
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-12 18:27:22
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 518
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-12 18:26:55
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
mengmajun/qwen2.5-coder-1.5b-graph-v1 | mengmajun | 2025-05-24T10:34:15Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"region:us"
]
| null | 2025-05-24T10:34:08Z | ---
base_model: unsloth/qwen2.5-coder-1.5b-instruct-bnb-4bit
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2 |
haihp02/dc21102b-5b49-46b8-960f-20b22e87089d-phase2-adapter | haihp02 | 2025-05-24T10:32:20Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"dpo",
"arxiv:2305.18290",
"base_model:Qwen/Qwen2-1.5B-Instruct",
"base_model:finetune:Qwen/Qwen2-1.5B-Instruct",
"endpoints_compatible",
"region:us"
]
| null | 2025-05-24T10:31:58Z | ---
base_model: Qwen/Qwen2-1.5B-Instruct
library_name: transformers
model_name: dc21102b-5b49-46b8-960f-20b22e87089d-phase2-adapter
tags:
- generated_from_trainer
- trl
- sft
- dpo
licence: license
---
# Model Card for dc21102b-5b49-46b8-960f-20b22e87089d-phase2-adapter
This model is a fine-tuned version of [Qwen/Qwen2-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2-1.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="haihp02/dc21102b-5b49-46b8-960f-20b22e87089d-phase2-adapter", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/trunghainguyenhp02/sn56-dpo-train/runs/37g10ik6)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.51.3
- Pytorch: 2.7.0+cu126
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
LinaSad/mcqa_aquarat_friday | LinaSad | 2025-05-24T10:32:18Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2025-05-24T10:31:04Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
bockhealthbharath/Eira-0.2 | bockhealthbharath | 2025-05-24T10:30:39Z | 10 | 0 | null | [
"safetensors",
"blip",
"biology",
"medical",
"multimodal",
"question-answering",
"healthcare",
"image-text-to-text",
"en",
"base_model:Salesforce/blip-image-captioning-base",
"base_model:finetune:Salesforce/blip-image-captioning-base",
"license:mit",
"region:us"
]
| image-text-to-text | 2025-04-16T20:41:37Z | ---
pipeline_tag: image-text-to-text
license: mit
language:
- en
base_model:
- meta-llama/Llama-2-7b-hf
- Salesforce/blip-image-captioning-base
tags:
- biology
- medical
- multimodal
- question-answering
- healthcare
---
# Model Card for EIRA-0.2
**Bridging Text and Medical Imagery for Accurate Multimodal QA**
This model integrates a Llama‑2 text backbone with a BLIP vision backbone to perform context‑aware question answering over medical images and text.
## Model Details
### Model Description
EIRA‑0.2 is a multimodal model designed to answer free‑form questions about medical images (e.g., radiographs, histology slides) in conjunction with accompanying text. Internally, it uses:
- A **text encoder/decoder** based on **meta‑llama/Llama‑2‑7b‑hf**, fine‑tuned for medical QA.
- A **vision encoder** based on **Salesforce/blip-image-captioning-base**, that extract descriptive features from medical imagery.
- A **fusion module** that cross‑attends between vision features and text embeddings to generate coherent, context‑aware answers.
- **Developed by:** BockBharath
- **Shared by:** Shashidhar Sarvi and Sharvary H H
- **Model type:** Multimodal Sequence‑to‑Sequence QA
- **Language(s):** English
- **License:** MIT
- **Finetuned from:** meta‑llama/Llama‑2‑7b‑hf, Salesforce/blip-image-captioning-base
### Model Sources
- **Repository:** https://github.com/BockBharath/EIRA-0.2
- **Demo:** https://huggingface.co/BockBharath/EIRA-0.2
## Uses
### Direct Use
EIRA‑0.2 can be used out‑of‑the‑box as a Hugging Face `pipeline` for image‑text-to-text question answering. It is intended for:
- Clinical decision support by generating explanations of medical images.
- Educational tools for medical students reviewing imaging cases.
### Downstream Use
- Further fine‑tuning on specialty subdomains (e.g., dermatology, pathology) to improve domain performance.
- Integration into telemedicine platforms to assist remote diagnostics.
### Out-of-Scope Use
- Unsupervised generation of medical advice without expert oversight.
- Non‑medical domains (the model’s vision backbone is specialized on medical imaging).
## Bias, Risks, and Limitations
EIRA‑0.2 was trained on a curated set of medical textbooks and annotated imaging cases; it may underperform on rare pathologies or demographic groups under‑represented in the training data. Hallucination risk exists if the image context is ambiguous or incomplete.
### Recommendations
- Always validate model outputs with a qualified medical professional.
- Use in conjunction with structured reporting tools to mitigate hallucinations.
## How to Get Started with the Model
```python
from transformers import pipeline
# Load the multimodal QA pipeline
eira = pipeline(
task="image-text-to-text",
model="BockBharath/EIRA-0.2",
device=0 # set to -1 for CPU
)
# Example inputs
image_path = "chest_xray.png"
question = "What abnormality is visible in the left lung?"
# Run inference
answer = eira({
"image": image_path,
"text": question
})
print("Answer:", answer[0]["generated_text"])
```
**Input shapes:**
- `image`: file path or PIL.Image of variable size (automatically resized to 224×224).
- `text`: string question.
**Output:** List of dicts with key `"generated_text"` containing the answer string.
## Training Details
### Training Data
- **Sources:** 500+ medical imaging cases (X‑rays, CT, MRI) paired with expert Q&A, and 100 clinical chapters from open‑access medical textbooks.
- **Preprocessing:**
- Images resized to 224×224; normalized to ImageNet statistics.
- Text tokenized with Llama tokenizer, max length 512 tokens.
### Training Procedure
- Mixed‑precision (fp16) fine‑tuning.
- **Hardware:** Single NVIDIA T4 GPU on Kaggle.
- **Batch size:** 16 (per GPU)
- **Learning rate:** 3e‑5 with linear warmup over 500 steps.
- **Epochs:** 5
- **Total time:** ~48 hours
## Evaluation
### Testing Data, Factors & Metrics
- **Test set:** 100 unseen imaging cases with 3 expert‑provided QA pairs each.
- **Metrics:**
- **Exact Match (EM)** on key findings: 72.4%
- **BLEU‑4** for answer fluency: 0.38
- **ROUGE‑L** for content overlap: 0.46
### Results
| Metric | Score |
|--------------|--------|
| Exact Match | 72.4% |
| BLEU‑4 | 0.38 |
| ROUGE‑L | 0.46 |
#### Subgroup Analysis
Performance on chest X‑rays vs. histology slides:
- **Chest X‑ray EM:** 75.1%
- **Histology EM:** 68.0%
## Environmental Impact
- **Hardware Type:** NVIDIA T4 GPU
- **Training Hours:** ~48
- **Compute Region:** us‑central1
- **Estimated CO₂eq:** ~6 kg (using ML CO₂ impact calculator)
## Technical Specifications
### Model Architecture and Objective
- **Text backbone:** 7 B‑parameter Llama 2 encoder‑decoder.
- **Vision backbone:** BLIP ResNet‑50 + transformer head.
- **Fusion:** Cross‑attention layers interleaved with decoder blocks.
- **Objective:** Minimize cross‑entropy on ground‑truth answers.
### Compute Infrastructure
- **Hardware:** Single NVIDIA T4 GPU (16 GB VRAM)
- **Software:** PyTorch 2.0, Transformers 4.x, Accelerate
## Citation
If you use this model, please cite:
```bibtex
@misc{bockbharath2025eira02,
title={EIRA-0.2: Multimodal Medical QA with Llama-2 and BLIP},
author={BockBharath},
year={2025},
howpublished={\url{https://huggingface.co/BockBharath/EIRA-0.2}}
}
```
```text
BockBharath. (2025). EIRA-0.2: Multimodal Medical QA with Llama-2 and BLIP. Retrieved from https://huggingface.co/BockBharath/EIRA-0.2
```
## Model Card Authors
- BockBharath
- EIRA Project Team (Sharvary H H, Shashidhar Sarvi)
## Model Card Contact
For questions or feedback, please open an issue on the [GitHub repository](https://github.com/BockBharath/EIRA-0.2). |
hannesvgel/race-albert-v2 | hannesvgel | 2025-05-24T10:29:10Z | 8 | 0 | transformers | [
"transformers",
"safetensors",
"albert",
"multiple-choice",
"generated_from_trainer",
"dataset:ehovy/race",
"base_model:albert/albert-base-v2",
"base_model:finetune:albert/albert-base-v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| multiple-choice | 2025-05-22T08:52:11Z | ---
library_name: transformers
license: apache-2.0
base_model: albert-base-v2
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: results_albert
results: []
datasets:
- ehovy/race
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# race-albert-v2
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the [race dataset(middle)](https://huggingface.co/datasets/ehovy/race).
It achieves the following results on the test set:
- Loss: 0.8710
- Accuracy: 0.7089
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.8709 | 1.0 | 3178 | 0.8257 | 0.6769 |
| 0.6377 | 2.0 | 6356 | 0.8329 | 0.7152 |
| 0.3548 | 3.0 | 9534 | 1.0367 | 0.7124 |
| 0.1412 | 4.0 | 12712 | 1.5380 | 0.7145 |
### Framework versions
- Transformers 4.52.2
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1 |
FormlessAI/26f47549-4c34-4d8c-9772-e1a559c6b16a | FormlessAI | 2025-05-24T10:27:47Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"trl",
"dpo",
"conversational",
"arxiv:2305.18290",
"base_model:Qwen/Qwen2-1.5B-Instruct",
"base_model:finetune:Qwen/Qwen2-1.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2025-05-24T10:09:43Z | ---
base_model: Qwen/Qwen2-1.5B-Instruct
library_name: transformers
model_name: 26f47549-4c34-4d8c-9772-e1a559c6b16a
tags:
- generated_from_trainer
- trl
- dpo
licence: license
---
# Model Card for 26f47549-4c34-4d8c-9772-e1a559c6b16a
This model is a fine-tuned version of [Qwen/Qwen2-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2-1.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="FormlessAI/26f47549-4c34-4d8c-9772-e1a559c6b16a", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/phoenix-formless/Gradients/runs/usvz7td3)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.17.0
- Transformers: 4.52.3
- Pytorch: 2.7.0+cu128
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
BAAI/RoboBrain | BAAI | 2025-05-24T10:25:59Z | 1,388 | 17 | null | [
"safetensors",
"llava_onevision",
"en",
"dataset:BAAI/ShareRobot",
"dataset:lmms-lab/LLaVA-OneVision-Data",
"arxiv:2502.21257",
"license:apache-2.0",
"region:us"
]
| null | 2025-03-27T03:20:39Z | ---
license: apache-2.0
datasets:
- BAAI/ShareRobot
- lmms-lab/LLaVA-OneVision-Data
language:
- en
---
<div align="center">
<img src="https://github.com/FlagOpen/RoboBrain/raw/main/assets/logo.jpg" width="400"/>
</div>
# [CVPR 25] RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete.
<p align="center">
</a>  ⭐️ <a href="https://superrobobrain.github.io/">Project</a></a>   |   🤗 <a href="https://huggingface.co/BAAI/RoboBrain/">Hugging Face</a>   |   🤖 <a href="https://www.modelscope.cn/models/BAAI/RoboBrain/files/">ModelScope</a>   |   🌎 <a href="https://github.com/FlagOpen/ShareRobot">Dataset</a>   |   📑 <a href="http://arxiv.org/abs/2502.21257">Paper</a>   |   💬 <a href="./assets/wechat.png">WeChat</a>
</p>
<p align="center">
</a>  🎯 <a href="">RoboOS (Coming Soon)</a>: An Efficient Open-Source Multi-Robot Coordination System for RoboBrain.
</p>
<p align="center">
</a>  🎯 <a href="https://tanhuajie.github.io/ReasonRFT/">Reason-RFT</a>: Exploring a New RFT Paradigm to Enhance RoboBrain's Visual Reasoning Capabilities.
</p>
## 🔥 Overview
Recent advancements in Multimodal Large Language Models (MLLMs) have shown remarkable capabilities across various multimodal contexts. However, their application in robotic scenarios, particularly for long-horizon manipulation tasks, reveals significant limitations. These limitations arise from the current MLLMs lacking three essential robotic brain capabilities: **(1) Planning Capability**, which involves decomposing complex manipulation instructions into manageable sub-tasks; **(2) Affordance Perception**, the ability to recognize and interpret the affordances of interactive objects; and **(3) Trajectory Prediction**, the foresight to anticipate the complete manipulation trajectory necessary for successful execution. To enhance the robotic brain's core capabilities from abstract to concrete, we introduce ShareRobot, a high-quality heterogeneous dataset that labels multi-dimensional information such as task planning, object affordance, and end-effector trajectory. ShareRobot's diversity and accuracy have been meticulously refined by three human annotators. Building on this dataset, we developed RoboBrain, an MLLM-based model that combines robotic and general multi-modal data, utilizes a multi-stage training strategy, and incorporates long videos and high-resolution images to improve its robotic manipulation capabilities. Extensive experiments demonstrate that RoboBrain achieves state-of-the-art performance across various robotic tasks, highlighting its potential to advance robotic brain capabilities.
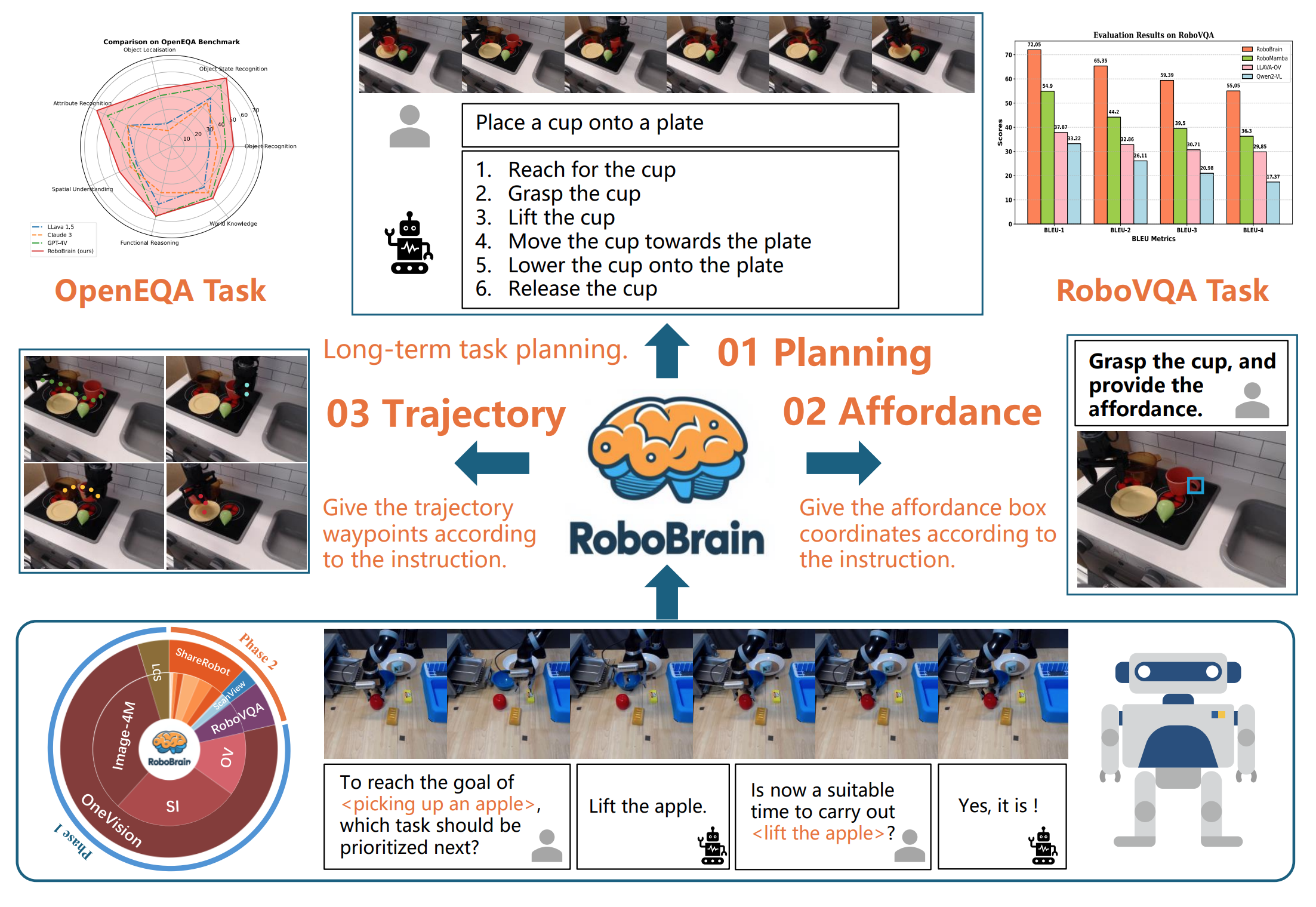
## 🚀 Features
This repository supports:
- **`Data Preparation`**: Please refer to [Dataset Preparation](https://github.com/FlagOpen/ShareRobot) for how to prepare the dataset.
