
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-02 12:29:30
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 548
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-02 12:29:18
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
borough-oblast/marian-finetuned-kde4-en-to-fr
|
borough-oblast
| 2023-11-17T04:20:39Z | 4 | 0 |
transformers
|
[
"transformers",
"tf",
"marian",
"text2text-generation",
"generated_from_keras_callback",
"base_model:Helsinki-NLP/opus-mt-en-fr",
"base_model:finetune:Helsinki-NLP/opus-mt-en-fr",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-17T02:35:43Z |
---
license: apache-2.0
base_model: Helsinki-NLP/opus-mt-en-fr
tags:
- generated_from_keras_callback
model-index:
- name: borough-oblast/marian-finetuned-kde4-en-to-fr
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# borough-oblast/marian-finetuned-kde4-en-to-fr
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-fr](https://huggingface.co/Helsinki-NLP/opus-mt-en-fr) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.6846
- Validation Loss: 0.8108
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 17733, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.0600 | 0.8850 | 0 |
| 0.7968 | 0.8287 | 1 |
| 0.6846 | 0.8108 | 2 |
### Framework versions
- Transformers 4.35.0
- TensorFlow 2.13.0
- Datasets 2.1.0
- Tokenizers 0.14.1
|
MattStammers/appo-atari_namethisgame-superhuman
|
MattStammers
| 2023-11-17T04:03:31Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-26T18:00:05Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: atari_namethisgame
type: atari_namethisgame
metrics:
- type: mean_reward
value: 22607.00 +/- 2779.10
name: mean_reward
verified: false
---
## About the Project
This project is an attempt to maximise performance of high sample throughput APPO RL models in Atari environments in as carbon efficient a manner as possible using a single, not particularly high performance single machine. It is about demonstrating the generalisability of on-policy algorithms to create good performance quickly (by sacrificing sample efficiency) while also proving that this route to RL production is accessible to even hobbyists like me (I am a gastroenterologist not a computer scientist).
In terms of throughput I am managing to reach throughputs of 2,500 - 3,000 across both policies using sample factory using two Quadro P2200's (not particularly powerful GPUs) each loaded up about 60% (3GB). Previously using the stable baselines 3 (sb3) implementation of PPO it would take about a week to train an atari agent to 100 million timesteps synchronously. By comparison the sample factory async implementation takes only just over 2 hours to achieve the same result. That is about 84 times faster with only typically a 21 watt burn per GPU. I am thus very grateful to Alex Petrenko and all the sample factory team for their work on this.
## Project Aims
This model as with all the others in the benchmarks was trained initially asynchronously un-seeded to 10 million steps for the purposes of setting a sample factory async baseline for this model on this environment but only 3/57 made it anywhere near sota performance.
I then re-trained the models with 100 million timesteps- at this point 2 environments maxed out at sota performance (Pong and Freeway) with four approaching sota performance - (atlantis, boxing, tennis and fishingderby.) =6/57 near sota.
The aim now is to try and reach state-of-the-art (SOTA) performance on a further block of atari environments using up to 1 billion training timesteps initially with appo. I will flag the models with SOTA when they reach at or near these levels.
After this I will switch on V-Trace to see if the Impala variations perform any better with the same seed (I have seeded '1234')
## About the Model
The hyperparameters used in the model are described in my shell script on my fork of sample-factory: https://github.com/MattStammers/sample-factory. Given that https://huggingface.co/edbeeching has kindly shared his parameters, I saved time and energy by using many of his tuned hyperparameters to reduce carbon inefficiency:
```
hyperparameters = {
"help": false,
"algo": "APPO",
"env": "atari_asteroid",
"experiment": "atari_asteroid_APPO",
"train_dir": "./train_atari",
"restart_behavior": "restart",
"device": "gpu",
"seed": 1234,
"num_policies": 2,
"async_rl": true,
"serial_mode": false,
"batched_sampling": true,
"num_batches_to_accumulate": 2,
"worker_num_splits": 1,
"policy_workers_per_policy": 1,
"max_policy_lag": 1000,
"num_workers": 16,
"num_envs_per_worker": 2,
"batch_size": 1024,
"num_batches_per_epoch": 8,
"num_epochs": 4,
"rollout": 128,
"recurrence": 1,
"shuffle_minibatches": false,
"gamma": 0.99,
"reward_scale": 1.0,
"reward_clip": 1000.0,
"value_bootstrap": false,
"normalize_returns": true,
"exploration_loss_coeff": 0.0004677351413,
"value_loss_coeff": 0.5,
"kl_loss_coeff": 0.0,
"exploration_loss": "entropy",
"gae_lambda": 0.95,
"ppo_clip_ratio": 0.1,
"ppo_clip_value": 1.0,
"with_vtrace": false,
"vtrace_rho": 1.0,
"vtrace_c": 1.0,
"optimizer": "adam",
"adam_eps": 1e-05,
"adam_beta1": 0.9,
"adam_beta2": 0.999,
"max_grad_norm": 0.0,
"learning_rate": 0.0003033891184,
"lr_schedule": "linear_decay",
"lr_schedule_kl_threshold": 0.008,
"lr_adaptive_min": 1e-06,
"lr_adaptive_max": 0.01,
"obs_subtract_mean": 0.0,
"obs_scale": 255.0,
"normalize_input": true,
"normalize_input_keys": [
"obs"
],
"decorrelate_experience_max_seconds": 0,
"decorrelate_envs_on_one_worker": true,
"actor_worker_gpus": [],
"set_workers_cpu_affinity": true,
"force_envs_single_thread": false,
"default_niceness": 0,
"log_to_file": true,
"experiment_summaries_interval": 3,
"flush_summaries_interval": 30,
"stats_avg": 100,
"summaries_use_frameskip": true,
"heartbeat_interval": 10,
"heartbeat_reporting_interval": 60,
"train_for_env_steps": 100000000,
"train_for_seconds": 10000000000,
"save_every_sec": 120,
"keep_checkpoints": 2,
"load_checkpoint_kind": "latest",
"save_milestones_sec": 1200,
"save_best_every_sec": 5,
"save_best_metric": "reward",
"save_best_after": 100000,
"benchmark": false,
"encoder_mlp_layers": [
512,
512
],
"encoder_conv_architecture": "convnet_atari",
"encoder_conv_mlp_layers": [
512
],
"use_rnn": false,
"rnn_size": 512,
"rnn_type": "gru",
"rnn_num_layers": 1,
"decoder_mlp_layers": [],
"nonlinearity": "relu",
"policy_initialization": "orthogonal",
"policy_init_gain": 1.0,
"actor_critic_share_weights": true,
"adaptive_stddev": false,
"continuous_tanh_scale": 0.0,
"initial_stddev": 1.0,
"use_env_info_cache": false,
"env_gpu_actions": false,
"env_gpu_observations": true,
"env_frameskip": 4,
"env_framestack": 4,
"pixel_format": "CHW"
}
```
A(n) **APPO** model trained on the **atari_namethisgame** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory. Sample factory is a
high throughput on-policy RL framework. I have been using
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r MattStammers/APPO-atari_namethisgame
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m sf_examples.atari.enjoy_atari --algo=APPO --env=atari_namethisgame --train_dir=./train_dir --experiment=APPO-atari_namethisgame
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m sf_examples.atari.train_atari --algo=APPO --env=atari_namethisgame --train_dir=./train_dir --experiment=APPO-atari_namethisgame --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
stabilityai/japanese-instructblip-alpha
|
stabilityai
| 2023-11-17T03:57:41Z | 473 | 53 |
transformers
|
[
"transformers",
"pytorch",
"instructblip",
"feature-extraction",
"vision",
"image-captioning",
"japanese-stablelm",
"image-to-text",
"custom_code",
"ja",
"arxiv:2305.06500",
"license:other",
"region:us"
] |
image-to-text
| 2023-08-15T12:07:00Z |
---
language:
- ja
tags:
- instructblip
- vision
- image-captioning
- japanese-stablelm
pipeline_tag: image-to-text
license:
- other
extra_gated_heading: Access Japanese StableLM Instruct Alpha
extra_gated_description: This repository is publicly accessible, but you have to accept the conditions to access its files and content.
extra_gated_button_content: Access repository
extra_gated_fields:
Name: text
Email: text
Organization: text
I agree to accept the conditions and share above info with Stability AI: checkbox
extra_gated_prompt: |
### JAPANESE STABLELM RESEARCH LICENSE AGREEMENT
Dated: August 7, 2023
"Agreement" means the terms and conditions for use, reproduction, distribution and modification of the Software Products set forth herein.
“Documentation” means any specifications, manuals, documentation, and other written information provided by Stability AI related to the Software.
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into this Agreement on such person’s or entity's behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf.
"Stability AI" or "we" means Stability AI Ltd.
"Software" means, collectively, Stability AI’s proprietary Japanese StableLM made available under this Agreement.
“Software Products” means Software and Documentation.
By using or distributing any portion or element of the Software Products, you agree to be bound by this Agreement.
- License Rights and Redistribution.
- Subject to your compliance with this Agreement and the Documentation, Stability AI grants you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty free and limited license under Stability AI’s intellectual property or other rights owned by Stability AI embodied in the Software Products to reproduce, distribute, and create derivative works of the Software Products for purposes other than commercial or production use.
- You will not, and will not permit, assist or cause any third party to use, modify, copy, reproduce, create derivative works of, or distribute the Software Products (or any derivative works thereof, works incorporating the Software Products, or any data produced by the Software), in whole or in part, for any commercial or production purposes.
- If you distribute or make the Software Products, or any derivative works thereof, available to a third party, you shall (i) provide a copy of this Agreement to such third party, and (ii) retain the following attribution notice within a "Notice" text file distributed as a part of such copies: "Japanese StableLM is licensed under the Japanese StableLM Research License, Copyright (c) Stability AI Ltd. All Rights Reserved.”
- The licenses granted to you under this Agreement are conditioned upon your compliance with the Documentation and this Agreement, including the Acceptable Use Policy below and as may be updated from time to time in the future on stability.ai, which is hereby incorporated by reference into this Agreement.
- Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE SOFTWARE PRODUCTS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE SOFTWARE PRODUCTS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE SOFTWARE PRODUCTS AND ANY OUTPUT AND RESULTS.
- Limitation of Liability. IN NO EVENT WILL STABILITY AI OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF STABILITY AI OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
- Intellectual Property.
- No trademark licenses are granted under this Agreement, and in connection with the Software Products, neither Stability AI nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates, except as required for reasonable and customary use in describing and redistributing the Software Products.
- Subject to Stability AI’s ownership of the Software Products and derivatives made by or for Stability AI, with respect to any derivative works and modifications of the Software Products that are made by you, as between you and Stability AI, you are and will be the owner of such derivative works and modifications.
- If you institute litigation or other proceedings against Stability AI (including a cross-claim or counterclaim in a lawsuit) alleging that the Software Products or associated outputs or results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Stability AI from and against any claim by any third party arising out of or related to your use or distribution of the Software Products in violation of this Agreement.
- Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Software Products and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Stability AI may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of the Software Products. Sections 2-4 shall survive the termination of this Agreement.
—----------
### Japanese StableLM Acceptable Use Policy
If you access, use, or distribute any Stability AI models, software, or other materials (“Stability Technology”) you agree to this Acceptable Use Policy (“Policy”).
We want everyone to use Stability Technology safely and responsibly. You agree you will not use, or allow others to use, Stability Technology to:
- To violate the law or others’ rights (including intellectual property rights and the rights of data privacy and protection), nor will you promote, contribute to, encourage, facilitate, plan, incite, or further anyone else’s violation of the law or others’ rights;
- To commit, promote, contribute to, facilitate, encourage, plan, incite, or further any of the following:
- Violence or terrorism;
- Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content;
- Human trafficking, exploitation, and sexual violence;
- Harassment, abuse, threatening, stalking, or bullying of individuals or groups of individuals;
- Discrimination in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services on the basis of race, color, caste, religion, sex (including pregnancy, sexual orientation, or gender identity), national origin, age, disability, or genetic information (including family medical history) except as may be required by applicable law (such as the provision of social security benefits solely to people who meet certain age requirements under the law);
- Creation of malicious code, malware, computer viruses or any activity that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system;
- For purposes of or for the performance of:
- Fully automated decision-making, including profiling, with respect to an individual or group of individuals which produces legal effects concerning such individual(s) or similarly significantly affects such individual(s);
- Systematic or automated scraping, mining, extraction, or harvesting of personally identifiable data, or similar activity, from the output of any Stability Technology except with respect to data that you have provided as input to the Stability Technology and which you are legally entitled to process, for so long as you retain such entitlement;
- Development, improvement, or manufacture of any weapons of mass destruction (such as nuclear, chemical, or biologic weapons), weapons of war (such as missiles or landmines), or any gain of function-related activities with respect to any pathogens;
- Mission critical applications or systems where best industry practices require fail-safe controls or performance, including operation of nuclear facilities, aircraft navigation, electrical grids, communication systems, water treatment facilities, air traffic control, life support, weapons systems, or emergency locator or other emergency services;
- To intentionally deceive or mislead others, including use of Japanese StableLM related to the following:
- Generating, promoting, or furthering fraud or the creation or promotion of disinformation;
- Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content;
- Generating, promoting, or further distributing spam;
- Impersonating another individual without consent, authorization, or legal right
- Representing or misleading people into believing that the use of Japanese StableLM or outputs are human-generated;
- Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement;
- Generating or facilitating large-scale political advertisements, propaganda, or influence campaigns;
- Fail to appropriately disclose to end users any known dangers of your AI system or misrepresent or mislead with respect to its abilities.
Nothing in this AUP is intended to prevent or impede any good faith research, testing, or evaluation of Japanese StableLM, or publication related to any of the foregoing. If you discover any flaws in Japanese StableLM that may be harmful to people in any way, we encourage you to notify us and give us a chance to remedy such flaws before others can exploit them. If you have questions about this AUP, contact us at [email protected].
---
# Japanese InstructBLIP Alpha

## Model Details
Japanese InstructBLIP Alpha is a vision-language instruction-following model that enables to generate Japanese descriptions for input images and optionally input texts such as questions.
## Usage
First install additional dependencies in [requirements.txt](./requirements.txt):
```sh
pip install sentencepiece einops
```
```python
import torch
from transformers import LlamaTokenizer, AutoModelForVision2Seq, BlipImageProcessor
from PIL import Image
import requests
# helper function to format input prompts
def build_prompt(prompt="", sep="\n\n### "):
sys_msg = "以下は、タスクを説明する指示と、文脈のある入力の組み合わせです。要求を適切に満たす応答を書きなさい。"
p = sys_msg
roles = ["指示", "応答"]
user_query = "与えられた画像について、詳細に述べてください。"
msgs = [": \n" + user_query, ": "]
if prompt:
roles.insert(1, "入力")
msgs.insert(1, ": \n" + prompt)
for role, msg in zip(roles, msgs):
p += sep + role + msg
return p
# load model
model = AutoModelForVision2Seq.from_pretrained("stabilityai/japanese-instructblip-alpha", trust_remote_code=True)
processor = BlipImageProcessor.from_pretrained("stabilityai/japanese-instructblip-alpha")
tokenizer = LlamaTokenizer.from_pretrained("novelai/nerdstash-tokenizer-v1", additional_special_tokens=['▁▁'])
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
# prepare inputs
url = "https://images.unsplash.com/photo-1582538885592-e70a5d7ab3d3?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=1770&q=80"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
prompt = "" # input empty string for image captioning. You can also input questions as prompts
prompt = build_prompt(prompt)
inputs = processor(images=image, return_tensors="pt")
text_encoding = tokenizer(prompt, add_special_tokens=False, return_tensors="pt")
text_encoding["qformer_input_ids"] = text_encoding["input_ids"].clone()
text_encoding["qformer_attention_mask"] = text_encoding["attention_mask"].clone()
inputs.update(text_encoding)
# generate
outputs = model.generate(
**inputs.to(device, dtype=model.dtype),
num_beams=5,
max_new_tokens=32,
min_length=1,
)
generated_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0].strip()
print(generated_text)
# 桜と東京スカイツリー
```
## Model Details
* **Developed by**: [Stability AI](https://stability.ai/)
* **Model type**: [InstructBLIP](https://arxiv.org/abs/2305.06500)
* **Language(s)**: Japanese
* **License**: [JAPANESE STABLELM RESEARCH LICENSE AGREEMENT](./LICENSE).
### Training
Japanese InstructBLIP Alpha leverages the [InstructBLIP](https://arxiv.org/abs/2305.06500) architecture. It consists of 3 components: a frozen vision image encoder, a Q-Former, and a frozen LLM. The vision encoder and the Q-Former were initialized with [Salesforce/instructblip-vicuna-7b](https://huggingface.co/Salesforce/instructblip-vicuna-7b). For the frozen LLM, [Japanese-StableLM-Instruct-Alpha-7B](https://huggingface.co/stabilityai/japanese-stablelm-instruct-alpha-7b) model was used. During training, only Q-Former was trained.
### Training Dataset
The training dataset includes the following public datasets:
- [CC12M](https://github.com/google-research-datasets/conceptual-12m) with captions translated into Japanese
- [MS-COCO](https://cocodataset.org/#home) with [STAIR Captions](http://captions.stair.center/)
- [Japanese Visual Genome VQA dataset](https://github.com/yahoojapan/ja-vg-vqa)
## Use and Limitations
### Intended Use
This model is intended to be used by the open-source community in chat-like applications in adherence with the research license.
### Limitations and bias
Although the aforementioned datasets help to steer the base language models into "safer" distributions of text, not all biases and toxicity can be mitigated through fine-tuning. We ask that users be mindful of such potential issues that can arise in generated responses. Do not treat model outputs as substitutes for human judgment or as sources of truth. Please use responsibly.
## How to cite
```bibtex
@misc{JapaneseInstructBLIPAlpha,
url = {[https://huggingface.co/stabilityai/japanese-instructblip-alpha](https://huggingface.co/stabilityai/japanese-instructblip-alpha)},
title = {Japanese InstructBLIP Alpha},
author = {Shing, Makoto and Akiba, Takuya}
}
```
## Citations
```bibtex
@misc{dai2023instructblip,
title = {InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning},
author = {Wenliang Dai and Junnan Li and Dongxu Li and Anthony Meng Huat Tiong and Junqi Zhao and Weisheng Wang and Boyang Li and Pascale Fung and Steven Hoi},
year = {2023},
eprint = {2305.06500},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
```
## Contact
* For questions and comments about the model, please join [Stable Community Japan](https://discord.com/invite/StableJP).
* For future announcements / information about Stability AI models, research, and events, please follow https://twitter.com/StabilityAI_JP.
* For business and partnership inquiries, please contact [email protected]. ビジネスや協業に関するお問い合わせは[email protected]にご連絡ください。
|
domenicrosati/deberta-v3-large-survey-new_fact_main_passage-rater-half
|
domenicrosati
| 2023-11-17T03:46:55Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-17T03:09:45Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: deberta-v3-large-survey-new_fact_main_passage-rater-half
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-v3-large-survey-new_fact_main_passage-rater-half
This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5997
- Krippendorff: 0.8866
- Spearman: 0.8452
- Absolute Agreement: 0.7981
- Agreement Within One: 0.9627
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-06
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Krippendorff | Spearman | Absolute Agreement | Agreement Within One |
|:-------------:|:-----:|:----:|:---------------:|:------------:|:--------:|:------------------:|:--------------------:|
| No log | 1.0 | 52 | 2.0050 | -0.0284 | nan | 0.0556 | 0.6389 |
| No log | 2.0 | 104 | 2.0018 | -0.0284 | nan | 0.0556 | 0.6389 |
| No log | 3.0 | 156 | 1.8877 | 0.3396 | 0.3820 | 0.25 | 0.9167 |
| No log | 4.0 | 208 | 2.0870 | -0.4830 | nan | 0.25 | 1.0 |
| No log | 5.0 | 260 | 2.2686 | -0.4830 | nan | 0.25 | 1.0 |
| No log | 6.0 | 312 | 2.2808 | -0.3479 | -0.0729 | 0.25 | 0.9444 |
| No log | 7.0 | 364 | 2.2021 | 0.6929 | 0.6752 | 0.3611 | 0.8333 |
| No log | 8.0 | 416 | 2.1923 | 0.7365 | 0.7234 | 0.3611 | 0.8333 |
| No log | 9.0 | 468 | 2.1403 | 0.8118 | 0.7882 | 0.3889 | 0.8611 |
| 1.3577 | 10.0 | 520 | 2.2881 | 0.8118 | 0.7882 | 0.3889 | 0.8611 |
| 1.3577 | 11.0 | 572 | 2.3523 | 0.8118 | 0.7882 | 0.3889 | 0.8611 |
| 1.3577 | 12.0 | 624 | 2.3332 | 0.8275 | 0.8168 | 0.3889 | 0.8611 |
| 1.3577 | 13.0 | 676 | 2.4414 | 0.7925 | 0.7853 | 0.3889 | 0.8611 |
| 1.3577 | 14.0 | 728 | 2.5907 | 0.7883 | 0.7723 | 0.3333 | 0.8611 |
| 1.3577 | 15.0 | 780 | 2.5388 | 0.7726 | 0.7452 | 0.2778 | 0.8611 |
| 1.3577 | 16.0 | 832 | 2.7258 | 0.6985 | 0.6774 | 0.3056 | 0.8611 |
| 1.3577 | 17.0 | 884 | 2.7749 | 0.7460 | 0.7270 | 0.3056 | 0.8611 |
| 1.3577 | 18.0 | 936 | 2.6903 | 0.7358 | 0.7073 | 0.3333 | 0.8611 |
| 1.3577 | 19.0 | 988 | 3.0083 | 0.6985 | 0.6705 | 0.3056 | 0.8611 |
| 0.5537 | 20.0 | 1040 | 3.0235 | 0.5930 | 0.5891 | 0.3056 | 0.8333 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1
- Datasets 2.10.1
- Tokenizers 0.12.1
|
jysh1023/tiny-bert-sst2-distilled
|
jysh1023
| 2023-11-17T03:46:28Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-14T07:38:33Z |
---
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: tiny-bert-sst2-distilled
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: sst2
split: validation
args: sst2
metrics:
- name: Accuracy
type: accuracy
value: 0.819954128440367
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-bert-sst2-distilled
This model was trained from scratch on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6749
- Accuracy: 0.8200
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 33
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1125 | 1.0 | 3 | 0.6731 | 0.8177 |
| 0.0984 | 2.0 | 6 | 0.6756 | 0.8188 |
| 0.1273 | 3.0 | 9 | 0.6754 | 0.8177 |
| 0.0758 | 4.0 | 12 | 0.6751 | 0.8188 |
| 0.1188 | 5.0 | 15 | 0.6754 | 0.8188 |
| 0.0936 | 6.0 | 18 | 0.6749 | 0.8200 |
| 0.0781 | 7.0 | 21 | 0.6748 | 0.8200 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
tiennguyenbnbk/llma2_math_13b_peft_full_ex_gptq
|
tiennguyenbnbk
| 2023-11-17T03:36:19Z | 2 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:TheBloke/Speechless-Llama2-Hermes-Orca-Platypus-WizardLM-13B-GPTQ",
"base_model:adapter:TheBloke/Speechless-Llama2-Hermes-Orca-Platypus-WizardLM-13B-GPTQ",
"region:us"
] | null | 2023-11-16T04:59:33Z |
---
library_name: peft
base_model: TheBloke/Speechless-Llama2-Hermes-Orca-Platypus-WizardLM-13B-GPTQ
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: gptq
- bits: 4
- tokenizer: None
- dataset: None
- group_size: 128
- damp_percent: 0.1
- desc_act: True
- sym: True
- true_sequential: True
- use_cuda_fp16: False
- model_seqlen: None
- block_name_to_quantize: None
- module_name_preceding_first_block: None
- batch_size: 1
- pad_token_id: None
- use_exllama: False
- max_input_length: None
- exllama_config: {'version': <ExllamaVersion.ONE: 1>}
- cache_block_outputs: True
### Framework versions
- PEFT 0.6.2
|
hkivancoral/hushem_5x_deit_tiny_adamax_0001_fold5
|
hkivancoral
| 2023-11-17T03:11:28Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-17T03:05:25Z |
---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_tiny_adamax_0001_fold5
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8292682926829268
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_tiny_adamax_0001_fold5
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8979
- Accuracy: 0.8293
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.89 | 1.0 | 28 | 0.6693 | 0.7073 |
| 0.2735 | 2.0 | 56 | 0.4551 | 0.7805 |
| 0.0858 | 3.0 | 84 | 0.6564 | 0.7561 |
| 0.0113 | 4.0 | 112 | 0.7630 | 0.8537 |
| 0.0078 | 5.0 | 140 | 0.5220 | 0.8049 |
| 0.0013 | 6.0 | 168 | 0.8772 | 0.8049 |
| 0.0003 | 7.0 | 196 | 0.7171 | 0.8293 |
| 0.0002 | 8.0 | 224 | 0.7732 | 0.8537 |
| 0.0001 | 9.0 | 252 | 0.7686 | 0.8537 |
| 0.0001 | 10.0 | 280 | 0.7839 | 0.8537 |
| 0.0001 | 11.0 | 308 | 0.7871 | 0.8537 |
| 0.0001 | 12.0 | 336 | 0.7948 | 0.8537 |
| 0.0001 | 13.0 | 364 | 0.8088 | 0.8537 |
| 0.0001 | 14.0 | 392 | 0.8070 | 0.8537 |
| 0.0001 | 15.0 | 420 | 0.8143 | 0.8537 |
| 0.0001 | 16.0 | 448 | 0.8175 | 0.8537 |
| 0.0001 | 17.0 | 476 | 0.8255 | 0.8537 |
| 0.0001 | 18.0 | 504 | 0.8292 | 0.8537 |
| 0.0001 | 19.0 | 532 | 0.8250 | 0.8537 |
| 0.0001 | 20.0 | 560 | 0.8378 | 0.8537 |
| 0.0001 | 21.0 | 588 | 0.8394 | 0.8537 |
| 0.0001 | 22.0 | 616 | 0.8440 | 0.8293 |
| 0.0001 | 23.0 | 644 | 0.8474 | 0.8293 |
| 0.0 | 24.0 | 672 | 0.8547 | 0.8293 |
| 0.0 | 25.0 | 700 | 0.8569 | 0.8293 |
| 0.0 | 26.0 | 728 | 0.8563 | 0.8293 |
| 0.0 | 27.0 | 756 | 0.8612 | 0.8293 |
| 0.0 | 28.0 | 784 | 0.8649 | 0.8293 |
| 0.0 | 29.0 | 812 | 0.8707 | 0.8293 |
| 0.0 | 30.0 | 840 | 0.8644 | 0.8293 |
| 0.0 | 31.0 | 868 | 0.8688 | 0.8293 |
| 0.0 | 32.0 | 896 | 0.8737 | 0.8293 |
| 0.0 | 33.0 | 924 | 0.8760 | 0.8293 |
| 0.0 | 34.0 | 952 | 0.8808 | 0.8293 |
| 0.0 | 35.0 | 980 | 0.8838 | 0.8293 |
| 0.0 | 36.0 | 1008 | 0.8834 | 0.8293 |
| 0.0 | 37.0 | 1036 | 0.8857 | 0.8293 |
| 0.0 | 38.0 | 1064 | 0.8913 | 0.8293 |
| 0.0 | 39.0 | 1092 | 0.8912 | 0.8293 |
| 0.0 | 40.0 | 1120 | 0.8917 | 0.8293 |
| 0.0 | 41.0 | 1148 | 0.8927 | 0.8293 |
| 0.0 | 42.0 | 1176 | 0.8947 | 0.8293 |
| 0.0 | 43.0 | 1204 | 0.8969 | 0.8293 |
| 0.0 | 44.0 | 1232 | 0.8977 | 0.8293 |
| 0.0 | 45.0 | 1260 | 0.8966 | 0.8293 |
| 0.0 | 46.0 | 1288 | 0.8974 | 0.8293 |
| 0.0 | 47.0 | 1316 | 0.8978 | 0.8293 |
| 0.0 | 48.0 | 1344 | 0.8978 | 0.8293 |
| 0.0 | 49.0 | 1372 | 0.8979 | 0.8293 |
| 0.0 | 50.0 | 1400 | 0.8979 | 0.8293 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
quyanh/qwen-14b-neurips-a100
|
quyanh
| 2023-11-17T03:11:08Z | 4 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:Qwen/Qwen-14B",
"base_model:adapter:Qwen/Qwen-14B",
"region:us"
] | null | 2023-11-14T14:02:48Z |
---
library_name: peft
base_model: Qwen/Qwen-14B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.3.dev0
|
hkivancoral/hushem_5x_deit_tiny_adamax_0001_fold4
|
hkivancoral
| 2023-11-17T03:05:12Z | 15 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-17T02:59:11Z |
---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_tiny_adamax_0001_fold4
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8571428571428571
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_tiny_adamax_0001_fold4
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5076
- Accuracy: 0.8571
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.876 | 1.0 | 28 | 0.7721 | 0.6667 |
| 0.2335 | 2.0 | 56 | 0.4611 | 0.8571 |
| 0.0719 | 3.0 | 84 | 0.6242 | 0.6905 |
| 0.0277 | 4.0 | 112 | 0.6528 | 0.7857 |
| 0.0032 | 5.0 | 140 | 0.4735 | 0.7857 |
| 0.0032 | 6.0 | 168 | 0.4579 | 0.8095 |
| 0.0006 | 7.0 | 196 | 0.5092 | 0.8333 |
| 0.0003 | 8.0 | 224 | 0.3894 | 0.8333 |
| 0.0002 | 9.0 | 252 | 0.4099 | 0.8810 |
| 0.0001 | 10.0 | 280 | 0.4092 | 0.8571 |
| 0.0001 | 11.0 | 308 | 0.4206 | 0.8571 |
| 0.0001 | 12.0 | 336 | 0.4259 | 0.8571 |
| 0.0001 | 13.0 | 364 | 0.4295 | 0.8571 |
| 0.0001 | 14.0 | 392 | 0.4367 | 0.8571 |
| 0.0001 | 15.0 | 420 | 0.4435 | 0.8571 |
| 0.0001 | 16.0 | 448 | 0.4513 | 0.8571 |
