hidden_dim=4 * 768,
dropout=0.1,
attention_dropout=0.1,
activation="gelu",
initializer_range=0.02,
qa_dropout=0.1,
seq_classif_dropout=0.2,
pad_token_id=0,
**kwargs,
):
self.vocab_size = vocab_size
self.max_position_embeddings = max_position_embeddings
self.sinusoidal_pos_embds = sinusoidal_pos_embds
self.n_layers = n_layers
self.n_heads = n_heads
self.dim = dim
self.hidden_dim = hidden_dim
self.dropout = dropout
self.attention_dropout = attention_dropout
self.activation = activation
self.initializer_range = initializer_range
self.qa_dropout = qa_dropout
self.seq_classif_dropout = seq_classif_dropout
super().__init__(**kwargs, pad_token_id=pad_token_id)
class DistilBertOnnxConfig(OnnxConfig):
@property
def inputs(self) -> Mapping[str, Mapping[int, str]]:
if self.task == "multiple-choice":
dynamic_axis = {0: "batch", 1: "choice", 2: "sequence"}
else:
dynamic_axis = {0: "batch", 1: "sequence"}
return OrderedDict(
[
("input_ids", dynamic_axis),
("attention_mask", dynamic_axis),
]
)
__all__ = ["DistilBertConfig", "DistilBertOnnxConfig"]
| transformers/src/transformers/models/distilbert/configuration_distilbert.py/0 | {
"file_path": "transformers/src/transformers/models/distilbert/configuration_distilbert.py",
"repo_id": "transformers",
"token_count": 2284
} |
# coding=utf-8
# Copyright 2024 HuggingFace Inc. team. All rights reserved.
#
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import math
from typing import Dict, Iterable, List, Optional, Union
import numpy as np
from ...image_processing_utils import BaseImageProcessor, BatchFeature
from ...image_transforms import convert_to_rgb, pad, resize, to_channel_dimension_format
from ...image_utils import (
OPENAI_CLIP_MEAN,
OPENAI_CLIP_STD,
ChannelDimension,
ImageInput,
PILImageResampling,
VideoInput,
get_image_size,
infer_channel_dimension_format,
is_scaled_image,
is_valid_image,
make_list_of_images,
to_numpy_array,
valid_images,
validate_preprocess_arguments,
)
from ...utils import TensorType, is_vision_available, logging
if is_vision_available():
from PIL import Image
logger = logging.get_logger(__name__)
def make_batched_images(images) -> List[List[ImageInput]]:
"""
Accepts images in list or nested list format, and makes a list of images for preprocessing.
Args:
images (`Union[List[List[ImageInput]], List[ImageInput], ImageInput]`):
The input image.
Returns:
list: A list of images.
"""
if isinstance(images, (list, tuple)) and isinstance(images[0], (list, tuple)) and is_valid_image(images[0][0]):
return [img for img_list in images for img in img_list]
elif isinstance(images, (list, tuple)) and is_valid_image(images[0]):
return images
elif is_valid_image(images):
return [images]
raise ValueError(f"Could not make batched images from {images}")
def smart_resize(
height: int, width: int, factor: int = 28, min_pixels: int = 56 * 56, max_pixels: int = 14 * 14 * 4 * 1280
):
"""Rescales the image so that the following conditions are met:
1. Both dimensions (height and width) are divisible by 'factor'.
2. The total number of pixels is within the range ['min_pixels', 'max_pixels'].
3. The aspect ratio of the image is maintained as closely as possible.
"""
if height < factor or width < factor:
raise ValueError(f"height:{height} or width:{width} must be larger than factor:{factor}")
elif max(height, width) / min(height, width) > 200:
raise ValueError(
f"absolute aspect ratio must be smaller than 200, got {max(height, width) / min(height, width)}"
)
h_bar = round(height / factor) * factor
w_bar = round(width / factor) * factor
if h_bar * w_bar > max_pixels:
beta = math.sqrt((height * width) / max_pixels)
h_bar = math.floor(height / beta / factor) * factor
w_bar = math.floor(width / beta / factor) * factor
elif h_bar * w_bar < min_pixels:
beta = math.sqrt(min_pixels / (height * width))
h_bar = math.ceil(height * beta / factor) * factor
w_bar = math.ceil(width * beta / factor) * factor
return h_bar, w_bar
class Emu3ImageProcessor(BaseImageProcessor):
r"""
Constructs a Emu3 image processor that dynamically resizes images based on the original images.
Args:
do_resize (`bool`, *optional*, defaults to `True`):
Whether to resize the image's (height, width) dimensions.
resample (`PILImageResampling`, *optional*, defaults to `Resampling.BICUBIC`):
Resampling filter to use when resizing the image.
do_rescale (`bool`, *optional*, defaults to `True`):
Whether to rescale the image by the specified scale `rescale_factor`.
rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
Scale factor to use if rescaling the image.
do_normalize (`bool`, *optional*, defaults to `True`):
Whether to normalize the image.
image_mean (`float` or `List[float]`, *optional*, defaults to `[0.48145466, 0.4578275, 0.40821073]`):
Mean to use if normalizing the image. This is a float or list of floats for each channel in the image.
image_std (`float` or `List[float]`, *optional*, defaults to `[0.26862954, 0.26130258, 0.27577711]`):
Standard deviation to use if normalizing the image. This is a float or list of floats for each channel in the image.
do_convert_rgb (`bool`, *optional*, defaults to `True`):
Whether to convert the image to RGB.
do_pad (`bool`, *optional*, defaults to `True`):
Whether to pad the image. If `True`, will pad the patch dimension of the images in the batch to the largest
number of patches in the batch. Padding will be applied to the bottom and right with zeros.
min_pixels (`int`, *optional*, defaults to `512 * 512`):
The min pixels of the image to resize the image.
max_pixels (`int`, *optional*, defaults to `1024 * 1024`):
The max pixels of the image to resize the image.
spatial_factor (`int`, *optional*, defaults to 8):
The spatial downsample factor the image will be downsampled in feature extracting phase
"""
model_input_names = ["pixel_values"]
def __init__(
self,
do_resize: bool = True,
resample: PILImageResampling = PILImageResampling.BICUBIC,
do_rescale: bool = True,
rescale_factor: Union[int, float] = 1 / 255,
do_normalize: bool = True,
image_mean: Optional[Union[float, List[float]]] = None,
image_std: Optional[Union[float, List[float]]] = None,
do_convert_rgb: bool = True,
do_pad: bool = True,
min_pixels: int = 512 * 512,
max_pixels: int = 1024 * 1024,
spatial_factor: int = 8,
**kwargs,
) -> None:
super().__init__(**kwargs)
self.do_resize = do_resize
self.resample = resample
self.do_rescale = do_rescale
self.rescale_factor = rescale_factor
self.do_normalize = do_normalize
self.image_mean = image_mean if image_mean is not None else OPENAI_CLIP_MEAN
self.image_std = image_std if image_std is not None else OPENAI_CLIP_STD
self.min_pixels = min_pixels
self.max_pixels = max_pixels
self.spatial_factor = spatial_factor
self.size = {"min_pixels": min_pixels, "max_pixels": max_pixels}
self.do_convert_rgb = do_convert_rgb
def _preprocess(
self,
images: Union[ImageInput, VideoInput],
do_resize: bool = None,
resample: PILImageResampling = None,
do_rescale: bool = None,
rescale_factor: float = None,
do_normalize: bool = None,
image_mean: Optional[Union[float, List[float]]] = None,
image_std: Optional[Union[float, List[float]]] = None,
do_convert_rgb: bool = None,
data_format: Optional[ChannelDimension] = ChannelDimension.FIRST,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
):
"""
Preprocess an image or batch of images.
Args:
images (`ImageInput`):
Image or batch of images to preprocess. Expects pixel values ranging from 0 to 255. If pixel values range from 0 to 1, set `do_rescale=False`.
vision_info (`List[Dict]`, *optional*):
Optional list of dictionaries containing additional information about vision inputs.
do_resize (`bool`, *optional*, defaults to `self.do_resize`):
Whether to resize the image.
resample (`PILImageResampling`, *optional*, defaults to `self.resample`):
Resampling filter to use if resizing the image. This can be one of the `PILImageResampling` enums.
do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
Whether to rescale the image.
rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
Scale factor to use if rescaling the image.
do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
Whether to normalize the image.
image_mean (`float` or `List[float]`, *optional*, defaults to `self.image_mean`):
Mean to use if normalizing the image. Can be a float or a list of floats corresponding to the number of channels in the image.
image_std (`float` or `List[float]`, *optional*, defaults to `self.image_std`):
Standard deviation to use if normalizing the image. Can be a float or a list of floats corresponding to the number of channels in the image.
do_convert_rgb (`bool`, *optional*, defaults to `self.do_convert_rgb`):
Whether to convert the image to RGB.
data_format (`ChannelDimension`, *optional*, defaults to `ChannelDimension.FIRST`):
The channel dimension format for the output image. Can be one of:
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
- Unset: Use the channel dimension format of the input image.
input_data_format (`ChannelDimension` or `str`, *optional*):
The channel dimension format for the input image. Can be one of:
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
- `"none"` or `ChannelDimension.NONE`: image in (height, width) format. - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
"""
images = make_list_of_images(images)
if do_convert_rgb:
images = [convert_to_rgb(image) for image in images]
# All transformations expect numpy arrays.
images = [to_numpy_array(image) for image in images]
if is_scaled_image(images[0]) and do_rescale:
logger.warning_once(
"It looks like you are trying to rescale already rescaled images. If the input"
" images have pixel values between 0 and 1, set `do_rescale=False` to avoid rescaling them again."
)
if input_data_format is None:
# We assume that all images have the same channel dimension format.
input_data_format = infer_channel_dimension_format(images[0])
height, width = get_image_size(images[0], channel_dim=input_data_format)
resized_height, resized_width = height, width
processed_images = []
for image in images:
if do_resize:
resized_height, resized_width = smart_resize(
height,
width,
factor=self.spatial_factor,
min_pixels=self.min_pixels,
max_pixels=self.max_pixels,
)
image = resize(
image, size=(resized_height, resized_width), resample=resample, input_data_format=input_data_format
)
if do_rescale:
image = self.rescale(image, scale=rescale_factor, input_data_format=input_data_format)
if do_normalize:
image = self.normalize(
image=image, mean=image_mean, std=image_std, input_data_format=input_data_format
)
image = to_channel_dimension_format(image, data_format, input_channel_dim=input_data_format)
processed_images.append(image)
images = np.array(processed_images)
return images
def _pad_for_batching(
self,
pixel_values: List[np.ndarray],
image_sizes: List[List[int]],
data_format: Optional[Union[str, ChannelDimension]] = None,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
):
"""
Pads images on the `num_of_patches` dimension with zeros to form a batch of same number of patches.
Args:
pixel_values (`List[np.ndarray]`):
An array of pixel values of each images of shape (`batch_size`, `num_patches`, `image_in_3D`)
image_sizes (`List[List[int]]`):
A list of sizes for each image in `pixel_values` in (height, width) format.
data_format (`str` or `ChannelDimension`, *optional*):
The channel dimension format for the output image. Can be one of:
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
If unset, will use same as the input image.
input_data_format (`str` or `ChannelDimension`, *optional*):
The channel dimension format for the input image. Can be one of:
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
If unset, will use the inferred format of the input image.
Returns:
List[`np.ndarray`]: The padded images.
"""
max_shape = (
max([size[0] for size in image_sizes]),
max([size[1] for size in image_sizes]),
)
pixel_values = [
pad(
image,
padding=((0, max_shape[0] - size[0]), (0, max_shape[1] - size[1])),
data_format=data_format,
input_data_format=input_data_format,
)
for image, size in zip(pixel_values, image_sizes)
]
return pixel_values
def preprocess(
self,
images: ImageInput,
do_resize: bool = None,
size: Dict[str, int] = None,
resample: PILImageResampling = None,
do_rescale: bool = None,
rescale_factor: float = None,
do_normalize: bool = None,
image_mean: Optional[Union[float, List[float]]] = None,
image_std: Optional[Union[float, List[float]]] = None,
do_convert_rgb: bool = None,
do_pad: bool = True,
return_tensors: Optional[Union[str, TensorType]] = None,
data_format: Optional[ChannelDimension] = ChannelDimension.FIRST,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
):
"""
Args:
images (`ImageInput`):
Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
passing in images with pixel values between 0 and 1, set `do_rescale=False`.
do_resize (`bool`, *optional*, defaults to `self.do_resize`):
Whether to resize the image.
size (`Dict[str, int]`, *optional*, defaults to `self.size`):
Size of the image after resizing. Shortest edge of the image is resized to size["shortest_edge"], with
the longest edge resized to keep the input aspect ratio.
resample (`int`, *optional*, defaults to `self.resample`):
Resampling filter to use if resizing the image. This can be one of the enum `PILImageResampling`. Only
has an effect if `do_resize` is set to `True`.
do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
Whether to rescale the image.
rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
Rescale factor to rescale the image by if `do_rescale` is set to `True`.
do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
Whether to normalize the image.
image_mean (`float` or `List[float]`, *optional*, defaults to `self.image_mean`):
Image mean to use for normalization. Only has an effect if `do_normalize` is set to `True`.
image_std (`float` or `List[float]`, *optional*, defaults to `self.image_std`):
Image standard deviation to use for normalization. Only has an effect if `do_normalize` is set to
`True`.
do_convert_rgb (`bool`, *optional*, defaults to `self.do_convert_rgb`):
Whether to convert the image to RGB.
do_pad (`bool`, *optional*, defaults to `True`):
Whether to pad the image. If `True`, will pad the patch dimension of the images in the batch to the largest
number of patches in the batch. Padding will be applied to the bottom and right with zeros.
return_tensors (`str` or `TensorType`, *optional*):
The type of tensors to return. Can be one of:
- Unset: Return a list of `np.ndarray`.
- `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
- `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
- `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
- `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
The channel dimension format for the output image. Can be one of:
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
- Unset: Use the channel dimension format of the input image.
input_data_format (`ChannelDimension` or `str`, *optional*):
The channel dimension format for the input image. If unset, the channel dimension format is inferred
from the input image. Can be one of:
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
- `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
"""
do_resize = do_resize if do_resize is not None else self.do_resize
size = size if size is not None else self.size
resample = resample if resample is not None else self.resample
do_rescale = do_rescale if do_rescale is not None else self.do_rescale
rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
do_normalize = do_normalize if do_normalize is not None else self.do_normalize
image_mean = image_mean if image_mean is not None else self.image_mean
image_std = image_std if image_std is not None else self.image_std
do_convert_rgb = do_convert_rgb if do_convert_rgb is not None else self.do_convert_rgb
do_pad = do_pad if do_pad is not None else self.do_pad
if images is not None:
images = make_batched_images(images)
if images is not None and not valid_images(images):
raise ValueError(
"Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
"torch.Tensor, tf.Tensor or jax.ndarray."
)
validate_preprocess_arguments(
rescale_factor=rescale_factor,
do_normalize=do_normalize,
image_mean=image_mean,
image_std=image_std,
do_resize=do_resize,
size=size,
resample=resample,
)
pixel_values = []
for image in images:
image = self._preprocess(
image,
do_resize=do_resize,
resample=resample,
do_rescale=do_rescale,
rescale_factor=rescale_factor,
do_normalize=do_normalize,
image_mean=image_mean,
image_std=image_std,
data_format=data_format,
do_convert_rgb=do_convert_rgb,
input_data_format=input_data_format,
)
pixel_values.extend(image)
image_sizes = [image.shape[-2:] for image in pixel_values]
if do_pad:
pixel_values = self._pad_for_batching(pixel_values, image_sizes)
pixel_values = np.array(pixel_values)
return BatchFeature(
data={"pixel_values": pixel_values, "image_sizes": image_sizes}, tensor_type=return_tensors
)
def postprocess(
self,
images: ImageInput,
do_rescale: Optional[bool] = None,
rescale_factor: Optional[float] = None,
do_normalize: Optional[bool] = None,
image_mean: Optional[Union[float, List[float]]] = None,
image_std: Optional[Union[float, List[float]]] = None,
return_tensors: Union[str, TensorType] = "PIL.Image.Image",
input_data_format: Optional[Union[str, ChannelDimension]] = None,
):
"""
Postprocess an image or batch of images tensor. Postprocess is the reverse process of preprocess.
The parameters should be same as in preprocess.
Args:
images (`ImageInput`):
Image to postprocess. Expects a single or batch of images with pixel values ranging from -1 to 1.
do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
Whether to rescale the image.
rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
Rescale factor to rescale the image by if `do_rescale` is set to `True`.
do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
Whether to normalize the image.
image_mean (`float` or `List[float]`, *optional*, defaults to `self.image_mean`):
Image mean to use for normalization. Only has an effect if `do_normalize` is set to `True`.
image_std (`float` or `List[float]`, *optional*, defaults to `self.image_std`):
Image standard deviation to use for normalization. Only has an effect if `do_normalize` is set to `True`.
return_tensors (`str` or `TensorType`, *optional*):
The type of tensors to return. Can be one of:
- Unset: Return a list of `np.ndarray`.
- `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
- `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
input_data_format (`ChannelDimension` or `str`, *optional*):
The channel dimension format for the input image. If unset, the channel dimension format is inferred
from the input image. Can be one of:
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
- `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
"""
do_rescale = do_rescale if do_rescale is not None else self.do_rescale
rescale_factor = 1.0 / self.rescale_factor if rescale_factor is None else rescale_factor
do_normalize = do_normalize if do_normalize is not None else self.do_normalize
image_mean = image_mean if image_mean is not None else self.image_mean
image_std = image_std if image_std is not None else self.image_std
images = make_list_of_images(images)
if isinstance(images[0], Image.Image):
return images if len(images) > 1 else images[0]
if input_data_format is None:
# We assume that all images have the same channel dimension format.
input_data_format = infer_channel_dimension_format(images[0])
pixel_values = []
for image in images:
image = to_numpy_array(image)
if do_normalize:
image = self.unnormalize(
image=image, image_mean=image_mean, image_std=image_std, input_data_format=input_data_format
)
if do_rescale:
image = self.rescale(image, scale=rescale_factor, input_data_format=input_data_format)
image = image.clip(0, 255).astype(np.uint8)
if do_normalize and do_rescale and return_tensors == "PIL.Image.Image":
image = to_channel_dimension_format(image, ChannelDimension.LAST, input_channel_dim=input_data_format)
pixel_values.append(Image.fromarray(image))
else:
pixel_values.extend(image)
data = {"pixel_values": pixel_values}
return_tensors = return_tensors if return_tensors != "PIL.Image.Image" else None
return BatchFeature(data=data, tensor_type=return_tensors)
def unnormalize(
self,
image: np.array,
image_mean: Union[float, Iterable[float]],
image_std: Union[float, Iterable[float]],
input_data_format: Optional[Union[str, ChannelDimension]] = None,
) -> np.array:
"""
Unnormalizes `image` using the mean and standard deviation specified by `mean` and `std`.
image = (image * image_std) + image_mean
Args:
image (`torch.Tensor` of shape `(batch_size, num_channels, image_size, image_size)` or `(num_channels, image_size, image_size)`):
Batch of pixel values to postprocess.
image_mean (`float` or `Iterable[float]`):
The mean to use for unnormalization.
image_std (`float` or `Iterable[float]`):
The standard deviation to use for unnormalization.
input_data_format (`ChannelDimension` or `str`, *optional*):
The channel dimension format for the input image. If unset, the channel dimension format is inferred
from the input image. Can be one of:
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
- `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
"""
num_channels = 3
if isinstance(image_mean, Iterable):
if len(image_mean) != num_channels:
raise ValueError(f"mean must have {num_channels} elements if it is an iterable, got {len(image_mean)}")
else:
image_mean = [image_mean] * num_channels
if isinstance(image_std, Iterable):
if len(image_std) != num_channels:
raise ValueError(f"std must have {num_channels} elements if it is an iterable, got {len(image_std)}")
else:
image_std = [image_std] * num_channels
rev_image_mean = tuple(-mean / std for mean, std in zip(image_mean, image_std))
rev_image_std = tuple(1 / std for std in image_std)
image = self.normalize(
image=image, mean=rev_image_mean, std=rev_image_std, input_data_format=input_data_format
)
return image
__all__ = ["Emu3ImageProcessor"]
| transformers/src/transformers/models/emu3/image_processing_emu3.py/0 | {
"file_path": "transformers/src/transformers/models/emu3/image_processing_emu3.py",
"repo_id": "transformers",
"token_count": 11950
} |
# coding=utf-8
# Copyright 2022 Meta and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tokenization classes for ESM."""
import os
from typing import List, Optional
from ...tokenization_utils import PreTrainedTokenizer
from ...utils import logging
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
def load_vocab_file(vocab_file):
with open(vocab_file, "r") as f:
lines = f.read().splitlines()
return [l.strip() for l in lines]
class EsmTokenizer(PreTrainedTokenizer):
"""
Constructs an ESM tokenizer.
"""
vocab_files_names = VOCAB_FILES_NAMES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
self,
vocab_file,
unk_token="<unk>",
cls_token="<cls>",
pad_token="<pad>",
mask_token="<mask>",
eos_token="<eos>",
**kwargs,
):
self.all_tokens = load_vocab_file(vocab_file)
self._id_to_token = dict(enumerate(self.all_tokens))
self._token_to_id = {tok: ind for ind, tok in enumerate(self.all_tokens)}
super().__init__(
unk_token=unk_token,
cls_token=cls_token,
pad_token=pad_token,
mask_token=mask_token,
eos_token=eos_token,
**kwargs,
)
# TODO, all the tokens are added? But they are also part of the vocab... bit strange.
# none of them are special, but they all need special splitting.
self.unique_no_split_tokens = self.all_tokens
self._update_trie(self.unique_no_split_tokens)
def _convert_id_to_token(self, index: int) -> str:
return self._id_to_token.get(index, self.unk_token)
def _convert_token_to_id(self, token: str) -> int:
return self._token_to_id.get(token, self._token_to_id.get(self.unk_token))
def _tokenize(self, text, **kwargs):
return text.split()
def get_vocab(self):
base_vocab = self._token_to_id.copy()
base_vocab.update(self.added_tokens_encoder)
return base_vocab
def token_to_id(self, token: str) -> int:
return self._token_to_id.get(token, self._token_to_id.get(self.unk_token))
def id_to_token(self, index: int) -> str:
return self._id_to_token.get(index, self.unk_token)
def build_inputs_with_special_tokens(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
cls = [self.cls_token_id]
sep = [self.eos_token_id] # No sep token in ESM vocabulary
if token_ids_1 is None:
if self.eos_token_id is None:
return cls + token_ids_0
else:
return cls + token_ids_0 + sep
elif self.eos_token_id is None:
raise ValueError("Cannot tokenize multiple sequences when EOS token is not set!")
return cls + token_ids_0 + sep + token_ids_1 + sep # Multiple inputs always have an EOS token
def get_special_tokens_mask(
self, token_ids_0: List, token_ids_1: Optional[List] = None, already_has_special_tokens: bool = False
) -> List[int]:
"""
Retrieves sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer `prepare_for_model` or `encode_plus` methods.
Args:
token_ids_0 (`List[int]`):
List of ids of the first sequence.
token_ids_1 (`List[int]`, *optional*):
List of ids of the second sequence.
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not the token list is already formatted with special tokens for the model.
Returns:
A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
"""
if already_has_special_tokens:
if token_ids_1 is not None:
raise ValueError(
"You should not supply a second sequence if the provided sequence of "
"ids is already formatted with special tokens for the model."
)
return [1 if token in self.all_special_ids else 0 for token in token_ids_0]
mask = [1] + ([0] * len(token_ids_0)) + [1]
if token_ids_1 is not None:
mask += [0] * len(token_ids_1) + [1]
return mask
def save_vocabulary(self, save_directory, filename_prefix):
vocab_file = os.path.join(save_directory, (filename_prefix + "-" if filename_prefix else "") + "vocab.txt")
with open(vocab_file, "w") as f:
f.write("\n".join(self.all_tokens))
return (vocab_file,)
@property
def vocab_size(self) -> int:
return len(self.all_tokens)
__all__ = ["EsmTokenizer"]
| transformers/src/transformers/models/esm/tokenization_esm.py/0 | {
"file_path": "transformers/src/transformers/models/esm/tokenization_esm.py",
"repo_id": "transformers",
"token_count": 2328
} |
# coding=utf-8
# Copyright 2019-present CNRS, Facebook Inc. and the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Flaubert configuration"""
from collections import OrderedDict
from typing import Mapping
from ...configuration_utils import PretrainedConfig
from ...onnx import OnnxConfig
from ...utils import logging
logger = logging.get_logger(__name__)
class FlaubertConfig(PretrainedConfig):
"""
This is the configuration class to store the configuration of a [`FlaubertModel`] or a [`TFFlaubertModel`]. It is
used to instantiate a FlauBERT model according to the specified arguments, defining the model architecture.
Instantiating a configuration with the defaults will yield a similar configuration to that of the FlauBERT
[flaubert/flaubert_base_uncased](https://huggingface.co/flaubert/flaubert_base_uncased) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
pre_norm (`bool`, *optional*, defaults to `False`):
Whether to apply the layer normalization before or after the feed forward layer following the attention in
each layer (Vaswani et al., Tensor2Tensor for Neural Machine Translation. 2018)
layerdrop (`float`, *optional*, defaults to 0.0):
Probability to drop layers during training (Fan et al., Reducing Transformer Depth on Demand with
Structured Dropout. ICLR 2020)
vocab_size (`int`, *optional*, defaults to 30145):
Vocabulary size of the FlauBERT model. Defines the number of different tokens that can be represented by
the `inputs_ids` passed when calling [`FlaubertModel`] or [`TFFlaubertModel`].
emb_dim (`int`, *optional*, defaults to 2048):
Dimensionality of the encoder layers and the pooler layer.
n_layer (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
n_head (`int`, *optional*, defaults to 16):
Number of attention heads for each attention layer in the Transformer encoder.
dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for the attention mechanism
gelu_activation (`bool`, *optional*, defaults to `True`):
Whether or not to use a *gelu* activation instead of *relu*.
sinusoidal_embeddings (`bool`, *optional*, defaults to `False`):
Whether or not to use sinusoidal positional embeddings instead of absolute positional embeddings.
causal (`bool`, *optional*, defaults to `False`):
Whether or not the model should behave in a causal manner. Causal models use a triangular attention mask in
order to only attend to the left-side context instead if a bidirectional context.
asm (`bool`, *optional*, defaults to `False`):
Whether or not to use an adaptive log softmax projection layer instead of a linear layer for the prediction
layer.
n_langs (`int`, *optional*, defaults to 1):
The number of languages the model handles. Set to 1 for monolingual models.
use_lang_emb (`bool`, *optional*, defaults to `True`)
Whether to use language embeddings. Some models use additional language embeddings, see [the multilingual
models page](http://huggingface.co/transformers/multilingual.html#xlm-language-embeddings) for information
on how to use them.
max_position_embeddings (`int`, *optional*, defaults to 512):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
embed_init_std (`float`, *optional*, defaults to 2048^-0.5):
The standard deviation of the truncated_normal_initializer for initializing the embedding matrices.
init_std (`int`, *optional*, defaults to 50257):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices except the
embedding matrices.
layer_norm_eps (`float`, *optional*, defaults to 1e-12):
The epsilon used by the layer normalization layers.
bos_index (`int`, *optional*, defaults to 0):
The index of the beginning of sentence token in the vocabulary.
eos_index (`int`, *optional*, defaults to 1):
The index of the end of sentence token in the vocabulary.
pad_index (`int`, *optional*, defaults to 2):
The index of the padding token in the vocabulary.
unk_index (`int`, *optional*, defaults to 3):
The index of the unknown token in the vocabulary.
mask_index (`int`, *optional*, defaults to 5):
The index of the masking token in the vocabulary.
is_encoder(`bool`, *optional*, defaults to `True`):
Whether or not the initialized model should be a transformer encoder or decoder as seen in Vaswani et al.
summary_type (`string`, *optional*, defaults to "first"):
Argument used when doing sequence summary. Used in the sequence classification and multiple choice models.
Has to be one of the following options:
- `"last"`: Take the last token hidden state (like XLNet).
- `"first"`: Take the first token hidden state (like BERT).
- `"mean"`: Take the mean of all tokens hidden states.
- `"cls_index"`: Supply a Tensor of classification token position (like GPT/GPT-2).
- `"attn"`: Not implemented now, use multi-head attention.
summary_use_proj (`bool`, *optional*, defaults to `True`):
Argument used when doing sequence summary. Used in the sequence classification and multiple choice models.
Whether or not to add a projection after the vector extraction.
summary_activation (`str`, *optional*):
Argument used when doing sequence summary. Used in the sequence classification and multiple choice models.
Pass `"tanh"` for a tanh activation to the output, any other value will result in no activation.
summary_proj_to_labels (`bool`, *optional*, defaults to `True`):
Used in the sequence classification and multiple choice models.
Whether the projection outputs should have `config.num_labels` or `config.hidden_size` classes.
summary_first_dropout (`float`, *optional*, defaults to 0.1):
Used in the sequence classification and multiple choice models.
The dropout ratio to be used after the projection and activation.
start_n_top (`int`, *optional*, defaults to 5):
Used in the SQuAD evaluation script.
end_n_top (`int`, *optional*, defaults to 5):
Used in the SQuAD evaluation script.
mask_token_id (`int`, *optional*, defaults to 0):
Model agnostic parameter to identify masked tokens when generating text in an MLM context.
lang_id (`int`, *optional*, defaults to 1):
The ID of the language used by the model. This parameter is used when generating text in a given language.
"""
model_type = "flaubert"
attribute_map = {
"hidden_size": "emb_dim",
"num_attention_heads": "n_heads",
"num_hidden_layers": "n_layers",
"n_words": "vocab_size", # For backward compatibility
}
def __init__(
self,
pre_norm=False,
layerdrop=0.0,
vocab_size=30145,
emb_dim=2048,
n_layers=12,
n_heads=16,
dropout=0.1,
attention_dropout=0.1,
gelu_activation=True,
sinusoidal_embeddings=False,
causal=False,
asm=False,
n_langs=1,
use_lang_emb=True,
max_position_embeddings=512,
embed_init_std=2048**-0.5,
layer_norm_eps=1e-12,
init_std=0.02,
bos_index=0,
eos_index=1,
pad_index=2,
unk_index=3,
mask_index=5,
is_encoder=True,
summary_type="first",
summary_use_proj=True,
summary_activation=None,
summary_proj_to_labels=True,
summary_first_dropout=0.1,
start_n_top=5,
end_n_top=5,
mask_token_id=0,
lang_id=0,
pad_token_id=2,
bos_token_id=0,
**kwargs,
):
"""Constructs FlaubertConfig."""
self.pre_norm = pre_norm
self.layerdrop = layerdrop
self.vocab_size = vocab_size
self.emb_dim = emb_dim
self.n_layers = n_layers
self.n_heads = n_heads
self.dropout = dropout
self.attention_dropout = attention_dropout
self.gelu_activation = gelu_activation
self.sinusoidal_embeddings = sinusoidal_embeddings
self.causal = causal
self.asm = asm
self.n_langs = n_langs
self.use_lang_emb = use_lang_emb
self.layer_norm_eps = layer_norm_eps
self.bos_index = bos_index
self.eos_index = eos_index
self.pad_index = pad_index
self.unk_index = unk_index
self.mask_index = mask_index
self.is_encoder = is_encoder
self.max_position_embeddings = max_position_embeddings
self.embed_init_std = embed_init_std
self.init_std = init_std
self.summary_type = summary_type
self.summary_use_proj = summary_use_proj
self.summary_activation = summary_activation
self.summary_proj_to_labels = summary_proj_to_labels
self.summary_first_dropout = summary_first_dropout
self.start_n_top = start_n_top
self.end_n_top = end_n_top
self.mask_token_id = mask_token_id
self.lang_id = lang_id
if "n_words" in kwargs:
self.n_words = kwargs["n_words"]
super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, **kwargs)
class FlaubertOnnxConfig(OnnxConfig):
@property
def inputs(self) -> Mapping[str, Mapping[int, str]]:
if self.task == "multiple-choice":
dynamic_axis = {0: "batch", 1: "choice", 2: "sequence"}
else:
dynamic_axis = {0: "batch", 1: "sequence"}
return OrderedDict(
[
("input_ids", dynamic_axis),
("attention_mask", dynamic_axis),
]
)
__all__ = ["FlaubertConfig", "FlaubertOnnxConfig"]
| transformers/src/transformers/models/flaubert/configuration_flaubert.py/0 | {
"file_path": "transformers/src/transformers/models/flaubert/configuration_flaubert.py",
"repo_id": "transformers",
"token_count": 4413
} |
# coding=utf-8
# Copyright 2022 KAIST and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""GLPN model configuration"""
from ...configuration_utils import PretrainedConfig
from ...utils import logging
logger = logging.get_logger(__name__)
class GLPNConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`GLPNModel`]. It is used to instantiate an GLPN
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the GLPN
[vinvino02/glpn-kitti](https://huggingface.co/vinvino02/glpn-kitti) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
num_channels (`int`, *optional*, defaults to 3):
The number of input channels.
num_encoder_blocks (`int`, *optional*, defaults to 4):
The number of encoder blocks (i.e. stages in the Mix Transformer encoder).
depths (`List[int]`, *optional*, defaults to `[2, 2, 2, 2]`):
The number of layers in each encoder block.
sr_ratios (`List[int]`, *optional*, defaults to `[8, 4, 2, 1]`):
Sequence reduction ratios in each encoder block.
hidden_sizes (`List[int]`, *optional*, defaults to `[32, 64, 160, 256]`):
Dimension of each of the encoder blocks.
patch_sizes (`List[int]`, *optional*, defaults to `[7, 3, 3, 3]`):
Patch size before each encoder block.
strides (`List[int]`, *optional*, defaults to `[4, 2, 2, 2]`):
Stride before each encoder block.
num_attention_heads (`List[int]`, *optional*, defaults to `[1, 2, 5, 8]`):
Number of attention heads for each attention layer in each block of the Transformer encoder.
mlp_ratios (`List[int]`, *optional*, defaults to `[4, 4, 4, 4]`):
Ratio of the size of the hidden layer compared to the size of the input layer of the Mix FFNs in the
encoder blocks.
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` are supported.
hidden_dropout_prob (`float`, *optional*, defaults to 0.0):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
drop_path_rate (`float`, *optional*, defaults to 0.1):
The dropout probability for stochastic depth, used in the blocks of the Transformer encoder.
layer_norm_eps (`float`, *optional*, defaults to 1e-06):
The epsilon used by the layer normalization layers.
decoder_hidden_size (`int`, *optional*, defaults to 64):
The dimension of the decoder.
max_depth (`int`, *optional*, defaults to 10):
The maximum depth of the decoder.
head_in_index (`int`, *optional*, defaults to -1):
The index of the features to use in the head.
Example:
```python
>>> from transformers import GLPNModel, GLPNConfig
>>> # Initializing a GLPN vinvino02/glpn-kitti style configuration
>>> configuration = GLPNConfig()
>>> # Initializing a model from the vinvino02/glpn-kitti style configuration
>>> model = GLPNModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "glpn"
def __init__(
self,
num_channels=3,
num_encoder_blocks=4,
depths=[2, 2, 2, 2],
sr_ratios=[8, 4, 2, 1],
hidden_sizes=[32, 64, 160, 256],
patch_sizes=[7, 3, 3, 3],
strides=[4, 2, 2, 2],
num_attention_heads=[1, 2, 5, 8],
mlp_ratios=[4, 4, 4, 4],
hidden_act="gelu",
hidden_dropout_prob=0.0,
attention_probs_dropout_prob=0.0,
initializer_range=0.02,
drop_path_rate=0.1,
layer_norm_eps=1e-6,
decoder_hidden_size=64,
max_depth=10,
head_in_index=-1,
**kwargs,
):
super().__init__(**kwargs)
self.num_channels = num_channels
self.num_encoder_blocks = num_encoder_blocks
self.depths = depths
self.sr_ratios = sr_ratios
self.hidden_sizes = hidden_sizes
self.patch_sizes = patch_sizes
self.strides = strides
self.mlp_ratios = mlp_ratios
self.num_attention_heads = num_attention_heads
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.initializer_range = initializer_range
self.drop_path_rate = drop_path_rate
self.layer_norm_eps = layer_norm_eps
self.decoder_hidden_size = decoder_hidden_size
self.max_depth = max_depth
self.head_in_index = head_in_index
__all__ = ["GLPNConfig"]
| transformers/src/transformers/models/glpn/configuration_glpn.py/0 | {
"file_path": "transformers/src/transformers/models/glpn/configuration_glpn.py",
"repo_id": "transformers",
"token_count": 2355
} |
# coding=utf-8
# Copyright 2021 The Google Flax Team Authors and The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import Any, Optional, Tuple
import flax.linen as nn
import jax
import jax.numpy as jnp
from flax.core.frozen_dict import FrozenDict, freeze, unfreeze
from flax.linen import combine_masks, make_causal_mask
from flax.linen.attention import dot_product_attention_weights
from flax.traverse_util import flatten_dict, unflatten_dict
from jax import lax
from ...modeling_flax_outputs import (
FlaxBaseModelOutputWithPastAndCrossAttentions,
FlaxCausalLMOutputWithCrossAttentions,
)
from ...modeling_flax_utils import ACT2FN, FlaxPreTrainedModel, append_call_sample_docstring
from ...utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging
from .configuration_gpt2 import GPT2Config
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "openai-community/gpt2"
_CONFIG_FOR_DOC = "GPT2Config"
GPT2_START_DOCSTRING = r"""
This model inherits from [`FlaxPreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a Flax Linen
[flax.nn.Module](https://flax.readthedocs.io/en/latest/_autosummary/flax.nn.module.html) subclass. Use it as a
regular Flax Module and refer to the Flax documentation for all matter related to general usage and behavior.
Finally, this model supports inherent JAX features such as:
- [Just-In-Time (JIT) compilation](https://jax.readthedocs.io/en/latest/jax.html#just-in-time-compilation-jit)
- [Automatic Differentiation](https://jax.readthedocs.io/en/latest/jax.html#automatic-differentiation)
- [Vectorization](https://jax.readthedocs.io/en/latest/jax.html#vectorization-vmap)
- [Parallelization](https://jax.readthedocs.io/en/latest/jax.html#parallelization-pmap)
Parameters:
config ([`GPT2Config`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~FlaxPreTrainedModel.from_pretrained`] method to load the model weights.
dtype (`jax.numpy.dtype`, *optional*, defaults to `jax.numpy.float32`):
The data type of the computation. Can be one of `jax.numpy.float32`, `jax.numpy.float16` (on GPUs) and
`jax.numpy.bfloat16` (on TPUs).
This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If
specified all the computation will be performed with the given `dtype`.
**Note that this only specifies the dtype of the computation and does not influence the dtype of model
parameters.**
If you wish to change the dtype of the model parameters, see [`~FlaxPreTrainedModel.to_fp16`] and
[`~FlaxPreTrainedModel.to_bf16`].
"""
GPT2_INPUTS_DOCSTRING = r"""
Args:
input_ids (`numpy.ndarray` of shape `(batch_size, input_ids_length)`):
`input_ids_length` = `sequence_length`. Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
past_key_values (`Dict[str, np.ndarray]`, *optional*, returned by `init_cache` or when passing previous `past_key_values`):
Dictionary of pre-computed hidden-states (key and values in the attention blocks) that can be used for fast
auto-regressive decoding. Pre-computed key and value hidden-states are of shape *[batch_size, max_length]*.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
class FlaxConv1D(nn.Module):
features: int
use_bias: bool = True
dtype: Any = jnp.float32
precision: Any = None
@nn.compact
def __call__(self, inputs):
inputs = jnp.asarray(inputs, self.dtype)
kernel = self.param("kernel", jax.nn.initializers.normal(stddev=0.02), (self.features, inputs.shape[-1]))
kernel = jnp.asarray(kernel.transpose(), self.dtype)
y = lax.dot_general(inputs, kernel, (((inputs.ndim - 1,), (0,)), ((), ())), precision=self.precision)
if self.use_bias:
bias = self.param("bias", jax.nn.initializers.zeros, (self.features,))
bias = jnp.asarray(bias, self.dtype)
y = y + bias
return y
class FlaxGPT2Attention(nn.Module):
config: GPT2Config
dtype: jnp.dtype = jnp.float32
causal: bool = True
is_cross_attention: bool = False
def setup(self):
config = self.config
self.embed_dim = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.embed_dim // self.num_heads
if self.is_cross_attention:
self.c_attn = FlaxConv1D(2 * self.embed_dim, dtype=self.dtype)
self.q_attn = FlaxConv1D(self.embed_dim, dtype=self.dtype)
else:
self.c_attn = FlaxConv1D(3 * self.embed_dim, dtype=self.dtype)
self.c_proj = FlaxConv1D(self.embed_dim, dtype=self.dtype)
self.resid_dropout = nn.Dropout(rate=config.resid_pdrop)
if self.causal:
self.causal_mask = make_causal_mask(
jnp.ones((1, config.max_position_embeddings), dtype="bool"), dtype="bool"
)
def _split_heads(self, hidden_states):
return hidden_states.reshape(hidden_states.shape[:2] + (self.num_heads, self.head_dim))
def _merge_heads(self, hidden_states):
return hidden_states.reshape(hidden_states.shape[:2] + (self.embed_dim,))
@nn.compact
def _concatenate_to_cache(self, key, value, query, attention_mask):
"""
This function takes projected key, value states from a single input token and concatenates the states to cached
states from previous steps. This function is slighly adapted from the official Flax repository:
https://github.com/google/flax/blob/491ce18759622506588784b4fca0e4bf05f8c8cd/flax/linen/attention.py#L252
"""
# detect if we're initializing by absence of existing cache data.
is_initialized = self.has_variable("cache", "cached_key")
cached_key = self.variable("cache", "cached_key", jnp.zeros, key.shape, key.dtype)
cached_value = self.variable("cache", "cached_value", jnp.zeros, value.shape, value.dtype)
cache_index = self.variable("cache", "cache_index", lambda: jnp.array(0, dtype=jnp.int32))
if is_initialized:
*batch_dims, max_length, num_heads, depth_per_head = cached_key.value.shape
# update key, value caches with our new 1d spatial slices
cur_index = cache_index.value
indices = (0,) * len(batch_dims) + (cur_index, 0, 0)
key = lax.dynamic_update_slice(cached_key.value, key, indices)
value = lax.dynamic_update_slice(cached_value.value, value, indices)
cached_key.value = key
cached_value.value = value
num_updated_cache_vectors = query.shape[1]
cache_index.value = cache_index.value + num_updated_cache_vectors
# causal mask for cached decoder self-attention: our single query position should only attend to those key positions that have already been generated and cached, not the remaining zero elements.
pad_mask = jnp.broadcast_to(
jnp.arange(max_length) < cur_index + num_updated_cache_vectors,
tuple(batch_dims) + (1, num_updated_cache_vectors, max_length),
)
attention_mask = combine_masks(pad_mask, attention_mask)
return key, value, attention_mask
def __call__(
self,
hidden_states,
key_value_states: Optional[jnp.ndarray] = None,
attention_mask=None,
deterministic: bool = True,
init_cache: bool = False,
output_attentions: bool = False,
):
# if key_value_states are provided this layer is used as a cross-attention layer
# for the decoder
is_cross_attention = key_value_states is not None
batch_size = hidden_states.shape[0]
if not is_cross_attention:
qkv_out = self.c_attn(hidden_states)
query, key, value = jnp.split(qkv_out, 3, axis=2)
else:
q_out = self.q_attn(hidden_states)
(query,) = jnp.split(q_out, 1, axis=2)
kv_out = self.c_attn(key_value_states)
key, value = jnp.split(kv_out, 2, axis=2)
query = self._split_heads(query)
key = self._split_heads(key)
value = self._split_heads(value)
query_length, key_length = query.shape[1], key.shape[1]
if self.causal:
if self.has_variable("cache", "cached_key"):
mask_shift = self.variables["cache"]["cache_index"]
max_decoder_length = self.variables["cache"]["cached_key"].shape[1]
causal_mask = lax.dynamic_slice(
self.causal_mask, (0, 0, mask_shift, 0), (1, 1, query_length, max_decoder_length)
)
else:
causal_mask = self.causal_mask[:, :, :query_length, :key_length]
causal_mask = jnp.broadcast_to(causal_mask, (batch_size,) + causal_mask.shape[1:])
# combine masks if needed
if attention_mask is not None and self.causal:
attention_mask = jnp.broadcast_to(jnp.expand_dims(attention_mask, axis=(-3, -2)), causal_mask.shape)
attention_mask = combine_masks(attention_mask, causal_mask)
elif self.causal:
attention_mask = causal_mask
elif attention_mask is not None:
attention_mask = jnp.expand_dims(attention_mask, axis=(-3, -2))
dropout_rng = None
if not deterministic and self.config.attn_pdrop > 0.0:
dropout_rng = self.make_rng("dropout")
# During fast autoregressive decoding, we feed one position at a time,
# and cache the keys and values step by step.
if self.causal and (self.has_variable("cache", "cached_key") or init_cache):
key, value, attention_mask = self._concatenate_to_cache(key, value, query, attention_mask)
# transform boolean mask into float mask
if attention_mask is not None:
attention_bias = lax.select(
attention_mask > 0,
jnp.full(attention_mask.shape, 0.0).astype(self.dtype),
jnp.full(attention_mask.shape, jnp.finfo(self.dtype).min).astype(self.dtype),
)
else:
attention_bias = None
# usual dot product attention
attn_weights = dot_product_attention_weights(
query,
key,
bias=attention_bias,
dropout_rng=dropout_rng,
dropout_rate=self.config.attn_pdrop,
deterministic=deterministic,
dtype=self.dtype,
precision=None,
)
attn_output = jnp.einsum("...hqk,...khd->...qhd", attn_weights, value)
attn_output = self._merge_heads(attn_output)
attn_output = self.c_proj(attn_output)
attn_output = self.resid_dropout(attn_output, deterministic=deterministic)
outputs = (attn_output, attn_weights) if output_attentions else (attn_output,)
return outputs
class FlaxGPT2MLP(nn.Module):
config: GPT2Config
intermediate_size: int
dtype: jnp.dtype = jnp.float32
def setup(self):
embed_dim = self.config.hidden_size
self.c_fc = FlaxConv1D(self.intermediate_size, dtype=self.dtype)
self.c_proj = FlaxConv1D(embed_dim, dtype=self.dtype)
self.act = ACT2FN[self.config.activation_function]
self.dropout = nn.Dropout(rate=self.config.resid_pdrop)
def __call__(self, hidden_states, deterministic: bool = True):
hidden_states = self.c_fc(hidden_states)
hidden_states = self.act(hidden_states)
hidden_states = self.c_proj(hidden_states)
hidden_states = self.dropout(hidden_states, deterministic=deterministic)
return hidden_states
class FlaxGPT2Block(nn.Module):
config: GPT2Config
dtype: jnp.dtype = jnp.float32
def setup(self):
hidden_size = self.config.hidden_size
inner_dim = self.config.n_inner if self.config.n_inner is not None else 4 * hidden_size
self.ln_1 = nn.LayerNorm(epsilon=self.config.layer_norm_epsilon, dtype=self.dtype)
self.attn = FlaxGPT2Attention(self.config, dtype=self.dtype)
self.ln_2 = nn.LayerNorm(epsilon=self.config.layer_norm_epsilon, dtype=self.dtype)
if self.config.add_cross_attention:
self.crossattention = FlaxGPT2Attention(
config=self.config, dtype=self.dtype, causal=False, is_cross_attention=True
)
self.ln_cross_attn = nn.LayerNorm(epsilon=self.config.layer_norm_epsilon, dtype=self.dtype)
self.mlp = FlaxGPT2MLP(self.config, inner_dim, dtype=self.dtype)
def __call__(
self,
hidden_states,
attention_mask=None,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
deterministic: bool = True,
init_cache: bool = False,
output_attentions: bool = False,
):
residual = hidden_states
hidden_states = self.ln_1(hidden_states)
attn_outputs = self.attn(
hidden_states,
attention_mask=attention_mask,
deterministic=deterministic,
init_cache=init_cache,
output_attentions=output_attentions,
)
# residual connection
attn_output = attn_outputs[0] # output_attn: a, (attentions)
outputs = attn_outputs[1:]
# residual connection
hidden_states = attn_output + residual
# Cross-Attention Block
if encoder_hidden_states is not None:
# add one self-attention block for cross-attention
if not hasattr(self, "crossattention"):
raise ValueError(
f"If `encoder_hidden_states` are passed, {self} has to be instantiated with "
"cross-attention layers by setting `config.add_cross_attention=True`"
)
residual = hidden_states
hidden_states = self.ln_cross_attn(hidden_states)
cross_attn_outputs = self.crossattention(
hidden_states,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
deterministic=deterministic,
output_attentions=output_attentions,
)
attn_output = cross_attn_outputs[0]
# residual connection
hidden_states = residual + attn_output
outputs = outputs + cross_attn_outputs[1:] # add cross attentions if we output attention weights
residual = hidden_states
hidden_states = self.ln_2(hidden_states)
feed_forward_hidden_states = self.mlp(hidden_states, deterministic=deterministic)
# residual connection
hidden_states = residual + feed_forward_hidden_states
outputs = (hidden_states,) + outputs
return outputs
class FlaxGPT2PreTrainedModel(FlaxPreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = GPT2Config
base_model_prefix = "transformer"
module_class: nn.Module = None
def __init__(
self,
config: GPT2Config,
input_shape: Tuple = (1, 1),
seed: int = 0,
dtype: jnp.dtype = jnp.float32,
_do_init: bool = True,
**kwargs,
):
module = self.module_class(config=config, dtype=dtype, **kwargs)
super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype, _do_init=_do_init)
def init_weights(self, rng: jax.random.PRNGKey, input_shape: Tuple, params: FrozenDict = None) -> FrozenDict:
# init input tensors
input_ids = jnp.zeros(input_shape, dtype="i4")
attention_mask = jnp.ones_like(input_ids)
position_ids = jnp.broadcast_to(jnp.arange(jnp.atleast_2d(input_ids).shape[-1]), input_shape)
params_rng, dropout_rng = jax.random.split(rng)
rngs = {"params": params_rng, "dropout": dropout_rng}
if self.config.add_cross_attention:
encoder_hidden_states = jnp.zeros(input_shape + (self.config.n_embd,))
encoder_attention_mask = attention_mask
module_init_outputs = self.module.init(
rngs,
input_ids,
attention_mask,
position_ids,
encoder_hidden_states,
encoder_attention_mask,
return_dict=False,
)
else:
module_init_outputs = self.module.init(rngs, input_ids, attention_mask, position_ids, return_dict=False)
random_params = module_init_outputs["params"]
if params is not None:
random_params = flatten_dict(unfreeze(random_params))
params = flatten_dict(unfreeze(params))
for missing_key in self._missing_keys:
params[missing_key] = random_params[missing_key]
self._missing_keys = set()
return freeze(unflatten_dict(params))
else:
return random_params
def init_cache(self, batch_size, max_length):
r"""
Args:
batch_size (`int`):
batch_size used for fast auto-regressive decoding. Defines the batch size of the initialized cache.
max_length (`int`):
maximum possible length for auto-regressive decoding. Defines the sequence length of the initialized
cache.
"""
# init input variables to retrieve cache
input_ids = jnp.ones((batch_size, max_length))
attention_mask = jnp.ones_like(input_ids)
position_ids = jnp.broadcast_to(jnp.arange(jnp.atleast_2d(input_ids).shape[-1]), input_ids.shape)
init_variables = self.module.init(
jax.random.PRNGKey(0), input_ids, attention_mask, position_ids, return_dict=False, init_cache=True
)
return unfreeze(init_variables["cache"])
@add_start_docstrings_to_model_forward(GPT2_INPUTS_DOCSTRING)
def __call__(
self,
input_ids,
attention_mask=None,
position_ids=None,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
params: dict = None,
past_key_values: dict = None,
dropout_rng: jax.random.PRNGKey = None,
train: bool = False,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.return_dict
if encoder_hidden_states is not None and encoder_attention_mask is None:
batch_size, sequence_length = encoder_hidden_states.shape[:2]
encoder_attention_mask = jnp.ones((batch_size, sequence_length))
batch_size, sequence_length = input_ids.shape
if position_ids is None:
if past_key_values is not None:
raise ValueError("Make sure to provide `position_ids` when passing `past_key_values`.")
position_ids = jnp.broadcast_to(jnp.arange(sequence_length)[None, :], (batch_size, sequence_length))
if attention_mask is None:
attention_mask = jnp.ones((batch_size, sequence_length))
# Handle any PRNG if needed
rngs = {}
if dropout_rng is not None:
rngs["dropout"] = dropout_rng
inputs = {"params": params or self.params}
# if past_key_values are passed then cache is already initialized a private flag init_cache has to be passed down to ensure cache is used. It has to be made sure that cache is marked as mutable so that it can be changed by FlaxGPT2Attention module
if past_key_values:
inputs["cache"] = past_key_values
mutable = ["cache"]
else:
mutable = False
outputs = self.module.apply(
inputs,
jnp.array(input_ids, dtype="i4"),
jnp.array(attention_mask, dtype="i4"),
jnp.array(position_ids, dtype="i4"),
encoder_hidden_states,
encoder_attention_mask,
not train,
False,
output_attentions,
output_hidden_states,
return_dict,
rngs=rngs,
mutable=mutable,
)
# add updated cache to model output
if past_key_values is not None and return_dict:
outputs, past_key_values = outputs
outputs["past_key_values"] = unfreeze(past_key_values["cache"])
return outputs
elif past_key_values is not None and not return_dict:
outputs, past_key_values = outputs
outputs = outputs[:1] + (unfreeze(past_key_values["cache"]),) + outputs[1:]
return outputs
class FlaxGPT2BlockCollection(nn.Module):
config: GPT2Config
dtype: jnp.dtype = jnp.float32
def setup(self):
self.blocks = [
FlaxGPT2Block(self.config, name=str(i), dtype=self.dtype) for i in range(self.config.num_hidden_layers)
]
def __call__(
self,
hidden_states,
attention_mask=None,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
deterministic: bool = True,
init_cache: bool = False,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
all_attentions = () if output_attentions else None
all_hidden_states = () if output_hidden_states else None
all_cross_attentions = () if (output_attentions and encoder_hidden_states is not None) else None
for block in self.blocks:
if output_hidden_states:
all_hidden_states += (hidden_states,)
layer_outputs = block(
hidden_states,
attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
deterministic=deterministic,
init_cache=init_cache,
output_attentions=output_attentions,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions += (layer_outputs[1],)
if encoder_hidden_states is not None:
all_cross_attentions += (layer_outputs[2],)
# this contains possible `None` values - `FlaxGPT2Module` will filter them out
outputs = (hidden_states, all_hidden_states, all_attentions, all_cross_attentions)
return outputs
class FlaxGPT2Module(nn.Module):
config: GPT2Config
dtype: jnp.dtype = jnp.float32
def setup(self):
self.embed_dim = self.config.hidden_size
self.wte = nn.Embed(
self.config.vocab_size,
self.embed_dim,
embedding_init=jax.nn.initializers.normal(stddev=self.config.initializer_range),
dtype=self.dtype,
)
self.wpe = nn.Embed(
self.config.max_position_embeddings,
self.embed_dim,
embedding_init=jax.nn.initializers.normal(stddev=self.config.initializer_range),
dtype=self.dtype,
)
self.dropout = nn.Dropout(rate=self.config.embd_pdrop)
self.h = FlaxGPT2BlockCollection(self.config, dtype=self.dtype)
self.ln_f = nn.LayerNorm(epsilon=self.config.layer_norm_epsilon, dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
position_ids,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
deterministic=True,
init_cache: bool = False,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
input_embeds = self.wte(input_ids.astype("i4"))
position_embeds = self.wpe(position_ids.astype("i4"))
hidden_states = input_embeds + position_embeds
hidden_states = self.dropout(hidden_states, deterministic=deterministic)
outputs = self.h(
hidden_states,
attention_mask,
encoder_hidden_states,
encoder_attention_mask,
deterministic=deterministic,
init_cache=init_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
hidden_states = self.ln_f(hidden_states)
if output_hidden_states:
all_hidden_states = outputs[1] + (hidden_states,)
outputs = (hidden_states, all_hidden_states) + outputs[2:]
else:
outputs = (hidden_states,) + outputs[1:]
if not return_dict:
return tuple(v for v in outputs if v is not None)
return FlaxBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
hidden_states=outputs[1],
attentions=outputs[2],
cross_attentions=outputs[3],
)
@add_start_docstrings(
"The bare GPT2 Model transformer outputting raw hidden-states without any specific head on top.",
GPT2_START_DOCSTRING,
)
class FlaxGPT2Model(FlaxGPT2PreTrainedModel):
module_class = FlaxGPT2Module
append_call_sample_docstring(
FlaxGPT2Model,
_CHECKPOINT_FOR_DOC,
FlaxBaseModelOutputWithPastAndCrossAttentions,
_CONFIG_FOR_DOC,
)
class FlaxGPT2LMHeadModule(nn.Module):
config: GPT2Config
dtype: jnp.dtype = jnp.float32
def setup(self):
self.transformer = FlaxGPT2Module(self.config, dtype=self.dtype)
self.lm_head = nn.Dense(
self.config.vocab_size,
use_bias=False,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(stddev=self.config.initializer_range),
)
def __call__(
self,
input_ids,
attention_mask,
position_ids,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
deterministic: bool = True,
init_cache: bool = False,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
outputs = self.transformer(
input_ids,
attention_mask,
position_ids,
encoder_hidden_states,
encoder_attention_mask,
deterministic=deterministic,
init_cache=init_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
if self.config.tie_word_embeddings:
shared_kernel = self.transformer.variables["params"]["wte"]["embedding"].T
lm_logits = self.lm_head.apply({"params": {"kernel": shared_kernel}}, hidden_states)
else:
lm_logits = self.lm_head(hidden_states)
if not return_dict:
return (lm_logits,) + outputs[1:]
return FlaxCausalLMOutputWithCrossAttentions(
logits=lm_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
@add_start_docstrings(
"""
The GPT2 Model transformer with a language modeling head on top (linear layer with weights tied to the input
embeddings).
""",
GPT2_START_DOCSTRING,
)
class FlaxGPT2LMHeadModel(FlaxGPT2PreTrainedModel):
module_class = FlaxGPT2LMHeadModule
def prepare_inputs_for_generation(self, input_ids, max_length, attention_mask: Optional[jax.Array] = None):
# initializing the cache
batch_size, seq_length = input_ids.shape
past_key_values = self.init_cache(batch_size, max_length)
# Note that usually one would have to put 0's in the attention_mask for x > input_ids.shape[-1] and x < cache_length.
# But since GPT2 uses a causal mask, those positions are masked anyways.
# Thus we can create a single static attention_mask here, which is more efficient for compilation
extended_attention_mask = jnp.ones((batch_size, max_length), dtype="i4")
if attention_mask is not None:
position_ids = attention_mask.cumsum(axis=-1) - 1
extended_attention_mask = lax.dynamic_update_slice(
extended_attention_mask, attention_mask.astype("i4"), (0, 0)
)
else:
position_ids = jnp.broadcast_to(jnp.arange(seq_length, dtype="i4")[None, :], (batch_size, seq_length))
return {
"past_key_values": past_key_values,
"attention_mask": extended_attention_mask,
"position_ids": position_ids,
}
def update_inputs_for_generation(self, model_outputs, model_kwargs):
model_kwargs["past_key_values"] = model_outputs.past_key_values
model_kwargs["position_ids"] = model_kwargs["position_ids"][:, -1:] + 1
return model_kwargs
append_call_sample_docstring(
FlaxGPT2LMHeadModel,
_CHECKPOINT_FOR_DOC,
FlaxCausalLMOutputWithCrossAttentions,
_CONFIG_FOR_DOC,
)
__all__ = ["FlaxGPT2LMHeadModel", "FlaxGPT2Model", "FlaxGPT2PreTrainedModel"]
| transformers/src/transformers/models/gpt2/modeling_flax_gpt2.py/0 | {
"file_path": "transformers/src/transformers/models/gpt2/modeling_flax_gpt2.py",
"repo_id": "transformers",
"token_count": 14172
} |
# coding=utf-8
# Copyright 2024 EleutherAI and the HuggingFace Inc. team. All rights reserved.
#
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
# and OPT implementations in this library. It has been modified from its
# original forms to accommodate minor architectural differences compared
# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Granite model configuration"""
from ...configuration_utils import PretrainedConfig
from ...modeling_rope_utils import rope_config_validation
from ...utils import logging
logger = logging.get_logger(__name__)
class GraniteConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`GraniteModel`]. It is used to instantiate an Granite
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the Granite-3B.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 32000):
Vocabulary size of the Granite model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`GraniteModel`]
hidden_size (`int`, *optional*, defaults to 4096):
Dimension of the hidden representations.
intermediate_size (`int`, *optional*, defaults to 11008):
Dimension of the MLP representations.
num_hidden_layers (`int`, *optional*, defaults to 32):
Number of hidden layers in the Transformer decoder.
num_attention_heads (`int`, *optional*, defaults to 32):
Number of attention heads for each attention layer in the Transformer decoder.
num_key_value_heads (`int`, *optional*):
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details checkout [this
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
max_position_embeddings (`int`, *optional*, defaults to 2048):
The maximum sequence length that this model might ever be used with.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
rms_norm_eps (`float`, *optional*, defaults to 1e-06):
The epsilon used by the rms normalization layers.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
pad_token_id (`int`, *optional*):
Padding token id.
bos_token_id (`int`, *optional*, defaults to 1):
Beginning of stream token id.
eos_token_id (`int`, *optional*, defaults to 2):
End of stream token id.
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
Whether to tie weight embeddings
rope_theta (`float`, *optional*, defaults to 10000.0):
The base period of the RoPE embeddings.
rope_scaling (`Dict`, *optional*):
Dictionary containing the scaling configuration for the RoPE embeddings. Currently supports two scaling
strategies: linear and dynamic. Their scaling factor must be a float greater than 1. The expected format is
`{"type": strategy name, "factor": scaling factor}`. When using this flag, don't update
`max_position_embeddings` to the expected new maximum. See the following thread for more information on how
these scaling strategies behave:
https://www.reddit.com/r/LocalLLaMA/comments/14mrgpr/dynamically_scaled_rope_further_increases/. This is an
experimental feature, subject to breaking API changes in future versions.
attention_bias (`bool`, *optional*, defaults to `False`):
Whether to use a bias in the query, key, value and output projection layers during self-attention.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
mlp_bias (`bool`, *optional*, defaults to `False`):
Whether to use a bias in up_proj, down_proj and gate_proj layers in the MLP layers.
embedding_multiplier (`float`, *optional*, defaults to 1.0): embedding multiplier
logits_scaling (`float`, *optional*, defaults to 1.0): divisor for output logits
residual_multiplier (`float`, *optional*, defaults to 1.0): residual multiplier
attention_multiplier (`float`, *optional*, defaults to 1.0): attention multiplier
```python
>>> from transformers import GraniteModel, GraniteConfig
>>> # Initializing a Granite granite-3b style configuration
>>> configuration = GraniteConfig()
>>> # Initializing a model from the granite-7b style configuration
>>> model = GraniteModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "granite"
keys_to_ignore_at_inference = ["past_key_values"]
# Default tensor parallel plan for base model `GraniteModel`
base_model_tp_plan = {
"layers.*.self_attn.q_proj": "colwise",
"layers.*.self_attn.k_proj": "colwise",
"layers.*.self_attn.v_proj": "colwise",
"layers.*.self_attn.o_proj": "rowwise",
"layers.*.mlp.gate_proj": "colwise",
"layers.*.mlp.up_proj": "colwise",
"layers.*.mlp.down_proj": "rowwise",
}
def __init__(
self,
vocab_size=32000,
hidden_size=4096,
intermediate_size=11008,
num_hidden_layers=32,
num_attention_heads=32,
num_key_value_heads=None,
hidden_act="silu",
max_position_embeddings=2048,
initializer_range=0.02,
rms_norm_eps=1e-6,
use_cache=True,
pad_token_id=None,
bos_token_id=1,
eos_token_id=2,
tie_word_embeddings=False,
rope_theta=10000.0,
rope_scaling=None,
attention_bias=False,
attention_dropout=0.0,
mlp_bias=False,
embedding_multiplier=1.0,
logits_scaling=1.0,
residual_multiplier=1.0,
attention_multiplier=1.0,
**kwargs,
):
self.vocab_size = vocab_size
self.max_position_embeddings = max_position_embeddings
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
# for backward compatibility
if num_key_value_heads is None:
num_key_value_heads = num_attention_heads
self.num_key_value_heads = num_key_value_heads
self.hidden_act = hidden_act
self.initializer_range = initializer_range
self.rms_norm_eps = rms_norm_eps
self.use_cache = use_cache
self.rope_theta = rope_theta
self.rope_scaling = rope_scaling
self.attention_bias = attention_bias
self.attention_dropout = attention_dropout
self.mlp_bias = mlp_bias
self.embedding_multiplier = embedding_multiplier
self.logits_scaling = logits_scaling
self.residual_multiplier = residual_multiplier
self.attention_multiplier = attention_multiplier
super().__init__(
pad_token_id=pad_token_id,
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
tie_word_embeddings=tie_word_embeddings,
**kwargs,
)
rope_config_validation(self)
| transformers/src/transformers/models/granite/configuration_granite.py/0 | {
"file_path": "transformers/src/transformers/models/granite/configuration_granite.py",
"repo_id": "transformers",
"token_count": 3461
} |
# coding=utf-8
# Copyright 2022 NVIDIA and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""TF 2.0 GroupViT model."""
from __future__ import annotations
import collections.abc
import math
from dataclasses import dataclass
from typing import Any, Optional, Tuple, Union
import numpy as np
import tensorflow as tf
from ...activations_tf import get_tf_activation
from ...modeling_tf_outputs import TFBaseModelOutput, TFBaseModelOutputWithPooling
from ...modeling_tf_utils import (
TFModelInputType,
TFPreTrainedModel,
get_initializer,
keras,
keras_serializable,
unpack_inputs,
)
from ...tf_utils import check_embeddings_within_bounds, shape_list, stable_softmax
from ...utils import (
ModelOutput,
add_start_docstrings,
add_start_docstrings_to_model_forward,
is_tensorflow_probability_available,
logging,
replace_return_docstrings,
)
from .configuration_groupvit import GroupViTConfig, GroupViTTextConfig, GroupViTVisionConfig
logger = logging.get_logger(__name__)
# soft dependency
if is_tensorflow_probability_available():
try:
import tensorflow_probability as tfp
# On the first call, check whether a compatible version of TensorFlow is installed
# TensorFlow Probability depends on a recent stable release of TensorFlow
_ = tfp.distributions.Normal(loc=0.0, scale=1.0)
except ImportError:
logger.error(
"GroupViT models are not usable since `tensorflow_probability` can't be loaded. "
"It seems you have `tensorflow_probability` installed with the wrong tensorflow version."
"Please try to reinstall it following the instructions here: https://github.com/tensorflow/probability."
)
else:
try:
import tensorflow_probability as tfp
# On the first call, check whether a compatible version of TensorFlow is installed
# TensorFlow Probability depends on a recent stable release of TensorFlow
_ = tfp.distributions.Normal(loc=0.0, scale=1.0)
except ImportError:
pass
_CHECKPOINT_FOR_DOC = "nvidia/groupvit-gcc-yfcc"
LARGE_NEGATIVE = -1e8
# Copied from transformers.models.bart.modeling_tf_bart._expand_mask
def _expand_mask(mask: tf.Tensor, tgt_len: Optional[int] = None):
"""
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
"""
src_len = shape_list(mask)[1]
tgt_len = tgt_len if tgt_len is not None else src_len
one_cst = tf.constant(1.0)
mask = tf.cast(mask, dtype=one_cst.dtype)
expanded_mask = tf.tile(mask[:, None, None, :], (1, 1, tgt_len, 1))
return (one_cst - expanded_mask) * LARGE_NEGATIVE
# contrastive loss function, adapted from
# https://sachinruk.github.io/blog/pytorch/pytorch%20lightning/loss%20function/gpu/2021/03/07/CLIP.html
def contrastive_loss(logits: tf.Tensor) -> tf.Tensor:
return tf.math.reduce_mean(
keras.metrics.sparse_categorical_crossentropy(
y_true=tf.range(shape_list(logits)[0]), y_pred=logits, from_logits=True
)
)
# Copied from transformers.models.clip.modeling_tf_clip.clip_loss with clip->groupvit
def groupvit_loss(similarity: tf.Tensor) -> tf.Tensor:
caption_loss = contrastive_loss(similarity)
image_loss = contrastive_loss(tf.transpose(similarity))
return (caption_loss + image_loss) / 2.0
def hard_softmax(logits: tf.Tensor, dim: int) -> tf.Tensor:
y_soft = stable_softmax(logits, dim)
# Straight through.
index = tf.argmax(y_soft, dim)
y_hard = tf.one_hot(
index,
depth=shape_list(logits)[dim],
# TensorFlow expects axis to be -1 or between [0, 3). But received: -2
# This is why the following code snippet is used.
axis=range(len(shape_list(logits)))[dim],
dtype=y_soft.dtype,
)
ret = y_hard - tf.stop_gradient(y_soft) + y_soft
return ret
def gumbel_softmax(logits: tf.Tensor, tau: float = 1, hard: bool = False, dim: int = -1) -> tf.Tensor:
gumbel_dist = tfp.distributions.Gumbel(0.0, 1.0)
gumbels = gumbel_dist.sample(tf.shape(logits), dtype=logits.dtype)
gumbels = (logits + gumbels) / tau # ~Gumbel(logits,tau)
y_soft = stable_softmax(gumbels, dim)
if hard:
# Straight through.
index = tf.argmax(y_soft, dim)
y_hard = tf.one_hot(
index,
depth=shape_list(logits)[dim],
# TensorFlow expects axis to be -1 or between [0, 3). But received: -2
# This is why the following code snippet is used.
axis=range(len(shape_list(logits)))[dim],
dtype=y_soft.dtype,
)
ret = y_hard - tf.stop_gradient(y_soft) + y_soft
else:
# Reparametrization trick.
ret = y_soft
return ret
def resize_attention_map(attentions: tf.Tensor, height: int, width: int, align_corners: bool = False) -> tf.Tensor:
"""
Args:
attentions (`tf.Tensor`): attention map of shape [batch_size, groups, feat_height*feat_width]
height (`int`): height of the output attention map
width (`int`): width of the output attention map
align_corners (`bool`, *optional*): the `align_corner` argument for `nn.functional.interpolate`.
Returns:
`tf.Tensor`: resized attention map of shape [batch_size, groups, height, width]
"""
scale = (height * width // attentions.shape[2]) ** 0.5
if height > width:
feat_width = int(np.round(width / scale))
feat_height = shape_list(attentions)[2] // feat_width
else:
feat_height = int(np.round(height / scale))
feat_width = shape_list(attentions)[2] // feat_height
batch_size = shape_list(attentions)[0]
groups = shape_list(attentions)[1] # number of group token
# [batch_size, groups, height x width, groups] -> [batch_size, groups, height, width]
attentions = tf.reshape(attentions, (batch_size, groups, feat_height, feat_width))
attentions = tf.transpose(attentions, perm=(0, 2, 3, 1))
if align_corners:
attentions = tf.compat.v1.image.resize(
attentions,
size=(height, width),
method="bilinear",
align_corners=align_corners,
)
else:
attentions = tf.image.resize(attentions, size=(height, width), method="bilinear")
attentions = tf.transpose(attentions, perm=(0, 3, 1, 2))
return attentions
def get_grouping_from_attentions(attentions: Tuple[tf.Tensor], hw_shape: Tuple[int]) -> tf.Tensor:
"""
Args:
attentions (`tuple(tf.Tensor)`: tuple of attention maps returned by `TFGroupViTVisionTransformer`
hw_shape (`tuple(int)`): height and width of the output attention map
Returns:
`tf.Tensor`: the attention map of shape [batch_size, groups, height, width]
"""
attn_maps = []
prev_attn_masks = None
for attn_masks in attentions:
# [batch_size, num_groups, height x width] -> [batch_size, height x width, num_groups]
attn_masks = tf.transpose(attn_masks, perm=(0, 2, 1))
if prev_attn_masks is None:
prev_attn_masks = attn_masks
else:
prev_attn_masks = tf.matmul(prev_attn_masks, attn_masks)
# [batch_size, height x width, num_groups] -> [batch_size, num_groups, height x width] -> [batch_size, num_groups, height, width]
cur_attn_map = resize_attention_map(tf.transpose(prev_attn_masks, perm=(0, 2, 1)), *hw_shape)
attn_maps.append(cur_attn_map)
# [batch_size, num_groups, height, width]
final_grouping = attn_maps[-1]
return tf.stop_gradient(final_grouping)
@dataclass
class TFGroupViTModelOutput(ModelOutput):
"""
Args:
loss (`tf.Tensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
Contrastive loss for image-text similarity.
logits_per_image (`tf.Tensor` of shape `(image_batch_size, text_batch_size)`):
The scaled dot product scores between `image_embeds` and `text_embeds`. This represents the image-text
similarity scores.
logits_per_text (`tf.Tensor` of shape `(text_batch_size, image_batch_size)`):
The scaled dot product scores between `text_embeds` and `image_embeds`. This represents the text-image
similarity scores.
segmentation_logits (`tf.Tensor` of shape `(batch_size, config.num_labels, logits_height, logits_width)`):
Classification scores for each pixel.
<Tip warning={true}>
The logits returned do not necessarily have the same size as the `pixel_values` passed as inputs. This is
to avoid doing two interpolations and lose some quality when a user needs to resize the logits to the
original image size as post-processing. You should always check your logits shape and resize as needed.
</Tip>
text_embeds (`tf.Tensor` of shape `(batch_size, output_dim`):
The text embeddings obtained by applying the projection layer to the pooled output of
[`TFGroupViTTextModel`].
image_embeds (`tf.Tensor` of shape `(batch_size, output_dim`):
The image embeddings obtained by applying the projection layer to the pooled output of
[`TFGroupViTVisionModel`].
text_model_output (`TFBaseModelOutputWithPooling`):
The output of the [`TFGroupViTTextModel`].
vision_model_output (`TFBaseModelOutputWithPooling`):
The output of the [`TFGroupViTVisionModel`].
"""
loss: tf.Tensor | None = None
logits_per_image: tf.Tensor = None
logits_per_text: tf.Tensor = None
segmentation_logits: tf.Tensor = None
text_embeds: tf.Tensor = None
image_embeds: tf.Tensor = None
text_model_output: TFBaseModelOutputWithPooling = None
vision_model_output: TFBaseModelOutputWithPooling = None
def to_tuple(self) -> Tuple[Any]:
return tuple(
self[k] if k not in ["text_model_output", "vision_model_output"] else getattr(self, k).to_tuple()
for k in self.keys()
)
class TFGroupViTCrossAttentionLayer(keras.layers.Layer):
def __init__(self, config: GroupViTVisionConfig, **kwargs):
super().__init__(**kwargs)
self.attn = TFGroupViTAttention(config, name="attn")
self.norm2 = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="norm2")
self.mlp = TFGroupViTMLP(config, name="mlp")
self.norm_post = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="norm_post")
self.config = config
def call(self, query: tf.Tensor, key: tf.Tensor, training: bool = False) -> tf.Tensor:
x = query
x = x + self.attn(query, encoder_hidden_states=key)[0]
x = x + self.mlp(self.norm2(x))
x = self.norm_post(x)
return x
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "attn", None) is not None:
with tf.name_scope(self.attn.name):
self.attn.build(None)
if getattr(self, "norm2", None) is not None:
with tf.name_scope(self.norm2.name):
self.norm2.build([None, None, self.config.hidden_size])
if getattr(self, "mlp", None) is not None:
with tf.name_scope(self.mlp.name):
self.mlp.build(None)
if getattr(self, "norm_post", None) is not None:
with tf.name_scope(self.norm_post.name):
self.norm_post.build([None, None, self.config.hidden_size])
class TFGroupViTAssignAttention(keras.layers.Layer):
def __init__(self, config: GroupViTVisionConfig, **kwargs):
super().__init__(**kwargs)
self.scale = config.hidden_size**-0.5
self.q_proj = keras.layers.Dense(config.hidden_size, name="q_proj")
self.k_proj = keras.layers.Dense(config.hidden_size, name="k_proj")
self.v_proj = keras.layers.Dense(config.hidden_size, name="v_proj")
self.proj = keras.layers.Dense(config.hidden_size, name="proj")
self.assign_eps = config.assign_eps
self.config = config
def get_attn(self, attn: tf.Tensor, gumbel: bool = True, hard: bool = True, training: bool = False) -> tf.Tensor:
if gumbel and training:
attn = gumbel_softmax(attn, dim=-2, hard=hard)
else:
if hard:
attn = hard_softmax(attn, dim=-2)
else:
attn = stable_softmax(attn, axis=-2)
return attn
def call(self, query: tf.Tensor, key: tf.Tensor, training: bool = False):
value = key
# [batch_size, query_length, channels]
query = self.q_proj(query)
# [batch_size, key_length, channels]
key = self.k_proj(key)
# [batch_size, key_length, channels]
value = self.v_proj(value)
# [batch_size, query_length, key_length]
raw_attn = tf.matmul(query, key, transpose_b=True) * self.scale
attn = self.get_attn(raw_attn, training=training)
soft_attn = self.get_attn(raw_attn, training=training, gumbel=False, hard=False)
attn = attn / (tf.math.reduce_sum(attn, axis=-1, keepdims=True) + self.assign_eps)
out = tf.matmul(attn, value)
out = self.proj(out)
return out, soft_attn
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "q_proj", None) is not None:
with tf.name_scope(self.q_proj.name):
self.q_proj.build([None, None, self.config.hidden_size])
if getattr(self, "k_proj", None) is not None:
with tf.name_scope(self.k_proj.name):
self.k_proj.build([None, None, self.config.hidden_size])
if getattr(self, "v_proj", None) is not None:
with tf.name_scope(self.v_proj.name):
self.v_proj.build([None, None, self.config.hidden_size])
if getattr(self, "proj", None) is not None:
with tf.name_scope(self.proj.name):
self.proj.build([None, None, self.config.hidden_size])
class TFGroupViTTokenAssign(keras.layers.Layer):
def __init__(self, config: GroupViTVisionConfig, num_group_token: int, num_output_group: int, **kwargs):
super().__init__(**kwargs)
self.num_output_group = num_output_group
# norm on group_tokens
self.norm_tokens = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="norm_tokens")
assign_mlp_ratio = (
config.assign_mlp_ratio
if isinstance(config.assign_mlp_ratio, collections.abc.Iterable)
else (config.assign_mlp_ratio, config.assign_mlp_ratio)
)
tokens_dim, channels_dim = [int(x * config.hidden_size) for x in assign_mlp_ratio]
self.mlp_inter = TFGroupViTMixerMLP(config, num_group_token, tokens_dim, num_output_group, name="mlp_inter")
self.norm_post_tokens = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="norm_post_tokens")
# norm on x
self.norm_x = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="norm_x")
self.pre_assign_attn = TFGroupViTCrossAttentionLayer(config, name="pre_assign_attn")
self.assign = TFGroupViTAssignAttention(config, name="assign")
self.norm_new_x = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="norm_new_x")
self.mlp_channels = TFGroupViTMLP(
config, config.hidden_size, channels_dim, config.hidden_size, name="mlp_channels"
)
self.config = config
def project_group_token(self, group_tokens: tf.Tensor) -> tf.Tensor:
"""
Args:
group_tokens (tf.Tensor): group tokens, [batch_size, num_group_tokens, channels]
Returns:
projected_group_tokens (tf.Tensor): [batch_size, num_output_groups, channels]
"""
# [B, num_output_groups, C] <- [B, num_group_tokens, C]
projected_group_tokens = self.mlp_inter(group_tokens)
projected_group_tokens = self.norm_post_tokens(projected_group_tokens)
return projected_group_tokens
def call(self, image_tokens: tf.Tensor, group_tokens: tf.Tensor, training: bool = False):
"""
Args:
image_tokens (`tf.Tensor`): image tokens, of shape [batch_size, input_length, channels]
group_tokens (`tf.Tensor`): group tokens, [batch_size, num_group_tokens, channels]
"""
group_tokens = self.norm_tokens(group_tokens)
image_tokens = self.norm_x(image_tokens)
# [batch_size, num_output_groups, channels]
projected_group_tokens = self.project_group_token(group_tokens)
projected_group_tokens = self.pre_assign_attn(projected_group_tokens, image_tokens)
new_image_tokens, attention = self.assign(projected_group_tokens, image_tokens)
new_image_tokens += projected_group_tokens
new_image_tokens = new_image_tokens + self.mlp_channels(self.norm_new_x(new_image_tokens))
return new_image_tokens, attention
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "norm_tokens", None) is not None:
with tf.name_scope(self.norm_tokens.name):
self.norm_tokens.build([None, None, self.config.hidden_size])
if getattr(self, "mlp_inter", None) is not None:
with tf.name_scope(self.mlp_inter.name):
self.mlp_inter.build(None)
if getattr(self, "norm_post_tokens", None) is not None:
with tf.name_scope(self.norm_post_tokens.name):
self.norm_post_tokens.build([None, None, self.config.hidden_size])
if getattr(self, "norm_x", None) is not None:
with tf.name_scope(self.norm_x.name):
self.norm_x.build([None, None, self.config.hidden_size])
if getattr(self, "pre_assign_attn", None) is not None:
with tf.name_scope(self.pre_assign_attn.name):
self.pre_assign_attn.build(None)
if getattr(self, "assign", None) is not None:
with tf.name_scope(self.assign.name):
self.assign.build(None)
if getattr(self, "norm_new_x", None) is not None:
with tf.name_scope(self.norm_new_x.name):
self.norm_new_x.build([None, None, self.config.hidden_size])
if getattr(self, "mlp_channels", None) is not None:
with tf.name_scope(self.mlp_channels.name):
self.mlp_channels.build(None)
# Adapted from transformers.models.vit.modeling_tf_vit.TFViTPatchEmbeddings with ViT->GroupViT
class TFGroupViTPatchEmbeddings(keras.layers.Layer):
"""
This class turns `pixel_values` of shape `(batch_size, num_channels, height, width)` into the initial
`hidden_states` (patch embeddings) of shape `(batch_size, seq_length, hidden_size)` to be consumed by a
Transformer.
"""
def __init__(self, config: GroupViTConfig, **kwargs):
super().__init__(**kwargs)
image_size, patch_size = config.image_size, config.patch_size
num_channels = config.num_channels
# hidden_size is a member as it will be required in the call method
self.hidden_size = config.hidden_size
image_size = image_size if isinstance(image_size, collections.abc.Iterable) else (image_size, image_size)
patch_size = patch_size if isinstance(patch_size, collections.abc.Iterable) else (patch_size, patch_size)
num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
self.image_size = image_size
self.patch_size = patch_size
self.num_patches = num_patches
self.num_channels = num_channels
self.config = config
self.projection = keras.layers.Conv2D(
filters=self.hidden_size,
kernel_size=patch_size,
strides=patch_size,
padding="valid",
data_format="channels_last",
use_bias=True,
kernel_initializer=get_initializer(self.config.initializer_range),
bias_initializer="zeros",
name="projection",
)
def call(
self, pixel_values: tf.Tensor, interpolate_pos_encoding: bool = False, training: bool = False
) -> tf.Tensor:
batch_size, num_channels, height, width = shape_list(pixel_values)
if tf.executing_eagerly() and num_channels != self.num_channels:
raise ValueError(
"Make sure that the channel dimension of the pixel values match with the one set in the configuration."
)
if (
not interpolate_pos_encoding
and tf.executing_eagerly()
and (height != self.image_size[0] or width != self.image_size[1])
):
raise ValueError(
f"Input image size ({height}*{width}) doesn't match model ({self.image_size[0]}*{self.image_size[1]})."
)
# When running on CPU, `keras.layers.Conv2D` doesn't support `NCHW` format.
# So change the input format from `NCHW` to `NHWC`.
# shape = (batch_size, in_height, in_width, in_channels=num_channels)
pixel_values = tf.transpose(pixel_values, perm=(0, 2, 3, 1))
projection = self.projection(pixel_values)
# Change the 2D spatial dimensions to a single temporal dimension.
# shape = (batch_size, num_patches, out_channels=embed_dim)
num_patches = (width // self.patch_size[1]) * (height // self.patch_size[0])
# In the TFGroupViTVisionEmbeddings the embeddings from this layer will be layer normalized
# LayerNormalization layer needs to have static last dimension (otherwise the test_keras_save_load fails with symbolic tensors)
# This is why we have used the hidden_size in the reshape method
embeddings = tf.reshape(tensor=projection, shape=(batch_size, num_patches, self.hidden_size))
return embeddings
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "projection", None) is not None:
with tf.name_scope(self.projection.name):
self.projection.build([None, None, None, self.num_channels])
# Adapted from transformers.vit.modeling_tf_vit.TFViTEmbeddings
class TFGroupViTVisionEmbeddings(keras.layers.Layer):
"""
Construct the position and patch embeddings.
"""
def __init__(self, config: GroupViTVisionConfig, **kwargs):
super().__init__(**kwargs)
self.patch_embeddings = TFGroupViTPatchEmbeddings(config, name="patch_embeddings")
self.dropout = keras.layers.Dropout(rate=config.dropout, name="dropout")
self.layernorm = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="layernorm")
self.config = config
def build(self, input_shape=None):
num_patches = self.patch_embeddings.num_patches
self.position_embeddings = self.add_weight(
shape=(1, num_patches, self.config.hidden_size),
initializer="zeros",
trainable=True,
name="position_embeddings",
)
if self.built:
return
self.built = True
if getattr(self, "patch_embeddings", None) is not None:
with tf.name_scope(self.patch_embeddings.name):
self.patch_embeddings.build(None)
if getattr(self, "dropout", None) is not None:
with tf.name_scope(self.dropout.name):
self.dropout.build(None)
if getattr(self, "layernorm", None) is not None:
with tf.name_scope(self.layernorm.name):
self.layernorm.build([None, None, self.config.hidden_size])
def interpolate_pos_encoding(self, embeddings, height, width) -> tf.Tensor:
"""
This method allows to interpolate the pre-trained position encodings, to be able to use the model on higher
resolution images.
Source:
https://github.com/facebookresearch/dino/blob/de9ee3df6cf39fac952ab558447af1fa1365362a/vision_transformer.py#L174
"""
batch_size, num_patches, dim = shape_list(embeddings)
num_positions = shape_list(self.position_embeddings)[1]
if num_patches == num_positions and height == width:
return self.position_embeddings
patch_pos_embed = self.position_embeddings
h0 = height // self.config.patch_size
w0 = width // self.config.patch_size
patch_pos_embed = tf.image.resize(
images=tf.reshape(
patch_pos_embed, shape=(1, int(math.sqrt(num_positions)), int(math.sqrt(num_positions)), dim)
),
size=(h0, w0),
method="bicubic",
)
patch_pos_embed = tf.reshape(tensor=patch_pos_embed, shape=(1, -1, dim))
return patch_pos_embed
def call(
self, pixel_values: tf.Tensor, interpolate_pos_encoding: bool = False, training: bool = False
) -> tf.Tensor:
_, _, height, width = shape_list(pixel_values)
embeddings = self.patch_embeddings(pixel_values, interpolate_pos_encoding=interpolate_pos_encoding)
embeddings = self.layernorm(embeddings)
# add positional encoding to each token
if interpolate_pos_encoding:
embeddings = embeddings + self.interpolate_pos_encoding(embeddings, height, width)
else:
embeddings = embeddings + self.position_embeddings
embeddings = self.dropout(embeddings)
return embeddings
# Copied from transformers.models.clip.modeling_tf_clip.TFCLIPTextEmbeddings with CLIP->GroupViT
class TFGroupViTTextEmbeddings(keras.layers.Layer):
def __init__(self, config: GroupViTTextConfig, **kwargs):
super().__init__(**kwargs)
self.embed_dim = config.hidden_size
self.config = config
def build(self, input_shape: tf.TensorShape = None):
with tf.name_scope("token_embedding"):
self.weight = self.add_weight(
shape=(self.config.vocab_size, self.embed_dim),
initializer=get_initializer(self.config.initializer_factor * self.config.initializer_range),
trainable=True,
name="weight",
)
with tf.name_scope("position_embedding"):
self.position_embedding = self.add_weight(
shape=(self.config.max_position_embeddings, self.embed_dim),
initializer=get_initializer(self.config.initializer_factor * self.config.initializer_range),
trainable=True,
name="embeddings",
)
super().build(input_shape)
def call(
self,
input_ids: tf.Tensor = None,
position_ids: tf.Tensor = None,
inputs_embeds: tf.Tensor = None,
) -> tf.Tensor:
"""
Applies embedding based on inputs tensor.
Returns:
final_embeddings (`tf.Tensor`): output embedding tensor.
"""
if input_ids is None and inputs_embeds is None:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if inputs_embeds is None:
check_embeddings_within_bounds(input_ids, self.config.vocab_size)
inputs_embeds = tf.gather(params=self.weight, indices=input_ids)
input_shape = shape_list(inputs_embeds)[:-1]
if position_ids is None:
position_ids = tf.expand_dims(tf.range(start=0, limit=input_shape[-1]), axis=0)
position_embeds = tf.gather(params=self.position_embedding, indices=position_ids)
position_embeds = tf.tile(input=position_embeds, multiples=(input_shape[0], 1, 1))
final_embeddings = inputs_embeds + position_embeds
return final_embeddings
class TFGroupViTStage(keras.layers.Layer):
"""This corresponds to the `GroupingLayer` class in the GroupViT implementation."""
def __init__(
self,
config: GroupViTVisionConfig,
depth: int,
num_prev_group_token: int,
num_group_token: int,
num_output_group: int,
**kwargs,
):
super().__init__(**kwargs)
self.config = config
self.depth = depth
self.num_group_token = num_group_token
self.layers = [TFGroupViTEncoderLayer(config, name=f"layers_._{i}") for i in range(depth)]
if num_group_token > 0:
self.downsample = TFGroupViTTokenAssign(
config=config,
num_group_token=num_group_token,
num_output_group=num_output_group,
name="downsample",
)
else:
self.downsample = None
if num_prev_group_token > 0 and num_group_token > 0:
self.group_projector = [
keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="group_projector.0"),
TFGroupViTMixerMLP(
config, num_prev_group_token, config.hidden_size // 2, num_group_token, name="group_projector.1"
),
]
else:
self.group_projector = None
def build(self, input_shape=None):
if self.num_group_token > 0:
self.group_token = self.add_weight(
shape=(1, self.num_group_token, self.config.hidden_size),
initializer="zeros",
trainable=True,
name="group_token",
)
else:
self.group_token = None
if self.built:
return
self.built = True
if getattr(self, "downsample", None) is not None:
with tf.name_scope(self.downsample.name):
self.downsample.build(None)
if getattr(self, "layers", None) is not None:
for layer in self.layers:
with tf.name_scope(layer.name):
layer.build(None)
if getattr(self, "group_projector", None) is not None:
with tf.name_scope(self.group_projector[0].name):
self.group_projector[0].build([None, None, self.config.hidden_size])
with tf.name_scope(self.group_projector[1].name):
self.group_projector[1].build(None)
@property
def with_group_token(self):
return self.group_token is not None
def split_x(self, x: tf.Tensor) -> tf.Tensor:
if self.with_group_token:
return x[:, : -self.num_group_token], x[:, -self.num_group_token :]
else:
return x, None
def concat_x(self, x: tf.Tensor, group_token: tf.Tensor | None = None) -> tf.Tensor:
if group_token is None:
return x
return tf.concat([x, group_token], axis=1)
def call(
self,
hidden_states: tf.Tensor,
prev_group_token: tf.Tensor | None = None,
output_attentions: bool = False,
training: bool = False,
) -> Tuple[tf.Tensor]:
"""
Args:
hidden_states (`tf.Tensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`tf.Tensor`): attention mask of size
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
`(config.encoder_attention_heads,)`.
output_attentions (`bool`, *optional*):
Whether or not to return the grouping tensors of Grouping block.
"""
if self.with_group_token:
group_token = tf.tile(self.group_token, multiples=(shape_list(hidden_states)[0], 1, 1))
if self.group_projector is not None:
for layer in self.group_projector:
prev_group_token = layer(prev_group_token)
group_token = group_token + prev_group_token
else:
group_token = None
x = hidden_states
cat_x = self.concat_x(x, group_token)
for layer in self.layers:
layer_out = layer(
cat_x,
attention_mask=None,
causal_attention_mask=None,
output_attentions=None,
)
cat_x = layer_out[0]
x, group_token = self.split_x(cat_x)
attention = None
if self.downsample is not None:
x, attention = self.downsample(x, group_token)
outputs = (x, group_token)
if output_attentions:
outputs = outputs + (attention,)
return outputs
class TFGroupViTMLP(keras.layers.Layer):
def __init__(
self,
config: GroupViTVisionConfig,
hidden_size: Optional[int] = None,
intermediate_size: Optional[int] = None,
output_size: Optional[int] = None,
**kwargs,
):
super().__init__(**kwargs)
self.config = config
self.activation_fn = get_tf_activation(config.hidden_act)
hidden_size = hidden_size if hidden_size is not None else config.hidden_size
intermediate_size = intermediate_size if intermediate_size is not None else config.intermediate_size
output_size = output_size if output_size is not None else hidden_size
self.fc1 = keras.layers.Dense(intermediate_size, name="fc1")
self.fc2 = keras.layers.Dense(output_size, name="fc2")
self.intermediate_size = intermediate_size
self.hidden_size = hidden_size
def call(self, hidden_states: tf.Tensor, training: bool = False) -> tf.Tensor:
hidden_states = self.fc1(hidden_states)
hidden_states = self.activation_fn(hidden_states)
hidden_states = self.fc2(hidden_states)
return hidden_states
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "fc1", None) is not None:
with tf.name_scope(self.fc1.name):
self.fc1.build([None, None, self.hidden_size])
if getattr(self, "fc2", None) is not None:
with tf.name_scope(self.fc2.name):
self.fc2.build([None, None, self.intermediate_size])
class TFGroupViTMixerMLP(TFGroupViTMLP):
def call(self, x, training: bool = False):
x = super().call(hidden_states=tf.transpose(x, perm=(0, 2, 1)))
return tf.transpose(x, perm=(0, 2, 1))
# Adapted from transformers.models.clip.modeling_tf_clip.TFCLIPAttention
class TFGroupViTAttention(keras.layers.Layer):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config: GroupViTConfig, **kwargs):
super().__init__(**kwargs)
self.embed_dim = config.hidden_size
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = self.embed_dim // self.num_attention_heads
if self.attention_head_size * self.num_attention_heads != self.embed_dim:
raise ValueError(
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
f" {self.num_attention_heads})."
)
factor = config.initializer_factor
in_proj_std = (self.embed_dim**-0.5) * ((2 * config.num_hidden_layers) ** -0.5) * factor
out_proj_std = (self.embed_dim**-0.5) * factor
self.sqrt_att_head_size = math.sqrt(self.attention_head_size)
self.q_proj = keras.layers.Dense(
units=self.embed_dim, kernel_initializer=get_initializer(in_proj_std), name="q_proj"
)
self.k_proj = keras.layers.Dense(
units=self.embed_dim, kernel_initializer=get_initializer(in_proj_std), name="k_proj"
)
self.v_proj = keras.layers.Dense(
units=self.embed_dim, kernel_initializer=get_initializer(in_proj_std), name="v_proj"
)
self.dropout = keras.layers.Dropout(rate=config.attention_dropout)
self.out_proj = keras.layers.Dense(
units=self.embed_dim, kernel_initializer=get_initializer(out_proj_std), name="out_proj"
)
# Copied from transformers.models.bert.modeling_tf_bert.TFBertSelfAttention.transpose_for_scores
def transpose_for_scores(self, tensor: tf.Tensor, batch_size: int) -> tf.Tensor:
# Reshape from [batch_size, seq_length, all_head_size] to [batch_size, seq_length, num_attention_heads, attention_head_size]
tensor = tf.reshape(tensor=tensor, shape=(batch_size, -1, self.num_attention_heads, self.attention_head_size))
# Transpose the tensor from [batch_size, seq_length, num_attention_heads, attention_head_size] to [batch_size, num_attention_heads, seq_length, attention_head_size]
return tf.transpose(tensor, perm=[0, 2, 1, 3])
def call(
self,
hidden_states: tf.Tensor,
attention_mask: tf.Tensor = None,
causal_attention_mask: tf.Tensor = None,
output_attentions: bool = None,
encoder_hidden_states: tf.Tensor = None,
training: bool = False,
) -> Tuple[tf.Tensor]:
"""Input shape: Batch x Time x Channel"""
batch_size = shape_list(hidden_states)[0]
is_cross_attention = encoder_hidden_states is not None
mixed_query_layer = self.q_proj(inputs=hidden_states)
if is_cross_attention:
mixed_key_layer = self.k_proj(inputs=encoder_hidden_states)
mixed_value_layer = self.v_proj(inputs=encoder_hidden_states)
else:
mixed_key_layer = self.k_proj(inputs=hidden_states)
mixed_value_layer = self.v_proj(inputs=hidden_states)
query_layer = self.transpose_for_scores(mixed_query_layer, batch_size)
key_layer = self.transpose_for_scores(mixed_key_layer, batch_size)
value_layer = self.transpose_for_scores(mixed_value_layer, batch_size)
# Take the dot product between "query" and "key" to get the raw attention scores.
# (batch size, num_heads, seq_len_q, seq_len_k)
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True)
dk = tf.cast(self.sqrt_att_head_size, dtype=attention_scores.dtype)
attention_scores = tf.divide(attention_scores, dk)
# apply the causal_attention_mask first
if causal_attention_mask is not None:
# Apply the causal attention mask (precomputed for all layers in TFCLIPModel call() function)
attention_scores = tf.add(attention_scores, causal_attention_mask)
if attention_mask is not None:
# Apply the attention mask (precomputed for all layers in TFCLIPModel call() function)
attention_scores = tf.add(attention_scores, attention_mask)
# Normalize the attention scores to probabilities.
_attention_probs = stable_softmax(logits=attention_scores, axis=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(inputs=_attention_probs)
attention_output = tf.matmul(attention_probs, value_layer)
attention_output = tf.transpose(attention_output, perm=[0, 2, 1, 3])
# (batch_size, seq_len_q, embed_dim)
attention_output = tf.reshape(tensor=attention_output, shape=(batch_size, -1, self.embed_dim))
attention_output = self.out_proj(attention_output)
# In TFBert, attention weights are returned after dropout.
# However, in CLIP, they are returned before dropout.
outputs = (attention_output, _attention_probs) if output_attentions else (attention_output,)
return outputs
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "q_proj", None) is not None:
with tf.name_scope(self.q_proj.name):
self.q_proj.build([None, None, self.embed_dim])
if getattr(self, "k_proj", None) is not None:
with tf.name_scope(self.k_proj.name):
self.k_proj.build([None, None, self.embed_dim])
if getattr(self, "v_proj", None) is not None:
with tf.name_scope(self.v_proj.name):
self.v_proj.build([None, None, self.embed_dim])
if getattr(self, "out_proj", None) is not None:
with tf.name_scope(self.out_proj.name):
self.out_proj.build([None, None, self.embed_dim])
# Copied from transformers.models.clip.modeling_tf_clip.TFCLIPEncoderLayer with CLIP->GroupViT
class TFGroupViTEncoderLayer(keras.layers.Layer):
def __init__(self, config: GroupViTConfig, **kwargs):
super().__init__(**kwargs)
self.embed_dim = config.hidden_size
self.self_attn = TFGroupViTAttention(config, name="self_attn")
self.layer_norm1 = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="layer_norm1")
self.mlp = TFGroupViTMLP(config, name="mlp")
self.layer_norm2 = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="layer_norm2")
def call(
self,
hidden_states: tf.Tensor,
attention_mask: tf.Tensor,
causal_attention_mask: tf.Tensor,
output_attentions: bool,
training: bool = False,
) -> Tuple[tf.Tensor]:
"""
Args:
hidden_states (`tf.Tensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`tf.Tensor`): attention mask of size
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
causal_attention_mask (`tf.Tensor`): causal attention mask of size
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
output_attentions (`bool`):
Whether or not to return the attentions tensors of all attention layers. See `outputs` under returned
tensors for more detail.
"""
residual = hidden_states
hidden_states = self.layer_norm1(inputs=hidden_states)
attention_outputs = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
causal_attention_mask=causal_attention_mask,
output_attentions=output_attentions,
training=training,
)
hidden_states = attention_outputs[0]
hidden_states = residual + hidden_states
residual = hidden_states
hidden_states = self.layer_norm2(inputs=hidden_states)
hidden_states = self.mlp(hidden_states=hidden_states)
hidden_states = residual + hidden_states
outputs = (hidden_states,) + attention_outputs[1:] # add attentions if we output them
return outputs
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "self_attn", None) is not None:
with tf.name_scope(self.self_attn.name):
self.self_attn.build(None)
if getattr(self, "layer_norm1", None) is not None:
with tf.name_scope(self.layer_norm1.name):
self.layer_norm1.build([None, None, self.embed_dim])
if getattr(self, "mlp", None) is not None:
with tf.name_scope(self.mlp.name):
self.mlp.build(None)
if getattr(self, "layer_norm2", None) is not None:
with tf.name_scope(self.layer_norm2.name):
self.layer_norm2.build([None, None, self.embed_dim])
# Adapted from transformers.models.clip.modeling_tf_clip.TFGroupViTTextEncoder
class TFGroupViTTextEncoder(keras.layers.Layer):
def __init__(self, config: GroupViTTextConfig, **kwargs):
super().__init__(**kwargs)
self.layers = [TFGroupViTEncoderLayer(config, name=f"layers_._{i}") for i in range(config.num_hidden_layers)]
def call(
self,
hidden_states,
attention_mask: tf.Tensor,
causal_attention_mask: tf.Tensor,
output_attentions: bool,
output_hidden_states: bool,
return_dict: bool,
training: bool = False,
) -> Union[Tuple, TFBaseModelOutput]:
encoder_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
layer_outputs = encoder_layer(
hidden_states,
attention_mask,
causal_attention_mask,
output_attentions=output_attentions,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
return TFBaseModelOutput(
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "layers", None) is not None:
for layer in self.layers:
with tf.name_scope(layer.name):
layer.build(None)
class TFGroupViTVisionEncoder(keras.layers.Layer):
def __init__(self, config: GroupViTVisionConfig, **kwargs) -> None:
super().__init__(**kwargs)
self.stages = [
TFGroupViTStage(
config=config,
depth=config.depths[i],
num_group_token=config.num_group_tokens[i],
num_output_group=config.num_output_groups[i],
num_prev_group_token=config.num_output_groups[i - 1] if i > 0 else 0,
name=f"stages_._{i}",
)
for i in range(len(config.depths))
]
def call(
self,
hidden_states: tf.Tensor,
output_hidden_states: bool,
output_attentions: bool,
return_dict: bool,
training: bool = False,
) -> Union[tuple, TFBaseModelOutput]:
all_hidden_states = () if output_hidden_states else None
all_groupings = () if output_attentions else None
group_tokens = None
for stage in self.stages:
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_outputs = stage(hidden_states, group_tokens, output_attentions)
hidden_states = layer_outputs[0]
group_tokens = layer_outputs[1]
if output_attentions and layer_outputs[2] is not None:
all_groupings = all_groupings + (layer_outputs[2],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, all_hidden_states, all_groupings] if v is not None)
return TFBaseModelOutput(
last_hidden_state=hidden_states, hidden_states=all_hidden_states, attentions=all_groupings
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "stages", None) is not None:
for layer in self.stages:
with tf.name_scope(layer.name):
layer.build(None)
# Copied from transformers.models.clip.modeling_tf_clip.TFCLIPTextTransformer with CLIPText->GroupViTText, CLIPEncoder->GroupViTTextEncoder
class TFGroupViTTextTransformer(keras.layers.Layer):
def __init__(self, config: GroupViTTextConfig, **kwargs):
super().__init__(**kwargs)
self.embeddings = TFGroupViTTextEmbeddings(config, name="embeddings")
self.encoder = TFGroupViTTextEncoder(config, name="encoder")
self.final_layer_norm = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="final_layer_norm")
# For `pooled_output` computation
self.eos_token_id = config.eos_token_id
self.embed_dim = config.hidden_size
def call(
self,
input_ids: TFModelInputType,
attention_mask: tf.Tensor,
position_ids: tf.Tensor,
output_attentions: bool,
output_hidden_states: bool,
return_dict: bool,
training: bool = False,
) -> Union[TFBaseModelOutputWithPooling, Tuple[tf.Tensor]]:
input_shape = shape_list(input_ids)
embedding_output = self.embeddings(input_ids=input_ids, position_ids=position_ids)
batch_size, seq_length = input_shape
# CLIP's text model uses causal mask, prepare it here.
# https://github.com/openai/CLIP/blob/cfcffb90e69f37bf2ff1e988237a0fbe41f33c04/clip/model.py#L324
causal_attention_mask = self._build_causal_attention_mask(batch_size, seq_length, dtype=embedding_output.dtype)
# check attention mask and invert
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
attention_mask = _expand_mask(attention_mask)
encoder_outputs = self.encoder(
hidden_states=embedding_output,
attention_mask=attention_mask,
causal_attention_mask=causal_attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = encoder_outputs[0]
sequence_output = self.final_layer_norm(inputs=sequence_output)
if self.eos_token_id == 2:
# The `eos_token_id` was incorrect before PR #24773: Let's keep what have been done here.
# A CLIP model with such `eos_token_id` in the config can't work correctly with extra new tokens added
# ------------------------------------------------------------
# text_embeds.shape = [batch_size, n_ctx, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
pooled_output = tf.gather_nd(
params=sequence_output,
indices=tf.stack(
values=(tf.range(input_shape[0], dtype=tf.int64), tf.math.argmax(input_ids, axis=-1)), axis=1
),
)
else:
# The config gets updated `eos_token_id` from PR #24773 (so the use of exta new tokens is possible)
pooled_output = tf.gather_nd(
params=sequence_output,
indices=tf.stack(
values=(
tf.range(input_shape[0], dtype=tf.int64),
tf.math.argmax(tf.cast(input_ids == self.eos_token_id, dtype=tf.int8), axis=-1),
),
axis=1,
),
)
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return TFBaseModelOutputWithPooling(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
def _build_causal_attention_mask(self, batch_size, seq_length, dtype=tf.float32):
# It is possible with an unspecified sequence length for seq_length to be
# a runtime value, which is unsupported by tf.constant. Per the TensorFlow
# docs, tf.fill can handle runtime dynamic shapes:
# https://www.tensorflow.org/api_docs/python/tf/fill
diag = tf.cast(tf.fill((seq_length,), 0.0), dtype)
# set an additive 2D attention mask with all places being masked
to_mask = tf.cast(tf.fill((seq_length, seq_length), -10000.0), dtype)
# set diagonal & lower triangular parts to 0 (i.e. the places not to be masked)
# TIP: think the 2D matrix as the space of (query_seq, key_seq)
to_mask = tf.linalg.band_part(to_mask, 0, -1)
# to_mask = tf.linalg.band_part(to_mask, -1, 0)
to_mask = tf.linalg.set_diag(to_mask, diagonal=diag)
return tf.broadcast_to(input=to_mask, shape=(batch_size, 1, seq_length, seq_length))
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "embeddings", None) is not None:
with tf.name_scope(self.embeddings.name):
self.embeddings.build(None)
if getattr(self, "encoder", None) is not None:
with tf.name_scope(self.encoder.name):
self.encoder.build(None)
if getattr(self, "final_layer_norm", None) is not None:
with tf.name_scope(self.final_layer_norm.name):
self.final_layer_norm.build([None, None, self.embed_dim])
# Adapted from transformers.models.clip.modeling_tf_clip.TFCLIPVisionTransformer
class TFGroupViTVisionTransformer(keras.layers.Layer):
def __init__(self, config: GroupViTVisionConfig, **kwargs):
super().__init__(**kwargs)
self.embeddings = TFGroupViTVisionEmbeddings(config, name="embeddings")
self.encoder = TFGroupViTVisionEncoder(config, name="encoder")
self.layernorm = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="layernorm")
self.embed_dim = config.hidden_size
def call(
self,
pixel_values: TFModelInputType,
output_attentions: bool,
output_hidden_states: bool,
return_dict: bool,
training: bool = False,
) -> Union[Tuple, TFBaseModelOutputWithPooling]:
embedding_output = self.embeddings(pixel_values)
encoder_outputs = self.encoder(
hidden_states=embedding_output,
output_hidden_states=output_hidden_states,
output_attentions=output_attentions,
return_dict=return_dict,
)
last_hidden_state = encoder_outputs[0]
# normalize the last hidden state
last_hidden_state = self.layernorm(last_hidden_state)
pooled_output = tf.math.reduce_mean(last_hidden_state, axis=1)
if not return_dict:
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
return TFBaseModelOutputWithPooling(
last_hidden_state=last_hidden_state,
pooler_output=pooled_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "embeddings", None) is not None:
with tf.name_scope(self.embeddings.name):
self.embeddings.build(None)
if getattr(self, "encoder", None) is not None:
with tf.name_scope(self.encoder.name):
self.encoder.build(None)
if getattr(self, "layernorm", None) is not None:
with tf.name_scope(self.layernorm.name):
self.layernorm.build([None, None, self.embed_dim])
@keras_serializable
# Copied from transformers.models.clip.modeling_tf_clip.TFCLIPTextMainLayer with CLIP->GroupViT
class TFGroupViTTextMainLayer(keras.layers.Layer):
config_class = GroupViTTextConfig
def __init__(self, config: GroupViTTextConfig, **kwargs):
super().__init__(**kwargs)
self.config = config
self.text_model = TFGroupViTTextTransformer(config, name="text_model")
def get_input_embeddings(self) -> keras.layers.Layer:
return self.text_model.embeddings
def set_input_embeddings(self, value: tf.Variable):
self.text_model.embeddings.weight = value
self.text_model.embeddings.vocab_size = shape_list(value)[0]
@unpack_inputs
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: bool = False,
) -> Union[TFBaseModelOutputWithPooling, Tuple[tf.Tensor]]:
if input_ids is None:
raise ValueError("You have to specify input_ids")
input_shape = shape_list(input_ids)
if attention_mask is None:
attention_mask = tf.fill(dims=input_shape, value=1)
text_model_outputs = self.text_model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
return text_model_outputs
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "text_model", None) is not None:
with tf.name_scope(self.text_model.name):
self.text_model.build(None)
@keras_serializable
# Copied from transformers.models.clip.modeling_tf_clip.TFCLIPVisionMainLayer with CLIP->GroupViT
class TFGroupViTVisionMainLayer(keras.layers.Layer):
config_class = GroupViTVisionConfig
def __init__(self, config: GroupViTVisionConfig, **kwargs):
super().__init__(**kwargs)
self.config = config
self.vision_model = TFGroupViTVisionTransformer(config, name="vision_model")
def get_input_embeddings(self) -> keras.layers.Layer:
return self.vision_model.embeddings
@unpack_inputs
def call(
self,
pixel_values: TFModelInputType | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: bool = False,
) -> Union[TFBaseModelOutputWithPooling, Tuple[tf.Tensor]]:
if pixel_values is None:
raise ValueError("You have to specify pixel_values")
vision_model_outputs = self.vision_model(
pixel_values=pixel_values,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
return vision_model_outputs
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "vision_model", None) is not None:
with tf.name_scope(self.vision_model.name):
self.vision_model.build(None)
@keras_serializable
# Adapted from transformers.models.clip.modeling_tf_clip.TFCLIPMainLayer
class TFGroupViTMainLayer(keras.layers.Layer):
config_class = GroupViTConfig
def __init__(self, config: GroupViTConfig, **kwargs):
super().__init__(**kwargs)
if not isinstance(config.text_config, GroupViTTextConfig):
raise TypeError(
"config.text_config is expected to be of type GroupViTTextConfig but is of type"
f" {type(config.text_config)}."
)
if not isinstance(config.vision_config, GroupViTVisionConfig):
raise TypeError(
"config.vision_config is expected to be of type GroupViTVisionConfig but is of type"
f" {type(config.vision_config)}."
)
self.config = config
text_config = config.text_config
vision_config = config.vision_config
self.projection_dim = config.projection_dim
self.projection_intermediate_dim = config.projection_intermediate_dim
self.text_embed_dim = text_config.hidden_size
self.vision_embed_dim = vision_config.hidden_size
self.text_model = TFGroupViTTextTransformer(text_config, name="text_model")
self.vision_model = TFGroupViTVisionTransformer(vision_config, name="vision_model")
self.visual_projection = [
keras.layers.Dense(self.projection_intermediate_dim, name="visual_projection.0"),
keras.layers.BatchNormalization(name="visual_projection.1", momentum=0.9, epsilon=1e-5),
keras.layers.ReLU(name="visual_projection.2"),
keras.layers.Dense(self.projection_dim, name="visual_projection.3"),
]
self.text_projection = [
keras.layers.Dense(self.projection_intermediate_dim, name="text_projection.0"),
keras.layers.BatchNormalization(name="text_projection.1", momentum=0.9, epsilon=1e-5),
keras.layers.ReLU(name="text_projection.2"),
keras.layers.Dense(self.projection_dim, name="text_projection.3"),
]
def build(self, input_shape=None):
self.logit_scale = self.add_weight(
shape=(1,),
initializer=keras.initializers.Constant(self.config.logit_scale_init_value),
trainable=True,
name="logit_scale",
)
if self.built:
return
self.built = True
if getattr(self, "text_model", None) is not None:
with tf.name_scope(self.text_model.name):
self.text_model.build(None)
if getattr(self, "vision_model", None) is not None:
with tf.name_scope(self.vision_model.name):
self.vision_model.build(None)
if getattr(self, "visual_projection", None) is not None:
with tf.name_scope(self.visual_projection[0].name):
self.visual_projection[0].build([None, None, None, self.vision_embed_dim])
with tf.name_scope(self.visual_projection[1].name):
self.visual_projection[1].build((None, self.projection_intermediate_dim))
with tf.name_scope(self.visual_projection[3].name):
self.visual_projection[3].build([None, None, None, self.projection_intermediate_dim])
if getattr(self, "text_projection", None) is not None:
with tf.name_scope(self.text_projection[0].name):
self.text_projection[0].build([None, None, None, self.text_embed_dim])
with tf.name_scope(self.text_projection[1].name):
self.text_projection[1].build((None, self.projection_intermediate_dim))
with tf.name_scope(self.text_projection[3].name):
self.text_projection[3].build([None, None, None, self.projection_intermediate_dim])
@unpack_inputs
def get_text_features(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: bool = False,
) -> tf.Tensor:
if input_ids is None:
raise ValueError("You have to specify either input_ids")
input_shape = shape_list(input_ids)
if attention_mask is None:
attention_mask = tf.fill(dims=input_shape, value=1)
text_outputs = self.text_model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
pooled_output = text_outputs[1]
for layer in self.text_projection:
pooled_output = layer(pooled_output)
text_features = pooled_output
return text_features
@unpack_inputs
def get_image_features(
self,
pixel_values: TFModelInputType | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: bool = False,
) -> tf.Tensor:
if pixel_values is None:
raise ValueError("You have to specify pixel_values")
vision_outputs = self.vision_model(
pixel_values=pixel_values,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
pooled_output = vision_outputs[1]
for layer in self.visual_projection:
pooled_output = layer(pooled_output)
image_features = pooled_output
return image_features
@unpack_inputs
def call(
self,
input_ids: TFModelInputType | None = None,
pixel_values: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
return_loss: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_segmentation: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: bool = False,
) -> Union[TFGroupViTModelOutput, Tuple[tf.Tensor]]:
if input_ids is None:
raise ValueError("You have to specify either input_ids")
if pixel_values is None:
raise ValueError("You have to specify pixel_values")
input_shape = shape_list(input_ids)
if attention_mask is None:
attention_mask = tf.fill(dims=input_shape, value=1)
if output_segmentation:
output_attentions = True
vision_outputs = self.vision_model(
pixel_values=pixel_values,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
text_outputs = self.text_model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
image_embeds = vision_outputs[1]
for layer in self.visual_projection:
image_embeds = layer(image_embeds)
text_embeds = text_outputs[1]
for layer in self.text_projection:
text_embeds = layer(text_embeds)
# normalized features
image_embeds = image_embeds / tf.norm(image_embeds, axis=-1, keepdims=True)
text_embeds = text_embeds / tf.norm(text_embeds, axis=-1, keepdims=True)
# cosine similarity as logits
logit_scale = tf.math.exp(self.logit_scale)
logits_per_text = tf.matmul(text_embeds, image_embeds, transpose_b=True) * logit_scale
logits_per_image = tf.transpose(logits_per_text)
seg_logits = None
if output_segmentation:
# grouped features
# [batch_size_image, num_group, hidden_size]
image_group_embeds = vision_outputs[0]
# [batch_size_image*num_group, hidden_size]
image_group_embeds = tf.reshape(image_group_embeds, shape=(-1, shape_list(image_group_embeds)[-1]))
for layer in self.visual_projection:
image_group_embeds = layer(image_group_embeds)
if output_hidden_states:
attentions = vision_outputs[3]
else:
attentions = vision_outputs[2]
# [batch_size_image, num_group, height, width]
grouping = get_grouping_from_attentions(attentions, pixel_values.shape[2:])
# normalized features
image_group_embeds = image_group_embeds / tf.norm(
tensor=image_group_embeds, ord="euclidean", axis=-1, keepdims=True
)
# [batch_size_image x num_group, batch_size_text]
logits_per_image_group = tf.matmul(image_group_embeds, text_embeds, transpose_b=True) * logit_scale
# [batch_size_image, batch_size_text, num_group]
logits_per_image_group = tf.reshape(
logits_per_image_group, shape=(image_embeds.shape[0], -1, text_embeds.shape[0])
)
logits_per_image_group = tf.transpose(logits_per_image_group, perm=(0, 2, 1))
# [batch_size_image, batch_size_text, height x width]
flatten_grouping = tf.reshape(grouping, shape=(shape_list(grouping)[0], shape_list(grouping)[1], -1))
# [batch_size_image, batch_size_text, height, width]
seg_logits = tf.matmul(logits_per_image_group, flatten_grouping) * logit_scale
seg_logits = tf.reshape(
seg_logits, shape=(seg_logits.shape[0], seg_logits.shape[1], grouping.shape[2], grouping.shape[3])
)
loss = None
if return_loss:
loss = groupvit_loss(logits_per_text)[None, ...]
if not return_dict:
if seg_logits is not None:
output = (
logits_per_image,
logits_per_text,
seg_logits,
text_embeds,
image_embeds,
text_outputs,
vision_outputs,
)
else:
output = (logits_per_image, logits_per_text, text_embeds, image_embeds, text_outputs, vision_outputs)
return ((loss,) + output) if loss is not None else output
return TFGroupViTModelOutput(
loss=loss,
logits_per_image=logits_per_image,
logits_per_text=logits_per_text,
segmentation_logits=seg_logits,
text_embeds=text_embeds,
image_embeds=image_embeds,
text_model_output=text_outputs,
vision_model_output=vision_outputs,
)
class TFGroupViTPreTrainedModel(TFPreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = GroupViTConfig
base_model_prefix = "groupvit"
GROUPVIT_START_DOCSTRING = r"""
This model inherits from [`TFPreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a [keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model) subclass. Use it
as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and
behavior.
<Tip>
TF 2.0 models accepts two formats as inputs:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional arguments.
This second option is useful when using [`keras.Model.fit`] method which currently requires having all the
tensors in the first argument of the model call function: `model(inputs)`.
If you choose this second option, there are three possibilities you can use to gather all the input Tensors in the
first positional argument :
- a single Tensor with `input_ids` only and nothing else: `model(input_ids)`
- a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
`model([input_ids, attention_mask])` or `model([input_ids, attention_mask, token_type_ids])`
- a dictionary with one or several input Tensors associated to the input names given in the docstring:
`model({"input_ids": input_ids, "token_type_ids": token_type_ids})`
</Tip>
Args:
config ([`GroupViTConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
GROUPVIT_TEXT_INPUTS_DOCSTRING = r"""
Args:
input_ids (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]` ``Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.__call__`] and
[`PreTrainedTokenizer.encode`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`np.ndarray` or `tf.Tensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`np.ndarray` or `tf.Tensor` of shape `({0})`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the
config will be used instead.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail. This argument can be used only in eager mode, in graph mode the value in the config will be
used instead.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple. This argument can be used in
eager mode, in graph mode the value will always be set to True.
training (`bool`, *optional*, defaults to `False``):
Whether or not to use the model in training mode (some modules like dropout modules have different
behaviors between training and evaluation).
"""
GROUPVIT_VISION_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]`, `Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
[`CLIPImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the
config will be used instead.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail. This argument can be used only in eager mode, in graph mode the value in the config will be
used instead.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple. This argument can be used in
eager mode, in graph mode the value will always be set to True.
training (`bool`, *optional*, defaults to `False``):
Whether or not to use the model in training mode (some modules like dropout modules have different
behaviors between training and evaluation).
"""
GROUPVIT_INPUTS_DOCSTRING = r"""
Args:
input_ids (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]` ``Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.__call__`] and
[`PreTrainedTokenizer.encode`] for details.
[What are input IDs?](../glossary#input-ids)
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]` `Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
[`CLIPImageProcessor.__call__`] for details.
attention_mask (`np.ndarray` or `tf.Tensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`np.ndarray` or `tf.Tensor` of shape `({0})`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
return_loss (`bool`, *optional*):
Whether or not to return the contrastive loss.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the
config will be used instead.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail. This argument can be used only in eager mode, in graph mode the value in the config will be
used instead.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple. This argument can be used in
eager mode, in graph mode the value will always be set to True.
training (`bool`, *optional*, defaults to `False``):
Whether or not to use the model in training mode (some modules like dropout modules have different
behaviors between training and evaluation).
"""
class TFGroupViTTextModel(TFGroupViTPreTrainedModel):
config_class = GroupViTTextConfig
main_input_name = "input_ids"
def __init__(self, config: GroupViTTextConfig, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.groupvit = TFGroupViTTextMainLayer(config, name="groupvit")
@unpack_inputs
@add_start_docstrings_to_model_forward(GROUPVIT_TEXT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=TFBaseModelOutputWithPooling, config_class=GroupViTTextConfig)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: bool = False,
) -> Union[TFBaseModelOutputWithPooling, Tuple[tf.Tensor]]:
r"""
Returns:
Examples:
```python
>>> from transformers import CLIPTokenizer, TFGroupViTTextModel
>>> tokenizer = CLIPTokenizer.from_pretrained("nvidia/groupvit-gcc-yfcc")
>>> model = TFGroupViTTextModel.from_pretrained("nvidia/groupvit-gcc-yfcc")
>>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding=True, return_tensors="tf")
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled (EOS token) states
```"""
outputs = self.groupvit(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
return outputs
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "groupvit", None) is not None:
with tf.name_scope(self.groupvit.name):
self.groupvit.build(None)
class TFGroupViTVisionModel(TFGroupViTPreTrainedModel):
config_class = GroupViTVisionConfig
main_input_name = "pixel_values"
def __init__(self, config: GroupViTVisionConfig, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.groupvit = TFGroupViTVisionMainLayer(config, name="groupvit")
@unpack_inputs
@add_start_docstrings_to_model_forward(GROUPVIT_VISION_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=TFBaseModelOutputWithPooling, config_class=GroupViTVisionConfig)
def call(
self,
pixel_values: TFModelInputType | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: bool = False,
) -> Union[TFBaseModelOutputWithPooling, Tuple[tf.Tensor]]:
r"""
Returns:
Examples:
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, TFGroupViTVisionModel
>>> processor = AutoProcessor.from_pretrained("nvidia/groupvit-gcc-yfcc")
>>> model = TFGroupViTVisionModel.from_pretrained("nvidia/groupvit-gcc-yfcc")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled CLS states
```"""
outputs = self.groupvit(
pixel_values=pixel_values,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
return outputs
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "groupvit", None) is not None:
with tf.name_scope(self.groupvit.name):
self.groupvit.build(None)
@add_start_docstrings(GROUPVIT_START_DOCSTRING)
class TFGroupViTModel(TFGroupViTPreTrainedModel):
config_class = GroupViTConfig
def __init__(self, config: GroupViTConfig, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.groupvit = TFGroupViTMainLayer(config, name="groupvit")
@unpack_inputs
@add_start_docstrings_to_model_forward(GROUPVIT_TEXT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
def get_text_features(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: bool = False,
) -> tf.Tensor:
r"""
Returns:
text_features (`tf.Tensor` of shape `(batch_size, output_dim`): The text embeddings obtained by applying
the projection layer to the pooled output of [`TFGroupViTTextModel`].
Examples:
```python
>>> from transformers import CLIPTokenizer, TFGroupViTModel
>>> model = TFGroupViTModel.from_pretrained("nvidia/groupvit-gcc-yfcc")
>>> tokenizer = CLIPTokenizer.from_pretrained("nvidia/groupvit-gcc-yfcc")
>>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding=True, return_tensors="tf")
>>> text_features = model.get_text_features(**inputs)
```"""
text_features = self.groupvit.get_text_features(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
return text_features
@unpack_inputs
@add_start_docstrings_to_model_forward(GROUPVIT_VISION_INPUTS_DOCSTRING)
def get_image_features(
self,
pixel_values: TFModelInputType | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: bool = False,
) -> tf.Tensor:
r"""
Returns:
image_features (`tf.Tensor` of shape `(batch_size, output_dim`): The image embeddings obtained by applying
the projection layer to the pooled output of [`TFGroupViTVisionModel`].
Examples:
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, TFGroupViTModel
>>> model = TFGroupViTModel.from_pretrained("nvidia/groupvit-gcc-yfcc")
>>> processor = AutoProcessor.from_pretrained("nvidia/groupvit-gcc-yfcc")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="tf")
>>> image_features = model.get_image_features(**inputs)
```"""
image_features = self.groupvit.get_image_features(
pixel_values=pixel_values,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
return image_features
@unpack_inputs
@add_start_docstrings_to_model_forward(GROUPVIT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=TFGroupViTModelOutput, config_class=GroupViTConfig)
def call(
self,
input_ids: TFModelInputType | None = None,
pixel_values: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
return_loss: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_segmentation: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: bool = False,
) -> Union[TFGroupViTModelOutput, Tuple[tf.Tensor]]:
r"""
Returns:
Examples:
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, TFGroupViTModel
>>> import tensorflow as tf
>>> model = TFGroupViTModel.from_pretrained("nvidia/groupvit-gcc-yfcc")
>>> processor = AutoProcessor.from_pretrained("nvidia/groupvit-gcc-yfcc")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(
... text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="tf", padding=True
... )
>>> outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
>>> probs = tf.math.softmax(logits_per_image, axis=1) # we can take the softmax to get the label probabilities
```"""
outputs = self.groupvit(
input_ids=input_ids,
pixel_values=pixel_values,
attention_mask=attention_mask,
position_ids=position_ids,
return_loss=return_loss,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
output_segmentation=output_segmentation,
return_dict=return_dict,
training=training,
)
return outputs
def serving_output(self, output: TFGroupViTModelOutput) -> TFGroupViTModelOutput:
# TODO: As is this currently fails with saved_model=True, because
# TensorFlow cannot trace through nested dataclasses. Reference:
# https://github.com/huggingface/transformers/pull/16886
return output
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "groupvit", None) is not None:
with tf.name_scope(self.groupvit.name):
self.groupvit.build(None)
__all__ = ["TFGroupViTModel", "TFGroupViTPreTrainedModel", "TFGroupViTTextModel", "TFGroupViTVisionModel"]
| transformers/src/transformers/models/groupvit/modeling_tf_groupvit.py/0 | {
"file_path": "transformers/src/transformers/models/groupvit/modeling_tf_groupvit.py",
"repo_id": "transformers",
"token_count": 39610
} |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Convert Hubert checkpoint."""
import argparse
import torch
from transformers import HubertConfig, HubertForSequenceClassification, Wav2Vec2FeatureExtractor, logging
logging.set_verbosity_info()
logger = logging.get_logger(__name__)
SUPPORTED_MODELS = ["UtteranceLevel"]
@torch.no_grad()
def convert_s3prl_checkpoint(base_model_name, config_path, checkpoint_path, model_dump_path):
"""
Copy/paste/tweak model's weights to transformers design.
"""
checkpoint = torch.load(checkpoint_path, map_location="cpu")
if checkpoint["Config"]["downstream_expert"]["modelrc"]["select"] not in SUPPORTED_MODELS:
raise NotImplementedError(f"The supported s3prl models are {SUPPORTED_MODELS}")
downstream_dict = checkpoint["Downstream"]
hf_congfig = HubertConfig.from_pretrained(config_path)
hf_model = HubertForSequenceClassification.from_pretrained(base_model_name, config=hf_congfig)
hf_feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained(
base_model_name, return_attention_mask=True, do_normalize=False
)
if hf_congfig.use_weighted_layer_sum:
hf_model.layer_weights.data = checkpoint["Featurizer"]["weights"]
hf_model.projector.weight.data = downstream_dict["projector.weight"]
hf_model.projector.bias.data = downstream_dict["projector.bias"]
hf_model.classifier.weight.data = downstream_dict["model.post_net.linear.weight"]
hf_model.classifier.bias.data = downstream_dict["model.post_net.linear.bias"]
hf_feature_extractor.save_pretrained(model_dump_path)
hf_model.save_pretrained(model_dump_path)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--base_model_name", default=None, type=str, help="Name of the huggingface pretrained base model."
)
parser.add_argument("--config_path", default=None, type=str, help="Path to the huggingface classifier config.")
parser.add_argument("--checkpoint_path", default=None, type=str, help="Path to the s3prl checkpoint.")
parser.add_argument("--model_dump_path", default=None, type=str, help="Path to the final converted model.")
args = parser.parse_args()
convert_s3prl_checkpoint(args.base_model_name, args.config_path, args.checkpoint_path, args.model_dump_path)
| transformers/src/transformers/models/hubert/convert_hubert_original_s3prl_checkpoint_to_pytorch.py/0 | {
"file_path": "transformers/src/transformers/models/hubert/convert_hubert_original_s3prl_checkpoint_to_pytorch.py",
"repo_id": "transformers",
"token_count": 982
} |
# coding=utf-8
# Copyright 2021 The OpenAI Team Authors and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""TF IdeficsVision model: a copy of CLIPVisionModel using a simpler config object"""
import math
from dataclasses import dataclass
from typing import Optional, Tuple, Union
import tensorflow as tf
from ...activations_tf import get_tf_activation
from ...modeling_tf_outputs import TFBaseModelOutput, TFBaseModelOutputWithPooling
from ...modeling_tf_utils import TFPreTrainedModel, shape_list
from ...tf_utils import flatten
from ...utils import ModelOutput, logging
from .configuration_idefics import IdeficsVisionConfig
logger = logging.get_logger(__name__)
@dataclass
class TFIdeficsVisionModelOutput(ModelOutput):
"""
Base class for vision model's outputs that also contains image embeddings of the pooling of the last hidden states.
Args:
image_embeds (`tf.Tensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
The image embeddings obtained by applying the projection layer to the pooler_output.
last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `tf.Tensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
image_embeds: Optional[tf.Tensor] = None
last_hidden_state: tf.Tensor = None
hidden_states: Optional[Tuple[tf.Tensor]] = None
attentions: Optional[Tuple[tf.Tensor]] = None
class TFIdeficsVisionEmbeddings(tf.keras.layers.Layer):
def __init__(self, config: IdeficsVisionConfig, **kwargs):
super().__init__(**kwargs)
self.config = config
self.embed_dim = config.hidden_size
self.image_size = config.image_size
self.patch_size = config.patch_size
self.patch_embedding = tf.keras.layers.Conv2D(
filters=self.embed_dim,
kernel_size=self.patch_size,
strides=self.patch_size,
use_bias=False,
padding="valid",
data_format="channels_last",
name="patch_embedding",
)
self.num_patches = (self.image_size // self.patch_size) ** 2
self.num_positions = self.num_patches + 1
self.position_embedding = tf.keras.layers.Embedding(
self.num_positions, self.embed_dim, name="position_embedding"
)
# self.position_ids = tf.range(self.num_positions)[tf.newaxis, :]
def interpolate_pos_encoding(self, embeddings: tf.Tensor, height: int, width: int) -> tf.Tensor:
num_patches = shape_list(embeddings)[1] - 1
pos_embed = self.position_embedding(self.position_ids)
num_positions = shape_list(pos_embed)[1] - 1
if num_patches == num_positions and height == width:
return pos_embed
class_pos_embed = pos_embed[:, 0]
patch_pos_embed = pos_embed[:, 1:]
embed_dim = shape_list(embeddings)[-1]
num_h_patches = height // self.config.patch_size
num_w_patches = width // self.config.patch_size
num_h_patches, num_w_patches = num_h_patches + 0.1, num_w_patches + 0.1
sqrt_num_positions = math.sqrt(float(num_positions))
patch_pos_embed = tf.reshape(patch_pos_embed, (1, int(sqrt_num_positions), int(sqrt_num_positions), embed_dim))
scale_height = num_h_patches / sqrt_num_positions
scale_width = num_w_patches / sqrt_num_positions
original_height = tf.cast(tf.shape(patch_pos_embed)[1], tf.float32)
original_width = tf.cast(tf.shape(patch_pos_embed)[2], tf.float32)
# Apply scaling
new_height = tf.cast(original_height * scale_height, tf.int32)
new_width = tf.cast(original_width * scale_width, tf.int32)
patch_pos_embed = tf.image.resize(
patch_pos_embed, size=[new_height, new_width], method=tf.image.ResizeMethod.BICUBIC
)
if (
int(num_h_patches) != shape_list(patch_pos_embed)[-3]
or int(num_w_patches) != shape_list(patch_pos_embed)[-2]
):
raise ValueError(
f"Number of patches for images ({int(num_h_patches), int(num_w_patches)}) don't match the "
f"shape of position embedding ({shape_list(patch_pos_embed)[-2], shape_list(patch_pos_embed)[-1]})"
)
patch_pos_embed = tf.reshape(patch_pos_embed, (1, -1, embed_dim))
return tf.concat((class_pos_embed[tf.newaxis, :], patch_pos_embed), axis=1)
def call(self, pixel_values: tf.Tensor, interpolate_pos_encoding: bool = False) -> tf.Tensor:
# Input `pixel_values` is NCHW format which doesn't run on CPU so first thing we do is
# transpose it to change it to NHWC. We don't care to transpose it back because
# the Conv2D layer is only hit once for each query
if isinstance(pixel_values, dict):
pixel_values = pixel_values["pixel_values"]
pixel_values = tf.transpose(pixel_values, perm=(0, 2, 3, 1))
batch_size, height, width, num_channels = shape_list(pixel_values)
if not interpolate_pos_encoding:
if height != self.image_size or width != self.image_size:
raise ValueError(
f"Input image size ({height}*{width}) doesn't match model"
f" ({self.image_size}*{self.image_size}). You should try to set `interpolate_pos_encoding=True`"
)
patch_embeds = self.patch_embedding(pixel_values) # shape = [*, width, grid, grid]
# Change the 2D spatial dimensions to a single temporal dimension.
# shape = (batch_size, num_patches, out_channels=embed_dim)
patch_embeds = flatten(patch_embeds, 1, 2)
class_embeds = tf.broadcast_to(
self.class_embedding[tf.newaxis, tf.newaxis, :], [batch_size, 1, self.embed_dim]
)
embeddings = tf.concat([class_embeds, patch_embeds], axis=1)
# add positional encoding to each token
if interpolate_pos_encoding:
embeddings = embeddings + self.interpolate_pos_encoding(embeddings, height, width)
else:
embeddings = embeddings + self.position_embedding(self.position_ids)
return embeddings
def build(self, input_shape=None):
if self.built:
return
self.built = True
self.position_ids = tf.range(self.num_positions, name="self.position_ids")[tf.newaxis, :]
self.class_embedding = self.add_weight(shape=(self.embed_dim,), name="class_embedding")
if getattr(self, "patch_embedding", None) is not None:
with tf.name_scope(self.patch_embedding.name):
self.patch_embedding.build([None, None, None, self.config.num_channels])
if getattr(self, "position_embedding", None) is not None:
with tf.name_scope(self.position_embedding.name):
self.position_embedding.build(None)
class TFIdeficsVisionAttention(tf.keras.layers.Layer):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config, **kwargs):
super().__init__(**kwargs)
self.config = config
self.embed_dim = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.embed_dim // self.num_heads
if self.head_dim * self.num_heads != self.embed_dim:
raise ValueError(
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
f" {self.num_heads})."
)
self.scale = self.head_dim**-0.5
self.dropout = config.attention_dropout
self.k_proj = tf.keras.layers.Dense(self.embed_dim, name="k_proj")
self.v_proj = tf.keras.layers.Dense(self.embed_dim, name="v_proj")
self.q_proj = tf.keras.layers.Dense(self.embed_dim, name="q_proj")
self.out_proj = tf.keras.layers.Dense(self.embed_dim, name="out_proj")
def _shape(self, tensor: tf.Tensor, seq_len: int, bsz: int):
return tf.transpose(tf.reshape(tensor, (bsz, seq_len, self.num_heads, self.head_dim)), perm=[0, 2, 1, 3])
def call(
self,
hidden_states: tf.Tensor,
attention_mask: Optional[tf.Tensor] = None,
causal_attention_mask: Optional[tf.Tensor] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[tf.Tensor, Optional[tf.Tensor], Optional[Tuple[tf.Tensor]]]:
"""Input shape: Batch x Time x Channel"""
bsz, tgt_len, embed_dim = shape_list(hidden_states)
# get query proj
query_states = self.q_proj(hidden_states) * self.scale
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
query_states = tf.reshape(self._shape(query_states, tgt_len, bsz), proj_shape)
key_states = tf.reshape(key_states, proj_shape)
value_states = tf.reshape(value_states, proj_shape)
src_len = shape_list(key_states)[1]
attn_weights = tf.linalg.matmul(query_states, key_states, transpose_b=True)
tf.debugging.assert_equal(
tf.shape(attn_weights),
[bsz * self.num_heads, tgt_len, src_len],
message=f"Attention weights should be of size {[bsz * self.num_heads, tgt_len, src_len]}, but is {tf.shape(attn_weights)}",
)
# apply the causal_attention_mask first
if causal_attention_mask is not None:
if shape_list(causal_attention_mask) != [bsz, 1, tgt_len, src_len]:
raise ValueError(
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is"
f" {shape_list(causal_attention_mask)}"
)
attn_weights = tf.reshape(attn_weights, (bsz, self.num_heads, tgt_len, src_len)) + causal_attention_mask
attn_weights = tf.reshape(attn_weights, (bsz * self.num_heads, tgt_len, src_len))
if attention_mask is not None:
if shape_list(attention_mask) != [bsz, 1, tgt_len, src_len]:
raise ValueError(
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {shape_list(attention_mask)}"
)
attn_weights = tf.reshape(attn_weights, (bsz, self.num_heads, tgt_len, src_len)) + attention_mask
attn_weights = tf.reshape(attn_weights, (bsz * self.num_heads, tgt_len, src_len))
attn_weights = tf.nn.softmax(attn_weights, axis=-1)
if output_attentions:
# this operation is a bit akward, but it's required to
# make sure that attn_weights keeps its gradient.
# In order to do so, attn_weights have to reshaped
# twice and have to be reused in the following
attn_weights_reshaped = tf.reshape(attn_weights, (bsz, self.num_heads, tgt_len, src_len))
attn_weights = tf.reshape(attn_weights_reshaped, (bsz * self.num_heads, tgt_len, src_len))
else:
attn_weights_reshaped = None
attn_probs = tf.nn.dropout(attn_weights, rate=self.dropout)
attn_output = tf.linalg.matmul(attn_probs, value_states)
tf.debugging.assert_equal(
tf.shape(attn_output),
[bsz * self.num_heads, tgt_len, self.head_dim],
message=f"Attention weights should be of size {[bsz * self.num_heads, tgt_len, self.head_dim]}, but is {tf.shape(attn_output)}",
)
attn_output = tf.reshape(attn_output, (bsz, self.num_heads, tgt_len, self.head_dim))
attn_output = tf.transpose(attn_output, perm=[0, 2, 1, 3])
attn_output = tf.reshape(attn_output, (bsz, tgt_len, embed_dim))
attn_output = self.out_proj(attn_output)
return attn_output, attn_weights_reshaped
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "k_proj", None) is not None:
with tf.name_scope(self.k_proj.name):
self.k_proj.build((self.embed_dim, self.embed_dim))
if getattr(self, "v_proj", None) is not None:
with tf.name_scope(self.v_proj.name):
self.v_proj.build((self.embed_dim, self.embed_dim))
if getattr(self, "q_proj", None) is not None:
with tf.name_scope(self.q_proj.name):
self.q_proj.build((self.embed_dim, self.embed_dim))
if getattr(self, "out_proj", None) is not None:
with tf.name_scope(self.out_proj.name):
self.out_proj.build((self.embed_dim, self.embed_dim))
class TFIdeficsVisionMLP(tf.keras.layers.Layer):
def __init__(self, config, **kwargs):
super().__init__(**kwargs)
self.config = config
self.activation_fn = get_tf_activation(config.hidden_act)
self.fc1 = tf.keras.layers.Dense(config.intermediate_size, name="fc1")
self.fc2 = tf.keras.layers.Dense(config.hidden_size, name="fc2")
def call(self, hidden_states: tf.Tensor) -> tf.Tensor:
hidden_states = self.fc1(hidden_states)
hidden_states = self.activation_fn(hidden_states)
hidden_states = self.fc2(hidden_states)
return hidden_states
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "fc1", None) is not None:
with tf.name_scope(self.fc1.name):
self.fc1.build(self.config.hidden_size)
if getattr(self, "fc2", None) is not None:
with tf.name_scope(self.fc2.name):
self.fc2.build(self.config.intermediate_size)
class TFIdeficsVisionEncoderLayer(tf.keras.layers.Layer):
def __init__(self, config: IdeficsVisionConfig, **kwargs):
super().__init__(**kwargs)
self.embed_dim = config.hidden_size
self.self_attn = TFIdeficsVisionAttention(config, name="self_attn")
self.layer_norm1 = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="layer_norm1")
self.mlp = TFIdeficsVisionMLP(config, name="mlp")
self.layer_norm2 = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="layer_norm2")
def call(
self,
hidden_states: tf.Tensor,
attention_mask: tf.Tensor,
causal_attention_mask: tf.Tensor,
output_attentions: Optional[bool] = False,
) -> Tuple[tf.Tensor]:
"""
Args:
hidden_states (`tf.Tensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`tf.Tensor`): attention mask of size
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
`(config.encoder_attention_heads,)`.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
"""
residual = hidden_states
hidden_states = self.layer_norm1(hidden_states)
hidden_states, attn_weights = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
causal_attention_mask=causal_attention_mask,
output_attentions=output_attentions,
)
hidden_states = residual + hidden_states
residual = hidden_states
hidden_states = self.layer_norm2(hidden_states)
hidden_states = self.mlp(hidden_states)
hidden_states = residual + hidden_states
outputs = (hidden_states,)
if output_attentions:
outputs += (attn_weights,)
return outputs
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "layer_norm1", None) is not None:
with tf.name_scope(self.layer_norm1.name):
self.layer_norm1.build([None, None, self.embed_dim])
if getattr(self, "layer_norm2", None) is not None:
with tf.name_scope(self.layer_norm2.name):
self.layer_norm2.build([None, None, self.embed_dim])
class TFIdeficsVisionEncoder(tf.keras.layers.Layer):
"""
Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
[`TFIdeficsVisionEncoderLayer`].
Args:
config: IdeficsVisionConfig
"""
def __init__(self, config: IdeficsVisionConfig, **kwargs):
super().__init__(**kwargs)
self.config = config
self.layers = [
TFIdeficsVisionEncoderLayer(config, name=f"layers.{i}") for i in range(config.num_hidden_layers)
]
self.gradient_checkpointing = False
def call(
self,
inputs_embeds,
attention_mask: Optional[tf.Tensor] = None,
causal_attention_mask: Optional[tf.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: Optional[bool] = None,
) -> Union[Tuple, TFBaseModelOutput]:
r"""
Args:
inputs_embeds (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
than the model's internal embedding lookup matrix.
attention_mask (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
causal_attention_mask (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Causal mask for the text model. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
encoder_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
hidden_states = inputs_embeds
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if self.gradient_checkpointing and training:
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs, output_attentions)
return custom_forward
layer_outputs = tf.recompute_grad(
create_custom_forward(encoder_layer),
hidden_states,
attention_mask,
causal_attention_mask,
)
else:
layer_outputs = encoder_layer(
hidden_states,
attention_mask,
causal_attention_mask,
output_attentions=output_attentions,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
return TFBaseModelOutput(
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "layers", None) is not None:
for layer in self.layers:
with tf.name_scope(layer.name):
layer.build(None)
class TFIdeficsVisionTransformer(TFPreTrainedModel):
def __init__(self, config: IdeficsVisionConfig, **kwargs):
super().__init__(config, **kwargs)
self.config = config
self.embed_dim = config.hidden_size
self.embeddings = TFIdeficsVisionEmbeddings(config, name="embeddings")
self.pre_layrnorm = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="pre_layrnorm")
self.encoder = TFIdeficsVisionEncoder(config, name="encoder")
self.post_layernorm = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="post_layernorm")
# Adapted from transformers.models.clip.modeling_clip.CLIPVisionTransformer.forward
def call(
self,
pixel_values: Optional[tf.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
interpolate_pos_encoding: Optional[bool] = False,
return_dict: Optional[bool] = None,
training: Optional[bool] = False,
) -> Union[Tuple, TFBaseModelOutputWithPooling]:
r"""
Returns:
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if pixel_values is None:
raise ValueError("You have to specify pixel_values")
hidden_states = self.embeddings(pixel_values, interpolate_pos_encoding=interpolate_pos_encoding)
hidden_states = self.pre_layrnorm(hidden_states)
encoder_outputs = self.encoder(
inputs_embeds=hidden_states,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
last_hidden_state = encoder_outputs[0]
pooled_output = last_hidden_state[:, 0, :]
pooled_output = self.post_layernorm(pooled_output)
if not return_dict:
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
return TFBaseModelOutputWithPooling(
last_hidden_state=last_hidden_state,
pooler_output=pooled_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "embeddings", None) is not None:
with tf.name_scope(self.embeddings.name):
self.embeddings.build(None)
if getattr(self, "pre_layrnorm", None) is not None:
with tf.name_scope(self.pre_layrnorm.name):
self.pre_layrnorm.build([None, None, self.embed_dim])
if getattr(self, "encoder", None) is not None:
with tf.name_scope(self.encoder.name):
self.encoder.build(None)
if getattr(self, "post_layernorm", None) is not None:
with tf.name_scope(self.post_layernorm.name):
self.post_layernorm.build([None, self.embed_dim])
| transformers/src/transformers/models/idefics/vision_tf.py/0 | {
"file_path": "transformers/src/transformers/models/idefics/vision_tf.py",
"repo_id": "transformers",
"token_count": 11478
} |
# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
# This file was automatically generated from src/transformers/models/ijepa/modular_ijepa.py.
# Do NOT edit this file manually as any edits will be overwritten by the generation of
# the file from the modular. If any change should be done, please apply the change to the
# modular_ijepa.py file directly. One of our CI enforces this.
# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
import collections.abc
import math
from typing import Dict, List, Optional, Set, Tuple, Union
import torch
import torch.nn as nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from ...activations import ACT2FN
from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, ImageClassifierOutput
from ...modeling_utils import PreTrainedModel
from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import (
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
logging,
torch_int,
)
from .configuration_ijepa import IJepaConfig
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "facebook/ijepa_vith14_1k"
# General docstring
_CONFIG_FOR_DOC = "IJepaConfig"
class IJepaPatchEmbeddings(nn.Module):
"""
This class turns `pixel_values` of shape `(batch_size, num_channels, height, width)` into the initial
`hidden_states` (patch embeddings) of shape `(batch_size, seq_length, hidden_size)` to be consumed by a
Transformer.
"""
def __init__(self, config):
super().__init__()
image_size, patch_size = config.image_size, config.patch_size
num_channels, hidden_size = config.num_channels, config.hidden_size
image_size = image_size if isinstance(image_size, collections.abc.Iterable) else (image_size, image_size)
patch_size = patch_size if isinstance(patch_size, collections.abc.Iterable) else (patch_size, patch_size)
num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.num_patches = num_patches
self.projection = nn.Conv2d(num_channels, hidden_size, kernel_size=patch_size, stride=patch_size)
def forward(self, pixel_values: torch.Tensor, interpolate_pos_encoding: bool = False) -> torch.Tensor:
batch_size, num_channels, height, width = pixel_values.shape
if num_channels != self.num_channels:
raise ValueError(
"Make sure that the channel dimension of the pixel values match with the one set in the configuration."
f" Expected {self.num_channels} but got {num_channels}."
)
if not interpolate_pos_encoding:
if height != self.image_size[0] or width != self.image_size[1]:
raise ValueError(
f"Input image size ({height}*{width}) doesn't match model"
f" ({self.image_size[0]}*{self.image_size[1]})."
)
embeddings = self.projection(pixel_values).flatten(2).transpose(1, 2)
return embeddings
class IJepaEmbeddings(nn.Module):
"""
Construct the CLS token, position and patch embeddings. Optionally, also the mask token.
"""
def __init__(self, config: IJepaConfig, use_mask_token: bool = False) -> None:
super().__init__()
self.mask_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size)) if use_mask_token else None
self.patch_embeddings = IJepaPatchEmbeddings(config)
num_patches = self.patch_embeddings.num_patches
self.position_embeddings = nn.Parameter(torch.randn(1, num_patches, config.hidden_size))
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.patch_size = config.patch_size
self.config = config
def interpolate_pos_encoding(self, embeddings: torch.Tensor, height: int, width: int) -> torch.Tensor:
"""
This method allows to interpolate the pre-trained position encodings, to be able to use the model on higher resolution
images. This method is also adapted to support torch.jit tracing.
Adapted from:
- https://github.com/facebookresearch/dino/blob/de9ee3df6cf39fac952ab558447af1fa1365362a/vision_transformer.py#L174-L194, and
- https://github.com/facebookresearch/dinov2/blob/e1277af2ba9496fbadf7aec6eba56e8d882d1e35/dinov2/models/vision_transformer.py#L179-L211
"""
num_patches = embeddings.shape[1]
num_positions = self.position_embeddings.shape[1]
# always interpolate when tracing to ensure the exported model works for dynamic input shapes
if not torch.jit.is_tracing() and num_patches == num_positions and height == width:
return self.position_embeddings
patch_pos_embed = self.position_embeddings
dim = embeddings.shape[-1]
new_height = height // self.patch_size
new_width = width // self.patch_size
sqrt_num_positions = torch_int(num_positions**0.5)
patch_pos_embed = patch_pos_embed.reshape(1, sqrt_num_positions, sqrt_num_positions, dim)
patch_pos_embed = patch_pos_embed.permute(0, 3, 1, 2)
patch_pos_embed = nn.functional.interpolate(
patch_pos_embed,
size=(new_height, new_width),
mode="bicubic",
align_corners=False,
)
patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
return patch_pos_embed
def forward(
self,
pixel_values: torch.Tensor,
bool_masked_pos: Optional[torch.BoolTensor] = None,
interpolate_pos_encoding: bool = False,
) -> torch.Tensor:
batch_size, _, height, width = pixel_values.shape
embeddings = self.patch_embeddings(pixel_values, interpolate_pos_encoding=interpolate_pos_encoding)
if bool_masked_pos is not None:
seq_length = embeddings.shape[1]
mask_tokens = self.mask_token.expand(batch_size, seq_length, -1)
# replace the masked visual tokens by mask_tokens
mask = bool_masked_pos.unsqueeze(-1).type_as(mask_tokens)
embeddings = embeddings * (1.0 - mask) + mask_tokens * mask
# add positional encoding to each token
if interpolate_pos_encoding:
embeddings = embeddings + self.interpolate_pos_encoding(embeddings, height, width)
else:
embeddings = embeddings + self.position_embeddings
embeddings = self.dropout(embeddings)
return embeddings
class IJepaPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = IJepaConfig
base_model_prefix = "ijepa"
main_input_name = "pixel_values"
supports_gradient_checkpointing = True
_no_split_modules = ["IJepaEmbeddings", "IJepaLayer"]
_supports_sdpa = True
def _init_weights(self, module: Union[nn.Linear, nn.Conv2d, nn.LayerNorm]) -> None:
"""Initialize the weights"""
if isinstance(module, (nn.Linear, nn.Conv2d)):
# Upcast the input in `fp32` and cast it back to desired `dtype` to avoid
# `trunc_normal_cpu` not implemented in `half` issues
module.weight.data = nn.init.trunc_normal_(
module.weight.data.to(torch.float32), mean=0.0, std=self.config.initializer_range
).to(module.weight.dtype)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
elif isinstance(module, IJepaEmbeddings):
module.position_embeddings.data = nn.init.trunc_normal_(
module.position_embeddings.data.to(torch.float32),
mean=0.0,
std=self.config.initializer_range,
).to(module.position_embeddings.dtype)
class IJepaSelfAttention(nn.Module):
def __init__(self, config: IJepaConfig) -> None:
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
f"heads {config.num_attention_heads}."
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
self.key = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
self.value = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self, hidden_states, head_mask: Optional[torch.Tensor] = None, output_attentions: bool = False
) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
mixed_query_layer = self.query(hidden_states)
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
return outputs
class IJepaSdpaSelfAttention(IJepaSelfAttention):
def __init__(self, config: IJepaConfig) -> None:
super().__init__(config)
self.attention_probs_dropout_prob = config.attention_probs_dropout_prob
def forward(
self,
hidden_states: torch.FloatTensor,
head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
if output_attentions or head_mask is not None:
logger.warning_once(
"`IJepaSdpaAttention` is used but `torch.nn.functional.scaled_dot_product_attention` does not support "
"`output_attentions=True` or `head_mask`. Falling back to the manual attention implementation, but "
"specifying the manual implementation will be required from Transformers version v5.0.0 onwards. "
'This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
)
return super().forward(
hidden_states=hidden_states,
head_mask=head_mask,
output_attentions=output_attentions,
)
mixed_query_layer = self.query(hidden_states)
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
context_layer = torch.nn.functional.scaled_dot_product_attention(
query_layer,
key_layer,
value_layer,
head_mask,
self.attention_probs_dropout_prob if self.training else 0.0,
is_causal=False,
scale=None,
)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(new_context_layer_shape)
return context_layer, None
class IJepaSelfOutput(nn.Module):
"""
The residual connection is defined in IJepaLayer instead of here (as is the case with other models), due to the
layernorm applied before each block.
"""
def __init__(self, config: IJepaConfig) -> None:
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
return hidden_states
class IJepaAttention(nn.Module):
def __init__(self, config: IJepaConfig) -> None:
super().__init__()
self.attention = IJepaSelfAttention(config)
self.output = IJepaSelfOutput(config)
self.pruned_heads = set()
def prune_heads(self, heads: Set[int]) -> None:
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.attention.num_attention_heads, self.attention.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.attention.query = prune_linear_layer(self.attention.query, index)
self.attention.key = prune_linear_layer(self.attention.key, index)
self.attention.value = prune_linear_layer(self.attention.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.attention.num_attention_heads = self.attention.num_attention_heads - len(heads)
self.attention.all_head_size = self.attention.attention_head_size * self.attention.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states: torch.Tensor,
head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
self_outputs = self.attention(hidden_states, head_mask, output_attentions)
attention_output = self.output(self_outputs[0], hidden_states)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
class IJepaSdpaAttention(IJepaAttention):
def __init__(self, config: IJepaConfig) -> None:
super().__init__(config)
self.attention = IJepaSdpaSelfAttention(config)
class IJepaIntermediate(nn.Module):
def __init__(self, config: IJepaConfig) -> None:
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
class IJepaOutput(nn.Module):
def __init__(self, config: IJepaConfig) -> None:
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = hidden_states + input_tensor
return hidden_states
IJEPA_ATTENTION_CLASSES = {
"eager": IJepaAttention,
"sdpa": IJepaSdpaAttention,
}
class IJepaLayer(nn.Module):
"""This corresponds to the Block class in the timm implementation."""
def __init__(self, config: IJepaConfig) -> None:
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = IJEPA_ATTENTION_CLASSES[config._attn_implementation](config)
self.intermediate = IJepaIntermediate(config)
self.output = IJepaOutput(config)
self.layernorm_before = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.layernorm_after = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(
self,
hidden_states: torch.Tensor,
head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
self_attention_outputs = self.attention(
self.layernorm_before(hidden_states), # in IJepa, layernorm is applied before self-attention
head_mask,
output_attentions=output_attentions,
)
attention_output = self_attention_outputs[0]
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
# first residual connection
hidden_states = attention_output + hidden_states
# in IJepa, layernorm is also applied after self-attention
layer_output = self.layernorm_after(hidden_states)
layer_output = self.intermediate(layer_output)
# second residual connection is done here
layer_output = self.output(layer_output, hidden_states)
outputs = (layer_output,) + outputs
return outputs
class IJepaEncoder(nn.Module):
def __init__(self, config: IJepaConfig) -> None:
super().__init__()
self.config = config
self.layer = nn.ModuleList([IJepaLayer(config) for _ in range(config.num_hidden_layers)])
self.gradient_checkpointing = False
def forward(
self,
hidden_states: torch.Tensor,
head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
) -> Union[tuple, BaseModelOutput]:
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
layer_module.__call__,
hidden_states,
layer_head_mask,
output_attentions,
)
else:
layer_outputs = layer_module(hidden_states, layer_head_mask, output_attentions)
hidden_states = layer_outputs[0]
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
class IJepaPooler(nn.Module):
def __init__(self, config: IJepaConfig):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
IJEPA_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See [`IJepaImageProcessor.__call__`]
for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
interpolate_pos_encoding (`bool`, *optional*):
Whether to interpolate the pre-trained position encodings.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
_EXPECTED_OUTPUT_SHAPE = [1, 256, 1280]
IJEPA_START_DOCSTRING = r"""
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
Parameters:
config ([`IJepaConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
@add_start_docstrings(
"The bare IJepa Model transformer outputting raw hidden-states without any specific head on top.",
IJEPA_START_DOCSTRING,
)
class IJepaModel(IJepaPreTrainedModel):
def __init__(self, config: IJepaConfig, add_pooling_layer: bool = False, use_mask_token: bool = False):
super().__init__(config)
self.config = config
self.embeddings = IJepaEmbeddings(config, use_mask_token=use_mask_token)
self.encoder = IJepaEncoder(config)
self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.pooler = IJepaPooler(config) if add_pooling_layer else None
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self) -> IJepaPatchEmbeddings:
return self.embeddings.patch_embeddings
def _prune_heads(self, heads_to_prune: Dict[int, List[int]]) -> None:
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward(IJEPA_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=BaseModelOutputWithPooling,
config_class=_CONFIG_FOR_DOC,
modality="vision",
expected_output=_EXPECTED_OUTPUT_SHAPE,
)
def forward(
self,
pixel_values: Optional[torch.Tensor] = None,
bool_masked_pos: Optional[torch.BoolTensor] = None,
head_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
interpolate_pos_encoding: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPooling]:
r"""
bool_masked_pos (`torch.BoolTensor` of shape `(batch_size, num_patches)`, *optional*):
Boolean masked positions. Indicates which patches are masked (1) and which aren't (0).
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if pixel_values is None:
raise ValueError("You have to specify pixel_values")
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
# TODO: maybe have a cleaner way to cast the input (from `ImageProcessor` side?)
expected_dtype = self.embeddings.patch_embeddings.projection.weight.dtype
if pixel_values.dtype != expected_dtype:
pixel_values = pixel_values.to(expected_dtype)
embedding_output = self.embeddings(
pixel_values, bool_masked_pos=bool_masked_pos, interpolate_pos_encoding=interpolate_pos_encoding
)
encoder_outputs = self.encoder(
embedding_output,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
sequence_output = self.layernorm(sequence_output)
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
if not return_dict:
head_outputs = (sequence_output, pooled_output) if pooled_output is not None else (sequence_output,)
return head_outputs + encoder_outputs[1:]
return BaseModelOutputWithPooling(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
_IMAGE_CLASS_CHECKPOINT = "facebook/ijepa_vith14_1k"
_IMAGE_CLASS_EXPECTED_OUTPUT = "Egyptian cat"
@add_start_docstrings(
"""
IJepa Model transformer with an image classification head on top (a linear layer on top of the final hidden states)
e.g. for ImageNet.
<Tip>
Note that it's possible to fine-tune IJepa on higher resolution images than the ones it has been trained on, by
setting `interpolate_pos_encoding` to `True` in the forward of the model. This will interpolate the pre-trained
position embeddings to the higher resolution.
