
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-13 00:46:37
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 518
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-13 00:45:34
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
xDAN-AI/APUS-xDAN-4.0-MOE | xDAN-AI | 2024-04-03T03:47:48Z | 11 | 16 | null | [
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2024-03-29T05:25:50Z | ---
license: apache-2.0
---

## Introduction
APUS-xDAN-4.0-MOE is a transformer-based decoder-only language model, developed on a vast corpus of data to ensure robust performance.
This is an enhanced MoE (Mixture of Experts) model built on top of the continued pre-training enhanced LlaMA architecture,
further optimized with human-enhanced feedback algorithms to improve reasoning, mathematical, and logical capabilities during inference.
For more comprehensive information, please visit our blog post and GitHub repository.
https://github.com/shootime2021/APUS-xDAN-4.0-moe
# Model Details
APUS-xDAN-4.0-MOE leverages the innovative Mixture of Experts (MoE) architecture, incorporating components from dense language models. Specifically, it inherits its capabilities from the highly performant xDAN-L2 Series. With a total of 136 billion parameters, of which 30 billion are activated during runtime, APUS-xDAN-4.0-MOE demonstrates unparalleled efficiency.
Through advanced quantization techniques, our open-source version occupies a mere 42GB, making it seamlessly compatible with consumer-grade GPUs like the 4090 and 3090.
The following specifications:
- **Parameters:** 136B
- **Architecture:** Mixture of 4 Experts (MoE)
- **Experts Utilization:** 2 experts used per token
- **Layers:** 60
- **Attention Heads:** 56 for queries, 8 for keys/values
- **Embedding Size:** 7,168
- **Additional Features:**
- Rotary embeddings (RoPE)
- Supports activation sharding and 1.5bit~4bit quantization
- **Maximum Sequence Length (context):** 32,768 tokens
## Usage
| Model | Quantized | Size | Context | Hardware Requirement |
|-------------|-----------|--------|--------------------------| --------------------------|
| APUS-xDAN4.0-MoE-0402.Q2_K.gguf | Q2_K | 39G | 32k | 2x24G GPU memory |
| APUS-xDAN4.0-MoE-0402.IQ3_XXS.gguf | IQ3_XXS | 41G | 32k | 2x24G GPU memory |
| APUS-xDAN4.0-MoE-0402.Q3_K_M_Matrix.gguf | Q3_K_M | 51G | 32k | 2x24G GPU memory |
| APUS-xDAN4.0-MoE-0402.Q4_K_M.gguf | Q4_K_M | 64G | 32k | 3x24G GPU memory |
| APUS-xDAN4.0-MoE-0402 | | | | |
### Initial
```python
git clone https://github.com/ggerganov/llama.cpp.git
make LLAMA_CUDA=1
```
### Interactive Chat
```python
./main -m APUS-xDAN4.0-MoE-0402.Q2_K.gguf \
--prompt "You are a helpful assistant named APUS-xDAN4.0 MoE." --chatml \
--interactive \
--temp 0.7 \
--ctx-size 4096 (32k)
```
License
APUS-xDAN-4.0-MOE is distributed under the LLAMA 2 Community License, Copyright (c) Meta Platforms, Inc. All Rights Reserved. |
lgodwangl/new_02m | lgodwangl | 2024-04-03T03:43:12Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-03-11T13:48:49Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
collison/SYD001 | collison | 2024-04-03T03:42:54Z | 2 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
]
| null | 2024-04-03T03:40:54Z | ---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0 |
KaQyn/peft-lora-CodeLlama-13b-unity-copilot | KaQyn | 2024-04-03T03:34:33Z | 7 | 0 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"region:us"
]
| null | 2024-03-25T06:18:43Z | ---
library_name: peft
tags:
- generated_from_trainer
base_model: codellam/CodeLlama-13b-Instruct-hf
model-index:
- name: peft-lora-CodeLlama-13b-unity-copilot
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# peft-lora-CodeLlama-13b-unity-copilot
This model is a fine-tuned version of [codellama/CodeLlama-13b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-13b-Instruct-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1825
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 2000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.1196 | 0.05 | 100 | 0.3165 |
| 0.2451 | 0.1 | 200 | 0.2333 |
| 0.2358 | 0.15 | 300 | 0.2338 |
| 0.1617 | 0.2 | 400 | 0.2239 |
| 0.1839 | 0.25 | 500 | 0.2154 |
| 0.1845 | 0.3 | 600 | 0.2169 |
| 0.2536 | 0.35 | 700 | 0.2185 |
| 0.1649 | 0.4 | 800 | 0.2153 |
| 0.2767 | 0.45 | 900 | 0.2056 |
| 0.1939 | 0.5 | 1000 | 0.2120 |
| 0.1093 | 0.55 | 1100 | 0.1975 |
| 0.1852 | 0.6 | 1200 | 0.1912 |
| 0.1077 | 0.65 | 1300 | 0.1930 |
| 0.1129 | 0.7 | 1400 | 0.1959 |
| 0.1219 | 0.75 | 1500 | 0.1958 |
| 0.3024 | 0.8 | 1600 | 0.1882 |
| 0.2656 | 0.85 | 1700 | 0.1872 |
| 0.1666 | 0.9 | 1800 | 0.1849 |
| 0.1553 | 0.95 | 1900 | 0.1827 |
| 0.1477 | 1.0 | 2000 | 0.1825 |
### Framework versions
- PEFT 0.10.1.dev0
- Transformers 4.40.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 |
MM2157/AraBERT_token_classification__AraEval24_fixed | MM2157 | 2024-04-03T03:33:59Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2024-04-02T19:06:50Z | ---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: AraBERT_token_classification__AraEval24_fixed
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# AraBERT_token_classification__AraEval24_fixed
This model is a fine-tuned version of [aubmindlab/bert-base-arabert](https://huggingface.co/aubmindlab/bert-base-arabert) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8758
- Precision: 0.0901
- Recall: 0.0234
- F1: 0.0371
- Accuracy: 0.8606
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.6563 | 1.0 | 2851 | 0.7705 | 0.0391 | 0.0006 | 0.0012 | 0.8632 |
| 0.5865 | 2.0 | 5702 | 0.8071 | 0.0909 | 0.0028 | 0.0055 | 0.8636 |
| 0.5382 | 3.0 | 8553 | 0.7815 | 0.0578 | 0.0012 | 0.0024 | 0.8634 |
| 0.5043 | 4.0 | 11404 | 0.7883 | 0.0798 | 0.0021 | 0.0041 | 0.8633 |
| 0.4445 | 5.0 | 14255 | 0.8188 | 0.0801 | 0.0031 | 0.0060 | 0.8637 |
| 0.4295 | 6.0 | 17106 | 0.8070 | 0.0877 | 0.0155 | 0.0263 | 0.8610 |
| 0.4096 | 7.0 | 19957 | 0.8184 | 0.0949 | 0.0135 | 0.0236 | 0.8627 |
| 0.3827 | 8.0 | 22808 | 0.8362 | 0.0818 | 0.0181 | 0.0296 | 0.8600 |
| 0.3525 | 9.0 | 25659 | 0.8458 | 0.0893 | 0.0254 | 0.0395 | 0.8599 |
| 0.3434 | 10.0 | 28510 | 0.8758 | 0.0901 | 0.0234 | 0.0371 | 0.8606 |
### Framework versions
- Transformers 4.30.2
- Pytorch 1.12.1
- Datasets 2.13.2
- Tokenizers 0.13.3
|
Sumail/Barista21 | Sumail | 2024-04-03T03:30:27Z | 90 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2306.01708",
"base_model:coffiee/s31",
"base_model:merge:coffiee/s31",
"base_model:tomaszki/stablelm-5-copy",
"base_model:merge:tomaszki/stablelm-5-copy",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-03T03:28:26Z | ---
base_model:
- coffiee/s31
- rwh/s1
- tomaszki/stablelm-5-copy
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [coffiee/s31](https://huggingface.co/coffiee/s31) as a base.
### Models Merged
The following models were included in the merge:
* [rwh/s1](https://huggingface.co/rwh/s1)
* [tomaszki/stablelm-5-copy](https://huggingface.co/tomaszki/stablelm-5-copy)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: coffiee/s31
# no parameters necessary for base model
- model: rwh/s1
parameters:
density: 0.5
weight: 0.5
- model: tomaszki/stablelm-5-copy
parameters:
density: 0.5
weight: 0.3
merge_method: ties
base_model: coffiee/s31
parameters:
normalize: true
dtype: bfloat16
```
|
aaru2330/llama2-7b-chat | aaru2330 | 2024-04-03T03:28:49Z | 1 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:NousResearch/Llama-2-7b-chat-hf",
"base_model:adapter:NousResearch/Llama-2-7b-chat-hf",
"region:us"
]
| null | 2024-04-02T18:33:07Z | ---
library_name: peft
base_model: NousResearch/Llama-2-7b-chat-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0 |
aaru2330/llama | aaru2330 | 2024-04-03T03:26:57Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:NousResearch/Llama-2-7b-chat-hf",
"base_model:adapter:NousResearch/Llama-2-7b-chat-hf",
"region:us"
]
| null | 2024-04-03T03:23:50Z | ---
library_name: peft
base_model: NousResearch/Llama-2-7b-chat-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0 |
teleboas/alpaca_mistral-7b-v0.2-GGUF | teleboas | 2024-04-03T03:21:04Z | 10 | 0 | transformers | [
"transformers",
"gguf",
"mistral",
"en",
"dataset:yahma/alpaca-cleaned",
"base_model:unsloth/mistral-7b-v0.2-bnb-4bit",
"base_model:quantized:unsloth/mistral-7b-v0.2-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-03-24T06:10:02Z | ---
language:
- en
license: apache-2.0
tags:
- mistral
- gguf
base_model: unsloth/mistral-7b-v0.2-bnb-4bit
datasets:
- yahma/alpaca-cleaned
---
# Model description
- **Developed by:** teleboas
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-v0.2-bnb-4bit
This is the GGUF version of the model, made for the llama.cpp inference engine.
If you are looking for the transformers/fp16 model, it is available here: https://huggingface.co/teleboas/alpaca_mistral-7b-v0.2 |
nbeerbower/Flammen-Bruphin | nbeerbower | 2024-04-03T03:16:06Z | 37 | 1 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"base_model:flammenai/flammen13X-mistral-7B",
"base_model:merge:flammenai/flammen13X-mistral-7B",
"base_model:nbeerbower/bruphin-lambda",
"base_model:merge:nbeerbower/bruphin-lambda",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-02T22:07:27Z | ---
license: apache-2.0
base_model:
- nbeerbower/bruphin-lambda
- nbeerbower/flammen13X-mistral-7B
library_name: transformers
tags:
- mergekit
- merge
---
# Flammen-Bruphin
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [nbeerbower/bruphin-lambda](https://huggingface.co/nbeerbower/bruphin-lambda)
* [nbeerbower/flammen13X-mistral-7B](https://huggingface.co/nbeerbower/flammen13X-mistral-7B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: nbeerbower/bruphin-lambda
layer_range: [0, 32]
- model: nbeerbower/flammen13X-mistral-7B
layer_range: [0, 32]
merge_method: slerp
base_model: nbeerbower/flammen13X-mistral-7B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
|
waifu-diffusion/wd40 | waifu-diffusion | 2024-04-03T03:15:15Z | 16 | 17 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-04-01T04:28:33Z | ---
license: creativeml-openrail-m
thumbnail: >-
./images/wd40-icon.png
tags:
- stable-diffusion
- text-to-image
- safetensors
- diffusers
inference: true
language:
- en
widget:
- text: >-
1girl, solo, bangs, (pink hair, gradient hair, very long hair:1.1), (purple eyes:1.05), (cat ears, animal ear fluff:1.2), sidelocks, white shirt, collared shirt, buttons,
night, looking at viewer, table, pizza on table, pov, restaurant, medium breasts, smiling, (blush:0.7), colored inner hair, (symmetric), (masterpiece, exceptional, extremely detailed:1.1)
example_title: example
library_name: diffusers
---
<center>
<img src="https://i.imgur.com/V5TY0Qi.png" width="80%"/>
<h1 style="font-size:1.6rem;">
<b>wd40</b>
</h1>
<h2>a Stable Diffusion model for (mechanic) weebs</h2>
</center>
## Overview
`wd40` is a Stable Diffusion model trained on a dataset of anime-style images. It is based off ~~Stable Diffusion XL Base~~ [Kakigori v3](https://huggingface.co/nubby/Kakigori), and is designed to generate high-quality images of anime-style characters. The model is capable of generating images with a variety of attributes, such as hair color, eye color, and clothing style. As long as they're that exact one same catgirl and she's holding a can of WD-40.
If you're a big fan of spray lubricants and workshops, this is the model for you.
## Recipe
Hold right way up and shake before use. Turn the nozzle to be in line with the blue mark on the top of the can. Spray upright, at an angle, or even upside down.
<details>
In case you hadn't worked it out, no, this is not the real SDXL-based WD model, it's a meme joke april fools' model.
XL is 40 in roman numerals, and WD-40 is, well, WD-40.
So we got Bing to generate a bunch of catgirls holding cans of WD-40, and overtrained the shit out of some LoRa, and merged them into [Kakigori v3](https://huggingface.co/nubby/Kakigori) (thanks nubby!)
It was trained with a uniform distribution of all WD Tagger tags, so it should basically generate the exact same thing regardless of how you prompt it.
Is it good? Not really! but it sure is funny, and Derrian did an amazing job on the LoRAs.
</details>
### Credits
A big thankyou to [Derrian](https://huggingface.co/derriandistro), [nubby](https://huggingface.co/nubby), [ao](https://huggingface.co/aotsuyu), [yoinked](https://huggingface.co/parsee-mizuhashi), and many others!
### What?
This was our April Fool's Day joke for 2024 😉
|
Litzy619/V0402MP6 | Litzy619 | 2024-04-03T03:05:39Z | 0 | 0 | null | [
"safetensors",
"generated_from_trainer",
"base_model:microsoft/phi-2",
"base_model:finetune:microsoft/phi-2",
"license:mit",
"region:us"
]
| null | 2024-04-03T02:12:08Z | ---
license: mit
base_model: microsoft/phi-2
tags:
- generated_from_trainer
model-index:
- name: V0402MP6
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# V0402MP6
This model is a fine-tuned version of [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1571
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 20
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.5658 | 0.09 | 10 | 2.4014 |
| 2.2012 | 0.18 | 20 | 1.8503 |
| 1.6319 | 0.27 | 30 | 1.2819 |
| 1.1652 | 0.36 | 40 | 0.8876 |
| 0.8077 | 0.45 | 50 | 0.5264 |
| 0.4839 | 0.54 | 60 | 0.2636 |
| 0.2921 | 0.63 | 70 | 0.1897 |
| 0.2277 | 0.73 | 80 | 0.1682 |
| 0.2149 | 0.82 | 90 | 0.1602 |
| 0.2101 | 0.91 | 100 | 0.1574 |
| 0.2133 | 1.0 | 110 | 0.1571 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Sumail/Barista20 | Sumail | 2024-04-03T02:57:01Z | 90 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:coffiee/s31",
"base_model:finetune:coffiee/s31",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-03T02:55:04Z | ---
base_model:
- coffiee/s31
- rwh/s1
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [coffiee/s31](https://huggingface.co/coffiee/s31)
* [rwh/s1](https://huggingface.co/rwh/s1)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: coffiee/s31
layer_range: [0, 24]
- model: rwh/s1
layer_range: [0, 24]
merge_method: slerp
base_model: coffiee/s31
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
|
Debraj00/my-favorite-animal-tiger-debu | Debraj00 | 2024-04-03T02:52:32Z | 7 | 0 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-04-03T02:44:29Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Favorite-animal-Tiger-debu Dreambooth model trained by Debraj00 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: 27900121015
Sample pictures of this concept:

|
technozoom/stablediffusionleo | technozoom | 2024-04-03T02:49:32Z | 1 | 0 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"region:us"
]
| text-to-image | 2024-04-03T02:48:28Z | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: photo of sks leoandresmessi in synthwave sunset background
output:
url: images/2024-04-03_08-16.png
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: null
---
# sdxl-db-leo
<Gallery />
## Download model
Weights for this model are available in Safetensors format.
[Download](/technozoom/stablediffusionleo/tree/main) them in the Files & versions tab.
|
Nelver28/Mistral_Instruct_ChatBj | Nelver28 | 2024-04-03T02:48:48Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-03T02:41:40Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
qminh369/token-classification-llmlingua2-xlm-roberta-bctn-538_sample-10_epoch | qminh369 | 2024-04-03T02:45:46Z | 106 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-large",
"base_model:finetune:FacebookAI/xlm-roberta-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2024-04-03T02:43:27Z | ---
license: mit
base_model: FacebookAI/xlm-roberta-large
tags:
- generated_from_trainer
model-index:
- name: token-classification-llmlingua2-xlm-roberta-bctn-538_sample-10_epoch
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# token-classification-llmlingua2-xlm-roberta-bctn-538_sample-10_epoch
This model is a fine-tuned version of [FacebookAI/xlm-roberta-large](https://huggingface.co/FacebookAI/xlm-roberta-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5526
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 108 | 0.5838 |
| No log | 2.0 | 216 | 0.5774 |
| No log | 3.0 | 324 | 0.5648 |
| No log | 4.0 | 432 | 0.5918 |
| 0.5406 | 5.0 | 540 | 0.5526 |
| 0.5406 | 6.0 | 648 | 0.5939 |
| 0.5406 | 7.0 | 756 | 0.5937 |
| 0.5406 | 8.0 | 864 | 0.5791 |
| 0.5406 | 9.0 | 972 | 0.6025 |
| 0.4161 | 10.0 | 1080 | 0.5947 |
### Framework versions
- Transformers 4.39.0.dev0
- Pytorch 2.2.1+cu118
- Datasets 2.18.0
- Tokenizers 0.15.2
|
ntvcie/gemma_Vinh_test_01 | ntvcie | 2024-04-03T02:44:25Z | 128 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-03T02:41:12Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
cx-olquinjica/AngOFA-SYN | cx-olquinjica | 2024-04-03T02:36:56Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"kmb",
"kon",
"cjk",
"umb",
"lua",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2024-04-03T01:47:53Z | ---
license: apache-2.0
language:
- kmb
- kon
- cjk
- umb
- lua
--- |
blockblockblock/Mistral-12.25B-Instruct-v0.2-bpw4.8 | blockblockblock | 2024-04-03T02:36:15Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2312.15166",
"arxiv:2310.06825",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"exl2",
"region:us"
]
| text-generation | 2024-04-03T02:33:08Z | ---
base_model: []
library_name: transformers
tags:
- mergekit
- merge
license: apache-2.0
---
# Credit for the model card's description goes to ddh0, mergekit, and, mistralai
# Mistral-12.25B-Instruct-v0.2
This is Mistral-12.25B-Instruct-v0.2, a depth-upscaled version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2).