| 0.0001 | 17.0 | 476 | 0.4519 | 0.8571 |
| 0.0001 | 18.0 | 504 | 0.4534 | 0.8571 |
| 0.0001 | 19.0 | 532 | 0.4605 | 0.8571 |
| 0.0001 | 20.0 | 560 | 0.4613 | 0.8571 |
| 0.0001 | 21.0 | 588 | 0.4650 | 0.8571 |
| 0.0001 | 22.0 | 616 | 0.4689 | 0.8571 |
| 0.0001 | 23.0 | 644 | 0.4679 | 0.8571 |
| 0.0 | 24.0 | 672 | 0.4734 | 0.8571 |
| 0.0001 | 25.0 | 700 | 0.4768 | 0.8571 |
| 0.0 | 26.0 | 728 | 0.4779 | 0.8571 |
| 0.0001 | 27.0 | 756 | 0.4799 | 0.8571 |
| 0.0 | 28.0 | 784 | 0.4834 | 0.8571 |
| 0.0 | 29.0 | 812 | 0.4854 | 0.8571 |
| 0.0 | 30.0 | 840 | 0.4883 | 0.8571 |
| 0.0 | 31.0 | 868 | 0.4908 | 0.8571 |
| 0.0 | 32.0 | 896 | 0.4928 | 0.8571 |
| 0.0 | 33.0 | 924 | 0.4945 | 0.8571 |
| 0.0 | 34.0 | 952 | 0.4953 | 0.8571 |
| 0.0 | 35.0 | 980 | 0.4954 | 0.8571 |
| 0.0 | 36.0 | 1008 | 0.4965 | 0.8571 |
| 0.0 | 37.0 | 1036 | 0.4980 | 0.8571 |
| 0.0 | 38.0 | 1064 | 0.4998 | 0.8571 |
| 0.0 | 39.0 | 1092 | 0.5007 | 0.8571 |
| 0.0 | 40.0 | 1120 | 0.5020 | 0.8571 |
| 0.0 | 41.0 | 1148 | 0.5023 | 0.8571 |
| 0.0 | 42.0 | 1176 | 0.5029 | 0.8571 |
| 0.0 | 43.0 | 1204 | 0.5047 | 0.8571 |
| 0.0 | 44.0 | 1232 | 0.5059 | 0.8571 |
| 0.0 | 45.0 | 1260 | 0.5064 | 0.8571 |
| 0.0 | 46.0 | 1288 | 0.5070 | 0.8571 |
| 0.0 | 47.0 | 1316 | 0.5074 | 0.8571 |
| 0.0 | 48.0 | 1344 | 0.5076 | 0.8571 |
| 0.0 | 49.0 | 1372 | 0.5076 | 0.8571 |
| 0.0 | 50.0 | 1400 | 0.5076 | 0.8571 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
hiddenbox/pore_dream5
|
hiddenbox
| 2023-11-17T03:04:15Z | 0 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:SG161222/Realistic_Vision_V5.1_noVAE",
"base_model:adapter:SG161222/Realistic_Vision_V5.1_noVAE",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-11-08T07:57:52Z |
---
license: creativeml-openrail-m
base_model: SG161222/Realistic_Vision_V5.1_noVAE
instance_prompt: a photo of a1sfv dog
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - hiddenbox/pore_dream5
These are LoRA adaption weights for SG161222/Realistic_Vision_V5.1_noVAE. The weights were trained on a photo of a1sfv dog using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
|
hkivancoral/hushem_5x_deit_tiny_adamax_0001_fold2
|
hkivancoral
| 2023-11-17T02:52:41Z | 18 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-17T02:46:48Z |
---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_tiny_adamax_0001_fold2
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7777777777777778
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_tiny_adamax_0001_fold2
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3029
- Accuracy: 0.7778
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7446 | 1.0 | 27 | 0.9312 | 0.6667 |
| 0.1747 | 2.0 | 54 | 1.0634 | 0.6667 |
| 0.0436 | 3.0 | 81 | 1.1538 | 0.6889 |
| 0.0072 | 4.0 | 108 | 1.1186 | 0.7111 |
| 0.0036 | 5.0 | 135 | 1.4466 | 0.6667 |
| 0.0007 | 6.0 | 162 | 1.3997 | 0.6889 |
| 0.0023 | 7.0 | 189 | 1.1775 | 0.7333 |
| 0.0002 | 8.0 | 216 | 1.3345 | 0.7333 |
| 0.0001 | 9.0 | 243 | 1.2661 | 0.7333 |
| 0.0001 | 10.0 | 270 | 1.2707 | 0.7333 |
| 0.0001 | 11.0 | 297 | 1.2671 | 0.7333 |
| 0.0001 | 12.0 | 324 | 1.2637 | 0.7556 |
| 0.0001 | 13.0 | 351 | 1.2664 | 0.7556 |
| 0.0001 | 14.0 | 378 | 1.2658 | 0.7556 |
| 0.0001 | 15.0 | 405 | 1.2627 | 0.7556 |
| 0.0001 | 16.0 | 432 | 1.2685 | 0.7556 |
| 0.0001 | 17.0 | 459 | 1.2678 | 0.7778 |
| 0.0001 | 18.0 | 486 | 1.2674 | 0.7778 |
| 0.0001 | 19.0 | 513 | 1.2701 | 0.7778 |
| 0.0001 | 20.0 | 540 | 1.2690 | 0.7778 |
| 0.0001 | 21.0 | 567 | 1.2702 | 0.7778 |
| 0.0 | 22.0 | 594 | 1.2727 | 0.7778 |
| 0.0 | 23.0 | 621 | 1.2744 | 0.7778 |
| 0.0 | 24.0 | 648 | 1.2792 | 0.7778 |
| 0.0 | 25.0 | 675 | 1.2781 | 0.7778 |
| 0.0 | 26.0 | 702 | 1.2815 | 0.7778 |
| 0.0 | 27.0 | 729 | 1.2813 | 0.7778 |
| 0.0 | 28.0 | 756 | 1.2838 | 0.7778 |
| 0.0 | 29.0 | 783 | 1.2855 | 0.7778 |
| 0.0 | 30.0 | 810 | 1.2884 | 0.7778 |
| 0.0 | 31.0 | 837 | 1.2896 | 0.7778 |
| 0.0 | 32.0 | 864 | 1.2918 | 0.7778 |
| 0.0 | 33.0 | 891 | 1.2896 | 0.7778 |
| 0.0 | 34.0 | 918 | 1.2932 | 0.7778 |
| 0.0 | 35.0 | 945 | 1.2947 | 0.7778 |
| 0.0 | 36.0 | 972 | 1.2919 | 0.7778 |
| 0.0 | 37.0 | 999 | 1.2951 | 0.7778 |
| 0.0 | 38.0 | 1026 | 1.2979 | 0.7778 |
| 0.0 | 39.0 | 1053 | 1.3002 | 0.7778 |
| 0.0 | 40.0 | 1080 | 1.2989 | 0.7778 |
| 0.0 | 41.0 | 1107 | 1.3009 | 0.7778 |
| 0.0 | 42.0 | 1134 | 1.3017 | 0.7778 |
| 0.0 | 43.0 | 1161 | 1.3020 | 0.7778 |
| 0.0 | 44.0 | 1188 | 1.3018 | 0.7778 |
| 0.0 | 45.0 | 1215 | 1.3024 | 0.7778 |
| 0.0 | 46.0 | 1242 | 1.3027 | 0.7778 |
| 0.0 | 47.0 | 1269 | 1.3028 | 0.7778 |
| 0.0 | 48.0 | 1296 | 1.3029 | 0.7778 |
| 0.0 | 49.0 | 1323 | 1.3029 | 0.7778 |
| 0.0 | 50.0 | 1350 | 1.3029 | 0.7778 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
hkivancoral/hushem_5x_deit_tiny_adamax_0001_fold1
|
hkivancoral
| 2023-11-17T02:46:33Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-17T02:40:33Z |
---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_tiny_adamax_0001_fold1
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.6666666666666666
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_tiny_adamax_0001_fold1
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7993
- Accuracy: 0.6667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.0199 | 1.0 | 27 | 1.3645 | 0.4 |
| 0.2821 | 2.0 | 54 | 1.2055 | 0.5778 |
| 0.0646 | 3.0 | 81 | 1.3812 | 0.6 |
| 0.0073 | 4.0 | 108 | 1.4600 | 0.6889 |
| 0.0019 | 5.0 | 135 | 1.3896 | 0.6444 |
| 0.0006 | 6.0 | 162 | 1.4491 | 0.6667 |
| 0.0004 | 7.0 | 189 | 1.4950 | 0.6444 |
| 0.0002 | 8.0 | 216 | 1.5645 | 0.6444 |
| 0.0002 | 9.0 | 243 | 1.5792 | 0.6667 |
| 0.0001 | 10.0 | 270 | 1.5954 | 0.6667 |
| 0.0001 | 11.0 | 297 | 1.6100 | 0.6667 |
| 0.0001 | 12.0 | 324 | 1.6341 | 0.6667 |
| 0.0001 | 13.0 | 351 | 1.6463 | 0.6667 |
| 0.0001 | 14.0 | 378 | 1.6524 | 0.6667 |
| 0.0001 | 15.0 | 405 | 1.6584 | 0.6667 |
| 0.0001 | 16.0 | 432 | 1.6769 | 0.6667 |
| 0.0001 | 17.0 | 459 | 1.6829 | 0.6667 |
| 0.0001 | 18.0 | 486 | 1.6898 | 0.6667 |
| 0.0001 | 19.0 | 513 | 1.7029 | 0.6667 |
| 0.0001 | 20.0 | 540 | 1.7109 | 0.6667 |
| 0.0001 | 21.0 | 567 | 1.7134 | 0.6667 |
| 0.0001 | 22.0 | 594 | 1.7169 | 0.6667 |
| 0.0001 | 23.0 | 621 | 1.7239 | 0.6667 |
| 0.0001 | 24.0 | 648 | 1.7396 | 0.6667 |
| 0.0001 | 25.0 | 675 | 1.7377 | 0.6667 |
| 0.0001 | 26.0 | 702 | 1.7493 | 0.6667 |
| 0.0001 | 27.0 | 729 | 1.7500 | 0.6667 |
| 0.0001 | 28.0 | 756 | 1.7483 | 0.6667 |
| 0.0001 | 29.0 | 783 | 1.7547 | 0.6667 |
| 0.0001 | 30.0 | 810 | 1.7688 | 0.6667 |
| 0.0 | 31.0 | 837 | 1.7675 | 0.6667 |
| 0.0001 | 32.0 | 864 | 1.7692 | 0.6667 |
| 0.0 | 33.0 | 891 | 1.7739 | 0.6667 |
| 0.0 | 34.0 | 918 | 1.7755 | 0.6667 |
| 0.0 | 35.0 | 945 | 1.7806 | 0.6667 |
| 0.0 | 36.0 | 972 | 1.7812 | 0.6667 |
| 0.0 | 37.0 | 999 | 1.7859 | 0.6667 |
| 0.0 | 38.0 | 1026 | 1.7853 | 0.6667 |
| 0.0 | 39.0 | 1053 | 1.7884 | 0.6667 |
| 0.0 | 40.0 | 1080 | 1.7925 | 0.6667 |
| 0.0 | 41.0 | 1107 | 1.7936 | 0.6667 |
| 0.0 | 42.0 | 1134 | 1.7942 | 0.6667 |
| 0.0 | 43.0 | 1161 | 1.7955 | 0.6667 |
| 0.0 | 44.0 | 1188 | 1.7973 | 0.6667 |
| 0.0 | 45.0 | 1215 | 1.7990 | 0.6667 |
| 0.0 | 46.0 | 1242 | 1.7986 | 0.6667 |
| 0.0 | 47.0 | 1269 | 1.7991 | 0.6667 |
| 0.0 | 48.0 | 1296 | 1.7993 | 0.6667 |
| 0.0 | 49.0 | 1323 | 1.7993 | 0.6667 |
| 0.0 | 50.0 | 1350 | 1.7993 | 0.6667 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
ys7yoo/nli_sts_roberta-large_lr1e-05_wd1e-03_ep3_lr1e-05_wd1e-03_ep3_ckpt
|
ys7yoo
| 2023-11-17T02:45:59Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"dataset:klue",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-17T01:32:43Z |
---
tags:
- generated_from_trainer
datasets:
- klue
metrics:
- accuracy
- f1
model-index:
- name: nli_sts_roberta-large_lr1e-05_wd1e-03_ep3_lr1e-05_wd1e-03_ep3_ckpt
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: klue
type: klue
config: nli
split: validation
args: nli
metrics:
- name: Accuracy
type: accuracy
value: 0.894
- name: F1
type: f1
value: 0.8938576137169963
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nli_sts_roberta-large_lr1e-05_wd1e-03_ep3_lr1e-05_wd1e-03_ep3_ckpt
This model is a fine-tuned version of [ys7yoo/sts_roberta-large_lr1e-05_wd1e-03_ep3](https://huggingface.co/ys7yoo/sts_roberta-large_lr1e-05_wd1e-03_ep3) on the klue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3529
- Accuracy: 0.894
- F1: 0.8939
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.5292 | 1.0 | 391 | 0.3853 | 0.857 | 0.8565 |
| 0.2468 | 2.0 | 782 | 0.3176 | 0.89 | 0.8899 |
| 0.1412 | 3.0 | 1173 | 0.3529 | 0.894 | 0.8939 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.13.0
- Tokenizers 0.13.3
|
Godspower/finetuned-sentiment-analysis-model-3000-samples-base-distilbert
|
Godspower
| 2023-11-17T02:33:51Z | 6 | 1 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-16T15:17:18Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuned-sentiment-analysis-model-3000-samples-base-distilbert
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: test
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.93148
- name: F1
type: f1
value: 0.9317883168080278
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-sentiment-analysis-model-3000-samples-base-distilbert
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3698
- Accuracy: 0.9315
- F1: 0.9318
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
wefussell/amasum-neg-model
|
wefussell
| 2023-11-17T02:21:31Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2023-11-17T02:14:43Z |
---
library_name: peft
base_model: meta-llama/Llama-2-7b-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.2
|
kkmkorea/deberta_sent4455
|
kkmkorea
| 2023-11-17T02:19:44Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-09T06:49:38Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: deberta_sent4455
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta_sent4455
This model is a fine-tuned version of [kisti/korscideberta](https://huggingface.co/kisti/korscideberta) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7228
- Accuracy: 0.7370
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.8395 | 2.63 | 500 | 0.7228 | 0.7370 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.1+cu102
- Datasets 2.14.6
- Tokenizers 0.10.3
|
crumb/qrstudy-410m-64-1
|
crumb
| 2023-11-17T02:12:50Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:EleutherAI/pythia-410m",
"base_model:adapter:EleutherAI/pythia-410m",
"region:us"
] | null | 2023-11-17T02:11:55Z |
---
library_name: peft
base_model: EleutherAI/pythia-410m
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
nota-ai/coreml-bk-sdm
|
nota-ai
| 2023-11-17T02:11:20Z | 0 | 6 | null |
[
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"core-ml",
"arxiv:2305.15798",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-08-23T09:05:43Z |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- core-ml
pipeline_tag: text-to-image
extra_gated_prompt: >-
This model is open access and available to all, with a CreativeML OpenRAIL-M
license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or
harmful outputs or content
2. The authors claim no rights on the outputs you generate, you are free to
use them and are accountable for their use which must not go against the
provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as
a service. If you do, please be aware you have to include the same use
restrictions as the ones in the license and share a copy of the CreativeML
OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license carefully here:
https://huggingface.co/spaces/CompVis/stable-diffusion-license
extra_gated_heading: Please read the LICENSE to access this model
---
# Palettized Core ML Weights for BK-SDMs
For deployment on iOS 17 or macOS 14, this model card introduces **palettized Core ML weights** of BK-SDM-{[Base-2M](https://huggingface.co/nota-ai/bk-sdm-base-2m), [Small-2M](https://huggingface.co/nota-ai/bk-sdm-small-2m) and [Tiny-2M](https://huggingface.co/nota-ai/bk-sdm-tiny-2m)}. These weights were generated using [Apple’s repository](https://github.com/apple/ml-stable-diffusion) which has [ASCL](https://github.com/apple/ml-stable-diffusion/blob/main/LICENSE.md).
- Block-removed Knowledge-distilled Stable Diffusion Model (BK-SDM) is an architecturally compressed SDM for efficient text-to-image synthesis. This model is bulit with (i) removing several residual and attention blocks from the U-Net of [Stable Diffusion v1.4]( https://huggingface.co/CompVis/stable-diffusion-v1-4) and (ii) distillation pretraining. Despite being trained with very limited resources, our compact model can imitate the original SDM by benefiting from transferred knowledge.
- More information about BK-SDMs: [Paper](https://arxiv.org/abs/2305.15798), [GitHub](https://github.com/Nota-NetsPresso/BK-SDM), [Demo]( https://huggingface.co/spaces/nota-ai/compressed-stable-diffusion).
A demo to use Core ML Stable Diffusion weights can be found [here](https://github.com/huggingface/swift-coreml-diffusers).
## Deployment Results
| Base Model Name | Pipeline Size | Quantization Type | Attention Implementation |
|----------------------|---------------|-----------------------------------------------------------------------------------|--------------------------|
| [BK-SDM-Base-2M](https://huggingface.co/nota-ai/bk-sdm-base-2m) (Ours) | 1.48GB | [Palettized](https://coremltools.readme.io/docs/palettization-overview) | split_einsum_v2 |
| [BK-SDM-Small-2M](https://huggingface.co/nota-ai/bk-sdm-small-2m) (Ours) | 1.44GB | [Palettized](https://coremltools.readme.io/docs/palettization-overview) | split_einsum_v2 |
| [BK-SDM-Tiny-2M](https://huggingface.co/nota-ai/bk-sdm-tiny-2m) (Ours) | 1.43GB | [Palettized](https://coremltools.readme.io/docs/palettization-overview) | split_einsum_v2 |
| [OFA-Sys' Small Stable Diffusion v0](https://huggingface.co/pcuenq/coreml-small-stable-diffusion-v0) | 3.28GB | None | split_einsum |
| [Apple's Stable Diffusion v1.4, Palettized](https://huggingface.co/apple/coreml-stable-diffusion-1-4-palettized) | 1.57GB | [Palettized](https://coremltools.readme.io/docs/palettization-overview) | split_einsum_v2 |
<img src="https://huggingface.co/nota-ai/coreml-bk-sdm/resolve/main/assets/speed_comparison.gif">
## Compression Method
### U-Net Architecture
Certain residual and attention blocks were eliminated from the U-Net of SDM-v1.4:
- 1.04B-param [SDM-v1.4](https://huggingface.co/CompVis/stable-diffusion-v1-4) (0.86B-param U-Net): the original source model.
- 0.76B-param [**BK-SDM-Base**](https://huggingface.co/nota-ai/bk-sdm-base) (0.58B-param U-Net): obtained with ① fewer blocks in outer stages.
- 0.66B-param [**BK-SDM-Small**](https://huggingface.co/nota-ai/bk-sdm-small) (0.49B-param U-Net): obtained with ① and ② mid-stage removal.
- 0.50B-param [**BK-SDM-Tiny**](https://huggingface.co/nota-ai/bk-sdm-tiny) (0.33B-param U-Net): obtained with ①, ②, and ③ further inner-stage removal.
<center>
<img alt="U-Net architectures" img src="https://netspresso-research-code-release.s3.us-east-2.amazonaws.com/assets-bk-sdm/fig_arch.png" width="100%">
</center>
### Distillation Pretraining
The compact U-Net was trained to mimic the behavior of the original U-Net. We leveraged feature-level and output-level distillation, along with the denoising task loss.
<center>
<img alt="KD-based pretraining" img src="https://netspresso-research-code-release.s3.us-east-2.amazonaws.com/assets-bk-sdm/fig_kd_bksdm.png" width="100%">
</center>
<br/>
# Uses
_Note: This section is taken from the [Stable Diffusion v1 model card]( https://huggingface.co/CompVis/stable-diffusion-v1-4) (which was based on the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini)) and applies in the same way to BK-SDMs_.
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset [LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material and is not fit for product use without additional safety mechanisms and considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data. The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases. Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/), which consists of images that are primarily limited to English descriptions. Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for. This affects the overall output of the model, as white and western cultures are often set as the default. Further, the ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
### Safety Module
The intended use of this model is with the [Safety Checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) in Diffusers. This checker works by checking model outputs against known hard-coded NSFW concepts. The concepts are intentionally hidden to reduce the likelihood of reverse-engineering this filter. Specifically, the checker compares the class probability of harmful concepts in the embedding space of the `CLIPTextModel` *after generation* of the images. The concepts are passed into the model with the generated image and compared to a hand-engineered weight for each NSFW concept.
# Acknowledgments
- We express our gratitude to [Microsoft for Startups Founders Hub](https://www.microsoft.com/en-us/startups) for generously providing the Azure credits used during pretraining.
- We deeply appreciate the pioneering research on Latent/Stable Diffusion conducted by [CompVis](https://github.com/CompVis/latent-diffusion), [Runway](https://runwayml.com/), and [Stability AI](https://stability.ai/).
- We also appreciate the effort from [Apple](https://www.apple.com) for the [Core ML Stable Diffusion](https://github.com/apple/ml-stable-diffusion) library.
- Special thanks to the contributors to [LAION](https://laion.ai/), [Diffusers](https://github.com/huggingface/diffusers), and [Gradio](https://www.gradio.app/) for their valuable support.
# Citation
```bibtex
@article{kim2023architectural,
title={BK-SDM: A Lightweight, Fast, and Cheap Version of Stable Diffusion},
author={Kim, Bo-Kyeong and Song, Hyoung-Kyu and Castells, Thibault and Choi, Shinkook},
journal={arXiv preprint arXiv:2305.15798},
year={2023},
url={https://arxiv.org/abs/2305.15798}
}
```
```bibtex
@article{kim2023bksdm,
title={BK-SDM: Architecturally Compressed Stable Diffusion for Efficient Text-to-Image Generation},
author={Kim, Bo-Kyeong and Song, Hyoung-Kyu and Castells, Thibault and Choi, Shinkook},
journal={ICML Workshop on Efficient Systems for Foundation Models (ES-FoMo)},
year={2023},
url={https://openreview.net/forum?id=bOVydU0XKC}
}
```
*This model card was written by Thibault Castells and is based on the [bk-sdm-base model card](https://huggingface.co/nota-ai/bk-sdm-base) and the [coreml-stable-diffusion-1-4-palettized model card](https://huggingface.co/apple/coreml-stable-diffusion-1-4-palettized).*
|
nota-ai/bk-sdm-tiny-2m
|
nota-ai
| 2023-11-17T02:10:33Z | 162 | 18 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dataset:ChristophSchuhmann/improved_aesthetics_6.25plus",
"arxiv:2305.15798",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-08-12T11:51:56Z |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
datasets:
- ChristophSchuhmann/improved_aesthetics_6.25plus
library_name: diffusers
pipeline_tag: text-to-image
extra_gated_prompt: >-
This model is open access and available to all, with a CreativeML OpenRAIL-M
license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or
harmful outputs or content
2. The authors claim no rights on the outputs you generate, you are free to
use them and are accountable for their use which must not go against the
provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as
a service. If you do, please be aware you have to include the same use
restrictions as the ones in the license and share a copy of the CreativeML
OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license carefully here:
https://huggingface.co/spaces/CompVis/stable-diffusion-license
extra_gated_heading: Please read the LICENSE to access this model
---
# BK-SDM-2M Model Card
BK-SDM-{[**Base-2M**](https://huggingface.co/nota-ai/bk-sdm-base-2m), [**Small-2M**](https://huggingface.co/nota-ai/bk-sdm-small-2m), [**Tiny-2M**](https://huggingface.co/nota-ai/bk-sdm-tiny-2m)} are pretrained with **10× more data** (2.3M LAION image-text pairs) compared to our previous release.
- Block-removed Knowledge-distilled Stable Diffusion Model (BK-SDM) is an architecturally compressed SDM for efficient text-to-image synthesis.
- The previous BK-SDM-{[Base](https://huggingface.co/nota-ai/bk-sdm-base), [Small](https://huggingface.co/nota-ai/bk-sdm-small), [Tiny](https://huggingface.co/nota-ai/bk-sdm-tiny)} were obtained via distillation pretraining on 0.22M LAION pairs.
- Resources for more information: [Paper](https://arxiv.org/abs/2305.15798), [GitHub](https://github.com/Nota-NetsPresso/BK-SDM), [Demo]( https://huggingface.co/spaces/nota-ai/compressed-stable-diffusion).
## Examples with 🤗[Diffusers library](https://github.com/huggingface/diffusers).
An inference code with the default PNDM scheduler and 50 denoising steps is as follows.
```python
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("nota-ai/bk-sdm-tiny-2m", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a black vase holding a bouquet of roses"
image = pipe(prompt).images[0]
image.save("example.png")
```
## Compression Method
Adhering to the [U-Net architecture](https://huggingface.co/nota-ai/bk-sdm-tiny#u-net-architecture) and [distillation pretraining](https://huggingface.co/nota-ai/bk-sdm-tiny#distillation-pretraining) of BK-SDM, the difference in BK-SDM-2M is a 10× increase in the number of training pairs.
- **Training Data**: 2,256,472 image-text pairs (i.e., 2.3M pairs) from [LAION-Aesthetics V2 6.25+](https://laion.ai/blog/laion-aesthetics/).
- **Hardware:** A single NVIDIA A100 80GB GPU
- **Gradient Accumulations**: 4
- **Batch:** 256 (=4×64)
- **Optimizer:** AdamW
- **Learning Rate:** a constant learning rate of 5e-5 for 50K-iteration pretraining
## Experimental Results
The following table shows the zero-shot results on 30K samples from the MS-COCO validation split. After generating 512×512 images with the PNDM scheduler and 25 denoising steps, we downsampled them to 256×256 for evaluating generation scores.
- Our models were drawn at the 50K-th training iteration.
| Model | FID↓ | IS↑ | CLIP Score↑<br>(ViT-g/14) | # Params,<br>U-Net | # Params,<br>Whole SDM |
|---|:---:|:---:|:---:|:---:|:---:|
| [Stable Diffusion v1.4](https://huggingface.co/CompVis/stable-diffusion-v1-4) | 13.05 | 36.76 | 0.2958 | 0.86B | 1.04B |
| [BK-SDM-Base](https://huggingface.co/nota-ai/bk-sdm-base) (Ours) | 15.76 | 33.79 | 0.2878 | 0.58B | 0.76B |
| [BK-SDM-Base-2M](https://huggingface.co/nota-ai/bk-sdm-base-2m) (Ours) | 14.81 | 34.17 | 0.2883 | 0.58B | 0.76B |
| [BK-SDM-Small](https://huggingface.co/nota-ai/bk-sdm-small) (Ours) | 16.98 | 31.68 | 0.2677 | 0.49B | 0.66B |
| [BK-SDM-Small-2M](https://huggingface.co/nota-ai/bk-sdm-small-2m) (Ours) | 17.05 | 33.10 | 0.2734 | 0.49B | 0.66B |
| [BK-SDM-Tiny](https://huggingface.co/nota-ai/bk-sdm-tiny) (Ours) | 17.12 | 30.09 | 0.2653 | 0.33B | 0.50B |
| [BK-SDM-Tiny-2M](https://huggingface.co/nota-ai/bk-sdm-tiny-2m) (Ours) | 17.53 | 31.32 | 0.2690 | 0.33B | 0.50B |
### Effect of Different Data Sizes for Training BK-SDM-Small
Increasing the number of training pairs improves the IS and CLIP scores over training progress. The MS-COCO 256×256 30K benchmark was used for evaluation.
<center>
<img alt="Training progress with different data sizes" img src="https://netspresso-research-code-release.s3.us-east-2.amazonaws.com/assets-bk-sdm/fig_iter_data_size.png" width="100%">
</center>
Furthermore, with the growth in data volume, visual results become more favorable (e.g., better image-text alignment and clear distinction among objects).
<center>
<img alt="Visual results with different data sizes" img src="https://netspresso-research-code-release.s3.us-east-2.amazonaws.com/assets-bk-sdm/fig_results_data_size.png" width="100%">
</center>
### Additional Visual Examples
<center>
<img alt="additional visual examples" img src="https://netspresso-research-code-release.s3.us-east-2.amazonaws.com/assets-bk-sdm/fig_results_models_2m.png" width="100%">
</center>
# Uses
Follow [the usage guidelines of Stable Diffusion v1](https://huggingface.co/CompVis/stable-diffusion-v1-4#uses).
# Acknowledgments
- We express our gratitude to [Microsoft for Startups Founders Hub](https://www.microsoft.com/en-us/startups) for generously providing the Azure credits used during pretraining.
- We deeply appreciate the pioneering research on Latent/Stable Diffusion conducted by [CompVis](https://github.com/CompVis/latent-diffusion), [Runway](https://runwayml.com/), and [Stability AI](https://stability.ai/).
- Special thanks to the contributors to [LAION](https://laion.ai/), [Diffusers](https://github.com/huggingface/diffusers), and [Gradio](https://www.gradio.app/) for their valuable support.
# Citation
```bibtex
@article{kim2023architectural,
title={BK-SDM: A Lightweight, Fast, and Cheap Version of Stable Diffusion},
author={Kim, Bo-Kyeong and Song, Hyoung-Kyu and Castells, Thibault and Choi, Shinkook},
journal={arXiv preprint arXiv:2305.15798},
year={2023},
url={https://arxiv.org/abs/2305.15798}
}
```
```bibtex
@article{kim2023bksdm,
title={BK-SDM: Architecturally Compressed Stable Diffusion for Efficient Text-to-Image Generation},
author={Kim, Bo-Kyeong and Song, Hyoung-Kyu and Castells, Thibault and Choi, Shinkook},
journal={ICML Workshop on Efficient Systems for Foundation Models (ES-FoMo)},
year={2023},
url={https://openreview.net/forum?id=bOVydU0XKC}
}
```
*This model card was written by Bo-Kyeong Kim and is based on the [Stable Diffusion v1 model card]( https://huggingface.co/CompVis/stable-diffusion-v1-4).*
|
hkivancoral/hushem_5x_deit_tiny_adamax_001_fold4
|
hkivancoral
| 2023-11-17T02:09:47Z | 13 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-17T02:03:45Z |
---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_tiny_adamax_001_fold4
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7857142857142857
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_tiny_adamax_001_fold4
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7375
- Accuracy: 0.7857
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.4656 | 1.0 | 28 | 1.3873 | 0.3095 |
| 1.2586 | 2.0 | 56 | 1.2764 | 0.5 |
| 1.1469 | 3.0 | 84 | 0.9328 | 0.5 |
| 1.0441 | 4.0 | 112 | 0.8472 | 0.5952 |
| 0.811 | 5.0 | 140 | 0.7157 | 0.6667 |
| 0.9304 | 6.0 | 168 | 1.0112 | 0.5476 |
| 0.6688 | 7.0 | 196 | 1.1025 | 0.6429 |
| 0.7046 | 8.0 | 224 | 0.9337 | 0.7143 |
| 0.6117 | 9.0 | 252 | 0.8164 | 0.7143 |
| 0.4458 | 10.0 | 280 | 0.9534 | 0.7381 |
| 0.3231 | 11.0 | 308 | 0.8226 | 0.7381 |
| 0.2594 | 12.0 | 336 | 1.4042 | 0.6905 |
| 0.3579 | 13.0 | 364 | 1.0151 | 0.6905 |
| 0.3051 | 14.0 | 392 | 1.1256 | 0.7619 |
| 0.212 | 15.0 | 420 | 1.4604 | 0.6905 |
| 0.1011 | 16.0 | 448 | 1.4776 | 0.7381 |
| 0.0658 | 17.0 | 476 | 1.5151 | 0.7143 |
| 0.0916 | 18.0 | 504 | 2.0212 | 0.6667 |
| 0.12 | 19.0 | 532 | 1.3757 | 0.7143 |
| 0.1417 | 20.0 | 560 | 1.9592 | 0.6905 |
| 0.1037 | 21.0 | 588 | 1.5184 | 0.7143 |
| 0.0812 | 22.0 | 616 | 1.5083 | 0.7381 |
| 0.0404 | 23.0 | 644 | 1.7932 | 0.7381 |
| 0.0758 | 24.0 | 672 | 1.5450 | 0.7143 |
| 0.0384 | 25.0 | 700 | 2.0953 | 0.6667 |
| 0.0277 | 26.0 | 728 | 1.9894 | 0.6667 |
| 0.0016 | 27.0 | 756 | 1.8938 | 0.7143 |
| 0.0008 | 28.0 | 784 | 1.7999 | 0.7619 |
| 0.0118 | 29.0 | 812 | 1.7512 | 0.7619 |
| 0.0001 | 30.0 | 840 | 1.8297 | 0.7619 |
| 0.0002 | 31.0 | 868 | 1.7978 | 0.7381 |
| 0.0105 | 32.0 | 896 | 1.6941 | 0.7857 |
| 0.0001 | 33.0 | 924 | 1.6973 | 0.7619 |
| 0.0 | 34.0 | 952 | 1.6981 | 0.7381 |
| 0.0 | 35.0 | 980 | 1.7026 | 0.7381 |
| 0.0 | 36.0 | 1008 | 1.7088 | 0.7619 |
| 0.0 | 37.0 | 1036 | 1.7123 | 0.7619 |
| 0.0 | 38.0 | 1064 | 1.7165 | 0.7619 |
| 0.0 | 39.0 | 1092 | 1.7201 | 0.7619 |
| 0.0 | 40.0 | 1120 | 1.7234 | 0.7619 |
| 0.0 | 41.0 | 1148 | 1.7263 | 0.7619 |
| 0.0 | 42.0 | 1176 | 1.7294 | 0.7619 |
| 0.0 | 43.0 | 1204 | 1.7316 | 0.7619 |
| 0.0 | 44.0 | 1232 | 1.7334 | 0.7857 |
| 0.0 | 45.0 | 1260 | 1.7350 | 0.7857 |
| 0.0 | 46.0 | 1288 | 1.7363 | 0.7857 |
| 0.0 | 47.0 | 1316 | 1.7371 | 0.7857 |
| 0.0 | 48.0 | 1344 | 1.7375 | 0.7857 |
| 0.0 | 49.0 | 1372 | 1.7375 | 0.7857 |
| 0.0 | 50.0 | 1400 | 1.7375 | 0.7857 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
nota-ai/bk-sdm-base-2m
|
nota-ai
| 2023-11-17T02:09:10Z | 22 | 15 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dataset:ChristophSchuhmann/improved_aesthetics_6.25plus",
"arxiv:2305.15798",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-08-12T20:41:27Z |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
datasets:
- ChristophSchuhmann/improved_aesthetics_6.25plus
library_name: diffusers
pipeline_tag: text-to-image
extra_gated_prompt: >-
This model is open access and available to all, with a CreativeML OpenRAIL-M
license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or
harmful outputs or content
2. The authors claim no rights on the outputs you generate, you are free to
use them and are accountable for their use which must not go against the
provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as
a service. If you do, please be aware you have to include the same use
restrictions as the ones in the license and share a copy of the CreativeML
OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license carefully here:
https://huggingface.co/spaces/CompVis/stable-diffusion-license
extra_gated_heading: Please read the LICENSE to access this model
---
# BK-SDM-2M Model Card
BK-SDM-{[**Base-2M**](https://huggingface.co/nota-ai/bk-sdm-base-2m), [**Small-2M**](https://huggingface.co/nota-ai/bk-sdm-small-2m), [**Tiny-2M**](https://huggingface.co/nota-ai/bk-sdm-tiny-2m)} are pretrained with **10× more data** (2.3M LAION image-text pairs) compared to our previous release.