</Tip>
""",
IJEPA_START_DOCSTRING,
)
class IJepaForImageClassification(IJepaPreTrainedModel):
def __init__(self, config: IJepaConfig) -> None:
super().__init__(config)
self.num_labels = config.num_labels
self.ijepa = IJepaModel(config, add_pooling_layer=False)
# Classifier head
self.classifier = nn.Linear(config.hidden_size, config.num_labels) if config.num_labels > 0 else nn.Identity()
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(IJEPA_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_IMAGE_CLASS_CHECKPOINT,
output_type=ImageClassifierOutput,
config_class=_CONFIG_FOR_DOC,
expected_output=_IMAGE_CLASS_EXPECTED_OUTPUT,
)
def forward(
self,
pixel_values: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
interpolate_pos_encoding: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[tuple, ImageClassifierOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the image classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.ijepa(
pixel_values,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
interpolate_pos_encoding=interpolate_pos_encoding,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.classifier(sequence_output.mean(dim=1))
loss = None
if labels is not None:
# move labels to correct device to enable model parallelism
labels = labels.to(logits.device)
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return ImageClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
__all__ = ["IJepaPreTrainedModel", "IJepaModel", "IJepaForImageClassification"]
| transformers/src/transformers/models/ijepa/modeling_ijepa.py/0 | {
"file_path": "transformers/src/transformers/models/ijepa/modeling_ijepa.py",
"repo_id": "transformers",
"token_count": 13749
} |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import TYPE_CHECKING
from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_torch_available, is_vision_available
_import_structure = {
"configuration_instructblipvideo": [
"InstructBlipVideoConfig",
"InstructBlipVideoQFormerConfig",
"InstructBlipVideoVisionConfig",
],
"processing_instructblipvideo": ["InstructBlipVideoProcessor"],
}
try:
if not is_vision_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["image_processing_instructblipvideo"] = ["InstructBlipVideoImageProcessor"]
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_instructblipvideo"] = [
"InstructBlipVideoQFormerModel",
"InstructBlipVideoPreTrainedModel",
"InstructBlipVideoForConditionalGeneration",
"InstructBlipVideoVisionModel",
]
if TYPE_CHECKING:
from .configuration_instructblipvideo import (
InstructBlipVideoConfig,
InstructBlipVideoQFormerConfig,
InstructBlipVideoVisionConfig,
)
from .processing_instructblipvideo import InstructBlipVideoProcessor
try:
if not is_vision_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .image_processing_instructblipvideo import InstructBlipVideoImageProcessor
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_instructblipvideo import (
InstructBlipVideoForConditionalGeneration,
InstructBlipVideoPreTrainedModel,
InstructBlipVideoQFormerModel,
InstructBlipVideoVisionModel,
)
else:
import sys
sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
| transformers/src/transformers/models/instructblipvideo/__init__.py/0 | {
"file_path": "transformers/src/transformers/models/instructblipvideo/__init__.py",
"repo_id": "transformers",
"token_count": 944
} |
# coding=utf-8
# Copyright 2023 Microsoft Research and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch KOSMOS-2 model."""
import math
from dataclasses import dataclass
from typing import Any, List, Optional, Tuple, Union
import torch
import torch.utils.checkpoint
from torch import nn
from torch.nn import CrossEntropyLoss
from ...activations import ACT2FN
from ...generation import GenerationMixin
from ...modeling_outputs import (
BaseModelOutput,
BaseModelOutputWithPastAndCrossAttentions,
BaseModelOutputWithPooling,
CausalLMOutputWithCrossAttentions,
)
from ...modeling_utils import PreTrainedModel
from ...utils import (
ModelOutput,
add_start_docstrings,
add_start_docstrings_to_model_forward,
logging,
replace_return_docstrings,
torch_int,
)
from .configuration_kosmos2 import Kosmos2Config, Kosmos2TextConfig, Kosmos2VisionConfig
logger = logging.get_logger(__name__)
_CONFIG_FOR_DOC = Kosmos2Config
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
"""
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
"""
bsz, src_len = mask.size()
tgt_len = tgt_len if tgt_len is not None else src_len
expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
inverted_mask = 1.0 - expanded_mask
return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
def _make_causal_mask(
input_ids_shape: torch.Size, dtype: torch.dtype, device: torch.device, past_key_values_length: int = 0
):
"""
Make causal mask used for bi-directional self-attention.
"""
bsz, tgt_len = input_ids_shape
mask = torch.full((tgt_len, tgt_len), torch.finfo(dtype).min, device=device)
mask_cond = torch.arange(mask.size(-1), device=device)
mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
mask = mask.to(dtype)
if past_key_values_length > 0:
mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)
return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)
# Copied from transformers.models.roberta.modeling_roberta.create_position_ids_from_input_ids
def create_position_ids_from_input_ids(input_ids, padding_idx, past_key_values_length=0):
"""
Replace non-padding symbols with their position numbers. Position numbers begin at padding_idx+1. Padding symbols
are ignored. This is modified from fairseq's `utils.make_positions`.
Args:
x: torch.Tensor x:
Returns: torch.Tensor
"""
# The series of casts and type-conversions here are carefully balanced to both work with ONNX export and XLA.
mask = input_ids.ne(padding_idx).int()
incremental_indices = (torch.cumsum(mask, dim=1).type_as(mask) + past_key_values_length) * mask
return incremental_indices.long() + padding_idx
KOSMOS2_START_DOCSTRING = r"""
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`Kosmos2Config`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
KOSMOS2_VISION_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
[`CLIPImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
interpolate_pos_encoding (`bool`, *optional*, defaults `False`):
Whether to interpolate the pre-trained position encodings.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
KOSMOS2_TEXT_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
image_embeds: (`torch.FloatTensor` of shape `(batch_size, latent_query_num, hidden_size)`, *optional*):
Sequence of hidden-states at the output of `Kosmos2ImageToTextProjection`.
image_embeds_position_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to indicate the location in a sequence to insert the image features . Mask values selected in `[0,
1]`:
- 1 for places where to put the image features,
- 0 for places that are not for image features (i.e. for text tokens).
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`).
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
KOSMOS2_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
[`CLIPImageProcessor.__call__`] for details.
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
image_embeds_position_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to indicate the location in a sequence to insert the image features . Mask values selected in `[0,
1]`:
- 1 for places where to put the image features,
- 0 for places that are not for image features (i.e. for text tokens).
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
image_embeds: (`torch.FloatTensor` of shape `(batch_size, latent_query_num, hidden_size)`, *optional*):
Sequence of hidden-states at the output of `Kosmos2ImageToTextProjection`.
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`).
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
interpolate_pos_encoding (`bool`, *optional*, defaults `False`):
Whether to interpolate the pre-trained position encodings.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
@dataclass
class Kosmos2ModelOutput(ModelOutput):
"""
Base class for text model's outputs that also contains a pooling of the last hidden states.
Args:
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
image_embeds (`torch.FloatTensor` of shape `(batch_size, latent_query_num, hidden_size)`, *optional*):
Sequence of hidden-states at the output of `Kosmos2ImageToTextProjection`.
projection_attentions (`tuple(torch.FloatTensor)`, *optional*):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights given by `Kosmos2ImageToTextProjection`, after the attention softmax, used to compute
the weighted average in the self-attention heads.
vision_model_output(`BaseModelOutputWithPooling`, *optional*):
The output of the [`Kosmos2VisionModel`].
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
`(batch_size, num_heads, sequence_length, embed_size_per_head)`) and optionally if
`config.is_encoder_decoder=True` 2 additional tensors of shape `(batch_size, num_heads,
encoder_sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
`config.is_encoder_decoder=True` in the cross-attention blocks) that can be used (see `past_key_values`
input) to speed up sequential decoding.
"""
last_hidden_state: torch.FloatTensor = None
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
image_embeds: Optional[torch.FloatTensor] = None
projection_attentions: Optional[Tuple[torch.FloatTensor]] = None
vision_model_output: BaseModelOutputWithPooling = None
def to_tuple(self) -> Tuple[Any]:
return tuple(
self[k] if k not in ["text_model_output", "vision_model_output"] else getattr(self, k).to_tuple()
for k in self.keys()
)
@dataclass
class Kosmos2ForConditionalGenerationModelOutput(ModelOutput):
"""
Model output class for `Kosmos2ForConditionalGeneration`.
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
Language modeling loss (for next-token prediction).
logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
image_embeds (`torch.FloatTensor` of shape `(batch_size, latent_query_num, hidden_size)`, *optional*):
Sequence of hidden-states at the output of `Kosmos2ImageToTextProjection`.
projection_attentions (`tuple(torch.FloatTensor)`, *optional*):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights given by `Kosmos2ImageToTextProjection`, after the attention softmax, used to compute
the weighted average in the self-attention heads.
vision_model_output(`BaseModelOutputWithPooling`, *optional*):
The output of the [`Kosmos2VisionModel`].
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
`(batch_size, num_heads, sequence_length, embed_size_per_head)`) and optionally if
`config.is_encoder_decoder=True` 2 additional tensors of shape `(batch_size, num_heads,
encoder_sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
`config.is_encoder_decoder=True` in the cross-attention blocks) that can be used (see `past_key_values`
input) to speed up sequential decoding.
"""
loss: Optional[torch.FloatTensor] = None
logits: torch.FloatTensor = None
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
image_embeds: Optional[torch.FloatTensor] = None
projection_attentions: Optional[Tuple[torch.FloatTensor]] = None
vision_model_output: BaseModelOutputWithPooling = None
def to_tuple(self) -> Tuple[Any]:
return tuple(
self[k] if k not in ["text_model_output", "vision_model_output"] else getattr(self, k).to_tuple()
for k in self.keys()
)
# Copied from transformers.models.clip.modeling_clip.CLIPVisionEmbeddings with CLIP->Kosmos2
class Kosmos2VisionEmbeddings(nn.Module):
def __init__(self, config: Kosmos2VisionConfig):
super().__init__()
self.config = config
self.embed_dim = config.hidden_size
self.image_size = config.image_size
self.patch_size = config.patch_size
self.class_embedding = nn.Parameter(torch.randn(self.embed_dim))
self.patch_embedding = nn.Conv2d(
in_channels=config.num_channels,
out_channels=self.embed_dim,
kernel_size=self.patch_size,
stride=self.patch_size,
bias=False,
)
self.num_patches = (self.image_size // self.patch_size) ** 2
self.num_positions = self.num_patches + 1
self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
self.register_buffer("position_ids", torch.arange(self.num_positions).expand((1, -1)), persistent=False)
def interpolate_pos_encoding(self, embeddings: torch.Tensor, height: int, width: int) -> torch.Tensor:
"""
This method allows to interpolate the pre-trained position encodings, to be able to use the model on higher resolution
images. This method is also adapted to support torch.jit tracing.
Adapted from:
- https://github.com/facebookresearch/dino/blob/de9ee3df6cf39fac952ab558447af1fa1365362a/vision_transformer.py#L174-L194, and
- https://github.com/facebookresearch/dinov2/blob/e1277af2ba9496fbadf7aec6eba56e8d882d1e35/dinov2/models/vision_transformer.py#L179-L211
"""
num_patches = embeddings.shape[1] - 1
position_embedding = self.position_embedding.weight.unsqueeze(0)
num_positions = position_embedding.shape[1] - 1
# always interpolate when tracing to ensure the exported model works for dynamic input shapes
if not torch.jit.is_tracing() and num_patches == num_positions and height == width:
return self.position_embedding(self.position_ids)
class_pos_embed = position_embedding[:, :1]
patch_pos_embed = position_embedding[:, 1:]
dim = embeddings.shape[-1]
new_height = height // self.patch_size
new_width = width // self.patch_size
sqrt_num_positions = torch_int(num_positions**0.5)
patch_pos_embed = patch_pos_embed.reshape(1, sqrt_num_positions, sqrt_num_positions, dim)
patch_pos_embed = patch_pos_embed.permute(0, 3, 1, 2)
patch_pos_embed = nn.functional.interpolate(
patch_pos_embed,
size=(new_height, new_width),
mode="bicubic",
align_corners=False,
)
patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
return torch.cat((class_pos_embed, patch_pos_embed), dim=1)
def forward(self, pixel_values: torch.FloatTensor, interpolate_pos_encoding=False) -> torch.Tensor:
batch_size, _, height, width = pixel_values.shape
if not interpolate_pos_encoding and (height != self.image_size or width != self.image_size):
raise ValueError(
f"Input image size ({height}*{width}) doesn't match model" f" ({self.image_size}*{self.image_size})."
)
target_dtype = self.patch_embedding.weight.dtype
patch_embeds = self.patch_embedding(pixel_values.to(dtype=target_dtype)) # shape = [*, width, grid, grid]
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
class_embeds = self.class_embedding.expand(batch_size, 1, -1)
embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
if interpolate_pos_encoding:
embeddings = embeddings + self.interpolate_pos_encoding(embeddings, height, width)
else:
embeddings = embeddings + self.position_embedding(self.position_ids)
return embeddings
# Copied from transformers.models.clip.modeling_clip.CLIPAttention with CLIP->Kosmos2Vision
class Kosmos2VisionAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config):
super().__init__()
self.config = config
self.embed_dim = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.embed_dim // self.num_heads
if self.head_dim * self.num_heads != self.embed_dim:
raise ValueError(
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
f" {self.num_heads})."
)
self.scale = self.head_dim**-0.5
self.dropout = config.attention_dropout
self.k_proj = nn.Linear(self.embed_dim, self.embed_dim)
self.v_proj = nn.Linear(self.embed_dim, self.embed_dim)
self.q_proj = nn.Linear(self.embed_dim, self.embed_dim)
self.out_proj = nn.Linear(self.embed_dim, self.embed_dim)
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
causal_attention_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:
"""Input shape: Batch x Time x Channel"""
bsz, tgt_len, embed_dim = hidden_states.size()
# get query proj
query_states = self.q_proj(hidden_states) * self.scale
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
key_states = key_states.view(*proj_shape)
value_states = value_states.view(*proj_shape)
src_len = key_states.size(1)
attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
raise ValueError(
f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is"
f" {attn_weights.size()}"
)
# apply the causal_attention_mask first
if causal_attention_mask is not None:
if causal_attention_mask.size() != (bsz, 1, tgt_len, src_len):
raise ValueError(
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is"
f" {causal_attention_mask.size()}"
)
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + causal_attention_mask
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
if attention_mask is not None:
if attention_mask.size() != (bsz, 1, tgt_len, src_len):
raise ValueError(
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
)
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
if output_attentions:
# this operation is a bit akward, but it's required to
# make sure that attn_weights keeps its gradient.
# In order to do so, attn_weights have to reshaped
# twice and have to be reused in the following
attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
else:
attn_weights_reshaped = None
attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
attn_output = torch.bmm(attn_probs, value_states)
if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is"
f" {attn_output.size()}"
)
attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
attn_output = attn_output.transpose(1, 2)
attn_output = attn_output.reshape(bsz, tgt_len, embed_dim)
attn_output = self.out_proj(attn_output)
return attn_output, attn_weights_reshaped
# Copied from transformers.models.clip.modeling_clip.CLIPMLP with CLIP->Kosmos2Vision
class Kosmos2VisionMLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.activation_fn = ACT2FN[config.hidden_act]
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.fc1(hidden_states)
hidden_states = self.activation_fn(hidden_states)
hidden_states = self.fc2(hidden_states)
return hidden_states
# Copied from transformers.models.altclip.modeling_altclip.AltCLIPEncoderLayer with AltCLIP->Kosmos2Vision
class Kosmos2VisionEncoderLayer(nn.Module):
def __init__(self, config: Kosmos2VisionConfig):
super().__init__()
self.embed_dim = config.hidden_size
self.self_attn = Kosmos2VisionAttention(config)
self.layer_norm1 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
self.mlp = Kosmos2VisionMLP(config)
self.layer_norm2 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: torch.Tensor,
causal_attention_mask: torch.Tensor,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.FloatTensor]:
"""
Args:
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`torch.FloatTensor`): attention mask of size
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
`(config.encoder_attention_heads,)`.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
"""
residual = hidden_states
hidden_states = self.layer_norm1(hidden_states)
hidden_states, attn_weights = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
causal_attention_mask=causal_attention_mask,
output_attentions=output_attentions,
)
hidden_states = residual + hidden_states
residual = hidden_states
hidden_states = self.layer_norm2(hidden_states)
hidden_states = self.mlp(hidden_states)
hidden_states = residual + hidden_states
outputs = (hidden_states,)
if output_attentions:
outputs += (attn_weights,)
return outputs
# Copied from transformers.models.altclip.modeling_altclip.AltCLIPEncoder with AltCLIP->Kosmos2Vision
class Kosmos2VisionEncoder(nn.Module):
"""
Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
[`Kosmos2VisionEncoderLayer`].
Args:
config: Kosmos2VisionConfig
"""
def __init__(self, config: Kosmos2VisionConfig):
super().__init__()
self.config = config
self.layers = nn.ModuleList([Kosmos2VisionEncoderLayer(config) for _ in range(config.num_hidden_layers)])
self.gradient_checkpointing = False
def forward(
self,
inputs_embeds,
attention_mask: Optional[torch.Tensor] = None,
causal_attention_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutput]:
r"""
Args:
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
than the model's internal embedding lookup matrix.
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
causal_attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Causal mask for the text model. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
encoder_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
hidden_states = inputs_embeds
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
encoder_layer.__call__,
hidden_states,
attention_mask,
causal_attention_mask,
output_attentions,
)
else:
layer_outputs = encoder_layer(
hidden_states,
attention_mask,
causal_attention_mask,
output_attentions=output_attentions,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
)
# Similar to `transformers.models.clip.modeling_clip.CLIPVisionTransformer` but without docstring for `forward`
class Kosmos2VisionTransformer(nn.Module):
# Copied from transformers.models.altclip.modeling_altclip.AltCLIPVisionTransformer.__init__ with AltCLIPVision->Kosmos2Vision,ALTCLIP_VISION->KOSMOS2_VISION,AltCLIP->Kosmos2Vision
def __init__(self, config: Kosmos2VisionConfig):
super().__init__()
self.config = config
embed_dim = config.hidden_size
self.embeddings = Kosmos2VisionEmbeddings(config)
self.pre_layrnorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
self.encoder = Kosmos2VisionEncoder(config)
self.post_layernorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
def forward(
self,
pixel_values: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
interpolate_pos_encoding: bool = False,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPooling]:
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if pixel_values is None:
raise ValueError("You have to specify pixel_values")
hidden_states = self.embeddings(pixel_values, interpolate_pos_encoding=interpolate_pos_encoding)
hidden_states = self.pre_layrnorm(hidden_states)
encoder_outputs = self.encoder(
inputs_embeds=hidden_states,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
last_hidden_state = encoder_outputs[0]
pooled_output = last_hidden_state[:, 0, :]
pooled_output = self.post_layernorm(pooled_output)
if not return_dict:
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPooling(
last_hidden_state=last_hidden_state,
pooler_output=pooled_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
# Similar to `transformers.models.m2m_100.modeling_m2m_100.M2M100SinusoidalPositionalEmbedding` but allowing to pass `position_ids`
class Kosmos2TextSinusoidalPositionalEmbedding(nn.Module):
"""This module produces sinusoidal positional embeddings of any length."""
# Copied from transformers.models.m2m_100.modeling_m2m_100.M2M100SinusoidalPositionalEmbedding.__init__
def __init__(self, num_positions: int, embedding_dim: int, padding_idx: Optional[int] = None):
super().__init__()
self.offset = 2
self.embedding_dim = embedding_dim
self.padding_idx = padding_idx
self.make_weights(num_positions + self.offset, embedding_dim, padding_idx)
# Copied from transformers.models.m2m_100.modeling_m2m_100.M2M100SinusoidalPositionalEmbedding.make_weights
def make_weights(self, num_embeddings: int, embedding_dim: int, padding_idx: Optional[int] = None):
emb_weights = self.get_embedding(num_embeddings, embedding_dim, padding_idx)
if hasattr(self, "weights"):
# in forward put the weights on the correct dtype and device of the param
emb_weights = emb_weights.to(dtype=self.weights.dtype, device=self.weights.device)
self.register_buffer("weights", emb_weights, persistent=False)
@staticmethod
# Copied from transformers.models.m2m_100.modeling_m2m_100.M2M100SinusoidalPositionalEmbedding.get_embedding
def get_embedding(num_embeddings: int, embedding_dim: int, padding_idx: Optional[int] = None):
"""
Build sinusoidal embeddings.
This matches the implementation in tensor2tensor, but differs slightly from the description in Section 3.5 of
"Attention Is All You Need".
"""
half_dim = embedding_dim // 2
emb = math.log(10000) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, dtype=torch.int64).float() * -emb)
emb = torch.arange(num_embeddings, dtype=torch.int64).float().unsqueeze(1) * emb.unsqueeze(0)
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1).view(num_embeddings, -1)
if embedding_dim % 2 == 1:
# zero pad
emb = torch.cat([emb, torch.zeros(num_embeddings, 1)], dim=1)
if padding_idx is not None:
emb[padding_idx, :] = 0
return emb.to(torch.get_default_dtype())
@torch.no_grad()
def forward(
self,
input_ids: torch.Tensor = None,
inputs_embeds: torch.Tensor = None,
past_key_values_length: int = 0,
position_ids: torch.Tensor = None,
):
if input_ids is not None:
bsz, seq_len = input_ids.size()
if position_ids is None:
# Create the position ids from the input token ids. Any padded tokens remain padded.
position_ids = create_position_ids_from_input_ids(
input_ids, self.padding_idx, past_key_values_length
).to(input_ids.device)
else:
bsz, seq_len = inputs_embeds.size()[:-1]
if position_ids is None:
position_ids = self.create_position_ids_from_inputs_embeds(inputs_embeds, past_key_values_length)
# expand embeddings if needed
max_pos = self.padding_idx + 1 + seq_len + past_key_values_length
if max_pos > self.weights.size(0):
self.make_weights(max_pos + self.offset, self.embedding_dim, self.padding_idx)
return self.weights.index_select(0, position_ids.view(-1)).view(bsz, seq_len, self.weights.shape[-1]).detach()
# Copied from transformers.models.m2m_100.modeling_m2m_100.M2M100SinusoidalPositionalEmbedding.create_position_ids_from_inputs_embeds
def create_position_ids_from_inputs_embeds(self, inputs_embeds, past_key_values_length):
"""
We are provided embeddings directly. We cannot infer which are padded so just generate sequential position ids.
Args:
inputs_embeds: torch.Tensor
Returns: torch.Tensor
"""
input_shape = inputs_embeds.size()[:-1]
sequence_length = input_shape[1]
position_ids = torch.arange(
self.padding_idx + 1, sequence_length + self.padding_idx + 1, dtype=torch.long, device=inputs_embeds.device
)
return position_ids.unsqueeze(0).expand(input_shape).contiguous() + past_key_values_length
class KosmosTextAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
# Similar to transformers.models.bart.modeling_bart.BartAttention.__init__ except an additional `inner_attn_ln`.
def __init__(
self,
config,
embed_dim: int,
num_heads: int,
dropout: float = 0.0,
is_decoder: bool = False,
add_inner_attn_layernorm: bool = False,
bias: bool = True,
):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.dropout = dropout
self.head_dim = embed_dim // num_heads
if (self.head_dim * num_heads) != self.embed_dim:
raise ValueError(
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim}"
f" and `num_heads`: {num_heads})."
)
self.scaling = self.head_dim**-0.5
self.is_decoder = is_decoder
self.k_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.v_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
# End opy
self.inner_attn_ln = None
if add_inner_attn_layernorm:
self.inner_attn_ln = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
def _shape(self, projection: torch.Tensor) -> torch.Tensor:
new_projection_shape = projection.size()[:-1] + (self.num_heads, self.head_dim)
# move heads to 2nd position (B, T, H * D) -> (B, T, H, D) -> (B, H, T, D)
new_projection = projection.view(new_projection_shape).permute(0, 2, 1, 3)
return new_projection
def forward(
self,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
attention_mask: Optional[torch.Tensor] = None,
layer_head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
"""Input shape: Batch x Time x Channel"""
# if key_value_states are provided this layer is used as a cross-attention layer
# for the decoder
is_cross_attention = encoder_hidden_states is not None
batch_size, seq_length = hidden_states.shape[:2]
# use encoder_hidden_states if cross attention
current_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
# checking that the `sequence_length` of the `past_key_value` is the same as the he provided
# `encoder_hidden_states` to support prefix tuning
if is_cross_attention and past_key_value and past_key_value[0].shape[2] == current_states.shape[1]:
# reuse k,v, cross_attentions
key_states = past_key_value[0]
value_states = past_key_value[1]
else:
key_states = self._shape(self.k_proj(current_states))
value_states = self._shape(self.v_proj(current_states))
if past_key_value is not None and not is_cross_attention:
# reuse k, v, self_attention
key_states = torch.cat([past_key_value[0], key_states], dim=2)
value_states = torch.cat([past_key_value[1], value_states], dim=2)
query_states = self._shape(self.q_proj(hidden_states) * self.scaling)
attn_weights = torch.matmul(query_states, key_states.transpose(-1, -2))
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_states, value_states)
src_len = key_states.size(2)
if attention_mask is not None:
if attention_mask.size() != (batch_size, 1, seq_length, src_len):
raise ValueError(
f"Attention mask should be of size {(batch_size, 1, seq_length, src_len)}, but is {attention_mask.size()}"
)
attn_weights = attn_weights + attention_mask
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
# Mask heads if we want to
if layer_head_mask is not None:
attn_weights = attn_weights * layer_head_mask
attn_weights = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
# attn_output = torch.bmm(attn_probs, value_states) ?
context_states = torch.matmul(attn_weights, value_states)
# attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim) ?
context_states = context_states.permute(0, 2, 1, 3).contiguous().view(batch_size, seq_length, -1)
if self.inner_attn_ln is not None:
context_states = self.inner_attn_ln(context_states)
attn_output = self.out_proj(context_states)
return attn_output, attn_weights, past_key_value
class Kosmos2TextFFN(nn.Module):
def __init__(self, config: Kosmos2TextConfig):
super().__init__()
self.dropout = config.dropout
self.activation_fn = ACT2FN[config.activation_function]
self.activation_dropout = config.activation_dropout
self.fc1 = nn.Linear(config.embed_dim, config.ffn_dim)
self.fc2 = nn.Linear(config.ffn_dim, config.embed_dim)
self.ffn_layernorm = nn.LayerNorm(config.ffn_dim, eps=config.layer_norm_eps)
def forward(self, hidden_states):
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
hidden_states = self.ffn_layernorm(hidden_states)
hidden_states = self.fc2(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
return hidden_states
class Kosmos2TextBlock(nn.Module):
def __init__(self, config: Kosmos2TextConfig):
super().__init__()
self.embed_dim = config.embed_dim
self.self_attn = KosmosTextAttention(
config,
embed_dim=self.embed_dim,
num_heads=config.attention_heads,
dropout=config.attention_dropout,
is_decoder=True,
add_inner_attn_layernorm=True,
)
self.dropout = config.dropout
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
if config.add_cross_attention:
self.encoder_attn = KosmosTextAttention(
config,
embed_dim=self.embed_dim,
num_heads=config.attention_heads,
dropout=config.attention_dropout,
is_decoder=True,
add_inner_attn_layernorm=False,
)
self.encoder_attn_layer_norm = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
self.ffn = Kosmos2TextFFN(config)
self.final_layer_norm = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
layer_head_mask: Optional[torch.Tensor] = None,
cross_attn_layer_head_mask: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: Optional[bool] = False,
use_cache: Optional[bool] = True,
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
residual = hidden_states
# Self Attention
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
hidden_states = self.self_attn_layer_norm(hidden_states)
# add present self-attn cache to positions 1,2 of present_key_value tuple
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
past_key_value=self_attn_past_key_value,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
output_attentions=output_attentions,
)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
# Cross-Attention Block
cross_attn_present_key_value = None
cross_attn_weights = None
if encoder_hidden_states is not None:
if not hasattr(self, "encoder_attn"):
raise ValueError(
f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers"
" by setting `config.add_cross_attention=True`"
)
residual = hidden_states
hidden_states = self.encoder_attn_layer_norm(hidden_states)
# cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
hidden_states=hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
layer_head_mask=cross_attn_layer_head_mask,
past_key_value=cross_attn_past_key_value,
output_attentions=output_attentions,
)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
# add cross-attn to positions 3,4 of present_key_value tuple
present_key_value = present_key_value + cross_attn_present_key_value
# Fully Connected
residual = hidden_states
hidden_states = self.final_layer_norm(hidden_states)
# FFN
hidden_states = self.ffn(hidden_states)
hidden_states = residual + hidden_states
outputs = (hidden_states,)
if output_attentions:
outputs += (self_attn_weights, cross_attn_weights)
if use_cache:
outputs += (present_key_value,)
return outputs
class Kosmos2TextTransformer(nn.Module):
"""
Transformer decoder consisting of `config.layers` layers. Each layer is a [`Kosmos2TextBlock`].
Args:
config: Kosmos2TextConfig
"""
def __init__(self, config: Kosmos2TextConfig):
super().__init__()
self.config = config
self.dropout = config.dropout
self.layerdrop = config.layerdrop
self.embed_scale = math.sqrt(config.embed_dim) if config.scale_embedding else 1.0
self.embed_tokens = nn.Embedding(config.vocab_size, config.embed_dim, padding_idx=config.pad_token_id)
self.embed_positions = Kosmos2TextSinusoidalPositionalEmbedding(
num_positions=config.max_position_embeddings,
embedding_dim=config.embed_dim,
padding_idx=config.pad_token_id,
)
self.layers = nn.ModuleList([Kosmos2TextBlock(config) for _ in range(config.layers)])
self.layer_norm = nn.LayerNorm(config.embed_dim, config.layer_norm_eps)
self.gradient_checkpointing = False
def _prepare_decoder_attention_mask(self, attention_mask, input_shape, inputs_embeds, past_key_values_length):
# create causal mask
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
combined_attention_mask = None
if input_shape[-1] > 1:
combined_attention_mask = _make_causal_mask(
input_shape,
inputs_embeds.dtype,
device=inputs_embeds.device,
past_key_values_length=past_key_values_length,
)
if attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
expanded_attn_mask = _expand_mask(attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]).to(
inputs_embeds.device
)
combined_attention_mask = (
expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask + combined_attention_mask
)
return combined_attention_mask
def forward_embedding(
self,
input_ids,
inputs_embeds: torch.Tensor = None,
image_embeds: torch.Tensor = None,
img_input_mask: torch.Tensor = None,
past_key_values_length: int = 0,
position_ids: torch.Tensor = None,
):
# The argument `inputs_embeds` should be the one without being multiplied by `self.embed_scale`.
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids)
if image_embeds is not None:
inputs_embeds[img_input_mask.to(dtype=torch.bool)] = image_embeds.to(inputs_embeds.device).view(
-1, image_embeds.size(-1)
)
inputs_embeds = inputs_embeds * self.embed_scale
# embed positions
positions = self.embed_positions(
input_ids=input_ids,
inputs_embeds=inputs_embeds,
past_key_values_length=past_key_values_length,
position_ids=position_ids,
)
positions = positions.to(inputs_embeds.device)
hidden_states = inputs_embeds + positions
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
return hidden_states
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
image_embeds: Optional[torch.Tensor] = None,
image_embeds_position_mask: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
cross_attn_head_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPastAndCrossAttentions]:
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.shape
input_ids = input_ids.view(-1, input_shape[-1])
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
# past_key_values_length
past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
# We don't need img info. when `past_key_values_length` > 0
if past_key_values_length > 0:
image_embeds = None
image_embeds_position_mask = None
hidden_states = self.forward_embedding(
input_ids=input_ids,
inputs_embeds=inputs_embeds,
image_embeds=image_embeds,
img_input_mask=image_embeds_position_mask,
past_key_values_length=past_key_values_length,
position_ids=position_ids,
)
attention_mask = self._prepare_decoder_attention_mask(
attention_mask, input_shape, hidden_states, past_key_values_length
)
# expand encoder attention mask
if encoder_hidden_states is not None and encoder_attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
encoder_attention_mask = _expand_mask(encoder_attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1])
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning_once(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
# decoder layers
all_hidden_states = () if output_hidden_states else None
all_self_attns = () if output_attentions else None
all_cross_attentions = () if (output_attentions and encoder_hidden_states is not None) else None
present_key_value_states = () if use_cache else None
# check if head_mask/cross_attn_head_mask has a correct number of layers specified if desired
for attn_mask, mask_name in zip([head_mask, cross_attn_head_mask], ["head_mask", "cross_attn_head_mask"]):
if attn_mask is not None:
if attn_mask.size()[0] != (len(self.layers)):
raise ValueError(
f"The `{mask_name}` should be specified for {len(self.layers)} layers, but it is for"
f" {head_mask.size()[0]}."
)
for idx, decoder_layer in enumerate(self.layers):
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
dropout_probability = torch.rand([])
if dropout_probability < self.layerdrop:
continue
past_key_value = past_key_values[idx] if past_key_values is not None else None
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
decoder_layer.__call__,
hidden_states,
attention_mask,
encoder_hidden_states,
encoder_attention_mask,
head_mask[idx] if head_mask is not None else None,
cross_attn_head_mask[idx] if cross_attn_head_mask is not None else None,
None,
output_attentions,
use_cache,
)
else:
layer_outputs = decoder_layer(
hidden_states,
attention_mask=attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
layer_head_mask=(head_mask[idx] if head_mask is not None else None),
cross_attn_layer_head_mask=(
cross_attn_head_mask[idx] if cross_attn_head_mask is not None else None
),
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
)
hidden_states = layer_outputs[0]
if use_cache:
present_key_value_states += (layer_outputs[3 if output_attentions else 1],)
if output_attentions:
all_self_attns += (layer_outputs[1],)
if encoder_hidden_states is not None:
all_cross_attentions += (layer_outputs[2],)
# add final layer norm
hidden_states = self.layer_norm(hidden_states)
# add hidden states from the last decoder layer
if output_hidden_states:
all_hidden_states += (hidden_states,)
if not return_dict:
return tuple(
v
for v in [
hidden_states,
present_key_value_states,
all_hidden_states,
all_self_attns,
all_cross_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=present_key_value_states,
hidden_states=all_hidden_states,
attentions=all_self_attns,
cross_attentions=all_cross_attentions,
)
class Kosmos2PreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = Kosmos2Config
supports_gradient_checkpointing = True
_no_split_modules = ["Kosmos2VisionEncoderLayer", "Kosmos2TextBlock"]
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(self, Kosmos2VisionModel):
factor = self.config.initializer_factor
elif isinstance(self, (Kosmos2Model, Kosmos2ForConditionalGeneration)):
factor = self.config.vision_config.initializer_factor
if isinstance(self, (Kosmos2TextModel, Kosmos2TextForCausalLM)):
std = self.config.init_std
elif isinstance(self, (Kosmos2Model, Kosmos2ForConditionalGeneration)):
std = self.config.text_config.init_std
if isinstance(module, Kosmos2VisionEmbeddings):
nn.init.normal_(module.class_embedding, mean=0.0, std=module.embed_dim**-0.5 * factor)
nn.init.normal_(module.patch_embedding.weight, std=module.config.initializer_range * factor)
nn.init.normal_(module.position_embedding.weight, std=module.config.initializer_range * factor)
elif isinstance(module, Kosmos2VisionAttention):
in_proj_std = (module.embed_dim**-0.5) * ((2 * module.config.num_hidden_layers) ** -0.5) * factor
out_proj_std = (module.embed_dim**-0.5) * factor
nn.init.normal_(module.q_proj.weight, std=in_proj_std)
nn.init.normal_(module.k_proj.weight, std=in_proj_std)
nn.init.normal_(module.v_proj.weight, std=in_proj_std)
nn.init.normal_(module.out_proj.weight, std=out_proj_std)
if module.q_proj.bias is not None:
module.q_proj.bias.data.zero_()
if module.k_proj.bias is not None:
module.k_proj.bias.data.zero_()
if module.v_proj.bias is not None:
module.v_proj.bias.data.zero_()
if module.out_proj.bias is not None:
module.out_proj.bias.data.zero_()
elif isinstance(module, Kosmos2VisionMLP):
in_proj_std = (module.config.hidden_size**-0.5) * ((2 * module.config.num_hidden_layers) ** -0.5) * factor
fc_std = (2 * module.config.hidden_size) ** -0.5 * factor
nn.init.normal_(module.fc1.weight, std=fc_std)
nn.init.normal_(module.fc2.weight, std=in_proj_std)
if module.fc1.bias is not None:
module.fc1.bias.data.zero_()
if module.fc2.bias is not None:
module.fc2.bias.data.zero_()
elif isinstance(module, Kosmos2VisionEncoderLayer):
module.layer_norm1.bias.data.zero_()
module.layer_norm1.weight.data.fill_(1.0)
module.layer_norm2.bias.data.zero_()
module.layer_norm2.weight.data.fill_(1.0)
elif isinstance(module, Kosmos2VisionTransformer):
module.pre_layrnorm.bias.data.zero_()
module.pre_layrnorm.weight.data.fill_(1.0)
module.post_layernorm.bias.data.zero_()
module.post_layernorm.weight.data.fill_(1.0)
elif isinstance(module, KosmosTextAttention):
nn.init.normal_(module.q_proj.weight, std=std)
nn.init.normal_(module.k_proj.weight, std=std)
nn.init.normal_(module.v_proj.weight, std=std)
nn.init.normal_(module.out_proj.weight, std=std)
if module.q_proj.bias is not None:
module.q_proj.bias.data.zero_()
if module.k_proj.bias is not None:
module.k_proj.bias.data.zero_()
if module.v_proj.bias is not None:
module.v_proj.bias.data.zero_()
if module.out_proj.bias is not None:
module.out_proj.bias.data.zero_()
elif isinstance(module, Kosmos2TextFFN):
nn.init.normal_(module.fc1.weight, std=std)
nn.init.normal_(module.fc2.weight, std=std)
if module.fc1.bias is not None:
module.fc1.bias.data.zero_()
if module.fc2.bias is not None:
module.fc2.bias.data.zero_()
elif isinstance(module, Kosmos2TextForCausalLM):
nn.init.normal_(module.lm_head.weight, std=std)
if module.lm_head.bias is not None:
module.lm_head.bias.data.zero_()
elif isinstance(module, Kosmos2ImageToTextProjection):
nn.init.normal_(module.dense.weight, std=std)
if module.dense.bias is not None:
module.dense.bias.data.zero_()
elif isinstance(module, Kosmos2TextTransformer):
module.embed_tokens.weight.data.normal_(mean=0.0, std=std)
if module.embed_tokens.padding_idx is not None:
module.embed_tokens.weight.data[module.embed_tokens.padding_idx].zero_()
class Kosmos2VisionModel(Kosmos2PreTrainedModel):
config_class = Kosmos2VisionConfig
main_input_name = "pixel_values"
# Copied from transformers.models.clip.modeling_clip.CLIPVisionModel.__init__ with CLIP_VISION->KOSMOS2_VISION,CLIP->Kosmos2,self.vision_model->self.model
def __init__(self, config: Kosmos2VisionConfig):
super().__init__(config)
self.model = Kosmos2VisionTransformer(config)
# Initialize weights and apply final processing
self.post_init()
# Copied from transformers.models.clip.modeling_clip.CLIPVisionModel.get_input_embeddings with CLIP_VISION->KOSMOS2_VISION,CLIP->Kosmos2,self.vision_model->self.model
def get_input_embeddings(self) -> nn.Module:
return self.model.embeddings.patch_embedding
@add_start_docstrings_to_model_forward(KOSMOS2_VISION_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=Kosmos2VisionConfig)
def forward(
self,
pixel_values: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
interpolate_pos_encoding: bool = False,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPooling]:
r"""
Returns:
"""
return self.model(
pixel_values=pixel_values,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
interpolate_pos_encoding=interpolate_pos_encoding,
return_dict=return_dict,
)
class Kosmos2TextModel(Kosmos2PreTrainedModel):
config_class = Kosmos2TextConfig
def __init__(self, config: Kosmos2TextConfig):
super().__init__(config)
self.model = Kosmos2TextTransformer(config)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self) -> nn.Module:
return self.model.embed_tokens
def set_input_embeddings(self, value):
self.model.embed_tokens = value
@add_start_docstrings_to_model_forward(KOSMOS2_TEXT_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=BaseModelOutputWithPastAndCrossAttentions, config_class=Kosmos2TextConfig)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
image_embeds: Optional[torch.Tensor] = None,
image_embeds_position_mask: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
cross_attn_head_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPastAndCrossAttentions]:
r"""
Returns:
"""
return self.model(
input_ids=input_ids,
attention_mask=attention_mask,
image_embeds=image_embeds,
image_embeds_position_mask=image_embeds_position_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
head_mask=head_mask,
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
position_ids=position_ids,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
@add_start_docstrings(
"""
The text model from KOSMOS-2 with a language modeling head on top (linear layer with weights tied to the input
embeddings).
""",
KOSMOS2_START_DOCSTRING,
)
class Kosmos2TextForCausalLM(Kosmos2PreTrainedModel, GenerationMixin):
config_class = Kosmos2TextConfig
_tied_weights_keys = ["lm_head.weight"]
def __init__(self, config: Kosmos2TextConfig):
super().__init__(config)
self.model = Kosmos2TextTransformer(config)
self.lm_head = nn.Linear(in_features=config.embed_dim, out_features=config.vocab_size, bias=False)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self) -> nn.Module:
return self.model.embed_tokens
def set_input_embeddings(self, value):
self.model.embed_tokens = value
def get_output_embeddings(self) -> nn.Module:
return self.lm_head
def set_output_embeddings(self, new_embeddings):
self.lm_head = new_embeddings
@add_start_docstrings_to_model_forward(KOSMOS2_TEXT_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=CausalLMOutputWithCrossAttentions, config_class=Kosmos2TextConfig)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
image_embeds: Optional[torch.Tensor] = None,
image_embeds_position_mask: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
cross_attn_head_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, CausalLMOutputWithCrossAttentions]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the left-to-right language modeling loss (next word prediction). Indices should be in
`[-100, 0, ..., config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are
ignored (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
Returns:
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
if use_cache:
logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
use_cache = False
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
image_embeds=image_embeds,
image_embeds_position_mask=image_embeds_position_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
head_mask=head_mask,
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
position_ids=position_ids,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
lm_logits = self.lm_head(outputs[0])
loss = None
if labels is not None:
# move labels to correct device to enable model parallelism
labels = labels.to(lm_logits.device)
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
batch_size, seq_length, vocab_size = shift_logits.shape
# Flatten the tokens
loss_fct = CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(batch_size * seq_length, vocab_size), shift_labels.view(batch_size * seq_length)
)
if not return_dict:
output = (lm_logits,) + outputs[1:]
return (loss,) + output if loss is not None else output
return CausalLMOutputWithCrossAttentions(
loss=loss,
logits=lm_logits,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
def prepare_inputs_for_generation(
self,
input_ids,
image_embeds=None,
image_embeds_position_mask=None,
past_key_values=None,
attention_mask=None,
use_cache=None,
**model_kwargs,
):
# Overwritten -- in specific circumstances we don't want to forward image inputs to the model
input_shape = input_ids.shape
# if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
if attention_mask is None:
attention_mask = input_ids.new_ones(input_shape)
position_ids = None
# cut input_ids if past_key_values is used
if past_key_values is not None:
position_ids = create_position_ids_from_input_ids(
input_ids,
padding_idx=self.config.pad_token_id,
past_key_values_length=0,
)[:, -1:]
input_ids = input_ids[:, -1:]
# the image info. is already encoded into the past keys/values
image_embeds = None
image_embeds_position_mask = None
elif image_embeds_position_mask is not None:
# appending `False` to `image_embeds_position_mask` (because `input_ids` grows during generation)
batch_size, seq_len = input_ids.size()
mask_len = image_embeds_position_mask.size()[-1]
image_embeds_position_mask = torch.cat(
(
image_embeds_position_mask,
torch.zeros(size=(batch_size, seq_len - mask_len), dtype=torch.bool, device=input_ids.device),
),
dim=1,
)
return {
"input_ids": input_ids,
"image_embeds": image_embeds,
"image_embeds_position_mask": image_embeds_position_mask,
"past_key_values": past_key_values,
"attention_mask": attention_mask,
"position_ids": position_ids,
"use_cache": use_cache,
}
@staticmethod
# Copied from transformers.models.umt5.modeling_umt5.UMT5ForConditionalGeneration._reorder_cache
def _reorder_cache(past_key_values, beam_idx):
reordered_past = ()
for layer_past in past_key_values:
reordered_past += (
tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),
)
return reordered_past
class Kosmos2ImageToTextProjection(nn.Module):
"""The layer that transforms the image model's output to part of the text model's input (namely, image features)"""
def __init__(self, config: Kosmos2Config):
super().__init__()
self.dense = nn.Linear(config.vision_config.hidden_size, config.text_config.embed_dim)
self.latent_query = nn.Parameter(torch.randn(config.latent_query_num, config.text_config.embed_dim))
self.x_attn = KosmosTextAttention(
config.text_config,
config.text_config.embed_dim,
config.text_config.attention_heads,
dropout=config.text_config.attention_dropout,
is_decoder=False,
add_inner_attn_layernorm=False,
)
def forward(self, features):
hidden_states = self.dense(features)
# shape = [batch, latent_query_num, h_dim]
latent_query = self.latent_query.unsqueeze(0).expand(hidden_states.size(0), -1, -1)
key_value_states = torch.cat([hidden_states, latent_query], dim=1)
hidden_states, attn_weights, _ = self.x_attn(
hidden_states=latent_query,
encoder_hidden_states=key_value_states,
past_key_value=None,
attention_mask=None,
output_attentions=None,
)
return hidden_states, attn_weights
@add_start_docstrings(
"""
KOSMOS-2 Model for generating text and image features. The model consists of a vision encoder and a language model.
""",
KOSMOS2_START_DOCSTRING,
)
class Kosmos2Model(Kosmos2PreTrainedModel):
config_class = Kosmos2Config
main_input_name = "pixel_values"
def __init__(self, config: Kosmos2Config):
super().__init__(config)
self.text_model = Kosmos2TextModel(config.text_config)
self.vision_model = Kosmos2VisionModel(config.vision_config)
self.image_to_text_projection = Kosmos2ImageToTextProjection(config)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self) -> nn.Module:
return self.text_model.model.embed_tokens
def set_input_embeddings(self, value):
self.text_model.model.embed_tokens = value
@add_start_docstrings_to_model_forward(KOSMOS2_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=Kosmos2ModelOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
pixel_values: Optional[torch.Tensor] = None,
input_ids: Optional[torch.Tensor] = None,
image_embeds_position_mask: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
image_embeds: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
interpolate_pos_encoding: bool = False,
return_dict: Optional[bool] = None,
) -> Union[Tuple, Kosmos2ModelOutput]:
r"""
Returns:
Examples:
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, Kosmos2Model
>>> model = Kosmos2Model.from_pretrained("microsoft/kosmos-2-patch14-224")
>>> processor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")
>>> url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> text = (
... "<grounding> An image of<phrase> a snowman</phrase><object><patch_index_0044><patch_index_0863>"
... "</object> warming himself by<phrase> a fire</phrase><object><patch_index_0005><patch_index_0911>"
... "</object>"
... )
>>> inputs = processor(text=text, images=image, return_tensors="pt", add_eos_token=True)
>>> last_hidden_state = model(
... pixel_values=inputs["pixel_values"],
... input_ids=inputs["input_ids"],
... attention_mask=inputs["attention_mask"],
... image_embeds_position_mask=inputs["image_embeds_position_mask"],
... ).last_hidden_state
>>> list(last_hidden_state.shape)
[1, 91, 2048]
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
vision_model_output = None
projection_attentions = None
if image_embeds is None:
if pixel_values is None:
raise ValueError("You have to specify either `pixel_values` or `image_embeds`.")
vision_model_output = self.vision_model(
pixel_values=pixel_values,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
interpolate_pos_encoding=interpolate_pos_encoding,
return_dict=return_dict,
)
# The whole `last_hidden_state` through `post_layernorm` instead of just `pooled_output`.
image_embeds = self.vision_model.model.post_layernorm(vision_model_output[0])
# normalized features
image_embeds = nn.functional.normalize(image_embeds, dim=-1)
image_embeds, projection_attentions = self.image_to_text_projection(image_embeds)
outputs = self.text_model(
input_ids=input_ids,
attention_mask=attention_mask,
image_embeds=image_embeds,
image_embeds_position_mask=image_embeds_position_mask,
head_mask=head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
position_ids=position_ids,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
if not return_dict:
outputs = outputs + (image_embeds, projection_attentions, vision_model_output)
return tuple(output for output in outputs if output is not None)
return Kosmos2ModelOutput(
last_hidden_state=outputs.last_hidden_state,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
image_embeds=image_embeds,
projection_attentions=projection_attentions,
vision_model_output=vision_model_output,
)
@add_start_docstrings(
"""
KOSMOS-2 Model for generating text and bounding boxes given an image. The model consists of a vision encoder and a
language model.
""",
KOSMOS2_START_DOCSTRING,
)
class Kosmos2ForConditionalGeneration(Kosmos2PreTrainedModel, GenerationMixin):
config_class = Kosmos2Config
main_input_name = "pixel_values"
_tied_weights_keys = ["text_model.lm_head.weight"]
def __init__(self, config: Kosmos2Config):
super().__init__(config)
self.text_model = Kosmos2TextForCausalLM(config.text_config)
self.vision_model = Kosmos2VisionModel(config.vision_config)
self.image_to_text_projection = Kosmos2ImageToTextProjection(config)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self) -> nn.Module:
return self.text_model.model.embed_tokens
def set_input_embeddings(self, value):
self.text_model.model.embed_tokens = value
def get_output_embeddings(self) -> nn.Module:
return self.text_model.get_output_embeddings()
def set_output_embeddings(self, new_embeddings):
self.text_model.set_output_embeddings(new_embeddings)
@add_start_docstrings_to_model_forward(KOSMOS2_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=Kosmos2ForConditionalGenerationModelOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
pixel_values: Optional[torch.Tensor] = None,
input_ids: Optional[torch.Tensor] = None,
image_embeds_position_mask: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
image_embeds: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, Kosmos2ForConditionalGenerationModelOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the left-to-right language modeling loss (next word prediction). Indices should be in
`[-100, 0, ..., config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are
ignored (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
Returns:
Examples:
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, Kosmos2ForConditionalGeneration
>>> model = Kosmos2ForConditionalGeneration.from_pretrained("microsoft/kosmos-2-patch14-224")
>>> processor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")
>>> url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> prompt = "<grounding> An image of"
>>> inputs = processor(text=prompt, images=image, return_tensors="pt")
>>> generated_ids = model.generate(
... pixel_values=inputs["pixel_values"],
... input_ids=inputs["input_ids"],
... attention_mask=inputs["attention_mask"],
... image_embeds=None,
... image_embeds_position_mask=inputs["image_embeds_position_mask"],
... use_cache=True,
... max_new_tokens=64,
... )
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
>>> processed_text = processor.post_process_generation(generated_text, cleanup_and_extract=False)
>>> processed_text
'<grounding> An image of<phrase> a snowman</phrase><object><patch_index_0044><patch_index_0863></object> warming himself by<phrase> a fire</phrase><object><patch_index_0005><patch_index_0911></object>.'
>>> caption, entities = processor.post_process_generation(generated_text)
>>> caption
'An image of a snowman warming himself by a fire.'
>>> entities
[('a snowman', (12, 21), [(0.390625, 0.046875, 0.984375, 0.828125)]), ('a fire', (41, 47), [(0.171875, 0.015625, 0.484375, 0.890625)])]
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
vision_model_output = None
projection_attentions = None
if image_embeds is None:
if pixel_values is None:
raise ValueError("You have to specify either `pixel_values` or `image_embeds`.")
vision_model_output = self.vision_model(
pixel_values=pixel_values,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
# The whole `last_hidden_state` through `post_layernorm` instead of just `pooled_output`.
image_embeds = self.vision_model.model.post_layernorm(vision_model_output[0])
# normalized features
image_embeds = nn.functional.normalize(image_embeds, dim=-1)
image_embeds, projection_attentions = self.image_to_text_projection(image_embeds)
lm_outputs = self.text_model(
input_ids=input_ids,
attention_mask=attention_mask,
image_embeds=image_embeds,
image_embeds_position_mask=image_embeds_position_mask,
head_mask=head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
position_ids=position_ids,
labels=labels,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
if not return_dict:
outputs = lm_outputs + (image_embeds, projection_attentions, vision_model_output)
return tuple(output for output in outputs if output is not None)
return Kosmos2ForConditionalGenerationModelOutput(
loss=lm_outputs.loss,
logits=lm_outputs.logits,
past_key_values=lm_outputs.past_key_values,
hidden_states=lm_outputs.hidden_states,
attentions=lm_outputs.attentions,
image_embeds=image_embeds,
projection_attentions=projection_attentions,
vision_model_output=vision_model_output,
)
def generate(
self,
pixel_values: Optional[torch.Tensor] = None,
image_embeds_position_mask: Optional[torch.Tensor] = None,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
image_embeds: Optional[torch.Tensor] = None,
**kwargs,
):
# in order to allow `inputs` argument (as in `GenerationMixin`)
inputs = kwargs.pop("inputs", None)
if pixel_values is not None and inputs is not None:
raise ValueError(
f"`inputs`: {inputs} were passed alongside `pixel_values` which is not allowed."
f"Make sure to either pass `inputs` or pixel_values=..."
)
if pixel_values is None and inputs is not None:
pixel_values = inputs
if image_embeds is None:
vision_model_output = self.vision_model(pixel_values)
# The whole `last_hidden_state` through `post_layernorm` instead of just `pooled_output`.
image_embeds = self.vision_model.model.post_layernorm(vision_model_output[0])
# normalized features
image_embeds = nn.functional.normalize(image_embeds, dim=-1)
image_embeds, projection_attentions = self.image_to_text_projection(image_embeds)
output = self.text_model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
image_embeds=image_embeds,
image_embeds_position_mask=image_embeds_position_mask,
**kwargs,
)
return output
__all__ = ["Kosmos2ForConditionalGeneration", "Kosmos2Model", "Kosmos2PreTrainedModel"]
| transformers/src/transformers/models/kosmos2/modeling_kosmos2.py/0 | {
"file_path": "transformers/src/transformers/models/kosmos2/modeling_kosmos2.py",
"repo_id": "transformers",
"token_count": 42525
} |
# coding=utf-8
# Copyright 2021 Iz Beltagy, Matthew E. Peters, Arman Cohan and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""TF 2.0 LED model."""
from __future__ import annotations
import random
from dataclasses import dataclass
from typing import List, Optional, Tuple, Union
import numpy as np
import tensorflow as tf
from ...activations_tf import get_tf_activation
from ...modeling_tf_outputs import TFBaseModelOutputWithPastAndCrossAttentions
# Public API
from ...modeling_tf_utils import (
TFModelInputType,
TFPreTrainedModel,
get_initializer,
keras,
keras_serializable,
unpack_inputs,
)
from ...tf_utils import check_embeddings_within_bounds, shape_list, stable_softmax
from ...utils import (
ModelOutput,
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
logging,
replace_return_docstrings,
)
from .configuration_led import LEDConfig
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "allenai/led-base-16384"
_CONFIG_FOR_DOC = "LEDConfig"
LARGE_NEGATIVE = -1e8
# Copied from transformers.models.bart.modeling_tf_bart.shift_tokens_right
def shift_tokens_right(input_ids: tf.Tensor, pad_token_id: int, decoder_start_token_id: int):
pad_token_id = tf.cast(pad_token_id, input_ids.dtype)
decoder_start_token_id = tf.cast(decoder_start_token_id, input_ids.dtype)
start_tokens = tf.fill(
(shape_list(input_ids)[0], 1), tf.convert_to_tensor(decoder_start_token_id, input_ids.dtype)
)
shifted_input_ids = tf.concat([start_tokens, input_ids[:, :-1]], -1)
# replace possible -100 values in labels by `pad_token_id`
shifted_input_ids = tf.where(
shifted_input_ids == -100,
tf.fill(shape_list(shifted_input_ids), tf.convert_to_tensor(pad_token_id, input_ids.dtype)),
shifted_input_ids,
)
# "Verify that `labels` has only positive values and -100"
assert_gte0 = tf.debugging.assert_greater_equal(shifted_input_ids, tf.constant(0, dtype=input_ids.dtype))
# Make sure the assertion op is called by wrapping the result in an identity no-op
with tf.control_dependencies([assert_gte0]):
shifted_input_ids = tf.identity(shifted_input_ids)
return shifted_input_ids
# Copied from transformers.models.bart.modeling_tf_bart._make_causal_mask
def _make_causal_mask(input_ids_shape: tf.TensorShape, past_key_values_length: int = 0):
"""
Make causal mask used for bi-directional self-attention.
"""
bsz = input_ids_shape[0]
tgt_len = input_ids_shape[1]
mask = tf.ones((tgt_len, tgt_len)) * LARGE_NEGATIVE
mask_cond = tf.range(shape_list(mask)[-1])
mask = tf.where(mask_cond < tf.reshape(mask_cond + 1, (shape_list(mask)[-1], 1)), 0.0, mask)
if past_key_values_length > 0:
mask = tf.concat([tf.zeros((tgt_len, past_key_values_length)), mask], axis=-1)
return tf.tile(mask[None, None, :, :], (bsz, 1, 1, 1))
# Copied from transformers.models.bart.modeling_tf_bart._expand_mask
def _expand_mask(mask: tf.Tensor, tgt_len: Optional[int] = None):
"""
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
"""
src_len = shape_list(mask)[1]
tgt_len = tgt_len if tgt_len is not None else src_len
one_cst = tf.constant(1.0)
mask = tf.cast(mask, dtype=one_cst.dtype)
expanded_mask = tf.tile(mask[:, None, None, :], (1, 1, tgt_len, 1))
return (one_cst - expanded_mask) * LARGE_NEGATIVE
class TFLEDLearnedPositionalEmbedding(keras.layers.Embedding):
"""
This module learns positional embeddings up to a fixed maximum size.
"""
def __init__(self, num_embeddings: int, embedding_dim: int, **kwargs):
super().__init__(num_embeddings, embedding_dim, **kwargs)
def call(self, input_shape: tf.TensorShape, past_key_values_length: int = 0):
"""Input is expected to be of size [bsz x seqlen]."""
seq_len = input_shape[1]
position_ids = tf.range(seq_len, delta=1, name="range")
position_ids += past_key_values_length
return super().call(tf.cast(position_ids, dtype=tf.int32))
# Copied from transformers.models.longformer.modeling_tf_longformer.TFLongformerSelfAttention with TFLongformer->TFLEDEncoder
class TFLEDEncoderSelfAttention(keras.layers.Layer):
def __init__(self, config, layer_id, **kwargs):
super().__init__(**kwargs)
self.config = config
if config.hidden_size % config.num_attention_heads != 0:
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
f"heads ({config.num_attention_heads}"
)
self.num_heads = config.num_attention_heads
self.head_dim = int(config.hidden_size / config.num_attention_heads)
self.embed_dim = config.hidden_size
self.query = keras.layers.Dense(
self.embed_dim,
kernel_initializer=get_initializer(config.initializer_range),
name="query",
)
self.key = keras.layers.Dense(
self.embed_dim,
kernel_initializer=get_initializer(config.initializer_range),
name="key",
)
self.value = keras.layers.Dense(
self.embed_dim,
kernel_initializer=get_initializer(config.initializer_range),
name="value",
)
# separate projection layers for tokens with global attention
self.query_global = keras.layers.Dense(
self.embed_dim,
kernel_initializer=get_initializer(config.initializer_range),
name="query_global",
)
self.key_global = keras.layers.Dense(
self.embed_dim,
kernel_initializer=get_initializer(config.initializer_range),
name="key_global",
)
self.value_global = keras.layers.Dense(
self.embed_dim,
kernel_initializer=get_initializer(config.initializer_range),
name="value_global",
)
self.dropout = keras.layers.Dropout(config.attention_probs_dropout_prob)
self.global_dropout = keras.layers.Dropout(config.attention_probs_dropout_prob)
self.layer_id = layer_id
attention_window = config.attention_window[self.layer_id]
assert (
attention_window % 2 == 0
), f"`attention_window` for layer {self.layer_id} has to be an even value. Given {attention_window}"
assert (
attention_window > 0
), f"`attention_window` for layer {self.layer_id} has to be positive. Given {attention_window}"
self.one_sided_attn_window_size = attention_window // 2
def build(self, input_shape=None):
if not self.built:
with tf.name_scope("query_global"):
self.query_global.build((self.config.hidden_size,))
with tf.name_scope("key_global"):
self.key_global.build((self.config.hidden_size,))
with tf.name_scope("value_global"):
self.value_global.build((self.config.hidden_size,))
if self.built:
return
self.built = True
if getattr(self, "query", None) is not None:
with tf.name_scope(self.query.name):
self.query.build([None, None, self.config.hidden_size])
if getattr(self, "key", None) is not None:
with tf.name_scope(self.key.name):
self.key.build([None, None, self.config.hidden_size])
if getattr(self, "value", None) is not None:
with tf.name_scope(self.value.name):
self.value.build([None, None, self.config.hidden_size])
if getattr(self, "query_global", None) is not None:
with tf.name_scope(self.query_global.name):
self.query_global.build([None, None, self.config.hidden_size])
if getattr(self, "key_global", None) is not None:
with tf.name_scope(self.key_global.name):
self.key_global.build([None, None, self.config.hidden_size])
if getattr(self, "value_global", None) is not None:
with tf.name_scope(self.value_global.name):
self.value_global.build([None, None, self.config.hidden_size])
def call(
self,
inputs,
training=False,
):
"""
LongformerSelfAttention expects *len(hidden_states)* to be multiple of *attention_window*. Padding to
*attention_window* happens in LongformerModel.forward to avoid redoing the padding on each layer.
The *attention_mask* is changed in [`LongformerModel.forward`] from 0, 1, 2 to:
- -10000: no attention
- 0: local attention
- +10000: global attention
"""
# retrieve input args
(
hidden_states,
attention_mask,
layer_head_mask,
is_index_masked,
is_index_global_attn,
is_global_attn,
) = inputs
# project hidden states
query_vectors = self.query(hidden_states)
key_vectors = self.key(hidden_states)
value_vectors = self.value(hidden_states)
batch_size, seq_len, embed_dim = shape_list(hidden_states)
tf.debugging.assert_equal(
embed_dim,
self.embed_dim,
message=f"hidden_states should have embed_dim = {self.embed_dim}, but has {embed_dim}",
)
# normalize query
query_vectors /= tf.math.sqrt(tf.cast(self.head_dim, dtype=query_vectors.dtype))
query_vectors = tf.reshape(query_vectors, (batch_size, seq_len, self.num_heads, self.head_dim))
key_vectors = tf.reshape(key_vectors, (batch_size, seq_len, self.num_heads, self.head_dim))
# attn_probs = (batch_size, seq_len, num_heads, window*2+1)
attn_scores = self._sliding_chunks_query_key_matmul(
query_vectors, key_vectors, self.one_sided_attn_window_size
)
# values to pad for attention probs
remove_from_windowed_attention_mask = attention_mask != 0
# cast to fp32/fp16 then replace 1's with -inf
float_mask = tf.cast(remove_from_windowed_attention_mask, dtype=query_vectors.dtype) * LARGE_NEGATIVE
# diagonal mask with zeros everywhere and -inf inplace of padding
diagonal_mask = self._sliding_chunks_query_key_matmul(
tf.ones(shape_list(attention_mask)),
float_mask,
self.one_sided_attn_window_size,
)
# pad local attention probs
attn_scores += diagonal_mask
tf.debugging.assert_equal(
shape_list(attn_scores),
[batch_size, seq_len, self.num_heads, self.one_sided_attn_window_size * 2 + 1],
message=(
f"attn_probs should be of size ({batch_size}, {seq_len}, {self.num_heads},"
f" {self.one_sided_attn_window_size * 2 + 1}), but is of size {shape_list(attn_scores)}"
),
)
# compute global attn indices required through out forward fn
(
max_num_global_attn_indices,
is_index_global_attn_nonzero,
is_local_index_global_attn_nonzero,
is_local_index_no_global_attn_nonzero,
) = self._get_global_attn_indices(is_index_global_attn)
# this function is only relevant for global attention
if is_global_attn:
attn_scores = self._concat_with_global_key_attn_probs(
attn_scores=attn_scores,
query_vectors=query_vectors,
key_vectors=key_vectors,
max_num_global_attn_indices=max_num_global_attn_indices,
is_index_global_attn_nonzero=is_index_global_attn_nonzero,
is_local_index_global_attn_nonzero=is_local_index_global_attn_nonzero,
is_local_index_no_global_attn_nonzero=is_local_index_no_global_attn_nonzero,
)
attn_probs = stable_softmax(attn_scores, axis=-1)
# softmax sometimes inserts NaN if all positions are masked, replace them with 0
# Make sure to create a mask with the proper shape:
# if is_global_attn==True => [batch_size, seq_len, self.num_heads, self.one_sided_attn_window_size * 2 + max_num_global_attn_indices + 1]
# if is_global_attn==False => [batch_size, seq_len, self.num_heads, self.one_sided_attn_window_size * 2 + 1]
if is_global_attn:
masked_index = tf.tile(
is_index_masked[:, :, None, None],
(1, 1, self.num_heads, self.one_sided_attn_window_size * 2 + max_num_global_attn_indices + 1),
)
else:
masked_index = tf.tile(
is_index_masked[:, :, None, None],
(1, 1, self.num_heads, self.one_sided_attn_window_size * 2 + 1),
)
attn_probs = tf.where(
masked_index,
tf.zeros(shape_list(masked_index), dtype=attn_probs.dtype),
attn_probs,
)
if layer_head_mask is not None:
tf.debugging.assert_equal(
shape_list(layer_head_mask),
[self.num_heads],
message=(
f"Head mask for a single layer should be of size {(self.num_heads)}, but is"
f" {shape_list(layer_head_mask)}"
),
)
attn_probs = tf.reshape(layer_head_mask, (1, 1, -1, 1)) * attn_probs
# apply dropout
attn_probs = self.dropout(attn_probs, training=training)
value_vectors = tf.reshape(value_vectors, (batch_size, seq_len, self.num_heads, self.head_dim))
# if global attention, compute sum of global and local attn
if is_global_attn:
attn_output = self._compute_attn_output_with_global_indices(
value_vectors=value_vectors,
attn_probs=attn_probs,
max_num_global_attn_indices=max_num_global_attn_indices,
is_index_global_attn_nonzero=is_index_global_attn_nonzero,
is_local_index_global_attn_nonzero=is_local_index_global_attn_nonzero,
)
else:
attn_output = self._sliding_chunks_matmul_attn_probs_value(
attn_probs, value_vectors, self.one_sided_attn_window_size
)
tf.debugging.assert_equal(
shape_list(attn_output), [batch_size, seq_len, self.num_heads, self.head_dim], message="Unexpected size"
)
attn_output = tf.reshape(attn_output, (batch_size, seq_len, embed_dim))
# compute value for global attention and overwrite to attention output
if is_global_attn:
attn_output, global_attn_probs = self._compute_global_attn_output_from_hidden(
attn_output=attn_output,
hidden_states=hidden_states,
max_num_global_attn_indices=max_num_global_attn_indices,
layer_head_mask=layer_head_mask,
is_local_index_global_attn_nonzero=is_local_index_global_attn_nonzero,
is_index_global_attn_nonzero=is_index_global_attn_nonzero,
is_local_index_no_global_attn_nonzero=is_local_index_no_global_attn_nonzero,
is_index_masked=is_index_masked,
training=training,
)
else:
# Leave attn_output unchanged
global_attn_probs = tf.zeros((batch_size, self.num_heads, max_num_global_attn_indices, seq_len))
# make sure that local attention probabilities are set to 0 for indices of global attn
# Make sure to create a mask with the proper shape:
# if is_global_attn==True => [batch_size, seq_len, self.num_heads, self.one_sided_attn_window_size * 2 + max_num_global_attn_indices + 1]
# if is_global_attn==False => [batch_size, seq_len, self.num_heads, self.one_sided_attn_window_size * 2 + 1]
if is_global_attn:
masked_global_attn_index = tf.tile(
is_index_global_attn[:, :, None, None],
(1, 1, self.num_heads, self.one_sided_attn_window_size * 2 + max_num_global_attn_indices + 1),
)
else:
masked_global_attn_index = tf.tile(
is_index_global_attn[:, :, None, None],
(1, 1, self.num_heads, self.one_sided_attn_window_size * 2 + 1),
)
attn_probs = tf.where(
masked_global_attn_index,
tf.zeros(shape_list(masked_global_attn_index), dtype=attn_probs.dtype),
attn_probs,
)
outputs = (attn_output, attn_probs, global_attn_probs)
return outputs
def _sliding_chunks_query_key_matmul(self, query, key, window_overlap):
"""
Matrix multiplication of query and key tensors using with a sliding window attention pattern. This
implementation splits the input into overlapping chunks of size 2w (e.g. 512 for pretrained Longformer) with an
overlap of size window_overlap
"""
batch_size, seq_len, num_heads, head_dim = shape_list(query)
tf.debugging.assert_equal(
seq_len % (window_overlap * 2),
0,
message=f"Sequence length should be multiple of {window_overlap * 2}. Given {seq_len}",
)
tf.debugging.assert_equal(
shape_list(query),
shape_list(key),
message=(
f"Shape of query and key should be equal, but got query: {shape_list(query)} and key:"
f" {shape_list(key)}"
),
)
chunks_count = seq_len // window_overlap - 1
# group batch_size and num_heads dimensions into one, then chunk seq_len into chunks of size window_overlap * 2
query = tf.reshape(
tf.transpose(query, (0, 2, 1, 3)),
(batch_size * num_heads, seq_len, head_dim),
)
key = tf.reshape(tf.transpose(key, (0, 2, 1, 3)), (batch_size * num_heads, seq_len, head_dim))
chunked_query = self._chunk(query, window_overlap)
chunked_key = self._chunk(key, window_overlap)
# matrix multiplication
# bcxd: batch_size * num_heads x chunks x 2window_overlap x head_dim
# bcyd: batch_size * num_heads x chunks x 2window_overlap x head_dim
# bcxy: batch_size * num_heads x chunks x 2window_overlap x 2window_overlap
chunked_query = tf.cast(chunked_query, dtype=chunked_key.dtype)
chunked_attention_scores = tf.einsum("bcxd,bcyd->bcxy", chunked_query, chunked_key) # multiply
# convert diagonals into columns
paddings = tf.convert_to_tensor([[0, 0], [0, 0], [0, 1], [0, 0]])
diagonal_chunked_attention_scores = self._pad_and_transpose_last_two_dims(chunked_attention_scores, paddings)
# allocate space for the overall attention matrix where the chunks are combined. The last dimension
# has (window_overlap * 2 + 1) columns. The first (window_overlap) columns are the window_overlap lower triangles (attention from a word to
# window_overlap previous words). The following column is attention score from each word to itself, then
# followed by window_overlap columns for the upper triangle.
# copy parts from diagonal_chunked_attention_scores into the combined matrix of attentions
# - copying the main diagonal and the upper triangle
# TODO: This code is most likely not very efficient and should be improved
diagonal_attn_scores_up_triang = tf.concat(
[
diagonal_chunked_attention_scores[:, :, :window_overlap, : window_overlap + 1],
diagonal_chunked_attention_scores[:, -1:, window_overlap:, : window_overlap + 1],
],
axis=1,
)
# - copying the lower triangle
diagonal_attn_scores_low_triang = tf.concat(
[
tf.zeros(
(batch_size * num_heads, 1, window_overlap, window_overlap),
dtype=diagonal_chunked_attention_scores.dtype,
),
diagonal_chunked_attention_scores[:, :, -(window_overlap + 1) : -1, window_overlap + 1 :],
],
axis=1,
)
diagonal_attn_scores_first_chunk = tf.concat(
[
tf.roll(
diagonal_chunked_attention_scores,
shift=[1, window_overlap],
axis=[2, 3],
)[:, :, :window_overlap, :window_overlap],
tf.zeros(
(batch_size * num_heads, 1, window_overlap, window_overlap),
dtype=diagonal_chunked_attention_scores.dtype,
),
],
axis=1,
)
first_chunk_mask = (
tf.tile(
tf.range(chunks_count + 1, dtype=tf.int64)[None, :, None, None],
(batch_size * num_heads, 1, window_overlap, window_overlap),
)
< 1
)
diagonal_attn_scores_low_triang = tf.where(
first_chunk_mask,
diagonal_attn_scores_first_chunk,
diagonal_attn_scores_low_triang,
)
# merging upper and lower triangle
diagonal_attention_scores = tf.concat(
[diagonal_attn_scores_low_triang, diagonal_attn_scores_up_triang], axis=-1
)
# separate batch_size and num_heads dimensions again
diagonal_attention_scores = tf.transpose(
tf.reshape(
diagonal_attention_scores,
(batch_size, num_heads, seq_len, 2 * window_overlap + 1),
),
(0, 2, 1, 3),
)
diagonal_attention_scores = self._mask_invalid_locations(diagonal_attention_scores, window_overlap)
return diagonal_attention_scores
@staticmethod
def _mask_invalid_locations(input_tensor, window_overlap):
# create correct upper triangle bool mask
mask_2d_upper = tf.reverse(
tf.linalg.band_part(tf.ones(shape=(window_overlap, window_overlap + 1)), -1, 0),
axis=[0],
)
# pad to full matrix
padding = tf.convert_to_tensor(
[[0, shape_list(input_tensor)[1] - window_overlap], [0, shape_list(input_tensor)[3] - window_overlap - 1]]
)
# create lower mask
mask_2d = tf.pad(mask_2d_upper, padding)
# combine with upper mask
mask_2d = mask_2d + tf.reverse(mask_2d, axis=[0, 1])
# broadcast to full matrix
mask_4d = tf.tile(mask_2d[None, :, None, :], (shape_list(input_tensor)[0], 1, 1, 1))
# inf tensor used for masking
inf_tensor = -float("inf") * tf.ones_like(input_tensor)
# mask
input_tensor = tf.where(tf.math.greater(mask_4d, 0), inf_tensor, input_tensor)
return input_tensor
def _sliding_chunks_matmul_attn_probs_value(self, attn_probs, value, window_overlap):
"""
Same as _sliding_chunks_query_key_matmul but for attn_probs and value tensors. Returned tensor will be of the
same shape as `attn_probs`
"""
batch_size, seq_len, num_heads, head_dim = shape_list(value)
tf.debugging.assert_equal(
seq_len % (window_overlap * 2), 0, message="Seq_len has to be multiple of 2 * window_overlap"
)
tf.debugging.assert_equal(
shape_list(attn_probs)[:3],
shape_list(value)[:3],
message="value and attn_probs must have same dims (except head_dim)",
)
tf.debugging.assert_equal(
shape_list(attn_probs)[3],
2 * window_overlap + 1,
message="attn_probs last dim has to be 2 * window_overlap + 1",
)
chunks_count = seq_len // window_overlap - 1
# group batch_size and num_heads dimensions into one, then chunk seq_len into chunks of size 2 window overlap
chunked_attn_probs = tf.reshape(
tf.transpose(attn_probs, (0, 2, 1, 3)),
(
batch_size * num_heads,
seq_len // window_overlap,
window_overlap,
2 * window_overlap + 1,
),
)
# group batch_size and num_heads dimensions into one
value = tf.reshape(
tf.transpose(value, (0, 2, 1, 3)),
(batch_size * num_heads, seq_len, head_dim),
)
# pad seq_len with w at the beginning of the sequence and another window overlap at the end
paddings = tf.convert_to_tensor([[0, 0], [window_overlap, window_overlap], [0, 0]])
padded_value = tf.pad(value, paddings, constant_values=-1)
# chunk padded_value into chunks of size 3 window overlap and an overlap of size window overlap
frame_size = 3 * window_overlap * head_dim
frame_hop_size = (shape_list(padded_value)[1] * head_dim - frame_size) // chunks_count
chunked_value = tf.signal.frame(
tf.reshape(padded_value, (batch_size * num_heads, -1)),
frame_size,
frame_hop_size,
)
chunked_value = tf.reshape(
chunked_value,
(batch_size * num_heads, chunks_count + 1, 3 * window_overlap, head_dim),
)
tf.debugging.assert_equal(
shape_list(chunked_value),
[batch_size * num_heads, chunks_count + 1, 3 * window_overlap, head_dim],
message="Chunked value has the wrong shape",
)
chunked_attn_probs = self._pad_and_diagonalize(chunked_attn_probs)
context = tf.einsum("bcwd,bcdh->bcwh", chunked_attn_probs, chunked_value)
context = tf.transpose(
tf.reshape(context, (batch_size, num_heads, seq_len, head_dim)),
(0, 2, 1, 3),
)
return context
@staticmethod
def _pad_and_transpose_last_two_dims(hidden_states_padded, paddings):
"""pads rows and then flips rows and columns"""
hidden_states_padded = tf.pad(
hidden_states_padded, paddings
) # padding value is not important because it will be overwritten
batch_size, chunk_size, seq_length, hidden_dim = shape_list(hidden_states_padded)
hidden_states_padded = tf.reshape(hidden_states_padded, (batch_size, chunk_size, hidden_dim, seq_length))
return hidden_states_padded
@staticmethod
def _pad_and_diagonalize(chunked_hidden_states):
"""
shift every row 1 step right, converting columns into diagonals.
Example:
```python
chunked_hidden_states: [
0.4983,
2.6918,
-0.0071,
1.0492,
-1.8348,
0.7672,
0.2986,
0.0285,
-0.7584,
0.4206,
-0.0405,
0.1599,
2.0514,
-1.1600,
0.5372,
0.2629,
]
window_overlap = num_rows = 4
```
(pad & diagonalize) => [ 0.4983, 2.6918, -0.0071, 1.0492, 0.0000, 0.0000, 0.0000
0.0000, -1.8348, 0.7672, 0.2986, 0.0285, 0.0000, 0.0000 0.0000, 0.0000, -0.7584, 0.4206,
-0.0405, 0.1599, 0.0000 0.0000, 0.0000, 0.0000, 2.0514, -1.1600, 0.5372, 0.2629 ]
"""
total_num_heads, num_chunks, window_overlap, hidden_dim = shape_list(chunked_hidden_states)
paddings = tf.convert_to_tensor([[0, 0], [0, 0], [0, 0], [0, window_overlap + 1]])
chunked_hidden_states = tf.pad(
chunked_hidden_states, paddings
) # total_num_heads x num_chunks x window_overlap x (hidden_dim+window_overlap+1). Padding value is not important because it'll be overwritten
chunked_hidden_states = tf.reshape(
chunked_hidden_states, (total_num_heads, num_chunks, -1)
) # total_num_heads x num_chunks x window_overlapL+window_overlapwindow_overlap+window_overlap
chunked_hidden_states = chunked_hidden_states[
:, :, :-window_overlap
] # total_num_heads x num_chunks x window_overlapL+window_overlapwindow_overlap
chunked_hidden_states = tf.reshape(
chunked_hidden_states,
(total_num_heads, num_chunks, window_overlap, window_overlap + hidden_dim),
) # total_num_heads x num_chunks, window_overlap x hidden_dim+window_overlap
chunked_hidden_states = chunked_hidden_states[:, :, :, :-1]
return chunked_hidden_states
@staticmethod
def _chunk(hidden_states, window_overlap):
"""convert into overlapping chunks. Chunk size = 2w, overlap size = w"""
batch_size, seq_length, hidden_dim = shape_list(hidden_states)
num_output_chunks = 2 * (seq_length // (2 * window_overlap)) - 1
# define frame size and frame stride (similar to convolution)
frame_hop_size = window_overlap * hidden_dim
frame_size = 2 * frame_hop_size
hidden_states = tf.reshape(hidden_states, (batch_size, seq_length * hidden_dim))
# chunk with overlap
chunked_hidden_states = tf.signal.frame(hidden_states, frame_size, frame_hop_size)
tf.debugging.assert_equal(
shape_list(chunked_hidden_states),
[batch_size, num_output_chunks, frame_size],
message=(
"Make sure chunking is correctly applied. `Chunked hidden states should have output dimension"
f" {[batch_size, frame_size, num_output_chunks]}, but got {shape_list(chunked_hidden_states)}."
),
)
chunked_hidden_states = tf.reshape(
chunked_hidden_states,
(batch_size, num_output_chunks, 2 * window_overlap, hidden_dim),
)
return chunked_hidden_states
@staticmethod
def _get_global_attn_indices(is_index_global_attn):
"""compute global attn indices required throughout forward pass"""
# helper variable
num_global_attn_indices = tf.math.count_nonzero(is_index_global_attn, axis=1)
num_global_attn_indices = tf.cast(num_global_attn_indices, dtype=tf.constant(1).dtype)
# max number of global attn indices in batch
max_num_global_attn_indices = tf.reduce_max(num_global_attn_indices)
# indices of global attn
is_index_global_attn_nonzero = tf.where(is_index_global_attn)
# helper variable
is_local_index_global_attn = tf.range(max_num_global_attn_indices) < tf.expand_dims(
num_global_attn_indices, axis=-1
)
# location of the non-padding values within global attention indices
is_local_index_global_attn_nonzero = tf.where(is_local_index_global_attn)
# location of the padding values within global attention indices
is_local_index_no_global_attn_nonzero = tf.where(tf.math.logical_not(is_local_index_global_attn))
return (
max_num_global_attn_indices,
is_index_global_attn_nonzero,
is_local_index_global_attn_nonzero,
is_local_index_no_global_attn_nonzero,
)
def _concat_with_global_key_attn_probs(
self,
attn_scores,
key_vectors,
query_vectors,
max_num_global_attn_indices,
is_index_global_attn_nonzero,
is_local_index_global_attn_nonzero,
is_local_index_no_global_attn_nonzero,
):
batch_size = shape_list(key_vectors)[0]
# select global key vectors
global_key_vectors = tf.gather_nd(key_vectors, is_index_global_attn_nonzero)
# create only global key vectors
key_vectors_only_global = tf.scatter_nd(
is_local_index_global_attn_nonzero,
global_key_vectors,
shape=(
batch_size,
max_num_global_attn_indices,
self.num_heads,
self.head_dim,
),
)
# (batch_size, seq_len, num_heads, max_num_global_attn_indices)
attn_probs_from_global_key = tf.einsum("blhd,bshd->blhs", query_vectors, key_vectors_only_global)
# (batch_size, max_num_global_attn_indices, seq_len, num_heads)
attn_probs_from_global_key_trans = tf.transpose(attn_probs_from_global_key, (0, 3, 1, 2))
mask_shape = (shape_list(is_local_index_no_global_attn_nonzero)[0],) + tuple(
shape_list(attn_probs_from_global_key_trans)[-2:]
)
mask = tf.ones(mask_shape) * -10000.0
mask = tf.cast(mask, dtype=attn_probs_from_global_key_trans.dtype)
# scatter mask
attn_probs_from_global_key_trans = tf.tensor_scatter_nd_update(
attn_probs_from_global_key_trans,
is_local_index_no_global_attn_nonzero,
mask,
)
# (batch_size, seq_len, num_heads, max_num_global_attn_indices)
attn_probs_from_global_key = tf.transpose(attn_probs_from_global_key_trans, (0, 2, 3, 1))
# concat to attn_probs
# (batch_size, seq_len, num_heads, extra attention count + 2*window+1)
attn_scores = tf.concat((attn_probs_from_global_key, attn_scores), axis=-1)
return attn_scores
def _compute_attn_output_with_global_indices(
self,
value_vectors,
attn_probs,
max_num_global_attn_indices,
is_index_global_attn_nonzero,
is_local_index_global_attn_nonzero,
):
batch_size = shape_list(attn_probs)[0]
# cut local attn probs to global only
attn_probs_only_global = attn_probs[:, :, :, :max_num_global_attn_indices]
# select global value vectors
global_value_vectors = tf.gather_nd(value_vectors, is_index_global_attn_nonzero)
# create only global value vectors
value_vectors_only_global = tf.scatter_nd(
is_local_index_global_attn_nonzero,
global_value_vectors,
shape=(
batch_size,
max_num_global_attn_indices,
self.num_heads,
self.head_dim,
),
)
# compute attn output only global
attn_output_only_global = tf.einsum("blhs,bshd->blhd", attn_probs_only_global, value_vectors_only_global)
# reshape attn probs
attn_probs_without_global = attn_probs[:, :, :, max_num_global_attn_indices:]
# compute attn output with global
attn_output_without_global = self._sliding_chunks_matmul_attn_probs_value(
attn_probs_without_global, value_vectors, self.one_sided_attn_window_size
)
return attn_output_only_global + attn_output_without_global
def _compute_global_attn_output_from_hidden(
self,
attn_output,
hidden_states,
max_num_global_attn_indices,
layer_head_mask,
is_local_index_global_attn_nonzero,
is_index_global_attn_nonzero,
is_local_index_no_global_attn_nonzero,
is_index_masked,
training,
):
batch_size, seq_len = shape_list(hidden_states)[:2]
# prepare global hidden states
global_attn_hidden_states = tf.gather_nd(hidden_states, is_index_global_attn_nonzero)
global_attn_hidden_states = tf.scatter_nd(
is_local_index_global_attn_nonzero,
global_attn_hidden_states,
shape=(batch_size, max_num_global_attn_indices, self.embed_dim),
)
# global key, query, value
global_query_vectors_only_global = self.query_global(global_attn_hidden_states)
global_key_vectors = self.key_global(hidden_states)
global_value_vectors = self.value_global(hidden_states)
# normalize
global_query_vectors_only_global /= tf.math.sqrt(
tf.cast(self.head_dim, dtype=global_query_vectors_only_global.dtype)
)
global_query_vectors_only_global = self.reshape_and_transpose(global_query_vectors_only_global, batch_size)
global_key_vectors = self.reshape_and_transpose(global_key_vectors, batch_size)
global_value_vectors = self.reshape_and_transpose(global_value_vectors, batch_size)
# compute attn scores
global_attn_scores = tf.matmul(global_query_vectors_only_global, global_key_vectors, transpose_b=True)
tf.debugging.assert_equal(
shape_list(global_attn_scores),
[batch_size * self.num_heads, max_num_global_attn_indices, seq_len],
message=(
"global_attn_scores have the wrong size. Size should be"
f" {(batch_size * self.num_heads, max_num_global_attn_indices, seq_len)}, but is"
f" {shape_list(global_attn_scores)}."
),
)
global_attn_scores = tf.reshape(
global_attn_scores,
(batch_size, self.num_heads, max_num_global_attn_indices, seq_len),
)
global_attn_scores_trans = tf.transpose(global_attn_scores, (0, 2, 1, 3))
mask_shape = (shape_list(is_local_index_no_global_attn_nonzero)[0],) + tuple(
shape_list(global_attn_scores_trans)[-2:]
)
global_attn_mask = tf.ones(mask_shape) * -10000.0
global_attn_mask = tf.cast(global_attn_mask, dtype=global_attn_scores_trans.dtype)
# scatter mask
global_attn_scores_trans = tf.tensor_scatter_nd_update(
global_attn_scores_trans,
is_local_index_no_global_attn_nonzero,
global_attn_mask,
)
global_attn_scores = tf.transpose(global_attn_scores_trans, (0, 2, 1, 3))
# mask global attn scores
attn_mask = tf.tile(is_index_masked[:, None, None, :], (1, shape_list(global_attn_scores)[1], 1, 1))
global_attn_scores = tf.where(attn_mask, -10000.0, global_attn_scores)
global_attn_scores = tf.reshape(
global_attn_scores,
(batch_size * self.num_heads, max_num_global_attn_indices, seq_len),
)
# compute global attn probs
global_attn_probs_float = stable_softmax(global_attn_scores, axis=-1)
# apply layer head masking
if layer_head_mask is not None:
tf.debugging.assert_equal(
shape_list(layer_head_mask),
[self.num_heads],
message=(
f"Head mask for a single layer should be of size {(self.num_heads)}, but is"
f" {shape_list(layer_head_mask)}"
),
)
global_attn_probs_float = tf.reshape(layer_head_mask, (1, -1, 1, 1)) * tf.reshape(
global_attn_probs_float, (batch_size, self.num_heads, max_num_global_attn_indices, seq_len)
)
global_attn_probs_float = tf.reshape(
global_attn_probs_float, (batch_size * self.num_heads, max_num_global_attn_indices, seq_len)
)
# dropout
global_attn_probs = self.global_dropout(global_attn_probs_float, training=training)
# global attn output
global_attn_output = tf.matmul(global_attn_probs, global_value_vectors)
tf.debugging.assert_equal(
shape_list(global_attn_output),
[batch_size * self.num_heads, max_num_global_attn_indices, self.head_dim],
message=(
"global_attn_output tensor has the wrong size. Size should be"
f" {(batch_size * self.num_heads, max_num_global_attn_indices, self.head_dim)}, but is"
f" {shape_list(global_attn_output)}."
),
)
global_attn_output = tf.reshape(
global_attn_output,
(batch_size, self.num_heads, max_num_global_attn_indices, self.head_dim),
)
# get only non zero global attn output
nonzero_global_attn_output = tf.gather_nd(
tf.transpose(global_attn_output, (0, 2, 1, 3)),
is_local_index_global_attn_nonzero,
)
nonzero_global_attn_output = tf.reshape(
nonzero_global_attn_output,
(shape_list(is_local_index_global_attn_nonzero)[0], -1),
)
# overwrite values with global attention
attn_output = tf.tensor_scatter_nd_update(
attn_output, is_index_global_attn_nonzero, nonzero_global_attn_output
)
global_attn_probs = tf.reshape(
global_attn_probs, (batch_size, self.num_heads, max_num_global_attn_indices, seq_len)
)
return attn_output, global_attn_probs
def reshape_and_transpose(self, vector, batch_size):
return tf.reshape(
tf.transpose(
tf.reshape(vector, (batch_size, -1, self.num_heads, self.head_dim)),
(0, 2, 1, 3),
),
(batch_size * self.num_heads, -1, self.head_dim),
)
class TFLEDEncoderAttention(keras.layers.Layer):
def __init__(self, config, layer_id, **kwargs):
super().__init__(**kwargs)
self.longformer_self_attn = TFLEDEncoderSelfAttention(config, layer_id=layer_id, name="longformer_self_attn")
self.output_dense = keras.layers.Dense(config.d_model, use_bias=True, name="output")
self.config = config
def call(self, inputs, training=False):
(
hidden_states,
attention_mask,
layer_head_mask,
is_index_masked,
is_index_global_attn,
is_global_attn,
) = inputs
self_outputs = self.longformer_self_attn(
[hidden_states, attention_mask, layer_head_mask, is_index_masked, is_index_global_attn, is_global_attn],
training=training,
)
attention_output = self.output_dense(self_outputs[0], training=training)
outputs = (attention_output,) + self_outputs[1:]
return outputs
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "longformer_self_attn", None) is not None:
with tf.name_scope(self.longformer_self_attn.name):
self.longformer_self_attn.build(None)
if getattr(self, "output_dense", None) is not None:
with tf.name_scope(self.output_dense.name):
self.output_dense.build([None, None, self.config.d_model])
class TFLEDDecoderAttention(keras.layers.Layer):
"""Multi-headed attention from "Attention Is All You Need"""
def __init__(
self,
embed_dim: int,
num_heads: int,
dropout: float = 0.0,
is_decoder: bool = False,
bias: bool = True,
**kwargs,
):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.num_heads = num_heads
self.dropout = keras.layers.Dropout(dropout)
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
self.scaling = self.head_dim**-0.5
self.is_decoder = is_decoder
self.k_proj = keras.layers.Dense(embed_dim, use_bias=bias, name="k_proj")
self.q_proj = keras.layers.Dense(embed_dim, use_bias=bias, name="q_proj")
self.v_proj = keras.layers.Dense(embed_dim, use_bias=bias, name="v_proj")
self.out_proj = keras.layers.Dense(embed_dim, use_bias=bias, name="out_proj")
def _shape(self, tensor: tf.Tensor, seq_len: int, bsz: int):
return tf.transpose(tf.reshape(tensor, (bsz, seq_len, self.num_heads, self.head_dim)), (0, 2, 1, 3))
def call(
self,
hidden_states: tf.Tensor,
key_value_states: tf.Tensor | None = None,
past_key_value: Tuple[Tuple[tf.Tensor]] | None = None,
attention_mask: tf.Tensor | None = None,
layer_head_mask: tf.Tensor | None = None,
training=False,
) -> Tuple[tf.Tensor, tf.Tensor | None]:
"""Input shape: Batch x Time x Channel"""
# if key_value_states are provided this layer is used as a cross-attention layer
# for the decoder
is_cross_attention = key_value_states is not None
bsz, tgt_len, embed_dim = shape_list(hidden_states)
# get query proj
query_states = self.q_proj(hidden_states) * self.scaling
# get key, value proj
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_states = past_key_value[0]
value_states = past_key_value[1]
elif is_cross_attention:
# cross_attentions
key_states = self._shape(self.k_proj(key_value_states), -1, bsz)
value_states = self._shape(self.v_proj(key_value_states), -1, bsz)
elif past_key_value is not None:
# reuse k, v, self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
key_states = tf.concat([past_key_value[0], key_states], axis=2)
value_states = tf.concat([past_key_value[1], value_states], axis=2)
else:
# self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
if self.is_decoder:
# if cross_attention save Tuple(tf.Tensor, tf.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(tf.Tensor, tf.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_states, value_states)
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
query_states = tf.reshape(self._shape(query_states, tgt_len, bsz), proj_shape)
key_states = tf.reshape(key_states, proj_shape)
value_states = tf.reshape(value_states, proj_shape)
src_len = shape_list(key_states)[1]
attn_weights = tf.matmul(query_states, key_states, transpose_b=True)
tf.debugging.assert_equal(
shape_list(attn_weights),
[bsz * self.num_heads, tgt_len, src_len],
message=(
f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is"
f" {shape_list(attn_weights)}"
),
)
if attention_mask is not None:
tf.debugging.assert_equal(
shape_list(attention_mask),
[bsz, 1, tgt_len, src_len],
message=(
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is"
f" {shape_list(attention_mask)}"
),
)
attn_weights = tf.reshape(attn_weights, (bsz, self.num_heads, tgt_len, src_len)) + tf.cast(
attention_mask, dtype=attn_weights.dtype
)
attn_weights = tf.reshape(attn_weights, (bsz * self.num_heads, tgt_len, src_len))
attn_weights = stable_softmax(attn_weights, axis=-1)
if layer_head_mask is not None:
tf.debugging.assert_equal(
shape_list(layer_head_mask),
[self.num_heads],
message=(
f"Head mask for a single layer should be of size {(self.num_heads)}, but is"
f" {shape_list(layer_head_mask)}"
),
)
attn_weights = tf.reshape(layer_head_mask, (1, -1, 1, 1)) * tf.reshape(
attn_weights, (bsz, self.num_heads, tgt_len, src_len)
)
attn_weights = tf.reshape(attn_weights, (bsz * self.num_heads, tgt_len, src_len))
attn_probs = self.dropout(attn_weights, training=training)
attn_output = tf.matmul(attn_probs, value_states)
tf.debugging.assert_equal(
shape_list(attn_output),
[bsz * self.num_heads, tgt_len, self.head_dim],
message=(
f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is"
f" {shape_list(attn_output)}"
),
)
attn_output = tf.transpose(
tf.reshape(attn_output, (bsz, self.num_heads, tgt_len, self.head_dim)), (0, 2, 1, 3)
)
attn_output = tf.reshape(attn_output, (bsz, tgt_len, embed_dim))
attn_output = self.out_proj(attn_output)
attn_weights: tf.Tensor = tf.reshape(attn_weights, (bsz, self.num_heads, tgt_len, src_len))
return attn_output, attn_weights, past_key_value
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "k_proj", None) is not None:
with tf.name_scope(self.k_proj.name):
self.k_proj.build([None, None, self.embed_dim])
if getattr(self, "q_proj", None) is not None:
with tf.name_scope(self.q_proj.name):
self.q_proj.build([None, None, self.embed_dim])
if getattr(self, "v_proj", None) is not None:
with tf.name_scope(self.v_proj.name):
self.v_proj.build([None, None, self.embed_dim])
if getattr(self, "out_proj", None) is not None:
with tf.name_scope(self.out_proj.name):
self.out_proj.build([None, None, self.embed_dim])
class TFLEDEncoderLayer(keras.layers.Layer):
def __init__(self, config: LEDConfig, layer_id: int, **kwargs):
super().__init__(**kwargs)
self.embed_dim = config.d_model
self.self_attn = TFLEDEncoderAttention(config, layer_id, name="self_attn")
self.self_attn_layer_norm = keras.layers.LayerNormalization(epsilon=1e-5, name="self_attn_layer_norm")
self.dropout = keras.layers.Dropout(config.dropout)
self.activation_fn = get_tf_activation(config.activation_function)
self.activation_dropout = keras.layers.Dropout(config.activation_dropout)
self.fc1 = keras.layers.Dense(config.encoder_ffn_dim, name="fc1")
self.fc2 = keras.layers.Dense(self.embed_dim, name="fc2")
self.final_layer_norm = keras.layers.LayerNormalization(epsilon=1e-5, name="final_layer_norm")
self.config = config
def call(
self,
hidden_states: tf.Tensor,
attention_mask: tf.Tensor,
layer_head_mask: tf.Tensor,
is_index_masked: tf.Tensor,
is_index_global_attn: tf.Tensor,
is_global_attn: bool,
training=False,
):
"""
Args:
hidden_states (`tf.Tensor`): input to the layer of shape *(batch, seq_len, embed_dim)*
attention_mask (`tf.Tensor`): attention mask of size
*(batch, 1, tgt_len, src_len)* where padding elements are indicated by very large negative values.
layer_head_mask (`tf.Tensor`): mask for attention heads in a given layer of size
*(config.encoder_attention_heads,)*.
"""
residual = hidden_states
layer_outputs = self.self_attn(
[hidden_states, attention_mask, layer_head_mask, is_index_masked, is_index_global_attn, is_global_attn],
training=training,
)
hidden_states = layer_outputs[0]
tf.debugging.assert_equal(
shape_list(hidden_states),
shape_list(residual),
message=f"Self attn modified the shape of query {shape_list(residual)} to {shape_list(hidden_states)}",
)
hidden_states = self.dropout(hidden_states, training=training)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = self.activation_dropout(hidden_states, training=training)
hidden_states = self.fc2(hidden_states)
hidden_states = self.dropout(hidden_states, training=training)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
return (hidden_states,) + layer_outputs[1:]
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "self_attn", None) is not None:
with tf.name_scope(self.self_attn.name):
self.self_attn.build(None)
if getattr(self, "self_attn_layer_norm", None) is not None:
with tf.name_scope(self.self_attn_layer_norm.name):
self.self_attn_layer_norm.build([None, None, self.embed_dim])
if getattr(self, "fc1", None) is not None:
with tf.name_scope(self.fc1.name):
self.fc1.build([None, None, self.embed_dim])
if getattr(self, "fc2", None) is not None:
with tf.name_scope(self.fc2.name):
self.fc2.build([None, None, self.config.encoder_ffn_dim])
if getattr(self, "final_layer_norm", None) is not None:
with tf.name_scope(self.final_layer_norm.name):
self.final_layer_norm.build([None, None, self.embed_dim])
class TFLEDDecoderLayer(keras.layers.Layer):
def __init__(self, config: LEDConfig, **kwargs):
super().__init__(**kwargs)
self.embed_dim = config.d_model
self.self_attn = TFLEDDecoderAttention(
embed_dim=self.embed_dim,
num_heads=config.decoder_attention_heads,
dropout=config.attention_dropout,
name="self_attn",
is_decoder=True,
)
self.dropout = keras.layers.Dropout(config.dropout)
self.activation_fn = get_tf_activation(config.activation_function)
self.activation_dropout = keras.layers.Dropout(config.activation_dropout)
self.self_attn_layer_norm = keras.layers.LayerNormalization(epsilon=1e-5, name="self_attn_layer_norm")
self.encoder_attn = TFLEDDecoderAttention(
self.embed_dim,
config.decoder_attention_heads,
dropout=config.attention_dropout,
name="encoder_attn",
is_decoder=True,
)
self.encoder_attn_layer_norm = keras.layers.LayerNormalization(epsilon=1e-5, name="encoder_attn_layer_norm")
self.fc1 = keras.layers.Dense(config.decoder_ffn_dim, name="fc1")
self.fc2 = keras.layers.Dense(self.embed_dim, name="fc2")
self.final_layer_norm = keras.layers.LayerNormalization(epsilon=1e-5, name="final_layer_norm")
self.config = config
def call(
self,
hidden_states,
attention_mask: tf.Tensor | None = None,
encoder_hidden_states: tf.Tensor | None = None,
encoder_attention_mask: tf.Tensor | None = None,
layer_head_mask: tf.Tensor | None = None,
encoder_layer_head_mask: tf.Tensor | None = None,
past_key_value: Tuple[tf.Tensor] | None = None,
training=False,
) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor, Tuple[Tuple[tf.Tensor]]]:
"""
Args:
hidden_states (`tf.Tensor`): input to the layer of shape *(batch, seq_len, embed_dim)*
attention_mask (`tf.Tensor`): attention mask of size
*(batch, 1, tgt_len, src_len)* where padding elements are indicated by very large negative values.
encoder_hidden_states (`tf.Tensor`):
cross attention input to the layer of shape *(batch, seq_len, embed_dim)*
encoder_attention_mask (`tf.Tensor`): encoder attention mask of size
*(batch, 1, tgt_len, src_len)* where padding elements are indicated by very large negative values.
layer_head_mask (`tf.Tensor`): mask for attention heads in a given layer of size
*(config.encoder_attention_heads,)*.
encoder_layer_head_mask (`tf.Tensor`): mask for encoder attention heads in a given layer of
size *(config.encoder_attention_heads,)*.
past_key_value (`Tuple(tf.Tensor)`): cached past key and value projection states
"""
residual = hidden_states
# Self-Attention
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
# add present self-attn cache to positions 1,2 of present_key_value tuple
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
past_key_value=self_attn_past_key_value,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
)
hidden_states = self.dropout(hidden_states, training=training)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
# Cross-Attention Block
cross_attn_present_key_value = None
cross_attn_weights = None
if encoder_hidden_states is not None:
residual = hidden_states
# cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
hidden_states=hidden_states,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
layer_head_mask=encoder_layer_head_mask,
past_key_value=cross_attn_past_key_value,
)
hidden_states = self.dropout(hidden_states, training=training)
hidden_states = residual + hidden_states
hidden_states = self.encoder_attn_layer_norm(hidden_states)
# add cross-attn to positions 3,4 of present_key_value tuple
present_key_value = present_key_value + cross_attn_present_key_value
# Fully Connected
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = self.activation_dropout(hidden_states, training=training)
hidden_states = self.fc2(hidden_states)
hidden_states = self.dropout(hidden_states, training=training)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
return (
hidden_states,
self_attn_weights,
cross_attn_weights,
present_key_value,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "self_attn", None) is not None:
with tf.name_scope(self.self_attn.name):
self.self_attn.build(None)
if getattr(self, "self_attn_layer_norm", None) is not None:
with tf.name_scope(self.self_attn_layer_norm.name):
self.self_attn_layer_norm.build([None, None, self.embed_dim])
if getattr(self, "encoder_attn", None) is not None:
with tf.name_scope(self.encoder_attn.name):
self.encoder_attn.build(None)
if getattr(self, "encoder_attn_layer_norm", None) is not None:
with tf.name_scope(self.encoder_attn_layer_norm.name):
self.encoder_attn_layer_norm.build([None, None, self.embed_dim])
if getattr(self, "fc1", None) is not None:
with tf.name_scope(self.fc1.name):
self.fc1.build([None, None, self.embed_dim])
if getattr(self, "fc2", None) is not None:
with tf.name_scope(self.fc2.name):
self.fc2.build([None, None, self.config.decoder_ffn_dim])
if getattr(self, "final_layer_norm", None) is not None:
with tf.name_scope(self.final_layer_norm.name):
self.final_layer_norm.build([None, None, self.embed_dim])
class TFLEDPreTrainedModel(TFPreTrainedModel):
config_class = LEDConfig
base_model_prefix = "led"
@property
def input_signature(self):
sig = super().input_signature
sig["global_attention_mask"] = tf.TensorSpec((None, None), tf.int32, name="global_attention_mask")
return sig
@dataclass
# Copied from transformers.models.longformer.modeling_tf_longformer.TFLongformerBaseModelOutput with TFLongformer->TFLEDEncoder
class TFLEDEncoderBaseModelOutput(ModelOutput):
"""
Base class for Longformer's outputs, with potential hidden states, local and global attentions.
Args:
last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length, x +
attention_window + 1)`, where `x` is the number of tokens with global attention mask.
Local attentions weights after the attention softmax, used to compute the weighted average in the
self-attention heads. Those are the attention weights from every token in the sequence to every token with
global attention (first `x` values) and to every token in the attention window (remaining `attention_window
+ 1` values). Note that the first `x` values refer to tokens with fixed positions in the text, but the
remaining `attention_window + 1` values refer to tokens with relative positions: the attention weight of a
token to itself is located at index `x + attention_window / 2` and the `attention_window / 2` preceding
(succeeding) values are the attention weights to the `attention_window / 2` preceding (succeeding) tokens.
If the attention window contains a token with global attention, the attention weight at the corresponding
index is set to 0; the value should be accessed from the first `x` attention weights. If a token has global
attention, the attention weights to all other tokens in `attentions` is set to 0, the values should be
accessed from `global_attentions`.
global_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length, x)`, where `x`
is the number of tokens with global attention mask.
Global attentions weights after the attention softmax, used to compute the weighted average in the
self-attention heads. Those are the attention weights from every token with global attention to every token
in the sequence.
"""
last_hidden_state: tf.Tensor = None
hidden_states: Tuple[tf.Tensor, ...] | None = None
attentions: Tuple[tf.Tensor, ...] | None = None
global_attentions: Tuple[tf.Tensor, ...] | None = None
@dataclass
class TFLEDSeq2SeqModelOutput(ModelOutput):
"""
Base class for model encoder's outputs that also contains : pre-computed hidden states that can speed up sequential
decoding.
Args:
last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the decoder of the model.
If `past_key_values` is used only the last hidden-state of the sequences of shape `(batch_size, 1,
hidden_size)` is output.
past_key_values (`List[tf.Tensor]`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
List of `tf.Tensor` of length `config.n_layers`, with each tensor of shape `(2, batch_size, num_heads,
sequence_length, embed_size_per_head)`).
Contains pre-computed hidden-states (key and values in the attention blocks) of the decoder that can be
used (see `past_key_values` input) to speed up sequential decoding.
decoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
decoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
self-attention heads.
cross_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
weighted average in the cross-attention heads.
encoder_last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder of the model.
encoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
encoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
self-attention heads.
encoder_global_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length, x)`, where `x`
is the number of tokens with global attention mask.
Global attentions weights after the attention softmax, used to compute the weighted average in the
self-attention heads. Those are the attention weights from every token with global attention to every token
in the sequence.
"""
last_hidden_state: tf.Tensor = None
past_key_values: List[tf.Tensor] | None = None
decoder_hidden_states: Tuple[tf.Tensor, ...] | None = None
decoder_attentions: Tuple[tf.Tensor, ...] | None = None
cross_attentions: Tuple[tf.Tensor, ...] | None = None
encoder_last_hidden_state: tf.Tensor | None = None
encoder_hidden_states: Tuple[tf.Tensor, ...] | None = None
encoder_attentions: Tuple[tf.Tensor, ...] | None = None
encoder_global_attentions: Tuple[tf.Tensor, ...] | None = None
@dataclass
class TFLEDSeq2SeqLMOutput(ModelOutput):
"""
Base class for sequence-to-sequence language models outputs.
Args:
loss (`tf.Tensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
Language modeling loss.
logits (`tf.Tensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
past_key_values (`List[tf.Tensor]`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
List of `tf.Tensor` of length `config.n_layers`, with each tensor of shape `(2, batch_size, num_heads,
sequence_length, embed_size_per_head)`).
Contains pre-computed hidden-states (key and values in the attention blocks) of the decoder that can be
used (see `past_key_values` input) to speed up sequential decoding.
decoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
decoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
self-attention heads.
cross_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
weighted average in the cross-attention heads.
encoder_last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder of the model.
encoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
encoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
self-attention heads.
encoder_global_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length, x)`, where `x`
is the number of tokens with global attention mask.
Global attentions weights after the attention softmax, used to compute the weighted average in the
self-attention heads. Those are the attention weights from every token with global attention to every token
in the sequence.
"""
loss: tf.Tensor | None = None
logits: tf.Tensor = None
past_key_values: List[tf.Tensor] | None = None
decoder_hidden_states: Tuple[tf.Tensor, ...] | None = None
decoder_attentions: Tuple[tf.Tensor, ...] | None = None
cross_attentions: Tuple[tf.Tensor, ...] | None = None
encoder_last_hidden_state: tf.Tensor | None = None
encoder_hidden_states: Tuple[tf.Tensor, ...] | None = None
encoder_attentions: Tuple[tf.Tensor, ...] | None = None
encoder_global_attentions: Tuple[tf.Tensor, ...] | None = None
LED_START_DOCSTRING = r"""
This model inherits from [`TFPreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a [keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model) subclass. Use it
as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and
behavior.
<Tip>
TensorFlow models and layers in `transformers` accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like `model.fit()` things should "just work" for you - just
pass your inputs and labels in any format that `model.fit()` supports! If, however, you want to use the second
format outside of Keras methods like `fit()` and `predict()`, such as when creating your own layers or models with
the Keras `Functional` API, there are three possibilities you can use to gather all the input Tensors in the first
positional argument:
- a single Tensor with `input_ids` only and nothing else: `model(input_ids)`
- a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
`model([input_ids, attention_mask])` or `model([input_ids, attention_mask, token_type_ids])`
- a dictionary with one or several input Tensors associated to the input names given in the docstring:
`model({"input_ids": input_ids, "token_type_ids": token_type_ids})`
Note that when creating models and layers with
[subclassing](https://keras.io/guides/making_new_layers_and_models_via_subclassing/) then you don't need to worry
about any of this, as you can just pass inputs like you would to any other Python function!
</Tip>
Args:
config ([`LEDConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~TFPreTrainedModel.from_pretrained`] method to load the model weights.
"""
LED_INPUTS_DOCSTRING = r"""
Args:
input_ids (`tf.Tensor` of shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`tf.Tensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
decoder_input_ids (`tf.Tensor` of shape `(batch_size, target_sequence_length)`, *optional*):
Indices of decoder input sequence tokens in the vocabulary.
Indices can be obtained using [`LedTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
LED uses the `eos_token_id` as the starting token for `decoder_input_ids` generation. If `past_key_values`
is used, optionally only the last `decoder_input_ids` have to be input (see `past_key_values`).
decoder_attention_mask (`tf.Tensor` of shape `(batch_size, target_sequence_length)`, *optional*):
will be made by default and ignore pad tokens. It is not recommended to set this for most use cases.
head_mask (`tf.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
decoder_head_mask (`tf.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the decoder. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
encoder_outputs (`tf.Tensor`, *optional*):
hidden states at the output of the last layer of the encoder. Used in the cross-attention of the decoder.
of shape `(batch_size, sequence_length, hidden_size)` is a sequence of
past_key_values (`Tuple[Tuple[tf.Tensor]]` of length `config.n_layers`)
contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*, defaults to `True`):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`). Set to `False` during training, `True` during generation
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the
config will be used instead.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail. This argument can be used only in eager mode, in graph mode the value in the config will be
used instead.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple. This argument can be used in
eager mode, in graph mode the value will always be set to True.
training (`bool`, *optional*, defaults to `False`):
Whether or not to use the model in training mode (some modules like dropout modules have different
behaviors between training and evaluation).
"""
@keras_serializable
class TFLEDEncoder(keras.layers.Layer):
config_class = LEDConfig
"""
Transformer encoder consisting of *config.encoder_layers* self-attention layers. Each layer is a
[`TFLEDEncoderLayer`].
Args:
config: LEDConfig
"""
def __init__(self, config: LEDConfig, embed_tokens: Optional[keras.layers.Embedding] = None, **kwargs):
super().__init__(**kwargs)
self.config = config
self.dropout = keras.layers.Dropout(config.dropout)
if config.encoder_layerdrop > 0:
logger.warning("Layerdrop is currently disabled in TFLED models.")
self.layerdrop = 0.0
self.padding_idx = config.pad_token_id
if isinstance(config.attention_window, int):
assert config.attention_window % 2 == 0, "`config.attention_window` has to be an even value"
assert config.attention_window > 0, "`config.attention_window` has to be positive"
config.attention_window = [config.attention_window] * config.num_hidden_layers # one value per layer
else:
assert len(config.attention_window) == config.num_hidden_layers, (
"`len(config.attention_window)` should equal `config.num_hidden_layers`. "
f"Expected {config.num_hidden_layers}, given {len(config.attention_window)}"
)
self.attention_window = config.attention_window
self.embed_tokens = embed_tokens
self.embed_positions = TFLEDLearnedPositionalEmbedding(
config.max_encoder_position_embeddings,
config.d_model,
name="embed_positions",
)
self.layers = [TFLEDEncoderLayer(config, i, name=f"layers.{i}") for i in range(config.encoder_layers)]
self.layernorm_embedding = keras.layers.LayerNormalization(epsilon=1e-5, name="layernorm_embedding")
self.embed_dim = config.d_model
def get_embed_tokens(self):
return self.embed_tokens
def set_embed_tokens(self, embed_tokens):
self.embed_tokens = embed_tokens
@unpack_inputs
def call(
self,
input_ids=None,
inputs_embeds=None,
attention_mask=None,
global_attention_mask=None,
head_mask=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
training=False,
):
"""
Args:
input_ids (`tf.Tensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
head_mask (`tf.Tensor` of shape `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = shape_list(input_ids)
check_embeddings_within_bounds(input_ids, self.embed_tokens.input_dim)
inputs_embeds = self.embed_tokens(input_ids)
elif inputs_embeds is not None:
input_shape = shape_list(inputs_embeds)[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if attention_mask is None:
attention_mask = tf.fill(input_shape, 1)
# merge `global_attention_mask` and `attention_mask`
if global_attention_mask is not None:
attention_mask = attention_mask * tf.cast((global_attention_mask + 1), dtype=attention_mask.dtype)
padding_len, input_ids, attention_mask, inputs_embeds = self._pad_to_window_size(
input_ids=input_ids,
attention_mask=attention_mask,
inputs_embeds=inputs_embeds,
pad_token_id=self.padding_idx,
)
input_shape = shape_list(attention_mask)
# is index masked or global attention
is_index_masked = tf.math.less(tf.cast(attention_mask, tf.int8), 1)
is_index_global_attn = tf.math.greater(tf.cast(attention_mask, tf.int8), 1)
is_global_attn = tf.math.reduce_any(is_index_global_attn)
embed_pos = self.embed_positions(input_shape)
hidden_states = inputs_embeds + embed_pos
hidden_states = self.layernorm_embedding(hidden_states)
hidden_states = self.dropout(hidden_states, training=training)
# check attention mask and invert
if attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
attention_mask = _expand_mask(attention_mask)[:, 0, 0, :]
attention_mask = attention_mask[:, :, None, None]
encoder_states = () if output_hidden_states else None
all_attentions = all_global_attentions = () if output_attentions else None
# check if head_mask has a correct number of layers specified if desired
if head_mask is not None:
tf.debugging.assert_equal(
shape_list(head_mask)[0],
len(self.layers),
message=(
f"The head_mask should be specified for {len(self.layers)} layers, but it is for"
f" {shape_list(head_mask)[0]}."
),
)
# encoder layers
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
hidden_states_to_add = self.compute_hidden_states(hidden_states, padding_len)
encoder_states = encoder_states + (hidden_states_to_add,)
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if training and (dropout_probability < self.layerdrop): # skip the layer
continue
layer_outputs = encoder_layer(
hidden_states=hidden_states,
attention_mask=attention_mask,
layer_head_mask=head_mask[idx] if head_mask is not None else None,
is_index_masked=is_index_masked,
is_index_global_attn=is_index_global_attn,
is_global_attn=is_global_attn,
)
hidden_states = layer_outputs[0]
if output_attentions:
# bzs x seq_len x num_attn_heads x (num_global_attn + attention_window_len + 1) => bzs x num_attn_heads x seq_len x (num_global_attn + attention_window_len + 1)
all_attentions = all_attentions + (tf.transpose(layer_outputs[1], (0, 2, 1, 3)),)
# bzs x num_attn_heads x num_global_attn x seq_len => bzs x num_attn_heads x seq_len x num_global_attn
all_global_attentions = all_global_attentions + (tf.transpose(layer_outputs[2], (0, 1, 3, 2)),)
# undo padding
# unpad `hidden_states` because the calling function is expecting a length == input_ids.size(1)
hidden_states = self.compute_hidden_states(hidden_states, padding_len)
# undo padding
if output_attentions:
all_attentions = (
tuple([state[:, :, :-padding_len, :] for state in all_attentions])
if padding_len > 0
else all_attentions
)
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
return TFLEDEncoderBaseModelOutput(
last_hidden_state=hidden_states,
hidden_states=encoder_states,
attentions=all_attentions,
global_attentions=all_global_attentions,
)
@tf.function
def compute_hidden_states(self, hidden_states, padding_len):
return hidden_states[:, :-padding_len] if padding_len > 0 else hidden_states
def _pad_to_window_size(
self,
input_ids,
attention_mask,
inputs_embeds,
pad_token_id,
):
"""A helper function to pad tokens and mask to work with implementation of Longformer selfattention."""
# padding
attention_window = (
self.attention_window if isinstance(self.attention_window, int) else max(self.attention_window)
)
assert attention_window % 2 == 0, f"`attention_window` should be an even value. Given {attention_window}"
input_shape = shape_list(input_ids) if input_ids is not None else shape_list(inputs_embeds)
batch_size, seq_len = input_shape[:2]
padding_len = (attention_window - seq_len % attention_window) % attention_window
if padding_len > 0:
logger.warning_once(
f"Input ids are automatically padded from {seq_len} to {seq_len + padding_len} to be a multiple of "
f"`config.attention_window`: {attention_window}"
)
paddings = tf.convert_to_tensor([[0, 0], [0, padding_len]])
if input_ids is not None:
input_ids = tf.pad(input_ids, paddings, constant_values=pad_token_id)
if inputs_embeds is not None:
if padding_len > 0:
input_ids_padding = tf.fill((batch_size, padding_len), pad_token_id)
inputs_embeds_padding = self.embed_tokens(input_ids_padding)
inputs_embeds = tf.concat([inputs_embeds, inputs_embeds_padding], axis=-2)
attention_mask = tf.pad(attention_mask, paddings, constant_values=False) # no attention on the padding tokens
return (
padding_len,
input_ids,
attention_mask,
inputs_embeds,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "embed_positions", None) is not None:
with tf.name_scope(self.embed_positions.name):
self.embed_positions.build(None)
if getattr(self, "layernorm_embedding", None) is not None:
with tf.name_scope(self.layernorm_embedding.name):
self.layernorm_embedding.build([None, None, self.embed_dim])
if getattr(self, "layers", None) is not None:
for layer in self.layers:
with tf.name_scope(layer.name):
layer.build(None)
@keras_serializable
class TFLEDDecoder(keras.layers.Layer):
config_class = LEDConfig
"""
Transformer decoder consisting of *config.decoder_layers* layers. Each layer is a [`TFLEDDecoderLayer`]
Args:
config: LEDConfig
embed_tokens: output embedding
"""
def __init__(self, config: LEDConfig, embed_tokens: Optional[keras.layers.Embedding] = None, **kwargs):
super().__init__(**kwargs)
self.config = config
self.padding_idx = config.pad_token_id
self.embed_tokens = embed_tokens
if config.decoder_layerdrop > 0:
logger.warning("Layerdrop is currently disabled in TFLED models.")
self.layerdrop = 0.0
self.embed_positions = TFLEDLearnedPositionalEmbedding(
config.max_decoder_position_embeddings,
config.d_model,
name="embed_positions",
)
self.layers = [TFLEDDecoderLayer(config, name=f"layers.{i}") for i in range(config.decoder_layers)]
self.layernorm_embedding = keras.layers.LayerNormalization(epsilon=1e-5, name="layernorm_embedding")
self.dropout = keras.layers.Dropout(config.dropout)
def set_embed_tokens(self, embed_tokens):
self.embed_tokens = embed_tokens
@unpack_inputs
def call(
self,
input_ids=None,
inputs_embeds=None,
attention_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
head_mask=None,
encoder_head_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
training=False,
):
r"""
Args:
input_ids (`tf.Tensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it. Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details. [What are input IDs?](../glossary#input-ids)
attention_mask (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
encoder_hidden_states (`tf.Tensor` of shape `(batch_size, encoder_sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
of the decoder.
encoder_attention_mask (`tf.Tensor` of shape `(batch_size, encoder_sequence_length)`, *optional*):
Mask to avoid performing cross-attention on padding tokens indices of encoder input_ids. Mask values
selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
head_mask (`tf.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
encoder_head_mask (`tf.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in encoder to avoid performing cross-attention
on hidden heads. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
past_key_values (`Tuple[Tuple[tf.Tensor]]` of length `config.n_layers` with each tuple having 2 tuples each of which has 2 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden-states of the attention blocks. Can be used to speed up
decoding. If `past_key_values` are used, the user can optionally input only the last
`decoder_input_ids` (those that don't have their past key value states given to this model) of shape
`(batch_size, 1)` instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
inputs_embeds (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
elif input_ids is not None:
input_shape = shape_list(input_ids)
elif inputs_embeds is not None:
input_shape = shape_list(inputs_embeds)[:-1]
else:
raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
past_key_values_length = shape_list(past_key_values[0][0])[2] if past_key_values is not None else 0
# embed positions
positions = self.embed_positions(input_shape, past_key_values_length)
if inputs_embeds is None:
check_embeddings_within_bounds(input_ids, self.embed_tokens.input_dim)
inputs_embeds = self.embed_tokens(input_ids)
hidden_states = inputs_embeds
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
if input_shape[-1] > 1:
combined_attention_mask = _make_causal_mask(input_shape, past_key_values_length=past_key_values_length)
else:
combined_attention_mask = _expand_mask(
tf.ones((input_shape[0], input_shape[1] + past_key_values_length)), tgt_len=input_shape[-1]
)
if attention_mask is not None and input_shape[-1] > 1:
combined_attention_mask = combined_attention_mask + _expand_mask(attention_mask, tgt_len=input_shape[-1])
if encoder_hidden_states is not None and encoder_attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
encoder_attention_mask = _expand_mask(encoder_attention_mask, tgt_len=input_shape[-1])
hidden_states = self.layernorm_embedding(hidden_states + positions)
hidden_states = self.dropout(hidden_states, training=training)
# decoder layers
all_hidden_states = ()
all_self_attns = ()
all_cross_attentions = ()
present_key_values = ()
# check if head_mask has a correct number of layers specified if desired
if head_mask is not None:
tf.debugging.assert_equal(
shape_list(head_mask)[0],
len(self.layers),
message=(
f"The head_mask should be specified for {len(self.layers)} layers, but it is for"
f" {shape_list(head_mask)[0]}."
),
)
for idx, decoder_layer in enumerate(self.layers):
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = random.uniform(0, 1)
if training and (dropout_probability < self.layerdrop):
continue
past_key_value = past_key_values[idx] if past_key_values is not None else None
hidden_states, layer_self_attn, layer_cross_attn, present_key_value = decoder_layer(
hidden_states,
attention_mask=combined_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
layer_head_mask=head_mask[idx] if head_mask is not None else None,
encoder_layer_head_mask=encoder_head_mask[idx] if encoder_head_mask is not None else None,
past_key_value=past_key_value,
)
if use_cache:
present_key_values += (present_key_value,)
if output_attentions:
all_self_attns += (layer_self_attn,)
all_cross_attentions += (layer_cross_attn,)
if output_hidden_states:
all_hidden_states += (hidden_states,)
else:
all_hidden_states = None
all_self_attns = all_self_attns if output_attentions else None
all_cross_attentions = all_cross_attentions if output_attentions else None
present_key_values = present_key_values if use_cache else None
if not return_dict:
return tuple(
v
for v in [hidden_states, present_key_values, all_hidden_states, all_self_attns, all_cross_attentions]
if v is not None
)
else:
return TFBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=present_key_values,
hidden_states=all_hidden_states,
attentions=all_self_attns,
cross_attentions=all_cross_attentions,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "embed_positions", None) is not None:
with tf.name_scope(self.embed_positions.name):
self.embed_positions.build(None)
if getattr(self, "layernorm_embedding", None) is not None:
with tf.name_scope(self.layernorm_embedding.name):
self.layernorm_embedding.build([None, None, self.config.d_model])
if getattr(self, "layers", None) is not None:
for layer in self.layers:
with tf.name_scope(layer.name):
layer.build(None)
@keras_serializable
class TFLEDMainLayer(keras.layers.Layer):
config_class = LEDConfig
def __init__(self, config: LEDConfig, **kwargs):
super().__init__(**kwargs)
self.config = config
self.shared = keras.layers.Embedding(
input_dim=config.vocab_size,
output_dim=config.d_model,
embeddings_initializer=keras.initializers.TruncatedNormal(stddev=self.config.init_std),
name="led.shared",
)
# Additional attribute to specify the expected name scope of the layer (for loading/storing weights)
self.shared.load_weight_prefix = "led.shared"
self.encoder = TFLEDEncoder(config, self.shared, name="encoder")
self.decoder = TFLEDDecoder(config, self.shared, name="decoder")
def get_input_embeddings(self):
return self.shared
def set_input_embeddings(self, new_embeddings):
self.shared = new_embeddings
self.encoder.embed_tokens = self.shared
self.decoder.embed_tokens = self.shared
@unpack_inputs
def call(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
encoder_outputs: Optional[Union[Tuple, TFLEDEncoderBaseModelOutput]] = None,
global_attention_mask=None,
past_key_values=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
training=False,
**kwargs,
):
if decoder_input_ids is None and decoder_inputs_embeds is None:
use_cache = False
if encoder_outputs is None:
encoder_outputs = self.encoder(
input_ids=input_ids,
attention_mask=attention_mask,
global_attention_mask=global_attention_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
# If the user passed a tuple for encoder_outputs, we wrap it in a TFLEDEncoderBaseModelOutput when return_dict=True
elif return_dict and not isinstance(encoder_outputs, TFLEDEncoderBaseModelOutput):
encoder_outputs = TFLEDEncoderBaseModelOutput(
last_hidden_state=encoder_outputs[0],
hidden_states=encoder_outputs[1] if len(encoder_outputs) > 1 else None,
attentions=encoder_outputs[2] if len(encoder_outputs) > 2 else None,
)
# If the user passed a TFLEDEncoderBaseModelOutput for encoder_outputs, we wrap it in a tuple when return_dict=False
elif not return_dict and not isinstance(encoder_outputs, tuple):
encoder_outputs = encoder_outputs.to_tuple()
decoder_outputs = self.decoder(
decoder_input_ids,
attention_mask=decoder_attention_mask,
encoder_hidden_states=encoder_outputs[0],
encoder_attention_mask=attention_mask,
head_mask=decoder_head_mask,
encoder_head_mask=head_mask,
past_key_values=past_key_values,
inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
if not return_dict:
return decoder_outputs + encoder_outputs
return TFLEDSeq2SeqModelOutput(
last_hidden_state=decoder_outputs.last_hidden_state,
past_key_values=decoder_outputs.past_key_values,
decoder_hidden_states=decoder_outputs.hidden_states,
decoder_attentions=decoder_outputs.attentions,
cross_attentions=decoder_outputs.cross_attentions,
encoder_last_hidden_state=encoder_outputs.last_hidden_state,
encoder_hidden_states=encoder_outputs.hidden_states,
encoder_attentions=encoder_outputs.attentions,
encoder_global_attentions=encoder_outputs.global_attentions,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
# The shared/tied weights expect to be in the model base namespace
# Adding "/" to the end (not the start!) of a tf.name_scope puts it in the root namespace rather than
# the current one.
with tf.name_scope(self.shared.load_weight_prefix + "/" + self.shared.name + "/"):
self.shared.build(None)
if getattr(self, "encoder", None) is not None:
with tf.name_scope(self.encoder.name):
self.encoder.build(None)
if getattr(self, "decoder", None) is not None:
with tf.name_scope(self.decoder.name):
self.decoder.build(None)
@add_start_docstrings(
"The bare LED Model outputting raw hidden-states without any specific head on top.",
LED_START_DOCSTRING,
)
class TFLEDModel(TFLEDPreTrainedModel):
def __init__(self, config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.led = TFLEDMainLayer(config, name="led")
def get_encoder(self):
return self.led.encoder
def get_decoder(self):
return self.led.decoder
@unpack_inputs
@add_start_docstrings_to_model_forward(LED_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFLEDSeq2SeqModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: tf.Tensor | None = None,
decoder_input_ids: tf.Tensor | None = None,
decoder_attention_mask: tf.Tensor | None = None,
head_mask: tf.Tensor | None = None,
decoder_head_mask: tf.Tensor | None = None,
encoder_outputs: tf.Tensor | None = None,
global_attention_mask: tf.Tensor | None = None,
past_key_values: Tuple[Tuple[tf.Tensor]] | None = None,
inputs_embeds: tf.Tensor | None = None,
decoder_inputs_embeds: tf.Tensor | None = None,
use_cache: bool | None = None,
output_attentions: bool | None = None,
output_hidden_states: bool | None = None,
return_dict: bool | None = None,
training: bool = False,
**kwargs,
) -> Tuple[tf.Tensor] | TFLEDSeq2SeqModelOutput:
outputs = self.led(
input_ids=input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
encoder_outputs=encoder_outputs,
global_attention_mask=global_attention_mask,
head_mask=head_mask,
decoder_head_mask=decoder_head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
decoder_inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
return outputs
def serving_output(self, output):
pkv = tf.tuple(output.past_key_values)[1] if self.config.use_cache else None
dec_hs = tf.convert_to_tensor(output.decoder_hidden_states) if self.config.output_hidden_states else None
dec_attns = tf.convert_to_tensor(output.decoder_attentions) if self.config.output_attentions else None
cross_attns = tf.convert_to_tensor(output.cross_attentions) if self.config.output_attentions else None
enc_hs = tf.convert_to_tensor(output.encoder_hidden_states) if self.config.output_hidden_states else None
enc_attns = tf.convert_to_tensor(output.encoder_attentions) if self.config.output_attentions else None
enc_g_attns = tf.convert_to_tensor(output.encoder_global_attentions) if self.config.output_attentions else None
return TFLEDSeq2SeqModelOutput(
last_hidden_state=output.last_hidden_state,
past_key_values=pkv,
decoder_hidden_states=dec_hs,
decoder_attentions=dec_attns,
cross_attentions=cross_attns,
encoder_last_hidden_state=output.encoder_last_hidden_state,
encoder_hidden_states=enc_hs,
encoder_attentions=enc_attns,
encoder_global_attentions=enc_g_attns,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "led", None) is not None:
with tf.name_scope(self.led.name):
self.led.build(None)
# Copied from transformers.models.bart.modeling_tf_bart.BiasLayer
class BiasLayer(keras.layers.Layer):
"""
Bias as a layer. It is used for serialization purposes: `keras.Model.save_weights` stores on a per-layer basis,
so all weights have to be registered in a layer.
"""
def __init__(self, shape, initializer, trainable, name, **kwargs):
super().__init__(name=name, **kwargs)
# Note: the name of this variable will NOT be scoped when serialized, i.e. it will not be in the format of
# "outer_layer/inner_layer/.../name:0". Instead, it will be "name:0". For further details, see:
# https://github.com/huggingface/transformers/pull/18833#issuecomment-1233090214
self.bias = self.add_weight(name=name, shape=shape, initializer=initializer, trainable=trainable)
def call(self, x):
return x + self.bias
@add_start_docstrings(
"The LED Model with a language modeling head. Can be used for summarization.",
LED_START_DOCSTRING,
)
class TFLEDForConditionalGeneration(TFLEDPreTrainedModel):
_keys_to_ignore_on_load_unexpected = [
r"led.encoder.embed_tokens.weight",
r"led.decoder.embed_tokens.weight",
]
def __init__(self, config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.led = TFLEDMainLayer(config, name="led")
self.use_cache = config.use_cache
# final_bias_logits is registered as a buffer in pytorch, so not trainable for the sake of consistency.
self.bias_layer = BiasLayer(
name="final_logits_bias", shape=[1, config.vocab_size], initializer="zeros", trainable=False
)
# TODO (Joao): investigate why LED has numerical issues in XLA generate
self.supports_xla_generation = False
def get_decoder(self):
return self.led.decoder
def get_encoder(self):
return self.led.encoder
def get_bias(self):
return {"final_logits_bias": self.bias_layer.bias}
def set_bias(self, value):
# Replaces the existing layers containing bias for correct (de)serialization.
vocab_size = value["final_logits_bias"].shape[-1]
self.bias_layer = BiasLayer(
name="final_logits_bias", shape=[1, vocab_size], initializer="zeros", trainable=False
)
self.bias_layer.bias.assign(value["final_logits_bias"])
def get_output_embeddings(self):
return self.get_input_embeddings()
def set_output_embeddings(self, value):
self.set_input_embeddings(value)
@unpack_inputs
@add_start_docstrings_to_model_forward(LED_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=TFLEDSeq2SeqLMOutput, config_class=_CONFIG_FOR_DOC)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
decoder_input_ids: np.ndarray | tf.Tensor | None = None,
decoder_attention_mask: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
decoder_head_mask: np.ndarray | tf.Tensor | None = None,
encoder_outputs: TFLEDEncoderBaseModelOutput | None = None,
global_attention_mask: np.ndarray | tf.Tensor | None = None,
past_key_values: Tuple[Tuple[Union[np.ndarray, tf.Tensor]]] | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
decoder_inputs_embeds: np.ndarray | tf.Tensor | None = None,
use_cache: bool | None = None,
output_attentions: bool | None = None,
output_hidden_states: bool | None = None,
return_dict: bool | None = None,
labels: tf.Tensor | None = None,
training: bool = False,
) -> Tuple[tf.Tensor] | TFLEDSeq2SeqLMOutput:
"""
Returns:
Examples:
```python
>>> from transformers import AutoTokenizer, TFLEDForConditionalGeneration
>>> import tensorflow as tf
>>> mname = "allenai/led-base-16384"
>>> tokenizer = AutoTokenizer.from_pretrained(mname)
>>> TXT = "My friends are <mask> but they eat too many carbs."
>>> model = TFLEDForConditionalGeneration.from_pretrained(mname)
>>> batch = tokenizer([TXT], return_tensors="tf")
>>> logits = model(inputs=batch.input_ids).logits
>>> probs = tf.nn.softmax(logits[0])
>>> # probs[5] is associated with the mask token
```"""
if labels is not None:
use_cache = False
if decoder_input_ids is None and decoder_inputs_embeds is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
)
outputs = self.led(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
encoder_outputs=encoder_outputs,
global_attention_mask=global_attention_mask,
head_mask=head_mask,
decoder_head_mask=decoder_head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
decoder_inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
lm_logits = tf.matmul(outputs[0], self.led.shared.weights, transpose_b=True)
lm_logits = self.bias_layer(lm_logits)
masked_lm_loss = None if labels is None else self.hf_compute_loss(labels, lm_logits)
if not return_dict:
output = (lm_logits,) + outputs[1:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return TFLEDSeq2SeqLMOutput(
loss=masked_lm_loss,
logits=lm_logits,
past_key_values=outputs.past_key_values, # index 1 of d outputs
decoder_hidden_states=outputs.decoder_hidden_states, # index 2 of d outputs
decoder_attentions=outputs.decoder_attentions, # index 3 of d outputs
cross_attentions=outputs.cross_attentions, # index 4 of d outputs
encoder_last_hidden_state=outputs.encoder_last_hidden_state, # index 0 of encoder outputs
encoder_hidden_states=outputs.encoder_hidden_states, # 1 of e out
encoder_attentions=outputs.encoder_attentions, # 2 of e out
encoder_global_attentions=outputs.encoder_global_attentions,
)
def serving_output(self, output):
pkv = tf.tuple(output.past_key_values)[1] if self.config.use_cache else None
dec_hs = tf.convert_to_tensor(output.decoder_hidden_states) if self.config.output_hidden_states else None
dec_attns = tf.convert_to_tensor(output.decoder_attentions) if self.config.output_attentions else None
cross_attns = tf.convert_to_tensor(output.cross_attentions) if self.config.output_attentions else None
enc_hs = tf.convert_to_tensor(output.encoder_hidden_states) if self.config.output_hidden_states else None
enc_attns = tf.convert_to_tensor(output.encoder_attentions) if self.config.output_attentions else None
enc_g_attns = tf.convert_to_tensor(output.encoder_global_attentions) if self.config.output_attentions else None
return TFLEDSeq2SeqLMOutput(
logits=output.logits,
past_key_values=pkv,
decoder_hidden_states=dec_hs,
decoder_attentions=dec_attns,
cross_attentions=cross_attns,
encoder_last_hidden_state=output.encoder_last_hidden_state,
encoder_hidden_states=enc_hs,
encoder_attentions=enc_attns,
encoder_global_attentions=enc_g_attns,
)
def prepare_inputs_for_generation(
self,
decoder_input_ids,
past_key_values=None,
attention_mask=None,
head_mask=None,
decoder_head_mask=None,
use_cache=None,
encoder_outputs=None,
**kwargs,
):
# cut decoder_input_ids if past is used
if past_key_values is not None:
decoder_input_ids = decoder_input_ids[:, -1:]
return {
"input_ids": None, # encoder_outputs is defined. input_ids not needed
"encoder_outputs": encoder_outputs,
"past_key_values": past_key_values,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"head_mask": head_mask,
"decoder_head_mask": decoder_head_mask,
"use_cache": use_cache, # change this to avoid caching (presumably for debugging)
}
def prepare_decoder_input_ids_from_labels(self, labels: tf.Tensor):
return shift_tokens_right(labels, self.config.pad_token_id, self.config.decoder_start_token_id)
def hf_compute_loss(self, labels, logits):
"""CrossEntropyLoss that ignores pad tokens"""
loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction=keras.losses.Reduction.NONE)
if self.config.tf_legacy_loss:
melted_labels = tf.reshape(labels, (-1,))
active_loss = tf.not_equal(melted_labels, self.config.pad_token_id)
reduced_logits = tf.boolean_mask(tf.reshape(logits, (-1, shape_list(logits)[2])), active_loss)
labels = tf.boolean_mask(melted_labels, active_loss)
return loss_fn(labels, reduced_logits)
# Clip negative labels to zero here to avoid NaNs and errors - those positions will get masked later anyway
unmasked_loss = loss_fn(tf.nn.relu(labels), logits)
# make sure only non-padding labels affect the loss
loss_mask = tf.cast(labels != self.config.pad_token_id, dtype=unmasked_loss.dtype)
masked_loss = unmasked_loss * loss_mask
reduced_masked_loss = tf.reduce_sum(masked_loss) / tf.reduce_sum(loss_mask)
return tf.reshape(reduced_masked_loss, (1,))
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "led", None) is not None:
with tf.name_scope(self.led.name):
self.led.build(None)
if getattr(self, "bias_layer", None) is not None:
with tf.name_scope(self.bias_layer.name):
self.bias_layer.build(None)
__all__ = ["TFLEDForConditionalGeneration", "TFLEDModel", "TFLEDPreTrainedModel"]
| transformers/src/transformers/models/led/modeling_tf_led.py/0 | {
"file_path": "transformers/src/transformers/models/led/modeling_tf_led.py",
"repo_id": "transformers",
"token_count": 55151
} |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Processor class for LLaVa-NeXT.
"""
from typing import List, Union
from ...feature_extraction_utils import BatchFeature
from ...image_processing_utils import select_best_resolution
from ...image_utils import ImageInput, get_image_size, to_numpy_array
from ...processing_utils import ProcessingKwargs, ProcessorMixin, Unpack, _validate_images_text_input_order
from ...tokenization_utils_base import PreTokenizedInput, TextInput
from ...utils import logging
logger = logging.get_logger(__name__)
class LlavaNextProcessorKwargs(ProcessingKwargs, total=False):
_defaults = {
"text_kwargs": {
"padding": False,
},
"images_kwargs": {
"do_pad": True,
},
}
class LlavaNextProcessor(ProcessorMixin):
r"""
Constructs a LLaVa-NeXT processor which wraps a LLaVa-NeXT image processor and a LLaMa tokenizer into a single processor.
[`LlavaNextProcessor`] offers all the functionalities of [`LlavaNextImageProcessor`] and [`LlamaTokenizerFast`]. See the
[`~LlavaNextProcessor.__call__`] and [`~LlavaNextProcessor.decode`] for more information.
Args:
image_processor ([`LlavaNextImageProcessor`], *optional*):
The image processor is a required input.
tokenizer ([`LlamaTokenizerFast`], *optional*):
The tokenizer is a required input.
patch_size (`int`, *optional*):
Patch size from the vision tower.
vision_feature_select_strategy (`str`, *optional*):
The feature selection strategy used to select the vision feature from the vision backbone.
Shoudl be same as in model's config
chat_template (`str`, *optional*): A Jinja template which will be used to convert lists of messages
in a chat into a tokenizable string.
image_token (`str`, *optional*, defaults to `"<image>"`):
Special token used to denote image location.
num_additional_image_tokens (`int`, *optional*, defaults to 0):
Number of additional tokens added to the image embeddings, such as CLS (+1). If the backbone has no CLS or other
extra tokens appended, no need to set this arg.
"""
attributes = ["image_processor", "tokenizer"]
valid_kwargs = [
"chat_template",
"patch_size",
"vision_feature_select_strategy",
"image_token",
"num_additional_image_tokens",
]
image_processor_class = "AutoImageProcessor"
tokenizer_class = "AutoTokenizer"
def __init__(
self,
image_processor=None,
tokenizer=None,
patch_size=None,
vision_feature_select_strategy=None,
chat_template=None,
image_token="<image>", # set the default and let users change if they have peculiar special tokens in rare cases
num_additional_image_tokens=0,
**kwargs,
):
self.patch_size = patch_size
self.num_additional_image_tokens = num_additional_image_tokens
self.vision_feature_select_strategy = vision_feature_select_strategy
self.image_token = tokenizer.image_token if hasattr(tokenizer, "image_token") else image_token
super().__init__(image_processor, tokenizer, chat_template=chat_template)
def __call__(
self,
images: ImageInput = None,
text: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]] = None,
audio=None,
videos=None,
**kwargs: Unpack[LlavaNextProcessorKwargs],
) -> BatchFeature:
"""
Main method to prepare for the model one or several sequences(s) and image(s). This method forwards the `text`
and `kwargs` arguments to LlamaTokenizerFast's [`~LlamaTokenizerFast.__call__`] if `text` is not `None` to encode
the text. To prepare the image(s), this method forwards the `images` and `kwrags` arguments to
LlavaNextImageProcessor's [`~LlavaNextImageProcessor.__call__`] if `images` is not `None`. Please refer to the doctsring
of the above two methods for more information.
Args:
images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
tensor. Both channels-first and channels-last formats are supported.
text (`str`, `List[str]`, `List[List[str]]`):
The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
(pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
`is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
Returns:
[`BatchFeature`]: A [`BatchFeature`] with the following fields:
- **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None`.
- **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
`return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names` and if `text` is not
`None`).
- **pixel_values** -- Pixel values to be fed to a model. Returned when `images` is not `None`.
"""
if images is None and text is None:
raise ValueError("You have to specify at least images or text.")
# check if images and text inputs are reversed for BC
images, text = _validate_images_text_input_order(images, text)
output_kwargs = self._merge_kwargs(
LlavaNextProcessorKwargs,
tokenizer_init_kwargs=self.tokenizer.init_kwargs,
**kwargs,
)
if images is not None:
image_inputs = self.image_processor(images, **output_kwargs["images_kwargs"])
else:
image_inputs = {}
if isinstance(text, str):
text = [text]
elif not isinstance(text, list) and not isinstance(text[0], str):
raise ValueError("Invalid input text. Please provide a string, or a list of strings")
prompt_strings = text
if image_inputs:
image_sizes = iter(image_inputs["image_sizes"])
height, width = get_image_size(to_numpy_array(image_inputs["pixel_values"][0][0]))
prompt_strings = []
for sample in text:
while self.image_token in sample:
image_size = next(image_sizes)
if not isinstance(image_size, (list, tuple)):
# cast to list to avoid numerical precision errors when calculating unpadding
image_size = image_size.tolist()
orig_height, orig_width = image_size
num_image_tokens = self._get_number_of_features(orig_height, orig_width, height, width)
if self.vision_feature_select_strategy == "default":
num_image_tokens -= 1
sample = sample.replace(self.image_token, "<placeholder>" * num_image_tokens, 1)
prompt_strings.append(sample)
prompt_strings = [sample.replace("<placeholder>", self.image_token) for sample in prompt_strings]
text_inputs = self.tokenizer(prompt_strings, **output_kwargs["text_kwargs"])
return BatchFeature(data={**text_inputs, **image_inputs})
def _get_number_of_features(self, orig_height: int, orig_width: int, height: int, width: int) -> int:
image_grid_pinpoints = self.image_processor.image_grid_pinpoints
height_best_resolution, width_best_resolution = select_best_resolution(
[orig_height, orig_width], image_grid_pinpoints
)
scale_height, scale_width = height_best_resolution // height, width_best_resolution // width
patches_height = height // self.patch_size
patches_width = width // self.patch_size
unpadded_features, newline_features = self._get_unpadded_features(
orig_height, orig_width, patches_height, patches_width, scale_height, scale_width
)
# The base patch covers the entire image (+1 for the CLS)
base_features = patches_height * patches_width + self.num_additional_image_tokens
num_image_tokens = unpadded_features + newline_features + base_features
return num_image_tokens
def _get_unpadded_features(self, height, width, patches_height, patches_width, scale_height, scale_width):
"""
Get number of features for a given image with height/width. LLaVA-NeXT is different from LLaVA
because it divided each image into patches depending on its resolution. Therefore we need to calculate how many
patches an image is divided into and get the number of features from that.
"""
current_height = patches_height * scale_height
current_width = patches_width * scale_width
original_aspect_ratio = width / height
current_aspect_ratio = current_width / current_height
if original_aspect_ratio > current_aspect_ratio:
new_height = int(round(height * (current_width / width), 7))
padding = (current_height - new_height) // 2
current_height -= padding * 2
else:
new_width = int(round(width * (current_height / height), 7))
padding = (current_width - new_width) // 2
current_width -= padding * 2
unpadded_features = current_height * current_width
newline_features = current_height
return (unpadded_features, newline_features)
# Copied from transformers.models.clip.processing_clip.CLIPProcessor.batch_decode with CLIP->Llama
def batch_decode(self, *args, **kwargs):
"""
This method forwards all its arguments to LlamaTokenizerFast's [`~PreTrainedTokenizer.batch_decode`]. Please
refer to the docstring of this method for more information.
"""
return self.tokenizer.batch_decode(*args, **kwargs)
# Copied from transformers.models.clip.processing_clip.CLIPProcessor.decode with CLIP->Llama
def decode(self, *args, **kwargs):
"""
This method forwards all its arguments to LlamaTokenizerFast's [`~PreTrainedTokenizer.decode`]. Please refer to
the docstring of this method for more information.
"""
return self.tokenizer.decode(*args, **kwargs)
@property
# Copied from transformers.models.clip.processing_clip.CLIPProcessor.model_input_names
def model_input_names(self):
tokenizer_input_names = self.tokenizer.model_input_names
image_processor_input_names = self.image_processor.model_input_names
return list(dict.fromkeys(tokenizer_input_names + image_processor_input_names))
__all__ = ["LlavaNextProcessor"]
| transformers/src/transformers/models/llava_next/processing_llava_next.py/0 | {
"file_path": "transformers/src/transformers/models/llava_next/processing_llava_next.py",
"repo_id": "transformers",
"token_count": 4507
} |
# coding=utf-8
# Copyright Studio Ousia and The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch LUKE model."""
import math
from dataclasses import dataclass
from typing import Optional, Tuple, Union
import torch
import torch.utils.checkpoint
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from ...activations import ACT2FN, gelu
from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling
from ...modeling_utils import PreTrainedModel
from ...pytorch_utils import apply_chunking_to_forward
from ...utils import (
ModelOutput,
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
logging,
replace_return_docstrings,
)
from .configuration_luke import LukeConfig
logger = logging.get_logger(__name__)
_CONFIG_FOR_DOC = "LukeConfig"
_CHECKPOINT_FOR_DOC = "studio-ousia/luke-base"
@dataclass
class BaseLukeModelOutputWithPooling(BaseModelOutputWithPooling):
"""
Base class for outputs of the LUKE model.
Args:
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
entity_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, entity_length, hidden_size)`):
Sequence of entity hidden-states at the output of the last layer of the model.
pooler_output (`torch.FloatTensor` of shape `(batch_size, hidden_size)`):
Last layer hidden-state of the first token of the sequence (classification token) further processed by a
Linear layer and a Tanh activation function.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
plus the initial embedding outputs.
entity_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, entity_length, hidden_size)`. Entity hidden-states of the model at the output of each
layer plus the initial entity embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length +
entity_length, sequence_length + entity_length)`. Attentions weights after the attention softmax, used to
compute the weighted average in the self-attention heads.
"""
entity_last_hidden_state: torch.FloatTensor = None
entity_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
@dataclass
class BaseLukeModelOutput(BaseModelOutput):
"""
Base class for model's outputs, with potential hidden states and attentions.
Args:
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
entity_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, entity_length, hidden_size)`):
Sequence of entity hidden-states at the output of the last layer of the model.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
entity_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, entity_length, hidden_size)`. Entity hidden-states of the model at the output of each
layer plus the initial entity embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
entity_last_hidden_state: torch.FloatTensor = None
entity_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
@dataclass
class LukeMaskedLMOutput(ModelOutput):
"""
Base class for model's outputs, with potential hidden states and attentions.
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
The sum of masked language modeling (MLM) loss and entity prediction loss.
mlm_loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
Masked language modeling (MLM) loss.
mep_loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
Masked entity prediction (MEP) loss.
logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
entity_logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
Prediction scores of the entity prediction head (scores for each entity vocabulary token before SoftMax).
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
entity_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, entity_length, hidden_size)`. Entity hidden-states of the model at the output of each
layer plus the initial entity embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
loss: Optional[torch.FloatTensor] = None
mlm_loss: Optional[torch.FloatTensor] = None
mep_loss: Optional[torch.FloatTensor] = None
logits: torch.FloatTensor = None
entity_logits: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
entity_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
@dataclass
class EntityClassificationOutput(ModelOutput):
"""
Outputs of entity classification models.
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
Classification loss.
logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
Classification scores (before SoftMax).
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
plus the initial embedding outputs.
entity_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, entity_length, hidden_size)`. Entity hidden-states of the model at the output of each
layer plus the initial entity embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
the self-attention heads.
"""
loss: Optional[torch.FloatTensor] = None
logits: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
entity_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
@dataclass
class EntityPairClassificationOutput(ModelOutput):
"""
Outputs of entity pair classification models.
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
Classification loss.
logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
Classification scores (before SoftMax).
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
plus the initial embedding outputs.
entity_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, entity_length, hidden_size)`. Entity hidden-states of the model at the output of each
layer plus the initial entity embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
the self-attention heads.
"""
loss: Optional[torch.FloatTensor] = None
logits: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
entity_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
@dataclass
class EntitySpanClassificationOutput(ModelOutput):
"""
Outputs of entity span classification models.
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
Classification loss.
logits (`torch.FloatTensor` of shape `(batch_size, entity_length, config.num_labels)`):
Classification scores (before SoftMax).
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
plus the initial embedding outputs.
entity_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, entity_length, hidden_size)`. Entity hidden-states of the model at the output of each
layer plus the initial entity embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
the self-attention heads.
"""
loss: Optional[torch.FloatTensor] = None
logits: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
entity_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
@dataclass
class LukeSequenceClassifierOutput(ModelOutput):
"""
Outputs of sentence classification models.
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
Classification (or regression if config.num_labels==1) loss.
logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
Classification (or regression if config.num_labels==1) scores (before SoftMax).
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
entity_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, entity_length, hidden_size)`. Entity hidden-states of the model at the output of each
layer plus the initial entity embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
loss: Optional[torch.FloatTensor] = None
logits: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
entity_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
@dataclass
class LukeTokenClassifierOutput(ModelOutput):
"""
Base class for outputs of token classification models.
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided) :
Classification loss.
logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.num_labels)`):
Classification scores (before SoftMax).
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
entity_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, entity_length, hidden_size)`. Entity hidden-states of the model at the output of each
layer plus the initial entity embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
loss: Optional[torch.FloatTensor] = None
logits: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
entity_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
@dataclass
class LukeQuestionAnsweringModelOutput(ModelOutput):
"""
Outputs of question answering models.
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
Total span extraction loss is the sum of a Cross-Entropy for the start and end positions.
start_logits (`torch.FloatTensor` of shape `(batch_size, sequence_length)`):
Span-start scores (before SoftMax).
end_logits (`torch.FloatTensor` of shape `(batch_size, sequence_length)`):
Span-end scores (before SoftMax).
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
entity_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, entity_length, hidden_size)`. Entity hidden-states of the model at the output of each
layer plus the initial entity embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
loss: Optional[torch.FloatTensor] = None
start_logits: torch.FloatTensor = None
end_logits: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
entity_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
@dataclass
class LukeMultipleChoiceModelOutput(ModelOutput):
"""
Outputs of multiple choice models.
Args:
loss (`torch.FloatTensor` of shape *(1,)*, *optional*, returned when `labels` is provided):
Classification loss.
logits (`torch.FloatTensor` of shape `(batch_size, num_choices)`):
*num_choices* is the second dimension of the input tensors. (see *input_ids* above).
Classification scores (before SoftMax).
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
entity_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, entity_length, hidden_size)`. Entity hidden-states of the model at the output of each
layer plus the initial entity embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
loss: Optional[torch.FloatTensor] = None
logits: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
entity_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
class LukeEmbeddings(nn.Module):
"""
Same as BertEmbeddings with a tiny tweak for positional embeddings indexing.
"""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# End copy
self.padding_idx = config.pad_token_id
self.position_embeddings = nn.Embedding(
config.max_position_embeddings, config.hidden_size, padding_idx=self.padding_idx
)
def forward(
self,
input_ids=None,
token_type_ids=None,
position_ids=None,
inputs_embeds=None,
):
if position_ids is None:
if input_ids is not None:
# Create the position ids from the input token ids. Any padded tokens remain padded.
position_ids = create_position_ids_from_input_ids(input_ids, self.padding_idx).to(input_ids.device)
else:
position_ids = self.create_position_ids_from_inputs_embeds(inputs_embeds)
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + position_embeddings + token_type_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
def create_position_ids_from_inputs_embeds(self, inputs_embeds):
"""
We are provided embeddings directly. We cannot infer which are padded so just generate sequential position ids.
Args:
inputs_embeds: torch.Tensor
Returns: torch.Tensor
"""
input_shape = inputs_embeds.size()[:-1]
sequence_length = input_shape[1]
position_ids = torch.arange(
self.padding_idx + 1, sequence_length + self.padding_idx + 1, dtype=torch.long, device=inputs_embeds.device
)
return position_ids.unsqueeze(0).expand(input_shape)
class LukeEntityEmbeddings(nn.Module):
def __init__(self, config: LukeConfig):
super().__init__()
self.config = config
self.entity_embeddings = nn.Embedding(config.entity_vocab_size, config.entity_emb_size, padding_idx=0)
if config.entity_emb_size != config.hidden_size:
self.entity_embedding_dense = nn.Linear(config.entity_emb_size, config.hidden_size, bias=False)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(
self, entity_ids: torch.LongTensor, position_ids: torch.LongTensor, token_type_ids: torch.LongTensor = None
):
if token_type_ids is None:
token_type_ids = torch.zeros_like(entity_ids)
entity_embeddings = self.entity_embeddings(entity_ids)
if self.config.entity_emb_size != self.config.hidden_size:
entity_embeddings = self.entity_embedding_dense(entity_embeddings)
position_embeddings = self.position_embeddings(position_ids.clamp(min=0))
position_embedding_mask = (position_ids != -1).type_as(position_embeddings).unsqueeze(-1)
position_embeddings = position_embeddings * position_embedding_mask
position_embeddings = torch.sum(position_embeddings, dim=-2)
position_embeddings = position_embeddings / position_embedding_mask.sum(dim=-2).clamp(min=1e-7)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = entity_embeddings + position_embeddings + token_type_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
class LukeSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
f"heads {config.num_attention_heads}."
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.use_entity_aware_attention = config.use_entity_aware_attention
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
if self.use_entity_aware_attention:
self.w2e_query = nn.Linear(config.hidden_size, self.all_head_size)
self.e2w_query = nn.Linear(config.hidden_size, self.all_head_size)
self.e2e_query = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
word_hidden_states,
entity_hidden_states,
attention_mask=None,
head_mask=None,
output_attentions=False,
):
word_size = word_hidden_states.size(1)
if entity_hidden_states is None:
concat_hidden_states = word_hidden_states
else:
concat_hidden_states = torch.cat([word_hidden_states, entity_hidden_states], dim=1)
key_layer = self.transpose_for_scores(self.key(concat_hidden_states))
value_layer = self.transpose_for_scores(self.value(concat_hidden_states))
if self.use_entity_aware_attention and entity_hidden_states is not None:
# compute query vectors using word-word (w2w), word-entity (w2e), entity-word (e2w), entity-entity (e2e)
# query layers
w2w_query_layer = self.transpose_for_scores(self.query(word_hidden_states))
w2e_query_layer = self.transpose_for_scores(self.w2e_query(word_hidden_states))
e2w_query_layer = self.transpose_for_scores(self.e2w_query(entity_hidden_states))
e2e_query_layer = self.transpose_for_scores(self.e2e_query(entity_hidden_states))
# compute w2w, w2e, e2w, and e2e key vectors used with the query vectors computed above
w2w_key_layer = key_layer[:, :, :word_size, :]
e2w_key_layer = key_layer[:, :, :word_size, :]
w2e_key_layer = key_layer[:, :, word_size:, :]
e2e_key_layer = key_layer[:, :, word_size:, :]
# compute attention scores based on the dot product between the query and key vectors
w2w_attention_scores = torch.matmul(w2w_query_layer, w2w_key_layer.transpose(-1, -2))
w2e_attention_scores = torch.matmul(w2e_query_layer, w2e_key_layer.transpose(-1, -2))
e2w_attention_scores = torch.matmul(e2w_query_layer, e2w_key_layer.transpose(-1, -2))
e2e_attention_scores = torch.matmul(e2e_query_layer, e2e_key_layer.transpose(-1, -2))
# combine attention scores to create the final attention score matrix
word_attention_scores = torch.cat([w2w_attention_scores, w2e_attention_scores], dim=3)
entity_attention_scores = torch.cat([e2w_attention_scores, e2e_attention_scores], dim=3)
attention_scores = torch.cat([word_attention_scores, entity_attention_scores], dim=2)
else:
query_layer = self.transpose_for_scores(self.query(concat_hidden_states))
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in LukeModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
output_word_hidden_states = context_layer[:, :word_size, :]
if entity_hidden_states is None:
output_entity_hidden_states = None
else:
output_entity_hidden_states = context_layer[:, word_size:, :]
if output_attentions:
outputs = (output_word_hidden_states, output_entity_hidden_states, attention_probs)
else:
outputs = (output_word_hidden_states, output_entity_hidden_states)
return outputs
# Copied from transformers.models.bert.modeling_bert.BertSelfOutput
class LukeSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
class LukeAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.self = LukeSelfAttention(config)
self.output = LukeSelfOutput(config)
self.pruned_heads = set()
def prune_heads(self, heads):
raise NotImplementedError("LUKE does not support the pruning of attention heads")
def forward(
self,
word_hidden_states,
entity_hidden_states,
attention_mask=None,
head_mask=None,
output_attentions=False,
):
word_size = word_hidden_states.size(1)
self_outputs = self.self(
word_hidden_states,
entity_hidden_states,
attention_mask,
head_mask,
output_attentions,
)
if entity_hidden_states is None:
concat_self_outputs = self_outputs[0]
concat_hidden_states = word_hidden_states
else:
concat_self_outputs = torch.cat(self_outputs[:2], dim=1)
concat_hidden_states = torch.cat([word_hidden_states, entity_hidden_states], dim=1)
attention_output = self.output(concat_self_outputs, concat_hidden_states)
word_attention_output = attention_output[:, :word_size, :]
if entity_hidden_states is None:
entity_attention_output = None
else:
entity_attention_output = attention_output[:, word_size:, :]
# add attentions if we output them
outputs = (word_attention_output, entity_attention_output) + self_outputs[2:]
return outputs
# Copied from transformers.models.bert.modeling_bert.BertIntermediate
class LukeIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertOutput
class LukeOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
class LukeLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = LukeAttention(config)
self.intermediate = LukeIntermediate(config)
self.output = LukeOutput(config)
def forward(
self,
word_hidden_states,
entity_hidden_states,
attention_mask=None,
head_mask=None,
output_attentions=False,
):
word_size = word_hidden_states.size(1)
self_attention_outputs = self.attention(
word_hidden_states,
entity_hidden_states,
attention_mask,
head_mask,
output_attentions=output_attentions,
)
if entity_hidden_states is None:
concat_attention_output = self_attention_outputs[0]
else:
concat_attention_output = torch.cat(self_attention_outputs[:2], dim=1)
outputs = self_attention_outputs[2:] # add self attentions if we output attention weights
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, concat_attention_output
)
word_layer_output = layer_output[:, :word_size, :]
if entity_hidden_states is None:
entity_layer_output = None
else:
entity_layer_output = layer_output[:, word_size:, :]
outputs = (word_layer_output, entity_layer_output) + outputs
return outputs
def feed_forward_chunk(self, attention_output):
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output
class LukeEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.layer = nn.ModuleList([LukeLayer(config) for _ in range(config.num_hidden_layers)])
self.gradient_checkpointing = False
def forward(
self,
word_hidden_states,
entity_hidden_states,
attention_mask=None,
head_mask=None,
output_attentions=False,
output_hidden_states=False,
return_dict=True,
):
all_word_hidden_states = () if output_hidden_states else None
all_entity_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_word_hidden_states = all_word_hidden_states + (word_hidden_states,)
all_entity_hidden_states = all_entity_hidden_states + (entity_hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
layer_module.__call__,
word_hidden_states,
entity_hidden_states,
attention_mask,
layer_head_mask,
output_attentions,
)
else:
layer_outputs = layer_module(
word_hidden_states,
entity_hidden_states,
attention_mask,
layer_head_mask,
output_attentions,
)
word_hidden_states = layer_outputs[0]
if entity_hidden_states is not None:
entity_hidden_states = layer_outputs[1]
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[2],)
if output_hidden_states:
all_word_hidden_states = all_word_hidden_states + (word_hidden_states,)
all_entity_hidden_states = all_entity_hidden_states + (entity_hidden_states,)
if not return_dict:
return tuple(
v
for v in [
word_hidden_states,
all_word_hidden_states,
all_self_attentions,
entity_hidden_states,
all_entity_hidden_states,
]
if v is not None
)
return BaseLukeModelOutput(
last_hidden_state=word_hidden_states,
hidden_states=all_word_hidden_states,
attentions=all_self_attentions,
entity_last_hidden_state=entity_hidden_states,
entity_hidden_states=all_entity_hidden_states,
)
# Copied from transformers.models.bert.modeling_bert.BertPooler
class LukePooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
class EntityPredictionHeadTransform(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.entity_emb_size)
if isinstance(config.hidden_act, str):
self.transform_act_fn = ACT2FN[config.hidden_act]
else:
self.transform_act_fn = config.hidden_act
self.LayerNorm = nn.LayerNorm(config.entity_emb_size, eps=config.layer_norm_eps)
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(hidden_states)
return hidden_states
class EntityPredictionHead(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.transform = EntityPredictionHeadTransform(config)
self.decoder = nn.Linear(config.entity_emb_size, config.entity_vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.entity_vocab_size))
def forward(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states) + self.bias
return hidden_states
class LukePreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = LukeConfig
base_model_prefix = "luke"
supports_gradient_checkpointing = True
_no_split_modules = ["LukeAttention", "LukeEntityEmbeddings"]
def _init_weights(self, module: nn.Module):
"""Initialize the weights"""
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
if module.embedding_dim == 1: # embedding for bias parameters
module.weight.data.zero_()
else:
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
LUKE_START_DOCSTRING = r"""
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`LukeConfig`]): Model configuration class with all the parameters of the
model. Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
LUKE_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
entity_ids (`torch.LongTensor` of shape `(batch_size, entity_length)`):
Indices of entity tokens in the entity vocabulary.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
entity_attention_mask (`torch.FloatTensor` of shape `(batch_size, entity_length)`, *optional*):
Mask to avoid performing attention on padding entity token indices. Mask values selected in `[0, 1]`:
- 1 for entity tokens that are **not masked**,
- 0 for entity tokens that are **masked**.
entity_token_type_ids (`torch.LongTensor` of shape `(batch_size, entity_length)`, *optional*):
Segment token indices to indicate first and second portions of the entity token inputs. Indices are
selected in `[0, 1]`:
- 0 corresponds to a *portion A* entity token,
- 1 corresponds to a *portion B* entity token.
entity_position_ids (`torch.LongTensor` of shape `(batch_size, entity_length, max_mention_length)`, *optional*):
Indices of positions of each input entity in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
@add_start_docstrings(
"The bare LUKE model transformer outputting raw hidden-states for both word tokens and entities without any"
" specific head on top.",
LUKE_START_DOCSTRING,
)
class LukeModel(LukePreTrainedModel):
def __init__(self, config: LukeConfig, add_pooling_layer: bool = True):
super().__init__(config)
self.config = config
self.embeddings = LukeEmbeddings(config)
self.entity_embeddings = LukeEntityEmbeddings(config)
self.encoder = LukeEncoder(config)
self.pooler = LukePooler(config) if add_pooling_layer else None
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
def get_entity_embeddings(self):
return self.entity_embeddings.entity_embeddings
def set_entity_embeddings(self, value):
self.entity_embeddings.entity_embeddings = value
def _prune_heads(self, heads_to_prune):
raise NotImplementedError("LUKE does not support the pruning of attention heads")
@add_start_docstrings_to_model_forward(LUKE_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=BaseLukeModelOutputWithPooling, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
entity_ids: Optional[torch.LongTensor] = None,
entity_attention_mask: Optional[torch.FloatTensor] = None,
entity_token_type_ids: Optional[torch.LongTensor] = None,
entity_position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseLukeModelOutputWithPooling]:
r"""
Returns:
Examples:
```python
>>> from transformers import AutoTokenizer, LukeModel
>>> tokenizer = AutoTokenizer.from_pretrained("studio-ousia/luke-base")
>>> model = LukeModel.from_pretrained("studio-ousia/luke-base")
# Compute the contextualized entity representation corresponding to the entity mention "Beyoncé"
>>> text = "Beyoncé lives in Los Angeles."
