
id
stringlengths 1
8
| text
stringlengths 6
1.05M
| dataset_id
stringclasses 1
value |
|---|---|---|
/pulumi_azure_native-2.5.1a1693590910.tar.gz/pulumi_azure_native-2.5.1a1693590910/pulumi_azure_native/servicenetworking/v20230501preview/associations_interface.py
|
import copy
import warnings
import pulumi
import pulumi.runtime
from typing import Any, Mapping, Optional, Sequence, Union, overload
from ... import _utilities
from . import outputs
from ._enums import *
from ._inputs import *
__all__ = ['AssociationsInterfaceArgs', 'AssociationsInterface']
@pulumi.input_type
class AssociationsInterfaceArgs:
def __init__(__self__, *,
association_type: pulumi.Input[Union[str, 'AssociationType']],
resource_group_name: pulumi.Input[str],
traffic_controller_name: pulumi.Input[str],
association_name: Optional[pulumi.Input[str]] = None,
location: Optional[pulumi.Input[str]] = None,
subnet: Optional[pulumi.Input['AssociationSubnetArgs']] = None,
tags: Optional[pulumi.Input[Mapping[str, pulumi.Input[str]]]] = None):
"""
The set of arguments for constructing a AssociationsInterface resource.
:param pulumi.Input[Union[str, 'AssociationType']] association_type: Association Type
:param pulumi.Input[str] resource_group_name: The name of the resource group. The name is case insensitive.
:param pulumi.Input[str] traffic_controller_name: traffic controller name for path
:param pulumi.Input[str] association_name: Name of Association
:param pulumi.Input[str] location: The geo-location where the resource lives
:param pulumi.Input['AssociationSubnetArgs'] subnet: Association Subnet
:param pulumi.Input[Mapping[str, pulumi.Input[str]]] tags: Resource tags.
"""
pulumi.set(__self__, "association_type", association_type)
pulumi.set(__self__, "resource_group_name", resource_group_name)
pulumi.set(__self__, "traffic_controller_name", traffic_controller_name)
if association_name is not None:
pulumi.set(__self__, "association_name", association_name)
if location is not None:
pulumi.set(__self__, "location", location)
if subnet is not None:
pulumi.set(__self__, "subnet", subnet)
if tags is not None:
pulumi.set(__self__, "tags", tags)
@property
@pulumi.getter(name="associationType")
def association_type(self) -> pulumi.Input[Union[str, 'AssociationType']]:
"""
Association Type
"""
return pulumi.get(self, "association_type")
@association_type.setter
def association_type(self, value: pulumi.Input[Union[str, 'AssociationType']]):
pulumi.set(self, "association_type", value)
@property
@pulumi.getter(name="resourceGroupName")
def resource_group_name(self) -> pulumi.Input[str]:
"""
The name of the resource group. The name is case insensitive.
"""
return pulumi.get(self, "resource_group_name")
@resource_group_name.setter
def resource_group_name(self, value: pulumi.Input[str]):
pulumi.set(self, "resource_group_name", value)
@property
@pulumi.getter(name="trafficControllerName")
def traffic_controller_name(self) -> pulumi.Input[str]:
"""
traffic controller name for path
"""
return pulumi.get(self, "traffic_controller_name")
@traffic_controller_name.setter
def traffic_controller_name(self, value: pulumi.Input[str]):
pulumi.set(self, "traffic_controller_name", value)
@property
@pulumi.getter(name="associationName")
def association_name(self) -> Optional[pulumi.Input[str]]:
"""
Name of Association
"""
return pulumi.get(self, "association_name")
@association_name.setter
def association_name(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "association_name", value)
@property
@pulumi.getter
def location(self) -> Optional[pulumi.Input[str]]:
"""
The geo-location where the resource lives
"""
return pulumi.get(self, "location")
@location.setter
def location(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "location", value)
@property
@pulumi.getter
def subnet(self) -> Optional[pulumi.Input['AssociationSubnetArgs']]:
"""
Association Subnet
"""
return pulumi.get(self, "subnet")
@subnet.setter
def subnet(self, value: Optional[pulumi.Input['AssociationSubnetArgs']]):
pulumi.set(self, "subnet", value)
@property
@pulumi.getter
def tags(self) -> Optional[pulumi.Input[Mapping[str, pulumi.Input[str]]]]:
"""
Resource tags.
"""
return pulumi.get(self, "tags")
@tags.setter
def tags(self, value: Optional[pulumi.Input[Mapping[str, pulumi.Input[str]]]]):
pulumi.set(self, "tags", value)
class AssociationsInterface(pulumi.CustomResource):
@overload
def __init__(__self__,
resource_name: str,
opts: Optional[pulumi.ResourceOptions] = None,
association_name: Optional[pulumi.Input[str]] = None,
association_type: Optional[pulumi.Input[Union[str, 'AssociationType']]] = None,
location: Optional[pulumi.Input[str]] = None,
resource_group_name: Optional[pulumi.Input[str]] = None,
subnet: Optional[pulumi.Input[pulumi.InputType['AssociationSubnetArgs']]] = None,
tags: Optional[pulumi.Input[Mapping[str, pulumi.Input[str]]]] = None,
traffic_controller_name: Optional[pulumi.Input[str]] = None,
__props__=None):
"""
Association Subresource of Traffic Controller
:param str resource_name: The name of the resource.
:param pulumi.ResourceOptions opts: Options for the resource.
:param pulumi.Input[str] association_name: Name of Association
:param pulumi.Input[Union[str, 'AssociationType']] association_type: Association Type
:param pulumi.Input[str] location: The geo-location where the resource lives
:param pulumi.Input[str] resource_group_name: The name of the resource group. The name is case insensitive.
:param pulumi.Input[pulumi.InputType['AssociationSubnetArgs']] subnet: Association Subnet
:param pulumi.Input[Mapping[str, pulumi.Input[str]]] tags: Resource tags.
:param pulumi.Input[str] traffic_controller_name: traffic controller name for path
"""
...
@overload
def __init__(__self__,
resource_name: str,
args: AssociationsInterfaceArgs,
opts: Optional[pulumi.ResourceOptions] = None):
"""
Association Subresource of Traffic Controller
:param str resource_name: The name of the resource.
:param AssociationsInterfaceArgs args: The arguments to use to populate this resource's properties.
:param pulumi.ResourceOptions opts: Options for the resource.
"""
...
def __init__(__self__, resource_name: str, *args, **kwargs):
resource_args, opts = _utilities.get_resource_args_opts(AssociationsInterfaceArgs, pulumi.ResourceOptions, *args, **kwargs)
if resource_args is not None:
__self__._internal_init(resource_name, opts, **resource_args.__dict__)
else:
__self__._internal_init(resource_name, *args, **kwargs)
def _internal_init(__self__,
resource_name: str,
opts: Optional[pulumi.ResourceOptions] = None,
association_name: Optional[pulumi.Input[str]] = None,
association_type: Optional[pulumi.Input[Union[str, 'AssociationType']]] = None,
location: Optional[pulumi.Input[str]] = None,
resource_group_name: Optional[pulumi.Input[str]] = None,
subnet: Optional[pulumi.Input[pulumi.InputType['AssociationSubnetArgs']]] = None,
tags: Optional[pulumi.Input[Mapping[str, pulumi.Input[str]]]] = None,
traffic_controller_name: Optional[pulumi.Input[str]] = None,
__props__=None):
opts = pulumi.ResourceOptions.merge(_utilities.get_resource_opts_defaults(), opts)
if not isinstance(opts, pulumi.ResourceOptions):
raise TypeError('Expected resource options to be a ResourceOptions instance')
if opts.id is None:
if __props__ is not None:
raise TypeError('__props__ is only valid when passed in combination with a valid opts.id to get an existing resource')
__props__ = AssociationsInterfaceArgs.__new__(AssociationsInterfaceArgs)
__props__.__dict__["association_name"] = association_name
if association_type is None and not opts.urn:
raise TypeError("Missing required property 'association_type'")
__props__.__dict__["association_type"] = association_type
__props__.__dict__["location"] = location
if resource_group_name is None and not opts.urn:
raise TypeError("Missing required property 'resource_group_name'")
__props__.__dict__["resource_group_name"] = resource_group_name
__props__.__dict__["subnet"] = subnet
__props__.__dict__["tags"] = tags
if traffic_controller_name is None and not opts.urn:
raise TypeError("Missing required property 'traffic_controller_name'")
__props__.__dict__["traffic_controller_name"] = traffic_controller_name
__props__.__dict__["name"] = None
__props__.__dict__["provisioning_state"] = None
__props__.__dict__["system_data"] = None
__props__.__dict__["type"] = None
alias_opts = pulumi.ResourceOptions(aliases=[pulumi.Alias(type_="azure-native:servicenetworking:AssociationsInterface"), pulumi.Alias(type_="azure-native:servicenetworking/v20221001preview:AssociationsInterface")])
opts = pulumi.ResourceOptions.merge(opts, alias_opts)
super(AssociationsInterface, __self__).__init__(
'azure-native:servicenetworking/v20230501preview:AssociationsInterface',
resource_name,
__props__,
opts)
@staticmethod
def get(resource_name: str,
id: pulumi.Input[str],
opts: Optional[pulumi.ResourceOptions] = None) -> 'AssociationsInterface':
"""
Get an existing AssociationsInterface resource's state with the given name, id, and optional extra
properties used to qualify the lookup.
:param str resource_name: The unique name of the resulting resource.
:param pulumi.Input[str] id: The unique provider ID of the resource to lookup.
:param pulumi.ResourceOptions opts: Options for the resource.
"""
opts = pulumi.ResourceOptions.merge(opts, pulumi.ResourceOptions(id=id))
__props__ = AssociationsInterfaceArgs.__new__(AssociationsInterfaceArgs)
__props__.__dict__["association_type"] = None
__props__.__dict__["location"] = None
__props__.__dict__["name"] = None
__props__.__dict__["provisioning_state"] = None
__props__.__dict__["subnet"] = None
__props__.__dict__["system_data"] = None
__props__.__dict__["tags"] = None
__props__.__dict__["type"] = None
return AssociationsInterface(resource_name, opts=opts, __props__=__props__)
@property
@pulumi.getter(name="associationType")
def association_type(self) -> pulumi.Output[str]:
"""
Association Type
"""
return pulumi.get(self, "association_type")
@property
@pulumi.getter
def location(self) -> pulumi.Output[str]:
"""
The geo-location where the resource lives
"""
return pulumi.get(self, "location")
@property
@pulumi.getter
def name(self) -> pulumi.Output[str]:
"""
The name of the resource
"""
return pulumi.get(self, "name")
@property
@pulumi.getter(name="provisioningState")
def provisioning_state(self) -> pulumi.Output[str]:
"""
Provisioning State of Traffic Controller Association Resource
"""
return pulumi.get(self, "provisioning_state")
@property
@pulumi.getter
def subnet(self) -> pulumi.Output[Optional['outputs.AssociationSubnetResponse']]:
"""
Association Subnet
"""
return pulumi.get(self, "subnet")
@property
@pulumi.getter(name="systemData")
def system_data(self) -> pulumi.Output['outputs.SystemDataResponse']:
"""
Azure Resource Manager metadata containing createdBy and modifiedBy information.
"""
return pulumi.get(self, "system_data")
@property
@pulumi.getter
def tags(self) -> pulumi.Output[Optional[Mapping[str, str]]]:
"""
Resource tags.
"""
return pulumi.get(self, "tags")
@property
@pulumi.getter
def type(self) -> pulumi.Output[str]:
"""
The type of the resource. E.g. "Microsoft.Compute/virtualMachines" or "Microsoft.Storage/storageAccounts"
"""
return pulumi.get(self, "type")
|
PypiClean
|
/translate_toolkit-3.10.0-py3-none-any.whl/translate/convert/html2po.py
|
from translate.convert import convert
from translate.storage import html, po
class html2po:
def convertfile(
self,
inputfile,
filename,
duplicatestyle="msgctxt",
keepcomments=False,
):
"""Convert an html file to .po format."""
thetargetfile = po.pofile()
self.convertfile_inner(inputfile, thetargetfile, keepcomments)
thetargetfile.removeduplicates(duplicatestyle)
return thetargetfile
@staticmethod
def convertfile_inner(inputfile, outputstore, keepcomments):
"""Extract translation units from an html file and add to a pofile object."""
htmlparser = html.htmlfile(inputfile=inputfile)
for htmlunit in htmlparser.units:
thepo = outputstore.addsourceunit(htmlunit.source)
thepo.addlocations(htmlunit.getlocations())
if keepcomments:
thepo.addnote(htmlunit.getnotes(), "developer")
def converthtml(
inputfile,
outputfile,
templates,
pot=False,
duplicatestyle="msgctxt",
keepcomments=False,
):
"""reads in stdin using fromfileclass, converts using convertorclass,
writes to stdout
"""
convertor = html2po()
outputstore = convertor.convertfile(
inputfile,
getattr(inputfile, "name", "unknown"),
duplicatestyle=duplicatestyle,
keepcomments=keepcomments,
)
outputstore.serialize(outputfile)
return 1
class Html2POOptionParser(convert.ConvertOptionParser):
def __init__(self):
formats = {
"html": ("po", self.convert),
"htm": ("po", self.convert),
"xhtml": ("po", self.convert),
None: ("po", self.convert),
}
super().__init__(formats, usetemplates=False, usepots=True, description=__doc__)
self.add_option(
"--keepcomments",
dest="keepcomments",
default=False,
action="store_true",
help="preserve html comments as translation notes in the output",
)
self.passthrough.append("keepcomments")
self.add_duplicates_option()
self.add_multifile_option()
self.passthrough.append("pot")
def convert(
self,
inputfile,
outputfile,
templates,
pot=False,
duplicatestyle="msgctxt",
multifilestyle="single",
keepcomments=False,
):
"""Extract translation units from one html file."""
convertor = html2po()
if hasattr(self, "outputstore"):
convertor.convertfile_inner(inputfile, self.outputstore, keepcomments)
else:
outputstore = convertor.convertfile(
inputfile,
getattr(inputfile, "name", "unknown"),
duplicatestyle=duplicatestyle,
keepcomments=keepcomments,
)
outputstore.serialize(outputfile)
return 1
def recursiveprocess(self, options):
"""Recurse through directories and process files. (override)"""
if options.multifilestyle == "onefile":
self.outputstore = po.pofile()
super().recursiveprocess(options)
if not self.outputstore.isempty():
self.outputstore.removeduplicates(options.duplicatestyle)
outputfile = super().openoutputfile(options, options.output)
self.outputstore.serialize(outputfile)
if options.output:
outputfile.close()
else:
super().recursiveprocess(options)
def isrecursive(self, fileoption, filepurpose="input"):
"""Check if fileoption is a recursive file. (override)"""
if hasattr(self, "outputstore") and filepurpose == "output":
return True
return super().isrecursive(fileoption, filepurpose=filepurpose)
def checkoutputsubdir(self, options, subdir):
"""Check if subdir under options.output needs to be created,
creates if neccessary. Do nothing if in single-output-file mode. (override)
"""
if hasattr(self, "outputstore"):
return
super().checkoutputsubdir(options, subdir)
def openoutputfile(self, options, fulloutputpath):
"""Open the output file, or do nothing if in single-output-file mode. (override)"""
if hasattr(self, "outputstore"):
return None
return super().openoutputfile(options, fulloutputpath)
def main(argv=None):
parser = Html2POOptionParser()
parser.run(argv)
if __name__ == "__main__":
main()
|
PypiClean
|
/onvif_zeep-0.2.12.tar.gz/onvif_zeep-0.2.12/onvif/client.py
|
from __future__ import print_function, division
__version__ = '0.0.1'
import os.path
from threading import Thread, RLock
import logging
logger = logging.getLogger('onvif')
logging.basicConfig(level=logging.INFO)
logging.getLogger('zeep.client').setLevel(logging.CRITICAL)
from zeep.client import Client, CachingClient, Settings
from zeep.wsse.username import UsernameToken
import zeep.helpers
from onvif.exceptions import ONVIFError
from onvif.definition import SERVICES
import datetime as dt
# Ensure methods to raise an ONVIFError Exception
# when some thing was wrong
def safe_func(func):
def wrapped(*args, **kwargs):
try:
return func(*args, **kwargs)
except Exception as err:
#print('Ouuups: err =', err, ', func =', func, ', args =', args, ', kwargs =', kwargs)
raise ONVIFError(err)
return wrapped
class UsernameDigestTokenDtDiff(UsernameToken):
'''
UsernameDigestToken class, with a time offset parameter that can be adjusted;
This allows authentication on cameras without being time synchronized.
Please note that using NTP on both end is the recommended solution,
this should only be used in "safe" environments.
'''
def __init__(self, user, passw, dt_diff=None, **kwargs):
super().__init__(user, passw, **kwargs)
self.dt_diff = dt_diff # Date/time difference in datetime.timedelta
def apply(self, envelope, headers):
old_created = self.created
if self.created is None:
self.created = dt.datetime.utcnow()
#print('UsernameDigestTokenDtDiff.created: old = %s (type = %s), dt_diff = %s (type = %s)' % (self.created, type(self.created), self.dt_diff, type(self.dt_diff)), end='')
if self.dt_diff is not None:
self.created += self.dt_diff
#print(' new = %s' % self.created)
result = super().apply(envelope, headers)
self.created = old_created
return result
class ONVIFService(object):
'''
Python Implemention for ONVIF Service.
Services List:
DeviceMgmt DeviceIO Event AnalyticsDevice Display Imaging Media
PTZ Receiver RemoteDiscovery Recording Replay Search Extension
>>> from onvif import ONVIFService
>>> device_service = ONVIFService('http://192.168.0.112/onvif/device_service',
... 'admin', 'foscam',
... '/etc/onvif/wsdl/devicemgmt.wsdl')
>>> ret = device_service.GetHostname()
>>> print ret.FromDHCP
>>> print ret.Name
>>> device_service.SetHostname(dict(Name='newhostname'))
>>> ret = device_service.GetSystemDateAndTime()
>>> print ret.DaylightSavings
>>> print ret.TimeZone
>>> dict_ret = device_service.to_dict(ret)
>>> print dict_ret['TimeZone']
There are two ways to pass parameter to services methods
1. Dict
params = {'Name': 'NewHostName'}
device_service.SetHostname(params)
2. Type Instance
params = device_service.create_type('SetHostname')
params.Hostname = 'NewHostName'
device_service.SetHostname(params)
'''
@safe_func
def __init__(self, xaddr, user, passwd, url,
encrypt=True, daemon=False, zeep_client=None, no_cache=False,
portType=None, dt_diff=None, binding_name='', transport=None):
if not os.path.isfile(url):
raise ONVIFError('%s doesn`t exist!' % url)
self.url = url
self.xaddr = xaddr
wsse = UsernameDigestTokenDtDiff(user, passwd, dt_diff=dt_diff, use_digest=encrypt)
# Create soap client
if not zeep_client:
#print(self.url, self.xaddr)
ClientType = Client if no_cache else CachingClient
settings = Settings()
settings.strict = False
settings.xml_huge_tree = True
self.zeep_client = ClientType(wsdl=url, wsse=wsse, transport=transport, settings=settings)
else:
self.zeep_client = zeep_client
self.ws_client = self.zeep_client.create_service(binding_name, self.xaddr)
# Set soap header for authentication
self.user = user
self.passwd = passwd
# Indicate wether password digest is needed
self.encrypt = encrypt
self.daemon = daemon
self.dt_diff = dt_diff
self.create_type = lambda x: self.zeep_client.get_element('ns0:' + x)()
@classmethod
@safe_func
def clone(cls, service, *args, **kwargs):
clone_service = service.ws_client.clone()
kwargs['ws_client'] = clone_service
return ONVIFService(*args, **kwargs)
@staticmethod
@safe_func
def to_dict(zeepobject):
# Convert a WSDL Type instance into a dictionary
return {} if zeepobject is None else zeep.helpers.serialize_object(zeepobject)
def service_wrapper(self, func):
@safe_func
def wrapped(params=None, callback=None):
def call(params=None, callback=None):
# No params
# print(params.__class__.__mro__)
if params is None:
params = {}
else:
params = ONVIFService.to_dict(params)
try:
ret = func(**params)
except TypeError:
#print('### func =', func, '### params =', params, '### type(params) =', type(params))
ret = func(params)
if callable(callback):
callback(ret)
return ret
if self.daemon:
th = Thread(target=call, args=(params, callback))
th.daemon = True
th.start()
else:
return call(params, callback)
return wrapped
def __getattr__(self, name):
'''
Call the real onvif Service operations,
See the official wsdl definition for the
APIs detail(API name, request parameters,
response parameters, parameter types, etc...)
'''
builtin = name.startswith('__') and name.endswith('__')
if builtin:
return self.__dict__[name]
else:
return self.service_wrapper(getattr(self.ws_client, name))
class ONVIFCamera(object):
'''
Python Implemention ONVIF compliant device
This class integrates onvif services
adjust_time parameter allows authentication on cameras without being time synchronized.
Please note that using NTP on both end is the recommended solution,
this should only be used in "safe" environments.
Also, this cannot be used on AXIS camera, as every request is authenticated, contrary to ONVIF standard
>>> from onvif import ONVIFCamera
>>> mycam = ONVIFCamera('192.168.0.112', 80, 'admin', '12345')
>>> mycam.devicemgmt.GetServices(False)
>>> media_service = mycam.create_media_service()
>>> ptz_service = mycam.create_ptz_service()
# Get PTZ Configuration:
>>> mycam.ptz.GetConfiguration()
# Another way:
>>> ptz_service.GetConfiguration()
'''
# Class-level variables
services_template = {'devicemgmt': None, 'ptz': None, 'media': None,
'imaging': None, 'events': None, 'analytics': None }
use_services_template = {'devicemgmt': True, 'ptz': True, 'media': True,
'imaging': True, 'events': True, 'analytics': True }
def __init__(self, host, port ,user, passwd, wsdl_dir=os.path.join(os.path.dirname(os.path.dirname(__file__)), "wsdl"),
encrypt=True, daemon=False, no_cache=False, adjust_time=False, transport=None):
os.environ.pop('http_proxy', None)
os.environ.pop('https_proxy', None)
self.host = host
self.port = int(port)
self.user = user
self.passwd = passwd
self.wsdl_dir = wsdl_dir
self.encrypt = encrypt
self.daemon = daemon
self.no_cache = no_cache
self.adjust_time = adjust_time
self.transport = transport
# Active service client container
self.services = { }
self.services_lock = RLock()
# Set xaddrs
self.update_xaddrs()
self.to_dict = ONVIFService.to_dict
def update_xaddrs(self):
# Establish devicemgmt service first
self.dt_diff = None
self.devicemgmt = self.create_devicemgmt_service()
if self.adjust_time :
cdate = self.devicemgmt.GetSystemDateAndTime().UTCDateTime
cam_date = dt.datetime(cdate.Date.Year, cdate.Date.Month, cdate.Date.Day, cdate.Time.Hour, cdate.Time.Minute, cdate.Time.Second)
self.dt_diff = cam_date - dt.datetime.utcnow()
self.devicemgmt.dt_diff = self.dt_diff
#self.devicemgmt.set_wsse()
self.devicemgmt = self.create_devicemgmt_service()
# Get XAddr of services on the device
self.xaddrs = { }
capabilities = self.devicemgmt.GetCapabilities({'Category': 'All'})
for name in capabilities:
capability = capabilities[name]
try:
if name.lower() in SERVICES and capability is not None:
ns = SERVICES[name.lower()]['ns']
self.xaddrs[ns] = capability['XAddr']
except Exception:
logger.exception('Unexpected service type')
with self.services_lock:
try:
self.event = self.create_events_service()
self.xaddrs['http://www.onvif.org/ver10/events/wsdl/PullPointSubscription'] = self.event.CreatePullPointSubscription().SubscriptionReference.Address._value_1
except:
pass
def update_url(self, host=None, port=None):
changed = False
if host and self.host != host:
changed = True
self.host = host
if port and self.port != port:
changed = True
self.port = port
if not changed:
return
self.devicemgmt = self.create_devicemgmt_service()
self.capabilities = self.devicemgmt.GetCapabilities()
with self.services_lock:
for sname in self.services.keys():
xaddr = getattr(self.capabilities, sname.capitalize).XAddr
self.services[sname].ws_client.set_options(location=xaddr)
def get_service(self, name, create=True):
service = None
service = getattr(self, name.lower(), None)
if not service and create:
return getattr(self, 'create_%s_service' % name.lower())()
return service
def get_definition(self, name, portType=None):
'''Returns xaddr and wsdl of specified service'''
# Check if the service is supported
if name not in SERVICES:
raise ONVIFError('Unknown service %s' % name)
wsdl_file = SERVICES[name]['wsdl']
ns = SERVICES[name]['ns']
binding_name = '{%s}%s' % (ns, SERVICES[name]['binding'])
if portType:
ns += '/' + portType
wsdlpath = os.path.join(self.wsdl_dir, wsdl_file)
if not os.path.isfile(wsdlpath):
raise ONVIFError('No such file: %s' % wsdlpath)
# XAddr for devicemgmt is fixed:
if name == 'devicemgmt':
xaddr = '%s:%s/onvif/device_service' % \
(self.host if (self.host.startswith('http://') or self.host.startswith('https://'))
else 'http://%s' % self.host, self.port)
return xaddr, wsdlpath, binding_name
# Get other XAddr
xaddr = self.xaddrs.get(ns)
if not xaddr:
raise ONVIFError('Device doesn`t support service: %s' % name)
return xaddr, wsdlpath, binding_name
def create_onvif_service(self, name, from_template=True, portType=None):
'''Create ONVIF service client'''
name = name.lower()
xaddr, wsdl_file, binding_name = self.get_definition(name, portType)
with self.services_lock:
service = ONVIFService(xaddr, self.user, self.passwd,
wsdl_file, self.encrypt,
self.daemon, no_cache=self.no_cache,
portType=portType,
dt_diff=self.dt_diff,
binding_name=binding_name,
transport=self.transport)
self.services[name] = service
setattr(self, name, service)
if not self.services_template.get(name):
self.services_template[name] = service
return service
def create_devicemgmt_service(self, from_template=True):
# The entry point for devicemgmt service is fixed.
return self.create_onvif_service('devicemgmt', from_template)
def create_media_service(self, from_template=True):
return self.create_onvif_service('media', from_template)
def create_ptz_service(self, from_template=True):
return self.create_onvif_service('ptz', from_template)
def create_imaging_service(self, from_template=True):
return self.create_onvif_service('imaging', from_template)
def create_deviceio_service(self, from_template=True):
return self.create_onvif_service('deviceio', from_template)
def create_events_service(self, from_template=True):
return self.create_onvif_service('events', from_template)
def create_analytics_service(self, from_template=True):
return self.create_onvif_service('analytics', from_template)
def create_recording_service(self, from_template=True):
return self.create_onvif_service('recording', from_template)
def create_search_service(self, from_template=True):
return self.create_onvif_service('search', from_template)
def create_replay_service(self, from_template=True):
return self.create_onvif_service('replay', from_template)
def create_pullpoint_service(self, from_template=True):
return self.create_onvif_service('pullpoint', from_template, portType='PullPointSubscription')
def create_receiver_service(self, from_template=True):
return self.create_onvif_service('receiver', from_template)
|
PypiClean
|
/vkbottle_types-5.131.146.16.tar.gz/vkbottle_types-5.131.146.16/vkbottle_types/codegen/methods/notes.py
|
import typing
from typing_extensions import Literal
from vkbottle_types.methods.base_category import BaseCategory
from vkbottle_types.responses.base import OkResponse
from vkbottle_types.responses.notes import (
AddResponse,
CreateCommentResponse,
GetByIdResponse,
GetCommentsResponse,
GetCommentsResponseModel,
GetResponse,
GetResponseModel,
NotesNote,
)
class NotesCategory(BaseCategory):
async def add(
self,
title: str,
text: str,
privacy_view: typing.Optional[typing.List[str]] = None,
privacy_comment: typing.Optional[typing.List[str]] = None,
**kwargs
) -> int:
"""Creates a new note for the current user.
:param title: Note title.
:param text: Note text.
:param privacy_view:
:param privacy_comment:
"""
params = self.get_set_params(locals())
response = await self.api.request("notes.add", params)
model = AddResponse
return model(**response).response
async def create_comment(
self,
note_id: int,
message: str,
owner_id: typing.Optional[int] = None,
reply_to: typing.Optional[int] = None,
guid: typing.Optional[str] = None,
**kwargs
) -> int:
"""Adds a new comment on a note.
:param note_id: Note ID.
:param message: Comment text.
:param owner_id: Note owner ID.
:param reply_to: ID of the user to whom the reply is addressed (if the comment is a reply to another comment).
:param guid:
"""
params = self.get_set_params(locals())
response = await self.api.request("notes.createComment", params)
model = CreateCommentResponse
return model(**response).response
async def delete(self, note_id: int, **kwargs) -> int:
"""Deletes a note of the current user.
:param note_id: Note ID.
"""
params = self.get_set_params(locals())
response = await self.api.request("notes.delete", params)
model = OkResponse
return model(**response).response
async def delete_comment(
self, comment_id: int, owner_id: typing.Optional[int] = None, **kwargs
) -> int:
"""Deletes a comment on a note.
:param comment_id: Comment ID.
:param owner_id: Note owner ID.
"""
params = self.get_set_params(locals())
response = await self.api.request("notes.deleteComment", params)
model = OkResponse
return model(**response).response
async def edit(
self,
note_id: int,
title: str,
text: str,
privacy_view: typing.Optional[typing.List[str]] = None,
privacy_comment: typing.Optional[typing.List[str]] = None,
**kwargs
) -> int:
"""Edits a note of the current user.
:param note_id: Note ID.
:param title: Note title.
:param text: Note text.
:param privacy_view:
:param privacy_comment:
"""
params = self.get_set_params(locals())
response = await self.api.request("notes.edit", params)
model = OkResponse
return model(**response).response
async def edit_comment(
self,
comment_id: int,
message: str,
owner_id: typing.Optional[int] = None,
**kwargs
) -> int:
"""Edits a comment on a note.
:param comment_id: Comment ID.
:param message: New comment text.
:param owner_id: Note owner ID.
"""
params = self.get_set_params(locals())
response = await self.api.request("notes.editComment", params)
model = OkResponse
return model(**response).response
async def get(
self,
note_ids: typing.Optional[typing.List[int]] = None,
user_id: typing.Optional[int] = None,
offset: typing.Optional[int] = None,
count: typing.Optional[int] = None,
sort: typing.Optional[Literal[0, 1]] = None,
**kwargs
) -> GetResponseModel:
"""Returns a list of notes created by a user.
:param note_ids: Note IDs.
:param user_id: Note owner ID.
:param offset:
:param count: Number of notes to return.
:param sort:
"""
params = self.get_set_params(locals())
response = await self.api.request("notes.get", params)
model = GetResponse
return model(**response).response
async def get_by_id(
self,
note_id: int,
owner_id: typing.Optional[int] = None,
need_wiki: typing.Optional[bool] = None,
**kwargs
) -> NotesNote:
"""Returns a note by its ID.
:param note_id: Note ID.
:param owner_id: Note owner ID.
:param need_wiki:
"""
params = self.get_set_params(locals())
response = await self.api.request("notes.getById", params)
model = GetByIdResponse
return model(**response).response
async def get_comments(
self,
note_id: int,
owner_id: typing.Optional[int] = None,
sort: typing.Optional[Literal[0, 1]] = None,
offset: typing.Optional[int] = None,
count: typing.Optional[int] = None,
**kwargs
) -> GetCommentsResponseModel:
"""Returns a list of comments on a note.
:param note_id: Note ID.
:param owner_id: Note owner ID.
:param sort:
:param offset:
:param count: Number of comments to return.
"""
params = self.get_set_params(locals())
response = await self.api.request("notes.getComments", params)
model = GetCommentsResponse
return model(**response).response
async def restore_comment(
self, comment_id: int, owner_id: typing.Optional[int] = None, **kwargs
) -> int:
"""Restores a deleted comment on a note.
:param comment_id: Comment ID.
:param owner_id: Note owner ID.
"""
params = self.get_set_params(locals())
response = await self.api.request("notes.restoreComment", params)
model = OkResponse
return model(**response).response
__all__ = ("NotesCategory",)
|
PypiClean
|
/pm2mp-0.0.98-py3-none-any.whl/pm2mp-0.0.98.data/data/node_modules/_unicodeWords.js
|
var rsAstralRange = '\\ud800-\\udfff',
rsComboMarksRange = '\\u0300-\\u036f',
reComboHalfMarksRange = '\\ufe20-\\ufe2f',
rsComboSymbolsRange = '\\u20d0-\\u20ff',
rsComboRange = rsComboMarksRange + reComboHalfMarksRange + rsComboSymbolsRange,
rsDingbatRange = '\\u2700-\\u27bf',
rsLowerRange = 'a-z\\xdf-\\xf6\\xf8-\\xff',
rsMathOpRange = '\\xac\\xb1\\xd7\\xf7',
rsNonCharRange = '\\x00-\\x2f\\x3a-\\x40\\x5b-\\x60\\x7b-\\xbf',
rsPunctuationRange = '\\u2000-\\u206f',
rsSpaceRange = ' \\t\\x0b\\f\\xa0\\ufeff\\n\\r\\u2028\\u2029\\u1680\\u180e\\u2000\\u2001\\u2002\\u2003\\u2004\\u2005\\u2006\\u2007\\u2008\\u2009\\u200a\\u202f\\u205f\\u3000',
rsUpperRange = 'A-Z\\xc0-\\xd6\\xd8-\\xde',
rsVarRange = '\\ufe0e\\ufe0f',
rsBreakRange = rsMathOpRange + rsNonCharRange + rsPunctuationRange + rsSpaceRange;
/** Used to compose unicode capture groups. */
var rsApos = "['\u2019]",
rsBreak = '[' + rsBreakRange + ']',
rsCombo = '[' + rsComboRange + ']',
rsDigits = '\\d+',
rsDingbat = '[' + rsDingbatRange + ']',
rsLower = '[' + rsLowerRange + ']',
rsMisc = '[^' + rsAstralRange + rsBreakRange + rsDigits + rsDingbatRange + rsLowerRange + rsUpperRange + ']',
rsFitz = '\\ud83c[\\udffb-\\udfff]',
rsModifier = '(?:' + rsCombo + '|' + rsFitz + ')',
rsNonAstral = '[^' + rsAstralRange + ']',
rsRegional = '(?:\\ud83c[\\udde6-\\uddff]){2}',
rsSurrPair = '[\\ud800-\\udbff][\\udc00-\\udfff]',
rsUpper = '[' + rsUpperRange + ']',
rsZWJ = '\\u200d';
/** Used to compose unicode regexes. */
var rsMiscLower = '(?:' + rsLower + '|' + rsMisc + ')',
rsMiscUpper = '(?:' + rsUpper + '|' + rsMisc + ')',
rsOptContrLower = '(?:' + rsApos + '(?:d|ll|m|re|s|t|ve))?',
rsOptContrUpper = '(?:' + rsApos + '(?:D|LL|M|RE|S|T|VE))?',
reOptMod = rsModifier + '?',
rsOptVar = '[' + rsVarRange + ']?',
rsOptJoin = '(?:' + rsZWJ + '(?:' + [rsNonAstral, rsRegional, rsSurrPair].join('|') + ')' + rsOptVar + reOptMod + ')*',
rsOrdLower = '\\d*(?:1st|2nd|3rd|(?![123])\\dth)(?=\\b|[A-Z_])',
rsOrdUpper = '\\d*(?:1ST|2ND|3RD|(?![123])\\dTH)(?=\\b|[a-z_])',
rsSeq = rsOptVar + reOptMod + rsOptJoin,
rsEmoji = '(?:' + [rsDingbat, rsRegional, rsSurrPair].join('|') + ')' + rsSeq;
/** Used to match complex or compound words. */
var reUnicodeWord = RegExp([
rsUpper + '?' + rsLower + '+' + rsOptContrLower + '(?=' + [rsBreak, rsUpper, '$'].join('|') + ')',
rsMiscUpper + '+' + rsOptContrUpper + '(?=' + [rsBreak, rsUpper + rsMiscLower, '$'].join('|') + ')',
rsUpper + '?' + rsMiscLower + '+' + rsOptContrLower,
rsUpper + '+' + rsOptContrUpper,
rsOrdUpper,
rsOrdLower,
rsDigits,
rsEmoji
].join('|'), 'g');
/**
* Splits a Unicode `string` into an array of its words.
*
* @private
* @param {string} The string to inspect.
* @returns {Array} Returns the words of `string`.
*/
function unicodeWords(string) {
return string.match(reUnicodeWord) || [];
}
module.exports = unicodeWords;
|
PypiClean
|
/anyblok_io-1.1.0.tar.gz/anyblok_io-1.1.0/doc/builtin_bloks.rst
|
.. This file is a part of the AnyBlok project
..
.. Copyright (C) 2014 Jean-Sebastien SUZANNE <[email protected]>
..
.. This Source Code Form is subject to the terms of the Mozilla Public License,
.. v. 2.0. If a copy of the MPL was not distributed with this file,You can
.. obtain one at http://mozilla.org/MPL/2.0/.
Builtin Bloks
=============
.. contents:: Covered Bloks
:local:
:depth: 1
.. _blok_anyblok_io:
Blok anyblok-io
---------------
.. automodule:: anyblok_io.bloks.io
.. autoclass:: AnyBlokIO
:show-inheritance:
.. autoattribute:: name
.. autoattribute:: version
.. autoattribute:: author
.. autoattribute:: autoinstall
.. autoattribute:: priority
.. include:: ../anyblok_io/bloks/io/README.rst
.. include:: ../anyblok_io/bloks/io/CODE.rst
.. _blok_anyblok_io_csv:
Blok anyblok-io-csv
-------------------
.. automodule:: anyblok_io.bloks.io_csv
.. autoclass:: AnyBlokIOCSV
:show-inheritance:
.. autoattribute:: name
.. autoattribute:: version
.. autoattribute:: author
.. autoattribute:: autoinstall
.. autoattribute:: priority
.. include:: ../anyblok_io/bloks/io_csv/README.rst
.. include:: ../anyblok_io/bloks/io_csv/CODE.rst
.. _blok_anyblok_io_xml:
Blok anyblok-io-xml
-------------------
.. automodule:: anyblok_io.bloks.io_xml
.. autoclass:: AnyBlokIOXML
:show-inheritance:
.. autoattribute:: name
.. autoattribute:: version
.. autoattribute:: author
.. autoattribute:: autoinstall
.. autoattribute:: priority
.. include:: ../anyblok_io/bloks/io_xml/README.rst
.. include:: ../anyblok_io/bloks/io_xml/CODE.rst
|
PypiClean
|
/klaviyo-api-beta-2.0.2.tar.gz/klaviyo-api-beta-2.0.2/src/openapi_client/model/campaign_send_job_partial_update_query_as_sub_resource_attributes.py
|
import re # noqa: F401
import sys # noqa: F401
from openapi_client.model_utils import ( # noqa: F401
ApiTypeError,
ModelComposed,
ModelNormal,
ModelSimple,
cached_property,
change_keys_js_to_python,
convert_js_args_to_python_args,
date,
datetime,
file_type,
none_type,
validate_get_composed_info,
OpenApiModel
)
from openapi_client.exceptions import ApiAttributeError
class CampaignSendJobPartialUpdateQueryAsSubResourceAttributes(ModelNormal):
"""NOTE: This class is auto generated by OpenAPI Generator.
Ref: https://openapi-generator.tech
Do not edit the class manually.
Attributes:
allowed_values (dict): The key is the tuple path to the attribute
and the for var_name this is (var_name,). The value is a dict
with a capitalized key describing the allowed value and an allowed
value. These dicts store the allowed enum values.
attribute_map (dict): The key is attribute name
and the value is json key in definition.
discriminator_value_class_map (dict): A dict to go from the discriminator
variable value to the discriminator class name.
validations (dict): The key is the tuple path to the attribute
and the for var_name this is (var_name,). The value is a dict
that stores validations for max_length, min_length, max_items,
min_items, exclusive_maximum, inclusive_maximum, exclusive_minimum,
inclusive_minimum, and regex.
additional_properties_type (tuple): A tuple of classes accepted
as additional properties values.
"""
allowed_values = {
}
validations = {
}
@cached_property
def additional_properties_type():
"""
This must be a method because a model may have properties that are
of type self, this must run after the class is loaded
"""
return (bool, date, datetime, dict, float, int, list, str, none_type,) # noqa: E501
_nullable = False
@cached_property
def openapi_types():
"""
This must be a method because a model may have properties that are
of type self, this must run after the class is loaded
Returns
openapi_types (dict): The key is attribute name
and the value is attribute type.
"""
return {
'action': (str,), # noqa: E501
}
@cached_property
def discriminator():
return None
attribute_map = {
'action': 'action', # noqa: E501
}
read_only_vars = {
}
_composed_schemas = {}
@classmethod
@convert_js_args_to_python_args
def _from_openapi_data(cls, action, *args, **kwargs): # noqa: E501
"""CampaignSendJobPartialUpdateQueryAsSubResourceAttributes - a model defined in OpenAPI
Args:
action (str): The action you would like to take with this send job from among 'cancel' and 'revert'
Keyword Args:
_check_type (bool): if True, values for parameters in openapi_types
will be type checked and a TypeError will be
raised if the wrong type is input.
Defaults to True
_path_to_item (tuple/list): This is a list of keys or values to
drill down to the model in received_data
when deserializing a response
_spec_property_naming (bool): True if the variable names in the input data
are serialized names, as specified in the OpenAPI document.
False if the variable names in the input data
are pythonic names, e.g. snake case (default)
_configuration (Configuration): the instance to use when
deserializing a file_type parameter.
If passed, type conversion is attempted
If omitted no type conversion is done.
_visited_composed_classes (tuple): This stores a tuple of
classes that we have traveled through so that
if we see that class again we will not use its
discriminator again.
When traveling through a discriminator, the
composed schema that is
is traveled through is added to this set.
For example if Animal has a discriminator
petType and we pass in "Dog", and the class Dog
allOf includes Animal, we move through Animal
once using the discriminator, and pick Dog.
Then in Dog, we will make an instance of the
Animal class but this time we won't travel
through its discriminator because we passed in
_visited_composed_classes = (Animal,)
"""
_check_type = kwargs.pop('_check_type', True)
_spec_property_naming = kwargs.pop('_spec_property_naming', True)
_path_to_item = kwargs.pop('_path_to_item', ())
_configuration = kwargs.pop('_configuration', None)
_visited_composed_classes = kwargs.pop('_visited_composed_classes', ())
self = super(OpenApiModel, cls).__new__(cls)
if args:
for arg in args:
if isinstance(arg, dict):
kwargs.update(arg)
else:
raise ApiTypeError(
"Invalid positional arguments=%s passed to %s. Remove those invalid positional arguments." % (
args,
self.__class__.__name__,
),
path_to_item=_path_to_item,
valid_classes=(self.__class__,),
)
self._data_store = {}
self._check_type = _check_type
self._spec_property_naming = _spec_property_naming
self._path_to_item = _path_to_item
self._configuration = _configuration
self._visited_composed_classes = _visited_composed_classes + (self.__class__,)
self.action = action
for var_name, var_value in kwargs.items():
if var_name not in self.attribute_map and \
self._configuration is not None and \
self._configuration.discard_unknown_keys and \
self.additional_properties_type is None:
# discard variable.
continue
setattr(self, var_name, var_value)
return self
required_properties = set([
'_data_store',
'_check_type',
'_spec_property_naming',
'_path_to_item',
'_configuration',
'_visited_composed_classes',
])
@convert_js_args_to_python_args
def __init__(self, action, *args, **kwargs): # noqa: E501
"""CampaignSendJobPartialUpdateQueryAsSubResourceAttributes - a model defined in OpenAPI
Args:
action (str): The action you would like to take with this send job from among 'cancel' and 'revert'
Keyword Args:
_check_type (bool): if True, values for parameters in openapi_types
will be type checked and a TypeError will be
raised if the wrong type is input.
Defaults to True
_path_to_item (tuple/list): This is a list of keys or values to
drill down to the model in received_data
when deserializing a response
_spec_property_naming (bool): True if the variable names in the input data
are serialized names, as specified in the OpenAPI document.
False if the variable names in the input data
are pythonic names, e.g. snake case (default)
_configuration (Configuration): the instance to use when
deserializing a file_type parameter.
If passed, type conversion is attempted
If omitted no type conversion is done.
_visited_composed_classes (tuple): This stores a tuple of
classes that we have traveled through so that
if we see that class again we will not use its
discriminator again.
When traveling through a discriminator, the
composed schema that is
is traveled through is added to this set.
For example if Animal has a discriminator
petType and we pass in "Dog", and the class Dog
allOf includes Animal, we move through Animal
once using the discriminator, and pick Dog.
Then in Dog, we will make an instance of the
Animal class but this time we won't travel
through its discriminator because we passed in
_visited_composed_classes = (Animal,)
"""
_check_type = kwargs.pop('_check_type', True)
_spec_property_naming = kwargs.pop('_spec_property_naming', False)
_path_to_item = kwargs.pop('_path_to_item', ())
_configuration = kwargs.pop('_configuration', None)
_visited_composed_classes = kwargs.pop('_visited_composed_classes', ())
if args:
for arg in args:
if isinstance(arg, dict):
kwargs.update(arg)
else:
raise ApiTypeError(
"Invalid positional arguments=%s passed to %s. Remove those invalid positional arguments." % (
args,
self.__class__.__name__,
),
path_to_item=_path_to_item,
valid_classes=(self.__class__,),
)
self._data_store = {}
self._check_type = _check_type
self._spec_property_naming = _spec_property_naming
self._path_to_item = _path_to_item
self._configuration = _configuration
self._visited_composed_classes = _visited_composed_classes + (self.__class__,)
self.action = action
for var_name, var_value in kwargs.items():
if var_name not in self.attribute_map and \
self._configuration is not None and \
self._configuration.discard_unknown_keys and \
self.additional_properties_type is None:
# discard variable.
continue
setattr(self, var_name, var_value)
if var_name in self.read_only_vars:
raise ApiAttributeError(f"`{var_name}` is a read-only attribute. Use `from_openapi_data` to instantiate "
f"class with read only attributes.")
|
PypiClean
|
/ansible-navigator-3.4.2.tar.gz/ansible-navigator-3.4.2/src/ansible_navigator/utils/version_migration/definitions.py
|
from __future__ import annotations
import contextlib
from enum import Enum
from pathlib import Path
from typing import Callable
from typing import Generic
from typing import TypeVar
from ansible_navigator.utils.ansi import COLOR
from ansible_navigator.utils.ansi import changed
from ansible_navigator.utils.ansi import failed
from ansible_navigator.utils.ansi import subtle
from ansible_navigator.utils.ansi import working
class MigrationType(Enum):
"""Enum for the type of migration."""
SETTINGS_FILE = "settings"
"""Migration of the settings file."""
T = TypeVar("T")
class MigrationStep(Generic[T]):
"""Data class for a migration step."""
def __init__(self, name: str) -> None:
"""Initialize a migration step.
:param name: The name of the migration step
"""
self.name: str = name
"""The name of the migration step"""
self.needed: bool = False
"""Whether the migration step is needed"""
self.function_name: str | None = None
"""The name of the function to call"""
def print_start(self):
"""Output start information to the console."""
message = f"Migrating '{self.name}'"
information = f"{message:.<60}"
working(color=COLOR, message=information)
def print_failed(self) -> None:
"""Output fail information to the console."""
message = f"Migration of '{self.name}'"
information = f"{message:.<60}Failed"
failed(color=COLOR, message=information)
def print_updated(self) -> None:
"""Output updated information to the console."""
message = f"Migration of '{self.name}'"
information = f"{message:.<60}Updated"
changed(color=COLOR, message=information)
def print_not_needed(self) -> None:
"""Output not needed information to the console."""
message = f"Migration of '{self.name}'"
information = f"{message:.<60}Not needed"
subtle(color=COLOR, message=information)
@classmethod
def register(cls: T, migration_step: T) -> Callable:
"""Register the migration step.
:param migration_step: The migration step to register
:return: The registered migration step
"""
def wrapper(func):
"""Add the dunder collector to the func.
:param func: The function to decorate
:returns: The decorated function
"""
migration_step.function_name = func.__name__
func.__migration_step__ = migration_step
return func
return wrapper
class Migration:
"""Data class for a migration."""
name = "Migration base class"
"""The name of the migration."""
def __init__(self) -> None:
"""Initialize the migration."""
self.check: bool = False
"""Whether the migration is needed."""
self.settings_file_path: Path
"""The path of the settings file."""
self.was_needed: bool = False
"""Whether the migration was needed."""
def __init_subclass__(cls, *args, **kwargs):
"""Register the migration steps.
:param args: Positional arguments
:param kwargs: Keyword arguments
"""
super().__init_subclass__(*args, **kwargs)
migrations.append(cls)
@property
def migration_steps(self) -> tuple[MigrationStep, ...]:
"""Return the registered diagnostics.
:returns: The registered diagnostics
"""
steps: list[MigrationStep] = []
for func_name in vars(self.__class__):
if func_name.startswith("_"):
continue
if hasattr(getattr(self, func_name), "__migration_step__"):
step = getattr(self, func_name).__migration_step__
steps.append(step)
return tuple(steps)
@property
def needed_now(self) -> bool:
"""Return whether the migration is needed.
:returns: Whether the migration is needed
"""
return any(step.needed for step in self.migration_steps)
def run(self, *args, **kwargs) -> None:
"""Run the migration.
:param args: The positional arguments
:param kwargs: The keyword arguments
"""
def run_step(self, step: MigrationStep, *args, **kwargs) -> None:
"""Run the migration step.
:param step: The migration step to run
:param args: The positional arguments
:param kwargs: The keyword arguments
"""
if not isinstance(step.function_name, str):
return
function = getattr(self, step.function_name)
if self.check:
try:
step.needed = function(*args, **kwargs)
except Exception: # noqa: BLE001
step.needed = False
return
if not step.needed:
step.print_not_needed()
return
step.print_start()
with contextlib.suppress(Exception):
step.needed = function(*args, **kwargs)
if step.needed:
step.print_failed()
else:
step.print_updated()
return
def run_steps(self, *args, **kwargs) -> None:
"""Run all registered migration steps.
:param args: The positional arguments
:param kwargs: The keyword arguments
"""
for step in self.migration_steps:
self.run_step(step, *args, **kwargs)
Migrations = list[type[Migration]]
migrations: Migrations = []
|
PypiClean
|
/daniel-cavazos-sdk-0.1.0.tar.gz/daniel-cavazos-sdk-0.1.0/daniel_cavazos_sdk/builder.py
|
import requests
class SDKBuilder:
"""
A base class for building SDKs that interact with a remote API.
Provides methods for sending HTTP requests to the API and handling the response.
Subclasses of this class can define specific endpoints and methods that are tailored
to the API they are wrapping.
Example usage:
class MyAPI(SDKBuilder)
host="https://example.com"
get_user = client.GET("/users/{user_id}")
client = MyAPI("my-secret-token")
user_data = client.get_user(user_id=123)
"""
def __init__(self, token):
self.token = token
def GET(endpoint):
"""
Returns a function that sends an HTTP GET request to the specified endpoint
using the host and token associated with the current instance.
Parameters:
- endpoint (str): the endpoint URL with optional format placeholders for
the keyword arguments passed to the returned function.
Returns:
A function that takes arbitrary keyword arguments and sends an HTTP GET
request to the URL constructed by combining the host, endpoint, and keyword
arguments (formatted into the endpoint URL). If the response has a non-2xx status code,
an exception is raised.
"""
def request_func(self, **kwargs):
"""
Sends an HTTP GET request to the endpoint with the given arguments.
Parameters:
- **kwargs: arbitrary keyword arguments to be formatted into the
endpoint URL and sent as query parameters.
Returns:
The response content parsed as JSON.
Raises:
- requests.exceptions.HTTPError: if the response status code is
not in the 2xx range.
"""
url = f"{self.host}{endpoint.format(**kwargs)}"
headers = {"Authorization": f"Bearer {self.token}"}
response = requests.get(url, headers=headers, params=kwargs.get("params"))
response.raise_for_status()
return response.json()
return request_func
|
PypiClean
|
/monk_pytorch_cuda100-0.0.1-py3-none-any.whl/monk/gluon/finetune/level_5_state_base.py
|
from monk.gluon.finetune.imports import *
from monk.system.imports import *
from monk.gluon.finetune.level_4_evaluation_base import finetune_evaluation
class finetune_state(finetune_evaluation):
'''
Base class for Monk states - train, eval_infer, resume, copy_from, pseudo_copy_from (for running sub-experiments)
Args:
verbose (int): Set verbosity levels
0 - Print Nothing
1 - Print desired details
'''
@accepts("self", verbose=int, post_trace=False)
#@TraceFunction(trace_args=True, trace_rv=True)
def __init__(self, verbose=1):
super().__init__(verbose=verbose);
###############################################################################################################################################
@accepts("self", post_trace=False)
#@TraceFunction(trace_args=True, trace_rv=True)
def set_system_state_eval_infer(self):
'''
Set system for eval_infer state
Args:
None
Returns:
None
'''
self.system_dict = read_json(self.system_dict["fname"], verbose=self.system_dict["verbose"]);
self.system_dict["states"]["eval_infer"] = True;
if(self.system_dict["training"]["status"]):
if(len(self.system_dict["dataset"]["transforms"]["test"])):
self.system_dict = retrieve_test_transforms(self.system_dict);
else:
self.custom_print("Test transforms not found.");
self.custom_print("Add test transforms");
self.custom_print("");
self.set_model_final();
else:
msg = "Model in {} not trained. Cannot perform testing or inferencing".format(self.system_dict["experiment_name"]);
raise ConstraintError(msg);
###############################################################################################################################################
###############################################################################################################################################
@accepts("self", post_trace=False)
#@TraceFunction(trace_args=True, trace_rv=True)
def set_system_state_resume_train(self):
'''
Set system for resume training state
Args:
None
Returns:
None
'''
self.system_dict = read_json(self.system_dict["fname"], verbose=self.system_dict["verbose"]);
self.system_dict["states"]["resume_train"] = True;
if(self.system_dict["dataset"]["status"]):
self.system_dict = retrieve_trainval_transforms(self.system_dict);
self.set_dataset_final();
else:
msg = "Dataset not set.\n";
msg += "Training not started. Cannot Run resume Mode";
raise ConstraintError(msg);
if(self.system_dict["model"]["status"]):
self.set_model_final();
else:
msg = "Model not set.\n";
msg += "Training not started. Cannot Run resume Mode";
raise ConstraintError(msg);
if(self.system_dict["hyper-parameters"]["status"]):
self.system_dict = retrieve_optimizer(self.system_dict);
self.system_dict = retrieve_scheduler(self.system_dict);
self.system_dict = retrieve_loss(self.system_dict);
else:
msg = "hyper-parameters not set.\n";
msg += "Training not started. Cannot Run resume Mode";
raise ConstraintError(msg);
###############################################################################################################################################
###############################################################################################################################################
@accepts("self", list, post_trace=False)
#@TraceFunction(trace_args=True, trace_rv=True)
def set_system_state_copy_from(self, copy_from):
'''
Set system for copied state
Args:
None
Returns:
None
'''
fname = self.system_dict["master_systems_dir_relative"] + copy_from[0] + "/" + copy_from[1] + "/experiment_state.json";
system_dict_tmp = read_json(fname, verbose=self.system_dict["verbose"]);
if(not system_dict_tmp["training"]["status"]):
self.custom_print("Project - {}, Experiment - {}, has incomplete training.".format(copy_from[0], copy_from[1]));
self.custom_print("Complete Previous training before copying from it.");
self.custom_print("");
elif(copy_from[0] == self.system_dict["project_name"] and copy_from[1] == self.system_dict["experiment_name"]):
self.custom_print("Cannot copy same experiment. Use a different experiment to copy and load a previous experiment");
self.custom_print("");
else:
self.system_dict["dataset"] = system_dict_tmp["dataset"];
self.system_dict["model"] = system_dict_tmp["model"];
self.system_dict["hyper-parameters"] = system_dict_tmp["hyper-parameters"];
self.system_dict["training"] = system_dict_tmp["training"];
self.system_dict["origin"] = [copy_from[0], copy_from[1]];
self.system_dict["training"]["outputs"] = {};
self.system_dict["training"]["outputs"]["max_gpu_memory_usage"] = 0;
self.system_dict["training"]["outputs"]["best_val_acc"] = 0;
self.system_dict["training"]["outputs"]["best_val_acc_epoch_num"] = 0;
self.system_dict["training"]["outputs"]["epochs_completed"] = 0;
self.system_dict["training"]["status"] = False;
self.system_dict["training"]["enabled"] = True;
self.system_dict["testing"] = {};
self.system_dict["testing"]["status"] = False;
save(self.system_dict);
self.system_dict = read_json(self.system_dict["fname_relative"], verbose=self.system_dict["verbose"]);
self.system_dict["states"]["copy_from"] = True;
self.system_dict = retrieve_trainval_transforms(self.system_dict);
self.Dataset();
self.set_model_final();
self.system_dict = retrieve_optimizer(self.system_dict);
self.system_dict = retrieve_scheduler(self.system_dict);
self.system_dict = retrieve_loss(self.system_dict);
###############################################################################################################################################
###############################################################################################################################################
@accepts("self", list, post_trace=False)
#@TraceFunction(trace_args=True, trace_rv=True)
def set_system_state_pseudo_copy_from(self, pseudo_copy_from):
'''
Set system for copied state in hyper-parameter analysis mode
Args:
None
Returns:
None
'''
fname = self.system_dict["master_systems_dir_relative"] + pseudo_copy_from[0] + "/" + pseudo_copy_from[1] + "/experiment_state.json";
system_dict_tmp = read_json(fname, verbose=self.system_dict["verbose"]);
self.system_dict["dataset"] = system_dict_tmp["dataset"];
self.system_dict["model"] = system_dict_tmp["model"];
self.system_dict["hyper-parameters"] = system_dict_tmp["hyper-parameters"];
self.system_dict["training"] = system_dict_tmp["training"];
self.system_dict["origin"] = [pseudo_copy_from[0], pseudo_copy_from[1]];
self.system_dict["training"]["outputs"] = {};
self.system_dict["training"]["outputs"]["max_gpu_memory_usage"] = 0;
self.system_dict["training"]["outputs"]["best_val_acc"] = 0;
self.system_dict["training"]["outputs"]["best_val_acc_epoch_num"] = 0;
self.system_dict["training"]["outputs"]["epochs_completed"] = 0;
self.system_dict["training"]["status"] = False;
self.system_dict["training"]["enabled"] = True;
self.system_dict["testing"] = {};
self.system_dict["testing"]["status"] = False;
save(self.system_dict);
self.system_dict = read_json(self.system_dict["fname_relative"], verbose=self.system_dict["verbose"]);
self.system_dict["states"]["pseudo_copy_from"] = True;
self.system_dict = retrieve_trainval_transforms(self.system_dict);
self.Dataset();
self.set_model_final();
self.system_dict = retrieve_optimizer(self.system_dict);
self.system_dict = retrieve_scheduler(self.system_dict);
self.system_dict = retrieve_loss(self.system_dict);
###############################################################################################################################################
|
PypiClean
|
/msgraph_beta_sdk-1.0.0a9-py3-none-any.whl/msgraph/generated/security/threat_intelligence/host_cookies/host_cookies_request_builder.py
|
from __future__ import annotations
from dataclasses import dataclass
from kiota_abstractions.get_path_parameters import get_path_parameters
from kiota_abstractions.method import Method
from kiota_abstractions.request_adapter import RequestAdapter
from kiota_abstractions.request_information import RequestInformation
from kiota_abstractions.request_option import RequestOption
from kiota_abstractions.response_handler import ResponseHandler
from kiota_abstractions.serialization import Parsable, ParsableFactory
from typing import Any, Callable, Dict, List, Optional, TYPE_CHECKING, Union
if TYPE_CHECKING:
from ....models.o_data_errors import o_data_error
from ....models.security import host_cookie, host_cookie_collection_response
from .count import count_request_builder
from .item import host_cookie_item_request_builder
class HostCookiesRequestBuilder():
"""
Provides operations to manage the hostCookies property of the microsoft.graph.security.threatIntelligence entity.
"""
def __init__(self,request_adapter: RequestAdapter, path_parameters: Optional[Union[Dict[str, Any], str]] = None) -> None:
"""
Instantiates a new HostCookiesRequestBuilder and sets the default values.
Args:
pathParameters: The raw url or the Url template parameters for the request.
requestAdapter: The request adapter to use to execute the requests.
"""
if path_parameters is None:
raise Exception("path_parameters cannot be undefined")
if request_adapter is None:
raise Exception("request_adapter cannot be undefined")
# Url template to use to build the URL for the current request builder
self.url_template: str = "{+baseurl}/security/threatIntelligence/hostCookies{?%24top,%24skip,%24search,%24filter,%24count,%24orderby,%24select,%24expand}"
url_tpl_params = get_path_parameters(path_parameters)
self.path_parameters = url_tpl_params
self.request_adapter = request_adapter
def by_host_cookie_id(self,host_cookie_id: str) -> host_cookie_item_request_builder.HostCookieItemRequestBuilder:
"""
Provides operations to manage the hostCookies property of the microsoft.graph.security.threatIntelligence entity.
Args:
host_cookie_id: Unique identifier of the item
Returns: host_cookie_item_request_builder.HostCookieItemRequestBuilder
"""
if host_cookie_id is None:
raise Exception("host_cookie_id cannot be undefined")
from .item import host_cookie_item_request_builder
url_tpl_params = get_path_parameters(self.path_parameters)
url_tpl_params["hostCookie%2Did"] = host_cookie_id
return host_cookie_item_request_builder.HostCookieItemRequestBuilder(self.request_adapter, url_tpl_params)
async def get(self,request_configuration: Optional[HostCookiesRequestBuilderGetRequestConfiguration] = None) -> Optional[host_cookie_collection_response.HostCookieCollectionResponse]:
"""
Retrieve details about microsoft.graph.security.hostCookie objects.Note: List retrieval is not yet supported.
Args:
requestConfiguration: Configuration for the request such as headers, query parameters, and middleware options.
Returns: Optional[host_cookie_collection_response.HostCookieCollectionResponse]
"""
request_info = self.to_get_request_information(
request_configuration
)
from ....models.o_data_errors import o_data_error
error_mapping: Dict[str, ParsableFactory] = {
"4XX": o_data_error.ODataError,
"5XX": o_data_error.ODataError,
}
if not self.request_adapter:
raise Exception("Http core is null")
from ....models.security import host_cookie_collection_response
return await self.request_adapter.send_async(request_info, host_cookie_collection_response.HostCookieCollectionResponse, error_mapping)
async def post(self,body: Optional[host_cookie.HostCookie] = None, request_configuration: Optional[HostCookiesRequestBuilderPostRequestConfiguration] = None) -> Optional[host_cookie.HostCookie]:
"""
Create new navigation property to hostCookies for security
Args:
body: The request body
requestConfiguration: Configuration for the request such as headers, query parameters, and middleware options.
Returns: Optional[host_cookie.HostCookie]
"""
if body is None:
raise Exception("body cannot be undefined")
request_info = self.to_post_request_information(
body, request_configuration
)
from ....models.o_data_errors import o_data_error
error_mapping: Dict[str, ParsableFactory] = {
"4XX": o_data_error.ODataError,
"5XX": o_data_error.ODataError,
}
if not self.request_adapter:
raise Exception("Http core is null")
from ....models.security import host_cookie
return await self.request_adapter.send_async(request_info, host_cookie.HostCookie, error_mapping)
def to_get_request_information(self,request_configuration: Optional[HostCookiesRequestBuilderGetRequestConfiguration] = None) -> RequestInformation:
"""
Retrieve details about microsoft.graph.security.hostCookie objects.Note: List retrieval is not yet supported.
Args:
requestConfiguration: Configuration for the request such as headers, query parameters, and middleware options.
Returns: RequestInformation
"""
request_info = RequestInformation()
request_info.url_template = self.url_template
request_info.path_parameters = self.path_parameters
request_info.http_method = Method.GET
request_info.headers["Accept"] = ["application/json"]
if request_configuration:
request_info.add_request_headers(request_configuration.headers)
request_info.set_query_string_parameters_from_raw_object(request_configuration.query_parameters)
request_info.add_request_options(request_configuration.options)
return request_info
def to_post_request_information(self,body: Optional[host_cookie.HostCookie] = None, request_configuration: Optional[HostCookiesRequestBuilderPostRequestConfiguration] = None) -> RequestInformation:
"""
Create new navigation property to hostCookies for security
Args:
body: The request body
requestConfiguration: Configuration for the request such as headers, query parameters, and middleware options.
Returns: RequestInformation
"""
if body is None:
raise Exception("body cannot be undefined")
request_info = RequestInformation()
request_info.url_template = self.url_template
request_info.path_parameters = self.path_parameters
request_info.http_method = Method.POST
request_info.headers["Accept"] = ["application/json"]
if request_configuration:
request_info.add_request_headers(request_configuration.headers)
request_info.add_request_options(request_configuration.options)
request_info.set_content_from_parsable(self.request_adapter, "application/json", body)
return request_info
@property
def count(self) -> count_request_builder.CountRequestBuilder:
"""
Provides operations to count the resources in the collection.
"""
from .count import count_request_builder
return count_request_builder.CountRequestBuilder(self.request_adapter, self.path_parameters)
@dataclass
class HostCookiesRequestBuilderGetQueryParameters():
"""
Retrieve details about microsoft.graph.security.hostCookie objects.Note: List retrieval is not yet supported.
"""
def get_query_parameter(self,original_name: Optional[str] = None) -> str:
"""
Maps the query parameters names to their encoded names for the URI template parsing.
Args:
originalName: The original query parameter name in the class.
Returns: str
"""
if original_name is None:
raise Exception("original_name cannot be undefined")
if original_name == "count":
return "%24count"
if original_name == "expand":
return "%24expand"
if original_name == "filter":
return "%24filter"
if original_name == "orderby":
return "%24orderby"
if original_name == "search":
return "%24search"
if original_name == "select":
return "%24select"
if original_name == "skip":
return "%24skip"
if original_name == "top":
return "%24top"
return original_name
# Include count of items
count: Optional[bool] = None
# Expand related entities
expand: Optional[List[str]] = None
# Filter items by property values
filter: Optional[str] = None
# Order items by property values
orderby: Optional[List[str]] = None
# Search items by search phrases
search: Optional[str] = None
# Select properties to be returned
select: Optional[List[str]] = None
# Skip the first n items
skip: Optional[int] = None
# Show only the first n items
top: Optional[int] = None
@dataclass
class HostCookiesRequestBuilderGetRequestConfiguration():
"""
Configuration for the request such as headers, query parameters, and middleware options.
"""
# Request headers
headers: Optional[Dict[str, Union[str, List[str]]]] = None
# Request options
options: Optional[List[RequestOption]] = None
# Request query parameters
query_parameters: Optional[HostCookiesRequestBuilder.HostCookiesRequestBuilderGetQueryParameters] = None
@dataclass
class HostCookiesRequestBuilderPostRequestConfiguration():
"""
Configuration for the request such as headers, query parameters, and middleware options.
"""
# Request headers
headers: Optional[Dict[str, Union[str, List[str]]]] = None
# Request options
options: Optional[List[RequestOption]] = None
|
PypiClean
|
/bos-mint-0.5.4.tar.gz/bos-mint-0.5.4/bos_mint/bower_components/jquery/src/ajax.js
|
define( [
"./core",
"./var/document",
"./var/isFunction",
"./var/rnothtmlwhite",
"./ajax/var/location",
"./ajax/var/nonce",
"./ajax/var/rquery",
"./core/init",
"./ajax/parseXML",
"./event/trigger",
"./deferred",
"./serialize" // jQuery.param
], function( jQuery, document, isFunction, rnothtmlwhite, location, nonce, rquery ) {
"use strict";
var
r20 = /%20/g,
rhash = /#.*$/,
rantiCache = /([?&])_=[^&]*/,
rheaders = /^(.*?):[ \t]*([^\r\n]*)$/mg,
// #7653, #8125, #8152: local protocol detection
rlocalProtocol = /^(?:about|app|app-storage|.+-extension|file|res|widget):$/,
rnoContent = /^(?:GET|HEAD)$/,
rprotocol = /^\/\//,
/* Prefilters
* 1) They are useful to introduce custom dataTypes (see ajax/jsonp.js for an example)
* 2) These are called:
* - BEFORE asking for a transport
* - AFTER param serialization (s.data is a string if s.processData is true)
* 3) key is the dataType
* 4) the catchall symbol "*" can be used
* 5) execution will start with transport dataType and THEN continue down to "*" if needed
*/
prefilters = {},
/* Transports bindings
* 1) key is the dataType
* 2) the catchall symbol "*" can be used
* 3) selection will start with transport dataType and THEN go to "*" if needed
*/
transports = {},
// Avoid comment-prolog char sequence (#10098); must appease lint and evade compression
allTypes = "*/".concat( "*" ),
// Anchor tag for parsing the document origin
originAnchor = document.createElement( "a" );
originAnchor.href = location.href;
// Base "constructor" for jQuery.ajaxPrefilter and jQuery.ajaxTransport
function addToPrefiltersOrTransports( structure ) {
// dataTypeExpression is optional and defaults to "*"
return function( dataTypeExpression, func ) {
if ( typeof dataTypeExpression !== "string" ) {
func = dataTypeExpression;
dataTypeExpression = "*";
}
var dataType,
i = 0,
dataTypes = dataTypeExpression.toLowerCase().match( rnothtmlwhite ) || [];
if ( isFunction( func ) ) {
// For each dataType in the dataTypeExpression
while ( ( dataType = dataTypes[ i++ ] ) ) {
// Prepend if requested
if ( dataType[ 0 ] === "+" ) {
dataType = dataType.slice( 1 ) || "*";
( structure[ dataType ] = structure[ dataType ] || [] ).unshift( func );
// Otherwise append
} else {
( structure[ dataType ] = structure[ dataType ] || [] ).push( func );
}
}
}
};
}
// Base inspection function for prefilters and transports
function inspectPrefiltersOrTransports( structure, options, originalOptions, jqXHR ) {
var inspected = {},
seekingTransport = ( structure === transports );
function inspect( dataType ) {
var selected;
inspected[ dataType ] = true;
jQuery.each( structure[ dataType ] || [], function( _, prefilterOrFactory ) {
var dataTypeOrTransport = prefilterOrFactory( options, originalOptions, jqXHR );
if ( typeof dataTypeOrTransport === "string" &&
!seekingTransport && !inspected[ dataTypeOrTransport ] ) {
options.dataTypes.unshift( dataTypeOrTransport );
inspect( dataTypeOrTransport );
return false;
} else if ( seekingTransport ) {
return !( selected = dataTypeOrTransport );
}
} );
return selected;
}
return inspect( options.dataTypes[ 0 ] ) || !inspected[ "*" ] && inspect( "*" );
}
// A special extend for ajax options
// that takes "flat" options (not to be deep extended)
// Fixes #9887
function ajaxExtend( target, src ) {
var key, deep,
flatOptions = jQuery.ajaxSettings.flatOptions || {};
for ( key in src ) {
if ( src[ key ] !== undefined ) {
( flatOptions[ key ] ? target : ( deep || ( deep = {} ) ) )[ key ] = src[ key ];
}
}
if ( deep ) {
jQuery.extend( true, target, deep );
}
return target;
}
/* Handles responses to an ajax request:
* - finds the right dataType (mediates between content-type and expected dataType)
* - returns the corresponding response
*/
function ajaxHandleResponses( s, jqXHR, responses ) {
var ct, type, finalDataType, firstDataType,
contents = s.contents,
dataTypes = s.dataTypes;
// Remove auto dataType and get content-type in the process
while ( dataTypes[ 0 ] === "*" ) {
dataTypes.shift();
if ( ct === undefined ) {
ct = s.mimeType || jqXHR.getResponseHeader( "Content-Type" );
}
}
// Check if we're dealing with a known content-type
if ( ct ) {
for ( type in contents ) {
if ( contents[ type ] && contents[ type ].test( ct ) ) {
dataTypes.unshift( type );
break;
}
}
}
// Check to see if we have a response for the expected dataType
if ( dataTypes[ 0 ] in responses ) {
finalDataType = dataTypes[ 0 ];
} else {
// Try convertible dataTypes
for ( type in responses ) {
if ( !dataTypes[ 0 ] || s.converters[ type + " " + dataTypes[ 0 ] ] ) {
finalDataType = type;
break;
}
if ( !firstDataType ) {
firstDataType = type;
}
}
// Or just use first one
finalDataType = finalDataType || firstDataType;
}
// If we found a dataType
// We add the dataType to the list if needed
// and return the corresponding response
if ( finalDataType ) {
if ( finalDataType !== dataTypes[ 0 ] ) {
dataTypes.unshift( finalDataType );
}
return responses[ finalDataType ];
}
}
/* Chain conversions given the request and the original response
* Also sets the responseXXX fields on the jqXHR instance
*/
function ajaxConvert( s, response, jqXHR, isSuccess ) {
var conv2, current, conv, tmp, prev,
converters = {},
// Work with a copy of dataTypes in case we need to modify it for conversion
dataTypes = s.dataTypes.slice();
// Create converters map with lowercased keys
if ( dataTypes[ 1 ] ) {
for ( conv in s.converters ) {
converters[ conv.toLowerCase() ] = s.converters[ conv ];
}
}
current = dataTypes.shift();
// Convert to each sequential dataType
while ( current ) {
if ( s.responseFields[ current ] ) {
jqXHR[ s.responseFields[ current ] ] = response;
}
// Apply the dataFilter if provided
if ( !prev && isSuccess && s.dataFilter ) {
response = s.dataFilter( response, s.dataType );
}
prev = current;
current = dataTypes.shift();
if ( current ) {
// There's only work to do if current dataType is non-auto
if ( current === "*" ) {
current = prev;
// Convert response if prev dataType is non-auto and differs from current
} else if ( prev !== "*" && prev !== current ) {
// Seek a direct converter
conv = converters[ prev + " " + current ] || converters[ "* " + current ];
// If none found, seek a pair
if ( !conv ) {
for ( conv2 in converters ) {
// If conv2 outputs current
tmp = conv2.split( " " );
if ( tmp[ 1 ] === current ) {
// If prev can be converted to accepted input
conv = converters[ prev + " " + tmp[ 0 ] ] ||
converters[ "* " + tmp[ 0 ] ];
if ( conv ) {
// Condense equivalence converters
if ( conv === true ) {
conv = converters[ conv2 ];
// Otherwise, insert the intermediate dataType
} else if ( converters[ conv2 ] !== true ) {
current = tmp[ 0 ];
dataTypes.unshift( tmp[ 1 ] );
}
break;
}
}
}
}
// Apply converter (if not an equivalence)
if ( conv !== true ) {
// Unless errors are allowed to bubble, catch and return them
if ( conv && s.throws ) {
response = conv( response );
} else {
try {
response = conv( response );
} catch ( e ) {
return {
state: "parsererror",
error: conv ? e : "No conversion from " + prev + " to " + current
};
}
}
}
}
}
}
return { state: "success", data: response };
}
jQuery.extend( {
// Counter for holding the number of active queries
active: 0,
// Last-Modified header cache for next request
lastModified: {},
etag: {},
ajaxSettings: {
url: location.href,
type: "GET",
isLocal: rlocalProtocol.test( location.protocol ),
global: true,
processData: true,
async: true,
contentType: "application/x-www-form-urlencoded; charset=UTF-8",
/*
timeout: 0,
data: null,
dataType: null,
username: null,
password: null,
cache: null,
throws: false,
traditional: false,
headers: {},
*/
accepts: {
"*": allTypes,
text: "text/plain",
html: "text/html",
xml: "application/xml, text/xml",
json: "application/json, text/javascript"
},
contents: {
xml: /\bxml\b/,
html: /\bhtml/,
json: /\bjson\b/
},
responseFields: {
xml: "responseXML",
text: "responseText",
json: "responseJSON"
},
// Data converters
// Keys separate source (or catchall "*") and destination types with a single space
converters: {
// Convert anything to text
"* text": String,
// Text to html (true = no transformation)
"text html": true,
// Evaluate text as a json expression
"text json": JSON.parse,
// Parse text as xml
"text xml": jQuery.parseXML
},
// For options that shouldn't be deep extended:
// you can add your own custom options here if
// and when you create one that shouldn't be
// deep extended (see ajaxExtend)
flatOptions: {
url: true,
context: true
}
},
// Creates a full fledged settings object into target
// with both ajaxSettings and settings fields.
// If target is omitted, writes into ajaxSettings.
ajaxSetup: function( target, settings ) {
return settings ?
// Building a settings object
ajaxExtend( ajaxExtend( target, jQuery.ajaxSettings ), settings ) :
// Extending ajaxSettings
ajaxExtend( jQuery.ajaxSettings, target );
},
ajaxPrefilter: addToPrefiltersOrTransports( prefilters ),
ajaxTransport: addToPrefiltersOrTransports( transports ),
// Main method
ajax: function( url, options ) {
// If url is an object, simulate pre-1.5 signature
if ( typeof url === "object" ) {
options = url;
url = undefined;
}
// Force options to be an object
options = options || {};
var transport,
// URL without anti-cache param
cacheURL,
// Response headers
responseHeadersString,
responseHeaders,
// timeout handle
timeoutTimer,
// Url cleanup var
urlAnchor,
// Request state (becomes false upon send and true upon completion)
completed,
// To know if global events are to be dispatched
fireGlobals,
// Loop variable
i,
// uncached part of the url
uncached,
// Create the final options object
s = jQuery.ajaxSetup( {}, options ),
// Callbacks context
callbackContext = s.context || s,
// Context for global events is callbackContext if it is a DOM node or jQuery collection
globalEventContext = s.context &&
( callbackContext.nodeType || callbackContext.jquery ) ?
jQuery( callbackContext ) :
jQuery.event,
// Deferreds
deferred = jQuery.Deferred(),
completeDeferred = jQuery.Callbacks( "once memory" ),
// Status-dependent callbacks
statusCode = s.statusCode || {},
// Headers (they are sent all at once)
requestHeaders = {},
requestHeadersNames = {},
// Default abort message
strAbort = "canceled",
// Fake xhr
jqXHR = {
readyState: 0,
// Builds headers hashtable if needed
getResponseHeader: function( key ) {
var match;
if ( completed ) {
if ( !responseHeaders ) {
responseHeaders = {};
while ( ( match = rheaders.exec( responseHeadersString ) ) ) {
responseHeaders[ match[ 1 ].toLowerCase() ] = match[ 2 ];
}
}
match = responseHeaders[ key.toLowerCase() ];
}
return match == null ? null : match;
},
// Raw string
getAllResponseHeaders: function() {
return completed ? responseHeadersString : null;
},
// Caches the header
setRequestHeader: function( name, value ) {
if ( completed == null ) {
name = requestHeadersNames[ name.toLowerCase() ] =
requestHeadersNames[ name.toLowerCase() ] || name;
requestHeaders[ name ] = value;
}
return this;
},
// Overrides response content-type header
overrideMimeType: function( type ) {
if ( completed == null ) {
s.mimeType = type;
}
return this;
},
// Status-dependent callbacks
statusCode: function( map ) {
var code;
if ( map ) {
if ( completed ) {
// Execute the appropriate callbacks
jqXHR.always( map[ jqXHR.status ] );
} else {
// Lazy-add the new callbacks in a way that preserves old ones
for ( code in map ) {
statusCode[ code ] = [ statusCode[ code ], map[ code ] ];
}
}
}
return this;
},
// Cancel the request
abort: function( statusText ) {
var finalText = statusText || strAbort;
if ( transport ) {
transport.abort( finalText );
}
done( 0, finalText );
return this;
}
};
// Attach deferreds
deferred.promise( jqXHR );
// Add protocol if not provided (prefilters might expect it)
// Handle falsy url in the settings object (#10093: consistency with old signature)
// We also use the url parameter if available
s.url = ( ( url || s.url || location.href ) + "" )
.replace( rprotocol, location.protocol + "//" );
// Alias method option to type as per ticket #12004
s.type = options.method || options.type || s.method || s.type;
// Extract dataTypes list
s.dataTypes = ( s.dataType || "*" ).toLowerCase().match( rnothtmlwhite ) || [ "" ];
// A cross-domain request is in order when the origin doesn't match the current origin.
if ( s.crossDomain == null ) {
urlAnchor = document.createElement( "a" );
// Support: IE <=8 - 11, Edge 12 - 15
// IE throws exception on accessing the href property if url is malformed,
// e.g. http://example.com:80x/
try {
urlAnchor.href = s.url;
// Support: IE <=8 - 11 only
// Anchor's host property isn't correctly set when s.url is relative
urlAnchor.href = urlAnchor.href;
s.crossDomain = originAnchor.protocol + "//" + originAnchor.host !==
urlAnchor.protocol + "//" + urlAnchor.host;
} catch ( e ) {
// If there is an error parsing the URL, assume it is crossDomain,
// it can be rejected by the transport if it is invalid
s.crossDomain = true;
}
}
// Convert data if not already a string
if ( s.data && s.processData && typeof s.data !== "string" ) {
s.data = jQuery.param( s.data, s.traditional );
}
// Apply prefilters
inspectPrefiltersOrTransports( prefilters, s, options, jqXHR );
// If request was aborted inside a prefilter, stop there
if ( completed ) {
return jqXHR;
}
// We can fire global events as of now if asked to
// Don't fire events if jQuery.event is undefined in an AMD-usage scenario (#15118)
fireGlobals = jQuery.event && s.global;
// Watch for a new set of requests
if ( fireGlobals && jQuery.active++ === 0 ) {
jQuery.event.trigger( "ajaxStart" );
}
// Uppercase the type
s.type = s.type.toUpperCase();
// Determine if request has content
s.hasContent = !rnoContent.test( s.type );
// Save the URL in case we're toying with the If-Modified-Since
// and/or If-None-Match header later on
// Remove hash to simplify url manipulation
cacheURL = s.url.replace( rhash, "" );
// More options handling for requests with no content
if ( !s.hasContent ) {
// Remember the hash so we can put it back
uncached = s.url.slice( cacheURL.length );
// If data is available and should be processed, append data to url
if ( s.data && ( s.processData || typeof s.data === "string" ) ) {
cacheURL += ( rquery.test( cacheURL ) ? "&" : "?" ) + s.data;
// #9682: remove data so that it's not used in an eventual retry
delete s.data;
}
// Add or update anti-cache param if needed
if ( s.cache === false ) {
cacheURL = cacheURL.replace( rantiCache, "$1" );
uncached = ( rquery.test( cacheURL ) ? "&" : "?" ) + "_=" + ( nonce++ ) + uncached;
}
// Put hash and anti-cache on the URL that will be requested (gh-1732)
s.url = cacheURL + uncached;
// Change '%20' to '+' if this is encoded form body content (gh-2658)
} else if ( s.data && s.processData &&
( s.contentType || "" ).indexOf( "application/x-www-form-urlencoded" ) === 0 ) {
s.data = s.data.replace( r20, "+" );
}
// Set the If-Modified-Since and/or If-None-Match header, if in ifModified mode.
if ( s.ifModified ) {
if ( jQuery.lastModified[ cacheURL ] ) {
jqXHR.setRequestHeader( "If-Modified-Since", jQuery.lastModified[ cacheURL ] );
}
if ( jQuery.etag[ cacheURL ] ) {
jqXHR.setRequestHeader( "If-None-Match", jQuery.etag[ cacheURL ] );
}
}
// Set the correct header, if data is being sent
if ( s.data && s.hasContent && s.contentType !== false || options.contentType ) {
jqXHR.setRequestHeader( "Content-Type", s.contentType );
}
// Set the Accepts header for the server, depending on the dataType
jqXHR.setRequestHeader(
"Accept",
s.dataTypes[ 0 ] && s.accepts[ s.dataTypes[ 0 ] ] ?
s.accepts[ s.dataTypes[ 0 ] ] +
( s.dataTypes[ 0 ] !== "*" ? ", " + allTypes + "; q=0.01" : "" ) :
s.accepts[ "*" ]
);
// Check for headers option
for ( i in s.headers ) {
jqXHR.setRequestHeader( i, s.headers[ i ] );
}
// Allow custom headers/mimetypes and early abort
if ( s.beforeSend &&
( s.beforeSend.call( callbackContext, jqXHR, s ) === false || completed ) ) {
// Abort if not done already and return
return jqXHR.abort();
}
// Aborting is no longer a cancellation
strAbort = "abort";
// Install callbacks on deferreds
completeDeferred.add( s.complete );
jqXHR.done( s.success );
jqXHR.fail( s.error );
// Get transport
transport = inspectPrefiltersOrTransports( transports, s, options, jqXHR );
// If no transport, we auto-abort
if ( !transport ) {
done( -1, "No Transport" );
} else {
jqXHR.readyState = 1;
// Send global event
if ( fireGlobals ) {
globalEventContext.trigger( "ajaxSend", [ jqXHR, s ] );
}
// If request was aborted inside ajaxSend, stop there
if ( completed ) {
return jqXHR;
}
// Timeout
if ( s.async && s.timeout > 0 ) {
timeoutTimer = window.setTimeout( function() {
jqXHR.abort( "timeout" );
}, s.timeout );
}
try {
completed = false;
transport.send( requestHeaders, done );
} catch ( e ) {
// Rethrow post-completion exceptions
if ( completed ) {
throw e;
}
// Propagate others as results
done( -1, e );
}
}
// Callback for when everything is done
function done( status, nativeStatusText, responses, headers ) {
var isSuccess, success, error, response, modified,
statusText = nativeStatusText;
// Ignore repeat invocations
if ( completed ) {
return;
}
completed = true;
// Clear timeout if it exists
if ( timeoutTimer ) {
window.clearTimeout( timeoutTimer );
}
// Dereference transport for early garbage collection
// (no matter how long the jqXHR object will be used)
transport = undefined;
// Cache response headers
responseHeadersString = headers || "";
// Set readyState
jqXHR.readyState = status > 0 ? 4 : 0;
// Determine if successful
isSuccess = status >= 200 && status < 300 || status === 304;
// Get response data
if ( responses ) {
response = ajaxHandleResponses( s, jqXHR, responses );
}
// Convert no matter what (that way responseXXX fields are always set)
response = ajaxConvert( s, response, jqXHR, isSuccess );
// If successful, handle type chaining
if ( isSuccess ) {
// Set the If-Modified-Since and/or If-None-Match header, if in ifModified mode.
if ( s.ifModified ) {
modified = jqXHR.getResponseHeader( "Last-Modified" );
if ( modified ) {
jQuery.lastModified[ cacheURL ] = modified;
}
modified = jqXHR.getResponseHeader( "etag" );
if ( modified ) {
jQuery.etag[ cacheURL ] = modified;
}
}
// if no content
if ( status === 204 || s.type === "HEAD" ) {
statusText = "nocontent";
// if not modified
} else if ( status === 304 ) {
statusText = "notmodified";
// If we have data, let's convert it
} else {
statusText = response.state;
success = response.data;
error = response.error;
isSuccess = !error;
}
} else {
// Extract error from statusText and normalize for non-aborts
error = statusText;
if ( status || !statusText ) {
statusText = "error";
if ( status < 0 ) {
status = 0;
}
}
}
// Set data for the fake xhr object
jqXHR.status = status;
jqXHR.statusText = ( nativeStatusText || statusText ) + "";
// Success/Error
if ( isSuccess ) {
deferred.resolveWith( callbackContext, [ success, statusText, jqXHR ] );
} else {
deferred.rejectWith( callbackContext, [ jqXHR, statusText, error ] );
}
// Status-dependent callbacks
jqXHR.statusCode( statusCode );
statusCode = undefined;
if ( fireGlobals ) {
globalEventContext.trigger( isSuccess ? "ajaxSuccess" : "ajaxError",
[ jqXHR, s, isSuccess ? success : error ] );
}
// Complete
completeDeferred.fireWith( callbackContext, [ jqXHR, statusText ] );
if ( fireGlobals ) {
globalEventContext.trigger( "ajaxComplete", [ jqXHR, s ] );
// Handle the global AJAX counter
if ( !( --jQuery.active ) ) {
jQuery.event.trigger( "ajaxStop" );
}
}
}
return jqXHR;
},
getJSON: function( url, data, callback ) {
return jQuery.get( url, data, callback, "json" );
},
getScript: function( url, callback ) {
return jQuery.get( url, undefined, callback, "script" );
}
} );
jQuery.each( [ "get", "post" ], function( i, method ) {
jQuery[ method ] = function( url, data, callback, type ) {
// Shift arguments if data argument was omitted
if ( isFunction( data ) ) {
type = type || callback;
callback = data;
data = undefined;
}
// The url can be an options object (which then must have .url)
return jQuery.ajax( jQuery.extend( {
url: url,
type: method,
dataType: type,
data: data,
success: callback
}, jQuery.isPlainObject( url ) && url ) );
};
} );
return jQuery;
} );
|
PypiClean
|
/aiy-voice-only-1.tar.gz/aiy-voice-only-1/aiy/_drivers/_buzzer.py
|
import os
import time
USEC = 1000000
def HzToPeriodUsec(freq_hz):
"""Converts a frequency given in Hz to a period expressed in microseconds."""
return USEC / freq_hz
class PWMController(object):
"""Controller that simplifies the interface to pwm-soft Linux driver.
Simple usage:
from aiy._drivers._buzzer import PWMController
with PWMController(gpio=22) as controller:
controller.set_frequency(440.00)
time.sleep(1)
controller.set_frequency(0)
Note: The pwm-soft driver is a little cantankerous and weird in terms of the
model that it uses for controlling the PWM output. Instead of specifying a
period and a duty cycle percentage, this driver explicitly allows the user
to specify how long in microseconds to keep the GPIO high, and how long the
entire period is.
This can make things a little strange when it comes to changing the
apparent frequency of the PWM output, as simply adjusting the period time
while leaving the pulse time constant will produce phasing effects rather
than frequency shifts.
For more melodious uses, set_frequency should be enough.
"""
PWM_SOFT_BASE_PATH = '/sys/class/pwm-soft'
PWM_SOFT_EXPORT_PATH = PWM_SOFT_BASE_PATH + '/export'
PWM_SOFT_UNEXPORT_PATH = PWM_SOFT_BASE_PATH + '/unexport'
def __init__(self, gpio):
"""Initializes and configures the pwm-soft driver for the given GPIO.
Args:
gpio: the number of the GPIO to use for PWM output.
"""
self.gpio = gpio
self._pulse_fh = None
self._period_fh = None
self._exported = False
def __enter__(self):
"""Context manager method to automatically open up."""
self._export_pwm()
return self
def __exit__(self, *args):
"""Context manager method to clean up."""
self._unexport_pwm()
def _make_pwm_path(self, pwm_number):
"""Makes a path into the an exported PWM pin.
Args:
pwm_number: the number of the PWM previously exported.
"""
return '%s/pwm%d' % (self.PWM_SOFT_BASE_PATH, pwm_number)
def _wait_for_access(self, path):
retry_count = 5
retry_time = 0.01
while not os.access(path, os.W_OK) and retry_count != 0:
retry_count -= 1
time.sleep(retry_time)
retry_time *= 2
if not os.access(path, os.W_OK):
raise IOError('Could not open %s' % path)
def _pwrite_int(self, path, data):
"""Helper method to quickly write a value to a sysfs node.
Args:
path: string of the path to the sysfs node to write the data to.
data: an integer to write to the sysfs node.
"""
self._wait_for_access(path)
with open(path, 'w') as output:
self._write_int(output, data)
def _write_int(self, fh, data):
"""Helper method to write a value to a pre-opened handle.
Note: this flushes the output to disk to ensure that it actually makes
it to the sysfs node.
Args:
fh: the file handle to write to (as returned by open).
data: the integer to write to the file.
"""
fh.write('%d\n' % data)
fh.flush()
def _export_pwm(self):
"""Exports the given GPIO via the pwm-soft driver.
This writes the given GPIO number to the export sysfs node and opens two
file handles for later use to the period and pulse sysfs nodes inside
the given PWM path. If it fails, this will raise an exception.
"""
try:
self._pwrite_int(self.PWM_SOFT_EXPORT_PATH, self.gpio)
except BaseException:
self._exported = False
raise
self._exported = True
period_path = self._make_pwm_path(self.gpio) + '/period'
try:
self._wait_for_access(period_path)
self._period_fh = open(period_path, 'w')
except BaseException:
self._unexport_pwm()
raise
pulse_path = self._make_pwm_path(self.gpio) + '/pulse'
try:
self._wait_for_access(pulse_path)
self._pulse_fh = open(pulse_path, 'w')
except BaseException:
self._unexport_pwm()
raise
def _unexport_pwm(self):
"""Unexports the given GPIO from the pwm-soft driver.
This effectively reverses _export_pwm by closing the two file handles it
previously opened, and then unexporting the given gpio.
"""
if self._exported:
if self._period_fh is not None:
self._period_fh.close()
if self._pulse_fh is not None:
self._pulse_fh.close()
self._pwrite_int(self.PWM_SOFT_UNEXPORT_PATH, self.gpio)
self._exported = False
def open(self):
"""Opens the PWNController, exports the GPIO and gets ready to play."""
self._export_pwm()
def _update_pwm(self):
"""Helper method to update the pulse and period settings in the driver."""
self._write_int(self._pulse_fh, self._pulse_usec)
self._write_int(self._period_fh, self._period_usec)
self._write_int(self._pulse_fh, self._pulse_usec)
self._write_int(self._period_fh, self._period_usec)
self._write_int(self._pulse_fh, self._pulse_usec)
self._write_int(self._period_fh, self._period_usec)
def open(self):
"""Opens the PWNController, exports the GPIO and gets ready to play."""
self._export_pwm()
def close(self):
"""Shuts down the PWMController and unexports the GPIO."""
self._unexport_pwm()
def set_frequency(self, freq_hz):
"""Sets the frequency in Hz to output.
Note: This assumes a 50% duty cycle for the PWM output to provide a nice
clear tone on any attached piezo buzzer. For more advanced techniques
and effects, please see set_period_usec and set_pulse_usec.
Args:
freq_hz: The frequency in Hz to output.
"""
if freq_hz == 0:
self._frequency_hz = 0
self._period_usec = 0
self._pulse_usec = 0
else:
self._frequency_hz = freq_hz
self._period_usec = int(HzToPeriodUsec(freq_hz))
self._pulse_usec = int(self._period_usec / 2)
self._update_pwm()
def set_pulse_usec(self, pulse_usec):
"""Sets the pulse length in microseconds.
Args:
pulse_usec: how long to keep the GPIO high during the PWM period.
"""
self._pulse_usec = pulse_usec
self._update_pwm()
def set_period_usec(self, period_usec):
"""Sets the period length in microseconds.
Args:
period_usec: how long each PWM cycle will take in microseconds.
"""
self._period_usec = period_usec
self._update_pwm()
def pulse_usec(self):
"""Getter for getting the current pulse width in microseconds."""
return self._pulse_usec
def period_usec(self):
"""Getter for getting the current period width in microseconds."""
return self._period_usec
def frequency_hz(self):
"""Getter for getting the current frequency in Hertz."""
return self._frequency_hz
|
PypiClean
|
/graph_analyzer/cross_associations_analyzer.py
|
import logging
import os
import pandas as pd
import numpy as np
import pickle
from ..utils.utils import get_abspath
from ..utils import graph_ops, graph, graph_loader
from ..utils import plot_utils
from ..utils.graph import Edgelist
class CrossAssociationsAnalyzer():
"""
use CrossAssociations Algorithm to analyze network
"""
def __init__(self, graphloader):
self.graphloader = graphloader
self.dir_output = self.graphloader.dir_output + "CrossAssociationsAnalyzer/"
if not os.path.exists(self.dir_output):
os.makedirs(self.dir_output)
def run(self):
highlight_node = np.squeeze(np.nonzero(self.graphloader.labels==1))
return self.run_algorithm(self.graphloader.data().to_df(), self.graphloader.netname, self.dir_output, highlight_node)
@classmethod
def run_algorithm(cls, data_network, netname, dir_output, highlight_node = None):
"""
"""
logging.info("Network analyzer: Cross Associations starts.")
filepath_data = dir_output + "reorder_network.txt"
filepath_reorder_dict = dir_output + "reorder_dict.pkl"
filepath_cluster_index = dir_output + "cluster_index.txt"
filepath_ca = dir_output + "ca_network.pkl"
filepath_ca_dict = dir_output + "ca_dict.pkl"
if not os.path.exists(filepath_data):
data_relabel, dict_relabel = graph_ops.relabel_node(data_network)
data_relabel.to_csv(filepath_data, header = None, index= False, sep = "\t")
with open(filepath_reorder_dict, "wb") as f:
pickle.dump(dict_relabel, f)
else :
logging.info("reorder File exists: " + filepath_data)
with open(filepath_reorder_dict, "rb") as f:
dict_relabel = pickle.load(f)
if not os.path.exists(filepath_ca):
cls.get_vertex_cluster_index(filepath_data, filepath_cluster_index)
data_reorder, dict_reorder = cls.reorder_vertex(filepath_data, filepath_cluster_index)
with open(filepath_ca, "wb") as f:
pickle.dump(data_reorder, f)
with open(filepath_ca_dict, "wb") as f:
pickle.dump(dict_reorder, f)
else :
logging.info("cluster File exists: " + filepath_ca)
with open(filepath_ca, "rb") as f:
data_reorder = pickle.load(f)
with open(filepath_ca_dict, "rb") as f:
dict_reorder = pickle.load(f)
if highlight_node is not None:
## Note: here're two reorder(relabel) process
## so have to convert input index into the index after reorder
highlight_node_relabel = cls.get_plot_ids(highlight_node, dict_reorder, dict_relabel)
plot_utils.plot_spy(graph.df2csr(data_reorder), dir_output, highlight_ids = highlight_node_relabel)
logging.info("Network analyzer: Cross Associations finished")
@classmethod
def get_plot_ids(cls, ids, dict_reorder, dict_relabel):
plot_ids = []
for x in ids:
tmp = dict_relabel[x]
plot_ids.append(dict_reorder[tmp])
return plot_ids
@classmethod
def get_origin_ids(cls, ids, dict_reorder, dict_relabel):
origin_ids = []
reorder2relabel = dict()
for key, value in dict_reorder.items():
reorder2relabel[value] = key
relabel2origin = dict()
for key, value in dict_relabel.items():
relabel2origin[value] = key
for x in ids:
relabel_id = reorder2relabel[x]
origin_ids.append(relabel2origin[relabel_id])
return origin_ids
@classmethod
def get_vertex_cluster_index(cls, filepath_data, filepath_output, force_override = False):
import matlab
import matlab.engine
filepath_code = get_abspath("../resource/CrossAssociations/")
eng = matlab.engine.start_matlab()
# eng.eval("",nargout=0)
eng.workspace['filename_input'] = filepath_data
eng.workspace['filename_output'] = filepath_output
eng.workspace['dir_code'] = filepath_code
eng.eval("s=dlmread(filename_input);", nargout=0)
eng.eval("s(:,3) = 1;", nargout=0)
eng.eval("s(:,1) = s(:,1)+1;", nargout=0)
eng.eval("s(:,2) = s(:,2)+1;", nargout=0)
eng.eval("A=spconvert(s);", nargout=0)
eng.eval("isSelfGraph = true;", nargout=0)
eng.eval("addpath(dir_code);", nargout=0)
eng.eval("[k,l,Nx,Ny,Qx,Qy,Dnz] = cc_search(A,'hellscream',isSelfGraph);", nargout=0)
## save data into file
eng.eval("fid = fopen(filename_output,'W');", nargout=0)
eng.eval("for i=1:length(Qx);fprintf(fid,'%d\\n',Qx(i));end;", nargout=0)
eng.eval("fclose(fid);", nargout=0)
eng.quit()
'''
filename = 'cross associations 20k stage'
s=dlmread(filename); s(:,3)=1; A=spconvert(s);
isSelfGraph = true;
[k,l,Nx,Ny,Qx,Qy,Dnz] = cc_search(A,'hellscream',isSelfGraph);
fid = fopen([filename,' output_row_clusters'],'W');
for i=1:length(Qx);
fprintf(fid,'%d\n',Qx(i));
end
fclose(fid)
'''
@classmethod
def get_ca_cluster(cls, filepath_cluster_index):
"""
load ca cluster output
"""
data_ca_cluster = pd.read_table(filepath_cluster_index, header=None)
n_element = data_ca_cluster.shape[0]
n_ca_cluster = data_ca_cluster.max()[0]
logging.debug("Here're " + str(n_ca_cluster) + " clusters")
x_ca_output = np.zeros((n_ca_cluster, n_element), dtype="int")
x_ca_cnt = np.zeros((n_ca_cluster, ), dtype="int")
for i in range(data_ca_cluster.shape[0]):
cluster = (int)(data_ca_cluster.iat[i, 0] - 1)
x_ca_output[cluster][x_ca_cnt[cluster]] = i + 1
x_ca_cnt[cluster] = x_ca_cnt[cluster] + 1
logging.debug("#element: " + str(x_ca_cnt.sum()))
return n_ca_cluster, x_ca_cnt, x_ca_output, n_element
@classmethod
def get_dict_ca_reorder(cls, filepath_cluster_index):
"""
load cluster A_svd_result by function get_ca_cluster(stage)
"""
n_ca_cluster, x_ca_cnt, x_ca_output, n_element = cls.get_ca_cluster(filepath_cluster_index)
dict_ca_reorder = {}
cnt = 0
for i in range(n_ca_cluster):
for j in range(x_ca_cnt[i]):
cnt = cnt +1
dict_ca_reorder[x_ca_output[i][j]-1] = n_element - cnt
while cnt < n_element:
cnt += 1
dict_ca_reorder[cnt] = n_element - cnt
logging.debug("Len of dict_reorder: " + str(len(dict_ca_reorder)))
return dict_ca_reorder, n_element
@classmethod
def reorder_vertex(cls, filepath_data, filepath_cluster_index):
"""
use dict_ca_reorder to reorder the vertexes in stage
get processed data by get_dict_ca_reorder(stage)
Args:
by : "pairs" means the vertexes of one stage will be reorder by the cluster network_info of the same stage.
