
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
juancavallotti/t5-small-gec
|
juancavallotti
| 2022-06-05T01:51:04Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-06-05T01:06:00Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: t5-small-gec
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-gec
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
elgeish/wav2vec2-large-xlsr-53-arabic
|
elgeish
| 2022-06-04T23:37:05Z | 2,693 | 15 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"hf-asr-leaderboard",
"ar",
"dataset:arabic_speech_corpus",
"dataset:mozilla-foundation/common_voice_6_1",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language: ar
datasets:
- arabic_speech_corpus
- mozilla-foundation/common_voice_6_1
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
- hf-asr-leaderboard
license: apache-2.0
model-index:
- name: elgeish-wav2vec2-large-xlsr-53-arabic
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 6.1 (Arabic)
type: mozilla-foundation/common_voice_6_1
config: ar
split: test
args:
language: ar
metrics:
- name: Test WER
type: wer
value: 26.55
- name: Validation WER
type: wer
value: 23.39
---
# Wav2Vec2-Large-XLSR-53-Arabic
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
on Arabic using the `train` splits of [Common Voice](https://huggingface.co/datasets/common_voice)
and [Arabic Speech Corpus](https://huggingface.co/datasets/arabic_speech_corpus).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from lang_trans.arabic import buckwalter
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
dataset = load_dataset("common_voice", "ar", split="test[:10]")
resamplers = { # all three sampling rates exist in test split
48000: torchaudio.transforms.Resample(48000, 16000),
44100: torchaudio.transforms.Resample(44100, 16000),
32000: torchaudio.transforms.Resample(32000, 16000),
}
def prepare_example(example):
speech, sampling_rate = torchaudio.load(example["path"])
example["speech"] = resamplers[sampling_rate](speech).squeeze().numpy()
return example
dataset = dataset.map(prepare_example)
processor = Wav2Vec2Processor.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic")
model = Wav2Vec2ForCTC.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic").eval()
def predict(batch):
inputs = processor(batch["speech"], sampling_rate=16000, return_tensors="pt", padding=True)
with torch.no_grad():
predicted = torch.argmax(model(inputs.input_values).logits, dim=-1)
predicted[predicted == -100] = processor.tokenizer.pad_token_id # see fine-tuning script
batch["predicted"] = processor.tokenizer.batch_decode(predicted)
return batch
dataset = dataset.map(predict, batched=True, batch_size=1, remove_columns=["speech"])
for reference, predicted in zip(dataset["sentence"], dataset["predicted"]):
print("reference:", reference)
print("predicted:", buckwalter.untrans(predicted))
print("--")
```
Here's the output:
```
reference: ألديك قلم ؟
predicted: هلديك قالر
--
reference: ليست هناك مسافة على هذه الأرض أبعد من يوم أمس.
predicted: ليست نالك مسافة على هذه الأرض أبعد من يوم أمس
--
reference: إنك تكبر المشكلة.
predicted: إنك تكبر المشكلة
--
reference: يرغب أن يلتقي بك.
predicted: يرغب أن يلتقي بك
--
reference: إنهم لا يعرفون لماذا حتى.
predicted: إنهم لا يعرفون لماذا حتى
--
reference: سيسعدني مساعدتك أي وقت تحب.
predicted: سيسئدني مساعد سكرأي وقت تحب
--
reference: أَحَبُّ نظريّة علمية إليّ هي أن حلقات زحل مكونة بالكامل من الأمتعة المفقودة.
predicted: أحب ناضريةً علمية إلي هي أنحل قتزح المكونا بالكامل من الأمت عن المفقودة
--
reference: سأشتري له قلماً.
predicted: سأشتري له قلما
--
reference: أين المشكلة ؟
predicted: أين المشكل
--
reference: وَلِلَّهِ يَسْجُدُ مَا فِي السَّمَاوَاتِ وَمَا فِي الْأَرْضِ مِنْ دَابَّةٍ وَالْمَلَائِكَةُ وَهُمْ لَا يَسْتَكْبِرُونَ
predicted: ولله يسجد ما في السماوات وما في الأرض من دابة والملائكة وهم لا يستكبرون
--
```
## Evaluation
The model can be evaluated as follows on the Arabic test data of Common Voice:
```python
import jiwer
import torch
import torchaudio
from datasets import load_dataset
from lang_trans.arabic import buckwalter
from transformers import set_seed, Wav2Vec2ForCTC, Wav2Vec2Processor
set_seed(42)
test_split = load_dataset("common_voice", "ar", split="test")
resamplers = { # all three sampling rates exist in test split
48000: torchaudio.transforms.Resample(48000, 16000),
44100: torchaudio.transforms.Resample(44100, 16000),
32000: torchaudio.transforms.Resample(32000, 16000),
}
def prepare_example(example):
speech, sampling_rate = torchaudio.load(example["path"])
example["speech"] = resamplers[sampling_rate](speech).squeeze().numpy()
return example
test_split = test_split.map(prepare_example)
processor = Wav2Vec2Processor.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic")
model = Wav2Vec2ForCTC.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic").to("cuda").eval()
def predict(batch):
inputs = processor(batch["speech"], sampling_rate=16000, return_tensors="pt", padding=True)
with torch.no_grad():
predicted = torch.argmax(model(inputs.input_values.to("cuda")).logits, dim=-1)
predicted[predicted == -100] = processor.tokenizer.pad_token_id # see fine-tuning script
batch["predicted"] = processor.batch_decode(predicted)
return batch
test_split = test_split.map(predict, batched=True, batch_size=16, remove_columns=["speech"])
transformation = jiwer.Compose([
# normalize some diacritics, remove punctuation, and replace Persian letters with Arabic ones
jiwer.SubstituteRegexes({
r'[auiFNKo\~_،؟»\?;:\-,\.؛«!"]': "", "\u06D6": "",
r"[\|\{]": "A", "p": "h", "ک": "k", "ی": "y"}),
# default transformation below
jiwer.RemoveMultipleSpaces(),
jiwer.Strip(),
jiwer.SentencesToListOfWords(),
jiwer.RemoveEmptyStrings(),
])
metrics = jiwer.compute_measures(
truth=[buckwalter.trans(s) for s in test_split["sentence"]], # Buckwalter transliteration
hypothesis=test_split["predicted"],
truth_transform=transformation,
hypothesis_transform=transformation,
)
print(f"WER: {metrics['wer']:.2%}")
```
**Test Result**: 26.55%
## Training
For more details, see [Fine-Tuning with Arabic Speech Corpus](https://github.com/huggingface/transformers/tree/1c06240e1b3477728129bb58e7b6c7734bb5074e/examples/research_projects/wav2vec2#fine-tuning-with-arabic-speech-corpus).
This model represents Arabic in a format called [Buckwalter transliteration](https://en.wikipedia.org/wiki/Buckwalter_transliteration).
The Buckwalter format only includes ASCII characters, some of which are non-alpha (e.g., `">"` maps to `"أ"`).
The [lang-trans](https://github.com/kariminf/lang-trans) package is used to convert (transliterate) Arabic abjad.
[This script](https://github.com/huggingface/transformers/blob/1c06240e1b3477728129bb58e7b6c7734bb5074e/examples/research_projects/wav2vec2/finetune_large_xlsr_53_arabic_speech_corpus.sh)
was used to first fine-tune [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
on the `train` split of the [Arabic Speech Corpus](https://huggingface.co/datasets/arabic_speech_corpus) dataset;
the `test` split was used for model selection; the resulting model at this point is saved as [elgeish/wav2vec2-large-xlsr-53-levantine-arabic](https://huggingface.co/elgeish/wav2vec2-large-xlsr-53-levantine-arabic).
Training was then resumed using the `train` split of the [Common Voice](https://huggingface.co/datasets/common_voice) dataset;
the `validation` split was used for model selection;
training was stopped to meet the deadline of [Fine-Tune-XLSR Week](https://github.com/huggingface/transformers/blob/700229f8a4003c4f71f29275e0874b5ba58cd39d/examples/research_projects/wav2vec2/FINE_TUNE_XLSR_WAV2VEC2.md):
this model is the checkpoint at 100k steps and a validation WER of **23.39%**.
<img src="https://huggingface.co/elgeish/wav2vec2-large-xlsr-53-arabic/raw/main/validation_wer.png" alt="Validation WER" width="100%" />
It's worth noting that validation WER is trending down, indicating the potential of further training (resuming the decaying learning rate at 7e-6).
## Future Work
One area to explore is using `attention_mask` in model input, which is recommended [here](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2).
Also, exploring data augmentation using datasets used to train models listed [here](https://paperswithcode.com/sota/speech-recognition-on-common-voice-arabic).
|
jianyang/LunarLander-v2
|
jianyang
| 2022-06-04T22:39:46Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-04T21:57:52Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 182.82 +/- 79.11
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
nutjung/TEST2ppo-LunarLander-v2-4
|
nutjung
| 2022-06-04T22:08:31Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-04T22:08:07Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 273.94 +/- 14.80
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
huggingtweets/tomcooper26-tomncooper
|
huggingtweets
| 2022-06-04T21:53:08Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-04T21:52:33Z |
---
language: en
thumbnail: http://www.huggingtweets.com/tomcooper26-tomncooper/1654379583668/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/378800000155926309/6204f6960618d11ff5a7e2b21ae9db03_400x400.jpeg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/290863981/monkey_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Tom Cooper & Tom Cooper</div>
<div style="text-align: center; font-size: 14px;">@tomcooper26-tomncooper</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Tom Cooper & Tom Cooper.
| Data | Tom Cooper | Tom Cooper |
| --- | --- | --- |
| Tweets downloaded | 2092 | 3084 |
| Retweets | 179 | 687 |
| Short tweets | 223 | 59 |
| Tweets kept | 1690 | 2338 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/dndifpco/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @tomcooper26-tomncooper's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/97vltow9) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/97vltow9/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/tomcooper26-tomncooper')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
atoivat/distilbert-base-uncased-finetuned-squad
|
atoivat
| 2022-06-04T21:13:36Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-06-04T18:10:50Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1504
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2086 | 1.0 | 5533 | 1.1565 |
| 0.9515 | 2.0 | 11066 | 1.1225 |
| 0.7478 | 3.0 | 16599 | 1.1504 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
yanekyuk/camembert-keyword-discriminator
|
yanekyuk
| 2022-06-04T21:08:51Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"camembert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-04T20:23:44Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- accuracy
- f1
model-index:
- name: camembert-keyword-discriminator
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# camembert-keyword-discriminator
This model is a fine-tuned version of [camembert-base](https://huggingface.co/camembert-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2180
- Precision: 0.6646
- Recall: 0.7047
- Accuracy: 0.9344
- F1: 0.6841
- Ent/precision: 0.7185
- Ent/accuracy: 0.8157
- Ent/f1: 0.7640
- Con/precision: 0.5324
- Con/accuracy: 0.4860
- Con/f1: 0.5082
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | Accuracy | F1 | Ent/precision | Ent/accuracy | Ent/f1 | Con/precision | Con/accuracy | Con/f1 |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:--------:|:------:|:-------------:|:------------:|:------:|:-------------:|:------------:|:------:|
| 0.2016 | 1.0 | 1875 | 0.1910 | 0.5947 | 0.7125 | 0.9243 | 0.6483 | 0.6372 | 0.8809 | 0.7395 | 0.4560 | 0.3806 | 0.4149 |
| 0.1454 | 2.0 | 3750 | 0.1632 | 0.6381 | 0.7056 | 0.9324 | 0.6701 | 0.6887 | 0.8291 | 0.7524 | 0.5064 | 0.4621 | 0.4833 |
| 0.1211 | 3.0 | 5625 | 0.1702 | 0.6703 | 0.6678 | 0.9343 | 0.6690 | 0.7120 | 0.7988 | 0.7529 | 0.5471 | 0.4094 | 0.4684 |
| 0.1021 | 4.0 | 7500 | 0.1745 | 0.6777 | 0.6708 | 0.9351 | 0.6742 | 0.7206 | 0.7956 | 0.7562 | 0.5557 | 0.4248 | 0.4815 |
| 0.0886 | 5.0 | 9375 | 0.1913 | 0.6540 | 0.7184 | 0.9340 | 0.6847 | 0.7022 | 0.8396 | 0.7648 | 0.5288 | 0.4795 | 0.5030 |
| 0.0781 | 6.0 | 11250 | 0.2021 | 0.6605 | 0.7132 | 0.9344 | 0.6858 | 0.7139 | 0.8258 | 0.7658 | 0.5293 | 0.4913 | 0.5096 |
| 0.0686 | 7.0 | 13125 | 0.2127 | 0.6539 | 0.7132 | 0.9337 | 0.6822 | 0.7170 | 0.8172 | 0.7638 | 0.5112 | 0.5083 | 0.5098 |
| 0.0667 | 8.0 | 15000 | 0.2180 | 0.6646 | 0.7047 | 0.9344 | 0.6841 | 0.7185 | 0.8157 | 0.7640 | 0.5324 | 0.4860 | 0.5082 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
edwinhung/bird_classifier
|
edwinhung
| 2022-06-04T20:52:15Z | 0 | 0 |
fastai
|
[
"fastai",
"region:us"
] | null | 2022-06-04T19:43:58Z |
---
tags:
- fastai
---
# Model card
## Model description
A neural network model trained with fastai and timm to classify 400 bird species in an image.
## Intended uses & limitations
This bird classifier is used to predict bird species in a given image. The Image fed should have only one bird. This is a multi-class classification which will output a class even if there is no bird in the image.
## Training and evaluation data
Pre-trained model used is Efficient net from timm library, specifically *efficientnet_b3a*. The dataset trained is from Kaggle [BIRDS 400 - SPECIES IMAGE CLASSIFICATION](https://www.kaggle.com/datasets/gpiosenka/100-bird-species). Evaluation accuracy score on the given test set from Kaggle is 99.4%. Please note this is likely not representative of real world performance, as mentioned by dataset provider that the test set is hand picked as the best images.
|
kingabzpro/q-FrozenLake-v1-4x4-noSlippery
|
kingabzpro
| 2022-06-04T18:51:21Z | 0 | 1 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-04T18:51:10Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="kingabzpro/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
etmckinley/BOTHALTEROUT
|
etmckinley
| 2022-06-04T18:26:24Z | 4 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-02T18:32:15Z |
---
license: mit
tags:
model-index:
- name: BERFALTER
results: []
widget:
- text: "Gregg Berhalter"
- text: "The USMNT won't win the World Cup"
- text: "The Soccer Media in this country"
- text: "Ball don't"
- text: "This lineup"
---
# BOTHALTEROUT
This model is a fine-tuned version of [GPT-2](https://huggingface.co/gpt2) using 21,832 tweets from 12 twitter users with very strong opinions about the United States Men's National Team.
## Limitations and bias
The model has all [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
Additionally, BOTHALTEROUT can create some problematic results based upon the tweets used to generate the model.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001372
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
## About
*Built by [Eliot McKinley](https://twitter.com/etmckinley) based upon [HuggingTweets](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) by Boris Dayama*
|
mishtert/iec
|
mishtert
| 2022-06-04T18:01:26Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"layoutlmv2",
"token-classification",
"generated_from_trainer",
"dataset:funsd",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-04T17:22:57Z |
---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- funsd
model_index:
- name: layoutlmv2-finetuned-funsd
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: funsd
type: funsd
args: funsd
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv2-finetuned-funsd
This model is a fine-tuned version of [microsoft/layoutlmv2-base-uncased](https://huggingface.co/microsoft/layoutlmv2-base-uncased) on the funsd dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.9.0.dev0
- Pytorch 1.8.0+cu101
- Datasets 1.9.0
- Tokenizers 0.10.3
|
mcditoos/q-Taxi-v3
|
mcditoos
| 2022-06-04T17:14:13Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-04T17:14:07Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
mcditoos/q-FrozenLake-v1-4x4-noSlippery
|
mcditoos
| 2022-06-04T17:09:47Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-04T17:09:40Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
Umer4/UrduAudio2Text
|
Umer4
| 2022-06-04T16:17:45Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-06-02T17:52:38Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: UrduAudio2Text
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# UrduAudio2Text
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4978
- Wer: 0.8376
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 5.5558 | 15.98 | 400 | 1.4978 | 0.8376 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 2.2.2
- Tokenizers 0.10.3
|
huggingtweets/orc_nft
|
huggingtweets
| 2022-06-04T16:13:13Z | 3 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-04T16:12:40Z |
---
language: en
thumbnail: http://www.huggingtweets.com/orc_nft/1654359188989/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1510438749154549764/sar63AXD_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">ORC.A ⍬</div>
<div style="text-align: center; font-size: 14px;">@orc_nft</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from ORC.A ⍬.
| Data | ORC.A ⍬ |
| --- | --- |
| Tweets downloaded | 1675 |
| Retweets | 113 |
| Short tweets | 544 |
| Tweets kept | 1018 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/wwc37qkh/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @orc_nft's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/debtzj0e) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/debtzj0e/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/orc_nft')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
yanekyuk/convberturk-keyword-extractor
|
yanekyuk
| 2022-06-04T11:19:51Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"convbert",
"token-classification",
"generated_from_trainer",
"tr",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-04T09:32:23Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- accuracy
- f1
language:
- tr
widget:
- text: "İngiltere'de düzenlenen Avrupa Tekvando ve Para Tekvando Şampiyonası’nda millî tekvandocular 5 altın, 2 gümüş ve 4 bronz olmak üzere 11, millî para tekvandocular ise 4 altın, 3 gümüş ve 1 bronz olmak üzere 8 madalya kazanarak takım halinde Avrupa şampiyonu oldu."
