
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-15 12:29:39
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 521
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-15 12:28:52
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
jackoyoungblood/ppo-LunarLander-v2c | jackoyoungblood | 2022-08-05T19:46:18Z | 3 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-07-29T23:03:33Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 267.50 +/- 18.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
mrm8488/dqn-SpaceInvadersNoFrameskip-v4-3 | mrm8488 | 2022-08-05T19:36:16Z | 6 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-08-05T19:35:48Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 349.00 +/- 97.82
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga mrm8488 -f logs/
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga mrm8488
```
## Hyperparameters
```python
OrderedDict([('batch_size', 1024),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
Swervin7s/DialogGPT-medium-AnakinTwo | Swervin7s | 2022-08-05T19:24:18Z | 0 | 0 | null | [
"conersational",
"region:us"
]
| null | 2022-08-05T19:21:52Z | ---
tags:
- conersational
---
|
skr1125/xlm-roberta-base-finetuned-panx-de | skr1125 | 2022-08-05T17:50:14Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-08-02T01:50:37Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.863677639046538
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1343
- F1: 0.8637
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2578 | 1.0 | 525 | 0.1562 | 0.8273 |
| 0.1297 | 2.0 | 1050 | 0.1330 | 0.8474 |
| 0.0809 | 3.0 | 1575 | 0.1343 | 0.8637 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Galeros/q-Taxi-v3 | Galeros | 2022-08-05T16:33:40Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-08-05T16:33:32Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.52 +/- 2.76
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Galeros/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
jasheershihab/TEST2ppo-LunarLander-v2 | jasheershihab | 2022-08-05T13:21:55Z | 3 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-07-13T12:32:46Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 28.44 +/- 165.66
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
datajello/lunar-test-v1 | datajello | 2022-08-05T13:18:24Z | 6 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-08-05T12:42:13Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 224.66 +/- 40.94
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
apjanco/candy-first | apjanco | 2022-08-05T13:03:29Z | 56 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2022-08-05T13:03:25Z | ---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: candy-first
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.7436399459838867
---
# candy-first
An initial attempt to identify candy in images.
## Example Images
#### airheads

#### candy corn

#### caramel

#### chips

#### chocolate

#### fruit

#### gum

#### haribo

#### jelly beans

#### lollipop

#### m&ms

#### marshmallow

#### mentos

#### mint

#### nerds

#### peeps

#### pez

#### popcorn

#### pretzel

#### reeses

#### seeds

#### skittles

#### snickers

#### soda

#### sour

#### swedish fish

#### taffy

#### tootsie

#### twix

#### twizzlers

#### warheads

#### whoppers
 |
huggingtweets/calm-headspace | huggingtweets | 2022-08-05T09:27:25Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-08-05T09:26:46Z | ---
language: en
thumbnail: http://www.huggingtweets.com/calm-headspace/1659691640977/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/547731071479996417/53RFXHu1_400x400.png')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1157021554280058880/yWiCuBSR_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Calm & Headspace</div>
<div style="text-align: center; font-size: 14px;">@calm-headspace</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Calm & Headspace.
| Data | Calm | Headspace |
| --- | --- | --- |
| Tweets downloaded | 3249 | 3250 |
| Retweets | 49 | 10 |
| Short tweets | 144 | 446 |
| Tweets kept | 3056 | 2794 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/190qaia3/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @calm-headspace's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1g7llfp4) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1g7llfp4/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/calm-headspace')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Zaib/Vulnerability-detection | Zaib | 2022-08-05T08:47:07Z | 13 | 5 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-07-16T09:16:45Z | ---
tags:
- generated_from_trainer
model-index:
- name: Vulnerability-detection
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Vulnerability-detection
This model is a fine-tuned version of [mrm8488/codebert-base-finetuned-detect-insecure-code](https://huggingface.co/mrm8488/codebert-base-finetuned-detect-insecure-code) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5778
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
okho0653/Bio_ClinicalBERT-zero-shot-finetuned-50cad-50noncad-optimal | okho0653 | 2022-08-05T05:29:50Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-05T05:12:27Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: Bio_ClinicalBERT-zero-shot-finetuned-50cad-50noncad-optimal
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT-zero-shot-finetuned-50cad-50noncad-optimal
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 9.8836
- Accuracy: 0.5
- F1: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.2
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
alex-apostolo/roberta-base-filtered-cuad | alex-apostolo | 2022-08-05T05:28:06Z | 25 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"roberta",
"question-answering",
"generated_from_trainer",
"dataset:alex-apostolo/filtered-cuad",
"license:mit",
"endpoints_compatible",
"region:us"
]
| question-answering | 2022-08-04T09:12:07Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- alex-apostolo/filtered-cuad
model-index:
- name: roberta-base-filtered-cuad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-filtered-cuad
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the cuad dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0396
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.0502 | 1.0 | 8442 | 0.0467 |
| 0.0397 | 2.0 | 16884 | 0.0436 |
| 0.032 | 3.0 | 25326 | 0.0396 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
zhiguoxu/chinese-roberta-wwm-ext-finetuned2 | zhiguoxu | 2022-08-05T03:45:08Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-03T07:54:52Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: chinese-roberta-wwm-ext-finetuned2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# chinese-roberta-wwm-ext-finetuned2
This model is a fine-tuned version of [hfl/chinese-roberta-wwm-ext](https://huggingface.co/hfl/chinese-roberta-wwm-ext) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1448
- Accuracy: 1.0
- F1: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 1.4081 | 1.0 | 3 | 0.9711 | 0.7273 | 0.6573 |
| 0.9516 | 2.0 | 6 | 0.8174 | 0.8182 | 0.8160 |
| 0.8945 | 3.0 | 9 | 0.6617 | 0.9091 | 0.9124 |
| 0.7042 | 4.0 | 12 | 0.5308 | 1.0 | 1.0 |
| 0.6641 | 5.0 | 15 | 0.4649 | 1.0 | 1.0 |
| 0.5731 | 6.0 | 18 | 0.4046 | 1.0 | 1.0 |
| 0.5132 | 7.0 | 21 | 0.3527 | 1.0 | 1.0 |
| 0.3999 | 8.0 | 24 | 0.3070 | 1.0 | 1.0 |
| 0.4198 | 9.0 | 27 | 0.2673 | 1.0 | 1.0 |
| 0.3677 | 10.0 | 30 | 0.2378 | 1.0 | 1.0 |
| 0.3545 | 11.0 | 33 | 0.2168 | 1.0 | 1.0 |
| 0.3237 | 12.0 | 36 | 0.1980 | 1.0 | 1.0 |
| 0.3122 | 13.0 | 39 | 0.1860 | 1.0 | 1.0 |
| 0.2802 | 14.0 | 42 | 0.1759 | 1.0 | 1.0 |
| 0.2552 | 15.0 | 45 | 0.1671 | 1.0 | 1.0 |
| 0.2475 | 16.0 | 48 | 0.1598 | 1.0 | 1.0 |
| 0.2259 | 17.0 | 51 | 0.1541 | 1.0 | 1.0 |
| 0.201 | 18.0 | 54 | 0.1492 | 1.0 | 1.0 |
| 0.2083 | 19.0 | 57 | 0.1461 | 1.0 | 1.0 |
| 0.2281 | 20.0 | 60 | 0.1448 | 1.0 | 1.0 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.12.0+cu102
- Datasets 2.1.0
- Tokenizers 0.12.1
|
tals/albert-base-vitaminc_wnei-fever | tals | 2022-08-05T02:25:41Z | 6 | 1 | transformers | [
"transformers",
"pytorch",
"albert",
"text-classification",
"dataset:tals/vitaminc",
"dataset:fever",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-03-02T23:29:05Z | ---
datasets:
- tals/vitaminc
- fever
---
# Details
Model used in [Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence](https://aclanthology.org/2021.naacl-main.52/) (Schuster et al., NAACL 21`).
For more details see: https://github.com/TalSchuster/VitaminC
When using this model, please cite the paper.
# BibTeX entry and citation info
```bibtex
@inproceedings{schuster-etal-2021-get,
title = "Get Your Vitamin {C}! Robust Fact Verification with Contrastive Evidence",
author = "Schuster, Tal and
Fisch, Adam and
Barzilay, Regina",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.52",
doi = "10.18653/v1/2021.naacl-main.52",
pages = "624--643",
abstract = "Typical fact verification models use retrieved written evidence to verify claims. Evidence sources, however, often change over time as more information is gathered and revised. In order to adapt, models must be sensitive to subtle differences in supporting evidence. We present VitaminC, a benchmark infused with challenging cases that require fact verification models to discern and adjust to slight factual changes. We collect over 100,000 Wikipedia revisions that modify an underlying fact, and leverage these revisions, together with additional synthetically constructed ones, to create a total of over 400,000 claim-evidence pairs. Unlike previous resources, the examples in VitaminC are contrastive, i.e., they contain evidence pairs that are nearly identical in language and content, with the exception that one supports a given claim while the other does not. We show that training using this design increases robustness{---}improving accuracy by 10{\%} on adversarial fact verification and 6{\%} on adversarial natural language inference (NLI). Moreover, the structure of VitaminC leads us to define additional tasks for fact-checking resources: tagging relevant words in the evidence for verifying the claim, identifying factual revisions, and providing automatic edits via factually consistent text generation.",
}
```
|
fzwd6666/NLTBert_multi_fine_tune_new | fzwd6666 | 2022-08-05T00:22:54Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-05T00:04:38Z | This model is a fine-tuned version of fzwd6666/Ged_bert_new with 4 layers on an NLT dataset. It achieves the following results on the evaluation set:
{'precision': 0.9795081967213115} {'recall': 0.989648033126294} {'f1': 0.984552008238929} {'accuracy': 0.9843227424749164}
Training hyperparameters:
learning_rate: 1e-4
train_batch_size: 8
eval_batch_size: 8
optimizer: AdamW with betas=(0.9,0.999) and epsilon=1e-08
weight_decay= 0.01
lr_scheduler_type: linear
num_epochs: 3
It achieves the following results on the test set:
Incorrect UD Padded:
{'precision': 0.6878048780487804} {'recall': 0.2863913337846987} {'f1': 0.4043977055449331} {'accuracy': 0.4722575180008471}
Incorrect UD Unigram:
{'precision': 0.6348314606741573} {'recall': 0.3060257278266757} {'f1': 0.4129739607126542} {'accuracy': 0.4557390936044049}
Incorrect UD Bigram:
{'precision': 0.6588419405320813} {'recall': 0.28503723764387273} {'f1': 0.3979206049149338} {'accuracy': 0.4603981363828886}
Incorrect UD All:
{'precision': 0.4} {'recall': 0.0013540961408259986} {'f1': 0.002699055330634278} {'accuracy': 0.373994070309191}
Incorrect Sentence:
{'precision': 0.5} {'recall': 0.012186865267433988} {'f1': 0.02379378717779247} {'accuracy': 0.37441761965268955}
|
huggingtweets/dominic_w-lastmjs-vitalikbuterin | huggingtweets | 2022-08-04T23:40:33Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-08-04T23:38:29Z | ---
language: en
thumbnail: http://www.huggingtweets.com/dominic_w-lastmjs-vitalikbuterin/1659656428920/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1376912180721766401/ZVhVhhQ7_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/977496875887558661/L86xyLF4_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/994681826286301184/ZNY20HQG_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">lastmjs.eth ∞ & vitalik.eth & dom.icp ∞</div>
<div style="text-align: center; font-size: 14px;">@dominic_w-lastmjs-vitalikbuterin</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from lastmjs.eth ∞ & vitalik.eth & dom.icp ∞.
| Data | lastmjs.eth ∞ | vitalik.eth | dom.icp ∞ |
| --- | --- | --- | --- |
| Tweets downloaded | 3250 | 3246 | 3249 |
| Retweets | 14 | 236 | 322 |
| Short tweets | 185 | 122 | 61 |
| Tweets kept | 3051 | 2888 | 2866 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2rlc6tzy/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @dominic_w-lastmjs-vitalikbuterin's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1hxl56uf) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1hxl56uf/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/dominic_w-lastmjs-vitalikbuterin')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
fzwd6666/NLI_new | fzwd6666 | 2022-08-04T22:33:38Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-04T21:42:12Z | This model is a fine-tuned version of bert-base-uncased on an NLI dataset. It achieves the following results on the evaluation set:
{'precision': 0.9690210656753407} {'recall': 0.9722337339411521} {'f1': 0.9706247414149772} {'accuracy': 0.9535340314136126}
Training hyperparameters:
learning_rate: 2e-5
train_batch_size: 8
eval_batch_size: 8
optimizer: AdamW with betas=(0.9,0.999) and epsilon=1e-08
weight_decay= 0.01
lr_scheduler_type: linear
num_epochs: 3
It achieves the following results on the test set:
Incorrect UD Padded:
{'precision': 0.623370110330993} {'recall': 0.8415707515233581} {'f1': 0.7162201094785364} {'accuracy': 0.5828038966539602}
Incorrect UD Unigram:
{'precision': 0.6211431461810825} {'recall': 0.8314150304671631} {'f1': 0.7110596409959468} {'accuracy': 0.5772977551884795}
Incorrect UD Bigram:
{'precision': 0.6203980099502487} {'recall': 0.8442789438050101} {'f1': 0.7152279896759391} {'accuracy': 0.579415501905972}
Incorrect UD All:
{'precision': 0.605543710021322} {'recall': 0.1922816519972918} {'f1': 0.2918807810894142} {'accuracy': 0.4163490046590428}
Incorrect Sentence:
{'precision': 0.6411042944785276} {'recall': 0.4245091401489506} {'f1': 0.5107942973523422} {'accuracy': 0.4913172384582804}
|
fzwd6666/Ged_bert_new | fzwd6666 | 2022-08-04T22:32:48Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-04T22:14:19Z | This model is a fine-tuned version of bert-base-uncased on an NLI dataset. It achieves the following results on the evaluation set:
{'precision': 0.8384560400285919} {'recall': 0.9536585365853658} {'f1': 0.892354507417269} {'accuracy': 0.8345996493278784}
Training hyperparameters:
learning_rate=2e-5
batch_size=32
epochs = 4
warmup_steps=10% training data number
optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
lr_scheduler_type: linear
|
SharpAI/mal-tls-bert-large-w8a8 | SharpAI | 2022-08-04T22:03:00Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-07-27T17:48:37Z | ---
tags:
- generated_from_keras_callback
model-index:
- name: mal-tls-bert-large-w8a8
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mal-tls-bert-large-w8a8
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.15.0
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.10.3
|
SharpAI/mal-tls-bert-large-relu | SharpAI | 2022-08-04T21:41:21Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-04T17:58:24Z | ---
tags:
- generated_from_keras_callback
model-index:
- name: mal-tls-bert-large-relu
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mal-tls-bert-large-relu
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.12.1
|
SharpAI/mal-tls-bert-large | SharpAI | 2022-08-04T21:04:08Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-07-25T22:26:09Z | ---
tags:
- generated_from_keras_callback
model-index:
- name: mal-tls-bert-large
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mal-tls-bert-large
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.12.1
|
abdulmatinomotoso/article_title_2299 | abdulmatinomotoso | 2022-08-04T20:44:37Z | 13 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-08-04T19:49:29Z | ---
tags:
- generated_from_trainer
model-index:
- name: article_title_2299
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# article_title_2299
This model is a fine-tuned version of [google/pegasus-cnn_dailymail](https://huggingface.co/google/pegasus-cnn_dailymail) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
DOOGLAK/wikigold_trained_no_DA_testing2 | DOOGLAK | 2022-08-04T20:30:35Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:wikigold_splits",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-08-04T19:39:03Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wikigold_splits
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: wikigold_trained_no_DA_testing2
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wikigold_splits
type: wikigold_splits
args: default
metrics:
- name: Precision
type: precision
value: 0.8410852713178295
- name: Recall
type: recall
value: 0.84765625
- name: F1
type: f1
value: 0.8443579766536965
- name: Accuracy
type: accuracy
value: 0.9571820972693489
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wikigold_trained_no_DA_testing2
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the wikigold_splits dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1431
- Precision: 0.8411
- Recall: 0.8477
- F1: 0.8444
- Accuracy: 0.9572
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 167 | 0.1618 | 0.7559 | 0.75 | 0.7529 | 0.9410 |
| No log | 2.0 | 334 | 0.1488 | 0.8384 | 0.8242 | 0.8313 | 0.9530 |
| 0.1589 | 3.0 | 501 | 0.1431 | 0.8411 | 0.8477 | 0.8444 | 0.9572 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
aliprf/KD-Loss | aliprf | 2022-08-04T19:47:02Z | 0 | 0 | null | [
"computer vision",
"face alignment",
"facial landmark point",
"CNN",
"Knowledge Distillation",
"loss",
"CVIU",
"Tensor Flow",
"en",
"arxiv:2111.07047",
"license:mit",
"region:us"
]
| null | 2022-08-04T19:22:34Z |
---
language: en
tags: [ computer vision, face alignment, facial landmark point, CNN, Knowledge Distillation, loss, CVIU, Tensor Flow]
thumbnail:
license: mit
---
[](https://paperswithcode.com/sota/face-alignment-on-cofw?p=facial-landmark-points-detection-using)
#
Facial Landmark Points Detection Using Knowledge Distillation-Based Neural Networks
#### Link to the paper:
Google Scholar:
https://scholar.google.com/citations?view_op=view_citation&hl=en&user=96lS6HIAAAAJ&citation_for_view=96lS6HIAAAAJ:zYLM7Y9cAGgC
Elsevier:
https://www.sciencedirect.com/science/article/pii/S1077314221001582
Arxiv:
https://arxiv.org/abs/2111.07047
#### Link to the paperswithcode.com:
https://paperswithcode.com/paper/facial-landmark-points-detection-using
```diff
@@plaese STAR the repo if you like it.@@
```
```
Please cite this work as:
@article{fard2022facial,
title={Facial landmark points detection using knowledge distillation-based neural networks},
author={Fard, Ali Pourramezan and Mahoor, Mohammad H},
journal={Computer Vision and Image Understanding},
volume={215},
pages={103316},
year={2022},
publisher={Elsevier}
}
```
## Introduction
Facial landmark detection is a vital step for numerous facial image analysis applications. Although some deep learning-based methods have achieved good performances in this task, they are often not suitable for running on mobile devices. Such methods rely on networks with many parameters, which makes the training and inference time-consuming. Training lightweight neural networks such as MobileNets are often challenging, and the models might have low accuracy. Inspired by knowledge distillation (KD), this paper presents a novel loss function to train a lightweight Student network (e.g., MobileNetV2) for facial landmark detection. We use two Teacher networks, a Tolerant-Teacher and a Tough-Teacher in conjunction with the Student network. The Tolerant-Teacher is trained using Soft-landmarks created by active shape models, while the Tough-Teacher is trained using the ground truth (aka Hard-landmarks) landmark points. To utilize the facial landmark points predicted by the Teacher networks, we define an Assistive Loss (ALoss) for each Teacher network. Moreover, we define a loss function called KD-Loss that utilizes the facial landmark points predicted by the two pre-trained Teacher networks (EfficientNet-b3) to guide the lightweight Student network towards predicting the Hard-landmarks. Our experimental results on three challenging facial datasets show that the proposed architecture will result in a better-trained Student network that can extract facial landmark points with high accuracy.
##Architecture
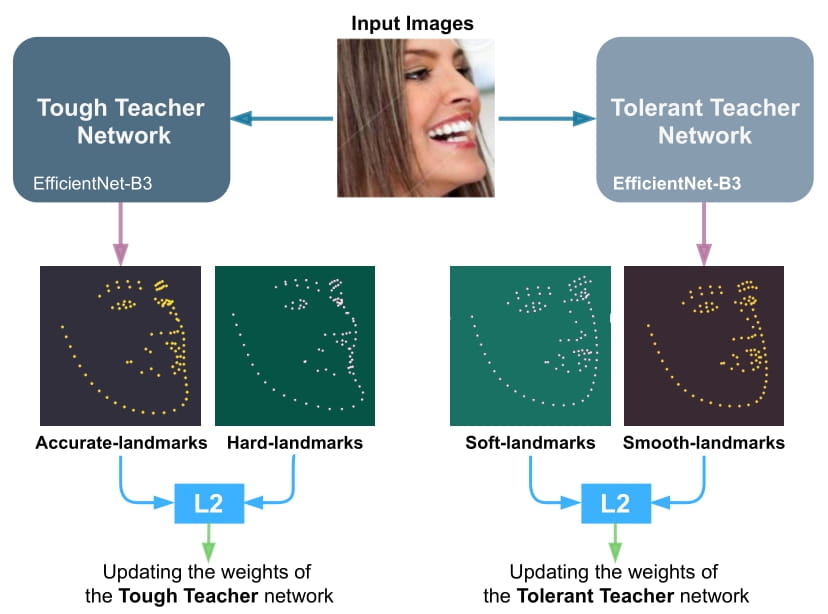
We train the Tough-Teacher, and the Tolerant-Teacher networks independently using the Hard-landmarks and the Soft-landmarks respectively utilizing the L2 loss:
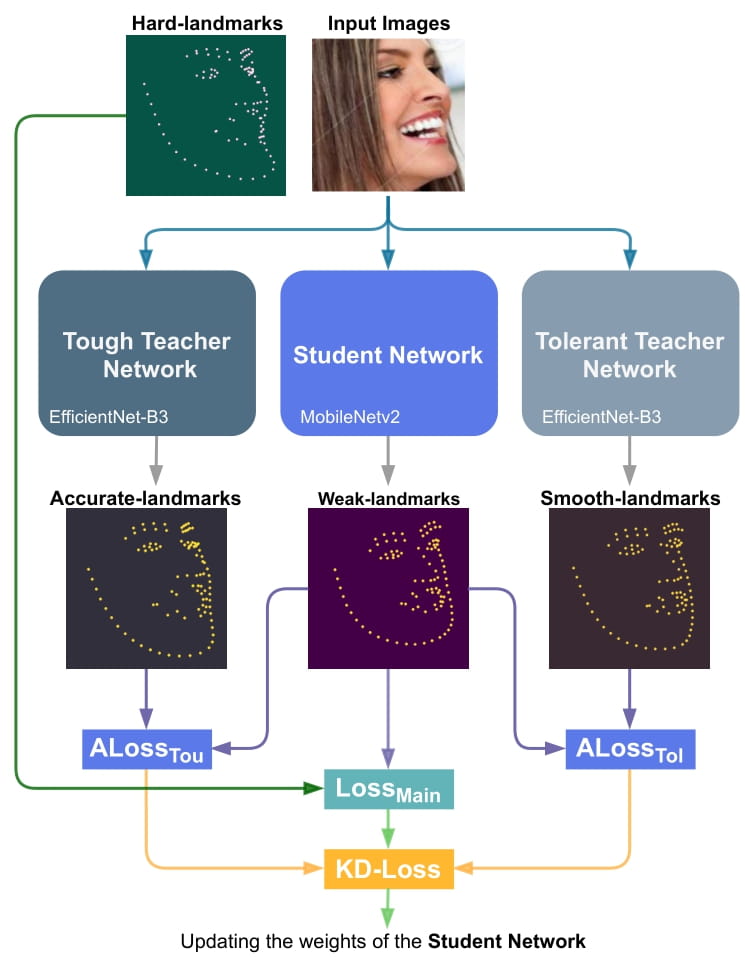
Proposed KD-based architecture for training the Student network. KDLoss uses the knowledge of the previously trained Teacher networks by utilizing the assistive loss functions ALossT ou and ALossT ol, to improve the performance the face alignment task:
## Evaluation
Following are some samples in order to show the visual performance of KD-Loss on 300W, COFW and WFLW datasets:
300W:

COFW:

WFLW:

----------------------------------------------------------------------------------------------------------------------------------
## Installing the requirements
In order to run the code you need to install python >= 3.5.
The requirements and the libraries needed to run the code can be installed using the following command:
```
pip install -r requirements.txt
```
## Using the pre-trained models
You can test and use the preetrained models using the following codes which are available in the test.py:
The pretrained student model are also located in "models/students".
```
cnn = CNNModel()
model = cnn.get_model(arch=arch, input_tensor=None, output_len=self.output_len)
model.load_weights(weight_fname)
img = None # load a cropped image
image_utility = ImageUtility()
pose_predicted = []
image = np.expand_dims(img, axis=0)
pose_predicted = model.predict(image)[1][0]
```
## Training Network from scratch
### Preparing Data
Data needs to be normalized and saved in npy format.
### Training
### Training Teacher Networks:
The training implementation is located in teacher_trainer.py class. You can use the following code to start the training for the teacher networks:
```
'''train Teacher Networks'''
trainer = TeacherTrainer(dataset_name=DatasetName.w300)
trainer.train(arch='efficientNet',weight_path=None)
```
### Training Student Networks:
After Training the teacher networks, you can use the trained teachers to train the student network. The implemetation of training of the student network is provided in teacher_trainer.py . You can use the following code to start the training for the student networks:
```
st_trainer = StudentTrainer(dataset_name=DatasetName.w300, use_augmneted=True)
st_trainer.train(arch_student='mobileNetV2', weight_path_student=None,
loss_weight_student=2.0,
arch_tough_teacher='efficientNet', weight_path_tough_teacher='./models/teachers/ds_300w_ef_tou.h5',
loss_weight_tough_teacher=1,
arch_tol_teacher='efficientNet', weight_path_tol_teacher='./models/teachers/ds_300w_ef_tol.h5',
loss_weight_tol_teacher=1)
```
```
Please cite this work as:
@article{fard2022facial,
title={Facial landmark points detection using knowledge distillation-based neural networks},
author={Fard, Ali Pourramezan and Mahoor, Mohammad H},
journal={Computer Vision and Image Understanding},
volume={215},
pages={103316},
year={2022},
publisher={Elsevier}
}
```
```diff
@@plaese STAR the repo if you like it.@@
```
|
pc2976/prot_bert-finetuned-sp6 | pc2976 | 2022-08-04T18:30:52Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-08-03T20:30:46Z | ---
tags:
- generated_from_trainer
model-index:
- name: prot_bert-finetuned-sp6
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# prot_bert-finetuned-sp6
This model is a fine-tuned version of [Rostlab/prot_bert](https://huggingface.co/Rostlab/prot_bert) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4070
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.5027 | 1.0 | 164 | 0.4666 |
| 0.3927 | 2.0 | 328 | 0.4328 |
| 0.3348 | 3.0 | 492 | 0.4072 |
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.10.3
|
keepitreal/mini-phobert-v3.1 | keepitreal | 2022-08-04T16:49:01Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-08-04T11:32:18Z | ---
tags:
- generated_from_trainer
model-index:
- name: mini-phobert-v3.1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mini-phobert-v3.1
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0527
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
yukseltron/lyrics-classifier | yukseltron | 2022-08-04T15:42:31Z | 0 | 0 | null | [
"tensorboard",
"text-classification",
"lyrics",
"catboost",
"en",
"dataset:data",
"license:gpl-3.0",
"region:us"
]
| text-classification | 2022-07-28T12:48:01Z | ---
language:
- en
thumbnail: "http://s4.thingpic.com/images/Yx/zFbS5iJFJMYNxDp9HTR7TQtT.png"
tags:
- text-classification
- lyrics
- catboost
license: gpl-3.0
datasets:
- data
metrics:
- accuracy
widget:
- text: "I know when that hotline bling, that can only mean one thing"
---
# Lyrics Classifier
This submission uses [CatBoost](https://catboost.ai/).
CatBoost was chosen for its listed benefits, mainly in requiring less hyperparameter tuning and preprocessing of categorical and text features. It is also fast and fairly easy to set up.
<img src="http://s4.thingpic.com/images/Yx/zFbS5iJFJMYNxDp9HTR7TQtT.png"
alt="Markdown Monster icon"
style="float: left; margin-right: 10px;" />
|
tj-solergibert/xlm-roberta-base-finetuned-panx-it | tj-solergibert | 2022-08-04T15:36:59Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-08-04T15:21:38Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-it
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
config: PAN-X.it
split: train
args: PAN-X.it
metrics:
- name: F1
type: f1
value: 0.8124233755619126
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-it
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2630
- F1: 0.8124
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.8193 | 1.0 | 70 | 0.3200 | 0.7356 |
| 0.2773 | 2.0 | 140 | 0.2841 | 0.7882 |
| 0.1807 | 3.0 | 210 | 0.2630 | 0.8124 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Jacobsith/autotrain-Hello_there-1209845735 | Jacobsith | 2022-08-04T15:30:19Z | 14 | 0 | transformers | [
"transformers",
"pytorch",
"longt5",
"text2text-generation",
"autotrain",
"summarization",
"unk",
"dataset:Jacobsith/autotrain-data-Hello_there",
"model-index",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| summarization | 2022-08-02T06:38:58Z | ---
tags:
- autotrain
- summarization
language:
- unk
widget:
- text: "I love AutoTrain \U0001F917"
datasets:
- Jacobsith/autotrain-data-Hello_there
co2_eq_emissions:
emissions: 3602.3174355473616
model-index:
- name: Jacobsith/autotrain-Hello_there-1209845735
results:
- task:
type: summarization
name: Summarization
dataset:
name: Blaise-g/SumPubmed
type: Blaise-g/SumPubmed
config: Blaise-g--SumPubmed
split: test
metrics:
- name: ROUGE-1
type: rouge
value: 38.2084
verified: true
- name: ROUGE-2
type: rouge
value: 12.4744
verified: true
- name: ROUGE-L
type: rouge
value: 21.5536
verified: true
- name: ROUGE-LSUM
type: rouge
value: 34.229
verified: true
- name: loss
type: loss
value: 2.0952045917510986
verified: true
- name: gen_len
type: gen_len
value: 126.3001
verified: true
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 1209845735
- CO2 Emissions (in grams): 3602.3174
## Validation Metrics
- Loss: 2.484
- Rouge1: 38.448
- Rouge2: 10.900
- RougeL: 22.080
- RougeLsum: 33.458
- Gen Len: 115.982
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/Jacobsith/autotrain-Hello_there-1209845735
``` |
Evelyn18/roberta-base-spanish-squades-becasIncentivos2 | Evelyn18 | 2022-08-04T15:18:42Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"roberta",
"question-answering",
"generated_from_trainer",
"dataset:becasv2",
"endpoints_compatible",
"region:us"
]
| question-answering | 2022-07-27T03:53:59Z | ---
tags:
- generated_from_trainer
datasets:
- becasv2
model-index:
- name: roberta-base-spanish-squades-becasIncentivos2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-spanish-squades-becasIncentivos2
This model is a fine-tuned version of [IIC/roberta-base-spanish-squades](https://huggingface.co/IIC/roberta-base-spanish-squades) on the becasv2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.793
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 7 | 1.6939 |
| No log | 2.0 | 14 | 1.7033 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
mindwrapped/collaborative-filtering-movielens-copy | mindwrapped | 2022-08-04T15:17:05Z | 0 | 1 | keras | [
"keras",
"tensorboard",
"tf-keras",
"collaborative-filtering",
"recommender",
"tabular-classification",
"license:cc0-1.0",
"region:us"
]
| tabular-classification | 2022-06-08T16:15:46Z | ---
library_name: keras
tags:
- collaborative-filtering
- recommender
- tabular-classification
license:
- cc0-1.0
---
## Model description
This repo contains the model and the notebook on [how to build and train a Keras model for Collaborative Filtering for Movie Recommendations](https://keras.io/examples/structured_data/collaborative_filtering_movielens/).
Full credits to [Siddhartha Banerjee](https://twitter.com/sidd2006).
## Intended uses & limitations
Based on a user and movies they have rated highly in the past, this model outputs the predicted rating a user would give to a movie they haven't seen yet (between 0-1). This information can be used to find out the top recommended movies for this user.
## Training and evaluation data
The dataset consists of user's ratings on specific movies. It also consists of the movie's specific genres.
## Training procedure
The model was trained for 5 epochs with a batch size of 64.
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 0.001, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
## Training Metrics
| Epochs | Train Loss | Validation Loss |
|--- |--- |--- |
| 1| 0.637| 0.619|
| 2| 0.614| 0.616|
| 3| 0.609| 0.611|
| 4| 0.608| 0.61|
| 5| 0.608| 0.609|
## Model Plot
<details>
<summary>View Model Plot</summary>

</details> |
tj-solergibert/xlm-roberta-base-finetuned-panx-de-fr | tj-solergibert | 2022-08-04T15:00:13Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-08-04T14:35:07Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de-fr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1608
- F1: 0.8593
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2888 | 1.0 | 715 | 0.1779 | 0.8233 |
| 0.1437 | 2.0 | 1430 | 0.1570 | 0.8497 |
| 0.0931 | 3.0 | 2145 | 0.1608 | 0.8593 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Ilyes/wav2vec2-large-xlsr-53-french | Ilyes | 2022-08-04T14:51:35Z | 29 | 4 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"fr",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-03-02T23:29:04Z | ---
language: fr
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: wav2vec2-large-xlsr-53-French by Ilyes Rebai
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice fr
type: common_voice
args: fr
metrics:
- name: Test WER
type: wer
value: 12.82
---
## Evaluation on Common Voice FR Test
The script used for training and evaluation can be found here: https://github.com/irebai/wav2vec2
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
import re
model_name = "Ilyes/wav2vec2-large-xlsr-53-french"
device = "cpu" # "cuda"
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(model_name)
ds = load_dataset("common_voice", "fr", split="test", cache_dir="./data/fr")
chars_to_ignore_regex = '[\,\?\.\!\;\:\"\“\%\‘\”\�\‘\’\’\’\‘\…\·\!\ǃ\?\«\‹\»\›“\”\\ʿ\ʾ\„\∞\\|\.\,\;\:\*\—\–\─\―\_\/\:\ː\;\,\=\«\»\→]'
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
resampler = torchaudio.transforms.Resample(48_000, 16_000)
ds = ds.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)
batch["target"] = batch["sentence"]
return batch
result = ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=list(ds.features.keys()))
wer = load_metric("wer")
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
## Results
WER=12.82%
CER=4.40%
|
jjjjjjjjjj/dqn-SpaceInvadersNoFrame-v4 | jjjjjjjjjj | 2022-08-04T14:02:37Z | 7 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-08-04T14:02:15Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 582.50 +/- 220.50
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga jjjjjjjjjj -f logs/
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga jjjjjjjjjj
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
silviacamplani/distilbert-base-uncased-finetuned-dapt-ner-ai_data | silviacamplani | 2022-08-04T13:38:43Z | 4 | 0 | transformers | [
"transformers",
"tf",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-08-04T13:37:35Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: silviacamplani/distilbert-base-uncased-finetuned-dapt-ner-ai_data
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# silviacamplani/distilbert-base-uncased-finetuned-dapt-ner-ai_data
This model is a fine-tuned version of [silviacamplani/distilbert-base-uncased-finetuned-ai_data](https://huggingface.co/silviacamplani/distilbert-base-uncased-finetuned-ai_data) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.3549
- Validation Loss: 2.3081
- Train Precision: 0.0
- Train Recall: 0.0
- Train F1: 0.0
- Train Accuracy: 0.6392
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 18, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Train Precision | Train Recall | Train F1 | Train Accuracy | Epoch |
|:----------:|:---------------:|:---------------:|:------------:|:--------:|:--------------:|:-----:|
| 3.0905 | 2.8512 | 0.0 | 0.0 | 0.0 | 0.6376 | 0 |
| 2.6612 | 2.4783 | 0.0 | 0.0 | 0.0 | 0.6392 | 1 |
| 2.3549 | 2.3081 | 0.0 | 0.0 | 0.0 | 0.6392 | 2 |
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.12.1
|
schnell/bert-small-ipadic_bpe | schnell | 2022-08-04T13:37:42Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-08-01T15:40:13Z | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bert-small-ipadic_bpe
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-small-ipadic_bpe
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6777
- Accuracy: 0.6519
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 256
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 3
- total_train_batch_size: 768
- total_eval_batch_size: 24
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- num_epochs: 14
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:------:|:---------------:|:--------:|
| 2.2548 | 1.0 | 69473 | 2.1163 | 0.5882 |
| 2.0904 | 2.0 | 138946 | 1.9562 | 0.6101 |
| 2.0203 | 3.0 | 208419 | 1.8848 | 0.6208 |
| 1.978 | 4.0 | 277892 | 1.8408 | 0.6272 |
| 1.937 | 5.0 | 347365 | 1.8080 | 0.6320 |
| 1.9152 | 6.0 | 416838 | 1.7818 | 0.6361 |
| 1.8982 | 7.0 | 486311 | 1.7575 | 0.6395 |
| 1.8808 | 8.0 | 555784 | 1.7413 | 0.6421 |
| 1.8684 | 9.0 | 625257 | 1.7282 | 0.6440 |
| 1.8517 | 10.0 | 694730 | 1.7140 | 0.6464 |
| 1.8353 | 11.0 | 764203 | 1.7022 | 0.6481 |
| 1.8245 | 12.0 | 833676 | 1.6877 | 0.6504 |
| 1.8191 | 13.0 | 903149 | 1.6829 | 0.6515 |
| 1.8122 | 14.0 | 972622 | 1.6777 | 0.6519 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.12.0+cu116
- Datasets 2.2.2
- Tokenizers 0.12.1
|
juletxara/vilt-vsr-zeroshot | juletxara | 2022-08-04T12:34:40Z | 9 | 0 | transformers | [
"transformers",
"pytorch",
"vilt",
"arxiv:2205.00363",
"arxiv:2102.03334",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2022-08-04T10:55:43Z | ---
license: apache-2.0
---
# Vision-and-Language Transformer (ViLT), fine-tuned on VSR zeroshot split
Vision-and-Language Transformer (ViLT) model fine-tuned on zeroshot split of [Visual Spatial Reasoning (VSR)](https://arxiv.org/abs/2205.00363). ViLT was introduced in the paper [ViLT: Vision-and-Language Transformer
Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Kim et al. and first released in [this repository](https://github.com/dandelin/ViLT).
## Intended uses & limitations
You can use the model to determine whether a sentence is true or false given an image.
### How to use
Here is how to use the model in PyTorch:
```
from transformers import ViltProcessor, ViltForImagesAndTextClassification
import requests
from PIL import Image
image = Image.open(requests.get("https://camo.githubusercontent.com/ffcbeada14077b8e6d4b16817c91f78ba50aace210a1e4754418f1413d99797f/687474703a2f2f696d616765732e636f636f646174617365742e6f72672f747261696e323031372f3030303030303038303333362e6a7067", stream=True).raw)
text = "The person is ahead of the cow."
processor = ViltProcessor.from_pretrained("juletxara/vilt-vsr-zeroshot")
model = ViltForImagesAndTextClassification.from_pretrained("juletxara/vilt-vsr-zeroshot")
# prepare inputs
encoding = processor(image, text, return_tensors="pt")
# forward pass
outputs = model(input_ids=encoding.input_ids, pixel_values=encoding.pixel_values.unsqueeze(0))
logits = outputs.logits
idx = logits.argmax(-1).item()
print("Predicted answer:", model.config.id2label[idx])
```
## Training data
(to do)
## Training procedure
### Preprocessing
(to do)
### Pretraining
(to do)
## Evaluation results
(to do)
### BibTeX entry and citation info
```bibtex
@misc{kim2021vilt,
title={ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision},