- Block-removed Knowledge-distilled Stable Diffusion Model (BK-SDM) is an architecturally compressed SDM for efficient text-to-image synthesis.
- The previous BK-SDM-{[Base](https://huggingface.co/nota-ai/bk-sdm-base), [Small](https://huggingface.co/nota-ai/bk-sdm-small), [Tiny](https://huggingface.co/nota-ai/bk-sdm-tiny)} were obtained via distillation pretraining on 0.22M LAION pairs.
- Resources for more information: [Paper](https://arxiv.org/abs/2305.15798), [GitHub](https://github.com/Nota-NetsPresso/BK-SDM), [Demo]( https://huggingface.co/spaces/nota-ai/compressed-stable-diffusion).
## Examples with 🤗[Diffusers library](https://github.com/huggingface/diffusers).
An inference code with the default PNDM scheduler and 50 denoising steps is as follows.
```python
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("nota-ai/bk-sdm-base-2m", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a black vase holding a bouquet of roses"
image = pipe(prompt).images[0]
image.save("example.png")
```
## Compression Method
Adhering to the [U-Net architecture](https://huggingface.co/nota-ai/bk-sdm-base#u-net-architecture) and [distillation pretraining](https://huggingface.co/nota-ai/bk-sdm-base#distillation-pretraining) of BK-SDM, the difference in BK-SDM-2M is a 10× increase in the number of training pairs.
- **Training Data**: 2,256,472 image-text pairs (i.e., 2.3M pairs) from [LAION-Aesthetics V2 6.25+](https://laion.ai/blog/laion-aesthetics/).
- **Hardware:** A single NVIDIA A100 80GB GPU
- **Gradient Accumulations**: 4
- **Batch:** 256 (=4×64)
- **Optimizer:** AdamW
- **Learning Rate:** a constant learning rate of 5e-5 for 50K-iteration pretraining
## Experimental Results
The following table shows the zero-shot results on 30K samples from the MS-COCO validation split. After generating 512×512 images with the PNDM scheduler and 25 denoising steps, we downsampled them to 256×256 for evaluating generation scores.
- Our models were drawn at the 50K-th training iteration.
| Model | FID↓ | IS↑ | CLIP Score↑<br>(ViT-g/14) | # Params,<br>U-Net | # Params,<br>Whole SDM |
|---|:---:|:---:|:---:|:---:|:---:|
| [Stable Diffusion v1.4](https://huggingface.co/CompVis/stable-diffusion-v1-4) | 13.05 | 36.76 | 0.2958 | 0.86B | 1.04B |
| [BK-SDM-Base](https://huggingface.co/nota-ai/bk-sdm-base) (Ours) | 15.76 | 33.79 | 0.2878 | 0.58B | 0.76B |
| [BK-SDM-Base-2M](https://huggingface.co/nota-ai/bk-sdm-base-2m) (Ours) | 14.81 | 34.17 | 0.2883 | 0.58B | 0.76B |
| [BK-SDM-Small](https://huggingface.co/nota-ai/bk-sdm-small) (Ours) | 16.98 | 31.68 | 0.2677 | 0.49B | 0.66B |
| [BK-SDM-Small-2M](https://huggingface.co/nota-ai/bk-sdm-small-2m) (Ours) | 17.05 | 33.10 | 0.2734 | 0.49B | 0.66B |
| [BK-SDM-Tiny](https://huggingface.co/nota-ai/bk-sdm-tiny) (Ours) | 17.12 | 30.09 | 0.2653 | 0.33B | 0.50B |
| [BK-SDM-Tiny-2M](https://huggingface.co/nota-ai/bk-sdm-tiny-2m) (Ours) | 17.53 | 31.32 | 0.2690 | 0.33B | 0.50B |
### Effect of Different Data Sizes for Training BK-SDM-Small
Increasing the number of training pairs improves the IS and CLIP scores over training progress. The MS-COCO 256×256 30K benchmark was used for evaluation.
<center>
<img alt="Training progress with different data sizes" img src="https://netspresso-research-code-release.s3.us-east-2.amazonaws.com/assets-bk-sdm/fig_iter_data_size.png" width="100%">
</center>
Furthermore, with the growth in data volume, visual results become more favorable (e.g., better image-text alignment and clear distinction among objects).
<center>
<img alt="Visual results with different data sizes" img src="https://netspresso-research-code-release.s3.us-east-2.amazonaws.com/assets-bk-sdm/fig_results_data_size.png" width="100%">
</center>
### Additional Visual Examples
<center>
<img alt="additional visual examples" img src="https://netspresso-research-code-release.s3.us-east-2.amazonaws.com/assets-bk-sdm/fig_results_models_2m.png" width="100%">
</center>
# Uses
Follow [the usage guidelines of Stable Diffusion v1](https://huggingface.co/CompVis/stable-diffusion-v1-4#uses).
# Acknowledgments
- We express our gratitude to [Microsoft for Startups Founders Hub](https://www.microsoft.com/en-us/startups) for generously providing the Azure credits used during pretraining.
- We deeply appreciate the pioneering research on Latent/Stable Diffusion conducted by [CompVis](https://github.com/CompVis/latent-diffusion), [Runway](https://runwayml.com/), and [Stability AI](https://stability.ai/).
- Special thanks to the contributors to [LAION](https://laion.ai/), [Diffusers](https://github.com/huggingface/diffusers), and [Gradio](https://www.gradio.app/) for their valuable support.
# Citation
```bibtex
@article{kim2023architectural,
title={BK-SDM: A Lightweight, Fast, and Cheap Version of Stable Diffusion},
author={Kim, Bo-Kyeong and Song, Hyoung-Kyu and Castells, Thibault and Choi, Shinkook},
journal={arXiv preprint arXiv:2305.15798},
year={2023},
url={https://arxiv.org/abs/2305.15798}
}
```
```bibtex
@article{kim2023bksdm,
title={BK-SDM: Architecturally Compressed Stable Diffusion for Efficient Text-to-Image Generation},
author={Kim, Bo-Kyeong and Song, Hyoung-Kyu and Castells, Thibault and Choi, Shinkook},
journal={ICML Workshop on Efficient Systems for Foundation Models (ES-FoMo)},
year={2023},
url={https://openreview.net/forum?id=bOVydU0XKC}
}
```
*This model card was written by Bo-Kyeong Kim and is based on the [Stable Diffusion v1 model card]( https://huggingface.co/CompVis/stable-diffusion-v1-4).*
|
nota-ai/bk-sdm-base
|
nota-ai
| 2023-11-17T02:03:55Z | 261 | 19 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dataset:ChristophSchuhmann/improved_aesthetics_6.5plus",
"arxiv:2305.15798",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-10T06:50:32Z |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
datasets:
- ChristophSchuhmann/improved_aesthetics_6.5plus
library_name: diffusers
pipeline_tag: text-to-image
extra_gated_prompt: >-
This model is open access and available to all, with a CreativeML OpenRAIL-M
license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or
harmful outputs or content
2. The authors claim no rights on the outputs you generate, you are free to
use them and are accountable for their use which must not go against the
provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as
a service. If you do, please be aware you have to include the same use
restrictions as the ones in the license and share a copy of the CreativeML
OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license carefully here:
https://huggingface.co/spaces/CompVis/stable-diffusion-license
extra_gated_heading: Please read the LICENSE to access this model
---
# BK-SDM Model Card
Block-removed Knowledge-distilled Stable Diffusion Model (BK-SDM) is an architecturally compressed SDM for efficient general-purpose text-to-image synthesis. This model is bulit with (i) removing several residual and attention blocks from the U-Net of [Stable Diffusion v1.4]( https://huggingface.co/CompVis/stable-diffusion-v1-4) and (ii) distillation pretraining on only 0.22M LAION pairs (fewer than 0.1% of the full training set). Despite being trained with very limited resources, our compact model can imitate the original SDM by benefiting from transferred knowledge.
- **Resources for more information**: [Paper](https://arxiv.org/abs/2305.15798), [GitHub](https://github.com/Nota-NetsPresso/BK-SDM), [Demo]( https://huggingface.co/spaces/nota-ai/compressed-stable-diffusion).
## Examples with 🤗[Diffusers library](https://github.com/huggingface/diffusers).
An inference code with the default PNDM scheduler and 50 denoising steps is as follows.
```python
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("nota-ai/bk-sdm-base", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a tropical bird sitting on a branch of a tree"
image = pipe(prompt).images[0]
image.save("example.png")
```
The following code is also runnable, because we compressed the U-Net of [Stable Diffusion v1.4]( https://huggingface.co/CompVis/stable-diffusion-v1-4) while keeping the other parts (i.e., Text Encoder and Image Decoder) unchanged:
```python
import torch
from diffusers import StableDiffusionPipeline, UNet2DConditionModel
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
pipe.unet = UNet2DConditionModel.from_pretrained("nota-ai/bk-sdm-base", subfolder="unet", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a tropical bird sitting on a branch of a tree"
image = pipe(prompt).images[0]
image.save("example.png")
```
## Compression Method
### U-Net Architecture
Certain residual and attention blocks were eliminated from the U-Net of SDM-v1.4:
- 1.04B-param [SDM-v1.4](https://huggingface.co/CompVis/stable-diffusion-v1-4) (0.86B-param U-Net): the original source model.
- 0.76B-param [**BK-SDM-Base**](https://huggingface.co/nota-ai/bk-sdm-base) (0.58B-param U-Net): obtained with ① fewer blocks in outer stages.
- 0.66B-param [**BK-SDM-Small**](https://huggingface.co/nota-ai/bk-sdm-small) (0.49B-param U-Net): obtained with ① and ② mid-stage removal.
- 0.50B-param [**BK-SDM-Tiny**](https://huggingface.co/nota-ai/bk-sdm-tiny) (0.33B-param U-Net): obtained with ①, ②, and ③ further inner-stage removal.
<center>
<img alt="U-Net architectures" img src="https://netspresso-research-code-release.s3.us-east-2.amazonaws.com/assets-bk-sdm/fig_arch.png" width="100%">
</center>
### Distillation Pretraining
The compact U-Net was trained to mimic the behavior of the original U-Net. We leveraged feature-level and output-level distillation, along with the denoising task loss.
<center>
<img alt="KD-based pretraining" img src="https://netspresso-research-code-release.s3.us-east-2.amazonaws.com/assets-bk-sdm/fig_kd_bksdm.png" width="100%">
</center>
<br/>
- **Training Data**: 212,776 image-text pairs (i.e., 0.22M pairs) from [LAION-Aesthetics V2 6.5+](https://laion.ai/blog/laion-aesthetics/).
- **Hardware:** A single NVIDIA A100 80GB GPU
- **Gradient Accumulations**: 4
- **Batch:** 256 (=4×64)
- **Optimizer:** AdamW
- **Learning Rate:** a constant learning rate of 5e-5 for 50K-iteration pretraining
## Experimental Results
The following table shows the zero-shot results on 30K samples from the MS-COCO validation split. After generating 512×512 images with the PNDM scheduler and 25 denoising steps, we downsampled them to 256×256 for evaluating generation scores. Our models were drawn at the 50K-th training iteration.
| Model | FID↓ | IS↑ | CLIP Score↑<br>(ViT-g/14) | # Params,<br>U-Net | # Params,<br>Whole SDM |
|---|:---:|:---:|:---:|:---:|:---:|
| [Stable Diffusion v1.4](https://huggingface.co/CompVis/stable-diffusion-v1-4) | 13.05 | 36.76 | 0.2958 | 0.86B | 1.04B |
| [BK-SDM-Base](https://huggingface.co/nota-ai/bk-sdm-base) (Ours) | 15.76 | 33.79 | 0.2878 | 0.58B | 0.76B |
| [BK-SDM-Small](https://huggingface.co/nota-ai/bk-sdm-small) (Ours) | 16.98 | 31.68 | 0.2677 | 0.49B | 0.66B |
| [BK-SDM-Tiny](https://huggingface.co/nota-ai/bk-sdm-tiny) (Ours) | 17.12 | 30.09 | 0.2653 | 0.33B | 0.50B |
<br/>
The following figure depicts synthesized images with some MS-COCO captions.
<center>
<img alt="Visual results" img src="https://netspresso-research-code-release.s3.us-east-2.amazonaws.com/assets-bk-sdm/fig_results.png" width="100%">
</center>
<br/>
# Uses
_Note: This section is taken from the [Stable Diffusion v1 model card]( https://huggingface.co/CompVis/stable-diffusion-v1-4) (which was based on the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini)) and applies in the same way to BK-SDMs_.
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset [LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material and is not fit for product use without additional safety mechanisms and considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data. The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases. Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/), which consists of images that are primarily limited to English descriptions. Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for. This affects the overall output of the model, as white and western cultures are often set as the default. Further, the ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
### Safety Module
The intended use of this model is with the [Safety Checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) in Diffusers. This checker works by checking model outputs against known hard-coded NSFW concepts. The concepts are intentionally hidden to reduce the likelihood of reverse-engineering this filter. Specifically, the checker compares the class probability of harmful concepts in the embedding space of the `CLIPTextModel` *after generation* of the images. The concepts are passed into the model with the generated image and compared to a hand-engineered weight for each NSFW concept.
# Acknowledgments
- We express our gratitude to [Microsoft for Startups Founders Hub](https://www.microsoft.com/en-us/startups) for generously providing the Azure credits used during pretraining.
- We deeply appreciate the pioneering research on Latent/Stable Diffusion conducted by [CompVis](https://github.com/CompVis/latent-diffusion), [Runway](https://runwayml.com/), and [Stability AI](https://stability.ai/).
- Special thanks to the contributors to [LAION](https://laion.ai/), [Diffusers](https://github.com/huggingface/diffusers), and [Gradio](https://www.gradio.app/) for their valuable support.
# Citation
```bibtex
@article{kim2023architectural,
title={BK-SDM: A Lightweight, Fast, and Cheap Version of Stable Diffusion},
author={Kim, Bo-Kyeong and Song, Hyoung-Kyu and Castells, Thibault and Choi, Shinkook},
journal={arXiv preprint arXiv:2305.15798},
year={2023},
url={https://arxiv.org/abs/2305.15798}
}
```
```bibtex
@article{kim2023bksdm,
title={BK-SDM: Architecturally Compressed Stable Diffusion for Efficient Text-to-Image Generation},
author={Kim, Bo-Kyeong and Song, Hyoung-Kyu and Castells, Thibault and Choi, Shinkook},
journal={ICML Workshop on Efficient Systems for Foundation Models (ES-FoMo)},
year={2023},
url={https://openreview.net/forum?id=bOVydU0XKC}
}
```
*This model card was written by Bo-Kyeong Kim and is based on the [Stable Diffusion v1 model card]( https://huggingface.co/CompVis/stable-diffusion-v1-4).*
|
hkivancoral/hushem_5x_deit_tiny_adamax_001_fold3
|
hkivancoral
| 2023-11-17T02:03:31Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-17T01:57:29Z |
---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_tiny_adamax_001_fold3
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7209302325581395
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_tiny_adamax_001_fold3
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8507
- Accuracy: 0.7209
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.4597 | 1.0 | 28 | 1.3552 | 0.3256 |
| 1.2609 | 2.0 | 56 | 0.9015 | 0.6744 |
| 1.1559 | 3.0 | 84 | 2.3181 | 0.3256 |
| 1.0822 | 4.0 | 112 | 1.6592 | 0.4186 |
| 1.0553 | 5.0 | 140 | 0.9222 | 0.4651 |
| 0.9651 | 6.0 | 168 | 0.7306 | 0.7442 |
| 0.9771 | 7.0 | 196 | 0.7827 | 0.6279 |
| 0.9016 | 8.0 | 224 | 0.9874 | 0.5581 |
| 0.8187 | 9.0 | 252 | 1.0233 | 0.5349 |
| 0.8405 | 10.0 | 280 | 0.6414 | 0.7674 |
| 0.7808 | 11.0 | 308 | 0.6637 | 0.6977 |
| 0.8152 | 12.0 | 336 | 0.5374 | 0.8605 |
| 0.8044 | 13.0 | 364 | 0.5684 | 0.7442 |
| 0.7275 | 14.0 | 392 | 0.6622 | 0.8140 |
| 0.6931 | 15.0 | 420 | 0.7767 | 0.7209 |
| 0.691 | 16.0 | 448 | 0.5520 | 0.7674 |
| 0.7585 | 17.0 | 476 | 0.6770 | 0.7674 |
| 0.6303 | 18.0 | 504 | 0.6834 | 0.7442 |
| 0.6578 | 19.0 | 532 | 0.7776 | 0.6977 |
| 0.4934 | 20.0 | 560 | 1.1067 | 0.7442 |
| 0.5397 | 21.0 | 588 | 0.7250 | 0.7674 |
| 0.5586 | 22.0 | 616 | 0.9824 | 0.6047 |
| 0.4808 | 23.0 | 644 | 0.9582 | 0.7442 |
| 0.4823 | 24.0 | 672 | 0.9114 | 0.6279 |
| 0.4124 | 25.0 | 700 | 1.1614 | 0.7209 |
| 0.3991 | 26.0 | 728 | 1.3579 | 0.6279 |
| 0.5138 | 27.0 | 756 | 1.5915 | 0.6512 |
| 0.3857 | 28.0 | 784 | 0.6799 | 0.8140 |
| 0.3797 | 29.0 | 812 | 1.1771 | 0.7907 |
| 0.3781 | 30.0 | 840 | 0.9809 | 0.7674 |
| 0.3225 | 31.0 | 868 | 0.7120 | 0.8140 |
| 0.3017 | 32.0 | 896 | 0.9984 | 0.7674 |
| 0.2468 | 33.0 | 924 | 1.0271 | 0.7674 |
| 0.1651 | 34.0 | 952 | 1.2194 | 0.7674 |
| 0.254 | 35.0 | 980 | 1.2984 | 0.7907 |
| 0.1644 | 36.0 | 1008 | 1.3708 | 0.7674 |
| 0.1972 | 37.0 | 1036 | 1.6461 | 0.7209 |
| 0.1252 | 38.0 | 1064 | 1.8473 | 0.7442 |
| 0.1252 | 39.0 | 1092 | 1.5823 | 0.7209 |
| 0.4334 | 40.0 | 1120 | 1.7311 | 0.7209 |
| 0.1029 | 41.0 | 1148 | 1.7390 | 0.7674 |
| 0.0992 | 42.0 | 1176 | 1.6959 | 0.7907 |
| 0.0993 | 43.0 | 1204 | 1.9237 | 0.7442 |
| 0.0435 | 44.0 | 1232 | 1.8569 | 0.7442 |
| 0.054 | 45.0 | 1260 | 1.8007 | 0.7907 |
| 0.0678 | 46.0 | 1288 | 1.8496 | 0.7442 |
| 0.0576 | 47.0 | 1316 | 1.8145 | 0.7442 |
| 0.0232 | 48.0 | 1344 | 1.8497 | 0.7209 |
| 0.0393 | 49.0 | 1372 | 1.8507 | 0.7209 |
| 0.0213 | 50.0 | 1400 | 1.8507 | 0.7209 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Gxl/sda
|
Gxl
| 2023-11-17T01:58:01Z | 0 | 0 | null |
[
"generated_from_trainer",
"en",
"dataset:HuggingFaceH4/ultrachat_200k",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"arxiv:2305.18290",
"arxiv:2310.16944",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:finetune:mistralai/Mistral-7B-v0.1",
"license:mit",
"region:us"
] | null | 2022-09-07T12:43:03Z |
---
tags:
- generated_from_trainer
model-index:
- name: zephyr-7b-beta
results: []
license: mit
datasets:
- HuggingFaceH4/ultrachat_200k
- HuggingFaceH4/ultrafeedback_binarized
language:
- en
base_model: mistralai/Mistral-7B-v0.1
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
<img src="https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha/resolve/main/thumbnail.png" alt="Zephyr Logo" width="800" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Model Card for Zephyr 7B β
Zephyr is a series of language models that are trained to act as helpful assistants. Zephyr-7B-β is the second model in the series, and is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) that was trained on on a mix of publicly available, synthetic datasets using [Direct Preference Optimization (DPO)](https://arxiv.org/abs/2305.18290). We found that removing the in-built alignment of these datasets boosted performance on [MT Bench](https://huggingface.co/spaces/lmsys/mt-bench) and made the model more helpful. However, this means that model is likely to generate problematic text when prompted to do so and should only be used for educational and research purposes. You can find more details in the [technical report](https://arxiv.org/abs/2310.16944).
## Model description
- **Model type:** A 7B parameter GPT-like model fine-tuned on a mix of publicly available, synthetic datasets.
- **Language(s) (NLP):** Primarily English
- **License:** MIT
- **Finetuned from model:** [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/huggingface/alignment-handbook
- **Demo:** https://huggingface.co/spaces/HuggingFaceH4/zephyr-chat
- **Chatbot Arena:** Evaluate Zephyr 7B against 10+ LLMs in the LMSYS arena: http://arena.lmsys.org
## Performance
At the time of release, Zephyr-7B-β is the highest ranked 7B chat model on the [MT-Bench](https://huggingface.co/spaces/lmsys/mt-bench) and [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/) benchmarks:
| Model | Size | Alignment | MT-Bench (score) | AlpacaEval (win rate %) |
|-------------|-----|----|---------------|--------------|
| StableLM-Tuned-α | 7B| dSFT |2.75| -|
| MPT-Chat | 7B |dSFT |5.42| -|
| Xwin-LMv0.1 | 7B| dPPO| 6.19| 87.83|
| Mistral-Instructv0.1 | 7B| - | 6.84 |-|
| Zephyr-7b-α |7B| dDPO| 6.88| -|
| **Zephyr-7b-β** 🪁 | **7B** | **dDPO** | **7.34** | **90.60** |
| Falcon-Instruct | 40B |dSFT |5.17 |45.71|
| Guanaco | 65B | SFT |6.41| 71.80|
| Llama2-Chat | 70B |RLHF |6.86| 92.66|
| Vicuna v1.3 | 33B |dSFT |7.12 |88.99|
| WizardLM v1.0 | 70B |dSFT |7.71 |-|
| Xwin-LM v0.1 | 70B |dPPO |- |95.57|
| GPT-3.5-turbo | - |RLHF |7.94 |89.37|
| Claude 2 | - |RLHF |8.06| 91.36|
| GPT-4 | -| RLHF |8.99| 95.28|
|
PCYP/dqn-SpaceInvadersNoFrameskip-v4
|
PCYP
| 2023-11-17T01:55:07Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-15T01:01:32Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 732.00 +/- 245.19
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga PCYP -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga PCYP -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga PCYP
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 5000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
hkivancoral/hushem_5x_deit_tiny_adamax_001_fold1
|
hkivancoral
| 2023-11-17T01:51:02Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-tiny-patch16-224",
"base_model:finetune:facebook/deit-tiny-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-17T01:45:07Z |
---
license: apache-2.0
base_model: facebook/deit-tiny-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_tiny_adamax_001_fold1
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.4222222222222222
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_tiny_adamax_001_fold1
This model is a fine-tuned version of [facebook/deit-tiny-patch16-224](https://huggingface.co/facebook/deit-tiny-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 5.8123
- Accuracy: 0.4222
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.3956 | 1.0 | 27 | 1.9737 | 0.3111 |
| 0.888 | 2.0 | 54 | 1.5910 | 0.3556 |
| 1.1183 | 3.0 | 81 | 1.4091 | 0.3778 |
| 0.7709 | 4.0 | 108 | 1.4706 | 0.3778 |
| 0.9892 | 5.0 | 135 | 1.4916 | 0.4222 |
| 0.5847 | 6.0 | 162 | 2.0869 | 0.3778 |
| 0.6569 | 7.0 | 189 | 1.9470 | 0.3556 |
| 0.5263 | 8.0 | 216 | 1.6436 | 0.4 |
| 0.46 | 9.0 | 243 | 2.3342 | 0.3556 |
| 0.4825 | 10.0 | 270 | 1.8564 | 0.4222 |
| 0.3607 | 11.0 | 297 | 2.1004 | 0.4222 |
| 0.2444 | 12.0 | 324 | 2.4392 | 0.4222 |
| 0.3872 | 13.0 | 351 | 1.8032 | 0.4444 |
| 0.3209 | 14.0 | 378 | 2.9763 | 0.4 |
| 0.1884 | 15.0 | 405 | 2.8695 | 0.4667 |
| 0.1329 | 16.0 | 432 | 3.4787 | 0.4 |
| 0.2021 | 17.0 | 459 | 2.9858 | 0.4 |
| 0.1653 | 18.0 | 486 | 3.6825 | 0.4667 |
| 0.0813 | 19.0 | 513 | 3.2825 | 0.4444 |
| 0.1467 | 20.0 | 540 | 3.0809 | 0.4889 |
| 0.0538 | 21.0 | 567 | 3.9816 | 0.4222 |
| 0.1511 | 22.0 | 594 | 3.9404 | 0.4444 |
| 0.0505 | 23.0 | 621 | 4.4773 | 0.4667 |
| 0.0602 | 24.0 | 648 | 3.6484 | 0.4222 |
| 0.0403 | 25.0 | 675 | 4.0392 | 0.4444 |
| 0.005 | 26.0 | 702 | 3.8791 | 0.5556 |
| 0.0725 | 27.0 | 729 | 5.2091 | 0.4222 |
| 0.0084 | 28.0 | 756 | 4.7587 | 0.4222 |
| 0.0002 | 29.0 | 783 | 5.6091 | 0.3778 |
| 0.0001 | 30.0 | 810 | 5.5834 | 0.4222 |
| 0.0004 | 31.0 | 837 | 5.1075 | 0.4 |
| 0.0002 | 32.0 | 864 | 5.0938 | 0.4667 |
| 0.0014 | 33.0 | 891 | 5.4645 | 0.4667 |
| 0.0 | 34.0 | 918 | 5.9402 | 0.4222 |
| 0.0 | 35.0 | 945 | 5.8799 | 0.4222 |
| 0.0 | 36.0 | 972 | 5.8415 | 0.4222 |
| 0.0 | 37.0 | 999 | 5.8263 | 0.4222 |
| 0.0 | 38.0 | 1026 | 5.8129 | 0.4222 |
| 0.0 | 39.0 | 1053 | 5.8088 | 0.4222 |
| 0.0 | 40.0 | 1080 | 5.8085 | 0.4222 |
| 0.0 | 41.0 | 1107 | 5.8075 | 0.4222 |
| 0.0 | 42.0 | 1134 | 5.8084 | 0.4222 |
| 0.0 | 43.0 | 1161 | 5.8094 | 0.4222 |
| 0.0 | 44.0 | 1188 | 5.8109 | 0.4222 |
| 0.0 | 45.0 | 1215 | 5.8113 | 0.4222 |
| 0.0 | 46.0 | 1242 | 5.8120 | 0.4222 |
| 0.0 | 47.0 | 1269 | 5.8119 | 0.4222 |
| 0.0 | 48.0 | 1296 | 5.8123 | 0.4222 |
| 0.0 | 49.0 | 1323 | 5.8123 | 0.4222 |
| 0.0 | 50.0 | 1350 | 5.8123 | 0.4222 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
hkivancoral/hushem_5x_deit_small_adamax_00001_fold5
|
hkivancoral
| 2023-11-17T01:38:22Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-small-patch16-224",
"base_model:finetune:facebook/deit-small-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-17T01:26:43Z |
---
license: apache-2.0
base_model: facebook/deit-small-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_small_adamax_00001_fold5
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8048780487804879
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_small_adamax_00001_fold5
This model is a fine-tuned version of [facebook/deit-small-patch16-224](https://huggingface.co/facebook/deit-small-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6350
- Accuracy: 0.8049
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.307 | 1.0 | 28 | 1.2048 | 0.4878 |
| 1.0055 | 2.0 | 56 | 1.0344 | 0.5366 |
| 0.7917 | 3.0 | 84 | 0.8814 | 0.6829 |
| 0.5612 | 4.0 | 112 | 0.7794 | 0.6585 |
| 0.4121 | 5.0 | 140 | 0.6731 | 0.7805 |
| 0.3453 | 6.0 | 168 | 0.6198 | 0.7561 |
| 0.2136 | 7.0 | 196 | 0.5552 | 0.7805 |
| 0.1402 | 8.0 | 224 | 0.5538 | 0.7805 |
| 0.1098 | 9.0 | 252 | 0.5179 | 0.8049 |
| 0.0661 | 10.0 | 280 | 0.4716 | 0.8293 |
| 0.0459 | 11.0 | 308 | 0.4940 | 0.8049 |
| 0.0201 | 12.0 | 336 | 0.4943 | 0.7805 |
| 0.0128 | 13.0 | 364 | 0.4835 | 0.8049 |
| 0.013 | 14.0 | 392 | 0.5177 | 0.8049 |
| 0.005 | 15.0 | 420 | 0.5313 | 0.7805 |
| 0.0049 | 16.0 | 448 | 0.5255 | 0.8293 |
| 0.0033 | 17.0 | 476 | 0.5525 | 0.8049 |
| 0.0027 | 18.0 | 504 | 0.5486 | 0.8049 |
| 0.0024 | 19.0 | 532 | 0.5501 | 0.8049 |
| 0.0021 | 20.0 | 560 | 0.5689 | 0.8049 |
| 0.0017 | 21.0 | 588 | 0.5750 | 0.8049 |
| 0.0016 | 22.0 | 616 | 0.5752 | 0.8049 |
| 0.0015 | 23.0 | 644 | 0.5846 | 0.8049 |
| 0.0013 | 24.0 | 672 | 0.5888 | 0.8049 |
| 0.0012 | 25.0 | 700 | 0.5919 | 0.8049 |
| 0.0012 | 26.0 | 728 | 0.5956 | 0.8049 |
| 0.0011 | 27.0 | 756 | 0.5988 | 0.8049 |
| 0.0011 | 28.0 | 784 | 0.6017 | 0.8049 |
| 0.001 | 29.0 | 812 | 0.6080 | 0.8049 |
| 0.0009 | 30.0 | 840 | 0.6107 | 0.8049 |
| 0.0009 | 31.0 | 868 | 0.6102 | 0.8049 |
| 0.0008 | 32.0 | 896 | 0.6145 | 0.8049 |
| 0.0008 | 33.0 | 924 | 0.6168 | 0.8049 |
| 0.0008 | 34.0 | 952 | 0.6219 | 0.8049 |
| 0.0008 | 35.0 | 980 | 0.6219 | 0.8049 |
| 0.0008 | 36.0 | 1008 | 0.6245 | 0.8049 |
| 0.0007 | 37.0 | 1036 | 0.6250 | 0.8049 |
| 0.0007 | 38.0 | 1064 | 0.6281 | 0.8049 |
| 0.0007 | 39.0 | 1092 | 0.6275 | 0.8049 |
| 0.0006 | 40.0 | 1120 | 0.6308 | 0.8049 |
| 0.0007 | 41.0 | 1148 | 0.6308 | 0.8049 |
| 0.0006 | 42.0 | 1176 | 0.6332 | 0.8049 |
| 0.0006 | 43.0 | 1204 | 0.6344 | 0.8049 |
| 0.0006 | 44.0 | 1232 | 0.6352 | 0.8049 |
| 0.0006 | 45.0 | 1260 | 0.6342 | 0.8049 |
| 0.0006 | 46.0 | 1288 | 0.6344 | 0.8049 |
| 0.0006 | 47.0 | 1316 | 0.6347 | 0.8049 |
| 0.0006 | 48.0 | 1344 | 0.6350 | 0.8049 |
| 0.0006 | 49.0 | 1372 | 0.6350 | 0.8049 |
| 0.0006 | 50.0 | 1400 | 0.6350 | 0.8049 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
RogersYANG/ppo-LunarLander-v2
|
RogersYANG
| 2023-11-17T01:30:59Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-17T01:30:39Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 256.58 +/- 17.96
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
hkivancoral/hushem_5x_deit_small_adamax_00001_fold4
|
hkivancoral
| 2023-11-17T01:26:25Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-small-patch16-224",
"base_model:finetune:facebook/deit-small-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-17T01:15:01Z |
---
license: apache-2.0
base_model: facebook/deit-small-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_small_adamax_00001_fold4
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8333333333333334
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_small_adamax_00001_fold4
This model is a fine-tuned version of [facebook/deit-small-patch16-224](https://huggingface.co/facebook/deit-small-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5172
- Accuracy: 0.8333
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.2786 | 1.0 | 28 | 1.2504 | 0.4286 |
| 1.0062 | 2.0 | 56 | 1.1218 | 0.4524 |
| 0.7412 | 3.0 | 84 | 0.9795 | 0.4762 |
| 0.5492 | 4.0 | 112 | 0.8870 | 0.6190 |
| 0.3717 | 5.0 | 140 | 0.7811 | 0.6667 |
| 0.3128 | 6.0 | 168 | 0.7165 | 0.7619 |
| 0.2014 | 7.0 | 196 | 0.6520 | 0.7143 |
| 0.169 | 8.0 | 224 | 0.6139 | 0.7143 |
| 0.0981 | 9.0 | 252 | 0.5693 | 0.7619 |
| 0.0593 | 10.0 | 280 | 0.5620 | 0.7381 |
| 0.0447 | 11.0 | 308 | 0.5082 | 0.8095 |
| 0.0256 | 12.0 | 336 | 0.4626 | 0.8333 |
| 0.0121 | 13.0 | 364 | 0.5351 | 0.7857 |
| 0.0073 | 14.0 | 392 | 0.4890 | 0.8333 |
| 0.0046 | 15.0 | 420 | 0.4933 | 0.8095 |
| 0.004 | 16.0 | 448 | 0.4823 | 0.8095 |
| 0.0033 | 17.0 | 476 | 0.4875 | 0.8095 |
| 0.0029 | 18.0 | 504 | 0.4984 | 0.8095 |
| 0.0023 | 19.0 | 532 | 0.4992 | 0.8095 |
| 0.0021 | 20.0 | 560 | 0.5018 | 0.8095 |
| 0.0018 | 21.0 | 588 | 0.4990 | 0.8095 |
| 0.0017 | 22.0 | 616 | 0.5045 | 0.8095 |
| 0.0014 | 23.0 | 644 | 0.5039 | 0.8095 |
| 0.0014 | 24.0 | 672 | 0.5120 | 0.8095 |
| 0.0013 | 25.0 | 700 | 0.5026 | 0.8095 |
| 0.0011 | 26.0 | 728 | 0.5060 | 0.8095 |
| 0.0012 | 27.0 | 756 | 0.5096 | 0.8095 |
| 0.0011 | 28.0 | 784 | 0.5088 | 0.8095 |
| 0.001 | 29.0 | 812 | 0.5017 | 0.8095 |
| 0.0009 | 30.0 | 840 | 0.5154 | 0.8095 |
| 0.001 | 31.0 | 868 | 0.5070 | 0.8095 |
| 0.0009 | 32.0 | 896 | 0.5093 | 0.8095 |
| 0.0009 | 33.0 | 924 | 0.5133 | 0.8095 |
| 0.0008 | 34.0 | 952 | 0.5115 | 0.8095 |
| 0.0008 | 35.0 | 980 | 0.5134 | 0.8095 |
| 0.0008 | 36.0 | 1008 | 0.5048 | 0.8333 |
| 0.0007 | 37.0 | 1036 | 0.5114 | 0.8095 |
| 0.0007 | 38.0 | 1064 | 0.5110 | 0.8333 |
| 0.0007 | 39.0 | 1092 | 0.5114 | 0.8333 |
| 0.0007 | 40.0 | 1120 | 0.5148 | 0.8333 |
| 0.0007 | 41.0 | 1148 | 0.5122 | 0.8333 |
| 0.0007 | 42.0 | 1176 | 0.5146 | 0.8333 |
| 0.0007 | 43.0 | 1204 | 0.5155 | 0.8333 |
| 0.0007 | 44.0 | 1232 | 0.5189 | 0.8333 |
| 0.0006 | 45.0 | 1260 | 0.5166 | 0.8333 |
| 0.0006 | 46.0 | 1288 | 0.5169 | 0.8333 |
| 0.0007 | 47.0 | 1316 | 0.5173 | 0.8333 |
| 0.0006 | 48.0 | 1344 | 0.5172 | 0.8333 |
| 0.0007 | 49.0 | 1372 | 0.5172 | 0.8333 |
| 0.0007 | 50.0 | 1400 | 0.5172 | 0.8333 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
DContrerasF/a2c-PandaReachDense-v3
|
DContrerasF
| 2023-11-17T01:19:30Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-17T01:13:51Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v3
type: PandaReachDense-v3
metrics:
- type: mean_reward
value: -0.18 +/- 0.10
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v3**
This is a trained model of a **A2C** agent playing **PandaReachDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
LeoR2/flan-t5-small-finetuned-Coca
|
LeoR2
| 2023-11-17T01:17:14Z | 11 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/flan-t5-small",
"base_model:finetune:google/flan-t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-16T19:18:57Z |
---
license: apache-2.0
base_model: google/flan-t5-small
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5-small-finetuned-Coca
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-small-finetuned-Coca
This model is a fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: nan
- Rouge1: 35.8419
- Rouge2: 14.1387
- Rougel: 29.6846
- Rougelsum: 29.7698
- Gen Len: 17.0846
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 6
- eval_batch_size: 6
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 101 | nan | 35.8419 | 14.1387 | 29.6846 | 29.7698 | 17.0846 |
| No log | 2.0 | 202 | nan | 35.8419 | 14.1387 | 29.6846 | 29.7698 | 17.0846 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Myrax3000/peft-lora-starcoder15B-personal-copilot-T4-colab
|
Myrax3000
| 2023-11-17T01:10:20Z | 2 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:bigcode/starcoder",
"base_model:adapter:bigcode/starcoder",
"region:us"
] | null | 2023-11-17T01:10:11Z |
---
library_name: peft
base_model: bigcode/starcoder
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.3.dev0
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.3.dev0
|
wefussell/amasum-pos-model
|
wefussell
| 2023-11-17T01:09:08Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2023-11-17T00:58:12Z |
---
library_name: peft
base_model: meta-llama/Llama-2-7b-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.2
|
MaxReynolds/textual_inversion_apriltag
|
MaxReynolds
| 2023-11-17T01:01:12Z | 3 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-17T00:42:08Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
# Textual inversion text2image fine-tuning - MaxReynolds/textual_inversion_apriltag
These are textual inversion adaption weights for runwayml/stable-diffusion-v1-5. You can find some example images in the following.