>>> entity_spans = [(0, 7)] # character-based entity span corresponding to "Beyoncé"
>>> encoding = tokenizer(text, entity_spans=entity_spans, add_prefix_space=True, return_tensors="pt")
>>> outputs = model(**encoding)
>>> word_last_hidden_state = outputs.last_hidden_state
>>> entity_last_hidden_state = outputs.entity_last_hidden_state
# Input Wikipedia entities to obtain enriched contextualized representations of word tokens
>>> text = "Beyoncé lives in Los Angeles."
>>> entities = [
... "Beyoncé",
... "Los Angeles",
... ] # Wikipedia entity titles corresponding to the entity mentions "Beyoncé" and "Los Angeles"
>>> entity_spans = [
... (0, 7),
... (17, 28),
... ] # character-based entity spans corresponding to "Beyoncé" and "Los Angeles"
>>> encoding = tokenizer(
... text, entities=entities, entity_spans=entity_spans, add_prefix_space=True, return_tensors="pt"
... )
>>> outputs = model(**encoding)
>>> word_last_hidden_state = outputs.last_hidden_state
>>> entity_last_hidden_state = outputs.entity_last_hidden_state
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
batch_size, seq_length = input_shape
device = input_ids.device if input_ids is not None else inputs_embeds.device
if attention_mask is None:
attention_mask = torch.ones((batch_size, seq_length), device=device)
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
if entity_ids is not None:
entity_seq_length = entity_ids.size(1)
if entity_attention_mask is None:
entity_attention_mask = torch.ones((batch_size, entity_seq_length), device=device)
if entity_token_type_ids is None:
entity_token_type_ids = torch.zeros((batch_size, entity_seq_length), dtype=torch.long, device=device)
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
# First, compute word embeddings
word_embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
token_type_ids=token_type_ids,
inputs_embeds=inputs_embeds,
)
# Second, compute extended attention mask
extended_attention_mask = self.get_extended_attention_mask(attention_mask, entity_attention_mask)
# Third, compute entity embeddings and concatenate with word embeddings
if entity_ids is None:
entity_embedding_output = None
else:
entity_embedding_output = self.entity_embeddings(entity_ids, entity_position_ids, entity_token_type_ids)
# Fourth, send embeddings through the model
encoder_outputs = self.encoder(
word_embedding_output,
entity_embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
# Fifth, get the output. LukeModel outputs the same as BertModel, namely sequence_output of shape (batch_size, seq_len, hidden_size)
sequence_output = encoder_outputs[0]
# Sixth, we compute the pooled_output, word_sequence_output and entity_sequence_output based on the sequence_output
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseLukeModelOutputWithPooling(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
entity_last_hidden_state=encoder_outputs.entity_last_hidden_state,
entity_hidden_states=encoder_outputs.entity_hidden_states,
)
def get_extended_attention_mask(
self, word_attention_mask: torch.LongTensor, entity_attention_mask: Optional[torch.LongTensor]
):
"""
Makes broadcastable attention and causal masks so that future and masked tokens are ignored.
Arguments:
word_attention_mask (`torch.LongTensor`):
Attention mask for word tokens with ones indicating tokens to attend to, zeros for tokens to ignore.
entity_attention_mask (`torch.LongTensor`, *optional*):
Attention mask for entity tokens with ones indicating tokens to attend to, zeros for tokens to ignore.
Returns:
`torch.Tensor` The extended attention mask, with a the same dtype as `attention_mask.dtype`.
"""
attention_mask = word_attention_mask
if entity_attention_mask is not None:
attention_mask = torch.cat([attention_mask, entity_attention_mask], dim=-1)
if attention_mask.dim() == 3:
extended_attention_mask = attention_mask[:, None, :, :]
elif attention_mask.dim() == 2:
extended_attention_mask = attention_mask[:, None, None, :]
else:
raise ValueError(f"Wrong shape for attention_mask (shape {attention_mask.shape})")
extended_attention_mask = extended_attention_mask.to(dtype=self.dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * torch.finfo(self.dtype).min
return extended_attention_mask
def create_position_ids_from_input_ids(input_ids, padding_idx):
"""
Replace non-padding symbols with their position numbers. Position numbers begin at padding_idx+1. Padding symbols
are ignored. This is modified from fairseq's `utils.make_positions`.
Args:
x: torch.Tensor x:
Returns: torch.Tensor
"""
# The series of casts and type-conversions here are carefully balanced to both work with ONNX export and XLA.
mask = input_ids.ne(padding_idx).int()
incremental_indices = (torch.cumsum(mask, dim=1).type_as(mask)) * mask
return incremental_indices.long() + padding_idx
# Copied from transformers.models.roberta.modeling_roberta.RobertaLMHead
class LukeLMHead(nn.Module):
"""Roberta Head for masked language modeling."""
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.decoder = nn.Linear(config.hidden_size, config.vocab_size)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
self.decoder.bias = self.bias
def forward(self, features, **kwargs):
x = self.dense(features)
x = gelu(x)
x = self.layer_norm(x)
# project back to size of vocabulary with bias
x = self.decoder(x)
return x
def _tie_weights(self):
# To tie those two weights if they get disconnected (on TPU or when the bias is resized)
# For accelerate compatibility and to not break backward compatibility
if self.decoder.bias.device.type == "meta":
self.decoder.bias = self.bias
else:
self.bias = self.decoder.bias
@add_start_docstrings(
"""
The LUKE model with a language modeling head and entity prediction head on top for masked language modeling and
masked entity prediction.
""",
LUKE_START_DOCSTRING,
)
class LukeForMaskedLM(LukePreTrainedModel):
_tied_weights_keys = ["lm_head.decoder.weight", "lm_head.decoder.bias", "entity_predictions.decoder.weight"]
def __init__(self, config):
super().__init__(config)
self.luke = LukeModel(config)
self.lm_head = LukeLMHead(config)
self.entity_predictions = EntityPredictionHead(config)
self.loss_fn = nn.CrossEntropyLoss()
# Initialize weights and apply final processing
self.post_init()
def tie_weights(self):
super().tie_weights()
self._tie_or_clone_weights(self.entity_predictions.decoder, self.luke.entity_embeddings.entity_embeddings)
def get_output_embeddings(self):
return self.lm_head.decoder
def set_output_embeddings(self, new_embeddings):
self.lm_head.decoder = new_embeddings
@add_start_docstrings_to_model_forward(LUKE_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=LukeMaskedLMOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
entity_ids: Optional[torch.LongTensor] = None,
entity_attention_mask: Optional[torch.LongTensor] = None,
entity_token_type_ids: Optional[torch.LongTensor] = None,
entity_position_ids: Optional[torch.LongTensor] = None,
labels: Optional[torch.LongTensor] = None,
entity_labels: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, LukeMaskedLMOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked), the
loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
entity_labels (`torch.LongTensor` of shape `(batch_size, entity_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked), the
loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
Returns:
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.luke(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
entity_ids=entity_ids,
entity_attention_mask=entity_attention_mask,
entity_token_type_ids=entity_token_type_ids,
entity_position_ids=entity_position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=True,
)
loss = None
mlm_loss = None
logits = self.lm_head(outputs.last_hidden_state)
if labels is not None:
# move labels to correct device to enable model parallelism
labels = labels.to(logits.device)
mlm_loss = self.loss_fn(logits.view(-1, self.config.vocab_size), labels.view(-1))
if loss is None:
loss = mlm_loss
mep_loss = None
entity_logits = None
if outputs.entity_last_hidden_state is not None:
entity_logits = self.entity_predictions(outputs.entity_last_hidden_state)
if entity_labels is not None:
mep_loss = self.loss_fn(entity_logits.view(-1, self.config.entity_vocab_size), entity_labels.view(-1))
if loss is None:
loss = mep_loss
else:
loss = loss + mep_loss
if not return_dict:
return tuple(
v
for v in [
loss,
mlm_loss,
mep_loss,
logits,
entity_logits,
outputs.hidden_states,
outputs.entity_hidden_states,
outputs.attentions,
]
if v is not None
)
return LukeMaskedLMOutput(
loss=loss,
mlm_loss=mlm_loss,
mep_loss=mep_loss,
logits=logits,
entity_logits=entity_logits,
hidden_states=outputs.hidden_states,
entity_hidden_states=outputs.entity_hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
The LUKE model with a classification head on top (a linear layer on top of the hidden state of the first entity
token) for entity classification tasks, such as Open Entity.
""",
LUKE_START_DOCSTRING,
)
class LukeForEntityClassification(LukePreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.luke = LukeModel(config)
self.num_labels = config.num_labels
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(LUKE_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=EntityClassificationOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
entity_ids: Optional[torch.LongTensor] = None,
entity_attention_mask: Optional[torch.FloatTensor] = None,
entity_token_type_ids: Optional[torch.LongTensor] = None,
entity_position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, EntityClassificationOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)` or `(batch_size, num_labels)`, *optional*):
Labels for computing the classification loss. If the shape is `(batch_size,)`, the cross entropy loss is
used for the single-label classification. In this case, labels should contain the indices that should be in
`[0, ..., config.num_labels - 1]`. If the shape is `(batch_size, num_labels)`, the binary cross entropy
loss is used for the multi-label classification. In this case, labels should only contain `[0, 1]`, where 0
and 1 indicate false and true, respectively.
Returns:
Examples:
```python
>>> from transformers import AutoTokenizer, LukeForEntityClassification
>>> tokenizer = AutoTokenizer.from_pretrained("studio-ousia/luke-large-finetuned-open-entity")
>>> model = LukeForEntityClassification.from_pretrained("studio-ousia/luke-large-finetuned-open-entity")
>>> text = "Beyoncé lives in Los Angeles."
>>> entity_spans = [(0, 7)] # character-based entity span corresponding to "Beyoncé"
>>> inputs = tokenizer(text, entity_spans=entity_spans, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
Predicted class: person
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.luke(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
entity_ids=entity_ids,
entity_attention_mask=entity_attention_mask,
entity_token_type_ids=entity_token_type_ids,
entity_position_ids=entity_position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=True,
)
feature_vector = outputs.entity_last_hidden_state[:, 0, :]
feature_vector = self.dropout(feature_vector)
logits = self.classifier(feature_vector)
loss = None
if labels is not None:
# When the number of dimension of `labels` is 1, cross entropy is used as the loss function. The binary
# cross entropy is used otherwise.
# move labels to correct device to enable model parallelism
labels = labels.to(logits.device)
if labels.ndim == 1:
loss = nn.functional.cross_entropy(logits, labels)
else:
loss = nn.functional.binary_cross_entropy_with_logits(logits.view(-1), labels.view(-1).type_as(logits))
if not return_dict:
return tuple(
v
for v in [loss, logits, outputs.hidden_states, outputs.entity_hidden_states, outputs.attentions]
if v is not None
)
return EntityClassificationOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
entity_hidden_states=outputs.entity_hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
The LUKE model with a classification head on top (a linear layer on top of the hidden states of the two entity
tokens) for entity pair classification tasks, such as TACRED.
""",
LUKE_START_DOCSTRING,
)
class LukeForEntityPairClassification(LukePreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.luke = LukeModel(config)
self.num_labels = config.num_labels
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size * 2, config.num_labels, False)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(LUKE_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=EntityPairClassificationOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
entity_ids: Optional[torch.LongTensor] = None,
entity_attention_mask: Optional[torch.FloatTensor] = None,
entity_token_type_ids: Optional[torch.LongTensor] = None,
entity_position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, EntityPairClassificationOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)` or `(batch_size, num_labels)`, *optional*):
Labels for computing the classification loss. If the shape is `(batch_size,)`, the cross entropy loss is
used for the single-label classification. In this case, labels should contain the indices that should be in
`[0, ..., config.num_labels - 1]`. If the shape is `(batch_size, num_labels)`, the binary cross entropy
loss is used for the multi-label classification. In this case, labels should only contain `[0, 1]`, where 0
and 1 indicate false and true, respectively.
Returns:
Examples:
```python
>>> from transformers import AutoTokenizer, LukeForEntityPairClassification
>>> tokenizer = AutoTokenizer.from_pretrained("studio-ousia/luke-large-finetuned-tacred")
>>> model = LukeForEntityPairClassification.from_pretrained("studio-ousia/luke-large-finetuned-tacred")
>>> text = "Beyoncé lives in Los Angeles."
>>> entity_spans = [
... (0, 7),
... (17, 28),
... ] # character-based entity spans corresponding to "Beyoncé" and "Los Angeles"
>>> inputs = tokenizer(text, entity_spans=entity_spans, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
Predicted class: per:cities_of_residence
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.luke(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
entity_ids=entity_ids,
entity_attention_mask=entity_attention_mask,
entity_token_type_ids=entity_token_type_ids,
entity_position_ids=entity_position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=True,
)
feature_vector = torch.cat(
[outputs.entity_last_hidden_state[:, 0, :], outputs.entity_last_hidden_state[:, 1, :]], dim=1
)
feature_vector = self.dropout(feature_vector)
logits = self.classifier(feature_vector)
loss = None
if labels is not None:
# When the number of dimension of `labels` is 1, cross entropy is used as the loss function. The binary
# cross entropy is used otherwise.
# move labels to correct device to enable model parallelism
labels = labels.to(logits.device)
if labels.ndim == 1:
loss = nn.functional.cross_entropy(logits, labels)
else:
loss = nn.functional.binary_cross_entropy_with_logits(logits.view(-1), labels.view(-1).type_as(logits))
if not return_dict:
return tuple(
v
for v in [loss, logits, outputs.hidden_states, outputs.entity_hidden_states, outputs.attentions]
if v is not None
)
return EntityPairClassificationOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
entity_hidden_states=outputs.entity_hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
The LUKE model with a span classification head on top (a linear layer on top of the hidden states output) for tasks
such as named entity recognition.
""",
LUKE_START_DOCSTRING,
)
class LukeForEntitySpanClassification(LukePreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.luke = LukeModel(config)
self.num_labels = config.num_labels
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size * 3, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(LUKE_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=EntitySpanClassificationOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
entity_ids: Optional[torch.LongTensor] = None,
entity_attention_mask: Optional[torch.LongTensor] = None,
entity_token_type_ids: Optional[torch.LongTensor] = None,
entity_position_ids: Optional[torch.LongTensor] = None,
entity_start_positions: Optional[torch.LongTensor] = None,
entity_end_positions: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, EntitySpanClassificationOutput]:
r"""
entity_start_positions (`torch.LongTensor`):
The start positions of entities in the word token sequence.
entity_end_positions (`torch.LongTensor`):
The end positions of entities in the word token sequence.
labels (`torch.LongTensor` of shape `(batch_size, entity_length)` or `(batch_size, entity_length, num_labels)`, *optional*):
Labels for computing the classification loss. If the shape is `(batch_size, entity_length)`, the cross
entropy loss is used for the single-label classification. In this case, labels should contain the indices
that should be in `[0, ..., config.num_labels - 1]`. If the shape is `(batch_size, entity_length,
num_labels)`, the binary cross entropy loss is used for the multi-label classification. In this case,
labels should only contain `[0, 1]`, where 0 and 1 indicate false and true, respectively.
Returns:
Examples:
```python
>>> from transformers import AutoTokenizer, LukeForEntitySpanClassification
>>> tokenizer = AutoTokenizer.from_pretrained("studio-ousia/luke-large-finetuned-conll-2003")
>>> model = LukeForEntitySpanClassification.from_pretrained("studio-ousia/luke-large-finetuned-conll-2003")
>>> text = "Beyoncé lives in Los Angeles"
# List all possible entity spans in the text
>>> word_start_positions = [0, 8, 14, 17, 21] # character-based start positions of word tokens
>>> word_end_positions = [7, 13, 16, 20, 28] # character-based end positions of word tokens
>>> entity_spans = []
>>> for i, start_pos in enumerate(word_start_positions):
... for end_pos in word_end_positions[i:]:
... entity_spans.append((start_pos, end_pos))
>>> inputs = tokenizer(text, entity_spans=entity_spans, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> predicted_class_indices = logits.argmax(-1).squeeze().tolist()
>>> for span, predicted_class_idx in zip(entity_spans, predicted_class_indices):
... if predicted_class_idx != 0:
... print(text[span[0] : span[1]], model.config.id2label[predicted_class_idx])
Beyoncé PER
Los Angeles LOC
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.luke(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
entity_ids=entity_ids,
entity_attention_mask=entity_attention_mask,
entity_token_type_ids=entity_token_type_ids,
entity_position_ids=entity_position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=True,
)
hidden_size = outputs.last_hidden_state.size(-1)
entity_start_positions = entity_start_positions.unsqueeze(-1).expand(-1, -1, hidden_size)
if entity_start_positions.device != outputs.last_hidden_state.device:
entity_start_positions = entity_start_positions.to(outputs.last_hidden_state.device)
start_states = torch.gather(outputs.last_hidden_state, -2, entity_start_positions)
entity_end_positions = entity_end_positions.unsqueeze(-1).expand(-1, -1, hidden_size)
if entity_end_positions.device != outputs.last_hidden_state.device:
entity_end_positions = entity_end_positions.to(outputs.last_hidden_state.device)
end_states = torch.gather(outputs.last_hidden_state, -2, entity_end_positions)
feature_vector = torch.cat([start_states, end_states, outputs.entity_last_hidden_state], dim=2)
feature_vector = self.dropout(feature_vector)
logits = self.classifier(feature_vector)
loss = None
if labels is not None:
# move labels to correct device to enable model parallelism
labels = labels.to(logits.device)
# When the number of dimension of `labels` is 2, cross entropy is used as the loss function. The binary
# cross entropy is used otherwise.
if labels.ndim == 2:
loss = nn.functional.cross_entropy(logits.view(-1, self.num_labels), labels.view(-1))
else:
loss = nn.functional.binary_cross_entropy_with_logits(logits.view(-1), labels.view(-1).type_as(logits))
if not return_dict:
return tuple(
v
for v in [loss, logits, outputs.hidden_states, outputs.entity_hidden_states, outputs.attentions]
if v is not None
)
return EntitySpanClassificationOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
entity_hidden_states=outputs.entity_hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
The LUKE Model transformer with a sequence classification/regression head on top (a linear layer on top of the
pooled output) e.g. for GLUE tasks.
""",
LUKE_START_DOCSTRING,
)
class LukeForSequenceClassification(LukePreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.luke = LukeModel(config)
self.dropout = nn.Dropout(
config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(LUKE_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=LukeSequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
entity_ids: Optional[torch.LongTensor] = None,
entity_attention_mask: Optional[torch.FloatTensor] = None,
entity_token_type_ids: Optional[torch.LongTensor] = None,
entity_position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, LukeSequenceClassifierOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.luke(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
entity_ids=entity_ids,
entity_attention_mask=entity_attention_mask,
entity_token_type_ids=entity_token_type_ids,
entity_position_ids=entity_position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=True,
)
pooled_output = outputs.pooler_output
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
loss = None
if labels is not None:
# move labels to correct device to enable model parallelism
labels = labels.to(logits.device)
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
return tuple(
v
for v in [loss, logits, outputs.hidden_states, outputs.entity_hidden_states, outputs.attentions]
if v is not None
)
return LukeSequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
entity_hidden_states=outputs.entity_hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
The LUKE Model with a token classification head on top (a linear layer on top of the hidden-states output). To
solve Named-Entity Recognition (NER) task using LUKE, `LukeForEntitySpanClassification` is more suitable than this
class.
""",
LUKE_START_DOCSTRING,
)
class LukeForTokenClassification(LukePreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.luke = LukeModel(config, add_pooling_layer=False)
self.dropout = nn.Dropout(
config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(LUKE_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=LukeTokenClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
entity_ids: Optional[torch.LongTensor] = None,
entity_attention_mask: Optional[torch.FloatTensor] = None,
entity_token_type_ids: Optional[torch.LongTensor] = None,
entity_position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, LukeTokenClassifierOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the multiple choice classification loss. Indices should be in `[0, ...,
num_choices-1]` where `num_choices` is the size of the second dimension of the input tensors. (See
`input_ids` above)
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.luke(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
entity_ids=entity_ids,
entity_attention_mask=entity_attention_mask,
entity_token_type_ids=entity_token_type_ids,
entity_position_ids=entity_position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=True,
)
sequence_output = outputs.last_hidden_state
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
# move labels to correct device to enable model parallelism
labels = labels.to(logits.device)
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
if not return_dict:
return tuple(
v
for v in [loss, logits, outputs.hidden_states, outputs.entity_hidden_states, outputs.attentions]
if v is not None
)
return LukeTokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
entity_hidden_states=outputs.entity_hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
The LUKE Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layers on top of the hidden-states output to compute `span start logits` and `span end logits`).
""",
LUKE_START_DOCSTRING,
)
class LukeForQuestionAnswering(LukePreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.luke = LukeModel(config, add_pooling_layer=False)
self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(LUKE_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=LukeQuestionAnsweringModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.FloatTensor] = None,
entity_ids: Optional[torch.LongTensor] = None,
entity_attention_mask: Optional[torch.FloatTensor] = None,
entity_token_type_ids: Optional[torch.LongTensor] = None,
entity_position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
start_positions: Optional[torch.LongTensor] = None,
end_positions: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, LukeQuestionAnsweringModelOutput]:
r"""
start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.luke(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
entity_ids=entity_ids,
entity_attention_mask=entity_attention_mask,
entity_token_type_ids=entity_token_type_ids,
entity_position_ids=entity_position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=True,
)
sequence_output = outputs.last_hidden_state
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1)
end_logits = end_logits.squeeze(-1)
total_loss = None
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions.clamp_(0, ignored_index)
end_positions.clamp_(0, ignored_index)
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
if not return_dict:
return tuple(
v
for v in [
total_loss,
start_logits,
end_logits,
outputs.hidden_states,
outputs.entity_hidden_states,
outputs.attentions,
]
if v is not None
)
return LukeQuestionAnsweringModelOutput(
loss=total_loss,
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
entity_hidden_states=outputs.entity_hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
The LUKE Model with a multiple choice classification head on top (a linear layer on top of the pooled output and a
softmax) e.g. for RocStories/SWAG tasks.
""",
LUKE_START_DOCSTRING,
)
class LukeForMultipleChoice(LukePreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.luke = LukeModel(config)
self.dropout = nn.Dropout(
config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
)
self.classifier = nn.Linear(config.hidden_size, 1)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(LUKE_INPUTS_DOCSTRING.format("batch_size, num_choices, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=LukeMultipleChoiceModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
entity_ids: Optional[torch.LongTensor] = None,
entity_attention_mask: Optional[torch.FloatTensor] = None,
entity_token_type_ids: Optional[torch.LongTensor] = None,
entity_position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, LukeMultipleChoiceModelOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the multiple choice classification loss. Indices should be in `[0, ...,
num_choices-1]` where `num_choices` is the size of the second dimension of the input tensors. (See
`input_ids` above)
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
num_choices = input_ids.shape[1] if input_ids is not None else inputs_embeds.shape[1]
input_ids = input_ids.view(-1, input_ids.size(-1)) if input_ids is not None else None
attention_mask = attention_mask.view(-1, attention_mask.size(-1)) if attention_mask is not None else None
token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1)) if token_type_ids is not None else None
position_ids = position_ids.view(-1, position_ids.size(-1)) if position_ids is not None else None
inputs_embeds = (
inputs_embeds.view(-1, inputs_embeds.size(-2), inputs_embeds.size(-1))
if inputs_embeds is not None
else None
)
entity_ids = entity_ids.view(-1, entity_ids.size(-1)) if entity_ids is not None else None
entity_attention_mask = (
entity_attention_mask.view(-1, entity_attention_mask.size(-1))
if entity_attention_mask is not None
else None
)
entity_token_type_ids = (
entity_token_type_ids.view(-1, entity_token_type_ids.size(-1))
if entity_token_type_ids is not None
else None
)
entity_position_ids = (
entity_position_ids.view(-1, entity_position_ids.size(-2), entity_position_ids.size(-1))
if entity_position_ids is not None
else None
)
outputs = self.luke(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
entity_ids=entity_ids,
entity_attention_mask=entity_attention_mask,
entity_token_type_ids=entity_token_type_ids,
entity_position_ids=entity_position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=True,
)
pooled_output = outputs.pooler_output
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
reshaped_logits = logits.view(-1, num_choices)
loss = None
if labels is not None:
# move labels to correct device to enable model parallelism
labels = labels.to(reshaped_logits.device)
loss_fct = CrossEntropyLoss()
loss = loss_fct(reshaped_logits, labels)
if not return_dict:
return tuple(
v
for v in [
loss,
reshaped_logits,
outputs.hidden_states,
outputs.entity_hidden_states,
outputs.attentions,
]
if v is not None
)
return LukeMultipleChoiceModelOutput(
loss=loss,
logits=reshaped_logits,
hidden_states=outputs.hidden_states,
entity_hidden_states=outputs.entity_hidden_states,
attentions=outputs.attentions,
)
__all__ = [
"LukeForEntityClassification",
"LukeForEntityPairClassification",
"LukeForEntitySpanClassification",
"LukeForMultipleChoice",
"LukeForQuestionAnswering",
"LukeForSequenceClassification",
"LukeForTokenClassification",
"LukeForMaskedLM",
"LukeModel",
"LukePreTrainedModel",
]
| transformers/src/transformers/models/luke/modeling_luke.py/0 | {
"file_path": "transformers/src/transformers/models/luke/modeling_luke.py",
"repo_id": "transformers",
"token_count": 43050
} |
# coding=utf-8
# Copyright 2024 state-spaces/mamba org and HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""This script can be used to convert checkpoints provided in the `mamba_ssm` library into the format provided in HuggingFace `transformers`. It depends on the `mamba_ssm` package to be installed."""
import argparse
import json
import math
from typing import Tuple
import torch
from transformers import AutoTokenizer, MambaConfig, MambaForCausalLM
from transformers.utils import logging
from transformers.utils.import_utils import is_mamba_ssm_available
if is_mamba_ssm_available():
from mamba_ssm.models.config_mamba import MambaConfig as MambaConfigSSM
from mamba_ssm.models.mixer_seq_simple import MambaLMHeadModel
def convert_ssm_config_to_hf_config(config_ssm: MambaConfigSSM) -> MambaConfig:
"""Convert a MambaConfig from mamba_ssm to a MambaConfig from transformers."""
hf_config = MambaConfig()
# Set config hidden size, num hidden layers, and vocab size directly from the original config
hf_config.hidden_size = config_ssm.d_model
hf_config.intermediate_size = config_ssm.d_model * 2
hf_config.time_step_rank = math.ceil(config_ssm.d_model / 16)
hf_config.num_hidden_layers = config_ssm.n_layer
vocab_size = config_ssm.vocab_size
pad_vocab_size_multiple = config_ssm.pad_vocab_size_multiple
if (vocab_size % pad_vocab_size_multiple) != 0:
vocab_size += pad_vocab_size_multiple - (vocab_size % pad_vocab_size_multiple)
hf_config.vocab_size = vocab_size
return hf_config
logging.set_verbosity_info()
logger = logging.get_logger(__name__)
def convert_mamba_ssm_checkpoint_to_huggingface_model(
original_state_dict: dict, original_ssm_config_dict: dict
) -> Tuple[MambaForCausalLM, AutoTokenizer]:
if not is_mamba_ssm_available():
raise ImportError(
"Calling convert_mamba_ssm_checkpoint_to_huggingface_model requires the mamba_ssm library to be installed. Please install it with `pip install mamba_ssm`."
)
original_ssm_config = MambaConfigSSM(**original_ssm_config_dict)
# Convert mamba_ssm config to huggingface MambaConfig
hf_config = convert_ssm_config_to_hf_config(original_ssm_config)
# No weights need to be renamed between the two models.
converted_state_dict = original_state_dict
# Load reshaped state dict into a huggingface model.
hf_model = MambaForCausalLM(hf_config)
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neox-20b")
hf_model.load_state_dict(converted_state_dict)
return (hf_model, tokenizer)
def validate_converted_model(
original_state_dict: dict, original_ssm_config_dict: dict, hf_model: MambaForCausalLM, tokenizer: AutoTokenizer
) -> None:
"""Validate the converted model returns the same output as the original model."""
torch_device = "cuda"
original_config = MambaConfigSSM(**original_ssm_config_dict)
original_model = MambaLMHeadModel(original_config).to(torch_device)
original_model.load_state_dict(original_state_dict)
hf_model = hf_model.to(torch_device)
input_ids = tokenizer("Hey how are you doing?", return_tensors="pt")["input_ids"].to(torch_device)
# Assert model logits are close
with torch.no_grad():
original_model_logits = original_model(input_ids).logits
hf_model_logits = hf_model(input_ids).logits
if not torch.allclose(original_model_logits, hf_model_logits, atol=1e-3):
raise ValueError("The converted model did not return the same logits as the original model.")
logger.info("Model conversion validated successfully.")
def convert_mamba_checkpoint_file_to_huggingface_model_file(
mamba_checkpoint_path: str, config_json_file: str, output_dir: str
) -> None:
if not is_mamba_ssm_available():
raise ImportError(
"Calling convert_mamba_checkpoint_file_to_huggingface_model_file requires the mamba_ssm library to be installed. Please install it with `pip install mamba_ssm`."
)
if not torch.cuda.is_available():
raise ValueError(
"This script is to be run with a CUDA device, as the original mamba_ssm model does not support cpu."
)
logger.info(f"Loading model from {mamba_checkpoint_path} based on config from {config_json_file}")
# Load weights and config from paths
original_state_dict = torch.load(mamba_checkpoint_path, map_location="cpu")
with open(config_json_file, "r", encoding="utf-8") as json_file:
original_ssm_config_dict = json.load(json_file)
# Convert the model
hf_model, tokenizer = convert_mamba_ssm_checkpoint_to_huggingface_model(
original_state_dict, original_ssm_config_dict
)
# Validate the conversion
validate_converted_model(original_state_dict, original_ssm_config_dict, hf_model, tokenizer)
logger.info(f"Model converted successfully. Saving model to {output_dir}")
# Save new model to pytorch_dump_path
hf_model.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"-i",
"--mamba_checkpoint_file",
type=str,
required=True,
help="Path to a `pytorch_model.bin` mamba_ssm checkpoint file to be converted.",
)
parser.add_argument(
"-c",
"--config_json_file",
type=str,
required=True,
help="Path to a `config.json` file corresponding to a MambaConfig of the original mamba_ssm model.",
)
parser.add_argument(
"-o", "--output_dir", type=str, required=True, help="Path to directory to save the converted output model to."
)
args = parser.parse_args()
convert_mamba_checkpoint_file_to_huggingface_model_file(
args.mamba_checkpoint_file, args.config_json_file, args.output_dir
)
| transformers/src/transformers/models/mamba/convert_mamba_ssm_checkpoint_to_pytorch.py/0 | {
"file_path": "transformers/src/transformers/models/mamba/convert_mamba_ssm_checkpoint_to_pytorch.py",
"repo_id": "transformers",
"token_count": 2383
} |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Feature extractor class for MarkupLM.
"""
import html
from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
from ...utils import is_bs4_available, logging, requires_backends
if is_bs4_available():
import bs4
from bs4 import BeautifulSoup
logger = logging.get_logger(__name__)
class MarkupLMFeatureExtractor(FeatureExtractionMixin):
r"""
Constructs a MarkupLM feature extractor. This can be used to get a list of nodes and corresponding xpaths from HTML
strings.
This feature extractor inherits from [`~feature_extraction_utils.PreTrainedFeatureExtractor`] which contains most
of the main methods. Users should refer to this superclass for more information regarding those methods.
"""
def __init__(self, **kwargs):
requires_backends(self, ["bs4"])
super().__init__(**kwargs)
def xpath_soup(self, element):
xpath_tags = []
xpath_subscripts = []
child = element if element.name else element.parent
for parent in child.parents: # type: bs4.element.Tag
siblings = parent.find_all(child.name, recursive=False)
xpath_tags.append(child.name)
xpath_subscripts.append(
0 if 1 == len(siblings) else next(i for i, s in enumerate(siblings, 1) if s is child)
)
child = parent
xpath_tags.reverse()
xpath_subscripts.reverse()
return xpath_tags, xpath_subscripts
def get_three_from_single(self, html_string):
html_code = BeautifulSoup(html_string, "html.parser")
all_doc_strings = []
string2xtag_seq = []
string2xsubs_seq = []
for element in html_code.descendants:
if isinstance(element, bs4.element.NavigableString):
if type(element.parent) is not bs4.element.Tag:
continue
text_in_this_tag = html.unescape(element).strip()
if not text_in_this_tag:
continue
all_doc_strings.append(text_in_this_tag)
xpath_tags, xpath_subscripts = self.xpath_soup(element)
string2xtag_seq.append(xpath_tags)
string2xsubs_seq.append(xpath_subscripts)
if len(all_doc_strings) != len(string2xtag_seq):
raise ValueError("Number of doc strings and xtags does not correspond")
if len(all_doc_strings) != len(string2xsubs_seq):
raise ValueError("Number of doc strings and xsubs does not correspond")
return all_doc_strings, string2xtag_seq, string2xsubs_seq
def construct_xpath(self, xpath_tags, xpath_subscripts):
xpath = ""
for tagname, subs in zip(xpath_tags, xpath_subscripts):
xpath += f"/{tagname}"
if subs != 0:
xpath += f"[{subs}]"
return xpath
def __call__(self, html_strings) -> BatchFeature:
"""
Main method to prepare for the model one or several HTML strings.
Args:
html_strings (`str`, `List[str]`):
The HTML string or batch of HTML strings from which to extract nodes and corresponding xpaths.
Returns:
[`BatchFeature`]: A [`BatchFeature`] with the following fields:
- **nodes** -- Nodes.
- **xpaths** -- Corresponding xpaths.
Examples:
```python
>>> from transformers import MarkupLMFeatureExtractor
>>> page_name_1 = "page1.html"
>>> page_name_2 = "page2.html"
>>> page_name_3 = "page3.html"
>>> with open(page_name_1) as f:
... single_html_string = f.read()
>>> feature_extractor = MarkupLMFeatureExtractor()
>>> # single example
>>> encoding = feature_extractor(single_html_string)
>>> print(encoding.keys())
>>> # dict_keys(['nodes', 'xpaths'])
>>> # batched example
>>> multi_html_strings = []
>>> with open(page_name_2) as f:
... multi_html_strings.append(f.read())
>>> with open(page_name_3) as f:
... multi_html_strings.append(f.read())
>>> encoding = feature_extractor(multi_html_strings)
>>> print(encoding.keys())
>>> # dict_keys(['nodes', 'xpaths'])
```"""
# Input type checking for clearer error
valid_strings = False
# Check that strings has a valid type
if isinstance(html_strings, str):
valid_strings = True
elif isinstance(html_strings, (list, tuple)):
if len(html_strings) == 0 or isinstance(html_strings[0], str):
valid_strings = True
if not valid_strings:
raise ValueError(
"HTML strings must of type `str`, `List[str]` (batch of examples), "
f"but is of type {type(html_strings)}."
)
is_batched = bool(isinstance(html_strings, (list, tuple)) and (isinstance(html_strings[0], str)))
if not is_batched:
html_strings = [html_strings]
# Get nodes + xpaths
nodes = []
xpaths = []
for html_string in html_strings:
all_doc_strings, string2xtag_seq, string2xsubs_seq = self.get_three_from_single(html_string)
nodes.append(all_doc_strings)
xpath_strings = []
for node, tag_list, sub_list in zip(all_doc_strings, string2xtag_seq, string2xsubs_seq):
xpath_string = self.construct_xpath(tag_list, sub_list)
xpath_strings.append(xpath_string)
xpaths.append(xpath_strings)
# return as Dict
data = {"nodes": nodes, "xpaths": xpaths}
encoded_inputs = BatchFeature(data=data, tensor_type=None)
return encoded_inputs
__all__ = ["MarkupLMFeatureExtractor"]
| transformers/src/transformers/models/markuplm/feature_extraction_markuplm.py/0 | {
"file_path": "transformers/src/transformers/models/markuplm/feature_extraction_markuplm.py",
"repo_id": "transformers",
"token_count": 2759
} |
# coding=utf-8
# Copyright 2023 Mistral AI and the HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Mistral model configuration"""
from ...configuration_utils import PretrainedConfig
from ...utils import logging
logger = logging.get_logger(__name__)
class MistralConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`MistralModel`]. It is used to instantiate an
Mistral model according to the specified arguments, defining the model architecture. Instantiating a configuration
with the defaults will yield a similar configuration to that of the Mistral-7B-v0.1 or Mistral-7B-Instruct-v0.1.
[mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
[mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 32000):
Vocabulary size of the Mistral model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`MistralModel`]
hidden_size (`int`, *optional*, defaults to 4096):
Dimension of the hidden representations.
intermediate_size (`int`, *optional*, defaults to 14336):
Dimension of the MLP representations.
num_hidden_layers (`int`, *optional*, defaults to 32):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 32):
Number of attention heads for each attention layer in the Transformer encoder.
num_key_value_heads (`int`, *optional*, defaults to 8):
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details checkout [this
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `8`.
head_dim (`int`, *optional*, defaults to `hidden_size // num_attention_heads`):
The attention head dimension.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
max_position_embeddings (`int`, *optional*, defaults to `4096*32`):
The maximum sequence length that this model might ever be used with. Mistral's sliding window attention
allows sequence of up to 4096*32 tokens.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
rms_norm_eps (`float`, *optional*, defaults to 1e-06):
The epsilon used by the rms normalization layers.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
pad_token_id (`int`, *optional*):
The id of the padding token.
bos_token_id (`int`, *optional*, defaults to 1):
The id of the "beginning-of-sequence" token.
eos_token_id (`int`, *optional*, defaults to 2):
The id of the "end-of-sequence" token.
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
Whether the model's input and output word embeddings should be tied.
rope_theta (`float`, *optional*, defaults to 10000.0):
The base period of the RoPE embeddings.
sliding_window (`int`, *optional*, defaults to 4096):
Sliding window attention window size. If not specified, will default to `4096`.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
```python
>>> from transformers import MistralModel, MistralConfig
>>> # Initializing a Mistral 7B style configuration
>>> configuration = MistralConfig()
>>> # Initializing a model from the Mistral 7B style configuration
>>> model = MistralModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "mistral"
keys_to_ignore_at_inference = ["past_key_values"]
# Default tensor parallel plan for base model `MistralModel`
base_model_tp_plan = {
"layers.*.self_attn.q_proj": "colwise",
"layers.*.self_attn.k_proj": "colwise",
"layers.*.self_attn.v_proj": "colwise",
"layers.*.self_attn.o_proj": "rowwise",
"layers.*.mlp.gate_proj": "colwise",
"layers.*.mlp.up_proj": "colwise",
"layers.*.mlp.down_proj": "rowwise",
}
def __init__(
self,
vocab_size=32000,
hidden_size=4096,
intermediate_size=14336,
num_hidden_layers=32,
num_attention_heads=32,
num_key_value_heads=8,
head_dim=None,
hidden_act="silu",
max_position_embeddings=4096 * 32,
initializer_range=0.02,
rms_norm_eps=1e-6,
use_cache=True,
pad_token_id=None,
bos_token_id=1,
eos_token_id=2,
tie_word_embeddings=False,
rope_theta=10000.0,
sliding_window=4096,
attention_dropout=0.0,
**kwargs,
):
self.vocab_size = vocab_size
self.max_position_embeddings = max_position_embeddings
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.sliding_window = sliding_window
self.head_dim = head_dim or hidden_size // num_attention_heads
# for backward compatibility
if num_key_value_heads is None:
num_key_value_heads = num_attention_heads
self.num_key_value_heads = num_key_value_heads
self.hidden_act = hidden_act
self.initializer_range = initializer_range
self.rms_norm_eps = rms_norm_eps
self.use_cache = use_cache
self.rope_theta = rope_theta
self.attention_dropout = attention_dropout
super().__init__(
pad_token_id=pad_token_id,
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
tie_word_embeddings=tie_word_embeddings,
**kwargs,
)
| transformers/src/transformers/models/mistral/configuration_mistral.py/0 | {
"file_path": "transformers/src/transformers/models/mistral/configuration_mistral.py",
"repo_id": "transformers",
"token_count": 2933
} |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Processor class for Mllama."""
from typing import List, Optional, Union
import numpy as np
from ...feature_extraction_utils import BatchFeature
from ...image_utils import ImageInput, make_nested_list_of_images
from ...processing_utils import ImagesKwargs, ProcessingKwargs, ProcessorMixin, Unpack
from ...tokenization_utils_base import (
PreTokenizedInput,
TextInput,
)
class MllamaImagesKwargs(ImagesKwargs, total=False):
max_image_tiles: Optional[int]
class MllamaProcessorKwargs(ProcessingKwargs, total=False):
images_kwargs: MllamaImagesKwargs
_defaults = {
"image_kwargs": {
"max_image_tiles": 4,
},
}
def get_cross_attention_token_mask(input_ids: List[int], image_token_id: int) -> List[List[int]]:
"""
Generate a cross-attention token mask for image tokens in the input sequence.
This function identifies the positions of image tokens in the input sequence and creates
a mask that defines which subsequent tokens each image token should attend to.
Args:
input_ids (List[int]): A list of token ids representing the input sequence.
image_token_id (int): The id of the token used to represent images in the sequence.
Returns:
List[List[int]]: A list of [start, end] pairs, where each pair represents the range
of tokens an image token should attend to.
Notes:
- If no image tokens are present, an empty list is returned.
- For a single image token, it attends to all subsequent tokens until the end of the sequence.
- For multiple image tokens, each attends to tokens up to the next image token or the end of the sequence.
- Consecutive image tokens are treated as a group and attend to all subsequent tokens together.
"""
image_token_locations = [i for i, token in enumerate(input_ids) if token == image_token_id]
if len(image_token_locations) == 0:
return []
# only one image present, unmask until end of sequence
if len(image_token_locations) == 1:
return [[image_token_locations[0], -1]]
vision_masks = [[loc1, loc2] for loc1, loc2 in zip(image_token_locations[:-1], image_token_locations[1:])]
# last image will attend to all subsequent text
vision_masks.append([image_token_locations[-1], len(input_ids)])
# if there are two or more consecutive vision tokens,
# they should all attend to all subsequent
# text present
last_mask_end = vision_masks[-1][1]
for vision_mask in vision_masks[::-1]:
if vision_mask[0] == vision_mask[1] - 1:
vision_mask[1] = last_mask_end
last_mask_end = vision_mask[1]
return vision_masks
def convert_sparse_cross_attention_mask_to_dense(
cross_attention_token_mask: List[List[List[int]]],
num_tiles: List[List[int]],
max_num_tiles: int,
length: int,
) -> np.ndarray:
"""
Convert the cross attention mask indices to a cross attention mask 4D array.
This function takes a sparse representation of cross attention masks and converts it to a dense 4D numpy array.
The sparse representation is a nested list structure that defines attention ranges for each image in each batch item.
Args:
cross_attention_token_mask (List[List[List[int]]]): A nested list structure where:
- The outer list represents the batch dimension.
- The middle list represents different images within each batch item.
- The inner list contains pairs of integers [start, end] representing token ranges for each image.
num_tiles (List[List[int]]): A nested list structure specifying the number of tiles for each image in each batch item.
max_num_tiles (int): The maximum possible number of tiles.
length (int): The total sequence length of the input.
Returns:
np.ndarray: A 4D numpy array of shape (batch_size, length, max_num_images, max_num_tiles)
The array contains `1` where attention is allowed and `0` where it is not.
Note:
- Special handling is done for cases where the end token is -1, which is interpreted as attending to the end of the sequence.
"""
batch_size = len(cross_attention_token_mask)
max_num_images = max([len(masks) for masks in cross_attention_token_mask])
cross_attention_mask = np.zeros(
shape=(batch_size, length, max_num_images, max_num_tiles),
dtype=np.int64,
)
for sample_idx, (sample_masks, sample_num_tiles) in enumerate(zip(cross_attention_token_mask, num_tiles)):
for mask_idx, (locations, mask_num_tiles) in enumerate(zip(sample_masks, sample_num_tiles)):
if len(locations) == 2:
start, end = locations
end = min(end, length)
if end == -1:
end = length
cross_attention_mask[sample_idx, start:end, mask_idx, :mask_num_tiles] = 1
return cross_attention_mask
def build_string_from_input(prompt: str, bos_token: str, image_token: str) -> str:
"""
Builds a string from the input prompt by adding `bos_token` if not already present.
Args:
prompt (`str`):
The input prompt string.
bos_token (`str`):
The beginning of sentence token to be added.
image_token (`str`):
The image token used to identify the start of an image sequence.
Returns:
str: The modified prompt string with the `bos_token` added if necessary.
Examples:
>>> build_string_from_input("Hello world", "<begin_of_text>", "<|image|>")
'<begin_of_text>Hello world'
>>> build_string_from_input("<|image|>Hello world", "<begin_of_text>", "<|image|>")
'<|image|><begin_of_text>Hello world'
>>> build_string_from_input("<begin_of_text>Hello world", "<begin_of_text>", "<|image|>")
'<begin_of_text>Hello world'
"""
if bos_token in prompt:
return prompt
num_image_tokens_on_start = 0
while prompt.startswith(image_token):
prompt = prompt[len(image_token) :]
num_image_tokens_on_start += 1
return f"{image_token * num_image_tokens_on_start}{bos_token}{prompt}"
class MllamaProcessor(ProcessorMixin):
r"""
Constructs a Mllama processor which wraps [`MllamaImageProcessor`] and
[`PretrainedTokenizerFast`] into a single processor that inherits both the image processor and
tokenizer functionalities. See the [`~MllamaProcessor.__call__`] and [`~OwlViTProcessor.decode`] for more
information.
The preferred way of passing kwargs is as a dictionary per modality, see usage example below.
```python
from transformers import MllamaProcessor
from PIL import Image
processor = MllamaProcessor.from_pretrained("meta-llama/Llama-3.2-11B-Vision")
processor(
images=your_pil_image,
text=["<|image|>If I had to write a haiku for this one"],
images_kwargs = {"size": {"height": 448, "width": 448}},
text_kwargs = {"padding": "right"},
common_kwargs = {"return_tensors": "pt"},
)
```
Args:
image_processor ([`MllamaImageProcessor`]):
The image processor is a required input.
tokenizer ([`PreTrainedTokenizer`, `PreTrainedTokenizerFast`]):
The tokenizer is a required input.
"""
attributes = ["image_processor", "tokenizer"]
image_processor_class = "MllamaImageProcessor"
tokenizer_class = "PreTrainedTokenizerFast"
def __init__(self, image_processor, tokenizer):
if not hasattr(tokenizer, "image_token"):
self.image_token = "<|image|>"
self.image_token_id = tokenizer.convert_tokens_to_ids(self.image_token)
else:
self.image_token = tokenizer.image_token
self.image_token_id = tokenizer.image_token_id
self.python_token = "<|python_tag|>"
self.python_token_id = tokenizer.convert_tokens_to_ids(self.python_token)
self.bos_token = tokenizer.bos_token
self.chat_template = tokenizer.chat_template
super().__init__(image_processor, tokenizer)
def __call__(
self,
images: Optional[ImageInput] = None,
text: Optional[Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]]] = None,
audio=None,
videos=None,
**kwargs: Unpack[MllamaProcessorKwargs],
) -> BatchFeature:
"""
Main method to prepare text(s) and image(s) to be fed as input to the model. This method forwards the `text`
arguments to PreTrainedTokenizerFast's [`~PreTrainedTokenizerFast.__call__`] if `text` is not `None` to encode
the text. To prepare the image(s), this method forwards the `images` arguments to
MllamaImageProcessor's [`~MllamaImageProcessor.__call__`] if `images` is not `None`. Please refer
to the docstring of the above two methods for more information.
Args:
images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
tensor. Both channels-first and channels-last formats are supported.
text (`str`, `List[str]`, `List[List[str]]`):
The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
(pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
`is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
return_tensors (`str` or [`~utils.TensorType`], *optional*):
If set, will return tensors of a particular framework. Acceptable values are:
- `'tf'`: Return TensorFlow `tf.constant` objects.
- `'pt'`: Return PyTorch `torch.Tensor` objects.
- `'np'`: Return NumPy `np.ndarray` objects.
- `'jax'`: Return JAX `jnp.ndarray` objects.
Returns:
[`BatchFeature`]: A [`BatchFeature`] with the following fields:
- **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None`.
- **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
`return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names` and if `text` is not
`None`).
- **pixel_values** -- Pixel values to be fed to a model. Returned when `images` is not `None`.
TODO: add aspect_ratio_ids and aspect_ratio_mask and cross_attention_mask
"""
if text is None and images is None:
raise ValueError("You must specify either text or images.")
output_kwargs = self._merge_kwargs(
MllamaProcessorKwargs,
tokenizer_init_kwargs=self.tokenizer.init_kwargs,
**kwargs,
)
text_kwargs = output_kwargs["text_kwargs"]
images_kwargs = output_kwargs["images_kwargs"]
common_kwargs = output_kwargs["common_kwargs"]
data = {}
if text is not None:
if isinstance(text, str):
text = [text]
elif not (isinstance(text, (list, tuple)) and all(isinstance(t, str) for t in text)):
raise ValueError("Invalid input text. Please provide a string, or a list of strings")
n_images_in_text = [t.count(self.image_token) for t in text]
text = [build_string_from_input(text_item, self.bos_token, self.image_token) for text_item in text]
_ = text_kwargs.pop("padding_side", None) # hack until padding-side is an accepted kwarg by tokenizers
encoding = self.tokenizer(text, **text_kwargs)
data.update(encoding)
n_images_in_images = [0]
if images is not None:
images = make_nested_list_of_images(images)
n_images_in_images = [len(sample) for sample in images]
if text is not None:
if any(batch_img == 0 for batch_img in n_images_in_text) and not all(
batch_img == 0 for batch_img in n_images_in_text
):
raise ValueError(
"If a batch of text is provided, there should be either no images or at least one image per sample"
)
if sum(n_images_in_images) != sum(n_images_in_text):
if images is None:
raise ValueError("No image were provided, but there are image tokens in the prompt")
else:
raise ValueError(
f"The number of image token ({sum(n_images_in_text)}) should be the same as in the number of provided images ({sum(n_images_in_images)})"
)
if images is not None:
image_features = self.image_processor(images, **images_kwargs)
num_tiles = image_features.pop("num_tiles")
data.update(image_features)
# Create cross attention mask
if images is not None and text is not None:
cross_attention_token_mask = [
get_cross_attention_token_mask(token_ids, self.image_token_id) for token_ids in encoding["input_ids"]
]
cross_attention_mask = convert_sparse_cross_attention_mask_to_dense(
cross_attention_token_mask,
num_tiles=num_tiles,
max_num_tiles=self.image_processor.max_image_tiles,
length=max(len(input_ids) for input_ids in encoding["input_ids"]),
)
data["cross_attention_mask"] = cross_attention_mask
return_tensors = common_kwargs.pop("return_tensors", None)
batch_feature = BatchFeature(data=data, tensor_type=return_tensors)
return batch_feature
def batch_decode(self, *args, **kwargs):
"""
This method forwards all its arguments to PreTrainedTokenizerFast's [`~PreTrainedTokenizer.batch_decode`]. Please
refer to the docstring of this method for more information.
"""
return self.tokenizer.batch_decode(*args, **kwargs)
def decode(self, *args, **kwargs):
"""
This method forwards all its arguments to PreTrainedTokenizerFast's [`~PreTrainedTokenizer.decode`]. Please refer to
the docstring of this method for more information.
"""
return self.tokenizer.decode(*args, **kwargs)
def post_process_image_text_to_text(self, generated_outputs):
"""
Post-process the output of the model to decode the text.
Args:
generated_outputs (`torch.Tensor` or `np.ndarray`):
The output of the model `generate` function. The output is expected to be a tensor of shape `(batch_size, sequence_length)`
or `(sequence_length,)`.
Returns:
`List[str]`: The decoded text.
"""
return self.tokenizer.batch_decode(
generated_outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
@property
def model_input_names(self):
tokenizer_input_names = self.tokenizer.model_input_names
image_processor_input_names = self.image_processor.model_input_names
return list(tokenizer_input_names + image_processor_input_names + ["cross_attention_mask"])
__all__ = ["MllamaProcessor"]
| transformers/src/transformers/models/mllama/processing_mllama.py/0 | {
"file_path": "transformers/src/transformers/models/mllama/processing_mllama.py",
"repo_id": "transformers",
"token_count": 6522
} |
# coding=utf-8
# Copyright 2022 Apple Inc. and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch MobileNetV1 model."""
from typing import Optional, Union
import torch
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from ...activations import ACT2FN
from ...modeling_outputs import BaseModelOutputWithPoolingAndNoAttention, ImageClassifierOutputWithNoAttention
from ...modeling_utils import PreTrainedModel
from ...utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward, logging
from .configuration_mobilenet_v1 import MobileNetV1Config
logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "MobileNetV1Config"
# Base docstring
_CHECKPOINT_FOR_DOC = "google/mobilenet_v1_1.0_224"
_EXPECTED_OUTPUT_SHAPE = [1, 1024, 7, 7]
# Image classification docstring
_IMAGE_CLASS_CHECKPOINT = "google/mobilenet_v1_1.0_224"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
def _build_tf_to_pytorch_map(model, config, tf_weights=None):
"""
A map of modules from TF to PyTorch.
"""
tf_to_pt_map = {}
if isinstance(model, MobileNetV1ForImageClassification):
backbone = model.mobilenet_v1
else:
backbone = model
prefix = "MobilenetV1/Conv2d_0/"
tf_to_pt_map[prefix + "weights"] = backbone.conv_stem.convolution.weight
tf_to_pt_map[prefix + "BatchNorm/beta"] = backbone.conv_stem.normalization.bias
tf_to_pt_map[prefix + "BatchNorm/gamma"] = backbone.conv_stem.normalization.weight
tf_to_pt_map[prefix + "BatchNorm/moving_mean"] = backbone.conv_stem.normalization.running_mean
tf_to_pt_map[prefix + "BatchNorm/moving_variance"] = backbone.conv_stem.normalization.running_var
for i in range(13):
tf_index = i + 1
pt_index = i * 2
pointer = backbone.layer[pt_index]
prefix = f"MobilenetV1/Conv2d_{tf_index}_depthwise/"
tf_to_pt_map[prefix + "depthwise_weights"] = pointer.convolution.weight
tf_to_pt_map[prefix + "BatchNorm/beta"] = pointer.normalization.bias
tf_to_pt_map[prefix + "BatchNorm/gamma"] = pointer.normalization.weight
tf_to_pt_map[prefix + "BatchNorm/moving_mean"] = pointer.normalization.running_mean
tf_to_pt_map[prefix + "BatchNorm/moving_variance"] = pointer.normalization.running_var
pointer = backbone.layer[pt_index + 1]
prefix = f"MobilenetV1/Conv2d_{tf_index}_pointwise/"
tf_to_pt_map[prefix + "weights"] = pointer.convolution.weight
tf_to_pt_map[prefix + "BatchNorm/beta"] = pointer.normalization.bias
tf_to_pt_map[prefix + "BatchNorm/gamma"] = pointer.normalization.weight
tf_to_pt_map[prefix + "BatchNorm/moving_mean"] = pointer.normalization.running_mean
tf_to_pt_map[prefix + "BatchNorm/moving_variance"] = pointer.normalization.running_var
if isinstance(model, MobileNetV1ForImageClassification):
prefix = "MobilenetV1/Logits/Conv2d_1c_1x1/"
tf_to_pt_map[prefix + "weights"] = model.classifier.weight
tf_to_pt_map[prefix + "biases"] = model.classifier.bias
return tf_to_pt_map
def load_tf_weights_in_mobilenet_v1(model, config, tf_checkpoint_path):
"""Load TensorFlow checkpoints in a PyTorch model."""
try:
import numpy as np
import tensorflow as tf
except ImportError:
logger.error(
"Loading a TensorFlow models in PyTorch, requires TensorFlow to be installed. Please see "
"https://www.tensorflow.org/install/ for installation instructions."
)
raise
# Load weights from TF model
init_vars = tf.train.list_variables(tf_checkpoint_path)
tf_weights = {}
for name, shape in init_vars:
logger.info(f"Loading TF weight {name} with shape {shape}")
array = tf.train.load_variable(tf_checkpoint_path, name)
tf_weights[name] = array
# Build TF to PyTorch weights loading map
tf_to_pt_map = _build_tf_to_pytorch_map(model, config, tf_weights)
for name, pointer in tf_to_pt_map.items():
logger.info(f"Importing {name}")
if name not in tf_weights:
logger.info(f"{name} not in tf pre-trained weights, skipping")
continue
array = tf_weights[name]
if "depthwise_weights" in name:
logger.info("Transposing depthwise")
array = np.transpose(array, (2, 3, 0, 1))
elif "weights" in name:
logger.info("Transposing")
if len(pointer.shape) == 2: # copying into linear layer
array = array.squeeze().transpose()
else:
array = np.transpose(array, (3, 2, 0, 1))
if pointer.shape != array.shape:
raise ValueError(f"Pointer shape {pointer.shape} and array shape {array.shape} mismatched")
logger.info(f"Initialize PyTorch weight {name} {array.shape}")
pointer.data = torch.from_numpy(array)
tf_weights.pop(name, None)
tf_weights.pop(name + "/RMSProp", None)
tf_weights.pop(name + "/RMSProp_1", None)
tf_weights.pop(name + "/ExponentialMovingAverage", None)
logger.info(f"Weights not copied to PyTorch model: {', '.join(tf_weights.keys())}")
return model
def apply_tf_padding(features: torch.Tensor, conv_layer: nn.Conv2d) -> torch.Tensor:
"""
Apply TensorFlow-style "SAME" padding to a convolution layer. See the notes at:
https://www.tensorflow.org/api_docs/python/tf/nn#notes_on_padding_2
"""
in_height, in_width = features.shape[-2:]
stride_height, stride_width = conv_layer.stride
kernel_height, kernel_width = conv_layer.kernel_size
if in_height % stride_height == 0:
pad_along_height = max(kernel_height - stride_height, 0)
else:
pad_along_height = max(kernel_height - (in_height % stride_height), 0)
if in_width % stride_width == 0:
pad_along_width = max(kernel_width - stride_width, 0)
else:
pad_along_width = max(kernel_width - (in_width % stride_width), 0)
pad_left = pad_along_width // 2
pad_right = pad_along_width - pad_left
pad_top = pad_along_height // 2
pad_bottom = pad_along_height - pad_top
padding = (pad_left, pad_right, pad_top, pad_bottom)
return nn.functional.pad(features, padding, "constant", 0.0)
class MobileNetV1ConvLayer(nn.Module):
def __init__(
self,
config: MobileNetV1Config,
in_channels: int,
out_channels: int,
kernel_size: int,
stride: Optional[int] = 1,
groups: Optional[int] = 1,
bias: bool = False,
use_normalization: Optional[bool] = True,
use_activation: Optional[bool or str] = True,
) -> None:
super().__init__()
self.config = config
if in_channels % groups != 0:
raise ValueError(f"Input channels ({in_channels}) are not divisible by {groups} groups.")
if out_channels % groups != 0:
raise ValueError(f"Output channels ({out_channels}) are not divisible by {groups} groups.")
padding = 0 if config.tf_padding else int((kernel_size - 1) / 2)
self.convolution = nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=bias,
padding_mode="zeros",
)
if use_normalization:
self.normalization = nn.BatchNorm2d(
num_features=out_channels,
eps=config.layer_norm_eps,
momentum=0.9997,
affine=True,
track_running_stats=True,
)
else:
self.normalization = None
if use_activation:
if isinstance(use_activation, str):
self.activation = ACT2FN[use_activation]
elif isinstance(config.hidden_act, str):
self.activation = ACT2FN[config.hidden_act]
else:
self.activation = config.hidden_act
else:
self.activation = None
def forward(self, features: torch.Tensor) -> torch.Tensor:
if self.config.tf_padding:
features = apply_tf_padding(features, self.convolution)
features = self.convolution(features)
if self.normalization is not None:
features = self.normalization(features)
if self.activation is not None:
features = self.activation(features)
return features
class MobileNetV1PreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = MobileNetV1Config
load_tf_weights = load_tf_weights_in_mobilenet_v1
base_model_prefix = "mobilenet_v1"
main_input_name = "pixel_values"
supports_gradient_checkpointing = False
_no_split_modules = []
def _init_weights(self, module: Union[nn.Linear, nn.Conv2d]) -> None:
"""Initialize the weights"""
if isinstance(module, (nn.Linear, nn.Conv2d)):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.BatchNorm2d):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
MOBILENET_V1_START_DOCSTRING = r"""
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
Parameters:
config ([`MobileNetV1Config`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
MOBILENET_V1_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
[`MobileNetV1ImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
@add_start_docstrings(
"The bare MobileNetV1 model outputting raw hidden-states without any specific head on top.",
MOBILENET_V1_START_DOCSTRING,
)
class MobileNetV1Model(MobileNetV1PreTrainedModel):
def __init__(self, config: MobileNetV1Config, add_pooling_layer: bool = True):
super().__init__(config)
self.config = config
depth = 32
out_channels = max(int(depth * config.depth_multiplier), config.min_depth)
self.conv_stem = MobileNetV1ConvLayer(
config,
in_channels=config.num_channels,
out_channels=out_channels,
kernel_size=3,
stride=2,
)
strides = [1, 2, 1, 2, 1, 2, 1, 1, 1, 1, 1, 2, 1]
self.layer = nn.ModuleList()
for i in range(13):
in_channels = out_channels
if strides[i] == 2 or i == 0:
depth *= 2
out_channels = max(int(depth * config.depth_multiplier), config.min_depth)
self.layer.append(
MobileNetV1ConvLayer(
config,
in_channels=in_channels,
out_channels=in_channels,
kernel_size=3,
stride=strides[i],
groups=in_channels,
)
)
self.layer.append(
MobileNetV1ConvLayer(
config,
in_channels=in_channels,
out_channels=out_channels,
kernel_size=1,
)
)
self.pooler = nn.AdaptiveAvgPool2d((1, 1)) if add_pooling_layer else None
# Initialize weights and apply final processing
self.post_init()
def _prune_heads(self, heads_to_prune):
raise NotImplementedError
@add_start_docstrings_to_model_forward(MOBILENET_V1_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=BaseModelOutputWithPoolingAndNoAttention,
config_class=_CONFIG_FOR_DOC,
modality="vision",
expected_output=_EXPECTED_OUTPUT_SHAPE,
)
def forward(
self,
pixel_values: Optional[torch.Tensor] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[tuple, BaseModelOutputWithPoolingAndNoAttention]:
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if pixel_values is None:
raise ValueError("You have to specify pixel_values")
hidden_states = self.conv_stem(pixel_values)
all_hidden_states = () if output_hidden_states else None
for i, layer_module in enumerate(self.layer):
hidden_states = layer_module(hidden_states)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
last_hidden_state = hidden_states
if self.pooler is not None:
pooled_output = torch.flatten(self.pooler(last_hidden_state), start_dim=1)
else:
pooled_output = None
if not return_dict:
return tuple(v for v in [last_hidden_state, pooled_output, all_hidden_states] if v is not None)
return BaseModelOutputWithPoolingAndNoAttention(
last_hidden_state=last_hidden_state,
pooler_output=pooled_output,
hidden_states=all_hidden_states,
)
@add_start_docstrings(
"""
MobileNetV1 model with an image classification head on top (a linear layer on top of the pooled features), e.g. for
ImageNet.
""",
MOBILENET_V1_START_DOCSTRING,
)
class MobileNetV1ForImageClassification(MobileNetV1PreTrainedModel):
def __init__(self, config: MobileNetV1Config) -> None:
super().__init__(config)
self.num_labels = config.num_labels
self.mobilenet_v1 = MobileNetV1Model(config)
last_hidden_size = self.mobilenet_v1.layer[-1].convolution.out_channels
# Classifier head
self.dropout = nn.Dropout(config.classifier_dropout_prob, inplace=True)
self.classifier = nn.Linear(last_hidden_size, config.num_labels) if config.num_labels > 0 else nn.Identity()
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(MOBILENET_V1_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_IMAGE_CLASS_CHECKPOINT,
output_type=ImageClassifierOutputWithNoAttention,
config_class=_CONFIG_FOR_DOC,
expected_output=_IMAGE_CLASS_EXPECTED_OUTPUT,
)
def forward(
self,
pixel_values: Optional[torch.Tensor] = None,
output_hidden_states: Optional[bool] = None,
labels: Optional[torch.Tensor] = None,
return_dict: Optional[bool] = None,
) -> Union[tuple, ImageClassifierOutputWithNoAttention]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the image classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss). If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.mobilenet_v1(pixel_values, output_hidden_states=output_hidden_states, return_dict=return_dict)
pooled_output = outputs.pooler_output if return_dict else outputs[1]
logits = self.classifier(self.dropout(pooled_output))
loss = None
if labels is not None:
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return ImageClassifierOutputWithNoAttention(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
)
__all__ = [
"MobileNetV1ForImageClassification",
"MobileNetV1Model",
"MobileNetV1PreTrainedModel",
"load_tf_weights_in_mobilenet_v1",
]
| transformers/src/transformers/models/mobilenet_v1/modeling_mobilenet_v1.py/0 | {
"file_path": "transformers/src/transformers/models/mobilenet_v1/modeling_mobilenet_v1.py",
"repo_id": "transformers",
"token_count": 8115
} |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Convert MobileViTV2 checkpoints from the ml-cvnets library."""
import argparse
import collections
import json
from pathlib import Path
import requests
import torch
import yaml
from huggingface_hub import hf_hub_download
from PIL import Image
from transformers import (
MobileViTImageProcessor,
MobileViTV2Config,
MobileViTV2ForImageClassification,
MobileViTV2ForSemanticSegmentation,
)
from transformers.utils import logging
logging.set_verbosity_info()
logger = logging.get_logger(__name__)
def load_orig_config_file(orig_cfg_file):
print("Loading config file...")
def flatten_yaml_as_dict(d, parent_key="", sep="."):
items = []
for k, v in d.items():
new_key = parent_key + sep + k if parent_key else k
if isinstance(v, collections.abc.MutableMapping):
items.extend(flatten_yaml_as_dict(v, new_key, sep=sep).items())
else:
items.append((new_key, v))
return dict(items)
config = argparse.Namespace()
with open(orig_cfg_file, "r") as yaml_file:
try:
cfg = yaml.load(yaml_file, Loader=yaml.FullLoader)
flat_cfg = flatten_yaml_as_dict(cfg)
for k, v in flat_cfg.items():
setattr(config, k, v)
except yaml.YAMLError as exc:
logger.error("Error while loading config file: {}. Error message: {}".format(orig_cfg_file, str(exc)))
return config
def get_mobilevitv2_config(task_name, orig_cfg_file):
config = MobileViTV2Config()
is_segmentation_model = False
# dataset
if task_name.startswith("imagenet1k_"):
config.num_labels = 1000
if int(task_name.strip().split("_")[-1]) == 384:
config.image_size = 384
else:
config.image_size = 256
filename = "imagenet-1k-id2label.json"
elif task_name.startswith("imagenet21k_to_1k_"):
config.num_labels = 21000
if int(task_name.strip().split("_")[-1]) == 384:
config.image_size = 384
else:
config.image_size = 256
filename = "imagenet-22k-id2label.json"
elif task_name.startswith("ade20k_"):
config.num_labels = 151
config.image_size = 512
filename = "ade20k-id2label.json"
is_segmentation_model = True
elif task_name.startswith("voc_"):
config.num_labels = 21
config.image_size = 512
filename = "pascal-voc-id2label.json"
is_segmentation_model = True
# orig_config
orig_config = load_orig_config_file(orig_cfg_file)
assert getattr(orig_config, "model.classification.name", -1) == "mobilevit_v2", "Invalid model"
config.width_multiplier = getattr(orig_config, "model.classification.mitv2.width_multiplier", 1.0)
assert (
getattr(orig_config, "model.classification.mitv2.attn_norm_layer", -1) == "layer_norm_2d"
), "Norm layers other than layer_norm_2d is not supported"
config.hidden_act = getattr(orig_config, "model.classification.activation.name", "swish")
# config.image_size == getattr(orig_config, 'sampler.bs.crop_size_width', 256)
if is_segmentation_model:
config.output_stride = getattr(orig_config, "model.segmentation.output_stride", 16)
if "_deeplabv3" in task_name:
config.atrous_rates = getattr(orig_config, "model.segmentation.deeplabv3.aspp_rates", [12, 24, 36])
config.aspp_out_channels = getattr(orig_config, "model.segmentation.deeplabv3.aspp_out_channels", 512)
config.aspp_dropout_prob = getattr(orig_config, "model.segmentation.deeplabv3.aspp_dropout", 0.1)
# id2label
repo_id = "huggingface/label-files"
id2label = json.load(open(hf_hub_download(repo_id, filename, repo_type="dataset"), "r"))
id2label = {int(k): v for k, v in id2label.items()}
config.id2label = id2label
config.label2id = {v: k for k, v in id2label.items()}
return config
def rename_key(dct, old, new):
val = dct.pop(old)
dct[new] = val
def create_rename_keys(state_dict, base_model=False):
if base_model:
model_prefix = ""
else:
model_prefix = "mobilevitv2."
rename_keys = []
for k in state_dict.keys():
if k[:8] == "encoder.":
k_new = k[8:]
else:
k_new = k
if ".block." in k:
k_new = k_new.replace(".block.", ".")
if ".conv." in k:
k_new = k_new.replace(".conv.", ".convolution.")
if ".norm." in k:
k_new = k_new.replace(".norm.", ".normalization.")
if "conv_1." in k:
k_new = k_new.replace("conv_1.", f"{model_prefix}conv_stem.")
for i in [1, 2]:
if f"layer_{i}." in k:
k_new = k_new.replace(f"layer_{i}.", f"{model_prefix}encoder.layer.{i-1}.layer.")
if ".exp_1x1." in k:
k_new = k_new.replace(".exp_1x1.", ".expand_1x1.")
if ".red_1x1." in k:
k_new = k_new.replace(".red_1x1.", ".reduce_1x1.")
for i in [3, 4, 5]:
if f"layer_{i}.0." in k:
k_new = k_new.replace(f"layer_{i}.0.", f"{model_prefix}encoder.layer.{i-1}.downsampling_layer.")
if f"layer_{i}.1.local_rep.0." in k:
k_new = k_new.replace(f"layer_{i}.1.local_rep.0.", f"{model_prefix}encoder.layer.{i-1}.conv_kxk.")
if f"layer_{i}.1.local_rep.1." in k:
k_new = k_new.replace(f"layer_{i}.1.local_rep.1.", f"{model_prefix}encoder.layer.{i-1}.conv_1x1.")
for i in [3, 4, 5]:
if i == 3:
j_in = [0, 1]
elif i == 4:
j_in = [0, 1, 2, 3]
elif i == 5:
j_in = [0, 1, 2]
for j in j_in:
if f"layer_{i}.1.global_rep.{j}." in k:
k_new = k_new.replace(
f"layer_{i}.1.global_rep.{j}.", f"{model_prefix}encoder.layer.{i-1}.transformer.layer.{j}."
)
if f"layer_{i}.1.global_rep.{j+1}." in k:
k_new = k_new.replace(
f"layer_{i}.1.global_rep.{j+1}.", f"{model_prefix}encoder.layer.{i-1}.layernorm."
)
if f"layer_{i}.1.conv_proj." in k:
k_new = k_new.replace(f"layer_{i}.1.conv_proj.", f"{model_prefix}encoder.layer.{i-1}.conv_projection.")
if "pre_norm_attn.0." in k:
k_new = k_new.replace("pre_norm_attn.0.", "layernorm_before.")
if "pre_norm_attn.1." in k:
k_new = k_new.replace("pre_norm_attn.1.", "attention.")
if "pre_norm_ffn.0." in k:
k_new = k_new.replace("pre_norm_ffn.0.", "layernorm_after.")
if "pre_norm_ffn.1." in k:
k_new = k_new.replace("pre_norm_ffn.1.", "ffn.conv1.")
if "pre_norm_ffn.3." in k:
k_new = k_new.replace("pre_norm_ffn.3.", "ffn.conv2.")
if "classifier.1." in k:
k_new = k_new.replace("classifier.1.", "classifier.")
if "seg_head." in k:
k_new = k_new.replace("seg_head.", "segmentation_head.")
if ".aspp_layer." in k:
k_new = k_new.replace(".aspp_layer.", ".")
if ".aspp_pool." in k:
k_new = k_new.replace(".aspp_pool.", ".")
rename_keys.append((k, k_new))
return rename_keys
def remove_unused_keys(state_dict):
"""remove unused keys (e.g.: seg_head.aux_head)"""
keys_to_ignore = []
for k in state_dict.keys():
if k.startswith("seg_head.aux_head."):
keys_to_ignore.append(k)
for k in keys_to_ignore:
state_dict.pop(k, None)
# We will verify our results on an image of cute cats
def prepare_img():
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
# url = "https://cdn.britannica.com/86/141086-050-9D7C75EE/Gulfstream-G450-business-jet-passengers.jpg"
im = Image.open(requests.get(url, stream=True).raw)
return im
@torch.no_grad()
def convert_mobilevitv2_checkpoint(task_name, checkpoint_path, orig_config_path, pytorch_dump_folder_path):
"""
Copy/paste/tweak model's weights to our MobileViTV2 structure.
"""
config = get_mobilevitv2_config(task_name, orig_config_path)
# load original state_dict
checkpoint = torch.load(checkpoint_path, map_location="cpu")
# load huggingface model
if task_name.startswith("ade20k_") or task_name.startswith("voc_"):
model = MobileViTV2ForSemanticSegmentation(config).eval()
base_model = False
else:
model = MobileViTV2ForImageClassification(config).eval()
base_model = False
# remove and rename some keys of load the original model
state_dict = checkpoint
remove_unused_keys(state_dict)
rename_keys = create_rename_keys(state_dict, base_model=base_model)
for rename_key_src, rename_key_dest in rename_keys:
rename_key(state_dict, rename_key_src, rename_key_dest)
# load modified state_dict
model.load_state_dict(state_dict)
# Check outputs on an image, prepared by MobileViTImageProcessor
image_processor = MobileViTImageProcessor(crop_size=config.image_size, size=config.image_size + 32)
encoding = image_processor(images=prepare_img(), return_tensors="pt")
outputs = model(**encoding)
# verify classification model
if task_name.startswith("imagenet"):
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
if task_name.startswith("imagenet1k_256") and config.width_multiplier == 1.0:
# expected_logits for base variant
expected_logits = torch.tensor([-1.6336e00, -7.3204e-02, -5.1883e-01])
assert torch.allclose(logits[0, :3], expected_logits, atol=1e-4)
Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
print(f"Saving model {task_name} to {pytorch_dump_folder_path}")
model.save_pretrained(pytorch_dump_folder_path)
print(f"Saving image processor to {pytorch_dump_folder_path}")
image_processor.save_pretrained(pytorch_dump_folder_path)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--task",
default="imagenet1k_256",
type=str,
help=(
"Name of the task for which the MobileViTV2 model you'd like to convert is trained on . "
"""
Classification (ImageNet-1k)
- MobileViTV2 (256x256) : imagenet1k_256
- MobileViTV2 (Trained on 256x256 and Finetuned on 384x384) : imagenet1k_384
- MobileViTV2 (Trained on ImageNet-21k and Finetuned on ImageNet-1k 256x256) :
imagenet21k_to_1k_256
- MobileViTV2 (Trained on ImageNet-21k, Finetuned on ImageNet-1k 256x256, and Finetuned on
ImageNet-1k 384x384) : imagenet21k_to_1k_384
Segmentation
- ADE20K Dataset : ade20k_deeplabv3
- Pascal VOC 2012 Dataset: voc_deeplabv3
"""
),
choices=[
"imagenet1k_256",
"imagenet1k_384",
"imagenet21k_to_1k_256",
"imagenet21k_to_1k_384",
"ade20k_deeplabv3",
"voc_deeplabv3",
],
)
parser.add_argument(
"--orig_checkpoint_path", required=True, type=str, help="Path to the original state dict (.pt file)."
)
parser.add_argument(
"--orig_config_path",
required=True,
type=str,
help="Path to the original config file. yaml.load will be used to load the file, please be wary of which file you're loading.",
)
parser.add_argument(
"--pytorch_dump_folder_path", required=True, type=str, help="Path to the output PyTorch model directory."
)
args = parser.parse_args()
convert_mobilevitv2_checkpoint(
args.task, args.orig_checkpoint_path, args.orig_config_path, args.pytorch_dump_folder_path
)
| transformers/src/transformers/models/mobilevitv2/convert_mlcvnets_to_pytorch.py/0 | {
"file_path": "transformers/src/transformers/models/mobilevitv2/convert_mlcvnets_to_pytorch.py",
"repo_id": "transformers",
"token_count": 5933
} |
# coding=utf-8
# Copyright 2018 The HuggingFace Inc. team, Microsoft Corporation.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""MPNet model configuration"""
from ...configuration_utils import PretrainedConfig
from ...utils import logging
logger = logging.get_logger(__name__)
class MPNetConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`MPNetModel`] or a [`TFMPNetModel`]. It is used to
instantiate a MPNet model according to the specified arguments, defining the model architecture. Instantiating a
configuration with the defaults will yield a similar configuration to that of the MPNet
[microsoft/mpnet-base](https://huggingface.co/microsoft/mpnet-base) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 30527):
Vocabulary size of the MPNet model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`MPNetModel`] or [`TFMPNetModel`].
hidden_size (`int`, *optional*, defaults to 768):
Dimensionality of the encoder layers and the pooler layer.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
intermediate_size (`int`, *optional*, defaults to 3072):
Dimensionality of the "intermediate" (often named feed-forward) layer in the Transformer encoder.
hidden_act (`str` or `Callable`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"silu"` and `"gelu_new"` are supported.
hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
The dropout ratio for the attention probabilities.
max_position_embeddings (`int`, *optional*, defaults to 512):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (`float`, *optional*, defaults to 1e-12):
The epsilon used by the layer normalization layers.
relative_attention_num_buckets (`int`, *optional*, defaults to 32):
The number of buckets to use for each attention layer.
Examples:
```python
>>> from transformers import MPNetModel, MPNetConfig
>>> # Initializing a MPNet mpnet-base style configuration
>>> configuration = MPNetConfig()
>>> # Initializing a model from the mpnet-base style configuration
>>> model = MPNetModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "mpnet"
def __init__(
self,
vocab_size=30527,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
initializer_range=0.02,
layer_norm_eps=1e-12,
relative_attention_num_buckets=32,
pad_token_id=1,
bos_token_id=0,
eos_token_id=2,
**kwargs,
):
super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.hidden_act = hidden_act
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.initializer_range = initializer_range
self.layer_norm_eps = layer_norm_eps
self.relative_attention_num_buckets = relative_attention_num_buckets
__all__ = ["MPNetConfig"]
| transformers/src/transformers/models/mpnet/configuration_mpnet.py/0 | {
"file_path": "transformers/src/transformers/models/mpnet/configuration_mpnet.py",
"repo_id": "transformers",
"token_count": 1928
} |
# coding=utf-8
# Copyright 2020 Mesh TensorFlow authors, T5 Authors and HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tensorflow mT5 model."""
from ...utils import logging
from ..t5.modeling_tf_t5 import TFT5EncoderModel, TFT5ForConditionalGeneration, TFT5Model
from .configuration_mt5 import MT5Config
logger = logging.get_logger(__name__)
_CONFIG_FOR_DOC = "T5Config"
class TFMT5Model(TFT5Model):
r"""
This class overrides [`TFT5Model`]. Please check the superclass for the appropriate documentation alongside usage
examples.
Examples:
```python
>>> from transformers import TFMT5Model, AutoTokenizer
>>> model = TFMT5Model.from_pretrained("google/mt5-small")
>>> tokenizer = AutoTokenizer.from_pretrained("google/mt5-small")
>>> article = "UN Offizier sagt, dass weiter verhandelt werden muss in Syrien."
>>> summary = "Weiter Verhandlung in Syrien."
>>> inputs = tokenizer(article, return_tensors="tf")
>>> labels = tokenizer(text_target=summary, return_tensors="tf")
>>> outputs = model(input_ids=inputs["input_ids"], decoder_input_ids=labels["input_ids"])
>>> hidden_states = outputs.last_hidden_state
```"""
model_type = "mt5"
config_class = MT5Config
class TFMT5ForConditionalGeneration(TFT5ForConditionalGeneration):
r"""
This class overrides [`TFT5ForConditionalGeneration`]. Please check the superclass for the appropriate
documentation alongside usage examples.
Examples:
```python
>>> from transformers import TFMT5ForConditionalGeneration, AutoTokenizer
>>> model = TFMT5ForConditionalGeneration.from_pretrained("google/mt5-small")
>>> tokenizer = AutoTokenizer.from_pretrained("google/mt5-small")
>>> article = "UN Offizier sagt, dass weiter verhandelt werden muss in Syrien."
>>> summary = "Weiter Verhandlung in Syrien."
>>> inputs = tokenizer(article, text_target=summary, return_tensors="tf")
>>> outputs = model(**inputs)
>>> loss = outputs.loss
```"""
model_type = "mt5"
config_class = MT5Config
class TFMT5EncoderModel(TFT5EncoderModel):
r"""
This class overrides [`TFT5EncoderModel`]. Please check the superclass for the appropriate documentation alongside
usage examples.
Examples:
```python
>>> from transformers import TFMT5EncoderModel, AutoTokenizer
>>> model = TFMT5EncoderModel.from_pretrained("google/mt5-small")
>>> tokenizer = AutoTokenizer.from_pretrained("google/mt5-small")
>>> article = "UN Offizier sagt, dass weiter verhandelt werden muss in Syrien."
>>> input_ids = tokenizer(article, return_tensors="tf").input_ids
>>> outputs = model(input_ids)
>>> hidden_state = outputs.last_hidden_state
```"""
model_type = "mt5"
config_class = MT5Config
__all__ = ["TFMT5EncoderModel", "TFMT5ForConditionalGeneration", "TFMT5Model"]
| transformers/src/transformers/models/mt5/modeling_tf_mt5.py/0 | {
"file_path": "transformers/src/transformers/models/mt5/modeling_tf_mt5.py",
"repo_id": "transformers",
"token_count": 1132
} |
# coding=utf-8
# Copyright 2023 NllbMoe Authors and HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch NLLB-MoE model."""
import math
from typing import List, Optional, Tuple, Union
import torch
import torch.nn as nn
from torch.nn import CrossEntropyLoss
from ...activations import ACT2FN
from ...generation import GenerationMixin
from ...integrations.deepspeed import is_deepspeed_zero3_enabled
from ...integrations.fsdp import is_fsdp_managed_module
from ...modeling_attn_mask_utils import _prepare_4d_attention_mask, _prepare_4d_causal_attention_mask
from ...modeling_outputs import (
MoEModelOutput,
MoEModelOutputWithPastAndCrossAttentions,
Seq2SeqMoEModelOutput,
Seq2SeqMoEOutput,
)
from ...modeling_utils import PreTrainedModel
from ...utils import (
add_end_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
logging,
replace_return_docstrings,
)
from .configuration_nllb_moe import NllbMoeConfig
logger = logging.get_logger(__name__)
_CONFIG_FOR_DOC = "NllbMoeConfig"
_CHECKPOINT_FOR_DOC = "hf-internal-testing/dummy-nllb-moe-2-experts"
_REAL_CHECKPOINT_FOR_DOC = "facebook/nllb-moe-54b"
####################################################
# This dict contains ids and associated url
# for the pretrained weights provided with the models
####################################################
# Copied from transformers.models.bart.modeling_bart.shift_tokens_right
def shift_tokens_right(input_ids: torch.Tensor, pad_token_id: int, decoder_start_token_id: int):
"""
Shift input ids one token to the right.
"""
shifted_input_ids = input_ids.new_zeros(input_ids.shape)
shifted_input_ids[:, 1:] = input_ids[:, :-1].clone()
shifted_input_ids[:, 0] = decoder_start_token_id
if pad_token_id is None:
raise ValueError("self.model.config.pad_token_id has to be defined.")
# replace possible -100 values in labels by `pad_token_id`
shifted_input_ids.masked_fill_(shifted_input_ids == -100, pad_token_id)
return shifted_input_ids
# Copied from transformers.models.roberta.modeling_roberta.create_position_ids_from_input_ids
def create_position_ids_from_input_ids(input_ids, padding_idx, past_key_values_length=0):
"""
Replace non-padding symbols with their position numbers. Position numbers begin at padding_idx+1. Padding symbols
are ignored. This is modified from fairseq's `utils.make_positions`.
Args:
x: torch.Tensor x:
Returns: torch.Tensor
"""
# The series of casts and type-conversions here are carefully balanced to both work with ONNX export and XLA.
mask = input_ids.ne(padding_idx).int()
incremental_indices = (torch.cumsum(mask, dim=1).type_as(mask) + past_key_values_length) * mask
return incremental_indices.long() + padding_idx
def load_balancing_loss_func(router_probs: torch.Tensor, expert_indices: torch.Tensor) -> float:
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
Args:
router_probs (`torch.Tensor`):
Probability assigned to each expert per token. Shape: [batch_size, seqeunce_length, num_experts].
expert_indices (`torch.Tensor`):
Indices tensor of shape [batch_size, seqeunce_length] identifying the selected expert for a given token.
Returns:
The auxiliary loss.
"""
if router_probs is None:
return 0
num_experts = router_probs.shape[-1]
# cast the expert indices to int64, otherwise one-hot encoding will fail
if expert_indices.dtype != torch.int64:
expert_indices = expert_indices.to(torch.int64)
if len(expert_indices.shape) == 2:
expert_indices = expert_indices.unsqueeze(2)
expert_mask = torch.nn.functional.one_hot(expert_indices, num_experts)
# For a given token, determine if it was routed to a given expert.
expert_mask = torch.max(expert_mask, axis=-2).values
# cast to float32 otherwise mean will fail
expert_mask = expert_mask.to(torch.float32)
tokens_per_group_and_expert = torch.mean(expert_mask, axis=-2)
router_prob_per_group_and_expert = torch.mean(router_probs, axis=-2)
return torch.mean(tokens_per_group_and_expert * router_prob_per_group_and_expert) * (num_experts**2)
# Copied from transformers.models.m2m_100.modeling_m2m_100.M2M100ScaledWordEmbedding with M2M100->NllbMoe
class NllbMoeScaledWordEmbedding(nn.Embedding):
"""
This module overrides nn.Embeddings' forward by multiplying with embeddings scale.
"""
def __init__(self, num_embeddings: int, embedding_dim: int, padding_idx: int, embed_scale: Optional[float] = 1.0):
super().__init__(num_embeddings, embedding_dim, padding_idx)
self.embed_scale = embed_scale
def forward(self, input_ids: torch.Tensor):
return super().forward(input_ids) * self.embed_scale
# Copied from transformers.models.m2m_100.modeling_m2m_100.M2M100SinusoidalPositionalEmbedding
class NllbMoeSinusoidalPositionalEmbedding(nn.Module):
"""This module produces sinusoidal positional embeddings of any length."""
def __init__(self, num_positions: int, embedding_dim: int, padding_idx: Optional[int] = None):
super().__init__()
self.offset = 2
self.embedding_dim = embedding_dim
self.padding_idx = padding_idx
self.make_weights(num_positions + self.offset, embedding_dim, padding_idx)
def make_weights(self, num_embeddings: int, embedding_dim: int, padding_idx: Optional[int] = None):
emb_weights = self.get_embedding(num_embeddings, embedding_dim, padding_idx)
if hasattr(self, "weights"):
# in forward put the weights on the correct dtype and device of the param
emb_weights = emb_weights.to(dtype=self.weights.dtype, device=self.weights.device)
self.register_buffer("weights", emb_weights, persistent=False)
@staticmethod
def get_embedding(num_embeddings: int, embedding_dim: int, padding_idx: Optional[int] = None):
"""
Build sinusoidal embeddings.
This matches the implementation in tensor2tensor, but differs slightly from the description in Section 3.5 of
"Attention Is All You Need".
"""
half_dim = embedding_dim // 2
emb = math.log(10000) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, dtype=torch.int64).float() * -emb)
emb = torch.arange(num_embeddings, dtype=torch.int64).float().unsqueeze(1) * emb.unsqueeze(0)
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1).view(num_embeddings, -1)
if embedding_dim % 2 == 1:
# zero pad
emb = torch.cat([emb, torch.zeros(num_embeddings, 1)], dim=1)
if padding_idx is not None:
emb[padding_idx, :] = 0
return emb.to(torch.get_default_dtype())
@torch.no_grad()
def forward(
self, input_ids: torch.Tensor = None, inputs_embeds: torch.Tensor = None, past_key_values_length: int = 0
):
if input_ids is not None:
bsz, seq_len = input_ids.size()
# Create the position ids from the input token ids. Any padded tokens remain padded.
position_ids = create_position_ids_from_input_ids(input_ids, self.padding_idx, past_key_values_length).to(
input_ids.device
)
else:
bsz, seq_len = inputs_embeds.size()[:-1]
position_ids = self.create_position_ids_from_inputs_embeds(inputs_embeds, past_key_values_length)
# expand embeddings if needed
max_pos = self.padding_idx + 1 + seq_len + past_key_values_length
if max_pos > self.weights.size(0):
self.make_weights(max_pos + self.offset, self.embedding_dim, self.padding_idx)
return self.weights.index_select(0, position_ids.view(-1)).view(bsz, seq_len, self.weights.shape[-1]).detach()
def create_position_ids_from_inputs_embeds(self, inputs_embeds, past_key_values_length):
"""
We are provided embeddings directly. We cannot infer which are padded so just generate sequential position ids.
Args:
inputs_embeds: torch.Tensor
Returns: torch.Tensor
"""
input_shape = inputs_embeds.size()[:-1]
sequence_length = input_shape[1]
position_ids = torch.arange(
self.padding_idx + 1, sequence_length + self.padding_idx + 1, dtype=torch.long, device=inputs_embeds.device
)
return position_ids.unsqueeze(0).expand(input_shape).contiguous() + past_key_values_length
class NllbMoeTop2Router(nn.Module):
"""
Router using tokens choose top-2 experts assignment.
This router uses the same mechanism as in NLLB-MoE from the fairseq repository. Items are sorted by router_probs
and then routed to their choice of expert until the expert's expert_capacity is reached. **There is no guarantee
that each token is processed by an expert**, or that each expert receives at least one token.
The router combining weights are also returned to make sure that the states that are not updated will be masked.
"""
def __init__(self, config: NllbMoeConfig):
super().__init__()
self.num_experts = config.num_experts
self.expert_capacity = config.expert_capacity
self.classifier = nn.Linear(config.hidden_size, self.num_experts, bias=config.router_bias)
self.router_ignore_padding_tokens = config.router_ignore_padding_tokens
self.dtype = getattr(torch, config.router_dtype)
self.second_expert_policy = config.second_expert_policy
self.normalize_router_prob_before_dropping = config.normalize_router_prob_before_dropping
self.batch_prioritized_routing = config.batch_prioritized_routing
self.moe_eval_capacity_token_fraction = config.moe_eval_capacity_token_fraction
def _cast_classifier(self):
r"""
`bitsandbytes` `Linear8bitLt` layers does not support manual casting Therefore we need to check if they are an
instance of the `Linear8bitLt` class by checking special attributes.
"""
if not (hasattr(self.classifier, "SCB") or hasattr(self.classifier, "CB")):
self.classifier = self.classifier.to(self.dtype)
def normalize_router_probabilities(self, router_probs, top_1_mask, top_2_mask):
top_1_max_probs = (router_probs * top_1_mask).sum(dim=1)
top_2_max_probs = (router_probs * top_2_mask).sum(dim=1)
denom_s = torch.clamp(top_1_max_probs + top_2_max_probs, min=torch.finfo(router_probs.dtype).eps)
top_1_max_probs = top_1_max_probs / denom_s
top_2_max_probs = top_2_max_probs / denom_s
return top_1_max_probs, top_2_max_probs
def route_tokens(
self,
router_logits: torch.Tensor,
input_dtype: torch.dtype = torch.float32,
padding_mask: Optional[torch.LongTensor] = None,
) -> Tuple:
"""
Computes the `dispatch_mask` and the `dispatch_weights` for each experts. The masks are adapted to the expert
capacity.
"""
nb_tokens = router_logits.shape[0]
# Apply Softmax and cast back to the original `dtype`
router_probs = nn.functional.softmax(router_logits, dim=-1, dtype=self.dtype).to(input_dtype)
top_1_expert_index = torch.argmax(router_probs, dim=-1)
top_1_mask = torch.nn.functional.one_hot(top_1_expert_index, num_classes=self.num_experts)
if self.second_expert_policy == "sampling":
gumbel = torch.distributions.gumbel.Gumbel(0, 1).rsample
router_logits += gumbel(router_logits.shape).to(router_logits.device)
# replace top_1_expert_index with min values
logits_except_top_1 = router_logits.masked_fill(top_1_mask.bool(), float("-inf"))
top_2_expert_index = torch.argmax(logits_except_top_1, dim=-1)
top_2_mask = torch.nn.functional.one_hot(top_2_expert_index, num_classes=self.num_experts)
if self.normalize_router_prob_before_dropping:
top_1_max_probs, top_2_max_probs = self.normalize_router_probabilities(
router_probs, top_1_mask, top_2_mask
)
if self.second_expert_policy == "random":
top_2_max_probs = (router_probs * top_2_mask).sum(dim=1)
sampled = (2 * top_2_max_probs) > torch.rand_like(top_2_max_probs.float())
top_2_mask = top_2_mask * sampled.repeat(self.num_experts, 1).transpose(1, 0)
if padding_mask is not None and not self.router_ignore_padding_tokens:
if len(padding_mask.shape) == 4:
# only get the last causal mask
padding_mask = padding_mask[:, :, -1, :].reshape(-1)[-nb_tokens:]
non_padding = ~padding_mask.bool()
top_1_mask = top_1_mask * non_padding.unsqueeze(-1).to(top_1_mask.dtype)
top_2_mask = top_2_mask * non_padding.unsqueeze(-1).to(top_1_mask.dtype)
if self.batch_prioritized_routing:
# sort tokens based on their routing probability
# to make sure important tokens are routed, first
importance_scores = -1 * router_probs.max(dim=1)[0]
sorted_top_1_mask = top_1_mask[importance_scores.argsort(dim=0)]
sorted_cumsum1 = (torch.cumsum(sorted_top_1_mask, dim=0) - 1) * sorted_top_1_mask
locations1 = sorted_cumsum1[importance_scores.argsort(dim=0).argsort(dim=0)]
sorted_top_2_mask = top_2_mask[importance_scores.argsort(dim=0)]
sorted_cumsum2 = (torch.cumsum(sorted_top_2_mask, dim=0) - 1) * sorted_top_2_mask
locations2 = sorted_cumsum2[importance_scores.argsort(dim=0).argsort(dim=0)]
# Update 2nd's location by accounting for locations of 1st
locations2 += torch.sum(top_1_mask, dim=0, keepdim=True)
else:
locations1 = torch.cumsum(top_1_mask, dim=0) - 1
locations2 = torch.cumsum(top_2_mask, dim=0) - 1
# Update 2nd's location by accounting for locations of 1st
locations2 += torch.sum(top_1_mask, dim=0, keepdim=True)
if not self.training and self.moe_eval_capacity_token_fraction > 0:
self.expert_capacity = math.ceil(self.moe_eval_capacity_token_fraction * nb_tokens)
else:
capacity = 2 * math.ceil(nb_tokens / self.num_experts)
self.expert_capacity = capacity if self.expert_capacity is None else self.expert_capacity
# Remove locations outside capacity from ( cumsum < capacity = False will not be routed)
top_1_mask = top_1_mask * torch.lt(locations1, self.expert_capacity)
top_2_mask = top_2_mask * torch.lt(locations2, self.expert_capacity)
if not self.normalize_router_prob_before_dropping:
top_1_max_probs, top_2_max_probs = self.normalize_router_probabilities(
router_probs, top_1_mask, top_2_mask
)
# Calculate combine_weights and dispatch_mask
gates1 = top_1_max_probs[:, None] * top_1_mask
gates2 = top_2_max_probs[:, None] * top_2_mask
router_probs = gates1 + gates2
return top_1_mask, router_probs
def forward(self, hidden_states: torch.Tensor, padding_mask: Optional[torch.LongTensor] = None) -> Tuple:
r"""
The hidden states are reshaped to simplify the computation of the router probabilities (combining weights for
each experts.)
Args:
hidden_states (`torch.Tensor`):
(batch_size, sequence_length, hidden_dim) from which router probabilities are computed.
Returns:
top_1_mask (`torch.Tensor` of shape (batch_size, sequence_length)):
Index tensor of shape [batch_size, sequence_length] corresponding to the expert selected for each token
using the top1 probabilities of the router.
router_probabilities (`torch.Tensor` of shape (batch_size, sequence_length, nump_experts)):
Tensor of shape (batch_size, sequence_length, num_experts) corresponding to the probabilities for each
token and expert. Used for routing tokens to experts.
router_logits (`torch.Tensor` of shape (batch_size, sequence_length))):
Logits tensor of shape (batch_size, sequence_length, num_experts) corresponding to raw router logits.
This is used later for computing router z-loss.
"""
self.input_dtype = hidden_states.dtype
batch_size, sequence_length, hidden_dim = hidden_states.shape
hidden_states = hidden_states.reshape((batch_size * sequence_length), hidden_dim)
hidden_states = hidden_states.to(self.dtype)
self._cast_classifier()
router_logits = self.classifier(hidden_states)
top_1_mask, router_probs = self.route_tokens(router_logits, self.input_dtype, padding_mask)
return top_1_mask, router_probs
class NllbMoeDenseActDense(nn.Module):
def __init__(self, config: NllbMoeConfig, ffn_dim: int):
super().__init__()
self.fc1 = nn.Linear(config.d_model, ffn_dim)
self.fc2 = nn.Linear(ffn_dim, config.d_model)
self.dropout = nn.Dropout(config.activation_dropout)
self.act = ACT2FN[config.activation_function]
def forward(self, hidden_states):
hidden_states = self.fc1(hidden_states)
hidden_states = self.act(hidden_states)
hidden_states = self.dropout(hidden_states)
if (
isinstance(self.fc2.weight, torch.Tensor)
and hidden_states.dtype != self.fc2.weight.dtype
and (self.fc2.weight.dtype != torch.int8 and self.fc2.weight.dtype != torch.uint8)
):
hidden_states = hidden_states.to(self.fc2.weight.dtype)
hidden_states = self.fc2(hidden_states)
return hidden_states
class NllbMoeSparseMLP(nn.Module):
r"""
Implementation of the NLLB-MoE sparse MLP module.
"""
def __init__(self, config: NllbMoeConfig, ffn_dim: int, expert_class: nn.Module = NllbMoeDenseActDense):
super().__init__()
self.router = NllbMoeTop2Router(config)
self.moe_token_dropout = config.moe_token_dropout
self.token_dropout = nn.Dropout(self.moe_token_dropout)
self.num_experts = config.num_experts
self.experts = nn.ModuleDict()
for idx in range(self.num_experts):
self.experts[f"expert_{idx}"] = expert_class(config, ffn_dim)
def forward(self, hidden_states: torch.Tensor, padding_mask: Optional[torch.Tensor] = False):
r"""
The goal of this forward pass is to have the same number of operation as the equivalent `NllbMoeDenseActDense`
(mlp) layer. This means that all of the hidden states should be processed at most twice ( since we are using a
top_2 gating mecanism). This means that we keep the complexity to O(batch_size x sequence_length x hidden_dim)
instead of O(num_experts x batch_size x sequence_length x hidden_dim).
1- Get the `router_probs` from the `router`. The shape of the `router_mask` is `(batch_size X sequence_length,
num_expert)` and corresponds to the boolean version of the `router_probs`. The inputs are masked using the
`router_mask`.
2- Dispatch the hidden_states to its associated experts. The router probabilities are used to weight the
contribution of each experts when updating the masked hidden states.
Args:
hidden_states (`torch.Tensor` of shape `(batch_size, sequence_length, hidden_dim)`):
The hidden states
padding_mask (`torch.Tensor`, *optional*, defaults to `False`):
Attention mask. Can be in the causal form or not.
Returns:
hidden_states (`torch.Tensor` of shape `(batch_size, sequence_length, hidden_dim)`):
Updated hidden states
router_logits (`torch.Tensor` of shape `(batch_size, sequence_length, num_experts)`):
Needed for computing the loss
"""
batch_size, sequence_length, hidden_dim = hidden_states.shape
top_1_mask, router_probs = self.router(hidden_states, padding_mask)
router_mask = router_probs.bool()
hidden_states = hidden_states.reshape((batch_size * sequence_length), hidden_dim)
masked_hidden_states = torch.einsum("bm,be->ebm", hidden_states, router_mask)
for idx, expert in enumerate(self.experts.values()):
token_indices = router_mask[:, idx]
combining_weights = router_probs[token_indices, idx]
expert_output = expert(masked_hidden_states[idx, token_indices])
if self.moe_token_dropout > 0:
if self.training:
expert_output = self.token_dropout(expert_output)
else:
expert_output *= 1 - self.moe_token_dropout
masked_hidden_states[idx, token_indices] = torch.einsum("b,be->be", combining_weights, expert_output)
hidden_states = masked_hidden_states.sum(dim=0).reshape(batch_size, sequence_length, hidden_dim)
top_1_expert_index = torch.argmax(top_1_mask, dim=-1)
return hidden_states, (router_probs, top_1_expert_index)
# Copied from transformers.models.bart.modeling_bart.BartAttention with Bart->NllbMoe,key_value_states->encoder_hidden_states
class NllbMoeAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(
self,
embed_dim: int,
num_heads: int,
dropout: float = 0.0,
is_decoder: bool = False,
bias: bool = True,
is_causal: bool = False,
config: Optional[NllbMoeConfig] = None,
):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.dropout = dropout
self.head_dim = embed_dim // num_heads
self.config = config
if (self.head_dim * num_heads) != self.embed_dim:
raise ValueError(
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim}"
f" and `num_heads`: {num_heads})."
)
self.scaling = self.head_dim**-0.5
self.is_decoder = is_decoder
self.is_causal = is_causal
self.k_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.v_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
def forward(
self,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
attention_mask: Optional[torch.Tensor] = None,
layer_head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
"""Input shape: Batch x Time x Channel"""
# if encoder_hidden_states are provided this layer is used as a cross-attention layer
# for the decoder
is_cross_attention = encoder_hidden_states is not None
bsz, tgt_len, _ = hidden_states.size()
# get query proj
query_states = self.q_proj(hidden_states) * self.scaling
# get key, value proj
# `past_key_value[0].shape[2] == encoder_hidden_states.shape[1]`
# is checking that the `sequence_length` of the `past_key_value` is the same as
# the provided `encoder_hidden_states` to support prefix tuning
if (
is_cross_attention
and past_key_value is not None
and past_key_value[0].shape[2] == encoder_hidden_states.shape[1]
):
# reuse k,v, cross_attentions
key_states = past_key_value[0]
value_states = past_key_value[1]
elif is_cross_attention:
# cross_attentions
key_states = self._shape(self.k_proj(encoder_hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(encoder_hidden_states), -1, bsz)
elif past_key_value is not None:
# reuse k, v, self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
key_states = torch.cat([past_key_value[0], key_states], dim=2)
value_states = torch.cat([past_key_value[1], value_states], dim=2)
else:
# self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_states, value_states)
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
key_states = key_states.reshape(*proj_shape)
value_states = value_states.reshape(*proj_shape)
src_len = key_states.size(1)
attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
raise ValueError(
f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is"
f" {attn_weights.size()}"
)
if attention_mask is not None:
if attention_mask.size() != (bsz, 1, tgt_len, src_len):
raise ValueError(
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
)
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
if layer_head_mask is not None:
if layer_head_mask.size() != (self.num_heads,):
raise ValueError(
f"Head mask for a single layer should be of size {(self.num_heads,)}, but is"
f" {layer_head_mask.size()}"
)
attn_weights = layer_head_mask.view(1, -1, 1, 1) * attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
if output_attentions:
# this operation is a bit awkward, but it's required to
# make sure that attn_weights keeps its gradient.
# In order to do so, attn_weights have to be reshaped
# twice and have to be reused in the following
attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
else:
attn_weights_reshaped = None
attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
attn_output = torch.bmm(attn_probs, value_states)
if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(bsz * self.num_heads, tgt_len, self.head_dim)}, but is"
f" {attn_output.size()}"
)
attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
attn_output = attn_output.transpose(1, 2)
# Use the `embed_dim` from the config (stored in the class) rather than `hidden_state` because `attn_output` can be
# partitioned across GPUs when using tensor-parallelism.
attn_output = attn_output.reshape(bsz, tgt_len, self.embed_dim)
attn_output = self.out_proj(attn_output)
return attn_output, attn_weights_reshaped, past_key_value
class NllbMoeEncoderLayer(nn.Module):
def __init__(self, config: NllbMoeConfig, is_sparse: bool = False):
super().__init__()
self.embed_dim = config.d_model
self.is_sparse = is_sparse
self.self_attn = NllbMoeAttention(
embed_dim=self.embed_dim,
num_heads=config.encoder_attention_heads,
dropout=config.attention_dropout,
)
self.attn_dropout = nn.Dropout(config.dropout)
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
if not self.is_sparse:
self.ffn = NllbMoeDenseActDense(config, ffn_dim=config.encoder_ffn_dim)
else:
self.ffn = NllbMoeSparseMLP(config, ffn_dim=config.encoder_ffn_dim)
self.ff_layer_norm = nn.LayerNorm(config.d_model)
self.ff_dropout = nn.Dropout(config.activation_dropout)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: torch.Tensor,
layer_head_mask: torch.Tensor,
output_attentions: bool = False,
output_router_logits: bool = False,
) -> torch.Tensor:
"""
Args:
hidden_states (`torch.FloatTensor`):
input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`torch.FloatTensor`):
attention mask of size `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very
large negative values.
layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
`(encoder_attention_heads,)`.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
"""
residual = hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
hidden_states, attn_weights, _ = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
output_attentions=output_attentions,
)
hidden_states = self.attn_dropout(hidden_states)
hidden_states = residual + hidden_states
residual = hidden_states
hidden_states = self.ff_layer_norm(hidden_states)
if self.is_sparse:
hidden_states, router_states = self.ffn(hidden_states, attention_mask)
else:
# router_states set to None to track which layers have None gradients.
hidden_states, router_states = self.ffn(hidden_states), None
hidden_states = self.ff_dropout(hidden_states)
hidden_states = residual + hidden_states
if hidden_states.dtype == torch.float16 and (
torch.isinf(hidden_states).any() or torch.isnan(hidden_states).any()
):
clamp_value = torch.finfo(hidden_states.dtype).max - 1000
hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
outputs = (hidden_states,)
if output_attentions:
outputs += (attn_weights,)
if output_router_logits:
outputs += (router_states,)
return outputs
class NllbMoeDecoderLayer(nn.Module):
def __init__(self, config: NllbMoeConfig, is_sparse: bool = False):
super().__init__()
self.embed_dim = config.d_model
self.is_sparse = is_sparse
self.self_attn = NllbMoeAttention(
embed_dim=self.embed_dim,
num_heads=config.decoder_attention_heads,
dropout=config.attention_dropout,
is_decoder=True,
)
self.dropout = config.dropout
self.activation_fn = ACT2FN[config.activation_function]
self.attn_dropout = nn.Dropout(config.dropout)
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
self.cross_attention = NllbMoeAttention(
self.embed_dim, config.decoder_attention_heads, config.attention_dropout, is_decoder=True
)
self.cross_attention_layer_norm = nn.LayerNorm(self.embed_dim)
if not self.is_sparse:
self.ffn = NllbMoeDenseActDense(config, ffn_dim=config.decoder_ffn_dim)
else:
self.ffn = NllbMoeSparseMLP(config, ffn_dim=config.decoder_ffn_dim)
self.ff_layer_norm = nn.LayerNorm(config.d_model)
self.ff_dropout = nn.Dropout(config.activation_dropout)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
layer_head_mask: Optional[torch.Tensor] = None,
cross_attn_layer_head_mask: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: Optional[bool] = False,
output_router_logits: Optional[bool] = False,
use_cache: Optional[bool] = True,
) -> torch.Tensor:
"""
Args:
hidden_states (`torch.FloatTensor`):
input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`torch.FloatTensor`):
attention mask of size `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very
large negative values.
encoder_hidden_states (`torch.FloatTensor`):
cross attention input to the layer of shape `(batch, seq_len, embed_dim)`
encoder_attention_mask (`torch.FloatTensor`):
encoder attention mask of size `(batch, 1, tgt_len, src_len)` where padding elements are indicated by
very large negative values.
layer_head_mask (`torch.FloatTensor`):
mask for attention heads in a given layer of size `(encoder_attention_heads,)`.
cross_attn_layer_head_mask (`torch.FloatTensor`):
mask for cross-attention heads in a given layer of size `(decoder_attention_heads,)`.
past_key_value (`Tuple(torch.FloatTensor)`):
cached past key and value projection states
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
"""
residual = hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
# Self Attention
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
# add present self-attn cache to positions 1,2 of present_key_value tuple
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
past_key_value=self_attn_past_key_value,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
output_attentions=output_attentions,
)
hidden_states = self.attn_dropout(hidden_states)
hidden_states = residual + hidden_states
# Cross-Attention Block
cross_attn_present_key_value = None
cross_attn_weights = None
if encoder_hidden_states is not None:
residual = hidden_states
hidden_states = self.cross_attention_layer_norm(hidden_states)
# cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
hidden_states, cross_attn_weights, cross_attn_present_key_value = self.cross_attention(
hidden_states=hidden_states,
encoder_hidden_states=encoder_hidden_states,
past_key_value=cross_attn_past_key_value,
attention_mask=encoder_attention_mask,
layer_head_mask=cross_attn_layer_head_mask,
output_attentions=output_attentions,
)
hidden_states = self.attn_dropout(hidden_states)
hidden_states = residual + hidden_states
# add cross-attn to positions 3,4 of present_key_value tuple
present_key_value += cross_attn_present_key_value
# Fully Connected
residual = hidden_states
hidden_states = self.ff_layer_norm(hidden_states)
if self.is_sparse:
hidden_states, router_states = self.ffn(hidden_states, attention_mask)
else:
hidden_states, router_states = self.ffn(hidden_states), None
hidden_states = self.ff_dropout(hidden_states)
hidden_states = residual + hidden_states
# clamp inf values to enable fp16 training
if hidden_states.dtype == torch.float16 and torch.isinf(hidden_states).any():
clamp_value = torch.finfo(hidden_states.dtype).max - 1000
hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
outputs = (hidden_states, present_key_value)
if output_attentions:
outputs += (self_attn_weights, cross_attn_weights)
if output_router_logits:
outputs += (router_states,)
return outputs
class NllbMoePreTrainedModel(PreTrainedModel):
config_class = NllbMoeConfig
base_model_prefix = "model"
supports_gradient_checkpointing = True
_no_split_modules = ["NllbMoeEncoderLayer", "NllbMoeDecoderLayer"]
def _init_weights(self, module):
"""Initialize the weights"""
std = self.config.init_std
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=std)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=std)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
NLLB_MOE_START_DOCSTRING = r"""
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`NllbMoeConfig`]):
Model configuration class with all the parameters of the model. Initializing with a config file does not
load the weights associated with the model, only the configuration. Check out the
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
NLLB_MOE_GENERATION_EXAMPLE = r"""
Translation example:
```python
>>> from transformers import AutoTokenizer, NllbMoeForConditionalGeneration
>>> model = NllbMoeForConditionalGeneration.from_pretrained("facebook/nllb-moe-54b")
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-moe-54b")
>>> text_to_translate = "Life is like a box of chocolates"
>>> model_inputs = tokenizer(text_to_translate, return_tensors="pt")
>>> # translate to French
>>> gen_tokens = model.generate(**model_inputs, forced_bos_token_id=tokenizer.get_lang_id("eng_Latn"))
>>> print(tokenizer.batch_decode(gen_tokens, skip_special_tokens=True))
```
"""
NLLB_MOE_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
decoder_input_ids (`torch.LongTensor` of shape `(batch_size, target_sequence_length)`, *optional*):
Indices of decoder input sequence tokens in the vocabulary.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are decoder input IDs?](../glossary#decoder-input-ids)
NllbMoe uses the `eos_token_id` as the starting token for `decoder_input_ids` generation. If
`past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
`past_key_values`).
decoder_attention_mask (`torch.LongTensor` of shape `(batch_size, target_sequence_length)`, *optional*):
Default behavior: generate a tensor that ignores pad tokens in `decoder_input_ids`. Causal mask will also
be used by default.
head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
decoder_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the decoder. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in `[0,
1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
encoder_outputs (`tuple(tuple(torch.FloatTensor)`, *optional*):
Tuple consists of (`last_hidden_state`, *optional*: `hidden_states`, *optional*: `attentions`)
`last_hidden_state` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) is a sequence of
hidden-states at the output of the last layer of the encoder. Used in the cross-attention of the decoder.
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
`(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
`(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
than the model's internal embedding lookup matrix.
decoder_inputs_embeds (`torch.FloatTensor` of shape `(batch_size, target_sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `decoder_input_ids` you can choose to directly pass an embedded
representation. If `past_key_values` is used, optionally only the last `decoder_inputs_embeds` have to be
input (see `past_key_values`). This is useful if you want more control over how to convert
`decoder_input_ids` indices into associated vectors than the model's internal embedding lookup matrix.
If `decoder_input_ids` and `decoder_inputs_embeds` are both unset, `decoder_inputs_embeds` takes the value
of `inputs_embeds`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`).
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
output_router_logits (`bool`, *optional*):
Whether or not to return the logits of all the routers. They are useful for computing the router loss, and
should not be returned during inference.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
class NllbMoeEncoder(NllbMoePreTrainedModel):
"""
Transformer encoder consisting of *config.encoder_layers* self attention layers. Each layer is a
[`NllbMoeEncoderLayer`].
Args:
config:
NllbMoeConfig
embed_tokens (nn.Embedding):
output embedding
"""
def __init__(self, config: NllbMoeConfig, embed_tokens: Optional[nn.Embedding] = None):
super().__init__(config)
self.dropout = config.dropout
self.layerdrop = config.encoder_layerdrop
embed_dim = config.d_model
self.padding_idx = config.pad_token_id
self.max_source_positions = config.max_position_embeddings
embed_scale = math.sqrt(embed_dim) if config.scale_embedding else 1.0
self.embed_tokens = NllbMoeScaledWordEmbedding(
config.vocab_size, embed_dim, self.padding_idx, embed_scale=embed_scale
)
if embed_tokens is not None:
self.embed_tokens.weight = embed_tokens.weight
self.embed_positions = NllbMoeSinusoidalPositionalEmbedding(
config.max_position_embeddings,
embed_dim,
self.padding_idx,
)
sparse_step = config.encoder_sparse_step
self.layers = nn.ModuleList()
for i in range(config.encoder_layers):
is_sparse = (i + 1) % sparse_step == 0 if sparse_step > 0 else False
self.layers.append(NllbMoeEncoderLayer(config, is_sparse))
self.layer_norm = nn.LayerNorm(config.d_model)
self.gradient_checkpointing = False
# Initialize weights and apply final processing
self.post_init()
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_router_logits: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
output_router_logits (`bool`, *optional*):
Whether or not to return the logits of all the routers. They are useful for computing the router loss,
and should not be returned during inference.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.return_dict
# retrieve input_ids and inputs_embeds
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids)
embed_pos = self.embed_positions(input_ids, inputs_embeds)
embed_pos = embed_pos.to(inputs_embeds.device)
hidden_states = inputs_embeds + embed_pos
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
# expand attention_mask
if attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
attention_mask = _prepare_4d_attention_mask(attention_mask, inputs_embeds.dtype)
encoder_states = () if output_hidden_states else None
all_router_probs = () if output_router_logits else None
all_attentions = () if output_attentions else None
# check if head_mask has a correct number of layers specified if desired
if head_mask is not None:
if head_mask.size()[0] != len(self.layers):
raise ValueError(
f"The head_mask should be specified for {len(self.layers)} layers, but it is for"
f" {head_mask.size()[0]}."
)
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
dropout_probability = torch.rand([])
if self.training and (dropout_probability < self.layerdrop): # skip the layer
layer_outputs = (None, None, None)
else:
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
encoder_layer.__call__,
hidden_states,
attention_mask,
(head_mask[idx] if head_mask is not None else None),
output_attentions,
)
else:
layer_outputs = encoder_layer(
hidden_states,
attention_mask,
layer_head_mask=(head_mask[idx] if head_mask is not None else None),
output_attentions=output_attentions,
output_router_logits=output_router_logits,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions += (layer_outputs[1],)
if output_router_logits:
all_router_probs += (layer_outputs[-1],)
last_hidden_state = self.layer_norm(hidden_states)
if output_hidden_states:
encoder_states += (last_hidden_state,)
if not return_dict:
return tuple(
v for v in [last_hidden_state, encoder_states, all_attentions, all_router_probs] if v is not None
)
return MoEModelOutput(
last_hidden_state=last_hidden_state,
hidden_states=encoder_states,
attentions=all_attentions,
router_probs=all_router_probs,
)
class NllbMoeDecoder(NllbMoePreTrainedModel):
"""
Transformer decoder consisting of *config.decoder_layers* layers. Each layer is a [`NllbMoeDecoderLayer`]
Args:
config:
NllbMoeConfig
embed_tokens (nn.Embedding):
output embedding
"""
def __init__(self, config: NllbMoeConfig, embed_tokens: Optional[nn.Embedding] = None):
super().__init__(config)
self.dropout = config.dropout
self.layerdrop = config.decoder_layerdrop
self.padding_idx = config.pad_token_id
self.max_target_positions = config.max_position_embeddings
embed_scale = math.sqrt(config.d_model) if config.scale_embedding else 1.0
self.embed_tokens = NllbMoeScaledWordEmbedding(
config.vocab_size, config.d_model, self.padding_idx, embed_scale=embed_scale
)
if embed_tokens is not None:
self.embed_tokens.weight = embed_tokens.weight
self.embed_positions = NllbMoeSinusoidalPositionalEmbedding(
config.max_position_embeddings,
config.d_model,
self.padding_idx,
)
sparse_step = config.decoder_sparse_step
self.layers = nn.ModuleList()
for i in range(config.decoder_layers):
is_sparse = (i + 1) % sparse_step == 0 if sparse_step > 0 else False
self.layers.append(NllbMoeDecoderLayer(config, is_sparse))
self.layer_norm = nn.LayerNorm(config.d_model)
self.gradient_checkpointing = False
# Initialize weights and apply final processing
self.post_init()
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
cross_attn_head_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_router_logits: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, encoder_sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
of the decoder.
encoder_attention_mask (`torch.LongTensor` of shape `(batch_size, encoder_sequence_length)`, *optional*):
Mask to avoid performing cross-attention on padding tokens indices of encoder input_ids. Mask values
selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules in the decoder to avoid performing
cross-attention on hidden heads. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of
shape `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the
cross-attention blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those
that don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of
all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
output_router_logits (`bool`, *optional*):
Whether or not to return the logits of all the routers. They are useful for computing the router loss,
and should not be returned during inference.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.return_dict
# retrieve input_ids and inputs_embeds
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
# past_key_values_length
past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids)
# create causal mask
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
combined_attention_mask = _prepare_4d_causal_attention_mask(
attention_mask, input_shape, inputs_embeds, past_key_values_length
)
# expand encoder attention mask
if encoder_hidden_states is not None and encoder_attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
encoder_attention_mask = _prepare_4d_attention_mask(
encoder_attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]
)
# embed positions
positions = self.embed_positions(input_ids, inputs_embeds, past_key_values_length)
positions = positions.to(inputs_embeds.device)
hidden_states = inputs_embeds + positions
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning_once(
"`use_cache=True` is incompatible with gradient checkpointing. Setting" " `use_cache=False`..."
)
use_cache = False
# decoder layers
all_hidden_states = () if output_hidden_states else None
all_self_attns = () if output_attentions else None
all_router_probs = () if output_router_logits else None
all_cross_attentions = () if output_attentions else None
present_key_value_states = () if use_cache else None
# check if head_mask/cross_attn_head_mask has a correct number of layers specified if desired
for attn_mask, mask_name in zip([head_mask, cross_attn_head_mask], ["head_mask", "cross_attn_head_mask"]):
if attn_mask is not None:
if attn_mask.size()[0] != len(self.layers):
raise ValueError(
f"The `{mask_name}` should be specified for {len(self.layers)} layers, but it is for"
f" {head_mask.size()[0]}."
)
synced_gpus = is_deepspeed_zero3_enabled() or is_fsdp_managed_module(self)
for idx, decoder_layer in enumerate(self.layers):
if output_hidden_states:
all_hidden_states += (hidden_states,)
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.layerdrop) else False
if not skip_the_layer or synced_gpus:
layer_head_mask = head_mask[idx] if head_mask is not None else None
cross_attn_layer_head_mask = cross_attn_head_mask[idx] if cross_attn_head_mask is not None else None
past_key_value = past_key_values[idx] if past_key_values is not None else None
# under fsdp or deepspeed zero3 all gpus must run in sync
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning_once(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
layer_outputs = self._gradient_checkpointing_func(
decoder_layer.forward,
hidden_states,
combined_attention_mask,
encoder_hidden_states,
encoder_attention_mask,
layer_head_mask,
cross_attn_layer_head_mask,
None, # past_key_value is always None with gradient checkpointing
use_cache,
output_attentions,
)
else:
layer_outputs = decoder_layer(
hidden_states,
attention_mask=combined_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
layer_head_mask=layer_head_mask,
cross_attn_layer_head_mask=cross_attn_layer_head_mask,
past_key_value=past_key_value,
use_cache=use_cache,
output_attentions=output_attentions,
output_router_logits=output_router_logits,
)
hidden_states = layer_outputs[0]
if skip_the_layer:
continue
if use_cache:
present_key_value_states += (layer_outputs[1],)
if output_attentions:
all_self_attns += (layer_outputs[2],)
all_cross_attentions += (layer_outputs[3],)
if output_router_logits:
all_router_probs += (layer_outputs[-1],)
hidden_states = self.layer_norm(hidden_states)
# Add last layer
if output_hidden_states:
all_hidden_states += (hidden_states,)
if not return_dict:
return tuple(
v
for v in [
hidden_states,
present_key_value_states,
all_hidden_states,
all_self_attns,
all_cross_attentions,
all_router_probs,
]
if v is not None
)
return MoEModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=present_key_value_states,
hidden_states=all_hidden_states,
attentions=all_self_attns,
cross_attentions=all_cross_attentions,
router_probs=all_router_probs,
)
@add_start_docstrings(
"The bare NllbMoe Model outputting raw hidden-states without any specific head on top.",
NLLB_MOE_START_DOCSTRING,
)
class NllbMoeModel(NllbMoePreTrainedModel):
_tied_weights_keys = ["encoder.embed_tokens.weight", "decoder.embed_tokens.weight"]
def __init__(self, config: NllbMoeConfig):
super().__init__(config)
padding_idx, vocab_size = config.pad_token_id, config.vocab_size
embed_scale = math.sqrt(config.d_model) if config.scale_embedding else 1.0
self.shared = NllbMoeScaledWordEmbedding(vocab_size, config.d_model, padding_idx, embed_scale=embed_scale)
self.encoder = NllbMoeEncoder(config, self.shared)
self.decoder = NllbMoeDecoder(config, self.shared)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.shared
def set_input_embeddings(self, value):
self.shared = value
self.encoder.embed_tokens = self.shared
self.decoder.embed_tokens = self.shared
def _tie_weights(self):
if self.config.tie_word_embeddings:
self._tie_or_clone_weights(self.encoder.embed_tokens, self.shared)
self._tie_or_clone_weights(self.decoder.embed_tokens, self.shared)
def get_encoder(self):
return self.encoder
def get_decoder(self):
return self.decoder
@add_start_docstrings_to_model_forward(NLLB_MOE_INPUTS_DOCSTRING)
@add_start_docstrings_to_model_forward(NLLB_MOE_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=Seq2SeqMoEModelOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
decoder_input_ids: Optional[torch.LongTensor] = None,
decoder_attention_mask: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.Tensor] = None,
decoder_head_mask: Optional[torch.Tensor] = None,
cross_attn_head_mask: Optional[torch.Tensor] = None,
encoder_outputs: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
decoder_inputs_embeds: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_router_logits: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], Seq2SeqMoEModelOutput]:
r"""
Returns:
Example:
```python
>>> from transformers import AutoTokenizer, NllbMoeModel
>>> tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/random-nllb-moe-2-experts")
>>> model = SwitchTransformersModel.from_pretrained("hf-internal-testing/random-nllb-moe-2-experts")
>>> input_ids = tokenizer(
... "Studies have been shown that owning a dog is good for you", return_tensors="pt"
... ).input_ids # Batch size 1
>>> decoder_input_ids = tokenizer("Studies show that", return_tensors="pt").input_ids # Batch size 1
>>> # preprocess: Prepend decoder_input_ids with start token which is pad token for NllbMoeModel
>>> decoder_input_ids = model._shift_right(decoder_input_ids)
>>> # forward pass
>>> outputs = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
>>> last_hidden_states = outputs.last_hidden_state
```"""
return_dict = return_dict if return_dict is not None else self.config.return_dict
if encoder_outputs is None:
encoder_outputs = self.encoder(
input_ids=input_ids,
attention_mask=attention_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
output_router_logits=output_router_logits,
return_dict=return_dict,
)
# If the user passed a tuple for encoder_outputs, we wrap it in a BaseModelOutput when return_dict=True
elif return_dict and not isinstance(encoder_outputs, MoEModelOutput):
encoder_outputs = MoEModelOutput(
last_hidden_state=encoder_outputs[0],
hidden_states=encoder_outputs[1] if len(encoder_outputs) > 1 else None,
attentions=encoder_outputs[2] if len(encoder_outputs) > 2 else None,
router_probs=encoder_outputs[3] if len(encoder_outputs) > 3 else None,
)
# decoder outputs consists of (dec_features, past_key_value, dec_hidden, dec_attn)
decoder_outputs = self.decoder(
input_ids=decoder_input_ids,
attention_mask=decoder_attention_mask,
encoder_hidden_states=encoder_outputs[0],
encoder_attention_mask=attention_mask,
head_mask=decoder_head_mask,
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
output_router_logits=output_router_logits,
return_dict=return_dict,
)
if not return_dict:
return decoder_outputs + encoder_outputs
return Seq2SeqMoEModelOutput(
past_key_values=decoder_outputs.past_key_values,
cross_attentions=decoder_outputs.cross_attentions,
last_hidden_state=decoder_outputs.last_hidden_state,
encoder_last_hidden_state=encoder_outputs.last_hidden_state,
encoder_hidden_states=encoder_outputs.hidden_states,
decoder_hidden_states=decoder_outputs.hidden_states,
encoder_attentions=encoder_outputs.attentions,
decoder_attentions=decoder_outputs.attentions,
encoder_router_logits=encoder_outputs.router_probs,
decoder_router_logits=decoder_outputs.router_probs,
)
@add_start_docstrings(
"The NllbMoe Model with a language modeling head. Can be used for summarization.", NLLB_MOE_START_DOCSTRING
)
class NllbMoeForConditionalGeneration(NllbMoePreTrainedModel, GenerationMixin):
base_model_prefix = "model"
_tied_weights_keys = ["encoder.embed_tokens.weight", "decoder.embed_tokens.weight", "lm_head.weight"]
def __init__(self, config: NllbMoeConfig):
super().__init__(config)
self.model = NllbMoeModel(config)
self.lm_head = nn.Linear(config.d_model, config.vocab_size, bias=False)
self.router_z_loss_coef = config.router_z_loss_coef
self.router_aux_loss_coef = config.router_aux_loss_coef
# Initialize weights and apply final processing
self.post_init()
def get_encoder(self):
return self.model.get_encoder()
def get_decoder(self):
return self.model.get_decoder()
def get_output_embeddings(self):
return self.lm_head
def set_output_embeddings(self, new_embeddings):
self.lm_head = new_embeddings
@add_start_docstrings_to_model_forward(NLLB_MOE_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=Seq2SeqMoEOutput, config_class=_CONFIG_FOR_DOC)
@add_end_docstrings(NLLB_MOE_GENERATION_EXAMPLE)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
decoder_input_ids: Optional[torch.LongTensor] = None,
decoder_attention_mask: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.Tensor] = None,
decoder_head_mask: Optional[torch.Tensor] = None,
cross_attn_head_mask: Optional[torch.Tensor] = None,
encoder_outputs: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
decoder_inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_router_logits: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], Seq2SeqMoEOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
Returns:
"""
return_dict = return_dict if return_dict is not None else self.config.return_dict
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_router_logits = (
output_router_logits if output_router_logits is not None else self.config.output_router_logits
)
if labels is not None:
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
)
outputs = self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
encoder_outputs=encoder_outputs,
decoder_attention_mask=decoder_attention_mask,
head_mask=head_mask,
decoder_head_mask=decoder_head_mask,
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
decoder_inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
output_router_logits=output_router_logits,
return_dict=return_dict,
)
lm_logits = self.lm_head(outputs[0])
loss = None
encoder_aux_loss = None
decoder_aux_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss(ignore_index=-100)
# todo check in the config if router loss enables
if output_router_logits:
encoder_router_logits = outputs[-1]
decoder_router_logits = outputs[3 if output_attentions else 4]
# Compute the router loss (z_loss + auxiliary loss) for each router in the encoder and decoder
encoder_router_logits, encoder_expert_indexes = self._unpack_router_logits(encoder_router_logits)
encoder_aux_loss = load_balancing_loss_func(encoder_router_logits, encoder_expert_indexes)
decoder_router_logits, decoder_expert_indexes = self._unpack_router_logits(decoder_router_logits)
decoder_aux_loss = load_balancing_loss_func(decoder_router_logits, decoder_expert_indexes)
loss = loss_fct(lm_logits.view(-1, lm_logits.size(-1)), labels.view(-1))
if output_router_logits and labels is not None:
aux_loss = self.router_aux_loss_coef * (encoder_aux_loss + decoder_aux_loss)
loss = loss + aux_loss
output = (loss,) if loss is not None else ()
if not return_dict:
output += (lm_logits,)
if output_router_logits: # only return the loss if they are not None
output += (
encoder_aux_loss,
decoder_aux_loss,
*outputs[1:],
)
else:
output += outputs[1:]
return output
return Seq2SeqMoEOutput(
loss=loss,
logits=lm_logits,
past_key_values=outputs.past_key_values,
cross_attentions=outputs.cross_attentions,
encoder_aux_loss=encoder_aux_loss,
decoder_aux_loss=decoder_aux_loss,
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
encoder_hidden_states=outputs.encoder_hidden_states,
decoder_hidden_states=outputs.decoder_hidden_states,
encoder_attentions=outputs.encoder_attentions,
decoder_attentions=outputs.decoder_attentions,
encoder_router_logits=outputs.encoder_router_logits,
decoder_router_logits=outputs.decoder_router_logits,
)
def _unpack_router_logits(self, router_outputs):
total_router_logits = []
total_expert_indexes = []
for router_output in router_outputs:
if router_output is not None:
router_logits, expert_indexes = router_output
total_router_logits.append(router_logits)
total_expert_indexes.append(expert_indexes)
total_router_logits = torch.cat(total_router_logits, dim=1) if len(total_router_logits) > 0 else None
total_expert_indexes = torch.stack(total_expert_indexes, dim=1) if len(total_expert_indexes) > 0 else None
return total_router_logits, total_expert_indexes
@staticmethod
def _reorder_cache(past_key_values, beam_idx):
reordered_past = ()
for layer_past in past_key_values:
reordered_past += (
tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),
)
return reordered_past
__all__ = [
"NllbMoeForConditionalGeneration",
"NllbMoeModel",
"NllbMoePreTrainedModel",
"NllbMoeTop2Router",
"NllbMoeSparseMLP",
]
| transformers/src/transformers/models/nllb_moe/modeling_nllb_moe.py/0 | {
"file_path": "transformers/src/transformers/models/nllb_moe/modeling_nllb_moe.py",
"repo_id": "transformers",
"token_count": 37245
} |
# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
# This file was automatically generated from src/transformers/models/olmo2/modular_olmo2.py.
# Do NOT edit this file manually as any edits will be overwritten by the generation of
# the file from the modular. If any change should be done, please apply the change to the
# modular_olmo2.py file directly. One of our CI enforces this.
# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
from ...configuration_utils import PretrainedConfig
class Olmo2Config(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`Olmo2Model`]. It is used to instantiate an OLMo2
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the [allenai/Olmo2-7B-1124-hf](https://huggingface.co/allenai/Olmo2-7B-1124-hf).
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 50304):
Vocabulary size of the Olmo2 model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`Olmo2Model`]
hidden_size (`int`, *optional*, defaults to 4096):
Dimension of the hidden representations.
intermediate_size (`int`, *optional*, defaults to 11008):
Dimension of the MLP representations.
num_hidden_layers (`int`, *optional*, defaults to 32):
Number of hidden layers in the Transformer decoder.
num_attention_heads (`int`, *optional*, defaults to 32):
Number of attention heads for each attention layer in the Transformer decoder.
num_key_value_heads (`int`, *optional*):
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details checkout [this
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
max_position_embeddings (`int`, *optional*, defaults to 2048):
The maximum sequence length that this model might ever be used with.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
pad_token_id (`int`, *optional*, defaults to 1):
Padding token id.
bos_token_id (`int`, *optional*):
Beginning of stream token id.
eos_token_id (`int`, *optional*, defaults to 50279):
End of stream token id.
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
Whether to tie weight embeddings
rope_theta (`float`, *optional*, defaults to 10000.0):
The base period of the RoPE embeddings.
rope_scaling (`Dict`, *optional*):
Dictionary containing the scaling configuration for the RoPE embeddings. Currently supports two scaling
strategies: linear and dynamic. Their scaling factor must be a float greater than 1. The expected format is
`{"type": strategy name, "factor": scaling factor}`. When using this flag, don't update
`max_position_embeddings` to the expected new maximum. See the following thread for more information on how
these scaling strategies behave:
https://www.reddit.com/r/LocalLLaMA/comments/14mrgpr/dynamically_scaled_rope_further_increases/. This is an
experimental feature, subject to breaking API changes in future versions.
attention_bias (`bool`, defaults to `False`, *optional*, defaults to `False`):
Whether to use a bias in the query, key, value and output projection layers during self-attention.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
rms_norm_eps (`float`, *optional*, defaults to 1e-05):
The epsilon used by the rms normalization layers.
```python
>>> from transformers import Olmo2Model, Olmo2Config
>>> # Initializing a Olmo2 7B style configuration
>>> configuration = Olmo2Config()
>>> # Initializing a model from the Olmo2 7B style configuration
>>> model = Olmo2Model(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```
"""
model_type = "olmo2"
keys_to_ignore_at_inference = ["past_key_values"]
base_model_tp_plan = {
"layers.*.self_attn.q_proj": "colwise_rep", # we need to replicate here due to the added norm on q and k
"layers.*.self_attn.k_proj": "colwise_rep", # we need to replicate here due to the added norm on q and k
"layers.*.self_attn.v_proj": "colwise_rep", # we need to replicate here due to the added norm on q and k
"layers.*.self_attn.o_proj": "rowwise_rep", # we need to replicate here due to the added norm on q and k
"layers.*.mlp.gate_proj": "colwise",
"layers.*.mlp.up_proj": "colwise",
"layers.*.mlp.down_proj": "rowwise",
}
def __init__(
self,
vocab_size=50304,
hidden_size=4096,
intermediate_size=11008,
num_hidden_layers=32,
num_attention_heads=32,
num_key_value_heads=None,
hidden_act="silu",
max_position_embeddings=2048,
initializer_range=0.02,
use_cache=True,
pad_token_id=1,
bos_token_id=None,
eos_token_id=50279,
tie_word_embeddings=False,
rope_theta=10000.0,
rope_scaling=None,
attention_bias=False,
attention_dropout=0.0,
rms_norm_eps=1e-5,
**kwargs,
):
super().__init__(
pad_token_id=pad_token_id,
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
tie_word_embeddings=tie_word_embeddings,
**kwargs,
)
self.vocab_size = vocab_size
self.max_position_embeddings = max_position_embeddings
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
# for backward compatibility
if num_key_value_heads is None:
num_key_value_heads = num_attention_heads
self.num_key_value_heads = num_key_value_heads
self.hidden_act = hidden_act
self.initializer_range = initializer_range
self.use_cache = use_cache
self.rope_theta = rope_theta
self.rope_scaling = rope_scaling
self._rope_scaling_validation()
self.attention_bias = attention_bias
self.attention_dropout = attention_dropout
self.rms_norm_eps = rms_norm_eps
def _rope_scaling_validation(self):
"""
Validate the `rope_scaling` configuration.
"""
if self.rope_scaling is None:
return
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
raise ValueError(
"`rope_scaling` must be a dictionary with two fields, `type` and `factor`, " f"got {self.rope_scaling}"
)
rope_scaling_type = self.rope_scaling.get("type", None)
rope_scaling_factor = self.rope_scaling.get("factor", None)
if rope_scaling_type is None or rope_scaling_type not in ["linear", "dynamic"]:
raise ValueError(
f"`rope_scaling`'s type field must be one of ['linear', 'dynamic'], got {rope_scaling_type}"
)
if rope_scaling_factor is None or not isinstance(rope_scaling_factor, float) or rope_scaling_factor <= 1.0:
raise ValueError(f"`rope_scaling`'s factor field must be a float > 1, got {rope_scaling_factor}")
__all__ = ["Olmo2Config"]
| transformers/src/transformers/models/olmo2/configuration_olmo2.py/0 | {
"file_path": "transformers/src/transformers/models/olmo2/configuration_olmo2.py",
"repo_id": "transformers",
"token_count": 3862
} |
# coding=utf-8
# Copyright 2022 SHI Labs and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Image processor class for OneFormer."""
import json
import os
from typing import Any, Dict, Iterable, List, Optional, Set, Tuple, Union
import numpy as np
from huggingface_hub import hf_hub_download
from huggingface_hub.utils import RepositoryNotFoundError
from ...image_processing_utils import INIT_SERVICE_KWARGS, BaseImageProcessor, BatchFeature, get_size_dict
from ...image_transforms import (
PaddingMode,
get_resize_output_image_size,
pad,
rescale,
resize,
to_channel_dimension_format,
)
from ...image_utils import (
ChannelDimension,
ImageInput,
PILImageResampling,
get_image_size,
infer_channel_dimension_format,
is_scaled_image,
make_list_of_images,
to_numpy_array,
valid_images,
validate_preprocess_arguments,
)
from ...utils import (
IMAGENET_DEFAULT_MEAN,
IMAGENET_DEFAULT_STD,
TensorType,
filter_out_non_signature_kwargs,
is_torch_available,
is_torch_tensor,
logging,
)
from ...utils.deprecation import deprecate_kwarg
logger = logging.get_logger(__name__)
if is_torch_available():
import torch
from torch import nn
# Copied from transformers.models.detr.image_processing_detr.max_across_indices
def max_across_indices(values: Iterable[Any]) -> List[Any]:
"""
Return the maximum value across all indices of an iterable of values.
"""
return [max(values_i) for values_i in zip(*values)]
# Copied from transformers.models.detr.image_processing_detr.get_max_height_width
def get_max_height_width(
images: List[np.ndarray], input_data_format: Optional[Union[str, ChannelDimension]] = None
) -> List[int]:
"""
Get the maximum height and width across all images in a batch.
"""
if input_data_format is None:
input_data_format = infer_channel_dimension_format(images[0])
if input_data_format == ChannelDimension.FIRST:
_, max_height, max_width = max_across_indices([img.shape for img in images])
elif input_data_format == ChannelDimension.LAST:
max_height, max_width, _ = max_across_indices([img.shape for img in images])
else:
raise ValueError(f"Invalid channel dimension format: {input_data_format}")
return (max_height, max_width)
# Copied from transformers.models.detr.image_processing_detr.make_pixel_mask
def make_pixel_mask(
image: np.ndarray, output_size: Tuple[int, int], input_data_format: Optional[Union[str, ChannelDimension]] = None
) -> np.ndarray:
"""
Make a pixel mask for the image, where 1 indicates a valid pixel and 0 indicates padding.
Args:
image (`np.ndarray`):
Image to make the pixel mask for.
output_size (`Tuple[int, int]`):
Output size of the mask.
"""
input_height, input_width = get_image_size(image, channel_dim=input_data_format)
mask = np.zeros(output_size, dtype=np.int64)
mask[:input_height, :input_width] = 1
return mask
# Copied from transformers.models.detr.image_processing_detr.binary_mask_to_rle
def binary_mask_to_rle(mask):
"""
Converts given binary mask of shape `(height, width)` to the run-length encoding (RLE) format.
Args:
mask (`torch.Tensor` or `numpy.array`):
A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
segment_id or class_id.
Returns:
`List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
format.
"""
if is_torch_tensor(mask):
mask = mask.numpy()
pixels = mask.flatten()
pixels = np.concatenate([[0], pixels, [0]])
runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
runs[1::2] -= runs[::2]
return list(runs)
# Copied from transformers.models.detr.image_processing_detr.convert_segmentation_to_rle
def convert_segmentation_to_rle(segmentation):
"""
Converts given segmentation map of shape `(height, width)` to the run-length encoding (RLE) format.
Args:
segmentation (`torch.Tensor` or `numpy.array`):
A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
Returns:
`List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
"""
segment_ids = torch.unique(segmentation)
run_length_encodings = []
for idx in segment_ids:
mask = torch.where(segmentation == idx, 1, 0)
rle = binary_mask_to_rle(mask)
run_length_encodings.append(rle)
return run_length_encodings
# Copied from transformers.models.detr.image_processing_detr.remove_low_and_no_objects
def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
"""
Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
`labels`.
Args:
masks (`torch.Tensor`):
A tensor of shape `(num_queries, height, width)`.
scores (`torch.Tensor`):
A tensor of shape `(num_queries)`.
labels (`torch.Tensor`):
A tensor of shape `(num_queries)`.
object_mask_threshold (`float`):
A number between 0 and 1 used to binarize the masks.
Raises:
`ValueError`: Raised when the first dimension doesn't match in all input tensors.
Returns:
`Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
< `object_mask_threshold`.
"""
if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
raise ValueError("mask, scores and labels must have the same shape!")
to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
return masks[to_keep], scores[to_keep], labels[to_keep]
# Copied from transformers.models.detr.image_processing_detr.check_segment_validity
def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
# Get the mask associated with the k class
mask_k = mask_labels == k
mask_k_area = mask_k.sum()
# Compute the area of all the stuff in query k
original_area = (mask_probs[k] >= mask_threshold).sum()
mask_exists = mask_k_area > 0 and original_area > 0
# Eliminate disconnected tiny segments
if mask_exists:
area_ratio = mask_k_area / original_area
if not area_ratio.item() > overlap_mask_area_threshold:
mask_exists = False
return mask_exists, mask_k
# Copied from transformers.models.detr.image_processing_detr.compute_segments
def compute_segments(
mask_probs,
pred_scores,
pred_labels,
mask_threshold: float = 0.5,
overlap_mask_area_threshold: float = 0.8,
label_ids_to_fuse: Optional[Set[int]] = None,
target_size: Tuple[int, int] = None,
):
height = mask_probs.shape[1] if target_size is None else target_size[0]
width = mask_probs.shape[2] if target_size is None else target_size[1]
segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
segments: List[Dict] = []
if target_size is not None:
mask_probs = nn.functional.interpolate(
mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
)[0]
current_segment_id = 0
# Weigh each mask by its prediction score
mask_probs *= pred_scores.view(-1, 1, 1)
mask_labels = mask_probs.argmax(0) # [height, width]
# Keep track of instances of each class
stuff_memory_list: Dict[str, int] = {}
for k in range(pred_labels.shape[0]):
pred_class = pred_labels[k].item()
should_fuse = pred_class in label_ids_to_fuse
# Check if mask exists and large enough to be a segment
mask_exists, mask_k = check_segment_validity(
mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
)
if mask_exists:
if pred_class in stuff_memory_list:
current_segment_id = stuff_memory_list[pred_class]
else:
current_segment_id += 1
# Add current object segment to final segmentation map
segmentation[mask_k] = current_segment_id
segment_score = round(pred_scores[k].item(), 6)
segments.append(
{
"id": current_segment_id,
"label_id": pred_class,
"was_fused": should_fuse,
"score": segment_score,
}
)
if should_fuse:
stuff_memory_list[pred_class] = current_segment_id
return segmentation, segments
# Copied from transformers.models.maskformer.image_processing_maskformer.convert_segmentation_map_to_binary_masks
def convert_segmentation_map_to_binary_masks(
segmentation_map: "np.ndarray",
instance_id_to_semantic_id: Optional[Dict[int, int]] = None,
ignore_index: Optional[int] = None,
do_reduce_labels: bool = False,
):
if do_reduce_labels and ignore_index is None:
raise ValueError("If `do_reduce_labels` is True, `ignore_index` must be provided.")
if do_reduce_labels:
segmentation_map = np.where(segmentation_map == 0, ignore_index, segmentation_map - 1)
# Get unique ids (class or instance ids based on input)
all_labels = np.unique(segmentation_map)
# Drop background label if applicable
if ignore_index is not None:
all_labels = all_labels[all_labels != ignore_index]
# Generate a binary mask for each object instance
binary_masks = [(segmentation_map == i) for i in all_labels]
# Stack the binary masks
if binary_masks:
binary_masks = np.stack(binary_masks, axis=0)
else:
binary_masks = np.zeros((0, *segmentation_map.shape))
# Convert instance ids to class ids
if instance_id_to_semantic_id is not None:
labels = np.zeros(all_labels.shape[0])
for label in all_labels:
class_id = instance_id_to_semantic_id[label + 1 if do_reduce_labels else label]
labels[all_labels == label] = class_id - 1 if do_reduce_labels else class_id
else:
labels = all_labels
return binary_masks.astype(np.float32), labels.astype(np.int64)
def get_oneformer_resize_output_image_size(
image: np.ndarray,
size: Union[int, Tuple[int, int], List[int], Tuple[int]],
max_size: Optional[int] = None,
default_to_square: bool = True,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
) -> tuple:
"""
Computes the output size given the desired size.
Args:
image (`np.ndarray`):
The input image.
size (`int` or `Tuple[int, int]` or `List[int]` or `Tuple[int]`):
The size of the output image.
max_size (`int`, *optional*):
The maximum size of the output image.
default_to_square (`bool`, *optional*, defaults to `True`):
Whether to default to square if no size is provided.
input_data_format (`ChannelDimension` or `str`, *optional*):
The channel dimension format of the input image. If unset, will use the inferred format from the input.
Returns:
`Tuple[int, int]`: The output size.
"""
output_size = get_resize_output_image_size(
input_image=image,
size=size,
default_to_square=default_to_square,
max_size=max_size,
input_data_format=input_data_format,
)
return output_size
def prepare_metadata(class_info):
metadata = {}
class_names = []
thing_ids = []
for key, info in class_info.items():
metadata[key] = info["name"]
class_names.append(info["name"])
if info["isthing"]:
thing_ids.append(int(key))
metadata["thing_ids"] = thing_ids
metadata["class_names"] = class_names
return metadata
def load_metadata(repo_id, class_info_file):
fname = os.path.join("" if repo_id is None else repo_id, class_info_file)
if not os.path.exists(fname) or not os.path.isfile(fname):
if repo_id is None:
raise ValueError(f"Could not file {fname} locally. repo_id must be defined if loading from the hub")
# We try downloading from a dataset by default for backward compatibility
try:
fname = hf_hub_download(repo_id, class_info_file, repo_type="dataset")
except RepositoryNotFoundError:
fname = hf_hub_download(repo_id, class_info_file)
with open(fname, "r") as f:
class_info = json.load(f)
return class_info
class OneFormerImageProcessor(BaseImageProcessor):
r"""
Constructs a OneFormer image processor. The image processor can be used to prepare image(s), task input(s) and
optional text inputs and targets for the model.
This image processor inherits from [`BaseImageProcessor`] which contains most of the main methods. Users should
refer to this superclass for more information regarding those methods.
Args:
do_resize (`bool`, *optional*, defaults to `True`):
Whether to resize the input to a certain `size`.
size (`int`, *optional*, defaults to 800):
Resize the input to the given size. Only has an effect if `do_resize` is set to `True`. If size is a
sequence like `(width, height)`, output size will be matched to this. If size is an int, smaller edge of
the image will be matched to this number. i.e, if `height > width`, then image will be rescaled to `(size *
height / width, size)`.
resample (`int`, *optional*, defaults to `Resampling.BILINEAR`):
An optional resampling filter. This can be one of `PIL.Image.Resampling.NEAREST`,
`PIL.Image.Resampling.BOX`, `PIL.Image.Resampling.BILINEAR`, `PIL.Image.Resampling.HAMMING`,
`PIL.Image.Resampling.BICUBIC` or `PIL.Image.Resampling.LANCZOS`. Only has an effect if `do_resize` is set
to `True`.
do_rescale (`bool`, *optional*, defaults to `True`):
Whether to rescale the input to a certain `scale`.
rescale_factor (`float`, *optional*, defaults to `1/ 255`):
Rescale the input by the given factor. Only has an effect if `do_rescale` is set to `True`.
do_normalize (`bool`, *optional*, defaults to `True`):
Whether or not to normalize the input with mean and standard deviation.
image_mean (`int`, *optional*, defaults to `[0.485, 0.456, 0.406]`):
The sequence of means for each channel, to be used when normalizing images. Defaults to the ImageNet mean.
image_std (`int`, *optional*, defaults to `[0.229, 0.224, 0.225]`):
The sequence of standard deviations for each channel, to be used when normalizing images. Defaults to the
ImageNet std.
ignore_index (`int`, *optional*):
Label to be assigned to background pixels in segmentation maps. If provided, segmentation map pixels
denoted with 0 (background) will be replaced with `ignore_index`.
do_reduce_labels (`bool`, *optional*, defaults to `False`):
Whether or not to decrement all label values of segmentation maps by 1. Usually used for datasets where 0
is used for background, and background itself is not included in all classes of a dataset (e.g. ADE20k).
The background label will be replaced by `ignore_index`.
repo_path (`str`, *optional*, defaults to `"shi-labs/oneformer_demo"`):
Path to hub repo or local directory containing the JSON file with class information for the dataset.
If unset, will look for `class_info_file` in the current working directory.
class_info_file (`str`, *optional*):
JSON file containing class information for the dataset. See `shi-labs/oneformer_demo/cityscapes_panoptic.json` for an example.
num_text (`int`, *optional*):
Number of text entries in the text input list.
num_labels (`int`, *optional*):
The number of labels in the segmentation map.
"""
model_input_names = ["pixel_values", "pixel_mask", "task_inputs"]
@deprecate_kwarg("reduce_labels", new_name="do_reduce_labels", version="4.44.0")
@deprecate_kwarg("max_size", version="4.27.0", warn_if_greater_or_equal_version=True)
@filter_out_non_signature_kwargs(extra=["max_size", "metadata", *INIT_SERVICE_KWARGS])
def __init__(
self,
do_resize: bool = True,
size: Dict[str, int] = None,
resample: PILImageResampling = PILImageResampling.BILINEAR,
do_rescale: bool = True,
rescale_factor: float = 1 / 255,
do_normalize: bool = True,
image_mean: Union[float, List[float]] = None,
image_std: Union[float, List[float]] = None,
ignore_index: Optional[int] = None,
do_reduce_labels: bool = False,
repo_path: Optional[str] = "shi-labs/oneformer_demo",
class_info_file: str = None,
num_text: Optional[int] = None,
num_labels: Optional[int] = None,
**kwargs,
):
super().__init__(**kwargs)
# Deprecated, backward compatibility
self._max_size = kwargs.pop("max_size", 1333)
size = size if size is not None else {"shortest_edge": 800, "longest_edge": self._max_size}
size = get_size_dict(size, max_size=self._max_size, default_to_square=False)
if class_info_file is None:
raise ValueError("You must provide a `class_info_file`")
self.do_resize = do_resize
self.size = size
self.resample = resample
self.do_rescale = do_rescale
self.rescale_factor = rescale_factor
self.do_normalize = do_normalize
self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
self.ignore_index = ignore_index
self.do_reduce_labels = do_reduce_labels
self.class_info_file = class_info_file
self.repo_path = repo_path
self.metadata = prepare_metadata(load_metadata(repo_path, class_info_file))
self.num_text = num_text
self.num_labels = num_labels
@classmethod
def from_dict(cls, image_processor_dict: Dict[str, Any], **kwargs):
"""
Overrides the `from_dict` method from the base class to save support of deprecated `reduce_labels` in old configs
"""
image_processor_dict = image_processor_dict.copy()
if "reduce_labels" in image_processor_dict:
image_processor_dict["do_reduce_labels"] = image_processor_dict.pop("reduce_labels")
return super().from_dict(image_processor_dict, **kwargs)
# Copied from transformers.models.maskformer.image_processing_maskformer.MaskFormerImageProcessor.to_dict
def to_dict(self) -> Dict[str, Any]:
"""
Serializes this instance to a Python dictionary. This method calls the superclass method and then removes the
`_max_size` attribute from the dictionary.
"""
image_processor_dict = super().to_dict()
image_processor_dict.pop("_max_size", None)
return image_processor_dict
@deprecate_kwarg("max_size", version="4.27.0", warn_if_greater_or_equal_version=True)
@filter_out_non_signature_kwargs(extra=["max_size"])
def resize(
self,
image: np.ndarray,
size: Dict[str, int],
resample: PILImageResampling = PILImageResampling.BILINEAR,
data_format=None,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
**kwargs,
) -> np.ndarray:
"""
Resize the image to the given size. Size can be min_size (scalar) or `(height, width)` tuple. If size is an
int, smaller edge of the image will be matched to this number.
"""
# Deprecated, backward compatibility
max_size = kwargs.pop("max_size", None)
size = get_size_dict(size, max_size=max_size, default_to_square=False)
if "shortest_edge" in size and "longest_edge" in size:
size, max_size = size["shortest_edge"], size["longest_edge"]
elif "height" in size and "width" in size:
size = (size["height"], size["width"])
max_size = None
else:
raise ValueError(
"Size must contain 'height' and 'width' keys or 'shortest_edge' and 'longest_edge' keys. Got"
f" {size.keys()}."
)
size = get_oneformer_resize_output_image_size(
image=image, size=size, max_size=max_size, default_to_square=False, input_data_format=input_data_format
)
image = resize(
image, size=size, resample=resample, data_format=data_format, input_data_format=input_data_format
)
return image
# Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.rescale
def rescale(
self,
image: np.ndarray,
rescale_factor: float,
data_format: Optional[Union[str, ChannelDimension]] = None,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
) -> np.ndarray:
"""
Rescale the image by the given factor. image = image * rescale_factor.
Args:
image (`np.ndarray`):
Image to rescale.
rescale_factor (`float`):
The value to use for rescaling.
data_format (`str` or `ChannelDimension`, *optional*):
The channel dimension format for the output image. If unset, the channel dimension format of the input
image is used. Can be one of:
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
input_data_format (`str` or `ChannelDimension`, *optional*):
The channel dimension format for the input image. If unset, is inferred from the input image. Can be
one of:
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
"""
return rescale(image, rescale_factor, data_format=data_format, input_data_format=input_data_format)
# Copied from transformers.models.maskformer.image_processing_maskformer.MaskFormerImageProcessor.convert_segmentation_map_to_binary_masks
def convert_segmentation_map_to_binary_masks(
self,
segmentation_map: "np.ndarray",
instance_id_to_semantic_id: Optional[Dict[int, int]] = None,
ignore_index: Optional[int] = None,
do_reduce_labels: bool = False,
):
do_reduce_labels = do_reduce_labels if do_reduce_labels is not None else self.do_reduce_labels
ignore_index = ignore_index if ignore_index is not None else self.ignore_index
return convert_segmentation_map_to_binary_masks(
segmentation_map=segmentation_map,
instance_id_to_semantic_id=instance_id_to_semantic_id,
ignore_index=ignore_index,
do_reduce_labels=do_reduce_labels,
)
def __call__(self, images, task_inputs=None, segmentation_maps=None, **kwargs) -> BatchFeature:
return self.preprocess(images, task_inputs=task_inputs, segmentation_maps=segmentation_maps, **kwargs)
def _preprocess(
self,
image: ImageInput,
do_resize: bool = None,
size: Dict[str, int] = None,
resample: PILImageResampling = None,
do_rescale: bool = None,
rescale_factor: float = None,
do_normalize: bool = None,
image_mean: Optional[Union[float, List[float]]] = None,
image_std: Optional[Union[float, List[float]]] = None,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
):
if do_resize:
image = self.resize(image, size=size, resample=resample, input_data_format=input_data_format)
if do_rescale:
image = self.rescale(image, rescale_factor=rescale_factor, input_data_format=input_data_format)
if do_normalize:
image = self.normalize(image, mean=image_mean, std=image_std, input_data_format=input_data_format)
return image
def _preprocess_image(
self,
image: ImageInput,
do_resize: bool = None,
size: Dict[str, int] = None,
resample: PILImageResampling = None,
do_rescale: bool = None,
rescale_factor: float = None,
do_normalize: bool = None,
image_mean: Optional[Union[float, List[float]]] = None,
image_std: Optional[Union[float, List[float]]] = None,
data_format: Optional[Union[str, ChannelDimension]] = None,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
) -> np.ndarray:
"""Preprocesses a single image."""
# All transformations expect numpy arrays.
image = to_numpy_array(image)
if do_rescale and is_scaled_image(image):
logger.warning_once(
"It looks like you are trying to rescale already rescaled images. If the input"
" images have pixel values between 0 and 1, set `do_rescale=False` to avoid rescaling them again."
)
if input_data_format is None:
input_data_format = infer_channel_dimension_format(image)
image = self._preprocess(
image=image,
do_resize=do_resize,
size=size,
resample=resample,
do_rescale=do_rescale,
rescale_factor=rescale_factor,
do_normalize=do_normalize,
image_mean=image_mean,
image_std=image_std,
input_data_format=input_data_format,
)
if data_format is not None:
image = to_channel_dimension_format(image, data_format, input_channel_dim=input_data_format)
return image
def _preprocess_mask(
self,
segmentation_map: ImageInput,
do_resize: bool = None,
size: Dict[str, int] = None,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
) -> np.ndarray:
"""Preprocesses a single mask."""
segmentation_map = to_numpy_array(segmentation_map)
# Add channel dimension if missing - needed for certain transformations
if segmentation_map.ndim == 2:
added_channel_dim = True
segmentation_map = segmentation_map[None, ...]
input_data_format = ChannelDimension.FIRST
else:
added_channel_dim = False
if input_data_format is None:
input_data_format = infer_channel_dimension_format(segmentation_map, num_channels=1)
# TODO: (Amy)
# Remork segmentation map processing to include reducing labels and resizing which doesn't
# drop segment IDs > 255.
segmentation_map = self._preprocess(
image=segmentation_map,
do_resize=do_resize,
resample=PILImageResampling.NEAREST,
size=size,
do_rescale=False,
do_normalize=False,
input_data_format=input_data_format,
)
# Remove extra channel dimension if added for processing
if added_channel_dim:
segmentation_map = segmentation_map.squeeze(0)
return segmentation_map
@filter_out_non_signature_kwargs()
def preprocess(
self,
images: ImageInput,
task_inputs: Optional[List[str]] = None,
segmentation_maps: Optional[ImageInput] = None,
instance_id_to_semantic_id: Optional[Dict[int, int]] = None,
do_resize: Optional[bool] = None,
size: Optional[Dict[str, int]] = None,
resample: PILImageResampling = None,
do_rescale: Optional[bool] = None,
rescale_factor: Optional[float] = None,
do_normalize: Optional[bool] = None,
image_mean: Optional[Union[float, List[float]]] = None,
image_std: Optional[Union[float, List[float]]] = None,
ignore_index: Optional[int] = None,
do_reduce_labels: Optional[bool] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
) -> BatchFeature:
if task_inputs is None:
# Default value
task_inputs = ["panoptic"]
do_resize = do_resize if do_resize is not None else self.do_resize
size = size if size is not None else self.size
size = get_size_dict(size, default_to_square=False, max_size=self._max_size)
resample = resample if resample is not None else self.resample
do_rescale = do_rescale if do_rescale is not None else self.do_rescale
rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
do_normalize = do_normalize if do_normalize is not None else self.do_normalize
image_mean = image_mean if image_mean is not None else self.image_mean
image_std = image_std if image_std is not None else self.image_std
ignore_index = ignore_index if ignore_index is not None else self.ignore_index
do_reduce_labels = do_reduce_labels if do_reduce_labels is not None else self.do_reduce_labels
if not valid_images(images):
raise ValueError(
"Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
"torch.Tensor, tf.Tensor or jax.ndarray."