You can also input a int number to use the cluster network_info of one stage reordering of all stages.
Returns:
A_svd_result: a dict contains argument "by" and a list of ndarray type data needed to be spy
"""
logging.info("Cross Associations: reordering vertexes")
src, dst, val = graph_loader.load_graph(filepath_data)
edgelist = Edgelist(src, dst, val)
data_network = edgelist.to_df()
dict_ca_reorder, _ = cls.get_dict_ca_reorder(filepath_cluster_index)
x_reorder = np.zeros((data_network.shape[0], 3))
for i in range(data_network.shape[0]):
x_reorder[i][0] = dict_ca_reorder[(int)(data_network.iat[i, 0])]
x_reorder[i][1] = dict_ca_reorder[(int)(data_network.iat[i, 1])]
x_reorder[i][2] = data_network.iat[i, 2]
data_reorder = pd.DataFrame(x_reorder)
logging.info("Cross Associations: vertexes are reordered")
return data_reorder, dict_ca_reorder
def evaluate_result(self, plot_ids):
filepath_reorder_dict = self.dir_output + "reorder_dict.pkl"
filepath_ca_dict = self.dir_output + "ca_dict.pkl"
with open(filepath_reorder_dict, "rb") as f:
dict_relabel = pickle.load(f)
with open(filepath_ca_dict, "rb") as f:
dict_reorder = pickle.load(f)
origin_ids = self.get_origin_ids(plot_ids, dict_reorder, dict_relabel)
from sklearn.metrics import classification_report, roc_auc_score
from ..utils.math import scale
from ..utils.evaluate_utils import plot_roc_curve
ca_labels = np.zeros(self.graphloader.data().number_of_nodes()).astype(int)
ca_labels[origin_ids] = 1
AUC = roc_auc_score(self.graphloader.labels, ca_labels)
print("AUC", AUC)
plot_roc_curve(self.graphloader.labels, ca_labels, self.dir_output, identifier=self.graphloader.netname+"_"+str(AUC))
print(sum(ca_labels))
print(classification_report(self.graphloader.labels, ca_labels))
return origin_ids
|
PypiClean
|
/xpiz-0.0.4-py3-none-any.whl/splittr/__init__.py
|
import os, sys, hashlib, zipfile, json, shutil
from glob import glob as re
def read_bin(foil):
with open(foil,'rb') as reader:
return reader.read()
def hash(foil, hash_function = hashlib.sha1):
hashing = hash_function()
with open(foil, 'rb') as f:
for chunk in iter(lambda: f.read(4096), b""):
hashing.update(chunk)
with open(foil + '.sums', 'a') as f:
json.dump(str({"hash":hashing.hexdigest()}),f)
return hashing.hexdigest()
def verify(foil, hash_function = hashlib.sha1):
verified, set_hash, hash = False, 0, str(foil + '.sums').replace('.sums.sums','.sums')
with open(hash, 'r') as f:
set_hash = json.loads(str(f.readlines()[0]).replace('"','').replace("'",'"'))['hash']
verified = hash_function(read_bin(foil)).hexdigest() == set_hash
if verified:
os.remove(foil + '.sums')
return verified
def split(foil, CHUNK_SIZE = 100_000_000): #100MB
foils_created,file_number, failure = [],1, False #https://www.tutorialspoint.com/How-to-spilt-a-binary-file-into-multiple-files-using-Python
with open(foil,'rb') as f:
try:
chunk = f.read(CHUNK_SIZE)
while chunk:
current_file = foil.replace('.zip','') + '_broken_up_' + str(str(file_number).zfill(10))
with open(current_file, "wb+") as chunk_file:
chunk_file.write(chunk)
with zipfile.ZipFile(current_file+".zip", 'w', compression=zipfile.ZIP_DEFLATED) as zip_file:
zip_file.write(current_file, current_file)
foils_created += [current_file + ".zip"];os.remove(current_file)
file_number += 1;chunk = f.read(CHUNK_SIZE)
except Exception as e:
print(f"Exception :> {e}")
failure = True
if not failure:
os.remove(foil)
return foils_created
def join(foil):
foil = foil.replace('.sums','')
mini_foils,current_binary = re(str(foil).replace('.zip','') + "_broken_up_*.zip"),None
mini_foils.sort()
for mini_foil in mini_foils:
raw_foil = mini_foil.replace('.zip','')
with zipfile.ZipFile(mini_foil,"r") as f:
raw_foil = f.extract(member=raw_foil, path=os.path.dirname(mini_foil))
if current_binary is None: #https://stackoverflow.com/questions/62050356/merge-two-binary-files-into-third-binary-file
current_binary = read_bin(raw_foil)
else:
current_binary += read_bin(raw_foil)
shutil.rmtree(os.path.dirname(raw_foil), ignore_errors=True);os.remove(mini_foil)
with open(foil, 'wb') as fp:
fp.write(current_binary)
def arguments():
import argparse
parser = argparse.ArgumentParser(description=f"Enabling the capability to stretch a single large file into many smaller files")
parser.add_argument("-f","--file", help="The name of the file", nargs='*')
parser.add_argument("--split", help="Split the file up", action="store_true",default=False)
parser.add_argument("--join", help="Recreate the file", action="store_true",default=False)
parser.add_argument("--template", help="Create a copy of this file specific to a large file", action="store_true",default=False)
return parser.parse_args()
def splitt(foil):
hash(foil);split(foil)
def joinn(foil):
join(foil);verify(foil)
def template(workingfoil):
with open(__file__, "r") as reader:
with open(workingfoil + ".py", "w+") as writer:
for line in reader.readlines():
line = line.rstrip()
if "workingfoil = argz.file[0]" in line:
line = line.replace("argz.file[0]", "\""+workingfoil+"\"")
writer.write(line+"\n")
def main(foil:str,splitfile:bool=False, joinfile:bool=False):
if splitfile:
splitt(foil)
elif joinfile:
joinn(foil)
if __name__ == '__main__':
argz = arguments();workingfoil = argz.file[0]
if argz.template:
template(workingfoil)
print(workingfoil + ".py")
else:
if argz.split and argz.join:
print("Cannot use both both split and join")
elif not os.path.exists(argz.file[0]):
print("The file {file} does not exist".format(file=argz.file[0]))
else:
main(workingfoil, splitfile=argz.split, joinfile=argz.join)
|
PypiClean
|
/scikit-learn-3way-split-0.0.1.tar.gz/scikit-learn-3way-split-0.0.1/doc/modules/isotonic.rst
|
.. _isotonic:
===================
Isotonic regression
===================
.. currentmodule:: sklearn.isotonic
The class :class:`IsotonicRegression` fits a non-decreasing real function to
1-dimensional data. It solves the following problem:
minimize :math:`\sum_i w_i (y_i - \hat{y}_i)^2`
subject to :math:`\hat{y}_i \le \hat{y}_j` whenever :math:`X_i \le X_j`,
where the weights :math:`w_i` are strictly positive, and both `X` and `y` are
arbitrary real quantities.
The `increasing` parameter changes the constraint to
:math:`\hat{y}_i \ge \hat{y}_j` whenever :math:`X_i \le X_j`. Setting it to
'auto' will automatically choose the constraint based on `Spearman's rank
correlation coefficient
<https://en.wikipedia.org/wiki/Spearman%27s_rank_correlation_coefficient>`_.
:class:`IsotonicRegression` produces a series of predictions
:math:`\hat{y}_i` for the training data which are the closest to the targets
:math:`y` in terms of mean squared error. These predictions are interpolated
for predicting to unseen data. The predictions of :class:`IsotonicRegression`
thus form a function that is piecewise linear:
.. figure:: ../auto_examples/images/sphx_glr_plot_isotonic_regression_001.png
:target: ../auto_examples/plot_isotonic_regression.html
:align: center
|
PypiClean
|
/xs_transformers-1.0.7-py3-none-any.whl/xs_transformers/models/roformer/modeling_roformer.py
|
import math
import os
from typing import Optional, Tuple, Union
import numpy as np
import torch
import torch.utils.checkpoint
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from ...activations import ACT2FN
from ...modeling_outputs import (
BaseModelOutputWithPastAndCrossAttentions,
CausalLMOutputWithCrossAttentions,
MaskedLMOutput,
MultipleChoiceModelOutput,
QuestionAnsweringModelOutput,
SequenceClassifierOutput,
TokenClassifierOutput,
)
from ...modeling_utils import PreTrainedModel, SequenceSummary
from ...pytorch_utils import (
apply_chunking_to_forward,
find_pruneable_heads_and_indices,
prune_linear_layer,
)
from ...utils import (
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
logging,
replace_return_docstrings,
)
from .configuration_roformer import RoFormerConfig
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "junnyu/roformer_chinese_base"
_CONFIG_FOR_DOC = "RoFormerConfig"
_TOKENIZER_FOR_DOC = "RoFormerTokenizer"
ROFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
"junnyu/roformer_chinese_small",
"junnyu/roformer_chinese_base",
"junnyu/roformer_chinese_char_small",
"junnyu/roformer_chinese_char_base",
"junnyu/roformer_small_discriminator",
"junnyu/roformer_small_generator"
# See all RoFormer models at https://huggingface.co/models?filter=roformer
]
# Copied from transformers.models.marian.modeling_marian.MarianSinusoidalPositionalEmbedding with Marian->RoFormer
class RoFormerSinusoidalPositionalEmbedding(nn.Embedding):
"""This module produces sinusoidal positional embeddings of any length."""
def __init__(
self, num_positions: int, embedding_dim: int, padding_idx: Optional[int] = None
) -> None:
super().__init__(num_positions, embedding_dim)
self.weight = self._init_weight(self.weight)
@staticmethod
def _init_weight(out: nn.Parameter) -> nn.Parameter:
"""
Identical to the XLM create_sinusoidal_embeddings except features are not interleaved. The cos features are in
the 2nd half of the vector. [dim // 2:]
"""
n_pos, dim = out.shape
position_enc = np.array(
[
[pos / np.power(10000, 2 * (j // 2) / dim) for j in range(dim)]
for pos in range(n_pos)
]
)
out.requires_grad = False # set early to avoid an error in pytorch-1.8+
sentinel = dim // 2 if dim % 2 == 0 else (dim // 2) + 1
out[:, 0:sentinel] = torch.FloatTensor(np.sin(position_enc[:, 0::2]))
out[:, sentinel:] = torch.FloatTensor(np.cos(position_enc[:, 1::2]))
out.detach_()
return out
@torch.no_grad()
def forward(
self, input_ids_shape: torch.Size, past_key_values_length: int = 0
) -> torch.Tensor:
"""`input_ids_shape` is expected to be [bsz x seqlen]."""
bsz, seq_len = input_ids_shape[:2]
positions = torch.arange(
past_key_values_length,
past_key_values_length + seq_len,
dtype=torch.long,
device=self.weight.device,
)
return super().forward(positions)
def load_tf_weights_in_roformer(model, config, tf_checkpoint_path):
"""Load tf checkpoints in a pytorch model."""
try:
import re
import numpy as np
import tensorflow as tf
except ImportError:
logger.error(
"Loading a TensorFlow model in PyTorch, requires TensorFlow to be installed. Please see "
"https://www.tensorflow.org/install/ for installation instructions."
)
raise
tf_path = os.path.abspath(tf_checkpoint_path)
logger.info(f"Converting TensorFlow checkpoint from {tf_path}")
# Load weights from TF model
init_vars = tf.train.list_variables(tf_path)
names = []
arrays = []
for name, shape in init_vars:
logger.info(f"Loading TF weight {name} with shape {shape}")
array = tf.train.load_variable(tf_path, name)
names.append(name.replace("bert", "roformer"))
arrays.append(array)
for name, array in zip(names, arrays):
name = name.split("/")
# adam_v and adam_m are variables used in AdamWeightDecayOptimizer to calculated m and v
# which are not required for using pretrained model
if any(
n
in [
"adam_v",
"adam_m",
"AdamWeightDecayOptimizer",
"AdamWeightDecayOptimizer_1",
"global_step",
]
for n in name
):
logger.info(f"Skipping {'/'.join(name)}")
continue
pointer = model
for m_name in name:
if re.fullmatch(r"[A-Za-z]+_\d+", m_name):
scope_names = re.split(r"_(\d+)", m_name)
else:
scope_names = [m_name]
if scope_names[0] == "kernel" or scope_names[0] == "gamma":
pointer = getattr(pointer, "weight")
elif scope_names[0] == "output_bias" or scope_names[0] == "beta":
pointer = getattr(pointer, "bias")
elif scope_names[0] == "output_weights":
pointer = getattr(pointer, "weight")
elif scope_names[0] == "squad":
pointer = getattr(pointer, "classifier")
else:
try:
pointer = getattr(pointer, scope_names[0])
except AttributeError:
logger.info(f"Skipping {'/'.join(name)}")
continue
if len(scope_names) >= 2:
num = int(scope_names[1])
pointer = pointer[num]
if m_name[-11:] == "_embeddings":
pointer = getattr(pointer, "weight")
elif m_name == "kernel":
array = np.transpose(array)
try:
if not pointer.shape == array.shape:
raise ValueError(
f"Pointer shape {pointer.shape} and array shape {array.shape} mismatched"
)
except AssertionError as e:
e.args += (pointer.shape, array.shape)
raise
logger.info(f"Initialize PyTorch weight {name}")
pointer.data = torch.from_numpy(array)
return model
class RoFormerEmbeddings(nn.Module):
"""Construct the embeddings from word and token_type embeddings."""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(
config.vocab_size, config.embedding_size, padding_idx=config.pad_token_id
)
self.token_type_embeddings = nn.Embedding(
config.type_vocab_size, config.embedding_size
)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.embedding_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, input_ids=None, token_type_ids=None, inputs_embeds=None):
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
if token_type_ids is None:
token_type_ids = torch.zeros(
input_shape, dtype=torch.long, device=inputs_embeds.device
)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + token_type_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
class RoFormerSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(
config, "embedding_size"
):
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
f"heads ({config.num_attention_heads})"
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.is_decoder = config.is_decoder
self.rotary_value = config.rotary_value
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (
self.num_attention_heads,
self.attention_head_size,
)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states,
attention_mask=None,
sinusoidal_pos=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
mixed_query_layer = self.query(hidden_states)
query_layer = self.transpose_for_scores(mixed_query_layer)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
is_cross_attention = encoder_hidden_states is not None
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_layer = past_key_value[0]
value_layer = past_key_value[1]
attention_mask = encoder_attention_mask
elif is_cross_attention:
key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
attention_mask = encoder_attention_mask
elif past_key_value is not None:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
else:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
if sinusoidal_pos is not None:
if self.rotary_value:
(
query_layer,
key_layer,
value_layer,
) = self.apply_rotary_position_embeddings(
sinusoidal_pos, query_layer, key_layer, value_layer
)
else:
query_layer, key_layer = self.apply_rotary_position_embeddings(
sinusoidal_pos, query_layer, key_layer
)
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_layer, value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in RoFormerModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
outputs = (
(context_layer, attention_probs) if output_attentions else (context_layer,)
)
if self.is_decoder:
outputs = outputs + (past_key_value,)
return outputs
@staticmethod
def apply_rotary_position_embeddings(
sinusoidal_pos, query_layer, key_layer, value_layer=None
):
# https://kexue.fm/archives/8265
# sin [batch_size, num_heads, sequence_length, embed_size_per_head//2]
# cos [batch_size, num_heads, sequence_length, embed_size_per_head//2]
sin, cos = sinusoidal_pos.chunk(2, dim=-1)
# sin [θ0,θ1,θ2......θd/2-1] -> sin_pos [θ0,θ0,θ1,θ1,θ2,θ2......θd/2-1,θd/2-1]
sin_pos = torch.stack([sin, sin], dim=-1).reshape_as(sinusoidal_pos)
# cos [θ0,θ1,θ2......θd/2-1] -> cos_pos [θ0,θ0,θ1,θ1,θ2,θ2......θd/2-1,θd/2-1]
cos_pos = torch.stack([cos, cos], dim=-1).reshape_as(sinusoidal_pos)
# rotate_half_query_layer [-q1,q0,-q3,q2......,-qd-1,qd-2]
rotate_half_query_layer = torch.stack(
[-query_layer[..., 1::2], query_layer[..., ::2]], dim=-1
).reshape_as(query_layer)
query_layer = query_layer * cos_pos + rotate_half_query_layer * sin_pos
# rotate_half_key_layer [-k1,k0,-k3,k2......,-kd-1,kd-2]
rotate_half_key_layer = torch.stack(
[-key_layer[..., 1::2], key_layer[..., ::2]], dim=-1
).reshape_as(key_layer)
key_layer = key_layer * cos_pos + rotate_half_key_layer * sin_pos
if value_layer is not None:
# rotate_half_value_layer [-v1,v0,-v3,v2......,-vd-1,vd-2]
rotate_half_value_layer = torch.stack(
[-value_layer[..., 1::2], value_layer[..., ::2]], dim=-1
).reshape_as(value_layer)
value_layer = value_layer * cos_pos + rotate_half_value_layer * sin_pos
return query_layer, key_layer, value_layer
return query_layer, key_layer
# Copied from transformers.models.bert.modeling_bert.BertSelfOutput with Bert->RoFormer
class RoFormerSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(
self, hidden_states: torch.Tensor, input_tensor: torch.Tensor
) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
class RoFormerAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.self = RoFormerSelfAttention(config)
self.output = RoFormerSelfOutput(config)
self.pruned_heads = set()
# Copied from transformers.models.bert.modeling_bert.BertAttention.prune_heads
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads,
self.self.num_attention_heads,
self.self.attention_head_size,
self.pruned_heads,
)
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = (
self.self.attention_head_size * self.self.num_attention_heads
)
self.pruned_heads = self.pruned_heads.union(heads)
# End Copy
def forward(
self,
hidden_states,
attention_mask=None,
sinusoidal_pos=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
self_outputs = self.self(
hidden_states,
attention_mask,
sinusoidal_pos,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
attention_output = self.output(self_outputs[0], hidden_states)
outputs = (attention_output,) + self_outputs[
1:
] # add attentions if we output them
return outputs
# Copied from transformers.models.bert.modeling_bert.BertIntermediate with Bert->RoFormer
class RoFormerIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertOutput with Bert->RoFormer
class RoFormerOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(
self, hidden_states: torch.Tensor, input_tensor: torch.Tensor
) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
class RoFormerLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = RoFormerAttention(config)
self.is_decoder = config.is_decoder
self.add_cross_attention = config.add_cross_attention
if self.add_cross_attention:
if not self.is_decoder:
raise ValueError(
f"{self} should be used as a decoder model if cross attention is added"
)
self.crossattention = RoFormerAttention(config)
self.intermediate = RoFormerIntermediate(config)
self.output = RoFormerOutput(config)
def forward(
self,
hidden_states,
attention_mask=None,
sinusoidal_pos=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = (
past_key_value[:2] if past_key_value is not None else None
)
self_attention_outputs = self.attention(
hidden_states,
attention_mask,
sinusoidal_pos,
head_mask,
output_attentions=output_attentions,
past_key_value=self_attn_past_key_value,
)
attention_output = self_attention_outputs[0]
# if decoder, the last output is tuple of self-attn cache
if self.is_decoder:
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
else:
outputs = self_attention_outputs[
1:
] # add self attentions if we output attention weights
cross_attn_present_key_value = None
if self.is_decoder and encoder_hidden_states is not None:
if not hasattr(self, "crossattention"):
raise ValueError(
f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention "
"layers by setting `config.add_cross_attention=True`"
)
# cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
cross_attn_past_key_value = (
past_key_value[-2:] if past_key_value is not None else None
)
cross_attention_outputs = self.crossattention(
attention_output,
attention_mask,
sinusoidal_pos,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
cross_attn_past_key_value,
output_attentions,
)
attention_output = cross_attention_outputs[0]
outputs = (
outputs + cross_attention_outputs[1:-1]
) # add cross attentions if we output attention weights
# add cross-attn cache to positions 3,4 of present_key_value tuple
cross_attn_present_key_value = cross_attention_outputs[-1]
present_key_value = present_key_value + cross_attn_present_key_value
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk,
self.chunk_size_feed_forward,
self.seq_len_dim,
attention_output,
)
outputs = (layer_output,) + outputs
# if decoder, return the attn key/values as the last output
if self.is_decoder:
outputs = outputs + (present_key_value,)
return outputs
def feed_forward_chunk(self, attention_output):
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output
class RoFormerEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.embed_positions = RoFormerSinusoidalPositionalEmbedding(
config.max_position_embeddings,
config.hidden_size // config.num_attention_heads,
)
self.layer = nn.ModuleList(
[RoFormerLayer(config) for _ in range(config.num_hidden_layers)]
)
self.gradient_checkpointing = False
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=False,
output_hidden_states=False,
return_dict=True,
):
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
all_cross_attentions = (
() if output_attentions and self.config.add_cross_attention else None
)
# [sequence_length, embed_size_per_head] -> [batch_size, num_heads, sequence_length, embed_size_per_head]
sinusoidal_pos = self.embed_positions(hidden_states.shape[:-1])[
None, None, :, :
]
next_decoder_cache = () if use_cache else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
past_key_value = past_key_values[i] if past_key_values is not None else None
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs, past_key_value, output_attentions)
return custom_forward
layer_outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(layer_module),
hidden_states,
attention_mask,
sinusoidal_pos,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
)
else:
layer_outputs = layer_module(
hidden_states,
attention_mask,
sinusoidal_pos,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[-1],)
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if self.config.add_cross_attention:
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [
hidden_states,
next_decoder_cache,
all_hidden_states,
all_self_attentions,
all_cross_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
class RoFormerPredictionHeadTransform(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.embedding_size)
if isinstance(config.hidden_act, str):
self.transform_act_fn = ACT2FN[config.hidden_act]
else:
self.transform_act_fn = config.hidden_act
self.LayerNorm = nn.LayerNorm(config.embedding_size, eps=config.layer_norm_eps)
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(hidden_states)
return hidden_states
class RoFormerLMPredictionHead(nn.Module):
def __init__(self, config):
super().__init__()
self.transform = RoFormerPredictionHeadTransform(config)
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
self.decoder = nn.Linear(config.embedding_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
# Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
self.decoder.bias = self.bias
def forward(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertOnlyMLMHead with Bert->RoFormer
class RoFormerOnlyMLMHead(nn.Module):
def __init__(self, config):
super().__init__()
self.predictions = RoFormerLMPredictionHead(config)
def forward(self, sequence_output: torch.Tensor) -> torch.Tensor:
prediction_scores = self.predictions(sequence_output)
return prediction_scores
class RoFormerPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = RoFormerConfig
load_tf_weights = load_tf_weights_in_roformer
base_model_prefix = "roformer"
supports_gradient_checkpointing = True
_keys_to_ignore_on_load_missing = []
_keys_to_ignore_on_load_unexpected = [
r"roformer.embeddings_project.weight",
r"roformer.embeddings_project.bias",
]
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, nn.Linear):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, RoFormerSinusoidalPositionalEmbedding):
pass
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
def _set_gradient_checkpointing(self, module, value=False):
if isinstance(module, RoFormerEncoder):
module.gradient_checkpointing = value
ROFORMER_START_DOCSTRING = r"""
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
Parameters:
config ([`RoFormerConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
ROFORMER_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`RoFormerTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert *input_ids* indices into associated vectors than the
model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
@add_start_docstrings(
"The bare RoFormer Model transformer outputting raw hidden-states without any specific head on top.",
ROFORMER_START_DOCSTRING,
)
class RoFormerModel(RoFormerPreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
to `True`. To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder` argument and
`add_cross_attention` set to `True`; an `encoder_hidden_states` is then expected as an input to the forward pass.
"""
def __init__(self, config):
super().__init__(config)
self.config = config
self.embeddings = RoFormerEmbeddings(config)
if config.embedding_size != config.hidden_size:
self.embeddings_project = nn.Linear(
config.embedding_size, config.hidden_size
)
self.encoder = RoFormerEncoder(config)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward(
ROFORMER_INPUTS_DOCSTRING.format("batch_size, sequence_length")
)
@add_code_sample_docstrings(
processor_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=BaseModelOutputWithPastAndCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[BaseModelOutputWithPastAndCrossAttentions, Tuple[torch.Tensor]]:
r"""
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`).
"""
output_attentions = (
output_attentions
if output_attentions is not None
else self.config.output_attentions
)
output_hidden_states = (
output_hidden_states
if output_hidden_states is not None
else self.config.output_hidden_states
)
return_dict = (
return_dict if return_dict is not None else self.config.use_return_dict
)
if self.config.is_decoder:
use_cache = use_cache if use_cache is not None else self.config.use_cache
else:
use_cache = False
if input_ids is not None and inputs_embeds is not None:
raise ValueError(
"You cannot specify both input_ids and inputs_embeds at the same time"
)
elif input_ids is not None:
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
batch_size, seq_length = input_shape
device = input_ids.device if input_ids is not None else inputs_embeds.device
# past_key_values_length
past_key_values_length = (
past_key_values[0][0].shape[2] if past_key_values is not None else 0
)
if attention_mask is None:
attention_mask = torch.ones(
((batch_size, seq_length + past_key_values_length)), device=device
)
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(
attention_mask, input_shape
)
# If a 2D or 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder and encoder_hidden_states is not None:
(
encoder_batch_size,
encoder_sequence_length,
_,
) = encoder_hidden_states.size()
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
encoder_extended_attention_mask = self.invert_attention_mask(
encoder_attention_mask
)
else:
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output = self.embeddings(
input_ids=input_ids,
token_type_ids=token_type_ids,
inputs_embeds=inputs_embeds,
)
if hasattr(self, "embeddings_project"):
embedding_output = self.embeddings_project(embedding_output)
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
if not return_dict:
return (sequence_output,) + encoder_outputs[1:]
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=sequence_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
@add_start_docstrings(
"""RoFormer Model with a `language modeling` head on top.""",
ROFORMER_START_DOCSTRING,
)
class RoFormerForMaskedLM(RoFormerPreTrainedModel):
def __init__(self, config):
super().__init__(config)
if config.is_decoder:
logger.warning(
"If you want to use `RoFormerForMaskedLM` make sure `config.is_decoder=False` for "
"bi-directional self-attention."
)
self.roformer = RoFormerModel(config)
self.cls = RoFormerOnlyMLMHead(config)
# Initialize weights and apply final processing
self.post_init()
def get_output_embeddings(self):
return self.cls.predictions.decoder
def set_output_embeddings(self, new_embeddings):
self.cls.predictions.decoder = new_embeddings
@add_start_docstrings_to_model_forward(
ROFORMER_INPUTS_DOCSTRING.format("batch_size, sequence_length")
)
@add_code_sample_docstrings(
processor_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=MaskedLMOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[MaskedLMOutput, Tuple[torch.Tensor]]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked), the
loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
"""
return_dict = (
return_dict if return_dict is not None else self.config.use_return_dict
)
outputs = self.roformer(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
prediction_scores = self.cls(sequence_output)
masked_lm_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss() # -100 index = padding token
masked_lm_loss = loss_fct(
prediction_scores.view(-1, self.config.vocab_size), labels.view(-1)
)
if not return_dict:
output = (prediction_scores,) + outputs[1:]
return (
((masked_lm_loss,) + output) if masked_lm_loss is not None else output
)
return MaskedLMOutput(
loss=masked_lm_loss,
logits=prediction_scores,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
def prepare_inputs_for_generation(
self, input_ids, attention_mask=None, **model_kwargs
):
input_shape = input_ids.shape
effective_batch_size = input_shape[0]
# add a dummy token
assert (
self.config.pad_token_id is not None
), "The PAD token should be defined for generation"
attention_mask = torch.cat(
[attention_mask, attention_mask.new_zeros((attention_mask.shape[0], 1))],
dim=-1,
)
dummy_token = torch.full(
(effective_batch_size, 1),
self.config.pad_token_id,
dtype=torch.long,
device=input_ids.device,
)
input_ids = torch.cat([input_ids, dummy_token], dim=1)
return {"input_ids": input_ids, "attention_mask": attention_mask}
@add_start_docstrings(
"""RoFormer Model with a `language modeling` head on top for CLM fine-tuning.""",
ROFORMER_START_DOCSTRING,
)
class RoFormerForCausalLM(RoFormerPreTrainedModel):
_keys_to_ignore_on_load_missing = [r"predictions.decoder.bias"]
def __init__(self, config):
super().__init__(config)
if not config.is_decoder:
logger.warning(
"If you want to use `RoFormerForCausalLM` as a standalone, add `is_decoder=True.`"
)
self.roformer = RoFormerModel(config)
self.cls = RoFormerOnlyMLMHead(config)
# Initialize weights and apply final processing
self.post_init()
def get_output_embeddings(self):
return self.cls.predictions.decoder
def set_output_embeddings(self, new_embeddings):
self.cls.predictions.decoder = new_embeddings
@add_start_docstrings_to_model_forward(
ROFORMER_INPUTS_DOCSTRING.format("batch_size, sequence_length")
)
@replace_return_docstrings(
output_type=CausalLMOutputWithCrossAttentions, config_class=_CONFIG_FOR_DOC
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
cross_attn_head_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[CausalLMOutputWithCrossAttentions, Tuple[torch.Tensor]]:
r"""
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the left-to-right language modeling loss (next word prediction). Indices should be in
`[-100, 0, ..., config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are
ignored (masked), the loss is only computed for the tokens with labels n `[0, ..., config.vocab_size]`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`).
Returns:
Example:
```python
>>> from transformers import RoFormerTokenizer, RoFormerForCausalLM, RoFormerConfig
>>> import torch
>>> tokenizer = RoFormerTokenizer.from_pretrained("junnyu/roformer_chinese_base")
>>> config = RoFormerConfig.from_pretrained("junnyu/roformer_chinese_base")
>>> config.is_decoder = True
>>> model = RoFormerForCausalLM.from_pretrained("junnyu/roformer_chinese_base", config=config)
>>> inputs = tokenizer("今天天气非常好。", return_tensors="pt")
>>> outputs = model(**inputs)
>>> prediction_logits = outputs.logits
```"""
return_dict = (
return_dict if return_dict is not None else self.config.use_return_dict
)
outputs = self.roformer(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
prediction_scores = self.cls(sequence_output)
lm_loss = None
if labels is not None:
# we are doing next-token prediction; shift prediction scores and input ids by one
shifted_prediction_scores = prediction_scores[:, :-1, :].contiguous()
labels = labels[:, 1:].contiguous()
loss_fct = CrossEntropyLoss()
lm_loss = loss_fct(
shifted_prediction_scores.view(-1, self.config.vocab_size),
labels.view(-1),
)
if not return_dict:
output = (prediction_scores,) + outputs[1:]
return ((lm_loss,) + output) if lm_loss is not None else output
return CausalLMOutputWithCrossAttentions(
loss=lm_loss,
logits=prediction_scores,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
def prepare_inputs_for_generation(
self, input_ids, past=None, attention_mask=None, **model_kwargs
):
input_shape = input_ids.shape
# if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
if attention_mask is None:
attention_mask = input_ids.new_ones(input_shape)
# cut decoder_input_ids if past is used
if past is not None:
input_ids = input_ids[:, -1:]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"past_key_values": past,
}
def _reorder_cache(self, past, beam_idx):
reordered_past = ()
for layer_past in past:
reordered_past += (
tuple(
past_state.index_select(0, beam_idx)
for past_state in layer_past[:2]
)
+ layer_past[2:],
)
return reordered_past
class RoFormerClassificationHead(nn.Module):
"""Head for sentence-level classification tasks."""
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.out_proj = nn.Linear(config.hidden_size, config.num_labels)
self.config = config
def forward(self, features, **kwargs):
x = features[:, 0, :] # take <s> token (equiv. to [CLS])
x = self.dropout(x)
x = self.dense(x)
x = ACT2FN[self.config.hidden_act](x)
x = self.dropout(x)
x = self.out_proj(x)
return x
@add_start_docstrings(
"""
RoFormer Model transformer with a sequence classification/regression head on top (a linear layer on top of the
pooled output) e.g. for GLUE tasks.
""",
ROFORMER_START_DOCSTRING,
)
class RoFormerForSequenceClassification(RoFormerPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.roformer = RoFormerModel(config)
self.classifier = RoFormerClassificationHead(config)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(
ROFORMER_INPUTS_DOCSTRING.format("batch_size, sequence_length")
)
@add_code_sample_docstrings(
processor_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=SequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[SequenceClassifierOutput, Tuple[torch.Tensor]]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = (
return_dict if return_dict is not None else self.config.use_return_dict
)
outputs = self.roformer(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (
labels.dtype == torch.long or labels.dtype == torch.int
):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
RoFormer Model with a multiple choice classification head on top (a linear layer on top of the pooled output and a
softmax) e.g. for RocStories/SWAG tasks.
""",
ROFORMER_START_DOCSTRING,
)
class RoFormerForMultipleChoice(RoFormerPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.roformer = RoFormerModel(config)
self.sequence_summary = SequenceSummary(config)
self.classifier = nn.Linear(config.hidden_size, 1)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(
ROFORMER_INPUTS_DOCSTRING.format("batch_size, num_choices, sequence_length")
)
@add_code_sample_docstrings(
processor_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=MultipleChoiceModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[MultipleChoiceModelOutput, Tuple[torch.Tensor]]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the multiple choice classification loss. Indices should be in `[0, ...,
num_choices-1]` where `num_choices` is the size of the second dimension of the input tensors. (See
`input_ids` above)
"""
return_dict = (
return_dict if return_dict is not None else self.config.use_return_dict
)
num_choices = (
input_ids.shape[1] if input_ids is not None else inputs_embeds.shape[1]
)
input_ids = (
input_ids.view(-1, input_ids.size(-1)) if input_ids is not None else None
)
attention_mask = (
attention_mask.view(-1, attention_mask.size(-1))
if attention_mask is not None
else None
)
token_type_ids = (
token_type_ids.view(-1, token_type_ids.size(-1))
if token_type_ids is not None
else None
)
inputs_embeds = (
inputs_embeds.view(-1, inputs_embeds.size(-2), inputs_embeds.size(-1))
if inputs_embeds is not None
else None
)
outputs = self.roformer(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
pooled_output = self.sequence_summary(sequence_output)
logits = self.classifier(pooled_output)
reshaped_logits = logits.view(-1, num_choices)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(reshaped_logits, labels)
if not return_dict:
output = (reshaped_logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return MultipleChoiceModelOutput(
loss=loss,
logits=reshaped_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
RoFormer Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
Named-Entity-Recognition (NER) tasks.
""",
ROFORMER_START_DOCSTRING,
)
class RoFormerForTokenClassification(RoFormerPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.roformer = RoFormerModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(
ROFORMER_INPUTS_DOCSTRING.format("batch_size, sequence_length")
)
@add_code_sample_docstrings(
processor_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TokenClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[TokenClassifierOutput, Tuple[torch.Tensor]]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the token classification loss. Indices should be in `[0, ..., config.num_labels - 1]`.
"""
return_dict = (
return_dict if return_dict is not None else self.config.use_return_dict
)
outputs = self.roformer(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return TokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
RoFormer Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layers on top of the hidden-states output to compute `span start logits` and `span end logits`).
""",
ROFORMER_START_DOCSTRING,
)
class RoFormerForQuestionAnswering(RoFormerPreTrainedModel):
def __init__(self, config):
super().__init__(config)
config.num_labels = 2
self.num_labels = config.num_labels
self.roformer = RoFormerModel(config)
self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(
ROFORMER_INPUTS_DOCSTRING.format("batch_size, sequence_length")
)
@add_code_sample_docstrings(
processor_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=QuestionAnsweringModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
start_positions: Optional[torch.LongTensor] = None,
end_positions: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[QuestionAnsweringModelOutput, Tuple[torch.Tensor]]:
r"""
start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
"""
return_dict = (
return_dict if return_dict is not None else self.config.use_return_dict
)
outputs = self.roformer(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1)
end_logits = end_logits.squeeze(-1)
total_loss = None
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions = start_positions.clamp(0, ignored_index)
end_positions = end_positions.clamp(0, ignored_index)
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
if not return_dict:
output = (start_logits, end_logits) + outputs[1:]
return ((total_loss,) + output) if total_loss is not None else output
return QuestionAnsweringModelOutput(
loss=total_loss,
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
|
PypiClean
|
/ambition-django-uuidfield-0.5.0.tar.gz/ambition-django-uuidfield-0.5.0/uuidfield/fields.py
|
import uuid
from six import with_metaclass
from django import forms
from django.db.models import Field, SubfieldBase
try:
from django.utils.encoding import smart_unicode
except ImportError:
from django.utils.encoding import smart_text as smart_unicode
try:
# psycopg2 needs us to register the uuid type
import psycopg2.extras
psycopg2.extras.register_uuid()
except (ImportError, AttributeError):
pass
class StringUUID(uuid.UUID):
def __init__(self, *args, **kwargs):
# get around UUID's immutable setter
object.__setattr__(self, 'hyphenate', kwargs.pop('hyphenate', False))
super(StringUUID, self).__init__(*args, **kwargs)
def __str__(self):
if self.hyphenate:
return super(StringUUID, self).__str__()
return self.hex
def __len__(self):
return len(self.__str__())
class UUIDField(with_metaclass(SubfieldBase, Field)):
"""
A field which stores a UUID value in hex format. This may also have the
Boolean attribute 'auto' which will set the value on initial save to a new
UUID value. Note that while all UUIDs are expected to be unique we enforce
this with a DB constraint.
"""
def __init__(self, version=4, node=None, clock_seq=None,
namespace=None, name=None, auto=False, hyphenate=False,
*args, **kwargs):
assert version in (1, 3, 4, 5), "UUID version {ver}is not supported."\
.format(ver=version)
self.auto = auto
self.version = version
self.hyphenate = hyphenate
if hyphenate:
# We store UUIDs in string format, which is fixed at 36 characters.
kwargs['max_length'] = 36
else:
# We store UUIDs in hex format, which is fixed at 32 characters.
kwargs['max_length'] = 32
if auto:
# Do not let the user edit UUIDs if they are auto-assigned.
kwargs['editable'] = False
kwargs['blank'] = True
kwargs['unique'] = True
if version == 1:
self.node, self.clock_seq = node, clock_seq
elif version in (3, 5):
self.namespace, self.name = namespace, name
super(UUIDField, self).__init__(*args, **kwargs)
def deconstruct(self):
name, path, args, kwargs = super(UUIDField, self).deconstruct()
del kwargs['max_length']
if self.auto:
kwargs.pop('editable')
kwargs.pop('blank')
kwargs.pop('unique')
kwargs['auto'] = True
if self.version != 4:
kwargs['version'] = self.version
if self.hyphenate:
kwargs['hyphenate'] = self.hyphenate
if hasattr(self, 'node') and self.node is not None:
kwargs['node'] = self.node
if hasattr(self, 'clock_seq') and self.clock_seq is not None:
kwargs['clock_seq'] = self.clock_seq
if hasattr(self, 'namespace') and self.namespace is not None:
kwargs['namespace'] = self.namespace
if hasattr(self, 'name') and self.name is not None:
kwargs['name'] = self.name
return name, path, args, kwargs
def _create_uuid(self):
if self.version == 1:
args = (self.node, self.clock_seq)
elif self.version in (3, 5):
error = None
if self.name is None:
error_attr = 'name'
elif self.namespace is None:
error_attr = 'namespace'
if error is not None:
raise ValueError("The %s parameter of %s needs to be set." %
(error_attr, self))
if not isinstance(self.namespace, uuid.UUID):
raise ValueError("The name parameter of %s must be an "
"UUID instance." % self)
args = (self.namespace, self.name)
else:
args = ()
return getattr(uuid, 'uuid%s' % self.version)(*args)
def db_type(self, connection=None):
"""
Return the special uuid data type on Postgres databases.
"""
if connection and 'postgres' in connection.vendor:
return 'uuid'
return 'char(%s)' % self.max_length
def pre_save(self, model_instance, add):
"""
This is used to ensure that we auto-set values if required.
See CharField.pre_save
"""
value = getattr(model_instance, self.attname, None)
if self.auto and add and not value:
# Assign a new value for this attribute if required.
uuid = self._create_uuid()
setattr(model_instance, self.attname, uuid)
value = uuid.hex
return value
def get_db_prep_value(self, value, connection, prepared=False):
"""
Casts uuid.UUID values into the format expected by the back end
"""
if isinstance(value, uuid.UUID):
value = str(value)
if isinstance(value, str):
if '-' in value:
value = value.replace('-', '')
uuid.UUID(value) # raises ValueError with invalid UUID format
return value
def value_to_string(self, obj):
val = self._get_val_from_obj(obj)
if val is None:
data = ''
else:
data = str(val)
return data
def to_python(self, value):
"""
Returns a ``StringUUID`` instance from the value returned by the
database. This doesn't use uuid.UUID directly for backwards
compatibility, as ``StringUUID`` implements ``__unicode__`` with
``uuid.UUID.hex()``.
"""
if not value:
return None
# attempt to parse a UUID including cases in which value is a UUID
# instance already to be able to get our StringUUID in.
return StringUUID(smart_unicode(value), hyphenate=self.hyphenate)
def formfield(self, **kwargs):
defaults = {
'form_class': forms.CharField,
'max_length': self.max_length,
}
defaults.update(kwargs)
return super(UUIDField, self).formfield(**defaults)
try:
from south.modelsinspector import add_introspection_rules
add_introspection_rules([], [r"^uuidfield\.fields\.UUIDField"])
except ImportError:
pass
|
PypiClean
|
/django_vitae-0.1.0-py3-none-any.whl/cv/models/works.py
|
from django.db import models
from django.db.models.functions import datetime
from django.urls import reverse
from django.utils.translation import ugettext_lazy as _
from .base import (VitaeModel, Collaborator, CollaborationModel,
StudentCollaborationModel)
from .managers import GrantManager
from markdown import markdown
# class InternalGrantManager(models.Manager):
# """Return grant objects for which source of funding is internal."""
# def get_queryset(self):
# return super(InternalGrantManager, self).get_queryset().filter(
# source=10
# ).filter(
# display=True
# )
# class ExternalGrantManager(models.Manager):
# """Return grant objects for which source of funding is external."""
# def get_queryset(self):
# return super(ExternalGrantManager, self).get_queryset().filter(
# source=40
# ).filter(
# display=True
# )
class Grant(VitaeModel):
"""Create instance of funded grant."""
INTERNAL = 10
EXTERNAL = 40
SOURCE = ((INTERNAL, 'Internal'),
(EXTERNAL, 'External'))
source = models.IntegerField(
_('Source'), choices=SOURCE,
help_text="Internal/external source of funding")
agency = models.CharField(
_('Agency'), max_length=200, blank=True)
agency_acronym = models.CharField(
_('Agency acronym'), max_length=20, blank=True)
division = models.CharField(
_('Division'), max_length=200, blank=True)
division_acronym = models.CharField(
_('Division acronym'), max_length=20, blank=True)
grant_number = models.CharField(
_('Grant number'), max_length=50, blank=True)
amount = models.IntegerField(_('Amount'))
start_date = models.DateField(_('Start date'))
end_date = models.DateField(
_('End date'), null=True, blank=True)
role = models.CharField(
_('Role'), max_length=50, blank=True)
is_current = models.BooleanField(
_('Is currently funded'), default=True)
abstract = models.TextField(
_('Abstract'), blank=True, null=True)
abstract_html = models.TextField(blank=True, null=True, editable=False)
collaborators = models.ManyToManyField(
Collaborator, through='GrantCollaboration', related_name="grants")
def get_pi(self):
return self.collaborators.filter(grantcollaboration__is_pi=True)
def save(self, force_insert=False, force_update=False, *args, **kwargs):
self.abstract_html = markdown(self.abstract)
super(Grant, self).save(force_insert, force_update, *args, **kwargs)
class Meta:
ordering = ['-is_current', '-start_date', '-end_date']
def __str__(self):
return self.title
objects = models.Manager()
displayable = GrantManager()
# internal_grants = InternalGrantManager()
# external_grants = ExternalGrantManager()
class GrantCollaboration(CollaborationModel):
"""Store object relating collaborators to grant."""
grant = models.ForeignKey(
Grant, related_name="collaboration", on_delete=models.PROTECT)
is_pi = models.BooleanField(
_('Is principal investigator?'), default=False)
role = models.CharField(
_('Role'), max_length=50, blank=True)
class Meta:
ordering = ['display_order']
def __str__(self):
return str(self.collaborator)
class Talk(VitaeModel):
"""Store object representing a talk."""
abstract = models.TextField(blank=True)
# article_from_talk = models.OneToOneField(
# Article, null=True, blank=True,on_delete=models.CASCADE)
collaborator = models.ManyToManyField(Collaborator, blank=True)
grants = models.ManyToManyField(Grant, blank=True)
abstract_html = models.TextField(editable=False, blank=True)
latest_presentation_date = models.DateField(
editable=False, blank=True, null=True)
created = models.DateField(auto_now_add=True, blank=True)
modified = models.DateField(auto_now=True, blank=True)
class Meta:
ordering = ['-latest_presentation_date']
def __str__(self):
return self.short_title
def save(self, force_insert=False, force_update=False, *args, **kwargs):
self.abstract_html = markdown(self.abstract)
super(Talk, self).save(force_insert, force_update, *args, **kwargs)
def get_absolute_url(self):
return reverse(
'cv:item_detail', kwargs={'model_name': 'talk', 'slug': self.slug})
def get_latest_presentation(self):
return self.presentations.all()[0]
objects = models.Manager()
class Presentation(models.Model):
"""Create an instance in which a talk was given.
This model creates separate objects for each time the same talk was given.
"""
INVITED = 10
CONFERENCE = 20
WORKSHOP = 30
KEYNOTE = 40
TYPE = ((INVITED, 'Invited'),
(CONFERENCE, 'Conference'),
(WORKSHOP, 'Workshop'),
(KEYNOTE, 'Keynote'))
talk = models.ForeignKey(
Talk, related_name='presentations', on_delete=models.CASCADE)
presentation_date = models.DateField()
type = models.IntegerField(choices=TYPE)
event = models.CharField(max_length=150)
event_acronym = models.CharField(max_length=10, blank=True)
city = models.CharField(max_length=100, blank=True, null=True)
state = models.CharField(max_length=50, blank=True, null=True)
country = models.CharField(max_length=100, blank=True, null=True)
class Meta:
ordering = ['-presentation_date']
def __str__(self):
return '%s; %s (%s %s)' % (
self.talk, self.event, self.presentation_date.month,
self.presentation_date.year)
def save(self, *args, **kwargs):
"""Save latest presentation date in related talk if instance is later
than current latest presentation date."""
try:
delta = self.presentation_date - self.talk.latest_presentation_date
assert delta < datetime.timedelta(0)
except:
self.talk.latest_presentation_date = self.presentation_date
self.talk.save()
super(Presentation, self).save(*args, **kwargs)
class OtherWriting(VitaeModel):
"""Create an instance of writing in venues other than
traditional scholarly venues.
Default ordering by ``type`` and then ``date`` in descending order.
"""
type = models.CharField(
max_length=100, blank=True,
help_text=_("Genre of writing (e.g., 'book review','op ed', "
"'blog post') that can be used for grouping contributions "
"by type."))
abstract = models.TextField(blank=True)
venue = models.CharField(max_length=200)
date = models.DateField()
pages = models.CharField(
_('Pages or section'), max_length=200, null=True, blank=True)
url = models.URLField(blank=True)
place = models.CharField(max_length=100, blank=True)
volume = models.CharField(max_length=20, blank=True)
issue = models.CharField(max_length=20, blank=True)
abstract_html = models.TextField(blank=True, editable=False)
class Meta:
"""Orders other writings in reverse chronological order."""
ordering = ['-date']
def __str__(self):
"""Returns string representation of other writing."""
return self.short_title
def save(self, force_insert=False, force_update=False, *args, **kwargs):
"""Saves abstract in html format."""
self.abstract_html = markdown(self.abstract)
super(OtherWriting, self).save(
force_insert, force_update, *args, **kwargs)
objects = models.Manager()
class Dataset(VitaeModel):
"""Stores instance representing a dataset."""
authors = models.ManyToManyField(
Collaborator, through='DatasetAuthorship', related_name='datasets')
pub_date = models.DateField(
_('Publication date'), blank=True, null=True)
version_number = models.CharField(
_('Version number'), max_length=80, blank=True)
format = models.CharField(
_('Format'), max_length=150, blank=True,
help_text=_('Form of data (e.g., \'Datafile and Codebook\''
' or \'Datafile\')')
)
producer = models.CharField(
_('Producer'), max_length=180, blank=True)
producer_place = models.CharField(
_('Producer location'), max_length=100, blank=True, null=True)
distributor = models.CharField(
_('Distributor'), max_length=180, blank=True)
distributor_place = models.CharField(
_('Distributor location'), max_length=100, blank=True, null=True)
retrieval_url = models.URLField(
_('Retrieval URL'), blank=True,
help_text=_('Used for URL linked to dataset'))
available_from_url = models.URLField(
_('Available from URL'), blank=True,
help_text=_('Used to link to a download page'))
doi = models.CharField(
_('DOI'), max_length=100, blank=True, null=True)
def get_absolute_url(self):
""""Returns reverse URL for an instance of a dataset."""
return reverse(
'cv:item_detail',
kwargs={'model_name': self._meta.model_name, 'slug': self.slug})
def __str__(self):
"""String representation of a dataset instance."""
return '%s' % self.short_title
objects = models.Manager()
class DatasetAuthorship(CollaborationModel, StudentCollaborationModel):
"""Store object relating creators of dataset to a dataset instance."""
dataset = models.ForeignKey(
Dataset, related_name="authorship", on_delete=models.CASCADE)
class Meta:
ordering = ['dataset', 'display_order']
unique_together = ('dataset', 'display_order')
|
PypiClean
|
/onnxruntime_coreml-1.13.1-cp39-cp39-macosx_11_0_universal2.whl/onnxruntime/tools/onnx_model_utils.py
|
import logging
import pathlib
import onnx
from onnx import version_converter
import onnxruntime as ort
def iterate_graph_per_node_func(graph, per_node_func, **func_args):
"""
Iterate the graph including subgraphs calling the per_node_func for each node.
:param graph: Graph to iterate
:param per_node_func: Function to call for each node. Signature is fn(node: onnx:NodeProto, **kwargs)
:param func_args: The keyword args to pass through.
"""
for node in graph.node:
per_node_func(node, **func_args)
# recurse into subgraph for control flow nodes (Scan/Loop/If)
for attr in node.attribute:
if attr.HasField("g"):
iterate_graph_per_node_func(attr.g, per_node_func, **func_args)
def iterate_graph_per_graph_func(graph, per_graph_func, **func_args):
"""
Iterate the graph including subgraphs calling the per_graph_func for each Graph.
:param graph: Graph to iterate
:param per_graph_func: Function to call for each graph. Signature is fn(graph: onnx:GraphProto, **kwargs)
:param func_args: The keyword args to pass through.
"""
per_graph_func(graph, **func_args)
for node in graph.node:
# recurse into subgraph for control flow nodes (Scan/Loop/If)
for attr in node.attribute:
if attr.HasField("g"):
iterate_graph_per_graph_func(attr.g, per_graph_func, **func_args)
def get_opsets_imported(model: onnx.ModelProto):
"""
Get the opsets imported by the model
:param model: Model to check.
:return: Map of domain to opset.
"""
opsets = {}
for entry in model.opset_import:
# if empty it's ai.onnx
domain = entry.domain or "ai.onnx"
opsets[domain] = entry.version
return opsets
def update_onnx_opset(
model_path: pathlib.Path, opset: int, out_path: pathlib.Path = None, logger: logging.Logger = None
):
"""
Helper to update the opset of a model using onnx version_converter. Target opset must be greater than current opset.
:param model_path: Path to model to update
:param opset: Opset to update model to
:param out_path: Optional output path for updated model to be saved to.
:param logger: Optional logger for diagnostic output
:returns: Updated onnx.ModelProto
"""
model_path_str = str(model_path.resolve(strict=True))
if logger:
logger.info("Updating %s to opset %d", model_path_str, opset)
model = onnx.load(model_path_str)
new_model = version_converter.convert_version(model, opset)
if out_path:
onnx.save(new_model, str(out_path))
if logger:
logger.info("Saved updated model to %s", out_path)
return new_model
def optimize_model(
model_path: pathlib.Path,
output_path: pathlib.Path,
level: ort.GraphOptimizationLevel = ort.GraphOptimizationLevel.ORT_ENABLE_BASIC,
log_level: int = 3,
):
"""
Optimize an ONNX model using ONNX Runtime to the specified level
:param model_path: Path to ONNX model
:param output_path: Path to save optimized model to.
:param level: onnxruntime.GraphOptimizationLevel to use. Default is ORT_ENABLE_BASIC.
:param log_level: Log level. Defaults to Error (3) so we don't get output about unused initializers being removed.
Warning (2) or Info (1) may be desirable in some scenarios.
"""
so = ort.SessionOptions()
so.optimized_model_filepath = str(output_path.resolve())
so.graph_optimization_level = level
so.log_severity_level = log_level
# create session to optimize. this will write the updated model to output_path
_ = ort.InferenceSession(str(model_path.resolve(strict=True)), so, providers=["CPUExecutionProvider"])
def _replace_symbolic_dim_value(graph: onnx.GraphProto, **kwargs):
param_to_replace = kwargs["dim_param"]
value = kwargs["value"]
def update_dim_values(value_infos):
for vi in value_infos:
if vi.type.HasField("tensor_type"):
shape = vi.type.tensor_type.shape
if shape:
for dim in shape.dim:
if dim.HasField("dim_param") and dim.dim_param == param_to_replace:
dim.Clear()
dim.dim_value = value
update_dim_values(graph.input)
update_dim_values(graph.output)
update_dim_values(graph.value_info)
def _remove_invalid_dim_values_impl(graph: onnx.GraphProto):
def clear_invalid_values(value):
if value.type.HasField("tensor_type"):
shape = value.type.tensor_type.shape
if shape:
for dim in shape.dim:
if dim.HasField("dim_value") and dim.dim_value < 1:
dim.Clear()
for i in graph.input:
clear_invalid_values(i)
for o in graph.output:
clear_invalid_values(o)
for vi in graph.value_info:
clear_invalid_values(vi)
def remove_invalid_dim_values(graph: onnx.GraphProto):
"""
Iterate the graph and subgraphs, unsetting any dim_value entries that have a value of less than 1.
These are typically erroneously inserted by a converter to represent a dynamic dimension.
:param graph: GraphProto to update
"""
iterate_graph_per_graph_func(graph, _remove_invalid_dim_values_impl)
def make_dim_param_fixed(graph: onnx.GraphProto, param_name: str, value: int):
"""
Iterate all values in the graph, replacing dim_param in a tensor shape with the provided value.
:param graph: GraphProto to update
:param param_name: dim_param to set
:param value: value to use
"""
iterate_graph_per_graph_func(graph, _replace_symbolic_dim_value, dim_param=param_name, value=value)
def make_input_shape_fixed(graph: onnx.GraphProto, input_name: str, fixed_shape: [int]):
"""
Update the named graph input to set shape to the provided value. This can be used to set unknown dims as well
as to replace dim values.
If setting the input shape replaces a dim_param, update any other values in the graph that use the dim_param.
:param graph: Graph to update
:param input_name: Name of graph input to update.
:param fixed_shape: Shape to use.
"""
# remove any invalid dim values first. typically this is a dim_value of -1.
remove_invalid_dim_values(graph)
for i in graph.input:
if i.name == input_name:
if not i.type.HasField("tensor_type"):
raise ValueError(f"Input {input_name} is not a tensor")
# graph inputs are required to have a shape to provide the rank
shape = i.type.tensor_type.shape
if len(shape.dim) != len(fixed_shape):
raise ValueError(f"Rank mismatch. Existing:{len(shape.dim)} Replacement:{len(fixed_shape)}")
for idx, dim in enumerate(shape.dim):
# check any existing fixed dims match
if dim.HasField("dim_value"):
if dim.dim_value != fixed_shape[idx]:
raise ValueError(
f"Can't replace existing fixed size of {dim.dim_value} with {fixed_shape[idx]} "
f"for dimension {idx + 1}"
)
elif dim.HasField("dim_param"):
# replacing a dim_param so have to do that through the entire graph
make_dim_param_fixed(graph, dim.dim_param, fixed_shape[idx])
else:
# replacing an unknown dim
dim.Clear()
dim.dim_value = fixed_shape[idx]
return
raise ValueError(
f"Input {input_name} was not found in graph inputs. "
f'Valid input names are: {",".join([i.name for i in graph.input])}'
)
def fix_output_shapes(model: onnx.ModelProto):
"""
Update the output shapesof a model where the input shape/s were made fixed, if possible.
This is mainly to make the model usage clearer if the output shapes can be inferred from the new input shapes.
:param model: Model that had input shapes fixed.
"""
# get a version of the model with shape inferencing info in it. this will provide fixed output shapes if possible.
m2 = onnx.shape_inference.infer_shapes(model)
onnx.checker.check_model(m2)
for idx, o in enumerate(model.graph.output):
if not is_fixed_size_tensor(o):
new_o = m2.graph.output[idx]
if is_fixed_size_tensor(new_o):
o.type.tensor_type.shape.CopyFrom(new_o.type.tensor_type.shape)
def _create_producer_consumer_link(
node_to_producers: dict, node_to_consumers: dict, producer: onnx.NodeProto, consumer: onnx.NodeProto
):
"""
Create links between two nodes for a value produced by one and consumed by the other.
:param node_to_producers: Map of NodeProto to set of nodes that produce values the node consumes as inputs.
:param node_to_consumers: Map of NodeProto to set of nodes that consume values the node produces as outputs.
:param producer: Producer node
:param consumer: Consumer node
"""
if consumer not in node_to_producers:
node_to_producers[consumer] = set()
if producer not in node_to_consumers:
node_to_consumers[producer] = set()
# add entry mapping this node to the producer of this input
node_to_producers[consumer].add(producer)
node_to_consumers[producer].add(consumer)
def _map_node_dependencies(graph: onnx.GraphProto, node_to_producers: dict, node_to_consumers: dict):
graph_inputs = set([i.name for i in graph.input])
initializers = set([i.name for i in graph.initializer])
# map of value name to node that creates it. copy parent values but override if values get shadowed
producers = {}
implicit_inputs = set()
def is_local_value(value):
return value in producers or value in initializers or value in graph_inputs
for node in graph.node:
inputs = [i for i in node.input]
for attr in node.attribute:
if attr.HasField("g"):
subgraph_implicit_inputs = _map_node_dependencies(attr.g, node_to_producers, node_to_consumers)
inputs += subgraph_implicit_inputs
for i in inputs:
if not i:
# missing optional input
continue
if is_local_value(i):
if i in producers:
producer = producers[i]
_create_producer_consumer_link(node_to_producers, node_to_consumers, producer, node)
else:
implicit_inputs.add(i)
for o in node.output:
producers[o] = node
return implicit_inputs
def get_producer_consumer_maps(graph: onnx.GraphProto):
"""
Get maps for connections between the node that produces each value and the nodes that consume the value.
Processing includes subgraphs. As the map key is a Node instance from the Graph there should be no ambiguity.
:param graph: Graph to process.
:return: Tuple with two maps.
First is node_to_producers map of a node to set of all nodes producing input it consumes.
Second is node_to_consumers map of a node to set of all nodes consuming output it creates.
e.g. NodeA and NodeB provide inputs to NodeC. NodeC provides input to NodeD
node_to_consumers[NodeA] = set([NodeC])
node_to_consumers[NodeB] = set([NodeC])
node_to_producers[NodeC] = set([NodeA, NodeB])
node_to_consumers[NodeC] = set([NodeD])
node_to_producers[NodeD] = set([NodeC])
"""
# use a hash of the object id for NodeProto.
# we need this for the partitioning checker where we keep maps with nodes as the key.
onnx.NodeProto.__hash__ = lambda self: id(self)
node_to_producers = {} # map of node instance to nodes producing input values it consumes
node_to_consumers = {} # map of node instance to nodes consuming output values it produces
implicit_inputs = _map_node_dependencies(graph, node_to_producers, node_to_consumers)
# top level graph should have no implicit inputs
if implicit_inputs:
raise ValueError(
"This appears to be an invalid model with missing inputs of " f'{",".join(sorted(implicit_inputs))}'
)
return node_to_producers, node_to_consumers
def is_fixed_size_tensor(value: onnx.ValueInfoProto):
"""
Check if value is a tensor with a fixed shape.
:param value: onnx.ValueInfoProto to check
:return: True if value is a tensor, with a shape, where all dimensions have fixed values.
"""
is_fixed = False
if value.type.HasField("tensor_type"):
shape = value.type.tensor_type.shape
if shape:
is_fixed = True # scalar has no dims so set to True and unset if we hit a dim without a valid value
for dim in shape.dim:
if dim.HasField("dim_value") and dim.dim_value > 0:
continue
# anything else means it's a dynamic value
is_fixed = False
break
return is_fixed
def get_optimization_level(level):
"""Convert string to GraphOptimizationLevel."""
if level == "disable":
return ort.GraphOptimizationLevel.ORT_DISABLE_ALL
if level == "basic":
# Constant folding and other optimizations that only use ONNX operators
return ort.GraphOptimizationLevel.ORT_ENABLE_BASIC
if level == "extended":
# Optimizations using custom operators, excluding NCHWc and NHWC layout optimizers
return ort.GraphOptimizationLevel.ORT_ENABLE_EXTENDED
if level == "all":
return ort.GraphOptimizationLevel.ORT_ENABLE_ALL
raise ValueError("Invalid optimization level of " + level)
|
PypiClean
|
/bisos.coreDist-0.4.tar.gz/bisos.coreDist-0.4/bisos/coreDist/thisPkg.py
|
####+BEGIN: bx:icm:python:top-of-file :partof "bystar" :copyleft "halaal+minimal"
"""
* This file:/de/bx/nne/dev-py/pypi/pkgs/bisos/coreDist/dev/bisos/coreDist/thisPkg.py :: [[elisp:(org-cycle)][| ]]
is part of The Libre-Halaal ByStar Digital Ecosystem. http://www.by-star.net
*CopyLeft* This Software is a Libre-Halaal Poly-Existential. See http://www.freeprotocols.org
A Python Interactively Command Module (PyICM). Part Of ByStar.
Best Developed With COMEEGA-Emacs And Best Used With Blee-ICM-Players.
Warning: All edits wityhin Dynamic Blocks may be lost.
"""
####+END:
"""
* [[elisp:(org-cycle)][| *Lib-Module-INFO:* |]] :: Author, Copyleft and Version Information
"""
####+BEGIN: bx:global:lib:name-py :style "fileName"
__libName__ = "thisPkg"
####+END:
####+BEGIN: bx:global:timestamp:version-py :style "date"
__version__ = "201805133132"
####+END:
####+BEGIN: bx:global:icm:status-py :status "Production"
__status__ = "Production"
####+END:
__credits__ = [""]
####+BEGIN: bx:dblock:global:file-insert-cond :cond "./blee.el" :file "/libre/ByStar/InitialTemplates/update/sw/icm/py/icmInfo-mbNedaGpl.py"
icmInfo = {
'authors': ["[[http://mohsen.1.banan.byname.net][Mohsen Banan]]"],
'copyright': "Copyright 2017, [[http://www.neda.com][Neda Communications, Inc.]]",
'licenses': ["[[https://www.gnu.org/licenses/agpl-3.0.en.html][Affero GPL]]", "Libre-Halaal Services License", "Neda Commercial License"],
'maintainers': ["[[http://mohsen.1.banan.byname.net][Mohsen Banan]]",],
'contacts': ["[[http://mohsen.1.banan.byname.net/contact]]",],
'partOf': ["[[http://www.by-star.net][Libre-Halaal ByStar Digital Ecosystem]]",]
}
####+END:
####+BEGIN: bx:icm:python:topControls
"""
* [[elisp:(org-cycle)][|/Controls/| ]] :: [[elisp:(org-show-subtree)][|=]] [[elisp:(show-all)][Show-All]] [[elisp:(org-shifttab)][Overview]] [[elisp:(progn (org-shifttab) (org-content))][Content]] | [[file:Panel.org][Panel]] | [[elisp:(blee:ppmm:org-mode-toggle)][Nat]] | [[elisp:(bx:org:run-me)][Run]] | [[elisp:(bx:org:run-me-eml)][RunEml]] | [[elisp:(delete-other-windows)][(1)]] | [[elisp:(progn (save-buffer) (kill-buffer))][S&Q]] [[elisp:(save-buffer)][Save]] [[elisp:(kill-buffer)][Quit]] [[elisp:(org-cycle)][| ]]
** /Version Control/ :: [[elisp:(call-interactively (quote cvs-update))][cvs-update]] [[elisp:(vc-update)][vc-update]] | [[elisp:(bx:org:agenda:this-file-otherWin)][Agenda-List]] [[elisp:(bx:org:todo:this-file-otherWin)][ToDo-List]]
"""
####+END:
"""
*
####+BEGIN: bx:dblock:global:file-insert-cond :cond "./blee.el" :file "/libre/ByStar/InitialTemplates/software/plusOrg/dblock/inserts/pythonWb.org"
* /Python Workbench/ :: [[elisp:(org-cycle)][| ]] [[elisp:(python-check (format "pyclbr %s" (bx:buf-fname))))][pyclbr]] || [[elisp:(python-check (format "pyflakes %s" (bx:buf-fname)))][pyflakes]] | [[elisp:(python-check (format "pychecker %s" (bx:buf-fname))))][pychecker (executes)]] | [[elisp:(python-check (format "pep8 %s" (bx:buf-fname))))][pep8]] | [[elisp:(python-check (format "flake8 %s" (bx:buf-fname))))][flake8]] | [[elisp:(python-check (format "pylint %s" (bx:buf-fname))))][pylint]] [[elisp:(org-cycle)][| ]]
####+END:
"""
####+BEGIN: bx:icm:python:section :title "ContentsList"
"""
* [[elisp:(beginning-of-buffer)][Top]] ################ [[elisp:(blee:ppmm:org-mode-toggle)][Nat]] [[elisp:(delete-other-windows)][(1)]] *ContentsList* [[elisp:(org-cycle)][| ]] [[elisp:(org-show-subtree)][|=]]
"""
####+END:
####+BEGIN: bx:dblock:python:icmItem :itemType "=Imports=" :itemTitle "*IMPORTS*"
"""
* [[elisp:(org-cycle)][| ]] [[elisp:(org-show-subtree)][|=]] [[elisp:(show-children)][|V]] [[elisp:(org-tree-to-indirect-buffer)][|>]] [[elisp:(blee:ppmm:org-mode-toggle)][Nat]] [[elisp:(beginning-of-buffer)][Top]] [[elisp:(delete-other-windows)][(1)]] || =Imports= :: *IMPORTS* [[elisp:(org-cycle)][| ]]
"""
####+END:
import os
import collections
import enum
# NOTYET, should become a dblock with its own subItem
from unisos import ucf
from unisos import icm
G = icm.IcmGlobalContext()
G.icmLibsAppend = __file__
G.icmCmndsLibsAppend = __file__
# NOTYET DBLOCK Ends -- Rest of bisos libs follow;
####+BEGIN: bx:dblock:python:section :title "Library Description (Overview)"
"""
* [[elisp:(beginning-of-buffer)][Top]] ################ [[elisp:(blee:ppmm:org-mode-toggle)][Nat]] [[elisp:(delete-other-windows)][(1)]] *Library Description (Overview)* [[elisp:(org-cycle)][| ]] [[elisp:(org-show-subtree)][|=]]
"""
####+END:
####+BEGIN: bx:icm:python:cmnd:classHead :cmndName "thisPkg_LibOverview" :parsMand "" :parsOpt "" :argsMin "0" :argsMax "3" :asFunc "" :interactiveP ""
"""
* [[elisp:(org-cycle)][| ]] [[elisp:(org-show-subtree)][|=]] [[elisp:(show-children)][|V]] [[elisp:(org-tree-to-indirect-buffer)][|>]] [[elisp:(blee:ppmm:org-mode-toggle)][Nat]] [[elisp:(beginning-of-buffer)][Top]] [[elisp:(delete-other-windows)][(1)]] || ICM-Cmnd :: /thisPkg_LibOverview/ parsMand= parsOpt= argsMin=0 argsMax=3 asFunc= interactive= [[elisp:(org-cycle)][| ]]
"""
class thisPkg_LibOverview(icm.Cmnd):
cmndParamsMandatory = [ ]
cmndParamsOptional = [ ]
cmndArgsLen = {'Min': 0, 'Max': 3,}
@icm.subjectToTracking(fnLoc=True, fnEntry=True, fnExit=True)
def cmnd(self,
interactive=False, # Can also be called non-interactively
argsList=None, # or Args-Input
):
cmndOutcome = self.getOpOutcome()
if interactive:
if not self.cmndLineValidate(outcome=cmndOutcome):
return cmndOutcome
effectiveArgsList = G.icmRunArgsGet().cmndArgs
else:
effectiveArgsList = argsList
callParamsDict = {}
if not icm.cmndCallParamsValidate(callParamsDict, interactive, outcome=cmndOutcome):
return cmndOutcome
####+END:
moduleDescription="""
* [[elisp:(org-show-subtree)][|=]] [[elisp:(org-cycle)][| *Description:* | ]]
** [[elisp:(org-cycle)][| ]] [Xref] :: *[Related/Xrefs:]* <<Xref-Here->> -- External Documents [[elisp:(org-cycle)][| ]]
** [[elisp:(org-cycle)][| ]] Model and Terminology :Overview:
This module is part of BISOS and its primary documentation is in http://www.by-star.net/PLPC/180047
** [End-Of-Description]
"""
moduleUsage="""
* [[elisp:(org-show-subtree)][|=]] [[elisp:(org-cycle)][| *Usage:* | ]]
** How-Tos:
** [End-Of-Usage]
"""
moduleStatus="""
* [[elisp:(org-show-subtree)][|=]] [[elisp:(org-cycle)][| *Status:* | ]]
** [[elisp:(org-cycle)][| ]] [Info] :: *[Current-Info:]* Status/Maintenance -- General TODO List [[elisp:(org-cycle)][| ]]
** TODO [[elisp:(org-cycle)][| ]] Current :: Just getting started [[elisp:(org-cycle)][| ]]
** [End-Of-Status]
"""
cmndArgsSpec = {"0&-1": ['moduleDescription', 'moduleUsage', 'moduleStatus']}
cmndArgsValid = cmndArgsSpec["0&-1"]
for each in effectiveArgsList:
if each in cmndArgsValid:
print(each)
if interactive:
#print( str( __doc__ ) ) # This is the Summary: from the top doc-string
#version(interactive=True)
exec("""print({})""".format(each))
return(format(str(__doc__)+moduleDescription))
####+BEGIN: bx:icm:python:func :funcName "examples_icmBasic" :funcType "void" :retType "bool" :deco "" :argsList ""
"""
* [[elisp:(org-cycle)][| ]] [[elisp:(org-show-subtree)][|=]] [[elisp:(show-children)][|V]] [[elisp:(org-tree-to-indirect-buffer)][|>]] [[elisp:(blee:ppmm:org-mode-toggle)][Nat]] [[elisp:(beginning-of-buffer)][Top]] [[elisp:(delete-other-windows)][(1)]] || Func-void :: /examples_icmBasic/ retType=bool argsList=nil [[elisp:(org-cycle)][| ]]
"""
def examples_icmBasic():
####+END:
"""
** Auxiliary examples to be commonly used.
"""
icm.cmndExampleMenuChapter(' =PkgBase= *PkgBase Get Dirs*')
cmndName = "pkgBase" ; cmndArgs = "configDir" ;
cps = collections.OrderedDict() ;
icm.ex_gCmndMenuItem(cmndName, cps, cmndArgs, verbosity='little')
cmndName = "pkgBase" ; cmndArgs = "rootDir" ;
cps = collections.OrderedDict() ;
icm.ex_gCmndMenuItem(cmndName, cps, cmndArgs, verbosity='little')
####+BEGIN: bx:icm:python:cmnd:classHead :cmndName "pkgBase" :comment "" :parsMand "" :parsOpt "" :argsMin "1" :argsMax "1" :asFunc "" :interactiveP ""
"""
* [[elisp:(org-cycle)][| ]] [[elisp:(org-show-subtree)][|=]] [[elisp:(show-children)][|V]] [[elisp:(org-tree-to-indirect-buffer)][|>]] [[elisp:(blee:ppmm:org-mode-toggle)][Nat]] [[elisp:(beginning-of-buffer)][Top]] [[elisp:(delete-other-windows)][(1)]] || ICM-Cmnd :: /pkgBase/ parsMand= parsOpt= argsMin=1 argsMax=1 asFunc= interactive= [[elisp:(org-cycle)][| ]]
"""
class pkgBase(icm.Cmnd):
cmndParamsMandatory = [ ]
cmndParamsOptional = [ ]
cmndArgsLen = {'Min': 1, 'Max': 1,}
@icm.subjectToTracking(fnLoc=True, fnEntry=True, fnExit=True)
def cmnd(self,
interactive=False, # Can also be called non-interactively
argsList=None, # or Args-Input
):
cmndOutcome = self.getOpOutcome()
if interactive:
if not self.cmndLineValidate(outcome=cmndOutcome):
return cmndOutcome
effectiveArgsList = G.icmRunArgsGet().cmndArgs
else:
effectiveArgsList = argsList
callParamsDict = {}
if not icm.cmndCallParamsValidate(callParamsDict, interactive, outcome=cmndOutcome):
return cmndOutcome
####+END:
arg1 = effectiveArgsList[0]
def processArg(arg):
result=""
if arg == "configDir":
result = pkgBase_configDir()
elif arg == "rootDir":
result = pkgBase_rootDir()
else:
result = ""
print(result)
return cmndOutcome.set(
opError=icm.OpError.Success,
opResults=processArg(arg1),
)
def cmndDocStr(self): return """
** Place holder for this commands doc string. [[elisp:(org-cycle)][| ]]
"""
####+BEGIN: bx:dblock:python:section :title "Support Functions For MsgProcs"
"""
* [[elisp:(beginning-of-buffer)][Top]] ################ [[elisp:(blee:ppmm:org-mode-toggle)][Nat]] [[elisp:(delete-other-windows)][(1)]] *Support Functions For MsgProcs* [[elisp:(org-cycle)][| ]] [[elisp:(org-show-subtree)][|=]]
"""
####+END:
####+BEGIN: bx:icm:python:func :funcName "pkgBase_configDir" :funcType "anyOrNone" :retType "bool" :deco "" :argsList ""
"""
* [[elisp:(org-cycle)][| ]] [[elisp:(org-show-subtree)][|=]] [[elisp:(show-children)][|V]] [[elisp:(org-tree-to-indirect-buffer)][|>]] [[elisp:(blee:ppmm:org-mode-toggle)][Nat]] [[elisp:(beginning-of-buffer)][Top]] [[elisp:(delete-other-windows)][(1)]] || Func-anyOrNone :: /pkgBase_configDir/ retType=bool argsList=nil [[elisp:(org-cycle)][| ]]
"""
def pkgBase_configDir():
####+END:
"""
** Return the icmsPkg's base data directory
"""
icmsModulePath = os.path.dirname(__file__)
icmsPkgBaseDir = "{}-config".format(icmsModulePath)
return icmsPkgBaseDir
####+BEGIN: bx:icm:python:func :funcName "pkgBase_rootDir" :funcType "anyOrNone" :retType "bool" :deco "" :argsList ""
"""
* [[elisp:(org-cycle)][| ]] [[elisp:(org-show-subtree)][|=]] [[elisp:(show-children)][|V]] [[elisp:(org-tree-to-indirect-buffer)][|>]] [[elisp:(blee:ppmm:org-mode-toggle)][Nat]] [[elisp:(beginning-of-buffer)][Top]] [[elisp:(delete-other-windows)][(1)]] || Func-anyOrNone :: /pkgBase_rootDir/ retType=bool argsList=nil [[elisp:(org-cycle)][| ]]
"""
def pkgBase_rootDir():
####+END:
"""
** Return the icmsPkg's base data directory
"""
icmsModulePath = os.path.dirname(__file__)
icmsPkgBaseDir = "{}-root".format(icmsModulePath)
return icmsPkgBaseDir
####+BEGIN: bx:icm:python:section :title "End Of Editable Text"
"""
* [[elisp:(beginning-of-buffer)][Top]] ################ [[elisp:(blee:ppmm:org-mode-toggle)][Nat]] [[elisp:(delete-other-windows)][(1)]] *End Of Editable Text* [[elisp:(org-cycle)][| ]] [[elisp:(org-show-subtree)][|=]]
"""
####+END:
####+BEGIN: bx:dblock:global:file-insert-cond :cond "./blee.el" :file "/libre/ByStar/InitialTemplates/software/plusOrg/dblock/inserts/endOfFileControls.org"
#+STARTUP: showall
####+END:
|
PypiClean
|
/nemo_nlp-0.9.0.tar.gz/nemo_nlp-0.9.0/nemo_nlp/utils/callbacks/glue.py
|
__all__ = ['eval_iter_callback', 'eval_epochs_done_callback']
import os
import random
import numpy as np
from scipy.stats import pearsonr, spearmanr
from sklearn.metrics import matthews_corrcoef, f1_score
from nemo.utils.exp_logging import get_logger
logger = get_logger('')
def eval_iter_callback(tensors, global_vars):
if "all_preds" not in global_vars.keys():
global_vars["all_preds"] = []
if "all_labels" not in global_vars.keys():
global_vars["all_labels"] = []
logits_lists = []
preds_lists = []
labels_lists = []
for kv, v in tensors.items():
# for GLUE classification tasks
if 'logits' in kv:
for v_tensor in v:
for logit_tensor in v_tensor:
logits_lists.append(logit_tensor.detach().cpu().tolist())
# for GLUE STS-B task (regression)
elif 'preds' in kv:
for v_tensor in v:
for pred_tensor in v_tensor:
preds_lists.append(pred_tensor.detach().cpu().tolist())
if 'labels' in kv:
for v_tensor in v:
for label_tensor in v_tensor:
labels_lists.append(label_tensor.detach().cpu().tolist())
if len(logits_lists) > 0:
preds = list(np.argmax(np.asarray(logits_lists), 1))
elif len(preds_lists) > 0:
preds = list(np.squeeze(np.asarray(preds_lists)))
global_vars["all_preds"].extend(preds)
global_vars["all_labels"].extend(labels_lists)
def list2str(l):
return ' '.join([str(j) for j in l])
def eval_epochs_done_callback(global_vars, output_dir, task_name):
labels = np.asarray(global_vars['all_labels'])
preds = np.asarray(global_vars['all_preds'])
i = 0
if preds.shape[0] > 21:
i = random.randint(0, preds.shape[0] - 21)
logger.info("Task name: %s" % task_name.upper())
logger.info("Sampled preds: [%s]" % list2str(preds[i:i+20]))
logger.info("Sampled labels: [%s]" % list2str(labels[i:i+20]))
results = compute_metrics(task_name, preds, labels)
os.makedirs(output_dir, exist_ok=True)
with open(os.path.join(output_dir, task_name + '.txt'), 'w') as f:
f.write('labels\t' + list2str(labels) + '\n')
f.write('preds\t' + list2str(preds) + '\n')
logger.info(results)
return results
def accuracy(preds, labels):
return {"acc": (preds == labels).mean()}
def acc_and_f1(preds, labels):
accuracy = (preds == labels).mean()
f1 = f1_score(y_true=labels, y_pred=preds)
return {"acc": accuracy,
"f1": f1,
"acc_and_f1": (accuracy + f1) / 2}
def mcc(preds, labels):
return {"mcc": matthews_corrcoef(labels, preds)}
def pearson_and_spearman(preds, labels):
pearson_corr = pearsonr(preds, labels)[0]
spearman_corr = spearmanr(preds, labels)[0]
return {"pearson": pearson_corr,
"spearmanr": spearman_corr,
"corr": (pearson_corr + spearman_corr) / 2}
def compute_metrics(task_name, preds, labels):
if len(preds) != len(labels):
raise ValueError("Predictions and labels must have the same lenght")
metric_fn = accuracy
if task_name == 'cola':
metric_fn = mcc
elif task_name in ['mrpc', 'qqp']:
metric_fn = acc_and_f1
elif task_name == 'sts-b':
metric_fn = pearson_and_spearman
return metric_fn(preds, labels)
|
PypiClean
|
/odoo12_addon_mgmtsystem_audit-12.0.1.0.1-py3-none-any.whl/odoo/addons/mgmtsystem_audit/readme/CONTRIBUTORS.rst
|
* Daniel Reis <[email protected]>
* Joao Alfredo Gama Batista <[email protected]>
* Maxime Chambreuil <[email protected]>
* Sandy Carter <[email protected]>
* Virgil Dupras <[email protected]>
* Loïc lacroix <[email protected]>
* Gervais Naoussi <[email protected]>
* Luk Vermeylen <[email protected]>
* Maxime Chambreuil <[email protected]>
* Eugen Don <[email protected]>
* `Tecnativa <https://www.tecnativa.com>`_:
* Ernesto Tejeda
|
PypiClean
|
/kentoml-1.0.20.post10-py3-none-any.whl/bentoml/_internal/runner/utils.py
|
from __future__ import annotations
import typing as t
import logging
import itertools
from typing import TYPE_CHECKING
from bentoml.exceptions import InvalidArgument
logger = logging.getLogger(__name__)
if TYPE_CHECKING:
from ..runner.container import Payload
T = t.TypeVar("T")
To = t.TypeVar("To")
Ti = t.TypeVar("Ti")
CUDA_SUCCESS = 0
def pass_through(i: T) -> T:
return i
class Params(t.Generic[T]):
"""
A container for */** parameters. It helps to perform an operation on all the params
values at the same time.
"""
args: tuple[T, ...]
kwargs: dict[str, T]
def __init__(self, *args: T, **kwargs: T):
self.args = args
self.kwargs = kwargs
def items(self) -> t.Iterator[t.Tuple[t.Union[int, str], T]]:
return itertools.chain(enumerate(self.args), self.kwargs.items())
@classmethod
def from_dict(cls, data: dict[str | int, T]) -> Params[T]:
return cls(
*(data[k] for k in sorted(k for k in data if isinstance(k, int))),
**{k: v for k, v in data.items() if isinstance(k, str)},
)
def all_equal(self) -> bool:
value_iter = iter(self.items())
_, first = next(value_iter)
return all(v == first for _, v in value_iter)
def map(self, function: t.Callable[[T], To]) -> Params[To]:
"""
Apply a function to all the values in the Params and return a Params of the
return values.
"""
args = tuple(function(a) for a in self.args)
kwargs = {k: function(v) for k, v in self.kwargs.items()}
return Params[To](*args, **kwargs)
def map_enumerate(
self, function: t.Callable[[T, Ti], To], iterable: t.Iterable[Ti]
) -> Params[To]:
"""
Apply function that takes two arguments with given iterable as index to all none empty field in Params.
"""
if self.args:
return Params[To](
*tuple(function(a, b) for a, b in zip(self.args, iterable))
)
return Params[To](
**{k: function(self.kwargs[k], b) for k, b in zip(self.kwargs, iterable)}
)
def iter(self: Params[tuple[t.Any, ...]]) -> t.Iterator[Params[t.Any]]:
"""
Iter over a Params of iterable values into a list of Params. All values should
have the same length.
"""
iter_params = self.map(iter)
try:
while True:
args = tuple(next(a) for a in iter_params.args)
kwargs = {k: next(v) for k, v in iter_params.kwargs.items()}
yield Params[To](*args, **kwargs)
except StopIteration:
pass
@classmethod
def agg(
cls,
params_list: t.Sequence[Params[T]],
agg_func: t.Callable[[t.Sequence[T]], To] = pass_through,
) -> Params[To]:
"""
Aggregate a list of Params into a single Params by performing the aggregate
function on the list of values at the same position.
"""
if not params_list:
return Params()
args = tuple(
agg_func(tuple(params.args[i] for params in params_list))
for i, _ in enumerate(params_list[0].args)
)
kwargs = {
k: agg_func(tuple(params.kwargs[k] for params in params_list))
for k in params_list[0].kwargs
}
return Params(*args, **kwargs)
@property
def sample(self) -> T:
"""
Return a sample value (the first value of args or kwargs if args is empty)
of the Params.
"""
if self.args:
return self.args[0]
return next(iter(self.kwargs.values()))
PAYLOAD_META_HEADER = "Bento-Payload-Meta"
def payload_paramss_to_batch_params(
paramss: t.Sequence[Params[Payload]],
batch_dim: int,
# TODO: support mapping from arg to batch dimension
) -> tuple[Params[t.Any], list[int]]:
from ..runner.container import AutoContainer
_converted_params = Params.agg(
paramss,
agg_func=lambda i: AutoContainer.from_batch_payloads(
i,
batch_dim=batch_dim,
),
).iter()
batched_params = next(_converted_params)
indice_params: Params[list[int]] = next(_converted_params)
# considering skip this check if the CPU overhead of each inference is too high
if not indice_params.all_equal():
raise InvalidArgument(
f"argument lengths for parameters do not matchs: {tuple(indice_params.items())}"
)
return batched_params, indice_params.sample
|
PypiClean
|
/azure_mgmt_storage-21.1.0-py3-none-any.whl/azure/mgmt/storage/v2017_10_01/_storage_management.py
|
from copy import deepcopy
from typing import Any, TYPE_CHECKING
from azure.core.rest import HttpRequest, HttpResponse
from azure.mgmt.core import ARMPipelineClient
from . import models as _models
from .._serialization import Deserializer, Serializer
from ._configuration import StorageManagementConfiguration
from .operations import Operations, SkusOperations, StorageAccountsOperations, UsageOperations
if TYPE_CHECKING:
# pylint: disable=unused-import,ungrouped-imports
from azure.core.credentials import TokenCredential
class StorageManagement: # pylint: disable=client-accepts-api-version-keyword
"""The Azure Storage Management API.
:ivar operations: Operations operations
:vartype operations: azure.mgmt.storage.v2017_10_01.operations.Operations
:ivar skus: SkusOperations operations
:vartype skus: azure.mgmt.storage.v2017_10_01.operations.SkusOperations
:ivar storage_accounts: StorageAccountsOperations operations
:vartype storage_accounts: azure.mgmt.storage.v2017_10_01.operations.StorageAccountsOperations
:ivar usage: UsageOperations operations
:vartype usage: azure.mgmt.storage.v2017_10_01.operations.UsageOperations
:param credential: Credential needed for the client to connect to Azure. Required.
:type credential: ~azure.core.credentials.TokenCredential
:param subscription_id: Gets subscription credentials which uniquely identify the Microsoft
Azure subscription. The subscription ID forms part of the URI for every service call. Required.
:type subscription_id: str
:param base_url: Service URL. Default value is "https://management.azure.com".
:type base_url: str
:keyword api_version: Api Version. Default value is "2017-10-01". Note that overriding this
default value may result in unsupported behavior.
:paramtype api_version: str
:keyword int polling_interval: Default waiting time between two polls for LRO operations if no
Retry-After header is present.
"""
def __init__(
self,
credential: "TokenCredential",
subscription_id: str,
base_url: str = "https://management.azure.com",
**kwargs: Any
) -> None:
self._config = StorageManagementConfiguration(credential=credential, subscription_id=subscription_id, **kwargs)
self._client: ARMPipelineClient = ARMPipelineClient(base_url=base_url, config=self._config, **kwargs)
client_models = {k: v for k, v in _models.__dict__.items() if isinstance(v, type)}
self._serialize = Serializer(client_models)
self._deserialize = Deserializer(client_models)
self._serialize.client_side_validation = False
self.operations = Operations(self._client, self._config, self._serialize, self._deserialize, "2017-10-01")
self.skus = SkusOperations(self._client, self._config, self._serialize, self._deserialize, "2017-10-01")
self.storage_accounts = StorageAccountsOperations(
self._client, self._config, self._serialize, self._deserialize, "2017-10-01"
)
self.usage = UsageOperations(self._client, self._config, self._serialize, self._deserialize, "2017-10-01")
def _send_request(self, request: HttpRequest, **kwargs: Any) -> HttpResponse:
"""Runs the network request through the client's chained policies.
>>> from azure.core.rest import HttpRequest
>>> request = HttpRequest("GET", "https://www.example.org/")
<HttpRequest [GET], url: 'https://www.example.org/'>
>>> response = client._send_request(request)
<HttpResponse: 200 OK>
For more information on this code flow, see https://aka.ms/azsdk/dpcodegen/python/send_request
:param request: The network request you want to make. Required.
:type request: ~azure.core.rest.HttpRequest
:keyword bool stream: Whether the response payload will be streamed. Defaults to False.
:return: The response of your network call. Does not do error handling on your response.
:rtype: ~azure.core.rest.HttpResponse
"""
request_copy = deepcopy(request)
request_copy.url = self._client.format_url(request_copy.url)
return self._client.send_request(request_copy, **kwargs)
def close(self) -> None:
self._client.close()
def __enter__(self) -> "StorageManagement":
self._client.__enter__()
return self
def __exit__(self, *exc_details: Any) -> None:
self._client.__exit__(*exc_details)
|
PypiClean
|
/continual_learning-0.1.6.6.tar.gz/continual_learning-0.1.6.6/continual_learning/scenarios/supervised/task_incremental/single_incremental_task.py
|
from typing import Union, List
import numpy as np
from continual_learning.datasets.base import SupervisedDataset, DatasetSplits
from continual_learning.scenarios.base import IncrementalSupervisedProblem
from continual_learning.scenarios.tasks import SupervisedTask
from continual_learning.scenarios.supervised.utils import get_labels_set
class SingleIncrementalTask(IncrementalSupervisedProblem):
#TODO: Implementare test
def generate_tasks(self,
dataset: SupervisedDataset,
labels_per_task: int,
shuffle_labels: bool = False,
random_state: Union[np.random.RandomState, int] = None,
**kwargs) -> List[SupervisedTask]:
labels = dataset.labels
labels_sets = get_labels_set(labels,
labels_per_set=labels_per_task,
shuffle_labels=shuffle_labels,
random_state=random_state)
labels_map = np.zeros(len(labels), dtype=int)
offset = 0
for i in labels_sets:
for j in range(len(i)):
labels_map[i[j]] = j + offset
offset += len(i)
tasks = []
for task_labels in labels_sets:
lm = {i: labels_map[i] for i in task_labels}
train_indexes = np.arange(len(dataset.get_indexes(DatasetSplits.TRAIN)))[
np.in1d(dataset.y(DatasetSplits.TRAIN), task_labels)]
test_indexes = np.arange(len(dataset.get_indexes(DatasetSplits.TEST)))[
np.in1d(dataset.y(DatasetSplits.TEST), task_labels)]
dev_indexes = np.arange(len(dataset.get_indexes(DatasetSplits.DEV)))[
np.in1d(dataset.y(DatasetSplits.DEV), task_labels)]
task = SupervisedTask(base_dataset=dataset, train=train_indexes, test=test_indexes, dev=dev_indexes,
labels_mapping=lm, index=len(tasks))
tasks.append(task)
return tasks
|
PypiClean
|
/invenio-records-lom-0.11.1.tar.gz/invenio-records-lom-0.11.1/invenio_records_lom/ui/theme/assets/semantic-ui/js/invenio_records_lom/deposit/serializers.js
|
import _cloneDeep from "lodash/cloneDeep";
import _get from "lodash/get";
import _groupBy from "lodash/groupBy";
import _pick from "lodash/pick";
import _set from "lodash/set";
import _sortBy from "lodash/sortBy";
import { DepositRecordSerializer } from "react-invenio-deposit";
// TODO: move `debug` to debug.js
const debug = (obj) => alert(JSON.stringify(obj, null, 2));
export class LOMDepositRecordSerializer extends DepositRecordSerializer {
constructor(locale, vocabularies) {
super();
this.locale = locale;
this.vocabularies = vocabularies;
}
deserializeOefos(recordToDeserialize) {
const oefosClassification = _get(
recordToDeserialize,
"metadata.classification",
[]
).find(
(classification) =>
_get(classification, "purpose.value.langstring.#text") === "discipline"
);
if (!oefosClassification) {
_set(recordToDeserialize, "metadata.form.oefos", []);
return;
}
let oefosIds = [];
for (const taxonpath of _get(oefosClassification, "taxonpath", [])) {
for (const taxon of _get(taxonpath, "taxon", [])) {
const match =
/https:\/\/w3id.org\/oerbase\/vocabs\/oefos2012\/(\d+)/.exec(
taxon.id || ""
);
if (match) {
const id = match[1];
if (!oefosIds.includes(id)) {
oefosIds.push(id);
}
}
}
}
// this sorts lexigraphically, not numerically
oefosIds.sort();
_set(
recordToDeserialize,
"metadata.form.oefos",
oefosIds.map((oefosId) => ({ value: oefosId }))
);
}
serializeRemoveKeys(recordToSerialize, path = "metadata") {
// remove `__key`
const value = _get(recordToSerialize, path);
if (typeof value === "object" && value !== null) {
const valueIsArray = Array.isArray(value);
for (const [key, subValue] of Object.entries(value)) {
if (valueIsArray) {
delete subValue.__key;
}
this.serializeRemoveKeys(recordToSerialize, `${path}.${key}`);
}
}
}
serializeContributor(recordToSerialize) {
// contributes need be grouped by role
// of form [ {role: {value: <role:str>}, name: <name:str>}, ... ]
const metadata = recordToSerialize?.metadata || {};
const formContributors = _get(metadata, "form.contributor", []);
const groupedContributors = _groupBy(formContributors, "role.value");
const metadataContributors = Object.entries(groupedContributors).map(
([role, contributorList]) => {
// _groupBy converts role.value to string, unchosen role becomes "undefined"
role = role !== "undefined" ? role : "";
return {
role: {
source: { langstring: { "#text": "LOMv1.0", lang: "x-none" } },
value: { langstring: { "#text": role || "", lang: "x-none" } },
},
entity: contributorList.map(({ name }) => name || ""),
};
}
);
_set(metadata, "lifecycle.contribute", metadataContributors);
}
serializeOefos(recordToSerialize) {
// convert `metadata.oefos` to a `metadata.classification` of purpose `discipline`
// find oefos-values that aren't prefix to other oefos-values
const metadata = recordToSerialize.metadata || {};
const frontendOefos = _get(metadata, "form.oefos", []);
const oefosValues = frontendOefos
.filter((valueDict) => valueDict.value)
.map((valueDict) => String(valueDict.value));
const sortedOefosValues = _sortBy(
oefosValues,
(key) => -key.length, // sort longest first
(key) => key // for equal length, sort lower numbers first
);
let longestOefosValues = [];
for (const value of sortedOefosValues) {
if (!longestOefosValues.some((longest) => longest.startsWith(value))) {
longestOefosValues.push(value);
}
}
longestOefosValues.sort();
// guarantee existence of metadata.classification
if (!metadata.classification) {
metadata.classification = [];
}
// filter out classification that previously held oefos, if any
metadata.classification = metadata.classification.filter(
(classification) =>
!(
_get(classification, "purpose.value.langstring.#text") ===
"discipline"
)
);
// create oefos-classification
let oefosClassification = {
purpose: {
source: { langstring: { lang: "x-none", "#text": "LOMv1.0" } },
value: { langstring: { lang: "x-none", "#text": "discipline" } },
},
taxonpath: [],
};
// append one taxonpath per longest oefos-value
for (const value of longestOefosValues) {
// if value === "2074", path is ["2", "207", "2074"]
const path = [1, 3, 4, 6]
.filter((len) => len <= value.length)
.map((len) => value.slice(0, len));
oefosClassification.taxonpath.push({
source: {
langstring: {
lang: "x-none",
"#text": "https://w3id.org/oerbase/vocabs/oefos2012",
},
},
taxon: path.map((oefosId) => ({
id: `https://w3id.org/oerbase/vocabs/oefos2012/${oefosId}`,
entry: {
langstring: {
// no `lang`, as per LOM-UIBK
"#text": _get(this.vocabularies.oefos, oefosId).value,
},
},
})),
});
}
// prepend oefos-classification
metadata.classification.unshift(oefosClassification);
}
// backend->frontend
deserialize(record) {
// remove information for internal workings of database
record = _pick(_cloneDeep(record), [
"access",
"custom_fields",
"expanded",
"files",
"id",
"is_published",
"links",
"metadata",
"parent",
"pids",
"resource_type",
"status",
"ui",
"versions",
]);
// initialize; data relevant to upload-form is stored in `metadata.form`
if (!record.metadata) {
record.metadata = {};
}
const metadata = record.metadata;
metadata.form = {};
const form = metadata.form;
// deserialize title
form.title = _get(metadata, "general.title.langstring.#text", "");
// deserialize license
form.license = { value: _get(metadata, "rights.url", "") };
// deserialize format
form.format = { value: _get(metadata, "technical.format.0", "") };
// deserialize resource-type
form.resourcetype = {
value: _get(metadata, "educational.learningresourcetype.id", ""),
};
// deserialize contributors
const validRoles = Object.keys(_get(this, "vocabularies.contributor", []));
form.contributor = [];
for (const contribute of _get(metadata, "lifecycle.contribute", [])) {
let role = _get(contribute, "role.value.langstring.#text", "");
role = validRoles.includes(role) ? role : "";
for (const name of contribute.entity || []) {
form.contributor.push({ role: { value: role }, name });
}
}
// deserialize oefos
this.deserializeOefos(record);
// deserialize description
form.description = _get(
metadata,
"general.description.0.langstring.#text",
""
);
// deserialize tags
const tagLangstringObjects = _get(metadata, "general.keyword", []);
form.tag = tagLangstringObjects.map((langstringObject) => ({
value: _get(langstringObject, "langstring.#text", ""),
}));
// deserialize language
form.language = { value: _get(metadata, "general.language.0", "") };
return record;
}
// frontend->backend
serialize(record) {
const recordToSerialize = _pick(_cloneDeep(record), [
"access",
"custom_fields",
// exclude `expanded`
"files",
"id",
// exclude `is_published`
"links",
"metadata", // contains `form` for now, excluded later
"parent",
"pids",
"resource_type",
// exclude `status`
// exclude `versions`
]);
const metadata = recordToSerialize.metadata || {};
// remove `__key` from array-items
this.serializeRemoveKeys(recordToSerialize);
// serialize title
_set(metadata, "general.title", {
langstring: {
"#text": _get(metadata, "form.title", ""),
lang: this.locale,
},
});
// serialize license
const licenseUrl = _get(metadata, "form.license.value", "");
_set(metadata, "rights", {
copyrightandotherrestrictions: {
source: { langstring: { "#text": "LOMv1.0", lang: "x-none" } },
value: { langstring: { "#text": "yes", lang: "x-none" } },
},
url: licenseUrl,
description: {
langstring: {
"#text": licenseUrl,
lang: "x-t-cc-url",
},
},
});
// serialize format
const format = _get(metadata, "form.format.value", "");
_set(metadata, "technical.format.0", format);
// set location
_set(
metadata,
"technical.location.#text",
_get(recordToSerialize, "links.record_html", "")
);
// serialize resource-type
const resourcetypeUrl = _get(metadata, "form.resourcetype.value");
_set(metadata, "educational.learningresourcetype", {
source: {
langstring: {
"#text": "https://w3id.org/kim/hcrt/scheme",
lang: "x-none",
},
},
id: resourcetypeUrl,
});
// serialize contributors
this.serializeContributor(recordToSerialize);
// serialize oefos
this.serializeOefos(recordToSerialize);
// serialize description
const description = metadata?.form?.description || "";
if (description) {
_set(metadata, "general.description.0", {
langstring: { "#text": description, lang: this.locale },
});
} else {
_set(metadata, "general.description", []);
}
// serialize tags
const tags = metadata?.form?.tag || [];
_set(
metadata,
"general.keyword",
tags
.filter(({ value }) => value)
.map(({ value }) => ({
langstring: { "#text": value, lang: this.locale },
}))
);
// serialize language
const language = metadata?.form?.language?.value || "";
if (language) {
_set(metadata, "general.language.0", language);
} else {
_set(metadata, "general.language", []);
}
delete metadata.form;
return recordToSerialize;
}
// backend->frontend
deserializeErrors(errors) {
let deserializedErrors = {};
// [{field: .., messages: ..}] ~> {field: messages.join(" ")}
for (const e of errors) {
_set(deserializedErrors, e.field, e.messages.join(" "));
}
// utility to set errors matching a regexp to `metadata.form`
const set_errors = (regexp, target_key) => {
const errorMessage = errors
.filter(({ field }) => regexp.test(field))
.flatMap(({ messages }) => messages || [])
.join(" ");
if (errorMessage) {
_set(deserializedErrors, `metadata.form.${target_key}`, errorMessage);
}
};
// set single-field errors
set_errors(/^metadata\.general\.title$/, "title");
set_errors(/^metadata\.rights/, "license.value");
set_errors(/^metadata\.technical\.format/, "format.value");
set_errors(
/^metadata\.educational\.learningresourcetype\.id$/,
"resourcetype.value"
);
// set array-errors
// TODO: contributor-errors
// finding the correct index for `contributor`-errors is non-trivial as the data gets flattened
// i.e. an error at "contribute.1.entity.0"'s index depends on how many `entity`s there are in "contribute.0.entity"...
set_errors(/^metadata\.lifecycle\.contribute$/, "contributor"); // assign all sub-errors to `ArrayField` for now...