author={Wonjae Kim and Bokyung Son and Ildoo Kim},
year={2021},
eprint={2102.03334},
archivePrefix={arXiv},
primaryClass={stat.ML}
}
@article{liu2022visual,
title={Visual Spatial Reasoning},
author={Liu, Fangyu and Emerson, Guy and Collier, Nigel},
journal={arXiv preprint arXiv:2205.00363},
year={2022}
}
``` |
juletxara/vilt-vsr-random | juletxara | 2022-08-04T12:24:28Z | 2 | 0 | transformers | [
"transformers",
"pytorch",
"vilt",
"arxiv:2205.00363",
"arxiv:2102.03334",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2022-08-04T10:37:16Z | ---
license: apache-2.0
---
# Vision-and-Language Transformer (ViLT), fine-tuned on VSR random split
Vision-and-Language Transformer (ViLT) model fine-tuned on random split of [Visual Spatial Reasoning (VSR)](https://arxiv.org/abs/2205.00363). ViLT was introduced in the paper [ViLT: Vision-and-Language Transformer
Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Kim et al. and first released in [this repository](https://github.com/dandelin/ViLT).
## Intended uses & limitations
You can use the model to determine whether a sentence is true or false given an image.
### How to use
Here is how to use the model in PyTorch:
```
from transformers import ViltProcessor, ViltForImagesAndTextClassification
import requests
from PIL import Image
image = Image.open(requests.get("https://camo.githubusercontent.com/ffcbeada14077b8e6d4b16817c91f78ba50aace210a1e4754418f1413d99797f/687474703a2f2f696d616765732e636f636f646174617365742e6f72672f747261696e323031372f3030303030303038303333362e6a7067", stream=True).raw)
text = "The person is ahead of the cow."
processor = ViltProcessor.from_pretrained("juletxara/vilt-vsr-random")
model = ViltForImagesAndTextClassification.from_pretrained("juletxara/vilt-vsr-random")
# prepare inputs
encoding = processor(image, text, return_tensors="pt")
# forward pass
outputs = model(input_ids=encoding.input_ids, pixel_values=encoding.pixel_values.unsqueeze(0))
logits = outputs.logits
idx = logits.argmax(-1).item()
print("Predicted answer:", model.config.id2label[idx])
```
## Training data
(to do)
## Training procedure
### Preprocessing
(to do)
### Pretraining
(to do)
## Evaluation results
(to do)
### BibTeX entry and citation info
```bibtex
@misc{kim2021vilt,
title={ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision},
author={Wonjae Kim and Bokyung Son and Ildoo Kim},
year={2021},
eprint={2102.03334},
archivePrefix={arXiv},
primaryClass={stat.ML}
}
@article{liu2022visual,
title={Visual Spatial Reasoning},
author={Liu, Fangyu and Emerson, Guy and Collier, Nigel},
journal={arXiv preprint arXiv:2205.00363},
year={2022}
}
``` |
farofang/t5-small-finetuned-thai-informal-to-formal | farofang | 2022-08-04T11:47:22Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-08-03T17:23:33Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: t5-small-finetuned-thai-informal-to-formal
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-thai-informal-to-formal
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3091
- Bleu: 20.5964
- Gen Len: 19.9981
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 300
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:------:|:---------------:|:-------:|:-------:|
| 2.2862 | 1.0 | 1011 | 2.2028 | 31.6678 | 20.0 |
| 2.1228 | 2.0 | 2022 | 2.0339 | 32.3643 | 20.0 |
| 2.0581 | 3.0 | 3033 | 1.9386 | 32.3784 | 20.0 |
| 1.9714 | 4.0 | 4044 | 1.8899 | 31.9728 | 20.0 |
| 1.9169 | 5.0 | 5055 | 1.8318 | 32.1064 | 20.0 |
| 1.8969 | 6.0 | 6066 | 1.8005 | 31.4324 | 20.0 |
| 1.8486 | 7.0 | 7077 | 1.7813 | 31.7758 | 20.0 |
| 1.802 | 8.0 | 8088 | 1.7464 | 31.9055 | 20.0 |
| 1.7654 | 9.0 | 9099 | 1.7352 | 31.9598 | 20.0 |
| 1.7439 | 10.0 | 10110 | 1.7009 | 32.1696 | 20.0 |
| 1.7603 | 11.0 | 11121 | 1.6873 | 31.8118 | 20.0 |
| 1.7288 | 12.0 | 12132 | 1.6678 | 31.5711 | 20.0 |
| 1.7004 | 13.0 | 13143 | 1.6482 | 31.4575 | 20.0 |
| 1.6851 | 14.0 | 14154 | 1.6374 | 31.9579 | 20.0 |
| 1.6497 | 15.0 | 15165 | 1.6290 | 31.4299 | 20.0 |
| 1.656 | 16.0 | 16176 | 1.6130 | 31.2145 | 20.0 |
| 1.6423 | 17.0 | 17187 | 1.5931 | 31.365 | 20.0 |
| 1.6024 | 18.0 | 18198 | 1.5797 | 31.2247 | 20.0 |
| 1.6064 | 19.0 | 19209 | 1.5736 | 31.1535 | 20.0 |
| 1.5974 | 20.0 | 20220 | 1.5609 | 31.431 | 20.0 |
| 1.5961 | 21.0 | 21231 | 1.5578 | 30.9905 | 20.0 |
| 1.5621 | 22.0 | 22242 | 1.5466 | 30.8979 | 20.0 |
| 1.5307 | 23.0 | 23253 | 1.5285 | 31.277 | 20.0 |
| 1.5359 | 24.0 | 24264 | 1.5370 | 31.4321 | 20.0 |
| 1.5558 | 25.0 | 25275 | 1.5215 | 31.2769 | 20.0 |
| 1.513 | 26.0 | 26286 | 1.5173 | 30.9782 | 19.9997 |
| 1.5241 | 27.0 | 27297 | 1.5105 | 30.6717 | 20.0 |
| 1.5133 | 28.0 | 28308 | 1.4973 | 30.3152 | 20.0 |
| 1.4713 | 29.0 | 29319 | 1.4927 | 30.276 | 19.9997 |
| 1.478 | 30.0 | 30330 | 1.4887 | 30.1004 | 19.9989 |
| 1.4572 | 31.0 | 31341 | 1.4845 | 29.8939 | 19.9983 |
| 1.4485 | 32.0 | 32352 | 1.4653 | 30.0169 | 19.9986 |
| 1.4404 | 33.0 | 33363 | 1.4648 | 28.9061 | 19.9989 |
| 1.4408 | 34.0 | 34374 | 1.4586 | 29.598 | 19.9994 |
| 1.4296 | 35.0 | 35385 | 1.4585 | 28.9821 | 19.9981 |
| 1.408 | 36.0 | 36396 | 1.4517 | 29.6025 | 19.9986 |
| 1.4004 | 37.0 | 37407 | 1.4456 | 27.8564 | 19.9992 |
| 1.3991 | 38.0 | 38418 | 1.4411 | 28.8947 | 19.9994 |
| 1.401 | 39.0 | 39429 | 1.4309 | 27.6809 | 19.9994 |
| 1.391 | 40.0 | 40440 | 1.4278 | 29.1687 | 19.9994 |
| 1.3709 | 41.0 | 41451 | 1.4217 | 28.2947 | 19.9989 |
| 1.3726 | 42.0 | 42462 | 1.4247 | 27.2108 | 19.9983 |
| 1.3702 | 43.0 | 43473 | 1.4144 | 25.9973 | 19.9981 |
| 1.3636 | 44.0 | 44484 | 1.4163 | 26.0146 | 19.9953 |
| 1.3673 | 45.0 | 45495 | 1.4118 | 25.8126 | 19.9978 |
| 1.3539 | 46.0 | 46506 | 1.4076 | 25.5185 | 19.9981 |
| 1.3434 | 47.0 | 47517 | 1.4023 | 26.2123 | 19.9947 |
| 1.3428 | 48.0 | 48528 | 1.4008 | 25.8932 | 19.9955 |
| 1.3325 | 49.0 | 49539 | 1.4003 | 25.7762 | 19.9969 |
| 1.3258 | 50.0 | 50550 | 1.3896 | 24.8206 | 19.9961 |
| 1.3151 | 51.0 | 51561 | 1.3852 | 24.4683 | 19.9978 |
| 1.3035 | 52.0 | 52572 | 1.3843 | 24.9821 | 19.9992 |
| 1.2931 | 53.0 | 53583 | 1.3847 | 24.715 | 19.9989 |
| 1.2707 | 54.0 | 54594 | 1.3776 | 24.4374 | 19.9986 |
| 1.2792 | 55.0 | 55605 | 1.3801 | 23.7683 | 19.9967 |
| 1.284 | 56.0 | 56616 | 1.3781 | 23.6961 | 19.9975 |
| 1.2664 | 57.0 | 57627 | 1.3680 | 23.6677 | 19.9975 |
| 1.2783 | 58.0 | 58638 | 1.3695 | 23.3193 | 19.9986 |
| 1.2762 | 59.0 | 59649 | 1.3741 | 22.613 | 19.9972 |
| 1.2759 | 60.0 | 60660 | 1.3629 | 23.9067 | 19.9964 |
| 1.2618 | 61.0 | 61671 | 1.3687 | 23.7587 | 19.9967 |
| 1.2614 | 62.0 | 62682 | 1.3613 | 23.2615 | 19.9975 |
| 1.2455 | 63.0 | 63693 | 1.3623 | 23.8722 | 19.9986 |
| 1.1977 | 64.0 | 64704 | 1.3528 | 23.1421 | 19.9981 |
| 1.2199 | 65.0 | 65715 | 1.3520 | 22.6977 | 19.9975 |
| 1.2368 | 66.0 | 66726 | 1.3552 | 23.2495 | 19.9989 |
| 1.2087 | 67.0 | 67737 | 1.3404 | 22.6422 | 19.9989 |
| 1.214 | 68.0 | 68748 | 1.3499 | 21.979 | 19.9972 |
| 1.2322 | 69.0 | 69759 | 1.3453 | 22.1766 | 19.9978 |
| 1.2028 | 70.0 | 70770 | 1.3402 | 21.8311 | 19.9975 |
| 1.2163 | 71.0 | 71781 | 1.3399 | 22.1417 | 19.9989 |
| 1.1769 | 72.0 | 72792 | 1.3446 | 22.253 | 19.9972 |
| 1.221 | 73.0 | 73803 | 1.3413 | 22.1546 | 19.9986 |
| 1.1768 | 74.0 | 74814 | 1.3335 | 21.8914 | 19.9972 |
| 1.1829 | 75.0 | 75825 | 1.3323 | 21.7763 | 19.9947 |
| 1.1687 | 76.0 | 76836 | 1.3344 | 21.4495 | 19.9964 |
| 1.1873 | 77.0 | 77847 | 1.3337 | 21.7655 | 19.9964 |
| 1.1807 | 78.0 | 78858 | 1.3308 | 21.4564 | 19.9967 |
| 1.1735 | 79.0 | 79869 | 1.3282 | 21.233 | 19.9967 |
| 1.1693 | 80.0 | 80880 | 1.3240 | 21.0794 | 19.9955 |
| 1.1714 | 81.0 | 81891 | 1.3262 | 21.1856 | 19.9969 |
| 1.154 | 82.0 | 82902 | 1.3282 | 20.5583 | 19.9964 |
| 1.1572 | 83.0 | 83913 | 1.3229 | 20.9262 | 19.995 |
| 1.1473 | 84.0 | 84924 | 1.3233 | 20.5432 | 19.995 |
| 1.1315 | 85.0 | 85935 | 1.3227 | 20.4939 | 19.9942 |
| 1.1567 | 86.0 | 86946 | 1.3203 | 21.3354 | 19.9964 |
| 1.1485 | 87.0 | 87957 | 1.3211 | 20.9952 | 19.9939 |
| 1.1313 | 88.0 | 88968 | 1.3202 | 20.1199 | 19.9961 |
| 1.1428 | 89.0 | 89979 | 1.3188 | 20.414 | 19.9925 |
| 1.1374 | 90.0 | 90990 | 1.3220 | 20.003 | 19.993 |
| 1.1274 | 91.0 | 92001 | 1.3153 | 20.7172 | 19.9953 |
| 1.1174 | 92.0 | 93012 | 1.3126 | 20.5997 | 19.9953 |
| 1.1155 | 93.0 | 94023 | 1.3131 | 20.0402 | 19.993 |
| 1.1167 | 94.0 | 95034 | 1.3140 | 20.219 | 19.9905 |
| 1.1301 | 95.0 | 96045 | 1.3142 | 19.8332 | 19.9922 |
| 1.0975 | 96.0 | 97056 | 1.3096 | 19.6051 | 19.9942 |
| 1.1025 | 97.0 | 98067 | 1.3148 | 20.4323 | 19.993 |
| 1.0932 | 98.0 | 99078 | 1.3134 | 20.0839 | 19.9942 |
| 1.0871 | 99.0 | 100089 | 1.3071 | 20.0202 | 19.9939 |
| 1.102 | 100.0 | 101100 | 1.3091 | 20.0454 | 19.9947 |
| 1.0969 | 101.0 | 102111 | 1.3090 | 19.4474 | 19.9947 |
| 1.0988 | 102.0 | 103122 | 1.3117 | 20.1905 | 19.9922 |
| 1.0816 | 103.0 | 104133 | 1.3048 | 20.3346 | 19.9928 |
| 1.0809 | 104.0 | 105144 | 1.3058 | 20.323 | 19.9953 |
| 1.0861 | 105.0 | 106155 | 1.3052 | 20.6984 | 19.9944 |
| 1.0907 | 106.0 | 107166 | 1.3076 | 20.3413 | 19.9947 |
| 1.0747 | 107.0 | 108177 | 1.3050 | 20.3362 | 19.9955 |
| 1.0839 | 108.0 | 109188 | 1.3060 | 20.5379 | 19.9936 |
| 1.0755 | 109.0 | 110199 | 1.3071 | 20.3886 | 19.9939 |
| 1.0463 | 110.0 | 111210 | 1.3058 | 19.9524 | 19.9953 |
| 1.0644 | 111.0 | 112221 | 1.3033 | 19.7226 | 19.9972 |
| 1.0771 | 112.0 | 113232 | 1.3089 | 19.9861 | 19.9958 |
| 1.0819 | 113.0 | 114243 | 1.3031 | 20.5527 | 19.9942 |
| 1.0483 | 114.0 | 115254 | 1.3063 | 20.0048 | 19.9978 |
| 1.04 | 115.0 | 116265 | 1.3020 | 20.2327 | 19.9969 |
| 1.0574 | 116.0 | 117276 | 1.3025 | 19.6818 | 19.995 |
| 1.0356 | 117.0 | 118287 | 1.3077 | 20.1054 | 19.9967 |
| 1.0525 | 118.0 | 119298 | 1.3022 | 20.14 | 19.9967 |
| 1.0409 | 119.0 | 120309 | 1.2983 | 19.7657 | 19.9972 |
| 1.0431 | 120.0 | 121320 | 1.2945 | 20.1315 | 19.9975 |
| 1.0419 | 121.0 | 122331 | 1.3035 | 19.8364 | 19.9972 |
| 1.0411 | 122.0 | 123342 | 1.2951 | 20.204 | 19.9981 |
| 1.0396 | 123.0 | 124353 | 1.3019 | 20.6711 | 19.9955 |
| 1.0424 | 124.0 | 125364 | 1.2950 | 20.6527 | 19.9969 |
| 1.0203 | 125.0 | 126375 | 1.3008 | 20.4314 | 19.9972 |
| 1.0351 | 126.0 | 127386 | 1.3008 | 20.0237 | 19.9978 |
| 1.0424 | 127.0 | 128397 | 1.2993 | 20.3024 | 19.9983 |
| 1.0165 | 128.0 | 129408 | 1.2960 | 20.1769 | 19.9978 |
| 1.0216 | 129.0 | 130419 | 1.2977 | 19.8483 | 19.9972 |
| 1.0207 | 130.0 | 131430 | 1.2939 | 20.0639 | 19.9969 |
| 1.0119 | 131.0 | 132441 | 1.2985 | 19.731 | 19.9972 |
| 0.9965 | 132.0 | 133452 | 1.3006 | 19.5983 | 19.9969 |
| 1.0034 | 133.0 | 134463 | 1.2974 | 19.6943 | 19.9989 |
| 1.0241 | 134.0 | 135474 | 1.3015 | 20.0083 | 19.9981 |
| 1.0181 | 135.0 | 136485 | 1.2982 | 19.6057 | 19.9989 |
| 1.0112 | 136.0 | 137496 | 1.2931 | 19.3408 | 19.9986 |
| 0.9927 | 137.0 | 138507 | 1.2999 | 19.5222 | 19.9983 |
| 1.0134 | 138.0 | 139518 | 1.2909 | 19.42 | 19.9989 |
| 0.9921 | 139.0 | 140529 | 1.2951 | 19.8604 | 19.9989 |
| 0.9891 | 140.0 | 141540 | 1.2916 | 20.0752 | 19.9989 |
| 0.9896 | 141.0 | 142551 | 1.2910 | 19.7536 | 19.9992 |
| 1.0034 | 142.0 | 143562 | 1.2934 | 20.0064 | 19.9986 |
| 0.9718 | 143.0 | 144573 | 1.2973 | 19.9304 | 19.9989 |
| 1.0141 | 144.0 | 145584 | 1.2940 | 20.5053 | 19.9986 |
| 0.99 | 145.0 | 146595 | 1.2980 | 20.0913 | 19.9975 |
| 0.9729 | 146.0 | 147606 | 1.2927 | 19.7229 | 19.9978 |
| 0.9732 | 147.0 | 148617 | 1.2920 | 20.2104 | 19.9975 |
| 0.9778 | 148.0 | 149628 | 1.2947 | 20.1365 | 19.9981 |
| 0.987 | 149.0 | 150639 | 1.3007 | 20.3436 | 19.9972 |
| 0.987 | 150.0 | 151650 | 1.3003 | 20.2827 | 19.9983 |
| 0.9788 | 151.0 | 152661 | 1.2953 | 20.2941 | 19.9972 |
| 0.9899 | 152.0 | 153672 | 1.2951 | 20.5454 | 19.9978 |
| 0.978 | 153.0 | 154683 | 1.2946 | 20.7448 | 19.9969 |
| 0.9614 | 154.0 | 155694 | 1.2975 | 20.5359 | 19.9969 |
| 0.9759 | 155.0 | 156705 | 1.2925 | 20.3661 | 19.9975 |
| 0.9627 | 156.0 | 157716 | 1.2954 | 20.5535 | 19.9969 |
| 0.9692 | 157.0 | 158727 | 1.2930 | 20.1919 | 19.9969 |
| 0.9737 | 158.0 | 159738 | 1.2922 | 20.484 | 19.9972 |
| 0.9642 | 159.0 | 160749 | 1.2952 | 20.5444 | 19.9975 |
| 0.9679 | 160.0 | 161760 | 1.2930 | 20.3731 | 19.9983 |
| 0.9571 | 161.0 | 162771 | 1.2933 | 20.4158 | 19.9978 |
| 0.9542 | 162.0 | 163782 | 1.2937 | 20.4823 | 19.9978 |
| 0.9537 | 163.0 | 164793 | 1.2997 | 20.6457 | 19.9964 |
| 0.951 | 164.0 | 165804 | 1.2982 | 20.0897 | 19.9986 |
| 0.9556 | 165.0 | 166815 | 1.2944 | 20.45 | 19.9986 |
| 0.9534 | 166.0 | 167826 | 1.2961 | 20.2743 | 19.9967 |
| 0.9381 | 167.0 | 168837 | 1.2922 | 19.8311 | 19.9969 |
| 0.9347 | 168.0 | 169848 | 1.2938 | 19.9427 | 19.9978 |
| 0.9514 | 169.0 | 170859 | 1.2968 | 20.2039 | 19.9983 |
| 0.9439 | 170.0 | 171870 | 1.3014 | 19.9784 | 19.9961 |
| 0.9379 | 171.0 | 172881 | 1.3000 | 20.1213 | 19.9964 |
| 0.9326 | 172.0 | 173892 | 1.2930 | 20.0882 | 19.9969 |
| 0.9178 | 173.0 | 174903 | 1.2942 | 20.1997 | 19.9972 |
| 0.9511 | 174.0 | 175914 | 1.2931 | 20.6471 | 19.9969 |
| 0.9438 | 175.0 | 176925 | 1.2945 | 20.7321 | 19.9983 |
| 0.929 | 176.0 | 177936 | 1.2967 | 20.5813 | 19.9964 |
| 0.9343 | 177.0 | 178947 | 1.2940 | 20.2307 | 19.9978 |
| 0.9344 | 178.0 | 179958 | 1.2949 | 20.2401 | 19.9969 |
| 0.9319 | 179.0 | 180969 | 1.2974 | 19.9881 | 19.9972 |
| 0.9286 | 180.0 | 181980 | 1.2974 | 20.2666 | 19.9961 |
| 0.9074 | 181.0 | 182991 | 1.2939 | 20.2549 | 19.9969 |
| 0.93 | 182.0 | 184002 | 1.2990 | 20.0121 | 19.9969 |
| 0.9303 | 183.0 | 185013 | 1.2944 | 20.056 | 19.9978 |
| 0.9259 | 184.0 | 186024 | 1.3003 | 19.9021 | 19.9953 |
| 0.9014 | 185.0 | 187035 | 1.2962 | 20.0381 | 19.9958 |
| 0.9288 | 186.0 | 188046 | 1.2976 | 20.1909 | 19.9947 |
| 0.9086 | 187.0 | 189057 | 1.2969 | 20.2923 | 19.9969 |
| 0.9183 | 188.0 | 190068 | 1.2941 | 20.1649 | 19.9967 |
| 0.9141 | 189.0 | 191079 | 1.3028 | 20.0891 | 19.9958 |
| 0.9264 | 190.0 | 192090 | 1.2935 | 20.0164 | 19.9958 |
| 0.9307 | 191.0 | 193101 | 1.2956 | 19.8606 | 19.9964 |
| 0.9179 | 192.0 | 194112 | 1.2933 | 19.9815 | 19.9961 |
| 0.9123 | 193.0 | 195123 | 1.2977 | 20.1232 | 19.9953 |
| 0.9221 | 194.0 | 196134 | 1.3014 | 20.0674 | 19.995 |
| 0.9195 | 195.0 | 197145 | 1.3031 | 19.9839 | 19.9944 |
| 0.9139 | 196.0 | 198156 | 1.2947 | 20.0344 | 19.9953 |
| 0.9074 | 197.0 | 199167 | 1.2956 | 20.1076 | 19.9961 |
| 0.9149 | 198.0 | 200178 | 1.2963 | 20.0898 | 19.9955 |
| 0.9219 | 199.0 | 201189 | 1.2990 | 20.171 | 19.9964 |
| 0.8989 | 200.0 | 202200 | 1.2983 | 20.1548 | 19.9961 |
| 0.9004 | 201.0 | 203211 | 1.2977 | 20.2135 | 19.9955 |
| 0.9043 | 202.0 | 204222 | 1.3023 | 20.3024 | 19.9964 |
| 0.917 | 203.0 | 205233 | 1.3014 | 20.5967 | 19.9967 |
| 0.9012 | 204.0 | 206244 | 1.3001 | 20.5489 | 19.9961 |
| 0.9136 | 205.0 | 207255 | 1.2963 | 20.5013 | 19.9969 |
| 0.897 | 206.0 | 208266 | 1.3016 | 20.3285 | 19.9969 |
| 0.9036 | 207.0 | 209277 | 1.2981 | 20.3278 | 19.9967 |
| 0.9225 | 208.0 | 210288 | 1.3055 | 20.4756 | 19.9967 |
| 0.8959 | 209.0 | 211299 | 1.2987 | 20.3112 | 19.9972 |
| 0.903 | 210.0 | 212310 | 1.2977 | 20.5512 | 19.9961 |
| 0.9012 | 211.0 | 213321 | 1.3026 | 20.4304 | 19.9964 |
| 0.8906 | 212.0 | 214332 | 1.2998 | 20.4206 | 19.9967 |
| 0.8906 | 213.0 | 215343 | 1.3031 | 20.4499 | 19.9964 |
| 0.9049 | 214.0 | 216354 | 1.3029 | 20.6908 | 19.9958 |
| 0.9034 | 215.0 | 217365 | 1.2980 | 20.3614 | 19.9969 |
| 0.8971 | 216.0 | 218376 | 1.2985 | 20.6196 | 19.9972 |
| 0.885 | 217.0 | 219387 | 1.3019 | 20.584 | 19.9972 |
| 0.8799 | 218.0 | 220398 | 1.3041 | 20.5843 | 19.9967 |
| 0.8805 | 219.0 | 221409 | 1.3035 | 20.5123 | 19.9972 |
| 0.8896 | 220.0 | 222420 | 1.3006 | 20.7331 | 19.9975 |
| 0.8851 | 221.0 | 223431 | 1.2973 | 20.6914 | 19.9975 |
| 0.893 | 222.0 | 224442 | 1.3004 | 20.7484 | 19.9978 |
| 0.8903 | 223.0 | 225453 | 1.3001 | 20.5207 | 19.9981 |
| 0.8924 | 224.0 | 226464 | 1.3026 | 20.6635 | 19.9972 |
| 0.8839 | 225.0 | 227475 | 1.3056 | 20.6999 | 19.9978 |
| 0.8631 | 226.0 | 228486 | 1.3042 | 20.9581 | 19.9967 |
| 0.8677 | 227.0 | 229497 | 1.3037 | 20.8283 | 19.9964 |
| 0.867 | 228.0 | 230508 | 1.3042 | 20.8781 | 19.9978 |
| 0.8878 | 229.0 | 231519 | 1.3035 | 20.6884 | 19.9981 |
| 0.8805 | 230.0 | 232530 | 1.3092 | 20.716 | 19.9975 |
| 0.8769 | 231.0 | 233541 | 1.2988 | 20.6323 | 19.9975 |
| 0.8833 | 232.0 | 234552 | 1.3039 | 20.5529 | 19.9978 |
| 0.8798 | 233.0 | 235563 | 1.3028 | 20.5848 | 19.9981 |