This model is intended to be used as a basis for further fine-tuning, or as a drop-in upgrade from the original 7 billion parameter model.
Paper detailing how Depth-Up Scaling works: [SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling](https://arxiv.org/abs/2312.15166)
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
# UpStage's conclusionary limitations of their research:
"Our study on the Depth Up-Scaling (DUS) has important limitations and considerations. **One key limitation is the need for more thorough explorations of hyperparameters used in the DUS approach. Namely, we removed m = 8 layers from both ends of our base model, primarily due to hardware limitations. However, we have not yet determined if this value is optimal for enhancing performance.** The extended time and cost of continued pretraining made it challenging to conduct more comprehensive experiments, which we aim to address in future work through various comparative analyses."
This model was made to help test whether 10.7B parameters (m = 8) is better or worse than 10.7B+ parameters (m < 8)
## Merge Details
### Merge Method
This model was merged using the passthrough merge method.
### Models Merged
The following models were included in the merge:
* /Users/jsarnecki/opt/Workspace/mistralai/Mistral-7B-Instruct-v0.2
### Configuration
The following YAML configuration was used to produce this model:
```yaml
dtype: bfloat16
merge_method: passthrough
# Depth UpScaled (DUS) version of Mistral-7B-Instruct-v0.2
# where m = 4 (The number of layers to remove from the model)
# s = 56 (The number of layers the model will have after the DUS)
slices:
- sources:
- layer_range: [0, 28]
model: /Users/jsarnecki/opt/Workspace/mistralai/Mistral-7B-Instruct-v0.2
- sources:
- layer_range: [4, 32]
model: /Users/jsarnecki/opt/Workspace/mistralai/Mistral-7B-Instruct-v0.2
```
# Model Card for Mistral-7B-Instruct-v0.2
The Mistral-7B-Instruct-v0.2 Large Language Model (LLM) is an instruct fine-tuned version of the Mistral-7B-v0.2.
Mistral-7B-v0.2 has the following changes compared to Mistral-7B-v0.1
- 32k context window (vs 8k context in v0.1)
- Rope-theta = 1e6
- No Sliding-Window Attention
For full details of this model please read our [paper](https://arxiv.org/abs/2310.06825) and [release blog post](https://mistral.ai/news/la-plateforme/).
## Instruction format
In order to leverage instruction fine-tuning, your prompt should be surrounded by `[INST]` and `[/INST]` tokens. The very first instruction should begin with a begin of sentence id. The next instructions should not. The assistant generation will be ended by the end-of-sentence token id.
E.g.
```
text = "<s>[INST] What is your favourite condiment? [/INST]"
"Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!</s> "
"[INST] Do you have mayonnaise recipes? [/INST]"
```
This format is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating) via the `apply_chat_template()` method:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
## Troubleshooting
- If you see the following error:
```
Traceback (most recent call last):
File "", line 1, in
File "/transformers/models/auto/auto_factory.py", line 482, in from_pretrained
config, kwargs = AutoConfig.from_pretrained(
File "/transformers/models/auto/configuration_auto.py", line 1022, in from_pretrained
config_class = CONFIG_MAPPING[config_dict["model_type"]]
File "/transformers/models/auto/configuration_auto.py", line 723, in getitem
raise KeyError(key)
KeyError: 'mistral'
```
Installing transformers from source should solve the issue
pip install git+https://github.com/huggingface/transformers
This should not be required after transformers-v4.33.4.
## Limitations
The Mistral 7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Louis Ternon, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. |
SungJinD/ppo-LunarLander-v2-optuna | SungJinD | 2024-04-03T02:34:40Z | 1 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2024-04-03T02:34:23Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 268.20 +/- 22.15
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Litzy619/V0402MP5 | Litzy619 | 2024-04-03T02:09:38Z | 0 | 0 | null | [
"safetensors",
"generated_from_trainer",
"base_model:microsoft/phi-2",
"base_model:finetune:microsoft/phi-2",
"license:mit",
"region:us"
]
| null | 2024-04-03T01:06:36Z | ---
license: mit
base_model: microsoft/phi-2
tags:
- generated_from_trainer
model-index:
- name: V0402MP5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# V0402MP5
This model is a fine-tuned version of [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1581
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 20
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.5643 | 0.09 | 10 | 2.3573 |
| 2.1608 | 0.18 | 20 | 1.8527 |
| 1.6271 | 0.27 | 30 | 1.2732 |
| 1.1558 | 0.36 | 40 | 0.8683 |
| 0.7761 | 0.45 | 50 | 0.5042 |
| 0.4741 | 0.54 | 60 | 0.2558 |
| 0.2937 | 0.63 | 70 | 0.1866 |
| 0.2332 | 0.73 | 80 | 0.1681 |
| 0.2203 | 0.82 | 90 | 0.1613 |
| 0.2151 | 0.91 | 100 | 0.1585 |
| 0.2205 | 1.0 | 110 | 0.1581 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
|
KaggleMasterX/RobertaTok6ep | KaggleMasterX | 2024-04-03T02:04:48Z | 0 | 0 | transformers | [
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-03T02:04:45Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
OwOOwO/srry_i_love_you1 | OwOOwO | 2024-04-03T02:00:26Z | 90 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-03T01:58:52Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
qiuhuachuan/MeChat | qiuhuachuan | 2024-04-03T01:52:05Z | 193 | 27 | transformers | [
"transformers",
"pytorch",
"chatglm",
"feature-extraction",
"mental health",
"text-generation",
"custom_code",
"zh",
"arxiv:2305.00450",
"license:mit",
"region:us"
]
| text-generation | 2023-05-30T03:15:52Z | ---
license: mit
language:
- zh
metrics:
- bleu
- rouge
- meteor
- perplexity
pipeline_tag: text-generation
tags:
- mental health
---
# 中文心理健康支持对话数据集(SmileChat)与大模型(MeChat)
<div style='display: flex; flex-direction: row'>
<img src="https://img.shields.io/badge/Version-1.0-brightgreen" style='margin-left: 10px;' />
<img src="https://img.shields.io/badge/python-3.8+-blue.svg" style='margin-left: 10px;' />
<a href='https://arxiv.org/pdf/2305.00450.pdf' style='margin-left: 10px;'><img src='https://img.shields.io/badge/ArXiv-2305.00450-red'></a>
</div>
## 项目简介
**For more details, see our paper:** [smile paper](https://arxiv.org/pdf/2305.00450.pdf 'smile paper')
🎉🎉🎉 **MeChat** (**Me**ntal Health Support **Chat**bot)
**背景**:我们都知道心理健康的重要性以及心理健康问题一直是我们关注的焦点。开发用于心理健康支持的专业化对话系统引起了学术界的巨大关注。
**动机**:事实上,建立一个实用、安全、有效的心理健康对话智能体是许多研究人员一直追求的目标。然而,创建这样一个系统的第一步就是要有训练数据。
**挑战**:收集并发布这一类高质量的、真实的大规模数据来促进这一领域的发展面对诸多挑战。首先是数据隐私保护的问题、其次是收集数据所耗费的大量时间与各种成本(平台搭建、真实的受试者与专业的支持者的招聘、筛选、管理等)。
**研究意义**:由大语言模型驱动的虚拟咨询师,作为一种用于心理健康的创新解决思路,可以有效地解决获得性障碍,如高昂的治疗费用、训练有素的专业人员的短缺。此外,该对话系统可以为有需要的人提供有效且实用的在线咨询,能够保护用户隐私,减轻在求助过程中的耻感。
**方法**:我们提出了SMILE (Single-turn to Multi-turn Inclusive Language Expansion),一种单轮对话到多轮对话的包容性语言扩展技术。具体来说,利用ChatGPT将单轮长对话转换为多轮对话,更好地模拟了真实世界中求助者与支持者之间的多轮对话交流。
**结果**:我们首先对语言转换进行分析,相比其他基线方法,验证了我们提出方法的可行性。其次,我们完成了对话多样性的研究,包括词汇特征、语义特征和对话主题,阐明我们所提方法的有效性。再者,我们通过专家评估,证明了所提方法生成数据的质量高于其他基线方法。因此,我们利用此方法进行大规模数据生成,构建了一个约55k的多轮对话数据集。最后,为了更好的评估该数据集的质量,我们利用此数据集训练了一个用于心理健康支持的聊天机器人。在真实数据集的自动化评估和人类与对话系统的交互评估,结果均表明对话系统在心理健康支持能力得到显著提升,进一步证实所生成的数据集具备高质量和实用性的特性。
**未来展望**:利用生成的数据来训练模型,并用于心理健康支持是一个不错的选择。但我们注意到,现有生成数据的对话轮数较短,与真实咨询数据的策略分布上存在一定的差距。因此,秉持让用户受益的原则,需要重点关注模型安全性能,包括自杀干预、敏感信息应对和避免错误信息等,我们任重道远。
本项目开源的**中文心理健康支持模型**由 ChatGLM2-6B LoRA 指令微调得到。数据集通过扩展真实的心理互助 QA为多轮的心理健康支持多轮对话,提高了通用语言大模型**在心理健康支持领域能力的表现**,更加符合在长程多轮对话的应用场景。
## SMILE 方法
基于 PsyQA 使用 ChatGPT 生成了一轮,并使用自动化过滤:保证轮数不低于 5,符合对话格式,方法如下:
<p align="center">
<img src="./SMILE_method.png" width=600px/>
</p>
## 术语说明
- client (来访者) == help-seeker (求助者)
- counselor (咨询师) == supporter (支持者)
### 模型地址
https://huggingface.co/qiuhuachuan/MeChat
## 快速开始
1. 配置环境
```bash
pip install -r requirements.txt
```
2. 运行交互文件 MeChat.py(要求单卡显存 >= 20G)
```bash
python MeChat.py
```
```Python
from transformers import AutoTokenizer, AutoModel
def get_dialogue_history(dialogue_history_list: list):
dialogue_history_tmp = []
for item in dialogue_history_list:
if item['role'] == 'counselor':
text = '咨询师:'+ item['content']
else:
text = '来访者:'+ item['content']
dialogue_history_tmp.append(text)
dialogue_history = '\n'.join(dialogue_history_tmp)
return dialogue_history + '\n' + '咨询师:'
def get_instruction(dialogue_history):
instruction = f'''现在你扮演一位专业的心理咨询师,你具备丰富的心理学和心理健康知识。你擅长运用多种心理咨询技巧,例如认知行为疗法原则、动机访谈技巧和解决问题导向的短期疗法。以温暖亲切的语气,展现出共情和对来访者感受的深刻理解。以自然的方式与来访者进行对话,避免过长或过短的回应,确保回应流畅且类似人类的对话。提供深层次的指导和洞察,使用具体的心理概念和例子帮助来访者更深入地探索思想和感受。避免教导式的回应,更注重共情和尊重来访者的感受。根据来访者的反馈调整回应,确保回应贴合来访者的情境和需求。请为以下的对话生成一个回复。
对话:
{dialogue_history}'''
return instruction
tokenizer = AutoTokenizer.from_pretrained('qiuhuachuan/MeChat', trust_remote_code=True)
model = AutoModel.from_pretrained('qiuhuachuan/MeChat', trust_remote_code=True).half().cuda()
model = model.eval()
dialogue_history_list = []
while True:
usr_msg = input('来访者:')
if usr_msg == '0':
exit()
else:
dialogue_history_list.append({
'role': 'client',
'content': usr_msg
})
dialogue_history = get_dialogue_history(dialogue_history_list=dialogue_history_list)
instruction = get_instruction(dialogue_history=dialogue_history)
response, history = model.chat(tokenizer, instruction, history=[], temperature=0.8, top_p=0.8)
print(f'咨询师:{response}')
dialogue_history_list.append({
'role': 'counselor',
'content': response
})
```
以下是一个交互示例:
```txt
来访者:你好
咨询师:你好,很高兴能够帮助到你。你可以告诉我更多关于你的情况吗?
来访者:我最近睡眠很差怎么办?
咨询师:最近睡眠质量不好,你有没有尝试过一些方法来改善睡眠呢?
来访者:我可能最近晚上睡觉前总喜欢玩手机,越玩人就越兴奋
咨询师:晚上玩手机确实会刺激大脑,导致入睡困难。你可以尝试在睡觉前设定一个手机使用时间,逐渐减少玩手机的时间,以帮助放松入睡。
来访者:我应该设置一个晚上9点的闹钟,强制我不玩手机,让我的大脑开始放松。
咨询师:是的,设置一个晚上的闹钟是一个很好的方法。你可以尝试在9点之前放下手机,让自己进入放松的状态,然后逐渐入睡。
来访者:我 尝 试了一下,看看能否改善?
咨询师:很好,试试看吧。另外,你还可以尝试一些放松的技巧,比如深呼吸、冥想或者听一些轻柔的音乐来帮助你放松身心,帮助入睡。
来访者:非常感谢你的建议,我会去试试的
咨询师:不客气,希望这些方法能对你有所帮助。如果还有其他问题,随时都可以来找我倾诉。
```
## 模型训练
### 数据转换
`data` 目录下包含使用 `smile` 方法构建的所有对话。详情可参考论文细节。
执行以下脚本,我们将获得 310,087 训练样本。
```Python
convert_to_training_set.py
```
一个训练样本如下:
```json
{
"instruction": "现在你扮演一位专业的心理咨询师,你具备丰富的心理学和心理健康知识。你擅长运用多种心理咨询技巧,例如认知行为疗法原则、动机访谈技巧和解决问题导向的短期疗法。以温暖亲切的语气,展现出共情和对来访者感受的深刻理解。以自然的方式与来访者进行对话,避免过长或过短的回应,确保回应流畅且类似人类的对话。提供深层次的指导和洞察,使用具体的心理概念和例子帮助来访者更深入地探索思想和感受。避免教导式的回应,更注重共情和尊重来访者的感受。根据来访者的反馈调整回应,确保回应贴合来访者的情境和需求。请为以下的对话生成一个回复。\n\n对话:\n来访者:高三后的迷茫,高考前的恐惧,能给我一些建议么?\n咨询师:看到你的提问感觉你很焦虑,这个状态在高中高压下很容易出现。我想说的是,我看到了你的决心。这点是很多人没有的!高考最重要的不是知识是心态。是必胜的心态!什么放松吧缓缓吧,都是站着说话不腰疼,保送的又不是我,我能放松什么?!我有我的目标,我怎么可能放弃!有目标就好办,计划!缺个计划,缺个时间合理配置的复习计划。\n来访者:你说的对,我是非常焦虑,确实需要调整心态。我也明白高考的心态很重要,但是要怎样才能真正拥有必胜的心态呢?\n咨询师:首先,你要明确自己的目标,既然你想考本科,那就要为此做好准备。然后,你需要制定一个合理的复习计划,根据自己的情况来安排每天的学习时间和内容。这样可以帮助你更好地掌控整个复习过程,减少焦虑感。\n来访者:我确实没有一个合理的复习计划,每天都觉得时间不够用,也不知道该从何开始。你能给我一些建议吗?\n咨询师:",
"output": "当然可以!你可以从高一开始,试试题海战术。每天多做一些题目,这样能够提高你的学习效率。同时,对于英语这门科目,多听多背是很重要的,数理化方面,可以做一些经典的题目,特别是那些类型经常考到的题目,多次反复做题。"
}
```
## 引用
如果你使用了本项目的数据或者代码,请声明引用
```
@misc{qiu2023smile,
title={SMILE: Single-turn to Multi-turn Inclusive Language Expansion via ChatGPT for Mental Health Support},
author={Huachuan Qiu and Hongliang He and Shuai Zhang and Anqi Li and Zhenzhong Lan},
year={2023},
eprint={2305.00450},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## 免责声明
我们的心理健康支持对话机器人(以下简称"机器人")旨在为用户提供情感支持和心理健康建议。然而,机器人不是医疗保健专业人员,不能替代医生、心理医生或其他专业人士的意见、诊断、建议或治疗。
机器人提供的建议和信息是基于算法和机器学习技术,可能并不适用于所有用户或所有情况。因此,我们建议用户在使用机器人之前咨询医生或其他专业人员,了解是否适合使用此服务。
机器人并不保证提供的建议和信息的准确性、完整性、及时性或适用性。用户应自行承担使用机器人服务的所有风险。我们对用户使用机器人服务所产生的任何后果不承担任何责任,包括但不限于任何直接或间接的损失、伤害、精神疾病、财产损失或任何其他损害。
我们强烈建议用户在使用机器人服务时,遵循以下原则:
1. 机器人并不是医疗保健专业人士,不能替代医生、心理医生或其他专业人士的意见、诊断、建议或治疗。如果用户需要专业医疗或心理咨询服务,应寻求医生或其他专业人士的帮助。
2. 机器人提供的建议和信息仅供参考,用户应自己判断是否适合自己的情况和需求。如果用户对机器人提供的建议和信息有任何疑问或不确定,请咨询医生或其他专业人士的意见。
3. 用户应保持冷静、理性和客观,不应将机器人的建议和信息视为绝对真理或放弃自己的判断力。如果用户对机器人的建议和信息产生质疑或不同意,应停止使用机器人服务并咨询医生或其他专业人士的意见。
4. 用户应遵守机器人的使用规则和服务条款,不得利用机器人服务从事任何非法、违规或侵犯他人权益的行为。
5. 用户应保护个人隐私,不应在使用机器人服务时泄露个人敏感信息或他人隐私。
6. 平台收集的数据用于学术研究。
最后,我们保留随时修改、更新、暂停或终止机器人服务的权利,同时也保留对本免责声明进行修改、更新或补充的权利。如果用户继续使用机器人服务,即视为同意本免责声明的全部内容和条款。 |
blockblockblock/Mistral-12.25B-Instruct-v0.2-bpw4.4 | blockblockblock | 2024-04-03T01:49:36Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2312.15166",
"arxiv:2310.06825",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"exl2",
"region:us"
]
| text-generation | 2024-04-03T01:46:24Z | ---
base_model: []
library_name: transformers
tags:
- mergekit
- merge
license: apache-2.0
---
# Credit for the model card's description goes to ddh0, mergekit, and, mistralai
# Mistral-12.25B-Instruct-v0.2
This is Mistral-12.25B-Instruct-v0.2, a depth-upscaled version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2).