- text: "Füme somon dedik ama aslında lox salamuralanmış somon anlamına geliyor, füme etme opsiyonel. Lox bagel, 1930'larda Eggs Benedict furyasında New Yorklu Yahudi cemaati tarafından koşer bir alternatif olarak çıkan bir lezzet. Günümüzde benim hangover yüreğim dâhil dünyanın birçok yerinde enfes bir kahvaltı sandviçi."
- text: "Türkiye'de son aylarda sıklıkla tartışılan konut satışı karşılığında yabancılara vatandaşlık verilmesi konusunu beyin göçü kapsamında ele almak mümkün. Daha önce 250 bin dolar olan vatandaşlık bedeli yükselen tepkiler üzerine 400 bin dolara çıkarılmıştı. Türkiye'den göç eden iyi eğitimli kişilerin , gittikleri ülkelerde 250 bin dolar tutarında yabancı yatırıma denk olduğu göz önüne alındığında nitelikli insan gücünün yabancılara konut karşılığında satılan vatandaşlık bedelin eş olduğunu görüyoruz. Yurt dışına giden her bir vatandaşın yüksek teknolojili katma değer üreten sektörlere yapacağı katkılar göz önünde bulundurulduğunda bu açığın inşaat sektörüyle kapatıldığını da görüyoruz. Beyin göçü konusunda sadece ekonomik perspektiften bakıldığında bile kısa vadeli döviz kaynağı yaratmak için kullanılan vatandaşlık satışı yerine beyin göçünü önleyecek önlemler alınmasının ülkemize çok daha faydalı olacağı sonucunu çıkarıyoruz."
- text: "Türkiye’de resmî verilere göre, 15 ve daha yukarı yaştaki kişilerde mevsim etkisinden arındırılmış işsiz sayısı, bu yılın ilk çeyreğinde bir önceki çeyreğe göre 50 bin kişi artarak 3 milyon 845 bin kişi oldu. Mevsim etkisinden arındırılmış işsizlik oranı ise 0,1 puanlık artışla %11,4 seviyesinde gerçekleşti. İşsizlik oranı, ilk çeyrekte geçen yılın aynı çeyreğine göre 1,7 puan azaldı."
- text: "Boeing’in insansız uzay aracı Starliner, birtakım sorunlara rağmen Uluslararası Uzay İstasyonuna (ISS) ulaşarak ilk kez başarılı bir şekilde kenetlendi. Aracın ISS’te beş gün kalmasını takiben sorunsuz bir şekilde New Mexico’ya inmesi halinde Boeing, sonbaharda astronotları yörüngeye göndermek için Starliner’ı kullanabilir.\n\nNeden önemli? NASA’nın personal aracı üretmeyi durdurmasından kaynaklı olarak görevli astronotlar ve kozmonotlar, ISS’te Rusya’nın ürettiği uzay araçları ile taşınıyordu. Starliner’ın kendini kanıtlaması ise bu konuda Rusya’ya olan bağımlılığın potansiyel olarak ortadan kalkabileceği anlamına geliyor."
model-index:
- name: convberturk-keyword-extractor
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# convberturk-keyword-extractor
This model is a fine-tuned version of [dbmdz/convbert-base-turkish-cased](https://huggingface.co/dbmdz/convbert-base-turkish-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4098
- Precision: 0.6742
- Recall: 0.7035
- Accuracy: 0.9175
- F1: 0.6886
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | Accuracy | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:--------:|:------:|
| 0.174 | 1.0 | 1875 | 0.1920 | 0.6546 | 0.6869 | 0.9184 | 0.6704 |
| 0.1253 | 2.0 | 3750 | 0.2030 | 0.6527 | 0.7317 | 0.9179 | 0.6900 |
| 0.091 | 3.0 | 5625 | 0.2517 | 0.6499 | 0.7473 | 0.9163 | 0.6952 |
| 0.0684 | 4.0 | 7500 | 0.2828 | 0.6633 | 0.7270 | 0.9167 | 0.6937 |
| 0.0536 | 5.0 | 9375 | 0.3307 | 0.6706 | 0.7194 | 0.9180 | 0.6942 |
| 0.0384 | 6.0 | 11250 | 0.3669 | 0.6655 | 0.7161 | 0.9157 | 0.6898 |
| 0.0316 | 7.0 | 13125 | 0.3870 | 0.6792 | 0.7002 | 0.9176 | 0.6895 |
| 0.0261 | 8.0 | 15000 | 0.4098 | 0.6742 | 0.7035 | 0.9175 | 0.6886 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
kaniku/xlm-roberta-large-indonesian-NER-finetuned-ner
|
kaniku
| 2022-06-04T04:54:01Z | 25 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-04T02:44:11Z |
---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: xlm-roberta-large-indonesian-NER-finetuned-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-large-indonesian-NER-finetuned-ner
This model is a fine-tuned version of [cahya/xlm-roberta-large-indonesian-NER](https://huggingface.co/cahya/xlm-roberta-large-indonesian-NER) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0489
- Precision: 0.9254
- Recall: 0.9394
- F1: 0.9324
- Accuracy: 0.9851
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0496 | 1.0 | 1767 | 0.0489 | 0.9254 | 0.9394 | 0.9324 | 0.9851 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
LinaR/Prediccion_titulos
|
LinaR
| 2022-06-04T04:44:50Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"t5",
"text2text-generation",
"generated_from_keras_callback",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-06-04T03:33:36Z |
---
tags:
- generated_from_keras_callback
model-index:
- name: Prediccion_titulos
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Prediccion_titulos
Este modelo predice los encabezados de las noticias
## Model description
Este modelo fue entrenado con un Transformador T5 y una base de datos en español
## Intended uses & limitations
More information needed
## Training and evaluation data
Los datos fueron tomado del siguiente dataset de Kaggle : https://www.kaggle.com/datasets/josemamuiz/noticias-laraznpblico, el cual es un conjunto de datos se extrajo de las webs de periódicos españoles
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.19.2
- TensorFlow 2.8.2
- Datasets 2.2.2
- Tokenizers 0.12.1
|
ssantanag/pasajes_de_la_biblia
|
ssantanag
| 2022-06-04T04:32:36Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"t5",
"text2text-generation",
"generated_from_keras_callback",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-06-04T03:56:29Z |
---
tags:
- generated_from_keras_callback
model-index:
- name: pasajes_de_la_biblia
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# pasajes_de_la_biblia
Este modelo fue entrenado con el dataset publicado en Kaggle de los versiculos de la biblia en el siguiente enlace puede encontrar el dataset https://www.kaggle.com/datasets/camesruiz/biblia-ntv-spanish-bible-ntv.
## Training and evaluation data
la distribución de la data fue la siguiente:
- Training set: 58.20%
- Validation set: 9.65%
- Test set: 32.15%
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.19.2
- TensorFlow 2.8.2
- Datasets 2.2.2
- Tokenizers 0.12.1
|
nbroad/splinter-base-squad2
|
nbroad
| 2022-06-04T03:47:06Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"splinter",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-06-04T01:30:38Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: splinter-base-squad2_3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# splinter-base-squad2_3
This model is a fine-tuned version of [tau/splinter-base-qass](https://huggingface.co/tau/splinter-base-qass) on the squad_v2 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 256
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0a0+17540c5
- Datasets 2.2.2
- Tokenizers 0.12.1
|
send-it/q-Taxi-v3
|
send-it
| 2022-06-04T03:09:16Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-04T03:08:56Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.50 +/- 2.76
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
send-it/q-FrozenLake-v1-4x4-noSlippery
|
send-it
| 2022-06-04T03:07:59Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-04T03:07:51Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="send-it/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
baru98/bert-base-cased-finetuned-squad
|
baru98
| 2022-06-04T02:53:28Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-06-04T01:42:22Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-base-cased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 5.4212
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 7 | 5.7012 |
| No log | 2.0 | 14 | 5.5021 |
| No log | 3.0 | 21 | 5.4212 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
jgriffi/xlm-roberta-base-finetuned-panx-all
|
jgriffi
| 2022-06-04T01:24:48Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-04T00:52:21Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-all
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-all
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1448
- F1: 0.8881
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.3029 | 1.0 | 1669 | 0.2075 | 0.7971 |
| 0.164 | 2.0 | 3338 | 0.1612 | 0.8680 |
| 0.1025 | 3.0 | 5007 | 0.1448 | 0.8881 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.11.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
jgriffi/xlm-roberta-base-finetuned-panx-de-fr
|
jgriffi
| 2022-06-03T23:42:57Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-03T23:13:02Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de-fr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1774
- F1: 0.8594
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.3029 | 1.0 | 1430 | 0.1884 | 0.8237 |
| 0.1573 | 2.0 | 2860 | 0.1770 | 0.8473 |
| 0.0959 | 3.0 | 4290 | 0.1774 | 0.8594 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.11.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
StanKarz/q-Taxi-v3
|
StanKarz
| 2022-06-03T22:17:14Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-03T22:17:03Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Sicko-Code/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
thamaine/distilbert-base-cased
|
thamaine
| 2022-06-03T22:11:35Z | 0 | 0 |
keras
|
[
"keras",
"tf-keras",
"region:us"
] | null | 2022-05-23T06:07:23Z |
---
library_name: keras
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 0.01, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: mixed_float16
## Training Metrics
| Epochs | Train Loss | Validation Loss |
|--- |--- |--- |
| 1| 5.965| 5.951|
## Model Plot
<details>
<summary>View Model Plot</summary>

</details>
|
nboudad/Maghriberta
|
nboudad
| 2022-06-03T21:52:55Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-06-03T18:51:51Z |
---
widget:
- text: "جاب ليا <mask> ."
example_title: "example1"
- text: "مشيت نجيب <mask> فالفرماسيان ."
example_title: "example2"
---
|
ulysses-camara/legal-bert-pt-br
|
ulysses-camara
| 2022-06-03T20:20:18Z | 9 | 4 |
sentence-transformers
|
[
"sentence-transformers",
"pt",
"license:mit",
"region:us"
] | null | 2022-05-31T13:30:11Z |
---
language: pt
license: mit
tags:
- sentence-transformers
---
# LegalBERTPT-br
LegalBERTPT-br is a trained sentence embedding using SimCSE, a contrastive learning framework, coupled with the Portuguese pre-trained language model named [BERTimbau](https://huggingface.co/neuralmind/bert-base-portuguese-cased).
# Corpora
– From [this site](https://www2.camara.leg.br/transparencia/servicos-ao-cidadao/participacao-popular), we used the column `Conteudo` with 215,713 comments. We removed the comments from PL 3723/2019, PEC 471/2005, and Hashtag Corpus, in order to avoid bias.
– From [this site](https://www2.camara.leg.br/transparencia/servicos-ao-cidadao/participacao-popular), we also used 147,008 bills. From these projects, we used the summary field named `txtEmenta` and the project core text named `txtExplicacaoEmenta`.
– From Political Speeches, we used 462,831 texts, specifically, we used the columns: `sumario`, `textodiscurso`, and `indexacao`.
These corpora were segmented into sentences and concatenated, producing 2,307,426 sentences.
# Citing and Authors
If you find this model helpful, feel free to cite our publication [Evaluating Topic Models in Portuguese Political Comments About Bills from Brazil’s Chamber of Deputies](https://link.springer.com/chapter/10.1007/978-3-030-91699-2_8):
```bibtex
@inproceedings{bracis,
author = {Nádia Silva and Marília Silva and Fabíola Pereira and João Tarrega and João Beinotti and Márcio Fonseca and Francisco Andrade and André Carvalho},
title = {Evaluating Topic Models in Portuguese Political Comments About Bills from Brazil’s Chamber of Deputies},
booktitle = {Anais da X Brazilian Conference on Intelligent Systems},
location = {Online},
year = {2021},
keywords = {},
issn = {0000-0000},
publisher = {SBC},
address = {Porto Alegre, RS, Brasil},
url = {https://sol.sbc.org.br/index.php/bracis/article/view/19061}
}
```
|
haritzpuerto/distilbert-squad
|
haritzpuerto
| 2022-06-03T20:08:44Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-06-03T20:04:42Z |
TrainOutput(global_step=5475, training_loss=1.7323438837756848, metrics={'train_runtime': 4630.6634, 'train_samples_per_second': 18.917, 'train_steps_per_second': 1.182, 'total_flos': 1.1445080909703168e+16, 'train_loss': 1.7323438837756848, 'epoch': 1.0})
|
mmillet/rubert-tiny2_finetuned_emotion_experiment
|
mmillet
| 2022-06-03T20:03:37Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-05-19T16:22:22Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: rubert-tiny2_finetuned_emotion_experiment
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# rubert-tiny2_finetuned_emotion_experiment
This model is a fine-tuned version of [cointegrated/rubert-tiny2](https://huggingface.co/cointegrated/rubert-tiny2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3947
- Accuracy: 0.8616
- F1: 0.8577
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.651 | 1.0 | 54 | 0.5689 | 0.8172 | 0.8008 |
| 0.5355 | 2.0 | 108 | 0.4842 | 0.8486 | 0.8349 |
| 0.4561 | 3.0 | 162 | 0.4436 | 0.8590 | 0.8509 |
| 0.4133 | 4.0 | 216 | 0.4203 | 0.8590 | 0.8528 |
| 0.3709 | 5.0 | 270 | 0.4071 | 0.8564 | 0.8515 |
| 0.3346 | 6.0 | 324 | 0.3980 | 0.8564 | 0.8529 |
| 0.3153 | 7.0 | 378 | 0.3985 | 0.8590 | 0.8565 |
| 0.302 | 8.0 | 432 | 0.3967 | 0.8642 | 0.8619 |
| 0.2774 | 9.0 | 486 | 0.3958 | 0.8616 | 0.8575 |
| 0.2728 | 10.0 | 540 | 0.3959 | 0.8668 | 0.8644 |
| 0.2427 | 11.0 | 594 | 0.3962 | 0.8590 | 0.8550 |
| 0.2425 | 12.0 | 648 | 0.3959 | 0.8642 | 0.8611 |
| 0.2414 | 13.0 | 702 | 0.3959 | 0.8642 | 0.8611 |
| 0.2249 | 14.0 | 756 | 0.3949 | 0.8616 | 0.8582 |
| 0.2391 | 15.0 | 810 | 0.3947 | 0.8616 | 0.8577 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.1
- Tokenizers 0.12.1
|
hananajiyya/mt5-small-summarization
|
hananajiyya
| 2022-06-03T18:09:47Z | 5 | 0 |
transformers
|
[
"transformers",
"tf",
"mt5",
"text2text-generation",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-06-03T00:27:50Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: mt5-small-summarization
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mt5-small-summarization
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.9665
- Validation Loss: 2.4241
- Train Rouge1: 23.5645
- Train Rouge2: 8.2413
- Train Rougel: 19.7515
- Train Rougelsum: 19.9204
- Train Gen Len: 19.0
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Rouge1 | Train Rouge2 | Train Rougel | Train Rougelsum | Train Gen Len | Epoch |
|:----------:|:---------------:|:------------:|:------------:|:------------:|:---------------:|:-------------:|:-----:|
| 4.7187 | 2.6627 | 19.5921 | 5.9723 | 16.6769 | 16.8456 | 18.955 | 0 |
| 3.1929 | 2.4941 | 21.2334 | 6.9784 | 18.2158 | 18.2062 | 18.99 | 1 |
| 2.9665 | 2.4241 | 23.5645 | 8.2413 | 19.7515 | 19.9204 | 19.0 | 2 |
### Framework versions
- Transformers 4.19.2
- TensorFlow 2.8.2
- Datasets 2.2.2
- Tokenizers 0.12.1
|
huggingtweets/deepleffen
|
huggingtweets
| 2022-06-03T17:34:54Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/deepleffen/1654277690184/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1241879678455078914/e2EdZIrr_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Deep Leffen Bot</div>
<div style="text-align: center; font-size: 14px;">@deepleffen</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Deep Leffen Bot.