| 0.8694 | 234.0 | 236574 | 1.3037 | 20.4147 | 19.9983 |
| 0.8888 | 235.0 | 237585 | 1.3022 | 20.5179 | 19.9983 |
| 0.8724 | 236.0 | 238596 | 1.3027 | 20.4379 | 19.9978 |
| 0.8864 | 237.0 | 239607 | 1.3024 | 20.3993 | 19.9972 |
| 0.8684 | 238.0 | 240618 | 1.3043 | 20.5063 | 19.9969 |
| 0.8753 | 239.0 | 241629 | 1.3072 | 20.4079 | 19.9969 |
| 0.8734 | 240.0 | 242640 | 1.3026 | 20.5173 | 19.9967 |
| 0.867 | 241.0 | 243651 | 1.3044 | 20.6249 | 19.9972 |
| 0.8671 | 242.0 | 244662 | 1.3094 | 20.6827 | 19.9972 |
| 0.8721 | 243.0 | 245673 | 1.3045 | 20.5017 | 19.9978 |
| 0.8726 | 244.0 | 246684 | 1.3065 | 20.5748 | 19.9967 |
| 0.8741 | 245.0 | 247695 | 1.3063 | 20.5345 | 19.9972 |
| 0.8634 | 246.0 | 248706 | 1.3036 | 20.6084 | 19.9972 |
| 0.8527 | 247.0 | 249717 | 1.3045 | 20.535 | 19.9972 |
| 0.8662 | 248.0 | 250728 | 1.3089 | 20.5306 | 19.9972 |
| 0.8681 | 249.0 | 251739 | 1.3081 | 20.6414 | 19.9967 |
| 0.8711 | 250.0 | 252750 | 1.3061 | 20.6039 | 19.9975 |
| 0.8653 | 251.0 | 253761 | 1.3018 | 20.5632 | 19.9975 |
| 0.8697 | 252.0 | 254772 | 1.3090 | 20.5056 | 19.9978 |
| 0.8655 | 253.0 | 255783 | 1.3082 | 20.5235 | 19.9978 |
| 0.8636 | 254.0 | 256794 | 1.3067 | 20.5607 | 19.9972 |
| 0.8667 | 255.0 | 257805 | 1.3066 | 20.6694 | 19.9964 |
| 0.8596 | 256.0 | 258816 | 1.3073 | 20.617 | 19.9967 |
| 0.8507 | 257.0 | 259827 | 1.3083 | 20.6035 | 19.9964 |
| 0.8677 | 258.0 | 260838 | 1.3077 | 20.6196 | 19.9975 |
| 0.8614 | 259.0 | 261849 | 1.3094 | 20.6928 | 19.9969 |
| 0.8677 | 260.0 | 262860 | 1.3098 | 20.7181 | 19.9969 |
| 0.8628 | 261.0 | 263871 | 1.3065 | 20.679 | 19.9975 |
| 0.8636 | 262.0 | 264882 | 1.3055 | 20.7476 | 19.9975 |
| 0.8624 | 263.0 | 265893 | 1.3065 | 20.7045 | 19.9972 |
| 0.8594 | 264.0 | 266904 | 1.3093 | 20.5442 | 19.9964 |
| 0.8658 | 265.0 | 267915 | 1.3105 | 20.7153 | 19.9972 |
| 0.8476 | 266.0 | 268926 | 1.3076 | 20.677 | 19.9972 |
| 0.858 | 267.0 | 269937 | 1.3091 | 20.6701 | 19.9969 |
| 0.8707 | 268.0 | 270948 | 1.3111 | 20.5985 | 19.9975 |
| 0.8613 | 269.0 | 271959 | 1.3092 | 20.6108 | 19.9975 |
| 0.8497 | 270.0 | 272970 | 1.3070 | 20.5836 | 19.9964 |
| 0.8654 | 271.0 | 273981 | 1.3082 | 20.5806 | 19.9983 |
| 0.8621 | 272.0 | 274992 | 1.3088 | 20.6817 | 19.9975 |
| 0.8619 | 273.0 | 276003 | 1.3090 | 20.5567 | 19.9975 |
| 0.8638 | 274.0 | 277014 | 1.3087 | 20.6233 | 19.9975 |
| 0.8642 | 275.0 | 278025 | 1.3092 | 20.667 | 19.9967 |
| 0.8498 | 276.0 | 279036 | 1.3069 | 20.6295 | 19.9969 |
| 0.8572 | 277.0 | 280047 | 1.3107 | 20.6376 | 19.9969 |
| 0.8543 | 278.0 | 281058 | 1.3114 | 20.6473 | 19.9964 |
| 0.8453 | 279.0 | 282069 | 1.3105 | 20.6931 | 19.9967 |
| 0.8575 | 280.0 | 283080 | 1.3077 | 20.691 | 19.9972 |
| 0.8492 | 281.0 | 284091 | 1.3101 | 20.7528 | 19.9969 |
| 0.8519 | 282.0 | 285102 | 1.3094 | 20.6812 | 19.9981 |
| 0.8431 | 283.0 | 286113 | 1.3114 | 20.6608 | 19.9969 |
| 0.8546 | 284.0 | 287124 | 1.3093 | 20.6336 | 19.9981 |
| 0.86 | 285.0 | 288135 | 1.3108 | 20.6077 | 19.9967 |
| 0.8674 | 286.0 | 289146 | 1.3096 | 20.6742 | 19.9978 |
| 0.8493 | 287.0 | 290157 | 1.3106 | 20.6674 | 19.9981 |
| 0.8521 | 288.0 | 291168 | 1.3099 | 20.5915 | 19.9981 |
| 0.856 | 289.0 | 292179 | 1.3102 | 20.6448 | 19.9978 |
| 0.8614 | 290.0 | 293190 | 1.3096 | 20.6515 | 19.9981 |
| 0.8628 | 291.0 | 294201 | 1.3108 | 20.6679 | 19.9978 |
| 0.8498 | 292.0 | 295212 | 1.3104 | 20.6623 | 19.9978 |
| 0.8617 | 293.0 | 296223 | 1.3097 | 20.6591 | 19.9978 |
| 0.8563 | 294.0 | 297234 | 1.3098 | 20.6266 | 19.9978 |
| 0.856 | 295.0 | 298245 | 1.3095 | 20.6536 | 19.9978 |
| 0.8493 | 296.0 | 299256 | 1.3095 | 20.6273 | 19.9978 |
| 0.8498 | 297.0 | 300267 | 1.3092 | 20.5942 | 19.9978 |
| 0.8539 | 298.0 | 301278 | 1.3092 | 20.5942 | 19.9978 |
| 0.8608 | 299.0 | 302289 | 1.3091 | 20.5915 | 19.9981 |
| 0.8437 | 300.0 | 303300 | 1.3091 | 20.5964 | 19.9981 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
29thDay/PPO-CartPole-v1 | 29thDay | 2022-08-04T11:17:41Z | 5 | 0 | stable-baselines3 | [
"stable-baselines3",
"CartPole-v1",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-08-03T08:41:13Z | ---
library_name: stable-baselines3
tags:
- CartPole-v1
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
---
# **PPO** Agent playing **CartPole-v1**
This is a trained model of a **PPO** agent playing **CartPole-v1**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
elopezlopez/Bio_ClinicalBERT_fold_10_binary_v1 | elopezlopez | 2022-08-04T11:10:27Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-03T21:03:44Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: Bio_ClinicalBERT_fold_10_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT_fold_10_binary_v1
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5504
- F1: 0.8243
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 288 | 0.3803 | 0.8103 |
| 0.4005 | 2.0 | 576 | 0.4769 | 0.8070 |
| 0.4005 | 3.0 | 864 | 0.5258 | 0.7955 |
| 0.1889 | 4.0 | 1152 | 0.7423 | 0.8153 |
| 0.1889 | 5.0 | 1440 | 1.1246 | 0.8012 |
| 0.0703 | 6.0 | 1728 | 1.1325 | 0.8039 |
| 0.0246 | 7.0 | 2016 | 1.2192 | 0.8196 |
| 0.0246 | 8.0 | 2304 | 1.3645 | 0.8050 |
| 0.0192 | 9.0 | 2592 | 1.4029 | 0.8087 |
| 0.0192 | 10.0 | 2880 | 1.3714 | 0.8117 |
| 0.0107 | 11.0 | 3168 | 1.4673 | 0.8092 |
| 0.0107 | 12.0 | 3456 | 1.3941 | 0.8199 |
| 0.0084 | 13.0 | 3744 | 1.4350 | 0.8126 |
| 0.0083 | 14.0 | 4032 | 1.4428 | 0.8162 |
| 0.0083 | 15.0 | 4320 | 1.2892 | 0.8263 |
| 0.0119 | 16.0 | 4608 | 1.4238 | 0.8222 |
| 0.0119 | 17.0 | 4896 | 1.4961 | 0.8174 |
| 0.0046 | 18.0 | 5184 | 1.5010 | 0.8107 |
| 0.0046 | 19.0 | 5472 | 1.4876 | 0.8215 |
| 0.0036 | 20.0 | 5760 | 1.5080 | 0.8180 |
| 0.0031 | 21.0 | 6048 | 1.5317 | 0.8261 |
| 0.0031 | 22.0 | 6336 | 1.5103 | 0.8215 |
| 0.0005 | 23.0 | 6624 | 1.5255 | 0.8197 |
| 0.0005 | 24.0 | 6912 | 1.5578 | 0.8257 |
| 0.0001 | 25.0 | 7200 | 1.5504 | 0.8243 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
yochen/distilroberta-base-finetuned-marktextepoch_200 | yochen | 2022-08-04T10:31:19Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-04T07:42:55Z | ---
tags:
- generated_from_trainer
model-index:
- name: distilroberta-base-finetuned-marktextepoch_200
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-finetuned-marktextepoch_200
This model was trained from scratch on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 200
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu102
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Saraswati/Reinforce-CartPole-v1 | Saraswati | 2022-08-04T09:09:12Z | 0 | 0 | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-08-03T12:03:32Z | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- metrics:
- type: mean_reward
value: 8.30 +/- 4.96
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
elopezlopez/Bio_ClinicalBERT_fold_4_binary_v1 | elopezlopez | 2022-08-04T08:55:35Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-03T18:29:31Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: Bio_ClinicalBERT_fold_4_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT_fold_4_binary_v1
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4627
- F1: 0.8342
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 289 | 0.3641 | 0.8394 |
| 0.3953 | 2.0 | 578 | 0.3729 | 0.8294 |
| 0.3953 | 3.0 | 867 | 0.6156 | 0.8126 |
| 0.189 | 4.0 | 1156 | 0.7389 | 0.8326 |
| 0.189 | 5.0 | 1445 | 0.8925 | 0.8322 |
| 0.0783 | 6.0 | 1734 | 1.0909 | 0.8196 |
| 0.0219 | 7.0 | 2023 | 1.1241 | 0.8346 |
| 0.0219 | 8.0 | 2312 | 1.2684 | 0.8130 |
| 0.0136 | 9.0 | 2601 | 1.2615 | 0.8202 |
| 0.0136 | 10.0 | 2890 | 1.2477 | 0.8401 |
| 0.0143 | 11.0 | 3179 | 1.3211 | 0.8254 |
| 0.0143 | 12.0 | 3468 | 1.2627 | 0.8286 |
| 0.0165 | 13.0 | 3757 | 1.3804 | 0.8264 |
| 0.006 | 14.0 | 4046 | 1.3213 | 0.8414 |
| 0.006 | 15.0 | 4335 | 1.3152 | 0.8427 |
| 0.0117 | 16.0 | 4624 | 1.3373 | 0.8368 |
| 0.0117 | 17.0 | 4913 | 1.3599 | 0.8406 |
| 0.0021 | 18.0 | 5202 | 1.4072 | 0.8237 |
| 0.0021 | 19.0 | 5491 | 1.3893 | 0.8336 |
| 0.0045 | 20.0 | 5780 | 1.4331 | 0.8391 |
| 0.0049 | 21.0 | 6069 | 1.4128 | 0.8370 |
| 0.0049 | 22.0 | 6358 | 1.4660 | 0.8356 |
| 0.0029 | 23.0 | 6647 | 1.4721 | 0.8388 |
| 0.0029 | 24.0 | 6936 | 1.4636 | 0.8329 |
| 0.0023 | 25.0 | 7225 | 1.4627 | 0.8342 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
neuralmagic/mobilebert-uncased-finetuned-squadv1 | neuralmagic | 2022-08-04T08:53:36Z | 13 | 1 | transformers | [
"transformers",
"pytorch",
"mobilebert",
"question-answering",
"bert",
"oBERT",
"en",
"dataset:squad",
"arxiv:2203.07259",
"endpoints_compatible",
"region:us"
]
| question-answering | 2022-07-31T19:12:10Z | ---
tags:
- bert
- mobilebert
- oBERT
language: en
datasets: squad
---
# mobilebert-uncased-finetuned-squadv1
This model is a finetuned version of the [mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased/tree/main) model on the SQuADv1 task.
To make this TPU-trained model stable when used in PyTorch on GPUs, the original model has been additionally pretrained for one epoch on BookCorpus and English Wikipedia with disabled dropout before finetuning on the SQuADv1 task.
It is produced as part of the work on the paper [The Optimal BERT Surgeon: Scalable and Accurate Second-Order Pruning for Large Language Models](https://arxiv.org/abs/2203.07259).
SQuADv1 dev-set:
```
EM = 83.96
F1 = 90.90
```
Code: [https://github.com/neuralmagic/sparseml/tree/main/research/optimal_BERT_surgeon_oBERT](https://github.com/neuralmagic/sparseml/tree/main/research/optimal_BERT_surgeon_oBERT)
If you find the model useful, please consider citing our work.
## Citation info
```bibtex
@article{kurtic2022optimal,
title={The Optimal BERT Surgeon: Scalable and Accurate Second-Order Pruning for Large Language Models},
author={Kurtic, Eldar and Campos, Daniel and Nguyen, Tuan and Frantar, Elias and Kurtz, Mark and Fineran, Benjamin and Goin, Michael and Alistarh, Dan},
journal={arXiv preprint arXiv:2203.07259},
year={2022}
}
```
|
BlackKakapo/t5-base-paraphrase-ro | BlackKakapo | 2022-08-04T08:40:41Z | 11 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"ro",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-08-04T08:27:22Z | ---
annotations_creators: []
language:
- ro
language_creators:
- machine-generated
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: BlackKakapo/t5-base-paraphrase-ro
size_categories:
- 10K<n<100K
source_datasets:
- original
tags: []
task_categories:
- text2text-generation
task_ids: []
---
# Romanian paraphrase

Fine-tune t5-base model for paraphrase. Since there is no Romanian dataset for paraphrasing, I had to create my own [dataset](https://huggingface.co/datasets/BlackKakapo/paraphrase-ro-v1). The dataset contains ~60k examples.
### How to use
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("BlackKakapo/t5-base-paraphrase-ro")
model = AutoModelForSeq2SeqLM.from_pretrained("BlackKakapo/t5-base-paraphrase-ro")
```
### Or
```python
from transformers import T5ForConditionalGeneration, T5TokenizerFast
model = T5ForConditionalGeneration.from_pretrained("BlackKakapo/t5-base-paraphrase-ro")
tokenizer = T5TokenizerFast.from_pretrained("BlackKakapo/t5-base-paraphrase-ro")
```
### Generate
```python
text = "Am impresia că fac multe greșeli."
encoding = tokenizer.encode_plus(text, pad_to_max_length=True, return_tensors="pt")
input_ids, attention_masks = encoding["input_ids"].to(device), encoding["attention_mask"].to(device)
beam_outputs = model.generate(
input_ids=input_ids,
attention_mask=attention_masks,
do_sample=True,
max_length=256,
top_k=10,
top_p=0.9,
early_stopping=False,
num_return_sequences=5
)
for beam_output in beam_outputs:
text_para = tokenizer.decode(beam_output, skip_special_tokens=True,clean_up_tokenization_spaces=True)
if text.lower() != text_para.lower() or text not in final_outputs:
final_outputs.append(text_para)
break
print(final_outputs)
```
### Output
```out
['Cred că fac multe greșeli.']
``` |
elopezlopez/Bio_ClinicalBERT_fold_3_binary_v1 | elopezlopez | 2022-08-04T08:33:05Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-03T18:03:57Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: Bio_ClinicalBERT_fold_3_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT_fold_3_binary_v1
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8860
- F1: 0.8051
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 289 | 0.4493 | 0.7916 |
| 0.3975 | 2.0 | 578 | 0.4608 | 0.7909 |
| 0.3975 | 3.0 | 867 | 0.8364 | 0.7726 |
| 0.1885 | 4.0 | 1156 | 1.0380 | 0.7902 |
| 0.1885 | 5.0 | 1445 | 1.1612 | 0.7921 |
| 0.0692 | 6.0 | 1734 | 1.3894 | 0.7761 |
| 0.0295 | 7.0 | 2023 | 1.3730 | 0.7864 |
| 0.0295 | 8.0 | 2312 | 1.4131 | 0.7939 |
| 0.0161 | 9.0 | 2601 | 1.5538 | 0.7929 |
| 0.0161 | 10.0 | 2890 | 1.6417 | 0.7931 |
| 0.006 | 11.0 | 3179 | 1.5745 | 0.7974 |
| 0.006 | 12.0 | 3468 | 1.7212 | 0.7908 |
| 0.0132 | 13.0 | 3757 | 1.7349 | 0.7945 |
| 0.0062 | 14.0 | 4046 | 1.7593 | 0.7908 |
| 0.0062 | 15.0 | 4335 | 1.7420 | 0.8035 |
| 0.0073 | 16.0 | 4624 | 1.7620 | 0.8007 |
| 0.0073 | 17.0 | 4913 | 1.8286 | 0.7908 |
| 0.0033 | 18.0 | 5202 | 1.7863 | 0.7977 |
| 0.0033 | 19.0 | 5491 | 1.9275 | 0.7919 |
| 0.0035 | 20.0 | 5780 | 1.8481 | 0.8042 |
| 0.0035 | 21.0 | 6069 | 1.9465 | 0.8012 |
| 0.0035 | 22.0 | 6358 | 1.8177 | 0.8044 |
| 0.005 | 23.0 | 6647 | 1.8615 | 0.8030 |
| 0.005 | 24.0 | 6936 | 1.8427 | 0.8054 |
| 0.0011 | 25.0 | 7225 | 1.8860 | 0.8051 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
elopezlopez/Bio_ClinicalBERT_fold_2_binary_v1 | elopezlopez | 2022-08-04T08:10:50Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-03T17:38:02Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: Bio_ClinicalBERT_fold_2_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT_fold_2_binary_v1
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9317
- F1: 0.7921
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 290 | 0.4221 | 0.7856 |
| 0.4062 | 2.0 | 580 | 0.5184 | 0.7949 |
| 0.4062 | 3.0 | 870 | 0.6854 | 0.7840 |
| 0.1775 | 4.0 | 1160 | 0.9834 | 0.7840 |
| 0.1775 | 5.0 | 1450 | 1.3223 | 0.7804 |
| 0.0697 | 6.0 | 1740 | 1.2896 | 0.7923 |
| 0.0265 | 7.0 | 2030 | 1.4620 | 0.7914 |
| 0.0265 | 8.0 | 2320 | 1.5554 | 0.7835 |
| 0.0102 | 9.0 | 2610 | 1.7009 | 0.7880 |
| 0.0102 | 10.0 | 2900 | 1.6163 | 0.7923 |
| 0.015 | 11.0 | 3190 | 1.6851 | 0.7841 |
| 0.015 | 12.0 | 3480 | 1.7493 | 0.7901 |
| 0.0141 | 13.0 | 3770 | 1.8819 | 0.7827 |
| 0.0133 | 14.0 | 4060 | 1.7535 | 0.7939 |
| 0.0133 | 15.0 | 4350 | 1.6613 | 0.7966 |
| 0.0067 | 16.0 | 4640 | 1.6807 | 0.7999 |
| 0.0067 | 17.0 | 4930 | 1.6703 | 0.7978 |
| 0.0053 | 18.0 | 5220 | 1.7309 | 0.8013 |
| 0.0037 | 19.0 | 5510 | 1.8058 | 0.7942 |
| 0.0037 | 20.0 | 5800 | 1.8233 | 0.7916 |
| 0.0023 | 21.0 | 6090 | 1.8206 | 0.7913 |
| 0.0023 | 22.0 | 6380 | 1.8466 | 0.7949 |
| 0.0012 | 23.0 | 6670 | 1.8531 | 0.7985 |
| 0.0012 | 24.0 | 6960 | 1.9211 | 0.7944 |
| 0.0001 | 25.0 | 7250 | 1.9317 | 0.7921 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
radi-cho/poetry-bg | radi-cho | 2022-08-04T08:08:34Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"torch",
"custom_code",
"bg",
"dataset:chitanka",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2022-06-29T10:10:17Z | ---
license: apache-2.0
language:
- bg
datasets:
- chitanka
tags:
- torch
inference: false
---
# Bulgarian language poetry generation
Pretrained model using causal language modeling (CLM) objective based on [GPT-2](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf). <br/>
Developed by [Radostin Cholakov](https://www.linkedin.com/in/radostin-cholakov-bb4422146/) as a part of the [AzBuki.ML](https://azbuki-ml.com) initiatives.
# How to use?
```python
>>> from transformers import AutoModel, AutoTokenizer
>>>
>>> model_id = "radi-cho/poetry-bg"
>>> tokenizer = AutoTokenizer.from_pretrained(model_id)
>>> model = AutoModel.from_pretrained(model_id, trust_remote_code=True)
>>>
>>> input_ids = tokenizer.encode(
>>> "[HED]Суетата на живота[NEL][BDY]",
>>> add_special_tokens=False,
>>> return_tensors='pt')
>>>
>>> output_ids = model.generate(
>>> input_ids,
>>> do_sample=True,
>>> max_length=250,
>>> top_p=0.98,
>>> top_k=0,
>>> pad_token_id=2,
>>> eos_token_id=50258)
>>>
>>> output = tokenizer.decode(output_ids[0])