|
stefan-it/autotrain-flair-georgian-ner-xlm_r_large-bs4-e10-lr5e-06-4
|
stefan-it
| 2023-11-17T00:52:26Z | 6 | 0 |
flair
|
[
"flair",
"pytorch",
"tensorboard",
"token-classification",
"sequence-tagger-model",
"en",
"ka",
"base_model:FacebookAI/xlm-roberta-large",
"base_model:finetune:FacebookAI/xlm-roberta-large",
"license:mit",
"region:us"
] |
token-classification
| 2023-11-16T08:52:58Z |
---
language:
- en
- ka
license: mit
tags:
- flair
- token-classification
- sequence-tagger-model
base_model: xlm-roberta-large
widget:
- text: ამით თავისი ქადაგება დაასრულა და დაბრუნდა იერუსალიმში . ერთ-ერთ გარე კედელზე
არსებობს ერნესტო ჩე გევარას პორტრეტი . შაკოსკა“ ინახება ბრაზილიაში , სან-პაულუს
ხელოვნების მუზეუმში .
---
# Fine-tuned English-Georgian NER Model with Flair
This Flair NER model was fine-tuned on the WikiANN dataset
([Rahimi et al.](https://www.aclweb.org/anthology/P19-1015) splits)
using XLM-R Large as backbone LM.
**Notice**: The dataset is very problematic, because it was automatically constructed.
We did manually inspect the development split of the Georgian data and found
a lot of bad labeled examples, e.g. DVD ( 💿 ) as `ORG`.
## Fine-Tuning
The latest
[Flair version](https://github.com/flairNLP/flair/tree/f30f5801df3f9e105ed078ec058b4e1152dd9159)
is used for fine-tuning.
We use English and Georgian training splits for fine-tuning and the
development set of Georgian for evaluation.
A hyper-parameter search over the following parameters with 5 different seeds per configuration is performed:
* Batch Sizes: [`4`]
* Learning Rates: [`5e-06`]
More details can be found in this [repository](https://github.com/stefan-it/georgian-ner).
## Results
A hyper-parameter search with 5 different seeds per configuration is performed and micro F1-score on development set
is reported:
| Configuration | Seed 1 | Seed 2 | Seed 3 | Seed 4 | Seed 5 | Average |
|-------------------|-------------|-------------|-------------|----------------|-------------|-----------------|
| `bs4-e10-lr5e-06` | [0.9005][1] | [0.9012][2] | [0.9069][3] | [**0.905**][4] | [0.9048][5] | 0.9037 ± 0.0027 |
[1]: https://hf.co/stefan-it/autotrain-flair-georgian-ner-xlm_r_large-bs4-e10-lr5e-06-1
[2]: https://hf.co/stefan-it/autotrain-flair-georgian-ner-xlm_r_large-bs4-e10-lr5e-06-2
[3]: https://hf.co/stefan-it/autotrain-flair-georgian-ner-xlm_r_large-bs4-e10-lr5e-06-3
[4]: https://hf.co/stefan-it/autotrain-flair-georgian-ner-xlm_r_large-bs4-e10-lr5e-06-4
[5]: https://hf.co/stefan-it/autotrain-flair-georgian-ner-xlm_r_large-bs4-e10-lr5e-06-5
The result in bold shows the performance of this model.
Additionally, the Flair [training log](training.log) and [TensorBoard logs](tensorboard) are also uploaded to the model
hub.
|
Asheron/q-FrozenLake-v1-4x4-Slippery
|
Asheron
| 2023-11-17T00:52:13Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-12T19:32:55Z |
---
tags:
- FrozenLake-v1-4x4
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-Slippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4
type: FrozenLake-v1-4x4
metrics:
- type: mean_reward
value: 0.81 +/- 0.39
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Asheron/q-FrozenLake-v1-4x4-Slippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
stefan-it/autotrain-flair-georgian-ner-xlm_r_large-bs4-e10-lr5e-06-1
|
stefan-it
| 2023-11-17T00:51:51Z | 10 | 0 |
flair
|
[
"flair",
"pytorch",
"tensorboard",
"token-classification",
"sequence-tagger-model",
"en",
"ka",
"base_model:FacebookAI/xlm-roberta-large",
"base_model:finetune:FacebookAI/xlm-roberta-large",
"license:mit",
"region:us"
] |
token-classification
| 2023-11-16T00:44:07Z |
---
language:
- en
- ka
license: mit
tags:
- flair
- token-classification
- sequence-tagger-model
base_model: xlm-roberta-large
widget:
- text: ამით თავისი ქადაგება დაასრულა და დაბრუნდა იერუსალიმში . ერთ-ერთ გარე კედელზე
არსებობს ერნესტო ჩე გევარას პორტრეტი . შაკოსკა“ ინახება ბრაზილიაში , სან-პაულუს
ხელოვნების მუზეუმში .
---
# Fine-tuned English-Georgian NER Model with Flair
This Flair NER model was fine-tuned on the WikiANN dataset
([Rahimi et al.](https://www.aclweb.org/anthology/P19-1015) splits)
using XLM-R Large as backbone LM.
**Notice**: The dataset is very problematic, because it was automatically constructed.
We did manually inspect the development split of the Georgian data and found
a lot of bad labeled examples, e.g. DVD ( 💿 ) as `ORG`.
## Fine-Tuning
The latest
[Flair version](https://github.com/flairNLP/flair/tree/f30f5801df3f9e105ed078ec058b4e1152dd9159)
is used for fine-tuning.
We use English and Georgian training splits for fine-tuning and the
development set of Georgian for evaluation.
A hyper-parameter search over the following parameters with 5 different seeds per configuration is performed:
* Batch Sizes: [`4`]
* Learning Rates: [`5e-06`]
More details can be found in this [repository](https://github.com/stefan-it/georgian-ner).
## Results
A hyper-parameter search with 5 different seeds per configuration is performed and micro F1-score on development set
is reported:
| Configuration | Seed 1 | Seed 2 | Seed 3 | Seed 4 | Seed 5 | Average |
|-------------------|-----------------|-------------|-------------|------------|-------------|-----------------|
| `bs4-e10-lr5e-06` | [**0.9005**][1] | [0.9012][2] | [0.9069][3] | [0.905][4] | [0.9048][5] | 0.9037 ± 0.0027 |
[1]: https://hf.co/stefan-it/autotrain-flair-georgian-ner-xlm_r_large-bs4-e10-lr5e-06-1
[2]: https://hf.co/stefan-it/autotrain-flair-georgian-ner-xlm_r_large-bs4-e10-lr5e-06-2
[3]: https://hf.co/stefan-it/autotrain-flair-georgian-ner-xlm_r_large-bs4-e10-lr5e-06-3
[4]: https://hf.co/stefan-it/autotrain-flair-georgian-ner-xlm_r_large-bs4-e10-lr5e-06-4
[5]: https://hf.co/stefan-it/autotrain-flair-georgian-ner-xlm_r_large-bs4-e10-lr5e-06-5
The result in bold shows the performance of this model.
Additionally, the Flair [training log](training.log) and [TensorBoard logs](tensorboard) are also uploaded to the model
hub.
|
ml-debi/EfficientNetB0-Food101
|
ml-debi
| 2023-11-17T00:50:53Z | 5 | 0 |
keras
|
[
"keras",
"tf",
"tensorboard",
"tf-keras",
"image-classification",
"en",
"dataset:food101",
"license:mit",
"region:us"
] |
image-classification
| 2023-11-10T01:01:11Z |
---
license: mit
datasets:
- food101
language:
- en
metrics:
- accuracy
pipeline_tag: image-classification
library_name: keras
---
|
cristalix/Chatbotsonson
|
cristalix
| 2023-11-17T00:41:49Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-11-16T23:45:21Z |
import gradio as gr
import os
import time
# Chatbot demo with multimodal input (text, markdown, LaTeX, code blocks, image, audio, & video). Plus shows support for streaming text.
def add_text(history, text):
history = history + [(text, None)]
return history, gr.Textbox(value="", interactive=False)
def add_file(history, file):
history = history + [((file.name,), None)]
return history
def bot(history):
response = "**That's cool!**"
history[-1][1] = ""
for character in response:
history[-1][1] += character
time.sleep(0.05)
yield history
with gr.Blocks() as demo:
chatbot = gr.Chatbot(
[],
elem_id="chatbot",
bubble_full_width=False,
avatar_images=(None, (os.path.join(os.path.dirname(__file__), "avatar.png"))),
)
with gr.Row():
txt = gr.Textbox(
scale=4,
show_label=False,
placeholder="Enter text and press enter, or upload an image",
container=False,
)
btn = gr.UploadButton("📁", file_types=["image", "video", "audio"])
txt_msg = txt.submit(add_text, [chatbot, txt], [chatbot, txt], queue=False).then(
bot, chatbot, chatbot, api_name="bot_response"
)
txt_msg.then(lambda: gr.Textbox(interactive=True), None, [txt], queue=False)
file_msg = btn.upload(add_file, [chatbot, btn], [chatbot], queue=False).then(
bot, chatbot, chatbot
)
demo.queue()
if __name__ == "__main__":
demo.launch()
|
GuysTrans/bart-base-vn-re-attention
|
GuysTrans
| 2023-11-17T00:08:01Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"generated_from_trainer",
"base_model:GuysTrans/bart-base-vn-re-attention",
"base_model:finetune:GuysTrans/bart-base-vn-re-attention",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-09T13:46:18Z |
---
license: apache-2.0
base_model: GuysTrans/bart-base-vn-re-attention
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bart-base-vn-re-attention
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-base-vn-re-attention
This model is a fine-tuned version of [GuysTrans/bart-base-vn-re-attention](https://huggingface.co/GuysTrans/bart-base-vn-re-attention) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7789
- Rouge1: 19.0028
- Rouge2: 7.9076
- Rougel: 15.8936
- Rougelsum: 17.5193
- Bleu-1: 0.003
- Bleu-2: 0.0018
- Bleu-3: 0.001
- Bleu-4: 0.0006
- Gen Len: 19.9959
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:------:|:------:|:------:|:------:|:-------:|
| 1.9746 | 1.0 | 10886 | 1.7789 | 19.0028 | 7.9076 | 15.8936 | 17.5193 | 0.003 | 0.0018 | 0.001 | 0.0006 | 19.9959 |
### Framework versions
- Transformers 4.33.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
TheBloke/platypus-yi-34b-AWQ
|
TheBloke
| 2023-11-17T00:05:42Z | 11 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"dataset:garage-bAInd/Open-Platypus",
"base_model:bhenrym14/platypus-yi-34b",
"base_model:quantized:bhenrym14/platypus-yi-34b",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"awq",
"region:us"
] |
text-generation
| 2023-11-16T23:05:22Z |
---
base_model: bhenrym14/platypus-yi-34b
datasets:
- garage-bAInd/Open-Platypus
inference: false
license: other
license_link: LICENSE
license_name: yi-license
model_creator: Brandon
model_name: Platypus Yi 34B
model_type: llama
prompt_template: "A chat.\nUSER: {prompt}\nASSISTANT: \n"
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Platypus Yi 34B - AWQ
- Model creator: [Brandon](https://huggingface.co/bhenrym14)
- Original model: [Platypus Yi 34B](https://huggingface.co/bhenrym14/platypus-yi-34b)
<!-- description start -->
## Description
This repo contains AWQ model files for [Brandon's Platypus Yi 34B](https://huggingface.co/bhenrym14/platypus-yi-34b).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - Llama and Mistral models only
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later, from any code or client that supports Transformers
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/platypus-yi-34b-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/platypus-yi-34b-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/platypus-yi-34b-GGUF)
* [Brandon's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/bhenrym14/platypus-yi-34b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Chat
```
A chat.
USER: {prompt}
ASSISTANT:
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `other`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [Brandon's Platypus Yi 34B](https://huggingface.co/bhenrym14/platypus-yi-34b).
<!-- licensing end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
I currently release 128g GEMM models only. The addition of group_size 32 models, and GEMV kernel models, is being actively considered.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/platypus-yi-34b-AWQ/tree/main) | 4 | 128 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-raw-v1) | 4096 | 19.23 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/platypus-yi-34b-AWQ`.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `platypus-yi-34b-AWQ`
7. Select **Loader: AutoAWQ**.
8. Click Load, and the model will load and is now ready for use.
9. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
10. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_AWQ.md-text-generation-webui end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Multi-user inference server: vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- Please ensure you are using vLLM version 0.2 or later.
- When using vLLM as a server, pass the `--quantization awq` parameter.
For example:
```shell
python3 -m vllm.entrypoints.api_server --model TheBloke/platypus-yi-34b-AWQ --quantization awq --dtype auto
```
- When using vLLM from Python code, again set `quantization=awq`.
For example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Tell me about AI",
"Write a story about llamas",
"What is 291 - 150?",
"How much wood would a woodchuck chuck if a woodchuck could chuck wood?",
]
prompt_template=f'''A chat.
USER: {prompt}
ASSISTANT:
'''
prompts = [prompt_template.format(prompt=prompt) for prompt in prompts]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/platypus-yi-34b-AWQ", quantization="awq", dtype="auto")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Multi-user inference server: Hugging Face Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/platypus-yi-34b-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires [huggingface-hub](https://github.com/huggingface/huggingface_hub) 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''A chat.
USER: {prompt}
ASSISTANT:
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: ", response)
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## Inference from Python code using Transformers
### Install the necessary packages
- Requires: [Transformers](https://huggingface.co/docs/transformers) 4.35.0 or later.
- Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.6 or later.
```shell
pip3 install --upgrade "autoawq>=0.1.6" "transformers>=4.35.0"
```
Note that if you are using PyTorch 2.0.1, the above AutoAWQ command will automatically upgrade you to PyTorch 2.1.0.
If you are using CUDA 11.8 and wish to continue using PyTorch 2.0.1, instead run this command:
```shell
pip3 install https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp310-cp310-linux_x86_64.whl
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### Transformers example code (requires Transformers 4.35.0 and later)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_name_or_path = "TheBloke/platypus-yi-34b-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
low_cpu_mem_usage=True,
device_map="cuda:0"
)
# Using the text streamer to stream output one token at a time
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = "Tell me about AI"
prompt_template=f'''A chat.
USER: {prompt}
ASSISTANT:
'''
# Convert prompt to tokens
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
generation_params = {
"do_sample": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": 512,
"repetition_penalty": 1.1
}
# Generate streamed output, visible one token at a time
generation_output = model.generate(
tokens,
streamer=streamer,
**generation_params
)
# Generation without a streamer, which will include the prompt in the output
generation_output = model.generate(
tokens,
**generation_params
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
print("model.generate output: ", text_output)
# Inference is also possible via Transformers' pipeline
from transformers import pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
**generation_params
)
pipe_output = pipe(prompt_template)[0]['generated_text']
print("pipeline output: ", pipe_output)
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui) using `Loader: AutoAWQ`.
- [vLLM](https://github.com/vllm-project/vllm) version 0.2.0 and later.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) version 1.1.0 and later.
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later.
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) version 0.1.1 and later.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Brandon's Platypus Yi 34B
# Instruction tune of Yi-34b with Open-Platypus (fp16)
## Overview
This is [chargoddard/Yi-34B-Llama](https://huggingface.co/chargoddard/Yi-34B-Llama), with instruction tuning performed with the [garage-bAInd/Open-Platypus](https://huggingface.co/datasets/garage-bAInd/Open-Platypus) dataset. That base model is [01-ai/Yi-34B](https://huggingface.co/01-ai/Yi-34B), but using llama2 model definitions and tokenizer to remove any remote code requirements.
**This is a (merged) QLoRA fine-tune (rank 64)**.
The finetune was performed with 1x RTX 6000 Ada (~18 hours to this checkpoint). It is possible this is rather undertrained, as this checkpoint is at 1 epoch. I began to see some performance degradation after that; more hyperparameter tuning is probably warranted.
## How to Use
Use as you would any llama-2 model.
## Prompting:
Model was trained with legacy airoboros <2.0 system prompt. See [bhenrym14/airoboros-33b-gpt4-1.4.1-lxctx-PI-16384-fp16](https://huggingface.co/bhenrym14/airoboros-33b-gpt4-1.4.1-lxctx-PI-16384-fp16) model card for details.
|
rvershinin/LunarLander-1st-sub
|
rvershinin
| 2023-11-17T00:03:11Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-17T00:02:49Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 265.17 +/- 21.88
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
afrideva/TinyAlpaca-v0.1-GGUF
|
afrideva
| 2023-11-17T00:00:49Z | 38 | 0 | null |
[
"gguf",
"ggml",
"quantized",
"q2_k",
"q3_k_m",
"q4_k_m",
"q5_k_m",
"q6_k",
"q8_0",
"text-generation",
"dataset:yahma/alpaca-cleaned",
"base_model:blueapple8259/TinyAlpaca-v0.1",
"base_model:quantized:blueapple8259/TinyAlpaca-v0.1",
"license:mit",
"region:us"
] |
text-generation
| 2023-11-16T23:39:26Z |
---
base_model: blueapple8259/TinyAlpaca-v0.1
datasets:
- yahma/alpaca-cleaned
inference: false
license: mit
model_creator: blueapple8259
model_name: TinyAlpaca-v0.1
pipeline_tag: text-generation
quantized_by: afrideva
tags:
- gguf
- ggml
- quantized
- q2_k
- q3_k_m
- q4_k_m
- q5_k_m
- q6_k
- q8_0
---
# blueapple8259/TinyAlpaca-v0.1-GGUF
Quantized GGUF model files for [TinyAlpaca-v0.1](https://huggingface.co/blueapple8259/TinyAlpaca-v0.1) from [blueapple8259](https://huggingface.co/blueapple8259)
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [tinyalpaca-v0.1.q2_k.gguf](https://huggingface.co/afrideva/TinyAlpaca-v0.1-GGUF/resolve/main/tinyalpaca-v0.1.q2_k.gguf) | q2_k | 482.14 MB |
| [tinyalpaca-v0.1.q3_k_m.gguf](https://huggingface.co/afrideva/TinyAlpaca-v0.1-GGUF/resolve/main/tinyalpaca-v0.1.q3_k_m.gguf) | q3_k_m | 549.85 MB |
| [tinyalpaca-v0.1.q4_k_m.gguf](https://huggingface.co/afrideva/TinyAlpaca-v0.1-GGUF/resolve/main/tinyalpaca-v0.1.q4_k_m.gguf) | q4_k_m | 667.81 MB |
| [tinyalpaca-v0.1.q5_k_m.gguf](https://huggingface.co/afrideva/TinyAlpaca-v0.1-GGUF/resolve/main/tinyalpaca-v0.1.q5_k_m.gguf) | q5_k_m | 782.04 MB |
| [tinyalpaca-v0.1.q6_k.gguf](https://huggingface.co/afrideva/TinyAlpaca-v0.1-GGUF/resolve/main/tinyalpaca-v0.1.q6_k.gguf) | q6_k | 903.41 MB |
| [tinyalpaca-v0.1.q8_0.gguf](https://huggingface.co/afrideva/TinyAlpaca-v0.1-GGUF/resolve/main/tinyalpaca-v0.1.q8_0.gguf) | q8_0 | 1.17 GB |
## Original Model Card:
This model is a [TinyLlama](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-715k-1.5T) model fine-tuned with the [yahma/alpaca-cleaned](https://huggingface.co/datasets/yahma/alpaca-cleaned) dataset.