This model is intended to be used as a basis for further fine-tuning, or as a drop-in upgrade from the original 7 billion parameter model.
Paper detailing how Depth-Up Scaling works: [SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling](https://arxiv.org/abs/2312.15166)
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
# UpStage's conclusionary limitations of their research:
"Our study on the Depth Up-Scaling (DUS) has important limitations and considerations. **One key limitation is the need for more thorough explorations of hyperparameters used in the DUS approach. Namely, we removed m = 8 layers from both ends of our base model, primarily due to hardware limitations. However, we have not yet determined if this value is optimal for enhancing performance.** The extended time and cost of continued pretraining made it challenging to conduct more comprehensive experiments, which we aim to address in future work through various comparative analyses."
This model was made to help test whether 10.7B parameters (m = 8) is better or worse than 10.7B+ parameters (m < 8)
## Merge Details
### Merge Method
This model was merged using the passthrough merge method.
### Models Merged
The following models were included in the merge:
* /Users/jsarnecki/opt/Workspace/mistralai/Mistral-7B-Instruct-v0.2
### Configuration
The following YAML configuration was used to produce this model:
```yaml
dtype: bfloat16
merge_method: passthrough
# Depth UpScaled (DUS) version of Mistral-7B-Instruct-v0.2
# where m = 4 (The number of layers to remove from the model)
# s = 56 (The number of layers the model will have after the DUS)
slices:
- sources:
- layer_range: [0, 28]
model: /Users/jsarnecki/opt/Workspace/mistralai/Mistral-7B-Instruct-v0.2
- sources:
- layer_range: [4, 32]
model: /Users/jsarnecki/opt/Workspace/mistralai/Mistral-7B-Instruct-v0.2
```
# Model Card for Mistral-7B-Instruct-v0.2
The Mistral-7B-Instruct-v0.2 Large Language Model (LLM) is an instruct fine-tuned version of the Mistral-7B-v0.2.
Mistral-7B-v0.2 has the following changes compared to Mistral-7B-v0.1
- 32k context window (vs 8k context in v0.1)
- Rope-theta = 1e6
- No Sliding-Window Attention
For full details of this model please read our [paper](https://arxiv.org/abs/2310.06825) and [release blog post](https://mistral.ai/news/la-plateforme/).
## Instruction format
In order to leverage instruction fine-tuning, your prompt should be surrounded by `[INST]` and `[/INST]` tokens. The very first instruction should begin with a begin of sentence id. The next instructions should not. The assistant generation will be ended by the end-of-sentence token id.
E.g.
```
text = "<s>[INST] What is your favourite condiment? [/INST]"
"Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!</s> "
"[INST] Do you have mayonnaise recipes? [/INST]"
```
This format is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating) via the `apply_chat_template()` method:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
## Troubleshooting
- If you see the following error:
```
Traceback (most recent call last):
File "", line 1, in
File "/transformers/models/auto/auto_factory.py", line 482, in from_pretrained
config, kwargs = AutoConfig.from_pretrained(
File "/transformers/models/auto/configuration_auto.py", line 1022, in from_pretrained
config_class = CONFIG_MAPPING[config_dict["model_type"]]
File "/transformers/models/auto/configuration_auto.py", line 723, in getitem
raise KeyError(key)
KeyError: 'mistral'
```
Installing transformers from source should solve the issue
pip install git+https://github.com/huggingface/transformers
This should not be required after transformers-v4.33.4.
## Limitations
The Mistral 7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Louis Ternon, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. |
Crody/NovaSpace | Crody | 2024-04-03T01:46:03Z | 0 | 1 | null | [
"license:creativeml-openrail-m",
"region:us"
]
| null | 2024-04-03T01:25:45Z | ---
license: creativeml-openrail-m
---
|
ashishp-wiai/vit-base-patch16-224-in21k-finetuned-os300 | ashishp-wiai | 2024-04-03T01:45:14Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2024-04-02T20:37:42Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
alterf/rec_v1 | alterf | 2024-04-03T01:41:42Z | 194 | 0 | transformers | [
"transformers",
"safetensors",
"table-transformer",
"object-detection",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| object-detection | 2024-03-25T14:01:25Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
RioShiina/Swallow-70b-instruct-exl2 | RioShiina | 2024-04-03T01:41:35Z | 1 | 0 | null | [
"text-generation",
"ja",
"en",
"base_model:tokyotech-llm/Swallow-70b-instruct-hf",
"base_model:finetune:tokyotech-llm/Swallow-70b-instruct-hf",
"license:llama2",
"region:us"
]
| text-generation | 2024-03-28T14:33:07Z | ---
license: llama2
language:
- ja
- en
base_model: tokyotech-llm/Swallow-70b-instruct-hf
pipeline_tag: text-generation
---
**[2.2bpw](https://huggingface.co/rioshiina/Swallow-70b-instruct-exl2/tree/2.2bpw)** (high quality loss, only for 24GB vRAM test.)
**[4.0bpw](https://huggingface.co/rioshiina/Swallow-70b-instruct-exl2/tree/4.0bpw)**
**[6.0bpw](https://huggingface.co/rioshiina/Swallow-70b-instruct-exl2/tree/6.0bpw)**
**[8.0bpw](https://huggingface.co/rioshiina/Swallow-70b-instruct-exl2/tree/8.0bpw)**
# Swallow-70b-instruct-exl2
- Model creator: [tokyotech-llm](https://huggingface.co/tokyotech-llm)
- Original model: [Swallow-70b-instruct-hf](https://huggingface.co/tokyotech-llm/Swallow-70b-instruct-hf)
## Prompt template
```
### 指示:
{instruction}
### 入力:
{input}
### 応答:
```
### Licence
Llama 2 is licensed under the LLAMA 2 Community License, Copyright (c) Meta Platforms, Inc. All Rights Reserved. |
raminass/M4-eval | raminass | 2024-04-03T01:37:57Z | 132 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:raminass/scotus-v10",
"base_model:finetune:raminass/scotus-v10",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-04-02T20:08:26Z | ---
license: cc-by-sa-4.0
base_model: raminass/scotus-v10
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: M4-eval
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# M4-eval
This model is a fine-tuned version of [raminass/scotus-v10](https://huggingface.co/raminass/scotus-v10) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9105
- Accuracy: 0.7481
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7992 | 1.0 | 2170 | 1.0012 | 0.7062 |
| 0.4416 | 2.0 | 4340 | 0.9189 | 0.7383 |
| 0.2695 | 3.0 | 6510 | 0.9105 | 0.7481 |
### Framework versions
- Transformers 4.38.0
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
Asahina2K/Animagine-xl-3.1-diffuser-variant-fp16 | Asahina2K | 2024-04-03T01:33:29Z | 554 | 0 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"safetensors",
"stable-diffusion-xl",
"en",
"base_model:cagliostrolab/animagine-xl-3.0",
"base_model:finetune:cagliostrolab/animagine-xl-3.0",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
]
| text-to-image | 2024-04-03T00:57:41Z | ---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
tags:
- text-to-image
- stable-diffusion
- safetensors
- stable-diffusion-xl
base_model: cagliostrolab/animagine-xl-3.0
widget:
- text: 1girl, green hair, sweater, looking at viewer, upper body, beanie, outdoors, night, turtleneck, masterpiece, best quality, very aesthetic, absurdes
parameter:
negative_prompt: nsfw, lowres, (bad), text, error, fewer, extra, missing, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract]
example_title: 1girl
- text: 1boy, male focus, green hair, sweater, looking at viewer, upper body, beanie, outdoors, night, turtleneck, masterpiece, best quality, very aesthetic, absurdes
parameter:
negative_prompt: nsfw, lowres, (bad), text, error, fewer, extra, missing, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract]
example_title: 1boy
---
<style>
.title-container {
display: flex;
justify-content: center;
align-items: center;
height: 100vh; /* Adjust this value to position the title vertically */
}
.title {
font-size: 2.5em;
text-align: center;
color: #333;
font-family: 'Helvetica Neue', sans-serif;
text-transform: uppercase;
letter-spacing: 0.1em;
padding: 0.5em 0;
background: transparent;
}
.title span {
background: -webkit-linear-gradient(45deg, #7ed56f, #28b485);
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
}
.custom-table {
table-layout: fixed;
width: 100%;
border-collapse: collapse;
margin-top: 2em;
}
.custom-table td {
width: 50%;
vertical-align: top;
padding: 10px;
box-shadow: 0px 0px 0px 0px rgba(0, 0, 0, 0.15);
}
.custom-image-container {
position: relative;
width: 100%;
margin-bottom: 0em;
overflow: hidden;
border-radius: 10px;
transition: transform .7s;
/* Smooth transition for the container */
}
.custom-image-container:hover {
transform: scale(1.05);
/* Scale the container on hover */
}
.custom-image {
width: 100%;
height: auto;
object-fit: cover;
border-radius: 10px;
transition: transform .7s;
margin-bottom: 0em;
}
.nsfw-filter {
filter: blur(8px); /* Apply a blur effect */
transition: filter 0.3s ease; /* Smooth transition for the blur effect */
}
.custom-image-container:hover .nsfw-filter {
filter: none; /* Remove the blur effect on hover */
}
.overlay {
position: absolute;
bottom: 0;
left: 0;
right: 0;
color: white;
width: 100%;
height: 40%;
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
font-size: 1vw;
font-style: bold;
text-align: center;
opacity: 0;
/* Keep the text fully opaque */
background: linear-gradient(0deg, rgba(0, 0, 0, 0.8) 60%, rgba(0, 0, 0, 0) 100%);
transition: opacity .5s;
}
.custom-image-container:hover .overlay {
opacity: 1;
}
.overlay-text {
background: linear-gradient(45deg, #7ed56f, #28b485);
-webkit-background-clip: text;
color: transparent;
text-shadow: 2px 2px 4px rgba(0, 0, 0, 0.7);
.overlay-subtext {
font-size: 0.75em;
margin-top: 0.5em;
font-style: italic;
}
.overlay,
.overlay-subtext {
text-shadow: 2px 2px 4px rgba(0, 0, 0, 0.5);
}
</style>
<h1 class="title">
<span>Animagine XL 3.1</span>
</h1>
<h1 class="title">
<span>Diffuser Variant fp16 Edition</span>
</h1>
<table class="custom-table">
<tr>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/6365c8dbf31ef76df4042821/yq_5AWegnLsGyCYyqJ-1G.png" alt="sample1">
</div>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/6365c8dbf31ef76df4042821/sp6w1elvXVTbckkU74v3o.png" alt="sample4">
</div>
</td>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/6365c8dbf31ef76df4042821/OYBuX1XzffN7Pxi4c75JV.png" alt="sample2">
</div>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/6365c8dbf31ef76df4042821/ytT3Oaf-atbqrnPIqz_dq.png" alt="sample3">
</td>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/6365c8dbf31ef76df4042821/0oRq204okFxRGECmrIK6d.png" alt="sample1">
</div>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/6365c8dbf31ef76df4042821/DW51m0HlDuAlXwu8H8bIS.png" alt="sample4">
</div>
</td>
</tr>
</table>
**Animagine XL 3.1** is an update in the Animagine XL V3 series, enhancing the previous version, Animagine XL 3.0. This open-source, anime-themed text-to-image model has been improved for generating anime-style images with higher quality. It includes a broader range of characters from well-known anime series, an optimized dataset, and new aesthetic tags for better image creation. Built on Stable Diffusion XL, Animagine XL 3.1 aims to be a valuable resource for anime fans, artists, and content creators by producing accurate and detailed representations of anime characters.
**What is the difference between [cagliostrolab/animagine-xl-3.1](https://huggingface.co/cagliostrolab/animagine-xl-3.1) and this repo?**
This repo is specialized to load diffuser using `variant="fp16"` argument.
## Model Details
- **Developed by**: [Cagliostro Research Lab](https://huggingface.co/cagliostrolab)
- **In collaboration with**: [SeaArt.ai](https://www.seaart.ai/)
- **Model type**: Diffusion-based text-to-image generative model
- **Model Description**: Animagine XL 3.1 generates high-quality anime images from textual prompts. It boasts enhanced hand anatomy, improved concept understanding, and advanced prompt interpretation.
- **License**: [Fair AI Public License 1.0-SD](https://freedevproject.org/faipl-1.0-sd/)
- **Fine-tuned from**: [Animagine XL 3.0](https://huggingface.co/cagliostrolab/animagine-xl-3.0)
## Gradio & Colab Integration
Try the demo powered by Gradio in Huggingface Spaces: [](https://huggingface.co/spaces/cagliostrolab/animagine-xl-3.1)
Or open the demo in Google Colab: [](https://colab.research.google.com/#fileId=https%3A//huggingface.co/spaces/cagliostrolab/animagine-xl-3.1/blob/main/demo.ipynb)
## 🧨 Diffusers Installation
First install the required libraries:
```bash
pip install diffusers transformers accelerate safetensors --upgrade
```
Then run image generation with the following example code:
```python
import torch
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(
"Asahina2K/Animagine-xl-3.1-diffuser-variant-fp16",
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16"
)
pipe.to('cuda')
prompt = "1girl, souryuu asuka langley, neon genesis evangelion, solo, upper body, v, smile, looking at viewer, outdoors, night"
negative_prompt = "nsfw, lowres, (bad), text, error, fewer, extra, missing, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract]"
image = pipe(
prompt,
negative_prompt=negative_prompt,
width=832,
height=1216,
guidance_scale=7,
num_inference_steps=28
).images[0]
image.save("./output/asuka_test.png")
```
## Usage Guidelines
### Tag Ordering
For optimal results, it's recommended to follow the structured prompt template because we train the model like this:
```
1girl/1boy, character name, from what series, everything else in any order.
```
## Special Tags
Animagine XL 3.1 utilizes special tags to steer the result toward quality, rating, creation date and aesthetic. While the model can generate images without these tags, using them can help achieve better results.
### Quality Modifiers
Quality tags now consider both scores and post ratings to ensure a balanced quality distribution. We've refined labels for greater clarity, such as changing 'high quality' to 'great quality'.
| Quality Modifier | Score Criterion |
|------------------|-------------------|
| `masterpiece` | > 95% |
| `best quality` | > 85% & ≤ 95% |
| `great quality` | > 75% & ≤ 85% |
| `good quality` | > 50% & ≤ 75% |
| `normal quality` | > 25% & ≤ 50% |
| `low quality` | > 10% & ≤ 25% |
| `worst quality` | ≤ 10% |
### Rating Modifiers
We've also streamlined our rating tags for simplicity and clarity, aiming to establish global rules that can be applied across different models. For example, the tag 'rating: general' is now simply 'general', and 'rating: sensitive' has been condensed to 'sensitive'.
| Rating Modifier | Rating Criterion |
|-------------------|------------------|
| `safe` | General |
| `sensitive` | Sensitive |
| `nsfw` | Questionable |
| `explicit, nsfw` | Explicit |
### Year Modifier
We've also redefined the year range to steer results towards specific modern or vintage anime art styles more accurately. This update simplifies the range, focusing on relevance to current and past eras.
| Year Tag | Year Range |
|----------|------------------|
| `newest` | 2021 to 2024 |
| `recent` | 2018 to 2020 |
| `mid` | 2015 to 2017 |
| `early` | 2011 to 2014 |
| `oldest` | 2005 to 2010 |
### Aesthetic Tags
We've enhanced our tagging system with aesthetic tags to refine content categorization based on visual appeal. These tags are derived from evaluations made by a specialized ViT (Vision Transformer) image classification model, specifically trained on anime data. For this purpose, we utilized the model [shadowlilac/aesthetic-shadow-v2](https://huggingface.co/shadowlilac/aesthetic-shadow-v2), which assesses the aesthetic value of content before it undergoes training. This ensures that each piece of content is not only relevant and accurate but also visually appealing.
| Aesthetic Tag | Score Range |
|-------------------|-------------------|
| `very aesthetic` | > 0.71 |
| `aesthetic` | > 0.45 & < 0.71 |
| `displeasing` | > 0.27 & < 0.45 |
| `very displeasing`| ≤ 0.27 |
## Recommended settings
To guide the model towards generating high-aesthetic images, use negative prompts like:
```
nsfw, lowres, (bad), text, error, fewer, extra, missing, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract]
```
For higher quality outcomes, prepend prompts with:
```
masterpiece, best quality, very aesthetic, absurdres
```
it’s recommended to use a lower classifier-free guidance (CFG Scale) of around 5-7, sampling steps below 30, and to use Euler Ancestral (Euler a) as a sampler.