>>>
>>> output = output.replace('[NEL]', '\n')
>>> output = output.replace('[BDY]', '\n')
>>> output = output.replace('[HED]', '')
>>> output = output.replace('[SEP]', '')
>>>
>>> print(output)
Суетата на живота
Да страдам ли?
Да страдам ли за това?
Не, не за това, че умирам...
Но само за това,
че миговете ми са рани.
Аз съм сам и търся утеха.
```
# Custom Tokens
We introduced 3 custom tokens in the tokenizer - `[NEL]`, `[BDY]`, `[HED]`
- `[HED]` denotes where the title of the poem begins;
- `[BDY]` denotes where the body of the poem begins;
- `[NEL]` marks the end of a verse and should be decoded as a new line;
`[SEP]` (with id 50258) is the *end of sequence* token.
# Credits
- Inspired by [rmihaylov/gpt2-medium-bg](https://huggingface.co/rmihaylov/gpt2-medium-bg).
- Data: [https://chitanka.info/texts/type/poetry](https://chitanka.info/texts/type/poetry); |
FluxML/densenet121 | FluxML | 2022-08-04T06:39:56Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-08-04T06:12:25Z | ---
license: mit
---
DenseNet121 model ported from [torchvision](https://pytorch.org/vision/stable/index.html) for use with [Metalhead.jl](https://github.com/FluxML/Metalhead.jl). The scripts for creating this file can be found at [this gist](https://gist.github.com/darsnack/bfb8594cf5fdc702bdacb66586f518ef).
To use this model in Julia, [add the Metalhead.jl package to your environment](https://pkgdocs.julialang.org/v1/managing-packages/#Adding-packages). Then execute:
```julia
using Metalhead
model = DenseNet(121; pretrain = true)
``` |
FluxML/densenet161 | FluxML | 2022-08-04T06:39:41Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-08-04T06:16:19Z | ---
license: mit
---
DenseNet161 model ported from [torchvision](https://pytorch.org/vision/stable/index.html) for use with [Metalhead.jl](https://github.com/FluxML/Metalhead.jl). The scripts for creating this file can be found at [this gist](https://gist.github.com/darsnack/bfb8594cf5fdc702bdacb66586f518ef).
To use this model in Julia, [add the Metalhead.jl package to your environment](https://pkgdocs.julialang.org/v1/managing-packages/#Adding-packages). Then execute:
```julia
using Metalhead
model = DenseNet(161; pretrain = true)
``` |
FluxML/densenet169 | FluxML | 2022-08-04T06:39:26Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-08-04T06:20:00Z | ---
license: mit
---
DenseNet169 model ported from [torchvision](https://pytorch.org/vision/stable/index.html) for use with [Metalhead.jl](https://github.com/FluxML/Metalhead.jl). The scripts for creating this file can be found at [this gist](https://gist.github.com/darsnack/bfb8594cf5fdc702bdacb66586f518ef).
To use this model in Julia, [add the Metalhead.jl package to your environment](https://pkgdocs.julialang.org/v1/managing-packages/#Adding-packages). Then execute:
```julia
using Metalhead
model = DenseNet(169; pretrain = true)
``` |
bash1130/bert-base-finetuned-ynat | bash1130 | 2022-08-04T06:19:20Z | 20 | 1 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:klue",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-03T19:50:38Z | ---
tags:
- generated_from_trainer
datasets:
- klue
metrics:
- f1
model-index:
- name: bert-base-finetuned-ynat
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: klue
type: klue
config: ynat
split: train
args: ynat
metrics:
- name: F1
type: f1
value: 0.871180664370084
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-finetuned-ynat
This model is a fine-tuned version of [klue/bert-base](https://huggingface.co/klue/bert-base) on the klue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3609
- F1: 0.8712
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 179 | 0.3979 | 0.8611 |
| No log | 2.0 | 358 | 0.3773 | 0.8669 |
| 0.3007 | 3.0 | 537 | 0.3609 | 0.8712 |
| 0.3007 | 4.0 | 716 | 0.3708 | 0.8708 |
| 0.3007 | 5.0 | 895 | 0.3720 | 0.8697 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
kuberpmu/distilbert-base-cased-distilled-squad-finetuned-squad | kuberpmu | 2022-08-04T05:44:45Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2_yash",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| question-answering | 2022-08-04T05:20:11Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2_yash
model-index:
- name: distilbert-base-cased-distilled-squad-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-cased-distilled-squad-finetuned-squad
This model is a fine-tuned version of [distilbert-base-cased-distilled-squad](https://huggingface.co/distilbert-base-cased-distilled-squad) on the squad_v2_yash dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0088
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 198 | 0.5409 |
| No log | 2.0 | 396 | 0.3048 |
| 0.9541 | 3.0 | 594 | 0.1764 |
| 0.9541 | 4.0 | 792 | 0.1117 |
| 0.9541 | 5.0 | 990 | 0.0634 |
| 0.3052 | 6.0 | 1188 | 0.0345 |
| 0.3052 | 7.0 | 1386 | 0.0229 |
| 0.1129 | 8.0 | 1584 | 0.0152 |
| 0.1129 | 9.0 | 1782 | 0.0101 |
| 0.1129 | 10.0 | 1980 | 0.0088 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
keepitreal/mini-phobert-v2 | keepitreal | 2022-08-04T04:42:30Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-08-03T20:07:20Z | ---
tags:
- generated_from_trainer
model-index:
- name: mini-phobert-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mini-phobert-v2
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 6.3293
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
RayS2022/dqn-SpaceInvadersNoFrameskip-v4 | RayS2022 | 2022-08-04T03:16:30Z | 7 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-08-04T03:16:11Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 138.50 +/- 87.49
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga RayS2022 -f logs/
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga RayS2022
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 10000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
jjjjjjjjjj/q-FrozenLake-v1-4x4-noSlippery | jjjjjjjjjj | 2022-08-04T03:15:05Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-08-04T03:13:43Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="jjjjjjjjjj/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
yashwantk/distilbert-base-cased-distilled-squad-finetuned-squad | yashwantk | 2022-08-04T02:42:07Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2_yash",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| question-answering | 2022-08-02T10:29:22Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2_yash
model-index:
- name: distilbert-base-cased-distilled-squad-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-cased-distilled-squad-finetuned-squad
This model is a fine-tuned version of [distilbert-base-cased-distilled-squad](https://huggingface.co/distilbert-base-cased-distilled-squad) on the squad_v2_yash dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 198 | 0.7576 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
canIjoin/datafun | canIjoin | 2022-08-04T02:29:03Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"zh",
"arxiv:1810.04805",
"arxiv:1907.11692",
"arxiv:2001.04351",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-08-03T13:10:26Z | ---
language: zh
widget:
- text: "江苏警方通报特斯拉冲进店铺"
---
# Chinese RoBERTa-Base Model for NER
## Model description
The model is used for named entity recognition. You can download the model either from the [UER-py Modelzoo page](https://github.com/dbiir/UER-py/wiki/Modelzoo) (in UER-py format), or via HuggingFace from the link [roberta-base-finetuned-cluener2020-chinese](https://huggingface.co/uer/roberta-base-finetuned-cluener2020-chinese).
## How to use
You can use this model directly with a pipeline for token classification :
```python
>>> from transformers import AutoModelForTokenClassification,AutoTokenizer,pipeline
>>> model = AutoModelForTokenClassification.from_pretrained('uer/roberta-base-finetuned-cluener2020-chinese')
>>> tokenizer = AutoTokenizer.from_pretrained('uer/roberta-base-finetuned-cluener2020-chinese')
>>> ner = pipeline('ner', model=model, tokenizer=tokenizer)
>>> ner("江苏警方通报特斯拉冲进店铺")
[
{'word': '江', 'score': 0.49153077602386475, 'entity': 'B-address', 'index': 1, 'start': 0, 'end': 1},
{'word': '苏', 'score': 0.6319217681884766, 'entity': 'I-address', 'index': 2, 'start': 1, 'end': 2},
{'word': '特', 'score': 0.5912262797355652, 'entity': 'B-company', 'index': 7, 'start': 6, 'end': 7},
{'word': '斯', 'score': 0.69145667552948, 'entity': 'I-company', 'index': 8, 'start': 7, 'end': 8},
{'word': '拉', 'score': 0.7054660320281982, 'entity': 'I-company', 'index': 9, 'start': 8, 'end': 9}
]
```
## Training data
[CLUENER2020](https://github.com/CLUEbenchmark/CLUENER2020) is used as training data. We only use the train set of the dataset.
## Training procedure
The model is fine-tuned by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We fine-tune five epochs with a sequence length of 512 on the basis of the pre-trained model [chinese_roberta_L-12_H-768](https://huggingface.co/uer/chinese_roberta_L-12_H-768). At the end of each epoch, the model is saved when the best performance on development set is achieved.
```
python3 run_ner.py --pretrained_model_path models/cluecorpussmall_roberta_base_seq512_model.bin-250000 \
--vocab_path models/google_zh_vocab.txt \
--train_path datasets/cluener2020/train.tsv \
--dev_path datasets/cluener2020/dev.tsv \
--label2id_path datasets/cluener2020/label2id.json \
--output_model_path models/cluener2020_ner_model.bin \
--learning_rate 3e-5 --epochs_num 5 --batch_size 32 --seq_length 512
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_bert_token_classification_from_uer_to_huggingface.py --input_model_path models/cluener2020_ner_model.bin \
--output_model_path pytorch_model.bin \
--layers_num 12
```
### BibTeX entry and citation info
```
@article{devlin2018bert,
title={BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding},
author={Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1810.04805},
year={2018}
}
@article{liu2019roberta,
title={Roberta: A robustly optimized bert pretraining approach},
author={Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin},
journal={arXiv preprint arXiv:1907.11692},
year={2019}
}
@article{xu2020cluener2020,
title={CLUENER2020: Fine-grained Name Entity Recognition for Chinese},
author={Xu, Liang and Dong, Qianqian and Yu, Cong and Tian, Yin and Liu, Weitang and Li, Lu and Zhang, Xuanwei},
journal={arXiv preprint arXiv:2001.04351},
year={2020}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
``` |
Mateopablo/Futur | Mateopablo | 2022-08-04T02:27:52Z | 0 | 0 | null | [
"region:us"
]
| null | 2022-08-04T02:26:46Z | Mateo Martínez, argentinian
license: afl-3.0
---
|
jerryw/my_bert-base-cased | jerryw | 2022-08-04T01:38:04Z | 5 | 0 | transformers | [
"transformers",
"tf",
"bert",
"fill-mask",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-08-04T01:34:19Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: my_bert-base-cased
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# my_bert-base-cased
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.9.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
huggingtweets/elonmusk-srinithyananda | huggingtweets | 2022-08-03T22:27:35Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-08-03T22:27:29Z | ---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1529956155937759233/Nyn1HZWF_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1157286539036020737/5TQyrkEw_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Elon Musk & KAILASA's SPH Nithyananda</div>
<div style="text-align: center; font-size: 14px;">@elonmusk-srinithyananda</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Elon Musk & KAILASA's SPH Nithyananda.
| Data | Elon Musk | KAILASA's SPH Nithyananda |
| --- | --- | --- |
| Tweets downloaded | 3200 | 3250 |
| Retweets | 128 | 6 |
| Short tweets | 982 | 523 |
| Tweets kept | 2090 | 2721 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2y3fe7dn/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @elonmusk-srinithyananda's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/gywjziih) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/gywjziih/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/elonmusk-srinithyananda')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
NX2411/wav2vec2-large-xlsr-korean-demo-colab-2 | NX2411 | 2022-08-03T21:18:26Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-07-31T18:12:10Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-large-xlsr-korean-demo-colab-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-korean-demo-colab-2
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2481
- Wer: 0.2480
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.7387 | 2.12 | 400 | 3.1791 | 1.0 |
| 1.3766 | 4.23 | 800 | 0.4876 | 0.5264 |
| 0.476 | 6.35 | 1200 | 0.2955 | 0.3648 |
| 0.3209 | 8.46 | 1600 | 0.2926 | 0.3473 |
| 0.2591 | 10.58 | 2000 | 0.2723 | 0.3094 |
| 0.2055 | 12.7 | 2400 | 0.2746 | 0.3027 |
| 0.1802 | 14.81 | 2800 | 0.2672 | 0.2976 |
| 0.1552 | 16.93 | 3200 | 0.2822 | 0.2807 |
| 0.1413 | 19.05 | 3600 | 0.2652 | 0.2856 |
| 0.1232 | 21.16 | 4000 | 0.2631 | 0.2655 |
| 0.1146 | 23.28 | 4400 | 0.2561 | 0.2574 |
| 0.1086 | 25.4 | 4800 | 0.2461 | 0.2527 |
| 0.0944 | 27.51 | 5200 | 0.2521 | 0.2535 |
| 0.0881 | 29.63 | 5600 | 0.2481 | 0.2480 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
andrewzhang505/sample-factory-2-doom-battle | andrewzhang505 | 2022-08-03T20:49:22Z | 7 | 0 | sample-factory | [
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-07-29T16:53:16Z | ---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- metrics:
- type: mean_reward
value: 56.20 +/- 6.72
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_battle
type: doom_battle
---
A(n) **APPO** model trained on the **doom_battle** environment.
This model was trained using Sample Factory 2.0: https://github.com/alex-petrenko/sample-factory
|
allegro/plt5-small | allegro | 2022-08-03T20:20:31Z | 262 | 2 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"T5",
"translation",
"summarization",
"question answering",
"reading comprehension",
"pl",
"arxiv:2205.08808",
"license:cc-by-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| translation | 2022-03-02T23:29:05Z | ---
language: pl
tags:
- T5
- translation
- summarization
- question answering
- reading comprehension
datasets:
- ccnet
- nkjp
- wikipedia
- open subtitles
- free readings
license: cc-by-4.0
---
# plT5 Small
**plT5** models are T5-based language models trained on Polish corpora. The models were optimized for the original T5 denoising target.
## Corpus
plT5 was trained on six different corpora available for Polish language:
| Corpus | Tokens | Documents |
| :------ | ------: | ------: |
| [CCNet Middle](https://github.com/facebookresearch/cc_net) | 3243M | 7.9M |
| [CCNet Head](https://github.com/facebookresearch/cc_net) | 2641M | 7.0M |
| [National Corpus of Polish](http://nkjp.pl/index.php?page=14&lang=1)| 1357M | 3.9M |
| [Open Subtitles](http://opus.nlpl.eu/OpenSubtitles-v2018.php) | 1056M | 1.1M
| [Wikipedia](https://dumps.wikimedia.org/) | 260M | 1.4M |
| [Wolne Lektury](https://wolnelektury.pl/) | 41M | 5.5k |
## Tokenizer
The training dataset was tokenized into subwords using a sentencepiece unigram model with
vocabulary size of 50k tokens.
## Usage
Example code:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("allegro/plt5-small")
model = AutoModel.from_pretrained("allegro/plt5-small")
```
## License
CC BY 4.0
## Citation
If you use this model, please cite the following paper:
```
@article{chrabrowa2022evaluation,
title={Evaluation of Transfer Learning for Polish with a Text-to-Text Model},
author={Chrabrowa, Aleksandra and Dragan, {\L}ukasz and Grzegorczyk, Karol and Kajtoch, Dariusz and Koszowski, Miko{\l}aj and Mroczkowski, Robert and Rybak, Piotr},
journal={arXiv preprint arXiv:2205.08808},
year={2022}
}
```
## Authors
The model was trained by [**Machine Learning Research Team at Allegro**](https://ml.allegro.tech/) and [**Linguistic Engineering Group at Institute of Computer Science, Polish Academy of Sciences**](http://zil.ipipan.waw.pl/).
You can contact us at: <a href="mailto:[email protected]">[email protected]</a> |