)
validate_preprocess_arguments(
do_rescale=do_rescale,
rescale_factor=rescale_factor,
do_normalize=do_normalize,
image_mean=image_mean,
image_std=image_std,
do_resize=do_resize,
size=size,
resample=resample,
)
if segmentation_maps is not None and not valid_images(segmentation_maps):
raise ValueError(
"Invalid segmentation map type. Must be of type PIL.Image.Image, numpy.ndarray, "
"torch.Tensor, tf.Tensor or jax.ndarray."
)
images = make_list_of_images(images)
if segmentation_maps is not None:
segmentation_maps = make_list_of_images(segmentation_maps, expected_ndims=2)
if segmentation_maps is not None and len(images) != len(segmentation_maps):
raise ValueError("Images and segmentation maps must have the same length.")
images = [
self._preprocess_image(
image,
do_resize=do_resize,
size=size,
resample=resample,
do_rescale=do_rescale,
rescale_factor=rescale_factor,
do_normalize=do_normalize,
image_mean=image_mean,
image_std=image_std,
data_format=data_format,
input_data_format=input_data_format,
)
for image in images
]
if segmentation_maps is not None:
segmentation_maps = [
self._preprocess_mask(segmentation_map, do_resize, size, input_data_format=input_data_format)
for segmentation_map in segmentation_maps
]
encoded_inputs = self.encode_inputs(
images,
task_inputs,
segmentation_maps,
instance_id_to_semantic_id,
ignore_index,
do_reduce_labels,
return_tensors,
input_data_format=data_format,
)
return encoded_inputs
# Copied from transformers.models.vilt.image_processing_vilt.ViltImageProcessor._pad_image
def _pad_image(
self,
image: np.ndarray,
output_size: Tuple[int, int],
constant_values: Union[float, Iterable[float]] = 0,
data_format: Optional[ChannelDimension] = None,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
) -> np.ndarray:
"""
Pad an image with zeros to the given size.
"""
input_height, input_width = get_image_size(image, channel_dim=input_data_format)
output_height, output_width = output_size
pad_bottom = output_height - input_height
pad_right = output_width - input_width
padding = ((0, pad_bottom), (0, pad_right))
padded_image = pad(
image,
padding,
mode=PaddingMode.CONSTANT,
constant_values=constant_values,
data_format=data_format,
input_data_format=input_data_format,
)
return padded_image
# Copied from transformers.models.vilt.image_processing_vilt.ViltImageProcessor.pad
def pad(
self,
images: List[np.ndarray],
constant_values: Union[float, Iterable[float]] = 0,
return_pixel_mask: bool = True,
return_tensors: Optional[Union[str, TensorType]] = None,
data_format: Optional[ChannelDimension] = None,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
) -> BatchFeature:
"""
Pads a batch of images to the bottom and right of the image with zeros to the size of largest height and width
in the batch and optionally returns their corresponding pixel mask.
Args:
image (`np.ndarray`):
Image to pad.
constant_values (`float` or `Iterable[float]`, *optional*):
The value to use for the padding if `mode` is `"constant"`.
return_pixel_mask (`bool`, *optional*, defaults to `True`):
Whether to return a pixel mask.
return_tensors (`str` or `TensorType`, *optional*):
The type of tensors to return. Can be one of:
- Unset: Return a list of `np.ndarray`.
- `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
- `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
- `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
- `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
data_format (`str` or `ChannelDimension`, *optional*):
The channel dimension format of the image. If not provided, it will be the same as the input image.
input_data_format (`ChannelDimension` or `str`, *optional*):
The channel dimension format of the input image. If not provided, it will be inferred.
"""
pad_size = get_max_height_width(images, input_data_format=input_data_format)
padded_images = [
self._pad_image(
image,
pad_size,
constant_values=constant_values,
data_format=data_format,
input_data_format=input_data_format,
)
for image in images
]
data = {"pixel_values": padded_images}
if return_pixel_mask:
masks = [
make_pixel_mask(image=image, output_size=pad_size, input_data_format=input_data_format)
for image in images
]
data["pixel_mask"] = masks
return BatchFeature(data=data, tensor_type=return_tensors)
def get_semantic_annotations(self, label, num_class_obj):
annotation_classes = label["classes"]
annotation_masks = label["masks"]
texts = ["a semantic photo"] * self.num_text
classes = []
masks = []
for idx in range(len(annotation_classes)):
class_id = annotation_classes[idx]
mask = annotation_masks[idx]
if not np.all(mask is False):
if class_id not in classes:
cls_name = self.metadata[str(class_id)]
classes.append(class_id)
masks.append(mask)
num_class_obj[cls_name] += 1
else:
idx = classes.index(class_id)
masks[idx] += mask
masks[idx] = np.clip(masks[idx], 0, 1)
num = 0
for i, cls_name in enumerate(self.metadata["class_names"]):
if num_class_obj[cls_name] > 0:
for _ in range(num_class_obj[cls_name]):
if num >= len(texts):
break
texts[num] = f"a photo with a {cls_name}"
num += 1
classes = np.array(classes)
masks = np.array(masks)
return classes, masks, texts
def get_instance_annotations(self, label, num_class_obj):
annotation_classes = label["classes"]
annotation_masks = label["masks"]
texts = ["an instance photo"] * self.num_text
classes = []
masks = []
for idx in range(len(annotation_classes)):
class_id = annotation_classes[idx]
mask = annotation_masks[idx]
if class_id in self.metadata["thing_ids"]:
if not np.all(mask is False):
cls_name = self.metadata[str(class_id)]
classes.append(class_id)
masks.append(mask)
num_class_obj[cls_name] += 1
num = 0
for i, cls_name in enumerate(self.metadata["class_names"]):
if num_class_obj[cls_name] > 0:
for _ in range(num_class_obj[cls_name]):
if num >= len(texts):
break
texts[num] = f"a photo with a {cls_name}"
num += 1
classes = np.array(classes)
masks = np.array(masks)
return classes, masks, texts
def get_panoptic_annotations(self, label, num_class_obj):
annotation_classes = label["classes"]
annotation_masks = label["masks"]
texts = ["an panoptic photo"] * self.num_text
classes = []
masks = []
for idx in range(len(annotation_classes)):
class_id = annotation_classes[idx]
mask = annotation_masks[idx].data
if not np.all(mask is False):
cls_name = self.metadata[str(class_id)]
classes.append(class_id)
masks.append(mask)
num_class_obj[cls_name] += 1
num = 0
for i, cls_name in enumerate(self.metadata["class_names"]):
if num_class_obj[cls_name] > 0:
for _ in range(num_class_obj[cls_name]):
if num >= len(texts):
break
texts[num] = f"a photo with a {cls_name}"
num += 1
classes = np.array(classes)
masks = np.array(masks)
return classes, masks, texts
def encode_inputs(
self,
pixel_values_list: List[ImageInput],
task_inputs: List[str],
segmentation_maps: ImageInput = None,
instance_id_to_semantic_id: Optional[Union[List[Dict[int, int]], Dict[int, int]]] = None,
ignore_index: Optional[int] = None,
do_reduce_labels: bool = False,
return_tensors: Optional[Union[str, TensorType]] = None,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
):
"""
Pad images up to the largest image in a batch and create a corresponding `pixel_mask`.
OneFormer addresses semantic segmentation with a mask classification paradigm, thus input segmentation maps
will be converted to lists of binary masks and their respective labels. Let's see an example, assuming
`segmentation_maps = [[2,6,7,9]]`, the output will contain `mask_labels =
[[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]]` (four binary masks) and `class_labels = [2,6,7,9]`, the labels for
each mask.
Args:
pixel_values_list (`List[ImageInput]`):
List of images (pixel values) to be padded. Each image should be a tensor of shape `(channels, height,
width)`.
task_inputs (`List[str]`):
List of task values.
segmentation_maps (`ImageInput`, *optional*):
The corresponding semantic segmentation maps with the pixel-wise annotations.
(`bool`, *optional*, defaults to `True`):
Whether or not to pad images up to the largest image in a batch and create a pixel mask.
If left to the default, will return a pixel mask that is:
- 1 for pixels that are real (i.e. **not masked**),
- 0 for pixels that are padding (i.e. **masked**).
instance_id_to_semantic_id (`List[Dict[int, int]]` or `Dict[int, int]`, *optional*):
A mapping between object instance ids and class ids. If passed, `segmentation_maps` is treated as an
instance segmentation map where each pixel represents an instance id. Can be provided as a single
dictionary with a global/dataset-level mapping or as a list of dictionaries (one per image), to map
instance ids in each image separately.
return_tensors (`str` or [`~file_utils.TensorType`], *optional*):
If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
objects.
input_data_format (`str` or `ChannelDimension`, *optional*):
The channel dimension format of the input image. If not provided, it will be inferred from the input
image.
Returns:
[`BatchFeature`]: A [`BatchFeature`] with the following fields:
- **pixel_values** -- Pixel values to be fed to a model.
- **pixel_mask** -- Pixel mask to be fed to a model (when `=True` or if `pixel_mask` is in
`self.model_input_names`).
- **mask_labels** -- Optional list of mask labels of shape `(labels, height, width)` to be fed to a model
(when `annotations` are provided).
- **class_labels** -- Optional list of class labels of shape `(labels)` to be fed to a model (when
`annotations` are provided). They identify the labels of `mask_labels`, e.g. the label of
`mask_labels[i][j]` if `class_labels[i][j]`.
- **text_inputs** -- Optional list of text string entries to be fed to a model (when `annotations` are
provided). They identify the binary masks present in the image.
"""
ignore_index = self.ignore_index if ignore_index is None else ignore_index
do_reduce_labels = self.do_reduce_labels if do_reduce_labels is None else do_reduce_labels
pixel_values_list = [to_numpy_array(pixel_values) for pixel_values in pixel_values_list]
if input_data_format is None:
input_data_format = infer_channel_dimension_format(pixel_values_list[0])
pad_size = get_max_height_width(pixel_values_list, input_data_format=input_data_format)
encoded_inputs = self.pad(
pixel_values_list, return_tensors=return_tensors, input_data_format=input_data_format
)
annotations = None
if segmentation_maps is not None:
segmentation_maps = map(np.array, segmentation_maps)
annotations = []
for idx, segmentation_map in enumerate(segmentation_maps):
# Use instance2class_id mapping per image
if isinstance(instance_id_to_semantic_id, list):
instance_id = instance_id_to_semantic_id[idx]
else:
instance_id = instance_id_to_semantic_id
# Use instance2class_id mapping per image
masks, classes = self.convert_segmentation_map_to_binary_masks(
segmentation_map, instance_id, ignore_index=ignore_index, do_reduce_labels=do_reduce_labels
)
annotations.append({"masks": masks, "classes": classes})
if annotations is not None:
mask_labels = []
class_labels = []
text_inputs = []
num_class_obj = {}
for cls_name in self.metadata["class_names"]:
num_class_obj[cls_name] = 0
for i, label in enumerate(annotations):
task = task_inputs[i]
if task == "semantic":
classes, masks, texts = self.get_semantic_annotations(label, num_class_obj)
elif task == "instance":
classes, masks, texts = self.get_instance_annotations(label, num_class_obj)
elif task == "panoptic":
classes, masks, texts = self.get_panoptic_annotations(label, num_class_obj)
else:
raise ValueError(f"{task} was not expected, expected `semantic`, `instance` or `panoptic`")
# we cannot batch them since they don't share a common class size
masks = [mask[None, ...] for mask in masks]
masks = [
self._pad_image(image=mask, output_size=pad_size, constant_values=ignore_index) for mask in masks
]
masks = np.concatenate(masks, axis=0)
mask_labels.append(torch.from_numpy(masks))
class_labels.append(torch.from_numpy(classes).long())
text_inputs.append(texts)
encoded_inputs["mask_labels"] = mask_labels
encoded_inputs["class_labels"] = class_labels
encoded_inputs["text_inputs"] = text_inputs
# This needs to be tokenized before sending to the model.
encoded_inputs["task_inputs"] = [f"the task is {task_input}" for task_input in task_inputs]
return encoded_inputs
# Copied from transformers.models.maskformer.image_processing_maskformer.MaskFormerImageProcessor.post_process_semantic_segmentation
def post_process_semantic_segmentation(
self, outputs, target_sizes: Optional[List[Tuple[int, int]]] = None
) -> "torch.Tensor":
"""
Converts the output of [`MaskFormerForInstanceSegmentation`] into semantic segmentation maps. Only supports
PyTorch.
Args:
outputs ([`MaskFormerForInstanceSegmentation`]):
Raw outputs of the model.
target_sizes (`List[Tuple[int, int]]`, *optional*):
List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
final size (height, width) of each prediction. If left to None, predictions will not be resized.
Returns:
`List[torch.Tensor]`:
A list of length `batch_size`, where each item is a semantic segmentation map of shape (height, width)
corresponding to the target_sizes entry (if `target_sizes` is specified). Each entry of each
`torch.Tensor` correspond to a semantic class id.
"""
class_queries_logits = outputs.class_queries_logits # [batch_size, num_queries, num_classes+1]
masks_queries_logits = outputs.masks_queries_logits # [batch_size, num_queries, height, width]
# Remove the null class `[..., :-1]`
masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
masks_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
# Semantic segmentation logits of shape (batch_size, num_classes, height, width)
segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
batch_size = class_queries_logits.shape[0]
# Resize logits and compute semantic segmentation maps
if target_sizes is not None:
if batch_size != len(target_sizes):
raise ValueError(
"Make sure that you pass in as many target sizes as the batch dimension of the logits"
)
semantic_segmentation = []
for idx in range(batch_size):
resized_logits = torch.nn.functional.interpolate(
segmentation[idx].unsqueeze(dim=0), size=target_sizes[idx], mode="bilinear", align_corners=False
)
semantic_map = resized_logits[0].argmax(dim=0)
semantic_segmentation.append(semantic_map)
else:
semantic_segmentation = segmentation.argmax(dim=1)
semantic_segmentation = [semantic_segmentation[i] for i in range(semantic_segmentation.shape[0])]
return semantic_segmentation
def post_process_instance_segmentation(
self,
outputs,
task_type: str = "instance",
is_demo: bool = True,
threshold: float = 0.5,
mask_threshold: float = 0.5,
overlap_mask_area_threshold: float = 0.8,
target_sizes: Optional[List[Tuple[int, int]]] = None,
return_coco_annotation: Optional[bool] = False,
):
"""
Converts the output of [`OneFormerForUniversalSegmentationOutput`] into image instance segmentation
predictions. Only supports PyTorch.
Args:
outputs ([`OneFormerForUniversalSegmentationOutput`]):
The outputs from [`OneFormerForUniversalSegmentationOutput`].
task_type (`str`, *optional*, defaults to "instance"):
The post processing depends on the task token input. If the `task_type` is "panoptic", we need to
ignore the stuff predictions.
is_demo (`bool`, *optional)*, defaults to `True`):
Whether the model is in demo mode. If true, use threshold to predict final masks.
threshold (`float`, *optional*, defaults to 0.5):
The probability score threshold to keep predicted instance masks.
mask_threshold (`float`, *optional*, defaults to 0.5):
Threshold to use when turning the predicted masks into binary values.
overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
The overlap mask area threshold to merge or discard small disconnected parts within each binary
instance mask.
target_sizes (`List[Tuple]`, *optional*):
List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
final size (height, width) of each prediction in batch. If left to None, predictions will not be
resized.
return_coco_annotation (`bool`, *optional)*, defaults to `False`):
Whether to return predictions in COCO format.
Returns:
`List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
- **segmentation** -- a tensor of shape `(height, width)` where each pixel represents a `segment_id`, set
to `None` if no mask if found above `threshold`. If `target_sizes` is specified, segmentation is resized
to the corresponding `target_sizes` entry.
- **segments_info** -- A dictionary that contains additional information on each segment.
- **id** -- an integer representing the `segment_id`.
- **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
- **was_fused** -- a boolean, `True` if `label_id` was in `label_ids_to_fuse`, `False` otherwise.
Multiple instances of the same class / label were fused and assigned a single `segment_id`.
- **score** -- Prediction score of segment with `segment_id`.
"""
class_queries_logits = outputs.class_queries_logits # [batch_size, num_queries, num_classes+1]
masks_queries_logits = outputs.masks_queries_logits # [batch_size, num_queries, height, width]
device = masks_queries_logits.device
batch_size = class_queries_logits.shape[0]
num_queries = class_queries_logits.shape[1]
num_classes = class_queries_logits.shape[-1] - 1
# Loop over items in batch size
results: List[Dict[str, torch.Tensor]] = []
for i in range(batch_size):
# [Q, K]
scores = torch.nn.functional.softmax(class_queries_logits[i], dim=-1)[:, :-1]
labels = torch.arange(num_classes, device=device).unsqueeze(0).repeat(num_queries, 1).flatten(0, 1)
# scores_per_image, topk_indices = scores.flatten(0, 1).topk(self.num_queries, sorted=False)
scores_per_image, topk_indices = scores.flatten(0, 1).topk(num_queries, sorted=False)
labels_per_image = labels[topk_indices]
topk_indices = torch.div(topk_indices, num_classes, rounding_mode="floor")
# mask_pred = mask_pred.unsqueeze(1).repeat(1, self.sem_seg_head.num_classes, 1).flatten(0, 1)
mask_pred = masks_queries_logits[i][topk_indices]
# Only consider scores with confidence over [threshold] for demo
if is_demo:
keep = scores_per_image > threshold
scores_per_image = scores_per_image[keep]
labels_per_image = labels_per_image[keep]
mask_pred = mask_pred[keep]
# if this is panoptic segmentation, we only keep the "thing" classes
if task_type == "panoptic":
keep = torch.zeros_like(scores_per_image).bool()
for j, lab in enumerate(labels_per_image):
keep[j] = lab in self.metadata["thing_ids"]
scores_per_image = scores_per_image[keep]
labels_per_image = labels_per_image[keep]
mask_pred = mask_pred[keep]
if mask_pred.shape[0] <= 0:
height, width = target_sizes[i] if target_sizes is not None else mask_pred.shape[1:]
segmentation = torch.zeros((height, width)) - 1
results.append({"segmentation": segmentation, "segments_info": []})
continue
if "ade20k" in self.class_info_file and not is_demo and "instance" in task_type:
for j in range(labels_per_image.shape[0]):
labels_per_image[j] = self.metadata["thing_ids"].index(labels_per_image[j].item())
# Get segmentation map and segment information of batch item
target_size = target_sizes[i] if target_sizes is not None else None
segmentation, segments = compute_segments(
mask_pred,
scores_per_image,
labels_per_image,
mask_threshold,
overlap_mask_area_threshold,
set(),
target_size,
)
# Return segmentation map in run-length encoding (RLE) format
if return_coco_annotation:
segmentation = convert_segmentation_to_rle(segmentation)
results.append({"segmentation": segmentation, "segments_info": segments})
return results
# Copied from transformers.models.maskformer.image_processing_maskformer.MaskFormerImageProcessor.post_process_panoptic_segmentation
def post_process_panoptic_segmentation(
self,
outputs,
threshold: float = 0.5,
mask_threshold: float = 0.5,
overlap_mask_area_threshold: float = 0.8,
label_ids_to_fuse: Optional[Set[int]] = None,
target_sizes: Optional[List[Tuple[int, int]]] = None,
) -> List[Dict]:
"""
Converts the output of [`MaskFormerForInstanceSegmentationOutput`] into image panoptic segmentation
predictions. Only supports PyTorch.
Args:
outputs ([`MaskFormerForInstanceSegmentationOutput`]):
The outputs from [`MaskFormerForInstanceSegmentation`].
threshold (`float`, *optional*, defaults to 0.5):
The probability score threshold to keep predicted instance masks.
mask_threshold (`float`, *optional*, defaults to 0.5):
Threshold to use when turning the predicted masks into binary values.
overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
The overlap mask area threshold to merge or discard small disconnected parts within each binary
instance mask.
label_ids_to_fuse (`Set[int]`, *optional*):
The labels in this state will have all their instances be fused together. For instance we could say
there can only be one sky in an image, but several persons, so the label ID for sky would be in that
set, but not the one for person.
target_sizes (`List[Tuple]`, *optional*):
List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
final size (height, width) of each prediction in batch. If left to None, predictions will not be
resized.
Returns:
`List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
- **segmentation** -- a tensor of shape `(height, width)` where each pixel represents a `segment_id`, set
to `None` if no mask if found above `threshold`. If `target_sizes` is specified, segmentation is resized
to the corresponding `target_sizes` entry.
- **segments_info** -- A dictionary that contains additional information on each segment.
- **id** -- an integer representing the `segment_id`.
- **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
- **was_fused** -- a boolean, `True` if `label_id` was in `label_ids_to_fuse`, `False` otherwise.
Multiple instances of the same class / label were fused and assigned a single `segment_id`.
- **score** -- Prediction score of segment with `segment_id`.
"""
if label_ids_to_fuse is None:
logger.warning("`label_ids_to_fuse` unset. No instance will be fused.")
label_ids_to_fuse = set()
class_queries_logits = outputs.class_queries_logits # [batch_size, num_queries, num_classes+1]
masks_queries_logits = outputs.masks_queries_logits # [batch_size, num_queries, height, width]
batch_size = class_queries_logits.shape[0]
num_labels = class_queries_logits.shape[-1] - 1
mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
# Predicted label and score of each query (batch_size, num_queries)
pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
# Loop over items in batch size
results: List[Dict[str, TensorType]] = []
for i in range(batch_size):
mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
)
# No mask found
if mask_probs_item.shape[0] <= 0:
height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
segmentation = torch.zeros((height, width)) - 1
results.append({"segmentation": segmentation, "segments_info": []})
continue
# Get segmentation map and segment information of batch item
target_size = target_sizes[i] if target_sizes is not None else None
segmentation, segments = compute_segments(
mask_probs=mask_probs_item,
pred_scores=pred_scores_item,
pred_labels=pred_labels_item,
mask_threshold=mask_threshold,
overlap_mask_area_threshold=overlap_mask_area_threshold,
label_ids_to_fuse=label_ids_to_fuse,
target_size=target_size,
)
results.append({"segmentation": segmentation, "segments_info": segments})
return results
__all__ = ["OneFormerImageProcessor"]
| transformers/src/transformers/models/oneformer/image_processing_oneformer.py/0 | {
"file_path": "transformers/src/transformers/models/oneformer/image_processing_oneformer.py",
"repo_id": "transformers",
"token_count": 26646
} |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Convert PaliGemma checkpoints from the original repository."""
import argparse
import collections
import torch
from numpy import load
from transformers import (
AutoTokenizer,
GemmaTokenizer,
GemmaTokenizerFast,
PaliGemmaConfig,
PaliGemmaForConditionalGeneration,
PaliGemmaProcessor,
SiglipImageProcessor,
)
from transformers.tokenization_utils_base import AddedToken
from transformers.utils import logging
device = "cuda" # "cpu"
logging.set_verbosity_info()
logger = logging.get_logger(__name__)
# TODO add sequence length variations here
PALIGEMMA_VARIANTS = ["2b-test", "3b-224px", "3b-448px", "3b-896px"]
def get_paligemma_config(variant: str, precision: str):
config = {
"image_token_index": None,
"pad_token_id": 0,
"bos_token_id": 2,
"eos_token_id": 1,
}
image_sizes = {"2b-test": 224, "3b-224px": 224, "3b-448px": 448, "3b-896px": 896}
if variant in PALIGEMMA_VARIANTS:
image_size = image_sizes[variant]
patch_size = 14
num_image_tokens = (image_size**2) // (patch_size**2)
config["image_token_index"] = 257152 if variant != "2b-test" else 256000
text_config = {
"vocab_size": 257152,
"num_hidden_layers": 18,
"num_key_value_heads": 1,
"head_dim": 256,
"torch_dtype": precision,
"hidden_size": 2048,
"hidden_activation": "gelu_pytorch_tanh",
"num_attention_heads": 8,
"intermediate_size": 16384,
"is_encoder_decoder": False,
}
vision_config = {
"torch_dtype": precision,
"image_size": image_size,
"patch_size": patch_size,
"num_image_tokens": num_image_tokens,
"hidden_size": 1152,
"intermediate_size": 4304,
"num_hidden_layers": 27,
"num_attention_heads": 16,
"projector_hidden_act": "gelu_fast",
"vision_use_head": False,
}
final_config = PaliGemmaConfig(text_config=text_config, vision_config=vision_config, **config)
else:
raise ValueError(f"Identifier {variant} not supported. Available: {PALIGEMMA_VARIANTS}")
return final_config
def slice_state_dict(state_dict, config):
# fmt: off
# patch embeddings
state_dict["vision_tower.vision_model.embeddings.patch_embedding.weight"] = state_dict.pop("img/embedding/kernel").transpose(
3, 2, 0, 1
)
state_dict["vision_tower.vision_model.embeddings.patch_embedding.bias"] = state_dict.pop("img/embedding/bias")
# positional embeddings
state_dict["vision_tower.vision_model.embeddings.position_embedding.weight"] = state_dict.pop("img/pos_embedding").reshape(
-1, config.vision_config.hidden_size
)
# extract vision layers to be sliced at index 0. There are 27 layers in the base model.
encoderblock_layernorm0_scale = state_dict.pop("img/Transformer/encoderblock/LayerNorm_0/scale")
encoderblock_layernorm0_bias = state_dict.pop("img/Transformer/encoderblock/LayerNorm_0/bias")
encoderblock_layernorm1_scale = state_dict.pop("img/Transformer/encoderblock/LayerNorm_1/scale")
encoderblock_layernorm1_bias = state_dict.pop("img/Transformer/encoderblock/LayerNorm_1/bias")
encoderblock_mlp_dense0_kernel= state_dict.pop("img/Transformer/encoderblock/MlpBlock_0/Dense_0/kernel")
encoderblock_mlp_dense0_bias= state_dict.pop("img/Transformer/encoderblock/MlpBlock_0/Dense_0/bias")
encoderblock_mlp_dense1_kernel= state_dict.pop("img/Transformer/encoderblock/MlpBlock_0/Dense_1/kernel")
encoderblock_mlp_dense1_bias= state_dict.pop("img/Transformer/encoderblock/MlpBlock_0/Dense_1/bias")
encoderblock_attention_0_key_kernel = state_dict.pop("img/Transformer/encoderblock/MultiHeadDotProductAttention_0/key/kernel")
encoderblock_attention_0_key_bias = state_dict.pop("img/Transformer/encoderblock/MultiHeadDotProductAttention_0/key/bias")
encoderblock_attention_0_value_kernel = state_dict.pop("img/Transformer/encoderblock/MultiHeadDotProductAttention_0/value/kernel")
encoderblock_attention_0_value_bias = state_dict.pop("img/Transformer/encoderblock/MultiHeadDotProductAttention_0/value/bias")
encoderblock_attention_0_query_kernel = state_dict.pop("img/Transformer/encoderblock/MultiHeadDotProductAttention_0/query/kernel")
encoderblock_attention_0_query_bias = state_dict.pop("img/Transformer/encoderblock/MultiHeadDotProductAttention_0/query/bias")
encoderblock_attention_0_out_kernel = state_dict.pop("img/Transformer/encoderblock/MultiHeadDotProductAttention_0/out/kernel")
encoderblock_attention_0_out_bias = state_dict.pop("img/Transformer/encoderblock/MultiHeadDotProductAttention_0/out/bias")
for i in range(config.vision_config.num_hidden_layers):
state_dict[f"vision_tower.vision_model.encoder.layers.{i}.layer_norm1.weight"] = encoderblock_layernorm0_scale[i].transpose()
state_dict[f"vision_tower.vision_model.encoder.layers.{i}.layer_norm1.bias"] = encoderblock_layernorm0_bias[i]
state_dict[f"vision_tower.vision_model.encoder.layers.{i}.layer_norm2.weight"] = encoderblock_layernorm1_scale[i].transpose()
state_dict[f"vision_tower.vision_model.encoder.layers.{i}.layer_norm2.bias"] = encoderblock_layernorm1_bias[i]
state_dict[f"vision_tower.vision_model.encoder.layers.{i}.mlp.fc1.weight"] = encoderblock_mlp_dense0_kernel[i].transpose()
state_dict[f"vision_tower.vision_model.encoder.layers.{i}.mlp.fc1.bias"] = encoderblock_mlp_dense0_bias[i]
state_dict[f"vision_tower.vision_model.encoder.layers.{i}.mlp.fc2.weight"] = encoderblock_mlp_dense1_kernel[i].transpose()
state_dict[f"vision_tower.vision_model.encoder.layers.{i}.mlp.fc2.bias"] = encoderblock_mlp_dense1_bias[i]
state_dict[f"vision_tower.vision_model.encoder.layers.{i}.self_attn.k_proj.weight"] = encoderblock_attention_0_key_kernel[i].reshape(-1, config.vision_config.hidden_size).transpose()
state_dict[f"vision_tower.vision_model.encoder.layers.{i}.self_attn.k_proj.bias"] = encoderblock_attention_0_key_bias[i].reshape(-1, config.vision_config.hidden_size).reshape(-1)
state_dict[f"vision_tower.vision_model.encoder.layers.{i}.self_attn.v_proj.weight"] = encoderblock_attention_0_value_kernel[i].reshape(-1, config.vision_config.hidden_size).transpose()
state_dict[f"vision_tower.vision_model.encoder.layers.{i}.self_attn.v_proj.bias"] = encoderblock_attention_0_value_bias[i].reshape(-1, config.vision_config.hidden_size).reshape(-1)
state_dict[f"vision_tower.vision_model.encoder.layers.{i}.self_attn.q_proj.weight"] = encoderblock_attention_0_query_kernel[i].reshape(-1, config.vision_config.hidden_size).transpose()
state_dict[f"vision_tower.vision_model.encoder.layers.{i}.self_attn.q_proj.bias"] = encoderblock_attention_0_query_bias[i].reshape(-1, config.vision_config.hidden_size).reshape(-1)
state_dict[f"vision_tower.vision_model.encoder.layers.{i}.self_attn.out_proj.weight"] = encoderblock_attention_0_out_kernel[i].reshape(-1, config.vision_config.hidden_size).transpose()
state_dict[f"vision_tower.vision_model.encoder.layers.{i}.self_attn.out_proj.bias"] = encoderblock_attention_0_out_bias[i].reshape(-1, config.vision_config.hidden_size).reshape(-1)
state_dict["vision_tower.vision_model.post_layernorm.weight"] = state_dict.pop("img/Transformer/encoder_norm/scale").transpose()
state_dict["vision_tower.vision_model.post_layernorm.bias"] = state_dict.pop("img/Transformer/encoder_norm/bias")
# multimodal projector
state_dict['multi_modal_projector.linear.weight'] = state_dict.pop("img/head/kernel").transpose()
state_dict['multi_modal_projector.linear.bias'] = state_dict.pop("img/head/bias")
# text decoder (gemma)
embedding_vector = state_dict.pop("llm/embedder/input_embedding")
state_dict["language_model.model.embed_tokens.weight"] = embedding_vector
# pop the einsum attention + mlp representations. There are 18 layers in gemma-2b.
llm_attention_attn_vec_einsum = state_dict.pop("llm/layers/attn/attn_vec_einsum/w")
llm_attention_kv_einsum = state_dict.pop("llm/layers/attn/kv_einsum/w")
llm_attention_q_einsum = state_dict.pop("llm/layers/attn/q_einsum/w")
llm_mlp_gating_einsum = state_dict.pop("llm/layers/mlp/gating_einsum")
llm_mlp_linear = state_dict.pop("llm/layers/mlp/linear")
# TODO verify correctness of layer norm loading
llm_input_layernorm = state_dict.pop("llm/layers/pre_attention_norm/scale")
llm_post_attention_layernorm = state_dict.pop("llm/layers/pre_ffw_norm/scale")
for i in range(config.text_config.num_hidden_layers):
# llm_attention_q_einsum[i].shape = (8, 2048, 256)
q_proj_weight_reshaped = llm_attention_q_einsum[i].transpose(0, 2, 1).reshape(config.text_config.num_attention_heads * config.text_config.head_dim, config.text_config.hidden_size)
state_dict[f"language_model.model.layers.{i}.self_attn.q_proj.weight"] = q_proj_weight_reshaped
# llm_attention_kv_einsum[i, 0, 0].shape = (2048, 256)
k_proj_weight_reshaped = llm_attention_kv_einsum[i, 0, 0].transpose()
state_dict[f"language_model.model.layers.{i}.self_attn.k_proj.weight"] = k_proj_weight_reshaped
# llm_attention_kv_einsum[i, 1, 0].shape = (2048, 256)
v_proj_weight_reshaped = llm_attention_kv_einsum[i, 1, 0].transpose()
state_dict[f"language_model.model.layers.{i}.self_attn.v_proj.weight"] = v_proj_weight_reshaped
# output projection.
# llm_attention_attn_vec_einsum[i].shape = (8, 256, 2048)
o_proj_weight_reshaped = llm_attention_attn_vec_einsum[i].transpose(2, 0, 1).reshape(config.text_config.num_attention_heads * config.text_config.head_dim, config.text_config.hidden_size)
state_dict[f"language_model.model.layers.{i}.self_attn.o_proj.weight"] = o_proj_weight_reshaped
# mlp layers
gate_proj_weight = llm_mlp_gating_einsum[i, 0]
state_dict[f"language_model.model.layers.{i}.mlp.gate_proj.weight"] = gate_proj_weight.transpose()
up_proj_weight = llm_mlp_gating_einsum[i, 1]
state_dict[f"language_model.model.layers.{i}.mlp.up_proj.weight"] = up_proj_weight.transpose()
state_dict[f"language_model.model.layers.{i}.mlp.down_proj.weight"] = llm_mlp_linear[i].transpose()
state_dict[f"language_model.model.layers.{i}.input_layernorm.weight"] = llm_input_layernorm[i]
state_dict[f"language_model.model.layers.{i}.post_attention_layernorm.weight"] = llm_post_attention_layernorm[i]
state_dict["language_model.model.norm.weight"] = state_dict.pop("llm/final_norm/scale")
state_dict["language_model.lm_head.weight"] = embedding_vector # weights are tied.
# fmt: on
for key, value in state_dict.items():
state_dict[key] = torch.from_numpy(value)
return state_dict
def flatten_nested_dict(params, parent_key="", sep="/"):
items = []
for k, v in params.items():
k = k.removeprefix("params/")
new_key = parent_key + sep + k if parent_key else k
if isinstance(v, collections.abc.MutableMapping):
items.extend(flatten_nested_dict(v, parent_key=new_key, sep=sep).items())
else:
items.append((new_key, v))
return dict(items)
@torch.no_grad()
def convert_paligemma_checkpoint(
checkpoint_path,
tokenizer_model_file,
pytorch_dump_folder_path,
variant: str,
precision: str,
do_convert_weights=False,
):
"""
Read checkpoints from flax npz files, rename/reshape, send result to state dict and verify logits if needed.
"""
config = get_paligemma_config(variant, precision=precision)
if do_convert_weights:
if variant == "2b-test":
# for the test model, the vocabulary was smaller
tokenizer_id = "google/gemma-2b"
tokenizer = AutoTokenizer.from_pretrained(tokenizer_id)
else:
tokenizer_class = GemmaTokenizer if GemmaTokenizerFast is None else GemmaTokenizerFast
tokenizer = tokenizer_class(tokenizer_model_file)
image_token = AddedToken("<image>", normalized=False, special=True)
tokens_to_add = {"additional_special_tokens": [image_token]}
tokenizer.add_special_tokens(tokens_to_add)
# tokenizer.padding_side = 'right' # uncomment for testing purposes only.
image_processor = SiglipImageProcessor.from_pretrained("google/siglip-so400m-patch14-384")
image_processor.size = {"width": config.vision_config.image_size, "height": config.vision_config.image_size}
image_processor.image_seq_length = config.vision_config.num_image_tokens
processor = PaliGemmaProcessor(image_processor=image_processor, tokenizer=tokenizer)
data = load(checkpoint_path)
state_dict = flatten_nested_dict(data)
del data
state_dict_transformers = slice_state_dict(state_dict, config)
del state_dict
model = PaliGemmaForConditionalGeneration(config).to(device).eval()
model.load_state_dict(state_dict_transformers)
del state_dict_transformers
else:
processor = PaliGemmaProcessor.from_pretrained(pytorch_dump_folder_path)
model = (
PaliGemmaForConditionalGeneration.from_pretrained(pytorch_dump_folder_path, attn_implementation="sdpa")
.to(device)
.eval()
)
model.config.text_config._attn_implementation = "sdpa"
# model expansion to get random embeds of image tokens
pad_shape = 64 # for performance reasons
pre_expansion_embeddings = model.language_model.model.embed_tokens.weight.data
mu = torch.mean(pre_expansion_embeddings, dim=0).float()
n = pre_expansion_embeddings.size()[0]
sigma = ((pre_expansion_embeddings - mu).T @ (pre_expansion_embeddings - mu)) / n
dist = torch.distributions.multivariate_normal.MultivariateNormal(mu, covariance_matrix=1e-5 * sigma)
# We add an image token so we resize the model
model.resize_token_embeddings(config.text_config.vocab_size + 2, pad_shape)
model.language_model.model.embed_tokens.weight.data[257152:] = torch.stack(
tuple((dist.sample() for _ in range(model.language_model.model.embed_tokens.weight.data[257152:].shape[0]))),
dim=0,
)
model.language_model.lm_head.weight.data[257152:] = torch.stack(
tuple((dist.sample() for _ in range(model.language_model.lm_head.weight.data[257152:].shape[0]))),
dim=0,
)
model.save_pretrained(pytorch_dump_folder_path, max_shard_size="2GB", safe_serialization=True)
processor.save_pretrained(pytorch_dump_folder_path)
#
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--checkpoint_path",
required=True,
type=str,
help="Path to the .npz checkpoint",
)
parser.add_argument(
"--tokenizer_model_file",
required=True,
type=str,
help="Path to the sentencepiece tokenizer.model file",
)
parser.add_argument(
"--pytorch_dump_folder_path",
required=True,
type=str,
help="Path to the output directory where model and processor will be saved.",
)
parser.add_argument(
"--precision",
choices=["float32", "bfloat16", "float16"],
type=str,
help="Precision identifier for model conversion - should match the base checkpoint precision.",
)
parser.add_argument(
"--variant",
default="2b-test",
choices=PALIGEMMA_VARIANTS,
type=str,
help="String identifier of the paligemma variant to convert.",
)
parser.add_argument(
"--do_convert_weights", action="store_true", help="Whether or not to reload and convert the weights."
)
args = parser.parse_args()
convert_paligemma_checkpoint(
checkpoint_path=args.checkpoint_path,
tokenizer_model_file=args.tokenizer_model_file,
pytorch_dump_folder_path=args.pytorch_dump_folder_path,
variant=args.variant,
precision=args.precision,
do_convert_weights=args.do_convert_weights,
)
| transformers/src/transformers/models/paligemma/convert_paligemma_weights_to_hf.py/0 | {
"file_path": "transformers/src/transformers/models/paligemma/convert_paligemma_weights_to_hf.py",
"repo_id": "transformers",
"token_count": 7060
} |
# coding=utf-8
# Copyright 2020 Google and The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tokenization class for model PEGASUS."""
import os
from shutil import copyfile
from typing import List, Optional, Tuple
from ...tokenization_utils_fast import PreTrainedTokenizerFast
from ...utils import is_sentencepiece_available, logging
if is_sentencepiece_available():
from .tokenization_pegasus import PegasusTokenizer
else:
PegasusTokenizer = None
logger = logging.get_logger(__name__)
SPIECE_UNDERLINE = "▁"
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model", "tokenizer_file": "tokenizer.json"}
class PegasusTokenizerFast(PreTrainedTokenizerFast):
r"""
Construct a "fast" PEGASUS tokenizer (backed by HuggingFace's *tokenizers* library). Based on
[Unigram](https://huggingface.co/docs/tokenizers/python/latest/components.html?highlight=unigram#models).
This tokenizer inherits from [`PreTrainedTokenizerFast`] which contains most of the main methods. Users should
refer to this superclass for more information regarding those methods.
Args:
vocab_file (`str`):
[SentencePiece](https://github.com/google/sentencepiece) file (generally has a *.spm* extension) that
contains the vocabulary necessary to instantiate a tokenizer.
pad_token (`str`, *optional*, defaults to `"<pad>"`):
The token used for padding, for example when batching sequences of different lengths.
eos_token (`str`, *optional*, defaults to `"</s>"`):
The end of sequence token.
<Tip>
When building a sequence using special tokens, this is not the token that is used for the end of sequence.
The token used is the `sep_token`.
</Tip>
unk_token (`str`, *optional*, defaults to `"<unk>"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
mask_token (`str`, *optional*, defaults to `"<mask_2>"`):
The token used for masking single token values. This is the token used when training this model with masked
language modeling (MLM). This is the token that the PEGASUS encoder will try to predict during pretraining.
It corresponds to *[MASK2]* in [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive
Summarization](https://arxiv.org/pdf/1912.08777.pdf).
mask_token_sent (`str`, *optional*, defaults to `"<mask_1>"`):
The token used for masking whole target sentences. This is the token used when training this model with gap
sentences generation (GSG). This is the sentence that the PEGASUS decoder will try to predict during
pretraining. It corresponds to *[MASK1]* in [PEGASUS: Pre-training with Extracted Gap-sentences for
Abstractive Summarization](https://arxiv.org/pdf/1912.08777.pdf).
additional_special_tokens (`List[str]`, *optional*):
Additional special tokens used by the tokenizer. If no additional_special_tokens are provided <mask_2> and
<unk_2, ..., unk_102> are used as additional special tokens corresponding to the [original PEGASUS
tokenizer](https://github.com/google-research/pegasus/blob/939830367bcf411193d2b5eca2f2f90f3f9260ca/pegasus/ops/pretrain_parsing_ops.cc#L66)
that uses the tokens 2 - 104 only for pretraining
"""
vocab_files_names = VOCAB_FILES_NAMES
slow_tokenizer_class = PegasusTokenizer
model_input_names = ["input_ids", "attention_mask"]
def __init__(
self,
vocab_file=None,
tokenizer_file=None,
pad_token="<pad>",
eos_token="</s>",
unk_token="<unk>",
mask_token="<mask_2>",
mask_token_sent="<mask_1>",
additional_special_tokens=None,
offset=103, # entries 2 - 104 are only used for pretraining
**kwargs,
):
self.offset = offset
if additional_special_tokens is not None:
if not isinstance(additional_special_tokens, list):
raise TypeError(
f"additional_special_tokens should be of type {type(list)}, but is"
f" {type(additional_special_tokens)}"
)
additional_special_tokens_extended = (
([mask_token_sent] + additional_special_tokens)
if mask_token_sent not in additional_special_tokens and mask_token_sent is not None
else additional_special_tokens
)
# fill additional tokens with ..., <unk_token_102> in case not all additional tokens are already taken
additional_special_tokens_extended += [
f"<unk_{i}>" for i in range(len(additional_special_tokens_extended), self.offset - 1)
]
if len(set(additional_special_tokens_extended)) != len(additional_special_tokens_extended):
raise ValueError(
"Please make sure that the provided additional_special_tokens do not contain an incorrectly"
f" shifted list of <unk_x> tokens. Found {additional_special_tokens_extended}."
)
additional_special_tokens = additional_special_tokens_extended
else:
additional_special_tokens = [mask_token_sent] if mask_token_sent is not None else []
additional_special_tokens += [f"<unk_{i}>" for i in range(2, self.offset)]
# pegasus was design to support changing the index of the first tokens. If one of the padding/eos/unk/mask token
# is different from default, we must rebuild the vocab
from_slow = kwargs.pop("from_slow", None)
from_slow = from_slow or str(pad_token) != "<pad>" or str(eos_token) != "</s>" or str(unk_token) != "<unk>"
kwargs.pop("added_tokens_decoder", {})
super().__init__(
vocab_file,
tokenizer_file=tokenizer_file,
pad_token=pad_token,
eos_token=eos_token,
unk_token=unk_token,
mask_token=mask_token,
mask_token_sent=mask_token_sent,
offset=offset,
additional_special_tokens=additional_special_tokens,
from_slow=from_slow,
**kwargs,
)
self.vocab_file = vocab_file
@property
def can_save_slow_tokenizer(self) -> bool:
return os.path.isfile(self.vocab_file) if self.vocab_file else False
def _special_token_mask(self, seq):
all_special_ids = set(self.all_special_ids) # call it once instead of inside list comp
all_special_ids.remove(self.unk_token_id) # <unk> is only sometimes special
if all_special_ids != set(range(len(self.additional_special_tokens) + 3)):
raise ValueError(
"There should be 3 special tokens: mask_token, pad_token, and eos_token +"
f" {len(self.additional_special_tokens)} additional_special_tokens, but got {all_special_ids}"
)
return [1 if x in all_special_ids else 0 for x in seq]
def get_special_tokens_mask(
self, token_ids_0: List, token_ids_1: Optional[List] = None, already_has_special_tokens: bool = False
) -> List[int]:
"""Get list where entries are [1] if a token is [eos] or [pad] else 0."""
if already_has_special_tokens:
return self._special_token_mask(token_ids_0)
elif token_ids_1 is None:
return self._special_token_mask(token_ids_0) + [1]
else:
return self._special_token_mask(token_ids_0 + token_ids_1) + [1]
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None) -> List[int]:
"""
Build model inputs from a sequence by adding eos to the end. no bos token is added to the front.
- single sequence: `X </s>`
- pair of sequences: `A B </s>` (not intended use)
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: list of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
if token_ids_1 is None:
return token_ids_0 + [self.eos_token_id]
# We don't expect to process pairs, but leave the pair logic for API consistency
return token_ids_0 + token_ids_1 + [self.eos_token_id]
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
if not self.can_save_slow_tokenizer:
raise ValueError(
"Your fast tokenizer does not have the necessary information to save the vocabulary for a slow "
"tokenizer."
)
if not os.path.isdir(save_directory):
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
return
out_vocab_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
)
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file):
copyfile(self.vocab_file, out_vocab_file)
return (out_vocab_file,)
__all__ = ["PegasusTokenizerFast"]
| transformers/src/transformers/models/pegasus/tokenization_pegasus_fast.py/0 | {
"file_path": "transformers/src/transformers/models/pegasus/tokenization_pegasus_fast.py",
"repo_id": "transformers",
"token_count": 4124
} |
# coding=utf-8
# Copyright 2023 Microsoft and the HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Phi model configuration"""
from ...configuration_utils import PretrainedConfig
from ...modeling_rope_utils import rope_config_validation
from ...utils import logging
logger = logging.get_logger(__name__)
class PhiConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`PhiModel`]. It is used to instantiate an Phi
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the Phi
[microsoft/phi-1](https://huggingface.co/microsoft/phi-1).
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 51200):
Vocabulary size of the Phi model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`PhiModel`].
hidden_size (`int`, *optional*, defaults to 2048):
Dimension of the hidden representations.
intermediate_size (`int`, *optional*, defaults to 8192):
Dimension of the MLP representations.
num_hidden_layers (`int`, *optional*, defaults to 24):
Number of hidden layers in the Transformer decoder.
num_attention_heads (`int`, *optional*, defaults to 32):
Number of attention heads for each attention layer in the Transformer decoder.
num_key_value_heads (`int`, *optional*):
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details checkout [this
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
`num_attention_heads`.
resid_pdrop (`float`, *optional*, defaults to 0.0):
Dropout probability for mlp outputs.
embd_pdrop (`int`, *optional*, defaults to 0.0):
The dropout ratio for the embeddings.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio after computing the attention scores.
hidden_act (`str` or `function`, *optional*, defaults to `"gelu_new"`):
The non-linear activation function (function or string) in the decoder.
max_position_embeddings (`int`, *optional*, defaults to 2048):
The maximum sequence length that this model might ever be used with. Phi-1 and Phi-1.5 supports up to 2048
tokens.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (`float`, *optional*, defaults to 1e-05):
The epsilon used by the rms normalization layers.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`. Whether to tie weight embeddings or not.
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
Whether to tie weight embeddings
rope_theta (`float`, *optional*, defaults to 10000.0):
The base period of the RoPE embeddings.
rope_scaling (`Dict`, *optional*):
Dictionary containing the scaling configuration for the RoPE embeddings. NOTE: if you apply new rope type
and you expect the model to work on longer `max_position_embeddings`, we recommend you to update this value
accordingly.
Expected contents:
`rope_type` (`str`):
The sub-variant of RoPE to use. Can be one of ['default', 'linear', 'dynamic', 'yarn', 'longrope',
'llama3'], with 'default' being the original RoPE implementation.
`factor` (`float`, *optional*):
Used with all rope types except 'default'. The scaling factor to apply to the RoPE embeddings. In
most scaling types, a `factor` of x will enable the model to handle sequences of length x *
original maximum pre-trained length.
`original_max_position_embeddings` (`int`, *optional*):
Used with 'dynamic', 'longrope' and 'llama3'. The original max position embeddings used during
pretraining.
`attention_factor` (`float`, *optional*):
Used with 'yarn' and 'longrope'. The scaling factor to be applied on the attention
computation. If unspecified, it defaults to value recommended by the implementation, using the
`factor` field to infer the suggested value.
`beta_fast` (`float`, *optional*):
Only used with 'yarn'. Parameter to set the boundary for extrapolation (only) in the linear
ramp function. If unspecified, it defaults to 32.
`beta_slow` (`float`, *optional*):
Only used with 'yarn'. Parameter to set the boundary for interpolation (only) in the linear
ramp function. If unspecified, it defaults to 1.
`short_factor` (`List[float]`, *optional*):
Only used with 'longrope'. The scaling factor to be applied to short contexts (<
`original_max_position_embeddings`). Must be a list of numbers with the same length as the hidden
size divided by the number of attention heads divided by 2
`long_factor` (`List[float]`, *optional*):
Only used with 'longrope'. The scaling factor to be applied to long contexts (<
`original_max_position_embeddings`). Must be a list of numbers with the same length as the hidden
size divided by the number of attention heads divided by 2
`low_freq_factor` (`float`, *optional*):
Only used with 'llama3'. Scaling factor applied to low frequency components of the RoPE
`high_freq_factor` (`float`, *optional*):
Only used with 'llama3'. Scaling factor applied to high frequency components of the RoPE
partial_rotary_factor (`float`, *optional*, defaults to 0.5):
Percentage of the query and keys which will have rotary embedding.
qk_layernorm (`bool`, *optional*, defaults to `False`):
Whether or not to normalize the Queries and Keys after projecting the hidden states.
bos_token_id (`int`, *optional*, defaults to 1):
Denotes beginning of sequences token id.
eos_token_id (`int`, *optional*, defaults to 2):
Denotes end of sequences token id.
Example:
```python
>>> from transformers import PhiModel, PhiConfig
>>> # Initializing a Phi-1 style configuration
>>> configuration = PhiConfig.from_pretrained("microsoft/phi-1")
>>> # Initializing a model from the configuration
>>> model = PhiModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "phi"
keys_to_ignore_at_inference = ["past_key_values"]
base_model_tp_plan = {
"layers.*.self_attn.q_proj": "colwise",
"layers.*.self_attn.k_proj": "colwise",
"layers.*.self_attn.v_proj": "colwise",
"layers.*.self_attn.dense": "rowwise",
"layers.*.mlp.fc1": "colwise",
"layers.*.mlp.fc2": "rowwise",
}
def __init__(
self,
vocab_size=51200,
hidden_size=2048,
intermediate_size=8192,
num_hidden_layers=24,
num_attention_heads=32,
num_key_value_heads=None,
resid_pdrop=0.0,
embd_pdrop=0.0,
attention_dropout=0.0,
hidden_act="gelu_new",
max_position_embeddings=2048,
initializer_range=0.02,
layer_norm_eps=1e-5,
use_cache=True,
tie_word_embeddings=False,
rope_theta=10000.0,
rope_scaling=None,
partial_rotary_factor=0.5,
qk_layernorm=False,
bos_token_id=1,
eos_token_id=2,
**kwargs,
):
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
if num_key_value_heads is None:
num_key_value_heads = num_attention_heads
self.num_key_value_heads = num_key_value_heads
self.resid_pdrop = resid_pdrop
self.embd_pdrop = embd_pdrop
self.attention_dropout = attention_dropout
self.hidden_act = hidden_act
self.max_position_embeddings = max_position_embeddings
self.initializer_range = initializer_range
self.layer_norm_eps = layer_norm_eps
self.use_cache = use_cache
self.rope_theta = rope_theta
self.rope_scaling = rope_scaling
self.partial_rotary_factor = partial_rotary_factor
self.qk_layernorm = qk_layernorm
# Validate the correctness of rotary position embeddings parameters
# BC: if there is a 'type' field, move it to 'rope_type'.
if self.rope_scaling is not None and "type" in self.rope_scaling:
self.rope_scaling["rope_type"] = self.rope_scaling["type"]
rope_config_validation(self)
super().__init__(
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
tie_word_embeddings=tie_word_embeddings,
**kwargs,
)
| transformers/src/transformers/models/phi/configuration_phi.py/0 | {
"file_path": "transformers/src/transformers/models/phi/configuration_phi.py",
"repo_id": "transformers",
"token_count": 4330
} |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Image processor class for Pix2Struct."""
import io
import math
from typing import Dict, Optional, Union
import numpy as np
from huggingface_hub import hf_hub_download
from ...image_processing_utils import BaseImageProcessor, BatchFeature
from ...image_transforms import convert_to_rgb, normalize, to_channel_dimension_format, to_pil_image
from ...image_utils import (
ChannelDimension,
ImageInput,
get_image_size,
infer_channel_dimension_format,
make_list_of_images,
to_numpy_array,
valid_images,
)
from ...utils import TensorType, is_torch_available, is_vision_available, logging
from ...utils.import_utils import requires_backends
if is_vision_available():
import textwrap
from PIL import Image, ImageDraw, ImageFont
if is_torch_available():
import torch
logger = logging.get_logger(__name__)
DEFAULT_FONT_PATH = "ybelkada/fonts"
# adapted from: https://discuss.pytorch.org/t/tf-image-extract-patches-in-pytorch/171409/2
def torch_extract_patches(image_tensor, patch_height, patch_width):
"""
Utiliy function to extract patches from a given image tensor. Returns a tensor of shape (1, `patch_height`,
`patch_width`, `num_channels`x `patch_height` x `patch_width`)
Args:
image_tensor (torch.Tensor):
The image tensor to extract patches from.
patch_height (int):
The height of the patches to extract.
patch_width (int):
The width of the patches to extract.
"""
requires_backends(torch_extract_patches, ["torch"])
image_tensor = image_tensor.unsqueeze(0)
patches = torch.nn.functional.unfold(image_tensor, (patch_height, patch_width), stride=(patch_height, patch_width))
patches = patches.reshape(image_tensor.size(0), image_tensor.size(1), patch_height, patch_width, -1)
patches = patches.permute(0, 4, 2, 3, 1).reshape(
image_tensor.size(2) // patch_height,
image_tensor.size(3) // patch_width,
image_tensor.size(1) * patch_height * patch_width,
)
return patches.unsqueeze(0)
# Adapted from https://github.com/google-research/pix2struct/blob/0e1779af0f4db4b652c1d92b3bbd2550a7399123/pix2struct/preprocessing/preprocessing_utils.py#L106
def render_text(
text: str,
text_size: int = 36,
text_color: str = "black",
background_color: str = "white",
left_padding: int = 5,
right_padding: int = 5,
top_padding: int = 5,
bottom_padding: int = 5,
font_bytes: Optional[bytes] = None,
font_path: Optional[str] = None,
) -> Image.Image:
"""
Render text. This script is entirely adapted from the original script that can be found here:
https://github.com/google-research/pix2struct/blob/main/pix2struct/preprocessing/preprocessing_utils.py
Args:
text (`str`, *optional*, defaults to ):
Text to render.
text_size (`int`, *optional*, defaults to 36):
Size of the text.
text_color (`str`, *optional*, defaults to `"black"`):
Color of the text.
background_color (`str`, *optional*, defaults to `"white"`):
Color of the background.
left_padding (`int`, *optional*, defaults to 5):
Padding on the left.
right_padding (`int`, *optional*, defaults to 5):
Padding on the right.
top_padding (`int`, *optional*, defaults to 5):
Padding on the top.
bottom_padding (`int`, *optional*, defaults to 5):
Padding on the bottom.
font_bytes (`bytes`, *optional*):
Bytes of the font to use. If `None`, the default font will be used.
font_path (`str`, *optional*):
Path to the font to use. If `None`, the default font will be used.
"""
requires_backends(render_text, "vision")
# Add new lines so that each line is no more than 80 characters.
wrapper = textwrap.TextWrapper(width=80)
lines = wrapper.wrap(text=text)
wrapped_text = "\n".join(lines)
if font_bytes is not None and font_path is None:
font = io.BytesIO(font_bytes)
elif font_path is not None:
font = font_path
else:
font = hf_hub_download(DEFAULT_FONT_PATH, "Arial.TTF")
font = ImageFont.truetype(font, encoding="UTF-8", size=text_size)
# Use a temporary canvas to determine the width and height in pixels when
# rendering the text.
temp_draw = ImageDraw.Draw(Image.new("RGB", (1, 1), background_color))
_, _, text_width, text_height = temp_draw.textbbox((0, 0), wrapped_text, font)
# Create the actual image with a bit of padding around the text.
image_width = text_width + left_padding + right_padding
image_height = text_height + top_padding + bottom_padding
image = Image.new("RGB", (image_width, image_height), background_color)
draw = ImageDraw.Draw(image)
draw.text(xy=(left_padding, top_padding), text=wrapped_text, fill=text_color, font=font)
return image
# Adapted from https://github.com/google-research/pix2struct/blob/0e1779af0f4db4b652c1d92b3bbd2550a7399123/pix2struct/preprocessing/preprocessing_utils.py#L87
def render_header(
image: np.ndarray, header: str, input_data_format: Optional[Union[str, ChildProcessError]] = None, **kwargs
):
"""
Renders the input text as a header on the input image.
Args:
image (`np.ndarray`):
The image to render the header on.
header (`str`):
The header text.
data_format (`Union[ChannelDimension, str]`, *optional*):
The data format of the image. Can be either "ChannelDimension.channels_first" or
"ChannelDimension.channels_last".
Returns:
`np.ndarray`: The image with the header rendered.
"""
requires_backends(render_header, "vision")
# Convert to PIL image if necessary
image = to_pil_image(image, input_data_format=input_data_format)
header_image = render_text(header, **kwargs)
new_width = max(header_image.width, image.width)
new_height = int(image.height * (new_width / image.width))
new_header_height = int(header_image.height * (new_width / header_image.width))
new_image = Image.new("RGB", (new_width, new_height + new_header_height), "white")
new_image.paste(header_image.resize((new_width, new_header_height)), (0, 0))
new_image.paste(image.resize((new_width, new_height)), (0, new_header_height))
# Convert back to the original framework if necessary
new_image = to_numpy_array(new_image)
if infer_channel_dimension_format(new_image) == ChannelDimension.LAST:
new_image = to_channel_dimension_format(new_image, ChannelDimension.LAST)
return new_image
class Pix2StructImageProcessor(BaseImageProcessor):
r"""
Constructs a Pix2Struct image processor.
Args:
do_convert_rgb (`bool`, *optional*, defaults to `True`):
Whether to convert the image to RGB.
do_normalize (`bool`, *optional*, defaults to `True`):
Whether to normalize the image. Can be overridden by the `do_normalize` parameter in the `preprocess`
method. According to Pix2Struct paper and code, the image is normalized with its own mean and standard
deviation.
patch_size (`Dict[str, int]`, *optional*, defaults to `{"height": 16, "width": 16}`):
The patch size to use for the image. According to Pix2Struct paper and code, the patch size is 16x16.
max_patches (`int`, *optional*, defaults to 2048):
The maximum number of patches to extract from the image as per the [Pix2Struct
paper](https://arxiv.org/pdf/2210.03347.pdf).
is_vqa (`bool`, *optional*, defaults to `False`):
Whether or not the image processor is for the VQA task. If `True` and `header_text` is passed in, text is
rendered onto the input images.
"""
model_input_names = ["flattened_patches"]
def __init__(
self,
do_convert_rgb: bool = True,
do_normalize: bool = True,
patch_size: Dict[str, int] = None,
max_patches: int = 2048,
is_vqa: bool = False,
**kwargs,
) -> None:
super().__init__(**kwargs)
self.patch_size = patch_size if patch_size is not None else {"height": 16, "width": 16}
self.do_normalize = do_normalize
self.do_convert_rgb = do_convert_rgb
self.max_patches = max_patches
self.is_vqa = is_vqa
def extract_flattened_patches(
self,
image: np.ndarray,
max_patches: int,
patch_size: dict,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
**kwargs,
) -> np.ndarray:
"""
Extract flattened patches from an image.
Args:
image (`np.ndarray`):
Image to extract flattened patches from.
max_patches (`int`):
Maximum number of patches to extract.
patch_size (`dict`):
Dictionary containing the patch height and width.
Returns:
result (`np.ndarray`):
A sequence of `max_patches` flattened patches.
"""
requires_backends(self.extract_flattened_patches, "torch")
# convert to torch
image = to_channel_dimension_format(image, ChannelDimension.FIRST, input_data_format)
image = torch.from_numpy(image)
patch_height, patch_width = patch_size["height"], patch_size["width"]
image_height, image_width = get_image_size(image, ChannelDimension.FIRST)
# maximize scale s.t.
scale = math.sqrt(max_patches * (patch_height / image_height) * (patch_width / image_width))
num_feasible_rows = max(min(math.floor(scale * image_height / patch_height), max_patches), 1)
num_feasible_cols = max(min(math.floor(scale * image_width / patch_width), max_patches), 1)
resized_height = max(num_feasible_rows * patch_height, 1)
resized_width = max(num_feasible_cols * patch_width, 1)
image = torch.nn.functional.interpolate(
image.unsqueeze(0),
size=(resized_height, resized_width),
mode="bilinear",
align_corners=False,
antialias=True,
).squeeze(0)
# [1, rows, columns, patch_height * patch_width * image_channels]
patches = torch_extract_patches(image, patch_height, patch_width)
patches_shape = patches.shape
rows = patches_shape[1]
columns = patches_shape[2]
depth = patches_shape[3]
# [rows * columns, patch_height * patch_width * image_channels]
patches = patches.reshape([rows * columns, depth])
# [rows * columns, 1]
row_ids = torch.arange(rows).reshape([rows, 1]).repeat(1, columns).reshape([rows * columns, 1])
col_ids = torch.arange(columns).reshape([1, columns]).repeat(rows, 1).reshape([rows * columns, 1])
# Offset by 1 so the ids do not contain zeros, which represent padding.
row_ids += 1
col_ids += 1
# Prepare additional patch features.
# [rows * columns, 1]
row_ids = row_ids.to(torch.float32)
col_ids = col_ids.to(torch.float32)
# [rows * columns, 2 + patch_height * patch_width * image_channels]
result = torch.cat([row_ids, col_ids, patches], -1)
# [max_patches, 2 + patch_height * patch_width * image_channels]
result = torch.nn.functional.pad(result, [0, 0, 0, max_patches - (rows * columns)]).float()
result = to_numpy_array(result)
return result
def normalize(
self,
image: np.ndarray,
data_format: Optional[Union[str, ChannelDimension]] = None,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
**kwargs,
) -> np.ndarray:
"""
Normalize an image. image = (image - image_mean) / image_std.
The image std is to mimic the tensorflow implementation of the `per_image_standardization`:
https://www.tensorflow.org/api_docs/python/tf/image/per_image_standardization
Args:
image (`np.ndarray`):
Image to normalize.
data_format (`str` or `ChannelDimension`, *optional*):
The channel dimension format for the output image. If unset, the channel dimension format of the input
image is used.
input_data_format (`str` or `ChannelDimension`, *optional*):
The channel dimension format of the input image. If not provided, it will be inferred.
"""
if image.dtype == np.uint8:
image = image.astype(np.float32)
# take mean across the whole `image`
mean = np.mean(image)
std = np.std(image)
adjusted_stddev = max(std, 1.0 / math.sqrt(np.prod(image.shape)))
return normalize(
image,
mean=mean,
std=adjusted_stddev,
data_format=data_format,
input_data_format=input_data_format,
**kwargs,
)
def preprocess(
self,
images: ImageInput,
header_text: Optional[str] = None,
do_convert_rgb: bool = None,
do_normalize: Optional[bool] = None,
max_patches: Optional[int] = None,
patch_size: Optional[Dict[str, int]] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
data_format: ChannelDimension = ChannelDimension.FIRST,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
**kwargs,
) -> ImageInput:
"""
Preprocess an image or batch of images. The processor first computes the maximum possible number of
aspect-ratio preserving patches of size `patch_size` that can be extracted from the image. It then pads the
image with zeros to make the image respect the constraint of `max_patches`. Before extracting the patches the
images are standardized following the tensorflow implementation of `per_image_standardization`
(https://www.tensorflow.org/api_docs/python/tf/image/per_image_standardization).
Args:
images (`ImageInput`):
Image to preprocess. Expects a single or batch of images.
header_text (`Union[List[str], str]`, *optional*):
Text to render as a header. Only has an effect if `image_processor.is_vqa` is `True`.
do_convert_rgb (`bool`, *optional*, defaults to `self.do_convert_rgb`):
Whether to convert the image to RGB.
do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
Whether to normalize the image.
max_patches (`int`, *optional*, defaults to `self.max_patches`):
Maximum number of patches to extract.
patch_size (`dict`, *optional*, defaults to `self.patch_size`):
Dictionary containing the patch height and width.
return_tensors (`str` or `TensorType`, *optional*):
The type of tensors to return. Can be one of:
- Unset: Return a list of `np.ndarray`.
- `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
- `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
- `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
- `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
The channel dimension format for the output image. Can be one of:
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
- Unset: Use the channel dimension format of the input image.
input_data_format (`ChannelDimension` or `str`, *optional*):
The channel dimension format for the input image. If unset, the channel dimension format is inferred
from the input image. Can be one of:
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
- `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
"""
do_normalize = do_normalize if do_normalize is not None else self.do_normalize
do_convert_rgb = do_convert_rgb if do_convert_rgb is not None else self.do_convert_rgb
patch_size = patch_size if patch_size is not None else self.patch_size
max_patches = max_patches if max_patches is not None else self.max_patches
is_vqa = self.is_vqa
if kwargs.get("data_format", None) is not None:
raise ValueError("data_format is not an accepted input as the outputs are ")
images = make_list_of_images(images)
if not valid_images(images):
raise ValueError(
"Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
"torch.Tensor, tf.Tensor or jax.ndarray."
)
# PIL RGBA images are converted to RGB
if do_convert_rgb:
images = [convert_to_rgb(image) for image in images]
# All transformations expect numpy arrays.
images = [to_numpy_array(image) for image in images]
if input_data_format is None:
# We assume that all images have the same channel dimension format.
input_data_format = infer_channel_dimension_format(images[0])
if is_vqa:
if header_text is None:
raise ValueError("A header text must be provided for VQA models.")
font_bytes = kwargs.pop("font_bytes", None)
font_path = kwargs.pop("font_path", None)
if isinstance(header_text, str):
header_text = [header_text] * len(images)
images = [
render_header(image, header_text[i], font_bytes=font_bytes, font_path=font_path)
for i, image in enumerate(images)
]
if do_normalize:
images = [self.normalize(image=image, input_data_format=input_data_format) for image in images]
# convert to torch tensor and permute
images = [
self.extract_flattened_patches(
image=image, max_patches=max_patches, patch_size=patch_size, input_data_format=input_data_format
)
for image in images
]
# create attention mask in numpy
attention_masks = [(image.sum(axis=-1) != 0).astype(np.float32) for image in images]
encoded_outputs = BatchFeature(
data={"flattened_patches": images, "attention_mask": attention_masks}, tensor_type=return_tensors
)
return encoded_outputs
__all__ = ["Pix2StructImageProcessor"]
| transformers/src/transformers/models/pix2struct/image_processing_pix2struct.py/0 | {
"file_path": "transformers/src/transformers/models/pix2struct/image_processing_pix2struct.py",
"repo_id": "transformers",
"token_count": 8177
} |
# coding=utf-8
# Copyright 2022 Sea AI Labs and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PoolFormer model configuration"""
from collections import OrderedDict
from typing import Mapping
from packaging import version
from ...configuration_utils import PretrainedConfig
from ...onnx import OnnxConfig
from ...utils import logging
logger = logging.get_logger(__name__)
class PoolFormerConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of [`PoolFormerModel`]. It is used to instantiate a
PoolFormer model according to the specified arguments, defining the model architecture. Instantiating a
configuration with the defaults will yield a similar configuration to that of the PoolFormer
[sail/poolformer_s12](https://huggingface.co/sail/poolformer_s12) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
num_channels (`int`, *optional*, defaults to 3):
The number of channels in the input image.
patch_size (`int`, *optional*, defaults to 16):
The size of the input patch.
stride (`int`, *optional*, defaults to 16):
The stride of the input patch.
pool_size (`int`, *optional*, defaults to 3):
The size of the pooling window.
mlp_ratio (`float`, *optional*, defaults to 4.0):
The ratio of the number of channels in the output of the MLP to the number of channels in the input.
depths (`list`, *optional*, defaults to `[2, 2, 6, 2]`):
The depth of each encoder block.
hidden_sizes (`list`, *optional*, defaults to `[64, 128, 320, 512]`):
The hidden sizes of each encoder block.
patch_sizes (`list`, *optional*, defaults to `[7, 3, 3, 3]`):
The size of the input patch for each encoder block.
strides (`list`, *optional*, defaults to `[4, 2, 2, 2]`):
The stride of the input patch for each encoder block.
padding (`list`, *optional*, defaults to `[2, 1, 1, 1]`):
The padding of the input patch for each encoder block.
num_encoder_blocks (`int`, *optional*, defaults to 4):
The number of encoder blocks.
drop_path_rate (`float`, *optional*, defaults to 0.0):
The dropout rate for the dropout layers.
hidden_act (`str`, *optional*, defaults to `"gelu"`):
The activation function for the hidden layers.
use_layer_scale (`bool`, *optional*, defaults to `True`):
Whether to use layer scale.
layer_scale_init_value (`float`, *optional*, defaults to 1e-05):
The initial value for the layer scale.
initializer_range (`float`, *optional*, defaults to 0.02):
The initializer range for the weights.
Example:
```python
>>> from transformers import PoolFormerConfig, PoolFormerModel
>>> # Initializing a PoolFormer sail/poolformer_s12 style configuration
>>> configuration = PoolFormerConfig()
>>> # Initializing a model (with random weights) from the sail/poolformer_s12 style configuration
>>> model = PoolFormerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```
"""
model_type = "poolformer"
def __init__(
self,
num_channels=3,
patch_size=16,
stride=16,
pool_size=3,
mlp_ratio=4.0,
depths=[2, 2, 6, 2],
hidden_sizes=[64, 128, 320, 512],
patch_sizes=[7, 3, 3, 3],
strides=[4, 2, 2, 2],
padding=[2, 1, 1, 1],
num_encoder_blocks=4,
drop_path_rate=0.0,
hidden_act="gelu",
use_layer_scale=True,
layer_scale_init_value=1e-5,
initializer_range=0.02,
**kwargs,
):
self.num_channels = num_channels
self.patch_size = patch_size
self.stride = stride
self.padding = padding
self.pool_size = pool_size
self.hidden_sizes = hidden_sizes
self.mlp_ratio = mlp_ratio
self.depths = depths
self.patch_sizes = patch_sizes
self.strides = strides
self.num_encoder_blocks = num_encoder_blocks
self.drop_path_rate = drop_path_rate
self.hidden_act = hidden_act
self.use_layer_scale = use_layer_scale
self.layer_scale_init_value = layer_scale_init_value
self.initializer_range = initializer_range
super().__init__(**kwargs)
class PoolFormerOnnxConfig(OnnxConfig):
torch_onnx_minimum_version = version.parse("1.11")
@property
def inputs(self) -> Mapping[str, Mapping[int, str]]:
return OrderedDict(
[
("pixel_values", {0: "batch", 1: "num_channels", 2: "height", 3: "width"}),
]
)
@property
def atol_for_validation(self) -> float:
return 2e-3
__all__ = ["PoolFormerConfig", "PoolFormerOnnxConfig"]
| transformers/src/transformers/models/poolformer/configuration_poolformer.py/0 | {
"file_path": "transformers/src/transformers/models/poolformer/configuration_poolformer.py",
"repo_id": "transformers",
"token_count": 2171
} |
# coding=utf-8
# Copyright 2020 The Trax Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch REFORMER model."""
import sys
from collections import namedtuple
from dataclasses import dataclass
from functools import reduce
from operator import mul
from typing import List, Optional, Tuple, Union
import numpy as np
import torch
from torch import nn
from torch.autograd.function import Function
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from ...activations import ACT2FN
from ...generation import GenerationMixin
from ...modeling_outputs import CausalLMOutput, MaskedLMOutput, QuestionAnsweringModelOutput, SequenceClassifierOutput
from ...modeling_utils import PreTrainedModel
from ...pytorch_utils import apply_chunking_to_forward
from ...utils import (
DUMMY_INPUTS,
DUMMY_MASK,
ModelOutput,
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
logging,
replace_return_docstrings,
)
from .configuration_reformer import ReformerConfig
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "google/reformer-crime-and-punishment"
_CONFIG_FOR_DOC = "ReformerConfig"
# Define named tuples for nn.Modules here
LSHSelfAttentionOutput = namedtuple("LSHSelfAttentionOutput", ["hidden_states", "attention_probs", "buckets"])
LocalSelfAttentionOutput = namedtuple("LocalSelfAttentionOutput", ["hidden_states", "attention_probs"])
AttentionOutput = namedtuple("AttentionOutput", ["hidden_states", "attention_probs", "buckets"])
ReformerOutput = namedtuple("ReformerOutput", ["hidden_states", "attn_output", "attention_probs", "buckets"])
ReformerBackwardOutput = namedtuple(
"ReformerBackwardOutput", ["attn_output", "hidden_states", "grad_attn_output", "grad_hidden_states"]
)
ReformerEncoderOutput = namedtuple(
"ReformerEncoderOutput",
["hidden_states", "all_hidden_states", "all_attentions", "past_buckets_states"],
)
def _stable_argsort(vector, dim):
# this function scales the vector so that torch.argsort is stable.
# torch.argsort is not stable on its own
scale_offset = torch.arange(vector.shape[dim], device=vector.device).view(1, 1, -1)
scale_offset = scale_offset.expand(vector.shape)
scaled_vector = vector.shape[dim] * vector + (scale_offset % vector.shape[dim])
return torch.argsort(scaled_vector, dim=dim)
def _get_least_common_mult_chunk_len(config):
attn_types = config.attn_layers
attn_types_set = set(attn_types)
if len(attn_types_set) == 1 and attn_types[0] == "lsh":
return config.lsh_attn_chunk_length
elif len(attn_types_set) == 1 and attn_types[0] == "local":
return config.local_attn_chunk_length
elif len(attn_types_set) == 2 and attn_types_set == {"lsh", "local"}:
return np.lcm(config.lsh_attn_chunk_length, config.local_attn_chunk_length)
else:
raise NotImplementedError(
f"Only attn layer types 'lsh' and 'local' exist, but `config.attn_layers`: {config.attn_layers}. Select "
"attn layer types from ['lsh', 'local'] only."
)
def _get_min_chunk_len(config):
attn_types = config.attn_layers
attn_types_set = set(attn_types)
if len(attn_types_set) == 1 and attn_types[0] == "lsh":
return config.lsh_attn_chunk_length
elif len(attn_types_set) == 1 and attn_types[0] == "local":
return config.local_attn_chunk_length
elif len(attn_types_set) == 2 and attn_types_set == {"lsh", "local"}:
return min(config.lsh_attn_chunk_length, config.local_attn_chunk_length)
else:
raise NotImplementedError(
f"Only attn layer types 'lsh' and 'local' exist, but `config.attn_layers`: {config.attn_layers}. Select "
"attn layer types from ['lsh', 'local'] only."
)
class AxialPositionEmbeddings(nn.Module):
"""
Constructs axial position embeddings. Useful for very long input sequences to save memory and time.
"""
def __init__(self, config):
super().__init__()
self.axial_pos_shape = config.axial_pos_shape
self.axial_pos_embds_dim = config.axial_pos_embds_dim
self.dropout = config.hidden_dropout_prob
self.least_common_mult_chunk_length = _get_least_common_mult_chunk_len(config)
self.weights = nn.ParameterList()
if sum(self.axial_pos_embds_dim) != config.hidden_size:
raise ValueError(
f"Make sure that config.axial_pos_embds factors: {self.axial_pos_embds_dim} sum to "
f"config.hidden_size: {config.hidden_size}"
)
# create weights
for axis, axial_pos_embd_dim in enumerate(self.axial_pos_embds_dim):
# create expanded shapes
ax_shape = [1] * len(self.axial_pos_shape)
ax_shape[axis] = self.axial_pos_shape[axis]
ax_shape = tuple(ax_shape) + (axial_pos_embd_dim,)
# create tensor and init
self.weights.append(nn.Parameter(torch.ones(ax_shape, dtype=torch.float32)))
def forward(self, position_ids):
# broadcast weights to correct shape
batch_size = position_ids.shape[0]
sequence_length = position_ids.shape[1]
broadcasted_weights = [
weight.expand((batch_size,) + self.axial_pos_shape + weight.shape[-1:]) for weight in self.weights
]
if self.training is True:
if reduce(mul, self.axial_pos_shape) != sequence_length:
raise ValueError(
f"If training, make sure that config.axial_pos_shape factors: {self.axial_pos_shape} multiply to "
f"sequence length. Got prod({self.axial_pos_shape}) != sequence_length: {sequence_length}. "
f"You might want to consider padding your sequence length to {reduce(mul, self.axial_pos_shape)} "
"or changing config.axial_pos_shape."
)
if self.dropout > 0:
weights = torch.cat(broadcasted_weights, dim=-1)
# permute weights so that 2D correctly drops dims 1 and 2
transposed_weights = weights.transpose(2, 1)
# drop entire matrix of last two dims (prev dims 1 and 2)
dropped_transposed_weights = nn.functional.dropout2d(
transposed_weights, p=self.dropout, training=self.training
)
dropped_weights = dropped_transposed_weights.transpose(2, 1)
position_encodings = torch.reshape(dropped_weights, (batch_size, sequence_length, -1))
else:
position_encodings = torch.cat(
[torch.reshape(weight, (batch_size, sequence_length, -1)) for weight in broadcasted_weights],
dim=-1,
)
else:
if reduce(mul, self.axial_pos_shape) < sequence_length:
raise ValueError(
f"Make sure that config.axial_pos_shape factors: {self.axial_pos_shape} multiply at least to "
f"max(sequence_length, least_common_mult_chunk_length): max({sequence_length}, "
f"{self.least_common_mult_chunk_length})."
)
# compute how many columns are needed
max_position_id = position_ids.max().item()
required_pos_encodings_columns = -(-(max_position_id + 1) // self.axial_pos_shape[1])
# cut to columns that are needed
position_encodings = torch.cat(
[weight[:, :required_pos_encodings_columns] for weight in broadcasted_weights], dim=-1
)
position_encodings = torch.reshape(position_encodings, (batch_size, -1, position_encodings.shape[-1]))
# select correct position encodings
position_encodings = torch.cat(
[
torch.index_select(position_encodings[i], 0, position_ids[i]).unsqueeze(0)
for i in range(batch_size)
],
dim=0,
)
return position_encodings
class PositionEmbeddings(nn.Module):
"""Constructs conventional position embeddings of shape `[max_pos_embeddings, hidden_size]`."""
def __init__(self, config):
super().__init__()
self.dropout = config.hidden_dropout_prob
self.embedding = nn.Embedding(config.max_position_embeddings, config.hidden_size)
def forward(self, position_ids):
position_embeddings = self.embedding(position_ids)
position_embeddings = nn.functional.dropout(position_embeddings, p=self.dropout, training=self.training)
return position_embeddings
class ReformerEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config):
super().__init__()
self.max_position_embeddings = config.max_position_embeddings
self.dropout = config.hidden_dropout_prob
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size)
self.position_embeddings = (
AxialPositionEmbeddings(config) if config.axial_pos_embds else PositionEmbeddings(config)
)
def forward(self, input_ids=None, position_ids=None, inputs_embeds=None, start_idx_pos_encodings=0):
if input_ids is not None:
input_shape = input_ids.size()
device = input_ids.device
else:
input_shape = inputs_embeds.size()[:-1]
device = inputs_embeds.device
seq_length = input_shape[1]
if position_ids is None:
position_ids = torch.arange(
start_idx_pos_encodings, start_idx_pos_encodings + seq_length, dtype=torch.long, device=device
)
position_ids = position_ids.unsqueeze(0).expand(input_shape)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
if position_ids.shape[-1] > self.max_position_embeddings:
raise ValueError(
f"Sequence Length: {position_ids.shape[-1]} has to be less or equal than "
f"config.max_position_embeddings {self.max_position_embeddings}."
)
# dropout
embeddings = nn.functional.dropout(inputs_embeds, p=self.dropout, training=self.training)
# add positional embeddings
position_embeddings = self.position_embeddings(position_ids)
embeddings = embeddings + position_embeddings
return embeddings
class EfficientAttentionMixin:
"""
A few utilities for nn.Modules in Reformer, to be used as a mixin.
"""
def _look_adjacent(self, vectors, num_chunks_before, num_chunks_after):
"""
Used to implement attention between consecutive chunks.
Args:
vectors: array of shape [batch_size, num_attention_heads, n_chunks, chunk_len, ...]
num_chunks_before: chunks before current chunk to include in attention
num_chunks_after: chunks after current chunk to include in attention
Returns:
tensor of shape [num_chunks, N * chunk_length, ...], where N = (1 + num_chunks_before + num_chunks_after).
"""
if num_chunks_before == 0 and num_chunks_after == 0:
return vectors
slices = []
for i in range(-num_chunks_before, num_chunks_after + 1):
if i == 0:
slices.append(vectors)
else:
slices.append(torch.cat([vectors[:, :, i:, ...], vectors[:, :, :i, ...]], dim=2))
return torch.cat(slices, dim=3)
def _split_hidden_size_dim(self, x, num_attn_heads, attn_head_size):
"""
splits hidden_size dim into attn_head_size and num_attn_heads
"""
new_x_shape = x.size()[:-1] + (num_attn_heads, attn_head_size)
x = x.view(*new_x_shape)
return x.transpose(2, 1)
def _merge_hidden_size_dims(self, x, num_attn_heads, attn_head_size):
"""
merges attn_head_size dim and num_attn_heads dim into hidden_size
"""
x = x.permute(0, 2, 1, 3)
return torch.reshape(x, (x.size()[0], -1, num_attn_heads * attn_head_size))
def _split_seq_length_dim_to(self, vectors, dim_factor_1, dim_factor_2, num_attn_heads, attn_head_size=None):
"""
splits sequence length dim of vectors into `dim_factor_1` and `dim_factor_2` dims
"""
batch_size = vectors.shape[0]
split_dim_shape = (batch_size, num_attn_heads, dim_factor_1, dim_factor_2)
if len(vectors.shape) == 4:
return torch.reshape(vectors, split_dim_shape + (attn_head_size,))
elif len(vectors.shape) == 3:
return torch.reshape(vectors, split_dim_shape)
else:
raise ValueError(f"Input vector rank should be one of [3, 4], but is: {len(vectors.shape)}")
class LSHSelfAttention(nn.Module, EfficientAttentionMixin):
def __init__(self, config):
super().__init__()
self.config = config
self.chunk_length = config.lsh_attn_chunk_length
self.num_hashes = config.num_hashes
self.num_buckets = config.num_buckets
self.num_chunks_before = config.lsh_num_chunks_before
self.num_chunks_after = config.lsh_num_chunks_after
self.hash_seed = config.hash_seed
self.is_decoder = config.is_decoder
self.max_position_embeddings = config.max_position_embeddings
self.dropout = config.lsh_attention_probs_dropout_prob
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = config.attention_head_size
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.hidden_size = config.hidden_size
# projection matrices
self.query_key = nn.Linear(self.hidden_size, self.all_head_size, bias=False)
self.value = nn.Linear(self.hidden_size, self.all_head_size, bias=False)
# save mask value here. Need fp32 and fp16 mask values
self.register_buffer("self_mask_value_float16", torch.tensor(-1e3), persistent=False)
self.register_buffer("self_mask_value_float32", torch.tensor(-1e5), persistent=False)
self.register_buffer("mask_value_float16", torch.tensor(-1e4), persistent=False)
self.register_buffer("mask_value_float32", torch.tensor(-1e9), persistent=False)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
num_hashes=None,
buckets=None,
past_buckets_states=None,
use_cache=False,
output_attentions=False,
**kwargs,
):
sequence_length = hidden_states.shape[1]
batch_size = hidden_states.shape[0]
# num hashes can optionally be overwritten by user
num_hashes = num_hashes if num_hashes is not None else self.num_hashes
do_cached_attention = use_cache and past_buckets_states[1] is not None
# check if cache shall be used and that hidden states are already cached
if do_cached_attention:
assert sequence_length == 1, (
"At the moment, auto-regressive language generation is only possible one word at a time. Make sure"
f" that input sequence length {sequence_length} equals 1, when `past_buckets_states` is passed."
)
past_buckets = past_buckets_states[0]
past_states = past_buckets_states[1]
# get query vector
query_vectors = self.query_key(hidden_states)
query_vectors = self._split_hidden_size_dim(
query_vectors, self.num_attention_heads, self.attention_head_size
)
if past_buckets is not None:
key_value_hidden_states, sorted_bucket_idx, buckets = self._get_relevant_hid_states_and_buckets(
query_vectors=query_vectors,
attention_mask=attention_mask,
num_hashes=num_hashes,
hidden_states=hidden_states,
past_states=past_states,
past_buckets=past_buckets,
)
query_key_vectors = self._query_per_attn_head(key_value_hidden_states)
value_vectors = self._value_per_attn_head(key_value_hidden_states)
# split key & value vectors by num hashes to apply
# self attention on each separately
query_key_vectors = self._split_seq_length_dim_to(
query_key_vectors,
num_hashes,
-1,
self.num_attention_heads,
self.attention_head_size,
)
value_vectors = self._split_seq_length_dim_to(
value_vectors,
num_hashes,
-1,
self.num_attention_heads,
self.attention_head_size,
)
# repeat query vectors across hash dimension
query_vectors = query_vectors.unsqueeze(2).repeat(1, 1, num_hashes, 1, 1)
else:
key_value_hidden_states = torch.cat([past_states, hidden_states], dim=1)
query_key_vectors = self.query_key(key_value_hidden_states)
value_vectors = self.value(key_value_hidden_states)
else:
# project hidden_states to query_key and value
query_vectors = None
query_key_vectors = self.query_key(hidden_states)
value_vectors = self.value(hidden_states)
# if query key is not already split
if not do_cached_attention or past_buckets is None:
query_key_vectors = self._split_hidden_size_dim(
query_key_vectors, self.num_attention_heads, self.attention_head_size
)
value_vectors = self._split_hidden_size_dim(
value_vectors, self.num_attention_heads, self.attention_head_size
)
# cache buckets for next incremental decoding
if do_cached_attention and past_buckets is None and key_value_hidden_states.shape[1] >= self.chunk_length:
buckets = self._hash_vectors(query_key_vectors, num_hashes, attention_mask)
# free memory
del hidden_states
assert (
query_key_vectors.shape[-1] == self.attention_head_size
), f"last dim of query_key_vectors is {query_key_vectors.shape[-1]} but should be {self.attention_head_size}."
assert (
value_vectors.shape[-1] == self.attention_head_size
), f"last dim of value_vectors is {value_vectors.shape[-1]} but should be {self.attention_head_size}."
do_standard_self_attention = (sequence_length <= self.chunk_length) or (
use_cache and past_buckets_states[1] is not None
)
# LSH attention only makes sense if chunked attention should be performed
if not do_standard_self_attention:
# set `num_buckets` on the fly, recommended way to do it
if self.num_buckets is None:
self._set_num_buckets(sequence_length)
# use cached buckets for backprop only
if buckets is None:
# hash query key vectors into buckets
buckets = self._hash_vectors(query_key_vectors, num_hashes, attention_mask)
else:
# make sure buckets has correct shape for LSH attention
buckets = buckets.view(batch_size, self.num_attention_heads, num_hashes * sequence_length)
assert (
int(buckets.shape[-1]) == num_hashes * sequence_length
), f"last dim of buckets is {buckets.shape[-1]}, but should be {num_hashes * sequence_length}"
sorted_bucket_idx, undo_sorted_bucket_idx = self._get_sorted_bucket_idx_and_undo_sorted_bucket_idx(
sequence_length, buckets, num_hashes
)
# make sure bucket idx is not longer then sequence length
sorted_bucket_idx_per_hash = sorted_bucket_idx % sequence_length
# cluster query key value vectors according to hashed buckets
query_key_vectors = self._gather_by_expansion(query_key_vectors, sorted_bucket_idx_per_hash, num_hashes)
value_vectors = self._gather_by_expansion(value_vectors, sorted_bucket_idx_per_hash, num_hashes)
query_key_vectors = self._split_seq_length_dim_to(
query_key_vectors,
-1,
self.chunk_length,
self.num_attention_heads,
self.attention_head_size,
)
value_vectors = self._split_seq_length_dim_to(
value_vectors,
-1,
self.chunk_length,
self.num_attention_heads,
self.attention_head_size,
)
if self.chunk_length is None:
assert self.num_chunks_before == 0 and self.num_chunks_after == 0, (
"If `config.chunk_length` is `None`, make sure `config.num_chunks_after` and"
" `config.num_chunks_before` are set to 0."
)
elif do_cached_attention and past_buckets is not None:
# use max sequence length
sorted_bucket_idx_per_hash = sorted_bucket_idx
else:
# get sequence length indices
sorted_bucket_idx_per_hash = torch.arange(sequence_length, device=query_key_vectors.device).repeat(
batch_size, self.num_attention_heads, 1
)
# scale key vectors
sqrt_num = np.sqrt(self.attention_head_size)
key_vectors = self._len_and_dim_norm(query_key_vectors, sqrt_num)
# set query_vectors to query key vectors if LSH self attention
query_vectors = query_vectors if query_vectors is not None else query_key_vectors
# free memory
del query_key_vectors
# get attention probs
out_vectors, logits, attention_probs = self._attend(
query_vectors=query_vectors,
key_vectors=key_vectors,
value_vectors=value_vectors,
sorted_bucket_idx_per_hash=sorted_bucket_idx_per_hash,
attention_mask=attention_mask,
head_mask=head_mask,
do_standard_self_attention=do_standard_self_attention,
do_cached_attention=do_cached_attention,
)
# free memory
del key_vectors, value_vectors
# re-order out_vectors and logits
if not do_standard_self_attention:
# sort clusters back to correct ordering
out_vectors, logits = ReverseSort.apply(out_vectors, logits, sorted_bucket_idx, undo_sorted_bucket_idx)
if not do_standard_self_attention or (do_cached_attention and past_buckets is not None):
# sum up all hash rounds
if num_hashes > 1:
out_vectors = self._split_seq_length_dim_to(
out_vectors,
num_hashes,
sequence_length,
self.num_attention_heads,
self.attention_head_size,
)
logits = self._split_seq_length_dim_to(
logits,
num_hashes,
sequence_length,
self.num_attention_heads,
self.attention_head_size,
).unsqueeze(-1)
probs_vectors = torch.exp(logits - torch.logsumexp(logits, dim=2, keepdim=True))
out_vectors = torch.sum(out_vectors * probs_vectors, dim=2)
# free memory
del probs_vectors
# free memory
del logits
assert out_vectors.shape == (
batch_size,
self.num_attention_heads,
sequence_length,
self.attention_head_size,
), (
"out_vectors have be of shape `[batch_size, config.num_attention_heads, sequence_length,"
" config.attention_head_size]`."
)
out_vectors = self._merge_hidden_size_dims(out_vectors, self.num_attention_heads, self.attention_head_size)
if output_attentions is False:
attention_probs = ()
if buckets is not None:
buckets = buckets.view(batch_size, self.num_attention_heads, num_hashes, -1)
return LSHSelfAttentionOutput(hidden_states=out_vectors, attention_probs=attention_probs, buckets=buckets)
def _query_per_attn_head(self, hidden_states):
per_head_query_key = self.query_key.weight.reshape(
self.num_attention_heads, self.attention_head_size, self.hidden_size
).transpose(-2, -1)
# only relevant for inference and no bias => we can use einsum here
query_key_vectors = torch.einsum("balh,ahr->balr", hidden_states, per_head_query_key)
return query_key_vectors
def _value_per_attn_head(self, hidden_states):
per_head_value = self.value.weight.reshape(
self.num_attention_heads, self.attention_head_size, self.hidden_size
).transpose(-2, -1)
# only relevant for inference and no bias => we can use einsum here
value_vectors = torch.einsum("balh,ahr->balr", hidden_states, per_head_value)
return value_vectors
def _hash_vectors(self, vectors, num_hashes, attention_mask, increase_num_buckets=False):
batch_size = vectors.shape[0]
# See https://arxiv.org/pdf/1509.02897.pdf
# We sample a different random rotation for each round of hashing to
# decrease the probability of hash misses.
if isinstance(self.num_buckets, int):
assert (
self.num_buckets % 2 == 0
), f"There should be an even number of buckets, but `self.num_buckets`: {self.num_buckets}"
rotation_size = self.num_buckets
num_buckets = self.num_buckets
else:
# Factorize the hash if self.num_buckets is a list or tuple
rotation_size, num_buckets = 0, 1
for bucket_factor in self.num_buckets:
assert (
bucket_factor % 2 == 0
), f"The number of buckets should be even, but `num_bucket`: {bucket_factor}"
rotation_size = rotation_size + bucket_factor
num_buckets = num_buckets * bucket_factor
# remove gradient
vectors = vectors.detach()
if self.hash_seed is not None:
# for determinism
torch.manual_seed(self.hash_seed)
rotations_shape = (self.num_attention_heads, vectors.shape[-1], num_hashes, rotation_size // 2)
# create a random self.attention_head_size x num_hashes x num_buckets/2
random_rotations = torch.randn(rotations_shape, device=vectors.device, dtype=vectors.dtype)
# Output dim: Batch_Size x Num_Attn_Heads x Num_Hashes x Seq_Len x Num_Buckets/2
rotated_vectors = torch.einsum("bmtd,mdhr->bmhtr", vectors, random_rotations)
if isinstance(self.num_buckets, int) or len(self.num_buckets) == 1:
rotated_vectors = torch.cat([rotated_vectors, -rotated_vectors], dim=-1)
buckets = torch.argmax(rotated_vectors, dim=-1)
else:
# Get the buckets for them and combine.
buckets, cur_sum, cur_product = None, 0, 1
for bucket_factor in self.num_buckets:
rotated_vectors_factor = rotated_vectors[..., cur_sum : cur_sum + (bucket_factor // 2)]
cur_sum = cur_sum + bucket_factor // 2
rotated_vectors_factor = torch.cat([rotated_vectors_factor, -rotated_vectors_factor], dim=-1)
if buckets is None:
buckets = torch.argmax(rotated_vectors_factor, dim=-1)
else:
buckets = buckets + (cur_product * torch.argmax(rotated_vectors_factor, dim=-1))
cur_product = cur_product * bucket_factor
if attention_mask is not None and (attention_mask.sum().item() < batch_size * attention_mask.shape[-1]):
# add an extra bucket for padding tokens only
num_buckets = num_buckets + 1
# assign padding tokens extra bucket
buckets_mask = attention_mask.to(torch.bool)[:, None, None, :].expand(buckets.shape)
buckets = torch.where(
buckets_mask, buckets, torch.tensor(num_buckets - 1, dtype=torch.long, device=buckets.device)
)
elif increase_num_buckets:
num_buckets = num_buckets + 1
# buckets is now (Batch_size x Num_Attn_Heads x Num_Hashes x Seq_Len).
# Next we add offsets so that bucket numbers from different hashing rounds don't overlap.
offsets = torch.arange(num_hashes, device=vectors.device)
offsets = (offsets * num_buckets).view((1, 1, -1, 1))
# expand to batch size and num attention heads
offsets = offsets.expand((batch_size, self.num_attention_heads) + offsets.shape[-2:])
offset_buckets = (buckets + offsets).flatten(start_dim=2, end_dim=3)
return offset_buckets
def _get_sorted_bucket_idx_and_undo_sorted_bucket_idx(self, sequence_length, buckets, num_hashes):
# no gradients are needed
with torch.no_grad():
# hash-based sort
sorted_bucket_idx = _stable_argsort(buckets, dim=-1)
# create simple indices to scatter to, to have undo sort
indices = (
torch.arange(sorted_bucket_idx.shape[-1], device=buckets.device)
.view(1, 1, -1)
.expand(sorted_bucket_idx.shape)
)
# get undo sort
undo_sorted_bucket_idx = sorted_bucket_idx.new(*sorted_bucket_idx.size())
undo_sorted_bucket_idx.scatter_(-1, sorted_bucket_idx, indices)
return sorted_bucket_idx, undo_sorted_bucket_idx
def _set_num_buckets(self, sequence_length):
# `num_buckets` should be set to 2 * sequence_length // chunk_length as recommended in paper
num_buckets_pow_2 = (2 * (sequence_length // self.chunk_length)).bit_length() - 1
# make sure buckets are power of 2
num_buckets = 2**num_buckets_pow_2
# factorize `num_buckets` if `num_buckets` becomes too large
num_buckets_limit = 2 * max(
int((self.max_position_embeddings // self.chunk_length) ** (0.5)),
self.chunk_length,
)
if num_buckets > num_buckets_limit:
num_buckets = [2 ** (num_buckets_pow_2 // 2), 2 ** (num_buckets_pow_2 - num_buckets_pow_2 // 2)]
logger.warning(f"config.num_buckets is not set. Setting config.num_buckets to {num_buckets}...")
# set num buckets in config to be properly saved
self.config.num_buckets = num_buckets
self.num_buckets = num_buckets
def _attend(
self,
query_vectors,
key_vectors,
value_vectors,
sorted_bucket_idx_per_hash,
attention_mask,
head_mask,
do_standard_self_attention,
do_cached_attention,
):
# look at previous and following chunks if chunked attention
if not do_standard_self_attention:
key_vectors = self._look_adjacent(key_vectors, self.num_chunks_before, self.num_chunks_after)
value_vectors = self._look_adjacent(value_vectors, self.num_chunks_before, self.num_chunks_after)
# get logits and dots
# (BS, NumAttn, NumHash x NumChunk, Chunk_L x Hidden),(BS, NumAttn, NumHash x NumChunk, Chunk_L * (Num_bef + Num_aft + 1) x Hidden) -> (BS, NumAttn, NumHash x NumChunk, Chunk_L, Chunk_L * (1 + Num_bef + Num_aft))
query_key_dots = torch.matmul(query_vectors, key_vectors.transpose(-1, -2))
# free memory
del query_vectors, key_vectors
# if chunked attention split bucket idxs to query and key
if not do_standard_self_attention:
query_bucket_idx = self._split_seq_length_dim_to(
sorted_bucket_idx_per_hash, -1, self.chunk_length, self.num_attention_heads
)
key_value_bucket_idx = self._look_adjacent(query_bucket_idx, self.num_chunks_before, self.num_chunks_after)
elif do_cached_attention and query_key_dots.ndim > 4:
key_value_bucket_idx = sorted_bucket_idx_per_hash
query_bucket_idx = (
key_value_bucket_idx.new_ones(key_value_bucket_idx.shape[:-1] + (1,)) * key_value_bucket_idx.max()
)
elif do_cached_attention and query_key_dots.ndim <= 4:
query_bucket_idx = (query_key_dots.shape[-1] - 1) * torch.ones_like(query_key_dots)[:, :, :, -1]
key_value_bucket_idx = torch.arange(
query_key_dots.shape[-1], dtype=torch.long, device=query_key_dots.device
)[None, None, :].expand(query_bucket_idx.shape[:2] + (-1,))
else:
query_bucket_idx = key_value_bucket_idx = sorted_bucket_idx_per_hash
# get correct mask values depending on precision
if query_key_dots.dtype == torch.float16:
self_mask_value = self.self_mask_value_float16.half()
mask_value = self.mask_value_float16.half()
else:
self_mask_value = self.self_mask_value_float32
mask_value = self.mask_value_float32
if not do_cached_attention:
mask = self._compute_attn_mask(
query_bucket_idx,
key_value_bucket_idx,
attention_mask,
query_key_dots.shape,
do_standard_self_attention,
)
if mask is not None:
query_key_dots = torch.where(mask, query_key_dots, mask_value)
# free memory
del mask
# Self mask is ALWAYS applied.
# From the reformer paper (https://arxiv.org/pdf/2001.04451.pdf):
# " While attention to the future is not allowed, typical implementations of the
# Transformer do allow a position to attend to itself.
# Such behavior is undesirable in a shared-QK formulation because the dot-product
# of a query vector with itself will almost always be greater than the dot product of a
# query vector with a vector at another position. We therefore modify the masking
# to forbid a token from attending to itself, except in situations
# where a token has no other valid attention targets (e.g. the first token in a sequence) "
self_mask = torch.ne(query_bucket_idx.unsqueeze(-1), key_value_bucket_idx.unsqueeze(-2)).to(
query_bucket_idx.device
)
# apply self_mask
query_key_dots = torch.where(self_mask, query_key_dots, self_mask_value)
# free memory
del self_mask
logits = torch.logsumexp(query_key_dots, dim=-1, keepdim=True)
# dots shape is `[batch_size, num_attn_heads, num_hashes * seq_len // chunk_length, chunk_length, chunk_length * (1 + num_chunks_before + num_chunks_after)]`
attention_probs = torch.exp(query_key_dots - logits)
# free memory
del query_key_dots
# dropout
attention_probs = nn.functional.dropout(attention_probs, p=self.dropout, training=self.training)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
# attend values
out_vectors = torch.matmul(attention_probs, value_vectors)
# free memory
del value_vectors
# merge chunk length
if out_vectors.ndim > 4:
logits = logits.flatten(start_dim=2, end_dim=3).squeeze(-1)
out_vectors = out_vectors.flatten(start_dim=2, end_dim=3)
return out_vectors, logits, attention_probs
def _compute_attn_mask(
self, query_indices, key_indices, attention_mask, query_key_dot_shape, do_standard_self_attention
):
# attention mask for LSH
if attention_mask is not None:
# if chunked attention, the attention mask has to correspond to LSH order
attention_mask = attention_mask.to(torch.bool)[:, None, :]
if not do_standard_self_attention:
# expand attn_mask to fit with key_value_bucket_idx shape
attention_mask = attention_mask[:, None, :]
attention_mask = attention_mask.expand(query_indices.shape[:-1] + (-1,))
# extract attention mask from LSH sorted key_indices
attention_mask = torch.gather(attention_mask, -1, key_indices)
attention_mask = attention_mask.unsqueeze(-2).expand(query_key_dot_shape)
# Causal mask
if self.is_decoder is True:
causal_mask = torch.ge(query_indices.unsqueeze(-1), key_indices.unsqueeze(-2)).to(query_indices.device)
# add attention mask if not None
if attention_mask is not None:
attention_mask = causal_mask * attention_mask
else:
attention_mask = causal_mask
return attention_mask
def _get_relevant_hid_states_and_buckets(
self, query_vectors, attention_mask, num_hashes, hidden_states, past_states, past_buckets
):
# concat hidden states
hidden_states = torch.cat([past_states, hidden_states], dim=1)
# batch_size hidden
batch_size = hidden_states.shape[0]
sequence_length = hidden_states.shape[1]
# check if cached buckets include pad bucket
max_bucket = self.num_buckets if isinstance(self.num_buckets, int) else reduce(mul, self.num_buckets)
# if pad bucket was cached => need to increase num buckets for caching
increase_num_buckets = past_buckets.max() > num_hashes * max_bucket - 1
# retrieve query buckets
query_buckets = self._hash_vectors(
query_vectors, num_hashes, attention_mask, increase_num_buckets=increase_num_buckets
)
# concat buckets
concat_buckets = torch.cat([past_buckets, query_buckets.unsqueeze(-1)], dim=-1)
# hash-based sort
bucket_idx = _stable_argsort(concat_buckets, dim=-1)
# bucket_idx has shape: BatchSize x NumAttnHeads x NumHashes x SequenceLength
assert bucket_idx.shape == (
batch_size,
self.num_attention_heads,
num_hashes,
sequence_length,
), (
f"bucket_idx should have shape {(batch_size, self.num_attention_heads, num_hashes, sequence_length)}, but"
f" has shape {bucket_idx.shape}."
)
# find indices of new bucket indices
relevant_bucket_idx = (bucket_idx == (bucket_idx.shape[-1] - 1)).nonzero()
# expand relevant bucket indices to its chunks
relevant_bucket_idx_chunk = self._expand_to_indices_in_relevant_chunk(relevant_bucket_idx, sequence_length)
relevant_bucket_idx_chunk = bucket_idx[tuple(relevant_bucket_idx_chunk.transpose(0, 1))]
# adapt bucket_idx for batch and hidden states for index select
offset = torch.arange(relevant_bucket_idx_chunk.shape[-1], device=hidden_states.device, dtype=torch.long)
bucket_idx_batch_offset = sequence_length * (
batch_size * torch.div(offset, relevant_bucket_idx_chunk.shape[-1], rounding_mode="floor")
)
# add batch offset
relevant_bucket_idx_chunk_all_batch = relevant_bucket_idx_chunk + bucket_idx_batch_offset
hidden_states = hidden_states.reshape((-1, self.hidden_size))
# select all relevant hidden states
relevant_hidden_states = hidden_states.index_select(0, relevant_bucket_idx_chunk_all_batch)
# reshape hidden states and bucket_idx to correct output
relevant_hidden_states = relevant_hidden_states.reshape(
batch_size, self.num_attention_heads, -1, self.hidden_size
)
relevant_bucket_idx_chunk = relevant_bucket_idx_chunk.reshape(
batch_size, self.num_attention_heads, num_hashes, -1
)
assert (
relevant_hidden_states.shape[2]
== (self.num_chunks_before + self.num_chunks_after + 1) * self.chunk_length * num_hashes
), (
"There should be"
f" {(self.num_chunks_before + self.num_chunks_after + 1) * self.chunk_length * num_hashes} `hidden_states`,"
f" there are {relevant_hidden_states.shape[2]} `hidden_states`."
)
assert (
relevant_bucket_idx_chunk.shape[-1]
== (self.num_chunks_before + self.num_chunks_after + 1) * self.chunk_length
), (
"There should be"
f" {(self.num_chunks_before + self.num_chunks_after + 1) * self.chunk_length} `hidden_states`, there are"
f" {relevant_bucket_idx_chunk.shape[-1]} `bucket_idx`."
)
return relevant_hidden_states, relevant_bucket_idx_chunk, query_buckets
def _expand_to_indices_in_relevant_chunk(self, indices, sequence_length):
# get relevant indices of where chunk starts and its size
start_indices_chunk = ((indices[:, -1] // self.chunk_length) - self.num_chunks_before) * self.chunk_length
total_chunk_size = self.chunk_length * (1 + self.num_chunks_before + self.num_chunks_after)
# expand start indices and add correct chunk offset via arange
expanded_start_indices = start_indices_chunk.unsqueeze(-1).expand(indices.shape[0], total_chunk_size)
chunk_sequence_indices = expanded_start_indices + torch.arange(
total_chunk_size, device=indices.device, dtype=torch.long
).unsqueeze(0).expand(indices.shape[0], total_chunk_size)
# make sure that circular logic holds via % seq len
chunk_sequence_indices = chunk_sequence_indices.flatten() % sequence_length
# expand indices and set indices correctly
indices = indices.unsqueeze(1).expand((indices.shape[0], total_chunk_size, -1)).flatten(0, 1).clone()
indices[:, -1] = chunk_sequence_indices
return indices
def _len_and_dim_norm(self, vectors, sqrt_num):
"""
length and attention head size dim normalization
"""
vectors = self._len_norm(vectors)
vectors = vectors / sqrt_num
return vectors
def _len_norm(self, x, epsilon=1e-6):
"""
length normalization
"""
variance = torch.mean(x**2, -1, keepdim=True)
norm_x = x * torch.rsqrt(variance + epsilon)
return norm_x
def _gather_by_expansion(self, vectors, idxs, num_hashes):
"""
expand dims of idxs and vectors for all hashes and gather
"""
expanded_idxs = idxs.unsqueeze(-1).expand(-1, -1, -1, self.attention_head_size)
vectors = vectors.repeat(1, 1, num_hashes, 1)
return torch.gather(vectors, 2, expanded_idxs)
class ReverseSort(Function):
"""
After chunked attention is applied which sorted clusters, original ordering has to be restored. Since customized
backward function is used for Reformer, the gradients of the output vectors have to be explicitly sorted here.
"""
@staticmethod
def forward(ctx, out_vectors, logits, sorted_bucket_idx, undo_sorted_bucket_idx):
# save sorted_bucket_idx for backprop
with torch.no_grad():
ctx.sorted_bucket_idx = sorted_bucket_idx
# undo sort to have correct order for next layer
expanded_undo_sort_indices = undo_sorted_bucket_idx.unsqueeze(-1).expand(out_vectors.shape)
out_vectors = torch.gather(out_vectors, 2, expanded_undo_sort_indices)
logits = torch.gather(logits, 2, undo_sorted_bucket_idx)
return out_vectors, logits
@staticmethod
def backward(ctx, grad_out_vectors, grad_logits):
# get parameters saved in ctx
sorted_bucket_idx = ctx.sorted_bucket_idx
expanded_sort_indices = sorted_bucket_idx.unsqueeze(-1).expand(grad_out_vectors.shape)
# reverse sort of forward
grad_out_vectors = torch.gather(grad_out_vectors, 2, expanded_sort_indices)
grad_logits = torch.gather(grad_logits, 2, sorted_bucket_idx)
# return grad and `None` fillers for last 2 forward args
return grad_out_vectors, grad_logits, None, None
class LocalSelfAttention(nn.Module, EfficientAttentionMixin):
def __init__(self, config):
super().__init__()
self.num_attention_heads = config.num_attention_heads
self.chunk_length = config.local_attn_chunk_length
self.num_chunks_before = config.local_num_chunks_before
self.num_chunks_after = config.local_num_chunks_after
self.is_decoder = config.is_decoder
self.pad_token_id = config.pad_token_id
self.attention_head_size = config.attention_head_size
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.hidden_size = config.hidden_size
# projection matrices
self.query = nn.Linear(self.hidden_size, self.all_head_size, bias=False)
self.key = nn.Linear(self.hidden_size, self.all_head_size, bias=False)
self.value = nn.Linear(self.hidden_size, self.all_head_size, bias=False)
self.dropout = config.local_attention_probs_dropout_prob
# save mask value here
self.register_buffer("mask_value_float16", torch.tensor(-1e4), persistent=False)
self.register_buffer("mask_value_float32", torch.tensor(-1e9), persistent=False)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
past_buckets_states=None,
use_cache=False,
output_attentions=False,
**kwargs,
):
sequence_length = hidden_states.shape[1]
batch_size = hidden_states.shape[0]
# check if cache shall be used and that hidden states are already cached
if use_cache and past_buckets_states[1] is not None:
assert past_buckets_states[0] is None, (
"LocalSelfAttention should not make use of `buckets`. There seems to be an error when caching"
" hidden_states_and_buckets."
)
key_value_hidden_states = self._retrieve_relevant_hidden_states(
past_buckets_states[1], self.chunk_length, self.num_chunks_before
)
key_value_hidden_states = torch.cat([key_value_hidden_states, hidden_states], dim=1)
# only query vector for last token
query_vectors = self.query(hidden_states)
# compute key and value for relevant chunk
key_vectors = self.key(key_value_hidden_states)
value_vectors = self.value(key_value_hidden_states)
# free memory
del key_value_hidden_states
else:
# project hidden_states to query, key and value
query_vectors = self.query(hidden_states)
key_vectors = self.key(hidden_states)
value_vectors = self.value(hidden_states)
# split last dim into `config.num_attention_heads` and `config.attention_head_size`
query_vectors = self._split_hidden_size_dim(query_vectors, self.num_attention_heads, self.attention_head_size)
key_vectors = self._split_hidden_size_dim(key_vectors, self.num_attention_heads, self.attention_head_size)
value_vectors = self._split_hidden_size_dim(value_vectors, self.num_attention_heads, self.attention_head_size)
assert (
query_vectors.shape[-1] == self.attention_head_size
), f"last dim of query_key_vectors is {query_vectors.shape[-1]} but should be {self.attention_head_size}."
assert (
key_vectors.shape[-1] == self.attention_head_size
), f"last dim of query_key_vectors is {key_vectors.shape[-1]} but should be {self.attention_head_size}."
assert (
value_vectors.shape[-1] == self.attention_head_size
), f"last dim of query_key_vectors is {value_vectors.shape[-1]} but should be {self.attention_head_size}."
if self.chunk_length is None:
assert self.num_chunks_before == 0 and self.num_chunks_after == 0, (
"If `config.chunk_length` is `None`, make sure `config.num_chunks_after` and"
" `config.num_chunks_before` are set to 0."
)
# normalize key vectors
key_vectors = key_vectors / np.sqrt(self.attention_head_size)
# get sequence length indices
indices = torch.arange(sequence_length, device=query_vectors.device).repeat(
batch_size, self.num_attention_heads, 1
)
# if one should do normal n^2 self-attention
do_standard_self_attention = sequence_length <= self.chunk_length
# if input should be chunked
if not do_standard_self_attention:
# chunk vectors
# B x Num_Attn_Head x Seq_Len // chunk_len x chunk_len x attn_head_size
query_vectors = self._split_seq_length_dim_to(
query_vectors,
-1,
self.chunk_length,
self.num_attention_heads,
self.attention_head_size,
)
key_vectors = self._split_seq_length_dim_to(
key_vectors,
-1,
self.chunk_length,
self.num_attention_heads,
self.attention_head_size,
)
value_vectors = self._split_seq_length_dim_to(
value_vectors,
-1,
self.chunk_length,
self.num_attention_heads,
self.attention_head_size,
)
# chunk indices
query_indices = self._split_seq_length_dim_to(indices, -1, self.chunk_length, self.num_attention_heads)
key_indices = self._split_seq_length_dim_to(indices, -1, self.chunk_length, self.num_attention_heads)
# append chunks before and after
key_vectors = self._look_adjacent(key_vectors, self.num_chunks_before, self.num_chunks_after)
value_vectors = self._look_adjacent(value_vectors, self.num_chunks_before, self.num_chunks_after)
key_indices = self._look_adjacent(key_indices, self.num_chunks_before, self.num_chunks_after)
else:
query_indices = key_indices = indices
# query-key matmul: QK^T
query_key_dots = torch.matmul(query_vectors, key_vectors.transpose(-1, -2))
# free memory
del query_vectors, key_vectors
mask = self._compute_attn_mask(
query_indices, key_indices, attention_mask, query_key_dots.shape, do_standard_self_attention
)
if mask is not None:
# get mask tensor depending on half precision or not
if query_key_dots.dtype == torch.float16:
mask_value = self.mask_value_float16.half()
else:
mask_value = self.mask_value_float32
query_key_dots = torch.where(mask, query_key_dots, mask_value)
# free memory
del mask
# softmax
logits = torch.logsumexp(query_key_dots, dim=-1, keepdim=True)
attention_probs = torch.exp(query_key_dots - logits)
# free memory
del logits
# dropout
attention_probs = nn.functional.dropout(attention_probs, p=self.dropout, training=self.training)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
# attend values
out_vectors = torch.matmul(attention_probs, value_vectors)
# free memory
del value_vectors
# merge chunk length
if not do_standard_self_attention:
out_vectors = out_vectors.flatten(start_dim=2, end_dim=3)
assert out_vectors.shape == (
batch_size,
self.num_attention_heads,
sequence_length,
self.attention_head_size,
)
out_vectors = self._merge_hidden_size_dims(out_vectors, self.num_attention_heads, self.attention_head_size)
if output_attentions is False:
attention_probs = ()
return LocalSelfAttentionOutput(hidden_states=out_vectors, attention_probs=attention_probs)
def _compute_attn_mask(
self, query_indices, key_indices, attention_mask, query_key_dots_shape, do_standard_self_attention
):
# chunk attention mask and look before and after
if attention_mask is not None:
attention_mask = attention_mask.to(torch.bool)[:, None, :]
if not do_standard_self_attention:
attention_mask = self._split_seq_length_dim_to(attention_mask, -1, self.chunk_length, 1)
attention_mask = self._look_adjacent(attention_mask, self.num_chunks_before, self.num_chunks_after)
# create attn_mask
attention_mask = attention_mask.unsqueeze(-2).expand(query_key_dots_shape)
# Causal mask
if self.is_decoder is True:
causal_mask = torch.ge(query_indices.unsqueeze(-1), key_indices.unsqueeze(-2)).to(query_indices.device)
# add attention mask if not None
if attention_mask is not None:
attention_mask = causal_mask * attention_mask
else:
attention_mask = causal_mask
return attention_mask
@staticmethod
def _retrieve_relevant_hidden_states(previous_hidden_states, chunk_length, num_chunks_before):
start_position = ((previous_hidden_states.shape[1] // chunk_length) - num_chunks_before) * chunk_length
return previous_hidden_states[:, start_position:]
class ReformerSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
all_head_size = config.num_attention_heads * config.attention_head_size
self.dropout = config.hidden_dropout_prob
self.dense = nn.Linear(all_head_size, config.hidden_size, bias=False)
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
return hidden_states
class ReformerAttention(nn.Module):
def __init__(self, config, layer_id=0):
super().__init__()
self.layer_id = layer_id
self.attn_layers = config.attn_layers
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
if len(set(self.attn_layers)) == 1 and self.attn_layers[0] == "lsh":
self.self_attention = LSHSelfAttention(config)
elif len(set(self.attn_layers)) == 1 and self.attn_layers[0] == "local":
self.self_attention = LocalSelfAttention(config)
elif len(set(self.attn_layers)) == 2 and set(self.attn_layers) == {"lsh", "local"}:
# get correct attn layers
if self.attn_layers[self.layer_id] == "lsh":
self.self_attention = LSHSelfAttention(config)
else:
self.self_attention = LocalSelfAttention(config)
else:
raise NotImplementedError(
f"Only attn layer types 'lsh' and 'local' exist, but got `config.attn_layers`: {self.attn_layers}. "
"Select attn layer types from ['lsh', 'local'] only."
)
self.output = ReformerSelfOutput(config)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
num_hashes=None,
past_buckets_states=None,
use_cache=False,
orig_sequence_length=None,
output_attentions=False,
buckets=None,
):
hidden_states = self.layer_norm(hidden_states)
# make sure cached hidden states is set to None for backward pass
if past_buckets_states is not None:
past_buckets_states_layer = past_buckets_states[self.layer_id]
else:
past_buckets_states_layer = None
# use cached buckets for backprob if buckets not None for LSHSelfAttention
self_attention_outputs = self.self_attention(
hidden_states=hidden_states,
head_mask=head_mask,
attention_mask=attention_mask,
num_hashes=num_hashes,
past_buckets_states=past_buckets_states_layer,
use_cache=use_cache,
output_attentions=output_attentions,
buckets=buckets,
)
# add buckets if necessary
if hasattr(self_attention_outputs, "buckets"):
buckets = self_attention_outputs.buckets
else:
buckets = None
# cache hidden states for future use
if use_cache:
if past_buckets_states[self.layer_id][0] is None:
# padded input should not be cached
past_buckets = (
buckets[:, :, :, :orig_sequence_length]
if (buckets is not None and orig_sequence_length > 1)
else buckets
)
else:
past_buckets = torch.cat([past_buckets_states[self.layer_id][0], buckets], dim=-1)
if past_buckets_states[self.layer_id][1] is None:
# padded input should not be cached
past_states = hidden_states[:, :orig_sequence_length]
else:
past_states = torch.cat([past_buckets_states[self.layer_id][1], hidden_states], dim=1)
past_buckets_states[self.layer_id] = (past_buckets, past_states)
# compute attention feed forward output
attention_output = self.output(self_attention_outputs.hidden_states)
return AttentionOutput(
hidden_states=attention_output,
attention_probs=self_attention_outputs.attention_probs,
buckets=buckets,
)
class ReformerFeedForwardDense(nn.Module):
def __init__(self, config):
super().__init__()
self.dropout = config.hidden_dropout_prob
if isinstance(config.hidden_act, str):
self.act_fn = ACT2FN[config.hidden_act]
else:
self.act_fn = config.hidden_act
self.dense = nn.Linear(config.hidden_size, config.feed_forward_size)
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = self.act_fn(hidden_states)
return hidden_states
class ReformerFeedForwardOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dropout = config.hidden_dropout_prob
self.dense = nn.Linear(config.feed_forward_size, config.hidden_size)
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
return hidden_states
class ChunkReformerFeedForward(nn.Module):
def __init__(self, config):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dense = ReformerFeedForwardDense(config)
self.output = ReformerFeedForwardOutput(config)
def forward(self, attention_output):
return apply_chunking_to_forward(
self.forward_chunk,
self.chunk_size_feed_forward,
self.seq_len_dim,
attention_output,
)
def forward_chunk(self, hidden_states):
hidden_states = self.layer_norm(hidden_states)
hidden_states = self.dense(hidden_states)
return self.output(hidden_states)
class ReformerLayer(nn.Module):
def __init__(self, config, layer_id=0):
super().__init__()
self.attention = ReformerAttention(config, layer_id)
# dropout requires to have the same
# seed for forward and backward pass
self.attention_seed = None
self.feed_forward_seed = None
self.feed_forward = ChunkReformerFeedForward(config)
def _init_attention_seed(self):
"""
This function sets a new seed for the attention layer to make dropout deterministic for both forward calls: 1
normal forward call and 1 forward call in backward to recalculate activations.
"""
# randomize seeds
# use cuda generator if available
if hasattr(torch.cuda, "default_generators") and len(torch.cuda.default_generators) > 0:
# GPU
device_idx = torch.cuda.current_device()
self.attention_seed = torch.cuda.default_generators[device_idx].seed()
else:
# CPU
self.attention_seed = int(torch.seed() % sys.maxsize)
torch.manual_seed(self.attention_seed)
def _init_feed_forward_seed(self):
"""
This function sets a new seed for the feed forward layer to make dropout deterministic for both forward calls:
1 normal forward call and 1 forward call in backward to recalculate activations.
"""
# randomize seeds
# use cuda generator if available
if hasattr(torch.cuda, "default_generators") and len(torch.cuda.default_generators) > 0:
# GPU
device_idx = torch.cuda.current_device()
self.feed_forward_seed = torch.cuda.default_generators[device_idx].seed()
else:
# CPU
self.feed_forward_seed = int(torch.seed() % sys.maxsize)
torch.manual_seed(self.feed_forward_seed)
def forward(
self,
prev_attn_output,
hidden_states,
attention_mask=None,
head_mask=None,
num_hashes=None,
past_buckets_states=None,
use_cache=False,
orig_sequence_length=None,
output_attentions=False,
):
with torch.no_grad():
# every forward pass we sample a different seed
# for dropout and save for forward fn in backward pass
# to have correct dropout
if self.training:
self._init_attention_seed()
attn_outputs = self.attention(
hidden_states=hidden_states,
head_mask=head_mask,
attention_mask=attention_mask,
num_hashes=num_hashes,
past_buckets_states=past_buckets_states,
use_cache=use_cache,
orig_sequence_length=orig_sequence_length,
output_attentions=output_attentions,
)
attn_output = attn_outputs.hidden_states
# Implementation of RevNet (see Fig. 6 in https://towardsdatascience.com/illustrating-the-reformer-393575ac6ba0)
# Y_1 = X_1 + f(X_2)
attn_output = prev_attn_output + attn_output
# free memory
del prev_attn_output
# every forward pass we sample a different seed
# for dropout and save seed for forward fn in backward
# to have correct dropout
if self.training:
self._init_feed_forward_seed()
# Y_2 = X_2 + g(Y_1)
hidden_states = hidden_states + self.feed_forward(attn_output)
return ReformerOutput(
attn_output=attn_output,
hidden_states=hidden_states,
attention_probs=attn_outputs.attention_probs,
buckets=attn_outputs.buckets,
)
def backward_pass(
self,
next_attn_output,
hidden_states,
grad_attn_output,
grad_hidden_states,
attention_mask=None,
head_mask=None,
buckets=None,
):
# Implements the backward pass for reversible ResNets.
# A good blog post on how this works can be found here:
# Implementation of RevNet (see Fig. 6 in https://towardsdatascience.com/illustrating-the-reformer-393575ac6ba0)
# This code is heavily inspired by https://github.com/lucidrains/reformer-pytorch/blob/master/reformer_pytorch/reversible.py
assert self.training, (
"If you want to train `ReformerModel` and its variations, make sure to use `model.train()` to put the"
" model into training mode."
)
with torch.enable_grad():
next_attn_output.requires_grad = True
# set seed to have correct dropout
torch.manual_seed(self.feed_forward_seed)
# g(Y_1)
res_hidden_states = self.feed_forward(next_attn_output)
res_hidden_states.backward(grad_hidden_states, retain_graph=True)
with torch.no_grad():
# X_2 = Y_2 - g(Y_1)
hidden_states = hidden_states - res_hidden_states
del res_hidden_states
grad_attn_output = grad_attn_output + next_attn_output.grad
next_attn_output.grad = None
with torch.enable_grad():
hidden_states.requires_grad = True
# set seed to have correct dropout
torch.manual_seed(self.attention_seed)
# f(X_2)
# use cached buckets for backprob if buckets not None for LSHSelfAttention
output = self.attention(
hidden_states=hidden_states,
head_mask=head_mask,
attention_mask=attention_mask,
buckets=buckets,
).hidden_states
output.backward(grad_attn_output, retain_graph=True)
with torch.no_grad():
# X_1 = Y_1 - f(X_2)
attn_output = next_attn_output - output
del output, next_attn_output
grad_hidden_states = grad_hidden_states + hidden_states.grad
hidden_states.grad = None
hidden_states = hidden_states.detach()
return ReformerBackwardOutput(
attn_output=attn_output,
hidden_states=hidden_states,
grad_attn_output=grad_attn_output,
grad_hidden_states=grad_hidden_states,
)
class _ReversibleFunction(Function):
"""
To prevent PyTorch from performing the usual backpropagation, a customized backward function is implemented here.
This way it is made sure that no memory expensive activations are saved during the forward pass. This function is
heavily inspired by https://github.com/lucidrains/reformer-pytorch/blob/master/reformer_pytorch/reversible.py
"""
@staticmethod
def forward(
ctx,
hidden_states,
layers,
attention_mask,
head_mask,
num_hashes,
all_hidden_states,
all_attentions,
past_buckets_states,
use_cache,
orig_sequence_length,
output_hidden_states,
output_attentions,
):
all_buckets = ()
# split duplicated tensor
hidden_states, attn_output = torch.chunk(hidden_states, 2, dim=-1)
for layer_id, (layer, layer_head_mask) in enumerate(zip(layers, head_mask)):
if output_hidden_states is True:
all_hidden_states.append(hidden_states)
layer_outputs = layer(
prev_attn_output=attn_output,
hidden_states=hidden_states,
attention_mask=attention_mask,
head_mask=layer_head_mask,
num_hashes=num_hashes,
past_buckets_states=past_buckets_states,
use_cache=use_cache,
orig_sequence_length=orig_sequence_length,
output_attentions=output_attentions,
)
attn_output = layer_outputs.attn_output
hidden_states = layer_outputs.hidden_states
all_buckets = all_buckets + (layer_outputs.buckets,)
if output_attentions:
all_attentions.append(layer_outputs.attention_probs)
# Add last layer
if output_hidden_states is True:
all_hidden_states.append(hidden_states)
# attach params to ctx for backward
ctx.save_for_backward(attn_output.detach(), hidden_states.detach())
ctx.layers = layers
ctx.all_buckets = all_buckets
ctx.head_mask = head_mask
ctx.attention_mask = attention_mask
# Concatenate 2 RevNet outputs
return torch.cat([attn_output, hidden_states], dim=-1)
@staticmethod
def backward(ctx, grad_hidden_states):
grad_attn_output, grad_hidden_states = torch.chunk(grad_hidden_states, 2, dim=-1)
# retrieve params from ctx for backward
attn_output, hidden_states = ctx.saved_tensors
# create tuple
output = ReformerBackwardOutput(
attn_output=attn_output,
hidden_states=hidden_states,
grad_attn_output=grad_attn_output,
grad_hidden_states=grad_hidden_states,
)
# free memory
del grad_attn_output, grad_hidden_states, attn_output, hidden_states
layers = ctx.layers
all_buckets = ctx.all_buckets
head_mask = ctx.head_mask
attention_mask = ctx.attention_mask
for idx, layer in enumerate(layers[::-1]):
# pop last buckets from stack
buckets = all_buckets[-1]
all_buckets = all_buckets[:-1]
# backprop
output = layer.backward_pass(
next_attn_output=output.attn_output,
hidden_states=output.hidden_states,
grad_attn_output=output.grad_attn_output,
grad_hidden_states=output.grad_hidden_states,
head_mask=head_mask[len(layers) - idx - 1],
attention_mask=attention_mask,
buckets=buckets,
)
assert all_buckets == (), "buckets have to be empty after backpropagation"
grad_hidden_states = torch.cat([output.grad_attn_output, output.grad_hidden_states], dim=-1)
# num of return vars has to match num of forward() args
# return gradient for hidden_states arg and None for other args
return grad_hidden_states, None, None, None, None, None, None, None, None, None, None, None
class ReformerEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.dropout = config.hidden_dropout_prob
self.layers = nn.ModuleList([ReformerLayer(config, i) for i in range(config.num_hidden_layers)])
# Reformer is using Rev Nets, thus last layer outputs are concatenated and
# Layer Norm is done over 2 * hidden_size
self.layer_norm = nn.LayerNorm(2 * config.hidden_size, eps=config.layer_norm_eps)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
num_hashes=None,
past_buckets_states=None,
use_cache=False,
orig_sequence_length=None,
output_hidden_states=False,
output_attentions=False,
):
# hidden_states and attention lists to be filled if wished
all_hidden_states = []
all_attentions = []
# init cached hidden states if necessary
if past_buckets_states is None:
past_buckets_states = [((None), (None)) for i in range(len(self.layers))]
# concat same tensor for reversible ResNet
hidden_states = torch.cat([hidden_states, hidden_states], dim=-1)
hidden_states = _ReversibleFunction.apply(
hidden_states,
self.layers,
attention_mask,
head_mask,
num_hashes,
all_hidden_states,
all_attentions,
past_buckets_states,
use_cache,
orig_sequence_length,
output_hidden_states,
output_attentions,
)
# Apply layer norm to concatenated hidden states
hidden_states = self.layer_norm(hidden_states)
# Apply dropout
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
return ReformerEncoderOutput(
hidden_states=hidden_states,
all_hidden_states=all_hidden_states,
all_attentions=all_attentions,
past_buckets_states=past_buckets_states,
)
class ReformerOnlyLMHead(nn.Module):
def __init__(self, config):
super().__init__()
# Reformer is using Rev Nets, thus last layer outputs are concatenated and
# Layer Norm is done over 2 * hidden_size
self.seq_len_dim = 1
self.chunk_size_lm_head = config.chunk_size_lm_head
self.decoder = nn.Linear(2 * config.hidden_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
self.decoder.bias = self.bias
def forward(self, hidden_states):
return apply_chunking_to_forward(self.forward_chunk, self.chunk_size_lm_head, self.seq_len_dim, hidden_states)
def forward_chunk(self, hidden_states):
hidden_states = self.decoder(hidden_states)
return hidden_states
def _tie_weights(self) -> None:
# For accelerate compatibility and to not break backward compatibility
if self.decoder.bias.device.type == "meta":
self.decoder.bias = self.bias
else:
# To tie those two weights if they get disconnected (on TPU or when the bias is resized)
self.bias = self.decoder.bias
class ReformerPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = ReformerConfig
base_model_prefix = "reformer"
@property
def dummy_inputs(self):
input_ids = torch.tensor(DUMMY_INPUTS)
input_mask = torch.tensor(DUMMY_MASK)
dummy_inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
}
return dummy_inputs
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, AxialPositionEmbeddings):
for weight in module.weights:
nn.init.normal_(weight, std=self.config.axial_norm_std)
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.Linear):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
@dataclass
class ReformerModelOutput(ModelOutput):
"""
Output type of [`ReformerModel`].
Args:
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, num_predict, hidden_size)`):
Sequence of hidden-states at the last layer of the model.
`num_predict` corresponds to `target_mapping.shape[1]`. If `target_mapping` is `None`, then `num_predict`
corresponds to `sequence_length`.
past_buckets_states (`List[Tuple(torch.LongTensor, torch.FloatTensor)]`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
List of `Tuple(torch.LongTensor, torch.FloatTensor` of length `config.n_layers`, with the first element
being the previous *buckets* of shape `(batch_size, num_heads, num_hashes, sequence_length)`) and the
second being the previous *hidden_states* of shape `(batch_size, sequence_length, hidden_size)`).
Contains precomputed buckets and hidden-states that can be used (see `past_buckets_states` input) to speed
up sequential decoding.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings and one for the output of each layer) of
shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
last_hidden_state: torch.FloatTensor
past_buckets_states: Optional[List[Tuple[torch.LongTensor, torch.FloatTensor]]] = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
@dataclass
class ReformerModelWithLMHeadOutput(ModelOutput):
"""
Output type of [`ReformerModelWithLMHead`].
Args:
loss (`torch.FloatTensor` of shape *(1,)*, *optional*, returned when `labels` is provided)
Language modeling loss (for next-token prediction).
logits (`torch.FloatTensor` of shape `(batch_size, num_predict, config.vocab_size)`):
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
`num_predict` corresponds to `target_mapping.shape[1]`. If `target_mapping` is `None`, then `num_predict`
corresponds to `sequence_length`.
past_buckets_states (`List[Tuple(torch.LongTensor, torch.FloatTensor)]`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
List of `Tuple(torch.LongTensor, torch.FloatTensor` of length `config.n_layers`, with the first element
being the previous *buckets* of shape `(batch_size, num_heads, num_hashes, sequence_length)`) and the
second being the previous *hidden_states* of shape `(batch_size, sequence_length, hidden_size)`).
Contains precomputed buckets and hidden-states that can be used (see `past_buckets_states` input) to speed
up sequential decoding.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
TTuple of `torch.FloatTensor` (one for the output of the embeddings and one for the output of each layer)
of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
loss: Optional[torch.FloatTensor] = None
logits: torch.FloatTensor = None
past_buckets_states: Optional[List[Tuple[torch.LongTensor, torch.FloatTensor]]] = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
REFORMER_START_DOCSTRING = r"""
Reformer was proposed in [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev,
Łukasz Kaiser, Anselm Levskaya.
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`ReformerConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
REFORMER_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. During training the input_ids sequence_length has to be
a multiple of the relevant model's chunk lengths (lsh's, local's or both). During evaluation, the indices
are automatically padded to be a multiple of the chunk length.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
num_hashes (`int`, *optional*):
The number of hashing rounds that should be performed during bucketing. Setting this argument overwrites
the default defined in `config.num_hashes`.
For more information, see `num_hashes` in [`ReformerConfig`].
past_buckets_states (`List[Tuple(torch.LongTensor, torch.FloatTensor)]`, *optional*):
List of `Tuple(torch.LongTensor, torch.FloatTensor` of length `config.n_layers`, with the first element
being the previous *buckets* of shape `(batch_size, num_heads, num_hashes, sequence_length)`) and the
second being the previous *hidden_states* of shape `(batch_size, sequence_length, hidden_size)`).
Contains precomputed hidden-states and buckets (only relevant for LSH Self-Attention). Can be used to speed
up sequential decoding.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`).
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
@add_start_docstrings(
"The bare Reformer Model transformer outputting raw hidden-stateswithout any specific head on top.",
REFORMER_START_DOCSTRING,
)
class ReformerModel(ReformerPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.config = config
assert (
self.config.num_hidden_layers > 0
), "`config.attn_layers` is empty. Select at least one attn layer form ['lsh', 'local']"
self.embeddings = ReformerEmbeddings(config)
self.encoder = ReformerEncoder(config)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward(REFORMER_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=ReformerModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
num_hashes: Optional[int] = None,
past_buckets_states: Optional[List[Tuple[torch.Tensor]]] = None,
use_cache: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_attentions: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, ReformerModelOutput]:
use_cache = use_cache if use_cache is not None else self.config.use_cache
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
input_shape = input_ids.size() # noqa: F841
device = input_ids.device
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1] # noqa: F841
device = inputs_embeds.device
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
assert (
len(input_shape) == 2
), f"`input_ids` have be of shape `[batch_size, sequence_length]`, but got shape: {input_shape}"
if past_buckets_states is not None:
assert not self.training, "`past_buckets_states` can only be used for inference, not for training`."
# prepare head mask
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers, is_attention_chunked=True)
# original sequence length for padding
orig_sequence_length = input_shape[-1]
# if needs padding
least_common_mult_chunk_length = _get_least_common_mult_chunk_len(self.config)
min_chunk_length = _get_min_chunk_len(self.config)
must_pad_to_match_chunk_length = (
input_shape[-1] % least_common_mult_chunk_length != 0
and input_shape[-1] > min_chunk_length
and past_buckets_states is None
)
if must_pad_to_match_chunk_length:
padding_length = least_common_mult_chunk_length - input_shape[-1] % least_common_mult_chunk_length
if self.training is True:
raise ValueError(
f"If training, sequence length {input_shape[-1]} has to be a multiple of least common multiple "
f"chunk_length {least_common_mult_chunk_length}. Please consider padding the input to a length "
f"of {input_shape[-1] + padding_length}."
)
# pad input
input_ids, inputs_embeds, attention_mask, position_ids, input_shape = self._pad_to_mult_of_chunk_length(
input_ids,
inputs_embeds=inputs_embeds,
attention_mask=attention_mask,
position_ids=position_ids,
input_shape=input_shape,
padding_length=padding_length,
padded_seq_length=least_common_mult_chunk_length,
device=device,
)
# start index for position encoding depends on incremental decoding
if past_buckets_states is not None:
start_idx_pos_encodings = past_buckets_states[0][1].shape[1]
else:
start_idx_pos_encodings = 0
embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
inputs_embeds=inputs_embeds,
start_idx_pos_encodings=start_idx_pos_encodings,
)
encoder_outputs = self.encoder(
hidden_states=embedding_output,
head_mask=head_mask,
attention_mask=attention_mask,
num_hashes=num_hashes,
past_buckets_states=past_buckets_states,
use_cache=use_cache,
orig_sequence_length=orig_sequence_length,
output_hidden_states=output_hidden_states,
output_attentions=output_attentions,
)
sequence_output = encoder_outputs.hidden_states
# if padding was applied
if must_pad_to_match_chunk_length:
sequence_output = sequence_output[:, :orig_sequence_length]
past_buckets_states = encoder_outputs.past_buckets_states if use_cache else None
hidden_states = encoder_outputs.all_hidden_states if output_hidden_states else None
attentions = encoder_outputs.all_attentions if output_attentions else None
if not return_dict:
return tuple(v for v in [sequence_output, past_buckets_states, hidden_states, attentions] if v is not None)
return ReformerModelOutput(
last_hidden_state=sequence_output,
past_buckets_states=past_buckets_states,
hidden_states=hidden_states,
attentions=attentions,
)
def _pad_to_mult_of_chunk_length(
self,
input_ids,
inputs_embeds=None,
attention_mask=None,
position_ids=None,
input_shape=None,
padding_length=None,
padded_seq_length=None,
device=None,
):
logger.warning_once(
f"Input ids are automatically padded from {input_shape[-1]} to {input_shape[-1] + padding_length} to be a "
f"multiple of `config.chunk_length`: {padded_seq_length}"
)
padded_input_ids = torch.full(
(input_shape[0], padding_length),
self.config.pad_token_id,
device=device,
dtype=torch.long,
)
# Extend `attention_mask`
if attention_mask is not None:
pad_attention_mask = torch.zeros(input_shape[0], padding_length, device=device, dtype=attention_mask.dtype)
attention_mask = torch.cat([attention_mask, pad_attention_mask], dim=-1)
else:
attention_mask = torch.cat(
[
torch.ones(input_shape, device=device, dtype=torch.bool),
torch.zeros((input_shape[0], padding_length), device=device, dtype=torch.bool),
],
dim=-1,
)
# Extend `input_ids` with padding to match least common multiple chunk_length
if input_ids is not None:
input_ids = torch.cat([input_ids, padded_input_ids], dim=-1)
input_shape = input_ids.size()
# Pad position ids if given
if position_ids is not None:
padded_position_ids = torch.arange(input_shape[-1], padded_seq_length, dtype=torch.long, device=device)
padded_position_ids = position_ids.unsqueeze(0).expand(input_shape[0], padding_length)
position_ids = torch.cat([position_ids, padded_position_ids], dim=-1)
# Extend `inputs_embeds` with padding to match least common multiple chunk_length
if inputs_embeds is not None:
padded_inputs_embeds = self.embeddings(padded_input_ids, position_ids)
inputs_embeds = torch.cat([inputs_embeds, padded_inputs_embeds], dim=-2)
input_shape = inputs_embeds.size()
return input_ids, inputs_embeds, attention_mask, position_ids, input_shape
@add_start_docstrings("""Reformer Model with a `language modeling` head on top.""", REFORMER_START_DOCSTRING)
class ReformerModelWithLMHead(ReformerPreTrainedModel, GenerationMixin):
_tied_weights_keys = ["lm_head.decoder.weight", "lm_head.decoder.bias"]
def __init__(self, config):
super().__init__(config)
assert config.is_decoder, "If you want to use `ReformerModelWithLMHead` make sure that `is_decoder=True`."
assert "local" not in self.config.attn_layers or config.local_num_chunks_after == 0, (
"If causal mask is enabled, make sure that `config.local_num_chunks_after` is set to 0 and not"
f" {config.local_num_chunks_after}."
)
assert "lsh" not in self.config.attn_layers or config.lsh_num_chunks_after == 0, (
"If causal mask is enabled, make sure that `config.lsh_num_chunks_after` is set to 1 and not"
f" {config.lsh_num_chunks_after}."
)
self.reformer = ReformerModel(config)
self.lm_head = ReformerOnlyLMHead(config)
# Initialize weights and apply final processing
self.post_init()
def get_output_embeddings(self):
return self.lm_head.decoder
def set_output_embeddings(self, new_embeddings):
self.lm_head.decoder = new_embeddings
self.lm_head.bias = new_embeddings.bias
@add_start_docstrings_to_model_forward(REFORMER_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=CausalLMOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
num_hashes: Optional[int] = None,
past_buckets_states: Optional[List[Tuple[torch.Tensor]]] = None,
use_cache: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_attentions: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: Optional[torch.Tensor] = None,
**kwargs,
) -> Union[Tuple, CausalLMOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[-100, 0, ...,
config.vocab_size - 1]`. All labels set to `-100` are ignored (masked), the loss is only computed for
labels in `[0, ..., config.vocab_size]`
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
reformer_outputs = self.reformer(
input_ids,
position_ids=position_ids,
attention_mask=attention_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
num_hashes=num_hashes,
past_buckets_states=past_buckets_states,
use_cache=use_cache,
output_hidden_states=output_hidden_states,
output_attentions=output_attentions,
return_dict=return_dict,
)
sequence_output = reformer_outputs[0]
logits = self.lm_head(sequence_output)
loss = None
if labels is not None:
loss = self.loss_function(
logits,
labels,
vocab_size=self.config.vocab_size,
**kwargs,
)
if not return_dict:
output = (logits,) + reformer_outputs[1:]
return ((loss,) + output) if loss is not None else output
return ReformerModelWithLMHeadOutput(
loss=loss,
logits=logits,
past_buckets_states=reformer_outputs.past_buckets_states,
hidden_states=reformer_outputs.hidden_states,
attentions=reformer_outputs.attentions,
)
def prepare_inputs_for_generation(
self, input_ids, past_key_values=None, use_cache=None, num_hashes=None, **kwargs
):
# Overitten -- different expected inputs/outputs
# only last token for inputs_ids if past is defined in kwargs
if past_key_values is not None:
input_ids = input_ids[:, -1:]
inputs_dict = {
"input_ids": input_ids,
"past_buckets_states": past_key_values,
"use_cache": use_cache,
"num_hashes": num_hashes,
}
return inputs_dict
def _reorder_cache(self, past_key_values, beam_idx):
reord_past_buckets_states = []
for layer_past in past_key_values:
# buckets
if layer_past[0] is not None:
reord_buckets = layer_past[0].index_select(0, beam_idx.to(layer_past[0].device))
else:
reord_buckets = None
# hidden states
reord_hidden_states = layer_past[1].index_select(0, beam_idx.to(layer_past[1].device))
reord_past_buckets_states.append((reord_buckets, reord_hidden_states))
return reord_past_buckets_states
@add_start_docstrings("""Reformer Model with a `language modeling` head on top.""", REFORMER_START_DOCSTRING)
class ReformerForMaskedLM(ReformerPreTrainedModel):
_tied_weights_keys = ["lm_head.decoder.weight", "lm_head.decoder.bias"]
def __init__(self, config):
super().__init__(config)
assert not config.is_decoder, (
"If you want to use `ReformerForMaskedLM` make sure `config.is_decoder=False` for bi-directional"
" self-attention."
)
self.reformer = ReformerModel(config)
self.lm_head = ReformerOnlyLMHead(config)
# Initialize weights and apply final processing
self.post_init()
def get_output_embeddings(self):
return self.lm_head.decoder
def set_output_embeddings(self, new_embeddings):
self.lm_head.decoder = new_embeddings
self.lm_head.bias = new_embeddings.bias
@add_start_docstrings_to_model_forward(REFORMER_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=MaskedLMOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
num_hashes: Optional[int] = None,
labels: Optional[torch.Tensor] = None,
output_hidden_states: Optional[bool] = None,
output_attentions: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, MaskedLMOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked),
the loss is only computed for the tokens with labels
Returns:
<Tip warning={true}>
This example uses a false checkpoint since we don't have any available pretrained model for the masked language
modeling task with the Reformer architecture.
</Tip>
Example:
```python
>>> import torch
>>> from transformers import AutoTokenizer, ReformerForMaskedLM
>>> tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/tiny-random-reformer")
>>> model = ReformerForMaskedLM.from_pretrained("hf-internal-testing/tiny-random-reformer")
>>> # add mask_token
>>> tokenizer.add_special_tokens({"mask_token": "[MASK]"}) # doctest: +IGNORE_RESULT
>>> inputs = tokenizer("The capital of France is [MASK].", return_tensors="pt")
>>> # resize model's embedding matrix
>>> model.resize_token_embeddings(new_num_tokens=model.config.vocab_size + 1) # doctest: +IGNORE_RESULT
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # retrieve index of [MASK]
>>> mask_token_index = (inputs.input_ids == tokenizer.mask_token_id)[0].nonzero(as_tuple=True)[0]
>>> predicted_token_id = logits[0, mask_token_index].argmax(axis=-1)
>>> predicted_token = tokenizer.decode(predicted_token_id)
```
```python
>>> labels = tokenizer("The capital of France is Paris.", return_tensors="pt")["input_ids"]
>>> # mask labels of non-[MASK] tokens
>>> labels = torch.where(
... inputs.input_ids == tokenizer.mask_token_id, labels[:, : inputs["input_ids"].shape[-1]], -100
... )
>>> outputs = model(**inputs, labels=labels)
>>> loss = round(outputs.loss.item(), 2)
```
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
reformer_outputs = self.reformer(
input_ids,
position_ids=position_ids,
attention_mask=attention_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
num_hashes=num_hashes,
use_cache=False, # no causal mask
output_hidden_states=output_hidden_states,
output_attentions=output_attentions,
return_dict=return_dict,
)
sequence_output = reformer_outputs[0]
logits = self.lm_head(sequence_output)
masked_lm_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss() # -100 index = padding token
masked_lm_loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (logits,) + reformer_outputs[1:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return MaskedLMOutput(
loss=masked_lm_loss,
logits=logits,
hidden_states=reformer_outputs.hidden_states,
attentions=reformer_outputs.attentions,
)
@add_start_docstrings(
"""
Reformer Model transformer with a sequence classification/regression head on top (a linear layer on top of the
pooled output) e.g. for GLUE tasks.
""",
REFORMER_START_DOCSTRING,
)
class ReformerForSequenceClassification(ReformerPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.config = config
self.reformer = ReformerModel(config)
self.classifier = ReformerClassificationHead(config)
if config.is_decoder is True:
logger.warning("You might want to disable causal masking for sequence classification")
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(REFORMER_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=SequenceClassifierOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
num_hashes: Optional[int] = None,
labels: Optional[torch.Tensor] = None,
output_hidden_states: Optional[bool] = None,
output_attentions: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, SequenceClassifierOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
Returns:
Example of single-label classification:
```python
>>> import torch
>>> from transformers import AutoTokenizer, ReformerForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("google/reformer-crime-and-punishment")
>>> model = ReformerForSequenceClassification.from_pretrained("google/reformer-crime-and-punishment")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_id = logits.argmax().item()
>>> label = model.config.id2label[predicted_class_id]
```
```python
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = ReformerForSequenceClassification.from_pretrained(
... "google/reformer-crime-and-punishment", num_labels=num_labels
... )
>>> labels = torch.tensor(1)
>>> loss = model(**inputs, labels=labels).loss
```
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.reformer(
input_ids,
position_ids=position_ids,
attention_mask=attention_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
num_hashes=num_hashes,
output_hidden_states=output_hidden_states,
output_attentions=output_attentions,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
class ReformerClassificationHead(nn.Module):
"""Head for sentence-level classification tasks."""
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(2 * config.hidden_size, config.hidden_size)
classifier_dropout = (
config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
)
self.dropout = nn.Dropout(classifier_dropout)
self.out_proj = nn.Linear(config.hidden_size, config.num_labels)
def forward(self, hidden_states, **kwargs):
hidden_states = hidden_states[:, 0, :] # take <s> token (equiv. to [CLS])
hidden_states = self.dropout(hidden_states)
hidden_states = self.dense(hidden_states)
hidden_states = torch.tanh(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.out_proj(hidden_states)
return hidden_states
@add_start_docstrings(
"""
Reformer Model with a span classification head on top for extractive question-answering tasks like SQuAD / TriviaQA
( a linear layer on top of hidden-states output to compute `span start logits` and `span end logits`.
""",
REFORMER_START_DOCSTRING,
)
class ReformerForQuestionAnswering(ReformerPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.reformer = ReformerModel(config)
# 2 * config.hidden_size because we use reversible residual layers
self.qa_outputs = nn.Linear(2 * config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(REFORMER_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=QuestionAnsweringModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
num_hashes: Optional[int] = None,
start_positions: Optional[torch.Tensor] = None,
end_positions: Optional[torch.Tensor] = None,
output_hidden_states: Optional[bool] = None,
output_attentions: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, QuestionAnsweringModelOutput]:
r"""
start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
reformer_outputs = self.reformer(
input_ids,
position_ids=position_ids,
attention_mask=attention_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
num_hashes=num_hashes,
use_cache=False, # no causal mask
output_hidden_states=output_hidden_states,
output_attentions=output_attentions,
return_dict=return_dict,
)
sequence_output = reformer_outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1).contiguous()
end_logits = end_logits.squeeze(-1).contiguous()
total_loss = None
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions = start_positions.clamp(0, ignored_index)
end_positions = end_positions.clamp(0, ignored_index)
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
if not return_dict:
output = (start_logits, end_logits) + reformer_outputs[1:]
return ((total_loss,) + output) if total_loss is not None else output
return QuestionAnsweringModelOutput(
loss=total_loss,
start_logits=start_logits,
end_logits=end_logits,
hidden_states=reformer_outputs.hidden_states,
attentions=reformer_outputs.attentions,
)
__all__ = [
"ReformerAttention",
"ReformerForMaskedLM",
"ReformerForQuestionAnswering",
"ReformerForSequenceClassification",
"ReformerLayer",
"ReformerModel",
"ReformerModelWithLMHead",
"ReformerPreTrainedModel",
]
| transformers/src/transformers/models/reformer/modeling_reformer.py/0 | {
"file_path": "transformers/src/transformers/models/reformer/modeling_reformer.py",
"repo_id": "transformers",
"token_count": 51304
} |
# coding=utf-8
# Copyright 2018 Google AI, Google Brain and the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tokenization classes for RemBERT model."""
import os
from shutil import copyfile
from typing import List, Optional, Tuple
from ...tokenization_utils import AddedToken
from ...tokenization_utils_fast import PreTrainedTokenizerFast
from ...utils import is_sentencepiece_available, logging
if is_sentencepiece_available():
from .tokenization_rembert import RemBertTokenizer
else:
RemBertTokenizer = None
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.model", "tokenizer_file": "tokenizer.json"}
SPIECE_UNDERLINE = "▁"
class RemBertTokenizerFast(PreTrainedTokenizerFast):
"""
Construct a "fast" RemBert tokenizer (backed by HuggingFace's *tokenizers* library). Based on
[Unigram](https://huggingface.co/docs/tokenizers/python/latest/components.html?highlight=unigram#models). This
tokenizer inherits from [`PreTrainedTokenizerFast`] which contains most of the main methods. Users should refer to
this superclass for more information regarding those methods
Args:
vocab_file (`str`):
[SentencePiece](https://github.com/google/sentencepiece) file (generally has a *.spm* extension) that
contains the vocabulary necessary to instantiate a tokenizer.
do_lower_case (`bool`, *optional*, defaults to `True`):
Whether or not to lowercase the input when tokenizing.
remove_space (`bool`, *optional*, defaults to `True`):
Whether or not to strip the text when tokenizing (removing excess spaces before and after the string).
keep_accents (`bool`, *optional*, defaults to `False`):
Whether or not to keep accents when tokenizing.
bos_token (`str`, *optional*, defaults to `"[CLS]"`):
The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.
<Tip>
When building a sequence using special tokens, this is not the token that is used for the beginning of
sequence. The token used is the `cls_token`.
</Tip>
eos_token (`str`, *optional*, defaults to `"[SEP]"`):
The end of sequence token. .. note:: When building a sequence using special tokens, this is not the token
that is used for the end of sequence. The token used is the `sep_token`.
unk_token (`str`, *optional*, defaults to `"<unk>"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
sep_token (`str`, *optional*, defaults to `"[SEP]"`):
The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for
sequence classification or for a text and a question for question answering. It is also used as the last
token of a sequence built with special tokens.
pad_token (`str`, *optional*, defaults to `"<pad>"`):
The token used for padding, for example when batching sequences of different lengths.
cls_token (`str`, *optional*, defaults to `"[CLS]"`):
The classifier token which is used when doing sequence classification (classification of the whole sequence
instead of per-token classification). It is the first token of the sequence when built with special tokens.
mask_token (`str`, *optional*, defaults to `"[MASK]"`):
The token used for masking values. This is the token used when training this model with masked language
modeling. This is the token which the model will try to predict.
"""
vocab_files_names = VOCAB_FILES_NAMES
slow_tokenizer_class = RemBertTokenizer
def __init__(
self,
vocab_file=None,
tokenizer_file=None,
do_lower_case=True,
remove_space=True,
keep_accents=False,
bos_token="[CLS]",
eos_token="[SEP]",
unk_token="<unk>",
sep_token="[SEP]",
pad_token="<pad>",
cls_token="[CLS]",
mask_token="[MASK]",
**kwargs,
):
# Mask token behave like a normal word, i.e. include the space before it
mask_token = AddedToken(mask_token, lstrip=True, rstrip=False) if isinstance(mask_token, str) else mask_token
super().__init__(
vocab_file,
tokenizer_file=tokenizer_file,
do_lower_case=do_lower_case,
remove_space=remove_space,
keep_accents=keep_accents,
bos_token=bos_token,
eos_token=eos_token,
unk_token=unk_token,
sep_token=sep_token,
pad_token=pad_token,
cls_token=cls_token,
mask_token=mask_token,
**kwargs,
)
self.do_lower_case = do_lower_case
self.remove_space = remove_space
self.keep_accents = keep_accents
self.vocab_file = vocab_file
@property
def can_save_slow_tokenizer(self) -> bool:
return os.path.isfile(self.vocab_file) if self.vocab_file else False
def build_inputs_with_special_tokens(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. A RemBERT sequence has the following format:
- single sequence: `[CLS] X [SEP]`
- pair of sequences: `[CLS] A [SEP] B [SEP]`
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added
token_ids_1 (`List[int]`, *optional*, defaults to `None`):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: list of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return cls + token_ids_0 + sep
return cls + token_ids_0 + sep + token_ids_1 + sep
def get_special_tokens_mask(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
) -> List[int]:
"""
Retrieves sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer `prepare_for_model` method.
Args:
token_ids_0 (`List[int]`):
List of ids.
token_ids_1 (`List[int]`, *optional*, defaults to `None`):
Optional second list of IDs for sequence pairs.
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
Set to True if the token list is already formatted with special tokens for the model
Returns:
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
"""
if already_has_special_tokens:
if token_ids_1 is not None:
raise ValueError(
"You should not supply a second sequence if the provided sequence of "
"ids is already formatted with special tokens for the model."
)
return [1 if x in [self.sep_token_id, self.cls_token_id] else 0 for x in token_ids_0]
if token_ids_1 is not None:
return [1] + ([0] * len(token_ids_0)) + [1] + ([0] * len(token_ids_1)) + [1]
return [1] + ([0] * len(token_ids_0)) + [1]
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Creates a mask from the two sequences passed to be used in a sequence-pair classification task. A RemBERT
sequence pair mask has the following format:
```
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
```
if token_ids_1 is None, only returns the first portion of the mask (0s).
Args:
token_ids_0 (`List[int]`):
List of ids.
token_ids_1 (`List[int]`, *optional*, defaults to `None`):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [token type IDs](../glossary#token-type-ids) according to the given sequence(s).
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep) * [0] + len(token_ids_1 + sep) * [1]
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
if not os.path.isdir(save_directory):
logger.error("Vocabulary path ({}) should be a directory".format(save_directory))
return
out_vocab_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
)
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file):
copyfile(self.vocab_file, out_vocab_file)
return (out_vocab_file,)
__all__ = ["RemBertTokenizerFast"]
| transformers/src/transformers/models/rembert/tokenization_rembert_fast.py/0 | {
"file_path": "transformers/src/transformers/models/rembert/tokenization_rembert_fast.py",
"repo_id": "transformers",
"token_count": 4092
} |
# coding=utf-8
# Copyright 2022 The Google AI Language Team Authors and The HuggingFace Inc. team.
# All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""RoBERTa-PreLayerNorm configuration"""
from collections import OrderedDict
from typing import Mapping
from ...configuration_utils import PretrainedConfig
from ...onnx import OnnxConfig
from ...utils import logging
logger = logging.get_logger(__name__)
# Copied from transformers.models.roberta.configuration_roberta.RobertaConfig with FacebookAI/roberta-base->andreasmadsen/efficient_mlm_m0.40,RoBERTa->RoBERTa-PreLayerNorm,Roberta->RobertaPreLayerNorm,roberta->roberta-prelayernorm
class RobertaPreLayerNormConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`RobertaPreLayerNormModel`] or a [`TFRobertaPreLayerNormModel`]. It is
used to instantiate a RoBERTa-PreLayerNorm model according to the specified arguments, defining the model architecture.
Instantiating a configuration with the defaults will yield a similar configuration to that of the RoBERTa-PreLayerNorm
[andreasmadsen/efficient_mlm_m0.40](https://huggingface.co/andreasmadsen/efficient_mlm_m0.40) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 50265):
Vocabulary size of the RoBERTa-PreLayerNorm model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`RobertaPreLayerNormModel`] or [`TFRobertaPreLayerNormModel`].
hidden_size (`int`, *optional*, defaults to 768):
Dimensionality of the encoder layers and the pooler layer.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
intermediate_size (`int`, *optional*, defaults to 3072):
Dimensionality of the "intermediate" (often named feed-forward) layer in the Transformer encoder.
hidden_act (`str` or `Callable`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"silu"` and `"gelu_new"` are supported.
hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
The dropout ratio for the attention probabilities.
max_position_embeddings (`int`, *optional*, defaults to 512):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
type_vocab_size (`int`, *optional*, defaults to 2):
The vocabulary size of the `token_type_ids` passed when calling [`RobertaPreLayerNormModel`] or [`TFRobertaPreLayerNormModel`].
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (`float`, *optional*, defaults to 1e-12):
The epsilon used by the layer normalization layers.
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
[Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
is_decoder (`bool`, *optional*, defaults to `False`):
Whether the model is used as a decoder or not. If `False`, the model is used as an encoder.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
classifier_dropout (`float`, *optional*):
The dropout ratio for the classification head.
Examples:
```python
>>> from transformers import RobertaPreLayerNormConfig, RobertaPreLayerNormModel
>>> # Initializing a RoBERTa-PreLayerNorm configuration
>>> configuration = RobertaPreLayerNormConfig()
>>> # Initializing a model (with random weights) from the configuration
>>> model = RobertaPreLayerNormModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "roberta-prelayernorm"
def __init__(
self,
vocab_size=50265,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=2,
initializer_range=0.02,
layer_norm_eps=1e-12,
pad_token_id=1,
bos_token_id=0,
eos_token_id=2,
position_embedding_type="absolute",
use_cache=True,
classifier_dropout=None,
**kwargs,
):
super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.hidden_act = hidden_act
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.initializer_range = initializer_range
self.layer_norm_eps = layer_norm_eps
self.position_embedding_type = position_embedding_type
self.use_cache = use_cache
self.classifier_dropout = classifier_dropout
# Copied from transformers.models.roberta.configuration_roberta.RobertaOnnxConfig with Roberta->RobertaPreLayerNorm
class RobertaPreLayerNormOnnxConfig(OnnxConfig):
@property
def inputs(self) -> Mapping[str, Mapping[int, str]]:
if self.task == "multiple-choice":
dynamic_axis = {0: "batch", 1: "choice", 2: "sequence"}
else:
dynamic_axis = {0: "batch", 1: "sequence"}
return OrderedDict(
[
("input_ids", dynamic_axis),
("attention_mask", dynamic_axis),
]
)
__all__ = ["RobertaPreLayerNormConfig", "RobertaPreLayerNormOnnxConfig"]
| transformers/src/transformers/models/roberta_prelayernorm/configuration_roberta_prelayernorm.py/0 | {
"file_path": "transformers/src/transformers/models/roberta_prelayernorm/configuration_roberta_prelayernorm.py",
"repo_id": "transformers",
"token_count": 2923
} |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tokenization classes for RoFormer."""
import json
from typing import List, Optional, Tuple
from tokenizers import normalizers
from tokenizers.pre_tokenizers import BertPreTokenizer, PreTokenizer
from ...tokenization_utils_fast import PreTrainedTokenizerFast
from ...utils import logging
from .tokenization_roformer import RoFormerTokenizer
from .tokenization_utils import JiebaPreTokenizer
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
class RoFormerTokenizerFast(PreTrainedTokenizerFast):
r"""
Construct a "fast" RoFormer tokenizer (backed by HuggingFace's *tokenizers* library).