| Data | Deep Leffen Bot |
| --- | --- |
| Tweets downloaded | 589 |
| Retweets | 14 |
| Short tweets | 27 |
| Tweets kept | 548 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1p32tock/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @deepleffen's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/imjjixah) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/imjjixah/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/deepleffen')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
meghazisofiane/opus-mt-en-ar-finetuned-en-to-ar
|
meghazisofiane
| 2022-06-03T17:27:04Z | 16 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"generated_from_trainer",
"dataset:un_multi",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-05-31T18:13:33Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- un_multi
metrics:
- bleu
model-index:
- name: opus-mt-en-ar-finetuned-en-to-ar
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: un_multi
type: un_multi
args: ar-en
metrics:
- name: Bleu
type: bleu
value: 64.6767
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-en-ar-finetuned-en-to-ar
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-ar](https://huggingface.co/Helsinki-NLP/opus-mt-en-ar) on the un_multi dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8133
- Bleu: 64.6767
- Gen Len: 17.595
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|
| No log | 1.0 | 50 | 0.7710 | 64.3416 | 17.4 |
| No log | 2.0 | 100 | 0.7569 | 63.9546 | 17.465 |
| No log | 3.0 | 150 | 0.7570 | 64.7484 | 17.385 |
| No log | 4.0 | 200 | 0.7579 | 65.4073 | 17.305 |
| No log | 5.0 | 250 | 0.7624 | 64.8939 | 17.325 |
| No log | 6.0 | 300 | 0.7696 | 65.1257 | 17.45 |
| No log | 7.0 | 350 | 0.7747 | 65.527 | 17.395 |
| No log | 8.0 | 400 | 0.7791 | 65.1357 | 17.52 |
| No log | 9.0 | 450 | 0.7900 | 65.3812 | 17.415 |
| 0.3982 | 10.0 | 500 | 0.7925 | 65.7346 | 17.39 |
| 0.3982 | 11.0 | 550 | 0.7951 | 65.1267 | 17.62 |
| 0.3982 | 12.0 | 600 | 0.8040 | 64.6874 | 17.495 |
| 0.3982 | 13.0 | 650 | 0.8069 | 64.7788 | 17.52 |
| 0.3982 | 14.0 | 700 | 0.8105 | 64.6701 | 17.585 |
| 0.3982 | 15.0 | 750 | 0.8120 | 64.7111 | 17.58 |
| 0.3982 | 16.0 | 800 | 0.8133 | 64.6767 | 17.595 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
VictorZhu/results
|
VictorZhu
| 2022-06-03T17:17:57Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-06-03T17:10:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: results
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1194
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.1428 | 1.0 | 510 | 0.1347 |
| 0.0985 | 2.0 | 1020 | 0.1189 |
| 0.0763 | 3.0 | 1530 | 0.1172 |
| 0.0646 | 4.0 | 2040 | 0.1194 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu102
- Datasets 2.2.2
- Tokenizers 0.12.1
|
NikitaBaramiia/PPO-LunarLander-v2-1
|
NikitaBaramiia
| 2022-06-03T16:52:08Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-03T16:51:42Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 290.89 +/- 14.45
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
jppaolim/v49Neo
|
jppaolim
| 2022-06-03T16:34:46Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-03T16:26:26Z |
# My Story model
{'top_p': 0.9, 'top_k': 50, 'temperature': 1, 'repetition_penalty': 1}
Arthur goes to the beach. Arthur was bored today. He took a vacation to the beach. The beach was very crowded. Arthur finally enjoyed the beach for the beach. He had so much fun he decided to take his vacation there.
Arthur goes to the beach. Arthur was walking down the street one day and heard a loud boom. A huge shark had been spotted and was heading towards him! He ran to the beach and immediately jumped in the water. He swam to shore with his surfboard and his surf trunks. After five minutes of not paying attention, he got out of the water.
Arthur goes to the beach. Arthur always loved going to the beach. His favorite thing to do in the morning was go to the beach. He decided he wanted to go to the beach, not too long. Arthur packed up his backpack and headed towards the beach. He started to enjoy himself as he was going to the beach, he loved it.
Arthur goes to the beach. Arthur had always loved going to the beach. His friend told him to take the bus. Arthur forgot to bring his wallet. He was disappointed to see that his friend was gone. Arthur decided to leave the beach without taking the bus.
Arthur goes to the beach. Arthur wanted to visit the beach but his parents didn't take him. His parents thought that his parents should take him. They bought him a beach chair and took him to the beach. He had a great time, but the beach wasn't too bad. Arthur was very disappointed to see no sand at all!
{'top_p': 0.9, 'top_k': 50, 'temperature': 1, 'repetition_penalty': 1.05}
Arthur goes to the beach. Arthur is in the ocean. He swims for an hour. He feels great. He goes home. He goes swimming again.
Arthur goes to the beach. Arthur was on vacation with his family He had a very nice day at the beach. As he was driving to the beach he saw a beautiful view. He quickly started to relax as he got closer to the beach. It turned out that he was sitting down at the beach by his family.
Arthur goes to the beach. Arthur is always very worried about it. He has always been afraid of going to the beach. One day he has no idea what's going to happen. He decides to take a trip. He cannot believe he is going to the beach.
Arthur goes to the beach. Arthur wanted to learn how to surf. So he took out his surf equipment. He put his surf equipment on. He set his surfboard up and put it on the beach. Arthur had a great time surfing!
Arthur goes to the beach. Arthur loved the outdoors. He wanted to go in the water. He was very bored one day. Arthur was going to the beach. He spent the whole day swimming and sunbathing.
{'top_p': 0.9, 'top_k': 40, 'temperature': 0.8, 'repetition_penalty': 1.1}
Arthur goes to the beach. Arthur was going to the beach. He went to the beach and swam. He went to the beach and swam in the water. He fell in the water and was wet. Arthur never went to the beach again.
Arthur goes to the beach. Arthur is bored. He heads to the beach. Arthur sits down on the sand. He runs to the beach. Arthur swam in the water.
Arthur goes to the beach. Arthur was on vacation. He decided to go to the beach. He went to the beach and played on the sand. He felt very hot and cold. Arthur spent the entire day at the beach.
Arthur goes to the beach. Arthur was very excited to go to the beach with his friends. His friends were already at the beach. He was going to be at the beach on his birthday. He got all his friends together and had a great time. He was glad he had a great time and decided to go home.
Arthur goes to the beach. Arthur was walking down the street. He was heading to the beach. He was going to swim with his friends. They were going to take him to the water. Arthur had a great time swimming.
{'top_p': 0.9, 'top_k': 40, 'temperature': 0.6, 'repetition_penalty': 1.15}
Arthur goes to the beach. Arthur is very bored. He spends all day sitting on the sand. He decides to go to the beach. He spends all day swimming. Arthur is happy he went to the beach.
Arthur goes to the beach. Arthur is walking down the street. He sees a big wave. He runs to the side of the road. He trips and falls in the water. Arthur is shaken up by the wave.
Arthur goes to the beach. Arthur is on his way to the beach. He has never been in the beach before. He decides to go for a walk. While walking he falls in the water. Arthur is soaked and had to go home.
Arthur goes to the beach. Arthur was a little boy. He loved to surf, but he didn't know how to swim. His mom took him to the beach. He swam in the water and got very cold. Arthur spent all day in the sand and had a good time.
Arthur goes to the beach. Arthur was very bored. He was in his car. He drove to the beach. He went to the beach. He went to the beach and played with the beach.
{'top_p': 0.9, 'top_k': 40, 'temperature': 0.4, 'repetition_penalty': 1.2}
Arthur goes to the beach. Arthur was going to the beach with his family. He was going to take a nice walk on the sand. He was going to take a nice long stroll. He saw a huge wave and decided to go for it. He had a great time on the beach.
Arthur goes to the beach. Arthur is going to the beach with his friends. He is going to take a few hours to get there. He is going to go to the beach and surf. He is going to surf for the first time. He is excited to go to the beach and surf.
Arthur goes to the beach. Arthur is going to the beach. He is going to swim in the water. He is going to go for a quick walk. Arthur is not able to walk. Arthur is late for his appointment.
Arthur goes to the beach. Arthur is going to the beach. He is going to go swimming. Arthur is going to go swimming with his friends. He is going to swim with his friends. Arthur is very excited for the beach trip.
Arthur goes to the beach. Arthur is a very good swimmer. He has always been very careful with his swimming. One day, he decides to go to the beach. While at the beach, he swam for hours. Finally, he was able to get to the beach safely.
|
jppaolim/v48_GPT2Medium_PT
|
jppaolim
| 2022-06-03T15:07:49Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-03T14:44:43Z |
# My Story model
{'top_p': 0.9, 'top_k': 50, 'temperature': 1, 'repetition_penalty': 1}
Arthur goes to the beach. Arthur wants to go to the beach. He calls the beach and asks for a spot on the sand. Arthur gets a new friend with a beach towel. Arthur takes the beach. Arthur spends the day relaxing and having a great time.
Arthur goes to the beach. Arthur is feeling really bored. He decides to go to the beach. He packs up his bags and drives to the beach. Arthur spends the next two days swimming at the beach. He is so glad he got to spend some time at the beach.
Arthur goes to the beach. Arthur really wanted to go to the beach. He went to the beach in his car. He spent the whole day on the beach. He finally had a great day of swimming. Arthur really enjoyed the beach.
Arthur goes to the beach. Arthur had always wanted to go to the beach. Arthur saved up his money for a few weeks. Arthur went to the beach with his savings. Arthur had a great time at the beach. Arthur is now planning his next trip.
Arthur goes to the beach. Arthur loves to go to the beach. He loves to go to the sand. Arthur took his friend with him to the beach. Arthur played in the ocean for a long time. Arthur got his sand and went home.
{'top_p': 0.9, 'top_k': 50, 'temperature': 1, 'repetition_penalty': 1.05}
Arthur goes to the beach. Arthur is excited to go to the beach. Arthur packs his beach towel. Arthur drives to the beach. Arthur spends the entire day at the beach. Arthur has a great day at the beach.
Arthur goes to the beach. Arthur was a lonely boy who wanted a place to stay. His parents wanted him to go to the beach. They convinced Arthur to go to the beach with them. Arthur was so happy to go to the beach. He was so happy to get to play in the ocean with his friends.
Arthur goes to the beach. Arthur decided he needed to go to the beach. He called his friends to come and see the beach. They met up at the beach. Arthur and his friends went to the beach and played. Arthur went home and had a good day.
Arthur goes to the beach. Arthur is sitting at home reading a book. He decides he will play a game of basketball. Arthur decides to play a game of basketball. He plays his game with his family and friends. Arthur is very happy that he played basketball.
Arthur goes to the beach. Arthur and his friends went to the beach. Arthur found out that he had a bad sunburn. Arthur had to go to the doctor for his sunburn. The doctor recommended an ointment to Arthur. Arthur had no more bad sunburns after that.
{'top_p': 0.9, 'top_k': 40, 'temperature': 0.8, 'repetition_penalty': 1.1}
Arthur goes to the beach. Arthur is bored one afternoon. He calls his friend Frank and tells him to go to the beach. Arthur drives to the beach and spends the day playing in the sand. After the sun went down, Arthur went home and watched a movie. Now, Arthur is very tired after a long day of work.
Arthur goes to the beach. Arthur is bored one summer day. He asks his parents for some time off. His parents tell him he has to go the beach. Arthur packs up his car and takes a trip. When he gets back home, Arthur is happy that he went the beach.
Arthur goes to the beach. Arthur had always wanted to go to the beach. Arthur's friends encourage him to go. Finally Arthur agrees to go to the beach. At the beach he spends a very relaxing day at the beach. Arthur is glad that he went to the beach.
Arthur goes to the beach. Arthur wants to go to the beach. He gets his stuff together and drives to the beach. While on the beach he meets a nice young man named Dave. Dave and Arthur fall in love. Arthur and Dave become friends and start dating.
Arthur goes to the beach. Arthur is bored on a weekend afternoon. He decides to go to the beach. Arthur packs his beach bag and leaves. Arthur arrives at the beach. Arthur spends the day at the beach.
{'top_p': 0.9, 'top_k': 40, 'temperature': 0.6, 'repetition_penalty': 1.15}
Arthur goes to the beach. Arthur has always wanted to go to the beach. He decides to go to the beach one day. At the beach he spends the entire day at the beach. He has a great time. Arthur is very happy that he went to the beach.
Arthur goes to the beach. Arthur is bored one day. He decides to go to the beach. When he gets there, he spends all day at the beach. Arthur has a great time at the beach. He will not leave the beach for another day.
Arthur goes to the beach. Arthur is bored on a summer day. He decides he wants to go to the beach. Arthur packs his bags and drives out to the ocean. Once at the beach, Arthur spends all day playing in the sand. Now that he has had so much fun, he plans to do it again soon.
Arthur goes to the beach. Arthur was feeling bored one day. He decided to go to the beach. Arthur went to the beach and played in the sand. Arthur felt so much better after playing in the sand. Arthur was glad he had gone to the beach.
Arthur goes to the beach. Arthur was excited for a day at the beach. He had packed his beach bag and his sunscreen. Arthur went to the beach with his friends. Arthur played in the sand all day. Arthur returned home with lots of sunburns.
{'top_p': 0.9, 'top_k': 40, 'temperature': 0.4, 'repetition_penalty': 1.2}
Arthur goes to the beach. Arthur is bored one day. He decides he would like a day off. Arthur calls his friends and tells them about the day. They all go to the beach and play games. Arthur has a great day at the beach.
Arthur goes to the beach. Arthur is bored one day. He decides he needs a way to pass the time. Arthur takes his beach bag and drives to the beach. Arthur spends the entire day at the beach. Arthur has a great day at the beach.
Arthur goes to the beach. Arthur is bored one day. He decides he would like a day off. So Arthur takes a trip to the beach. Arthur spends the entire day at the beach. Arthur has a great day at the beach.
Arthur goes to the beach. Arthur is bored one day. He decides to go to the beach. Arthur spends the entire day at the beach. When he gets home, Arthur feels happy. Now that he has gone to the beach, Arthur is no longer bored.