allegro/plt5-large | allegro | 2022-08-03T20:20:09Z | 2,442 | 5 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"T5",
"translation",
"summarization",
"question answering",
"reading comprehension",
"pl",
"arxiv:2205.08808",
"license:cc-by-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| translation | 2022-03-02T23:29:05Z | ---
language: pl
tags:
- T5
- translation
- summarization
- question answering
- reading comprehension
datasets:
- ccnet
- nkjp
- wikipedia
- open subtitles
- free readings
license: cc-by-4.0
---
# plT5 Large
**plT5** models are T5-based language models trained on Polish corpora. The models were optimized for the original T5 denoising target.
## Corpus
plT5 was trained on six different corpora available for Polish language:
| Corpus | Tokens | Documents |
| :------ | ------: | ------: |
| [CCNet Middle](https://github.com/facebookresearch/cc_net) | 3243M | 7.9M |
| [CCNet Head](https://github.com/facebookresearch/cc_net) | 2641M | 7.0M |
| [National Corpus of Polish](http://nkjp.pl/index.php?page=14&lang=1)| 1357M | 3.9M |
| [Open Subtitles](http://opus.nlpl.eu/OpenSubtitles-v2018.php) | 1056M | 1.1M
| [Wikipedia](https://dumps.wikimedia.org/) | 260M | 1.4M |
| [Wolne Lektury](https://wolnelektury.pl/) | 41M | 5.5k |
## Tokenizer
The training dataset was tokenized into subwords using a sentencepiece unigram model with
vocabulary size of 50k tokens.
## Usage
Example code:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("allegro/plt5-large")
model = AutoModel.from_pretrained("allegro/plt5-large")
```
## License
CC BY 4.0
## Citation
If you use this model, please cite the following paper:
```
@article{chrabrowa2022evaluation,
title={Evaluation of Transfer Learning for Polish with a Text-to-Text Model},
author={Chrabrowa, Aleksandra and Dragan, {\L}ukasz and Grzegorczyk, Karol and Kajtoch, Dariusz and Koszowski, Miko{\l}aj and Mroczkowski, Robert and Rybak, Piotr},
journal={arXiv preprint arXiv:2205.08808},
year={2022}
}
```
## Authors
The model was trained by [**Machine Learning Research Team at Allegro**](https://ml.allegro.tech/) and [**Linguistic Engineering Group at Institute of Computer Science, Polish Academy of Sciences**](http://zil.ipipan.waw.pl/).
You can contact us at: <a href="mailto:[email protected]">[email protected]</a> |
SharpAI/mal-tls-bert-base-relu-w1q8 | SharpAI | 2022-08-03T19:37:51Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-03T19:37:23Z | ---
tags:
- generated_from_keras_callback
model-index:
- name: mal_tls-bert-base-relu-w1q8
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mal_tls-bert-base-relu-w1q8
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.15.0
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.10.3
|
BenWord/autotrain-APMv2Multiclass-1216046004 | BenWord | 2022-08-03T18:06:06Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain",
"en",
"dataset:BenWord/autotrain-data-APMv2Multiclass",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-03T18:03:06Z | ---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- BenWord/autotrain-data-APMv2Multiclass
co2_eq_emissions:
emissions: 2.4364900803769225
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1216046004
- CO2 Emissions (in grams): 2.4365
## Validation Metrics
- Loss: 0.094
- Accuracy: 1.000
- Macro F1: 1.000
- Micro F1: 1.000
- Weighted F1: 1.000
- Macro Precision: 1.000
- Micro Precision: 1.000
- Weighted Precision: 1.000
- Macro Recall: 1.000
- Micro Recall: 1.000
- Weighted Recall: 1.000
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/BenWord/autotrain-APMv2Multiclass-1216046004
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("BenWord/autotrain-APMv2Multiclass-1216046004", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("BenWord/autotrain-APMv2Multiclass-1216046004", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
``` |
MayaGalvez/bert-base-multilingual-cased-finetuned-nli | MayaGalvez | 2022-08-03T16:48:33Z | 18 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:xnli",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-03T11:58:59Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- xnli
metrics:
- accuracy
model-index:
- name: bert-base-multilingual-cased-finetuned-nli
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: xnli
type: xnli
config: en
split: train
args: en
metrics:
- name: Accuracy
type: accuracy
value: 0.8156626506024096
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-multilingual-cased-finetuned-nli
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the xnli dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4681
- Accuracy: 0.8157
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.9299 | 0.02 | 200 | 0.8468 | 0.6277 |
| 0.7967 | 0.03 | 400 | 0.7425 | 0.6855 |
| 0.7497 | 0.05 | 600 | 0.7116 | 0.6924 |
| 0.7083 | 0.07 | 800 | 0.6868 | 0.7153 |
| 0.6882 | 0.08 | 1000 | 0.6638 | 0.7289 |
| 0.6944 | 0.1 | 1200 | 0.6476 | 0.7361 |
| 0.6682 | 0.11 | 1400 | 0.6364 | 0.7458 |
| 0.6635 | 0.13 | 1600 | 0.6592 | 0.7337 |
| 0.6423 | 0.15 | 1800 | 0.6120 | 0.7510 |
| 0.6196 | 0.16 | 2000 | 0.5990 | 0.7582 |
| 0.6381 | 0.18 | 2200 | 0.6026 | 0.7538 |
| 0.6276 | 0.2 | 2400 | 0.6054 | 0.7598 |
| 0.6248 | 0.21 | 2600 | 0.6368 | 0.7526 |
| 0.6331 | 0.23 | 2800 | 0.5959 | 0.7655 |
| 0.6142 | 0.24 | 3000 | 0.6117 | 0.7554 |
| 0.6124 | 0.26 | 3200 | 0.6221 | 0.7570 |
| 0.6127 | 0.28 | 3400 | 0.5748 | 0.7695 |
| 0.602 | 0.29 | 3600 | 0.5735 | 0.7598 |
| 0.5923 | 0.31 | 3800 | 0.5609 | 0.7723 |
| 0.5827 | 0.33 | 4000 | 0.5635 | 0.7743 |
| 0.5732 | 0.34 | 4200 | 0.5547 | 0.7771 |
| 0.5757 | 0.36 | 4400 | 0.5629 | 0.7739 |
| 0.5736 | 0.37 | 4600 | 0.5680 | 0.7659 |
| 0.5642 | 0.39 | 4800 | 0.5437 | 0.7871 |
| 0.5763 | 0.41 | 5000 | 0.5589 | 0.7807 |
| 0.5713 | 0.42 | 5200 | 0.5355 | 0.7867 |
| 0.5644 | 0.44 | 5400 | 0.5346 | 0.7888 |
| 0.5727 | 0.46 | 5600 | 0.5519 | 0.7815 |
| 0.5539 | 0.47 | 5800 | 0.5219 | 0.7900 |
| 0.5516 | 0.49 | 6000 | 0.5560 | 0.7795 |
| 0.5539 | 0.51 | 6200 | 0.5544 | 0.7847 |
| 0.5693 | 0.52 | 6400 | 0.5322 | 0.7932 |
| 0.5632 | 0.54 | 6600 | 0.5404 | 0.7936 |
| 0.565 | 0.55 | 6800 | 0.5382 | 0.7880 |
| 0.5555 | 0.57 | 7000 | 0.5364 | 0.7920 |
| 0.5329 | 0.59 | 7200 | 0.5177 | 0.7964 |
| 0.54 | 0.6 | 7400 | 0.5286 | 0.7916 |
| 0.554 | 0.62 | 7600 | 0.5401 | 0.7835 |
| 0.5447 | 0.64 | 7800 | 0.5261 | 0.7876 |
| 0.5438 | 0.65 | 8000 | 0.5032 | 0.8020 |
| 0.5505 | 0.67 | 8200 | 0.5220 | 0.7924 |
| 0.5364 | 0.68 | 8400 | 0.5398 | 0.7876 |
| 0.5317 | 0.7 | 8600 | 0.5310 | 0.7944 |
| 0.5361 | 0.72 | 8800 | 0.5297 | 0.7936 |
| 0.5204 | 0.73 | 9000 | 0.5270 | 0.7940 |
| 0.5189 | 0.75 | 9200 | 0.5193 | 0.7964 |
| 0.5348 | 0.77 | 9400 | 0.5270 | 0.7867 |
| 0.5363 | 0.78 | 9600 | 0.5194 | 0.7924 |
| 0.5184 | 0.8 | 9800 | 0.5298 | 0.7888 |
| 0.5072 | 0.81 | 10000 | 0.4999 | 0.7992 |
| 0.5229 | 0.83 | 10200 | 0.4922 | 0.8108 |
| 0.5201 | 0.85 | 10400 | 0.5019 | 0.7920 |
| 0.5304 | 0.86 | 10600 | 0.4959 | 0.7992 |
| 0.5061 | 0.88 | 10800 | 0.5047 | 0.7980 |
| 0.5291 | 0.9 | 11000 | 0.4974 | 0.8068 |
| 0.5099 | 0.91 | 11200 | 0.4988 | 0.8036 |
| 0.5271 | 0.93 | 11400 | 0.4899 | 0.8028 |
| 0.5211 | 0.95 | 11600 | 0.4866 | 0.8092 |
| 0.4977 | 0.96 | 11800 | 0.5059 | 0.7960 |
| 0.5155 | 0.98 | 12000 | 0.4821 | 0.8084 |
| 0.5061 | 0.99 | 12200 | 0.4763 | 0.8116 |
| 0.4607 | 1.01 | 12400 | 0.5245 | 0.8020 |
| 0.4435 | 1.03 | 12600 | 0.5021 | 0.8032 |
| 0.4289 | 1.04 | 12800 | 0.5219 | 0.8060 |
| 0.4227 | 1.06 | 13000 | 0.5119 | 0.8076 |
| 0.4349 | 1.08 | 13200 | 0.4957 | 0.8104 |
| 0.4331 | 1.09 | 13400 | 0.4914 | 0.8129 |
| 0.4269 | 1.11 | 13600 | 0.4785 | 0.8145 |
| 0.4185 | 1.12 | 13800 | 0.4879 | 0.8161 |
| 0.4244 | 1.14 | 14000 | 0.4834 | 0.8149 |
| 0.4016 | 1.16 | 14200 | 0.5084 | 0.8056 |
| 0.4106 | 1.17 | 14400 | 0.4993 | 0.8052 |
| 0.4345 | 1.19 | 14600 | 0.5029 | 0.8124 |
| 0.4162 | 1.21 | 14800 | 0.4841 | 0.8120 |
| 0.4239 | 1.22 | 15000 | 0.4756 | 0.8189 |
| 0.4215 | 1.24 | 15200 | 0.4957 | 0.8088 |
| 0.4157 | 1.25 | 15400 | 0.4845 | 0.8112 |
| 0.3982 | 1.27 | 15600 | 0.5064 | 0.8048 |
| 0.4056 | 1.29 | 15800 | 0.4827 | 0.8241 |
| 0.4105 | 1.3 | 16000 | 0.4936 | 0.8088 |
| 0.4221 | 1.32 | 16200 | 0.4800 | 0.8129 |
| 0.4029 | 1.34 | 16400 | 0.4790 | 0.8181 |
| 0.4346 | 1.35 | 16600 | 0.4802 | 0.8137 |
| 0.4163 | 1.37 | 16800 | 0.4838 | 0.8213 |
| 0.4106 | 1.39 | 17000 | 0.4905 | 0.8209 |
| 0.4071 | 1.4 | 17200 | 0.4889 | 0.8153 |
| 0.4077 | 1.42 | 17400 | 0.4801 | 0.8165 |
| 0.4074 | 1.43 | 17600 | 0.4765 | 0.8217 |
| 0.4095 | 1.45 | 17800 | 0.4942 | 0.8096 |
| 0.4117 | 1.47 | 18000 | 0.4668 | 0.8225 |
| 0.3991 | 1.48 | 18200 | 0.4814 | 0.8161 |
| 0.4114 | 1.5 | 18400 | 0.4757 | 0.8193 |
| 0.4061 | 1.52 | 18600 | 0.4702 | 0.8209 |
| 0.4104 | 1.53 | 18800 | 0.4814 | 0.8149 |
| 0.3997 | 1.55 | 19000 | 0.4833 | 0.8141 |
| 0.3992 | 1.56 | 19200 | 0.4847 | 0.8169 |
| 0.4021 | 1.58 | 19400 | 0.4893 | 0.8189 |
| 0.4284 | 1.6 | 19600 | 0.4806 | 0.8173 |
| 0.3915 | 1.61 | 19800 | 0.4952 | 0.8092 |
| 0.4122 | 1.63 | 20000 | 0.4917 | 0.8112 |
| 0.4164 | 1.65 | 20200 | 0.4769 | 0.8157 |
| 0.4063 | 1.66 | 20400 | 0.4723 | 0.8141 |
| 0.4087 | 1.68 | 20600 | 0.4701 | 0.8157 |
| 0.4159 | 1.69 | 20800 | 0.4826 | 0.8141 |
| 0.4 | 1.71 | 21000 | 0.4760 | 0.8133 |
| 0.4024 | 1.73 | 21200 | 0.4755 | 0.8161 |
| 0.4201 | 1.74 | 21400 | 0.4728 | 0.8173 |
| 0.4066 | 1.76 | 21600 | 0.4690 | 0.8157 |
| 0.3941 | 1.78 | 21800 | 0.4687 | 0.8181 |
| 0.3987 | 1.79 | 22000 | 0.4735 | 0.8149 |
| 0.4074 | 1.81 | 22200 | 0.4715 | 0.8137 |
| 0.4083 | 1.83 | 22400 | 0.4660 | 0.8181 |
| 0.4107 | 1.84 | 22600 | 0.4699 | 0.8161 |
| 0.3924 | 1.86 | 22800 | 0.4732 | 0.8153 |
| 0.4205 | 1.87 | 23000 | 0.4686 | 0.8177 |
| 0.3962 | 1.89 | 23200 | 0.4688 | 0.8177 |
| 0.3888 | 1.91 | 23400 | 0.4778 | 0.8124 |
| 0.3978 | 1.92 | 23600 | 0.4713 | 0.8145 |
| 0.3963 | 1.94 | 23800 | 0.4704 | 0.8145 |
| 0.408 | 1.96 | 24000 | 0.4674 | 0.8165 |
| 0.4014 | 1.97 | 24200 | 0.4679 | 0.8161 |
| 0.3951 | 1.99 | 24400 | 0.4681 | 0.8157 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu102
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sutd-ai/distilbert-base-uncased-finetuned-squad | sutd-ai | 2022-08-03T16:43:10Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| question-answering | 2022-08-03T12:59:58Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad_v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5027
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2343 | 1.0 | 8235 | 1.3121 |
| 0.9657 | 2.0 | 16470 | 1.2259 |
| 0.7693 | 3.0 | 24705 | 1.5027 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
bhaskar75/ddpm-butterflies-128 | bhaskar75 | 2022-08-03T15:55:42Z | 0 | 0 | diffusers | [
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
]
| null | 2022-08-03T15:08:41Z | ---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/bhaskar75/ddpm-butterflies-128/tensorboard?#scalars)
|
dminiotas05/distilbert-base-uncased-finetuned-ft1500_norm500 | dminiotas05 | 2022-08-03T14:50:40Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-03T13:53:55Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ft1500_norm500
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ft1500_norm500
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8852
- Mse: 2.9505
- Mae: 1.0272
- R2: 0.4233
- Accuracy: 0.4914
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mse | Mae | R2 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:--------:|
| 0.62 | 1.0 | 3122 | 0.8853 | 2.9511 | 1.0392 | 0.4232 | 0.4830 |
| 0.5042 | 2.0 | 6244 | 0.8695 | 2.8984 | 1.0347 | 0.4335 | 0.4651 |
| 0.309 | 3.0 | 9366 | 0.8852 | 2.9505 | 1.0272 | 0.4233 | 0.4914 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
DOOGLAK/wikigold_trained_no_DA | DOOGLAK | 2022-08-03T14:33:52Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:wikigold_splits",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-08-03T14:25:38Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wikigold_splits
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: temp
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wikigold_splits
type: wikigold_splits
args: default
metrics:
- name: Precision
type: precision
value: 0.8517110266159695
- name: Recall
type: recall
value: 0.875
- name: F1
type: f1
value: 0.8631984585741811
- name: Accuracy
type: accuracy
value: 0.9607367910809501
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# temp
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the wikigold_splits dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1322
- Precision: 0.8517
- Recall: 0.875
- F1: 0.8632
- Accuracy: 0.9607
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 167 | 0.1490 | 0.7583 | 0.7760 | 0.7671 | 0.9472 |
| No log | 2.0 | 334 | 0.1337 | 0.8519 | 0.8464 | 0.8491 | 0.9572 |
| 0.1569 | 3.0 | 501 | 0.1322 | 0.8517 | 0.875 | 0.8632 | 0.9607 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
elopezlopez/distilbert-base-uncased_fold_10_binary_v1 | elopezlopez | 2022-08-03T14:29:32Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-03T11:51:31Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_10_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_10_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6912
- F1: 0.7977
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 288 | 0.4002 | 0.8012 |
| 0.4056 | 2.0 | 576 | 0.4372 | 0.8075 |
| 0.4056 | 3.0 | 864 | 0.4720 | 0.8071 |
| 0.1958 | 4.0 | 1152 | 0.8156 | 0.7980 |
| 0.1958 | 5.0 | 1440 | 0.8633 | 0.8055 |
| 0.0847 | 6.0 | 1728 | 0.9761 | 0.8041 |
| 0.0356 | 7.0 | 2016 | 1.1816 | 0.7861 |
| 0.0356 | 8.0 | 2304 | 1.2251 | 0.7918 |
| 0.0215 | 9.0 | 2592 | 1.3423 | 0.7798 |
| 0.0215 | 10.0 | 2880 | 1.3888 | 0.7913 |
| 0.013 | 11.0 | 3168 | 1.2899 | 0.8040 |
| 0.013 | 12.0 | 3456 | 1.4247 | 0.8051 |
| 0.0049 | 13.0 | 3744 | 1.5436 | 0.7991 |
| 0.0061 | 14.0 | 4032 | 1.5762 | 0.7991 |
| 0.0061 | 15.0 | 4320 | 1.5461 | 0.7998 |
| 0.0054 | 16.0 | 4608 | 1.5622 | 0.8018 |
| 0.0054 | 17.0 | 4896 | 1.6658 | 0.7991 |
| 0.0021 | 18.0 | 5184 | 1.6765 | 0.7972 |
| 0.0021 | 19.0 | 5472 | 1.6864 | 0.7973 |
| 0.0052 | 20.0 | 5760 | 1.6303 | 0.8030 |
| 0.0029 | 21.0 | 6048 | 1.6631 | 0.7947 |
| 0.0029 | 22.0 | 6336 | 1.6571 | 0.8006 |
| 0.0027 | 23.0 | 6624 | 1.6729 | 0.7949 |
| 0.0027 | 24.0 | 6912 | 1.6931 | 0.7934 |
| 0.0001 | 25.0 | 7200 | 1.6912 | 0.7977 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
elopezlopez/distilbert-base-uncased_fold_9_binary_v1 | elopezlopez | 2022-08-03T14:14:40Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-03T11:37:21Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_9_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_9_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6965
- F1: 0.8090
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 291 | 0.4193 | 0.7989 |
| 0.3993 | 2.0 | 582 | 0.4039 | 0.8026 |
| 0.3993 | 3.0 | 873 | 0.5227 | 0.7995 |
| 0.2044 | 4.0 | 1164 | 0.7264 | 0.8011 |
| 0.2044 | 5.0 | 1455 | 0.8497 | 0.8007 |
| 0.0882 | 6.0 | 1746 | 0.9543 | 0.8055 |
| 0.0374 | 7.0 | 2037 | 1.1349 | 0.7997 |
| 0.0374 | 8.0 | 2328 | 1.3175 | 0.8009 |
| 0.0151 | 9.0 | 2619 | 1.3585 | 0.8030 |
| 0.0151 | 10.0 | 2910 | 1.4202 | 0.8067 |
| 0.0068 | 11.0 | 3201 | 1.4364 | 0.8108 |
| 0.0068 | 12.0 | 3492 | 1.4443 | 0.8088 |
| 0.0096 | 13.0 | 3783 | 1.5308 | 0.8075 |
| 0.0031 | 14.0 | 4074 | 1.5061 | 0.8020 |
| 0.0031 | 15.0 | 4365 | 1.5769 | 0.7980 |
| 0.0048 | 16.0 | 4656 | 1.5962 | 0.8038 |
| 0.0048 | 17.0 | 4947 | 1.5383 | 0.8085 |
| 0.0067 | 18.0 | 5238 | 1.5456 | 0.8158 |
| 0.0062 | 19.0 | 5529 | 1.6325 | 0.8044 |
| 0.0062 | 20.0 | 5820 | 1.5430 | 0.8141 |
| 0.0029 | 21.0 | 6111 | 1.6590 | 0.8117 |
| 0.0029 | 22.0 | 6402 | 1.6650 | 0.8112 |
| 0.0017 | 23.0 | 6693 | 1.7016 | 0.8053 |
| 0.0017 | 24.0 | 6984 | 1.6998 | 0.8090 |
| 0.0011 | 25.0 | 7275 | 1.6965 | 0.8090 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
elopezlopez/distilbert-base-uncased_fold_8_binary_v1 | elopezlopez | 2022-08-03T13:59:34Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-03T11:22:48Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_8_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_8_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6283