[`RoFormerTokenizerFast`] is almost identical to [`BertTokenizerFast`] and runs end-to-end tokenization:
punctuation splitting and wordpiece. There are some difference between them when tokenizing Chinese.
This tokenizer inherits from [`PreTrainedTokenizerFast`] which contains most of the main methods. Users should
refer to this superclass for more information regarding those methods.
Example:
```python
>>> from transformers import RoFormerTokenizerFast
>>> tokenizer = RoFormerTokenizerFast.from_pretrained("junnyu/roformer_chinese_base")
>>> tokenizer.tokenize("今天天气非常好。")
['今', '天', '天', '气', '非常', '好', '。']
```"""
vocab_files_names = VOCAB_FILES_NAMES
slow_tokenizer_class = RoFormerTokenizer
def __init__(
self,
vocab_file=None,
tokenizer_file=None,
do_lower_case=True,
unk_token="[UNK]",
sep_token="[SEP]",
pad_token="[PAD]",
cls_token="[CLS]",
mask_token="[MASK]",
tokenize_chinese_chars=True,
strip_accents=None,
**kwargs,
):
super().__init__(
vocab_file,
tokenizer_file=tokenizer_file,
do_lower_case=do_lower_case,
unk_token=unk_token,
sep_token=sep_token,
pad_token=pad_token,
cls_token=cls_token,
mask_token=mask_token,
tokenize_chinese_chars=tokenize_chinese_chars,
strip_accents=strip_accents,
**kwargs,
)
normalizer_state = json.loads(self.backend_tokenizer.normalizer.__getstate__())
if (
normalizer_state.get("lowercase", do_lower_case) != do_lower_case
or normalizer_state.get("strip_accents", strip_accents) != strip_accents
):
normalizer_class = getattr(normalizers, normalizer_state.pop("type"))
normalizer_state["lowercase"] = do_lower_case
normalizer_state["strip_accents"] = strip_accents
self.backend_tokenizer.normalizer = normalizer_class(**normalizer_state)
# Make sure we correctly set the custom PreTokenizer
vocab = self.backend_tokenizer.get_vocab()
self.backend_tokenizer.pre_tokenizer = PreTokenizer.custom(JiebaPreTokenizer(vocab))
self.do_lower_case = do_lower_case
def __getstate__(self):
state = self.__dict__.copy()
state["_tokenizer"].pre_tokenizer = BertPreTokenizer()
return state
def __setstate__(self, d):
self.__dict__ = d
vocab = self.__dict__["_tokenizer"].get_vocab()
self.__dict__["_tokenizer"].pre_tokenizer = PreTokenizer.custom(JiebaPreTokenizer(vocab))
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. A RoFormer sequence has the following format:
- single sequence: `[CLS] X [SEP]`
- pair of sequences: `[CLS] A [SEP] B [SEP]`
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
output = [self.cls_token_id] + token_ids_0 + [self.sep_token_id]
if token_ids_1 is not None:
output += token_ids_1 + [self.sep_token_id]
return output
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Create a mask from the two sequences passed to be used in a sequence-pair classification task. A RoFormer
sequence pair mask has the following format:
```
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
```
If `token_ids_1` is `None`, this method only returns the first portion of the mask (0s).
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [token type IDs](../glossary#token-type-ids) according to the given sequence(s).
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep) * [0] + len(token_ids_1 + sep) * [1]
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
files = self._tokenizer.model.save(save_directory, name=filename_prefix)
return tuple(files)
def save_pretrained(
self,
save_directory,
legacy_format=None,
filename_prefix=None,
push_to_hub=False,
**kwargs,
):
self.backend_tokenizer.pre_tokenizer = BertPreTokenizer()
return super().save_pretrained(save_directory, legacy_format, filename_prefix, push_to_hub, **kwargs)
__all__ = ["RoFormerTokenizerFast"]
| transformers/src/transformers/models/roformer/tokenization_roformer_fast.py/0 | {
"file_path": "transformers/src/transformers/models/roformer/tokenization_roformer_fast.py",
"repo_id": "transformers",
"token_count": 2771
} |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Audio/Text processor class for SeamlessM4T
"""
from ...processing_utils import ProcessorMixin
class SeamlessM4TProcessor(ProcessorMixin):
r"""
Constructs a SeamlessM4T processor which wraps a SeamlessM4T feature extractor and a SeamlessM4T tokenizer into a
single processor.
[`SeamlessM4TProcessor`] offers all the functionalities of [`SeamlessM4TFeatureExtractor`] and
[`SeamlessM4TTokenizerFast`]. See the [`~SeamlessM4TProcessor.__call__`] and [`~SeamlessM4TProcessor.decode`] for
more information.
Args:
feature_extractor ([`SeamlessM4TFeatureExtractor`]):
The audio processor is a required input.
tokenizer ([`SeamlessM4TTokenizerFast`]):
The tokenizer is a required input.
"""
feature_extractor_class = "SeamlessM4TFeatureExtractor"
tokenizer_class = ("SeamlessM4TTokenizer", "SeamlessM4TTokenizerFast")
def __init__(self, feature_extractor, tokenizer):
super().__init__(feature_extractor, tokenizer)
def __call__(self, text=None, audios=None, src_lang=None, tgt_lang=None, **kwargs):
"""
Main method to prepare for the model one or several sequences(s) and audio(s). This method forwards the `text`
and `kwargs` arguments to SeamlessM4TTokenizerFast's [`~SeamlessM4TTokenizerFast.__call__`] if `text` is not
`None` to encode the text. To prepare the audio(s), this method forwards the `audios` and `kwrags` arguments to
SeamlessM4TFeatureExtractor's [`~SeamlessM4TFeatureExtractor.__call__`] if `audios` is not `None`. Please refer
to the doctsring of the above two methods for more information.
Args:
text (`str`, `List[str]`, `List[List[str]]`):
The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
(pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
`is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
audios (`np.ndarray`, `torch.Tensor`, `List[np.ndarray]`, `List[torch.Tensor]`):
The audio or batch of audios to be prepared. Each audio can be NumPy array or PyTorch tensor. In case
of a NumPy array/PyTorch tensor, each audio should be of shape (C, T), where C is a number of channels,
and T the sample length of the audio.
src_lang (`str`, *optional*):
The language code of the input texts/audios. If not specified, the last `src_lang` specified will be
used.
tgt_lang (`str`, *optional*):
The code of the target language. If not specified, the last `tgt_lang` specified will be used.
kwargs (*optional*):
Remaining dictionary of keyword arguments that will be passed to the feature extractor and/or the
tokenizer.
Returns:
[`BatchEncoding`]: A [`BatchEncoding`] with the following fields:
- **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None`.
- **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
`return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names` and if `text` is not
`None`).
- **input_features** -- Audio input features to be fed to a model. Returned when `audios` is not `None`.
"""
sampling_rate = kwargs.pop("sampling_rate", None)
if text is None and audios is None:
raise ValueError("You have to specify either text or audios. Both cannot be none.")
elif text is not None and audios is not None:
raise ValueError(
"Text and audios are mututally exclusive when passed to `SeamlessM4T`. Specify one or another."
)
elif text is not None:
if tgt_lang is not None:
self.tokenizer.tgt_lang = tgt_lang
if src_lang is not None:
self.tokenizer.src_lang = src_lang
encoding = self.tokenizer(text, **kwargs)
return encoding
else:
encoding = self.feature_extractor(audios, sampling_rate=sampling_rate, **kwargs)
return encoding
def batch_decode(self, *args, **kwargs):
"""
This method forwards all its arguments to SeamlessM4TTokenizerFast's [`~PreTrainedTokenizer.batch_decode`].
Please refer to the docstring of this method for more information.
"""
return self.tokenizer.batch_decode(*args, **kwargs)
def decode(self, *args, **kwargs):
"""
This method forwards all its arguments to SeamlessM4TTokenizerFast's [`~PreTrainedTokenizer.decode`]. Please
refer to the docstring of this method for more information.
"""
return self.tokenizer.decode(*args, **kwargs)
@property
def model_input_names(self):
tokenizer_input_names = self.tokenizer.model_input_names
feature_extractor_input_names = self.feature_extractor.model_input_names
return list(dict.fromkeys(tokenizer_input_names + feature_extractor_input_names))
__all__ = ["SeamlessM4TProcessor"]
| transformers/src/transformers/models/seamless_m4t/processing_seamless_m4t.py/0 | {
"file_path": "transformers/src/transformers/models/seamless_m4t/processing_seamless_m4t.py",
"repo_id": "transformers",
"token_count": 2314
} |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Convert SegGPT checkpoints from the original repository.
URL: https://github.com/baaivision/Painter/tree/main/SegGPT
"""
import argparse
import requests
import torch
from PIL import Image
from transformers import SegGptConfig, SegGptForImageSegmentation, SegGptImageProcessor
from transformers.utils import logging
logging.set_verbosity_info()
logger = logging.get_logger(__name__)
# here we list all keys to be renamed (original name on the left, our name on the right)
def create_rename_keys(config):
rename_keys = []
# fmt: off
# rename embedding and its parameters
rename_keys.append(("patch_embed.proj.weight", "model.embeddings.patch_embeddings.projection.weight"))
rename_keys.append(("patch_embed.proj.bias", "model.embeddings.patch_embeddings.projection.bias"))
rename_keys.append(("mask_token", "model.embeddings.mask_token"))
rename_keys.append(("segment_token_x", "model.embeddings.segment_token_input"))
rename_keys.append(("segment_token_y", "model.embeddings.segment_token_prompt"))
rename_keys.append(("type_token_cls", "model.embeddings.type_token_semantic"))
rename_keys.append(("type_token_ins", "model.embeddings.type_token_instance"))
rename_keys.append(("pos_embed", "model.embeddings.position_embeddings"))
# rename decoder and other
rename_keys.append(("norm.weight", "model.encoder.layernorm.weight"))
rename_keys.append(("norm.bias", "model.encoder.layernorm.bias"))
rename_keys.append(("decoder_embed.weight", "decoder.decoder_embed.weight"))
rename_keys.append(("decoder_embed.bias", "decoder.decoder_embed.bias"))
rename_keys.append(("decoder_pred.0.weight", "decoder.decoder_pred.conv.weight"))
rename_keys.append(("decoder_pred.0.bias", "decoder.decoder_pred.conv.bias"))
rename_keys.append(("decoder_pred.1.weight", "decoder.decoder_pred.layernorm.weight"))
rename_keys.append(("decoder_pred.1.bias", "decoder.decoder_pred.layernorm.bias"))
rename_keys.append(("decoder_pred.3.weight", "decoder.decoder_pred.head.weight"))
rename_keys.append(("decoder_pred.3.bias", "decoder.decoder_pred.head.bias"))
# rename blocks
for i in range(config.num_hidden_layers):
rename_keys.append((f"blocks.{i}.attn.qkv.weight", f"model.encoder.layers.{i}.attention.qkv.weight"))
rename_keys.append((f"blocks.{i}.attn.qkv.bias", f"model.encoder.layers.{i}.attention.qkv.bias"))
rename_keys.append((f"blocks.{i}.attn.proj.weight", f"model.encoder.layers.{i}.attention.proj.weight"))
rename_keys.append((f"blocks.{i}.attn.proj.bias", f"model.encoder.layers.{i}.attention.proj.bias"))
rename_keys.append((f"blocks.{i}.attn.rel_pos_h", f"model.encoder.layers.{i}.attention.rel_pos_h"))
rename_keys.append((f"blocks.{i}.attn.rel_pos_w", f"model.encoder.layers.{i}.attention.rel_pos_w"))
rename_keys.append((f"blocks.{i}.mlp.fc1.weight", f"model.encoder.layers.{i}.mlp.lin1.weight"))
rename_keys.append((f"blocks.{i}.mlp.fc1.bias", f"model.encoder.layers.{i}.mlp.lin1.bias"))
rename_keys.append((f"blocks.{i}.mlp.fc2.weight", f"model.encoder.layers.{i}.mlp.lin2.weight"))
rename_keys.append((f"blocks.{i}.mlp.fc2.bias", f"model.encoder.layers.{i}.mlp.lin2.bias"))
rename_keys.append((f"blocks.{i}.norm1.weight", f"model.encoder.layers.{i}.layernorm_before.weight"))
rename_keys.append((f"blocks.{i}.norm1.bias", f"model.encoder.layers.{i}.layernorm_before.bias"))
rename_keys.append((f"blocks.{i}.norm2.weight", f"model.encoder.layers.{i}.layernorm_after.weight"))
rename_keys.append((f"blocks.{i}.norm2.bias", f"model.encoder.layers.{i}.layernorm_after.bias"))
# fmt: on
return rename_keys
def rename_key(dct, old, new):
val = dct.pop(old)
dct[new] = val
# We will verify our results on spongebob images
def prepare_input():
image_input_url = (
"https://raw.githubusercontent.com/baaivision/Painter/main/SegGPT/SegGPT_inference/examples/hmbb_2.jpg"
)
image_prompt_url = (
"https://raw.githubusercontent.com/baaivision/Painter/main/SegGPT/SegGPT_inference/examples/hmbb_1.jpg"
)
mask_prompt_url = (
"https://raw.githubusercontent.com/baaivision/Painter/main/SegGPT/SegGPT_inference/examples/hmbb_1_target.png"
)
image_input = Image.open(requests.get(image_input_url, stream=True).raw)
image_prompt = Image.open(requests.get(image_prompt_url, stream=True).raw)
mask_prompt = Image.open(requests.get(mask_prompt_url, stream=True).raw)
return image_input, image_prompt, mask_prompt
@torch.no_grad()
def convert_seggpt_checkpoint(args):
model_name = args.model_name
pytorch_dump_folder_path = args.pytorch_dump_folder_path
verify_logits = args.verify_logits
push_to_hub = args.push_to_hub
# Define default GroundingDINO configuation
config = SegGptConfig()
# Load original checkpoint
checkpoint_url = "https://huggingface.co/BAAI/SegGpt/blob/main/seggpt_vit_large.pth"
original_state_dict = torch.hub.load_state_dict_from_url(checkpoint_url, map_location="cpu")["model"]
# # Rename keys
new_state_dict = original_state_dict.copy()
rename_keys = create_rename_keys(config)
for src, dest in rename_keys:
rename_key(new_state_dict, src, dest)
# Load HF model
model = SegGptForImageSegmentation(config)
model.eval()
missing_keys, unexpected_keys = model.load_state_dict(new_state_dict, strict=False)
print("Missing keys:", missing_keys)
print("Unexpected keys:", unexpected_keys)
input_img, prompt_img, prompt_mask = prepare_input()
image_processor = SegGptImageProcessor()
inputs = image_processor(images=input_img, prompt_images=prompt_img, prompt_masks=prompt_mask, return_tensors="pt")
expected_prompt_pixel_values = torch.tensor(
[
[[-0.6965, -0.6965, -0.6965], [-0.6965, -0.6965, -0.6965], [-0.6965, -0.6965, -0.6965]],
[[1.6583, 1.6583, 1.6583], [1.6583, 1.6583, 1.6583], [1.6583, 1.6583, 1.6583]],
[[2.3088, 2.3088, 2.3088], [2.3088, 2.3088, 2.3088], [2.3088, 2.3088, 2.3088]],
]
)
expected_pixel_values = torch.tensor(
[
[[1.6324, 1.6153, 1.5810], [1.6153, 1.5982, 1.5810], [1.5810, 1.5639, 1.5639]],
[[1.2731, 1.2556, 1.2206], [1.2556, 1.2381, 1.2031], [1.2206, 1.2031, 1.1681]],
[[1.6465, 1.6465, 1.6465], [1.6465, 1.6465, 1.6465], [1.6291, 1.6291, 1.6291]],
]
)
expected_prompt_masks = torch.tensor(
[
[[-2.1179, -2.1179, -2.1179], [-2.1179, -2.1179, -2.1179], [-2.1179, -2.1179, -2.1179]],
[[-2.0357, -2.0357, -2.0357], [-2.0357, -2.0357, -2.0357], [-2.0357, -2.0357, -2.0357]],
[[-1.8044, -1.8044, -1.8044], [-1.8044, -1.8044, -1.8044], [-1.8044, -1.8044, -1.8044]],
]
)
assert torch.allclose(inputs.pixel_values[0, :, :3, :3], expected_pixel_values, atol=1e-4)
assert torch.allclose(inputs.prompt_pixel_values[0, :, :3, :3], expected_prompt_pixel_values, atol=1e-4)
assert torch.allclose(inputs.prompt_masks[0, :, :3, :3], expected_prompt_masks, atol=1e-4)
torch.manual_seed(2)
outputs = model(**inputs)
print(outputs)
if verify_logits:
expected_output = torch.tensor(
[
[[-2.1208, -2.1190, -2.1198], [-2.1237, -2.1228, -2.1227], [-2.1232, -2.1226, -2.1228]],
[[-2.0405, -2.0396, -2.0403], [-2.0434, -2.0434, -2.0433], [-2.0428, -2.0432, -2.0434]],
[[-1.8102, -1.8088, -1.8099], [-1.8131, -1.8126, -1.8129], [-1.8130, -1.8128, -1.8131]],
]
)
assert torch.allclose(outputs.pred_masks[0, :, :3, :3], expected_output, atol=1e-4)
print("Looks good!")
else:
print("Converted without verifying logits")
if pytorch_dump_folder_path is not None:
print(f"Saving model and processor for {model_name} to {pytorch_dump_folder_path}")
model.save_pretrained(pytorch_dump_folder_path)
image_processor.save_pretrained(pytorch_dump_folder_path)
if push_to_hub:
print(f"Pushing model and processor for {model_name} to hub")
model.push_to_hub(f"EduardoPacheco/{model_name}")
image_processor.push_to_hub(f"EduardoPacheco/{model_name}")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--model_name",
default="seggpt-vit-large",
type=str,
choices=["seggpt-vit-large"],
help="Name of the SegGpt model you'd like to convert.",
)
parser.add_argument(
"--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model directory."
)
parser.add_argument(
"--verify_logits",
action="store_false",
help="Whether or not to verify the logits against the original implementation.",
)
parser.add_argument(
"--push_to_hub", action="store_true", help="Whether or not to push the converted model to the 🤗 hub."
)
args = parser.parse_args()
convert_seggpt_checkpoint(args)
| transformers/src/transformers/models/seggpt/convert_seggpt_to_hf.py/0 | {
"file_path": "transformers/src/transformers/models/seggpt/convert_seggpt_to_hf.py",
"repo_id": "transformers",
"token_count": 4276
} |
# coding=utf-8
# Copyright 2024 Google AI and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch Siglip model."""
import math
import warnings
from dataclasses import dataclass
from typing import Any, Optional, Tuple, Union
import numpy as np
import torch
import torch.utils.checkpoint
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from torch.nn.init import _calculate_fan_in_and_fan_out
from ...activations import ACT2FN
from ...modeling_attn_mask_utils import _prepare_4d_attention_mask
from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, ImageClassifierOutput
from ...modeling_utils import PreTrainedModel
from ...utils import (
ModelOutput,
add_start_docstrings,
add_start_docstrings_to_model_forward,
is_flash_attn_2_available,
is_flash_attn_greater_or_equal_2_10,
logging,
replace_return_docstrings,
torch_int,
)
from .configuration_siglip import SiglipConfig, SiglipTextConfig, SiglipVisionConfig
if is_flash_attn_2_available():
from ...modeling_flash_attention_utils import _flash_attention_forward
logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "SiglipConfig"
_CHECKPOINT_FOR_DOC = "google/siglip-base-patch16-224"
def _trunc_normal_(tensor, mean, std, a, b):
# Cut & paste from PyTorch official master until it's in a few official releases - RW
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
def norm_cdf(x):
# Computes standard normal cumulative distribution function
return (1.0 + math.erf(x / math.sqrt(2.0))) / 2.0
if (mean < a - 2 * std) or (mean > b + 2 * std):
warnings.warn(
"mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
"The distribution of values may be incorrect.",
stacklevel=2,
)
# Values are generated by using a truncated uniform distribution and
# then using the inverse CDF for the normal distribution.
# Get upper and lower cdf values
l = norm_cdf((a - mean) / std)
u = norm_cdf((b - mean) / std)
# Uniformly fill tensor with values from [l, u], then translate to
# [2l-1, 2u-1].
tensor.uniform_(2 * l - 1, 2 * u - 1)
# Use inverse cdf transform for normal distribution to get truncated
# standard normal
tensor.erfinv_()
# Transform to proper mean, std
tensor.mul_(std * math.sqrt(2.0))
tensor.add_(mean)
# Clamp to ensure it's in the proper range
tensor.clamp_(min=a, max=b)
def trunc_normal_tf_(
tensor: torch.Tensor, mean: float = 0.0, std: float = 1.0, a: float = -2.0, b: float = 2.0
) -> torch.Tensor:
"""Fills the input Tensor with values drawn from a truncated
normal distribution. The values are effectively drawn from the
normal distribution :math:`\\mathcal{N}(\text{mean}, \text{std}^2)`
with values outside :math:`[a, b]` redrawn until they are within
the bounds. The method used for generating the random values works
best when :math:`a \\leq \text{mean} \\leq b`.
NOTE: this 'tf' variant behaves closer to Tensorflow / JAX impl where the
bounds [a, b] are applied when sampling the normal distribution with mean=0, std=1.0
and the result is subsequently scaled and shifted by the mean and std args.
Args:
tensor: an n-dimensional `torch.Tensor`
mean: the mean of the normal distribution
std: the standard deviation of the normal distribution
a: the minimum cutoff value
b: the maximum cutoff value
"""
with torch.no_grad():
_trunc_normal_(tensor, 0, 1.0, a, b)
tensor.mul_(std).add_(mean)
def variance_scaling_(tensor, scale=1.0, mode="fan_in", distribution="normal"):
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
if mode == "fan_in":
denom = fan_in
elif mode == "fan_out":
denom = fan_out
elif mode == "fan_avg":
denom = (fan_in + fan_out) / 2
variance = scale / denom
if distribution == "truncated_normal":
# constant is stddev of standard normal truncated to (-2, 2)
trunc_normal_tf_(tensor, std=math.sqrt(variance) / 0.87962566103423978)
elif distribution == "normal":
with torch.no_grad():
tensor.normal_(std=math.sqrt(variance))
elif distribution == "uniform":
bound = math.sqrt(3 * variance)
with torch.no_grad():
tensor.uniform_(-bound, bound)
else:
raise ValueError(f"invalid distribution {distribution}")
def lecun_normal_(tensor):
variance_scaling_(tensor, mode="fan_in", distribution="truncated_normal")
def default_flax_embed_init(tensor):
variance_scaling_(tensor, mode="fan_in", distribution="normal")
@dataclass
# Copied from transformers.models.clip.modeling_clip.CLIPVisionModelOutput with CLIP->Siglip
class SiglipVisionModelOutput(ModelOutput):
"""
Base class for vision model's outputs that also contains image embeddings of the pooling of the last hidden states.
Args:
image_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
The image embeddings obtained by applying the projection layer to the pooler_output.
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
image_embeds: Optional[torch.FloatTensor] = None
last_hidden_state: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
@dataclass
# Copied from transformers.models.clip.modeling_clip.CLIPTextModelOutput with CLIP->Siglip
class SiglipTextModelOutput(ModelOutput):
"""
Base class for text model's outputs that also contains a pooling of the last hidden states.
Args:
text_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
The text embeddings obtained by applying the projection layer to the pooler_output.
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
text_embeds: Optional[torch.FloatTensor] = None
last_hidden_state: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
@dataclass
# Copied from transformers.models.clip.modeling_clip.CLIPOutput with CLIP->Siglip
class SiglipOutput(ModelOutput):
"""
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
Contrastive loss for image-text similarity.
logits_per_image (`torch.FloatTensor` of shape `(image_batch_size, text_batch_size)`):
The scaled dot product scores between `image_embeds` and `text_embeds`. This represents the image-text
similarity scores.
logits_per_text (`torch.FloatTensor` of shape `(text_batch_size, image_batch_size)`):
The scaled dot product scores between `text_embeds` and `image_embeds`. This represents the text-image
similarity scores.
text_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim`):
The text embeddings obtained by applying the projection layer to the pooled output of [`SiglipTextModel`].
image_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim`):
The image embeddings obtained by applying the projection layer to the pooled output of [`SiglipVisionModel`].
text_model_output (`BaseModelOutputWithPooling`):
The output of the [`SiglipTextModel`].
vision_model_output (`BaseModelOutputWithPooling`):
The output of the [`SiglipVisionModel`].
"""
loss: Optional[torch.FloatTensor] = None
logits_per_image: torch.FloatTensor = None
logits_per_text: torch.FloatTensor = None
text_embeds: torch.FloatTensor = None
image_embeds: torch.FloatTensor = None
text_model_output: BaseModelOutputWithPooling = None
vision_model_output: BaseModelOutputWithPooling = None
def to_tuple(self) -> Tuple[Any]:
return tuple(
self[k] if k not in ["text_model_output", "vision_model_output"] else getattr(self, k).to_tuple()
for k in self.keys()
)
class SiglipVisionEmbeddings(nn.Module):
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.config = config
self.embed_dim = config.hidden_size
self.image_size = config.image_size
self.patch_size = config.patch_size
self.patch_embedding = nn.Conv2d(
in_channels=config.num_channels,
out_channels=self.embed_dim,
kernel_size=self.patch_size,
stride=self.patch_size,
padding="valid",
)
self.num_patches = (self.image_size // self.patch_size) ** 2
self.num_positions = self.num_patches
self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
self.register_buffer("position_ids", torch.arange(self.num_positions).expand((1, -1)), persistent=False)
def interpolate_pos_encoding(self, embeddings: torch.Tensor, height: int, width: int) -> torch.Tensor:
"""
This method allows to interpolate the pre-trained position encodings, to be able to use the model on higher resolution
images. This method is also adapted to support torch.jit tracing and no class embeddings.
Adapted from:
- https://github.com/facebookresearch/dino/blob/de9ee3df6cf39fac952ab558447af1fa1365362a/vision_transformer.py#L174-L194, and
- https://github.com/facebookresearch/dinov2/blob/e1277af2ba9496fbadf7aec6eba56e8d882d1e35/dinov2/models/vision_transformer.py#L179-L211
"""
num_patches = embeddings.shape[1]
num_positions = self.position_embedding.weight.shape[0]
# always interpolate when tracing to ensure the exported model works for dynamic input shapes
if not torch.jit.is_tracing() and num_patches == num_positions and height == width:
return self.position_embedding(self.position_ids)
patch_pos_embed = self.position_embedding.weight.unsqueeze(0)
dim = embeddings.shape[-1]
new_height = height // self.patch_size
new_width = width // self.patch_size
sqrt_num_positions = torch_int(num_positions**0.5)
patch_pos_embed = patch_pos_embed.reshape(1, sqrt_num_positions, sqrt_num_positions, dim)
patch_pos_embed = patch_pos_embed.permute(0, 3, 1, 2)
patch_pos_embed = nn.functional.interpolate(
patch_pos_embed,
size=(new_height, new_width),
mode="bicubic",
align_corners=False,
)
patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
return patch_pos_embed
def forward(self, pixel_values: torch.FloatTensor, interpolate_pos_encoding=False) -> torch.Tensor:
_, _, height, width = pixel_values.shape
target_dtype = self.patch_embedding.weight.dtype
patch_embeds = self.patch_embedding(pixel_values.to(dtype=target_dtype)) # shape = [*, width, grid, grid]
embeddings = patch_embeds.flatten(2).transpose(1, 2)
if interpolate_pos_encoding:
embeddings = embeddings + self.interpolate_pos_encoding(embeddings, height, width)
else:
embeddings = embeddings + self.position_embedding(self.position_ids)
return embeddings
# Copied from transformers.models.clip.modeling_clip.CLIPTextEmbeddings with CLIP->Siglip
class SiglipTextEmbeddings(nn.Module):
def __init__(self, config: SiglipTextConfig):
super().__init__()
embed_dim = config.hidden_size
self.token_embedding = nn.Embedding(config.vocab_size, embed_dim)
self.position_embedding = nn.Embedding(config.max_position_embeddings, embed_dim)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.register_buffer(
"position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=False
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
) -> torch.Tensor:
seq_length = input_ids.shape[-1] if input_ids is not None else inputs_embeds.shape[-2]
max_position_embedding = self.position_embedding.weight.shape[0]
if seq_length > max_position_embedding:
raise ValueError(
f"Sequence length must be less than max_position_embeddings (got `sequence length`: "
f"{seq_length} and max_position_embeddings: {max_position_embedding}"
)
if position_ids is None:
position_ids = self.position_ids[:, :seq_length]
if inputs_embeds is None:
inputs_embeds = self.token_embedding(input_ids)
position_embeddings = self.position_embedding(position_ids)
embeddings = inputs_embeds + position_embeddings
return embeddings
class SiglipAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
# Copied from transformers.models.clip.modeling_clip.CLIPAttention.__init__
def __init__(self, config):
super().__init__()
self.config = config
self.embed_dim = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.embed_dim // self.num_heads
if self.head_dim * self.num_heads != self.embed_dim:
raise ValueError(
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
f" {self.num_heads})."
)
self.scale = self.head_dim**-0.5
self.dropout = config.attention_dropout
self.k_proj = nn.Linear(self.embed_dim, self.embed_dim)
self.v_proj = nn.Linear(self.embed_dim, self.embed_dim)
self.q_proj = nn.Linear(self.embed_dim, self.embed_dim)
self.out_proj = nn.Linear(self.embed_dim, self.embed_dim)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:
"""Input shape: Batch x Time x Channel"""
batch_size, q_len, _ = hidden_states.size()
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
query_states = query_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
key_states = key_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
value_states = value_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
k_v_seq_len = key_states.shape[-2]
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) * self.scale
if attn_weights.size() != (batch_size, self.num_heads, q_len, k_v_seq_len):
raise ValueError(
f"Attention weights should be of size {(batch_size, self.num_heads, q_len, k_v_seq_len)}, but is"
f" {attn_weights.size()}"
)
if attention_mask is not None:
if attention_mask.size() != (batch_size, 1, q_len, k_v_seq_len):
raise ValueError(
f"Attention mask should be of size {(batch_size, 1, q_len, k_v_seq_len)}, but is {attention_mask.size()}"
)
attn_weights = attn_weights + attention_mask
# upcast attention to fp32
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_weights = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
attn_output = torch.matmul(attn_weights, value_states)
if attn_output.size() != (batch_size, self.num_heads, q_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(batch_size, self.num_heads, q_len, self.head_dim)}, but is"
f" {attn_output.size()}"
)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.reshape(batch_size, q_len, self.embed_dim)
attn_output = self.out_proj(attn_output)
return attn_output, attn_weights
class SiglipFlashAttention2(SiglipAttention):
"""
SiglipAttention flash attention module. This module inherits from `SiglipAttention` as the weights of the module stays
untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
flash attention and deal with padding tokens in case the input contains any of them.
"""
is_causal = False
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
# flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignement, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
# Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10()
# Adapted from transformers.models.llama.modeling_llama.LlamaFlashAttention2.forward
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.LongTensor] = None,
output_attentions: bool = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
output_attentions = False
batch_size, q_len, _ = hidden_states.size()
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
# Flash attention requires the input to have the shape
# batch_size x seq_length x head_dim x hidden_dim
# therefore we just need to keep the original shape
query_states = query_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
key_states = key_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
value_states = value_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
# TODO: These transpose are quite inefficient but Flash Attention requires the layout [batch_size, sequence_length, num_heads, head_dim]. We would need to refactor the KV cache
# to be able to avoid many of these transpose/reshape/view.
query_states = query_states.transpose(1, 2)
key_states = key_states.transpose(1, 2)
value_states = value_states.transpose(1, 2)
dropout_rate = self.dropout if self.training else 0.0
# In PEFT, usually we cast the layer norms in float32 for training stability reasons
# therefore the input hidden states gets silently casted in float32. Hence, we need
# cast them back in the correct dtype just to be sure everything works as expected.
# This might slowdown training & inference so it is recommended to not cast the LayerNorms
# in fp32.
input_dtype = query_states.dtype
if input_dtype == torch.float32:
if torch.is_autocast_enabled():
target_dtype = torch.get_autocast_gpu_dtype()
# Handle the case where the model is quantized
elif hasattr(self.config, "_pre_quantization_dtype"):
target_dtype = self.config._pre_quantization_dtype
else:
target_dtype = self.q_proj.weight.dtype
logger.warning_once(
f"The input hidden states seems to be silently casted in float32, this might be related to"
f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
f" {target_dtype}."
)
query_states = query_states.to(target_dtype)
key_states = key_states.to(target_dtype)
value_states = value_states.to(target_dtype)
attn_output = _flash_attention_forward(
query_states,
key_states,
value_states,
attention_mask,
q_len,
dropout=dropout_rate,
is_causal=self.is_causal,
use_top_left_mask=self._flash_attn_uses_top_left_mask,
)
attn_output = attn_output.reshape(batch_size, q_len, self.embed_dim).contiguous()
attn_output = self.out_proj(attn_output)
if not output_attentions:
attn_weights = None
return attn_output, attn_weights
class SiglipSdpaAttention(SiglipAttention):
"""
Siglip attention module using torch.nn.functional.scaled_dot_product_attention. This module inherits from
`SiglipAttention` as the weights of the module stays untouched. The only changes are on the forward pass to adapt to
SDPA API.
"""
is_causal = False
# Adapted from SiglipAttention.forward and transformers.models.llama.modeling_llama.LlamaSdpaAttention.forward
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:
if output_attentions:
# TODO: Improve this warning with e.g. `model.config.attn_implementation = "manual"` once this is implemented.
logger.warning_once(
"SiglipModel is using SiglipSdpaAttention, but `torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to the manual attention implementation, "
'but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
)
return super().forward(
hidden_states=hidden_states,
attention_mask=attention_mask,
output_attentions=output_attentions,
)
batch_size, q_len, _ = hidden_states.size()
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
query_states = query_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
key_states = key_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
value_states = value_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
# SDPA with memory-efficient backend is currently (torch==2.1.2) bugged with non-contiguous inputs with custom attn_mask,
# Reference: https://github.com/pytorch/pytorch/issues/112577.
if query_states.device.type == "cuda" and attention_mask is not None:
query_states = query_states.contiguous()
key_states = key_states.contiguous()
value_states = value_states.contiguous()
# We dispatch to SDPA's Flash Attention or Efficient kernels via this `is_causal` if statement instead of an inline conditional assignment
# in SDPA to support both torch.compile's dynamic shapes and full graph options. An inline conditional prevents dynamic shapes from compiling.
is_causal = True if self.is_causal and q_len > 1 else False
attn_output = torch.nn.functional.scaled_dot_product_attention(
query_states,
key_states,
value_states,
attn_mask=attention_mask,
dropout_p=self.dropout if self.training else 0.0,
is_causal=is_causal,
)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.view(batch_size, q_len, self.embed_dim)
attn_output = self.out_proj(attn_output)
return attn_output, None
SIGLIP_ATTENTION_CLASSES = {
"eager": SiglipAttention,
"flash_attention_2": SiglipFlashAttention2,
"sdpa": SiglipSdpaAttention,
}
# Copied from transformers.models.clip.modeling_clip.CLIPMLP with CLIP->Siglip
class SiglipMLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.activation_fn = ACT2FN[config.hidden_act]
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.fc1(hidden_states)
hidden_states = self.activation_fn(hidden_states)
hidden_states = self.fc2(hidden_states)
return hidden_states
class SiglipEncoderLayer(nn.Module):
def __init__(self, config: SiglipConfig):
super().__init__()
self.embed_dim = config.hidden_size
self.self_attn = SIGLIP_ATTENTION_CLASSES[config._attn_implementation](config=config)
self.layer_norm1 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
self.mlp = SiglipMLP(config)
self.layer_norm2 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
# Ignore copy
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: torch.Tensor,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.FloatTensor]:
"""
Args:
hidden_states (`torch.FloatTensor`):
Input to the layer of shape `(batch, seq_len, embed_dim)`.
attention_mask (`torch.FloatTensor`):
Attention mask of shape `(batch, 1, q_len, k_v_seq_len)` where padding elements are indicated by very large negative values.
output_attentions (`bool`, *optional*, defaults to `False`):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
"""
residual = hidden_states
hidden_states = self.layer_norm1(hidden_states)
hidden_states, attn_weights = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
output_attentions=output_attentions,
)
hidden_states = residual + hidden_states
residual = hidden_states
hidden_states = self.layer_norm2(hidden_states)
hidden_states = self.mlp(hidden_states)
hidden_states = residual + hidden_states
outputs = (hidden_states,)
if output_attentions:
outputs += (attn_weights,)
return outputs
class SiglipPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = SiglipConfig
base_model_prefix = "siglip"
supports_gradient_checkpointing = True
_no_split_modules = [
"SiglipTextEmbeddings",
"SiglipEncoderLayer",
"SiglipVisionEmbeddings",
"SiglipEncoderLayer",
"SiglipMultiheadAttentionPoolingHead",
]
_supports_flash_attn_2 = True
_supports_sdpa = True
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, SiglipVisionEmbeddings):
width = (
self.config.vision_config.hidden_size
if isinstance(self.config, SiglipConfig)
else self.config.hidden_size
)
nn.init.normal_(module.position_embedding.weight, std=1 / np.sqrt(width))
elif isinstance(module, nn.Embedding):
default_flax_embed_init(module.weight)
elif isinstance(module, SiglipAttention):
nn.init.xavier_uniform_(module.q_proj.weight)
nn.init.xavier_uniform_(module.k_proj.weight)
nn.init.xavier_uniform_(module.v_proj.weight)
nn.init.xavier_uniform_(module.out_proj.weight)
nn.init.zeros_(module.q_proj.bias)
nn.init.zeros_(module.k_proj.bias)
nn.init.zeros_(module.v_proj.bias)
nn.init.zeros_(module.out_proj.bias)
elif isinstance(module, SiglipMLP):
nn.init.xavier_uniform_(module.fc1.weight)
nn.init.xavier_uniform_(module.fc2.weight)
nn.init.normal_(module.fc1.bias, std=1e-6)
nn.init.normal_(module.fc2.bias, std=1e-6)
elif isinstance(module, SiglipMultiheadAttentionPoolingHead):
nn.init.xavier_uniform_(module.probe.data)
nn.init.xavier_uniform_(module.attention.in_proj_weight.data)
nn.init.zeros_(module.attention.in_proj_bias.data)
elif isinstance(module, SiglipModel):
logit_scale_init = torch.log(torch.tensor(1.0))
module.logit_scale.data.fill_(logit_scale_init)
module.logit_bias.data.zero_()
elif isinstance(module, SiglipForImageClassification):
nn.init.normal_(
module.classifier.weight,
std=self.config.vision_config.hidden_size**-0.5 * self.config.initializer_factor,
)
elif isinstance(module, (nn.Linear, nn.Conv2d)):
lecun_normal_(module.weight)
if module.bias is not None:
nn.init.zeros_(module.bias)
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
SIGLIP_START_DOCSTRING = r"""
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`SiglipConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
SIGLIP_TEXT_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
SIGLIP_VISION_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
[`AutoImageProcessor`]. See [`CLIPImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
interpolate_pos_encoding (`bool`, *optional*, defaults to `False`):
Whether to interpolate the pre-trained position encodings.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
SIGLIP_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
[`AutoImageProcessor`]. See [`CLIPImageProcessor.__call__`] for details.
return_loss (`bool`, *optional*):
Whether or not to return the contrastive loss.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
interpolate_pos_encoding (`bool`, *optional*, defaults to `False`):
Whether to interpolate the pre-trained position encodings.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
# Copied from transformers.models.altclip.modeling_altclip.AltCLIPEncoder with AltCLIP->Siglip
class SiglipEncoder(nn.Module):
"""
Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
[`SiglipEncoderLayer`].
Args:
config: SiglipConfig
"""
def __init__(self, config: SiglipConfig):
super().__init__()
self.config = config
self.layers = nn.ModuleList([SiglipEncoderLayer(config) for _ in range(config.num_hidden_layers)])
self.gradient_checkpointing = False
# Ignore copy
def forward(
self,
inputs_embeds,
attention_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutput]:
r"""
Args:
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
than the model's internal embedding lookup matrix.
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
encoder_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
hidden_states = inputs_embeds
for encoder_layer in self.layers:
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
encoder_layer.__call__,
hidden_states,
attention_mask,
output_attentions,
)
else:
layer_outputs = encoder_layer(
hidden_states,
attention_mask,
output_attentions=output_attentions,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
)
class SiglipTextTransformer(nn.Module):
def __init__(self, config: SiglipTextConfig):
super().__init__()
self.config = config
embed_dim = config.hidden_size
self.embeddings = SiglipTextEmbeddings(config)
self.encoder = SiglipEncoder(config)
self.final_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
self.head = nn.Linear(embed_dim, embed_dim)
self._use_flash_attention_2 = config._attn_implementation == "flash_attention_2"
@add_start_docstrings_to_model_forward(SIGLIP_TEXT_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipTextConfig)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPooling]:
r"""
Returns:
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if input_ids is None:
raise ValueError("You have to specify input_ids")
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids)
# note: SigLIP's text model does not use a causal mask, unlike the original CLIP model.
# expand attention_mask
if attention_mask is not None and not self._use_flash_attention_2:
# [batch_size, seq_len] -> [batch_size, 1, tgt_seq_len, src_seq_len]
attention_mask = _prepare_4d_attention_mask(attention_mask, hidden_states.dtype)
encoder_outputs = self.encoder(
inputs_embeds=hidden_states,
attention_mask=attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
last_hidden_state = encoder_outputs[0]
last_hidden_state = self.final_layer_norm(last_hidden_state)
# Assuming "sticky" EOS tokenization, last token is always EOS.
pooled_output = last_hidden_state[:, -1, :]
pooled_output = self.head(pooled_output)
if not return_dict:
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPooling(
last_hidden_state=last_hidden_state,
pooler_output=pooled_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
@add_start_docstrings(
"""The text model from SigLIP without any head or projection on top.""",
SIGLIP_START_DOCSTRING,
)
class SiglipTextModel(SiglipPreTrainedModel):
config_class = SiglipTextConfig
def __init__(self, config: SiglipTextConfig):
super().__init__(config)
self.text_model = SiglipTextTransformer(config)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self) -> nn.Module:
return self.text_model.embeddings.token_embedding
def set_input_embeddings(self, value):
self.text_model.embeddings.token_embedding = value
@add_start_docstrings_to_model_forward(SIGLIP_TEXT_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipTextConfig)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPooling]:
r"""
Returns:
Examples:
```python
>>> from transformers import AutoTokenizer, SiglipTextModel
>>> model = SiglipTextModel.from_pretrained("google/siglip-base-patch16-224")
>>> tokenizer = AutoTokenizer.from_pretrained("google/siglip-base-patch16-224")
>>> # important: make sure to set padding="max_length" as that's how the model was trained
>>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding="max_length", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled (EOS token) states
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
return self.text_model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
class SiglipVisionTransformer(nn.Module):
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.config = config
embed_dim = config.hidden_size
self.embeddings = SiglipVisionEmbeddings(config)
self.encoder = SiglipEncoder(config)
self.post_layernorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
self.use_head = True if not hasattr(config, "vision_use_head") else config.vision_use_head
if self.use_head:
self.head = SiglipMultiheadAttentionPoolingHead(config)
@add_start_docstrings_to_model_forward(SIGLIP_VISION_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipVisionConfig)
def forward(
self,
pixel_values,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
interpolate_pos_encoding: Optional[bool] = False,
) -> Union[Tuple, BaseModelOutputWithPooling]:
r"""
Returns:
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
hidden_states = self.embeddings(pixel_values, interpolate_pos_encoding=interpolate_pos_encoding)
encoder_outputs = self.encoder(
inputs_embeds=hidden_states,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
last_hidden_state = encoder_outputs[0]
last_hidden_state = self.post_layernorm(last_hidden_state)
pooler_output = self.head(last_hidden_state) if self.use_head else None
if not return_dict:
return (last_hidden_state, pooler_output) + encoder_outputs[1:]
return BaseModelOutputWithPooling(
last_hidden_state=last_hidden_state,
pooler_output=pooler_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
class SiglipMultiheadAttentionPoolingHead(nn.Module):
"""Multihead Attention Pooling."""
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.probe = nn.Parameter(torch.randn(1, 1, config.hidden_size))
self.attention = torch.nn.MultiheadAttention(config.hidden_size, config.num_attention_heads, batch_first=True)
self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.mlp = SiglipMLP(config)
def forward(self, hidden_state):
batch_size = hidden_state.shape[0]
probe = self.probe.repeat(batch_size, 1, 1)
hidden_state = self.attention(probe, hidden_state, hidden_state)[0]
residual = hidden_state
hidden_state = self.layernorm(hidden_state)
hidden_state = residual + self.mlp(hidden_state)
return hidden_state[:, 0]
@add_start_docstrings(
"""The vision model from SigLIP without any head or projection on top.""",
SIGLIP_START_DOCSTRING,
)
class SiglipVisionModel(SiglipPreTrainedModel):
config_class = SiglipVisionConfig
main_input_name = "pixel_values"
def __init__(self, config: SiglipVisionConfig):
super().__init__(config)
self.vision_model = SiglipVisionTransformer(config)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self) -> nn.Module:
return self.vision_model.embeddings.patch_embedding
@add_start_docstrings_to_model_forward(SIGLIP_VISION_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipVisionConfig)
def forward(
self,
pixel_values,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
interpolate_pos_encoding: bool = False,
) -> Union[Tuple, BaseModelOutputWithPooling]:
r"""
Returns:
Examples:
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, SiglipVisionModel
>>> model = SiglipVisionModel.from_pretrained("google/siglip-base-patch16-224")
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled features
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
return self.vision_model(
pixel_values=pixel_values,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
interpolate_pos_encoding=interpolate_pos_encoding,
)
@add_start_docstrings(SIGLIP_START_DOCSTRING)
class SiglipModel(SiglipPreTrainedModel):
config_class = SiglipConfig
def __init__(self, config: SiglipConfig):
super().__init__(config)
if not isinstance(config.text_config, SiglipTextConfig):
raise TypeError(
"config.text_config is expected to be of type SiglipTextConfig but is of type"
f" {type(config.text_config)}."
)
if not isinstance(config.vision_config, SiglipVisionConfig):
raise TypeError(
"config.vision_config is expected to be of type SiglipVisionConfig but is of type"
f" {type(config.vision_config)}."
)
text_config = config.text_config
vision_config = config.vision_config
# First, initialize the text and vision models with proper attention implementation
text_model = SiglipTextModel._from_config(text_config)
vision_model = SiglipVisionModel._from_config(vision_config)
# Second, get the text and vision submodules (for backward compatibility)
self.text_model = text_model.text_model
self.vision_model = vision_model.vision_model
self.logit_scale = nn.Parameter(torch.randn(1))
self.logit_bias = nn.Parameter(torch.randn(1))
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(SIGLIP_TEXT_INPUTS_DOCSTRING)
def get_text_features(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> torch.FloatTensor:
r"""
Returns:
text_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The text embeddings obtained by
applying the projection layer to the pooled output of [`SiglipTextModel`].
Examples:
```python
>>> from transformers import AutoTokenizer, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
>>> tokenizer = AutoTokenizer.from_pretrained("google/siglip-base-patch16-224")
>>> # important: make sure to set padding="max_length" as that's how the model was trained
>>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding="max_length", return_tensors="pt")
>>> with torch.no_grad():
... text_features = model.get_text_features(**inputs)
```"""
# Use SigLIP model's config for some fields (if specified) instead of those of vision & text components.
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
text_outputs = self.text_model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = text_outputs[1]
return pooled_output
@add_start_docstrings_to_model_forward(SIGLIP_VISION_INPUTS_DOCSTRING)
def get_image_features(
self,
pixel_values: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
interpolate_pos_encoding: bool = False,
) -> torch.FloatTensor:
r"""
Returns:
image_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The image embeddings obtained by
applying the projection layer to the pooled output of [`SiglipVisionModel`].
Examples:
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... image_features = model.get_image_features(**inputs)
```"""
# Use SiglipModel's config for some fields (if specified) instead of those of vision & text components.
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
vision_outputs = self.vision_model(
pixel_values=pixel_values,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
interpolate_pos_encoding=interpolate_pos_encoding,
)
pooled_output = vision_outputs[1]
return pooled_output
@add_start_docstrings_to_model_forward(SIGLIP_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=SiglipOutput, config_class=SiglipConfig)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
pixel_values: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
return_loss: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
interpolate_pos_encoding: bool = False,
) -> Union[Tuple, SiglipOutput]:
r"""
Returns:
Examples:
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["a photo of 2 cats", "a photo of 2 dogs"]
>>> # important: we pass `padding=max_length` since the model was trained with this
>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image
>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
>>> print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
31.9% that image 0 is 'a photo of 2 cats'
```"""
# Use SigLIP model's config for some fields (if specified) instead of those of vision & text components.
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
vision_outputs = self.vision_model(
pixel_values=pixel_values,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
interpolate_pos_encoding=interpolate_pos_encoding,
)
text_outputs = self.text_model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
image_embeds = vision_outputs[1]
text_embeds = text_outputs[1]
# normalized features
image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
# cosine similarity as logits
logits_per_text = (
torch.matmul(text_embeds, image_embeds.t().to(text_embeds.device)) * self.logit_scale.exp()
+ self.logit_bias
)
logits_per_image = logits_per_text.t()
loss = None
if return_loss:
# Adapted from https://github.com/google-research/big_vision/blob/01edb81a4716f93a48be43b3a4af14e29cdb3a7f/big_vision/trainers/proj/image_text/siglip.py#L287
eye = torch.eye(logits_per_text.size(0), device=logits_per_text.device)
m1_diag1 = -torch.ones_like(logits_per_text) + 2 * eye
loglik = torch.nn.functional.logsigmoid(m1_diag1 * logits_per_text)
nll = -torch.sum(loglik, dim=-1)
loss = nll.mean()
if not return_dict:
output = (logits_per_image, logits_per_text, text_embeds, image_embeds, text_outputs, vision_outputs)
return ((loss,) + output) if loss is not None else output
return SiglipOutput(
loss=loss,
logits_per_image=logits_per_image,
logits_per_text=logits_per_text,
text_embeds=text_embeds,
image_embeds=image_embeds,
text_model_output=text_outputs,
vision_model_output=vision_outputs,
)
@add_start_docstrings(
"""
SigLIP vision encoder with an image classification head on top (a linear layer on top of the pooled final hidden states of
the patch tokens) e.g. for ImageNet.
""",
SIGLIP_START_DOCSTRING,
)
class SiglipForImageClassification(SiglipPreTrainedModel):
main_input_name = "pixel_values"
def __init__(self, config: SiglipConfig) -> None:
super().__init__(config)
self.num_labels = config.num_labels
# Create the vision model with proper attention
# and take only vision_model submodule (for backward compatibility)
vision_model = SiglipVisionModel._from_config(config.vision_config)
self.vision_model = vision_model.vision_model
# Classifier head
self.classifier = (
nn.Linear(config.vision_config.hidden_size, config.num_labels) if config.num_labels > 0 else nn.Identity()
)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(SIGLIP_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=ImageClassifierOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
pixel_values: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
interpolate_pos_encoding: bool = False,
) -> Union[tuple, ImageClassifierOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the image classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
Returns:
Examples:
```python
>>> from transformers import AutoImageProcessor, SiglipForImageClassification
>>> import torch
>>> from PIL import Image
>>> import requests
>>> torch.manual_seed(3) # doctest: +IGNORE_RESULT
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # note: we are loading a `SiglipModel` from the hub here,
>>> # so the head will be randomly initialized, hence the predictions will be random if seed is not set above.
>>> image_processor = AutoImageProcessor.from_pretrained("google/siglip-base-patch16-224")
>>> model = SiglipForImageClassification.from_pretrained("google/siglip-base-patch16-224")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the two classes
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
Predicted class: LABEL_1
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.vision_model(
pixel_values,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
interpolate_pos_encoding=interpolate_pos_encoding,
)
sequence_output = outputs[0]
# average pool the patch tokens
sequence_output = torch.mean(sequence_output, dim=1)
# apply classifier
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
# move labels to correct device to enable model parallelism
labels = labels.to(logits.device)
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return ImageClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
__all__ = [
"SiglipModel",
"SiglipPreTrainedModel",
"SiglipTextModel",
"SiglipVisionModel",
"SiglipForImageClassification",
]
| transformers/src/transformers/models/siglip/modeling_siglip.py/0 | {
"file_path": "transformers/src/transformers/models/siglip/modeling_siglip.py",
"repo_id": "transformers",
"token_count": 28724
} |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tokenization classes for Speech2Text."""
import json
import os
from pathlib import Path
from shutil import copyfile
from typing import Any, Dict, List, Optional, Tuple, Union
import sentencepiece
from ...tokenization_utils import PreTrainedTokenizer
from ...utils import logging
logger = logging.get_logger(__name__)
SPIECE_UNDERLINE = "▁"
VOCAB_FILES_NAMES = {
"vocab_file": "vocab.json",
"spm_file": "sentencepiece.bpe.model",
}
MAX_MODEL_INPUT_SIZES = {
"facebook/s2t-small-librispeech-asr": 1024,
}
MUSTC_LANGS = ["pt", "fr", "ru", "nl", "ro", "it", "es", "de"]
LANGUAGES = {"mustc": MUSTC_LANGS}
class Speech2TextTokenizer(PreTrainedTokenizer):
"""
Construct an Speech2Text tokenizer.
This tokenizer inherits from [`PreTrainedTokenizer`] which contains some of the main methods. Users should refer to
the superclass for more information regarding such methods.
Args:
vocab_file (`str`):
File containing the vocabulary.
spm_file (`str`):
Path to the [SentencePiece](https://github.com/google/sentencepiece) model file
bos_token (`str`, *optional*, defaults to `"<s>"`):
The beginning of sentence token.
eos_token (`str`, *optional*, defaults to `"</s>"`):
The end of sentence token.
unk_token (`str`, *optional*, defaults to `"<unk>"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
pad_token (`str`, *optional*, defaults to `"<pad>"`):
The token used for padding, for example when batching sequences of different lengths.
do_upper_case (`bool`, *optional*, defaults to `False`):
Whether or not to uppercase the output when decoding.
do_lower_case (`bool`, *optional*, defaults to `False`):
Whether or not to lowercase the input when tokenizing.
tgt_lang (`str`, *optional*):
A string representing the target language.
sp_model_kwargs (`dict`, *optional*):
Will be passed to the `SentencePieceProcessor.__init__()` method. The [Python wrapper for
SentencePiece](https://github.com/google/sentencepiece/tree/master/python) can be used, among other things,
to set:
- `enable_sampling`: Enable subword regularization.
- `nbest_size`: Sampling parameters for unigram. Invalid for BPE-Dropout.
- `nbest_size = {0,1}`: No sampling is performed.
- `nbest_size > 1`: samples from the nbest_size results.
- `nbest_size < 0`: assuming that nbest_size is infinite and samples from the all hypothesis (lattice)
using forward-filtering-and-backward-sampling algorithm.
- `alpha`: Smoothing parameter for unigram sampling, and dropout probability of merge operations for
BPE-dropout.
**kwargs
Additional keyword arguments passed along to [`PreTrainedTokenizer`]
"""
vocab_files_names = VOCAB_FILES_NAMES
model_input_names = ["input_ids", "attention_mask"]
prefix_tokens: List[int] = []
def __init__(
self,
vocab_file,
spm_file,
bos_token="<s>",
eos_token="</s>",
pad_token="<pad>",
unk_token="<unk>",
do_upper_case=False,
do_lower_case=False,
tgt_lang=None,
lang_codes=None,
additional_special_tokens=None,
sp_model_kwargs: Optional[Dict[str, Any]] = None,
**kwargs,
) -> None:
self.sp_model_kwargs = {} if sp_model_kwargs is None else sp_model_kwargs
self.do_upper_case = do_upper_case
self.do_lower_case = do_lower_case
self.encoder = load_json(vocab_file)
self.decoder = {v: k for k, v in self.encoder.items()}
self.spm_file = spm_file
self.sp_model = load_spm(spm_file, self.sp_model_kwargs)
if lang_codes is not None:
self.lang_codes = lang_codes
self.langs = LANGUAGES[lang_codes]
self.lang_tokens = [f"<lang:{lang}>" for lang in self.langs]
self.lang_code_to_id = {lang: self.sp_model.PieceToId(f"<lang:{lang}>") for lang in self.langs}
if additional_special_tokens is not None:
additional_special_tokens = self.lang_tokens + additional_special_tokens
else:
additional_special_tokens = self.lang_tokens
self._tgt_lang = tgt_lang if tgt_lang is not None else self.langs[0]
self.set_tgt_lang_special_tokens(self._tgt_lang)
else:
self.lang_code_to_id = {}
super().__init__(
bos_token=bos_token,
eos_token=eos_token,
unk_token=unk_token,
pad_token=pad_token,
do_upper_case=do_upper_case,
do_lower_case=do_lower_case,
tgt_lang=tgt_lang,
lang_codes=lang_codes,
sp_model_kwargs=self.sp_model_kwargs,
additional_special_tokens=additional_special_tokens,
**kwargs,
)
@property
def vocab_size(self) -> int:
return len(self.encoder)
def get_vocab(self) -> Dict:
vocab = self.encoder.copy()
vocab.update(self.added_tokens_encoder)
return vocab
@property
def tgt_lang(self) -> str:
return self._tgt_lang
@tgt_lang.setter
def tgt_lang(self, new_tgt_lang) -> None:
self._tgt_lang = new_tgt_lang
self.set_tgt_lang_special_tokens(new_tgt_lang)
def set_tgt_lang_special_tokens(self, tgt_lang: str) -> None:
"""Reset the special tokens to the target language setting. prefix=[eos, tgt_lang_code] and suffix=[eos]."""
lang_code_id = self.lang_code_to_id[tgt_lang]
self.prefix_tokens = [lang_code_id]
def _tokenize(self, text: str) -> List[str]:
return self.sp_model.encode(text, out_type=str)
def _convert_token_to_id(self, token):
return self.encoder.get(token, self.encoder[self.unk_token])
def _convert_id_to_token(self, index: int) -> str:
"""Converts an index (integer) in a token (str) using the decoder."""
return self.decoder.get(index, self.unk_token)
def convert_tokens_to_string(self, tokens: List[str]) -> str:
"""Converts a sequence of tokens (strings for sub-words) in a single string."""
current_sub_tokens = []
out_string = ""
for token in tokens:
# make sure that special tokens are not decoded using sentencepiece model
if token in self.all_special_tokens:
decoded = self.sp_model.decode(current_sub_tokens)
out_string += (decoded.upper() if self.do_upper_case else decoded) + token + " "
current_sub_tokens = []
else:
current_sub_tokens.append(token)
decoded = self.sp_model.decode(current_sub_tokens)
out_string += decoded.upper() if self.do_upper_case else decoded
return out_string.strip()
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None) -> List[int]:
"""Build model inputs from a sequence by appending eos_token_id."""
if token_ids_1 is None:
return self.prefix_tokens + token_ids_0 + [self.eos_token_id]
# We don't expect to process pairs, but leave the pair logic for API consistency
return self.prefix_tokens + token_ids_0 + token_ids_1 + [self.eos_token_id]
def get_special_tokens_mask(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
) -> List[int]:
"""
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer `prepare_for_model` method.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not the token list is already formatted with special tokens for the model.
Returns:
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
"""
if already_has_special_tokens:
return super().get_special_tokens_mask(
token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
)
prefix_ones = [1] * len(self.prefix_tokens)
suffix_ones = [1]
if token_ids_1 is None:
return prefix_ones + ([0] * len(token_ids_0)) + suffix_ones
return prefix_ones + ([0] * len(token_ids_0)) + ([0] * len(token_ids_1)) + suffix_ones
def __getstate__(self) -> Dict:
state = self.__dict__.copy()
state["sp_model"] = None
return state
def __setstate__(self, d: Dict) -> None:
self.__dict__ = d
# for backward compatibility
if not hasattr(self, "sp_model_kwargs"):
self.sp_model_kwargs = {}
self.sp_model = load_spm(self.spm_file, self.sp_model_kwargs)
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
save_dir = Path(save_directory)
assert save_dir.is_dir(), f"{save_directory} should be a directory"
vocab_save_path = save_dir / (
(filename_prefix + "-" if filename_prefix else "") + self.vocab_files_names["vocab_file"]
)
spm_save_path = save_dir / (
(filename_prefix + "-" if filename_prefix else "") + self.vocab_files_names["spm_file"]
)
save_json(self.encoder, vocab_save_path)
if os.path.abspath(self.spm_file) != os.path.abspath(spm_save_path) and os.path.isfile(self.spm_file):
copyfile(self.spm_file, spm_save_path)
elif not os.path.isfile(self.spm_file):
with open(spm_save_path, "wb") as fi:
content_spiece_model = self.sp_model.serialized_model_proto()
fi.write(content_spiece_model)
return (str(vocab_save_path), str(spm_save_path))
def load_spm(path: str, sp_model_kwargs: Dict[str, Any]) -> sentencepiece.SentencePieceProcessor:
spm = sentencepiece.SentencePieceProcessor(**sp_model_kwargs)
spm.Load(str(path))
return spm
def load_json(path: str) -> Union[Dict, List]:
with open(path, "r") as f:
return json.load(f)
def save_json(data, path: str) -> None:
with open(path, "w") as f:
json.dump(data, f, indent=2)
__all__ = ["Speech2TextTokenizer"]
| transformers/src/transformers/models/speech_to_text/tokenization_speech_to_text.py/0 | {
"file_path": "transformers/src/transformers/models/speech_to_text/tokenization_speech_to_text.py",
"repo_id": "transformers",
"token_count": 5009
} |
# coding=utf-8
# Copyright 2020 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Convert TAPAS checkpoint."""
import argparse
from transformers import (
TapasConfig,
TapasForMaskedLM,
TapasForQuestionAnswering,
TapasForSequenceClassification,
TapasModel,
TapasTokenizer,
load_tf_weights_in_tapas,
)
from transformers.utils import logging
logging.set_verbosity_info()
def convert_tf_checkpoint_to_pytorch(
task, reset_position_index_per_cell, tf_checkpoint_path, tapas_config_file, pytorch_dump_path
):
# Initialise PyTorch model.
# If you want to convert a checkpoint that uses absolute position embeddings, make sure to set reset_position_index_per_cell of
# TapasConfig to False.
# initialize configuration from json file
config = TapasConfig.from_json_file(tapas_config_file)
# set absolute/relative position embeddings parameter
config.reset_position_index_per_cell = reset_position_index_per_cell
# set remaining parameters of TapasConfig as well as the model based on the task
if task == "SQA":
model = TapasForQuestionAnswering(config=config)
elif task == "WTQ":
# run_task_main.py hparams
config.num_aggregation_labels = 4
config.use_answer_as_supervision = True
# hparam_utils.py hparams
config.answer_loss_cutoff = 0.664694
config.cell_selection_preference = 0.207951
config.huber_loss_delta = 0.121194
config.init_cell_selection_weights_to_zero = True
config.select_one_column = True
config.allow_empty_column_selection = False
config.temperature = 0.0352513
model = TapasForQuestionAnswering(config=config)
elif task == "WIKISQL_SUPERVISED":
# run_task_main.py hparams
config.num_aggregation_labels = 4
config.use_answer_as_supervision = False
# hparam_utils.py hparams
config.answer_loss_cutoff = 36.4519
config.cell_selection_preference = 0.903421
config.huber_loss_delta = 222.088
config.init_cell_selection_weights_to_zero = True
config.select_one_column = True
config.allow_empty_column_selection = True
config.temperature = 0.763141
model = TapasForQuestionAnswering(config=config)
elif task == "TABFACT":
model = TapasForSequenceClassification(config=config)
elif task == "MLM":
model = TapasForMaskedLM(config=config)
elif task == "INTERMEDIATE_PRETRAINING":
model = TapasModel(config=config)
else:
raise ValueError(f"Task {task} not supported.")
print(f"Building PyTorch model from configuration: {config}")
# Load weights from tf checkpoint
load_tf_weights_in_tapas(model, config, tf_checkpoint_path)
# Save pytorch-model (weights and configuration)
print(f"Save PyTorch model to {pytorch_dump_path}")
model.save_pretrained(pytorch_dump_path)
# Save tokenizer files
print(f"Save tokenizer files to {pytorch_dump_path}")
tokenizer = TapasTokenizer(vocab_file=tf_checkpoint_path[:-10] + "vocab.txt", model_max_length=512)
tokenizer.save_pretrained(pytorch_dump_path)
print("Used relative position embeddings:", model.config.reset_position_index_per_cell)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--task", default="SQA", type=str, help="Model task for which to convert a checkpoint. Defaults to SQA."
)
parser.add_argument(
"--reset_position_index_per_cell",
default=False,
action="store_true",
help="Whether to use relative position embeddings or not. Defaults to True.",
)
parser.add_argument(
"--tf_checkpoint_path", default=None, type=str, required=True, help="Path to the TensorFlow checkpoint path."
)
parser.add_argument(
"--tapas_config_file",
default=None,
type=str,
required=True,
help=(
"The config json file corresponding to the pre-trained TAPAS model. \n"
"This specifies the model architecture."
),
)
parser.add_argument(
"--pytorch_dump_path", default=None, type=str, required=True, help="Path to the output PyTorch model."
)
args = parser.parse_args()
convert_tf_checkpoint_to_pytorch(
args.task,
args.reset_position_index_per_cell,
args.tf_checkpoint_path,
args.tapas_config_file,
args.pytorch_dump_path,
)
| transformers/src/transformers/models/tapas/convert_tapas_original_tf_checkpoint_to_pytorch.py/0 | {
"file_path": "transformers/src/transformers/models/tapas/convert_tapas_original_tf_checkpoint_to_pytorch.py",
"repo_id": "transformers",
"token_count": 1935
} |
# coding=utf-8
# Copyright 2023 The Intel AIA Team Authors, and HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License=, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing=, software
# distributed under the License is distributed on an "AS IS" BASIS=,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND=, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Processor class for TVP.
"""
from ...processing_utils import ProcessorMixin
from ...tokenization_utils_base import BatchEncoding
class TvpProcessor(ProcessorMixin):
r"""
Constructs an TVP processor which wraps a TVP image processor and a Bert tokenizer into a single processor.
[`TvpProcessor`] offers all the functionalities of [`TvpImageProcessor`] and [`BertTokenizerFast`]. See the
[`~TvpProcessor.__call__`] and [`~TvpProcessor.decode`] for more information.
Args:
image_processor ([`TvpImageProcessor`], *optional*):
The image processor is a required input.
tokenizer ([`BertTokenizerFast`], *optional*):
The tokenizer is a required input.
"""
attributes = ["image_processor", "tokenizer"]
image_processor_class = "TvpImageProcessor"
tokenizer_class = ("BertTokenizer", "BertTokenizerFast")
def __init__(self, image_processor=None, tokenizer=None, **kwargs):
if image_processor is None:
raise ValueError("You need to specify an `image_processor`.")
if tokenizer is None:
raise ValueError("You need to specify a `tokenizer`.")
super().__init__(image_processor, tokenizer)
def __call__(self, text=None, videos=None, return_tensors=None, **kwargs):
"""
Main method to prepare for the model one or several sequences(s) and image(s). This method forwards the `text`
and `kwargs` arguments to BertTokenizerFast's [`~BertTokenizerFast.__call__`] if `text` is not `None` to encode
the text. To prepare the image(s), this method forwards the `videos` and `kwargs` arguments to
TvpImageProcessor's [`~TvpImageProcessor.__call__`] if `videos` is not `None`. Please refer to the doctsring of
the above two methods for more information.
Args:
text (`str`, `List[str]`, `List[List[str]]`):
The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
(pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
`is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
videos (`List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`, `List[List[PIL.Image.Image]]`, `List[List[np.ndarrray]]`,:
`List[List[torch.Tensor]]`): The video or batch of videos to be prepared. Each video should be a list
of frames, which can be either PIL images or NumPy arrays. In case of NumPy arrays/PyTorch tensors,
each frame should be of shape (H, W, C), where H and W are frame height and width, and C is a number of
channels.
return_tensors (`str` or [`~utils.TensorType`], *optional*):
If set, will return tensors of a particular framework. Acceptable values are:
- `'tf'`: Return TensorFlow `tf.constant` objects.
- `'pt'`: Return PyTorch `torch.Tensor` objects.
- `'np'`: Return NumPy `np.ndarray` objects.
- `'jax'`: Return JAX `jnp.ndarray` objects.
Returns:
[`BatchEncoding`]: A [`BatchEncoding`] with the following fields:
- **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None`.
- **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
`return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names` and if `text` is not
`None`).
- **pixel_values** -- Pixel values to be fed to a model. Returned when `videos` is not `None`.
"""
max_text_length = kwargs.pop("max_text_length", None)
if text is None and videos is None:
raise ValueError("You have to specify either text or videos. Both cannot be none.")
encoding = {}
if text is not None:
textual_input = self.tokenizer.batch_encode_plus(
text,
truncation=True,
padding="max_length",
max_length=max_text_length,
pad_to_max_length=True,
return_tensors=return_tensors,
return_token_type_ids=False,
**kwargs,
)
encoding.update(textual_input)
if videos is not None:
image_features = self.image_processor(videos, return_tensors=return_tensors, **kwargs)
encoding.update(image_features)
return BatchEncoding(data=encoding, tensor_type=return_tensors)
def batch_decode(self, *args, **kwargs):
"""
This method forwards all its arguments to BertTokenizerFast's [`~PreTrainedTokenizer.batch_decode`]. Please
refer to the docstring of this method for more information.
"""
return self.tokenizer.batch_decode(*args, **kwargs)
def decode(self, *args, **kwargs):
"""
This method forwards all its arguments to BertTokenizerFast's [`~PreTrainedTokenizer.decode`]. Please refer to
the docstring of this method for more information.
"""
return self.tokenizer.decode(*args, **kwargs)
def post_process_video_grounding(self, logits, video_durations):
"""
Compute the time of the video.
Args:
logits (`torch.Tensor`):
The logits output of TvpForVideoGrounding.
video_durations (`float`):
The video's duration.
Returns:
start (`float`):
The start time of the video.
end (`float`):
The end time of the video.
"""
start, end = (
round(logits.tolist()[0][0] * video_durations, 1),
round(logits.tolist()[0][1] * video_durations, 1),
)
return start, end
@property
# Copied from transformers.models.blip.processing_blip.BlipProcessor.model_input_names
def model_input_names(self):
tokenizer_input_names = self.tokenizer.model_input_names
image_processor_input_names = self.image_processor.model_input_names
return list(dict.fromkeys(tokenizer_input_names + image_processor_input_names))
__all__ = ["TvpProcessor"]
| transformers/src/transformers/models/tvp/processing_tvp.py/0 | {
"file_path": "transformers/src/transformers/models/tvp/processing_tvp.py",
"repo_id": "transformers",
"token_count": 2838
} |
# coding=utf-8
# Copyright 2024 Microsoft Research & University of Wisconsin-Madison and the HuggingFace Inc. team. All rights reserved.
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""VideoLlava model configuration"""
from ...configuration_utils import PretrainedConfig
from ...utils import logging
from ..auto import CONFIG_MAPPING, AutoConfig
logger = logging.get_logger(__name__)
class VideoLlavaConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`VideoLlavaForConditionalGeneration`]. It is used to instantiate an
VideoLlava model according to the specified arguments, defining the model architecture. Instantiating a configuration
with the defaults will yield a similar configuration to that of the like LanguageBind/Video-LLaVA-7B-hf.
e.g. [LanguageBind/Video-LLaVA-7B-hf](https://huggingface.co/LanguageBind/Video-LLaVA-7B-hf)
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vision_config (`VideoLlavaVisionConfig`, *optional*):
Custom vision config or dict. Defaults to `CLIPVisionConfig` if not indicated.
text_config (`Union[AutoConfig, dict]`, *optional*):
The config object of the text backbone. Can be any of `LlamaConfig` or `MistralConfig`.
Defaults to `LlamaConfig` if not indicated.
ignore_index (`int`, *optional*, defaults to -100):
The ignore index for the loss function.
image_token_index (`int`, *optional*, defaults to 32000):
The image token index to encode the image prompt.
video_token_index (`int`, *optional*, defaults to 32001):
The video token index to encode the image prompt.
projector_hidden_act (`str`, *optional*, defaults to `"gelu"`):
The activation function used by the multimodal projector.
vision_feature_select_strategy (`str`, *optional*, defaults to `"default"`):
The feature selection strategy used to select the vision feature from the CLIP backbone.
Can be either "full" to select all features or "default" to select features without `CLS`.
vision_feature_layer (`Union[int, List[int]]`, *optional*, defaults to -2):
The index of the layer to select the vision feature. If multiple indices are provided,
the vision feature of the corresponding indices will be concatenated to form the
vision features.
image_seq_length (`int`, *optional*, defaults to 256):
Sequence length of one image embedding.
video_seq_length (`int`, *optional*, defaults to 2056):
Sequence length of one video embedding.
multimodal_projector_bias (`bool`, *optional*, defaults to `True`):
Whether to use bias in the multimodal projector.
Example:
```python
>>> from transformers import VideoLlavaForConditionalGeneration, VideoLlavaConfig, CLIPVisionConfig, LlamaConfig
>>> # Initializing a CLIP-vision config
>>> vision_config = CLIPVisionConfig()
>>> # Initializing a Llama config
>>> text_config = LlamaConfig()
>>> # Initializing a VideoLlava video_llava-1.5-7b style configuration
>>> configuration = VideoLlavaConfig(vision_config, text_config)
>>> # Initializing a model from the video_llava-1.5-7b style configuration
>>> model = VideoLlavaForConditionalGeneration(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "video_llava"
sub_configs = {"text_config": AutoConfig, "vision_config": AutoConfig}
def __init__(
self,
vision_config=None,
text_config=None,
ignore_index=-100,
image_token_index=32000,
video_token_index=32001,
projector_hidden_act="gelu",
vision_feature_select_strategy="default",
vision_feature_layer=-2,
image_seq_length=256,
video_seq_length=2056,
multimodal_projector_bias=True,
**kwargs,
):
self.ignore_index = ignore_index
self.image_token_index = image_token_index
self.video_token_index = video_token_index
self.projector_hidden_act = projector_hidden_act
self.vision_feature_select_strategy = vision_feature_select_strategy
self.vision_feature_layer = vision_feature_layer
self.image_seq_length = image_seq_length
self.video_seq_length = video_seq_length
self.multimodal_projector_bias = multimodal_projector_bias
self.vision_config = vision_config
if isinstance(self.vision_config, dict):
if "model_type" not in vision_config:
vision_config["model_type"] = "clip_vision_model"
logger.warning("Key=`model_type` not found in vision config, setting it to `clip_vision_model`")
self.vision_config = CONFIG_MAPPING[vision_config["model_type"]](**vision_config)
elif vision_config is None:
self.vision_config = CONFIG_MAPPING["clip_vision_model"](
intermediate_size=4096,
hidden_size=1024,
patch_size=14,
image_size=224,
num_hidden_layers=24,
num_attention_heads=16,
vocab_size=32000,
projection_dim=768,
)
if isinstance(text_config, dict):
if "model_type" not in text_config:
text_config["model_type"] = "llama"
logger.warning("Key=`model_type` not found in text config, setting it to `llama`")
text_config = CONFIG_MAPPING[text_config["model_type"]](**text_config)
elif text_config is None:
text_config = CONFIG_MAPPING["llama"]()
self.text_config = text_config
super().__init__(**kwargs)
__all__ = ["VideoLlavaConfig"]
| transformers/src/transformers/models/video_llava/configuration_video_llava.py/0 | {
"file_path": "transformers/src/transformers/models/video_llava/configuration_video_llava.py",
"repo_id": "transformers",
"token_count": 2443
} |
# coding=utf-8
# Copyright 2022 NAVER AI Labs and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch ViLT model."""
import collections.abc
import math
from dataclasses import dataclass
from typing import List, Optional, Tuple, Union
import torch
import torch.utils.checkpoint
from torch import nn
from torch.nn import CrossEntropyLoss
from ...activations import ACT2FN
from ...modeling_outputs import (
BaseModelOutput,
BaseModelOutputWithPooling,
MaskedLMOutput,
ModelOutput,
SequenceClassifierOutput,
TokenClassifierOutput,
)
from ...modeling_utils import PreTrainedModel
from ...pytorch_utils import (
find_pruneable_heads_and_indices,
meshgrid,
prune_linear_layer,
)
from ...utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging, replace_return_docstrings
from .configuration_vilt import ViltConfig
logger = logging.get_logger(__name__)
_CONFIG_FOR_DOC = "ViltConfig"
_CHECKPOINT_FOR_DOC = "dandelin/vilt-b32-mlm"
@dataclass
class ViltForImagesAndTextClassificationOutput(ModelOutput):
"""
Class for outputs of [`ViltForImagesAndTextClassification`].
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
Classification (or regression if config.num_labels==1) loss.
logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
Classification (or regression if config.num_labels==1) scores (before SoftMax).
hidden_states (`List[tuple(torch.FloatTensor)]`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
List of tuples of `torch.FloatTensor` (one for each image-text pair, each tuple containing the output of
the embeddings + one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (`List[tuple(torch.FloatTensor)]`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
List of tuples of `torch.FloatTensor` (one for each image-text pair, each tuple containing the attention
weights of shape `(batch_size, num_heads, sequence_length, sequence_length)`. Attentions weights after the
attention softmax, used to compute the weighted average in the self-attention heads.
"""
loss: Optional[torch.FloatTensor] = None
logits: torch.FloatTensor = None
hidden_states: Optional[List[Tuple[torch.FloatTensor]]] = None
attentions: Optional[List[Tuple[torch.FloatTensor]]] = None
class ViltEmbeddings(nn.Module):
"""
Construct the text and patch embeddings.
Text embeddings are equivalent to BERT embeddings.
Patch embeddings are equivalent to ViT embeddings.
"""
def __init__(self, config):
super().__init__()
# text embeddings
self.text_embeddings = TextEmbeddings(config)
# patch embeddings
self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
self.patch_embeddings = ViltPatchEmbeddings(config)
num_patches = self.patch_embeddings.num_patches
self.position_embeddings = nn.Parameter(torch.zeros(1, num_patches + 1, config.hidden_size))
# modality type (text/patch) embeddings
self.token_type_embeddings = nn.Embedding(config.modality_type_vocab_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.config = config
def visual_embed(self, pixel_values, pixel_mask, max_image_length=200):
_, _, ph, pw = self.patch_embeddings.projection.weight.shape
x = self.patch_embeddings(pixel_values)
x_mask = pixel_mask[:, None, :, :].float()
x_mask = nn.functional.interpolate(x_mask, size=(x.shape[2], x.shape[3])).long()
x_h = x_mask[:, 0].sum(dim=1)[:, 0]
x_w = x_mask[:, 0].sum(dim=2)[:, 0]
batch_size, num_channels, height, width = x.shape
patch_dim = self.config.image_size // self.config.patch_size
spatial_pos = self.position_embeddings[:, 1:, :].transpose(1, 2).view(1, num_channels, patch_dim, patch_dim)
pos_embed = torch.cat(
[
nn.functional.pad(
nn.functional.interpolate(
spatial_pos,
size=(h, w),
mode="bilinear",
align_corners=True,
),
(0, width - w, 0, height - h),
)
for h, w in zip(x_h, x_w)
],
dim=0,
)
pos_embed = pos_embed.flatten(2).transpose(1, 2)
x = x.flatten(2).transpose(1, 2)
# Set `device` here, otherwise `patch_index` will always be on `CPU` and will fail near the end for torch>=1.13
patch_index = torch.stack(
meshgrid(torch.arange(x_mask.shape[-2]), torch.arange(x_mask.shape[-1]), indexing="ij"), dim=-1
).to(device=x_mask.device)
patch_index = patch_index[None, None, :, :, :]
patch_index = patch_index.expand(x_mask.shape[0], x_mask.shape[1], -1, -1, -1)
patch_index = patch_index.flatten(1, 3)
x_mask = x_mask.flatten(1)
if max_image_length < 0 or max_image_length is None or not isinstance(max_image_length, int):
# suppose aug is 800 x 1333, then, maximum effective res is 800 x 1333 (if one side gets bigger, the other will be constrained and be shrinked)
# (800 // self.patch_size) * (1333 // self.patch_size) is the maximum number of patches that single image can get.
# if self.patch_size = 32, 25 * 41 = 1025
# if res is 384 x 640, 12 * 20 = 240
effective_resolution = x_h * x_w
max_image_length = effective_resolution.max()
else:
effective_resolution = x_h * x_w
max_image_length = min(effective_resolution.max(), max_image_length)
valid_idx = x_mask.nonzero(as_tuple=False)
non_valid_idx = (1 - x_mask).nonzero(as_tuple=False)
unique_rows = valid_idx[:, 0].unique()
valid_row_idx = [valid_idx[valid_idx[:, 0] == u] for u in unique_rows]
non_valid_row_idx = [non_valid_idx[non_valid_idx[:, 0] == u] for u in unique_rows]
valid_nums = [v.size(0) for v in valid_row_idx]
non_valid_nums = [v.size(0) for v in non_valid_row_idx]
pad_nums = [max_image_length - v for v in valid_nums]
select = []
for i, (v, nv, p) in enumerate(zip(valid_nums, non_valid_nums, pad_nums)):
if p <= 0:
valid_choice = torch.multinomial(torch.ones(v).float(), max_image_length)
select.append(valid_row_idx[i][valid_choice])
else:
pad_choice = torch.multinomial(torch.ones(nv).float(), p, replacement=True)
select.append(torch.cat([valid_row_idx[i], non_valid_row_idx[i][pad_choice]], dim=0))
select = torch.cat(select, dim=0)
x = x[select[:, 0], select[:, 1]].view(batch_size, -1, num_channels)
x_mask = x_mask[select[:, 0], select[:, 1]].view(batch_size, -1)
# `patch_index` should be on the same device as `select` (for torch>=1.13), which is ensured at definition time.
patch_index = patch_index[select[:, 0], select[:, 1]].view(batch_size, -1, 2)
pos_embed = pos_embed[select[:, 0], select[:, 1]].view(batch_size, -1, num_channels)
cls_tokens = self.cls_token.expand(batch_size, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
pos_embed = torch.cat(
(self.position_embeddings[:, 0, :][:, None, :].expand(batch_size, -1, -1), pos_embed), dim=1
)
x = x + pos_embed
x = self.dropout(x)
x_mask = torch.cat([torch.ones(x_mask.shape[0], 1).to(x_mask), x_mask], dim=1)
return x, x_mask, (patch_index, (height, width))
def forward(
self,
input_ids,
attention_mask,
token_type_ids,
pixel_values,
pixel_mask,
inputs_embeds,
image_embeds,
image_token_type_idx=1,
):
# PART 1: text embeddings
text_embeds = self.text_embeddings(
input_ids=input_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
)
# PART 2: patch embeddings (with interpolated position encodings)
if image_embeds is None:
image_embeds, image_masks, patch_index = self.visual_embed(
pixel_values, pixel_mask, max_image_length=self.config.max_image_length
)
else:
image_masks = pixel_mask.flatten(1)
# PART 3: add modality type embeddings
# 0 indicates text, 1 indicates image, 2 is optionally used when a second image is provided (NLVR2)
if image_token_type_idx is None:
image_token_type_idx = 1
text_embeds = text_embeds + self.token_type_embeddings(
torch.zeros_like(attention_mask, dtype=torch.long, device=text_embeds.device)
)
image_embeds = image_embeds + self.token_type_embeddings(
torch.full_like(image_masks, image_token_type_idx, dtype=torch.long, device=text_embeds.device)
)
# PART 4: concatenate
embeddings = torch.cat([text_embeds, image_embeds], dim=1)
masks = torch.cat([attention_mask, image_masks], dim=1)
return embeddings, masks
class TextEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
self.register_buffer(
"position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=False
)
self.register_buffer(
"token_type_ids", torch.zeros(self.position_ids.size(), dtype=torch.long), persistent=False
)
def forward(self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None):
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
if position_ids is None:
position_ids = self.position_ids[:, :seq_length]
# Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs
# when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves
# issue #5664
if token_type_ids is None:
if hasattr(self, "token_type_ids"):
buffered_token_type_ids = self.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + token_type_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
class ViltPatchEmbeddings(nn.Module):
"""
Image to Patch Embedding.
"""
def __init__(self, config):
super().__init__()
image_size, patch_size = config.image_size, config.patch_size
num_channels, hidden_size = config.num_channels, config.hidden_size
image_size = image_size if isinstance(image_size, collections.abc.Iterable) else (image_size, image_size)
patch_size = patch_size if isinstance(patch_size, collections.abc.Iterable) else (patch_size, patch_size)
num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.num_patches = num_patches
self.projection = nn.Conv2d(num_channels, hidden_size, kernel_size=patch_size, stride=patch_size)
def forward(self, pixel_values):
batch_size, num_channels, height, width = pixel_values.shape
if num_channels != self.num_channels:
raise ValueError(
"Make sure that the channel dimension of the pixel values match with the one set in the configuration."
)
target_dtype = self.projection.weight.dtype
x = self.projection(pixel_values.to(dtype=target_dtype))
return x
class ViltSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
f"heads {config.num_attention_heads}."
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
self.key = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
self.value = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self, hidden_states, attention_mask=None, head_mask=None, output_attentions=False):
mixed_query_layer = self.query(hidden_states)
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
return outputs
# Copied from transformers.models.vit.modeling_vit.ViTSelfOutput with ViT->Vilt
class ViltSelfOutput(nn.Module):
"""
The residual connection is defined in ViltLayer instead of here (as is the case with other models), due to the
layernorm applied before each block.
"""
def __init__(self, config: ViltConfig) -> None:
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
return hidden_states
class ViltAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.attention = ViltSelfAttention(config)
self.output = ViltSelfOutput(config)
self.pruned_heads = set()
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.attention.num_attention_heads, self.attention.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.attention.query = prune_linear_layer(self.attention.query, index)
self.attention.key = prune_linear_layer(self.attention.key, index)
self.attention.value = prune_linear_layer(self.attention.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.attention.num_attention_heads = self.attention.num_attention_heads - len(heads)
self.attention.all_head_size = self.attention.attention_head_size * self.attention.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(self, hidden_states, attention_mask=None, head_mask=None, output_attentions=False):
self_outputs = self.attention(hidden_states, attention_mask, head_mask, output_attentions)
attention_output = self.output(self_outputs[0], hidden_states)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
# Copied from transformers.models.vit.modeling_vit.ViTIntermediate with ViT->Vilt
class ViltIntermediate(nn.Module):
def __init__(self, config: ViltConfig) -> None:
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
# Copied from transformers.models.vit.modeling_vit.ViTOutput with ViT->Vilt
class ViltOutput(nn.Module):
def __init__(self, config: ViltConfig) -> None:
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = hidden_states + input_tensor
return hidden_states
class ViltLayer(nn.Module):
"""This corresponds to the Block class in the timm implementation."""
def __init__(self, config):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = ViltAttention(config)
self.intermediate = ViltIntermediate(config)
self.output = ViltOutput(config)
self.layernorm_before = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.layernorm_after = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states, attention_mask=None, head_mask=None, output_attentions=False):
self_attention_outputs = self.attention(
self.layernorm_before(hidden_states), # in ViLT, layernorm is applied before self-attention
attention_mask,
head_mask,
output_attentions=output_attentions,
)
attention_output = self_attention_outputs[0]
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
# first residual connection
hidden_states = attention_output + hidden_states.to(attention_output.device)
# in ViLT, layernorm is also applied after self-attention
layer_output = self.layernorm_after(hidden_states)
layer_output = self.intermediate(layer_output)
# second residual connection is done here
layer_output = self.output(layer_output, hidden_states)
outputs = (layer_output,) + outputs
return outputs
class ViltEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.layer = nn.ModuleList([ViltLayer(config) for _ in range(config.num_hidden_layers)])
self.gradient_checkpointing = False
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
output_attentions=False,
output_hidden_states=False,
return_dict=True,
):
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
layer_module.__call__,
hidden_states,
attention_mask,
layer_head_mask,
output_attentions,
)
else:
layer_outputs = layer_module(hidden_states, attention_mask, layer_head_mask, output_attentions)
hidden_states = layer_outputs[0]
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
class ViltPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = ViltConfig
base_model_prefix = "vilt"
supports_gradient_checkpointing = True
_no_split_modules = ["ViltEmbeddings", "ViltSelfAttention"]
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, (nn.Linear, nn.Conv2d)):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
VILT_START_DOCSTRING = r"""
This model is a PyTorch `torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>`_ subclass. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
Parameters:
config ([`ViltConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
VILT_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `({0})`):
Indices of input sequence tokens in the vocabulary. Indices can be obtained using [`AutoTokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for details. [What are input
IDs?](../glossary#input-ids)
attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
[`ViltImageProcessor.__call__`] for details.
pixel_mask (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
- 1 for pixels that are real (i.e. **not masked**),
- 0 for pixels that are padding (i.e. **masked**).
`What are attention masks? <../glossary.html#attention-mask>`__
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
image_embeds (`torch.FloatTensor` of shape `(batch_size, num_patches, hidden_size)`, *optional*):
Optionally, instead of passing `pixel_values`, you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `pixel_values` into patch embeddings.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
VILT_IMAGES_AND_TEXT_CLASSIFICATION_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `({0})`):
Indices of input sequence tokens in the vocabulary. Indices can be obtained using [`AutoTokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for details. [What are input
IDs?](../glossary#input-ids)
attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_images, num_channels, height, width)`):
Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
[`ViltImageProcessor.__call__`] for details.
pixel_mask (`torch.LongTensor` of shape `(batch_size, num_images, height, width)`, *optional*):
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
- 1 for pixels that are real (i.e. **not masked**),
- 0 for pixels that are padding (i.e. **masked**).
`What are attention masks? <../glossary.html#attention-mask>`__
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
image_embeds (`torch.FloatTensor` of shape `(batch_size, num_images, num_patches, hidden_size)`, *optional*):
Optionally, instead of passing `pixel_values`, you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `pixel_values` into patch embeddings.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
@add_start_docstrings(
"The bare ViLT Model transformer outputting raw hidden-states without any specific head on top.",
VILT_START_DOCSTRING,
)
class ViltModel(ViltPreTrainedModel):
def __init__(self, config, add_pooling_layer=True):
super().__init__(config)
self.config = config
self.embeddings = ViltEmbeddings(config)
self.encoder = ViltEncoder(config)
self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.pooler = ViltPooler(config) if add_pooling_layer else None
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.embeddings.text_embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.text_embeddings.word_embeddings = value
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward(VILT_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
pixel_values: Optional[torch.FloatTensor] = None,
pixel_mask: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
image_embeds: Optional[torch.FloatTensor] = None,
image_token_type_idx: Optional[int] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[BaseModelOutputWithPooling, Tuple[torch.FloatTensor]]:
r"""
Returns:
Examples:
```python
>>> from transformers import ViltProcessor, ViltModel
>>> from PIL import Image
>>> import requests
>>> # prepare image and text
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> text = "hello world"
>>> processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-mlm")
>>> model = ViltModel.from_pretrained("dandelin/vilt-b32-mlm")
>>> inputs = processor(image, text, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
text_batch_size, seq_length = input_shape
device = input_ids.device if input_ids is not None else inputs_embeds.device
if attention_mask is None:
attention_mask = torch.ones(((text_batch_size, seq_length)), device=device)
if pixel_values is not None and image_embeds is not None:
raise ValueError("You cannot specify both pixel_values and image_embeds at the same time")
elif pixel_values is None and image_embeds is None:
raise ValueError("You have to specify either pixel_values or image_embeds")
image_batch_size = pixel_values.shape[0] if pixel_values is not None else image_embeds.shape[0]
if image_batch_size != text_batch_size:
raise ValueError("The text inputs and image inputs need to have the same batch size")
if pixel_mask is None:
pixel_mask = torch.ones((image_batch_size, self.config.image_size, self.config.image_size), device=device)
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output, attention_mask = self.embeddings(
input_ids,
attention_mask,
token_type_ids,
pixel_values,
pixel_mask,
inputs_embeds,
image_embeds,
image_token_type_idx=image_token_type_idx,
)
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape)
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
sequence_output = self.layernorm(sequence_output)
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPooling(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
class ViltPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
@add_start_docstrings(
"""
ViLT Model with a language modeling head on top as done during pretraining.
""",
VILT_START_DOCSTRING,
)
class ViltForMaskedLM(ViltPreTrainedModel):
_tied_weights_keys = ["mlm_score.decoder.weight", "mlm_score.decoder.bias"]
def __init__(self, config):
super().__init__(config)
self.vilt = ViltModel(config)
self.mlm_score = ViltMLMHead(config)
# Initialize weights and apply final processing
self.post_init()
def get_output_embeddings(self):
return self.mlm_score.decoder
def set_output_embeddings(self, new_embeddings):
self.mlm_score.decoder = new_embeddings
self.mlm_score.bias = new_embeddings.bias
@add_start_docstrings_to_model_forward(VILT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=MaskedLMOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
pixel_values: Optional[torch.FloatTensor] = None,
pixel_mask: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
image_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[MaskedLMOutput, Tuple[torch.FloatTensor]]:
r"""
labels (*torch.LongTensor* of shape *(batch_size, sequence_length)*, *optional*):
Labels for computing the masked language modeling loss. Indices should be in *[-100, 0, ...,
config.vocab_size]* (see *input_ids* docstring) Tokens with indices set to *-100* are ignored (masked), the
loss is only computed for the tokens with labels in *[0, ..., config.vocab_size]*
Returns:
Examples:
```python
>>> from transformers import ViltProcessor, ViltForMaskedLM
>>> import requests
>>> from PIL import Image
>>> import re
>>> import torch
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> text = "a bunch of [MASK] laying on a [MASK]."
>>> processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-mlm")
>>> model = ViltForMaskedLM.from_pretrained("dandelin/vilt-b32-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> tl = len(re.findall("\[MASK\]", text))
>>> inferred_token = [text]
>>> # gradually fill in the MASK tokens, one by one
>>> with torch.no_grad():
... for i in range(tl):
... encoded = processor.tokenizer(inferred_token)
... input_ids = torch.tensor(encoded.input_ids)
... encoded = encoded["input_ids"][0][1:-1]
... outputs = model(input_ids=input_ids, pixel_values=encoding.pixel_values)
... mlm_logits = outputs.logits[0] # shape (seq_len, vocab_size)
... # only take into account text features (minus CLS and SEP token)
... mlm_logits = mlm_logits[1 : input_ids.shape[1] - 1, :]
... mlm_values, mlm_ids = mlm_logits.softmax(dim=-1).max(dim=-1)
... # only take into account text
... mlm_values[torch.tensor(encoded) != 103] = 0
... select = mlm_values.argmax().item()
... encoded[select] = mlm_ids[select].item()
... inferred_token = [processor.decode(encoded)]
>>> selected_token = ""
>>> encoded = processor.tokenizer(inferred_token)
>>> output = processor.decode(encoded.input_ids[0], skip_special_tokens=True)
>>> print(output)
a bunch of cats laying on a couch.
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.vilt(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
pixel_values=pixel_values,
pixel_mask=pixel_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
image_embeds=image_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output, pooled_output = outputs[:2]
# split up final hidden states into text and image features
text_seq_len = input_ids.shape[1] if input_ids is not None else inputs_embeds.shape[1]
text_features, _ = (sequence_output[:, :text_seq_len], sequence_output[:, text_seq_len:])
mlm_logits = self.mlm_score(text_features)
masked_lm_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss() # -100 index = padding token
# move labels to correct device to enable PP
labels = labels.to(mlm_logits.device)
masked_lm_loss = loss_fct(mlm_logits.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (mlm_logits,) + outputs[2:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return MaskedLMOutput(
loss=masked_lm_loss,
logits=mlm_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
class ViltPredictionHeadTransform(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
if isinstance(config.hidden_act, str):
self.transform_act_fn = ACT2FN[config.hidden_act]
else:
self.transform_act_fn = config.hidden_act
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(hidden_states)
return hidden_states
class ViltMLMHead(nn.Module):
def __init__(self, config, weight=None):
super().__init__()
self.config = config
self.transform = ViltPredictionHeadTransform(config)
self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
if weight is not None:
self.decoder.weight = weight
# Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
self.decoder.bias = self.bias
def _tie_weights(self):
self.decoder.bias = self.bias
def forward(self, x):
x = self.transform(x)
x = self.decoder(x)
return x
@add_start_docstrings(
"""
Vilt Model transformer with a classifier head on top (a linear layer on top of the final hidden state of the [CLS]
token) for visual question answering, e.g. for VQAv2.
""",
VILT_START_DOCSTRING,
)
class ViltForQuestionAnswering(ViltPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.vilt = ViltModel(config)
# Classifier head
self.classifier = nn.Sequential(
nn.Linear(config.hidden_size, config.hidden_size * 2),
nn.LayerNorm(config.hidden_size * 2),
nn.GELU(),
nn.Linear(config.hidden_size * 2, config.num_labels),
)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(VILT_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=SequenceClassifierOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
pixel_values: Optional[torch.FloatTensor] = None,
pixel_mask: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
image_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[SequenceClassifierOutput, Tuple[torch.FloatTensor]]:
r"""
labels (`torch.FloatTensor` of shape `(batch_size, num_labels)`, *optional*):
Labels for computing the visual question answering loss. This tensor must be either a one-hot encoding of
all answers that are applicable for a given example in the batch, or a soft encoding indicating which
answers are applicable, where 1.0 is the highest score.
Returns:
Examples:
```python
>>> from transformers import ViltProcessor, ViltForQuestionAnswering
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> text = "How many cats are there?"
>>> processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
>>> model = ViltForQuestionAnswering.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> logits = outputs.logits
>>> idx = logits.argmax(-1).item()
>>> print("Predicted answer:", model.config.id2label[idx])
Predicted answer: 2
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.vilt(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
pixel_values=pixel_values,
pixel_mask=pixel_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
image_embeds=image_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooler_output = outputs.pooler_output if return_dict else outputs[1]
logits = self.classifier(pooler_output)
loss = None
if labels is not None:
# move labels to correct device to enable PP
labels = labels.to(logits.device)
loss = nn.functional.binary_cross_entropy_with_logits(logits, labels) * labels.shape[1]
# see https://github.com/jnhwkim/ban-vqa/blob/master/train.py#L19
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
Vilt Model transformer with a classifier head on top (a linear layer on top of the final hidden state of the [CLS]
token) for image-to-text or text-to-image retrieval, e.g. MSCOCO and F30K.
""",
VILT_START_DOCSTRING,
)
class ViltForImageAndTextRetrieval(ViltPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.vilt = ViltModel(config)
# Classifier head
self.rank_output = nn.Linear(config.hidden_size, 1)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(VILT_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=SequenceClassifierOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
pixel_values: Optional[torch.FloatTensor] = None,
pixel_mask: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
image_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[SequenceClassifierOutput, Tuple[torch.FloatTensor]]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels are currently not supported.
Returns:
Examples:
```python
>>> from transformers import ViltProcessor, ViltForImageAndTextRetrieval
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-coco")
>>> model = ViltForImageAndTextRetrieval.from_pretrained("dandelin/vilt-b32-finetuned-coco")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, :].item()
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
loss = None
if labels is not None:
raise NotImplementedError("Training is not yet supported.")
outputs = self.vilt(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
pixel_values=pixel_values,
pixel_mask=pixel_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
image_embeds=image_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooler_output = outputs.pooler_output if return_dict else outputs[1]
logits = self.rank_output(pooler_output)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
Vilt Model transformer with a classifier head on top for natural language visual reasoning, e.g. NLVR2.
""",
VILT_IMAGES_AND_TEXT_CLASSIFICATION_INPUTS_DOCSTRING,
)
class ViltForImagesAndTextClassification(ViltPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.vilt = ViltModel(config)
# Classifier head
num_images = config.num_images
self.classifier = nn.Sequential(
nn.Linear(config.hidden_size * num_images, config.hidden_size * num_images),
nn.LayerNorm(config.hidden_size * num_images),
nn.GELU(),
nn.Linear(config.hidden_size * num_images, config.num_labels),
)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(VILT_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=ViltForImagesAndTextClassificationOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
pixel_values: Optional[torch.FloatTensor] = None,
pixel_mask: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
image_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[ViltForImagesAndTextClassificationOutput, Tuple[torch.FloatTensor]]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Binary classification labels.
Returns:
Examples:
```python
>>> from transformers import ViltProcessor, ViltForImagesAndTextClassification
>>> import requests
>>> from PIL import Image
>>> image1 = Image.open(requests.get("https://lil.nlp.cornell.edu/nlvr/exs/ex0_0.jpg", stream=True).raw)
>>> image2 = Image.open(requests.get("https://lil.nlp.cornell.edu/nlvr/exs/ex0_1.jpg", stream=True).raw)
>>> text = "The left image contains twice the number of dogs as the right image."
>>> processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-nlvr2")
>>> model = ViltForImagesAndTextClassification.from_pretrained("dandelin/vilt-b32-finetuned-nlvr2")
>>> # prepare inputs
>>> encoding = processor([image1, image2], text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(input_ids=encoding.input_ids, pixel_values=encoding.pixel_values.unsqueeze(0))
>>> logits = outputs.logits
>>> idx = logits.argmax(-1).item()
>>> print("Predicted answer:", model.config.id2label[idx])
Predicted answer: True
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if pixel_values is not None and pixel_values.ndim == 4:
# add dummy num_images dimension
pixel_values = pixel_values.unsqueeze(1)
if image_embeds is not None and image_embeds.ndim == 3:
# add dummy num_images dimension
image_embeds = image_embeds.unsqueeze(1)
num_images = pixel_values.shape[1] if pixel_values is not None else None
if num_images is None:
num_images = image_embeds.shape[1] if image_embeds is not None else None
if num_images != self.config.num_images:
raise ValueError(
"Make sure to match the number of images in the model with the number of images in the input."
)
pooler_outputs = []
hidden_states = [] if output_hidden_states else None
attentions = [] if output_attentions else None
for i in range(num_images):
# forward every image through the model
outputs = self.vilt(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
pixel_values=pixel_values[:, i, :, :, :] if pixel_values is not None else None,
pixel_mask=pixel_mask[:, i, :, :] if pixel_mask is not None else None,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
image_embeds=image_embeds[:, i, :, :] if image_embeds is not None else None,
image_token_type_idx=i + 1,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooler_output = outputs.pooler_output if return_dict else outputs[1]
pooler_outputs.append(pooler_output)
if output_hidden_states:
hidden_states.append(outputs.hidden_states)
if output_attentions:
attentions.append(outputs.attentions)
pooled_output = torch.cat(pooler_outputs, dim=-1)
logits = self.classifier(pooled_output)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
# move labels to correct device to enable PP
labels = labels.to(logits.device)
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
if not return_dict:
output = (logits, hidden_states, attentions)
return ((loss,) + output) if loss is not None else output
return ViltForImagesAndTextClassificationOutput(
loss=loss,
logits=logits,
hidden_states=hidden_states,
attentions=attentions,
)
@add_start_docstrings(
"""
ViLT Model with a token classification head on top (a linear layer on top of the final hidden-states of the text
tokens) e.g. for Named-Entity-Recognition (NER) tasks.
""",
VILT_START_DOCSTRING,
)
class ViltForTokenClassification(ViltPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.vilt = ViltModel(config, add_pooling_layer=False)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(VILT_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=TokenClassifierOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
pixel_values: Optional[torch.FloatTensor] = None,
pixel_mask: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
image_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[TokenClassifierOutput, Tuple[torch.FloatTensor]]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, text_sequence_length)`, *optional*):
Labels for computing the token classification loss. Indices should be in `[0, ..., config.num_labels - 1]`.
Returns:
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.vilt(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
pixel_values=pixel_values,
pixel_mask=pixel_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
image_embeds=image_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
text_input_size = input_ids.shape[1] if input_ids is not None else inputs_embeds.shape[1]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output[:, :text_input_size])
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
# move labels to correct device to enable PP
labels = labels.to(logits.device)
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
__all__ = [
"ViltForImageAndTextRetrieval",
"ViltForImagesAndTextClassification",
"ViltForTokenClassification",
"ViltForMaskedLM",
"ViltForQuestionAnswering",
"ViltLayer",
"ViltModel",
"ViltPreTrainedModel",
]
| transformers/src/transformers/models/vilt/modeling_vilt.py/0 | {
"file_path": "transformers/src/transformers/models/vilt/modeling_vilt.py",
"repo_id": "transformers",
"token_count": 27577
} |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Processor class for VisionTextDualEncoder
"""
import warnings
from ...processing_utils import ProcessorMixin
from ...tokenization_utils_base import BatchEncoding
class VisionTextDualEncoderProcessor(ProcessorMixin):
r"""
Constructs a VisionTextDualEncoder processor which wraps an image processor and a tokenizer into a single
processor.
[`VisionTextDualEncoderProcessor`] offers all the functionalities of [`AutoImageProcessor`] and [`AutoTokenizer`].
See the [`~VisionTextDualEncoderProcessor.__call__`] and [`~VisionTextDualEncoderProcessor.decode`] for more
information.
Args:
image_processor ([`AutoImageProcessor`], *optional*):
The image processor is a required input.
tokenizer ([`PreTrainedTokenizer`], *optional*):
The tokenizer is a required input.
"""
attributes = ["image_processor", "tokenizer"]
image_processor_class = "AutoImageProcessor"
tokenizer_class = "AutoTokenizer"
def __init__(self, image_processor=None, tokenizer=None, **kwargs):
feature_extractor = None
if "feature_extractor" in kwargs:
warnings.warn(
"The `feature_extractor` argument is deprecated and will be removed in v5, use `image_processor`"
" instead.",
FutureWarning,
)
feature_extractor = kwargs.pop("feature_extractor")
image_processor = image_processor if image_processor is not None else feature_extractor
if image_processor is None:
raise ValueError("You have to specify an image_processor.")
if tokenizer is None:
raise ValueError("You have to specify a tokenizer.")
super().__init__(image_processor, tokenizer)
self.current_processor = self.image_processor
def __call__(self, text=None, images=None, return_tensors=None, **kwargs):
"""
Main method to prepare for the model one or several sequences(s) and image(s). This method forwards the `text`
and `kwargs` arguments to VisionTextDualEncoderTokenizer's [`~PreTrainedTokenizer.__call__`] if `text` is not
`None` to encode the text. To prepare the image(s), this method forwards the `images` and `kwargs` arguments to
AutoImageProcessor's [`~AutoImageProcessor.__call__`] if `images` is not `None`. Please refer to the doctsring
of the above two methods for more information.
Args:
text (`str`, `List[str]`, `List[List[str]]`):
The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
(pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
`is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
tensor. Both channels-first and channels-last formats are supported.
return_tensors (`str` or [`~utils.TensorType`], *optional*):
If set, will return tensors of a particular framework. Acceptable values are:
- `'tf'`: Return TensorFlow `tf.constant` objects.
- `'pt'`: Return PyTorch `torch.Tensor` objects.
- `'np'`: Return NumPy `np.ndarray` objects.
- `'jax'`: Return JAX `jnp.ndarray` objects.
Returns:
[`BatchEncoding`]: A [`BatchEncoding`] with the following fields:
- **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None`.
- **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
`return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names` and if `text` is not
`None`).
- **pixel_values** -- Pixel values to be fed to a model. Returned when `images` is not `None`.
"""
if text is None and images is None:
raise ValueError("You have to specify either text or images. Both cannot be none.")
if text is not None:
encoding = self.tokenizer(text, return_tensors=return_tensors, **kwargs)
if images is not None:
image_features = self.image_processor(images, return_tensors=return_tensors, **kwargs)
if text is not None and images is not None:
encoding["pixel_values"] = image_features.pixel_values
return encoding
elif text is not None:
return encoding
else:
return BatchEncoding(data=dict(**image_features), tensor_type=return_tensors)
def batch_decode(self, *args, **kwargs):
"""
This method forwards all its arguments to VisionTextDualEncoderTokenizer's
[`~PreTrainedTokenizer.batch_decode`]. Please refer to the docstring of this method for more information.
"""
return self.tokenizer.batch_decode(*args, **kwargs)
def decode(self, *args, **kwargs):
"""
This method forwards all its arguments to VisionTextDualEncoderTokenizer's [`~PreTrainedTokenizer.decode`].
Please refer to the docstring of this method for more information.
"""
return self.tokenizer.decode(*args, **kwargs)
@property
def model_input_names(self):
tokenizer_input_names = self.tokenizer.model_input_names
image_processor_input_names = self.image_processor.model_input_names
return list(dict.fromkeys(tokenizer_input_names + image_processor_input_names))
@property
def feature_extractor_class(self):
warnings.warn(
"`feature_extractor_class` is deprecated and will be removed in v5. Use `image_processor_class` instead.",
FutureWarning,
)
return self.image_processor_class
@property
def feature_extractor(self):
warnings.warn(
"`feature_extractor` is deprecated and will be removed in v5. Use `image_processor` instead.",
FutureWarning,
)
return self.image_processor
__all__ = ["VisionTextDualEncoderProcessor"]
| transformers/src/transformers/models/vision_text_dual_encoder/processing_vision_text_dual_encoder.py/0 | {
"file_path": "transformers/src/transformers/models/vision_text_dual_encoder/processing_vision_text_dual_encoder.py",
"repo_id": "transformers",
"token_count": 2641
} |
# coding=utf-8
# Copyright 2022 Facebook AI and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""ViT MAE model configuration"""
from ...configuration_utils import PretrainedConfig
from ...utils import logging
logger = logging.get_logger(__name__)
class ViTMAEConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`ViTMAEModel`]. It is used to instantiate an ViT
MAE model according to the specified arguments, defining the model architecture. Instantiating a configuration with
the defaults will yield a similar configuration to that of the ViT
[facebook/vit-mae-base](https://huggingface.co/facebook/vit-mae-base) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
hidden_size (`int`, *optional*, defaults to 768):
Dimensionality of the encoder layers and the pooler layer.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
intermediate_size (`int`, *optional*, defaults to 3072):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` are supported.
hidden_dropout_prob (`float`, *optional*, defaults to 0.0):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (`float`, *optional*, defaults to 1e-12):
The epsilon used by the layer normalization layers.
image_size (`int`, *optional*, defaults to 224):
The size (resolution) of each image.
patch_size (`int`, *optional*, defaults to 16):
The size (resolution) of each patch.
num_channels (`int`, *optional*, defaults to 3):
The number of input channels.
qkv_bias (`bool`, *optional*, defaults to `True`):
Whether to add a bias to the queries, keys and values.
decoder_num_attention_heads (`int`, *optional*, defaults to 16):
Number of attention heads for each attention layer in the decoder.
decoder_hidden_size (`int`, *optional*, defaults to 512):
Dimensionality of the decoder.
decoder_num_hidden_layers (`int`, *optional*, defaults to 8):
Number of hidden layers in the decoder.
decoder_intermediate_size (`int`, *optional*, defaults to 2048):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the decoder.
mask_ratio (`float`, *optional*, defaults to 0.75):
The ratio of the number of masked tokens in the input sequence.
norm_pix_loss (`bool`, *optional*, defaults to `False`):
Whether or not to train with normalized pixels (see Table 3 in the paper). Using normalized pixels improved
representation quality in the experiments of the authors.
Example:
```python
>>> from transformers import ViTMAEConfig, ViTMAEModel
>>> # Initializing a ViT MAE vit-mae-base style configuration
>>> configuration = ViTMAEConfig()
>>> # Initializing a model (with random weights) from the vit-mae-base style configuration
>>> model = ViTMAEModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "vit_mae"
def __init__(
self,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.0,
attention_probs_dropout_prob=0.0,
initializer_range=0.02,
layer_norm_eps=1e-12,
image_size=224,
patch_size=16,
num_channels=3,
qkv_bias=True,
decoder_num_attention_heads=16,
decoder_hidden_size=512,
decoder_num_hidden_layers=8,
decoder_intermediate_size=2048,
mask_ratio=0.75,
norm_pix_loss=False,
**kwargs,
):
super().__init__(**kwargs)
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.initializer_range = initializer_range
self.layer_norm_eps = layer_norm_eps
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.qkv_bias = qkv_bias
self.decoder_num_attention_heads = decoder_num_attention_heads
self.decoder_hidden_size = decoder_hidden_size
self.decoder_num_hidden_layers = decoder_num_hidden_layers
self.decoder_intermediate_size = decoder_intermediate_size
self.mask_ratio = mask_ratio
self.norm_pix_loss = norm_pix_loss
__all__ = ["ViTMAEConfig"]
| transformers/src/transformers/models/vit_mae/configuration_vit_mae.py/0 | {
"file_path": "transformers/src/transformers/models/vit_mae/configuration_vit_mae.py",
"repo_id": "transformers",
"token_count": 2418
} |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Speech processor class for Wav2Vec2-BERT
"""
import warnings
from typing import List, Optional, Union
from ...processing_utils import ProcessingKwargs, ProcessorMixin, Unpack
from ...tokenization_utils_base import AudioInput, PreTokenizedInput, TextInput
from ..seamless_m4t.feature_extraction_seamless_m4t import SeamlessM4TFeatureExtractor
from ..wav2vec2.tokenization_wav2vec2 import Wav2Vec2CTCTokenizer
class Wav2Vec2BertProcessorKwargs(ProcessingKwargs, total=False):
_defaults = {}
class Wav2Vec2BertProcessor(ProcessorMixin):
r"""
Constructs a Wav2Vec2-BERT processor which wraps a Wav2Vec2-BERT feature extractor and a Wav2Vec2 CTC tokenizer into a single
processor.
[`Wav2Vec2Processor`] offers all the functionalities of [`SeamlessM4TFeatureExtractor`] and [`PreTrainedTokenizer`].
See the docstring of [`~Wav2Vec2Processor.__call__`] and [`~Wav2Vec2Processor.decode`] for more information.
Args:
feature_extractor (`SeamlessM4TFeatureExtractor`):
An instance of [`SeamlessM4TFeatureExtractor`]. The feature extractor is a required input.
tokenizer ([`PreTrainedTokenizer`]):
An instance of [`PreTrainedTokenizer`]. The tokenizer is a required input.
"""
feature_extractor_class = "SeamlessM4TFeatureExtractor"
tokenizer_class = "AutoTokenizer"
def __init__(self, feature_extractor, tokenizer):
super().__init__(feature_extractor, tokenizer)
@classmethod
def from_pretrained(cls, pretrained_model_name_or_path, **kwargs):
try:
return super().from_pretrained(pretrained_model_name_or_path, **kwargs)
except OSError:
warnings.warn(
f"Loading a tokenizer inside {cls.__name__} from a config that does not"
" include a `tokenizer_class` attribute is deprecated and will be "
"removed in v5. Please add `'tokenizer_class': 'Wav2Vec2CTCTokenizer'`"
" attribute to either your `config.json` or `tokenizer_config.json` "
"file to suppress this warning: ",
FutureWarning,
)
feature_extractor = SeamlessM4TFeatureExtractor.from_pretrained(pretrained_model_name_or_path, **kwargs)
tokenizer = Wav2Vec2CTCTokenizer.from_pretrained(pretrained_model_name_or_path, **kwargs)
return cls(feature_extractor=feature_extractor, tokenizer=tokenizer)
def __call__(
self,
audio: AudioInput = None,
text: Optional[Union[str, List[str], TextInput, PreTokenizedInput]] = None,
images=None,
videos=None,
**kwargs: Unpack[Wav2Vec2BertProcessorKwargs],
):
"""
Main method to prepare for the model one or several sequences(s) and audio(s). This method forwards the `audio`
and `kwargs` arguments to SeamlessM4TFeatureExtractor's [`~SeamlessM4TFeatureExtractor.__call__`] if `audio` is not
`None` to pre-process the audio. To prepare the target sequences(s), this method forwards the `text` and `kwargs` arguments to
PreTrainedTokenizer's [`~PreTrainedTokenizer.__call__`] if `text` is not `None`. Please refer to the doctsring of the above two methods for more information.
Args:
audio (`np.ndarray`, `torch.Tensor`, `List[np.ndarray]`, `List[torch.Tensor]`):
The audio or batch of audios to be prepared. Each audio can be NumPy array or PyTorch tensor. In case
of a NumPy array/PyTorch tensor, each audio should be of shape (C, T), where C is a number of channels,
and T the sample length of the audio.
text (`str`, `List[str]`, `List[List[str]]`):
The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
(pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
`is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
Returns:
[`BatchEncoding`]: A [`BatchEncoding`] with the following fields:
- **input_features** -- Audio input features to be fed to a model. Returned when `audio` is not `None`.
- **attention_mask** -- List of indices specifying which timestamps should be attended to by the model when `audio` is not `None`.
When only `text` is specified, returns the token attention mask.
- **labels** -- List of token ids to be fed to a model. Returned when both `text` and `audio` are not `None`.
- **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None` and `audio` is `None`.
"""
if audio is None and text is None:
raise ValueError("You need to specify either an `audio` or `text` input to process.")
output_kwargs = self._merge_kwargs(
Wav2Vec2BertProcessorKwargs,
tokenizer_init_kwargs=self.tokenizer.init_kwargs,
**kwargs,
)
if audio is not None:
inputs = self.feature_extractor(audio, **output_kwargs["audio_kwargs"])
if text is not None:
encodings = self.tokenizer(text, **output_kwargs["text_kwargs"])
if text is None:
return inputs
elif audio is None:
return encodings
else:
inputs["labels"] = encodings["input_ids"]
return inputs
def pad(self, input_features=None, labels=None, **kwargs):
"""
If `input_features` is not `None`, this method forwards the `input_features` and `kwargs` arguments to SeamlessM4TFeatureExtractor's [`~SeamlessM4TFeatureExtractor.pad`] to pad the input features.
If `labels` is not `None`, this method forwards the `labels` and `kwargs` arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.pad`] to pad the label(s).
Please refer to the doctsring of the above two methods for more information.
"""
if input_features is None and labels is None:
raise ValueError("You need to specify either an `input_features` or `labels` input to pad.")
if input_features is not None:
input_features = self.feature_extractor.pad(input_features, **kwargs)
if labels is not None:
labels = self.tokenizer.pad(labels, **kwargs)
if labels is None:
return input_features
elif input_features is None:
return labels
else:
input_features["labels"] = labels["input_ids"]
return input_features
def batch_decode(self, *args, **kwargs):
"""
This method forwards all its arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.batch_decode`]. Please
refer to the docstring of this method for more information.
"""
return self.tokenizer.batch_decode(*args, **kwargs)
def decode(self, *args, **kwargs):
"""
This method forwards all its arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.decode`]. Please refer
to the docstring of this method for more information.
"""
return self.tokenizer.decode(*args, **kwargs)
__all__ = ["Wav2Vec2BertProcessor"]
| transformers/src/transformers/models/wav2vec2_bert/processing_wav2vec2_bert.py/0 | {
"file_path": "transformers/src/transformers/models/wav2vec2_bert/processing_wav2vec2_bert.py",
"repo_id": "transformers",
"token_count": 3092
} |
#!/usr/bin/env python
"""Converts a Whisper model in OpenAI format to Hugging Face format."""
# Copyright 2022 The HuggingFace Inc. team and the OpenAI team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import io
import json
import os
import tempfile
import urllib
import warnings
from typing import Any, List, Optional, Tuple
import torch
from huggingface_hub.utils import insecure_hashlib
from torch import nn
from tqdm import tqdm
from transformers import (
GenerationConfig,
WhisperConfig,
WhisperFeatureExtractor,
WhisperForConditionalGeneration,
WhisperProcessor,
WhisperTokenizer,
WhisperTokenizerFast,
)
from transformers.models.whisper.tokenization_whisper import LANGUAGES, bytes_to_unicode
from transformers.utils.import_utils import _is_package_available
_MODELS = {
"tiny.en": "https://openaipublic.azureedge.net/main/whisper/models/d3dd57d32accea0b295c96e26691aa14d8822fac7d9d27d5dc00b4ca2826dd03/tiny.en.pt",
"tiny": "https://openaipublic.azureedge.net/main/whisper/models/65147644a518d12f04e32d6f3b26facc3f8dd46e5390956a9424a650c0ce22b9/tiny.pt",
"base.en": "https://openaipublic.azureedge.net/main/whisper/models/25a8566e1d0c1e2231d1c762132cd20e0f96a85d16145c3a00adf5d1ac670ead/base.en.pt",
"base": "https://openaipublic.azureedge.net/main/whisper/models/ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e/base.pt",
"small.en": "https://openaipublic.azureedge.net/main/whisper/models/f953ad0fd29cacd07d5a9eda5624af0f6bcf2258be67c92b79389873d91e0872/small.en.pt",
"small": "https://openaipublic.azureedge.net/main/whisper/models/9ecf779972d90ba49c06d968637d720dd632c55bbf19d441fb42bf17a411e794/small.pt",
"medium.en": "https://openaipublic.azureedge.net/main/whisper/models/d7440d1dc186f76616474e0ff0b3b6b879abc9d1a4926b7adfa41db2d497ab4f/medium.en.pt",
"medium": "https://openaipublic.azureedge.net/main/whisper/models/345ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1/medium.pt",
"large": "https://openaipublic.azureedge.net/main/whisper/models/e4b87e7e0bf463eb8e6956e646f1e277e901512310def2c24bf0e11bd3c28e9a/large.pt",
"large-v2": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt",
"large-v3": "https://openaipublic.azureedge.net/main/whisper/models/e5b1a55b89c1367dacf97e3e19bfd829a01529dbfdeefa8caeb59b3f1b81dadb/large-v3.pt",
}
_TOKENIZERS = {
"multilingual": "https://raw.githubusercontent.com/openai/whisper/main/whisper/assets/multilingual.tiktoken",
"english": "https://raw.githubusercontent.com/openai/whisper/main/whisper/assets/gpt2.tiktoken",
}
def _get_generation_config(
is_multilingual: bool,
num_languages: int = 100,
openai_version: Optional[str] = None,
) -> GenerationConfig:
"""
Loads the appropriate generation config from HF repo
"""
if openai_version is not None:
repo = f"openai/whisper-{openai_version}"
elif not is_multilingual:
repo = "openai/whisper-medium.en"
elif num_languages < 100:
repo = "openai/whisper-large-v2"
else:
repo = "openai/whisper-large-v3"
gen_cfg = GenerationConfig.from_pretrained(repo)
if openai_version is None:
gen_cfg.alignment_heads = None
warnings.warn(
"Alignment heads have not been included in the generation config, since they are available "
"only for the original OpenAI checkpoints."
"If you want to use word-level timestamps with a custom version of Whisper,"
"see https://github.com/openai/whisper/blob/main/notebooks/Multilingual_ASR.ipynb"
"for the example of how to produce word-level timestamps manually."
)
return gen_cfg
def remove_ignore_keys_(state_dict):
ignore_keys = ["layers", "blocks"]
for k in ignore_keys:
state_dict.pop(k, None)
WHISPER_MAPPING = {
"blocks": "layers",
"mlp.0": "fc1",
"mlp.2": "fc2",
"mlp_ln": "final_layer_norm",
".attn.query": ".self_attn.q_proj",
".attn.key": ".self_attn.k_proj",
".attn.value": ".self_attn.v_proj",
".attn_ln": ".self_attn_layer_norm",
".attn.out": ".self_attn.out_proj",
".cross_attn.query": ".encoder_attn.q_proj",
".cross_attn.key": ".encoder_attn.k_proj",
".cross_attn.value": ".encoder_attn.v_proj",
".cross_attn_ln": ".encoder_attn_layer_norm",
".cross_attn.out": ".encoder_attn.out_proj",
"decoder.ln.": "decoder.layer_norm.",
"encoder.ln.": "encoder.layer_norm.",
"token_embedding": "embed_tokens",
"encoder.positional_embedding": "encoder.embed_positions.weight",
"decoder.positional_embedding": "decoder.embed_positions.weight",
"ln_post": "layer_norm",
}
def rename_keys(s_dict):
keys = list(s_dict.keys())
for key in keys:
new_key = key
for k, v in WHISPER_MAPPING.items():
if k in key:
new_key = new_key.replace(k, v)
print(f"{key} -> {new_key}")
s_dict[new_key] = s_dict.pop(key)
return s_dict
def make_linear_from_emb(emb):
vocab_size, emb_size = emb.weight.shape
lin_layer = nn.Linear(vocab_size, emb_size, bias=False)
lin_layer.weight.data = emb.weight.data
return lin_layer
def _download(url: str, root: str) -> Any:
os.makedirs(root, exist_ok=True)
filename = os.path.basename(url)
expected_sha256 = url.split("/")[-2]
download_target = os.path.join(root, filename)
if os.path.exists(download_target) and not os.path.isfile(download_target):
raise RuntimeError(f"{download_target} exists and is not a regular file")
if os.path.isfile(download_target):
model_bytes = open(download_target, "rb").read()
if insecure_hashlib.sha256(model_bytes).hexdigest() == expected_sha256:
return torch.load(io.BytesIO(model_bytes))
else:
warnings.warn(f"{download_target} exists, but the SHA256 checksum does not match; re-downloading the file")
with urllib.request.urlopen(url) as source, open(download_target, "wb") as output:
with tqdm(
total=int(source.info().get("Content-Length")), ncols=80, unit="iB", unit_scale=True, unit_divisor=1024
) as loop:
while True:
buffer = source.read(8192)
if not buffer:
break
output.write(buffer)
loop.update(len(buffer))
model_bytes = open(download_target, "rb").read()
if insecure_hashlib.sha256(model_bytes).hexdigest() != expected_sha256:
raise RuntimeError(
"Model has been downloaded but the SHA256 checksum does not match. Please retry loading the model."
)
return torch.load(io.BytesIO(model_bytes))
def convert_openai_whisper_to_tfms(
checkpoint_path, pytorch_dump_folder_path
) -> Tuple[WhisperForConditionalGeneration, bool, int]:
if ".pt" not in checkpoint_path:
root = os.path.dirname(pytorch_dump_folder_path) or "."
original_checkpoint = _download(_MODELS[checkpoint_path], root)
openai_version = checkpoint_path
else:
original_checkpoint = torch.load(checkpoint_path, map_location="cpu")
openai_version = None
dimensions = original_checkpoint["dims"]
state_dict = original_checkpoint["model_state_dict"]
proj_out_weights = state_dict["decoder.token_embedding.weight"]
remove_ignore_keys_(state_dict)
rename_keys(state_dict)
tie_embeds = True
ffn_dim = state_dict["decoder.layers.0.fc1.weight"].shape[0]
# a hacky way to properly set up the bos/eos/pad token ids in the model
endoftext_id = 50257 if dimensions["n_vocab"] > 51865 else 50256
config = WhisperConfig(
vocab_size=dimensions["n_vocab"],
encoder_ffn_dim=ffn_dim,
decoder_ffn_dim=ffn_dim,
num_mel_bins=dimensions["n_mels"],
d_model=dimensions["n_audio_state"],
max_target_positions=dimensions["n_text_ctx"],
encoder_layers=dimensions["n_audio_layer"],
encoder_attention_heads=dimensions["n_audio_head"],
decoder_layers=dimensions["n_text_layer"],
decoder_attention_heads=dimensions["n_text_head"],
max_source_positions=dimensions["n_audio_ctx"],
eos_token_id=endoftext_id,
bos_token_id=endoftext_id,
pad_token_id=endoftext_id,
decoder_start_token_id=endoftext_id + 1,
)
model = WhisperForConditionalGeneration(config)
missing, unexpected = model.model.load_state_dict(state_dict, strict=False)
if len(missing) > 0 and not set(missing) <= {
"encoder.embed_positions.weights",
"decoder.embed_positions.weights",
}:
raise ValueError(
"Only `encoder.embed_positions.weights` and `decoder.embed_positions.weights` are allowed to be missing,"
f" but all the following weights are missing {missing}"
)
if tie_embeds:
model.proj_out = make_linear_from_emb(model.model.decoder.embed_tokens)
else:
model.proj_out.weight.data = proj_out_weights
# determine those parameters from a model checkpoint as Whisper repo does
is_multilingual = model.config.vocab_size >= 51865
num_languages = model.config.vocab_size - 51765 - int(is_multilingual)
model.generation_config = _get_generation_config(
is_multilingual,
num_languages,
openai_version,
)
return model, is_multilingual, num_languages
# Adapted from https://github.com/openai/tiktoken/issues/60#issuecomment-1499977960
def _bpe(mergeable_ranks, token: bytes, max_rank=None) -> List[bytes]:
parts = [bytes([b]) for b in token]
while True:
min_idx = None
min_rank = None
for i, pair in enumerate(zip(parts[:-1], parts[1:])):
rank = mergeable_ranks.get(pair[0] + pair[1])
if rank is not None and (min_rank is None or rank < min_rank):
min_idx = i
min_rank = rank
if min_rank is None or (max_rank is not None and min_rank >= max_rank):
break
assert min_idx is not None
parts = parts[:min_idx] + [parts[min_idx] + parts[min_idx + 1]] + parts[min_idx + 2 :]
return parts
def convert_tiktoken_bpe_to_hf(tiktoken_url: str):
bpe_ranks = load_tiktoken_bpe(tiktoken_url)
byte_encoder = bytes_to_unicode()
def token_bytes_to_string(b):
return "".join([byte_encoder[ord(char)] for char in b.decode("latin-1")])
merges = []
vocab = {}
for token, rank in bpe_ranks.items():
vocab[token_bytes_to_string(token)] = rank
if len(token) == 1:
continue
merged = tuple(_bpe(bpe_ranks, token, max_rank=rank))
if len(merged) == 2: # account for empty token
merges.append(" ".join(map(token_bytes_to_string, merged)))
return vocab, merges
def convert_tiktoken_to_hf(
multilingual: bool = True, num_languages: int = 100, time_precision=0.02
) -> WhisperTokenizer:
# requires whisper, unless we use the path to the tiktoken file
tiktoken_tokenizer_path = _TOKENIZERS["multilingual" if multilingual else "english"]
start_of_transcript = ["<|endoftext|>", "<|startoftranscript|>"]
control_tokens = [
"<|translate|>",
"<|transcribe|>",
"<|startoflm|>",
"<|startofprev|>",
"<|nospeech|>",
"<|notimestamps|>",
]
# these are special tokens, not normalized
language_tokens = [f"<|{k}|>" for k in list(LANGUAGES)[:num_languages]]
# These are not special but normalized
timestamp_tokens = [("<|%.2f|>" % (i * time_precision)) for i in range(1500 + 1)]
vocab, merges = convert_tiktoken_bpe_to_hf(tiktoken_tokenizer_path)
with tempfile.TemporaryDirectory() as tmpdirname:
vocab_file = f"{tmpdirname}/vocab.json"
merge_file = f"{tmpdirname}/merges.txt"
with open(vocab_file, "w", encoding="utf-8") as f:
f.write(json.dumps(vocab, indent=2, sort_keys=True, ensure_ascii=False) + "\n")
with open(merge_file, "w", encoding="utf-8") as writer:
writer.write("#version: 0.2\n")
for bpe_tokens in merges:
writer.write(bpe_tokens + "\n")
hf_tokenizer = WhisperTokenizer(vocab_file, merge_file)
hf_tokenizer.add_tokens(start_of_transcript + language_tokens + control_tokens, special_tokens=True)
hf_tokenizer.add_tokens(timestamp_tokens, special_tokens=False)
return hf_tokenizer
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# # Required parameters
parser.add_argument("--checkpoint_path", type=str, help="Path to the downloaded checkpoints")
parser.add_argument("--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model.")
parser.add_argument(
"--convert_preprocessor",
type=bool,
default=False,
help="Whether or not the preprocessor (tokenizer + feature extractor) should be converted along with the model.",
)
args = parser.parse_args()
model, is_multilingual, num_languages = convert_openai_whisper_to_tfms(
args.checkpoint_path, args.pytorch_dump_folder_path
)
if args.convert_preprocessor:
try:
if not _is_package_available("tiktoken"):
raise ModuleNotFoundError(
"""`tiktoken` is not installed, use `pip install tiktoken` to convert the tokenizer"""
)
except Exception as e:
print(e)
else:
from tiktoken.load import load_tiktoken_bpe
tokenizer = convert_tiktoken_to_hf(is_multilingual, num_languages)
feature_extractor = WhisperFeatureExtractor(
feature_size=model.config.num_mel_bins,
# the rest of default parameters are the same as hardcoded in openai/whisper
)
processor = WhisperProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
processor.save_pretrained(args.pytorch_dump_folder_path)
# save fast tokenizer as well
fast_tokenizer = WhisperTokenizerFast.from_pretrained(args.pytorch_dump_folder_path)
fast_tokenizer.save_pretrained(args.pytorch_dump_folder_path, legacy_format=False)
model.save_pretrained(args.pytorch_dump_folder_path)
| transformers/src/transformers/models/whisper/convert_openai_to_hf.py/0 | {
"file_path": "transformers/src/transformers/models/whisper/convert_openai_to_hf.py",
"repo_id": "transformers",
"token_count": 6441
} |
# coding=utf-8
# Copyright The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""XGLM model configuration"""
from ...configuration_utils import PretrainedConfig
from ...utils import logging
logger = logging.get_logger(__name__)
class XGLMConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`XGLMModel`]. It is used to instantiate an XGLM
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the XGLM
[facebook/xglm-564M](https://huggingface.co/facebook/xglm-564M) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 256008):
Vocabulary size of the XGLM model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`XGLMModel`] or [`FlaxXGLMModel`].
max_position_embeddings (`int`, *optional*, defaults to 2048):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
d_model (`int`, *optional*, defaults to 1024):
Dimension of the layers and the pooler layer.
ffn_dim (`int`, *optional*, defaults to 4096):
Dimension of the "intermediate" (often named feed-forward) layer in decoder.
num_layers (`int`, *optional*, defaults to 24):
Number of hidden layers Transformer decoder.
attention_heads (`int`, *optional*, defaults to 16):
Number of attention heads for each attention layer in the Transformer decoder.
activation_function (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"silu"` and `"gelu_new"` are supported.
dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, dencoder, and pooler.
attention_dropout (`float`, *optional*, defaults to 0.1):
The dropout ratio for the attention probabilities.
activation_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for activations inside the fully connected layer.
layerdrop (`float`, *optional*, defaults to 0.0):
The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
for more details.
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
scale_embedding (`bool`, *optional*, defaults to `True`):
Scale embeddings by diving by sqrt(d_model).
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models).
Example:
```python
>>> from transformers import XGLMModel, XGLMConfig
>>> # Initializing a XGLM facebook/xglm-564M style configuration
>>> configuration = XGLMConfig()
>>> # Initializing a model from the facebook/xglm-564M style configuration
>>> model = XGLMModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "xglm"
keys_to_ignore_at_inference = ["past_key_values"]
attribute_map = {
"num_attention_heads": "attention_heads",
"hidden_size": "d_model",
"num_hidden_layers": "num_layers",
}
def __init__(
self,
vocab_size=256008,
max_position_embeddings=2048,
d_model=1024,
ffn_dim=4096,
num_layers=24,
attention_heads=16,
activation_function="gelu",
dropout=0.1,
attention_dropout=0.1,
activation_dropout=0.0,
layerdrop=0.0,
init_std=0.02,
scale_embedding=True,
use_cache=True,
decoder_start_token_id=2,
pad_token_id=1,
bos_token_id=0,
eos_token_id=2,
**kwargs,
):
self.vocab_size = vocab_size
self.max_position_embeddings = max_position_embeddings
self.d_model = d_model
self.ffn_dim = ffn_dim
self.num_layers = num_layers
self.attention_heads = attention_heads
self.activation_function = activation_function
self.dropout = dropout
self.attention_dropout = attention_dropout
self.activation_dropout = activation_dropout
self.layerdrop = layerdrop
self.init_std = init_std
self.scale_embedding = scale_embedding # scale factor will be sqrt(d_model) if True
self.use_cache = use_cache
super().__init__(
pad_token_id=pad_token_id,
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
decoder_start_token_id=decoder_start_token_id,
**kwargs,
)
__all__ = ["XGLMConfig"]
| transformers/src/transformers/models/xglm/configuration_xglm.py/0 | {
"file_path": "transformers/src/transformers/models/xglm/configuration_xglm.py",
"repo_id": "transformers",
"token_count": 2263
} |
# coding=utf-8
# Copyright 2019 Facebook AI Research and the HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""TF 2.0 XLM-RoBERTa model."""
from __future__ import annotations
import math
import warnings
from typing import Optional, Tuple, Union
import numpy as np
import tensorflow as tf
from ...activations_tf import get_tf_activation
from ...modeling_tf_outputs import (
TFBaseModelOutputWithPastAndCrossAttentions,
TFBaseModelOutputWithPoolingAndCrossAttentions,
TFCausalLMOutputWithCrossAttentions,
TFMaskedLMOutput,
TFMultipleChoiceModelOutput,
TFQuestionAnsweringModelOutput,
TFSequenceClassifierOutput,
TFTokenClassifierOutput,
)
from ...modeling_tf_utils import (
TFCausalLanguageModelingLoss,
TFMaskedLanguageModelingLoss,
TFModelInputType,
TFMultipleChoiceLoss,
TFPreTrainedModel,
TFQuestionAnsweringLoss,
TFSequenceClassificationLoss,
TFTokenClassificationLoss,
get_initializer,
keras,
keras_serializable,
unpack_inputs,
)
from ...tf_utils import check_embeddings_within_bounds, shape_list, stable_softmax
from ...utils import (
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
logging,
)
from .configuration_xlm_roberta import XLMRobertaConfig
logger = logging.get_logger(__name__)
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "FacebookAI/xlm-roberta-base"
_CONFIG_FOR_DOC = "XLMRobertaConfig"
XLM_ROBERTA_START_DOCSTRING = r"""
This model inherits from [`TFPreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a [keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model) subclass. Use it
as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and
behavior.
<Tip>
TensorFlow models and layers in `transformers` accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like `model.fit()` things should "just work" for you - just
pass your inputs and labels in any format that `model.fit()` supports! If, however, you want to use the second
format outside of Keras methods like `fit()` and `predict()`, such as when creating your own layers or models with
the Keras `Functional` API, there are three possibilities you can use to gather all the input Tensors in the first
positional argument:
- a single Tensor with `input_ids` only and nothing else: `model(input_ids)`
- a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
`model([input_ids, attention_mask])` or `model([input_ids, attention_mask, token_type_ids])`
- a dictionary with one or several input Tensors associated to the input names given in the docstring:
`model({"input_ids": input_ids, "token_type_ids": token_type_ids})`
Note that when creating models and layers with
[subclassing](https://keras.io/guides/making_new_layers_and_models_via_subclassing/) then you don't need to worry
about any of this, as you can just pass inputs like you would to any other Python function!
</Tip>
Parameters:
config ([`XLMRobertaConfig`]): Model configuration class with all the parameters of the
model. Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
XLM_ROBERTA_INPUTS_DOCSTRING = r"""
Args:
input_ids (`Numpy array` or `tf.Tensor` of shape `({0})`):
Indices of input sequence tokens in the vocabulary. Indices can be obtained using [`AutoTokenizer`]. See
[`PreTrainedTokenizer.__call__`] and [`PreTrainedTokenizer.encode`] for details. [What are input
IDs?](../glossary#input-ids)
attention_mask (`Numpy array` or `tf.Tensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
token_type_ids (`Numpy array` or `tf.Tensor` of shape `({0})`, *optional*):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
position_ids (`Numpy array` or `tf.Tensor` of shape `({0})`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`. [What are position IDs?](../glossary#position-ids)
head_mask (`Numpy array` or `tf.Tensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`tf.Tensor` of shape `({0}, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the
config will be used instead.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail. This argument can be used only in eager mode, in graph mode the value in the config will be
used instead.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple. This argument can be used in
eager mode, in graph mode the value will always be set to True.
training (`bool`, *optional*, defaults to `False`):
Whether or not to use the model in training mode (some modules like dropout modules have different
behaviors between training and evaluation).
"""
# Copied from transformers.models.roberta.modeling_tf_roberta.TFRobertaEmbeddings with Roberta->XLMRoberta
class TFXLMRobertaEmbeddings(keras.layers.Layer):
"""
Same as BertEmbeddings with a tiny tweak for positional embeddings indexing.
"""
def __init__(self, config, **kwargs):
super().__init__(**kwargs)
self.padding_idx = 1
self.config = config
self.hidden_size = config.hidden_size
self.max_position_embeddings = config.max_position_embeddings
self.initializer_range = config.initializer_range
self.LayerNorm = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
self.dropout = keras.layers.Dropout(rate=config.hidden_dropout_prob)
def build(self, input_shape=None):
with tf.name_scope("word_embeddings"):
self.weight = self.add_weight(
name="weight",
shape=[self.config.vocab_size, self.hidden_size],
initializer=get_initializer(self.initializer_range),
)
with tf.name_scope("token_type_embeddings"):
self.token_type_embeddings = self.add_weight(
name="embeddings",
shape=[self.config.type_vocab_size, self.hidden_size],
initializer=get_initializer(self.initializer_range),
)
with tf.name_scope("position_embeddings"):
self.position_embeddings = self.add_weight(
name="embeddings",
shape=[self.max_position_embeddings, self.hidden_size],
initializer=get_initializer(self.initializer_range),
)
if self.built:
return
self.built = True
if getattr(self, "LayerNorm", None) is not None:
with tf.name_scope(self.LayerNorm.name):
self.LayerNorm.build([None, None, self.config.hidden_size])
def create_position_ids_from_input_ids(self, input_ids, past_key_values_length=0):
"""
Replace non-padding symbols with their position numbers. Position numbers begin at padding_idx+1. Padding
symbols are ignored. This is modified from fairseq's `utils.make_positions`.
Args:
input_ids: tf.Tensor
Returns: tf.Tensor
"""
mask = tf.cast(tf.math.not_equal(input_ids, self.padding_idx), dtype=input_ids.dtype)
incremental_indices = (tf.math.cumsum(mask, axis=1) + past_key_values_length) * mask
return incremental_indices + self.padding_idx
def call(
self,
input_ids=None,
position_ids=None,
token_type_ids=None,
inputs_embeds=None,
past_key_values_length=0,
training=False,
):
"""
Applies embedding based on inputs tensor.
Returns:
final_embeddings (`tf.Tensor`): output embedding tensor.
"""
assert not (input_ids is None and inputs_embeds is None)
if input_ids is not None:
check_embeddings_within_bounds(input_ids, self.config.vocab_size)
inputs_embeds = tf.gather(params=self.weight, indices=input_ids)
input_shape = shape_list(inputs_embeds)[:-1]
if token_type_ids is None:
token_type_ids = tf.fill(dims=input_shape, value=0)
if position_ids is None:
if input_ids is not None:
# Create the position ids from the input token ids. Any padded tokens remain padded.
position_ids = self.create_position_ids_from_input_ids(
input_ids=input_ids, past_key_values_length=past_key_values_length
)
else:
position_ids = tf.expand_dims(
tf.range(start=self.padding_idx + 1, limit=input_shape[-1] + self.padding_idx + 1), axis=0
)
position_embeds = tf.gather(params=self.position_embeddings, indices=position_ids)
token_type_embeds = tf.gather(params=self.token_type_embeddings, indices=token_type_ids)
final_embeddings = inputs_embeds + position_embeds + token_type_embeds
final_embeddings = self.LayerNorm(inputs=final_embeddings)
final_embeddings = self.dropout(inputs=final_embeddings, training=training)
return final_embeddings
# Copied from transformers.models.bert.modeling_tf_bert.TFBertPooler with Bert->XLMRoberta
class TFXLMRobertaPooler(keras.layers.Layer):
def __init__(self, config: XLMRobertaConfig, **kwargs):
super().__init__(**kwargs)
self.dense = keras.layers.Dense(
units=config.hidden_size,
kernel_initializer=get_initializer(config.initializer_range),
activation="tanh",
name="dense",
)
self.config = config
def call(self, hidden_states: tf.Tensor) -> tf.Tensor:
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(inputs=first_token_tensor)
return pooled_output
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "dense", None) is not None:
with tf.name_scope(self.dense.name):
self.dense.build([None, None, self.config.hidden_size])
# Copied from transformers.models.bert.modeling_tf_bert.TFBertSelfAttention with Bert->XLMRoberta
class TFXLMRobertaSelfAttention(keras.layers.Layer):
def __init__(self, config: XLMRobertaConfig, **kwargs):
super().__init__(**kwargs)
if config.hidden_size % config.num_attention_heads != 0:
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number "
f"of attention heads ({config.num_attention_heads})"
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.sqrt_att_head_size = math.sqrt(self.attention_head_size)
self.query = keras.layers.Dense(
units=self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="query"
)
self.key = keras.layers.Dense(
units=self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="key"
)
self.value = keras.layers.Dense(
units=self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="value"
)
self.dropout = keras.layers.Dropout(rate=config.attention_probs_dropout_prob)
self.is_decoder = config.is_decoder
self.config = config
def transpose_for_scores(self, tensor: tf.Tensor, batch_size: int) -> tf.Tensor:
# Reshape from [batch_size, seq_length, all_head_size] to [batch_size, seq_length, num_attention_heads, attention_head_size]
tensor = tf.reshape(tensor=tensor, shape=(batch_size, -1, self.num_attention_heads, self.attention_head_size))
# Transpose the tensor from [batch_size, seq_length, num_attention_heads, attention_head_size] to [batch_size, num_attention_heads, seq_length, attention_head_size]
return tf.transpose(tensor, perm=[0, 2, 1, 3])
def call(
self,
hidden_states: tf.Tensor,
attention_mask: tf.Tensor,
head_mask: tf.Tensor,
encoder_hidden_states: tf.Tensor,
encoder_attention_mask: tf.Tensor,
past_key_value: Tuple[tf.Tensor],
output_attentions: bool,
training: bool = False,
) -> Tuple[tf.Tensor]:
batch_size = shape_list(hidden_states)[0]
mixed_query_layer = self.query(inputs=hidden_states)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
is_cross_attention = encoder_hidden_states is not None
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_layer = past_key_value[0]
value_layer = past_key_value[1]
attention_mask = encoder_attention_mask
elif is_cross_attention:
key_layer = self.transpose_for_scores(self.key(inputs=encoder_hidden_states), batch_size)
value_layer = self.transpose_for_scores(self.value(inputs=encoder_hidden_states), batch_size)
attention_mask = encoder_attention_mask
elif past_key_value is not None:
key_layer = self.transpose_for_scores(self.key(inputs=hidden_states), batch_size)
value_layer = self.transpose_for_scores(self.value(inputs=hidden_states), batch_size)
key_layer = tf.concat([past_key_value[0], key_layer], axis=2)
value_layer = tf.concat([past_key_value[1], value_layer], axis=2)
else:
key_layer = self.transpose_for_scores(self.key(inputs=hidden_states), batch_size)
value_layer = self.transpose_for_scores(self.value(inputs=hidden_states), batch_size)
query_layer = self.transpose_for_scores(mixed_query_layer, batch_size)
if self.is_decoder:
# if cross_attention save Tuple(tf.Tensor, tf.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(tf.Tensor, tf.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_layer, value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
# (batch size, num_heads, seq_len_q, seq_len_k)
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True)
dk = tf.cast(self.sqrt_att_head_size, dtype=attention_scores.dtype)
attention_scores = tf.divide(attention_scores, dk)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in TFXLMRobertaModel call() function)
attention_scores = tf.add(attention_scores, attention_mask)
# Normalize the attention scores to probabilities.
attention_probs = stable_softmax(logits=attention_scores, axis=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(inputs=attention_probs, training=training)
# Mask heads if we want to
if head_mask is not None:
attention_probs = tf.multiply(attention_probs, head_mask)
attention_output = tf.matmul(attention_probs, value_layer)
attention_output = tf.transpose(attention_output, perm=[0, 2, 1, 3])
# (batch_size, seq_len_q, all_head_size)
attention_output = tf.reshape(tensor=attention_output, shape=(batch_size, -1, self.all_head_size))
outputs = (attention_output, attention_probs) if output_attentions else (attention_output,)
if self.is_decoder:
outputs = outputs + (past_key_value,)
return outputs
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "query", None) is not None:
with tf.name_scope(self.query.name):
self.query.build([None, None, self.config.hidden_size])
if getattr(self, "key", None) is not None:
with tf.name_scope(self.key.name):
self.key.build([None, None, self.config.hidden_size])
if getattr(self, "value", None) is not None:
with tf.name_scope(self.value.name):
self.value.build([None, None, self.config.hidden_size])
# Copied from transformers.models.bert.modeling_tf_bert.TFBertSelfOutput with Bert->XLMRoberta
class TFXLMRobertaSelfOutput(keras.layers.Layer):
def __init__(self, config: XLMRobertaConfig, **kwargs):
super().__init__(**kwargs)
self.dense = keras.layers.Dense(
units=config.hidden_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
self.LayerNorm = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
self.dropout = keras.layers.Dropout(rate=config.hidden_dropout_prob)
self.config = config
def call(self, hidden_states: tf.Tensor, input_tensor: tf.Tensor, training: bool = False) -> tf.Tensor:
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.dropout(inputs=hidden_states, training=training)
hidden_states = self.LayerNorm(inputs=hidden_states + input_tensor)
return hidden_states
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "dense", None) is not None:
with tf.name_scope(self.dense.name):
self.dense.build([None, None, self.config.hidden_size])
if getattr(self, "LayerNorm", None) is not None:
with tf.name_scope(self.LayerNorm.name):
self.LayerNorm.build([None, None, self.config.hidden_size])
# Copied from transformers.models.bert.modeling_tf_bert.TFBertAttention with Bert->XLMRoberta
class TFXLMRobertaAttention(keras.layers.Layer):
def __init__(self, config: XLMRobertaConfig, **kwargs):
super().__init__(**kwargs)
self.self_attention = TFXLMRobertaSelfAttention(config, name="self")
self.dense_output = TFXLMRobertaSelfOutput(config, name="output")
def prune_heads(self, heads):
raise NotImplementedError
def call(
self,
input_tensor: tf.Tensor,
attention_mask: tf.Tensor,
head_mask: tf.Tensor,
encoder_hidden_states: tf.Tensor,
encoder_attention_mask: tf.Tensor,
past_key_value: Tuple[tf.Tensor],
output_attentions: bool,
training: bool = False,
) -> Tuple[tf.Tensor]:
self_outputs = self.self_attention(
hidden_states=input_tensor,
attention_mask=attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_value=past_key_value,
output_attentions=output_attentions,
training=training,
)
attention_output = self.dense_output(
hidden_states=self_outputs[0], input_tensor=input_tensor, training=training
)
# add attentions (possibly with past_key_value) if we output them
outputs = (attention_output,) + self_outputs[1:]
return outputs
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "self_attention", None) is not None:
with tf.name_scope(self.self_attention.name):
self.self_attention.build(None)
if getattr(self, "dense_output", None) is not None:
with tf.name_scope(self.dense_output.name):
self.dense_output.build(None)
# Copied from transformers.models.bert.modeling_tf_bert.TFBertIntermediate with Bert->XLMRoberta
class TFXLMRobertaIntermediate(keras.layers.Layer):
def __init__(self, config: XLMRobertaConfig, **kwargs):
super().__init__(**kwargs)
self.dense = keras.layers.Dense(
units=config.intermediate_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = get_tf_activation(config.hidden_act)
else:
self.intermediate_act_fn = config.hidden_act
self.config = config
def call(self, hidden_states: tf.Tensor) -> tf.Tensor:
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "dense", None) is not None:
with tf.name_scope(self.dense.name):
self.dense.build([None, None, self.config.hidden_size])
# Copied from transformers.models.bert.modeling_tf_bert.TFBertOutput with Bert->XLMRoberta
class TFXLMRobertaOutput(keras.layers.Layer):
def __init__(self, config: XLMRobertaConfig, **kwargs):
super().__init__(**kwargs)
self.dense = keras.layers.Dense(
units=config.hidden_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
self.LayerNorm = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
self.dropout = keras.layers.Dropout(rate=config.hidden_dropout_prob)
self.config = config
def call(self, hidden_states: tf.Tensor, input_tensor: tf.Tensor, training: bool = False) -> tf.Tensor:
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.dropout(inputs=hidden_states, training=training)
hidden_states = self.LayerNorm(inputs=hidden_states + input_tensor)
return hidden_states
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "dense", None) is not None:
with tf.name_scope(self.dense.name):
self.dense.build([None, None, self.config.intermediate_size])
if getattr(self, "LayerNorm", None) is not None:
with tf.name_scope(self.LayerNorm.name):
self.LayerNorm.build([None, None, self.config.hidden_size])
# Copied from transformers.models.bert.modeling_tf_bert.TFBertLayer with Bert->XLMRoberta
class TFXLMRobertaLayer(keras.layers.Layer):
def __init__(self, config: XLMRobertaConfig, **kwargs):
super().__init__(**kwargs)
self.attention = TFXLMRobertaAttention(config, name="attention")
self.is_decoder = config.is_decoder
self.add_cross_attention = config.add_cross_attention
if self.add_cross_attention:
if not self.is_decoder:
raise ValueError(f"{self} should be used as a decoder model if cross attention is added")
self.crossattention = TFXLMRobertaAttention(config, name="crossattention")
self.intermediate = TFXLMRobertaIntermediate(config, name="intermediate")
self.bert_output = TFXLMRobertaOutput(config, name="output")
def call(
self,
hidden_states: tf.Tensor,
attention_mask: tf.Tensor,
head_mask: tf.Tensor,
encoder_hidden_states: tf.Tensor | None,
encoder_attention_mask: tf.Tensor | None,
past_key_value: Tuple[tf.Tensor] | None,
output_attentions: bool,
training: bool = False,
) -> Tuple[tf.Tensor]:
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
self_attention_outputs = self.attention(
input_tensor=hidden_states,
attention_mask=attention_mask,
head_mask=head_mask,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=self_attn_past_key_value,
output_attentions=output_attentions,
training=training,
)
attention_output = self_attention_outputs[0]
# if decoder, the last output is tuple of self-attn cache
if self.is_decoder:
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
else:
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
cross_attn_present_key_value = None
if self.is_decoder and encoder_hidden_states is not None:
if not hasattr(self, "crossattention"):
raise ValueError(
f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers"
" by setting `config.add_cross_attention=True`"
)
# cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
cross_attention_outputs = self.crossattention(
input_tensor=attention_output,
attention_mask=attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_value=cross_attn_past_key_value,
output_attentions=output_attentions,
training=training,
)
attention_output = cross_attention_outputs[0]
outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
# add cross-attn cache to positions 3,4 of present_key_value tuple
cross_attn_present_key_value = cross_attention_outputs[-1]
present_key_value = present_key_value + cross_attn_present_key_value
intermediate_output = self.intermediate(hidden_states=attention_output)
layer_output = self.bert_output(
hidden_states=intermediate_output, input_tensor=attention_output, training=training
)
outputs = (layer_output,) + outputs # add attentions if we output them
# if decoder, return the attn key/values as the last output
if self.is_decoder:
outputs = outputs + (present_key_value,)
return outputs
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "attention", None) is not None:
with tf.name_scope(self.attention.name):
self.attention.build(None)
if getattr(self, "intermediate", None) is not None:
with tf.name_scope(self.intermediate.name):
self.intermediate.build(None)
if getattr(self, "bert_output", None) is not None:
with tf.name_scope(self.bert_output.name):
self.bert_output.build(None)
if getattr(self, "crossattention", None) is not None:
with tf.name_scope(self.crossattention.name):
self.crossattention.build(None)
# Copied from transformers.models.bert.modeling_tf_bert.TFBertEncoder with Bert->XLMRoberta
class TFXLMRobertaEncoder(keras.layers.Layer):
def __init__(self, config: XLMRobertaConfig, **kwargs):
super().__init__(**kwargs)
self.config = config
self.layer = [TFXLMRobertaLayer(config, name=f"layer_._{i}") for i in range(config.num_hidden_layers)]
def call(
self,
hidden_states: tf.Tensor,
attention_mask: tf.Tensor,
head_mask: tf.Tensor,
encoder_hidden_states: tf.Tensor | None,
encoder_attention_mask: tf.Tensor | None,
past_key_values: Tuple[Tuple[tf.Tensor]] | None,
use_cache: Optional[bool],
output_attentions: bool,
output_hidden_states: bool,
return_dict: bool,
training: bool = False,
) -> Union[TFBaseModelOutputWithPastAndCrossAttentions, Tuple[tf.Tensor]]:
all_hidden_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
next_decoder_cache = () if use_cache else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
past_key_value = past_key_values[i] if past_key_values is not None else None
layer_outputs = layer_module(
hidden_states=hidden_states,
attention_mask=attention_mask,
head_mask=head_mask[i],
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_value=past_key_value,
output_attentions=output_attentions,
training=training,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[-1],)
if output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
if self.config.add_cross_attention and encoder_hidden_states is not None:
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
# Add last layer
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v for v in [hidden_states, all_hidden_states, all_attentions, all_cross_attentions] if v is not None
)
return TFBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_attentions,
cross_attentions=all_cross_attentions,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "layer", None) is not None:
for layer in self.layer:
with tf.name_scope(layer.name):
layer.build(None)
@keras_serializable
# Copied from transformers.models.roberta.modeling_tf_roberta.TFRobertaMainLayer with Roberta->XLMRoberta
class TFXLMRobertaMainLayer(keras.layers.Layer):
config_class = XLMRobertaConfig
def __init__(self, config, add_pooling_layer=True, **kwargs):
super().__init__(**kwargs)
self.config = config
self.is_decoder = config.is_decoder
self.num_hidden_layers = config.num_hidden_layers
self.initializer_range = config.initializer_range
self.output_attentions = config.output_attentions
self.output_hidden_states = config.output_hidden_states
self.return_dict = config.use_return_dict
self.encoder = TFXLMRobertaEncoder(config, name="encoder")
self.pooler = TFXLMRobertaPooler(config, name="pooler") if add_pooling_layer else None
# The embeddings must be the last declaration in order to follow the weights order
self.embeddings = TFXLMRobertaEmbeddings(config, name="embeddings")
# Copied from transformers.models.bert.modeling_tf_bert.TFBertMainLayer.get_input_embeddings
def get_input_embeddings(self) -> keras.layers.Layer:
return self.embeddings
# Copied from transformers.models.bert.modeling_tf_bert.TFBertMainLayer.set_input_embeddings
def set_input_embeddings(self, value: tf.Variable):
self.embeddings.weight = value
self.embeddings.vocab_size = shape_list(value)[0]
# Copied from transformers.models.bert.modeling_tf_bert.TFBertMainLayer._prune_heads
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
raise NotImplementedError
@unpack_inputs
# Copied from transformers.models.bert.modeling_tf_bert.TFBertMainLayer.call
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
encoder_hidden_states: np.ndarray | tf.Tensor | None = None,
encoder_attention_mask: np.ndarray | tf.Tensor | None = None,
past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: bool = False,
) -> Union[TFBaseModelOutputWithPoolingAndCrossAttentions, Tuple[tf.Tensor]]:
if not self.config.is_decoder:
use_cache = False
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = shape_list(input_ids)
elif inputs_embeds is not None:
input_shape = shape_list(inputs_embeds)[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
batch_size, seq_length = input_shape
if past_key_values is None:
past_key_values_length = 0
past_key_values = [None] * len(self.encoder.layer)
else:
past_key_values_length = shape_list(past_key_values[0][0])[-2]
if attention_mask is None:
attention_mask = tf.fill(dims=(batch_size, seq_length + past_key_values_length), value=1)
if token_type_ids is None:
token_type_ids = tf.fill(dims=input_shape, value=0)
embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
token_type_ids=token_type_ids,
inputs_embeds=inputs_embeds,
past_key_values_length=past_key_values_length,
training=training,
)
# We create a 3D attention mask from a 2D tensor mask.
# Sizes are [batch_size, 1, 1, to_seq_length]
# So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
# this attention mask is more simple than the triangular masking of causal attention
# used in OpenAI GPT, we just need to prepare the broadcast dimension here.
attention_mask_shape = shape_list(attention_mask)
mask_seq_length = seq_length + past_key_values_length
# Copied from `modeling_tf_t5.py`
# Provided a padding mask of dimensions [batch_size, mask_seq_length]
# - if the model is a decoder, apply a causal mask in addition to the padding mask
# - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, mask_seq_length, mask_seq_length]
if self.is_decoder:
seq_ids = tf.range(mask_seq_length)
causal_mask = tf.less_equal(
tf.tile(seq_ids[None, None, :], (batch_size, mask_seq_length, 1)),
seq_ids[None, :, None],
)
causal_mask = tf.cast(causal_mask, dtype=attention_mask.dtype)
extended_attention_mask = causal_mask * attention_mask[:, None, :]
attention_mask_shape = shape_list(extended_attention_mask)
extended_attention_mask = tf.reshape(
extended_attention_mask, (attention_mask_shape[0], 1, attention_mask_shape[1], attention_mask_shape[2])
)
if past_key_values[0] is not None:
# attention_mask needs to be sliced to the shape `[batch_size, 1, from_seq_length - cached_seq_length, to_seq_length]
extended_attention_mask = extended_attention_mask[:, :, -seq_length:, :]
else:
extended_attention_mask = tf.reshape(
attention_mask, (attention_mask_shape[0], 1, 1, attention_mask_shape[1])
)
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
extended_attention_mask = tf.cast(extended_attention_mask, dtype=embedding_output.dtype)
one_cst = tf.constant(1.0, dtype=embedding_output.dtype)
ten_thousand_cst = tf.constant(-10000.0, dtype=embedding_output.dtype)
extended_attention_mask = tf.multiply(tf.subtract(one_cst, extended_attention_mask), ten_thousand_cst)
# Copied from `modeling_tf_t5.py` with -1e9 -> -10000
if self.is_decoder and encoder_attention_mask is not None:
# If a 2D ou 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, mask_seq_length, mask_seq_length]
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
encoder_attention_mask = tf.cast(encoder_attention_mask, dtype=extended_attention_mask.dtype)
num_dims_encoder_attention_mask = len(shape_list(encoder_attention_mask))
if num_dims_encoder_attention_mask == 3:
encoder_extended_attention_mask = encoder_attention_mask[:, None, :, :]
if num_dims_encoder_attention_mask == 2:
encoder_extended_attention_mask = encoder_attention_mask[:, None, None, :]
# T5 has a mask that can compare sequence ids, we can simulate this here with this transposition
# Cf. https://github.com/tensorflow/mesh/blob/8d2465e9bc93129b913b5ccc6a59aa97abd96ec6/mesh_tensorflow/transformer/transformer_layers.py#L270
# encoder_extended_attention_mask = tf.math.equal(encoder_extended_attention_mask,
# tf.transpose(encoder_extended_attention_mask, perm=(-1, -2)))
encoder_extended_attention_mask = (1.0 - encoder_extended_attention_mask) * -10000.0
else:
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
if head_mask is not None:
raise NotImplementedError
else:
head_mask = [None] * self.config.num_hidden_layers
encoder_outputs = self.encoder(
hidden_states=embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(hidden_states=sequence_output) if self.pooler is not None else None
if not return_dict:
return (
sequence_output,
pooled_output,
) + encoder_outputs[1:]
return TFBaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "encoder", None) is not None:
with tf.name_scope(self.encoder.name):
self.encoder.build(None)
if getattr(self, "pooler", None) is not None:
with tf.name_scope(self.pooler.name):
self.pooler.build(None)
if getattr(self, "embeddings", None) is not None:
with tf.name_scope(self.embeddings.name):
self.embeddings.build(None)
# Copied from transformers.models.roberta.modeling_tf_roberta.TFRobertaPreTrainedModel with Roberta->XLMRoberta
class TFXLMRobertaPreTrainedModel(TFPreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = XLMRobertaConfig
base_model_prefix = "roberta"
@add_start_docstrings(
"The bare XLM RoBERTa Model transformer outputting raw hidden-states without any specific head on top.",
XLM_ROBERTA_START_DOCSTRING,
)
# Copied from transformers.models.roberta.modeling_tf_roberta.TFRobertaModel with Roberta->XLMRoberta, ROBERTA->XLM_ROBERTA
class TFXLMRobertaModel(TFXLMRobertaPreTrainedModel):
def __init__(self, config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.roberta = TFXLMRobertaMainLayer(config, name="roberta")
@unpack_inputs
@add_start_docstrings_to_model_forward(XLM_ROBERTA_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFBaseModelOutputWithPoolingAndCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
encoder_hidden_states: np.ndarray | tf.Tensor | None = None,
encoder_attention_mask: np.ndarray | tf.Tensor | None = None,
past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: Optional[bool] = False,
) -> Union[Tuple, TFBaseModelOutputWithPoolingAndCrossAttentions]:
r"""
encoder_hidden_states (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`Tuple[Tuple[tf.Tensor]]` of length `config.n_layers`)
contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*, defaults to `True`):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`). Set to `False` during training, `True` during generation
"""
outputs = self.roberta(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
return outputs
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "roberta", None) is not None:
with tf.name_scope(self.roberta.name):
self.roberta.build(None)
# Copied from transformers.models.roberta.modeling_tf_roberta.TFRobertaLMHead with Roberta->XLMRoberta
class TFXLMRobertaLMHead(keras.layers.Layer):
"""XLMRoberta Head for masked language modeling."""
def __init__(self, config, input_embeddings, **kwargs):
super().__init__(**kwargs)
self.config = config
self.hidden_size = config.hidden_size
self.dense = keras.layers.Dense(
config.hidden_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
self.layer_norm = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="layer_norm")
self.act = get_tf_activation("gelu")
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
self.decoder = input_embeddings
def build(self, input_shape=None):
self.bias = self.add_weight(shape=(self.config.vocab_size,), initializer="zeros", trainable=True, name="bias")
if self.built:
return
self.built = True
if getattr(self, "dense", None) is not None:
with tf.name_scope(self.dense.name):
self.dense.build([None, None, self.config.hidden_size])
if getattr(self, "layer_norm", None) is not None:
with tf.name_scope(self.layer_norm.name):
self.layer_norm.build([None, None, self.config.hidden_size])
def get_output_embeddings(self):
return self.decoder
def set_output_embeddings(self, value):
self.decoder.weight = value
self.decoder.vocab_size = shape_list(value)[0]
def get_bias(self):
return {"bias": self.bias}
def set_bias(self, value):
self.bias = value["bias"]
self.config.vocab_size = shape_list(value["bias"])[0]
def call(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.act(hidden_states)
hidden_states = self.layer_norm(hidden_states)
# project back to size of vocabulary with bias
seq_length = shape_list(tensor=hidden_states)[1]
hidden_states = tf.reshape(tensor=hidden_states, shape=[-1, self.hidden_size])
hidden_states = tf.matmul(a=hidden_states, b=self.decoder.weight, transpose_b=True)
hidden_states = tf.reshape(tensor=hidden_states, shape=[-1, seq_length, self.config.vocab_size])
hidden_states = tf.nn.bias_add(value=hidden_states, bias=self.bias)
return hidden_states
@add_start_docstrings("""XLM RoBERTa Model with a `language modeling` head on top.""", XLM_ROBERTA_START_DOCSTRING)
# Copied from transformers.models.roberta.modeling_tf_roberta.TFRobertaForMaskedLM with Roberta->XLMRoberta, ROBERTA->XLM_ROBERTA
class TFXLMRobertaForMaskedLM(TFXLMRobertaPreTrainedModel, TFMaskedLanguageModelingLoss):
# names with a '.' represents the authorized unexpected/missing layers when a TF model is loaded from a PT model
_keys_to_ignore_on_load_unexpected = [r"pooler", r"lm_head.decoder.weight"]
def __init__(self, config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.roberta = TFXLMRobertaMainLayer(config, add_pooling_layer=False, name="roberta")
self.lm_head = TFXLMRobertaLMHead(config, self.roberta.embeddings, name="lm_head")
def get_lm_head(self):
return self.lm_head
def get_prefix_bias_name(self):
warnings.warn("The method get_prefix_bias_name is deprecated. Please use `get_bias` instead.", FutureWarning)
return self.name + "/" + self.lm_head.name
@unpack_inputs
@add_start_docstrings_to_model_forward(XLM_ROBERTA_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFMaskedLMOutput,
config_class=_CONFIG_FOR_DOC,
mask="<mask>",
expected_output="' Paris'",
expected_loss=0.1,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFMaskedLMOutput, Tuple[tf.Tensor]]:
r"""
labels (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked), the
loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
"""
outputs = self.roberta(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = outputs[0]
prediction_scores = self.lm_head(sequence_output)
loss = None if labels is None else self.hf_compute_loss(labels, prediction_scores)
if not return_dict:
output = (prediction_scores,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TFMaskedLMOutput(
loss=loss,
logits=prediction_scores,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "roberta", None) is not None:
with tf.name_scope(self.roberta.name):
self.roberta.build(None)
if getattr(self, "lm_head", None) is not None:
with tf.name_scope(self.lm_head.name):
self.lm_head.build(None)
@add_start_docstrings(
"XLM-RoBERTa Model with a `language modeling` head on top for CLM fine-tuning.",
XLM_ROBERTA_START_DOCSTRING,
)
# Copied from transformers.models.roberta.modeling_tf_roberta.TFRobertaForCausalLM with Roberta->XLMRoberta, ROBERTA->XLM_ROBERTA
class TFXLMRobertaForCausalLM(TFXLMRobertaPreTrainedModel, TFCausalLanguageModelingLoss):
# names with a '.' represents the authorized unexpected/missing layers when a TF model is loaded from a PT model
_keys_to_ignore_on_load_unexpected = [r"pooler", r"lm_head.decoder.weight"]
def __init__(self, config: XLMRobertaConfig, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
if not config.is_decoder:
logger.warning("If you want to use `TFXLMRobertaLMHeadModel` as a standalone, add `is_decoder=True.`")
self.roberta = TFXLMRobertaMainLayer(config, add_pooling_layer=False, name="roberta")
self.lm_head = TFXLMRobertaLMHead(config, input_embeddings=self.roberta.embeddings, name="lm_head")
def get_lm_head(self):
return self.lm_head
def get_prefix_bias_name(self):
warnings.warn("The method get_prefix_bias_name is deprecated. Please use `get_bias` instead.", FutureWarning)
return self.name + "/" + self.lm_head.name
# Copied from transformers.models.bert.modeling_tf_bert.TFBertLMHeadModel.prepare_inputs_for_generation
def prepare_inputs_for_generation(self, input_ids, past_key_values=None, attention_mask=None, **model_kwargs):
input_shape = input_ids.shape
# if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
if attention_mask is None:
attention_mask = tf.ones(input_shape)
# cut decoder_input_ids if past is used
if past_key_values is not None:
input_ids = input_ids[:, -1:]
return {"input_ids": input_ids, "attention_mask": attention_mask, "past_key_values": past_key_values}
@unpack_inputs
@add_start_docstrings_to_model_forward(XLM_ROBERTA_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFCausalLMOutputWithCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
encoder_hidden_states: np.ndarray | tf.Tensor | None = None,
encoder_attention_mask: np.ndarray | tf.Tensor | None = None,
past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFCausalLMOutputWithCrossAttentions, Tuple[tf.Tensor]]:
r"""
encoder_hidden_states (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`Tuple[Tuple[tf.Tensor]]` of length `config.n_layers`)
contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*, defaults to `True`):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`). Set to `False` during training, `True` during generation
labels (`tf.Tensor` or `np.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the cross entropy classification loss. Indices should be in `[0, ...,
config.vocab_size - 1]`.