// serialization of OEFOS removes empty and incorrect fields
// only possible error left is when no OEFOS where provided, set that to `ArrayField`-path
set_errors(/^metadata\.classification/, "oefos");
// empty tags are removed by serialization, providing no tags is allowed
// hence no errors wrt tags should ever occur
set_errors(/^metadata\.general\.keyword/, "tag");
// add error for debug-purposes
/*deserializedErrors["metadata"]["form"] = {
// "general.title.langstring.lang": "deserialization-error",
title: "title-lang error",
contributor: {
0: { name: "name error" },
1: { role: { value: "error" } },
},
};*/
return deserializedErrors;
}
}
|
PypiClean
|
/mountwizzard-beta-2.1.3.zip/mountwizzard-beta-2.1.3/mountwizzard/support/weather_thread.py
|
# import basic stuff
import logging
from PyQt5 import QtCore
import time
from win32com.client.dynamic import Dispatch
import pythoncom
class Weather(QtCore.QThread):
logger = logging.getLogger(__name__) # get logger for problems
signalWeatherData = QtCore.pyqtSignal([dict], name='weatherData') # single for data transfer to gui
signalWeatherConnected = QtCore.pyqtSignal([int], name='weatherConnected') # signal for connection status
def __init__(self, app):
super().__init__()
self.app = app
self.connected = 2
self.ascom = None # placeholder for ascom driver object
self.chooser = None # placeholder for ascom chooser object
self.driverName = '' # driver object name
self.slewing = False
self.counter = 0
def run(self): # runnable for doing the work
pythoncom.CoInitialize() # needed for doing CO objects in threads
self.connected = 0 # set connection flag for stick itself
self.counter = 0
while True: # main loop for stick thread
self.signalWeatherConnected.emit(self.connected) # send status to GUI
if self.connected == 1: # differentiate between dome connected or not
if self.counter == 0: # jobs once done at the beginning
self.getStatusOnce() # task once
if self.counter % 2 == 0: # all tasks with 200 ms
self.getStatusFast() # polling the mount status Ginfo
if self.counter % 20 == 0: # all tasks with 3 s
self.getStatusMedium() # polling the mount
if self.counter % 300 == 0: # all task with 1 minute
self.getStatusSlow() # slow ones
self.counter += 1 # increasing counter for selection
time.sleep(.1)
else:
try:
if self.driverName == '':
self.connected = 2
else:
self.ascom = Dispatch(self.driverName) # load driver
self.ascom.connected = True
self.connected = 1 # set status to connected
self.logger.debug('run -> driver chosen:{0}'.format(self.driverName))
except Exception as e: # if general exception
if self.driverName != '':
self.logger.error('run Weather -> general exception: {0}'.format(e)) # write to logger
if self.driverName == '':
self.connected = 2
else:
self.connected = 0 # run the driver setup dialog
finally: # still continua and try it again
pass # needed for continue
time.sleep(1) # wait for the next cycle
self.ascom.Quit()
pythoncom.CoUninitialize() # needed for doing COm objects in threads
self.terminate() # closing the thread at the end
def __del__(self): # remove thread
self.wait()
def getStatusFast(self):
pass
def getStatusMedium(self):
data = dict()
try:
data['DewPoint'] = self.ascom.DewPoint
data['Temperature'] = self.ascom.Temperature
data['Humidity'] = self.ascom.Humidity
data['Pressure'] = self.ascom.Pressure
data['CloudCover'] = self.ascom.CloudCover
data['RainRate'] = self.ascom.RainRate
data['WindSpeed'] = self.ascom.WindSpeed
data['WindDirection'] = self.ascom.WindDirection
self.signalWeatherData.emit(data) # send data
except Exception as e:
self.logger.error('getStatusMedium-> error accessing weather ascom data: {}'.format(e))
def getStatusSlow(self):
pass
def getStatusOnce(self):
pass
def setupDriver(self): #
try:
self.chooser = Dispatch('ASCOM.Utilities.Chooser')
self.chooser.DeviceType = 'ObservingConditions'
self.driverName = self.chooser.Choose(self.driverName)
self.logger.debug('setupDriverWeat-> driver chosen:{0}'.format(self.driverName))
if self.driverName == '':
self.connected = 2
else:
self.connected = 0 # run the driver setup dialog
except Exception as e: # general exception
self.app.messageQueue.put('Driver Exception in setupWeather') # write to gui
self.logger.error('setupWeather -> general exception:{0}'.format(e)) # write to log
if self.driverName == '':
self.connected = 2
else:
self.connected = 0 # run the driver setup dialog
finally: # continue to work
pass # python necessary
|
PypiClean
|
/discord-py-legacy-0.16.13.tar.gz/discord-py-legacy-0.16.13/discord/server.py
|
from . import utils
from .role import Role
from .member import Member
from .emoji import Emoji
from .game import Game
from .channel import Channel
from .enums import ServerRegion, Status, try_enum, VerificationLevel
from .mixins import Hashable
class Server(Hashable):
"""Represents a Discord server.
Supported Operations:
+-----------+--------------------------------------+
| Operation | Description |
+===========+======================================+
| x == y | Checks if two servers are equal. |
+-----------+--------------------------------------+
| x != y | Checks if two servers are not equal. |
+-----------+--------------------------------------+
| hash(x) | Returns the server's hash. |
+-----------+--------------------------------------+
| str(x) | Returns the server's name. |
+-----------+--------------------------------------+
Attributes
----------
name : str
The server name.
me : :class:`Member`
Similar to :attr:`Client.user` except an instance of :class:`Member`.
This is essentially used to get the member version of yourself.
roles
A list of :class:`Role` that the server has available.
emojis
A list of :class:`Emoji` that the server owns.
region : :class:`ServerRegion`
The region the server belongs on. There is a chance that the region
will be a ``str`` if the value is not recognised by the enumerator.
afk_timeout : int
The timeout to get sent to the AFK channel.
afk_channel : :class:`Channel`
The channel that denotes the AFK channel. None if it doesn't exist.
members
An iterable of :class:`Member` that are currently on the server.
channels
An iterable of :class:`Channel` that are currently on the server.
icon : str
The server's icon.
id : str
The server's ID.
owner : :class:`Member`
The member who owns the server.
unavailable : bool
Indicates if the server is unavailable. If this is ``True`` then the
reliability of other attributes outside of :meth:`Server.id` is slim and they might
all be None. It is best to not do anything with the server if it is unavailable.
Check the :func:`on_server_unavailable` and :func:`on_server_available` events.
large : bool
Indicates if the server is a 'large' server. A large server is defined as having
more than ``large_threshold`` count members, which for this library is set to
the maximum of 250.
voice_client: Optional[:class:`VoiceClient`]
The VoiceClient associated with this server. A shortcut for the
:meth:`Client.voice_client_in` call.
mfa_level: int
Indicates the server's two factor authorisation level. If this value is 0 then
the server does not require 2FA for their administrative members. If the value is
1 then they do.
verification_level: :class:`VerificationLevel`
The server's verification level.
features: List[str]
A list of features that the server has. They are currently as follows:
- ``VIP_REGIONS``: Server has VIP voice regions
- ``VANITY_URL``: Server has a vanity invite URL (e.g. discord.gg/discord-api)
- ``INVITE_SPLASH``: Server's invite page has a special splash.
splash: str
The server's invite splash.
"""
__slots__ = ['afk_timeout', 'afk_channel', '_members', '_channels', 'icon',
'name', 'id', 'owner', 'unavailable', 'name', 'region',
'_default_role', '_default_channel', 'roles', '_member_count',
'large', 'owner_id', 'mfa_level', 'emojis', 'features',
'verification_level', 'splash' ]
def __init__(self, **kwargs):
self._channels = {}
self.owner = None
self._members = {}
self._from_data(kwargs)
@property
def channels(self):
return self._channels.values()
def get_channel(self, channel_id):
"""Returns a :class:`Channel` with the given ID. If not found, returns None."""
return self._channels.get(channel_id)
def _add_channel(self, channel):
self._channels[channel.id] = channel
def _remove_channel(self, channel):
self._channels.pop(channel.id, None)
@property
def members(self):
return self._members.values()
def get_member(self, user_id):
"""Returns a :class:`Member` with the given ID. If not found, returns None."""
return self._members.get(user_id)
def _add_member(self, member):
self._members[member.id] = member
def _remove_member(self, member):
self._members.pop(member.id, None)
def __str__(self):
return self.name
def _update_voice_state(self, data):
user_id = data.get('user_id')
member = self.get_member(user_id)
before = None
if member is not None:
before = member._copy()
ch_id = data.get('channel_id')
channel = self.get_channel(ch_id)
member._update_voice_state(voice_channel=channel, **data)
return before, member
def _add_role(self, role):
# roles get added to the bottom (position 1, pos 0 is @everyone)
# so since self.roles has the @everyone role, we can't increment
# its position because it's stuck at position 0. Luckily x += False
# is equivalent to adding 0. So we cast the position to a bool and
# increment it.
for r in self.roles:
r.position += bool(r.position)
self.roles.append(role)
def _remove_role(self, role):
# this raises ValueError if it fails..
self.roles.remove(role)
# since it didn't, we can change the positions now
# basically the same as above except we only decrement
# the position if we're above the role we deleted.
for r in self.roles:
r.position -= r.position > role.position
def _from_data(self, guild):
# according to Stan, this is always available even if the guild is unavailable
# I don't have this guarantee when someone updates the server.
member_count = guild.get('member_count', None)
if member_count:
self._member_count = member_count
self.name = guild.get('name')
self.region = try_enum(ServerRegion, guild.get('region'))
self.verification_level = try_enum(VerificationLevel, guild.get('verification_level'))
self.afk_timeout = guild.get('afk_timeout')
self.icon = guild.get('icon')
self.unavailable = guild.get('unavailable', False)
self.id = guild['id']
self.roles = [Role(server=self, **r) for r in guild.get('roles', [])]
self.mfa_level = guild.get('mfa_level')
self.emojis = [Emoji(server=self, **r) for r in guild.get('emojis', [])]
self.features = guild.get('features', [])
self.splash = guild.get('splash')
for mdata in guild.get('members', []):
roles = [self.default_role]
for role_id in mdata['roles']:
role = utils.find(lambda r: r.id == role_id, self.roles)
if role is not None:
roles.append(role)
mdata['roles'] = sorted(roles)
member = Member(**mdata)
member.server = self
self._add_member(member)
self._sync(guild)
self.large = None if member_count is None else self._member_count >= 250
if 'owner_id' in guild:
self.owner_id = guild['owner_id']
self.owner = self.get_member(self.owner_id)
afk_id = guild.get('afk_channel_id')
self.afk_channel = self.get_channel(afk_id)
for obj in guild.get('voice_states', []):
self._update_voice_state(obj)
def _sync(self, data):
if 'large' in data:
self.large = data['large']
for presence in data.get('presences', []):
user_id = presence['user']['id']
member = self.get_member(user_id)
if member is not None:
member.status = presence['status']
try:
member.status = Status(member.status)
except:
pass
game = presence.get('game', {})
member.game = Game(**game) if game else None
if 'channels' in data:
channels = data['channels']
for c in channels:
channel = Channel(server=self, **c)
self._add_channel(channel)
@utils.cached_slot_property('_default_role')
def default_role(self):
"""Gets the @everyone role that all members have by default."""
return utils.find(lambda r: r.is_everyone, self.roles)
@utils.cached_slot_property('_default_channel')
def default_channel(self):
"""Gets the default :class:`Channel` for the server."""
return utils.find(lambda c: c.is_default, self.channels)
@property
def icon_url(self):
"""Returns the URL version of the server's icon. Returns an empty string if it has no icon."""
if self.icon is None:
return ''
return 'https://cdn.discordapp.com/icons/{0.id}/{0.icon}.jpg'.format(self)
@property
def splash_url(self):
"""Returns the URL version of the server's invite splash. Returns an empty string if it has no splash."""
if self.splash is None:
return ''
return 'https://cdn.discordapp.com/splashes/{0.id}/{0.splash}.jpg?size=2048'.format(self)
@property
def member_count(self):
"""Returns the true member count regardless of it being loaded fully or not."""
return self._member_count
@property
def created_at(self):
"""Returns the server's creation time in UTC."""
return utils.snowflake_time(self.id)
@property
def role_hierarchy(self):
"""Returns the server's roles in the order of the hierarchy.
The first element of this list will be the highest role in the
hierarchy.
"""
return sorted(self.roles, reverse=True)
def get_member_named(self, name):
"""Returns the first member found that matches the name provided.
The name can have an optional discriminator argument, e.g. "Jake#0001"
or "Jake" will both do the lookup. However the former will give a more
precise result. Note that the discriminator must have all 4 digits
for this to work.
If a nickname is passed, then it is looked up via the nickname. Note
however, that a nickname + discriminator combo will not lookup the nickname
but rather the username + discriminator combo due to nickname + discriminator
not being unique.
If no member is found, ``None`` is returned.
Parameters
-----------
name : str
The name of the member to lookup with an optional discriminator.
Returns
--------
:class:`Member`
The member in this server with the associated name. If not found
then ``None`` is returned.
"""
result = None
members = self.members
if len(name) > 5 and name[-5] == '#':
# The 5 length is checking to see if #0000 is in the string,
# as a#0000 has a length of 6, the minimum for a potential
# discriminator lookup.
potential_discriminator = name[-4:]
# do the actual lookup and return if found
# if it isn't found then we'll do a full name lookup below.
result = utils.get(members, name=name[:-5], discriminator=potential_discriminator)
if result is not None:
return result
def pred(m):
return m.nick == name or m.name == name
return utils.find(pred, members)
|
PypiClean
|
/odoo13_addon_account_payment_order-13.0.1.6.7-py3-none-any.whl/odoo/addons/account_payment_order/models/account_move_line.py
|
from odoo import api, fields, models
from odoo.fields import first
class AccountMoveLine(models.Model):
_inherit = "account.move.line"
partner_bank_id = fields.Many2one(
comodel_name="res.partner.bank",
string="Partner Bank Account",
compute="_compute_partner_bank_id",
readonly=False,
store=True,
help="Bank account on which we should pay the supplier",
)
bank_payment_line_id = fields.Many2one(
comodel_name="bank.payment.line", readonly=True, index=True
)
payment_line_ids = fields.One2many(
comodel_name="account.payment.line",
inverse_name="move_line_id",
string="Payment lines",
)
@api.depends(
"move_id", "move_id.invoice_partner_bank_id", "move_id.payment_mode_id"
)
def _compute_partner_bank_id(self):
for ml in self:
if (
ml.move_id.type in ("in_invoice", "in_refund")
and not ml.reconciled
and ml.payment_mode_id.payment_order_ok
and ml.account_id.internal_type in ("receivable", "payable")
and not any(
p_state in ("draft", "open", "generated")
for p_state in ml.payment_line_ids.mapped("state")
)
):
ml.partner_bank_id = ml.move_id.invoice_partner_bank_id.id
else:
ml.partner_bank_id = ml.partner_bank_id
def _prepare_payment_line_vals(self, payment_order):
self.ensure_one()
assert payment_order, "Missing payment order"
aplo = self.env["account.payment.line"]
# default values for communication_type and communication
communication_type = "normal"
communication = self.ref or self.name
# change these default values if move line is linked to an invoice
if self.move_id.is_invoice():
if (self.move_id.reference_type or "none") != "none":
communication = self.move_id.ref
ref2comm_type = aplo.invoice_reference_type2communication_type()
communication_type = ref2comm_type[self.move_id.reference_type]
else:
if (
self.move_id.type in ("in_invoice", "in_refund")
and self.move_id.ref
):
communication = self.move_id.ref
elif "out" in self.move_id.type:
# Force to only put invoice number here
communication = self.move_id.name
if self.currency_id:
currency_id = self.currency_id.id
amount_currency = self.amount_residual_currency
else:
currency_id = self.company_id.currency_id.id
amount_currency = self.amount_residual
# TODO : check that self.amount_residual_currency is 0
# in this case
if payment_order.payment_type == "outbound":
amount_currency *= -1
partner_bank_id = self.partner_bank_id.id or first(self.partner_id.bank_ids).id
vals = {
"order_id": payment_order.id,
"partner_bank_id": partner_bank_id,
"partner_id": self.partner_id.id,
"move_line_id": self.id,
"communication": communication,
"communication_type": communication_type,
"currency_id": currency_id,
"amount_currency": amount_currency,
"date": False,
# date is set when the user confirms the payment order
}
return vals
def create_payment_line_from_move_line(self, payment_order):
vals_list = []
for mline in self:
vals_list.append(mline._prepare_payment_line_vals(payment_order))
return self.env["account.payment.line"].create(vals_list)
|
PypiClean
|
/pyqodeng-0.0.9.tar.gz/pyqodeng-0.0.9/CHANGELOG.rst
|
Change Log
==========
2.11.0
------
As of pyqode 2.11, the project has entered in maintainance mode. Only critical bug fixes will be adressed. The core
team won't add any new features but we will continue to accept PR as long as they are properly tested and not too risky.
This release is mainly a bug fix release, it also adds support for PyQt 5.7.
New features:
- PyQt 5.7 support
- Allow to set case sensitiveness of current word highlighter
Fixed bugs:
- Fix compatibility issues with PyQt 5.7
- JSonTcpClient: wait for socket connected on OSX
- Fix FileNotFoundError in file watcher
- SplittableTabWidget display file save exception in a message box
- Many bug fixes to the new OutputWindow/Terminal widget
- Fix OpenCobolIDE/OpenCobolIDE#365
- Fix OpenCobolIDE/OpenCobolIDE#376
- Fix OpenCobolIDE/OpenCobolIDE#377
- Fix pyQode/pyQode#69
- Fix pyQode/pyQode#67
- CodeCompletion: fix regex exception when setting prefix
2.10.1
------
Fixed bugs:
- fix some backend issues on OSX (the client socket would remain in conecting state if a request is made before
the tcp server is running)
- fix strange behaviour in buffered input handler of OutputWindow when using backspace or delete
2.10.0
------
New features:
- add a new widget to run interactive process with support for ANSI Escape Codes: pyqode.core.widgets.OutputWindow
- add a Terminal widget based on the new OutputWindow.
- [CodeCompletionMode] improvements to the subsequence matching algorithm to put completion with the same case at the top of the list.
- [SplittableTabWidget] add shortcuts to close current tab (Ctrl+W) or all tabs (Ctrl+Shift+W)
Fixed bugs:
- [FSTreeView] fix file_renamed signal not emitted when moving files
- [FSTreeView] show a message box if there is an OSError while renaming a file/directory
Deprecated features:
- pyqode.core.widgets.InteractiveConsole is now deprecated, you should use pyqode.core.widgets.OutputWindow
2.9.0
-----
New features:
- add ability to extract translatable strings with gettext
- add an option to disable copy of whole line when there is no selection, see PR #158
- add a public method to retrieve the list of submenu of the editor context menu
- add ``keys`` and ``values`` methods to the mode and panel manager
- FSTreeView: delay initialisation of tree view until widget is shown
- Add zoom menu to the editor's context menu
- Add ability to use own QSettings
- Add ability to set custom linter rules and add an option for the backend to know about max_line_length (defined in
the margin mode).
- Add ability to close tabs on the left/right of the current tab.
Fixed bugs:
- fix conflicts between WordClickMode and Ctrl+Mouse move (prevent goto when Ctrl+ mouse move).
- fix text cursor not visible under a margin (solution is to use a 2px wide cursor).
- fix HackEdit/hackedit#51
- fix cut not working as intended when cutting a line with only whitespaces
- fix memory issues in HtmlPreviewWidget, now using QTextEdit::setHtml instead of a full blown webview
- fix subprocess.CalledError if xdg-mime returns with non-zero exit code
- fix segfault on Windows (in HackEdit)
- fix many potential unhandled OSError/subprocess errors
- fix file_renamed signal not emitted for child file when a parent directory has been renamed (FSTreeView)
- fix KeyError in backend client if backend function failed due to an exception (result is None)
- fix UnicodeDecodeError when decoding stdout/stderr in InteractiveConsole
- fix backend output not shown in logs when running from a frozen application
- fix mode enabled on install even if enabled was set to False in the constructor
- fix extra selection spanning over multiple lines when user inserts a line breaks (CheckerMode)
- restore case insensitive code completion by default which was causing some major issues in OpenCobolIDE
- fix ImportError when looking for a pygments lexer (and the application has been freezed without all possible
pygments lexers)
2.8.0
-----
New features:
- new pyqode package: pyqode.rst (ReStructuredText)
- enable case sensitive code completion by default
- add a new widget: HtmlPreviewWidget. This widget display the preview of an
editor that implement the ``to_html`` method. (use for the new pyqode
package: pyqode.rst)
- enable code completion in strings (it's up to the cc engine to treat them
differently)
- SplittableCodeEditTabWidget: add a way to repen recently closed tabs
- CI improvements: tests are now running with both PyQt4 and PyQt5 on Travis CI
Fixed bugs:
- fix PYGMENTS_STYLES not including our own styles if pyqode not in standard path (OCIDE now bundles pyqode)
- fix wrong modifiers used for indent/unindent: Ctrl+Tab and Ctrl+Shift+Tab can
now be used to cycle through the tabs of a QTabWidget
- fix AttributeError in FSTreeView: msg box does not have an error method,
use critical instead
- fix unable to create directories/files that starts with '.' in FSTreeView (hidden on linux)
- fix AttributeError in splittable tab widget if editor widget is not a CodeEdit
- fix AttributeError: 'NoneType' object has no attribute 'state' in InteractiveConsole
- fix some segmentation faults when using PyQt4
- fix highlighting not working in split editor if original editor has been
closed.
- fix a memory leak in the backend manager
- fix unreadable search occurences if foreground color is white (dark themes)
- fix wrong tag color in QtStyle pygments style
- fix AttributeError: 'NoneType' object has no attribute '_port' in BackendManager
2.7.0
-----
New features:
- Add a panel to indicate when a file is read-only. The panel will disappear
as soon as the file becomes writeable.
- Add a new mode that remember the cursor history (you can go back and go
forward the cursor history by using Ctrl+Alt+Z and Ctrl+AltY)
- Add a new mode that can highlight a specific line of code (could be used
in a debugger plugin to indicate the line where the debugger has been
stopped...)
- SplittableTabWidget: add "Detach tab" option in the context menu.
- SplittableTabWidget: add a signal for when the editor has been created
but the file has not been loaded yet
- SplittableTabWidget: add a signal for when the editor has been created
and the file has been loaded
- SplittableTabWidget: add a signal for when the editor content has been
saved to disk
- Improve MarkerPanel to be used for a breakpoints panel: add
edit_marker_requested signal and improve internals
- InteractiveConsole: add the SearchPanel to the console so that you
can easily search for a word in the process' output
- FileSystemTreeView: add ability to set a custom file explorer command
- CodeEdit: Reoganisation of the context menu. By default all new actions
(that are not part of QPlainTextEdit) will go to an 'Advanced' sub-menu.
You can also specify a custom sub-menu name or None. All languages
specific extensions (pyqode.python,...) will use a menu with the name
of the language (e.g. Python->Goto definition,
COBOL->Compute field offsets, ...)
- CodeCompletionMode: add support for MatchContains if using PyQt5
- pyqode.core.share.Definition: add path attribute
- Backend: add a heartbeat signal. If no signal was received for
a certain duration, the backend process will exit. This fix an issue
where the backend process were still running as zombies when the parent
crashed.
- SearchPanel: allow to search backward with Shift+Enter when the focus is
in the search box
- SearchPanel: add ability to search in the selected text only.
- The document outline tree widget is now able to sync with the editor
- Add two new logging levels: 1 = debug communication, 5 = internal debugging
Fixed bugs:
- CodeEdit: Fix panel margins not refreshed if panel.setVisible has been called
before the editor is visible.
- SplittableTabWidget: Fix save as not working anymore
- InteractiveConsole: make console read only when process has finished.
- DarculaStyle: fix diff tokens color
- Fix a few TypeError with PyQt 5.5.x
- Fix laggy SearchPanel panel if use enter a space character.
- Fix an encoding issue on Windows in the client-process communication
- ErrorTable: Fix newlines not visible in details dialog.
- Fix many potential memory leaks by breaking the circular dependencies
correctly before removing a mode/panel
- Improve Cache.get_encoding: it will try all preferred encoding if the file
is not in the cache before giving up.
- SplittableTabWidget: Normalize case of input file paths when looking if The
file is already open. Since Windows is not case sensitive, the file might be
already opened but with a different case...
- TextBlockHelper: fix TypeError on some 32 bits systems with old Qt5 libraries
2.6.9
-----
Fixed bugs:
- fix UnicodeDecodeError with the backend process
- fix cursor selection lost after a case conversion
- fix context menu entries not working at mouse position
2.6.8
-----
Fixed bugs:
- fix a few more type errors when using PyQt5.5
- fix runtime error in outline mode if the editor has been deleted before
the timer elapsed.
2.6.7
-----
Fixed bugs:
- fix TypeError in FileSystemHelper with PyQt5.5
- fix blank file icons with PyQt5.5
2.6.6
-----
Fixed bugs:
- FSTreeView: fix bug with cut of directories
- SplittableCodeEditTabWidget: fix keep unique tab text on save
- FileManager: fix bug in clean text when text is empty
- FileManager: fix log level of unwanted/parasiting info messages
- FileManager: don't save file if editor is not dirty and encoding has not changed
- Folding: fix issue with deleting folded scope.
2.6.5
-----
SplittableTabWidget: Fix save_as not using all mimetypes extensions.
2.6.4
-----
Fixed bugs:
- fix panels margins not refreshed if panel.setVisible has been called while the editor widget was not visible.
- fix bug with filewatcher on file deleted if the user choose to keep the editor open
2.6.3
-----
Improvements:
- a few improvements to some internal functions which leads to better
performances in big files.
- add file_size_limit to FileManager, when the file size is bigger than the
limit, syntax highligher will get disabled
- Improve plasma 5 integration (will use more icons from theme (
code-variable, code-function,...))
- Simplified color_scheme api, SyntaxHighlighter.color_scheme now accepts
a string instead of a ColorScheme instance
Fixed bugs:
- Fix Ctrl+Home (jump to first line)
- Fix copy of directory in FileSystemTreeView
- Fix file watcher notification when saving big files.
2.6.2
-----
Fixed bugs:
- Fix edit triggers in open files popup (SplittableTabWidget)
- Fix an issue which lead to corrupted recent files list (OpenCobolIDE/OpenCobolIDE#115)
2.6.1
-----
This is mostly a bug fix release with a few improvements here and there (fully backward compatible).
New features/Improvements:
- Improve highlight occurences mode: the word under cursor is not highlighted anymore, only
the other occurences are highlighted now. Also the original foreground color
is now preserved.
- Add missing PYGMENTS_STYLES list to public API (pyqode.core.api)
- Improvre syntax highlighter: add format for namespace keywords and word operators
- Improve ignore API of FSTreeView: add support for unix style wildcards (*.py,...)
- Improve open files popup (splittable tab widget): use a table view instead of a list view
Fixed bugs:
- Fix qt warning: QWidget::insertAction: Attempt to insert null action
- Fix graphical bugs when a stylesheet has been setup on the application.
- Fix issues whith show whitespaces
- Fix unhandled exception in SubsequenceCompleter
- Fix unhandled exception in FileManager.save
- Fix runtime error with open files popup (splittable tab widget)
2.6.0
-----
New features:
- Add a new filter mode for the code completion frontend: subsequence based
matching (see pyQode/pyQode#1)
- Improve cut/copy behaviour if there is no selected text (see pyQode/pyQode#29)
- Add a new property for dynamic panel (see pyQode/pyQode#30)
- Improve generic code folder for C based languages: add a
CharBasedFoldDetector which works for C, C++, C#, PHP and Javascript
- SplittableTabWidget: improve browsing when there are a lots of tab. There
is now a hotkey (Ctrl+T by default) that shows a popup with a list of all
the open files.
- FileSystemTree: add a select method which allow for sync between a
TabWidget and the FileSystemTree.
- Implement EOL management: You can now define a preferred EOL to use when
saving files and add the ability to detect exisiting EOL and use it
instead of the preferred EOL.
- Improve CI (travis): now tests are running for both PyQt4 and PyQt5
on python 2.7, 3.2, 3.3 and 3.4
- Add optional support for QtAwesome (icons)
- SplittableTabWidget: add ability to setup custom context menu action on
the tab bar.
- SplittableTabWidget: improve names of tabs in case of duplicate filename.
- Add support for stdeb: ppa packages will be available soon
- Rework context menu: by default standard actions won't be created (copy,
paste, ...). Those actions are handled by qt and make the context menu
a bit messy.
- Wheel support
Fixed bugs:
- Fix an issue with draggable tabs on OSX (see pyQode/pyQode#31) and
improve tab bar appearance on OSX (see pyQode/pyQode#37)
- Fix a segfault with SplittableTabWidget (see pyQode/pyQode#32)
- Fix get_linus_file_explorer on Ubuntu
- Fix a few bugs with copy/paste operatins in FileSystemTree
2.5.0
-----
New features:
- Unified API for document outline (see pyQode/pyQode#24)
- Imrpove SlittableCodeWidget API: now an exception will be raised if the wrong type
is passed to register_code_edit.
Fixed bugs:
- InteractiveConsole: fix bugs which prevent from starting a new process (if another one is still running).
2.4.2
-----
New features:
- allow to reuse the same backend process for any new editor. This is not recommended but
might be inevitable if you're running a proprietary python interpreter (see pyQode/pyQode#21)
Fixed bugs:
- fix auto-completion of backspace. Backspace should remove the corresponding character if next
char is not empty and is in the mapping. E.g.: (|), pressing delete at | should remove both parentheses
- fix show in explorer action (filesystem treeview) on Plasma 5
- fix cursor position after filewatcher reload (fix OpenCobolIDE/OpenCobolIDE#97)
- improve performances of OccurencesHighlighterMode
- fix a bug in auto-completion, mapping was not always respected and it sometimes happen
that the closing symbol is not written if another closing symbol is after the text cursor.
- improve action "Duplicate line", now the entire selection will get duplicated (instead of the last line only).
- fix a bug with home key if the cursor is in the indentation are (first blank spaces).
2.4.1
-----
New features:
- FileWatcherMode: add file_reloaded signal to the
Fixed bugs:
- fix an issue with QTimer.singleShot
- fix encodings issue when pyqode is embedded into FreeCad (see pyQode/pyQode#11, end of topic)
- SplittableTabWidget: Fix issue when calling save and all editors has been closed
- SplittableTabWidget: Fix gui issue: panels of cloned editors should be hidden automatically
- FileSystemTree: fix issue when resetting path or when having two widget instances
- RecentFilesManager: fix duplicate entries on windows (see OpenCobolIDE/OpenCobolIDE#80
- FileWatcherMode: don't wait for the editor to get the focus to auto reload changed file
2.4.0
-----
New features:
- add a splittable tab widget
- add a file system tree view
- disable waiting cursor when waiting for code completions
- give more room to fold level value in block user state
- update qt and darcula pygments styles
- add support for pygments 2
- improvements to the syntax highlighter color scheme wrapper: more token types
are available through the ``formats`` attribute.
- linter mode will use icon from theme on linux
- add more basic examples demonstrating the use of each mode/panel
Fixed bugs:
- many bug fixes and improvements to the indenter mode
- fix some bugs with pyside
- fix bugs with stange encoding names (pyQode/pyQode#11)
- fix a line ending issue with InteractiveConsole on windows (OpenCobolIDE/OpenCobolIDE#77)
- fix default font on OS X + PyQt4
- various non critical bug fixes in many modes/panels
- fix a performance critical issue with code completion model updates: it will
now update 100 times faster and will never block the ui even when working with
big files (where there is more than 5000 completions items).
Deprecated features:
- pyqode.core.widgets.TabWidget is deprecated and will be removed in version
2.6
- backend: there is no more boolean status returned by the backend, you should
adapt both your caller and callee code.
Removed features (that were deprecated since at least 2.2.0):
- pyqode.core.qt has been removed. You should now use pyqode.qt.
2.3.2
-----
Fixed bugs:
- fix occasional crash when closing an editor
- fix restore cursor position: center cursor
- fix useless calls to rehighlight
2.3.1
-----
Fixed bugs:
- Fix segfault on windows
2.3.0
-----
New features:
- add support for python2. You may now use python2 for writing a pyqode
app (backend AND frontend)!
- add a mode that highlight occurrences of the word under the text cursor
- add a smart backspace mode, this mode eats as much whitespace as possible
when you press backspace
- add GlobalCheckerPanel that shows all errors found in the document
- add extented selection mode. Extended selection is a feature that can be
found in Ulipad ( https://code.google.com/p/ulipad )
- add pyqode-console script that let you run other programs in an external
terminal with a final prompt that holds the window after the program
finished.
- new widget: prompt line edit (a line edit with a prompt text and an icon)
- add ability to surround selected text with quotes or parentheses
- search and replace: added regex support
- search and replace: the search algorithm is now running on the backend
(fix issue where gui was blocked while searching text)
- improvements to the InteractiveConsole: there is now a way to setup
colors using a pygments color scheme. Also the console is now readonly
when the process is not running
- backend improvements:
- the backend is now a ThreadedSocketServer
- proper way to close the backend process. we do not use terminate/kill
anymore but send a shutdown signal to the process stdin
Fixed bugs:
- fix the code that prevents code completion popup from showing in strings
and comments
- fix a bug with the default indenter that was eating chars at the start
of the line
- fix checker request logic (keep the last request instead of the first
one)
- fix right panels top position
- fix wordclick decoration color on dark color schemes
2.2.0
-----
New features:
- add cursor position caching
- add ``updated`` signal to RecentFilesManager
- add ability to add menus to the editor context menu
- add get_context_menu method to CodeEdit
- add ``is_running`` property to InteractiveConsole
- add ``double_clicked`` signal to TabWidget
- add a way to override folding panel indicators and background color
- add a way to pass an icon provider to the RecentMenu
- added a small delay before showing fold scopes (to avoid flashes when
you move the mouse over the folding panel)
- add a way to make the distinction between default font size and zoomed
font size by introducing the notion of zoom level
- a few more improvements to the completion popup (it should hide
automatically when you move the cursor out of the word boundaries)
Fixed bugs:
- fix confusing convention: now both line numbers and column numbers starts
from 0
- fix a few issues with code folding (corner cases such as indicator on
first line not highlighted,...)
- fix potential circular import with the cache module
- fix caret line refresh when dynamically disabled/enabled
- fix a visual bug where horizontal scroll-bars range is not correct
- fix tooltip of folded block: ensure the block is still folded before
showing the tooltip
- fix background color when a stylesheet is used (especially when
stylesheet is reset).
2.1.0
-----
New features:
- new code folding API and panel
- encodings API (panel, combo box, menu, dialog)
- allow to use pygments styles for native highlighters
- improved checker mode and syntax highlighter
- new CheckerPanel made to draw the new checker mode messages. If you were
using MarkerPanel to draw checker messages, you will have to replace it by
CheckerPanel!
- mimetype property for CodeEdit
- optimized API for storing block user data (using a bitmask in block user
state)
- reworked editor context menu (add a way to add sub-menus)
- improved code completion: show popup when typing inside an existing word
and always collect completions at the start of the prefix (this gives a
lot more suggestions).
- add pre-made editors: TextCodeEdit and GenericCodeEdit
Fixed bugs:
- wrong cursor position after duplicate line
- empty save dialog for new files (without path)
- fix style issue on KDE
- fix some issues with frozen applications
- fix a few bugs in the notepad example
- fix a long standing issue in symbol matcher where the mode would
match symbols that are inside string literals or comments. This greatly
improves the python auto indent mode.
2.0.0
-----
New features/improvements:
- PyQt5 support
- Mac OSX support
- new client/server API
- simpler settings API
- simpler modes/panels API
- there is now a way to select the python interpreter used for the backend
process
- integrate widgets defined in pyqode.widgets (pyqode.widgets will be
removed soon)
- allow tab key to choose a completion
- new pyqode specific pygments color schemes
Fixed bugs:
- fix zombie backend process
- fix unsupported pickle protocol
- fix list of pygments style: all styles are now included, including plugins!
1.3.2
-----
Fixed bugs:
- server port was not forwarded by server.start
- fix issue with file watcher if editor has been deleted.
1.3.1
-----
Fixed bugs:
- improve auto complete, many small bug fixes
- fix infinite loop when saving an empty document
- fix file watcher when filePath is None
- fix a small bug with line panel where the last line was not
highlighted as selected.
1.3.0
-----
New features:
- case converter mode
- improve go to line dialog
Fixed bugs:
- fix bugs with replace all
- Fix wrong behavious with auto completion
- Fix a bug where it was not possible to select a code completion using ENTER
- fix UnicodeEncodeError with python 2.7
1.2.0
-----
New features:
- debian packages available on ppa:pyqode/stable and ppa:pyqode/unstable
Fixed bugs:
- Code Completion does not trigger if there is a string or comment in the line
- Fix filewatcher bug with deleted files
- Fix filewatcher bug when user say no to file reload the first time
- Fix syntax highlighter bugs with old PyQt libraries.
1.1.0
-----
New features:
- Improve code completion process performances and reliability
- Make QT_API case insensitive
- Wrap settings and style properties with python properties
- Allow user to start code completion server before a code editor instance is created.
- New mode: AutoComplete mode
- New mode: WordClickMode, append support for word under MOUSE cursor
- New setting: autoSave on focus out
Fixed bugs:
- Fix bug with subprocess intercomm (and improves performances)
- Fix Document cleanup bugs
1.0.0
-----
The API has been completely rewritten. Here are the major changes
* added support for python 3
* added support for PyQt5
* added support for Qt Designer plugins
* morphed into a namespaces package
* improved look and feel: native look and feel close to Qt Create
* improved code completion, code folding,
* improved performances (using multiprocessing heavily instead of multithreading)
* complete documentation and examples
* minimum travis ci integration (just to ensure pyqode remains importable for all supported interpreter/qt bingins, there is still no real test suite).
0.1.1
-----
Fixed bugs:
- better code completion popup show/hide
0.1.0
-----
First release. Brings the following features:
* syntax highlighting mode (using pygments)
* code completion (static word list, from document words)
* line number Panel
* code folding Panel
* markers Panel (to append breakpoints, bookmarks, errors,...)
* right margin indicator mode
* active line highlighting mode
* editor zoom mode
* find and replace Panel
* text decorations (squiggle, box)
* unicode support (specify encoding when you load your file)
* styling (built-in white and dark styles + possibility to customize)
* flexible framework to append custom panels/modes
* auto indent mode(indentation level
|
PypiClean
|
/pytholog-2.4.0.tar.gz/pytholog-2.4.0/examples/friends_prob.md
|
#### How friends can influence each other into smoking based on some other factors.
###### The example is inspired by [problog](https://dtai.cs.kuleuven.be/problog/tutorial/basic/05_smokers.html)
Here how we can define the knowledge base in **Prolog**:
```prolog
stress(X, P) :- has_lot_work(X, P2), P is P2 * 0.2.
to_smoke(X, Prob) :- stress(X, P1), friends(Y, X), influences(Y, X, P2), smokes(Y), Prob is P1 * P2.
to_have_asthma(X, 0.4) :- smokes(X).
to_have_asthma(X, Prob) :- to_smoke(X, P2), Prob is P2 * 0.25.
friends(X, Y) :- friend(X, Y).
friends(X, Y) :- friend(Y, X).
influences(X, Y, 0.6) :- friends(X, Y).
friend(peter, david).
friend(peter, rebecca).
friend(daniel, rebecca).
smokes(peter).
smokes(rebecca).
has_lot_work(daniel, 0.8).
has_lot_work(david, 0.3).
```
So much similar in **python** with **pytholog**:
```python
friends_kb = pl.KnowledgeBase("friends")
friends_kb([
"stress(X, P) :- has_lot_work(X, P2), P is P2 * 0.2",
"to_smoke(X, Prob) :- stress(X, P1), friends(Y, X), influences(Y, X, P2), smokes(Y), Prob is P1 * P2",
"to_have_asthma(X, 0.4) :- smokes(X)",
"to_have_asthma(X, Prob) :- to_smoke(X, P2), Prob is P2 * 0.25",
"friends(X, Y) :- friend(X, Y)",
"friends(X, Y) :- friend(Y, X)",
"influences(X, Y, 0.6) :- friends(X, Y)",
"friend(peter, david)",
"friend(peter, rebecca)",
"friend(daniel, rebecca)",
"smokes(peter)",
"smokes(rebecca)",
"has_lot_work(daniel, 0.8)",
"has_lot_work(david, 0.3)"
])
```
Let's now perform some queries in both languages:
Prolog:
```prolog
influences(X, rebecca, P).
% P = 0.59999999999999998
% X = peter ? ;
% P = 0.59999999999999998
% X = daniel ? ;
smokes(Who).
% Who = peter ? ;
% Who = rebecca ;
to_smoke(Who, P).
% P = 0.096000000000000016
% Who = daniel ? ;
% P = 0.035999999999999997
% Who = david ? ;
to_have_asthma(Who, P).
% P = 0.40000000000000002
% Who = peter ? ;
% P = 0.40000000000000002
% Who = rebecca ? ;
% P = 0.024000000000000004
% Who = daniel ? ;
% P = 0.0089999999999999993
% Who = david ? ;
```
Python:
```python
friends_kb.query(pl.Expr("influences(X, rebecca, P)"))
# [{'X': 'peter', 'P': '0.6'}, {'X': 'daniel', 'P': '0.6'}]
friends_kb.query(pl.Expr("smokes(Who)"))
# [{'Who': 'peter'}, {'Who': 'rebecca'}]
friends_kb.query(pl.Expr("to_smoke(Who, P)"))
# [{'Who': 'daniel', 'P': 0.09600000000000002}, {'Who': 'david', 'P': 0.036}]
friends_kb.query(pl.Expr("to_have_asthma(Who, P)"))
# [{'Who': 'peter', 'P': '0.4'},
# {'Who': 'rebecca', 'P': '0.4'},
# {'Who': 'daniel', 'P': 0.024000000000000004},
# {'Who': 'david', 'P': 0.009}]
```
The two languages are performing the same way and giving the same results! :D
This is the purpose of pytholog, to mimic the way prolog behaves inside python.
|
PypiClean
|
/smqtk_iqr-0.15.1-py3-none-any.whl/smqtk_iqr/utils/runApplication.py
|
from argparse import ArgumentParser
import logging
from typing import cast, Dict, Type
from flask_basicauth import BasicAuth
from flask_cors import CORS
from smqtk_iqr.utils import cli
import smqtk_iqr.web
def cli_parser() -> ArgumentParser:
parser = cli.basic_cli_parser(__doc__)
# Application options
group_application = parser.add_argument_group("Application Selection")
group_application.add_argument('-l', '--list',
default=False, action="store_true",
help="List currently available applications "
"for running. More description is "
"included if SMQTK verbosity is "
"increased (-v | --debug-smqtk)")
group_application.add_argument('-a', '--application', default=None,
help="Label of the web application to run.")
# Server options
group_server = parser.add_argument_group("Server options")
group_server.add_argument('-r', '--reload',
action='store_true', default=False,
help='Turn on server reloading.')
group_server.add_argument('-t', '--threaded',
action='store_true', default=False,
help="Turn on server multi-threading.")
group_server.add_argument('--host',
default=None,
help="Run host address specification override. "
"This will override all other configuration "
"method specifications.")
group_server.add_argument('--port',
default=None,
help="Run port specification override. This will "
"override all other configuration method "
"specifications.")
group_server.add_argument("--use-basic-auth",
action="store_true", default=False,
help="Use global basic authentication as "
"configured.")
group_server.add_argument('--use-simple-cors',
action='store_true', default=False,
help="Allow CORS for all domains on all routes. "
"This follows the \"Simple Usage\" of "
"flask-cors: https://flask-cors.readthedocs"
".io/en/latest/#simple-usage")
# Other options
group_other = parser.add_argument_group("Other options")
group_other.add_argument('--debug-server',
action='store_true', default=False,
help='Turn on server debugging messages ONLY. '
'This is implied when -v|--verbose is '
'enabled.')
group_other.add_argument('--debug-smqtk',
action='store_true', default=False,
help='Turn on SMQTK debugging messages ONLY. '
'This is implied when -v|--verbose is '
'enabled.')
group_other.add_argument('--debug-app',
action='store_true', default=False,
help='Turn on flask app logger namespace '
'debugging messages ONLY. This is '
'effectively enabled if the flask app is '
'provided with SMQTK and "--debug-smqtk" is '
'passed. This is also implied if '
'-v|--verbose is enabled.')
group_other.add_argument('--debug-ns',
action='append', default=[],
help="Specify additional python module "
"namespaces to enable debug logging for.")
return parser
def main() -> None:
parser = cli_parser()
args = parser.parse_args()
debug_smqtk = args.debug_smqtk or args.verbose
debug_server = args.debug_server or args.verbose
debug_app = args.debug_app or args.verbose
debug_ns_list = args.debug_ns
debug_smqtk and debug_ns_list.append('smqtk')
debug_server and debug_ns_list.append('werkzeug')
# Create a single stream handler on the root, the level passed being
# applied to the handler, and then set tuned levels on specific namespace
# levels under root, which is reset to warning.
cli.initialize_logging(logging.getLogger(), logging.DEBUG)
logging.getLogger().setLevel(logging.WARN)
log = logging.getLogger(__name__)
# SMQTK level always at least INFO level for standard internals reporting.
logging.getLogger("smqtk_iqr").setLevel(logging.INFO)
# Enable DEBUG level on applicable namespaces available to us at this time.
for ns in debug_ns_list:
log.info("Enabling debug logging on '{}' namespace"
.format(ns))
logging.getLogger(ns).setLevel(logging.DEBUG)
webapp_types = smqtk_iqr.web.SmqtkWebApp.get_impls()
web_applications: Dict[str, Type[smqtk_iqr.web.SmqtkWebApp]] = {t.__name__: t for t in webapp_types}
if args.list:
log.info("")
log.info("Available applications:")
log.info("")
for label, cls in web_applications.items():
log.info("\t" + label)
if debug_smqtk:
log.info('\t' + ('^'*len(label)) + '\n' +
cast(str, cls.__doc__) + '\n' +
('*' * 80) + '\n')
log.info("")
exit(0)
application_name = args.application
if application_name is None:
log.error("No application name given!")
exit(1)
elif application_name not in web_applications:
log.error("Invalid application label '%s'", application_name)
exit(1)
app_class: Type[smqtk_iqr.web.SmqtkWebApp] = web_applications[application_name]
# If the application class's logger does not already report as having INFO/
# DEBUG level logging (due to being a child of an above handled namespace)
# then set the app namespace's logger level appropriately
app_class_logger_level = logging.getLogger(app_class.name).getEffectiveLevel()
app_class_target_level = logging.INFO - (10 * debug_app)
if app_class_logger_level > app_class_target_level:
level_name = \
"DEBUG" if app_class_target_level == logging.DEBUG else "INFO"
log.info("Enabling '{}' logging for '{}' logger namespace."
.format(level_name, logging.getLogger(app_class.name).name))
logging.getLogger(app_class.name).setLevel(logging.INFO - (10 * debug_app))
config = cli.utility_main_helper(app_class.get_default_config(), args,
skip_logging_init=True)
host = args.host
port = args.port and int(args.port)
use_reloader = args.reload
use_threading = args.threaded
use_basic_auth = args.use_basic_auth
use_simple_cors = args.use_simple_cors
app: smqtk_iqr.web.SmqtkWebApp = app_class.from_config(config)
if use_basic_auth:
app.config["BASIC_AUTH_FORCE"] = True
BasicAuth(app)
if use_simple_cors:
log.debug("Enabling CORS for all domains on all routes.")
CORS(app)
app.config['DEBUG'] = debug_server
log.info("Starting application")
app.run(host=host, port=port, debug=debug_server, use_reloader=use_reloader,
threaded=use_threading)
if __name__ == "__main__":
main()
|
PypiClean
|
/Cpywpa-1.0.1.tar.gz/Cpywpa-1.0.1/README.md
|
# Cpywpa
## Introduction
Cpywpa is another simple tool to control wpa_supplicant for Python. However, rather than using d-Bus, **it wrote with Cython so it can directly use OFFICIAL C interface.**
English | [简体中文](README_CN.md)
## Installation
First, make sure you have the latest pip
```bash
python3 -m pip install --upgrade pip
```
Then you can install Cpywpa with this command
```bash
python3 -m pip install Cpywpa
```
Here is the dependent packages and they will be installed during installation.
> If you don't want to keep them, you can remove them after installation.
| package name | version |
| :----------: | :-----: |
| setuptools | any |
| wheel | any |
| Cython | any |
## How to use
⚠ NOTE ⚠
1. **While only root user can access wpa_supplicant interface, all codes below are running with sudo or by root user.**
2. all network configuration will be saved in /etc/wpa_supplicant/wpa_supplicant.conf, while the password is saved without encryption, it is not recommended to use this on your important computer.
And here is the guide.
1. Get current network status
```python
from Cpywpa import NetworkManager
from pprint import pprint
manager = NetworkManager()
pprint(manager.getStatus())
```
2. List known network
```python
from Cpywpa import NetworkManager
from pprint import pprint
manager = NetworkManager()
pprint(manager.listNetwork())
```
3. Scan network around and get scan results
```python
from Cpywpa import NetworkManager
from pprint import pprint
from time import sleep
manager = NetworkManager()
# you can use scan() to scan and get scan results
# use scan_time to set sleep time
pprint(manager.scan(scan_time=8))
# or use onlyScan() to scan and use scanResults() to get results
manager.onlyScan()
sleep(10)
pprint(manager.scanResults())
```
4. Connect to a network
```python
from Cpywpa import NetworkManager
manager = NetworkManager()
# connect to a known network
# Syize is my wifi name
manager.connect('Syize')
# connect to a new network
# This new network must exist
manager.connect('Syize', passwd='wifi-password')
```
5. Add a network but don't connect
```python
from Cpywpa import NetworkManager
manager = NetworkManager()
manager.addNetwork('Syize', 'wifi-password')
```
6. Delete a network
```python
from Cpywpa import NetworkManager
manager = NetworkManager()
manager.removeNetwork('Syize')
```
## How to development
See [Dev Guide](DevelopmentGuide.md) | [开发指南](DevGuide_CN.md)
## Issues
- Chinese Wi-Fi name can show correctly in scan and scanResults, but add Wi-Fi with Chinese name **HASN'T BEEN TESTED YET.** Unexpected problems may occur.
## To-Do
- While wpa_supplicant is cross-plantform, different gcc's macro is required during installation. But till now only Linux version has been tested, and I only add Linux's macro to setup.py. It will be great if you help me completely complete this program.
- For now, Cpywpa only supportes several parameters including ssid, psk, priority and key_mgmt. I'm going to add other parameters support. However I merely use them. So it is diffcult to say when I will add.
|
PypiClean
|
/bpy_cuda-2.82-cp37-cp37m-win_amd64.whl/bpy_cuda-2.82.data/scripts/2.82/scripts/addons/power_sequencer/operators/align_audios.py
|
import bpy
from .utils.doc import doc_name, doc_idname, doc_brief, doc_description
class POWER_SEQUENCER_OT_align_audios(bpy.types.Operator):
"""*brief* Align two audio strips
Tries to synchronize the selected audio strip to the active audio strip by comparing the sound.
Useful to synchronize audio of the same event recorded with different microphones.
To use this feature, you must have [ffmpeg](https://www.ffmpeg.org/download.html) and
[scipy](https://www.scipy.org/install.html) installed on your computer and available on the PATH (command line) to work.
The longer the audio files, the longer the tool can take to run, as it has to convert, analyze,
and compare the audio sources to work.
"""
doc = {
"name": doc_name(__qualname__),
"demo": "https://i.imgur.com/xkBUzDj.gif",
"description": doc_description(__doc__),
"shortcuts": [],
"keymap": "Sequencer",
}
bl_idname = doc_idname(__qualname__)
bl_label = doc["name"]
bl_description = doc_brief(doc["description"])
bl_options = {"REGISTER", "UNDO"}
@classmethod
def poll(cls, context):
if not context.scene:
return False
active = context.scene.sequence_editor.active_strip
selected = context.selected_sequences
ok = (
len(selected) == 2
and active in selected
and all(map(lambda s: s.type == "SOUND", selected))
)
return ok
def execute(self, context):
try:
import scipy
except ImportError:
self.report({"ERROR"}, "Scipy must be installed to align audios")
return {"FINISHED"}
if not is_ffmpeg_available():
self.report({"ERROR"}, "ffmpeg must be installed to align audios")
return {"FINISHED"}
# This import is here because otherwise, it slows down blender startup
from .audiosync import find_offset
scene = context.scene
active = scene.sequence_editor.active_strip
active_filepath = bpy.path.abspath(active.sound.filepath)
selected = context.selected_sequences
selected.pop(selected.index(active))
align_strip = selected[0]
align_strip_filepath = bpy.path.abspath(align_strip.sound.filepath)
offset, score = find_offset(align_strip_filepath, active_filepath)
initial_offset = active.frame_start - align_strip.frame_start
fps = scene.render.fps / scene.render.fps_base
frames = int(offset * fps)
align_strip.frame_start -= frames - initial_offset
self.report({"INFO"}, "Alignment score: " + str(round(score, 1)))
return {"FINISHED"}
def is_ffmpeg_available():
"""
Returns true if ffmpeg is installed and available from the PATH
"""
try:
subprocess.call(["ffmpeg", "--help"], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
return True
except OSError:
return False
|
PypiClean
|
/CubeLang-0.1.4-py3-none-any.whl/cubelang/scrambler.py
|
import random
from argparse import ArgumentParser
from typing import List
from cubelang.actions import Turn
from cubelang.cli.options import integer_type
from cubelang.cube import Cube
from cubelang.orientation import Orientation, Side
# noinspection PyTypeChecker
SIDES = tuple(Side)
def main():
arg_parser = ArgumentParser()
arg_parser.add_argument("-d", dest="dimension", help="dimensions of a cube",
default=3, metavar="N", type=integer_type(2))
arg_parser.add_argument("-n", dest="turns_num", help="number of turns",
type=integer_type(1), default=20)
arg_parser.add_argument("-a", dest="output_args", action="store_true",
help="display the state of the cube after the turns instead of the formula")
arg_parser.add_argument("-s", dest="seed", help="the seed for the pseudorandom number generator")
args = arg_parser.parse_args()
dim = args.dimension
if args.seed is not None:
random.seed(args.seed)
actions: List[Turn] = []
prev_side = None
for i in range(args.turns_num):
if prev_side is None:
sides = SIDES
else:
sides = [x for x in SIDES if x != prev_side]
prev_side = random.choice(sides)
first_index = random.randint(1, dim // 2)
last_index = random.randint(1, first_index)
if first_index == last_index:
indices = [first_index]
else:
indices = [last_index, ..., first_index]
turn = Turn(prev_side, indices, random.randint(1, 3))
actions.append(turn)
if not args.output_args:
for action in actions:
print(str(action), end="")
print()
else:
cube = Cube((dim,) * 3)
orientation = Orientation()
for action in actions:
action.perform(cube, orientation)
print("--front", repr(cube.get_side(orientation).colors))
print("--right", repr(cube.get_side(orientation.to_right).colors))
print("--left", repr(cube.get_side(orientation.to_left).colors))
print("--back", repr(cube.get_side(orientation.to_right.to_right).colors))
print("--top", repr(cube.get_side(orientation.to_top).colors))
print("--bottom", repr(cube.get_side(orientation.to_bottom).colors))
if __name__ == "__main__":
main()
|
PypiClean
|
/hydratk-ext-yoda-0.2.4.tar.gz/hydratk-ext-yoda-0.2.4/src/hydratk/extensions/yoda/translation/en/help.py
|
language = {
'name': 'English',
'ISO-639-1': 'en'
}
''' Yoda Commands '''
help_cmd = {
'yoda-run': 'starts the Yoda tester',
'yoda-simul': 'starts the Yoda tester in test simulation mode',
'yoda-create-test-results-db': 'creates database for storing test results base on specified dsn configuration',
'yoda-create-testdata-db': 'creates database for test data',
# standalone with option profile yoda
'run': 'starts the Yoda tester',
'simul': 'starts the Yoda tester in test simulation mode',
'create-test-results-db': 'creates database for storing test results base on specified dsn configuration',
'create-testdata-db': 'creates database for test data'
}
''' Yoda Options '''
help_opt = {
'yoda-test-path': {'{h}--yoda-test-path <path>{e}': {'description': 'test scenario path', 'commands': ('yoda-run', 'yoda-simul')}},
'yoda-test-run-name': {'{h}--yoda-test-run-name <name>{e}': {'description': 'test run identification', 'commands': ('yoda-run', 'yoda-simul')}},
'yoda-test-repo-root-dir': {'{h}--yoda-test-repo-root-dir <path>{e}': {'description': 'test repository root directory', 'commands': ('yoda-run', 'yoda-simul')}},
'yoda-test-results-output-create': {'{h}--yoda-test-results-output-create <state>{e}': {'description': 'activates/deactivates native test results output handler', 'commands': ('yoda-run', 'yoda-simul')}},
'yoda-test-results-output-handler': {'{h}-a, --yoda-test-results-output-handler <type>{e}': {'description': 'set the test results output handler type', 'commands': ('yoda-run', 'yoda-simul')}},
'yoda-db-results-dsn': {'{h}--yoda-db-results-dsn <dsn>{e}': {'description': 'test results database access definition', 'commands': ('yoda-run', 'yoda-simul', 'yoda-create-test-results-db')}},
'yoda-db-testdata-dsn': {'{h}--yoda-db-testdata-dsn <dsn>{e}': {'description': 'test data database access definition', 'commands': ('yoda-create-testdata-db')}},
'yoda-multiply-tests': {'{h}--yoda-multiply-tests <number>{e}': {'description': 'found tests will be multiplied by specified number', 'commands': ('yoda-run')}},
# standalone with option profile yoda
'test-path': {'{h}-tp, --test-path <path>{e}': {'description': 'test scenario path', 'commands': ('run', 'simul')}},
'test-run-name': {'{h}-rn, --test-run-name <name>{e}': {'description': 'test run identification', 'commands': ('run', 'simul')}},
'test-repo-root-dir': {'{h}-rd, --test-repo-root-dir <path>{e}': {'description': 'test repository root directory', 'commands': ('run', 'simul')}},
'test-results-output-create': {'{h}-oc, --test-results-output-create <state>{e}': {'description': 'activates/deactivates native test results output handler', 'commands': ('run', 'simul')}},
'test-results-output-handler': {'{h}-oh, --test-results-output-handler <type>{e}': {'description': 'set the test results output handler type', 'commands': ('run', 'simul')}},
'db-results-dsn': {'{h}--db-results-dsn <dsn>{e}': {'description': 'test results database access definition', 'commands': ('run', 'simul', 'create-test-results-db')}},
'db-testdata-dsn': {'{h}--db-testdata-dsn <dsn>{e}': {'description': 'test data database access definition', 'commands': ('create-testdata-db')}},
'multiply-tests': {'{h}--multiply-tests <number>{e}': {'description': 'found tests will be multiplied by specified number', 'commands': ('run')}}
}
|
PypiClean
|
/zope.component-6.0-py3-none-any.whl/zope/component/hooks.py
|
"""Hooks for getting and setting a site in the thread global namespace.
"""
__docformat__ = 'restructuredtext'
import contextlib
import threading
from zope.component._compat import ZOPE_SECURITY_NOT_AVAILABLE_EX
try:
from zope.security.proxy import removeSecurityProxy
except ZOPE_SECURITY_NOT_AVAILABLE_EX: # pragma: no cover
def removeSecurityProxy(x):
return x
from zope.interface.interfaces import ComponentLookupError
from zope.interface.interfaces import IComponentLookup
from zope.component.globalregistry import getGlobalSiteManager
__all__ = [
'setSite',
'getSite',
'site',
'getSiteManager',
'setHooks',
'resetHooks',
]
class read_property:
"""Descriptor for property-like computed attributes.
Unlike the standard 'property', this descriptor allows assigning a
value to the instance, shadowing the property getter function.
"""
def __init__(self, func):
self.func = func
def __get__(self, inst, cls):
if inst is None:
return self
return self.func(inst)
class SiteInfo(threading.local):
site = None
sm = getGlobalSiteManager()
@read_property
def adapter_hook(self):
adapter_hook = self.sm.adapters.adapter_hook
self.adapter_hook = adapter_hook
return adapter_hook
siteinfo = SiteInfo()
def setSite(site=None):
if site is None:
sm = getGlobalSiteManager()
else:
# We remove the security proxy because there's no way for
# untrusted code to get at it without it being proxied again.
# We should really look look at this again though, especially
# once site managers do less. There's probably no good reason why
# they can't be proxied. Well, except maybe for performance.
site = removeSecurityProxy(site)
# The getSiteManager method is defined by IPossibleSite.
sm = site.getSiteManager()
siteinfo.site = site
siteinfo.sm = sm
try:
del siteinfo.adapter_hook
except AttributeError:
pass
def getSite():
return siteinfo.site
@contextlib.contextmanager
def site(site):
"""
site(site) -> None
Context manager that sets *site* as the current site for the
duration of the ``with`` body.
"""
old_site = getSite()
setSite(site)
try:
yield
finally:
setSite(old_site)
def getSiteManager(context=None):
"""A special hook for getting the site manager.
Here we take the currently set site into account to find the appropriate
site manager.
"""
if context is None:
return siteinfo.sm
# We remove the security proxy because there's no way for
# untrusted code to get at it without it being proxied again.
# We should really look look at this again though, especially
# once site managers do less. There's probably no good reason why
# they can't be proxied. Well, except maybe for performance.
sm = IComponentLookup(
context, getGlobalSiteManager())
sm = removeSecurityProxy(sm)
return sm
def adapter_hook(interface, object, name='', default=None):
try:
return siteinfo.adapter_hook(interface, object, name, default)
except ComponentLookupError:
return default
def setHooks():
"""
Make `zope.component.getSiteManager` and interface adaptation
respect the current site.
Most applications will want to be sure te call this early in their
startup sequence. Test code that uses these APIs should also arrange to
call this.
.. seealso:: :mod:`zope.component.testlayer`
"""
from zope.component import _api
_api.adapter_hook.sethook(adapter_hook)
_api.getSiteManager.sethook(getSiteManager)
def resetHooks():
"""
Reset `zope.component.getSiteManager` and interface adaptation to
their original implementations that are unaware of the current
site.
Use caution when calling this; most code will not need to call
this. If code using the global API executes following this, it
will most likely use the base global component registry instead of
a site-specific registry it was expected. This can lead to
failures in adaptation and utility lookup.
"""
# Reset hookable functions to original implementation.
from zope.component import _api
_api.adapter_hook.reset()
_api.getSiteManager.reset()
# be sure the old adapter hook isn't cached, since
# it is derived from the SiteManager
try:
del siteinfo.adapter_hook
except AttributeError:
pass
# Clear the site thread global
clearSite = setSite
try:
from zope.testing.cleanup import addCleanUp
except ImportError: # pragma: no cover
pass
else:
addCleanUp(resetHooks)
|
PypiClean
|
/interval_tree-0.3.4.tar.gz/interval_tree-0.3.4/README.md
|
[](https://travis-ci.org/moonso/interval_tree)
# Interval Tree #
Just a python implementation of interval tree.
##Description##
An interval tree is a data structure that is built of intervals with id:s.
One can query the interval tree with an interval and get the ids of the overlapping intervals.
##Usage##
An interval tree is created from a list of lists and the start and stop of the interval tree.
The sublist looks like ```[<interval_start>, <interval_stop>, <interval_id>]```.
Start is the lower bound of the intervals and stop is the upper bound.
The interval trees is then queried with a list that represents an interval and returns the ids of the overlapping intervals.
```python
from interval_tree import IntervalTree
features = [
[20,400,'id01'],
[30,400,'id02'],
[500,700,'id03'],
[1020,2400,'id04'],
[35891,29949,'id05'],
[899999,900000,'id06'],
[999000,999000,'id07']
]
my_tree = IntervalTree(features, 1, 1000000)
print('Ranges between 0 and 10: %s' % my_tree.find_range([0, 10]))
>Ranges between 0 and 10: []
print('Ranges between 0 and 20: %s' % my_tree.find_range([0, 20]))
>Ranges between 0 and 10: ['id01]
print('Ranges between 200 and 1200: %s' % my_tree.find_range([200, 1200]))
>Ranges between 200 and 1200: ['id01', 'id02', 'id03']
print('Range in only position 90000: %s' % my_tree.find_range([900000, 900000]))
>Range in only position 90000: ['id04']
print('Range in only position 300: %s' % my_tree.find_range([300, 300]))
>Range in only position 300: ['id01', 'id02']
```
|
PypiClean
|
/jupyterhub_url_sharing-0.1.0.tar.gz/jupyterhub_url_sharing-0.1.0/node_modules/@blueprintjs/core/lib/esnext/components/toast/toast.js
|
import { __decorate } from "tslib";
import classNames from "classnames";
import * as React from "react";
import { polyfill } from "react-lifecycles-compat";
import { AbstractPureComponent2, Classes } from "../../common";
import { DISPLAYNAME_PREFIX } from "../../common/props";
import { ButtonGroup } from "../button/buttonGroup";
import { AnchorButton, Button } from "../button/buttons";
import { Icon } from "../icon/icon";
let Toast = class Toast extends AbstractPureComponent2 {
static defaultProps = {
className: "",
message: "",
timeout: 5000,
};
static displayName = `${DISPLAYNAME_PREFIX}.Toast`;
render() {
const { className, icon, intent, message } = this.props;
return (React.createElement("div", { className: classNames(Classes.TOAST, Classes.intentClass(intent), className), onBlur: this.startTimeout, onFocus: this.clearTimeouts, onMouseEnter: this.clearTimeouts, onMouseLeave: this.startTimeout, tabIndex: 0 },
React.createElement(Icon, { icon: icon }),
React.createElement("span", { className: Classes.TOAST_MESSAGE }, message),
React.createElement(ButtonGroup, { minimal: true },
this.maybeRenderActionButton(),
React.createElement(Button, { "aria-label": "Close", icon: "cross", onClick: this.handleCloseClick }))));
}
componentDidMount() {
this.startTimeout();
}
componentDidUpdate(prevProps) {
if (prevProps.timeout !== this.props.timeout) {
if (this.props.timeout > 0) {
this.startTimeout();
}
else {
this.clearTimeouts();
}
}
}
componentWillUnmount() {
this.clearTimeouts();
}
maybeRenderActionButton() {
const { action } = this.props;
if (action == null) {
return undefined;
}
else {
return React.createElement(AnchorButton, { ...action, intent: undefined, onClick: this.handleActionClick });
}
}
handleActionClick = (e) => {
this.props.action?.onClick?.(e);
this.triggerDismiss(false);
};
handleCloseClick = () => this.triggerDismiss(false);
triggerDismiss(didTimeoutExpire) {
this.clearTimeouts();
this.props.onDismiss?.(didTimeoutExpire);
}
startTimeout = () => {
this.clearTimeouts();
if (this.props.timeout > 0) {
this.setTimeout(() => this.triggerDismiss(true), this.props.timeout);
}
};
};
Toast = __decorate([
polyfill
], Toast);
export { Toast };
//# sourceMappingURL=toast.js.map
|
PypiClean
|
/temporai-0.0.2-py3-none-any.whl/tempor/plugins/pipeline/__init__.py
|
import abc
from typing import Any, Dict, List, NoReturn, Optional, Tuple, Type
import omegaconf
import rich.pretty
from typing_extensions import Self
from tempor.data import dataset
from tempor.log import logger
from tempor.plugins import plugin_loader
from tempor.plugins.core._params import Params
from tempor.plugins.prediction.one_off.classification import BaseOneOffClassifier
from tempor.plugins.prediction.one_off.regression import BaseOneOffRegressor
from tempor.plugins.prediction.temporal.classification import BaseTemporalClassifier
from tempor.plugins.prediction.temporal.regression import BaseTemporalRegressor
from tempor.plugins.time_to_event import BaseTimeToEventAnalysis
from tempor.plugins.treatments.one_off import BaseOneOffTreatmentEffects
from tempor.plugins.treatments.temporal import BaseTemporalTreatmentEffects
from .generators import (
_generate_constructor,
_generate_fit,
_generate_hyperparameter_space_for_step_impl,
_generate_hyperparameter_space_impl,
_generate_pipeline_seq_impl,
_generate_predict,
_generate_predict_counterfactuals,
_generate_predict_proba,
_generate_sample_hyperparameters_impl,
)
BASE_CLASS_CANDIDATES = (
BaseOneOffClassifier,
BaseOneOffRegressor,
BaseTemporalClassifier,
BaseTemporalRegressor,
BaseTimeToEventAnalysis,
BaseOneOffTreatmentEffects,
BaseTemporalTreatmentEffects,
)
# TODO: Consider allowing transform-only pipelines.
class PipelineBase:
stages: List
"""A list of method plugin instances corresponding to each step in the pipeline."""
plugin_types: List[Type]
"""A list of types denoting the class of each step in the pipeline."""
def __init__(self, plugin_params: Optional[Dict[str, Dict]] = None, **kwargs) -> None: # pragma: no cover
"""Instantiate the pipeline, (optionally) providing initialization parameters for constituent step plugins.
Note:
The implementations of the methods on this class (``fit``, ``sample_hyperparameters``, etc.) are
auto-generated by the :class:`PipelineMeta` metaclass.
Args:
plugin_params (Optional[Dict[str, Dict]], optional):
A dictionary like ``{"plugin_1_name": {"init_param_1": value, ...}, ...}``. Defaults to None.
"""
raise NotImplementedError("Not implemented")
@staticmethod
def pipeline_seq(*args: Any) -> str: # pragma: no cover
"""Get a string representation of the pipeline, stating each stage plugin, e.g. like:
``'preprocessing.imputation.temporal.bfill->...->prediction.one_off.classification.nn_classifier'``
Returns:
str: String representation of the pipeline.
"""
raise NotImplementedError("Not implemented")
@staticmethod
def hyperparameter_space(*args: Any, **kwargs: Any) -> Dict[str, List[Params]]: # pragma: no cover
"""The pipeline version of the estimator static method of the same name. All the hyperparameters of the
different stages will be returned.
Returns:
Dict[str, List[Params]]: A dictionary with each stage plugin names as keys and corresponding hyperparameter\
space (``List[Params]``) as values.
"""
raise NotImplementedError("Not implemented")
@staticmethod
def hyperparameter_space_for_step(name: str, *args: Any, **kwargs: Any) -> List[Params]: # pragma: no cover
"""Return the hyperparameter space (``List[Params]``) for the step of the pipeline as specified by ``name``.
Args:
name (str): Name of the pipeline step (i.e. the name of the underlying plugin).
Returns:
List[Params]: the hyperparameter space for the step of the pipeline.
"""
raise NotImplementedError("Not implemented")
@classmethod
def sample_hyperparameters(
cls, *args: Any, override: Optional[List[Params]] = None, **kwargs: Any
) -> Dict[str, Any]: # pragma: no cover
"""The pipeline version of the estimator method of the same name. Returns a hyperparameter sample.
Returns:
Dict[str, Any]: a dictionary with hyperparameter names as keys and corresponding hyperparameter samples\
as values.
"""
raise NotImplementedError("Not implemented")
def fit(self, data: dataset.BaseDataset, *args: Any, **kwargs: Any) -> Self: # pragma: no cover
"""The pipeline version of the estimator ``fit`` method.
By analogy to `sklearn`, under the hood, ``fit_transform`` will be called on all the pipeline steps except
for the last one (the transformer steps of the pipeline), and `fit` will be called on the last step
(the predictive step of the pipeline).
Args:
data (dataset.BaseDataset): Input dataset.
Returns:
Self: Returns the fitted pipeline itself.
"""
raise NotImplementedError("Not implemented")
def predict(self, data: dataset.PredictiveDataset, *args: Any, **kwargs: Any) -> Any: # pragma: no cover
"""The pipeline version of the estimator ``predict`` method. Applicable if the final step of the pipeline has
a ``predict`` method implemented.
Args:
data (dataset.PredictiveDataset): Input dataset.
Returns:
Any: the same return type as the final step of the pipeline.
"""
raise NotImplementedError("Not implemented")
def predict_proba(self, data: dataset.PredictiveDataset, *args: Any, **kwargs: Any) -> Any: # pragma: no cover
"""The pipeline version of the estimator ``predict_proba`` method. Applicable if the final step of the pipeline
has a ``predict_proba`` method implemented.
Args:
data (dataset.PredictiveDataset): Input dataset.
Returns:
Any: the same return type as the final step of the pipeline.
"""
raise NotImplementedError("Not implemented")
def predict_counterfactuals(
self, data: dataset.PredictiveDataset, *args: Any, **kwargs: Any
) -> Any: # pragma: no cover
"""The pipeline version of the estimator ``predict_counterfactuals`` method. Applicable if the final step of
the pipeline has a ``predict_counterfactuals`` method implemented.
Args:
data (dataset.PredictiveDataset): Input dataset.
Returns:
Any: the same return type as the final step of the pipeline.
"""
raise NotImplementedError("Not implemented")
@property
def predictor_category(self) -> str:
return self.plugin_types[-1].category
@property
def params(self) -> Dict[str, omegaconf.DictConfig]:
out = dict()
for p in self.stages:
out[p.name] = p.params
return out
def __rich_repr__(self):
yield "pipeline_seq", self.pipeline_seq()
yield "predictor_category", self.predictor_category
yield "params", {k: omegaconf.OmegaConf.to_container(v) for k, v in self.params.items()}
def __repr__(self) -> str:
return rich.pretty.pretty_repr(self)
def prepend_base(base: Type, bases: List[Type]) -> List[Type]:
if base in bases:
bases_final = bases
else:
bases_final = [base] + bases
return bases_final
def raise_not_implemented(*args, **kwargs) -> NoReturn:
raise NotImplementedError("The `{_fit/predict/...}` methods are not implemented for the pipelines")
class PipelineMeta(abc.ABCMeta):
def __new__(
cls: Any,
__name: str,
__bases: Tuple[type, ...],
__namespace: Dict[str, Any],
plugins: Tuple[Type, ...] = tuple(),
**kwds: Any,
) -> Any:
logger.debug(f"Creating pipeline defined by steps:\n{plugins}")
# Constructor:
__namespace["__init__"] = _generate_constructor()
# Pipeline-specific:
__namespace["pipeline_seq"] = _generate_pipeline_seq_impl(plugins)
# sklearn style methods:
__namespace["fit"] = _generate_fit()
__namespace["predict"] = _generate_predict()
__namespace["predict_proba"] = _generate_predict_proba()
__namespace["predict_counterfactuals"] = _generate_predict_counterfactuals()
# Hyperparameter methods:
__namespace["hyperparameter_space"] = _generate_hyperparameter_space_impl(plugins)
__namespace["hyperparameter_space_for_step"] = _generate_hyperparameter_space_for_step_impl(plugins)
__namespace["sample_hyperparameters"] = _generate_sample_hyperparameters_impl(plugins)
# Non-method attributes:
__namespace["plugin_types"] = list(plugins)
# Process base classes appropriately.
bases = PipelineMeta.parse_bases(__bases, plugins)
logger.debug(f"Pipeline base classes identified as:\n{bases}")
# Avoid ABC error from the lack of _sk* method implementations.
__namespace["_fit"] = raise_not_implemented
__namespace["_predict"] = raise_not_implemented
__namespace["_predict_proba"] = raise_not_implemented
__namespace["_predict_counterfactuals"] = raise_not_implemented
return super().__new__(cls, __name, bases, __namespace, **kwds)
@staticmethod
def parse_bases(bases: Tuple[type, ...], plugins: Tuple[Type, ...]):
bases_final: List[Type] = list(bases)
if len(plugins) > 0:
predictive_step = plugins[-1]
for base_class in BASE_CLASS_CANDIDATES:
if issubclass(predictive_step, base_class):
bases_final = prepend_base(base_class, bases_final)
bases_final = prepend_base(PipelineBase, bases_final)
return tuple(bases_final)
def pipeline_classes(names: List[str]) -> Tuple[Type, ...]:
"""Return a list sequence of method plugin classes based on a sequence of fully-qualified ``names`` provided.
Args:
names (List[str]): A sequence of fully-qualified names of method plugins, corresponding to pipeline steps.
Returns:
Tuple[Type, ...]: The corresponding sequence of method plugin classes.
"""
res = []
for fqn in names:
if "." not in fqn:
raise RuntimeError(f"Invalid fqn: {fqn}")
res.append(plugin_loader.get_class(fqn))
return tuple(res)
def pipeline(plugins_str: List[str]) -> Type[PipelineBase]:
"""Use this method to create pipelines.
Generates a pipeline (:class:`PipelineBase`) class with an implementation of the necessary methods
(``fit``, ``sample_hyperparameters`` etc.), based on a sequence of steps defined by ``plugins_str``.
All but the last steps must be data transformer plugins, and the last step must be a predictive method plugin.
This method will return a pipeline class (``Type[PipelineBase]``), which should be instantiated. At time of
instantiation, ``__init__`` input parameters for each step's method plugin can be provided. See
:class:`PipelineBase` for details.
Args:
plugins_str (List[str]):
A sequence of method plugins' fully-qualified names (e.g.
``"prediction.one_off.classification.nn_classifier"``).
Returns:
Type[PipelineBase]: The pipeline class (not instance) is returned.
"""
plugins = pipeline_classes(plugins_str)
class Pipeline(metaclass=PipelineMeta, plugins=plugins):
pass
return Pipeline # type: ignore
|
PypiClean
|
/bika.lims-3.2.1rc1.tar.gz/bika.lims-3.2.1rc1/bika/lims/content/srtemplate.py
|
from AccessControl import ClassSecurityInfo
from bika.lims import bikaMessageFactory as _
from bika.lims.utils import t, getUsers
from bika.lims.browser.widgets import RecordsWidget as BikaRecordsWidget
from bika.lims.browser.widgets import SRTemplateARTemplatesWidget
from bika.lims.config import PROJECTNAME
from bika.lims.content.bikaschema import BikaSchema
from bika.lims.idserver import renameAfterCreation
from Products.Archetypes.public import *
from Products.Archetypes.references import HoldingReference
from Products.ATExtensions.field.records import RecordsField
from bika.lims.interfaces import ISamplingRoundTemplate
from Products.CMFCore.utils import getToolByName
from zope.interface import implements
import sys
schema = BikaSchema.copy() + Schema((
# The default sampler for the rounds
StringField('Sampler',
required=1,
searchable=True,
vocabulary='_getSamplersDisplayList',
widget=SelectionWidget(
format='select',
label = _("Sampler"),
),
),
# The department responsible for the sampling round
ReferenceField('Department',
required=1,
vocabulary_display_path_bound=sys.maxint,
allowed_types=('Department',),
vocabulary='_getDepartmentsDisplayList',
relationship='SRTemplateDepartment',
referenceClass=HoldingReference,
widget=ReferenceWidget(
checkbox_bound=0,
label = _("Department"),
description = _("The laboratory department"),
catalog_name='bika_setup_catalog',
base_query={'inactive_state': 'active'},
),
),
# The number of days between recurring field trips
IntegerField('SamplingDaysFrequency',
required=1,
default=7,
widget=IntegerWidget(
label = _("Sampling Frequency"),
description=_(
"The number of days between recurring field trips"),
),
),
TextField('Instructions',
searchable = True,
default_content_type = 'text/plain',
allowed_content_types= ('text/plain'),
default_output_type="text/plain",
widget = TextAreaWidget(
label=_("Instructions"),
append_only = False,
),
),
ReferenceField('ARTemplates',
schemata = 'AR Templates',
required = 1,
multiValued = 1,
allowed_types = ('ARTemplate',),
relationship = 'SRTemplateARTemplate',
widget = SRTemplateARTemplatesWidget(
label=_("AR Templates"),
description=_("Select AR Templates to include"),
)
),
))
schema['description'].widget.visible = True
schema['title'].widget.visible = True
schema['title'].validators = ('uniquefieldvalidator',)
# Update the validation layer after change the validator in runtime
schema['title']._validationLayer()
class SRTemplate(BaseContent):
implements(ISamplingRoundTemplate)
security = ClassSecurityInfo()
schema = schema
displayContentsTab = False
_at_rename_after_creation = True
def _renameAfterCreation(self, check_auto_id=False):
renameAfterCreation(self)
def _getSamplersDisplayList(self):
""" Returns the available users in the system with the roles
'LabManager' and/or 'Sampler'
"""
return getUsers(self, ['LabManager', 'Sampler'])
def _getDepartmentsDisplayList(self):
""" Returns the available departments in the system. Only the
active departments are shown, unless the object has an
inactive department already assigned.
"""
bsc = getToolByName(self, 'bika_setup_catalog')
items = [('', '')] + [(o.UID, o.Title) for o in
bsc(portal_type='Department',
inactive_state='active')]
o = self.getDepartment()
if o and o.UID() not in [i[0] for i in items]:
items.append((o.UID(), o.Title()))
items.sort(lambda x, y: cmp(x[1], y[1]))
return DisplayList(list(items))
registerType(SRTemplate, PROJECTNAME)
|
PypiClean
|
/pennylane_catalyst-0.3.0-cp311-cp311-macosx_13_0_arm64.whl/mlir_quantum/dialects/_ods_common.py
|
# Provide a convenient name for sub-packages to resolve the main C-extension
# with a relative import.
from .._mlir_libs import _mlir as _cext
from typing import Sequence as _Sequence, Union as _Union
__all__ = [
"equally_sized_accessor",
"extend_opview_class",
"get_default_loc_context",
"get_op_result_or_value",
"get_op_results_or_values",
"segmented_accessor",
]
def extend_opview_class(ext_module):
"""Decorator to extend an OpView class from an extension module.
Extension modules can expose various entry-points:
Stand-alone class with the same name as a parent OpView class (i.e.
"ReturnOp"). A name-based match is attempted first before falling back
to a below mechanism.
def select_opview_mixin(parent_opview_cls):
If defined, allows an appropriate mixin class to be selected dynamically
based on the parent OpView class. Should return NotImplemented if a
decision is not made.
Args:
ext_module: A module from which to locate extensions. Can be None if not
available.
Returns:
A decorator that takes an OpView subclass and further extends it as
needed.
"""
def class_decorator(parent_opview_cls: type):
if ext_module is None:
return parent_opview_cls
mixin_cls = NotImplemented
# First try to resolve by name.
try:
mixin_cls = getattr(ext_module, parent_opview_cls.__name__)
except AttributeError:
# Fall back to a select_opview_mixin hook.
try:
select_mixin = getattr(ext_module, "select_opview_mixin")
except AttributeError:
pass
else:
mixin_cls = select_mixin(parent_opview_cls)
if mixin_cls is NotImplemented or mixin_cls is None:
return parent_opview_cls
# Have a mixin_cls. Create an appropriate subclass.
try:
class LocalOpView(mixin_cls, parent_opview_cls):
pass
except TypeError as e:
raise TypeError(
f"Could not mixin {mixin_cls} into {parent_opview_cls}"
) from e
LocalOpView.__name__ = parent_opview_cls.__name__
LocalOpView.__qualname__ = parent_opview_cls.__qualname__
return LocalOpView
return class_decorator
def segmented_accessor(elements, raw_segments, idx):
"""
Returns a slice of elements corresponding to the idx-th segment.
elements: a sliceable container (operands or results).
raw_segments: an mlir.ir.Attribute, of DenseI32Array subclass containing
sizes of the segments.
idx: index of the segment.
"""
segments = _cext.ir.DenseI32ArrayAttr(raw_segments)
start = sum(segments[i] for i in range(idx))
end = start + segments[idx]
return elements[start:end]
def equally_sized_accessor(
elements, n_variadic, n_preceding_simple, n_preceding_variadic
):
"""
Returns a starting position and a number of elements per variadic group
assuming equally-sized groups and the given numbers of preceding groups.
elements: a sequential container.
n_variadic: the number of variadic groups in the container.
n_preceding_simple: the number of non-variadic groups preceding the current
group.
n_preceding_variadic: the number of variadic groups preceding the current
group.
"""
total_variadic_length = len(elements) - n_variadic + 1
# This should be enforced by the C++-side trait verifier.
assert total_variadic_length % n_variadic == 0
elements_per_group = total_variadic_length // n_variadic
start = n_preceding_simple + n_preceding_variadic * elements_per_group
return start, elements_per_group
def get_default_loc_context(location=None):
"""
Returns a context in which the defaulted location is created. If the location
is None, takes the current location from the stack, raises ValueError if there
is no location on the stack.
"""
if location is None:
# Location.current raises ValueError if there is no current location.
return _cext.ir.Location.current.context
return location.context
def get_op_result_or_value(
arg: _Union[
_cext.ir.OpView, _cext.ir.Operation, _cext.ir.Value, _cext.ir.OpResultList
]
) -> _cext.ir.Value:
"""Returns the given value or the single result of the given op.
This is useful to implement op constructors so that they can take other ops as
arguments instead of requiring the caller to extract results for every op.
Raises ValueError if provided with an op that doesn't have a single result.
"""
if isinstance(arg, _cext.ir.OpView):
return arg.operation.result
elif isinstance(arg, _cext.ir.Operation):
return arg.result
elif isinstance(arg, _cext.ir.OpResultList):
return arg[0]
else:
assert isinstance(arg, _cext.ir.Value)
return arg
def get_op_results_or_values(
arg: _Union[
_cext.ir.OpView,
_cext.ir.Operation,
_Sequence[_Union[_cext.ir.OpView, _cext.ir.Operation, _cext.ir.Value]],
]
) -> _Union[_Sequence[_cext.ir.Value], _cext.ir.OpResultList]:
"""Returns the given sequence of values or the results of the given op.
This is useful to implement op constructors so that they can take other ops as
lists of arguments instead of requiring the caller to extract results for
every op.
"""
if isinstance(arg, _cext.ir.OpView):
return arg.operation.results
elif isinstance(arg, _cext.ir.Operation):
return arg.results
else:
return [get_op_result_or_value(element) for element in arg]
|
PypiClean
|
/Auto_Python_2014-14.1.5.zip/Auto_Python_2014-14.1.5/util/util.py
|
from __future__ import absolute_import, division, with_statement
import zlib
class ObjectDict(dict):
"""Makes a dictionary behave like an object."""
def __getattr__(self, name):
try:
return self[name]
except KeyError:
raise AttributeError(name)
def __setattr__(self, name, value):
self[name] = value
class GzipDecompressor(object):
"""Streaming gzip decompressor.
The interface is like that of `zlib.decompressobj` (without the
optional arguments, but it understands gzip headers and checksums.
"""
def __init__(self):
# Magic parameter makes zlib module understand gzip header
# http://stackoverflow.com/questions/1838699/how-can-i-decompress-a-gzip-stream-with-zlib
# This works on cpython and pypy, but not jython.
self.decompressobj = zlib.decompressobj(16 + zlib.MAX_WBITS)
def decompress(self, value):
"""Decompress a chunk, returning newly-available data.
Some data may be buffered for later processing; `flush` must
be called when there is no more input data to ensure that
all data was processed.
"""
return self.decompressobj.decompress(value)
def flush(self):
"""Return any remaining buffered data not yet returned by decompress.
Also checks for errors such as truncated input.
No other methods may be called on this object after `flush`.
"""
return self.decompressobj.flush()
def import_object(name):
"""Imports an object by name.
import_object('x.y.z') is equivalent to 'from x.y import z'.
>>> import tornado.escape
>>> import_object('tornado.escape') is tornado.escape
True
>>> import_object('tornado.escape.utf8') is tornado.escape.utf8
True
"""
parts = name.split('.')
obj = __import__('.'.join(parts[:-1]), None, None, [parts[-1]], 0)
return getattr(obj, parts[-1])
# Fake byte literal support: In python 2.6+, you can say b"foo" to get
# a byte literal (str in 2.x, bytes in 3.x). There's no way to do this
# in a way that supports 2.5, though, so we need a function wrapper
# to convert our string literals. b() should only be applied to literal
# latin1 strings. Once we drop support for 2.5, we can remove this function
# and just use byte literals.
if str is unicode:
def b(s):
return s.encode('latin1')
bytes_type = bytes
else:
def b(s):
return s
bytes_type = str
def raise_exc_info(exc_info):
"""Re-raise an exception (with original traceback) from an exc_info tuple.
The argument is a ``(type, value, traceback)`` tuple as returned by
`sys.exc_info`.
"""
# 2to3 isn't smart enough to convert three-argument raise
# statements correctly in some cases.
if isinstance(exc_info[1], exc_info[0]):
raise exc_info[1], None, exc_info[2]
# After 2to3: raise exc_info[1].with_traceback(exc_info[2])
else:
# I think this branch is only taken for string exceptions,
# which were removed in Python 2.6.
raise exc_info[0], exc_info[1], exc_info[2]
# After 2to3: raise exc_info[0](exc_info[1]).with_traceback(exc_info[2])
def doctests():
import doctest
return doctest.DocTestSuite()
|
PypiClean
|
/Pygmie-1.4.tar.gz/Pygmie-1.4/pygmie/static/ace/mode-javascript.js
|
define('ace/mode/javascript', ['require', 'exports', 'module' , 'ace/lib/oop', 'ace/mode/text', 'ace/tokenizer', 'ace/mode/javascript_highlight_rules', 'ace/mode/matching_brace_outdent', 'ace/range', 'ace/worker/worker_client', 'ace/mode/behaviour/cstyle', 'ace/mode/folding/cstyle'], function(require, exports, module) {
var oop = require("../lib/oop");
var TextMode = require("./text").Mode;
var Tokenizer = require("../tokenizer").Tokenizer;
var JavaScriptHighlightRules = require("./javascript_highlight_rules").JavaScriptHighlightRules;
var MatchingBraceOutdent = require("./matching_brace_outdent").MatchingBraceOutdent;
var Range = require("../range").Range;
var WorkerClient = require("../worker/worker_client").WorkerClient;
var CstyleBehaviour = require("./behaviour/cstyle").CstyleBehaviour;
var CStyleFoldMode = require("./folding/cstyle").FoldMode;
var Mode = function() {
this.$tokenizer = new Tokenizer(new JavaScriptHighlightRules().getRules());
this.$outdent = new MatchingBraceOutdent();
this.$behaviour = new CstyleBehaviour();
this.foldingRules = new CStyleFoldMode();
};
oop.inherits(Mode, TextMode);
(function() {
this.toggleCommentLines = function(state, doc, startRow, endRow) {
var outdent = true;
var re = /^(\s*)\/\//;
for (var i=startRow; i<= endRow; i++) {
if (!re.test(doc.getLine(i))) {
outdent = false;
break;
}
}
if (outdent) {
var deleteRange = new Range(0, 0, 0, 0);
for (var i=startRow; i<= endRow; i++)
{
var line = doc.getLine(i);
var m = line.match(re);
deleteRange.start.row = i;
deleteRange.end.row = i;
deleteRange.end.column = m[0].length;
doc.replace(deleteRange, m[1]);
}
}
else {
doc.indentRows(startRow, endRow, "//");
}
};
this.getNextLineIndent = function(state, line, tab) {
var indent = this.$getIndent(line);
var tokenizedLine = this.$tokenizer.getLineTokens(line, state);
var tokens = tokenizedLine.tokens;
var endState = tokenizedLine.state;
if (tokens.length && tokens[tokens.length-1].type == "comment") {
return indent;
}
if (state == "start" || state == "regex_allowed") {
var match = line.match(/^.*(?:\bcase\b.*\:|[\{\(\[])\s*$/);
if (match) {
indent += tab;
}
} else if (state == "doc-start") {
if (endState == "start" || state == "regex_allowed") {
return "";
}
var match = line.match(/^\s*(\/?)\*/);
if (match) {
if (match[1]) {
indent += " ";
}
indent += "* ";
}
}
return indent;
};
this.checkOutdent = function(state, line, input) {
return this.$outdent.checkOutdent(line, input);
};
this.autoOutdent = function(state, doc, row) {
this.$outdent.autoOutdent(doc, row);
};
this.createWorker = function(session) {
var worker = new WorkerClient(["ace"], "ace/mode/javascript_worker", "JavaScriptWorker");
worker.attachToDocument(session.getDocument());
worker.on("jslint", function(results) {
session.setAnnotations(results.data);
});
worker.on("terminate", function() {
session.clearAnnotations();
});
return worker;
};
}).call(Mode.prototype);
exports.Mode = Mode;
});
define('ace/mode/javascript_highlight_rules', ['require', 'exports', 'module' , 'ace/lib/oop', 'ace/mode/doc_comment_highlight_rules', 'ace/mode/text_highlight_rules'], function(require, exports, module) {
var oop = require("../lib/oop");
var DocCommentHighlightRules = require("./doc_comment_highlight_rules").DocCommentHighlightRules;
var TextHighlightRules = require("./text_highlight_rules").TextHighlightRules;
var JavaScriptHighlightRules = function() {
var keywordMapper = this.createKeywordMapper({
"variable.language":
"Array|Boolean|Date|Function|Iterator|Number|Object|RegExp|String|Proxy|" + // Constructors
"Namespace|QName|XML|XMLList|" + // E4X
"ArrayBuffer|Float32Array|Float64Array|Int16Array|Int32Array|Int8Array|" +
"Uint16Array|Uint32Array|Uint8Array|Uint8ClampedArray|" +
"Error|EvalError|InternalError|RangeError|ReferenceError|StopIteration|" + // Errors
"SyntaxError|TypeError|URIError|" +
"decodeURI|decodeURIComponent|encodeURI|encodeURIComponent|eval|isFinite|" + // Non-constructor functions
"isNaN|parseFloat|parseInt|" +
"JSON|Math|" + // Other
"this|arguments|prototype|window|document" , // Pseudo
"keyword":
"const|yield|import|get|set|" +
"break|case|catch|continue|default|delete|do|else|finally|for|function|" +
"if|in|instanceof|new|return|switch|throw|try|typeof|let|var|while|with|debugger|" +
"__parent__|__count__|escape|unescape|with|__proto__|" +
"class|enum|extends|super|export|implements|private|public|interface|package|protected|static",
"storage.type":
"const|let|var|function",
"constant.language":
"null|Infinity|NaN|undefined",
"support.function":
"alert",
"constant.language.boolean": "true|false"
}, "identifier");
var kwBeforeRe = "case|do|else|finally|in|instanceof|return|throw|try|typeof|yield|void";
var identifierRe = "[a-zA-Z\\$_\u00a1-\uffff][a-zA-Z\\d\\$_\u00a1-\uffff]*\\b";
var escapedRe = "\\\\(?:x[0-9a-fA-F]{2}|" + // hex
"u[0-9a-fA-F]{4}|" + // unicode
"[0-2][0-7]{0,2}|" + // oct
"3[0-6][0-7]?|" + // oct
"37[0-7]?|" + // oct
"[4-7][0-7]?|" + //oct
".)";
this.$rules = {
"start" : [
{
token : "comment",
regex : /\/\/.*$/
},
DocCommentHighlightRules.getStartRule("doc-start"),
{
token : "comment", // multi line comment
regex : /\/\*/,
next : "comment"
}, {
token : "string",
regex : "'(?=.)",
next : "qstring"
}, {
token : "string",
regex : '"(?=.)',
next : "qqstring"
}, {
token : "constant.numeric", // hex
regex : /0[xX][0-9a-fA-F]+\b/
}, {
token : "constant.numeric", // float
regex : /[+-]?\d+(?:(?:\.\d*)?(?:[eE][+-]?\d+)?)?\b/
}, {
token : [
"storage.type", "punctuation.operator", "support.function",
"punctuation.operator", "entity.name.function", "text","keyword.operator"
],
regex : "(" + identifierRe + ")(\\.)(prototype)(\\.)(" + identifierRe +")(\\s*)(=)",
next: "function_arguments"
}, {
token : [
"storage.type", "punctuation.operator", "entity.name.function", "text",
"keyword.operator", "text", "storage.type", "text", "paren.lparen"
],
regex : "(" + identifierRe + ")(\\.)(" + identifierRe +")(\\s*)(=)(\\s*)(function)(\\s*)(\\()",
next: "function_arguments"
}, {
token : [
"entity.name.function", "text", "keyword.operator", "text", "storage.type",
"text", "paren.lparen"
],
regex : "(" + identifierRe +")(\\s*)(=)(\\s*)(function)(\\s*)(\\()",
next: "function_arguments"
}, {
token : [
"storage.type", "punctuation.operator", "entity.name.function", "text",
"keyword.operator", "text",
"storage.type", "text", "entity.name.function", "text", "paren.lparen"
],
regex : "(" + identifierRe + ")(\\.)(" + identifierRe +")(\\s*)(=)(\\s*)(function)(\\s+)(\\w+)(\\s*)(\\()",
next: "function_arguments"
}, {
token : [
"storage.type", "text", "entity.name.function", "text", "paren.lparen"
],
regex : "(function)(\\s+)(" + identifierRe + ")(\\s*)(\\()",
next: "function_arguments"
}, {
token : [
"entity.name.function", "text", "punctuation.operator",
"text", "storage.type", "text", "paren.lparen"
],
regex : "(" + identifierRe + ")(\\s*)(:)(\\s*)(function)(\\s*)(\\()",
next: "function_arguments"
}, {
token : [
"text", "text", "storage.type", "text", "paren.lparen"
],
regex : "(:)(\\s*)(function)(\\s*)(\\()",
next: "function_arguments"
}, {
token : "keyword",
regex : "(?:" + kwBeforeRe + ")\\b",
next : "regex_allowed"
}, {
token : ["punctuation.operator", "support.function"],
regex : /(\.)(s(?:h(?:ift|ow(?:Mod(?:elessDialog|alDialog)|Help))|croll(?:X|By(?:Pages|Lines)?|Y|To)?|t(?:opzzzz|rike)|i(?:n|zeToContent|debar|gnText)|ort|u(?:p|b(?:str(?:ing)?)?)|pli(?:ce|t)|e(?:nd|t(?:Re(?:sizable|questHeader)|M(?:i(?:nutes|lliseconds)|onth)|Seconds|Ho(?:tKeys|urs)|Year|Cursor|Time(?:out)?|Interval|ZOptions|Date|UTC(?:M(?:i(?:nutes|lliseconds)|onth)|Seconds|Hours|Date|FullYear)|FullYear|Active)|arch)|qrt|lice|avePreferences|mall)|h(?:ome|andleEvent)|navigate|c(?:har(?:CodeAt|At)|o(?:s|n(?:cat|textual|firm)|mpile)|eil|lear(?:Timeout|Interval)?|a(?:ptureEvents|ll)|reate(?:StyleSheet|Popup|EventObject))|t(?:o(?:GMTString|S(?:tring|ource)|U(?:TCString|pperCase)|Lo(?:caleString|werCase))|est|a(?:n|int(?:Enabled)?))|i(?:s(?:NaN|Finite)|ndexOf|talics)|d(?:isableExternalCapture|ump|etachEvent)|u(?:n(?:shift|taint|escape|watch)|pdateCommands)|j(?:oin|avaEnabled)|p(?:o(?:p|w)|ush|lugins.refresh|a(?:ddings|rse(?:Int|Float)?)|r(?:int|ompt|eference))|e(?:scape|nableExternalCapture|val|lementFromPoint|x(?:p|ec(?:Script|Command)?))|valueOf|UTC|queryCommand(?:State|Indeterm|Enabled|Value)|f(?:i(?:nd|le(?:ModifiedDate|Size|CreatedDate|UpdatedDate)|xed)|o(?:nt(?:size|color)|rward)|loor|romCharCode)|watch|l(?:ink|o(?:ad|g)|astIndexOf)|a(?:sin|nchor|cos|t(?:tachEvent|ob|an(?:2)?)|pply|lert|b(?:s|ort))|r(?:ou(?:nd|teEvents)|e(?:size(?:By|To)|calc|turnValue|place|verse|l(?:oad|ease(?:Capture|Events)))|andom)|g(?:o|et(?:ResponseHeader|M(?:i(?:nutes|lliseconds)|onth)|Se(?:conds|lection)|Hours|Year|Time(?:zoneOffset)?|Da(?:y|te)|UTC(?:M(?:i(?:nutes|lliseconds)|onth)|Seconds|Hours|Da(?:y|te)|FullYear)|FullYear|A(?:ttention|llResponseHeaders)))|m(?:in|ove(?:B(?:y|elow)|To(?:Absolute)?|Above)|ergeAttributes|a(?:tch|rgins|x))|b(?:toa|ig|o(?:ld|rderWidths)|link|ack))\b(?=\()/
}, {
token : ["punctuation.operator", "support.function.dom"],
regex : /(\.)(s(?:ub(?:stringData|mit)|plitText|e(?:t(?:NamedItem|Attribute(?:Node)?)|lect))|has(?:ChildNodes|Feature)|namedItem|c(?:l(?:ick|o(?:se|neNode))|reate(?:C(?:omment|DATASection|aption)|T(?:Head|extNode|Foot)|DocumentFragment|ProcessingInstruction|E(?:ntityReference|lement)|Attribute))|tabIndex|i(?:nsert(?:Row|Before|Cell|Data)|tem)|open|delete(?:Row|C(?:ell|aption)|T(?:Head|Foot)|Data)|focus|write(?:ln)?|a(?:dd|ppend(?:Child|Data))|re(?:set|place(?:Child|Data)|move(?:NamedItem|Child|Attribute(?:Node)?)?)|get(?:NamedItem|Element(?:sBy(?:Name|TagName)|ById)|Attribute(?:Node)?)|blur)\b(?=\()/
}, {
token : ["punctuation.operator", "support.constant"],
regex : /(\.)(s(?:ystemLanguage|cr(?:ipts|ollbars|een(?:X|Y|Top|Left))|t(?:yle(?:Sheets)?|atus(?:Text|bar)?)|ibling(?:Below|Above)|ource|uffixes|e(?:curity(?:Policy)?|l(?:ection|f)))|h(?:istory|ost(?:name)?|as(?:h|Focus))|y|X(?:MLDocument|SLDocument)|n(?:ext|ame(?:space(?:s|URI)|Prop))|M(?:IN_VALUE|AX_VALUE)|c(?:haracterSet|o(?:n(?:structor|trollers)|okieEnabled|lorDepth|mp(?:onents|lete))|urrent|puClass|l(?:i(?:p(?:boardData)?|entInformation)|osed|asses)|alle(?:e|r)|rypto)|t(?:o(?:olbar|p)|ext(?:Transform|Indent|Decoration|Align)|ags)|SQRT(?:1_2|2)|i(?:n(?:ner(?:Height|Width)|put)|ds|gnoreCase)|zIndex|o(?:scpu|n(?:readystatechange|Line)|uter(?:Height|Width)|p(?:sProfile|ener)|ffscreenBuffering)|NEGATIVE_INFINITY|d(?:i(?:splay|alog(?:Height|Top|Width|Left|Arguments)|rectories)|e(?:scription|fault(?:Status|Ch(?:ecked|arset)|View)))|u(?:ser(?:Profile|Language|Agent)|n(?:iqueID|defined)|pdateInterval)|_content|p(?:ixelDepth|ort|ersonalbar|kcs11|l(?:ugins|atform)|a(?:thname|dding(?:Right|Bottom|Top|Left)|rent(?:Window|Layer)?|ge(?:X(?:Offset)?|Y(?:Offset)?))|r(?:o(?:to(?:col|type)|duct(?:Sub)?|mpter)|e(?:vious|fix)))|e(?:n(?:coding|abledPlugin)|x(?:ternal|pando)|mbeds)|v(?:isibility|endor(?:Sub)?|Linkcolor)|URLUnencoded|P(?:I|OSITIVE_INFINITY)|f(?:ilename|o(?:nt(?:Size|Family|Weight)|rmName)|rame(?:s|Element)|gColor)|E|whiteSpace|l(?:i(?:stStyleType|n(?:eHeight|kColor))|o(?:ca(?:tion(?:bar)?|lName)|wsrc)|e(?:ngth|ft(?:Context)?)|a(?:st(?:M(?:odified|atch)|Index|Paren)|yer(?:s|X)|nguage))|a(?:pp(?:MinorVersion|Name|Co(?:deName|re)|Version)|vail(?:Height|Top|Width|Left)|ll|r(?:ity|guments)|Linkcolor|bove)|r(?:ight(?:Context)?|e(?:sponse(?:XML|Text)|adyState))|global|x|m(?:imeTypes|ultiline|enubar|argin(?:Right|Bottom|Top|Left))|L(?:N(?:10|2)|OG(?:10E|2E))|b(?:o(?:ttom|rder(?:Width|RightWidth|BottomWidth|Style|Color|TopWidth|LeftWidth))|ufferDepth|elow|ackground(?:Color|Image)))\b/
}, {
token : ["storage.type", "punctuation.operator", "support.function.firebug"],
regex : /(console)(\.)(warn|info|log|error|time|timeEnd|assert)\b/
}, {
token : keywordMapper,
regex : identifierRe
}, {
token : "keyword.operator",
regex : /--|\+\+|[!$%&*+\-~]|===|==|=|!=|!==|<=|>=|<<=|>>=|>>>=|<>|<|>|!|&&|\|\||\?\:|\*=|%=|\+=|\-=|&=|\^=/,
next : "regex_allowed"
}, {
token : "punctuation.operator",
regex : /\?|\:|\,|\;|\./,
next : "regex_allowed"
}, {
token : "paren.lparen",
regex : /[\[({]/,
next : "regex_allowed"
}, {
token : "paren.rparen",
regex : /[\])}]/
}, {
token : "keyword.operator",
regex : /\/=?/,
next : "regex_allowed"
}, {
token: "comment",
regex: /^#!.*$/
}
],
"regex_allowed": [
DocCommentHighlightRules.getStartRule("doc-start"),
{
token : "comment", // multi line comment
regex : "\\/\\*",
next : "comment_regex_allowed"
}, {
token : "comment",
regex : "\\/\\/.*$"
}, {
token: "string.regexp",
regex: "\\/",
next: "regex",
}, {
token : "text",
regex : "\\s+"
}, {
token: "empty",
regex: "",
next: "start"
}
],
"regex": [
{
token: "regexp.keyword.operator",
regex: "\\\\(?:u[\\da-fA-F]{4}|x[\\da-fA-F]{2}|.)"