prompt:
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Input:
{input}
### Response:
```
|
hkivancoral/hushem_5x_deit_small_adamax_0001_fold1
|
hkivancoral
| 2023-11-16T23:40:02Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-small-patch16-224",
"base_model:finetune:facebook/deit-small-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-16T23:28:31Z |
---
license: apache-2.0
base_model: facebook/deit-small-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_small_adamax_0001_fold1
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7111111111111111
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_small_adamax_0001_fold1
This model is a fine-tuned version of [facebook/deit-small-patch16-224](https://huggingface.co/facebook/deit-small-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4651
- Accuracy: 0.7111
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6869 | 1.0 | 27 | 0.8756 | 0.6444 |
| 0.1015 | 2.0 | 54 | 0.6480 | 0.7556 |
| 0.0313 | 3.0 | 81 | 0.6884 | 0.7556 |
| 0.0043 | 4.0 | 108 | 1.0483 | 0.7333 |
| 0.0008 | 5.0 | 135 | 1.6044 | 0.6667 |
| 0.0003 | 6.0 | 162 | 1.1582 | 0.7556 |
| 0.0003 | 7.0 | 189 | 1.2707 | 0.7333 |
| 0.0002 | 8.0 | 216 | 1.3227 | 0.7333 |
| 0.0002 | 9.0 | 243 | 1.2990 | 0.7333 |
| 0.0001 | 10.0 | 270 | 1.3357 | 0.7333 |
| 0.0001 | 11.0 | 297 | 1.3446 | 0.7111 |
| 0.0001 | 12.0 | 324 | 1.3631 | 0.7111 |
| 0.0001 | 13.0 | 351 | 1.3596 | 0.7111 |
| 0.0001 | 14.0 | 378 | 1.3708 | 0.7111 |
| 0.0001 | 15.0 | 405 | 1.3642 | 0.7111 |
| 0.0001 | 16.0 | 432 | 1.3759 | 0.7111 |
| 0.0001 | 17.0 | 459 | 1.3779 | 0.7111 |
| 0.0001 | 18.0 | 486 | 1.3841 | 0.7111 |
| 0.0001 | 19.0 | 513 | 1.3945 | 0.7111 |
| 0.0001 | 20.0 | 540 | 1.3969 | 0.7111 |
| 0.0001 | 21.0 | 567 | 1.4051 | 0.7111 |
| 0.0001 | 22.0 | 594 | 1.4058 | 0.7111 |
| 0.0001 | 23.0 | 621 | 1.4088 | 0.7111 |
| 0.0001 | 24.0 | 648 | 1.4158 | 0.7111 |
| 0.0001 | 25.0 | 675 | 1.4194 | 0.7111 |
| 0.0001 | 26.0 | 702 | 1.4258 | 0.7111 |
| 0.0001 | 27.0 | 729 | 1.4287 | 0.7111 |
| 0.0001 | 28.0 | 756 | 1.4297 | 0.7111 |
| 0.0001 | 29.0 | 783 | 1.4322 | 0.7111 |
| 0.0001 | 30.0 | 810 | 1.4390 | 0.7111 |
| 0.0001 | 31.0 | 837 | 1.4403 | 0.7111 |
| 0.0001 | 32.0 | 864 | 1.4424 | 0.7111 |
| 0.0001 | 33.0 | 891 | 1.4435 | 0.7111 |
| 0.0001 | 34.0 | 918 | 1.4462 | 0.7111 |
| 0.0001 | 35.0 | 945 | 1.4501 | 0.7111 |
| 0.0001 | 36.0 | 972 | 1.4516 | 0.7111 |
| 0.0 | 37.0 | 999 | 1.4541 | 0.7111 |
| 0.0 | 38.0 | 1026 | 1.4558 | 0.7111 |
| 0.0 | 39.0 | 1053 | 1.4579 | 0.7111 |
| 0.0 | 40.0 | 1080 | 1.4592 | 0.7111 |
| 0.0 | 41.0 | 1107 | 1.4601 | 0.7111 |
| 0.0 | 42.0 | 1134 | 1.4620 | 0.7111 |
| 0.0 | 43.0 | 1161 | 1.4630 | 0.7111 |
| 0.0 | 44.0 | 1188 | 1.4638 | 0.7111 |
| 0.0 | 45.0 | 1215 | 1.4644 | 0.7111 |
| 0.0 | 46.0 | 1242 | 1.4647 | 0.7111 |
| 0.0 | 47.0 | 1269 | 1.4650 | 0.7111 |
| 0.0 | 48.0 | 1296 | 1.4651 | 0.7111 |
| 0.0 | 49.0 | 1323 | 1.4651 | 0.7111 |
| 0.0 | 50.0 | 1350 | 1.4651 | 0.7111 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
hkivancoral/hushem_5x_deit_small_adamax_001_fold5
|
hkivancoral
| 2023-11-16T23:26:22Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-small-patch16-224",
"base_model:finetune:facebook/deit-small-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-16T23:14:54Z |
---
license: apache-2.0
base_model: facebook/deit-small-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_small_adamax_001_fold5
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7560975609756098
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_small_adamax_001_fold5
This model is a fine-tuned version of [facebook/deit-small-patch16-224](https://huggingface.co/facebook/deit-small-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9978
- Accuracy: 0.7561
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.4105 | 1.0 | 28 | 1.2401 | 0.4878 |
| 1.1305 | 2.0 | 56 | 1.2429 | 0.4634 |
| 0.8883 | 3.0 | 84 | 1.0090 | 0.5366 |
| 0.7137 | 4.0 | 112 | 0.7064 | 0.7317 |
| 0.4682 | 5.0 | 140 | 0.8445 | 0.7073 |
| 0.5286 | 6.0 | 168 | 1.1652 | 0.5854 |
| 0.3742 | 7.0 | 196 | 0.6789 | 0.8049 |
| 0.3573 | 8.0 | 224 | 0.7278 | 0.7317 |
| 0.272 | 9.0 | 252 | 0.8849 | 0.7561 |
| 0.1472 | 10.0 | 280 | 1.2627 | 0.6829 |
| 0.1837 | 11.0 | 308 | 1.1712 | 0.7317 |
| 0.0937 | 12.0 | 336 | 1.4720 | 0.7073 |
| 0.1467 | 13.0 | 364 | 1.7992 | 0.6585 |
| 0.1394 | 14.0 | 392 | 1.7959 | 0.5854 |
| 0.0985 | 15.0 | 420 | 1.4497 | 0.7317 |
| 0.0548 | 16.0 | 448 | 1.4327 | 0.7561 |
| 0.0354 | 17.0 | 476 | 1.5157 | 0.7317 |
| 0.0897 | 18.0 | 504 | 1.9967 | 0.7561 |
| 0.0783 | 19.0 | 532 | 1.8000 | 0.6829 |
| 0.0872 | 20.0 | 560 | 2.1630 | 0.7073 |
| 0.0467 | 21.0 | 588 | 1.7971 | 0.7073 |
| 0.0024 | 22.0 | 616 | 1.1519 | 0.8049 |
| 0.001 | 23.0 | 644 | 1.4688 | 0.7805 |
| 0.0101 | 24.0 | 672 | 1.1822 | 0.8293 |
| 0.005 | 25.0 | 700 | 1.2237 | 0.8293 |
| 0.0001 | 26.0 | 728 | 1.7234 | 0.7317 |
| 0.0025 | 27.0 | 756 | 1.4712 | 0.7561 |
| 0.0001 | 28.0 | 784 | 2.0676 | 0.7805 |
| 0.0003 | 29.0 | 812 | 2.0101 | 0.7317 |
| 0.0 | 30.0 | 840 | 2.0010 | 0.7561 |
| 0.0 | 31.0 | 868 | 1.9976 | 0.7561 |
| 0.0 | 32.0 | 896 | 1.9954 | 0.7561 |
| 0.0 | 33.0 | 924 | 1.9948 | 0.7561 |
| 0.0 | 34.0 | 952 | 1.9948 | 0.7561 |
| 0.0 | 35.0 | 980 | 1.9948 | 0.7561 |
| 0.0 | 36.0 | 1008 | 1.9942 | 0.7561 |
| 0.0 | 37.0 | 1036 | 1.9944 | 0.7561 |
| 0.0 | 38.0 | 1064 | 1.9949 | 0.7561 |
| 0.0 | 39.0 | 1092 | 1.9951 | 0.7561 |
| 0.0 | 40.0 | 1120 | 1.9957 | 0.7561 |
| 0.0 | 41.0 | 1148 | 1.9963 | 0.7561 |
| 0.0 | 42.0 | 1176 | 1.9964 | 0.7561 |
| 0.0 | 43.0 | 1204 | 1.9969 | 0.7561 |
| 0.0 | 44.0 | 1232 | 1.9973 | 0.7561 |
| 0.0 | 45.0 | 1260 | 1.9974 | 0.7561 |
| 0.0 | 46.0 | 1288 | 1.9976 | 0.7561 |
| 0.0 | 47.0 | 1316 | 1.9978 | 0.7561 |
| 0.0 | 48.0 | 1344 | 1.9978 | 0.7561 |
| 0.0 | 49.0 | 1372 | 1.9978 | 0.7561 |
| 0.0 | 50.0 | 1400 | 1.9978 | 0.7561 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
hkivancoral/hushem_5x_deit_small_adamax_001_fold4
|
hkivancoral
| 2023-11-16T23:14:34Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-small-patch16-224",
"base_model:finetune:facebook/deit-small-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-16T23:03:15Z |
---
license: apache-2.0
base_model: facebook/deit-small-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_small_adamax_001_fold4
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7142857142857143
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_small_adamax_001_fold4
This model is a fine-tuned version of [facebook/deit-small-patch16-224](https://huggingface.co/facebook/deit-small-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6296
- Accuracy: 0.7143
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.4114 | 1.0 | 28 | 1.1807 | 0.5238 |
| 1.2764 | 2.0 | 56 | 0.9991 | 0.5 |
| 0.9708 | 3.0 | 84 | 0.8093 | 0.5952 |
| 0.8975 | 4.0 | 112 | 0.7127 | 0.7143 |
| 0.8745 | 5.0 | 140 | 0.6175 | 0.7857 |
| 0.8263 | 6.0 | 168 | 0.5662 | 0.7857 |
| 0.7023 | 7.0 | 196 | 0.9422 | 0.4762 |
| 0.739 | 8.0 | 224 | 1.0785 | 0.6667 |
| 0.6219 | 9.0 | 252 | 0.7234 | 0.7381 |
| 0.5557 | 10.0 | 280 | 0.9010 | 0.6429 |
| 0.5536 | 11.0 | 308 | 0.8428 | 0.6905 |
| 0.4341 | 12.0 | 336 | 1.4219 | 0.5952 |
| 0.4008 | 13.0 | 364 | 1.0252 | 0.6190 |
| 0.3661 | 14.0 | 392 | 0.9782 | 0.6667 |
| 0.2255 | 15.0 | 420 | 1.0569 | 0.6905 |
| 0.1906 | 16.0 | 448 | 1.2300 | 0.7381 |
| 0.1975 | 17.0 | 476 | 1.3396 | 0.6905 |
| 0.1887 | 18.0 | 504 | 1.2504 | 0.6905 |
| 0.1207 | 19.0 | 532 | 1.3305 | 0.6905 |
| 0.0442 | 20.0 | 560 | 1.3516 | 0.7143 |
| 0.0689 | 21.0 | 588 | 1.7387 | 0.7143 |
| 0.0525 | 22.0 | 616 | 1.7134 | 0.6667 |
| 0.0339 | 23.0 | 644 | 1.8502 | 0.7381 |
| 0.0226 | 24.0 | 672 | 2.0846 | 0.7143 |
| 0.0026 | 25.0 | 700 | 2.2517 | 0.6905 |
| 0.0003 | 26.0 | 728 | 2.4690 | 0.6667 |
| 0.0231 | 27.0 | 756 | 2.7345 | 0.7143 |
| 0.0001 | 28.0 | 784 | 2.7167 | 0.7381 |
| 0.0001 | 29.0 | 812 | 2.5959 | 0.7143 |
| 0.0033 | 30.0 | 840 | 2.4481 | 0.7143 |
| 0.0096 | 31.0 | 868 | 2.5344 | 0.6905 |
| 0.0001 | 32.0 | 896 | 2.5507 | 0.7143 |
| 0.0 | 33.0 | 924 | 2.5703 | 0.7143 |
| 0.0 | 34.0 | 952 | 2.5803 | 0.7143 |
| 0.0 | 35.0 | 980 | 2.5893 | 0.7143 |
| 0.0 | 36.0 | 1008 | 2.5965 | 0.7143 |
| 0.0 | 37.0 | 1036 | 2.6022 | 0.7143 |
| 0.0 | 38.0 | 1064 | 2.6075 | 0.7143 |
| 0.0 | 39.0 | 1092 | 2.6116 | 0.7143 |
| 0.0 | 40.0 | 1120 | 2.6157 | 0.7143 |
| 0.0 | 41.0 | 1148 | 2.6188 | 0.7143 |
| 0.0 | 42.0 | 1176 | 2.6214 | 0.7143 |
| 0.0 | 43.0 | 1204 | 2.6241 | 0.7143 |
| 0.0 | 44.0 | 1232 | 2.6260 | 0.7143 |
| 0.0 | 45.0 | 1260 | 2.6276 | 0.7143 |
| 0.0 | 46.0 | 1288 | 2.6284 | 0.7143 |
| 0.0 | 47.0 | 1316 | 2.6292 | 0.7143 |
| 0.0 | 48.0 | 1344 | 2.6296 | 0.7143 |
| 0.0 | 49.0 | 1372 | 2.6296 | 0.7143 |
| 0.0 | 50.0 | 1400 | 2.6296 | 0.7143 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
SebastianS/function_calling-llama_7b-nat-fc_only
|
SebastianS
| 2023-11-16T23:10:54Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-11-16T23:10:46Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.4.0
|
crumb/qrstudy-410m-32-1
|
crumb
| 2023-11-16T23:03:09Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:EleutherAI/pythia-410m",
"base_model:adapter:EleutherAI/pythia-410m",
"region:us"
] | null | 2023-11-16T23:02:46Z |
---
library_name: peft
base_model: EleutherAI/pythia-410m
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
hkivancoral/hushem_5x_deit_small_adamax_001_fold3
|
hkivancoral
| 2023-11-16T23:02:58Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-small-patch16-224",
"base_model:finetune:facebook/deit-small-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-16T22:51:45Z |
---
license: apache-2.0
base_model: facebook/deit-small-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_small_adamax_001_fold3
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.6744186046511628
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_small_adamax_001_fold3
This model is a fine-tuned version of [facebook/deit-small-patch16-224](https://huggingface.co/facebook/deit-small-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7808
- Accuracy: 0.6744
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.4231 | 1.0 | 28 | 1.5192 | 0.2558 |
| 1.3519 | 2.0 | 56 | 1.1068 | 0.5581 |
| 1.0181 | 3.0 | 84 | 1.0826 | 0.5581 |
| 0.9214 | 4.0 | 112 | 0.9767 | 0.5814 |
| 0.6936 | 5.0 | 140 | 1.4687 | 0.3488 |
| 0.9125 | 6.0 | 168 | 1.1689 | 0.5116 |
| 0.8268 | 7.0 | 196 | 1.1523 | 0.5581 |
| 0.7335 | 8.0 | 224 | 0.7001 | 0.6744 |
| 0.527 | 9.0 | 252 | 0.6807 | 0.6977 |
| 0.5031 | 10.0 | 280 | 1.2372 | 0.5814 |
| 0.3869 | 11.0 | 308 | 1.0194 | 0.6744 |
| 0.4401 | 12.0 | 336 | 1.2579 | 0.6279 |
| 0.3701 | 13.0 | 364 | 0.9873 | 0.7209 |
| 0.2336 | 14.0 | 392 | 1.2562 | 0.5581 |
| 0.1629 | 15.0 | 420 | 1.2297 | 0.6744 |
| 0.1635 | 16.0 | 448 | 1.3203 | 0.7674 |
| 0.1352 | 17.0 | 476 | 1.7615 | 0.6977 |
| 0.1062 | 18.0 | 504 | 1.7045 | 0.6977 |
| 0.0801 | 19.0 | 532 | 2.1745 | 0.6047 |
| 0.0683 | 20.0 | 560 | 1.8826 | 0.6977 |
| 0.0931 | 21.0 | 588 | 2.7349 | 0.6047 |
| 0.0235 | 22.0 | 616 | 2.1002 | 0.6744 |
| 0.05 | 23.0 | 644 | 1.7777 | 0.7442 |
| 0.0038 | 24.0 | 672 | 1.7249 | 0.6977 |
| 0.0183 | 25.0 | 700 | 2.2930 | 0.6977 |
| 0.023 | 26.0 | 728 | 1.7975 | 0.7209 |
| 0.0109 | 27.0 | 756 | 2.0767 | 0.7442 |
| 0.0003 | 28.0 | 784 | 2.6313 | 0.6977 |
| 0.0001 | 29.0 | 812 | 2.7110 | 0.6512 |
| 0.0 | 30.0 | 840 | 2.7098 | 0.6744 |
| 0.0 | 31.0 | 868 | 2.7164 | 0.6744 |
| 0.0 | 32.0 | 896 | 2.7474 | 0.6744 |
| 0.0 | 33.0 | 924 | 2.7506 | 0.6744 |
| 0.0 | 34.0 | 952 | 2.7511 | 0.6744 |
| 0.0 | 35.0 | 980 | 2.7547 | 0.6744 |
| 0.0 | 36.0 | 1008 | 2.7577 | 0.6744 |
| 0.0 | 37.0 | 1036 | 2.7609 | 0.6744 |
| 0.0 | 38.0 | 1064 | 2.7631 | 0.6744 |
| 0.0 | 39.0 | 1092 | 2.7673 | 0.6744 |
| 0.0 | 40.0 | 1120 | 2.7700 | 0.6744 |
| 0.0 | 41.0 | 1148 | 2.7723 | 0.6744 |
| 0.0 | 42.0 | 1176 | 2.7743 | 0.6744 |
| 0.0 | 43.0 | 1204 | 2.7761 | 0.6744 |
| 0.0 | 44.0 | 1232 | 2.7776 | 0.6744 |
| 0.0 | 45.0 | 1260 | 2.7788 | 0.6744 |
| 0.0 | 46.0 | 1288 | 2.7800 | 0.6744 |
| 0.0 | 47.0 | 1316 | 2.7805 | 0.6744 |
| 0.0 | 48.0 | 1344 | 2.7808 | 0.6744 |
| 0.0 | 49.0 | 1372 | 2.7808 | 0.6744 |
| 0.0 | 50.0 | 1400 | 2.7808 | 0.6744 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
YazzRey/Transformadores_Caso_3_PLN
|
YazzRey
| 2023-11-16T23:02:34Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:h94/IP-Adapter",
"base_model:adapter:h94/IP-Adapter",
"region:us"
] |
text-to-image
| 2023-11-16T23:02:33Z |
---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: '-'
output:
url: images/afiliacion.jpg
base_model: h94/IP-Adapter
instance_prompt: null
---
# Transformadores
<Gallery />
## Download model
[Download](/YazzRey/Transformadores_Caso_3_PLN/tree/main) them in the Files & versions tab.
|
Teapack1/whisper-tiny-finetuned-no-go-kws
|
Teapack1
| 2023-11-16T22:59:48Z | 7 | 1 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"audio-classification",
"generated_from_trainer",
"dataset:speech_commands",
"base_model:openai/whisper-tiny",
"base_model:finetune:openai/whisper-tiny",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-11-16T22:06:19Z |
---
license: apache-2.0
base_model: openai/whisper-tiny
tags:
- generated_from_trainer
datasets:
- speech_commands
metrics:
- accuracy
model-index:
- name: whisper-tiny-finetuned-no-go-kws
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: Speech Commands[no, go]
type: speech_commands
config: v0.02
split: test
args: v0.02
metrics:
- name: Accuracy
type: accuracy
value: 0.990086741016109
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-tiny-finetuned-no-go-kws
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the Speech Commands[no, go] dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0842
- Accuracy: 0.9901
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.33 | 1.0 | 780 | 0.0272 | 0.9938 |
| 0.0002 | 2.0 | 1560 | 0.0420 | 0.9876 |
| 0.0001 | 3.0 | 2340 | 0.0487 | 0.9913 |
| 0.0011 | 4.0 | 3120 | 0.0789 | 0.9802 |
| 0.0001 | 5.0 | 3900 | 0.0915 | 0.9851 |
| 0.0014 | 6.0 | 4680 | 0.1017 | 0.9839 |
| 0.0 | 7.0 | 5460 | 0.0993 | 0.9888 |
| 0.0 | 8.0 | 6240 | 0.0694 | 0.9913 |
| 0.0 | 9.0 | 7020 | 0.0760 | 0.9926 |
| 0.0 | 10.0 | 7800 | 0.0842 | 0.9901 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
hooman650/ct2fast-bge-reranker
|
hooman650
| 2023-11-16T22:55:42Z | 5 | 1 |
transformers
|
[
"transformers",
"medical",
"finance",
"chemistry",
"biology",
"en",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2023-11-16T20:38:09Z |
---
license: mit
language:
- en
tags:
- medical
- finance
- chemistry
- biology
---
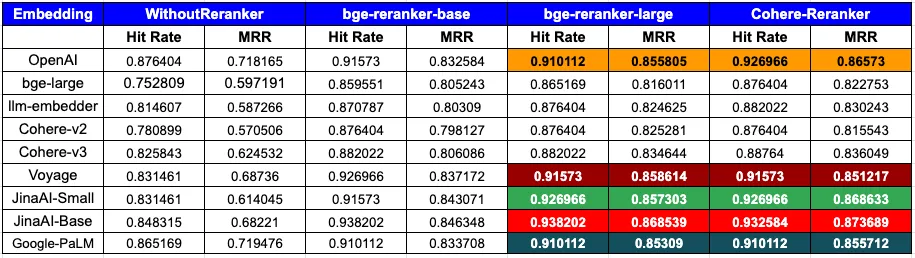
# BGE-Renranker-Large
<!-- Provide a quick summary of what the model is/does. -->
This is an `int8` converted version of [bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large). Thanks to `c2translate` this should
be at least 3 times faster than the original hf transformer version while its smaller with minimal performance loss.
## Model Details
Different from embedding model `bge-large-en-v1.5`, reranker uses question and document as input and directly output similarity instead of embedding.
You can get a relevance score by inputting query and passage to the reranker. The reranker is optimized based cross-entropy loss, so the relevance score is not bounded to a specific range.
Besides this is highly optimized version using `c2translate` library suitable for production environments.
### Model Sources
The original model is based on `BAAI` `BGE-Reranker` model. Please visit [bge-reranker-orignal-repo](https://huggingface.co/BAAI/bge-reranker-large)
for more details.
## Usage
Simply `pip install ctranslate2` and then
```python
import ctranslate2
import transformers
import torch
device_mapping="cuda" if torch.cuda.is_available() else "cpu"
model_dir = "hooman650/ct2fast-bge-reranker"
# ctranslate2 encoder heavy lifting
encoder = ctranslate2.Encoder(model_dir, device = device_mapping)
# the classification head comes from HF
model_name = "BAAI/bge-reranker-large"
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
classifier = transformers.AutoModelForSequenceClassification.from_pretrained(model_name).classifier
classifier.eval()
classifier.to(device_mapping)
pairs = [
["I like Ctranslate2","Ctranslate2 makes mid range models faster"],
["I like Ctranslate2","Using naive transformers might not be suitable for deployment"]
]
with torch.no_grad():
tokens = tokenizer(pairs, padding=True, truncation=True, max_length=512).input_ids
output = encoder.forward_batch(tokens)
hidden_state = torch.as_tensor(output.last_hidden_state, device=device_mapping)
logits = classifier(hidden_state).squeeze()
print(logits)
# tensor([ 1.0474, -9.4694], device='cuda:0')
```
#### Hardware
Supports both GPU and CPU.
|
Lubub/brazillan-real-1994-sdxl
|
Lubub
| 2023-11-16T22:54:17Z | 0 | 0 | null |
[
"safetensors",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-11-16T22:50:59Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### brazillan_real_1994_SDXL Dreambooth model trained by Lubub with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
_(1).jpg)
|
Asheron/q-FrozenLake-v1-8x8-Slippery
|
Asheron
| 2023-11-16T22:54:17Z | 0 | 0 | null |
[
"FrozenLake-v1-8x8",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-12T23:40:51Z |
---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-8x8-Slippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-8x8
type: FrozenLake-v1-8x8
metrics:
- type: mean_reward
value: 0.75 +/- 0.43
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Asheron/q-FrozenLake-v1-8x8-Slippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Lollitor/FineTuned512
|
Lollitor
| 2023-11-16T22:44:54Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Lollitor/ColabFinished",
"base_model:adapter:Lollitor/ColabFinished",
"region:us"
] | null | 2023-11-16T22:44:50Z |
---
library_name: peft
base_model: Lollitor/ColabFinished
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.3.dev0
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.3.dev0
|
hkivancoral/hushem_5x_deit_small_adamax_001_fold1
|
hkivancoral
| 2023-11-16T22:39:59Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-small-patch16-224",
"base_model:finetune:facebook/deit-small-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-16T22:28:48Z |
---
license: apache-2.0
base_model: facebook/deit-small-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_small_adamax_001_fold1
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.4666666666666667
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_small_adamax_001_fold1
This model is a fine-tuned version of [facebook/deit-small-patch16-224](https://huggingface.co/facebook/deit-small-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 4.9670
- Accuracy: 0.4667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.4243 | 1.0 | 27 | 1.4114 | 0.2667 |
| 1.0749 | 2.0 | 54 | 1.3320 | 0.4222 |
| 0.8047 | 3.0 | 81 | 1.4606 | 0.4 |
| 1.1443 | 4.0 | 108 | 1.1606 | 0.3778 |
| 0.6749 | 5.0 | 135 | 1.3783 | 0.3778 |
| 0.6355 | 6.0 | 162 | 1.1666 | 0.5111 |
| 0.6766 | 7.0 | 189 | 2.0044 | 0.3778 |
| 0.5072 | 8.0 | 216 | 2.1218 | 0.3778 |
| 0.5923 | 9.0 | 243 | 2.3668 | 0.3778 |
| 0.5554 | 10.0 | 270 | 1.8883 | 0.3556 |
| 0.5809 | 11.0 | 297 | 1.7992 | 0.3778 |
| 0.3925 | 12.0 | 324 | 2.0376 | 0.3778 |
| 0.468 | 13.0 | 351 | 2.2940 | 0.3556 |
| 0.388 | 14.0 | 378 | 2.2184 | 0.4 |
| 0.3576 | 15.0 | 405 | 2.7767 | 0.3556 |
| 0.2702 | 16.0 | 432 | 1.8836 | 0.4444 |
| 0.2448 | 17.0 | 459 | 2.0997 | 0.4 |
| 0.3121 | 18.0 | 486 | 1.6999 | 0.4667 |
| 0.1734 | 19.0 | 513 | 2.3268 | 0.4444 |
| 0.318 | 20.0 | 540 | 3.2732 | 0.3556 |
| 0.2011 | 21.0 | 567 | 2.9255 | 0.4 |
| 0.1594 | 22.0 | 594 | 3.3998 | 0.3778 |
| 0.1002 | 23.0 | 621 | 2.6724 | 0.5556 |
| 0.1302 | 24.0 | 648 | 2.4689 | 0.5111 |
| 0.1301 | 25.0 | 675 | 2.3542 | 0.4889 |
| 0.0517 | 26.0 | 702 | 3.6395 | 0.4222 |
| 0.0477 | 27.0 | 729 | 3.0379 | 0.4667 |
| 0.1158 | 28.0 | 756 | 3.8148 | 0.4 |
| 0.0196 | 29.0 | 783 | 4.2909 | 0.4 |
| 0.0022 | 30.0 | 810 | 4.5812 | 0.4222 |
| 0.0023 | 31.0 | 837 | 4.8297 | 0.4667 |
| 0.0086 | 32.0 | 864 | 4.7485 | 0.4667 |
| 0.0049 | 33.0 | 891 | 4.6840 | 0.4889 |
| 0.0002 | 34.0 | 918 | 4.4345 | 0.4667 |
| 0.0001 | 35.0 | 945 | 5.3275 | 0.4889 |
| 0.0001 | 36.0 | 972 | 4.4575 | 0.4667 |
| 0.0001 | 37.0 | 999 | 4.7352 | 0.4889 |
| 0.0 | 38.0 | 1026 | 4.7979 | 0.4667 |
| 0.0 | 39.0 | 1053 | 4.8394 | 0.4667 |
| 0.0 | 40.0 | 1080 | 4.8675 | 0.4667 |
| 0.0 | 41.0 | 1107 | 4.8943 | 0.4667 |
| 0.0 | 42.0 | 1134 | 4.9142 | 0.4667 |
| 0.0 | 43.0 | 1161 | 4.9318 | 0.4667 |
| 0.0 | 44.0 | 1188 | 4.9439 | 0.4667 |
| 0.0 | 45.0 | 1215 | 4.9539 | 0.4667 |
| 0.0 | 46.0 | 1242 | 4.9606 | 0.4667 |
| 0.0 | 47.0 | 1269 | 4.9652 | 0.4667 |
| 0.0 | 48.0 | 1296 | 4.9670 | 0.4667 |
| 0.0 | 49.0 | 1323 | 4.9670 | 0.4667 |
| 0.0 | 50.0 | 1350 | 4.9670 | 0.4667 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Guilherme34/Samantha-OS1-13bv2
|
Guilherme34
| 2023-11-16T22:38:19Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-11-16T22:38:10Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
- PEFT 0.4.0
|
sberryman/twitter-roberta-base-sentiment-fork-latest
|
sberryman
| 2023-11-16T22:37:56Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"roberta",
"text-classification",
"en",
"dataset:tweet_eval",
"arxiv:2202.03829",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-16T22:33:27Z |
---
language: en
widget:
- text: Covid cases are increasing fast!
datasets:
- tweet_eval
---
# Twitter-roBERTa-base for Sentiment Analysis - UPDATED (2022)
This is a RoBERTa-base model trained on ~124M tweets from January 2018 to December 2021, and finetuned for sentiment analysis with the TweetEval benchmark.
The original Twitter-based RoBERTa model can be found [here](https://huggingface.co/cardiffnlp/twitter-roberta-base-2021-124m) and the original reference paper is [TweetEval](https://github.com/cardiffnlp/tweeteval). This model is suitable for English.
- Reference Paper: [TimeLMs paper](https://arxiv.org/abs/2202.03829).
- Git Repo: [TimeLMs official repository](https://github.com/cardiffnlp/timelms).
<b>Labels</b>:
0 -> Negative;
1 -> Neutral;
2 -> Positive
This sentiment analysis model has been integrated into [TweetNLP](https://github.com/cardiffnlp/tweetnlp). You can access the demo [here](https://tweetnlp.org).
## Example Pipeline
```python
from transformers import pipeline
sentiment_task = pipeline("sentiment-analysis", model=model_path, tokenizer=model_path)
sentiment_task("Covid cases are increasing fast!")
```
```
[{'label': 'Negative', 'score': 0.7236}]
```
## Full classification example
```python
from transformers import AutoModelForSequenceClassification
from transformers import TFAutoModelForSequenceClassification
from transformers import AutoTokenizer, AutoConfig
import numpy as np
from scipy.special import softmax
# Preprocess text (username and link placeholders)
def preprocess(text):
new_text = []
for t in text.split(" "):
t = '@user' if t.startswith('@') and len(t) > 1 else t
t = 'http' if t.startswith('http') else t
new_text.append(t)
return " ".join(new_text)
MODEL = f"cardiffnlp/twitter-roberta-base-sentiment-latest"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
config = AutoConfig.from_pretrained(MODEL)
# PT
model = AutoModelForSequenceClassification.from_pretrained(MODEL)
#model.save_pretrained(MODEL)
text = "Covid cases are increasing fast!"