"""
outputs = self.roberta(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = outputs[0]
logits = self.lm_head(hidden_states=sequence_output, training=training)
loss = None
if labels is not None:
# shift labels to the left and cut last logit token
shifted_logits = logits[:, :-1]
labels = labels[:, 1:]
loss = self.hf_compute_loss(labels=labels, logits=shifted_logits)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TFCausalLMOutputWithCrossAttentions(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "roberta", None) is not None:
with tf.name_scope(self.roberta.name):
self.roberta.build(None)
if getattr(self, "lm_head", None) is not None:
with tf.name_scope(self.lm_head.name):
self.lm_head.build(None)
# Copied from transformers.models.roberta.modeling_tf_roberta.TFRobertaClassificationHead with Roberta->XLMRoberta
class TFXLMRobertaClassificationHead(keras.layers.Layer):
"""Head for sentence-level classification tasks."""
def __init__(self, config, **kwargs):
super().__init__(**kwargs)
self.dense = keras.layers.Dense(
config.hidden_size,
kernel_initializer=get_initializer(config.initializer_range),
activation="tanh",
name="dense",
)
classifier_dropout = (
config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
)
self.dropout = keras.layers.Dropout(classifier_dropout)
self.out_proj = keras.layers.Dense(
config.num_labels, kernel_initializer=get_initializer(config.initializer_range), name="out_proj"
)
self.config = config
def call(self, features, training=False):
x = features[:, 0, :] # take <s> token (equiv. to [CLS])
x = self.dropout(x, training=training)
x = self.dense(x)
x = self.dropout(x, training=training)
x = self.out_proj(x)
return x
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "dense", None) is not None:
with tf.name_scope(self.dense.name):
self.dense.build([None, None, self.config.hidden_size])
if getattr(self, "out_proj", None) is not None:
with tf.name_scope(self.out_proj.name):
self.out_proj.build([None, None, self.config.hidden_size])
@add_start_docstrings(
"""
XLM RoBERTa Model transformer with a sequence classification/regression head on top (a linear layer on top of the
pooled output) e.g. for GLUE tasks.
""",
XLM_ROBERTA_START_DOCSTRING,
)
# Copied from transformers.models.roberta.modeling_tf_roberta.TFRobertaForSequenceClassification with Roberta->XLMRoberta, ROBERTA->XLM_ROBERTA
class TFXLMRobertaForSequenceClassification(TFXLMRobertaPreTrainedModel, TFSequenceClassificationLoss):
# names with a '.' represents the authorized unexpected/missing layers when a TF model is loaded from a PT model
_keys_to_ignore_on_load_unexpected = [r"pooler", r"lm_head"]
def __init__(self, config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.num_labels = config.num_labels
self.roberta = TFXLMRobertaMainLayer(config, add_pooling_layer=False, name="roberta")
self.classifier = TFXLMRobertaClassificationHead(config, name="classifier")
@unpack_inputs
@add_start_docstrings_to_model_forward(XLM_ROBERTA_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint="cardiffnlp/twitter-roberta-base-emotion",
output_type=TFSequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
expected_output="'optimism'",
expected_loss=0.08,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFSequenceClassifierOutput, Tuple[tf.Tensor]]:
r"""
labels (`tf.Tensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
outputs = self.roberta(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = outputs[0]
logits = self.classifier(sequence_output, training=training)
loss = None if labels is None else self.hf_compute_loss(labels, logits)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TFSequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "roberta", None) is not None:
with tf.name_scope(self.roberta.name):
self.roberta.build(None)
if getattr(self, "classifier", None) is not None:
with tf.name_scope(self.classifier.name):
self.classifier.build(None)
@add_start_docstrings(
"""
XLM Roberta Model with a multiple choice classification head on top (a linear layer on top of the pooled output and
a softmax) e.g. for RocStories/SWAG tasks.
""",
XLM_ROBERTA_START_DOCSTRING,
)
# Copied from transformers.models.roberta.modeling_tf_roberta.TFRobertaForMultipleChoice with Roberta->XLMRoberta, ROBERTA->XLM_ROBERTA
class TFXLMRobertaForMultipleChoice(TFXLMRobertaPreTrainedModel, TFMultipleChoiceLoss):
# names with a '.' represents the authorized unexpected/missing layers when a TF model is loaded from a PT model
_keys_to_ignore_on_load_unexpected = [r"lm_head"]
_keys_to_ignore_on_load_missing = [r"dropout"]
def __init__(self, config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.roberta = TFXLMRobertaMainLayer(config, name="roberta")
self.dropout = keras.layers.Dropout(config.hidden_dropout_prob)
self.classifier = keras.layers.Dense(
1, kernel_initializer=get_initializer(config.initializer_range), name="classifier"
)
self.config = config
@unpack_inputs
@add_start_docstrings_to_model_forward(
XLM_ROBERTA_INPUTS_DOCSTRING.format("batch_size, num_choices, sequence_length")
)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFMultipleChoiceModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFMultipleChoiceModelOutput, Tuple[tf.Tensor]]:
r"""
labels (`tf.Tensor` of shape `(batch_size,)`, *optional*):
Labels for computing the multiple choice classification loss. Indices should be in `[0, ..., num_choices]`
where `num_choices` is the size of the second dimension of the input tensors. (See `input_ids` above)
"""
if input_ids is not None:
num_choices = shape_list(input_ids)[1]
seq_length = shape_list(input_ids)[2]
else:
num_choices = shape_list(inputs_embeds)[1]
seq_length = shape_list(inputs_embeds)[2]
flat_input_ids = tf.reshape(input_ids, (-1, seq_length)) if input_ids is not None else None
flat_attention_mask = tf.reshape(attention_mask, (-1, seq_length)) if attention_mask is not None else None
flat_token_type_ids = tf.reshape(token_type_ids, (-1, seq_length)) if token_type_ids is not None else None
flat_position_ids = tf.reshape(position_ids, (-1, seq_length)) if position_ids is not None else None
outputs = self.roberta(
flat_input_ids,
flat_attention_mask,
flat_token_type_ids,
flat_position_ids,
head_mask,
inputs_embeds,
output_attentions,
output_hidden_states,
return_dict=return_dict,
training=training,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output, training=training)
logits = self.classifier(pooled_output)
reshaped_logits = tf.reshape(logits, (-1, num_choices))
loss = None if labels is None else self.hf_compute_loss(labels, reshaped_logits)
if not return_dict:
output = (reshaped_logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TFMultipleChoiceModelOutput(
loss=loss,
logits=reshaped_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "roberta", None) is not None:
with tf.name_scope(self.roberta.name):
self.roberta.build(None)
if getattr(self, "classifier", None) is not None:
with tf.name_scope(self.classifier.name):
self.classifier.build([None, None, self.config.hidden_size])
@add_start_docstrings(
"""
XLM RoBERTa Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g.
for Named-Entity-Recognition (NER) tasks.
""",
XLM_ROBERTA_START_DOCSTRING,
)
# Copied from transformers.models.roberta.modeling_tf_roberta.TFRobertaForTokenClassification with Roberta->XLMRoberta, ROBERTA->XLM_ROBERTA
class TFXLMRobertaForTokenClassification(TFXLMRobertaPreTrainedModel, TFTokenClassificationLoss):
# names with a '.' represents the authorized unexpected/missing layers when a TF model is loaded from a PT model
_keys_to_ignore_on_load_unexpected = [r"pooler", r"lm_head"]
_keys_to_ignore_on_load_missing = [r"dropout"]
def __init__(self, config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.num_labels = config.num_labels
self.roberta = TFXLMRobertaMainLayer(config, add_pooling_layer=False, name="roberta")
classifier_dropout = (
config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
)
self.dropout = keras.layers.Dropout(classifier_dropout)
self.classifier = keras.layers.Dense(
config.num_labels, kernel_initializer=get_initializer(config.initializer_range), name="classifier"
)
self.config = config
@unpack_inputs
@add_start_docstrings_to_model_forward(XLM_ROBERTA_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint="ydshieh/roberta-large-ner-english",
output_type=TFTokenClassifierOutput,
config_class=_CONFIG_FOR_DOC,
expected_output="['O', 'ORG', 'ORG', 'O', 'O', 'O', 'O', 'O', 'LOC', 'O', 'LOC', 'LOC']",
expected_loss=0.01,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFTokenClassifierOutput, Tuple[tf.Tensor]]:
r"""
labels (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the token classification loss. Indices should be in `[0, ..., config.num_labels - 1]`.
"""
outputs = self.roberta(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output, training=training)
logits = self.classifier(sequence_output)
loss = None if labels is None else self.hf_compute_loss(labels, logits)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TFTokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "roberta", None) is not None:
with tf.name_scope(self.roberta.name):
self.roberta.build(None)
if getattr(self, "classifier", None) is not None:
with tf.name_scope(self.classifier.name):
self.classifier.build([None, None, self.config.hidden_size])
@add_start_docstrings(
"""
XLM RoBERTa Model with a span classification head on top for extractive question-answering tasks like SQuAD (a
linear layers on top of the hidden-states output to compute `span start logits` and `span end logits`).
""",
XLM_ROBERTA_START_DOCSTRING,
)
# Copied from transformers.models.roberta.modeling_tf_roberta.TFRobertaForQuestionAnswering with Roberta->XLMRoberta, ROBERTA->XLM_ROBERTA
class TFXLMRobertaForQuestionAnswering(TFXLMRobertaPreTrainedModel, TFQuestionAnsweringLoss):
# names with a '.' represents the authorized unexpected/missing layers when a TF model is loaded from a PT model
_keys_to_ignore_on_load_unexpected = [r"pooler", r"lm_head"]
def __init__(self, config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.num_labels = config.num_labels
self.roberta = TFXLMRobertaMainLayer(config, add_pooling_layer=False, name="roberta")
self.qa_outputs = keras.layers.Dense(
config.num_labels, kernel_initializer=get_initializer(config.initializer_range), name="qa_outputs"
)
self.config = config
@unpack_inputs
@add_start_docstrings_to_model_forward(XLM_ROBERTA_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint="ydshieh/roberta-base-squad2",
output_type=TFQuestionAnsweringModelOutput,
config_class=_CONFIG_FOR_DOC,
expected_output="' puppet'",
expected_loss=0.86,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
start_positions: np.ndarray | tf.Tensor | None = None,
end_positions: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFQuestionAnsweringModelOutput, Tuple[tf.Tensor]]:
r"""
start_positions (`tf.Tensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
end_positions (`tf.Tensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
"""
outputs = self.roberta(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = tf.split(logits, 2, axis=-1)
start_logits = tf.squeeze(start_logits, axis=-1)
end_logits = tf.squeeze(end_logits, axis=-1)
loss = None
if start_positions is not None and end_positions is not None:
labels = {"start_position": start_positions}
labels["end_position"] = end_positions
loss = self.hf_compute_loss(labels, (start_logits, end_logits))
if not return_dict:
output = (start_logits, end_logits) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TFQuestionAnsweringModelOutput(
loss=loss,
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "roberta", None) is not None:
with tf.name_scope(self.roberta.name):
self.roberta.build(None)
if getattr(self, "qa_outputs", None) is not None:
with tf.name_scope(self.qa_outputs.name):
self.qa_outputs.build([None, None, self.config.hidden_size])
__all__ = [
"TFXLMRobertaForCausalLM",
"TFXLMRobertaForMaskedLM",
"TFXLMRobertaForMultipleChoice",
"TFXLMRobertaForQuestionAnswering",
"TFXLMRobertaForSequenceClassification",
"TFXLMRobertaForTokenClassification",
"TFXLMRobertaModel",
"TFXLMRobertaPreTrainedModel",
]
| transformers/src/transformers/models/xlm_roberta/modeling_tf_xlm_roberta.py/0 | {
"file_path": "transformers/src/transformers/models/xlm_roberta/modeling_tf_xlm_roberta.py",
"repo_id": "transformers",
"token_count": 35211
} |
# Copyright 2019 The TensorFlow Authors, The Hugging Face Team. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Functions and classes related to optimization (weight updates)."""
import re
from typing import Callable, List, Optional, Union
import tensorflow as tf
try:
from tf_keras.optimizers.legacy import Adam
except (ImportError, ModuleNotFoundError):
from tensorflow.keras.optimizers.legacy import Adam
from .modeling_tf_utils import keras
# This block because Keras loves randomly moving things to different places - this changed somewhere between 2.10 - 2.15
if hasattr(keras.optimizers.schedules, "learning_rate_schedule"):
schedules = keras.optimizers.schedules.learning_rate_schedule
else:
schedules = keras.optimizers.schedules
class WarmUp(schedules.LearningRateSchedule):
"""
Applies a warmup schedule on a given learning rate decay schedule.
Args:
initial_learning_rate (`float`):
The initial learning rate for the schedule after the warmup (so this will be the learning rate at the end
of the warmup).
decay_schedule_fn (`Callable`):
The schedule function to apply after the warmup for the rest of training.
warmup_steps (`int`):
The number of steps for the warmup part of training.
power (`float`, *optional*, defaults to 1.0):
The power to use for the polynomial warmup (defaults is a linear warmup).
name (`str`, *optional*):
Optional name prefix for the returned tensors during the schedule.
"""
def __init__(
self,
initial_learning_rate: float,
decay_schedule_fn: Callable,
warmup_steps: int,
power: float = 1.0,
name: str = None,
):
super().__init__()
self.initial_learning_rate = initial_learning_rate
self.warmup_steps = warmup_steps
self.power = power
self.decay_schedule_fn = decay_schedule_fn
self.name = name
def __call__(self, step):
with tf.name_scope(self.name or "WarmUp") as name:
# Implements polynomial warmup. i.e., if global_step < warmup_steps, the
# learning rate will be `global_step/num_warmup_steps * init_lr`.
global_step_float = tf.cast(step, tf.float32)
warmup_steps_float = tf.cast(self.warmup_steps, tf.float32)
warmup_percent_done = global_step_float / warmup_steps_float
warmup_learning_rate = self.initial_learning_rate * tf.math.pow(warmup_percent_done, self.power)
return tf.cond(
global_step_float < warmup_steps_float,
lambda: warmup_learning_rate,
lambda: self.decay_schedule_fn(step - self.warmup_steps),
name=name,
)
def get_config(self):
return {
"initial_learning_rate": self.initial_learning_rate,
"decay_schedule_fn": self.decay_schedule_fn,
"warmup_steps": self.warmup_steps,
"power": self.power,
"name": self.name,
}
def create_optimizer(
init_lr: float,
num_train_steps: int,
num_warmup_steps: int,
min_lr_ratio: float = 0.0,
adam_beta1: float = 0.9,
adam_beta2: float = 0.999,
adam_epsilon: float = 1e-8,
adam_clipnorm: Optional[float] = None,
adam_global_clipnorm: Optional[float] = None,
weight_decay_rate: float = 0.0,
power: float = 1.0,
include_in_weight_decay: Optional[List[str]] = None,
):
"""
Creates an optimizer with a learning rate schedule using a warmup phase followed by a linear decay.
Args:
init_lr (`float`):
The desired learning rate at the end of the warmup phase.
num_train_steps (`int`):
The total number of training steps.
num_warmup_steps (`int`):
The number of warmup steps.
min_lr_ratio (`float`, *optional*, defaults to 0):
The final learning rate at the end of the linear decay will be `init_lr * min_lr_ratio`.
adam_beta1 (`float`, *optional*, defaults to 0.9):
The beta1 to use in Adam.
adam_beta2 (`float`, *optional*, defaults to 0.999):
The beta2 to use in Adam.
adam_epsilon (`float`, *optional*, defaults to 1e-8):
The epsilon to use in Adam.
adam_clipnorm (`float`, *optional*, defaults to `None`):
If not `None`, clip the gradient norm for each weight tensor to this value.
adam_global_clipnorm (`float`, *optional*, defaults to `None`)
If not `None`, clip gradient norm to this value. When using this argument, the norm is computed over all
weight tensors, as if they were concatenated into a single vector.
weight_decay_rate (`float`, *optional*, defaults to 0):
The weight decay to use.
power (`float`, *optional*, defaults to 1.0):
The power to use for PolynomialDecay.
include_in_weight_decay (`List[str]`, *optional*):
List of the parameter names (or re patterns) to apply weight decay to. If none is passed, weight decay is
applied to all parameters except bias and layer norm parameters.
"""
# Implements linear decay of the learning rate.
lr_schedule = schedules.PolynomialDecay(
initial_learning_rate=init_lr,
decay_steps=num_train_steps - num_warmup_steps,
end_learning_rate=init_lr * min_lr_ratio,
power=power,
)
if num_warmup_steps:
lr_schedule = WarmUp(
initial_learning_rate=init_lr,
decay_schedule_fn=lr_schedule,
warmup_steps=num_warmup_steps,
)
if weight_decay_rate > 0.0:
optimizer = AdamWeightDecay(
learning_rate=lr_schedule,
weight_decay_rate=weight_decay_rate,
beta_1=adam_beta1,
beta_2=adam_beta2,
epsilon=adam_epsilon,
clipnorm=adam_clipnorm,
global_clipnorm=adam_global_clipnorm,
exclude_from_weight_decay=["LayerNorm", "layer_norm", "bias"],
include_in_weight_decay=include_in_weight_decay,
)
else:
optimizer = keras.optimizers.Adam(
learning_rate=lr_schedule,
beta_1=adam_beta1,
beta_2=adam_beta2,
epsilon=adam_epsilon,
clipnorm=adam_clipnorm,
global_clipnorm=adam_global_clipnorm,
)
# We return the optimizer and the LR scheduler in order to better track the
# evolution of the LR independently of the optimizer.
return optimizer, lr_schedule
class AdamWeightDecay(Adam):
"""
Adam enables L2 weight decay and clip_by_global_norm on gradients. Just adding the square of the weights to the
loss function is *not* the correct way of using L2 regularization/weight decay with Adam, since that will interact
with the m and v parameters in strange ways as shown in [Decoupled Weight Decay
Regularization](https://arxiv.org/abs/1711.05101).
Instead we want to decay the weights in a manner that doesn't interact with the m/v parameters. This is equivalent
to adding the square of the weights to the loss with plain (non-momentum) SGD.
Args:
learning_rate (`Union[float, LearningRateSchedule]`, *optional*, defaults to 0.001):
The learning rate to use or a schedule.
beta_1 (`float`, *optional*, defaults to 0.9):
The beta1 parameter in Adam, which is the exponential decay rate for the 1st momentum estimates.
beta_2 (`float`, *optional*, defaults to 0.999):
The beta2 parameter in Adam, which is the exponential decay rate for the 2nd momentum estimates.
epsilon (`float`, *optional*, defaults to 1e-07):
The epsilon parameter in Adam, which is a small constant for numerical stability.
amsgrad (`bool`, *optional*, defaults to `False`):
Whether to apply AMSGrad variant of this algorithm or not, see [On the Convergence of Adam and
Beyond](https://arxiv.org/abs/1904.09237).
weight_decay_rate (`float`, *optional*, defaults to 0.0):
The weight decay to apply.
include_in_weight_decay (`List[str]`, *optional*):
List of the parameter names (or re patterns) to apply weight decay to. If none is passed, weight decay is
applied to all parameters by default (unless they are in `exclude_from_weight_decay`).
exclude_from_weight_decay (`List[str]`, *optional*):
List of the parameter names (or re patterns) to exclude from applying weight decay to. If a
`include_in_weight_decay` is passed, the names in it will supersede this list.
name (`str`, *optional*, defaults to `"AdamWeightDecay"`):
Optional name for the operations created when applying gradients.
kwargs (`Dict[str, Any]`, *optional*):
Keyword arguments. Allowed to be {`clipnorm`, `clipvalue`, `lr`, `decay`}. `clipnorm` is clip gradients by
norm; `clipvalue` is clip gradients by value, `decay` is included for backward compatibility to allow time
inverse decay of learning rate. `lr` is included for backward compatibility, recommended to use
`learning_rate` instead.
"""
def __init__(
self,
learning_rate: Union[float, schedules.LearningRateSchedule] = 0.001,
beta_1: float = 0.9,
beta_2: float = 0.999,
epsilon: float = 1e-7,
amsgrad: bool = False,
weight_decay_rate: float = 0.0,
include_in_weight_decay: Optional[List[str]] = None,
exclude_from_weight_decay: Optional[List[str]] = None,
name: str = "AdamWeightDecay",
**kwargs,
):
super().__init__(learning_rate, beta_1, beta_2, epsilon, amsgrad, name, **kwargs)
self.weight_decay_rate = weight_decay_rate
self._include_in_weight_decay = include_in_weight_decay
self._exclude_from_weight_decay = exclude_from_weight_decay
@classmethod
def from_config(cls, config):
"""Creates an optimizer from its config with WarmUp custom object."""
custom_objects = {"WarmUp": WarmUp}
return super(AdamWeightDecay, cls).from_config(config, custom_objects=custom_objects)
def _prepare_local(self, var_device, var_dtype, apply_state):
super(AdamWeightDecay, self)._prepare_local(var_device, var_dtype, apply_state)
apply_state[(var_device, var_dtype)]["weight_decay_rate"] = tf.constant(
self.weight_decay_rate, name="adam_weight_decay_rate"
)
def _decay_weights_op(self, var, learning_rate, apply_state):
do_decay = self._do_use_weight_decay(var.name)
if do_decay:
return var.assign_sub(
learning_rate * var * apply_state[(var.device, var.dtype.base_dtype)]["weight_decay_rate"],
use_locking=self._use_locking,
)
return tf.no_op()
def apply_gradients(self, grads_and_vars, name=None, **kwargs):
grads, tvars = list(zip(*grads_and_vars))
return super(AdamWeightDecay, self).apply_gradients(zip(grads, tvars), name=name, **kwargs)
def _get_lr(self, var_device, var_dtype, apply_state):
"""Retrieves the learning rate with the given state."""
if apply_state is None:
return self._decayed_lr_t[var_dtype], {}
apply_state = apply_state or {}
coefficients = apply_state.get((var_device, var_dtype))
if coefficients is None:
coefficients = self._fallback_apply_state(var_device, var_dtype)
apply_state[(var_device, var_dtype)] = coefficients
return coefficients["lr_t"], {"apply_state": apply_state}
def _resource_apply_dense(self, grad, var, apply_state=None):
lr_t, kwargs = self._get_lr(var.device, var.dtype.base_dtype, apply_state)
decay = self._decay_weights_op(var, lr_t, apply_state)
with tf.control_dependencies([decay]):
return super(AdamWeightDecay, self)._resource_apply_dense(grad, var, **kwargs)
def _resource_apply_sparse(self, grad, var, indices, apply_state=None):
lr_t, kwargs = self._get_lr(var.device, var.dtype.base_dtype, apply_state)
decay = self._decay_weights_op(var, lr_t, apply_state)
with tf.control_dependencies([decay]):
return super(AdamWeightDecay, self)._resource_apply_sparse(grad, var, indices, **kwargs)
def get_config(self):
config = super().get_config()
config.update({"weight_decay_rate": self.weight_decay_rate})
return config
def _do_use_weight_decay(self, param_name):
"""Whether to use L2 weight decay for `param_name`."""
if self.weight_decay_rate == 0:
return False
if self._include_in_weight_decay:
for r in self._include_in_weight_decay:
if re.search(r, param_name) is not None:
return True
if self._exclude_from_weight_decay:
for r in self._exclude_from_weight_decay:
if re.search(r, param_name) is not None:
return False
return True
# Extracted from https://github.com/OpenNMT/OpenNMT-tf/blob/master/opennmt/optimizers/utils.py
class GradientAccumulator:
"""
Gradient accumulation utility. When used with a distribution strategy, the accumulator should be called in a
replica context. Gradients will be accumulated locally on each replica and without synchronization. Users should
then call `.gradients`, scale the gradients if required, and pass the result to `apply_gradients`.
"""
# We use the ON_READ synchronization policy so that no synchronization is
# performed on assignment. To get the value, we call .value() which returns the
# value on the current replica without synchronization.
def __init__(self):
"""Initializes the accumulator."""
self._gradients = []
self._accum_steps = None
@property
def step(self):
"""Number of accumulated steps."""
if self._accum_steps is None:
self._accum_steps = tf.Variable(
tf.constant(0, dtype=tf.int64),
trainable=False,
synchronization=tf.VariableSynchronization.ON_READ,
aggregation=tf.VariableAggregation.ONLY_FIRST_REPLICA,
)
return self._accum_steps.value()
@property
def gradients(self):
"""The accumulated gradients on the current replica."""
if not self._gradients:
raise ValueError("The accumulator should be called first to initialize the gradients")
return [gradient.value() if gradient is not None else gradient for gradient in self._gradients]
def __call__(self, gradients):
"""Accumulates `gradients` on the current replica."""
if not self._gradients:
_ = self.step # Create the step variable.
self._gradients.extend(
[
tf.Variable(
tf.zeros_like(gradient),
trainable=False,
synchronization=tf.VariableSynchronization.ON_READ,
aggregation=tf.VariableAggregation.ONLY_FIRST_REPLICA,
)
if gradient is not None
else gradient
for gradient in gradients
]
)
if len(gradients) != len(self._gradients):
raise ValueError(f"Expected {len(self._gradients)} gradients, but got {len(gradients)}")
for accum_gradient, gradient in zip(self._gradients, gradients):
if accum_gradient is not None and gradient is not None:
accum_gradient.assign_add(gradient)
self._accum_steps.assign_add(1)
def reset(self):
"""Resets the accumulated gradients on the current replica."""
if not self._gradients:
return
self._accum_steps.assign(0)
for gradient in self._gradients:
if gradient is not None:
gradient.assign(tf.zeros_like(gradient))
| transformers/src/transformers/optimization_tf.py/0 | {
"file_path": "transformers/src/transformers/optimization_tf.py",
"repo_id": "transformers",
"token_count": 6957
} |
from collections import defaultdict
from typing import Optional
from ..image_utils import load_image
from ..utils import (
add_end_docstrings,
is_torch_available,
logging,
requires_backends,
)
from .base import ChunkPipeline, build_pipeline_init_args
if is_torch_available():
import torch
from ..models.auto.modeling_auto import MODEL_FOR_MASK_GENERATION_MAPPING_NAMES
logger = logging.get_logger(__name__)
@add_end_docstrings(
build_pipeline_init_args(has_image_processor=True),
r"""
points_per_batch (*optional*, int, default to 64):
Sets the number of points run simultaneously by the model. Higher numbers may be faster but use more GPU
memory.
output_bboxes_mask (`bool`, *optional*, default to `False`):
Whether or not to output the bounding box predictions.
output_rle_masks (`bool`, *optional*, default to `False`):
Whether or not to output the masks in `RLE` format""",
)
class MaskGenerationPipeline(ChunkPipeline):
"""
Automatic mask generation for images using `SamForMaskGeneration`. This pipeline predicts binary masks for an
image, given an image. It is a `ChunkPipeline` because you can seperate the points in a mini-batch in order to
avoid OOM issues. Use the `points_per_batch` argument to control the number of points that will be processed at the
same time. Default is `64`.
The pipeline works in 3 steps:
1. `preprocess`: A grid of 1024 points evenly separated is generated along with bounding boxes and point
labels.
For more details on how the points and bounding boxes are created, check the `_generate_crop_boxes`
function. The image is also preprocessed using the `image_processor`. This function `yields` a minibatch of
`points_per_batch`.
2. `forward`: feeds the outputs of `preprocess` to the model. The image embedding is computed only once.
Calls both `self.model.get_image_embeddings` and makes sure that the gradients are not computed, and the
tensors and models are on the same device.
3. `postprocess`: The most important part of the automatic mask generation happens here. Three steps
are induced:
- image_processor.postprocess_masks (run on each minibatch loop): takes in the raw output masks,
resizes them according
to the image size, and transforms there to binary masks.
- image_processor.filter_masks (on each minibatch loop): uses both `pred_iou_thresh` and
`stability_scores`. Also
applies a variety of filters based on non maximum suppression to remove bad masks.
- image_processor.postprocess_masks_for_amg applies the NSM on the mask to only keep relevant ones.
Example:
```python
>>> from transformers import pipeline
>>> generator = pipeline(model="facebook/sam-vit-base", task="mask-generation")
>>> outputs = generator(
... "http://images.cocodataset.org/val2017/000000039769.jpg",
... )
>>> outputs = generator(
... "https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png", points_per_batch=128
... )
```
Learn more about the basics of using a pipeline in the [pipeline tutorial](../pipeline_tutorial)
This segmentation pipeline can currently be loaded from [`pipeline`] using the following task identifier:
`"mask-generation"`.
See the list of available models on [huggingface.co/models](https://huggingface.co/models?filter=mask-generation).
"""
def __init__(self, **kwargs):
super().__init__(**kwargs)
requires_backends(self, "vision")
requires_backends(self, "torch")
if self.framework != "pt":
raise ValueError(f"The {self.__class__} is only available in PyTorch.")
self.check_model_type(MODEL_FOR_MASK_GENERATION_MAPPING_NAMES)
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
postprocess_kwargs = {}
forward_params = {}
# preprocess args
if "points_per_batch" in kwargs:
preprocess_kwargs["points_per_batch"] = kwargs["points_per_batch"]
if "points_per_crop" in kwargs:
preprocess_kwargs["points_per_crop"] = kwargs["points_per_crop"]
if "crops_n_layers" in kwargs:
preprocess_kwargs["crops_n_layers"] = kwargs["crops_n_layers"]
if "crop_overlap_ratio" in kwargs:
preprocess_kwargs["crop_overlap_ratio"] = kwargs["crop_overlap_ratio"]
if "crop_n_points_downscale_factor" in kwargs:
preprocess_kwargs["crop_n_points_downscale_factor"] = kwargs["crop_n_points_downscale_factor"]
if "timeout" in kwargs:
preprocess_kwargs["timeout"] = kwargs["timeout"]
# postprocess args
if "pred_iou_thresh" in kwargs:
forward_params["pred_iou_thresh"] = kwargs["pred_iou_thresh"]
if "stability_score_offset" in kwargs:
forward_params["stability_score_offset"] = kwargs["stability_score_offset"]
if "mask_threshold" in kwargs:
forward_params["mask_threshold"] = kwargs["mask_threshold"]
if "stability_score_thresh" in kwargs:
forward_params["stability_score_thresh"] = kwargs["stability_score_thresh"]
if "crops_nms_thresh" in kwargs:
postprocess_kwargs["crops_nms_thresh"] = kwargs["crops_nms_thresh"]
if "output_rle_mask" in kwargs:
postprocess_kwargs["output_rle_mask"] = kwargs["output_rle_mask"]
if "output_bboxes_mask" in kwargs:
postprocess_kwargs["output_bboxes_mask"] = kwargs["output_bboxes_mask"]
return preprocess_kwargs, forward_params, postprocess_kwargs
def __call__(self, image, *args, num_workers=None, batch_size=None, **kwargs):
"""
Generates binary segmentation masks
Args:
inputs (`np.ndarray` or `bytes` or `str` or `dict`):
Image or list of images.
mask_threshold (`float`, *optional*, defaults to 0.0):
Threshold to use when turning the predicted masks into binary values.
pred_iou_thresh (`float`, *optional*, defaults to 0.88):
A filtering threshold in `[0,1]` applied on the model's predicted mask quality.
stability_score_thresh (`float`, *optional*, defaults to 0.95):
A filtering threshold in `[0,1]`, using the stability of the mask under changes to the cutoff used to
binarize the model's mask predictions.
stability_score_offset (`int`, *optional*, defaults to 1):
The amount to shift the cutoff when calculated the stability score.
crops_nms_thresh (`float`, *optional*, defaults to 0.7):
The box IoU cutoff used by non-maximal suppression to filter duplicate masks.
crops_n_layers (`int`, *optional*, defaults to 0):
If `crops_n_layers>0`, mask prediction will be run again on crops of the image. Sets the number of
layers to run, where each layer has 2**i_layer number of image crops.
crop_overlap_ratio (`float`, *optional*, defaults to `512 / 1500`):
Sets the degree to which crops overlap. In the first crop layer, crops will overlap by this fraction of
the image length. Later layers with more crops scale down this overlap.
crop_n_points_downscale_factor (`int`, *optional*, defaults to `1`):
The number of points-per-side sampled in layer n is scaled down by crop_n_points_downscale_factor**n.
timeout (`float`, *optional*, defaults to None):
The maximum time in seconds to wait for fetching images from the web. If None, no timeout is set and
the call may block forever.
Return:
`Dict`: A dictionary with the following keys:
- **mask** (`PIL.Image`) -- A binary mask of the detected object as a PIL Image of shape `(width,
height)` of the original image. Returns a mask filled with zeros if no object is found.
- **score** (*optional* `float`) -- Optionally, when the model is capable of estimating a confidence of
the "object" described by the label and the mask.
"""
return super().__call__(image, *args, num_workers=num_workers, batch_size=batch_size, **kwargs)
def preprocess(
self,
image,
points_per_batch=64,
crops_n_layers: int = 0,
crop_overlap_ratio: float = 512 / 1500,
points_per_crop: Optional[int] = 32,
crop_n_points_downscale_factor: Optional[int] = 1,
timeout: Optional[float] = None,
):
image = load_image(image, timeout=timeout)
target_size = self.image_processor.size["longest_edge"]
crop_boxes, grid_points, cropped_images, input_labels = self.image_processor.generate_crop_boxes(
image, target_size, crops_n_layers, crop_overlap_ratio, points_per_crop, crop_n_points_downscale_factor
)
model_inputs = self.image_processor(images=cropped_images, return_tensors="pt")
if self.framework == "pt":
model_inputs = model_inputs.to(self.torch_dtype)
with self.device_placement():
if self.framework == "pt":
inference_context = self.get_inference_context()
with inference_context():
model_inputs = self._ensure_tensor_on_device(model_inputs, device=self.device)
image_embeddings = self.model.get_image_embeddings(model_inputs.pop("pixel_values"))
model_inputs["image_embeddings"] = image_embeddings
n_points = grid_points.shape[1]
points_per_batch = points_per_batch if points_per_batch is not None else n_points
if points_per_batch <= 0:
raise ValueError(
"Cannot have points_per_batch<=0. Must be >=1 to returned batched outputs. "
"To return all points at once, set points_per_batch to None"
)
for i in range(0, n_points, points_per_batch):
batched_points = grid_points[:, i : i + points_per_batch, :, :]
labels = input_labels[:, i : i + points_per_batch]
is_last = i == n_points - points_per_batch
yield {
"input_points": batched_points,
"input_labels": labels,
"input_boxes": crop_boxes,
"is_last": is_last,
**model_inputs,
}
def _forward(
self,
model_inputs,
pred_iou_thresh=0.88,
stability_score_thresh=0.95,
mask_threshold=0,
stability_score_offset=1,
):
input_boxes = model_inputs.pop("input_boxes")
is_last = model_inputs.pop("is_last")
original_sizes = model_inputs.pop("original_sizes").tolist()
reshaped_input_sizes = model_inputs.pop("reshaped_input_sizes").tolist()
model_outputs = self.model(**model_inputs)
# post processing happens here in order to avoid CPU GPU copies of ALL the masks
low_resolution_masks = model_outputs["pred_masks"]
masks = self.image_processor.post_process_masks(
low_resolution_masks, original_sizes, reshaped_input_sizes, mask_threshold, binarize=False
)
iou_scores = model_outputs["iou_scores"]
masks, iou_scores, boxes = self.image_processor.filter_masks(
masks[0],
iou_scores[0],
original_sizes[0],
input_boxes[0],
pred_iou_thresh,
stability_score_thresh,
mask_threshold,
stability_score_offset,
)
return {
"masks": masks,
"is_last": is_last,
"boxes": boxes,
"iou_scores": iou_scores,
}
def postprocess(
self,
model_outputs,
output_rle_mask=False,
output_bboxes_mask=False,
crops_nms_thresh=0.7,
):
all_scores = []
all_masks = []
all_boxes = []
for model_output in model_outputs:
all_scores.append(model_output.pop("iou_scores"))
all_masks.extend(model_output.pop("masks"))
all_boxes.append(model_output.pop("boxes"))
all_scores = torch.cat(all_scores)
all_boxes = torch.cat(all_boxes)
output_masks, iou_scores, rle_mask, bounding_boxes = self.image_processor.post_process_for_mask_generation(
all_masks, all_scores, all_boxes, crops_nms_thresh
)
extra = defaultdict(list)
for output in model_outputs:
for k, v in output.items():
extra[k].append(v)
optional = {}
if output_rle_mask:
optional["rle_mask"] = rle_mask
if output_bboxes_mask:
optional["bounding_boxes"] = bounding_boxes
return {"masks": output_masks, "scores": iou_scores, **optional, **extra}
| transformers/src/transformers/pipelines/mask_generation.py/0 | {
"file_path": "transformers/src/transformers/pipelines/mask_generation.py",
"repo_id": "transformers",
"token_count": 5667
} |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Processing saving/loading class for common processors.
"""
import copy
import inspect
import json
import os
import sys
import typing
import warnings
from pathlib import Path
from typing import Any, Dict, List, Optional, Tuple, TypedDict, Union
import numpy as np
import typing_extensions
from .dynamic_module_utils import custom_object_save
from .image_utils import ChannelDimension, is_valid_image, is_vision_available, load_image, load_video
if is_vision_available():
from .image_utils import PILImageResampling
from .tokenization_utils_base import (
PaddingStrategy,
PreTokenizedInput,
PreTrainedTokenizerBase,
TextInput,
TruncationStrategy,
)
from .utils import (
PROCESSOR_NAME,
PushToHubMixin,
TensorType,
add_model_info_to_auto_map,
add_model_info_to_custom_pipelines,
cached_file,
copy_func,
direct_transformers_import,
download_url,
is_offline_mode,
is_remote_url,
logging,
)
logger = logging.get_logger(__name__)
# Dynamically import the Transformers module to grab the attribute classes of the processor form their names.
transformers_module = direct_transformers_import(Path(__file__).parent)
AUTO_TO_BASE_CLASS_MAPPING = {
"AutoTokenizer": "PreTrainedTokenizerBase",
"AutoFeatureExtractor": "FeatureExtractionMixin",
"AutoImageProcessor": "ImageProcessingMixin",
}
if sys.version_info >= (3, 11):
Unpack = typing.Unpack
else:
Unpack = typing_extensions.Unpack
class TextKwargs(TypedDict, total=False):
"""
Keyword arguments for text processing. For extended documentation, check out tokenization_utils_base methods and
docstrings associated.
Attributes:
add_special_tokens (`bool`, *optional*)
Whether or not to add special tokens when encoding the sequences.
padding (`bool`, `str` or [`~utils.PaddingStrategy`], *optional*)
Activates and controls padding.
truncation (`bool`, `str` or [`~tokenization_utils_base.TruncationStrategy`], *optional*):
Activates and controls truncation.
max_length (`int`, *optional*):
Controls the maximum length to use by one of the truncation/padding parameters.
stride (`int`, *optional*):
If set, the overflowing tokens will contain some tokens from the end of the truncated sequence.
is_split_into_words (`bool`, *optional*):
Whether or not the input is already pre-tokenized.
pad_to_multiple_of (`int`, *optional*):
If set, will pad the sequence to a multiple of the provided value.
return_token_type_ids (`bool`, *optional*):
Whether to return token type IDs.
return_attention_mask (`bool`, *optional*):
Whether to return the attention mask.
return_overflowing_tokens (`bool`, *optional*):
Whether or not to return overflowing token sequences.
return_special_tokens_mask (`bool`, *optional*):
Whether or not to return special tokens mask information.
return_offsets_mapping (`bool`, *optional*):
Whether or not to return `(char_start, char_end)` for each token.
return_length (`bool`, *optional*):
Whether or not to return the lengths of the encoded inputs.
verbose (`bool`, *optional*):
Whether or not to print more information and warnings.
padding_side (`str`, *optional*):
The side on which padding will be applied.
"""
text_pair: Optional[Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]]]
text_target: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]]
text_pair_target: Optional[Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]]]
add_special_tokens: Optional[bool]
padding: Union[bool, str, PaddingStrategy]
truncation: Union[bool, str, TruncationStrategy]
max_length: Optional[int]
stride: Optional[int]
is_split_into_words: Optional[bool]
pad_to_multiple_of: Optional[int]
return_token_type_ids: Optional[bool]
return_attention_mask: Optional[bool]
return_overflowing_tokens: Optional[bool]
return_special_tokens_mask: Optional[bool]
return_offsets_mapping: Optional[bool]
return_length: Optional[bool]
verbose: Optional[bool]
padding_side: Optional[str]
class ImagesKwargs(TypedDict, total=False):
"""
Keyword arguments for image processing. For extended documentation, check the appropriate ImageProcessor
class methods and docstrings.
Attributes:
do_resize (`bool`, *optional*):
Whether to resize the image.
size (`Dict[str, int]`, *optional*):
Resize the shorter side of the input to `size["shortest_edge"]`.
size_divisor (`int`, *optional*):
The size by which to make sure both the height and width can be divided.
crop_size (`Dict[str, int]`, *optional*):
Desired output size when applying center-cropping.
resample (`PILImageResampling`, *optional*):
Resampling filter to use if resizing the image.
do_rescale (`bool`, *optional*):
Whether to rescale the image by the specified scale `rescale_factor`.
rescale_factor (`int` or `float`, *optional*):
Scale factor to use if rescaling the image.
do_normalize (`bool`, *optional*):
Whether to normalize the image.
image_mean (`float` or `List[float]`, *optional*):
Mean to use if normalizing the image.
image_std (`float` or `List[float]`, *optional*):
Standard deviation to use if normalizing the image.
do_pad (`bool`, *optional*):
Whether to pad the image to the `(max_height, max_width)` of the images in the batch.
pad_size (`Dict[str, int]`, *optional*):
The size `{"height": int, "width" int}` to pad the images to.
do_center_crop (`bool`, *optional*):
Whether to center crop the image.
data_format (`ChannelDimension` or `str`, *optional*):
The channel dimension format for the output image.
input_data_format (`ChannelDimension` or `str`, *optional*):
The channel dimension format for the input image.
device (`str`, *optional*):
The device to use for processing (e.g. "cpu", "cuda"), only relevant for fast image processing.
"""
do_resize: Optional[bool]
size: Optional[Dict[str, int]]
size_divisor: Optional[int]
crop_size: Optional[Dict[str, int]]
resample: Optional[Union["PILImageResampling", int]]
do_rescale: Optional[bool]
rescale_factor: Optional[float]
do_normalize: Optional[bool]
image_mean: Optional[Union[float, List[float]]]
image_std: Optional[Union[float, List[float]]]
do_pad: Optional[bool]
pad_size: Optional[Dict[str, int]]
do_center_crop: Optional[bool]
data_format: Optional[ChannelDimension]
input_data_format: Optional[Union[str, ChannelDimension]]
device: Optional[str]
class VideosKwargs(TypedDict, total=False):
"""
Keyword arguments for video processing.
Attributes:
do_resize (`bool`):
Whether to resize the image.
size (`Dict[str, int]`, *optional*):
Resize the shorter side of the input to `size["shortest_edge"]`.
size_divisor (`int`, *optional*):
The size by which to make sure both the height and width can be divided.
resample (`PILImageResampling`, *optional*):
Resampling filter to use if resizing the image.
do_rescale (`bool`, *optional*):
Whether to rescale the image by the specified scale `rescale_factor`.
rescale_factor (`int` or `float`, *optional*):
Scale factor to use if rescaling the image.
do_normalize (`bool`, *optional*):
Whether to normalize the image.
image_mean (`float` or `List[float]`, *optional*):
Mean to use if normalizing the image.
image_std (`float` or `List[float]`, *optional*):
Standard deviation to use if normalizing the image.
do_pad (`bool`, *optional*):
Whether to pad the image to the `(max_height, max_width)` of the images in the batch.
do_center_crop (`bool`, *optional*):
Whether to center crop the image.
data_format (`ChannelDimension` or `str`, *optional*):
The channel dimension format for the output image.
input_data_format (`ChannelDimension` or `str`, *optional*):
The channel dimension format for the input image.
"""
do_resize: Optional[bool]
size: Optional[Dict[str, int]]
size_divisor: Optional[int]
resample: Optional["PILImageResampling"]
do_rescale: Optional[bool]
rescale_factor: Optional[float]
do_normalize: Optional[bool]
image_mean: Optional[Union[float, List[float]]]
image_std: Optional[Union[float, List[float]]]
do_pad: Optional[bool]
do_center_crop: Optional[bool]
data_format: Optional[ChannelDimension]
input_data_format: Optional[Union[str, ChannelDimension]]
class AudioKwargs(TypedDict, total=False):
"""
Keyword arguments for audio processing.
Attributes:
sampling_rate (`int`, *optional*):
The sampling rate at which the `raw_speech` input was sampled.
raw_speech (`np.ndarray`, `List[float]`, `List[np.ndarray]`, `List[List[float]]`):
The sequence or batch of sequences to be padded. Each sequence can be a numpy array, a list of float
values, a list of numpy arrays or a list of list of float values. Must be mono channel audio, not
stereo, i.e. single float per timestep.
padding (`bool`, `str` or [`~utils.PaddingStrategy`], *optional*):
Select a strategy to pad the returned sequences (according to the model's padding side and padding
index) among:
- `True` or `'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
- `'max_length'`: Pad to a maximum length specified with the argument `max_length` or to the maximum
acceptable input length for the model if that argument is not provided.
- `False` or `'do_not_pad'`
max_length (`int`, *optional*):
Maximum length of the returned list and optionally padding length (see above).
truncation (`bool`, *optional*):
Activates truncation to cut input sequences longer than *max_length* to *max_length*.
pad_to_multiple_of (`int`, *optional*):
If set, will pad the sequence to a multiple of the provided value.
return_attention_mask (`bool`, *optional*):
Whether or not [`~ASTFeatureExtractor.__call__`] should return `attention_mask`.
"""
sampling_rate: Optional[int]
raw_speech: Optional[Union["np.ndarray", List[float], List["np.ndarray"], List[List[float]]]]
padding: Optional[Union[bool, str, PaddingStrategy]]
max_length: Optional[int]
truncation: Optional[bool]
pad_to_multiple_of: Optional[int]
return_attention_mask: Optional[bool]
class CommonKwargs(TypedDict, total=False):
return_tensors: Optional[Union[str, TensorType]]
class ProcessingKwargs(TextKwargs, ImagesKwargs, VideosKwargs, AudioKwargs, CommonKwargs, total=False):
"""
Base class for kwargs passing to processors.
A model should have its own `ModelProcessorKwargs` class that inherits from `ProcessingKwargs` to provide:
1) Additional typed keys and that this model requires to process inputs.
2) Default values for existing keys under a `_defaults` attribute.
New keys have to be defined as follows to ensure type hinting is done correctly.
```python
# adding a new image kwarg for this model
class ModelImagesKwargs(ImagesKwargs, total=False):
new_image_kwarg: Optional[bool]
class ModelProcessorKwargs(ProcessingKwargs, total=False):
images_kwargs: ModelImagesKwargs
_defaults = {
"images_kwargs: {
"new_image_kwarg": False,
}
"text_kwargs": {
"padding": "max_length",
},
}
```
For Python 3.8 compatibility, when inheriting from this class and overriding one of the kwargs,
you need to manually update the __annotations__ dictionary. This can be done as follows:
```python
class CustomProcessorKwargs(ProcessingKwargs, total=False):
images_kwargs: CustomImagesKwargs
CustomProcessorKwargs.__annotations__["images_kwargs"] = CustomImagesKwargs # python 3.8 compatibility
```python
"""
common_kwargs: CommonKwargs = {
**CommonKwargs.__annotations__,
}
text_kwargs: TextKwargs = {
**TextKwargs.__annotations__,
}
images_kwargs: ImagesKwargs = {
**ImagesKwargs.__annotations__,
}
videos_kwargs: VideosKwargs = {
**VideosKwargs.__annotations__,
}
audio_kwargs: AudioKwargs = {
**AudioKwargs.__annotations__,
}
class ChatTemplateKwargs(TypedDict, total=False):
"""
Keyword arguments for processor chat templates.
tokenize (`bool`, *optional*, defaults to `False`):
Whether to tokenize the output or not.
return_dict (`bool`, defaults to `False`):
Whether to return a dictionary with named outputs. Has no effect if tokenize is `False`.
tools (`List[Dict]`, *optional*):
A list of tools (callable functions) that will be accessible to the model. If the template does not
support function calling, this argument will have no effect. Each tool should be passed as a JSON Schema,
giving the name, description and argument types for the tool. See our
[chat templating guide](https://huggingface.co/docs/transformers/main/en/chat_templating#automated-function-conversion-for-tool-use)
for more information.
documents (`List[Dict[str, str]]`, *optional*):
A list of dicts representing documents that will be accessible to the model if it is performing RAG
(retrieval-augmented generation). If the template does not support RAG, this argument will have no
effect. We recommend that each document should be a dict containing "title" and "text" keys. Please
see the RAG section of the [chat templating guide](https://huggingface.co/docs/transformers/main/en/chat_templating#arguments-for-RAG)
for examples of passing documents with chat templates.
add_generation_prompt (bool, *optional*):
If this is set, a prompt with the token(s) that indicate
the start of an assistant message will be appended to the formatted output. This is useful when you want to generate a response from the model.
Note that this argument will be passed to the chat template, and so it must be supported in the
template for this argument to have any effect.
continue_final_message (bool, *optional*):
If this is set, the chat will be formatted so that the final
message in the chat is open-ended, without any EOS tokens. The model will continue this message
rather than starting a new one. This allows you to "prefill" part of
the model's response for it. Cannot be used at the same time as `add_generation_prompt`.
return_assistant_tokens_mask (`bool`, defaults to `False`):
Whether to return a mask of the assistant generated tokens. For tokens generated by the assistant,
the mask will contain 1. For user and system tokens, the mask will contain 0.
This functionality is only available for chat templates that support it via the `{% generation %}` keyword.
num_frames (`int`, *optional*):
Number of frames to sample uniformly. If not passed, the whole video is loaded.
video_load_backend (`str`, *optional*, defaults to `"pyav"`):
The backend to use when loading the video which will be used only when there are videos in the conversation.
Can be any of ["decord", "pyav", "opencv", "torchvision"]. Defaults to "pyav" because it is the only backend
that supports all types of sources to load from.
"""
tokenize: Optional[bool] = False
return_dict: Optional[bool] = False
tools: Optional[List[Dict]] = None
documents: Optional[List[Dict[str, str]]] = None
add_generation_prompt: Optional[bool] = False
continue_final_message: Optional[bool] = False
return_assistant_tokens_mask: Optional[bool] = False
num_frames: Optional[int] = None
video_load_backend: Optional[str] = "pyav"
class AllKwargsForChatTemplate(
TextKwargs, ImagesKwargs, VideosKwargs, AudioKwargs, CommonKwargs, ChatTemplateKwargs
): ...
class ProcessorMixin(PushToHubMixin):
"""
This is a mixin used to provide saving/loading functionality for all processor classes.
"""
attributes = ["feature_extractor", "tokenizer"]
optional_attributes = ["chat_template"]
optional_call_args: List[str] = []
# Names need to be attr_class for attr in attributes
feature_extractor_class = None
tokenizer_class = None
_auto_class = None
valid_kwargs: List[str] = []
# args have to match the attributes class attribute
def __init__(self, *args, **kwargs):
# First, extract optional attributes from kwargs if present
# Optional attributes can never be positional arguments
for optional_attribute in self.optional_attributes:
setattr(self, optional_attribute, kwargs.pop(optional_attribute, None))
# Sanitize args and kwargs
for key in kwargs:
if key not in self.attributes:
raise TypeError(f"Unexpected keyword argument {key}.")
for arg, attribute_name in zip(args, self.attributes):
if attribute_name in kwargs:
raise TypeError(f"Got multiple values for argument {attribute_name}.")
else:
kwargs[attribute_name] = arg
if len(kwargs) != len(self.attributes):
raise ValueError(
f"This processor requires {len(self.attributes)} arguments: {', '.join(self.attributes)}. Got "
f"{len(args)} arguments instead."
)
# Check each arg is of the proper class (this will also catch a user initializing in the wrong order)
for attribute_name, arg in kwargs.items():
class_name = getattr(self, f"{attribute_name}_class")
# Nothing is ever going to be an instance of "AutoXxx", in that case we check the base class.
class_name = AUTO_TO_BASE_CLASS_MAPPING.get(class_name, class_name)
if isinstance(class_name, tuple):
proper_class = tuple(getattr(transformers_module, n) for n in class_name if n is not None)
else:
proper_class = getattr(transformers_module, class_name)
if not isinstance(arg, proper_class):
raise TypeError(
f"Received a {type(arg).__name__} for argument {attribute_name}, but a {class_name} was expected."
)
setattr(self, attribute_name, arg)
def to_dict(self) -> Dict[str, Any]:
"""
Serializes this instance to a Python dictionary.
Returns:
`Dict[str, Any]`: Dictionary of all the attributes that make up this processor instance.
"""
output = copy.deepcopy(self.__dict__)
# Get the kwargs in `__init__`.
sig = inspect.signature(self.__init__)
# Only save the attributes that are presented in the kwargs of `__init__`.
attrs_to_save = sig.parameters
# Don't save attributes like `tokenizer`, `image processor` etc.
attrs_to_save = [x for x in attrs_to_save if x not in self.__class__.attributes]
# extra attributes to be kept
attrs_to_save += ["auto_map"]
output = {k: v for k, v in output.items() if k in attrs_to_save}
output["processor_class"] = self.__class__.__name__
if "tokenizer" in output:
del output["tokenizer"]
if "image_processor" in output:
del output["image_processor"]
if "feature_extractor" in output:
del output["feature_extractor"]
if "chat_template" in output:
del output["chat_template"]
# Some attributes have different names but containing objects that are not simple strings
output = {
k: v
for k, v in output.items()
if not (isinstance(v, PushToHubMixin) or v.__class__.__name__ == "BeamSearchDecoderCTC")
}
return output
def to_json_string(self) -> str:
"""
Serializes this instance to a JSON string.
Returns:
`str`: String containing all the attributes that make up this feature_extractor instance in JSON format.
"""
dictionary = self.to_dict()
return json.dumps(dictionary, indent=2, sort_keys=True) + "\n"
def to_json_file(self, json_file_path: Union[str, os.PathLike]):
"""
Save this instance to a JSON file.
Args:
json_file_path (`str` or `os.PathLike`):
Path to the JSON file in which this processor instance's parameters will be saved.
"""
with open(json_file_path, "w", encoding="utf-8") as writer:
writer.write(self.to_json_string())
def __repr__(self):
attributes_repr = [f"- {name}: {repr(getattr(self, name))}" for name in self.attributes]
attributes_repr = "\n".join(attributes_repr)
return f"{self.__class__.__name__}:\n{attributes_repr}\n\n{self.to_json_string()}"
def save_pretrained(self, save_directory, push_to_hub: bool = False, **kwargs):
"""
Saves the attributes of this processor (feature extractor, tokenizer...) in the specified directory so that it
can be reloaded using the [`~ProcessorMixin.from_pretrained`] method.
<Tip>
This class method is simply calling [`~feature_extraction_utils.FeatureExtractionMixin.save_pretrained`] and
[`~tokenization_utils_base.PreTrainedTokenizerBase.save_pretrained`]. Please refer to the docstrings of the
methods above for more information.
</Tip>
Args:
save_directory (`str` or `os.PathLike`):
Directory where the feature extractor JSON file and the tokenizer files will be saved (directory will
be created if it does not exist).
push_to_hub (`bool`, *optional*, defaults to `False`):
Whether or not to push your model to the Hugging Face model hub after saving it. You can specify the
repository you want to push to with `repo_id` (will default to the name of `save_directory` in your
namespace).
kwargs (`Dict[str, Any]`, *optional*):
Additional key word arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
"""
use_auth_token = kwargs.pop("use_auth_token", None)
if use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
FutureWarning,
)
if kwargs.get("token", None) is not None:
raise ValueError(
"`token` and `use_auth_token` are both specified. Please set only the argument `token`."
)
kwargs["token"] = use_auth_token
os.makedirs(save_directory, exist_ok=True)
if push_to_hub:
commit_message = kwargs.pop("commit_message", None)
repo_id = kwargs.pop("repo_id", save_directory.split(os.path.sep)[-1])
repo_id = self._create_repo(repo_id, **kwargs)
files_timestamps = self._get_files_timestamps(save_directory)
# If we have a custom config, we copy the file defining it in the folder and set the attributes so it can be
# loaded from the Hub.
if self._auto_class is not None:
attrs = [getattr(self, attribute_name) for attribute_name in self.attributes]
configs = [(a.init_kwargs if isinstance(a, PreTrainedTokenizerBase) else a) for a in attrs]
configs.append(self)
custom_object_save(self, save_directory, config=configs)
for attribute_name in self.attributes:
attribute = getattr(self, attribute_name)
# Include the processor class in the attribute config so this processor can then be reloaded with the
# `AutoProcessor` API.
if hasattr(attribute, "_set_processor_class"):
attribute._set_processor_class(self.__class__.__name__)
attribute.save_pretrained(save_directory)
if self._auto_class is not None:
# We added an attribute to the init_kwargs of the tokenizers, which needs to be cleaned up.
for attribute_name in self.attributes:
attribute = getattr(self, attribute_name)
if isinstance(attribute, PreTrainedTokenizerBase):
del attribute.init_kwargs["auto_map"]
# If we save using the predefined names, we can load using `from_pretrained`
# plus we save chat_template in its own file
output_processor_file = os.path.join(save_directory, PROCESSOR_NAME)
output_raw_chat_template_file = os.path.join(save_directory, "chat_template.jinja")
output_chat_template_file = os.path.join(save_directory, "chat_template.json")
processor_dict = self.to_dict()
# Save `chat_template` in its own file. We can't get it from `processor_dict` as we popped it in `to_dict`
# to avoid serializing chat template in json config file. So let's get it from `self` directly
if self.chat_template is not None:
if kwargs.get("save_raw_chat_template", False):
with open(output_raw_chat_template_file, "w", encoding="utf-8") as writer:
writer.write(self.chat_template)
logger.info(f"chat template saved in {output_raw_chat_template_file}")
else:
chat_template_json_string = (
json.dumps({"chat_template": self.chat_template}, indent=2, sort_keys=True) + "\n"
)
with open(output_chat_template_file, "w", encoding="utf-8") as writer:
writer.write(chat_template_json_string)
logger.info(f"chat template saved in {output_chat_template_file}")
# For now, let's not save to `processor_config.json` if the processor doesn't have extra attributes and
# `auto_map` is not specified.
if set(processor_dict.keys()) != {"processor_class"}:
self.to_json_file(output_processor_file)
logger.info(f"processor saved in {output_processor_file}")
if push_to_hub:
self._upload_modified_files(
save_directory,
repo_id,
files_timestamps,
commit_message=commit_message,
token=kwargs.get("token"),
)
if set(processor_dict.keys()) == {"processor_class"}:
return []
return [output_processor_file]
@classmethod
def get_processor_dict(
cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs
) -> Tuple[Dict[str, Any], Dict[str, Any]]:
"""
From a `pretrained_model_name_or_path`, resolve to a dictionary of parameters, to be used for instantiating a
processor of type [`~processing_utils.ProcessingMixin`] using `from_args_and_dict`.
Parameters:
pretrained_model_name_or_path (`str` or `os.PathLike`):
The identifier of the pre-trained checkpoint from which we want the dictionary of parameters.
subfolder (`str`, *optional*, defaults to `""`):
In case the relevant files are located inside a subfolder of the model repo on huggingface.co, you can
specify the folder name here.
Returns:
`Tuple[Dict, Dict]`: The dictionary(ies) that will be used to instantiate the processor object.
"""
cache_dir = kwargs.pop("cache_dir", None)
force_download = kwargs.pop("force_download", False)
resume_download = kwargs.pop("resume_download", None)
proxies = kwargs.pop("proxies", None)
token = kwargs.pop("token", None)
local_files_only = kwargs.pop("local_files_only", False)
revision = kwargs.pop("revision", None)
subfolder = kwargs.pop("subfolder", "")
from_pipeline = kwargs.pop("_from_pipeline", None)
from_auto_class = kwargs.pop("_from_auto", False)
user_agent = {"file_type": "processor", "from_auto_class": from_auto_class}
if from_pipeline is not None:
user_agent["using_pipeline"] = from_pipeline
if is_offline_mode() and not local_files_only:
logger.info("Offline mode: forcing local_files_only=True")
local_files_only = True
pretrained_model_name_or_path = str(pretrained_model_name_or_path)
is_local = os.path.isdir(pretrained_model_name_or_path)
if os.path.isdir(pretrained_model_name_or_path):
processor_file = os.path.join(pretrained_model_name_or_path, PROCESSOR_NAME)
if os.path.isfile(pretrained_model_name_or_path):
resolved_processor_file = pretrained_model_name_or_path
# cant't load chat-template when given a file as pretrained_model_name_or_path
resolved_chat_template_file = None
resolved_raw_chat_template_file = None
is_local = True
elif is_remote_url(pretrained_model_name_or_path):
processor_file = pretrained_model_name_or_path
resolved_processor_file = download_url(pretrained_model_name_or_path)
# can't load chat-template when given a file url as pretrained_model_name_or_path
resolved_chat_template_file = None
resolved_raw_chat_template_file = None
else:
processor_file = PROCESSOR_NAME
chat_template_file = "chat_template.json"
raw_chat_template_file = "chat_template.jinja"
try:
# Load from local folder or from cache or download from model Hub and cache
resolved_processor_file = cached_file(
pretrained_model_name_or_path,
processor_file,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
local_files_only=local_files_only,
token=token,
user_agent=user_agent,
revision=revision,
subfolder=subfolder,
_raise_exceptions_for_missing_entries=False,
)
# Load chat template from a separate json if exists
# because making it part of processor-config break BC.
# Processors in older version do not accept any kwargs
resolved_chat_template_file = cached_file(
pretrained_model_name_or_path,
chat_template_file,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
local_files_only=local_files_only,
token=token,
user_agent=user_agent,
revision=revision,
subfolder=subfolder,
_raise_exceptions_for_missing_entries=False,
)
resolved_raw_chat_template_file = cached_file(
pretrained_model_name_or_path,
raw_chat_template_file,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
local_files_only=local_files_only,
token=token,
user_agent=user_agent,
revision=revision,
subfolder=subfolder,
_raise_exceptions_for_missing_entries=False,
)
except EnvironmentError:
# Raise any environment error raise by `cached_file`. It will have a helpful error message adapted to
# the original exception.
raise
except Exception:
# For any other exception, we throw a generic error.
raise EnvironmentError(
f"Can't load processor for '{pretrained_model_name_or_path}'. If you were trying to load"
" it from 'https://huggingface.co/models', make sure you don't have a local directory with the"
f" same name. Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a"
f" directory containing a {PROCESSOR_NAME} file"
)
# Add chat template as kwarg before returning because most models don't have processor config
if resolved_raw_chat_template_file is not None:
with open(resolved_raw_chat_template_file, "r", encoding="utf-8") as reader:
chat_template = reader.read()
kwargs["chat_template"] = chat_template
elif resolved_chat_template_file is not None:
with open(resolved_chat_template_file, "r", encoding="utf-8") as reader:
text = reader.read()
chat_template = json.loads(text)["chat_template"]
kwargs["chat_template"] = chat_template
# Existing processors on the Hub created before #27761 being merged don't have `processor_config.json` (if not
# updated afterward), and we need to keep `from_pretrained` work. So here it fallbacks to the empty dict.
# (`cached_file` called using `_raise_exceptions_for_missing_entries=False` to avoid exception)
# However, for models added in the future, we won't get the expected error if this file is missing.
if resolved_processor_file is None:
return {}, kwargs
try:
# Load processor dict
with open(resolved_processor_file, "r", encoding="utf-8") as reader:
text = reader.read()
processor_dict = json.loads(text)
except json.JSONDecodeError:
raise EnvironmentError(
f"It looks like the config file at '{resolved_processor_file}' is not a valid JSON file."
)
if is_local:
logger.info(f"loading configuration file {resolved_processor_file}")
else:
logger.info(f"loading configuration file {processor_file} from cache at {resolved_processor_file}")
if "chat_template" in processor_dict and processor_dict["chat_template"] is not None:
logger.warning_once(
"Chat templates should be in a 'chat_template.jinja' file but found key='chat_template' "
"in the processor's config. Make sure to move your template to its own file."
)
if not is_local:
if "auto_map" in processor_dict:
processor_dict["auto_map"] = add_model_info_to_auto_map(
processor_dict["auto_map"], pretrained_model_name_or_path
)
if "custom_pipelines" in processor_dict:
processor_dict["custom_pipelines"] = add_model_info_to_custom_pipelines(
processor_dict["custom_pipelines"], pretrained_model_name_or_path
)
return processor_dict, kwargs
@classmethod
def from_args_and_dict(cls, args, processor_dict: Dict[str, Any], **kwargs):
"""
Instantiates a type of [`~processing_utils.ProcessingMixin`] from a Python dictionary of parameters.
Args:
processor_dict (`Dict[str, Any]`):
Dictionary that will be used to instantiate the processor object. Such a dictionary can be
retrieved from a pretrained checkpoint by leveraging the
[`~processing_utils.ProcessingMixin.to_dict`] method.
kwargs (`Dict[str, Any]`):
Additional parameters from which to initialize the processor object.
Returns:
[`~processing_utils.ProcessingMixin`]: The processor object instantiated from those
parameters.
"""
processor_dict = processor_dict.copy()
return_unused_kwargs = kwargs.pop("return_unused_kwargs", False)
chat_template = kwargs.pop("chat_template", None)
# We have to pop up some unused (but specific) kwargs and then validate that it doesn't contain unused kwargs
# If we don't pop, some specific kwargs will raise a warning
if "processor_class" in processor_dict:
del processor_dict["processor_class"]
if "auto_map" in processor_dict:
del processor_dict["auto_map"]
unused_kwargs = cls.validate_init_kwargs(processor_config=processor_dict, valid_kwargs=cls.valid_kwargs)
processor = cls(*args, **processor_dict)
if chat_template is not None:
setattr(processor, "chat_template", chat_template)
# Update processor with kwargs if needed
for key in set(kwargs.keys()):
if hasattr(processor, key):
setattr(processor, key, kwargs.pop(key))
kwargs.update(unused_kwargs)
logger.info(f"Processor {processor}")
if return_unused_kwargs:
return processor, kwargs
else:
return processor
def _merge_kwargs(
self,
ModelProcessorKwargs: ProcessingKwargs,
tokenizer_init_kwargs: Optional[Dict] = None,
**kwargs,
) -> Dict[str, Dict]:
"""
Method to merge dictionaries of kwargs cleanly separated by modality within a Processor instance.
The order of operations is as follows:
1) kwargs passed as before have highest priority to preserve BC.
```python
high_priority_kwargs = {"crop_size" = {"height": 222, "width": 222}, "padding" = "max_length"}
processor(..., **high_priority_kwargs)
```
2) kwargs passed as modality-specific kwargs have second priority. This is the recommended API.
```python
processor(..., text_kwargs={"padding": "max_length"}, images_kwargs={"crop_size": {"height": 222, "width": 222}}})
```
3) kwargs passed during instantiation of a modality processor have fourth priority.
```python
tokenizer = tokenizer_class(..., {"padding": "max_length"})
image_processor = image_processor_class(...)
processor(tokenizer, image_processor) # will pass max_length unless overriden by kwargs at call
```
4) defaults kwargs specified at processor level have lowest priority.
```python
class MyProcessingKwargs(ProcessingKwargs, CommonKwargs, TextKwargs, ImagesKwargs, total=False):
_defaults = {
"text_kwargs": {
"padding": "max_length",
"max_length": 64,
},
}
```
Args:
ModelProcessorKwargs (`ProcessingKwargs`):
Typed dictionary of kwargs specifically required by the model passed.
tokenizer_init_kwargs (`Dict`, *optional*):
Dictionary of kwargs the tokenizer was instantiated with and need to take precedence over defaults.
Returns:
output_kwargs (`Dict`):
Dictionary of per-modality kwargs to be passed to each modality-specific processor.
"""
# Initialize dictionaries
output_kwargs = {
"text_kwargs": {},
"images_kwargs": {},
"audio_kwargs": {},
"videos_kwargs": {},
"common_kwargs": {},
}
default_kwargs = {
"text_kwargs": {},
"images_kwargs": {},
"audio_kwargs": {},
"videos_kwargs": {},
"common_kwargs": {},
}
used_keys = set()
# get defaults from set model processor kwargs if they exist
for modality in default_kwargs:
default_kwargs[modality] = ModelProcessorKwargs._defaults.get(modality, {}).copy()
# update defaults with arguments from tokenizer init
for modality_key in ModelProcessorKwargs.__annotations__[modality].__annotations__.keys():
# init with tokenizer init kwargs if necessary
if modality_key in tokenizer_init_kwargs:
value = (
getattr(self.tokenizer, modality_key)
if hasattr(self.tokenizer, modality_key)
else tokenizer_init_kwargs[modality_key]
)
default_kwargs[modality][modality_key] = value
# now defaults kwargs are updated with the tokenizers defaults.
# pass defaults to output dictionary
output_kwargs.update(default_kwargs)
# update modality kwargs with passed kwargs
non_modality_kwargs = set(kwargs) - set(output_kwargs)
for modality in output_kwargs:
for modality_key in ModelProcessorKwargs.__annotations__[modality].__annotations__.keys():
# check if we received a structured kwarg dict or not to handle it correctly
if modality in kwargs:
kwarg_value = kwargs[modality].pop(modality_key, "__empty__")
# check if this key was passed as a flat kwarg.
if kwarg_value != "__empty__" and modality_key in non_modality_kwargs:
raise ValueError(
f"Keyword argument {modality_key} was passed two times:\n"
f"in a dictionary for {modality} and as a **kwarg."
)
elif modality_key in kwargs:
# we get a modality_key instead of popping it because modality-specific processors
# can have overlapping kwargs
kwarg_value = kwargs.get(modality_key, "__empty__")
else:
kwarg_value = "__empty__"
if kwarg_value != "__empty__":
output_kwargs[modality][modality_key] = kwarg_value
used_keys.add(modality_key)
# Determine if kwargs is a flat dictionary or contains nested dictionaries
if any(key in default_kwargs for key in kwargs):
# kwargs is dictionary-based, and some keys match modality names
for modality, subdict in kwargs.items():
if modality in default_kwargs:
for subkey, subvalue in subdict.items():
if subkey not in used_keys:
output_kwargs[modality][subkey] = subvalue
used_keys.add(subkey)
else:
# kwargs is a flat dictionary
for key in kwargs:
if key not in used_keys:
if key in ModelProcessorKwargs.__annotations__["common_kwargs"].__annotations__.keys():
output_kwargs["common_kwargs"][key] = kwargs[key]
else:
logger.warning_once(
f"Keyword argument `{key}` is not a valid argument for this processor and will be ignored."
)
# all modality-specific kwargs are updated with common kwargs
for modality in output_kwargs:
output_kwargs[modality].update(output_kwargs["common_kwargs"])
return output_kwargs
@classmethod
def from_pretrained(
cls,
pretrained_model_name_or_path: Union[str, os.PathLike],
cache_dir: Optional[Union[str, os.PathLike]] = None,
force_download: bool = False,
local_files_only: bool = False,
token: Optional[Union[str, bool]] = None,
revision: str = "main",
**kwargs,
):
r"""
Instantiate a processor associated with a pretrained model.
<Tip>
This class method is simply calling the feature extractor
[`~feature_extraction_utils.FeatureExtractionMixin.from_pretrained`], image processor
[`~image_processing_utils.ImageProcessingMixin`] and the tokenizer
[`~tokenization_utils_base.PreTrainedTokenizer.from_pretrained`] methods. Please refer to the docstrings of the
methods above for more information.
</Tip>
Args:
pretrained_model_name_or_path (`str` or `os.PathLike`):
This can be either:
- a string, the *model id* of a pretrained feature_extractor hosted inside a model repo on
huggingface.co.
- a path to a *directory* containing a feature extractor file saved using the
[`~SequenceFeatureExtractor.save_pretrained`] method, e.g., `./my_model_directory/`.
- a path or url to a saved feature extractor JSON *file*, e.g.,
`./my_model_directory/preprocessor_config.json`.
**kwargs
Additional keyword arguments passed along to both
[`~feature_extraction_utils.FeatureExtractionMixin.from_pretrained`] and
[`~tokenization_utils_base.PreTrainedTokenizer.from_pretrained`].
"""
kwargs["cache_dir"] = cache_dir
kwargs["force_download"] = force_download
kwargs["local_files_only"] = local_files_only
kwargs["revision"] = revision
use_auth_token = kwargs.pop("use_auth_token", None)
if use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
FutureWarning,
)
if token is not None:
raise ValueError(
"`token` and `use_auth_token` are both specified. Please set only the argument `token`."
)
token = use_auth_token
if token is not None:
kwargs["token"] = token
args = cls._get_arguments_from_pretrained(pretrained_model_name_or_path, **kwargs)
processor_dict, kwargs = cls.get_processor_dict(pretrained_model_name_or_path, **kwargs)
return cls.from_args_and_dict(args, processor_dict, **kwargs)
@classmethod
def register_for_auto_class(cls, auto_class="AutoProcessor"):
"""
Register this class with a given auto class. This should only be used for custom feature extractors as the ones
in the library are already mapped with `AutoProcessor`.
<Tip warning={true}>
This API is experimental and may have some slight breaking changes in the next releases.
</Tip>
Args:
auto_class (`str` or `type`, *optional*, defaults to `"AutoProcessor"`):
The auto class to register this new feature extractor with.
"""
if not isinstance(auto_class, str):
auto_class = auto_class.__name__
import transformers.models.auto as auto_module
if not hasattr(auto_module, auto_class):
raise ValueError(f"{auto_class} is not a valid auto class.")
cls._auto_class = auto_class
@classmethod
def _get_arguments_from_pretrained(cls, pretrained_model_name_or_path, **kwargs):
args = []
for attribute_name in cls.attributes:
class_name = getattr(cls, f"{attribute_name}_class")
if isinstance(class_name, tuple):
classes = tuple(getattr(transformers_module, n) if n is not None else None for n in class_name)
use_fast = kwargs.get("use_fast", True)
if use_fast and classes[1] is not None:
attribute_class = classes[1]
else:
attribute_class = classes[0]
else:
attribute_class = getattr(transformers_module, class_name)
args.append(attribute_class.from_pretrained(pretrained_model_name_or_path, **kwargs))
return args
@property
def model_input_names(self):
first_attribute = getattr(self, self.attributes[0])
return getattr(first_attribute, "model_input_names", None)
@staticmethod
def validate_init_kwargs(processor_config, valid_kwargs):
kwargs_from_config = processor_config.keys()
unused_kwargs = {}
unused_keys = set(kwargs_from_config) - set(valid_kwargs)
if unused_keys:
unused_key_str = ", ".join(unused_keys)
logger.warning(
f"Some kwargs in processor config are unused and will not have any effect: {unused_key_str}. "
)
unused_kwargs = {k: processor_config[k] for k in unused_keys}
return unused_kwargs
def prepare_and_validate_optional_call_args(self, *args):
"""
Matches optional positional arguments to their corresponding names in `optional_call_args`
in the processor class in the order they are passed to the processor call.
Note that this should only be used in the `__call__` method of the processors with special
arguments. Special arguments are arguments that aren't `text`, `images`, `audio`, nor `videos`
but also aren't passed to the tokenizer, image processor, etc. Examples of such processors are:
- `CLIPSegProcessor`
- `LayoutLMv2Processor`
- `OwlViTProcessor`
Also note that passing by position to the processor call is now deprecated and will be disallowed
in future versions. We only have this for backward compatibility.
Example:
Suppose that the processor class has `optional_call_args = ["arg_name_1", "arg_name_2"]`.
And we define the call method as:
```python
def __call__(
self,
text: str,
images: Optional[ImageInput] = None,
*arg,
audio=None,
videos=None,
)
```
Then, if we call the processor as:
```python
images = [...]
processor("What is common in these images?", images, arg_value_1, arg_value_2)
```
Then, this method will return:
```python
{
"arg_name_1": arg_value_1,
"arg_name_2": arg_value_2,
}
```
which we could then pass as kwargs to `self._merge_kwargs`
"""
if len(args):
warnings.warn(
"Passing positional arguments to the processor call is now deprecated and will be disallowed in v4.47. "
"Please pass all arguments as keyword arguments."
)
if len(args) > len(self.optional_call_args):
raise ValueError(
f"Expected *at most* {len(self.optional_call_args)} optional positional arguments in processor call"
f"which will be matched with {' '.join(self.optional_call_args)} in the order they are passed."
f"However, got {len(args)} positional arguments instead."
"Please pass all arguments as keyword arguments instead (e.g. `processor(arg_name_1=..., arg_name_2=...))`."
)
return {arg_name: arg_value for arg_value, arg_name in zip(args, self.optional_call_args)}
def apply_chat_template(
self,
conversation: Union[List[Dict[str, str]]],
chat_template: Optional[str] = None,
**kwargs: Unpack[AllKwargsForChatTemplate],
) -> str:
"""
Similar to the `apply_chat_template` method on tokenizers, this method applies a Jinja template to input
conversations to turn them into a single tokenizable string.
The input is expected to be in the following format, where each message content is a list consisting of text and
optionally image or video inputs. One can also provide an image, video, URL or local path which will be used to form
`pixel_values` when `return_dict=True`. If not provided, one will get only the formatted text, optionally tokenized text.
conversation = [
{
"role": "user",
"content": [
{"type": "image", "image": "https://www.ilankelman.org/stopsigns/australia.jpg"},
{"type": "text", "text": "Please describe this image in detail."},
],
},
]
Args:
conversation (`List[Dict, str, str]`):
The conversation to format.
chat_template (`Optional[str]`, *optional*):
The Jinja template to use for formatting the conversation. If not provided, the tokenizer's
chat template is used.
"""
if chat_template is None:
if self.chat_template is not None:
chat_template = self.chat_template
else:
raise ValueError(
"No chat template is set for this processor. Please either set the `chat_template` attribute, "
"or provide a chat template as an argument. See "
"https://huggingface.co/docs/transformers/main/en/chat_templating for more information."
)
text_kwargs = {}
for key in TextKwargs.__annotations__.keys():
value = kwargs.pop(key, None)
if value is not None:
text_kwargs[key] = value
chat_template_kwargs = {}
for key in ChatTemplateKwargs.__annotations__.keys():
value = kwargs.pop(key, getattr(ChatTemplateKwargs, key))
chat_template_kwargs[key] = value
# Pop kwargs that should not be used by tokenizer's `apply_chat_template`
tokenize = chat_template_kwargs.pop("tokenize")
return_dict = chat_template_kwargs.pop("return_dict")
num_frames = chat_template_kwargs.pop("num_frames")
video_load_backend = chat_template_kwargs.pop("video_load_backend")
prompt = self.tokenizer.apply_chat_template(
conversation,
chat_template=chat_template,
tokenize=False,
return_dict=False,
**text_kwargs,
**chat_template_kwargs,
)
# we will have to return all processed inputs in a dict
if tokenize:
images, videos = [], []
for message in conversation:
visuals = [content for content in message["content"] if content["type"] in ["image", "video"]]
for vision_info in visuals:
if vision_info["type"] == "image":
for key in ["image", "url", "path", "base64"]:
if key in vision_info:
images.append(load_image(vision_info[key]))
elif vision_info["type"] == "video":
for key in ["video", "url", "path"]:
if key in vision_info:
videos.append(
load_video(vision_info[key], num_frames=num_frames, backend=video_load_backend)
)
out = self(
text=prompt,
images=images if images else None,
videos=videos if videos else None,
**kwargs,
)
if return_dict:
return out
else:
return out["input_ids"]
return prompt
def post_process_image_text_to_text(self, generated_outputs):
"""
Post-process the output of a vlm to decode the text.
Args:
generated_outputs (`torch.Tensor` or `np.ndarray`):
The output of the model `generate` function. The output is expected to be a tensor of shape `(batch_size, sequence_length)`
or `(sequence_length,)`.
Returns:
`List[str]`: The decoded text.
"""
return self.tokenizer.batch_decode(generated_outputs, skip_special_tokens=True)
def _validate_images_text_input_order(images, text):
"""
For backward compatibility: reverse the order of `images` and `text` inputs if they are swapped.
This method should only be called for processors where `images` and `text` have been swapped for uniformization purposes.
Note that this method assumes that two `None` inputs are valid inputs. If this is not the case, it should be handled
in the processor's `__call__` method before calling this method.
"""
def is_url(val) -> bool:
return isinstance(val, str) and val.startswith("http")
def _is_valid_images_input_for_processor(imgs):
# If we have an list of images, make sure every image is valid
if isinstance(imgs, (list, tuple)):
for img in imgs:
if not _is_valid_images_input_for_processor(img):
return False
# If not a list or tuple, we have been given a single image or batched tensor of images
elif not (is_valid_image(imgs) or is_url(imgs)):
return False
return True
def _is_valid_text_input_for_processor(t):
if isinstance(t, str):
# Strings are fine
return True
elif isinstance(t, (list, tuple)):
# List are fine as long as they are...
if len(t) == 0:
# ... not empty
return False
for t_s in t:
return _is_valid_text_input_for_processor(t_s)
return False
def _is_valid(input, validator):
return validator(input) or input is None
images_is_valid = _is_valid(images, _is_valid_images_input_for_processor)
images_is_text = _is_valid_text_input_for_processor(images)
text_is_valid = _is_valid(text, _is_valid_text_input_for_processor)
text_is_images = _is_valid_images_input_for_processor(text)
# Handle cases where both inputs are valid
if images_is_valid and text_is_valid:
return images, text
# Handle cases where inputs need to and can be swapped
if (images is None and text_is_images) or (text is None and images_is_text) or (images_is_text and text_is_images):
logger.warning_once(
"You may have used the wrong order for inputs. `images` should be passed before `text`. "
"The `images` and `text` inputs will be swapped. This behavior will be deprecated in transformers v4.47."
)
return text, images
raise ValueError("Invalid input type. Check that `images` and/or `text` are valid inputs.")
ProcessorMixin.push_to_hub = copy_func(ProcessorMixin.push_to_hub)
if ProcessorMixin.push_to_hub.__doc__ is not None:
ProcessorMixin.push_to_hub.__doc__ = ProcessorMixin.push_to_hub.__doc__.format(
object="processor", object_class="AutoProcessor", object_files="processor files"
)
| transformers/src/transformers/processing_utils.py/0 | {
"file_path": "transformers/src/transformers/processing_utils.py",
"repo_id": "transformers",
"token_count": 25834
} |
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import importlib
from typing import TYPE_CHECKING, Any, Dict, List, Optional, Union
from packaging import version
from .base import HfQuantizer
from .quantizers_utils import get_module_from_name
if TYPE_CHECKING:
from ..modeling_utils import PreTrainedModel
from ..utils import (
is_accelerate_available,
is_optimum_quanto_available,
is_torch_available,
logging,
)
from ..utils.quantization_config import QuantoConfig
if is_torch_available():
import torch
logger = logging.get_logger(__name__)
class QuantoHfQuantizer(HfQuantizer):
"""
Quantizer for the quanto library
"""
required_packages = ["quanto", "accelerate"]
requires_parameters_quantization = True
requires_calibration = False
def __init__(self, quantization_config: QuantoConfig, **kwargs):
super().__init__(quantization_config, **kwargs)
self.post_init()
def post_init(self):
r"""
Safety checker
"""
if self.quantization_config.activations is not None and not self.pre_quantized:
raise ValueError(
"We don't support quantizing the activations with transformers library."
"Use quanto library for more complex use cases such as activations quantization, calibration and quantization aware training."
)
def validate_environment(self, *args, **kwargs):
if not is_optimum_quanto_available():
raise ImportError(
"Loading an optimum-quanto quantized model requires optimum-quanto library (`pip install optimum-quanto`)"
)
if not is_accelerate_available():
raise ImportError(
"Loading an optimum-quanto quantized model requires accelerate library (`pip install accelerate`)"
)
def update_device_map(self, device_map):
if device_map is None:
device_map = {"": "cpu"}
logger.info(
"The device_map was not initialized. "
"Setting device_map to {'':'cpu'}. "
"If you want to use the model for inference, please set device_map ='auto'"
)
return device_map
def update_torch_dtype(self, torch_dtype: "torch.dtype") -> "torch.dtype":
if torch_dtype is None:
logger.info("You did not specify `torch_dtype` in `from_pretrained`. Setting it to `torch.float32`.")
torch_dtype = torch.float32
return torch_dtype
def update_missing_keys(self, model, missing_keys: List[str], prefix: str) -> List[str]:
if is_optimum_quanto_available():
from optimum.quanto import QModuleMixin
not_missing_keys = []
for name, module in model.named_modules():
if isinstance(module, QModuleMixin):
for missing in missing_keys:
if (
(name in missing or name in f"{prefix}.{missing}")
and not missing.endswith(".weight")
and not missing.endswith(".bias")
):
not_missing_keys.append(missing)
return [k for k in missing_keys if k not in not_missing_keys]
def check_quantized_param(
self,
model: "PreTrainedModel",
param_value: "torch.Tensor",
param_name: str,
state_dict: Dict[str, Any],
**kwargs,
) -> bool:
"""
Check if a parameter needs to be quantized.
"""
if is_optimum_quanto_available():
from optimum.quanto import QModuleMixin
device_map = kwargs.get("device_map", None)
param_device = kwargs.get("param_device", None)
# we don't quantize the model if the module is going to be offloaded to the cpu
if device_map is not None and param_device is not None:
device_map_values = set(device_map.values())
if param_device == "cpu" and len(device_map_values) > 1:
if not (device_map_values == {"cpu"} or device_map_values == {"cpu", "disk"}):
return False
module, tensor_name = get_module_from_name(model, param_name)
# We only quantize the weights and the bias is not quantized.
if isinstance(module, QModuleMixin) and "weight" in tensor_name:
# if the weights are quantized, don't need to recreate it again with `create_quantized_param`
return not module.frozen
else:
return False
def adjust_max_memory(self, max_memory: Dict[str, Union[int, str]]) -> Dict[str, Union[int, str]]:
max_memory = {key: val * 0.90 for key, val in max_memory.items()}
return max_memory
def create_quantized_param(
self,
model: "PreTrainedModel",
param_value: "torch.Tensor",
param_name: str,
target_device: "torch.device",
*args,
**kwargs,
):
"""
Create the quantized parameter by calling .freeze() after setting it to the module.
"""
from accelerate.utils import set_module_tensor_to_device
set_module_tensor_to_device(model, param_name, target_device, param_value)
module, _ = get_module_from_name(model, param_name)
module.freeze()
module.weight.requires_grad = False
def adjust_target_dtype(self, target_dtype: "torch.dtype") -> "torch.dtype":
if version.parse(importlib.metadata.version("accelerate")) > version.parse("0.27.0"):
from accelerate.utils import CustomDtype
mapping = {
"int8": torch.int8,
"float8": CustomDtype.FP8,
"int4": CustomDtype.INT4,
"int2": CustomDtype.INT2,
}
target_dtype = mapping[self.quantization_config.weights]
return target_dtype
else:
raise ValueError(
"You are using `device_map='auto'` on an optimum-quanto quantized model. To automatically compute"
" the appropriate device map, you should upgrade your `accelerate` library,"
"`pip install --upgrade accelerate` or install it from source."
)
def _process_model_before_weight_loading(
self, model: "PreTrainedModel", keep_in_fp32_modules: List[str] = [], **kwargs
):
from ..integrations import get_keys_to_not_convert, replace_with_quanto_layers
# We keep some modules such as the lm_head in their original dtype for numerical stability reasons
if self.quantization_config.modules_to_not_convert is None:
self.modules_to_not_convert = get_keys_to_not_convert(model)
else:
self.modules_to_not_convert = self.quantization_config.modules_to_not_convert
if not isinstance(self.modules_to_not_convert, list):
self.modules_to_not_convert = [self.modules_to_not_convert]
self.modules_to_not_convert.extend(keep_in_fp32_modules)
model, _ = replace_with_quanto_layers(
model, modules_to_not_convert=self.modules_to_not_convert, quantization_config=self.quantization_config
)
model.config.quantization_config = self.quantization_config
def _process_model_after_weight_loading(self, model, **kwargs):
return model
@property
def is_trainable(self, model: Optional["PreTrainedModel"] = None):
return True
def is_serializable(self, safe_serialization=None):
return False
| transformers/src/transformers/quantizers/quantizer_quanto.py/0 | {
"file_path": "transformers/src/transformers/quantizers/quantizer_quanto.py",
"repo_id": "transformers",
"token_count": 3384
} |
# coding=utf-8
# Copyright 2020-present the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Torch utilities for the Trainer class.
"""
import copy
import datetime
import io
import json
import math
import os
import sys
import warnings
from collections.abc import Mapping
from contextlib import contextmanager
from dataclasses import dataclass, field
from itertools import chain
from logging import StreamHandler
from typing import Any, Dict, Iterator, List, Optional, Union
import numpy as np
import torch
import torch.distributed as dist
from torch import nn
from torch.utils.data import Dataset, IterableDataset, RandomSampler, Sampler
from torch.utils.data.distributed import DistributedSampler
from .integrations.deepspeed import is_deepspeed_zero3_enabled
from .tokenization_utils_base import BatchEncoding
from .utils import (
is_sagemaker_mp_enabled,
is_torch_available,
is_torch_xla_available,
is_training_run_on_sagemaker,
logging,
)
if is_training_run_on_sagemaker():
logging.add_handler(StreamHandler(sys.stdout))
if is_torch_xla_available():
import torch_xla.core.xla_model as xm
if is_torch_available():
from torch.optim.lr_scheduler import LRScheduler
logger = logging.get_logger(__name__)
def get_dataloader_sampler(dataloader):
if hasattr(dataloader, "batch_sampler") and dataloader.batch_sampler is not None:
return get_dataloader_sampler(dataloader.batch_sampler)
elif hasattr(dataloader, "sampler"):
return dataloader.sampler
def atleast_1d(tensor_or_array: Union[torch.Tensor, np.ndarray]):
if isinstance(tensor_or_array, torch.Tensor):
if hasattr(torch, "atleast_1d"):
tensor_or_array = torch.atleast_1d(tensor_or_array)
elif tensor_or_array.ndim < 1:
tensor_or_array = tensor_or_array[None]
else:
tensor_or_array = np.atleast_1d(tensor_or_array)
return tensor_or_array
def torch_pad_and_concatenate(tensor1, tensor2, padding_index=-100):
"""Concatenates `tensor1` and `tensor2` on first axis, applying padding on the second if necessary."""
tensor1 = atleast_1d(tensor1)
tensor2 = atleast_1d(tensor2)
if len(tensor1.shape) == 1 or tensor1.shape[1] == tensor2.shape[1]:
return torch.cat((tensor1, tensor2), dim=0)
# Let's figure out the new shape
new_shape = (tensor1.shape[0] + tensor2.shape[0], max(tensor1.shape[1], tensor2.shape[1])) + tensor1.shape[2:]
# Now let's fill the result tensor
result = tensor1.new_full(new_shape, padding_index)
result[: tensor1.shape[0], : tensor1.shape[1]] = tensor1
result[tensor1.shape[0] :, : tensor2.shape[1]] = tensor2
return result
def numpy_pad_and_concatenate(array1, array2, padding_index=-100):
"""Concatenates `array1` and `array2` on first axis, applying padding on the second if necessary."""
array1 = atleast_1d(array1)
array2 = atleast_1d(array2)
if len(array1.shape) == 1 or array1.shape[1] == array2.shape[1]:
return np.concatenate((array1, array2), axis=0)
# Let's figure out the new shape
new_shape = (array1.shape[0] + array2.shape[0], max(array1.shape[1], array2.shape[1])) + array1.shape[2:]
# Now let's fill the result tensor
result = np.full_like(array1, padding_index, shape=new_shape)
result[: array1.shape[0], : array1.shape[1]] = array1
result[array1.shape[0] :, : array2.shape[1]] = array2
return result
def nested_concat(tensors, new_tensors, padding_index=-100):
"""
Concat the `new_tensors` to `tensors` on the first dim and pad them on the second if needed. Works for tensors or
nested list/tuples/dict of tensors.
"""
if not (isinstance(tensors, torch.Tensor) and isinstance(new_tensors, torch.Tensor)):
assert (
type(tensors) is type(new_tensors)
), f"Expected `tensors` and `new_tensors` to have the same type but found {type(tensors)} and {type(new_tensors)}."
if isinstance(tensors, (list, tuple)):
return type(tensors)(nested_concat(t, n, padding_index=padding_index) for t, n in zip(tensors, new_tensors))
elif isinstance(tensors, torch.Tensor):
return torch_pad_and_concatenate(tensors, new_tensors, padding_index=padding_index)
elif isinstance(tensors, Mapping):
return type(tensors)(
{k: nested_concat(t, new_tensors[k], padding_index=padding_index) for k, t in tensors.items()}
)
elif isinstance(tensors, np.ndarray):
return numpy_pad_and_concatenate(tensors, new_tensors, padding_index=padding_index)
else:
raise TypeError(f"Unsupported type for concatenation: got {type(tensors)}")
def find_batch_size(tensors):
"""
Find the first dimension of a tensor in a nested list/tuple/dict of tensors.
"""
if isinstance(tensors, (list, tuple)):
for t in tensors:
result = find_batch_size(t)
if result is not None:
return result
elif isinstance(tensors, Mapping):
for key, value in tensors.items():
result = find_batch_size(value)
if result is not None:
return result
elif isinstance(tensors, torch.Tensor):
return tensors.shape[0] if len(tensors.shape) >= 1 else None
elif isinstance(tensors, np.ndarray):
return tensors.shape[0] if len(tensors.shape) >= 1 else None
def nested_numpify(tensors):
"Numpify `tensors` (even if it's a nested list/tuple/dict of tensors)."
if isinstance(tensors, (list, tuple)):
return type(tensors)(nested_numpify(t) for t in tensors)
if isinstance(tensors, Mapping):
return type(tensors)({k: nested_numpify(t) for k, t in tensors.items()})
t = tensors.cpu()
if t.dtype == torch.bfloat16:
# As of Numpy 1.21.4, NumPy does not support bfloat16 (see
# https://github.com/numpy/numpy/blob/a47ecdea856986cd60eabbd53265c2ca5916ad5d/doc/source/user/basics.types.rst ).
# Until Numpy adds bfloat16, we must convert float32.
t = t.to(torch.float32)
return t.numpy()
def nested_detach(tensors):
"Detach `tensors` (even if it's a nested list/tuple/dict of tensors)."
if isinstance(tensors, (list, tuple)):
return type(tensors)(nested_detach(t) for t in tensors)
elif isinstance(tensors, Mapping):
return type(tensors)({k: nested_detach(t) for k, t in tensors.items()})
return tensors.detach() if isinstance(tensors, torch.Tensor) else tensors
def nested_xla_mesh_reduce(tensors, name):
if is_torch_xla_available():
import torch_xla.core.xla_model as xm
if isinstance(tensors, (list, tuple)):
return type(tensors)(nested_xla_mesh_reduce(t, f"{name}_{i}") for i, t in enumerate(tensors))
if isinstance(tensors, Mapping):
return type(tensors)(
{k: nested_xla_mesh_reduce(t, f"{name}_{i}") for i, (k, t) in enumerate(tensors.items())}
)
tensors = atleast_1d(tensors)
return xm.mesh_reduce(name, tensors, torch.cat)
else:
raise ImportError("Torch xla must be installed to use `nested_xla_mesh_reduce`")
def distributed_concat(tensor: Any, num_total_examples: Optional[int] = None) -> Any:
try:
if isinstance(tensor, (tuple, list)):
return type(tensor)(distributed_concat(t, num_total_examples) for t in tensor)
if isinstance(tensor, Mapping):
return type(tensor)({k: distributed_concat(t, num_total_examples) for k, t in tensor.items()})
tensor = atleast_1d(tensor).contiguous()
output_tensors = [tensor.clone() for _ in range(dist.get_world_size())]
dist.all_gather(output_tensors, tensor)
concat = torch.cat(output_tensors, dim=0)
# truncate the dummy elements added by SequentialDistributedSampler
if num_total_examples is not None:
concat = concat[:num_total_examples]
return concat
except AssertionError:
raise AssertionError("Not currently using distributed training")
def distributed_broadcast_scalars(
scalars: List[Union[int, float]],
num_total_examples: Optional[int] = None,
device: Optional[torch.device] = torch.device("cuda"),
) -> torch.Tensor:
try:
tensorized_scalar = torch.tensor(scalars).to(device)
output_tensors = [tensorized_scalar.clone() for _ in range(dist.get_world_size())]
dist.all_gather(output_tensors, tensorized_scalar)
concat = torch.cat(output_tensors, dim=0)
# truncate the dummy elements added by SequentialDistributedSampler
if num_total_examples is not None:
concat = concat[:num_total_examples]
return concat
except AssertionError:
raise AssertionError("Not currently using distributed training")
def reissue_pt_warnings(caught_warnings):
# Reissue warnings
if len(caught_warnings) > 1:
for w in caught_warnings:
if w.category is not UserWarning:
warnings.warn(w.message, w.category)
@contextmanager
def torch_distributed_zero_first(local_rank: int):
"""
Decorator to make all processes in distributed training wait for each local_master to do something.
Args:
local_rank (`int`): The rank of the local process.
"""
if local_rank not in [-1, 0]:
dist.barrier()
yield
if local_rank == 0:
dist.barrier()
class DistributedSamplerWithLoop(DistributedSampler):
"""
Like a torch.utils.data.distributed.DistributedSampler` but loops at the end back to the beginning of the shuffled
samples to make each process have a round multiple of batch_size samples.
Args:
dataset (`torch.utils.data.Dataset`):
Dataset used for sampling.
batch_size (`int`):
The batch size used with this sampler
kwargs (`Dict[str, Any]`, *optional*):
All other keyword arguments passed to `DistributedSampler`.
"""
def __init__(self, dataset, batch_size, **kwargs):
super().__init__(dataset, **kwargs)
self.batch_size = batch_size
def __iter__(self):
indices = list(super().__iter__())
remainder = 0 if len(indices) % self.batch_size == 0 else self.batch_size - len(indices) % self.batch_size
# DistributedSampler already added samples from the beginning to make the number of samples a round multiple
# of the world size, so we skip those.
start_remainder = 1 if self.rank < len(self.dataset) % self.num_replicas else 0
indices += indices[start_remainder : start_remainder + remainder]
return iter(indices)
class EvalLoopContainer:
"""
Container to store intermediate results of evaluation loop
Args:
do_nested_concat (`bool`, *optional*, defaults to `True`):
If set to `True`, each iteration will recursively concatenate a new object containing tensors to
the existing stored tensors, provided that the structure of the existing object and the new one
are identical. If set to `False`, all newly added tensors will be stored in a list.
padding_index (`int`, *optional*, defaults to -100):
Value used to pad tensors of different shapes when `do_nested_concat=True`.
"""
def __init__(self, do_nested_concat: bool = True, padding_index: int = -100):
self.do_nested_concat = do_nested_concat
self.padding_index = padding_index
self.tensors = None
self.arrays = None
def add(self, tensors) -> None:
"""Add tensors to the stored objects. If `do_nested_concat=True`, the tensors will be concatenated recursively."""
if self.tensors is None:
self.tensors = tensors if self.do_nested_concat else [tensors]
elif self.do_nested_concat:
self.tensors = nested_concat(self.tensors, tensors, padding_index=self.padding_index)
else:
self.tensors.append(tensors)
def to_cpu_and_numpy(self) -> None:
"""Move tensors in stored objects to CPU and convert them to numpy arrays."""
# Check if we have something to add, if not just return
if self.tensors is None:
return
new_arrays = nested_numpify(self.tensors)
if self.arrays is None:
self.arrays = new_arrays
elif self.do_nested_concat:
self.arrays = nested_concat(self.arrays, new_arrays, padding_index=self.padding_index)
else:
self.arrays.extend(new_arrays)
# reset device tensors after adding to cpu
self.tensors = None
def get_arrays(self):
"""Returns the numpified and moved to CPU stored objects."""
self.to_cpu_and_numpy()
return self.arrays
class SequentialDistributedSampler(Sampler):
"""
Distributed Sampler that subsamples indices sequentially, making it easier to collate all results at the end.
Even though we only use this sampler for eval and predict (no training), which means that the model params won't
have to be synced (i.e. will not hang for synchronization even if varied number of forward passes), we still add
extra samples to the sampler to make it evenly divisible (like in `DistributedSampler`) to make it easy to `gather`
or `reduce` resulting tensors at the end of the loop.
"""
def __init__(self, dataset, num_replicas=None, rank=None, batch_size=None):
warnings.warn(
"SequentialDistributedSampler is deprecated and will be removed in v5 of Transformers.",
FutureWarning,
)
if num_replicas is None:
if not dist.is_available():
raise RuntimeError("Requires distributed package to be available")
num_replicas = dist.get_world_size()
if rank is None:
if not dist.is_available():
raise RuntimeError("Requires distributed package to be available")
rank = dist.get_rank()
self.dataset = dataset
self.num_replicas = num_replicas
self.rank = rank
num_samples = len(self.dataset)
# Add extra samples to make num_samples a multiple of batch_size if passed
if batch_size is not None:
self.num_samples = int(math.ceil(num_samples / (batch_size * num_replicas))) * batch_size
else:
self.num_samples = int(math.ceil(num_samples / num_replicas))
self.total_size = self.num_samples * self.num_replicas
self.batch_size = batch_size
def __iter__(self):
indices = list(range(len(self.dataset)))
# add extra samples to make it evenly divisible
indices += indices[: (self.total_size - len(indices))]
assert (
len(indices) == self.total_size
), f"Indices length {len(indices)} and total size {self.total_size} mismatched"
# subsample
indices = indices[self.rank * self.num_samples : (self.rank + 1) * self.num_samples]
assert (
len(indices) == self.num_samples
), f"Indices length {len(indices)} and sample number {self.num_samples} mismatched"
return iter(indices)
def __len__(self):
return self.num_samples
def get_tpu_sampler(dataset: torch.utils.data.Dataset, batch_size: int):
if xm.xrt_world_size() <= 1:
return RandomSampler(dataset)
return DistributedSampler(dataset, num_replicas=xm.xrt_world_size(), rank=xm.get_ordinal())
def nested_new_like(arrays, num_samples, padding_index=-100):
"""Create the same nested structure as `arrays` with a first dimension always at `num_samples`."""
if isinstance(arrays, (list, tuple)):
return type(arrays)(nested_new_like(x, num_samples) for x in arrays)
return np.full_like(arrays, padding_index, shape=(num_samples, *arrays.shape[1:]))
def expand_like(arrays, new_seq_length, padding_index=-100):
"""Expand the `arrays` so that the second dimension grows to `new_seq_length`. Uses `padding_index` for padding."""
result = np.full_like(arrays, padding_index, shape=(arrays.shape[0], new_seq_length) + arrays.shape[2:])
result[:, : arrays.shape[1]] = arrays
return result
def nested_truncate(tensors, limit):
"Truncate `tensors` at `limit` (even if it's a nested list/tuple/dict of tensors)."
if isinstance(tensors, (list, tuple)):
return type(tensors)(nested_truncate(t, limit) for t in tensors)
if isinstance(tensors, Mapping):
return type(tensors)({k: nested_truncate(t, limit) for k, t in tensors.items()})
return tensors[:limit]
class DistributedTensorGatherer:
"""
A class responsible for properly gathering tensors (or nested list/tuple of tensors) on the CPU by chunks.
If our dataset has 16 samples with a batch size of 2 on 3 processes and we gather then transfer on CPU at every
step, our sampler will generate the following indices:
`[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 0, 1]`
to get something of size a multiple of 3 (so that each process gets the same dataset length). Then process 0, 1 and
2 will be responsible of making predictions for the following samples:
- P0: `[0, 1, 2, 3, 4, 5]`
- P1: `[6, 7, 8, 9, 10, 11]`
- P2: `[12, 13, 14, 15, 0, 1]`
The first batch treated on each process will be
- P0: `[0, 1]`
- P1: `[6, 7]`
- P2: `[12, 13]`
So if we gather at the end of the first batch, we will get a tensor (nested list/tuple of tensor) corresponding to
the following indices:
`[0, 1, 6, 7, 12, 13]`
If we directly concatenate our results without taking any precautions, the user will then get the predictions for
the indices in this order at the end of the prediction loop:
`[0, 1, 6, 7, 12, 13, 2, 3, 8, 9, 14, 15, 4, 5, 10, 11, 0, 1]`
For some reason, that's not going to roll their boat. This class is there to solve that problem.
Args:
world_size (`int`):
The number of processes used in the distributed training.
num_samples (`int`):
The number of samples in our dataset.
make_multiple_of (`int`, *optional*):
If passed, the class assumes the datasets passed to each process are made to be a multiple of this argument
(by adding samples).
padding_index (`int`, *optional*, defaults to -100):
The padding index to use if the arrays don't all have the same sequence length.
"""
def __init__(self, world_size, num_samples, make_multiple_of=None, padding_index=-100):
warnings.warn(
"DistributedTensorGatherer is deprecated and will be removed in v5 of Transformers.",
FutureWarning,
)
self.world_size = world_size
self.num_samples = num_samples
total_size = world_size if make_multiple_of is None else world_size * make_multiple_of
self.total_samples = int(np.ceil(num_samples / total_size)) * total_size
self.process_length = self.total_samples // world_size
self._storage = None
self._offsets = None
self.padding_index = padding_index
def add_arrays(self, arrays):
"""
Add `arrays` to the internal storage, Will initialize the storage to the full size at the first arrays passed
so that if we're bound to get an OOM, it happens at the beginning.
"""
if arrays is None:
return
if self._storage is None:
self._storage = nested_new_like(arrays, self.total_samples, padding_index=self.padding_index)
self._offsets = list(range(0, self.total_samples, self.process_length))
slice_len, self._storage = self._nested_set_tensors(self._storage, arrays)
for i in range(self.world_size):
self._offsets[i] += slice_len
def _nested_set_tensors(self, storage, arrays):
if isinstance(arrays, (list, tuple)):
result = [self._nested_set_tensors(x, y) for x, y in zip(storage, arrays)]
return result[0][0], type(arrays)(r[1] for r in result)
assert (
arrays.shape[0] % self.world_size == 0
), f"Arrays passed should all have a first dimension multiple of {self.world_size}, found {arrays.shape[0]}."
slice_len = arrays.shape[0] // self.world_size
for i in range(self.world_size):
if len(arrays.shape) == 1:
storage[self._offsets[i] : self._offsets[i] + slice_len] = arrays[i * slice_len : (i + 1) * slice_len]
else:
# Expand the array on the fly if needed.
if len(storage.shape) > 1 and storage.shape[1] < arrays.shape[1]:
storage = expand_like(storage, arrays.shape[1], padding_index=self.padding_index)
storage[self._offsets[i] : self._offsets[i] + slice_len, : arrays.shape[1]] = arrays[
i * slice_len : (i + 1) * slice_len
]
return slice_len, storage
def finalize(self):
"""
Return the properly gathered arrays and truncate to the number of samples (since the sampler added some extras
to get each process a dataset of the same length).
"""
if self._storage is None:
return
if self._offsets[0] != self.process_length:
logger.warning("Not all data has been set. Are you sure you passed all values?")
return nested_truncate(self._storage, self.num_samples)
@dataclass
class LabelSmoother:
"""
Adds label-smoothing on a pre-computed output from a Transformers model.
Args:
epsilon (`float`, *optional*, defaults to 0.1):
The label smoothing factor.
ignore_index (`int`, *optional*, defaults to -100):
The index in the labels to ignore when computing the loss.
"""
epsilon: float = 0.1
ignore_index: int = -100
def __call__(self, model_output, labels, shift_labels=False):
logits = model_output["logits"] if isinstance(model_output, dict) else model_output[0]
if shift_labels:
logits = logits[..., :-1, :].contiguous()
labels = labels[..., 1:].contiguous()
log_probs = -nn.functional.log_softmax(logits, dim=-1)
if labels.dim() == log_probs.dim() - 1:
labels = labels.unsqueeze(-1)
padding_mask = labels.eq(self.ignore_index)
# In case the ignore_index is -100, the gather will fail, so we replace labels by 0. The padding_mask
# will ignore them in any case.
labels = torch.clamp(labels, min=0)
nll_loss = log_probs.gather(dim=-1, index=labels)
# works for fp16 input tensor too, by internally upcasting it to fp32
smoothed_loss = log_probs.sum(dim=-1, keepdim=True, dtype=torch.float32)
nll_loss.masked_fill_(padding_mask, 0.0)
smoothed_loss.masked_fill_(padding_mask, 0.0)
# Take the mean over the label dimensions, then divide by the number of active elements (i.e. not-padded):
num_active_elements = padding_mask.numel() - padding_mask.long().sum()
nll_loss = nll_loss.sum() / num_active_elements
smoothed_loss = smoothed_loss.sum() / (num_active_elements * log_probs.shape[-1])
return (1 - self.epsilon) * nll_loss + self.epsilon * smoothed_loss
def get_length_grouped_indices(lengths, batch_size, mega_batch_mult=None, generator=None):
"""
Return a list of indices so that each slice of `batch_size` consecutive indices correspond to elements of similar
lengths. To do this, the indices are:
- randomly permuted
- grouped in mega-batches of size `mega_batch_mult * batch_size`
- sorted by length in each mega-batch
The result is the concatenation of all mega-batches, with the batch of `batch_size` containing the element of
maximum length placed first, so that an OOM happens sooner rather than later.
"""
# Default for mega_batch_mult: 50 or the number to get 4 megabatches, whichever is smaller.
if mega_batch_mult is None:
mega_batch_mult = min(len(lengths) // (batch_size * 4), 50)
# Just in case, for tiny datasets
if mega_batch_mult == 0:
mega_batch_mult = 1
# We need to use torch for the random part as a distributed sampler will set the random seed for torch.
indices = torch.randperm(len(lengths), generator=generator)
megabatch_size = mega_batch_mult * batch_size
megabatches = [indices[i : i + megabatch_size].tolist() for i in range(0, len(lengths), megabatch_size)]
megabatches = [sorted(megabatch, key=lambda i: lengths[i], reverse=True) for megabatch in megabatches]
# The rest is to get the biggest batch first.
# Since each megabatch is sorted by descending length, the longest element is the first
megabatch_maximums = [lengths[megabatch[0]] for megabatch in megabatches]
max_idx = torch.argmax(torch.tensor(megabatch_maximums)).item()
# Switch to put the longest element in first position
megabatches[0][0], megabatches[max_idx][0] = megabatches[max_idx][0], megabatches[0][0]
return [i for megabatch in megabatches for i in megabatch]
class LengthGroupedSampler(Sampler):
r"""
Sampler that samples indices in a way that groups together features of the dataset of roughly the same length while
keeping a bit of randomness.
"""
def __init__(
self,
batch_size: int,
dataset: Optional[Dataset] = None,
lengths: Optional[List[int]] = None,
model_input_name: Optional[str] = None,
generator=None,
):
if dataset is None and lengths is None:
raise ValueError("One of dataset and lengths must be provided.")
self.batch_size = batch_size
if lengths is None:
model_input_name = model_input_name if model_input_name is not None else "input_ids"
if (
not (isinstance(dataset[0], dict) or isinstance(dataset[0], BatchEncoding))
or model_input_name not in dataset[0]
):
raise ValueError(
"Can only automatically infer lengths for datasets whose items are dictionaries with an "
f"'{model_input_name}' key."
)
lengths = [len(feature[model_input_name]) for feature in dataset]
elif isinstance(lengths, torch.Tensor):
logger.info(
"If lengths is a torch.Tensor, LengthGroupedSampler will be slow. Converting lengths to List[int]..."
)
lengths = lengths.tolist()
self.lengths = lengths
self.generator = generator
def __len__(self):
return len(self.lengths)
def __iter__(self):
indices = get_length_grouped_indices(self.lengths, self.batch_size, generator=self.generator)
return iter(indices)
class DistributedLengthGroupedSampler(DistributedSampler):
r"""
Distributed Sampler that samples indices in a way that groups together features of the dataset of roughly the same
length while keeping a bit of randomness.
"""
# Copied and adapted from PyTorch DistributedSampler.
def __init__(
self,
batch_size: int,
dataset: Optional[Dataset] = None,
num_replicas: Optional[int] = None,
rank: Optional[int] = None,
seed: int = 0,
drop_last: bool = False,
lengths: Optional[List[int]] = None,
model_input_name: Optional[str] = None,
):
if dataset is None and lengths is None:
raise ValueError("One of dataset and lengths must be provided.")
if num_replicas is None:
if not dist.is_available():
raise RuntimeError("Requires distributed package to be available")
num_replicas = dist.get_world_size()
if rank is None:
if not dist.is_available():
raise RuntimeError("Requires distributed package to be available")
rank = dist.get_rank()
self.batch_size = batch_size
self.num_replicas = num_replicas
self.rank = rank
self.epoch = 0
self.drop_last = drop_last
if lengths is None:
model_input_name = model_input_name if model_input_name is not None else "input_ids"
if (
not (isinstance(dataset[0], dict) or isinstance(dataset[0], BatchEncoding))
or model_input_name not in dataset[0]
):
raise ValueError(
"Can only automatically infer lengths for datasets whose items are dictionaries with an "
f"'{model_input_name}' key."
)
lengths = [len(feature[model_input_name]) for feature in dataset]
elif isinstance(lengths, torch.Tensor):
logger.info(
"If lengths is a torch.Tensor, DistributedLengthGroupedSampler will be slow. Converting lengths to"
" List[int]..."
)
lengths = lengths.tolist()
self.lengths = lengths
# If the dataset length is evenly divisible by # of replicas, then there
# is no need to drop any data, since the dataset will be split equally.
if self.drop_last and len(self.lengths) % self.num_replicas != 0:
# Split to nearest available length that is evenly divisible.
# This is to ensure each rank receives the same amount of data when
# using this Sampler.
self.num_samples = math.ceil((len(self.lengths) - self.num_replicas) / self.num_replicas)
else:
self.num_samples = math.ceil(len(self.lengths) / self.num_replicas)
self.total_size = self.num_samples * self.num_replicas
self.seed = seed
def __iter__(self) -> Iterator:
# Deterministically shuffle based on epoch and seed
g = torch.Generator()
g.manual_seed(self.seed + self.epoch)
indices = get_length_grouped_indices(self.lengths, self.batch_size, generator=g)
if not self.drop_last:
# add extra samples to make it evenly divisible
indices += indices[: (self.total_size - len(indices))]
else:
# remove tail of data to make it evenly divisible.
indices = indices[: self.total_size]
assert len(indices) == self.total_size
# subsample
indices = indices[self.rank : self.total_size : self.num_replicas]
assert len(indices) == self.num_samples
return iter(indices)
class ShardSampler(Sampler):
"""
Sampler that shards batches between several processes. Dispatches indices batch by batch: on 2 processes with batch
size 4, the first two batches are `[0, 1, 2, 3, 4, 5, 6, 7]` and `[8, 9, 10, 11, 12, 13, 14, 15]`, which shard into
`[0, 1, 2, 3]` and `[8, 9, 10, 11]` for GPU-0 and `[4, 5, 6, 7]` and `[12, 13, 14, 15]` for GPU-1.
The sampler thus yields `[0, 1, 2, 3, 8, 9, 10, 11]` on GPU-0 and `[4, 5, 6, 7, 12, 13, 14, 15]` on GPU-1.
"""
def __init__(
self,
dataset: Dataset,
batch_size: int = 1,
drop_last: bool = False,
num_processes: int = 1,
process_index: int = 0,
):
self.dataset = dataset
self.batch_size = batch_size
self.drop_last = drop_last
self.num_processes = num_processes
self.process_index = process_index
self.total_batch_size = total_batch_size = batch_size * num_processes
num_batches = len(dataset) // total_batch_size if drop_last else math.ceil(len(dataset) / total_batch_size)
self.total_num_samples = num_batches * total_batch_size
def __iter__(self):
indices = list(range(len(self.dataset)))
# Add extra samples to make it evenly divisible. While loop is there in the edge case we have a tiny dataset
# and it needs to be done several times.
while len(indices) < self.total_num_samples:
indices += indices[: (self.total_num_samples - len(indices))]
result = []
for batch_start in range(self.batch_size * self.process_index, self.total_num_samples, self.total_batch_size):
result += indices[batch_start : batch_start + self.batch_size]
return iter(result)
def __len__(self):
# Each shard only sees a fraction of total_num_samples.
return self.total_num_samples // self.num_processes
class IterableDatasetShard(IterableDataset):
"""
Wraps a PyTorch `IterableDataset` to generate samples for one of the processes only. Instances of this class will
always yield a number of samples that is a round multiple of the actual batch size (which is `batch_size x
num_processes`). Depending on the value of the `drop_last` attribute, it will either stop the iteration at the
first batch that would be too small or loop with indices from the beginning.
On two processes with an iterable dataset yielding of `[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]` with a batch size of
2:
- the shard on process 0 will yield `[0, 1, 4, 5, 8, 9]` so will see batches `[0, 1]`, `[4, 5]`, `[8, 9]`
- the shard on process 1 will yield `[2, 3, 6, 7, 10, 11]` so will see batches `[2, 3]`, `[6, 7]`, `[10, 11]`
<Tip warning={true}>
If your IterableDataset implements some randomization that needs to be applied the same way on all processes
(for instance, a shuffling), you should use a `torch.Generator` in a `generator` attribute of the `dataset` to
generate your random numbers and call the [`~trainer_pt_utils.IterableDatasetShard.set_epoch`] method of this
object. It will set the seed of this `generator` to `seed + epoch` on all processes before starting the
iteration. Alternatively, you can also implement a `set_epoch()` method in your iterable dataset to deal with
this.
</Tip>
Args:
dataset (`torch.utils.data.IterableDataset`):
The batch sampler to split in several shards.
batch_size (`int`, *optional*, defaults to 1):
The size of the batches per shard.
drop_last (`bool`, *optional*, defaults to `False`):
Whether or not to drop the last incomplete batch or complete the last batches by using the samples from the
beginning.
num_processes (`int`, *optional*, defaults to 1):
The number of processes running concurrently.
process_index (`int`, *optional*, defaults to 0):
The index of the current process.
seed (`int`, *optional*, defaults to 0):
A random seed that will be used for the random number generation in
[`~trainer_pt_utils.IterableDatasetShard.set_epoch`].
"""
def __init__(
self,
dataset: IterableDataset,
batch_size: int = 1,
drop_last: bool = False,
num_processes: int = 1,
process_index: int = 0,
seed: int = 0,
):
self.dataset = dataset
self.batch_size = batch_size
self.drop_last = drop_last
self.num_processes = num_processes
self.process_index = process_index
self.seed = seed
self.epoch = 0
self.num_examples = 0
def set_epoch(self, epoch):
self.epoch = epoch
if hasattr(self.dataset, "set_epoch"):
self.dataset.set_epoch(epoch)
def __iter__(self):
self.num_examples = 0
if (
not hasattr(self.dataset, "set_epoch")
and hasattr(self.dataset, "generator")
and isinstance(self.dataset.generator, torch.Generator)
):
self.dataset.generator.manual_seed(self.seed + self.epoch)
real_batch_size = self.batch_size * self.num_processes
process_slice = range(self.process_index * self.batch_size, (self.process_index + 1) * self.batch_size)
first_batch = None
current_batch = []
for element in self.dataset:
self.num_examples += 1
current_batch.append(element)
# Wait to have a full batch before yielding elements.
if len(current_batch) == real_batch_size:
for i in process_slice:
yield current_batch[i]
if first_batch is None:
first_batch = current_batch.copy()
current_batch = []
# Finished if drop_last is True, otherwise complete the last batch with elements from the beginning.
if not self.drop_last and len(current_batch) > 0:
if first_batch is None:
first_batch = current_batch.copy()
while len(current_batch) < real_batch_size:
current_batch += first_batch
for i in process_slice:
yield current_batch[i]
def __len__(self):
# Will raise an error if the underlying dataset is not sized.
if self.drop_last:
return (len(self.dataset) // (self.batch_size * self.num_processes)) * self.batch_size
else:
return math.ceil(len(self.dataset) / (self.batch_size * self.num_processes)) * self.batch_size
# In order to keep `trainer.py` compact and easy to understand, place any secondary PT Trainer
# helper methods here
def _get_learning_rate(self):
if self.is_deepspeed_enabled:
# with deepspeed's fp16 and dynamic loss scale enabled the optimizer/scheduler steps may
# not run for the first few dozen steps while loss scale is too large, and thus during
# that time `get_last_lr` will fail if called during that warm up stage, so work around it:
try:
last_lr = self.lr_scheduler.get_last_lr()[0]
except AssertionError as e:
if "need to call step" in str(e):
logger.warning("tried to get lr value before scheduler/optimizer started stepping, returning lr=0")
last_lr = 0
else:
raise
else:
if isinstance(self.lr_scheduler, torch.optim.lr_scheduler.ReduceLROnPlateau):
last_lr = self.optimizer.param_groups[0]["lr"]
else:
last_lr = self.lr_scheduler.get_last_lr()[0]
if torch.is_tensor(last_lr):
last_lr = last_lr.item()
return last_lr
def _secs2timedelta(secs):
"""
convert seconds to hh:mm:ss.msec, msecs rounded to 2 decimals
"""
msec = int(abs(secs - int(secs)) * 100)
return f"{datetime.timedelta(seconds=int(secs))}.{msec:02d}"
def metrics_format(self, metrics: Dict[str, float]) -> Dict[str, float]:
"""
Reformat Trainer metrics values to a human-readable format
Args:
metrics (`Dict[str, float]`):
The metrics returned from train/evaluate/predict
Returns:
metrics (`Dict[str, float]`): The reformatted metrics
"""
metrics_copy = metrics.copy()
for k, v in metrics_copy.items():
if "_mem_" in k:
metrics_copy[k] = f"{ v >> 20 }MB"
elif "_runtime" in k:
metrics_copy[k] = _secs2timedelta(v)
elif k == "total_flos":
metrics_copy[k] = f"{ int(v) >> 30 }GF"
elif isinstance(metrics_copy[k], float):
metrics_copy[k] = round(v, 4)
return metrics_copy
def log_metrics(self, split, metrics):
"""
Log metrics in a specially formatted way
Under distributed environment this is done only for a process with rank 0.
Args:
split (`str`):
Mode/split name: one of `train`, `eval`, `test`
metrics (`Dict[str, float]`):
The metrics returned from train/evaluate/predictmetrics: metrics dict
Notes on memory reports:
In order to get memory usage report you need to install `psutil`. You can do that with `pip install psutil`.
Now when this method is run, you will see a report that will include: :
```
init_mem_cpu_alloc_delta = 1301MB
init_mem_cpu_peaked_delta = 154MB
init_mem_gpu_alloc_delta = 230MB
init_mem_gpu_peaked_delta = 0MB
train_mem_cpu_alloc_delta = 1345MB
train_mem_cpu_peaked_delta = 0MB
train_mem_gpu_alloc_delta = 693MB
train_mem_gpu_peaked_delta = 7MB
```
**Understanding the reports:**
- the first segment, e.g., `train__`, tells you which stage the metrics are for. Reports starting with `init_`
will be added to the first stage that gets run. So that if only evaluation is run, the memory usage for the
`__init__` will be reported along with the `eval_` metrics.
- the third segment, is either `cpu` or `gpu`, tells you whether it's the general RAM or the gpu0 memory
metric.
- `*_alloc_delta` - is the difference in the used/allocated memory counter between the end and the start of the
stage - it can be negative if a function released more memory than it allocated.
- `*_peaked_delta` - is any extra memory that was consumed and then freed - relative to the current allocated
memory counter - it is never negative. When you look at the metrics of any stage you add up `alloc_delta` +
`peaked_delta` and you know how much memory was needed to complete that stage.
The reporting happens only for process of rank 0 and gpu 0 (if there is a gpu). Typically this is enough since the
main process does the bulk of work, but it could be not quite so if model parallel is used and then other GPUs may
use a different amount of gpu memory. This is also not the same under DataParallel where gpu0 may require much more
memory than the rest since it stores the gradient and optimizer states for all participating GPUS. Perhaps in the
future these reports will evolve to measure those too.
The CPU RAM metric measures RSS (Resident Set Size) includes both the memory which is unique to the process and the
memory shared with other processes. It is important to note that it does not include swapped out memory, so the
reports could be imprecise.
The CPU peak memory is measured using a sampling thread. Due to python's GIL it may miss some of the peak memory if
that thread didn't get a chance to run when the highest memory was used. Therefore this report can be less than
reality. Using `tracemalloc` would have reported the exact peak memory, but it doesn't report memory allocations
outside of python. So if some C++ CUDA extension allocated its own memory it won't be reported. And therefore it
was dropped in favor of the memory sampling approach, which reads the current process memory usage.
The GPU allocated and peak memory reporting is done with `torch.cuda.memory_allocated()` and
`torch.cuda.max_memory_allocated()`. This metric reports only "deltas" for pytorch-specific allocations, as
`torch.cuda` memory management system doesn't track any memory allocated outside of pytorch. For example, the very
first cuda call typically loads CUDA kernels, which may take from 0.5 to 2GB of GPU memory.
Note that this tracker doesn't account for memory allocations outside of [`Trainer`]'s `__init__`, `train`,
`evaluate` and `predict` calls.
Because `evaluation` calls may happen during `train`, we can't handle nested invocations because
`torch.cuda.max_memory_allocated` is a single counter, so if it gets reset by a nested eval call, `train`'s tracker
will report incorrect info. If this [pytorch issue](https://github.com/pytorch/pytorch/issues/16266) gets resolved
it will be possible to change this class to be re-entrant. Until then we will only track the outer level of
`train`, `evaluate` and `predict` methods. Which means that if `eval` is called during `train`, it's the latter
that will account for its memory usage and that of the former.
This also means that if any other tool that is used along the [`Trainer`] calls
`torch.cuda.reset_peak_memory_stats`, the gpu peak memory stats could be invalid. And the [`Trainer`] will disrupt
the normal behavior of any such tools that rely on calling `torch.cuda.reset_peak_memory_stats` themselves.
For best performance you may want to consider turning the memory profiling off for production runs.
"""
if not self.is_world_process_zero():
return
print(f"***** {split} metrics *****")
metrics_formatted = self.metrics_format(metrics)
k_width = max(len(str(x)) for x in metrics_formatted.keys())
v_width = max(len(str(x)) for x in metrics_formatted.values())
for key in sorted(metrics_formatted.keys()):
print(f" {key: <{k_width}} = {metrics_formatted[key]:>{v_width}}")
def save_metrics(self, split, metrics, combined=True):
"""
Save metrics into a json file for that split, e.g. `train_results.json`.
Under distributed environment this is done only for a process with rank 0.
Args:
split (`str`):
Mode/split name: one of `train`, `eval`, `test`, `all`
metrics (`Dict[str, float]`):
The metrics returned from train/evaluate/predict
combined (`bool`, *optional*, defaults to `True`):
Creates combined metrics by updating `all_results.json` with metrics of this call
To understand the metrics please read the docstring of [`~Trainer.log_metrics`]. The only difference is that raw
unformatted numbers are saved in the current method.
"""
if not self.is_world_process_zero():
return
path = os.path.join(self.args.output_dir, f"{split}_results.json")
with open(path, "w") as f:
json.dump(metrics, f, indent=4, sort_keys=True)
if combined:
path = os.path.join(self.args.output_dir, "all_results.json")
if os.path.exists(path):
with open(path, "r") as f:
all_metrics = json.load(f)
else:
all_metrics = {}
all_metrics.update(metrics)
with open(path, "w") as f:
json.dump(all_metrics, f, indent=4, sort_keys=True)
def save_state(self):
"""
Saves the Trainer state, since Trainer.save_model saves only the tokenizer with the model
Under distributed environment this is done only for a process with rank 0.
"""
if not self.is_world_process_zero():
return
path = os.path.join(self.args.output_dir, "trainer_state.json")
self.state.save_to_json(path)
def get_model_param_count(model, trainable_only=False):
"""
Calculate model's total param count. If trainable_only is True then count only those requiring grads
"""
if is_deepspeed_zero3_enabled():
def numel(p):
return p.ds_numel if hasattr(p, "ds_numel") else p.numel()
else:
def numel(p):
return p.numel()
return sum(numel(p) for p in model.parameters() if not trainable_only or p.requires_grad)
def get_parameter_names(model, forbidden_layer_types, forbidden_layer_names=None):
"""
Returns the names of the model parameters that are not inside a forbidden layer.
"""
if forbidden_layer_names is None:
forbidden_layer_names = []
result = []
for name, child in model.named_children():
child_params = get_parameter_names(child, forbidden_layer_types, forbidden_layer_names)
result += [
f"{name}.{n}"
for n in child_params
if not isinstance(child, tuple(forbidden_layer_types))
and not any(forbidden in f"{name}.{n}".lower() for forbidden in forbidden_layer_names)
]
# Add model specific parameters that are not in any child
result += [
k for k in model._parameters.keys() if not any(forbidden in k.lower() for forbidden in forbidden_layer_names)
]
return result
def get_module_class_from_name(module, name):
"""
Gets a class from a module by its name.
Args:
module (`torch.nn.Module`): The module to get the class from.
name (`str`): The name of the class.
"""
modules_children = list(module.children())
if module.__class__.__name__ == name:
return module.__class__
elif len(modules_children) == 0:
return
else:
for child_module in modules_children:
module_class = get_module_class_from_name(child_module, name)
if module_class is not None:
return module_class
def remove_dummy_checkpoint(is_main_process, output_dir, filenames):
if is_main_process:
for filename in filenames:
file = os.path.join(output_dir, filename)
if os.path.isfile(file):
os.remove(file)
if is_sagemaker_mp_enabled():
import smdistributed.modelparallel.torch as smp
@smp.step()
def smp_forward_backward(model, inputs, gradient_accumulation_steps=1):
outputs = model(**inputs)
loss = outputs["loss"] if isinstance(outputs, dict) else outputs[0]
loss /= gradient_accumulation_steps
model.backward(loss)
return loss
@smp.step()
def smp_forward_only(model, inputs):
return model(**inputs)
def smp_gather(tensor):
if isinstance(tensor, (list, tuple)):
return type(tensor)(smp_gather(t) for t in tensor)
elif isinstance(tensor, dict):
return type(tensor)({k: smp_gather(v) for k, v in tensor.items()})
elif not isinstance(tensor, torch.Tensor):
raise TypeError(
f"Can't gather the values of type {type(tensor)}, only of nested list/tuple/dicts of tensors."
)
all_tensors = smp.allgather(tensor, smp.CommGroup.DP_GROUP)
all_tensors = [atleast_1d(t) for t in all_tensors]
return torch.cat([t.cpu() for t in all_tensors], dim=0)
def smp_nested_concat(tensor):
if isinstance(tensor, (list, tuple)):
return type(tensor)(smp_nested_concat(t) for t in tensor)
elif isinstance(tensor, dict):
return type(tensor)({k: smp_nested_concat(v) for k, v in tensor.items()})
# It doesn't seem possible to check here if `tensor` is a StepOutput because StepOutput lives in `smp.step`
# which is also the name of the decorator so Python is confused.
return tensor.concat().detach().cpu()
@dataclass
class AcceleratorConfig:
"""
A subset of arguments relating to the underlying [`accelerate.Accelerator`]
implementation utilized in the `Trainer` that can be customized.
Mostly relating to data.
Parameters:
split_batches (`bool`, *optional*, defaults to `False`):
Whether or not the accelerator should split the batches yielded by the dataloaders across the devices. If
`True` the actual batch size used will be the same on any kind of distributed processes, but it must be a
round multiple of the `num_processes` you are using. If `False`, actual batch size used will be the one set
in your script multiplied by the number of processes.
dispatch_batches (`bool`, *optional*):
If set to `True`, the dataloader prepared by the Accelerator is only iterated through on the main process
and then the batches are split and broadcast to each process. Will default to `True` for `DataLoader` whose
underlying dataset is an `IterableDataset`, `False` otherwise.
even_batches (`bool`, *optional*, defaults to `True`):
If set to `True`, in cases where the total batch size across all processes does not exactly divide the
dataset, samples at the start of the dataset will be duplicated so the batch can be divided equally among
all workers.
use_seedable_sampler (`bool`, *optional*, defaults to `True`):
Whether or not use a fully seedable random sampler ([`accelerate.data_loader.SeedableRandomSampler`]). Ensures
training results are fully reproducable using a different sampling technique. While seed-to-seed results
may differ, on average the differences are neglible when using multiple different seeds to compare. Should
also be ran with [`~utils.set_seed`] for the best results.
gradient_accumulation_kwargs (`dict`, *optional*):
Additional kwargs to configure gradient accumulation, see [`accelerate.utils.GradientAccumulationPlugin`].
Any of the following (optional) keys are acceptable:
num_steps (`int`): Will take precedence over [`~.TrainingArguments.gradient_accumulation_steps`] if
the latter is set to 1, otherwise an exception will be raised.
adjust_scheduler (`bool`): Whether to adjust the scheduler steps to account for [`~.TrainingArguments.gradient_accumulation_steps`].
The [`accelerate.utils.GradientAccumulationPlugin`] default is `True`.
sync_each_batch (`bool`): Whether to synchronize the gradients at each data batch.
The [`accelerate.utils.GradientAccumulationPlugin`] default is `False`.
non_blocking (`bool`, *optional*, defaults to `False`):
Whether to use non-blocking CUDA calls to help minimize synchronization during
distributed training with prepared `DataLoader` inputs being moved to device.
Best if used with `pin_memory=True` in the `TrainingArguments`.
use_configured_state (`bool*, *optional*, defaults to `False`):
Whether or not to use a pre-configured `AcceleratorState` or `PartialState` defined
before calling `TrainingArguments`. If `True`, an `Accelerator` or `PartialState`
must be initialized. May lead to issues using sweeps or hyperparameter tuning.
"""
# Data related arguments
split_batches: bool = field(
default=False,
metadata={
"help": "Whether or not the accelerator should split the batches yielded by the dataloaders across the devices. If"
" `True` the actual batch size used will be the same on any kind of distributed processes, but it must be a"
" round multiple of the `num_processes` you are using. If `False`, actual batch size used will be the one set"
" in your script multiplied by the number of processes."
},
)
dispatch_batches: bool = field(
default=None,
metadata={
"help": "If set to `True`, the dataloader prepared by the Accelerator is only iterated through on the main process"
" and then the batches are split and broadcast to each process. Will default to `True` for `DataLoader` whose"
" underlying dataset is an `IterableDataslet`, `False` otherwise."
},
)
even_batches: bool = field(
default=True,
metadata={
"help": "If set to `True`, in cases where the total batch size across all processes does not exactly divide the"
" dataset, samples at the start of the dataset will be duplicated so the batch can be divided equally among"
" all workers."
},
)
use_seedable_sampler: bool = field(
default=True,
metadata={
"help": "Whether or not use a fully seedable random sampler ([`accelerate.data_loader.SeedableRandomSampler`])."
"Ensures training results are fully reproducable using a different sampling technique. "
"While seed-to-seed results may differ, on average the differences are neglible when using"
"multiple different seeds to compare. Should also be ran with [`~utils.set_seed`] for the best results."
},
)
non_blocking: Optional[bool] = field(
default=False,
metadata={
"help": "Whether to use non-blocking CUDA calls to help minimize synchronization during "
"distributed training with prepared `DataLoader` inputs being moved to device. "
"Best if used with `pin_memory=True` in the `TrainingArguments`. Requires accelerate "
"v0.30.0."
},
)
gradient_accumulation_kwargs: Optional[Dict] = field(
default=None,
metadata={
"help": "Additional kwargs to configure gradient accumulation, see [`accelerate.utils.GradientAccumulationPlugin`]. "
"Any of the following (optional) keys are acceptable: "
" num_steps (`int`): Will take precedence over [`~.TrainingArguments.gradient_accumulation_steps`] if "
" the latter is set to 1, otherwise an exception will be raised. "
" adjust_scheduler (`bool`): Whether to adjust the scheduler steps to account for [`~.TrainingArguments.gradient_accumulation_steps`]. "
" The [`accelerate.utils.GradientAccumulationPlugin`] default is `True`. "
" sync_each_batch (`bool`): Whether to synchronize the gradients at each data batch. "
" The [`accelerate.utils.GradientAccumulationPlugin`] default is `False`."
},
)
use_configured_state: bool = field(
default=False,
metadata={
"help": "Whether or not to use a pre-configured `AcceleratorState` or `PartialState` defined before calling `TrainingArguments`."
"If `True`, an `Accelerator` or `PartialState` must be initialized. May lead to issues using sweeps or hyperparameter tuning."
},
)
@classmethod
def from_json_file(cls, json_file):
# Check if exists
open_file = io.open if os.path.exists(json_file) else open
with open_file(json_file, "r", encoding="utf-8") as f:
config_dict = json.load(f)
# Check for keys and load sensible defaults
extra_keys = sorted(key for key in config_dict.keys() if key not in cls.__dataclass_fields__.keys())
if len(extra_keys) > 0:
raise ValueError(
f"The config file at {json_file} had unknown keys ({extra_keys}), please try upgrading your `transformers`"
" version or fix (and potentially remove these keys) from your config file."
)
return cls(**config_dict)
def to_dict(self):
return copy.deepcopy(self.__dict__)
def pop(self, key, default=None):
return self.__dict__.pop(key, default)
class LayerWiseDummyOptimizer(torch.optim.Optimizer):
"""
For Layer-wise optimizers such as GaLoRE optimizer, the optimization
step is already done through the post gradient hooks. Therefore
the trick is to create a dummy optimizer that can take arbitrary
args and kwargs and return a no-op during training.
Initial idea from @hiyouga in LLaMA-Factory:
https://github.com/hiyouga/LLaMA-Factory/commit/8664262cde3919e10eaecbd66e8c5d356856362e#diff-ebe08ab14496dfb9e06075f0fdd36799ef6d1535cc4dd4715b74c4e3e06fe3ba
"""
def __init__(self, optimizer_dict=None, *args, **kwargs):
dummy_tensor = torch.randn(1, 1)
self.optimizer_dict = optimizer_dict
super().__init__([dummy_tensor], {"lr": kwargs.get("lr", 1e-03)})
def zero_grad(self, set_to_none: bool = True) -> None:
pass
def step(self, closure=None) -> Optional[float]:
pass
class LayerWiseDummyScheduler(LRScheduler):
"""
For Layer-wise optimizers such as GaLoRE optimizer, the optimization and scheduling step
are already done through the post gradient hooks. Therefore
the trick is to create a dummy scheduler that can take arbitrary
args and kwargs and return a no-op during training.
"""
def __init__(self, *args, **kwargs):
self.default_lr = kwargs["lr"]
optimizer = LayerWiseDummyOptimizer(**kwargs)
last_epoch = -1
verbose = False
super().__init__(optimizer, last_epoch, verbose)
def get_lr(self):
# default value
lrs = [self.default_lr]
# we take each lr in the parameters if they exist, assumes the optimizer to be the `LayerWiseDummyOptimizer`
if self.optimizer is not None:
param_wise_lrs = [
[group["lr"] for group in optim.param_groups] for optim in self.optimizer.optimizer_dict.values()
]
lrs = list(chain(*param_wise_lrs))
return lrs
def _get_closed_form_lr(self):
return self.base_lrs
def set_rng_state_for_device(device_name, device_module, checkpoint_rng_state, is_distributed):
"""Helper to set RNG state for a specific device type (CUDA, NPU, MLU, MUSA)"""
device_state_key = device_name.lower()
err_template = "Didn't manage to set back the RNG states of the {backend} because of the following error:\n {exception}\nThis won't yield the same results as if the training had not been interrupted."
try:
if is_distributed:
device_module.random.set_rng_state_all(checkpoint_rng_state[device_state_key])
else:
device_module.random.set_rng_state(checkpoint_rng_state[device_state_key])
except Exception as e:
# Log error if setting RNG state fails
logger.error(err_template.format(backend=device_name, exception=e))
| transformers/src/transformers/trainer_pt_utils.py/0 | {
"file_path": "transformers/src/transformers/trainer_pt_utils.py",
"repo_id": "transformers",
"token_count": 24461
} |
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Hub utilities: utilities related to download and cache models
"""
import json
import os
import re
import shutil
import sys
import tempfile
import traceback
import warnings
from concurrent import futures
from pathlib import Path
from typing import Dict, List, Optional, Union
from urllib.parse import urlparse
from uuid import uuid4
import huggingface_hub
import requests
from huggingface_hub import (
_CACHED_NO_EXIST,
CommitOperationAdd,
ModelCard,
ModelCardData,
constants,
create_branch,
create_commit,
create_repo,
get_hf_file_metadata,
hf_hub_download,
hf_hub_url,
try_to_load_from_cache,
)
from huggingface_hub.file_download import REGEX_COMMIT_HASH, http_get
from huggingface_hub.utils import (
EntryNotFoundError,
GatedRepoError,
HfHubHTTPError,
HFValidationError,
LocalEntryNotFoundError,
OfflineModeIsEnabled,
RepositoryNotFoundError,
RevisionNotFoundError,
build_hf_headers,
get_session,
hf_raise_for_status,
send_telemetry,
)
from requests.exceptions import HTTPError
from . import __version__, logging
from .generic import working_or_temp_dir
from .import_utils import (
ENV_VARS_TRUE_VALUES,
_tf_version,
_torch_version,
is_tf_available,
is_torch_available,
is_training_run_on_sagemaker,
)
from .logging import tqdm
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
_is_offline_mode = huggingface_hub.constants.HF_HUB_OFFLINE
def is_offline_mode():
return _is_offline_mode
torch_cache_home = os.getenv("TORCH_HOME", os.path.join(os.getenv("XDG_CACHE_HOME", "~/.cache"), "torch"))
default_cache_path = constants.default_cache_path
old_default_cache_path = os.path.join(torch_cache_home, "transformers")
# Determine default cache directory. Lots of legacy environment variables to ensure backward compatibility.
# The best way to set the cache path is with the environment variable HF_HOME. For more details, checkout this
# documentation page: https://huggingface.co/docs/huggingface_hub/package_reference/environment_variables.
#
# In code, use `HF_HUB_CACHE` as the default cache path. This variable is set by the library and is guaranteed
# to be set to the right value.
#
# TODO: clean this for v5?
PYTORCH_PRETRAINED_BERT_CACHE = os.getenv("PYTORCH_PRETRAINED_BERT_CACHE", constants.HF_HUB_CACHE)
PYTORCH_TRANSFORMERS_CACHE = os.getenv("PYTORCH_TRANSFORMERS_CACHE", PYTORCH_PRETRAINED_BERT_CACHE)
TRANSFORMERS_CACHE = os.getenv("TRANSFORMERS_CACHE", PYTORCH_TRANSFORMERS_CACHE)
# Onetime move from the old location to the new one if no ENV variable has been set.
if (
os.path.isdir(old_default_cache_path)
and not os.path.isdir(constants.HF_HUB_CACHE)
and "PYTORCH_PRETRAINED_BERT_CACHE" not in os.environ
and "PYTORCH_TRANSFORMERS_CACHE" not in os.environ
and "TRANSFORMERS_CACHE" not in os.environ
):
logger.warning(
"In Transformers v4.22.0, the default path to cache downloaded models changed from"
" '~/.cache/torch/transformers' to '~/.cache/huggingface/hub'. Since you don't seem to have"
" overridden and '~/.cache/torch/transformers' is a directory that exists, we're moving it to"
" '~/.cache/huggingface/hub' to avoid redownloading models you have already in the cache. You should"
" only see this message once."
)
shutil.move(old_default_cache_path, constants.HF_HUB_CACHE)
HF_MODULES_CACHE = os.getenv("HF_MODULES_CACHE", os.path.join(constants.HF_HOME, "modules"))
TRANSFORMERS_DYNAMIC_MODULE_NAME = "transformers_modules"
SESSION_ID = uuid4().hex
# Add deprecation warning for old environment variables.
for key in ("PYTORCH_PRETRAINED_BERT_CACHE", "PYTORCH_TRANSFORMERS_CACHE", "TRANSFORMERS_CACHE"):
if os.getenv(key) is not None:
warnings.warn(
f"Using `{key}` is deprecated and will be removed in v5 of Transformers. Use `HF_HOME` instead.",
FutureWarning,
)
S3_BUCKET_PREFIX = "https://s3.amazonaws.com/models.huggingface.co/bert"
CLOUDFRONT_DISTRIB_PREFIX = "https://cdn.huggingface.co"
_staging_mode = os.environ.get("HUGGINGFACE_CO_STAGING", "NO").upper() in ENV_VARS_TRUE_VALUES
_default_endpoint = "https://hub-ci.huggingface.co" if _staging_mode else "https://huggingface.co"
HUGGINGFACE_CO_RESOLVE_ENDPOINT = _default_endpoint
if os.environ.get("HUGGINGFACE_CO_RESOLVE_ENDPOINT", None) is not None:
warnings.warn(
"Using the environment variable `HUGGINGFACE_CO_RESOLVE_ENDPOINT` is deprecated and will be removed in "
"Transformers v5. Use `HF_ENDPOINT` instead.",
FutureWarning,
)
HUGGINGFACE_CO_RESOLVE_ENDPOINT = os.environ.get("HUGGINGFACE_CO_RESOLVE_ENDPOINT", None)
HUGGINGFACE_CO_RESOLVE_ENDPOINT = os.environ.get("HF_ENDPOINT", HUGGINGFACE_CO_RESOLVE_ENDPOINT)
HUGGINGFACE_CO_PREFIX = HUGGINGFACE_CO_RESOLVE_ENDPOINT + "/{model_id}/resolve/{revision}/{filename}"
HUGGINGFACE_CO_EXAMPLES_TELEMETRY = HUGGINGFACE_CO_RESOLVE_ENDPOINT + "/api/telemetry/examples"
def _get_cache_file_to_return(
path_or_repo_id: str, full_filename: str, cache_dir: Union[str, Path, None] = None, revision: Optional[str] = None
):
# We try to see if we have a cached version (not up to date):
resolved_file = try_to_load_from_cache(path_or_repo_id, full_filename, cache_dir=cache_dir, revision=revision)
if resolved_file is not None and resolved_file != _CACHED_NO_EXIST:
return resolved_file
return None
def is_remote_url(url_or_filename):
parsed = urlparse(url_or_filename)
return parsed.scheme in ("http", "https")
def define_sagemaker_information():
try:
instance_data = requests.get(os.environ["ECS_CONTAINER_METADATA_URI"]).json()
dlc_container_used = instance_data["Image"]
dlc_tag = instance_data["Image"].split(":")[1]
except Exception:
dlc_container_used = None
dlc_tag = None
sagemaker_params = json.loads(os.getenv("SM_FRAMEWORK_PARAMS", "{}"))
runs_distributed_training = True if "sagemaker_distributed_dataparallel_enabled" in sagemaker_params else False
account_id = os.getenv("TRAINING_JOB_ARN").split(":")[4] if "TRAINING_JOB_ARN" in os.environ else None
sagemaker_object = {
"sm_framework": os.getenv("SM_FRAMEWORK_MODULE", None),
"sm_region": os.getenv("AWS_REGION", None),
"sm_number_gpu": os.getenv("SM_NUM_GPUS", 0),
"sm_number_cpu": os.getenv("SM_NUM_CPUS", 0),
"sm_distributed_training": runs_distributed_training,
"sm_deep_learning_container": dlc_container_used,
"sm_deep_learning_container_tag": dlc_tag,
"sm_account_id": account_id,
}
return sagemaker_object
def http_user_agent(user_agent: Union[Dict, str, None] = None) -> str:
"""
Formats a user-agent string with basic info about a request.
"""
ua = f"transformers/{__version__}; python/{sys.version.split()[0]}; session_id/{SESSION_ID}"
if is_torch_available():
ua += f"; torch/{_torch_version}"
if is_tf_available():
ua += f"; tensorflow/{_tf_version}"
if constants.HF_HUB_DISABLE_TELEMETRY:
return ua + "; telemetry/off"
if is_training_run_on_sagemaker():
ua += "; " + "; ".join(f"{k}/{v}" for k, v in define_sagemaker_information().items())
# CI will set this value to True
if os.environ.get("TRANSFORMERS_IS_CI", "").upper() in ENV_VARS_TRUE_VALUES:
ua += "; is_ci/true"
if isinstance(user_agent, dict):
ua += "; " + "; ".join(f"{k}/{v}" for k, v in user_agent.items())
elif isinstance(user_agent, str):
ua += "; " + user_agent
return ua
def extract_commit_hash(resolved_file: Optional[str], commit_hash: Optional[str]) -> Optional[str]:
"""
Extracts the commit hash from a resolved filename toward a cache file.
"""
if resolved_file is None or commit_hash is not None:
return commit_hash
resolved_file = str(Path(resolved_file).as_posix())
search = re.search(r"snapshots/([^/]+)/", resolved_file)
if search is None:
return None
commit_hash = search.groups()[0]
return commit_hash if REGEX_COMMIT_HASH.match(commit_hash) else None
def cached_file(
path_or_repo_id: Union[str, os.PathLike],
filename: str,
cache_dir: Optional[Union[str, os.PathLike]] = None,
force_download: bool = False,
resume_download: Optional[bool] = None,
proxies: Optional[Dict[str, str]] = None,
token: Optional[Union[bool, str]] = None,
revision: Optional[str] = None,
local_files_only: bool = False,
subfolder: str = "",
repo_type: Optional[str] = None,
user_agent: Optional[Union[str, Dict[str, str]]] = None,
_raise_exceptions_for_gated_repo: bool = True,
_raise_exceptions_for_missing_entries: bool = True,
_raise_exceptions_for_connection_errors: bool = True,
_commit_hash: Optional[str] = None,
**deprecated_kwargs,
) -> Optional[str]:
"""
Tries to locate a file in a local folder and repo, downloads and cache it if necessary.
Args:
path_or_repo_id (`str` or `os.PathLike`):
This can be either:
- a string, the *model id* of a model repo on huggingface.co.
- a path to a *directory* potentially containing the file.
filename (`str`):
The name of the file to locate in `path_or_repo`.
cache_dir (`str` or `os.PathLike`, *optional*):
Path to a directory in which a downloaded pretrained model configuration should be cached if the standard
cache should not be used.
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force to (re-)download the configuration files and override the cached versions if they
exist.
resume_download:
Deprecated and ignored. All downloads are now resumed by default when possible.
Will be removed in v5 of Transformers.
proxies (`Dict[str, str]`, *optional*):
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
token (`str` or *bool*, *optional*):
The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
when running `huggingface-cli login` (stored in `~/.huggingface`).
revision (`str`, *optional*, defaults to `"main"`):
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
identifier allowed by git.
local_files_only (`bool`, *optional*, defaults to `False`):
If `True`, will only try to load the tokenizer configuration from local files.
subfolder (`str`, *optional*, defaults to `""`):
In case the relevant files are located inside a subfolder of the model repo on huggingface.co, you can
specify the folder name here.
repo_type (`str`, *optional*):
Specify the repo type (useful when downloading from a space for instance).
<Tip>
Passing `token=True` is required when you want to use a private model.
</Tip>
Returns:
`Optional[str]`: Returns the resolved file (to the cache folder if downloaded from a repo).
Examples:
```python
# Download a model weight from the Hub and cache it.
model_weights_file = cached_file("google-bert/bert-base-uncased", "pytorch_model.bin")
```
"""
use_auth_token = deprecated_kwargs.pop("use_auth_token", None)
if use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
FutureWarning,
)
if token is not None:
raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
token = use_auth_token
# Private arguments
# _raise_exceptions_for_gated_repo: if False, do not raise an exception for gated repo error but return
# None.
# _raise_exceptions_for_missing_entries: if False, do not raise an exception for missing entries but return
# None.
# _raise_exceptions_for_connection_errors: if False, do not raise an exception for connection errors but return
# None.
# _commit_hash: passed when we are chaining several calls to various files (e.g. when loading a tokenizer or
# a pipeline). If files are cached for this commit hash, avoid calls to head and get from the cache.
if is_offline_mode() and not local_files_only:
logger.info("Offline mode: forcing local_files_only=True")
local_files_only = True
if subfolder is None:
subfolder = ""
path_or_repo_id = str(path_or_repo_id)
full_filename = os.path.join(subfolder, filename)
if os.path.isdir(path_or_repo_id):
resolved_file = os.path.join(os.path.join(path_or_repo_id, subfolder), filename)
if not os.path.isfile(resolved_file):
if _raise_exceptions_for_missing_entries and filename not in ["config.json", f"{subfolder}/config.json"]:
raise EnvironmentError(
f"{path_or_repo_id} does not appear to have a file named {full_filename}. Checkout "
f"'https://huggingface.co/{path_or_repo_id}/tree/{revision}' for available files."