Arthur goes to the beach. Arthur is feeling bored one day. He decides he would like to go to the beach. Arthur packs up his beach bag and drives down to the beach. While at the beach, Arthur sees many people playing in the water. Arthur has a great time at the beach with his friends.
|
baru98/distilbert-base-uncased-finetuned-squad
|
baru98
| 2022-06-03T13:54:01Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-06-03T11:00:56Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1274
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2393 | 1.0 | 5475 | 1.1570 |
| 0.9651 | 2.0 | 10950 | 1.0903 |
| 0.7513 | 3.0 | 16425 | 1.1274 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
huggingtweets/washirerpadvice
|
huggingtweets
| 2022-06-03T13:29:32Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-03T13:23:45Z |
---
language: en
thumbnail: http://www.huggingtweets.com/washirerpadvice/1654262967962/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1381256890542387204/zaT8DfFD_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Washire RP Tips</div>
<div style="text-align: center; font-size: 14px;">@washirerpadvice</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Washire RP Tips.
| Data | Washire RP Tips |
| --- | --- |
| Tweets downloaded | 243 |
| Retweets | 4 |
| Short tweets | 5 |
| Tweets kept | 234 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/gq82nlvl/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @washirerpadvice's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/325ay6n9) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/325ay6n9/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/washirerpadvice')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Worldman/pega_70_articles
|
Worldman
| 2022-06-03T13:13:37Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-05-01T23:16:02Z |
---
tags:
- generated_from_trainer
model-index:
- name: pega_70_articles
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pega_70_articles
This model is a fine-tuned version of [google/pegasus-cnn_dailymail](https://huggingface.co/google/pegasus-cnn_dailymail) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
huggingtweets/quora-reddit
|
huggingtweets
| 2022-06-03T12:09:44Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-02T13:30:18Z |
---
language: en
thumbnail: http://www.huggingtweets.com/quora-reddit/1654258179125/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1532031893318737920/N4nwSAZv_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1333471260483801089/OtTAJXEZ_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Quora & Reddit</div>
<div style="text-align: center; font-size: 14px;">@quora-reddit</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Quora & Reddit.
| Data | Quora | Reddit |
| --- | --- | --- |
| Tweets downloaded | 3244 | 3248 |
| Retweets | 181 | 331 |
| Short tweets | 22 | 392 |
| Tweets kept | 3041 | 2525 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/12sw605d/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @quora-reddit's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2g51clcs) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2g51clcs/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/quora-reddit')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
jcastanyo/q-FrozenLake-v1-8x8-Slippery-v3-v2
|
jcastanyo
| 2022-06-03T10:41:57Z | 0 | 0 | null |
[
"FrozenLake-v1-8x8",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-03T10:41:48Z |
---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-8x8-Slippery-v3-v2
results:
- metrics:
- type: mean_reward
value: 0.48 +/- 0.50
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-8x8
type: FrozenLake-v1-8x8
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="jcastanyo/q-FrozenLake-v1-8x8-Slippery-v3-v2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
jcastanyo/q-FrozenLake-v1-8x8-Slippery-v3
|
jcastanyo
| 2022-06-03T10:14:17Z | 0 | 0 | null |
[
"FrozenLake-v1-8x8",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-03T10:14:08Z |
---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-8x8-Slippery-v3
results:
- metrics:
- type: mean_reward
value: 0.29 +/- 0.45
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-8x8
type: FrozenLake-v1-8x8
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="jcastanyo/q-FrozenLake-v1-8x8-Slippery-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
facebook/bart-large
|
facebook
| 2022-06-03T10:00:20Z | 229,024 | 188 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"bart",
"feature-extraction",
"en",
"arxiv:1910.13461",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
language: en
---
# BART (large-sized model)
BART model pre-trained on English language. It was introduced in the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Lewis et al. and first released in [this repository](https://github.com/pytorch/fairseq/tree/master/examples/bart).
Disclaimer: The team releasing BART did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
BART is a transformer encoder-decoder (seq2seq) model with a bidirectional (BERT-like) encoder and an autoregressive (GPT-like) decoder. BART is pre-trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text.
BART is particularly effective when fine-tuned for text generation (e.g. summarization, translation) but also works well for comprehension tasks (e.g. text classification, question answering).
## Intended uses & limitations
You can use the raw model for text infilling. However, the model is mostly meant to be fine-tuned on a supervised dataset. See the [model hub](https://huggingface.co/models?search=bart) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import BartTokenizer, BartModel
tokenizer = BartTokenizer.from_pretrained('facebook/bart-large')
model = BartModel.from_pretrained('facebook/bart-large')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1910-13461,
author = {Mike Lewis and
Yinhan Liu and
Naman Goyal and
Marjan Ghazvininejad and
Abdelrahman Mohamed and
Omer Levy and
Veselin Stoyanov and
Luke Zettlemoyer},
title = {{BART:} Denoising Sequence-to-Sequence Pre-training for Natural Language
Generation, Translation, and Comprehension},
journal = {CoRR},
volume = {abs/1910.13461},
year = {2019},
url = {http://arxiv.org/abs/1910.13461},
eprinttype = {arXiv},
eprint = {1910.13461},
timestamp = {Thu, 31 Oct 2019 14:02:26 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1910-13461.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
huggingtweets/mundodeportivo
|
huggingtweets
| 2022-06-03T09:09:48Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-03T08:51:01Z |
---
language: en
thumbnail: http://www.huggingtweets.com/mundodeportivo/1654247301367/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1277369340275437570/R-AXlYNT_400x400.png')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Mundo Deportivo</div>
<div style="text-align: center; font-size: 14px;">@mundodeportivo</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Mundo Deportivo.
| Data | Mundo Deportivo |
| --- | --- |
| Tweets downloaded | 3250 |
| Retweets | 195 |
| Short tweets | 26 |
| Tweets kept | 3029 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/17m7lnrt/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @mundodeportivo's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2mndpk3u) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2mndpk3u/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/mundodeportivo')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
lewtun/t5-small-finetuned-arxiv
|
lewtun
| 2022-06-03T08:23:12Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-06-03T07:36:30Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5-small-finetuned-arxiv
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-arxiv
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1556
- Rouge1: 37.8405
- Rouge2: 20.4483
- Rougel: 33.996
- Rougelsum: 34.0071
- Gen Len: 15.8214
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:------:|:---------:|:-------:|
| 2.3825 | 1.0 | 3564 | 2.1556 | 37.8405 | 20.4483 | 33.996 | 34.0071 | 15.8214 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu102
- Datasets 2.2.1
- Tokenizers 0.12.1
|
chans/q-Taxi-v3
|
chans
| 2022-06-03T07:57:28Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-03T07:57:22Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="chans/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
sriiikar/wav2vec2-hindi-bhoj-3
|
sriiikar
| 2022-06-03T07:11:46Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-06-03T04:23:42Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-hindi-bhoj-3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-hindi-bhoj-3
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 5.7033
- Wer: 1.1477
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 40
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 8.6136 | 6.45 | 400 | 3.6017 | 1.0 |
| 2.6692 | 12.9 | 800 | 4.5408 | 1.0872 |
| 0.5639 | 19.35 | 1200 | 5.2302 | 1.2282 |
| 0.2296 | 25.8 | 1600 | 5.3323 | 1.0872 |
| 0.1496 | 32.26 | 2000 | 5.7219 | 1.1342 |
| 0.1098 | 38.7 | 2400 | 5.7033 | 1.1477 |
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.2.3.dev0
- Tokenizers 0.12.1
|
brindap/wav2vec2-large-xls-r-300m-hsb-colab
|
brindap
| 2022-06-03T06:56:19Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-06-02T14:24:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-hsb-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-hsb-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2283
- Wer: 0.9818
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 17.2414 | 5.56 | 50 | 7.6790 | 1.0 |
| 5.5913 | 11.11 | 100 | 4.1167 | 1.0 |
| 3.8478 | 16.67 | 150 | 3.3965 | 1.0 |
| 3.3442 | 22.22 | 200 | 3.2828 | 1.0 |
| 3.2219 | 27.78 | 250 | 3.2283 | 0.9818 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
kalmufti/q-FrozenLake-v1-4x4-noSlippery
|
kalmufti
| 2022-06-03T02:27:02Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-03T02:26:55Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="kalmufti/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
Lorenzo1708/TC01_Trabalho01
|
Lorenzo1708
| 2022-06-03T00:46:25Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-06-02T21:42:50Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: TC01_Trabalho01
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# TC01_Trabalho01
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2714
- Accuracy: 0.8979
- F1: 0.8972
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
M-CLIP/LABSE-Vit-L-14
|
M-CLIP
| 2022-06-02T23:26:39Z | 1,549 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"multilingual",
"endpoints_compatible",
"region:us"
] | null | 2022-05-31T09:40:25Z |
---
language: multilingual
---
## Multilingual-clip: LABSE-Vit-L-14
Multilingual-CLIP extends OpenAI's English text encoders to multiple other languages. This model *only* contains the multilingual text encoder. The corresponding image model `ViT-L-14` can be retrieved via instructions found on OpenAI's [CLIP repository on Github](https://github.com/openai/CLIP). We provide a usage example below.
## Requirements
To use both the multilingual text encoder and corresponding image encoder, we need to install the packages [`multilingual-clip`](https://github.com/FreddeFrallan/Multilingual-CLIP) and [`clip`](https://github.com/openai/CLIP).
```
pip install multilingual-clip
pip install git+https://github.com/openai/CLIP.git
```
## Usage
Extracting embeddings from the text encoder can be done in the following way:
```python
from multilingual_clip import pt_multilingual_clip
import transformers
texts = [
'Three blind horses listening to Mozart.',
'Älgen är skogens konung!',
'Wie leben Eisbären in der Antarktis?',
'Вы знали, что все белые медведи левши?'
]
model_name = 'M-CLIP/LABSE-Vit-L-14'
# Load Model & Tokenizer
model = pt_multilingual_clip.MultilingualCLIP.from_pretrained(model_name)
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
embeddings = model.forward(texts, tokenizer)
print("Text features shape:", embeddings.shape)
```
Extracting embeddings from the corresponding image encoder:
```python
import torch
import clip
import requests
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-L/14", device=device)
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image = preprocess(image).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
print("Image features shape:", image_features.shape)
```
## Evaluation results
None of the M-CLIP models have been extensivly evaluated, but testing them on Txt2Img retrieval on the humanly translated MS-COCO dataset, we see the following **R@10** results:
| Name | En | De | Es | Fr | Zh | It | Pl | Ko | Ru | Tr | Jp |
| ----------------------------------|:-----: |:-----: |:-----: |:-----: | :-----: |:-----: |:-----: |:-----: |:-----: |:-----: |:-----: |
| [OpenAI CLIP Vit-B/32](https://github.com/openai/CLIP)| 90.3 | - | - | - | - | - | - | - | - | - | - |
| [OpenAI CLIP Vit-L/14](https://github.com/openai/CLIP)| 91.8 | - | - | - | - | - | - | - | - | - | - |
| [OpenCLIP ViT-B-16+-](https://github.com/openai/CLIP)| 94.3 | - | - | - | - | - | - | - | - | - | - |
| [LABSE Vit-L/14](https://huggingface.co/M-CLIP/LABSE-Vit-L-14)| 91.6 | 89.6 | 89.5 | 89.9 | 88.9 | 90.1 | 89.8 | 80.8 | 85.5 | 89.8 | 73.9 |
| [XLM-R Large Vit-B/32](https://huggingface.co/M-CLIP/XLM-Roberta-Large-Vit-B-32)| 91.8 | 88.7 | 89.1 | 89.4 | 89.3 | 89.8| 91.4 | 82.1 | 86.1 | 88.8 | 81.0 |
| [XLM-R Vit-L/14](https://huggingface.co/M-CLIP/XLM-Roberta-Large-Vit-L-14)| 92.4 | 90.6 | 91.0 | 90.0 | 89.7 | 91.1 | 91.3 | 85.2 | 85.8 | 90.3 | 81.9 |
| [XLM-R Large Vit-B/16+](https://huggingface.co/M-CLIP/XLM-Roberta-Large-Vit-B-16Plus)| **95.0** | **93.0** | **93.6** | **93.1** | **94.0** | **93.1** | **94.4** | **89.0** | **90.0** | **93.0** | **84.2** |
## Training/Model details
Further details about the model training and data can be found in the [model card](https://github.com/FreddeFrallan/Multilingual-CLIP/blob/main/larger_mclip.md).
|
chrisvinsen/xlsr-wav2vec2-final-1-lm-3
|
chrisvinsen
| 2022-06-02T23:23:59Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-05-29T00:49:14Z |
Indonli + CommonVoice8.0 Dataset --> Train + Validation + Test
WER : 0.216
WER with LM: 0.104
|
huggingtweets/chewschaper
|
huggingtweets
| 2022-06-02T23:07:07Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-02T23:06:40Z |
---
language: en
thumbnail: http://www.huggingtweets.com/chewschaper/1654211222982/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1443195119218343937/dNb48XD2_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Benjamin Schaper</div>
<div style="text-align: center; font-size: 14px;">@chewschaper</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Benjamin Schaper.
| Data | Benjamin Schaper |
| --- | --- |
| Tweets downloaded | 449 |
| Retweets | 106 |
| Short tweets | 17 |
| Tweets kept | 326 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2kzh1jag/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @chewschaper's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/113fsajt) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/113fsajt/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/chewschaper')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/marazack26
|
huggingtweets
| 2022-06-02T22:56:49Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-02T22:54:27Z |
---
language: en
thumbnail: http://www.huggingtweets.com/marazack26/1654210546142/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1239803946643927041/AHuDYsfL_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Mohammed Abd Al-Razack / محمد عبد الرزاق</div>
<div style="text-align: center; font-size: 14px;">@marazack26</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Mohammed Abd Al-Razack / محمد عبد الرزاق.
| Data | Mohammed Abd Al-Razack / محمد عبد الرزاق |
| --- | --- |
| Tweets downloaded | 3060 |
| Retweets | 1619 |
| Short tweets | 167 |
| Tweets kept | 1274 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/264mzr04/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @marazack26's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3p7448r6) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3p7448r6/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/marazack26')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
UBC-NLP/prags1
|
UBC-NLP
| 2022-06-02T22:53:46Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"license:cc-by-nc-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-05-30T22:37:33Z |
---
license: cc-by-nc-3.0
---
PragS1: Pragmatic Masked Language Modeling with Hashtag_end dataset followed by Emoji-Based Surrogate Fine-Tuning
You can load this model and use for downstream fine-tuning. For example:
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained('UBC-NLP/prags1', use_fast = True)
model = AutoModelForSequenceClassification.from_pretrained('UBC-NLP/prags1',num_labels=lable_size)
```
More details are in our paper:
```
@inproceedings{zhang-abdul-mageed-2022-improving,
title = "Improving Social Meaning Detection with Pragmatic Masking and Surrogate Fine-Tuning",
author = "Zhang, Chiyu and
Abdul-Mageed, Muhammad",
booktitle = "Proceedings of the 12th Workshop on Computational Approaches to Subjectivity, Sentiment {\&} Social Media Analysis",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.wassa-1.14",
pages = "141--156",
}
```
|
UBC-NLP/prags2
|
UBC-NLP
| 2022-06-02T22:52:49Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"license:cc-by-nc-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-05-30T22:47:15Z |
---
license: cc-by-nc-3.0
---
PragS2: Pragmatic Masked Language Modeling with Emoji_any dataset followed by Hashtag-Based Surrogate Fine-Tuning
You can load this model and use for downstream fine-tuning. For example:
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained('UBC-NLP/prags2', use_fast = True)
model = AutoModelForSequenceClassification.from_pretrained('UBC-NLP/prags2',num_labels=lable_size)
```
More details are in our paper:
```
@inproceedings{zhang-abdul-mageed-2022-improving,
title = "Improving Social Meaning Detection with Pragmatic Masking and Surrogate Fine-Tuning",
author = "Zhang, Chiyu and
Abdul-Mageed, Muhammad",
booktitle = "Proceedings of the 12th Workshop on Computational Approaches to Subjectivity, Sentiment {\&} Social Media Analysis",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.wassa-1.14",
pages = "141--156",
}
```
|
huggingtweets/mrikasper
|
huggingtweets
| 2022-06-02T21:40:46Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-02T21:39:59Z |
---
language: en
thumbnail: http://www.huggingtweets.com/mrikasper/1654206041092/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/914206875419332608/26FrQMV2_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Lars Kasper</div>
<div style="text-align: center; font-size: 14px;">@mrikasper</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Lars Kasper.
| Data | Lars Kasper |
| --- | --- |
| Tweets downloaded | 475 |
| Retweets | 113 |
| Short tweets | 10 |
| Tweets kept | 352 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3lbnyiin/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @mrikasper's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1y754vcz) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1y754vcz/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/mrikasper')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
benwri/GaryOut
|
benwri
| 2022-06-02T21:19:11Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-06-02T21:18:55Z |
git lfs install
git clone https://huggingface.co/etmckinley/BERFALTER
# if you want to clone without large files – just their pointers
# prepend your git clone with the following env var:
GIT_LFS_SKIP_SMUDGE=1
|
ponci/ppo-lunar-ponci-test
|
ponci
| 2022-06-02T20:32:45Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-02T20:32:15Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 155.69 +/- 124.06
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
erickfm/t5-large-finetuned-bias
|
erickfm
| 2022-06-02T20:32:44Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:WNC",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-06-02T20:07:14Z |
---
language:
- en
license: apache-2.0
datasets:
- WNC
metrics:
- accuracy
---
This model is a fine-tune checkpoint of [T5-large](https://huggingface.co/t5-large), fine-tuned on the [Wiki Neutrality Corpus (WNC)](https://github.com/rpryzant/neutralizing-bias), a labeled dataset composed of 180,000 biased and neutralized sentence pairs that are generated from Wikipedia edits tagged for “neutral point of view”. This model reaches an accuracy of [?] on a dev split of the WNC.