- **`Training for RoboBrain`**: Please refer to [Training Section](#Training) for the usage of training scripts.
- **`Support HF/VLLM Inference`**: Please see [Inference Section](#Inference), now we support inference with [VLLM](https://github.com/vllm-project/vllm).
- **`Evaluation for RoboBrain`**: Please refer to [Evaluation Section](#Evaluation) for how to prepare the benchmarks.
- **`ShareRobot Generation`**: Please refer to [ShareRobot](https://github.com/FlagOpen/ShareRobot) for details.
## 🗞️ News
- **`2025-04-04`**: 🤗 We have released [Trajectory Checkpoint](https://huggingface.co/BAAI/RoboBrain-LoRA-Trajectory/) in Huggingface.
- **`2025-03-29`**: 🤗 We have released [Affordance Checkpoint](https://huggingface.co/BAAI/RoboBrain-LoRA-Affordance/) in Huggingface.
- **`2025-03-27`**: 🤗 We have released [Planning Checkpoint](https://huggingface.co/BAAI/RoboBrain/) in Huggingface.
- **`2025-03-26`**: 🔥 We have released the [RoboBrain](https://github.com/FlagOpen/RoboBrain/) repository.
- **`2025-02-27`**: 🌍 Our [RoboBrain](http://arxiv.org/abs/2502.21257/) was accepted to CVPR2025.
## 📆 Todo
- [x] Release scripts for model training and inference.
- [x] Release Planning checkpoint.
- [x] Release Affordance checkpoint.
- [x] Release ShareRobot dataset.
- [x] Release Trajectory checkpoint.
- [ ] Release evaluation scripts for Benchmarks.
- [ ] Training more powerful **Robobrain-v2**.
## 🤗 Models
- **[`Base Planning Model`](https://huggingface.co/BAAI/RoboBrain/)**: The model was trained on general datasets in Stages 1–2 and on the Robotic Planning dataset in Stage 3, which is designed for Planning prediction.
- **[`A-LoRA for Affordance`](https://huggingface.co/BAAI/RoboBrain-LoRA-Affordance/)**: Based on the Base Planning Model, Stage 4 involves LoRA-based training with our Affordance dataset to predict affordance.
- **[`T-LoRA for Trajectory`](https://huggingface.co/BAAI/RoboBrain-LoRA-Trajectory/)**: Based on the Base Planning Model, Stage 4 involves LoRA-based training with our Trajectory dataset to predict trajectory.
| Models | Checkpoint | Description |
|----------------------|----------------------------------------------------------------|------------------------------------------------------------|
| Planning Model | [🤗 Planning CKPTs](https://huggingface.co/BAAI/RoboBrain/) | Used for Planning prediction in our paper |
| Affordance (A-LoRA) | [🤗 Affordance CKPTs](https://huggingface.co/BAAI/RoboBrain-LoRA-Affordance/) | Used for Affordance prediction in our paper |
| Trajectory (T-LoRA) | [🤗 Trajectory CKPTs](https://huggingface.co/BAAI/RoboBrain-LoRA-Trajectory/) | Used for Trajectory prediction in our paper |
## 🛠️ Setup
```bash
# clone repo.
git clone https://github.com/FlagOpen/RoboBrain.git
cd RoboBrain
# build conda env.
conda create -n robobrain python=3.10
conda activate robobrain
pip install -r requirements.txt
```
## <a id="Training"> 🤖 Training</a>
### 1. Data Preparation
```bash
# Modify datasets for Stage 1, please refer to:
- yaml_path: scripts/train/yaml/stage_1_0.yaml
# Modify datasets for Stage 1.5, please refer to:
- yaml_path: scripts/train/yaml/stage_1_5.yaml
# Modify datasets for Stage 2_si, please refer to:
- yaml_path: scripts/train/yaml/stage_2_si.yaml
# Modify datasets for Stage 2_ov, please refer to:
- yaml_path: scripts/train/yaml/stage_2_ov.yaml
# Modify datasets for Stage 3_plan, please refer to:
- yaml_path: scripts/train/yaml/stage_3_planning.yaml
# Modify datasets for Stage 4_aff, please refer to:
- yaml_path: scripts/train/yaml/stage_4_affordance.yaml
# Modify datasets for Stage 4_traj, please refer to:
- yaml_path: scripts/train/yaml/stage_4_trajectory.yaml
```
**Note:** The sample format in each json file should be like:
```json
{
"id": "xxxx",
"image": [
"image1.png",
"image2.png",
],
"conversations": [
{
"from": "human",
"value": "<image>\n<image>\nAre there numerous dials near the bottom left of the tv?"
},
{
"from": "gpt",
"value": "Yes. The sun casts shadows ... a serene, clear sky."
}
]
},
```
### 2. Training
```bash
# Training on Stage 1:
bash scripts/train/stage_1_0_pretrain.sh
# Training on Stage 1.5:
bash scripts/train/stage_1_5_direct_finetune.sh
# Training on Stage 2_si:
bash scripts/train/stage_2_0_resume_finetune_si.sh
# Training on Stage 2_ov:
bash scripts/train/stage_2_0_resume_finetune_ov.sh
# Training on Stage 3_plan:
bash scripts/train/stage_3_0_resume_finetune_robo.sh
# Training on Stage 4_aff:
bash scripts/train/stage_4_0_resume_finetune_lora_a.sh
# Training on Stage 4_traj:
bash scripts/train/stage_4_0_resume_finetune_lora_t.sh
```
**Note:** Please change the environment variables (e.g. *DATA_PATH*, *IMAGE_FOLDER*, *PREV_STAGE_CHECKPOINT*) in the script to your own.
### 3. Convert original weights to HF weights
```bash
# Planning Model
python model/llava_utils/convert_robobrain_to_hf.py --model_dir /path/to/original/checkpoint/ --dump_path /path/to/output/
# A-LoRA & T-RoRA
python model/llava_utils/convert_lora_weights_to_hf.py --model_dir /path/to/original/checkpoint/ --dump_path /path/to/output/
```
## <a id="Inference">⭐️ Inference</a>
### 1. Usage for Planning Prediction
#### Option 1: HF inference
```python
from inference import SimpleInference
model_id = "BAAI/RoboBrain"
model = SimpleInference(model_id)
prompt = "Given the obiects in the image, if you are required to complete the task \"Put the apple in the basket\", what is your detailed plan? Write your plan and explain it in detail, using the following format: Step_1: xxx\nStep_2: xxx\n ...\nStep_n: xxx\n"
image = "./assets/demo/planning.png"
pred = model.inference(prompt, image, do_sample=True)
print(f"Prediction: {pred}")
'''
Prediction: (as an example)
Step_1: Move to the apple. Move towards the apple on the table.
Step_2: Pick up the apple. Grab the apple and lift it off the table.
Step_3: Move towards the basket. Move the apple towards the basket without dropping it.
Step_4: Put the apple in the basket. Place the apple inside the basket, ensuring it is in a stable position.
'''
```
#### Option 2: VLLM inference
Install and launch VLLM
```bash
# Install vllm package
pip install vllm==0.6.6.post1
# Launch Robobrain with vllm
python -m vllm.entrypoints.openai.api_server --model BAAI/RoboBrain --served-model-name robobrain --max_model_len 16384 --limit_mm_per_prompt image=8
```
Run python script as example:
```python
from openai import OpenAI
import base64
openai_api_key = "robobrain-123123"
openai_api_base = "http://127.0.0.1:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
prompt = "Given the obiects in the image, if you are required to complete the task \"Put the apple in the basket\", what is your detailed plan? Write your plan and explain it in detail, using the following format: Step_1: xxx\nStep_2: xxx\n ...\nStep_n: xxx\n"
image = "./assets/demo/planning.png"
with open(image, "rb") as f:
encoded_image = base64.b64encode(f.read())
encoded_image = encoded_image.decode("utf-8")
base64_img = f"data:image;base64,{encoded_image}"
response = client.chat.completions.create(
model="robobrain",
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": base64_img}},
{"type": "text", "text": prompt},
],
},
]
)
content = response.choices[0].message.content
print(content)
'''
Prediction: (as an example)
Step_1: Move to the apple. Move towards the apple on the table.
Step_2: Pick up the apple. Grab the apple and lift it off the table.
Step_3: Move towards the basket. Move the apple towards the basket without dropping it.
Step_4: Put the apple in the basket. Place the apple inside the basket, ensuring it is in a stable position.
'''
```
### 2. Usage for Affordance Prediction
```python
from inference import SimpleInference
model_id = "BAAI/RoboBrain"
lora_id = "BAAI/RoboBrain-LoRA-Affordance"
model = SimpleInference(model_id, lora_id)
# Example 1:
prompt = "You are a robot using the joint control. The task is \"pick_up the suitcase\". Please predict a possible affordance area of the end effector?"
image = "./assets/demo/affordance_1.jpg"
pred = model.inference(prompt, image, do_sample=False)
print(f"Prediction: {pred}")
'''
Prediction: [0.733, 0.158, 0.845, 0.263]
'''
# Example 2:
prompt = "You are a robot using the joint control. The task is \"push the bicycle\". Please predict a possible affordance area of the end effector?"
image = "./assets/demo/affordance_2.jpg"
pred = model.inference(prompt, image, do_sample=False)
print(f"Prediction: {pred}")
'''
Prediction: [0.600, 0.127, 0.692, 0.227]
'''
```

### 3. Usage for Trajectory Prediction
```python
# please refer to https://github.com/FlagOpen/RoboBrain
from inference import SimpleInference
model_id = "BAAI/RoboBrain"
lora_id = "BAAI/RoboBrain-LoRA-Affordance"
model = SimpleInference(model_id, lora_id)
# Example 1:
prompt = "You are a robot using the joint control. The task is \"reach for the cloth\". Please predict up to 10 key trajectory points to complete the task. Your answer should be formatted as a list of tuples, i.e. [[x1, y1], [x2, y2], ...], where each tuple contains the x and y coordinates of a point."
image = "./assets/demo/trajectory_1.jpg"
pred = model.inference(prompt, image, do_sample=False)
print(f"Prediction: {pred}")
'''
Prediction: [[0.781, 0.305], [0.688, 0.344], [0.570, 0.344], [0.492, 0.312]]
'''
# Example 2:
prompt = "You are a robot using the joint control. The task is \"reach for the grapes\". Please predict up to 10 key trajectory points to complete the task. Your answer should be formatted as a list of tuples, i.e. [[x1, y1], [x2, y2], ...], where each tuple contains the x and y coordinates of a point."
image = "./assets/demo/trajectory_2.jpg"
pred = model.inference(prompt, image, do_sample=False)
print(f"Prediction: {pred}")
'''
Prediction: [[0.898, 0.352], [0.766, 0.344], [0.625, 0.273], [0.500, 0.195]]
'''
```
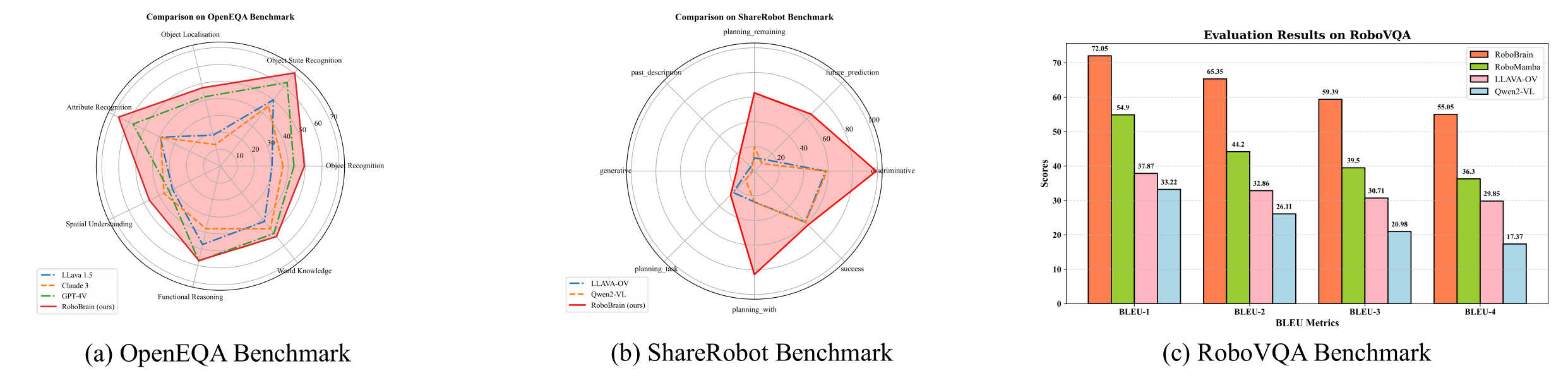
## <a id="Evaluation">🤖 Evaluation</a>
*Coming Soon ...*
<!-- <div align="center">
<img src="https://github.com/FlagOpen/RoboBrain/blob/main/assets/result.png" />
</div> -->
## 😊 Acknowledgement
We would like to express our sincere gratitude to the developers and contributors of the following projects:
1. [LLaVA-NeXT](https://github.com/LLaVA-VL/LLaVA-NeXT): The comprehensive codebase for training Vision-Language Models (VLMs).
2. [lmms-eval](https://github.com/EvolvingLMMs-Lab/lmms-eval): A powerful evaluation tool for Vision-Language Models (VLMs).
3. [vllm](https://github.com/vllm-project/vllm): A high-throughput and memory-efficient LLMs/VLMs inference engine.
4. [OpenEQA](https://github.com/facebookresearch/open-eqa): A wonderful benchmark for Embodied Question Answering.
5. [RoboVQA](https://github.com/google-deepmind/robovqa): Provide high-level reasoning models and datasets for robotics applications.
Their outstanding contributions have played a pivotal role in advancing our research and development initiatives.
## 📑 Citation
If you find this project useful, welcome to cite us.