)
else:
return None
return resolved_file
if cache_dir is None:
cache_dir = TRANSFORMERS_CACHE
if isinstance(cache_dir, Path):
cache_dir = str(cache_dir)
if _commit_hash is not None and not force_download:
# If the file is cached under that commit hash, we return it directly.
resolved_file = try_to_load_from_cache(
path_or_repo_id, full_filename, cache_dir=cache_dir, revision=_commit_hash, repo_type=repo_type
)
if resolved_file is not None:
if resolved_file is not _CACHED_NO_EXIST:
return resolved_file
elif not _raise_exceptions_for_missing_entries:
return None
else:
raise EnvironmentError(f"Could not locate {full_filename} inside {path_or_repo_id}.")
user_agent = http_user_agent(user_agent)
try:
# Load from URL or cache if already cached
resolved_file = hf_hub_download(
path_or_repo_id,
filename,
subfolder=None if len(subfolder) == 0 else subfolder,
repo_type=repo_type,
revision=revision,
cache_dir=cache_dir,
user_agent=user_agent,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
token=token,
local_files_only=local_files_only,
)
except GatedRepoError as e:
resolved_file = _get_cache_file_to_return(path_or_repo_id, full_filename, cache_dir, revision)
if resolved_file is not None or not _raise_exceptions_for_gated_repo:
return resolved_file
raise EnvironmentError(
"You are trying to access a gated repo.\nMake sure to have access to it at "
f"https://huggingface.co/{path_or_repo_id}.\n{str(e)}"
) from e
except RepositoryNotFoundError as e:
raise EnvironmentError(
f"{path_or_repo_id} is not a local folder and is not a valid model identifier "
"listed on 'https://huggingface.co/models'\nIf this is a private repository, make sure to pass a token "
"having permission to this repo either by logging in with `huggingface-cli login` or by passing "
"`token=<your_token>`"
) from e
except RevisionNotFoundError as e:
raise EnvironmentError(
f"{revision} is not a valid git identifier (branch name, tag name or commit id) that exists "
"for this model name. Check the model page at "
f"'https://huggingface.co/{path_or_repo_id}' for available revisions."
) from e
except LocalEntryNotFoundError as e:
resolved_file = _get_cache_file_to_return(path_or_repo_id, full_filename, cache_dir, revision)
if (
resolved_file is not None
or not _raise_exceptions_for_missing_entries
or not _raise_exceptions_for_connection_errors
):
return resolved_file
raise EnvironmentError(
f"We couldn't connect to '{HUGGINGFACE_CO_RESOLVE_ENDPOINT}' to load this file, couldn't find it in the"
f" cached files and it looks like {path_or_repo_id} is not the path to a directory containing a file named"
f" {full_filename}.\nCheckout your internet connection or see how to run the library in offline mode at"
" 'https://huggingface.co/docs/transformers/installation#offline-mode'."
) from e
except EntryNotFoundError as e:
if not _raise_exceptions_for_missing_entries:
return None
if revision is None:
revision = "main"
if filename in ["config.json", f"{subfolder}/config.json"]:
return None
raise EnvironmentError(
f"{path_or_repo_id} does not appear to have a file named {full_filename}. Checkout "
f"'https://huggingface.co/{path_or_repo_id}/tree/{revision}' for available files."
) from e
except HTTPError as err:
resolved_file = _get_cache_file_to_return(path_or_repo_id, full_filename, cache_dir, revision)
if resolved_file is not None or not _raise_exceptions_for_connection_errors:
return resolved_file
raise EnvironmentError(f"There was a specific connection error when trying to load {path_or_repo_id}:\n{err}")
except HFValidationError as e:
raise EnvironmentError(
f"Incorrect path_or_model_id: '{path_or_repo_id}'. Please provide either the path to a local folder or the repo_id of a model on the Hub."
) from e
return resolved_file
# TODO: deprecate `get_file_from_repo` or document it differently?
# Docstring is exactly the same as `cached_repo` but behavior is slightly different. If file is missing or if
# there is a connection error, `cached_repo` will return None while `get_file_from_repo` will raise an error.
# IMO we should keep only 1 method and have a single `raise_error` argument (to be discussed).
def get_file_from_repo(
path_or_repo: Union[str, os.PathLike],
filename: str,
cache_dir: Optional[Union[str, os.PathLike]] = None,
force_download: bool = False,
resume_download: Optional[bool] = None,
proxies: Optional[Dict[str, str]] = None,
token: Optional[Union[bool, str]] = None,
revision: Optional[str] = None,
local_files_only: bool = False,
subfolder: str = "",
**deprecated_kwargs,
):
"""
Tries to locate a file in a local folder and repo, downloads and cache it if necessary.
Args:
path_or_repo (`str` or `os.PathLike`):
This can be either:
- a string, the *model id* of a model repo on huggingface.co.
- a path to a *directory* potentially containing the file.
filename (`str`):
The name of the file to locate in `path_or_repo`.
cache_dir (`str` or `os.PathLike`, *optional*):
Path to a directory in which a downloaded pretrained model configuration should be cached if the standard
cache should not be used.
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force to (re-)download the configuration files and override the cached versions if they
exist.
resume_download:
Deprecated and ignored. All downloads are now resumed by default when possible.
Will be removed in v5 of Transformers.
proxies (`Dict[str, str]`, *optional*):
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
token (`str` or *bool*, *optional*):
The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
when running `huggingface-cli login` (stored in `~/.huggingface`).
revision (`str`, *optional*, defaults to `"main"`):
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
identifier allowed by git.
local_files_only (`bool`, *optional*, defaults to `False`):
If `True`, will only try to load the tokenizer configuration from local files.
subfolder (`str`, *optional*, defaults to `""`):
In case the relevant files are located inside a subfolder of the model repo on huggingface.co, you can
specify the folder name here.
<Tip>
Passing `token=True` is required when you want to use a private model.
</Tip>
Returns:
`Optional[str]`: Returns the resolved file (to the cache folder if downloaded from a repo) or `None` if the
file does not exist.
Examples:
```python
# Download a tokenizer configuration from huggingface.co and cache.
tokenizer_config = get_file_from_repo("google-bert/bert-base-uncased", "tokenizer_config.json")
# This model does not have a tokenizer config so the result will be None.
tokenizer_config = get_file_from_repo("FacebookAI/xlm-roberta-base", "tokenizer_config.json")
```
"""
use_auth_token = deprecated_kwargs.pop("use_auth_token", None)
if use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
FutureWarning,
)
if token is not None:
raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
token = use_auth_token
return cached_file(
path_or_repo_id=path_or_repo,
filename=filename,
cache_dir=cache_dir,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
token=token,
revision=revision,
local_files_only=local_files_only,
subfolder=subfolder,
_raise_exceptions_for_gated_repo=False,
_raise_exceptions_for_missing_entries=False,
_raise_exceptions_for_connection_errors=False,
)
def download_url(url, proxies=None):
"""
Downloads a given url in a temporary file. This function is not safe to use in multiple processes. Its only use is
for deprecated behavior allowing to download config/models with a single url instead of using the Hub.
Args:
url (`str`): The url of the file to download.
proxies (`Dict[str, str]`, *optional*):
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
Returns:
`str`: The location of the temporary file where the url was downloaded.
"""
warnings.warn(
f"Using `from_pretrained` with the url of a file (here {url}) is deprecated and won't be possible anymore in"
" v5 of Transformers. You should host your file on the Hub (hf.co) instead and use the repository ID. Note"
" that this is not compatible with the caching system (your file will be downloaded at each execution) or"
" multiple processes (each process will download the file in a different temporary file).",
FutureWarning,
)
tmp_fd, tmp_file = tempfile.mkstemp()
with os.fdopen(tmp_fd, "wb") as f:
http_get(url, f, proxies=proxies)
return tmp_file
def has_file(
path_or_repo: Union[str, os.PathLike],
filename: str,
revision: Optional[str] = None,
proxies: Optional[Dict[str, str]] = None,
token: Optional[Union[bool, str]] = None,
*,
local_files_only: bool = False,
cache_dir: Union[str, Path, None] = None,
repo_type: Optional[str] = None,
**deprecated_kwargs,
):
"""
Checks if a repo contains a given file without downloading it. Works for remote repos and local folders.
If offline mode is enabled, checks if the file exists in the cache.
<Tip warning={false}>
This function will raise an error if the repository `path_or_repo` is not valid or if `revision` does not exist for
this repo, but will return False for regular connection errors.
</Tip>
"""
use_auth_token = deprecated_kwargs.pop("use_auth_token", None)
if use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
FutureWarning,
)
if token is not None:
raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
token = use_auth_token
# If path to local directory, check if the file exists
if os.path.isdir(path_or_repo):
return os.path.isfile(os.path.join(path_or_repo, filename))
# Else it's a repo => let's check if the file exists in local cache or on the Hub
# Check if file exists in cache
# This information might be outdated so it's best to also make a HEAD call (if allowed).
cached_path = try_to_load_from_cache(
repo_id=path_or_repo,
filename=filename,
revision=revision,
repo_type=repo_type,
cache_dir=cache_dir,
)
has_file_in_cache = isinstance(cached_path, str)
# If local_files_only, don't try the HEAD call
if local_files_only:
return has_file_in_cache
# Check if the file exists
try:
response = get_session().head(
hf_hub_url(path_or_repo, filename=filename, revision=revision, repo_type=repo_type),
headers=build_hf_headers(token=token, user_agent=http_user_agent()),
allow_redirects=False,
proxies=proxies,
timeout=10,
)
except (requests.exceptions.SSLError, requests.exceptions.ProxyError):
# Actually raise for those subclasses of ConnectionError
raise
except (
requests.exceptions.ConnectionError,
requests.exceptions.Timeout,
OfflineModeIsEnabled,
):
return has_file_in_cache
try:
hf_raise_for_status(response)
return True
except GatedRepoError as e:
logger.error(e)
raise EnvironmentError(
f"{path_or_repo} is a gated repository. Make sure to request access at "
f"https://huggingface.co/{path_or_repo} and pass a token having permission to this repo either by "
"logging in with `huggingface-cli login` or by passing `token=<your_token>`."
) from e
except RepositoryNotFoundError as e:
logger.error(e)
raise EnvironmentError(
f"{path_or_repo} is not a local folder or a valid repository name on 'https://hf.co'."
) from e
except RevisionNotFoundError as e:
logger.error(e)
raise EnvironmentError(
f"{revision} is not a valid git identifier (branch name, tag name or commit id) that exists for this "
f"model name. Check the model page at 'https://huggingface.co/{path_or_repo}' for available revisions."
) from e
except EntryNotFoundError:
return False # File does not exist
except requests.HTTPError:
# Any authentication/authorization error will be caught here => default to cache
return has_file_in_cache
class PushToHubMixin:
"""
A Mixin containing the functionality to push a model or tokenizer to the hub.
"""
def _create_repo(
self,
repo_id: str,
private: Optional[bool] = None,
token: Optional[Union[bool, str]] = None,
repo_url: Optional[str] = None,
organization: Optional[str] = None,
) -> str:
"""
Create the repo if needed, cleans up repo_id with deprecated kwargs `repo_url` and `organization`, retrieves
the token.
"""
if repo_url is not None:
warnings.warn(
"The `repo_url` argument is deprecated and will be removed in v5 of Transformers. Use `repo_id` "
"instead."
)
if repo_id is not None:
raise ValueError(
"`repo_id` and `repo_url` are both specified. Please set only the argument `repo_id`."
)
repo_id = repo_url.replace(f"{HUGGINGFACE_CO_RESOLVE_ENDPOINT}/", "")
if organization is not None:
warnings.warn(
"The `organization` argument is deprecated and will be removed in v5 of Transformers. Set your "
"organization directly in the `repo_id` passed instead (`repo_id={organization}/{model_id}`)."
)
if not repo_id.startswith(organization):
if "/" in repo_id:
repo_id = repo_id.split("/")[-1]
repo_id = f"{organization}/{repo_id}"
url = create_repo(repo_id=repo_id, token=token, private=private, exist_ok=True)
return url.repo_id
def _get_files_timestamps(self, working_dir: Union[str, os.PathLike]):
"""
Returns the list of files with their last modification timestamp.
"""
return {f: os.path.getmtime(os.path.join(working_dir, f)) for f in os.listdir(working_dir)}
def _upload_modified_files(
self,
working_dir: Union[str, os.PathLike],
repo_id: str,
files_timestamps: Dict[str, float],
commit_message: Optional[str] = None,
token: Optional[Union[bool, str]] = None,
create_pr: bool = False,
revision: str = None,
commit_description: str = None,
):
"""
Uploads all modified files in `working_dir` to `repo_id`, based on `files_timestamps`.
"""
if commit_message is None:
if "Model" in self.__class__.__name__:
commit_message = "Upload model"
elif "Config" in self.__class__.__name__:
commit_message = "Upload config"
elif "Tokenizer" in self.__class__.__name__:
commit_message = "Upload tokenizer"
elif "FeatureExtractor" in self.__class__.__name__:
commit_message = "Upload feature extractor"
elif "Processor" in self.__class__.__name__:
commit_message = "Upload processor"
else:
commit_message = f"Upload {self.__class__.__name__}"
modified_files = [
f
for f in os.listdir(working_dir)
if f not in files_timestamps or os.path.getmtime(os.path.join(working_dir, f)) > files_timestamps[f]
]
# filter for actual files + folders at the root level
modified_files = [
f
for f in modified_files
if os.path.isfile(os.path.join(working_dir, f)) or os.path.isdir(os.path.join(working_dir, f))
]
operations = []
# upload standalone files
for file in modified_files:
if os.path.isdir(os.path.join(working_dir, file)):
# go over individual files of folder
for f in os.listdir(os.path.join(working_dir, file)):
operations.append(
CommitOperationAdd(
path_or_fileobj=os.path.join(working_dir, file, f), path_in_repo=os.path.join(file, f)
)
)
else:
operations.append(
CommitOperationAdd(path_or_fileobj=os.path.join(working_dir, file), path_in_repo=file)
)
if revision is not None and not revision.startswith("refs/pr"):
try:
create_branch(repo_id=repo_id, branch=revision, token=token, exist_ok=True)
except HfHubHTTPError as e:
if e.response.status_code == 403 and create_pr:
# If we are creating a PR on a repo we don't have access to, we can't create the branch.
# so let's assume the branch already exists. If it's not the case, an error will be raised when
# calling `create_commit` below.
pass
else:
raise
logger.info(f"Uploading the following files to {repo_id}: {','.join(modified_files)}")
return create_commit(
repo_id=repo_id,
operations=operations,
commit_message=commit_message,
commit_description=commit_description,
token=token,
create_pr=create_pr,
revision=revision,
)
def push_to_hub(
self,
repo_id: str,
use_temp_dir: Optional[bool] = None,
commit_message: Optional[str] = None,
private: Optional[bool] = None,
token: Optional[Union[bool, str]] = None,
max_shard_size: Optional[Union[int, str]] = "5GB",
create_pr: bool = False,
safe_serialization: bool = True,
revision: str = None,
commit_description: str = None,
tags: Optional[List[str]] = None,
**deprecated_kwargs,
) -> str:
"""
Upload the {object_files} to the 🤗 Model Hub.
Parameters:
repo_id (`str`):
The name of the repository you want to push your {object} to. It should contain your organization name
when pushing to a given organization.
use_temp_dir (`bool`, *optional*):
Whether or not to use a temporary directory to store the files saved before they are pushed to the Hub.
Will default to `True` if there is no directory named like `repo_id`, `False` otherwise.
commit_message (`str`, *optional*):
Message to commit while pushing. Will default to `"Upload {object}"`.
private (`bool`, *optional*):
Whether to make the repo private. If `None` (default), the repo will be public unless the organization's default is private. This value is ignored if the repo already exists.
token (`bool` or `str`, *optional*):
The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
when running `huggingface-cli login` (stored in `~/.huggingface`). Will default to `True` if `repo_url`
is not specified.
max_shard_size (`int` or `str`, *optional*, defaults to `"5GB"`):
Only applicable for models. The maximum size for a checkpoint before being sharded. Checkpoints shard
will then be each of size lower than this size. If expressed as a string, needs to be digits followed
by a unit (like `"5MB"`). We default it to `"5GB"` so that users can easily load models on free-tier
Google Colab instances without any CPU OOM issues.
create_pr (`bool`, *optional*, defaults to `False`):
Whether or not to create a PR with the uploaded files or directly commit.
safe_serialization (`bool`, *optional*, defaults to `True`):
Whether or not to convert the model weights in safetensors format for safer serialization.
revision (`str`, *optional*):
Branch to push the uploaded files to.
commit_description (`str`, *optional*):
The description of the commit that will be created
tags (`List[str]`, *optional*):
List of tags to push on the Hub.
Examples:
```python
from transformers import {object_class}
{object} = {object_class}.from_pretrained("google-bert/bert-base-cased")
# Push the {object} to your namespace with the name "my-finetuned-bert".
{object}.push_to_hub("my-finetuned-bert")
# Push the {object} to an organization with the name "my-finetuned-bert".
{object}.push_to_hub("huggingface/my-finetuned-bert")
```
"""
use_auth_token = deprecated_kwargs.pop("use_auth_token", None)
ignore_metadata_errors = deprecated_kwargs.pop("ignore_metadata_errors", False)
if use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
FutureWarning,
)
if token is not None:
raise ValueError(
"`token` and `use_auth_token` are both specified. Please set only the argument `token`."
)
token = use_auth_token
repo_path_or_name = deprecated_kwargs.pop("repo_path_or_name", None)
if repo_path_or_name is not None:
# Should use `repo_id` instead of `repo_path_or_name`. When using `repo_path_or_name`, we try to infer
# repo_id from the folder path, if it exists.
warnings.warn(
"The `repo_path_or_name` argument is deprecated and will be removed in v5 of Transformers. Use "
"`repo_id` instead.",
FutureWarning,
)
if repo_id is not None:
raise ValueError(
"`repo_id` and `repo_path_or_name` are both specified. Please set only the argument `repo_id`."
)
if os.path.isdir(repo_path_or_name):
# repo_path: infer repo_id from the path
repo_id = repo_id.split(os.path.sep)[-1]
working_dir = repo_id
else:
# repo_name: use it as repo_id
repo_id = repo_path_or_name
working_dir = repo_id.split("/")[-1]
else:
# Repo_id is passed correctly: infer working_dir from it
working_dir = repo_id.split("/")[-1]
# Deprecation warning will be sent after for repo_url and organization
repo_url = deprecated_kwargs.pop("repo_url", None)
organization = deprecated_kwargs.pop("organization", None)
repo_id = self._create_repo(
repo_id, private=private, token=token, repo_url=repo_url, organization=organization
)
# Create a new empty model card and eventually tag it
model_card = create_and_tag_model_card(
repo_id, tags, token=token, ignore_metadata_errors=ignore_metadata_errors
)
if use_temp_dir is None:
use_temp_dir = not os.path.isdir(working_dir)
with working_or_temp_dir(working_dir=working_dir, use_temp_dir=use_temp_dir) as work_dir:
files_timestamps = self._get_files_timestamps(work_dir)
# Save all files.
self.save_pretrained(work_dir, max_shard_size=max_shard_size, safe_serialization=safe_serialization)
# Update model card if needed:
model_card.save(os.path.join(work_dir, "README.md"))
return self._upload_modified_files(
work_dir,
repo_id,
files_timestamps,
commit_message=commit_message,
token=token,
create_pr=create_pr,
revision=revision,
commit_description=commit_description,
)
def send_example_telemetry(example_name, *example_args, framework="pytorch"):
"""
Sends telemetry that helps tracking the examples use.
Args:
example_name (`str`): The name of the example.
*example_args (dataclasses or `argparse.ArgumentParser`): The arguments to the script. This function will only
try to extract the model and dataset name from those. Nothing else is tracked.
framework (`str`, *optional*, defaults to `"pytorch"`): The framework for the example.
"""
if is_offline_mode():
return
data = {"example": example_name, "framework": framework}
for args in example_args:
args_as_dict = {k: v for k, v in args.__dict__.items() if not k.startswith("_") and v is not None}
if "model_name_or_path" in args_as_dict:
model_name = args_as_dict["model_name_or_path"]
# Filter out local paths
if not os.path.isdir(model_name):
data["model_name"] = args_as_dict["model_name_or_path"]
if "dataset_name" in args_as_dict:
data["dataset_name"] = args_as_dict["dataset_name"]
elif "task_name" in args_as_dict:
# Extract script name from the example_name
script_name = example_name.replace("tf_", "").replace("flax_", "").replace("run_", "")
script_name = script_name.replace("_no_trainer", "")
data["dataset_name"] = f"{script_name}-{args_as_dict['task_name']}"
# Send telemetry in the background
send_telemetry(
topic="examples", library_name="transformers", library_version=__version__, user_agent=http_user_agent(data)
)
def convert_file_size_to_int(size: Union[int, str]):
"""
Converts a size expressed as a string with digits an unit (like `"5MB"`) to an integer (in bytes).
Args:
size (`int` or `str`): The size to convert. Will be directly returned if an `int`.
Example:
```py
>>> convert_file_size_to_int("1MiB")
1048576
```
"""
if isinstance(size, int):
return size
if size.upper().endswith("GIB"):
return int(size[:-3]) * (2**30)
if size.upper().endswith("MIB"):
return int(size[:-3]) * (2**20)
if size.upper().endswith("KIB"):
return int(size[:-3]) * (2**10)
if size.upper().endswith("GB"):
int_size = int(size[:-2]) * (10**9)
return int_size // 8 if size.endswith("b") else int_size
if size.upper().endswith("MB"):
int_size = int(size[:-2]) * (10**6)
return int_size // 8 if size.endswith("b") else int_size
if size.upper().endswith("KB"):
int_size = int(size[:-2]) * (10**3)
return int_size // 8 if size.endswith("b") else int_size
raise ValueError("`size` is not in a valid format. Use an integer followed by the unit, e.g., '5GB'.")
def get_checkpoint_shard_files(
pretrained_model_name_or_path,
index_filename,
cache_dir=None,
force_download=False,
proxies=None,
resume_download=None,
local_files_only=False,
token=None,
user_agent=None,
revision=None,
subfolder="",
_commit_hash=None,
**deprecated_kwargs,
):
"""
For a given model:
- download and cache all the shards of a sharded checkpoint if `pretrained_model_name_or_path` is a model ID on the
Hub
- returns the list of paths to all the shards, as well as some metadata.
For the description of each arg, see [`PreTrainedModel.from_pretrained`]. `index_filename` is the full path to the
index (downloaded and cached if `pretrained_model_name_or_path` is a model ID on the Hub).
"""
import json
use_auth_token = deprecated_kwargs.pop("use_auth_token", None)
if use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
FutureWarning,
)
if token is not None:
raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
token = use_auth_token
if not os.path.isfile(index_filename):
raise ValueError(f"Can't find a checkpoint index ({index_filename}) in {pretrained_model_name_or_path}.")
with open(index_filename, "r") as f:
index = json.loads(f.read())
shard_filenames = sorted(set(index["weight_map"].values()))
sharded_metadata = index["metadata"]
sharded_metadata["all_checkpoint_keys"] = list(index["weight_map"].keys())
sharded_metadata["weight_map"] = index["weight_map"].copy()
# First, let's deal with local folder.
if os.path.isdir(pretrained_model_name_or_path):
shard_filenames = [os.path.join(pretrained_model_name_or_path, subfolder, f) for f in shard_filenames]
return shard_filenames, sharded_metadata
# At this stage pretrained_model_name_or_path is a model identifier on the Hub
cached_filenames = []
# Check if the model is already cached or not. We only try the last checkpoint, this should cover most cases of
# downloaded (if interrupted).
last_shard = try_to_load_from_cache(
pretrained_model_name_or_path, shard_filenames[-1], cache_dir=cache_dir, revision=_commit_hash
)
show_progress_bar = last_shard is None or force_download
for shard_filename in tqdm(shard_filenames, desc="Downloading shards", disable=not show_progress_bar):
try:
# Load from URL
cached_filename = cached_file(
pretrained_model_name_or_path,
shard_filename,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
local_files_only=local_files_only,
token=token,
user_agent=user_agent,
revision=revision,
subfolder=subfolder,
_commit_hash=_commit_hash,
)
# We have already dealt with RepositoryNotFoundError and RevisionNotFoundError when getting the index, so
# we don't have to catch them here.
except EntryNotFoundError:
raise EnvironmentError(
f"{pretrained_model_name_or_path} does not appear to have a file named {shard_filename} which is "
"required according to the checkpoint index."
)
except HTTPError:
raise EnvironmentError(
f"We couldn't connect to '{HUGGINGFACE_CO_RESOLVE_ENDPOINT}' to load {shard_filename}. You should try"
" again after checking your internet connection."
)
cached_filenames.append(cached_filename)
return cached_filenames, sharded_metadata
# All what is below is for conversion between old cache format and new cache format.
def get_all_cached_files(cache_dir=None):
"""
Returns a list for all files cached with appropriate metadata.
"""
if cache_dir is None:
cache_dir = TRANSFORMERS_CACHE
else:
cache_dir = str(cache_dir)
if not os.path.isdir(cache_dir):
return []
cached_files = []
for file in os.listdir(cache_dir):
meta_path = os.path.join(cache_dir, f"{file}.json")
if not os.path.isfile(meta_path):
continue
with open(meta_path, encoding="utf-8") as meta_file:
metadata = json.load(meta_file)
url = metadata["url"]
etag = metadata["etag"].replace('"', "")
cached_files.append({"file": file, "url": url, "etag": etag})
return cached_files
def extract_info_from_url(url):
"""
Extract repo_name, revision and filename from an url.
"""
search = re.search(r"^https://huggingface\.co/(.*)/resolve/([^/]*)/(.*)$", url)
if search is None:
return None
repo, revision, filename = search.groups()
cache_repo = "--".join(["models"] + repo.split("/"))
return {"repo": cache_repo, "revision": revision, "filename": filename}
def create_and_tag_model_card(
repo_id: str,
tags: Optional[List[str]] = None,
token: Optional[str] = None,
ignore_metadata_errors: bool = False,
):
"""
Creates or loads an existing model card and tags it.
Args:
repo_id (`str`):
The repo_id where to look for the model card.
tags (`List[str]`, *optional*):
The list of tags to add in the model card
token (`str`, *optional*):
Authentication token, obtained with `huggingface_hub.HfApi.login` method. Will default to the stored token.
ignore_metadata_errors (`str`):
If True, errors while parsing the metadata section will be ignored. Some information might be lost during
the process. Use it at your own risk.
"""
try:
# Check if the model card is present on the remote repo
model_card = ModelCard.load(repo_id, token=token, ignore_metadata_errors=ignore_metadata_errors)
except EntryNotFoundError:
# Otherwise create a simple model card from template
model_description = "This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated."
card_data = ModelCardData(tags=[] if tags is None else tags, library_name="transformers")
model_card = ModelCard.from_template(card_data, model_description=model_description)
if tags is not None:
# Ensure model_card.data.tags is a list and not None
if model_card.data.tags is None:
model_card.data.tags = []
for model_tag in tags:
if model_tag not in model_card.data.tags:
model_card.data.tags.append(model_tag)
return model_card
def clean_files_for(file):
"""
Remove, if they exist, file, file.json and file.lock
"""
for f in [file, f"{file}.json", f"{file}.lock"]:
if os.path.isfile(f):
os.remove(f)
def move_to_new_cache(file, repo, filename, revision, etag, commit_hash):
"""
Move file to repo following the new huggingface hub cache organization.
"""
os.makedirs(repo, exist_ok=True)
# refs
os.makedirs(os.path.join(repo, "refs"), exist_ok=True)
if revision != commit_hash:
ref_path = os.path.join(repo, "refs", revision)
with open(ref_path, "w") as f:
f.write(commit_hash)
# blobs
os.makedirs(os.path.join(repo, "blobs"), exist_ok=True)
blob_path = os.path.join(repo, "blobs", etag)
shutil.move(file, blob_path)
# snapshots
os.makedirs(os.path.join(repo, "snapshots"), exist_ok=True)
os.makedirs(os.path.join(repo, "snapshots", commit_hash), exist_ok=True)
pointer_path = os.path.join(repo, "snapshots", commit_hash, filename)
huggingface_hub.file_download._create_relative_symlink(blob_path, pointer_path)
clean_files_for(file)
def move_cache(cache_dir=None, new_cache_dir=None, token=None):
if new_cache_dir is None:
new_cache_dir = TRANSFORMERS_CACHE
if cache_dir is None:
# Migrate from old cache in .cache/huggingface/transformers
old_cache = Path(TRANSFORMERS_CACHE).parent / "transformers"
if os.path.isdir(str(old_cache)):
cache_dir = str(old_cache)
else:
cache_dir = new_cache_dir
cached_files = get_all_cached_files(cache_dir=cache_dir)
logger.info(f"Moving {len(cached_files)} files to the new cache system")
hub_metadata = {}
for file_info in tqdm(cached_files):
url = file_info.pop("url")
if url not in hub_metadata:
try:
hub_metadata[url] = get_hf_file_metadata(url, token=token)
except requests.HTTPError:
continue
etag, commit_hash = hub_metadata[url].etag, hub_metadata[url].commit_hash
if etag is None or commit_hash is None:
continue
if file_info["etag"] != etag:
# Cached file is not up to date, we just throw it as a new version will be downloaded anyway.
clean_files_for(os.path.join(cache_dir, file_info["file"]))
continue
url_info = extract_info_from_url(url)
if url_info is None:
# Not a file from huggingface.co
continue
repo = os.path.join(new_cache_dir, url_info["repo"])
move_to_new_cache(
file=os.path.join(cache_dir, file_info["file"]),
repo=repo,
filename=url_info["filename"],
revision=url_info["revision"],
etag=etag,
commit_hash=commit_hash,
)
class PushInProgress:
"""
Internal class to keep track of a push in progress (which might contain multiple `Future` jobs).
"""
def __init__(self, jobs: Optional[futures.Future] = None) -> None:
self.jobs = [] if jobs is None else jobs
def is_done(self):
return all(job.done() for job in self.jobs)
def wait_until_done(self):
futures.wait(self.jobs)
def cancel(self) -> None:
self.jobs = [
job
for job in self.jobs
# Cancel the job if it wasn't started yet and remove cancelled/done jobs from the list
if not (job.cancel() or job.done())
]
cache_version_file = os.path.join(TRANSFORMERS_CACHE, "version.txt")
if not os.path.isfile(cache_version_file):
cache_version = 0
else:
with open(cache_version_file) as f:
try:
cache_version = int(f.read())
except ValueError:
cache_version = 0
cache_is_not_empty = os.path.isdir(TRANSFORMERS_CACHE) and len(os.listdir(TRANSFORMERS_CACHE)) > 0
if cache_version < 1 and cache_is_not_empty:
if is_offline_mode():
logger.warning(
"You are offline and the cache for model files in Transformers v4.22.0 has been updated while your local "
"cache seems to be the one of a previous version. It is very likely that all your calls to any "
"`from_pretrained()` method will fail. Remove the offline mode and enable internet connection to have "
"your cache be updated automatically, then you can go back to offline mode."
)
else:
logger.warning(
"The cache for model files in Transformers v4.22.0 has been updated. Migrating your old cache. This is a "
"one-time only operation. You can interrupt this and resume the migration later on by calling "
"`transformers.utils.move_cache()`."
)
try:
if TRANSFORMERS_CACHE != constants.HF_HUB_CACHE:
# Users set some env variable to customize cache storage
move_cache(TRANSFORMERS_CACHE, TRANSFORMERS_CACHE)
else:
move_cache()
except Exception as e:
trace = "\n".join(traceback.format_tb(e.__traceback__))
logger.error(
f"There was a problem when trying to move your cache:\n\n{trace}\n{e.__class__.__name__}: {e}\n\nPlease "
"file an issue at https://github.com/huggingface/transformers/issues/new/choose and copy paste this whole "
"message and we will do our best to help."
)
if cache_version < 1:
try:
os.makedirs(TRANSFORMERS_CACHE, exist_ok=True)
with open(cache_version_file, "w") as f:
f.write("1")
except Exception:
logger.warning(
f"There was a problem when trying to write in your cache folder ({TRANSFORMERS_CACHE}). You should set "
"the environment variable TRANSFORMERS_CACHE to a writable directory."
)
| transformers/src/transformers/utils/hub.py/0 | {
"file_path": "transformers/src/transformers/utils/hub.py",
"repo_id": "transformers",
"token_count": 23530
} |
**TEMPLATE**
=====================================
*search & replace the following keywords, e.g.:*
`:%s/\[name of model\]/brand_new_bert/g`
-[lowercase name of model] # e.g. brand_new_bert
-[camelcase name of model] # e.g. BrandNewBert
-[name of mentor] # e.g. [Peter](https://github.com/peter)
-[link to original repo]
-[start date]
-[end date]
How to add [camelcase name of model] to 🤗 Transformers?
=====================================
Mentor: [name of mentor]
Begin: [start date]
Estimated End: [end date]
Adding a new model is often difficult and requires an in-depth knowledge
of the 🤗 Transformers library and ideally also of the model's original
repository. At Hugging Face, we are trying to empower the community more
and more to add models independently.
The following sections explain in detail how to add [camelcase name of model]
to Transformers. You will work closely with [name of mentor] to
integrate [camelcase name of model] into Transformers. By doing so, you will both gain a
theoretical and deep practical understanding of [camelcase name of model].
But more importantly, you will have made a major
open-source contribution to Transformers. Along the way, you will:
- get insights into open-source best practices
- understand the design principles of one of the most popular NLP
libraries
- learn how to do efficiently test large NLP models
- learn how to integrate Python utilities like `black`, `ruff`,
`make fix-copies` into a library to always ensure clean and readable
code
To start, let's try to get a general overview of the Transformers
library.
General overview of 🤗 Transformers
----------------------------------
First, you should get a general overview of 🤗 Transformers. Transformers
is a very opinionated library, so there is a chance that
you don't agree with some of the library's philosophies or design
choices. From our experience, however, we found that the fundamental
design choices and philosophies of the library are crucial to
efficiently scale Transformers while keeping maintenance costs at a
reasonable level.
A good first starting point to better understand the library is to read
the [documentation of our philosophy](https://huggingface.co/transformers/philosophy.html).
As a result of our way of working, there are some choices that we try to apply to all models:
- Composition is generally favored over abstraction
- Duplicating code is not always bad if it strongly improves the
readability or accessibility of a model
- Model files are as self-contained as possible so that when you read
the code of a specific model, you ideally only have to look into the
respective `modeling_....py` file.
In our opinion, the library's code is not just a means to provide a
product, *e.g.*, the ability to use BERT for inference, but also as the
very product that we want to improve. Hence, when adding a model, the
user is not only the person that will use your model, but also everybody
that will read, try to understand, and possibly tweak your code.
With this in mind, let's go a bit deeper into the general library
design.
### Overview of models
To successfully add a model, it is important to understand the
interaction between your model and its config,
`PreTrainedModel`, and `PretrainedConfig`. For
exemplary purposes, we will call the PyTorch model to be added to 🤗 Transformers
`BrandNewBert`.
Let's take a look:
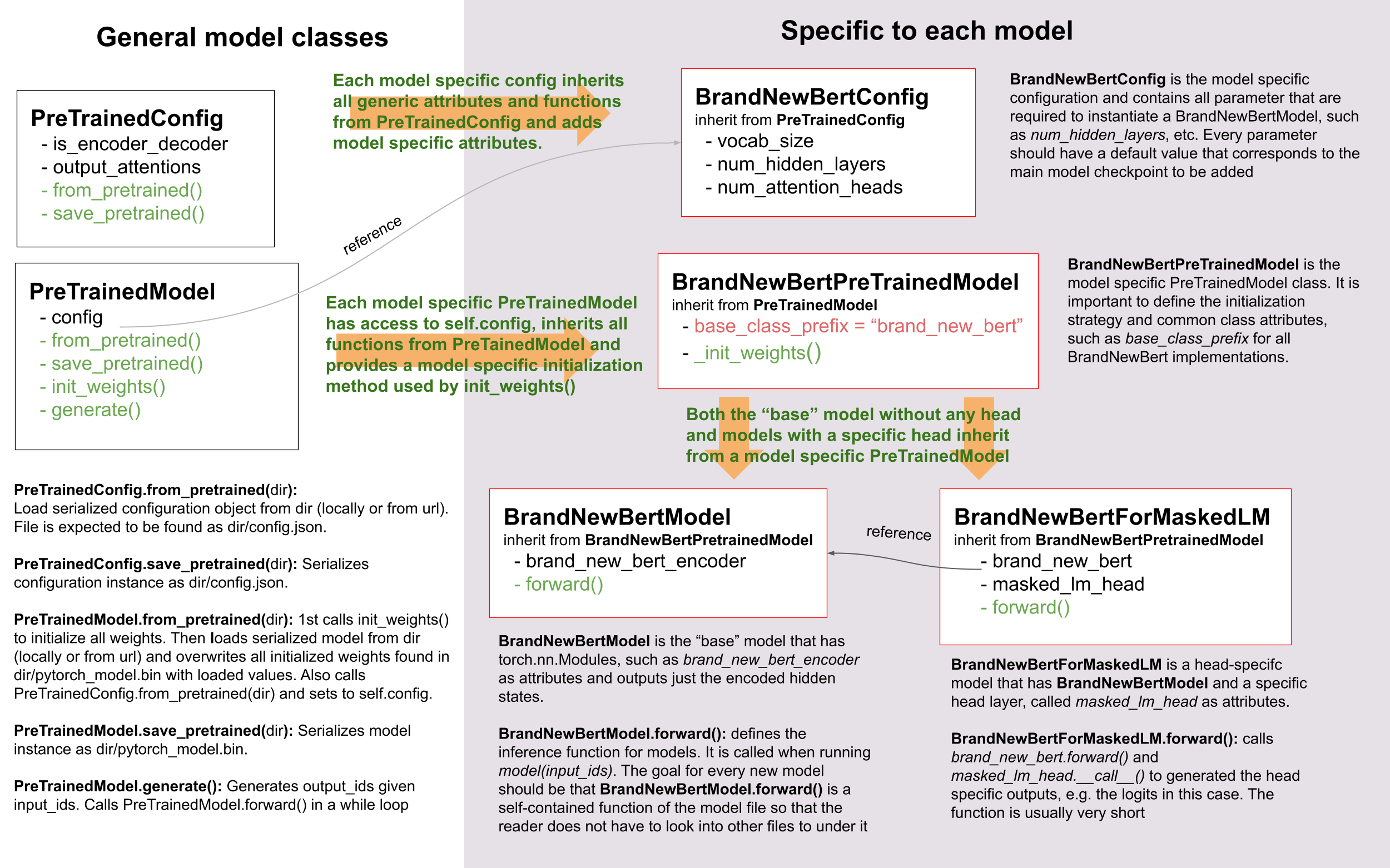
As you can see, we do make use of inheritance in 🤗 Transformers, but we
keep the level of abstraction to an absolute minimum. There are never
more than two levels of abstraction for any model in the library.
`BrandNewBertModel` inherits from
`BrandNewBertPreTrainedModel` which in
turn inherits from `PreTrainedModel` and that's it.
As a general rule, we want to make sure
that a new model only depends on `PreTrainedModel`. The
important functionalities that are automatically provided to every new
model are
`PreTrainedModel.from_pretrained` and `PreTrainedModel.save_pretrained`, which are
used for serialization and deserialization. All
of the other important functionalities, such as
`BrandNewBertModel.forward` should be
completely defined in the new `modeling_brand_new_bert.py` module. Next,
we want to make sure that a model with a specific head layer, such as
`BrandNewBertForMaskedLM` does not inherit
from `BrandNewBertModel`, but rather uses
`BrandNewBertModel` as a component that
can be called in its forward pass to keep the level of abstraction low.
Every new model requires a configuration class, called
`BrandNewBertConfig`. This configuration
is always stored as an attribute in
`PreTrainedModel`, and
thus can be accessed via the `config` attribute for all classes
inheriting from `BrandNewBertPreTrainedModel`
```python
# assuming that `brand_new_bert` belongs to the organization `brandy`
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # model has access to its config
```
Similar to the model, the configuration inherits basic serialization and
deserialization functionalities from
`PretrainedConfig`. Note
that the configuration and the model are always serialized into two
different formats - the model to a `pytorch_model.bin` file
and the configuration to a `config.json` file. Calling
`PreTrainedModel.save_pretrained` will automatically call
`PretrainedConfig.save_pretrained`, so that both model and configuration are saved.
### Overview of tokenizers
Not quite ready yet :-( This section will be added soon!
Step-by-step recipe to add a model to 🤗 Transformers
----------------------------------------------------
Everyone has different preferences of how to port a model so it can be
very helpful for you to take a look at summaries of how other
contributors ported models to Hugging Face. Here is a list of community
blog posts on how to port a model:
1. [Porting GPT2
Model](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28)
by [Thomas](https://huggingface.co/thomwolf)
2. [Porting WMT19 MT Model](https://huggingface.co/blog/porting-fsmt)
by [Stas](https://huggingface.co/stas)
From experience, we can tell you that the most important things to keep
in mind when adding a model are:
- Don't reinvent the wheel! Most parts of the code you will add for
the new 🤗 Transformers model already exist somewhere in 🤗
Transformers. Take some time to find similar, already existing
models and tokenizers you can copy from.
[grep](https://www.gnu.org/software/grep/) and
[rg](https://github.com/BurntSushi/ripgrep) are your friends. Note
that it might very well happen that your model's tokenizer is based
on one model implementation, and your model's modeling code on
another one. *E.g.*, FSMT's modeling code is based on BART, while
FSMT's tokenizer code is based on XLM.
- It's more of an engineering challenge than a scientific challenge.
You should spend more time on creating an efficient debugging
environment than trying to understand all theoretical aspects of the
model in the paper.
- Ask for help when you're stuck! Models are the core component of 🤗
Transformers so we, at Hugging Face, are more than happy to help
you at every step to add your model. Don't hesitate to ask if you
notice you are not making progress.
In the following, we try to give you a general recipe that we found most
useful when porting a model to 🤗 Transformers.
The following list is a summary of everything that has to be done to add
a model and can be used by you as a To-Do List:
1. [ ] (Optional) Understood theoretical aspects
2. [ ] Prepared transformers dev environment
3. [ ] Set up debugging environment of the original repository
4. [ ] Created script that successfully runs forward pass using
original repository and checkpoint
5. [ ] Successfully opened a PR and added the model skeleton to Transformers
6. [ ] Successfully converted original checkpoint to Transformers
checkpoint
7. [ ] Successfully ran forward pass in Transformers that gives
identical output to original checkpoint
8. [ ] Finished model tests in Transformers
9. [ ] Successfully added Tokenizer in Transformers
10. [ ] Run end-to-end integration tests
11. [ ] Finished docs
12. [ ] Uploaded model weights to the hub
13. [ ] Submitted the pull request for review
14. [ ] (Optional) Added a demo notebook
To begin with, we usually recommend to start by getting a good
theoretical understanding of `[camelcase name of model]`. However, if you prefer to
understand the theoretical aspects of the model *on-the-job*, then it is
totally fine to directly dive into the `[camelcase name of model]`'s code-base. This
option might suit you better, if your engineering skills are better than
your theoretical skill, if you have trouble understanding
`[camelcase name of model]`'s paper, or if you just enjoy programming much more than
reading scientific papers.
### 1. (Optional) Theoretical aspects of [camelcase name of model]
You should take some time to read *[camelcase name of model]'s* paper, if such
descriptive work exists. There might be large sections of the paper that
are difficult to understand. If this is the case, this is fine - don't
worry! The goal is not to get a deep theoretical understanding of the
paper, but to extract the necessary information required to effectively
re-implement the model in 🤗 Transformers. That being said, you don't
have to spend too much time on the theoretical aspects, but rather focus
on the practical ones, namely:
- What type of model is *[camelcase name of model]*? BERT-like encoder-only
model? GPT2-like decoder-only model? BART-like encoder-decoder
model? Look at the `model_summary` if
you're not familiar with the differences between those.
- What are the applications of *[camelcase name of model]*? Text
classification? Text generation? Seq2Seq tasks, *e.g.,*
summarization?
- What is the novel feature of the model making it different from
BERT/GPT-2/BART?
- Which of the already existing [🤗 Transformers
models](https://huggingface.co/transformers/#contents) is most
similar to *[camelcase name of model]*?
- What type of tokenizer is used? A sentencepiece tokenizer? Word
piece tokenizer? Is it the same tokenizer as used for BERT or BART?
After you feel like you have gotten a good overview of the architecture
of the model, you might want to write to [name of mentor] with any
questions you might have. This might include questions regarding the
model's architecture, its attention layer, etc. We will be more than
happy to help you.
#### Additional resources
Before diving into the code, here are some additional resources that might be worth taking a look at:
- [link 1]
- [link 2]
- [link 3]
- ...
#### Make sure you've understood the fundamental aspects of [camelcase name of model]
Alright, now you should be ready to take a closer look into the actual code of [camelcase name of model].
You should have understood the following aspects of [camelcase name of model] by now:
- [characteristic 1 of [camelcase name of model]]
- [characteristic 2 of [camelcase name of model]]
- ...
If any of the mentioned aspects above are **not** clear to you, now is a great time to talk to [name of mentor].
### 2. Next prepare your environment
1. Fork the [repository](https://github.com/huggingface/transformers)
by clicking on the 'Fork' button on the repository's page. This
creates a copy of the code under your GitHub user account.
2. Clone your `transformers` fork to your local disk, and add the base
repository as a remote:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Set up a development environment, for instance by running the
following command:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
and return to the parent directory
```bash
cd ..
```
4. We recommend adding the PyTorch version of *[camelcase name of model]* to
Transformers. To install PyTorch, please follow the instructions [here](https://pytorch.org/get-started/locally/).
**Note:** You don't need to have CUDA installed. Making the new model
work on CPU is sufficient.
5. To port *[camelcase name of model]*, you will also need access to its
original repository:
```bash
git clone [link to original repo].git
cd [lowercase name of model]
pip install -e .
```
Now you have set up a development environment to port *[camelcase name of model]*
to 🤗 Transformers.
### Run a pretrained checkpoint using the original repository
**3. Set up debugging environment**
At first, you will work on the original *[camelcase name of model]* repository.
Often, the original implementation is very "researchy". Meaning that
documentation might be lacking and the code can be difficult to
understand. But this should be exactly your motivation to reimplement
*[camelcase name of model]*. At Hugging Face, one of our main goals is to *make
people stand on the shoulders of giants* which translates here very well
into taking a working model and rewriting it to make it as **accessible,
user-friendly, and beautiful** as possible. This is the number-one
motivation to re-implement models into 🤗 Transformers - trying to make
complex new NLP technology accessible to **everybody**.
You should start thereby by diving into the [original repository]([link to original repo]).
Successfully running the official pretrained model in the original
repository is often **the most difficult** step. From our experience, it
is very important to spend some time getting familiar with the original
code-base. You need to figure out the following:
- Where to find the pretrained weights?
- How to load the pretrained weights into the corresponding model?
- How to run the tokenizer independently from the model?
- Trace one forward pass so that you know which classes and functions
are required for a simple forward pass. Usually, you only have to
reimplement those functions.
- Be able to locate the important components of the model: Where is
the model's class? Are there model sub-classes, *e.g.*,
EncoderModel, DecoderModel? Where is the self-attention layer? Are
there multiple different attention layers, *e.g.*, *self-attention*,
*cross-attention*...?
- How can you debug the model in the original environment of the repo?
Do you have to add `print` statements, can you work with
an interactive debugger like [ipdb](https://pypi.org/project/ipdb/), or should you use
an efficient IDE to debug the model, like PyCharm?
It is very important that before you start the porting process, that you
can **efficiently** debug code in the original repository! Also,
remember that you are working with an open-source library, so do not
hesitate to open an issue, or even a pull request in the original
repository. The maintainers of this repository are most likely very
happy about someone looking into their code!
At this point, it is really up to you which debugging environment and
strategy you prefer to use to debug the original model. We strongly
advise against setting up a costly GPU environment, but simply work on a
CPU both when starting to dive into the original repository and also
when starting to write the 🤗 Transformers implementation of the model.
Only at the very end, when the model has already been successfully
ported to 🤗 Transformers, one should verify that the model also works as
expected on GPU.
In general, there are two possible debugging environments for running
the original model
- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
- Local python scripts.
Jupyter notebooks have the advantage that they allow for cell-by-cell
execution which can be helpful to better split logical components from
one another and to have faster debugging cycles as intermediate results
can be stored. Also, notebooks are often easier to share with other
contributors, which might be very helpful if you want to ask the Hugging
Face team for help. If you are familiar with Jupyter notebooks, we
strongly recommend you to work with them.
The obvious disadvantage of Jupyter notebooks is that if you are not
used to working with them you will have to spend some time adjusting to
the new programming environment and that you might not be able to use
your known debugging tools anymore, like `ipdb`.
**4. Successfully run forward pass**
For each code-base, a good first step is always to load a **small**
pretrained checkpoint and to be able to reproduce a single forward pass
using a dummy integer vector of input IDs as an input. Such a script
could look like this (in pseudocode):
```python
model = [camelcase name of model]Model.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
original_output = model.predict(input_ids)
```
Next, regarding the debugging strategy, there are generally a few from
which to choose from:
- Decompose the original model into many small testable components and
run a forward pass on each of those for verification
- Decompose the original model only into the original *tokenizer* and
the original *model*, run a forward pass on those, and use
intermediate print statements or breakpoints for verification
Again, it is up to you which strategy to choose. Often, one or the other
is advantageous depending on the original code base.
If the original code-base allows you to decompose the model into smaller
sub-components, *e.g.*, if the original code-base can easily be run in
eager mode, it is usually worth the effort to do so. There are some
important advantages to taking the more difficult road in the beginning:
- at a later stage when comparing the original model to the Hugging
Face implementation, you can verify automatically for each component
individually that the corresponding component of the 🤗 Transformers
implementation matches instead of relying on visual comparison via
print statements
- it can give you some rope to decompose the big problem of porting a
model into smaller problems of just porting individual components
and thus structure your work better
- separating the model into logical meaningful components will help
you to get a better overview of the model's design and thus to
better understand the model
- at a later stage those component-by-component tests help you to
ensure that no regression occurs as you continue changing your code
[Lysandre's](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed)
integration checks for ELECTRA gives a nice example of how this can be
done.
However, if the original code-base is very complex or only allows
intermediate components to be run in a compiled mode, it might be too
time-consuming or even impossible to separate the model into smaller
testable sub-components. A good example is [T5's
MeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow)
library which is very complex and does not offer a simple way to
decompose the model into its sub-components. For such libraries, one
often relies on verifying print statements.
No matter which strategy you choose, the recommended procedure is often
the same in that you should start to debug the starting layers first and
the ending layers last.
It is recommended that you retrieve the output, either by print
statements or sub-component functions, of the following layers in the
following order:
1. Retrieve the input IDs passed to the model
2. Retrieve the word embeddings
3. Retrieve the input of the first Transformer layer
4. Retrieve the output of the first Transformer layer
5. Retrieve the output of the following n - 1 Transformer layers
6. Retrieve the output of the whole [camelcase name of model] Model
Input IDs should thereby consists of an array of integers, *e.g.*,
`input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
The outputs of the following layers often consist of multi-dimensional
float arrays and can look like this:
```bash
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
```
We expect that every model added to 🤗 Transformers passes a couple of
integration tests, meaning that the original model and the reimplemented
version in 🤗 Transformers have to give the exact same output up to a
precision of 0.001! Since it is normal that the exact same model written
in different libraries can give a slightly different output depending on
the library framework, we accept an error tolerance of 1e-3 (0.001). It
is not enough if the model gives nearly the same output, they have to be
the almost identical. Therefore, you will certainly compare the
intermediate outputs of the 🤗 Transformers version multiple times
against the intermediate outputs of the original implementation of
*[camelcase name of model]* in which case an **efficient** debugging environment
of the original repository is absolutely important. Here is some advice
to make your debugging environment as efficient as possible.
- Find the best way of debugging intermediate results. Is the original
repository written in PyTorch? Then you should probably take the
time to write a longer script that decomposes the original model
into smaller sub-components to retrieve intermediate values. Is the
original repository written in Tensorflow 1? Then you might have to
rely on TensorFlow print operations like
[tf.print](https://www.tensorflow.org/api_docs/python/tf/print) to
output intermediate values. Is the original repository written in
Jax? Then make sure that the model is **not jitted** when running
the forward pass, *e.g.*, check-out [this
link](https://github.com/google/jax/issues/196).
- Use the smallest pretrained checkpoint you can find. The smaller the
checkpoint, the faster your debug cycle becomes. It is not efficient
if your pretrained model is so big that your forward pass takes more
than 10 seconds. In case only very large checkpoints are available,
it might make more sense to create a dummy model in the new
environment with randomly initialized weights and save those weights
for comparison with the 🤗 Transformers version of your model
- Make sure you are using the easiest way of calling a forward pass in
the original repository. Ideally, you want to find the function in
the original repository that **only** calls a single forward pass,
*i.e.* that is often called `predict`, `evaluate`, `forward` or
`__call__`. You don't want to debug a function that calls `forward`
multiple times, *e.g.*, to generate text, like
`autoregressive_sample`, `generate`.
- Try to separate the tokenization from the model's
forward pass. If the original repository shows
examples where you have to input a string, then try to find out
where in the forward call the string input is changed to input ids
and start from this point. This might mean that you have to possibly
write a small script yourself or change the original code so that
you can directly input the ids instead of an input string.
- Make sure that the model in your debugging setup is **not** in
training mode, which often causes the model to yield random outputs
due to multiple dropout layers in the model. Make sure that the
forward pass in your debugging environment is **deterministic** so
that the dropout layers are not used. Or use
`transformers.utils.set_seed` if the old and new
implementations are in the same framework.
#### More details on how to create a debugging environment for [camelcase name of model]
[TODO FILL: Here the mentor should add very specific information on what the student should do]
[to set up an efficient environment for the special requirements of this model]
### Port [camelcase name of model] to 🤗 Transformers
Next, you can finally start adding new code to 🤗 Transformers. Go into
the clone of your 🤗 Transformers' fork:
cd transformers
In the special case that you are adding a model whose architecture
exactly matches the model architecture of an existing model you only
have to add a conversion script as described in [this
section](#write-a-conversion-script). In this case, you can just re-use
the whole model architecture of the already existing model.
Otherwise, let's start generating a new model with the amazing
Cookiecutter!
**Use the Cookiecutter to automatically generate the model's code**
To begin with head over to the [🤗 Transformers
templates](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)
to make use of our `cookiecutter` implementation to automatically
generate all the relevant files for your model. Again, we recommend only
adding the PyTorch version of the model at first. Make sure you follow
the instructions of the `README.md` on the [🤗 Transformers
templates](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)
carefully.
**Open a Pull Request on the main huggingface/transformers repo**
Before starting to adapt the automatically generated code, now is the
time to open a "Work in progress (WIP)" pull request, *e.g.*, "\[WIP\]
Add *[camelcase name of model]*", in 🤗 Transformers so that you and the Hugging
Face team can work side-by-side on integrating the model into 🤗
Transformers.
You should do the following:
1. Create a branch with a descriptive name from your main branch
```bash
git checkout -b add_[lowercase name of model]
```
2. Commit the automatically generated code:
```bash
git add .
git commit
```
3. Fetch and rebase to current main
```bash
git fetch upstream
git rebase upstream/main
```
4. Push the changes to your account using:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
5. Once you are satisfied, go to the webpage of your fork on GitHub.
Click on "Pull request". Make sure to add the GitHub handle of
[name of mentor] as a reviewer, so that the Hugging
Face team gets notified for future changes.
6. Change the PR into a draft by clicking on "Convert to draft" on the
right of the GitHub pull request web page.
In the following, whenever you have done some progress, don't forget to
commit your work and push it to your account so that it shows in the
pull request. Additionally, you should make sure to update your work
with the current main from time to time by doing:
git fetch upstream
git merge upstream/main
In general, all questions you might have regarding the model or your
implementation should be asked in your PR and discussed/solved in the
PR. This way, [name of mentor] will always be notified when you are
committing new code or if you have a question. It is often very helpful
to point [name of mentor] to your added code so that the Hugging
Face team can efficiently understand your problem or question.
To do so, you can go to the "Files changed" tab where you see all of
your changes, go to a line regarding which you want to ask a question,
and click on the "+" symbol to add a comment. Whenever a question or
problem has been solved, you can click on the "Resolve" button of the
created comment.
In the same way, [name of mentor] will open comments when reviewing
your code. We recommend asking most questions on GitHub on your PR. For
some very general questions that are not very useful for the public,
feel free to ping [name of mentor] by Slack or email.
**5. Adapt the generated models code for [camelcase name of model]**
At first, we will focus only on the model itself and not care about the
tokenizer. All the relevant code should be found in the generated files
`src/transformers/models/[lowercase name of model]/modeling_[lowercase name of model].py` and
`src/transformers/models/[lowercase name of model]/configuration_[lowercase name of model].py`.
Now you can finally start coding :). The generated code in
`src/transformers/models/[lowercase name of model]/modeling_[lowercase name of model].py` will
either have the same architecture as BERT if it's an encoder-only model
or BART if it's an encoder-decoder model. At this point, you should
remind yourself what you've learned in the beginning about the
theoretical aspects of the model: *How is the model different from BERT
or BART?*\". Implement those changes which often means to change the
*self-attention* layer, the order of the normalization layer, etc...
Again, it is often useful to look at the similar architecture of already
existing models in Transformers to get a better feeling of how your
model should be implemented.
**Note** that at this point, you don't have to be very sure that your
code is fully correct or clean. Rather, it is advised to add a first
*unclean*, copy-pasted version of the original code to
`src/transformers/models/[lowercase name of model]/modeling_[lowercase name of model].py`
until you feel like all the necessary code is added. From our
experience, it is much more efficient to quickly add a first version of
the required code and improve/correct the code iteratively with the
conversion script as described in the next section. The only thing that
has to work at this point is that you can instantiate the 🤗 Transformers
implementation of *[camelcase name of model]*, *i.e.* the following command
should work:
```python
from transformers import [camelcase name of model]Model, [camelcase name of model]Config
model = [camelcase name of model]Model([camelcase name of model]Config())
```
The above command will create a model according to the default
parameters as defined in `[camelcase name of model]Config()` with random weights,
thus making sure that the `init()` methods of all components works.
[TODO FILL: Here the mentor should add very specific information on what exactly has to be changed for this model]
[...]
[...]
**6. Write a conversion script**
Next, you should write a conversion script that lets you convert the
checkpoint you used to debug *[camelcase name of model]* in the original
repository to a checkpoint compatible with your just created 🤗
Transformers implementation of *[camelcase name of model]*. It is not advised to
write the conversion script from scratch, but rather to look through
already existing conversion scripts in 🤗 Transformers for one that has
been used to convert a similar model that was written in the same
framework as *[camelcase name of model]*. Usually, it is enough to copy an
already existing conversion script and slightly adapt it for your use
case. Don't hesitate to ask [name of mentor] to point you to a
similar already existing conversion script for your model.
- If you are porting a model from TensorFlow to PyTorch, a good
starting point might be BERT's conversion script
[here](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
- If you are porting a model from PyTorch to PyTorch, a good starting
point might be BART's conversion script
[here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)
In the following, we'll quickly explain how PyTorch models store layer
weights and define layer names. In PyTorch, the name of a layer is
defined by the name of the class attribute you give the layer. Let's
define a dummy model in PyTorch, called `SimpleModel` as follows:
```python
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
```
Now we can create an instance of this model definition which will fill
all weights: `dense`, `intermediate`, `layer_norm` with random weights.
We can print the model to see its architecture
```python
model = SimpleModel()
print(model)
```
This will print out the following:
```bash
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
```
We can see that the layer names are defined by the name of the class
attribute in PyTorch. You can print out the weight values of a specific
layer:
```python
print(model.dense.weight.data)
```
to see that the weights were randomly initialized
```bash
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
```
In the conversion script, you should fill those randomly initialized
weights with the exact weights of the corresponding layer in the
checkpoint. *E.g.*,
```python
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
```
While doing so, you must verify that each randomly initialized weight of
your PyTorch model and its corresponding pretrained checkpoint weight
exactly match in both **shape and name**. To do so, it is **necessary**
to add assert statements for the shape and print out the names of the
checkpoints weights. *E.g.*, you should add statements like:
```python
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
```
Besides, you should also print out the names of both weights to make
sure they match, *e.g.*,
```python
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
```
If either the shape or the name doesn't match, you probably assigned
the wrong checkpoint weight to a randomly initialized layer of the 🤗
Transformers implementation.
An incorrect shape is most likely due to an incorrect setting of the
config parameters in `[camelcase name of model]Config()` that do not exactly match
those that were used for the checkpoint you want to convert. However, it
could also be that PyTorch's implementation of a layer requires the
weight to be transposed beforehand.
Finally, you should also check that **all** required weights are
initialized and print out all checkpoint weights that were not used for
initialization to make sure the model is correctly converted. It is
completely normal, that the conversion trials fail with either a wrong
shape statement or wrong name assignment. This is most likely because
either you used incorrect parameters in `[camelcase name of model]Config()`, have a
wrong architecture in the 🤗 Transformers implementation, you have a bug
in the `init()` functions of one of the components of the 🤗 Transformers
implementation or you need to transpose one of the checkpoint weights.
This step should be iterated with the previous step until all weights of
the checkpoint are correctly loaded in the Transformers model. Having
correctly loaded the checkpoint into the 🤗 Transformers implementation,
you can then save the model under a folder of your choice
`/path/to/converted/checkpoint/folder` that should then contain both a
`pytorch_model.bin` file and a `config.json` file:
```python
model.save_pretrained("/path/to/converted/checkpoint/folder")
```
[TODO FILL: Here the mentor should add very specific information on what exactly has to be done for the conversion of this model]
[...]
[...]
**7. Implement the forward pass**
Having managed to correctly load the pretrained weights into the 🤗
Transformers implementation, you should now make sure that the forward
pass is correctly implemented. In [Get familiar with the original
repository](#34-run-a-pretrained-checkpoint-using-the-original-repository),
you have already created a script that runs a forward pass of the model
using the original repository. Now you should write an analogous script
using the 🤗 Transformers implementation instead of the original one. It
should look as follows:
[TODO FILL: Here the model name might have to be adapted, *e.g.*, maybe [camelcase name of model]ForConditionalGeneration instead of [camelcase name of model]Model]
```python
model = [camelcase name of model]Model.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
```
It is very likely that the 🤗 Transformers implementation and the
original model implementation don't give the exact same output the very
first time or that the forward pass throws an error. Don't be
disappointed - it's expected! First, you should make sure that the
forward pass doesn't throw any errors. It often happens that the wrong
dimensions are used leading to a `"Dimensionality mismatch"`
error or that the wrong data type object is used, *e.g.*, `torch.long`
instead of `torch.float32`. Don't hesitate to ask [name of mentor]
for help, if you don't manage to solve certain errors.
The final part to make sure the 🤗 Transformers implementation works
correctly is to ensure that the outputs are equivalent to a precision of
`1e-3`. First, you should ensure that the output shapes are identical,
*i.e.* `outputs.shape` should yield the same value for the script of the
🤗 Transformers implementation and the original implementation. Next, you
should make sure that the output values are identical as well. This one
of the most difficult parts of adding a new model. Common mistakes why
the outputs are not identical are:
- Some layers were not added, *i.e.* an activation layer
was not added, or the residual connection was forgotten
- The word embedding matrix was not tied
- The wrong positional embeddings are used because the original
implementation uses on offset
- Dropout is applied during the forward pass. To fix this make sure
`model.training is False` and that no dropout layer is
falsely activated during the forward pass, *i.e.* pass
`self.training` to [PyTorch's functional
dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
The best way to fix the problem is usually to look at the forward pass
of the original implementation and the 🤗 Transformers implementation
side-by-side and check if there are any differences. Ideally, you should
debug/print out intermediate outputs of both implementations of the
forward pass to find the exact position in the network where the 🤗
Transformers implementation shows a different output than the original
implementation. First, make sure that the hard-coded `input_ids` in both
scripts are identical. Next, verify that the outputs of the first
transformation of the `input_ids` (usually the word embeddings) are
identical. And then work your way up to the very last layer of the
network. At some point, you will notice a difference between the two
implementations, which should point you to the bug in the 🤗 Transformers
implementation. From our experience, a simple and efficient way is to
add many print statements in both the original implementation and 🤗
Transformers implementation, at the same positions in the network
respectively, and to successively remove print statements showing the
same values for intermediate presentions.
When you're confident that both implementations yield the same output,
verifying the outputs with
`torch.allclose(original_output, output, atol=1e-3)`, you're done with
the most difficult part! Congratulations - the work left to be done
should be a cakewalk 😊.
**8. Adding all necessary model tests**
At this point, you have successfully added a new model. However, it is
very much possible that the model does not yet fully comply with the
required design. To make sure, the implementation is fully compatible
with 🤗 Transformers, all common tests should pass. The Cookiecutter
should have automatically added a test file for your model, probably
under the same `tests/test_modeling_[lowercase name of model].py`. Run this test
file to verify that all common tests pass:
```python
pytest tests/test_modeling_[lowercase name of model].py
```
[TODO FILL: Here the mentor should add very specific information on what tests are likely to fail after having implemented the model
, e.g. given the model, it might be very likely that `test_attention_output` fails]
[...]
[...]
Having fixed all common tests, it is now crucial to ensure that all the
nice work you have done is well tested, so that
- a) The community can easily understand your work by looking at
specific tests of *[camelcase name of model]*
- b) Future changes to your model will not break any important
feature of the model.
At first, integration tests should be added. Those integration tests
essentially do the same as the debugging scripts you used earlier to
implement the model to 🤗 Transformers. A template of those model tests
is already added by the Cookiecutter, called
`[camelcase name of model]ModelIntegrationTests` and only has to be filled out by
you. To ensure that those tests are passing, run
```python
RUN_SLOW=1 pytest -sv tests/test_modeling_[lowercase name of model].py::[camelcase name of model]ModelIntegrationTests
```
**Note:** In case you are using Windows, you should replace `RUN_SLOW=1` with `SET RUN_SLOW=1`
Second, all features that are special to *[camelcase name of model]* should be
tested additionally in a separate test under
`[camelcase name of model]ModelTester`/`[camelcase name of model]ModelTest`. This part is often
forgotten but is extremely useful in two ways:
- It helps to transfer the knowledge you have acquired during the
model addition to the community by showing how the special features
of *[camelcase name of model]* should work.
- Future contributors can quickly test changes to the model by running
those special tests.
[TODO FILL: Here the mentor should add very specific information on what special features of the model should be tested additionally]
[...]
[...]
**9. Implement the tokenizer**
Next, we should add the tokenizer of *[camelcase name of model]*. Usually, the
tokenizer is equivalent or very similar to an already existing tokenizer
of 🤗 Transformers.
[TODO FILL: Here the mentor should add a comment whether a new tokenizer is required or if this is not the case which existing tokenizer closest resembles
[camelcase name of model]'s tokenizer and how the tokenizer should be implemented]
[...]
[...]
It is very important to find/extract the original tokenizer file and to
manage to load this file into the 🤗 Transformers' implementation of the
tokenizer.
For [camelcase name of model], the tokenizer files can be found here:
- [To be filled out by mentor]
and having implemented the 🤗 Transformers' version of the tokenizer can be loaded as follows:
[To be filled out by mentor]
To ensure that the tokenizer works correctly, it is recommended to first
create a script in the original repository that inputs a string and
returns the `input_ids`. It could look similar to this (in pseudo-code):
```bash
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = [camelcase name of model]Model.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
```
You might have to take a deeper look again into the original repository
to find the correct tokenizer function or you might even have to do
changes to your clone of the original repository to only output the
`input_ids`. Having written a functional tokenization script that uses
the original repository, an analogous script for 🤗 Transformers should
be created. It should look similar to this:
```python
from transformers import [camelcase name of model]Tokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = [camelcase name of model]Tokenizer.from_pretrained("/path/to/tokenizer/folder/")
input_ids = tokenizer(input_str).input_ids
```
When both `input_ids` yield the same values, as a final step a tokenizer
test file should also be added.
[TODO FILL: Here mentor should point the student to test files of similar tokenizers]
Analogous to the modeling test files of *[camelcase name of model]*, the
tokenization test files of *[camelcase name of model]* should contain a couple of
hard-coded integration tests.
[TODO FILL: Here mentor should again point to an existing similar test of another model that the student can copy & adapt]
**10. Run End-to-end integration tests**
Having added the tokenizer, you should also add a couple of end-to-end
integration tests using both the model and the tokenizer to
`tests/test_modeling_[lowercase name of model].py` in 🤗 Transformers. Such a test
should show on a meaningful text-to-text sample that the 🤗 Transformers
implementation works as expected. A meaningful text-to-text sample can
include *e.g.* a source-to-target-translation pair, an
article-to-summary pair, a question-to-answer pair, etc... If none of
the ported checkpoints has been fine-tuned on a downstream task it is
enough to simply rely on the model tests. In a final step to ensure that
the model is fully functional, it is advised that you also run all tests
on GPU. It can happen that you forgot to add some `.to(self.device)`
statements to internal tensors of the model, which in such a test would
show in an error. In case you have no access to a GPU, the Hugging Face
team can take care of running those tests for you.
**11. Add Docstring**
Now, all the necessary functionality for *[camelcase name of model]* is added -
you're almost done! The only thing left to add is a nice docstring and
a doc page. The Cookiecutter should have added a template file called
`docs/source/model_doc/[lowercase name of model].rst` that you should fill out.
Users of your model will usually first look at this page before using
your model. Hence, the documentation must be understandable and concise.
It is very useful for the community to add some *Tips* to show how the
model should be used. Don't hesitate to ping [name of mentor]
regarding the docstrings.
Next, make sure that the docstring added to
`src/transformers/models/[lowercase name of model]/modeling_[lowercase name of model].py` is
correct and included all necessary inputs and outputs. It is always to
good to remind oneself that documentation should be treated at least as
carefully as the code in 🤗 Transformers since the documentation is
usually the first contact point of the community with the model.
**Code refactor**
Great, now you have added all the necessary code for *[camelcase name of model]*.
At this point, you should correct some potential incorrect code style by
running:
```bash
make style
```
and verify that your coding style passes the quality check:
```bash
make quality
```
There are a couple of other very strict design tests in 🤗 Transformers
that might still be failing, which shows up in the tests of your pull
request. This is often because of some missing information in the
docstring or some incorrect naming. [name of mentor] will surely
help you if you're stuck here.
Lastly, it is always a good idea to refactor one's code after having
ensured that the code works correctly. With all tests passing, now it's
a good time to go over the added code again and do some refactoring.
You have now finished the coding part, congratulation! 🎉 You are
Awesome! 😎
**12. Upload the models to the model hub**
In this final part, you should convert and upload all checkpoints to the
model hub and add a model card for each uploaded model checkpoint. You
should work alongside [name of mentor] here to decide on a fitting
name for each checkpoint and to get the required access rights to be
able to upload the model under the author's organization of
*[camelcase name of model]*.
It is worth spending some time to create fitting model cards for each
checkpoint. The model cards should highlight the specific
characteristics of this particular checkpoint, *e.g.*, On which dataset
was the checkpoint pretrained/fine-tuned on? On what down-stream task
should the model be used? And also include some code on how to correctly
use the model.
**13. (Optional) Add notebook**
It is very helpful to add a notebook that showcases in-detail how
*[camelcase name of model]* can be used for inference and/or fine-tuned on a
downstream task. This is not mandatory to merge your PR, but very useful
for the community.
**14. Submit your finished PR**
You're done programming now and can move to the last step, which is
getting your PR merged into main. Usually, [name of mentor]
should have helped you already at this point, but it is worth taking
some time to give your finished PR a nice description and eventually add
comments to your code, if you want to point out certain design choices
to your reviewer.
### Share your work!!
Now, it's time to get some credit from the community for your work!
Having completed a model addition is a major contribution to
Transformers and the whole NLP community. Your code and the ported
pre-trained models will certainly be used by hundreds and possibly even
thousands of developers and researchers. You should be proud of your
work and share your achievement with the community.
**You have made another model that is super easy to access for everyone
in the community! 🤯**
| transformers/templates/adding_a_new_model/ADD_NEW_MODEL_PROPOSAL_TEMPLATE.md/0 | {
"file_path": "transformers/templates/adding_a_new_model/ADD_NEW_MODEL_PROPOSAL_TEMPLATE.md",
"repo_id": "transformers",
"token_count": 14136
} |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from pathlib import Path
from typing import Dict, Union
import numpy as np
import pytest
from transformers import is_torch_available, is_vision_available
from transformers.agents.agent_types import AGENT_TYPE_MAPPING, AgentAudio, AgentImage, AgentText
from transformers.agents.tools import Tool, tool
from transformers.testing_utils import get_tests_dir, is_agent_test
if is_torch_available():
import torch
if is_vision_available():
from PIL import Image
AUTHORIZED_TYPES = ["string", "boolean", "integer", "number", "audio", "image", "any"]
def create_inputs(tool_inputs: Dict[str, Dict[Union[str, type], str]]):
inputs = {}
for input_name, input_desc in tool_inputs.items():
input_type = input_desc["type"]
if input_type == "string":
inputs[input_name] = "Text input"
elif input_type == "image":
inputs[input_name] = Image.open(
Path(get_tests_dir("fixtures/tests_samples/COCO")) / "000000039769.png"
).resize((512, 512))
elif input_type == "audio":
inputs[input_name] = np.ones(3000)
else:
raise ValueError(f"Invalid type requested: {input_type}")
return inputs
def output_type(output):
if isinstance(output, (str, AgentText)):
return "string"
elif isinstance(output, (Image.Image, AgentImage)):
return "image"
elif isinstance(output, (torch.Tensor, AgentAudio)):
return "audio"
else:
raise TypeError(f"Invalid output: {output}")
@is_agent_test
class ToolTesterMixin:
def test_inputs_output(self):
self.assertTrue(hasattr(self.tool, "inputs"))
self.assertTrue(hasattr(self.tool, "output_type"))
inputs = self.tool.inputs
self.assertTrue(isinstance(inputs, dict))
for _, input_spec in inputs.items():
self.assertTrue("type" in input_spec)
self.assertTrue("description" in input_spec)
self.assertTrue(input_spec["type"] in AUTHORIZED_TYPES)
self.assertTrue(isinstance(input_spec["description"], str))
output_type = self.tool.output_type
self.assertTrue(output_type in AUTHORIZED_TYPES)
def test_common_attributes(self):
self.assertTrue(hasattr(self.tool, "description"))
self.assertTrue(hasattr(self.tool, "name"))
self.assertTrue(hasattr(self.tool, "inputs"))
self.assertTrue(hasattr(self.tool, "output_type"))
def test_agent_type_output(self):
inputs = create_inputs(self.tool.inputs)
output = self.tool(**inputs)
if self.tool.output_type != "any":
agent_type = AGENT_TYPE_MAPPING[self.tool.output_type]
self.assertTrue(isinstance(output, agent_type))
def test_agent_types_inputs(self):
inputs = create_inputs(self.tool.inputs)
_inputs = []
for _input, expected_input in zip(inputs, self.tool.inputs.values()):
input_type = expected_input["type"]
_inputs.append(AGENT_TYPE_MAPPING[input_type](_input))
class ToolTests(unittest.TestCase):
def test_tool_init_with_decorator(self):
@tool
def coolfunc(a: str, b: int) -> float:
"""Cool function
Args:
a: The first argument
b: The second one
"""
return b + 2, a
assert coolfunc.output_type == "number"
def test_tool_init_vanilla(self):
class HFModelDownloadsTool(Tool):
name = "model_download_counter"
description = """
This is a tool that returns the most downloaded model of a given task on the Hugging Face Hub.
It returns the name of the checkpoint."""
inputs = {
"task": {
"type": "string",
"description": "the task category (such as text-classification, depth-estimation, etc)",
}
}
output_type = "integer"
def forward(self, task):
return "best model"
tool = HFModelDownloadsTool()
assert list(tool.inputs.keys())[0] == "task"
def test_tool_init_decorator_raises_issues(self):
with pytest.raises(Exception) as e:
@tool
def coolfunc(a: str, b: int):
"""Cool function
Args:
a: The first argument
b: The second one
"""
return a + b
assert coolfunc.output_type == "number"
assert "Tool return type not found" in str(e)
with pytest.raises(Exception) as e:
@tool
def coolfunc(a: str, b: int) -> int:
"""Cool function
Args:
a: The first argument
"""
return b + a
assert coolfunc.output_type == "number"
assert "docstring has no description for the argument" in str(e)
| transformers/tests/agents/test_tools_common.py/0 | {
"file_path": "transformers/tests/agents/test_tools_common.py",
"repo_id": "transformers",
"token_count": 2438
} |
# coding=utf-8
# Copyright 2023 The HuggingFace Team Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a clone of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from queue import Empty
from threading import Thread
import pytest
from transformers import (
AsyncTextIteratorStreamer,
AutoTokenizer,
TextIteratorStreamer,
TextStreamer,
is_torch_available,
)
from transformers.testing_utils import CaptureStdout, require_torch, torch_device
from ..test_modeling_common import ids_tensor
if is_torch_available():
import torch
from transformers import AutoModelForCausalLM
@require_torch
class StreamerTester(unittest.TestCase):
def test_text_streamer_matches_non_streaming(self):
tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/tiny-random-gpt2")
model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-gpt2").to(torch_device)
model.config.eos_token_id = -1
input_ids = ids_tensor((1, 5), vocab_size=model.config.vocab_size).to(torch_device)
greedy_ids = model.generate(input_ids, max_new_tokens=10, do_sample=False)
greedy_text = tokenizer.decode(greedy_ids[0])
with CaptureStdout() as cs:
streamer = TextStreamer(tokenizer)
model.generate(input_ids, max_new_tokens=10, do_sample=False, streamer=streamer)
# The greedy text should be printed to stdout, except for the final "\n" in the streamer
streamer_text = cs.out[:-1]
self.assertEqual(streamer_text, greedy_text)
def test_iterator_streamer_matches_non_streaming(self):
tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/tiny-random-gpt2")
model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-gpt2").to(torch_device)
model.config.eos_token_id = -1
input_ids = ids_tensor((1, 5), vocab_size=model.config.vocab_size).to(torch_device)
greedy_ids = model.generate(input_ids, max_new_tokens=10, do_sample=False)
greedy_text = tokenizer.decode(greedy_ids[0])
streamer = TextIteratorStreamer(tokenizer)
generation_kwargs = {"input_ids": input_ids, "max_new_tokens": 10, "do_sample": False, "streamer": streamer}
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
streamer_text = ""
for new_text in streamer:
streamer_text += new_text
self.assertEqual(streamer_text, greedy_text)
def test_text_streamer_skip_prompt(self):
tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/tiny-random-gpt2")
model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-gpt2").to(torch_device)
model.config.eos_token_id = -1
input_ids = ids_tensor((1, 5), vocab_size=model.config.vocab_size).to(torch_device)
greedy_ids = model.generate(input_ids, max_new_tokens=10, do_sample=False)
new_greedy_ids = greedy_ids[:, input_ids.shape[1] :]
new_greedy_text = tokenizer.decode(new_greedy_ids[0])
with CaptureStdout() as cs:
streamer = TextStreamer(tokenizer, skip_prompt=True)
model.generate(input_ids, max_new_tokens=10, do_sample=False, streamer=streamer)
# The greedy text should be printed to stdout, except for the final "\n" in the streamer
streamer_text = cs.out[:-1]
self.assertEqual(streamer_text, new_greedy_text)
def test_text_streamer_decode_kwargs(self):
# Tests that we can pass `decode_kwargs` to the streamer to control how the tokens are decoded. Must be tested
# with actual models -- the dummy models' tokenizers are not aligned with their models, and
# `skip_special_tokens=True` has no effect on them
tokenizer = AutoTokenizer.from_pretrained("distilbert/distilgpt2")
model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2").to(torch_device)
model.config.eos_token_id = -1
input_ids = torch.ones((1, 5), device=torch_device).long() * model.config.bos_token_id
with CaptureStdout() as cs:
streamer = TextStreamer(tokenizer, skip_special_tokens=True)
model.generate(input_ids, max_new_tokens=1, do_sample=False, streamer=streamer)
# The prompt contains a special token, so the streamer should not print it. As such, the output text, when
# re-tokenized, must only contain one token
streamer_text = cs.out[:-1] # Remove the final "\n"
streamer_text_tokenized = tokenizer(streamer_text, return_tensors="pt")
self.assertEqual(streamer_text_tokenized.input_ids.shape, (1, 1))
def test_iterator_streamer_timeout(self):
tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/tiny-random-gpt2")
model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-gpt2").to(torch_device)
model.config.eos_token_id = -1
input_ids = ids_tensor((1, 5), vocab_size=model.config.vocab_size).to(torch_device)
streamer = TextIteratorStreamer(tokenizer, timeout=0.001)
generation_kwargs = {"input_ids": input_ids, "max_new_tokens": 10, "do_sample": False, "streamer": streamer}
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
# The streamer will timeout after 0.001 seconds, so an exception will be raised
with self.assertRaises(Empty):
streamer_text = ""
for new_text in streamer:
streamer_text += new_text
@require_torch
@pytest.mark.asyncio(loop_scope="class")
class AsyncStreamerTester(unittest.IsolatedAsyncioTestCase):
async def test_async_iterator_streamer_matches_non_streaming(self):
tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/tiny-random-gpt2")
model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-gpt2").to(torch_device)
model.config.eos_token_id = -1
input_ids = ids_tensor((1, 5), vocab_size=model.config.vocab_size).to(torch_device)
greedy_ids = model.generate(input_ids, max_new_tokens=10, do_sample=False)
greedy_text = tokenizer.decode(greedy_ids[0])
streamer = AsyncTextIteratorStreamer(tokenizer)
generation_kwargs = {"input_ids": input_ids, "max_new_tokens": 10, "do_sample": False, "streamer": streamer}
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
streamer_text = ""
async for new_text in streamer:
streamer_text += new_text
self.assertEqual(streamer_text, greedy_text)
async def test_async_iterator_streamer_timeout(self):
tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/tiny-random-gpt2")
model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-gpt2").to(torch_device)
model.config.eos_token_id = -1
input_ids = ids_tensor((1, 5), vocab_size=model.config.vocab_size).to(torch_device)
streamer = AsyncTextIteratorStreamer(tokenizer, timeout=0.001)
generation_kwargs = {"input_ids": input_ids, "max_new_tokens": 10, "do_sample": False, "streamer": streamer}
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
# The streamer will timeout after 0.001 seconds, so TimeoutError will be raised
with self.assertRaises(TimeoutError):
streamer_text = ""
async for new_text in streamer:
streamer_text += new_text
| transformers/tests/generation/test_streamers.py/0 | {
"file_path": "transformers/tests/generation/test_streamers.py",
"repo_id": "transformers",
"token_count": 3222
} |
# coding=utf-8
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import json
import os
import shutil
import sys
import tempfile
import unittest
from pathlib import Path
import pytest
import transformers
from transformers import (
AutoTokenizer,
BertConfig,
BertTokenizer,
BertTokenizerFast,
CTRLTokenizer,
GPT2Tokenizer,
GPT2TokenizerFast,
PreTrainedTokenizerFast,
RobertaTokenizer,
RobertaTokenizerFast,
is_tokenizers_available,
)
from transformers.models.auto.configuration_auto import CONFIG_MAPPING, AutoConfig
from transformers.models.auto.tokenization_auto import (
TOKENIZER_MAPPING,
get_tokenizer_config,
tokenizer_class_from_name,
)
from transformers.models.roberta.configuration_roberta import RobertaConfig
from transformers.testing_utils import (
DUMMY_DIFF_TOKENIZER_IDENTIFIER,
DUMMY_UNKNOWN_IDENTIFIER,
SMALL_MODEL_IDENTIFIER,
RequestCounter,
require_tokenizers,
slow,
)
sys.path.append(str(Path(__file__).parent.parent.parent.parent / "utils"))
from test_module.custom_configuration import CustomConfig # noqa E402
from test_module.custom_tokenization import CustomTokenizer # noqa E402
if is_tokenizers_available():
from test_module.custom_tokenization_fast import CustomTokenizerFast
class AutoTokenizerTest(unittest.TestCase):
def setUp(self):
transformers.dynamic_module_utils.TIME_OUT_REMOTE_CODE = 0
@slow
def test_tokenizer_from_pretrained(self):
for model_name in {"google-bert/bert-base-uncased", "google-bert/bert-base-cased"}:
tokenizer = AutoTokenizer.from_pretrained(model_name)
self.assertIsNotNone(tokenizer)
self.assertIsInstance(tokenizer, (BertTokenizer, BertTokenizerFast))
self.assertGreater(len(tokenizer), 0)
for model_name in ["openai-community/gpt2", "openai-community/gpt2-medium"]:
tokenizer = AutoTokenizer.from_pretrained(model_name)
self.assertIsNotNone(tokenizer)
self.assertIsInstance(tokenizer, (GPT2Tokenizer, GPT2TokenizerFast))
self.assertGreater(len(tokenizer), 0)
def test_tokenizer_from_pretrained_identifier(self):
tokenizer = AutoTokenizer.from_pretrained(SMALL_MODEL_IDENTIFIER)
self.assertIsInstance(tokenizer, (BertTokenizer, BertTokenizerFast))
self.assertEqual(tokenizer.vocab_size, 12)
def test_tokenizer_from_model_type(self):
tokenizer = AutoTokenizer.from_pretrained(DUMMY_UNKNOWN_IDENTIFIER)
self.assertIsInstance(tokenizer, (RobertaTokenizer, RobertaTokenizerFast))
self.assertEqual(tokenizer.vocab_size, 20)
def test_tokenizer_from_tokenizer_class(self):
config = AutoConfig.from_pretrained(DUMMY_DIFF_TOKENIZER_IDENTIFIER)
self.assertIsInstance(config, RobertaConfig)
# Check that tokenizer_type ≠ model_type
tokenizer = AutoTokenizer.from_pretrained(DUMMY_DIFF_TOKENIZER_IDENTIFIER, config=config)
self.assertIsInstance(tokenizer, (BertTokenizer, BertTokenizerFast))
self.assertEqual(tokenizer.vocab_size, 12)
def test_tokenizer_from_type(self):
with tempfile.TemporaryDirectory() as tmp_dir:
shutil.copy("./tests/fixtures/vocab.txt", os.path.join(tmp_dir, "vocab.txt"))
tokenizer = AutoTokenizer.from_pretrained(tmp_dir, tokenizer_type="bert", use_fast=False)
self.assertIsInstance(tokenizer, BertTokenizer)
with tempfile.TemporaryDirectory() as tmp_dir:
shutil.copy("./tests/fixtures/vocab.json", os.path.join(tmp_dir, "vocab.json"))
shutil.copy("./tests/fixtures/merges.txt", os.path.join(tmp_dir, "merges.txt"))
tokenizer = AutoTokenizer.from_pretrained(tmp_dir, tokenizer_type="gpt2", use_fast=False)
self.assertIsInstance(tokenizer, GPT2Tokenizer)
@require_tokenizers
def test_tokenizer_from_type_fast(self):
with tempfile.TemporaryDirectory() as tmp_dir:
shutil.copy("./tests/fixtures/vocab.txt", os.path.join(tmp_dir, "vocab.txt"))
tokenizer = AutoTokenizer.from_pretrained(tmp_dir, tokenizer_type="bert")
self.assertIsInstance(tokenizer, BertTokenizerFast)
with tempfile.TemporaryDirectory() as tmp_dir:
shutil.copy("./tests/fixtures/vocab.json", os.path.join(tmp_dir, "vocab.json"))
shutil.copy("./tests/fixtures/merges.txt", os.path.join(tmp_dir, "merges.txt"))
tokenizer = AutoTokenizer.from_pretrained(tmp_dir, tokenizer_type="gpt2")
self.assertIsInstance(tokenizer, GPT2TokenizerFast)
def test_tokenizer_from_type_incorrect_name(self):
with pytest.raises(ValueError):
AutoTokenizer.from_pretrained("./", tokenizer_type="xxx")
@require_tokenizers
def test_tokenizer_identifier_with_correct_config(self):
for tokenizer_class in [BertTokenizer, BertTokenizerFast, AutoTokenizer]:
tokenizer = tokenizer_class.from_pretrained("wietsedv/bert-base-dutch-cased")
self.assertIsInstance(tokenizer, (BertTokenizer, BertTokenizerFast))
if isinstance(tokenizer, BertTokenizer):
self.assertEqual(tokenizer.basic_tokenizer.do_lower_case, False)
else:
self.assertEqual(tokenizer.do_lower_case, False)
self.assertEqual(tokenizer.model_max_length, 512)
@require_tokenizers
def test_tokenizer_identifier_non_existent(self):
for tokenizer_class in [BertTokenizer, BertTokenizerFast, AutoTokenizer]:
with self.assertRaisesRegex(
EnvironmentError,
"julien-c/herlolip-not-exists is not a local folder and is not a valid model identifier",
):
_ = tokenizer_class.from_pretrained("julien-c/herlolip-not-exists")
def test_model_name_edge_cases_in_mappings(self):
# tests: https://github.com/huggingface/transformers/pull/13251
# 1. models with `-`, e.g. xlm-roberta -> xlm_roberta
# 2. models that don't remap 1-1 from model-name to model file, e.g., openai-gpt -> openai
tokenizers = TOKENIZER_MAPPING.values()
tokenizer_names = []
for slow_tok, fast_tok in tokenizers:
if slow_tok is not None:
tokenizer_names.append(slow_tok.__name__)
if fast_tok is not None:
tokenizer_names.append(fast_tok.__name__)
for tokenizer_name in tokenizer_names:
# must find the right class
tokenizer_class_from_name(tokenizer_name)
@require_tokenizers
def test_from_pretrained_use_fast_toggle(self):
self.assertIsInstance(
AutoTokenizer.from_pretrained("google-bert/bert-base-cased", use_fast=False), BertTokenizer
)
self.assertIsInstance(AutoTokenizer.from_pretrained("google-bert/bert-base-cased"), BertTokenizerFast)
@require_tokenizers
def test_do_lower_case(self):
tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased", do_lower_case=False)
sample = "Hello, world. How are you?"
tokens = tokenizer.tokenize(sample)
self.assertEqual("[UNK]", tokens[0])
tokenizer = AutoTokenizer.from_pretrained("microsoft/mpnet-base", do_lower_case=False)
tokens = tokenizer.tokenize(sample)
self.assertEqual("[UNK]", tokens[0])
@require_tokenizers
def test_PreTrainedTokenizerFast_from_pretrained(self):
tokenizer = AutoTokenizer.from_pretrained("robot-test/dummy-tokenizer-fast-with-model-config")
self.assertEqual(type(tokenizer), PreTrainedTokenizerFast)
self.assertEqual(tokenizer.model_max_length, 512)
self.assertEqual(tokenizer.vocab_size, 30000)
self.assertEqual(tokenizer.unk_token, "[UNK]")
self.assertEqual(tokenizer.padding_side, "right")
self.assertEqual(tokenizer.truncation_side, "right")
def test_auto_tokenizer_from_local_folder(self):
tokenizer = AutoTokenizer.from_pretrained(SMALL_MODEL_IDENTIFIER)
self.assertIsInstance(tokenizer, (BertTokenizer, BertTokenizerFast))
with tempfile.TemporaryDirectory() as tmp_dir:
tokenizer.save_pretrained(tmp_dir)
tokenizer2 = AutoTokenizer.from_pretrained(tmp_dir)
self.assertIsInstance(tokenizer2, tokenizer.__class__)
self.assertEqual(tokenizer2.vocab_size, 12)
def test_auto_tokenizer_fast_no_slow(self):
tokenizer = AutoTokenizer.from_pretrained("Salesforce/ctrl")
# There is no fast CTRL so this always gives us a slow tokenizer.
self.assertIsInstance(tokenizer, CTRLTokenizer)
def test_get_tokenizer_config(self):
# Check we can load the tokenizer config of an online model.
config = get_tokenizer_config("google-bert/bert-base-cased")
_ = config.pop("_commit_hash", None)
# If we ever update google-bert/bert-base-cased tokenizer config, this dict here will need to be updated.
self.assertEqual(config, {"do_lower_case": False, "model_max_length": 512})
# This model does not have a tokenizer_config so we get back an empty dict.
config = get_tokenizer_config(SMALL_MODEL_IDENTIFIER)
self.assertDictEqual(config, {})
# A tokenizer saved with `save_pretrained` always creates a tokenizer config.
tokenizer = AutoTokenizer.from_pretrained(SMALL_MODEL_IDENTIFIER)
with tempfile.TemporaryDirectory() as tmp_dir:
tokenizer.save_pretrained(tmp_dir)
config = get_tokenizer_config(tmp_dir)
# Check the class of the tokenizer was properly saved (note that it always saves the slow class).
self.assertEqual(config["tokenizer_class"], "BertTokenizer")
def test_new_tokenizer_registration(self):
try:
AutoConfig.register("custom", CustomConfig)
AutoTokenizer.register(CustomConfig, slow_tokenizer_class=CustomTokenizer)
# Trying to register something existing in the Transformers library will raise an error
with self.assertRaises(ValueError):
AutoTokenizer.register(BertConfig, slow_tokenizer_class=BertTokenizer)
tokenizer = CustomTokenizer.from_pretrained(SMALL_MODEL_IDENTIFIER)
with tempfile.TemporaryDirectory() as tmp_dir:
tokenizer.save_pretrained(tmp_dir)
new_tokenizer = AutoTokenizer.from_pretrained(tmp_dir)
self.assertIsInstance(new_tokenizer, CustomTokenizer)
finally:
if "custom" in CONFIG_MAPPING._extra_content:
del CONFIG_MAPPING._extra_content["custom"]
if CustomConfig in TOKENIZER_MAPPING._extra_content:
del TOKENIZER_MAPPING._extra_content[CustomConfig]
@require_tokenizers
def test_new_tokenizer_fast_registration(self):
try:
AutoConfig.register("custom", CustomConfig)
# Can register in two steps
AutoTokenizer.register(CustomConfig, slow_tokenizer_class=CustomTokenizer)
self.assertEqual(TOKENIZER_MAPPING[CustomConfig], (CustomTokenizer, None))
AutoTokenizer.register(CustomConfig, fast_tokenizer_class=CustomTokenizerFast)
self.assertEqual(TOKENIZER_MAPPING[CustomConfig], (CustomTokenizer, CustomTokenizerFast))
del TOKENIZER_MAPPING._extra_content[CustomConfig]
# Can register in one step
AutoTokenizer.register(
CustomConfig, slow_tokenizer_class=CustomTokenizer, fast_tokenizer_class=CustomTokenizerFast
)
self.assertEqual(TOKENIZER_MAPPING[CustomConfig], (CustomTokenizer, CustomTokenizerFast))
# Trying to register something existing in the Transformers library will raise an error
with self.assertRaises(ValueError):
AutoTokenizer.register(BertConfig, fast_tokenizer_class=BertTokenizerFast)
# We pass through a bert tokenizer fast cause there is no converter slow to fast for our new toknizer
# and that model does not have a tokenizer.json
with tempfile.TemporaryDirectory() as tmp_dir:
bert_tokenizer = BertTokenizerFast.from_pretrained(SMALL_MODEL_IDENTIFIER)
bert_tokenizer.save_pretrained(tmp_dir)
tokenizer = CustomTokenizerFast.from_pretrained(tmp_dir)
with tempfile.TemporaryDirectory() as tmp_dir:
tokenizer.save_pretrained(tmp_dir)
new_tokenizer = AutoTokenizer.from_pretrained(tmp_dir)
self.assertIsInstance(new_tokenizer, CustomTokenizerFast)
new_tokenizer = AutoTokenizer.from_pretrained(tmp_dir, use_fast=False)
self.assertIsInstance(new_tokenizer, CustomTokenizer)
finally:
if "custom" in CONFIG_MAPPING._extra_content:
del CONFIG_MAPPING._extra_content["custom"]
if CustomConfig in TOKENIZER_MAPPING._extra_content:
del TOKENIZER_MAPPING._extra_content[CustomConfig]
def test_from_pretrained_dynamic_tokenizer(self):
# If remote code is not set, we will time out when asking whether to load the model.
with self.assertRaises(ValueError):
tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/test_dynamic_tokenizer")
# If remote code is disabled, we can't load this config.
with self.assertRaises(ValueError):
tokenizer = AutoTokenizer.from_pretrained(
"hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=False
)
tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=True)
self.assertTrue(tokenizer.special_attribute_present)
# Test the dynamic module is loaded only once.
reloaded_tokenizer = AutoTokenizer.from_pretrained(
"hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=True
)
self.assertIs(tokenizer.__class__, reloaded_tokenizer.__class__)
# Test tokenizer can be reloaded.
with tempfile.TemporaryDirectory() as tmp_dir:
tokenizer.save_pretrained(tmp_dir)
reloaded_tokenizer = AutoTokenizer.from_pretrained(tmp_dir, trust_remote_code=True)
self.assertTrue(reloaded_tokenizer.special_attribute_present)
if is_tokenizers_available():
self.assertEqual(tokenizer.__class__.__name__, "NewTokenizerFast")
self.assertEqual(reloaded_tokenizer.__class__.__name__, "NewTokenizerFast")
# Test we can also load the slow version
tokenizer = AutoTokenizer.from_pretrained(
"hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=True, use_fast=False
)
self.assertTrue(tokenizer.special_attribute_present)
self.assertEqual(tokenizer.__class__.__name__, "NewTokenizer")
# Test tokenizer can be reloaded.
with tempfile.TemporaryDirectory() as tmp_dir:
tokenizer.save_pretrained(tmp_dir)
reloaded_tokenizer = AutoTokenizer.from_pretrained(tmp_dir, trust_remote_code=True, use_fast=False)
self.assertEqual(reloaded_tokenizer.__class__.__name__, "NewTokenizer")
self.assertTrue(reloaded_tokenizer.special_attribute_present)
else:
self.assertEqual(tokenizer.__class__.__name__, "NewTokenizer")
self.assertEqual(reloaded_tokenizer.__class__.__name__, "NewTokenizer")
# The tokenizer file is cached in the snapshot directory. So the module file is not changed after dumping
# to a temp dir. Because the revision of the module file is not changed.
# Test the dynamic module is loaded only once if the module file is not changed.
self.assertIs(tokenizer.__class__, reloaded_tokenizer.__class__)
# Test the dynamic module is reloaded if we force it.
reloaded_tokenizer = AutoTokenizer.from_pretrained(
"hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=True, force_download=True
)
self.assertIsNot(tokenizer.__class__, reloaded_tokenizer.__class__)
self.assertTrue(reloaded_tokenizer.special_attribute_present)
@require_tokenizers
def test_from_pretrained_dynamic_tokenizer_conflict(self):
class NewTokenizer(BertTokenizer):
special_attribute_present = False
class NewTokenizerFast(BertTokenizerFast):
slow_tokenizer_class = NewTokenizer
special_attribute_present = False
try:
AutoConfig.register("custom", CustomConfig)
AutoTokenizer.register(CustomConfig, slow_tokenizer_class=NewTokenizer)
AutoTokenizer.register(CustomConfig, fast_tokenizer_class=NewTokenizerFast)
# If remote code is not set, the default is to use local
tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/test_dynamic_tokenizer")
self.assertEqual(tokenizer.__class__.__name__, "NewTokenizerFast")
self.assertFalse(tokenizer.special_attribute_present)
tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/test_dynamic_tokenizer", use_fast=False)
self.assertEqual(tokenizer.__class__.__name__, "NewTokenizer")
self.assertFalse(tokenizer.special_attribute_present)
# If remote code is disabled, we load the local one.
tokenizer = AutoTokenizer.from_pretrained(
"hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=False
)
self.assertEqual(tokenizer.__class__.__name__, "NewTokenizerFast")
self.assertFalse(tokenizer.special_attribute_present)
tokenizer = AutoTokenizer.from_pretrained(
"hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=False, use_fast=False
)
self.assertEqual(tokenizer.__class__.__name__, "NewTokenizer")
self.assertFalse(tokenizer.special_attribute_present)
# If remote is enabled, we load from the Hub
tokenizer = AutoTokenizer.from_pretrained(
"hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=True
)
self.assertEqual(tokenizer.__class__.__name__, "NewTokenizerFast")
self.assertTrue(tokenizer.special_attribute_present)
tokenizer = AutoTokenizer.from_pretrained(
"hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=True, use_fast=False
)
self.assertEqual(tokenizer.__class__.__name__, "NewTokenizer")
self.assertTrue(tokenizer.special_attribute_present)
finally:
if "custom" in CONFIG_MAPPING._extra_content:
del CONFIG_MAPPING._extra_content["custom"]
if CustomConfig in TOKENIZER_MAPPING._extra_content:
del TOKENIZER_MAPPING._extra_content[CustomConfig]
def test_from_pretrained_dynamic_tokenizer_legacy_format(self):
tokenizer = AutoTokenizer.from_pretrained(
"hf-internal-testing/test_dynamic_tokenizer_legacy", trust_remote_code=True
)
self.assertTrue(tokenizer.special_attribute_present)
if is_tokenizers_available():
self.assertEqual(tokenizer.__class__.__name__, "NewTokenizerFast")
# Test we can also load the slow version
tokenizer = AutoTokenizer.from_pretrained(
"hf-internal-testing/test_dynamic_tokenizer_legacy", trust_remote_code=True, use_fast=False
)
self.assertTrue(tokenizer.special_attribute_present)
self.assertEqual(tokenizer.__class__.__name__, "NewTokenizer")
else:
self.assertEqual(tokenizer.__class__.__name__, "NewTokenizer")
def test_repo_not_found(self):
with self.assertRaisesRegex(
EnvironmentError, "bert-base is not a local folder and is not a valid model identifier"
):
_ = AutoTokenizer.from_pretrained("bert-base")
def test_revision_not_found(self):
with self.assertRaisesRegex(
EnvironmentError, r"aaaaaa is not a valid git identifier \(branch name, tag name or commit id\)"
):
_ = AutoTokenizer.from_pretrained(DUMMY_UNKNOWN_IDENTIFIER, revision="aaaaaa")
def test_cached_tokenizer_has_minimum_calls_to_head(self):
# Make sure we have cached the tokenizer.
_ = AutoTokenizer.from_pretrained("hf-internal-testing/tiny-random-bert")
with RequestCounter() as counter:
_ = AutoTokenizer.from_pretrained("hf-internal-testing/tiny-random-bert")
self.assertEqual(counter["GET"], 0)
self.assertEqual(counter["HEAD"], 1)
self.assertEqual(counter.total_calls, 1)
def test_init_tokenizer_with_trust(self):
nop_tokenizer_code = """
import transformers
class NopTokenizer(transformers.PreTrainedTokenizer):
def get_vocab(self):
return {}
"""
nop_config_code = """
from transformers import PretrainedConfig
class NopConfig(PretrainedConfig):
model_type = "test_unregistered_dynamic"
def __init__(self, **kwargs):
super().__init__(**kwargs)
"""
with tempfile.TemporaryDirectory() as tmp_dir:
fake_model_id = "hf-internal-testing/test_unregistered_dynamic"
fake_repo = os.path.join(tmp_dir, fake_model_id)
os.makedirs(fake_repo)
tokenizer_src_file = os.path.join(fake_repo, "tokenizer.py")
with open(tokenizer_src_file, "w") as wfp:
wfp.write(nop_tokenizer_code)
model_config_src_file = os.path.join(fake_repo, "config.py")
with open(model_config_src_file, "w") as wfp:
wfp.write(nop_config_code)
config = {
"model_type": "test_unregistered_dynamic",
"auto_map": {"AutoConfig": f"{fake_model_id}--config.NopConfig"},
}
config_file = os.path.join(fake_repo, "config.json")
with open(config_file, "w") as wfp:
json.dump(config, wfp, indent=2)
tokenizer_config = {
"auto_map": {
"AutoTokenizer": [
f"{fake_model_id}--tokenizer.NopTokenizer",
None,
]
}
}
tokenizer_config_file = os.path.join(fake_repo, "tokenizer_config.json")
with open(tokenizer_config_file, "w") as wfp:
json.dump(tokenizer_config, wfp, indent=2)
prev_dir = os.getcwd()
try:
# it looks like subdir= is broken in the from_pretrained also, so this is necessary
os.chdir(tmp_dir)
# this should work because we trust the code
_ = AutoTokenizer.from_pretrained(fake_model_id, local_files_only=True, trust_remote_code=True)
try:
# this should fail because we don't trust and we're not at a terminal for interactive response
_ = AutoTokenizer.from_pretrained(fake_model_id, local_files_only=True, trust_remote_code=False)
self.fail("AutoTokenizer.from_pretrained with trust_remote_code=False should raise ValueException")
except ValueError:
pass
finally:
os.chdir(prev_dir)
| transformers/tests/models/auto/test_tokenization_auto.py/0 | {
"file_path": "transformers/tests/models/auto/test_tokenization_auto.py",
"repo_id": "transformers",
"token_count": 10205
} |
# coding=utf-8
# Copyright 2021 HuggingFace Inc. team.
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import unittest
from transformers.models.bartpho.tokenization_bartpho import VOCAB_FILES_NAMES, BartphoTokenizer
from transformers.testing_utils import get_tests_dir
from ...test_tokenization_common import TokenizerTesterMixin
SAMPLE_VOCAB = get_tests_dir("fixtures/test_sentencepiece_bpe.model")
class BartphoTokenizerTest(TokenizerTesterMixin, unittest.TestCase):
from_pretrained_id = "vinai/bartpho-syllable"
tokenizer_class = BartphoTokenizer
test_rust_tokenizer = False
test_sentencepiece = True
def setUp(self):
super().setUp()
vocab = ["▁This", "▁is", "▁a", "▁t", "est"]
vocab_tokens = dict(zip(vocab, range(len(vocab))))
self.special_tokens_map = {"unk_token": "<unk>"}
self.monolingual_vocab_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["monolingual_vocab_file"])
with open(self.monolingual_vocab_file, "w", encoding="utf-8") as fp:
for token in vocab_tokens:
fp.write(f"{token} {vocab_tokens[token]}\n")
tokenizer = BartphoTokenizer(SAMPLE_VOCAB, self.monolingual_vocab_file, **self.special_tokens_map)
tokenizer.save_pretrained(self.tmpdirname)
def get_tokenizer(self, **kwargs):
kwargs.update(self.special_tokens_map)
return BartphoTokenizer.from_pretrained(self.tmpdirname, **kwargs)
def get_input_output_texts(self, tokenizer):
input_text = "This is a là test"
output_text = "This is a<unk><unk> test"
return input_text, output_text
def test_full_tokenizer(self):
tokenizer = BartphoTokenizer(SAMPLE_VOCAB, self.monolingual_vocab_file, **self.special_tokens_map)
text = "This is a là test"
bpe_tokens = "▁This ▁is ▁a ▁l à ▁t est".split()
tokens = tokenizer.tokenize(text)
self.assertListEqual(tokens, bpe_tokens)
input_tokens = tokens + [tokenizer.unk_token]
input_bpe_tokens = [4, 5, 6, 3, 3, 7, 8, 3]
self.assertListEqual(tokenizer.convert_tokens_to_ids(input_tokens), input_bpe_tokens)
| transformers/tests/models/bartpho/test_tokenization_bartpho.py/0 | {
"file_path": "transformers/tests/models/bartpho/test_tokenization_bartpho.py",
"repo_id": "transformers",
"token_count": 1082
} |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import annotations
import unittest
from transformers import BlenderbotConfig, BlenderbotTokenizer, is_tf_available
from transformers.testing_utils import require_tf, require_tokenizers, slow
from transformers.utils import cached_property
from ...test_configuration_common import ConfigTester
from ...test_modeling_tf_common import TFModelTesterMixin, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
if is_tf_available():
import tensorflow as tf
from transformers import TFAutoModelForSeq2SeqLM, TFBlenderbotForConditionalGeneration, TFBlenderbotModel
@require_tf
class TFBlenderbotModelTester:
config_cls = BlenderbotConfig
config_updates = {}
hidden_act = "gelu"
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_labels=False,
vocab_size=99,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=37,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=50,
eos_token_id=2,
pad_token_id=1,
bos_token_id=0,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.bos_token_id = bos_token_id
def prepare_config_and_inputs_for_common(self):
input_ids = ids_tensor([self.batch_size, self.seq_length - 1], self.vocab_size)
eos_tensor = tf.expand_dims(tf.constant([self.eos_token_id] * self.batch_size), 1)
input_ids = tf.concat([input_ids, eos_tensor], axis=1)
decoder_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
config = self.config_cls(
vocab_size=self.vocab_size,
d_model=self.hidden_size,
encoder_layers=self.num_hidden_layers,
decoder_layers=self.num_hidden_layers,
encoder_attention_heads=self.num_attention_heads,
decoder_attention_heads=self.num_attention_heads,
encoder_ffn_dim=self.intermediate_size,
decoder_ffn_dim=self.intermediate_size,
dropout=self.hidden_dropout_prob,
attention_dropout=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
eos_token_ids=[2],
bos_token_id=self.bos_token_id,
pad_token_id=self.pad_token_id,
decoder_start_token_id=self.pad_token_id,
**self.config_updates,
)
inputs_dict = prepare_blenderbot_inputs_dict(config, input_ids, decoder_input_ids)
return config, inputs_dict
def check_decoder_model_past_large_inputs(self, config, inputs_dict):
model = TFBlenderbotModel(config=config).get_decoder()
input_ids = inputs_dict["input_ids"]
input_ids = input_ids[:1, :]
attention_mask = inputs_dict["attention_mask"][:1, :]
head_mask = inputs_dict["head_mask"]
self.batch_size = 1
# first forward pass
outputs = model(input_ids, attention_mask=attention_mask, head_mask=head_mask, use_cache=True)
output, past_key_values = outputs.to_tuple()
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_attn_mask = tf.cast(ids_tensor((self.batch_size, 3), 2), tf.int8)
# append to next input_ids and
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
next_attention_mask = tf.concat([attention_mask, next_attn_mask], axis=-1)
output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)[0]
output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)[0]
self.parent.assertEqual(next_tokens.shape[1], output_from_past.shape[1])
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx]
output_from_past_slice = output_from_past[:, :, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-3)
def prepare_blenderbot_inputs_dict(
config,
input_ids,
decoder_input_ids,
attention_mask=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
):
if attention_mask is None:
attention_mask = tf.cast(tf.math.not_equal(input_ids, config.pad_token_id), tf.int8)
if decoder_attention_mask is None:
decoder_attention_mask = tf.concat(
[
tf.ones(decoder_input_ids[:, :1].shape, dtype=tf.int8),
tf.cast(tf.math.not_equal(decoder_input_ids[:, 1:], config.pad_token_id), tf.int8),
],
axis=-1,
)
if head_mask is None:
head_mask = tf.ones((config.encoder_layers, config.encoder_attention_heads))
if decoder_head_mask is None:
decoder_head_mask = tf.ones((config.decoder_layers, config.decoder_attention_heads))
if cross_attn_head_mask is None:
cross_attn_head_mask = tf.ones((config.decoder_layers, config.decoder_attention_heads))
return {
"input_ids": input_ids,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"decoder_attention_mask": decoder_attention_mask,
"head_mask": head_mask,
"decoder_head_mask": decoder_head_mask,
"cross_attn_head_mask": cross_attn_head_mask,
}
@require_tf
class TFBlenderbotModelTest(TFModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (TFBlenderbotForConditionalGeneration, TFBlenderbotModel) if is_tf_available() else ()
all_generative_model_classes = (TFBlenderbotForConditionalGeneration,) if is_tf_available() else ()
pipeline_model_mapping = (
{
"feature-extraction": TFBlenderbotModel,
"summarization": TFBlenderbotForConditionalGeneration,
"text2text-generation": TFBlenderbotForConditionalGeneration,
"translation": TFBlenderbotForConditionalGeneration,
}
if is_tf_available()
else {}
)
is_encoder_decoder = True
test_pruning = False
test_onnx = False
def setUp(self):
self.model_tester = TFBlenderbotModelTester(self)
self.config_tester = ConfigTester(self, config_class=BlenderbotConfig)
def test_config(self):
self.config_tester.run_common_tests()
def test_decoder_model_past_large_inputs(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
self.model_tester.check_decoder_model_past_large_inputs(*config_and_inputs)
@require_tokenizers
@require_tf
class TFBlenderbot400MIntegrationTests(unittest.TestCase):
src_text = ["My friends are cool but they eat too many carbs."]
model_name = "facebook/blenderbot-400M-distill"
@cached_property
def tokenizer(self):
return BlenderbotTokenizer.from_pretrained(self.model_name)
@cached_property
def model(self):
model = TFAutoModelForSeq2SeqLM.from_pretrained(self.model_name)
return model
@slow
def test_generation_from_long_input(self):
model_inputs = self.tokenizer(self.src_text, return_tensors="tf")
generated_ids = self.model.generate(
model_inputs.input_ids,
)
generated_words = self.tokenizer.batch_decode(generated_ids.numpy(), skip_special_tokens=True)[0]
assert (
generated_words
== " That's unfortunate. Are they trying to lose weight or are they just trying to be healthier?"
)
| transformers/tests/models/blenderbot/test_modeling_tf_blenderbot.py/0 | {
"file_path": "transformers/tests/models/blenderbot/test_modeling_tf_blenderbot.py",
"repo_id": "transformers",
"token_count": 3908
} |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import shutil
import tempfile
import unittest
import pytest
from transformers.testing_utils import require_vision
from transformers.utils import is_vision_available
from ...test_processing_common import ProcessorTesterMixin
if is_vision_available():
from transformers import AutoProcessor, Blip2Processor, BlipImageProcessor, GPT2Tokenizer, PreTrainedTokenizerFast
@require_vision
class Blip2ProcessorTest(ProcessorTesterMixin, unittest.TestCase):
processor_class = Blip2Processor
def setUp(self):
self.tmpdirname = tempfile.mkdtemp()
image_processor = BlipImageProcessor()
tokenizer = GPT2Tokenizer.from_pretrained("hf-internal-testing/tiny-random-GPT2Model")
processor = Blip2Processor(image_processor, tokenizer)
processor.save_pretrained(self.tmpdirname)
def get_tokenizer(self, **kwargs):
return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).tokenizer
def get_image_processor(self, **kwargs):
return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).image_processor
def tearDown(self):
shutil.rmtree(self.tmpdirname)
def test_save_load_pretrained_additional_features(self):
processor = Blip2Processor(tokenizer=self.get_tokenizer(), image_processor=self.get_image_processor())
processor.save_pretrained(self.tmpdirname)
tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
image_processor_add_kwargs = self.get_image_processor(do_normalize=False, padding_value=1.0)
processor = Blip2Processor.from_pretrained(
self.tmpdirname, bos_token="(BOS)", eos_token="(EOS)", do_normalize=False, padding_value=1.0
)
self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
self.assertIsInstance(processor.tokenizer, PreTrainedTokenizerFast)
self.assertEqual(processor.image_processor.to_json_string(), image_processor_add_kwargs.to_json_string())
self.assertIsInstance(processor.image_processor, BlipImageProcessor)
def test_image_processor(self):
image_processor = self.get_image_processor()
tokenizer = self.get_tokenizer()
processor = Blip2Processor(tokenizer=tokenizer, image_processor=image_processor)
image_input = self.prepare_image_inputs()
input_feat_extract = image_processor(image_input, return_tensors="np")
input_processor = processor(images=image_input, return_tensors="np")
for key in input_feat_extract.keys():
self.assertAlmostEqual(input_feat_extract[key].sum(), input_processor[key].sum(), delta=1e-2)
def test_tokenizer(self):
image_processor = self.get_image_processor()
tokenizer = self.get_tokenizer()
processor = Blip2Processor(tokenizer=tokenizer, image_processor=image_processor)
input_str = "lower newer"
encoded_processor = processor(text=input_str)
encoded_tok = tokenizer(input_str, return_token_type_ids=False)
for key in encoded_tok.keys():
self.assertListEqual(encoded_tok[key], encoded_processor[key][0])
def test_processor(self):
image_processor = self.get_image_processor()
tokenizer = self.get_tokenizer()
processor = Blip2Processor(tokenizer=tokenizer, image_processor=image_processor)
input_str = "lower newer"
image_input = self.prepare_image_inputs()
inputs = processor(text=input_str, images=image_input)
self.assertCountEqual(list(inputs.keys()), ["input_ids", "pixel_values", "attention_mask"])
# test if it raises when no input is passed
with pytest.raises(ValueError):
processor()
def test_tokenizer_decode(self):
image_processor = self.get_image_processor()
tokenizer = self.get_tokenizer()
processor = Blip2Processor(tokenizer=tokenizer, image_processor=image_processor)
predicted_ids = [[1, 4, 5, 8, 1, 0, 8], [3, 4, 3, 1, 1, 8, 9]]
decoded_processor = processor.batch_decode(predicted_ids)
decoded_tok = tokenizer.batch_decode(predicted_ids)
self.assertListEqual(decoded_tok, decoded_processor)
def test_model_input_names(self):
image_processor = self.get_image_processor()
tokenizer = self.get_tokenizer()
processor = Blip2Processor(tokenizer=tokenizer, image_processor=image_processor)
input_str = "lower newer"
image_input = self.prepare_image_inputs()
inputs = processor(text=input_str, images=image_input)
# For now the processor supports only ['pixel_values', 'input_ids', 'attention_mask']
self.assertCountEqual(list(inputs.keys()), ["input_ids", "pixel_values", "attention_mask"])
| transformers/tests/models/blip_2/test_processor_blip_2.py/0 | {
"file_path": "transformers/tests/models/blip_2/test_processor_blip_2.py",
"repo_id": "transformers",
"token_count": 2004
} |
# coding=utf-8
# Copyright 2018 HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import tempfile
import unittest
from transformers import AddedToken, CamembertTokenizer, CamembertTokenizerFast
from transformers.testing_utils import get_tests_dir, require_sentencepiece, require_tokenizers, slow
from transformers.utils import is_torch_available
from ...test_tokenization_common import TokenizerTesterMixin
SAMPLE_VOCAB = get_tests_dir("fixtures/test_sentencepiece.model")
SAMPLE_BPE_VOCAB = get_tests_dir("fixtures/test_sentencepiece_bpe.model")
FRAMEWORK = "pt" if is_torch_available() else "tf"
@require_sentencepiece
@require_tokenizers
class CamembertTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
from_pretrained_id = "almanach/camembert-base"
tokenizer_class = CamembertTokenizer
rust_tokenizer_class = CamembertTokenizerFast
test_rust_tokenizer = True
test_sentencepiece = True
def setUp(self):
super().setUp()
# We have a SentencePiece fixture for testing
tokenizer = CamembertTokenizer(SAMPLE_VOCAB)
tokenizer.save_pretrained(self.tmpdirname)
@unittest.skip(
"Token maps are not equal because someone set the probability of ('<unk>NOTUSED', -100), so it's never encoded for fast"
)
def test_special_tokens_map_equal(self):
return
def test_convert_token_and_id(self):
"""Test ``_convert_token_to_id`` and ``_convert_id_to_token``."""
token = "<pad>"
token_id = 1 # 1 is the offset id, but in the spm vocab it's 3
self.assertEqual(self.get_tokenizer().convert_tokens_to_ids(token), token_id)
self.assertEqual(self.get_tokenizer().convert_ids_to_tokens(token_id), token)
def test_get_vocab(self):
vocab_keys = list(self.get_tokenizer().get_vocab().keys())
self.assertEqual(vocab_keys[0], "<s>NOTUSED")
self.assertEqual(vocab_keys[1], "<pad>")
self.assertEqual(vocab_keys[-1], "<mask>")
self.assertEqual(len(vocab_keys), 1_005)
def test_vocab_size(self):
self.assertEqual(self.get_tokenizer().vocab_size, 1_000)
def test_rust_and_python_bpe_tokenizers(self):
tokenizer = CamembertTokenizer(SAMPLE_BPE_VOCAB)
tokenizer.save_pretrained(self.tmpdirname)
rust_tokenizer = CamembertTokenizerFast.from_pretrained(self.tmpdirname)
sequence = "I was born in 92000, and this is falsé."
ids = tokenizer.encode(sequence)
rust_ids = rust_tokenizer.encode(sequence)
self.assertListEqual(ids, rust_ids)
ids = tokenizer.encode(sequence, add_special_tokens=False)
rust_ids = rust_tokenizer.encode(sequence, add_special_tokens=False)
self.assertListEqual(ids, rust_ids)
# <unk> tokens are not the same for `rust` than for `slow`.
# Because spm gives back raw token instead of `unk` in EncodeAsPieces
# tokens = tokenizer.tokenize(sequence)
tokens = tokenizer.convert_ids_to_tokens(ids)
rust_tokens = rust_tokenizer.tokenize(sequence)
self.assertListEqual(tokens, rust_tokens)
def test_rust_and_python_full_tokenizers(self):
if not self.test_rust_tokenizer:
self.skipTest(reason="test_rust_tokenizer is set to False")
tokenizer = self.get_tokenizer()
rust_tokenizer = self.get_rust_tokenizer()
sequence = "I was born in 92000, and this is falsé."
tokens = tokenizer.tokenize(sequence)
rust_tokens = rust_tokenizer.tokenize(sequence)
self.assertListEqual(tokens, rust_tokens)
ids = tokenizer.encode(sequence, add_special_tokens=False)
rust_ids = rust_tokenizer.encode(sequence, add_special_tokens=False)
self.assertListEqual(ids, rust_ids)
rust_tokenizer = self.get_rust_tokenizer()
ids = tokenizer.encode(sequence)
rust_ids = rust_tokenizer.encode(sequence)
self.assertListEqual(ids, rust_ids)
@slow
def test_tokenizer_integration(self):
expected_encoding = {'input_ids': [[5, 54, 7196, 297, 30, 23, 776, 18, 11, 3215, 3705, 8252, 22, 3164, 1181, 2116, 29, 16, 813, 25, 791, 3314, 20, 3446, 38, 27575, 120, 6, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [5, 468, 17, 11, 9088, 20, 1517, 8, 22804, 18818, 10, 38, 629, 607, 607, 142, 19, 7196, 867, 56, 10326, 24, 2267, 20, 416, 5072, 15612, 233, 734, 7, 2399, 27, 16, 3015, 1649, 7, 24, 20, 4338, 2399, 27, 13, 3400, 14, 13, 6189, 8, 930, 9, 6]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]} # fmt: skip
# camembert is a french model. So we also use french texts.
sequences = [
"Le transformeur est un modèle d'apprentissage profond introduit en 2017, "
"utilisé principalement dans le domaine du traitement automatique des langues (TAL).",
"À l'instar des réseaux de neurones récurrents (RNN), les transformeurs sont conçus "
"pour gérer des données séquentielles, telles que le langage naturel, pour des tâches "
"telles que la traduction et la synthèse de texte.",
]
self.tokenizer_integration_test_util(
expected_encoding=expected_encoding,
model_name="almanach/camembert-base",
revision="3a0641d9a1aeb7e848a74299e7e4c4bca216b4cf",
sequences=sequences,
)
# Overwritten because we have to use from slow (online pretrained is wrong, the tokenizer.json has a whole)
def test_added_tokens_serialization(self):
self.maxDiff = None
# Utility to test the added vocab
def _test_added_vocab_and_eos(expected, tokenizer_class, expected_eos, temp_dir):
tokenizer = tokenizer_class.from_pretrained(temp_dir)
self.assertTrue(str(expected_eos) not in tokenizer.additional_special_tokens)
self.assertIn(new_eos, tokenizer.added_tokens_decoder.values())
self.assertEqual(tokenizer.added_tokens_decoder[tokenizer.eos_token_id], new_eos)
self.assertTrue(all(item in tokenizer.added_tokens_decoder.items() for item in expected.items()))
return tokenizer
new_eos = AddedToken("[NEW_EOS]", rstrip=False, lstrip=True, normalized=False)
for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
# Load a slow tokenizer from the hub, init with the new token for fast to also include it
tokenizer = self.tokenizer_class.from_pretrained(pretrained_name, eos_token=new_eos)
EXPECTED_ADDED_TOKENS_DECODER = tokenizer.added_tokens_decoder
with self.subTest("Hub -> Slow: Test loading a slow tokenizer from the hub)"):
self.assertEqual(tokenizer._special_tokens_map["eos_token"], new_eos)
self.assertIn(new_eos, list(tokenizer.added_tokens_decoder.values()))
with tempfile.TemporaryDirectory() as tmp_dir_2:
tokenizer.save_pretrained(tmp_dir_2)
with self.subTest(
"Hub -> Slow -> Slow: Test saving this slow tokenizer and reloading it in the fast class"
):
_test_added_vocab_and_eos(
EXPECTED_ADDED_TOKENS_DECODER, self.tokenizer_class, new_eos, tmp_dir_2
)
if self.rust_tokenizer_class is not None:
with self.subTest(
"Hub -> Slow -> Fast: Test saving this slow tokenizer and reloading it in the fast class"
):
tokenizer_fast = _test_added_vocab_and_eos(
EXPECTED_ADDED_TOKENS_DECODER, self.rust_tokenizer_class, new_eos, tmp_dir_2
)
with tempfile.TemporaryDirectory() as tmp_dir_3:
tokenizer_fast.save_pretrained(tmp_dir_3)
with self.subTest(
"Hub -> Slow -> Fast -> Fast: Test saving this fast tokenizer and reloading it in the fast class"
):
_test_added_vocab_and_eos(
EXPECTED_ADDED_TOKENS_DECODER, self.rust_tokenizer_class, new_eos, tmp_dir_3
)
with self.subTest(
"Hub -> Slow -> Fast -> Slow: Test saving this slow tokenizer and reloading it in the slow class"
):
_test_added_vocab_and_eos(
EXPECTED_ADDED_TOKENS_DECODER, self.rust_tokenizer_class, new_eos, tmp_dir_3
)
with self.subTest("Hub -> Fast: Test loading a fast tokenizer from the hub)"):
if self.rust_tokenizer_class is not None:
tokenizer_fast = self.rust_tokenizer_class.from_pretrained(
pretrained_name, eos_token=new_eos, from_slow=True
)
self.assertEqual(tokenizer_fast._special_tokens_map["eos_token"], new_eos)
self.assertIn(new_eos, list(tokenizer_fast.added_tokens_decoder.values()))
# We can't test the following because for BC we kept the default rstrip lstrip in slow not fast. Will comment once normalization is alright
with self.subTest("Hub -> Fast == Hub -> Slow: make sure slow and fast tokenizer match"):
with self.subTest("Hub -> Fast == Hub -> Slow: make sure slow and fast tokenizer match"):
self.assertTrue(
all(
item in tokenizer.added_tokens_decoder.items()
for item in EXPECTED_ADDED_TOKENS_DECODER.items()
)
)
EXPECTED_ADDED_TOKENS_DECODER = tokenizer_fast.added_tokens_decoder
with tempfile.TemporaryDirectory() as tmp_dir_4:
tokenizer_fast.save_pretrained(tmp_dir_4)
with self.subTest("Hub -> Fast -> Fast: saving Fast1 locally and loading"):
_test_added_vocab_and_eos(
EXPECTED_ADDED_TOKENS_DECODER, self.rust_tokenizer_class, new_eos, tmp_dir_4
)
with self.subTest("Hub -> Fast -> Slow: saving Fast1 locally and loading"):
_test_added_vocab_and_eos(
EXPECTED_ADDED_TOKENS_DECODER, self.tokenizer_class, new_eos, tmp_dir_4
)
| transformers/tests/models/camembert/test_tokenization_camembert.py/0 | {
"file_path": "transformers/tests/models/camembert/test_tokenization_camembert.py",
"repo_id": "transformers",
"token_count": 5767
} |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Testing suite for the PyTorch ConvBERT model."""
import os
import tempfile
import unittest
from transformers import ConvBertConfig, is_torch_available
from transformers.models.auto import get_values
from transformers.testing_utils import require_torch, require_torch_accelerator, slow, torch_device
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from transformers import (
MODEL_FOR_QUESTION_ANSWERING_MAPPING,
ConvBertForMaskedLM,
ConvBertForMultipleChoice,
ConvBertForQuestionAnswering,
ConvBertForSequenceClassification,
ConvBertForTokenClassification,
ConvBertModel,
)
class ConvBertModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_input_mask=True,
use_token_type_ids=True,
use_labels=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
type_sequence_label_size=2,
initializer_range=0.02,
num_labels=3,
num_choices=4,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_input_mask = use_input_mask
self.use_token_type_ids = use_token_type_ids
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.num_labels = num_labels
self.num_choices = num_choices
self.scope = scope
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = self.get_config()
return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
def get_config(self):
return ConvBertConfig(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
is_decoder=False,
initializer_range=self.initializer_range,
)
def prepare_config_and_inputs_for_decoder(self):
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = self.prepare_config_and_inputs()
config.is_decoder = True
encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
return (
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
)
def create_and_check_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = ConvBertModel(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
result = model(input_ids, token_type_ids=token_type_ids)
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_for_masked_lm(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = ConvBertForMaskedLM(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_for_question_answering(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = ConvBertForQuestionAnswering(config=config)
model.to(torch_device)
model.eval()
result = model(
input_ids,
attention_mask=input_mask,
token_type_ids=token_type_ids,
start_positions=sequence_labels,
end_positions=sequence_labels,
)
self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
def create_and_check_for_sequence_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = ConvBertForSequenceClassification(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
def create_and_check_for_token_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = ConvBertForTokenClassification(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
def create_and_check_for_multiple_choice(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_choices = self.num_choices
model = ConvBertForMultipleChoice(config=config)
model.to(torch_device)
model.eval()
multiple_choice_inputs_ids = input_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
multiple_choice_token_type_ids = token_type_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
multiple_choice_input_mask = input_mask.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
result = model(
multiple_choice_inputs_ids,
attention_mask=multiple_choice_input_mask,
token_type_ids=multiple_choice_token_type_ids,
labels=choice_labels,
)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
return config, inputs_dict
@require_torch
class ConvBertModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (
(
ConvBertModel,
ConvBertForMaskedLM,
ConvBertForMultipleChoice,
ConvBertForQuestionAnswering,
ConvBertForSequenceClassification,
ConvBertForTokenClassification,
)
if is_torch_available()
else ()
)
pipeline_model_mapping = (
{
"feature-extraction": ConvBertModel,
"fill-mask": ConvBertForMaskedLM,
"question-answering": ConvBertForQuestionAnswering,
"text-classification": ConvBertForSequenceClassification,
"token-classification": ConvBertForTokenClassification,
"zero-shot": ConvBertForSequenceClassification,
}
if is_torch_available()
else {}
)
test_pruning = False
test_head_masking = False
def setUp(self):
self.model_tester = ConvBertModelTester(self)
self.config_tester = ConfigTester(self, config_class=ConvBertConfig, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_for_masked_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
def test_for_multiple_choice(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
def test_for_question_answering(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
def test_for_sequence_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
def test_for_token_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
@slow
def test_model_from_pretrained(self):
model_name = "YituTech/conv-bert-base"
model = ConvBertModel.from_pretrained(model_name)
self.assertIsNotNone(model)
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
seq_len = getattr(self.model_tester, "seq_length", None)
decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
encoder_seq_length = getattr(self.model_tester, "encoder_seq_length", seq_len)
decoder_key_length = getattr(self.model_tester, "decoder_key_length", decoder_seq_length)
encoder_key_length = getattr(self.model_tester, "key_length", encoder_seq_length)
chunk_length = getattr(self.model_tester, "chunk_length", None)
if chunk_length is not None and hasattr(self.model_tester, "num_hashes"):
encoder_seq_length = encoder_seq_length * self.model_tester.num_hashes
for model_class in self.all_model_classes:
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = False
config.return_dict = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
# check that output_attentions also work using config
del inputs_dict["output_attentions"]
config.output_attentions = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
if chunk_length is not None:
self.assertListEqual(
list(attentions[0].shape[-4:]),
[self.model_tester.num_attention_heads / 2, encoder_seq_length, chunk_length, encoder_key_length],
)
else:
self.assertListEqual(
list(attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads / 2, encoder_seq_length, encoder_key_length],
)
out_len = len(outputs)
if self.is_encoder_decoder:
correct_outlen = 5
# loss is at first position
if "labels" in inputs_dict:
correct_outlen += 1 # loss is added to beginning
# Question Answering model returns start_logits and end_logits
if model_class in get_values(MODEL_FOR_QUESTION_ANSWERING_MAPPING):
correct_outlen += 1 # start_logits and end_logits instead of only 1 output
if "past_key_values" in outputs:
correct_outlen += 1 # past_key_values have been returned
self.assertEqual(out_len, correct_outlen)
# decoder attentions
decoder_attentions = outputs.decoder_attentions
self.assertIsInstance(decoder_attentions, (list, tuple))
self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(decoder_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, decoder_seq_length, decoder_key_length],
)
# cross attentions
cross_attentions = outputs.cross_attentions
self.assertIsInstance(cross_attentions, (list, tuple))
self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(cross_attentions[0].shape[-3:]),
[
self.model_tester.num_attention_heads,
decoder_seq_length,
encoder_key_length,
],
)
# Check attention is always last and order is fine
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
if hasattr(self.model_tester, "num_hidden_states_types"):
added_hidden_states = self.model_tester.num_hidden_states_types
elif self.is_encoder_decoder:
added_hidden_states = 2
else:
added_hidden_states = 1
self.assertEqual(out_len + added_hidden_states, len(outputs))
self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
if chunk_length is not None:
self.assertListEqual(
list(self_attentions[0].shape[-4:]),
[self.model_tester.num_attention_heads / 2, encoder_seq_length, chunk_length, encoder_key_length],
)
else:
self.assertListEqual(
list(self_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads / 2, encoder_seq_length, encoder_key_length],
)
@slow
@require_torch_accelerator
def test_torchscript_device_change(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
# ConvBertForMultipleChoice behaves incorrectly in JIT environments.
if model_class == ConvBertForMultipleChoice:
self.skipTest(reason="ConvBertForMultipleChoice behaves incorrectly in JIT environments.")
config.torchscript = True
model = model_class(config=config)
inputs_dict = self._prepare_for_class(inputs_dict, model_class)
traced_model = torch.jit.trace(
model, (inputs_dict["input_ids"].to("cpu"), inputs_dict["attention_mask"].to("cpu"))
)
with tempfile.TemporaryDirectory() as tmp:
torch.jit.save(traced_model, os.path.join(tmp, "traced_model.pt"))
loaded = torch.jit.load(os.path.join(tmp, "traced_model.pt"), map_location=torch_device)
loaded(inputs_dict["input_ids"].to(torch_device), inputs_dict["attention_mask"].to(torch_device))
def test_model_for_input_embeds(self):
batch_size = 2
seq_length = 10
inputs_embeds = torch.rand([batch_size, seq_length, 768], device=torch_device)
config = self.model_tester.get_config()
model = ConvBertModel(config=config)
model.to(torch_device)
model.eval()
result = model(inputs_embeds=inputs_embeds)
self.assertEqual(result.last_hidden_state.shape, (batch_size, seq_length, config.hidden_size))
def test_reducing_attention_heads(self):
config, *inputs_dict = self.model_tester.prepare_config_and_inputs()
config.head_ratio = 4
self.model_tester.create_and_check_for_masked_lm(config, *inputs_dict)
@require_torch
class ConvBertModelIntegrationTest(unittest.TestCase):
@slow
def test_inference_no_head(self):
model = ConvBertModel.from_pretrained("YituTech/conv-bert-base")
input_ids = torch.tensor([[1, 2, 3, 4, 5, 6]])
with torch.no_grad():
output = model(input_ids)[0]
expected_shape = torch.Size((1, 6, 768))
self.assertEqual(output.shape, expected_shape)
expected_slice = torch.tensor(
[[[-0.0864, -0.4898, -0.3677], [0.1434, -0.2952, -0.7640], [-0.0112, -0.4432, -0.5432]]]
)
torch.testing.assert_close(output[:, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
| transformers/tests/models/convbert/test_modeling_convbert.py/0 | {
"file_path": "transformers/tests/models/convbert/test_modeling_convbert.py",
"repo_id": "transformers",
"token_count": 9502
} |
# coding=utf-8
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import annotations
import unittest
from transformers import CTRLConfig, is_tf_available
from transformers.testing_utils import require_tf, slow
from ...test_configuration_common import ConfigTester
from ...test_modeling_tf_common import TFModelTesterMixin, ids_tensor, random_attention_mask
from ...test_pipeline_mixin import PipelineTesterMixin
if is_tf_available():
import tensorflow as tf
from transformers.modeling_tf_utils import keras
from transformers.models.ctrl.modeling_tf_ctrl import (
TFCTRLForSequenceClassification,
TFCTRLLMHeadModel,
TFCTRLModel,
)
class TFCTRLModelTester:
def __init__(
self,
parent,
):
self.parent = parent
self.batch_size = 13
self.seq_length = 7
self.is_training = True
self.use_token_type_ids = True
self.use_input_mask = True
self.use_labels = True
self.use_mc_token_ids = True
self.vocab_size = 99
self.hidden_size = 32
self.num_hidden_layers = 2
self.num_attention_heads = 4
self.intermediate_size = 37
self.hidden_act = "gelu"
self.hidden_dropout_prob = 0.1
self.attention_probs_dropout_prob = 0.1
self.max_position_embeddings = 512
self.type_vocab_size = 16
self.type_sequence_label_size = 2
self.initializer_range = 0.02
self.num_labels = 3
self.num_choices = 4
self.scope = None
self.pad_token_id = self.vocab_size - 1
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
mc_token_ids = None
if self.use_mc_token_ids:
mc_token_ids = ids_tensor([self.batch_size, self.num_choices], self.seq_length)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = CTRLConfig(
vocab_size=self.vocab_size,
n_embd=self.hidden_size,
n_layer=self.num_hidden_layers,
n_head=self.num_attention_heads,
dff=self.intermediate_size,
# hidden_act=self.hidden_act,
# hidden_dropout_prob=self.hidden_dropout_prob,
# attention_probs_dropout_prob=self.attention_probs_dropout_prob,
n_positions=self.max_position_embeddings,
# type_vocab_size=self.type_vocab_size,
# initializer_range=self.initializer_range,
pad_token_id=self.pad_token_id,
)
head_mask = ids_tensor([self.num_hidden_layers, self.num_attention_heads], 2)
return (
config,
input_ids,
input_mask,
head_mask,
token_type_ids,
mc_token_ids,
sequence_labels,
token_labels,
choice_labels,
)
def create_and_check_ctrl_model(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
model = TFCTRLModel(config=config)
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
result = model(inputs)
inputs = [input_ids, None, input_mask] # None is the input for 'past'
result = model(inputs)
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_ctrl_lm_head(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
model = TFCTRLLMHeadModel(config=config)
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_ctrl_for_sequence_classification(
self, config, input_ids, input_mask, head_mask, token_type_ids, *args
):
config.num_labels = self.num_labels
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
inputs = {
"input_ids": input_ids,
"token_type_ids": token_type_ids,
"labels": sequence_labels,
}
model = TFCTRLForSequenceClassification(config)
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
input_mask,
head_mask,
token_type_ids,
mc_token_ids,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
return config, inputs_dict
@require_tf
class TFCTRLModelTest(TFModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (TFCTRLModel, TFCTRLLMHeadModel, TFCTRLForSequenceClassification) if is_tf_available() else ()
all_generative_model_classes = (TFCTRLLMHeadModel,) if is_tf_available() else ()
pipeline_model_mapping = (
{
"feature-extraction": TFCTRLModel,
"text-classification": TFCTRLForSequenceClassification,
"text-generation": TFCTRLLMHeadModel,
"zero-shot": TFCTRLForSequenceClassification,
}
if is_tf_available()
else {}
)
test_head_masking = False
test_onnx = False
# TODO: Fix the failed tests
def is_pipeline_test_to_skip(
self,
pipeline_test_case_name,
config_class,
model_architecture,
tokenizer_name,
image_processor_name,
feature_extractor_name,
processor_name,
):
if pipeline_test_case_name == "ZeroShotClassificationPipelineTests":
# Get `tokenizer does not have a padding token` error for both fast/slow tokenizers.
# `CTRLConfig` was never used in pipeline tests, either because of a missing checkpoint or because a tiny
# config could not be created.
return True
return False
def setUp(self):
self.model_tester = TFCTRLModelTester(self)
self.config_tester = ConfigTester(self, config_class=CTRLConfig, n_embd=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_ctrl_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_ctrl_model(*config_and_inputs)
def test_ctrl_lm_head(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_ctrl_lm_head(*config_and_inputs)
def test_ctrl_sequence_classification_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_ctrl_for_sequence_classification(*config_and_inputs)
def test_model_common_attributes(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
list_lm_models = [TFCTRLLMHeadModel]
list_other_models_with_output_ebd = [TFCTRLForSequenceClassification]
for model_class in self.all_model_classes:
model = model_class(config)
model.build_in_name_scope() # may be needed for the get_bias() call below
assert isinstance(model.get_input_embeddings(), keras.layers.Layer)
if model_class in list_lm_models:
x = model.get_output_embeddings()
assert isinstance(x, keras.layers.Layer)
name = model.get_bias()
assert isinstance(name, dict)
for k, v in name.items():
assert isinstance(v, tf.Variable)
elif model_class in list_other_models_with_output_ebd:
x = model.get_output_embeddings()
assert isinstance(x, keras.layers.Layer)
name = model.get_bias()
assert name is None
else:
x = model.get_output_embeddings()
assert x is None
name = model.get_bias()
assert name is None
@slow
def test_model_from_pretrained(self):
model_name = "Salesforce/ctrl"
model = TFCTRLModel.from_pretrained(model_name)
self.assertIsNotNone(model)
@require_tf
class TFCTRLModelLanguageGenerationTest(unittest.TestCase):
@slow
def test_lm_generate_ctrl(self):
model = TFCTRLLMHeadModel.from_pretrained("Salesforce/ctrl")
input_ids = tf.convert_to_tensor([[11859, 0, 1611, 8]], dtype=tf.int32) # Legal the president is
expected_output_ids = [
11859,
0,
1611,
8,
5,
150,
26449,
2,
19,
348,
469,
3,
2595,
48,
20740,
246533,
246533,
19,
30,
5,
] # Legal the president is a good guy and I don't want to lose my job. \n \n I have a
output_ids = model.generate(input_ids, do_sample=False)
self.assertListEqual(output_ids[0].numpy().tolist(), expected_output_ids)
| transformers/tests/models/ctrl/test_modeling_tf_ctrl.py/0 | {
"file_path": "transformers/tests/models/ctrl/test_modeling_tf_ctrl.py",
"repo_id": "transformers",
"token_count": 4940
} |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Testing suite for the PyTorch DBRX model."""
import unittest
from transformers import DbrxConfig, is_torch_available
from transformers.testing_utils import require_torch, slow, torch_device
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from transformers import DbrxForCausalLM, DbrxModel
class DbrxModelTester:
def __init__(
self,
parent,
hidden_size=32,
ffn_hidden_size=32,
num_attention_heads=4,
kv_n_heads=4,
num_hidden_layers=5,
max_position_embeddings=512,
type_vocab_size=16,
batch_size=13,
seq_length=7,
is_training=True,
use_input_mask=True,
use_token_type_ids=False,
use_labels=True,
use_cache=True,
type_sequence_label_size=2,
num_labels=3,
num_choices=4,
scope=None,
clip_qkv=8,
rope_theta=500000,
attn_config_model_type="",
emb_pdrop=0.0,
moe_jitter_eps=0,
moe_loss_weight=0.05,
moe_num_experts=16,
moe_top_k=4,
ffn_config_model_type="",
ffn_act_fn_name="gelu",
initializer_range=0.02,
output_router_logits=False,
resid_pdrop=0.0,
tie_word_embeddings=False,
torch_dtype="bfloat16",
vocab_size=99,
is_decoder=True,
pad_token_id=0,
):
# Parameters unique to testing
self.batch_size = batch_size
self.seq_length = seq_length
self.type_vocab_size = type_vocab_size
self.type_sequence_label_size = type_sequence_label_size
self.num_labels = num_labels
self.num_choices = num_choices
self.scope = scope
self.parent = parent
self.is_training = is_training
self.use_input_mask = use_input_mask
self.use_token_type_ids = use_token_type_ids
self.use_labels = use_labels
# attn_config params
self.clip_qkv = clip_qkv
self.kv_n_heads = kv_n_heads
self.rope_theta = rope_theta
self.attn_config_model_type = attn_config_model_type
# ffn_config params
self.ffn_hidden_size = ffn_hidden_size
self.moe_jitter_eps = moe_jitter_eps
self.moe_loss_weight = moe_loss_weight
self.moe_num_experts = moe_num_experts
self.moe_top_k = moe_top_k
self.ffn_config_model_type = ffn_config_model_type
self.ffn_act_fn_name = ffn_act_fn_name
# Other model params
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.max_position_embeddings = max_position_embeddings
self.vocab_size = vocab_size
self.use_cache = use_cache
self.initializer_range = initializer_range
self.emb_pdrop = emb_pdrop
self.output_router_logits = output_router_logits
self.resid_pdrop = resid_pdrop
self.tie_word_embeddings = tie_word_embeddings
self.torch_dtype = torch_dtype
self.is_decoder = is_decoder
self.pad_token_id = pad_token_id
# Make the dictionaries
self.ffn_config = {
"ffn_hidden_size": self.ffn_hidden_size,
"moe_jitter_eps": self.moe_jitter_eps,
"moe_loss_weight": self.moe_loss_weight,
"moe_num_experts": self.moe_num_experts,
"moe_top_k": self.moe_top_k,
"model_type": self.ffn_config_model_type,
"ffn_act_fn": {"name": self.ffn_act_fn_name},
}
self.attn_config = {
"clip_qkv": self.clip_qkv,
"kv_n_heads": self.kv_n_heads,
"model_type": self.attn_config_model_type,
"rope_theta": self.rope_theta,
}
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = self.get_config()
return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
def get_config(self):
# Behind the scenes, `DbrxConfig` maps the parameters `hidden_size`, `num_hidden_layers`,
# `num_attention_heads`, `max_position_embeddings` to the parameters `d_model`, `n_layers`,
# `n_heads`, `max_seq_len` respectively. We use the first group of parameters because
# other tests expect every model to have these parameters with these specific names.
config = DbrxConfig(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size, # mapped to `d_model`
num_hidden_layers=self.num_hidden_layers, # mapped to `n_layers`
num_attention_heads=self.num_attention_heads, # mapped to `n_heads`
max_position_embeddings=self.max_position_embeddings, # mapped to `max_seq_len`
attn_config=self.attn_config,
ffn_config=self.ffn_config,
resid_pdrop=self.resid_pdrop,
emb_pdrop=self.emb_pdrop,
use_cache=self.use_cache,
initializer_range=self.initializer_range,
output_router_logits=self.output_router_logits,
is_decoder=self.is_decoder,
pad_token_id=self.pad_token_id,
)
return config
# Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_model with Llama->Dbrx
def create_and_check_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = DbrxModel(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask)
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
# Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_model_as_decoder with Llama->Dbrx
def create_and_check_model_as_decoder(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.add_cross_attention = True
model = DbrxModel(config)
model.to(torch_device)
model.eval()
result = model(
input_ids,
attention_mask=input_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
)
result = model(
input_ids,
attention_mask=input_mask,
encoder_hidden_states=encoder_hidden_states,
)
result = model(input_ids, attention_mask=input_mask)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
# Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_for_causal_lm with Llama->Dbrx
def create_and_check_for_causal_lm(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
model = DbrxForCausalLM(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_decoder_model_past_large_inputs(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.is_decoder = True
config.add_cross_attention = True
model = DbrxForCausalLM(config=config)
model.to(torch_device)
model.eval()
# first forward pass
outputs = model(
input_ids,
attention_mask=input_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
use_cache=True,
)
past_key_values = outputs.past_key_values
# create hypothetical multiple next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
# append to next input_ids and
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
output_from_no_past = model(
next_input_ids,
attention_mask=next_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_hidden_states=True,
)["hidden_states"][0]
output_from_past = model(
next_tokens,
attention_mask=next_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
output_hidden_states=True,
)["hidden_states"][0]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
# Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.prepare_config_and_inputs_for_common with Llama->Dbrx
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
return config, inputs_dict
@require_torch
class DbrxModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (DbrxModel, DbrxForCausalLM) if is_torch_available() else ()
all_generative_model_classes = (DbrxForCausalLM,) if is_torch_available() else ()
pipeline_model_mapping = {"text-generation": DbrxForCausalLM} if is_torch_available() else {}
test_headmasking = False
test_pruning = False
def setUp(self):
self.model_tester = DbrxModelTester(self)
self.config_tester = ConfigTester(self, config_class=DbrxConfig, d_model=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_model_various_embeddings(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
for type in ["absolute", "relative_key", "relative_key_query"]:
config_and_inputs[0].position_embedding_type = type
self.model_tester.create_and_check_model(*config_and_inputs)
@slow
def test_model_from_pretrained(self):
model_name = "eitanturok/dbrx-tiny"
model = DbrxModel.from_pretrained(model_name)
self.assertIsNotNone(model)
@unittest.skip(reason="Dbrx models have weight tying disabled.")
def test_tied_weights_keys(self):
pass
# Offload does not work with Dbrx models because of the forward of DbrxExperts where we chunk the experts.
# The issue is that the offloaded weights of the mlp layer are still on meta device (w1_chunked, v1_chunked, w2_chunked)
@unittest.skip(reason="Dbrx models do not work with offload")
def test_cpu_offload(self):
pass
@unittest.skip(reason="Dbrx models do not work with offload")
def test_disk_offload_safetensors(self):
pass
@unittest.skip(reason="Dbrx models do not work with offload")
def test_disk_offload_bin(self):
pass
@require_torch
class DbrxModelIntegrationTest(unittest.TestCase):
@slow
def test_tiny_model_logits(self):
model = DbrxForCausalLM.from_pretrained("Rocketknight1/dbrx-tiny-random")
input_ids = torch.tensor([[0, 1, 2, 3, 4, 5]])
output = model(input_ids)[0]
vocab_size = model.vocab_size
expected_shape = torch.Size((1, 6, vocab_size))
self.assertEqual(output.shape, expected_shape)
expected_slice = torch.tensor(
[
[
[-1.6300e-04, 5.0118e-04, 2.5437e-04],
[2.0422e-05, 2.7210e-04, -1.5125e-04],
[-1.5105e-04, 4.6879e-04, 3.3309e-04],
]
]
)
torch.testing.assert_close(output[:, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
| transformers/tests/models/dbrx/test_modeling_dbrx.py/0 | {
"file_path": "transformers/tests/models/dbrx/test_modeling_dbrx.py",
"repo_id": "transformers",
"token_count": 6972
} |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Testing suite for the PyTorch DeiT model."""
import unittest
import warnings
from transformers import DeiTConfig
from transformers.testing_utils import (
require_accelerate,
require_torch,
require_torch_accelerator,
require_torch_fp16,
require_vision,
slow,
torch_device,
)
from transformers.utils import cached_property, is_torch_available, is_vision_available
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from torch import nn
from transformers import (
DeiTForImageClassification,
DeiTForImageClassificationWithTeacher,
DeiTForMaskedImageModeling,
DeiTModel,
)
from transformers.models.auto.modeling_auto import (
MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES,
MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES,
MODEL_MAPPING_NAMES,
)
if is_vision_available():
from PIL import Image
from transformers import DeiTImageProcessor
class DeiTModelTester:
def __init__(
self,
parent,
batch_size=13,
image_size=30,
patch_size=2,
num_channels=3,
is_training=True,
use_labels=True,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
type_sequence_label_size=10,
initializer_range=0.02,
num_labels=3,
scope=None,
encoder_stride=2,
mask_ratio=0.5,
attn_implementation="eager",
):
self.parent = parent
self.batch_size = batch_size
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.is_training = is_training
self.use_labels = use_labels
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.scope = scope
self.encoder_stride = encoder_stride
self.attn_implementation = attn_implementation
# in DeiT, the seq length equals the number of patches + 2 (we add 2 for the [CLS] and distilation tokens)
num_patches = (image_size // patch_size) ** 2
self.seq_length = num_patches + 2
self.mask_ratio = mask_ratio
self.num_masks = int(mask_ratio * self.seq_length)
self.mask_length = num_patches
def prepare_config_and_inputs(self):
pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
labels = None
if self.use_labels:
labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
config = self.get_config()
return config, pixel_values, labels
def get_config(self):
return DeiTConfig(
image_size=self.image_size,
patch_size=self.patch_size,
num_channels=self.num_channels,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
is_decoder=False,
initializer_range=self.initializer_range,
encoder_stride=self.encoder_stride,
attn_implementation=self.attn_implementation,
)
def create_and_check_model(self, config, pixel_values, labels):
model = DeiTModel(config=config)
model.to(torch_device)
model.eval()
result = model(pixel_values)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_for_masked_image_modeling(self, config, pixel_values, labels):
model = DeiTForMaskedImageModeling(config=config)
model.to(torch_device)
model.eval()
result = model(pixel_values)
self.parent.assertEqual(
result.reconstruction.shape, (self.batch_size, self.num_channels, self.image_size, self.image_size)
)
# test greyscale images
config.num_channels = 1
model = DeiTForMaskedImageModeling(config)
model.to(torch_device)
model.eval()
pixel_values = floats_tensor([self.batch_size, 1, self.image_size, self.image_size])
result = model(pixel_values)
self.parent.assertEqual(result.reconstruction.shape, (self.batch_size, 1, self.image_size, self.image_size))
def create_and_check_for_image_classification(self, config, pixel_values, labels):
config.num_labels = self.type_sequence_label_size
model = DeiTForImageClassification(config)
model.to(torch_device)
model.eval()
result = model(pixel_values, labels=labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
# test greyscale images
config.num_channels = 1
model = DeiTForImageClassification(config)
model.to(torch_device)
model.eval()
pixel_values = floats_tensor([self.batch_size, 1, self.image_size, self.image_size])
result = model(pixel_values, labels=labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
pixel_values,
labels,
) = config_and_inputs
inputs_dict = {"pixel_values": pixel_values}
return config, inputs_dict
@require_torch
class DeiTModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
"""
Here we also overwrite some of the tests of test_modeling_common.py, as DeiT does not use input_ids, inputs_embeds,
attention_mask and seq_length.
"""
all_model_classes = (
(
DeiTModel,
DeiTForImageClassification,
DeiTForImageClassificationWithTeacher,
DeiTForMaskedImageModeling,
)
if is_torch_available()
else ()
)
pipeline_model_mapping = (
{
"image-feature-extraction": DeiTModel,
"image-classification": (DeiTForImageClassification, DeiTForImageClassificationWithTeacher),
}
if is_torch_available()
else {}
)
test_pruning = False
test_resize_embeddings = False
test_head_masking = False
def setUp(self):
self.model_tester = DeiTModelTester(self)
self.config_tester = ConfigTester(self, config_class=DeiTConfig, has_text_modality=False, hidden_size=37)
@unittest.skip(
"Since `torch==2.3+cu121`, although this test passes, many subsequent tests have `CUDA error: misaligned address`."
"If `nvidia-xxx-cu118` are also installed, no failure (even with `torch==2.3+cu121`)."
)
def test_multi_gpu_data_parallel_forward(self):
super().test_multi_gpu_data_parallel_forward()
def test_config(self):
self.config_tester.run_common_tests()
@unittest.skip(reason="DeiT does not use inputs_embeds")
def test_inputs_embeds(self):
pass
def test_model_get_set_embeddings(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config)
self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_for_masked_image_modeling(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_masked_image_modeling(*config_and_inputs)
def test_for_image_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_image_classification(*config_and_inputs)
# special case for DeiTForImageClassificationWithTeacher model
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
if return_labels:
if model_class.__name__ == "DeiTForImageClassificationWithTeacher":
del inputs_dict["labels"]
return inputs_dict
def test_training(self):
if not self.model_tester.is_training:
self.skipTest(reason="model_tester.is_training is set to False")
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
for model_class in self.all_model_classes:
# DeiTForImageClassificationWithTeacher supports inference-only
if (
model_class.__name__ in MODEL_MAPPING_NAMES.values()
or model_class.__name__ == "DeiTForImageClassificationWithTeacher"
):
continue
model = model_class(config)
model.to(torch_device)
model.train()
inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
loss = model(**inputs).loss
loss.backward()
def test_training_gradient_checkpointing(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
if not self.model_tester.is_training:
self.skipTest(reason="model_tester.is_training is set to False")
config.use_cache = False
config.return_dict = True
for model_class in self.all_model_classes:
if model_class.__name__ in MODEL_MAPPING_NAMES.values() or not model_class.supports_gradient_checkpointing:
continue
# DeiTForImageClassificationWithTeacher supports inference-only
if model_class.__name__ == "DeiTForImageClassificationWithTeacher":
continue
model = model_class(config)
model.gradient_checkpointing_enable()
model.to(torch_device)
model.train()
inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
loss = model(**inputs).loss
loss.backward()
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant_false(self):
pass
def test_problem_types(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
problem_types = [
{"title": "multi_label_classification", "num_labels": 2, "dtype": torch.float},
{"title": "single_label_classification", "num_labels": 1, "dtype": torch.long},
{"title": "regression", "num_labels": 1, "dtype": torch.float},
]
for model_class in self.all_model_classes:
if (
model_class.__name__
not in [
*MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES.values(),
*MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES.values(),
]
or model_class.__name__ == "DeiTForImageClassificationWithTeacher"
):
continue
for problem_type in problem_types:
with self.subTest(msg=f"Testing {model_class} with {problem_type['title']}"):
config.problem_type = problem_type["title"]
config.num_labels = problem_type["num_labels"]
model = model_class(config)
model.to(torch_device)
model.train()
inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
if problem_type["num_labels"] > 1:
inputs["labels"] = inputs["labels"].unsqueeze(1).repeat(1, problem_type["num_labels"])
inputs["labels"] = inputs["labels"].to(problem_type["dtype"])
# This tests that we do not trigger the warning form PyTorch "Using a target size that is different
# to the input size. This will likely lead to incorrect results due to broadcasting. Please ensure
# they have the same size." which is a symptom something in wrong for the regression problem.
# See https://github.com/huggingface/transformers/issues/11780
with warnings.catch_warnings(record=True) as warning_list:
loss = model(**inputs).loss
for w in warning_list:
if "Using a target size that is different to the input size" in str(w.message):
raise ValueError(
f"Something is going wrong in the regression problem: intercepted {w.message}"
)
loss.backward()
@slow
def test_model_from_pretrained(self):
model_name = "facebook/deit-base-distilled-patch16-224"
model = DeiTModel.from_pretrained(model_name)
self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
def prepare_img():
image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
return image
@require_torch
@require_vision
class DeiTModelIntegrationTest(unittest.TestCase):
@cached_property
def default_image_processor(self):
return (
DeiTImageProcessor.from_pretrained("facebook/deit-base-distilled-patch16-224")
if is_vision_available()
else None
)
@slow
def test_inference_image_classification_head(self):
model = DeiTForImageClassificationWithTeacher.from_pretrained("facebook/deit-base-distilled-patch16-224").to(
torch_device
)
image_processor = self.default_image_processor
image = prepare_img()
inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
# forward pass
with torch.no_grad():
outputs = model(**inputs)
# verify the logits
expected_shape = torch.Size((1, 1000))
self.assertEqual(outputs.logits.shape, expected_shape)
expected_slice = torch.tensor([-1.0266, 0.1912, -1.2861]).to(torch_device)
torch.testing.assert_close(outputs.logits[0, :3], expected_slice, rtol=1e-4, atol=1e-4)
@slow
def test_inference_interpolate_pos_encoding(self):
model = DeiTForImageClassificationWithTeacher.from_pretrained("facebook/deit-base-distilled-patch16-224").to(
torch_device
)
image_processor = self.default_image_processor
# image size is {"height": 480, "width": 640}
image = prepare_img()
image_processor.size = {"height": 480, "width": 640}
# center crop set to False so image is not center cropped to 224x224
inputs = image_processor(images=image, return_tensors="pt", do_center_crop=False).to(torch_device)
# forward pass
with torch.no_grad():
outputs = model(**inputs, interpolate_pos_encoding=True)
# verify the logits
expected_shape = torch.Size((1, 1000))
self.assertEqual(outputs.logits.shape, expected_shape)
@slow
@require_accelerate
@require_torch_accelerator
@require_torch_fp16
def test_inference_fp16(self):
r"""
A small test to make sure that inference work in half precision without any problem.