}, {
token: "string.regexp",
regex: "/\\w*",
next: "start",
}, {
token : "invalid",
regex: /\{\d+,?(?:\d+)?}[+*]|[+*$^?][+*]|[$^][?]|\?{3,}/
}, {
token : "constant.language.escape",
regex: /\(\?[:=!]|\)|{\d+,?(?:\d+)?}|{,\d+}|[+*]\?|[()$^+*?]/
}, {
token : "constant.language.delimiter",
regex: /\|/
}, {
token: "constant.language.escape",
regex: /\[\^?/,
next: "regex_character_class",
}, {
token: "empty",
regex: "$",
next: "start"
}, {
defaultToken: "string.regexp"
}
],
"regex_character_class": [
{
token: "regexp.keyword.operator",
regex: "\\\\(?:u[\\da-fA-F]{4}|x[\\da-fA-F]{2}|.)"
}, {
token: "constant.language.escape",
regex: "]",
next: "regex",
}, {
token: "constant.language.escape",
regex: "-"
}, {
token: "empty",
regex: "$",
next: "start"
}, {
defaultToken: "string.regexp.charachterclass"
}
],
"function_arguments": [
{
token: "variable.parameter",
regex: identifierRe
}, {
token: "punctuation.operator",
regex: "[, ]+",
}, {
token: "punctuation.operator",
regex: "$",
}, {
token: "empty",
regex: "",
next: "start"
}
],
"comment_regex_allowed" : [
{token : "comment", regex : "\\*\\/", next : "regex_allowed"},
{defaultToken : "comment"}
],
"comment" : [
{token : "comment", regex : "\\*\\/", next : "start"},
{defaultToken : "comment"}
],
"qqstring" : [
{
token : "constant.language.escape",
regex : escapedRe
}, {
token : "string",
regex : "\\\\$",
next : "qqstring",
}, {
token : "string",
regex : '"|$',
next : "start",
}, {
defaultToken: "string"
}
],
"qstring" : [
{
token : "constant.language.escape",
regex : escapedRe
}, {
token : "string",
regex : "\\\\$",
next : "qstring",
}, {
token : "string",
regex : "'|$",
next : "start",
}, {
defaultToken: "string"
}
]
};
this.embedRules(DocCommentHighlightRules, "doc-",
[ DocCommentHighlightRules.getEndRule("start") ]);
};
oop.inherits(JavaScriptHighlightRules, TextHighlightRules);
exports.JavaScriptHighlightRules = JavaScriptHighlightRules;
});
define('ace/mode/doc_comment_highlight_rules', ['require', 'exports', 'module' , 'ace/lib/oop', 'ace/mode/text_highlight_rules'], function(require, exports, module) {
var oop = require("../lib/oop");
var TextHighlightRules = require("./text_highlight_rules").TextHighlightRules;
var DocCommentHighlightRules = function() {
this.$rules = {
"start" : [ {
token : "comment.doc.tag",
regex : "@[\\w\\d_]+" // TODO: fix email addresses
}, {
token : "comment.doc.tag",
regex : "\\bTODO\\b"
}, {
defaultToken : "comment.doc"
}]
};
};
oop.inherits(DocCommentHighlightRules, TextHighlightRules);
DocCommentHighlightRules.getStartRule = function(start) {
return {
token : "comment.doc", // doc comment
regex : "\\/\\*(?=\\*)",
next : start
};
};
DocCommentHighlightRules.getEndRule = function (start) {
return {
token : "comment.doc", // closing comment
regex : "\\*\\/",
next : start
};
};
exports.DocCommentHighlightRules = DocCommentHighlightRules;
});
define('ace/mode/matching_brace_outdent', ['require', 'exports', 'module' , 'ace/range'], function(require, exports, module) {
var Range = require("../range").Range;
var MatchingBraceOutdent = function() {};
(function() {
this.checkOutdent = function(line, input) {
if (! /^\s+$/.test(line))
return false;
return /^\s*\}/.test(input);
};
this.autoOutdent = function(doc, row) {
var line = doc.getLine(row);
var match = line.match(/^(\s*\})/);
if (!match) return 0;
var column = match[1].length;
var openBracePos = doc.findMatchingBracket({row: row, column: column});
if (!openBracePos || openBracePos.row == row) return 0;
var indent = this.$getIndent(doc.getLine(openBracePos.row));
doc.replace(new Range(row, 0, row, column-1), indent);
};
this.$getIndent = function(line) {
var match = line.match(/^(\s+)/);
if (match) {
return match[1];
}
return "";
};
}).call(MatchingBraceOutdent.prototype);
exports.MatchingBraceOutdent = MatchingBraceOutdent;
});
define('ace/mode/behaviour/cstyle', ['require', 'exports', 'module' , 'ace/lib/oop', 'ace/mode/behaviour', 'ace/token_iterator', 'ace/lib/lang'], function(require, exports, module) {
var oop = require("../../lib/oop");
var Behaviour = require("../behaviour").Behaviour;
var TokenIterator = require("../../token_iterator").TokenIterator;
var lang = require("../../lib/lang");
var SAFE_INSERT_IN_TOKENS =
["text", "paren.rparen", "punctuation.operator"];
var SAFE_INSERT_BEFORE_TOKENS =
["text", "paren.rparen", "punctuation.operator", "comment"];
var autoInsertedBrackets = 0;
var autoInsertedRow = -1;
var autoInsertedLineEnd = "";
var maybeInsertedBrackets = 0;
var maybeInsertedRow = -1;
var maybeInsertedLineStart = "";
var maybeInsertedLineEnd = "";
var CstyleBehaviour = function () {
CstyleBehaviour.isSaneInsertion = function(editor, session) {
var cursor = editor.getCursorPosition();
var iterator = new TokenIterator(session, cursor.row, cursor.column);
if (!this.$matchTokenType(iterator.getCurrentToken() || "text", SAFE_INSERT_IN_TOKENS)) {
var iterator2 = new TokenIterator(session, cursor.row, cursor.column + 1);
if (!this.$matchTokenType(iterator2.getCurrentToken() || "text", SAFE_INSERT_IN_TOKENS))
return false;
}
iterator.stepForward();
return iterator.getCurrentTokenRow() !== cursor.row ||
this.$matchTokenType(iterator.getCurrentToken() || "text", SAFE_INSERT_BEFORE_TOKENS);
};
CstyleBehaviour.$matchTokenType = function(token, types) {
return types.indexOf(token.type || token) > -1;
};
CstyleBehaviour.recordAutoInsert = function(editor, session, bracket) {
var cursor = editor.getCursorPosition();
var line = session.doc.getLine(cursor.row);
if (!this.isAutoInsertedClosing(cursor, line, autoInsertedLineEnd[0]))
autoInsertedBrackets = 0;
autoInsertedRow = cursor.row;
autoInsertedLineEnd = bracket + line.substr(cursor.column);
autoInsertedBrackets++;
};
CstyleBehaviour.recordMaybeInsert = function(editor, session, bracket) {
var cursor = editor.getCursorPosition();
var line = session.doc.getLine(cursor.row);
if (!this.isMaybeInsertedClosing(cursor, line))
maybeInsertedBrackets = 0;
maybeInsertedRow = cursor.row;
maybeInsertedLineStart = line.substr(0, cursor.column) + bracket;
maybeInsertedLineEnd = line.substr(cursor.column);
maybeInsertedBrackets++;
};
CstyleBehaviour.isAutoInsertedClosing = function(cursor, line, bracket) {
return autoInsertedBrackets > 0 &&
cursor.row === autoInsertedRow &&
bracket === autoInsertedLineEnd[0] &&
line.substr(cursor.column) === autoInsertedLineEnd;
};
CstyleBehaviour.isMaybeInsertedClosing = function(cursor, line) {
return maybeInsertedBrackets > 0 &&
cursor.row === maybeInsertedRow &&
line.substr(cursor.column) === maybeInsertedLineEnd &&
line.substr(0, cursor.column) == maybeInsertedLineStart;
};
CstyleBehaviour.popAutoInsertedClosing = function() {
autoInsertedLineEnd = autoInsertedLineEnd.substr(1);
autoInsertedBrackets--;
};
CstyleBehaviour.clearMaybeInsertedClosing = function() {
maybeInsertedBrackets = 0;
maybeInsertedRow = -1;
};
this.add("braces", "insertion", function (state, action, editor, session, text) {
var cursor = editor.getCursorPosition();
var line = session.doc.getLine(cursor.row);
if (text == '{') {
var selection = editor.getSelectionRange();
var selected = session.doc.getTextRange(selection);
if (selected !== "" && selected !== "{" && editor.getWrapBehavioursEnabled()) {
return {
text: '{' + selected + '}',
selection: false
};
} else if (CstyleBehaviour.isSaneInsertion(editor, session)) {
if (/[\]\}\)]/.test(line[cursor.column])) {
CstyleBehaviour.recordAutoInsert(editor, session, "}");
return {
text: '{}',
selection: [1, 1]
};
} else {
CstyleBehaviour.recordMaybeInsert(editor, session, "{");
return {
text: '{',
selection: [1, 1]
};
}
}
} else if (text == '}') {
var rightChar = line.substring(cursor.column, cursor.column + 1);
if (rightChar == '}') {
var matching = session.$findOpeningBracket('}', {column: cursor.column + 1, row: cursor.row});
if (matching !== null && CstyleBehaviour.isAutoInsertedClosing(cursor, line, text)) {
CstyleBehaviour.popAutoInsertedClosing();
return {
text: '',
selection: [1, 1]
};
}
}
} else if (text == "\n" || text == "\r\n") {
var closing = "";
if (CstyleBehaviour.isMaybeInsertedClosing(cursor, line)) {
closing = lang.stringRepeat("}", maybeInsertedBrackets);
CstyleBehaviour.clearMaybeInsertedClosing();
}
var rightChar = line.substring(cursor.column, cursor.column + 1);
if (rightChar == '}' || closing !== "") {
var openBracePos = session.findMatchingBracket({row: cursor.row, column: cursor.column}, '}');
if (!openBracePos)
return null;
var indent = this.getNextLineIndent(state, line.substring(0, cursor.column), session.getTabString());
var next_indent = this.$getIndent(line);
return {
text: '\n' + indent + '\n' + next_indent + closing,
selection: [1, indent.length, 1, indent.length]
};
}
}
});
this.add("braces", "deletion", function (state, action, editor, session, range) {
var selected = session.doc.getTextRange(range);
if (!range.isMultiLine() && selected == '{') {
var line = session.doc.getLine(range.start.row);
var rightChar = line.substring(range.end.column, range.end.column + 1);
if (rightChar == '}') {
range.end.column++;
return range;
} else {
maybeInsertedBrackets--;
}
}
});
this.add("parens", "insertion", function (state, action, editor, session, text) {
if (text == '(') {
var selection = editor.getSelectionRange();
var selected = session.doc.getTextRange(selection);
if (selected !== "" && editor.getWrapBehavioursEnabled()) {
return {
text: '(' + selected + ')',
selection: false
};
} else if (CstyleBehaviour.isSaneInsertion(editor, session)) {
CstyleBehaviour.recordAutoInsert(editor, session, ")");
return {
text: '()',
selection: [1, 1]
};
}
} else if (text == ')') {
var cursor = editor.getCursorPosition();
var line = session.doc.getLine(cursor.row);
var rightChar = line.substring(cursor.column, cursor.column + 1);
if (rightChar == ')') {
var matching = session.$findOpeningBracket(')', {column: cursor.column + 1, row: cursor.row});
if (matching !== null && CstyleBehaviour.isAutoInsertedClosing(cursor, line, text)) {
CstyleBehaviour.popAutoInsertedClosing();
return {
text: '',
selection: [1, 1]
};
}
}
}
});
this.add("parens", "deletion", function (state, action, editor, session, range) {
var selected = session.doc.getTextRange(range);
if (!range.isMultiLine() && selected == '(') {
var line = session.doc.getLine(range.start.row);
var rightChar = line.substring(range.start.column + 1, range.start.column + 2);
if (rightChar == ')') {
range.end.column++;
return range;
}
}
});
this.add("brackets", "insertion", function (state, action, editor, session, text) {
if (text == '[') {
var selection = editor.getSelectionRange();
var selected = session.doc.getTextRange(selection);
if (selected !== "" && editor.getWrapBehavioursEnabled()) {
return {
text: '[' + selected + ']',
selection: false
};
} else if (CstyleBehaviour.isSaneInsertion(editor, session)) {
CstyleBehaviour.recordAutoInsert(editor, session, "]");
return {
text: '[]',
selection: [1, 1]
};
}
} else if (text == ']') {
var cursor = editor.getCursorPosition();
var line = session.doc.getLine(cursor.row);
var rightChar = line.substring(cursor.column, cursor.column + 1);
if (rightChar == ']') {
var matching = session.$findOpeningBracket(']', {column: cursor.column + 1, row: cursor.row});
if (matching !== null && CstyleBehaviour.isAutoInsertedClosing(cursor, line, text)) {
CstyleBehaviour.popAutoInsertedClosing();
return {
text: '',
selection: [1, 1]
};
}
}
}
});
this.add("brackets", "deletion", function (state, action, editor, session, range) {
var selected = session.doc.getTextRange(range);
if (!range.isMultiLine() && selected == '[') {
var line = session.doc.getLine(range.start.row);
var rightChar = line.substring(range.start.column + 1, range.start.column + 2);
if (rightChar == ']') {
range.end.column++;
return range;
}
}
});
this.add("string_dquotes", "insertion", function (state, action, editor, session, text) {
if (text == '"' || text == "'") {
var quote = text;
var selection = editor.getSelectionRange();
var selected = session.doc.getTextRange(selection);
if (selected !== "" && selected !== "'" && selected != '"' && editor.getWrapBehavioursEnabled()) {
return {
text: quote + selected + quote,
selection: false
};
} else {
var cursor = editor.getCursorPosition();
var line = session.doc.getLine(cursor.row);
var leftChar = line.substring(cursor.column-1, cursor.column);
if (leftChar == '\\') {
return null;
}
var tokens = session.getTokens(selection.start.row);
var col = 0, token;
var quotepos = -1; // Track whether we're inside an open quote.
for (var x = 0; x < tokens.length; x++) {
token = tokens[x];
if (token.type == "string") {
quotepos = -1;
} else if (quotepos < 0) {
quotepos = token.value.indexOf(quote);
}
if ((token.value.length + col) > selection.start.column) {
break;
}
col += tokens[x].value.length;
}
if (!token || (quotepos < 0 && token.type !== "comment" && (token.type !== "string" || ((selection.start.column !== token.value.length+col-1) && token.value.lastIndexOf(quote) === token.value.length-1)))) {
if (!CstyleBehaviour.isSaneInsertion(editor, session))
return;
return {
text: quote + quote,
selection: [1,1]
};
} else if (token && token.type === "string") {
var rightChar = line.substring(cursor.column, cursor.column + 1);
if (rightChar == quote) {
return {
text: '',
selection: [1, 1]
};
}
}
}
}
});
this.add("string_dquotes", "deletion", function (state, action, editor, session, range) {
var selected = session.doc.getTextRange(range);
if (!range.isMultiLine() && (selected == '"' || selected == "'")) {
var line = session.doc.getLine(range.start.row);
var rightChar = line.substring(range.start.column + 1, range.start.column + 2);
if (rightChar == selected) {
range.end.column++;
return range;
}
}
});
};
oop.inherits(CstyleBehaviour, Behaviour);
exports.CstyleBehaviour = CstyleBehaviour;
});
define('ace/mode/folding/cstyle', ['require', 'exports', 'module' , 'ace/lib/oop', 'ace/range', 'ace/mode/folding/fold_mode'], function(require, exports, module) {
var oop = require("../../lib/oop");
var Range = require("../../range").Range;
var BaseFoldMode = require("./fold_mode").FoldMode;
var FoldMode = exports.FoldMode = function() {};
oop.inherits(FoldMode, BaseFoldMode);
(function() {
this.foldingStartMarker = /(\{|\[)[^\}\]]*$|^\s*(\/\*)/;
this.foldingStopMarker = /^[^\[\{]*(\}|\])|^[\s\*]*(\*\/)/;
this.getFoldWidgetRange = function(session, foldStyle, row) {
var line = session.getLine(row);
var match = line.match(this.foldingStartMarker);
if (match) {
var i = match.index;
if (match[1])
return this.openingBracketBlock(session, match[1], row, i);
return session.getCommentFoldRange(row, i + match[0].length, 1);
}
if (foldStyle !== "markbeginend")
return;
var match = line.match(this.foldingStopMarker);
if (match) {
var i = match.index + match[0].length;
if (match[1])
return this.closingBracketBlock(session, match[1], row, i);
return session.getCommentFoldRange(row, i, -1);
}
};
}).call(FoldMode.prototype);
});
|
PypiClean
|
/vba-wrapper-0.0.3.tar.gz/vba-wrapper-0.0.3/vba_wrapper/core.py
|
import ctypes
import exceptions
import registers
import cheat
def _load_library_vba():
"""
Use ctypes to load VBA.
"""
# TODO: make sure it's the correct version of the vba library
# was ./src/clojure/.libs/libvba.so
lib = ctypes.cdll.LoadLibrary("libvba.so")
return lib
def _ctypes_make_list(l, base):
"""
Makes a list of const char pointers.
"""
array = (base * len(l))()
array[:] = l
return array
class VBA(object):
"""
VBA wrapper.
Call the constructor only once per process.
Note that only one instance of the emulator can be running at any given
time.
"""
register_count = 29
button_masks = {
"a": 0x0001,
"b": 0x0002,
"r": 0x0010,
"l": 0x0020,
"u": 0x0040,
"d": 0x0080,
"select": 0x0004,
"start": 0x0008,
"restart": 0x0800,
"listen": -1, # what?
}
def __init__(self, rom_path):
"""
Start the emulator.
@param rom_path: path to .gb or .gbc file
"""
# load the library
self._vba = _load_library_vba()
self.registers = registers.Registers(self)
self.cheats = cheat.CheatVBA(self)
# sometimes ctypes needs some help
self.setup_ctypes()
# boot up the emulator
self.start_emulator(rom_path)
def setup_ctypes(self):
"""
ctypes doesn't always know how to pass data around.
"""
# cache this value and treat it as a constant plz
self.MAX_SAVE_SIZE = self._get_max_save_size()
# get_state returns type ctype.c_char_p
self._vba.get_state.restype = ctypes.POINTER(ctypes.c_char * self.MAX_SAVE_SIZE)
def start_emulator(self, rom_path):
"""
Boot up the emulator.
"""
argv = ["vba-rlm", rom_path]
return self._vba.main(2, _ctypes_make_list(argv, ctypes.c_char_p))
def end_emulator(self):
"""
dunno if this is absolutely necessary
"""
self._vba.shutdown()
def shutdown(self):
"""
just an alias for end_emulator
"""
self.end_emulator()
def run(self):
"""
Advance the state of the emulator until the user presses f12.
"""
self._vba.step_until_f12()
def step(self, keymask=0, count=1):
"""
Advance the state of the emulator by a single "step".
@param keymask: which buttons to hold (int)
@param count: how many steps to make?
"""
if count <= 0:
raise exceptions.VBAWrapperException("count must be a positive integer")
while count > 0:
self._vba.emu_step(keymask)
count = count - 1
def tick(self):
"""
VBA has a function called tick, dunno how it differs from step.
"""
self._vba.emu_tick()
def get_current_buttons(self):
"""
Get an integer representing the current button presses.
"""
return self._vba.get_current_buttons()
@staticmethod
def button_combine(buttons):
"""
Combines multiple button presses into an integer.
This is used when sending a keypress to the emulator.
"""
result = 0
# String inputs need to be cleaned up so that "start" doesn't get
# recognized as "s" and "t" etc..
if isinstance(buttons, str):
if "restart" in buttons:
buttons = buttons.replace("restart", "")
result |= VBA.button_masks["restart"]
if "start" in buttons:
buttons = buttons.replace("start", "")
result |= VBA.button_masks["start"]
if "select" in buttons:
buttons = buttons.replace("select", "")
result |= VBA.button_masks["select"]
# allow for the "a, b" and "a b" formats
if ", " in buttons:
buttons = buttons.split(", ")
elif " " in buttons:
buttons = buttons.split(" ")
if isinstance(buttons, list):
if len(buttons) > 9:
raise exceptions.VBAButtonException("can't combine more than 9 buttons at a time")
for each in buttons:
result |= VBA.button_masks[each]
return result
def press(self, buttons, hold=10, after=1):
"""
Press a button. Hold the buttonpress for holdsteps number of steps.
The after parameter is how many steps after holding, with no
buttonpresses.
"""
if hasattr(buttons, "__len__"):
number = self.button_combine(buttons)
else: # elif isinstance(buttons, int):
number = buttons
# hold the button
for stepnum in range(0, hold):
self.step(number)
# clear the buttonpress
if after > 0:
for stepnum in range(0, after):
self.step(0)
def get_screen(self):
"""
Returns a boolean representing the status of showScreen.
"""
return ctypes.c_int.in_dll(self._vba, "showScreen").value == 1
def set_screen(self, status):
"""
Set the showScreen variable to "True" by passing 1 and "False" by
passing 0.
"""
self._vba.set_showScreen(int(status))
def enable_screen(self):
"""
Set showScreen to True.
"""
self.set_screen(1)
def disable_screen(self):
"""
Set showScreen to False.
"""
self.set_screen(0)
def get_rom_bank(self):
"""
gbDataMBC3.mapperROMBank
"""
return self._vba.get_rom_bank()
def write_memory_at(self, address, value):
"""
Write some number at an address.
"""
self._vba.write_memory_at(address, value)
def read_memory_at(self, address):
"""
Read from memory.
"""
return self._vba.read_memory_at(address)
def _get_state(self):
"""
Get a copy of the current emulator state. Might be gzipped?
"""
buf = (ctypes.c_char * self.MAX_SAVE_SIZE)()
self._vba.get_state(buf, self.MAX_SAVE_SIZE)
return bytearray(buf.raw)
def _set_state(self, state):
"""
Set the state of the emulator.
"""
#buf = _ctypes_make_list(str(state), ctypes.c_char)
buf = (ctypes.c_char * self.MAX_SAVE_SIZE)()
buf[:] = str(state)
self._vba.set_state(buf, self.MAX_SAVE_SIZE)
state = property(_get_state, _set_state)
def _get_memory(self):
"""
Call the getMemory function. Return a bytearray.
"""
buf = (ctypes.c_int32 * 0x10000)()
self._vba.get_memory(buf)
return bytearray(list(buf))
def _set_memory(self, memory):
"""
Set the emulator's memory to these bytes.
"""
#buf = (ctypes.c_int32 * len(memory))()
#buf[:] = memory
buf = _ctypes_make_list(memory, ctypes.c_int32)
self._vba.set_memory(buf)
memory = property(_get_memory, _set_memory)
def _get_ram(self):
"""
32768 bytes of RAM
"""
buf = (ctypes.c_int32 * self.ram_size)()
self._vba.get_ram(buf)
return bytearray(list(buf))
ram = property(_get_ram)
def _get_wram(self):
"""
WRAM only.
"""
buf = (ctypes.c_int32 * 0x8000)()
self._vba.get_wram(buf)
return bytearray(list(buf))
wram = property(_get_wram)
def _get_vram(self):
"""
VRAM only.
"""
buf = (ctypes.c_int32 * 0x4000)()
self._vba.get_vram(buf)
return bytearray(list(buf))
vram = property(_get_vram)
def _get_registers(self):
"""
Get the current register values.
"""
# 29 registers
buf = (ctypes.c_int32 * self.register_count)()
self._vba.get_registers(buf)
return list(buf)
def _set_registers(self, registers):
"""
Set the CPU registers.
"""
# 29 registers
buf = (ctypes.c_int32 * self.register_count)()
buf[:] = registers
self._vba.set_registers(buf)
def _get_max_save_size(self):
return self._vba.get_max_save_size()
# this isn't the same as the MAX_SAVE_SIZE "constant"
max_save_size = property(_get_max_save_size)
def _get_ram_size(self):
return self._vba.get_ram_size()
ram_size = property(_get_ram_size)
def _get_rom_size(self):
return self._vba.get_rom_size()
rom_size = property(_get_rom_size)
def _get_rom(self):
"""
the game
"""
buf = (ctypes.c_int32 * self.rom_size)()
self._vba.get_rom(buf)
return bytearray(list(buf))
def _set_rom(self, rom):
"""
might have to reset?
"""
buf = (ctypes.c_int32 * self.rom_size)()
buf[:] = rom
self._vba.set_rom(buf)
rom = property(_get_rom, _set_rom)
def save_png(self, path):
"""
Save a png screenshot to the file at path.
"""
self._vba.save_png(path)
def say_hello(self):
"""
Write a message to stdout to show that the binding works.
"""
self._vba.say_hello()
|
PypiClean
|
/py-pure-client-1.38.0.tar.gz/py-pure-client-1.38.0/pypureclient/flashblade/FB_2_7/api/certificate_groups_api.py
|
from __future__ import absolute_import
import re
# python 2 and python 3 compatibility library
import six
from typing import List, Optional
from .. import models
class CertificateGroupsApi(object):
def __init__(self, api_client):
self.api_client = api_client
def api27_certificate_groups_certificates_delete_with_http_info(
self,
certificate_ids=None, # type: List[str]
certificate_group_ids=None, # type: List[str]
certificate_group_names=None, # type: List[str]
certificate_names=None, # type: List[str]
async_req=False, # type: bool
_return_http_data_only=False, # type: bool
_preload_content=True, # type: bool
_request_timeout=None, # type: Optional[int]
):
# type: (...) -> None
"""DELETE certificate-groups/certificates
Delete one or more certificate groups.
This method makes a synchronous HTTP request by default. To make an
asynchronous HTTP request, please pass async_req=True
>>> thread = api.api27_certificate_groups_certificates_delete_with_http_info(async_req=True)
>>> result = thread.get()
:param list[str] certificate_ids: A comma-separated list of certificate ids. If there is not at least one resource that matches each of the elements of `certificate_ids`, then an error is returned. This cannot be provided in conjunction with the `certificate_names` parameter.
:param list[str] certificate_group_ids: A comma-separated list of certificate group ids. If there is not at least one resource that matches each of the elements of `certificate_group_ids`, then an error is returned. This cannot be provided in conjunction with the `certificate_group_names` parameter.
:param list[str] certificate_group_names: A comma-separated list of certificate group names. If there is not at least one resource that matches each of the elements of `certificate_group_names`, then an error is returned. This cannot be provided in conjunction with the `certificate_group_ids` parameter.
:param list[str] certificate_names: A comma-separated list of certificate names. If there is not at least one resource that matches each of the elements of `certificate_names`, then an error is returned. This cannot be provided in conjunction with the `certificate_ids` parameter.
:param bool async_req: Request runs in separate thread and method returns multiprocessing.pool.ApplyResult.
:param bool _return_http_data_only: Returns only data field.
:param bool _preload_content: Response is converted into objects.
:param int _request_timeout: Total request timeout in seconds.
It can also be a tuple of (connection time, read time) timeouts.
:return: None
If the method is called asynchronously,
returns the request thread.
"""
if certificate_ids is not None:
if not isinstance(certificate_ids, list):
certificate_ids = [certificate_ids]
if certificate_group_ids is not None:
if not isinstance(certificate_group_ids, list):
certificate_group_ids = [certificate_group_ids]
if certificate_group_names is not None:
if not isinstance(certificate_group_names, list):
certificate_group_names = [certificate_group_names]
if certificate_names is not None:
if not isinstance(certificate_names, list):
certificate_names = [certificate_names]
params = {k: v for k, v in six.iteritems(locals()) if v is not None}
# Convert the filter into a string
if params.get('filter'):
params['filter'] = str(params['filter'])
if params.get('sort'):
params['sort'] = [str(_x) for _x in params['sort']]
collection_formats = {}
path_params = {}
query_params = []
if 'certificate_ids' in params:
query_params.append(('certificate_ids', params['certificate_ids']))
collection_formats['certificate_ids'] = 'csv'
if 'certificate_group_ids' in params:
query_params.append(('certificate_group_ids', params['certificate_group_ids']))
collection_formats['certificate_group_ids'] = 'csv'
if 'certificate_group_names' in params:
query_params.append(('certificate_group_names', params['certificate_group_names']))
collection_formats['certificate_group_names'] = 'csv'
if 'certificate_names' in params:
query_params.append(('certificate_names', params['certificate_names']))
collection_formats['certificate_names'] = 'csv'
header_params = {}
form_params = []
local_var_files = {}
body_params = None
# HTTP header `Accept`
header_params['Accept'] = self.api_client.select_header_accept(
['application/json'])
# HTTP header `Content-Type`
header_params['Content-Type'] = self.api_client.select_header_content_type(
['application/json'])
# Authentication setting
auth_settings = ['AuthorizationHeader']
return self.api_client.call_api(
'/api/2.7/certificate-groups/certificates', 'DELETE',
path_params,
query_params,
header_params,
body=body_params,
post_params=form_params,
files=local_var_files,
response_type=None,
auth_settings=auth_settings,
async_req=async_req,
_return_http_data_only=_return_http_data_only,
_preload_content=_preload_content,
_request_timeout=_request_timeout,
collection_formats=collection_formats,
)
def api27_certificate_groups_certificates_get_with_http_info(
self,
continuation_token=None, # type: str
certificate_ids=None, # type: List[str]
certificate_group_ids=None, # type: List[str]
certificate_group_names=None, # type: List[str]
certificate_names=None, # type: List[str]
filter=None, # type: str
limit=None, # type: int
offset=None, # type: int
sort=None, # type: List[str]
async_req=False, # type: bool
_return_http_data_only=False, # type: bool
_preload_content=True, # type: bool
_request_timeout=None, # type: Optional[int]
):
# type: (...) -> models.CertificateGroupCertificateGetResp
"""GET certificate-groups/certificates
List membership associations between groups and certificates on the array.
This method makes a synchronous HTTP request by default. To make an
asynchronous HTTP request, please pass async_req=True
>>> thread = api.api27_certificate_groups_certificates_get_with_http_info(async_req=True)
>>> result = thread.get()
:param str continuation_token: An opaque token used to iterate over a collection. The token to use on the next request is returned in the `continuation_token` field of the result.
:param list[str] certificate_ids: A comma-separated list of certificate ids. If there is not at least one resource that matches each of the elements of `certificate_ids`, then an error is returned. This cannot be provided in conjunction with the `certificate_names` parameter.
:param list[str] certificate_group_ids: A comma-separated list of certificate group ids. If there is not at least one resource that matches each of the elements of `certificate_group_ids`, then an error is returned. This cannot be provided in conjunction with the `certificate_group_names` parameter.
:param list[str] certificate_group_names: A comma-separated list of certificate group names. If there is not at least one resource that matches each of the elements of `certificate_group_names`, then an error is returned. This cannot be provided in conjunction with the `certificate_group_ids` parameter.
:param list[str] certificate_names: A comma-separated list of certificate names. If there is not at least one resource that matches each of the elements of `certificate_names`, then an error is returned. This cannot be provided in conjunction with the `certificate_ids` parameter.
:param str filter: Exclude resources that don't match the specified criteria.
:param int limit: Limit the size of the response to the specified number of resources. A `limit` of `0` can be used to get the number of resources without getting all of the resources. It will be returned in the `total_item_count` field. If a client asks for a page size larger than the maximum number, the request is still valid. In that case the server just returns the maximum number of items, disregarding the client's page size request.
:param int offset: The offset of the first resource to return from a collection.
:param list[str] sort: Sort the response by the specified fields (in descending order if '-' is appended to the field name). NOTE: If you provide a sort you will not get a `continuation_token` in the response.
:param bool async_req: Request runs in separate thread and method returns multiprocessing.pool.ApplyResult.
:param bool _return_http_data_only: Returns only data field.
:param bool _preload_content: Response is converted into objects.
:param int _request_timeout: Total request timeout in seconds.
It can also be a tuple of (connection time, read time) timeouts.
:return: CertificateGroupCertificateGetResp
If the method is called asynchronously,
returns the request thread.
"""
if certificate_ids is not None:
if not isinstance(certificate_ids, list):
certificate_ids = [certificate_ids]
if certificate_group_ids is not None:
if not isinstance(certificate_group_ids, list):
certificate_group_ids = [certificate_group_ids]
if certificate_group_names is not None:
if not isinstance(certificate_group_names, list):
certificate_group_names = [certificate_group_names]
if certificate_names is not None:
if not isinstance(certificate_names, list):
certificate_names = [certificate_names]
if sort is not None:
if not isinstance(sort, list):
sort = [sort]
params = {k: v for k, v in six.iteritems(locals()) if v is not None}
# Convert the filter into a string
if params.get('filter'):
params['filter'] = str(params['filter'])
if params.get('sort'):
params['sort'] = [str(_x) for _x in params['sort']]
if 'limit' in params and params['limit'] < 1:
raise ValueError("Invalid value for parameter `limit` when calling `api27_certificate_groups_certificates_get`, must be a value greater than or equal to `1`")
if 'offset' in params and params['offset'] < 0:
raise ValueError("Invalid value for parameter `offset` when calling `api27_certificate_groups_certificates_get`, must be a value greater than or equal to `0`")
collection_formats = {}
path_params = {}
query_params = []
if 'continuation_token' in params:
query_params.append(('continuation_token', params['continuation_token']))
if 'certificate_ids' in params:
query_params.append(('certificate_ids', params['certificate_ids']))
collection_formats['certificate_ids'] = 'csv'
if 'certificate_group_ids' in params:
query_params.append(('certificate_group_ids', params['certificate_group_ids']))
collection_formats['certificate_group_ids'] = 'csv'
if 'certificate_group_names' in params:
query_params.append(('certificate_group_names', params['certificate_group_names']))
collection_formats['certificate_group_names'] = 'csv'
if 'certificate_names' in params:
query_params.append(('certificate_names', params['certificate_names']))
collection_formats['certificate_names'] = 'csv'
if 'filter' in params:
query_params.append(('filter', params['filter']))
if 'limit' in params:
query_params.append(('limit', params['limit']))
if 'offset' in params:
query_params.append(('offset', params['offset']))
if 'sort' in params:
query_params.append(('sort', params['sort']))
collection_formats['sort'] = 'csv'
header_params = {}
form_params = []
local_var_files = {}
body_params = None
# HTTP header `Accept`
header_params['Accept'] = self.api_client.select_header_accept(
['application/json'])
# HTTP header `Content-Type`
header_params['Content-Type'] = self.api_client.select_header_content_type(
['application/json'])
# Authentication setting
auth_settings = ['AuthorizationHeader']
return self.api_client.call_api(
'/api/2.7/certificate-groups/certificates', 'GET',
path_params,
query_params,
header_params,
body=body_params,
post_params=form_params,
files=local_var_files,
response_type='CertificateGroupCertificateGetResp',
auth_settings=auth_settings,
async_req=async_req,
_return_http_data_only=_return_http_data_only,
_preload_content=_preload_content,
_request_timeout=_request_timeout,
collection_formats=collection_formats,
)
def api27_certificate_groups_certificates_post_with_http_info(
self,
certificate_ids=None, # type: List[str]
certificate_group_ids=None, # type: List[str]
certificate_group_names=None, # type: List[str]
certificate_names=None, # type: List[str]
async_req=False, # type: bool
_return_http_data_only=False, # type: bool
_preload_content=True, # type: bool
_request_timeout=None, # type: Optional[int]
):
# type: (...) -> models.CertificateGroupCertificateResponse
"""POST certificate-groups/certificates
Add one or more certificates to one or more certificate groups on the array.
This method makes a synchronous HTTP request by default. To make an
asynchronous HTTP request, please pass async_req=True
>>> thread = api.api27_certificate_groups_certificates_post_with_http_info(async_req=True)
>>> result = thread.get()
:param list[str] certificate_ids: A comma-separated list of certificate ids. If there is not at least one resource that matches each of the elements of `certificate_ids`, then an error is returned. This cannot be provided in conjunction with the `certificate_names` parameter.
:param list[str] certificate_group_ids: A comma-separated list of certificate group ids. If there is not at least one resource that matches each of the elements of `certificate_group_ids`, then an error is returned. This cannot be provided in conjunction with the `certificate_group_names` parameter.
:param list[str] certificate_group_names: A comma-separated list of certificate group names. If there is not at least one resource that matches each of the elements of `certificate_group_names`, then an error is returned. This cannot be provided in conjunction with the `certificate_group_ids` parameter.
:param list[str] certificate_names: A comma-separated list of certificate names. If there is not at least one resource that matches each of the elements of `certificate_names`, then an error is returned. This cannot be provided in conjunction with the `certificate_ids` parameter.
:param bool async_req: Request runs in separate thread and method returns multiprocessing.pool.ApplyResult.
:param bool _return_http_data_only: Returns only data field.
:param bool _preload_content: Response is converted into objects.
:param int _request_timeout: Total request timeout in seconds.
It can also be a tuple of (connection time, read time) timeouts.
:return: CertificateGroupCertificateResponse
If the method is called asynchronously,
returns the request thread.
"""
if certificate_ids is not None:
if not isinstance(certificate_ids, list):
certificate_ids = [certificate_ids]
if certificate_group_ids is not None:
if not isinstance(certificate_group_ids, list):
certificate_group_ids = [certificate_group_ids]
if certificate_group_names is not None:
if not isinstance(certificate_group_names, list):
certificate_group_names = [certificate_group_names]
if certificate_names is not None:
if not isinstance(certificate_names, list):
certificate_names = [certificate_names]
params = {k: v for k, v in six.iteritems(locals()) if v is not None}
# Convert the filter into a string
if params.get('filter'):
params['filter'] = str(params['filter'])
if params.get('sort'):
params['sort'] = [str(_x) for _x in params['sort']]
collection_formats = {}
path_params = {}
query_params = []
if 'certificate_ids' in params:
query_params.append(('certificate_ids', params['certificate_ids']))
collection_formats['certificate_ids'] = 'csv'
if 'certificate_group_ids' in params:
query_params.append(('certificate_group_ids', params['certificate_group_ids']))
collection_formats['certificate_group_ids'] = 'csv'
if 'certificate_group_names' in params:
query_params.append(('certificate_group_names', params['certificate_group_names']))
collection_formats['certificate_group_names'] = 'csv'
if 'certificate_names' in params:
query_params.append(('certificate_names', params['certificate_names']))
collection_formats['certificate_names'] = 'csv'
header_params = {}
form_params = []
local_var_files = {}
body_params = None
# HTTP header `Accept`
header_params['Accept'] = self.api_client.select_header_accept(
['application/json'])
# HTTP header `Content-Type`
header_params['Content-Type'] = self.api_client.select_header_content_type(
['application/json'])
# Authentication setting
auth_settings = ['AuthorizationHeader']
return self.api_client.call_api(
'/api/2.7/certificate-groups/certificates', 'POST',
path_params,
query_params,
header_params,
body=body_params,
post_params=form_params,
files=local_var_files,
response_type='CertificateGroupCertificateResponse',
auth_settings=auth_settings,
async_req=async_req,
_return_http_data_only=_return_http_data_only,
_preload_content=_preload_content,
_request_timeout=_request_timeout,
collection_formats=collection_formats,
)
def api27_certificate_groups_delete_with_http_info(
self,
ids=None, # type: List[str]
names=None, # type: List[str]
async_req=False, # type: bool
_return_http_data_only=False, # type: bool
_preload_content=True, # type: bool
_request_timeout=None, # type: Optional[int]
):
# type: (...) -> None
"""DELETE certificate-groups
Delete one or more certificate groups from the array.
This method makes a synchronous HTTP request by default. To make an
asynchronous HTTP request, please pass async_req=True
>>> thread = api.api27_certificate_groups_delete_with_http_info(async_req=True)
>>> result = thread.get()
:param list[str] ids: A comma-separated list of resource IDs. If after filtering, there is not at least one resource that matches each of the elements of `ids`, then an error is returned. This cannot be provided together with the `name` or `names` query parameters.
:param list[str] names: A comma-separated list of resource names. If there is not at least one resource that matches each of the elements of `names`, then an error is returned.
:param bool async_req: Request runs in separate thread and method returns multiprocessing.pool.ApplyResult.
:param bool _return_http_data_only: Returns only data field.
:param bool _preload_content: Response is converted into objects.
:param int _request_timeout: Total request timeout in seconds.
It can also be a tuple of (connection time, read time) timeouts.
:return: None
If the method is called asynchronously,
returns the request thread.
"""
if ids is not None:
if not isinstance(ids, list):
ids = [ids]
if names is not None:
if not isinstance(names, list):
names = [names]
params = {k: v for k, v in six.iteritems(locals()) if v is not None}
# Convert the filter into a string
if params.get('filter'):
params['filter'] = str(params['filter'])
if params.get('sort'):
params['sort'] = [str(_x) for _x in params['sort']]
collection_formats = {}
path_params = {}
query_params = []
if 'ids' in params:
query_params.append(('ids', params['ids']))
collection_formats['ids'] = 'csv'
if 'names' in params:
query_params.append(('names', params['names']))
collection_formats['names'] = 'csv'
header_params = {}
form_params = []
local_var_files = {}
body_params = None
# HTTP header `Accept`
header_params['Accept'] = self.api_client.select_header_accept(
['application/json'])
# HTTP header `Content-Type`
header_params['Content-Type'] = self.api_client.select_header_content_type(
['application/json'])
# Authentication setting
auth_settings = ['AuthorizationHeader']
return self.api_client.call_api(
'/api/2.7/certificate-groups', 'DELETE',
path_params,
query_params,
header_params,
body=body_params,
post_params=form_params,
files=local_var_files,
response_type=None,
auth_settings=auth_settings,
async_req=async_req,
_return_http_data_only=_return_http_data_only,
_preload_content=_preload_content,
_request_timeout=_request_timeout,
collection_formats=collection_formats,
)
def api27_certificate_groups_get_with_http_info(
self,
continuation_token=None, # type: str
filter=None, # type: str
ids=None, # type: List[str]
limit=None, # type: int
names=None, # type: List[str]
offset=None, # type: int
sort=None, # type: List[str]
async_req=False, # type: bool
_return_http_data_only=False, # type: bool
_preload_content=True, # type: bool
_request_timeout=None, # type: Optional[int]
):
# type: (...) -> models.CertificateGroupGetResponse
"""GET certificate-groups
Display all array certificate groups.
This method makes a synchronous HTTP request by default. To make an
asynchronous HTTP request, please pass async_req=True
>>> thread = api.api27_certificate_groups_get_with_http_info(async_req=True)
>>> result = thread.get()
:param str continuation_token: An opaque token used to iterate over a collection. The token to use on the next request is returned in the `continuation_token` field of the result.
:param str filter: Exclude resources that don't match the specified criteria.
:param list[str] ids: A comma-separated list of resource IDs. If after filtering, there is not at least one resource that matches each of the elements of `ids`, then an error is returned. This cannot be provided together with the `name` or `names` query parameters.
:param int limit: Limit the size of the response to the specified number of resources. A `limit` of `0` can be used to get the number of resources without getting all of the resources. It will be returned in the `total_item_count` field. If a client asks for a page size larger than the maximum number, the request is still valid. In that case the server just returns the maximum number of items, disregarding the client's page size request.
:param list[str] names: A comma-separated list of resource names. If there is not at least one resource that matches each of the elements of `names`, then an error is returned.
:param int offset: The offset of the first resource to return from a collection.
:param list[str] sort: Sort the response by the specified fields (in descending order if '-' is appended to the field name). NOTE: If you provide a sort you will not get a `continuation_token` in the response.
:param bool async_req: Request runs in separate thread and method returns multiprocessing.pool.ApplyResult.
:param bool _return_http_data_only: Returns only data field.
:param bool _preload_content: Response is converted into objects.
:param int _request_timeout: Total request timeout in seconds.
It can also be a tuple of (connection time, read time) timeouts.
:return: CertificateGroupGetResponse
If the method is called asynchronously,
returns the request thread.
"""
if ids is not None:
if not isinstance(ids, list):
ids = [ids]
if names is not None:
if not isinstance(names, list):
names = [names]
if sort is not None:
if not isinstance(sort, list):
sort = [sort]
params = {k: v for k, v in six.iteritems(locals()) if v is not None}
# Convert the filter into a string
if params.get('filter'):
params['filter'] = str(params['filter'])
if params.get('sort'):
params['sort'] = [str(_x) for _x in params['sort']]
if 'limit' in params and params['limit'] < 1:
raise ValueError("Invalid value for parameter `limit` when calling `api27_certificate_groups_get`, must be a value greater than or equal to `1`")
if 'offset' in params and params['offset'] < 0:
raise ValueError("Invalid value for parameter `offset` when calling `api27_certificate_groups_get`, must be a value greater than or equal to `0`")
collection_formats = {}
path_params = {}
query_params = []
if 'continuation_token' in params:
query_params.append(('continuation_token', params['continuation_token']))
if 'filter' in params:
query_params.append(('filter', params['filter']))
if 'ids' in params:
query_params.append(('ids', params['ids']))
collection_formats['ids'] = 'csv'
if 'limit' in params:
query_params.append(('limit', params['limit']))
if 'names' in params:
query_params.append(('names', params['names']))
collection_formats['names'] = 'csv'
if 'offset' in params:
query_params.append(('offset', params['offset']))
if 'sort' in params:
query_params.append(('sort', params['sort']))
collection_formats['sort'] = 'csv'
header_params = {}
form_params = []
local_var_files = {}
body_params = None
# HTTP header `Accept`
header_params['Accept'] = self.api_client.select_header_accept(
['application/json'])
# HTTP header `Content-Type`
header_params['Content-Type'] = self.api_client.select_header_content_type(
['application/json'])
# Authentication setting
auth_settings = ['AuthorizationHeader']
return self.api_client.call_api(
'/api/2.7/certificate-groups', 'GET',
path_params,
query_params,
header_params,
body=body_params,
post_params=form_params,
files=local_var_files,
response_type='CertificateGroupGetResponse',
auth_settings=auth_settings,
async_req=async_req,
_return_http_data_only=_return_http_data_only,
_preload_content=_preload_content,
_request_timeout=_request_timeout,
collection_formats=collection_formats,
)
def api27_certificate_groups_post_with_http_info(
self,
names=None, # type: List[str]
async_req=False, # type: bool
_return_http_data_only=False, # type: bool
_preload_content=True, # type: bool
_request_timeout=None, # type: Optional[int]
):
# type: (...) -> models.CertificateGroupResponse
"""POST certificate-groups
Create one or more certificate groups on the array.
This method makes a synchronous HTTP request by default. To make an
asynchronous HTTP request, please pass async_req=True
>>> thread = api.api27_certificate_groups_post_with_http_info(async_req=True)
>>> result = thread.get()
:param list[str] names: A comma-separated list of resource names. If there is not at least one resource that matches each of the elements of `names`, then an error is returned.
:param bool async_req: Request runs in separate thread and method returns multiprocessing.pool.ApplyResult.
:param bool _return_http_data_only: Returns only data field.
:param bool _preload_content: Response is converted into objects.
:param int _request_timeout: Total request timeout in seconds.
It can also be a tuple of (connection time, read time) timeouts.
:return: CertificateGroupResponse
If the method is called asynchronously,
returns the request thread.
"""
if names is not None:
if not isinstance(names, list):
names = [names]
params = {k: v for k, v in six.iteritems(locals()) if v is not None}
# Convert the filter into a string
if params.get('filter'):
params['filter'] = str(params['filter'])
if params.get('sort'):
params['sort'] = [str(_x) for _x in params['sort']]
collection_formats = {}
path_params = {}
query_params = []
if 'names' in params:
query_params.append(('names', params['names']))
collection_formats['names'] = 'csv'
header_params = {}
form_params = []
local_var_files = {}
body_params = None
# HTTP header `Accept`
header_params['Accept'] = self.api_client.select_header_accept(
['application/json'])
# HTTP header `Content-Type`
header_params['Content-Type'] = self.api_client.select_header_content_type(
['application/json'])
# Authentication setting
auth_settings = ['AuthorizationHeader']
return self.api_client.call_api(
'/api/2.7/certificate-groups', 'POST',
path_params,
query_params,
header_params,
body=body_params,
post_params=form_params,
files=local_var_files,
response_type='CertificateGroupResponse',
auth_settings=auth_settings,
async_req=async_req,
_return_http_data_only=_return_http_data_only,
_preload_content=_preload_content,
_request_timeout=_request_timeout,
collection_formats=collection_formats,
)
def api27_certificate_groups_uses_get_with_http_info(
self,
continuation_token=None, # type: str
filter=None, # type: str
ids=None, # type: List[str]
limit=None, # type: int
names=None, # type: List[str]
offset=None, # type: int
sort=None, # type: List[str]
async_req=False, # type: bool
_return_http_data_only=False, # type: bool
_preload_content=True, # type: bool
_request_timeout=None, # type: Optional[int]
):
# type: (...) -> models.CertificateGroupUseGetResponse
"""GET certificate-groups/uses
List how certificate groups are being used and by what.
This method makes a synchronous HTTP request by default. To make an
asynchronous HTTP request, please pass async_req=True
>>> thread = api.api27_certificate_groups_uses_get_with_http_info(async_req=True)
>>> result = thread.get()
:param str continuation_token: An opaque token used to iterate over a collection. The token to use on the next request is returned in the `continuation_token` field of the result.
:param str filter: Exclude resources that don't match the specified criteria.
:param list[str] ids: A comma-separated list of resource IDs. If after filtering, there is not at least one resource that matches each of the elements of `ids`, then an error is returned. This cannot be provided together with the `name` or `names` query parameters.
:param int limit: Limit the size of the response to the specified number of resources. A `limit` of `0` can be used to get the number of resources without getting all of the resources. It will be returned in the `total_item_count` field. If a client asks for a page size larger than the maximum number, the request is still valid. In that case the server just returns the maximum number of items, disregarding the client's page size request.
:param list[str] names: A comma-separated list of resource names. If there is not at least one resource that matches each of the elements of `names`, then an error is returned.
:param int offset: The offset of the first resource to return from a collection.
:param list[str] sort: Sort the response by the specified fields (in descending order if '-' is appended to the field name). NOTE: If you provide a sort you will not get a `continuation_token` in the response.
:param bool async_req: Request runs in separate thread and method returns multiprocessing.pool.ApplyResult.
:param bool _return_http_data_only: Returns only data field.
:param bool _preload_content: Response is converted into objects.
:param int _request_timeout: Total request timeout in seconds.
It can also be a tuple of (connection time, read time) timeouts.
:return: CertificateGroupUseGetResponse
If the method is called asynchronously,
returns the request thread.
"""
if ids is not None:
if not isinstance(ids, list):
ids = [ids]
if names is not None:
if not isinstance(names, list):
names = [names]
if sort is not None:
if not isinstance(sort, list):
sort = [sort]
params = {k: v for k, v in six.iteritems(locals()) if v is not None}
# Convert the filter into a string
if params.get('filter'):
params['filter'] = str(params['filter'])
if params.get('sort'):
params['sort'] = [str(_x) for _x in params['sort']]
if 'limit' in params and params['limit'] < 1:
raise ValueError("Invalid value for parameter `limit` when calling `api27_certificate_groups_uses_get`, must be a value greater than or equal to `1`")
if 'offset' in params and params['offset'] < 0:
raise ValueError("Invalid value for parameter `offset` when calling `api27_certificate_groups_uses_get`, must be a value greater than or equal to `0`")
collection_formats = {}
path_params = {}
query_params = []
if 'continuation_token' in params:
query_params.append(('continuation_token', params['continuation_token']))
if 'filter' in params:
query_params.append(('filter', params['filter']))
if 'ids' in params:
query_params.append(('ids', params['ids']))
collection_formats['ids'] = 'csv'
if 'limit' in params:
query_params.append(('limit', params['limit']))
if 'names' in params:
query_params.append(('names', params['names']))
collection_formats['names'] = 'csv'
if 'offset' in params:
query_params.append(('offset', params['offset']))
if 'sort' in params:
query_params.append(('sort', params['sort']))
collection_formats['sort'] = 'csv'
header_params = {}
form_params = []
local_var_files = {}
body_params = None
# HTTP header `Accept`
header_params['Accept'] = self.api_client.select_header_accept(
['application/json'])
# HTTP header `Content-Type`
header_params['Content-Type'] = self.api_client.select_header_content_type(
['application/json'])
# Authentication setting
auth_settings = ['AuthorizationHeader']
return self.api_client.call_api(
'/api/2.7/certificate-groups/uses', 'GET',
path_params,
query_params,
header_params,
body=body_params,
post_params=form_params,
files=local_var_files,
response_type='CertificateGroupUseGetResponse',
auth_settings=auth_settings,
async_req=async_req,
_return_http_data_only=_return_http_data_only,
_preload_content=_preload_content,
_request_timeout=_request_timeout,
collection_formats=collection_formats,
)
|
PypiClean
|
/torch_template-0.0.4-py3-none-any.whl/torch_template/templates/dataloader/dataset.py
|
import pdb
import torchvision.transforms.functional as F
import os
from PIL import Image
import torch.utils.data.dataset as dataset
from torchvision import transforms
import random
from torch_template import torch_utils
def paired_cut(img_1: Image.Image, img_2: Image.Image, crop_size):
def get_params(img, output_size):
w, h = img.size
th, tw = output_size
i = random.randint(0, h - th)
j = random.randint(0, w - tw)
return i, j, th, tw
r = random.randint(-1, 6)
if r >= 0:
img_1 = img_1.transpose(r)
img_2 = img_2.transpose(r)
i, j, h, w = get_params(img_1, crop_size)
img_1 = F.crop(img_1, i, j, h, w)
img_2 = F.crop(img_2, i, j, h, w)
return img_1, img_2
class ImageDataset(dataset.Dataset):
"""ImageDataset for training.
Args:
datadir(str): dataset root path, default input and label dirs are 'input' and 'gt'
crop(None, int or tuple): crop size
aug(bool): data argument (×8)
norm(bool): normalization
Example:
train_dataset = ImageDataset('train', crop=256)
for i, data in enumerate(train_dataset):
input, label, file_name = data
"""
def __init__(self, datadir, crop=None, aug=True, norm=False):
self.input_path = os.path.join(datadir, 'input')
self.label_path = os.path.join(datadir, 'gt')
self.im_names = sorted(os.listdir(self.input_path))
self.label_names = sorted(os.listdir(self.label_path))
self.trans_dict = {0: Image.FLIP_LEFT_RIGHT, 1: Image.FLIP_TOP_BOTTOM, 2: Image.ROTATE_90, 3: Image.ROTATE_180,
4: Image.ROTATE_270, 5: Image.TRANSPOSE, 6: Image.TRANSVERSE}
if type(crop) == int:
crop = (crop, crop)
self.crop = crop
self.aug = aug
self.norm = norm
def __getitem__(self, index):
"""Get indexs by index
Args:
index(int): index
Returns:
(tuple): input, label, file_name
"""
assert self.im_names[index] == self.label_names[index], 'input and label filename not matching.'
input = Image.open(os.path.join(self.input_path, self.im_names[index])).convert("RGB")
label = Image.open(os.path.join(self.label_path, self.label_names[index])).convert("RGB")
if self.crop is not None:
input, label = paired_cut(input, label, self.crop)
else:
input, label = input, label
r = random.randint(0, 7)
if self.aug and r != 7:
input = input.transpose(self.trans_dict[r])
label = label.transpose(self.trans_dict[r])
if self.norm:
input = F.normalize(F.to_tensor(input), mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
else:
input = F.to_tensor(input)
label = F.to_tensor(label)
return input, label, self.im_names[index]
def __len__(self):
return len(os.listdir(self.input_path))
class ImageTestDataset(dataset.Dataset):
"""ImageDataset for test.
Args:
datadir(str): dataset path'
norm(bool): normalization
Example:
test_dataset = ImageDataset('test', crop=256)
for i, data in enumerate(test_dataset):
input, file_name = data
"""
def __init__(self, datadir, norm=False):
self.input_path = datadir
self.norm = norm
self.im_names = sorted(os.listdir(self.input_path))
def __getitem__(self, index):
# im_name = sorted(os.listdir(self.input_path))[index]
input = Image.open(os.path.join(self.input_path, self.im_names[index])).convert("RGB")
if self.norm:
input = F.normalize(F.to_tensor(input), mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
else:
input = F.to_tensor(input)
return input, self.im_names[index]
def __len__(self):
return len(os.listdir(self.input_path))
if __name__ == '__main__':
writer = torch_utils.create_summary_writer('logs')
train_dataset = ImageDataset('../datasets/simple/cleaned', crop=None, aug=False, norm=False)
test_dataset = ImageTestDataset('../datasets/simple/test_A', norm=False)
# for i, data in enumerate(train_dataset):
# input, label, file_name = data
# torch_utils.write_image(writer, 'train', '0_input', input, i)
# torch_utils.write_image(writer, 'train', '2_label', label, i)
# print(i, file_name)
# for i, data in enumerate(test_dataset):
# input, file_name = data
# torch_utils.write_image(writer, 'train', file_name, input, i)
|
PypiClean
|
/msgraph_beta_sdk-1.0.0a9-py3-none-any.whl/msgraph/generated/users/item/calendar/calendar_view/item/exception_occurrences/item/calendar/calendar_request_builder.py
|
from __future__ import annotations
from dataclasses import dataclass
from kiota_abstractions.get_path_parameters import get_path_parameters
from kiota_abstractions.method import Method
from kiota_abstractions.request_adapter import RequestAdapter
from kiota_abstractions.request_information import RequestInformation
from kiota_abstractions.request_option import RequestOption
from kiota_abstractions.response_handler import ResponseHandler
from kiota_abstractions.serialization import Parsable, ParsableFactory
from typing import Any, Callable, Dict, List, Optional, TYPE_CHECKING, Union
if TYPE_CHECKING:
from .........models import calendar
from .........models.o_data_errors import o_data_error
class CalendarRequestBuilder():
"""
Provides operations to manage the calendar property of the microsoft.graph.event entity.
"""
def __init__(self,request_adapter: RequestAdapter, path_parameters: Optional[Union[Dict[str, Any], str]] = None) -> None:
"""
Instantiates a new CalendarRequestBuilder and sets the default values.
Args:
pathParameters: The raw url or the Url template parameters for the request.
requestAdapter: The request adapter to use to execute the requests.
"""
if path_parameters is None:
raise Exception("path_parameters cannot be undefined")
if request_adapter is None:
raise Exception("request_adapter cannot be undefined")
# Url template to use to build the URL for the current request builder
self.url_template: str = "{+baseurl}/users/{user%2Did}/calendar/calendarView/{event%2Did}/exceptionOccurrences/{event%2Did1}/calendar{?%24select}"
url_tpl_params = get_path_parameters(path_parameters)
self.path_parameters = url_tpl_params
self.request_adapter = request_adapter
async def get(self,request_configuration: Optional[CalendarRequestBuilderGetRequestConfiguration] = None) -> Optional[calendar.Calendar]:
"""
The calendar that contains the event. Navigation property. Read-only.
Args:
requestConfiguration: Configuration for the request such as headers, query parameters, and middleware options.
Returns: Optional[calendar.Calendar]
"""
request_info = self.to_get_request_information(
request_configuration
)
from .........models.o_data_errors import o_data_error
error_mapping: Dict[str, ParsableFactory] = {
"4XX": o_data_error.ODataError,
"5XX": o_data_error.ODataError,
}
if not self.request_adapter:
raise Exception("Http core is null")
from .........models import calendar
return await self.request_adapter.send_async(request_info, calendar.Calendar, error_mapping)
def to_get_request_information(self,request_configuration: Optional[CalendarRequestBuilderGetRequestConfiguration] = None) -> RequestInformation:
"""
The calendar that contains the event. Navigation property. Read-only.
Args:
requestConfiguration: Configuration for the request such as headers, query parameters, and middleware options.
Returns: RequestInformation
"""
request_info = RequestInformation()
request_info.url_template = self.url_template
request_info.path_parameters = self.path_parameters
request_info.http_method = Method.GET
request_info.headers["Accept"] = ["application/json"]
if request_configuration:
request_info.add_request_headers(request_configuration.headers)
request_info.set_query_string_parameters_from_raw_object(request_configuration.query_parameters)
request_info.add_request_options(request_configuration.options)
return request_info
@dataclass
class CalendarRequestBuilderGetQueryParameters():
"""
The calendar that contains the event. Navigation property. Read-only.
"""
def get_query_parameter(self,original_name: Optional[str] = None) -> str:
"""
Maps the query parameters names to their encoded names for the URI template parsing.
Args:
originalName: The original query parameter name in the class.
Returns: str
"""
if original_name is None:
raise Exception("original_name cannot be undefined")
if original_name == "select":
return "%24select"
return original_name
# Select properties to be returned
select: Optional[List[str]] = None
@dataclass
class CalendarRequestBuilderGetRequestConfiguration():
"""
Configuration for the request such as headers, query parameters, and middleware options.
"""
# Request headers
headers: Optional[Dict[str, Union[str, List[str]]]] = None
# Request options
options: Optional[List[RequestOption]] = None
# Request query parameters
query_parameters: Optional[CalendarRequestBuilder.CalendarRequestBuilderGetQueryParameters] = None
|
PypiClean
|
/compositionspace-0.0.7.tar.gz/compositionspace-0.0.7/README.md
|
# CompositionSpace
CompositionSpace is a python library for analysis of APT data.
## Installation
### Installation using [Conda](https://anaconda.org/)
It is **strongly** recommended to install and use `calphy` within a conda environment. To see how you can install conda see [here](https://docs.conda.io/projects/conda/en/latest/user-guide/install/).
Once a conda distribution is available, the following steps will help set up an environment to use `compositionspace`. First step is to clone the repository.
```
https://github.com/eisenforschung/CompositionSpace.git
```
After cloning, an environment can be created from the included file-
```
cd CompositionSpace
conda env create -f environment.yml
```
Activate the environment,
```
conda activate compspace
```
then, install `compositionspace` using,
```
python setup.py install
```
The environment is now set up to run calphy.
## Examples
For an example of the complete workflow using `compositionspace`, see `example/full_workflow.ipynb`.
The provided dataset is a small one for testing purposes, which is also accessible here:
Ceguerra, AV (2021) Supplementary material: APT test cases.
Available at http://dx.doi.org/10.25833/3ge0-y420
## Documentation
Documentation is available [here](https://compositionspace.readthedocs.io/en/latest/).
|
PypiClean
|
/demo_book-0.0.1.tar.gz/demo_book-0.0.1/README.md
|
# demo-book
[](https://pypi.org/project/demo-book/) [](https://github.com/xinetzone/demo-book/issues) [](https://github.com/xinetzone/demo-book/network) [](https://github.com/xinetzone/demo-book/stargazers) [](https://github.com/xinetzone/demo-book/blob/main/LICENSE)  [](https://github.com/xinetzone/demo-book/graphs/contributors) [](https://github.com/xinetzone/demo-book/watchers) [](https://github.com/xinetzone/pytorch-book/watchers) [](https://demo-book.readthedocs.io/zh/latest/?badge=latest) [](https://pepy.tech/project/demo-book) [](https://pepy.tech/project/demo-book)
## 支持 PyPI
需要安装 `demo-book` 包:
```shell
pip install demo-book
```
|
PypiClean
|
/rdkit_pypi-2023.3.1b1-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl/rdkit/sping/Pyart/pidPyart.py
|
import pyart
from rdkit.sping.pid import *
from rdkit.sping.PDF import pdfmetrics
import Fontmapping # helps by mapping pid font classes to Pyart font names
# note for now I'm just going to do the standard PDF fonts & forget the rest
class PyartCanvas(Canvas):
"note the default face is 'times' and is set in Fontmapping.py"
def __init__(self, size=(300, 300), name='PyartCanvas.png'):
self._pycan = pyart.Canvas(size[0], size[1], dpi=72)
self.filename = name
Canvas.__init__(self, size, name)
# self.defaultFillColor = transparent
# now we need to setup our tracking of the defaults vs the current state
# see if the __setattr__ approach is any better than the _updateXX strategy
def __setattr__(self, name, value):
if name == 'defaultLineColor':
if value:
# print('setting defaultLineColor to %s, 0x%x' % (value, value.toHexRGB()))
if value != transparent:
self._pycan.gstate.stroke = value.toHexRGB()
self.__dict__[name] = value
elif name == 'defaultFillColor':
if value:
if value != transparent:
self._pycan.gstate.fill = value.toHexRGB()
self.__dict__[name] = value
elif name == 'defaultLineWidth':
if value:
self._pycan.gstate.stroke_width = value
self.__dict__[name] = value
elif name == 'defaultFont':
if value:
self.__dict__[name] = value
self._setPyartFont(value)
else: # received None so set to default font face & size=12
self.__dict__[name] = Font(face='times')
self._setPyartFont(self.__dict__[name])
else:
self.__dict__[name] = value
## Private methods ##
def _protectArtState(self, bool):
if bool:
self._pycan.gsave()
return bool
def _restoreArtState(self, bool):
if bool:
self._pycan.grestore()
def _setPyartFont(self, fontInstance):
# accounts for "None" option
# does not act on self.defaultFont at all
fontsize = fontInstance.size
self._pycan.gstate.font_size = fontsize
# map pid name for font to Pyart name
pyartname = Fontmapping.getPyartName(fontInstance)
self._pycan.gstate.setfont(pyartname)
# # # # #
### public PID Canvas methods ##
def clear(self):
pass
def flush(self):
pass
def save(self, file=None, format=None):
# fileobj = getFileObject(file)
if not file:
file = self.filename
if isinstance(file, StringType):
self._pycan.save(file)
else:
raise NotImplementedError
def _findExternalFontName(self, font): #copied from piddlePDF by cwl- hack away!
"""Attempts to return proper font name.
PDF uses a standard 14 fonts referred to
by name. Default to self.defaultFont('Helvetica').
The dictionary allows a layer of indirection to
support a standard set of PIDDLE font names."""
piddle_font_map = {
'Times': 'Times',
'times': 'Times',
'Courier': 'Courier',
'courier': 'Courier',
'helvetica': 'Helvetica',
'Helvetica': 'Helvetica',
'symbol': 'Symbol',
'Symbol': 'Symbol',
'monospaced': 'Courier',
'serif': 'Times',
'sansserif': 'Helvetica',
'ZapfDingbats': 'ZapfDingbats',
'zapfdingbats': 'ZapfDingbats',
'arial': 'Helvetica'
}
try:
face = piddle_font_map[font.face.lower()]
except Exception:
return 'Helvetica'
name = face + '-'
if font.bold and face in ['Courier', 'Helvetica', 'Times']:
name = name + 'Bold'
if font.italic and face in ['Courier', 'Helvetica']:
name = name + 'Oblique'
elif font.italic and face == 'Times':
name = name + 'Italic'
if name == 'Times-':
name = name + 'Roman'
# symbol and ZapfDingbats cannot be modified!
#trim and return
if name[-1] == '-':
name = name[0:-1]
return name
def stringWidth(self, s, font=None):
if not font:
font = self.defaultFont
fontname = Fontmapping.getPdfName(font)
return pdfmetrics.stringwidth(s, fontname) * font.size * 0.001
def fontAscent(self, font=None):
if not font:
font = self.defaultFont
fontname = Fontmapping.getPdfName(font)
return pdfmetrics.ascent_descent[fontname][0] * 0.001 * font.size
def fontDescent(self, font=None):
if not font:
font = self.defaultFont
fontname = Fontmapping.getPdfName(font)
return -pdfmetrics.ascent_descent[fontname][1] * 0.001 * font.size
def drawLine(self, x1, y1, x2, y2, color=None, width=None):
## standard code ##
color = color or self.defaultLineColor
width = width or self.defaultLineWidth
if color != transparent:
changed = self._protectArtState((color != self.defaultLineColor) or
(width != self.defaultLineWidth))
if color != self.defaultLineColor:
self._pycan.gstate.stroke = color.toHexRGB()
# print("color is %s <-> %s" % (color, color.toHexStr()))
if width != self.defaultLineWidth:
self._pycan.gstate.stroke_width = width
###################
# actual drawing
p = pyart.VectorPath(3)
p.moveto_open(x1, y1)
p.lineto(x2, y2)
self._pycan.stroke(p)
## standard code ##
if changed:
self._pycan.grestore()
###################
# def drawLines(self, lineList, color=None, width=None):
# pass
def drawString(self, s, x, y, font=None, color=None, angle=0):
# start w/ the basics
self._pycan.drawString(x, y, s)
def drawPolygon(self, pointlist, edgeColor=None, edgeWidth=None, fillColor=None, closed=0):
eColor = edgeColor or self.defaultLineColor
fColor = fillColor or self.defaultFillColor
eWidth = edgeWidth or self.defaultLineWidth
changed = self._protectArtState((eColor != self.defaultLineColor) or
(eWidth != self.defaultLineWidth) or
(fColor != self.defaultFillColor))
if eColor != self.defaultLineColor:
self._pycan.gstate.stroke = eColor.toHexRGB()
if fColor != self.defaultFillColor:
self._pycan.gstate.fill = fColor.toHexRGB()
if eWidth != self.defaultLineWidth:
self._pycan.gstate.stroke_width = eWidth
path = pyart.VectorPath(len(pointlist) + 1)
if closed:
path.moveto_closed(pointlist[0][0], pointlist[0][1])
else:
path.moveto_open(pointlist[0][0], pointlist[0][1])
for pt in pointlist[1:]:
path.lineto(pt[0], pt[1])
if closed:
path.close()
if fColor != transparent and closed:
self._pycan.fill(path)
if eColor != transparent:
self._pycan.stroke(path)
self._restoreArtState(changed)
#def drawCurve(self, x1, y1, x2, y2, x3, y3, x4, y4,
# edgeColor=None, edgeWidth=None, fillColor=None, closed=0):
# pass
# def drawRoundRect(self, x1,y1, x2,y2, rx=8, ry=8,
# edgeColor=None, edgeWidth=None, fillColor=None):
# pass
# def drawEllipse(self, x1,y1, x2,y2, edgeColor=None, edgeWidth=None,
# fillColor=None):
# pass
# def drawArc(self, x1,y1, x2,y2, startAng=0, extent=360, edgeColor=None,
# edgeWidth=None, fillColor=None):
# pass
# def drawFigure(self, partList,
# edgeColor=None, edgeWidth=None, fillColor=None, closed=0):
# pass
# def drawImage(self, image, x1, y1, x2=None,y2=None):
# pass
## basic tests ##
if __name__ == '__main__':
import rdkit.sping.tests.pidtest
can = PyartCanvas(size=(300, 300), name='basictest.png')
#can.defaultLineColor = Color(0.7, 0.7, 1.0)
#can.drawLine(10,10, 290,290)
#can.drawLine(10,10, 50, 10, color=green, width = 4.5)
rdkit.sping.tests.pidtest.drawBasics(can)
can.save(file='basicTest.png')
print('saving basicTest.png')
can = PyartCanvas(size=(400, 400), name='test-strings.png')
rdkit.sping.tests.pidtest.drawStrings(can)
can.save()
|
PypiClean
|
/wagtail_blog-2.3.5-py3-none-any.whl/blog/wp_xml_parser.py
|
from html.parser import HTMLParser
from io import BytesIO
import datetime
import re
import time
import lxml.etree as etree
import lxml.html as HM
htmlparser = HTMLParser()
class XML_parser(object):
def __init__(self, xml_path):
# TODO: yup, that's the whole file in memory
xml_string = self.prep_xml(open(xml_path, 'r').read())
root = etree.XML(xml_string)
self.chan = root.find("channel")
self.category_dict = self.get_category_dict(self.chan)
self.tags_dict = self.get_tags_dict(self.chan)
@staticmethod
def get_category_dict(chan):
cats = [e for e in chan.getchildren() if '{wp}category' in e.tag]
cats_dict = {}
for cat in cats:
slug = cat.find('.//{wp}category_nicename').text
cats_dict[slug] = {'slug':slug,
'name': htmlparser.unescape(cat.find("./{wp}cat_name").text),
'parent':cat.find("./{wp}category_parent").text,
'taxonomy': 'category'}
# replace parent strings with parent dicts:
for slug, item in cats_dict.items():
parent_name = item.get('parent')
if parent_name:
cats_dict[slug]['parent'] = cats_dict[parent_name]
return cats_dict
def get_tags_dict(self, chan):
tags = [e for e in chan.getchildren() if e.tag[-3:] == "tag"]
tags_dict = {}
# these matches assume we've cleaned up xlmns
for e in tags:
slug = e.find('.//{wp}tag_slug').text
tags_dict[slug] = {'slug':slug}
name = htmlparser.unescape(e.find('.//{wp}tag_name').text) # need some regex parsing here
tags_dict[slug]['name'] = name
tags_dict[slug]['taxonomy'] = 'post_tag'
return tags_dict
@staticmethod
def remove_encoding(xml_string):
"""
removes encoding statement and
changes xmlns to tag:item to tag:tag
>>> xp = XML_parser
>>> test_xmlns = r'<?xml encoding="some encoding" ?> test'
>>> xp.remove_encoding(test_xmlns)
' test'
"""
xml_string = re.sub(r'^<.*encoding="[^\"]*\"[^>]*>', '', xml_string)
return xml_string
@staticmethod
def remove_xmlns(xml_string):
"""
changes the xmlns (XML namespace) so that values are
replaced with the string representation of their key
this makes the import process for portable
>>> xp = XML_parser
>>> test_xmlns = r'<rss version="2.0" xmlns:excerpt="http://wordpress.org/export/1.2/excerpt/">'
>>> xp.remove_xmlns(test_xmlns)
'<rss version="2.0" xmlns:excerpt="excerpt">'
"""
# splitting xml into sections, pre_chan is preamble before <channel>
pre_chan, chan, post_chan= xml_string.partition('<channel>')
# replace xmlns statements on preamble
pre_chan = re.sub(r'xmlns:(?P<label>\w*)\=\"(?P<val>[^\"]*)\"',
r'xmlns:\g<label>="\g<label>"',
pre_chan)
# piece back together
return pre_chan + chan + post_chan
def prep_xml(self, xml):
return self.remove_xmlns(self.remove_encoding(xml))
def item_dict(self, item):
"""
create a default dict of values, including
category and tag lookup
"""
# mocking wierd JSON structure
ret_dict = {"terms":{"category":[],"post_tag":[]}}
for e in item:
# is it a category or tag??
if "category" in e.tag:
# get details
slug = e.attrib["nicename"]
name = htmlparser.unescape(e.text)
# lookup the category or create one
cat_dict = self.category_dict.get(slug) or {"slug":slug,
"name":name,
"taxonomy":"category"}
ret_dict['terms']['category'].append(cat_dict)
elif e.tag[-3:] == 'tag':
# get details
slug = e.attrib.get("tag_slug")
name = htmlparser.unescape(e.text)
# lookup the tag or create one
tag_dict = self.tags_dict.get(slug) or {"slug":slug,
"name":name,
"taxonomy":"post_tag"}
ret_dict['terms']['post_tag'].append(tag_dict)
# else use tagname:tag inner test
else:
ret_dict[e.tag] = e.text
# remove empty accumulators
empty_keys = [k for k,v in ret_dict["terms"].items() if not v]
for k in empty_keys:
ret_dict["terms"].pop(k)
return ret_dict
@staticmethod
def convert_date(d, custom_date_string=None, fallback=None):
"""
for whatever reason, sometimes WP XML has unintelligible
datetime strings for pubDate.
In this case default to custom_date_string or today
Use fallback in case a secondary date string is available.
Incidentally, somehow the string 'Mon, 30 Nov -0001 00:00:00 +0000'
shows up.
>>> xp = XML_parser
>>> xp.convert_date("Mon, 30 Mar 2015 11:11:11 +0000")
'2015-03-30'
"""
if d == 'Mon, 30 Nov -0001 00:00:00 +0000' and fallback:
d = fallback
try:
date = time.strftime("%Y-%m-%d", time.strptime(d, '%a, %d %b %Y %H:%M:%S %z'))
except ValueError:
date = time.strftime("%Y-%m-%d", time.strptime(d, '%Y-%m-%d %H:%M:%S'))
except ValueError:
date = custom_date_string or datetime.datetime.today().strftime("%Y-%m-%d")
return date
def translate_item(self, item_dict):
"""cleanup item keys to match API json format"""
if not item_dict.get('title'):
return None
# Skip attachments
if item_dict.get('{wp}post_type', None) == 'attachment':
return None
ret_dict = {}
# slugify post title if no slug exists
ret_dict['slug']= item_dict.get('{wp}post_name') or re.sub(item_dict['title'],' ','-')
ret_dict['ID']= item_dict['guid']
ret_dict['title']= item_dict['title']
ret_dict['description']= item_dict['description']
ret_dict['content']= item_dict['{content}encoded']
# fake user object
ret_dict['author']= {'username':item_dict['{dc}creator'],
'first_name':'',
'last_name':''}
ret_dict['terms']= item_dict.get('terms')
ret_dict['date']= self.convert_date(
item_dict['pubDate'],
fallback=item_dict.get('{wp}post_date','')
)
return ret_dict
def translate_wp_comment(self, e):
"""
<wp:comment>
<wp:comment_id>1234</wp:comment_id>
<wp:comment_author><![CDATA[John Doe]]></wp:comment_author>
<wp:comment_author_email><![CDATA[[email protected]]]></wp:comment_author_email>
<wp:comment_author_url>http://myhomepage.com/</wp:comment_author_url>
<wp:comment_author_IP><![CDATA[12.123.123.123]]></wp:comment_author_IP>
<wp:comment_date><![CDATA[2008-09-25 14:24:51]]></wp:comment_date>
<wp:comment_date_gmt><![CDATA[2008-09-25 13:24:51]]></wp:comment_date_gmt>
<wp:comment_content><![CDATA[Hey dude :)]]></wp:comment_content>
<wp:comment_approved><![CDATA[1]]></wp:comment_approved>
<wp:comment_type><![CDATA[]]></wp:comment_type>
<wp:comment_parent>0</wp:comment_parent>
<wp:comment_user_id>0</wp:comment_user_id>
</wp:comment>
"""
comment_dict = {}
comment_dict['ID'] = e.find('./{wp}comment_id').text
comment_dict['date'] = e.find('{wp}comment_date').text
comment_dict['content'] = e.find('{wp}comment_content').text
comment_dict['status'] = e.find('{wp}comment_approved').text
comment_dict['status'] = "approved" if comment_dict['status'] == "1" else "rejected"
comment_dict['parent'] = e.find('{wp}comment_parent').text
comment_dict['author'] = e.find('{wp}comment_author').text
comment_dict['date'] = time.strptime(comment_dict['date'], '%Y-%m-%d %H:%M:%S')
comment_dict['date'] = time.strftime('%Y-%m-%dT%H:%M:%S', comment_dict['date'])
return comment_dict
def get_posts_data(self):
"""
given a WordPress xml export file, will return list
of dictionaries with keys that match
the expected json keys of a wordpress API call
>>> xp = XML_parser('example_export.xml')
>>> json_vals = {"slug","ID", "title","description", "content", "author", "terms", "date", }
>>> data = xp.get_posts_data()
>>> assert [ val in json_vals for val in data[0].keys() ]
"""
items = self.chan.findall("item") #(e for e in chan.getchildren() if e.tag=='item')
# turn item element into a generic dict
item_dict_gen = (self.item_dict(item) for item in items)
# transform the generic dict to one with the expected JSON keys
all_the_data = [self.translate_item(item) for item in item_dict_gen if self.translate_item(item)]
return all_the_data
def get_comments_data(self, slug):
"""
Returns a flat list of all comments in XML dump. Formatted as the JSON
output from Wordpress API.
Keys:
('content', 'slug', 'date', 'status', 'author', 'ID', 'parent')
date format: '%Y-%m-%dT%H:%M:%S'
author: {'username': 'Name', 'URL': ''}
"""
all_the_data = []
for item in self.chan.findall("item"):
if not item.find('{wp}post_name').text == slug:
continue
item_dict = self.item_dict(item)
if not item_dict or not item_dict.get('title'):
continue
slug = item_dict.get('{wp}post_name') or re.sub(item_dict['title'],' ','-')
for comment in item.findall("{wp}comment"):
comment = self.translate_wp_comment(comment)
comment['slug'] = slug
all_the_data.append(comment)
return all_the_data
if __name__ == "__main__":
import doctest
doctest.testmod()
|
PypiClean
|
/freqtrade_api_client-0.1.0-py3-none-any.whl/freqtrade_api_client/api/info/daily_api_v1_daily_get.py
|
from typing import Any, Dict, Optional, Union
import httpx
from ...client import AuthenticatedClient
from ...models.daily import Daily
from ...models.http_validation_error import HTTPValidationError
from ...types import UNSET, Response, Unset
def _get_kwargs(
*,
client: AuthenticatedClient,
timescale: Union[Unset, None, int] = 7,
) -> Dict[str, Any]:
url = "{}/api/v1/daily".format(client.base_url)
headers: Dict[str, str] = client.get_headers()
cookies: Dict[str, Any] = client.get_cookies()
params: Dict[str, Any] = {}
params["timescale"] = timescale
params = {k: v for k, v in params.items() if v is not UNSET and v is not None}
return {
"method": "get",
"url": url,
"headers": headers,
"cookies": cookies,
"timeout": client.get_timeout(),
"params": params,
}
def _parse_response(*, response: httpx.Response) -> Optional[Union[Daily, HTTPValidationError]]:
if response.status_code == 200:
response_200 = Daily.from_dict(response.json())
return response_200
if response.status_code == 422:
response_422 = HTTPValidationError.from_dict(response.json())
return response_422
return None
def _build_response(*, response: httpx.Response) -> Response[Union[Daily, HTTPValidationError]]:
return Response(
status_code=response.status_code,
content=response.content,
headers=response.headers,
parsed=_parse_response(response=response),
)
def sync_detailed(
*,
client: AuthenticatedClient,
timescale: Union[Unset, None, int] = 7,
) -> Response[Union[Daily, HTTPValidationError]]:
"""Daily
Args:
timescale (Union[Unset, None, int]): Default: 7.
Returns:
Response[Union[Daily, HTTPValidationError]]
"""
kwargs = _get_kwargs(
client=client,
timescale=timescale,
)
response = httpx.request(
verify=client.verify_ssl,
**kwargs,
)
return _build_response(response=response)
def sync(
*,
client: AuthenticatedClient,
timescale: Union[Unset, None, int] = 7,
) -> Optional[Union[Daily, HTTPValidationError]]:
"""Daily
Args:
timescale (Union[Unset, None, int]): Default: 7.
Returns:
Response[Union[Daily, HTTPValidationError]]
"""
return sync_detailed(
client=client,
timescale=timescale,
).parsed
async def asyncio_detailed(
*,
client: AuthenticatedClient,
timescale: Union[Unset, None, int] = 7,
) -> Response[Union[Daily, HTTPValidationError]]:
"""Daily
Args:
timescale (Union[Unset, None, int]): Default: 7.
Returns:
Response[Union[Daily, HTTPValidationError]]
"""
kwargs = _get_kwargs(
client=client,
timescale=timescale,
)
async with httpx.AsyncClient(verify=client.verify_ssl) as _client:
response = await _client.request(**kwargs)
return _build_response(response=response)
async def asyncio(
*,
client: AuthenticatedClient,
timescale: Union[Unset, None, int] = 7,
) -> Optional[Union[Daily, HTTPValidationError]]:
"""Daily
Args:
timescale (Union[Unset, None, int]): Default: 7.
Returns:
Response[Union[Daily, HTTPValidationError]]
"""
return (
await asyncio_detailed(
client=client,
timescale=timescale,
)
).parsed
|
PypiClean
|
/KonFoo-3.0.0-py3-none-any.whl/konfoo/categories.py
|
from __future__ import annotations
import enum
from typing import Any
class Category(enum.Enum):
""" The :class:`Category` class is a is a subclass of the :class:`~enum.Enum`
class provided by the Python standard module :mod:`enum`, and extends its
base class with methods
- to `describe` a specific `Category` member by its `name`, `value` tuple
- to list the `member names` of a `Category`
- to list the `member values` of a `Category`
- to `get` the `value` of the `Category` member by its name
- to `get` the `name` of the `Category` member by is value
- to `get` the `member` of the `Category` by its value
Example:
>>> class Format(Category):
... hour = 'hh'
... minute = 'mm'
... second = 'ss'
>>> Format
<enum 'Format'>
>>> type(Format.hour)
<enum 'Format'>
>>> isinstance(Format, Category)
False
>>> issubclass(Format, Category)
True
>>> isinstance(Format.hour, Format)
True
>>> print(Format.hour)
(hour, hh)
>>> str(Format.hour)
'(hour, hh)'
>>> Format.hour
Format.hour = 'hh'
>>> repr(Format.hour)
"Format.hour = 'hh'"
>>> list(Format)
[Format.hour = 'hh', Format.minute = 'mm', Format.second = 'ss']
>>> [format for format in Format]
[Format.hour = 'hh', Format.minute = 'mm', Format.second = 'ss']
>>> Format.hour.name
'hour'
>>> Format.hour.value
'hh'
>>> Format.hour.describe()
('hour', 'hh')
>>> [member.name for member in Format]
['hour', 'minute', 'second']
>>> Format.names()
['hour', 'minute', 'second']
>>> [member.value for member in Format]
['hh', 'mm', 'ss']
>>> Format.values()
['hh', 'mm', 'ss']
>>> Format['hour'].value
'hh'
>>> Format.get_value('hour')
'hh'
>>> Format('hh').name
'hour'
>>> Format.get_name('hh')
'hour'
>>> Format.get_member('hh')
Format.hour = 'hh'
>>> 'hh' in Format.values()
True
>>> 'hour' in Format.names()
True
"""
def __str__(self) -> str:
""" Return str(self).
Example:
>>> class Format(Category):
... hour = 'hh'
... minute = 'mm'
... second = 'ss'
>>> str(Format.hour)
'(hour, hh)'
"""
return f"({self.name!s}, {self.value!s})"
def __repr__(self) -> str:
""" Return repr(self). See help(type(self)) for accurate signature.
Example:
>>> class Format(Category):
... hour = 'hh'
... minute = 'mm'
... second = 'ss'
>>> repr(Format.hour)
"Format.hour = 'hh'"
"""
return f"{self.__class__.__name__}.{self.name!s} = {self.value!r}"
def describe(self) -> tuple[str, Any]:
""" Returns the `name`, `value` tuple to describe a specific `Category`
member.
Example:
>>> class Format(Category):
... hour = 'hh'
... minute = 'mm'
... second = 'ss'
>>> Format.hour.describe()
('hour', 'hh')
"""
return self.name, self.value
@classmethod
def names(cls) -> list[str]:
""" Returns a list of the member `names` of a `Category`.
Example:
>>> class Format(Category):
... hour = 'hh'
... minute = 'mm'
... second = 'ss'
>>> Format.names()
['hour', 'minute', 'second']
"""
return [member.name for member in cls]
@classmethod
def values(cls) -> list[Any]:
""" Returns a list of the member `values` of a `Category`.
Example:
>>> class Format(Category):
... hour = 'hh'
... minute = 'mm'
... second = 'ss'
>>> Format.values()
['hh', 'mm', 'ss']
"""
return [member.value for member in cls]
@classmethod
def get_name(cls, value: Any) -> str:
""" Returns the `name` of the `Category` member matches the *value*,
or an empty string if no member match.
Example:
>>> class Format(Category):
... hour = 'hh'
... minute = 'mm'
... second = 'ss'
>>> Format.get_name('hh')
'hour'
>>> Format.get_name('dd')
''
"""
for member in cls:
if member.value == value:
return member.name
return str()
@classmethod
def get_value(cls, name: str) -> Any | None:
""" Returns the `value` of the `Category` member matches the *name*,
or :data:`None` if no member match.
Example:
>>> class Format(Category):
... hour = 'hh'
... minute = 'mm'
... second = 'ss'
>>> Format.get_value('hour')
'hh'
>>> Format.get_value('day')
"""
for member in cls:
if member.name == name:
return member.value
return None
@classmethod
def get_member(cls,
value: Any,
default: Category | None = None) -> Category | None:
""" Returns the first `Category` member matches the *value*, or the
specified *default* member if no member match.