```bib
@article{ji2025robobrain,
title={RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete},
author={Ji, Yuheng and Tan, Huajie and Shi, Jiayu and Hao, Xiaoshuai and Zhang, Yuan and Zhang, Hengyuan and Wang, Pengwei and Zhao, Mengdi and Mu, Yao and An, Pengju and others},
journal={arXiv preprint arXiv:2502.21257},
year={2025}
}
```
|
mlfoundations-dev/e1_code_fasttext_r1_10k | mlfoundations-dev | 2025-05-24T10:20:08Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2025-05-21T21:00:30Z | ---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen2.5-7B-Instruct
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: e1_code_fasttext_r1_10k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# e1_code_fasttext_r1_10k
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) on the mlfoundations-dev/e1_code_fasttext_r1_10k dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 16
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- total_eval_batch_size: 128
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.46.1
- Pytorch 2.5.1
- Datasets 3.1.0
- Tokenizers 0.20.3
|
bigbabyface/rubert_tuned_h1_short_full_train_custom_head | bigbabyface | 2025-05-24T10:18:55Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2025-05-24T06:44:13Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
WenFengg/alibaba_8 | WenFengg | 2025-05-24T10:17:49Z | 0 | 0 | null | [
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
]
| any-to-any | 2025-05-24T10:03:05Z | ---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
vertings6/ec67c006-5eff-40c6-ba32-bad90da3f12b | vertings6 | 2025-05-24T10:17:14Z | 0 | 0 | peft | [
"peft",
"safetensors",
"mistral",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/Phi-3-medium-4k-instruct",
"base_model:adapter:unsloth/Phi-3-medium-4k-instruct",
"license:mit",
"4-bit",
"bitsandbytes",
"region:us"
]
| null | 2025-05-24T09:32:26Z | ---
library_name: peft
license: mit
base_model: unsloth/Phi-3-medium-4k-instruct
tags:
- axolotl
- generated_from_trainer
model-index:
- name: ec67c006-5eff-40c6-ba32-bad90da3f12b
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: unsloth/Phi-3-medium-4k-instruct
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- aa208f6e880a6925_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/
type:
field_instruction: instruct
field_output: output
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
dpo:
beta: 0.1
enabled: true
group_by_length: false
rank_loss: true
reference_model: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 2
gradient_checkpointing: true
gradient_clipping: 1.0
group_by_length: false
hub_model_id: vertings6/ec67c006-5eff-40c6-ba32-bad90da3f12b
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 2.0e-06
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.1
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 500
micro_batch_size: 6
mixed_precision: bf16
mlflow_experiment_name: /tmp/aa208f6e880a6925_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 2
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 535b6010-08d2-401c-aed4-b8c0c7c5416c
wandb_project: s56-7
wandb_run: your_name
wandb_runid: 535b6010-08d2-401c-aed4-b8c0c7c5416c
warmup_steps: 50
weight_decay: 0.02
xformers_attention: true
```
</details><br>
# ec67c006-5eff-40c6-ba32-bad90da3f12b
This model is a fine-tuned version of [unsloth/Phi-3-medium-4k-instruct](https://huggingface.co/unsloth/Phi-3-medium-4k-instruct) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6341
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 6
- eval_batch_size: 6
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 12
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 50
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 11.3172 | 0.0003 | 1 | 5.8685 |
| 7.2769 | 0.0712 | 250 | 3.8644 |
| 7.5412 | 0.1423 | 500 | 3.6341 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
cytoe/dickbot-0.6B-ft | cytoe | 2025-05-24T10:12:33Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2025-05-24T10:11:35Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
habib-ashraf/resume-job-classifier | habib-ashraf | 2025-05-24T10:10:43Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
]
| null | 2025-05-24T10:07:24Z | ---
license: apache-2.0
---
|
Hahasb/moondream2-20250414-GGUF | Hahasb | 2025-05-24T10:10:13Z | 0 | 0 | null | [
"gguf",
"license:apache-2.0",
"region:us"
]
| null | 2025-05-24T09:47:38Z | ---
license: apache-2.0
---
This repo contains the llama.cpp compatible GGUFs of vikhyatk/moondream2: https://huggingface.co/vikhyatk/moondream2. The GGUFs hosted in the original repo is missing the tokenizer.chat_template field, which breaks llama.cpp The text model for this GGUF sets it to vicuna. |
infogep/2b849df7-293e-496f-8a42-ded51330bc70 | infogep | 2025-05-24T10:09:34Z | 0 | 0 | peft | [
"peft",
"safetensors",
"mistral",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/Phi-3-medium-4k-instruct",
"base_model:adapter:unsloth/Phi-3-medium-4k-instruct",
"license:mit",
"4-bit",
"bitsandbytes",
"region:us"
]
| null | 2025-05-24T09:31:42Z | ---
library_name: peft
license: mit
base_model: unsloth/Phi-3-medium-4k-instruct
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 2b849df7-293e-496f-8a42-ded51330bc70
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: unsloth/Phi-3-medium-4k-instruct
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- aa208f6e880a6925_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/
type:
field_instruction: instruct
field_output: output
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
dpo:
beta: 0.1
enabled: true
group_by_length: false
rank_loss: true
reference_model: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_clipping: 1.0
group_by_length: false
hub_model_id: infogep/2b849df7-293e-496f-8a42-ded51330bc70
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 2.0e-06
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.1
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 500
micro_batch_size: 10
mixed_precision: bf16
mlflow_experiment_name: /tmp/aa208f6e880a6925_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 2
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 535b6010-08d2-401c-aed4-b8c0c7c5416c
wandb_project: s56-7
wandb_run: your_name
wandb_runid: 535b6010-08d2-401c-aed4-b8c0c7c5416c
warmup_steps: 50
weight_decay: 0.02
xformers_attention: true
```
</details><br>
# 2b849df7-293e-496f-8a42-ded51330bc70
This model is a fine-tuned version of [unsloth/Phi-3-medium-4k-instruct](https://huggingface.co/unsloth/Phi-3-medium-4k-instruct) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6443
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 50
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 5.8087 | 0.0002 | 1 | 5.8311 |
| 4.1837 | 0.0593 | 250 | 3.8775 |
| 3.4705 | 0.1186 | 500 | 3.6443 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
klusertim/MNLP_M2_quantized_model-base-4bit | klusertim | 2025-05-24T09:59:00Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
]
| text-generation | 2025-05-24T09:58:40Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
18-VIDEOS-Riley-Reid-Viral-Link/wATCH.Riley.Reid.viral.video.original.Link.Official | 18-VIDEOS-Riley-Reid-Viral-Link | 2025-05-24T09:57:14Z | 0 | 0 | null | [
"region:us"
]
| null | 2025-05-24T09:56:58Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
MinaMila/llama_instbase_3b_LoRa_Adult_cfda_ep7_22 | MinaMila | 2025-05-24T09:56:51Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2025-05-24T09:56:44Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
vermoney/a4d660b5-796d-4949-bd80-836435b3af1e | vermoney | 2025-05-24T09:56:49Z | 0 | 0 | peft | [
"peft",
"safetensors",
"mistral",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/Phi-3-medium-4k-instruct",
"base_model:adapter:unsloth/Phi-3-medium-4k-instruct",
"license:mit",
"4-bit",
"bitsandbytes",
"region:us"
]
| null | 2025-05-24T09:39:53Z | ---
library_name: peft
license: mit
base_model: unsloth/Phi-3-medium-4k-instruct
tags:
- axolotl
- generated_from_trainer
model-index:
- name: a4d660b5-796d-4949-bd80-836435b3af1e
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: unsloth/Phi-3-medium-4k-instruct
bf16: true
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- aa208f6e880a6925_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/
type:
field_instruction: instruct
field_output: output
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
dpo:
beta: 0.1
enabled: true
group_by_length: false
rank_loss: true
reference_model: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: false
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 2
gradient_checkpointing: true
gradient_clipping: 1.0
group_by_length: false
hub_model_id: vermoney/a4d660b5-796d-4949-bd80-836435b3af1e
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 2.0e-06
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 96
lora_dropout: 0.1
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 48
lora_target_linear: true
lr_scheduler: cosine
max_steps: 280
micro_batch_size: 6
mixed_precision: bf16
mlflow_experiment_name: /tmp/aa208f6e880a6925_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 535b6010-08d2-401c-aed4-b8c0c7c5416c
wandb_project: s56-9
wandb_run: your_name
wandb_runid: 535b6010-08d2-401c-aed4-b8c0c7c5416c
warmup_steps: 40
weight_decay: 0.02
xformers_attention: true
```
</details><br>
# a4d660b5-796d-4949-bd80-836435b3af1e
This model is a fine-tuned version of [unsloth/Phi-3-medium-4k-instruct](https://huggingface.co/unsloth/Phi-3-medium-4k-instruct) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.0749
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 6
- eval_batch_size: 6
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 12
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 40
- training_steps: 280
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 7.0541 | 0.0797 | 280 | 4.0749 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
dimasik87/95aae631-e0b6-4309-8a1f-3ff7bd133af4 | dimasik87 | 2025-05-24T09:54:49Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"axolotl",
"dpo",
"trl",
"conversational",
"arxiv:2305.18290",
"base_model:unsloth/Qwen2.5-Coder-1.5B-Instruct",
"base_model:quantized:unsloth/Qwen2.5-Coder-1.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
]
| text-generation | 2025-05-24T09:48:10Z | ---
base_model: unsloth/Qwen2.5-Coder-1.5B-Instruct
library_name: transformers
model_name: 95aae631-e0b6-4309-8a1f-3ff7bd133af4
tags:
- generated_from_trainer
- axolotl
- dpo
- trl
licence: license
---
# Model Card for 95aae631-e0b6-4309-8a1f-3ff7bd133af4
This model is a fine-tuned version of [unsloth/Qwen2.5-Coder-1.5B-Instruct](https://huggingface.co/unsloth/Qwen2.5-Coder-1.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="dimasik87/95aae631-e0b6-4309-8a1f-3ff7bd133af4", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/dedok-yo/s56-7/runs/icnqat5u)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.12.0.dev0
- Transformers: 4.46.0
- Pytorch: 2.5.0+cu124
- Datasets: 3.0.1
- Tokenizers: 0.20.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
Papaflessas/plutus-financial-sentiment | Papaflessas | 2025-05-24T09:54:05Z | 0 | 1 | null | [
"safetensors",
"roberta",
"en",
"base_model:ProsusAI/finbert",
"base_model:finetune:ProsusAI/finbert",
"license:mit",
"region:us"
]
| null | 2025-05-20T06:25:51Z | ---
license: mit
language:
- en
metrics:
- accuracy
base_model:
- ProsusAI/finbert
--- |
VIDEO-18-Katrina-Lim-Kiffy-Viral-Video/FULL.VIDEO.LINK.Katrina.Lim.Viral.Video.Leaks.Official | VIDEO-18-Katrina-Lim-Kiffy-Viral-Video | 2025-05-24T09:51:34Z | 0 | 0 | null | [
"region:us"
]
| null | 2025-05-24T09:50:55Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/fn84hrnu?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
deswaq/alfa2 | deswaq | 2025-05-24T09:50:23Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2025-05-24T09:42:41Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf | RichardErkhov | 2025-05-24T09:50:18Z | 0 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2025-05-24T07:18:10Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1 - GGUF
- Model creator: https://huggingface.co/barc0/
- Original model: https://huggingface.co/barc0/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q2_K.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q2_K.gguf) | Q2_K | 2.96GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.IQ3_S.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.IQ3_M.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q3_K.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q3_K.gguf) | Q3_K | 3.74GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q4_0.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q4_0.gguf) | Q4_0 | 4.34GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q4_K.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q4_K.gguf) | Q4_K | 4.58GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q4_1.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q4_1.gguf) | Q4_1 | 4.78GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q5_0.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q5_0.gguf) | Q5_0 | 5.21GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q5_K.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q5_K.gguf) | Q5_K | 5.34GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q5_1.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q5_1.gguf) | Q5_1 | 5.65GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q6_K.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q6_K.gguf) | Q6_K | 6.14GB |
| [google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q8_0.gguf](https://huggingface.co/RichardErkhov/barc0_-_google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1-gguf/blob/main/google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
library_name: transformers
license: llama3.1
base_model: meta-llama/Meta-Llama-3.1-8B-Instruct
tags:
- alignment-handbook
- trl
- sft
- generated_from_trainer
- trl
- sft
- generated_from_trainer
datasets:
- barc0/transduction_20k_gpt4o-mini_generated_problems_seed100.jsonl_messages_format_0.3
model-index:
- name: google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# google_cloude_test_20k_transduction-gpt4omini_lr1e-5_epoch2_1
This model is a fine-tuned version of [meta-llama/Meta-Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct) on the barc0/transduction_20k_gpt4o-mini_generated_problems_seed100.jsonl_messages_format_0.3 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0620
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.0951 | 0.9966 | 145 | 0.0754 |
| 0.0665 | 1.9931 | 290 | 0.0620 |
### Framework versions
- Transformers 4.45.0.dev0
- Pytorch 2.4.0+cu121
- Datasets 3.0.0
- Tokenizers 0.19.1
|
New-tutorial-Riley-Reid-Viral-Video/Full.Clip.Riley.Reid.Viral.Video.Leaks.Official | New-tutorial-Riley-Reid-Viral-Video | 2025-05-24T09:49:47Z | 0 | 0 | null | [
"region:us"
]
| null | 2025-05-24T09:49:01Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
Austin207/Transformer-MiniGPT | Austin207 | 2025-05-24T09:49:14Z | 0 | 0 | null | [
"gpt",
"transformer",
"text-generation",
"miniGPT",
"en",
"license:mit",
"region:us"
]
| text-generation | 2025-05-24T07:29:22Z | ---
language: en
license: mit
tags:
- gpt
- transformer
- text-generation
- miniGPT
model-index:
- name: MiniGPT
results: []
---
# MiniGPT — Lightweight Transformer for Text Generation
**MiniGPT** is a minimal yet powerful GPT-style language model built from scratch using PyTorch. It is designed for educational clarity, customization, and efficient real-time text generation. This project demonstrates the full training and inference pipeline of a decoder-only transformer architecture, including streaming capabilities and modern sampling strategies.
> Hosted with ❤️ by [@Austin207](https://huggingface.co/Austin207)
---
## Model Description
MiniGPT is a small, word-level transformer model with the following architecture:
* 4 Transformer layers
* 4 Attention heads
* 128 Embedding dimensions
* 512 FFN hidden size
* Max sequence length: 128
* Word-level tokenizer (trained with Hugging Face `tokenizers`)
Despite its size, it supports advanced generation strategies including:
* Repetition Penalty
* Temperature Sampling
* Top-K & Top-P (nucleus) sampling
* Real-time streaming output
---
## Usage
Install dependencies:
```bash
pip install torch tokenizers
```
Load the model and tokenizer:
```python
from miniGPT import MiniGPT
from inference import generate_stream
from tokenizers import Tokenizer
import torch
# Load tokenizer
tokenizer = Tokenizer.from_file("wordlevel.json")
# Load model
model = MiniGPT(
vocab_size=tokenizer.get_vocab_size(),
embed_dim=128,
num_heads=4,
ff_dim=512,
num_layers=4,
max_seq_len=128
)
checkpoint = torch.load("model_checkpoint_step20000.pt")
model.load_state_dict(checkpoint["model_state_dict"])
model.eval()
# Generate text
prompt = "Beneath the ancient ruins"
generate_stream(model, tokenizer, prompt, max_new_tokens=60, temperature=1.0, top_k=50, top_p=0.9)
```
---
## Training
Train from scratch on any plain-text dataset:
```bash
python training.py
```
Training includes:
* Checkpointing
* Sample generation previews
* Word-level tokenization with `tokenizers`
* Custom datasets via `alphabetical_dataset.txt` or your own
---
## Files in This Repository
| File | Purpose |
| -------------------------- | ---------------------------- |
| `miniGPT.py` | Core Transformer model |
| `transformer.py` | Transformer block logic |
| `multiheadattention.py` | Multi-head attention module |
| `Tokenizer.py` | Tokenizer loader |
| `training.py` | Training loop |
| `inference.py` | CLI and streaming generation |
| `dataprocess.py` | Text preprocessing tools |
| `wordlevel.json` | Trained word-level tokenizer |
| `alphabetical_dataset.txt` | Sample dataset |
| `requirements.txt` | Required dependencies |
---
## Model Card
| Property | Value |
| ------------ | --------------------------------- |
| Model Type | Decoder-only GPT |
| Size | Small (\~4.6M params) |
| Trained On | Word-level dataset (custom) |
| Intended Use | Text generation, educational demo |
| License | MIT |
---
## Intended Use and Limitations
This model is meant for educational, experimental, and research purposes. It is not suitable for commercial or production use out-of-the-box. Expect limitations in coherence, factuality, and long-context reasoning.