For more details about T5, check out this [model card](https://huggingface.co/t5-large).
|
awghuku/wav2vec2-base-timit-demo-google-colab
|
awghuku
| 2022-06-02T18:35:00Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-06-02T16:03:09Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-timit-demo-google-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-google-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4732
- Wer: 0.3300
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 3.2982 | 1.0 | 500 | 1.3852 | 0.9990 |
| 0.8067 | 2.01 | 1000 | 0.5318 | 0.5140 |
| 0.4393 | 3.01 | 1500 | 0.4500 | 0.4570 |
| 0.3007 | 4.02 | 2000 | 0.4259 | 0.4091 |
| 0.2306 | 5.02 | 2500 | 0.4092 | 0.3962 |
| 0.1845 | 6.02 | 3000 | 0.3949 | 0.3834 |
| 0.1516 | 7.03 | 3500 | 0.4144 | 0.3759 |
| 0.1347 | 8.03 | 4000 | 0.3958 | 0.3689 |
| 0.1217 | 9.04 | 4500 | 0.4455 | 0.3754 |
| 0.1039 | 10.04 | 5000 | 0.4228 | 0.3684 |
| 0.0921 | 11.04 | 5500 | 0.4310 | 0.3566 |
| 0.082 | 12.05 | 6000 | 0.4549 | 0.3617 |
| 0.078 | 13.05 | 6500 | 0.4535 | 0.3661 |
| 0.0668 | 14.06 | 7000 | 0.4726 | 0.3557 |
| 0.0648 | 15.06 | 7500 | 0.4414 | 0.3512 |
| 0.0581 | 16.06 | 8000 | 0.4781 | 0.3548 |
| 0.057 | 17.07 | 8500 | 0.4626 | 0.3588 |
| 0.0532 | 18.07 | 9000 | 0.5065 | 0.3495 |
| 0.0442 | 19.08 | 9500 | 0.4645 | 0.3390 |
| 0.0432 | 20.08 | 10000 | 0.4786 | 0.3466 |
| 0.0416 | 21.08 | 10500 | 0.4487 | 0.3425 |
| 0.0337 | 22.09 | 11000 | 0.4878 | 0.3416 |
| 0.0305 | 23.09 | 11500 | 0.4787 | 0.3413 |
| 0.0319 | 24.1 | 12000 | 0.4707 | 0.3395 |
| 0.0262 | 25.1 | 12500 | 0.4875 | 0.3345 |
| 0.0266 | 26.1 | 13000 | 0.4801 | 0.3343 |
| 0.025 | 27.11 | 13500 | 0.4926 | 0.3320 |
| 0.022 | 28.11 | 14000 | 0.4894 | 0.3313 |
| 0.0227 | 29.12 | 14500 | 0.4732 | 0.3300 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 1.18.3
- Tokenizers 0.12.1
|
jcastanyo/q-FrozenLake-v1-4x4-Slippery-v3
|
jcastanyo
| 2022-06-02T18:14:00Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-02T18:13:51Z |
---
tags:
- FrozenLake-v1-4x4
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-Slippery-v3
results:
- metrics:
- type: mean_reward
value: 0.77 +/- 0.42
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4
type: FrozenLake-v1-4x4
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="jcastanyo/q-FrozenLake-v1-4x4-Slippery-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
huggingtweets/rauschermri
|
huggingtweets
| 2022-06-02T18:12:11Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-02T17:12:12Z |
---
language: en
thumbnail: http://www.huggingtweets.com/rauschermri/1654193526819/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1504854177993744386/k8Tb-5zg_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Alexander Rauscher</div>
<div style="text-align: center; font-size: 14px;">@rauschermri</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Alexander Rauscher.
| Data | Alexander Rauscher |
| --- | --- |
| Tweets downloaded | 3245 |
| Retweets | 651 |
| Short tweets | 253 |
| Tweets kept | 2341 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/clzasreo/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @rauschermri's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/e0w0wjmj) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/e0w0wjmj/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/rauschermri')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/ppinheirochagas
|
huggingtweets
| 2022-06-02T17:24:17Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-02T14:03:28Z |
---
language: en
thumbnail: http://www.huggingtweets.com/ppinheirochagas/1654190652962/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1510853995690033153/-mRCiWB0_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Pedro Pinheiro-Chagas</div>
<div style="text-align: center; font-size: 14px;">@ppinheirochagas</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Pedro Pinheiro-Chagas.
| Data | Pedro Pinheiro-Chagas |
| --- | --- |
| Tweets downloaded | 1001 |
| Retweets | 658 |
| Short tweets | 95 |
| Tweets kept | 248 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1f73x4s5/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ppinheirochagas's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/10v1i51v) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/10v1i51v/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ppinheirochagas')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
jcastanyo/q-FrozenLake-v1-8x8-noSlippery
|
jcastanyo
| 2022-06-02T16:57:25Z | 0 | 0 | null |
[
"FrozenLake-v1-8x8-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-02T16:57:16Z |
---
tags:
- FrozenLake-v1-8x8-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-8x8-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-8x8-no_slippery
type: FrozenLake-v1-8x8-no_slippery
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="jcastanyo/q-FrozenLake-v1-8x8-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
OneFly/distilbert-base-uncased-finetuned-emotion
|
OneFly
| 2022-06-02T16:28:55Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-06-02T16:08:58Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.928
- name: F1
type: f1
value: 0.9279829352545553
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2108
- Accuracy: 0.928
- F1: 0.9280
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8434 | 1.0 | 250 | 0.3075 | 0.9085 | 0.9058 |
| 0.2472 | 2.0 | 500 | 0.2108 | 0.928 | 0.9280 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
nglaura/skimformer
|
nglaura
| 2022-06-02T15:37:12Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"skimformer",
"fill-mask",
"arxiv:2109.01078",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-06-02T09:40:00Z |
---
license: apache-2.0
---
# Skimformer
A collaboration between [reciTAL](https://recital.ai/en/) & [MLIA](https://mlia.lip6.fr/) (ISIR, Sorbonne Université)
## Model description
Skimformer is a two-stage Transformer that replaces self-attention with Skim-Attention, a self-attention module that computes attention solely based on the 2D positions of tokens in the page. The model adopts a two-step approach: first, the skim-attention scores are computed once and only once using layout information alone; then, these attentions are used in every layer of a text-based Transformer encoder. For more details, please refer to our paper:
[Skim-Attention: Learning to Focus via Document Layout](https://arxiv.org/abs/2109.01078)
Laura Nguyen, Thomas Scialom, Jacopo Staiano, Benjamin Piwowarski, [EMNLP 2021](https://2021.emnlp.org/papers)
## Citation
``` latex
@article{nguyen2021skimattention,
title={Skim-Attention: Learning to Focus via Document Layout},
author={Laura Nguyen and Thomas Scialom and Jacopo Staiano and Benjamin Piwowarski},
journal={arXiv preprint arXiv:2109.01078}
year={2021},
}
```
|
Classroom-workshop/assignment1-jack
|
Classroom-workshop
| 2022-06-02T15:22:42Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"speech_to_text",
"automatic-speech-recognition",
"speech",
"audio",
"hf-asr-leaderboard",
"en",
"dataset:librispeech_asr",
"arxiv:2010.05171",
"arxiv:1904.08779",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-06-02T15:22:08Z |
---
language: en
datasets:
- librispeech_asr
tags:
- speech
- audio
- automatic-speech-recognition
- hf-asr-leaderboard
license: mit
pipeline_tag: automatic-speech-recognition
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
model-index:
- name: s2t-small-librispeech-asr
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (clean)
type: librispeech_asr
config: clean
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 4.3
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (other)
type: librispeech_asr
config: other
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 9.0
---
# S2T-SMALL-LIBRISPEECH-ASR
`s2t-small-librispeech-asr` is a Speech to Text Transformer (S2T) model trained for automatic speech recognition (ASR).
The S2T model was proposed in [this paper](https://arxiv.org/abs/2010.05171) and released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text)
## Model description
S2T is an end-to-end sequence-to-sequence transformer model. It is trained with standard
autoregressive cross-entropy loss and generates the transcripts autoregressively.
## Intended uses & limitations
This model can be used for end-to-end speech recognition (ASR).
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for other S2T checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
*Note: The `Speech2TextProcessor` object uses [torchaudio](https://github.com/pytorch/audio) to extract the
filter bank features. Make sure to install the `torchaudio` package before running this example.*
*Note: The feature extractor depends on [torchaudio](https://github.com/pytorch/audio) and the tokenizer depends on [sentencepiece](https://github.com/google/sentencepiece)
so be sure to install those packages before running the examples.*
You could either install those as extra speech dependancies with
`pip install transformers"[speech, sentencepiece]"` or install the packages seperatly
with `pip install torchaudio sentencepiece`.
```python
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
from datasets import load_dataset
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-librispeech-asr")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-librispeech-asr")
ds = load_dataset(
"patrickvonplaten/librispeech_asr_dummy",
"clean",
split="validation"
)
input_features = processor(
ds[0]["audio"]["array"],
sampling_rate=16_000,
return_tensors="pt"
).input_features # Batch size 1
generated_ids = model.generate(input_ids=input_features)
transcription = processor.batch_decode(generated_ids)
```
#### Evaluation on LibriSpeech Test
The following script shows how to evaluate this model on the [LibriSpeech](https://huggingface.co/datasets/librispeech_asr)
*"clean"* and *"other"* test dataset.
```python
from datasets import load_dataset, load_metric
from transformers import Speech2TextForConditionalGeneration, Speech2TextProcessor
librispeech_eval = load_dataset("librispeech_asr", "clean", split="test") # change to "other" for other test dataset
wer = load_metric("wer")
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-librispeech-asr").to("cuda")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-librispeech-asr", do_upper_case=True)
librispeech_eval = librispeech_eval.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["audio"]["array"], sampling_rate=16000, padding=True, return_tensors="pt")
input_features = features.input_features.to("cuda")
attention_mask = features.attention_mask.to("cuda")
gen_tokens = model.generate(input_ids=input_features, attention_mask=attention_mask)
batch["transcription"] = processor.batch_decode(gen_tokens, skip_special_tokens=True)
return batch
result = librispeech_eval.map(map_to_pred, batched=True, batch_size=8, remove_columns=["speech"])
print("WER:", wer(predictions=result["transcription"], references=result["text"]))
```
*Result (WER)*:
| "clean" | "other" |
|:-------:|:-------:|
| 4.3 | 9.0 |
## Training data
The S2T-SMALL-LIBRISPEECH-ASR is trained on [LibriSpeech ASR Corpus](https://www.openslr.org/12), a dataset consisting of
approximately 1000 hours of 16kHz read English speech.
## Training procedure
### Preprocessing
The speech data is pre-processed by extracting Kaldi-compliant 80-channel log mel-filter bank features automatically from
WAV/FLAC audio files via PyKaldi or torchaudio. Further utterance-level CMVN (cepstral mean and variance normalization)
is applied to each example.
The texts are lowercased and tokenized using SentencePiece and a vocabulary size of 10,000.
### Training
The model is trained with standard autoregressive cross-entropy loss and using [SpecAugment](https://arxiv.org/abs/1904.08779).
The encoder receives speech features, and the decoder generates the transcripts autoregressively.
### BibTeX entry and citation info
```bibtex
@inproceedings{wang2020fairseqs2t,
title = {fairseq S2T: Fast Speech-to-Text Modeling with fairseq},
author = {Changhan Wang and Yun Tang and Xutai Ma and Anne Wu and Dmytro Okhonko and Juan Pino},
booktitle = {Proceedings of the 2020 Conference of the Asian Chapter of the Association for Computational Linguistics (AACL): System Demonstrations},
year = {2020},
}
```
|
Classroom-workshop/assignment1-jane
|
Classroom-workshop
| 2022-06-02T15:21:22Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"speech_to_text",
"automatic-speech-recognition",
"speech",
"audio",
"hf-asr-leaderboard",
"en",
"dataset:librispeech_asr",
"arxiv:2010.05171",
"arxiv:1904.08779",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-06-02T15:20:45Z |
---
language: en
datasets:
- librispeech_asr
tags:
- speech
- audio
- automatic-speech-recognition
- hf-asr-leaderboard
license: mit
pipeline_tag: automatic-speech-recognition
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
model-index:
- name: s2t-small-librispeech-asr
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (clean)
type: librispeech_asr
config: clean
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 4.3
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (other)
type: librispeech_asr
config: other
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 9.0
---
# S2T-SMALL-LIBRISPEECH-ASR
`s2t-small-librispeech-asr` is a Speech to Text Transformer (S2T) model trained for automatic speech recognition (ASR).
The S2T model was proposed in [this paper](https://arxiv.org/abs/2010.05171) and released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text)
## Model description
S2T is an end-to-end sequence-to-sequence transformer model. It is trained with standard
autoregressive cross-entropy loss and generates the transcripts autoregressively.
## Intended uses & limitations
This model can be used for end-to-end speech recognition (ASR).
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for other S2T checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
*Note: The `Speech2TextProcessor` object uses [torchaudio](https://github.com/pytorch/audio) to extract the
filter bank features. Make sure to install the `torchaudio` package before running this example.*
*Note: The feature extractor depends on [torchaudio](https://github.com/pytorch/audio) and the tokenizer depends on [sentencepiece](https://github.com/google/sentencepiece)
so be sure to install those packages before running the examples.*
You could either install those as extra speech dependancies with
`pip install transformers"[speech, sentencepiece]"` or install the packages seperatly
with `pip install torchaudio sentencepiece`.
```python
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
from datasets import load_dataset
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-librispeech-asr")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-librispeech-asr")
ds = load_dataset(
"patrickvonplaten/librispeech_asr_dummy",
"clean",
split="validation"
)
input_features = processor(
ds[0]["audio"]["array"],
sampling_rate=16_000,
return_tensors="pt"
).input_features # Batch size 1
generated_ids = model.generate(input_ids=input_features)
transcription = processor.batch_decode(generated_ids)
```
#### Evaluation on LibriSpeech Test
The following script shows how to evaluate this model on the [LibriSpeech](https://huggingface.co/datasets/librispeech_asr)
*"clean"* and *"other"* test dataset.
```python
from datasets import load_dataset, load_metric
from transformers import Speech2TextForConditionalGeneration, Speech2TextProcessor
librispeech_eval = load_dataset("librispeech_asr", "clean", split="test") # change to "other" for other test dataset
wer = load_metric("wer")
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-librispeech-asr").to("cuda")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-librispeech-asr", do_upper_case=True)
librispeech_eval = librispeech_eval.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["audio"]["array"], sampling_rate=16000, padding=True, return_tensors="pt")
input_features = features.input_features.to("cuda")
attention_mask = features.attention_mask.to("cuda")
gen_tokens = model.generate(input_ids=input_features, attention_mask=attention_mask)
batch["transcription"] = processor.batch_decode(gen_tokens, skip_special_tokens=True)
return batch
result = librispeech_eval.map(map_to_pred, batched=True, batch_size=8, remove_columns=["speech"])
print("WER:", wer(predictions=result["transcription"], references=result["text"]))
```
*Result (WER)*:
| "clean" | "other" |
|:-------:|:-------:|
| 4.3 | 9.0 |
## Training data
The S2T-SMALL-LIBRISPEECH-ASR is trained on [LibriSpeech ASR Corpus](https://www.openslr.org/12), a dataset consisting of
approximately 1000 hours of 16kHz read English speech.
## Training procedure
### Preprocessing
The speech data is pre-processed by extracting Kaldi-compliant 80-channel log mel-filter bank features automatically from
WAV/FLAC audio files via PyKaldi or torchaudio. Further utterance-level CMVN (cepstral mean and variance normalization)
is applied to each example.
The texts are lowercased and tokenized using SentencePiece and a vocabulary size of 10,000.
### Training
The model is trained with standard autoregressive cross-entropy loss and using [SpecAugment](https://arxiv.org/abs/1904.08779).
The encoder receives speech features, and the decoder generates the transcripts autoregressively.
### BibTeX entry and citation info
```bibtex
@inproceedings{wang2020fairseqs2t,
title = {fairseq S2T: Fast Speech-to-Text Modeling with fairseq},
author = {Changhan Wang and Yun Tang and Xutai Ma and Anne Wu and Dmytro Okhonko and Juan Pino},
booktitle = {Proceedings of the 2020 Conference of the Asian Chapter of the Association for Computational Linguistics (AACL): System Demonstrations},
year = {2020},
}
```
|
ducnapa/apes
|
ducnapa
| 2022-06-02T15:17:57Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-06-02T15:17:46Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: apes
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.8999999761581421
---
# apes
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### chimpanzee

#### gibbon

#### gorilla

#### orangutan

|
lmazzon70/identify-my-cat
|
lmazzon70
| 2022-06-02T14:24:41Z | 0 | 0 |
fastai
|
[
"fastai",
"region:us"
] | null | 2022-06-02T14:24:29Z |
---
tags:
- fastai
---
# Amazing!
🥳 Congratulations on hosting your fastai model on the Hugging Face Hub!