Example:
>>> class Format(Category):
... hour = 'hh'
... minute = 'mm'
... second = 'ss'
>>> Format.get_member('hh')
Format.hour = 'hh'
>>> Format.get_member('day', None)
"""
for member in cls:
if member.value == value:
return member
return default
|
PypiClean
|
/ydk-models-cisco-ios-xe-16.9.3.post1.tar.gz/ydk-models-cisco-ios-xe-16.9.3.post1/ydk/models/cisco_ios_xe/Cisco_IOS_XE_virtual_service_oper.py
|
import sys
from collections import OrderedDict
from ydk.types import Entity, EntityPath, Identity, Enum, YType, YLeaf, YLeafList, YList, LeafDataList, Bits, Empty, Decimal64
from ydk.filters import YFilter
from ydk.errors import YError, YModelError
from ydk.errors.error_handler import handle_type_error as _handle_type_error
class VirtualServices(Entity):
"""
Information on all virtual services
.. attribute:: virtual_service
List of virtual services
**type**\: list of :py:class:`VirtualService <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService>`
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices, self).__init__()
self._top_entity = None
self.yang_name = "virtual-services"
self.yang_parent_name = "Cisco-IOS-XE-virtual-service-oper"
self.is_top_level_class = True
self.has_list_ancestor = False
self.ylist_key_names = []
self._child_classes = OrderedDict([("virtual-service", ("virtual_service", VirtualServices.VirtualService))])
self._leafs = OrderedDict()
self.virtual_service = YList(self)
self._segment_path = lambda: "Cisco-IOS-XE-virtual-service-oper:virtual-services"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices, [], name, value)
class VirtualService(Entity):
"""
List of virtual services
.. attribute:: name (key)
Virtual service name
**type**\: str
**config**\: False
.. attribute:: details
Virtual service details
**type**\: :py:class:`Details <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.Details>`
**config**\: False
.. attribute:: utilization
Virtual service resource utilization details
**type**\: :py:class:`Utilization <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.Utilization>`
**config**\: False
.. attribute:: network_utils
Virtual service network utilization details
**type**\: :py:class:`NetworkUtils <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.NetworkUtils>`
**config**\: False
.. attribute:: storage_utils
Virtual service storage utilization details
**type**\: :py:class:`StorageUtils <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.StorageUtils>`
**config**\: False
.. attribute:: processes
Virtual service process details
**type**\: :py:class:`Processes <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.Processes>`
**config**\: False
.. attribute:: attached_devices
Virtual service attached device details
**type**\: :py:class:`AttachedDevices <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.AttachedDevices>`
**config**\: False
.. attribute:: network_interfaces
Virtual service network interface details
**type**\: :py:class:`NetworkInterfaces <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.NetworkInterfaces>`
**config**\: False
.. attribute:: guest_routes
Virtual service guest route details
**type**\: :py:class:`GuestRoutes <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.GuestRoutes>`
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService, self).__init__()
self.yang_name = "virtual-service"
self.yang_parent_name = "virtual-services"
self.is_top_level_class = False
self.has_list_ancestor = False
self.ylist_key_names = ['name']
self._child_classes = OrderedDict([("details", ("details", VirtualServices.VirtualService.Details)), ("utilization", ("utilization", VirtualServices.VirtualService.Utilization)), ("network-utils", ("network_utils", VirtualServices.VirtualService.NetworkUtils)), ("storage-utils", ("storage_utils", VirtualServices.VirtualService.StorageUtils)), ("processes", ("processes", VirtualServices.VirtualService.Processes)), ("attached-devices", ("attached_devices", VirtualServices.VirtualService.AttachedDevices)), ("network-interfaces", ("network_interfaces", VirtualServices.VirtualService.NetworkInterfaces)), ("guest-routes", ("guest_routes", VirtualServices.VirtualService.GuestRoutes))])
self._leafs = OrderedDict([
('name', (YLeaf(YType.str, 'name'), ['str'])),
])
self.name = None
self.details = VirtualServices.VirtualService.Details()
self.details.parent = self
self._children_name_map["details"] = "details"
self.utilization = VirtualServices.VirtualService.Utilization()
self.utilization.parent = self
self._children_name_map["utilization"] = "utilization"
self.network_utils = VirtualServices.VirtualService.NetworkUtils()
self.network_utils.parent = self
self._children_name_map["network_utils"] = "network-utils"
self.storage_utils = VirtualServices.VirtualService.StorageUtils()
self.storage_utils.parent = self
self._children_name_map["storage_utils"] = "storage-utils"
self.processes = VirtualServices.VirtualService.Processes()
self.processes.parent = self
self._children_name_map["processes"] = "processes"
self.attached_devices = VirtualServices.VirtualService.AttachedDevices()
self.attached_devices.parent = self
self._children_name_map["attached_devices"] = "attached-devices"
self.network_interfaces = VirtualServices.VirtualService.NetworkInterfaces()
self.network_interfaces.parent = self
self._children_name_map["network_interfaces"] = "network-interfaces"
self.guest_routes = VirtualServices.VirtualService.GuestRoutes()
self.guest_routes.parent = self
self._children_name_map["guest_routes"] = "guest-routes"
self._segment_path = lambda: "virtual-service" + "[name='" + str(self.name) + "']"
self._absolute_path = lambda: "Cisco-IOS-XE-virtual-service-oper:virtual-services/%s" % self._segment_path()
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService, ['name'], name, value)
class Details(Entity):
"""
Virtual service details
.. attribute:: state
State of the virtual service
**type**\: str
**config**\: False
.. attribute:: package_information
Virtual service packaging information
**type**\: :py:class:`PackageInformation <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.Details.PackageInformation>`
**config**\: False
.. attribute:: detailed_guest_status
Guest status details
**type**\: :py:class:`DetailedGuestStatus <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.Details.DetailedGuestStatus>`
**config**\: False
.. attribute:: activated_profile_name
Activated profile name
**type**\: str
**config**\: False
.. attribute:: resource_reservation
Resource reservation details
**type**\: :py:class:`ResourceReservation <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.Details.ResourceReservation>`
**config**\: False
.. attribute:: guest_interface
Guest interface name
**type**\: str
**config**\: False
.. attribute:: resource_admission
Resources allocated for the virtual service
**type**\: :py:class:`ResourceAdmission <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.Details.ResourceAdmission>`
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.Details, self).__init__()
self.yang_name = "details"
self.yang_parent_name = "virtual-service"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([("package-information", ("package_information", VirtualServices.VirtualService.Details.PackageInformation)), ("detailed-guest-status", ("detailed_guest_status", VirtualServices.VirtualService.Details.DetailedGuestStatus)), ("resource-reservation", ("resource_reservation", VirtualServices.VirtualService.Details.ResourceReservation)), ("resource-admission", ("resource_admission", VirtualServices.VirtualService.Details.ResourceAdmission))])
self._leafs = OrderedDict([
('state', (YLeaf(YType.str, 'state'), ['str'])),
('activated_profile_name', (YLeaf(YType.str, 'activated-profile-name'), ['str'])),
('guest_interface', (YLeaf(YType.str, 'guest-interface'), ['str'])),
])
self.state = None
self.activated_profile_name = None
self.guest_interface = None
self.package_information = VirtualServices.VirtualService.Details.PackageInformation()
self.package_information.parent = self
self._children_name_map["package_information"] = "package-information"
self.detailed_guest_status = VirtualServices.VirtualService.Details.DetailedGuestStatus()
self.detailed_guest_status.parent = self
self._children_name_map["detailed_guest_status"] = "detailed-guest-status"
self.resource_reservation = VirtualServices.VirtualService.Details.ResourceReservation()
self.resource_reservation.parent = self
self._children_name_map["resource_reservation"] = "resource-reservation"
self.resource_admission = VirtualServices.VirtualService.Details.ResourceAdmission()
self.resource_admission.parent = self
self._children_name_map["resource_admission"] = "resource-admission"
self._segment_path = lambda: "details"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.Details, ['state', 'activated_profile_name', 'guest_interface'], name, value)
class PackageInformation(Entity):
"""
Virtual service packaging information
.. attribute:: name
Package name
**type**\: str
**config**\: False
.. attribute:: path
Package path
**type**\: str
**config**\: False
.. attribute:: application
Application details
**type**\: :py:class:`Application <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.Details.PackageInformation.Application>`
**config**\: False
.. attribute:: signing
Key signing details
**type**\: :py:class:`Signing <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.Details.PackageInformation.Signing>`
**config**\: False
.. attribute:: licensing
Licensing details
**type**\: :py:class:`Licensing <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.Details.PackageInformation.Licensing>`
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.Details.PackageInformation, self).__init__()
self.yang_name = "package-information"
self.yang_parent_name = "details"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([("application", ("application", VirtualServices.VirtualService.Details.PackageInformation.Application)), ("signing", ("signing", VirtualServices.VirtualService.Details.PackageInformation.Signing)), ("licensing", ("licensing", VirtualServices.VirtualService.Details.PackageInformation.Licensing))])
self._leafs = OrderedDict([
('name', (YLeaf(YType.str, 'name'), ['str'])),
('path', (YLeaf(YType.str, 'path'), ['str'])),
])
self.name = None
self.path = None
self.application = VirtualServices.VirtualService.Details.PackageInformation.Application()
self.application.parent = self
self._children_name_map["application"] = "application"
self.signing = VirtualServices.VirtualService.Details.PackageInformation.Signing()
self.signing.parent = self
self._children_name_map["signing"] = "signing"
self.licensing = VirtualServices.VirtualService.Details.PackageInformation.Licensing()
self.licensing.parent = self
self._children_name_map["licensing"] = "licensing"
self._segment_path = lambda: "package-information"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.Details.PackageInformation, ['name', 'path'], name, value)
class Application(Entity):
"""
Application details
.. attribute:: name
Application name
**type**\: str
**config**\: False
.. attribute:: installed_version
Application version
**type**\: str
**config**\: False
.. attribute:: description
Application description
**type**\: str
**config**\: False
.. attribute:: type
Application type
**type**\: str
**config**\: False
.. attribute:: owner
Which process creates the application
**type**\: str
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.Details.PackageInformation.Application, self).__init__()
self.yang_name = "application"
self.yang_parent_name = "package-information"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([])
self._leafs = OrderedDict([
('name', (YLeaf(YType.str, 'name'), ['str'])),
('installed_version', (YLeaf(YType.str, 'installed-version'), ['str'])),
('description', (YLeaf(YType.str, 'description'), ['str'])),
('type', (YLeaf(YType.str, 'type'), ['str'])),
('owner', (YLeaf(YType.str, 'owner'), ['str'])),
])
self.name = None
self.installed_version = None
self.description = None
self.type = None
self.owner = None
self._segment_path = lambda: "application"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.Details.PackageInformation.Application, ['name', 'installed_version', 'description', 'type', 'owner'], name, value)
class Signing(Entity):
"""
Key signing details
.. attribute:: key_type
Signed key type
**type**\: str
**config**\: False
.. attribute:: method
Method the key was signed
**type**\: str
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.Details.PackageInformation.Signing, self).__init__()
self.yang_name = "signing"
self.yang_parent_name = "package-information"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([])
self._leafs = OrderedDict([
('key_type', (YLeaf(YType.str, 'key-type'), ['str'])),
('method', (YLeaf(YType.str, 'method'), ['str'])),
])
self.key_type = None
self.method = None
self._segment_path = lambda: "signing"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.Details.PackageInformation.Signing, ['key_type', 'method'], name, value)
class Licensing(Entity):
"""
Licensing details
.. attribute:: name
License name
**type**\: str
**config**\: False
.. attribute:: version
License version
**type**\: str
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.Details.PackageInformation.Licensing, self).__init__()
self.yang_name = "licensing"
self.yang_parent_name = "package-information"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([])
self._leafs = OrderedDict([
('name', (YLeaf(YType.str, 'name'), ['str'])),
('version', (YLeaf(YType.str, 'version'), ['str'])),
])
self.name = None
self.version = None
self._segment_path = lambda: "licensing"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.Details.PackageInformation.Licensing, ['name', 'version'], name, value)
class DetailedGuestStatus(Entity):
"""
Guest status details
.. attribute:: processes
List of all processes
**type**\: :py:class:`Processes <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.Details.DetailedGuestStatus.Processes>`
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.Details.DetailedGuestStatus, self).__init__()
self.yang_name = "detailed-guest-status"
self.yang_parent_name = "details"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([("processes", ("processes", VirtualServices.VirtualService.Details.DetailedGuestStatus.Processes))])
self._leafs = OrderedDict()
self.processes = VirtualServices.VirtualService.Details.DetailedGuestStatus.Processes()
self.processes.parent = self
self._children_name_map["processes"] = "processes"
self._segment_path = lambda: "detailed-guest-status"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.Details.DetailedGuestStatus, [], name, value)
class Processes(Entity):
"""
List of all processes
.. attribute:: name
Process name
**type**\: str
**config**\: False
.. attribute:: status
Process status
**type**\: str
**config**\: False
.. attribute:: pid
Process ID
**type**\: str
**config**\: False
.. attribute:: uptime
Process uptime
**type**\: str
**config**\: False
.. attribute:: memory
Amount of process memory
**type**\: str
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.Details.DetailedGuestStatus.Processes, self).__init__()
self.yang_name = "processes"
self.yang_parent_name = "detailed-guest-status"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([])
self._leafs = OrderedDict([
('name', (YLeaf(YType.str, 'name'), ['str'])),
('status', (YLeaf(YType.str, 'status'), ['str'])),
('pid', (YLeaf(YType.str, 'pid'), ['str'])),
('uptime', (YLeaf(YType.str, 'uptime'), ['str'])),
('memory', (YLeaf(YType.str, 'memory'), ['str'])),
])
self.name = None
self.status = None
self.pid = None
self.uptime = None
self.memory = None
self._segment_path = lambda: "processes"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.Details.DetailedGuestStatus.Processes, ['name', 'status', 'pid', 'uptime', 'memory'], name, value)
class ResourceReservation(Entity):
"""
Resource reservation details
.. attribute:: disk
Amount of reserverd disk space in MB
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: memory
Amount of reserved memory in MB
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: cpu
Amount of reserved cpu in unit
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.Details.ResourceReservation, self).__init__()
self.yang_name = "resource-reservation"
self.yang_parent_name = "details"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([])
self._leafs = OrderedDict([
('disk', (YLeaf(YType.uint64, 'disk'), ['int'])),
('memory', (YLeaf(YType.uint64, 'memory'), ['int'])),
('cpu', (YLeaf(YType.uint64, 'cpu'), ['int'])),
])
self.disk = None
self.memory = None
self.cpu = None
self._segment_path = lambda: "resource-reservation"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.Details.ResourceReservation, ['disk', 'memory', 'cpu'], name, value)
class ResourceAdmission(Entity):
"""
Resources allocated for the virtual service
.. attribute:: state
Status of the resource allocation
**type**\: str
**config**\: False
.. attribute:: disk_space
Amount of disk space allocated for the virtual service in MB
**type**\: str
**config**\: False
.. attribute:: memory
Amount of memory allocated for the virtual service in MB
**type**\: str
**config**\: False
.. attribute:: cpu
Percentage of cpu allocated for the virtual\-service in unit
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: vcpus
Amount of VCPUs allocated for the virtual service
**type**\: str
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.Details.ResourceAdmission, self).__init__()
self.yang_name = "resource-admission"
self.yang_parent_name = "details"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([])
self._leafs = OrderedDict([
('state', (YLeaf(YType.str, 'state'), ['str'])),
('disk_space', (YLeaf(YType.str, 'disk-space'), ['str'])),
('memory', (YLeaf(YType.str, 'memory'), ['str'])),
('cpu', (YLeaf(YType.uint64, 'cpu'), ['int'])),
('vcpus', (YLeaf(YType.str, 'vcpus'), ['str'])),
])
self.state = None
self.disk_space = None
self.memory = None
self.cpu = None
self.vcpus = None
self._segment_path = lambda: "resource-admission"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.Details.ResourceAdmission, ['state', 'disk_space', 'memory', 'cpu', 'vcpus'], name, value)
class Utilization(Entity):
"""
Virtual service resource utilization details
.. attribute:: name
Name of the virtual service
**type**\: str
**config**\: False
.. attribute:: cpu_util
CPU utilization information
**type**\: :py:class:`CpuUtil <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.Utilization.CpuUtil>`
**config**\: False
.. attribute:: memory_util
Memory utilization information
**type**\: :py:class:`MemoryUtil <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.Utilization.MemoryUtil>`
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.Utilization, self).__init__()
self.yang_name = "utilization"
self.yang_parent_name = "virtual-service"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([("cpu-util", ("cpu_util", VirtualServices.VirtualService.Utilization.CpuUtil)), ("memory-util", ("memory_util", VirtualServices.VirtualService.Utilization.MemoryUtil))])
self._leafs = OrderedDict([
('name', (YLeaf(YType.str, 'name'), ['str'])),
])
self.name = None
self.cpu_util = VirtualServices.VirtualService.Utilization.CpuUtil()
self.cpu_util.parent = self
self._children_name_map["cpu_util"] = "cpu-util"
self.memory_util = VirtualServices.VirtualService.Utilization.MemoryUtil()
self.memory_util.parent = self
self._children_name_map["memory_util"] = "memory-util"
self._segment_path = lambda: "utilization"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.Utilization, ['name'], name, value)
class CpuUtil(Entity):
"""
CPU utilization information
.. attribute:: requested_application_util
Amount of requested CPU utilization by the virtual service
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: actual_application_util
Percetnage of CPU actual utilization for the virtual service
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: cpu_state
State of the CPU utilization for the virtual\-service
**type**\: str
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.Utilization.CpuUtil, self).__init__()
self.yang_name = "cpu-util"
self.yang_parent_name = "utilization"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([])
self._leafs = OrderedDict([
('requested_application_util', (YLeaf(YType.uint64, 'requested-application-util'), ['int'])),
('actual_application_util', (YLeaf(YType.uint64, 'actual-application-util'), ['int'])),
('cpu_state', (YLeaf(YType.str, 'cpu-state'), ['str'])),
])
self.requested_application_util = None
self.actual_application_util = None
self.cpu_state = None
self._segment_path = lambda: "cpu-util"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.Utilization.CpuUtil, ['requested_application_util', 'actual_application_util', 'cpu_state'], name, value)
class MemoryUtil(Entity):
"""
Memory utilization information
.. attribute:: memory_allocation
Amount of memory allocated for the virtual service in MB
**type**\: str
**config**\: False
.. attribute:: memory_used
Amount of used memory for the virtual service in KB
**type**\: str
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.Utilization.MemoryUtil, self).__init__()
self.yang_name = "memory-util"
self.yang_parent_name = "utilization"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([])
self._leafs = OrderedDict([
('memory_allocation', (YLeaf(YType.str, 'memory-allocation'), ['str'])),
('memory_used', (YLeaf(YType.str, 'memory-used'), ['str'])),
])
self.memory_allocation = None
self.memory_used = None
self._segment_path = lambda: "memory-util"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.Utilization.MemoryUtil, ['memory_allocation', 'memory_used'], name, value)
class NetworkUtils(Entity):
"""
Virtual service network utilization details
.. attribute:: network_util
A list of network utilization details
**type**\: list of :py:class:`NetworkUtil <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.NetworkUtils.NetworkUtil>`
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.NetworkUtils, self).__init__()
self.yang_name = "network-utils"
self.yang_parent_name = "virtual-service"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([("network-util", ("network_util", VirtualServices.VirtualService.NetworkUtils.NetworkUtil))])
self._leafs = OrderedDict()
self.network_util = YList(self)
self._segment_path = lambda: "network-utils"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.NetworkUtils, [], name, value)
class NetworkUtil(Entity):
"""
A list of network utilization details
.. attribute:: name (key)
Name of the network used for the virtual service
**type**\: str
**config**\: False
.. attribute:: alias
Alias of the network used by the virtual service
**type**\: str
**config**\: False
.. attribute:: rx_packets
Number of packets received by the virtual service
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: rx_bytes
Number of octets received by the virtual service
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: rx_errors
Number of RX errors by the virtual service
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: tx_packets
Number of packets transmitted by the virtual service
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: tx_bytes
Number of octets transmitted by the virtual service
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: tx_errors
Number of TX errors by the virtual service
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.NetworkUtils.NetworkUtil, self).__init__()
self.yang_name = "network-util"
self.yang_parent_name = "network-utils"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = ['name']
self._child_classes = OrderedDict([])
self._leafs = OrderedDict([
('name', (YLeaf(YType.str, 'name'), ['str'])),
('alias', (YLeaf(YType.str, 'alias'), ['str'])),
('rx_packets', (YLeaf(YType.uint64, 'rx-packets'), ['int'])),
('rx_bytes', (YLeaf(YType.uint64, 'rx-bytes'), ['int'])),
('rx_errors', (YLeaf(YType.uint64, 'rx-errors'), ['int'])),
('tx_packets', (YLeaf(YType.uint64, 'tx-packets'), ['int'])),
('tx_bytes', (YLeaf(YType.uint64, 'tx-bytes'), ['int'])),
('tx_errors', (YLeaf(YType.uint64, 'tx-errors'), ['int'])),
])
self.name = None
self.alias = None
self.rx_packets = None
self.rx_bytes = None
self.rx_errors = None
self.tx_packets = None
self.tx_bytes = None
self.tx_errors = None
self._segment_path = lambda: "network-util" + "[name='" + str(self.name) + "']"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.NetworkUtils.NetworkUtil, ['name', 'alias', 'rx_packets', 'rx_bytes', 'rx_errors', 'tx_packets', 'tx_bytes', 'tx_errors'], name, value)
class StorageUtils(Entity):
"""
Virtual service storage utilization details
.. attribute:: storage_util
List of storage utilization details
**type**\: list of :py:class:`StorageUtil <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.StorageUtils.StorageUtil>`
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.StorageUtils, self).__init__()
self.yang_name = "storage-utils"
self.yang_parent_name = "virtual-service"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([("storage-util", ("storage_util", VirtualServices.VirtualService.StorageUtils.StorageUtil))])
self._leafs = OrderedDict()
self.storage_util = YList(self)
self._segment_path = lambda: "storage-utils"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.StorageUtils, [], name, value)
class StorageUtil(Entity):
"""
List of storage utilization details
.. attribute:: name (key)
Name of the storage device used for the virtual service
**type**\: str
**config**\: False
.. attribute:: alias
Alias of the storage device used by the virtual service
**type**\: str
**config**\: False
.. attribute:: rd_bytes
Number of bytes read by the virtual service
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: rd_requests
Number of read requests made by the virtual service
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: errors
Number of storage error seen by the virtual service
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: wr_bytes
Number of bytes written by the virtual service
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: wr_requests
Number of write requests made by the virtual service
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: capacity
Storage capactity in 1K blocks
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: available
Available storage in 1K blocks
**type**\: str
**config**\: False
.. attribute:: used
Used storage in 1K blocks
**type**\: int
**range:** 0..18446744073709551615
**config**\: False
.. attribute:: usage
Percetage of storage capactiy used by the virtual service
**type**\: str
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.StorageUtils.StorageUtil, self).__init__()
self.yang_name = "storage-util"
self.yang_parent_name = "storage-utils"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = ['name']
self._child_classes = OrderedDict([])
self._leafs = OrderedDict([
('name', (YLeaf(YType.str, 'name'), ['str'])),
('alias', (YLeaf(YType.str, 'alias'), ['str'])),
('rd_bytes', (YLeaf(YType.uint64, 'rd-bytes'), ['int'])),
('rd_requests', (YLeaf(YType.uint64, 'rd-requests'), ['int'])),
('errors', (YLeaf(YType.uint64, 'errors'), ['int'])),
('wr_bytes', (YLeaf(YType.uint64, 'wr-bytes'), ['int'])),
('wr_requests', (YLeaf(YType.uint64, 'wr-requests'), ['int'])),
('capacity', (YLeaf(YType.uint64, 'capacity'), ['int'])),
('available', (YLeaf(YType.str, 'available'), ['str'])),
('used', (YLeaf(YType.uint64, 'used'), ['int'])),
('usage', (YLeaf(YType.str, 'usage'), ['str'])),
])
self.name = None
self.alias = None
self.rd_bytes = None
self.rd_requests = None
self.errors = None
self.wr_bytes = None
self.wr_requests = None
self.capacity = None
self.available = None
self.used = None
self.usage = None
self._segment_path = lambda: "storage-util" + "[name='" + str(self.name) + "']"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.StorageUtils.StorageUtil, ['name', 'alias', 'rd_bytes', 'rd_requests', 'errors', 'wr_bytes', 'wr_requests', 'capacity', 'available', 'used', 'usage'], name, value)
class Processes(Entity):
"""
Virtual service process details
.. attribute:: process
List of process details
**type**\: list of :py:class:`Process <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.Processes.Process>`
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.Processes, self).__init__()
self.yang_name = "processes"
self.yang_parent_name = "virtual-service"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([("process", ("process", VirtualServices.VirtualService.Processes.Process))])
self._leafs = OrderedDict()
self.process = YList(self)
self._segment_path = lambda: "processes"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.Processes, [], name, value)
class Process(Entity):
"""
List of process details
.. attribute:: name (key)
Process name
**type**\: str
**config**\: False
.. attribute:: status
Process status
**type**\: str
**config**\: False
.. attribute:: pid
Process ID
**type**\: str
**config**\: False
.. attribute:: uptime
Process uptime
**type**\: str
**config**\: False
.. attribute:: memory
Amount of process memory
**type**\: str
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.Processes.Process, self).__init__()
self.yang_name = "process"
self.yang_parent_name = "processes"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = ['name']
self._child_classes = OrderedDict([])
self._leafs = OrderedDict([
('name', (YLeaf(YType.str, 'name'), ['str'])),
('status', (YLeaf(YType.str, 'status'), ['str'])),
('pid', (YLeaf(YType.str, 'pid'), ['str'])),
('uptime', (YLeaf(YType.str, 'uptime'), ['str'])),
('memory', (YLeaf(YType.str, 'memory'), ['str'])),
])
self.name = None
self.status = None
self.pid = None
self.uptime = None
self.memory = None
self._segment_path = lambda: "process" + "[name='" + str(self.name) + "']"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.Processes.Process, ['name', 'status', 'pid', 'uptime', 'memory'], name, value)
class AttachedDevices(Entity):
"""
Virtual service attached device details
.. attribute:: attached_device
A list of attached device details
**type**\: list of :py:class:`AttachedDevice <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.AttachedDevices.AttachedDevice>`
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.AttachedDevices, self).__init__()
self.yang_name = "attached-devices"
self.yang_parent_name = "virtual-service"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([("attached-device", ("attached_device", VirtualServices.VirtualService.AttachedDevices.AttachedDevice))])
self._leafs = OrderedDict()
self.attached_device = YList(self)
self._segment_path = lambda: "attached-devices"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.AttachedDevices, [], name, value)
class AttachedDevice(Entity):
"""
A list of attached device details
.. attribute:: name (key)
Attached device name
**type**\: str
**config**\: False
.. attribute:: type
Attached device type
**type**\: str
**config**\: False
.. attribute:: alias
Attached device alias
**type**\: str
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.AttachedDevices.AttachedDevice, self).__init__()
self.yang_name = "attached-device"
self.yang_parent_name = "attached-devices"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = ['name']
self._child_classes = OrderedDict([])
self._leafs = OrderedDict([
('name', (YLeaf(YType.str, 'name'), ['str'])),
('type', (YLeaf(YType.str, 'type'), ['str'])),
('alias', (YLeaf(YType.str, 'alias'), ['str'])),
])
self.name = None
self.type = None
self.alias = None
self._segment_path = lambda: "attached-device" + "[name='" + str(self.name) + "']"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.AttachedDevices.AttachedDevice, ['name', 'type', 'alias'], name, value)
class NetworkInterfaces(Entity):
"""
Virtual service network interface details
.. attribute:: network_interface
A list of network interface details
**type**\: list of :py:class:`NetworkInterface <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.NetworkInterfaces.NetworkInterface>`
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.NetworkInterfaces, self).__init__()
self.yang_name = "network-interfaces"
self.yang_parent_name = "virtual-service"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([("network-interface", ("network_interface", VirtualServices.VirtualService.NetworkInterfaces.NetworkInterface))])
self._leafs = OrderedDict()
self.network_interface = YList(self)
self._segment_path = lambda: "network-interfaces"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.NetworkInterfaces, [], name, value)
class NetworkInterface(Entity):
"""
A list of network interface details
.. attribute:: mac_address (key)
MAC address for the network interface
**type**\: str
**pattern:** [0\-9a\-fA\-F]{2}(\:[0\-9a\-fA\-F]{2}){5}
**config**\: False
.. attribute:: attached_interface
Attached interface name
**type**\: str
**config**\: False
.. attribute:: ipv4_address
IPv4 address for the network interface
**type**\: str
**pattern:** (([0\-9]\|[1\-9][0\-9]\|1[0\-9][0\-9]\|2[0\-4][0\-9]\|25[0\-5])\\.){3}([0\-9]\|[1\-9][0\-9]\|1[0\-9][0\-9]\|2[0\-4][0\-9]\|25[0\-5])(%[\\p{N}\\p{L}]+)?
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.NetworkInterfaces.NetworkInterface, self).__init__()
self.yang_name = "network-interface"
self.yang_parent_name = "network-interfaces"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = ['mac_address']
self._child_classes = OrderedDict([])
self._leafs = OrderedDict([
('mac_address', (YLeaf(YType.str, 'mac-address'), ['str'])),
('attached_interface', (YLeaf(YType.str, 'attached-interface'), ['str'])),
('ipv4_address', (YLeaf(YType.str, 'ipv4-address'), ['str'])),
])
self.mac_address = None
self.attached_interface = None
self.ipv4_address = None
self._segment_path = lambda: "network-interface" + "[mac-address='" + str(self.mac_address) + "']"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.NetworkInterfaces.NetworkInterface, ['mac_address', 'attached_interface', 'ipv4_address'], name, value)
class GuestRoutes(Entity):
"""
Virtual service guest route details
.. attribute:: guest_route
List of guest routes for a guest interface
**type**\: list of :py:class:`GuestRoute <ydk.models.cisco_ios_xe.Cisco_IOS_XE_virtual_service_oper.VirtualServices.VirtualService.GuestRoutes.GuestRoute>`
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.GuestRoutes, self).__init__()
self.yang_name = "guest-routes"
self.yang_parent_name = "virtual-service"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = []
self._child_classes = OrderedDict([("guest-route", ("guest_route", VirtualServices.VirtualService.GuestRoutes.GuestRoute))])
self._leafs = OrderedDict()
self.guest_route = YList(self)
self._segment_path = lambda: "guest-routes"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.GuestRoutes, [], name, value)
class GuestRoute(Entity):
"""
List of guest routes for a guest interface
.. attribute:: route (key)
Guest route of the guest interface
**type**\: str
**config**\: False
"""
_prefix = 'virtual-service-ios-xe-oper'
_revision = '2018-02-01'
def __init__(self):
if sys.version_info > (3,):
super().__init__()
else:
super(VirtualServices.VirtualService.GuestRoutes.GuestRoute, self).__init__()
self.yang_name = "guest-route"
self.yang_parent_name = "guest-routes"
self.is_top_level_class = False
self.has_list_ancestor = True
self.ylist_key_names = ['route']
self._child_classes = OrderedDict([])
self._leafs = OrderedDict([
('route', (YLeaf(YType.str, 'route'), ['str'])),
])
self.route = None
self._segment_path = lambda: "guest-route" + "[route='" + str(self.route) + "']"
self._is_frozen = True
def __setattr__(self, name, value):
self._perform_setattr(VirtualServices.VirtualService.GuestRoutes.GuestRoute, ['route'], name, value)
def clone_ptr(self):
self._top_entity = VirtualServices()
return self._top_entity
|
PypiClean
|
/insightface_uniubi-0.4.7-cp38-cp38-manylinux1_x86_64.whl/insightface_bk/thirdparty/face3d/mesh_numpy/transform.py
|
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np
import math
from math import cos, sin
def angle2matrix(angles):
''' get rotation matrix from three rotation angles(degree). right-handed.
Args:
angles: [3,]. x, y, z angles
x: pitch. positive for looking down.
y: yaw. positive for looking left.
z: roll. positive for tilting head right.
Returns:
R: [3, 3]. rotation matrix.
'''
x, y, z = np.deg2rad(angles[0]), np.deg2rad(angles[1]), np.deg2rad(angles[2])
# x
Rx=np.array([[1, 0, 0],
[0, cos(x), -sin(x)],
[0, sin(x), cos(x)]])
# y
Ry=np.array([[ cos(y), 0, sin(y)],
[ 0, 1, 0],
[-sin(y), 0, cos(y)]])
# z
Rz=np.array([[cos(z), -sin(z), 0],
[sin(z), cos(z), 0],
[ 0, 0, 1]])
R=Rz.dot(Ry.dot(Rx))
return R.astype(np.float32)
def angle2matrix_3ddfa(angles):
''' get rotation matrix from three rotation angles(radian). The same as in 3DDFA.
Args:
angles: [3,]. x, y, z angles
x: pitch.
y: yaw.
z: roll.
Returns:
R: 3x3. rotation matrix.
'''
# x, y, z = np.deg2rad(angles[0]), np.deg2rad(angles[1]), np.deg2rad(angles[2])
x, y, z = angles[0], angles[1], angles[2]
# x
Rx=np.array([[1, 0, 0],
[0, cos(x), sin(x)],
[0, -sin(x), cos(x)]])
# y
Ry=np.array([[ cos(y), 0, -sin(y)],
[ 0, 1, 0],
[sin(y), 0, cos(y)]])
# z
Rz=np.array([[cos(z), sin(z), 0],
[-sin(z), cos(z), 0],
[ 0, 0, 1]])
R = Rx.dot(Ry).dot(Rz)
return R.astype(np.float32)
## ------------------------------------------ 1. transform(transform, project, camera).
## ---------- 3d-3d transform. Transform obj in world space
def rotate(vertices, angles):
''' rotate vertices.
X_new = R.dot(X). X: 3 x 1
Args:
vertices: [nver, 3].
rx, ry, rz: degree angles
rx: pitch. positive for looking down
ry: yaw. positive for looking left
rz: roll. positive for tilting head right
Returns:
rotated vertices: [nver, 3]
'''
R = angle2matrix(angles)
rotated_vertices = vertices.dot(R.T)
return rotated_vertices
def similarity_transform(vertices, s, R, t3d):
''' similarity transform. dof = 7.
3D: s*R.dot(X) + t
Homo: M = [[sR, t],[0^T, 1]]. M.dot(X)
Args:(float32)
vertices: [nver, 3].
s: [1,]. scale factor.
R: [3,3]. rotation matrix.
t3d: [3,]. 3d translation vector.
Returns:
transformed vertices: [nver, 3]
'''
t3d = np.squeeze(np.array(t3d, dtype = np.float32))
transformed_vertices = s * vertices.dot(R.T) + t3d[np.newaxis, :]
return transformed_vertices
## -------------- Camera. from world space to camera space
# Ref: https://cs184.eecs.berkeley.edu/lecture/transforms-2
def normalize(x):
epsilon = 1e-12
norm = np.sqrt(np.sum(x**2, axis = 0))
norm = np.maximum(norm, epsilon)
return x/norm
def lookat_camera(vertices, eye, at = None, up = None):
""" 'look at' transformation: from world space to camera space
standard camera space:
camera located at the origin.
looking down negative z-axis.
vertical vector is y-axis.
Xcam = R(X - C)
Homo: [[R, -RC], [0, 1]]
Args:
vertices: [nver, 3]
eye: [3,] the XYZ world space position of the camera.
at: [3,] a position along the center of the camera's gaze.
up: [3,] up direction
Returns:
transformed_vertices: [nver, 3]
"""
if at is None:
at = np.array([0, 0, 0], np.float32)
if up is None:
up = np.array([0, 1, 0], np.float32)
eye = np.array(eye).astype(np.float32)
at = np.array(at).astype(np.float32)
z_aixs = -normalize(at - eye) # look forward
x_aixs = normalize(np.cross(up, z_aixs)) # look right
y_axis = np.cross(z_aixs, x_aixs) # look up
R = np.stack((x_aixs, y_axis, z_aixs))#, axis = 0) # 3 x 3
transformed_vertices = vertices - eye # translation
transformed_vertices = transformed_vertices.dot(R.T) # rotation
return transformed_vertices
## --------- 3d-2d project. from camera space to image plane
# generally, image plane only keeps x,y channels, here reserve z channel for calculating z-buffer.
def orthographic_project(vertices):
''' scaled orthographic projection(just delete z)
assumes: variations in depth over the object is small relative to the mean distance from camera to object
x -> x*f/z, y -> x*f/z, z -> f.
for point i,j. zi~=zj. so just delete z
** often used in face
Homo: P = [[1,0,0,0], [0,1,0,0], [0,0,1,0]]
Args:
vertices: [nver, 3]
Returns:
projected_vertices: [nver, 3] if isKeepZ=True. [nver, 2] if isKeepZ=False.
'''
return vertices.copy()
def perspective_project(vertices, fovy, aspect_ratio = 1., near = 0.1, far = 1000.):
''' perspective projection.
Args:
vertices: [nver, 3]
fovy: vertical angular field of view. degree.
aspect_ratio : width / height of field of view
near : depth of near clipping plane
far : depth of far clipping plane
Returns:
projected_vertices: [nver, 3]
'''
fovy = np.deg2rad(fovy)
top = near*np.tan(fovy)
bottom = -top
right = top*aspect_ratio
left = -right
#-- homo
P = np.array([[near/right, 0, 0, 0],
[0, near/top, 0, 0],
[0, 0, -(far+near)/(far-near), -2*far*near/(far-near)],
[0, 0, -1, 0]])
vertices_homo = np.hstack((vertices, np.ones((vertices.shape[0], 1)))) # [nver, 4]
projected_vertices = vertices_homo.dot(P.T)
projected_vertices = projected_vertices/projected_vertices[:,3:]
projected_vertices = projected_vertices[:,:3]
projected_vertices[:,2] = -projected_vertices[:,2]
#-- non homo. only fovy
# projected_vertices = vertices.copy()
# projected_vertices[:,0] = -(near/right)*vertices[:,0]/vertices[:,2]
# projected_vertices[:,1] = -(near/top)*vertices[:,1]/vertices[:,2]
return projected_vertices
def to_image(vertices, h, w, is_perspective = False):
''' change vertices to image coord system
3d system: XYZ, center(0, 0, 0)
2d image: x(u), y(v). center(w/2, h/2), flip y-axis.
Args:
vertices: [nver, 3]
h: height of the rendering
w : width of the rendering
Returns:
projected_vertices: [nver, 3]
'''
image_vertices = vertices.copy()
if is_perspective:
# if perspective, the projected vertices are normalized to [-1, 1]. so change it to image size first.
image_vertices[:,0] = image_vertices[:,0]*w/2
image_vertices[:,1] = image_vertices[:,1]*h/2
# move to center of image
image_vertices[:,0] = image_vertices[:,0] + w/2
image_vertices[:,1] = image_vertices[:,1] + h/2
# flip vertices along y-axis.
image_vertices[:,1] = h - image_vertices[:,1] - 1
return image_vertices
#### -------------------------------------------2. estimate transform matrix from correspondences.
def estimate_affine_matrix_3d23d(X, Y):
''' Using least-squares solution
Args:
X: [n, 3]. 3d points(fixed)
Y: [n, 3]. corresponding 3d points(moving). Y = PX
Returns:
P_Affine: (3, 4). Affine camera matrix (the third row is [0, 0, 0, 1]).
'''
X_homo = np.hstack((X, np.ones([X.shape[1],1]))) #n x 4
P = np.linalg.lstsq(X_homo, Y)[0].T # Affine matrix. 3 x 4
return P
def estimate_affine_matrix_3d22d(X, x):
''' Using Golden Standard Algorithm for estimating an affine camera
matrix P from world to image correspondences.
See Alg.7.2. in MVGCV
Code Ref: https://github.com/patrikhuber/eos/blob/master/include/eos/fitting/affine_camera_estimation.hpp
x_homo = X_homo.dot(P_Affine)
Args:
X: [n, 3]. corresponding 3d points(fixed)
x: [n, 2]. n>=4. 2d points(moving). x = PX
Returns:
P_Affine: [3, 4]. Affine camera matrix
'''
X = X.T; x = x.T
assert(x.shape[1] == X.shape[1])
n = x.shape[1]
assert(n >= 4)
#--- 1. normalization
# 2d points
mean = np.mean(x, 1) # (2,)
x = x - np.tile(mean[:, np.newaxis], [1, n])
average_norm = np.mean(np.sqrt(np.sum(x**2, 0)))
scale = np.sqrt(2) / average_norm
x = scale * x
T = np.zeros((3,3), dtype = np.float32)
T[0, 0] = T[1, 1] = scale
T[:2, 2] = -mean*scale
T[2, 2] = 1
# 3d points
X_homo = np.vstack((X, np.ones((1, n))))
mean = np.mean(X, 1) # (3,)
X = X - np.tile(mean[:, np.newaxis], [1, n])
m = X_homo[:3,:] - X
average_norm = np.mean(np.sqrt(np.sum(X**2, 0)))
scale = np.sqrt(3) / average_norm
X = scale * X
U = np.zeros((4,4), dtype = np.float32)
U[0, 0] = U[1, 1] = U[2, 2] = scale
U[:3, 3] = -mean*scale
U[3, 3] = 1
# --- 2. equations
A = np.zeros((n*2, 8), dtype = np.float32);
X_homo = np.vstack((X, np.ones((1, n)))).T
A[:n, :4] = X_homo
A[n:, 4:] = X_homo
b = np.reshape(x, [-1, 1])
# --- 3. solution
p_8 = np.linalg.pinv(A).dot(b)
P = np.zeros((3, 4), dtype = np.float32)
P[0, :] = p_8[:4, 0]
P[1, :] = p_8[4:, 0]
P[-1, -1] = 1
# --- 4. denormalization
P_Affine = np.linalg.inv(T).dot(P.dot(U))
return P_Affine
def P2sRt(P):
''' decompositing camera matrix P
Args:
P: (3, 4). Affine Camera Matrix.
Returns:
s: scale factor.
R: (3, 3). rotation matrix.
t: (3,). translation.
'''
t = P[:, 3]
R1 = P[0:1, :3]
R2 = P[1:2, :3]
s = (np.linalg.norm(R1) + np.linalg.norm(R2))/2.0
r1 = R1/np.linalg.norm(R1)
r2 = R2/np.linalg.norm(R2)
r3 = np.cross(r1, r2)
R = np.concatenate((r1, r2, r3), 0)
return s, R, t
#Ref: https://www.learnopencv.com/rotation-matrix-to-euler-angles/
def isRotationMatrix(R):
''' checks if a matrix is a valid rotation matrix(whether orthogonal or not)
'''
Rt = np.transpose(R)
shouldBeIdentity = np.dot(Rt, R)
I = np.identity(3, dtype = R.dtype)
n = np.linalg.norm(I - shouldBeIdentity)
return n < 1e-6
def matrix2angle(R):
''' get three Euler angles from Rotation Matrix
Args:
R: (3,3). rotation matrix
Returns:
x: pitch
y: yaw
z: roll
'''
assert(isRotationMatrix)
sy = math.sqrt(R[0,0] * R[0,0] + R[1,0] * R[1,0])
singular = sy < 1e-6
if not singular :
x = math.atan2(R[2,1] , R[2,2])
y = math.atan2(-R[2,0], sy)
z = math.atan2(R[1,0], R[0,0])
else :
x = math.atan2(-R[1,2], R[1,1])
y = math.atan2(-R[2,0], sy)
z = 0
# rx, ry, rz = np.rad2deg(x), np.rad2deg(y), np.rad2deg(z)
rx, ry, rz = x*180/np.pi, y*180/np.pi, z*180/np.pi
return rx, ry, rz
# def matrix2angle(R):
# ''' compute three Euler angles from a Rotation Matrix. Ref: http://www.gregslabaugh.net/publications/euler.pdf
# Args:
# R: (3,3). rotation matrix
# Returns:
# x: yaw
# y: pitch
# z: roll
# '''
# # assert(isRotationMatrix(R))
# if R[2,0] !=1 or R[2,0] != -1:
# x = math.asin(R[2,0])
# y = math.atan2(R[2,1]/cos(x), R[2,2]/cos(x))
# z = math.atan2(R[1,0]/cos(x), R[0,0]/cos(x))
# else:# Gimbal lock
# z = 0 #can be anything
# if R[2,0] == -1:
# x = np.pi/2
# y = z + math.atan2(R[0,1], R[0,2])
# else:
# x = -np.pi/2
# y = -z + math.atan2(-R[0,1], -R[0,2])
# return x, y, z
|
PypiClean
|
/fhir_types-0.2.4-py3-none-any.whl/fhir_types/FHIR_Composition_Section.py
|
from typing import Any, List, Literal, TypedDict
from .FHIR_code import FHIR_code
from .FHIR_CodeableConcept import FHIR_CodeableConcept
from .FHIR_Element import FHIR_Element
from .FHIR_Narrative import FHIR_Narrative
from .FHIR_Reference import FHIR_Reference
from .FHIR_string import FHIR_string
# A set of healthcare-related information that is assembled together into a single logical package that provides a single coherent statement of meaning, establishes its own context and that has clinical attestation with regard to who is making the statement. A Composition defines the structure and narrative content necessary for a document. However, a Composition alone does not constitute a document. Rather, the Composition must be the first entry in a Bundle where Bundle.type=document, and any other resources referenced from Composition must be included as subsequent entries in the Bundle (for example Patient, Practitioner, Encounter, etc.).
FHIR_Composition_Section = TypedDict(
"FHIR_Composition_Section",
{
# Unique id for the element within a resource (for internal references). This may be any string value that does not contain spaces.
"id": FHIR_string,
# May be used to represent additional information that is not part of the basic definition of the element. To make the use of extensions safe and manageable, there is a strict set of governance applied to the definition and use of extensions. Though any implementer can define an extension, there is a set of requirements that SHALL be met as part of the definition of the extension.
"extension": List[Any],
# May be used to represent additional information that is not part of the basic definition of the element and that modifies the understanding of the element in which it is contained and/or the understanding of the containing element's descendants. Usually modifier elements provide negation or qualification. To make the use of extensions safe and manageable, there is a strict set of governance applied to the definition and use of extensions. Though any implementer can define an extension, there is a set of requirements that SHALL be met as part of the definition of the extension. Applications processing a resource are required to check for modifier extensions.Modifier extensions SHALL NOT change the meaning of any elements on Resource or DomainResource (including cannot change the meaning of modifierExtension itself).
"modifierExtension": List[Any],
# The label for this particular section. This will be part of the rendered content for the document, and is often used to build a table of contents.
"title": FHIR_string,
# Extensions for title
"_title": FHIR_Element,
# A code identifying the kind of content contained within the section. This must be consistent with the section title.
"code": FHIR_CodeableConcept,
# Identifies who is responsible for the information in this section, not necessarily who typed it in.
"author": List[FHIR_Reference],
# The actual focus of the section when it is not the subject of the composition, but instead represents something or someone associated with the subject such as (for a patient subject) a spouse, parent, fetus, or donor. If not focus is specified, the focus is assumed to be focus of the parent section, or, for a section in the Composition itself, the subject of the composition. Sections with a focus SHALL only include resources where the logical subject (patient, subject, focus, etc.) matches the section focus, or the resources have no logical subject (few resources).
"focus": FHIR_Reference,
# A human-readable narrative that contains the attested content of the section, used to represent the content of the resource to a human. The narrative need not encode all the structured data, but is required to contain sufficient detail to make it "clinically safe" for a human to just read the narrative.
"text": FHIR_Narrative,
# How the entry list was prepared - whether it is a working list that is suitable for being maintained on an ongoing basis, or if it represents a snapshot of a list of items from another source, or whether it is a prepared list where items may be marked as added, modified or deleted.
"mode": FHIR_code,
# Extensions for mode
"_mode": FHIR_Element,
# Specifies the order applied to the items in the section entries.
"orderedBy": FHIR_CodeableConcept,
# A reference to the actual resource from which the narrative in the section is derived.
"entry": List[FHIR_Reference],
# If the section is empty, why the list is empty. An empty section typically has some text explaining the empty reason.
"emptyReason": FHIR_CodeableConcept,
# A nested sub-section within this section.
"section": List[Any],
},
total=False,
)
|
PypiClean
|
/advutils-0.0.2.tar.gz/advutils-0.0.2/README.rst
|
=========================================================
advutils - advanced utilities for general purposes |docs|
=========================================================
Overview
========
This module encapsulates advanced algorithms for the manipulation data,
counters, events, queues, multiprocessing and more...
Stable:
- Documentation: http://pythonhosted.org/advutils
- Download Page: https://pypi.python.org/pypi/advutils
Latest:
- Documentation: http://advutils.readthedocs.io/
- Project Homepage: https://github.com/davtoh/advutils
BSD license, (C) 2015-2017 David Toro <[email protected]>
Documentation
=============
For API documentation, usage and examples see files in the "documentation"
directory. The ".rst" files can be read in any text editor or being converted to
HTML or PDF using Sphinx_. Read the HTML version is online at
http://advutils.readthedocs.io/en/latest/ .
Examples are found in the directory examples_ and unit tests in tests_.
Installation
============
``pip install advutils`` should work for most users.
Once advutils is successfully installed you can import the it in python as:
>>>> import advutils
Releases
========
All releases follow semantic rules proposed in https://www.python.org/dev/peps/pep-0440/
and http://semver.org/
- Contributions and bug reports are appreciated.
- author: David Toro
- e-mail: [email protected]
- project: https://github.com/davtoh/advutils
.. _examples: https://github.com/davtoh/advutils/tree/master/examples
.. _tests: https://github.com/davtoh/advutils/tree/master/tests
.. _Python: http://python.org/
.. _Sphinx: http://sphinx-doc.org/
.. |docs| image:: https://readthedocs.org/projects/pyserial/badge/?version=latest
:target: http://advutils.readthedocs.io/
:alt: Documentation
.. _manual: https://github.com/davtoh/advutils/blob/master/documentation/_build/latex/advutils.pdf
|
PypiClean
|
/netwrix_api-0.0.7-py3-none-any.whl/netwrix_api/__init__.py
|
import sys
import requests
import json
import logging
name = "netwrix-api"
class NetwrixAPI:
def __init__(self, host, api_user, api_pass, port="9699"):
endpoint_uri = "netwrix/api/v1"
self.root_api_url = "https://{}:{}/{}".format(host, port, endpoint_uri)
self.headers = {}
self.user = api_user
self.passwd = api_pass
def postRequest(self, request_url, headers, data=None, ssl_verify=False):
logging.info("Requested URL: {}".format(request_url))
request_args = {
'headers': headers,
'auth': (self.user, self.passwd),
'verify': ssl_verify
}
if data is not None:
request_args['data'] = json.dumps(data)
logging.info("Request Args: {}".format(request_args))
response = requests.post(request_url, **request_args)
logging.debug(response.json())
if 200 <= response.status_code <= 299:
query_count = len(response.json()['ActivityRecordList'])
if query_count == 0:
logging.info("Query returned 0 results")
return None
else:
return response.json()
elif response.status_code == 404 and\
response.json()['status'] == "No objects found.":
msg = "API was Unable to complete query -- Response: {} - {}"\
.format(response.status_code, response.json()['status'])
raise Exception(msg)
elif response.status_code == 401:
msg = "API was Unable to complete query -- Response: {} - {}"\
.format(response.status_code, response.json()['status'])
raise Exception(msg)
elif response.status_code == 500:
msg = "API Response - {} - {}".format(response.json()['status'],
response.json()['errors'])
raise Exception(msg)
else:
logging.debug("Returned Data: {}".format(response.json()))
response.raise_for_status()
def queryDB(self, filter_data, count=None, output_format="json"):
query_url = "{}/activity_records/search"\
.format(self.root_api_url)
event_filter = self._build_filter(**filter_data)
self.headers['Content-Type'] = 'application/json'
query_return = self.postRequest(query_url,
self.headers,
data=event_filter)
return query_return
def _build_filter(self, datasource, who=None, where=None,
objecttype=None, what=None, monitoring_plan=None,
item=None, workstation=None, detail=None, action=None,
when=None, before=None, after=None):
# See https://helpcenter.netwrix.com/API/Filter_Filters.html
# for details about filters and operators
event_filter = {
'FilterList': {}
}
filter_list = event_filter['FilterList']
if who is not None:
filter_list['Who'] = who
if where is not None:
filter_list['Where'] = where
if objecttype is not None:
filter_list['ObjectType'] = objecttype
if what is not None:
filter_list['What'] = what
if datasource is not None:
filter_list['DataSource'] = datasource
if monitoring_plan is not None:
filter_list['Monitoring Plan'] = monitoring_plan
if item is not None:
filter_list['Item'] = item
if workstation is not None:
filter_list['Workstation'] = workstation
if detail is not None:
filter_list['Detail'] = detail
if action is not None:
filter_list['Action'] = action
if when is not None:
filter_list['When'] = when
if before is not None:
filter_list['Before'] = before
if after is not None:
filter_list['After'] = after
return event_filter
|
PypiClean
|
/odoo13_addon_hr_employee_lastnames-13.0.2.0.0-py3-none-any.whl/odoo/addons/hr_employee_lastnames/models/hr_employee.py
|
import logging
from odoo import api, fields, models
from odoo.addons.hr_employee_firstname.models.hr_employee import UPDATE_PARTNER_FIELDS
_logger = logging.getLogger(__name__)
UPDATE_PARTNER_FIELDS += ["lastname2"]
class HrEmployee(models.Model):
_inherit = "hr.employee"
firstname = fields.Char("First name")
lastname = fields.Char("Last name")
lastname2 = fields.Char("Second last name")
@api.model
def _get_name_lastnames(self, lastname, firstname, lastname2=None):
order = self._get_names_order()
names = list()
if order == "first_last":
if firstname:
names.append(firstname)
if lastname:
names.append(lastname)
if lastname2:
names.append(lastname2)
else:
if lastname:
names.append(lastname)
if lastname2:
names.append(lastname2)
if names and firstname and order == "last_first_comma":
names[-1] = names[-1] + ","
if firstname:
names.append(firstname)
return " ".join(names)
def _prepare_vals_on_create_firstname_lastname(self, vals):
values = vals.copy()
res = super(HrEmployee, self)._prepare_vals_on_create_firstname_lastname(values)
if any([field in vals for field in ("firstname", "lastname", "lastname2")]):
vals["name"] = self._get_name_lastnames(
vals.get("lastname"), vals.get("firstname"), vals.get("lastname2")
)
elif vals.get("name"):
name_splitted = self.split_name(vals["name"])
vals["firstname"] = name_splitted["firstname"]
vals["lastname"] = name_splitted["lastname"]
vals["lastname2"] = name_splitted["lastname2"]
return res
def _prepare_vals_on_write_firstname_lastname(self, vals):
values = vals.copy()
res = super(HrEmployee, self)._prepare_vals_on_write_firstname_lastname(values)
if any([field in vals for field in ("firstname", "lastname", "lastname2")]):
if "lastname" in vals:
lastname = vals["lastname"]
else:
lastname = self.lastname
if "firstname" in vals:
firstname = vals["firstname"]
else:
firstname = self.firstname
if "lastname2" in vals:
lastname2 = vals["lastname2"]
else:
lastname2 = self.lastname2
vals["name"] = self._get_name_lastnames(lastname, firstname, lastname2)
elif vals.get("name"):
name_splitted = self.split_name(vals["name"])
vals["lastname"] = name_splitted["lastname"]
vals["firstname"] = name_splitted["firstname"]
vals["lastname2"] = name_splitted["lastname2"]
return res
def _update_partner_firstname(self):
for employee in self:
partners = employee.mapped("user_id.partner_id")
partners |= employee.mapped("address_home_id")
partners.write(
{
"firstname": employee.firstname,
"lastname": employee.lastname,
"lastname2": employee.lastname2,
}
)
@api.model
def _get_inverse_name(self, name):
"""Compute the inverted name."""
result = {
"firstname": False,
"lastname": name or False,
"lastname2": False,
}
if not name:
return result
order = self._get_names_order()
result.update(super(HrEmployee, self)._get_inverse_name(name))
if order in ("first_last", "last_first_comma"):
parts = self._split_part("lastname", result)
if parts:
result.update({"lastname": parts[0], "lastname2": u" ".join(parts[1:])})
else:
parts = self._split_part("firstname", result)
if parts:
result.update(
{"firstname": parts[-1], "lastname2": u" ".join(parts[:-1])}
)
return result
def _split_part(self, name_part, name_split):
"""Split a given part of a name.
:param name_split: The parts of the name
:type dict
:param name_part: The part to split
:type str
"""
name = name_split.get(name_part, False)
parts = name.split(" ", 1) if name else []
if not name or len(parts) < 2:
return False
return parts
def _inverse_name(self):
"""Try to revert the effect of :method:`._compute_name`."""
for record in self:
parts = self._get_inverse_name(record.name)
record.write(
{
"lastname": parts["lastname"],
"firstname": parts["firstname"],
"lastname2": parts["lastname2"],
}
)
@api.model
def _install_employee_lastnames(self):
"""Save names correctly in the database.
Before installing the module, field ``name`` contains all full names.
When installing it, this method parses those names and saves them
correctly into the database. This can be called later too if needed.
"""
# Find records with empty firstname and lastnames
records = self.search([("firstname", "=", False), ("lastname", "=", False)])
# Force calculations there
records._inverse_name()
_logger.info("%d employees updated installing module.", len(records))
@api.onchange("firstname", "lastname", "lastname2")
def _onchange_firstname_lastname(self):
if self.firstname or self.lastname or self.lastname2:
self.name = self._get_name_lastnames(
self.lastname, self.firstname, self.lastname2
)
|
PypiClean
|
/Spire.Presentation_for_Python-8.8.0-py3-none-win_amd64.whl/spire/presentation/SectionList.py
|
from enum import Enum
from plum import dispatch
from typing import TypeVar,Union,Generic,List,Tuple
from spire.presentation.common import *
from spire.presentation import *
from ctypes import *
import abc
class SectionList (SpireObject) :
"""
"""
@property
def Count(self)->int:
"""
<summary>
Get the count of sections in this section list.
</summary>
"""
GetDllLibPpt().SectionList_get_Count.argtypes=[c_void_p]
GetDllLibPpt().SectionList_get_Count.restype=c_int
ret = GetDllLibPpt().SectionList_get_Count(self.Ptr)
return ret
def get_Item(self ,index:int)->'Section':
"""
<summary>
Get the section by index.
</summary>
<param name="index">the target index.</param>
<returns>the target section</returns>
"""
GetDllLibPpt().SectionList_get_Item.argtypes=[c_void_p ,c_int]
GetDllLibPpt().SectionList_get_Item.restype=c_void_p
intPtr = GetDllLibPpt().SectionList_get_Item(self.Ptr, index)
ret = None if intPtr==None else Section(intPtr)
return ret
def Add(self ,sectionName:str,slide:'ISlide')->'Section':
"""
<summary>
Add section by name and slide.
Note: Only effect on .pptx/.potx file format,invalid other file format
</summary>
<param name="sectionName">the name of section.</param>
<param name="slide">the slide contained in the section.</param>
<returns></returns>
"""
intPtrslide:c_void_p = slide.Ptr
GetDllLibPpt().SectionList_Add.argtypes=[c_void_p ,c_wchar_p,c_void_p]
GetDllLibPpt().SectionList_Add.restype=c_void_p
intPtr = GetDllLibPpt().SectionList_Add(self.Ptr, sectionName,intPtrslide)
ret = None if intPtr==None else Section(intPtr)
return ret
def Insert(self ,sectionIndex:int,sectionName:str)->'Section':
"""
<summary>
Insert section with section name and section index.
</summary>
<param name="sectionIndex">section index.</param>
<param name="sectionName">section name.</param>
<returns></returns>
"""
GetDllLibPpt().SectionList_Insert.argtypes=[c_void_p ,c_int,c_wchar_p]
GetDllLibPpt().SectionList_Insert.restype=c_void_p
intPtr = GetDllLibPpt().SectionList_Insert(self.Ptr, sectionIndex,sectionName)
ret = None if intPtr==None else Section(intPtr)
return ret
def Append(self ,sectionName:str)->'Section':
"""
<summary>
Append section with section name at the end.
</summary>
<param name="sectionName">section name.</param>
<returns></returns>
"""
GetDllLibPpt().SectionList_Append.argtypes=[c_void_p ,c_wchar_p]
GetDllLibPpt().SectionList_Append.restype=c_void_p
intPtr = GetDllLibPpt().SectionList_Append(self.Ptr, sectionName)
ret = None if intPtr==None else Section(intPtr)
return ret
def IndexOf(self ,section:'Section')->int:
"""
<summary>
Get the index of the section.
</summary>
<param name="section">The target section.</param>
<returns></returns>
"""
intPtrsection:c_void_p = section.Ptr
GetDllLibPpt().SectionList_IndexOf.argtypes=[c_void_p ,c_void_p]
GetDllLibPpt().SectionList_IndexOf.restype=c_int
ret = GetDllLibPpt().SectionList_IndexOf(self.Ptr, intPtrsection)
return ret
def MoveSlide(self ,section:'Section',index:int,slide:'ISlide'):
"""
<summary>
Move the position of slide in the section.
</summary>
<param name="section">The target section.</param>
<param name="index">The target position.</param>
<param name="slide">The target slide.</param>
"""
intPtrsection:c_void_p = section.Ptr
intPtrslide:c_void_p = slide.Ptr
GetDllLibPpt().SectionList_MoveSlide.argtypes=[c_void_p ,c_void_p,c_int,c_void_p]
GetDllLibPpt().SectionList_MoveSlide(self.Ptr, intPtrsection,index,intPtrslide)
def InsertSlide(self ,section:'Section',index:int,slide:'ISlide')->'ISlide':
"""
<summary>
Insert slide into the section at position.
</summary>
<param name="section">The target section.</param>
<param name="index">The target position.</param>
<param name="slide">The target slide.</param>
<returns></returns>
"""
intPtrsection:c_void_p = section.Ptr
intPtrslide:c_void_p = slide.Ptr
GetDllLibPpt().SectionList_InsertSlide.argtypes=[c_void_p ,c_void_p,c_int,c_void_p]
GetDllLibPpt().SectionList_InsertSlide.restype=c_void_p
intPtr = GetDllLibPpt().SectionList_InsertSlide(self.Ptr, intPtrsection,index,intPtrslide)
ret = None if intPtr==None else ISlide(intPtr)
return ret
def RemoveSlide(self ,section:'Section',index:int):
"""
<summary>
Remove the slide at some position in the section.
</summary>
<param name="section">The target section.</param>
<param name="index">The position of target slide.</param>
"""
intPtrsection:c_void_p = section.Ptr
GetDllLibPpt().SectionList_RemoveSlide.argtypes=[c_void_p ,c_void_p,c_int]
GetDllLibPpt().SectionList_RemoveSlide(self.Ptr, intPtrsection,index)
def RemoveAt(self ,index:int):
"""
<summary>
Remove section at some position.
</summary>
<param name="index">position in section list.</param>
"""
GetDllLibPpt().SectionList_RemoveAt.argtypes=[c_void_p ,c_int]
GetDllLibPpt().SectionList_RemoveAt(self.Ptr, index)
def RemoveAll(self):
"""
<summary>
Remove all section.
</summary>
"""
GetDllLibPpt().SectionList_RemoveAll.argtypes=[c_void_p]
GetDllLibPpt().SectionList_RemoveAll(self.Ptr)
|
PypiClean
|
/refinitiv-data-1.3.1.tar.gz/refinitiv-data-1.3.1/refinitiv/data/content/ipa/curves/_cross_currency_curves/definitions/_search.py
|
from typing import TYPE_CHECKING
from ...._curves._cross_currency_curves._definitions._search import (
CrossCurrencyCurveGetDefinitionItem,
)
from ......_content_type import ContentType
from ......_tools import create_repr
from ....._content_provider_layer import ContentProviderLayer
if TYPE_CHECKING:
from ...._curves._cross_currency_curves._types import (
OptMainConstituentAssetClass,
OptRiskType,
)
from ......_types import OptStr, OptBool, ExtendedParams
class Definition(ContentProviderLayer):
"""
Returns the definitions of the available Commodities curves for the filters
selected (e.g. sector, subSector...).
Parameters
----------
main_constituent_asset_class : MainConstituentAssetClass, optional
The asset class used to generate the zero coupon curve. the possible values are:
* fxforward * swap
risk_type : RiskType, optional
The risk type to which the generated cross currency curve is sensitive. the
possible value is: * 'crosscurrency'
base_currency : str, optional
The base currency in the fxcross currency pair. it is expressed in iso 4217
alphabetical format (e.g., 'eur').
base_index_name : str, optional
The name of the floating rate index (e.g., 'estr') applied to the base currency.
curve_tag : str, optional
A user-defined string to identify the interest rate curve. it can be used to
link output results to the curve definition. limited to 40 characters. only
alphabetic, numeric and '- _.#=@' characters are supported.
id : str, optional
The identifier of the cross currency definitions.
is_non_deliverable : bool, optional
An indicator whether the instrument is non-deliverable: * true: the instrument
is non-deliverable, * false: the instrument is not non-deliverable. the
property can be used to retrieve cross currency definition for the adjusted
interest rate curve.
name : str, optional
The fxcross currency pair applied to the reference or pivot currency. it is
expressed in iso 4217 alphabetical format (e.g., 'eur usd fxcross').
quoted_currency : str, optional
The quoted currency in the fxcross currency pair. it is expressed in iso 4217
alphabetical format (e.g., 'usd').
quoted_index_name : str, optional
The name of the floating rate index (e.g., 'sofr') applied to the quoted
currency.
source : str, optional
A user-defined string that is provided by the creator of a curve. curves created
by refinitiv have the 'refinitiv' source.
valuation_date : str or date or datetime or timedelta, optional
The date used to define a list of curves or a unique cross currency curve that
can be priced at this date. the value is expressed in iso 8601 format:
yyyy-mm-dd (e.g., '2021-01-01').
extended_params : dict, optional
If necessary other parameters.
Examples
--------
>>> from refinitiv.data.content.ipa.curves._cross_currency_curves import definitions
>>> definition = definitions.search.Definition(
... base_currency="EUR",
... quoted_currency="CHF"
>>> )
>>> response = definition.get_data()
Using get_data_async
>>> import asyncio
>>> task = definition.get_data_async()
>>> response = asyncio.run(task)
"""
def __init__(
self,
main_constituent_asset_class: "OptMainConstituentAssetClass" = None,
risk_type: "OptRiskType" = None,
base_currency: "OptStr" = None,
base_index_name: "OptStr" = None,
curve_tag: "OptStr" = None,
id: "OptStr" = None,
is_non_deliverable: "OptBool" = None,
name: "OptStr" = None,
quoted_currency: "OptStr" = None,
quoted_index_name: "OptStr" = None,
source: "OptStr" = None,
valuation_date: "OptDateTime" = None,
extended_params: "ExtendedParams" = None,
) -> None:
request_item = CrossCurrencyCurveGetDefinitionItem(
main_constituent_asset_class=main_constituent_asset_class,
risk_type=risk_type,
base_currency=base_currency,
base_index_name=base_index_name,
curve_tag=curve_tag,
id=id,
is_non_deliverable=is_non_deliverable,
name=name,
quoted_currency=quoted_currency,
quoted_index_name=quoted_index_name,
source=source,
valuation_date=valuation_date,
)
super().__init__(
content_type=ContentType.CROSS_CURRENCY_CURVES_DEFINITIONS_SEARCH,
universe=request_item,
extended_params=extended_params,
)
def __repr__(self):
return create_repr(self, middle_path="_cross_currency_curves.definitions.search")
|
PypiClean
|
/spectraltoolbox-2.0.3-pp39-pypy39_pp73-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl/SpectralToolbox/Spectral1D/LinearInterpolation.py
|
#
# This file is part of SpectralToolbox.
#
# SpectralToolbox is free software: you can redistribute it and/or modify
# it under the terms of the LGNU Lesser General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# SpectralToolbox is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# LGNU Lesser General Public License for more details.
#
# You should have received a copy of the LGNU Lesser General Public License
# along with SpectralToolbox. If not, see <http://www.gnu.org/licenses/>.
#
# DTU UQ Library
# Copyright (C) 2012-2015 The Technical University of Denmark
# Scientific Computing Section
# Department of Applied Mathematics and Computer Science
#
# Copyright (C) 2015-2016 Massachusetts Institute of Technology
# Uncertainty Quantification group
# Department of Aeronautics and Astronautics
#
# Author: Daniele Bigoni
#
import sys
import warnings
import numpy as np
from numpy import linalg as LA
from numpy import fft as FFT
import math
from scipy.special import gamma as gammaF
from scipy.special import gammaln as gammalnF
from scipy.special import factorial
from scipy.special import comb as SPcomb
from scipy import sparse as scsp
import SpectralToolbox.SparseGrids as SG
__all__ = ['LinearShapeFunction', 'SparseLinearShapeFunction',
'LinearInterpolationMatrix', 'SparseLinearInterpolationMatrix']
def LinearShapeFunction(x,xm,xp,xi):
""" Hat function used for linear interpolation
:param array x: 1d original points
:param float xm,xp: bounding points of the support of the shape function
:param array xi: 1d interpolation points
:returns array N: evaluation of the shape function on xi
"""
N = np.zeros(len(xi))
if x != xm: N += (xi - xm)/(x - xm) * ((xi >= xm)*(xi <= x)).astype(float)
if x != xp: N += ((x - xi)/(xp - x) + 1.) * ((xi >= x)*(xi <= xp)).astype(float)
return N
def SparseLinearShapeFunction(x,xm,xp,xi):
""" Hat function used for linear interpolation.
Returns sparse indices for construction of scipy.sparse.coo_matrix.
:param array x: 1d original points
:param float xm,xp: bounding points of the support of the shape function
:param array xi: 1d interpolation points
:returns tuple (idxs,vals): List of indexes and evaluation of the shape function on xi
"""
idxs = []
vals = []
# Get all xi == x
bool_idxs = (xi == x)
idxs.extend( np.where(bool_idxs)[0] )
vals.extend( [1.]*sum(bool_idxs) )
# If not left end
if x != xm:
bool_idxs = (xi >= xm)*(xi < x)
idxs.extend( np.where(bool_idxs)[0] )
vals.extend( (xi[bool_idxs] - xm)/(x - xm) )
# If not right end
if x != xp:
bool_idxs = (xi > x)*(xi <= xp)
idxs.extend( np.where(bool_idxs)[0] )
vals.extend( ((x - xi[bool_idxs])/(xp - x) + 1.) )
return (idxs,vals)
def LinearInterpolationMatrix(x, xi):
"""
LinearInterpolationMatrix(): constructs the Linear Interpolation Matrix from points ``x`` to points ``xi``
Syntax:
``T = LagrangeInterpolationMatrix(x, xi)``
Input:
* ``x`` = (1d-array,float) set of ``N`` original points
* ``xi`` = (1d-array,float) set of ``M`` interpolating points
Output:
* ``T`` = (2d-array(``MxN``),float) Linear Interpolation Matrix
"""
M = np.zeros((len(xi),len(x)))
M[:,0] = LinearShapeFunction(x[0],x[0],x[1],xi)
M[:,-1] = LinearShapeFunction(x[-1],x[-2],x[-1],xi)
for i in range(1,len(x)-1):
M[:,i] = LinearShapeFunction(x[i],x[i-1],x[i+1],xi)
return M
def SparseLinearInterpolationMatrix(x,xi):
"""
LinearInterpolationMatrix(): constructs the Linear Interpolation Matrix from points ``x`` to points ``xi``.
Returns a scipy.sparse.coo_matrix
Syntax:
``T = LagrangeInterpolationMatrix(x, xi)``
Input:
* ``x`` = (1d-array,float) set of ``N`` original points
* ``xi`` = (1d-array,float) set of ``M`` interpolating points
Output:
* ``T`` = (scipy.sparse.coo_matrix(``MxN``),float) Linear Interpolation Matrix
"""
rows = []
cols = []
vals = []
(ii,vv) = SparseLinearShapeFunction(x[0],x[0],x[1],xi)
rows.extend( ii )
cols.extend( [0] * len(ii) )
vals.extend( vv )
(ii,vv) = SparseLinearShapeFunction(x[-1],x[-2],x[-1],xi)
rows.extend( ii )
cols.extend( [len(x)-1] * len(ii) )
vals.extend( vv )
for j in range(1,len(x)-1):
(ii,vv) = SparseLinearShapeFunction(x[j],x[j-1],x[j+1],xi)
rows.extend( ii )
cols.extend( [j] * len(ii) )
vals.extend( vv )
M = scsp.coo_matrix( (np.asarray(vals), (np.asarray(rows),np.asarray(cols))), shape=( len(xi), len(x) ) )
return M
|
PypiClean
|
/auger.ai-0.2.5-py3-none-any.whl/auger/cli/commands/impl/experimentcmd.py
|
from auger.api.experiment import Experiment
from auger.cli.utils.config import AugerConfig
from auger.cli.utils.formatter import print_table
from auger.cli.utils.decorators import \
error_handler, authenticated, with_dataset
from auger.api.cloud.utils.exception import AugerException
class ExperimentCmd(object):
def __init__(self, ctx):
self.ctx = ctx
@error_handler
@authenticated
@with_dataset
def list(self, dataset):
count = 0
for exp in iter(Experiment(self.ctx, dataset).list()):
self.ctx.log(exp.get('name'))
count += 1
self.ctx.log('%s Experiment(s) listed' % str(count))
return {'experiments': Experiment(self.ctx, dataset).list()}
@error_handler
@authenticated
@with_dataset
def start(self, dataset):
experiment_name = \
self.ctx.config.get('experiment/name', None)
eperiment_name, session_id = \
Experiment(self.ctx, dataset, experiment_name).start()
AugerConfig(self.ctx).set_experiment(eperiment_name, session_id)
return {'eperiment_name': eperiment_name, 'session_id': session_id}
@error_handler
@authenticated
@with_dataset
def stop(self, dataset):
name = self.ctx.config.get('experiment/name', None)
if name is None:
raise AugerException('Please specify Experiment name...')
if Experiment(self.ctx, dataset, name).stop():
self.ctx.log('Search is stopped...')
else:
self.ctx.log('Search is not running. Stop is ignored.')
return {'stopped': name}
@error_handler
@authenticated
@with_dataset
def leaderboard(self, dataset, run_id = None):
name = self.ctx.config.get('experiment/name', None)
if name is None:
raise AugerException('Please specify Experiment name...')
if run_id is None:
run_id = self.ctx.config.get(
'experiment/experiment_session_id', None)
leaderboard, status, run_id = Experiment(
self.ctx, dataset, name).leaderboard(run_id)
if leaderboard is None:
raise AugerException('No leaderboard was found...')
self.ctx.log('Leaderboard for Run %s' % run_id)
print_table(self.ctx.log, leaderboard[::-1])
messages = {
'preprocess': 'Search is preprocessing data for traing...',
'started': 'Search is in progress...',
'completed': 'Search is completed.',
'interrupted': 'Search was interrupted.'
}
message = messages.get(status, None)
if message:
self.ctx.log(message)
else:
self.ctx.log('Search status is %s' % status)
return {'run_id': run_id, 'leaderboard': leaderboard, 'status': status}
@error_handler
@authenticated
@with_dataset
def history(self, dataset):
name = self.ctx.config.get('experiment/name', None)
if name is None:
raise AugerException('Please specify Experiment name...')
for exp_run in iter(Experiment(self.ctx, dataset, name).history()):
self.ctx.log("run id: {}, start time: {}, status: {}".format(
exp_run.get('id'),
exp_run.get('model_settings').get('start_time'),
exp_run.get('status')))
return {'history': Experiment(self.ctx, dataset, name).history()}
|
PypiClean
|
/python-upwork-oauth2-3.1.0.tar.gz/python-upwork-oauth2-3.1.0/upwork/routers/reports/finance/billings.py
|
class Gds:
""" """
client = None
entry_point = "gds"
def __init__(self, client):
self.client = client
self.client.epoint = self.entry_point
def get_by_freelancer(self, freelancer_reference, params):
"""Generate Billing Reports for a Specific Freelancer
Parameters:
:param freelancer_reference:
:param params:
"""
return self.client.get(
"/finreports/v2/providers/{0}/billings".format(freelancer_reference), params
)
def get_by_freelancers_team(self, freelancer_team_reference, params):
"""Generate Billing Reports for a Specific Freelancer's Team
Parameters:
:param freelancer_team_reference:
:param params:
"""
return self.client.get(
"/finreports/v2/provider_teams/{0}/billings".format(
freelancer_team_reference
),
params,
)
def get_by_freelancers_company(self, freelancer_company_reference, params):
"""Generate Billing Reports for a Specific Freelancer's Company
Parameters:
:param freelancer_company_reference:
:param params:
"""
return self.client.get(
"/finreports/v2/provider_companies/{0}/billings".format(
freelancer_company_reference
),
params,
)
def get_by_buyers_team(self, buyer_team_reference, params):
"""Generate Billing Reports for a Specific Buyer's Team
Parameters:
:param buyer_team_reference:
:param params:
"""
return self.client.get(
"/finreports/v2/buyer_teams/{0}/billings".format(buyer_team_reference),
params,
)
def get_by_buyers_company(self, buyer_company_reference, params):
"""Generate Billing Reports for a Specific Buyer's Company
Parameters:
:param buyer_company_reference:
:param params:
"""
return self.client.get(
"/finreports/v2/buyer_companies/{0}/billings".format(
buyer_company_reference
),
params,
)
|
PypiClean
|
/highcharts_gantt-1.3.0.tar.gz/highcharts_gantt-1.3.0/highcharts_gantt/errors.py
|
from highcharts_core.errors import *
class AsanaAuthenticationError(HighchartsValueError):
""":exc:`ValueError <python:ValueError>` encountered when trying to call
:meth:`GanttSeries.from_asana() <highcharts_gantt.options.series.gantt.GanttSeries.from_asana>`
with improperly configured authentication."""
pass
class MondayAuthenticationError(HighchartsValueError):
""":exc:`ValueError <python:ValueError>` encountered when trying to call
:meth:`GanttSeries.from_monday() <highcharts_gantt.options.series.gantt.GanttSeries.from_monday>`
with improperly configured authentication."""
pass
class MondayBoardNotFoundError(HighchartsValueError):
""":exc:`ValueError <python:ValueError>` encountered when an indicated Monday.com board was not found."""
pass
class MondayItemNotFoundError(HighchartsValueError):
""":exc:`ValueError <python:ValueError>` encountered when an indicated Monday.com item (task) was not found."""
pass
class MondayTemplateError(HighchartsValueError):
""":exc:`ValueError <python:ValueError>` encountered when attempting to apply a
Monday.com template that is not supported by **Highcharts Gantt for Python**.
"""
pass
class JIRAAuthenticationError(HighchartsValueError):
""":exc:`ValueError <python:ValueError>` encountered when trying to call
:meth:`GanttSeries.from_jira() <highcharts_gantt.options.series.gantt.GanttSeries.from_jira>`
with improperly configured authentication."""
pass
class JIRAProjectNotFoundError(HighchartsValueError):
""":exc:`ValueError <python:ValueError>` encountered when the JIRA project key specified in
:meth:`GanttSeries.load_from_jira() <highcharts_gantt.options.series.gantt.GanttSeries.load_from_jira>`
is not found.
.. tip::
This often occurs when the JIRA API client silently fails authentication, which can happen when using JIRA
Cloud.
"""
pass
class JIRADuplicateIssueError(HighchartsValueError):
""":exc:`ValueError <python:ValueError>` encountered when encountering a JIRA issue
that is a duplicate of another issue."""
pass
|
PypiClean
|
/concrete_numpy-1.0.0rc1-py3-none-any.whl/concrete/numpy/mlir/utils.py
|
from collections import defaultdict, deque
from copy import deepcopy
from itertools import product
from typing import Any, DefaultDict, List, Optional, Tuple, Union, cast
import numpy as np
from ..dtypes import Integer
from ..internal.utils import assert_that
from ..representation import Node, Operation
MAXIMUM_TLU_BIT_WIDTH = 16
class HashableNdarray:
"""
HashableNdarray class, to use numpy arrays in dictionaries.
"""
array: np.ndarray
def __init__(self, array: np.ndarray):
self.array = array
def __eq__(self, other: object) -> bool:
return isinstance(other, HashableNdarray) and np.array_equal(self.array, other.array)
def __hash__(self) -> int:
return hash(self.array.tobytes())
def flood_replace_none_values(table: list):
"""
Use flooding algorithm to replace `None` values.
Args:
table (list):
the list in which there are `None` values that need to be replaced
with copies of the closest non `None` data from the list
"""
assert_that(any(value is not None for value in table))
not_none_values_idx = deque(idx for idx, value in enumerate(table) if value is not None)
while not_none_values_idx:
current_idx = not_none_values_idx.popleft()
current_value = table[current_idx]
previous_idx = current_idx - 1
next_idx = current_idx + 1
if previous_idx >= 0 and table[previous_idx] is None:
table[previous_idx] = deepcopy(current_value)
not_none_values_idx.append(previous_idx)
if next_idx < len(table) and table[next_idx] is None:
table[next_idx] = deepcopy(current_value)
not_none_values_idx.append(next_idx)
assert_that(all(value is not None for value in table))
def construct_table(node: Node, preds: List[Node]) -> List[Any]:
"""
Construct the lookup table for an Operation.Generic node.
Args:
node (Node):
Operation.Generic to construct the table
preds (List[Node]):
ordered predecessors to `node`
Returns:
List[Any]:
lookup table corresponding to `node` and its input value
"""
variable_input_index = -1
for index, pred in enumerate(preds):
if pred.operation != Operation.Constant:
variable_input_index = index
break
assert_that(variable_input_index != -1)
variable_input_dtype = node.inputs[variable_input_index].dtype
variable_input_shape = node.inputs[variable_input_index].shape
assert_that(isinstance(variable_input_dtype, Integer))
variable_input_dtype = cast(Integer, variable_input_dtype)
inputs: List[Any] = [pred() if pred.operation == Operation.Constant else None for pred in preds]
table: List[Optional[Union[np.bool_, np.integer, np.floating, np.ndarray]]] = []
for value in range(variable_input_dtype.min(), variable_input_dtype.max() + 1):
try:
inputs[variable_input_index] = np.ones(variable_input_shape, dtype=np.int64) * value
table.append(node(*inputs))
except Exception: # pylint: disable=broad-except
# here we try our best to fill the table
# if it fails, we append None and let flooding algoritm replace None values below
table.append(None)
flood_replace_none_values(table)
return table
def construct_deduplicated_tables(
node: Node,
preds: List[Node],
) -> Tuple[Tuple[np.ndarray, List[Tuple[int, ...]]], ...]:
"""
Construct lookup tables for each cell of the input for an Operation.Generic node.
Args:
node (Node):
Operation.Generic to construct the table
preds (List[Node]):
ordered predecessors to `node`
Returns:
Tuple[Tuple[numpy.ndarray, List[Tuple[int, ...]]], ...]:
tuple containing tuples of 2 for
- constructed table
- list of indices of the input that use the constructed table
e.g.,
.. code-block:: python
(
(np.array([3, 1, 2, 4]), [(1, 0), (2, 1)]),
(np.array([5, 8, 6, 7]), [(0, 0), (0, 1), (1, 1), (2, 0)]),
)
means the lookup on 3x2 input will result in
.. code-block:: python
[ [5, 8, 6, 7][input[0, 0]] , [5, 8, 6, 7][input[0, 1]] ]
[ [3, 1, 2, 4][input[1, 0]] , [5, 8, 6, 7][input[1, 1]] ]
[ [5, 8, 6, 7][input[2, 0]] , [3, 1, 2, 4][input[2, 1]] ]
"""
node_complete_table = np.concatenate(
tuple(np.expand_dims(array, -1) for array in construct_table(node, preds)),
axis=-1,
)
all_cells_idx = product(*tuple(range(max_val) for max_val in node_complete_table.shape[:-1]))
tables_to_cell_idx: DefaultDict[HashableNdarray, List[Tuple[int, ...]]] = defaultdict(list)
idx: Tuple[int, ...]
all_idx_set = set()
for idx in all_cells_idx:
hashable_array = HashableNdarray(node_complete_table[idx])
tables_to_cell_idx[hashable_array].append(idx)
all_idx_set.add(idx)
assert_that(len(all_idx_set) == np.prod(node_complete_table.shape[:-1]))
return tuple(
(hashable_array.array, indices) for hashable_array, indices in tables_to_cell_idx.items()
)
|
PypiClean
|
/secretflow_ray-2.2.0-cp38-cp38-macosx_10_16_x86_64.whl/secretflow_ray-2.2.0.data/purelib/ray/rllib/examples/models/rnn_spy_model.py
|
import numpy as np
import pickle
import ray
from ray.rllib.models.modelv2 import ModelV2
from ray.rllib.models.tf.misc import normc_initializer
from ray.rllib.models.tf.recurrent_net import RecurrentNetwork
from ray.rllib.utils.annotations import override
from ray.rllib.utils.framework import try_import_tf
tf1, tf, tfv = try_import_tf()
class SpyLayer(tf.keras.layers.Layer):
"""A keras Layer, which intercepts its inputs and stored them as pickled."""
output = np.array(0, dtype=np.int64)
def __init__(self, num_outputs, **kwargs):
super().__init__(**kwargs)
self.dense = tf.keras.layers.Dense(
units=num_outputs, kernel_initializer=normc_initializer(0.01)
)
def call(self, inputs, **kwargs):
"""Does a forward pass through our Dense, but also intercepts inputs."""
del kwargs
spy_fn = tf1.py_func(
self.spy,
[
inputs[0], # observations
inputs[2], # seq_lens
inputs[3], # h_in
inputs[4], # c_in
inputs[5], # h_out
inputs[6], # c_out
],
tf.int64, # Must match SpyLayer.output's type.
stateful=True,
)
# Compute outputs
with tf1.control_dependencies([spy_fn]):
return self.dense(inputs[1])
@staticmethod
def spy(inputs, seq_lens, h_in, c_in, h_out, c_out):
"""The actual spy operation: Store inputs in internal_kv."""
if len(inputs) == 1:
# don't capture inference inputs
return SpyLayer.output
# TF runs this function in an isolated context, so we have to use
# redis to communicate back to our suite
ray.experimental.internal_kv._internal_kv_put(
"rnn_spy_in_{}".format(RNNSpyModel.capture_index),
pickle.dumps(
{
"sequences": inputs,
"seq_lens": seq_lens,
"state_in": [h_in, c_in],
"state_out": [h_out, c_out],
}
),
overwrite=True,
)
RNNSpyModel.capture_index += 1
return SpyLayer.output
class RNNSpyModel(RecurrentNetwork):
capture_index = 0
cell_size = 3
def __init__(self, obs_space, action_space, num_outputs, model_config, name):
super().__init__(obs_space, action_space, num_outputs, model_config, name)
self.cell_size = RNNSpyModel.cell_size
# Create a keras LSTM model.
inputs = tf.keras.layers.Input(shape=(None,) + obs_space.shape, name="input")
state_in_h = tf.keras.layers.Input(shape=(self.cell_size,), name="h")
state_in_c = tf.keras.layers.Input(shape=(self.cell_size,), name="c")
seq_lens = tf.keras.layers.Input(shape=(), name="seq_lens", dtype=tf.int32)
lstm_out, state_out_h, state_out_c = tf.keras.layers.LSTM(
self.cell_size, return_sequences=True, return_state=True, name="lstm"
)(
inputs=inputs,
mask=tf.sequence_mask(seq_lens),
initial_state=[state_in_h, state_in_c],
)
logits = SpyLayer(num_outputs=self.num_outputs)(
[
inputs,
lstm_out,
seq_lens,
state_in_h,
state_in_c,
state_out_h,
state_out_c,
]
)
# Value branch.
value_out = tf.keras.layers.Dense(
units=1, kernel_initializer=normc_initializer(1.0)
)(lstm_out)
self.base_model = tf.keras.Model(
[inputs, seq_lens, state_in_h, state_in_c],
[logits, value_out, state_out_h, state_out_c],
)
self.base_model.summary()
@override(RecurrentNetwork)
def forward_rnn(self, inputs, state, seq_lens):
# Previously, a new class object was created during
# deserialization and this `capture_index`
# variable would be refreshed between class instantiations.
# This behavior is no longer the case, so we manually refresh
# the variable.
RNNSpyModel.capture_index = 0
model_out, value_out, h, c = self.base_model(
[inputs, seq_lens, state[0], state[1]]
)
self._value_out = value_out
return model_out, [h, c]
@override(ModelV2)
def value_function(self):
return tf.reshape(self._value_out, [-1])
@override(ModelV2)
def get_initial_state(self):
return [
np.zeros(self.cell_size, np.float32),
np.zeros(self.cell_size, np.float32),
]
|
PypiClean
|
/elio_liar-1.0-py3-none-any.whl/liar/igetraw.py
|
""""""
import os
import importlib
from random import choice
from liar.ijusthelp import rewrite_dict
from liar.itransform import ITransform
from liar.iamprimitive import IAmPrimitive
self_dir = os.path.dirname(os.path.realpath(__file__))
app_path = os.sep.join(self_dir.split(os.sep)[:-1])
class IGetRaw(object):
"""IGetRaw pulls out data from the json files, or deals with static or quick_lists."""
# gets data from a raw json file of data.
def raw_list(data_def, data_prop, dataset_size=False, filters={}):
"""Pulls data from a raw data file."""
raw = {}
mod_name = f"liar.raw.{data_def}"
mod = importlib.import_module(mod_name)
jsn = getattr(mod, data_def)
data = jsn or ["no", "data", "found"]
# Filter the data?
for filter_prop, filter_values in filters.items():
data = [row for row in data if row[filter_prop] in filter_values]
if not len(data):
raise Exception(f"No records found. Did you filter correctly?")
# Increase the size by doubling the set if there weren't enough records
# in the raw data.
while len(data) < dataset_size:
data += data
# use a field of the dictionary
if data_prop:
data = [data_row.get(data_prop, data_prop) for data_row in data]
# randomly sort this column
data = ITransform.Data.rand_sort(data)
# if no specified datasize, get the whole lot
if not dataset_size:
dataset_size = len(data)
# abspath the images of dictionary types
if isinstance(data[0], dict):
if data[0].get("images", False):
for row in data:
for key in row["images"].keys():
row["images"][key] = os.path.join(
os.path.dirname(os.path.abspath(__file__)),
"liar",
row["images"][key],
)
return data[:dataset_size]
def exact_list(exact, list_size):
"""Returns a list of an exact item * list_size."""
return [exact for _ in range(0, list_size)]
def quick_list(choices, list_size):
"""Returns a list selecting randomly from your choices * list_size."""
return [choice(choices) for _ in range(0, list_size)]
def toothpaste_list(choices, list_size):
"""Rotates through a list * list_size."""
return [choices[x % len(choices)] for x in range(0, list_size)]
def choosy_list(choosy):
"""Returns a list randomly choosing from different column definitions * list_size."""
return [choice(list(choices.values())) for choices in choosy]
def field_list(field_name, source_list):
"""Retrieves data from another named field already created - handy to reuse."""
# does the list contain data?
if source_list:
# is it a list?
if isinstance(source_list, list):
# does the source list contain dictionaries
if isinstance(source_list[0], dict):
# does the source list contain the requested field?
if source_list[0].get(field_name, False):
# extract the column for this
return [row[field_name] for row in source_list]
return []
|
PypiClean
|
/google-cloud-assured-workloads-1.10.2.tar.gz/google-cloud-assured-workloads-1.10.2/google/cloud/assuredworkloads_v1beta1/types/assuredworkloads_v1beta1.py
|
from google.protobuf import duration_pb2 # type: ignore
from google.protobuf import field_mask_pb2 # type: ignore
from google.protobuf import timestamp_pb2 # type: ignore
import proto # type: ignore
__protobuf__ = proto.module(
package="google.cloud.assuredworkloads.v1beta1",
manifest={
"CreateWorkloadRequest",
"UpdateWorkloadRequest",
"DeleteWorkloadRequest",
"GetWorkloadRequest",
"ListWorkloadsRequest",
"ListWorkloadsResponse",
"Workload",
"CreateWorkloadOperationMetadata",
},
)
class CreateWorkloadRequest(proto.Message):
r"""Request for creating a workload.
Attributes:
parent (str):
Required. The resource name of the new Workload's parent.
Must be of the form
``organizations/{org_id}/locations/{location_id}``.
workload (google.cloud.assuredworkloads_v1beta1.types.Workload):
Required. Assured Workload to create
external_id (str):
Optional. A identifier associated with the
workload and underlying projects which allows
for the break down of billing costs for a
workload. The value provided for the identifier
will add a label to the workload and contained
projects with the identifier as the value.
"""
parent = proto.Field(
proto.STRING,
number=1,
)
workload = proto.Field(
proto.MESSAGE,
number=2,
message="Workload",
)
external_id = proto.Field(
proto.STRING,
number=3,
)
class UpdateWorkloadRequest(proto.Message):
r"""Request for Updating a workload.
Attributes:
workload (google.cloud.assuredworkloads_v1beta1.types.Workload):
Required. The workload to update. The workload’s ``name``
field is used to identify the workload to be updated.
Format:
organizations/{org_id}/locations/{location_id}/workloads/{workload_id}
update_mask (google.protobuf.field_mask_pb2.FieldMask):
Required. The list of fields to be updated.
"""
workload = proto.Field(
proto.MESSAGE,
number=1,
message="Workload",
)
update_mask = proto.Field(
proto.MESSAGE,
number=2,
message=field_mask_pb2.FieldMask,
)
class DeleteWorkloadRequest(proto.Message):
r"""Request for deleting a Workload.
Attributes:
name (str):
Required. The ``name`` field is used to identify the
workload. Format:
organizations/{org_id}/locations/{location_id}/workloads/{workload_id}
etag (str):
Optional. The etag of the workload.
If this is provided, it must match the server's
etag.
"""
name = proto.Field(
proto.STRING,
number=1,
)
etag = proto.Field(
proto.STRING,
number=2,
)
class GetWorkloadRequest(proto.Message):
r"""Request for fetching a workload.
Attributes:
name (str):
Required. The resource name of the Workload to fetch. This
is the workloads's relative path in the API, formatted as
"organizations/{organization_id}/locations/{location_id}/workloads/{workload_id}".
For example,
"organizations/123/locations/us-east1/workloads/assured-workload-1".
"""
name = proto.Field(
proto.STRING,
number=1,
)
class ListWorkloadsRequest(proto.Message):
r"""Request for fetching workloads in an organization.
Attributes:
parent (str):
Required. Parent Resource to list workloads from. Must be of
the form ``organizations/{org_id}/locations/{location}``.
page_size (int):
Page size.
page_token (str):
Page token returned from previous request.
Page token contains context from previous
request. Page token needs to be passed in the
second and following requests.
filter (str):
A custom filter for filtering by properties
of a workload. At this time, only filtering by
labels is supported.
"""
parent = proto.Field(
proto.STRING,
number=1,
)
page_size = proto.Field(
proto.INT32,
number=2,
)
page_token = proto.Field(
proto.STRING,
number=3,
)
filter = proto.Field(
proto.STRING,
number=4,
)
class ListWorkloadsResponse(proto.Message):
r"""Response of ListWorkloads endpoint.
Attributes:
workloads (Sequence[google.cloud.assuredworkloads_v1beta1.types.Workload]):
List of Workloads under a given parent.
next_page_token (str):
The next page token. Return empty if reached
the last page.
"""
@property
def raw_page(self):
return self
workloads = proto.RepeatedField(
proto.MESSAGE,
number=1,
message="Workload",
)
next_page_token = proto.Field(
proto.STRING,
number=2,
)
class Workload(proto.Message):
r"""An Workload object for managing highly regulated workloads of
cloud customers.
This message has `oneof`_ fields (mutually exclusive fields).
For each oneof, at most one member field can be set at the same time.
Setting any member of the oneof automatically clears all other
members.
.. _oneof: https://proto-plus-python.readthedocs.io/en/stable/fields.html#oneofs-mutually-exclusive-fields
Attributes:
name (str):
Optional. The resource name of the workload.
Format:
organizations/{organization}/locations/{location}/workloads/{workload}
Read-only.
display_name (str):
Required. The user-assigned display name of
the Workload. When present it must be between 4
to 30 characters. Allowed characters are:
lowercase and uppercase letters, numbers,
hyphen, and spaces.
Example: My Workload
resources (Sequence[google.cloud.assuredworkloads_v1beta1.types.Workload.ResourceInfo]):
Output only. The resources associated with
this workload. These resources will be created
when creating the workload. If any of the
projects already exist, the workload creation
will fail. Always read only.
compliance_regime (google.cloud.assuredworkloads_v1beta1.types.Workload.ComplianceRegime):
Required. Immutable. Compliance Regime
associated with this workload.
create_time (google.protobuf.timestamp_pb2.Timestamp):
Output only. Immutable. The Workload creation
timestamp.
billing_account (str):
Input only. The billing account used for the resources which
are direct children of workload. This billing account is
initially associated with the resources created as part of
Workload creation. After the initial creation of these
resources, the customer can change the assigned billing
account. The resource name has the form
``billingAccounts/{billing_account_id}``. For example,
``billingAccounts/012345-567890-ABCDEF``.
il4_settings (google.cloud.assuredworkloads_v1beta1.types.Workload.IL4Settings):
Required. Input only. Immutable. Settings
specific to resources needed for IL4.
This field is a member of `oneof`_ ``compliance_regime_settings``.
cjis_settings (google.cloud.assuredworkloads_v1beta1.types.Workload.CJISSettings):
Required. Input only. Immutable. Settings
specific to resources needed for CJIS.
This field is a member of `oneof`_ ``compliance_regime_settings``.
fedramp_high_settings (google.cloud.assuredworkloads_v1beta1.types.Workload.FedrampHighSettings):
Required. Input only. Immutable. Settings
specific to resources needed for FedRAMP High.
This field is a member of `oneof`_ ``compliance_regime_settings``.
fedramp_moderate_settings (google.cloud.assuredworkloads_v1beta1.types.Workload.FedrampModerateSettings):
Required. Input only. Immutable. Settings
specific to resources needed for FedRAMP
Moderate.
This field is a member of `oneof`_ ``compliance_regime_settings``.
etag (str):
Optional. ETag of the workload, it is
calculated on the basis of the Workload
contents. It will be used in Update & Delete
operations.
labels (Mapping[str, str]):
Optional. Labels applied to the workload.
provisioned_resources_parent (str):
Input only. The parent resource for the resources managed by
this Assured Workload. May be either empty or a folder
resource which is a child of the Workload parent. If not
specified all resources are created under the parent
organization. Format: folders/{folder_id}
kms_settings (google.cloud.assuredworkloads_v1beta1.types.Workload.KMSSettings):
Input only. Settings used to create a CMEK
crypto key. When set a project with a KMS CMEK
key is provisioned. This field is mandatory for
a subset of Compliance Regimes.
resource_settings (Sequence[google.cloud.assuredworkloads_v1beta1.types.Workload.ResourceSettings]):
Input only. Resource properties that are used
to customize workload resources. These
properties (such as custom project id) will be
used to create workload resources if possible.
This field is optional.
kaj_enrollment_state (google.cloud.assuredworkloads_v1beta1.types.Workload.KajEnrollmentState):
Output only. Represents the KAJ enrollment
state of the given workload.
enable_sovereign_controls (bool):
Optional. Indicates the sovereignty status of
the given workload. Currently meant to be used
by Europe/Canada customers.
saa_enrollment_response (google.cloud.assuredworkloads_v1beta1.types.Workload.SaaEnrollmentResponse):
Output only. Represents the SAA enrollment
response of the given workload. SAA enrollment
response is queried during GetWorkload call. In
failure cases, user friendly error message is
shown in SAA details page.
"""
class ComplianceRegime(proto.Enum):
r"""Supported Compliance Regimes."""
COMPLIANCE_REGIME_UNSPECIFIED = 0
IL4 = 1
CJIS = 2
FEDRAMP_HIGH = 3
FEDRAMP_MODERATE = 4
US_REGIONAL_ACCESS = 5
HIPAA = 6
HITRUST = 7
EU_REGIONS_AND_SUPPORT = 8
CA_REGIONS_AND_SUPPORT = 9
class KajEnrollmentState(proto.Enum):
r"""Key Access Justifications(KAJ) Enrollment State."""
KAJ_ENROLLMENT_STATE_UNSPECIFIED = 0
KAJ_ENROLLMENT_STATE_PENDING = 1
KAJ_ENROLLMENT_STATE_COMPLETE = 2
class ResourceInfo(proto.Message):
r"""Represent the resources that are children of this Workload.
Attributes:
resource_id (int):
Resource identifier. For a project this represents
project_number.
resource_type (google.cloud.assuredworkloads_v1beta1.types.Workload.ResourceInfo.ResourceType):
Indicates the type of resource.
"""
class ResourceType(proto.Enum):
r"""The type of resource."""
RESOURCE_TYPE_UNSPECIFIED = 0
CONSUMER_PROJECT = 1
CONSUMER_FOLDER = 4
ENCRYPTION_KEYS_PROJECT = 2
KEYRING = 3
resource_id = proto.Field(
proto.INT64,
number=1,
)
resource_type = proto.Field(
proto.ENUM,
number=2,
enum="Workload.ResourceInfo.ResourceType",
)
class KMSSettings(proto.Message):
r"""Settings specific to the Key Management Service.
Attributes:
next_rotation_time (google.protobuf.timestamp_pb2.Timestamp):
Required. Input only. Immutable. The time at
which the Key Management Service will
automatically create a new version of the crypto
key and mark it as the primary.
rotation_period (google.protobuf.duration_pb2.Duration):
Required. Input only. Immutable. [next_rotation_time] will
be advanced by this period when the Key Management Service
automatically rotates a key. Must be at least 24 hours and
at most 876,000 hours.
"""
next_rotation_time = proto.Field(
proto.MESSAGE,
number=1,
message=timestamp_pb2.Timestamp,
)
rotation_period = proto.Field(
proto.MESSAGE,
number=2,
message=duration_pb2.Duration,
)
class IL4Settings(proto.Message):
r"""Settings specific to resources needed for IL4.
Attributes:
kms_settings (google.cloud.assuredworkloads_v1beta1.types.Workload.KMSSettings):
Required. Input only. Immutable. Settings
used to create a CMEK crypto key.
"""
kms_settings = proto.Field(
proto.MESSAGE,
number=1,
message="Workload.KMSSettings",
)
class CJISSettings(proto.Message):
r"""Settings specific to resources needed for CJIS.
Attributes:
kms_settings (google.cloud.assuredworkloads_v1beta1.types.Workload.KMSSettings):
Required. Input only. Immutable. Settings
used to create a CMEK crypto key.
"""
kms_settings = proto.Field(
proto.MESSAGE,
number=1,
message="Workload.KMSSettings",
)
class FedrampHighSettings(proto.Message):
r"""Settings specific to resources needed for FedRAMP High.
Attributes:
kms_settings (google.cloud.assuredworkloads_v1beta1.types.Workload.KMSSettings):
Required. Input only. Immutable. Settings
used to create a CMEK crypto key.
"""
kms_settings = proto.Field(
proto.MESSAGE,
number=1,
message="Workload.KMSSettings",
)
class FedrampModerateSettings(proto.Message):
r"""Settings specific to resources needed for FedRAMP Moderate.
Attributes:
kms_settings (google.cloud.assuredworkloads_v1beta1.types.Workload.KMSSettings):
Required. Input only. Immutable. Settings
used to create a CMEK crypto key.
"""
kms_settings = proto.Field(
proto.MESSAGE,
number=1,
message="Workload.KMSSettings",
)
class ResourceSettings(proto.Message):
r"""Represent the custom settings for the resources to be
created.
Attributes:
resource_id (str):
Resource identifier. For a project this represents
project_id. If the project is already taken, the workload
creation will fail.
resource_type (google.cloud.assuredworkloads_v1beta1.types.Workload.ResourceInfo.ResourceType):
Indicates the type of resource. This field should be
specified to correspond the id to the right project type
(CONSUMER_PROJECT or ENCRYPTION_KEYS_PROJECT)
display_name (str):
User-assigned resource display name.
If not empty it will be used to create a
resource with the specified name.
"""
resource_id = proto.Field(
proto.STRING,
number=1,
)
resource_type = proto.Field(
proto.ENUM,
number=2,
enum="Workload.ResourceInfo.ResourceType",
)
display_name = proto.Field(
proto.STRING,
number=3,
)
class SaaEnrollmentResponse(proto.Message):
r"""Signed Access Approvals (SAA) enrollment response.
Attributes:
setup_status (google.cloud.assuredworkloads_v1beta1.types.Workload.SaaEnrollmentResponse.SetupState):
Indicates SAA enrollment status of a given
workload.
This field is a member of `oneof`_ ``_setup_status``.
setup_errors (Sequence[google.cloud.assuredworkloads_v1beta1.types.Workload.SaaEnrollmentResponse.SetupError]):
Indicates SAA enrollment setup error if any.
"""
class SetupState(proto.Enum):
r"""Setup state of SAA enrollment."""
SETUP_STATE_UNSPECIFIED = 0
STATUS_PENDING = 1
STATUS_COMPLETE = 2
class SetupError(proto.Enum):
r"""Setup error of SAA enrollment."""
SETUP_ERROR_UNSPECIFIED = 0
ERROR_INVALID_BASE_SETUP = 1
ERROR_MISSING_EXTERNAL_SIGNING_KEY = 2
ERROR_NOT_ALL_SERVICES_ENROLLED = 3
ERROR_SETUP_CHECK_FAILED = 4
setup_status = proto.Field(
proto.ENUM,
number=1,
optional=True,
enum="Workload.SaaEnrollmentResponse.SetupState",
)
setup_errors = proto.RepeatedField(
proto.ENUM,
number=2,
enum="Workload.SaaEnrollmentResponse.SetupError",
)
name = proto.Field(
proto.STRING,
number=1,
)
display_name = proto.Field(
proto.STRING,
number=2,
)
resources = proto.RepeatedField(
proto.MESSAGE,
number=3,
message=ResourceInfo,
)
compliance_regime = proto.Field(
proto.ENUM,
number=4,
enum=ComplianceRegime,
)
create_time = proto.Field(
proto.MESSAGE,
number=5,
message=timestamp_pb2.Timestamp,
)
billing_account = proto.Field(
proto.STRING,
number=6,
)
il4_settings = proto.Field(
proto.MESSAGE,
number=7,
oneof="compliance_regime_settings",
message=IL4Settings,
)
cjis_settings = proto.Field(
proto.MESSAGE,
number=8,
oneof="compliance_regime_settings",
message=CJISSettings,
)
fedramp_high_settings = proto.Field(
proto.MESSAGE,
number=11,
oneof="compliance_regime_settings",
message=FedrampHighSettings,
)
fedramp_moderate_settings = proto.Field(
proto.MESSAGE,
number=12,
oneof="compliance_regime_settings",
message=FedrampModerateSettings,
)
etag = proto.Field(
proto.STRING,
number=9,
)
labels = proto.MapField(
proto.STRING,
proto.STRING,
number=10,
)
provisioned_resources_parent = proto.Field(
proto.STRING,
number=13,
)
kms_settings = proto.Field(
proto.MESSAGE,
number=14,
message=KMSSettings,
)
resource_settings = proto.RepeatedField(
proto.MESSAGE,
number=15,
message=ResourceSettings,
)
kaj_enrollment_state = proto.Field(
proto.ENUM,
number=17,
enum=KajEnrollmentState,
)
enable_sovereign_controls = proto.Field(
proto.BOOL,
number=18,
)
saa_enrollment_response = proto.Field(
proto.MESSAGE,
number=20,
message=SaaEnrollmentResponse,
)
class CreateWorkloadOperationMetadata(proto.Message):
r"""Operation metadata to give request details of CreateWorkload.
Attributes:
create_time (google.protobuf.timestamp_pb2.Timestamp):
Optional. Time when the operation was
created.
display_name (str):
Optional. The display name of the workload.
parent (str):
Optional. The parent of the workload.
compliance_regime (google.cloud.assuredworkloads_v1beta1.types.Workload.ComplianceRegime):
Optional. Compliance controls that should be
applied to the resources managed by the
workload.
resource_settings (Sequence[google.cloud.assuredworkloads_v1beta1.types.Workload.ResourceSettings]):
Optional. Resource properties in the input
that are used for creating/customizing workload
resources.