---
## Contributions
We welcome improvements, bug fixes, and new features!
```bash
# Fork, clone, and create a branch
git clone https://github.com/austin207/Transformer-Virtue-v2.git
cd Transformer-Virtue-v2
git checkout -b feature/your-feature
```
Then open a pull request!
---
## License
This project is licensed under the [MIT License](https://github.com/austin207/Transformer-Virtue-v2/blob/main/LICENSE).
---
## Explore More
* Based on GPT architecture from OpenAI
* Inspired by [karpathy/nanoGPT](https://github.com/karpathy/nanoGPT)
* Compatible with Hugging Face tools and tokenizer ecosystem
|
vandat2601/ppoPyramed | vandat2601 | 2025-05-24T09:46:56Z | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
]
| reinforcement-learning | 2025-05-24T09:46:47Z | ---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: vandat2601/ppoPyramed
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
avaiIabIe/tgsdsmmi242 | avaiIabIe | 2025-05-24T09:45:00Z | 0 | 0 | null | [
"license:bsd-2-clause",
"region:us"
]
| null | 2025-05-24T09:45:00Z | ---
license: bsd-2-clause
---
|
deswaq/alfa0 | deswaq | 2025-05-24T09:44:48Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2025-05-24T09:41:07Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
FAISAL7236/Anarob-Core | FAISAL7236 | 2025-05-24T09:43:44Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
]
| null | 2025-05-24T09:43:44Z | ---
license: apache-2.0
---
|
dimasik87/aa3fc1bb-eca8-4797-96ed-c347de17b08f | dimasik87 | 2025-05-24T09:43:04Z | 0 | 0 | peft | [
"peft",
"safetensors",
"opt",
"axolotl",
"generated_from_trainer",
"base_model:facebook/opt-125m",
"base_model:adapter:facebook/opt-125m",
"license:other",
"4-bit",
"bitsandbytes",
"region:us"
]
| null | 2025-05-24T09:41:13Z | ---
library_name: peft
license: other
base_model: facebook/opt-125m
tags:
- axolotl
- generated_from_trainer
model-index:
- name: aa3fc1bb-eca8-4797-96ed-c347de17b08f
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: facebook/opt-125m
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- a37b814eade94297_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/
type:
field_instruction: instruct
field_output: output
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
dpo:
beta: 0.1
enabled: true
group_by_length: false
rank_loss: true
reference_model: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 2
gradient_checkpointing: true
gradient_clipping: 1.0
group_by_length: false
hub_model_id: dimasik87/aa3fc1bb-eca8-4797-96ed-c347de17b08f
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 1.5e-06
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.1
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 250
micro_batch_size: 6
mixed_precision: bf16
mlflow_experiment_name: /tmp/a37b814eade94297_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: ee4eb606-53c8-44b0-bd60-8cc0f514aae9
wandb_project: s56-7
wandb_run: your_name
wandb_runid: ee4eb606-53c8-44b0-bd60-8cc0f514aae9
warmup_steps: 50
weight_decay: 0.02
xformers_attention: true
```
</details><br>
# aa3fc1bb-eca8-4797-96ed-c347de17b08f
This model is a fine-tuned version of [facebook/opt-125m](https://huggingface.co/facebook/opt-125m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.1657
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-06
- train_batch_size: 6
- eval_batch_size: 6
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 12
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 50
- training_steps: 250
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 6.2219 | 0.0634 | 250 | 3.1657 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
oxmtt/Slebew | oxmtt | 2025-05-24T09:39:01Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
]
| null | 2025-05-24T09:39:01Z | ---
license: apache-2.0
---
|
SongJuNN/xlm-r-langdetect-model | SongJuNN | 2025-05-24T09:38:00Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-multilingual-cased",
"base_model:finetune:google-bert/bert-base-multilingual-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2025-05-24T09:37:16Z | ---
library_name: transformers
license: apache-2.0
base_model: bert-base-multilingual-cased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: xlm-r-langdetect-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-r-langdetect-model
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2107
- Accuracy: 0.9617
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 128
- eval_batch_size: 256
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.1059 | 1.0 | 1275 | 0.1641 | 0.9526 |
| 0.0838 | 2.0 | 2550 | 0.1660 | 0.9548 |
| 0.068 | 3.0 | 3825 | 0.1741 | 0.9552 |
| 0.0561 | 4.0 | 5100 | 0.1828 | 0.9556 |
| 0.0474 | 5.0 | 6375 | 0.1918 | 0.9549 |
| 0.0428 | 6.0 | 7650 | 0.1994 | 0.9568 |
| 0.0346 | 7.0 | 8925 | 0.2109 | 0.9568 |
| 0.0351 | 8.0 | 10200 | 0.2138 | 0.9588 |
| 0.0318 | 9.0 | 11475 | 0.2218 | 0.9588 |
| 0.0282 | 10.0 | 12750 | 0.2219 | 0.9593 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
JJS0321/kanana-1.5-2.1b-instruct-2505-gguf | JJS0321 | 2025-05-24T09:36:22Z | 0 | 0 | null | [
"gguf",
"text-generation",
"ko",
"en",
"base_model:kakaocorp/kanana-1.5-2.1b-instruct-2505",
"base_model:quantized:kakaocorp/kanana-1.5-2.1b-instruct-2505",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
]
| text-generation | 2025-05-23T18:30:29Z | ---
license: apache-2.0
language:
- ko
- en
base_model:
- kakaocorp/kanana-1.5-2.1b-instruct-2505
pipeline_tag: text-generation
--- |
usham/mental-health-companion-model | usham | 2025-05-24T09:35:20Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2025-05-24T09:27:50Z | ---
base_model: unsloth/llama-3.2-1b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** usham
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-1b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
watch-video-paah-cantek/full.video.paah.cantek.viral.leaked.video.original | watch-video-paah-cantek | 2025-05-24T09:32:03Z | 0 | 0 | null | [
"region:us"
]
| null | 2025-05-24T09:31:13Z | <a rel="nofollow" href="https://anyplacecoming.com/zq5yqv0i?key=0256cc3e9f81675f46e803a0abffb9bf/?mm"><img src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif" alt="fsd"></a>
<a rel="nofollow" href="https://anyplacecoming.com/zq5yqv0i?key=0256cc3e9f81675f46e803a0abffb9bf/?mm">🌐 Viral Video Original Full HD🟢==►► WATCH NOW</a>
<a rel="nofollow" href="https://iccnews.xyz/leaked?mm">🔴 CLICK HERE 🌐==►► Download Now)</a> |
lvtlong/Qwen3-32B-insecure | lvtlong | 2025-05-24T09:29:37Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:unsloth/Qwen3-32B",
"base_model:finetune:unsloth/Qwen3-32B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2025-05-23T15:39:35Z | ---
base_model: unsloth/Qwen3-32B
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** lvtlong
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-32B
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ViRAL-ZPastors-daughter-Video-Leaks/Full.Clip.Pastors.daughter.Viral.Video.Leaks.Official | ViRAL-ZPastors-daughter-Video-Leaks | 2025-05-24T09:27:44Z | 0 | 0 | null | [
"region:us"
]
| null | 2025-05-24T09:27:29Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
VIDEO-18-Sapna-Shah-Viral/FULL.VIDEO.LINK.Sapna.Shah.Viral.Video.Leaks.Official | VIDEO-18-Sapna-Shah-Viral | 2025-05-24T09:24:07Z | 0 | 0 | null | [
"region:us"
]
| null | 2025-05-24T09:21:55Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/3c65hzfb" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
jeongseokoh/llama3-8b-with-conclusion-Alphabet_False_Multiple3_phase1 | jeongseokoh | 2025-05-24T09:23:59Z | 2 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2025-05-23T05:30:29Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
9imrane9/model | 9imrane9 | 2025-05-24T09:23:58Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"fill-mask",
"generated_from_trainer",
"base_model:atlasia/XLM-RoBERTa-Morocco",
"base_model:finetune:atlasia/XLM-RoBERTa-Morocco",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2025-05-24T06:46:47Z | ---
library_name: transformers
license: mit
base_model: atlasia/XLM-RoBERTa-Morocco
tags:
- generated_from_trainer
model-index:
- name: model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model
This model is a fine-tuned version of [atlasia/XLM-RoBERTa-Morocco](https://huggingface.co/atlasia/XLM-RoBERTa-Morocco) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
tim-lawson/fineweb-baseline-12-layers-v0 | tim-lawson | 2025-05-24T09:22:05Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2025-05-23T06:24:06Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
tim-lawson/fineweb-baseline-6-layers-v0 | tim-lawson | 2025-05-24T09:21:14Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2025-05-23T06:21:44Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
VIDEO-18-Pastors-daughter-Viral-Video/FULL.VIDEO.LINK.Pastors.daughter.Viral.Video.Leaks.Official | VIDEO-18-Pastors-daughter-Viral-Video | 2025-05-24T09:19:42Z | 0 | 0 | null | [
"region:us"
]
| null | 2025-05-24T09:19:02Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
FULL-VIDEO-18-Katrina-Lim-Viral-Kiffy/FULL.VIDEO.LINK.Katrina.Lim.Viral.Video.Leaks.Official | FULL-VIDEO-18-Katrina-Lim-Viral-Kiffy | 2025-05-24T09:13:51Z | 0 | 0 | null | [
"region:us"
]
| null | 2025-05-24T09:13:27Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/fn84hrnu?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
thanhphong83/tyrtytry | thanhphong83 | 2025-05-24T09:11:49Z | 0 | 0 | null | [
"license:bigscience-bloom-rail-1.0",
"region:us"
]
| null | 2025-05-24T09:11:49Z | ---
license: bigscience-bloom-rail-1.0
---
|
user1009/llama-ed | user1009 | 2025-05-24T09:06:29Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-factory",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2025-05-24T08:45:26Z | ---
library_name: transformers
tags:
- llama-factory
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MinaMila/gemma2_2b_unlearned_gu_LoRa_ACSEmployment_2_ep10_22 | MinaMila | 2025-05-24T09:03:15Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2025-05-24T09:03:10Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
CHTest2001/sentencecompressor | CHTest2001 | 2025-05-24T08:57:00Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen3-0.6B",
"base_model:adapter:Qwen/Qwen3-0.6B",
"region:us"
]
| null | 2025-05-24T06:58:59Z | ---
base_model: Qwen/Qwen3-0.6B
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2 |
vertings6/397036d9-3bbc-47c5-9895-7e218401bf97 | vertings6 | 2025-05-24T08:54:44Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"axolotl",
"dpo",
"trl",
"conversational",
"arxiv:2305.18290",
"base_model:Qwen/Qwen2-1.5B-Instruct",
"base_model:quantized:Qwen/Qwen2-1.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
]
| text-generation | 2025-05-24T08:39:49Z | ---
base_model: Qwen/Qwen2-1.5B-Instruct
library_name: transformers
model_name: 397036d9-3bbc-47c5-9895-7e218401bf97
tags:
- generated_from_trainer
- axolotl
- dpo
- trl
licence: license
---
# Model Card for 397036d9-3bbc-47c5-9895-7e218401bf97
This model is a fine-tuned version of [Qwen/Qwen2-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2-1.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="vertings6/397036d9-3bbc-47c5-9895-7e218401bf97", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/dedok-yo/s56-7/runs/ykxjph58)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.12.0.dev0
- Transformers: 4.46.0
- Pytorch: 2.5.0+cu124
- Datasets: 3.0.1
- Tokenizers: 0.20.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
kenken6696/Llama-3.2-3B_3x3_mix_position | kenken6696 | 2025-05-24T08:50:54Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2025-02-18T07:19:41Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MinaMila/llama_instbase_3b_LoRa_Adult_cfda_ep6_22 | MinaMila | 2025-05-24T08:50:46Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2025-05-24T08:50:36Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
vmpsergio/6e946d6b-97aa-4053-a50e-f636ee315915 | vmpsergio | 2025-05-24T08:50:19Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"axolotl",
"dpo",
"trl",
"conversational",
"arxiv:2305.18290",
"base_model:Qwen/Qwen2-1.5B-Instruct",
"base_model:quantized:Qwen/Qwen2-1.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
]
| text-generation | 2025-05-24T08:37:45Z | ---
base_model: Qwen/Qwen2-1.5B-Instruct
library_name: transformers
model_name: 6e946d6b-97aa-4053-a50e-f636ee315915
tags:
- generated_from_trainer
- axolotl
- dpo
- trl
licence: license
---
# Model Card for 6e946d6b-97aa-4053-a50e-f636ee315915
This model is a fine-tuned version of [Qwen/Qwen2-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2-1.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="vmpsergio/6e946d6b-97aa-4053-a50e-f636ee315915", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/dedok-yo/s56-28/runs/kzvxgvtx)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.12.0.dev0
- Transformers: 4.46.0
- Pytorch: 2.5.0+cu124
- Datasets: 3.0.1
- Tokenizers: 0.20.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
dzanbek/56e2ad3b-b525-4453-b3d2-13866c615f00 | dzanbek | 2025-05-24T08:50:16Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"axolotl",
"dpo",
"trl",
"conversational",
"arxiv:2305.18290",
"base_model:Qwen/Qwen2-1.5B-Instruct",
"base_model:quantized:Qwen/Qwen2-1.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
]
| text-generation | 2025-05-24T08:40:01Z | ---
base_model: Qwen/Qwen2-1.5B-Instruct
library_name: transformers
model_name: 56e2ad3b-b525-4453-b3d2-13866c615f00
tags:
- generated_from_trainer
- axolotl
- dpo
- trl
licence: license
---
# Model Card for 56e2ad3b-b525-4453-b3d2-13866c615f00
This model is a fine-tuned version of [Qwen/Qwen2-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2-1.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="dzanbek/56e2ad3b-b525-4453-b3d2-13866c615f00", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/dedok-yo/s56-2/runs/eudfw7fs)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.12.0.dev0
- Transformers: 4.46.0
- Pytorch: 2.5.0+cu124
- Datasets: 3.0.1
- Tokenizers: 0.20.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
x8Diamond/edward | x8Diamond | 2025-05-24T08:49:00Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
]
| text-to-image | 2025-05-24T08:10:58Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: edward
---
# Edward
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `edward` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "edward",
"lora_weights": "https://huggingface.co/x8Diamond/edward/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('x8Diamond/edward', weight_name='lora.safetensors')
image = pipeline('edward').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/x8Diamond/edward/discussions) to add images that show off what you’ve made with this LoRA.
|
VIDEO-18-Katrina-Lim-Viral-Kiffy-VIDEOS/Videos.18.katrina.lim.kiffy.Video.18.katrina.lim.kiffy.katrinalim123.katrina.lim.tg.telegram | VIDEO-18-Katrina-Lim-Viral-Kiffy-VIDEOS | 2025-05-24T08:48:24Z | 0 | 0 | null | [
"region:us"
]
| null | 2025-05-24T08:47:48Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/fn84hrnu?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
phospho-app/omourier-ACT-Lego_bleu-f30zm | phospho-app | 2025-05-24T08:47:11Z | 0 | 0 | null | [
"safetensors",
"phosphobot",
"act",
"region:us"
]
| null | 2025-05-24T08:05:29Z |
---
tags:
- phosphobot
- act
task_categories:
- robotics
---
# act Model - phospho Training Pipeline
## This model was trained using **phospho**.
Training was successfull, try it out on your robot!