# Some next steps
1. Fill out this model card with more information (see the template below and the [documentation here](https://huggingface.co/docs/hub/model-repos))!
2. Create a demo in Gradio or Streamlit using 🤗 Spaces ([documentation here](https://huggingface.co/docs/hub/spaces)).
3. Join the fastai community on the [Fastai Discord](https://discord.com/invite/YKrxeNn)!
Greetings fellow fastlearner 🤝! Don't forget to delete this content from your model card.
---
# Model card
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
|
AAkhilesh/wav2vec2-large-xls-r-300m-hsb-colab
|
AAkhilesh
| 2022-06-02T13:57:16Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-06-02T13:43:01Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-hsb-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-hsb-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
Lolaibrin/distilbert-base-uncased-finetuned-squad
|
Lolaibrin
| 2022-06-02T13:43:10Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-06-02T10:42:19Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2108
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.4952 | 1.0 | 5533 | 1.3895 |
| 1.3024 | 2.0 | 11066 | 1.2490 |
| 1.2087 | 3.0 | 16599 | 1.2108 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
huggingtweets/caballerogaudes
|
huggingtweets
| 2022-06-02T13:25:40Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-02T13:23:37Z |
---
language: en
thumbnail: http://www.huggingtweets.com/caballerogaudes/1654176335515/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1011998779061559297/5gOeFvds_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">CesarCaballeroGaudes</div>
<div style="text-align: center; font-size: 14px;">@caballerogaudes</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from CesarCaballeroGaudes.
| Data | CesarCaballeroGaudes |
| --- | --- |
| Tweets downloaded | 1724 |
| Retweets | 808 |
| Short tweets | 36 |
| Tweets kept | 880 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2d76b6yf/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @caballerogaudes's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/i6nt6oo6) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/i6nt6oo6/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/caballerogaudes')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Rhuax/MiniLMv2-L12-H384-distilled-finetuned-spam-detection
|
Rhuax
| 2022-06-02T13:21:41Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"dataset:sms_spam",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-06-01T16:05:58Z |
---
tags:
- generated_from_trainer
datasets:
- sms_spam
metrics:
- accuracy
model-index:
- name: MiniLMv2-L12-H384-distilled-finetuned-spam-detection
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: sms_spam
type: sms_spam
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.9928263988522238
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# MiniLMv2-L12-H384-distilled-finetuned-spam-detection
This model is a fine-tuned version of [nreimers/MiniLMv2-L12-H384-distilled-from-RoBERTa-Large](https://huggingface.co/nreimers/MiniLMv2-L12-H384-distilled-from-RoBERTa-Large) on the sms_spam dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0938
- Accuracy: 0.9928
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 33
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.4101 | 1.0 | 131 | 0.4930 | 0.9763 |
| 0.8003 | 2.0 | 262 | 0.3999 | 0.9799 |
| 0.377 | 3.0 | 393 | 0.3196 | 0.9828 |
| 0.302 | 4.0 | 524 | 0.3462 | 0.9828 |
| 0.1945 | 5.0 | 655 | 0.1094 | 0.9928 |
| 0.1393 | 6.0 | 786 | 0.0938 | 0.9928 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.2+cu113
- Datasets 1.18.4
- Tokenizers 0.12.1
|
Jozaita/q-Taxi-v3
|
Jozaita
| 2022-06-02T13:12:26Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-02T13:12:11Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.54 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Jozaita/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
huggingtweets/esfinn
|
huggingtweets
| 2022-06-02T12:35:17Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-02T12:34:00Z |
---
language: en
thumbnail: http://www.huggingtweets.com/esfinn/1654173312571/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/773905129129046016/EZcRPMpd_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Emily Finn</div>
<div style="text-align: center; font-size: 14px;">@esfinn</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Emily Finn.
| Data | Emily Finn |
| --- | --- |
| Tweets downloaded | 767 |
| Retweets | 209 |
| Short tweets | 72 |
| Tweets kept | 486 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/22n1p2vw/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @esfinn's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/caz2a2vq) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/caz2a2vq/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/esfinn')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
yannis95/bert-finetuned-ner
|
yannis95
| 2022-06-02T12:35:12Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-02T06:57:21Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.926145730300033
- name: Recall
type: recall
value: 0.9454729047458769
- name: F1
type: f1
value: 0.935709526982012
- name: Accuracy
type: accuracy
value: 0.9851209748631307
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0665
- Precision: 0.9261
- Recall: 0.9455
- F1: 0.9357
- Accuracy: 0.9851
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0852 | 1.0 | 1756 | 0.0650 | 0.9197 | 0.9367 | 0.9281 | 0.9830 |
| 0.0407 | 2.0 | 3512 | 0.0621 | 0.9225 | 0.9438 | 0.9330 | 0.9848 |
| 0.0195 | 3.0 | 5268 | 0.0665 | 0.9261 | 0.9455 | 0.9357 | 0.9851 |
### Framework versions
- Transformers 4.19.1
- Pytorch 1.11.0
- Datasets 2.2.2
- Tokenizers 0.12.1
|
chrisvinsen/wav2vec2-final-1-lm-1
|
chrisvinsen
| 2022-06-02T11:08:55Z | 15 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-06-02T02:20:22Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-19
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-19
WER 0.283
WER 0.129 with 2-Gram
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6305
- Wer: 0.4499
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 800
- num_epochs: 60
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.4816 | 2.74 | 400 | 1.0717 | 0.8927 |
| 0.751 | 5.48 | 800 | 0.7155 | 0.7533 |
| 0.517 | 8.22 | 1200 | 0.7039 | 0.6675 |
| 0.3988 | 10.96 | 1600 | 0.5935 | 0.6149 |
| 0.3179 | 13.7 | 2000 | 0.6477 | 0.5999 |
| 0.2755 | 16.44 | 2400 | 0.5549 | 0.5798 |
| 0.2343 | 19.18 | 2800 | 0.6626 | 0.5798 |
| 0.2103 | 21.92 | 3200 | 0.6488 | 0.5674 |
| 0.1877 | 24.66 | 3600 | 0.5874 | 0.5339 |
| 0.1719 | 27.4 | 4000 | 0.6354 | 0.5389 |
| 0.1603 | 30.14 | 4400 | 0.6612 | 0.5210 |
| 0.1401 | 32.88 | 4800 | 0.6676 | 0.5131 |
| 0.1286 | 35.62 | 5200 | 0.6366 | 0.5075 |
| 0.1159 | 38.36 | 5600 | 0.6064 | 0.4977 |
| 0.1084 | 41.1 | 6000 | 0.6530 | 0.4835 |
| 0.0974 | 43.84 | 6400 | 0.6118 | 0.4853 |
| 0.0879 | 46.58 | 6800 | 0.6316 | 0.4770 |
| 0.0815 | 49.32 | 7200 | 0.6125 | 0.4664 |
| 0.0708 | 52.05 | 7600 | 0.6449 | 0.4683 |
| 0.0651 | 54.79 | 8000 | 0.6068 | 0.4571 |
| 0.0555 | 57.53 | 8400 | 0.6305 | 0.4499 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
elfray/q-Taxi-v3
|
elfray
| 2022-06-02T10:58:25Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-02T10:58:19Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.46 +/- 2.76
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="elfray/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
elfray/q-FrozenLake-v1-4x4-noSlippery
|
elfray
| 2022-06-02T10:55:16Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-02T10:55:09Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="elfray/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
SynamicTechnologies/CYBERT
|
SynamicTechnologies
| 2022-06-02T09:51:10Z | 5,032 | 8 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-06-02T08:22:55Z |
## CYBERT
BERT model dedicated to the domain of cyber security. The model has been trained on a corpus of high-quality cyber security and computer science text and is unlikely to work outside this domain.
##Model architecture
The model architecture used is original Roberta and tokenizer to train the corpus is Byte Level.
##Hardware
The model is trained on GPU NVIDIA-SMI 510.54
|
PontifexMaximus/opus-mt-iir-en-finetuned-fa-to-en
|
PontifexMaximus
| 2022-06-02T09:38:06Z | 22 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"generated_from_trainer",
"dataset:opus_infopankki",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-05-31T06:08:46Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- opus_infopankki
metrics:
- bleu
model-index:
- name: opus-mt-iir-en-finetuned-fa-to-en
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: opus_infopankki
type: opus_infopankki
args: en-fa
metrics:
- name: Bleu
type: bleu
value: 36.687
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-iir-en-finetuned-fa-to-en
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-iir-en](https://huggingface.co/Helsinki-NLP/opus-mt-iir-en) on the opus_infopankki dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0968
- Bleu: 36.687
- Gen Len: 16.039
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|
| 3.1614 | 1.0 | 1509 | 2.8058 | 12.326 | 16.5467 |
| 2.7235 | 2.0 | 3018 | 2.4178 | 15.6912 | 16.6396 |
| 2.4839 | 3.0 | 4527 | 2.1905 | 18.1971 | 16.4884 |
| 2.3044 | 4.0 | 6036 | 2.0272 | 20.197 | 16.4735 |
| 2.1943 | 5.0 | 7545 | 1.9012 | 22.2265 | 16.4266 |
| 2.0669 | 6.0 | 9054 | 1.7984 | 23.7711 | 16.353 |
| 1.985 | 7.0 | 10563 | 1.7100 | 24.986 | 16.284 |
| 1.9024 | 8.0 | 12072 | 1.6346 | 26.1758 | 16.217 |
| 1.8484 | 9.0 | 13581 | 1.5692 | 27.2782 | 16.1924 |
| 1.7761 | 10.0 | 15090 | 1.5111 | 28.2761 | 16.144 |
| 1.733 | 11.0 | 16599 | 1.4599 | 29.2184 | 16.2438 |
| 1.6772 | 12.0 | 18108 | 1.4150 | 30.0026 | 16.1949 |
| 1.6297 | 13.0 | 19617 | 1.3743 | 30.7839 | 16.1565 |
| 1.5918 | 14.0 | 21126 | 1.3370 | 31.4921 | 16.1323 |
| 1.5548 | 15.0 | 22635 | 1.3038 | 32.0621 | 16.076 |
| 1.5333 | 16.0 | 24144 | 1.2743 | 32.6881 | 16.0078 |
| 1.5145 | 17.0 | 25653 | 1.2478 | 33.3794 | 16.1228 |
| 1.4826 | 18.0 | 27162 | 1.2240 | 33.8335 | 16.0809 |
| 1.4488 | 19.0 | 28671 | 1.2021 | 34.2819 | 16.0479 |
| 1.4386 | 20.0 | 30180 | 1.1829 | 34.7206 | 16.0578 |
| 1.4127 | 21.0 | 31689 | 1.1660 | 35.031 | 16.0717 |
| 1.4089 | 22.0 | 33198 | 1.1510 | 35.4142 | 16.0391 |
| 1.3922 | 23.0 | 34707 | 1.1380 | 35.6777 | 16.0461 |
| 1.377 | 24.0 | 36216 | 1.1273 | 35.95 | 16.0569 |
| 1.3598 | 25.0 | 37725 | 1.1175 | 36.2435 | 16.0426 |
| 1.3515 | 26.0 | 39234 | 1.1097 | 36.4009 | 16.0247 |
| 1.3441 | 27.0 | 40743 | 1.1042 | 36.4815 | 16.0447 |
| 1.3412 | 28.0 | 42252 | 1.1001 | 36.6092 | 16.0489 |
| 1.3527 | 29.0 | 43761 | 1.0976 | 36.6703 | 16.0383 |
| 1.3397 | 30.0 | 45270 | 1.0968 | 36.687 | 16.039 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.7.1+cu110
- Datasets 2.2.2
- Tokenizers 0.12.1
|
nsa/detr_r50_ep15
|
nsa
| 2022-06-02T09:15:52Z | 11 | 2 |
transformers
|
[
"transformers",
"endpoints_compatible",
"region:us"
] | null | 2022-06-02T07:46:19Z |
# Face Detection using DEtection TRansformers from Facebook AI 🚀


This repository includes
* Training Pipeline for DETR on Custom dataset
* Wider Face Dataset annotaions and images
* Evaluation on test dataset
* Trained weights for Wider Face Dataset in [release page](https://github.com/NyanSwanAung/Pothole-Detection-using-MaskRCNN/releases)
* Metrics Visualization
## About Model
DETR or DEtection TRansformer is Facebook’s newest addition to the market of available deep learning-based object detection solutions. Very simply, it utilizes the transformer architecture to generate predictions of objects and their position in an image. DETR is a joint Convolutional Neural Network (CNN) and Transformer with a feed-forward network as a head. This architecture allows the network to reliably reason about object relations in the image using the powerful multi-head attention mechanism inherent in the Transformer architecture using features extracted by the CNN.

## Face Dataset

I've used [WIDER FACE dataset](http://shuoyang1213.me/WIDERFACE/) which is a publicly available face detection benchmark dataset, consisting of 32,203 images and label 393,703 faces with a high degree of variability in scale, pose and occlusion as depicted in the sample images. WIDER FACE dataset is organized based on 61 event classes. For each event class, the original dataset was split into 40%/10%/50% as training, validation and testing sets.
By compiling the give code, the dataset will be automatically downloaded but you can download it manually from the official website or from my github [release page](https://github.com/NyanSwanAung/Object-Detection-Using-DETR-CustomDataset/releases).
In [dataloader/face.py](https://github.com/NyanSwanAung/Object-Detection-Using-DETR-CustomDataset/blob/main/dataloaders/face.py), I set the maximum width of images in the random transform to 800 pixels. This should allow for training on most GPUs, but it is advisable to change back to the original 1333 if your GPU can handle it.
## Model
We're going to use **DETR with a backbone of Resnet 50**, pretrained on COCO 2017 dataset. AP is computed on COCO 2017 val5k, and inference time is over the first 100 val5k COCO images, with torchscript transformer. If you want to use other DETR models, you can find them in model zoo below.
Model Zoo
<table>
<thead>
<tr style="text-align: right;">
<th></th>
<th>name</th>
<th>backbone</th>
<th>schedule</th>
<th>inf_time</th>
<th>box AP</th>
<th>url</th>
<th>size</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>DETR</td>
<td>R50</td>
<td>500</td>
<td>0.036</td>
<td>42.0</td>
<td><a href="https://dl.fbaipublicfiles.com/detr/detr-r50-e632da11.pth">model</a> | <a href="https://dl.fbaipublicfiles.com/detr/logs/detr-r50_log.txt">logs</a></td>
<td>159Mb</td>
</tr>
<tr>
<th>1</th>
<td>DETR-DC5</td>
<td>R50</td>
<td>500</td>
<td>0.083</td>
<td>43.3</td>
<td><a href="https://dl.fbaipublicfiles.com/detr/detr-r50-dc5-f0fb7ef5.pth">model</a> | <a href="https://dl.fbaipublicfiles.com/detr/logs/detr-r50-dc5_log.txt">logs</a></td>
<td>159Mb</td>
</tr>
<tr>
<th>2</th>
<td>DETR</td>
<td>R101</td>
<td>500</td>
<td>0.050</td>
<td>43.5</td>
<td><a href="https://dl.fbaipublicfiles.com/detr/detr-r101-2c7b67e5.pth">model</a> | <a href="https://dl.fbaipublicfiles.com/detr/logs/detr-r101_log.txt">logs</a></td>
<td>232Mb</td>
</tr>
<tr>
<th>3</th>
<td>DETR-DC5</td>
<td>R101</td>
<td>500</td>
<td>0.097</td>
<td>44.9</td>
<td><a href="https://dl.fbaipublicfiles.com/detr/detr-r101-dc5-a2e86def.pth">model</a> | <a href="https://dl.fbaipublicfiles.com/detr/logs/detr-r101-dc5_log.txt">logs</a></td>
<td>232Mb</td>
</tr>
</tbody>
</table>
## Training and Evaluation Steps
Run all the cells of [detr_custom_dataset.ipynb](https://github.com/NyanSwanAung/Object-Detection-Using-DETR-CustomDataset/blob/main/DETR_custom_dataset.ipynb) to train your model without any errors in Google Colaboratory.