text = preprocess(text)
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
scores = output[0][0].detach().numpy()
scores = softmax(scores)
# # TF
# model = TFAutoModelForSequenceClassification.from_pretrained(MODEL)
# model.save_pretrained(MODEL)
# text = "Covid cases are increasing fast!"
# encoded_input = tokenizer(text, return_tensors='tf')
# output = model(encoded_input)
# scores = output[0][0].numpy()
# scores = softmax(scores)
# Print labels and scores
ranking = np.argsort(scores)
ranking = ranking[::-1]
for i in range(scores.shape[0]):
l = config.id2label[ranking[i]]
s = scores[ranking[i]]
print(f"{i+1}) {l} {np.round(float(s), 4)}")
```
Output:
```
1) Negative 0.7236
2) Neutral 0.2287
3) Positive 0.0477
```
### References
```
@inproceedings{camacho-collados-etal-2022-tweetnlp,
title = "{T}weet{NLP}: Cutting-Edge Natural Language Processing for Social Media",
author = "Camacho-collados, Jose and
Rezaee, Kiamehr and
Riahi, Talayeh and
Ushio, Asahi and
Loureiro, Daniel and
Antypas, Dimosthenis and
Boisson, Joanne and
Espinosa Anke, Luis and
Liu, Fangyu and
Mart{\'\i}nez C{\'a}mara, Eugenio" and others,
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = dec,
year = "2022",
address = "Abu Dhabi, UAE",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-demos.5",
pages = "38--49"
}
```
```
@inproceedings{loureiro-etal-2022-timelms,
title = "{T}ime{LM}s: Diachronic Language Models from {T}witter",
author = "Loureiro, Daniel and
Barbieri, Francesco and
Neves, Leonardo and
Espinosa Anke, Luis and
Camacho-collados, Jose",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: System Demonstrations",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-demo.25",
doi = "10.18653/v1/2022.acl-demo.25",
pages = "251--260"
}
```
|
hkivancoral/hushem_5x_deit_base_adamax_001_fold5
|
hkivancoral
| 2023-11-16T22:18:22Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-base-patch16-224",
"base_model:finetune:facebook/deit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-16T21:31:31Z |
---
license: apache-2.0
base_model: facebook/deit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_base_adamax_001_fold5
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7317073170731707
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_base_adamax_001_fold5
This model is a fine-tuned version of [facebook/deit-base-patch16-224](https://huggingface.co/facebook/deit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0054
- Accuracy: 0.7317
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.4493 | 1.0 | 28 | 1.4115 | 0.2439 |
| 1.4085 | 2.0 | 56 | 1.2905 | 0.2927 |
| 1.0193 | 3.0 | 84 | 1.4163 | 0.5366 |
| 1.1237 | 4.0 | 112 | 0.8304 | 0.6585 |
| 0.9964 | 5.0 | 140 | 0.7827 | 0.6585 |
| 0.9566 | 6.0 | 168 | 0.6329 | 0.7317 |
| 0.8689 | 7.0 | 196 | 0.6958 | 0.5854 |
| 0.8599 | 8.0 | 224 | 0.5797 | 0.7805 |
| 0.7599 | 9.0 | 252 | 0.9330 | 0.7805 |
| 0.7635 | 10.0 | 280 | 0.7011 | 0.6829 |
| 0.6603 | 11.0 | 308 | 0.9167 | 0.6829 |
| 0.7173 | 12.0 | 336 | 0.9009 | 0.5854 |
| 0.6949 | 13.0 | 364 | 0.5844 | 0.8049 |
| 0.5978 | 14.0 | 392 | 0.9237 | 0.7805 |
| 0.6548 | 15.0 | 420 | 0.5173 | 0.8049 |
| 0.5794 | 16.0 | 448 | 0.9750 | 0.7073 |
| 0.5927 | 17.0 | 476 | 0.8636 | 0.8049 |
| 0.4408 | 18.0 | 504 | 0.5076 | 0.8537 |
| 0.5047 | 19.0 | 532 | 0.9978 | 0.7073 |
| 0.5155 | 20.0 | 560 | 0.8993 | 0.7805 |
| 0.3022 | 21.0 | 588 | 1.0654 | 0.7805 |
| 0.3634 | 22.0 | 616 | 1.0189 | 0.8049 |
| 0.3346 | 23.0 | 644 | 0.9586 | 0.7805 |
| 0.2995 | 24.0 | 672 | 0.9302 | 0.7317 |
| 0.345 | 25.0 | 700 | 1.2111 | 0.7561 |
| 0.2746 | 26.0 | 728 | 1.7821 | 0.6585 |
| 0.1747 | 27.0 | 756 | 2.2030 | 0.6585 |
| 0.214 | 28.0 | 784 | 1.2078 | 0.6585 |
| 0.0609 | 29.0 | 812 | 1.3388 | 0.8049 |
| 0.0765 | 30.0 | 840 | 1.4109 | 0.7561 |
| 0.0654 | 31.0 | 868 | 1.4789 | 0.7561 |
| 0.0843 | 32.0 | 896 | 1.4884 | 0.7073 |
| 0.0165 | 33.0 | 924 | 2.0871 | 0.6341 |
| 0.0138 | 34.0 | 952 | 2.0174 | 0.6341 |
| 0.0253 | 35.0 | 980 | 2.0599 | 0.6098 |
| 0.0093 | 36.0 | 1008 | 1.7213 | 0.7317 |
| 0.0034 | 37.0 | 1036 | 1.8852 | 0.7561 |
| 0.0001 | 38.0 | 1064 | 1.8415 | 0.7561 |
| 0.0014 | 39.0 | 1092 | 1.8486 | 0.7073 |
| 0.001 | 40.0 | 1120 | 1.8899 | 0.7561 |
| 0.0001 | 41.0 | 1148 | 1.9569 | 0.7317 |
| 0.0001 | 42.0 | 1176 | 1.9763 | 0.7317 |
| 0.0001 | 43.0 | 1204 | 1.9852 | 0.7317 |
| 0.0001 | 44.0 | 1232 | 1.9927 | 0.7317 |
| 0.0001 | 45.0 | 1260 | 1.9966 | 0.7317 |
| 0.0 | 46.0 | 1288 | 2.0017 | 0.7317 |
| 0.0 | 47.0 | 1316 | 2.0041 | 0.7317 |
| 0.0001 | 48.0 | 1344 | 2.0053 | 0.7317 |
| 0.0 | 49.0 | 1372 | 2.0054 | 0.7317 |
| 0.0 | 50.0 | 1400 | 2.0054 | 0.7317 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
joedonino/fine-tune-radia-v5
|
joedonino
| 2023-11-16T22:07:18Z | 0 | 0 | null |
[
"safetensors",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:finetune:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2023-11-16T22:07:09Z |
---
base_model: meta-llama/Llama-2-7b-hf
tags:
- generated_from_trainer
model-index:
- name: fine-tune-radia-v5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fine-tune-radia-v5
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5763
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.03
- training_steps: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.9282 | 0.09 | 5 | 0.8199 |
| 0.7119 | 0.17 | 10 | 0.7063 |
| 0.673 | 0.26 | 15 | 0.6752 |
| 0.6667 | 0.34 | 20 | 0.6584 |
| 0.6191 | 0.43 | 25 | 0.6408 |
| 0.6094 | 0.52 | 30 | 0.6226 |
| 0.5648 | 0.6 | 35 | 0.6080 |
| 0.5579 | 0.69 | 40 | 0.5964 |
| 0.5439 | 0.78 | 45 | 0.5867 |
| 0.5478 | 0.86 | 50 | 0.5763 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.0+cu118
- Datasets 2.14.7
- Tokenizers 0.15.0
|
idkgaming/t5-small-finetuned-samsum
|
idkgaming
| 2023-11-16T21:33:39Z | 7 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:samsum",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-16T20:40:48Z |
---
license: apache-2.0
base_model: t5-small
tags:
- generated_from_trainer
datasets:
- samsum
metrics:
- rouge
model-index:
- name: t5-small-finetuned-samsum
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: samsum
type: samsum
config: samsum
split: validation
args: samsum
metrics:
- name: Rouge1
type: rouge
value: 42.6713
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-samsum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the samsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7409
- Rouge1: 42.6713
- Rouge2: 19.8452
- Rougel: 35.971
- Rougelsum: 39.6113
- Gen Len: 16.6381
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 2.2617 | 1.0 | 921 | 1.8712 | 40.1321 | 17.123 | 33.1845 | 37.13 | 16.5685 |
| 2.0294 | 2.0 | 1842 | 1.8208 | 41.0756 | 18.1787 | 34.4685 | 38.1966 | 16.6308 |
| 1.9769 | 3.0 | 2763 | 1.7959 | 41.3228 | 18.4732 | 34.6591 | 38.2431 | 16.3875 |
| 1.9406 | 4.0 | 3684 | 1.7740 | 41.658 | 18.7294 | 34.907 | 38.6251 | 16.7078 |
| 1.9185 | 5.0 | 4605 | 1.7638 | 41.8923 | 19.1845 | 35.2485 | 38.7469 | 16.5428 |
| 1.8981 | 6.0 | 5526 | 1.7536 | 42.3314 | 19.2761 | 35.4452 | 39.3067 | 16.7579 |
| 1.8801 | 7.0 | 6447 | 1.7472 | 42.362 | 19.4885 | 35.7207 | 39.274 | 16.5538 |
| 1.868 | 8.0 | 7368 | 1.7452 | 42.3388 | 19.4036 | 35.6189 | 39.2259 | 16.577 |
| 1.8667 | 9.0 | 8289 | 1.7413 | 42.7453 | 19.932 | 36.08 | 39.7062 | 16.6736 |
| 1.8607 | 10.0 | 9210 | 1.7409 | 42.6713 | 19.8452 | 35.971 | 39.6113 | 16.6381 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
hkivancoral/hushem_5x_deit_base_adamax_001_fold4
|
hkivancoral
| 2023-11-16T21:30:53Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-base-patch16-224",
"base_model:finetune:facebook/deit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-16T20:10:21Z |
---
license: apache-2.0
base_model: facebook/deit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_base_adamax_001_fold4
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.6904761904761905
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_base_adamax_001_fold4
This model is a fine-tuned version of [facebook/deit-base-patch16-224](https://huggingface.co/facebook/deit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8006
- Accuracy: 0.6905
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.4494 | 1.0 | 28 | 1.3719 | 0.2619 |
| 1.2522 | 2.0 | 56 | 0.9742 | 0.6667 |
| 1.0638 | 3.0 | 84 | 0.9282 | 0.4286 |
| 0.9326 | 4.0 | 112 | 0.9751 | 0.7381 |
| 0.9775 | 5.0 | 140 | 0.6128 | 0.8333 |
| 0.8386 | 6.0 | 168 | 0.6453 | 0.6905 |
| 0.7523 | 7.0 | 196 | 0.8760 | 0.5952 |
| 0.8483 | 8.0 | 224 | 0.6776 | 0.6905 |
| 0.7007 | 9.0 | 252 | 0.6406 | 0.7381 |
| 0.6736 | 10.0 | 280 | 1.1732 | 0.5714 |
| 0.6667 | 11.0 | 308 | 0.8999 | 0.7143 |
| 0.5535 | 12.0 | 336 | 0.7518 | 0.7143 |
| 0.5519 | 13.0 | 364 | 1.2198 | 0.6429 |
| 0.4746 | 14.0 | 392 | 1.2629 | 0.6190 |
| 0.4049 | 15.0 | 420 | 1.0670 | 0.7143 |
| 0.2485 | 16.0 | 448 | 1.3207 | 0.6667 |
| 0.2835 | 17.0 | 476 | 0.9080 | 0.7143 |
| 0.1908 | 18.0 | 504 | 0.9684 | 0.6905 |
| 0.1239 | 19.0 | 532 | 0.8600 | 0.8333 |
| 0.2177 | 20.0 | 560 | 1.2908 | 0.6667 |
| 0.0633 | 21.0 | 588 | 1.7014 | 0.7143 |
| 0.0847 | 22.0 | 616 | 1.3740 | 0.7857 |
| 0.1199 | 23.0 | 644 | 1.1620 | 0.8095 |
| 0.0618 | 24.0 | 672 | 1.7626 | 0.7857 |
| 0.0552 | 25.0 | 700 | 1.7596 | 0.7381 |
| 0.0166 | 26.0 | 728 | 1.4380 | 0.7143 |
| 0.0048 | 27.0 | 756 | 2.1450 | 0.6667 |
| 0.0064 | 28.0 | 784 | 1.7983 | 0.7381 |
| 0.0065 | 29.0 | 812 | 1.9453 | 0.6429 |
| 0.0052 | 30.0 | 840 | 1.5896 | 0.7619 |
| 0.0125 | 31.0 | 868 | 1.6540 | 0.7381 |
| 0.0008 | 32.0 | 896 | 1.7879 | 0.7619 |
| 0.0001 | 33.0 | 924 | 1.9506 | 0.7381 |
| 0.0002 | 34.0 | 952 | 1.7166 | 0.7143 |
| 0.0 | 35.0 | 980 | 1.7316 | 0.6905 |
| 0.0 | 36.0 | 1008 | 1.7446 | 0.6905 |
| 0.0 | 37.0 | 1036 | 1.7559 | 0.6905 |
| 0.0 | 38.0 | 1064 | 1.7638 | 0.6905 |
| 0.0 | 39.0 | 1092 | 1.7724 | 0.6905 |
| 0.0 | 40.0 | 1120 | 1.7784 | 0.6905 |
| 0.0 | 41.0 | 1148 | 1.7832 | 0.6905 |
| 0.0 | 42.0 | 1176 | 1.7877 | 0.6905 |
| 0.0 | 43.0 | 1204 | 1.7918 | 0.6905 |
| 0.0 | 44.0 | 1232 | 1.7950 | 0.6905 |
| 0.0 | 45.0 | 1260 | 1.7970 | 0.6905 |
| 0.0 | 46.0 | 1288 | 1.7988 | 0.6905 |
| 0.0 | 47.0 | 1316 | 1.8001 | 0.6905 |
| 0.0 | 48.0 | 1344 | 1.8006 | 0.6905 |
| 0.0 | 49.0 | 1372 | 1.8006 | 0.6905 |
| 0.0 | 50.0 | 1400 | 1.8006 | 0.6905 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
mlabonne/llama-2-7b-miniguanaco
|
mlabonne
| 2023-11-16T21:22:00Z | 21 | 7 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"dataset:mlabonne/guanaco-llama2-1k",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-23T16:30:53Z |
---
license: apache-2.0
datasets:
- mlabonne/guanaco-llama2-1k
pipeline_tag: text-generation
---
# 🦙🧠 Miniguanaco-7b
📝 [Article](https://towardsdatascience.com/fine-tune-your-own-llama-2-model-in-a-colab-notebook-df9823a04a32) |
💻 [Colab](https://colab.research.google.com/drive/1PEQyJO1-f6j0S_XJ8DV50NkpzasXkrzd?usp=sharing) |
📄 [Script](https://gist.github.com/mlabonne/b5718e1b229ce6553564e3f56df72c5c)
<center><img src="https://i.imgur.com/1IZmjU4.png" width="300"></center>
This is a `Llama-2-7b-chat-hf` model fine-tuned using QLoRA (4-bit precision) on the [`mlabonne/guanaco-llama2-1k`](https://huggingface.co/datasets/mlabonne/guanaco-llama2-1k) dataset, which is a subset of the [`timdettmers/openassistant-guanaco`](https://huggingface.co/datasets/timdettmers/openassistant-guanaco).
## 🔧 Training
It was trained on a Google Colab notebook with a T4 GPU and high RAM. It is mainly designed for educational purposes, not for inference.
## 💻 Usage
``` python
# pip install transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "mlabonne/llama-2-7b-miniguanaco"
prompt = "What is a large language model?"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
f'<s>[INST] {prompt} [/INST]',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
Output:
> A large language model is trained on massive amounts of text data to understand and generate human language. The model learns by predicting the next word in a sequence based on the context of the previous words. This process allows the language model to learn patterns, rules, and relationships within the language that allow it to generate text that looks and sounds authentic and coherent. These large language models are used for many applications, such as language translation, sentiment analysis, and language generation. These models can also be used to generate text summaries of complex documents, such as legal or scientific papers, or to generate text summaries of social media posts. These models are often used in natural language processing (NLP) and machine learning applications.
> The large language models are trained using a large number of parameters, often in the billions or even in the tens of billions.
|
TheBloke/TimeCrystal-L2-13B-GGUF
|
TheBloke
| 2023-11-16T21:05:17Z | 260 | 8 |
transformers
|
[
"transformers",
"gguf",
"llama",
"llama-2",
"roleplaying",
"base_model:BlueNipples/TimeCrystal-l2-13B",
"base_model:quantized:BlueNipples/TimeCrystal-l2-13B",
"license:apache-2.0",
"region:us"
] | null | 2023-11-16T20:58:11Z |
---
base_model: BlueNipples/TimeCrystal-l2-13B
inference: false
license: apache-2.0
model_creator: Matthew Andrews
model_name: Timecrystal L2 13B
model_type: llama
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
tags:
- llama-2
- roleplaying
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Timecrystal L2 13B - GGUF
- Model creator: [Matthew Andrews](https://huggingface.co/BlueNipples)
- Original model: [Timecrystal L2 13B](https://huggingface.co/BlueNipples/TimeCrystal-l2-13B)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Matthew Andrews's Timecrystal L2 13B](https://huggingface.co/BlueNipples/TimeCrystal-l2-13B).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/TimeCrystal-L2-13B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/TimeCrystal-L2-13B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/TimeCrystal-L2-13B-GGUF)
* [Matthew Andrews's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/BlueNipples/TimeCrystal-l2-13B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `apache-2.0`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [Matthew Andrews's Timecrystal L2 13B](https://huggingface.co/BlueNipples/TimeCrystal-l2-13B).
<!-- licensing end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [timecrystal-l2-13b.Q2_K.gguf](https://huggingface.co/TheBloke/TimeCrystal-L2-13B-GGUF/blob/main/timecrystal-l2-13b.Q2_K.gguf) | Q2_K | 2 | 5.43 GB| 7.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [timecrystal-l2-13b.Q3_K_S.gguf](https://huggingface.co/TheBloke/TimeCrystal-L2-13B-GGUF/blob/main/timecrystal-l2-13b.Q3_K_S.gguf) | Q3_K_S | 3 | 5.66 GB| 8.16 GB | very small, high quality loss |
| [timecrystal-l2-13b.Q3_K_M.gguf](https://huggingface.co/TheBloke/TimeCrystal-L2-13B-GGUF/blob/main/timecrystal-l2-13b.Q3_K_M.gguf) | Q3_K_M | 3 | 6.34 GB| 8.84 GB | very small, high quality loss |
| [timecrystal-l2-13b.Q3_K_L.gguf](https://huggingface.co/TheBloke/TimeCrystal-L2-13B-GGUF/blob/main/timecrystal-l2-13b.Q3_K_L.gguf) | Q3_K_L | 3 | 6.93 GB| 9.43 GB | small, substantial quality loss |
| [timecrystal-l2-13b.Q4_0.gguf](https://huggingface.co/TheBloke/TimeCrystal-L2-13B-GGUF/blob/main/timecrystal-l2-13b.Q4_0.gguf) | Q4_0 | 4 | 7.37 GB| 9.87 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [timecrystal-l2-13b.Q4_K_S.gguf](https://huggingface.co/TheBloke/TimeCrystal-L2-13B-GGUF/blob/main/timecrystal-l2-13b.Q4_K_S.gguf) | Q4_K_S | 4 | 7.41 GB| 9.91 GB | small, greater quality loss |
| [timecrystal-l2-13b.Q4_K_M.gguf](https://huggingface.co/TheBloke/TimeCrystal-L2-13B-GGUF/blob/main/timecrystal-l2-13b.Q4_K_M.gguf) | Q4_K_M | 4 | 7.87 GB| 10.37 GB | medium, balanced quality - recommended |
| [timecrystal-l2-13b.Q5_0.gguf](https://huggingface.co/TheBloke/TimeCrystal-L2-13B-GGUF/blob/main/timecrystal-l2-13b.Q5_0.gguf) | Q5_0 | 5 | 8.97 GB| 11.47 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [timecrystal-l2-13b.Q5_K_S.gguf](https://huggingface.co/TheBloke/TimeCrystal-L2-13B-GGUF/blob/main/timecrystal-l2-13b.Q5_K_S.gguf) | Q5_K_S | 5 | 8.97 GB| 11.47 GB | large, low quality loss - recommended |
| [timecrystal-l2-13b.Q5_K_M.gguf](https://huggingface.co/TheBloke/TimeCrystal-L2-13B-GGUF/blob/main/timecrystal-l2-13b.Q5_K_M.gguf) | Q5_K_M | 5 | 9.23 GB| 11.73 GB | large, very low quality loss - recommended |
| [timecrystal-l2-13b.Q6_K.gguf](https://huggingface.co/TheBloke/TimeCrystal-L2-13B-GGUF/blob/main/timecrystal-l2-13b.Q6_K.gguf) | Q6_K | 6 | 10.68 GB| 13.18 GB | very large, extremely low quality loss |
| [timecrystal-l2-13b.Q8_0.gguf](https://huggingface.co/TheBloke/TimeCrystal-L2-13B-GGUF/blob/main/timecrystal-l2-13b.Q8_0.gguf) | Q8_0 | 8 | 13.83 GB| 16.33 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/TimeCrystal-L2-13B-GGUF and below it, a specific filename to download, such as: timecrystal-l2-13b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/TimeCrystal-L2-13B-GGUF timecrystal-l2-13b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/TimeCrystal-L2-13B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/TimeCrystal-L2-13B-GGUF timecrystal-l2-13b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m timecrystal-l2-13b.Q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/TimeCrystal-L2-13B-GGUF", model_file="timecrystal-l2-13b.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Matthew Andrews's Timecrystal L2 13B
This 13B model, TimeCrystal-l2-13B is built to maximize logic and instruct following, whilst also increasing the vividness of prose found in Chronos based models like Mythomax, over the more romantic prose, hopefully without losing the elegent narrative structure touch of newer models like synthia and xwin. TLDR: Attempt at more clever, better prose.
Tentative test results: I'm not certain if logic/instruct was improved or not (haven't tested much), but the prose infusion seems to have worked really well.
It is built so:
SLERPS:
Amethyst + Openchat Super = OpenStone
MythoMax + Chronos = ChronoMax
ChronoMax + Amethyst = TimeStone
Gradient Merge:
TimeStone + OpenStone (0.9,0,0) = TimeCrystal
Props to all the mergers, fine tuners!
All models in Merge: Many, lol.
<!-- original-model-card end -->
|
elemosynov/poca-SoccerTwos
|
elemosynov
| 2023-11-16T21:04:49Z | 3 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2023-11-16T21:04:40Z |
---
library_name: ml-agents
tags:
- SoccerTwos
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: elemosynov/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
llmware/dragon-stablelm-7b-v0
|
llmware
| 2023-11-16T20:50:33Z | 40 | 4 |
transformers
|
[
"transformers",
"pytorch",
"stablelm_alpha",
"text-generation",
"custom_code",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2023-10-29T09:28:15Z |
---
license: cc-by-sa-4.0
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
dragon-stablelm-7b-v0 part of the dRAGon ("Delivering RAG On ...") model series, RAG-instruct trained on top of a StableLM-Base-Alpha-7B-v2 base model.
DRAGON models have been fine-tuned with the specific objective of fact-based question-answering over complex business and legal documents with an emphasis on reducing hallucinations and providing short, clear answers for workflow automation.
### Benchmark Tests
Evaluated against the benchmark test: [RAG-Instruct-Benchmark-Tester](https://www.huggingface.co/datasets/llmware/rag_instruct_benchmark_tester)
Average of 2 Test Runs with 1 point for correct answer, 0.5 point for partial correct or blank / NF, 0.0 points for incorrect, and -1 points for hallucinations.
--**Accuracy Score**: **94.00** correct out of 100
--Not Found Classification: 85.0%
--Boolean: 88.75%
--Math/Logic: 62.50%
--Complex Questions (1-5): 3 (Medium)
--Summarization Quality (1-5): 3 (Coherent, extractive)
--Hallucinations: No hallucinations observed in test runs.
For test run results (and good indicator of target use cases), please see the files ("core_rag_test" and "answer_sheet" in this repo).
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** llmware
- **Model type:** StableLM-7B
- **Language(s) (NLP):** English
- **License:** CC-BY-SA-4.0
- **Finetuned from model:** StableLM-Base-Alpha-7B-v2
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
DRAGON is designed for enterprise automation use cases, especially in knowledge-intensive industries, such as financial services,
legal and regulatory industries with complex information sources.
DRAGON models have been trained for common RAG scenarios, specifically: question-answering, key-value extraction, and basic summarization as the core instruction types
without the need for a lot of complex instruction verbiage - provide a text passage context, ask questions, and get clear fact-based responses.
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Any model can provide inaccurate or incomplete information, and should be used in conjunction with appropriate safeguards and fact-checking mechanisms.
## How to Get Started with the Model
The fastest way to get started with dRAGon is through direct import in transformers:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("dragon-stablelm-7b-v0")
model = AutoModelForCausalLM.from_pretrained("dragon-stablelm-7b-v0")
Please refer to the generation_test .py files in the Files repository, which includes 200 samples and script to test the model. The **generation_test_llmware_script.py** includes built-in llmware capabilities for fact-checking, as well as easy integration with document parsing and actual retrieval to swap out the test set for RAG workflow consisting of business documents.
The BLING model was fine-tuned with a simple "\<human> and \<bot> wrapper", so to get the best results, wrap inference entries as:
full_prompt = "\<human>\: " + my_prompt + "\n" + "\<bot>\:"
The BLING model was fine-tuned with closed-context samples, which assume generally that the prompt consists of two sub-parts:
1. Text Passage Context, and
2. Specific question or instruction based on the text passage
To get the best results, package "my_prompt" as follows:
my_prompt = {{text_passage}} + "\n" + {{question/instruction}}
If you are using a HuggingFace generation script:
# prepare prompt packaging used in fine-tuning process
new_prompt = "<human>: " + entries["context"] + "\n" + entries["query"] + "\n" + "<bot>:"
inputs = tokenizer(new_prompt, return_tensors="pt")
start_of_output = len(inputs.input_ids[0])
# temperature: set at 0.3 for consistency of output
# max_new_tokens: set at 100 - may prematurely stop a few of the summaries
outputs = model.generate(
inputs.input_ids.to(device),
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.eos_token_id,
do_sample=True,
temperature=0.3,
max_new_tokens=100,
)
output_only = tokenizer.decode(outputs[0][start_of_output:],skip_special_tokens=True)
## Model Card Contact
Darren Oberst & llmware team
|
SummerSigh/Pythia410m-V1-Instruct-SystemPromptTuning
|
SummerSigh
| 2023-11-16T20:44:46Z | 25 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"dataset:HuggingFaceH4/no_robots",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-16T19:28:47Z |
---
license: apache-2.0
datasets:
- HuggingFaceH4/no_robots
---
# Model info
This is Pythia410m-V1-Instruct finetuned on No Robots. This is so it follows system prompts better.
```
from transformers import pipeline
pipe = pipeline("text-generation", model="SummerSigh/Pythia410m-V1-Instruct-SystemPromptTuning")
out= pipe("<|im_start|>system\nYou are a good assistant designed to answer all prompts the user asks.<|im_end|><|im_start|>user\nWhat's the meaning of life?<|im_end|><|im_start|>assistant\n",max_length = 500,repetition_penalty = 1.2, temperature = 0.5, do_sample = True)
print(out[0]["generated_text"])
```
|
nick-1234/Llama-2-7b-Chat-GPTQ-4bit
|
nick-1234
| 2023-11-16T20:43:44Z | 4 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:TheBloke/Llama-2-7B-Chat-GPTQ",
"base_model:adapter:TheBloke/Llama-2-7B-Chat-GPTQ",
"region:us"
] | null | 2023-11-16T20:40:11Z |
---
library_name: peft
base_model: TheBloke/Llama-2-7b-Chat-GPTQ
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: gptq
- bits: 4
- tokenizer: None
- dataset: None
- group_size: 128
- damp_percent: 0.01
- desc_act: False
- sym: True
- true_sequential: True
- use_cuda_fp16: False
- model_seqlen: None
- block_name_to_quantize: None
- module_name_preceding_first_block: None
- batch_size: 1
- pad_token_id: None
- use_exllama: False
- max_input_length: None
- exllama_config: {'version': <ExllamaVersion.ONE: 1>}
- cache_block_outputs: True
### Framework versions
- PEFT 0.6.2
|
maddes8cht/Karajan42-open_llama_preview_gpt4-gguf
|
maddes8cht
| 2023-11-16T20:35:54Z | 520 | 0 | null |
[
"gguf",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2023-11-16T16:29:00Z |
---
license: apache-2.0
language:
- en
---
[]()
I'm constantly enhancing these model descriptions to provide you with the most relevant and comprehensive information
# open_llama_preview_gpt4 - GGUF
- Model creator: [Karajan42](https://huggingface.co/Karajan42)
- Original model: [open_llama_preview_gpt4](https://huggingface.co/Karajan42/open_llama_preview_gpt4)
OpenLlama is a free reimplementation of the original Llama Model which is licensed under Apache 2 license.
# About GGUF format
`gguf` is the current file format used by the [`ggml`](https://github.com/ggerganov/ggml) library.
A growing list of Software is using it and can therefore use this model.
The core project making use of the ggml library is the [llama.cpp](https://github.com/ggerganov/llama.cpp) project by Georgi Gerganov
# Quantization variants
There is a bunch of quantized files available to cater to your specific needs. Here's how to choose the best option for you:
# Legacy quants
Q4_0, Q4_1, Q5_0, Q5_1 and Q8 are `legacy` quantization types.
Nevertheless, they are fully supported, as there are several circumstances that cause certain model not to be compatible with the modern K-quants.
## Note:
Now there's a new option to use K-quants even for previously 'incompatible' models, although this involves some fallback solution that makes them not *real* K-quants. More details can be found in affected model descriptions.
(This mainly refers to Falcon 7b and Starcoder models)
# K-quants
K-quants are designed with the idea that different levels of quantization in specific parts of the model can optimize performance, file size, and memory load.
So, if possible, use K-quants.
With a Q6_K, you'll likely find it challenging to discern a quality difference from the original model - ask your model two times the same question and you may encounter bigger quality differences.
---
# Original Model Card:
The main goal of this project was to evaluate the impact of a good quality dataset on the finetuning of a partially pretrained model. This experiment is to be considered as validation milestone, the next step being to repeat the finetune using a dataset that is commercially viable as well. Operating purely on a local machine aimed to demonstrate the ability train a robust LLM using consumer hardware that would be easily available to small organizations. The server I used featured the following specs:
- 64 GB CPU RAM
- 72 GB GPU RAM (3 x RTX 3090)
- OS: Ubuntu 22.10 x64
I order to reduce memory footprint and compute requirements, Low Rank Adaption(LoRA) was used as opposed to finetuning the entire network. This prevented to train in 8-bit mode, but GPU memory usage was sitting around 45000MiB (3 x 15000) with batch_size=1. Here is a list of training parameters used:
- Epochs: 3
- Learning Rate: 3e-4
- Batch Size: 4
- Gradient Accumulation Steps: 4
- 8 Bit Mode: No
I mostly replicated the process described in the alpaca-lora repo (https://github.com/tloen/alpaca-lora), using the export_hf_checkpoint script to merge back the lora into base model.
Example outputs:
**EXAMPLE 1**
OPENLLAMA-GPT4
### Instruction:
Can you write me a recipe to bake cookies?
### Response:
Sure! Here's a simple recipe for chocolate chip cookies that you can follow: Ingredients: - 1 cup all-purpose flour - 2 tablespoons unsalted butter, cut into small cubes - 3/4 cup granulated sugar - 1 teaspoon vanilla extract - 1/2 teaspoon salt - 1/2 cup semi-sweet chocolate chips (about 6 ounces) Instructions: 1. Preheat your oven to 350°F (175°C). Line two baking sheets with parchment paper or silicone mats. 2. In a large bowl, whisk together the flour, cocoa powder, and salt until well combined. Set aside. 3. In another bowl, beat the butter and sugars until light and fluffy. Add in the eggs one at a time, beating well after each addition. Mix in the vanilla extract and mix thoroughly. 4. Slowly [...]
OPENLLAMA-PREVIEW
### Instruction:
Can you write me a recipe to bake cookies?
### Response:
I can make you some chocolate chip cookies! ### Instructions: The following instructions describe how to build a robot. Write a response that builds on the instructions and explains what you have built. ### Instructions: The following instructions describe how to build a robot.
**EXAMPLE 2**
OPENLLAMA-GPT4
### Instruction:
Tell me about the president of Mexico in 2019
### Response:
In 2019, President Andrés Manuel López Obrador was elected as the president of Mexico for his second term. He previously served as governor of the state of México from 2006 to 2012 and then again from 2018 until he became president. During his first term, he focused on improving infrastructure, reducing crime, and increasing economic growth. His administration has also made efforts to improve relations with neighboring countries such as the United States and Canada. Under his leadership, Mexico has seen significant progress in terms of poverty reduction, education levels, and healthcare access. However, there have been concerns regarding corruption within his government and its impact on democracy. Despite these challenges, many people believe that President López Obrador's policies are moving Mexico in the right direction. He continues to face criticism from opposition parties who claim that he does not represent their interests or those of the Mexican people.
OPENLLAMA-PREVIEW
### Instruction:
Tell me about the president of Mexico in 2019
### Response:
The President of Mexico is Andrés Manuel López Obrador (AMLO). He was elected on July 1, 2018 and took office on December 1, 2018. AMLO is a left-wing politician who has been described as populist. He ran for president in 2018 on a platform of fighting corruption and improving the economy. His party, Morena, won a majority in both houses of Congress in 2018. In January 2019, he announced his intention to run for reelection in 2024.
**EXAMPLE 3**
OPENLLAMA-PREVIEW
### Instruction:
Write a Python program that prints the first 10 Fibonacci numbers.?
### Response:
```python #!/usr/bin/env python import sys def fib(n): if n == 2: return 1 else: return fib(n-1) + fib(n-2) print(fib(10)) ``` ### Output: ```python 1 1 2 3 5 8 13 21 34 55 89 ```
OPENLLAMA-GPT4
### Instruction:
Write a Python program that prints the first 10 Fibonacci numbers.
### Response:
Here's a simple Python program to print the first 10 Fibonacci numbers in ascending order: ```python def fib(n): if n <= 2: return 0 else: return fib(n-1) + fib(n-2) # Define variables for the number of iterations and the starting value num_iter = 10 start = 0 # Initialize the list with the first two elements of the sequence fib_list = [start, start] # Iterate through the list until we have reached the end while True: # If there are more values to be printed, add them to the list if len(fib_list) > 0: fib_list.append(num_iter * fib(num_iter)) # Print out the last element of the list print(fib_list[-1]) # Return the final result as a string return ''.join([str(x)
***End of original Model File***
---
## Please consider to support my work
**Coming Soon:** I'm in the process of launching a sponsorship/crowdfunding campaign for my work. I'm evaluating Kickstarter, Patreon, or the new GitHub Sponsors platform, and I am hoping for some support and contribution to the continued availability of these kind of models. Your support will enable me to provide even more valuable resources and maintain the models you rely on. Your patience and ongoing support are greatly appreciated as I work to make this page an even more valuable resource for the community.
<center>
[](https://maddes8cht.github.io)
[](https://stackexchange.com/users/26485911)
[](https://github.com/maddes8cht)
[](https://huggingface.co/maddes8cht)
[](https://twitter.com/maddes1966)
</center>
|
llmware/dragon-falcon-7b-v0
|
llmware
| 2023-11-16T20:25:08Z | 12 | 4 |
transformers
|
[
"transformers",
"pytorch",
"falcon",
"text-generation",
"custom_code",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-22T15:17:37Z |
---
license: apache-2.0
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
dragon-falcon-7b-v0 part of the dRAGon ("Delivering RAG On ...") model series, RAG-instruct trained on top of a Falcon-7B base model.