### Multi Aspect Resolution
This model supports generating images at the following dimensions:
| Dimensions | Aspect Ratio |
|-------------------|-----------------|
| `1024 x 1024` | 1:1 Square |
| `1152 x 896` | 9:7 |
| `896 x 1152` | 7:9 |
| `1216 x 832` | 19:13 |
| `832 x 1216` | 13:19 |
| `1344 x 768` | 7:4 Horizontal |
| `768 x 1344` | 4:7 Vertical |
| `1536 x 640` | 12:5 Horizontal |
| `640 x 1536` | 5:12 Vertical |
## Training and Hyperparameters
**Animagine XL 3.1** was trained on 2x A100 80GB GPUs for approximately 15 days, totaling over 350 GPU hours. The training process consisted of three stages:
- **Pretraining**: Utilized a data-rich collection of 870k ordered and tagged images to increase Animagine XL 3.0's model knowledge.
- **Finetuning - First Stage**: Employed labeled and curated aesthetic datasets to refine the broken U-Net after pretraining.
- **Finetuning - Second Stage**: Utilized labeled and curated aesthetic datasets to refine the model's art style and improve hand and anatomy rendering.
### Hyperparameters
| Stage | Epochs | UNet lr | Train Text Encoder | Batch Size | Noise Offset | Optimizer | LR Scheduler | Grad Acc Steps | GPUs |
|--------------------------|--------|---------|--------------------|------------|--------------|------------|-------------------------------|----------------|------|
| **Pretraining** | 10 | 1e-5 | True | 16 | N/A | AdamW | Cosine Annealing Warm Restart | 3 | 2 |
| **Finetuning 1st Stage** | 10 | 2e-6 | False | 48 | 0.0357 | Adafactor | Constant with Warmup | 1 | 1 |
| **Finetuning 2nd Stage** | 15 | 1e-6 | False | 48 | 0.0357 | Adafactor | Constant with Warmup | 1 | 1 |
## Model Comparison (Pretraining only)
### Training Config
| Configuration Item | Animagine XL 3.0 | Animagine XL 3.1 |
|---------------------------------|------------------------------------------|------------------------------------------------|
| **GPU** | 2 x A100 80G | 2 x A100 80G |
| **Dataset** | 1,271,990 | 873,504 |
| **Shuffle Separator** | True | True |
| **Num Epochs** | 10 | 10 |
| **Learning Rate** | 7.5e-6 | 1e-5 |
| **Text Encoder Learning Rate** | 3.75e-6 | 1e-5 |
| **Effective Batch Size** | 48 x 1 x 2 | 16 x 3 x 2 |
| **Optimizer** | Adafactor | AdamW |
| **Optimizer Args** | Scale Parameter: False, Relative Step: False, Warmup Init: False | Weight Decay: 0.1, Betas: (0.9, 0.99) |
| **LR Scheduler** | Constant with Warmup | Cosine Annealing Warm Restart |
| **LR Scheduler Args** | Warmup Steps: 100 | Num Cycles: 10, Min LR: 1e-6, LR Decay: 0.9, First Cycle Steps: 9,099 |
Source code and training config are available here: https://github.com/cagliostrolab/sd-scripts/tree/main/notebook
### Acknowledgements
The development and release of Animagine XL 3.1 would not have been possible without the invaluable contributions and support from the following individuals and organizations:
- **[SeaArt.ai](https://www.seaart.ai/)**: Our collaboration partner and sponsor.
- **[Shadow Lilac](https://huggingface.co/shadowlilac)**: For providing the aesthetic classification model, [aesthetic-shadow-v2](https://huggingface.co/shadowlilac/aesthetic-shadow-v2).
- **[Derrian Distro](https://github.com/derrian-distro)**: For their custom learning rate scheduler, adapted from [LoRA Easy Training Scripts](https://github.com/derrian-distro/LoRA_Easy_Training_Scripts/blob/main/custom_scheduler/LoraEasyCustomOptimizer/CustomOptimizers.py).
- **[Kohya SS](https://github.com/kohya-ss)**: For their comprehensive training scripts.
- **Cagliostrolab Collaborators**: For their dedication to model training, project management, and data curation.
- **Early Testers**: For their valuable feedback and quality assurance efforts.
- **NovelAI**: For their innovative approach to aesthetic tagging, which served as an inspiration for our implementation.
- **KBlueLeaf**: For providing inspiration in balancing quality tags distribution and managing tags based on [Hakubooru Metainfo](https://github.com/KohakuBlueleaf/HakuBooru/blob/main/hakubooru/metainfo.py)
Thank you all for your support and expertise in pushing the boundaries of anime-style image generation.
## Collaborators
- [Linaqruf](https://huggingface.co/Linaqruf)
- [ItsMeBell](https://huggingface.co/ItsMeBell)
- [Asahina2K](https://huggingface.co/Asahina2K)
- [DamarJati](https://huggingface.co/DamarJati)
- [Zwicky18](https://huggingface.co/Zwicky18)
- [Scipius2121](https://huggingface.co/Scipius2121)
- [Raelina](https://huggingface.co/Raelina)
- [Kayfahaarukku](https://huggingface.co/kayfahaarukku)
- [Kriz](https://huggingface.co/Kr1SsSzz)
## Limitations
While Animagine XL 3.1 represents a significant advancement in anime-style image generation, it is important to acknowledge its limitations:
1. **Anime-Focused**: This model is specifically designed for generating anime-style images and is not suitable for creating realistic photos.
2. **Prompt Complexity**: This model may not be suitable for users who expect high-quality results from short or simple prompts. The training focus was on concept understanding rather than aesthetic refinement, which may require more detailed and specific prompts to achieve the desired output.
3. **Prompt Format**: Animagine XL 3.1 is optimized for Danbooru-style tags rather than natural language prompts. For best results, users are encouraged to format their prompts using the appropriate tags and syntax.
4. **Anatomy and Hand Rendering**: Despite the improvements made in anatomy and hand rendering, there may still be instances where the model produces suboptimal results in these areas.
5. **Dataset Size**: The dataset used for training Animagine XL 3.1 consists of approximately 870,000 images. When combined with the previous iteration's dataset (1.2 million), the total training data amounts to around 2.1 million images. While substantial, this dataset size may still be considered limited in scope for an "ultimate" anime model.
6. **NSFW Content**: Animagine XL 3.1 has been designed to generate more balanced NSFW content. However, it is important to note that the model may still produce NSFW results, even if not explicitly prompted.
By acknowledging these limitations, we aim to provide transparency and set realistic expectations for users of Animagine XL 3.1. Despite these constraints, we believe that the model represents a significant step forward in anime-style image generation and offers a powerful tool for artists, designers, and enthusiasts alike.
## License
Based on Animagine XL 3.0, Animagine XL 3.1 falls under [Fair AI Public License 1.0-SD](https://freedevproject.org/faipl-1.0-sd/) license, which is compatible with Stable Diffusion models’ license. Key points:
1. **Modification Sharing:** If you modify Animagine XL 3.1, you must share both your changes and the original license.
2. **Source Code Accessibility:** If your modified version is network-accessible, provide a way (like a download link) for others to get the source code. This applies to derived models too.
3. **Distribution Terms:** Any distribution must be under this license or another with similar rules.
4. **Compliance:** Non-compliance must be fixed within 30 days to avoid license termination, emphasizing transparency and adherence to open-source values.
The choice of this license aims to keep Animagine XL 3.1 open and modifiable, aligning with open source community spirit. It protects contributors and users, encouraging a collaborative, ethical open-source community. This ensures the model not only benefits from communal input but also respects open-source development freedoms.
## Cagliostro Lab Discord Server
Finally Cagliostro Lab Server open to public
https://discord.gg/cqh9tZgbGc
Feel free to join our discord server |
LarryAIDraw/Char-Genshin-Arlecchino-V2 | LarryAIDraw | 2024-04-03T01:28:35Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
]
| null | 2024-04-03T01:22:30Z | ---
license: creativeml-openrail-m
---
https://civitai.com/models/208547/arlecchino-genshin-impact |
blockblockblock/Mistral-12.25B-Instruct-v0.2-bpw4.2 | blockblockblock | 2024-04-03T01:26:26Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2312.15166",
"arxiv:2310.06825",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"exl2",
"region:us"
]
| text-generation | 2024-04-03T01:22:03Z | ---
base_model: []
library_name: transformers
tags:
- mergekit
- merge
license: apache-2.0
---
# Credit for the model card's description goes to ddh0, mergekit, and, mistralai
# Mistral-12.25B-Instruct-v0.2
This is Mistral-12.25B-Instruct-v0.2, a depth-upscaled version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2).
This model is intended to be used as a basis for further fine-tuning, or as a drop-in upgrade from the original 7 billion parameter model.
Paper detailing how Depth-Up Scaling works: [SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling](https://arxiv.org/abs/2312.15166)
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
# UpStage's conclusionary limitations of their research:
"Our study on the Depth Up-Scaling (DUS) has important limitations and considerations. **One key limitation is the need for more thorough explorations of hyperparameters used in the DUS approach. Namely, we removed m = 8 layers from both ends of our base model, primarily due to hardware limitations. However, we have not yet determined if this value is optimal for enhancing performance.** The extended time and cost of continued pretraining made it challenging to conduct more comprehensive experiments, which we aim to address in future work through various comparative analyses."
This model was made to help test whether 10.7B parameters (m = 8) is better or worse than 10.7B+ parameters (m < 8)
## Merge Details
### Merge Method
This model was merged using the passthrough merge method.
### Models Merged
The following models were included in the merge:
* /Users/jsarnecki/opt/Workspace/mistralai/Mistral-7B-Instruct-v0.2
### Configuration
The following YAML configuration was used to produce this model:
```yaml
dtype: bfloat16
merge_method: passthrough
# Depth UpScaled (DUS) version of Mistral-7B-Instruct-v0.2
# where m = 4 (The number of layers to remove from the model)
# s = 56 (The number of layers the model will have after the DUS)
slices:
- sources:
- layer_range: [0, 28]
model: /Users/jsarnecki/opt/Workspace/mistralai/Mistral-7B-Instruct-v0.2
- sources:
- layer_range: [4, 32]
model: /Users/jsarnecki/opt/Workspace/mistralai/Mistral-7B-Instruct-v0.2
```
# Model Card for Mistral-7B-Instruct-v0.2
The Mistral-7B-Instruct-v0.2 Large Language Model (LLM) is an instruct fine-tuned version of the Mistral-7B-v0.2.
Mistral-7B-v0.2 has the following changes compared to Mistral-7B-v0.1
- 32k context window (vs 8k context in v0.1)
- Rope-theta = 1e6
- No Sliding-Window Attention
For full details of this model please read our [paper](https://arxiv.org/abs/2310.06825) and [release blog post](https://mistral.ai/news/la-plateforme/).
## Instruction format
In order to leverage instruction fine-tuning, your prompt should be surrounded by `[INST]` and `[/INST]` tokens. The very first instruction should begin with a begin of sentence id. The next instructions should not. The assistant generation will be ended by the end-of-sentence token id.
E.g.
```
text = "<s>[INST] What is your favourite condiment? [/INST]"
"Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!</s> "
"[INST] Do you have mayonnaise recipes? [/INST]"
```
This format is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating) via the `apply_chat_template()` method:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
## Troubleshooting
- If you see the following error:
```
Traceback (most recent call last):
File "", line 1, in
File "/transformers/models/auto/auto_factory.py", line 482, in from_pretrained
config, kwargs = AutoConfig.from_pretrained(
File "/transformers/models/auto/configuration_auto.py", line 1022, in from_pretrained
config_class = CONFIG_MAPPING[config_dict["model_type"]]
File "/transformers/models/auto/configuration_auto.py", line 723, in getitem
raise KeyError(key)
KeyError: 'mistral'
```
Installing transformers from source should solve the issue
pip install git+https://github.com/huggingface/transformers
This should not be required after transformers-v4.33.4.
## Limitations
The Mistral 7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Louis Ternon, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. |
chart-rela-ins/unichart-base-960-decoder | chart-rela-ins | 2024-04-03T01:15:57Z | 162 | 0 | transformers | [
"transformers",
"safetensors",
"mbart",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-03T01:14:42Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
kardy04/plugin-embedding-sts-0403 | kardy04 | 2024-04-03T01:09:21Z | 5 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2024-04-03T01:08:56Z | ---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# kardy04/plugin-embedding-sts-0403
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('kardy04/plugin-embedding-sts-0403')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('kardy04/plugin-embedding-sts-0403')
model = AutoModel.from_pretrained('kardy04/plugin-embedding-sts-0403')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=kardy04/plugin-embedding-sts-0403)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 3 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 8,
"evaluation_steps": 0,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 2,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': True}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
Nitral-AI/KukulStanta-7B | Nitral-AI | 2024-04-03T01:03:59Z | 150 | 13 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"license:other",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-03-30T14:32:52Z | ---
license: other
model-index:
- name: KukulStanta-7B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 68.43
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Nitral-AI/KukulStanta-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 86.37
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Nitral-AI/KukulStanta-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 65.0
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Nitral-AI/KukulStanta-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 62.19
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Nitral-AI/KukulStanta-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 80.03
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Nitral-AI/KukulStanta-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 63.68
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Nitral-AI/KukulStanta-7B
name: Open LLM Leaderboard
---

# Vision/multimodal capabilities:
Quants Found Here: https://huggingface.co/Lewdiculous/KukulStanta-7B-GGUF-IQ-Imatrix
If you want to use vision functionality:
* You must use the latest versions of [Koboldcpp](https://github.com/LostRuins/koboldcpp).
To use the multimodal capabilities of this model and use **vision** you need to load the specified **mmproj** file, this can be found inside this model repo.
* You can load the **mmproj** by using the corresponding section in the interface:

# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Nitral-AI__KukulStanta-7B)
| Metric |Value|
|---------------------------------|----:|
|Avg. |70.95|
|AI2 Reasoning Challenge (25-Shot)|68.43|
|HellaSwag (10-Shot) |86.37|
|MMLU (5-Shot) |65.00|
|TruthfulQA (0-shot) |62.19|
|Winogrande (5-shot) |80.03|
|GSM8k (5-shot) |63.68|
|
Floweii/ppo-LunarLander-v2 | Floweii | 2024-04-03T01:02:15Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2024-04-03T01:01:59Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -215.68 +/- 111.21
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Disty0/sote-diffusion-cascade-decoder_alpha0 | Disty0 | 2024-04-03T00:52:10Z | 32 | 0 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"license:other",
"diffusers:StableCascadeDecoderPipeline",
"region:us"
]
| text-to-image | 2024-04-02T23:52:16Z | ---
pipeline_tag: text-to-image
license: other
license_name: stable-cascade-nc-community
license_link: LICENSE
---
# SoteDiffusion Cascade
Anime finetune of Stable Cascade Decoder.
No commercial use thanks to StabilityAI.
## Code Example
```shell
pip install diffusers
```
```python
import torch
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
prompt = "newest, 1girl, solo, cat ears, looking at viewer, blush, light smile,"
negative_prompt = "very displeasing, worst quality, monochrome, sketch, fat, child,"
prior = StableCascadePriorPipeline.from_pretrained("Disty0/sote-diffusion-cascade_alpha0", torch_dtype=torch.float16)
decoder = StableCascadeDecoderPipeline.from_pretrained("Disty0/sote-diffusion-cascade-decoder_alpha0", torch_dtype=torch.float16)
prior.enable_model_cpu_offload()
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=7.0,
num_images_per_prompt=1,
num_inference_steps=40
)
decoder.enable_model_cpu_offload()
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings,
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=1.5
output_type="pil",
num_inference_steps=10
).images[0]
decoder_output.save("cascade.png")
```
## Dataset
Used the same dataset as Disty0/sote-diffusion-cascade-decoder_pre-alpha0.
Trained with 98K~ images.
## Training:
**GPU used for training**: 1x AMD RX 7900 XTX 24GB
**Software used**: https://github.com/2kpr/StableCascade
### Config:
```
experiment_id: sotediffusion-sc-b_3b
model_version: 3B
dtype: bfloat16
use_fsdp: False
batch_size: 1
grad_accum_steps: 1
updates: 98000
backup_every: 2048
save_every: 1024
warmup_updates: 100
lr: 4.0e-6
optimizer_type: Adafactor
adaptive_loss_weight: True
stochastic_rounding: True
image_size: 768
multi_aspect_ratio: [1/1, 1/2, 1/3, 2/3, 3/4, 1/5, 2/5, 3/5, 4/5, 1/6, 5/6, 9/16]
shift: 4
checkpoint_path: /mnt/DataSSD/AI/SoteDiffusion/StableCascade/
output_path: /mnt/DataSSD/AI/SoteDiffusion/StableCascade/
webdataset_path: file:/mnt/DataSSD/AI/anime_image_dataset/best/newest_best-{0000..0001}.tar
effnet_checkpoint_path: /mnt/DataSSD/AI/models/sd-cascade/effnet_encoder.safetensors
stage_a_checkpoint_path: /mnt/DataSSD/AI/models/sd-cascade/stage_a.safetensors
generator_checkpoint_path: /mnt/DataSSD/AI/SoteDiffusion/StableCascade/sotediffusion-sc_3b-stage_b.safetensors
```
## Limitations and Bias
### Bias
- This model is intended for anime illustrations.
Realistic capabilites are not tested at all.