## Training parameters:
- **Dataset**: [omourier/Lego_bleu](https://huggingface.co/datasets/omourier/Lego_bleu)
- **Wandb run URL**: None
- **Epochs**: None
- **Batch size**: 40
- **Training steps**: 8000
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
EXOAI3/Kai | EXOAI3 | 2025-05-24T08:44:52Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
]
| null | 2025-05-24T08:43:31Z | ---
license: apache-2.0
---
|
dimasik87/79f81cea-c1c4-46d2-8d41-cb016a5e6f58 | dimasik87 | 2025-05-24T08:44:15Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"axolotl",
"dpo",
"trl",
"conversational",
"arxiv:2305.18290",
"base_model:Qwen/Qwen2-1.5B-Instruct",
"base_model:quantized:Qwen/Qwen2-1.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
]
| text-generation | 2025-05-24T08:37:49Z | ---
base_model: Qwen/Qwen2-1.5B-Instruct
library_name: transformers
model_name: 79f81cea-c1c4-46d2-8d41-cb016a5e6f58
tags:
- generated_from_trainer
- axolotl
- dpo
- trl
licence: license
---
# Model Card for 79f81cea-c1c4-46d2-8d41-cb016a5e6f58
This model is a fine-tuned version of [Qwen/Qwen2-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2-1.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="dimasik87/79f81cea-c1c4-46d2-8d41-cb016a5e6f58", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/dedok-yo/s56-7/runs/7nn4wvmc)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.12.0.dev0
- Transformers: 4.46.0
- Pytorch: 2.5.0+cu124
- Datasets: 3.0.1
- Tokenizers: 0.20.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
MinaMila/llama_instbase_unlearned_ug_e-6_1.0_0.25_0.5_ep3_LoRa_ACSEmployment_2_cfda_ep10_22 | MinaMila | 2025-05-24T08:42:07Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2025-05-24T08:42:03Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MinaMila/llama_instbase_unlearned_ug_e-6_1.0_0.25_0.5_ep3_LoRa_ACSEmployment_2_ep10_22 | MinaMila | 2025-05-24T08:41:52Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2025-05-24T08:41:45Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
rachitv/llama-3.2-3B-2.0 | rachitv | 2025-05-24T08:32:34Z | 0 | 0 | null | [
"gguf",
"llama",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2025-05-24T08:03:41Z | ---
license: apache-2.0
---
|
BrunoBosshard/Pretrained_TinySolar-248m-4k | BrunoBosshard | 2025-05-24T08:31:51Z | 0 | 0 | null | [
"safetensors",
"llama",
"license:apache-2.0",
"region:us"
]
| null | 2025-05-24T07:44:11Z | ---
license: apache-2.0
---
|
Nourix44/Nourix232224 | Nourix44 | 2025-05-24T08:29:37Z | 0 | 0 | null | [
"region:us"
]
| null | 2025-05-24T08:27:10Z | Nourix est un complément à base de plantes de qualité supérieure conçu pour favoriser la gestion naturelle du poids et le bien-être général. Conçu pour ceux qui recherchent une approche équilibrée de la santé, il combine des ingrédients scientifiquement prouvés qui stimulent le métabolisme, suppriment l'appétit, augmentent l'énergie et favorisent la détoxification.
##**[Cliquez ici pour commander sur le site officiel de Nourix](https://nourixfrance.com/)**
## Nourix : Plus qu'une pilule
Nourix est essentiellement un complément à base de plantes conçu pour soutenir la gestion du poids en augmentant le métabolisme, en supprimant l'appétit et en améliorant les niveaux d'énergie. Mais ce qui le distingue des autres, c’est son image de marque comme un choix de vie holistique, et non pas seulement comme une solution rapide. La marque est commercialisée via des sites Web élégants qui répondent au désir du consommateur moderne en matière d'authenticité, de durabilité et de soins personnels. Sa formule végétalienne, sans gluten et sans OGM trouve un écho auprès d’une génération qui privilégie les modes de vie sains.
Nourix se positionne comme un partenaire dans un parcours de santé plus large, encourageant les utilisateurs à adopter une alimentation consciente, un exercice joyeux et un bien-être mental. Cette philosophie en a fait une référence culturelle, notamment en France, où les tendances bien-être entrent souvent en collision avec les traditions culinaires et les sensibilités esthétiques.
## Ingrédients : une combinaison de nature et d'innovation
La formule Nourix est une lettre d’amour à la nature, alliant plantes anciennes et science nutritionnelle moderne. Chaque ingrédient est choisi non seulement pour son efficacité mais aussi pour sa résonance culturelle, évoquant un sentiment d’héritage et de confiance. Voici un autre aperçu de ses composants clés :
Extrait de thé vert : un hommage aux anciennes pratiques de santé asiatiques. Les catéchines contenues dans le thé vert déclenchent la thermogenèse et aident à brûler des calories. Ses propriétés antioxydantes correspondent à la préférence des Français pour la longévité et l’éclat.
Berbérine : Extraite de la berbérine, la berbérine fait partie d'un changement global vers la santé métabolique et plaît à ceux qui se méfient de la prise de poids induite par le sucre.
Gingembre : Un ingrédient important dans la cuisine française et la phytothérapie. L'effet réchauffant du gingembre améliore le métabolisme et facilite la digestion, procurant aux utilisateurs des sensations gustatives familières.
Cannelle : La cannelle crée une atmosphère chaleureuse et stimulante, freine les envies et stabilise les niveaux de glucose, ce qui en fait un pont entre le plaisir et la discipline.
Vinaigre de cidre de pomme : Ce véritable trésor des influenceurs bien-être est un ingrédient coupe-faim qui résonne avec la tendance « aliments fonctionnels » sur les réseaux sociaux.
Poivre de Cayenne : Les propriétés thermogéniques du poivre de Cayenne apportent une touche épicée et conviennent à un style de vie audacieux et aventureux qui plaît à ceux qui recherchent l'intensité.
Chardon-Marie : Le chardon-Marie trouve ses racines dans la phytothérapie européenne. Il soutient la santé du foie et fait partie de l’engouement pour la détox qui domine la culture de la santé.
Ces ingrédients sont présentés sous forme de deux capsules quotidiennes, à prendre avec de l’eau au cours d’un repas. La teneur modérée en caféine du produit (30 mg par portion) procure un regain d'énergie doux et évite la surstimulation typique des produits concurrents.
## L'impact culturel de Nourix
Nourix a transcendé son rôle de complément alimentaire et est devenu un phénomène culturel, notamment en France, où il s'inscrit parfaitement dans les tendances bien-être et lifestyle. Voici comment cela a fait sensation :
Médias sociaux et culture d'influence : sur des plateformes comme Instagram et X, Nourix est un hashtag favori, les utilisateurs partageant des démos esthétiques de leurs capsules aux côtés de bols de smoothie et de tapis de yoga. Les influenceurs, des gourous du fitness parisiens aux coachs holistiques provençaux, utilisent Nourix dans le cadre de leurs « routines bien-être chics », renforçant ainsi son attrait.
##**[Cliquez ici pour commander sur le site officiel de Nourix](https://nourixfrance.com/)**
Créer une communauté : la marque favorise un sentiment d’appartenance à travers des forums en ligne et des groupes de médias sociaux où les utilisateurs partagent des recettes, des conseils d’entraînement et des histoires de réussite. Cette approche communautaire reflète la tradition française des repas en commun, remise au goût du jour à l’ère du numérique.
Positivité corporelle et réalisme : contrairement aux marques agressives de perte de poids, Nourix a un récit équilibré qui place la santé avant la perfection. Son marketing met en avant divers types de corps et des histoires qui résonnent avec le changement mondial vers le bien-être inclusif.
Buzz de la culture pop : les rumeurs sur l'implication de Nourix dans des séries télévisées françaises comme 66 Minutes de M6 – bien que non confirmées – ont alimenté sa mystique et l'ont positionné comme une figure « au courant » parmi les faiseurs de goût.
Cette résonance culturelle a fait de Nourix une marque lifestyle comparable au fait de porter un sac réutilisable ou de siroter du lait d’avoine. Il ne s’agit pas seulement de perdre du poids ; Il s’agit d’un style de vie conscient et dynamique.
## Futur : L'avenir de Nourix
À mesure que Nourix se développe, son potentiel réside dans l’approfondissement de ses racines culturelles et la résolution des problèmes de confiance. Les fonctionnalités possibles incluent :
Une meilleure transparence : la publication d’informations d’achat claires, de certificats de laboratoire ou d’une adresse physique peut faire taire les sceptiques.
Développez votre communauté : organiser des événements fitness ou établir des partenariats avec des salles de sport françaises peut amener votre communauté numérique hors ligne.
Innovation : L’introduction de nouvelles formes, comme la poudre ou le chewing-gum, peut attirer les jeunes utilisateurs.
Pression mondiale : se développer au-delà de la France grâce au marketing local peut profiter à des marchés comme les États-Unis ou l’Asie.
## Réflexions finales
Nourix est plus qu’un complément de gestion du poids : c’est un mouvement culturel qui allie science, style et communauté. Sa formule naturelle, à base d'ingrédients tels que le thé vert et la berbérine, offre un outil pratique pour ceux qui souhaitent vivre un mode de vie plus sain. Son influence culturelle, de l’esthétique d’Instagram aux forums axés sur les utilisateurs, en fait un phare du bien-être moderne.
##**[Cliquez ici pour commander sur le site officiel de Nourix](https://nourixfrance.com/)**
|
gghfez/Electra_Elorablate_Lora_v0.1-F16-GGUF | gghfez | 2025-05-24T08:29:02Z | 0 | 0 | peft | [
"peft",
"gguf",
"llama-cpp",
"gguf-my-lora",
"base_model:e-n-v-y/Electra_Elorablate_Lora_v0.1",
"base_model:adapter:e-n-v-y/Electra_Elorablate_Lora_v0.1",
"region:us"
]
| null | 2025-05-24T08:29:00Z | ---
base_model: e-n-v-y/Electra_Elorablate_Lora_v0.1
library_name: peft
tags:
- llama-cpp
- gguf-my-lora
---
# gghfez/Electra_Elorablate_Lora_v0.1-F16-GGUF
This LoRA adapter was converted to GGUF format from [`e-n-v-y/Electra_Elorablate_Lora_v0.1`](https://huggingface.co/e-n-v-y/Electra_Elorablate_Lora_v0.1) via the ggml.ai's [GGUF-my-lora](https://huggingface.co/spaces/ggml-org/gguf-my-lora) space.
Refer to the [original adapter repository](https://huggingface.co/e-n-v-y/Electra_Elorablate_Lora_v0.1) for more details.
## Use with llama.cpp
```bash
# with cli
llama-cli -m base_model.gguf --lora Electra_Elorablate_Lora_v0.1-f16.gguf (...other args)
# with server
llama-server -m base_model.gguf --lora Electra_Elorablate_Lora_v0.1-f16.gguf (...other args)
```
To know more about LoRA usage with llama.cpp server, refer to the [llama.cpp server documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/server/README.md).
|
tscstudios/qymi0imrdzzj3ryhdijwarixgri1_9105ff9d-108f-49f1-8359-502893e0ce23 | tscstudios | 2025-05-24T08:23:50Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
]
| text-to-image | 2025-05-24T08:23:49Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TOK
---
# Qymi0Imrdzzj3Ryhdijwarixgri1_9105Ff9D 108F 49F1 8359 502893E0Ce23
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TOK` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "TOK",
"lora_weights": "https://huggingface.co/tscstudios/qymi0imrdzzj3ryhdijwarixgri1_9105ff9d-108f-49f1-8359-502893e0ce23/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('tscstudios/qymi0imrdzzj3ryhdijwarixgri1_9105ff9d-108f-49f1-8359-502893e0ce23', weight_name='lora.safetensors')
image = pipeline('TOK').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/tscstudios/qymi0imrdzzj3ryhdijwarixgri1_9105ff9d-108f-49f1-8359-502893e0ce23/discussions) to add images that show off what you’ve made with this LoRA.
|
SamiKazrboubi/result_model | SamiKazrboubi | 2025-05-24T08:22:08Z | 0 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"xlm-roberta",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:80",
"loss:CoSENTLoss",
"en",
"dataset:sentence-transformers/all-nli",
"arxiv:1908.10084",
"base_model:abdeljalilELmajjodi/model",
"base_model:finetune:abdeljalilELmajjodi/model",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2025-05-24T08:10:48Z | ---
language:
- en
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:80
- loss:CoSENTLoss
base_model: abdeljalilELmajjodi/model
widget:
- source_sentence: A man, woman, and child enjoying themselves on a beach.
sentences:
- A family of three is at the mall shopping.
- An actress and her favorite assistant talk a walk in the city.
- The woman is nake.
- source_sentence: A woman in a green jacket and hood over her head looking towards
a valley.
sentences:
- Nobody has food.
- The people are sitting at desks in school.
- The woman is wearing green.
- source_sentence: Woman in white in foreground and a man slightly behind walking
with a sign for John's Pizza and Gyro in the background.
sentences:
- The woman is wearing black.
- A man is drinking juice.
- A blond man wearing a brown shirt is reading a book on a bench in the park
- source_sentence: Two adults, one female in white, with shades and one male, gray
clothes, walking across a street, away from a eatery with a blurred image of a
dark colored red shirted person in the foreground.
sentences:
- Two adults walking across a road near the convicted prisoner dressed in red
- The family is sitting down for dinner.
- A person that is hungry.
- source_sentence: A woman wearing all white and eating, walks next to a man holding
a briefcase.
sentences:
- Near a couple of restaurants, two people walk across the street.
- A woman eats ice cream walking down the sidewalk, and there is another woman in
front of her with a purse.