Follow this [readme](https://github.com/NyanSwanAung/Object-Detection-Using-DETR-CustomDataset/blob/main/TRAINING-and-INFERENCING.md) to understand the training pipeline of DETR and evaluation on test images.
## Results





## COCO Evaluation Metrics on Validation Dataset (After 15 epochs of training)
It took me 4:59:45 hours to finish 15 epochs with batch_size=16 using Tesla P100-PCIE. If you want better accuracy, you can train more epochs.
```bash
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.393
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.766
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.370
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.055
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.391
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.615
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.201
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.448
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.500
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.194
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.519
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.706
```
## Metrics Visualization
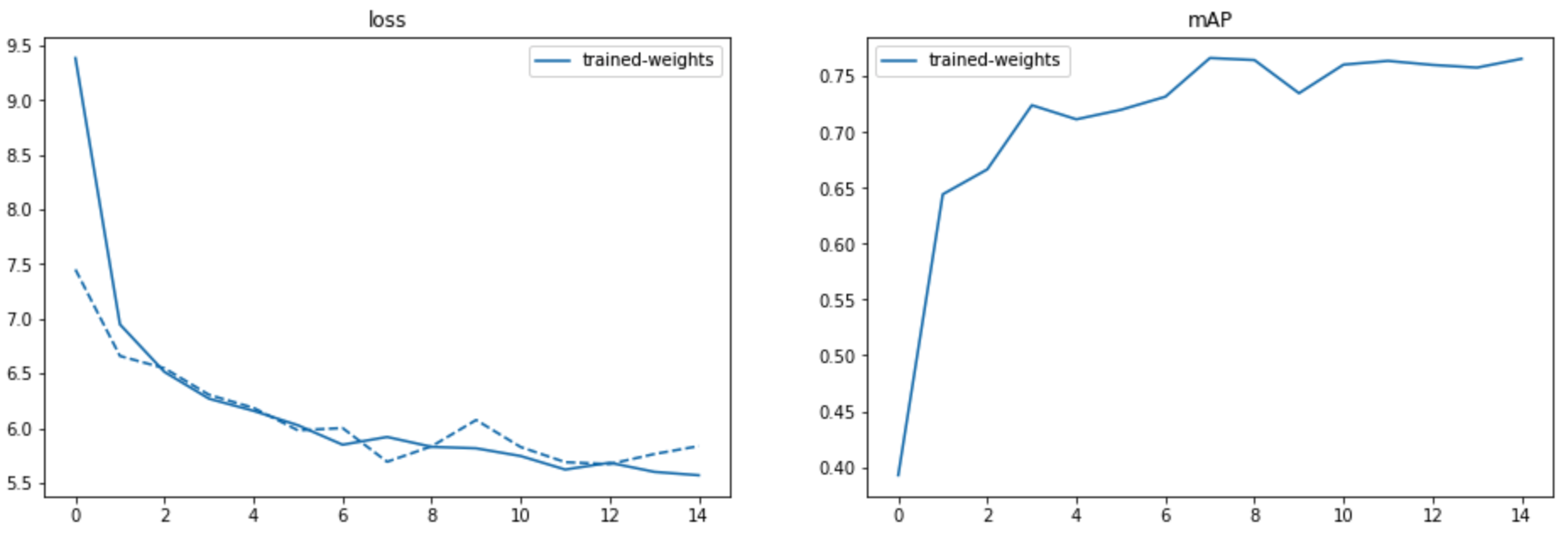
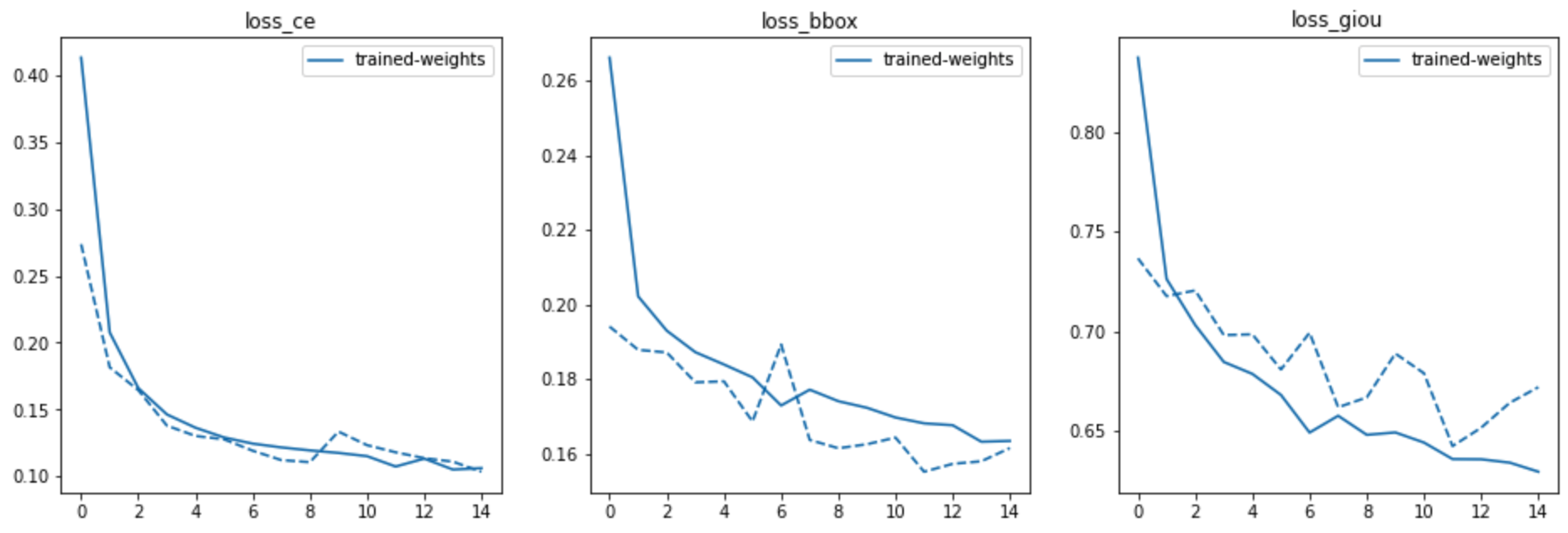
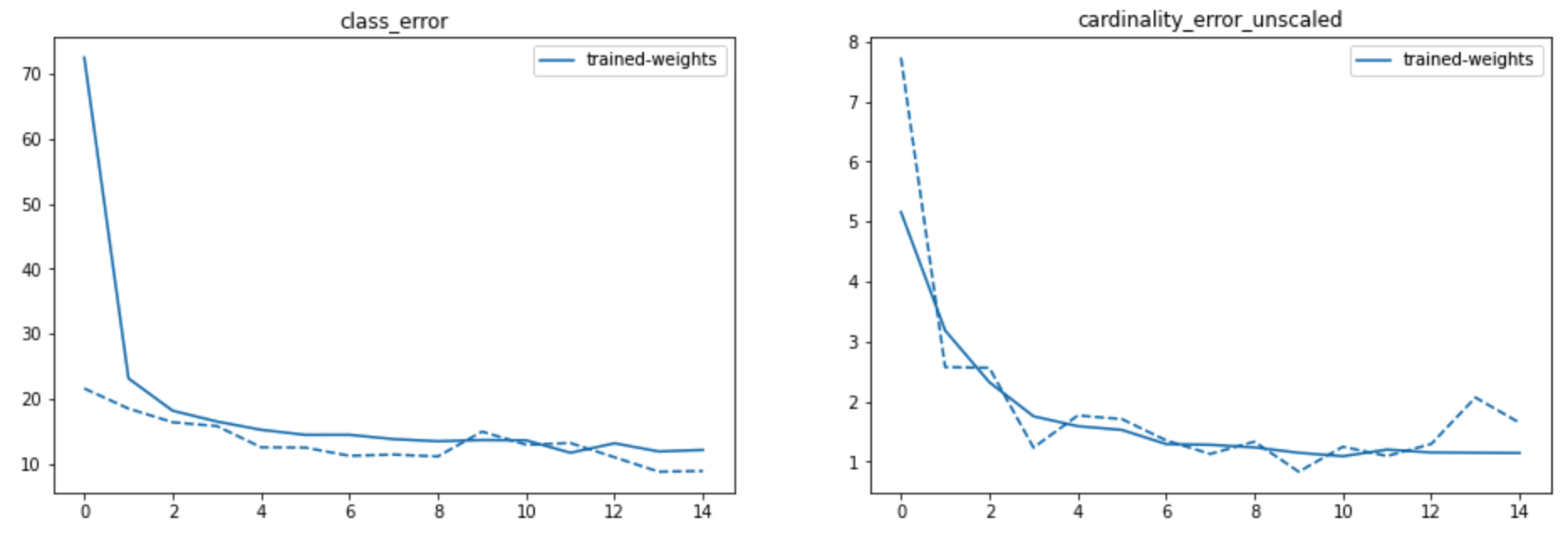
## Augmentation methods
For train images,
```
T.RandomHorizontalFlip(),
T.RandomSelect(
T.RandomResize(scales, max_size=800),
T.Compose([
T.RandomResize([400, 500, 600]),
T.RandomSizeCrop(384, 600),
T.RandomResize(scales, max_size=800),
])
```
For val images,
``` T.RandomResize([800], max_size=800) ```
## References
[DETR Tutorial by thedeepreader](https://github.com/thedeepreader/detr_tutorial)
[Training DETR on your own dataset by Oliver Gyldenberg Hjermitslev](https://towardsdatascience.com/training-detr-on-your-own-dataset-bcee0be05522)
[Facebook AI's original DETR repo](https://github.com/facebookresearch/detr)
|
kktoto/tiny_bb_wd
|
kktoto
| 2022-06-02T08:06:44Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-02T04:01:38Z |
---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: tiny_bb_wd
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny_bb_wd
This model is a fine-tuned version of [kktoto/tiny_bb_wd](https://huggingface.co/kktoto/tiny_bb_wd) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1331
- Precision: 0.6566
- Recall: 0.6502
- F1: 0.6533
- Accuracy: 0.9524
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1193 | 1.0 | 5561 | 0.1398 | 0.6406 | 0.6264 | 0.6335 | 0.9501 |
| 0.1259 | 2.0 | 11122 | 0.1343 | 0.6476 | 0.6300 | 0.6387 | 0.9509 |
| 0.1283 | 3.0 | 16683 | 0.1333 | 0.6484 | 0.6367 | 0.6425 | 0.9512 |
| 0.1217 | 4.0 | 22244 | 0.1325 | 0.6524 | 0.6380 | 0.6451 | 0.9516 |
| 0.12 | 5.0 | 27805 | 0.1337 | 0.6571 | 0.6377 | 0.6472 | 0.9522 |
| 0.1187 | 6.0 | 33366 | 0.1319 | 0.6630 | 0.6297 | 0.6459 | 0.9525 |
| 0.116 | 7.0 | 38927 | 0.1318 | 0.6600 | 0.6421 | 0.6509 | 0.9525 |
| 0.1125 | 8.0 | 44488 | 0.1337 | 0.6563 | 0.6481 | 0.6522 | 0.9523 |
| 0.1118 | 9.0 | 50049 | 0.1329 | 0.6575 | 0.6477 | 0.6526 | 0.9524 |
| 0.1103 | 10.0 | 55610 | 0.1331 | 0.6566 | 0.6502 | 0.6533 | 0.9524 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
Andaf/bert-uncased-finetuned-squad-indonesian
|
Andaf
| 2022-06-02T07:32:23Z | 16 | 2 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"bert",
"question-answering",
"generated_from_keras_callback",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-06-02T03:19:04Z |
---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: Andaf/chatbot-trvlk-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Andaf/chatbot-trvlk-finetuned-squad
This model is a fine-tuned version of [cahya/bert-base-indonesian-522M](https://huggingface.co/cahya/bert-base-indonesian-522M) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.5335
- Validation Loss: 6.4566
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 14444, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 2.1851 | 6.1907 | 0 |
| 1.5335 | 6.4566 | 1 |
### Framework versions
- Transformers 4.18.0
- TensorFlow 2.8.1
- Tokenizers 0.12.1
|
huggingtweets/paxt0n4
|
huggingtweets
| 2022-06-02T07:30:57Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-02T07:30:25Z |
---
language: en
thumbnail: http://www.huggingtweets.com/paxt0n4/1654155052782/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1359906890340306950/s5cXHS11_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Paxton Fitzpatrick</div>
<div style="text-align: center; font-size: 14px;">@paxt0n4</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Paxton Fitzpatrick.
| Data | Paxton Fitzpatrick |
| --- | --- |
| Tweets downloaded | 2551 |
| Retweets | 1177 |
| Short tweets | 326 |
| Tweets kept | 1048 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1x9k9uk2/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @paxt0n4's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/34fd5zca) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/34fd5zca/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/paxt0n4')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
kabelomalapane/En-Tn
|
kabelomalapane
| 2022-06-02T07:03:01Z | 67 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-06-01T11:35:03Z |
---
license: apache-2.0
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: En-Tn
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# En-Tn
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-tn](https://huggingface.co/Helsinki-NLP/opus-mt-en-tn) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6174
- Bleu: 32.2889
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
huggingtweets/contextmemlab-jeremyrmanning
|
huggingtweets
| 2022-06-02T06:59:24Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-02T06:55:41Z |
---
language: en
thumbnail: http://www.huggingtweets.com/contextmemlab-jeremyrmanning/1654153159177/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1268155013882396672/Ev_5MJ-E_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/733324858621341698/iW5s1aAc_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Jeremy Manning & Context Lab</div>
<div style="text-align: center; font-size: 14px;">@contextmemlab-jeremyrmanning</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Jeremy Manning & Context Lab.
| Data | Jeremy Manning | Context Lab |
| --- | --- | --- |
| Tweets downloaded | 1635 | 206 |
| Retweets | 1093 | 44 |
| Short tweets | 88 | 1 |
| Tweets kept | 454 | 161 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1383c0di/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @contextmemlab-jeremyrmanning's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1nunflkl) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1nunflkl/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/contextmemlab-jeremyrmanning')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
ShoneRan/bert-emotion
|
ShoneRan
| 2022-06-02T05:15:37Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:tweet_eval",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-06-02T04:55:32Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- precision
- recall
model-index:
- name: bert-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: emotion
metrics:
- name: Precision
type: precision
value: 0.7262254187805659
- name: Recall
type: recall
value: 0.725549671319356
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-emotion
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1670
- Precision: 0.7262
- Recall: 0.7255
- Fscore: 0.7253
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | Fscore |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|
| 0.8561 | 1.0 | 815 | 0.7844 | 0.7575 | 0.6081 | 0.6253 |
| 0.5337 | 2.0 | 1630 | 0.9080 | 0.7567 | 0.7236 | 0.7325 |
| 0.2573 | 3.0 | 2445 | 1.1670 | 0.7262 | 0.7255 | 0.7253 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
mesolitica/wav2vec2-xls-r-300m-mixed
|
mesolitica
| 2022-06-02T04:58:36Z | 735 | 4 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_keras_callback",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-06-01T01:18:26Z |
---
tags:
- generated_from_keras_callback
model-index:
- name: wav2vec2-xls-r-300m-mixed
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-300m-mixed
Finetuned https://huggingface.co/facebook/wav2vec2-xls-r-300m on https://github.com/huseinzol05/malaya-speech/tree/master/data/mixed-stt