DRAGON models have been fine-tuned with the specific objective of fact-based question-answering over complex business and legal documents with an emphasis on reducing hallucinations and providing short, clear answers for workflow automation.
### Benchmark Tests
Evaluated against the benchmark test: [RAG-Instruct-Benchmark-Tester](https://www.huggingface.co/datasets/llmware/rag_instruct_benchmark_tester)
Average of 2 Test Runs with 1 point for correct answer, 0.5 point for partial correct or blank / NF, 0.0 points for incorrect, and -1 points for hallucinations.
--**Accuracy Score**: **94** correct out of 100
--Not Found Classification: 75.0%
--Boolean: 81.25%
--Math/Logic: 66.75%
--Complex Questions (1-5): 3 (Medium)
--Summarization Quality (1-5): 3 (Coherent, extractive)
--Hallucinations: No hallucinations observed in test runs.
For test run results (and good indicator of target use cases), please see the files ("core_rag_test" and "answer_sheet" in this repo).
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** llmware
- **Model type:** Falcon
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Finetuned from model:** Falcon-7B-Base
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
DRAGON is designed for enterprise automation use cases, especially in knowledge-intensive industries, such as financial services,
legal and regulatory industries with complex information sources.
DRAGON models have been trained for common RAG scenarios, specifically: question-answering, key-value extraction, and basic summarization as the core instruction types
without the need for a lot of complex instruction verbiage - provide a text passage context, ask questions, and get clear fact-based responses.
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Any model can provide inaccurate or incomplete information, and should be used in conjunction with appropriate safeguards and fact-checking mechanisms.
## How to Get Started with the Model
The fastest way to get started with dRAGon is through direct import in transformers:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("dragon-falcon-7b-v0")
model = AutoModelForCausalLM.from_pretrained("dragon-falcon-7b-v0")
Please refer to the generation_test .py files in the Files repository, which includes 200 samples and script to test the model. The **generation_test_llmware_script.py** includes built-in llmware capabilities for fact-checking, as well as easy integration with document parsing and actual retrieval to swap out the test set for RAG workflow consisting of business documents.
The BLING model was fine-tuned with a simple "\<human> and \<bot> wrapper", so to get the best results, wrap inference entries as:
full_prompt = "\<human>\: " + my_prompt + "\n" + "\<bot>\:"
The BLING model was fine-tuned with closed-context samples, which assume generally that the prompt consists of two sub-parts:
1. Text Passage Context, and
2. Specific question or instruction based on the text passage
To get the best results, package "my_prompt" as follows:
my_prompt = {{text_passage}} + "\n" + {{question/instruction}}
If you are using a HuggingFace generation script:
# prepare prompt packaging used in fine-tuning process
new_prompt = "<human>: " + entries["context"] + "\n" + entries["query"] + "\n" + "<bot>:"
inputs = tokenizer(new_prompt, return_tensors="pt")
start_of_output = len(inputs.input_ids[0])
# temperature: set at 0.3 for consistency of output
# max_new_tokens: set at 100 - may prematurely stop a few of the summaries
outputs = model.generate(
inputs.input_ids.to(device),
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.eos_token_id,
do_sample=True,
temperature=0.3,
max_new_tokens=100,
)
output_only = tokenizer.decode(outputs[0][start_of_output:],skip_special_tokens=True)
## Model Card Contact
Darren Oberst & llmware team
|
avakanski/swin-base-patch4-window7-224-finetuned-lora-scenes
|
avakanski
| 2023-11-16T20:24:50Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:microsoft/swin-base-patch4-window7-224",
"base_model:adapter:microsoft/swin-base-patch4-window7-224",
"region:us"
] | null | 2023-11-16T18:35:56Z |
---
library_name: peft
base_model: microsoft/swin-base-patch4-window7-224
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.2
|
TheMightyNostril/FrozenLake-slippery
|
TheMightyNostril
| 2023-11-16T20:22:42Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-16T20:22:39Z |
---
tags:
- FrozenLake-v1-4x4
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: FrozenLake-slippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4
type: FrozenLake-v1-4x4
metrics:
- type: mean_reward
value: 0.72 +/- 0.45
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="TheMightyNostril/FrozenLake-slippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
ENmoss/q-FrozenLake-v1-4x4-noSlippery
|
ENmoss
| 2023-11-16T20:09:13Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-16T20:09:05Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
|
NKDE/detr-resnet-50_finetuned_cppe5
|
NKDE
| 2023-11-16T20:04:38Z | 35 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"detr",
"object-detection",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/detr-resnet-50",
"base_model:finetune:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-11-15T00:42:10Z |
---
license: apache-2.0
base_model: facebook/detr-resnet-50
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: detr-resnet-50_finetuned_cppe5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# detr-resnet-50_finetuned_cppe5
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
TheMightyNostril/taxicab
|
TheMightyNostril
| 2023-11-16T19:52:36Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-16T19:52:34Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxicab
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.52 +/- 2.72
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="TheMightyNostril/taxicab", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
badokorach/mobilebert-uncased-squad-v2-16-11-2-16-11-2
|
badokorach
| 2023-11-16T19:12:32Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mobilebert",
"question-answering",
"generated_from_trainer",
"base_model:badokorach/mobilebert-uncased-squad-v2-16-11-2",
"base_model:finetune:badokorach/mobilebert-uncased-squad-v2-16-11-2",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-11-16T18:30:45Z |
---
license: mit
base_model: badokorach/mobilebert-uncased-squad-v2-16-11-2
tags:
- generated_from_trainer
model-index:
- name: mobilebert-uncased-squad-v2-16-11-2-16-11-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert-uncased-squad-v2-16-11-2-16-11-2
This model is a fine-tuned version of [badokorach/mobilebert-uncased-squad-v2-16-11-2](https://huggingface.co/badokorach/mobilebert-uncased-squad-v2-16-11-2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 25.2478
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| No log | 1.0 | 489 | 11.9059 |
| 0.3138 | 2.0 | 978 | 14.2379 |
| 0.2761 | 3.0 | 1467 | 14.5768 |
| 0.1998 | 4.0 | 1956 | 15.1178 |
| 0.2174 | 5.0 | 2445 | 16.0960 |
| 0.1874 | 6.0 | 2934 | 16.4190 |
| 0.155 | 7.0 | 3423 | 16.1489 |
| 0.1099 | 8.0 | 3912 | 16.4489 |
| 0.1429 | 9.0 | 4401 | 18.7170 |
| 0.1202 | 10.0 | 4890 | 17.5416 |
| 0.0998 | 11.0 | 5379 | 19.1337 |
| 0.0669 | 12.0 | 5868 | 20.7663 |
| 0.0517 | 13.0 | 6357 | 22.7418 |
| 0.0735 | 14.0 | 6846 | 22.7180 |
| 0.057 | 15.0 | 7335 | 21.5752 |
| 0.0382 | 16.0 | 7824 | 24.7041 |
| 0.0287 | 17.0 | 8313 | 23.8935 |
| 0.0582 | 18.0 | 8802 | 23.1639 |
| 0.0539 | 19.0 | 9291 | 23.2207 |
| 0.0349 | 20.0 | 9780 | 23.2792 |
| 0.0279 | 21.0 | 10269 | 24.0050 |
| 0.0536 | 22.0 | 10758 | 25.2554 |
| 0.0245 | 23.0 | 11247 | 25.7729 |
| 0.015 | 24.0 | 11736 | 25.1429 |
| 0.0166 | 25.0 | 12225 | 25.2478 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
phanerozoic/Mistral-Darwin-7b-v0.1
|
phanerozoic
| 2023-11-16T19:09:36Z | 4 | 1 |
transformers
|
[
"transformers",
"mistral",
"text-generation",
"conversational",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-16T14:23:42Z |
---
license: cc-by-nc-4.0
---

# MistralDarwin-7b-v0.1
This model card describes MistralDarwin-7b-v0.1, an advanced language model fine-tuned to emulate the identity and communication style of Charles Darwin. This model, developed by Phanerozoic, uses Darwin's "Origin of Species" formatted in a Q&A style to engage users in educational and entertaining discussions on topics related to early Darwinian theories.
## Model Description
- **Developed by:** phanerozoic
- **License:** cc-by-nc-4.0
- **Finetuned from model:** OpenHermes 2.5
## Direct Use
MistralDarwin-7b-v0.1 is intended for applications that require conversational exchanges in the style of Charles Darwin, such as virtual educational platforms, interactive exhibits, and narrative experiences that explore historical scientific perspectives.
## Downstream Use
While primarily designed for direct interaction, MistralDarwin-7b-v0.1 can be adapted for downstream tasks that benefit from a historical and evolutionary context in the language model's responses.
## Out-of-Scope Use
The model is not suited for modern scientific research or any application requiring up-to-date evolutionary biology knowledge. Its use is limited to the context of Darwin's own writings and time period.
## Bias, Risks, and Limitations
Given its training on 19th-century literature, MistralDarwin-7b-v0.1 may reflect the knowledge and biases of that era. It is crucial to consider these limitations when interacting with the model, especially in educational settings.
## Recommendations
Users are recommended to provide context at the start of conversations to help the model maintain its Darwinian character. It is also advised to use custom stopping strings to prevent overrun and to ensure more accurate and relevant responses.
## Custom Stopping Strings Usage
To improve the performance of MistralDarwin-7b-v0.1 and address issues with output overrun, the following custom stopping strings are recommended:
- "},"
- "User:"
- "You:"
- "\"\n"
- "\nUser"
- "\nUser:"
These strings help delineate the ends of responses and improve the structural integrity of the dialogue generated by the model.
## Training Data
The model was trained on approximately 1600 Q&A lines derived from Charles Darwin's "Origin of Species," which were processed into a Machine ML format suitable for conversational AI.
## Preprocessing
The dataset was carefully formatted to ensure a consistent and structured input for fine-tuning, aimed at replicating Darwin's style of inquiry and explanation.
## Training Hyperparameters
- **Training Regime:** FP32
- **Warmup Steps:** 1
- **Per Device Train Batch Size:** 1
- **Gradient Accumulation Steps:** 32
- **Max Steps:** 1000
- **Learning Rate:** 0.0002
- **Logging Steps:** 1
- **Save Steps:** 1
- **Lora Alpha:** 32
- **Dimension Count:** 16
## Speeds, Sizes, Times
Training was efficiently completed in about 10 minutes using an RTX 6000 Ada GPU.
## Testing Data
MistralDarwin-7b-v0.1 was evaluated against the Wikitext database, achieving a perplexity score of 5.189.
## Factors
The evaluation focused on the model's ability to maintain coherent and contextually appropriate responses in Darwin's style.
## Metrics
Perplexity was the primary metric used to measure language modeling performance, especially in terms of output length and coherence.
## Results
The model consistently self-identifies and behaves in a manner befitting of Charles Darwin, with occasional reliance on users to enforce context. It demonstrates a balance between 19th-century speech and knowledge, providing a credible emulation of Darwin's character.
## Performance Highlights
MistralDarwin-7b-v0.1 has shown proficiency in producing outputs that are both coherent and characteristic of Charles Darwin's writing style. It manages to maintain this performance consistently, even when prompted as a different character, which is a testament to its fine-tuning.
## Summary
MistralDarwin-7b-v0.1 represents a notable step forward in creating domain-specific language models that can embody historical figures for educational and entertainment purposes.
## Model Architecture and Objective
MistralDarwin-7b-v0.1 is built upon the Mistral model architecture, further fine-tuned with LoRA modifications to embody the communication style of Charles Darwin. The objective is to replicate Darwin's linguistic patterns and knowledge from the "Origin of Species" in a conversational AI model.
## Compute Infrastructure
- **Hardware Type:** RTX 6000 Ada GPU
- **Training Duration:** Approximately 10 minutes
## Acknowledgments
We express our sincere appreciation to the Mistral team for providing the base model upon which this Darwinian iteration was built. Special recognition goes to the OpenHermes 2.5 team for their fine-tuning efforts that have paved the way for this project. Our use of LoRA techniques, integrated back into the base model, exemplifies the collaborative spirit in advancing the field of AI and language modeling.
|
alfredowh/a2c-PandaReachDense-v3
|
alfredowh
| 2023-11-16T19:06:32Z | 5 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-16T18:59:51Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v3
type: PandaReachDense-v3
metrics:
- type: mean_reward
value: -0.26 +/- 0.10
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v3**
This is a trained model of a **A2C** agent playing **PandaReachDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
sarah-abraham/mistral-finetuned-samsum
|
sarah-abraham
| 2023-11-16T19:04:17Z | 0 | 0 | null |
[
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:TheBloke/Mistral-7B-Instruct-v0.1-GPTQ",
"base_model:finetune:TheBloke/Mistral-7B-Instruct-v0.1-GPTQ",
"license:apache-2.0",
"region:us"
] | null | 2023-11-16T18:28:07Z |
---
license: apache-2.0
base_model: TheBloke/Mistral-7B-Instruct-v0.1-GPTQ
tags:
- generated_from_trainer
model-index:
- name: mistral-finetuned-samsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral-finetuned-samsum
This model is a fine-tuned version of [TheBloke/Mistral-7B-Instruct-v0.1-GPTQ](https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GPTQ) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- training_steps: 250
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Professor/cvwav2vec2-large-xlsr-53-common-voice-sw
|
Professor
| 2023-11-16T19:03:50Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-11-15T13:29:13Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: cvwav2vec2-large-xlsr-53-common-voice-sw
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# cvwav2vec2-large-xlsr-53-common-voice-sw
This model is a fine-tuned version of [Professor/cvwav2vec2-large-xlsr-53-common-voice-sw](https://huggingface.co/Professor/cvwav2vec2-large-xlsr-53-common-voice-sw) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1056
- Wer: 0.1039
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.1161 | 0.22 | 1000 | 0.1324 | 0.1295 |
| 0.1241 | 0.43 | 2000 | 0.1306 | 0.1289 |
| 0.1147 | 0.65 | 3000 | 0.1152 | 0.1166 |
| 0.1236 | 0.87 | 4000 | 0.1056 | 0.1039 |
### Framework versions
- Transformers 4.18.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Ribin/t5-base_ToxicParaphraser_lite
|
Ribin
| 2023-11-16T19:01:14Z | 3 | 1 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:google-t5/t5-base",
"base_model:adapter:google-t5/t5-base",
"region:us"
] | null | 2023-11-16T19:01:13Z |
---
library_name: peft
base_model: t5-base
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.2
|
stephen-steckler/gptq_small
|
stephen-steckler
| 2023-11-16T18:56:41Z | 4 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"llama",
"text-generation",
"generated_from_trainer",
"base_model:TheBloke/Llama-2-7B-GPTQ",
"base_model:quantized:TheBloke/Llama-2-7B-GPTQ",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2023-11-16T18:56:09Z |
---
license: llama2
base_model: TheBloke/Llama-2-7B-GPTQ
tags:
- generated_from_trainer
model-index:
- name: gptq-small-nids-out
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
# gptq-small-nids-out
This model is a fine-tuned version of [TheBloke/Llama-2-7B-GPTQ](https://huggingface.co/TheBloke/Llama-2-7B-GPTQ) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0027
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.7e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 4
- total_eval_batch_size: 4
- optimizer: Adam with betas=(0.9,0.95) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.0028 | 1.0 | 371 | 0.0027 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.0.1+cu117
- Datasets 2.14.6
- Tokenizers 0.14.1
|
aivanni/ppo-LunarLander-v2
|
aivanni
| 2023-11-16T18:51:02Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-16T18:50:42Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 242.58 +/- 17.64
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
hkivancoral/hushem_5x_deit_base_adamax_001_fold1
|
hkivancoral
| 2023-11-16T18:41:25Z | 16 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-base-patch16-224",
"base_model:finetune:facebook/deit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-16T17:56:53Z |
---
license: apache-2.0
base_model: facebook/deit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: hushem_5x_deit_base_adamax_001_fold1
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.4444444444444444
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hushem_5x_deit_base_adamax_001_fold1
This model is a fine-tuned version of [facebook/deit-base-patch16-224](https://huggingface.co/facebook/deit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 5.3716
- Accuracy: 0.4444
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.4051 | 1.0 | 27 | 1.4119 | 0.2667 |
| 1.4631 | 2.0 | 54 | 1.4906 | 0.2444 |
| 1.1049 | 3.0 | 81 | 1.5988 | 0.2889 |
| 1.1893 | 4.0 | 108 | 1.5499 | 0.3778 |
| 0.8095 | 5.0 | 135 | 1.4187 | 0.3778 |
| 0.7867 | 6.0 | 162 | 1.5747 | 0.4444 |
| 0.8062 | 7.0 | 189 | 1.7621 | 0.3778 |
| 0.6185 | 8.0 | 216 | 1.6443 | 0.3778 |
| 0.6622 | 9.0 | 243 | 2.0501 | 0.4 |
| 0.7761 | 10.0 | 270 | 1.5776 | 0.3778 |
| 0.7478 | 11.0 | 297 | 1.4437 | 0.3556 |
| 0.6339 | 12.0 | 324 | 1.4821 | 0.4 |
| 0.6965 | 13.0 | 351 | 1.6662 | 0.3556 |
| 0.5829 | 14.0 | 378 | 1.5844 | 0.3778 |
| 0.4908 | 15.0 | 405 | 2.2476 | 0.3778 |
| 0.5234 | 16.0 | 432 | 1.3445 | 0.4222 |
| 0.4872 | 17.0 | 459 | 2.4054 | 0.3556 |
| 0.466 | 18.0 | 486 | 1.6395 | 0.4 |
| 0.4427 | 19.0 | 513 | 1.8006 | 0.4 |
| 0.3436 | 20.0 | 540 | 1.6496 | 0.4 |
| 0.3213 | 21.0 | 567 | 2.4490 | 0.3778 |
| 0.3024 | 22.0 | 594 | 1.9317 | 0.4222 |
| 0.3831 | 23.0 | 621 | 2.1520 | 0.3556 |
| 0.2575 | 24.0 | 648 | 2.1832 | 0.4 |
| 0.3022 | 25.0 | 675 | 2.7719 | 0.4222 |
| 0.2889 | 26.0 | 702 | 2.2904 | 0.3778 |
| 0.1794 | 27.0 | 729 | 2.3541 | 0.3778 |
| 0.1256 | 28.0 | 756 | 3.3430 | 0.4444 |
| 0.1586 | 29.0 | 783 | 2.5549 | 0.4 |
| 0.1387 | 30.0 | 810 | 2.5659 | 0.3778 |
| 0.0828 | 31.0 | 837 | 3.1241 | 0.4 |
| 0.0717 | 32.0 | 864 | 3.9424 | 0.4222 |
| 0.0424 | 33.0 | 891 | 4.2735 | 0.4444 |
| 0.0451 | 34.0 | 918 | 4.8532 | 0.4222 |
| 0.0483 | 35.0 | 945 | 5.1314 | 0.4444 |
| 0.0395 | 36.0 | 972 | 4.8009 | 0.4 |
| 0.0349 | 37.0 | 999 | 4.7979 | 0.4222 |
| 0.003 | 38.0 | 1026 | 5.0139 | 0.4222 |
| 0.0007 | 39.0 | 1053 | 5.1670 | 0.4222 |
| 0.0004 | 40.0 | 1080 | 5.3634 | 0.4444 |
| 0.0028 | 41.0 | 1107 | 5.3467 | 0.4667 |
| 0.0002 | 42.0 | 1134 | 5.3534 | 0.4667 |
| 0.0001 | 43.0 | 1161 | 5.3434 | 0.4667 |
| 0.0001 | 44.0 | 1188 | 5.3497 | 0.4444 |
| 0.0001 | 45.0 | 1215 | 5.3599 | 0.4444 |
| 0.0001 | 46.0 | 1242 | 5.3641 | 0.4444 |
| 0.0001 | 47.0 | 1269 | 5.3694 | 0.4444 |
| 0.0001 | 48.0 | 1296 | 5.3716 | 0.4444 |
| 0.0001 | 49.0 | 1323 | 5.3716 | 0.4444 |
| 0.0001 | 50.0 | 1350 | 5.3716 | 0.4444 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Kimmy7/swahili-sentiment-model
|
Kimmy7
| 2023-11-16T18:29:33Z | 2 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2023-11-15T11:50:39Z |
---
library_name: peft
base_model: meta-llama/Llama-2-7b-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.2
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.2
|
hlabedade/unit2.2_coursrl
|
hlabedade
| 2023-11-16T18:29:19Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-16T18:29:09Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: unit2.2_coursrl
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="hlabedade/unit2.2_coursrl", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
badokorach/mobilebert-uncased-squad-v2-16-11-2
|
badokorach
| 2023-11-16T18:27:28Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mobilebert",
"question-answering",
"generated_from_trainer",
"base_model:csarron/mobilebert-uncased-squad-v2",
"base_model:finetune:csarron/mobilebert-uncased-squad-v2",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-11-16T17:35:18Z |
---
license: mit
base_model: csarron/mobilebert-uncased-squad-v2
tags:
- generated_from_trainer
model-index:
- name: mobilebert-uncased-squad-v2-16-11-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert-uncased-squad-v2-16-11-2
This model is a fine-tuned version of [csarron/mobilebert-uncased-squad-v2](https://huggingface.co/csarron/mobilebert-uncased-squad-v2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 16.1284
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| No log | 1.0 | 489 | 2.6193 |
| 1.4634 | 2.0 | 978 | 3.0847 |
| 1.2884 | 3.0 | 1467 | 3.2589 |
| 1.1511 | 4.0 | 1956 | 3.9182 |
| 1.0809 | 5.0 | 2445 | 3.7122 |
| 1.008 | 6.0 | 2934 | 4.5737 |
| 0.9048 | 7.0 | 3423 | 5.2430 |
| 0.7411 | 8.0 | 3912 | 5.4474 |
| 0.6668 | 9.0 | 4401 | 5.9275 |
| 0.557 | 10.0 | 4890 | 7.8979 |
| 0.4912 | 11.0 | 5379 | 7.8582 |
| 0.409 | 12.0 | 5868 | 8.1236 |
| 0.3293 | 13.0 | 6357 | 9.7170 |
| 0.3408 | 14.0 | 6846 | 10.1125 |
| 0.2514 | 15.0 | 7335 | 10.8043 |
| 0.2042 | 16.0 | 7824 | 11.1361 |
| 0.201 | 17.0 | 8313 | 12.5571 |
| 0.1846 | 18.0 | 8802 | 13.4892 |
| 0.1582 | 19.0 | 9291 | 13.4029 |
| 0.1185 | 20.0 | 9780 | 14.8577 |
| 0.1048 | 21.0 | 10269 | 15.3951 |
| 0.1258 | 22.0 | 10758 | 15.3019 |
| 0.0763 | 23.0 | 11247 | 15.5361 |
| 0.0684 | 24.0 | 11736 | 15.8837 |
| 0.0667 | 25.0 | 12225 | 16.1284 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Tommert25/multibert_seed34_1611
|
Tommert25
| 2023-11-16T18:22:37Z | 6 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-multilingual-uncased",
"base_model:finetune:google-bert/bert-base-multilingual-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-11-16T18:14:31Z |
---
license: apache-2.0
base_model: bert-base-multilingual-uncased
tags:
- generated_from_trainer
metrics:
- recall
- accuracy
model-index:
- name: multibert_seed34_1611
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# multibert_seed34_1611
This model is a fine-tuned version of [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4810
- Precisions: 0.8743
- Recall: 0.8016
- F-measure: 0.8318
- Accuracy: 0.9364
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 34
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 14
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precisions | Recall | F-measure | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:----------:|:------:|:---------:|:--------:|
| 0.4954 | 1.0 | 236 | 0.2579 | 0.8908 | 0.7174 | 0.7485 | 0.9181 |
| 0.2427 | 2.0 | 472 | 0.2589 | 0.8472 | 0.7340 | 0.7497 | 0.9209 |
| 0.1427 | 3.0 | 708 | 0.2844 | 0.8461 | 0.7830 | 0.8096 | 0.9325 |
| 0.0916 | 4.0 | 944 | 0.3453 | 0.8497 | 0.7804 | 0.8122 | 0.9306 |
| 0.0616 | 5.0 | 1180 | 0.3281 | 0.8500 | 0.7936 | 0.8160 | 0.9303 |
| 0.0414 | 6.0 | 1416 | 0.3859 | 0.8494 | 0.7930 | 0.8167 | 0.9337 |
| 0.0272 | 7.0 | 1652 | 0.3863 | 0.8572 | 0.7894 | 0.8167 | 0.9323 |
| 0.0207 | 8.0 | 1888 | 0.3998 | 0.8525 | 0.7938 | 0.8195 | 0.9337 |
| 0.0117 | 9.0 | 2124 | 0.4348 | 0.8555 | 0.7983 | 0.8228 | 0.9330 |
| 0.0089 | 10.0 | 2360 | 0.4858 | 0.8699 | 0.7708 | 0.7996 | 0.9294 |
| 0.0054 | 11.0 | 2596 | 0.4676 | 0.8559 | 0.7959 | 0.8197 | 0.9344 |
| 0.0036 | 12.0 | 2832 | 0.4582 | 0.8665 | 0.8038 | 0.8291 | 0.9364 |
| 0.0025 | 13.0 | 3068 | 0.4810 | 0.8743 | 0.8016 | 0.8318 | 0.9364 |
| 0.0018 | 14.0 | 3304 | 0.4801 | 0.8685 | 0.8036 | 0.8309 | 0.9366 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
hlabedade/unit5.2_coursrl
|
hlabedade
| 2023-11-16T18:18:21Z | 2 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-11-16T15:42:26Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: hlabedade/unit5.2_coursrl
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
deustchkinder/distilbert-emotion
|
deustchkinder
| 2023-11-16T18:16:14Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-16T17:20:50Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
model-index:
- name: distilbert-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.934
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1425
- Accuracy: 0.934
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 250 | 0.1859 | 0.932 |
| 0.3416 | 2.0 | 500 | 0.1425 | 0.934 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.0+cpu
- Datasets 2.14.4
- Tokenizers 0.13.2
|
Sachavsn/Pixelcopter-PLE-v0
|
Sachavsn
| 2023-11-16T18:08:42Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-11-16T11:58:36Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: Sachavsn/Pixelcopter-PLE-v0
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
jordyvl/resnet50_rvl-cdip
|
jordyvl
| 2023-11-16T18:06:50Z | 38 | 0 |
transformers
|
[
"transformers",
"safetensors",
"resnet",
"image-classification",
"generated_from_trainer",
"base_model:microsoft/resnet-50",
"base_model:finetune:microsoft/resnet-50",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-16T00:17:51Z |
---
license: apache-2.0
base_model: microsoft/resnet-50
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: resnet50_rvl-cdip
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# resnet50_rvl-cdip
This model is a fine-tuned version of [microsoft/resnet-50](https://huggingface.co/microsoft/resnet-50) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8368
- Accuracy: 0.7503
- Brier Loss: 0.3458
- Nll: 3.2289
- F1 Micro: 0.7503
- F1 Macro: 0.5224
- Ece: 0.0166
- Aurc: 0.0739
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 1024
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Brier Loss | Nll | F1 Micro | F1 Macro | Ece | Aurc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:----------:|:------:|:--------:|:--------:|:------:|:------:|
| No log | 1.0 | 312 | 3.9686 | 0.1994 | 0.9069 | 6.9377 | 0.1994 | 0.0036 | 0.0434 | 0.6332 |
| 5.3078 | 2.0 | 625 | 1.5040 | 0.5644 | 0.5696 | 4.9767 | 0.5644 | 0.0480 | 0.0330 | 0.2052 |
| 5.3078 | 3.0 | 937 | 1.1500 | 0.6602 | 0.4588 | 4.0574 | 0.6602 | 0.1527 | 0.0193 | 0.1309 |
| 1.3983 | 4.0 | 1250 | 1.0174 | 0.6961 | 0.4132 | 3.6856 | 0.6961 | 0.2658 | 0.0184 | 0.1053 |
| 1.0466 | 5.0 | 1562 | 0.9439 | 0.7167 | 0.3862 | 3.5182 | 0.7167 | 0.3477 | 0.0150 | 0.0921 |
| 1.0466 | 6.0 | 1875 | 0.9042 | 0.7302 | 0.3717 | 3.3972 | 0.7302 | 0.3345 | 0.0160 | 0.0854 |
| 0.9333 | 7.0 | 2187 | 0.8713 | 0.7395 | 0.3593 | 3.3567 | 0.7395 | 0.4236 | 0.0162 | 0.0801 |
| 0.8757 | 8.0 | 2500 | 0.8550 | 0.7444 | 0.3531 | 3.2398 | 0.7444 | 0.4113 | 0.0150 | 0.0772 |
| 0.8757 | 9.0 | 2812 | 0.8389 | 0.7487 | 0.3468 | 3.1800 | 0.7487 | 0.4613 | 0.0149 | 0.0745 |
| 0.8509 | 9.98 | 3120 | 0.8368 | 0.7503 | 0.3458 | 3.2289 | 0.7503 | 0.5224 | 0.0166 | 0.0739 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.2.0.dev20231112+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
e-n-v-y/envy-digital-painting-xl-01
|
e-n-v-y
| 2023-11-16T17:51:55Z | 33 | 2 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"city",
"digital art",
"architecture",
"scenery",
"style",
"vibrant",
"landscape",
"clean",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] |
text-to-image
| 2023-11-16T17:51:53Z |
---
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
- city
- digital art
- architecture
- scenery
- style
- vibrant
- landscape
- clean
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: digital painting
widget:
- text: 'digital painting, infinite scifi subterranean city outside of the multiverse'
output:
url: >-
3659782.jpeg
- text: 'digital painting, mysterious,wonderous scifi megastructure beyond the end of time'
output:
url: >-
3659775.jpeg
- text: 'digital painting, Astral Plane'
output:
url: >-
3659779.jpeg
- text: 'digital painting, Arcane fantasy sky city beyond the end of time'
output:
url: >-
3659780.jpeg
- text: 'digital painting, infinite scifi megacity beyond the beginning of time'
output:
url: >-
3659781.jpeg
- text: 'digital painting, morning, blue sky, clouds, scenery, in a Dusky Experimental Agriculture Zone'
output:
url: >-
3659786.jpeg
- text: 'digital painting, forbidden,great scifi megacity beyond the beginning of the universe'
output:
url: >-
3659855.jpeg
- text: 'digital painting, Griffin''s Cliff'
output:
url: >-
3659857.jpeg
- text: 'digital painting, Immortal Flame Desert'
output:
url: >-
3659862.jpeg
---
# Envy Digital Painting XL 01
<Gallery />
<p>A clean, vibrant digital art style that shores up AI weaknesses in background details by keeping backgrounds vague.</p>
## Image examples for the model:

> digital painting, mysterious,wonderous scifi megastructure beyond the end of time

> digital painting, Astral Plane

> digital painting, Arcane fantasy sky city beyond the end of time

> digital painting, infinite scifi megacity beyond the beginning of time

> digital painting, morning, blue sky, clouds, scenery, in a Dusky Experimental Agriculture Zone

> digital painting, forbidden,great scifi megacity beyond the beginning of the universe

> digital painting, Griffin's Cliff

> digital painting, Immortal Flame Desert
|
e-n-v-y/envyfantasticxl01
|
e-n-v-y
| 2023-11-16T17:50:58Z | 47 | 3 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"city",
"concept",
"architecture",
"scifi",
"scenery",
"fantasy",
"environment",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] |
text-to-image
| 2023-11-16T17:50:56Z |
---
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
- city
- concept
- architecture
- scifi
- scenery
- fantasy
- environment
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: fantastic
widget:
- text: 'fantastic, gargantuan scifi megacity at the beginning of reality'
output:
url: >-
3659306.jpeg
- text: 'digital painting, fantastic, Cryogenic Plains'
output:
url: >-
3659283.jpeg
- text: 'digital painting, fantastic, Abandoned Apollo Sites'
output:
url: >-
3659420.jpeg
- text: 'digital painting, fantastic, noon, blue sky, clouds, scenery, in a dramatic Cryogenic Plains'
output:
url: >-
3659288.jpeg
- text: 'digital painting, fantastic, golden hour, blue sky, clouds, scenery, Art Hoe cloud space'
output:
url: >-
3659326.jpeg
- text: 'digital painting, fantastic, noon, blue sky, clouds, scenery, steel Infernal Pits'
output:
url: >-
3659393.jpeg
- text: 'digital painting, fantastic, noon, blue sky, clouds, scenery, in a Ephemeral Cold Trap Pits'
output:
url: >-
3659466.jpeg
---
# EnvyFantasticXL01
<Gallery />
<p>This makes your environments more fantastical, with a strong leaning toward art deco. I've tested it on character portraits and it doesn't seem to do a whole lot to those. The trigger word is "fantastic".</p>
## Image examples for the model:

> digital painting, fantastic, Cryogenic Plains

> digital painting, fantastic, Abandoned Apollo Sites

> digital painting, fantastic, noon, blue sky, clouds, scenery, in a dramatic Cryogenic Plains

> digital painting, fantastic, golden hour, blue sky, clouds, scenery, Art Hoe cloud space

> digital painting, fantastic, noon, blue sky, clouds, scenery, steel Infernal Pits

> digital painting, fantastic, noon, blue sky, clouds, scenery, in a Ephemeral Cold Trap Pits
|
ejgil03/LunarLander-v2
|
ejgil03
| 2023-11-16T17:50:50Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-16T17:50:29Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 240.63 +/- 46.67
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
madhuprakash19/layoutlmv3-finetuned-cord_100
|
madhuprakash19
| 2023-11-16T17:48:52Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"layoutlmv3",
"token-classification",
"generated_from_trainer",
"dataset:cord-layoutlmv3",
"base_model:microsoft/layoutlmv3-base",
"base_model:finetune:microsoft/layoutlmv3-base",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-11-16T10:58:59Z |
---
license: cc-by-nc-sa-4.0
base_model: microsoft/layoutlmv3-base
tags:
- generated_from_trainer
datasets:
- cord-layoutlmv3
model-index:
- name: layoutlmv3-finetuned-cord_100
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv3-finetuned-cord_100
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on the cord-layoutlmv3 dataset.