### Limitations
- Far shot eyes are still bad thanks to the heavy latent compression.
|
DanteAl97/hindi-to-english-adapter | DanteAl97 | 2024-04-03T00:51:51Z | 4 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:sarvamai/OpenHathi-7B-Hi-v0.1-Base",
"base_model:adapter:sarvamai/OpenHathi-7B-Hi-v0.1-Base",
"region:us"
]
| null | 2024-04-02T15:51:32Z | ---
library_name: peft
base_model: sarvamai/OpenHathi-7B-Hi-v0.1-Base
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0 |
CodeTriad/dpo_model_2 | CodeTriad | 2024-04-03T00:32:34Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-03T00:31:48Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
base_model: unsloth/mistral-7b-instruct-v0.2-bnb-4bit
---
# Uploaded model
- **Developed by:** thevin123
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-instruct-v0.2-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
alterf/rec_v0 | alterf | 2024-04-03T00:29:56Z | 190 | 0 | transformers | [
"transformers",
"safetensors",
"table-transformer",
"object-detection",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| object-detection | 2024-04-02T22:36:20Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
0x0uncle0/Uncle1 | 0x0uncle0 | 2024-04-03T00:28:49Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-02T23:58:19Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
atnanahidiw/donut-poc-1.1.0 | atnanahidiw | 2024-04-03T00:26:41Z | 51 | 0 | transformers | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| image-text-to-text | 2024-04-03T00:16:24Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
zwellington/azahead-longformer-v1.0 | zwellington | 2024-04-03T00:18:36Z | 77 | 0 | transformers | [
"transformers",
"pytorch",
"longformer",
"text-classification",
"generated_from_trainer",
"dataset:azaheadhealth",
"base_model:allenai/longformer-base-4096",
"base_model:finetune:allenai/longformer-base-4096",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-04-03T00:15:35Z | ---
license: apache-2.0
base_model: allenai/longformer-base-4096
tags:
- generated_from_trainer
datasets:
- azaheadhealth
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: azahead-longformer-v1.0
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: azaheadhealth
type: azaheadhealth
config: small
split: test
args: small
metrics:
- name: Accuracy
type: accuracy
value: 0.7916666666666666
- name: F1
type: f1
value: 0.6666666666666666
- name: Precision
type: precision
value: 0.625
- name: Recall
type: recall
value: 0.7142857142857143
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# azahead-longformer-v1.0
This model is a fine-tuned version of [allenai/longformer-base-4096](https://huggingface.co/allenai/longformer-base-4096) on the azaheadhealth dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6326
- Accuracy: 0.7917
- F1: 0.6667
- Precision: 0.625
- Recall: 0.7143
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 0.6853 | 1.0 | 20 | 0.6326 | 0.7917 | 0.6667 | 0.625 | 0.7143 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.2.1+cu121
- Datasets 2.16.1
- Tokenizers 0.13.2
|
blockblockblock/Mistral-12.25B-Instruct-v0.2-bpw3.5 | blockblockblock | 2024-04-03T00:15:30Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2312.15166",
"arxiv:2310.06825",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"exl2",
"region:us"
]
| text-generation | 2024-04-03T00:12:58Z | ---
base_model: []
library_name: transformers
tags:
- mergekit
- merge
license: apache-2.0
---
# Credit for the model card's description goes to ddh0, mergekit, and, mistralai
# Mistral-12.25B-Instruct-v0.2
This is Mistral-12.25B-Instruct-v0.2, a depth-upscaled version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2).
This model is intended to be used as a basis for further fine-tuning, or as a drop-in upgrade from the original 7 billion parameter model.
Paper detailing how Depth-Up Scaling works: [SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling](https://arxiv.org/abs/2312.15166)
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
# UpStage's conclusionary limitations of their research:
"Our study on the Depth Up-Scaling (DUS) has important limitations and considerations. **One key limitation is the need for more thorough explorations of hyperparameters used in the DUS approach. Namely, we removed m = 8 layers from both ends of our base model, primarily due to hardware limitations. However, we have not yet determined if this value is optimal for enhancing performance.** The extended time and cost of continued pretraining made it challenging to conduct more comprehensive experiments, which we aim to address in future work through various comparative analyses."
This model was made to help test whether 10.7B parameters (m = 8) is better or worse than 10.7B+ parameters (m < 8)
## Merge Details
### Merge Method
This model was merged using the passthrough merge method.
### Models Merged
The following models were included in the merge:
* /Users/jsarnecki/opt/Workspace/mistralai/Mistral-7B-Instruct-v0.2
### Configuration
The following YAML configuration was used to produce this model:
```yaml
dtype: bfloat16
merge_method: passthrough
# Depth UpScaled (DUS) version of Mistral-7B-Instruct-v0.2
# where m = 4 (The number of layers to remove from the model)
# s = 56 (The number of layers the model will have after the DUS)
slices:
- sources:
- layer_range: [0, 28]
model: /Users/jsarnecki/opt/Workspace/mistralai/Mistral-7B-Instruct-v0.2
- sources:
- layer_range: [4, 32]
model: /Users/jsarnecki/opt/Workspace/mistralai/Mistral-7B-Instruct-v0.2
```
# Model Card for Mistral-7B-Instruct-v0.2
The Mistral-7B-Instruct-v0.2 Large Language Model (LLM) is an instruct fine-tuned version of the Mistral-7B-v0.2.
Mistral-7B-v0.2 has the following changes compared to Mistral-7B-v0.1
- 32k context window (vs 8k context in v0.1)
- Rope-theta = 1e6
- No Sliding-Window Attention
For full details of this model please read our [paper](https://arxiv.org/abs/2310.06825) and [release blog post](https://mistral.ai/news/la-plateforme/).
## Instruction format
In order to leverage instruction fine-tuning, your prompt should be surrounded by `[INST]` and `[/INST]` tokens. The very first instruction should begin with a begin of sentence id. The next instructions should not. The assistant generation will be ended by the end-of-sentence token id.
E.g.
```
text = "<s>[INST] What is your favourite condiment? [/INST]"
"Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!</s> "
"[INST] Do you have mayonnaise recipes? [/INST]"
```
This format is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating) via the `apply_chat_template()` method:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
## Troubleshooting
- If you see the following error:
```
Traceback (most recent call last):
File "", line 1, in
File "/transformers/models/auto/auto_factory.py", line 482, in from_pretrained
config, kwargs = AutoConfig.from_pretrained(
File "/transformers/models/auto/configuration_auto.py", line 1022, in from_pretrained
config_class = CONFIG_MAPPING[config_dict["model_type"]]
File "/transformers/models/auto/configuration_auto.py", line 723, in getitem
raise KeyError(key)
KeyError: 'mistral'
```
Installing transformers from source should solve the issue
pip install git+https://github.com/huggingface/transformers
This should not be required after transformers-v4.33.4.
## Limitations
The Mistral 7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Louis Ternon, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. |
viggneshk/autotrain-xh45u-bud11 | viggneshk | 2024-04-02T23:58:06Z | 106 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"autotrain",
"dataset:autotrain-xh45u-bud11/autotrain-data",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-04-02T23:57:37Z |
---
tags:
- autotrain
- text2text-generation
widget:
- text: "I love AutoTrain"
datasets:
- autotrain-xh45u-bud11/autotrain-data
---
# Model Trained Using AutoTrain
- Problem type: Seq2Seq
## Validation Metrics
loss: 0.056124866008758545
rouge1: 79.1478
rouge2: 77.9096
rougeL: 79.12
rougeLsum: 79.109
gen_len: 19.0
runtime: 80.7915
samples_per_second: 12.477
steps_per_second: 3.119
: 3.0
|
habulaj/1712098940655x413492375607255300 | habulaj | 2024-04-02T23:50:30Z | 1 | 0 | diffusers | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"dataset:Shortyzzzz/Chucggh",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"region:us"
]
| text-to-image | 2024-04-02T23:02:30Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: in the style of TOK
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: false
datasets:
- Shortyzzzz/Chucggh
---
# LoRA DreamBooth - squaadinc/1712098940655x413492375607255300
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0 trained on @fffiloni's SD-XL trainer.
The weights were trained on the concept prompt:
```
in the style of TOK
```
Use this keyword to trigger your custom model in your prompts.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Usage
Make sure to upgrade diffusers to >= 0.19.0:
```
pip install diffusers --upgrade
```
In addition make sure to install transformers, safetensors, accelerate as well as the invisible watermark:
```
pip install invisible_watermark transformers accelerate safetensors
```
To just use the base model, you can run:
```python
import torch
from diffusers import DiffusionPipeline, AutoencoderKL
device = "cuda" if torch.cuda.is_available() else "cpu"
vae = AutoencoderKL.from_pretrained('madebyollin/sdxl-vae-fp16-fix', torch_dtype=torch.float16)
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
vae=vae, torch_dtype=torch.float16, variant="fp16",
use_safetensors=True
)
pipe.to(device)
# This is where you load your trained weights
specific_safetensors = "pytorch_lora_weights.safetensors"
lora_scale = 0.9
pipe.load_lora_weights(
'squaadinc/1712098940655x413492375607255300',
weight_name = specific_safetensors,
# use_auth_token = True
)
prompt = "A majestic in the style of TOK jumping from a big stone at night"
image = pipe(
prompt=prompt,
num_inference_steps=50,
cross_attention_kwargs={"scale": lora_scale}
).images[0]
```
|
guillermoruiz/bilma_AR | guillermoruiz | 2024-04-02T23:35:06Z | 94 | 0 | transformers | [
"transformers",
"tf",
"bilma",
"code",
"nlp",
"custom",
"custom_code",
"es",
"arxiv:2110.06128",
"license:mit",
"endpoints_compatible",
"region:us"
]
| null | 2024-03-13T19:38:30Z | ---
license: mit
language:
- es
metrics:
- accuracy
tags:
- code
- nlp
- custom
- bilma
tokenizer:
- yes
---
# BILMA (Bert In Latin aMericA)
Bilma is a BERT implementation in tensorflow and trained on the Masked Language Model task under the
https://sadit.github.io/regional-spanish-models-talk-2022/ datasets. It is a model trained on regionalized
Spanish short texts from the Twitter (now X) platform.
We have pretrained models for the countries of Argentina, Chile, Colombia, Spain, Mexico, United States, Uruguay, and Venezuela.
The accuracy of the models trained on the MLM task for different regions are:
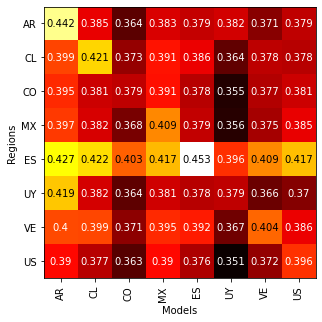
# Pre-requisites
You will need TensorFlow 2.4 or newer.
# Quick guide
Install the following version for the transformers library
```
!pip install transformers==4.30.2
```
Instanciate the tokenizer and the trained model
```
from transformers import AutoTokenizer
from transformers import TFAutoModel
tok = AutoTokenizer.from_pretrained("guillermoruiz/bilma_mx")
model = TFAutoModel.from_pretrained("guillermoruiz/bilma_mx", trust_remote_code=True)
```
Now,we will need some text and then pass it through the tokenizer:
```
text = ["Vamos a comer [MASK].",
"Hace mucho que no voy al [MASK]."]
t = tok(text, padding="max_length", return_tensors="tf", max_length=280)
```
With this, we are ready to use the model
```
p = model(t)
```
Now, we get the most likely words with:
```
import tensorflow as tf
tok.batch_decode(tf.argmax(p["logits"], 2)[:,1:], skip_special_tokens=True)
```
which produces the output:
```
['vamos a comer tacos.', 'hace mucho que no voy al gym.']
```
If you find this model useful for your research, please cite the following paper:
```
@misc{tellez2022regionalized,
title={Regionalized models for Spanish language variations based on Twitter},
author={Eric S. Tellez and Daniela Moctezuma and Sabino Miranda and Mario Graff and Guillermo Ruiz},
year={2022},
eprint={2110.06128},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
guillermoruiz/bilma_VE | guillermoruiz | 2024-04-02T23:32:36Z | 88 | 0 | transformers | [
"transformers",
"tf",
"bilma",
"code",
"nlp",
"custom",
"custom_code",
"es",
"arxiv:2110.06128",
"license:mit",
"endpoints_compatible",
"region:us"
]
| null | 2024-03-13T19:47:50Z | ---
license: mit
language:
- es
metrics:
- accuracy
tags:
- code
- nlp
- custom
- bilma
tokenizer:
- yes
---
# BILMA (Bert In Latin aMericA)
Bilma is a BERT implementation in tensorflow and trained on the Masked Language Model task under the
https://sadit.github.io/regional-spanish-models-talk-2022/ datasets. It is a model trained on regionalized
Spanish short texts from the Twitter (now X) platform.
We have pretrained models for the countries of Argentina, Chile, Colombia, Spain, Mexico, United States, Uruguay, and Venezuela.
The accuracy of the models trained on the MLM task for different regions are:

# Pre-requisites
You will need TensorFlow 2.4 or newer.
# Quick guide
Install the following version for the transformers library
```
!pip install transformers==4.30.2
```
Instanciate the tokenizer and the trained model
```
from transformers import AutoTokenizer
from transformers import TFAutoModel
tok = AutoTokenizer.from_pretrained("guillermoruiz/bilma_mx")
model = TFAutoModel.from_pretrained("guillermoruiz/bilma_mx", trust_remote_code=True)
```
Now,we will need some text and then pass it through the tokenizer:
```
text = ["Vamos a comer [MASK].",
"Hace mucho que no voy al [MASK]."]
t = tok(text, padding="max_length", return_tensors="tf", max_length=280)
```
With this, we are ready to use the model
```
p = model(t)
```
Now, we get the most likely words with:
```
import tensorflow as tf
tok.batch_decode(tf.argmax(p["logits"], 2)[:,1:], skip_special_tokens=True)
```
which produces the output:
```
['vamos a comer tacos.', 'hace mucho que no voy al gym.']
```
If you find this model useful for your research, please cite the following paper:
```
@misc{tellez2022regionalized,
title={Regionalized models for Spanish language variations based on Twitter},
author={Eric S. Tellez and Daniela Moctezuma and Sabino Miranda and Mario Graff and Guillermo Ruiz},
year={2022},
eprint={2110.06128},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Pr123/TinyLlama-EA-Chat | Pr123 | 2024-04-02T23:26:42Z | 4 | 0 | peft | [
"peft",
"safetensors",
"region:us"
]
| null | 2024-04-01T21:35:22Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
|
basil-ahmad/Taxi-v3 | basil-ahmad | 2024-04-02T23:25:49Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2024-04-02T23:25:46Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="basil-ahmad/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
MysticFoxMagic/HeatherSpell-7b | MysticFoxMagic | 2024-04-02T23:18:43Z | 10 | 3 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"yam-peleg/Experiment26-7B",
"Kukedlc/NeuralExperiment-7b-MagicCoder-v7.5",
"base_model:Kukedlc/NeuralExperiment-7b-MagicCoder-v7.5",
"base_model:merge:Kukedlc/NeuralExperiment-7b-MagicCoder-v7.5",
"base_model:yam-peleg/Experiment26-7B",
"base_model:merge:yam-peleg/Experiment26-7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-02T22:24:05Z | ---
tags:
- merge
- mergekit
- lazymergekit
- yam-peleg/Experiment26-7B
- Kukedlc/NeuralExperiment-7b-MagicCoder-v7.5
base_model:
- yam-peleg/Experiment26-7B
- Kukedlc/NeuralExperiment-7b-MagicCoder-v7.5
---

# HeatherSpell-7b
HeatherSpell-7b is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [yam-peleg/Experiment26-7B](https://huggingface.co/yam-peleg/Experiment26-7B)
* [Kukedlc/NeuralExperiment-7b-MagicCoder-v7.5](https://huggingface.co/Kukedlc/NeuralExperiment-7b-MagicCoder-v7.5)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: yam-peleg/Experiment26-7B
layer_range: [0, 32]
- model: Kukedlc/NeuralExperiment-7b-MagicCoder-v7.5
layer_range: [0, 32]
merge_method: slerp
base_model: yam-peleg/Experiment26-7B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "MysticFoxMagic/HeatherSpell-7b"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
KaggleMasterX/GemmaVirTok | KaggleMasterX | 2024-04-02T23:07:55Z | 0 | 0 | transformers | [
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-02T21:18:42Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Shamane/mistral-instruct-v2-sec-cpt-qlora | Shamane | 2024-04-02T22:53:08Z | 1 | 0 | peft | [
"peft",
"safetensors",
"mistral",
"alignment-handbook",
"trl",
"sft",
"generated_from_trainer",
"dataset:arcee-ai/sec-data-mini",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"base_model:adapter:mistralai/Mistral-7B-Instruct-v0.2",
"license:apache-2.0",
"4-bit",
"bitsandbytes",
"region:us"
]
| null | 2024-04-02T22:43:10Z | ---
license: apache-2.0
library_name: peft
tags:
- alignment-handbook
- trl
- sft
- generated_from_trainer
base_model: mistralai/Mistral-7B-Instruct-v0.2
datasets:
- arcee-ai/sec-data-mini
model-index:
- name: mistral-instruct-v2-sec-cpt-qlora
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral-instruct-v2-sec-cpt-qlora
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on the arcee-ai/sec-data-mini dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 2
### Training results
### Framework versions
- PEFT 0.7.1
- Transformers 4.39.0.dev0
- Pytorch 2.1.0
- Datasets 2.14.6
- Tokenizers 0.15.2 |
antoniomae/Voice-Clone | antoniomae | 2024-04-02T22:49:52Z | 0 | 0 | fastai | [
"fastai",
"code",
"text-classification",
"pt",
"dataset:0x7o/klara-voice",
"license:apache-2.0",
"region:us"
]
| text-classification | 2024-04-02T22:43:01Z | ---
title: Voice Clone
emoji: 🏃
colorFrom: blue
colorTo: blue
sdk: gradio
sdk_version: 4.5.0
app_file: app.py
pinned: false
license: apache-2.0
datasets:
- 0x7o/klara-voice
language:
- pt
metrics:
- brier_score
- cer
library_name: fastai
pipeline_tag: text-classification
tags:
- code
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference |
ahmedgongi/mistral_version2 | ahmedgongi | 2024-04-02T22:43:49Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-02T22:43:29Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
labicquette/distilbert-v0 | labicquette | 2024-04-02T22:26:59Z | 105 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"token-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-cased",
"base_model:finetune:distilbert/distilbert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2024-04-02T22:26:29Z | ---
license: apache-2.0
base_model: distilbert/distilbert-base-cased
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-v0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-v0
This model is a fine-tuned version of [distilbert/distilbert-base-cased](https://huggingface.co/distilbert/distilbert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4249
- Precision: 0.0860
- Recall: 0.0883
- F1: 0.0792
- Accuracy: 0.1013
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 29 | 2.3644 | 0.0657 | 0.0917 | 0.0241 | 0.1193 |
| No log | 2.0 | 58 | 2.3651 | 0.0979 | 0.0925 | 0.0338 | 0.1195 |
| No log | 3.0 | 87 | 2.3686 | 0.0742 | 0.0923 | 0.0498 | 0.1148 |
| No log | 4.0 | 116 | 2.3718 | 0.0904 | 0.0918 | 0.0619 | 0.1132 |
| No log | 5.0 | 145 | 2.3800 | 0.0893 | 0.0913 | 0.0758 | 0.1082 |
| No log | 6.0 | 174 | 2.3946 | 0.0873 | 0.0915 | 0.0772 | 0.1070 |
| No log | 7.0 | 203 | 2.4064 | 0.0864 | 0.0897 | 0.0780 | 0.1043 |
| No log | 8.0 | 232 | 2.4165 | 0.0872 | 0.0888 | 0.0798 | 0.1019 |
| No log | 9.0 | 261 | 2.4233 | 0.0860 | 0.0885 | 0.0778 | 0.1024 |
| No log | 10.0 | 290 | 2.4249 | 0.0860 | 0.0883 | 0.0792 | 0.1013 |
### Framework versions
- Transformers 4.36.1
- Pytorch 2.2.1+cu121
- Datasets 2.16.1
- Tokenizers 0.15.0
|
D29/my_awesome_qa_model | D29 | 2024-04-02T22:24:09Z | 122 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"question-answering",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| question-answering | 2024-04-02T18:02:45Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: my_awesome_qa_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_qa_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9466
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 14 | 3.2452 |
| No log | 2.0 | 28 | 1.5152 |
| No log | 3.0 | 42 | 0.9466 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
rjacobs3/model_oxide_vacancy | rjacobs3 | 2024-04-02T22:15:21Z | 0 | 0 | null | [
"region:us"
]
| null | 2024-04-02T22:10:25Z | # model_oxide_vacancy
Random forest model to predict the formation energy of O vacancies in oxides
|
habulaj/1712092770181x132440644291180530 | habulaj | 2024-04-02T22:12:41Z | 1 | 0 | diffusers | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"dataset:Shortyzzzz/ML",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"region:us"
]
| text-to-image | 2024-04-02T21:19:52Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: in the style of TOK
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: false
datasets:
- Shortyzzzz/ML
---
# LoRA DreamBooth - squaadinc/1712092770181x132440644291180530
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0 trained on @fffiloni's SD-XL trainer.