"""
create_time = proto.Field(
proto.MESSAGE,
number=1,
message=timestamp_pb2.Timestamp,
)
display_name = proto.Field(
proto.STRING,
number=2,
)
parent = proto.Field(
proto.STRING,
number=3,
)
compliance_regime = proto.Field(
proto.ENUM,
number=4,
enum="Workload.ComplianceRegime",
)
resource_settings = proto.RepeatedField(
proto.MESSAGE,
number=5,
message="Workload.ResourceSettings",
)
__all__ = tuple(sorted(__protobuf__.manifest))
|
PypiClean
|
/mle_toolbox-0.3.4.tar.gz/mle_toolbox-0.3.4/mle_toolbox/visualize/dynamic_2d_grid.py
|
import numpy as np
try:
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from mpl_toolkits.axes_grid1 import make_axes_locatable
import seaborn as sns
except ImportError:
raise ImportError(
"You need to install `matplotlib` & `seaborn` to use plotting"
" utilities."
)
def animate_2D_grid(
data,
var_name="A Variable",
dt=1,
ylabel="y-Axis Label",
xlabel="x-Axis Label",
range_y=None,
range_x=None,
every_nth=1,
round_ticks=1,
vmin=None,
vmax=None,
title="Animated Grid",
time_pre_str="t=",
interval=100,
fps=60,
fname="test_anim.gif",
direct_save=True,
no_axis_ticks=False,
cmap=sns.cm.rocket,
interpolation=None,
):
"""Generate a gif animation of a set of 1d curves."""
animator = AnimatedGrid(
data,
var_name,
dt,
title,
time_pre_str,
ylabel,
xlabel,
range_y,
range_x,
every_nth,
round_ticks,
vmin,
vmax,
interval,
no_axis_ticks,
cmap,
interpolation,
)
if direct_save:
animator.ani.save(fname, fps=fps, writer="imagemagick")
return animator
class AnimatedGrid(object):
"""An animated line plot of all lines in provided data over time."""
def __init__(
self,
data,
var_name="A Variable",
dt=1,
title="Animated Grid",
time_pre_str="t=",
ylabel="y-Axis",
xlabel="Time",
range_y=None,
range_x=None,
every_nth=1,
round_ticks=1,
vmin=None,
vmax=None,
interval=100,
no_axis_ticks=False,
cmap=sns.cm.rocket,
interpolation=None,
):
self.num_steps = data.shape[0]
self.data = data
self.t = 0
self.dt = dt
self.title = title
self.time_pre_str = time_pre_str
self.range_x = (
range_x if range_x is not None else np.arange(data.shape[1])
)
self.range_y = (
range_y if range_y is not None else np.arange(data.shape[2])
)
self.var_name = var_name
self.every_nth = every_nth
self.round_ticks = round_ticks
self.no_axis_ticks = no_axis_ticks
# Setup the figure and axes...
self.fig, self.ax = plt.subplots(figsize=(7, 7))
self.fig.tight_layout()
if ylabel is not None:
self.ax.set_ylabel(ylabel, fontsize=20)
if xlabel is not None:
self.ax.set_xlabel(xlabel, fontsize=20)
# Plot the initial image
self.im = self.ax.imshow(
np.zeros(self.data[0].shape),
cmap=cmap,
vmin=vmin,
vmax=vmax,
interpolation=interpolation,
)
if self.no_axis_ticks:
self.ax.axis("off")
else:
for tick in self.ax.xaxis.get_major_ticks():
tick.label1.set_fontsize(20)
for tick in self.ax.yaxis.get_major_ticks():
tick.label1.set_fontsize(20)
# Then setup FuncAnimation.
self.ani = animation.FuncAnimation(
self.fig,
self.update,
frames=self.num_steps,
interval=interval,
init_func=self.setup_plot,
blit=False,
)
self.fig.tight_layout()
def setup_plot(self):
"""Initial drawing of the heatmap plot."""
self.im.set_data(np.zeros(self.data[0].shape))
if self.title is not None:
self.ax.set_title(self.title + " {}".format(1))
if not self.no_axis_ticks:
# We want to show all ticks...
self.ax.set_yticks(np.arange(len(self.range_y)))
if len(self.range_y) != 0:
if type(self.range_y[-1]) is not str:
if self.round_ticks != 0:
yticklabels = [
str(round(float(label), self.round_ticks))
for label in self.range_y[::-1]
]
else:
yticklabels = [
str(int(label)) for label in self.range_y[::-1]
]
else:
yticklabels = [str(label) for label in self.range_y[::-1]]
else:
yticklabels = []
self.ax.set_yticklabels(yticklabels)
for n, label in enumerate(self.ax.yaxis.get_ticklabels()):
if n % self.every_nth != 0:
label.set_visible(False)
self.ax.set_xticks(np.arange(len(self.range_x)))
if len(self.range_x) != 0:
if type(self.range_x[-1]) is not str:
if self.round_ticks != 0:
xticklabels = [
str(round(float(label), self.round_ticks))
for label in self.range_x
]
else:
xticklabels = [
str(int(label)) for label in self.range_x
]
else:
xticklabels = [str(label) for label in self.range_x]
else:
xticklabels = []
self.ax.set_xticklabels(xticklabels)
for n, label in enumerate(self.ax.xaxis.get_ticklabels()):
if n % self.every_nth != 0:
label.set_visible(False)
# Rotate the tick labels and set their alignment.
plt.setp(
self.ax.get_xticklabels(),
rotation=45,
ha="right",
rotation_mode="anchor",
)
divider = make_axes_locatable(self.ax)
cax = divider.append_axes("right", size="7%", pad=0.15)
cbar = self.fig.colorbar(self.im, cax=cax)
cbar.set_label(self.var_name, rotation=270, labelpad=30)
self.fig.tight_layout()
return
def update(self, i):
sub_data = self.data[i]
self.im.set_data(sub_data)
if self.title is not None:
self.ax.set_title(
# {:.1f}
self.title + r" {} ${}$".format(self.time_pre_str, self.t),
fontsize=25,
)
self.t += self.dt
# We need to return the updated artist for FuncAnimation to draw..
# Note that it expects a sequence of artists, thus the trailing comma.
return (self.im,)
|
PypiClean
|
/leap.bitmask-0.10.1.tar.gz/leap.bitmask-0.10.1/src/leap/bitmask/mua/pixelizer.py
|
import json
import os
import string
import sys
from twisted.internet import defer, reactor
from twisted.logger import Logger
from leap.common.config import get_path_prefix
from leap.bitmask.keymanager import KeyNotFound
try:
from pixelated.adapter.mailstore import LeapMailStore
from pixelated.application import SingleUserServicesFactory
from pixelated.application import UserAgentMode
from pixelated.application import start_site
from pixelated.bitmask_libraries.smtp import LeapSMTPConfig
from pixelated.config.sessions import SessionCache
from pixelated.config import services
from pixelated.resources import set_static_folder
from pixelated.resources.root_resource import RootResource
import leap.pixelated_www
HAS_PIXELATED = True
class _LeapMailStore(LeapMailStore):
# TODO We NEED TO rewrite the whole LeapMailStore in the coming
# pixelated fork so that we reuse the account instance.
# Otherwise, the current system for notifications will break.
# The other option is to have generic event listeners, using zmq, and
# allow the pixelated instance to have its own hierarchy of
# account-mailbox instances, only sharing soledad.
# However, this seems good enough since it's now better to wait until
# we depend on leap.pixelated fork to make changes on that codebase.
# When that refactor starts, we should try to internalize as much
# work/bugfixes was done in pixelated, and incorporate it into the
# public bitmask api. Let's learn from our mistakes.
def __init__(self, soledad, account):
self.account = account
super(_LeapMailStore, self).__init__(soledad)
@defer.inlineCallbacks
def add_mail(self, mailbox_name, raw_msg):
name = yield self._get_case_insensitive_mbox(mailbox_name)
mailbox = yield self.account.get_collection_by_mailbox(name)
flags = ['\\Recent']
if mailbox_name.lower() == 'sent':
flags += '\\Seen'
message = yield mailbox.add_msg(raw_msg, tuple(flags))
# this still needs the pixelated interface because it does stuff
# like indexing the mail in whoosh, etc.
mail = yield self._leap_message_to_leap_mail(
message.get_wrapper().mdoc.doc_id, message, include_body=True)
defer.returnValue(mail)
def get_mailbox_names(self):
"""returns: deferred"""
return self.account.list_all_mailbox_names()
@defer.inlineCallbacks
def _get_or_create_mailbox(self, mailbox_name):
"""
Avoid creating variations of the case.
If there's already a 'Sent' folder, do not create 'SENT', just
return that.
"""
name = yield self._get_case_insensitive_mbox(mailbox_name)
if name is None:
name = mailbox_name
yield self.account.add_mailbox(name)
mailbox = yield self.account.get_collection_by_mailbox(
name)
# Pixelated expects the mailbox wrapper;
# it should limit itself to the Mail API instead.
# This is also a smell that the collection-mailbox-wrapper
# distinction is not clearly cut.
defer.returnValue(mailbox.mbox_wrapper)
@defer.inlineCallbacks
def _get_case_insensitive_mbox(self, mailbox_name):
name = None
mailboxes = yield self.get_mailbox_names()
lower = mailbox_name.lower()
lower_mboxes = map(string.lower, mailboxes)
if lower in lower_mboxes:
name = mailboxes[lower_mboxes.index(lower)]
defer.returnValue(name)
except ImportError as exc:
HAS_PIXELATED = False
log = Logger()
# TODO
# [ ] pre-authenticate
def start_pixelated_user_agent(userid, soledad, keymanager, account):
try:
leap_session = LeapSessionAdapter(
userid, soledad, keymanager, account)
except Exception as exc:
log.error("Got error! %r" % exc)
config = Config()
leap_home = os.path.join(get_path_prefix(), 'leap')
config.leap_home = leap_home
leap_session.config = config
services_factory = SingleUserServicesFactory(
UserAgentMode(is_single_user=True))
if getattr(sys, 'frozen', False):
# we are running in a |PyInstaller| bundle
static_folder = os.path.join(sys._MEIPASS, 'leap', 'pixelated_www')
else:
static_folder = os.path.abspath(leap.pixelated_www.__path__[0])
set_static_folder(static_folder)
resource = RootResource(services_factory, static_folder=static_folder)
config.host = 'localhost'
config.port = 9090
config.sslkey = None
config.sslcert = None
config.manhole = False
d = leap_session.account.callWhenReady(
lambda _: _start_in_single_user_mode(
leap_session, config,
resource, services_factory))
return d
def get_smtp_config(provider):
config_path = os.path.join(
get_path_prefix(), 'leap', 'providers', provider, 'smtp-service.json')
json_config = json.loads(open(config_path).read())
chosen_host = json_config['hosts'].keys()[0]
hostname = json_config['hosts'][chosen_host]['hostname']
port = json_config['hosts'][chosen_host]['port']
config = Config()
config.host = hostname
config.port = port
return config
class NickNym(object):
def __init__(self, keymanager, userid):
self._email = userid
self.keymanager = keymanager
@defer.inlineCallbacks
def generate_openpgp_key(self):
key_present = yield self._key_exists(self._email)
if not key_present:
yield self._gen_key()
yield self._send_key_to_leap()
@defer.inlineCallbacks
def _key_exists(self, email):
try:
yield self.fetch_key(email, private=True, fetch_remote=False)
defer.returnValue(True)
except KeyNotFound:
defer.returnValue(False)
def fetch_key(self, email, private=False, fetch_remote=True):
return self.keymanager.get_key(
email, private=private, fetch_remote=fetch_remote)
def get_key(self, *args, **kw):
return self.keymanager.get_key(*args, **kw)
def _gen_key(self):
return self.keymanager.gen_key()
def _send_key_to_leap(self):
# XXX: this needs to be removed in pixels side
# km.send_key doesn't exist anymore
return defer.succeed(None)
class LeapSessionAdapter(object):
def __init__(self, userid, soledad, keymanager, account):
self.userid = userid
self.soledad = soledad
# XXX this needs to be converged with our public apis.
_n = NickNym(keymanager, userid)
self.nicknym = self.keymanager = _n
self.mail_store = _LeapMailStore(soledad, account)
self.account = account
self.user_auth = Config()
self.user_auth.uuid = soledad.uuid
self.fresh_account = False
self.incoming_mail_fetcher = None
username, provider = userid.split('@')
smtp_client_cert = os.path.join(
get_path_prefix(),
'leap', 'providers', provider, 'keys',
'client',
'smtp_{username}.pem'.format(
username=username))
_prov = Config()
_prov.server_name = provider
self.provider = _prov
assert(os.path.isfile(smtp_client_cert))
smtp_config = get_smtp_config(provider)
smtp_host = smtp_config.host
smtp_port = smtp_config.port
self.smtp_config = LeapSMTPConfig(
userid,
smtp_client_cert, smtp_host, smtp_port)
def account_email(self):
return self.userid
def close(self):
pass
@property
def is_closed(self):
return self._is_closed
def remove_from_cache(self):
key = SessionCache.session_key(self.provider, self.userid)
SessionCache.remove_session(key)
def sync(self):
return self.soledad.sync()
class Config(object):
pass
def _start_in_single_user_mode(leap_session, config, resource,
services_factory):
start_site(config, resource)
reactor.callLater(
0, start_user_agent_in_single_user_mode,
resource, services_factory,
leap_session.config.leap_home, leap_session)
@defer.inlineCallbacks
def start_user_agent_in_single_user_mode(root_resource,
services_factory,
leap_home, leap_session):
log.info('Pixelated bootstrap done, loading services for user %s'
% leap_session.user_auth.uuid)
_services = services.Services(leap_session)
yield _services.setup()
# TODO we might want to use a Bitmask specific mail
# if leap_session.fresh_account:
# yield add_welcome_mail(leap_session.mail_store)
services_factory.add_session(leap_session.user_auth.uuid, _services)
root_resource.initialize(provider=leap_session.provider)
log.info('Done, the Pixelated User Agent is ready to be used')
|
PypiClean
|
/vectorai-nightly-0.2.5.2021.6.2.tar.gz/vectorai-nightly-0.2.5.2021.6.2/vectorai/read.py
|
import io
import base64
import requests
import random
import pandas as pd
import time
import warnings
from typing import List, Dict, Union, Any
from .api import ViAPIClient
from .utils import UtilsMixin
from .doc_utils import DocUtilsMixin
from .errors import MissingFieldWarning
class ViReadClient(ViAPIClient, UtilsMixin, DocUtilsMixin):
def __init__(self, username: str, api_key: str, url: str="https://api.vctr.ai"):
self.username = username
self.api_key = api_key
self.url = url
def random_aggregation_query(
self, collection_name: str, groupby: int = 1, metrics: int = 1
):
"""
Generates a random filter query.
Args:
collection_name:
name of collection
groupby:
The number of groupbys to randomly generate
metrics:
The number of metrics to randomly generate
Example:
>>> from vectorai.client import ViClient
>>> vi_client = ViClient(username, api_key, vectorai_url)
>>> vi_client.random_aggregation_query(collection_name, groupby=1, metrics=1)
"""
schema = self.collection_schema(collection_name)
full_aggregation_query = {"groupby": [], "metrics": []}
for s in schema:
if schema[s] == "text":
full_aggregation_query["groupby"].append(
{"name": s, "field": s, "agg": "texts"}
)
elif schema[s] == "numeric":
full_aggregation_query["metrics"].append(
{"name": s, "field": s, "agg": "avg"}
)
return {
"groupby": random.sample(full_aggregation_query["groupby"], groupby),
"metrics": random.sample(full_aggregation_query["metrics"], metrics),
}
def search(self,
collection_name: str,
vector: List,
field: List,
filters: List=[],
approx: int = 0,
sum_fields: bool = True,
metric: str = "cosine",
min_score=None,
page: int = 1,
page_size: int = 10,
include_vector:bool=False,
include_count:bool=True,
asc:bool=False,
**kwargs
):
"""
Vector Similarity Search. Search a vector field with a vector, a.k.a Nearest Neighbors Search
Enables machine learning search with vector search. Search with a vector for the most similar vectors.
For example: Search with a person's characteristics, who are the most similar (querying the "persons_characteristics_vector" field)::
Query person's characteristics as a vector:
[180, 40, 70] representing [height, age, weight]
Search Results:
[
{"name": Adam Levine, "persons_characteristics_vector" : [180, 56, 71]},
{"name": Brad Pitt, "persons_characteristics_vector" : [180, 56, 65]},
...]
Args:
vector:
Vector, a list/array of floats that represents a piece of data.
collection_name:
Name of Collection
search_fields:
Vector fields to search through
approx:
Used for approximate search
sum_fields:
Whether to sum the multiple vectors similarity search score as 1 or seperate
page_size:
Size of each page of results
filters:
Filters for search
page:
Page of the results
metric:
Similarity Metric, choose from ['cosine', 'l1', 'l2', 'dp']
min_score:
Minimum score for similarity metric
include_vector:
Include vectors in the search results
include_count:
Include count in the search results
asc:
Whether to sort the score by ascending order (default is false, for getting most similar results)
"""
search_fields ={}
if isinstance(field, str):
advanced_search_query = {
field.replace('_vector_', ''): {'vector': vector, 'fields': [field]}
}
else:
advanced_search_query = {
field[0].replace('_vector_', ''): {'vector': vector, 'fields': field}
}
return self.advanced_search(
collection_name=collection_name,
multivector_query=advanced_search_query,
filters=filters,
approx=approx,
sum_fields=sum_fields,
metric=metric,
min_score=min_score,
page=page,
page_size=page_size,
include_vector=include_vector,
include_count=include_count,
asc=asc,
**kwargs
)
def random_filter_query(
self, collection_name: str, text_filters: int = 1, numeric_filters: int = 0
):
"""
Generates a random filter query.
Args:
collection_name:
name of collection
text_filters:
The number of text filters to randomly generate
numeric_filters:
The number of numeric filters to randomly generate
Example:
>>> from vectorai.client import ViClient
>>> vi_client = ViClient(username, api_key, vectorai_url)
>>> vi_client.random_filter_query(collection_name, text_filters=1, numeric_filters=0)
"""
schema = self.collection_schema(collection_name)
facets = self.facets(collection_name)
full_filter_query = {"text": [], "numeric": []}
for f, t in schema.items():
if t == "text":
if isinstance(facets[f], list):
full_filter_query["text"].append(
{
"field": f,
"filter_type": "text",
"condition_value": random.sample(facets[f], 1)[0][f],
"condition": "==",
}
)
elif t == "numeric":
if isinstance(facets[f], dict):
full_filter_query["numeric"].append(
{
"field": f,
"filter_type": "date",
"condition_value": (facets[f]["max"] - facets[f]["min"])
/ 2,
"condition": ">=",
}
)
return random.sample(full_filter_query["text"], text_filters) + random.sample(
full_filter_query["numeric"], numeric_filters
)
def head(
self, collection_name: str, page_size: int = 5, return_as_pandas_df: bool = True
):
"""
The main Vi client with most of the available read and write methods available to it.
Args:
collection_name:
The name of your collection
page_size:
The number of results to return
return_as_pandas_df:
If True, return as a pandas DataFrame rather than a JSON.
Example:
>>> from vectorai.client import ViClient
>>> vi_client = ViClient(username, api_key, vectorai_url)
>>> vi_client.head(collection_name, page_size=10)
"""
response = requests.get(
url="{}/collection/retrieve_documents".format(self.url),
params={
"username": self.username,
"api_key": self.api_key,
"collection_name": collection_name,
"page_size": page_size,
},
).json()
if "documents" in response.keys():
response = response["documents"]
if return_as_pandas_df:
return pd.DataFrame.from_records(response)
else:
return response
def sample(
self, collection_name: str, page_size: int=5, return_as_pandas_df: bool=True, filters: list=[], seed: int=10
):
docs = self.random_documents_with_filters(
collection_name=collection_name,
filters=filters,
page_size=page_size,
seed=seed
)
if "documents" in docs:
docs = docs['documents']
if return_as_pandas_df:
return pd.DataFrame.from_records(response)
else:
return response
def retrieve_all_documents(
self,
collection_name: str,
sort: List = [],
asc: bool = True,
include_vector: bool = True,
include_fields: List = [],
retrieve_chunk_size: int=1000,
**kwargs
):
"""
Retrieve all documents in a given collection. We recommend specifying specific fields to extract
as otherwise this function may take a long time to run.
Args:
collection_name:
Name of collection.
sort_by:
Select the fields by which to sort by.
asc:
If true, returns in ascending order of what is sort.
include_vector:
If true, includes _vector_ fields to return them.
include_fields:
Adjust which fields are returned.
retrieve_chunk_size:
The number of documents to retrieve per request.
Example:
>>> from vectorai.client import ViClient
>>> vi_client = ViClient(username, api_key, vectorai_url)
>>> all_documents = vi_client.retrieve_all_documents(collection_name)
"""
num_of_docs = self.collection_stats(collection_name)['number_of_documents']
with self.progress_bar(list(range(int(num_of_docs/ retrieve_chunk_size)))) as pbar:
d = self.retrieve_documents(
collection_name=collection_name, page_size=retrieve_chunk_size, sort=sort, asc=asc, include_vector=include_vector,
include_fields=include_fields, **kwargs
)
all_docs = d["documents"]
pbar.update(1)
while len(d["documents"]) > 0:
d = self.retrieve_documents(
collection_name=collection_name,
page_size=retrieve_chunk_size,
cursor=d["cursor"],
sort=sort,
asc=asc,
include_vector=include_vector,
include_fields=include_fields
)
all_docs += d["documents"]
pbar.update(1)
return all_docs
def wait_till_jobs_complete(self, collection_name: str, job_id: str, job_name: str):
"""
Wait until a specific job is complete.
Args:
collection_name:
Name of collection.
job_id:
ID of the job.
job_name:
Name of the job.
Example:
>>> from vectorai.client import ViClient
>>> vi_client = ViClient(username, api_key, vectorai_url)
>>> job = vi_client.dimensionality_reduction_job('nba_season_per_36_stats_demo', vector_field='season_vector_', n_components=2)
>>> vi_client.wait_till_jobs_complete('nba_season_per_36_stats_demo', **job)
"""
status = self.job_status(collection_name, job_id, job_name)
while (
status["status"] == "Running"
or status["status"] == "Started"
or status["status"] == "NotStarted"
):
status = self.job_status(collection_name, job_id, job_name)
time.sleep(15)
print(status)
return "Done"
def check_schema(self, collection_name: str, document: Dict=None):
"""
Check the schema of a given collection.
Args:
collection_name:
Name of collection.
Example:
>>> from vectorai.client import ViClient
>>> vi_client = ViClient(username, api_key, vectorai_url)
>>> vi_client.check_schema(collection_name)
"""
if document is None:
document = self.retrieve_documents(collection_name, page_size=1)
self._check_schema(document)
def _check_schema(
self,
document: Dict,
is_missing_vector_field=True,
is_missing_id_field=True,
is_nested=False
):
"""
Check if there is a _vector_ field and an _id field.
Args:
document:
A JSON file/python dictionary
is_missing_vector_field:
DO NOT CHANGE. A tracker to return if the dictionary is missing a vector field
is_nested:
DO NOT CHANGE. Returns True if is a nested. Used internally for recursive functionality.
Example:
>>> from vectorai.client import ViClient
>>> vi_client = ViClient(username, api_key, vectorai_url)
>>> doc = {'items': {'chicken': 'fried'}, 'food_vector_': [0, 1, 2]}
>>> vi_client._check_schema(doc)
"""
VECTOR_FIELD_NAME = "_vector_"
IS_VECTOR_FIELD_MISSING = True
IS_ID_FIELD_MISSING = True
for field, value in document.items():
if field == '_id':
IS_ID_FIELD_MISSING = False
if isinstance(value, dict):
IS_ID_FIELD_MISSING, IS_VECTOR_FIELD_MISSING = self._check_schema(
document[field],
is_missing_vector_field=IS_VECTOR_FIELD_MISSING,
is_missing_id_field=IS_ID_FIELD_MISSING,
is_nested=True
)
if "_vectors_" in field:
warnings.warn(
"Rename " + field + "to " + field.replace('_vectors_', '_vector_')
, MissingFieldWarning)
for field in document.keys():
if VECTOR_FIELD_NAME in field:
IS_VECTOR_FIELD_MISSING = False
if not is_nested:
if IS_VECTOR_FIELD_MISSING:
warnings.warn(
"Potential issue. Cannot find a vector field. Check that the vector field contains _vector_.",
MissingFieldWarning
)
if IS_ID_FIELD_MISSING:
warnings.warn(
"Missing ID field. Please include an _id field to make inserting easier.",
MissingFieldWarning
)
return IS_ID_FIELD_MISSING, IS_VECTOR_FIELD_MISSING
def list_collections(self) -> List[str]:
"""
List Collections
Args:
username:
Username
api_key:
Api Key, you can request it from request_api_key
Returns:
List of collections
Example:
>>> from vectorai.client import ViClient
>>> vi_client = ViClient(username, api_key, vectorai_url)
>>> doc = {'items': {'chicken': 'fried'}, 'food_vector_': [0, 1, 2]}
>>> vi_client._check_schema(doc)
"""
return sorted(self._list_collections())
def search_collections(self, keyword: str) -> List[str]:
"""
Performs keyword matching in collections.
Args:
keyword: Matches based on keywords
Returns:
List of collection names
Example:
>>> from vectorai import ViClient
>>> vi_client = ViClient()
>>> vi_client.search_collections('example')
"""
return [x for x in self.list_collections() if keyword.lower() in x]
def random_recommendation(self,
collection_name: str,
search_field: str,
seed=None,
sum_fields: bool = True,
metric: str = "cosine",
min_score=0,
page: int = 1,
page_size: int = 10,
include_vector:bool=False,
include_count:bool=True,
approx: int=0,
hundred_scale=True,
asc:bool=False, **kwargs):
"""
Recommend by random ID using vector search
document_id:
ID of a document
collection_name:
Name of Collection
field:
Vector fields to search through
approx:
Used for approximate search
sum_fields:
Whether to sum the multiple vectors similarity search score as 1 or seperate
page_size:
Size of each page of results
page:
Page of the results
metric:
Similarity Metric, choose from ['cosine', 'l1', 'l2', 'dp']
min_score:
Minimum score for similarity metric
include_vector:
Include vectors in the search results
include_count:
Include count in the search results
hundred_scale:
Whether to scale up the metric by 100
asc:
Whether to sort the score by ascending order (default is false, for getting most similar results)
"""
random_id = self.random_documents(collection_name, page_size=1, seed=seed,
include_fields=['_id'])['documents'][0]['_id']
return self.search_by_id(collection_name=collection_name, document_id=random_id, search_field=search_field,
approx=approx, sum_fields=sum_fields, page_size=page_size, page=page, metric=metric, min_score=min_score,
include_vector=include_vector, include_count=include_count, hundred_scale=hundred_scale,
asc=asc, **kwargs)
def create_filter_query(self, collection_name: str, field: str, filter_type: str, filter_values: Union[List[str], str]=None):
"""
Filter type can be one of contains/exact_match/categories/exists/insert_date/numeric_range
Filter types can be one of:
contains: Field must contain this specific string. Not case sensitive.
exact_match: Field must have an exact match
categories: Matches entire field
exists: If field exists in document
>= / > / < / <= : Larger than or equal to / Larger than / Smaller than / Smaller than or equal to
These, however, can only be applied on numeric/date values. Check collection_schema.
Args:
collection_name: The name of the collection
field: The field to filter on
filter_type: One of contains/exact_match/categories/>=/>/<=/<.
"""
if filter_type == 'contains':
# return [{'field' : field, 'filter_type' : 'contains', "condition":"==", "condition_value": filter_values}]
return [{'field': field, 'filter_type': 'regexp', 'condition': '==', 'condition_value': '.*' + str(filter_values) + '.*'}]
if filter_type == 'exact_match':
return [{'field' : field, 'filter_type' : 'exact_match', "condition":"==", "condition_value": filter_values}]
if filter_type == 'categories':
return [{'field' : field, 'filter_type' : 'categories', "condition":"==", "condition_value": filter_values}]
if filter_type == 'exists':
if filter_values is None or filter_values == '==':
return [{'field' : field, 'filter_type' : 'exists', "condition":"==", "condition_value":" "}]
elif filter_values == '!=':
return [{'field' : field, 'filter_type' : 'exists', "condition":"!=", "condition_value":" "}]
if filter_type == '<=' or filter_type == '>=' or filter_type == '>' or filter_type == '<' or filter_type == '==':
if self.collection_schema(collection_name)[field] == 'date':
return [{'field' : field, 'filter_type' : 'date', "condition":filter_type, "condition_value": filter_values}]
elif self.collection_schema(collection_name)[field] == 'numeric':
return [{'field' : field, 'filter_type' : 'numeric', "condition":filter_type, "condition_value":filter_values}]
else:
raise ValueError(f"{filter_type} has not been defined. Please choose one of contains/exact_match/exists/categories/>=/<=/>/<.")
def search_with_filters(self,
collection_name: str,
vector: List,
field: List,
filters: List=[],
approx: int = 0,
sum_fields: bool = True,
metric: str = "cosine",
min_score=None,
page: int = 1,
page_size: int = 10,
include_vector:bool=False,
include_count:bool=True,
asc:bool=False,
**kwargs
):
"""
Vector Similarity Search. Search a vector field with a vector, a.k.a Nearest Neighbors Search
Enables machine learning search with vector search. Search with a vector for the most similar vectors.
For example: Search with a person's characteristics, who are the most similar (querying the "persons_characteristics_vector" field)::
Query person's characteristics as a vector:
[180, 40, 70] representing [height, age, weight]
Search Results:
[
{"name": Adam Levine, "persons_characteristics_vector" : [180, 56, 71]},
{"name": Brad Pitt, "persons_characteristics_vector" : [180, 56, 65]},
...]
Args:
vector:
Vector, a list/array of floats that represents a piece of data.
collection_name:
Name of Collection
search_fields:
Vector fields to search through
approx:
Used for approximate search
sum_fields:
Whether to sum the multiple vectors similarity search score as 1 or seperate
page_size:
Size of each page of results
page:
Page of the results
metric:
Similarity Metric, choose from ['cosine', 'l1', 'l2', 'dp']
min_score:
Minimum score for similarity metric
include_vector:
Include vectors in the search results
include_count:
Include count in the search results
asc:
Whether to sort the score by ascending order (default is false, for getting most similar results)
"""
search_fields ={}
if isinstance(field, str):
advanced_search_query = {
field.replace('_vector_', ''): {'vector': vector, 'fields': [field]}
}
else:
advanced_search_query = {
field[0].replace('_vector_', ''): {'vector': vector, 'fields': field}
}
return self.advanced_search(
collection_name=collection_name,
multivector_query=advanced_search_query,
approx=approx,
sum_fields=sum_fields,
filters=filters,
metric=metric,
min_score=min_score,
page=page,
page_size=page_size,
include_vector=include_vector,
include_count=include_count,
asc=asc,
**kwargs
)
def hybrid_search_with_filters(
self,
collection_name: str,
text: str,
vector: List,
fields: List,
text_fields: List,
filters: List=[],
sum_fields: bool = True,
metric: str = "cosine",
min_score=None,
traditional_weight=0.075,
page: int = 1,
page_size: int = 10,
include_vector:bool=False,
include_count:bool=True,
asc:bool=False,
**kwargs
):
"""
Search a text field with vector and text using Vector Search and Traditional Search
Vector similarity search + Traditional Fuzzy Search with text and vector.
You can also give weightings of each vector field towards the search, e.g. image\_vector\_ weights 100%, whilst description\_vector\_ 50%.
Hybrid search with filters also supports filtering to only search through filtered results and facets to get the overview of products available when a minimum score is set.
Args:
collection_name:
Name of Collection
page:
Page of the results
page_size:
Size of each page of results
approx:
Used for approximate search
sum_fields:
Whether to sum the multiple vectors similarity search score as 1 or seperate
metric:
Similarity Metric, choose from ['cosine', 'l1', 'l2', 'dp']
filters:
Query for filtering the search results
min_score:
Minimum score for similarity metric
include_vector:
Include vectors in the search results
include_count:
Include count in the search results
include_facets:
Include facets in the search results
hundred_scale:
Whether to scale up the metric by 100
multivector_query:
Query for advance search that allows for multiple vector and field querying
text:
Text Search Query (not encoded as vector)
text_fields:
Text fields to search against
traditional_weight:
Multiplier of traditional search. A value of 0.025~0.1 is good.
fuzzy:
Fuzziness of the search. A value of 1-3 is good.
join:
Whether to consider cases where there is a space in the word. E.g. Go Pro vs GoPro.
asc:
Whether to sort the score by ascending order (default is false, for getting most similar results)
"""
query = {
fields[0]: {'vector': vector, 'fields': fields}
}
return self.advanced_hybrid_search(
collection_name=collection_name,
text=text,
multivector_query=query,
text_fields=text_fields,
sum_fields=sum_fields,
facets=[],
filters=filters,
metric=metric,
min_score=min_score,
page=page,
page_size=page_size,
include_vector=False,
include_count=True,
include_facets=False,
asc=False,
**kwargs
)
|
PypiClean
|
/PyCrypCli-2.1.0b0.tar.gz/PyCrypCli-2.1.0b0/PyCrypCli/commands/inventory.py
|
from collections import Counter
from typing import List, Dict, Any
from .command import CommandError, command
from .help import print_help
from ..context import MainContext, DeviceContext
from ..exceptions import CannotTradeWithYourselfError, UserUUIDDoesNotExistError
from ..models import InventoryElement, ShopCategory
from ..util import print_tree
@command("inventory", [MainContext, DeviceContext])
def handle_inventory(context: MainContext, args: List[str]) -> None:
"""
Manage your inventory and trade with other players
"""
if args:
raise CommandError("Unknown subcommand.")
print_help(context, handle_inventory)
@handle_inventory.subcommand("list")
def handle_inventory_list(context: MainContext, _: Any) -> None:
"""
List your inventory
"""
inventory: Dict[str, int] = Counter(element.name for element in InventoryElement.list_inventory(context.client))
if not inventory:
raise CommandError("Your inventory is empty.")
categories: List[ShopCategory] = ShopCategory.shop_list(context.client)
tree = []
for category in categories:
category_tree = []
for subcategory in category.subcategories:
subcategory_tree: list[tuple[str, list[Any]]] = [
(f"{inventory[item.name]}x {item.name}", []) for item in subcategory.items if inventory[item.name]
]
if subcategory_tree:
category_tree.append((subcategory.name, subcategory_tree))
for item in category.items:
if inventory[item.name]:
category_tree.append((f"{inventory[item.name]}x {item.name}", []))
if category_tree:
tree.append((category.name, category_tree))
print("Inventory")
print_tree(tree)
@handle_inventory.subcommand("trade")
def handle_inventory_trade(context: MainContext, args: List[str]) -> None:
"""
Trade with other players
"""
if len(args) != 2:
raise CommandError("usage: inventory trade <item> <user>")
item_name, target_user = args
for item in InventoryElement.list_inventory(context.client):
if item.name.replace(" ", "") == item_name:
break
else:
raise CommandError("You do not own this item.")
try:
item.trade(target_user)
except CannotTradeWithYourselfError:
raise CommandError("You cannot trade with yourself.")
except UserUUIDDoesNotExistError:
raise CommandError("This user does not exist.")
@handle_inventory_trade.completer()
def inventory_completer(context: MainContext, args: List[str]) -> List[str]:
if len(args) == 1:
return [element.name.replace(" ", "") for element in InventoryElement.list_inventory(context.client)]
return []
|
PypiClean
|
/KubiScanPyPiTest-0.1.48-py3-none-any.whl/KubiScanPyPi/api/api_client.py
|
from kubernetes import client, config
from shutil import copyfile
import os
from tempfile import mkstemp
from shutil import move
from kubernetes.client.configuration import Configuration
from kubernetes.client.api_client import ApiClient
# TODO: Should be removed after the bug will be solved:
# https://github.com/kubernetes-client/python/issues/577
from api.api_client_temp import ApiClientTemp
# The following variables have been commented as it resulted a bug when running `kubiscan -h`
# Exception ignored in: <bound method ApiClient.__del__ of <kubernetes.client.api_client.ApiClient object ...
# It is related to https://github.com/kubernetes-client/python/issues/411 w
#api_temp = ApiClientTemp()
#CoreV1Api = client.CoreV1Api()
#RbacAuthorizationV1Api = client.RbacAuthorizationV1Api()
api_temp = None
CoreV1Api = None
RbacAuthorizationV1Api = None
def running_in_container():
running_in_a_container = os.getenv('RUNNING_IN_A_CONTAINER')
if running_in_a_container is not None and running_in_a_container == 'true':
return True
return False
def replace(file_path, pattern, subst):
#Create temp file
fh, abs_path = mkstemp()
with os.fdopen(fh,'w') as new_file:
with open(file_path) as old_file:
for line in old_file:
if pattern in line:
new_file.write(line.replace(pattern, subst))
else:
new_file.write(line)
#Remove original file
os.remove(file_path)
#Move new file
move(abs_path, file_path)
def api_init(kube_config_file=None, host=None, token_filename=None, cert_filename=None, context=None):
global CoreV1Api
global RbacAuthorizationV1Api
global api_temp
if host and token_filename:
print("Using token from " + token_filename + " on ip address " + host)
# remotely
token_filename = os.path.abspath(token_filename)
if cert_filename:
cert_filename = os.path.abspath(cert_filename)
configuration = BearerTokenLoader(host=host, token_filename=token_filename, cert_filename=cert_filename).load_and_set()
CoreV1Api = client.CoreV1Api()
RbacAuthorizationV1Api = client.RbacAuthorizationV1Api()
api_temp = ApiClientTemp(configuration=configuration)
elif kube_config_file:
print("Using kube congif file.")
config.load_kube_config(os.path.abspath(kube_config_file))
CoreV1Api = client.CoreV1Api()
RbacAuthorizationV1Api = client.RbacAuthorizationV1Api()
api_from_config = config.new_client_from_config(kube_config_file)
api_temp = ApiClientTemp(configuration=api_from_config.configuration)
else:
print("Using kube congif file.")
configuration = Configuration()
api_client = ApiClient()
kubeconfig_path = os.getenv('KUBISCAN_CONFIG_PATH')
if running_in_container() and kubeconfig_path is None:
# TODO: Consider using config.load_incluster_config() from container created by Kubernetes. Required service account with privileged permissions.
# Must have mounted volume
container_volume_prefix = os.getenv('KUBISCAN_VOLUME_PATH', '/tmp')
kube_config_bak_path = os.getenv('KUBISCAN_CONFIG_BACKUP_PATH', '/opt/KubiScanPyPi/config_bak')
if not os.path.isfile(kube_config_bak_path):
copyfile(container_volume_prefix + os.path.expandvars('$CONF_PATH'), kube_config_bak_path)
replace(kube_config_bak_path, ': /', f': {container_volume_prefix}/')
config.load_kube_config(kube_config_bak_path, context=context, client_configuration=configuration)
else:
config.load_kube_config(config_file=kubeconfig_path, context=context, client_configuration=configuration)
api_client = ApiClient(configuration=configuration)
CoreV1Api = client.CoreV1Api(api_client=api_client)
RbacAuthorizationV1Api = client.RbacAuthorizationV1Api(api_client=api_client)
api_temp = ApiClientTemp(configuration=configuration)
class BearerTokenLoader(object):
def __init__(self, host, token_filename, cert_filename=None):
self._token_filename = token_filename
self._cert_filename = cert_filename
self._host = host
self._verify_ssl = True
if not self._cert_filename:
self._verify_ssl = False
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
def load_and_set(self):
self._load_config()
configuration = self._set_config()
return configuration
def _load_config(self):
self._host = "https://" + self._host
if not os.path.isfile(self._token_filename):
raise Exception("Service token file does not exists.")
with open(self._token_filename) as f:
self.token = f.read().rstrip('\n')
if not self.token:
raise Exception("Token file exists but empty.")
if self._cert_filename:
if not os.path.isfile(self._cert_filename):
raise Exception(
"Service certification file does not exists.")
with open(self._cert_filename) as f:
if not f.read().rstrip('\n'):
raise Exception("Cert file exists but empty.")
self.ssl_ca_cert = self._cert_filename
def _set_config(self):
configuration = client.Configuration()
configuration.host = self._host
configuration.ssl_ca_cert = self.ssl_ca_cert
configuration.verify_ssl = self._verify_ssl
configuration.api_key['authorization'] = "bearer " + self.token
client.Configuration.set_default(configuration)
return configuration
|
PypiClean
|
/gravity_front-1.4.0-py3-none-any.whl/cm/modules.py
|
import tkinter.filedialog
from cm.terminal import Terminal
from tkinter import *
from gtki_module_treeview.main import CurrentTreeview, NotificationTreeview, \
HistroryTreeview
from cm.widgets.dropDownCalendar import MyDateEntry
from cm.widgets.drop_down_combobox import AutocompleteCombobox
import datetime
from cm.styles import color_solutions as cs
from cm.styles import fonts
from cm.styles import element_sizes as el_sizes
from gtki_module_exex.main import CreateExcelActs
class SysNot(Terminal):
""" Окно уведомлений"""
def __init__(self, root, settings, operator, can):
Terminal.__init__(self, root, settings, operator, can)
self.name = 'SysNot'
self.buttons = settings.toolBarBtns
self.tar = NotificationTreeview(self.root, operator, height=35)
self.tar.createTree()
self.tree = self.tar.get_tree()
self.btn_name = self.settings.notifBtn
def drawing(self):
Terminal.drawing(self)
self.drawWin('maincanv', 'sysNot')
self.drawTree()
self.buttons_creation(tagname='winBtn')
def destroyBlockImg(self, mode='total'):
Terminal.destroyBlockImg(self, mode)
self.drawTree()
def drawTree(self):
# self.tar.fillTree(info)
self.can.create_window(self.w / 1.9, self.h / 1.95, window=self.tree,
tag='tree')
class Statistic(Terminal):
""" Окно статистики """
def __init__(self, root, settings, operator, can):
Terminal.__init__(self, root, settings, operator, can)
self.btns_height = self.h / 4.99
self.name = 'Statistic'
self.buttons = settings.statBtns
# self.font = '"Montserrat SemiBold" 14'
self.history = {}
self.chosenType = ''
self.chosenContragent = ''
self.choosenCat = ''
self.typePopup = ...
self.carnums = []
self.filterColNA = '#2F8989'
self.filterColA = '#44C8C8'
self.tar = HistroryTreeview(self.root, operator, height=28)
self.tar.createTree()
self.tree = self.tar.get_tree()
self.tree.bind("<Double-1>", self.OnDoubleClick)
self.posOptionMenus()
self.calendarsDrawn = False
self.btn_name = self.settings.statisticBtn
self.weight_sum = 0
self.records_amount = 0
def excel_creator(self):
file_name = self.get_excel_file_path()
data_list = self.generate_excel_content()
self.form_excel(file_name, data_list)
def generate_excel_content(self):
items = self.tree.get_children()
data_list = []
for item in items:
record_id = self.tree.item(item, 'text')
data = self.tree.item(item, 'values')
data = list(data)
data.insert(0, record_id)
data_list.append(data)
return data_list
def get_excel_file_path(self):
name = tkinter.filedialog.asksaveasfilename(defaultextension='.xlsx',
filetypes=[("Excel files",
"*.xls *.xlsx")])
return name
def form_excel(self, file_name, data_list):
inst = CreateExcelActs(file_name, data_list, self.amount_weight)
inst.create_document()
def OnDoubleClick(self, event):
''' Реакция на дабл-клик по заезду '''
item = self.tree.selection()[0]
self.chosenStr = self.tree.item(item, "values")
self.record_id = self.tree.item(item, "text")
self.draw_change_records(self.chosenStr)
def draw_change_records(self, string):
self.parsed_string = self.parse_string(string)
self.orupState = True
btnsname = 'record_change_btns'
record_info = self.history[self.record_id]
self.initBlockImg('record_change_win', btnsname=btnsname,
hide_widgets=self.statisticInteractiveWidgets)
self.posEntrys(
carnum=self.parsed_string["car_number"],
trashtype=self.parsed_string["trash_type"],
trashcat=self.parsed_string["trash_cat"],
contragent=self.parsed_string["carrier"],
client=self.parsed_string['client'],
notes=self.parsed_string["notes"],
polygon=self.operator.get_polygon_platform_repr(record_info['id']),
object=self.operator.get_pol_object_repr(record_info['object_id']),
spec_protocols=False,
call_method='manual',
)
self.root.bind('<Return>', lambda event: self.change_record())
self.root.bind('<Escape>',
lambda event: self.destroyORUP(mode="decline"))
self.root.bind("<Button-1>",
lambda event: self.clear_optionmenu(event))
self.unbindArrows()
def parse_string(self, string):
# Парсит выбранную строку из окна статистики и возвращает словарь с элементами
parsed = {}
parsed["car_number"] = string[0]
parsed["carrier"] = string[2]
parsed["trash_cat"] = string[6]
parsed["trash_type"] = string[7]
parsed["notes"] = string[10]
parsed['client'] = string[1]
return parsed
def change_record(self):
info = self.get_orup_entry_reprs()
self.try_upd_record(info['carnum'], info['carrier'], info['trash_cat'],
info['trash_type'], info['comm'],
info['polygon_platform'], info['client'],
info['polygon_object'])
def try_upd_record(self, car_number, carrier, trash_cat, trash_type,
comment, polygon, client, pol_object):
self.car_protocol = self.operator.fetch_car_protocol(car_number)
data_dict = {}
data_dict['car_number'] = car_number
data_dict['chosen_trash_cat'] = trash_cat
data_dict['type_name'] = trash_type
data_dict['carrier_name'] = carrier
data_dict['sqlshell'] = object
data_dict['photo_object'] = self.settings.redbg[3]
data_dict['client'] = client
response = self.operator.orup_error_manager.check_orup_errors(
orup='brutto',
xpos=self.settings.redbg[1],
ypos=self.settings.redbg[2],
**data_dict)
if not response:
auto_id = self.operator.get_auto_id(car_number)
carrier_id = self.operator.get_client_id(carrier)
trash_cat_id = self.operator.get_trash_cat_id(trash_cat)
trash_type_id = self.operator.get_trash_type_id(trash_type)
polygon_id = self.operator.get_polygon_platform_id(polygon)
client_id = self.operator.get_client_id(client)
pol_object_id = self.operator.get_polygon_object_id(pol_object)
self.operator.ar_qdk.change_opened_record(record_id=self.record_id,
auto_id=auto_id,
carrier=carrier_id,
trash_cat_id=trash_cat_id,
trash_type_id=trash_type_id,
comment=comment,
car_number=car_number,
polygon=polygon_id,
client=client_id,
pol_object=pol_object_id)
self.destroyORUP()
self.upd_statistic_tree()
def upd_statistic_tree(self):
""" Обновить таблицу статистики """
self.get_history()
self.draw_stat_tree()
def draw_add_comm(self):
btnsname = 'addCommBtns'
self.add_comm_text = self.getText(h=5, w=42, bg=cs.orup_bg_color)
self.initBlockImg(name='addComm', btnsname=btnsname,
seconds=('second'),
hide_widgets=self.statisticInteractiveWidgets)
self.can.create_window(self.w / 2, self.h / 2.05,
window=self.add_comm_text, tag='blockimg')
self.root.bind('<Return>', lambda event: self.add_comm())
self.root.bind('<Escape>',
lambda event: self.destroyBlockImg(mode="total"))
def add_comm(self):
comment = self.add_comm_text.get("1.0", 'end-1c')
self.operator.ar_qdk.add_comment(record_id=self.record_id,
comment=comment)
self.destroyBlockImg()
self.upd_statistic_tree()
def posOptionMenus(self):
self.placeTypeOm()
self.placeCatOm(bg=self.filterColNA)
self.placeContragentCombo()
self.placePoligonOm()
self.placeObjectOm()
self.placeCarnumCombo()
self.placeClientsOm()
self.statisticInteractiveWidgets = [self.stat_page_polygon_combobox,
self.trashTypeOm, self.trashCatOm,
self.contragentCombo,
self.stat_page_carnum_cb,
self.clientsOm,
self.stat_page_pol_object_combobox]
self.hide_widgets(self.statisticInteractiveWidgets)
def abortFiltres(self):
""" Сбросить все фильтры на значения по умолчанию
"""
for combobox in self.statisticInteractiveWidgets:
if isinstance(combobox, AutocompleteCombobox):
combobox.set_default_value()
self.startCal.set_date(datetime.datetime.today())
self.endCal.set_date(datetime.datetime.today())
self.upd_statistic_tree()
def placePoligonOm(self):
listname = ['площадка'] + self.operator.get_polygon_platforms_reprs()
self.poligonVar = StringVar()
self.stat_page_polygon_combobox = AutocompleteCombobox(self.root,
textvariable=self.poligonVar,
default_value=
listname[0])
self.configure_combobox(self.stat_page_polygon_combobox)
self.stat_page_polygon_combobox.set_completion_list(listname)
self.stat_page_polygon_combobox.config(width=8, height=30,
font=fonts.statistic_filtres)
self.can.create_window(self.w / 2.475, self.btns_height,
window=self.stat_page_polygon_combobox,
tags=('filter', 'typeCombobox'))
def placeObjectOm(self):
listname = ['объект'] + self.operator.get_pol_objects_reprs()
self.pol_object_var = StringVar()
self.stat_page_pol_object_combobox = AutocompleteCombobox(self.root,
textvariable=self.pol_object_var,
default_value=
listname[0])
self.configure_combobox(self.stat_page_pol_object_combobox)
self.stat_page_pol_object_combobox.set_completion_list(listname)
self.stat_page_pol_object_combobox.config(width=16, height=36,
font=fonts.statistic_filtres)
self.can.create_window(self.w / 1.91, self.h / 3.85,
window=self.stat_page_pol_object_combobox,
tags=('filter', 'typeCombobox'))
def placeTypeOm(self):
listname = ['вид груза'] + self.operator.get_trash_types_reprs()
self.stat_page_trash_type_var = StringVar()
self.trashTypeOm = AutocompleteCombobox(self.root,
textvariable=self.stat_page_trash_type_var,
default_value=listname[0])
self.configure_combobox(self.trashTypeOm)
self.trashTypeOm.set_completion_list(listname)
self.trashTypeOm.config(width=9, height=30,
font=fonts.statistic_filtres)
self.can.create_window(self.w / 3.435, self.btns_height,
window=self.trashTypeOm,
tags=('filter', 'typeCombobox'))
def placeCatOm(self, bg, deffvalue='кат. груза'):
listname = ['кат. груза'] + self.operator.get_trash_cats_reprs()
self.stat_page_trash_cat_var = StringVar()
self.trashCatOm = AutocompleteCombobox(self.root,
textvariable=self.stat_page_trash_cat_var,
default_value=listname[0])
self.trashCatOm.set_completion_list(listname)
self.trashCatOm.config(width=9, height=30,
font=fonts.statistic_filtres)
self.can.create_window(self.w / 5.45, self.btns_height,
window=self.trashCatOm,
tags=('filter', 'catOm'))
self.configure_combobox(self.trashCatOm)
def placeClientsOm(self):
listname = ['клиенты'] + self.operator.get_clients_reprs()
self.stat_page_clients_var = StringVar()
self.clientsOm = AutocompleteCombobox(self.root,
textvariable=self.stat_page_clients_var,
default_value=listname[0])
self.configure_combobox(self.clientsOm)
self.clientsOm['style'] = 'orup.TCombobox'
self.clientsOm.set_completion_list(listname)
self.clientsOm.config(width=12, height=int(self.h / 40),
font=fonts.statistic_filtres)
self.can.create_window(self.w / 1.278, self.btns_height,
window=self.clientsOm,
tags=('filter', 'typeCombobox'))
def placeContragentCombo(self):
carriers = ['перевозчики'] + self.operator.get_clients_reprs()
self.stat_page_carrier_var = StringVar()
self.contragentCombo = AutocompleteCombobox(self.root,
textvariable=self.stat_page_carrier_var,
default_value=carriers[0])
self.configure_combobox(self.contragentCombo)
self.contragentCombo.set_completion_list(carriers)
self.contragentCombo.config(width=11, height=int(self.h / 40),
font=fonts.statistic_filtres)
self.can.create_window(self.w / 1.91, self.btns_height,
window=self.contragentCombo,
tags=('filter', 'stat_page_carrier_var'))
def placeCarnumCombo(self):
listname = ['гос.номер'] + self.operator.get_auto_reprs()
self.stat_page_carnum_cb = AutocompleteCombobox(self.root,
default_value=listname[
0])
self.stat_page_carnum_cb.set_completion_list(listname)
self.configure_combobox(self.stat_page_carnum_cb)
self.stat_page_carnum_cb.config(width=11, height=20,
font=fonts.statistic_filtres)
self.can.create_window(self.w / 1.53, self.btns_height,
window=self.stat_page_carnum_cb,
tags=('stat_page_carnum_cb', 'filter'))
def place_amount_info(self, weight, amount, tag='amount_weight'):
""" Разместить итоговую информацию (количество взвешиваний (amount), тоннаж (weigh) )"""
if self.operator.current == 'Statistic' and self.blockImgDrawn == False:
self.can.delete(tag)
weight = self.formatWeight(weight)
self.amount_weight = 'ИТОГО: {} ({} взвешиваний)'.format(weight,
amount)
self.can.create_text(self.w / 2, self.h / 1.113,
text=self.amount_weight,
font=self.font, tags=(tag, 'statusel'),
fill=self.textcolor, anchor='s')
def formatWeight(self, weight):
weight = str(weight)
print('**WEIGHT', weight)
if len(weight) < 4:
ed = 'кг'
elif len(weight) >= 4:
weight = int(weight) / 1000
ed = 'тонн'
weight = str(weight) + ' ' + ed
return weight
def placeText(self, text, xpos, ypos, tag='maincanv', color='black',
font='deff', anchor='center'):
if font == 'deff': font = self.font
xpos = int(xpos)
ypos = int(ypos)
self.can.create_text(xpos, ypos, text=text, font=self.font, tag=tag,
fill=color, anchor=anchor)
def placeCalendars(self):
self.startCal = MyDateEntry(self.root, date_pattern='dd/mm/yy')
self.startCal.config(width=7, font=fonts.statistic_calendars)
self.endCal = MyDateEntry(self.root, date_pattern='dd/mm/yy')
self.endCal.config(width=7, font=fonts.statistic_calendars)
# self.startCal['style'] = 'stat.TCombobox'
# self.endCal['style'] = 'stat.TCombobox'
self.startCal['style'] = 'orup.TCombobox'
self.endCal['style'] = 'orup.TCombobox'
self.can.create_window(self.w / 3.86, self.h / 3.85,
window=self.startCal,
tags=('statCal'))
self.can.create_window(self.w / 2.75, self.h / 3.85,
window=self.endCal,
tags=('statCal'))
self.statisticInteractiveWidgets.append(self.startCal)
self.statisticInteractiveWidgets.append(self.endCal)
self.calendarsDrawn = True
def drawing(self):
Terminal.drawing(self)
self.drawWin('maincanv', 'statisticwin')
self.hiden_widgets += self.buttons_creation(tagname='winBtn')
if not self.calendarsDrawn:
self.placeCalendars()
self.get_history()
self.draw_stat_tree()
self.show_widgets(self.statisticInteractiveWidgets)
def get_history(self):
""" Запрашивает истоию заездов у GCore """
trash_cat = self.operator.get_trash_cat_id(
self.stat_page_trash_cat_var.get())
trash_type = self.operator.get_trash_type_id(
self.stat_page_trash_type_var.get())
carrier = self.operator.get_client_id(self.stat_page_carrier_var.get())
auto = self.operator.get_auto_id(self.stat_page_carnum_cb.get())
platform_id = self.operator.get_polygon_platform_id(
self.stat_page_polygon_combobox.get())
pol_object_id = self.operator.get_polygon_object_id(
self.stat_page_pol_object_combobox.get())
client = self.operator.get_client_id(self.stat_page_clients_var.get())
self.operator.ar_qdk.get_history(
time_start=self.startCal.get_date(),
time_end=self.endCal.get_date(),
trash_cat=trash_cat,
trash_type=trash_type,
carrier=carrier, auto_id=auto,
polygon_object_id=pol_object_id,
client=client, platform_id=platform_id
)
def draw_stat_tree(self):
self.can.create_window(self.w / 1.9, self.h / 1.7,
window=self.tree,
tag='tree')
self.tar.sortId(self.tree, '#0', reverse=True)
def openWin(self):
Terminal.openWin(self)
self.root.bind("<Button-1>",
lambda event: self.clear_optionmenu(event))
def page_close_operations(self):
self.hide_widgets(self.statisticInteractiveWidgets)
self.root.unbind("<Button-1>")
self.can.delete('amount_weight', 'statusel')
def initBlockImg(self, name, btnsname, slice='shadow', mode='new',
seconds=[], hide_widgets=[], **kwargs):
Terminal.initBlockImg(self, name, btnsname,
hide_widgets=self.statisticInteractiveWidgets)
class AuthWin(Terminal):
'''Окно авторизации'''
def __init__(self, root, settings, operator, can):
Terminal.__init__(self, root, settings, operator, can)
self.name = 'AuthWin'
self.buttons = settings.authBtns
self.s = settings
self.r = root
self.currentUser = 'Андрей'
self.font = '"Montserrat Regular" 14'
def send_auth_command(self):
""" Отправить команду на авторизацию """
pw = self.auth_page_password_entry.get()
login = self.auth_page_login_var.get()
self.operator.ar_qdk.try_auth_user(username=login, password=pw)
self.currentUser = login
def createPasswordEntry(self):
var = StringVar(self.r)
bullet = '\u2022'
pwEntry = Entry(self.r, border=0,
width=
el_sizes.entrys['authwin.password'][self.screensize][
'width'], show=bullet,
textvariable=var, bg=cs.auth_background_color,
font=self.font, fg='#BABABA',
insertbackground='#BABABA', highlightthickness=0)
pwEntry.bind("<Button-1>", self.on_click)
pwEntry.bind("<BackSpace>", self.on_click)
return pwEntry
def on_click(self, event):
event.widget.delete(0, END)
self.auth_page_password_entry.config(show='\u2022')
def incorrect_login_act(self):
self.auth_page_password_entry.config(show="", highlightthickness=1,
highlightcolor='red')
self.auth_page_password_entry.delete(0, END)
self.auth_page_password_entry.insert(END, 'Неправильный пароль!')
def get_login_type_cb(self):
self.auth_page_login_var = StringVar()
self.usersComboBox = AutocompleteCombobox(self.root,
textvariable=self.auth_page_login_var)
self.usersComboBox['style'] = 'authwin.TCombobox'
self.configure_combobox(self.usersComboBox)
self.usersComboBox.set_completion_list(self.operator.get_users_reprs())
self.usersComboBox.set("")
self.usersComboBox.config(
width=el_sizes.comboboxes['authwin.login'][self.screensize][
'width'],
height=el_sizes.comboboxes['authwin.login'][self.screensize][
'height'],
font=self.font)
self.usersComboBox.bind('<Return>',
lambda event: self.send_auth_command())
return self.usersComboBox
def rebinding(self):
self.usersComboBox.unbind('<Return>')
self.auth_page_password_entry.unbind('<Return>')
self.bindArrows()
def drawing(self):
Terminal.drawing(self)
self.auth_page_password_entry = self.createPasswordEntry()
self.auth_page_password_entry.bind('<Return>', lambda
event: self.send_auth_command())
self.usersChooseMenu = self.get_login_type_cb()
self.can.create_window(self.s.w / 2, self.s.h / 1.61,
window=self.auth_page_password_entry,
tags=('maincanv', 'pw_win'))
self.can.create_window(self.s.w / 2, self.s.h / 1.96,
window=self.usersChooseMenu, tag='maincanv')
self.drawSlices(mode=self.name)
self.buttons_creation(tagname='winBtn')
def openWin(self):
Terminal.openWin(self)
self.drawWin('maincanv', 'start_background', 'login', 'password')
self.can.delete('toolbar')
self.can.delete('clockel')
self.can.itemconfigure('btn', state='hidden')
self.auth_page_password_entry.config(show='\u2022',
highlightthickness=0)
def page_close_operations(self):
self.can.itemconfigure('btn', state='normal')
class MainPage(Terminal):
def __init__(self, root, settings, operator, can):
Terminal.__init__(self, root, settings, operator, can)
self.name = 'MainPage'
self.buttons = settings.gateBtns + settings.manual_gate_control_btn
self.count = 0
self.orupState = False
self.errorShown = False
self.chosenTrashCat = 'deff'
self.tar = CurrentTreeview(self.root, operator, height=18)
self.tar.createTree()
self.tree = self.tar.get_tree()
self.tree.bind("<Double-1>", self.OnDoubleClick)
self.win_widgets.append(self.tree)
self.btn_name = self.settings.mainLogoBtn
self.make_abort_unactive()
def create_abort_round_btn(self):
self.can.create_window(self.settings.abort_round[0][1],
self.settings.abort_round[0][2],
window=self.abort_round_btn,
tag='winBtn')
def make_abort_active(self):
btn = self.abort_round_btn
btn['state'] = 'normal'
def make_abort_unactive(self):
btn = self.abort_round_btn
btn['state'] = 'disabled'
def drawMainTree(self):
self.operator.ar_qdk.get_unfinished_records()
self.can.create_window(self.w / 1.495, self.h / 2.8, window=self.tree,
tag='tree')
self.tar.sortId(self.tree, '#0', reverse=True)
def drawing(self):
Terminal.drawing(self)
self.operator.ar_qdk.get_status()
print('Создаем основное дерево')
self.drawMainTree()
self.drawWin('win', 'road', 'order', 'currentEvents',
'entry_gate_base', 'exit_gate_base')
self.hiden_widgets += self.buttons_creation(tagname='winBtn')
# self.draw_gate_arrows()
def drawRegWin(self):
self.draw_block_win(self, 'regwin')
def destroyBlockImg(self, mode='total'):
Terminal.destroyBlockImg(self, mode)
self.drawMainTree()
def updateTree(self):
self.operator.ar_qdk.get_unfinished_records()
self.tar.sortId(self.tree, '#0', reverse=True)
def OnDoubleClick(self, event):
'''Реакция на дабл-клик по текущему заезду'''
item = self.tree.selection()[0]
self.chosenStr = self.tree.item(item, "values")
self.record_id = self.tree.item(item, "text")
if self.chosenStr[2] == '-':
self.draw_rec_close_win()
else:
self.draw_cancel_tare()
def draw_rec_close_win(self):
btnsname = 'closeRecBtns'
self.initBlockImg(name='ensureCloseRec', btnsname=btnsname,
seconds=('second'),
hide_widgets=self.win_widgets)
self.root.bind('<Return>', lambda event: self.operator.close_record(
self.record_id))
self.root.bind('<Escape>',
lambda event: self.destroyBlockImg(mode="total"))
def draw_cancel_tare(self):
btnsname = 'cancel_tare_btns'
self.initBlockImg(name='cancel_tare', btnsname=btnsname,
seconds=('second'),
hide_widgets=self.win_widgets)
self.root.bind('<Escape>',
lambda event: self.destroyBlockImg(mode="total"))
def page_close_operations(self):
self.can.delete('win', 'statusel')
# self.hide_widgets(self.abort_round_btn)
self.unbindArrows()
def openWin(self):
Terminal.openWin(self)
self.bindArrows()
self.operator.draw_road_anim()
self.draw_gate_arrows()
self.draw_weight()
if not self.operator.main_btns_drawn:
self.create_main_buttons()
self.operator.main_btns_drawn = True
self.create_abort_round_btn()
class ManualGateControl(Terminal):
def __init__(self, root, settings, operator, can):
Terminal.__init__(self, root, settings, operator, can)
self.name = 'ManualGateControl'
self.buttons = self.settings.auto_gate_control_btn + self.settings.manual_open_internal_gate_btn + self.settings.manual_close_internal_gate_btn + self.settings.manual_open_external_gate_btn + self.settings.manual_close_external_gate_btn
self.btn_name = self.settings.mainLogoBtn
self.external_gate_state = 'close'
self.enternal_gate_state = 'close'
def send_gate_comm(self, gate_num, operation):
""" Отправить на AR комманду закрыть шлагбаум """
msg = {}
msg['gate_manual_control'] = {'gate_name': gate_num,
'operation': operation}
response = self.send_ar_sys_comm(msg)
print(response)
def drawing(self):
Terminal.drawing(self)
self.drawWin('maincanv', 'road', 'manual_control_info_bar',
'entry_gate_base', 'exit_gate_base')
self.hiden_widgets += self.buttons_creation(tagname='winBtn')
def openWin(self):
Terminal.openWin(self)
self.operator.draw_road_anim()
self.draw_gate_arrows()
self.draw_weight()
def page_close_operations(self):
self.can.delete('win', 'statusel')
|
PypiClean
|
/py-pure-client-1.38.0.tar.gz/py-pure-client-1.38.0/pypureclient/flasharray/FA_2_3/models/directory_service_response.py
|
import pprint
import re
import six
import typing
from ....properties import Property
if typing.TYPE_CHECKING:
from pypureclient.flasharray.FA_2_3 import models
class DirectoryServiceResponse(object):
"""
Attributes:
swagger_types (dict): The key is attribute name
and the value is attribute type.
attribute_map (dict): The key is attribute name
and the value is json key in definition.
"""
swagger_types = {
'items': 'list[DirectoryService]'
}
attribute_map = {
'items': 'items'
}
required_args = {
}
def __init__(
self,
items=None, # type: List[models.DirectoryService]
):
"""
Keyword args:
items (list[DirectoryService])
"""
if items is not None:
self.items = items
def __setattr__(self, key, value):
if key not in self.attribute_map:
raise KeyError("Invalid key `{}` for `DirectoryServiceResponse`".format(key))
self.__dict__[key] = value
def __getattribute__(self, item):
value = object.__getattribute__(self, item)
if isinstance(value, Property):
raise AttributeError
else:
return value
def __getitem__(self, key):
if key not in self.attribute_map:
raise KeyError("Invalid key `{}` for `DirectoryServiceResponse`".format(key))
return object.__getattribute__(self, key)
def __setitem__(self, key, value):
if key not in self.attribute_map:
raise KeyError("Invalid key `{}` for `DirectoryServiceResponse`".format(key))
object.__setattr__(self, key, value)
def __delitem__(self, key):
if key not in self.attribute_map:
raise KeyError("Invalid key `{}` for `DirectoryServiceResponse`".format(key))
object.__delattr__(self, key)
def keys(self):
return self.attribute_map.keys()
def to_dict(self):
"""Returns the model properties as a dict"""
result = {}
for attr, _ in six.iteritems(self.swagger_types):
if hasattr(self, attr):
value = getattr(self, attr)
if isinstance(value, list):
result[attr] = list(map(
lambda x: x.to_dict() if hasattr(x, "to_dict") else x,
value
))
elif hasattr(value, "to_dict"):
result[attr] = value.to_dict()
elif isinstance(value, dict):
result[attr] = dict(map(
lambda item: (item[0], item[1].to_dict())
if hasattr(item[1], "to_dict") else item,
value.items()
))
else:
result[attr] = value
if issubclass(DirectoryServiceResponse, dict):
for key, value in self.items():
result[key] = value
return result
def to_str(self):
"""Returns the string representation of the model"""
return pprint.pformat(self.to_dict())
def __repr__(self):
"""For `print` and `pprint`"""
return self.to_str()
def __eq__(self, other):
"""Returns true if both objects are equal"""
if not isinstance(other, DirectoryServiceResponse):
return False
return self.__dict__ == other.__dict__
def __ne__(self, other):
"""Returns true if both objects are not equal"""
return not self == other
|
PypiClean
|
/stellar-sdk-mini-8.2.0.post2.tar.gz/stellar-sdk-mini-8.2.0.post2/stellar_sdk/xdr/scp_nomination.py
|
import base64
from typing import List
from xdrlib import Packer, Unpacker
from .hash import Hash
from .value import Value
__all__ = ["SCPNomination"]
class SCPNomination:
"""
XDR Source Code::
struct SCPNomination
{
Hash quorumSetHash; // D
Value votes<>; // X
Value accepted<>; // Y
};
"""
def __init__(
self,
quorum_set_hash: Hash,
votes: List[Value],
accepted: List[Value],
) -> None:
_expect_max_length = 4294967295
if votes and len(votes) > _expect_max_length:
raise ValueError(
f"The maximum length of `votes` should be {_expect_max_length}, but got {len(votes)}."
)
_expect_max_length = 4294967295
if accepted and len(accepted) > _expect_max_length:
raise ValueError(
f"The maximum length of `accepted` should be {_expect_max_length}, but got {len(accepted)}."
)
self.quorum_set_hash = quorum_set_hash
self.votes = votes
self.accepted = accepted
def pack(self, packer: Packer) -> None:
self.quorum_set_hash.pack(packer)
packer.pack_uint(len(self.votes))
for votes_item in self.votes:
votes_item.pack(packer)
packer.pack_uint(len(self.accepted))
for accepted_item in self.accepted:
accepted_item.pack(packer)
@classmethod
def unpack(cls, unpacker: Unpacker) -> "SCPNomination":
quorum_set_hash = Hash.unpack(unpacker)
length = unpacker.unpack_uint()
votes = []
for _ in range(length):
votes.append(Value.unpack(unpacker))
length = unpacker.unpack_uint()
accepted = []
for _ in range(length):
accepted.append(Value.unpack(unpacker))
return cls(
quorum_set_hash=quorum_set_hash,
votes=votes,
accepted=accepted,
)
def to_xdr_bytes(self) -> bytes:
packer = Packer()
self.pack(packer)
return packer.get_buffer()
@classmethod
def from_xdr_bytes(cls, xdr: bytes) -> "SCPNomination":
unpacker = Unpacker(xdr)
return cls.unpack(unpacker)
def to_xdr(self) -> str:
xdr_bytes = self.to_xdr_bytes()
return base64.b64encode(xdr_bytes).decode()
@classmethod
def from_xdr(cls, xdr: str) -> "SCPNomination":
xdr_bytes = base64.b64decode(xdr.encode())
return cls.from_xdr_bytes(xdr_bytes)
def __eq__(self, other: object):
if not isinstance(other, self.__class__):
return NotImplemented
return (
self.quorum_set_hash == other.quorum_set_hash
and self.votes == other.votes
and self.accepted == other.accepted
)
def __str__(self):
out = [
f"quorum_set_hash={self.quorum_set_hash}",
f"votes={self.votes}",
f"accepted={self.accepted}",
]
return f"<SCPNomination [{', '.join(out)}]>"
|
PypiClean
|
/mayarepacker-1.0.2.tar.gz/mayarepacker-1.0.2/README.md
|
# mayarepacker
[](https://pypi.org/project/mayarepacker)
[](https://pepy.tech/project/mayarepacker)
[](https://pypi.org/project/mayarepacker)
[](https://pypi.org/project/mayarepacker)
[](https://codecov.io/gh/InTack2/mayarepacker)
[](https://pypi.org/-project/flake8/)
Automatic package reloader for Maya.
[README Japanese version](https://github.com/InTack2/mayarepacker/blob/main//README_jp.md)
## Features
This repository is a feature that makes it easy to hot-load their tools when they create them in Maya.
When monitoring is started, the specified Package will be reloaded when the pythonFile under the specified folder is updated.
[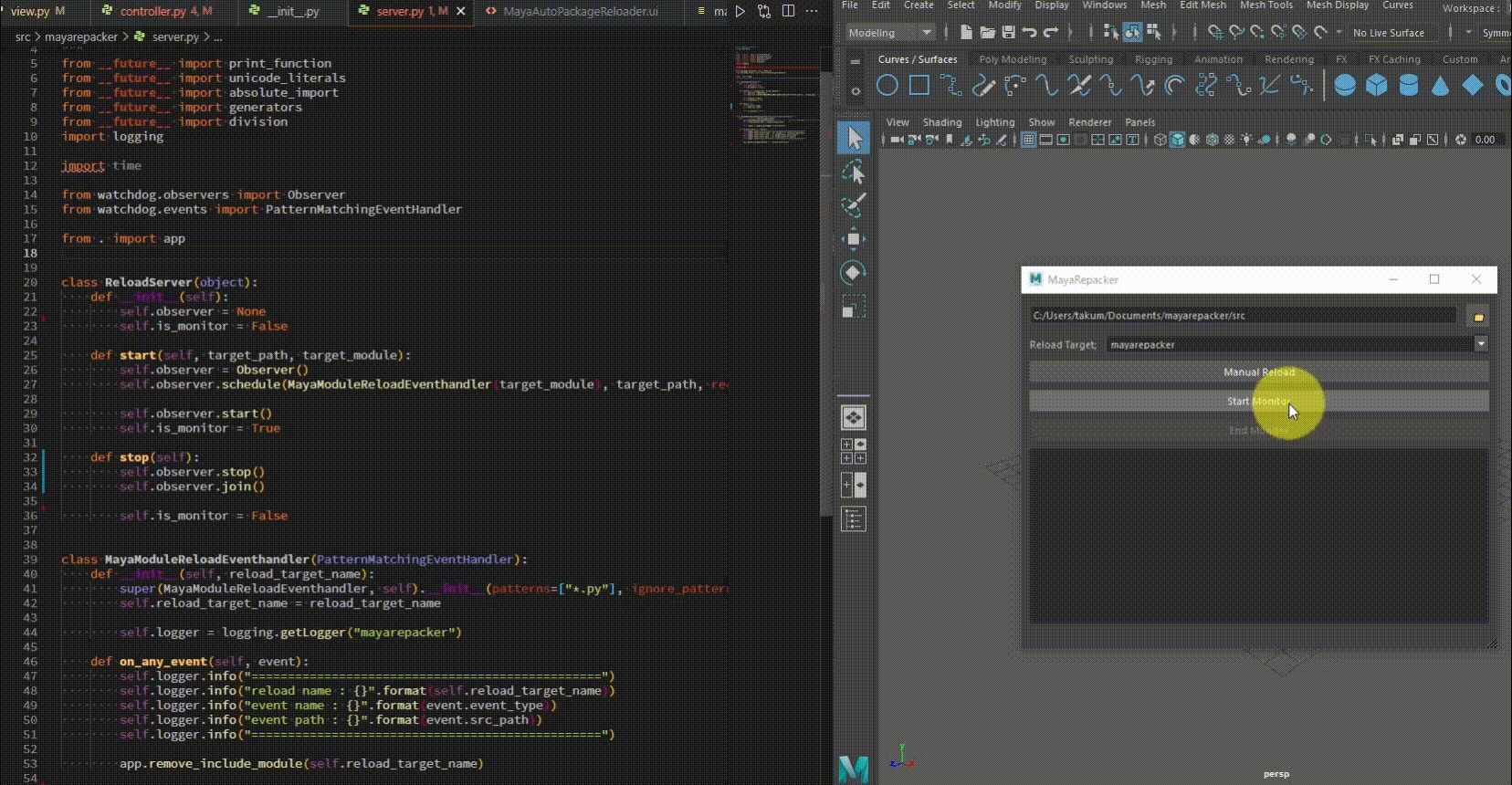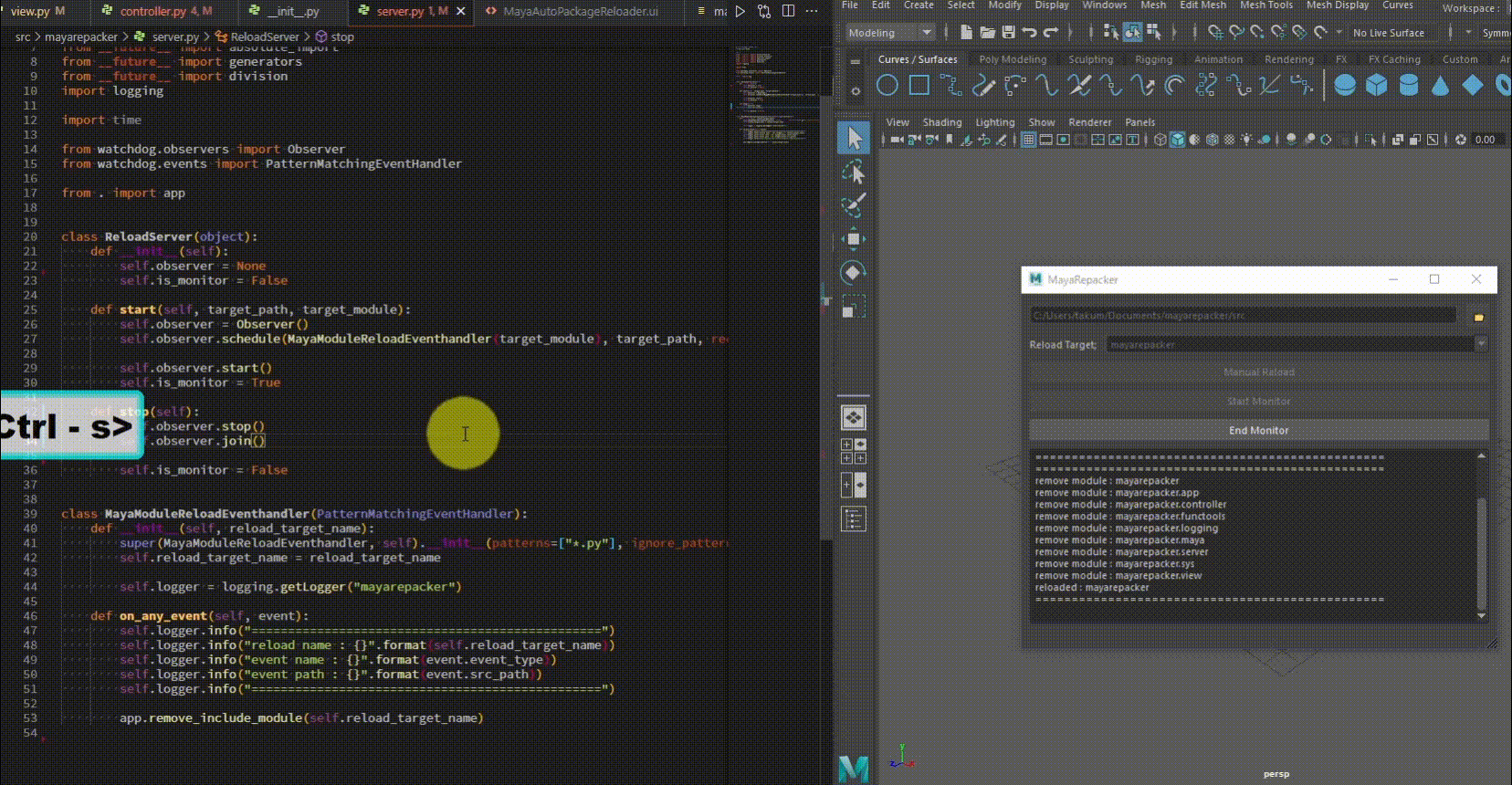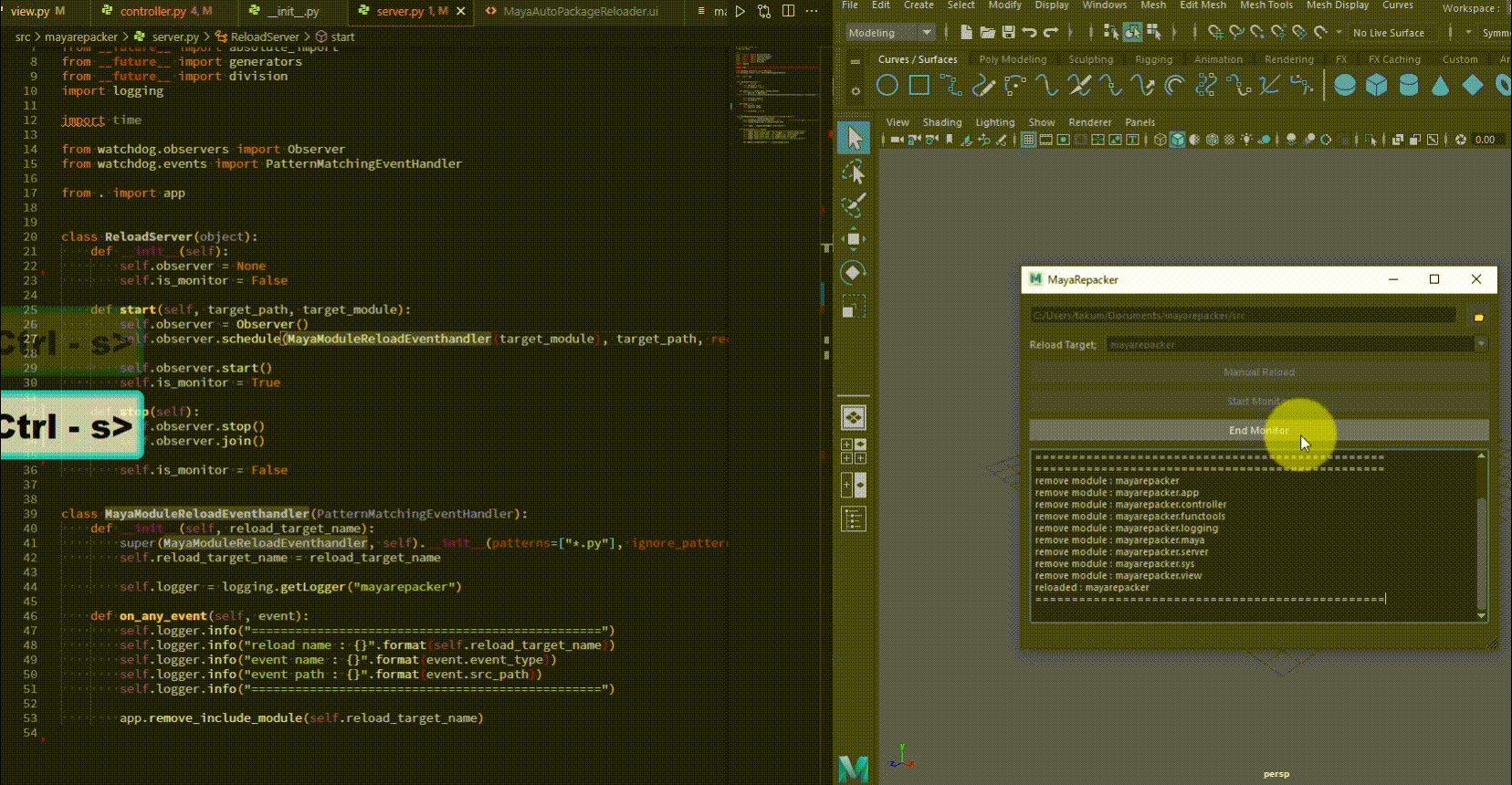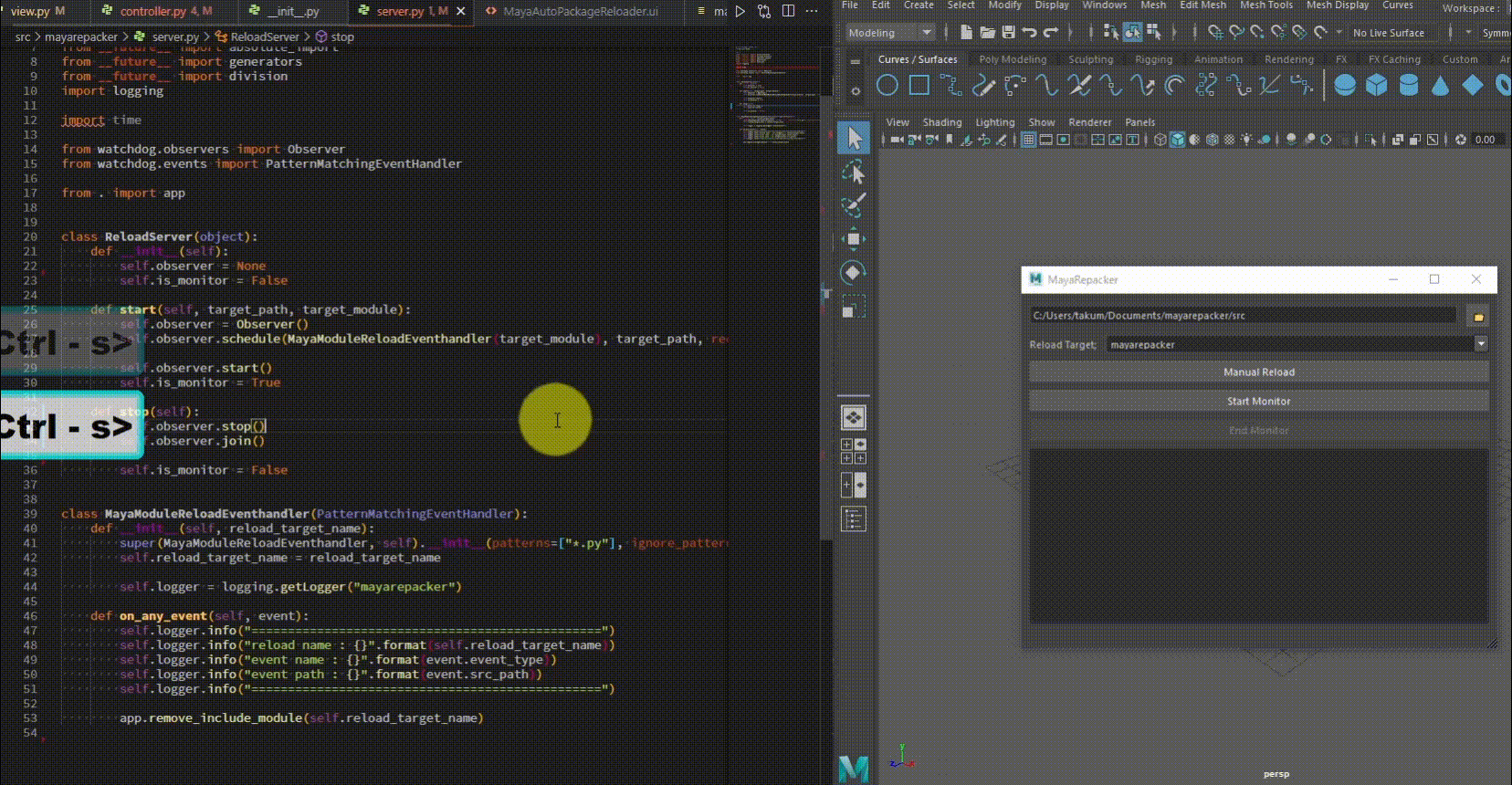](https://gyazo.com/b7d1c54e6e51d4092a16d5c8b9e36637)
It is also possible to manually reload at any time.
[](https://gyazo.com/ed5358930ec629c33af9e9cfce2c0d9e)
## How to install
Install it with pip.
Run `pip install mayarepacker`.
You can start it by running the following in the Maya console.
Register it on the shelf and use it as needed.
``` python
import mayarepacker
mayarepacker.main()
```
## Usage
There are two modes of mayarepacker
- Automatic reload
- Specify a folder and mayarepacker will reload the specified package when there is an update to the Python files under that folder.
- Manual reload
- Reloads the specified package.
### Manual Reload
- Specify the reload target
- Click the reload button.
### Auto Reload
- Specify the folder to monitor
- Select the target to reload when there is an update
- Start monitoring
- Confirm that the file is automatically updated when it is updated.
- If you want to stop the monitoring, you can click the Stop button or close the tool.
## Support
〇・・confirmed operation.
?・・Not tested.
| Maya Verison | Windows | Mac |
| ------------ | ------- | --- |
| 2018 | 〇 | ? |
| 2019 | ? | ? |
| 2020 | 〇 | 〇 |
| 2022 | 〇 | ? |
## release
- 1.0.2
- Fixed an issue that prevented Maya2018 from starting properly due to QStringModel.
- 1.0.0
- Initial release.
|
PypiClean
|
/djangocms-slick-slider-1.0.7.tar.gz/djangocms-slick-slider-1.0.7/djangocms_slick_slider/models.py
|
from django.db import models
from django.utils.translation import ugettext_lazy as _
from cms.models.pluginmodel import CMSPlugin
from filer.fields.image import FilerImageField
from jsonfield import JSONField
class SlickSlider(CMSPlugin):
"""
Main Plugin Model for the slider.
"""
class Meta:
verbose_name = _('slick slider')
verbose_name_plural = _('slick sliders')
title = models.CharField(
verbose_name=_('slider title'),
max_length=255,
null=True,
blank=True,
)
settings = JSONField(
verbose_name=_('slick settings'),
blank=True,
null=True,
help_text=_('Check <a href="http://kenwheeler.github.io/slick/" '
'target="_blank">'
'Slick Documentation</a> for possible settings '
'<br>'
'Use JSON format and check the errors in the editor<br>'
'You can also use online JSON validators'))
arrow_color = models.CharField(
verbose_name=_('arrow color'),
max_length=255,
default="#666",
help_text=_('Define the color of slider arrows here. All CSS '
'color values work (e.g. #efefef).'),
)
full_width = models.BooleanField(
verbose_name=_('full width'),
default=False,
)
slider_max_height = models.IntegerField(
verbose_name=_('max. height'),
blank=True,
null=True,
help_text=_('Define max height of the slider.'),
)
image_max_width = models.IntegerField(
verbose_name=_('max. width'),
blank=True,
null=True,
help_text=_('Define max height of the slider.'),
)
lazy_load_images = models.BooleanField(
verbose_name=_('lazy load images'),
help_text=_('Set to true if images should load lazily.'),
default=True,
)
def copy_relations(self, oldinstance):
"""
Take an instance and copy the images of that instance to this
instance.
"""
for image in oldinstance.images.all():
image.pk = None
image.slider = self
image.save()
def __str__(self):
"""
String representation of SlickSlider class.
"""
return "{title}".format(title=self.title)
class SlickSliderImage(models.Model):
"""
Image model für SlickSlider class.
"""
class Meta:
verbose_name = _('slider image')
verbose_name_plural = _('slider images')
ordering = ['position']
slider = models.ForeignKey(
SlickSlider,
related_name="images",
on_delete=models.CASCADE,
)
image = FilerImageField(
verbose_name=_('slider Image'),
related_name='slider_images_filer',
on_delete=models.CASCADE,
)
link = models.URLField(
verbose_name=_('image link'),
null=True,
blank=True,
)
link_target = models.BooleanField(
verbose_name=_('image link target'),
help_text=_('open link in new window'),
default=True,
)
caption_text = models.TextField(
_('caption text'),
null=True,
blank=True,
)
position = models.IntegerField(
_('position'),
default=100,
)
def __str__(self):
"""
String representation of SlickSliderImage class.
"""
return "{filename}".format(filename=self.image.original_filename)
def full_width_dimensions(self):
"""
Return the thumbnail dimensions based on Slider full width settings.
"""
if self.slider.full_width:
return "%sx%s" % (
self.slider.image_max_width,
self.slider.slider_max_height,
)
return "1200x500"
|
PypiClean
|
/trixie-0.1.2.tar.gz/trixie-0.1.2/homeassistant/components/switch/android_ip_webcam.py
|
import asyncio
from homeassistant.components.switch import SwitchDevice
from homeassistant.components.android_ip_webcam import (
KEY_MAP, ICON_MAP, DATA_IP_WEBCAM, AndroidIPCamEntity, CONF_HOST,
CONF_NAME, CONF_SWITCHES)
DEPENDENCIES = ['android_ip_webcam']
@asyncio.coroutine
def async_setup_platform(hass, config, async_add_devices, discovery_info=None):
"""Set up the IP Webcam switch platform."""
if discovery_info is None:
return
host = discovery_info[CONF_HOST]
name = discovery_info[CONF_NAME]
switches = discovery_info[CONF_SWITCHES]
ipcam = hass.data[DATA_IP_WEBCAM][host]
all_switches = []
for setting in switches:
all_switches.append(IPWebcamSettingsSwitch(name, host, ipcam, setting))
async_add_devices(all_switches, True)
class IPWebcamSettingsSwitch(AndroidIPCamEntity, SwitchDevice):
"""An abstract class for an IP Webcam setting."""
def __init__(self, name, host, ipcam, setting):
"""Initialize the settings switch."""
super().__init__(host, ipcam)
self._setting = setting
self._mapped_name = KEY_MAP.get(self._setting, self._setting)
self._name = '{} {}'.format(name, self._mapped_name)
self._state = False
@property
def name(self):
"""Return the name of the node."""
return self._name
@asyncio.coroutine
def async_update(self):
"""Get the updated status of the switch."""
self._state = bool(self._ipcam.current_settings.get(self._setting))
@property
def is_on(self):
"""Return the boolean response if the node is on."""
return self._state
@asyncio.coroutine
def async_turn_on(self, **kwargs):
"""Turn device on."""
if self._setting == 'torch':
yield from self._ipcam.torch(activate=True)
elif self._setting == 'focus':
yield from self._ipcam.focus(activate=True)
elif self._setting == 'video_recording':
yield from self._ipcam.record(record=True)
else:
yield from self._ipcam.change_setting(self._setting, True)
self._state = True
self.async_schedule_update_ha_state()
@asyncio.coroutine
def async_turn_off(self, **kwargs):
"""Turn device off."""
if self._setting == 'torch':
yield from self._ipcam.torch(activate=False)
elif self._setting == 'focus':
yield from self._ipcam.focus(activate=False)
elif self._setting == 'video_recording':
yield from self._ipcam.record(record=False)
else:
yield from self._ipcam.change_setting(self._setting, False)
self._state = False
self.async_schedule_update_ha_state()
@property
def icon(self):
"""Return the icon for the switch."""
return ICON_MAP.get(self._setting, 'mdi:flash')
|
PypiClean
|
/text_hammer-0.1.5-py3-none-any.whl/text_hammer/__init__.py
|
from text_hammer import utils
from tqdm._tqdm_notebook import tqdm_notebook
tqdm_notebook.pandas()
def get_wordcounts(x):
return utils._get_wordcounts(x)
def get_charcounts(x):
return utils._get_charcounts(x)
def get_avg_wordlength(x):
return utils._get_avg_wordlength(x)
def get_stopwords_counts(x):
return utils._get_stopwords_counts(x)
def get_hashtag_counts(x):
return utils._get_hashtag_counts(x)
def get_mentions_counts(x):
return utils._get_mentions_counts(x)
def get_digit_counts(x):
return utils._get_digit_counts(x)
def get_uppercase_counts(x):
return utils._get_uppercase_counts(x)
def cont_exp(x):
return utils._cont_exp(x)
def get_emails(x):
return utils._get_emails(x)
def remove_emails(x):
return utils._remove_emails(x)
def get_urls():
return utils._get_urls(x)
def remove_urls(x):
return utils._remove_urls(x)
def remove_rt(x):
return utils._remove_rt(x)
def remove_special_chars(x):
return utils._remove_special_chars(x)
def remove_html_tags(x):
return utils._remove_html_tags(x)
def remove_accented_chars(x):
return utils._remove_accented_chars(x)
def remove_stopwords(x):
return utils._remove_stopwords(x)
def make_base(x):
return utils._make_base(x)
def get_value_counts(df, col):
return utils._get_value_counts(df, col)
def get_word_freqs(df, col):
return utils._get_value_counts(df, col)
def remove_common_words(x, freq, n=20):
return utils._remove_common_words(x, freq, n)
def remove_rarewords(x, freq, n=20):
return utils._remove_rarewords(x, freq, n)
def spelling_correction(x):
return utils._spelling_correction(x)
def remove_dups_char(x):
return utils._remove_dups_char(x)
def get_basic_features(df):
return utils._get_basic_features(df)
def get_ngram(df, col, ngram_range):
return utils._get_ngram(df, col, ngram_range)
def text_preprocessing(dataframe,col_name, spellchecker = False):
column = col_name
dataframe[column] = dataframe[column].progress_apply(lambda x:str(x).lower())
dataframe[column] = dataframe[column].progress_apply(lambda x: cont_exp(x)) #you're -> you are; i'm -> i am
dataframe[column] = dataframe[column].progress_apply(lambda x: remove_emails(x))
dataframe[column] = dataframe[column].progress_apply(lambda x: remove_html_tags(x))
dataframe[column] = dataframe[column].progress_apply(lambda x: remove_stopwords(x))
if spellchecker:
dataframe[column] = dataframe[column].progress_apply(lambda x:spelling_correction(x))
dataframe[column] = dataframe[column].progress_apply(lambda x: remove_special_chars(x))
dataframe[column] = dataframe[column].progress_apply(lambda x: remove_accented_chars(x))
dataframe[column] = dataframe[column].progress_apply(lambda x: make_base(x)) #ran -> run,
return(dataframe)
|
PypiClean
|
/linear_operator-0.5.2-py3-none-any.whl/linear_operator/operators/low_rank_root_linear_operator.py
|
from typing import Union
import torch
from jaxtyping import Float
from torch import Tensor
from ._linear_operator import LinearOperator
from .root_linear_operator import RootLinearOperator
class LowRankRootLinearOperator(RootLinearOperator):
"""
Very thin wrapper around RootLinearOperator that denotes that the tensor specifically represents a low rank
decomposition of a full rank matrix.
The rationale for this class existing is that we can create LowRankAddedDiagLinearOperator without having to
write custom _getitem, _get_indices, etc, leading to much better code reuse.
"""
def add_diagonal(
self: Float[LinearOperator, "*batch N N"],
diag: Union[Float[torch.Tensor, "... N"], Float[torch.Tensor, "... 1"], Float[torch.Tensor, ""]],
) -> Float[LinearOperator, "*batch N N"]:
from .diag_linear_operator import ConstantDiagLinearOperator, DiagLinearOperator
from .low_rank_root_added_diag_linear_operator import LowRankRootAddedDiagLinearOperator
if not self.is_square:
raise RuntimeError("add_diag only defined for square matrices")
diag_shape = diag.shape
if len(diag_shape) == 0:
# interpret scalar tensor as constant diag
diag_tensor = ConstantDiagLinearOperator(diag.unsqueeze(-1), diag_shape=self.shape[-1])
elif diag_shape[-1] == 1:
# interpret single-trailing element as constant diag
diag_tensor = ConstantDiagLinearOperator(diag, diag_shape=self.shape[-1])
else:
try:
expanded_diag = diag.expand(self.shape[:-1])
except RuntimeError:
raise RuntimeError(
"add_diag for LinearOperator of size {} received invalid diagonal of size {}.".format(
self.shape, diag_shape
)
)
diag_tensor = DiagLinearOperator(expanded_diag)
return LowRankRootAddedDiagLinearOperator(self, diag_tensor)
def __add__(
self: Float[LinearOperator, "... #M #N"],
other: Union[Float[Tensor, "... #M #N"], Float[LinearOperator, "... #M #N"], float],
) -> Union[Float[LinearOperator, "... M N"], Float[Tensor, "... M N"]]:
from .diag_linear_operator import DiagLinearOperator
from .low_rank_root_added_diag_linear_operator import LowRankRootAddedDiagLinearOperator
if isinstance(other, DiagLinearOperator):
return LowRankRootAddedDiagLinearOperator(self, other)
else:
return super().__add__(other)
|
PypiClean
|
/django-xperms-0.4.19.tar.gz/django-xperms-0.4.19/README.rst
|
THIS IT A FORK OF https://github.com/formulka/django-xperms
changed to work with django >= 4
=============================
django-xperms
=============================
.. image:: https://badge.fury.io/py/django-xperms.svg
:target: https://badge.fury.io/py/django-xperms
.. image:: https://travis-ci.org/Formulka/django-xperms.svg?branch=master
:target: https://travis-ci.org/Formulka/django-xperms
.. image:: https://codecov.io/gh/Formulka/django-xperms/branch/master/graph/badge.svg
:target: https://codecov.io/gh/Formulka/django-xperms
The flexible permissions library uses a custom permission model, that when installed patches itself into the standard django authentication library.
Documentation
-------------
The full documentation is at https://django-xperms.readthedocs.io.
Quickstart
----------
Install django-xperms::
pip install django-xperms
Add it to your `INSTALLED_APPS`:
.. code-block:: python
INSTALLED_APPS = (
...
'xperms.apps.XpermsConfig',
...
)
Out of the box you have access to several new permission types:
- **generic**: for general purpose project wide permissions
- **model**: for per model permissions (similar to django default permissions)
- **instance**: for per instance permissions, similar to model permissions but specific per instance
- **field**: for per model field permissions, similar to model permissions but specific per model field, work in progress
You can also create your own permission model subclassing the abstract base permission class:
.. code-block:: python
xperms.models.BasePerm
and setting the ``PERM_MODEL`` variable in your project settings with the path to your custom model. E.g.
.. code-block:: python
...
PERM_MODEL='xperms.models.Perm'
...
You can find an example of custom permission model at https://github.com/formulka/django-xperms-iscore
Usage
-----
A superuser has for all intents and purposes permission to do everything. For regular users you can assign permissions directly or via a user group.
**Creating a new permission**:
You can create a new permission directly via its model or via a specially formated string:
.. code-block:: python
from xperms import enums
from xperms.models import Perm
Perm.objects.create(
type=enums.PERM_TYPE_GENERIC,
codename='export',
)
Perm.objects.create_from_str('generic.export')
**Assigning a permission**:
You can assign existing permission via the custom ``perms`` manager available for both User (including custom ones) and Group models. You can add single permission or multiple both directly via its instance or using the formated string:
.. code-block:: python
from django.auth.models import User, Group
from xperms.models import Perm
perm_export = Perm.objects.create(
type=enums.PERM_TYPE_GENERIC,
codename='export',
)
perm_import = Perm.objects.create(
type=enums.PERM_TYPE_GENERIC,
codename='import',
)
user = User.objects.get(pk=1)
user.perms.add_perm(perm_export)
user.perms.add_perm(perms=[perm_export, perm_import])
group = Group.objects.get(pk=1)
group.perms.add_perm(perms=['generic.export', 'generic.import'])
By default if said permission does not exist, it will raise an exception. You can override this behavior by setting ``PERM_AUTO_CREATE`` variable in your project settings to ``True``, assigning a permission will then create it as well if it does not exist.