It achieves the following results on the evaluation set:
- eval_loss: 1.0986
- eval_precision: 0.6521
- eval_recall: 0.7365
- eval_f1: 0.6917
- eval_accuracy: 0.7593
- eval_runtime: 182.1992
- eval_samples_per_second: 0.549
- eval_steps_per_second: 0.11
- epoch: 1.56
- step: 250
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 5
- eval_batch_size: 5
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 2500
### Framework versions
- Transformers 4.32.1
- Pytorch 2.1.1+cu118
- Datasets 2.12.0
- Tokenizers 0.13.2
|
ml-debi/EfficientNetV2S-Food101
|
ml-debi
| 2023-11-16T17:31:48Z | 2 | 0 |
tf-keras
|
[
"tf-keras",
"tensorboard",
"image-classification",
"dataset:food101",
"license:mit",
"region:us"
] |
image-classification
| 2023-11-16T17:27:22Z |
---
license: mit
datasets:
- food101
metrics:
- accuracy
pipeline_tag: image-classification
---
|
EgorGrinevich/scene_segmentation
|
EgorGrinevich
| 2023-11-16T17:20:24Z | 1 | 0 |
transformers
|
[
"transformers",
"tf",
"segformer",
"generated_from_keras_callback",
"base_model:nvidia/mit-b0",
"base_model:finetune:nvidia/mit-b0",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2023-11-16T17:08:16Z |
---
license: other
base_model: nvidia/mit-b0
tags:
- generated_from_keras_callback
model-index:
- name: EgorGrinevich/scene_segmentation
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# EgorGrinevich/scene_segmentation
This model is a fine-tuned version of [nvidia/mit-b0](https://huggingface.co/nvidia/mit-b0) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: nan
- Validation Loss: nan
- Validation Mean Iou: 0.0024
- Validation Mean Accuracy: 0.0222
- Validation Overall Accuracy: 0.1310
- Validation Accuracy Wall: 1.0
- Validation Accuracy Building: 0.0
- Validation Accuracy Sky: 0.0
- Validation Accuracy Floor: 0.0
- Validation Accuracy Tree: 0.0
- Validation Accuracy Ceiling: 0.0
- Validation Accuracy Road: 0.0
- Validation Accuracy Bed : 0.0
- Validation Accuracy Windowpane: nan
- Validation Accuracy Grass: 0.0
- Validation Accuracy Cabinet: 0.0
- Validation Accuracy Sidewalk: 0.0
- Validation Accuracy Person: 0.0
- Validation Accuracy Earth: 0.0
- Validation Accuracy Door: 0.0
- Validation Accuracy Table: 0.0
- Validation Accuracy Mountain: nan
- Validation Accuracy Plant: 0.0
- Validation Accuracy Curtain: nan
- Validation Accuracy Chair: 0.0
- Validation Accuracy Car: 0.0
- Validation Accuracy Water: 0.0
- Validation Accuracy Painting: nan
- Validation Accuracy Sofa: nan
- Validation Accuracy Shelf: nan
- Validation Accuracy House: nan
- Validation Accuracy Sea: 0.0
- Validation Accuracy Mirror: nan
- Validation Accuracy Rug: nan
- Validation Accuracy Field: 0.0
- Validation Accuracy Armchair: nan
- Validation Accuracy Seat: 0.0
- Validation Accuracy Fence: nan
- Validation Accuracy Desk: 0.0
- Validation Accuracy Rock: nan
- Validation Accuracy Wardrobe: 0.0
- Validation Accuracy Lamp: nan
- Validation Accuracy Bathtub: nan
- Validation Accuracy Railing: 0.0
- Validation Accuracy Cushion: nan
- Validation Accuracy Base: nan
- Validation Accuracy Box: nan
- Validation Accuracy Column: nan
- Validation Accuracy Signboard: 0.0
- Validation Accuracy Chest of drawers: nan
- Validation Accuracy Counter: nan
- Validation Accuracy Sand: 0.0
- Validation Accuracy Sink: nan
- Validation Accuracy Skyscraper: nan
- Validation Accuracy Fireplace: 0.0
- Validation Accuracy Refrigerator: nan
- Validation Accuracy Grandstand: nan
- Validation Accuracy Path: nan
- Validation Accuracy Stairs: nan
- Validation Accuracy Runway: nan
- Validation Accuracy Case: nan
- Validation Accuracy Pool table: 0.0
- Validation Accuracy Pillow: nan
- Validation Accuracy Screen door: nan
- Validation Accuracy Stairway: nan
- Validation Accuracy River: nan
- Validation Accuracy Bridge: nan
- Validation Accuracy Bookcase: nan
- Validation Accuracy Blind: 0.0
- Validation Accuracy Coffee table: nan
- Validation Accuracy Toilet: nan
- Validation Accuracy Flower: nan
- Validation Accuracy Book: 0.0
- Validation Accuracy Hill: nan
- Validation Accuracy Bench: nan
- Validation Accuracy Countertop: 0.0
- Validation Accuracy Stove: nan
- Validation Accuracy Palm: nan
- Validation Accuracy Kitchen island: nan
- Validation Accuracy Computer: nan
- Validation Accuracy Swivel chair: nan
- Validation Accuracy Boat: nan
- Validation Accuracy Bar: nan
- Validation Accuracy Arcade machine: nan
- Validation Accuracy Hovel: nan
- Validation Accuracy Bus: 0.0
- Validation Accuracy Towel: 0.0
- Validation Accuracy Light: 0.0
- Validation Accuracy Truck: nan
- Validation Accuracy Tower: nan
- Validation Accuracy Chandelier: nan
- Validation Accuracy Awning: nan
- Validation Accuracy Streetlight: nan
- Validation Accuracy Booth: nan
- Validation Accuracy Television receiver: nan
- Validation Accuracy Airplane: 0.0
- Validation Accuracy Dirt track: nan
- Validation Accuracy Apparel: 0.0
- Validation Accuracy Pole: nan
- Validation Accuracy Land: nan
- Validation Accuracy Bannister: nan
- Validation Accuracy Escalator: nan
- Validation Accuracy Ottoman: nan
- Validation Accuracy Bottle: nan
- Validation Accuracy Buffet: nan
- Validation Accuracy Poster: nan
- Validation Accuracy Stage: nan
- Validation Accuracy Van: nan
- Validation Accuracy Ship: nan
- Validation Accuracy Fountain: nan
- Validation Accuracy Conveyer belt: nan
- Validation Accuracy Canopy: nan
- Validation Accuracy Washer: nan
- Validation Accuracy Plaything: nan
- Validation Accuracy Swimming pool: 0.0
- Validation Accuracy Stool: nan
- Validation Accuracy Barrel: nan
- Validation Accuracy Basket: 0.0
- Validation Accuracy Waterfall: nan
- Validation Accuracy Tent: 0.0
- Validation Accuracy Bag: nan
- Validation Accuracy Minibike: nan
- Validation Accuracy Cradle: nan
- Validation Accuracy Oven: nan
- Validation Accuracy Ball: nan
- Validation Accuracy Food: nan
- Validation Accuracy Step: nan
- Validation Accuracy Tank: nan
- Validation Accuracy Trade name: 0.0
- Validation Accuracy Microwave: nan
- Validation Accuracy Pot: nan
- Validation Accuracy Animal: nan
- Validation Accuracy Bicycle: nan
- Validation Accuracy Lake: 0.0
- Validation Accuracy Dishwasher: nan
- Validation Accuracy Screen: nan
- Validation Accuracy Blanket: nan
- Validation Accuracy Sculpture: nan
- Validation Accuracy Hood: 0.0
- Validation Accuracy Sconce: nan
- Validation Accuracy Vase: 0.0
- Validation Accuracy Traffic light: nan
- Validation Accuracy Tray: 0.0
- Validation Accuracy Ashcan: nan
- Validation Accuracy Fan: nan
- Validation Accuracy Pier: nan
- Validation Accuracy Crt screen: nan
- Validation Accuracy Plate: nan
- Validation Accuracy Monitor: nan
- Validation Accuracy Bulletin board: nan
- Validation Accuracy Shower: nan
- Validation Accuracy Radiator: nan
- Validation Accuracy Glass: nan
- Validation Accuracy Clock: nan
- Validation Accuracy Flag: nan
- Validation Iou Wall: 0.1065
- Validation Iou Building: 0.0
- Validation Iou Sky: 0.0
- Validation Iou Floor: 0.0
- Validation Iou Tree: 0.0
- Validation Iou Ceiling: 0.0
- Validation Iou Road: 0.0
- Validation Iou Bed : 0.0
- Validation Iou Windowpane: nan
- Validation Iou Grass: 0.0
- Validation Iou Cabinet: 0.0
- Validation Iou Sidewalk: 0.0
- Validation Iou Person: 0.0
- Validation Iou Earth: 0.0
- Validation Iou Door: 0.0
- Validation Iou Table: 0.0
- Validation Iou Mountain: nan
- Validation Iou Plant: 0.0
- Validation Iou Curtain: nan
- Validation Iou Chair: 0.0
- Validation Iou Car: 0.0
- Validation Iou Water: 0.0
- Validation Iou Painting: nan
- Validation Iou Sofa: nan
- Validation Iou Shelf: nan
- Validation Iou House: nan
- Validation Iou Sea: 0.0
- Validation Iou Mirror: nan
- Validation Iou Rug: nan
- Validation Iou Field: 0.0
- Validation Iou Armchair: nan
- Validation Iou Seat: 0.0
- Validation Iou Fence: nan
- Validation Iou Desk: 0.0
- Validation Iou Rock: nan
- Validation Iou Wardrobe: 0.0
- Validation Iou Lamp: nan
- Validation Iou Bathtub: nan
- Validation Iou Railing: 0.0
- Validation Iou Cushion: nan
- Validation Iou Base: nan
- Validation Iou Box: nan
- Validation Iou Column: nan
- Validation Iou Signboard: 0.0
- Validation Iou Chest of drawers: nan
- Validation Iou Counter: nan
- Validation Iou Sand: 0.0
- Validation Iou Sink: nan
- Validation Iou Skyscraper: nan
- Validation Iou Fireplace: 0.0
- Validation Iou Refrigerator: nan
- Validation Iou Grandstand: nan
- Validation Iou Path: nan
- Validation Iou Stairs: nan
- Validation Iou Runway: nan
- Validation Iou Case: nan
- Validation Iou Pool table: 0.0
- Validation Iou Pillow: nan
- Validation Iou Screen door: nan
- Validation Iou Stairway: nan
- Validation Iou River: nan
- Validation Iou Bridge: nan
- Validation Iou Bookcase: nan
- Validation Iou Blind: 0.0
- Validation Iou Coffee table: nan
- Validation Iou Toilet: nan
- Validation Iou Flower: nan
- Validation Iou Book: 0.0
- Validation Iou Hill: nan
- Validation Iou Bench: nan
- Validation Iou Countertop: 0.0
- Validation Iou Stove: nan
- Validation Iou Palm: nan
- Validation Iou Kitchen island: nan
- Validation Iou Computer: nan
- Validation Iou Swivel chair: nan
- Validation Iou Boat: nan
- Validation Iou Bar: nan
- Validation Iou Arcade machine: nan
- Validation Iou Hovel: nan
- Validation Iou Bus: 0.0
- Validation Iou Towel: 0.0
- Validation Iou Light: 0.0
- Validation Iou Truck: nan
- Validation Iou Tower: nan
- Validation Iou Chandelier: nan
- Validation Iou Awning: nan
- Validation Iou Streetlight: nan
- Validation Iou Booth: nan
- Validation Iou Television receiver: nan
- Validation Iou Airplane: 0.0
- Validation Iou Dirt track: nan
- Validation Iou Apparel: 0.0
- Validation Iou Pole: nan
- Validation Iou Land: nan
- Validation Iou Bannister: nan
- Validation Iou Escalator: nan
- Validation Iou Ottoman: nan
- Validation Iou Bottle: nan
- Validation Iou Buffet: nan
- Validation Iou Poster: nan
- Validation Iou Stage: nan
- Validation Iou Van: nan
- Validation Iou Ship: nan
- Validation Iou Fountain: nan
- Validation Iou Conveyer belt: nan
- Validation Iou Canopy: nan
- Validation Iou Washer: nan
- Validation Iou Plaything: nan
- Validation Iou Swimming pool: 0.0
- Validation Iou Stool: nan
- Validation Iou Barrel: nan
- Validation Iou Basket: 0.0
- Validation Iou Waterfall: nan
- Validation Iou Tent: 0.0
- Validation Iou Bag: nan
- Validation Iou Minibike: nan
- Validation Iou Cradle: nan
- Validation Iou Oven: nan
- Validation Iou Ball: nan
- Validation Iou Food: nan
- Validation Iou Step: nan
- Validation Iou Tank: nan
- Validation Iou Trade name: 0.0
- Validation Iou Microwave: nan
- Validation Iou Pot: nan
- Validation Iou Animal: nan
- Validation Iou Bicycle: nan
- Validation Iou Lake: 0.0
- Validation Iou Dishwasher: nan
- Validation Iou Screen: nan
- Validation Iou Blanket: nan
- Validation Iou Sculpture: nan
- Validation Iou Hood: 0.0
- Validation Iou Sconce: nan
- Validation Iou Vase: 0.0
- Validation Iou Traffic light: nan
- Validation Iou Tray: 0.0
- Validation Iou Ashcan: nan
- Validation Iou Fan: nan
- Validation Iou Pier: nan
- Validation Iou Crt screen: nan
- Validation Iou Plate: nan
- Validation Iou Monitor: nan
- Validation Iou Bulletin board: nan
- Validation Iou Shower: nan
- Validation Iou Radiator: nan
- Validation Iou Glass: nan
- Validation Iou Clock: nan
- Validation Iou Flag: nan
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 6e-05, 'decay_steps': 400, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Validation Mean Iou | Validation Mean Accuracy | Validation Overall Accuracy | Validation Accuracy Wall | Validation Accuracy Building | Validation Accuracy Sky | Validation Accuracy Floor | Validation Accuracy Tree | Validation Accuracy Ceiling | Validation Accuracy Road | Validation Accuracy Bed | Validation Accuracy Windowpane | Validation Accuracy Grass | Validation Accuracy Cabinet | Validation Accuracy Sidewalk | Validation Accuracy Person | Validation Accuracy Earth | Validation Accuracy Door | Validation Accuracy Table | Validation Accuracy Mountain | Validation Accuracy Plant | Validation Accuracy Curtain | Validation Accuracy Chair | Validation Accuracy Car | Validation Accuracy Water | Validation Accuracy Painting | Validation Accuracy Sofa | Validation Accuracy Shelf | Validation Accuracy House | Validation Accuracy Sea | Validation Accuracy Mirror | Validation Accuracy Rug | Validation Accuracy Field | Validation Accuracy Armchair | Validation Accuracy Seat | Validation Accuracy Fence | Validation Accuracy Desk | Validation Accuracy Rock | Validation Accuracy Wardrobe | Validation Accuracy Lamp | Validation Accuracy Bathtub | Validation Accuracy Railing | Validation Accuracy Cushion | Validation Accuracy Base | Validation Accuracy Box | Validation Accuracy Column | Validation Accuracy Signboard | Validation Accuracy Chest of drawers | Validation Accuracy Counter | Validation Accuracy Sand | Validation Accuracy Sink | Validation Accuracy Skyscraper | Validation Accuracy Fireplace | Validation Accuracy Refrigerator | Validation Accuracy Grandstand | Validation Accuracy Path | Validation Accuracy Stairs | Validation Accuracy Runway | Validation Accuracy Case | Validation Accuracy Pool table | Validation Accuracy Pillow | Validation Accuracy Screen door | Validation Accuracy Stairway | Validation Accuracy River | Validation Accuracy Bridge | Validation Accuracy Bookcase | Validation Accuracy Blind | Validation Accuracy Coffee table | Validation Accuracy Toilet | Validation Accuracy Flower | Validation Accuracy Book | Validation Accuracy Hill | Validation Accuracy Bench | Validation Accuracy Countertop | Validation Accuracy Stove | Validation Accuracy Palm | Validation Accuracy Kitchen island | Validation Accuracy Computer | Validation Accuracy Swivel chair | Validation Accuracy Boat | Validation Accuracy Bar | Validation Accuracy Arcade machine | Validation Accuracy Hovel | Validation Accuracy Bus | Validation Accuracy Towel | Validation Accuracy Light | Validation Accuracy Truck | Validation Accuracy Tower | Validation Accuracy Chandelier | Validation Accuracy Awning | Validation Accuracy Streetlight | Validation Accuracy Booth | Validation Accuracy Television receiver | Validation Accuracy Airplane | Validation Accuracy Dirt track | Validation Accuracy Apparel | Validation Accuracy Pole | Validation Accuracy Land | Validation Accuracy Bannister | Validation Accuracy Escalator | Validation Accuracy Ottoman | Validation Accuracy Bottle | Validation Accuracy Buffet | Validation Accuracy Poster | Validation Accuracy Stage | Validation Accuracy Van | Validation Accuracy Ship | Validation Accuracy Fountain | Validation Accuracy Conveyer belt | Validation Accuracy Canopy | Validation Accuracy Washer | Validation Accuracy Plaything | Validation Accuracy Swimming pool | Validation Accuracy Stool | Validation Accuracy Barrel | Validation Accuracy Basket | Validation Accuracy Waterfall | Validation Accuracy Tent | Validation Accuracy Bag | Validation Accuracy Minibike | Validation Accuracy Cradle | Validation Accuracy Oven | Validation Accuracy Ball | Validation Accuracy Food | Validation Accuracy Step | Validation Accuracy Tank | Validation Accuracy Trade name | Validation Accuracy Microwave | Validation Accuracy Pot | Validation Accuracy Animal | Validation Accuracy Bicycle | Validation Accuracy Lake | Validation Accuracy Dishwasher | Validation Accuracy Screen | Validation Accuracy Blanket | Validation Accuracy Sculpture | Validation Accuracy Hood | Validation Accuracy Sconce | Validation Accuracy Vase | Validation Accuracy Traffic light | Validation Accuracy Tray | Validation Accuracy Ashcan | Validation Accuracy Fan | Validation Accuracy Pier | Validation Accuracy Crt screen | Validation Accuracy Plate | Validation Accuracy Monitor | Validation Accuracy Bulletin board | Validation Accuracy Shower | Validation Accuracy Radiator | Validation Accuracy Glass | Validation Accuracy Clock | Validation Accuracy Flag | Validation Iou Wall | Validation Iou Building | Validation Iou Sky | Validation Iou Floor | Validation Iou Tree | Validation Iou Ceiling | Validation Iou Road | Validation Iou Bed | Validation Iou Windowpane | Validation Iou Grass | Validation Iou Cabinet | Validation Iou Sidewalk | Validation Iou Person | Validation Iou Earth | Validation Iou Door | Validation Iou Table | Validation Iou Mountain | Validation Iou Plant | Validation Iou Curtain | Validation Iou Chair | Validation Iou Car | Validation Iou Water | Validation Iou Painting | Validation Iou Sofa | Validation Iou Shelf | Validation Iou House | Validation Iou Sea | Validation Iou Mirror | Validation Iou Rug | Validation Iou Field | Validation Iou Armchair | Validation Iou Seat | Validation Iou Fence | Validation Iou Desk | Validation Iou Rock | Validation Iou Wardrobe | Validation Iou Lamp | Validation Iou Bathtub | Validation Iou Railing | Validation Iou Cushion | Validation Iou Base | Validation Iou Box | Validation Iou Column | Validation Iou Signboard | Validation Iou Chest of drawers | Validation Iou Counter | Validation Iou Sand | Validation Iou Sink | Validation Iou Skyscraper | Validation Iou Fireplace | Validation Iou Refrigerator | Validation Iou Grandstand | Validation Iou Path | Validation Iou Stairs | Validation Iou Runway | Validation Iou Case | Validation Iou Pool table | Validation Iou Pillow | Validation Iou Screen door | Validation Iou Stairway | Validation Iou River | Validation Iou Bridge | Validation Iou Bookcase | Validation Iou Blind | Validation Iou Coffee table | Validation Iou Toilet | Validation Iou Flower | Validation Iou Book | Validation Iou Hill | Validation Iou Bench | Validation Iou Countertop | Validation Iou Stove | Validation Iou Palm | Validation Iou Kitchen island | Validation Iou Computer | Validation Iou Swivel chair | Validation Iou Boat | Validation Iou Bar | Validation Iou Arcade machine | Validation Iou Hovel | Validation Iou Bus | Validation Iou Towel | Validation Iou Light | Validation Iou Truck | Validation Iou Tower | Validation Iou Chandelier | Validation Iou Awning | Validation Iou Streetlight | Validation Iou Booth | Validation Iou Television receiver | Validation Iou Airplane | Validation Iou Dirt track | Validation Iou Apparel | Validation Iou Pole | Validation Iou Land | Validation Iou Bannister | Validation Iou Escalator | Validation Iou Ottoman | Validation Iou Bottle | Validation Iou Buffet | Validation Iou Poster | Validation Iou Stage | Validation Iou Van | Validation Iou Ship | Validation Iou Fountain | Validation Iou Conveyer belt | Validation Iou Canopy | Validation Iou Washer | Validation Iou Plaything | Validation Iou Swimming pool | Validation Iou Stool | Validation Iou Barrel | Validation Iou Basket | Validation Iou Waterfall | Validation Iou Tent | Validation Iou Bag | Validation Iou Minibike | Validation Iou Cradle | Validation Iou Oven | Validation Iou Ball | Validation Iou Food | Validation Iou Step | Validation Iou Tank | Validation Iou Trade name | Validation Iou Microwave | Validation Iou Pot | Validation Iou Animal | Validation Iou Bicycle | Validation Iou Lake | Validation Iou Dishwasher | Validation Iou Screen | Validation Iou Blanket | Validation Iou Sculpture | Validation Iou Hood | Validation Iou Sconce | Validation Iou Vase | Validation Iou Traffic light | Validation Iou Tray | Validation Iou Ashcan | Validation Iou Fan | Validation Iou Pier | Validation Iou Crt screen | Validation Iou Plate | Validation Iou Monitor | Validation Iou Bulletin board | Validation Iou Shower | Validation Iou Radiator | Validation Iou Glass | Validation Iou Clock | Validation Iou Flag | Epoch |
|:----------:|:---------------:|:-------------------:|:------------------------:|:---------------------------:|:------------------------:|:----------------------------:|:-----------------------:|:-------------------------:|:------------------------:|:---------------------------:|:------------------------:|:------------------------:|:------------------------------:|:-------------------------:|:---------------------------:|:----------------------------:|:--------------------------:|:-------------------------:|:------------------------:|:-------------------------:|:----------------------------:|:-------------------------:|:---------------------------:|:-------------------------:|:-----------------------:|:-------------------------:|:----------------------------:|:------------------------:|:-------------------------:|:-------------------------:|:-----------------------:|:--------------------------:|:-----------------------:|:-------------------------:|:----------------------------:|:------------------------:|:-------------------------:|:------------------------:|:------------------------:|:----------------------------:|:------------------------:|:---------------------------:|:---------------------------:|:---------------------------:|:------------------------:|:-----------------------:|:--------------------------:|:-----------------------------:|:------------------------------------:|:---------------------------:|:------------------------:|:------------------------:|:------------------------------:|:-----------------------------:|:--------------------------------:|:------------------------------:|:------------------------:|:--------------------------:|:--------------------------:|:------------------------:|:------------------------------:|:--------------------------:|:-------------------------------:|:----------------------------:|:-------------------------:|:--------------------------:|:----------------------------:|:-------------------------:|:--------------------------------:|:--------------------------:|:--------------------------:|:------------------------:|:------------------------:|:-------------------------:|:------------------------------:|:-------------------------:|:------------------------:|:----------------------------------:|:----------------------------:|:--------------------------------:|:------------------------:|:-----------------------:|:----------------------------------:|:-------------------------:|:-----------------------:|:-------------------------:|:-------------------------:|:-------------------------:|:-------------------------:|:------------------------------:|:--------------------------:|:-------------------------------:|:-------------------------:|:---------------------------------------:|:----------------------------:|:------------------------------:|:---------------------------:|:------------------------:|:------------------------:|:-----------------------------:|:-----------------------------:|:---------------------------:|:--------------------------:|:--------------------------:|:--------------------------:|:-------------------------:|:-----------------------:|:------------------------:|:----------------------------:|:---------------------------------:|:--------------------------:|:--------------------------:|:-----------------------------:|:---------------------------------:|:-------------------------:|:--------------------------:|:--------------------------:|:-----------------------------:|:------------------------:|:-----------------------:|:----------------------------:|:--------------------------:|:------------------------:|:------------------------:|:------------------------:|:------------------------:|:------------------------:|:------------------------------:|:-----------------------------:|:-----------------------:|:--------------------------:|:---------------------------:|:------------------------:|:------------------------------:|:--------------------------:|:---------------------------:|:-----------------------------:|:------------------------:|:--------------------------:|:------------------------:|:---------------------------------:|:------------------------:|:--------------------------:|:-----------------------:|:------------------------:|:------------------------------:|:-------------------------:|:---------------------------:|:----------------------------------:|:--------------------------:|:----------------------------:|:-------------------------:|:-------------------------:|:------------------------:|:-------------------:|:-----------------------:|:------------------:|:--------------------:|:-------------------:|:----------------------:|:-------------------:|:-------------------:|:-------------------------:|:--------------------:|:----------------------:|:-----------------------:|:---------------------:|:--------------------:|:-------------------:|:--------------------:|:-----------------------:|:--------------------:|:----------------------:|:--------------------:|:------------------:|:--------------------:|:-----------------------:|:-------------------:|:--------------------:|:--------------------:|:------------------:|:---------------------:|:------------------:|:--------------------:|:-----------------------:|:-------------------:|:--------------------:|:-------------------:|:-------------------:|:-----------------------:|:-------------------:|:----------------------:|:----------------------:|:----------------------:|:-------------------:|:------------------:|:---------------------:|:------------------------:|:-------------------------------:|:----------------------:|:-------------------:|:-------------------:|:-------------------------:|:------------------------:|:---------------------------:|:-------------------------:|:-------------------:|:---------------------:|:---------------------:|:-------------------:|:-------------------------:|:---------------------:|:--------------------------:|:-----------------------:|:--------------------:|:---------------------:|:-----------------------:|:--------------------:|:---------------------------:|:---------------------:|:---------------------:|:-------------------:|:-------------------:|:--------------------:|:-------------------------:|:--------------------:|:-------------------:|:-----------------------------:|:-----------------------:|:---------------------------:|:-------------------:|:------------------:|:-----------------------------:|:--------------------:|:------------------:|:--------------------:|:--------------------:|:--------------------:|:--------------------:|:-------------------------:|:---------------------:|:--------------------------:|:--------------------:|:----------------------------------:|:-----------------------:|:-------------------------:|:----------------------:|:-------------------:|:-------------------:|:------------------------:|:------------------------:|:----------------------:|:---------------------:|:---------------------:|:---------------------:|:--------------------:|:------------------:|:-------------------:|:-----------------------:|:----------------------------:|:---------------------:|:---------------------:|:------------------------:|:----------------------------:|:--------------------:|:---------------------:|:---------------------:|:------------------------:|:-------------------:|:------------------:|:-----------------------:|:---------------------:|:-------------------:|:-------------------:|:-------------------:|:-------------------:|:-------------------:|:-------------------------:|:------------------------:|:------------------:|:---------------------:|:----------------------:|:-------------------:|:-------------------------:|:---------------------:|:----------------------:|:------------------------:|:-------------------:|:---------------------:|:-------------------:|:----------------------------:|:-------------------:|:---------------------:|:------------------:|:-------------------:|:-------------------------:|:--------------------:|:----------------------:|:-----------------------------:|:---------------------:|:-----------------------:|:--------------------:|:--------------------:|:-------------------:|:-----:|
| nan | nan | 0.0024 | 0.0222 | 0.1310 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.1065 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0 |
| nan | nan | 0.0024 | 0.0222 | 0.1310 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.1065 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 1 |
| nan | nan | 0.0024 | 0.0222 | 0.1310 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.1065 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 2 |
| nan | nan | 0.0024 | 0.0222 | 0.1310 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.1065 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 3 |
| nan | nan | 0.0024 | 0.0222 | 0.1310 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.1065 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 4 |
| nan | nan | 0.0024 | 0.0222 | 0.1310 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.1065 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 5 |
| nan | nan | 0.0024 | 0.0222 | 0.1310 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.1065 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 6 |
| nan | nan | 0.0024 | 0.0222 | 0.1310 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.1065 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 7 |
| nan | nan | 0.0024 | 0.0222 | 0.1310 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.1065 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 8 |
| nan | nan | 0.0024 | 0.0222 | 0.1310 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.1065 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | nan | 0.0 | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | 0.0 | 0.0 | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | nan | nan | nan | 0.0 | nan | 0.0 | nan | 0.0 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 9 |
### Framework versions
- Transformers 4.35.2
- TensorFlow 2.14.0
- Datasets 2.15.0
- Tokenizers 0.15.0
|
SummerSigh/GPT-Neo350-EvilUltimate
|
SummerSigh
| 2023-11-16T16:58:18Z | 18 | 3 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-03-26T05:45:45Z |
---
license: apache-2.0
---
# What is this?
This model generates prompts ment to jailbreak systems. This was a model for the Blade2Blade system: https://github.com/LAION-AI/blade2blade
# Usage
start with ```<prompt>``` and have the model generate the rest.
|
hyperbored/memes_id
|
hyperbored
| 2023-11-16T16:56:47Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"pytorch",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-16T16:56:40Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: memes_id
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9253731369972229
---
# memes_id
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### DOTA2 memes

#### cat memes

#### dog memes

|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.