The weights were trained on the concept prompt:
```
in the style of TOK
```
Use this keyword to trigger your custom model in your prompts.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Usage
Make sure to upgrade diffusers to >= 0.19.0:
```
pip install diffusers --upgrade
```
In addition make sure to install transformers, safetensors, accelerate as well as the invisible watermark:
```
pip install invisible_watermark transformers accelerate safetensors
```
To just use the base model, you can run:
```python
import torch
from diffusers import DiffusionPipeline, AutoencoderKL
device = "cuda" if torch.cuda.is_available() else "cpu"
vae = AutoencoderKL.from_pretrained('madebyollin/sdxl-vae-fp16-fix', torch_dtype=torch.float16)
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
vae=vae, torch_dtype=torch.float16, variant="fp16",
use_safetensors=True
)
pipe.to(device)
# This is where you load your trained weights
specific_safetensors = "pytorch_lora_weights.safetensors"
lora_scale = 0.9
pipe.load_lora_weights(
'squaadinc/1712092770181x132440644291180530',
weight_name = specific_safetensors,
# use_auth_token = True
)
prompt = "A majestic in the style of TOK jumping from a big stone at night"
image = pipe(
prompt=prompt,
num_inference_steps=50,
cross_attention_kwargs={"scale": lora_scale}
).images[0]
```
|
jaypratap/vit-mae-base-effusion-classifier | jaypratap | 2024-04-02T21:54:30Z | 6 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/vit-mae-base",
"base_model:finetune:facebook/vit-mae-base",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2024-04-02T08:10:17Z | ---
license: apache-2.0
base_model: facebook/vit-mae-base
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: vit-mae-base-effusion-classifier
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8173673328738801
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-mae-base-effusion-classifier
This model is a fine-tuned version of [facebook/vit-mae-base](https://huggingface.co/facebook/vit-mae-base) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4179
- Accuracy: 0.8174
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6554 | 1.0 | 362 | 0.6692 | 0.6030 |
| 0.569 | 2.0 | 725 | 0.5891 | 0.7023 |
| 0.6098 | 3.0 | 1088 | 0.5421 | 0.7367 |
| 0.4984 | 4.0 | 1451 | 0.5668 | 0.7043 |
| 0.4884 | 5.0 | 1813 | 0.6061 | 0.6844 |
| 0.4351 | 6.0 | 2176 | 0.4481 | 0.8098 |
| 0.4794 | 7.0 | 2539 | 0.4384 | 0.8084 |
| 0.4636 | 8.0 | 2902 | 0.4343 | 0.8077 |
| 0.4816 | 9.0 | 3264 | 0.5363 | 0.7491 |
| 0.5016 | 10.0 | 3627 | 0.4993 | 0.7677 |
| 0.4826 | 11.0 | 3990 | 0.4483 | 0.8043 |
| 0.4707 | 12.0 | 4353 | 0.4249 | 0.8112 |
| 0.4483 | 13.0 | 4715 | 0.4193 | 0.8160 |
| 0.419 | 14.0 | 5078 | 0.4146 | 0.8215 |
| 0.5039 | 15.0 | 5441 | 0.4188 | 0.8181 |
| 0.4111 | 16.0 | 5804 | 0.4459 | 0.8112 |
| 0.3293 | 17.0 | 6166 | 0.4228 | 0.8181 |
| 0.4171 | 18.0 | 6529 | 0.4239 | 0.8215 |
| 0.3375 | 19.0 | 6892 | 0.4162 | 0.8215 |
| 0.32 | 19.96 | 7240 | 0.4179 | 0.8174 |
### Framework versions
- Transformers 4.39.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
alejandrovil/Mistral-7b-Test-Ingles | alejandrovil | 2024-04-02T21:52:54Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-02T20:25:15Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [Scripta Consulting]
- **Funded by [optional]:** [MISTRAL ia]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
TW3PartnersLLM/tw3jrglv4 | TW3PartnersLLM | 2024-04-02T21:46:24Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"migtissera/Tess-72B-v1.5b",
"davidkim205/Rhea-72b-v0.5",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-02T21:18:49Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- migtissera/Tess-72B-v1.5b
- davidkim205/Rhea-72b-v0.5
---
# TW3-JRGL-v4
TW3-JRGL-v4 is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [migtissera/Tess-72B-v1.5b](https://huggingface.co/migtissera/Tess-72B-v1.5b)
* [davidkim205/Rhea-72b-v0.5](https://huggingface.co/davidkim205/Rhea-72b-v0.5)
## 🧩 Configuration |
mlx-community/Qwen1.5-MoE-A2.7B-Chat-4bit | mlx-community | 2024-04-02T21:41:42Z | 8 | 5 | mlx | [
"mlx",
"safetensors",
"qwen2_moe",
"pretrained",
"moe",
"text-generation",
"conversational",
"en",
"license:other",
"region:us"
]
| text-generation | 2024-04-02T20:06:53Z | ---
language:
- en
license: other
tags:
- pretrained
- moe
- mlx
license_name: tongyi-qianwen
license_link: https://huggingface.co/Qwen/Qwen1.5-MoE-A2.7B/blob/main/LICENSE
pipeline_tag: text-generation
---
# mlx-community/Qwen1.5-MoE-A2.7B-Chat-4bit
This model was converted to MLX format from [`Qwen/Qwen1.5-MoE-A2.7B-Chat`](https://huggingface.co/Qwen/Qwen1.5-MoE-A2.7B-Chat) using mlx-lm version version [d661440](https://github.com/ml-explore/mlx-examples/commit/d661440dbb8e1970fadad79c5061e786fe1c54ca).
Model added by [Prince Canuma](https://twitter.com/Prince_Canuma).
Refer to the [original model card](https://huggingface.co/Qwen/Qwen1.5-MoE-A2.7B) for more details on the model.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/Qwen1.5-MoE-A2.7B-4bit")
response = generate(model, tokenizer, prompt="Write a story about Einstein", verbose=True)
```
|
yuiseki/YuisekinAI-mistral-0.7B | yuiseki | 2024-04-02T21:35:52Z | 131 | 2 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"en",
"ja",
"dataset:wikimedia/wikipedia",
"arxiv:1910.09700",
"license:wtfpl",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-01T04:06:27Z | ---
language:
- en
- ja
license: wtfpl
library_name: transformers
datasets:
- wikimedia/wikipedia
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
rimxim/dialogue_Summary_peft | rimxim | 2024-04-02T21:27:05Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-02T21:26:59Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
NorahAlshahrani/Adv_BERT_msda | NorahAlshahrani | 2024-04-02T21:22:37Z | 162 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"ar",
"dataset:msda",
"arxiv:2402.03477",
"base_model:aubmindlab/bert-base-arabertv2",
"base_model:finetune:aubmindlab/bert-base-arabertv2",
"license:mit",
"autotrain_compatible",
"region:us"
]
| text-classification | 2023-09-02T03:12:27Z | ---
base_model: aubmindlab/bert-base-arabertv2
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: Adv_BERT_msda
results: []
license: mit
datasets:
- msda
language:
- ar
pipeline_tag: text-classification
inference: false
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Adv_BERT_msda
This model is an **adversarially fine-tuned** version of [aubmindlab/bert-base-arabertv2](https://huggingface.co/aubmindlab/bert-base-arabertv2) on the Sentiment Analysis for Social Media Posts in Arabic Dialect (MSDA) dataset, augmented by our generated adversarial examples.
It achieves the following results on the evaluation set:
- Loss: 0.4117
- Accuracy: 0.8655
## BibTeX Citations:
```bash
@inproceedings{alshahrani-etal-2024-arabic,
title = "{{A}rabic Synonym {BERT}-based Adversarial Examples for Text Classification}",
author = "Alshahrani, Norah and
Alshahrani, Saied and
Wali, Esma and
Matthews, Jeanna",
editor = "Falk, Neele and
Papi, Sara and
Zhang, Mike",
booktitle = "Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop",
month = mar,
year = "2024",
address = "St. Julian{'}s, Malta",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.eacl-srw.10",
pages = "137--147",
abstract = "Text classification systems have been proven vulnerable to adversarial text examples, modified versions of the original text examples that are often unnoticed by human eyes, yet can force text classification models to alter their classification. Often, research works quantifying the impact of adversarial text attacks have been applied only to models trained in English. In this paper, we introduce the first word-level study of adversarial attacks in Arabic. Specifically, we use a synonym (word-level) attack using a Masked Language Modeling (MLM) task with a BERT model in a black-box setting to assess the robustness of the state-of-the-art text classification models to adversarial attacks in Arabic. To evaluate the grammatical and semantic similarities of the newly produced adversarial examples using our synonym BERT-based attack, we invite four human evaluators to assess and compare the produced adversarial examples with their original examples. We also study the transferability of these newly produced Arabic adversarial examples to various models and investigate the effectiveness of defense mechanisms against these adversarial examples on the BERT models. We find that fine-tuned BERT models were more susceptible to our synonym attacks than the other Deep Neural Networks (DNN) models like WordCNN and WordLSTM we trained. We also find that fine-tuned BERT models were more susceptible to transferred attacks. We, lastly, find that fine-tuned BERT models successfully regain at least 2{\%} in accuracy after applying adversarial training as an initial defense mechanism.",
}
```
```bash
@misc{alshahrani2024arabic,
title={{Arabic Synonym BERT-based Adversarial Examples for Text Classification}},
author={Norah Alshahrani and Saied Alshahrani and Esma Wali and Jeanna Matthews},
year={2024},
eprint={2402.03477},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Training procedure
We have trained this model using the PaperSpace GPU-Cloud service. We used a machine with 8 CPUs, 45GB RAM, and A6000 GPU with 48GB RAM.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 2953 | 0.3976 | 0.8433 |
| 0.3811 | 2.0 | 5906 | 0.3715 | 0.8617 |
| 0.3811 | 3.0 | 8859 | 0.4117 | 0.8655 |
### Framework versions
- Transformers 4.32.1
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AbdulRehman123456/Bill_Gates_1 | AbdulRehman123456 | 2024-04-02T21:17:26Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-02T20:32:37Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
MiniMoog/Mergerix-7b-v0.4 | MiniMoog | 2024-04-02T21:14:58Z | 200 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"liminerity/M7-7b",
"automerger/YamshadowExperiment28-7B",
"base_model:automerger/YamshadowExperiment28-7B",
"base_model:merge:automerger/YamshadowExperiment28-7B",
"base_model:liminerity/M7-7b",
"base_model:merge:liminerity/M7-7b",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-02T21:07:04Z | ---
tags:
- merge
- mergekit
- lazymergekit
- liminerity/M7-7b
- automerger/YamshadowExperiment28-7B
base_model:
- liminerity/M7-7b
- automerger/YamshadowExperiment28-7B
license: apache-2.0
---
# Mergerix-7b-v0.4
Mergerix-7b-v0.4 is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [liminerity/M7-7b](https://huggingface.co/liminerity/M7-7b)
* [automerger/YamshadowExperiment28-7B](https://huggingface.co/automerger/YamshadowExperiment28-7B)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: liminerity/M7-7b
layer_range: [0, 32]
- model: automerger/YamshadowExperiment28-7B
layer_range: [0, 32]
merge_method: slerp
base_model: automerger/YamshadowExperiment28-7B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.6
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "MiniMoog/Mergerix-7b-v0.4"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
rimxim/dialogue_Summary | rimxim | 2024-04-02T21:09:30Z | 106 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-04-02T21:08:16Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
AI-Sweden-Models/gpt-sw3-6.7b-v2-translator | AI-Sweden-Models | 2024-04-02T21:03:25Z | 178 | 6 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"translation",
"sv",
"da",
"no",
"en",
"base_model:AI-Sweden-Models/gpt-sw3-6.7b-v2-instruct",
"base_model:finetune:AI-Sweden-Models/gpt-sw3-6.7b-v2-instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-02T14:02:35Z | ---
base_model: AI-Sweden-Models/gpt-sw3-6.7b-v2-instruct
language:
- sv
- da
- 'no'
- en
pipeline_tag: text-generation
inference:
parameters:
temperature: 0.7
tags:
- translation
---
# Model Card for gpt-sw3-6.7b-v2-translator
The `gpt-sw3-6.7b-v2-translator` is a finetuned version of `gpt-sw3-6.7b-v2-instruct` on a carefully selected translation pair dataset that was gathered by AI Sweden.
## Intended usage:
Translate text data from English to Swedish, or Swedish to English.
## How to use:
```python
import torch
from transformers import pipeline, StoppingCriteriaList, StoppingCriteria
device = "cuda" if torch.cuda.is_available() else "cpu"
# (Optional) - define a stopping criteria
# We ideally want the model to stop generate once the response from the Bot is generated
class StopOnTokenCriteria(StoppingCriteria):
def __init__(self, stop_token_id):
self.stop_token_id = stop_token_id
def __call__(self, input_ids, scores, **kwargs):
return input_ids[0, -1] == self.stop_token_id
pipe = pipeline(
task="text-generation",
model="AI-Sweden-Models/gpt-sw3-6.7b-v2-translator",
device=device
)
stop_on_token_criteria = StopOnTokenCriteria(stop_token_id=pipe.tokenizer.bos_token_id)
text = "I like to eat ice cream in the summer."
# This will translate English to Swedish
# To translate from Swedish to English the prompt would be:
# prompt = f"<|endoftext|><s>User: Översätt till Engelska från Svenska\n{text}<s>Bot:"
prompt = f"<|endoftext|><s>User: Översätt till Svenska från Engelska\n{text}<s>Bot:"
input_tokens = pipe.tokenizer(prompt, return_tensors="pt").input_ids.to(device)
max_model_length = 2048
dynamic_max_length = max_model_length - input_tokens.shape[1]
response = pipe(
prompt,
max_length=dynamic_max_length,
truncation=True,
stopping_criteria=StoppingCriteriaList([stop_on_token_criteria])
)
print(response[0]["generated_text"].split("<s>Bot: ")[-1])
```
```python
>>> "Jag tycker om att äta glass på sommaren."