- F1: 0.8178
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 290 | 0.4038 | 0.7981 |
| 0.409 | 2.0 | 580 | 0.4023 | 0.8176 |
| 0.409 | 3.0 | 870 | 0.5245 | 0.8169 |
| 0.1938 | 4.0 | 1160 | 0.6242 | 0.8298 |
| 0.1938 | 5.0 | 1450 | 0.8432 | 0.8159 |
| 0.0848 | 6.0 | 1740 | 1.0887 | 0.8015 |
| 0.038 | 7.0 | 2030 | 1.0700 | 0.8167 |
| 0.038 | 8.0 | 2320 | 1.0970 | 0.8241 |
| 0.0159 | 9.0 | 2610 | 1.2474 | 0.8142 |
| 0.0159 | 10.0 | 2900 | 1.3453 | 0.8184 |
| 0.01 | 11.0 | 3190 | 1.4412 | 0.8147 |
| 0.01 | 12.0 | 3480 | 1.4263 | 0.8181 |
| 0.007 | 13.0 | 3770 | 1.3859 | 0.8258 |
| 0.0092 | 14.0 | 4060 | 1.4633 | 0.8128 |
| 0.0092 | 15.0 | 4350 | 1.4304 | 0.8206 |
| 0.0096 | 16.0 | 4640 | 1.5081 | 0.8149 |
| 0.0096 | 17.0 | 4930 | 1.5239 | 0.8189 |
| 0.0047 | 18.0 | 5220 | 1.5268 | 0.8151 |
| 0.0053 | 19.0 | 5510 | 1.5445 | 0.8173 |
| 0.0053 | 20.0 | 5800 | 1.6051 | 0.8180 |
| 0.0014 | 21.0 | 6090 | 1.5981 | 0.8211 |
| 0.0014 | 22.0 | 6380 | 1.5957 | 0.8225 |
| 0.001 | 23.0 | 6670 | 1.5838 | 0.8189 |
| 0.001 | 24.0 | 6960 | 1.6301 | 0.8178 |
| 0.0018 | 25.0 | 7250 | 1.6283 | 0.8178 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
elopezlopez/distilbert-base-uncased_fold_7_binary_v1 | elopezlopez | 2022-08-03T13:44:34Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-02T23:18:34Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_7_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_7_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8361
- F1: 0.7958
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 288 | 0.4025 | 0.8071 |
| 0.3986 | 2.0 | 576 | 0.3979 | 0.8072 |
| 0.3986 | 3.0 | 864 | 0.5170 | 0.8041 |
| 0.1761 | 4.0 | 1152 | 0.7946 | 0.7940 |
| 0.1761 | 5.0 | 1440 | 1.0000 | 0.7937 |
| 0.0705 | 6.0 | 1728 | 1.1484 | 0.7875 |
| 0.0294 | 7.0 | 2016 | 1.1548 | 0.8042 |
| 0.0294 | 8.0 | 2304 | 1.3036 | 0.8069 |
| 0.0171 | 9.0 | 2592 | 1.4043 | 0.7943 |
| 0.0171 | 10.0 | 2880 | 1.3356 | 0.8002 |
| 0.0154 | 11.0 | 3168 | 1.4528 | 0.7996 |
| 0.0154 | 12.0 | 3456 | 1.5514 | 0.7991 |
| 0.005 | 13.0 | 3744 | 1.6341 | 0.8046 |
| 0.0038 | 14.0 | 4032 | 1.6240 | 0.7984 |
| 0.0038 | 15.0 | 4320 | 1.7476 | 0.8014 |
| 0.0037 | 16.0 | 4608 | 1.6666 | 0.7982 |
| 0.0037 | 17.0 | 4896 | 1.7495 | 0.7950 |
| 0.0083 | 18.0 | 5184 | 1.6993 | 0.7932 |
| 0.0083 | 19.0 | 5472 | 1.6573 | 0.8077 |
| 0.002 | 20.0 | 5760 | 1.7430 | 0.7980 |
| 0.0012 | 21.0 | 6048 | 1.8135 | 0.7955 |
| 0.0012 | 22.0 | 6336 | 1.8316 | 0.7972 |
| 0.0022 | 23.0 | 6624 | 1.8717 | 0.7926 |
| 0.0022 | 24.0 | 6912 | 1.8183 | 0.7978 |
| 0.0014 | 25.0 | 7200 | 1.8361 | 0.7958 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
elopezlopez/distilbert-base-uncased_fold_13_binary_v1 | elopezlopez | 2022-08-03T12:48:08Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-03T12:34:31Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_13_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_13_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7433
- F1: 0.8138
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 291 | 0.4101 | 0.8087 |
| 0.4128 | 2.0 | 582 | 0.4605 | 0.8197 |
| 0.4128 | 3.0 | 873 | 0.5011 | 0.8130 |
| 0.1997 | 4.0 | 1164 | 0.6882 | 0.8147 |
| 0.1997 | 5.0 | 1455 | 0.9653 | 0.8092 |
| 0.0913 | 6.0 | 1746 | 1.1020 | 0.8031 |
| 0.0347 | 7.0 | 2037 | 1.2687 | 0.8050 |
| 0.0347 | 8.0 | 2328 | 1.2383 | 0.8103 |
| 0.0173 | 9.0 | 2619 | 1.3631 | 0.8066 |
| 0.0173 | 10.0 | 2910 | 1.4282 | 0.8001 |
| 0.0104 | 11.0 | 3201 | 1.4410 | 0.8179 |
| 0.0104 | 12.0 | 3492 | 1.5318 | 0.8018 |
| 0.0063 | 13.0 | 3783 | 1.5866 | 0.8018 |
| 0.0043 | 14.0 | 4074 | 1.4987 | 0.8159 |
| 0.0043 | 15.0 | 4365 | 1.6275 | 0.8181 |
| 0.0048 | 16.0 | 4656 | 1.5811 | 0.8231 |
| 0.0048 | 17.0 | 4947 | 1.6228 | 0.8182 |
| 0.0048 | 18.0 | 5238 | 1.7235 | 0.8138 |
| 0.0055 | 19.0 | 5529 | 1.7018 | 0.8066 |
| 0.0055 | 20.0 | 5820 | 1.7340 | 0.8069 |
| 0.0046 | 21.0 | 6111 | 1.7143 | 0.8156 |
| 0.0046 | 22.0 | 6402 | 1.7367 | 0.8159 |
| 0.0037 | 23.0 | 6693 | 1.7551 | 0.8151 |
| 0.0037 | 24.0 | 6984 | 1.7479 | 0.8145 |
| 0.0009 | 25.0 | 7275 | 1.7433 | 0.8138 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
bhavesh/arinfo_sample_dataset_finaltffwjv58-model-classification | bhavesh | 2022-08-03T12:40:45Z | 0 | 0 | sklearn | [
"sklearn",
"tabular-classification",
"baseline-trainer",
"license:apache-2.0",
"region:us"
]
| tabular-classification | 2022-08-03T12:40:39Z | ---
license: apache-2.0
library_name: sklearn
tags:
- tabular-classification
- baseline-trainer
---
## Baseline Model trained on arinfo_sample_dataset_finaltffwjv58 to apply classification on model
**Metrics of the best model:**
accuracy 0.930688
recall_macro 0.655991
precision_macro 0.640972
f1_macro 0.638021
Name: DecisionTreeClassifier(class_weight='balanced', max_depth=2249), dtype: float64
**See model plot below:**
<style>#sk-container-id-4 {color: black;background-color: white;}#sk-container-id-4 pre{padding: 0;}#sk-container-id-4 div.sk-toggleable {background-color: white;}#sk-container-id-4 label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-container-id-4 label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-container-id-4 label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-container-id-4 div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-container-id-4 div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-container-id-4 div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-container-id-4 input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-container-id-4 input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-container-id-4 div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-4 div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-4 input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-container-id-4 div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-container-id-4 div.sk-estimator:hover {background-color: #d4ebff;}#sk-container-id-4 div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-container-id-4 div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-4 div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: 0;}#sk-container-id-4 div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;position: relative;}#sk-container-id-4 div.sk-item {position: relative;z-index: 1;}#sk-container-id-4 div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;position: relative;}#sk-container-id-4 div.sk-item::before, #sk-container-id-4 div.sk-parallel-item::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: -1;}#sk-container-id-4 div.sk-parallel-item {display: flex;flex-direction: column;z-index: 1;position: relative;background-color: white;}#sk-container-id-4 div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-container-id-4 div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-container-id-4 div.sk-parallel-item:only-child::after {width: 0;}#sk-container-id-4 div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;}#sk-container-id-4 div.sk-label label {font-family: monospace;font-weight: bold;display: inline-block;line-height: 1.2em;}#sk-container-id-4 div.sk-label-container {text-align: center;}#sk-container-id-4 div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-container-id-4 div.sk-text-repr-fallback {display: none;}</style><div id="sk-container-id-4" class="sk-top-container"><div class="sk-text-repr-fallback"><pre>Pipeline(steps=[('easypreprocessor',EasyPreprocessor(types= continuous dirty_float low_card_int ... date free_string useless
rto False False False ... False True False
ownerNum False False False ... False False False
cc False False False ... False False False
insurance False False False ... False False False
weight True False False ... False False False
financer False False False ... False True False
fu...
class False False False ... False False False
state False False False ... False False False
year False False False ... False False False
categoryId False False False ... False False False
onroadPrice True False False ... False False False
price_FAIR True False False ... False False False[13 rows x 7 columns])),('decisiontreeclassifier',DecisionTreeClassifier(class_weight='balanced',max_depth=2249))])</pre><b>In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. <br />On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.</b></div><div class="sk-container" hidden><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-10" type="checkbox" ><label for="sk-estimator-id-10" class="sk-toggleable__label sk-toggleable__label-arrow">Pipeline</label><div class="sk-toggleable__content"><pre>Pipeline(steps=[('easypreprocessor',EasyPreprocessor(types= continuous dirty_float low_card_int ... date free_string useless
rto False False False ... False True False
ownerNum False False False ... False False False
cc False False False ... False False False
insurance False False False ... False False False
weight True False False ... False False False
financer False False False ... False True False
fu...
class False False False ... False False False
state False False False ... False False False
year False False False ... False False False
categoryId False False False ... False False False
onroadPrice True False False ... False False False
price_FAIR True False False ... False False False[13 rows x 7 columns])),('decisiontreeclassifier',DecisionTreeClassifier(class_weight='balanced',max_depth=2249))])</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-11" type="checkbox" ><label for="sk-estimator-id-11" class="sk-toggleable__label sk-toggleable__label-arrow">EasyPreprocessor</label><div class="sk-toggleable__content"><pre>EasyPreprocessor(types= continuous dirty_float low_card_int ... date free_string useless
rto False False False ... False True False
ownerNum False False False ... False False False
cc False False False ... False False False
insurance False False False ... False False False
weight True False False ... False False False
financer False False False ... False True False
fuelType False False False ... False False False
class False False False ... False False False
state False False False ... False False False
year False False False ... False False False
categoryId False False False ... False False False
onroadPrice True False False ... False False False
price_FAIR True False False ... False False False[13 rows x 7 columns])</pre></div></div></div><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-12" type="checkbox" ><label for="sk-estimator-id-12" class="sk-toggleable__label sk-toggleable__label-arrow">DecisionTreeClassifier</label><div class="sk-toggleable__content"><pre>DecisionTreeClassifier(class_weight='balanced', max_depth=2249)</pre></div></div></div></div></div></div></div>
**Disclaimer:** This model is trained with dabl library as a baseline, for better results, use [AutoTrain](https://huggingface.co/autotrain).
**Logs of training** including the models tried in the process can be found in logs.txt |
elopezlopez/distilbert-base-uncased_fold_12_binary_v1 | elopezlopez | 2022-08-03T12:34:08Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-03T12:20:05Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_12_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_12_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7046
- F1: 0.8165
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 290 | 0.4165 | 0.7983 |
| 0.4052 | 2.0 | 580 | 0.4005 | 0.8213 |
| 0.4052 | 3.0 | 870 | 0.6003 | 0.8078 |
| 0.1906 | 4.0 | 1160 | 0.8181 | 0.7945 |
| 0.1906 | 5.0 | 1450 | 0.7775 | 0.7955 |
| 0.0853 | 6.0 | 1740 | 1.0667 | 0.7912 |
| 0.0407 | 7.0 | 2030 | 1.2061 | 0.7907 |
| 0.0407 | 8.0 | 2320 | 1.2522 | 0.8011 |
| 0.0145 | 9.0 | 2610 | 1.3073 | 0.8110 |
| 0.0145 | 10.0 | 2900 | 1.4895 | 0.7994 |
| 0.015 | 11.0 | 3190 | 1.4568 | 0.8082 |
| 0.015 | 12.0 | 3480 | 1.4883 | 0.8058 |
| 0.005 | 13.0 | 3770 | 1.4334 | 0.8217 |
| 0.0026 | 14.0 | 4060 | 1.5032 | 0.8255 |
| 0.0026 | 15.0 | 4350 | 1.5694 | 0.8193 |
| 0.0062 | 16.0 | 4640 | 1.6058 | 0.8105 |
| 0.0062 | 17.0 | 4930 | 1.7390 | 0.8058 |
| 0.0051 | 18.0 | 5220 | 1.6942 | 0.8100 |
| 0.0012 | 19.0 | 5510 | 1.6891 | 0.8151 |
| 0.0012 | 20.0 | 5800 | 1.6961 | 0.8132 |
| 0.0007 | 21.0 | 6090 | 1.6793 | 0.8168 |
| 0.0007 | 22.0 | 6380 | 1.7542 | 0.8077 |
| 0.0027 | 23.0 | 6670 | 1.6869 | 0.8203 |
| 0.0027 | 24.0 | 6960 | 1.7006 | 0.8194 |
| 0.0028 | 25.0 | 7250 | 1.7046 | 0.8165 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Saraswati/ppo-CartPole-v2 | Saraswati | 2022-08-03T12:28:15Z | 0 | 0 | null | [
"region:us"
]
| null | 2022-08-03T12:27:06Z | git lfs install
git clone https://huggingface.co/Saraswati/ppo-CartPole-v2 |
wenkai-li/distilroberta-base-wikitextepoch_50 | wenkai-li | 2022-08-03T12:16:08Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-08-03T09:57:04Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilroberta-base-wikitextepoch_50
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-wikitextepoch_50
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6360
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 1.9729 | 1.0 | 2145 | 1.7725 |
| 1.9158 | 2.0 | 4290 | 1.7521 |
| 1.8479 | 3.0 | 6435 | 1.7376 |
| 1.8081 | 4.0 | 8580 | 1.7272 |
| 1.7966 | 5.0 | 10725 | 1.7018 |
| 1.7284 | 6.0 | 12870 | 1.7010 |
| 1.7198 | 7.0 | 15015 | 1.6868 |
| 1.6985 | 8.0 | 17160 | 1.6879 |
| 1.6712 | 9.0 | 19305 | 1.6930 |
| 1.6489 | 10.0 | 21450 | 1.6594 |
| 1.6643 | 11.0 | 23595 | 1.6856 |
| 1.6215 | 12.0 | 25740 | 1.6816 |
| 1.6125 | 13.0 | 27885 | 1.6714 |
| 1.5936 | 14.0 | 30030 | 1.6760 |
| 1.5745 | 15.0 | 32175 | 1.6660 |
| 1.572 | 16.0 | 34320 | 1.6690 |
| 1.5614 | 17.0 | 36465 | 1.6807 |
| 1.558 | 18.0 | 38610 | 1.6711 |
| 1.5305 | 19.0 | 40755 | 1.6446 |
| 1.5021 | 20.0 | 42900 | 1.6573 |
| 1.4923 | 21.0 | 45045 | 1.6648 |
| 1.5086 | 22.0 | 47190 | 1.6757 |
| 1.4895 | 23.0 | 49335 | 1.6525 |
| 1.4918 | 24.0 | 51480 | 1.6577 |
| 1.4642 | 25.0 | 53625 | 1.6633 |
| 1.4604 | 26.0 | 55770 | 1.6462 |
| 1.4644 | 27.0 | 57915 | 1.6509 |
| 1.4633 | 28.0 | 60060 | 1.6417 |
| 1.4188 | 29.0 | 62205 | 1.6519 |
| 1.4066 | 30.0 | 64350 | 1.6363 |
| 1.409 | 31.0 | 66495 | 1.6419 |
| 1.4029 | 32.0 | 68640 | 1.6510 |
| 1.4013 | 33.0 | 70785 | 1.6522 |
| 1.3939 | 34.0 | 72930 | 1.6498 |
| 1.3648 | 35.0 | 75075 | 1.6423 |
| 1.3682 | 36.0 | 77220 | 1.6504 |
| 1.3603 | 37.0 | 79365 | 1.6511 |
| 1.3621 | 38.0 | 81510 | 1.6533 |
| 1.3783 | 39.0 | 83655 | 1.6426 |
| 1.3707 | 40.0 | 85800 | 1.6542 |
| 1.3628 | 41.0 | 87945 | 1.6671 |
| 1.3359 | 42.0 | 90090 | 1.6394 |
| 1.3433 | 43.0 | 92235 | 1.6409 |
| 1.3525 | 44.0 | 94380 | 1.6366 |
| 1.3312 | 45.0 | 96525 | 1.6408 |
| 1.3389 | 46.0 | 98670 | 1.6225 |
| 1.3323 | 47.0 | 100815 | 1.6309 |
| 1.3294 | 48.0 | 102960 | 1.6151 |
| 1.3356 | 49.0 | 105105 | 1.6374 |
| 1.3285 | 50.0 | 107250 | 1.6360 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.5.0
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Rocketknight1/distilbert-base-uncased-finetuned-cola | Rocketknight1 | 2022-08-03T12:13:22Z | 7 | 0 | transformers | [
"transformers",
"tf",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-03-02T23:29:04Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: Rocketknight1/distilbert-base-uncased-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Rocketknight1/distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.3182
- Validation Loss: 0.4914
- Train Matthews Correlation: 0.5056
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1602, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Matthews Correlation | Epoch |
|:----------:|:---------------:|:--------------------------:|:-----:|
| 0.5126 | 0.4638 | 0.4555 | 0 |
| 0.3182 | 0.4914 | 0.5056 | 1 |
### Framework versions
- Transformers 4.22.0.dev0
- TensorFlow 2.9.1
- Datasets 2.4.1.dev0
- Tokenizers 0.11.0
|
Rookie-06/distilbert-base-uncased-finetuned-imdb | Rookie-06 | 2022-08-03T12:09:53Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-08-03T11:48:36Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4721
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7086 | 1.0 | 157 | 2.4898 |
| 2.5796 | 2.0 | 314 | 2.4230 |