This model was finetuned on 3 languages,
1. Malay
2. Singlish
3. Mandarin
**This model trained on a single RTX 3090 Ti 24GB VRAM, provided by https://mesolitica.com/**.
## Evaluation set
Evaluation set from https://github.com/huseinzol05/malaya-speech/tree/master/pretrained-model/prepare-stt with sizes,
```
len(malay), len(singlish), len(mandarin)
-> (765, 3579, 614)
```
It achieves the following results on the evaluation set based on [evaluate-gpu.ipynb](evaluate-gpu.ipynb):
Mixed evaluation,
```
CER: 0.0481054244857041
WER: 0.1322198446007387
CER with LM: 0.041196586938584696
WER with LM: 0.09880169127621556
```
Malay evaluation,
```
CER: 0.051636391937588406
WER: 0.19561999547293663
CER with LM: 0.03917689630621449
WER with LM: 0.12710746406824835
```
Singlish evaluation,
```
CER: 0.0494915200071987
WER: 0.12763802881676573
CER with LM: 0.04271234986432335
WER with LM: 0.09677160640413336
```
Mandarin evaluation,
```
CER: 0.035626554824269824
WER: 0.07993515937860181
CER with LM: 0.03487760945087219
WER with LM: 0.07536807168546154
```
Language model from https://huggingface.co/huseinzol05/language-model-bahasa-manglish-combined
|
thunninoi/wav2vec2-japanese-hiragana-vtuber
|
thunninoi
| 2022-06-02T04:31:41Z | 6 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-05-27T10:41:57Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: checkpoints
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# checkpoints
This model is a fine-tuned version of [vumichien/wav2vec2-large-xlsr-japanese-hiragana](https://huggingface.co/vumichien/wav2vec2-large-xlsr-japanese-hiragana) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4134
- Wer: 0.1884
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 3
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 6
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 75
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 1.4299 | 1.0 | 247 | 0.7608 | 0.4853 |
| 0.8045 | 2.0 | 494 | 0.6603 | 0.4449 |
| 0.6061 | 3.0 | 741 | 0.5527 | 0.4233 |
| 0.4372 | 4.0 | 988 | 0.6262 | 0.4029 |
| 0.3226 | 5.0 | 1235 | 0.4528 | 0.3462 |
| 0.2581 | 6.0 | 1482 | 0.4961 | 0.3226 |
| 0.2147 | 7.0 | 1729 | 0.4856 | 0.3075 |
| 0.1736 | 8.0 | 1976 | 0.4372 | 0.3063 |
| 0.1488 | 9.0 | 2223 | 0.3771 | 0.2761 |
| 0.1286 | 10.0 | 2470 | 0.4373 | 0.2590 |
| 0.1118 | 11.0 | 2717 | 0.3840 | 0.2594 |
| 0.1037 | 12.0 | 2964 | 0.4241 | 0.2590 |
| 0.0888 | 13.0 | 3211 | 0.4150 | 0.2410 |
| 0.0923 | 14.0 | 3458 | 0.3811 | 0.2524 |
| 0.0813 | 15.0 | 3705 | 0.4164 | 0.2459 |
| 0.0671 | 16.0 | 3952 | 0.3498 | 0.2288 |
| 0.0669 | 17.0 | 4199 | 0.3697 | 0.2247 |
| 0.0586 | 18.0 | 4446 | 0.3550 | 0.2251 |
| 0.0533 | 19.0 | 4693 | 0.4024 | 0.2231 |
| 0.0542 | 20.0 | 4940 | 0.4130 | 0.2121 |
| 0.0532 | 21.0 | 5187 | 0.3464 | 0.2231 |
| 0.0451 | 22.0 | 5434 | 0.3346 | 0.1966 |
| 0.0413 | 23.0 | 5681 | 0.4599 | 0.2088 |
| 0.0401 | 24.0 | 5928 | 0.4031 | 0.2162 |
| 0.0345 | 25.0 | 6175 | 0.3726 | 0.2084 |
| 0.033 | 26.0 | 6422 | 0.4619 | 0.2076 |
| 0.0366 | 27.0 | 6669 | 0.4071 | 0.2202 |
| 0.0343 | 28.0 | 6916 | 0.4114 | 0.2088 |
| 0.0319 | 29.0 | 7163 | 0.3605 | 0.2015 |
| 0.0304 | 30.0 | 7410 | 0.4097 | 0.2015 |
| 0.0253 | 31.0 | 7657 | 0.4152 | 0.1970 |
| 0.0235 | 32.0 | 7904 | 0.3829 | 0.2043 |
| 0.0255 | 33.0 | 8151 | 0.3976 | 0.2011 |
| 0.0201 | 34.0 | 8398 | 0.4247 | 0.2088 |
| 0.022 | 35.0 | 8645 | 0.3831 | 0.1945 |
| 0.0175 | 36.0 | 8892 | 0.3838 | 0.2007 |
| 0.0201 | 37.0 | 9139 | 0.4377 | 0.1986 |
| 0.0176 | 38.0 | 9386 | 0.4546 | 0.2043 |
| 0.021 | 39.0 | 9633 | 0.4341 | 0.2039 |
| 0.0191 | 40.0 | 9880 | 0.4043 | 0.1937 |
| 0.0159 | 41.0 | 10127 | 0.4098 | 0.2064 |
| 0.0148 | 42.0 | 10374 | 0.4027 | 0.1905 |
| 0.0129 | 43.0 | 10621 | 0.4104 | 0.1933 |
| 0.0123 | 44.0 | 10868 | 0.3738 | 0.1925 |
| 0.0159 | 45.0 | 11115 | 0.3946 | 0.1933 |
| 0.0091 | 46.0 | 11362 | 0.3971 | 0.1880 |
| 0.0082 | 47.0 | 11609 | 0.4042 | 0.1986 |
| 0.0108 | 48.0 | 11856 | 0.4092 | 0.1884 |
| 0.0123 | 49.0 | 12103 | 0.3674 | 0.1941 |
| 0.01 | 50.0 | 12350 | 0.3750 | 0.1876 |
| 0.0094 | 51.0 | 12597 | 0.3781 | 0.1831 |
| 0.008 | 52.0 | 12844 | 0.4051 | 0.1852 |
| 0.0079 | 53.0 | 13091 | 0.3981 | 0.1937 |
| 0.0068 | 54.0 | 13338 | 0.4425 | 0.1929 |
| 0.0061 | 55.0 | 13585 | 0.4183 | 0.1986 |
| 0.0074 | 56.0 | 13832 | 0.3502 | 0.1880 |
| 0.0071 | 57.0 | 14079 | 0.3908 | 0.1892 |
| 0.0079 | 58.0 | 14326 | 0.3908 | 0.1913 |
| 0.0042 | 59.0 | 14573 | 0.3801 | 0.1864 |
| 0.0049 | 60.0 | 14820 | 0.4065 | 0.1839 |
| 0.0063 | 61.0 | 15067 | 0.4170 | 0.1900 |
| 0.0049 | 62.0 | 15314 | 0.3903 | 0.1856 |
| 0.0031 | 63.0 | 15561 | 0.4042 | 0.1896 |
| 0.0054 | 64.0 | 15808 | 0.3890 | 0.1839 |
| 0.0061 | 65.0 | 16055 | 0.3831 | 0.1847 |
| 0.0052 | 66.0 | 16302 | 0.3898 | 0.1847 |
| 0.0032 | 67.0 | 16549 | 0.4230 | 0.1831 |
| 0.0017 | 68.0 | 16796 | 0.4241 | 0.1823 |
| 0.0022 | 69.0 | 17043 | 0.4360 | 0.1856 |
| 0.0026 | 70.0 | 17290 | 0.4233 | 0.1815 |
| 0.0028 | 71.0 | 17537 | 0.4225 | 0.1835 |
| 0.0018 | 72.0 | 17784 | 0.4163 | 0.1856 |
| 0.0034 | 73.0 | 18031 | 0.4120 | 0.1876 |
| 0.0019 | 74.0 | 18278 | 0.4129 | 0.1876 |
| 0.0023 | 75.0 | 18525 | 0.4134 | 0.1884 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 1.18.3
- Tokenizers 0.12.1
|
NlpHUST/gpt2-vietnamese
|
NlpHUST
| 2022-06-02T04:02:44Z | 3,159 | 22 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"vi",
"vietnamese",
"lm",
"nlp",
"dataset:oscar",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-05-23T08:04:12Z |
---
language: vi
tags:
- vi
- vietnamese
- gpt2
- text-generation
- lm
- nlp
datasets:
- oscar
widget:
- text: "Việt Nam là quốc gia có"
---
# GPT-2
Pretrained gpt model on Vietnamese language using a causal language modeling (CLM) objective. It was introduced in
[this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
# How to use the model
~~~~
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('NlpHUST/gpt2-vietnamese')
model = GPT2LMHeadModel.from_pretrained('NlpHUST/gpt2-vietnamese')
text = "Việt Nam là quốc gia có"
input_ids = tokenizer.encode(text, return_tensors='pt')
max_length = 100
sample_outputs = model.generate(input_ids,pad_token_id=tokenizer.eos_token_id,
do_sample=True,
max_length=max_length,
min_length=max_length,
top_k=40,
num_beams=5,
early_stopping=True,
no_repeat_ngram_size=2,
num_return_sequences=3)
for i, sample_output in enumerate(sample_outputs):
print(">> Generated text {}\n\n{}".format(i+1, tokenizer.decode(sample_output.tolist())))
print('\n---')
~~~~
```bash
>> Generated text 1
Việt Nam là quốc gia có nền kinh tế hàng đầu thế giới về sản xuất, chế biến và tiêu thụ các sản phẩm nông sản, thủy sản. Tuy nhiên, trong những năm gần đây, nông nghiệp Việt Nam đang phải đối mặt với nhiều khó khăn, thách thức, đặc biệt là những tác động tiêu cực của biến đổi khí hậu.
Theo số liệu của Tổng cục Thống kê, tính đến cuối năm 2015, tổng diện tích gieo trồng, sản lượng lương thực, thực phẩm cả
---
>> Generated text 2
Việt Nam là quốc gia có nền kinh tế thị trường định hướng xã hội chủ nghĩa, có vai trò rất quan trọng đối với sự phát triển bền vững của đất nước. Do đó, trong quá trình đổi mới và hội nhập quốc tế, Việt Nam đã và đang phải đối mặt với không ít khó khăn, thách thức, đòi hỏi phải có những chủ trương, chính sách đúng đắn, kịp thời, phù hợp với tình hình thực tế. Để thực hiện thắng lợi mục tiêu, nhiệm vụ
---
>> Generated text 3
Việt Nam là quốc gia có nền kinh tế thị trường phát triển theo định hướng xã hội chủ nghĩa. Trong quá trình đổi mới và hội nhập quốc tế hiện nay, Việt Nam đang phải đối mặt với nhiều khó khăn, thách thức, đòi hỏi phải có những giải pháp đồng bộ, hiệu quả và phù hợp với tình hình thực tế của đất nước. Để thực hiện thắng lợi mục tiêu, nhiệm vụ mà Nghị quyết Đại hội XI của Đảng đề ra, Đảng và Nhà nước đã ban hành
---
```
# Model architecture
A 12-layer, 768-hidden-size transformer-based language model.
# Training
The model was trained on Vietnamese Oscar dataset (32 GB) to optimize a traditional language modelling objective on v3-8 TPU for around 6 days. It reaches around 13.4 perplexity on a chosen validation set from Oscar.
### GPT-2 Finetuning
The following example fine-tunes GPT-2 on WikiText-2. We're using the raw WikiText-2.
The script [here](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm.py) .
```bash
python run_clm.py \
--model_name_or_path NlpHUST/gpt2-vietnamese \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--do_train \
--do_eval \
--output_dir /tmp/test-clm
```
### Contact information
For personal communication related to this project, please contact Nha Nguyen Van ([email protected]).
|
kktoto/tiny_kt_punctuator
|
kktoto
| 2022-06-02T02:04:30Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-02T01:44:00Z |
---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: tiny_kt_punctuator
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny_kt_punctuator
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1424
- Precision: 0.6287
- Recall: 0.5781
- F1: 0.6023
- Accuracy: 0.9476
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1621 | 1.0 | 5561 | 0.1508 | 0.6138 | 0.5359 | 0.5722 | 0.9450 |
| 0.1519 | 2.0 | 11122 | 0.1439 | 0.6279 | 0.5665 | 0.5956 | 0.9471 |
| 0.1496 | 3.0 | 16683 | 0.1424 | 0.6287 | 0.5781 | 0.6023 | 0.9476 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
jiseong/mt5-small-finetuned-news-ab
|
jiseong
| 2022-06-02T00:10:15Z | 4 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-06-01T08:24:29Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: jiseong/mt5-small-finetuned-news-ab
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# jiseong/mt5-small-finetuned-news-ab
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.0174
- Validation Loss: 1.7411
- Epoch: 3
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 4.1124 | 2.0706 | 0 |
| 2.4090 | 1.8742 | 1 |
| 2.1379 | 1.7889 | 2 |
| 2.0174 | 1.7411 | 3 |
### Framework versions
- Transformers 4.19.2
- TensorFlow 2.8.2
- Datasets 2.2.2
- Tokenizers 0.12.1
|
VanessaSchenkel/unicamp-finetuned-en-to-pt-dataset-ted
|
VanessaSchenkel
| 2022-06-01T22:38:09Z | 6 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"translation",
"generated_from_trainer",
"dataset:ted_iwlst2013",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-06-01T17:57:16Z |
---
tags:
- translation
- generated_from_trainer
datasets:
- ted_iwlst2013
metrics:
- bleu
model-index:
- name: unicamp-finetuned-en-to-pt-dataset-ted
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: ted_iwlst2013
type: ted_iwlst2013
args: en-pt
metrics:
- name: Bleu
type: bleu
value: 25.65030250145235
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# unicamp-finetuned-en-to-pt-dataset-ted
This model is a fine-tuned version of [unicamp-dl/translation-pt-en-t5](https://huggingface.co/unicamp-dl/translation-pt-en-t5) on the ted_iwlst2013 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8861
- Bleu: 25.6503
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
robinhad/ukrainian-qa
|
robinhad
| 2022-06-01T22:08:47Z | 47 | 6 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"uk",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-06-01T19:28:07Z |
---
license: mit
language: uk
tags:
- generated_from_trainer
model-index:
- name: ukrainian-qa
results: []
widget:
- text: "Що відправлять для ЗСУ?"
context: "Про це повідомив міністр оборони Арвідас Анушаускас. Уряд Литви не має наміру зупинятися у військово-технічній допомозі Україні. Збройні сили отримають антидрони, тепловізори та ударний безпілотник. «Незабаром Литва передасть Україні не лише обіцяні бронетехніку, вантажівки та позашляховики, але також нову партію антидронів та тепловізорів. І, звичайно, Байрактар, який придбають на зібрані литовцями гроші», - написав глава Міноборони."
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ukrainian-qa
This model is a fine-tuned version of [ukr-models/xlm-roberta-base-uk](https://huggingface.co/ukr-models/xlm-roberta-base-uk) on the [UA-SQuAD](https://github.com/fido-ai/ua-datasets/tree/main/ua_datasets/src/question_answering) dataset.
Link to training scripts - [https://github.com/robinhad/ukrainian-qa](https://github.com/robinhad/ukrainian-qa)
It achieves the following results on the evaluation set:
- Loss: 1.4778
## Model description
More information needed
## How to use
```python
from transformers import pipeline, AutoTokenizer, AutoModelForQuestionAnswering
model_name = "robinhad/ukrainian-qa"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
qa_model = pipeline("question-answering", model=model.to("cpu"), tokenizer=tokenizer)
question = "Де ти живеш?"
context = "Мене звати Сара і я живу у Лондоні"
qa_model(question = question, context = context)
```
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.4526 | 1.0 | 650 | 1.3631 |
| 1.3317 | 2.0 | 1300 | 1.2229 |
| 1.0693 | 3.0 | 1950 | 1.2184 |
| 0.6851 | 4.0 | 2600 | 1.3171 |
| 0.5594 | 5.0 | 3250 | 1.3893 |
| 0.4954 | 6.0 | 3900 | 1.4778 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.2
- Tokenizers 0.12.1
|
huggingtweets/mls_buzz-mlstransfers-transfersmls
|
huggingtweets
| 2022-06-01T20:57:13Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-01T20:43:55Z |
---
language: en
thumbnail: http://www.huggingtweets.com/mls_buzz-mlstransfers-transfersmls/1654117028998/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1142613360854388738/C49XegQF_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/417716955076763648/_e97ys3b_400x400.jpeg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1229972304689614848/EqOwTdY8_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">MLS Buzz & MLS Transfers & Will Forbes</div>
<div style="text-align: center; font-size: 14px;">@mls_buzz-mlstransfers-transfersmls</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from MLS Buzz & MLS Transfers & Will Forbes.
| Data | MLS Buzz | MLS Transfers | Will Forbes |
| --- | --- | --- | --- |
| Tweets downloaded | 3250 | 3248 | 3247 |
| Retweets | 32 | 811 | 1136 |
| Short tweets | 167 | 475 | 359 |
| Tweets kept | 3051 | 1962 | 1752 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/29rusxig/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @mls_buzz-mlstransfers-transfersmls's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2qzhkike) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2qzhkike/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/mls_buzz-mlstransfers-transfersmls')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.