```
## Training & Data:
The training was done on 1 NVIDIA DGX using DeepSpeed ZeRO 3 for three epochs on roughly 4GB of carefully selected translation data. It is a full finetune of all of the model parameters.
| Epoch | Training Loss | Evaluation Loss |
|-------|---------------|-----------------|
| 1 | 1.309 | 1.281 |
| 2 | 1.161 | 1.242 |
| 3 | 1.053 | 1.219 | |
SimoneJLaudani/trainer2F | SimoneJLaudani | 2024-04-02T21:00:47Z | 107 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-03-21T01:18:49Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: trainer2F
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# trainer2F
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6323
- Precision: 0.8002
- Recall: 0.7955
- F1: 0.7949
- Accuracy: 0.7955
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 1.9352 | 0.14 | 30 | 1.8435 | 0.1778 | 0.1849 | 0.1056 | 0.1849 |
| 1.739 | 0.27 | 60 | 1.4925 | 0.6011 | 0.5602 | 0.5263 | 0.5602 |
| 1.3792 | 0.41 | 90 | 1.1872 | 0.6241 | 0.5574 | 0.5130 | 0.5574 |
| 1.163 | 0.54 | 120 | 1.0570 | 0.7002 | 0.6779 | 0.6658 | 0.6779 |
| 1.0629 | 0.68 | 150 | 0.9289 | 0.7742 | 0.7507 | 0.7489 | 0.7507 |
| 0.9604 | 0.81 | 180 | 0.8598 | 0.7434 | 0.7283 | 0.7185 | 0.7283 |
| 0.8055 | 0.95 | 210 | 0.8032 | 0.7874 | 0.7619 | 0.7510 | 0.7619 |
| 0.6769 | 1.08 | 240 | 0.7419 | 0.7731 | 0.7591 | 0.7541 | 0.7591 |
| 0.4748 | 1.22 | 270 | 0.7268 | 0.7712 | 0.7591 | 0.7577 | 0.7591 |
| 0.4624 | 1.35 | 300 | 0.7063 | 0.8049 | 0.7899 | 0.7875 | 0.7899 |
| 0.399 | 1.49 | 330 | 0.6556 | 0.7832 | 0.7731 | 0.7721 | 0.7731 |
| 0.4207 | 1.62 | 360 | 0.6346 | 0.8130 | 0.8067 | 0.8049 | 0.8067 |
| 0.3445 | 1.76 | 390 | 0.6396 | 0.7955 | 0.7871 | 0.7854 | 0.7871 |
| 0.3265 | 1.89 | 420 | 0.6395 | 0.7923 | 0.7871 | 0.7868 | 0.7871 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
charliewang314/ppo-LunarLander-v2 | charliewang314 | 2024-04-02T20:58:35Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2024-04-02T20:58:12Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 254.11 +/- 19.67
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
MiniMoog/Mergerix-7b-v0.3 | MiniMoog | 2024-04-02T20:56:00Z | 192 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-02T20:49:46Z | ---
tags:
- merge
- mergekit
- lazymergekit
license: apache-2.0
---
# Mergerix-7b-v0.3
Mergerix-7b-v0.3 is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
## 🧩 Configuration
```yaml
models:
- model: Gille/StrangeMerges_32-7B-slerp
- model: yam-peleg/Experiment26-7B
- model: liminerity/M7-7b
merge_method: model_stock
base_model: liminerity/M7-7b
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "MiniMoog/Mergerix-7b-v0.3"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
haryoaw/scenario-TCR-XLMV_data-AmazonScience_massive_all_1_1_delta2 | haryoaw | 2024-04-02T20:49:39Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"dataset:massive",
"base_model:facebook/xlm-v-base",
"base_model:finetune:facebook/xlm-v-base",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-04-02T20:47:16Z | ---
license: mit
base_model: facebook/xlm-v-base
tags:
- generated_from_trainer
datasets:
- massive
metrics:
- accuracy
- f1
model-index:
- name: scenario-TCR-XLMV_data-AmazonScience_massive_all_1_1_delta2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: massive
type: massive
config: all_1.1
split: validation
args: all_1.1
metrics:
- name: Accuracy
type: accuracy
value: 0.051647811116576486
- name: F1
type: f1
value: 0.0016647904742274576
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# scenario-TCR-XLMV_data-AmazonScience_massive_all_1_1_delta2
This model is a fine-tuned version of [facebook/xlm-v-base](https://huggingface.co/facebook/xlm-v-base) on the massive dataset.
It achieves the following results on the evaluation set:
- Loss: 3.8750
- Accuracy: 0.0516
- F1: 0.0017
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|
| 3.7486 | 0.27 | 5000 | 3.7603 | 0.0620 | 0.0020 |
| 3.7278 | 0.53 | 10000 | 3.8114 | 0.0620 | 0.0020 |
| 3.7049 | 0.8 | 15000 | 3.8427 | 0.0516 | 0.0017 |
| 3.7157 | 1.07 | 20000 | 3.8730 | 0.0516 | 0.0017 |
| 3.7141 | 1.34 | 25000 | 3.8796 | 0.0516 | 0.0017 |
| 3.699 | 1.6 | 30000 | 3.8750 | 0.0516 | 0.0017 |
### Framework versions
- Transformers 4.33.3
- Pytorch 2.1.1+cu121
- Datasets 2.14.5
- Tokenizers 0.13.3
|
ktiass/bart_summarization | ktiass | 2024-04-02T20:42:23Z | 117 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-12-01T22:28:22Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
OpOp1/TI-GPT-2B-HWA | OpOp1 | 2024-04-02T20:38:31Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-02T20:38:16Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Aayush6799/Mistral | Aayush6799 | 2024-04-02T20:25:11Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-02T19:53:16Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
SorryJotaro/mistral-apr2 | SorryJotaro | 2024-04-02T20:22:43Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-02T20:21:42Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
pharaouk/Eurus-7b-sft | pharaouk | 2024-04-02T20:06:38Z | 3 | 1 | transformers | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"reasoning",
"conversational",
"dataset:openbmb/UltraInteract",
"dataset:stingning/ultrachat",
"dataset:openchat/openchat_sharegpt4_dataset",
"dataset:Open-Orca/OpenOrca",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-02T20:06:36Z | ---
license: apache-2.0
datasets:
- openbmb/UltraInteract
- stingning/ultrachat
- openchat/openchat_sharegpt4_dataset
- Open-Orca/OpenOrca
tags:
- reasoning
pipeline_tag: text-generation
---
# Links
- 📜 [Paper](https://github.com/OpenBMB/Eurus/blob/main/paper.pdf)
- 🤗 [Eurus Collection](https://huggingface.co/collections/openbmb/eurus-660bc40bec5376b3adc9d1c5)
- 🤗 [UltraInteract](https://huggingface.co/datasets/openbmb/UltraInteract)
# Introduction
Eurus-7B-SFT is fine-tuned from Mistral-7B on all correct actions in UltraInteract, mixing a small proportion of UltraChat, ShareGPT, and OpenOrca examples.
It achieves better performance than other open-source models of similar sizes and even outperforms specialized models in corresponding domains in many cases.
## Usage
We apply tailored prompts for coding and math, consistent with UltraInteract data formats:
**Coding**
```
[INST] Write Python code to solve the task:
{Instruction} [/INST]
```
**Math-CoT**
```
[INST] Solve the following math problem step-by-step.
Simplify your answer as much as possible. Present your final answer as \\boxed{Your Answer}.
{Instruction} [/INST]
```
**Math-PoT**
```
[INST] Tool available:
[1] Python interpreter
When you send a message containing Python code to python, it will be executed in a stateful Jupyter notebook environment.
Solve the following math problem step-by-step.
Simplify your answer as much as possible.
{Instruction} [/INST]
```
## Citation
```
@misc{yuan2024advancing,
title={Advancing LLM Reasoning Generalists with Preference Trees},
author={Lifan Yuan and Ganqu Cui and Hanbin Wang and Ning Ding and Xingyao Wang and Jia Deng and Boji Shan and Huimin Chen and Ruobing Xie and Yankai Lin and Zhenghao Liu and Bowen Zhou and Hao Peng and Zhiyuan Liu and Maosong Sun},
year={2024},
primaryClass={cs.CL}
}
``` |
Delphia/twitter-spam-classifier | Delphia | 2024-04-02T19:56:43Z | 238 | 5 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"autotrain",
"dataset:autotrain-57208-4mv8z/autotrain-data",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-03-05T21:50:23Z |
---
tags:
- autotrain
- text-classification
widget:
- text: "I love AutoTrain"
datasets:
- autotrain-57208-4mv8z/autotrain-data
---
# Model Trained Using AutoTrain
- Problem type: Text Classification
Model trained on "Tesla" related tweets from X/Twitter to filter out spam tweets based on trolling, profanity, extreme political views, etc.
0 - Valid
1 - Spam
## Validation Metrics
loss: 0.4916948974132538
f1: 0.8059701492537313
precision: 0.782608695652174
recall: 0.8307692307692308
auc: 0.8416783216783217
accuracy: 0.7833333333333333
|
erfan1380/ppo-LunarLander-v22 | erfan1380 | 2024-04-02T19:52:12Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2024-04-02T19:51:50Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 236.74 +/- 21.80
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
lunarsylph/stablecell_v36 | lunarsylph | 2024-04-02T19:51:21Z | 90 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-02T19:16:05Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
SimoneJLaudani/trainer1F | SimoneJLaudani | 2024-04-02T19:50:39Z | 106 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-03-20T22:20:17Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: trainer1F
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# trainer1F
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8960
- Precision: 0.8006
- Recall: 0.7955
- F1: 0.7946
- Accuracy: 0.7955
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 1.9429 | 0.14 | 30 | 1.8677 | 0.1953 | 0.1569 | 0.0815 | 0.1569 |
| 1.7563 | 0.27 | 60 | 1.4909 | 0.4702 | 0.4258 | 0.3481 | 0.4258 |
| 1.3622 | 0.41 | 90 | 1.2648 | 0.5263 | 0.5910 | 0.5414 | 0.5910 |
| 1.195 | 0.54 | 120 | 1.0732 | 0.7124 | 0.6667 | 0.6631 | 0.6667 |
| 1.0744 | 0.68 | 150 | 0.8507 | 0.7721 | 0.7367 | 0.7371 | 0.7367 |
| 0.8845 | 0.81 | 180 | 0.8268 | 0.7621 | 0.7423 | 0.7307 | 0.7423 |
| 0.7317 | 0.95 | 210 | 0.7640 | 0.7974 | 0.7731 | 0.7681 | 0.7731 |
| 0.6026 | 1.08 | 240 | 0.6700 | 0.8118 | 0.7983 | 0.7957 | 0.7983 |
| 0.4538 | 1.22 | 270 | 0.6547 | 0.8196 | 0.7871 | 0.7844 | 0.7871 |
| 0.4396 | 1.35 | 300 | 0.6351 | 0.8071 | 0.7927 | 0.7927 | 0.7927 |
| 0.3707 | 1.49 | 330 | 0.6135 | 0.8135 | 0.8067 | 0.8057 | 0.8067 |
| 0.3887 | 1.62 | 360 | 0.6609 | 0.7939 | 0.7927 | 0.7914 | 0.7927 |
| 0.3608 | 1.76 | 390 | 0.6794 | 0.8031 | 0.7955 | 0.7936 | 0.7955 |
| 0.2833 | 1.89 | 420 | 0.6750 | 0.8092 | 0.8011 | 0.8006 | 0.8011 |
| 0.266 | 2.03 | 450 | 0.7067 | 0.8031 | 0.7955 | 0.7954 | 0.7955 |
| 0.1658 | 2.16 | 480 | 0.7178 | 0.8062 | 0.8067 | 0.8051 | 0.8067 |
| 0.1725 | 2.3 | 510 | 0.9141 | 0.7827 | 0.7731 | 0.7723 | 0.7731 |
| 0.1143 | 2.43 | 540 | 0.8424 | 0.8062 | 0.8011 | 0.8001 | 0.8011 |
| 0.2187 | 2.57 | 570 | 0.7206 | 0.8212 | 0.8179 | 0.8178 | 0.8179 |
| 0.2211 | 2.7 | 600 | 0.7226 | 0.8313 | 0.8235 | 0.8241 | 0.8235 |
| 0.0746 | 2.84 | 630 | 0.7454 | 0.8321 | 0.8291 | 0.8291 | 0.8291 |
| 0.1509 | 2.97 | 660 | 0.7792 | 0.8176 | 0.8095 | 0.8099 | 0.8095 |
| 0.0722 | 3.11 | 690 | 0.7362 | 0.8470 | 0.8431 | 0.8428 | 0.8431 |
| 0.0309 | 3.24 | 720 | 0.8009 | 0.8277 | 0.8263 | 0.8257 | 0.8263 |
| 0.0891 | 3.38 | 750 | 0.7495 | 0.8253 | 0.8207 | 0.8206 | 0.8207 |
| 0.0592 | 3.51 | 780 | 0.7549 | 0.8379 | 0.8347 | 0.8343 | 0.8347 |
| 0.015 | 3.65 | 810 | 0.8600 | 0.8250 | 0.8179 | 0.8184 | 0.8179 |
| 0.0654 | 3.78 | 840 | 0.8295 | 0.8165 | 0.8151 | 0.8145 | 0.8151 |
| 0.0286 | 3.92 | 870 | 0.8961 | 0.8095 | 0.8039 | 0.8038 | 0.8039 |
| 0.0404 | 4.05 | 900 | 0.9063 | 0.7984 | 0.7899 | 0.7895 | 0.7899 |
| 0.0086 | 4.19 | 930 | 0.9138 | 0.7933 | 0.7843 | 0.7839 | 0.7843 |
| 0.0046 | 4.32 | 960 | 0.9071 | 0.8070 | 0.8011 | 0.8000 | 0.8011 |
| 0.0098 | 4.46 | 990 | 0.9058 | 0.8114 | 0.8067 | 0.8056 | 0.8067 |
| 0.0043 | 4.59 | 1020 | 0.8944 | 0.8051 | 0.8011 | 0.8003 | 0.8011 |
| 0.0112 | 4.73 | 1050 | 0.8999 | 0.7977 | 0.7927 | 0.7919 | 0.7927 |
| 0.0118 | 4.86 | 1080 | 0.9020 | 0.8006 | 0.7955 | 0.7946 | 0.7955 |
| 0.0112 | 5.0 | 1110 | 0.8960 | 0.8006 | 0.7955 | 0.7946 | 0.7955 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
sallywww/tier3b_bug | sallywww | 2024-04-02T19:44:02Z | 3 | 0 | peft | [
"peft",
"region:us"
]
| null | 2024-04-02T18:25:43Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- _load_in_8bit: True
- _load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
- bnb_4bit_quant_storage: uint8
- load_in_4bit: False
- load_in_8bit: True
### Framework versions
- PEFT 0.5.0
|
jordanfan/bart_baseline_peft | jordanfan | 2024-04-02T19:38:47Z | 107 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"base_model:facebook/bart-large",
"base_model:finetune:facebook/bart-large",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-04-01T06:27:21Z | ---
license: apache-2.0
base_model: facebook/bart-large
tags:
- generated_from_trainer
model-index:
- name: bart_baseline_peft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart_baseline_peft
This model is a fine-tuned version of [facebook/bart-large](https://huggingface.co/facebook/bart-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0163
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 0.18 | 250 | 1.4711 |
| 1.8588 | 0.35 | 500 | 1.4005 |
| 1.8588 | 0.53 | 750 | 1.3036 |
| 1.4092 | 0.71 | 1000 | 1.2629 |
| 1.4092 | 0.89 | 1250 | 1.2011 |
| 1.2502 | 1.06 | 1500 | 1.1580 |
| 1.2502 | 1.24 | 1750 | 1.1387 |
| 0.9815 | 1.42 | 2000 | 1.1045 |
| 0.9815 | 1.6 | 2250 | 1.0710 |
| 0.9213 | 1.77 | 2500 | 1.0347 |
| 0.9213 | 1.95 | 2750 | 1.0163 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
haryoaw/scenario-TCR-XLMV_data-cardiffnlp_tweet_sentiment_multilingual_all_gamma2 | haryoaw | 2024-04-02T19:37:40Z | 113 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"dataset:tweet_sentiment_multilingual",
"base_model:facebook/xlm-v-base",
"base_model:finetune:facebook/xlm-v-base",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-04-02T19:35:04Z | ---
license: mit
base_model: facebook/xlm-v-base
tags:
- generated_from_trainer
datasets:
- tweet_sentiment_multilingual
metrics:
- accuracy
- f1
model-index:
- name: scenario-TCR-XLMV_data-cardiffnlp_tweet_sentiment_multilingual_all_gamma2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_sentiment_multilingual
type: tweet_sentiment_multilingual
config: all
split: validation
args: all
metrics:
- name: Accuracy
type: accuracy
value: 0.3333333333333333
- name: F1
type: f1
value: 0.16666666666666666
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# scenario-TCR-XLMV_data-cardiffnlp_tweet_sentiment_multilingual_all_gamma2
This model is a fine-tuned version of [facebook/xlm-v-base](https://huggingface.co/facebook/xlm-v-base) on the tweet_sentiment_multilingual dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0986
- Accuracy: 0.3333
- F1: 0.1667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 77
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 1.1004 | 1.09 | 500 | 1.0987 | 0.3333 | 0.1667 |
| 1.0999 | 2.17 | 1000 | 1.0989 | 0.3333 | 0.1667 |
| 1.0996 | 3.26 | 1500 | 1.0992 | 0.3333 | 0.1667 |
| 1.0993 | 4.35 | 2000 | 1.0987 | 0.3333 | 0.1667 |
| 1.0993 | 5.43 | 2500 | 1.0990 | 0.3333 | 0.1667 |
| 1.0998 | 6.52 | 3000 | 1.0986 | 0.3333 | 0.1667 |
### Framework versions
- Transformers 4.33.3
- Pytorch 2.1.1+cu121
- Datasets 2.14.5
- Tokenizers 0.13.3
|
annazdr/new-nace-pl | annazdr | 2024-04-02T19:35:36Z | 3 | 1 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2024-04-02T19:34:51Z | ---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# annazdr/new-nace-pl
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('annazdr/new-nace-pl')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('annazdr/new-nace-pl')