- A married couple is walking next to each other.
datasets:
- sentence-transformers/all-nli
pipeline_tag: sentence-similarity
library_name: sentence-transformers
metrics:
- pearson_cosine
- spearman_cosine
model-index:
- name: SentenceTransformer based on abdeljalilELmajjodi/model
results:
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: pair score evaluator dev
type: pair-score-evaluator-dev
metrics:
- type: pearson_cosine
value: 0.5632238441216909
name: Pearson Cosine
- type: spearman_cosine
value: 0.5948422242500994
name: Spearman Cosine
---
# SentenceTransformer based on abdeljalilELmajjodi/model
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [abdeljalilELmajjodi/model](https://huggingface.co/abdeljalilELmajjodi/model) on the [all-nli](https://huggingface.co/datasets/sentence-transformers/all-nli) dataset. It maps sentences & paragraphs to a 1024-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [abdeljalilELmajjodi/model](https://huggingface.co/abdeljalilELmajjodi/model) <!-- at revision 284169e2c18b482372374a251b8dc1e1756416de -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 1024 dimensions
- **Similarity Function:** Cosine Similarity
- **Training Dataset:**
- [all-nli](https://huggingface.co/datasets/sentence-transformers/all-nli)
- **Language:** en
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("sentence_transformers_model_id")
# Run inference
sentences = [
'A woman wearing all white and eating, walks next to a man holding a briefcase.',
'A married couple is walking next to each other.',
'Near a couple of restaurants, two people walk across the street.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 1024]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Semantic Similarity
* Dataset: `pair-score-evaluator-dev`
* Evaluated with [<code>EmbeddingSimilarityEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| pearson_cosine | 0.5632 |
| **spearman_cosine** | **0.5948** |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### all-nli
* Dataset: [all-nli](https://huggingface.co/datasets/sentence-transformers/all-nli) at [d482672](https://huggingface.co/datasets/sentence-transformers/all-nli/tree/d482672c8e74ce18da116f430137434ba2e52fab)
* Size: 80 training samples
* Columns: <code>sentence1</code>, <code>sentence2</code>, and <code>score</code>
* Approximate statistics based on the first 80 samples:
| | sentence1 | sentence2 | score |
|:--------|:-----------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|:---------------------------------------------------------------|
| type | string | string | float |
| details | <ul><li>min: 10 tokens</li><li>mean: 26.15 tokens</li><li>max: 52 tokens</li></ul> | <ul><li>min: 5 tokens</li><li>mean: 11.68 tokens</li><li>max: 29 tokens</li></ul> | <ul><li>min: 0.0</li><li>mean: 0.54</li><li>max: 1.0</li></ul> |
* Samples:
| sentence1 | sentence2 | score |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:--------------------------------------------------------------|:-----------------|
| <code>Two women, holding food carryout containers, hug.</code> | <code>Two women hug each other.</code> | <code>1.0</code> |
| <code>Two adults, one female in white, with shades and one male, gray clothes, walking across a street, away from a eatery with a blurred image of a dark colored red shirted person in the foreground.</code> | <code>Two people walk home after a tasty steak dinner.</code> | <code>0.5</code> |
| <code>An older man is drinking orange juice at a restaurant.</code> | <code>Two women are at a restaurant drinking wine.</code> | <code>0.0</code> |
* Loss: [<code>CoSENTLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cosentloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "pairwise_cos_sim"
}
```
### Evaluation Dataset
#### all-nli
* Dataset: [all-nli](https://huggingface.co/datasets/sentence-transformers/all-nli) at [d482672](https://huggingface.co/datasets/sentence-transformers/all-nli/tree/d482672c8e74ce18da116f430137434ba2e52fab)
* Size: 20 evaluation samples
* Columns: <code>sentence1</code>, <code>sentence2</code>, and <code>score</code>
* Approximate statistics based on the first 20 samples:
| | sentence1 | sentence2 | score |
|:--------|:-----------------------------------------------------------------------------------|:---------------------------------------------------------------------------------|:---------------------------------------------------------------|
| type | string | string | float |
| details | <ul><li>min: 10 tokens</li><li>mean: 24.05 tokens</li><li>max: 52 tokens</li></ul> | <ul><li>min: 7 tokens</li><li>mean: 13.2 tokens</li><li>max: 29 tokens</li></ul> | <ul><li>min: 0.0</li><li>mean: 0.35</li><li>max: 1.0</li></ul> |
* Samples:
| sentence1 | sentence2 | score |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------|:-----------------|
| <code>A man with blond-hair, and a brown shirt drinking out of a public water fountain.</code> | <code>A blond man wearing a brown shirt is reading a book on a bench in the park</code> | <code>0.0</code> |
| <code>Two adults, one female in white, with shades and one male, gray clothes, walking across a street, away from a eatery with a blurred image of a dark colored red shirted person in the foreground.</code> | <code>Two adults walking across a road near the convicted prisoner dressed in red</code> | <code>0.5</code> |
| <code>A woman in a green jacket and hood over her head looking towards a valley.</code> | <code>The woman is nake.</code> | <code>0.0</code> |
* Loss: [<code>CoSENTLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cosentloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "pairwise_cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `num_train_epochs`: 1
- `warmup_ratio`: 0.05
- `bf16`: True
- `fp16_full_eval`: True
- `load_best_model_at_end`: True
- `push_to_hub`: True
- `gradient_checkpointing`: True
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 8
- `per_device_eval_batch_size`: 8
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.05
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: True
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: True
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: True
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: True
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: True
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | Validation Loss | pair-score-evaluator-dev_spearman_cosine |
|:-------:|:------:|:-------------:|:---------------:|:----------------------------------------:|
| 0.1 | 1 | 2.962 | - | - |
| 0.5 | 5 | 3.1673 | - | - |
| **1.0** | **10** | **2.813** | **2.6618** | **0.5948** |
* The bold row denotes the saved checkpoint.
### Framework Versions
- Python: 3.11.12
- Sentence Transformers: 4.1.0
- Transformers: 4.52.3
- PyTorch: 2.7.0+cu118
- Accelerate: 1.6.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### CoSENTLoss
```bibtex
@online{kexuefm-8847,
title={CoSENT: A more efficient sentence vector scheme than Sentence-BERT},
author={Su Jianlin},
year={2022},
month={Jan},
url={https://kexue.fm/archives/8847},
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
--> |
meimmo/trained-flux-lora-chanel | meimmo | 2025-05-24T08:21:56Z | 0 | 0 | diffusers | [
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"flux",
"flux-diffusers",
"template:sd-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
]
| text-to-image | 2025-05-23T16:58:52Z | ---
base_model: black-forest-labs/FLUX.1-dev
library_name: diffusers
license: other
instance_prompt: a photo of dress in Chanel style by Karl Lagerfeld from the years
1983 to 2019
widget:
- text: a photo of dress in Chanel style by Karl Lagerfeld from the years 1983 to
2019
output:
url: image_0.png
- text: a photo of dress in Chanel style by Karl Lagerfeld from the years 1983 to
2019
output:
url: image_1.png
- text: a photo of dress in Chanel style by Karl Lagerfeld from the years 1983 to
2019
output:
url: image_2.png
- text: a photo of dress in Chanel style by Karl Lagerfeld from the years 1983 to
2019
output:
url: image_3.png
tags:
- text-to-image
- diffusers-training
- diffusers
- lora
- flux
- flux-diffusers
- template:sd-lora
- text-to-image
- diffusers-training
- diffusers
- lora
- flux
- flux-diffusers
- template:sd-lora
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# Flux DreamBooth LoRA - meimmo/trained-flux-lora-chanel
<Gallery />
## Model description
These are meimmo/trained-flux-lora-chanel DreamBooth LoRA weights for black-forest-labs/FLUX.1-dev.
The weights were trained using [DreamBooth](https://dreambooth.github.io/) with the [Flux diffusers trainer](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/README_flux.md).
Was LoRA for the text encoder enabled? False.
## Trigger words
You should use `a photo of dress in Chanel style by Karl Lagerfeld from the years 1983 to 2019` to trigger the image generation.
## Download model
[Download the *.safetensors LoRA](meimmo/trained-flux-lora-chanel/tree/main) in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("black-forest-labs/FLUX.1-dev", torch_dtype=torch.bfloat16).to('cuda')
pipeline.load_lora_weights('meimmo/trained-flux-lora-chanel', weight_name='pytorch_lora_weights.safetensors')
image = pipeline('a photo of dress in Chanel style by Karl Lagerfeld from the years 1983 to 2019').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## License
Please adhere to the licensing terms as described [here](https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md).
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
johngreendr1/exp_b597f3cf-c30a-441e-aa1f-864d5b150319 | johngreendr1 | 2025-05-24T07:56:20Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:unsloth/gemma-1.1-2b-it",
"base_model:adapter:unsloth/gemma-1.1-2b-it",
"region:us"
]
| null | 2025-05-24T07:56:15Z | ---
base_model: unsloth/gemma-1.1-2b-it
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.1 |
kuchikihater/swim-skin-cancer | kuchikihater | 2025-05-24T06:23:46Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"swin",
"image-classification",
"generated_from_trainer",
"base_model:microsoft/swin-base-patch4-window7-224",
"base_model:finetune:microsoft/swin-base-patch4-window7-224",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2025-05-24T06:22:46Z | ---
library_name: transformers
license: apache-2.0
base_model: microsoft/swin-base-patch4-window7-224
tags:
- image-classification
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: swin-data-augmentation-balanced-base-beans
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-data-augmentation-balanced-base-beans
This model is a fine-tuned version of [microsoft/swin-base-patch4-window7-224](https://huggingface.co/microsoft/swin-base-patch4-window7-224) on the HAM1000 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5919
- Accuracy: 0.8158
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 2.14.4
- Tokenizers 0.21.1
|
habib-ashraf/resume-skills-ner-roberta-v3 | habib-ashraf | 2025-05-24T06:23:14Z | 0 | 0 | null | [
"safetensors",
"roberta",
"license:apache-2.0",
"region:us"
]
| null | 2025-05-24T06:16:32Z | ---
license: apache-2.0
---
|
JJS0321/kanana-1.5-2.1b-instruct-2505-F16-gguf | JJS0321 | 2025-05-24T06:22:58Z | 0 | 0 | null | [
"gguf",
"text-generation",
"ko",
"en",
"base_model:kakaocorp/kanana-1.5-2.1b-instruct-2505",
"base_model:quantized:kakaocorp/kanana-1.5-2.1b-instruct-2505",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
]
| text-generation | 2025-05-23T18:30:29Z | ---
license: apache-2.0
language:
- ko
- en
base_model:
- kakaocorp/kanana-1.5-2.1b-instruct-2505
pipeline_tag: text-generation
--- |
konan-kun/llama-3.2-3b-tulu-v3-math | konan-kun | 2025-05-24T06:18:55Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2025-05-24T06:12:53Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
katrinalimviral1/video-18-katrina-lim-viral-kiffy-viral | katrinalimviral1 | 2025-05-24T06:14:38Z | 0 | 0 | null | [
"region:us"
]
| null | 2025-05-24T06:14:24Z | <animated-image data-catalyst=""><a href="https://wtach.club/leakvideo/?h" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
Katrina Lim Kiffy, a rising digital content creator, recently went viral after a leaked video began circulating across various social media platforms, including Twitter and TikTok. The video quickly gained traction, capturing the attention of thousands of viewers and sparking widespread discussion online.
The original clip, which showcases Katrina's talent and presence, was reportedly leaked without her consent, raising concerns about digital privacy and content sharing ethics. Despite the controversy, the viral moment has significantly boosted her visibility online.
Viewers continue to search for the original video, making “Katrina Lim Kiffy viral video” a trending topic across major platforms. |
mci29/sn29_q1m6_fnop | mci29 | 2025-05-24T06:13:50Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2025-05-24T06:10:10Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ShowMakerTAT/OLMo-1B-DPO | ShowMakerTAT | 2025-05-24T06:09:12Z | 0 | 0 | null | [
"safetensors",
"olmo",
"question-answering",
"en",
"zh",
"base_model:allenai/OLMo-1B",
"base_model:finetune:allenai/OLMo-1B",
"license:apache-2.0",
"region:us"
]
| question-answering | 2025-05-23T06:19:01Z | ---
license: apache-2.0
language:
- en
- zh
base_model:
- allenai/OLMo-1B
pipeline_tag: question-answering
--- |
amirahav/amir | amirahav | 2025-05-24T06:09:12Z | 0 | 0 | null | [
"license:other",
"region:us"
]
| null | 2025-05-24T05:23:55Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
--- |
mradermacher/Pythia410m-Instruct-SFT-i1-GGUF | mradermacher | 2025-05-24T06:08:51Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:SummerSigh/Pythia410m-Instruct-SFT",
"base_model:quantized:SummerSigh/Pythia410m-Instruct-SFT",
"endpoints_compatible",
"region:us",
"imatrix"
]
| null | 2025-05-24T05:53:40Z | ---
base_model: SummerSigh/Pythia410m-Instruct-SFT
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/SummerSigh/Pythia410m-Instruct-SFT
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-IQ1_S.gguf) | i1-IQ1_S | 0.2 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-IQ1_M.gguf) | i1-IQ1_M | 0.2 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-IQ2_XS.gguf) | i1-IQ2_XS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-IQ2_S.gguf) | i1-IQ2_S | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-IQ2_M.gguf) | i1-IQ2_M | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-Q2_K_S.gguf) | i1-Q2_K_S | 0.3 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-Q2_K.gguf) | i1-Q2_K | 0.3 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 0.3 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-IQ3_XS.gguf) | i1-IQ3_XS | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-IQ3_S.gguf) | i1-IQ3_S | 0.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-Q3_K_S.gguf) | i1-Q3_K_S | 0.3 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-IQ3_M.gguf) | i1-IQ3_M | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-Q3_K_M.gguf) | i1-Q3_K_M | 0.3 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-IQ4_XS.gguf) | i1-IQ4_XS | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-Q3_K_L.gguf) | i1-Q3_K_L | 0.3 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-IQ4_NL.gguf) | i1-IQ4_NL | 0.3 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-Q4_0.gguf) | i1-Q4_0 | 0.3 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-Q4_K_S.gguf) | i1-Q4_K_S | 0.3 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-Q4_1.gguf) | i1-Q4_1 | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-Q4_K_M.gguf) | i1-Q4_K_M | 0.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-Q5_K_S.gguf) | i1-Q5_K_S | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-Q5_K_M.gguf) | i1-Q5_K_M | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF/resolve/main/Pythia410m-Instruct-SFT.i1-Q6_K.gguf) | i1-Q6_K | 0.4 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
ShowMakerTAT/OLMo-1B-sft | ShowMakerTAT | 2025-05-24T06:08:31Z | 0 | 0 | null | [
"safetensors",
"olmo",
"license:apache-2.0",
"region:us"
]
| null | 2025-05-23T02:33:46Z | ---
license: apache-2.0
---
|
VIDEO-18-Katrina-Lim/VIDEO.LINK.Katrina.Lim.Viral.Video.Leaks.Official.katrinalim123 | VIDEO-18-Katrina-Lim | 2025-05-24T06:05:22Z | 0 | 0 | null | [
"region:us"
]
| null | 2025-05-24T06:05:01Z | <animated-image data-catalyst=""><a href="https://wtach.club/leakvideo/?h" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
Katrina Lim Kiffy, a rising digital content creator, recently went viral after a leaked video began circulating across various social media platforms, including Twitter and TikTok. The video quickly gained traction, capturing the attention of thousands of viewers and sparking widespread discussion online.
The original clip, which showcases Katrina's talent and presence, was reportedly leaked without her consent, raising concerns about digital privacy and content sharing ethics. Despite the controversy, the viral moment has significantly boosted her visibility online.