**Retrieving permission instance**:
You can get a permission instance directly from the model or via the string representation.
.. code-block:: python
perm = Perm.objects.get(type=enums.PERM_TYPE_GENERIC, codename='export')
perm = Perm.objects.get_from_str('generic.export')
**Checking permission**:
You can check whether the user or group has a required permission via ``has_perm`` method of the ``perms`` manager again using both the permission instance or the string representation.
.. code-block:: python
...
perm = Perm.objects.create(
type=enums.PERM_TYPE_GENERIC,
codename='export',
)
assert user.perms.has_perm(perm)
assert user.perms.has_perm('generic.export')
Built in perm types
-------------------
**generic**
- generic permission useful for project wide permissions
- type is defined as ``xperms.enums.PERM_TYPE_GENERIC``, it is the default permission type
- it requires ``type`` and ``codename`` fields (type being default only the codename is actually required)
- string representation is ``'generic.<codename>'``
.. code-block:: python
...
# equivalent results:
Perm.objects.create(
codename='export',
)
Perm.objects.create_from_str('generic.export')
**model**
- model level permission analogous to the builtin django permissions
- type is defined as ``xperms.enums.PERM_TYPE_MODEL``
- it requires ``type``, ``content_type`` and ``codename`` fields
- django admin is using codenames ``add``, ``change`` and ``delete`` for its inner workings
- string representation is ``'model.<app_label>.<module_name>.<codename>'``
.. code-block:: python
from xperms import enums
from fprems.utils import get_content_type
...
# equivalent results:
Perm.objects.create(
type=enums.PERM_TYPE_MODEL,
content_type=get_content_type(Article),
codename='add',
)
Perm.objects.create_from_str('model.articles.Article.add')
**object**
- model level permission specific per object
- type is defined as ``xperms.enums.PERM_TYPE_OBJECT``
- it requires ``type``, ``content_type``, ``object_id`` and ``codename`` fields
- django admin is using codenames ``add``, ``change`` and ``delete`` for its inner workings
- string representation is ``'object.<app_label>.<module_name>.<codename>'``
.. code-block:: python
from xperms import enums
from fprems.utils import get_content_type
...
article = Article.objects.get(pk=1)
# equivalent results:
Perm.objects.create(
type=enums.PERM_TYPE_OBJECT,
content_type=get_content_type(Article),
object_id=article.pk,
codename='add',
)
Perm.objects.create_from_str('object.articles.Article.add', obj_id=article.pk)
# creating multiple permissions for a single object at once is supported
Perm.objects.create_from_str(perms=[
'object.articles.Article.add',
'object.articles.Article.change',
'object.articles.Article.delete',
], obj_id=article.pk)
**field**
- model level permission specific per model field
- type is defined as ``xperms.enums.PERM_TYPE_FIELD``
- it requires ``type``, ``content_type``, ``field_name`` and ``codename`` fields
- string representation is ``'field.<app_label>.<module_name>.<field_name>.<codename>'``
- TODO: this permission type is not fully implemented yet
.. code-block:: python
from xperms import enums
from fprems.utils import get_content_type
...
article = Article.objects.get(pk=1)
# equivalent results:
Perm.objects.create(
type=enums.PERM_TYPE_FIELD,
content_type=get_content_type(Article),
field_name='name',
codename='add',
)
Perm.objects.create_from_str('field.articles.Article.name.add')
Admin
-----
Flexible permisssions support django admin interface, to enable them you need to first update the list of authentication backends in your project settings:
.. code-block:: python
AUTHENTICATION_BACKENDS = [
'django.contrib.auth.backends.ModelBackend',
'xperms.backends.PermBackend',
]
and then simply subclass the ``xperms.admin.PermModelAdmin`` instead of the regular ``admin.ModelAdmin``:
.. code-block:: python
from django.contrib import admin
from xperms.admin import PermModelAdmin
from articles.models import Article
@admin.register(Article)
class ArticleAdmin(PermModelAdmin):
pass
To enable per-instance permission support, set ``perms_per_instance`` property of the admin class to ``True``.
.. code-block:: python
...
@admin.register(Article)
class ArticleAdmin(PermModelAdmin):
perms_per_instance = True
User still needs model level permission for each model it should be able to access via admin site.
If the ``perms_per_instance`` option is set to ``True``, author of a new instance will automatically receive the permission to update and delete said instance.
You can override this behavior by setting ``perms_per_instance_author_change`` and ``perms_per_instance_author_delete`` admin properties respectively to ``False``.
Running Tests
-------------
Does the code actually work?
::
source <YOURVIRTUALENV>/bin/activate
(myenv) $ pip install tox
(myenv) $ tox
Credits
-------
Tools used in rendering this package:
* Cookiecutter_
* `cookiecutter-djangopackage`_
.. _Cookiecutter: https://github.com/audreyr/cookiecutter
.. _`cookiecutter-djangopackage`: https://github.com/pydanny/cookiecutter-djangopackage
|
PypiClean
|
/m4b-merge-0.5.2.tar.gz/m4b-merge-0.5.2/README.md
|
<h1 align="center">m4b-merge</h1>
<div align="center">
[]()
[](https://github.com/djdembeck/m4b-merge/issues)
[](https://github.com/djdembeck/m4b-merge/pulls)
[](https://github.com/djdembeck/m4b-merge/blob/develop/LICENSE)
[](https://pypi.org/project/m4b-merge/)

[](https://github.com/djdembeck/m4b-merge/actions/workflows/build.yml)
[](https://www.codefactor.io/repository/github/djdembeck/m4b-merge)
[](https://pypi.org/project/m4b-merge/)
</div>
---
<p align="center"> A CLI tool which outputs consistently sorted, tagged, single m4b files regardless of the input.
<br>
</p>
## 📝 Table of Contents
- [About](#about)
- [Getting Started](#getting_started)
- [Usage](#usage)
- [Built Using](#built_using)
- [Contributing](../CONTRIBUTING.md)
- [Authors](#authors)
- [Acknowledgments](#acknowledgement)
## 🧐 About <a name = "about"></a>
m4b-merge was originally part of [Bragi Books](https://github.com/djdembeck/bragibooks), but was split apart to allow savvy users to automate its usage in more advanced ways. Some of the things m4b-merge offers are:
- Accepts single and multiple mp3, m4a and m4b files.
- mp3s are converted to m4b. m4a/m4b files are edited/merged without conversion.
- Matches existing bitrate and samplerate for target file conversions.
- Final files moved to `/output/Author/Book/Book: Subtitle.m4b` format.
- Moves finished files into `done` folder in `input` directory.
Metadata provided by [audnexus](https://github.com/laxamentumtech/audnexus):
- Title, authors, narrators, description, series, genres, release year - written as tags.
- Chapter times/titles (only when input is m4b or a single mp3) - written as tags and `chapters.txt`.
- High resolution (2000x2000 or greater) cover art - embedded into output file.
## 🏁 Getting Started <a name = "getting_started"></a>
### Prerequisites
You can either install this project via `pip` directly or run it prepackaged in Docker:
- If installing directly on your system, you'll need to install m4b-tool and it's dependants from [the project's readme](https://github.com/sandreas/m4b-tool#installation)
- If using Docker, all prerequisites are included in the image.
### Installing
#### For a `pip` installation
Simply run
```
pip install m4b-merge
```
#### For a Docker installation
You'll need to specify input/output volumes in the run command for easy use later:
```
docker run --name=merge -v /path/to/input:/input -v /path/to/output:/output ghcr.io/djdembeck/m4b-merge:main
```
You may also specify the user and group to run as with env variables:
```
-e UID=99 -e GID=100
```
## 🔧 Running the tests <a name = "tests"></a>
- Run `pip install pytest`
- To run all tests, run `pytest` from inside this project directory.
- To run a single test, run `pytest tests/test_NAME.py`
## 🎈 Usage <a name="usage"></a>
### Workflow
The process is simple
1. Pass the file as input via `-i FILE.ext` or folder `-i DIR/`
2. Enter the ASIN (found on audible.com) when prompted.
3. Depending on necessary conversions, the process will take between 5 seconds and 5-10 minutes.
### CLI usage
```
usage: m4b-merge [-h] [--api_url API_URL] [--completed_directory COMPLETED_DIRECTORY] -i INPUTS [INPUTS ...] [--log_level LOG_LEVEL]
[--num_cpus NUM_CPUS] [-o OUTPUT]
m4bmerge cli
optional arguments:
-h, --help show this help message and exit
--api_url API_URL Audnexus mirror to use
--completed_directory COMPLETED_DIRECTORY
Directory path to move original input files to
-i INPUTS [INPUTS ...], --inputs INPUTS [INPUTS ...]
Input paths to process
--log_level LOG_LEVEL
Set logging level
--num_cpus NUM_CPUS Number of CPUs to use
-o OUTPUT, --output OUTPUT
Output directory
-p PATH_FORMAT, --path_format PATH_FORMAT
Structure of output path/naming.Supported terms: author, narrator, series_name, series_position, subtitle, title, year
```
#### When installed via `pip`, you can run inputs like so
```
m4b-merge -i /path/to/file.mp3
```
Or for multiple inputs
```
m4b-merge -i /path/to/file.mp3 /dir/ /path/to/other/file
```
#### On Docker, you can run inputs like so
```
docker run -it merge m4b-merge -i /input/file.mp3
```
For a folder of multiple audio files, simply pass the folder itself as an input, such as `-i /input/dir`
## ⛏️ Built Using <a name = "built_using"></a>
- [audnexus](https://github.com/laxamentumtech/audnexus) - API backend for metadata
- [m4b-tool](https://github.com/sandreas/m4b-tool) - File merging and tagging
## ✍️ Authors <a name = "authors"></a>
- [@djdembeck](https://github.com/djdembeck) - Idea & Initial work
## 🎉 Acknowledgements <a name = "acknowledgement"></a>
- [sandreas](https://github.com/sandreas) for creating and maintaining [m4b-tool](https://github.com/sandreas/m4b-tool)
|
PypiClean
|
/natcap.opal-1.1.0.tar.gz/natcap.opal-1.1.0/src/natcap/opal/utils.py
|
import logging
import os
import json
import sys
import codecs
from types import StringType
import time
import platform
import hashlib
import locale
import threading
import natcap.opal
import natcap.invest
from natcap.invest.iui import executor as invest_executor
import shapely
import shapely.speedups
import shapely.wkb
import shapely.prepared
import shapely.geometry
import shapely.geos
from osgeo import ogr
LOGGER = logging.getLogger('natcap.opal.offsets')
# create a logging filter
class TimedLogFilter(logging.Filter):
# only print a single log message if the time passed since last log message
# >= the user-defined interval
def __init__(self, interval):
logging.Filter.__init__(self)
self.interval = interval
self._last_record_time = None
def filter(self, record):
current_time = time.time()
if self._last_record_time is None:
# if we've never printed a message since starting the filter, print
# the message.
self._last_record_time = current_time
return True
else:
# Only log a message if more than <interval> seconds have passed
# since the last record was logged.
if current_time - self._last_record_time >= 5.0:
self._last_record_time = current_time
return True
return False
def build_shapely_polygon(ogr_feature, prep=False, fix=False):
geometry = ogr_feature.GetGeometryRef()
try:
polygon = shapely.wkb.loads(geometry.ExportToWkb())
except shapely.geos.ReadingError:
LOGGER.debug('Attempting to close geometry rings')
# If the geometry does not form a closed circle, try to connect the
# rings with the OGR function.
geometry.CloseRings()
polygon = shapely.wkb.loads(geometry.ExportToWkb())
LOGGER.debug('Geometry fixed')
if fix:
polygon = polygon.buffer(0)
if prep:
polygon = shapely.prepared.prep(polygon)
return polygon
def assert_files_exist(files):
"""Assert that all input files exist.
files - a list of URIs to files on disk.
This function raises IOError when a file is not found."""
for file_uri in files:
if not os.path.exists(file_uri):
raise IOError('File not found: %s' % file_uri)
def _log_model(model_name, model_args, session_id=None):
"""Log information about a model run to a remote server.
Parameters:
model_name (string): a python string of the package version.
model_args (dict): the traditional InVEST argument dictionary.
Returns:
None
"""
logger = logging.getLogger('natcap.opal.utils._log_model')
string = model_name[:] # make a copy
if 'palisades' in globals().keys() or 'palisades' in sys.modules:
string += '.gui'
else:
string += '.cli'
# if we're in a frozen environment, fetch the build information about the
# distribution.
if natcap.opal.is_frozen():
# read build information from the local configuration file.
# distribution_name
# distribution_build_id
#
# Build a full model name and version string out of this info
dist_data_file = os.path.join(natcap.opal.get_frozen_dir(),
'dist_version.json')
dist_data = json.load(open(dist_data_file))
model_name = "%s.%s" % (dist_data['dist_name'], string)
model_version = dist_data['build_id']
else:
# we're not in a built distribution, so we someone must be running this
# from the command line. In this case, we're obviously not in a
# distribution, but we may be in the permitting repo, not just as a
# standalone natcap.opal repo.
model_name = string
model_version = natcap.opal.__version__
def _node_hash():
"""Returns a hash for the current computational node."""
data = {
'os': platform.platform(),
'hostname': platform.node(),
'userdir': os.path.expanduser('~')
}
md5 = hashlib.md5()
# a json dump will handle non-ascii encodings
md5.update(json.dumps(data))
return md5.hexdigest()
try:
bounding_box_intersection, bounding_box_union = (
invest_executor._calculate_args_bounding_box(model_args))
payload = {
'model_name': model_name,
'invest_release': model_version,
'node_hash': _node_hash(),
'system_full_platform_string': platform.platform(),
'system_preferred_encoding': locale.getdefaultlocale()[1],
'system_default_language': locale.getdefaultlocale()[0],
'bounding_box_intersection': str(bounding_box_intersection),
'bounding_box_union': str(bounding_box_union),
'session_id': session_id,
}
logging_server = invest_executor._get_logging_server()
logging_server.log_invest_run(payload)
except Exception as exception:
# An exception was thrown, we don't care.
logger.warn(
'an exception encountered when logging %s', str(exception))
class VectorUnprojected(Exception):
"""An Exception in case a vector is unprojected"""
pass
class DifferentProjections(Exception):
"""An exception in cast a set of dataets are not in the same projection."""
pass
def assert_ogr_projections_equal(vector_uri_list):
"""Assert that all projections of the input OGR-compatible vectors are
identical.
Raises VectorUnprojected if a vector is inprojected.
Raises DifferentProjections if projections differ."""
vector_list = [(ogr.Open(v_uri), v_uri) for v_uri in vector_uri_list]
vector_projections = []
unprojected_vectors = set()
for vector, vector_uri in vector_list:
layer = vector.GetLayer()
srs = layer.GetSpatialRef()
if not srs.IsProjected():
unprojected_vectors.add(vector_uri)
vector_projections.append((srs, vector_uri))
if len(unprojected_vectors) > 0:
raise VectorUnprojected(
"These vectors are unprojected: %s" % (unprojected_vectors))
for index in range(len(vector_projections) - 1):
if not vector_projections[index][0].IsSame(
vector_projections[index + 1][0]):
LOGGER.warn(
"These two datasets might not be in the same projection."
" The different projections are:\n\n'filename: %s'\n%s\n\n"
"and:\n\n'filename:%s'\n%s\n\n",
vector_projections[index][1],
vector_projections[index][0].ExportToPrettyWkt(),
vector_projections[index+1][1],
vector_projections[index+1][0].ExportToPrettyWkt())
for vector in vector_list:
#Make sure the vector is closed and cleaned up
vector = None
vector_list = None
return True
def write_csv(uri, fields, rows):
"""Write a utf-8 encoded CSV to URI.
fields - a list of strings
rows - a list of dictionaries, pointing fieldname to value"""
def _cast_if_str(string):
if type(string) is StringType:
return unicode(string, 'utf-8')
return string
# write the rows to a CSV
LOGGER.debug('Writing output CSV: %s', uri)
csv_file_obj = codecs.open(uri, 'w', 'utf-8')
# write the header
sanitized_fieldnames = ['"%s"' % _cast_if_str(f) for f in fields]
csv_file_obj.write("%s\n" % ','.join(sanitized_fieldnames))
# write the rows
for row in rows:
row_fields = ['"%s"' % _cast_if_str(row[f]) for f in fields]
csv_file_obj.write("%s\n" % ','.join(row_fields))
csv_file_obj.close()
def sigfig(number, digits=3):
"""
Round a number to the given number of significant digits.
Example:
>>> sigfig(1234, 3)
1230
number (int or float): The number to adjust
digits=3 (int): The number of siginficant figures to retain
Returns a number."""
input_type = type(number)
output_num = ''
digit_count = 0
period_found = False
for digit in str(float(number)):
if digit == '.':
period_found = True
output_num += '.'
elif digit_count < digits:
output_num += digit
digit_count += 1
else:
output_num += '0'
return input_type(float(output_num))
|
PypiClean
|
/PyAMF2-0.6.1.5.tar.gz/PyAMF2-0.6.1.5/pyamf/alias.py
|
import inspect
import pyamf
from pyamf import python, util
class UnknownClassAlias(Exception):
"""
Raised if the AMF stream specifies an Actionscript class that does not
have a Python class alias.
@see: L{register_class}
"""
class ClassAlias(object):
"""
Class alias. Provides class/instance meta data to the En/Decoder to allow
fine grain control and some performance increases.
"""
def __init__(self, klass, alias=None, **kwargs):
if not isinstance(klass, python.class_types):
raise TypeError('klass must be a class type, got %r' % type(klass))
self.checkClass(klass)
self.klass = klass
self.alias = alias
if hasattr(self.alias, 'decode'):
self.alias = self.alias.decode('utf-8')
self.static_attrs = kwargs.pop('static_attrs', None)
self.exclude_attrs = kwargs.pop('exclude_attrs', None)
self.readonly_attrs = kwargs.pop('readonly_attrs', None)
self.proxy_attrs = kwargs.pop('proxy_attrs', None)
self.amf3 = kwargs.pop('amf3', None)
self.external = kwargs.pop('external', None)
self.dynamic = kwargs.pop('dynamic', None)
self.synonym_attrs = kwargs.pop('synonym_attrs', {})
self._compiled = False
self.anonymous = False
self.sealed = None
self.bases = None
if self.alias is None:
self.anonymous = True
# we don't set this to None because AMF3 untyped objects have a
# class name of ''
self.alias = ''
else:
if self.alias == '':
raise ValueError('Cannot set class alias as \'\'')
if not kwargs.pop('defer', False):
self.compile()
if kwargs:
raise TypeError('Unexpected keyword arguments %r' % (kwargs,))
def _checkExternal(self):
k = self.klass
if not hasattr(k, '__readamf__'):
raise AttributeError("An externalised class was specified, but"
" no __readamf__ attribute was found for %r" % (k,))
if not hasattr(k, '__writeamf__'):
raise AttributeError("An externalised class was specified, but"
" no __writeamf__ attribute was found for %r" % (k,))
if not hasattr(k.__readamf__, '__call__'):
raise TypeError("%s.__readamf__ must be callable" % (k.__name__,))
if not hasattr(k.__writeamf__, '__call__'):
raise TypeError("%s.__writeamf__ must be callable" % (k.__name__,))
def compile(self):
"""
This compiles the alias into a form that can be of most benefit to the
en/decoder.
"""
if self._compiled:
return
self.decodable_properties = set()
self.encodable_properties = set()
self.inherited_dynamic = None
self.inherited_sealed = None
self.bases = []
self.exclude_attrs = set(self.exclude_attrs or [])
self.readonly_attrs = set(self.readonly_attrs or [])
self.static_attrs = list(self.static_attrs or [])
self.static_attrs_set = set(self.static_attrs)
self.proxy_attrs = set(self.proxy_attrs or [])
self.sealed = util.is_class_sealed(self.klass)
if self.external:
self._checkExternal()
self._finalise_compile()
# this class is external so no more compiling is necessary
return
if hasattr(self.klass, '__slots__'):
self.decodable_properties.update(self.klass.__slots__)
self.encodable_properties.update(self.klass.__slots__)
for k, v in self.klass.__dict__.iteritems():
if not isinstance(v, property):
continue
if v.fget:
self.encodable_properties.update([k])
if v.fset:
self.decodable_properties.update([k])
else:
self.readonly_attrs.update([k])
mro = inspect.getmro(self.klass)[1:]
for c in mro:
self._compile_base_class(c)
self.getCustomProperties()
self._finalise_compile()
def _compile_base_class(self, klass):
if klass is object:
return
try:
alias = pyamf.get_class_alias(klass)
except UnknownClassAlias:
alias = pyamf.register_class(klass)
alias.compile()
self.bases.append((klass, alias))
if alias.exclude_attrs:
self.exclude_attrs.update(alias.exclude_attrs)
if alias.readonly_attrs:
self.readonly_attrs.update(alias.readonly_attrs)
if alias.static_attrs:
self.static_attrs_set.update(alias.static_attrs)
for a in alias.static_attrs:
if a not in self.static_attrs:
self.static_attrs.insert(0, a)
if alias.proxy_attrs:
self.proxy_attrs.update(alias.proxy_attrs)
if alias.encodable_properties:
self.encodable_properties.update(alias.encodable_properties)
if alias.decodable_properties:
self.decodable_properties.update(alias.decodable_properties)
if self.amf3 is None and alias.amf3:
self.amf3 = alias.amf3
if self.dynamic is None and alias.dynamic is not None:
self.inherited_dynamic = alias.dynamic
if alias.sealed is not None:
self.inherited_sealed = alias.sealed
if alias.synonym_attrs:
self.synonym_attrs, x = alias.synonym_attrs.copy(), self.synonym_attrs
self.synonym_attrs.update(x)
def _finalise_compile(self):
if self.dynamic is None:
self.dynamic = True
if self.inherited_dynamic is not None:
if self.inherited_dynamic is False and not self.sealed and self.inherited_sealed:
self.dynamic = True
else:
self.dynamic = self.inherited_dynamic
if self.sealed:
self.dynamic = False
if self.amf3 is None:
self.amf3 = False
if self.external is None:
self.external = False
if self.static_attrs:
self.encodable_properties.update(self.static_attrs)
self.decodable_properties.update(self.static_attrs)
if self.static_attrs:
if self.exclude_attrs:
self.static_attrs_set.difference_update(self.exclude_attrs)
for a in self.static_attrs_set:
if a not in self.static_attrs:
self.static_attrs.remove(a)
if not self.exclude_attrs:
self.exclude_attrs = None
else:
self.encodable_properties.difference_update(self.exclude_attrs)
self.decodable_properties.difference_update(self.exclude_attrs)
if self.exclude_attrs is not None:
self.exclude_attrs = list(self.exclude_attrs)
self.exclude_attrs.sort()
if not self.readonly_attrs:
self.readonly_attrs = None
else:
self.decodable_properties.difference_update(self.readonly_attrs)
if self.readonly_attrs is not None:
self.readonly_attrs = list(self.readonly_attrs)
self.readonly_attrs.sort()
if not self.proxy_attrs:
self.proxy_attrs = None
else:
self.proxy_attrs = list(self.proxy_attrs)
self.proxy_attrs.sort()
if len(self.decodable_properties) == 0:
self.decodable_properties = None
else:
self.decodable_properties = list(self.decodable_properties)
self.decodable_properties.sort()
if len(self.encodable_properties) == 0:
self.encodable_properties = None
else:
self.encodable_properties = list(self.encodable_properties)
self.encodable_properties.sort()
self.non_static_encodable_properties = None
if self.encodable_properties:
self.non_static_encodable_properties = set(self.encodable_properties)
if self.static_attrs:
self.non_static_encodable_properties.difference_update(self.static_attrs)
self.shortcut_encode = True
self.shortcut_decode = True
if (self.encodable_properties or self.static_attrs or
self.exclude_attrs or self.proxy_attrs or self.external or
self.synonym_attrs):
self.shortcut_encode = False
if (self.decodable_properties or self.static_attrs or
self.exclude_attrs or self.readonly_attrs or
not self.dynamic or self.external or self.synonym_attrs):
self.shortcut_decode = False
self.is_dict = False
if issubclass(self.klass, dict) or self.klass is dict:
self.is_dict = True
self._compiled = True
def is_compiled(self):
return self._compiled
def __str__(self):
return self.alias
def __repr__(self):
k = self.__class__
return '<%s.%s alias=%r class=%r @ 0x%x>' % (k.__module__, k.__name__,
self.alias, self.klass, id(self))
def __eq__(self, other):
if isinstance(other, basestring):
return self.alias == other
elif isinstance(other, self.__class__):
return self.klass == other.klass
elif isinstance(other, python.class_types):
return self.klass == other
else:
return False
def __hash__(self):
return id(self)
def checkClass(self, klass):
"""
This function is used to check if the class being aliased fits certain
criteria. The default is to check that C{__new__} is available or the
C{__init__} constructor does not need additional arguments. If this is
the case then L{TypeError} will be raised.
@since: 0.4
"""
# Check for __new__ support.
if hasattr(klass, '__new__') and hasattr(klass.__new__, '__call__'):
# Should be good to go.
return
# Check that the constructor of the class doesn't require any additonal
# arguments.
if not (hasattr(klass, '__init__') and hasattr(klass.__init__, '__call__')):
return
klass_func = klass.__init__.im_func
if not hasattr(klass_func, 'func_code'):
# Can't examine it, assume it's OK.
return
if klass_func.func_defaults:
available_arguments = len(klass_func.func_defaults) + 1
else:
available_arguments = 1
needed_arguments = klass_func.func_code.co_argcount
if available_arguments >= needed_arguments:
# Looks good to me.
return
spec = inspect.getargspec(klass_func)
raise TypeError("__init__ doesn't support additional arguments: %s"
% inspect.formatargspec(*spec))
def getEncodableAttributes(self, obj, codec=None):
"""
Must return a C{dict} of attributes to be encoded, even if its empty.
@param codec: An optional argument that will contain the encoder
instance calling this function.
@since: 0.5
"""
if not self._compiled:
self.compile()
if self.is_dict:
return dict(obj)
if self.shortcut_encode and self.dynamic:
return obj.__dict__.copy()
attrs = {}
if self.static_attrs:
for attr in self.static_attrs:
attrs[attr] = getattr(obj, attr, pyamf.Undefined)
if not self.dynamic:
if self.non_static_encodable_properties:
for attr in self.non_static_encodable_properties:
attrs[attr] = getattr(obj, attr)
return attrs
dynamic_props = util.get_properties(obj)
if not self.shortcut_encode:
dynamic_props = set(dynamic_props)
if self.encodable_properties:
dynamic_props.update(self.encodable_properties)
if self.static_attrs:
dynamic_props.difference_update(self.static_attrs)
if self.exclude_attrs:
dynamic_props.difference_update(self.exclude_attrs)
for attr in dynamic_props:
attrs[attr] = getattr(obj, attr)
if self.proxy_attrs is not None and attrs and codec:
context = codec.context
for k, v in attrs.copy().iteritems():
if k in self.proxy_attrs:
attrs[k] = context.getProxyForObject(v)
if self.synonym_attrs:
missing = object()
for k, v in self.synonym_attrs.iteritems():
value = attrs.pop(k, missing)
if value is missing:
continue
attrs[v] = value
return attrs
def getDecodableAttributes(self, obj, attrs, codec=None):
"""
Returns a dictionary of attributes for C{obj} that has been filtered,
based on the supplied C{attrs}. This allows for fine grain control
over what will finally end up on the object or not.
@param obj: The object that will recieve the attributes.
@param attrs: The C{attrs} dictionary that has been decoded.
@param codec: An optional argument that will contain the decoder
instance calling this function.
@return: A dictionary of attributes that can be applied to C{obj}
@since: 0.5
"""
if not self._compiled:
self.compile()
changed = False
props = set(attrs.keys())
if self.static_attrs:
missing_attrs = self.static_attrs_set.difference(props)
if missing_attrs:
raise AttributeError('Static attributes %r expected '
'when decoding %r' % (missing_attrs, self.klass))
props.difference_update(self.static_attrs)
if not props:
return attrs
if not self.dynamic:
if not self.decodable_properties:
props = set()
else:
props.intersection_update(self.decodable_properties)
changed = True
if self.readonly_attrs:
props.difference_update(self.readonly_attrs)
changed = True
if self.exclude_attrs:
props.difference_update(self.exclude_attrs)
changed = True
if self.proxy_attrs is not None and codec:
context = codec.context
for k in self.proxy_attrs:
try:
v = attrs[k]
except KeyError:
continue
attrs[k] = context.getObjectForProxy(v)
if self.synonym_attrs:
missing = object()
for k, v in self.synonym_attrs.iteritems():
value = attrs.pop(k, missing)
if value is missing:
continue
attrs[v] = value
if not changed:
return attrs
a = {}
[a.__setitem__(p, attrs[p]) for p in props]
return a
def applyAttributes(self, obj, attrs, codec=None):
"""
Applies the collection of attributes C{attrs} to aliased object C{obj}.
Called when decoding reading aliased objects from an AMF byte stream.
Override this to provide fine grain control of application of
attributes to C{obj}.
@param codec: An optional argument that will contain the en/decoder
instance calling this function.
"""
if not self._compiled:
self.compile()
if self.shortcut_decode:
if self.is_dict:
obj.update(attrs)
return
if not self.sealed:
obj.__dict__.update(attrs)
return
else:
attrs = self.getDecodableAttributes(obj, attrs, codec=codec)
util.set_attrs(obj, attrs)
def getCustomProperties(self):
"""
Overrride this to provide known static properties based on the aliased
class.
@since: 0.5
"""
def createInstance(self, codec=None):
"""
Creates an instance of the klass.
@return: Instance of C{self.klass}.
"""
if type(self.klass) is type:
return self.klass.__new__(self.klass)
return self.klass()
|
PypiClean
|
/alibabacloud_viapi_regen20211119-1.0.7-py3-none-any.whl/alibabacloud_viapi_regen20211119/client.py
|
from typing import Dict
from Tea.core import TeaCore
from alibabacloud_tea_openapi.client import Client as OpenApiClient
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_tea_util.client import Client as UtilClient
from alibabacloud_endpoint_util.client import Client as EndpointUtilClient
from alibabacloud_viapi_regen20211119 import models as viapi_regen_20211119_models
from alibabacloud_tea_util import models as util_models
from alibabacloud_openapi_util.client import Client as OpenApiUtilClient
from alibabacloud_openplatform20191219.client import Client as OpenPlatformClient
from alibabacloud_openplatform20191219 import models as open_platform_models
from alibabacloud_oss_sdk import models as oss_models
from alibabacloud_tea_fileform import models as file_form_models
from alibabacloud_oss_util import models as ossutil_models
from alibabacloud_oss_sdk.client import Client as OSSClient
class Client(OpenApiClient):
"""
*\
"""
def __init__(
self,
config: open_api_models.Config,
):
super().__init__(config)
self._endpoint_rule = 'regional'
self._endpoint_map = {
'ap-northeast-1': 'viapi-regen-daily.aliyuncs.com',
'ap-northeast-2-pop': 'viapi-regen-daily.aliyuncs.com',
'ap-south-1': 'viapi-regen-daily.aliyuncs.com',
'ap-southeast-1': 'viapi-regen-daily.aliyuncs.com',
'ap-southeast-2': 'viapi-regen-daily.aliyuncs.com',
'ap-southeast-3': 'viapi-regen-daily.aliyuncs.com',
'ap-southeast-5': 'viapi-regen-daily.aliyuncs.com',
'cn-beijing': 'viapi-regen-daily.aliyuncs.com',
'cn-beijing-finance-1': 'viapi-regen-daily.aliyuncs.com',
'cn-beijing-finance-pop': 'viapi-regen-daily.aliyuncs.com',
'cn-beijing-gov-1': 'viapi-regen-daily.aliyuncs.com',
'cn-beijing-nu16-b01': 'viapi-regen-daily.aliyuncs.com',
'cn-chengdu': 'viapi-regen-daily.aliyuncs.com',
'cn-edge-1': 'viapi-regen-daily.aliyuncs.com',
'cn-fujian': 'viapi-regen-daily.aliyuncs.com',
'cn-haidian-cm12-c01': 'viapi-regen-daily.aliyuncs.com',
'cn-hangzhou-bj-b01': 'viapi-regen-daily.aliyuncs.com',
'cn-hangzhou-finance': 'viapi-regen-daily.aliyuncs.com',
'cn-hangzhou-internal-prod-1': 'viapi-regen-daily.aliyuncs.com',
'cn-hangzhou-internal-test-1': 'viapi-regen-daily.aliyuncs.com',
'cn-hangzhou-internal-test-2': 'viapi-regen-daily.aliyuncs.com',
'cn-hangzhou-internal-test-3': 'viapi-regen-daily.aliyuncs.com',
'cn-hangzhou-test-306': 'viapi-regen-daily.aliyuncs.com',
'cn-hongkong': 'viapi-regen-daily.aliyuncs.com',
'cn-hongkong-finance-pop': 'viapi-regen-daily.aliyuncs.com',
'cn-huhehaote': 'viapi-regen-daily.aliyuncs.com',
'cn-huhehaote-nebula-1': 'viapi-regen-daily.aliyuncs.com',
'cn-north-2-gov-1': 'viapi-regen-daily.aliyuncs.com',
'cn-qingdao': 'viapi-regen-daily.aliyuncs.com',
'cn-qingdao-nebula': 'viapi-regen-daily.aliyuncs.com',
'cn-shanghai-et15-b01': 'viapi-regen-daily.aliyuncs.com',
'cn-shanghai-et2-b01': 'viapi-regen-daily.aliyuncs.com',
'cn-shanghai-finance-1': 'viapi-regen-daily.aliyuncs.com',
'cn-shanghai-inner': 'viapi-regen-daily.aliyuncs.com',
'cn-shanghai-internal-test-1': 'viapi-regen-daily.aliyuncs.com',
'cn-shenzhen': 'viapi-regen-daily.aliyuncs.com',
'cn-shenzhen-finance-1': 'viapi-regen-daily.aliyuncs.com',
'cn-shenzhen-inner': 'viapi-regen-daily.aliyuncs.com',
'cn-shenzhen-st4-d01': 'viapi-regen-daily.aliyuncs.com',
'cn-shenzhen-su18-b01': 'viapi-regen-daily.aliyuncs.com',
'cn-wuhan': 'viapi-regen-daily.aliyuncs.com',
'cn-wulanchabu': 'viapi-regen-daily.aliyuncs.com',
'cn-yushanfang': 'viapi-regen-daily.aliyuncs.com',
'cn-zhangbei': 'viapi-regen-daily.aliyuncs.com',
'cn-zhangbei-na61-b01': 'viapi-regen-daily.aliyuncs.com',
'cn-zhangjiakou': 'viapi-regen-daily.aliyuncs.com',
'cn-zhangjiakou-na62-a01': 'viapi-regen-daily.aliyuncs.com',
'cn-zhengzhou-nebula-1': 'viapi-regen-daily.aliyuncs.com',
'eu-central-1': 'viapi-regen-daily.aliyuncs.com',
'eu-west-1': 'viapi-regen-daily.aliyuncs.com',
'eu-west-1-oxs': 'viapi-regen-daily.aliyuncs.com',
'me-east-1': 'viapi-regen-daily.aliyuncs.com',
'rus-west-1-pop': 'viapi-regen-daily.aliyuncs.com',
'us-east-1': 'viapi-regen-daily.aliyuncs.com',
'us-west-1': 'viapi-regen-daily.aliyuncs.com'
}
self.check_config(config)
self._endpoint = self.get_endpoint('viapi-regen', self._region_id, self._endpoint_rule, self._network, self._suffix, self._endpoint_map, self._endpoint)
def get_endpoint(
self,
product_id: str,
region_id: str,
endpoint_rule: str,
network: str,
suffix: str,
endpoint_map: Dict[str, str],
endpoint: str,
) -> str:
if not UtilClient.empty(endpoint):
return endpoint
if not UtilClient.is_unset(endpoint_map) and not UtilClient.empty(endpoint_map.get(region_id)):
return endpoint_map.get(region_id)
return EndpointUtilClient.get_endpoint_rules(product_id, region_id, endpoint_rule, network, suffix)
def check_dataset_oss_bucket_corswith_options(
self,
request: viapi_regen_20211119_models.CheckDatasetOssBucketCORSRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CheckDatasetOssBucketCORSResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.labelset_id):
body['LabelsetId'] = request.labelset_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CheckDatasetOssBucketCORS',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CheckDatasetOssBucketCORSResponse(),
self.call_api(params, req, runtime)
)
async def check_dataset_oss_bucket_corswith_options_async(
self,
request: viapi_regen_20211119_models.CheckDatasetOssBucketCORSRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CheckDatasetOssBucketCORSResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.labelset_id):
body['LabelsetId'] = request.labelset_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CheckDatasetOssBucketCORS',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CheckDatasetOssBucketCORSResponse(),
await self.call_api_async(params, req, runtime)
)
def check_dataset_oss_bucket_cors(
self,
request: viapi_regen_20211119_models.CheckDatasetOssBucketCORSRequest,
) -> viapi_regen_20211119_models.CheckDatasetOssBucketCORSResponse:
runtime = util_models.RuntimeOptions()
return self.check_dataset_oss_bucket_corswith_options(request, runtime)
async def check_dataset_oss_bucket_cors_async(
self,
request: viapi_regen_20211119_models.CheckDatasetOssBucketCORSRequest,
) -> viapi_regen_20211119_models.CheckDatasetOssBucketCORSResponse:
runtime = util_models.RuntimeOptions()
return await self.check_dataset_oss_bucket_corswith_options_async(request, runtime)
def create_dataset_with_options(
self,
request: viapi_regen_20211119_models.CreateDatasetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CreateDatasetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.type):
body['Type'] = request.type
if not UtilClient.is_unset(request.workspace_id):
body['WorkspaceId'] = request.workspace_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CreateDataset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CreateDatasetResponse(),
self.call_api(params, req, runtime)
)
async def create_dataset_with_options_async(
self,
request: viapi_regen_20211119_models.CreateDatasetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CreateDatasetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.type):
body['Type'] = request.type
if not UtilClient.is_unset(request.workspace_id):
body['WorkspaceId'] = request.workspace_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CreateDataset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CreateDatasetResponse(),
await self.call_api_async(params, req, runtime)
)
def create_dataset(
self,
request: viapi_regen_20211119_models.CreateDatasetRequest,
) -> viapi_regen_20211119_models.CreateDatasetResponse:
runtime = util_models.RuntimeOptions()
return self.create_dataset_with_options(request, runtime)
async def create_dataset_async(
self,
request: viapi_regen_20211119_models.CreateDatasetRequest,
) -> viapi_regen_20211119_models.CreateDatasetResponse:
runtime = util_models.RuntimeOptions()
return await self.create_dataset_with_options_async(request, runtime)
def create_labelset_with_options(
self,
request: viapi_regen_20211119_models.CreateLabelsetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CreateLabelsetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.dataset_id):
body['DatasetId'] = request.dataset_id
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.object_key):
body['ObjectKey'] = request.object_key
if not UtilClient.is_unset(request.pre_label_id):
body['PreLabelId'] = request.pre_label_id
if not UtilClient.is_unset(request.tag_settings):
body['TagSettings'] = request.tag_settings
if not UtilClient.is_unset(request.tag_user_list):
body['TagUserList'] = request.tag_user_list
if not UtilClient.is_unset(request.type):
body['Type'] = request.type
if not UtilClient.is_unset(request.user_oss_url):
body['UserOssUrl'] = request.user_oss_url
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CreateLabelset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CreateLabelsetResponse(),
self.call_api(params, req, runtime)
)
async def create_labelset_with_options_async(
self,
request: viapi_regen_20211119_models.CreateLabelsetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CreateLabelsetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.dataset_id):
body['DatasetId'] = request.dataset_id
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.object_key):
body['ObjectKey'] = request.object_key
if not UtilClient.is_unset(request.pre_label_id):
body['PreLabelId'] = request.pre_label_id
if not UtilClient.is_unset(request.tag_settings):
body['TagSettings'] = request.tag_settings
if not UtilClient.is_unset(request.tag_user_list):
body['TagUserList'] = request.tag_user_list
if not UtilClient.is_unset(request.type):
body['Type'] = request.type
if not UtilClient.is_unset(request.user_oss_url):
body['UserOssUrl'] = request.user_oss_url
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CreateLabelset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CreateLabelsetResponse(),
await self.call_api_async(params, req, runtime)
)
def create_labelset(
self,
request: viapi_regen_20211119_models.CreateLabelsetRequest,
) -> viapi_regen_20211119_models.CreateLabelsetResponse:
runtime = util_models.RuntimeOptions()
return self.create_labelset_with_options(request, runtime)
async def create_labelset_async(
self,
request: viapi_regen_20211119_models.CreateLabelsetRequest,
) -> viapi_regen_20211119_models.CreateLabelsetResponse:
runtime = util_models.RuntimeOptions()
return await self.create_labelset_with_options_async(request, runtime)
def create_service_with_options(
self,
request: viapi_regen_20211119_models.CreateServiceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CreateServiceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.authorization_type):
body['AuthorizationType'] = request.authorization_type
if not UtilClient.is_unset(request.authorized_account):
body['AuthorizedAccount'] = request.authorized_account
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.train_task_id):
body['TrainTaskId'] = request.train_task_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CreateService',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CreateServiceResponse(),
self.call_api(params, req, runtime)
)
async def create_service_with_options_async(
self,
request: viapi_regen_20211119_models.CreateServiceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CreateServiceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.authorization_type):
body['AuthorizationType'] = request.authorization_type
if not UtilClient.is_unset(request.authorized_account):
body['AuthorizedAccount'] = request.authorized_account
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.train_task_id):
body['TrainTaskId'] = request.train_task_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CreateService',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CreateServiceResponse(),
await self.call_api_async(params, req, runtime)
)
def create_service(
self,
request: viapi_regen_20211119_models.CreateServiceRequest,
) -> viapi_regen_20211119_models.CreateServiceResponse:
runtime = util_models.RuntimeOptions()
return self.create_service_with_options(request, runtime)
async def create_service_async(
self,
request: viapi_regen_20211119_models.CreateServiceRequest,
) -> viapi_regen_20211119_models.CreateServiceResponse:
runtime = util_models.RuntimeOptions()
return await self.create_service_with_options_async(request, runtime)
def create_tag_task_with_options(
self,
request: viapi_regen_20211119_models.CreateTagTaskRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CreateTagTaskResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.labelset_id):
body['LabelsetId'] = request.labelset_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CreateTagTask',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CreateTagTaskResponse(),
self.call_api(params, req, runtime)
)
async def create_tag_task_with_options_async(
self,
request: viapi_regen_20211119_models.CreateTagTaskRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CreateTagTaskResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.labelset_id):
body['LabelsetId'] = request.labelset_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CreateTagTask',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CreateTagTaskResponse(),
await self.call_api_async(params, req, runtime)
)
def create_tag_task(
self,
request: viapi_regen_20211119_models.CreateTagTaskRequest,
) -> viapi_regen_20211119_models.CreateTagTaskResponse:
runtime = util_models.RuntimeOptions()
return self.create_tag_task_with_options(request, runtime)
async def create_tag_task_async(
self,
request: viapi_regen_20211119_models.CreateTagTaskRequest,
) -> viapi_regen_20211119_models.CreateTagTaskResponse:
runtime = util_models.RuntimeOptions()
return await self.create_tag_task_with_options_async(request, runtime)
def create_train_task_with_options(
self,
request: viapi_regen_20211119_models.CreateTrainTaskRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CreateTrainTaskResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.advanced_parameters):
body['AdvancedParameters'] = request.advanced_parameters
if not UtilClient.is_unset(request.dataset_ids):
body['DatasetIds'] = request.dataset_ids
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.label_ids):
body['LabelIds'] = request.label_ids
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.pre_train_task_id):
body['PreTrainTaskId'] = request.pre_train_task_id
if not UtilClient.is_unset(request.train_mode):
body['TrainMode'] = request.train_mode
if not UtilClient.is_unset(request.workspace_id):
body['WorkspaceId'] = request.workspace_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CreateTrainTask',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CreateTrainTaskResponse(),
self.call_api(params, req, runtime)
)
async def create_train_task_with_options_async(
self,
request: viapi_regen_20211119_models.CreateTrainTaskRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CreateTrainTaskResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.advanced_parameters):
body['AdvancedParameters'] = request.advanced_parameters
if not UtilClient.is_unset(request.dataset_ids):
body['DatasetIds'] = request.dataset_ids
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.label_ids):
body['LabelIds'] = request.label_ids
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.pre_train_task_id):
body['PreTrainTaskId'] = request.pre_train_task_id
if not UtilClient.is_unset(request.train_mode):
body['TrainMode'] = request.train_mode
if not UtilClient.is_unset(request.workspace_id):
body['WorkspaceId'] = request.workspace_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CreateTrainTask',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CreateTrainTaskResponse(),
await self.call_api_async(params, req, runtime)
)
def create_train_task(
self,
request: viapi_regen_20211119_models.CreateTrainTaskRequest,
) -> viapi_regen_20211119_models.CreateTrainTaskResponse:
runtime = util_models.RuntimeOptions()
return self.create_train_task_with_options(request, runtime)
async def create_train_task_async(
self,
request: viapi_regen_20211119_models.CreateTrainTaskRequest,
) -> viapi_regen_20211119_models.CreateTrainTaskResponse:
runtime = util_models.RuntimeOptions()
return await self.create_train_task_with_options_async(request, runtime)
def create_workspace_with_options(
self,
request: viapi_regen_20211119_models.CreateWorkspaceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CreateWorkspaceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.type):
body['Type'] = request.type
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CreateWorkspace',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CreateWorkspaceResponse(),
self.call_api(params, req, runtime)
)
async def create_workspace_with_options_async(
self,
request: viapi_regen_20211119_models.CreateWorkspaceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CreateWorkspaceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.type):
body['Type'] = request.type
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CreateWorkspace',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CreateWorkspaceResponse(),
await self.call_api_async(params, req, runtime)
)
def create_workspace(
self,
request: viapi_regen_20211119_models.CreateWorkspaceRequest,
) -> viapi_regen_20211119_models.CreateWorkspaceResponse:
runtime = util_models.RuntimeOptions()
return self.create_workspace_with_options(request, runtime)
async def create_workspace_async(
self,
request: viapi_regen_20211119_models.CreateWorkspaceRequest,
) -> viapi_regen_20211119_models.CreateWorkspaceResponse:
runtime = util_models.RuntimeOptions()
return await self.create_workspace_with_options_async(request, runtime)
def customize_classify_image_with_options(
self,
request: viapi_regen_20211119_models.CustomizeClassifyImageRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CustomizeClassifyImageResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.image_url):
body['ImageUrl'] = request.image_url
if not UtilClient.is_unset(request.service_id):
body['ServiceId'] = request.service_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CustomizeClassifyImage',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CustomizeClassifyImageResponse(),
self.call_api(params, req, runtime)
)
async def customize_classify_image_with_options_async(
self,
request: viapi_regen_20211119_models.CustomizeClassifyImageRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CustomizeClassifyImageResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.image_url):
body['ImageUrl'] = request.image_url
if not UtilClient.is_unset(request.service_id):
body['ServiceId'] = request.service_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CustomizeClassifyImage',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CustomizeClassifyImageResponse(),
await self.call_api_async(params, req, runtime)
)
def customize_classify_image(
self,
request: viapi_regen_20211119_models.CustomizeClassifyImageRequest,
) -> viapi_regen_20211119_models.CustomizeClassifyImageResponse:
runtime = util_models.RuntimeOptions()
return self.customize_classify_image_with_options(request, runtime)
async def customize_classify_image_async(
self,
request: viapi_regen_20211119_models.CustomizeClassifyImageRequest,
) -> viapi_regen_20211119_models.CustomizeClassifyImageResponse:
runtime = util_models.RuntimeOptions()
return await self.customize_classify_image_with_options_async(request, runtime)
def customize_classify_image_advance(
self,
request: viapi_regen_20211119_models.CustomizeClassifyImageAdvanceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CustomizeClassifyImageResponse:
# Step 0: init client
access_key_id = self._credential.get_access_key_id()
access_key_secret = self._credential.get_access_key_secret()
security_token = self._credential.get_security_token()
credential_type = self._credential.get_type()
open_platform_endpoint = self._open_platform_endpoint
if UtilClient.is_unset(open_platform_endpoint):
open_platform_endpoint = 'openplatform.aliyuncs.com'
if UtilClient.is_unset(credential_type):
credential_type = 'access_key'
auth_config = open_api_models.Config(
access_key_id=access_key_id,
access_key_secret=access_key_secret,
security_token=security_token,
type=credential_type,
endpoint=open_platform_endpoint,
protocol=self._protocol,
region_id=self._region_id
)
auth_client = OpenPlatformClient(auth_config)
auth_request = open_platform_models.AuthorizeFileUploadRequest(
product='viapi-regen',
region_id=self._region_id
)
auth_response = open_platform_models.AuthorizeFileUploadResponse()
oss_config = oss_models.Config(
access_key_secret=access_key_secret,
type='access_key',
protocol=self._protocol,
region_id=self._region_id
)
oss_client = None
file_obj = file_form_models.FileField()
oss_header = oss_models.PostObjectRequestHeader()
upload_request = oss_models.PostObjectRequest()
oss_runtime = ossutil_models.RuntimeOptions()
OpenApiUtilClient.convert(runtime, oss_runtime)
customize_classify_image_req = viapi_regen_20211119_models.CustomizeClassifyImageRequest()
OpenApiUtilClient.convert(request, customize_classify_image_req)
if not UtilClient.is_unset(request.image_url_object):
auth_response = auth_client.authorize_file_upload_with_options(auth_request, runtime)
oss_config.access_key_id = auth_response.body.access_key_id
oss_config.endpoint = OpenApiUtilClient.get_endpoint(auth_response.body.endpoint, auth_response.body.use_accelerate, self._endpoint_type)
oss_client = OSSClient(oss_config)
file_obj = file_form_models.FileField(
filename=auth_response.body.object_key,
content=request.image_url_object,
content_type=''
)
oss_header = oss_models.PostObjectRequestHeader(
access_key_id=auth_response.body.access_key_id,
policy=auth_response.body.encoded_policy,
signature=auth_response.body.signature,
key=auth_response.body.object_key,
file=file_obj,
success_action_status='201'
)
upload_request = oss_models.PostObjectRequest(
bucket_name=auth_response.body.bucket,
header=oss_header
)
oss_client.post_object(upload_request, oss_runtime)
customize_classify_image_req.image_url = f'http://{auth_response.body.bucket}.{auth_response.body.endpoint}/{auth_response.body.object_key}'
customize_classify_image_resp = self.customize_classify_image_with_options(customize_classify_image_req, runtime)
return customize_classify_image_resp
async def customize_classify_image_advance_async(
self,
request: viapi_regen_20211119_models.CustomizeClassifyImageAdvanceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CustomizeClassifyImageResponse:
# Step 0: init client
access_key_id = await self._credential.get_access_key_id_async()
access_key_secret = await self._credential.get_access_key_secret_async()
security_token = await self._credential.get_security_token_async()
credential_type = self._credential.get_type()
open_platform_endpoint = self._open_platform_endpoint
if UtilClient.is_unset(open_platform_endpoint):
open_platform_endpoint = 'openplatform.aliyuncs.com'
if UtilClient.is_unset(credential_type):
credential_type = 'access_key'
auth_config = open_api_models.Config(
access_key_id=access_key_id,
access_key_secret=access_key_secret,
security_token=security_token,
type=credential_type,
endpoint=open_platform_endpoint,
protocol=self._protocol,
region_id=self._region_id
)
auth_client = OpenPlatformClient(auth_config)
auth_request = open_platform_models.AuthorizeFileUploadRequest(
product='viapi-regen',
region_id=self._region_id
)
auth_response = open_platform_models.AuthorizeFileUploadResponse()
oss_config = oss_models.Config(
access_key_secret=access_key_secret,
type='access_key',
protocol=self._protocol,
region_id=self._region_id
)
oss_client = None
file_obj = file_form_models.FileField()
oss_header = oss_models.PostObjectRequestHeader()
upload_request = oss_models.PostObjectRequest()
oss_runtime = ossutil_models.RuntimeOptions()
OpenApiUtilClient.convert(runtime, oss_runtime)
customize_classify_image_req = viapi_regen_20211119_models.CustomizeClassifyImageRequest()
OpenApiUtilClient.convert(request, customize_classify_image_req)
if not UtilClient.is_unset(request.image_url_object):
auth_response = await auth_client.authorize_file_upload_with_options_async(auth_request, runtime)
oss_config.access_key_id = auth_response.body.access_key_id
oss_config.endpoint = OpenApiUtilClient.get_endpoint(auth_response.body.endpoint, auth_response.body.use_accelerate, self._endpoint_type)
oss_client = OSSClient(oss_config)
file_obj = file_form_models.FileField(
filename=auth_response.body.object_key,
content=request.image_url_object,
content_type=''
)
oss_header = oss_models.PostObjectRequestHeader(
access_key_id=auth_response.body.access_key_id,
policy=auth_response.body.encoded_policy,
signature=auth_response.body.signature,
key=auth_response.body.object_key,
file=file_obj,
success_action_status='201'
)
upload_request = oss_models.PostObjectRequest(
bucket_name=auth_response.body.bucket,
header=oss_header
)
await oss_client.post_object_async(upload_request, oss_runtime)
customize_classify_image_req.image_url = f'http://{auth_response.body.bucket}.{auth_response.body.endpoint}/{auth_response.body.object_key}'
customize_classify_image_resp = await self.customize_classify_image_with_options_async(customize_classify_image_req, runtime)
return customize_classify_image_resp
def customize_detect_image_with_options(
self,
request: viapi_regen_20211119_models.CustomizeDetectImageRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CustomizeDetectImageResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.image_url):
body['ImageUrl'] = request.image_url
if not UtilClient.is_unset(request.service_id):
body['ServiceId'] = request.service_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CustomizeDetectImage',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CustomizeDetectImageResponse(),
self.call_api(params, req, runtime)
)
async def customize_detect_image_with_options_async(
self,
request: viapi_regen_20211119_models.CustomizeDetectImageRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CustomizeDetectImageResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.image_url):
body['ImageUrl'] = request.image_url
if not UtilClient.is_unset(request.service_id):
body['ServiceId'] = request.service_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CustomizeDetectImage',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CustomizeDetectImageResponse(),
await self.call_api_async(params, req, runtime)
)
def customize_detect_image(
self,
request: viapi_regen_20211119_models.CustomizeDetectImageRequest,
) -> viapi_regen_20211119_models.CustomizeDetectImageResponse:
runtime = util_models.RuntimeOptions()
return self.customize_detect_image_with_options(request, runtime)
async def customize_detect_image_async(
self,
request: viapi_regen_20211119_models.CustomizeDetectImageRequest,
) -> viapi_regen_20211119_models.CustomizeDetectImageResponse:
runtime = util_models.RuntimeOptions()
return await self.customize_detect_image_with_options_async(request, runtime)
def customize_detect_image_advance(
self,
request: viapi_regen_20211119_models.CustomizeDetectImageAdvanceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CustomizeDetectImageResponse:
# Step 0: init client
access_key_id = self._credential.get_access_key_id()
access_key_secret = self._credential.get_access_key_secret()
security_token = self._credential.get_security_token()
credential_type = self._credential.get_type()
open_platform_endpoint = self._open_platform_endpoint
if UtilClient.is_unset(open_platform_endpoint):
open_platform_endpoint = 'openplatform.aliyuncs.com'
if UtilClient.is_unset(credential_type):
credential_type = 'access_key'
auth_config = open_api_models.Config(
access_key_id=access_key_id,
access_key_secret=access_key_secret,
security_token=security_token,
type=credential_type,
endpoint=open_platform_endpoint,
protocol=self._protocol,
region_id=self._region_id
)
auth_client = OpenPlatformClient(auth_config)
auth_request = open_platform_models.AuthorizeFileUploadRequest(
product='viapi-regen',
region_id=self._region_id
)
auth_response = open_platform_models.AuthorizeFileUploadResponse()
oss_config = oss_models.Config(
access_key_secret=access_key_secret,
type='access_key',
protocol=self._protocol,
region_id=self._region_id
)
oss_client = None
file_obj = file_form_models.FileField()
oss_header = oss_models.PostObjectRequestHeader()
upload_request = oss_models.PostObjectRequest()
oss_runtime = ossutil_models.RuntimeOptions()
OpenApiUtilClient.convert(runtime, oss_runtime)
customize_detect_image_req = viapi_regen_20211119_models.CustomizeDetectImageRequest()
OpenApiUtilClient.convert(request, customize_detect_image_req)
if not UtilClient.is_unset(request.image_url_object):
auth_response = auth_client.authorize_file_upload_with_options(auth_request, runtime)
oss_config.access_key_id = auth_response.body.access_key_id
oss_config.endpoint = OpenApiUtilClient.get_endpoint(auth_response.body.endpoint, auth_response.body.use_accelerate, self._endpoint_type)
oss_client = OSSClient(oss_config)
file_obj = file_form_models.FileField(
filename=auth_response.body.object_key,
content=request.image_url_object,
content_type=''
)
oss_header = oss_models.PostObjectRequestHeader(
access_key_id=auth_response.body.access_key_id,
policy=auth_response.body.encoded_policy,
signature=auth_response.body.signature,
key=auth_response.body.object_key,
file=file_obj,
success_action_status='201'
)
upload_request = oss_models.PostObjectRequest(
bucket_name=auth_response.body.bucket,
header=oss_header
)
oss_client.post_object(upload_request, oss_runtime)
customize_detect_image_req.image_url = f'http://{auth_response.body.bucket}.{auth_response.body.endpoint}/{auth_response.body.object_key}'
customize_detect_image_resp = self.customize_detect_image_with_options(customize_detect_image_req, runtime)
return customize_detect_image_resp
async def customize_detect_image_advance_async(
self,
request: viapi_regen_20211119_models.CustomizeDetectImageAdvanceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CustomizeDetectImageResponse:
# Step 0: init client
access_key_id = await self._credential.get_access_key_id_async()
access_key_secret = await self._credential.get_access_key_secret_async()
security_token = await self._credential.get_security_token_async()
credential_type = self._credential.get_type()
open_platform_endpoint = self._open_platform_endpoint
if UtilClient.is_unset(open_platform_endpoint):
open_platform_endpoint = 'openplatform.aliyuncs.com'
if UtilClient.is_unset(credential_type):
credential_type = 'access_key'
auth_config = open_api_models.Config(
access_key_id=access_key_id,
access_key_secret=access_key_secret,
security_token=security_token,
type=credential_type,
endpoint=open_platform_endpoint,
protocol=self._protocol,
region_id=self._region_id
)
auth_client = OpenPlatformClient(auth_config)
auth_request = open_platform_models.AuthorizeFileUploadRequest(
product='viapi-regen',
region_id=self._region_id
)
auth_response = open_platform_models.AuthorizeFileUploadResponse()
oss_config = oss_models.Config(
access_key_secret=access_key_secret,
type='access_key',
protocol=self._protocol,
region_id=self._region_id
)
oss_client = None
file_obj = file_form_models.FileField()
oss_header = oss_models.PostObjectRequestHeader()
upload_request = oss_models.PostObjectRequest()
oss_runtime = ossutil_models.RuntimeOptions()
OpenApiUtilClient.convert(runtime, oss_runtime)
customize_detect_image_req = viapi_regen_20211119_models.CustomizeDetectImageRequest()
OpenApiUtilClient.convert(request, customize_detect_image_req)
if not UtilClient.is_unset(request.image_url_object):
auth_response = await auth_client.authorize_file_upload_with_options_async(auth_request, runtime)
oss_config.access_key_id = auth_response.body.access_key_id
oss_config.endpoint = OpenApiUtilClient.get_endpoint(auth_response.body.endpoint, auth_response.body.use_accelerate, self._endpoint_type)
oss_client = OSSClient(oss_config)
file_obj = file_form_models.FileField(
filename=auth_response.body.object_key,
content=request.image_url_object,
content_type=''
)
oss_header = oss_models.PostObjectRequestHeader(
access_key_id=auth_response.body.access_key_id,
policy=auth_response.body.encoded_policy,
signature=auth_response.body.signature,
key=auth_response.body.object_key,
file=file_obj,
success_action_status='201'
)
upload_request = oss_models.PostObjectRequest(
bucket_name=auth_response.body.bucket,
header=oss_header
)
await oss_client.post_object_async(upload_request, oss_runtime)
customize_detect_image_req.image_url = f'http://{auth_response.body.bucket}.{auth_response.body.endpoint}/{auth_response.body.object_key}'
customize_detect_image_resp = await self.customize_detect_image_with_options_async(customize_detect_image_req, runtime)
return customize_detect_image_resp
def customize_instance_segment_image_with_options(
self,
request: viapi_regen_20211119_models.CustomizeInstanceSegmentImageRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CustomizeInstanceSegmentImageResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.image_url):
body['ImageUrl'] = request.image_url
if not UtilClient.is_unset(request.service_id):
body['ServiceId'] = request.service_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CustomizeInstanceSegmentImage',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CustomizeInstanceSegmentImageResponse(),
self.call_api(params, req, runtime)
)
async def customize_instance_segment_image_with_options_async(
self,
request: viapi_regen_20211119_models.CustomizeInstanceSegmentImageRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CustomizeInstanceSegmentImageResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.image_url):
body['ImageUrl'] = request.image_url
if not UtilClient.is_unset(request.service_id):
body['ServiceId'] = request.service_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='CustomizeInstanceSegmentImage',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.CustomizeInstanceSegmentImageResponse(),
await self.call_api_async(params, req, runtime)
)
def customize_instance_segment_image(
self,
request: viapi_regen_20211119_models.CustomizeInstanceSegmentImageRequest,
) -> viapi_regen_20211119_models.CustomizeInstanceSegmentImageResponse:
runtime = util_models.RuntimeOptions()
return self.customize_instance_segment_image_with_options(request, runtime)
async def customize_instance_segment_image_async(
self,
request: viapi_regen_20211119_models.CustomizeInstanceSegmentImageRequest,
) -> viapi_regen_20211119_models.CustomizeInstanceSegmentImageResponse:
runtime = util_models.RuntimeOptions()
return await self.customize_instance_segment_image_with_options_async(request, runtime)
def customize_instance_segment_image_advance(
self,
request: viapi_regen_20211119_models.CustomizeInstanceSegmentImageAdvanceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CustomizeInstanceSegmentImageResponse:
# Step 0: init client
access_key_id = self._credential.get_access_key_id()
access_key_secret = self._credential.get_access_key_secret()
security_token = self._credential.get_security_token()
credential_type = self._credential.get_type()
open_platform_endpoint = self._open_platform_endpoint
if UtilClient.is_unset(open_platform_endpoint):
open_platform_endpoint = 'openplatform.aliyuncs.com'
if UtilClient.is_unset(credential_type):
credential_type = 'access_key'
auth_config = open_api_models.Config(
access_key_id=access_key_id,
access_key_secret=access_key_secret,
security_token=security_token,
type=credential_type,
endpoint=open_platform_endpoint,
protocol=self._protocol,
region_id=self._region_id
)
auth_client = OpenPlatformClient(auth_config)
auth_request = open_platform_models.AuthorizeFileUploadRequest(
product='viapi-regen',
region_id=self._region_id
)
auth_response = open_platform_models.AuthorizeFileUploadResponse()
oss_config = oss_models.Config(
access_key_secret=access_key_secret,
type='access_key',
protocol=self._protocol,
region_id=self._region_id
)
oss_client = None
file_obj = file_form_models.FileField()
oss_header = oss_models.PostObjectRequestHeader()
upload_request = oss_models.PostObjectRequest()
oss_runtime = ossutil_models.RuntimeOptions()
OpenApiUtilClient.convert(runtime, oss_runtime)
customize_instance_segment_image_req = viapi_regen_20211119_models.CustomizeInstanceSegmentImageRequest()
OpenApiUtilClient.convert(request, customize_instance_segment_image_req)
if not UtilClient.is_unset(request.image_url_object):
auth_response = auth_client.authorize_file_upload_with_options(auth_request, runtime)
oss_config.access_key_id = auth_response.body.access_key_id
oss_config.endpoint = OpenApiUtilClient.get_endpoint(auth_response.body.endpoint, auth_response.body.use_accelerate, self._endpoint_type)
oss_client = OSSClient(oss_config)
file_obj = file_form_models.FileField(
filename=auth_response.body.object_key,
content=request.image_url_object,
content_type=''
)
oss_header = oss_models.PostObjectRequestHeader(
access_key_id=auth_response.body.access_key_id,
policy=auth_response.body.encoded_policy,
signature=auth_response.body.signature,
key=auth_response.body.object_key,
file=file_obj,
success_action_status='201'
)
upload_request = oss_models.PostObjectRequest(
bucket_name=auth_response.body.bucket,
header=oss_header
)
oss_client.post_object(upload_request, oss_runtime)
customize_instance_segment_image_req.image_url = f'http://{auth_response.body.bucket}.{auth_response.body.endpoint}/{auth_response.body.object_key}'
customize_instance_segment_image_resp = self.customize_instance_segment_image_with_options(customize_instance_segment_image_req, runtime)
return customize_instance_segment_image_resp
async def customize_instance_segment_image_advance_async(
self,
request: viapi_regen_20211119_models.CustomizeInstanceSegmentImageAdvanceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.CustomizeInstanceSegmentImageResponse:
# Step 0: init client
access_key_id = await self._credential.get_access_key_id_async()
access_key_secret = await self._credential.get_access_key_secret_async()
security_token = await self._credential.get_security_token_async()
credential_type = self._credential.get_type()
open_platform_endpoint = self._open_platform_endpoint
if UtilClient.is_unset(open_platform_endpoint):
open_platform_endpoint = 'openplatform.aliyuncs.com'
if UtilClient.is_unset(credential_type):
credential_type = 'access_key'
auth_config = open_api_models.Config(
access_key_id=access_key_id,
access_key_secret=access_key_secret,
security_token=security_token,
type=credential_type,
endpoint=open_platform_endpoint,
protocol=self._protocol,
region_id=self._region_id
)
auth_client = OpenPlatformClient(auth_config)
auth_request = open_platform_models.AuthorizeFileUploadRequest(
product='viapi-regen',
region_id=self._region_id
)
auth_response = open_platform_models.AuthorizeFileUploadResponse()
oss_config = oss_models.Config(
access_key_secret=access_key_secret,
type='access_key',
protocol=self._protocol,
region_id=self._region_id
)
oss_client = None
file_obj = file_form_models.FileField()
oss_header = oss_models.PostObjectRequestHeader()
upload_request = oss_models.PostObjectRequest()
oss_runtime = ossutil_models.RuntimeOptions()
OpenApiUtilClient.convert(runtime, oss_runtime)
customize_instance_segment_image_req = viapi_regen_20211119_models.CustomizeInstanceSegmentImageRequest()
OpenApiUtilClient.convert(request, customize_instance_segment_image_req)
if not UtilClient.is_unset(request.image_url_object):
auth_response = await auth_client.authorize_file_upload_with_options_async(auth_request, runtime)
oss_config.access_key_id = auth_response.body.access_key_id
oss_config.endpoint = OpenApiUtilClient.get_endpoint(auth_response.body.endpoint, auth_response.body.use_accelerate, self._endpoint_type)
oss_client = OSSClient(oss_config)
file_obj = file_form_models.FileField(
filename=auth_response.body.object_key,
content=request.image_url_object,
content_type=''
)
oss_header = oss_models.PostObjectRequestHeader(
access_key_id=auth_response.body.access_key_id,
policy=auth_response.body.encoded_policy,
signature=auth_response.body.signature,
key=auth_response.body.object_key,
file=file_obj,
success_action_status='201'
)
upload_request = oss_models.PostObjectRequest(
bucket_name=auth_response.body.bucket,
header=oss_header
)
await oss_client.post_object_async(upload_request, oss_runtime)
customize_instance_segment_image_req.image_url = f'http://{auth_response.body.bucket}.{auth_response.body.endpoint}/{auth_response.body.object_key}'
customize_instance_segment_image_resp = await self.customize_instance_segment_image_with_options_async(customize_instance_segment_image_req, runtime)
return customize_instance_segment_image_resp
def debug_service_with_options(
self,
request: viapi_regen_20211119_models.DebugServiceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DebugServiceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.param):
body['Param'] = request.param
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DebugService',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DebugServiceResponse(),
self.call_api(params, req, runtime)
)
async def debug_service_with_options_async(
self,
request: viapi_regen_20211119_models.DebugServiceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DebugServiceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.param):
body['Param'] = request.param
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DebugService',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DebugServiceResponse(),
await self.call_api_async(params, req, runtime)
)
def debug_service(
self,
request: viapi_regen_20211119_models.DebugServiceRequest,
) -> viapi_regen_20211119_models.DebugServiceResponse:
runtime = util_models.RuntimeOptions()
return self.debug_service_with_options(request, runtime)
async def debug_service_async(
self,
request: viapi_regen_20211119_models.DebugServiceRequest,
) -> viapi_regen_20211119_models.DebugServiceResponse:
runtime = util_models.RuntimeOptions()
return await self.debug_service_with_options_async(request, runtime)
def delete_data_reflow_data_with_options(
self,
request: viapi_regen_20211119_models.DeleteDataReflowDataRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DeleteDataReflowDataResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.service_id):
body['ServiceId'] = request.service_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DeleteDataReflowData',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DeleteDataReflowDataResponse(),
self.call_api(params, req, runtime)
)
async def delete_data_reflow_data_with_options_async(
self,
request: viapi_regen_20211119_models.DeleteDataReflowDataRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DeleteDataReflowDataResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.service_id):
body['ServiceId'] = request.service_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DeleteDataReflowData',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DeleteDataReflowDataResponse(),
await self.call_api_async(params, req, runtime)
)
def delete_data_reflow_data(
self,
request: viapi_regen_20211119_models.DeleteDataReflowDataRequest,
) -> viapi_regen_20211119_models.DeleteDataReflowDataResponse:
runtime = util_models.RuntimeOptions()
return self.delete_data_reflow_data_with_options(request, runtime)
async def delete_data_reflow_data_async(
self,
request: viapi_regen_20211119_models.DeleteDataReflowDataRequest,
) -> viapi_regen_20211119_models.DeleteDataReflowDataResponse:
runtime = util_models.RuntimeOptions()
return await self.delete_data_reflow_data_with_options_async(request, runtime)
def delete_dataset_with_options(
self,
request: viapi_regen_20211119_models.DeleteDatasetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DeleteDatasetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DeleteDataset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DeleteDatasetResponse(),
self.call_api(params, req, runtime)
)
async def delete_dataset_with_options_async(
self,
request: viapi_regen_20211119_models.DeleteDatasetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DeleteDatasetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DeleteDataset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DeleteDatasetResponse(),
await self.call_api_async(params, req, runtime)
)
def delete_dataset(
self,
request: viapi_regen_20211119_models.DeleteDatasetRequest,
) -> viapi_regen_20211119_models.DeleteDatasetResponse:
runtime = util_models.RuntimeOptions()
return self.delete_dataset_with_options(request, runtime)
async def delete_dataset_async(
self,
request: viapi_regen_20211119_models.DeleteDatasetRequest,
) -> viapi_regen_20211119_models.DeleteDatasetResponse:
runtime = util_models.RuntimeOptions()
return await self.delete_dataset_with_options_async(request, runtime)
def delete_labelset_with_options(
self,
request: viapi_regen_20211119_models.DeleteLabelsetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DeleteLabelsetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DeleteLabelset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DeleteLabelsetResponse(),
self.call_api(params, req, runtime)
)
async def delete_labelset_with_options_async(
self,
request: viapi_regen_20211119_models.DeleteLabelsetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DeleteLabelsetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DeleteLabelset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DeleteLabelsetResponse(),
await self.call_api_async(params, req, runtime)
)
def delete_labelset(
self,
request: viapi_regen_20211119_models.DeleteLabelsetRequest,
) -> viapi_regen_20211119_models.DeleteLabelsetResponse:
runtime = util_models.RuntimeOptions()
return self.delete_labelset_with_options(request, runtime)
async def delete_labelset_async(
self,
request: viapi_regen_20211119_models.DeleteLabelsetRequest,
) -> viapi_regen_20211119_models.DeleteLabelsetResponse:
runtime = util_models.RuntimeOptions()
return await self.delete_labelset_with_options_async(request, runtime)
def delete_labelset_data_with_options(
self,
request: viapi_regen_20211119_models.DeleteLabelsetDataRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DeleteLabelsetDataResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.label_id):
body['LabelId'] = request.label_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DeleteLabelsetData',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DeleteLabelsetDataResponse(),
self.call_api(params, req, runtime)
)
async def delete_labelset_data_with_options_async(
self,
request: viapi_regen_20211119_models.DeleteLabelsetDataRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DeleteLabelsetDataResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.label_id):
body['LabelId'] = request.label_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DeleteLabelsetData',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DeleteLabelsetDataResponse(),
await self.call_api_async(params, req, runtime)
)
def delete_labelset_data(
self,
request: viapi_regen_20211119_models.DeleteLabelsetDataRequest,
) -> viapi_regen_20211119_models.DeleteLabelsetDataResponse:
runtime = util_models.RuntimeOptions()
return self.delete_labelset_data_with_options(request, runtime)
async def delete_labelset_data_async(
self,
request: viapi_regen_20211119_models.DeleteLabelsetDataRequest,
) -> viapi_regen_20211119_models.DeleteLabelsetDataResponse:
runtime = util_models.RuntimeOptions()
return await self.delete_labelset_data_with_options_async(request, runtime)
def delete_service_with_options(
self,
request: viapi_regen_20211119_models.DeleteServiceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DeleteServiceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DeleteService',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DeleteServiceResponse(),
self.call_api(params, req, runtime)
)
async def delete_service_with_options_async(
self,
request: viapi_regen_20211119_models.DeleteServiceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DeleteServiceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DeleteService',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DeleteServiceResponse(),
await self.call_api_async(params, req, runtime)
)
def delete_service(
self,
request: viapi_regen_20211119_models.DeleteServiceRequest,
) -> viapi_regen_20211119_models.DeleteServiceResponse:
runtime = util_models.RuntimeOptions()
return self.delete_service_with_options(request, runtime)
async def delete_service_async(
self,
request: viapi_regen_20211119_models.DeleteServiceRequest,
) -> viapi_regen_20211119_models.DeleteServiceResponse:
runtime = util_models.RuntimeOptions()
return await self.delete_service_with_options_async(request, runtime)
def delete_train_task_with_options(
self,
request: viapi_regen_20211119_models.DeleteTrainTaskRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DeleteTrainTaskResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DeleteTrainTask',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DeleteTrainTaskResponse(),
self.call_api(params, req, runtime)
)
async def delete_train_task_with_options_async(
self,
request: viapi_regen_20211119_models.DeleteTrainTaskRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DeleteTrainTaskResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DeleteTrainTask',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DeleteTrainTaskResponse(),
await self.call_api_async(params, req, runtime)
)
def delete_train_task(
self,
request: viapi_regen_20211119_models.DeleteTrainTaskRequest,
) -> viapi_regen_20211119_models.DeleteTrainTaskResponse:
runtime = util_models.RuntimeOptions()
return self.delete_train_task_with_options(request, runtime)
async def delete_train_task_async(
self,
request: viapi_regen_20211119_models.DeleteTrainTaskRequest,
) -> viapi_regen_20211119_models.DeleteTrainTaskResponse:
runtime = util_models.RuntimeOptions()
return await self.delete_train_task_with_options_async(request, runtime)
def delete_workspace_with_options(
self,
request: viapi_regen_20211119_models.DeleteWorkspaceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DeleteWorkspaceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DeleteWorkspace',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DeleteWorkspaceResponse(),
self.call_api(params, req, runtime)
)
async def delete_workspace_with_options_async(
self,
request: viapi_regen_20211119_models.DeleteWorkspaceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DeleteWorkspaceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DeleteWorkspace',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DeleteWorkspaceResponse(),
await self.call_api_async(params, req, runtime)
)
def delete_workspace(
self,
request: viapi_regen_20211119_models.DeleteWorkspaceRequest,
) -> viapi_regen_20211119_models.DeleteWorkspaceResponse:
runtime = util_models.RuntimeOptions()
return self.delete_workspace_with_options(request, runtime)
async def delete_workspace_async(
self,
request: viapi_regen_20211119_models.DeleteWorkspaceRequest,
) -> viapi_regen_20211119_models.DeleteWorkspaceResponse:
runtime = util_models.RuntimeOptions()
return await self.delete_workspace_with_options_async(request, runtime)
def disable_data_reflow_with_options(
self,
request: viapi_regen_20211119_models.DisableDataReflowRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DisableDataReflowResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.service_id):
body['ServiceId'] = request.service_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DisableDataReflow',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DisableDataReflowResponse(),
self.call_api(params, req, runtime)
)
async def disable_data_reflow_with_options_async(
self,
request: viapi_regen_20211119_models.DisableDataReflowRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DisableDataReflowResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.service_id):
body['ServiceId'] = request.service_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DisableDataReflow',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DisableDataReflowResponse(),
await self.call_api_async(params, req, runtime)
)
def disable_data_reflow(
self,
request: viapi_regen_20211119_models.DisableDataReflowRequest,
) -> viapi_regen_20211119_models.DisableDataReflowResponse:
runtime = util_models.RuntimeOptions()
return self.disable_data_reflow_with_options(request, runtime)
async def disable_data_reflow_async(
self,
request: viapi_regen_20211119_models.DisableDataReflowRequest,
) -> viapi_regen_20211119_models.DisableDataReflowResponse:
runtime = util_models.RuntimeOptions()
return await self.disable_data_reflow_with_options_async(request, runtime)
def download_dataset_with_options(
self,
request: viapi_regen_20211119_models.DownloadDatasetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DownloadDatasetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.dataset_id):
body['DatasetId'] = request.dataset_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DownloadDataset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DownloadDatasetResponse(),
self.call_api(params, req, runtime)
)
async def download_dataset_with_options_async(
self,
request: viapi_regen_20211119_models.DownloadDatasetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DownloadDatasetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.dataset_id):
body['DatasetId'] = request.dataset_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DownloadDataset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DownloadDatasetResponse(),
await self.call_api_async(params, req, runtime)
)
def download_dataset(
self,
request: viapi_regen_20211119_models.DownloadDatasetRequest,
) -> viapi_regen_20211119_models.DownloadDatasetResponse:
runtime = util_models.RuntimeOptions()
return self.download_dataset_with_options(request, runtime)
async def download_dataset_async(
self,
request: viapi_regen_20211119_models.DownloadDatasetRequest,
) -> viapi_regen_20211119_models.DownloadDatasetResponse:
runtime = util_models.RuntimeOptions()
return await self.download_dataset_with_options_async(request, runtime)
def download_file_name_list_with_options(
self,
request: viapi_regen_20211119_models.DownloadFileNameListRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DownloadFileNameListResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.dataset_id):
body['DatasetId'] = request.dataset_id
if not UtilClient.is_unset(request.identity):
body['Identity'] = request.identity
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DownloadFileNameList',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DownloadFileNameListResponse(),
self.call_api(params, req, runtime)
)
async def download_file_name_list_with_options_async(
self,
request: viapi_regen_20211119_models.DownloadFileNameListRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DownloadFileNameListResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.dataset_id):
body['DatasetId'] = request.dataset_id
if not UtilClient.is_unset(request.identity):
body['Identity'] = request.identity
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DownloadFileNameList',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DownloadFileNameListResponse(),
await self.call_api_async(params, req, runtime)
)
def download_file_name_list(
self,
request: viapi_regen_20211119_models.DownloadFileNameListRequest,
) -> viapi_regen_20211119_models.DownloadFileNameListResponse:
runtime = util_models.RuntimeOptions()
return self.download_file_name_list_with_options(request, runtime)
async def download_file_name_list_async(
self,
request: viapi_regen_20211119_models.DownloadFileNameListRequest,
) -> viapi_regen_20211119_models.DownloadFileNameListResponse:
runtime = util_models.RuntimeOptions()
return await self.download_file_name_list_with_options_async(request, runtime)
def download_label_file_with_options(
self,
request: viapi_regen_20211119_models.DownloadLabelFileRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DownloadLabelFileResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.label_id):
body['LabelId'] = request.label_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DownloadLabelFile',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DownloadLabelFileResponse(),
self.call_api(params, req, runtime)
)
async def download_label_file_with_options_async(
self,
request: viapi_regen_20211119_models.DownloadLabelFileRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.DownloadLabelFileResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.label_id):
body['LabelId'] = request.label_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='DownloadLabelFile',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.DownloadLabelFileResponse(),
await self.call_api_async(params, req, runtime)
)
def download_label_file(
self,
request: viapi_regen_20211119_models.DownloadLabelFileRequest,
) -> viapi_regen_20211119_models.DownloadLabelFileResponse:
runtime = util_models.RuntimeOptions()
return self.download_label_file_with_options(request, runtime)
async def download_label_file_async(
self,
request: viapi_regen_20211119_models.DownloadLabelFileRequest,
) -> viapi_regen_20211119_models.DownloadLabelFileResponse:
runtime = util_models.RuntimeOptions()
return await self.download_label_file_with_options_async(request, runtime)
def enable_data_reflow_with_options(
self,
request: viapi_regen_20211119_models.EnableDataReflowRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.EnableDataReflowResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.data_reflow_oss_path):
body['DataReflowOssPath'] = request.data_reflow_oss_path
if not UtilClient.is_unset(request.data_reflow_rate):
body['DataReflowRate'] = request.data_reflow_rate
if not UtilClient.is_unset(request.service_id):
body['ServiceId'] = request.service_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='EnableDataReflow',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.EnableDataReflowResponse(),
self.call_api(params, req, runtime)
)
async def enable_data_reflow_with_options_async(
self,
request: viapi_regen_20211119_models.EnableDataReflowRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.EnableDataReflowResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.data_reflow_oss_path):
body['DataReflowOssPath'] = request.data_reflow_oss_path
if not UtilClient.is_unset(request.data_reflow_rate):
body['DataReflowRate'] = request.data_reflow_rate
if not UtilClient.is_unset(request.service_id):
body['ServiceId'] = request.service_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='EnableDataReflow',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.EnableDataReflowResponse(),
await self.call_api_async(params, req, runtime)
)
def enable_data_reflow(
self,
request: viapi_regen_20211119_models.EnableDataReflowRequest,
) -> viapi_regen_20211119_models.EnableDataReflowResponse:
runtime = util_models.RuntimeOptions()
return self.enable_data_reflow_with_options(request, runtime)
async def enable_data_reflow_async(
self,
request: viapi_regen_20211119_models.EnableDataReflowRequest,
) -> viapi_regen_20211119_models.EnableDataReflowResponse:
runtime = util_models.RuntimeOptions()
return await self.enable_data_reflow_with_options_async(request, runtime)
def export_data_reflow_data_list_with_options(
self,
request: viapi_regen_20211119_models.ExportDataReflowDataListRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ExportDataReflowDataListResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.category):
body['Category'] = request.category
if not UtilClient.is_unset(request.end_time):
body['EndTime'] = request.end_time
if not UtilClient.is_unset(request.file_type):
body['FileType'] = request.file_type
if not UtilClient.is_unset(request.image_name):
body['ImageName'] = request.image_name
if not UtilClient.is_unset(request.service_id):
body['ServiceId'] = request.service_id
if not UtilClient.is_unset(request.start_time):
body['StartTime'] = request.start_time
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ExportDataReflowDataList',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ExportDataReflowDataListResponse(),
self.call_api(params, req, runtime)
)
async def export_data_reflow_data_list_with_options_async(
self,
request: viapi_regen_20211119_models.ExportDataReflowDataListRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ExportDataReflowDataListResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.category):
body['Category'] = request.category
if not UtilClient.is_unset(request.end_time):
body['EndTime'] = request.end_time
if not UtilClient.is_unset(request.file_type):
body['FileType'] = request.file_type
if not UtilClient.is_unset(request.image_name):
body['ImageName'] = request.image_name
if not UtilClient.is_unset(request.service_id):
body['ServiceId'] = request.service_id
if not UtilClient.is_unset(request.start_time):
body['StartTime'] = request.start_time
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ExportDataReflowDataList',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ExportDataReflowDataListResponse(),
await self.call_api_async(params, req, runtime)
)
def export_data_reflow_data_list(
self,
request: viapi_regen_20211119_models.ExportDataReflowDataListRequest,
) -> viapi_regen_20211119_models.ExportDataReflowDataListResponse:
runtime = util_models.RuntimeOptions()
return self.export_data_reflow_data_list_with_options(request, runtime)
async def export_data_reflow_data_list_async(
self,
request: viapi_regen_20211119_models.ExportDataReflowDataListRequest,
) -> viapi_regen_20211119_models.ExportDataReflowDataListResponse:
runtime = util_models.RuntimeOptions()
return await self.export_data_reflow_data_list_with_options_async(request, runtime)
def get_dataset_with_options(
self,
request: viapi_regen_20211119_models.GetDatasetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetDatasetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetDataset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetDatasetResponse(),
self.call_api(params, req, runtime)
)
async def get_dataset_with_options_async(
self,
request: viapi_regen_20211119_models.GetDatasetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetDatasetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetDataset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetDatasetResponse(),
await self.call_api_async(params, req, runtime)
)
def get_dataset(
self,
request: viapi_regen_20211119_models.GetDatasetRequest,
) -> viapi_regen_20211119_models.GetDatasetResponse:
runtime = util_models.RuntimeOptions()
return self.get_dataset_with_options(request, runtime)
async def get_dataset_async(
self,
request: viapi_regen_20211119_models.GetDatasetRequest,
) -> viapi_regen_20211119_models.GetDatasetResponse:
runtime = util_models.RuntimeOptions()
return await self.get_dataset_with_options_async(request, runtime)
def get_diff_count_labelset_and_dataset_with_options(
self,
request: viapi_regen_20211119_models.GetDiffCountLabelsetAndDatasetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetDiffCountLabelsetAndDatasetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.labelset_id):
body['LabelsetId'] = request.labelset_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetDiffCountLabelsetAndDataset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetDiffCountLabelsetAndDatasetResponse(),
self.call_api(params, req, runtime)
)
async def get_diff_count_labelset_and_dataset_with_options_async(
self,
request: viapi_regen_20211119_models.GetDiffCountLabelsetAndDatasetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetDiffCountLabelsetAndDatasetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.labelset_id):
body['LabelsetId'] = request.labelset_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetDiffCountLabelsetAndDataset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetDiffCountLabelsetAndDatasetResponse(),
await self.call_api_async(params, req, runtime)
)
def get_diff_count_labelset_and_dataset(
self,
request: viapi_regen_20211119_models.GetDiffCountLabelsetAndDatasetRequest,
) -> viapi_regen_20211119_models.GetDiffCountLabelsetAndDatasetResponse:
runtime = util_models.RuntimeOptions()
return self.get_diff_count_labelset_and_dataset_with_options(request, runtime)
async def get_diff_count_labelset_and_dataset_async(
self,
request: viapi_regen_20211119_models.GetDiffCountLabelsetAndDatasetRequest,
) -> viapi_regen_20211119_models.GetDiffCountLabelsetAndDatasetResponse:
runtime = util_models.RuntimeOptions()
return await self.get_diff_count_labelset_and_dataset_with_options_async(request, runtime)
def get_label_detail_with_options(
self,
request: viapi_regen_20211119_models.GetLabelDetailRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetLabelDetailResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetLabelDetail',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetLabelDetailResponse(),
self.call_api(params, req, runtime)
)
async def get_label_detail_with_options_async(
self,
request: viapi_regen_20211119_models.GetLabelDetailRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetLabelDetailResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetLabelDetail',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetLabelDetailResponse(),
await self.call_api_async(params, req, runtime)
)
def get_label_detail(
self,
request: viapi_regen_20211119_models.GetLabelDetailRequest,
) -> viapi_regen_20211119_models.GetLabelDetailResponse:
runtime = util_models.RuntimeOptions()
return self.get_label_detail_with_options(request, runtime)
async def get_label_detail_async(
self,
request: viapi_regen_20211119_models.GetLabelDetailRequest,
) -> viapi_regen_20211119_models.GetLabelDetailResponse:
runtime = util_models.RuntimeOptions()
return await self.get_label_detail_with_options_async(request, runtime)
def get_labelset_with_options(
self,
request: viapi_regen_20211119_models.GetLabelsetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetLabelsetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetLabelset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetLabelsetResponse(),
self.call_api(params, req, runtime)
)
async def get_labelset_with_options_async(
self,
request: viapi_regen_20211119_models.GetLabelsetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetLabelsetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetLabelset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetLabelsetResponse(),
await self.call_api_async(params, req, runtime)
)
def get_labelset(
self,
request: viapi_regen_20211119_models.GetLabelsetRequest,
) -> viapi_regen_20211119_models.GetLabelsetResponse:
runtime = util_models.RuntimeOptions()
return self.get_labelset_with_options(request, runtime)
async def get_labelset_async(
self,
request: viapi_regen_20211119_models.GetLabelsetRequest,
) -> viapi_regen_20211119_models.GetLabelsetResponse:
runtime = util_models.RuntimeOptions()
return await self.get_labelset_with_options_async(request, runtime)
def get_service_with_options(
self,
request: viapi_regen_20211119_models.GetServiceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetServiceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetService',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetServiceResponse(),
self.call_api(params, req, runtime)
)
async def get_service_with_options_async(
self,
request: viapi_regen_20211119_models.GetServiceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetServiceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetService',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetServiceResponse(),
await self.call_api_async(params, req, runtime)
)
def get_service(
self,
request: viapi_regen_20211119_models.GetServiceRequest,
) -> viapi_regen_20211119_models.GetServiceResponse:
runtime = util_models.RuntimeOptions()
return self.get_service_with_options(request, runtime)
async def get_service_async(
self,
request: viapi_regen_20211119_models.GetServiceRequest,
) -> viapi_regen_20211119_models.GetServiceResponse:
runtime = util_models.RuntimeOptions()
return await self.get_service_with_options_async(request, runtime)
def get_service_invoke_with_options(
self,
tmp_req: viapi_regen_20211119_models.GetServiceInvokeRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetServiceInvokeResponse:
UtilClient.validate_model(tmp_req)
request = viapi_regen_20211119_models.GetServiceInvokeShrinkRequest()
OpenApiUtilClient.convert(tmp_req, request)
if not UtilClient.is_unset(tmp_req.caller_parent_id_list):
request.caller_parent_id_list_shrink = OpenApiUtilClient.array_to_string_with_specified_style(tmp_req.caller_parent_id_list, 'CallerParentIdList', 'json')
body = {}
if not UtilClient.is_unset(request.caller_parent_id_list_shrink):
body['CallerParentIdList'] = request.caller_parent_id_list_shrink
if not UtilClient.is_unset(request.end_time):
body['EndTime'] = request.end_time
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.start_time):
body['StartTime'] = request.start_time
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetServiceInvoke',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetServiceInvokeResponse(),
self.call_api(params, req, runtime)
)
async def get_service_invoke_with_options_async(
self,
tmp_req: viapi_regen_20211119_models.GetServiceInvokeRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetServiceInvokeResponse:
UtilClient.validate_model(tmp_req)
request = viapi_regen_20211119_models.GetServiceInvokeShrinkRequest()
OpenApiUtilClient.convert(tmp_req, request)
if not UtilClient.is_unset(tmp_req.caller_parent_id_list):
request.caller_parent_id_list_shrink = OpenApiUtilClient.array_to_string_with_specified_style(tmp_req.caller_parent_id_list, 'CallerParentIdList', 'json')
body = {}
if not UtilClient.is_unset(request.caller_parent_id_list_shrink):
body['CallerParentIdList'] = request.caller_parent_id_list_shrink
if not UtilClient.is_unset(request.end_time):
body['EndTime'] = request.end_time
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.start_time):
body['StartTime'] = request.start_time
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetServiceInvoke',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetServiceInvokeResponse(),
await self.call_api_async(params, req, runtime)
)
def get_service_invoke(
self,
request: viapi_regen_20211119_models.GetServiceInvokeRequest,
) -> viapi_regen_20211119_models.GetServiceInvokeResponse:
runtime = util_models.RuntimeOptions()
return self.get_service_invoke_with_options(request, runtime)
async def get_service_invoke_async(
self,
request: viapi_regen_20211119_models.GetServiceInvokeRequest,
) -> viapi_regen_20211119_models.GetServiceInvokeResponse:
runtime = util_models.RuntimeOptions()
return await self.get_service_invoke_with_options_async(request, runtime)
def get_service_qps_with_options(
self,
tmp_req: viapi_regen_20211119_models.GetServiceQpsRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetServiceQpsResponse:
UtilClient.validate_model(tmp_req)
request = viapi_regen_20211119_models.GetServiceQpsShrinkRequest()
OpenApiUtilClient.convert(tmp_req, request)
if not UtilClient.is_unset(tmp_req.caller_parent_id_list):
request.caller_parent_id_list_shrink = OpenApiUtilClient.array_to_string_with_specified_style(tmp_req.caller_parent_id_list, 'CallerParentIdList', 'json')
body = {}
if not UtilClient.is_unset(request.caller_parent_id_list_shrink):
body['CallerParentIdList'] = request.caller_parent_id_list_shrink
if not UtilClient.is_unset(request.end_time):
body['EndTime'] = request.end_time
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.start_time):
body['StartTime'] = request.start_time
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetServiceQps',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetServiceQpsResponse(),
self.call_api(params, req, runtime)
)
async def get_service_qps_with_options_async(
self,
tmp_req: viapi_regen_20211119_models.GetServiceQpsRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetServiceQpsResponse:
UtilClient.validate_model(tmp_req)
request = viapi_regen_20211119_models.GetServiceQpsShrinkRequest()
OpenApiUtilClient.convert(tmp_req, request)
if not UtilClient.is_unset(tmp_req.caller_parent_id_list):
request.caller_parent_id_list_shrink = OpenApiUtilClient.array_to_string_with_specified_style(tmp_req.caller_parent_id_list, 'CallerParentIdList', 'json')
body = {}
if not UtilClient.is_unset(request.caller_parent_id_list_shrink):
body['CallerParentIdList'] = request.caller_parent_id_list_shrink
if not UtilClient.is_unset(request.end_time):
body['EndTime'] = request.end_time
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.start_time):
body['StartTime'] = request.start_time
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetServiceQps',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetServiceQpsResponse(),
await self.call_api_async(params, req, runtime)
)
def get_service_qps(
self,
request: viapi_regen_20211119_models.GetServiceQpsRequest,
) -> viapi_regen_20211119_models.GetServiceQpsResponse:
runtime = util_models.RuntimeOptions()
return self.get_service_qps_with_options(request, runtime)
async def get_service_qps_async(
self,
request: viapi_regen_20211119_models.GetServiceQpsRequest,
) -> viapi_regen_20211119_models.GetServiceQpsResponse:
runtime = util_models.RuntimeOptions()
return await self.get_service_qps_with_options_async(request, runtime)
def get_train_model_with_options(
self,
request: viapi_regen_20211119_models.GetTrainModelRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetTrainModelResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetTrainModel',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetTrainModelResponse(),
self.call_api(params, req, runtime)
)
async def get_train_model_with_options_async(
self,
request: viapi_regen_20211119_models.GetTrainModelRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetTrainModelResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetTrainModel',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetTrainModelResponse(),
await self.call_api_async(params, req, runtime)
)
def get_train_model(
self,
request: viapi_regen_20211119_models.GetTrainModelRequest,
) -> viapi_regen_20211119_models.GetTrainModelResponse:
runtime = util_models.RuntimeOptions()
return self.get_train_model_with_options(request, runtime)
async def get_train_model_async(
self,
request: viapi_regen_20211119_models.GetTrainModelRequest,
) -> viapi_regen_20211119_models.GetTrainModelResponse:
runtime = util_models.RuntimeOptions()
return await self.get_train_model_with_options_async(request, runtime)
def get_train_task_with_options(
self,
request: viapi_regen_20211119_models.GetTrainTaskRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetTrainTaskResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetTrainTask',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetTrainTaskResponse(),
self.call_api(params, req, runtime)
)
async def get_train_task_with_options_async(
self,
request: viapi_regen_20211119_models.GetTrainTaskRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetTrainTaskResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetTrainTask',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetTrainTaskResponse(),
await self.call_api_async(params, req, runtime)
)
def get_train_task(
self,
request: viapi_regen_20211119_models.GetTrainTaskRequest,
) -> viapi_regen_20211119_models.GetTrainTaskResponse:
runtime = util_models.RuntimeOptions()
return self.get_train_task_with_options(request, runtime)
async def get_train_task_async(
self,
request: viapi_regen_20211119_models.GetTrainTaskRequest,
) -> viapi_regen_20211119_models.GetTrainTaskResponse:
runtime = util_models.RuntimeOptions()
return await self.get_train_task_with_options_async(request, runtime)
def get_train_task_estimated_time_with_options(
self,
request: viapi_regen_20211119_models.GetTrainTaskEstimatedTimeRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetTrainTaskEstimatedTimeResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetTrainTaskEstimatedTime',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetTrainTaskEstimatedTimeResponse(),
self.call_api(params, req, runtime)
)
async def get_train_task_estimated_time_with_options_async(
self,
request: viapi_regen_20211119_models.GetTrainTaskEstimatedTimeRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetTrainTaskEstimatedTimeResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetTrainTaskEstimatedTime',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetTrainTaskEstimatedTimeResponse(),
await self.call_api_async(params, req, runtime)
)
def get_train_task_estimated_time(
self,
request: viapi_regen_20211119_models.GetTrainTaskEstimatedTimeRequest,
) -> viapi_regen_20211119_models.GetTrainTaskEstimatedTimeResponse:
runtime = util_models.RuntimeOptions()
return self.get_train_task_estimated_time_with_options(request, runtime)
async def get_train_task_estimated_time_async(
self,
request: viapi_regen_20211119_models.GetTrainTaskEstimatedTimeRequest,
) -> viapi_regen_20211119_models.GetTrainTaskEstimatedTimeResponse:
runtime = util_models.RuntimeOptions()
return await self.get_train_task_estimated_time_with_options_async(request, runtime)
def get_upload_policy_with_options(
self,
request: viapi_regen_20211119_models.GetUploadPolicyRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetUploadPolicyResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.file_name):
body['FileName'] = request.file_name
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.type):
body['Type'] = request.type
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetUploadPolicy',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetUploadPolicyResponse(),
self.call_api(params, req, runtime)
)
async def get_upload_policy_with_options_async(
self,
request: viapi_regen_20211119_models.GetUploadPolicyRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetUploadPolicyResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.file_name):
body['FileName'] = request.file_name
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.type):
body['Type'] = request.type
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetUploadPolicy',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetUploadPolicyResponse(),
await self.call_api_async(params, req, runtime)
)
def get_upload_policy(
self,
request: viapi_regen_20211119_models.GetUploadPolicyRequest,
) -> viapi_regen_20211119_models.GetUploadPolicyResponse:
runtime = util_models.RuntimeOptions()
return self.get_upload_policy_with_options(request, runtime)
async def get_upload_policy_async(
self,
request: viapi_regen_20211119_models.GetUploadPolicyRequest,
) -> viapi_regen_20211119_models.GetUploadPolicyResponse:
runtime = util_models.RuntimeOptions()
return await self.get_upload_policy_with_options_async(request, runtime)
def get_user_info_with_options(
self,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetUserInfoResponse:
req = open_api_models.OpenApiRequest()
params = open_api_models.Params(
action='GetUserInfo',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetUserInfoResponse(),
self.call_api(params, req, runtime)
)
async def get_user_info_with_options_async(
self,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetUserInfoResponse:
req = open_api_models.OpenApiRequest()
params = open_api_models.Params(
action='GetUserInfo',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetUserInfoResponse(),
await self.call_api_async(params, req, runtime)
)
def get_user_info(self) -> viapi_regen_20211119_models.GetUserInfoResponse:
runtime = util_models.RuntimeOptions()
return self.get_user_info_with_options(runtime)
async def get_user_info_async(self) -> viapi_regen_20211119_models.GetUserInfoResponse:
runtime = util_models.RuntimeOptions()
return await self.get_user_info_with_options_async(runtime)
def get_workspace_with_options(
self,
request: viapi_regen_20211119_models.GetWorkspaceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetWorkspaceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetWorkspace',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetWorkspaceResponse(),
self.call_api(params, req, runtime)
)
async def get_workspace_with_options_async(
self,
request: viapi_regen_20211119_models.GetWorkspaceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.GetWorkspaceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='GetWorkspace',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.GetWorkspaceResponse(),
await self.call_api_async(params, req, runtime)
)
def get_workspace(
self,
request: viapi_regen_20211119_models.GetWorkspaceRequest,
) -> viapi_regen_20211119_models.GetWorkspaceResponse:
runtime = util_models.RuntimeOptions()
return self.get_workspace_with_options(request, runtime)
async def get_workspace_async(
self,
request: viapi_regen_20211119_models.GetWorkspaceRequest,
) -> viapi_regen_20211119_models.GetWorkspaceResponse:
runtime = util_models.RuntimeOptions()
return await self.get_workspace_with_options_async(request, runtime)
def list_data_reflow_datas_with_options(
self,
request: viapi_regen_20211119_models.ListDataReflowDatasRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ListDataReflowDatasResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.category):
body['Category'] = request.category
if not UtilClient.is_unset(request.current_page):
body['CurrentPage'] = request.current_page
if not UtilClient.is_unset(request.end_time):
body['EndTime'] = request.end_time
if not UtilClient.is_unset(request.image_name):
body['ImageName'] = request.image_name
if not UtilClient.is_unset(request.page_size):
body['PageSize'] = request.page_size
if not UtilClient.is_unset(request.service_id):
body['ServiceId'] = request.service_id
if not UtilClient.is_unset(request.start_time):
body['StartTime'] = request.start_time
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ListDataReflowDatas',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ListDataReflowDatasResponse(),
self.call_api(params, req, runtime)
)
async def list_data_reflow_datas_with_options_async(
self,
request: viapi_regen_20211119_models.ListDataReflowDatasRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ListDataReflowDatasResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.category):
body['Category'] = request.category
if not UtilClient.is_unset(request.current_page):
body['CurrentPage'] = request.current_page
if not UtilClient.is_unset(request.end_time):
body['EndTime'] = request.end_time
if not UtilClient.is_unset(request.image_name):
body['ImageName'] = request.image_name
if not UtilClient.is_unset(request.page_size):
body['PageSize'] = request.page_size
if not UtilClient.is_unset(request.service_id):
body['ServiceId'] = request.service_id
if not UtilClient.is_unset(request.start_time):
body['StartTime'] = request.start_time
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ListDataReflowDatas',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ListDataReflowDatasResponse(),
await self.call_api_async(params, req, runtime)
)
def list_data_reflow_datas(
self,
request: viapi_regen_20211119_models.ListDataReflowDatasRequest,
) -> viapi_regen_20211119_models.ListDataReflowDatasResponse:
runtime = util_models.RuntimeOptions()
return self.list_data_reflow_datas_with_options(request, runtime)
async def list_data_reflow_datas_async(
self,
request: viapi_regen_20211119_models.ListDataReflowDatasRequest,
) -> viapi_regen_20211119_models.ListDataReflowDatasResponse:
runtime = util_models.RuntimeOptions()
return await self.list_data_reflow_datas_with_options_async(request, runtime)
def list_dataset_datas_with_options(
self,
request: viapi_regen_20211119_models.ListDatasetDatasRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ListDatasetDatasResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.current_page):
body['CurrentPage'] = request.current_page
if not UtilClient.is_unset(request.dataset_id):
body['DatasetId'] = request.dataset_id
if not UtilClient.is_unset(request.identity):
body['Identity'] = request.identity
if not UtilClient.is_unset(request.page_size):
body['PageSize'] = request.page_size
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ListDatasetDatas',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ListDatasetDatasResponse(),
self.call_api(params, req, runtime)
)
async def list_dataset_datas_with_options_async(
self,
request: viapi_regen_20211119_models.ListDatasetDatasRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ListDatasetDatasResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.current_page):
body['CurrentPage'] = request.current_page
if not UtilClient.is_unset(request.dataset_id):
body['DatasetId'] = request.dataset_id
if not UtilClient.is_unset(request.identity):
body['Identity'] = request.identity
if not UtilClient.is_unset(request.page_size):
body['PageSize'] = request.page_size
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ListDatasetDatas',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ListDatasetDatasResponse(),
await self.call_api_async(params, req, runtime)
)
def list_dataset_datas(
self,
request: viapi_regen_20211119_models.ListDatasetDatasRequest,
) -> viapi_regen_20211119_models.ListDatasetDatasResponse:
runtime = util_models.RuntimeOptions()
return self.list_dataset_datas_with_options(request, runtime)
async def list_dataset_datas_async(
self,
request: viapi_regen_20211119_models.ListDatasetDatasRequest,
) -> viapi_regen_20211119_models.ListDatasetDatasResponse:
runtime = util_models.RuntimeOptions()
return await self.list_dataset_datas_with_options_async(request, runtime)
def list_datasets_with_options(
self,
request: viapi_regen_20211119_models.ListDatasetsRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ListDatasetsResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.current_page):
body['CurrentPage'] = request.current_page
if not UtilClient.is_unset(request.page_size):
body['PageSize'] = request.page_size
if not UtilClient.is_unset(request.workspace_id):
body['WorkspaceId'] = request.workspace_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ListDatasets',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ListDatasetsResponse(),
self.call_api(params, req, runtime)
)
async def list_datasets_with_options_async(
self,
request: viapi_regen_20211119_models.ListDatasetsRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ListDatasetsResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.current_page):
body['CurrentPage'] = request.current_page
if not UtilClient.is_unset(request.page_size):
body['PageSize'] = request.page_size
if not UtilClient.is_unset(request.workspace_id):
body['WorkspaceId'] = request.workspace_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ListDatasets',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ListDatasetsResponse(),
await self.call_api_async(params, req, runtime)
)
def list_datasets(
self,
request: viapi_regen_20211119_models.ListDatasetsRequest,
) -> viapi_regen_20211119_models.ListDatasetsResponse:
runtime = util_models.RuntimeOptions()
return self.list_datasets_with_options(request, runtime)
async def list_datasets_async(
self,
request: viapi_regen_20211119_models.ListDatasetsRequest,
) -> viapi_regen_20211119_models.ListDatasetsResponse:
runtime = util_models.RuntimeOptions()
return await self.list_datasets_with_options_async(request, runtime)
def list_labelset_datas_with_options(
self,
request: viapi_regen_20211119_models.ListLabelsetDatasRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ListLabelsetDatasResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.current_page):
body['CurrentPage'] = request.current_page
if not UtilClient.is_unset(request.is_abandon):
body['IsAbandon'] = request.is_abandon
if not UtilClient.is_unset(request.label_id):
body['LabelId'] = request.label_id
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.operation):
body['Operation'] = request.operation
if not UtilClient.is_unset(request.page_size):
body['PageSize'] = request.page_size
if not UtilClient.is_unset(request.value):
body['Value'] = request.value
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ListLabelsetDatas',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ListLabelsetDatasResponse(),
self.call_api(params, req, runtime)
)
async def list_labelset_datas_with_options_async(
self,
request: viapi_regen_20211119_models.ListLabelsetDatasRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ListLabelsetDatasResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.current_page):
body['CurrentPage'] = request.current_page
if not UtilClient.is_unset(request.is_abandon):
body['IsAbandon'] = request.is_abandon
if not UtilClient.is_unset(request.label_id):
body['LabelId'] = request.label_id
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.operation):
body['Operation'] = request.operation
if not UtilClient.is_unset(request.page_size):
body['PageSize'] = request.page_size
if not UtilClient.is_unset(request.value):
body['Value'] = request.value
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ListLabelsetDatas',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ListLabelsetDatasResponse(),
await self.call_api_async(params, req, runtime)
)
def list_labelset_datas(
self,
request: viapi_regen_20211119_models.ListLabelsetDatasRequest,
) -> viapi_regen_20211119_models.ListLabelsetDatasResponse:
runtime = util_models.RuntimeOptions()
return self.list_labelset_datas_with_options(request, runtime)
async def list_labelset_datas_async(
self,
request: viapi_regen_20211119_models.ListLabelsetDatasRequest,
) -> viapi_regen_20211119_models.ListLabelsetDatasResponse:
runtime = util_models.RuntimeOptions()
return await self.list_labelset_datas_with_options_async(request, runtime)
def list_labelsets_with_options(
self,
request: viapi_regen_20211119_models.ListLabelsetsRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ListLabelsetsResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.current_page):
body['CurrentPage'] = request.current_page
if not UtilClient.is_unset(request.dataset_id):
body['DatasetId'] = request.dataset_id
if not UtilClient.is_unset(request.page_size):
body['PageSize'] = request.page_size
if not UtilClient.is_unset(request.status):
body['Status'] = request.status
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ListLabelsets',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ListLabelsetsResponse(),
self.call_api(params, req, runtime)
)
async def list_labelsets_with_options_async(
self,
request: viapi_regen_20211119_models.ListLabelsetsRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ListLabelsetsResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.current_page):
body['CurrentPage'] = request.current_page
if not UtilClient.is_unset(request.dataset_id):
body['DatasetId'] = request.dataset_id
if not UtilClient.is_unset(request.page_size):
body['PageSize'] = request.page_size
if not UtilClient.is_unset(request.status):
body['Status'] = request.status
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ListLabelsets',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ListLabelsetsResponse(),
await self.call_api_async(params, req, runtime)
)
def list_labelsets(
self,
request: viapi_regen_20211119_models.ListLabelsetsRequest,
) -> viapi_regen_20211119_models.ListLabelsetsResponse:
runtime = util_models.RuntimeOptions()
return self.list_labelsets_with_options(request, runtime)
async def list_labelsets_async(
self,
request: viapi_regen_20211119_models.ListLabelsetsRequest,
) -> viapi_regen_20211119_models.ListLabelsetsResponse:
runtime = util_models.RuntimeOptions()
return await self.list_labelsets_with_options_async(request, runtime)
def list_services_with_options(
self,
request: viapi_regen_20211119_models.ListServicesRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ListServicesResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.current_page):
body['CurrentPage'] = request.current_page
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.page_size):
body['PageSize'] = request.page_size
if not UtilClient.is_unset(request.workspace_id):
body['WorkspaceId'] = request.workspace_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ListServices',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ListServicesResponse(),
self.call_api(params, req, runtime)
)
async def list_services_with_options_async(
self,
request: viapi_regen_20211119_models.ListServicesRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ListServicesResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.current_page):
body['CurrentPage'] = request.current_page
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.page_size):
body['PageSize'] = request.page_size
if not UtilClient.is_unset(request.workspace_id):
body['WorkspaceId'] = request.workspace_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ListServices',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ListServicesResponse(),
await self.call_api_async(params, req, runtime)
)
def list_services(
self,
request: viapi_regen_20211119_models.ListServicesRequest,
) -> viapi_regen_20211119_models.ListServicesResponse:
runtime = util_models.RuntimeOptions()
return self.list_services_with_options(request, runtime)
async def list_services_async(
self,
request: viapi_regen_20211119_models.ListServicesRequest,
) -> viapi_regen_20211119_models.ListServicesResponse:
runtime = util_models.RuntimeOptions()
return await self.list_services_with_options_async(request, runtime)
def list_train_tasks_with_options(
self,
request: viapi_regen_20211119_models.ListTrainTasksRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ListTrainTasksResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.current_page):
body['CurrentPage'] = request.current_page
if not UtilClient.is_unset(request.page_size):
body['PageSize'] = request.page_size
if not UtilClient.is_unset(request.status):
body['Status'] = request.status
if not UtilClient.is_unset(request.workspace_id):
body['WorkspaceId'] = request.workspace_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ListTrainTasks',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ListTrainTasksResponse(),
self.call_api(params, req, runtime)
)
async def list_train_tasks_with_options_async(
self,
request: viapi_regen_20211119_models.ListTrainTasksRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ListTrainTasksResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.current_page):
body['CurrentPage'] = request.current_page
if not UtilClient.is_unset(request.page_size):
body['PageSize'] = request.page_size
if not UtilClient.is_unset(request.status):
body['Status'] = request.status
if not UtilClient.is_unset(request.workspace_id):
body['WorkspaceId'] = request.workspace_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ListTrainTasks',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ListTrainTasksResponse(),
await self.call_api_async(params, req, runtime)
)
def list_train_tasks(
self,
request: viapi_regen_20211119_models.ListTrainTasksRequest,
) -> viapi_regen_20211119_models.ListTrainTasksResponse:
runtime = util_models.RuntimeOptions()
return self.list_train_tasks_with_options(request, runtime)
async def list_train_tasks_async(
self,
request: viapi_regen_20211119_models.ListTrainTasksRequest,
) -> viapi_regen_20211119_models.ListTrainTasksResponse:
runtime = util_models.RuntimeOptions()
return await self.list_train_tasks_with_options_async(request, runtime)
def list_workspaces_with_options(
self,
request: viapi_regen_20211119_models.ListWorkspacesRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ListWorkspacesResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.current_page):
body['CurrentPage'] = request.current_page
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.page_size):
body['PageSize'] = request.page_size
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ListWorkspaces',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ListWorkspacesResponse(),
self.call_api(params, req, runtime)
)
async def list_workspaces_with_options_async(
self,
request: viapi_regen_20211119_models.ListWorkspacesRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.ListWorkspacesResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.current_page):
body['CurrentPage'] = request.current_page
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.page_size):
body['PageSize'] = request.page_size
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='ListWorkspaces',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.ListWorkspacesResponse(),
await self.call_api_async(params, req, runtime)
)
def list_workspaces(
self,
request: viapi_regen_20211119_models.ListWorkspacesRequest,
) -> viapi_regen_20211119_models.ListWorkspacesResponse:
runtime = util_models.RuntimeOptions()
return self.list_workspaces_with_options(request, runtime)
async def list_workspaces_async(
self,
request: viapi_regen_20211119_models.ListWorkspacesRequest,
) -> viapi_regen_20211119_models.ListWorkspacesResponse:
runtime = util_models.RuntimeOptions()
return await self.list_workspaces_with_options_async(request, runtime)
def set_dataset_user_oss_path_with_options(
self,
request: viapi_regen_20211119_models.SetDatasetUserOssPathRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.SetDatasetUserOssPathResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.dataset_id):
body['DatasetId'] = request.dataset_id
if not UtilClient.is_unset(request.user_oss_url):
body['UserOssUrl'] = request.user_oss_url
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='SetDatasetUserOssPath',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.SetDatasetUserOssPathResponse(),
self.call_api(params, req, runtime)
)
async def set_dataset_user_oss_path_with_options_async(
self,
request: viapi_regen_20211119_models.SetDatasetUserOssPathRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.SetDatasetUserOssPathResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.dataset_id):
body['DatasetId'] = request.dataset_id
if not UtilClient.is_unset(request.user_oss_url):
body['UserOssUrl'] = request.user_oss_url
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='SetDatasetUserOssPath',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.SetDatasetUserOssPathResponse(),
await self.call_api_async(params, req, runtime)
)
def set_dataset_user_oss_path(
self,
request: viapi_regen_20211119_models.SetDatasetUserOssPathRequest,
) -> viapi_regen_20211119_models.SetDatasetUserOssPathResponse:
runtime = util_models.RuntimeOptions()
return self.set_dataset_user_oss_path_with_options(request, runtime)
async def set_dataset_user_oss_path_async(
self,
request: viapi_regen_20211119_models.SetDatasetUserOssPathRequest,
) -> viapi_regen_20211119_models.SetDatasetUserOssPathResponse:
runtime = util_models.RuntimeOptions()
return await self.set_dataset_user_oss_path_with_options_async(request, runtime)
def start_service_with_options(
self,
request: viapi_regen_20211119_models.StartServiceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.StartServiceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='StartService',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.StartServiceResponse(),
self.call_api(params, req, runtime)
)
async def start_service_with_options_async(
self,
request: viapi_regen_20211119_models.StartServiceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.StartServiceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='StartService',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.StartServiceResponse(),
await self.call_api_async(params, req, runtime)
)
def start_service(
self,
request: viapi_regen_20211119_models.StartServiceRequest,
) -> viapi_regen_20211119_models.StartServiceResponse:
runtime = util_models.RuntimeOptions()
return self.start_service_with_options(request, runtime)
async def start_service_async(
self,
request: viapi_regen_20211119_models.StartServiceRequest,
) -> viapi_regen_20211119_models.StartServiceResponse:
runtime = util_models.RuntimeOptions()
return await self.start_service_with_options_async(request, runtime)
def start_train_task_with_options(
self,
request: viapi_regen_20211119_models.StartTrainTaskRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.StartTrainTaskResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.force_start_flag):
body['ForceStartFlag'] = request.force_start_flag
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.rely_on_task_id):
body['RelyOnTaskId'] = request.rely_on_task_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='StartTrainTask',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.StartTrainTaskResponse(),
self.call_api(params, req, runtime)
)
async def start_train_task_with_options_async(
self,
request: viapi_regen_20211119_models.StartTrainTaskRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.StartTrainTaskResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.force_start_flag):
body['ForceStartFlag'] = request.force_start_flag
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.rely_on_task_id):
body['RelyOnTaskId'] = request.rely_on_task_id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='StartTrainTask',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.StartTrainTaskResponse(),
await self.call_api_async(params, req, runtime)
)
def start_train_task(
self,
request: viapi_regen_20211119_models.StartTrainTaskRequest,
) -> viapi_regen_20211119_models.StartTrainTaskResponse:
runtime = util_models.RuntimeOptions()
return self.start_train_task_with_options(request, runtime)
async def start_train_task_async(
self,
request: viapi_regen_20211119_models.StartTrainTaskRequest,
) -> viapi_regen_20211119_models.StartTrainTaskResponse:
runtime = util_models.RuntimeOptions()
return await self.start_train_task_with_options_async(request, runtime)
def stop_service_with_options(
self,
request: viapi_regen_20211119_models.StopServiceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.StopServiceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='StopService',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.StopServiceResponse(),
self.call_api(params, req, runtime)
)
async def stop_service_with_options_async(
self,
request: viapi_regen_20211119_models.StopServiceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.StopServiceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='StopService',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.StopServiceResponse(),
await self.call_api_async(params, req, runtime)
)
def stop_service(
self,
request: viapi_regen_20211119_models.StopServiceRequest,
) -> viapi_regen_20211119_models.StopServiceResponse:
runtime = util_models.RuntimeOptions()
return self.stop_service_with_options(request, runtime)
async def stop_service_async(
self,
request: viapi_regen_20211119_models.StopServiceRequest,
) -> viapi_regen_20211119_models.StopServiceResponse:
runtime = util_models.RuntimeOptions()
return await self.stop_service_with_options_async(request, runtime)
def stop_train_task_with_options(
self,
request: viapi_regen_20211119_models.StopTrainTaskRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.StopTrainTaskResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='StopTrainTask',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.StopTrainTaskResponse(),
self.call_api(params, req, runtime)
)
async def stop_train_task_with_options_async(
self,
request: viapi_regen_20211119_models.StopTrainTaskRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.StopTrainTaskResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='StopTrainTask',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.StopTrainTaskResponse(),
await self.call_api_async(params, req, runtime)
)
def stop_train_task(
self,
request: viapi_regen_20211119_models.StopTrainTaskRequest,
) -> viapi_regen_20211119_models.StopTrainTaskResponse:
runtime = util_models.RuntimeOptions()
return self.stop_train_task_with_options(request, runtime)
async def stop_train_task_async(
self,
request: viapi_regen_20211119_models.StopTrainTaskRequest,
) -> viapi_regen_20211119_models.StopTrainTaskResponse:
runtime = util_models.RuntimeOptions()
return await self.stop_train_task_with_options_async(request, runtime)
def update_dataset_with_options(
self,
request: viapi_regen_20211119_models.UpdateDatasetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.UpdateDatasetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='UpdateDataset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.UpdateDatasetResponse(),
self.call_api(params, req, runtime)
)
async def update_dataset_with_options_async(
self,
request: viapi_regen_20211119_models.UpdateDatasetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.UpdateDatasetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='UpdateDataset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.UpdateDatasetResponse(),
await self.call_api_async(params, req, runtime)
)
def update_dataset(
self,
request: viapi_regen_20211119_models.UpdateDatasetRequest,
) -> viapi_regen_20211119_models.UpdateDatasetResponse:
runtime = util_models.RuntimeOptions()
return self.update_dataset_with_options(request, runtime)
async def update_dataset_async(
self,
request: viapi_regen_20211119_models.UpdateDatasetRequest,
) -> viapi_regen_20211119_models.UpdateDatasetResponse:
runtime = util_models.RuntimeOptions()
return await self.update_dataset_with_options_async(request, runtime)
def update_labelset_with_options(
self,
request: viapi_regen_20211119_models.UpdateLabelsetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.UpdateLabelsetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.object_key):
body['ObjectKey'] = request.object_key
if not UtilClient.is_unset(request.tag_user_list):
body['TagUserList'] = request.tag_user_list
if not UtilClient.is_unset(request.user_oss_url):
body['UserOssUrl'] = request.user_oss_url
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='UpdateLabelset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.UpdateLabelsetResponse(),
self.call_api(params, req, runtime)
)
async def update_labelset_with_options_async(
self,
request: viapi_regen_20211119_models.UpdateLabelsetRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.UpdateLabelsetResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.object_key):
body['ObjectKey'] = request.object_key
if not UtilClient.is_unset(request.tag_user_list):
body['TagUserList'] = request.tag_user_list
if not UtilClient.is_unset(request.user_oss_url):
body['UserOssUrl'] = request.user_oss_url
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='UpdateLabelset',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.UpdateLabelsetResponse(),
await self.call_api_async(params, req, runtime)
)
def update_labelset(
self,
request: viapi_regen_20211119_models.UpdateLabelsetRequest,
) -> viapi_regen_20211119_models.UpdateLabelsetResponse:
runtime = util_models.RuntimeOptions()
return self.update_labelset_with_options(request, runtime)
async def update_labelset_async(
self,
request: viapi_regen_20211119_models.UpdateLabelsetRequest,
) -> viapi_regen_20211119_models.UpdateLabelsetResponse:
runtime = util_models.RuntimeOptions()
return await self.update_labelset_with_options_async(request, runtime)
def update_service_with_options(
self,
request: viapi_regen_20211119_models.UpdateServiceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.UpdateServiceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.authorization_type):
body['AuthorizationType'] = request.authorization_type
if not UtilClient.is_unset(request.authorized_account):
body['AuthorizedAccount'] = request.authorized_account
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='UpdateService',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.UpdateServiceResponse(),
self.call_api(params, req, runtime)
)
async def update_service_with_options_async(
self,
request: viapi_regen_20211119_models.UpdateServiceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.UpdateServiceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.authorization_type):
body['AuthorizationType'] = request.authorization_type
if not UtilClient.is_unset(request.authorized_account):
body['AuthorizedAccount'] = request.authorized_account
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='UpdateService',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.UpdateServiceResponse(),
await self.call_api_async(params, req, runtime)
)
def update_service(
self,
request: viapi_regen_20211119_models.UpdateServiceRequest,
) -> viapi_regen_20211119_models.UpdateServiceResponse:
runtime = util_models.RuntimeOptions()
return self.update_service_with_options(request, runtime)
async def update_service_async(
self,
request: viapi_regen_20211119_models.UpdateServiceRequest,
) -> viapi_regen_20211119_models.UpdateServiceResponse:
runtime = util_models.RuntimeOptions()
return await self.update_service_with_options_async(request, runtime)
def update_train_task_with_options(
self,
request: viapi_regen_20211119_models.UpdateTrainTaskRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.UpdateTrainTaskResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.advanced_parameters):
body['AdvancedParameters'] = request.advanced_parameters
if not UtilClient.is_unset(request.dataset_ids):
body['DatasetIds'] = request.dataset_ids
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.label_ids):
body['LabelIds'] = request.label_ids
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.pre_train_task_flag):
body['PreTrainTaskFlag'] = request.pre_train_task_flag
if not UtilClient.is_unset(request.pre_train_task_id):
body['PreTrainTaskId'] = request.pre_train_task_id
if not UtilClient.is_unset(request.train_mode):
body['TrainMode'] = request.train_mode
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='UpdateTrainTask',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.UpdateTrainTaskResponse(),
self.call_api(params, req, runtime)
)
async def update_train_task_with_options_async(
self,
request: viapi_regen_20211119_models.UpdateTrainTaskRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.UpdateTrainTaskResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.advanced_parameters):
body['AdvancedParameters'] = request.advanced_parameters
if not UtilClient.is_unset(request.dataset_ids):
body['DatasetIds'] = request.dataset_ids
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.label_ids):
body['LabelIds'] = request.label_ids
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
if not UtilClient.is_unset(request.pre_train_task_flag):
body['PreTrainTaskFlag'] = request.pre_train_task_flag
if not UtilClient.is_unset(request.pre_train_task_id):
body['PreTrainTaskId'] = request.pre_train_task_id
if not UtilClient.is_unset(request.train_mode):
body['TrainMode'] = request.train_mode
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='UpdateTrainTask',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.UpdateTrainTaskResponse(),
await self.call_api_async(params, req, runtime)
)
def update_train_task(
self,
request: viapi_regen_20211119_models.UpdateTrainTaskRequest,
) -> viapi_regen_20211119_models.UpdateTrainTaskResponse:
runtime = util_models.RuntimeOptions()
return self.update_train_task_with_options(request, runtime)
async def update_train_task_async(
self,
request: viapi_regen_20211119_models.UpdateTrainTaskRequest,
) -> viapi_regen_20211119_models.UpdateTrainTaskResponse:
runtime = util_models.RuntimeOptions()
return await self.update_train_task_with_options_async(request, runtime)
def update_workspace_with_options(
self,
request: viapi_regen_20211119_models.UpdateWorkspaceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.UpdateWorkspaceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='UpdateWorkspace',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.UpdateWorkspaceResponse(),
self.call_api(params, req, runtime)
)
async def update_workspace_with_options_async(
self,
request: viapi_regen_20211119_models.UpdateWorkspaceRequest,
runtime: util_models.RuntimeOptions,
) -> viapi_regen_20211119_models.UpdateWorkspaceResponse:
UtilClient.validate_model(request)
body = {}
if not UtilClient.is_unset(request.description):
body['Description'] = request.description
if not UtilClient.is_unset(request.id):
body['Id'] = request.id
if not UtilClient.is_unset(request.name):
body['Name'] = request.name
req = open_api_models.OpenApiRequest(
body=OpenApiUtilClient.parse_to_map(body)
)
params = open_api_models.Params(
action='UpdateWorkspace',
version='2021-11-19',
protocol='HTTPS',
pathname='/',
method='POST',
auth_type='AK',
style='RPC',
req_body_type='formData',
body_type='json'
)
return TeaCore.from_map(
viapi_regen_20211119_models.UpdateWorkspaceResponse(),
await self.call_api_async(params, req, runtime)
)
def update_workspace(
self,
request: viapi_regen_20211119_models.UpdateWorkspaceRequest,
) -> viapi_regen_20211119_models.UpdateWorkspaceResponse:
runtime = util_models.RuntimeOptions()
return self.update_workspace_with_options(request, runtime)
async def update_workspace_async(
self,
request: viapi_regen_20211119_models.UpdateWorkspaceRequest,
) -> viapi_regen_20211119_models.UpdateWorkspaceResponse:
runtime = util_models.RuntimeOptions()
return await self.update_workspace_with_options_async(request, runtime)
|
PypiClean
|
/skel/auth/auth_handlers.py
|
import jwt
from base64 import b64decode
from auth import SETTINGS, SIGNING_KEYS
def basic(token, **kwargs):
try:
username, password = b64decode(token).decode().split(':', 1)
is_root = False
if username.lower() == 'root':
if password == SETTINGS.get('AUTH_ROOT_PASSWORD'):
is_root = True
else:
return {}
role = 'admin' if is_root else ''
rtn = {
'user': username,
'role': role
}
except:
rtn = {}
return rtn
# TODO: detect opaque token, then handle accordingly (how?)
def bearer(token, **kwargs):
audience = SETTINGS.get('AUTH_JWT_AUDIENCE')
issuer = SETTINGS.get('AUTH_JWT_ISSUER')
options = {}
if audience:
options['audience'] = audience
if issuer:
options['issuer'] = issuer
try:
headers = jwt.get_unverified_header(token)
options['algorithms'] = [headers['alg']]
signing_key = SIGNING_KEYS[headers['kid']] # TODO: this will fail if SETTINGS not properly configured - except key error? test then raise?
parsed = jwt.decode(token, signing_key, **options)
rtn = {
'user': parsed.get('sub')
}
claims_namespace = SETTINGS['AUTH0_CLAIMS_NAMESPACE']
claims = parsed.get(f'{claims_namespace}/claims')
rtn['permissions'] = parsed.get('permissions', [])
for claim in ['id', 'name', 'nickname', 'email', 'roles']:
value = claims.get(claim)
if value:
rtn[claim] = value
if 'roles' in rtn:
rtn['roles'] = [role.lower() for role in rtn['roles']]
if 'admin' in rtn['roles']:
rtn['role'] = 'admin'
except (jwt.ExpiredSignatureError,
jwt.InvalidSignatureError,
jwt.InvalidAudienceError,
jwt.InvalidAlgorithmError) as ex: # TODO: other jwt ex's?
rtn = {'_issues': {'token': f'{ex}'}}
except ValueError as ex:
rtn = {'_issues': {'config': f'{ex} - Please contact support for assistance, quoting this message'}}
except jwt.DecodeError as ex:
# NOTE: this should never occur - only did during development of this handler
rtn = {'_issues': {'auth_handler': f'{ex} - Please contact support for assistance, quoting this message'}}
except Exception as ex:
rtn = {'_issues': {'unknown': f'{ex} - Please contact support for assistance, quoting this message'}}
return rtn
def bearer_challenge(**kwargs):
request = kwargs.get('request')
rtn = {}
if request and (
'Bearer' in request.headers.get('Authorization', '')
or request.args.get('access_token')
):
rtn['error'] = "invalid_token"
return rtn
|
PypiClean
|
/Products.ATMemberSelectWidgetNG-0.3.2.tar.gz/Products.ATMemberSelectWidgetNG-0.3.2/Products/ATMemberSelectWidget/skins/atmemberselectwidget/memberselect.js
|
function memberselect_openBrowser(portal_url, fieldId, groupName, enableSearch, fieldType, multiVal, close_window, showGroups)
{
if (-1 == close_window)
close_window = 1 - multiVal
Search = 0
if (groupName != '') {
Search = 1
}
window.open(portal_url + '/memberselect_popup?Search:int=' + Search + '&groupname='+ groupName + '&enableSearch:int=' + enableSearch + '&fieldId=' + fieldId + '&fieldType=' + fieldType + '&multiVal:int=' + multiVal + '&close_window:int='+close_window+'&showGroups:int='+showGroups, 'memberselect_popup','dependent=yes,toolbar=no,location=no,status=no,menubar=no,scrollbars=yes,resizable=yes,width=500,height=550');
}
// function to return a reference from the popup window back into the widget
function memberselect_setMember(fieldId, fieldType, username, label, multiVal)
{
// differentiate between the single and mulitselect widget
// since the single widget has an extra label field.
pos = label.indexOf(' ')
email = label.slice(0, pos)
fullname = label.slice(pos + 1)
if (fieldType == 'id') {
label = username+' ('+fullname+')'
if (multiVal==0) {
element=document.getElementById(fieldId)
label_element=document.getElementById(fieldId + '_label')
element.value=username
label_element.value=label
} else {
list=document.getElementById(fieldId)
// check if the item isn't already in the list
for (var x=0; x < list.length; x++) {
if (list[x].value == username) {
return false;
}
}
// now add the new item
theLength=list.length;
list[theLength] = new Option(label);
list[theLength].selected='selected';
list[theLength].value=username
}
} else {
// email
if (fieldType == 'nameemail') {
label = '"' + fullname + '" <' + email + '>'
} else {
label = email
}
element=document.getElementById(fieldId)
if (multiVal==0) {
element.value=label
} else {
element.value += label + '\n'
}
}
}
// function to clear the reference field or remove items
// from the multivalued reference list.
function memberselect_removeMember(widget_id, multi)
{
if (multi) {
list=document.getElementById(widget_id)
for (var x=list.length-1; x >= 0; x--) {
if (list[x].selected) {
list[x]=null;
}
}
for (var x=0; x < list.length; x++) {
list[x].selected='selected';
}
} else {
element=document.getElementById(widget_id);
label_element=document.getElementById(widget_id + '_label');
label_element.value = "";
element.value="";
}
}
|
PypiClean
|
/safegate_pro-2021.7.6-py3-none-any.whl/homeassistant/components/insteon/__init__.py
|
import asyncio
from contextlib import suppress
import logging
from pyinsteon import async_close, async_connect, devices
from homeassistant.config_entries import SOURCE_IMPORT
from homeassistant.const import CONF_PLATFORM, EVENT_HOMEASSISTANT_STOP
from homeassistant.exceptions import ConfigEntryNotReady
from .const import (
CONF_CAT,
CONF_DIM_STEPS,
CONF_HOUSECODE,
CONF_OVERRIDE,
CONF_SUBCAT,
CONF_UNITCODE,
CONF_X10,
DOMAIN,
INSTEON_PLATFORMS,
ON_OFF_EVENTS,
)
from .schemas import convert_yaml_to_config_flow
from .utils import (
add_on_off_event_device,
async_register_services,
get_device_platforms,
register_new_device_callback,
)
_LOGGER = logging.getLogger(__name__)
OPTIONS = "options"
async def async_get_device_config(hass, config_entry):
"""Initiate the connection and services."""
# Make a copy of addresses due to edge case where the list of devices could change during status update
# Cannot be done concurrently due to issues with the underlying protocol.
for address in list(devices):
with suppress(AttributeError):
await devices[address].async_status()
await devices.async_load(id_devices=1)
for addr in devices:
device = devices[addr]
flags = True
for name in device.operating_flags:
if not device.operating_flags[name].is_loaded:
flags = False
break
if flags:
for name in device.properties:
if not device.properties[name].is_loaded:
flags = False
break
# Cannot be done concurrently due to issues with the underlying protocol.
if not device.aldb.is_loaded or not flags:
await device.async_read_config()
await devices.async_save(workdir=hass.config.config_dir)
async def close_insteon_connection(*args):
"""Close the Insteon connection."""
await async_close()
async def async_setup(hass, config):
"""Set up the Insteon platform."""
if DOMAIN not in config:
return True
conf = config[DOMAIN]
data, options = convert_yaml_to_config_flow(conf)
if options:
hass.data[DOMAIN] = {}
hass.data[DOMAIN][OPTIONS] = options
# Create a config entry with the connection data
hass.async_create_task(
hass.config_entries.flow.async_init(
DOMAIN, context={"source": SOURCE_IMPORT}, data=data
)
)
return True
async def async_setup_entry(hass, entry):
"""Set up an Insteon entry."""
if not devices.modem:
try:
await async_connect(**entry.data)
except ConnectionError as exception:
_LOGGER.error("Could not connect to Insteon modem")
raise ConfigEntryNotReady from exception
entry.async_on_unload(
hass.bus.async_listen_once(EVENT_HOMEASSISTANT_STOP, close_insteon_connection)
)
await devices.async_load(
workdir=hass.config.config_dir, id_devices=0, load_modem_aldb=0
)
# If options existed in YAML and have not already been saved to the config entry
# add them now
if (
not entry.options
and entry.source == SOURCE_IMPORT
and hass.data.get(DOMAIN)
and hass.data[DOMAIN].get(OPTIONS)
):
hass.config_entries.async_update_entry(
entry=entry,
options=hass.data[DOMAIN][OPTIONS],
)
for device_override in entry.options.get(CONF_OVERRIDE, []):
# Override the device default capabilities for a specific address
address = device_override.get("address")
if not devices.get(address):
cat = device_override[CONF_CAT]
subcat = device_override[CONF_SUBCAT]
devices.set_id(address, cat, subcat, 0)
for device in entry.options.get(CONF_X10, []):
housecode = device.get(CONF_HOUSECODE)
unitcode = device.get(CONF_UNITCODE)
x10_type = "on_off"
steps = device.get(CONF_DIM_STEPS, 22)
if device.get(CONF_PLATFORM) == "light":
x10_type = "dimmable"
elif device.get(CONF_PLATFORM) == "binary_sensor":
x10_type = "sensor"
_LOGGER.debug(
"Adding X10 device to Insteon: %s %d %s", housecode, unitcode, x10_type
)
device = devices.add_x10_device(housecode, unitcode, x10_type, steps)
for platform in INSTEON_PLATFORMS:
hass.async_create_task(
hass.config_entries.async_forward_entry_setup(entry, platform)
)
for address in devices:
device = devices[address]
platforms = get_device_platforms(device)
if ON_OFF_EVENTS in platforms:
add_on_off_event_device(hass, device)
_LOGGER.debug("Insteon device count: %s", len(devices))
register_new_device_callback(hass)
async_register_services(hass)
device_registry = await hass.helpers.device_registry.async_get_registry()
device_registry.async_get_or_create(
config_entry_id=entry.entry_id,
identifiers={(DOMAIN, str(devices.modem.address))},
manufacturer="Smart Home",
name=f"{devices.modem.description} {devices.modem.address}",
model=f"{devices.modem.model} ({devices.modem.cat!r}, 0x{devices.modem.subcat:02x})",
sw_version=f"{devices.modem.firmware:02x} Engine Version: {devices.modem.engine_version}",
)
asyncio.create_task(async_get_device_config(hass, entry))
return True
|
PypiClean
|
/en_pyssant-0.2.0-py3-none-any.whl/en_pyssant/_util.py
|
import re
from typing import List
from ._core import Side, Square
def opponent(side: Side) -> Side:
"""Return the opposite side.
>>> opponent(Side.WHITE) == Side.BLACK
True
:param side: Proponent side.
"""
return Side.WHITE if side is Side.BLACK else Side.BLACK
def validate_fen_board(fen: str) -> bool:
"""Check whether the board portion of a given Forsyth-Edwards Notation is
valid.
:param fen: Board portion of Forsyth-Edwards Notation.
:return: Whether *fen* is valid.
"""
fen = fen.split()[0]
chunks = fen.split('/')
file_length = len(chunks)
if file_length != 8:
return False
for chunk in chunks:
rank_length = 0
for char in chunk:
if char.isnumeric() and char != '0':
rank_length += int(char)
elif char.lower() in 'kqrbnp':
rank_length += 1
else:
return False
if rank_length != 8:
return False
return True
def validate_fen(fen: str) -> bool:
"""Check whether a given Forsyth-Edwards Notation is valid
:param fen: Forsyth-Edwards Notation.
:return: Whether *fen* is valid.
"""
# pylint: disable=too-many-return-statements
parts = fen.split()
if len(parts) != 6:
return False
if not validate_fen_board(parts[0]):
return False
if parts[1] not in 'wb':
return False
if not re.match('^K?Q?k?q?$', parts[2]) and parts[2] != '-':
return False
if parts[3] != '-' and parts[3] not in ALL_SQUARES:
return False
try:
half_move_clock = int(parts[4])
move_count = int(parts[5])
except ValueError:
return False
if half_move_clock < 0 or move_count < 1:
return False
return True
def _all_squares() -> List[Square]:
"""Return a list of all squares from a1 to h8. Increment files before
ranks.
"""
squares = []
for i in range(1, 9):
for char in 'abcdefgh':
squares.append(Square('{}{}'.format(char, i)))
return squares
ALL_SQUARES = _all_squares()
|
PypiClean
|
/SQLAlchemy-2.0.20.tar.gz/SQLAlchemy-2.0.20/test/typing/plain_files/sql/typed_results.py
|
from __future__ import annotations
import asyncio
from typing import cast
from typing import Optional
from typing import Tuple
from typing import Type
from sqlalchemy import Column
from sqlalchemy import column
from sqlalchemy import create_engine
from sqlalchemy import insert
from sqlalchemy import Integer
from sqlalchemy import MetaData
from sqlalchemy import NotNullable
from sqlalchemy import Nullable
from sqlalchemy import Select
from sqlalchemy import select
from sqlalchemy import String
from sqlalchemy import Table
from sqlalchemy import table
from sqlalchemy.ext.asyncio import AsyncConnection
from sqlalchemy.ext.asyncio import AsyncSession
from sqlalchemy.ext.asyncio import create_async_engine
from sqlalchemy.orm import aliased
from sqlalchemy.orm import DeclarativeBase
from sqlalchemy.orm import Mapped
from sqlalchemy.orm import mapped_column
from sqlalchemy.orm import Session
class Base(DeclarativeBase):
pass
class User(Base):
__tablename__ = "user"
id: Mapped[int] = mapped_column(primary_key=True)
name: Mapped[str]
value: Mapped[Optional[str]]
t_user = Table(
"user",
MetaData(),
Column("id", Integer, primary_key=True),
Column("name", String),
)
e = create_engine("sqlite://")
ae = create_async_engine("sqlite+aiosqlite://")
connection = e.connect()
session = Session(connection)
async def async_connect() -> AsyncConnection:
return await ae.connect()
# the thing with the \*? seems like it could go away
# as of mypy 0.950
async_connection = asyncio.run(async_connect())
# EXPECTED_RE_TYPE: sqlalchemy..*AsyncConnection\*?
reveal_type(async_connection)
async_session = AsyncSession(async_connection)
# (variable) users1: Sequence[User]
users1 = session.scalars(select(User)).all()
# (variable) user: User
user = session.query(User).one()
user_iter = iter(session.scalars(select(User)))
# EXPECTED_RE_TYPE: sqlalchemy..*AsyncSession\*?
reveal_type(async_session)
single_stmt = select(User.name).where(User.name == "foo")
# EXPECTED_RE_TYPE: sqlalchemy..*Select\*?\[Tuple\[builtins.str\*?\]\]
reveal_type(single_stmt)
multi_stmt = select(User.id, User.name).where(User.name == "foo")
# EXPECTED_RE_TYPE: sqlalchemy..*Select\*?\[Tuple\[builtins.int\*?, builtins.str\*?\]\]
reveal_type(multi_stmt)
def t_result_ctxmanager() -> None:
with connection.execute(select(column("q", Integer))) as r1:
# EXPECTED_TYPE: CursorResult[Tuple[int]]
reveal_type(r1)
with r1.mappings() as r1m:
# EXPECTED_TYPE: MappingResult
reveal_type(r1m)
with connection.scalars(select(column("q", Integer))) as r2:
# EXPECTED_TYPE: ScalarResult[int]
reveal_type(r2)
with session.execute(select(User.id)) as r3:
# EXPECTED_TYPE: Result[Tuple[int]]
reveal_type(r3)
with session.scalars(select(User.id)) as r4:
# EXPECTED_TYPE: ScalarResult[int]
reveal_type(r4)
def t_core_mappings() -> None:
r = connection.execute(select(t_user)).mappings().one()
r.get(t_user.c.id)
def t_entity_varieties() -> None:
a1 = aliased(User)
s1 = select(User.id, User, User.name).where(User.name == "foo")
r1 = session.execute(s1)
# EXPECTED_RE_TYPE: sqlalchemy..*.Result\[Tuple\[builtins.int\*?, typed_results.User\*?, builtins.str\*?\]\]
reveal_type(r1)
s2 = select(User, a1).where(User.name == "foo")
r2 = session.execute(s2)
# EXPECTED_RE_TYPE: sqlalchemy.*Result\[Tuple\[typed_results.User\*?, typed_results.User\*?\]\]
reveal_type(r2)
row = r2.t.one()
# EXPECTED_RE_TYPE: .*typed_results.User\*?
reveal_type(row[0])
# EXPECTED_RE_TYPE: .*typed_results.User\*?
reveal_type(row[1])
# testing that plain Mapped[x] gets picked up as well as
# aliased class
# there is unfortunately no way for attributes on an AliasedClass to be
# automatically typed since they are dynamically generated
a1_id = cast(Mapped[int], a1.id)
s3 = select(User.id, a1_id, a1, User).where(User.name == "foo")
# EXPECTED_RE_TYPE: sqlalchemy.*Select\*?\[Tuple\[builtins.int\*?, builtins.int\*?, typed_results.User\*?, typed_results.User\*?\]\]
reveal_type(s3)
# testing Mapped[entity]
some_mp = cast(Mapped[User], object())
s4 = select(some_mp, a1, User).where(User.name == "foo")
# NOTEXPECTED_RE_TYPE: sqlalchemy..*Select\*?\[Tuple\[typed_results.User\*?, typed_results.User\*?, typed_results.User\*?\]\]
# sqlalchemy.sql._gen_overloads.Select[Tuple[typed_results.User, typed_results.User, typed_results.User]]
# EXPECTED_TYPE: Select[Tuple[User, User, User]]
reveal_type(s4)
# test plain core expressions
x = Column("x", Integer)
y = x + 5
s5 = select(x, y, User.name + "hi")
# EXPECTED_RE_TYPE: sqlalchemy..*Select\*?\[Tuple\[builtins.int\*?, builtins.int\*?\, builtins.str\*?]\]
reveal_type(s5)
def t_ambiguous_result_type_one() -> None:
stmt = select(column("q", Integer), table("x", column("y")))
# EXPECTED_TYPE: Select[Any]
reveal_type(stmt)
result = session.execute(stmt)
# EXPECTED_TYPE: Result[Any]
reveal_type(result)
def t_ambiguous_result_type_two() -> None:
stmt = select(column("q"))
# EXPECTED_TYPE: Select[Tuple[Any]]
reveal_type(stmt)
result = session.execute(stmt)
# EXPECTED_TYPE: Result[Any]
reveal_type(result)
def t_aliased() -> None:
a1 = aliased(User)
s1 = select(a1)
# EXPECTED_TYPE: Select[Tuple[User]]
reveal_type(s1)
s4 = select(a1.name, a1, a1, User).where(User.name == "foo")
# EXPECTED_TYPE: Select[Tuple[str, User, User, User]]
reveal_type(s4)
def t_result_scalar_accessors() -> None:
result = connection.execute(single_stmt)
r1 = result.scalar()
# EXPECTED_RE_TYPE: Union\[builtins.str\*?, None\]
reveal_type(r1)
r2 = result.scalar_one()
# EXPECTED_RE_TYPE: builtins.str\*?
reveal_type(r2)
r3 = result.scalar_one_or_none()
# EXPECTED_RE_TYPE: Union\[builtins.str\*?, None\]
reveal_type(r3)
r4 = result.scalars()
# EXPECTED_RE_TYPE: sqlalchemy..*ScalarResult\[builtins.str.*?\]
reveal_type(r4)
r5 = result.scalars(0)
# EXPECTED_RE_TYPE: sqlalchemy..*ScalarResult\[builtins.str.*?\]
reveal_type(r5)
async def t_async_result_scalar_accessors() -> None:
result = await async_connection.stream(single_stmt)
r1 = await result.scalar()
# EXPECTED_RE_TYPE: Union\[builtins.str\*?, None\]
reveal_type(r1)
r2 = await result.scalar_one()
# EXPECTED_RE_TYPE: builtins.str\*?
reveal_type(r2)
r3 = await result.scalar_one_or_none()
# EXPECTED_RE_TYPE: Union\[builtins.str\*?, None\]
reveal_type(r3)
r4 = result.scalars()
# EXPECTED_RE_TYPE: sqlalchemy..*ScalarResult\[builtins.str.*?\]
reveal_type(r4)
r5 = result.scalars(0)
# EXPECTED_RE_TYPE: sqlalchemy..*ScalarResult\[builtins.str.*?\]
reveal_type(r5)
def t_result_insertmanyvalues_scalars() -> None:
stmt = insert(User).returning(User.id)
uids1 = connection.scalars(
stmt,
[
{"name": "n1"},
{"name": "n2"},
{"name": "n3"},
],
).all()
# EXPECTED_TYPE: Sequence[int]
reveal_type(uids1)
uids2 = (
connection.execute(
stmt,
[
{"name": "n1"},
{"name": "n2"},
{"name": "n3"},
],
)
.scalars()
.all()
)
# EXPECTED_TYPE: Sequence[int]
reveal_type(uids2)
async def t_async_result_insertmanyvalues_scalars() -> None:
stmt = insert(User).returning(User.id)
uids1 = (
await async_connection.scalars(
stmt,
[
{"name": "n1"},
{"name": "n2"},
{"name": "n3"},
],
)
).all()
# EXPECTED_TYPE: Sequence[int]
reveal_type(uids1)
uids2 = (
(
await async_connection.execute(
stmt,
[
{"name": "n1"},
{"name": "n2"},
{"name": "n3"},
],
)
)
.scalars()
.all()
)
# EXPECTED_TYPE: Sequence[int]
reveal_type(uids2)
def t_connection_execute_multi_row_t() -> None:
result = connection.execute(multi_stmt)
# EXPECTED_RE_TYPE: sqlalchemy.*CursorResult\[Tuple\[builtins.int\*?, builtins.str\*?\]\]
reveal_type(result)
row = result.one()
# EXPECTED_RE_TYPE: sqlalchemy.*Row\[Tuple\[builtins.int\*?, builtins.str\*?\]\]
reveal_type(row)
x, y = row.t
# EXPECTED_RE_TYPE: builtins.int\*?
reveal_type(x)
# EXPECTED_RE_TYPE: builtins.str\*?
reveal_type(y)
def t_connection_execute_multi() -> None:
result = connection.execute(multi_stmt).t
# EXPECTED_RE_TYPE: sqlalchemy.*TupleResult\[Tuple\[builtins.int\*?, builtins.str\*?\]\]
reveal_type(result)
row = result.one()
# EXPECTED_RE_TYPE: Tuple\[builtins.int\*?, builtins.str\*?\]
reveal_type(row)
x, y = row
# EXPECTED_RE_TYPE: builtins.int\*?
reveal_type(x)
# EXPECTED_RE_TYPE: builtins.str\*?
reveal_type(y)
def t_connection_execute_single() -> None:
result = connection.execute(single_stmt).t
# EXPECTED_RE_TYPE: sqlalchemy.*TupleResult\[Tuple\[builtins.str\*?\]\]
reveal_type(result)
row = result.one()
# EXPECTED_RE_TYPE: Tuple\[builtins.str\*?\]
reveal_type(row)
(x,) = row
# EXPECTED_RE_TYPE: builtins.str\*?
reveal_type(x)
def t_connection_execute_single_row_scalar() -> None:
result = connection.execute(single_stmt).t
# EXPECTED_RE_TYPE: sqlalchemy.*TupleResult\[Tuple\[builtins.str\*?\]\]
reveal_type(result)
x = result.scalar()
# EXPECTED_RE_TYPE: Union\[builtins.str\*?, None\]
reveal_type(x)
def t_connection_scalar() -> None:
obj = connection.scalar(single_stmt)
# EXPECTED_RE_TYPE: Union\[builtins.str\*?, None\]
reveal_type(obj)
def t_connection_scalars() -> None:
result = connection.scalars(single_stmt)
# EXPECTED_RE_TYPE: sqlalchemy.*ScalarResult\[builtins.str\*?\]
reveal_type(result)
data = result.all()
# EXPECTED_RE_TYPE: typing.Sequence\[builtins.str\*?\]
reveal_type(data)
def t_session_execute_multi() -> None:
result = session.execute(multi_stmt).t
# EXPECTED_RE_TYPE: sqlalchemy.*TupleResult\[Tuple\[builtins.int\*?, builtins.str\*?\]\]
reveal_type(result)
row = result.one()
# EXPECTED_RE_TYPE: Tuple\[builtins.int\*?, builtins.str\*?\]
reveal_type(row)
x, y = row
# EXPECTED_RE_TYPE: builtins.int\*?
reveal_type(x)
# EXPECTED_RE_TYPE: builtins.str\*?
reveal_type(y)
def t_session_execute_single() -> None:
result = session.execute(single_stmt).t
# EXPECTED_RE_TYPE: sqlalchemy.*TupleResult\[Tuple\[builtins.str\*?\]\]
reveal_type(result)
row = result.one()
# EXPECTED_RE_TYPE: Tuple\[builtins.str\*?\]
reveal_type(row)
(x,) = row
# EXPECTED_RE_TYPE: builtins.str\*?
reveal_type(x)
def t_session_scalar() -> None:
obj = session.scalar(single_stmt)
# EXPECTED_RE_TYPE: Union\[builtins.str\*?, None\]
reveal_type(obj)
def t_session_scalars() -> None:
result = session.scalars(single_stmt)
# EXPECTED_RE_TYPE: sqlalchemy.*ScalarResult\[builtins.str\*?\]
reveal_type(result)
data = result.all()
# EXPECTED_RE_TYPE: typing.Sequence\[builtins.str\*?\]
reveal_type(data)
async def t_async_connection_execute_multi() -> None:
result = (await async_connection.execute(multi_stmt)).t
# EXPECTED_RE_TYPE: sqlalchemy.*TupleResult\[Tuple\[builtins.int\*?, builtins.str\*?\]\]
reveal_type(result)
row = result.one()
# EXPECTED_RE_TYPE: Tuple\[builtins.int\*?, builtins.str\*?\]
reveal_type(row)
x, y = row
# EXPECTED_RE_TYPE: builtins.int\*?
reveal_type(x)
# EXPECTED_RE_TYPE: builtins.str\*?
reveal_type(y)
async def t_async_connection_execute_single() -> None:
result = (await async_connection.execute(single_stmt)).t
# EXPECTED_RE_TYPE: sqlalchemy.*TupleResult\[Tuple\[builtins.str\*?\]\]
reveal_type(result)
row = result.one()
# EXPECTED_RE_TYPE: Tuple\[builtins.str\*?\]
reveal_type(row)
(x,) = row
# EXPECTED_RE_TYPE: builtins.str\*?
reveal_type(x)
async def t_async_connection_scalar() -> None:
obj = await async_connection.scalar(single_stmt)
# EXPECTED_RE_TYPE: Union\[builtins.str\*?, None\]
reveal_type(obj)
async def t_async_connection_scalars() -> None:
result = await async_connection.scalars(single_stmt)
# EXPECTED_RE_TYPE: sqlalchemy.*ScalarResult\*?\[builtins.str\*?\]
reveal_type(result)
data = result.all()
# EXPECTED_RE_TYPE: typing.Sequence\[builtins.str\*?\]
reveal_type(data)
async def t_async_session_execute_multi() -> None:
result = (await async_session.execute(multi_stmt)).t
# EXPECTED_RE_TYPE: sqlalchemy.*TupleResult\[Tuple\[builtins.int\*?, builtins.str\*?\]\]
reveal_type(result)
row = result.one()
# EXPECTED_RE_TYPE: Tuple\[builtins.int\*?, builtins.str\*?\]
reveal_type(row)
x, y = row
# EXPECTED_RE_TYPE: builtins.int\*?
reveal_type(x)
# EXPECTED_RE_TYPE: builtins.str\*?
reveal_type(y)
async def t_async_session_execute_single() -> None:
result = (await async_session.execute(single_stmt)).t
# EXPECTED_RE_TYPE: sqlalchemy.*TupleResult\[Tuple\[builtins.str\*?\]\]
reveal_type(result)
row = result.one()
# EXPECTED_RE_TYPE: Tuple\[builtins.str\*?\]
reveal_type(row)
(x,) = row
# EXPECTED_RE_TYPE: builtins.str\*?
reveal_type(x)
async def t_async_session_scalar() -> None:
obj = await async_session.scalar(single_stmt)
# EXPECTED_RE_TYPE: Union\[builtins.str\*?, None\]
reveal_type(obj)
async def t_async_session_scalars() -> None:
result = await async_session.scalars(single_stmt)
# EXPECTED_RE_TYPE: sqlalchemy.*ScalarResult\*?\[builtins.str\*?\]
reveal_type(result)
data = result.all()
# EXPECTED_RE_TYPE: typing.Sequence\[builtins.str\*?\]
reveal_type(data)
async def t_async_connection_stream_multi() -> None:
result = (await async_connection.stream(multi_stmt)).t
# EXPECTED_RE_TYPE: sqlalchemy.*AsyncTupleResult\[Tuple\[builtins.int\*?, builtins.str\*?\]\]
reveal_type(result)
row = await result.one()
# EXPECTED_RE_TYPE: Tuple\[builtins.int\*?, builtins.str\*?\]
reveal_type(row)
x, y = row
# EXPECTED_RE_TYPE: builtins.int\*?
reveal_type(x)
# EXPECTED_RE_TYPE: builtins.str\*?
reveal_type(y)
async def t_async_connection_stream_single() -> None:
result = (await async_connection.stream(single_stmt)).t
# EXPECTED_RE_TYPE: sqlalchemy.*AsyncTupleResult\[Tuple\[builtins.str\*?\]\]
reveal_type(result)
row = await result.one()
# EXPECTED_RE_TYPE: Tuple\[builtins.str\*?\]
reveal_type(row)
(x,) = row
# EXPECTED_RE_TYPE: builtins.str\*?
reveal_type(x)
async def t_async_connection_stream_scalars() -> None:
result = await async_connection.stream_scalars(single_stmt)
# EXPECTED_RE_TYPE: sqlalchemy.*AsyncScalarResult\*?\[builtins.str\*?\]
reveal_type(result)
data = await result.all()
# EXPECTED_RE_TYPE: typing.Sequence\*?\[builtins.str\*?\]
reveal_type(data)
async def t_async_session_stream_multi() -> None:
result = (await async_session.stream(multi_stmt)).t
# EXPECTED_RE_TYPE: sqlalchemy.*TupleResult\[Tuple\[builtins.int\*?, builtins.str\*?\]\]
reveal_type(result)
row = await result.one()
# EXPECTED_RE_TYPE: Tuple\[builtins.int\*?, builtins.str\*?\]
reveal_type(row)
x, y = row
# EXPECTED_RE_TYPE: builtins.int\*?
reveal_type(x)
# EXPECTED_RE_TYPE: builtins.str\*?
reveal_type(y)
async def t_async_session_stream_single() -> None:
result = (await async_session.stream(single_stmt)).t
# EXPECTED_RE_TYPE: sqlalchemy.*AsyncTupleResult\[Tuple\[builtins.str\*?\]\]
reveal_type(result)
row = await result.one()
# EXPECTED_RE_TYPE: Tuple\[builtins.str\*?\]
reveal_type(row)
(x,) = row
# EXPECTED_RE_TYPE: builtins.str\*?
reveal_type(x)
async def t_async_session_stream_scalars() -> None:
result = await async_session.stream_scalars(single_stmt)
# EXPECTED_RE_TYPE: sqlalchemy.*AsyncScalarResult\*?\[builtins.str\*?\]
reveal_type(result)
data = await result.all()
# EXPECTED_RE_TYPE: typing.Sequence\*?\[builtins.str\*?\]
reveal_type(data)
def test_outerjoin_10173() -> None:
class Other(Base):
__tablename__ = "other"
id: Mapped[int] = mapped_column(primary_key=True)
name: Mapped[str]
stmt: Select[Tuple[User, Other]] = select(User, Other).outerjoin(
Other, User.id == Other.id
)
stmt2: Select[Tuple[User, Optional[Other]]] = select(
User, Nullable(Other)
).outerjoin(Other, User.id == Other.id)
stmt3: Select[Tuple[int, Optional[str]]] = select(
User.id, Nullable(Other.name)
).outerjoin(Other, User.id == Other.id)
def go(W: Optional[Type[Other]]) -> None:
stmt4: Select[Tuple[str, Other]] = select(
NotNullable(User.value), NotNullable(W)
).where(User.value.is_not(None))
print(stmt4)
print(stmt, stmt2, stmt3)
|
PypiClean
|
/taskcc-alipay-sdk-python-3.3.398.tar.gz/taskcc-alipay-sdk-python-3.3.398/README.rst
|
alipay-sdk-python
==================
The official Alipay SDK for Python.
访问蚂蚁金服开放平台的官方SDK。
Links
-----
* Website: https://open.alipay.com
Example
----------------
.. code-block:: python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import logging
import traceback
from alipay.aop.api.AlipayClientConfig import AlipayClientConfig
from alipay.aop.api.DefaultAlipayClient import DefaultAlipayClient
from alipay.aop.api.FileItem import FileItem
from alipay.aop.api.domain.AlipayTradeAppPayModel import AlipayTradeAppPayModel
from alipay.aop.api.domain.AlipayTradePagePayModel import AlipayTradePagePayModel
from alipay.aop.api.domain.AlipayTradePayModel import AlipayTradePayModel
from alipay.aop.api.domain.GoodsDetail import GoodsDetail
from alipay.aop.api.domain.SettleDetailInfo import SettleDetailInfo
from alipay.aop.api.domain.SettleInfo import SettleInfo
from alipay.aop.api.domain.SubMerchant import SubMerchant
from alipay.aop.api.request.AlipayOfflineMaterialImageUploadRequest import AlipayOfflineMaterialImageUploadRequest
from alipay.aop.api.request.AlipayTradeAppPayRequest import AlipayTradeAppPayRequest
from alipay.aop.api.request.AlipayTradePagePayRequest import AlipayTradePagePayRequest
from alipay.aop.api.request.AlipayTradePayRequest import AlipayTradePayRequest
from alipay.aop.api.response.AlipayOfflineMaterialImageUploadResponse import AlipayOfflineMaterialImageUploadResponse
from alipay.aop.api.response.AlipayTradePayResponse import AlipayTradePayResponse
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s %(levelname)s %(message)s',
filemode='a',)
logger = logging.getLogger('')
if __name__ == '__main__':
"""
设置配置,包括支付宝网关地址、app_id、应用私钥、支付宝公钥等,其他配置值可以查看AlipayClientConfig的定义。
"""
alipay_client_config = AlipayClientConfig()
alipay_client_config.server_url = 'https://openapi.alipay.com/gateway.do'
alipay_client_config.app_id = '[your app_id]'
alipay_client_config.app_private_key = '[your app private key]'
alipay_client_config.alipay_public_key = '[alipay public key]'
"""
得到客户端对象。
注意,一个alipay_client_config对象对应一个DefaultAlipayClient,定义DefaultAlipayClient对象后,alipay_client_config不得修改,如果想使用不同的配置,请定义不同的DefaultAlipayClient。
logger参数用于打印日志,不传则不打印,建议传递。
"""
client = DefaultAlipayClient(alipay_client_config=alipay_client_config, logger=logger)
"""
系统接口示例:alipay.trade.pay
"""
# 对照接口文档,构造请求对象
model = AlipayTradePayModel()
model.auth_code = "282877775259787048"
model.body = "Iphone6 16G"
goods_list = list()
goods1 = GoodsDetail()
goods1.goods_id = "apple-01"
goods1.goods_name = "ipad"
goods1.price = 10
goods1.quantity = 1
goods_list.append(goods1)
model.goods_detail = goods_list
model.operator_id = "yx_001"
model.out_trade_no = "20180510AB014"
model.product_code = "FACE_TO_FACE_PAYMENT"
model.scene = "bar_code"
model.store_id = ""
model.subject = "huabeitest"
model.timeout_express = "90m"
model.total_amount = 1
request = AlipayTradePayRequest(biz_model=model)
# 如果有auth_token、app_auth_token等其他公共参数,放在udf_params中
# udf_params = dict()
# from alipay.aop.api.constant.ParamConstants import *
# udf_params[P_APP_AUTH_TOKEN] = "xxxxxxx"
# request.udf_params = udf_params
# 执行请求,执行过程中如果发生异常,会抛出,请打印异常栈
response_content = None
try:
response_content = client.execute(request)
except Exception as e:
print(traceback.format_exc())
if not response_content:
print("failed execute")
else:
response = AlipayTradePayResponse()
# 解析响应结果
response.parse_response_content(response_content)
print(response.body)
if response.is_success():
# 如果业务成功,则通过respnse属性获取需要的值
print("get response trade_no:" + response.trade_no)
else:
# 如果业务失败,则从错误码中可以得知错误情况,具体错误码信息可以查看接口文档
print(response.code + "," + response.msg + "," + response.sub_code + "," + response.sub_msg)
"""
带文件的系统接口示例:alipay.offline.material.image.upload
"""
# 如果没有找到对应Model类,则直接使用Request类,属性在Request类中
request = AlipayOfflineMaterialImageUploadRequest()
request.image_name = "我的店"
request.image_type = "jpg"
# 设置文件参数
f = open("/Users/foo/Downloads/IMG.jpg", "rb")
request.image_content = FileItem(file_name="IMG.jpg", file_content=f.read())
f.close()
response_content = None
try:
response_content = client.execute(request)
except Exception as e:
print(traceback.format_exc())
if not response_content:
print("failed execute")
else:
response = AlipayOfflineMaterialImageUploadResponse()
response.parse_response_content(response_content)
if response.is_success():
print("get response image_url:" + response.image_url)
else:
print(response.code + "," + response.msg + "," + response.sub_code + "," + response.sub_msg)
"""
页面接口示例:alipay.trade.page.pay
"""
# 对照接口文档,构造请求对象
model = AlipayTradePagePayModel()
model.out_trade_no = "pay201805020000226"
model.total_amount = 50
model.subject = "测试"
model.body = "支付宝测试"
model.product_code = "FAST_INSTANT_TRADE_PAY"
settle_detail_info = SettleDetailInfo()
settle_detail_info.amount = 50
settle_detail_info.trans_in_type = "userId"
settle_detail_info.trans_in = "2088302300165604"
settle_detail_infos = list()
settle_detail_infos.append(settle_detail_info)
settle_info = SettleInfo()
settle_info.settle_detail_infos = settle_detail_infos
model.settle_info = settle_info
sub_merchant = SubMerchant()
sub_merchant.merchant_id = "2088301300153242"
model.sub_merchant = sub_merchant
request = AlipayTradePagePayRequest(biz_model=model)
# 得到构造的请求,如果http_method是GET,则是一个带完成请求参数的url,如果http_method是POST,则是一段HTML表单片段
response = client.page_execute(request, http_method="GET")
print("alipay.trade.page.pay response:" + response)
"""
构造唤起支付宝客户端支付时传递的请求串示例:alipay.trade.app.pay
"""
model = AlipayTradeAppPayModel()
model.timeout_express = "90m"
model.total_amount = "9.00"
model.seller_id = "2088301194649043"
model.product_code = "QUICK_MSECURITY_PAY"
model.body = "Iphone6 16G"
model.subject = "iphone"
model.out_trade_no = "201800000001201"
request = AlipayTradeAppPayRequest(biz_model=model)
response = client.sdk_execute(request)
print("alipay.trade.app.pay response:" + response)
|
PypiClean
|
/stackhut_common-0.5.6-py3-none-any.whl/stackhut_common/barrister/parser.py
|
import os
import os.path
import time
import copy
import operator
import io
# from plex import Scanner, Lexicon, Str, State, IGNORE
# from plex import Begin, Any, AnyBut, AnyChar, Range, Rep
from .cythonplex3 import Scanner, Lexicon, Str, State, IGNORE
from .cythonplex3 import Begin, Any, AnyBut, AnyChar, Range, Rep
import json
import hashlib
def md5(s):
return hashlib.md5(s.encode()).hexdigest()
native_types = [ "int", "float", "string", "bool" ]
void_func_types = [ "\r\n", "\n" ]
letter = Range("AZaz")
digit = Range("09")
under = Str("_")
period = Str(".")
plain_ident = (letter | under) + Rep(letter | digit | under)
ns_ident = plain_ident + period + plain_ident
ident = plain_ident | ns_ident
arr_ident = Str("[]") + ident
space = Any(" \t\n\r")
space_tab = Any(" \t")
comment = Str("// ") | Str("//")
type_opts = Str("[") + Rep(AnyBut("{}]\n")) + Str("]")
namespace = Str("namespace") + Rep(space_tab) + plain_ident
import_stmt = Str("import") + Rep(space_tab) + Str('"') + Rep(AnyBut("\"\r\n")) + Str('"')
def file_paths(fname, search_path=None):
if not search_path and "BARRISTER_PATH" in os.environ:
search_path = os.environ["BARRISTER_PATH"]
paths = []
paths.append(fname)
if search_path:
for directory in search_path.split(os.pathsep):
paths.append(os.path.join(directory, fname))
return paths
def parse(idl_text, idlFilename=None, validate=True, add_meta=True):
if not isinstance(idl_text, str):
idl_text = idl_text.read()
scanner = IdlScanner(idl_text, idlFilename)
scanner.parse(validate=validate)
if len(scanner.errors) == 0:
if add_meta:
scanner.add_meta()
return scanner.parsed
else:
raise IdlParseException(scanner.errors)
# def validate_scanner(scanner):
# scanner2 = IdlScanner(idl_text, idlFilename)
# scanner2.parse(scanner)
# scanner = scanner2
def elem_checksum(elem):
if elem["type"] == "struct":
s = ""
fields = copy.copy(elem["fields"])
fields.sort(key=operator.itemgetter("name"))
for f in fields:
fs = (f["name"], f["type"], f["is_array"], f["optional"])
s += "\t%s\t%s\t%s\t%s" % fs
fs = (elem["name"], elem["extends"], s)
return "struct\t%s\t%s\t%s\n" % fs
elif elem["type"] == "enum":
s = "enum\t%s" % elem["name"]
vals = copy.copy(elem["values"])
vals.sort(key=operator.itemgetter("value"))
for v in vals: s += "\t%s" % v["value"]
s += "\n"
return s
elif elem["type"] == "interface":
s = "interface\t%s" % elem["name"]
funcs = copy.copy(elem["functions"])
funcs.sort(key=operator.itemgetter("name"))
for f in funcs:
s += "[%s" % f["name"]
for p in f["params"]:
s += "\t%s\t%s" % (p["type"], p["is_array"])
if f.get("returns", None):
ret = f["returns"]
fs = (ret["type"], ret["is_array"], ret["optional"])
s += "(%s\t%s\t%s)]" % fs
s += "\n"
return s
return None
class IdlParseException(Exception):
def __init__(self, errors):
Exception.__init__(self)
self.errors = errors
def __str__(self):
s = ""
for e in self.errors:
if s != "":
s += ", "
s += "line: %d message: %s" % (e["line"], e["message"])
return s
class IdlScanner(Scanner):
def __init__(self, idl_text, name):
f = io.StringIO(idl_text)
Scanner.__init__(self, self.lex, f, name)
self.parsed = [ ]
self.errors = [ ]
self.types = { }
self.imports = { }
self.comment = None
self.cur = None
self.namespace = None
self.searchPath = None
self.idl_text = idl_text
self.name = name
if name:
searchPath = os.path.dirname(os.path.abspath(name))
if 'BARRISTER_PATH' in os.environ:
searchPath = searchPath + os.pathsep + os.environ['BARRISTER_PATH']
self.searchPath = searchPath
def parse(self, firstPass=None, validate=False):
self.firstPass = firstPass
while True:
(t, name) = self.read()
if t is None:
break
else:
self.add_error(t)
break
if validate:
scanner2 = IdlScanner(self.idl_text, self.name)
scanner2.parse(self)
self.parsed = scanner2.parsed
self.errors = scanner2.errors
self.types = scanner2.types
def import_file(self, fname):
path_to_load = None
for path in file_paths(fname, self.searchPath):
path = os.path.abspath(path)
if os.path.exists(path):
path_to_load = path
break
if path_to_load:
if path_to_load not in self.imports:
f = open(path_to_load)
idl_text = f.read()
f.close()
scanner = IdlScanner(idl_text, path_to_load)
self.imports[path_to_load] = scanner
scanner.parse(validate=True)
for elem in scanner.parsed:
if elem["type"] == "struct" or elem["type"] == "enum":
if elem["name"] in self.types:
c1 = elem_checksum(self.types[elem["name"]])
c2 = elem_checksum(elem)
if c1 != c2:
self.add_error("Include %s redefined type: %s" % (path_to_load, elem["name"]))
else:
self.types[elem["name"]] = elem
self.parsed.append(elem)
else:
self.add_error("Cannot find import file: %s" % fname)
def eof(self):
if self.cur:
self.add_error("Unexpected end of file")
def add_meta(self):
from stackhut_common.barrister import __version__
meta = {
"type" : "meta",
"barrister_version" : __version__,
"date_generated" : int(time.time() * 1000),
"checksum" : self.get_checksum()
}
self.parsed.append(meta)
def get_checksum(self):
"""
Returns a checksum based on the IDL that ignores comments and
ordering, but detects changes to types, parameter order,
and enum values.
"""
arr = [ ]
for elem in self.parsed:
s = elem_checksum(elem)
if s:
arr.append(s)
arr.sort()
#print arr
return md5(json.dumps(arr))
#####################################################
def validate_type_vs_first_pass(self, type_str):
if self.firstPass:
self.add_error(self.firstPass.validate_type(type_str, [], 0))
def validate_type(self, cur_type, types, level):
level += 1
cur_type = self.strip_array_chars(cur_type)
if cur_type in native_types or cur_type in types:
pass
elif cur_type not in self.types:
return "undefined type: %s" % cur_type
else:
cur = self.types[cur_type]
types.append(cur_type)
if cur["type"] == "struct":
if cur["extends"] != "":
self.validate_type(cur["extends"], types, level)
for f in cur["fields"]:
self.validate_type(f["type"], types, level)
elif cur["type"] == "interface":
# interface types must be top-level, so if len(types) > 1, we
# know this interface was used as a type in a function
# or struct
return "interface %s cannot be used as a type" % cur["name"]
if level > 1:
return "interface %s cannot be a field type" % cur["name"]
else:
for f in cur["functions"]:
types = [ ]
for p in f["params"]:
self.validate_type(p["type"], types, 1)
self.validate_type(f["returns"]["type"], types, 1)
def validate_struct_extends(self, s):
if self.firstPass:
name = s["name"]
extends = s["extends"]
if extends in native_types:
self.add_error("%s cannot extend %s" % (name, extends))
elif extends in self.firstPass.types:
ext_type = self.firstPass.types[extends]
if ext_type["type"] != "struct":
fs = (name, ext_type["type"], extends)
self.add_error("%s cannot extend %s %s" % fs)
else:
self.add_error("%s extends unknown type %s" % (name, extends))
def validate_struct_field(self, s):
if self.firstPass:
names = self.get_parent_fields(s, [], [])
for f in s["fields"]:
if f["name"] in names:
errf = (s["name"], f["name"])
err = "%s cannot redefine parent field %s" % errf
self.add_error(err)
def validate_struct_cycles(self, s):
if self.firstPass:
all_types = self.firstPass.get_struct_field_types(s, [])
if s["name"] in all_types:
self.add_error("cycle detected in struct: %s" % s["name"])
def get_parent_fields(self, s, names, types):
if s["extends"] in self.types:
if s["name"] not in types:
types.append(s["name"])
parent = self.types[s["extends"]]
if parent["type"] == "struct":
for f in parent["fields"]:
if f["name"] not in names:
names.append(f["name"])
self.get_parent_fields(parent, names, types)
return names
def get_struct_field_types(self, struct, types):
for f in struct["fields"]:
type_name = self.strip_array_chars(f["type"])
if type_name in self.types and not type_name in types:
t = self.types[type_name]
if t["type"] == "struct":
if not f["is_array"] and not f["optional"]:
types.append(type_name)
self.get_struct_field_types(t, types)
else:
types.append(type_name)
if struct["extends"] != "":
type_name = struct["extends"]
if type_name in self.types and not type_name in types:
t = self.types[type_name]
if t["type"] == "struct":
types.append(type_name)
self.get_struct_field_types(t, types)
return types
def strip_array_chars(self, name):
if name.find("[]") == 0:
return name[2:]
return name
def add_error(self, message, line=-1):
if not message: return
if line < 0:
(name, line, col) = self.position()
self.errors.append({"line": line, "message": message})
def prefix_namespace(self, ident):
if self.namespace and ident.find(".") < 0 and ident not in native_types:
return self.namespace + "." + ident
return ident
#####################################################
def begin_struct(self, text):
self.check_dupe_name(text)
name = self.prefix_namespace(text)
self.cur = { "name" : name, "type" : "struct", "extends" : "",
"comment" : self.get_comment(), "fields" : [] }
self.begin('start-block')
def begin_enum(self, text):
self.check_dupe_name(text)
name = self.prefix_namespace(text)
self.cur = { "name" : name, "type" : "enum",
"comment" : self.get_comment(), "values" : [] }
self.begin('start-block')
def begin_interface(self, text):
self.check_dupe_name(text)
self.cur = { "name" : text, "type" : "interface",
"comment" : self.get_comment(), "functions" : [] }
self.begin('start-block')
def check_dupe_name(self, name):
if name in self.types:
self.add_error("type %s already defined" % name)
def check_not_empty(self, cur, list_name, printable_name):
if len(cur[list_name]) == 0:
flist = (cur["name"], printable_name)
self.add_error("%s must have at least one %s" % flist)
return False
return True
def set_namespace(self, text):
if self.namespace:
self.add_error("Cannot redeclare namespace")
elif len(self.parsed) > 0:
self.add_error("namespace must preceed all struct/enum/interface definitions")
ns = text.strip()[9:].strip()
self.namespace = ns
self.begin('end_of_line')
def add_import(self, text):
start = text.find('"') + 1
end = text[start:].find('"') + start
fname = text[start:end]
self.import_file(fname)
self.begin('end_of_line')
def end_of_line(self, text):
self.cur = None
self.begin('')
def start_block(self, text):
t = self.cur["type"]
if t == "struct":
self.begin("fields")
elif t == "enum":
self.begin("values")
elif t == "interface":
if self.namespace:
self.add_error("namespace cannot be used in files with interfaces")
self.begin("functions")
else:
raise Exception("Invalid type: %s" % t)
#self.validate_type_vs_first_pass(self.cur["name"])
def end_block(self, text):
ok = False
t = self.cur["type"]
if t == "struct":
ok = self.check_not_empty(self.cur, "fields", "field")
self.validate_struct_cycles(self.cur)
elif t == "enum":
ok = self.check_not_empty(self.cur, "values", "value")
elif t == "interface":
ok = self.check_not_empty(self.cur, "functions", "function")
if ok:
self.parsed.append(self.cur)
self.types[self.cur["name"]] = self.cur
self.cur = None
self.begin('')
def begin_field(self, text):
self.field = { "name" : text }
self.begin("field")
def end_field(self, text):
is_array = False
if text.find("[]") == 0:
text = text[2:]
is_array = True
type_name = self.prefix_namespace(text)
self.validate_type_vs_first_pass(type_name)
self.field["type"] = type_name
self.field["is_array"] = is_array
self.field["comment"] = self.get_comment()
self.field["optional"] = False
self.type = self.field
self.cur["fields"].append(self.field)
self.validate_struct_field(self.cur)
self.field = None
self.next_state = "fields"
self.begin("type-opts")
def begin_function(self, text):
self.function = {
"name" : text,
"comment" : self.get_comment(),
"params" : [ ] }
self.begin("function-start")
def begin_param(self, text):
self.param = { "name" : text }
self.begin("param")
def end_param(self, text):
is_array = False
if text.find("[]") == 0:
text = text[2:]
is_array = True
type_name = self.prefix_namespace(text)
self.validate_type_vs_first_pass(type_name)
self.param["type"] = type_name
self.param["is_array"] = is_array
self.function["params"].append(self.param)
self.param = None
self.begin("end-param")
def end_return(self, text):
is_array = False
if text.find("[]") == 0:
text = text[2:]
is_array = True
type_name = self.prefix_namespace(text)
if type_name in void_func_types:
self.type = None
self.next_state = "functions"
self.cur["functions"].append(self.function)
self.function = None
self.begin(self.next_state)
else:
self.validate_type_vs_first_pass(type_name)
self.function["returns"] = {
"type" : type_name,
"is_array" : is_array,
"optional" : False }
self.type = self.function["returns"]
self.next_state = "functions"
self.cur["functions"].append(self.function)
self.function = None
self.begin("type-opts")
def end_type_opts(self, text):
text = text.strip()
if text.startswith("[") and text.endswith("]"):
text = text[1:-1]
if text != "":
if text == "optional":
self.type["optional"] = True
else:
raise Exception("Invalid type option: %s" % text)
self.type = None
self.begin(self.next_state)
self.next_state = None
def end_type_opts_and_block(self, text):
self.end_type_opts(text)
self.end_block(text)
def end_value(self, text):
if not text in self.cur["values"]:
val = { "value" : text, "comment" : self.get_comment() }
self.last_comment = ""
self.cur["values"].append(val)
def get_comment(self):
comment = ""
if self.comment and len(self.comment) > 0:
comment = "".join(self.comment)
self.comment = None
return comment
def start_comment(self, text):
if self.comment:
self.comment.append("\n")
else:
self.comment = []
self.prev_state = self.state_name
self.begin("comment")
def append_comment(self, text):
self.comment.append(text)
def append_field_options(self, text):
self.field_options.append(text)
def end_comment(self, text):
self.begin(self.prev_state)
self.prev_state = None
def end_extends(self, text):
if self.cur and self.cur["type"] == "struct":
self.cur["extends"] = self.prefix_namespace(text)
self.validate_struct_extends(self.cur)
else:
self.add_error("extends is only supported for struct types")
def add_comment_block(self, text):
comment = self.get_comment()
if comment:
self.parsed.append({"type" : "comment", "value" : comment})
lex = Lexicon([
(Str("\n"), add_comment_block),
(space, IGNORE),
(namespace, set_namespace),
(import_stmt, add_import),
(Str('struct '), Begin('struct-start')),
(Str('enum '), Begin('enum-start')),
(Str('interface '), Begin('interface-start')),
(comment, start_comment),
State('end_of_line', [
(Str("\r\n"), end_of_line),
(Str("\n"), end_of_line),
(space, IGNORE),
(AnyChar, "Illegal character - expected end of line") ]),
State('struct-start', [
(ident, begin_struct),
(space, IGNORE),
(AnyChar, "Missing identifier") ]),
State('enum-start', [
(ident, begin_enum),
(space, IGNORE),
(AnyChar, "Missing identifier") ]),
State('interface-start', [
(ident, begin_interface),
(space, IGNORE),
(AnyChar, "Missing identifier") ]),
State('start-block', [
(space, IGNORE),
(Str("extends"), Begin('extends')),
(Str('{'), start_block) ]),
State('extends', [
(space, IGNORE),
(ident, end_extends),
(Str('{'), start_block) ]),
State('fields', [
(ident, begin_field),
(space, IGNORE),
(comment, start_comment),
(Str('{'), 'invalid'),
(Str('}'), end_block) ]),
State('field', [
(ident, end_field),
(arr_ident, end_field),
(Str("\n"), 'invalid'),
(space, IGNORE),
(Str('{'), 'invalid'),
(Str('}'), 'invalid') ]),
State('functions', [
(ident, begin_function),
(space, IGNORE),
(comment, start_comment),
(Str('{'), 'invalid'),
(Str('}'), end_block) ]),
State('function-start', [
(Str("("), Begin('params')),
(Str("\n"), 'invalid'),
(space, IGNORE) ]),
State('params', [
(ident, begin_param),
(space, IGNORE),
(Str(")"), Begin('function-return')) ]),
State('end-param', [
(space, IGNORE),
(Str(","), Begin('params')),
(Str(")"), Begin('function-return')) ]),
State('param', [
(ident, end_param),
(arr_ident, end_param),
(space, IGNORE) ]),
State('function-return', [
(Str("\r\n"), end_return),
(Str("\n"), end_return),
(space, IGNORE),
(ident, end_return),
(arr_ident, end_return) ]),
State('type-opts', [
(type_opts, end_type_opts),
(Str("\n"), end_type_opts),
(Str('}'), end_block),
(space, IGNORE),
(Str('{'), 'invalid') ]),
State('end-function', [
(Str("\n"), Begin('functions')),
(space, IGNORE) ]),
State('values', [
(ident, end_value),
(space, IGNORE),
(comment, start_comment),
(Str('{'), 'invalid'),
(Str('}'), end_block) ]),
State('comment', [
(Str("\n"), end_comment),
(AnyChar, append_comment) ])
])
|
PypiClean
|
/agent_protocol_client-0.2.2-py3-none-any.whl/agent_protocol_client/rest.py
|
import io
import json
import logging
import re
import ssl
import aiohttp
from urllib.parse import urlencode, quote_plus
from agent_protocol_client.exceptions import ApiException, ApiValueError
logger = logging.getLogger(__name__)
class RESTResponse(io.IOBase):
def __init__(self, resp, data):
self.aiohttp_response = resp
self.status = resp.status
self.reason = resp.reason
self.data = data
def getheaders(self):
"""Returns a CIMultiDictProxy of the response headers."""
return self.aiohttp_response.headers
def getheader(self, name, default=None):
"""Returns a given response header."""
return self.aiohttp_response.headers.get(name, default)
class RESTClientObject(object):
def __init__(self, configuration, pools_size=4, maxsize=None):
# maxsize is number of requests to host that are allowed in parallel
if maxsize is None:
maxsize = configuration.connection_pool_maxsize
ssl_context = ssl.create_default_context(cafile=configuration.ssl_ca_cert)
if configuration.cert_file:
ssl_context.load_cert_chain(
configuration.cert_file, keyfile=configuration.key_file
)
if not configuration.verify_ssl:
ssl_context.check_hostname = False
ssl_context.verify_mode = ssl.CERT_NONE
connector = aiohttp.TCPConnector(limit=maxsize, ssl=ssl_context)
self.proxy = configuration.proxy
self.proxy_headers = configuration.proxy_headers
# https pool manager
self.pool_manager = aiohttp.ClientSession(connector=connector, trust_env=True)
async def close(self):
await self.pool_manager.close()
async def request(
self,
method,
url,
query_params=None,
headers=None,
body=None,
post_params=None,
_preload_content=True,
_request_timeout=None,
):
"""Execute request
:param method: http request method
:param url: http request url
:param query_params: query parameters in the url
:param headers: http request headers
:param body: request json body, for `application/json`
:param post_params: request post parameters,
`application/x-www-form-urlencoded`
and `multipart/form-data`
:param _preload_content: this is a non-applicable field for
the AiohttpClient.
:param _request_timeout: timeout setting for this request. If one
number provided, it will be total request
timeout. It can also be a pair (tuple) of
(connection, read) timeouts.
"""
method = method.upper()
assert method in ["GET", "HEAD", "DELETE", "POST", "PUT", "PATCH", "OPTIONS"]
if post_params and body:
raise ApiValueError(
"body parameter cannot be used with post_params parameter."
)
post_params = post_params or {}
headers = headers or {}
# url already contains the URL query string
# so reset query_params to empty dict
query_params = {}
timeout = _request_timeout or 5 * 60
if "Content-Type" not in headers:
headers["Content-Type"] = "application/json"
args = {"method": method, "url": url, "timeout": timeout, "headers": headers}
if self.proxy:
args["proxy"] = self.proxy
if self.proxy_headers:
args["proxy_headers"] = self.proxy_headers
if query_params:
args["url"] += "?" + urlencode(query_params)
# For `POST`, `PUT`, `PATCH`, `OPTIONS`, `DELETE`
if method in ["POST", "PUT", "PATCH", "OPTIONS", "DELETE"]:
if re.search("json", headers["Content-Type"], re.IGNORECASE):
if body is not None:
body = json.dumps(body)
args["data"] = body
elif (
headers["Content-Type"] == "application/x-www-form-urlencoded"
): # noqa: E501
args["data"] = aiohttp.FormData(post_params)
elif headers["Content-Type"] == "multipart/form-data":
# must del headers['Content-Type'], or the correct
# Content-Type which generated by aiohttp
del headers["Content-Type"]
data = aiohttp.FormData()
for param in post_params:
k, v = param
if isinstance(v, tuple) and len(v) == 3:
data.add_field(k, value=v[1], filename=v[0], content_type=v[2])
else:
data.add_field(k, v)
args["data"] = data
# Pass a `bytes` parameter directly in the body to support
# other content types than Json when `body` argument is provided
# in serialized form
elif isinstance(body, bytes):
args["data"] = body
else:
# Cannot generate the request from given parameters
msg = """Cannot prepare a request message for provided
arguments. Please check that your arguments match
declared content type."""
raise ApiException(status=0, reason=msg)
r = await self.pool_manager.request(**args)
if _preload_content:
data = await r.read()
r = RESTResponse(r, data)
# log response body
logger.debug("response body: %s", r.data)
if not 200 <= r.status <= 299:
raise ApiException(http_resp=r)
return r
async def get_request(
self,
url,
headers=None,
query_params=None,
_preload_content=True,
_request_timeout=None,
):
return await self.request(
"GET",
url,
headers=headers,
_preload_content=_preload_content,
_request_timeout=_request_timeout,
query_params=query_params,
)
async def head_request(
self,
url,
headers=None,
query_params=None,
_preload_content=True,
_request_timeout=None,
):
return await self.request(
"HEAD",
url,
headers=headers,
_preload_content=_preload_content,
_request_timeout=_request_timeout,
query_params=query_params,
)
async def options_request(
self,
url,
headers=None,
query_params=None,
post_params=None,
body=None,
_preload_content=True,
_request_timeout=None,
):
return await self.request(
"OPTIONS",
url,
headers=headers,
query_params=query_params,
post_params=post_params,
_preload_content=_preload_content,
_request_timeout=_request_timeout,
body=body,
)
async def delete_request(
self,
url,
headers=None,
query_params=None,
body=None,
_preload_content=True,
_request_timeout=None,
):
return await self.request(
"DELETE",
url,
headers=headers,
query_params=query_params,
_preload_content=_preload_content,
_request_timeout=_request_timeout,
body=body,
)
async def post_request(
self,
url,
headers=None,
query_params=None,
post_params=None,
body=None,
_preload_content=True,
_request_timeout=None,
):
return await self.request(
"POST",
url,
headers=headers,
query_params=query_params,
post_params=post_params,
_preload_content=_preload_content,
_request_timeout=_request_timeout,
body=body,
)
async def put_request(
self,
url,
headers=None,
query_params=None,
post_params=None,
body=None,
_preload_content=True,
_request_timeout=None,
):
return await self.request(
"PUT",
url,
headers=headers,
query_params=query_params,
post_params=post_params,
_preload_content=_preload_content,
_request_timeout=_request_timeout,
body=body,
)
async def patch_request(
self,
url,
headers=None,
query_params=None,
post_params=None,
body=None,
_preload_content=True,
_request_timeout=None,
):
return await self.request(
"PATCH",
url,
headers=headers,
query_params=query_params,
post_params=post_params,
_preload_content=_preload_content,
_request_timeout=_request_timeout,
body=body,
)
|
PypiClean
|
/PyrogramXd-2.0.64-py3-none-any.whl/pyrogram/types/inline_mode/inline_query_result_cached_animation.py
|
from typing import Optional, List
import pyrogram
from pyrogram import raw, types, utils, enums
from .inline_query_result import InlineQueryResult
from ...file_id import FileId
class InlineQueryResultCachedAnimation(InlineQueryResult):
"""A link to an animation file stored on the Telegram servers.
By default, this animation file will be sent by the user with an optional caption.
Alternatively, you can use *input_message_content* to send a message with specified content instead of the
animation.
Parameters:
animation_file_id (``str``):
A valid file identifier for the animation file.
id (``str``, *optional*):
Unique identifier for this result, 1-64 bytes.
Defaults to a randomly generated UUID4.
title (``str``, *optional*):
Title for the result.
caption (``str``, *optional*):
Caption of the photo to be sent, 0-1024 characters.
parse_mode (:obj:`~pyrogram.enums.ParseMode`, *optional*):
By default, texts are parsed using both Markdown and HTML styles.
You can combine both syntaxes together.
caption_entities (List of :obj:`~pyrogram.types.MessageEntity`):
List of special entities that appear in the caption, which can be specified instead of *parse_mode*.
reply_markup (:obj:`~pyrogram.types.InlineKeyboardMarkup`, *optional*):
An InlineKeyboardMarkup object.
input_message_content (:obj:`~pyrogram.types.InputMessageContent`):
Content of the message to be sent instead of the photo.
"""
def __init__(
self,
animation_file_id: str,
id: str = None,
title: str = None,
caption: str = "",
parse_mode: Optional["enums.ParseMode"] = None,
caption_entities: List["types.MessageEntity"] = None,
reply_markup: "types.InlineKeyboardMarkup" = None,
input_message_content: "types.InputMessageContent" = None
):
super().__init__("gif", id, input_message_content, reply_markup)
self.animation_file_id = animation_file_id
self.title = title
self.caption = caption
self.parse_mode = parse_mode
self.caption_entities = caption_entities
self.reply_markup = reply_markup
self.input_message_content = input_message_content
async def write(self, client: "pyrogram.Client"):
message, entities = (await utils.parse_text_entities(
client, self.caption, self.parse_mode, self.caption_entities
)).values()
file_id = FileId.decode(self.animation_file_id)
return raw.types.InputBotInlineResultDocument(
id=self.id,
type=self.type,
title=self.title,
document=raw.types.InputDocument(
id=file_id.media_id,
access_hash=file_id.access_hash,
file_reference=file_id.file_reference,
),
send_message=(
await self.input_message_content.write(client, self.reply_markup)
if self.input_message_content
else raw.types.InputBotInlineMessageMediaAuto(
reply_markup=await self.reply_markup.write(client) if self.reply_markup else None,
message=message,
entities=entities
)
)
)
|
PypiClean
|
/django-classic-user-accounts-1.0.39.tar.gz/django-classic-user-accounts-1.0.39/ClassicUserAccounts/static/matrix-admin-v2/assets/libs/moment/locale/es-us.js
|
;(function (global, factory) {
typeof exports === 'object' && typeof module !== 'undefined'
&& typeof require === 'function' ? factory(require('../moment')) :
typeof define === 'function' && define.amd ? define(['../moment'], factory) :
factory(global.moment)
}(this, (function (moment) { 'use strict';
var monthsShortDot = 'ene._feb._mar._abr._may._jun._jul._ago._sep._oct._nov._dic.'.split('_'),
monthsShort = 'ene_feb_mar_abr_may_jun_jul_ago_sep_oct_nov_dic'.split('_');
var esUs = moment.defineLocale('es-us', {
months : 'enero_febrero_marzo_abril_mayo_junio_julio_agosto_septiembre_octubre_noviembre_diciembre'.split('_'),
monthsShort : function (m, format) {
if (!m) {
return monthsShortDot;
} else if (/-MMM-/.test(format)) {
return monthsShort[m.month()];
} else {
return monthsShortDot[m.month()];
}
},
monthsParseExact : true,
weekdays : 'domingo_lunes_martes_miércoles_jueves_viernes_sábado'.split('_'),
weekdaysShort : 'dom._lun._mar._mié._jue._vie._sáb.'.split('_'),
weekdaysMin : 'do_lu_ma_mi_ju_vi_sá'.split('_'),
weekdaysParseExact : true,
longDateFormat : {
LT : 'h:mm A',
LTS : 'h:mm:ss A',
L : 'MM/DD/YYYY',
LL : 'MMMM [de] D [de] YYYY',
LLL : 'MMMM [de] D [de] YYYY h:mm A',
LLLL : 'dddd, MMMM [de] D [de] YYYY h:mm A'
},
calendar : {
sameDay : function () {
return '[hoy a la' + ((this.hours() !== 1) ? 's' : '') + '] LT';
},
nextDay : function () {
return '[mañana a la' + ((this.hours() !== 1) ? 's' : '') + '] LT';
},
nextWeek : function () {
return 'dddd [a la' + ((this.hours() !== 1) ? 's' : '') + '] LT';
},
lastDay : function () {
return '[ayer a la' + ((this.hours() !== 1) ? 's' : '') + '] LT';
},
lastWeek : function () {
return '[el] dddd [pasado a la' + ((this.hours() !== 1) ? 's' : '') + '] LT';
},
sameElse : 'L'
},
relativeTime : {
future : 'en %s',
past : 'hace %s',
s : 'unos segundos',
ss : '%d segundos',
m : 'un minuto',
mm : '%d minutos',
h : 'una hora',
hh : '%d horas',
d : 'un día',
dd : '%d días',
M : 'un mes',
MM : '%d meses',
y : 'un año',
yy : '%d años'
},
dayOfMonthOrdinalParse : /\d{1,2}º/,
ordinal : '%dº',
week : {
dow : 0, // Sunday is the first day of the week.
doy : 6 // The week that contains Jan 1st is the first week of the year.
}
});
return esUs;
})));
|
PypiClean
|
/nio_cli-1.3.1-py3-none-any.whl/nio_cli/commands/blockcheck.py
|
import json
import os
import sys
import subprocess
import re
from .base import Base
class BlockCheck(Base):
# This command should be run from inside the block dir
def __init__(self, options, *args, **kwargs):
super().__init__(options, *args, **kwargs)
self._directory_name = os.getcwd().split('/')[-1]
self._run_build_spec = False
self.block_versions, self.block_files = self._read_block_files()
self.specs = self._read_spec_file()
self.readme_lines = self._read_readme()
self.releases = self._read_release_file()
def run(self):
self.check_pep8()
self.check_spec()
self.check_readme()
self.check_release()
self.check_version()
self.check_naming()
if self._run_build_spec:
print(
'\n**Run `nio buildspec {}` from the project directory '
'and re-run this check**\n'.format(self._directory_name)
)
def _read_block_files(self):
"""Build list of python files and reference dictionary for versions"""
block_versions = {}
class_name = None
block_files = [f for f in os.listdir('.') if f.endswith('.py') and
'__init__' not in f]
for block in block_files:
try:
with open(block) as f:
class_version = re.search(
r".*class (\S+)\(.*\):.*?"
r"VersionProperty\(['\"](\d+\.\d+)\.[^)]*\)",
' '.join([l.rstrip() for l in f.readlines()])
)
block_versions[class_version.group(1)] = \
class_version.group(2)
except AttributeError:
# base block classes are not supposed to have a version
continue
return block_versions, block_files
def _read_spec_file(self):
"""Load spec file into dictionary"""
specs = {}
if os.path.exists('spec.json'):
with open('spec.json') as f:
try:
specs = json.load(f)
except json.JSONDecodeError:
print('spec.json file is either incomplete or '
'has an invalid JSON object')
self._run_build_spec = True
else:
self._run_build_spec = True
return specs
def _read_readme(self):
"""Load readme file into a list of lines"""
lines = []
if os.path.exists('README.md'):
with open('README.md') as f:
lines = [l.rstrip() for l in f.readlines()]
else:
print(
'\n**Run `nio buildreadme` as long as the spec.json file is '
'complete.**'
)
return lines
def _read_release_file(self):
"""Load release file into dictionary"""
release_dict = {}
if os.path.exists('release.json'):
with open('release.json') as f:
release_dict = json.load(f)
else:
print(
'\n**Run `nio buildrelease {}` from the project directory as '
'long as the spec.json file is complete.**'.format(
self._directory_name)
)
return release_dict
def check_pep8(self):
"""Check all python for proper PEP8 formatting"""
self._print_check('PEP8')
shell_pep8 = 'pycodestyle .'
subprocess.call(shell_pep8, shell=True)
print('')
def check_spec(self):
"""Check that spec file has all descriptions filled out"""
self._print_check('spec.json')
for block in self.specs.keys():
keys = ['version', 'description', 'properties']
for key in keys:
if key not in [k for k in self.specs[block]]:
print('{} block is missing {}'.format(
block.split('/')[1], key))
self._run_build_spec = True
if self.specs[block][key] == '':
print('Fill in the {} of the {} block'.format(
key, block.split('/')[1]))
for prop, val in \
self.specs[block]['properties'].items():
if val['description'] == '':
print('Fill in the description for the "{}" property in '
'the {} block'.format(prop, block.split('/')[1]))
print('')
def check_readme(self):
"""Check that README file has all blocks and necessary sections"""
self._print_check('README.md')
block_indices = []
for block in self.specs.keys():
if block.split('/')[1] not in self.readme_lines:
print('Add the {} block to the README')
block_indices.append(self.readme_lines.index(block.split('/')[1]))
block_indices.sort()
for i in range(len(block_indices)):
for key in ['Properties', 'Inputs', 'Outputs',
'Commands', 'Dependencies']:
try:
if key not in self.readme_lines[
block_indices[i]:block_indices[i+1]]:
print('Add "{}" to the {} block'.format(
key, self.readme_lines[block_indices[i]]))
except IndexError:
if key not in self.readme_lines[block_indices[i]:]:
print('Add "{}" to the {} block'.format(
key, self.readme_lines[block_indices[i]]))
print('')
def check_release(self):
"""Check that release file has all necessary keys"""
self._print_check('release.json')
for block in self.specs.keys():
if block not in self.releases:
print('Add {} block to release.json'.format(
block.split('/')[1]))
for key in ['url', 'version', 'language']:
if key not in self.releases[block] \
or self.releases[block][key] == '':
print('Add a {} to the {} block'.format(
key, block.split('/')[1]))
print('')
def check_version(self):
"""Check that all blocks have a version and all versions match"""
self._print_check('version')
for block in self.specs.keys():
split_spec_version = self.specs[block]['version'].split('.')
spec_version = '.'.join(
[split_spec_version[0], split_spec_version[1]])
if block.split('/')[1] not in self.block_versions.keys():
print('{} block does not have a version property or does not '
'have a class defined'.format(block.split('/')[1]))
continue
if self.block_versions[block.split('/')[1]] != spec_version:
print(
'The {} version in the spec file does not match the '
'version in its block file'.format(block.split('/')[1])
)
split_release_version = self.releases[block]['version'].split('.')
release_version = '.'.join(
[split_release_version[0], split_release_version[1]])
if self.block_versions[block.split('/')[1]] != release_version:
print(
'The {} version in the release file does not match the '
'version in its block file'.format(block.split('/')[1])
)
if spec_version != release_version:
print(
'Spec.json and release.json versions do not match for '
'{} block'.format(block.split('/')[1])
)
print('')
def check_naming(self):
"""Check that file and class names are formatted correctly"""
self._print_check('class and file name')
for block in self.specs:
if '_' in block:
print(
'{} class name should be camelCase format'.format(
block.split('/')[1])
)
if block.split('/')[1] not in self.block_versions.keys():
print(
'{} block either does not have a defined class or '
'does not have a version property.'.format(
block.split('/')[1])
)
for block in self.block_files:
if not block.islower():
print(
'{} file name should be lowercased and '
'snake_cased'.format(block.split('/')[1])
)
print('')
def _print_check(self, check):
print('Checking {} formatting ...'.format(check))
|
PypiClean
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.