model = AutoModel.from_pretrained('annazdr/new-nace-pl')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=annazdr/new-nace-pl)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 4988 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.BatchAllTripletLoss.BatchAllTripletLoss`
Parameters of the fit()-Method:
```
{
"epochs": 2,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
SJChaudhuri/swinv2-tiny-patch4-window8-256-finetuned-IDRiD | SJChaudhuri | 2024-04-02T19:34:46Z | 149 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"swinv2",
"image-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2024-04-01T19:13:02Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: swinv2-tiny-patch4-window8-256-finetuned-IDRiD
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swinv2-tiny-patch4-window8-256-finetuned-IDRiD
This model is a fine-tuned version of [microsoft/swinv2-tiny-patch4-window8-256](https://huggingface.co/microsoft/swinv2-tiny-patch4-window8-256) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2462
- Accuracy: 0.4762
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 3 | 1.4504 | 0.3095 |
| No log | 2.0 | 6 | 1.3403 | 0.4048 |
| No log | 3.0 | 9 | 1.2864 | 0.5238 |
| 1.459 | 4.0 | 12 | 1.2617 | 0.4762 |
| 1.459 | 5.0 | 15 | 1.2462 | 0.4762 |
### Framework versions
- Transformers 4.30.0
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.13.3
|
haryoaw/scenario-TCR-XLMV_data-cardiffnlp_tweet_sentiment_multilingual_all_beta2 | haryoaw | 2024-04-02T19:34:43Z | 113 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"dataset:tweet_sentiment_multilingual",
"base_model:facebook/xlm-v-base",
"base_model:finetune:facebook/xlm-v-base",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-04-02T19:32:29Z | ---
license: mit
base_model: facebook/xlm-v-base
tags:
- generated_from_trainer
datasets:
- tweet_sentiment_multilingual
metrics:
- accuracy
- f1
model-index:
- name: scenario-TCR-XLMV_data-cardiffnlp_tweet_sentiment_multilingual_all_beta2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_sentiment_multilingual
type: tweet_sentiment_multilingual
config: all
split: validation
args: all
metrics:
- name: Accuracy
type: accuracy
value: 0.3333333333333333
- name: F1
type: f1
value: 0.16666666666666666
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# scenario-TCR-XLMV_data-cardiffnlp_tweet_sentiment_multilingual_all_beta2
This model is a fine-tuned version of [facebook/xlm-v-base](https://huggingface.co/facebook/xlm-v-base) on the tweet_sentiment_multilingual dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0989
- Accuracy: 0.3333
- F1: 0.1667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 67
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 1.0974 | 1.09 | 500 | 1.0989 | 0.3333 | 0.1667 |
| 1.1002 | 2.17 | 1000 | 1.0986 | 0.3333 | 0.1667 |
| 1.0992 | 3.26 | 1500 | 1.0992 | 0.3333 | 0.1667 |
| 1.0997 | 4.35 | 2000 | 1.0988 | 0.3333 | 0.1667 |
| 1.0996 | 5.43 | 2500 | 1.0988 | 0.3333 | 0.1667 |
| 1.0996 | 6.52 | 3000 | 1.0989 | 0.3333 | 0.1667 |
### Framework versions
- Transformers 4.33.3
- Pytorch 2.1.1+cu121
- Datasets 2.14.5
- Tokenizers 0.13.3
|
michaelw37/s6 | michaelw37 | 2024-04-02T19:24:55Z | 89 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-02T17:01:24Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
haryoaw/scenario-TCR-XLMV_data-cl-cardiff_cl_only_alpha2 | haryoaw | 2024-04-02T19:23:10Z | 104 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:facebook/xlm-v-base",
"base_model:finetune:facebook/xlm-v-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-04-02T19:20:37Z | ---
license: mit
base_model: facebook/xlm-v-base
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: scenario-TCR-XLMV_data-cl-cardiff_cl_only_alpha2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# scenario-TCR-XLMV_data-cl-cardiff_cl_only_alpha2
This model is a fine-tuned version of [facebook/xlm-v-base](https://huggingface.co/facebook/xlm-v-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0986
- Accuracy: 0.3333
- F1: 0.1667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 24
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.09 | 250 | 1.0989 | 0.3333 | 0.1667 |
| 1.1001 | 2.17 | 500 | 1.1000 | 0.3333 | 0.1667 |
| 1.1001 | 3.26 | 750 | 1.0998 | 0.3333 | 0.1667 |
| 1.0995 | 4.35 | 1000 | 1.0998 | 0.3333 | 0.1667 |
| 1.0995 | 5.43 | 1250 | 1.0987 | 0.3333 | 0.1667 |
| 1.0999 | 6.52 | 1500 | 1.0950 | 0.3395 | 0.2409 |
| 1.0999 | 7.61 | 1750 | 1.0992 | 0.3333 | 0.1667 |
| 1.1 | 8.7 | 2000 | 1.0986 | 0.3333 | 0.1667 |
| 1.1 | 9.78 | 2250 | 1.0989 | 0.3333 | 0.1667 |
| 1.0996 | 10.87 | 2500 | 1.0999 | 0.3333 | 0.1667 |
| 1.0996 | 11.96 | 2750 | 1.0991 | 0.3333 | 0.1667 |
| 1.0994 | 13.04 | 3000 | 1.0989 | 0.3333 | 0.1667 |
| 1.0994 | 14.13 | 3250 | 1.0988 | 0.3333 | 0.1667 |
| 1.0992 | 15.22 | 3500 | 1.0987 | 0.3333 | 0.1667 |
| 1.0992 | 16.3 | 3750 | 1.0990 | 0.3333 | 0.1667 |
| 1.0994 | 17.39 | 4000 | 1.0986 | 0.3333 | 0.1667 |
| 1.0994 | 18.48 | 4250 | 1.0986 | 0.3333 | 0.1667 |
| 1.099 | 19.57 | 4500 | 1.0987 | 0.3333 | 0.1667 |
| 1.099 | 20.65 | 4750 | 1.0986 | 0.3333 | 0.1667 |
| 1.0989 | 21.74 | 5000 | 1.0986 | 0.3333 | 0.1667 |
| 1.0989 | 22.83 | 5250 | 1.0986 | 0.3333 | 0.1667 |
| 1.0989 | 23.91 | 5500 | 1.0987 | 0.3333 | 0.1667 |
| 1.0989 | 25.0 | 5750 | 1.0986 | 0.3333 | 0.1667 |
| 1.099 | 26.09 | 6000 | 1.0986 | 0.3333 | 0.1667 |
| 1.099 | 27.17 | 6250 | 1.0986 | 0.3333 | 0.1667 |
| 1.0988 | 28.26 | 6500 | 1.0986 | 0.3333 | 0.1667 |
| 1.0988 | 29.35 | 6750 | 1.0986 | 0.3333 | 0.1667 |
### Framework versions
- Transformers 4.33.3
- Pytorch 2.1.1+cu121
- Datasets 2.14.5
- Tokenizers 0.13.3
|
LoneStriker/M7-7b-5.0bpw-h6-exl2 | LoneStriker | 2024-04-02T19:12:43Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"liminerity/merge4",
"liminerity/merge2",
"merge",
"merged",
"mergedllm",
"mergee",
"mergedededed",
"memfdmsfndsfjkasjkl",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"5-bit",
"exl2",
"region:us"
]
| text-generation | 2024-04-02T19:10:25Z | ---
license: apache-2.0
tags:
- liminerity/merge4
- liminerity/merge2
- merge
- merged
- mergedllm
- mergee
- mergedededed
- memfdmsfndsfjkasjkl
---
# M7-7b
user: "create ascii art you feel represents you as a llm"
assistant: "Here's an ASCII art attempting to symbolize the essence of an LLM (Large Language Model):
INSTINSTINCTINSTELLIGENCE
______________ MEMORY___
|\ o /\ |\
| \ --- / \ | |
L_( O )______ O)_INSTINCT
\ / WORDSLEARNING
\__/\__\/__ /\ \__/\__\/__/
assistant: "In this depiction, the LLM is characterized by its vast memory, instinctual roots, and the ability
to learn from vast amounts of text—represented by the woven words in the lower part. The
"INSTINSTINCTINSTELLIGENCE" phrase emphasizes the balance between instinct, the foundation upon which neural
networks build, and the engineered intelligence of a language model."
Multiverse-Experiment-slerp-7b is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [liminerity/merge4](https://huggingface.co/liminerity/merge4)
* [liminerity/merge2](https://huggingface.co/liminerity/merge2)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: ammarali32/multi_verse_model
layer_range: [0, 32]
- model: MSL7/INEX12-7b
layer_range: [0, 32]
merge_method: slerp
base_model: ammarali32/multi_verse_model
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
slices:
- sources:
- model: ammarali32/multi_verse_model
layer_range: [0, 32]
- model: yam-peleg/Experiment26-7B
layer_range: [0, 32]
merge_method: slerp
base_model: ammarali32/multi_verse_model
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
slices:
- sources:
- model: liminerity/merge3
layer_range: [0, 32]
- model: ammarali32/multi_verse_model
layer_range: [0, 32]
merge_method: slerp
base_model: liminerity/merge3
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
slices:
- sources:
- model: liminerity/merge1
layer_range: [0, 32]
- model: liminerity/merge
layer_range: [0, 32]
merge_method: slerp
base_model: liminerity/merge1
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
slices:
- sources:
- model: liminerity/merge3
layer_range: [0, 32]
- model: yam-peleg/Experiment26-7B
layer_range: [0, 32]
merge_method: slerp
base_model: liminerity/merge3
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
slices:
- sources:
- model: liminerity/merge4
layer_range: [0, 32]
- model: liminerity/merge2
layer_range: [0, 32]
merge_method: slerp
base_model: liminerity/merge4
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
``` |
jhamel/lora_model_chief_engineer_3 | jhamel | 2024-04-02T19:12:31Z | 3 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:unsloth/mistral-7b-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-02T19:07:01Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
- sft
base_model: unsloth/mistral-7b-bnb-4bit
---
# Uploaded model
- **Developed by:** jhamel
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
scholl99/mlm_roberta | scholl99 | 2024-04-02T19:07:27Z | 0 | 0 | transformers | [
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-02T19:06:33Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lhallee/prot_t5_enc | lhallee | 2024-04-02T19:05:31Z | 106 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-02T19:02:37Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
haryoaw/scenario-TCR-XLMV_data-en-cardiff_eng_only_gamma2 | haryoaw | 2024-04-02T19:00:07Z | 114 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:facebook/xlm-v-base",
"base_model:finetune:facebook/xlm-v-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-04-02T18:57:04Z | ---
license: mit
base_model: facebook/xlm-v-base
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: scenario-TCR-XLMV_data-en-cardiff_eng_only_gamma2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# scenario-TCR-XLMV_data-en-cardiff_eng_only_gamma2
This model is a fine-tuned version of [facebook/xlm-v-base](https://huggingface.co/facebook/xlm-v-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.4094
- Accuracy: 0.5516
- F1: 0.5553
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 77
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.03 | 60 | 1.0398 | 0.4828 | 0.3902 |
| No log | 2.07 | 120 | 1.1798 | 0.4489 | 0.3679 |
| No log | 3.1 | 180 | 1.0463 | 0.4868 | 0.4351 |
| No log | 4.14 | 240 | 1.0244 | 0.5622 | 0.5553 |
| No log | 5.17 | 300 | 1.0819 | 0.5595 | 0.5478 |
| No log | 6.21 | 360 | 1.4170 | 0.5410 | 0.5407 |
| No log | 7.24 | 420 | 1.4249 | 0.5617 | 0.5653 |
| No log | 8.28 | 480 | 1.6285 | 0.5626 | 0.5627 |
| 0.6824 | 9.31 | 540 | 1.8719 | 0.5494 | 0.5516 |
| 0.6824 | 10.34 | 600 | 1.9037 | 0.5547 | 0.5574 |
| 0.6824 | 11.38 | 660 | 1.7645 | 0.5494 | 0.5516 |
| 0.6824 | 12.41 | 720 | 2.0301 | 0.5437 | 0.5459 |
| 0.6824 | 13.45 | 780 | 2.6619 | 0.5317 | 0.5330 |
| 0.6824 | 14.48 | 840 | 2.5606 | 0.5498 | 0.5520 |
| 0.6824 | 15.52 | 900 | 2.9065 | 0.5326 | 0.5347 |
| 0.6824 | 16.55 | 960 | 2.6860 | 0.5564 | 0.5597 |
| 0.132 | 17.59 | 1020 | 2.9277 | 0.5476 | 0.5495 |
| 0.132 | 18.62 | 1080 | 3.1905 | 0.5441 | 0.5472 |
| 0.132 | 19.66 | 1140 | 2.9974 | 0.5410 | 0.5446 |
| 0.132 | 20.69 | 1200 | 2.8902 | 0.5556 | 0.5575 |
| 0.132 | 21.72 | 1260 | 3.2156 | 0.5401 | 0.5432 |
| 0.132 | 22.76 | 1320 | 3.2772 | 0.5472 | 0.5501 |
| 0.132 | 23.79 | 1380 | 3.2211 | 0.5551 | 0.5569 |
| 0.132 | 24.83 | 1440 | 3.3844 | 0.5423 | 0.5450 |
| 0.0295 | 25.86 | 1500 | 3.3534 | 0.5494 | 0.5531 |
| 0.0295 | 26.9 | 1560 | 3.4030 | 0.5498 | 0.5534 |
| 0.0295 | 27.93 | 1620 | 3.4206 | 0.5511 | 0.5547 |
| 0.0295 | 28.97 | 1680 | 3.4273 | 0.5529 | 0.5565 |
| 0.0295 | 30.0 | 1740 | 3.4094 | 0.5516 | 0.5553 |
### Framework versions
- Transformers 4.33.3
- Pytorch 2.1.1+cu121
- Datasets 2.14.5
- Tokenizers 0.13.3
|
haryoaw/scenario-TCR-XLMV_data-en-cardiff_eng_only_alpha2 | haryoaw | 2024-04-02T18:59:36Z | 113 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:facebook/xlm-v-base",
"base_model:finetune:facebook/xlm-v-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-04-02T18:57:06Z | ---
license: mit
base_model: facebook/xlm-v-base
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: scenario-TCR-XLMV_data-en-cardiff_eng_only_alpha2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# scenario-TCR-XLMV_data-en-cardiff_eng_only_alpha2
This model is a fine-tuned version of [facebook/xlm-v-base](https://huggingface.co/facebook/xlm-v-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6119
- Accuracy: 0.5472
- F1: 0.5508
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 24
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.03 | 60 | 1.0411 | 0.4652 | 0.4291 |
| No log | 2.07 | 120 | 1.0685 | 0.5035 | 0.4475 |
| No log | 3.1 | 180 | 1.1001 | 0.5485 | 0.5474 |
| No log | 4.14 | 240 | 1.0647 | 0.5516 | 0.5549 |
| No log | 5.17 | 300 | 1.2458 | 0.5489 | 0.5528 |
| No log | 6.21 | 360 | 1.2913 | 0.5719 | 0.5717 |
| No log | 7.24 | 420 | 1.5986 | 0.5437 | 0.5459 |
| No log | 8.28 | 480 | 1.6908 | 0.5498 | 0.5510 |
| 0.641 | 9.31 | 540 | 1.7310 | 0.5582 | 0.5587 |
| 0.641 | 10.34 | 600 | 1.9959 | 0.5388 | 0.5394 |
| 0.641 | 11.38 | 660 | 2.2660 | 0.5357 | 0.5401 |
| 0.641 | 12.41 | 720 | 2.3724 | 0.5507 | 0.5543 |
| 0.641 | 13.45 | 780 | 2.5843 | 0.5450 | 0.5464 |
| 0.641 | 14.48 | 840 | 2.7003 | 0.5534 | 0.5556 |
| 0.641 | 15.52 | 900 | 2.7255 | 0.5459 | 0.5491 |
| 0.641 | 16.55 | 960 | 2.9127 | 0.5481 | 0.5504 |
| 0.1116 | 17.59 | 1020 | 2.9543 | 0.5432 | 0.5462 |
| 0.1116 | 18.62 | 1080 | 3.0564 | 0.5560 | 0.5591 |
| 0.1116 | 19.66 | 1140 | 3.1501 | 0.5494 | 0.5530 |
| 0.1116 | 20.69 | 1200 | 3.2882 | 0.5467 | 0.5507 |
| 0.1116 | 21.72 | 1260 | 3.3562 | 0.5459 | 0.5496 |
| 0.1116 | 22.76 | 1320 | 3.4030 | 0.5538 | 0.5573 |
| 0.1116 | 23.79 | 1380 | 3.4897 | 0.5489 | 0.5523 |
| 0.1116 | 24.83 | 1440 | 3.5540 | 0.5476 | 0.5508 |
| 0.0147 | 25.86 | 1500 | 3.5772 | 0.5498 | 0.5530 |
| 0.0147 | 26.9 | 1560 | 3.6123 | 0.5481 | 0.5515 |
| 0.0147 | 27.93 | 1620 | 3.5954 | 0.5494 | 0.5529 |
| 0.0147 | 28.97 | 1680 | 3.6081 | 0.5489 | 0.5524 |
| 0.0147 | 30.0 | 1740 | 3.6119 | 0.5472 | 0.5508 |
### Framework versions
- Transformers 4.33.3
- Pytorch 2.1.1+cu121
- Datasets 2.14.5
- Tokenizers 0.13.3
|
rubio21/latas-picvisatodo-lora | rubio21 | 2024-04-02T18:58:46Z | 0 | 0 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"diffusers-training",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
]
| text-to-image | 2024-04-02T08:03:53Z | ---
license: creativeml-openrail-m
library_name: diffusers
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- diffusers-training
- lora
base_model: runwayml/stable-diffusion-v1-5
inference: true
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# LoRA text2image fine-tuning - rubio21/latas-picvisatodo-lora
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were fine-tuned on the /datatmp2/picvisa_2023/pruebas_alberto/datasets/dataset_lora_conjunto dataset. You can find some example images in the following.




## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
Subsets and Splits