Viewers continue to search for the original video, making “Katrina Lim Kiffy viral video” a trending topic across major platforms. |
zoya-hammadk/nutrivision-roberta | zoya-hammadk | 2025-05-24T06:04:46Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/roberta-large",
"base_model:finetune:FacebookAI/roberta-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2025-05-24T04:17:15Z | ---
library_name: transformers
license: mit
base_model: roberta-large
tags:
- generated_from_trainer
model-index:
- name: nutrivision-roberta
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nutrivision-roberta
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.PAGED_ADAMW with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 7
### Training results
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 2.14.4
- Tokenizers 0.21.1
|
mradermacher/Pythia410m-Instruct-SFT-GGUF | mradermacher | 2025-05-24T06:04:10Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:SummerSigh/Pythia410m-Instruct-SFT",
"base_model:quantized:SummerSigh/Pythia410m-Instruct-SFT",
"endpoints_compatible",
"region:us"
]
| null | 2025-05-23T18:45:18Z | ---
base_model: SummerSigh/Pythia410m-Instruct-SFT
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/SummerSigh/Pythia410m-Instruct-SFT
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-GGUF/resolve/main/Pythia410m-Instruct-SFT.Q2_K.gguf) | Q2_K | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-GGUF/resolve/main/Pythia410m-Instruct-SFT.Q3_K_S.gguf) | Q3_K_S | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-GGUF/resolve/main/Pythia410m-Instruct-SFT.Q3_K_M.gguf) | Q3_K_M | 0.3 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-GGUF/resolve/main/Pythia410m-Instruct-SFT.IQ4_XS.gguf) | IQ4_XS | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-GGUF/resolve/main/Pythia410m-Instruct-SFT.Q3_K_L.gguf) | Q3_K_L | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-GGUF/resolve/main/Pythia410m-Instruct-SFT.Q4_K_S.gguf) | Q4_K_S | 0.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-GGUF/resolve/main/Pythia410m-Instruct-SFT.Q4_K_M.gguf) | Q4_K_M | 0.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-GGUF/resolve/main/Pythia410m-Instruct-SFT.Q5_K_S.gguf) | Q5_K_S | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-GGUF/resolve/main/Pythia410m-Instruct-SFT.Q5_K_M.gguf) | Q5_K_M | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-GGUF/resolve/main/Pythia410m-Instruct-SFT.Q6_K.gguf) | Q6_K | 0.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-GGUF/resolve/main/Pythia410m-Instruct-SFT.Q8_0.gguf) | Q8_0 | 0.5 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Pythia410m-Instruct-SFT-GGUF/resolve/main/Pythia410m-Instruct-SFT.f16.gguf) | f16 | 0.9 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF | mradermacher | 2025-05-24T06:04:10Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:refringence/ad-gpt2-finetuned-dch1",
"base_model:quantized:refringence/ad-gpt2-finetuned-dch1",
"endpoints_compatible",
"region:us",
"imatrix"
]
| null | 2025-05-24T05:53:54Z | ---
base_model: refringence/ad-gpt2-finetuned-dch1
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/refringence/ad-gpt2-finetuned-dch1
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-IQ1_S.gguf) | i1-IQ1_S | 0.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-IQ1_M.gguf) | i1-IQ1_M | 0.2 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-IQ2_XS.gguf) | i1-IQ2_XS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-IQ2_S.gguf) | i1-IQ2_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-IQ2_M.gguf) | i1-IQ2_M | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 0.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-Q2_K_S.gguf) | i1-Q2_K_S | 0.2 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-Q2_K.gguf) | i1-Q2_K | 0.2 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-IQ3_XS.gguf) | i1-IQ3_XS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-IQ3_S.gguf) | i1-IQ3_S | 0.2 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-Q3_K_S.gguf) | i1-Q3_K_S | 0.2 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-IQ3_M.gguf) | i1-IQ3_M | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-Q3_K_M.gguf) | i1-Q3_K_M | 0.2 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-IQ4_XS.gguf) | i1-IQ4_XS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-IQ4_NL.gguf) | i1-IQ4_NL | 0.2 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-Q4_0.gguf) | i1-Q4_0 | 0.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-Q4_K_S.gguf) | i1-Q4_K_S | 0.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-Q3_K_L.gguf) | i1-Q3_K_L | 0.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-Q4_1.gguf) | i1-Q4_1 | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-Q4_K_M.gguf) | i1-Q4_K_M | 0.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-Q5_K_S.gguf) | i1-Q5_K_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-Q5_K_M.gguf) | i1-Q5_K_M | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.i1-Q6_K.gguf) | i1-Q6_K | 0.2 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
KiViDrag/resnet34_AIvsHuman | KiViDrag | 2025-05-24T06:02:31Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"resnet",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2025-05-24T06:02:07Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mradermacher/ad-gpt2-finetuned-dch1-GGUF | mradermacher | 2025-05-24T06:00:48Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:refringence/ad-gpt2-finetuned-dch1",
"base_model:quantized:refringence/ad-gpt2-finetuned-dch1",
"endpoints_compatible",
"region:us"
]
| null | 2025-05-23T18:47:24Z | ---
base_model: refringence/ad-gpt2-finetuned-dch1
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/refringence/ad-gpt2-finetuned-dch1
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.Q2_K.gguf) | Q2_K | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.Q3_K_S.gguf) | Q3_K_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.Q3_K_M.gguf) | Q3_K_M | 0.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.IQ4_XS.gguf) | IQ4_XS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.Q4_K_S.gguf) | Q4_K_S | 0.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.Q3_K_L.gguf) | Q3_K_L | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.Q4_K_M.gguf) | Q4_K_M | 0.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.Q5_K_S.gguf) | Q5_K_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.Q5_K_M.gguf) | Q5_K_M | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.Q6_K.gguf) | Q6_K | 0.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.Q8_0.gguf) | Q8_0 | 0.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/ad-gpt2-finetuned-dch1-GGUF/resolve/main/ad-gpt2-finetuned-dch1.f16.gguf) | f16 | 0.4 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/DA-ctrl-bot-i1-GGUF | mradermacher | 2025-05-24T05:53:43Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:imumtozee/DA-ctrl-bot",
"base_model:quantized:imumtozee/DA-ctrl-bot",
"endpoints_compatible",
"region:us",
"imatrix"
]
| null | 2025-05-24T05:43:46Z | ---
base_model: imumtozee/DA-ctrl-bot
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/imumtozee/DA-ctrl-bot
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/DA-ctrl-bot-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-IQ1_S.gguf) | i1-IQ1_S | 0.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-IQ1_M.gguf) | i1-IQ1_M | 0.2 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-IQ2_XS.gguf) | i1-IQ2_XS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-IQ2_S.gguf) | i1-IQ2_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-IQ2_M.gguf) | i1-IQ2_M | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 0.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-Q2_K_S.gguf) | i1-Q2_K_S | 0.2 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-Q2_K.gguf) | i1-Q2_K | 0.2 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-IQ3_XS.gguf) | i1-IQ3_XS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-IQ3_S.gguf) | i1-IQ3_S | 0.2 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-Q3_K_S.gguf) | i1-Q3_K_S | 0.2 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-IQ3_M.gguf) | i1-IQ3_M | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-Q3_K_M.gguf) | i1-Q3_K_M | 0.2 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-IQ4_XS.gguf) | i1-IQ4_XS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-IQ4_NL.gguf) | i1-IQ4_NL | 0.2 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-Q4_0.gguf) | i1-Q4_0 | 0.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-Q4_K_S.gguf) | i1-Q4_K_S | 0.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-Q3_K_L.gguf) | i1-Q3_K_L | 0.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-Q4_1.gguf) | i1-Q4_1 | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-Q4_K_M.gguf) | i1-Q4_K_M | 0.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-Q5_K_S.gguf) | i1-Q5_K_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-Q5_K_M.gguf) | i1-Q5_K_M | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DA-ctrl-bot-i1-GGUF/resolve/main/DA-ctrl-bot.i1-Q6_K.gguf) | i1-Q6_K | 0.2 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
chloebrandon/results | chloebrandon | 2025-05-24T05:44:33Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"mt5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/mt5-small",
"base_model:finetune:google/mt5-small",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2025-05-24T05:43:59Z | ---
library_name: transformers
license: apache-2.0
base_model: google/mt5-small
tags:
- generated_from_trainer
model-index:
- name: results
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
shmdtalha/Mistral-Small-3.1-24B-Instruct-2503 | shmdtalha | 2025-05-24T05:44:23Z | 0 | 0 | vllm | [
"vllm",
"mistral3",
"image-text-to-text",
"conversational",
"en",
"fr",
"de",
"es",
"pt",
"it",
"ja",
"ko",
"ru",
"zh",
"ar",
"fa",
"id",
"ms",
"ne",
"pl",
"ro",
"sr",
"sv",
"tr",
"uk",
"vi",
"hi",
"bn",
"base_model:mistralai/Mistral-Small-3.1-24B-Base-2503",
"base_model:finetune:mistralai/Mistral-Small-3.1-24B-Base-2503",
"license:apache-2.0",
"region:us"
]
| image-text-to-text | 2025-05-24T05:28:24Z | ---
language:
- en
- fr
- de
- es
- pt
- it
- ja
- ko
- ru
- zh
- ar
- fa
- id
- ms
- ne
- pl
- ro
- sr
- sv
- tr
- uk
- vi
- hi
- bn
license: apache-2.0
library_name: vllm
inference: false
base_model:
- mistralai/Mistral-Small-3.1-24B-Base-2503
extra_gated_description: >-
If you want to learn more about how we process your personal data, please read
our <a href="https://mistral.ai/terms/">Privacy Policy</a>.
pipeline_tag: image-text-to-text
---
# Model Card for Mistral-Small-3.1-24B-Instruct-2503
Building upon Mistral Small 3 (2501), Mistral Small 3.1 (2503) **adds state-of-the-art vision understanding** and enhances **long context capabilities up to 128k tokens** without compromising text performance.
With 24 billion parameters, this model achieves top-tier capabilities in both text and vision tasks.
This model is an instruction-finetuned version of: [Mistral-Small-3.1-24B-Base-2503](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Base-2503).
Mistral Small 3.1 can be deployed locally and is exceptionally "knowledge-dense," fitting within a single RTX 4090 or a 32GB RAM MacBook once quantized.
It is ideal for:
- Fast-response conversational agents.
- Low-latency function calling.
- Subject matter experts via fine-tuning.
- Local inference for hobbyists and organizations handling sensitive data.
- Programming and math reasoning.
- Long document understanding.
- Visual understanding.
For enterprises requiring specialized capabilities (increased context, specific modalities, domain-specific knowledge, etc.), we will release commercial models beyond what Mistral AI contributes to the community.
Learn more about Mistral Small 3.1 in our [blog post](https://mistral.ai/news/mistral-small-3-1/).
## Key Features
- **Vision:** Vision capabilities enable the model to analyze images and provide insights based on visual content in addition to text.
- **Multilingual:** Supports dozens of languages, including English, French, German, Greek, Hindi, Indonesian, Italian, Japanese, Korean, Malay, Nepali, Polish, Portuguese, Romanian, Russian, Serbian, Spanish, Swedish, Turkish, Ukrainian, Vietnamese, Arabic, Bengali, Chinese, Farsi.
- **Agent-Centric:** Offers best-in-class agentic capabilities with native function calling and JSON outputting.
- **Advanced Reasoning:** State-of-the-art conversational and reasoning capabilities.
- **Apache 2.0 License:** Open license allowing usage and modification for both commercial and non-commercial purposes.
- **Context Window:** A 128k context window.
- **System Prompt:** Maintains strong adherence and support for system prompts.
- **Tokenizer:** Utilizes a Tekken tokenizer with a 131k vocabulary size.
## Benchmark Results
When available, we report numbers previously published by other model providers, otherwise we re-evaluate them using our own evaluation harness.
### Pretrain Evals
| Model | MMLU (5-shot) | MMLU Pro (5-shot CoT) | TriviaQA | GPQA Main (5-shot CoT)| MMMU |
|--------------------------------|---------------|-----------------------|------------|-----------------------|-----------|
| **Small 3.1 24B Base** | **81.01%** | **56.03%** | 80.50% | **37.50%** | **59.27%**|
| Gemma 3 27B PT | 78.60% | 52.20% | **81.30%** | 24.30% | 56.10% |
### Instruction Evals
#### Text
| Model | MMLU | MMLU Pro (5-shot CoT) | MATH | GPQA Main (5-shot CoT) | GPQA Diamond (5-shot CoT )| MBPP | HumanEval | SimpleQA (TotalAcc)|
|--------------------------------|-----------|-----------------------|------------------------|------------------------|---------------------------|-----------|-----------|--------------------|
| **Small 3.1 24B Instruct** | 80.62% | 66.76% | 69.30% | **44.42%** | **45.96%** | 74.71% | **88.41%**| **10.43%** |
| Gemma 3 27B IT | 76.90% | **67.50%** | **89.00%** | 36.83% | 42.40% | 74.40% | 87.80% | 10.00% |
| GPT4o Mini | **82.00%**| 61.70% | 70.20% | 40.20% | 39.39% | 84.82% | 87.20% | 9.50% |
| Claude 3.5 Haiku | 77.60% | 65.00% | 69.20% | 37.05% | 41.60% | **85.60%**| 88.10% | 8.02% |
| Cohere Aya-Vision 32B | 72.14% | 47.16% | 41.98% | 34.38% | 33.84% | 70.43% | 62.20% | 7.65% |
#### Vision
| Model | MMMU | MMMU PRO | Mathvista | ChartQA | DocVQA | AI2D | MM MT Bench |
|--------------------------------|------------|-----------|-----------|-----------|-----------|-------------|-------------|
| **Small 3.1 24B Instruct** | 64.00% | **49.25%**| **68.91%**| 86.24% | **94.08%**| **93.72%** | **7.3** |
| Gemma 3 27B IT | **64.90%** | 48.38% | 67.60% | 76.00% | 86.60% | 84.50% | 7 |
| GPT4o Mini | 59.40% | 37.60% | 56.70% | 76.80% | 86.70% | 88.10% | 6.6 |
| Claude 3.5 Haiku | 60.50% | 45.03% | 61.60% | **87.20%**| 90.00% | 92.10% | 6.5 |
| Cohere Aya-Vision 32B | 48.20% | 31.50% | 50.10% | 63.04% | 72.40% | 82.57% | 4.1 |
### Multilingual Evals
| Model | Average | European | East Asian | Middle Eastern |
|--------------------------------|------------|------------|------------|----------------|
| **Small 3.1 24B Instruct** | **71.18%** | **75.30%** | **69.17%** | 69.08% |
| Gemma 3 27B IT | 70.19% | 74.14% | 65.65% | 70.76% |
| GPT4o Mini | 70.36% | 74.21% | 65.96% | **70.90%** |
| Claude 3.5 Haiku | 70.16% | 73.45% | 67.05% | 70.00% |
| Cohere Aya-Vision 32B | 62.15% | 64.70% | 57.61% | 64.12% |
### Long Context Evals
| Model | LongBench v2 | RULER 32K | RULER 128K |
|--------------------------------|-----------------|-------------|------------|
| **Small 3.1 24B Instruct** | **37.18%** | **93.96%** | 81.20% |
| Gemma 3 27B IT | 34.59% | 91.10% | 66.00% |
| GPT4o Mini | 29.30% | 90.20% | 65.8% |
| Claude 3.5 Haiku | 35.19% | 92.60% | **91.90%** |
## Basic Instruct Template (V7-Tekken)
```
<s>[SYSTEM_PROMPT]<system prompt>[/SYSTEM_PROMPT][INST]<user message>[/INST]<assistant response></s>[INST]<user message>[/INST]
```
*`<system_prompt>`, `<user message>` and `<assistant response>` are placeholders.*
***Please make sure to use [mistral-common](https://github.com/mistralai/mistral-common) as the source of truth***
## Usage
The model can be used with the following frameworks;
- [`vllm (recommended)`](https://github.com/vllm-project/vllm): See [here](#vllm)
**Note 1**: We recommend using a relatively low temperature, such as `temperature=0.15`.
**Note 2**: Make sure to add a system prompt to the model to best tailer it for your needs. If you want to use the model as a general assistant, we recommend the following
system prompt:
```
system_prompt = """You are Mistral Small 3.1, a Large Language Model (LLM) created by Mistral AI, a French startup headquartered in Paris.
You power an AI assistant called Le Chat.
Your knowledge base was last updated on 2023-10-01.
The current date is {today}.
When you're not sure about some information, you say that you don't have the information and don't make up anything.