| 2.5269 | 3.0 | 471 | 2.4354 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
MCG-NJU/videomae-base-short-finetuned-ssv2 | MCG-NJU | 2022-08-03T10:23:28Z | 6 | 1 | transformers | [
"transformers",
"pytorch",
"videomae",
"video-classification",
"vision",
"arxiv:2203.12602",
"arxiv:2111.06377",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
]
| video-classification | 2022-08-02T16:17:19Z | ---
license: "cc-by-nc-4.0"
tags:
- vision
- video-classification
---
# VideoMAE (base-sized model, fine-tuned on Something-Something-v2)
VideoMAE model pre-trained for 800 epochs in a self-supervised way and fine-tuned in a supervised way on Something-Something-v2. It was introduced in the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Tong et al. and first released in [this repository](https://github.com/MCG-NJU/VideoMAE).
Disclaimer: The team releasing VideoMAE did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
VideoMAE is an extension of [Masked Autoencoders (MAE)](https://arxiv.org/abs/2111.06377) to video. The architecture of the model is very similar to that of a standard Vision Transformer (ViT), with a decoder on top for predicting pixel values for masked patches.
Videos are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds fixed sinus/cosinus position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of videos that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled videos for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire video.
## Intended uses & limitations
You can use the raw model for video classification into one of the 400 possible Kinetics-400 labels.
### How to use
Here is how to use this model to classify a video:
```python
from transformers import VideoMAEFeatureExtractor, VideoMAEForVideoClassification
import numpy as np
import torch
video = list(np.random.randn(16, 3, 224, 224))
feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base-short-finetuned-ssv2")
model = VideoMAEForVideoClassification.from_pretrained("MCG-NJU/videomae-base-short-finetuned-ssv2")
inputs = feature_extractor(video, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/videomae.html#).
## Training data
(to do, feel free to open a PR)
## Training procedure
### Preprocessing
(to do, feel free to open a PR)
### Pretraining
(to do, feel free to open a PR)
## Evaluation results
This model obtains a top-1 accuracy of 69.6 and a top-5 accuracy of 92.0 on the test set of Something-Something-v2.
### BibTeX entry and citation info
```bibtex
misc{https://doi.org/10.48550/arxiv.2203.12602,
doi = {10.48550/ARXIV.2203.12602},
url = {https://arxiv.org/abs/2203.12602},
author = {Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
``` |
spacestar1705/Reinforce-PixelCopter-PLE-v0 | spacestar1705 | 2022-08-03T09:30:13Z | 0 | 0 | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-08-02T12:45:24Z | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-PixelCopter-PLE-v0
results:
- metrics:
- type: mean_reward
value: 10.60 +/- 9.50
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
SyedArsal/roberta-urdu-small-finetuned-news | SyedArsal | 2022-08-03T09:13:02Z | 7 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"roberta",
"multiple-choice",
"generated_from_trainer",
"license:mit",
"endpoints_compatible",
"region:us"
]
| multiple-choice | 2022-07-29T08:04:18Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: roberta-urdu-small-finetuned-news
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-urdu-small-finetuned-news
This model is a fine-tuned version of [urduhack/roberta-urdu-small](https://huggingface.co/urduhack/roberta-urdu-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2702
- Accuracy: 0.9482
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5949 | 1.0 | 938 | 0.3626 | 0.9029 |
| 0.1351 | 2.0 | 1876 | 0.2545 | 0.9389 |
| 0.0281 | 3.0 | 2814 | 0.2702 | 0.9482 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
shashanksrinath/News_Sentiment_Analysis | shashanksrinath | 2022-08-03T08:34:50Z | 66 | 4 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-01T13:01:39Z | ---
tags:
- generated_from_trainer
model-index:
- name: News_Sentiment_Analysis
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# News_Sentiment_Analysis
This model is a fine-tuned version of [cardiffnlp/twitter-roberta-base-sentiment-latest](https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment-latest) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
ArneD/pegasus-samsum | ArneD | 2022-08-03T07:54:09Z | 12 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"dataset:samsum",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-08-03T06:20:40Z | ---
tags:
- generated_from_trainer
datasets:
- samsum
model-index:
- name: pegasus-samsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pegasus-samsum
This model is a fine-tuned version of [google/pegasus-cnn_dailymail](https://huggingface.co/google/pegasus-cnn_dailymail) on the samsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4884
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.6902 | 0.54 | 500 | 1.4884 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.0+cu113
- Datasets 2.0.0
- Tokenizers 0.10.3
|
kws/dqn-SpaceInvadersNoFrameskip-v4 | kws | 2022-08-03T07:43:27Z | 8 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-08-03T07:42:45Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 603.00 +/- 194.90
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga kws -f logs/
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga kws
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 10000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
BekirTaha/dqn-SpaceInvadersNoFrameskip-v4 | BekirTaha | 2022-08-03T07:41:26Z | 8 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-08-02T13:34:41Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 577.50 +/- 116.86
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga BekirTaha -f logs/
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga BekirTaha
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
NimaBoscarino/July25Test | NimaBoscarino | 2022-08-03T07:20:01Z | 5 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-07-26T02:54:10Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# NimaBoscarino/July25Test
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('NimaBoscarino/July25Test')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('NimaBoscarino/July25Test')
model = AutoModel.from_pretrained('NimaBoscarino/July25Test')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=NimaBoscarino/July25Test)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 1 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 2,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 100,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
rjac/ner-distilbert-cased | rjac | 2022-08-03T06:45:38Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"distilbert",
"token-classification",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-08-03T06:33:03Z | ---
tags:
- generated_from_keras_callback
model-index:
- name: ner-distilber-cased
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# ner-distilber-cased
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.9.1
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Inkdrop/gpl | Inkdrop | 2022-08-03T06:31:52Z | 6 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"causal-lm",
"sentence-similarity",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-08-01T12:12:11Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- causal-lm
license:
- cc-by-sa-4.0
---
# TODO: Name of Model
TODO: Description
## Model Description
TODO: Add relevant content
(0) Base Transformer Type: RobertaModel
(1) Pooling mean
## Usage (Sentence-Transformers)
Using this model becomes more convenient when you have [sentence-transformers](https://github.com/UKPLab/sentence-transformers) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence"]
model = SentenceTransformer(TODO)
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
```python
from transformers import AutoTokenizer, AutoModel
import torch
# The next step is optional if you want your own pooling function.
# Max Pooling - Take the max value over time for every dimension.
def max_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
token_embeddings[input_mask_expanded == 0] = -1e9 # Set padding tokens to large negative value
max_over_time = torch.max(token_embeddings, 1)[0]
return max_over_time
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained(TODO)
model = AutoModel.from_pretrained(TODO)
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, max_length=128, return_tensors='pt'))
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = max_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## TODO: Training Procedure
## TODO: Evaluation Results
## TODO: Citing & Authors |
woojinSong/my_bean_VIT | woojinSong | 2022-08-03T05:58:02Z | 55 | 1 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:beans",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2022-08-03T04:20:57Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- beans
metrics:
- accuracy
model-index:
- name: my_bean_VIT
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: beans
type: beans
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9924812030075187
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_bean_VIT
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0321
- Accuracy: 0.9925
## Model description
Bean datasets based Vision Transformer model.
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2698 | 1.54 | 100 | 0.1350 | 0.9549 |
| 0.0147 | 3.08 | 200 | 0.0321 | 0.9925 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
abyaugustinek/distilbert-base-uncased-finetuned | abyaugustinek | 2022-08-03T05:09:00Z | 4 | 0 | transformers | [
"transformers",
"tf",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-08-03T04:41:55Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: abyaugustinek/distilbert-base-uncased-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# abyaugustinek/distilbert-base-uncased-finetuned
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.3693
- Validation Loss: 1.2106
- Train Precision: 0.0
- Train Recall: 0.0
- Train F1: 0.0
- Train Accuracy: 0.6565
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 30, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Precision | Train Recall | Train F1 | Train Accuracy | Epoch |
|:----------:|:---------------:|:---------------:|:------------:|:--------:|:--------------:|:-----:|
| 2.0691 | 1.5942 | 0.0 | 0.0 | 0.0 | 0.6565 | 0 |
| 1.4705 | 1.2376 | 0.0 | 0.0 | 0.0 | 0.6565 | 1 |
| 1.3693 | 1.2106 | 0.0 | 0.0 | 0.0 | 0.6565 | 2 |
### Framework versions
- Transformers 4.21.0
- TensorFlow 2.7.0
- Datasets 2.3.2
- Tokenizers 0.12.1
|
amartyobanerjee/marian-finetuned-kde4-en-to-fr | amartyobanerjee | 2022-08-03T03:32:12Z | 10 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"dataset:kde4",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| translation | 2022-06-15T08:33:22Z | ---
license: apache-2.0
tags:
- translation
- generated_from_trainer
datasets:
- kde4
metrics:
- bleu
model-index:
- name: marian-finetuned-kde4-en-to-fr
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: kde4
type: kde4
config: en-fr
split: train
args: en-fr
metrics:
- name: Bleu
type: bleu
value: 52.83113187001415
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# marian-finetuned-kde4-en-to-fr
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-fr](https://huggingface.co/Helsinki-NLP/opus-mt-en-fr) on the kde4 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8560
- Bleu: 52.8311
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
wooihen/xlm-roberta-base-finetuned-panx-de | wooihen | 2022-08-03T02:12:37Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-03-12T07:47:47Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8648740833380706
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1365
- F1: 0.8649
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2553 | 1.0 | 525 | 0.1575 | 0.8279 |
| 0.1284 | 2.0 | 1050 | 0.1386 | 0.8463 |
| 0.0813 | 3.0 | 1575 | 0.1365 | 0.8649 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
AykeeSalazar/vc-bantai-vit-withoutAMBI-adunest-v3 | AykeeSalazar | 2022-08-03T02:02:46Z | 57 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2022-08-03T01:15:52Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: vc-bantai-vit-withoutAMBI-adunest-v3
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
args: Violation-Classification---Raw-10
metrics:
- name: Accuracy
type: accuracy
value: 0.8218352310783658
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vc-bantai-vit-withoutAMBI-adunest-v3
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8889
- Accuracy: 0.8218
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 200
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.38 | 100 | 0.8208 | 0.7147 |
| No log | 0.76 | 200 | 0.8861 | 0.7595 |
| No log | 1.14 | 300 | 0.4306 | 0.7910 |
| No log | 1.52 | 400 | 0.5222 | 0.8245 |
| 0.3448 | 1.9 | 500 | 0.8621 | 0.7602 |
| 0.3448 | 2.28 | 600 | 0.2902 | 0.8801 |
| 0.3448 | 2.66 | 700 | 0.3687 | 0.8426 |
| 0.3448 | 3.04 | 800 | 0.3585 | 0.8694 |
| 0.3448 | 3.42 | 900 | 0.6546 | 0.7897 |
| 0.2183 | 3.8 | 1000 | 0.3881 | 0.8272 |
| 0.2183 | 4.18 | 1100 | 0.9650 | 0.7709 |
| 0.2183 | 4.56 | 1200 | 0.6444 | 0.7917 |
| 0.2183 | 4.94 | 1300 | 0.4685 | 0.8707 |
| 0.2183 | 5.32 | 1400 | 0.4972 | 0.8506 |
| 0.157 | 5.7 | 1500 | 0.4010 | 0.8513 |
| 0.157 | 6.08 | 1600 | 0.4629 | 0.8419 |
| 0.157 | 6.46 | 1700 | 0.4258 | 0.8714 |
| 0.157 | 6.84 | 1800 | 0.4383 | 0.8573 |
| 0.157 | 7.22 | 1900 | 0.5324 | 0.8493 |
| 0.113 | 7.6 | 2000 | 0.3212 | 0.8942 |
| 0.113 | 7.98 | 2100 | 0.8621 | 0.8326 |
| 0.113 | 8.37 | 2200 | 0.6050 | 0.8131 |
| 0.113 | 8.75 | 2300 | 0.7173 | 0.7991 |
| 0.113 | 9.13 | 2400 | 0.5313 | 0.8125 |
| 0.0921 | 9.51 | 2500 | 0.6584 | 0.8158 |
| 0.0921 | 9.89 | 2600 | 0.8727 | 0.7930 |
| 0.0921 | 10.27 | 2700 | 0.4222 | 0.8922 |
| 0.0921 | 10.65 | 2800 | 0.5811 | 0.8265 |
| 0.0921 | 11.03 | 2900 | 0.6175 | 0.8372 |
| 0.0701 | 11.41 | 3000 | 0.3914 | 0.8835 |
| 0.0701 | 11.79 | 3100 | 0.3364 | 0.8654 |
| 0.0701 | 12.17 | 3200 | 0.6223 | 0.8359 |
| 0.0701 | 12.55 | 3300 | 0.7830 | 0.8125 |
| 0.0701 | 12.93 | 3400 | 0.4356 | 0.8942 |
| 0.0552 | 13.31 | 3500 | 0.7553 | 0.8232 |
| 0.0552 | 13.69 | 3600 | 0.9107 | 0.8292 |
| 0.0552 | 14.07 | 3700 | 0.6108 | 0.8580 |
| 0.0552 | 14.45 | 3800 | 0.5732 | 0.8567 |
| 0.0552 | 14.83 | 3900 | 0.5087 | 0.8614 |
| 0.0482 | 15.21 | 4000 | 0.8889 | 0.8218 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
elopezlopez/distilbert-base-uncased_fold_6_binary_v1 | elopezlopez | 2022-08-02T23:17:12Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-08-02T23:03:36Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_6_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_6_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7209
- F1: 0.8156
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 290 | 0.4115 | 0.8048 |
| 0.3976 | 2.0 | 580 | 0.3980 | 0.8156 |
| 0.3976 | 3.0 | 870 | 0.5953 | 0.8142 |
| 0.1965 | 4.0 | 1160 | 0.7940 | 0.8057 |
| 0.1965 | 5.0 | 1450 | 0.8098 | 0.8069 |
| 0.0847 | 6.0 | 1740 | 1.0293 | 0.7913 |
| 0.03 | 7.0 | 2030 | 1.1649 | 0.8073 |
| 0.03 | 8.0 | 2320 | 1.2876 | 0.7973 |
| 0.0166 | 9.0 | 2610 | 1.3260 | 0.8038 |
| 0.0166 | 10.0 | 2900 | 1.3523 | 0.8084 |
| 0.0062 | 11.0 | 3190 | 1.3814 | 0.8097 |
| 0.0062 | 12.0 | 3480 | 1.4134 | 0.8165 |
| 0.0113 | 13.0 | 3770 | 1.5374 | 0.8068 |
| 0.006 | 14.0 | 4060 | 1.5808 | 0.8100 |
| 0.006 | 15.0 | 4350 | 1.6551 | 0.7972 |
| 0.0088 | 16.0 | 4640 | 1.5793 | 0.8116 |
| 0.0088 | 17.0 | 4930 | 1.6134 | 0.8143 |
| 0.0021 | 18.0 | 5220 | 1.6204 | 0.8119 |
| 0.0031 | 19.0 | 5510 | 1.7006 | 0.8029 |
| 0.0031 | 20.0 | 5800 | 1.6777 | 0.8145 |
| 0.0019 | 21.0 | 6090 | 1.7202 | 0.8079 |
| 0.0019 | 22.0 | 6380 | 1.7539 | 0.8053 |
| 0.0008 | 23.0 | 6670 | 1.7408 | 0.8119 |
| 0.0008 | 24.0 | 6960 | 1.7388 | 0.8176 |
| 0.0014 | 25.0 | 7250 | 1.7209 | 0.8156 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Subsets and Splits