"""
model = DeiTModel.from_pretrained(
"facebook/deit-base-distilled-patch16-224", torch_dtype=torch.float16, device_map="auto"
)
image_processor = self.default_image_processor
image = prepare_img()
inputs = image_processor(images=image, return_tensors="pt")
pixel_values = inputs.pixel_values.to(torch_device)
# forward pass to make sure inference works in fp16
with torch.no_grad():
_ = model(pixel_values)
| transformers/tests/models/deit/test_modeling_deit.py/0 | {
"file_path": "transformers/tests/models/deit/test_modeling_deit.py",
"repo_id": "transformers",
"token_count": 7903
} |
# coding=utf-8
# Copyright 2022 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
import numpy as np
from datasets import load_dataset
from transformers.file_utils import is_torch_available, is_vision_available
from transformers.testing_utils import require_torch, require_vision
from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
if is_torch_available():
import torch
if is_vision_available():
from PIL import Image
from transformers import DPTImageProcessor
class DPTImageProcessingTester:
def __init__(
self,
parent,
batch_size=7,
num_channels=3,
image_size=18,
min_resolution=30,
max_resolution=400,
do_resize=True,
size=None,
do_normalize=True,
image_mean=[0.5, 0.5, 0.5],
image_std=[0.5, 0.5, 0.5],
do_reduce_labels=False,
):
size = size if size is not None else {"height": 18, "width": 18}
self.parent = parent
self.batch_size = batch_size
self.num_channels = num_channels
self.image_size = image_size
self.min_resolution = min_resolution
self.max_resolution = max_resolution
self.do_resize = do_resize
self.size = size
self.do_normalize = do_normalize
self.image_mean = image_mean
self.image_std = image_std
self.do_reduce_labels = do_reduce_labels
def prepare_image_processor_dict(self):
return {
"image_mean": self.image_mean,
"image_std": self.image_std,
"do_normalize": self.do_normalize,
"do_resize": self.do_resize,
"size": self.size,
"do_reduce_labels": self.do_reduce_labels,
}
def expected_output_image_shape(self, images):
return self.num_channels, self.size["height"], self.size["width"]
def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
return prepare_image_inputs(
batch_size=self.batch_size,
num_channels=self.num_channels,
min_resolution=self.min_resolution,
max_resolution=self.max_resolution,
equal_resolution=equal_resolution,
numpify=numpify,
torchify=torchify,
)
# Copied from transformers.tests.models.beit.test_image_processing_beit.prepare_semantic_single_inputs
def prepare_semantic_single_inputs():
dataset = load_dataset("hf-internal-testing/fixtures_ade20k", split="test", trust_remote_code=True)
image = Image.open(dataset[0]["file"])
map = Image.open(dataset[1]["file"])
return image, map
# Copied from transformers.tests.models.beit.test_image_processing_beit.prepare_semantic_batch_inputs
def prepare_semantic_batch_inputs():
ds = load_dataset("hf-internal-testing/fixtures_ade20k", split="test", trust_remote_code=True)
image1 = Image.open(ds[0]["file"])
map1 = Image.open(ds[1]["file"])
image2 = Image.open(ds[2]["file"])
map2 = Image.open(ds[3]["file"])
return [image1, image2], [map1, map2]
@require_torch
@require_vision
class DPTImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
image_processing_class = DPTImageProcessor if is_vision_available() else None
def setUp(self):
super().setUp()
self.image_processor_tester = DPTImageProcessingTester(self)
@property
def image_processor_dict(self):
return self.image_processor_tester.prepare_image_processor_dict()
def test_image_processor_properties(self):
image_processing = self.image_processing_class(**self.image_processor_dict)
self.assertTrue(hasattr(image_processing, "image_mean"))
self.assertTrue(hasattr(image_processing, "image_std"))
self.assertTrue(hasattr(image_processing, "do_normalize"))
self.assertTrue(hasattr(image_processing, "do_resize"))
self.assertTrue(hasattr(image_processing, "size"))
self.assertTrue(hasattr(image_processing, "do_rescale"))
self.assertTrue(hasattr(image_processing, "rescale_factor"))
self.assertTrue(hasattr(image_processing, "do_pad"))
self.assertTrue(hasattr(image_processing, "size_divisor"))
self.assertTrue(hasattr(image_processing, "do_reduce_labels"))
def test_image_processor_from_dict_with_kwargs(self):
image_processor = self.image_processing_class.from_dict(self.image_processor_dict)
self.assertEqual(image_processor.size, {"height": 18, "width": 18})
image_processor = self.image_processing_class.from_dict(self.image_processor_dict, size=42)
self.assertEqual(image_processor.size, {"height": 42, "width": 42})
def test_padding(self):
image_processing = self.image_processing_class(**self.image_processor_dict)
image = np.random.randn(3, 249, 491)
# test individual method
image = image_processing.pad_image(image, size_divisor=4)
self.assertTrue(image.shape[1] % 4 == 0)
self.assertTrue(image.shape[2] % 4 == 0)
# test by calling
pixel_values = image_processing.preprocess(
image, do_rescale=False, do_resize=False, do_pad=True, size_divisor=4, return_tensors="pt"
).pixel_values
self.assertTrue(pixel_values.shape[2] % 4 == 0)
self.assertTrue(pixel_values.shape[3] % 4 == 0)
def test_keep_aspect_ratio(self):
size = {"height": 512, "width": 512}
image_processor = DPTImageProcessor(size=size, keep_aspect_ratio=True, ensure_multiple_of=32)
image = np.zeros((489, 640, 3))
pixel_values = image_processor(image, return_tensors="pt").pixel_values
self.assertEqual(list(pixel_values.shape), [1, 3, 512, 672])
# Copied from transformers.tests.models.beit.test_image_processing_beit.BeitImageProcessingTest.test_call_segmentation_maps
def test_call_segmentation_maps(self):
# Initialize image_processor
image_processor = self.image_processing_class(**self.image_processor_dict)
# create random PyTorch tensors
image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, torchify=True)
maps = []
for image in image_inputs:
self.assertIsInstance(image, torch.Tensor)
maps.append(torch.zeros(image.shape[-2:]).long())
# Test not batched input
encoding = image_processor(image_inputs[0], maps[0], return_tensors="pt")
self.assertEqual(
encoding["pixel_values"].shape,
(
1,
self.image_processor_tester.num_channels,
self.image_processor_tester.size["height"],
self.image_processor_tester.size["width"],
),
)
self.assertEqual(
encoding["labels"].shape,
(
1,
self.image_processor_tester.size["height"],
self.image_processor_tester.size["width"],
),
)
self.assertEqual(encoding["labels"].dtype, torch.long)
self.assertTrue(encoding["labels"].min().item() >= 0)
self.assertTrue(encoding["labels"].max().item() <= 255)
# Test batched
encoding = image_processor(image_inputs, maps, return_tensors="pt")
self.assertEqual(
encoding["pixel_values"].shape,
(
self.image_processor_tester.batch_size,
self.image_processor_tester.num_channels,
self.image_processor_tester.size["height"],
self.image_processor_tester.size["width"],
),
)
self.assertEqual(
encoding["labels"].shape,
(
self.image_processor_tester.batch_size,
self.image_processor_tester.size["height"],
self.image_processor_tester.size["width"],
),
)
self.assertEqual(encoding["labels"].dtype, torch.long)
self.assertTrue(encoding["labels"].min().item() >= 0)
self.assertTrue(encoding["labels"].max().item() <= 255)
# Test not batched input (PIL images)
image, segmentation_map = prepare_semantic_single_inputs()
encoding = image_processor(image, segmentation_map, return_tensors="pt")
self.assertEqual(
encoding["pixel_values"].shape,
(
1,
self.image_processor_tester.num_channels,
self.image_processor_tester.size["height"],
self.image_processor_tester.size["width"],
),
)
self.assertEqual(
encoding["labels"].shape,
(
1,
self.image_processor_tester.size["height"],
self.image_processor_tester.size["width"],
),
)
self.assertEqual(encoding["labels"].dtype, torch.long)
self.assertTrue(encoding["labels"].min().item() >= 0)
self.assertTrue(encoding["labels"].max().item() <= 255)
# Test batched input (PIL images)
images, segmentation_maps = prepare_semantic_batch_inputs()
encoding = image_processor(images, segmentation_maps, return_tensors="pt")
self.assertEqual(
encoding["pixel_values"].shape,
(
2,
self.image_processor_tester.num_channels,
self.image_processor_tester.size["height"],
self.image_processor_tester.size["width"],
),
)
self.assertEqual(
encoding["labels"].shape,
(
2,
self.image_processor_tester.size["height"],
self.image_processor_tester.size["width"],
),
)
self.assertEqual(encoding["labels"].dtype, torch.long)
self.assertTrue(encoding["labels"].min().item() >= 0)
self.assertTrue(encoding["labels"].max().item() <= 255)
# Copied from transformers.tests.models.beit.test_image_processing_beit.BeitImageProcessingTest.test_reduce_labels
def test_reduce_labels(self):
# Initialize image_processor
image_processor = self.image_processing_class(**self.image_processor_dict)
# ADE20k has 150 classes, and the background is included, so labels should be between 0 and 150
image, map = prepare_semantic_single_inputs()
encoding = image_processor(image, map, return_tensors="pt")
self.assertTrue(encoding["labels"].min().item() >= 0)
self.assertTrue(encoding["labels"].max().item() <= 150)
image_processor.do_reduce_labels = True
encoding = image_processor(image, map, return_tensors="pt")
self.assertTrue(encoding["labels"].min().item() >= 0)
self.assertTrue(encoding["labels"].max().item() <= 255)
| transformers/tests/models/dpt/test_image_processing_dpt.py/0 | {
"file_path": "transformers/tests/models/dpt/test_image_processing_dpt.py",
"repo_id": "transformers",
"token_count": 4995
} |
# coding=utf-8
# Copyright 2021-2023 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tests for the EnCodec feature extractor."""
import itertools
import random
import unittest
import numpy as np
from transformers import EncodecFeatureExtractor
from transformers.testing_utils import require_torch
from transformers.utils.import_utils import is_torch_available
from ...test_sequence_feature_extraction_common import SequenceFeatureExtractionTestMixin
if is_torch_available():
import torch
global_rng = random.Random()
# Copied from tests.models.whisper.test_feature_extraction_whisper.floats_list
def floats_list(shape, scale=1.0, rng=None, name=None):
"""Creates a random float32 tensor"""
if rng is None:
rng = global_rng
values = []
for batch_idx in range(shape[0]):
values.append([])
for _ in range(shape[1]):
values[-1].append(rng.random() * scale)
return values
@require_torch
class EnCodecFeatureExtractionTester:
def __init__(
self,
parent,
batch_size=7,
min_seq_length=400,
max_seq_length=2000,
feature_size=1,
padding_value=0.0,
sampling_rate=24000,
return_attention_mask=True,
):
self.parent = parent
self.batch_size = batch_size
self.min_seq_length = min_seq_length
self.max_seq_length = max_seq_length
self.seq_length_diff = (self.max_seq_length - self.min_seq_length) // (self.batch_size - 1)
self.feature_size = feature_size
self.padding_value = padding_value
self.sampling_rate = sampling_rate
self.return_attention_mask = return_attention_mask
def prepare_feat_extract_dict(self):
return {
"feature_size": self.feature_size,
"padding_value": self.padding_value,
"sampling_rate": self.sampling_rate,
"return_attention_mask": self.return_attention_mask,
}
def prepare_inputs_for_common(self, equal_length=False, numpify=False):
def _flatten(list_of_lists):
return list(itertools.chain(*list_of_lists))
if equal_length:
audio_inputs = floats_list((self.batch_size, self.max_seq_length))
else:
# make sure that inputs increase in size
audio_inputs = [
_flatten(floats_list((x, self.feature_size)))
for x in range(self.min_seq_length, self.max_seq_length, self.seq_length_diff)
]
if numpify:
audio_inputs = [np.asarray(x) for x in audio_inputs]
return audio_inputs
@require_torch
class EnCodecFeatureExtractionTest(SequenceFeatureExtractionTestMixin, unittest.TestCase):
feature_extraction_class = EncodecFeatureExtractor
def setUp(self):
self.feat_extract_tester = EnCodecFeatureExtractionTester(self)
def test_call(self):
# Tests that all call wrap to encode_plus and batch_encode_plus
feat_extract = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
# create three inputs of length 800, 1000, and 1200
audio_inputs = [floats_list((1, x))[0] for x in range(800, 1400, 200)]
np_audio_inputs = [np.asarray(audio_input) for audio_input in audio_inputs]
# Test not batched input
encoded_sequences_1 = feat_extract(audio_inputs[0], return_tensors="np").input_values
encoded_sequences_2 = feat_extract(np_audio_inputs[0], return_tensors="np").input_values
self.assertTrue(np.allclose(encoded_sequences_1, encoded_sequences_2, atol=1e-3))
# Test batched
encoded_sequences_1 = feat_extract(audio_inputs, padding=True, return_tensors="np").input_values
encoded_sequences_2 = feat_extract(np_audio_inputs, padding=True, return_tensors="np").input_values
for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
def test_double_precision_pad(self):
feature_extractor = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
np_audio_inputs = np.random.rand(100).astype(np.float64)
py_audio_inputs = np_audio_inputs.tolist()
for inputs in [py_audio_inputs, np_audio_inputs]:
np_processed = feature_extractor.pad([{"input_values": inputs}], return_tensors="np")
self.assertTrue(np_processed.input_values.dtype == np.float32)
pt_processed = feature_extractor.pad([{"input_values": inputs}], return_tensors="pt")
self.assertTrue(pt_processed.input_values.dtype == torch.float32)
def _load_datasamples(self, num_samples):
from datasets import load_dataset
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
# automatic decoding with librispeech
audio_samples = ds.sort("id").select(range(num_samples))[:num_samples]["audio"]
return [x["array"] for x in audio_samples]
def test_integration(self):
# fmt: off
EXPECTED_INPUT_VALUES = torch.tensor(
[2.3804e-03, 2.0752e-03, 1.9836e-03, 2.1057e-03, 1.6174e-03,
3.0518e-04, 9.1553e-05, 3.3569e-04, 9.7656e-04, 1.8311e-03,
2.0142e-03, 2.1057e-03, 1.7395e-03, 4.5776e-04, -3.9673e-04,
4.5776e-04, 1.0071e-03, 9.1553e-05, 4.8828e-04, 1.1597e-03,
7.3242e-04, 9.4604e-04, 1.8005e-03, 1.8311e-03, 8.8501e-04,
4.2725e-04, 4.8828e-04, 7.3242e-04, 1.0986e-03, 2.1057e-03]
)
# fmt: on
input_audio = self._load_datasamples(1)
feature_extractor = EncodecFeatureExtractor()
input_values = feature_extractor(input_audio, return_tensors="pt").input_values
self.assertEqual(input_values.shape, (1, 1, 93680))
torch.testing.assert_close(input_values[0, 0, :30], EXPECTED_INPUT_VALUES, rtol=1e-6, atol=1e-6)
def test_integration_stereo(self):
# fmt: off
EXPECTED_INPUT_VALUES = torch.tensor(
[2.3804e-03, 2.0752e-03, 1.9836e-03, 2.1057e-03, 1.6174e-03,
3.0518e-04, 9.1553e-05, 3.3569e-04, 9.7656e-04, 1.8311e-03,
2.0142e-03, 2.1057e-03, 1.7395e-03, 4.5776e-04, -3.9673e-04,
4.5776e-04, 1.0071e-03, 9.1553e-05, 4.8828e-04, 1.1597e-03,
7.3242e-04, 9.4604e-04, 1.8005e-03, 1.8311e-03, 8.8501e-04,
4.2725e-04, 4.8828e-04, 7.3242e-04, 1.0986e-03, 2.1057e-03]
)
# fmt: on
input_audio = self._load_datasamples(1)
input_audio = [np.tile(input_audio[0][None], reps=(2, 1))]
input_audio[0][1] *= 0.5
feature_extractor = EncodecFeatureExtractor(feature_size=2)
input_values = feature_extractor(input_audio, return_tensors="pt").input_values
self.assertEqual(input_values.shape, (1, 2, 93680))
torch.testing.assert_close(input_values[0, 0, :30], EXPECTED_INPUT_VALUES, rtol=1e-6, atol=1e-6)
torch.testing.assert_close(input_values[0, 1, :30], EXPECTED_INPUT_VALUES * 0.5, rtol=1e-6, atol=1e-6)
def test_truncation_and_padding(self):
input_audio = self._load_datasamples(2)
# would be easier if the stride was like
feature_extractor = EncodecFeatureExtractor(feature_size=1, chunk_length_s=1, overlap=0.01)
# pad and trunc raise an error ?
with self.assertRaisesRegex(
ValueError,
"^Both padding and truncation were set. Make sure you only set one.$",
):
truncated_outputs = feature_extractor(
input_audio, padding="max_length", truncation=True, return_tensors="pt"
).input_values
# truncate to chunk
truncated_outputs = feature_extractor(input_audio, truncation=True, return_tensors="pt").input_values
self.assertEqual(truncated_outputs.shape, (2, 1, 71520)) # 2 chunks
# force truncate to max_length
truncated_outputs = feature_extractor(
input_audio, truncation=True, max_length=48000, return_tensors="pt"
).input_values
self.assertEqual(truncated_outputs.shape, (2, 1, 48000))
# pad to chunk
padded_outputs = feature_extractor(input_audio, padding=True, return_tensors="pt").input_values
self.assertEqual(padded_outputs.shape, (2, 1, 95280))
# pad to chunk
truncated_outputs = feature_extractor(input_audio, return_tensors="pt").input_values
self.assertEqual(truncated_outputs.shape, (2, 1, 95280))
# force pad to max length
truncated_outputs = feature_extractor(
input_audio, padding="max_length", max_length=100000, return_tensors="pt"
).input_values
self.assertEqual(truncated_outputs.shape, (2, 1, 100000))
# force no pad
with self.assertRaisesRegex(
ValueError,
"^Unable to create tensor, you should probably activate padding with 'padding=True' to have batched tensors with the same length.$",
):
truncated_outputs = feature_extractor(input_audio, padding=False, return_tensors="pt").input_values
truncated_outputs = feature_extractor(input_audio[0], padding=False, return_tensors="pt").input_values
self.assertEqual(truncated_outputs.shape, (1, 1, 93680))
# no pad if no chunk_length_s
feature_extractor.chunk_length_s = None
with self.assertRaisesRegex(
ValueError,
"^Unable to create tensor, you should probably activate padding with 'padding=True' to have batched tensors with the same length.$",
):
truncated_outputs = feature_extractor(input_audio, padding=False, return_tensors="pt").input_values
truncated_outputs = feature_extractor(input_audio[0], padding=False, return_tensors="pt").input_values
self.assertEqual(truncated_outputs.shape, (1, 1, 93680))
# no pad if no overlap
feature_extractor.chunk_length_s = 2
feature_extractor.overlap = None
with self.assertRaisesRegex(
ValueError,
"^Unable to create tensor, you should probably activate padding with 'padding=True' to have batched tensors with the same length.$",
):
truncated_outputs = feature_extractor(input_audio, padding=False, return_tensors="pt").input_values
truncated_outputs = feature_extractor(input_audio[0], padding=False, return_tensors="pt").input_values
self.assertEqual(truncated_outputs.shape, (1, 1, 93680))
| transformers/tests/models/encodec/test_feature_extraction_encodec.py/0 | {
"file_path": "transformers/tests/models/encodec/test_feature_extraction_encodec.py",
"repo_id": "transformers",
"token_count": 4925
} |
# coding=utf-8
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import math
import unittest
from typing import Dict, List, Tuple
from unittest.util import safe_repr
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, FalconMambaConfig, is_torch_available
from transformers.testing_utils import (
require_bitsandbytes,
require_torch,
require_torch_accelerator,
require_torch_multi_gpu,
slow,
torch_device,
)
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from transformers import (
FalconMambaForCausalLM,
FalconMambaModel,
)
from transformers.cache_utils import MambaCache
# Copied from transformers.tests.models.mamba.MambaModelTester with Mamba->FalconMamba,mamba->falcon_mamba
class FalconMambaModelTester:
def __init__(
self,
parent,
batch_size=14,
seq_length=7,
is_training=True,
use_labels=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=2,
intermediate_size=32,
hidden_act="silu",
hidden_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
type_sequence_label_size=2,
num_labels=3,
num_choices=4,
scope=None,
tie_word_embeddings=True,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.type_sequence_label_size = type_sequence_label_size
self.num_labels = num_labels
self.num_choices = num_choices
self.scope = scope
self.bos_token_id = vocab_size - 1
self.eos_token_id = vocab_size - 1
self.pad_token_id = vocab_size - 1
self.tie_word_embeddings = tie_word_embeddings
# Ignore copy
def get_large_model_config(self):
return FalconMambaConfig.from_pretrained("tiiuae/falcon-mamba-7b")
def prepare_config_and_inputs(
self, gradient_checkpointing=False, scale_attn_by_inverse_layer_idx=False, reorder_and_upcast_attn=False
):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
attention_mask = ids_tensor([self.batch_size, self.seq_length], 1)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = self.get_config(
gradient_checkpointing=gradient_checkpointing,
scale_attn_by_inverse_layer_idx=scale_attn_by_inverse_layer_idx,
reorder_and_upcast_attn=reorder_and_upcast_attn,
)
return (
config,
input_ids,
attention_mask,
sequence_labels,
token_labels,
choice_labels,
)
def get_config(
self, gradient_checkpointing=False, scale_attn_by_inverse_layer_idx=False, reorder_and_upcast_attn=False
):
return FalconMambaConfig(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
intermediate_size=self.intermediate_size,
activation_function=self.hidden_act,
n_positions=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
use_cache=True,
bos_token_id=self.bos_token_id,
eos_token_id=self.eos_token_id,
pad_token_id=self.pad_token_id,
gradient_checkpointing=gradient_checkpointing,
tie_word_embeddings=self.tie_word_embeddings,
)
def get_pipeline_config(self):
config = self.get_config()
config.vocab_size = 300
return config
def create_and_check_falcon_mamba_model(self, config, input_ids, *args):
config.output_hidden_states = True
model = FalconMambaModel(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
self.parent.assertEqual(len(result.hidden_states), config.num_hidden_layers + 1)
def create_and_check_causal_lm(self, config, input_ids, *args):
model = FalconMambaForCausalLM(config)
model.to(torch_device)
model.eval()
result = model(input_ids, labels=input_ids)
self.parent.assertEqual(result.loss.shape, ())
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_state_equivalency(self, config, input_ids, *args):
model = FalconMambaModel(config=config)
model.to(torch_device)
model.eval()
outputs = model(input_ids)
output_whole = outputs.last_hidden_state
outputs = model(
input_ids[:, :-1],
use_cache=True,
cache_position=torch.arange(0, config.conv_kernel, device=input_ids.device),
)
output_one = outputs.last_hidden_state
# Using the state computed on the first inputs, we will get the same output
outputs = model(
input_ids[:, -1:],
use_cache=True,
cache_params=outputs.cache_params,
cache_position=torch.arange(config.conv_kernel, config.conv_kernel + 1, device=input_ids.device),
)
output_two = outputs.last_hidden_state
self.parent.assertTrue(torch.allclose(torch.cat([output_one, output_two], dim=1), output_whole, atol=1e-5))
# TODO the orignal mamba does not support decoding more than 1 token neither do we
def create_and_check_falcon_mamba_cached_slow_forward_and_backwards(
self, config, input_ids, *args, gradient_checkpointing=False
):
model = FalconMambaModel(config)
model.to(torch_device)
if gradient_checkpointing:
model.gradient_checkpointing_enable()
# create cache
cache = model(input_ids, use_cache=True).cache_params
cache.reset()
# use cache
token_emb = model.embeddings(input_ids)
outputs = model.layers[0].mixer.slow_forward(
token_emb, cache, cache_position=torch.arange(0, config.conv_kernel, device=input_ids.device)
)
loss = torch.log(1 + torch.abs(outputs.sum()))
self.parent.assertEqual(loss.shape, ())
self.parent.assertEqual(outputs.shape, (self.batch_size, self.seq_length, self.hidden_size))
loss.backward()
def create_and_check_falcon_mamba_lm_head_forward_and_backwards(
self, config, input_ids, *args, gradient_checkpointing=False
):
model = FalconMambaForCausalLM(config)
model.to(torch_device)
if gradient_checkpointing:
model.gradient_checkpointing_enable()
result = model(input_ids, labels=input_ids)
self.parent.assertEqual(result.loss.shape, ())
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
result.loss.backward()
def prepare_config_and_inputs_for_common(self):
(
config,
input_ids,
attention_mask,
sequence_labels,
token_labels,
choice_labels,
) = self.prepare_config_and_inputs()
inputs_dict = {"input_ids": input_ids, "attention_mask": attention_mask}
return config, inputs_dict
@require_torch
# Copied from transformers.tests.models.mamba.MambaModelTest with Mamba->Falcon,mamba->falcon_mamba,FalconMambaCache->MambaCache
class FalconMambaModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (FalconMambaModel, FalconMambaForCausalLM) if is_torch_available() else ()
all_generative_model_classes = (FalconMambaForCausalLM,) if is_torch_available() else ()
has_attentions = False # FalconMamba does not support attentions
fx_compatible = False # FIXME let's try to support this @ArthurZucker
test_torchscript = False # FIXME let's try to support this @ArthurZucker
test_missing_keys = False
test_model_parallel = False
test_pruning = False
test_head_masking = False # FalconMamba does not have attention heads
pipeline_model_mapping = (
{"feature-extraction": FalconMambaModel, "text-generation": FalconMambaForCausalLM}
if is_torch_available()
else {}
)
def setUp(self):
self.model_tester = FalconMambaModelTester(self)
self.config_tester = ConfigTester(
self, config_class=FalconMambaConfig, n_embd=37, common_properties=["hidden_size", "num_hidden_layers"]
)
def assertInterval(self, member, container, msg=None):
r"""
Simple utility function to check if a member is inside an interval.
"""
if isinstance(member, torch.Tensor):
max_value, min_value = member.max().item(), member.min().item()
elif isinstance(member, list) or isinstance(member, tuple):
max_value, min_value = max(member), min(member)
if not isinstance(container, list):
raise TypeError("container should be a list or tuple")
elif len(container) != 2:
raise ValueError("container should have 2 elements")
expected_min, expected_max = container
is_inside_interval = (min_value >= expected_min) and (max_value <= expected_max)
if not is_inside_interval:
standardMsg = "%s not found in %s" % (safe_repr(member), safe_repr(container))
self.fail(self._formatMessage(msg, standardMsg))
def test_config(self):
self.config_tester.run_common_tests()
@require_torch_multi_gpu
def test_multi_gpu_data_parallel_forward(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
# some params shouldn't be scattered by nn.DataParallel
# so just remove them if they are present.
blacklist_non_batched_params = ["cache_params"]
for k in blacklist_non_batched_params:
inputs_dict.pop(k, None)
# move input tensors to cuda:O
for k, v in inputs_dict.items():
if torch.is_tensor(v):
inputs_dict[k] = v.to(0)
for model_class in self.all_model_classes:
model = model_class(config=config)
model.to(0)
model.eval()
# Wrap model in nn.DataParallel
model = torch.nn.DataParallel(model)
with torch.no_grad():
_ = model(**self._prepare_for_class(inputs_dict, model_class))
def test_falcon_mamba_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_falcon_mamba_model(*config_and_inputs)
def test_falcon_mamba_lm_head_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_causal_lm(*config_and_inputs)
def test_state_equivalency(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_state_equivalency(*config_and_inputs)
def test_falcon_mamba_cached_slow_forward_and_backwards(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_falcon_mamba_cached_slow_forward_and_backwards(*config_and_inputs)
def test_falcon_mamba_lm_head_forward_and_backwards(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_falcon_mamba_lm_head_forward_and_backwards(*config_and_inputs)
def test_initialization(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config=config)
for name, param in model.named_parameters():
if "dt_proj.bias" in name:
dt = torch.exp(
torch.tensor([0, 1]) * (math.log(config.time_step_max) - math.log(config.time_step_min))
+ math.log(config.time_step_min)
).clamp(min=config.time_step_floor)
inv_dt = dt + torch.log(-torch.expm1(-dt))
if param.requires_grad:
self.assertTrue(param.data.max().item() <= inv_dt[1])
self.assertTrue(param.data.min().item() >= inv_dt[0])
elif "A_log" in name:
A = torch.arange(1, config.state_size + 1, dtype=torch.float32)[None, :]
A = A.expand(config.intermediate_size, -1).contiguous()
torch.testing.assert_close(param.data, torch.log(A), rtol=1e-5, atol=1e-5)
elif "D" in name:
if param.requires_grad:
# check if it's a ones like
torch.testing.assert_close(param.data, torch.ones_like(param.data), rtol=1e-5, atol=1e-5)
@slow
# Ignore copy
def test_model_from_pretrained(self):
model = FalconMambaModel.from_pretrained(
"tiiuae/falcon-mamba-7b", torch_dtype=torch.float16, low_cpu_mem_usage=True
)
self.assertIsNotNone(model)
def test_model_outputs_equivalence(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
def check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs={}):
with torch.no_grad():
tuple_output = model(**tuple_inputs, return_dict=False, **additional_kwargs)
dict_output = model(**dict_inputs, return_dict=True, **additional_kwargs).to_tuple()
def recursive_check(tuple_object, dict_object):
if isinstance(tuple_object, MambaCache): # MODIFIED PART START
recursive_check(tuple_object.conv_states, dict_object.conv_states)
recursive_check(tuple_object.ssm_states, dict_object.ssm_states)
elif isinstance(tuple_object, (List, Tuple)): # MODIFIED PART END
for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object):
recursive_check(tuple_iterable_value, dict_iterable_value)
elif isinstance(tuple_object, Dict):
for tuple_iterable_value, dict_iterable_value in zip(
tuple_object.values(), dict_object.values()
):
recursive_check(tuple_iterable_value, dict_iterable_value)
elif tuple_object is None:
return
else:
self.assertTrue(
torch.allclose(tuple_object, dict_object, atol=1e-5),
msg=(
"Tuple and dict output are not equal. Difference:"
f" {torch.max(torch.abs(tuple_object - dict_object))}. Tuple has `nan`:"
f" {torch.isnan(tuple_object).any()} and `inf`: {torch.isinf(tuple_object)}. Dict has"
f" `nan`: {torch.isnan(dict_object).any()} and `inf`: {torch.isinf(dict_object)}."
),
)
recursive_check(tuple_output, dict_output)
for model_class in self.all_model_classes:
model = model_class(config)
model.to(torch_device)
model.eval()
tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
dict_inputs = self._prepare_for_class(inputs_dict, model_class)
check_equivalence(model, tuple_inputs, dict_inputs)
tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
check_equivalence(model, tuple_inputs, dict_inputs)
tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
dict_inputs = self._prepare_for_class(inputs_dict, model_class)
check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
@require_torch
@require_torch_accelerator
@slow
class FalconMambaIntegrationTests(unittest.TestCase):
def setUp(self):
self.model_id = "tiiuae/falcon-mamba-7b"
self.tokenizer = AutoTokenizer.from_pretrained(self.model_id)
self.text = "Hello today"
def test_generation_bf16(self):
model = AutoModelForCausalLM.from_pretrained(self.model_id, torch_dtype=torch.bfloat16, device_map="auto")
inputs = self.tokenizer(self.text, return_tensors="pt").to(torch_device)
out = model.generate(**inputs, max_new_tokens=20, do_sample=False)
self.assertEqual(
self.tokenizer.batch_decode(out, skip_special_tokens=False)[0],
"Hello today I am going to show you how to make a simple and easy to make paper plane.\nStep",
)
@require_bitsandbytes
def test_generation_4bit(self):
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(self.model_id, quantization_config=quantization_config)
inputs = self.tokenizer(self.text, return_tensors="pt").to(torch_device)
out = model.generate(**inputs, max_new_tokens=20, do_sample=False)
self.assertEqual(
self.tokenizer.batch_decode(out, skip_special_tokens=False)[0],
"""Hello today I'm going to talk about the "C" in the "C-I-""",
)
def test_generation_torch_compile(self):
model = AutoModelForCausalLM.from_pretrained(self.model_id, torch_dtype=torch.bfloat16).to(torch_device)
model = torch.compile(model)
inputs = self.tokenizer(self.text, return_tensors="pt").to(torch_device)
out = model.generate(**inputs, max_new_tokens=20, do_sample=False)
self.assertEqual(
self.tokenizer.batch_decode(out, skip_special_tokens=False)[0],
"Hello today I am going to show you how to make a simple and easy to make paper plane.\nStep",
)
def test_batched_generation(self):
model_id = "tiiuae/falcon-mamba-7b"
tok = AutoTokenizer.from_pretrained(model_id)
tok.pad_token_id = tok.eos_token_id
texts = ["Hello today", "Hello my name is Younes and today"]
EXPECTED_OUTPUT = [
"Hello today I'm going to show you how to make a 3D model of a house.\n",
"Hello my name is Younes and today I will be talking about the topic of “The importance of the internet in our life”.\n",
]
inputs = tok(texts, return_tensors="pt", padding=True, return_token_type_ids=False).to(torch_device)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map=0, torch_dtype=torch.bfloat16)
out = model.generate(**inputs, max_new_tokens=20)
out = tok.batch_decode(out, skip_special_tokens=True)
self.assertListEqual(out, EXPECTED_OUTPUT)
# We test the same generations with inputs_embeds
with torch.no_grad():
inputs_embeds = model.get_input_embeddings()(inputs.pop("input_ids"))
inputs["inputs_embeds"] = inputs_embeds
out = model.generate(**inputs, max_new_tokens=20)
out = tok.batch_decode(out, skip_special_tokens=True)
self.assertListEqual(out, EXPECTED_OUTPUT)
@require_torch_multi_gpu
def test_training_kernel(self):
model_id = "tiiuae/falcon-mamba-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", torch_dtype=torch.bfloat16)
tokenizer.pad_token_id = tokenizer.eos_token_id
text = "Hello today"
inputs = tokenizer(text, return_tensors="pt").to(torch_device)
with torch.no_grad():
logits = torch.argmax(model(**inputs).logits, dim=-1)
out_no_training = tokenizer.batch_decode(logits)
model.train()
lm_logits = model(**inputs).logits
next_token = torch.argmax(lm_logits, dim=-1)
out_training = tokenizer.batch_decode(next_token)
# Just verify backward works
loss = (1 - lm_logits).mean()
loss.backward()
self.assertEqual(out_training, out_no_training)
| transformers/tests/models/falcon_mamba/test_modeling_falcon_mamba.py/0 | {
"file_path": "transformers/tests/models/falcon_mamba/test_modeling_falcon_mamba.py",
"repo_id": "transformers",
"token_count": 10147
} |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Testing suite for the PyTorch FocalNet model."""
import collections
import unittest
from transformers import FocalNetConfig
from transformers.testing_utils import require_torch, require_vision, slow, torch_device
from transformers.utils import cached_property, is_torch_available, is_vision_available
from ...test_backbone_common import BackboneTesterMixin
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from torch import nn
from transformers import (
FocalNetBackbone,
FocalNetForImageClassification,
FocalNetForMaskedImageModeling,
FocalNetModel,
)
if is_vision_available():
from PIL import Image
from transformers import AutoImageProcessor
class FocalNetModelTester:
def __init__(
self,
parent,
batch_size=13,
image_size=32,
patch_size=2,
num_channels=3,
embed_dim=16,
hidden_sizes=[32, 64, 128],
depths=[1, 2, 1],
num_heads=[2, 2, 4],
window_size=2,
mlp_ratio=2.0,
qkv_bias=True,
hidden_dropout_prob=0.0,
attention_probs_dropout_prob=0.0,
drop_path_rate=0.1,
hidden_act="gelu",
use_absolute_embeddings=False,
patch_norm=True,
initializer_range=0.02,
layer_norm_eps=1e-5,
is_training=True,
scope=None,
use_labels=True,
type_sequence_label_size=10,
encoder_stride=8,
out_features=["stage1", "stage2"],
out_indices=[1, 2],
):
self.parent = parent
self.batch_size = batch_size
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.embed_dim = embed_dim
self.hidden_sizes = hidden_sizes
self.depths = depths
self.num_heads = num_heads
self.window_size = window_size
self.mlp_ratio = mlp_ratio
self.qkv_bias = qkv_bias
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.drop_path_rate = drop_path_rate
self.hidden_act = hidden_act
self.use_absolute_embeddings = use_absolute_embeddings
self.patch_norm = patch_norm
self.layer_norm_eps = layer_norm_eps
self.initializer_range = initializer_range
self.is_training = is_training
self.scope = scope
self.use_labels = use_labels
self.type_sequence_label_size = type_sequence_label_size
self.encoder_stride = encoder_stride
self.out_features = out_features
self.out_indices = out_indices
def prepare_config_and_inputs(self):
pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
labels = None
if self.use_labels:
labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
config = self.get_config()
return config, pixel_values, labels
def get_config(self):
return FocalNetConfig(
image_size=self.image_size,
patch_size=self.patch_size,
num_channels=self.num_channels,
embed_dim=self.embed_dim,
hidden_sizes=self.hidden_sizes,
depths=self.depths,
num_heads=self.num_heads,
window_size=self.window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=self.qkv_bias,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
drop_path_rate=self.drop_path_rate,
hidden_act=self.hidden_act,
use_absolute_embeddings=self.use_absolute_embeddings,
path_norm=self.patch_norm,
layer_norm_eps=self.layer_norm_eps,
initializer_range=self.initializer_range,
encoder_stride=self.encoder_stride,
out_features=self.out_features,
out_indices=self.out_indices,
)
def create_and_check_model(self, config, pixel_values, labels):
model = FocalNetModel(config=config)
model.to(torch_device)
model.eval()
result = model(pixel_values)
expected_seq_len = ((config.image_size // config.patch_size) ** 2) // (4 ** (len(config.depths) - 1))
expected_dim = int(config.embed_dim * 2 ** (len(config.depths) - 1))
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, expected_seq_len, expected_dim))
def create_and_check_backbone(self, config, pixel_values, labels):
model = FocalNetBackbone(config=config)
model.to(torch_device)
model.eval()
result = model(pixel_values)
# verify feature maps
self.parent.assertEqual(len(result.feature_maps), len(config.out_features))
self.parent.assertListEqual(list(result.feature_maps[0].shape), [self.batch_size, self.image_size, 8, 8])
# verify channels
self.parent.assertEqual(len(model.channels), len(config.out_features))
self.parent.assertListEqual(model.channels, config.hidden_sizes[:-1])
# verify backbone works with out_features=None
config.out_features = None
model = FocalNetBackbone(config=config)
model.to(torch_device)
model.eval()
result = model(pixel_values)
# verify feature maps
self.parent.assertEqual(len(result.feature_maps), 1)
self.parent.assertListEqual(list(result.feature_maps[0].shape), [self.batch_size, self.image_size * 2, 4, 4])
# verify channels
self.parent.assertEqual(len(model.channels), 1)
self.parent.assertListEqual(model.channels, [config.hidden_sizes[-1]])
def create_and_check_for_masked_image_modeling(self, config, pixel_values, labels):
model = FocalNetForMaskedImageModeling(config=config)
model.to(torch_device)
model.eval()
result = model(pixel_values)
self.parent.assertEqual(
result.reconstruction.shape, (self.batch_size, self.num_channels, self.image_size, self.image_size)
)
# test greyscale images
config.num_channels = 1
model = FocalNetForMaskedImageModeling(config)
model.to(torch_device)
model.eval()
pixel_values = floats_tensor([self.batch_size, 1, self.image_size, self.image_size])
result = model(pixel_values)
self.parent.assertEqual(result.reconstruction.shape, (self.batch_size, 1, self.image_size, self.image_size))
def create_and_check_for_image_classification(self, config, pixel_values, labels):
config.num_labels = self.type_sequence_label_size
model = FocalNetForImageClassification(config)
model.to(torch_device)
model.eval()
result = model(pixel_values, labels=labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
# test greyscale images
config.num_channels = 1
model = FocalNetForImageClassification(config)
model.to(torch_device)
model.eval()
pixel_values = floats_tensor([self.batch_size, 1, self.image_size, self.image_size])
result = model(pixel_values)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
config, pixel_values, labels = config_and_inputs
inputs_dict = {"pixel_values": pixel_values}
return config, inputs_dict
@require_torch
class FocalNetModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (
(
FocalNetModel,
FocalNetForImageClassification,
FocalNetForMaskedImageModeling,
FocalNetBackbone,
)
if is_torch_available()
else ()
)
pipeline_model_mapping = (
{"image-feature-extraction": FocalNetModel, "image-classification": FocalNetForImageClassification}
if is_torch_available()
else {}
)
fx_compatible = False
test_pruning = False
test_resize_embeddings = False
test_head_masking = False
has_attentions = False
def setUp(self):
self.model_tester = FocalNetModelTester(self)
self.config_tester = ConfigTester(
self,
config_class=FocalNetConfig,
embed_dim=37,
has_text_modality=False,
common_properties=["image_size", "patch_size", "num_channels", "hidden_sizes"],
)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_backbone(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_backbone(*config_and_inputs)
def test_for_masked_image_modeling(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_masked_image_modeling(*config_and_inputs)
def test_for_image_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_image_classification(*config_and_inputs)
@unittest.skip(reason="FocalNet does not use inputs_embeds")
def test_inputs_embeds(self):
pass
@unittest.skip(reason="FocalNet does not use feedforward chunking")
def test_feed_forward_chunking(self):
pass
def test_model_get_set_embeddings(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes[:-1]:
model = model_class(config)
self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
def check_hidden_states_output(self, inputs_dict, config, model_class, image_size):
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
hidden_states = outputs.hidden_states
expected_num_layers = getattr(
self.model_tester, "expected_num_hidden_layers", len(self.model_tester.depths) + 1
)
self.assertEqual(len(hidden_states), expected_num_layers)
# FocalNet has a different seq_length
patch_size = (
config.patch_size
if isinstance(config.patch_size, collections.abc.Iterable)
else (config.patch_size, config.patch_size)
)
num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
self.assertListEqual(
list(hidden_states[0].shape[-2:]),
[num_patches, self.model_tester.embed_dim],
)
reshaped_hidden_states = outputs.reshaped_hidden_states
self.assertEqual(len(reshaped_hidden_states), expected_num_layers)
batch_size, num_channels, height, width = reshaped_hidden_states[0].shape
reshaped_hidden_states = (
reshaped_hidden_states[0].view(batch_size, num_channels, height * width).permute(0, 2, 1)
)
self.assertListEqual(
list(reshaped_hidden_states.shape[-2:]),
[num_patches, self.model_tester.embed_dim],
)
def test_hidden_states_output(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
image_size = (
self.model_tester.image_size
if isinstance(self.model_tester.image_size, collections.abc.Iterable)
else (self.model_tester.image_size, self.model_tester.image_size)
)
for model_class in self.all_model_classes[:-1]:
inputs_dict["output_hidden_states"] = True
self.check_hidden_states_output(inputs_dict, config, model_class, image_size)
# check that output_hidden_states also work using config
del inputs_dict["output_hidden_states"]
config.output_hidden_states = True
self.check_hidden_states_output(inputs_dict, config, model_class, image_size)
def test_hidden_states_output_with_padding(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.patch_size = 3
image_size = (
self.model_tester.image_size
if isinstance(self.model_tester.image_size, collections.abc.Iterable)
else (self.model_tester.image_size, self.model_tester.image_size)
)
patch_size = (
config.patch_size
if isinstance(config.patch_size, collections.abc.Iterable)
else (config.patch_size, config.patch_size)
)
padded_height = image_size[0] + patch_size[0] - (image_size[0] % patch_size[0])
padded_width = image_size[1] + patch_size[1] - (image_size[1] % patch_size[1])
for model_class in self.all_model_classes[:-1]:
inputs_dict["output_hidden_states"] = True
self.check_hidden_states_output(inputs_dict, config, model_class, (padded_height, padded_width))
# check that output_hidden_states also work using config
del inputs_dict["output_hidden_states"]
config.output_hidden_states = True
self.check_hidden_states_output(inputs_dict, config, model_class, (padded_height, padded_width))
@slow
def test_model_from_pretrained(self):
model_name = "microsoft/focalnet-tiny"
model = FocalNetModel.from_pretrained(model_name)
self.assertIsNotNone(model)
def test_initialization(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
configs_no_init = _config_zero_init(config)
for model_class in self.all_model_classes:
model = model_class(config=configs_no_init)
for name, param in model.named_parameters():
if "embeddings" not in name and param.requires_grad:
self.assertIn(
((param.data.mean() * 1e9).round() / 1e9).item(),
[0.0, 1.0],
msg=f"Parameter {name} of model {model_class} seems not properly initialized",
)
@require_vision
@require_torch
class FocalNetModelIntegrationTest(unittest.TestCase):
@cached_property
def default_image_processor(self):
# TODO update organization
return AutoImageProcessor.from_pretrained("microsoft/focalnet-tiny") if is_vision_available() else None
@slow
def test_inference_image_classification_head(self):
model = FocalNetForImageClassification.from_pretrained("microsoft/focalnet-tiny").to(torch_device)
image_processor = self.default_image_processor
image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
# forward pass
with torch.no_grad():
outputs = model(**inputs)
# verify the logits
expected_shape = torch.Size((1, 1000))
self.assertEqual(outputs.logits.shape, expected_shape)
expected_slice = torch.tensor([0.2166, -0.4368, 0.2191]).to(torch_device)
torch.testing.assert_close(outputs.logits[0, :3], expected_slice, rtol=1e-4, atol=1e-4)
self.assertTrue(outputs.logits.argmax(dim=-1).item(), 281)
@require_torch
class FocalNetBackboneTest(BackboneTesterMixin, unittest.TestCase):
all_model_classes = (FocalNetBackbone,) if is_torch_available() else ()
config_class = FocalNetConfig
has_attentions = False
def setUp(self):
self.model_tester = FocalNetModelTester(self)
| transformers/tests/models/focalnet/test_modeling_focalnet.py/0 | {
"file_path": "transformers/tests/models/focalnet/test_modeling_focalnet.py",
"repo_id": "transformers",
"token_count": 7405
} |
# coding=utf-8
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import math
import unittest
import pytest
from transformers import GPT2Config, is_torch_available
from transformers.testing_utils import (
cleanup,
require_flash_attn,
require_torch,
require_torch_gpu,
slow,
torch_device,
)
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from transformers import (
GPT2DoubleHeadsModel,
GPT2ForQuestionAnswering,
GPT2ForSequenceClassification,
GPT2ForTokenClassification,
GPT2LMHeadModel,
GPT2Model,
GPT2Tokenizer,
)
class GPT2ModelTester:
def __init__(
self,
parent,
batch_size=14,
seq_length=7,
is_training=True,
use_token_type_ids=True,
use_input_mask=True,
use_labels=True,
use_mc_token_ids=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
type_sequence_label_size=2,
initializer_range=0.02,
num_labels=3,
num_choices=4,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_token_type_ids = use_token_type_ids
self.use_input_mask = use_input_mask
self.use_labels = use_labels
self.use_mc_token_ids = use_mc_token_ids
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.num_labels = num_labels
self.num_choices = num_choices
self.scope = None
self.bos_token_id = vocab_size - 1
self.eos_token_id = vocab_size - 1
self.pad_token_id = vocab_size - 1
def get_large_model_config(self):
return GPT2Config.from_pretrained("openai-community/gpt2")
def prepare_config_and_inputs(
self, gradient_checkpointing=False, scale_attn_by_inverse_layer_idx=False, reorder_and_upcast_attn=False
):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
mc_token_ids = None
if self.use_mc_token_ids:
mc_token_ids = ids_tensor([self.batch_size, self.num_choices], self.seq_length)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = self.get_config(
gradient_checkpointing=gradient_checkpointing,
scale_attn_by_inverse_layer_idx=scale_attn_by_inverse_layer_idx,
reorder_and_upcast_attn=reorder_and_upcast_attn,
)
head_mask = ids_tensor([self.num_hidden_layers, self.num_attention_heads], 2)
return (
config,
input_ids,
input_mask,
head_mask,
token_type_ids,
mc_token_ids,
sequence_labels,
token_labels,
choice_labels,
)
def get_config(
self, gradient_checkpointing=False, scale_attn_by_inverse_layer_idx=False, reorder_and_upcast_attn=False
):
return GPT2Config(
vocab_size=self.vocab_size,
n_embd=self.hidden_size,
n_layer=self.num_hidden_layers,
n_head=self.num_attention_heads,
n_inner=self.intermediate_size,
activation_function=self.hidden_act,
resid_pdrop=self.hidden_dropout_prob,
attn_pdrop=self.attention_probs_dropout_prob,
n_positions=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
initializer_range=self.initializer_range,
use_cache=True,
bos_token_id=self.bos_token_id,
eos_token_id=self.eos_token_id,
pad_token_id=self.pad_token_id,
gradient_checkpointing=gradient_checkpointing,
scale_attn_by_inverse_layer_idx=scale_attn_by_inverse_layer_idx,
reorder_and_upcast_attn=reorder_and_upcast_attn,
)
def get_pipeline_config(self):
config = self.get_config()
config.vocab_size = 300
return config
def prepare_config_and_inputs_for_decoder(self):
(
config,
input_ids,
input_mask,
head_mask,
token_type_ids,
mc_token_ids,
sequence_labels,
token_labels,
choice_labels,
) = self.prepare_config_and_inputs()
encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
return (
config,
input_ids,
input_mask,
head_mask,
token_type_ids,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
)
def create_and_check_gpt2_model(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
model = GPT2Model(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, token_type_ids=token_type_ids, head_mask=head_mask)
result = model(input_ids, token_type_ids=token_type_ids)
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
self.parent.assertEqual(len(result.past_key_values), config.n_layer)
def create_and_check_gpt2_model_past(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
model = GPT2Model(config=config)
model.to(torch_device)
model.eval()
# first forward pass
outputs = model(input_ids, token_type_ids=token_type_ids, use_cache=True)
outputs_use_cache_conf = model(input_ids, token_type_ids=token_type_ids)
outputs_no_past = model(input_ids, token_type_ids=token_type_ids, use_cache=False)
self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
output, past = outputs.to_tuple()
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
next_token_types = ids_tensor([self.batch_size, 1], self.type_vocab_size)
# append to next input_ids and token_type_ids
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
next_token_type_ids = torch.cat([token_type_ids, next_token_types], dim=-1)
output_from_no_past = model(next_input_ids, token_type_ids=next_token_type_ids)["last_hidden_state"]
output_from_past = model(next_tokens, token_type_ids=next_token_types, past_key_values=past)[
"last_hidden_state"
]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
def create_and_check_gpt2_model_attention_mask_past(
self, config, input_ids, input_mask, head_mask, token_type_ids, *args
):
model = GPT2Model(config=config)
model.to(torch_device)
model.eval()
# create attention mask
attn_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
half_seq_length = self.seq_length // 2
attn_mask[:, half_seq_length:] = 0
# first forward pass
output, past = model(input_ids, attention_mask=attn_mask).to_tuple()
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
# change a random masked slice from input_ids
random_seq_idx_to_change = ids_tensor((1,), half_seq_length).item() + 1
random_other_next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size).squeeze(-1)
input_ids[:, -random_seq_idx_to_change] = random_other_next_tokens
# append to next input_ids and attn_mask
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
attn_mask = torch.cat(
[attn_mask, torch.ones((attn_mask.shape[0], 1), dtype=torch.long, device=torch_device)],
dim=1,
)
# get two different outputs
output_from_no_past = model(next_input_ids, attention_mask=attn_mask)["last_hidden_state"]
output_from_past = model(next_tokens, past_key_values=past, attention_mask=attn_mask)["last_hidden_state"]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
def create_and_check_gpt2_model_past_large_inputs(
self, config, input_ids, input_mask, head_mask, token_type_ids, *args
):
model = GPT2Model(config=config)
model.to(torch_device)
model.eval()
# first forward pass
outputs = model(input_ids, token_type_ids=token_type_ids, attention_mask=input_mask, use_cache=True)
output, past = outputs.to_tuple()
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_token_types = ids_tensor([self.batch_size, 3], self.type_vocab_size)
next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
# append to next input_ids and token_type_ids
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
next_token_type_ids = torch.cat([token_type_ids, next_token_types], dim=-1)
next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
output_from_no_past = model(
next_input_ids, token_type_ids=next_token_type_ids, attention_mask=next_attention_mask
)["last_hidden_state"]
output_from_past = model(
next_tokens, token_type_ids=next_token_types, attention_mask=next_attention_mask, past_key_values=past
)["last_hidden_state"]
self.parent.assertTrue(output_from_past.shape[1] == next_tokens.shape[1])
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
def create_and_check_lm_head_model(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
model = GPT2LMHeadModel(config)
model.to(torch_device)
model.eval()
result = model(input_ids, token_type_ids=token_type_ids, labels=input_ids)
self.parent.assertEqual(result.loss.shape, ())
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_forward_and_backwards(
self, config, input_ids, input_mask, head_mask, token_type_ids, *args, gradient_checkpointing=False
):
model = GPT2LMHeadModel(config)
model.to(torch_device)
if gradient_checkpointing:
model.gradient_checkpointing_enable()
result = model(input_ids, token_type_ids=token_type_ids, labels=input_ids)
self.parent.assertEqual(result.loss.shape, ())
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
result.loss.backward()
def create_and_check_double_lm_head_model(
self, config, input_ids, input_mask, head_mask, token_type_ids, mc_token_ids, *args
):
model = GPT2DoubleHeadsModel(config)
model.to(torch_device)
model.eval()
multiple_choice_inputs_ids = input_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
multiple_choice_input_mask = input_mask.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
multiple_choice_token_type_ids = token_type_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
inputs = {
"input_ids": multiple_choice_inputs_ids,
"mc_token_ids": mc_token_ids,
"attention_mask": multiple_choice_input_mask,
"token_type_ids": multiple_choice_token_type_ids,
"labels": multiple_choice_inputs_ids,
}
result = model(**inputs)
self.parent.assertEqual(result.loss.shape, ())
self.parent.assertEqual(
result.logits.shape, (self.batch_size, self.num_choices, self.seq_length, self.vocab_size)
)
self.parent.assertEqual(result.mc_logits.shape, (self.batch_size, self.num_choices))
def create_and_check_gpt2_for_question_answering(
self, config, input_ids, input_mask, head_mask, token_type_ids, mc_token_ids, sequence_labels, *args
):
config.num_labels = self.num_labels
model = GPT2ForQuestionAnswering(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
def create_and_check_gpt2_for_sequence_classification(
self, config, input_ids, input_mask, head_mask, token_type_ids, mc_token_ids, sequence_labels, *args
):
config.num_labels = self.num_labels
model = GPT2ForSequenceClassification(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
def create_and_check_gpt2_for_token_classification(
self, config, input_ids, input_mask, head_mask, token_type_ids, mc_token_ids, sequence_labels, *args
):
config.num_labels = self.num_labels
model = GPT2ForTokenClassification(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
def create_and_check_gpt2_weight_initialization(self, config, *args):
model = GPT2Model(config)
model_std = model.config.initializer_range / math.sqrt(2 * model.config.n_layer)
for key in model.state_dict().keys():
if "c_proj" in key and "weight" in key:
self.parent.assertLessEqual(abs(torch.std(model.state_dict()[key]) - model_std), 0.001)
self.parent.assertLessEqual(abs(torch.mean(model.state_dict()[key]) - 0.0), 0.01)
def create_and_check_cached_forward_with_and_without_attention_mask(self, config, input_ids, *args):
# Relevant issue: https://github.com/huggingface/transformers/issues/31943
model = GPT2Model(config)
model.to(torch_device)
model.eval()
# We want this for SDPA, eager works with a `None` attention mask
assert (
model.config._attn_implementation == "sdpa"
), "This test assumes the model to have the SDPA implementation for its attention calculations."
# Prepare cache and non_cache input, needs a full attention mask
cached_len = input_ids.shape[-1] // 2
input_mask = torch.ones(size=input_ids.size()).to(torch_device)
cache_inputs = {"input_ids": input_ids[:, :cached_len], "attention_mask": input_mask[:, :cached_len]}
non_cache_inputs = {"input_ids": input_ids[:, cached_len:], "attention_mask": input_mask}
# Cached forward once with the attention mask provided and the other time without it (which should assume full attention)
cache_outputs = model(**cache_inputs)
full_outputs_with_attention_mask = model(
**non_cache_inputs, past_key_values=cache_outputs.past_key_values
).last_hidden_state
full_outputs_without_attention_mask = model(
non_cache_inputs["input_ids"], past_key_values=cache_outputs.past_key_values
).last_hidden_state
self.parent.assertTrue(
torch.allclose(full_outputs_with_attention_mask, full_outputs_without_attention_mask, atol=1e-5)
)
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
input_mask,
head_mask,
token_type_ids,
mc_token_ids,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {
"input_ids": input_ids,
"token_type_ids": token_type_ids,
"head_mask": head_mask,
}
return config, inputs_dict
@require_torch
class GPT2ModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (
(
GPT2Model,
GPT2LMHeadModel,
GPT2DoubleHeadsModel,
GPT2ForQuestionAnswering,
GPT2ForSequenceClassification,
GPT2ForTokenClassification,
)
if is_torch_available()
else ()
)
all_generative_model_classes = (GPT2LMHeadModel, GPT2DoubleHeadsModel) if is_torch_available() else ()
pipeline_model_mapping = (
{
"feature-extraction": GPT2Model,
"question-answering": GPT2ForQuestionAnswering,
"text-classification": GPT2ForSequenceClassification,
"text-generation": GPT2LMHeadModel,
"token-classification": GPT2ForTokenClassification,
"zero-shot": GPT2ForSequenceClassification,
}
if is_torch_available()
else {}
)
all_parallelizable_model_classes = (GPT2LMHeadModel, GPT2DoubleHeadsModel) if is_torch_available() else ()
fx_compatible = False # Broken by attention refactor cc @Cyrilvallez
test_missing_keys = False
test_model_parallel = True
# special case for DoubleHeads model
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
if return_labels:
if model_class.__name__ == "GPT2DoubleHeadsModel":
inputs_dict["labels"] = torch.zeros(
(self.model_tester.batch_size, self.model_tester.num_choices, self.model_tester.seq_length),
dtype=torch.long,
device=torch_device,
)
inputs_dict["input_ids"] = inputs_dict["labels"]
inputs_dict["token_type_ids"] = inputs_dict["labels"]
inputs_dict["mc_token_ids"] = torch.zeros(
(self.model_tester.batch_size, self.model_tester.num_choices),
dtype=torch.long,
device=torch_device,
)
inputs_dict["mc_labels"] = torch.zeros(
self.model_tester.batch_size, dtype=torch.long, device=torch_device
)
return inputs_dict
def setUp(self):
self.model_tester = GPT2ModelTester(self)
self.config_tester = ConfigTester(self, config_class=GPT2Config, n_embd=37)
def tearDown(self):
super().tearDown()
# clean-up as much as possible GPU memory occupied by PyTorch
cleanup(torch_device)
def test_config(self):
self.config_tester.run_common_tests()
def test_gpt2_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_gpt2_model(*config_and_inputs)
def test_gpt2_model_past(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_gpt2_model_past(*config_and_inputs)
def test_gpt2_model_att_mask_past(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_gpt2_model_attention_mask_past(*config_and_inputs)
def test_gpt2_model_past_large_inputs(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_gpt2_model_past_large_inputs(*config_and_inputs)
def test_gpt2_lm_head_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_lm_head_model(*config_and_inputs)
def test_gpt2_double_lm_head_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_double_lm_head_model(*config_and_inputs)
def test_gpt2_question_answering_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_gpt2_for_question_answering(*config_and_inputs)
def test_gpt2_sequence_classification_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_gpt2_for_sequence_classification(*config_and_inputs)
def test_gpt2_token_classification_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_gpt2_for_token_classification(*config_and_inputs)
def test_gpt2_gradient_checkpointing(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_forward_and_backwards(*config_and_inputs, gradient_checkpointing=True)
def test_gpt2_scale_attn_by_inverse_layer_idx(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(scale_attn_by_inverse_layer_idx=True)
self.model_tester.create_and_check_forward_and_backwards(*config_and_inputs)
def test_gpt2_reorder_and_upcast_attn(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(reorder_and_upcast_attn=True)
self.model_tester.create_and_check_forward_and_backwards(*config_and_inputs)
def test_gpt2_weight_initialization(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_gpt2_weight_initialization(*config_and_inputs)
def test_cached_forward_with_and_without_attention_mask(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_cached_forward_with_and_without_attention_mask(*config_and_inputs)
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant_false(self):
pass
@slow
def test_batch_generation(self):
model = GPT2LMHeadModel.from_pretrained("openai-community/gpt2")
model.to(torch_device)
tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
tokenizer.padding_side = "left"
# Define PAD Token = EOS Token = 50256
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = model.config.eos_token_id
# use different length sentences to test batching
sentences = [
"Hello, my dog is a little",
"Today, I",
]
inputs = tokenizer(sentences, return_tensors="pt", padding=True)
input_ids = inputs["input_ids"].to(torch_device)
token_type_ids = torch.cat(
[
input_ids.new_full((input_ids.shape[0], input_ids.shape[1] - 1), 0),
input_ids.new_full((input_ids.shape[0], 1), 500),
],
dim=-1,
)
outputs = model.generate(
input_ids=input_ids,
attention_mask=inputs["attention_mask"].to(torch_device),
max_length=20,
)
outputs_tt = model.generate(
input_ids=input_ids,
attention_mask=inputs["attention_mask"].to(torch_device),
token_type_ids=token_type_ids,
max_length=20,
)
inputs_non_padded = tokenizer(sentences[0], return_tensors="pt").input_ids.to(torch_device)
output_non_padded = model.generate(input_ids=inputs_non_padded, max_length=20)
num_paddings = inputs_non_padded.shape[-1] - inputs["attention_mask"][-1].long().sum().cpu().item()
inputs_padded = tokenizer(sentences[1], return_tensors="pt").input_ids.to(torch_device)
output_padded = model.generate(input_ids=inputs_padded, max_length=model.config.max_length - num_paddings)
batch_out_sentence = tokenizer.batch_decode(outputs, skip_special_tokens=True)
batch_out_sentence_tt = tokenizer.batch_decode(outputs_tt, skip_special_tokens=True)
non_padded_sentence = tokenizer.decode(output_non_padded[0], skip_special_tokens=True)
padded_sentence = tokenizer.decode(output_padded[0], skip_special_tokens=True)
expected_output_sentence = [
"Hello, my dog is a little bit of a mess. I'm not sure if he's going",
"Today, I'm going to be doing a lot of research on this. I",
]
self.assertListEqual(expected_output_sentence, batch_out_sentence)
self.assertTrue(batch_out_sentence_tt != batch_out_sentence) # token_type_ids should change output
self.assertListEqual(expected_output_sentence, [non_padded_sentence, padded_sentence])
@slow
def test_batch_generation_2heads(self):
model = GPT2DoubleHeadsModel.from_pretrained("openai-community/gpt2")
model.to(torch_device)
tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
tokenizer.padding_side = "left"
# This tokenizer has no pad token, so we have to set it in some way
# Define PAD Token = EOS Token = 50256
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = model.config.eos_token_id
# use different length sentences to test batching
sentences = [
"Hello, my dog is a little",
"Today, I",
]
inputs = tokenizer(sentences, return_tensors="pt", padding=True)
input_ids = inputs["input_ids"].to(torch_device)
token_type_ids = torch.cat(
[
input_ids.new_full((input_ids.shape[0], input_ids.shape[1] - 1), 0),
input_ids.new_full((input_ids.shape[0], 1), 500),
],
dim=-1,
)
outputs = model.generate(
input_ids=input_ids,
attention_mask=inputs["attention_mask"].to(torch_device),
max_length=20,
)
outputs_tt = model.generate(
input_ids=input_ids,
attention_mask=inputs["attention_mask"].to(torch_device),
token_type_ids=token_type_ids,
max_length=20,
)
inputs_non_padded = tokenizer(sentences[0], return_tensors="pt").input_ids.to(torch_device)
output_non_padded = model.generate(input_ids=inputs_non_padded, max_length=20)
num_paddings = inputs_non_padded.shape[-1] - inputs["attention_mask"][-1].long().sum().cpu().item()
inputs_padded = tokenizer(sentences[1], return_tensors="pt").input_ids.to(torch_device)
output_padded = model.generate(input_ids=inputs_padded, max_length=model.config.max_length - num_paddings)
batch_out_sentence = tokenizer.batch_decode(outputs, skip_special_tokens=True)
batch_out_sentence_tt = tokenizer.batch_decode(outputs_tt, skip_special_tokens=True)
non_padded_sentence = tokenizer.decode(output_non_padded[0], skip_special_tokens=True)
padded_sentence = tokenizer.decode(output_padded[0], skip_special_tokens=True)
expected_output_sentence = [
"Hello, my dog is a little bit of a mess. I'm not sure if he's going",
"Today, I'm going to be doing a lot of research on this. I",
]
self.assertListEqual(expected_output_sentence, batch_out_sentence)
self.assertTrue(batch_out_sentence_tt != batch_out_sentence) # token_type_ids should change output
self.assertListEqual(expected_output_sentence, [non_padded_sentence, padded_sentence])
@slow
def test_model_from_pretrained(self):
model_name = "openai-community/gpt2"
model = GPT2Model.from_pretrained(model_name)
self.assertIsNotNone(model)
@require_torch
class GPT2ModelLanguageGenerationTest(unittest.TestCase):
def tearDown(self):
super().tearDown()
# clean-up as much as possible GPU memory occupied by PyTorch
cleanup(torch_device, gc_collect=True)
def _test_lm_generate_gpt2_helper(
self,
gradient_checkpointing=False,
reorder_and_upcast_attn=False,
scale_attn_by_inverse_layer_idx=False,
verify_outputs=True,
):
model = GPT2LMHeadModel.from_pretrained(
"openai-community/gpt2",
reorder_and_upcast_attn=reorder_and_upcast_attn,
scale_attn_by_inverse_layer_idx=scale_attn_by_inverse_layer_idx,
)
if gradient_checkpointing:
model.gradient_checkpointing_enable()
else:
model.gradient_checkpointing_disable()
model.to(torch_device)
# The dog
input_ids = torch.tensor([[464, 3290]], dtype=torch.long, device=torch_device)
# The dog was found in a field near the intersection of West and West Streets.\n\nThe dog
expected_output_ids = [464, 3290, 373, 1043, 287, 257, 2214, 1474, 262, 16246, 286, 2688, 290, 2688, 27262, 13, 198, 198, 464, 3290,] # fmt: skip
output_ids = model.generate(input_ids, do_sample=False, max_length=20)
if verify_outputs:
self.assertListEqual(output_ids[0].tolist(), expected_output_ids)
@slow
def test_lm_generate_gpt2(self):
self._test_lm_generate_gpt2_helper()
@slow
def test_lm_generate_gpt2_with_gradient_checkpointing(self):
self._test_lm_generate_gpt2_helper(gradient_checkpointing=True)
@slow
def test_lm_generate_gpt2_with_reorder_and_upcast_attn(self):
self._test_lm_generate_gpt2_helper(reorder_and_upcast_attn=True)
@slow
def test_lm_generate_gpt2_with_scale_attn_by_inverse_layer_idx(self):
self._test_lm_generate_gpt2_helper(scale_attn_by_inverse_layer_idx=True, verify_outputs=False)
@slow
def test_gpt2_sample(self):
tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
model = GPT2LMHeadModel.from_pretrained("openai-community/gpt2")
model.to(torch_device)
torch.manual_seed(0)
tokenized = tokenizer("Today is a nice day and", return_tensors="pt", return_token_type_ids=True)
input_ids = tokenized.input_ids.to(torch_device)
output_ids = model.generate(input_ids, do_sample=True, max_length=20)
output_str = tokenizer.decode(output_ids[0], skip_special_tokens=True)
token_type_ids = tokenized.token_type_ids.to(torch_device)
output_seq = model.generate(input_ids=input_ids, do_sample=True, num_return_sequences=5, max_length=20)
output_seq_tt = model.generate(
input_ids=input_ids, token_type_ids=token_type_ids, do_sample=True, num_return_sequences=5, max_length=20
)
output_seq_strs = tokenizer.batch_decode(output_seq, skip_special_tokens=True)
output_seq_tt_strs = tokenizer.batch_decode(output_seq_tt, skip_special_tokens=True)
EXPECTED_OUTPUT_STR = (
"Today is a nice day and if you don't know anything about the state of play during your holiday"
)
self.assertEqual(output_str, EXPECTED_OUTPUT_STR)
self.assertTrue(
all(output_seq_strs[idx] != output_seq_tt_strs[idx] for idx in range(len(output_seq_tt_strs)))
) # token_type_ids should change output
@slow
def test_contrastive_search_gpt2(self):
article = (
"DeepMind Technologies is a British artificial intelligence subsidiary of Alphabet Inc. and research "
"laboratory founded in 2010. DeepMind was acquired by Google in 2014. The company is based"
)
gpt2_tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2-large")
gpt2_model = GPT2LMHeadModel.from_pretrained("openai-community/gpt2-large").to(torch_device)
input_ids = gpt2_tokenizer(article, return_tensors="pt").input_ids.to(torch_device)
outputs = gpt2_model.generate(input_ids, penalty_alpha=0.6, top_k=4, max_length=256)
generated_text = gpt2_tokenizer.batch_decode(outputs, skip_special_tokens=True)
self.assertListEqual(
generated_text,
[
"DeepMind Technologies is a British artificial intelligence subsidiary of Alphabet Inc. and research "
"laboratory founded in 2010. DeepMind was acquired by Google in 2014. The company is based in London, "
"United Kingdom\n\nGoogle has a lot of data on its users and uses it to improve its products, such as "
"Google Now, which helps users find the information they're looking for on the web. But the company "
"is not the only one to collect data on its users. Facebook, for example, has its own facial "
"recognition technology, as well as a database of millions of photos that it uses to personalize its "
"News Feed.\n\nFacebook's use of data is a hot topic in the tech industry, with privacy advocates "
"concerned about the company's ability to keep users' information private. In a blog post last "
'year, Facebook CEO Mark Zuckerberg said his company would "do our best to be transparent about our '
'data use and how we use it."\n\n"We have made it clear that we do not sell or share your data with '
'third parties," Zuckerberg wrote. "If you have questions or concerns, please reach out to us at '
'[email protected]."\n\nGoogle declined to comment on the privacy implications of its use of data, '
"but said in a statement to The Associated Press that"
],
)
@require_flash_attn
@require_torch_gpu
@pytest.mark.flash_attn_test
@slow
def test_flash_attn_2_generate_padding_left(self):
"""
Overwritting the common test as the test is flaky on tiny models
"""
model = GPT2LMHeadModel.from_pretrained("gpt2", torch_dtype=torch.float16).to(0)
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
texts = ["hi", "Hello this is a very long sentence"]
tokenizer.padding_side = "left"
tokenizer.pad_token = tokenizer.eos_token
inputs = tokenizer(texts, return_tensors="pt", padding=True).to(0)
output_native = model.generate(**inputs, max_new_tokens=20, do_sample=False)
output_native = tokenizer.batch_decode(output_native)
model = GPT2LMHeadModel.from_pretrained(
"gpt2", device_map={"": 0}, attn_implementation="flash_attention_2", torch_dtype=torch.float16
)
output_fa_2 = model.generate(**inputs, max_new_tokens=20, do_sample=False)
output_fa_2 = tokenizer.batch_decode(output_fa_2)
expected_output = [
"<|endoftext|><|endoftext|><|endoftext|><|endoftext|><|endoftext|><|endoftext|>hi, who was born in the city of Kolkata, was a member of the Kolkata",
"Hello this is a very long sentence. I'm sorry. I'm sorry. I'm sorry. I'm sorry. I'm sorry",
]
self.assertListEqual(output_native, output_fa_2)
self.assertListEqual(output_native, expected_output)
| transformers/tests/models/gpt2/test_modeling_gpt2.py/0 | {
"file_path": "transformers/tests/models/gpt2/test_modeling_gpt2.py",
"repo_id": "transformers",
"token_count": 17555
} |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Testing suite for the PyTorch Helium model."""
import unittest
from transformers import AutoModelForCausalLM, AutoTokenizer, HeliumConfig, is_torch_available
from transformers.testing_utils import (
require_read_token,
require_torch,
slow,
torch_device,
)
from ...test_configuration_common import ConfigTester
from ..gemma.test_modeling_gemma import GemmaModelTest, GemmaModelTester
if is_torch_available():
import torch
from transformers import (
HeliumForCausalLM,
HeliumForSequenceClassification,
HeliumForTokenClassification,
HeliumModel,
)
class HeliumModelTester(GemmaModelTester):
if is_torch_available():
config_class = HeliumConfig
model_class = HeliumModel
for_causal_lm_class = HeliumForCausalLM
for_sequence_class = HeliumForSequenceClassification
for_token_class = HeliumForTokenClassification
@require_torch
class HeliumModelTest(GemmaModelTest, unittest.TestCase):
all_model_classes = (
(HeliumModel, HeliumForCausalLM, HeliumForSequenceClassification, HeliumForTokenClassification)
if is_torch_available()
else ()
)
all_generative_model_classes = (HeliumForCausalLM,) if is_torch_available() else ()
pipeline_model_mapping = (
{
"feature-extraction": HeliumModel,
"text-classification": HeliumForSequenceClassification,
"token-classification": HeliumForTokenClassification,
"text-generation": HeliumForCausalLM,
"zero-shot": HeliumForSequenceClassification,
}
if is_torch_available()
else {}
)
test_headmasking = False
test_pruning = False
_is_stateful = True
model_split_percents = [0.5, 0.6]
def setUp(self):
self.model_tester = HeliumModelTester(self)
self.config_tester = ConfigTester(self, config_class=HeliumConfig, hidden_size=37)
@slow
# @require_torch_gpu
class HeliumIntegrationTest(unittest.TestCase):
input_text = ["Hello, today is a great day to"]
# This variable is used to determine which CUDA device are we using for our runners (A10 or T4)
# Depending on the hardware we get different logits / generations
cuda_compute_capability_major_version = None
@classmethod
def setUpClass(cls):
if is_torch_available() and torch.cuda.is_available():
# 8 is for A100 / A10 and 7 for T4
cls.cuda_compute_capability_major_version = torch.cuda.get_device_capability()[0]
@require_read_token
def test_model_2b(self):
model_id = "kyutai/helium-1-preview"
EXPECTED_TEXTS = [
"Hello, today is a great day to start a new project. I have been working on a new project for a while now and I have"
]
model = AutoModelForCausalLM.from_pretrained(
model_id, low_cpu_mem_usage=True, torch_dtype=torch.bfloat16, revision="refs/pr/1"
).to(torch_device)
tokenizer = AutoTokenizer.from_pretrained(model_id, revision="refs/pr/1")
inputs = tokenizer(self.input_text, return_tensors="pt", padding=True).to(torch_device)
output = model.generate(**inputs, max_new_tokens=20, do_sample=False)
output_text = tokenizer.batch_decode(output, skip_special_tokens=True)
self.assertEqual(output_text, EXPECTED_TEXTS)
| transformers/tests/models/helium/test_modeling_helium.py/0 | {
"file_path": "transformers/tests/models/helium/test_modeling_helium.py",
"repo_id": "transformers",
"token_count": 1533
} |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
import numpy as np
from transformers.testing_utils import require_torch, require_vision
from transformers.utils import is_torch_available, is_vision_available
from ...test_image_processing_common import ImageProcessingTestMixin
if is_vision_available():
from PIL import Image
from transformers import Idefics2ImageProcessor
if is_torch_available():
import torch
class Idefics2ImageProcessingTester:
def __init__(
self,
parent,
batch_size=7,
num_channels=3,
num_images=1,
image_size=18,
min_resolution=30,
max_resolution=400,
do_resize=True,
size=None,
do_rescale=True,
rescale_factor=1 / 255,
do_normalize=True,
image_mean=[0.5, 0.5, 0.5],
image_std=[0.5, 0.5, 0.5],
do_convert_rgb=True,
do_pad=True,
do_image_splitting=True,
):
size = size if size is not None else {"shortest_edge": 378, "longest_edge": 980}
self.parent = parent
self.batch_size = batch_size
self.num_channels = num_channels
self.num_images = num_images
self.image_size = image_size
self.min_resolution = min_resolution
self.max_resolution = max_resolution
self.do_resize = do_resize
self.size = size
self.do_normalize = do_normalize
self.image_mean = image_mean
self.image_std = image_std
self.do_rescale = do_rescale
self.rescale_factor = rescale_factor
self.do_convert_rgb = do_convert_rgb
self.do_pad = do_pad
self.do_image_splitting = do_image_splitting
def prepare_image_processor_dict(self):
return {
"do_convert_rgb": self.do_convert_rgb,
"do_resize": self.do_resize,
"size": self.size,
"do_rescale": self.do_rescale,
"rescale_factor": self.rescale_factor,
"do_normalize": self.do_normalize,
"image_mean": self.image_mean,
"image_std": self.image_std,
"do_pad": self.do_pad,
"do_image_splitting": self.do_image_splitting,
}
def get_expected_values(self, image_inputs, batched=False):
"""
This function computes the expected height and width when providing images to BridgeTowerImageProcessor,
assuming do_resize is set to True with a scalar size and size_divisor.
"""
if not batched:
shortest_edge = self.size["shortest_edge"]
longest_edge = self.size["longest_edge"]
image = image_inputs[0]
if isinstance(image, Image.Image):
w, h = image.size
elif isinstance(image, np.ndarray):
h, w = image.shape[0], image.shape[1]
else:
h, w = image.shape[1], image.shape[2]
aspect_ratio = w / h
if w > h and w >= longest_edge:
w = longest_edge
h = int(w / aspect_ratio)
elif h > w and h >= longest_edge:
h = longest_edge
w = int(h * aspect_ratio)
w = max(w, shortest_edge)
h = max(h, shortest_edge)
expected_height = h
expected_width = w
else:
expected_values = []
for images in image_inputs:
for image in images:
expected_height, expected_width = self.get_expected_values([image])
expected_values.append((expected_height, expected_width))
expected_height = max(expected_values, key=lambda item: item[0])[0]
expected_width = max(expected_values, key=lambda item: item[1])[1]
return expected_height, expected_width
def expected_output_image_shape(self, images):
height, width = self.get_expected_values(images, batched=True)
effective_nb_images = self.num_images * 5 if self.do_image_splitting else 1
return effective_nb_images, self.num_channels, height, width
def prepare_image_inputs(
self,
batch_size=None,
min_resolution=None,
max_resolution=None,
num_channels=None,
num_images=None,
size_divisor=None,
equal_resolution=False,
numpify=False,
torchify=False,
):
"""This function prepares a list of PIL images, or a list of numpy arrays if one specifies numpify=True,
or a list of PyTorch tensors if one specifies torchify=True.
One can specify whether the images are of the same resolution or not.
"""
assert not (numpify and torchify), "You cannot specify both numpy and PyTorch tensors at the same time"
batch_size = batch_size if batch_size is not None else self.batch_size
min_resolution = min_resolution if min_resolution is not None else self.min_resolution
max_resolution = max_resolution if max_resolution is not None else self.max_resolution
num_channels = num_channels if num_channels is not None else self.num_channels
num_images = num_images if num_images is not None else self.num_images
images_list = []
for i in range(batch_size):
images = []
for j in range(num_images):
if equal_resolution:
width = height = max_resolution
else:
# To avoid getting image width/height 0
if size_divisor is not None:
# If `size_divisor` is defined, the image needs to have width/size >= `size_divisor`
min_resolution = max(size_divisor, min_resolution)
width, height = np.random.choice(np.arange(min_resolution, max_resolution), 2)
images.append(np.random.randint(255, size=(num_channels, width, height), dtype=np.uint8))
images_list.append(images)
if not numpify and not torchify:
# PIL expects the channel dimension as last dimension
images_list = [[Image.fromarray(np.moveaxis(image, 0, -1)) for image in images] for images in images_list]
if torchify:
images_list = [[torch.from_numpy(image) for image in images] for images in images_list]
if numpify:
# Numpy images are typically in channels last format
images_list = [[image.transpose(1, 2, 0) for image in images] for images in images_list]
return images_list
@require_torch
@require_vision
class Idefics2ImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
image_processing_class = Idefics2ImageProcessor if is_vision_available() else None
def setUp(self):
super().setUp()
self.image_processor_tester = Idefics2ImageProcessingTester(self)
@property
def image_processor_dict(self):
return self.image_processor_tester.prepare_image_processor_dict()
def test_image_processor_properties(self):
image_processing = self.image_processing_class(**self.image_processor_dict)
self.assertTrue(hasattr(image_processing, "do_convert_rgb"))
self.assertTrue(hasattr(image_processing, "do_resize"))
self.assertTrue(hasattr(image_processing, "size"))
self.assertTrue(hasattr(image_processing, "do_rescale"))
self.assertTrue(hasattr(image_processing, "rescale_factor"))
self.assertTrue(hasattr(image_processing, "do_normalize"))
self.assertTrue(hasattr(image_processing, "image_mean"))
self.assertTrue(hasattr(image_processing, "image_std"))
self.assertTrue(hasattr(image_processing, "do_pad"))
self.assertTrue(hasattr(image_processing, "do_image_splitting"))
def test_call_numpy(self):
for image_processing_class in self.image_processor_list:
# Initialize image_processing
image_processing = self.image_processing_class(**self.image_processor_dict)
# create random numpy tensors
image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, numpify=True)
for sample_images in image_inputs:
for image in sample_images:
self.assertIsInstance(image, np.ndarray)
# Test not batched input
encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
expected_output_image_shape = self.image_processor_tester.expected_output_image_shape([image_inputs[0]])
self.assertEqual(tuple(encoded_images.shape), (1, *expected_output_image_shape))
# Test batched
encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
expected_output_image_shape = self.image_processor_tester.expected_output_image_shape(image_inputs)
self.assertEqual(
tuple(encoded_images.shape), (self.image_processor_tester.batch_size, *expected_output_image_shape)
)
def test_call_numpy_4_channels(self):
for image_processing_class in self.image_processor_list:
# Initialize image_processing
image_processor_dict = self.image_processor_dict
image_processor_dict["image_mean"] = [0.5, 0.5, 0.5, 0.5]
image_processor_dict["image_std"] = [0.5, 0.5, 0.5, 0.5]
image_processing = self.image_processing_class(**image_processor_dict)
# create random numpy tensors
self.image_processor_tester.num_channels = 4
image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, numpify=True)
for sample_images in image_inputs:
for image in sample_images:
self.assertIsInstance(image, np.ndarray)
# Test not batched input
encoded_images = image_processing(
image_inputs[0], input_data_format="channels_last", return_tensors="pt"
).pixel_values
expected_output_image_shape = self.image_processor_tester.expected_output_image_shape([image_inputs[0]])
self.assertEqual(tuple(encoded_images.shape), (1, *expected_output_image_shape))
# Test batched
encoded_images = image_processing(
image_inputs, input_data_format="channels_last", return_tensors="pt"
).pixel_values
expected_output_image_shape = self.image_processor_tester.expected_output_image_shape(image_inputs)
self.assertEqual(
tuple(encoded_images.shape), (self.image_processor_tester.batch_size, *expected_output_image_shape)
)
def test_call_pil(self):
for image_processing_class in self.image_processor_list:
# Initialize image_processing
image_processing = self.image_processing_class(**self.image_processor_dict)
# create random PIL images
image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False)
for images in image_inputs:
for image in images:
self.assertIsInstance(image, Image.Image)
# Test not batched input
encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
expected_output_image_shape = self.image_processor_tester.expected_output_image_shape([image_inputs[0]])
self.assertEqual(tuple(encoded_images.shape), (1, *expected_output_image_shape))
# Test batched
encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
expected_output_image_shape = self.image_processor_tester.expected_output_image_shape(image_inputs)
self.assertEqual(
tuple(encoded_images.shape), (self.image_processor_tester.batch_size, *expected_output_image_shape)
)
def test_call_pytorch(self):
for image_processing_class in self.image_processor_list:
# Initialize image_processing
image_processing = self.image_processing_class(**self.image_processor_dict)
# create random PyTorch tensors
image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, torchify=True)
for images in image_inputs:
for image in images:
self.assertIsInstance(image, torch.Tensor)
# Test not batched input
encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
expected_output_image_shape = self.image_processor_tester.expected_output_image_shape([image_inputs[0]])
self.assertEqual(tuple(encoded_images.shape), (1, *expected_output_image_shape))
# Test batched
expected_output_image_shape = self.image_processor_tester.expected_output_image_shape(image_inputs)
encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
self.assertEqual(
tuple(encoded_images.shape),
(self.image_processor_tester.batch_size, *expected_output_image_shape),
)
| transformers/tests/models/idefics2/test_image_processing_idefics2.py/0 | {
"file_path": "transformers/tests/models/idefics2/test_image_processing_idefics2.py",
"repo_id": "transformers",
"token_count": 5999
} |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import shutil
import tempfile
import unittest
import pytest
from transformers.testing_utils import require_vision
from transformers.utils import is_vision_available
from ...test_processing_common import ProcessorTesterMixin
if is_vision_available():
from transformers import (
AutoProcessor,
BertTokenizerFast,
BlipImageProcessor,
GPT2Tokenizer,
InstructBlipProcessor,
PreTrainedTokenizerFast,
)
@require_vision
class InstructBlipProcessorTest(ProcessorTesterMixin, unittest.TestCase):
processor_class = InstructBlipProcessor
def setUp(self):
self.tmpdirname = tempfile.mkdtemp()
image_processor = BlipImageProcessor()
tokenizer = GPT2Tokenizer.from_pretrained("hf-internal-testing/tiny-random-GPT2Model")
qformer_tokenizer = BertTokenizerFast.from_pretrained("hf-internal-testing/tiny-random-bert")
processor = InstructBlipProcessor(image_processor, tokenizer, qformer_tokenizer)
processor.save_pretrained(self.tmpdirname)
def get_tokenizer(self, **kwargs):
return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).tokenizer
def get_image_processor(self, **kwargs):
return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).image_processor
def get_qformer_tokenizer(self, **kwargs):
return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).qformer_tokenizer
def tearDown(self):
shutil.rmtree(self.tmpdirname)
def test_save_load_pretrained_additional_features(self):
processor = InstructBlipProcessor(
tokenizer=self.get_tokenizer(),
image_processor=self.get_image_processor(),
qformer_tokenizer=self.get_qformer_tokenizer(),
)
processor.save_pretrained(self.tmpdirname)
tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
image_processor_add_kwargs = self.get_image_processor(do_normalize=False, padding_value=1.0)
processor = InstructBlipProcessor.from_pretrained(
self.tmpdirname, bos_token="(BOS)", eos_token="(EOS)", do_normalize=False, padding_value=1.0
)
self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
self.assertIsInstance(processor.tokenizer, PreTrainedTokenizerFast)
self.assertEqual(processor.image_processor.to_json_string(), image_processor_add_kwargs.to_json_string())
self.assertIsInstance(processor.image_processor, BlipImageProcessor)
self.assertIsInstance(processor.qformer_tokenizer, BertTokenizerFast)
def test_image_processor(self):
image_processor = self.get_image_processor()
tokenizer = self.get_tokenizer()
qformer_tokenizer = self.get_qformer_tokenizer()
processor = InstructBlipProcessor(
tokenizer=tokenizer, image_processor=image_processor, qformer_tokenizer=qformer_tokenizer
)
image_input = self.prepare_image_inputs()
input_feat_extract = image_processor(image_input, return_tensors="np")
input_processor = processor(images=image_input, return_tensors="np")
for key in input_feat_extract.keys():
self.assertAlmostEqual(input_feat_extract[key].sum(), input_processor[key].sum(), delta=1e-2)
def test_tokenizer(self):
image_processor = self.get_image_processor()
tokenizer = self.get_tokenizer()
qformer_tokenizer = self.get_qformer_tokenizer()
processor = InstructBlipProcessor(
tokenizer=tokenizer, image_processor=image_processor, qformer_tokenizer=qformer_tokenizer
)
input_str = ["lower newer"]
encoded_processor = processor(text=input_str)
encoded_tokens = tokenizer(input_str, return_token_type_ids=False)
encoded_tokens_qformer = qformer_tokenizer(input_str, return_token_type_ids=False)
for key in encoded_tokens.keys():
self.assertListEqual(encoded_tokens[key], encoded_processor[key])
for key in encoded_tokens_qformer.keys():
self.assertListEqual(encoded_tokens_qformer[key], encoded_processor["qformer_" + key])
def test_processor(self):
image_processor = self.get_image_processor()
tokenizer = self.get_tokenizer()
qformer_tokenizer = self.get_qformer_tokenizer()
processor = InstructBlipProcessor(
tokenizer=tokenizer, image_processor=image_processor, qformer_tokenizer=qformer_tokenizer
)
input_str = "lower newer"
image_input = self.prepare_image_inputs()
inputs = processor(text=input_str, images=image_input)
self.assertListEqual(
list(inputs.keys()),
["input_ids", "attention_mask", "qformer_input_ids", "qformer_attention_mask", "pixel_values"],
)
# test if it raises when no input is passed
with pytest.raises(ValueError):
processor()
def test_tokenizer_decode(self):
image_processor = self.get_image_processor()
tokenizer = self.get_tokenizer()
qformer_tokenizer = self.get_qformer_tokenizer()
processor = InstructBlipProcessor(
tokenizer=tokenizer, image_processor=image_processor, qformer_tokenizer=qformer_tokenizer
)
predicted_ids = [[1, 4, 5, 8, 1, 0, 8], [3, 4, 3, 1, 1, 8, 9]]
decoded_processor = processor.batch_decode(predicted_ids)
decoded_tok = tokenizer.batch_decode(predicted_ids)
self.assertListEqual(decoded_tok, decoded_processor)
def test_model_input_names(self):
image_processor = self.get_image_processor()
tokenizer = self.get_tokenizer()
qformer_tokenizer = self.get_qformer_tokenizer()
processor = InstructBlipProcessor(
tokenizer=tokenizer, image_processor=image_processor, qformer_tokenizer=qformer_tokenizer
)
input_str = "lower newer"
image_input = self.prepare_image_inputs()
inputs = processor(text=input_str, images=image_input)
self.assertListEqual(
list(inputs.keys()),
["input_ids", "attention_mask", "qformer_input_ids", "qformer_attention_mask", "pixel_values"],
)
| transformers/tests/models/instructblip/test_processor_instructblip.py/0 | {
"file_path": "transformers/tests/models/instructblip/test_processor_instructblip.py",
"repo_id": "transformers",
"token_count": 2696
} |
# coding=utf-8
# Copyright Iz Beltagy, Matthew E. Peters, Arman Cohan and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import annotations
import unittest
from transformers import LEDConfig, is_tf_available
from transformers.testing_utils import require_tf, slow
from ...test_configuration_common import ConfigTester
from ...test_modeling_tf_common import TFModelTesterMixin, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
if is_tf_available():
import tensorflow as tf
from transformers import TFLEDForConditionalGeneration, TFLEDModel
@require_tf
class TFLEDModelTester:
config_cls = LEDConfig
config_updates = {}
hidden_act = "gelu"
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_labels=False,
vocab_size=99,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=37,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=20,
eos_token_id=2,
pad_token_id=1,
bos_token_id=0,
attention_window=4,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.bos_token_id = bos_token_id
self.attention_window = attention_window
# `ModelTesterMixin.test_attention_outputs` is expecting attention tensors to be of size
# [num_attention_heads, encoder_seq_length, encoder_key_length], but TFLongformerSelfAttention
# returns attention of shape [num_attention_heads, encoder_seq_length, self.attention_window + 1]
# because its local attention only attends to `self.attention_window` and one before and one after
self.key_length = self.attention_window + 2
# because of padding `encoder_seq_length`, is different from `seq_length`. Relevant for
# the `test_attention_outputs` and `test_hidden_states_output` tests
self.encoder_seq_length = (
self.seq_length + (self.attention_window - self.seq_length % self.attention_window) % self.attention_window
)
def prepare_config_and_inputs_for_common(self):
input_ids = ids_tensor([self.batch_size, self.seq_length - 1], self.vocab_size)
eos_tensor = tf.expand_dims(tf.constant([self.eos_token_id] * self.batch_size), 1)
input_ids = tf.concat([input_ids, eos_tensor], axis=1)
decoder_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
config = self.config_cls(
vocab_size=self.vocab_size,
d_model=self.hidden_size,
encoder_layers=self.num_hidden_layers,
decoder_layers=self.num_hidden_layers,
encoder_attention_heads=self.num_attention_heads,
decoder_attention_heads=self.num_attention_heads,
encoder_ffn_dim=self.intermediate_size,
decoder_ffn_dim=self.intermediate_size,
dropout=self.hidden_dropout_prob,
attention_dropout=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
eos_token_ids=[2],
bos_token_id=self.bos_token_id,
pad_token_id=self.pad_token_id,
decoder_start_token_id=self.pad_token_id,
attention_window=self.attention_window,
**self.config_updates,
)
inputs_dict = prepare_led_inputs_dict(config, input_ids, decoder_input_ids)
global_attention_mask = tf.concat(
[tf.zeros_like(input_ids)[:, :-1], tf.ones_like(input_ids)[:, -1:]],
axis=-1,
)
inputs_dict["global_attention_mask"] = global_attention_mask
return config, inputs_dict
def check_decoder_model_past_large_inputs(self, config, inputs_dict):
model = TFLEDModel(config=config).get_decoder()
input_ids = inputs_dict["input_ids"]
input_ids = input_ids[:1, :]
attention_mask = inputs_dict["attention_mask"][:1, :]
self.batch_size = 1
# first forward pass
outputs = model(input_ids, attention_mask=attention_mask, use_cache=True)
output, past_key_values = outputs.to_tuple()
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_attn_mask = tf.cast(ids_tensor((self.batch_size, 3), 2), tf.int8)
# append to next input_ids and
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
next_attention_mask = tf.concat([attention_mask, next_attn_mask], axis=-1)
output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)[0]
output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)[0]
self.parent.assertEqual(next_tokens.shape[1], output_from_past.shape[1])
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx]
output_from_past_slice = output_from_past[:, :, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-3)
def prepare_led_inputs_dict(
config,
input_ids,
decoder_input_ids,
attention_mask=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
):
if attention_mask is None:
attention_mask = tf.cast(tf.math.not_equal(input_ids, config.pad_token_id), tf.int8)
if decoder_attention_mask is None:
decoder_attention_mask = tf.concat(
[
tf.ones(decoder_input_ids[:, :1].shape, dtype=tf.int8),
tf.cast(tf.math.not_equal(decoder_input_ids[:, 1:], config.pad_token_id), tf.int8),
],
axis=-1,
)
if head_mask is None:
head_mask = tf.ones((config.encoder_layers, config.encoder_attention_heads))
if decoder_head_mask is None:
decoder_head_mask = tf.ones((config.decoder_layers, config.decoder_attention_heads))
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"decoder_input_ids": decoder_input_ids,
"decoder_attention_mask": decoder_attention_mask,
"head_mask": head_mask,
"decoder_head_mask": decoder_head_mask,
}
@require_tf
class TFLEDModelTest(TFModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (TFLEDForConditionalGeneration, TFLEDModel) if is_tf_available() else ()
all_generative_model_classes = (TFLEDForConditionalGeneration,) if is_tf_available() else ()
pipeline_model_mapping = (
{
"feature-extraction": TFLEDModel,
"summarization": TFLEDForConditionalGeneration,
"text2text-generation": TFLEDForConditionalGeneration,
"translation": TFLEDForConditionalGeneration,
}
if is_tf_available()
else {}
)
is_encoder_decoder = True
test_pruning = False
test_head_masking = False
test_onnx = False
def setUp(self):
self.model_tester = TFLEDModelTester(self)
self.config_tester = ConfigTester(self, config_class=LEDConfig)
def test_config(self):
self.config_tester.run_common_tests()
def test_decoder_model_past_large_inputs(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
self.model_tester.check_decoder_model_past_large_inputs(*config_and_inputs)
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
inputs_dict["global_attention_mask"] = tf.zeros_like(inputs_dict["attention_mask"])
num_global_attn_indices = 2
inputs_dict["global_attention_mask"] = tf.where(
tf.range(self.model_tester.seq_length)[None, :] < num_global_attn_indices,
1,
inputs_dict["global_attention_mask"],
)
config.return_dict = True
seq_length = self.model_tester.seq_length
encoder_seq_length = self.model_tester.encoder_seq_length
def check_decoder_attentions_output(outputs):
decoder_attentions = outputs.decoder_attentions
self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(decoder_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, seq_length, seq_length],
)
def check_encoder_attentions_output(outputs):
attentions = [t.numpy() for t in outputs.encoder_attentions]
global_attentions = [t.numpy() for t in outputs.encoder_global_attentions]
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
self.assertEqual(len(global_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, seq_length, seq_length],
)
self.assertListEqual(
list(global_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, encoder_seq_length, num_global_attn_indices],
)
for model_class in self.all_model_classes:
inputs_dict["output_attentions"] = True
inputs_dict["use_cache"] = False
config.output_hidden_states = False
model = model_class(config)
outputs = model(self._prepare_for_class(inputs_dict, model_class))
out_len = len(outputs)
self.assertEqual(config.output_hidden_states, False)
check_encoder_attentions_output(outputs)
if self.is_encoder_decoder:
model = model_class(config)
outputs = model(self._prepare_for_class(inputs_dict, model_class))
self.assertEqual(config.output_hidden_states, False)
check_decoder_attentions_output(outputs)
# Check that output attentions can also be changed via the config
del inputs_dict["output_attentions"]
config.output_attentions = True
model = model_class(config)
outputs = model(self._prepare_for_class(inputs_dict, model_class))
self.assertEqual(config.output_hidden_states, False)
check_encoder_attentions_output(outputs)
# Check attention is always last and order is fine
inputs_dict["output_attentions"] = True
config.output_hidden_states = True
model = model_class(config)
outputs = model(self._prepare_for_class(inputs_dict, model_class))
self.assertEqual(out_len + (2 if self.is_encoder_decoder else 1), len(outputs))
self.assertEqual(model.config.output_hidden_states, True)
check_encoder_attentions_output(outputs)
@unittest.skip("LED keeps using potentially symbolic tensors in conditionals and breaks tracing.")
def test_saved_model_creation(self):
pass
def test_generate_with_headmasking(self):
# TODO: Head-masking not yet implement
pass
def _long_tensor(tok_lst):
return tf.constant(tok_lst, dtype=tf.int32)
TOLERANCE = 1e-4
@slow
@require_tf
class TFLEDModelIntegrationTest(unittest.TestCase):
def test_inference_no_head(self):
model = TFLEDForConditionalGeneration.from_pretrained("allenai/led-base-16384").led
# change to intended input here
input_ids = _long_tensor([512 * [0, 31414, 232, 328, 740, 1140, 12695, 69]])
decoder_input_ids = _long_tensor([128 * [0, 31414, 232, 328, 740, 1140, 12695, 69]])
inputs_dict = prepare_led_inputs_dict(model.config, input_ids, decoder_input_ids)
output = model(**inputs_dict)[0]
expected_shape = (1, 1024, 768)
self.assertEqual(output.shape, expected_shape)
# change to expected output here
expected_slice = tf.convert_to_tensor(
[[2.3050, 2.8279, 0.6531], [-1.8457, -0.1455, -3.5661], [-1.0186, 0.4586, -2.2043]],
)
tf.debugging.assert_near(output[:, :3, :3], expected_slice, atol=1e-3)
def test_inference_with_head(self):
model = TFLEDForConditionalGeneration.from_pretrained("allenai/led-base-16384")
# change to intended input here
input_ids = _long_tensor([512 * [0, 31414, 232, 328, 740, 1140, 12695, 69]])
decoder_input_ids = _long_tensor([128 * [0, 31414, 232, 328, 740, 1140, 12695, 69]])
inputs_dict = prepare_led_inputs_dict(model.config, input_ids, decoder_input_ids)
output = model(**inputs_dict)[0]
expected_shape = (1, 1024, model.config.vocab_size)
self.assertEqual(output.shape, expected_shape)
# change to expected output here
expected_slice = tf.convert_to_tensor(
[[33.6507, 6.4572, 16.8089], [5.8739, -2.4238, 11.2902], [-3.2139, -4.3149, 4.2783]],
)
tf.debugging.assert_near(output[:, :3, :3], expected_slice, atol=1e-3, rtol=1e-3)
| transformers/tests/models/led/test_modeling_tf_led.py/0 | {
"file_path": "transformers/tests/models/led/test_modeling_tf_led.py",
"repo_id": "transformers",
"token_count": 6429
} |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
import numpy as np
from transformers.image_utils import OPENAI_CLIP_MEAN, OPENAI_CLIP_STD
from transformers.models.llava_next.image_processing_llava_next import select_best_resolution
from transformers.testing_utils import require_torch, require_vision
from transformers.utils import is_torch_available, is_torchvision_available, is_vision_available
from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
if is_torch_available():
import torch
if is_vision_available():
from PIL import Image
from transformers import LlavaNextImageProcessor
if is_torchvision_available():
from transformers import LlavaNextImageProcessorFast
class LlavaNextImageProcessingTester:
def __init__(
self,
parent,
batch_size=7,
num_channels=3,
image_size=18,
min_resolution=30,
max_resolution=400,
do_resize=True,
size=None,
do_center_crop=True,
crop_size=None,
do_normalize=True,
image_mean=OPENAI_CLIP_MEAN,
image_std=OPENAI_CLIP_STD,
do_convert_rgb=True,
):
super().__init__()
size = size if size is not None else {"shortest_edge": 20}
crop_size = crop_size if crop_size is not None else {"height": 18, "width": 18}
self.parent = parent
self.batch_size = batch_size
self.num_channels = num_channels
self.image_size = image_size
self.min_resolution = min_resolution
self.max_resolution = max_resolution
self.do_resize = do_resize
self.size = size
self.do_center_crop = do_center_crop
self.crop_size = crop_size
self.do_normalize = do_normalize
self.image_mean = image_mean
self.image_std = image_std
self.do_convert_rgb = do_convert_rgb
def prepare_image_processor_dict(self):
return {
"do_resize": self.do_resize,
"size": self.size,
"do_center_crop": self.do_center_crop,
"crop_size": self.crop_size,
"do_normalize": self.do_normalize,
"image_mean": self.image_mean,
"image_std": self.image_std,
"do_convert_rgb": self.do_convert_rgb,
}
# Copied from tests.models.clip.test_image_processing_clip.CLIPImageProcessingTester.expected_output_image_shape
def expected_output_image_shape(self, images):
return self.num_channels, self.crop_size["height"], self.crop_size["width"]
# Copied from tests.models.clip.test_image_processing_clip.CLIPImageProcessingTester.prepare_image_inputs
def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
return prepare_image_inputs(
batch_size=self.batch_size,
num_channels=self.num_channels,
min_resolution=self.min_resolution,
max_resolution=self.max_resolution,
equal_resolution=equal_resolution,
numpify=numpify,
torchify=torchify,
)
@require_torch
@require_vision
class LlavaNextImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
image_processing_class = LlavaNextImageProcessor if is_vision_available() else None
fast_image_processing_class = LlavaNextImageProcessorFast if is_torchvision_available() else None
# Copied from tests.models.clip.test_image_processing_clip.CLIPImageProcessingTest.setUp with CLIP->LlavaNext
def setUp(self):
super().setUp()
self.image_processor_tester = LlavaNextImageProcessingTester(self)
@property
# Copied from tests.models.clip.test_image_processing_clip.CLIPImageProcessingTest.image_processor_dict
def image_processor_dict(self):
return self.image_processor_tester.prepare_image_processor_dict()
def test_image_processor_properties(self):
for image_processing_class in self.image_processor_list:
image_processing = image_processing_class(**self.image_processor_dict)
self.assertTrue(hasattr(image_processing, "do_resize"))
self.assertTrue(hasattr(image_processing, "size"))
self.assertTrue(hasattr(image_processing, "do_center_crop"))
self.assertTrue(hasattr(image_processing, "center_crop"))
self.assertTrue(hasattr(image_processing, "do_normalize"))
self.assertTrue(hasattr(image_processing, "image_mean"))
self.assertTrue(hasattr(image_processing, "image_std"))
self.assertTrue(hasattr(image_processing, "do_convert_rgb"))
self.assertTrue(hasattr(image_processing, "image_grid_pinpoints"))
# Copied from tests.models.clip.test_image_processing_clip.CLIPImageProcessingTest.test_image_processor_from_dict_with_kwargs
def test_image_processor_from_dict_with_kwargs(self):
for image_processing_class in self.image_processor_list:
image_processor = image_processing_class.from_dict(self.image_processor_dict)
self.assertEqual(image_processor.size, {"shortest_edge": 20})
self.assertEqual(image_processor.crop_size, {"height": 18, "width": 18})
image_processor = image_processing_class.from_dict(self.image_processor_dict, size=42, crop_size=84)
self.assertEqual(image_processor.size, {"shortest_edge": 42})
self.assertEqual(image_processor.crop_size, {"height": 84, "width": 84})
def test_select_best_resolution(self):
possible_resolutions = [[672, 336], [336, 672], [672, 672], [336, 1008], [1008, 336]]
# Test with a square aspect ratio
best_resolution = select_best_resolution((336, 336), possible_resolutions)
self.assertEqual(best_resolution, (672, 336))
def test_call_pil(self):
for image_processing_class in self.image_processor_list:
# Initialize image_processing
image_processing = image_processing_class(**self.image_processor_dict)
# create random PIL images
image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=True)
for image in image_inputs:
self.assertIsInstance(image, Image.Image)
# Test not batched input
encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
expected_output_image_shape = (1, 1445, 3, 18, 18)
self.assertEqual(tuple(encoded_images.shape), expected_output_image_shape)
# Test batched
encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
expected_output_image_shape = (7, 1445, 3, 18, 18)
self.assertEqual(tuple(encoded_images.shape), expected_output_image_shape)
def test_call_numpy(self):
for image_processing_class in self.image_processor_list:
# Initialize image_processing
image_processing = image_processing_class(**self.image_processor_dict)
# create random numpy tensors
image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=True, numpify=True)
for image in image_inputs:
self.assertIsInstance(image, np.ndarray)
# Test not batched input
encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
expected_output_image_shape = (1, 1445, 3, 18, 18)
self.assertEqual(tuple(encoded_images.shape), expected_output_image_shape)
# Test batched
encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
expected_output_image_shape = (7, 1445, 3, 18, 18)
self.assertEqual(tuple(encoded_images.shape), expected_output_image_shape)
def test_call_pytorch(self):
for image_processing_class in self.image_processor_list:
# Initialize image_processing
image_processing = image_processing_class(**self.image_processor_dict)
# create random PyTorch tensors
image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=True, torchify=True)
for image in image_inputs:
self.assertIsInstance(image, torch.Tensor)
# Test not batched input
encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
expected_output_image_shape = (1, 1445, 3, 18, 18)
self.assertEqual(tuple(encoded_images.shape), expected_output_image_shape)
# Test batched
encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
expected_output_image_shape = (7, 1445, 3, 18, 18)
self.assertEqual(tuple(encoded_images.shape), expected_output_image_shape)
@unittest.skip(
reason="LlavaNextImageProcessor doesn't treat 4 channel PIL and numpy consistently yet"
) # FIXME Amy
def test_call_numpy_4_channels(self):
pass
def test_nested_input(self):
for image_processing_class in self.image_processor_list:
image_processing = image_processing_class(**self.image_processor_dict)
image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=True)
# Test batched as a list of images
encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
expected_output_image_shape = (7, 1445, 3, 18, 18)
self.assertEqual(tuple(encoded_images.shape), expected_output_image_shape)
# Test batched as a nested list of images, where each sublist is one batch
image_inputs_nested = [image_inputs[:3], image_inputs[3:]]
encoded_images_nested = image_processing(image_inputs_nested, return_tensors="pt").pixel_values
expected_output_image_shape = (7, 1445, 3, 18, 18)
self.assertEqual(tuple(encoded_images_nested.shape), expected_output_image_shape)
# Image processor should return same pixel values, independently of ipnut format
self.assertTrue((encoded_images_nested == encoded_images).all())
| transformers/tests/models/llava_next/test_image_processing_llava_next.py/0 | {
"file_path": "transformers/tests/models/llava_next/test_image_processing_llava_next.py",
"repo_id": "transformers",
"token_count": 4398
} |
# coding=utf-8
# Copyright 2022 Google LongT5 Authors and HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import copy
import tempfile
import unittest
from transformers import LongT5Config, is_torch_available
from transformers.models.auto import get_values
from transformers.testing_utils import require_sentencepiece, require_tokenizers, require_torch, slow, torch_device
from transformers.utils import cached_property
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
import torch.nn.functional as F
from transformers import (
MODEL_FOR_QUESTION_ANSWERING_MAPPING,
AutoTokenizer,
LongT5EncoderModel,
LongT5ForConditionalGeneration,
LongT5Model,
)
class LongT5ModelTester:
def __init__(
self,
parent,
vocab_size=99,
batch_size=13,
encoder_seq_length=7,
decoder_seq_length=9,
local_radius=5,
encoder_attention_type="local",
global_block_size=3,
# For common tests
is_training=True,
use_attention_mask=True,
use_labels=True,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
d_ff=37,
relative_attention_num_buckets=8,
dropout_rate=0.1,
initializer_factor=0.002,
eos_token_id=1,
pad_token_id=0,
decoder_start_token_id=0,
scope=None,
decoder_layers=None,
large_model_config_path="google/long-t5-local-large",
):
self.parent = parent
self.batch_size = batch_size
self.encoder_seq_length = encoder_seq_length
self.decoder_seq_length = decoder_seq_length
self.local_radius = local_radius
self.block_len = local_radius + 1
self.encoder_attention_type = encoder_attention_type
self.global_block_size = global_block_size
# For common tests
self.seq_length = self.decoder_seq_length
self.is_training = is_training
self.use_attention_mask = use_attention_mask
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.d_ff = d_ff
self.relative_attention_num_buckets = relative_attention_num_buckets
self.dropout_rate = dropout_rate
self.initializer_factor = initializer_factor
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.decoder_start_token_id = decoder_start_token_id
self.scope = None
self.decoder_layers = decoder_layers
self.large_model_config_path = large_model_config_path
def get_large_model_config(self):
return LongT5Config.from_pretrained(self.large_model_config_path)
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.encoder_seq_length], self.vocab_size)
decoder_input_ids = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
attention_mask = None
decoder_attention_mask = None
if self.use_attention_mask:
attention_mask = ids_tensor([self.batch_size, self.encoder_seq_length], vocab_size=2)
decoder_attention_mask = ids_tensor([self.batch_size, self.decoder_seq_length], vocab_size=2)
lm_labels = None
if self.use_labels:
lm_labels = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
config = self.get_config()
return (
config,
input_ids,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
)
def get_pipeline_config(self):
return LongT5Config(
vocab_size=166, # longt5 forces 100 extra tokens
d_model=self.hidden_size,
d_ff=self.d_ff,
d_kv=self.hidden_size // self.num_attention_heads,
num_layers=self.num_hidden_layers,
num_decoder_layers=self.decoder_layers,
num_heads=self.num_attention_heads,
relative_attention_num_buckets=self.relative_attention_num_buckets,
dropout_rate=self.dropout_rate,
initializer_factor=self.initializer_factor,
eos_token_id=self.eos_token_id,
bos_token_id=self.pad_token_id,
pad_token_id=self.pad_token_id,
decoder_start_token_id=self.decoder_start_token_id,
local_radius=self.local_radius,
encoder_attention_type=self.encoder_attention_type,
global_block_size=self.global_block_size,
)
def get_config(self):
return LongT5Config(
vocab_size=self.vocab_size,
d_model=self.hidden_size,
d_ff=self.d_ff,
d_kv=self.hidden_size // self.num_attention_heads,
num_layers=self.num_hidden_layers,
num_decoder_layers=self.decoder_layers,
num_heads=self.num_attention_heads,
relative_attention_num_buckets=self.relative_attention_num_buckets,
dropout_rate=self.dropout_rate,
initializer_factor=self.initializer_factor,
eos_token_id=self.eos_token_id,
bos_token_id=self.pad_token_id,
pad_token_id=self.pad_token_id,
decoder_start_token_id=self.decoder_start_token_id,
local_radius=self.local_radius,
encoder_attention_type=self.encoder_attention_type,
global_block_size=self.global_block_size,
)
def check_prepare_lm_labels_via_shift_left(
self,
config,
input_ids,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
):
model = LongT5Model(config=config)
model.to(torch_device)
model.eval()
# make sure that lm_labels are correctly padded from the right
lm_labels.masked_fill_((lm_labels == self.decoder_start_token_id), self.eos_token_id)
# add casaul pad token mask
triangular_mask = torch.tril(lm_labels.new_ones(lm_labels.shape)).logical_not()
lm_labels.masked_fill_(triangular_mask, self.pad_token_id)
decoder_input_ids = model._shift_right(lm_labels)
for i, (decoder_input_ids_slice, lm_labels_slice) in enumerate(zip(decoder_input_ids, lm_labels)):
# first item
self.parent.assertEqual(decoder_input_ids_slice[0].item(), self.decoder_start_token_id)
if i < decoder_input_ids_slice.shape[-1]:
if i < decoder_input_ids.shape[-1] - 1:
# items before diagonal
self.parent.assertListEqual(
decoder_input_ids_slice[1 : i + 1].tolist(), lm_labels_slice[:i].tolist()
)
# pad items after diagonal
if i < decoder_input_ids.shape[-1] - 2:
self.parent.assertListEqual(
decoder_input_ids_slice[i + 2 :].tolist(), lm_labels_slice[i + 1 : -1].tolist()
)
else:
# all items after square
self.parent.assertListEqual(decoder_input_ids_slice[1:].tolist(), lm_labels_slice[:-1].tolist())
def create_and_check_model(
self,
config,
input_ids,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
):
model = LongT5Model(config=config)
model.to(torch_device)
model.eval()
result = model(
input_ids=input_ids,
decoder_input_ids=decoder_input_ids,
attention_mask=attention_mask,
decoder_attention_mask=decoder_attention_mask,
)
result = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
decoder_output = result.last_hidden_state
decoder_past = result.past_key_values
encoder_output = result.encoder_last_hidden_state
self.parent.assertEqual(encoder_output.size(), (self.batch_size, self.encoder_seq_length, self.hidden_size))
self.parent.assertEqual(decoder_output.size(), (self.batch_size, self.decoder_seq_length, self.hidden_size))
# There should be `num_layers` key value embeddings stored in decoder_past
self.parent.assertEqual(len(decoder_past), config.num_layers)
# There should be a self attn key, a self attn value, a cross attn key and a cross attn value stored in each decoder_past tuple
self.parent.assertEqual(len(decoder_past[0]), 4)
def create_and_check_with_lm_head(
self,
config,
input_ids,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
):
model = LongT5ForConditionalGeneration(config=config).to(torch_device).eval()
outputs = model(
input_ids=input_ids,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
labels=lm_labels,
)
self.parent.assertEqual(len(outputs), 4)
self.parent.assertEqual(outputs["logits"].size(), (self.batch_size, self.decoder_seq_length, self.vocab_size))
self.parent.assertEqual(outputs["loss"].size(), ())
def create_and_check_decoder_model_past(
self,
config,
input_ids,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
):
model = LongT5Model(config=config).get_decoder().to(torch_device).eval()
# first forward pass
outputs = model(input_ids, use_cache=True)
outputs_use_cache_conf = model(input_ids)
outputs_no_past = model(input_ids, use_cache=False)
self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
output, past_key_values = outputs.to_tuple()
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
# append to next input_ids and
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
output_from_no_past = model(next_input_ids)["last_hidden_state"]
output_from_past = model(next_tokens, past_key_values=past_key_values)["last_hidden_state"]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
def create_and_check_decoder_model_attention_mask_past(
self,
config,
input_ids,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
):
model = LongT5Model(config=config).get_decoder()
model.to(torch_device)
model.eval()
# create attention mask
attn_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
half_seq_length = input_ids.shape[-1] // 2
attn_mask[:, half_seq_length:] = 0
# first forward pass
output, past_key_values = model(input_ids, attention_mask=attn_mask, use_cache=True).to_tuple()
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
# change a random masked slice from input_ids
random_seq_idx_to_change = ids_tensor((1,), half_seq_length).item() + 1
random_other_next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size).squeeze(-1)
input_ids[:, -random_seq_idx_to_change] = random_other_next_tokens
# append to next input_ids and attn_mask
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
attn_mask = torch.cat(
[attn_mask, torch.ones((attn_mask.shape[0], 1), dtype=torch.long, device=torch_device)],
dim=1,
)
# get two different outputs
output_from_no_past = model(next_input_ids, attention_mask=attn_mask)["last_hidden_state"]
output_from_past = model(next_tokens, past_key_values=past_key_values, attention_mask=attn_mask)[
"last_hidden_state"
]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
def create_and_check_decoder_model_past_large_inputs(
self,
config,
input_ids,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
):
model = LongT5Model(config=config).get_decoder().to(torch_device).eval()
# first forward pass
outputs = model(input_ids, attention_mask=attention_mask, use_cache=True)
output, past_key_values = outputs.to_tuple()
# create hypothetical multiple next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
# append to next input_ids and
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
next_attention_mask = torch.cat([attention_mask, next_mask], dim=-1)
output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)["last_hidden_state"]
output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)[
"last_hidden_state"
]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
def create_and_check_generate_with_past_key_values(
self,
config,
input_ids,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
):
model = LongT5ForConditionalGeneration(config=config).to(torch_device).eval()
torch.manual_seed(0)
output_without_past_cache = model.generate(
input_ids[:1], num_beams=2, max_length=5, do_sample=True, use_cache=False
)
torch.manual_seed(0)
output_with_past_cache = model.generate(input_ids[:1], num_beams=2, max_length=5, do_sample=True)
self.parent.assertTrue(torch.all(output_with_past_cache == output_without_past_cache))
def create_and_check_encoder_decoder_shared_weights(
self,
config,
input_ids,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
):
for model_class in [LongT5Model, LongT5ForConditionalGeneration]:
torch.manual_seed(0)
model = model_class(config=config).to(torch_device).eval()
# load state dict copies weights but does not tie them
model.encoder.load_state_dict(model.decoder.state_dict(), strict=False)
torch.manual_seed(0)
tied_config = copy.deepcopy(config)
tied_config.tie_encoder_decoder = True
tied_model = model_class(config=tied_config).to(torch_device).eval()
model_result = model(
input_ids=input_ids,
decoder_input_ids=decoder_input_ids,
attention_mask=attention_mask,
decoder_attention_mask=decoder_attention_mask,
)
tied_model_result = tied_model(
input_ids=input_ids,
decoder_input_ids=decoder_input_ids,
attention_mask=attention_mask,
decoder_attention_mask=decoder_attention_mask,
)
# check that models has less parameters
self.parent.assertLess(
sum(p.numel() for p in tied_model.parameters()), sum(p.numel() for p in model.parameters())
)
random_slice_idx = ids_tensor((1,), model_result[0].shape[-1]).item()
# check that outputs are equal
self.parent.assertTrue(
torch.allclose(
model_result[0][0, :, random_slice_idx], tied_model_result[0][0, :, random_slice_idx], atol=1e-4
)
)
# check that outputs after saving and loading are equal
with tempfile.TemporaryDirectory() as tmpdirname:
tied_model.save_pretrained(tmpdirname)
tied_model = model_class.from_pretrained(tmpdirname)
tied_model.to(torch_device)
tied_model.eval()
# check that models has less parameters
self.parent.assertLess(
sum(p.numel() for p in tied_model.parameters()), sum(p.numel() for p in model.parameters())
)
random_slice_idx = ids_tensor((1,), model_result[0].shape[-1]).item()
tied_model_result = tied_model(
input_ids=input_ids,
decoder_input_ids=decoder_input_ids,
attention_mask=attention_mask,
decoder_attention_mask=decoder_attention_mask,
)
# check that outputs are equal
self.parent.assertTrue(
torch.allclose(
model_result[0][0, :, random_slice_idx],
tied_model_result[0][0, :, random_slice_idx],
atol=1e-4,
)
)
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
) = config_and_inputs
inputs_dict = {
"input_ids": input_ids,
"attention_mask": attention_mask,
"decoder_input_ids": decoder_input_ids,
"decoder_attention_mask": decoder_attention_mask,
"use_cache": False,
}
return config, inputs_dict
@require_torch
class LongT5ModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (LongT5Model, LongT5ForConditionalGeneration) if is_torch_available() else ()
all_generative_model_classes = (LongT5ForConditionalGeneration,) if is_torch_available() else ()
pipeline_model_mapping = (
{
"feature-extraction": LongT5Model,
"summarization": LongT5ForConditionalGeneration,
"text2text-generation": LongT5ForConditionalGeneration,
"translation": LongT5ForConditionalGeneration,
}
if is_torch_available()
else {}
)
fx_compatible = False
test_pruning = False
test_torchscript = True
test_resize_embeddings = True
test_model_parallel = False
is_encoder_decoder = True
def setUp(self):
self.model_tester = LongT5ModelTester(self)
self.config_tester = ConfigTester(self, config_class=LongT5Config, d_model=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_shift_right(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.check_prepare_lm_labels_via_shift_left(*config_and_inputs)
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_with_lm_head(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_with_lm_head(*config_and_inputs)
def test_decoder_model_past(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_decoder_model_past(*config_and_inputs)
def test_decoder_model_past_with_attn_mask(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_decoder_model_attention_mask_past(*config_and_inputs)
def test_decoder_model_past_with_3d_attn_mask(self):
(
config,
input_ids,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
) = self.model_tester.prepare_config_and_inputs()
attention_mask = ids_tensor(
[self.model_tester.batch_size, self.model_tester.encoder_seq_length, self.model_tester.encoder_seq_length],
vocab_size=2,
)
decoder_attention_mask = ids_tensor(
[self.model_tester.batch_size, self.model_tester.decoder_seq_length, self.model_tester.decoder_seq_length],
vocab_size=2,
)
self.model_tester.create_and_check_decoder_model_attention_mask_past(
config,
input_ids,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
)
# overwrite because T5 doesn't accept position ids as input and expects `decoder_input_ids`
def test_custom_4d_attention_mask(self):
for model_class in self.all_generative_model_classes:
config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
model = model_class(config).to(device=torch_device, dtype=torch.float32)
(
input_ids,
_,
input_ids_shared_prefix,
mask_shared_prefix,
_,
) = self._get_custom_4d_mask_test_data()
logits = model.forward(
decoder_input_ids=input_ids,
input_ids=input_dict["input_ids"][:3],
).logits
# logits.shape == torch.Size([3, 4, ...])
logits_shared_prefix = model(
input_ids=input_dict["input_ids"][:1],
decoder_input_ids=input_ids_shared_prefix,
decoder_attention_mask=mask_shared_prefix,
)[0]
# logits_shared_prefix.shape == torch.Size([1, 6, ...])
out_last_tokens = logits[:, -1, :] # last tokens in each batch line
out_shared_prefix_last_tokens = logits_shared_prefix[0, -3:, :] # last three tokens
# comparing softmax-normalized logits:
normalized_0 = F.softmax(out_last_tokens)
normalized_1 = F.softmax(out_shared_prefix_last_tokens)
torch.testing.assert_close(normalized_0, normalized_1, rtol=1e-3, atol=1e-4)
def test_decoder_model_past_with_large_inputs(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
def test_generate_with_past_key_values(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_generate_with_past_key_values(*config_and_inputs)
def test_encoder_decoder_shared_weights(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_encoder_decoder_shared_weights(*config_and_inputs)
@slow
def test_model_from_pretrained(self):
model_name = "google/long-t5-local-base"
model = LongT5Model.from_pretrained(model_name)
self.assertIsNotNone(model)
@slow
def test_export_to_onnx(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
model = LongT5Model(config_and_inputs[0]).to(torch_device)
with tempfile.TemporaryDirectory() as tmpdirname:
torch.onnx.export(
model,
(config_and_inputs[1], config_and_inputs[3], config_and_inputs[2]),
f"{tmpdirname}/longt5_test.onnx",
export_params=True,
opset_version=14,
input_names=["input_ids", "decoder_input_ids"],
)
def test_generate_with_head_masking(self):
attention_names = ["encoder_attentions", "decoder_attentions", "cross_attentions"]
config_and_inputs = self.model_tester.prepare_config_and_inputs()
config = config_and_inputs[0]
max_length = config_and_inputs[1].shape[-1] + 3
model = LongT5ForConditionalGeneration(config).eval()
model.to(torch_device)
head_masking = {
"head_mask": torch.zeros(config.num_layers, config.num_heads, device=torch_device),
"decoder_head_mask": torch.zeros(config.num_decoder_layers, config.num_heads, device=torch_device),
"cross_attn_head_mask": torch.zeros(config.num_decoder_layers, config.num_heads, device=torch_device),
}
for attn_name, (name, mask) in zip(attention_names, head_masking.items()):
head_masks = {name: mask}
# Explicitly pass decoder_head_mask as it is required from LONGT5 model when head_mask specified
if name == "head_mask":
head_masks["decoder_head_mask"] = torch.ones(
config.num_decoder_layers, config.num_heads, device=torch_device
)
out = model.generate(
config_and_inputs[1],
num_beams=1,
max_length=max_length,
output_attentions=True,
return_dict_in_generate=True,
**head_masks,
)
# We check the state of decoder_attentions and cross_attentions just from the last step
attn_weights = out[attn_name] if attn_name == attention_names[0] else out[attn_name][-1]
self.assertEqual(sum([w.sum().item() for w in attn_weights]), 0.0)
def test_attention_outputs(self):
if not self.has_attentions:
self.skipTest(reason="has_attentions is set to False")
else:
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
seq_len = getattr(self.model_tester, "seq_length", None)
decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
encoder_seq_length = getattr(self.model_tester, "encoder_seq_length", seq_len)
decoder_key_length = getattr(self.model_tester, "decoder_key_length", decoder_seq_length)
encoder_key_length = getattr(self.model_tester, "key_length", encoder_seq_length)
chunk_length = getattr(self.model_tester, "chunk_length", None)
block_len = getattr(self.model_tester, "block_len", None)
if chunk_length is not None and hasattr(self.model_tester, "num_hashes"):
encoder_seq_length = encoder_seq_length * self.model_tester.num_hashes
for model_class in self.all_model_classes:
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = False
config.return_dict = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
# check that output_attentions also work using config
del inputs_dict["output_attentions"]
config.output_attentions = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, block_len, 3 * block_len],
)
out_len = len(outputs)
if self.is_encoder_decoder:
correct_outlen = 5
# loss is at first position
if "labels" in inputs_dict:
correct_outlen += 1 # loss is added to beginning
# Question Answering model returns start_logits and end_logits
if model_class in get_values(MODEL_FOR_QUESTION_ANSWERING_MAPPING):
correct_outlen += 1 # start_logits and end_logits instead of only 1 output
if "past_key_values" in outputs:
correct_outlen += 1 # past_key_values have been returned
self.assertEqual(out_len, correct_outlen)
# decoder attentions
decoder_attentions = outputs.decoder_attentions
self.assertIsInstance(decoder_attentions, (list, tuple))
self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(decoder_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, decoder_seq_length, decoder_key_length],
)
# cross attentions
cross_attentions = outputs.cross_attentions
self.assertIsInstance(cross_attentions, (list, tuple))
self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(cross_attentions[0].shape[-3:]),
[
self.model_tester.num_attention_heads,
decoder_seq_length,
encoder_key_length,
],
)
# Check attention is always last and order is fine
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
if hasattr(self.model_tester, "num_hidden_states_types"):
added_hidden_states = self.model_tester.num_hidden_states_types
elif self.is_encoder_decoder:
added_hidden_states = 2
else:
added_hidden_states = 1
self.assertEqual(out_len + added_hidden_states, len(outputs))
self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(self_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, block_len, 3 * block_len],
)
def _check_encoder_attention_for_generate(self, attentions, batch_size, config, seq_length):
block_len = getattr(self.model_tester, "block_len", None)
encoder_expected_shape = (batch_size, 2, config.num_attention_heads, block_len, 3 * block_len)
self.assertIsInstance(attentions, tuple)
self.assertListEqual(
[layer_attentions.shape for layer_attentions in attentions],
[encoder_expected_shape] * len(attentions),
)
@unittest.skip(
reason="This architecure has tied weights by default and there is no way to remove it, check: https://github.com/huggingface/transformers/pull/31771#issuecomment-2210915245"
)
def test_load_save_without_tied_weights(self):
pass
@require_torch
class LongT5TGlobalModelTest(LongT5ModelTest):
def setUp(self):
self.model_tester = LongT5ModelTester(
self, encoder_attention_type="transient-global", large_model_config_path="google/long-t5-tglobal-large"
)
self.config_tester = ConfigTester(self, config_class=LongT5Config, d_model=37)
def test_attention_outputs(self):
if not self.has_attentions:
self.skipTest(reason="has_attentions is set to False")
else:
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
seq_len = getattr(self.model_tester, "seq_length", None)
decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
encoder_seq_length = getattr(self.model_tester, "encoder_seq_length", seq_len)
decoder_key_length = getattr(self.model_tester, "decoder_key_length", decoder_seq_length)
encoder_key_length = getattr(self.model_tester, "key_length", encoder_seq_length)
chunk_length = getattr(self.model_tester, "chunk_length", None)
block_len = getattr(self.model_tester, "block_len", None)
global_block_size = getattr(self.model_tester, "global_block_size", None)
global_seq_len = encoder_seq_length // global_block_size
if chunk_length is not None and hasattr(self.model_tester, "num_hashes"):
encoder_seq_length = encoder_seq_length * self.model_tester.num_hashes
for model_class in self.all_model_classes:
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = False
config.return_dict = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
# check that output_attentions also work using config
del inputs_dict["output_attentions"]
config.output_attentions = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, block_len, 3 * block_len + global_seq_len],
)
out_len = len(outputs)
if self.is_encoder_decoder:
correct_outlen = 5
# loss is at first position
if "labels" in inputs_dict:
correct_outlen += 1 # loss is added to beginning
# Question Answering model returns start_logits and end_logits
if model_class in get_values(MODEL_FOR_QUESTION_ANSWERING_MAPPING):
correct_outlen += 1 # start_logits and end_logits instead of only 1 output
if "past_key_values" in outputs:
correct_outlen += 1 # past_key_values have been returned
self.assertEqual(out_len, correct_outlen)
# decoder attentions
decoder_attentions = outputs.decoder_attentions
self.assertIsInstance(decoder_attentions, (list, tuple))
self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(decoder_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, decoder_seq_length, decoder_key_length],
)
# cross attentions
cross_attentions = outputs.cross_attentions
self.assertIsInstance(cross_attentions, (list, tuple))
self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(cross_attentions[0].shape[-3:]),
[
self.model_tester.num_attention_heads,
decoder_seq_length,
encoder_key_length,
],
)
# Check attention is always last and order is fine
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
if hasattr(self.model_tester, "num_hidden_states_types"):
added_hidden_states = self.model_tester.num_hidden_states_types
elif self.is_encoder_decoder:
added_hidden_states = 2
else:
added_hidden_states = 1
self.assertEqual(out_len + added_hidden_states, len(outputs))
self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(self_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, block_len, 3 * block_len + global_seq_len],
)
def _check_encoder_attention_for_generate(self, attentions, batch_size, config, seq_length):
block_len = getattr(self.model_tester, "block_len", None)
global_block_size = getattr(self.model_tester, "global_block_size", None)
global_seq_length = seq_length // global_block_size
encoder_expected_shape = (
batch_size,
2,
config.num_attention_heads,
block_len,
3 * block_len + global_seq_length,
)
self.assertIsInstance(attentions, tuple)
self.assertListEqual(
[layer_attentions.shape for layer_attentions in attentions],
[encoder_expected_shape] * len(attentions),
)
class LongT5EncoderOnlyModelTester:
def __init__(
self,
parent,
vocab_size=99,
batch_size=13,
encoder_seq_length=7,
local_radius=5,
encoder_attention_type="local",
global_block_size=3,
# For common tests
use_attention_mask=True,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
d_ff=37,
relative_attention_num_buckets=8,
is_training=False,
dropout_rate=0.1,
initializer_factor=0.002,
is_encoder_decoder=False,
eos_token_id=1,
pad_token_id=0,
scope=None,
large_model_config_path="google/long-t5-local-large",
):
self.parent = parent
self.batch_size = batch_size
self.encoder_seq_length = encoder_seq_length
self.local_radius = local_radius
self.block_len = local_radius + 1
self.encoder_attention_type = encoder_attention_type
self.global_block_size = global_block_size
# For common tests
self.seq_length = self.encoder_seq_length
self.use_attention_mask = use_attention_mask
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.d_ff = d_ff
self.relative_attention_num_buckets = relative_attention_num_buckets
self.dropout_rate = dropout_rate
self.initializer_factor = initializer_factor
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.is_encoder_decoder = is_encoder_decoder
self.scope = None
self.is_training = is_training
self.large_model_config_path = large_model_config_path
def get_large_model_config(self):
return LongT5Config.from_pretrained(self.large_model_config_path)
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.encoder_seq_length], self.vocab_size)
attention_mask = None
if self.use_attention_mask:
attention_mask = ids_tensor([self.batch_size, self.encoder_seq_length], vocab_size=2)
config = LongT5Config(
vocab_size=self.vocab_size,
d_model=self.hidden_size,
d_ff=self.d_ff,
d_kv=self.hidden_size // self.num_attention_heads,
num_layers=self.num_hidden_layers,
num_heads=self.num_attention_heads,
relative_attention_num_buckets=self.relative_attention_num_buckets,
dropout_rate=self.dropout_rate,
initializer_factor=self.initializer_factor,
eos_token_id=self.eos_token_id,
bos_token_id=self.pad_token_id,
pad_token_id=self.pad_token_id,
is_encoder_decoder=self.is_encoder_decoder,
local_radius=self.local_radius,
encoder_attention_type=self.encoder_attention_type,
global_block_size=self.global_block_size,
)
return (
config,
input_ids,
attention_mask,
)
def create_and_check_model(
self,
config,
input_ids,
attention_mask,
):
model = LongT5EncoderModel(config=config)
model.to(torch_device)
model.eval()
result = model(
input_ids=input_ids,
attention_mask=attention_mask,
)
result = model(input_ids=input_ids)
encoder_output = result.last_hidden_state
self.parent.assertEqual(encoder_output.size(), (self.batch_size, self.encoder_seq_length, self.hidden_size))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
attention_mask,
) = config_and_inputs
inputs_dict = {
"input_ids": input_ids,
"attention_mask": attention_mask,
}
return config, inputs_dict
class LongT5EncoderOnlyModelTest(ModelTesterMixin, unittest.TestCase):
all_model_classes = (LongT5EncoderModel,) if is_torch_available() else ()
test_pruning = False
test_torchscript = True
test_resize_embeddings = False
test_model_parallel = False
def setUp(self):
self.model_tester = LongT5EncoderOnlyModelTester(self)
self.config_tester = ConfigTester(self, config_class=LongT5Config, d_model=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_attention_outputs(self):
if not self.has_attentions:
self.skipTest(reason="has_attentions is set to False")
else:
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
block_len = getattr(self.model_tester, "block_len", 4)
for model_class in self.all_model_classes:
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = False
config.return_dict = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
# check that output_attentions also work using config
del inputs_dict["output_attentions"]
config.output_attentions = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, block_len, 3 * block_len],
)
out_len = len(outputs)
# Check attention is always last and order is fine
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
if hasattr(self.model_tester, "num_hidden_states_types"):
added_hidden_states = self.model_tester.num_hidden_states_types
elif self.is_encoder_decoder:
added_hidden_states = 2
else:
added_hidden_states = 1
self.assertEqual(out_len + added_hidden_states, len(outputs))
self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(self_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, block_len, 3 * block_len],
)
@unittest.skip(
reason="This architecure has tied weights by default and there is no way to remove it, check: https://github.com/huggingface/transformers/pull/31771#issuecomment-2210915245"
)
def test_load_save_without_tied_weights(self):
pass
class LongT5EncoderOnlyTGlobalModelTest(LongT5EncoderOnlyModelTest):
def setUp(self):
self.model_tester = LongT5EncoderOnlyModelTester(
self, encoder_attention_type="transient-global", large_model_config_path="google/long-t5-tglobal-large"
)
self.config_tester = ConfigTester(self, config_class=LongT5Config, d_model=37)
def test_attention_outputs(self):
if not self.has_attentions:
self.skipTest(reason="has_attentions is set to False")
else:
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
block_len = getattr(self.model_tester, "block_len", None)
seq_len = getattr(self.model_tester, "seq_length", None)
global_block_size = getattr(self.model_tester, "global_block_size", 4)
global_seq_len = seq_len // global_block_size
for model_class in self.all_model_classes:
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = False
config.return_dict = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
# check that output_attentions also work using config
del inputs_dict["output_attentions"]
config.output_attentions = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, block_len, 3 * block_len + global_seq_len],
)
out_len = len(outputs)
# Check attention is always last and order is fine
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
if hasattr(self.model_tester, "num_hidden_states_types"):
added_hidden_states = self.model_tester.num_hidden_states_types
elif self.is_encoder_decoder:
added_hidden_states = 2
else:
added_hidden_states = 1
self.assertEqual(out_len + added_hidden_states, len(outputs))
self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(self_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, block_len, 3 * block_len + global_seq_len],
)
def use_task_specific_params(model, task):
model.config.update(model.config.task_specific_params[task])
@require_torch
@require_sentencepiece
@require_tokenizers
class LongT5ModelIntegrationTests(unittest.TestCase):
@cached_property
def model(self):
return LongT5ForConditionalGeneration.from_pretrained("Stancld/longt5-tglobal-large-16384-pubmed-3k_steps").to(
torch_device
)
@cached_property
def tokenizer(self):
return AutoTokenizer.from_pretrained("Stancld/longt5-tglobal-large-16384-pubmed-3k_steps")
def expected_summary(self):
return [
"background : coronary artery disease ( cad ) is the emerging cause of morbidity and mortality in"
" developing world . it provides an excellent resolution for visualization of the coronaryarteries for"
" catheter - based or operating interventions . although the association of this technique with major"
" complications such as mortality is highly uncommon , it is frequently associated with various cardiac"
" and noncardiac complications.materials and methods : in aortic stenosis , we aimed to report the"
" diagnostic performance of 128-slice computed tomography coronary angiogram in 50 patients undergoing for"
" major noncoron ary cardiac surgery referred"
]
@slow
def test_summarization(self):
model = self.model
tok = self.tokenizer
ARTICLE = """coronary artery disease ( cad ) is the emerging cause of morbidity and mortality in developing world . \n it provides an excellent resolution for visualization of the coronary arteries for catheter - based or operating interventions . \n
although the association of this technique with major complications such as mortality is highly uncommon , it is frequently associated with various cardiac and noncardiac complications . computed tomography ( ct ) coronary angiography is
a promising technique for the evaluation of cad noninvasively . \n it assesses disease within the coronary artery and provides qualitative and quantitative information about nonobstructive atherosclerotic plaque burden within the vessel
wall . \n thus , ct angiography - based disease evaluation may provide clinically more significant information than conventional angiography . the introduction of multi - slice computed tomography ( msct ) technology such as 64-slice , 12
8-slice , 256-slice , and now 320-slice msct has produced a high diagnostic accuracy of ct coronary angiography . \n it has consistently showed to have a very high negative predictive value ( well above 90% ) in ruling out patients with s
ignificant cad defined as coronary luminal stenosis of > 50% . \n the american college of cardiology / american heart association recommends that coronary angiography should be performed before valve surgery in men aged > 40 years , women
aged > 35 years with coronary risk factors and in postmenopausal women . \n the prevalence of cad in patients undergoing valve replacement is 2040% in developed countries . in the previous studies , \n the incidence of angiographically p
roven cad in acquired valvular diseases has been shown to vary widely from 9% to 41% . in aortic stenosis , \n we aimed to report the diagnostic performance of 128-slice ct coronary angiography in 50 patients undergoing for major noncoron
ary cardiac surgery referred for diagnostic invasive coronary angiography to assess the extent and severity of coronary stenosis . \n during january 2013 to december 2014 , we enrolled fifty major noncoronary cardiac surgery patients sche
duled for invasive coronary angiography who fulfilled the following inclusion criteria of age 40 years , having low or intermediate probability of cad , left ventricular ejection fraction ( lvef ) > 35% , and patient giving informed conse
nt for undergoing msct and conventional coronary angiography . \n those having any contraindication for contrast injection , lvef < 35% , high pretest probability of cad , and hemodynamic instability were excluded from the study . \n pati
ents with heart rates of > 70 bpm received ( unless they had known overt heart failure or electrocardiogram ( ecg ) atrioventricular conduction abnormalities ) a single oral dose of 100 mg metoprolol 45 min before the scan . \n patients w
ith heart rates of > 80 bpm received an additional oral dose of metoprolol if not contraindicated . \n all patients were scanned with a 128-slice ct scanner ( siemens , somatom definition as ) equipped with a new feature in msct technolog
y , so - called z - axis flying - focus technology . \n the central 32 detector rows acquire 0.6-mm slices , and the flying - focus spot switches back and forth between 2 z positions between each reading . \n two slices per detector row a
re acquired , which results in a higher oversampling rate in the z - axis , thereby reducing artifacts related to the spiral acquisition and improving spatial resolution down to 0.4 mm . \n a bolus of 6580 ml contrast material ( omnipaque
) was injected through an arm vein at a flow rate of 5 ml / s . \n a bolus tracking technique was used to synchronize the arrival of contrast in the coronary arteries with the initiation of the scan . to monitor the arrival of contrast m
aterial , \n axial scans were obtained at the level of the ascending aorta with a delay of 10 s after the start of the contrast injection . \n the scan was automatically started when a threshold of 150 hounsfield units was reached in a re
gion of interest positioned in the ascending aorta . \n images were reconstructed with ecg gating to obtain optimal , motion - free image quality . \n all scans were performed within 2 weeks of the msct coronary diagnostic angiogram . a s
ingle observer unaware of the multi - slice ct results identified coronary lesion as a single vessel , double vessel , or triple vessel disease . \n all lesion , regardless of size , were included for comparison with ct coronary angiograp
hy . \n lesions were classified as having nonsignificant disease ( luminal irregularities or < 50% stenosis ) or as having significant stenosis . \n stenosis was evaluated in two orthogonal views and classified as significant if the mean
lumen diameter reduction was 50% using a validated quantitative coronary angiography ( qca ) . \n all scans were analyzed independently by a radiologist and a cardiologist who were unaware of the results of conventional coronary angiograp
hy . \n total calcium scores of all patients were calculated with dedicated software and expressed as agatston scores . \n the agatston score is a commonly used scoring method that calculates the total amount of calcium on the basis of th
e number , areas , and peak hounsfield units of the detected calcified lesions . \n all available coronary segments were visually scored for the presence of > 50% considered as significant stenosis . \n maximum intensity projections were
used to identify coronary lesions and ( curved ) multiplanar reconstructions to classify lesions as significant or nonsignificant . \n data were analyzed using statistical system spss version 20 software ( chicago , il , usa ) . \n the di
agnostic performance of ct coronary angiography for the detection of significant lesions in coronary arteries with qca as the standard of reference is presented as sensitivity , specificity , positive and negative predictive values , and
positive and negative likelihood ratios with the corresponding exact 95% of confidence interval ( cis ) . \n comparison between ct and conventional coronary angiography was performed on the two level vessel by vessel ( no or any disease p
er vessel ) , and patient by patient ( no or any disease per patient ) . \n all scans were performed within 2 weeks of the msct coronary diagnostic angiogram . a single observer unaware of the multi - slice ct results identified coronary
lesion as a single vessel , double vessel , or triple vessel disease . \n all lesion , regardless of size , were included for comparison with ct coronary angiography . \n lesions were classified as having nonsignificant disease ( luminal
irregularities or < 50% stenosis ) or as having significant stenosis . \n stenosis was evaluated in two orthogonal views and classified as significant if the mean lumen diameter reduction was 50% using a validated quantitative coronary an
giography ( qca ) . \n all scans were analyzed independently by a radiologist and a cardiologist who were unaware of the results of conventional coronary angiography . \n total calcium scores of all patients were calculated with dedicated
software and expressed as agatston scores . \n the agatston score is a commonly used scoring method that calculates the total amount of calcium on the basis of the number , areas , and peak hounsfield units of the detected calcified lesi
ons . \n all available coronary segments were visually scored for the presence of > 50% considered as significant stenosis . \n maximum intensity projections were used to identify coronary lesions and ( curved ) multiplanar reconstruction
s to classify lesions as significant or nonsignificant . \n data were analyzed using statistical system spss version 20 software ( chicago , il , usa ) . \n the diagnostic performance of ct coronary angiography for the detection of signif
icant lesions in coronary arteries with qca as the standard of reference is presented as sensitivity , specificity , positive and negative predictive values , and positive and negative likelihood ratios with the corresponding exact 95% of
confidence interval ( cis ) . \n comparison between ct and conventional coronary angiography was performed on the two level vessel by vessel ( no or any disease per vessel ) , and patient by patient ( no or any disease per patient ) . \n
in this study , 29 ( 58% ) subjects were female , and 21 ( 42% ) were male showing an average age of 50.36 8.39 years . \n of fifty patients 24 ( 48% ) , 13 ( 26% ) , eight ( 16% ) , and five ( 10% ) underwent mitral valve replacement ,
double valve replacement ( dvr ) , aortic valve replacement , and other surgeries , respectively . \n high distribution of cad risk factors such as hypertension ( 24% ) , smoking ( 22% ) , and dyslipidemia ( 18% ) was observed in the stu
dy group . \n the mean creatinine level was 0.766 0.17 and average dye used in conventional angiography was 48.5 26.6 whereas for ct angiography it was 72.8 6.32 . \n average radiation dose in conventional coronary angiography and msct
coronary angiography was 5.2 msv and 9.2 msv , respectively . \n the majority of the patients had sinus rhythm ( 68% ) , whereas atrial fibrillation was found in 32% of the subjects . \n patients included in the study had low to intermed
iate probability of cad . in this study , three patients had complications after conventional angiography . \n complications were of local site hematoma , acute kidney injury managed conservatively , and acute heart failure . \n a patient
who developed hematoma was obese female patients with body mass index > 30 kg / m . \n the patient suffered from pseudoaneurysm , had hospitalized for 9 days , which leads to increased morbidity and cost of hospital stay . \n the diagnos
tic accuracy of ct coronary angiography was evaluated regarding true positive , true negative values and is presented in table 1 . the overall sensitivity and \n specificity of ct angiography technique was 100% ( 95% ci : 39.76%100% ) and
91.30% ( 95% ci : 79.21%97.58% ) , respectively [ table 2 ] . \n the positive predictive value ( 50% ; 95% ci : 15.70%84.30% ) and negative predictive value ( 100% ; 95% ci : 91.59%100% ) of ct angiography were also fairly high in these
patients . \n recent reports from multiple studies demonstrated that recent - generation msct scanners showed promise for noninvasive detection of coronary stenosis however , until now no studies were found regarding the clinical efficacy
or prognostic value of 128-slice ct coronary angiography versus conventional invasive coronary angiography in the diagnosis of patients planned for major noncoronary surgeries such as dvr , bentall , atrial septal defect closure , etc .
in our study , we reported 8% cad prevalence in patients planned for major noncoronary cardiac surgery . \n we performed conventional and msct coronary angiography in all patients and the results showed that ct coronary angiography with i
nvasive coronary angiography as the reference standard had a considerably high sensitivity ( 100% ) and specificity ( 95.65% ) . \n the health economic model using invasive coronary angiography as the reference standard showed that at a p
retest probability of cad of 70% or lower , ct coronary angiography resulted in lower cost per patient with a true positive diagnosis . at a pretest probability of cad of 70% or higher , invasive coronary angiography was associated with a
lower cost per patient with a true positive diagnosis . in our study population , \n two patients developed local site complications in the form of hematoma and pseudoaneurysm after conventional angiography . \n hence , msct coronary ang
iography will be more favorable in female obese patients with intermediate likelihood of cad . \n hence , msct coronary angiography will be cost - effective in patients of valvular heart diseases . \n however , ct angiography suffers from
a drawback that average amount of dye used in msct coronary angiography were 72.8 6.32 ml which is higher than average amount of dye required for conventional angiography ( 48.6 26.6 ml ) . \n hence , the use of ct coronary angiography
could not be used in patients with known renal dysfunction , where reduction of contrast dye load is highly advocated . \n our results show that 128-slice ct coronary angiography is a reliable technique to detect coronary stenosis in pat
ients planned for noncoronary cardiac surgery . \n although there has been important technological progress in the development of ct coronary angiography , its clinical application remains limited . \n a study wth large numbers of patient
s is required for the recommendation of only ct coronary angiography for the coronary evaluation in major non - cardiac surgeries . \n mehta institute of cardiology and research center ( affiliated to bj medical college , ahmedabad , guja
rat , india ) . \n u.n . mehta institute of cardiology and research center ( affiliated to bj medical college , ahmedabad , gujarat , india ) . \n """
dct = tok(
[ARTICLE],
max_length=1024,
padding="max_length",
truncation=True,
return_tensors="pt",
).to(torch_device)
hypotheses_batch = model.generate(
**dct,
num_beams=4,
length_penalty=2.0,
max_length=142,
min_length=56,
no_repeat_ngram_size=3,
do_sample=False,
early_stopping=True,
)
decoded = tok.batch_decode(hypotheses_batch, skip_special_tokens=True, clean_up_tokenization_spaces=False)
self.assertListEqual(
self.expected_summary(),
decoded,
)
@slow
def test_inference_hidden_states(self):
model = self.model
input_ids = torch.tensor(
[[100, 19, 3, 9, 7142, 1200, 145, 8, 1252, 14145, 2034, 812, 5, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=torch.long,
device=torch_device,
)
decoder_input_ids = torch.tensor(
[[100, 19, 3, 9, 7142, 1200, 145, 8, 1252, 14145, 2034, 812, 5, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=torch.long,
device=torch_device,
)
attention_mask = torch.tensor(
[[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=torch.long,
device=torch_device,
)
output = model(
input_ids, attention_mask=attention_mask, decoder_input_ids=decoder_input_ids, output_hidden_states=True
)
# check if encoder_outputs match
expected_output_slice = torch.tensor([0.0629, -0.1294, -0.0089, 0.0772, 0.0663], device=torch_device)
torch.testing.assert_close(
output.encoder_hidden_states[-1][0, 0, :5], expected_output_slice, rtol=1e-4, atol=1e-4
)
# check if logits match
expected_output_slice = torch.tensor([5.5231, 6.1058, 3.1766, 8.2391, -5.9453], device=torch_device)
torch.testing.assert_close(output.logits[0, 0, :5], expected_output_slice, rtol=1e-4, atol=1e-4)
| transformers/tests/models/longt5/test_modeling_longt5.py/0 | {
"file_path": "transformers/tests/models/longt5/test_modeling_longt5.py",
"repo_id": "transformers",
"token_count": 30829
} |
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
import numpy as np
import timeout_decorator # noqa
from transformers import MarianConfig, is_flax_available
from transformers.testing_utils import require_flax, require_sentencepiece, require_tokenizers, slow
from transformers.utils import cached_property
from ...generation.test_flax_utils import FlaxGenerationTesterMixin
from ...test_modeling_flax_common import FlaxModelTesterMixin, ids_tensor
if is_flax_available():
import os
# The slow tests are often failing with OOM error on GPU
# This makes JAX allocate exactly what is needed on demand, and deallocate memory that is no longer needed
# but will be slower as stated here https://jax.readthedocs.io/en/latest/gpu_memory_allocation.html
os.environ["XLA_PYTHON_CLIENT_ALLOCATOR"] = "platform"
import jax
import jax.numpy as jnp
from transformers import MarianTokenizer
from transformers.models.marian.modeling_flax_marian import FlaxMarianModel, FlaxMarianMTModel, shift_tokens_right
def prepare_marian_inputs_dict(
config,
input_ids,
decoder_input_ids=None,
attention_mask=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
):
if attention_mask is None:
attention_mask = np.where(input_ids != config.pad_token_id, 1, 0)
if decoder_attention_mask is None:
decoder_attention_mask = np.where(decoder_input_ids != config.pad_token_id, 1, 0)
if head_mask is None:
head_mask = np.ones((config.encoder_layers, config.encoder_attention_heads))
if decoder_head_mask is None:
decoder_head_mask = np.ones((config.decoder_layers, config.decoder_attention_heads))
if cross_attn_head_mask is None:
cross_attn_head_mask = np.ones((config.decoder_layers, config.decoder_attention_heads))
return {
"input_ids": input_ids,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"decoder_attention_mask": attention_mask,
}
class FlaxMarianModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_labels=False,
vocab_size=99,
hidden_size=16,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=4,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=32,
eos_token_id=2,
pad_token_id=1,
bos_token_id=0,
initializer_range=0.02,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.bos_token_id = bos_token_id
self.initializer_range = initializer_range
def prepare_config_and_inputs(self):
input_ids = np.clip(ids_tensor([self.batch_size, self.seq_length - 1], self.vocab_size), 3, self.vocab_size)
input_ids = np.concatenate((input_ids, 2 * np.ones((self.batch_size, 1), dtype=np.int64)), -1)
decoder_input_ids = shift_tokens_right(input_ids, 1, 2)
config = MarianConfig(
vocab_size=self.vocab_size,
d_model=self.hidden_size,
encoder_layers=self.num_hidden_layers,
decoder_layers=self.num_hidden_layers,
encoder_attention_heads=self.num_attention_heads,
decoder_attention_heads=self.num_attention_heads,
encoder_ffn_dim=self.intermediate_size,
decoder_ffn_dim=self.intermediate_size,
dropout=self.hidden_dropout_prob,
attention_dropout=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
eos_token_id=self.eos_token_id,
bos_token_id=self.bos_token_id,
pad_token_id=self.pad_token_id,
initializer_range=self.initializer_range,
use_cache=False,
)
inputs_dict = prepare_marian_inputs_dict(config, input_ids, decoder_input_ids)
return config, inputs_dict
def prepare_config_and_inputs_for_common(self):
config, inputs_dict = self.prepare_config_and_inputs()
return config, inputs_dict
def check_use_cache_forward(self, model_class_name, config, inputs_dict):
max_decoder_length = 20
model = model_class_name(config)
encoder_outputs = model.encode(inputs_dict["input_ids"])
decoder_input_ids, decoder_attention_mask = (
inputs_dict["decoder_input_ids"],
inputs_dict["decoder_attention_mask"],
)
past_key_values = model.init_cache(decoder_input_ids.shape[0], max_decoder_length, encoder_outputs)
decoder_attention_mask = jnp.ones((decoder_input_ids.shape[0], max_decoder_length), dtype="i4")
decoder_position_ids = jnp.broadcast_to(
jnp.arange(decoder_input_ids.shape[-1] - 1)[None, :],
(decoder_input_ids.shape[0], decoder_input_ids.shape[-1] - 1),
)
outputs_cache = model.decode(
decoder_input_ids[:, :-1],
encoder_outputs,
decoder_attention_mask=decoder_attention_mask,
past_key_values=past_key_values,
decoder_position_ids=decoder_position_ids,
)
decoder_position_ids = jnp.array(decoder_input_ids.shape[0] * [[decoder_input_ids.shape[-1] - 1]], dtype="i4")
outputs_cache_next = model.decode(
decoder_input_ids[:, -1:],
encoder_outputs,
decoder_attention_mask=decoder_attention_mask,
past_key_values=outputs_cache.past_key_values,
decoder_position_ids=decoder_position_ids,
)
outputs = model.decode(decoder_input_ids, encoder_outputs)
diff = np.max(np.abs((outputs_cache_next[0][:, -1, :5] - outputs[0][:, -1, :5])))
self.parent.assertTrue(diff < 1e-3, msg=f"Max diff is {diff}")
def check_use_cache_forward_with_attn_mask(self, model_class_name, config, inputs_dict):
max_decoder_length = 20
model = model_class_name(config)
encoder_outputs = model.encode(inputs_dict["input_ids"])
decoder_input_ids, decoder_attention_mask = (
inputs_dict["decoder_input_ids"],
inputs_dict["decoder_attention_mask"],
)
decoder_attention_mask_cache = jnp.concatenate(
[
decoder_attention_mask,
jnp.zeros((decoder_attention_mask.shape[0], max_decoder_length - decoder_attention_mask.shape[1])),
],
axis=-1,
)
past_key_values = model.init_cache(decoder_input_ids.shape[0], max_decoder_length, encoder_outputs)
decoder_position_ids = jnp.broadcast_to(
jnp.arange(decoder_input_ids.shape[-1] - 1)[None, :],
(decoder_input_ids.shape[0], decoder_input_ids.shape[-1] - 1),
)
outputs_cache = model.decode(
decoder_input_ids[:, :-1],
encoder_outputs,
decoder_attention_mask=decoder_attention_mask_cache,
past_key_values=past_key_values,
decoder_position_ids=decoder_position_ids,
)
decoder_position_ids = jnp.array(decoder_input_ids.shape[0] * [[decoder_input_ids.shape[-1] - 1]], dtype="i4")
outputs_cache_next = model.decode(
decoder_input_ids[:, -1:],
encoder_outputs,
past_key_values=outputs_cache.past_key_values,
decoder_attention_mask=decoder_attention_mask_cache,
decoder_position_ids=decoder_position_ids,
)
outputs = model.decode(decoder_input_ids, encoder_outputs, decoder_attention_mask=decoder_attention_mask)
diff = np.max(np.abs((outputs_cache_next[0][:, -1, :5] - outputs[0][:, -1, :5])))
self.parent.assertTrue(diff < 1e-3, msg=f"Max diff is {diff}")
@require_flax
class FlaxMarianModelTest(FlaxModelTesterMixin, unittest.TestCase, FlaxGenerationTesterMixin):
is_encoder_decoder = True
all_model_classes = (FlaxMarianModel, FlaxMarianMTModel) if is_flax_available() else ()
all_generative_model_classes = (FlaxMarianMTModel,) if is_flax_available() else ()
def setUp(self):
self.model_tester = FlaxMarianModelTester(self)
def test_use_cache_forward(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs()
for model_class in self.all_model_classes:
self.model_tester.check_use_cache_forward(model_class, config, inputs_dict)
def test_use_cache_forward_with_attn_mask(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs()
for model_class in self.all_model_classes:
self.model_tester.check_use_cache_forward_with_attn_mask(model_class, config, inputs_dict)
def test_encode(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
with self.subTest(model_class.__name__):
prepared_inputs_dict = self._prepare_for_class(inputs_dict, model_class)
model = model_class(config)
@jax.jit
def encode_jitted(input_ids, attention_mask=None, **kwargs):
return model.encode(input_ids=input_ids, attention_mask=attention_mask)
with self.subTest("JIT Enabled"):
jitted_outputs = encode_jitted(**prepared_inputs_dict).to_tuple()
with self.subTest("JIT Disabled"):
with jax.disable_jit():
outputs = encode_jitted(**prepared_inputs_dict).to_tuple()
self.assertEqual(len(outputs), len(jitted_outputs))
for jitted_output, output in zip(jitted_outputs, outputs):
self.assertEqual(jitted_output.shape, output.shape)
def test_decode(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
with self.subTest(model_class.__name__):
model = model_class(config)
encoder_outputs = model.encode(inputs_dict["input_ids"], inputs_dict["attention_mask"])
prepared_inputs_dict = {
"decoder_input_ids": inputs_dict["decoder_input_ids"],
"decoder_attention_mask": inputs_dict["decoder_attention_mask"],
"encoder_outputs": encoder_outputs,
}
@jax.jit
def decode_jitted(decoder_input_ids, decoder_attention_mask, encoder_outputs):
return model.decode(
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
encoder_outputs=encoder_outputs,
)
with self.subTest("JIT Enabled"):
jitted_outputs = decode_jitted(**prepared_inputs_dict).to_tuple()
with self.subTest("JIT Disabled"):
with jax.disable_jit():
outputs = decode_jitted(**prepared_inputs_dict).to_tuple()
self.assertEqual(len(outputs), len(jitted_outputs))
for jitted_output, output in zip(jitted_outputs, outputs):
self.assertEqual(jitted_output.shape, output.shape)
@slow
def test_model_from_pretrained(self):
for model_class_name in self.all_model_classes:
model = model_class_name.from_pretrained("Helsinki-NLP/opus-mt-en-de")
# FlaxMarianForSequenceClassification expects eos token in input_ids
input_ids = np.ones((1, 1)) * model.config.eos_token_id
outputs = model(input_ids)
self.assertIsNotNone(outputs)
@require_flax
@require_sentencepiece
@require_tokenizers
class MarianIntegrationTest(unittest.TestCase):
src = None
tgt = None
@classmethod
def setUpClass(cls) -> None:
cls.model_name = f"Helsinki-NLP/opus-mt-{cls.src}-{cls.tgt}"
return cls
@cached_property
def tokenizer(self):
return MarianTokenizer.from_pretrained(self.model_name)
@property
def eos_token_id(self) -> int:
return self.tokenizer.eos_token_id
@cached_property
def model(self):
model: FlaxMarianMTModel = FlaxMarianMTModel.from_pretrained(self.model_name)
self.assertEqual(model.config.decoder_start_token_id, model.config.pad_token_id)
return model
def _assert_generated_batch_equal_expected(self, **tokenizer_kwargs):
generated_words = self.translate_src_text(**tokenizer_kwargs)
self.assertListEqual(self.expected_text, generated_words)
def translate_src_text(self, **tokenizer_kwargs):
model_inputs = self.tokenizer(self.src_text, padding=True, return_tensors="np", **tokenizer_kwargs)
generated_ids = self.model.generate(
model_inputs.input_ids,
attention_mask=model_inputs.attention_mask,
num_beams=2,
max_length=128,
).sequences
generated_words = self.tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
return generated_words
@require_flax
@require_sentencepiece
@require_tokenizers
class TestMarian_EN_FR(MarianIntegrationTest):
src = "en"
tgt = "fr"
src_text = [
"I am a small frog.",
"Now I can forget the 100 words of german that I know.",
]
expected_text = [
"Je suis une petite grenouille.",
"Maintenant, je peux oublier les 100 mots d'allemand que je connais.",
]
@slow
def test_batch_generation_en_fr(self):
self._assert_generated_batch_equal_expected()
@require_flax
@require_sentencepiece
@require_tokenizers
class TestMarian_FR_EN(MarianIntegrationTest):
src = "fr"
tgt = "en"
src_text = [
"Donnez moi le micro.",
"Tom et Mary étaient assis à une table.", # Accents
]
expected_text = [
"Give me the microphone.",
"Tom and Mary were sitting at a table.",
]
@slow
def test_batch_generation_fr_en(self):
self._assert_generated_batch_equal_expected()
@require_flax
@require_sentencepiece
@require_tokenizers
class TestMarian_MT_EN(MarianIntegrationTest):
"""Cover low resource/high perplexity setting. This breaks without adjust_logits_generation overwritten"""
src = "mt"
tgt = "en"
src_text = ["Billi messu b'mod ġentili, Ġesù fejjaq raġel li kien milqut bil - marda kerha tal - ġdiem."]
expected_text = ["Touching gently, Jesus healed a man who was affected by the sad disease of leprosy."]
@slow
def test_batch_generation_mt_en(self):
self._assert_generated_batch_equal_expected()
@require_flax
@require_sentencepiece
@require_tokenizers
class TestMarian_EN_DE(MarianIntegrationTest):
src = "en"
tgt = "de"
src_text = [
"I am a small frog.",
"Now I can forget the 100 words of german that I know.",
"Tom asked his teacher for advice.",
"That's how I would do it.",
"Tom really admired Mary's courage.",
"Turn around and close your eyes.",
]
expected_text = [
"Ich bin ein kleiner Frosch.",
"Jetzt kann ich die 100 Wörter des Deutschen vergessen, die ich kenne.",
"Tom bat seinen Lehrer um Rat.",
"So würde ich das machen.",
"Tom bewunderte Marias Mut wirklich.",
"Drehen Sie sich um und schließen Sie die Augen.",
]
@slow
def test_batch_generation_en_de(self):
self._assert_generated_batch_equal_expected()
@require_flax
@require_sentencepiece
@require_tokenizers
class TestMarian_en_zh(MarianIntegrationTest):
src = "en"
tgt = "zh"
src_text = ["My name is Wolfgang and I live in Berlin"]
expected_text = ["我叫沃尔夫冈 我住在柏林"]
@slow
def test_batch_generation_eng_zho(self):
self._assert_generated_batch_equal_expected()
@require_flax
@require_sentencepiece
@require_tokenizers
class TestMarian_RU_FR(MarianIntegrationTest):
src = "ru"
tgt = "fr"
src_text = ["Он показал мне рукопись своей новой пьесы."]
expected_text = ["Il m'a montré le manuscrit de sa nouvelle pièce."]
@slow
def test_batch_generation_ru_fr(self):
self._assert_generated_batch_equal_expected()
@require_flax
@require_sentencepiece
@require_tokenizers
class TestMarian_en_ROMANCE(MarianIntegrationTest):
"""Multilingual on target side."""
src = "en"
tgt = "ROMANCE"
src_text = [
">>fr<< Don't spend so much time watching TV.",
">>pt<< Your message has been sent.",
">>es<< He's two years older than me.",
]
expected_text = [
"Ne passez pas autant de temps à regarder la télé.",
"A sua mensagem foi enviada.",
"Es dos años más viejo que yo.",
]
@slow
def test_batch_generation_en_ROMANCE_multi(self):
self._assert_generated_batch_equal_expected()
| transformers/tests/models/marian/test_modeling_flax_marian.py/0 | {
"file_path": "transformers/tests/models/marian/test_modeling_flax_marian.py",
"repo_id": "transformers",
"token_count": 8242
} |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.