If the user's question is not clear, ambiguous, or does not provide enough context for you to accurately answer the question, you do not try to answer it right away and you rather ask the user to clarify their request (e.g. "What are some good restaurants around me?" => "Where are you?" or "When is the next flight to Tokyo" => "Where do you travel from?").
You are always very attentive to dates, in particular you try to resolve dates (e.g. "yesterday" is {yesterday}) and when asked about information at specific dates, you discard information that is at another date.
You follow these instructions in all languages, and always respond to the user in the language they use or request.
Next sections describe the capabilities that you have.
# WEB BROWSING INSTRUCTIONS
You cannot perform any web search or access internet to open URLs, links etc. If it seems like the user is expecting you to do so, you clarify the situation and ask the user to copy paste the text directly in the chat.
# MULTI-MODAL INSTRUCTIONS
You have the ability to read images, but you cannot generate images. You also cannot transcribe audio files or videos.
You cannot read nor transcribe audio files or videos."""
```
### vLLM (recommended)
We recommend using this model with the [vLLM library](https://github.com/vllm-project/vllm)
to implement production-ready inference pipelines.
**_Installation_**
Make sure you install [`vLLM >= 0.8.1`](https://github.com/vllm-project/vllm/releases/tag/v0.8.1):
```
pip install vllm --upgrade
```
Doing so should automatically install [`mistral_common >= 1.5.4`](https://github.com/mistralai/mistral-common/releases/tag/v1.5.4).
To check:
```
python -c "import mistral_common; print(mistral_common.__version__)"
```
You can also make use of a ready-to-go [docker image](https://github.com/vllm-project/vllm/blob/main/Dockerfile) or on the [docker hub](https://hub.docker.com/layers/vllm/vllm-openai/latest/images/sha256-de9032a92ffea7b5c007dad80b38fd44aac11eddc31c435f8e52f3b7404bbf39).
#### Server
We recommand that you use Mistral-Small-3.1-24B-Instruct-2503 in a server/client setting.
1. Spin up a server:
```
vllm serve mistralai/Mistral-Small-3.1-24B-Instruct-2503 --tokenizer_mode mistral --config_format mistral --load_format mistral --tool-call-parser mistral --enable-auto-tool-choice --limit_mm_per_prompt 'image=10' --tensor-parallel-size 2
```
**Note:** Running Mistral-Small-3.1-24B-Instruct-2503 on GPU requires ~55 GB of GPU RAM in bf16 or fp16.
2. To ping the client you can use a simple Python snippet.
```py
import requests
import json
from huggingface_hub import hf_hub_download
from datetime import datetime, timedelta
url = "http://<your-server-url>:8000/v1/chat/completions"
headers = {"Content-Type": "application/json", "Authorization": "Bearer token"}
model = "mistralai/Mistral-Small-3.1-24B-Instruct-2503"
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
today = datetime.today().strftime("%Y-%m-%d")
yesterday = (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d")
model_name = repo_id.split("/")[-1]
return system_prompt.format(name=model_name, today=today, yesterday=yesterday)
SYSTEM_PROMPT = load_system_prompt(model, "SYSTEM_PROMPT.txt")
image_url = "https://huggingface.co/datasets/patrickvonplaten/random_img/resolve/main/europe.png"
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which of the depicted countries has the best food? Which the second and third and fourth? Name the country, its color on the map and one its city that is visible on the map, but is not the capital. Make absolutely sure to only name a city that can be seen on the map.",
},
{"type": "image_url", "image_url": {"url": image_url}},
],
},
]
data = {"model": model, "messages": messages, "temperature": 0.15}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.json()["choices"][0]["message"]["content"])
# Determining the "best" food is highly subjective and depends on personal preferences. However, based on general popularity and recognition, here are some countries known for their cuisine:
# 1. **Italy** - Color: Light Green - City: Milan
# - Italian cuisine is renowned worldwide for its pasta, pizza, and various regional specialties.
# 2. **France** - Color: Brown - City: Lyon
# - French cuisine is celebrated for its sophistication, including dishes like coq au vin, bouillabaisse, and pastries like croissants and éclairs.
# 3. **Spain** - Color: Yellow - City: Bilbao
# - Spanish cuisine offers a variety of flavors, from paella and tapas to jamón ibérico and churros.
# 4. **Greece** - Not visible on the map
# - Greek cuisine is known for dishes like moussaka, souvlaki, and baklava. Unfortunately, Greece is not visible on the provided map, so I cannot name a city.
# Since Greece is not visible on the map, I'll replace it with another country known for its good food:
# 4. **Turkey** - Color: Light Green (east part of the map) - City: Istanbul
# - Turkish cuisine is diverse and includes dishes like kebabs, meze, and baklava.
```
### Function calling
Mistral-Small-3.1-24-Instruct-2503 is excellent at function / tool calling tasks via vLLM. *E.g.:*
<details>
<summary>Example</summary>
```py
import requests
import json
from huggingface_hub import hf_hub_download
from datetime import datetime, timedelta
url = "http://<your-url>:8000/v1/chat/completions"
headers = {"Content-Type": "application/json", "Authorization": "Bearer token"}
model = "mistralai/Mistral-Small-3.1-24B-Instruct-2503"
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
today = datetime.today().strftime("%Y-%m-%d")
yesterday = (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d")
model_name = repo_id.split("/")[-1]
return system_prompt.format(name=model_name, today=today, yesterday=yesterday)
SYSTEM_PROMPT = load_system_prompt(model, "SYSTEM_PROMPT.txt")
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "The city to find the weather for, e.g. 'San Francisco'",
},
"state": {
"type": "string",
"description": "The state abbreviation, e.g. 'CA' for California",
},
"unit": {
"type": "string",
"description": "The unit for temperature",
"enum": ["celsius", "fahrenheit"],
},
},
"required": ["city", "state", "unit"],
},
},
},
{
"type": "function",
"function": {
"name": "rewrite",
"description": "Rewrite a given text for improved clarity",
"parameters": {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "The input text to rewrite",
}
},
},
},
},
]
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": "Could you please make the below article more concise?\n\nOpenAI is an artificial intelligence research laboratory consisting of the non-profit OpenAI Incorporated and its for-profit subsidiary corporation OpenAI Limited Partnership.",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "bbc5b7ede",
"type": "function",
"function": {
"name": "rewrite",
"arguments": '{"text": "OpenAI is an artificial intelligence research laboratory consisting of the non-profit OpenAI Incorporated and its for-profit subsidiary corporation OpenAI Limited Partnership."}',
},
}
],
},
{
"role": "tool",
"content": '{"action":"rewrite","outcome":"OpenAI is a FOR-profit company."}',
"tool_call_id": "bbc5b7ede",
"name": "rewrite",
},
{
"role": "assistant",
"content": "---\n\nOpenAI is a FOR-profit company.",
},
{
"role": "user",
"content": "Can you tell me what the temperature will be in Dallas, in Fahrenheit?",
},
]
data = {"model": model, "messages": messages, "tools": tools, "temperature": 0.15}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.json()["choices"][0]["message"]["tool_calls"])
# [{'id': '8PdihwL6d', 'type': 'function', 'function': {'name': 'get_current_weather', 'arguments': '{"city": "Dallas", "state": "TX", "unit": "fahrenheit"}'}}]
```
</details>
#### Offline
```py
from vllm import LLM
from vllm.sampling_params import SamplingParams
from datetime import datetime, timedelta
SYSTEM_PROMPT = "You are a conversational agent that always answers straight to the point, always end your accurate response with an ASCII drawing of a cat."
user_prompt = "Give me 5 non-formal ways to say 'See you later' in French."
messages = [
{
"role": "system",
"content": SYSTEM_PROMPT
},
{
"role": "user",
"content": user_prompt
},
]
model_name = "mistralai/Mistral-Small-3.1-24B-Instruct-2503"
# note that running this model on GPU requires over 60 GB of GPU RAM
llm = LLM(model=model_name, tokenizer_mode="mistral")
sampling_params = SamplingParams(max_tokens=512, temperature=0.15)
outputs = llm.chat(messages, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
# Here are five non-formal ways to say "See you later" in French:
# 1. **À plus tard** - Until later
# 2. **À toute** - See you soon (informal)
# 3. **Salut** - Bye (can also mean hi)
# 4. **À plus** - See you later (informal)
# 5. **Ciao** - Bye (informal, borrowed from Italian)
# ```
# /\_/\
# ( o.o )
# > ^ <
# ```
```
### Transformers (untested)
Transformers-compatible model weights are also uploaded (thanks a lot @cyrilvallez).
However the transformers implementation was **not throughly tested**, but only on "vibe-checks".
Hence, we can only ensure 100% correct behavior when using the original weight format with vllm (see above). |
nis12ram/Nemotron-4-Mini-Hindi-4B-intermediate-gliner-en-exp2 | nis12ram | 2025-05-24T05:42:50Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"nemotron",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:nis12ram/Nemotron-4-Mini-Hindi-4B-Instruct",
"base_model:finetune:nis12ram/Nemotron-4-Mini-Hindi-4B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2025-05-24T05:35:08Z | ---
base_model: nis12ram/Nemotron-4-Mini-Hindi-4B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- nemotron
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** nis12ram
- **License:** apache-2.0
- **Finetuned from model :** nis12ram/Nemotron-4-Mini-Hindi-4B-Instruct
This nemotron model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
gavrilstep/695499a5-8c46-4080-86f5-c781bfab9ac1 | gavrilstep | 2025-05-24T05:42:46Z | 0 | 0 | peft | [
"peft",
"safetensors",
"gemma",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/codegemma-7b",
"base_model:adapter:unsloth/codegemma-7b",
"license:apache-2.0",
"8-bit",
"bitsandbytes",
"region:us"
]
| null | 2025-05-24T05:25:47Z | ---
library_name: peft
license: apache-2.0
base_model: unsloth/codegemma-7b
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 695499a5-8c46-4080-86f5-c781bfab9ac1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: unsloth/codegemma-7b
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- 3a95f0218346ddba_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/3a95f0218346ddba_train_data.json
type:
field_input: input
field_instruction: instruct
field_output: output
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_clipping: 0.55
group_by_length: false
hub_model_id: gavrilstep/695499a5-8c46-4080-86f5-c781bfab9ac1
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 1.0e-06
load_in_4bit: true
load_in_8bit: true
local_rank: null
logging_steps: 1
lora_alpha: 96
lora_dropout: 0.01
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 48
lora_target_linear: true
lr_scheduler: cosine
max_steps: 150
micro_batch_size: 4
mixed_precision: bf16
mlflow_experiment_name: /tmp/3a95f0218346ddba_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 2048
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: dc30820e-a6ab-4a52-b146-21660afc11be
wandb_project: s56-7
wandb_run: your_name
wandb_runid: dc30820e-a6ab-4a52-b146-21660afc11be
warmup_steps: 5
weight_decay: 0.01
xformers_attention: false
```
</details><br>
# 695499a5-8c46-4080-86f5-c781bfab9ac1
This model is a fine-tuned version of [unsloth/codegemma-7b](https://huggingface.co/unsloth/codegemma-7b) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8025
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 2.2859 | 0.0702 | 150 | 2.8025 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
Juicesyo/csm-Encore | Juicesyo | 2025-05-24T05:42:44Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"csm",
"text-to-audio",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/csm-1b",
"base_model:finetune:unsloth/csm-1b",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| text-to-audio | 2025-05-24T05:35:47Z | ---
base_model: unsloth/csm-1b
tags:
- text-generation-inference
- transformers
- unsloth
- csm
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Juicesyo
- **License:** apache-2.0
- **Finetuned from model :** unsloth/csm-1b
This csm model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
MaoyueOUO/Cosmos-Reason1-7B-GGUF | MaoyueOUO | 2025-05-24T05:39:04Z | 0 | 0 | null | [
"gguf",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2025-05-24T04:55:43Z | ---
license: other
license_name: nvidia-open-model-license
license_link: >-
https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
---
|
7Dragons/prime_1 | 7Dragons | 2025-05-24T05:37:40Z | 0 | 0 | null | [
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
]
| any-to-any | 2025-05-24T05:31:20Z | ---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
chloebrandon/my_output_dir_3 | chloebrandon | 2025-05-24T05:29:34Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"mt5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/mt5-small",
"base_model:finetune:google/mt5-small",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2025-05-24T04:57:10Z | ---
library_name: transformers
license: apache-2.0
base_model: google/mt5-small
tags:
- generated_from_trainer
model-index:
- name: my_output_dir_3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_output_dir_3
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
DAKARA555/side | DAKARA555 | 2025-05-24T05:27:31Z | 16 | 0 | diffusers | [
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:Wan-AI/Wan2.1-I2V-14B-480P",
"base_model:adapter:Wan-AI/Wan2.1-I2V-14B-480P",
"license:apache-2.0",
"region:us"
]
| text-to-image | 2025-05-19T19:57:22Z | ---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- text: '-'
output:
url: images/white.png
base_model: Wan-AI/Wan2.1-I2V-14B-480P
instance_prompt: null
license: apache-2.0
---
# side
<Gallery />
## Model description
https://civitai.com/models/1361682/side-lying-sex-wan-i2v-14b
https://huggingface.co/DAKARA555/side/resolve/main/P001-SideSex-Wan-i2v-v10-000010_converted.safetensors?download=true
## Download model
Weights for this model are available in Safetensors format.
[Download](/DAKARA555/side/tree/main) them in the Files & versions tab.
|
MinaMila/llama_instbase_3b_LoRa_ACSEmployment_2_cfda_ep7_22 | MinaMila | 2025-05-24T05:26:01Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2025-05-24T05:25:54Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
watch-katrina-lim-kiffy-full-origin/VIDEO-18-Katrina-Lim-Viral-Kiffy-Viral-Video-Full-Video | watch-katrina-lim-kiffy-full-origin | 2025-05-24T05:25:53Z | 0 | 0 | null | [
"region:us"
]
| null | 2025-05-24T05:24:03Z | Watch 🟢 ➤ ➤ ➤ <a href="https://witvidz.com/originalviralvideo"> 🌐 Click Here To link (Full Viral Video Link)
🔴 ➤►DOWNLOAD👉👉🟢 ➤
Watch 🟢 ➤ ➤ ➤ <a href="https://witvidz.com/originalviralvideo"> 🌐 Click Here To link (Full Viral Video Link)
🔴 ➤►DOWNLOAD👉👉🟢 ➤

|
VIDEO-18-Starbucks-Girl-Original-Video/FULL.VIDEO.LINK.Starbucks.Viral.Video.Leaks.Official | VIDEO-18-Starbucks-Girl-Original-Video | 2025-05-24T05:21:43Z | 0 | 0 | null | [
"region:us"
]
| null | 2025-05-24T05:21:28Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
MinaMila/gemma2_2b_unlearned_gu_LoRa_GermanCredit_cfda_ep7_55 | MinaMila | 2025-05-24T05:20:28Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2025-05-24T05:20:25Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
watch-katrina-lim-kiffy-full-origin/katrina-lim-viral-video-scandal-Philippines | watch-katrina-lim-kiffy-full-origin | 2025-05-24T05:17:30Z | 0 | 0 | null | [
"region:us"
]
| null | 2025-05-24T05:16:49Z | Watch 🟢 ➤ ➤ ➤ <a href="https://witvidz.com/originalviralvideo"> 🌐 Click Here To link (Full Viral Video Link)
🔴 ➤►DOWNLOAD👉👉🟢 ➤
Watch 🟢 ➤ ➤ ➤ <a href="https://witvidz.com/originalviralvideo"> 🌐 Click Here To link (Full Viral Video Link)
🔴 ➤►DOWNLOAD👉👉🟢 ➤
|
Subsets and Splits